9. EXPRESSCLUSTER命令参考¶
在本章中对EXPRESSCLUSTER中可以使用的命令进行说明。
本章中主要说明以下内容。
9.1. 从命令行操作集群¶
EXPRESSCLUSTER提供了多种命令用于从命令行窗口操作集群。构筑集群以及不能使用Cluster WebUI等时可以使用这些命令。
注解
通过监视资源的异常查出时的设置将恢复对象指定为组资源(磁盘资源,应用程序资源,...),监视资源查出异常时,恢复运行变化过程(重新启动 -> 失效切换 -> 最终运行)中,请不要通过以下命令或Cluster WebUI执行对集群以及组的控制操作。
停止/挂起集群
开始/停止/移动组
监视资源异常导致恢复运行变化的过程中,若执行上述控制操作,该组的其他组资源有可执行不会停止。
另外,即使监视资源状态异常,执行最终运行后也可执行上述控制操作。
9.2. EXPRESSCLUSTER命令一览¶
集群构筑相关
命令 |
说明 |
参考 |
|---|---|---|
clpcfctrl.exe |
将Cluster WebUI创建的配置信息发送给服务器。
通过Cluster WebUI备份使用所需的集群配置信息。
|
|
clplcnsc.exe |
管理本制品的正式版・试用版License。 |
|
clpcfchk.exe |
检查集群配置信息。 |
|
clpcfconv.bat |
集群配置信息文件从旧版本更换到现在版本中。 |
|
clpcfset.exe
clpcfadm.py
|
生成集群配置信息文件。 |
|
clpencrypt.exe |
加密。 |
|
clpdiskctrl.exe |
操作驱动的GUID和HBA信息。 |
|
clpfwctrl.bat |
添加防火墙规则。 |
状态显示相关
命令 |
说明 |
参考 |
|---|---|---|
clpstat.exe |
显示集群的状态及配置信息。 |
|
clphealthchk.exe |
确认进程的健全性。 |
集群操作相关
命令 |
说明 |
参考 |
|---|---|---|
clpcl.exe |
执行EXPRESSCLUSTER服务的启动,停止,挂起,恢复等。 |
|
clpdown.exe |
停止EXPRESSCLUSTER服务,关闭服务器。 |
|
clpstdn.exe |
在集群整体中停止EXPRESSCLUSTER服务,关闭所有服务器。 |
|
clpgrp.exe |
执行组的启动,停止,移动。 |
|
clptoratio.exe |
延长,显示集群内所有服务器的各种超时值。 |
|
clpmonctrl.exe |
进行监视资源的控制 |
|
clprsc.exe |
暂时停止/重新开始组资源。 |
|
clprexec.exe |
外部监视请求EXPRESSCLUSTER服务器执行处理。 |
|
clpbwctrl.exe |
控制集群启动同步等待处理。 |
|
clpregctrl.exe |
显示/初始化单个服务器上的重启次数。 |
|
clpstdncnf.exe |
通过集群外部的操作设置关闭OS时的动作。 |
日志相关
命令 |
说明 |
参考 |
|---|---|---|
clplogcc.exe |
收集日志,OS信息等。 |
|
clplogcf.exe |
更改,显示日志级别,日志输出文件大小的设置。 |
|
clpperfc.exe |
显示与组,监视资源相关的集群统计信息。 |
脚本相关
命令 |
说明 |
参考 |
|---|---|---|
clplogcmd.exe |
在脚本资源的脚本中描述,将任意消息输出到输出目标。 |
重要
在安装目录下有在本手册中未记载的执行格式文件及脚本文件,只能从EXPRESSCLUSTER执行这些文件。否则,不支持执行后造成的影响。
镜像相关(仅使用Replicator/ Replicator DR时)
命令 |
说明 |
参考 |
|---|---|---|
clpmdstat.exe |
显示镜像磁盘相关的状态和设置信息。 |
|
clpmdctrl.exe |
进行镜像磁盘资源的启动/停止、镜像复归等。 |
|
clphdstat.exe |
显示共享型镜像磁盘相关的状态和设置信息。 |
|
clphdctrl.exe |
进行共享型镜像磁盘资源的启动/停止、镜像复归等。 |
|
clpvolsz.exe |
确认/调整镜像连接对象分区的大小。 |
|
clpvolctrl.exe |
执行访问未登录资源卷的操作。 |
|
clpkeygen.exe |
生成镜像数据通信加密的加密密钥文件。 |
|
clphdsnapshot.exe |
控制采集共享型镜像磁盘资源的数据分区快照备份时的访问限制。 |
|
clpbackup.bat |
使镜像对象分区为可以进行磁盘映像备份的状态。 |
|
clprestore.bat |
已恢复的镜像磁盘映像处于可以使用的状态。 |
通知相关(仅使用Alert Service时)
命令 |
说明 |
参考 |
|---|---|---|
clplamp.exe |
关闭网络警告灯 |
数据库静止点相关
命令 |
说明 |
参考 |
|---|---|---|
clpdb2still |
控制确保/释放DB2的静止点。 |
|
clporclstill |
控制确保/释放Oracle的静止点。 |
|
clppsqlstill |
控制确保/释放PostgreSQL的静止点。 |
|
clpmssqlstill |
控制确保/释放SQL Server的静止点。 |
9.3. 显示集群的状态(clpstat命令)¶
显示集群的状态和配置信息。
-
命令行 - clpstat -s [--long] [-h <hostname>]clpstat -g [-h <hostname>]clpstat -m [-h <hostname>]clpstat -n [-h <hostname>]clpstat -f [-h <hostname>]clpstat -i [--detail] [-h <hostname>]clpstat --cl [--detail] [-h <hostname>]clpstat --sv [<srvname>] [--detail] [-h <hostname>]clpstat --hb [<hbname>] [--detail] [-h <hostname>]clpstat --fnc [<fncname>] [--detail] [-h <hostname>]clpstat --svg [<svgname>] [-h <hostname>]clpstat --grp [<grpname>] [--detail] [-h <hostname>]clpstat --rsc [<rscname>] [--detail] [-h <hostname>]clpstat --mon [<monname>] [--detail] [-h <hostname>]clpstat --xcl [<xclname>] [--detail] [-h <hostname>]clpstat --local
-
说明 显示集群的状态和配置信息。
-
选项 -
无选项¶
-
-s¶ 显示集群的状态
-
--long¶ 显示所有的集群名,资源名等名称
-
-g¶ 显示集群的组图。
-
-m¶ 显示各服务器中各监视资源的状态。
-
-n¶ 显示各服务器中各心跳资源的状态。
-
-f¶ 显示各服务器中Fencing功能(网络分区解决资源以及强制停止资源)的状态。
-
-i¶ 显示集群整体的配置信息。
-
--cl¶ 显示集群的配置信息。使用了Replicator/ Replicator DR时,还显示磁盘Agent的信息。
-
--sv[<srvname>]¶ 显示服务器的配置信息。通过指定服务器名,可以只显示指定的服务器信息。
-
--hb[<hbname>]¶ 显示心跳资源的配置信息。通过指定心跳资源名,可以只显示指定的心跳资源信息。
-
--fnc[<fncname>]¶ 显示Fencing功能(网络分区解决资源以及强制停止资源)的设置信息。通过指定资源名,只能显示指定的网络分区解决资源或者强制停止资源的信息。
-
--svg[svgname]¶ 显示服务器组的设置信息。通过指定服务器组名可以仅显示指定服务器组的信息。
-
--grp[<grpname>]¶ 显示组的配置信息。通过指定组名,可以只显示指定的组信息。
-
--rsc[<rscname>]¶ 显示组资源的配置信息。通过指定组资源名,可以只显示指定的组资源信息。
-
--mon[<monname>]¶ 显示监视资源的配置信息。通过指定监视资源名,可以只显示指定的监视资源信息。
-
--xcl[<xclname>]¶ 显示互斥规则的设置信息。通过指定互斥规则名,可仅显示指定的互斥规则信息。
-
--detail¶ 通过使用此选项,可以显示更详细的配置信息。
-
-h<hostname>¶ 从host_name指定的服务器获取信息。省略了[-h]选项时,从命令执行服务器(自身服务器)获取信息。
-
--local¶ - 显示集群的状态。虽然同-s或无选项时显示同样的信息,但不执行与其他服务器之间的通信,只显示执行命令的服务器上的信息。
-
-
返回值 0
成功
上述以外
异常
-
备注 根据配置信息显示选项的不同组合,可以多种形式显示信息。
在显示结果的服务器名旁边显示的*号,代表执行此命令的服务器。
-
注意事项 请由Administrator权限的用户执行本命令。
请将[-h]选项中的服务器名指定为集群内的服务器名。
没有指定参数或指定了-s参数的情况下,集群名,资源名等名,在中途不会被输出。
-
显示示例 后面将对显示示例进行说明。
-
错误消息 消息
原因/处理方法
Log in as administrator.
请由具有Administrator权限的用户执行。
Invalid configuration file. Create valid cluster configuration data.
请使用Cluster WebUI创建正确的集群配置信息。
Invalid option.
请指定正确的选项。
Could not connect to the server. Check if the cluster service is active.
请确认EXPRESSCLUSTER Information Base服务是否已启动。
Invalid server status.
请确认EXPRESSCLUSTER服务是否已启动。
Server is not active. Check if the cluster service is active.
