1. はじめに¶
1.1. 対象読者と目的¶
『CLUSTERPRO X メンテナンスガイド』は、管理者を対象に、メンテナンス関連情報について記載しています。クラスタ運用時に必要な情報を参照してください。
1.3. CLUSTERPRO マニュアル体系¶
CLUSTERPRO のマニュアルは、以下の 4 つに分類されます。各ガイドのタイトルと役割を以下に示します。
『CLUSTERPRO X スタートアップガイド』 (Getting Started Guide)
すべてのユーザを対象読者とし、製品概要、動作環境、アップデート情報、既知の問題などについて記載します。
『CLUSTERPRO X インストール&設定ガイド』 (Install and Configuration Guide)
CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアと、クラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO を使用したクラスタシステム導入から運用開始前までに必須の事項について説明します。実際にクラスタシステムを導入する際の順番に則して、CLUSTERPRO を使用したクラスタシステムの設計方法、CLUSTERPRO のインストールと設定手順、設定後の確認、運用開始前の評価方法について説明します。
『CLUSTERPRO X リファレンスガイド』 (Reference Guide)
管理者、および CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアを対象とし、CLUSTERPRO の運用手順、各モジュールの機能説明およびトラブルシューティング情報等を記載します。『インストール&設定ガイド』を補完する役割を持ちます。
『CLUSTERPRO X メンテナンスガイド』 (Maintenance Guide)
管理者、および CLUSTERPRO を使用したクラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO のメンテナンス関連情報を記載します。
1.4. 本書の表記規則¶
本書では、注意すべき事項、重要な事項および関連情報を以下のように表記します。
注釈
この表記は、重要ではあるがデータ損失やシステムおよび機器の損傷には関連しない情報を表します。
重要
この表記は、データ損失やシステムおよび機器の損傷を回避するために必要な情報を表します。
参考
この表記は、参照先の情報の場所を表します。
また、本書では以下の表記法を使用します。
表記 |
使用方法 |
例 |
|---|---|---|
[ ] 角かっこ |
コマンド名の前後
画面に表示される語 (ダイアログボックス、メニューなど) の前後
|
[スタート] をクリックします。
[プロパティ] ダイアログ ボックス
|
コマンドライン中の [ ] 角かっこ |
かっこ内の値の指定が省略可能であることを示します。 |
|
モノスペースフォント |
パス名、コマンド ライン、システムからの出力 (メッセージ、プロンプトなど)、ディレクトリ、ファイル名、関数、パラメータ |
|
太字 |
ユーザが実際にコマンドプロンプトから入力する値を示します。 |
以下を入力します。
clpcl -s -a
|
斜体 |
ユーザが有効な値に置き換えて入力する項目 |
|
 本書の図では、CLUSTERPROを表すために このアイコンを使用します。
本書の図では、CLUSTERPROを表すために このアイコンを使用します。
2. 保守情報¶
本章では、CLUSTERPRO のメンテナンスを行う上で必要な情報について説明します。管理対象となるリソースの詳細について説明します。
本章で説明する項目は以下の通りです。
2.1. CLUSTERPRO のディレクトリ構成¶
注釈
インストールディレクトリ配下に『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」に記載されていない実行形式ファイルやスクリプトファイルがありますが、CLUSTERPRO以外からは実行しないでください。実行した場合の影響については、サポート対象外とします。
CLUSTERPRO は、以下のディレクトリ構成で構成されます。
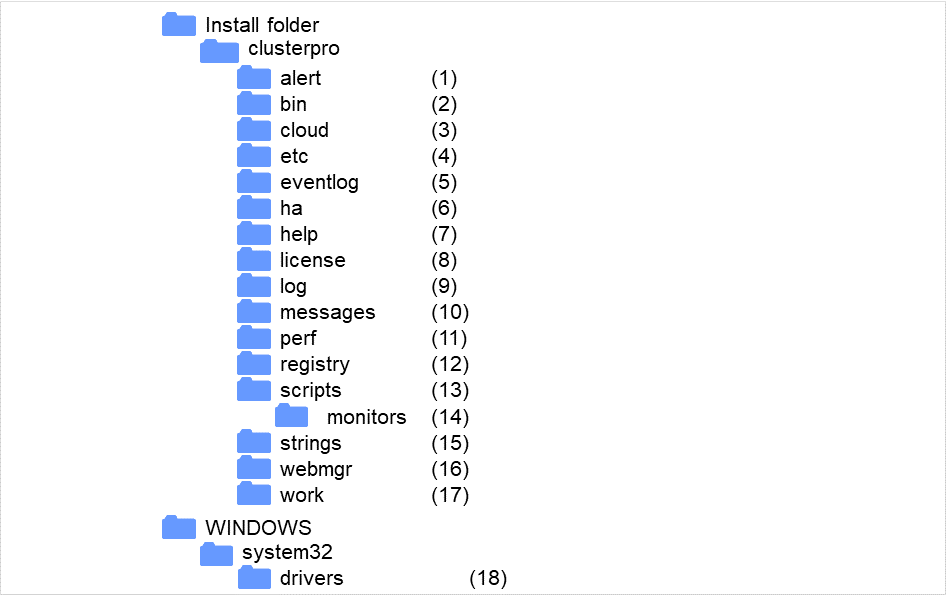
図 2.1 ディレクトリ構成¶
- アラート同期関連CLUSTERPRO アラート同期のモジュールおよび管理ファイルが格納されます。
- クラスタモジュール関連CLUSTERPRO サーバの実行形式ファイル、およびライブラリが格納されます。
- クラウド連携製品関連クラウド連携用のスクリプトモジュールなどが格納されます。
- クラスタ構成情報関連クラスタ構成情報ファイル、各モジュールのポリシーファイルが格納されます。
- イベントログ関連CLUSTERPRO のイベントログ関連のライブラリが格納されています。
- HA製品関連Java Resource Agent, System Resource Agent のバイナリ、設定ファイルが格納されています。
- ヘルプ関連現在未使用です。
- ライセンス関連ライセンス製品のライセンスが格納されます。
- モジュールログ関連各モジュールから出力されるログが格納されます。
- 通報メッセージ (アラート、イベントログ) 関連各モジュールが アラート、イベントログを通報するときのメッセージが格納されます。
- パフォーマンスログ関連ディスクやシステムのパフォーマンス情報が格納されます。
- レジストリ関連現在未使用です。
- グループリソースのスクリプトリソーススクリプト関連グループリソースのスクリプトリソースのスクリプトが格納されます。
- 回復スクリプト関連グループリソースやモニタリソースの異常検出時に実行されるスクリプトが格納されています。
- ストリングテーブル関連CLUSTERPRO で使用するストリングテーブルを格納しています。
- WebManager サーバ、Cluster WebUI 関連WebManager サーバのモジュールおよび管理ファイルが格納されます。
- モジュール作業関連各モジュールの作業用ディレクトリです。
- クラスタドライバ関連カーネルモード LAN ハートビートドライバ、ディスクフィルタドライバが格納されます。
2.2. CLUSTERPRO のログ、アラート削除方法¶
CLUSTERPRO のログ、アラートを削除するには下記の手順を実行してください。
クラスタ内の全サーバ上でサービスのスタートアップの種類を手動起動に変更します。
clpsvcctrl.bat --disable -a
Cluster WebUI または clpstdn コマンドでクラスタシャットダウン、リブートを実行し再起動します。
ログを削除するには下記のフォルダに存在するファイルを削除します。ログを削除したいサーバ上で実行してください。
<CLUSTERPROのインストールパス>\log
アラートを削除するには下記のフォルダに存在するファイルを削除します。アラートを削除したいサーバ上で実行してください。
<CLUSTERPROのインストールパス>\alert\log
クラスタ内の全サーバ上でサービスのスタートアップの種類を自動起動に変更します。
clpsvcctrl.bat --enable -a
クラスタ内の全サーバを再起動してください。
2.3. ミラー統計情報採取機能¶
2.3.1. ミラー統計情報採取機能とは?¶
ミラー統計情報採取機能とは、ミラーディスク構成およびハイブリッドディスク構成において各ミラーリソースから得られる、ミラーリング機能に関する統計的な情報を採取する機能のことです。
ミラー統計情報採取機能では、Windows OS 機能であるパフォーマンスモニタや typeperf コマンドを利用して、CLUSTERPRO X のミラー統計情報を採取したり、採取した情報をリアルタイムで表示することができます。また、ミラー構築時より継続的にミラー統計情報を統計ログファイルへ出力できます。
採取したミラー統計情報は、ミラー構築時・ミラー運用時それぞれにおいて以下のように利用できます。
ミラー構築時 |
現在の環境においてミラー設定項目のチューニングを行うために、どの設定項目が現環境にどのように影響しているかを確認してより最適な設定の調整ができます。 |
ミラー運用時 |
問題が発生しそうな状況かどうかをモニタリング可能になります。
また障害発生時点の前後のミラー統計情報を採取できることで、より解析性能が向上します。
|
2.3.2. ミラー統計情報採取機能と OS 標準機能との連携¶
OS標準機能の利用
パフォーマンスモニタや typeperf コマンドを利用して、ミラー統計情報を採取したり、採取した情報をリアルタイムで表示します。以降の「カウンタ名について」一覧より任意のカウンタを選択し、表示および採取を一定期間続けることで、ミラー関連の設定値が構築した環境に適しているか、あるいは統計情報の採取期間中に異常が発生していなかったかを、視覚的に確認できます。
実際にパフォーマンスモニタや typeperf コマンドを利用する手順については、以降の「パフォーマンスモニタでミラー統計情報を表示する」、「パフォーマンスモニタからミラー統計情報を採取する」、および「typeperf コマンドからミラー統計情報を採取する」の項を参照してください。
オブジェクト名を指定する
ミラー統計情報採取機能で扱うオブジェクト名は「Cluster Disk Resource Performance」です。オブジェクト「Cluster Disk Resource Performance」を指定することでミラー統計情報を採取できます。
カウンタ名を指定する
ミラー統計情報採取機能で扱うカウンタ名は以下の通りです。
カウンタ名
意味
単位
説明
% Compress Ratio
圧縮率
%
相手サーバに送信されるミラーデータの圧縮率です。元データに対する圧縮後データサイズの比率で表し、データサイズ100MBが80MBに圧縮される場合の圧縮率は80%です。
Async Application Queue BytesAsync Application Queue Bytes, Maxアプリケーションキューサイズ(瞬間値/最大値)
Byte
非同期ミラー通信において、ユーザ空間メモリで保持されている送信待ちデータ量です。最新データ採取時点での値が瞬間値、保持するデータ量が最も多かった時点での値が最大値です。
Async Kernel Queue BytesAsync Kernel Queue Bytes, Maxカーネルキューサイズ(瞬間値/最大値)
Byte
非同期ミラー通信において、カーネル空間メモリで保持されている送信待ちデータ量です。最新データ採取時点での値が瞬間値、保持するデータ量が最も多かった時点での値が最大値です。
Async Mirror Queue Transfer TimeAsync Mirror Queue Transfer Time, Maxカーネルキューからアプリケーションキューへの転送時間(平均値/最大値)
msec
非同期ミラー通信において、カーネル空間メモリからユーザ空間メモリへデータを送信する転送時間の平均値/最大値です。
Async Mirror Send Wait History Files Total BytesAsync Mirror Send Wait History Files Total Bytes, Max履歴ファイル使用量(瞬間値/最大値)
Byte
非同期ミラー通信において、履歴ファイル格納フォルダに蓄積されている送信待ちデータファイルのサイズ総量です。最新データ採取時点での値が瞬間値、蓄積されているデータ量が最も多かった時点での値が最大値です。
Async Mirror Send Wait Total BytesAsync Mirror Send Wait Total Bytes, Max送信待ちデータ量(瞬間値/最大値)
Byte
非同期ミラー通信において、相手サーバに送信される送信待ちミラーデータの総量です。最新データ採取時点での値が瞬間値、送信待ちとなっているデータ量が最も多かった時点での値が最大値です。
Mirror Bytes SentMirror Bytes Sent/secミラー送信量(合計値/平均値)
Byte(Byte/sec)相手サーバに送信されたミラーデータ量のバイト数です。最新データ採取時点までの合計バイト数が合計値、1秒あたりの送信バイト数が平均値です。
Request Queue BytesRequest Queue Bytes, Maxリクエストキューサイズ(瞬間値/最大値)
Byte
ミラー通信においてIO要求を受信する際に使われるキューの使用サイズです。最新データ採取時点での値が瞬間値、キューサイズが最も大きかった時点での値が最大値です。
Transfer Time, AvgTransfer Time, Maxミラー通信時間(平均値/最大値)
msec/回
ミラーデータ送信に掛かったミラー通信1回あたりの通信時間です。最新データ採取時点までに掛かったミラー通信回数で平均した通信時間が平均値、ミラー通信1回あたりで最も大きかった通信時間が最大値です。
- インスタンス名を指定するミラー統計情報採取機能で扱うインスタンス名は「MD,HD ResourceX」です。X には 1から 22 までのミラーディスク番号/ハイブリッドディスク番号が入ります。たとえばミラーディスクリソース「MD」のミラーディスク番号が「2」に設定されている場合、リソース「MD」に関するミラー統計情報はインスタンス「MD,HD Resource2」を指定することで採取できます。また、複数のリソースを設定している場合にインスタンス「_Total」を指定することで、設定しているすべてのリソースに関するミラー統計情報を合計した情報を採取できます。
注釈
実際にリソースを設定しているミラーディスク番号/ハイブリッドディスク番号に対応するインスタンス名を指定してください。リソース未設定のインスタンスも指定できますが、ミラー統計情報は表示/採取できません。
ミラー統計情報の利用
実際に採取したミラー統計情報を、ミラー関連の設定値の調整に役立てることができます。たとえば、採取したミラー統計情報から通信速度や通信負荷が確認できる場合は、ミラー関連の設定値をチューニングすることで、通信速度が改善できる場合があります。
パフォーマンスモニタでミラー統計情報を表示する
採取するミラー統計情報をリアルタイムで表示させる手順
[スタート]メニューから[管理ツール]-[パフォーマンスモニタ]を起動
パフォーマンスモニタを選択
「+」ボタン、または右クリックでメニューから[カウンターの追加]を実行
[ファイル]-[名前を付けて保存]で追加したカウンタ設定を新しく保存
保存した設定から起動することで同じカウンタ設定を繰り返し利用可能
以下に、手順の詳細を説明します。ここでは例としてミラー統計情報の1項目である「Mirror Bytes Sent」を採取します。対象インスタンスは「MD,HD Resource1」とします。[スタート]メニューから[管理ツール]-[パフォーマンス]を起動します。
- ウインドウの左側のメニューツリーから[パフォーマンスモニタ]を選択します。
 ウインドウの右側にパフォーマンスモニタ画面が表示されます。
ウインドウの右側にパフォーマンスモニタ画面が表示されます。 - 「+」ボタン、または右クリックでメニューから[カウンターの追加]を実行します。
 動作条件を満たしている場合、追加カウンター/インスタンスが表示されます。「Cluster Disk Resource Performance」を選択し、カウンタ「Mirror Bytes Sent」、インスタンス「MD,HD Resource1」を選択して [追加] します。
動作条件を満たしている場合、追加カウンター/インスタンスが表示されます。「Cluster Disk Resource Performance」を選択し、カウンタ「Mirror Bytes Sent」、インスタンス「MD,HD Resource1」を選択して [追加] します。注釈
「Cluster Disk Resource Performance」が存在しない場合、連携機能が無効になっています。 このような場合はコマンドプロンプトから以下のコマンドを実行し、連携機能を有効にした後、再度手順1から実行してください。
>lodctr.exe <CLUSTERPRO インストールパス>\perf\clpdiskperf.ini
[ファイル] - [名前を付けて保存]で追加したカウンタ設定を新しく保存します。
保存した設定から起動することで同じカウンタ設定を繰り返し利用可能です。
パフォーマンスモニタからミラー統計情報を採取する
パフォーマンスモニタからミラー統計情報のログファイルを採取する手順を以下に説明します。
ログファイルを採取する手順
[スタート]メニューから[管理ツール]-[パフォーマンスモニタ]を起動
[データコレクタセット]-[ユーザー定義]で、データコレクトセットを新規作成
「データログを作成する」で「パフォーマンスカウンタ」を選択し、[追加]を実行
- [Cluster Disk Resource Performance] を選択し、採取したいカウンタおよびインスタンスを追加
ログ採取開始
以下に、手順の詳細を説明します。ここでは例としてミラー統計情報の1項目である「Mirror Bytes Sent」を採取します。対象インスタンスは「MD,HD Resource1」とします。[スタート]メニューから[管理ツール]-[パフォーマンスモニタ]を起動します。
[データコレクターセット] - [ユーザー定義]で、メニューの[操作] - [新規作成] または右クリックの[新規作成]から、「データコレクターセット」を指定します。
データコレクターセット名は任意の名称を入力してください。
データコレクターセットの作成方法は [手動で作成する(詳細)(C)] を選択してください。
「データログを作成する」で「パフォーマンスカウンタ」を選択し、[追加]を実行します。
- カウンターを追加します。ここでは「Cluster Disk Resource Performance」の中から「Mirror Bytes Sent」を選択したのち、「選択したオブジェクトのインスタンス」の中から「MD,HD Resource1」を選択し、[追加]を実行します。「追加されたカウンター」に「Mirror Bytes Sent」の「MD,HD Resource1」が追加されます。採取したいカウンターを全て追加し終えたら、[OK] を実行し、[完了] を選択します。
注釈
「Cluster Disk Resource Performance」が存在しない場合、連携機能が無効になっています。 このような場合はコマンドプロンプトから以下のコマンドを実行し、連携機能を有効にした後、再度手順1から実行してください。
>lodctr.exe <CLUSTERPRO インストールパス>\perf\clpdiskperf.ini
ログ採取を開始します。[データコレクターセット] - [ユーザー定義] - [(データコレクターセット名)]で、メニューの [開始] を実行します。
typeperfコマンドからミラー統計情報を採取する
typeperfコマンドからミラー統計情報を採取する手順を以下に説明します。
[スタート]メニューから[すべてのプログラム] - [アクセサリ] - [コマンドプロンプト]を起動
typeperf.exeを実行
以下に、具体的な使用例の詳細を説明します。
【使用例1】:ミラー通信時間の採取(全インスタンス[CLUSTERPROリソース]指定)
MDリソース:md01~md04、HDリソース:hd05~hd08まで登録済の場合ただし、各リソースの設定は以下の通りであるとする。md01のミラーディスク番号は1 md02のミラーディスク番号は2 : hd07のハイブリッドディスク番号は7 hd08のハイブリッドディスク番号は8以下の 1行目でtypeperf コマンドを実行し、ミラー通信時間の採取を行っています。2~11行目は見出しです。ここでは、読みやすいよう見出しを1カラムごとに改行していますが、実際には 1行で出力されます。12行目以降は実際に採取した統計情報です。"," で区切られたカラムは、左から順に以下の値が並んでいます。"サンプリング時間","md01", "md02", "md03", "md04", "hd05", "hd06", "hd07", "hd08"の通信時間
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
C:\>typeperf "\Cluster Disk Resource Performance(*)\Transfer Time, Avg" "(PDH-CSV 4.0)","\\v-ra1w2012\\Cluster Disk Resource Performance(*)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource1)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource2)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource3)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource4)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource5)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource6)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource7)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource8)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(_Total)\Transfer Time, Avg" "03/03/2010 15:21:24.546","0.24245658","0.3588965","0.488589","0.24245658","0.3588965","0.488577","0.3588965","0.488589" "03/03/2010 15:21:24.546","0.21236597","0.6465466","0.488589","0.24245658","0.3588965","0.488589","0.2588965","0.288589" "03/03/2010 15:21:24.546","0.24465858","0.7797976","0.488589","0.13123213","0.4654699","0.488544","0.6588965","0.288589" "03/03/2010 15:21:24.546","0.85466658","0.5555565","0.488589","0.24245658","0.3588965","0.485689","0.7588965","0.388589" "03/03/2010 15:21:24.546","0.46564468","0.3123213","0.488589","0.24245658","0.4388965","0.482289","0.8888965","0.338589" "03/03/2010 15:21:24.546","0.85858998","0.3588965","0.488589","0.44245658","0.2288965","0.483289","0.3768965","0.228589" "03/03/2010 15:21:24.546","0.47987964","0.3588965","0.488589","0.64245658","0.1288965","0.488214","0.3488965","0.428589" "03/03/2010 15:21:24.546","0.88588596","0.3588965","0.488589","0.84245658","0.1588965","0.484449","0.3668965","0.422589"