请确认EXPRESSCLUSTER服务是否已启动。
Invalid server name. Specify a valid server name in the cluster.
请指定集群内正确的服务器名。
Invalid heartbeat resource name. Specify a valid heartbeat resource name in the cluster.
请指定集群内正确的心跳资源名。
Invalid network partition resource name. Specify a valid network partition resource name in the cluster.
请指定集群内正确的网络分区解决资源名。
Invalid group name. Specify a valid group name in the cluster.
请指定集群内正确的组名。
Invalid group resource name. Specify a valid group resource name in the cluster.
请指定集群内正确的组资源名。
Invalid monitor resource name. Specify a valid monitor resource name in the cluster.
请指定集群内正确的监视资源名。
Connection was lost. Check if there is a server where the cluster service is stopped in the cluster.
请确认集群内是否存在EXPRESSCLUSTER服务已停止的服务器。
Invalid parameter.
可执行是命令的参数中设置了非法的值。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
EXPRESSCLUSTER的内部通信中发生了超时。如果频繁发生超时,请延长内部通信超时。Internal error. Check if memory or OS resources are sufficient.
请确认是否是内存不足或OS资源不足。
The cluster is not created.
请做成集群的配置文件并上传。
Could not connect to the server. Internal error. Check if memory or OS resources are sufficient.
内存不足或者OS资源不足。请确认。
Cluster is stopped. Check if the cluster daemon is active.
请确认EXPRESSCLUSTER Daemon是否启动。
Cluster is suspended. To display the cluster status, use --local option.
集群处于暂停状态。请指定--local选项来显示集群状态。
-
执行示例
显示集群状态(-s选项)
指定了-s选项及不指定选项时的示例:
-
执行示例 # clpstat -s
-
显示示例 ===================== CLUSTER STATUS ======================== Cluster : cluster <server> *server1........... : Online server1 lankhb1 : Normal LAN Heartbeat lankhb2 : Normal LAN Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop server2 ........... : Online server2 lankhb1 : Normal LAN Heartbeat lankhb2 : Normal LAN Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop <group> ManagementGroup : Online Management Group current : server1 ManagementIP : Online 10.0.0.10 failover1.......... : Online failover group1 current : server1 fip1 : Online 10.0.0.11 md1 : Online I: script1 : Online script resource1 failover2 ......... : Online failover group2 current : server2 fip2 : Online 10.0.0.12 md2 : Online J: script1 : Online script resource2 <monitor> fipw1 : Normal fip1 fipw2 : Normal fip2 ipw1 : Normal ip monitor1 mdw1 : Normal md1 mdw2 : Normal md2 ===============================================================
关于各种状态的说明参见"各种状态"。
显示组图(-g选项)
要显示组图时,在[clpstat]命令中指定[-g]选项并执行该命令。
-
执行示例 # clpstat -g
-
显示示例 ================= GROUPMAP INFORMATION ======================== Cluster : cluster *server0 : server1 server1 : server2 ---------------------------------------------------------------- server0 [o] : failover1[o] failover2[o] server1 [o] : failover3[o] ================================================================
不显示已停止的组。
关于各种状态的说明参见"各种状态"。
显示监视资源的状态(-m选项)
要显示监视资源的状态时,在[clpstat]命令中指定[-m]选项并执行该命令。
-
执行示例 # clpstat -m
-
显示示例 =================== MONITOR RESOURCE STATUS ================== Cluster : cluster *server0 : server1 server1 : server2 Monitor0 [fipw1 : Normal] --------------------------------------------------------------- server0 [o] : Online server1 [o] : Offline Monitor1 [fipw2 : Normal] --------------------------------------------------------------- server0 [o] : Offline server1 [o] : Online Monitor2 [ipw1 : Normal] --------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor3 [mdw1 : Normal] --------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor4 [mdw2 : Normal] --------------------------------------------------------------- server0 [o] : Online server1 [o] : Online ===============================================================
关于各种状态的说明参见"各种状态"。如果监视资源发生模拟故障,状态后面会显示 "(Dummy Falilure)"。
显示心跳资源的状态(-n选项)
要显示心跳资源的状态时,在[clpstat]命令中指定[-n]选项并执行该命令。
-
执行示例 # clpstat -n
-
显示示例 ================== HEARTBEAT RESOURCE STATUS =================== Cluster : cluster *server0 : server1 server1 : server2 HB0 : lankhb1 HB1 : lankhb2 HB2 : witnesshb1 [on server0 : Online] HB 0 1 2 ----------------------------------------------------------------- server0 : o o o server1 : o x o [on server1 : Online] HB 0 1 2 ----------------------------------------------------------------- server0 : o x o server1 : o o o =================================================================
关于各种状态的说明参见"各种状态"。
显示示例的状态说明
以上显示示例中显示的是,当优先级第2的内核模式LAN心跳资源线路中断时,从server0,server1各自的服务器所见的所有心跳资源的状态。
内核模式LAN心跳资源lankhb1处于不能在两台服务器之间进行通信的状态,因此在server0上不能对server1进行通信,在server1上也不能对server0进行通信。
其它的心跳资源在两台服务器中均处于可通信状态。
显示Fencing功能的状态(-f命令扩展)
如需显示Fencing功能(网络分区解决资源以及强制停止资源)的状态,在[clpstat]命令中指定[-f]选项并执行该命令。
-
执行示例 # clpstat -f
-
显示示例 ======================== FENCING STATUS ========================= Cluster : cluster *server0 : server1 server1 : server2 NP0 : disknp1 NP1 : pingnp1 NP2 : httpnp1 FST : forcestop1 [on server0 : Online] NP/FST 0 1 2 F ----------------------------------------------------------------- server0 : o o o o server1 : o o o - [on server1 : Online] NP/FST 0 1 2 F ----------------------------------------------------------------- server0 : o o o - server1 : o o o o =================================================================
关于各种状态的说明参见"各种状态"。
显示集群配置信息(--cl选项)
要显示集群的配置信息时,在[clpstat]命令中指定[-i]选项或[--cl],[--sv],[--hb],[--fnc],[--svg],[--grp],[--rsc],[--mon]并执行该命令。另外,指定[--detail]选项后,可以显示更加详细的信息。
关于各项目的详细设定信息请参照本指南的"2. 参数的详细信息"。
要显示集群配置信息时,在[clpstat]命令中指定[--cl]选项并执行该命令。
-
执行示例 # clpstat -cl
-
显示示例 ===================== CLUSTER INFORMATION ==================== [Cluster Name: cluster] Comment : failover cluster ===============================================================
仅显示特定服务器的配置信息(--sv选项)
仅要显示指定的服务器的集群配置信息时,在[clpstat]命令的[--sv]选项后指定服务器名并执行该命令。需要显示详细信息时,请指定[-detail]选项。如果不指定服务器名,则显示所有服务器的集群配置信息。
-
执行示例 # clpstat --sv server1
-
显示示例 ====================== CLUSTER INFORMATION ===================== [Server0 : server1] Comment : server1 Virtual Infrastructure : vSphere Product : EXPRESSCLUSTER 5.1 for Windows Internal Version : 13.10 Install Path : C:\Program Files\EXPRESSCLUSTER =================================================================
仅显示特定的心跳资源信息(--hb选项)
仅要显示指定的心跳资源的集群配置信息时,在[clpstat]命令的[--hb]选项后指定心跳资源名并执行该命令。想要显示详细内容时,指定[--detail]选项。不指定心跳资源名时,则显示所有心跳资源的集群配置信息。
-
执行示例 内核模式LAN心跳资源
# clpstat --hb lankhb1
-
显示示例 ======================== CLUSTER INFORMATION =================== [HB0 : lankhb1] Type : lankhb Comment : LAN Heartbeat =================================================================
-
重点 通过同时使用[--sv]选项和[--hb]选项,还可以显示如下内容。
-
执行示例 # clpstat --sv --hb
-
显示示例 ====================== CLUSTER INFORMATION ===================== [Server0 :server1] Comment : server1 Virtual Infrastructure : Product : EXPRESSCLUSTER X 5.1 for Windows Version : 13.10 Install Path : C: \Program Files\ EXPRESSCLUSTER [HB0 : lankhb1] Type : lankhb Comment : LAN Heartbeat [HB1 : lankhb2] Type : lankhb Comment : LAN Heartbeat [HB2 : witnesshb1] Type : witnesshb Comment : Witness Heartbeat [Server1 :server2] Comment : server2 Virtual Infrastructure : Product : EXPRESSCLUSTER X 5.1 for Windows Version : 13.10 Install Path : C: \Program Files\ EXPRESSCLUSTER [HB0 : lankhb1] Type : lankhb Comment : LAN Heartbeat [HB1 : lankhb2] Type : lankhb Comment : LAN Heartbeat [HB2 : witnesshb1] Type : witnesshb Comment : Witness Heartbeat =================================================================
只显示特定的Fencing功能的信息(--fnc选项)
如果只想显示指定的fencing功能(网络分区解决资源和强制停止资源)的集群设置信息,请在[clpstat]中的[--fnc]选项后,指定并执行网络分区解决资源名或强制停止资源名。 想要显示详细内容时,指定[--detail]选项。 未指定网络分区名或者强制停止资源名时,显示所有的Fencing功能的集群配置信息。
-
执行示例 DISK网络分区解决资源
# clpstat --fnc disknp1
-
显示示例 ======================== CLUSTER INFORMATION =================== [NP0 : disknp1] Type : disknp Comment : disk resolution =================================================================
-
执行示例 Ping网络分区解决资源
# clpstat --fnc pingnp1
-
显示示例 ====================== CLUSTER INFORMATION ===================== [NP0 : pingnp1] Type : pingnp Comment : ping resolution =================================================================
-
执行示例 HTTP 网络分区解决资源
# clpstat --fnc httpnp1
-
显示示例 ==================== CLUSTER INFORMATION ======================= [NP0 : httpnp1] Type : httpnp Comment : http resolution ================================================================
-
执行示例 MAJORITY网络分区解决资源
# clpstat --fnc majonp1
-
显示示例 ==================== CLUSTER INFORMATION ======================== [NP0 : majonp1] Type : majonp Comment : majority resolution =================================================================
-
执行示例 强制停止资源
# clpstat --fnc forcestop1
-
显示示例 ==================== CLUSTER INFORMATION ======================= [FST : forcestop1] Type : bmc Comment : Forced stop =================================================================
仅显示特定服务器组的信息 (--svg 选项)
想只显示指定服务器组的集群配置信息时,可在[clpstat]命令中的[--svg]选项后指定服务器组名。不指定服务器组名时,则显示所有服务器组的集群配置信息。
-
执行示例 # clpstat --svg servergroup1
-
显示示例 ===================== CLUSTER INFORMATION ===================== [Server group 0 : servergroup1] Server0 : server1 Server1 : server2 Server2 : server3 =================================================================
仅显示特定组的信息( --grp选项)
仅要显示指定的组的集群配置信息时,在[clpstat]命令的[--grp]的选项后指定组名并执行该命令。想要显示详细内容时,指定[--detail]选项。不指定组名时,则显示所有组的集群配置信息。
-
执行示例 # clpstat --grp
-
显示示例 ====================== CLUSTER INFORMATION ===================== [Group0 : ManagementGroup] Type : cluster Comment : [Group1 : failover1] Type : failover Comment : failover group1 [Group2 : failover2] Type : failover Comment : failover group2 [Group3: virtualmachine] Type : virtualmachine Comment : =================================================================
仅显示特定组资源的信息(--rsc选项)
仅要显示指定的组资源的集群配置信息时,在[clpstat]命令的[--rsc]选项后指定组资源并执行该命令。想要显示详细内容时,指定[--detail]选项。不指定组资源名时,则显示所有组资源的集群配置信息。
-
执行示例 浮动IP资源
# clpstat --rsc fip1
-
显示示例 ======================= CLUSTER INFORMATION ===================== [Resource0 : fip1] Type : fip Comment : 10.0.0.11 IP Address : 10.0.0.11 =================================================================
-
重点 通过同时使用[--grp]选项和[--rsc]选项,还可以显示如下内容。
-
执行示例 # clpstat --grp --rsc
-
显示示例 ====================== CLUSTER INFORMATION ===================== [Group0 : ManagementGroup] Type : cluster Comment : [Resource0 : ManagementIP] Type : fip Comment : IP Address : 10.0.0.10 [Group1 : failover1] Type : failover Comment : failover group1 [Resource0 : fip1] Type : fip Comment : 10.0.0.11 IP Address : 10.0.0.11 [Resource1 : md1] Type : md Comment : I: Mirror Disk No. : 1 Drive Letter : I: Mirror Disk Connect : mdc1 [Group2 : failover2] Type : failover Comment : failover group2 [Resource0 : fip2] Type : fip Comment : 10.0.0.12 IP Address : 10.0.0.12 [Resource1 : md2] Type : md Comment : J: Mirror Disk No. : 2 Drive Letter : J: Mirror Disk Connect : mdc1 =================================================================
仅显示特定监视资源的信息(--mon选项)
仅要显示指定的监视资源的集群配置信息时,在[clpstat]命令的[--mon]选项后指定监视资源名并执行该命令。想要显示详细内容时,指定[--detail]选项。不指定监视资源名时,则显示所有监视资源的集群配置信息。
-
执行示例 浮动IP监视资源
# clpstat --mon fipw1
-
显示示例 ====================== CLUSTER INFORMATION ===================== [Monitor0 : fipw1] Type : fipw Comment : fip1 =================================================================
仅显示特定互斥规则的信息(--xcl选项)
仅要显示指定的互斥规则信息时,在clpstat 命令的--rsc 选项后,指定互斥规则名,
并执行该命令。
-
执行示例 # clpstat --xcl excl1
-
显示示例 ===================== CLUSTER INFORMATION ===================== [Exclusive Rule0 : excl1] Exclusive Attribute : Normal group0 : failover1 group1 : failover2 =================================================================
显示所有集群信息( -i选项)
如果指定-i选项,可以显示指定了所有[--cl],[--sv],[--hb],[--fnc],[--svg],[--grp],[--rsc],[--mon]选项后的配置信息。
如果还附带指定[--detail]选项并执行该命令,可以显示所有集群配置信息的详细内容。
使用该命令时一次显示的信息量过大,因此实际使用时,请使用pipe或[more]命令等来显示,或者使用Redirect输出到文件中等来进行浏览。
-
执行示例 # clpstat -i
-
重点 指定[-i]选项后会在控制台中显示所有信息。想要显示某一部分的信息时,使用[--cl],[--sv],[--hb],[--fnc],[--svg],[--grp],[--rsc],[--mon]选项的各种组合方式就可以轻松实现。例如,可以如下进行使用。
-
执行示例 要显示服务器名server0的信息,组名failover1的信息和该指定的组中存在的所有组资源的信息时
# clpstat --sv server0 --grp failover1 --rsc --detail
显示集群状态(--local选项)
如果指定—local选项,不执行同其他服务器的通信,只显示执行命令的服务器上的信息。
-
执行示例 # clpstat --local
-
显示示例 ===================== CLUSTER STATUS ======================== Cluster : cluster cluster.............: Start cluster <server> *server1..............: Online server1 lankhb1 : Normal LAN Heartbeat lankhb2 : Normal LAN Heartbeat pingnp1 : Normal ping resolution forcestop1 : Normal Forced stop server2................: Online server2 lankhb1 : - LAN Heartbeat lankhb2 : - LAN Heartbeat pingnp1 : - ping resolution forcestop1 : - Forced stop <group> ManagementGroup : Online Management Group current : server1 ManagementIP : Online 10.0.0.10 failover1 .............: Online failover group1 current : server1 fip1 : Online 10.0.0.11 md1 : Online I: script1 : Online script resource1 failover2..............: - failover group2 current : server2 fip2 : - 10.0.0.12 md2 : - J: script1 : - script resource2 <monitor> fipw1 : Online fip1 fipw2 : Online fip2 ipw1 : Online ip monitor1 mdw1 : Online md1 mdw2 : Online md2 ===============================================================