【使用例2】:ミラーデータ送信量の採取(インスタンスにhd05リソース指定)
MDリソース:md01~md04、HDリソース:hd05~hd08まで登録済の場合ただし、各リソースの設定は以下の通りであるとする。md01のミラーディスク番号は1 md02のミラーディスク番号は2 : hd07のハイブリッドディスク番号は7 hd08のハイブリッドディスク番号は8以下の 1行目でtypeperf コマンドを実行し、ミラーデータ送信量の採取を行っています。2行目は見出しです。3行目以降は実際に採取した統計情報です。"," で区切られたカラムは、左から順に以下の値が並んでいます。"サンプリング時間","hd05"のデータ送信量
1 2 3 4 5 6 7 8 9 10
C:\>typeperf "\Cluster Disk Resource Performance(MD/HD Resource5)\Mirror Bytes Sent/sec" "(PDH-CSV 4.0)","\\v-ra1w2012\\Cluster Disk Resource Performance(MD/HD Resource5)\Mirror Bytes Sent/sec" "03/03/2010 15:21:24.546","52362", "03/03/2010 15:21:24.546","45564", "03/03/2010 15:21:24.546","25560", "03/03/2010 15:21:24.546","25450", "03/03/2010 15:21:24.546","22560", "03/03/2010 15:21:24.546","21597", "03/03/2010 15:21:24.546","35999", "03/03/2010 15:21:24.546","25668",
【使用例3】:圧縮率のログ出力(インスタンスにhd01リソース指定)
MDリソース:md01~md04、HDリソース:hd05~hd08まで登録済の場合ただし、各リソースの設定は以下の通りであるとする。md01のミラーディスク番号は1 md02のミラーディスク番号は2 : hd07のハイブリッドディスク番号は7 hd08のハイブリッドディスク番号は8ログファイル形式にCSV、ファイル出力先パスにC:\PerfData\hd01.csv指定とする。C:\>typeperf "\Cluster Disk Resource Performance(MD/HD Resource1)\% Compress Ratio" -f CSV -o C:\PerfData\hd01.csv
コマンド実行後、ログ出力を停止したい場合は[Ctrl]+[C] で停止してください。【使用例4】:カウンタ一覧表示(インスタンス指定なし)
MDリソース:md01~md04、HDリソース:hd05~hd08まで登録済の場合ただし、各リソースの設定は以下の通りであるとする。md01のミラーディスク番号は1 md02のミラーディスク番号は2 : hd07のハイブリッドディスク番号は7 hd08のハイブリッドディスク番号は8以下の 1行目でtypeperf コマンドを実行し、カウンタ一覧を表示しています。2行目以降がカウンタの一覧です。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
C:\>typeperf -q "\ Cluster Disk Resource Performance" \Cluster Disk Resource Performance(*)\% Compress Ratio \Cluster Disk Resource Performance(*)\Async Application Queue Bytes \Cluster Disk Resource Performance(*)\Async Application Queue Bytes, Max \Cluster Disk Resource Performance(*)\Async Kernel Queue Bytes \Cluster Disk Resource Performance(*)\Async Kernel Queue Bytes, Max \Cluster Disk Resource Performance(*)\Async Mirror Queue Transfer Time \Cluster Disk Resource Performance(*)\Async Mirror Queue Transfer Time, Max \Cluster Disk Resource Performance(*)\Async Mirror Send Wait History Files Total Bytes \Cluster Disk Resource Performance(*)\Async Mirror Send Wait History Files Total Bytes, Max \Cluster Disk Resource Performance(*)\Async Mirror Send Wait Total Bytes \Cluster Disk Resource Performance(*)\Async Mirror Send Wait Total Bytes, Max \Cluster Disk Resource Performance(*)\Mirror Bytes Sent \Cluster Disk Resource Performance(*)\Mirror Bytes Sent/sec \Cluster Disk Resource Performance(*)\Request Queue Bytes \Cluster Disk Resource Performance(*)\Request Queue Bytes, Max \Cluster Disk Resource Performance(*)\Transfer Time, Avg \Cluster Disk Resource Performance(*)\Transfer Time, Max
その他、オプション指定で、サンプリング間隔変更やリモートサーバへのコマンド発行等も可能です。
オプションの詳細は"typeperf -?"で確認してください。
2.3.3. ミラー統計情報採取機能の動作¶
運用中のミラー統計情報ログ出力動作(自動)
ミラー統計情報採取機能では、動作条件を満たす環境において継続的に統計情報の採取を行い、統計ログファイルに出力します。 ミラー統計情報の採取およびログ出力動作は自動で行われます。 統計ログ出力動作の内容は下記のとおりです。
項目
動作内容
説明
出力ファイル名
nmp_<n>.curnmp_<n>.pre<x>nmp_total.curnmp_total.pre<x>totalはすべてのミラーディスクリソース/ハイブリッドディスクリソースの合計データです。<n>はミラーディスク番号orハイブリッドディスク番号を示します。curが最も新しく、続いて新しい順にpre, pre1, pre2,...となり、以後番号が増えるに従い古くなります。所定のログファイル数を超えた場合は古いログから削除されます。出力ファイル形式
テキストファイル
カンマ区切りのテキスト形式でファイルに出力します。1回の情報採取あたり1行のデータを出力します。出力先フォルダ
CLUSTERPROインストールフォルダ\perf\disk
CLUSTERPROインストールフォルダ下のperf\diskフォルダ内に出力します。
出力対象リソース
リソースごと+合計分設定済みのミラーディスクリソースまたはハイブリッドディスクリソースごとに、1つのファイルにログを出力します。リソースが設定されていない場合、ログファイルは作成されません。1つ以上のログファイルが作成された場合、全リソースでの合計値を表すtotalログファイルも作成されます。出力タイミング
毎分
1分ごとに情報を出力します。ミラー統計情報出力機能を無効にしている場合、ログ出力は行いません。ミラー統計情報ログ出力動作を無効にしている場合、ミラー統計情報採取機能は動作していますがログ出力は行いません。出力ファイルサイズ
約16MB
1つのファイルサイズは最大で約16MBになります。サイズの上限値を超える場合、自動的にログファイルはローテートされ、過去のログファイルは保存されます。上限値を超えない場合でも、出力内容が変更になるタイミングで自動的にログファイルがローテートされることがあります。ログローテート数
12世代
ログファイルのローテートによって保存されるログファイルの世代数は、最大12世代です。ローテートの上限値を超える場合、一番古い世代のログファイルは自動的に削除されます。
2.3.4. ミラー統計情報採取機能の動作条件¶
ミラー統計情報採取機能は以下の条件を満たす場合に動作します。
CLUSTERPRO Disk Agentサービスが正常に起動している。
1つ以上のミラーディスクリソース、またはハイブリッドディスクリソースを設定している。
クラスタのプロパティでミラー統計情報採取機能を有効にしている。
CLUSTERPRO Disk Agentサービスの状態を確認します。
[スタート]メニューから[サーバーの管理]-[サービス]を起動CLUSTERPRO Disk Agent サービスの状態が「開始」になっていることを確認[スタートアップの種類]が「自動」になっていることを確認サービスの状態が「開始」になっていない場合はサーバの再起動が必要
ミラー設定を確認します。
Cluster WebUI を起動ミラーディスクリソースまたはハイブリッドディスクリソースが設定されていることを確認
ミラー統計情報採取機能の設定を確認します。
Cluster WebUI を起動[設定モード]に変更「クラスタ」プロパティの「ミラーディスク」タブ中の「統計情報を採取する」の設定を確認
Cluster WebUI の詳細につきましては、Cluster WebUI のオンラインマニュアルをご参照ください。
2.3.5. ミラー統計情報採取機能に関する注意事項¶
ミラー統計情報採取機能を動作させる場合、ミラー統計情報の統計ログファイルを出力するためのディスクの空き容量(最大約 8.9GB)が必要です。
1 つのサーバに対して、パフォーマンスモニタとtypeperfコマンドをあわせて最大32プロセスまで起動することができます。1 つのサーバに対して 32 個を超えるパフォーマンスモニタまたはtypeperfコマンドを実行した場合、ミラー統計情報を採取できません。また1プロセス内で複数個の統計情報取得はできません。
1 プロセス内で複数個の統計情報取得はできません。例えば、複数のパフォーマンスモニタから対象のコンピュータを指定しての情報採取、1 つのパフォーマンスモニタで複数のデータコレクトを採取する場合等がこれに当たります。
- 採取したミラー統計情報はclplogcc コマンドや Cluster WebUI によるログ収集で採取されます。clplogcc コマンドでのログ収集時には type5 を、Cluster WebUI でのログ収集時にはパターン5を指定してください。ログ収集の詳細については、『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ログを収集する (clplogcc コマンド)」または、オンラインマニュアルを参照してください。
2.4. システムリソース統計情報採取機能¶
Cluster WebUI の設定モードで [クラスタのプロパティ] の [監視] タブにある「システムリソース情報を収集する」のチェックボックスにチェックした場合、あるいはクラスタにシステム監視リソースまたはプロセスリソース監視リソースを追加した場合には、システムリソースに関する情報が採取され、インストールパス\perf\system配下に以下のファイル名規則で保存されます。本ファイルはテキスト形式(CSV)です。以下説明文中では本ファイルをシステムリソース統計情報ファイルとして表記します。
system.cur
system.pre
|
|
|---|---|
cur |
最新の情報出力先であることを示しています。 |
pre |
ローテートされた以前の情報出力先であることを示しています。 |
採取された情報はシステムリソース統計情報ファイルに保存されます。本ファイルへの統計情報の出力間隔(=サンプリング間隔)は 60 秒です。ファイルのサイズが 16MB でローテートされ、2 世代分保存されます。システムリソース統計情報ファイルに記録された情報を利用することでシステムのパフォーマンス解析の参考にすることが可能です。採取される統計情報には以下のような項目が含まれています。
統計値名 |
単位 |
説明 |
|---|---|---|
CPUCount |
個 |
CPU数 |
CPUUtilization |
% |
CPU使用率 |
MemoryTotalSize |
KByte |
総メモリサイズ |
MemoryCurrentSize |
KByte |
メモリ使用量 |
SwapTotalSize |
KByte |
総スワップサイズ |
SwapCurrentSize |
KByte |
スワップ使用量 |
ThreadCurrentSize |
個 |
スレッド数 |
FileCurrentSize |
個 |
オープンファイル数 |
ProcessCurrentCount |
個 |
プロセス数 |
AvgDiskReadQueueLength__Total |
個 |
ディスクのキューに入った読み取り要求の数 |
AvgDiskWriteQueueLength__Total |
個 |
ディスクのキューに入った書き込み要求の数 |
DiskReadBytesPersec__Total |
Byte |
読み取り操作にてディスクから転送されたバイト数 |
DiskWriteBytesPersec__Total |
Byte |
書き込み操作にてディスクに転送したバイト数 |
PercentDiskReadTime__Total |
tick |
ディスクが読み取り要求を処理していてビジー状態にあった時間 |
PercentDiskWriteTime__Total |
tick |
ディスクが書き込み要求を処理していてビジー状態にあった時間 |
PercentIdleTime__Total |
tick |
ディスクがアイドル状態にあった時間 |
CurrentDiskQueueLength__Total |
個 |
パフォーマンスデータの収集時にディスクに残っている要求の数 |
出力されるシステムリソース統計情報ファイルの例を記載します。
system.cur
"Date","CPUCount","CPUUtilization","MemoryTotalSize","MemoryCurrentSize","SwapTotalSize","SwapCurrentSize","ThreadCurrentSize","FileCurrentSize","ProcessCurrentCount","AvgDiskReadQueueLength__Total","AvgDiskWriteQueueLength__Total","DiskReadBytesPersec__Total","DiskWriteBytesPersec__Total","PercentDiskReadTime__Total","PercentDiskWriteTime__Total","PercentIdleTime__Total","CurrentDiskQueueLength__Total" "2019/11/14 17:18:57.751","2","11","2096744","1241876","393216","0","1042","32672","79","623078737","241067820","95590912","5116928","623078737","241067820","305886514","0" "2019/11/14 17:19:57.689","2","3","2096744","1234892","393216","0","926","31767","77","14688814","138463292","3898368","7112192","14688814","138463292","530778498","0" "2019/11/14 17:20:57.782","2","2","2096744","1194400","393216","26012","890","30947","74","8535798","189735393","3802624","34398208","8535798","189735393","523400261","0" :
2.5. クラスタ統計情報採取機能¶
Cluster WebUI の設定モードで [クラスタのプロパティ] の [拡張] タブにある「統計情報を採取する」のチェックボックスにチェックをしていた場合、ハートビートリソースの受信間隔やグループのフェイルオーバ、グループリソースの起動、モニタリソースの監視処理等、それぞれの処理の結果や要した時間の情報を採取します。本ファイルはテキスト形式(CSV)です。以下説明文中では本ファイルをクラスタ統計情報ファイルとして表記します。
ハートビートリソースの場合
ハートビートリソースのタイプ毎に同じファイルに出力されます。 カーネルモードLANハートビートリソースが対応しています。
[ハートビートリソースタイプ].cur[ハートビートリソースタイプ].precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/heartbeat/
グループの場合
group.curgroup.precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/group/
グループリソースの場合
グループリソースのタイプ毎に同じファイルに出力されます。
[グループリソースタイプ].cur[グループリソースタイプ].precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/group/
モニタリソースの場合
モニタリソースのタイプ毎に同じファイルに出力されます。
[モニタリソースタイプ].cur[モニタリソースタイプ].precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/monitor/
注釈
クラスタ統計情報ファイルへの統計情報の出力タイミングは以下です。
採取される統計情報には以下の項目が含まれています。
ハートビートリソースの場合
統計値名
説明
Date
統計情報の出力時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000Name
ハートビートリソースの名前です。
Type
ハートビートリソースのタイプ名です。
Local
自サーバのホスト名です。
Remote
相手サーバのホスト名です。
RecvCount
ログ出力間隔以内のハートビート受信回数です。
RecvError
ログ出力間隔以内の受信エラー回数です。
RecvTime(Min)
ログ出力間隔以内のハートビート受信間隔の最小値です。(単位:ミリ秒)
RecvTime(Max)
ログ出力間隔以内のハートビート受信間隔の最大値です。(単位:ミリ秒)
RecvTime(Avg)
ログ出力間隔以内のハートビート受信間隔の平均値です。(単位:ミリ秒)
SendCount
ログ出力間隔以内のハートビート送信回数です。
SendError
ログ出力間隔以内の送信エラー回数です。
SendTime(Min)
ログ出力間隔以内のハートビート送信処理時間の最小値です。(単位:ミリ秒)
SendTime(Max)
ログ出力間隔以内のハートビート送信処理時間の最大値です。(単位:ミリ秒)
SendTime(Avg)
ログ出力間隔以内のハートビート送信処理時間の平均値です。(単位:ミリ秒)
ハートビートリソース以外の場合
統計値名
説明
Date
統計情報の出力時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000Name
グループ / グループリソース / モニタリソースの名前です。
Action
実行した処理の名称です。以下の文字列が出力されます。グループの場合: Start(起動時), Stop(停止時), Move(移動/フェイルオーバ時)グループリソースの場合: Start(活性時), Stop(非活性時)モニタリソースの場合: Monitor(監視処理実行時)Result
実行した処理結果の名称です。以下の文字列が出力されます。成功の場合: Success (監視正常, 活性/非活性正常)失敗の場合: Failure (監視異常, 活性/非活性異常)警告の場合: Warning(モニタの場合のみ, 警告の場合)タイムアウトの場合: Timeout (監視タイムアウト)キャンセルの場合: Cancel(処理のキャンセル(グループ起動中のクラスタ停止等))ReturnCode
実行した処理の戻り値です。
StartTime
実行した処理の開始時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000EndTime
実行した処理の終了時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000ResponseTime(ms)
実行した処理の所要時間です。(単位:ミリ秒)ミリ秒表記で出力されます。
下記構成例のグループを起動した場合に出力される統計情報ファイルの例を記載します。
サーバ - ホスト名: server1, server2
ハートビートリソース
- カーネルモードLANハートビートリソースリソース名: lankhb1, lankhb2
グループ
グループ名: failoverA
グループ (failoverA) に属するグループリソース