有关各种状态的说明参见"各种状态"。
9.3.1. 各种状态¶
-
集群
功能 |
状态 |
说明 |
|---|---|---|
显示状态(--local) |
Start |
启动中 |
Suspend |
暂停中 |
|
Stop |
停止中 |
|
Unknown |
状态不明 |
-
服务器 功能
状态
说明
状态显示心跳资源状态显示Online
正在启动
Offline
正在停止
Caution
心跳资源异常
Isolated
保留(宕机后重启)
Online Pending
正在处理启动
Offline Pending
正在处理停止中
Pending
保留(网络分区未解决)
Unknown
状态不明
-
状态不明
组图显示监视资源状态显示o
正在启动
s
保留(宕机后重启)
p
启动处理中,停止处理中,保留(网络分区未解决)
x
正在停止
-
状态不明
-
心跳资源 功能
状态
说明
状态显示
Normal
正常
Caution
异常(部分)
Error
异常(全部)
Unused
未使用
Unknown
状态不明
-
状态不明
心跳资源状态显示
o
可通信
x
不可通信
-
未使用,状态不明
-
网络分区解决资源 以及 强制停止资源 功能
状态
说明
状态显示
Normal
正常
Caution
异常(部分)
Error
异常(全部)
Unused
未使用
Unknown
状态不明
-
状态不明
网络分区解决资源强制停止资源状态显示o
可通信
x
不可通信
-
未使用,状态不明
-
组 功能
状态
说明
状态显示
Online
已启动
Offline
已停止
Online Pending
正在处理启动
Offline Pending
正在处理停止
Error
异常
Unknown
状态不明
-
状态不明
组图显示
o
已启动
e
异常
p
正在处理启动,正在处理停止
-
组资源 功能
状态
说明
状态显示
Online
已启动
Offline
已停止
Online Pending
正在处理启动
Offline Pending
正在处理停止
Online Failure
启动失败
Offline Failure
停止失败
Unknown
状态不明
-
状态不明
-
监视资源 功能
状态
说明
状态显示
Normal
正常
Caution
异常(部分)
Error
异常(全部)
Unused
未使用
Unknown
状态不明
Normal (Dummy failure)
正常(模拟故障中)
Caution (Dummy failure)
异常(部分) (模拟故障中)
Error (Dummy failure)
异常(全部) (模拟故障中)
状态显示(--local)监视资源状态显示Online
启动完成且正常
Offline
已停止
Caution
警告
Suspend
暂停
Online Pending
正在处理启动
Offline Pending
正在处理停止
Online Failure
异常
Offline Failure
停止失败
Unused
未使用
Unknown
状态不明
Online (Dummy failure)
已启动(模拟故障中)
Offline (Dummy failure)
已停止(模拟故障中)
Caution (Dummy failure)
警告(模拟故障中)
Suspend (Dummy failure)
暂停(模拟故障中)
Online Pending (Dummy failure)
正在处理启动(模拟故障中)
Offline Pending (Dummy failure)
正在处理停止(模拟故障中)
Online Failure (Dummy failure)
启动失败(模拟故障中)
Offline Failure (Dummy failure)
停止失败(模拟故障中)
-
状态不明
9.4. 操作集群(clpcl命令)¶
操作集群。
-
命令行 - clpcl -s [-a] [-h <hostname>]clpcl -t [-a] [-h <hostname>] [-w <timeout>] [--apito timeout]clpcl -r [-a] [-h <hostname>] [-w <timeout>] [--apito timeout]clpcl --return [-h <hostname>]clpcl --suspend [--force] [-w <timeout>] [--apito timeout]clpcl --resume
-
说明 执行EXPRESSCLUSTER服务的启动,停止,复原,挂起,恢复等操作。
-
选项 -
-s¶ 启动EXPRESSCLUSTER服务。
-
-t¶ 停止EXPRESSCLUSTER服务。
-
-r¶ 重启EXPRESSCLUSTER服务。
-
--return¶ 将服务器从保留(宕机后重启)状态恢复到正常状态。
-
--suspend¶ 挂起集群整体。
-
--resume¶ 恢复集群整体。
-
-a¶ 在所有服务器上执行。
-
-h<hostname>¶ 向通过hostname指定的服务器请求处理。如果省略了[-h]选项,则向命令执行服务器(自身服务器)请求处理。
-
-w<timeout>¶ - 使用了[-t],[-r],[--suspend]选项时,以秒为单位指定[clpcl]命令等待EXPRESSCLUSTER服务停止或等待完成挂起的等待时间。未指定timeout时,一直进行等待。timeout中指定了"0"时,不作等待。未指定-w选项时(默认),等待时间为心跳超时×2秒。
-
--force¶ 通过和[--suspend]选项一起使用,不论集群内的服务器处于何种状态都强制执行挂起。
-
--apitotimeout¶ - 可以秒为单位指定EXPRESSCLUSTER Daemon的停止,重新启动,挂起的等待时间(内部通信超时)。可指定为1-9999的值。不指定[--apito]选项时,请按照集群属性的内部通信超时所设置的值,进行等待。
-
-
返回值 0
成功
0以外
异常
-
备注 - 使用 -s 或 --resume 选项执行本命令时,在目标服务器开始处理的时机时返回控制。使用-t 或 --suspend 选项执行时,等待处理结束后才返回控制。使用-r 选项执行时,目标服务器上的EXPRESSCLUSTER Damon会停止一次,然后在开始启动的时机时返回控制。EXPRESSCLUSTER Damon的启动或者复原状态可通过clpstat命令来确认。
-
注意事项 由具有Administrator权限的用户执行本命令。
在组的启动处理中和停止处理中,该命令不能执行。
请将-h选项中的服务器名指定为可以名称解析的集群内的服务器名。
请在集群内所有服务器的EXPRESSCLUSTER服务处于已启动的状态下执行挂起。如果使用[--force]选项,即使集群内存在已停止的服务器,也强制执行挂起。
集群启动时以及复原时,按照私网的优先级顺序连接到集群服务器的IP地址,使用成功的路由。
执行恢复时,请使用[clpstat]命令确认集群内是否有已启动的服务器。
-
执行示例 例1: 启动自身服务器的EXPRESSCLUSTER服务时
# clpcl -s Command succeeded.
例2: 从server0启动server1的EXPRESSCLUSTER服务时
# clpcl -s -h server1 Start server1 : Command succeeded.
如果指定了服务器名,显示内容如上所示。
Start 服务器名 : 执行结果
例3: 启动所有服务器的EXPRESSCLUSTER服务时
# clpcl -s -a Start server0 : Command succeeded. Start server1 : Performed startup processing to the active cluster service.
启动所有服务器时,显示内容如上所示。
Start 服务器名 : 执行结果
例4: 停止所有服务器的EXPRESSCLUSTER服务时
# clpcl -t -a Stop server0 : Command succeeded. Stop server1 : Command succeeded.
停止所有服务器时,显示内容如上所示。
Stop 服务器名 : 执行结果
如果停止失败,则不同过程有可执行显示和上面不同的内容。
等待各服务器的EXPRESSCLUSTER服务停止。
-
错误消息 消息
原因/处理方法
Log in as administrator.
请以拥有Administrator权限的用户身份执行该命令。
Invalid configuration file. Create valid cluster configuration data.
请用Cluster WebUI创建正确的集群配置信息。
Invalid option.
请指定正确的选项。
Performed stop processing to the stopped cluster service.
对已停止的EXPRESSCLUSTER服务执行了停止处理。
Performed startup processing to the active cluster service.
对已启动的EXPRESSCLUSTER服务执行了启动处理。
Command timeout.
命令超时。
Failed to return the server. Check the status of failed server.
复原服务器失败。请确认处理失败的服务器的状态。
Could not connect to the server. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Could not connect to the data transfer server. Check if the server has started up.
请确认是否启动了服务器。
Failed to obtain the list of nodes. Specify a valid server name in the cluster.
请指定集群中正确的服务器名。
Failed to obtain the service name.
获取服务名失败。
Failed to operate the service.
服务控制失败。
Resumed the cluster service that is not suspended.
对不是挂起状态的EXPRESSCLUSTER服务执行了恢复处理。
Invalid server status.
请确认是否启动了EXPRESSCLUSTER服务。
Server is busy. Check if this command is already run.
可执行已经执行本命令。请确认。
Server is not active. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
There is one or more servers of which cluster service is active. If you want to perform resume, check if there is any server whose cluster service is active in the cluster.
执行恢复时,请确认集群中是否有已启动EXPRESSCLUSTER服务的服务器。
All servers must be activated. When suspending the server, the cluster service need to be active on all servers in the cluster.
执行挂起时,需要集群中的所有服务器都启动EXPRESSCLUSTER服务。
Resume the server because there is one or more suspended servers in the cluster.
集群中有挂起的服务器,请执行恢复。
Invalid server name. Specify a valid server name in the cluster.
请指定集群中正确的服务器名。
Connection was lost. Check if there is a server where the cluster service is stopped in the cluster.
请确认集群中是否有停止了EXPRESSCLUSTER服务的服务器。
invalid parameter.
命令参数中可执行设置了错误的值。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
EXPRESSCLUSTER的内部通信超时。如果频繁出现该现象,请将内部通信超时设为更长的时间。Processing failed on some servers. Check the status of failed servers.
对所有的服务器执行了停止处理时,有处理失败的服务器。请确认处理失败的服务器的状态。Internal error. Check if memory or OS resources are sufficient.
内存不足或OS资源不足。请确认。
Failed to shutdown the server.
关闭或重启服务器失败。
Failed to get privilege.
获取关闭或重启服务器的特权失败。
9.5. 关闭指定的服务器(clpdown命令)¶
关闭指定的服务器。
-
命令行 clpdown [-r] [-h <hostname>]
-
说明 停止EXPRESSCLUSTER服务,关闭服务器。
-
返回值 0
成功
0以外
异常
-
备注 本命令在结束组的停止处理的时机时返回控制。
使用本命令,即使ExpressCluster服务处于停止状态也可以关闭服务器。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
在组的启动处理中和停止处理中,该命令不能执行。
[-h]选项的服务器名请指定集群中的服务器。
-
执行示例 例1:停止并关闭自身服务器的ExpressCluster服务时
# clpdown
例2:从server0关闭重启server1时
# clpdown -r -h server1
-
错误消息 请参考"操作集群(clpcl命令)"。
9.6. 关闭整个集群(clpstdn命令)¶
关闭整个集群。
-
命令行 clpstdn [-r] [-h <hostname>]
-
说明 停止整个集群的EXPRESSCLUSTER服务,关闭所有服务器。
-
返回值 0
成功
0以外
异常
-
备注 本命令在结束组的停止处理的时机时返回控制。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
在组的启动处理中和停止处理中,该命令不能执行。
[-h]选项的服务器名请指定集群中的服务器。
无法与执行命令的服务器进行通信的服务器(所有的LAN心跳资源都为Offline的服务器)将不被关闭。
-
执行示例 例1:进行集群关机时
# clpstdn
例2:进行集群关机重启时
# clpstdn -r
-
错误消息 请参考"操作集群(clpcl命令)"。
9.7. 操作组(clpgrp命令)¶
操作组。
-
命令行 - clpgrp -s [grpname] [-h <hostname>] [-f] [--apito timeout]clpgrp -t [grpname] [-h <hostname>] [-f] [--apito timeout]clpgrp -m [grpname] [-h <hostname>] [-a <hostname>] [--apito timeout]clpgrp -n <grpname>
-
说明 执行组的启动,停止,移动。
-
选项 -
-s[grpname]¶ 启动组。指定组名,则仅启动指定的组。如果未指定组名,则启动所有组。
-
-t[grpname]¶ 停止组。指定组名,则仅停止指定的组。如果未指定组名,则停止所有组。
-
-m[grpname]¶ 移动组。指定组名,则仅移动指定的组。如果不指定组名时,则移动所有组。
-
-h<hostname>¶ 对hostname指定的服务器请求处理。如果省略了[-h]选项,则对命令执行服务器(自身服务器)请求处理。
-
-a<hostname>¶ 将hostname指定的服务器作为组的移动目标服务器。如果省略了[-a]选项,则组的移动目标由失效切换策略决定。
-
-f¶ - 对于其它服务器启动的组,如果与[-s]选项一起使用,则在强行请求处理的服务器上启动。如果与[-t]选项一起使用,则强行停止。
-
-n<grpname>¶ 显示组的已启动服务器名。
-
--apito<timeout>¶ - 可以秒为单位指定组的启动,停止,移动(内部通信超时)。可指定为1-9999的值。不指定[--apito]选项时,请按照集群属性的内部通信超时所设置的值,进行等待。
-
-
返回值 0
成功
0以外
异常
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行本命令的服务器必须启动EXPRESSCLUSTER服务。
[-h],[-a]选项的服务器名请指定集群中的服务器。
指定[-m]选项进行组迁移时,在目标服务器上,组的启动处理开始执行后则认为操作成功(返回值:0)。因此,该命令即使执行成功,在目标服务器上也会出现资源启动失败的情况,请注意。如果要通过返回值判断目标服务器上的组启动处理的结果时,请使用以下命令移动组。# clpgrp -s [group_name] [-h hostname] -f
对于互斥属性为[普通互斥]的互斥规则中指定的组,在通过-m选项迁移组时,请务必通过-a选项明确指定迁移的目标服务器。
如果省略了-a选项,在可移动的所有服务器中,对于互斥属性为[普通互斥]的互斥规则中指定的组,且组为启动中的状态时,组的迁移将失败。
-
执行示例 通过简单的状态变化的示例对执行组操作进行说明。
2台结构的服务器上,有两个组时
组的失效切换策略
groupA server1 -> server2groupB server2 -> server1两个组都停止的状态。
图 9.1 clpgrp执行时状态 (1)¶
在server1上执行以下命令。
# clpgrp -s groupA
server1中启动groupA。
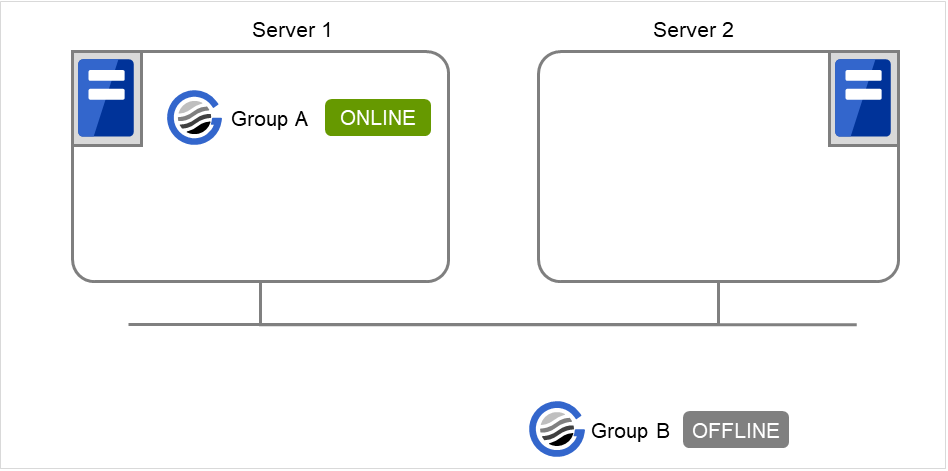
图 9.2 clpgrp执行时状态 (2)¶
在server2上执行以下命令。
# clpgrp -s
在server2中启动当前已停止的,可启动的所有组。
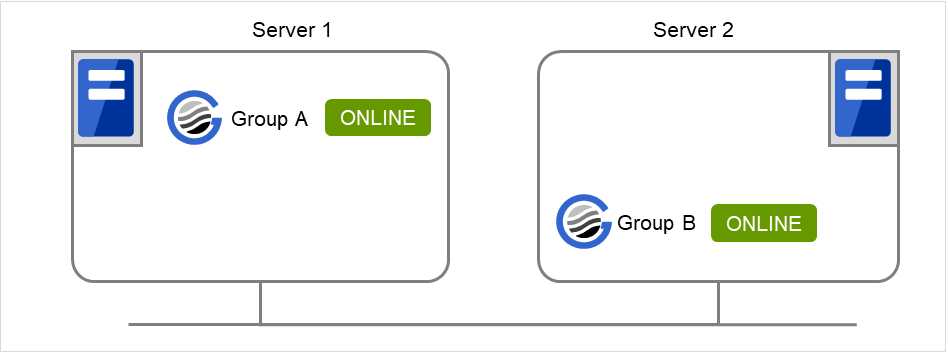
图 9.3 clpgrp执行时状态 (3)¶
在server1上执行以下命令。
# clpgrp -m groupA
groupA移动到server2中。
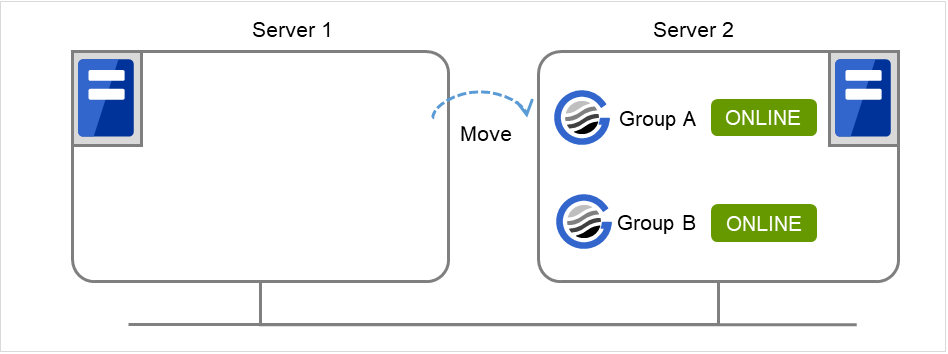
图 9.4 clpgrp执行时状态 (4)¶
在server1上执行以下命令。
# clpgrp -t groupA -h server2
groupA停止。
图 9.5 clpgrp执行时状态 (5)¶
在server1上执行以下命令。
# clpgrp -t Command Succeeded.
执行以上指令时,在server1不存在动作中的组,因此,显示"Command Succeeded."
在server1上执行在(6)中执行的命令上加上了[-f]的选项。
# clpgrp -t -f
可从server1强行停止server2上启动的组。
图 9.6 clpgrp执行时状态 (6)¶
-
错误消息 消息
原因/处理
Log in as administrator.
请以拥有Administrator权限的用户身份执行。
Invalid configuration data. Create valid cluster configuration data.
请使用Cluster WebUI创建正确的集群配置信息。
Invalid option.
请指定正确的选项。
Could not connect to the server. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Invalid server status. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Server is not active. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Invalid server name. Specify a valid server name in the cluster.
请指定集群中正确的服务器名。
Connection was lost. Check if there is a server where the cluster service is stopped in the cluster.
请确认集群中是否有停止了EXPRESSCLUSTER服务的服务器。
Invalid parameter.
命令参数中可执行设置了错误的值。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
EXPRESSCLUSTER的内部通信超时。如果频繁出现该现象,则请将内部通信超时设为更长的时间。Invalid server. Specify a server that can run and stop the group, or a server that can be a target when you move the group.
启动,停止,移动组的目标服务器有误。请指定正确的服务器。Could not start the group. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
请等待其它服务器启动或等待启动等待时间超时,启动组。
No operable group exists in the server.
请确认请求处理的服务器中是否存在可处理的组。
The group has already been started on the local server.
请通过Cluster WebUI或[clpstat]命令确认组的状态。
The group has already been started on the other server. To start /stop the group on the local server, use -f option.
请通过Cluster WebUI或[clpstat]命令确认组的状态。如果要在本地服务器上启动/停止其它服务器上启动的组,请执行组的移动,或加上[-f]选项执行。The group has already been stopped.
请通过Cluster WebUI或[clpstat]命令确认组的状态。
Failed to start one or more resources. Check the status of group.
请通过Cluster WebUI或[clpstat]命令确认组的状态。
Failed to stop one or more resources. Check the status of group.
请通过Cluster WebUI或[clpstat]命令确认组的状态。
The group is busy. Try again later.
组正处于启动处理或停止处理中,请稍后再执行。
An error occurred on one or more groups. Check the status of group.
请通过Cluster WebUI或[clpstat]命令确认组的状态。
Invalid group name. Specify a valid group name in the cluster.
请指定集群中的正确的组名。
Server is isolated.
服务器处于保留(宕机后重启)状态。
Some invalid status. Check the status of cluster.
出现某种错误的状态。请确认集群的状态。
Log in as administrator.
内存不足或OS的资源不足。请确认。
Server is not in a condition to start group. Critical monitor error is detected.
请通过Cluster WebUI或[clpstat]命令确认服务器的状态。在准备启动组的服务器中检测出包含在可排除列表中的监视器的异常。There is no appropriate destination for the group. Critical monitor error is detected.