- script リソースリソース名: script 01, script02, script03
lankhb.cur
"Date","Name","Type","Local","Remote","RecvCount","RecvError","RecvTime(Min)","RecvTime(Max)","RecvTime(Avg)","SendCount","SendError","SendTime(Min)","SendTime(Max)","SendTime(Avg)" "2018/12/18 09:35:36.237","lankhb1","lankhb","server1","server1","20","0","3000","3000","3000","20","0","0","0","0" "2018/12/18 09:35:36.237","lankhb1","lankhb","server1","server2","20","0","3000","3000","3000","20","0","0","0","0" "2018/12/18 09:35:36.237","lankhb2","lankhb","server1","server1","20","0","3000","3000","3000","20","0","0","0","0" "2018/12/18 09:35:36.237","lankhb2","lankhb","server1","server2","20","0","3000","3000","3000","20","0","0","0","0" :
group.cur
"Date","Name","Action","Result","ReturnCode","StartTime","EndTime","ResponseTime(ms)" "2018/12/19 14:32:46.232","failoverA","Start","Success",,"2018/12/19 14:32:40.419","2018/12/19 14:32:46.232","5813" :
script.cur
"Date","Name","Action","Result","ReturnCode","StartTime","EndTime","ResponseTime(ms)" "2018/12/19 14:32:41.138","script01","Start","Success",,"2018/12/19 14:32:40.466","2018/12/19 14:32:41.138","672" "2018/12/19 14:32:43.185","script02","Start","Success",,"2018/12/19 14:32:41.154","2018/12/19 14:32:43.185","2031" "2018/12/19 14:32:46.216","script03","Start","Success",,"2018/12/19 14:32:43.185","2018/12/19 14:32:46.216","3031" :
2.5.1. クラスタ統計情報ファイルのファイルサイズに関する注意事項¶
クラスタ統計情報ファイルは構成によって生成される数が異なります。構成によっては大量のファイルが生成されるため、構成に合わせてクラスタ統計情報のファイルサイズの設定をご検討ください。クラスタ統計情報ファイルの最大サイズは以下の式で計算します。
クラスタ統計情報のファイルサイズ =([ハートビートリソースのファイルサイズ] x [設定されているハートビートリソースのタイプ数]) x (世代数(2)) +([グループのファイルサイズ]) x (世代数(2)) +([グループリソースのファイルサイズ] x [設定されているグループリソースのタイプ数]) x (世代数(2)) +([モニタリソースのファイルサイズ] x [設定されているモニタリソースのタイプ数]) x (世代数(2))例: 下記構成例の場合に保存されるクラスタ統計情報ファイルの合計最大サイズは 332MB になります。((((50MB) x 1) x 2) + ((1MB) x 2) + ((3MB x 5) x 2) + ((10MB x 10) x 2) = 332MB)
ハートビートリソースタイプ数: 1 (ファイルサイズ: 50MB)
グループ (ファイルサイズ: 1MB)
グループリソースタイプ数: 5 (ファイルサイズ: 3MB)
モニタリソースタイプ数: 10 (ファイルサイズ: 10MB)
2.6. Cluster WebUI 操作ログ出力機能¶
Cluster WebUI の設定モードで [クラスタのプロパティ] の [WebManager] タブにある「Cluster WebUI の操作ログを出力する」のチェックボックスにチェックをしていた場合、Cluster WebUI で操作した情報をログファイルに出力します。本ファイルはテキスト形式(CSV)です。以下説明文中では本ファイルをCluster WebUI 操作ログファイルとして表記します。
cur
最新の情報出力先であることを示しています。
pre<x>
保存先
Cluster WebUI の設定モードで「ログ出力先」に指定したディレクトリ
出力する操作情報には以下の項目が含まれています。
項目名 |
説明 |
|---|---|
Date |
操作情報の出力時刻です。
以下の形式で出力されます。(000はミリ秒)
YYYY/MM/DD HH:MM:SS.000
|
Operation |
Cluster WebUI で実行した操作です。 |
Request |
Cluster WebUI から WebManager サーバへ発行したリクエスト URL です。 |
IP |
Cluster WebUI を操作したクライアントの IP アドレスです。 |
UserName |
操作を実行したユーザ名です。
Cluster WebUI にログインする方法として「OS 認証方式」を利用している場合に Cluster WebUI にログインしたユーザ名が出力されます。
|
HTTP-Status |
HTTPステータスコードです。
200 : 成功
200以外 : 失敗
|
ErrorCode |
実行した操作の戻り値です。 |
ResponseTime(ms) |
実行した操作の所要時間です。(単位:ミリ秒)
ミリ秒表記で出力されます。
|
ServerName |
操作対象のサーバ名です。
サーバ名、または、IP アドレスが出力されます。
操作対象としてサーバ名が指定された操作の場合に出力されます。
|
GroupName |
操作対象のグループ名です。
操作対象としてグループ名が指定された操作の場合に出力されます。
|
ResourceName |
操作対象のリソース名です。
ハートビートリソース名/ネットワークパーティション解決リソース名/グループリソース名/モニタリソース名が出力されます。
操作対象としてリソース名が指定された操作の場合に出力されます。
|
ResourceType |
操作対象のリソースタイプです。
操作対象としてリソースタイプが指定された操作の場合に出力されます。
|
Parameters… |
操作固有のパラメータです。 |
出力される Cluster WebUI 操作ログファイルの例を記載します。
"Date","Operation","Request","IP","UserName","HTTP-Status","ErrorCode","ResponseTime(ms)","ServerName","GroupName","ResourceName","ResourceType","Parameters..." "2020/08/14 17:08:39.902","Cluster properties","/GetClusterproInfo.js","10.0.0.15","user1",200,0,141,,,, "2020/08/14 17:08:46.659","Monitor properties","/GetMonitorResourceProperty.js","10.0.0.15","user1",200,0,47,,,"fipw1","fipw" "2020/08/14 17:15:31.093","Resource properties","/GetGroupResourceProperty.js","10.0.0.15","user1",200,0,47,,"failoverA","fip1","fip" "2020/08/14 17:15:45.309","Start group","/GroupStart.js","10.0.0.15","user1",200,0,0,"server1","failoverA",, "2020/08/14 17:16:23.862","Suspend all monitors","/AllMonitorSuspend.js","10.0.0.15","user1",200,0,453,"server1",,,,"server2" :
認証失敗時に出力される Cluster WebUI 操作ログファイルの例です。
クラスタパスワード方式の場合
"Date","Operation","Request","IP","UserName","HTTP-Status","ErrorCode","ResponseTime(ms)","ServerName","GroupName","ResourceName","ResourceType","Parameters..." "2020/11/20 09:29:59.710","Login","/Login.js","10.0.0.15","",403,,0,,,,
OS認証方式の場合
"Date","Operation","Request","IP","UserName","HTTP-Status","ErrorCode","ResponseTime(ms)","ServerName","GroupName","ResourceName","ResourceType","Parameters..." "2020/11/20 09:29:59.710","Login User","/LoginUser.js","10.0.0.15","user1",401,,0,,,,
2.7. 通信ポート情報¶
CLUSTERPRO では、デフォルトで以下のポート番号を使用します。このポート番号については Cluster WebUI での変更が可能です。
下記ポート番号には、CLUSTERPRO 以外のプログラムからアクセスしないようにしてください。
サーバにファイアウォールの設定を行う場合には、下記のポート番号がアクセスできるように してください。
クラウド環境の場合は、インスタンス側のファイアウォール設定の他に、クラウド基盤側のセキュリティ設定においても、下記のポート番号にアクセスできるようにしてください。
CLUSTERPRO が使用するポート番号については、『スタートアップガイド』-「注意制限事項」-「CLUSTERPRO インストール前」-「通信ポート番号」を参照してください。
2.8. ミラーコネクト通信の帯域制限¶
Windows標準のローカルグループポリシーエディタ(ポリシーベースのQoS設定)を利用してミラーコネクト通信に使用する通信帯域を制限することができます。設定はミラーディスクコネクト単位に行いますので、指定したミラーディスクコネクトを使用している全てのミラーディスクリソース/ハイブリッドディスクリソースに対して通信帯域の制限を行う場合に有効です。
2.8.1. ミラーコネクト通信の帯域制限設定手順¶
ミラーコネクト通信の帯域を制限する場合、以下の手順で設定してください。
ネットワークアダプタのプロパティ設定
[スタート]メニュー→ [コントロールパネル] → [ネットワークと共有センター] から、ミラーディスクコネクトの [プロパティ] を開きます。
プロパティ中に [QoSパケットスケジューラ] 項目が存在する場合はチェックボックスをオンにします。
プロパティ中に [QoSパケットスケジューラ] 項目が存在しない場合は [インストール] ボタン→ [サービス] → [追加] ボタンにて QoS パケットスケジューラを選択します。
- ローカルグループポリシーエディタ起動帯域制限の設定にはローカルグループポリシーエディタを使用します。[スタート] メニュー→ [ファイル名を指定して実行] から以下のコマンドを実行してください。
gpedit.msc
ポリシーの作成
帯域制限用のポリシーを作成します。左ペインから [ローカルコンピューターポリシー] →[コンピュータの構成] → [Windowsの設定] → [ポリシーベースのQoS] を選択し右クリックして [新規ポリシーの作成] を選択します。
[ポリシーベースのQoS]-[QoSポリシーの作成] 画面
以下の説明に従い設定を行います。
ポリシー名
識別用のポリシー名を設定します。
DSCP値
IPの優先順位を設定します。設定は任意に行ってください。詳細は [QoSポリシーの詳細] を参照してください。
出力方向のスロットル率を指定する
[出力方向のスロットル率を指定する] チェックボックスをオンにします。次にミラーディスクコネクトで使用する通信帯域の上限を [KBps](1秒あたりのキロバイト数) または [MBps] (1秒あたりのメガバイト数)のどちらかの単位で指定します。
設定後 [次へ] ボタンをクリックします。
[ポリシーベースのQoS]-[このポリシーの適用対象]画面
以下の説明に従い設定を行います。
このQoSポリシーの適用対象(アプリケーション指定)
[すべてのアプリケーション] を選択します。
設定後 [次へ] ボタンをクリックします。
[ポリシーベースのQoS]-[発信元と宛先のIPアドレスを指定してください。] 画面
以下の説明に従い設定を行います。
このQoSポリシーの適用対象(発信元IPアドレス指定)
[次の発信元IPアドレスのみ] を選択しIPアドレスにはミラーディスクコネクトで使用している発信元のIPアドレス値を入力します。
このQoSポリシーの適用対象(宛先IPアドレス指定)
[次の宛先IPアドレスのみ] を選択しIPアドレスにはミラーディスクコネクトで使用している相手先のIPアドレス値を入力します。
設定後 [次へ] ボタンをクリックします。
[ポリシーベースのQoS]-[プロトコルとポート番号を指定してください。] 画面
以下の説明に従い設定を行います。
このQoSポリシーを適用するプロトコルを指定してください(S)
[TCP]を選択します。
発信元ポート番号を指定してください
[任意の発信元ポート番号]を選択します。
宛先ポート番号を指定してください
[次の宛先ポート番号か範囲]を選択し、ミラードライバポート番号を指定します(既定値29005)。
- ポリシーの反映[完了]ボタンをクリックすると設定を反映します。設定したポリシーは即座に反映されず、ポリシーの自動更新間隔に従って反映されます(既定値:90分以内)。設定したポリシーを即座に反映させるには手動で更新を行います。[スタート]メニュー→[ファイル名を指定して実行]から以下のコマンドを実行してください。
gpupdate /force
以上でポリシーの設定は完了になります。
2.8.2. ミラーコネクト通信の帯域制限一時停止/解除手順¶
ミラーコネクト通信の帯域制限を一時停止または解除する場合、以下の手順で設定してください。
- ローカルグループポリシーエディタ起動帯域制限の一時停止/解除にはローカルグループポリシーエディタを使用します。[スタート] メニュー→ [ファイル名を指定して実行] から以下のコマンドを実行してください。
gpedit.msc
ポリシーの設定変更による一時停止、もしくはポリシーの削除
- 帯域制限を一時的に停止する場合帯域制限を一時的に停止する場合、帯域制限用のポリシー設定を変更します。対象の QoS ポリシーを右クリックし [既存ポリシーの編集] を選択してください。その後、[出力方向のスロットル率] チェックボックスをオフにしてください。設定後 [OK] ボタンをクリックします。
- 帯域制限を解除する場合帯域制限を解除する場合、帯域制限用のポリシーを削除します。対象のQoSポリシーを右クリックし[ポリシーの削除]を選択してください。[このポリシーを削除してもよろしいですか?] というポップアップメッセージが表示されますので、[はい] をクリックします。
- ポリシーの反映設定変更もしくは削除したポリシーは即座に反映されず、ポリシーの自動更新間隔に従って反映されます(既定値:90分以内)。削除もしくは設定変更したポリシーを即座に反映させるには手動で更新を行います。[スタート] メニュー→ [ファイル名を指定して実行] から以下のコマンドを実行してください。
gpupdate /force
以上でポリシーの設定は完了になります。
2.9. CLUSTERPRO からのサーバダウンの発生条件¶
CLUSTERPRO では、以下の異常が発生した場合、リソースなどを保護することを目的としサーバをシャットダウンまたはリセットします。
2.9.1. グループリソース活性/非活性異常時の最終動作¶
リソース活性/非活性異常時の最終動作に以下が設定されている場合
最終動作 |
挙動 |
|---|---|
クラスタサービス停止と OS シャットダウン |
グループリソース停止後、通常のシャットダウンを発生させます。 |
クラスタサービス停止と OS リブート |
グループリソース停止後、通常のリブートを発生させます。 |
意図的なストップエラーの発生 |
グループリソース活性/非活性異常時に、意図的にストップエラー (Panic) を発生させます。 |
2.9.2. リソース活性/非活性ストール発生時の動作¶
リソースの活性/非活性ストール発生時動作に以下が設定されていて、リソース活性/非活性処理で想定以上の時間がかかった場合
ストール発生時動作 |
挙動 |
|---|---|
緊急シャットダウン |
グループリソース活性/非活性ストール発生時に、OS シャットダウン を発生させます。 |
意図的なストップエラーの発生 |
グループリソース活性/非活性ストール発生時に、意図的にストップエラー (Panic) を発生させます。 |
リソース活性ストールが発生した場合、イベントログおよびアラートメッセージに下記のメッセージが出力されます。
モジュールタイプ : rc
イベントID : 1032
メッセージ : リソース %1 の起動に失敗しました。(99 : command is timeout)
説明 : リソース起動失敗
リソース非活性ストールが発生した場合、イベントログおよびアラートメッセージに下記のメッセージが出力されます。
モジュールタイプ : rc
イベントID : 1042
メッセージ : リソース %1 の停止に失敗しました。(99 : command is timeout)
説明 : リソース停止失敗
2.9.3. モニタリソース異常検出時の最終動作¶
モニタリソース監視異常時の最終動作に以下が設定されている場合
最終動作 |
挙動 |
|---|---|
クラスタサービス停止と OS シャットダウン |
グループリソース停止後、通常のシャットダウンを発生させます。 |
クラスタサービス停止と OS リブート |
グループリソース停止後、通常のリブートを発生させます。 |
意図的なストップエラーの発生 |
モニタリソース異常検出時に、意図的にストップエラー (Panic) を発生させます。 |
2.9.4. 強制停止動作¶
強制停止のタイプが [BMC] に設定されている場合
強制停止アクション
挙動
BMC リセット
フェイルオーバグループが存在していたダウンサーバでリセットを発生させます。
BMC パワーオフ
フェイルオーバグループが存在していたダウンサーバでパワーオフを発生させます。
BMC パワーサイクル
フェイルオーバグループが存在していたダウンサーバでパワーサイクルを発生させます。
BMC NMI
フェイルオーバグループが存在していたダウンサーバで NMI を発生させます。
強制停止のタイプが [vCenter] に設定されている場合
強制停止アクション
挙動
パワーオフ
フェイルオーバグループが存在していたダウンサーバでパワーオフを発生させます。
リセット
フェイルオーバグループが存在していたダウンサーバでリセットを発生させます。
強制停止のタイプが [AWS] または [OCI] に設定されている場合
強制停止アクション
挙動
stop
フェイルオーバグループが存在していたダウンサーバのインスタンスを停止します。
reboot
フェイルオーバグループが存在していたダウンサーバのインスタンスを再起動します。
2.9.5. 緊急サーバシャットダウン¶
以下のプロセスが異常終了した場合、クラスタとして正常に動作できないため、これらのプロセスが異常終了したサーバを停止させます。これを緊急サーバシャットダウンと呼びます。
clprc.exe
サーバの停止方法は Cluster WebUI の設定モードから [クラスタのプロパティ] の [クラスタサービスのプロセス異常時動作] で変更できます。設定可能な停止方法は下記になります。
2.9.6. CLUSTERPRO Server サービス停止時のリソース非活性異常¶
clpcl -t による CLUSTERPRO Server サービス停止でリソースの非活性に失敗した場合、シャットダウンを発生させます。
2.9.7. ネットワークパーティションからの復帰¶
全てのハートビートが遮断された場合、ネットワークパーティション解決が行われ、いずれかのサーバ、あるいは全てのサーバでシャットダウンを発生させます。 [クラスタのプロパティ] で自動復帰モードが設定されていない場合には、シャットダウン後に起動したサーバはダウン後再起動状態となり、クラスタ復帰していない状態になります。
ハートビートが遮断した原因を解消した後、クラスタ復帰を行ってください。
ネットワークパーティションについては『リファレンスガイド』の「ネットワークパーティション解決リソースの詳細」を参照してください。
クラスタ復帰についてはオンラインマニュアルを参照してください。
2.9.8. 緊急サーバ再起動¶
以下のサービス (プロセス) が異常終了した場合、OS の再起動を行います。これを緊急 サーバ再起動と呼びます。
CLUSTERPRO Disk Agent (clpdiskagent.exe)
CLUSTERPRO Server (clppmsvc.exe)
CLUSTERPRO Transaction (clptrnsv.exe)
2.9.9. クラスタサスペンド・リジューム失敗時¶
クラスタサスペンド・リジュームに失敗したサーバはシャットダウンします。
2.10. 一時的にフェイルオーバを実行させないように設定するには¶
サーバダウンによるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
例) HBタイムアウトが 90秒のときに、1時間、HBタイムアウトを 3600秒に延長する場合
clptoratio -r 40 -t 1hタイムアウトの一時調整の解除