请通过Cluster WebUI或[clpstat]命令确认服务器的状态。在其他服务器中检测出包含在可排除列表中的监视器的异常。
9.8. 收集日志(clplogcc命令)¶
收集日志。
-
命令行 clplogcc [ [-n targetnode1 -n targetnode2 ......] ] [-t collect_type] [-o path] [--local] [--evt event_type ...]
-
说明 连接到数据传送服务器,收集日志,OS信息等。
-
选项 -
无¶ 收集集群中的日志。
-
-tcollect_type¶ 指定日志收集模式。如果省略则日志收集模式为type1。关于日志收集类型,将在"指定类型收集日志 (-t选项)"进行说明。
-
-opath¶ 指定收集文件的输出目标。如果省略则将日志输出到安装路径的tmp下。
-
-ntargetnode¶ 指定收集日志的服务器名。此时可以不收集整个集群的日志,而仅收集指定的服务器的日志。
-
--local¶ - 不经过数据传送服务器,收集本地服务器的日志。不能与[-n]选项同时指定。
-
--evtevent_type¶ - 指定收集的事件日志的种类。省略时收集应用程序日志,系统日志,安全日志。如果指定none,则不收集事件日志。仅在[--local]选项被指定时有效。详细请参考"指定收集的事件日志种类(--evt选项)"。
-
-
返回值 0
成功
0以外
异常
-
备注 使用zip对日志文件进行了压缩,请使用可以对zip进行解压缩的应用程序解压缩。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
[-n]选项的服务器名请指定可以名称解析的服务器名。如果无法进行名称解析,则请指定私网或公网地址。
执行本命令时,按照私网的优先级顺序连接到集群服务器的IP地址,使用成功的路由。 本命令已超时时,请稍后再次执行。
-
执行示例 例1:从集群中的所有服务器收集日志时
# clplogcc please wait, now collecting.. server status result --------------------------------------------- server0 Completion Normal server1 Completion Normal
显示执行了日志收集的服务器的执行结果。
服务器名 处理过程 执行结果
-
执行结果 该命令的结果所显示的处理过程如下所示。
处理过程
说明
Preparing
正在初始化
Connecting
正在连接服务器
Compressing
正在压缩日志文件
Transmitting
正在发送日志文件
Disconnecting
正在断开服务器
Completion
日志收集完毕
执行结果(服务器状态)如下所示。
执行结果(服务器状态)
说明
Normal
正常结束。
Canceled
用户取消。
Invalid Parameters
参数有误。
Compression Error
发生压缩错误。
Communication Error
发生发送错误。
Timeout
超时。
Busy
服务器正忙。
No Free Space
磁盘没有剩余空间。
File I/O Error
出现了文件I/O错误。
Unknown Error
其它错误导致的失败。
-
错误消息 消息
原因/处理
Log in as administrator.
请以拥有Administrator权限的用户执行。
Invalid option.
请指定正确的选项。
Collect type must be specified 'type1' or 'type2' or 'type3' or ‘type5’ or ‘type6’. Incorrect collection type is specified.
收集类型指定有误。
Specifiable number of servers is the max number of servers that can constitute a cluster.
可指定的服务器数为可进行集群配置的最大服务器数。
Failed to obtain properties.
获取属性失败。
Failed to obtain the list of nodes. Specify a valid server name in the cluster.
请指定集群中正确的服务器名。
Invalid server name. Specify a valid server name in the cluster.
请指定集群中正确的服务器名。
Failed to collect log.
收集日志失败。
Server is busy. Check if this command is already run.
可执行已执行该命令。请确认。
Internal error. Check if memory or OS resources are sufficient.
内存不足或OS的资源不足。请确认。
9.8.1. 指定类型收集日志 (-t选项)¶
仅想收集指定类型的日志时,请使用[clplogcc]命令指定[-t]选项。
日志的收集类型可指定为type1 ~ 6。
type1 |
type2 |
type3 |
type4 |
type5 |
type6 |
|
|---|---|---|---|---|---|---|
|
✓ |
✓ |
✓ |
n/a |
n/a |
n/a |
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
|
✓ |
✓ |
✓ |
n/a |
n/a |
n/a |
|
✓ |
✓ |
✓ |
n/a |
n/a |
n/a |
|
✓ |
✓ |
✓ |
n/a |
n/a |
n/a |
|
n/a |
✓ |
n/a |
n/a |
n/a |
n/a |
|
n/a |
n/a |
n/a |
n/a |
✓ |
n/a |
|
n/a |
n/a |
n/a |
n/a |
n/a |
✓ |
|
✓ |
✓ |
✓ |
n/a |
n/a |
✓ |
如下执行命令行。
执行示例:以收集类型type2收集日志时。
# clplogcc -t type2
未指定选项时的日志收集类型为type1。
默认收集信息
EXPRESSCLUSTER服务器的各模块日志
EXPRESSCLUSTER服务器的各模块的属性信息(dir)
bin下
alert\bin,webmgr\bin下
%SystemRoot%\system32\drivers下
EXPRESSCLUSTER的版本信息
OS信息
更新日志
License信息
设置文件
策略文件
云环境设置目录
共享内存的转储
EXPRESSCLUSTER的自节点状态(clpstat --local的执行结果)
主机名,域名信息(hostname的执行结果)
网络信息(netstat的执行结果)
IP路径表信息(route print的执行结果)
进程存在情况(tasklist的执行结果)
ipconfig (ipconfig的执行结果)
文件共享设置(net share的执行结果)
session信息(net session的执行结果)
Windows 防火墙的设置 (netsh的执行结果)
SNP (Scalable Networking Pack) 的设置(netsh的执行结果)
任务Scheduler的设置 (schtasks 的执行结果)
VSS的Shadow copy area (卷影复制区域) 的使用状况(vssadmin list shadowstorage的执行结果)
Cluster WebUI的操作日志(参考《维护指南》 - “维护信息” - “Cluster WebUI操作日志输出功能”)
AWS相关信息
以下命令的执行结果
where aws
aws --version
aws configure list
aws ec2 describe-network-interfaces
aws ec2 describe-instance-attribute --attribute disableApiStop
事件日志
应用程序日志(AppEvent.Evt, Application.evtx, Application.txt)
系统日志(SysEvent.Evt, System.evtx, System.txt)
安全日志 (SecEvent.Evt, Security.evtx, Security.txt)
Windows错误报告
***.wer
用户转储
***.mdmp
诊断程序报告
[msinfo32.exe]命令的执行结果
Registry
EXPRESSCLUSTER服务器的Registry信息
HKLM\SOFTWARE\ EXPRESSCLUSTER \Alert
HKLM\SOFTWARE\ EXPRESSCLUSTER \MirrorList
HKLM\SOFTWARE\ EXPRESSCLUSTER \RC
HKLM\SOFTWARE\ EXPRESSCLUSTER \VCOM
Diskfltr的Registry信息
OS的Registry信息
HKLM\SYSTEM\CurrentControlSet\Services\Disk
HKLM\SYSTEM\CurrentControlSet\Control\Session Manager\DOS Devices
HKLM\SYSTEM\MountedDevices
HKLM\SYSTEM\CurrentControlSet\Enum\SCSI
HKLM\SYSTEM\CurrentControlSet\Enum\STORAGE
HKLM\SYSTEM\CurrentControlSet\Services\symc8xx
HKLM\SYSTEM\CurrentControlSet\Control\FileSystem
脚本
Cluster WebUI创建的组启动/停止脚本
如果指定了上述以外的用户定义脚本,则由于不包含在日志收集的采集信息中,需要另外采集。
ESMPRO/AC,ESMPRO/UPSC的日志
通过执行[acupslog.exe]命令收集到的文件
HA的日志
系统资源信息
JVM监视日志
系统监视日志
镜像统计信息
镜像统计信息
Perf\cluster下
集群统计信息
集群统计信息
Perf\cluster 下
系统资源统计信息
系统统计信息
perf\system 下
9.8.2. 日志文件的输出目标 (-o选项)¶
文件名保存为"服务器名-log.zip"。
日志文件使用zip进行压缩,因此请使用可对zip解压缩的应用程序解压缩。
未指定[-o]选项时
在安装路径的tmp下输出日志。
指定[-o]选项时
若执行以下命令,则将日志输出到指定的目录C:\tmp下。
# clplogcc -o C:\tmp
9.8.3. 指定日志收集服务器 (-n选项)¶
使用[-n]选项可以仅收集指定的服务器的日志。
例)收集集群中的Server1和Server3的日志时
# clplogcc -n Server1 -n Server3
请指定同一集群中的服务器。
可指定的服务器数为集群配置可用的最大服务器数。
9.8.4. 指定收集的事件日志种类(--evt选项)¶
可指定日志收集时所收集信息中包含的事件日志的种类。
接在[--evt]选项之后,指定收集事件日志的如下所示任意一个或一个以上组合。
事件日志的种类 |
指定文字 |
|---|---|
应用程序日志 |
App |
系统日志 |
Sys |
安全日志 |
Sec |
不收集 |
none |
例)收集系统日志和安全日志时
# clplogcc --local --evt sys sec
仅在[--local]选项被指定时有效。
9.8.5. 异常发生时的信息采集¶
发生以下的异常时,会采集用于问题解析的信息。
构成集群的服务由于内部状态异常而导致结束等异常结束时
组资源的启动异常,停止异常发生时
监视资源的监视异常发生时
采集的信息如下。
集群的信息
EXPRESSCLUSTER 服务器一部分的模块的log
执行命令产生的信息
主机名,域名信息(hostname的执行结果)
网络信息(netstat的执行结果)
进程存在情况(tasklist的执行结果)
ipconfig (ipconfig的执行结果)
文件共享设置(net share的执行结果)
session信息(net session的执行结果)
由于该信息作为日志收集的默认收集信息进行采集,因此无须单独采集。
9.9. 生成集群,备份集群配置信息(clpcfctrl命令)¶
9.9.1. 生成集群(clpcfctrl -push)¶
向服务器发送集群配置信息。
-
命令行 clpcfctrl --push [-w] [-x <path>] [-h <hostname>|<IP>] [-p <portnumber>] [--force] [--nocheck]
-
说明 向服务器发送Cluster WebUI创建的配置信息。
-
选项 -
--push¶ - 发送时指定。不能省略。
-
-x¶ 发送指定目录下的配置信息时指定。
-
-w¶ - 表示发送的集群配置信息文件的字符编码为SJIS。通常可以省略该选项。
-
-h¶ - 指定发送配置信息的服务器。指定主机名或IP地址。如果省略则向配置信息中有的所有服务器发送。
-
-p¶ - 指定数据发送端口的端口号。如果省略则使用初始值。一般无需指定。
-
--force¶ 即使有未启动的服务器,也强行发送配置信息。
-
--nocheck¶ 没有执行可反映集群变更的必要操作的检查就发送。要将发送的配置信息反映到集群,需根据需要进行手动操作。
-
-
返回值 0
成功
0以外
异常
-
备注 按照以下步骤,使用 clpcfctrl --push 命令将 Cluster WebUI 导出的集群配置信息文件分发到集群服务器。
启动Cluster WebUI,切换到[编辑模式]。
根据需要从Cluster WebUI更改集群配置。
从Cluster WebUI选择[导出配置文件],将集群配置信息文件(zip格式)保存在任意的文件夹中。
将Cluster WebUI导出的集群配置信息文件(zip格式)解压到集群服务器可以访问的任意文件夹中。
在集群内任意一个集群服务器上,从命令提示符执行clpcfctrl --push。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行本命令时,按照私网的优先级顺序连接到集群服务器的IP地址,使用成功的路由。
发送集群配置信息时,将当前的集群配置信息与要发送的集群配置信息进行比较。
如果配置内容有更改,则输出下列消息。请根据消息指示进行集群操作/组操作,然后再次执行该命令。
消息
处理
Please stop EXPRESSCLUSTER Server.