タイムアウトの一時調整を解除します。クラスタ内のいずれかのサーバ上で [clptoratio] コマンドを実行してください。
clptoratio -i
モニタリソースの監視を一時停止することにより監視異常によるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
例) コマンド実行サーバ上の全ての監視を停止する場合
clpmonctrl -s例) -hオプションにて指定したサーバ上の全ての監視を停止する場合
clpmonctrl -s -h <サーバ名>例) コマンド実行サーバ上の全ての監視を再開する場合
clpmonctrl -r例) -hオプションにて指定したサーバ上の全ての監視を再開する場合
clpmonctrl -r -h <サーバ名>
モニタリソース異常時の回復動作を無効化することにより監視異常によるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
グループリソース活性異常時の復旧動作を無効化することにより活性異常によるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
2.11. chkdsk/デフラグの実施手順¶
2.11.2. ミラーディスク/ハイブリッドディスクのchkdsk/デフラグ実施手順¶
ミラーディスクリソースとして設定されているパーティションでchkdskまたはデフラグを実施する場合は、現用系で行う場合と、待機系で行う場合で手順が異なります。
[現用系でchkdsk/デフラグを実施する場合]
ミラーディスク/ハイブリッドディスクリソースとして設定されているパーティションに対して、現用系サーバ上で chkdsk またはデフラグを実施する場合は、「 2.11.1. 共有ディスクのchkdsk/デフラグ実施手順 」と同様の手順で実施してください。
[待機系でchkdsk/デフラグを実施する場合(ミラーディスク)]
ミラーディスクとして設定されているパーティションに対して、待機系サーバ上で修復モードのchkdsk またはデフラグを実施した場合は、ミラーコピーによって現用系ディスクイメージで上書きされるため、ファイルシステムの修復や最適化の効果は失われます。本書では、メディアのエラーチェックを目的とした chkdsk についての手順を記載します。
Cluster WebUI またはclpmonctrlコマンドで、chkdsk の対象ミラーディスクを監視するミラーディスク監視リソースを一時停止します。
例:
clpmonctrl -s -m <mdw(ミラーディスク監視リソース名)>ミラーディスクを切り離した状態にします。
例:
clpmdctrl --break <md(ミラーディスクリソース名)>ミラーディスクへのアクセスを許可します。
例:
clpmdctrl --active <md(ミラーディスクリソース名)> -fコマンドプロンプトより、ミラーディスクのパーティションに対して chkdsk またはデフラグを実行します。
重要
「ボリュームが別のプロセスで使用されているため、CHKDSK を実行できません。次回のシステム再起動時に、このボリュームのチェックをスケジュールしますか」という旨のメッセージが出た場合、キャンセルを選択してください。
ミラーディスクへのアクセスを禁止状態にします。
例:
clpmdctrl --deactive <md(ミラーディスクリソース名)>Cluster WebUI またはclpmonctrlコマンドで、ミラーディスクを監視するミラーディスク監視リソースを再開します。
例:
clpmonctrl -r -m <mdw(ミラーディスク監視リソース名)>自動ミラー復帰を無効に設定している場合は、ミラーディスクリストからの手動操作によりミラー復帰を実施します。
[待機系でchkdsk/デフラグを実施する場合(ハイブリッドディスク)]
ハイブリッドディスクとして設定されているパーティションに対して、待機系サーバ上で修復モードのchkdskまたはデフラグを実施した場合は、ミラーコピーによって現用系ディスクイメージで上書きされるため、ファイルシステムの修復や最適化の効果は失われます。本書では、メディアのエラーチェックを目的としたchkdskについての手順を記載します。
Cluster WebUI またはclpmonctrlコマンドで、chkdsk対象のハイブリッドディスクを監視するハイブリッドディスク監視リソースを一時停止します。
例:
clpmonctrl -s -m <hdw(ハイブリッドディスク監視リソース名)>clphdsnapshotコマンドを使用して、ハイブリッドディスクを切り離し、アクセスを許可します。
clphdsnapshot --open <hd(ハイブリッドディスクリソース名)>コマンドプロンプトより、ハイブリッドディスクのパーティションに対してchkdskまたはデフラグを実行します。
重要
「ボリュームが別のプロセスで使用されているため、CHKDSK を実行できません。次回のシステム再起動時に、このボリュームのチェックをスケジュールしますか」という旨のメッセージが出た場合、キャンセルを選択してください。
clphdsnapshotコマンドを使用して、ハイブリッドディスクへのアクセスを禁止状態にします。
clphdsnapshot --close <hd(ハイブリッドディスクリソース名)>Cluster WebUI またはclpmonctrlコマンドで、chkdsk対象のハイブリッドディスクを監視するハイブリッドディスク監視リソースを再開します。
例:
clpmonctrl -r -m <hdw(ハイブリッドディスク監視リソース名)>自動ミラー復帰を無効に設定している場合は、ミラーディスクリストからの手動操作によりミラー復帰を実施します。
2.12. サーバを交換するには¶
クラスタ環境でサーバを交換する場合、以下の手順で行ってください。
新規サーバを故障したサーバと同じようにセットアップします。
共有ディスクを使用する場合、新規サーバは、まだ共有ディスクに接続しないでくだ さい。
コンピュータ名・IP アドレスを、故障したサーバと同じ値に設定します。
CLUSTERPRO のライセンス登録・アップデート適用も元通りに実施してください。
故障したサーバのローカルディスク上にミラーディスク/ハイブリッドディスクのクラスタパーティション・データパーティションが存在していた場合、故障したサーバと同じようにパーティションの確保とドライブ文字の設定を行ってください。故障したサーバの ディスクを流用する場合は、パーティションの確保は必要ありませんが、ドライブ文字は元通りに設定してください。
共有ディスクを使用する場合、CLUSTERPRO Server のインストールの際に、[共有ディスクのフィルタリング設定] で、共有ディスクを接続する SCSI コントローラまたは HBA に対してフィルタリングを行うよう設定してください。
セットアップ後は一旦シャットダウンして電源を切ります。
重要
[共有ディスクのフィルタリング設定] で、共有ディスクを接続する SCSI コントローラまたは HBA に対してフィルタリングを行うよう設定してください。フィルタリングの設定を行っていない状態で共有ディスクを接続した場合、共有ディスク上のデータが破壊される可能性があります。
故障したサーバがまだ稼動しているならシャットダウンして共有ディスクや LAN から切り離し、クラスタ内の他サーバの状態を正常状態にします。(故障したサーバが停止していることに起因する異常は無視して構いません。)
新規サーバを LAN に接続した状態で起動します。共有ディスクを使用する場合、共有ディスクにも接続した状態で起動します。
共有ディスクを使用する場合、新規サーバでディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) を使用して共有ディスクが見える ことを確認し、故障したサーバと同じようにドライブ文字を設定します。
この時点で共有ディスクにはアクセス制限がかかっているため、ディスクの内容は参照できません。
クラスタ内の正常動作中のサーバに Web ブラウザで接続して Cluster WebUI の設定モードを起動します。共有ディスクを使用する場合は、新規サーバの [プロパティ]→[HBA] タブで [接続] を クリックし、HBA とパーティションの情報を確認・修正してください。
重要
新規サーバの [プロパティ] → [HBA] タブで、共有ディスクを接続する SCSI コントローラまたは HBA に対してフィルタリングを行うよう設定してください。フィルタリングの設定を行っていない状態で共有ディスクを接続した場合、共有ディスク上のデータが破壊される可能性があります。
新規サーバで使用するリソースの中にミラーディスクリソースかハイブリッドディスクリソースが存在する場合は、これらのリソースを含むフェイルオーバグループを Cluster WebUI の操作モードから停止します。
クラスタ内の正常動作中のサーバ上でコマンドプロンプトから "clpcl --suspend --force" を実行し、クラスタをサスペンドします。
サーバが 1 台停止している状態と認識されているため、Cluster WebUI からサスペンドを実行することはできません。
Cluster WebUI の設定モードで[設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
[構成情報にあるディスク情報とサーバ上のディスク情報が異なっています。自動修正 しますか?] というポップアップメッセージが表示された場合は、[はい] を選択してください。
期限付きライセンスを使用している場合は、以下のコマンドを実行します。
clplcnsc --reregister <ライセンスファイル格納フォルダのパス>
Cluster WebUI の操作モードからクラスタをリジュームし、6. で停止したグループがあれば開始します。
注釈
Cluster WebUI からリジュームを実行すると、[クラスタをリジュームできません。最新情報を取得ボタンをクリックするか、後でやり直してください。] とエラーメッセージが出力されますが無視してください。新規サーバがサスペンド状態でないために出力されたものです。
新規サーバで OS を再起動します。
[クラスタのプロパティ] → [拡張] タブで [自動復帰] が [しない] に設定されている場合、Cluster WebUI の操作モードで CLUSTERPRO を再インストールしたサーバの [サーバ復帰] をクリックします。
新規サーバで使用するリソースの中にミラーディスクリソースかハイブリッドディスクリソースが存在していて、[クラスタのプロパティ] → [ミラーディスク] タブ で [自動ミラー復帰] のチェックボックスを外している場合は、ミラーディスクリストからミラーディスク/ハイブリッドディスクのフルコピーを実施します。
重要
既に他のミラーディスク型のクラスタとして動作しているサーバとの交換を行った場合、差分コピーが自動で実行されますが、差分コピー完了後、改めてフルコピーを手動で行ってください。フルコピーを行わなかった場合、ミラーディスクのデータ不整合が発生します。
必要であれば、グループを移動します。ミラーディスク/ハイブリッドディスクがフルコピー中の場合は、コピーが完了してから移動してください。
2.13. クラスタ起動同期待ち時間について¶
クラスタ内の全てのサーバで同時に電源を投入したとしても CLUSTERPRO が同時に起動されるとは限りません。クラスタのシャットダウン後再起動を実行した場合も同様に CLUSTERPRO が同時に起動されるとは限りません。
このため、CLUSTERPRO は起動されるとクラスタ内の他のサーバの起動を待ち合わせます。
初期設定値として 5 分が設定されます。この待ち合わせ時間は、Cluster WebUI の [クラスタのプロパティ] - [タイムアウト] タブの [同期待ち時間] で変更することができます。
詳細については『リファレンスガイド』 - 「パラメータの詳細」 - 「クラスタプロパティ」 - 「タイムアウトタブ」を参照してください。
2.14. サーバ構成の変更 (追加、削除)¶
2.14.1. サーバ追加(ミラーディスク、ハイブリッドディスクを使用していない環境の場合)¶
サーバの追加を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの追加を行う場合、その他の変更 (グループリソースの追加等) は行わないでください。
- 追加するサーバのライセンス登録が必要です。ライセンスの登録は『インストール & 設定ガイド』の「ライセンスを登録する」を参照してください。
クラスタの状態を正常状態にします。
追加サーバを起動します。共有ディスクを使用する場合は追加サーバに共有ディスクが接続されていない状態で起動してください。
重要
共有ディスクを使用する場合、セットアップが完了し電源を切るまでは共有ディスクに接続しないでください。共有ディスク上のデータが破壊される可能性があります。
追加サーバで CLUSTERPRO サーバのセットアップ前の設定を行います。ただし共有ディスクを使用する場合、ディスクの設定はここでは行わないでください。
参考
セットアップ前の設定については『インストール & 設定ガイド』の「システム構成を決定する」の「ハードウェア構成後の設定」を参照してください。
追加サーバに CLUSTERPRO サーバをセットアップします。通信ポート番号設定で Cluster WebUI 、およびディスクエージェントのポート番号を入力してください。ポート番号は既にセットアップされているサーバと同じに設定してください。共有ディスクを使用する場合は共有ディスクを接続する HBA をフィルタリングに設定してください。必要に応じてライセンスを登録してください。セットアップ後、追加するサーバをシャットダウンして電源を切ります。
重要
セットアップを行う際に [共有ディスクのフィルタリング設定] で共有ディスクのフィルタリング設定を行わなかった場合、セットアップ完了後も共有ディスクを接続しないでください。共有ディスク上のデータが破壊される可能性があります。CLUSTERPRO を再インストールして共有ディスクのフィルタリングの設定を行ってください。
追加サーバを起動します。共有ディスクを使用する場合は追加サーバに共有ディスクを 接続した後でサーバを起動してください。
共有ディスクを使用する場合、追加サーバでディスクの設定を行います。
ディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) を使用して共有ディスクが見えることを確認します。
ディスクリソースの切替パーティションやハイブリッドディスクリソースのクラスタパーティション・データパーティションとして使用しているパーティションに全サーバから同じドライブ文字でアクセスできるよう設定してください。
ディスクネットワークパーティション解決リソースに使用するディスクハートビート用パーティションに全サーバで同じドライブ文字を設定してください。
この時点で共有ディスクにはアクセス制限がかかっているため、ディスクの内容は参照できません。
注釈
共有ディスクのパーティションに対してドライブ文字の変更/削除を行うと操作が失敗することがあります。以下の回避手順に従って、設定を行ってください。
コマンドプロンプトから以下のコマンドを実行して、ドライブ文字を削除して下さい。
> mountvol (変更対象の)ドライブ文字: /P
ディスクの管理([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理])を使用して変更対象ドライブからドライブ文字が削除されていることを確認してください。
[ディスクの管理]からドライブ文字を追加してください。
クラスタ内の他サーバに Web ブラウザで接続して Cluster WebUI の設定モードの [サーバの追加] をクリックします。
Cluster WebUI の設定モードから追加サーバの以下の情報を再設定します。
追加サーバの [プロパティ]→[HBA] タブにある HBA とパーティションの情報 (共有ディスクを使用する場合)
[クラスタのプロパティ]→[NP 解決] タブのディスクハートビート用パーティションの情報 (共有ディスクを使用する場合)
仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの送信元 IP アドレスの情報 (仮想 IP リソースを使用する場合)
NIC Link Up/Down 監視リソースの [プロパティ]→[監視 (固有)] タブで追加サーバのIP アドレス (NIC Link Up/Down 監視リソースを使用する場合)
AWS Elastic IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS Elastic IP リソースを使用する場合)
AWS 仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS 仮想 IP リソースを使用する場合)
AWS セカンダリ IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS セカンダリ IP リソースを使用する場合)
Azure DNS リソースの [プロパティ]→[詳細] タブにある追加サーバの IP アドレス の情報 (Azure DNS リソースを使用する場合)
重要
追加サーバの [プロパティ]→[HBA] タブで、共有ディスクを接続する SCSI コントローラまたは HBA に対してフィルタリングを行うよう設定してください。フィルタリングの設定を行っていない状態で共有ディスクを接続した場合、共有ディスク上のデータが破壊される可能性があります。
Cluster WebUI の設定モードでフェイルオーバグループの [プロパティ] を クリックします。[起動サーバ] タブで起動可能なサーバに追加します。起動可能なサーバの追加は必要なフェイルオーバグループのみ行ってください。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
反映動作の実行を問う画面が表示されます。画面に従って反映してください。
Cluster WebUI の操作モードから追加したサーバの [サーバサービス開始] を実行します。
Cluster WebUI の操作モードで [最新情報を取得] をクリックし、表示された情報でクラスタが正常になっていることを確認します。
サーバ復帰が必要な場合は、Cluster WebUI の操作モードから手動で復帰させてください。
2.14.2. サーバ追加(ミラーディスク、ハイブリッドディスクを使用している環境の場合)¶
サーバの追加を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの追加を行う場合、その他の変更 (グループリソースの追加等) は行わないでください。
- 追加するサーバのライセンス登録が必要です。ライセンスの登録は『インストール & 設定ガイド』の「ライセンスを登録する」を参照してください。
クラスタの状態を正常状態にします。
追加サーバを起動します。共有ディスクを使用する場合は追加サーバに共有ディスクが接続されていない状態で起動してください。
重要
共有ディスクを使用する場合、セットアップが完了し電源を切るまでは共有ディスクに接続しないでください。共有ディスク上のデータが破壊される可能性があります。
追加サーバで CLUSTERPRO サーバのセットアップ前の設定を行います。ただし共有ディスクを使用する場合、ディスクの設定はここでは行わないでください。
参考
セットアップ前の設定については『インストール & 設定ガイド』の「システム構成を決定する」の「ハードウェア構成後の設定」を参照してください。
追加サーバに CLUSTERPRO サーバをセットアップします。通信ポート番号設定で Cluster WebUI 、およびディスクエージェントのポート番号を入力してください。ポート番号は既にセットアップされているサーバと同じに設定してください。共有ディスクを使用する場合は共有ディスクを接続する HBA をフィルタリングに設定してください。必要に応じてライセンスを登録してください。セットアップ後、追加するサーバをシャットダウンして電源を切ります。
重要
セットアップを行う際に [共有ディスクのフィルタリング設定] で共有ディスクのフィルタリング設定を行わなかった場合、セットアップ完了後も共有ディスクを接続しないでください。共有ディスク上のデータが破壊される可能性があります。CLUSTERPRO を再インストールして共有ディスクのフィルタリングの設定を行ってください。
追加サーバを起動します。共有ディスクを使用する場合は追加サーバに共有ディスクを 接続した後でサーバを起動してください。
共有ディスクを使用する場合、追加サーバでディスクの設定を行います。
ディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) を使用して共有ディスクが見えることを確認します。
ディスクリソースの切替パーティションやハイブリッドディスクリソースのクラスタパーティション・データパーティションとして使用しているパーティションに全サーバから同じドライブ文字でアクセスできるよう設定してください。
ディスクネットワークパーティション解決リソースに使用するディスクハートビート用パーティションに全サーバで同じドライブ文字を設定してください。
この時点で共有ディスクにはアクセス制限がかかっているため、ディスクの内容は参照できません。
注釈
共有ディスクのパーティションに対してドライブ文字の変更/削除を行うと操作が失敗することがあります。以下の回避手順に従って、設定を行ってください。
コマンドプロンプトから以下のコマンドを実行して、ドライブ文字を削除して下さい。
> mountvol (変更対象の)ドライブ文字: /P
ディスクの管理([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理])を使用して変更対象ドライブからドライブ文字が削除されていることを確認してください。
[ディスクの管理]からドライブ文字を追加してください。
クラスタ内の他サーバに Web ブラウザで接続して Cluster WebUI の設定モードの [サーバの追加] をクリックします。
Cluster WebUI の設定モードから追加サーバの以下の情報を再設定します。
追加サーバの [プロパティ]→[HBA] タブにある HBA とパーティションの情報 (共有ディスクを使用する場合)
[クラスタのプロパティ]→[NP 解決] タブのディスクハートビート用パーティションの情報 (共有ディスクを使用する場合)
仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの送信元 IP アドレスの情報 (仮想 IP リソースを使用する場合)
NIC Link Up/Down 監視リソースの [プロパティ]→[監視 (固有)] タブで追加サーバのIP アドレス (NIC Link Up/Down 監視リソースを使用する場合)