请停止服务器。
Please suspend EXPRESSCLUSTER Server.
请挂起服务器。
Please stop the following groups.
请停止更改了设置的组。
Reboot of a cluster is necessary to reflect setting.
要反映设置,请执行集群关机/重启。
To apply the changes you made, restart the EXPRESSCLUSTER Web Alert service.
要反映设置,请重启EXPRESSCLUSTER Web Alert服务。
To apply the changes you made, restart the EXPRESSCLUSTER Manager service.
要反映设置,请重启EXPRESSCLUSTER Manager服务。
To apply the changes you made, restart the EXPRESSCLUSTER Information Base service.
要反映设置,请重启EXPRESSCLUSTER Information Base服务。
To apply the changes you made, restart the EXPRESSCLUSTER API service.
要反映设置,请重启EXPRESSCLUSTER API服务。
To apply the changes you made, restart the EXPRESSCLUSTER Node Manager service.
要反映设置,请重启EXPRESSCLUSTER Node Manager服务。
Start of a cluster is necessary to reflect setting.
第一次构筑集群时的消息。请启动集群。
--nocheck选项只在维护步骤等特殊用途上使用。请不要在通常操作上使用。
-
执行示例 例1: 在Windows上使用Cluster WebUI发送文件系统上保存的配置信息时
# clpcfctrl --push -x C:\tmp\config file delivery to server 10.0.0.11 success. file delivery to server 10.0.0.12 success. Command succeeded.(code:0)
例2: 在Windows上使用Cluster WebUI向指定服务器发送文件系统上保存的配置信息时
# clpcfctrl --push -x C:\tmp\config -h 10.0.0.11 Command succeeded.(code:0)
-
错误消息 消息
原因/处理
Command succeeded.
命令成功。
Log in as administrator.
请以拥有Administrator权限的用户身份执行该命令。
This command is already run.
已启动该命令。
Invalid option.
选项有误。请确认选项。
Invalid mode. Check if --push or --pull option is specified.
请确认是否指定了[--push]。
The target directory does not exist.
指定目录不存在。请确认所指定的目录是否正确。
Invalid host name. Server specified by -h option is not included in the configuration data
配置信息中不包含[-h]指定的服务器。请确认指定的服务器名或IP地址是否正确。
Invalid type of file.
请确认配置信息的文字编码是否正确。
Failed to initialize the xml library. Check if memory or OS resources are sufficient.或者Failed to load the configuration file. Check if memory or OS resources are sufficient.或者Failed to change the configuration file. Check if memory or OS resources are sufficient.内存不足或OS资源不足。请确认。
Failed to load the all.pol file. Reinstall the cluster.
请重装EXPRESSCLUSTER服务器。
Failed to load the cfctrl.pol file. Reinstall the cluster.
请重装EXPRESSCLUSTER服务器。
Failed to get the install path. Reinstall the cluster.
请重装EXPRESSCLUSTER服务器。
Failed to get the list of group.
组列表取得失败。
Failed to get the list of resource.
资源列表取得失败。
Failed to initialize the trncl library. Check if memory or OS resources are sufficient.
内存不足或OS的资源不足。请确认。
Failed to connect to trnsv. Check if the other server is active.
与服务器连接失败。请确认是否启动了其它服务器。
Failed to get the list of node. Check if the server name or ip addresses are correct.
请确认服务器和IP地址是否正确。
File delivery failed. Failed to deliver the configuration data. Check if the other server is active and run the command again.
发送配置信息失败。请确认是否启动了其它服务器。启动服务器后请再次执行命令。Multi file delivery failed. Failed to deliver the configuration data. Check if the other server is active and run the command again.
发送配置信息失败。请确认是否启动了其它服务器。启动服务器后请再次执行命令。Failed to deliver the configuration data. Check if the other server is active and run the command again.
发送配置信息失败。请确认是否启动了其它服务器。启动服务器后请再次执行命令。Failed to upload the configuration file. Check if the other server is active and run the command again.
发送配置信息失败。请确认是否启动了其它服务器。
Failed to get the collect size.
获取收集文件的大小失败。请确认是否已启动其他服务器。
Failed to collect the file.
文件收集失败。请确认是否已启动其他服务器。
Canceled to deliver the configuration file since it failed to connect to one or more server. If you want to deliver the configuration file to servers that can be connected, run the command again with "--force" option.
中止了配置信息的发送。有服务器连接失败。如果仅想对可连接的服务器发送配置信息,则请使用[--force]选项再次执行命令。
The directory "work" is not found. Reinstall the cluster.
请重新安装EXPRESSCLUSTER服务器。
Failed to make a working directory.
内存不足或OS资源不足。请确认。
The directory does not exist.或者This is not a directory.或者The source file does not exist.或者The source file is a directory.或者The source directory does not exist.或者The source file is not a directory.请确认集群配置信息的路径是否正确。
Failed to change the character code set (EUC to SJIS).或者Failed to change the character code set (SJIS to EUC).内存不足或OS资源不足。请确认。
Failed to allocate memory.或者Failed to change the directory.或者Failed to make a directory.或者Failed to remove the directory.或者Failed to remove the file.内存不足或OS资源不足。请确认。
Failed to open the file.
请确认集群配置信息的路径是否正确。
Failed to read the file.或者Failed to copy the file.或者Failed to create the mutex.或者Internal error. Check if memory or OS resources are sufficient.内存不足或OS资源不足。请确认。
Failed to check server property. Check if the server name or ip addresses are correct.
请确认服务器和IP地址是否正确。
Please stop the following resources.
请停止要进行变更的资源。
Failed to get server status.
服务器状态的取得失败。请确认服务器是否处于正常状态。
target does not exist.
指定目录不存在。请确认所指定的目录是否正确。
connect to server succeeded.
连接服务器成功。
connect to server failed.
连接服务器失败。请确认服务器是否已经启动。
connect to server failed. (please retry later)
连接服务器失败。请确认服务器是否已经启动。请稍后重试。
clp.conf delivered.
已发送配置信息。
To apply the changes you made, reboot the cluster.
请重启集群以反映配置信息。
To apply the changes you made, start the cluster service.
请启动集群以反映配置信息。
Failed to deliver the configuration file.Check if the other server is active and run the command again.
配置信息的发送失败。请确认是否已启动其他服务器。请在启动服务器后再次执行命令。
Failed to apply the setting due to ongoing mirror recovery. After the mirror recovery is completed, execute the command again.