AWS Elastic IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS Elastic IP リソースを使用する場合)
AWS 仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS 仮想 IP リソースを使用する場合)
AWS セカンダリ IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS セカンダリ IP リソースを使用する場合)
Azure DNS リソースの [プロパティ]→[詳細] タブにある追加サーバの IP アドレス の情報 (Azure DNS リソースを使用する場合)
重要
追加サーバの [プロパティ]→[HBA] タブで、共有ディスクを接続する SCSI コントローラまたは HBA に対してフィルタリングを行うよう設定してください。フィルタリングの設定を行っていない状態で共有ディスクを接続した場合、共有ディスク上のデータが破壊される可能性があります。
追加サーバでハイブリッドディスクリソースを使用する場合、Cluster WebUI の設定モードの [サーバ] の [プロパティ] をクリックします。 [サーバグループ] タブから起動可能なサーバに追加します。起動可能なサーバの追加は必要なサーバグループにのみ行ってください。
Cluster WebUI の設定モードでフェイルオーバグループの [プロパティ] を クリックします。[起動サーバ] タブで起動可能なサーバに追加します。起動可能なサーバの追加は必要なフェイルオーバグループのみ行ってください。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。画面に従って操作してください(OS再起動が必要な場合があります)。
サーバ復帰が必要な場合は、Cluster WebUI の操作モードから手動で復帰させてください。
2.14.3. サーバ削除(ミラーディスク、ハイブリッドディスクを使用していない環境の場合)¶
サーバの削除を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの削除を行う場合、その他の変更 (グループリソースの追加等) は行わないでください。
削除するサーバに登録したライセンスに関しては以下を参照してください。
CPUライセンスは対処不要です。
- VMノードライセンス、ノードライセンスは、CLUSTERPRO アンインストール時に破棄されます。必要であれば、ライセンスのシリアルナンバーとライセンスキーを退避してください。
期限付きライセンスは対処不要です。未開始のライセンスがあれば自動で回収し他サーバに配布されます。
クラスタの状態を正常状態にします。削除するサーバでグループが活性している場合には他のサーバにグループを移動してください。
削除するサーバがサーバグループに登録されている場合は、Cluster WebUI の設定モードの[サーバ] の [プロパティ] をクリックします。[サーバグループ] タブで起動可能なサーバから対象サーバを削除します。
Cluster WebUI の設定モードで削除するサーバの [サーバの削除] をクリックします。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
反映動作の実行を問う画面が表示されます。画面に従って反映してください。
Cluster WebUI の操作モードで [最新情報を取得] をクリックし、表示された情報でクラスタが正常になっていることを確認します。
削除したサーバは、クラスタ未構築状態になります。削除するサーバの CLUSTERPRO サーバをアンインストールする場合、『インストール & 設定ガイド』 - 「CLUSTERPRO をアンインストール/再インストールする」 - 「アンインストール手順」を参照してください。
2.14.4. サーバ削除(ミラーディスク、ハイブリッドディスクを使用している環境の場合)¶
サーバの削除を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの削除を行う場合、後述の手順以外の設定変更 (グループリソースの追加等) は行わないでください。
削除するサーバに登録したライセンスに関しては以下を参照してください。
CPUライセンスは対処不要です。
- VMノードライセンス、ノードライセンスは、CLUSTERPRO アンインストール時に破棄されます。必要であれば、ライセンスのシリアルナンバーとライセンスキーを退避してください。
期限付きライセンスは対処不要です。未開始のライセンスがあれば自動で回収し他サーバに配布されます。
Cluster WebUI の操作モードからミラーディスクリソース、ハイブリッドディスクリソースを使用しているグループを停止します。
クラスタの状態を正常状態にします。(ただし削除するサーバの異常は除きます。)
クラスタ内の他サーバに Web ブラウザで接続して Cluster WebUI を起動します。
削除するサーバがサーバグループに登録されている場合は、Cluster WebUI の設定モードの[サーバ] の [プロパティ] をクリックします。[サーバグループ] タブで起動可能なサーバから対象サーバを削除します。
Cluster WebUI の設定モードで削除するサーバの [サーバの削除] をクリックします。
Cluster WebUI の設定モードでミラーディスクリソース、ハイブリッドディスクリソースの [リソースの削除] をクリックします。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。画面に従って操作してください(OS再起動が必要な場合があります)。
Cluster WebUI の操作モードで [最新情報を取得] をクリックし、表示された情報でクラスタが正常になっていることを確認します。
削除したサーバは、クラスタ未構築状態になります。削除するサーバの CLUSTERPRO サーバをアンインストールする場合、『インストール & 設定ガイド』 - 「CLUSTERPRO をアンインストール/再インストールする」 - 「アンインストール手順」を参照してください。
2.15. サーバ IP アドレスの変更手順¶
運用を開始した後で、サーバの IP アドレスを変更したい場合、以下の手順で行ってください。
2.15.1. ミラーコネクトの IP アドレスの変更が不要な場合¶
クラスタの状態を正常状態にします。
Cluster WebUI の操作モードからクラスタをサスペンドします。
[マイネットワーク] のプロパティから OS のネットワークの構成を変更します。
Cluster WebUI の設定モードから [クラスタのプロパティ] の [インタコネクト] タブの IP アドレスを変更した IP アドレスに応じて変更します。
変更した IP アドレスを NIC Link Up/Down 監視リソースで使用している場合はモニタ リソースのプロパティの[監視 (固有)]タブで IP アドレスを変更します。
Cluster WebUI の設定モードから[設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
Cluster WebUI の操作モードからクラスタをリジュームします。
2.15.2. ミラーコネクトの IP アドレスの変更が必要な場合¶
クラスタの状態を正常状態にします。
Cluster WebUI の操作モードからクラスタを停止します。
[マイネットワーク] のプロパティから OS のネットワークの構成を変更します。
Cluster WebUI の設定モードから [クラスタのプロパティ] の [インタコネクト] タブの IP アドレスを変更した IP アドレスに応じて変更します。
変更した IP アドレスを NIC Link Up/Down 監視リソースで使用している場合はモニタ リソースのプロパティの [監視 (固有)] タブで IP アドレスを変更します。
Cluster WebUI の設定モードから [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
全てのサーバで OS を再起動します。
2.16. ホスト名の変更手順¶
運用を開始した後で、サーバのホスト名を変更したい場合、以下の手順で行ってください。
2.16.1. ミラーディスク/ハイブリッドディスクが存在しない環境の場合¶
クラスタの状態を正常状態にします。
ホスト名を変更するサーバでグループが起動している場合、グループを移動します。
Cluster WebUI の操作モードからクラスタをサスペンドします。
[マイコンピュータ] のプロパティからホスト名を変更します。
注釈
ここでは OS を再起動しないでください。OS の再起動が完了するまでクラスタ構成情報が反映できなくなります。
Cluster WebUI の設定モードでサーバの [サーバの名称変更] をクリックします。
Cluster WebUI の設定モードでサーバ名の変更を行ったクラスタ構成情報を、クラスタサーバからアクセス可能なディスク領域に一旦保存します。
クラスタサーバ上で Cluster WebUI を使用している場合はローカルディスクに保存します。他の PC で Cluster WebUI を使用している場合は、クラスタサーバからアクセス可能な共有フォルダに保存するか、外部メディアなどに一旦保存してクラスタサーバのローカルディスクにコピーします。
いずれかのクラスタサーバ上で下記のコマンドを実行して、保存したクラスタ構成情報をアップロードします。
clpcfctrl --push -x <クラスタ構成情報のパス> --nocheck
注釈
クラスタ構成情報チェックを行う場合、クラスタ構成情報アップロード前に行ってください。
全てのサーバで [管理ツール] の [サービス] を開き、CLUSTERPRO Node Manager サービスを再起動します。
全てのサーバで [管理ツール] の [サービス] を開き、CLUSTERPRO Information Base サービスを再起動します。
ホスト名を変更したサーバで OS をシャットダウンします。
Cluster WebUI の操作モードからクラスタをリジュームします。
Cluster WebUI の操作モードからマネージャ再起動します。
ホスト名を変更したサーバを起動します。[クラスタのプロパティ]→[拡張] タブで [自動復帰] が [しない] に設定されている場合は、Cluster WebUI の操作モードから手動で復帰させてください。
2.16.2. ミラーディスク/ハイブリッドディスクが存在する環境の場合¶
クラスタの状態を正常状態にします。
Cluster WebUI の操作モードからクラスタを停止します。
[マイコンピュータ] のプロパティからホスト名を変更します。
注釈
ここでは OS を再起動しないでください。OS の再起動が完了するまでクラスタ構成情報が反映できなくなります。
Cluster WebUI の設定モードでサーバの [サーバの名称変更] をクリックします。
Cluster WebUI でサーバ名の変更を行ったクラスタ構成情報を、クラスタサーバからアクセス可能なディスク領域に一旦保存します。
クラスタサーバ上で Cluster WebUI を使用している場合はローカルディスクに保存します。他の PC で Cluster WebUI を使用している場合は、クラスタサーバからアクセス可能な共有フォルダに保存するか、外部メディアなどに一旦保存してクラスタサーバのローカル ディスクにコピーします。
全てのサーバで [管理ツール] の [サービス] を開き、CLUSTERPRO Disk Agent サービスを停止します。
いずれかのクラスタサーバ上で下記のコマンドを実行して、保存したクラスタ構成情報をアップロードします。
clpcfctrl --push -x <クラスタ構成情報のパス> --nocheck
注釈
クラスタ構成情報チェックを行う場合、クラスタ構成情報アップロード前に行ってください。
全てのサーバで OS を再起動します。
2.17. ネットワークカードの交換¶
ネットワークカードを交換する場合以下の手順で行います。ミラーコネクトで使用しているネットワークカードを交換する場合も同様の手順となります。
クラスタの状態を正常状態にします。(ただし交換するネットワークカードの異常は除きます。)
ネットワークカードを交換するサーバでグループが起動している場合、グループを移動します。交換するネットワークカードをミラーコネクトに使用していて、かつ他にミラーコネクトに使用しているネットワークカードがない場合は、ネットワークカードを交換してミラー ディスクを復旧するまでグループ移動ができませんので、Cluster WebUI からグループを停止しておきます。
ネットワークカードを交換するサーバでサービスのスタートアップの種類を手動起動に変更します。
clpsvcctrl.bat --disable -a
Cluster WebUI からネットワークカードを交換するサーバの[サーバシャットダウン] をクリックします。
シャットダウンが完了した後、ネットワークカードを交換します。
ネットワークカードを交換したサーバを起動します。
[マイネットワーク] のプロパティから OS のネットワークの構成を設定します。ネットワークの設定はネットワークカード交換前と同じに設定してください。
ネットワークカードを交換したサーバでサービスのスタートアップの種類を自動起動に変更します。
clpsvcctrl.bat --enable -a
サーバを OS 再起動します
[クラスタのプロパティ] → [拡張] タブで [自動復帰] が [しない] に設定されている場合は、Cluster WebUI から手動で復帰させてください。
必要であれば、グループを移動します。
2.19. ディスク構成の変更 -ミラーディスクの場合-¶
2.19.1. ディスクの交換¶
ミラーディスクの交換については「2.27. ミラーディスクの交換 」を参照してください。
2.19.2. ディスクの追加¶
ミラーディスクに使用するディスクを追加する場合は、以下の手順で行ってください。
クラスタの状態を正常状態にします。
ディスクを追加するサーバでグループが起動している場合、グループを移動します。
一方のサーバのみ Cluster WebUI の操作モードからシャットダウンし、電源を切ります。
ディスクを増設し、サーバを起動します。
サーバをクラスタに復帰させ、既存のミラーディスクがあればミラーの再構築を行います。
ディスクを増設したサーバでディスクを設定します。
ディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) を使用してミラーディスク用のデータパーティションとクラスタパーティションを確保します。両サーバで同じになるようにデータパーティションとクラスタパーティションのドライブ文字を設定します。
2~6 の手順を他のサーバで行います。
Cluster WebUI の操作モードからミラーディスクリソースを追加するグループを停止します。
Cluster WebUI の操作モードからクラスタをサスペンドします。
Cluster WebUI の設定モードでミラーディスクリソースを追加するグループの [リソースの追加] をクリックし、ミラーディスクリソースを追加します。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
Cluster WebUI の操作モードからクラスタをリジュームします。
追加したミラーディスクリソース、またはミラーディスクリソースを追加したグループを起動します。[クラスタのプロパティ] で [自動ミラー初期構築] をする設定の場合、ミラーの初期構築が開始されます。[自動ミラー初期構築] をしない設定の場合、手動でミラーの初期構築を行ってください。
必要であれば、グループを移動します。
2.19.3. ディスクの削除¶
ミラーディスクに使用しているディスクを削除する場合は、以下の手順で行ってください。
クラスタの状態を正常状態にします。
Cluster WebUI の操作モードからミラーディスクリソースを削除するグループを停止します。
Cluster WebUI の操作モードからクラスタをサスペンドします。
Cluster WebUI の設定モードでミラーディスクリソースを削除するグループをクリックします。ミラーディスクリソースの [リソースの削除] をクリックします。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
Cluster WebUI の操作モードからクラスタをリジュームします。
Cluster WebUI の操作モードからグループを起動します。
グループが起動していないサーバを Cluster WebUI の操作モードからシャットダウンし、電源を切ります。
ディスクを抜き、サーバを起動します。
グループを移動させ、8~9 の手順を他のサーバで行います。
必要であれば、グループを移動します。
2.20. データのバックアップ/リストアを行う¶
データのバックアップ/リストアは、以下のようなイメージで行います。バックアップ方法の詳細は各バックアップソフトのマニュアルを参照してください。
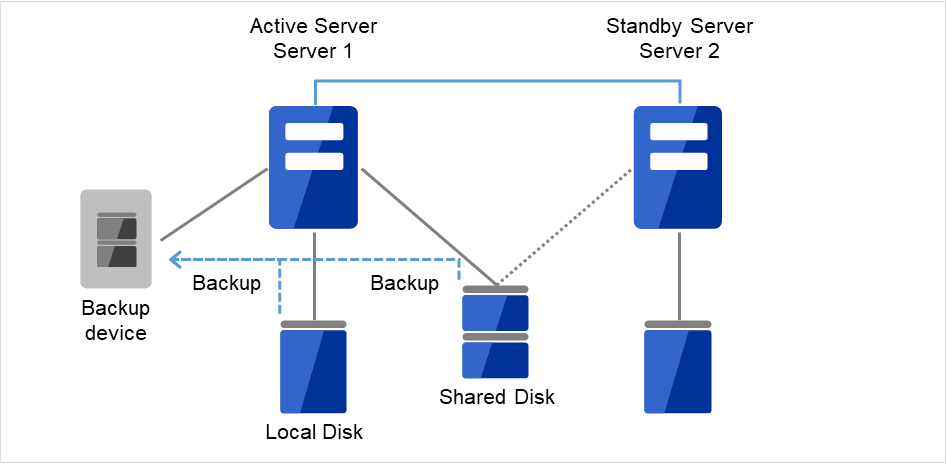
図 2.2 片方向スタンバイでのバックアップの例 (1)¶
現用系サーバ(Server1)に障害が発生した場合、待機系サーバ(Server 2)に接続されたデバイスに共有ディスク(Shared Disk)、ローカルディスク(Local Disk)のデータをバックアップします。
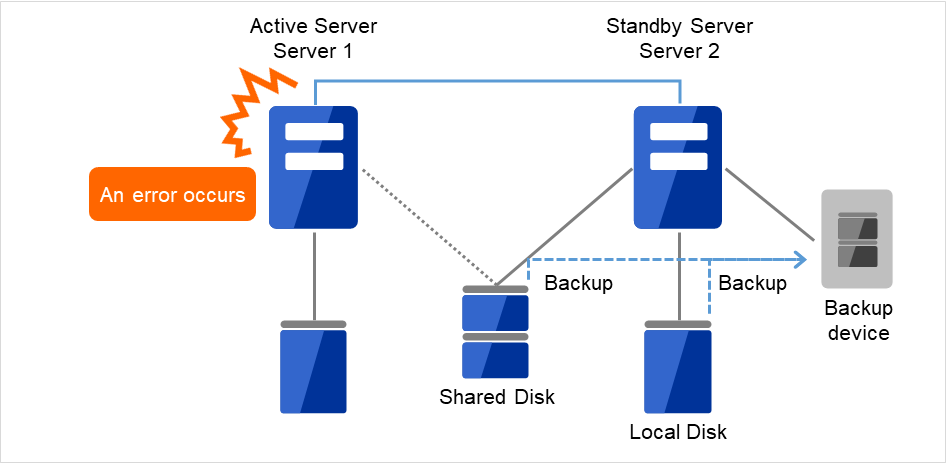
図 2.3 片方向スタンバイでのバックアップの例 (2)¶
2.21. スナップショットバックアップを行う¶
ミラーディスク/ハイブリッドディスクを使用している場合、ミラーリングを中断して待機系の データパーティションをスナップショットイメージとしてバックアップすることが可能です。これをスナップショットバックアップと呼びます。
スナップショットバックアップ実施中は、ミラーリングを一時的に解除するため、コピー先の待機系サーバ/サーバグループにはフェイルオーバができない状態となります。この状態で待機系サーバのデータパーティションへのアクセス制限を解除し、バックアップを採取します。
スナップショット状態から復帰させるときには、ディスクアクセスを制限したうえで、ミラーを再構築します。
バックアップの採取方法についての詳細は各バックアップソフトの説明書を参照してください。
注釈
ミラーリングを中断する際、ミラーリングを中断するタイミングによってはミラーリングのコピー先のデータは必ずしも NTFS およびアプリケーションデータとして、整合性を保てない場合がありますので注意してください。
2.21.1. スナップショットバックアップ実行手順¶
ミラーディスクに対してスナップショットバックアップを実施する場合、以下の手順で行います。
バックアップを行うサーバ側でバックアップ対象のミラーディスクを監視しているミラーディスク監視リソースを停止します。
clpmonctrl -s -m <mdw(ミラーディスク監視リソース名)>
ミラーディスクを切り離した状態にします。
clpmdctrl --break <md(ミラーディスクリソース名)>
ミラーディスクへのアクセスを許可した状態にします。
clpmdctrl --active <md(ミラーディスクリソース名)> -f
ここで、必要なファイルをバックアップしてください。
ミラーディスクへのアクセスを禁止した状態にします。
clpmdctrl --deactive <md(ミラーディスクリソース名)>
ミラーディスクを監視しているミラーディスク監視リソースを開始します。
clpmonctrl -r -m <mdw(ミラーディスク監視リソース名)>
自動ミラー復帰を無効に設定している場合は、ミラーディスクリストからの手動操作によりミラー復帰を実施します。
ハイブリッドディスクに対してスナップショットバックアップを実施する場合、コピー先の待機系サーバグループのいずれかのサーバで以下の手順によりバックアップを採取します。
バックアップを採取するサーバで以下のコマンドを実行します。
clphdsnapshot --open <ハイブリッドディスクリソース名>
データパーティションのアクセス制限が解除されますので、必要なファイルをバックアップ してください。
バックアップを採取したサーバで以下のコマンドを実行してミラーリングを再開します。
clphdsnapshot --close <ハイブリッドディスクリソース名>
自動ミラー復帰を無効に設定している場合は、ミラーディスクリストからの手動操作によりミラー復帰を実施します。
各コマンドについては、『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」を参照してください。
2.22. ミラー/ハイブリッドディスクをディスクイメージでバックアップする¶
ミラーディスク/ハイブリッドディスク用のパーティション(クラスタパーティションとデータパーティション)を ディスクイメージでバックアップする場合は、以下の該当するいずれかの手順でおこなってください。
注釈
clpbackup --preまたはclpbackup --postを実行して、 次にサーバグループ内の残りのサーバでclpbackup --pre --only-shutdownまたはclpbackup --post --only-rebootを実行するよう、記述しています。手順の中では、前者のサーバの目安として、サーバグループ内のカレントサーバを記述していますが、 サーバグループ内で最初にコマンドを実行する1つめのサーバは必ずしもカレントサーバでなくても問題ありません。なお、サーバグループにサーバが1つしかない場合には、 後者のサーバグループ内の残りのサーバでおこなうclpbackup --pre --only-shutdownやclpbackup --post --only-rebootの作業は必要ありません。※ カレントサーバとは、サーバグループ内のサーバのうち、ミラーデータの送受信やディスクへの書き込み処理を、 その時点で受け持っているサーバのことを示します。現用系側では、ハイブリッドディスクリソースが起動しているサーバが、カレントサーバです。その現用系側のカレントサーバから送られて来るミラーデータを受信して、待機系側のミラーディスクに書き込むのが、待機系側のカレントサーバです。Some invalid status. Check the status of cluster.などのエラーが表示されてサーバがシャットダウンしない場合は、 しばらく待ってから、再度 [clpbackup] コマンドを度実行してください。保留(ダウン後再起動)Suspension (Isolated)になります。この場合は、[clpcl] コマンド(--return オプション)、または、Cluster WebUI の [ステータス] タブで、[サーバ復帰] の操作をおこなってください。clpcl --returnまた、サーバ復帰後、フェイルオーバグループが起動していない場合は必要に応じて起動してください。参考
clpbackup コマンドに関しては『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「ディスクイメージバックアップの準備をする (clpbackup コマンド)」 を参照してください。
2.22.1. 現用系/待機系のミラーディスクを両方同時にバックアップする場合¶
ミラーの状態を、Cluster WebUI の [ミラーディスク] タブ、または [clpmdstat] / [clphdstat] コマンドを使って、確認してください。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名> clphdstat --active <hdリソース名>
注釈
ハイブリッドディスクリソースの場合は、現用系側/待機系側の両サーバグループのカレントサーバが、 それぞれどのサーバになっているかについても、確認してください。フェイルオーバグループ(業務)が起動している場合は、Cluster WebUI または [clpgrp] コマンドを使って、フェイルオーバグループを停止してください。
- 現用系側/待機系側の両サーバにて、それぞれ下記コマンドを実行してください。※ ハイブリッドディスクの場合は、各サーバグループのカレントサーバにて、それぞれ実行してください。
clpbackup --pre
注釈
実行すると、ミラーの状態がバックアップ用に変更され、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
- ハイブリッドディスクリソースの場合は、カレントサーバのシャットダウン後に、残りのサーバで、それぞれ下記コマンドを実行してください。
clpbackup --pre --only-shutdown
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
現用系側/待機系側の両サーバにて、バックアップを実行してください。
- バックアップ作業が完了したら、現用系側/待機系側の両サーバを起動して、それぞれ下記コマンドを実行してください。※ ハイブリッドディスクリソースの場合は、全サーバを起動して、まず現用系側/待機系側の各カレントサーバで、それぞれ下記コマンドを実行してください。
clpbackup --post
注釈
実行すると、ミラーの状態が通常用に戻り、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。ハイブリッドディスクの場合は、処理に時間がかかる場合があります。 ハイブリッドディスクの場合は、先の各カレントサーバがリブートを開始したら、残りの全サーバで、それぞれ下記コマンドを実行してください。
clpbackup --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
両系の全サーバが起動したら、 ミラーの状態を、Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。
2.22.2. 現用系/待機系のミラーディスクを片サーバずつバックアップする場合¶
下記の手順で、「待機系側のミラーディスクをバックアップする場合」を参照して、交互にバックアップをおこなってください。
待機系側のディスクのバックアップ作業を、「待機系側のミラーディスクをバックアップする場合」を参照しておこなってください。
バックアップ作業完了後、ミラー復帰が完了して現用系と待機系のミラーディスクが同期状態になったら、 現用系から待機系へフェイルオーバグループの移動をおこなってください。
元現用系のディスクのバックアップ作業を、「待機系側のミラーディスクをバックアップする場合」を参照しておこなってください。
バックアップ作業完了後、ミラー復帰が完了して現用系と待機系のミラーディスクが同期状態になったら、 必要に応じてフェイルオーバグループの移動をおこなってください。
2.22.3. 待機系側のミラーディスクをバックアップする場合¶
ミラーが正常に同期できていることを、Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名> clphdstat --active <hdリソース名>
注釈
ハイブリッドディスクリソースの場合は、待機系側のサーバグループのカレントサーバが、どのサーバになっているかについても、確認してください。
ミラー領域に書き込んでいるデータの静止点を確保するために、 Cluster WebUI または [clpgrp] コマンドを使って、 ミラーディスクリソースやハイブリッドディスクリソースを含むフェイルオーバグループ(業務)を、停止してください。
注釈
フェイルオーバグループを停止することによって、データが書き込み途中の状態でバックアップされることや、 キャッシュによりデータがミラー領域に書き込まれずにバックアップされないことを、防ぎます。
- ミラー同期を中断させます。まず、自動ミラー復帰が動作しないようにするために、Cluster WebUI または [clpmonctrl] コマンドで、 現用系/待機系両方の全てのミラーディスク監視リソース/ハイブリッドディスク監視リソースを、一時停止してください。
clpmonctrl -s -h <サーバ名> -m <監視リソース名>
次に、Cluster WebUI の [ミラーディスク] タブで 待機系側(バックアップする側)の全てのミラーディスクリソース/ハイブリッドディスクリソースに対して [ミラーブレイク] 操作をおこなって ステータスを "異常" (RED) へ変更するか、 または、[clpmdctrl] / [clphdctrl] コマンド(--breakオプション)を全てのミラーディスクリソース/ハイブリッドディスクリソースに対して 待機系側(バックアップする側)のサーバ上で実行して、 全てのミラー同期を中断させてください。ミラーディスクリソースの場合:
clpmdctrl --break <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --break <hdリソース名>
注釈
ハイブリッドディスクリソースに対して上記の [clphdctrl] コマンドを実行する場合、待機系側のカレントサーバ上で実行してください。カレントサーバ以外で実行した場合は、コマンドがエラーになります。
参考
[clpmonctrl] コマンドに関しては『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「モニタリソースを制御する (clpmonctrl コマンド)」 を参照してください。
業務をすぐに再開したい場合は、Cluster WebUI または [clpgrp] コマンドを使って、 現用系側(バックアップしない側)のサーバでフェイルオーバグループ(業務)を起動してください。
- 待機系側(バックアップする側)のサーバにて、下記コマンドを実行してください。※ ハイブリッドディスクの場合は、待機系側サーバグループ内の1つのサーバにて、実行してください。
clpbackup --pre
注釈
実行すると、ミラーの状態がバックアップ用に変更され、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
ハイブリッドディスクの場合は、待機系側のサーバグループ内の残りの全サーバで、下記コマンドを実行してください。
clpbackup --pre --only-shutdown
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
待機系側サーバにて、ディスクイメージでのバックアップをおこなってください。
- バックアップ作業が完了したら、待機系側サーバを起動して、そのサーバにて下記コマンドを実行してください。※ ハイブリッドディスクリソースの場合は、待機系側の全サーバを起動してから、待機系側サーバグループ内の1つのサーバで下記コマンドを実行してください。
clpbackup --post
注釈
実行すると、ミラーの状態が通常用に戻り、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
ハイブリッドディスクの場合は、待機系側のサーバグループ内の残りの全サーバで、下記コマンドを実行してください。
clpbackup --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
- 待機系側サーバが起動します。ミラーディスク監視リソース/ハイブリッドディスク監視リソースが一時停止のままになっている場合は、 Cluster WebUI または [clpmonctrl] コマンドで、再開してください。
clpmonctrl -r -h <サーバ名> -m <監視リソース名>
もしも、フェイルオーバグループ(業務)を停止したままにしていた場合は(先の手順ですぐに再開しなかった場合には)、 現用系側のサーバで、フェイルオーバグループ(業務)を起動可能です。
- 自動ミラー復帰が有効な場合には、ミラー復帰が自動でおこなわれて、ミラーが正常な状態になります。自動ミラー復帰がおこなわれずに、正常な状態にならない場合には、Cluster WebUI または [clpmdctrl] / [clphdctrl] コマンドを現用系側サーバで実行して、 ミラー復帰をおこなってください。
ミラーディスクリソースの場合:
clpmdctrl --recovery <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --recovery <hdリソース名>
注釈
ハイブリッドディスクリソースの場合、現用系側のカレントサーバ上で実行してください。
2.23. ミラー/ハイブリッドディスクにディスクイメージをリストアする¶
ミラーディスク/ハイブリッドディスク用のパーティション(クラスタパーティションとデータパーティション)に、 「ミラー/ハイブリッドディスクをディスクイメージでバックアップする」でバックアップしたディスクイメージをリストアする場合は、 以下のいずれかの手順でおこなってください。
注釈
clprestore --postまたはclprestore --post --skip-copyを実行して、 次にサーバグループ内の残りのサーバでclprestore --post --only-rebootを実行するよう、記述しています。手順の中では、前者のサーバの例として、サーバグループ内のカレントサーバを記述していますが、 サーバグループ内で最初にコマンドを実行する1つめのサーバは必ずしもカレントサーバでなくても問題ありません。なお、サーバグループにサーバが1つしかない場合には、 後者のサーバグループ内の残りのサーバでおこなうclprestore --post --only-rebootの作業は必要ありません。※ カレントサーバとは、サーバグループ内のサーバのうち、ミラーデータの送受信やディスクへの書き込み処理を、 その時点で受け持っているサーバのことを示します。現用系側では、ハイブリッドディスクリソースが起動しているサーバが、カレントサーバです。その現用系側のカレントサーバから送られて来るミラーデータを受信して、待機系側のミラーディスクに書き込むのが、待機系側のカレントサーバです。Some invalid status. Check the status of cluster.などのエラーが表示されてサーバがシャットダウンしない場合は、 しばらく待ってから、再度 [clprestore] コマンドを実行してください。Invalid configuration file.などのエラーが表示されて再起動しない場合は、 構成情報が登録されているか、また、CLUSTERPROのインストールやファイアウォールの設定等に問題がないか、 確認してください。保留(ダウン後再起動)Suspension (Isolated)になります。この場合は、[clpcl] コマンド、または、Cluster WebUI の [ステータス] タブで、[サーバ復帰] の操作をおこなってください。clpcl --returnまた、サーバ復帰後、フェイルオーバグループが起動していない場合は必要に応じて起動してください。
コマンドプロンプトから以下のコマンドを実行して、ドライブ文字を削除して下さい。
mountvol <変更対象のドライブ文字>: /Pディスクの管理 ( [コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理] ) を使用して変更対象ドライブからドライブ文字が削除されていることを確認してください。
ディスクの管理でドライブ文字を追加してください。
Cluster WebUI の [設定のエクスポート] で、構成情報ファイル(zip形式)をディスク上に保存してください。
クラスタに属するいずれかのサーバからアクセスできるディスク上に、そのzip形式ファイルから、構成情報ファイルを展開してください。
[clpcfctrl] コマンドをサーバ上で実行して、展開した構成情報ファイル(clp.conf)を全サーバへ配信してください。
clpcfctrl --push -x <展開した構成情報ファイルclp.confがあるディレクトリのパス> --force --nocheck参考
clprestore コマンドに関しては、『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「ディスクイメージリストア後の処理をする (clprestore コマンド)」 を参照してください。
clpcfctrl コマンドに関しては、『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「クラスタ生成、クラスタ構成情報バックアップを実行する (clpcfctrl コマンド)」 を参照してください。
2.23.1. 現用系/待機系の両サーバに同一のミラーディスクイメージを同時にリストアする場合¶
重要
本手順では、ミラーディスクリソース/ハイブリッドディスクリソースの設定にて、[初期ミラー構築を行う] をあらかじめオフにしておく必要があります。[初期ミラー構築を行う] がオンになっている場合は、エラーとなりますので、Cluster WebUI を使ってオフに設定してください。
フェイルオーバグループ(業務)が起動している場合は、Cluster WebUI または [clpgrp] コマンドを使って、フェイルオーバグループを停止してください。
- 現用系/待機系の全サーバにて、それぞれ下記コマンドを実行してください。※ OSが起動できず、OSやCLUSTERPROの再インストールやリストアをおこなう必要がある場合には、そのサーバでは、その作業をおこなった後にて、下記コマンドを実行してください。
clprestore --pre
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
- 現用系/待機系の両方のサーバにて、クラスタパーティションおよびデータパーティションのリストアをおこなってください。※ 現用系と待機系に同一のディスクイメージをリストアしてください。
現用系/待機系の両方のリストア作業が完了したら、全サーバを起動してください。
- 各サーバで、ディスクの管理([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理])を使用して、 リストアしたデータパーティションやクラスタパーティション等のドライブ文字を、再設定してください。※ ドライブ文字が変わっていなくても、明示的に再設定してください。
注釈
ハイブリッドディスクの場合、共有ディスクのパーティションに対してドライブ文字の変更/削除をおこなうと、操作が失敗することがあります。この場合は、[mountvol] コマンド使ってドライブ文字を削除してから、ディスクの管理で再設定してください。mountvol <変更対象のドライブ文字>: /P
- Cluster WebUI を起動して、[設定モード] にしてください。各ミラーディスクリソース/ハイブリッドディスクリソースの設定で、それぞれ各サーバのクラスタパーティションとデータパーティションを、確認/再選択してください。
- ミラーディスクリソースの場合は、 リソースのプロパティの [詳細] タブの [起動可能サーバ] にある各サーバについて、サーバを選択して、[編集] ボタンを押してください。[パーティションの選択] で [接続] ボタンを押して、データパーティションおよびクラスタパーティションがそれぞれ正しく選択されていることを確認してください。 正しく選択されていない場合には、正しいパーティションを選択して、[OK] ボタンを押してください。
- ハイブリッドディスクリソースの場合は、 リソースのプロパティの [詳細] タブの [サーバグループ] の [情報取得] ボタンを押してください。各パーティションのGUIDが更新されたら、[OK] ボタンを押してください。
参考
設定個所の詳細については『リファレンスガイド』の「グループリソースの詳細」にある、 「ミラーディスクリソースを理解する」の「詳細タブ」や、 「ハイブリッドディスクリソースを理解する」の「詳細タブ」 を参照してください。 また、各ミラーディスクリソース/ハイブリッドディスクリソースの設定で、 もしも、[初期ミラー構築を行う] がオンになっているものがあったら、オフに変更してください。
参考
設定個所の詳細については『リファレンスガイド』の「グループリソースの詳細」にある、「ミラーディスクリソースを理解する」の「詳細タブ」(「ハイブリッドディスクリソースを理解する」の「詳細タブ」)の「調整」「ミラータブ」「初期ミラー構築を行う」を参照してください。
Cluster WebUI で設定を確認/修正したら、[設定の反映] を実行してください。
注釈
[設定の反映] の際、もしも、[構成情報にあるディスク情報とサーバ上のディスク情報が異なっています。自動修正しますか?] というメッセージが表示された場合は、[はい] を選択してください。
- 設定の反映が完了したら、現用系側/待機系側の両サーバにて、それぞれ下記コマンドを実行してください。※ ハイブリッドディスクの場合は、現用系側/待機系側の各サーバグループ内の1つのサーバにて(例えば各サーバグループのカレントサーバにて)、それぞれ実行してください。
clprestore --post --skip-copy
注釈
実行すると、クラスタパーティションが更新され、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。ハイブリッドディスクの場合は、処理に時間がかかる場合があります。 - ハイブリッドディスクの場合は、前述の手順9のコマンドを実行したサーバがリブートを開始したら、 サーバグループ内の残りの全サーバにて、それぞれ下記コマンドを実行してください。
clprestore --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
- 現用系/待機系の両方の全サーバが起動したら、各ミラーの状態を、Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。現用系/待機系の両方のミラーのステータスが、"正常" (GREEN) となります。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名>
注釈
ミラーのステータスが "正常" (GREEN) - "異常" (RED) となっている場合は、 Cluster WebUI の [ミラーディスク] タブの [差分コピー] 操作、 または [clpmdctrl] / [clphdctrl] コマンド(--recoveryオプション)を "正常" (GREEN) 側サーバで実行して、 ミラー復帰をおこなってください。ミラーディスクリソースの場合:
clpmdctrl --recovery <mdリソース名>
- ハイブリッドディスクリソースの場合:(※ カレントサーバ上で実行してください。)
clphdctrl --recovery <hdリソース名>
また、フェイルオーバグループの状態を、Cluster WebUI または [clpstat] コマンドを使って確認してください。 起動に失敗しているフェイルオーバグループがあったら、Cluster WebUI または [clpgrp] コマンドを使って、そのフェイルオーバグループを停止してください。 その後、フェイルオーバグループを起動(業務を開始)できます。注釈
もしも、現用系/待機系の両方のミラーのステータスが "異常" (RED) となっている場合は、 Cluster WebUI の [ミラーディスク] タブの [強制ミラー復帰] 操作、または [clpmdctrl] / [clphdctrl] コマンド(--forceオプション)を使い、 コピー元としたい側のミラーのステータスを "正常" (GREEN) に変更してください。また、フェイルオーバグループの状態を、Cluster WebUI または [clpstat] コマンドを使って確認してください。起動に失敗しているフェイルオーバグループがあったら、Cluster WebUI または [clpgrp] コマンドを使って、そのフェイルオーバグループを停止してください。その後、最新とした側のサーバで、フェイルオーバグループを起動(業務を開始)できます。その後、ミラー復帰をおこなってください。参考
[clpmdctrl] / [clphdctrl] コマンドに関しては『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「ミラーディスクリソースを操作する (clpmdctrl コマンド)」 「ハイブリッドディスクリソースを操作する (clphdctrlコマンド)」 を参照してください。
- [初期ミラー構築を行う] の設定を変更した場合は、必要に応じて、Cluster WebUI を使って設定を元に戻してください。なお、設定を反映する際に、リソースの停止が必要となります。
2.23.2. 現用系/待機系の両サーバにミラーディスクイメージをそれぞれ同時にリストアする場合¶
参考
現用系/待機系の両系のミラーディスクに同一イメージをリストアする手順については、 「現用系/待機系の両サーバに同一のミラーディスクイメージを同時にリストアする場合」を参照してください。
フェイルオーバグループ(業務)が起動している場合は、Cluster WebUI または [clpgrp] コマンドを使って、フェイルオーバグループを停止してください。
- 現用系/待機系の全サーバにて、それぞれ下記コマンドを実行してください。※ OSが起動できず、OSやCLUSTERPROの再インストールやリストアをおこなう必要がある場合には、そのサーバでは、その作業をおこなった後にて、下記コマンドを実行してください。
clprestore --pre
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
現用系/待機系の両方のサーバにて、クラスタパーティションおよびデータパーティションのリストアをおこなってください。
現用系/待機系の両方のリストア作業が完了したら、全サーバを起動してください。
- 各サーバで、ディスクの管理([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) を使用して、リストアしたデータパーティションやクラスタパーティション等のドライブ文字を、再設定してください。※ ドライブ文字が変わっていなくても、明示的に再設定してください。
- Cluster WebUI を起動して、[設定モード] にしてください。各ミラーディスクリソース/ハイブリッドディスクリソースの設定で、それぞれ各サーバのクラスタパーティションとデータパーティションを、 確認/再選択してください。
- ミラーディスクリソースの場合は、 リソースのプロパティの [詳細] タブの [起動可能サーバ] にある各サーバについて、サーバを選択して、[編集] ボタンを押してください。[パーティションの選択] で [接続] ボタンを押して、データパーティションおよびクラスタパーティションがそれぞれ正しく選択されていることを確認してください。 正しく選択されていない場合には、正しいパーティションを選択して、[OK] ボタンを押してください。
- ハイブリッドディスクリソースの場合は、 リソースのプロパティの [詳細] タブの [サーバグループ] の [情報取得] ボタンを押してください。各パーティションのGUIDが更新されたら、[OK] ボタンを押してください。
参考
設定個所の詳細については『リファレンスガイド』の「グループリソースの詳細」にある、 「ミラーディスクリソースを理解する」の「詳細タブ」や、 「ハイブリッドディスクリソースを理解する」の「詳細タブ」 を参照してください。 Cluster WebUI で設定を確認/修正したら、[設定の反映] を実行してください。
注釈
もしも、[設定の反映] の際、[構成情報にあるディスク情報とサーバ上のディスク情報が異なっています。自動修正しますか?] というメッセージが表示された場合は、[はい] を選択してください。
- 設定の反映が完了したら、現用系側/待機系側の両サーバにて、それぞれ下記コマンドを実行してください。※ ハイブリッドディスクの場合は、現用系側/待機系側の各サーバグループ内の1つのサーバにて(例えば各サーバグループのカレントサーバにて)、それぞれ実行してください。
clprestore --post
注釈
実行すると、クラスタパーティションが更新され、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。ハイブリッドディスクの場合は、処理に時間がかかる場合があります。 - ハイブリッドディスクの場合は、前述の手順8のコマンドを実行したサーバがリブートを開始したら、 サーバグループ内の残りの全サーバにて、それぞれ下記コマンドを実行してください。
clprestore --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
- 現用系/待機系の両方の全サーバが起動したら、各ミラーの状態を、Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。現用系/待機系の両方のミラーのステータスが、"異常" (RED) となります。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名>
フェイルオーバグループの状態を、Cluster WebUI または [clpstat] コマンドを使って確認してください。
起動に失敗しているフェイルオーバグループがあったら、Cluster WebUI または [clpgrp] コマンドを使って、そのフェイルオーバグループを停止してください。
- Cluster WebUI の [ミラーディスク] タブでの [強制ミラー復帰] 操作、または [clpmdctrl] / [clphdctrl] コマンド(--forceオプション)を使って、 最新としたい側のミラーのステータスを "正常" (GREEN) に変更してください。※ コマンドで実行する場合は、ステータスを "正常" (GREEN) にしたい側のサーバ上で実行します。
ミラーディスクリソースの場合:
clpmdctrl --force <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --force <hdリソース名>
Cluster WebUI の [ステータス] タブ または [clpgrp] コマンドを使って、最新とした側のサーバで、フェイルオーバグループを起動(業務を開始)できます。
Cluster WebUI の [ミラーディスク] タブでの [フルコピー] 操作、または [clpmdctrl] / [clphdctrl] コマンドをコピー元側のサーバ上で実行して、 ミラー復帰(フルコピー)をおこなってください。
ミラーディスクリソースの場合:
clpmdctrl --recovery <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --recovery <hdリソース名>
注釈
ハイブリッドディスクリソースの場合、コピー元側のカレントサーバ上で実行してください。
参考
[clpmdctrl] / [clphdctrl] コマンドに関しては、『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「ミラーディスクリソースを操作する (clpmdctrl コマンド)」 「ハイブリッドディスクリソースを操作する (clphdctrlコマンド)」 を参照してください。
2.24. ESMPRO/AlertManager と連携する¶
CLUSTERPRO は ESMPRO/AlertManager と連携することで、システムの異常を示すイベントログをきっかけにフェイルオーバすることができます。イベントログ監視を行うためには、クラスタサーバ上に ESMPRO/ServerAgent および ESMPRO/AlertManager がセットアップされている必要があります。
2.24.1. 環境設定¶
クラスタを構成する全てのサーバで、ESMPRO/AlertManager から監視対象イベントログの通報設定で、フェイルオーバコマンドの実行を登録します。
ESMPRO/AlertManager の設定方法の詳細は ESMPRO/AlertManager のマニュアルを 参照してください。
2.24.2. UPS の設定¶
多機能 UPS が接続されている構成でサーバの電源を投入する場合は、サーバに接続される UPS 背面の「AUTO/LOCAL スイッチ」を「LOCAL」にして、UPS 前面の「ON/OFF スイッチ」で電源を投入後「AUTO/LOCAL スイッチ」を「AUTO」に戻してください。
共有ディスクのシステムの場合、共有ディスクに接続される UPS の「AUTO/LOCAL スイッチ」の操作は必要ありません。
また、すべてのサーバの電源投入は、Cluster WebUI で設定する [クラスタのプロパティ] - [タイムアウト] タブ - [同期待ち時間] (既定値 5 分) 以内に行ってください。この時間以内にサーバの電源が投入されない場合、フェイルオーバが発生するので注意してください。
また、共有ディスクシステムの場合、共有ディスクは電源投入後、数分間の時間をかけて、初期化処理を行います。この初期化処理中に、サーバ (OS) が起動すると共有ディスクを認識できませんので、この時間内にサーバが起動しないようにしてください。
2.24.3. UPS の交換¶
多機能 UPS を交換する場合は、以下の手順で行ってください。
Cluster WebUI で OS をシャットダウンさせてください。
正常にシャットダウンが終了したら、UPS のイネーブルスイッチを「OFF」にしてください。
UPS の「Server」(RS232C) ポートに接続されている、サーバとの通信ケーブルを外してください。
UPS に接続されている負荷装置の電源ケーブルを、UPS から外してください。
UPS 本体の電源ケーブルを電源元から外してください。
UPS を交換してください。なお、交換時に以下の事を確認してください。
共有ディスクの UPS を交換する場合は、新しく設置する UPS 背面のディップスイッチが「スレーブ」に設定されていることを確認してください。
サーバに接続される UPS を交換する場合は、新しく設置する UPS 背面のディップスイッチが「マスター」に設定されていることを確認してください。
UPS 本体の電源ケーブルを電源元へ接続してください。
UPS に接続されている負荷装置の電源ケーブルを、UPS へ接続してください。(この時に、「Switch-out」「UnSwitch-out」を間違えないように注意してください。)
UPS の「Server」(RS232C) ポートに、サーバとの通信ケーブルを接続してください。
UPS のイネーブルスイッチを「ON」し、続けて、UPS の「ON/OFF」スイッチを「ON」にしてください。(この時、「AUTO/LOCAL スイッチ」が、「LOCAL」になっていることを確認 してください。)
各々、UPS の出力に接続されている負荷装置に電源が供給された UPS の「AUTO/LOCAL スイッチ」を「AUTO」にしてください。
OS が正常に起動されたら、通常「ESMPRO/UPSController」を利用されているユーザ(Administrator 等) でログインしてください。
「スタートメニュー」より、「ESMPRO/UPSController」のマネージャを起動し、現在 UPSの交換を行っているサーバを選択し、UPS の情報取得を行ってください。
UPS 情報が正常に表示されれば、作業終了です。
ここで、UPS 情報が表示されない場合は、再度、「ESMPRO/UPSController」メニューの「設定」/「動作環境の設定」を表示し、各項目に対し設定が正しくされているか確認してください。
COM ポート
使用 UPS
上記の設定を正しく行っても、UPS の情報が表示されない場合は、UPS 側 (RS232C通信ケーブル、ディップスイッチ等) の設定と、サーバ側 (シリアルポート等) の設定も確認してください。
2.25. システムディスクのリストア¶
2.25.1. システムディスクのリストア手順¶
サーバのシステムディスクに異常が発生した場合、以下の手順でディスクを交換し、バック アップデータのリストアを行ってください。バックアップ採取後に CLUSTERPRO のアップ デート適用や構成変更を行っている場合は、リストア実施後に一旦 CLUSTERPRO をアン インストールし、このサーバを新規サーバとしてサーバ交換の手順を実施してください。
システムディスクをリストアするサーバ (以下、対象サーバ) で起動しているグループが あれば、グループの移動を行ってください。ミラーディスクリソース/ハイブリッドディスクリソースを使用している場合は、グループの移動が完了した後、これらのリソースが正常に起動していることを確認してください。
重要
リストアを行わない側のサーバでミラーディスクリソース/ハイブリッドディスクリソースが最新の状態でない場合にシステムディスクのリストアを行うと、データパーティション上のデータが破壊される可能性があります。
ミラーディスクリソース/ハイブリッドディスクリソースを使用している場合は、以下を実施します。
Cluster WebUI の設定モードの [クラスタのプロパティ] の [ミラーディスク] タブで [自動ミラー復帰]のチェックボックスをオフにします。
Cluster WebUI の設定モードの[設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
対象サーバが稼動中の場合、このサーバを [スタート] メニューの [シャットダウン] よりシャットダウンします。
対象サーバに共有ディスクが接続されている場合、対象サーバと共有ディスクを接続している接続ケーブルを取り外します。ケーブルの取り外しは以下の点に注意して行ってください。
SCSI ディスクアレイ装置を使用する場合、二股ケーブルの根元から抜いてください。
Fibre Channel ディスクアレイ装置を使用する場合、障害サーバと Fibre Channel-HUB または Fibre Channel-Switch 間のケーブルを抜いてください。
リストアを行うサーバのシステムディスクを交換します。交換方法の詳細は装置添付のユーザーズガイドを参照してください。
OS を通常のインストール手順でインストールします。
OS のインストール方法はサーバ添付のユーザーズガイドを参照してください。
OS インストール時にネットワークの設定は必ず行ってください。また、OS のサービスパックもディスク交換前と同じ状態に適用してください。
OS が正常に起動することを確認した後、バックアップソフトウェアをインストールします。(詳細はバックアップソフトウェアの説明書を参照してください。)
バックアップソフトウェアで、バックアップからシステムディスクをリストアします。
クラスタに依存する注意点はありません。通常通りにレジストリが復元でき、同一ファイルを上書きする設定でリストアしてください。詳細はバックアップソフトウェアの説明書を参照してください。
対象サーバの CLUSTERPRO Server サービスが自動起動になっている場合は、手動起動に変更します。
リストアしたサーバでドライブ文字がリストア前と変わっていないことを確認します。ドライブ文字が変わっている場合は元通りに再設定してください。また、OS の日付/時刻がクラスタ内の他のサーバと同じであることを確認してください。
SCSI コントローラや FC-HBA (Host Bus Adapter) のドライバがリストアできない場合は、上記のドライバを再インストールしてください。詳細はバックアップソフトウェアの説明書を参照してください。
対象サーバを再起動します。対象サーバに共有ディスクが接続されていない場合は、以降の 16 までの作業は不要です。
リストアしていない方のサーバに Web ブラウザで接続して Cluster WebUI を起動し、対象 サーバのプロパティを開いて、共有ディスクを接続する HBA に対してフィルタ設定を行います。
HBA タブの [接続] をクリックして、対象サーバのディスク構成情報を取得し、共有ディスクを接続する HBA にチェックを入れます。
上記の設定以外は変更しないでください。
Cluster WebUI で HBA のフィルタ設定を行ったクラスタ構成情報を、クラスタサーバからアクセス可能なディスク領域に一旦保存します。
クラスタサーバ上で Cluster WebUI を使用している場合はローカルディスクに保存します。他の PC で Cluster WebUI を使用している場合は、クラスタサーバからアクセス可能な共有フォルダに保存するか、外部メディアなどに一旦保存してクラスタサーバのローカル ディスクにコピーします。
いずれかのクラスタサーバ上で下記のコマンドを実行して、保存したクラスタ構成情報をアップロードします。
clpcfctrl --push -x <クラスタ構成情報のパス> --nocheck
対象サーバをシャットダウンし、ディスクケーブルを接続して再起動します。
リストア前の対象サーバの構成が以下のいずれかに該当する場合は、[ディスクの管理]で当該パーティションを再作成してください。
ミラーディスクリソース/ハイブリッドディスクリソースのクラスタパーティションがシステムディスク上に存在した
ミラーディスクリソース/ハイブリッドディスクリソースのデータパーティションがシステムディスク上に存在した
注釈
データパーティションを再作成する場合は、リストアしていない方のサーバ上のデータパーティションにサイズを合わせてください。対象サーバの [ディスクの管理] で共有ディスクとミラーディスク (データパーティションとクラスタパーティション) のドライブ文字を確認します。もしドライブ文字が変わっている場合は、元通りに再設定し、サーバを再起動してドライブ文字が正しく設定されていることを確認します。
リストアしていない方のサーバに Web ブラウザで接続して Cluster WebUI を起動します。対象サーバに共有ディスクが接続されていて、その共有ディスク上にフィルタリング対象外のボリュームがある場合は、対象サーバの [プロパティ] → [HBA] タブにあるフィルタリング対象外のパーティションの情報を更新してください。
上記の手順 14,15 と同様にして、クラスタ構成情報を一旦保存し、クラスタサーバ上から[clpcfctrl] コマンドでアップロードします。
構成情報を保存する際に [構成情報にあるディスク情報とサーバ上のディスク情報が異なっています。自動修正しますか?] というポップアップメッセージが表示された場合は、[はい] を選択してください。
対象サーバの CLUSTERPRO Server サービスを自動起動に戻し、対象サーバをリブートします。
[クラスタのプロパティ] → [拡張] タブで [自動復帰] が [しない] に設定されている場合 Cluster WebUI の操作モードで対象サーバの [サーバ復帰] をクリックします。対象サーバでミラーディスクリソース/ハイブリッドディスクリソースを使用しない場合、以降の手順は不要です。
システムディスク上にミラーディスクリソース/ハイブリッドディスクリソースを作成している場合、ミラー復帰前にリソースの再作成が必要です。以下の手順を実施してください。
Cluster WebUI の操作モードより、対象となるミラーディスクリソース / ハイブリッドディスクリソースを含むグループを停止します。
クラスタをサスペンドします。
Cluster WebUI の設定モード より、対象となるミラーディスクリソース / ハイブリッドディスクリソースの [リソースの削除] を実行します。削除前に、リソースの再作成に必要な各パラメータを控えておいてください。
[設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
フェイルオーバグループの [リソースの追加] を実行します。このとき指定する各パラメータは、削除前のリソースと同じ値にしてください。
再度、[設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
クラスタをリジュームします。
Cluster WebUI のミラーディスクリストから、すべてのミラーディスクリソースとハイブリッドディスクリソースのミラー復帰 (フルコピー) を行います。
注釈
リストア(ディスク交換)を実施したサーバ上のデータは最新ではない可能性があります。リストアを実施していない側のサーバがコピー元になるようにしてください。また、リストアの過程で差分情報が不正になっている可能性があるため、差分コピーではなくフルコピーを指定してください。手順2.で自動ミラー復帰をオフにした場合は、Cluster WebUI の設定モードの [クラスタのプロパティ] の [ミラーディスク] タブで [自動ミラー復帰] のチェックボックスをオンにします。
Cluster WebUI の設定モードの[設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
グループを起動します。
2.27. ミラーディスクの交換¶
ミラーセットを組んでいるディスクに障害が発生した場合、以下の手順でディスクを交換することが可能です。また、ディスクアレイが構成されている場合、ディスクアレイの再構築を行った場合や DAC 交換等で新規ディスクとして認識される場合も、本手順を実施する必要があります。
ハイブリッドディスクリソースでミラーリングしているローカルディスクを交換する際も、下記の 手順で交換可能です。この場合、以下の記述の「ミラーディスクリソース」を「ハイブリッドディスクリソース」と読み替えてください。3 台以上のサーバで構成するハイブリッドディスクリソースでミラーリングしている共有ディスクを交換する場合は、「ハイブリッドディスクの交換」の手順を参照してください。
クラスタの状態を正常状態にします。(ただし交換するディスクの異常は除きます。)
ディスクを交換するサーバでグループが起動している場合、グループを移動します。
[クラスタのプロパティ] で [自動ミラー復帰] のチェックボックスをオンにしている場合は、Cluster WebUI の設定モードで [クラスタのプロパティ]→[ミラーディスク] タブを開いて[自動ミラー復帰] のチェックを外し、[設定の反映] をクリックしてクラスタ構成情報をクラスタに反映します。
Cluster WebUI の操作モードから、ディスクを交換するサーバをシャットダウンして電源を切ります。
ディスクを交換し、サーバを起動します。
ディスクを交換したサーバでディスクを設定します。
ディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) を使用してミラーディスク用のデータパーティションとクラスタパーティションを確保します。データパーティションとクラスタパーティションのドライブ文字、および データパーティションのサイズが両サーバで同じになるように設定します。
[クラスタのプロパティ]→[拡張] タブで [自動復帰] を [しない] に設定している場合は、交換したサーバを Cluster WebUI の操作モードからクラスタに復帰します。
クラスタをサスペンドします。
Cluster WebUI を起動します。手順 3 で [自動ミラー復帰] をオフにした場合は、オンに戻します。
Cluster WebUI の設定モードの[設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
[構成情報にあるディスク情報とサーバ上のディスク情報が異なっています。自動修正しますか?] というポップアップメッセージが表示された場合は、[はい] を選択してください。
Cluster WebUI の操作モードからクラスタをリジュームします。
[自動ミラー復帰] を行う設定であれば自動的にミラーの再構築 (フルコピー) が行われます。[自動ミラー復帰] を行わない設定の場合、手動でミラーの再構築を行ってください。
必要であれば、グループを移動します。
2.28. ハイブリッドディスクの交換¶
3 台以上のサーバで構成するハイブリッドディスクリソース環境で、ミラーセットを組んでいる共有ディスクに障害が発生した場合、以下の手順でディスクを交換することが可能です。また、ディスクアレイが構成されている場合、ディスクアレイの再構築を行った場合や DAC 交換等で新規ディスクとして認識される場合も、本手順を実施する必要があります。
ハイブリッドディスクリソースでミラーリングしているローカルディスクを交換する場合は、「2.27. ミラーディスクの交換 」の手順を参照してください。
クラスタの状態を正常状態にします。(ただし交換するディスクの異常は除きます。)
ディスクを交換するサーバでグループが起動している場合、グループを移動します。
[クラスタのプロパティ] で [自動ミラー復帰] のチェックボックスをオンにしている場合は、Cluster WebUI の設定モードで [クラスタのプロパティ]→[ミラーディスク] タブを開いて[自動ミラー復帰] のチェックを外し、[設定の反映] をクリックしてクラスタ構成情報をクラスタに反映します。
Cluster WebUI の操作モードから、交換する共有ディスクに接続されている全サーバに対して[サーバサービス停止] でクラスタ停止を行います。
交換する共有ディスクに接続されている全サーバで、[CLUSTERPRO Server] サービスの [スタートアップの種類] を [手動] に設定します。
交換する共有ディスクに接続されている全てのサーバのシャットダウンを行い、電源を切ります。
共有ディスクの電源を切り、ディスクを交換します。
共有ディスクの電源を入れ、共有ディスクの設定を行います。
RAID 再構築/LUN の構成変更が必要な場合は共有ディスク添付の設定ツールを使用して行ってください。詳細は共有ディスク添付の説明書をご覧ください。
1 台のみサーバを起動し、ディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) から交換前と同じようにパーティションを作成し、ドライブ文字を設定します。OSが自動で割り当てたドライブ文字が割り当てようとしていたドライブ文字と同一であっても、一度削除して設定しなおすなど、手動で明示的に割り当ててください。
注釈
作成したパーティションには、作成した時点でアクセス制限がかかるためフォーマットはできません。ここではドライブ文字の設定のみ行ってください。
注釈
ディスクリソースに使用する切替パーティションはこのタイミングでサイズを変更できますが、ハイブリッドディスクリソースのデータパーティションは両サーバグループでサイズが一致している必要があるため、サイズを変更するには一旦リソースを削除して両サーバグループでパーティションサイズを変更してからリソースを再作成する必要があります。
注釈
共有ディスクのパーティションに対してドライブ文字の変更/削除を行うと操作が失敗することがあります。以下の回避手順に従って、設定を行ってください。
コマンドプロンプトから以下のコマンドを実行して、ドライブ文字を削除して下さい。
> mountvol (変更対象の)ドライブ文字: /P
ディスクの管理([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理])を使用して変更対象ドライブからドライブ文字が削除されていることを確認してください。
[ディスクの管理]からドライブ文字を追加してください。
ディスクリソースとして使用するパーティションのフォーマットを行うため、下記のコマンドを実行し、アクセス制限を一時的に解除します。
clpvolctrl --open <ディスクリソースに使用するパーティションのドライブ文字>
ディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) からディスクリソースに使用するパーティションのフォーマットを実行します。
上記の手順 10 で一時的に解除していたアクセス制限を元に戻すため、下記のコマンドを実行してください。
clpvolctrl --close <ディスクリソースに使用するパーティションのドライブ文字>
交換した共有ディスクに接続されている他のサーバを起動し、ディスクの管理 ([コントロールパネル] > [管理ツール] > [コンピュータの管理] > [ディスクの管理]) から 1 台目のサーバで作成したパーティションが見えることを確認します。
1 台目のサーバと同様に、共有ディスク上の各パーティションのドライブ文字をディスク 交換前と同じように設定します。
交換した共有ディスクに接続されている全サーバで、[CLUSTERPRO Server] サービスの [スタートアップの種類] を [自動] に戻します。
Cluster WebUI を起動し、交換した共有ディスクに接続されている全てのサーバに対して [サーバサービス開始] でクラスタ開始を行います。
注釈
このとき hdw および hdtw による警告メッセージが表示されることがありますが、問題ありませんのでそのまま手順を続けてください。
クラスタをサスペンドします。
交換した共有ディスク上にアクセス制限を行わないパーティションがある場合は、共有ディスクに接続された各サーバの [プロパティ] の [HBA] タブを開き、[接続] をクリックして、[クラスタ管理から除外するパーティション] にそれらのパーティションを追加します。
注釈
交換する前の共有ディスクで [クラスタ管理から除外するパーティション] が設定されていた場合、一度設定を削除してから再度設定をやり直す必要があります。下記の手順を実施してください。
Cluster WebUI の設定モードより、交換したディスクに接続しているサーバの [プロパティ] の [HBA] タブを開き、[接続] をクリックします。
フィルタリングがチェックされている HBA を選択し、[クラスタ管理から除外するパーティション] に表示されるパーティションをすべて [削除] します。
改めて [追加] をクリックし、手順 18-2 で削除したパーティションをすべて追加します。
クラスタ管理から除外するパーティションのボリューム、ディスク番号、パーティション番号、容量、GUID がそれぞれ表示されていることを確認してください。
Cluster WebUI を起動し、手順 3 で [自動ミラー復帰] をオフにした場合は、オンに戻します。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
[構成情報にあるディスク情報とサーバ上のディスク情報が異なっています。自動修正しますか?] というポップアップメッセージが表示された場合は、[はい] を選択してください。
Cluster WebUI の操作モードからクラスタをリジュームします。
[自動ミラー復帰] を行う設定であれば自動的にミラーの再構築 (フルコピー) が行われます。[自動ミラー復帰] を行わない設定の場合、手動でミラーの再構築を行ってください。
必要であれば、グループを移動します。
2.30. ミラーディスクのサイズ拡張¶
注釈
クラスタの状態を正常状態にします。
拡張するミラーディスクリソースを正常状態にします。
Cluster WebUIの操作モードからミラーディスク監視リソースをすべて「一時停止」にし、自動でミラー復帰が行われない状態にします。
ミラーディスクリソースが活性していない側のサーバで、以下のclpmdctrlコマンドを実行します。どちらのサーバでもリソースが活性してない場合は、どちらから実行しても構いません。以下は、md01のデータパーティションを500ギビバイトに拡張する場合の例です。
clpmdctrl --resize md01 500G
もう一方のサーバで、以下のclpmdctrlコマンドを実行します。以下は、md01のデータパーティションを500ギビバイトに拡張する場合の例です。
clpmdctrl --resize md01 500G
重要
下記のコマンドを実行し、両方の対象サーバでボリュームサイズが一致していることを確認します。
clpvolsz <ミラーディスクリソースに使用するパーティションのドライブ文字>:
活性している側のサーバでdiskpartコマンドを実行します。
diskpartDISKPARTプロンプトでlist volumeを実行し、対象のデータパーティションのボリューム番号(###のカラム)を確認します。以下は実行例です。
DISKPART> list volume Volume ### Ltr Label Fs Type Size Status Info ---------- --- ----------- ----- ---------- ------- ------------ -------- Volume 0 E DVD-ROM 0 B メディアなし Volume 1 C NTFS Partition 99 GB 正常 ブート Volume 2 D NTFS Partition 500 GB 正常 Volume 3 FAT32 Partition 100 MB 正常 システム
DISKPARTプロンプトで select volumeを実行し、対象ボリュームを選択します。
DISKPART> select volume 2
DISKPARTプロンプトで extend filesystem を実行し、対象ボリュームのファイルシステムを拡張します。
DISKPART> extend filesystem
DISKPARTプロンプトで exit を実行し、diskpartを終了します。
DISKPART> exit
手順3で「一時停止」にしたミラーディスク監視リソースを、Cluster WebUI の操作モードからすべて「再開」します。
重要
clpmdctrl --resize md01 500G -force
2.31. ハイブリッドディスクのサイズ拡張¶
注釈
クラスタの状態を正常状態にします。
拡張するハイブリッドディスクリソースを正常状態にします。
Cluster WebUIの操作モードからハイブリッドディスク監視リソースをすべて「一時停止」にし、自動でミラー復帰が行われない状態にします。
各サーバグループのカレントサーバのみを残し、他のサーバをすべてシャットダウンしてください。カレントサーバはclphdstatの-aオプションで確認できます。以下は、リソースhd01のカレントサーバを確認する場合の例です。
clphdstat -a hd01
- ハイブリッドディスクリソースが活性していない側のサーバグループ上のカレントサーバで、以下のclphdctrlコマンドを実行します。どちらのサーバグループでもリソースが活性してない場合は、どちらから実行しても構いません。以下は、hd01のデータパーティションを500ギビバイトに拡張する場合の例です。
clphdctrl --resize hd01 500G
- もう一方のサーバグループ上のカレントサーバで、同様に以下のclphdctrlコマンドを実行します。以下は、hd01のデータパーティションを500ギビバイトに拡張する場合の例です。
clphdctrl --resize hd01 500G
重要
ハイブリッドディスクリソースがいずれかのサーバで活性中の場合は、必ず活性してない方のサーバグループから実行してください。活性している側のサーバグループから実行すると、ミラーブレイク発生の原因となります。
下記のコマンドを実行し、両方のサーバグループでボリュームサイズが一致していることを確認します。
clpvolsz <ハイブリッドディスクリソースに使用するパーティションのドライブ文字>:
活性しているサーバでdiskpartコマンドを実行します。
diskpartDISKPARTプロンプトでlist volumeを実行し、対象のデータパーティションのボリューム番号(###のカラム)を確認します。以下は実行例です。
DISKPART> list volume Volume ### Ltr Label Fs Type Size Status Info ---------- --- ----------- ----- ---------- ------- ------------ -------- Volume 0 E DVD-ROM 0 B メディアなし Volume 1 C NTFS Partition 99 GB 正常 ブート Volume 2 D NTFS Partition 500 GB 正常 Volume 3 FAT32 Partition 100 MB 正常 システム
DISKPARTプロンプトで select volumeを実行し、対象ボリュームを選択します。
DISKPART> select volume 2
DISKPARTプロンプトで extend filesystem を実行し、対象ボリュームのファイルシステムを拡張します。
DISKPART> extend filesystem
DISKPARTプロンプトで exit を実行し、diskpartを終了します。
DISKPART> exit
手順3で「一時停止」にしたハイブリッドディスク監視リソースを、Cluster WebUI の操作モードからすべて「再開」します。
手順4でシャットダウンしていたサーバをすべて起動します。
重要
clphdctrl --resize hd01 500G -force
2.32. ディスクアレイコントローラ(DAC)の交換 / ファームウェア アップデート¶
ディスクアレイコントローラ(DAC)の交換またはファームウェア アップデートを実施すると、実際にはディスク交換を行っていない場合でも、既存のディスクが、OS から新しいディスクとして認識される場合があります。OSからどのようにディスクが認識されるかによって必要な作業が異なるため、DACの交換またはファームウェア アップデートを実施する際は、必ず以下の手順に従ってください。
クラスタの状態を正常状態にします。
DACを交換またはファームウェア アップデートを実施するサーバ (以下、対象サーバ) でグループが起動している場合、グループを移動します。
DAC の交換またはファームウェア アップデートを実施する前に、以下のコマンドを実行して、すべてのミラーディスクリソースおよびハイブリッドディスクリソースのパーティションの「ドライブ文字」と「GUID」の組を確認します。
mountvol出力例:
以下に出力例を示します。"C:\" の部分はドライブ文字です。また、"123da03b-e7e0-11e0-a2aa-806d6172696f" の部分は GUIDです。C:> mountvol 現在のマウント ポイントとボリューム名の考えられる値: \\?\Volume{123da03a-e7e0-11e0-a2aa-806d6172696f}\ C:\ \\?\Volume{123da03b-e7e0-11e0-a2aa-806d6172696f}\ Z:\ \\?\Volume{123da03c-e7e0-11e0-a2aa-806d6172696f}\ P:\DAC の交換の場合は Cluster WebUI の操作モードから対象サーバをシャットダウンして電源を切ります。
- DAC の交換またはファームウェア アップデートを実施します。DAC の交換の場合は対象サーバの電源を入れてOSを起動します。
- DACの交換またはファームウェア アップデート完了後、ミラーディスクリソースおよびハイブリッドディスクリソースの使用しているディスクが、OSから既存のディスクとして認識されていることを確認するため、以下の手順を行います。対象サーバ上で以下のコマンドを実行し、ミラーディスクリソースおよびハイブリッドディスクリソースの「ドライブ文字」と「GUID」の組み合わせが、手順3. で確認した内容から変化しているかどうかを確認します。
mountvol - すべてのミラーディスクリソースおよびハイブリッドディスクリソースの「ドライブ文字」と「GUID」の組み合わせが、手順3. で確認した内容から変化していない場合は、OSから既存のディスクとして認識されています。この場合は、続けて手順10. 以降を実施します。(手順8~9. は不要です)手順3. で確認した内容から変化している場合は、OSから新しいディスクとして認識されています。この場合は、続けて次の手順8. 以降を実施します。
対象サーバでディスクの設定を確認します。
ディスクの管理([コントロールパネル]>[管理ツール]>[コンピュータの管理]>[ディスクの管理])を使用して、データパーティションとクラスタパーティションのドライブ文字を確認します。もしドライブ文字が変わっている場合は、元通りにドライブ文字を再設定します。
Cluster WebUI の操作モードから対象サーバを再起動します。
手順8. にてドライブ文字の修正を行った場合は、「2.27. ミラーディスクの交換 」の手順の手順7. から手順11. に従い、クラスタの情報の再設定を行ってください。その際、「ディスクを交換したサーバ」を「対象サーバ」と読み替えてください。
対象サーバをクラスタに復帰します。
自動復帰モードの場合には自動的にクラスタに復帰します。
[クラスタのプロパティ]→[ミラーディスク]タブで[自動ミラー復帰]を行う設定であれば自動的にミラーの再構築(差分コピーまたはフルコピー)が行われます。[自動ミラー復帰]を行わない設定の場合、 手動でミラーの再構築を行ってください。
ミラーの再構築が異常終了した場合は、「2.27. ミラーディスクの交換 」の手順8. から手順12. に従い、クラスタの情報の再設定を行ってください。その際、「ディスクを交換したサーバ」を「対象サーバ」と読み替えてください。
必要であれば、グループを移動します。
2.33. FibreChannel HBA/SCSI/SAS コントローラの交換¶
共有ディスクを接続している HBA を交換する場合、以下の手順を実施する必要があります。
HBA を交換するサーバ (以下、対象サーバ) でグループが動作している場合は、他のサーバに移動します。
対象サーバの CLUSTERPRO Server サービスを手動起動に変更します。
対象サーバをシャットダウンし、HBA を交換します。
ディスクケーブルを抜いた状態で対象サーバを起動します。
Cluster WebUI の設定モードから、対象サーバのプロパティを開いて、交換した HBA に 対してフィルタ設定を行います。
[HBA] タブの [接続] をクリックして、対象サーバのディスク構成情報を取得し、交換した HBA にチェックを入れます。
上記の設定以外は変更しないでください。
Cluster WebUI で HBA のフィルタ設定を行ったクラスタ構成情報を、クラスタサーバからアクセス可能なディスク領域に一旦保存します。
クラスタサーバ上で Cluster WebUI を使用している場合はローカルディスクに保存します。他の PC で Cluster WebUI を使用している場合は、クラスタサーバからアクセス可能な共有フォルダに保存するか、外部メディアなどに一旦保存してクラスタサーバのローカルディスクにコピーします。
いずれかのクラスタサーバ上で下記のコマンドを実行して、保存したクラスタ構成情報をアップロードします。
clpcfctrl --push -x <クラスタ構成情報のパス> --nocheck
対象サーバをシャットダウンし、ディスクケーブルを接続します。
- 対象サーバを起動して、[ディスクの管理] でドライブ文字を確認します。もしドライブ文字が変わっている場合は、元通りに再設定し、サーバを再起動してドライブ文字が正しく設定されていることを確認します。
Cluster WebUI の設定モードから、対象サーバのプロパティを開いて、[HBA] タブの設定を確認します。共有ディスク上にアクセス制限を行わないパーティションがある場合は、[クラスタ管理から除外するパーティション] 欄にパーティション情報が登録されていることを確認します。
上記の手順 6,7 と同様にして、クラスタ構成情報を一旦保存し、クラスタサーバ上から 下記のコマンドでアップロードします。
clpcfctrl --push -x <クラスタ構成情報のパス> --nocheck
構成情報を保存する際に [構成情報にあるディスク情報とサーバ上のディスク情報が異なっています。自動修正しますか?] というポップアップメッセージが表示された場合は、[はい] を選択してください。
対象サーバの CLUSTERPRO Server サービスを自動起動に戻し、対象サーバをリブートします。
[クラスタのプロパティ]→[拡張] タブで [自動復帰] が [しない] に設定されている場合、Cluster WebUI の操作モードで対象サーバの [サーバ復帰] を選択します。
必要であれば、グループを移動します。
2.34. ミラーディスクリソース/ハイブリッドディスクリソースの暗号鍵を更新する¶
ミラーディスクリソースおよびハイブリッドディスクリソースのミラー通信暗号化に使用する暗号鍵を更新する場合は、以下の手順で実施します。
注釈
下記手順は、ミラーディスクリソースおよびハイブリッドディスクリソースが活性した状態のまま実行可能です。ただし、ミラーリング中の場合は、ミラーリングが中断しますので、手順完了後にミラー復帰を実行してください。
clpkeygenコマンドを使用し、新しく暗号鍵ファイルを生成します。clpkeygenコマンドの詳細は、『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」「通信暗号化用の鍵ファイルを作成する (clpkeygenコマンド)」を参照してください。
clpkeygen 256 newkeyfile.bin
ミラーディスクリソースまたはハイブリッドディスクリソースが活性可能な全サーバの暗号鍵ファイルを、手順1で生成したファイルで上書きします(ファイル名は元のままにする)。
clpmdctrlまたはclphdctrlの--updatekeyオプションを実行してください。
ミラーディスクリソースの場合
clpmdctrl --updatekey md01
ハイブリッドディスクリソースの場合
clphdctrl --updatekey hd01
リソースが活性可能ないずれかのサーバ上で1度実行するのみで、更新が必要な全サーバの鍵情報を更新します。この時、ミラーリング中の場合は、ミラーリングが中断されます。暗号鍵情報の更新が完了します。以後、新しい暗号鍵を使用してミラー通信の暗号化および復号が実施されます。
必要に応じて、ミラー復帰を実行してミラーリングを再開してください。
2.35. 問い合わせの際に必要な情報¶
問い合わせを行う際に必要な情報を、以下に記します。
- 現象障害の内容について、記述してください。
例) フェイルオーバグループ (failover1) が server1 から server2 へのフェイルオーバに失敗した。
現象発生日時
例) 2018/01/01 00:00頃
現象が発生したサーバの名前
例) server2
CLUSTERPRO のバージョン
例) CLUSTERPRO X 5.0
- 現象発生時の CLUSTERPRO のログ、およびイベントログCluster WebUI からログ収集を実行していただくか、ログ収集コマンドを実行していただくことによって採取可能です。Cluster WebUI を使用する場合はオンラインマニュアルを、ログ収集コマンドを使用する場合は『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ログを収集する (clplogcc コマンド)」を参照してください。