正在进行镜像恢复,无法反映设置。请在镜像恢复完成后重新执行命令。
9.9.2. 备份集群配置信息(clpcfctrl --pull)¶
备份集群配置信息。
-
命令行 clpcfctrl --pull [-w] [-x <path>] [-p <portnumber>]
-
说明 为了在Cluster WebUI上使用,备份集群配置信息。
-
选项 -
--pull¶ - 备份时指定。不能省略。
-
-x¶ 在指定目录中备份配置信息。
-
-w¶ 以字符编码SJIS保存配置信息。
-
-h¶ - 指定备份源服务器。指定主机名或IP地址。如果省略则使用命令执行服务器的配置信息。
-
-p¶ - 指定数据发送端口的端口号。如果省略则使用初始值。一般无需指定。
-
-
返回值 0
成功
0以外
异常
-
备注 按照以下步骤,将通过 clpcfctrl --pull 命令获取的集群配置信息文件通过 Cluster WebUI 发送到集群服务器。
执行clpcfctrl --pull命令,将集群配置信息文件(zip格式)保存在任意的文件夹中。
解压zip,选择clp.conf 和scripts,然后创建一个zip格式的压缩文件(文件名任意)。
在 Cluster WebUI 的设置模式中点击[导入配置文件],读入保存的文件。
根据需要,从Cluster WebUI更改集群配置,点击[应用配置文件]。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行本命令时,按照私网的优先级顺序连接到集群服务器的IP地址,使用成功的路由。
-
执行示例 例1: 在指定目录中备份配置信息时
# clpcfctrl --pull -x C:\tmp\config Command succeeded.(code:0)
例2:将指定服务器的配置信息备份到指定目录中时
# clpcfctrl --push -x C:\tmp\config -h 10.0.0.11 Command succeeded.(code:0)
-
错误消息 消息
原因/处理
Log in as administrator.
请以拥有Administrator权限的用户身份执行该命令。
This command is already run.
已启动。
Invalid option.
选项有误。请确认选项。
Invalid mode. Check if --push or --pull option is specified.
请确认是否指定了[--pull]。
Failed to initialize the xml library. Check if memory or OS resources are sufficient.或者Failed to load the configuration file. Check if memory or OS resources are sufficient.或者Failed to change the configuration file. Check if memory or OS resources are sufficient.内存不足或OS的资源不足。请确认。
Failed to load the all.pol file. Reinstall the cluster.
请重装EXPRESSCLUSTER服务器。
Failed to load the cfctrl.pol file. Reinstall the cluster.
请重装EXPRESSCLUSTER服务器。
Failed to get the install path. Reinstall the cluster.
请重装EXPRESSCLUSTER服务器。
Failed to initialize the trncl library. Check if memory or OS resources are sufficient.
内存不足或OS资源不足。请确认。
Failed to connect to trnsv. Check if the other server is active.
连接服务器失败。请确认是否启动了其它服务器。
The directory "work" is not found. Reinstall the cluster.
请重装EXPRESSCLUSTER服务器。
Failed to make a working directory.或者The directory does not exist.或者This is not a directory.或者The source file does not exist.或者The source file is a directory.或者The source directory does not exist.或者The source file is not a directory.或者Failed to change the character code set (EUC to SJIS).或者Failed to change the character code set (SJIS to EUC).内存不足或OS资源不足。请确认。
Failed to allocate memory.或者Failed to change the directory.或者Failed to make a directory.或者Failed to remove the directory.或者Failed to remove the file.或者Failed to open the file.或者Failed to read he file.或者Failed to write the file.或者Failed to copy the file.或者Failed to create the mutex.或者Internal error. Check if memory or OS resources are sufficient.内存不足或OS资源不足。请确认。
9.10. 超时临时调整命令(clptoratio命令)¶
延长,显示当前的超时倍率。
-
命令行 - clptoratio -r <ratio> -t <time>clptoratio -iclptoratio -s
-
说明 临时延长集群中所有服务器的下列各种超时值和显示当前超时倍率。
监视资源
心跳资源
磁盘Agent
警报同步服务
WebManager服务
但不支持以下资源。
Kernel mode LAN心跳资源
-
选项 -
-rratio¶ - 指定超时倍率。请设置为大于等于1的整数值。最大超时倍率为10000倍。如果指定"1",则与[-i]选项一样,可将已更改的超时倍率还原。
-
-ttime¶ - 指定延长期间。可指定分m,小时h,日d。最大延长期间为30日。例)2m,3h,4d
-
-i¶ 还原更改的超时倍率。
-
-s¶ 查看当前的超时倍率。
-
-
返回值 0
成功
0以外
异常
-
备注 如果执行集群关机。则设置的超时倍率无效。只要集群中有一台服务器未关闭,则设置的超时倍率,延长期间有效。
[-s]选项可查看的只有当前的超时倍率。不能查看延长期间的剩余时间等。
使用状态显示命令可查看原来的超时值。
心跳超时
# clpstat --cl --detail
监视资源超时
# clpstat --mon 监视资源名 --detail
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
请在启动了集群中的所有服务器的EXPRESSCLUSTER服务的状态下执行。
设置超时倍率时,请务必指定延长期间。但如果超时倍率指定为"1",则无法指定延长期间。
指定延长期间时不能指定为"2m3h"等组合。
倍率延长期间内重启服务器,即使超过延长期间,超时倍率也无法还原。这时,请执行clptoratio -i 命令进行超时倍率还原。
本命令不支持强制停止资源的各种超时值。
-
执行示例 例1:将超时倍率设为3天2倍时
# clptoratio -r 2 -t 3d
例2:还原超时倍率时
# clptoratio -i
例3:查看当前超时倍率时
# clptoratio -s present toratio : 2
即可知当前的超时倍率为2。
-
错误消息 消息
原因/处理
Log in as administrator.
请以拥有Administrator权限的用户身份执行。
Invalid configuration file. Create valid cluster configuration data.
请使用Cluster WebUI创建正确的集群配置信息。
Invalid option.
请指定正确的选项。
Specify a number in a valid range.
请指定正确范围内的数字。
Specify a correct number.
请指定正确的数字。
Scale factor must be specified by integer value of 1 or more.
请将倍率指定为大于等于1的整数值。
Specify scale factor in a range less than the maximum scale factor.
请指定不超过最大倍率的倍率。
Set the correct extension period. Ex) 2m, 3h, 4d
请设置正确的延长期间。
Set the extension period in a range less than the maximum extension period.
请指定不超过最大延长期间的延长期间。
Could not connect to the server. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Server is not active. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Connection was lost. Check if there is a server where the cluster service is stopped in the cluster.
请确认集群中是否有停止了EXPRESSCLUSTER服务的服务器。
Invalid parameter.
命令参数中可执行设置了错误的值。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
EXPRESSCLUSTER的内部通信超时。如果频繁出现该现象,则请将内部通信超时设为更长的时间。Processing failed on some servers. Check the status of failed servers.
有处理失败的服务器。请确认集群中的服务器状态。请在启动了集群中的所有服务器的状态下执行。Internal error. Check if memory or OS resources are sufficient.
内存不足或OS资源不足。请确认。
9.11. 日志级别/大小更改命令(clplogcf命令)¶
更改,显示日志级别,日志输出文件大小的设置。
-
命令行 clplogcf -t <type> -l <level> -s <size>
-
说明 - 更改日志级别,日志输出文件大小的设置。显示当前设置值。
-
选项 -
-t¶ - 指定要更改设置的模块类型。省略[-l]和[-s]时,则显示指定的模块类型中设置的信息。可指定的类型请参考"-t选项中可指定的类型"表。
-
-l¶ - 指定日志级别。可指定的日志级别为以下任何一个。1,2,4,8,16,32数值越大,输出的日志越详细。
-
-s¶ - 指定输出日志的文件大小。单位为byte。
-
无¶ 显示当前设置的所有信息。
-
-
返回值 0
成功
0以外
异常
-
备注 EXPRESSCLUSTER输出的日志使用各类型的两个日志文件。因此需要[-s]指定的磁盘空间的两倍大小的空间。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行该命令时需要运行EXPRESSCLUSTER Event服务。
设定变更只在执行本命令的服务器上有效。此外,重启服务器时设定就会返回默认值。
显示/更改以下共享型镜像磁盘相关模块的设置时,必须指定相对应的镜像磁盘相关模块的模块类型。详细内容请参考"-t选项中可以指定的类型"的表格。clphd.dll
clphdctrl.exe
clphdstat.exe
clphdw.dll
-
执行示例 例1:更改pm的日志级别时
# clplogcf -t pm -l 8
例2:查看pm的日志级别,日志文件大小时
# clplogcf -t pm TYPE, LEVEL, SIZE pm, 8, 1000000
例3:显示当前设置值时
# clplogcf TYPE, LEVEL, SIZE trnsv, 4, 1000000 xml, 4, 1000000 logcf, 4, 1000000
-
错误消息 消息
原因/处理
Log in as administrator.
请以拥有Administrator权限的用户身份执行该命令。
Invalid option.
选项有误。请确认选项。
Failed to change configuration. Check if the event service is running.
可执行未启动EXPRESSCLUSTER Event服务。
Invalid level.
指定的级别有误。
Invalid size.
指定的大小有误。
Failed to initialize the xml library. Check if memory or OS resources are sufficient.
内存不足或OS资源不足。请确认。
Failed to print current configuration. Check if the event service is running.
可执行未启动EXPRESSCLUSTER Event 服务。
-
[-t]选项中可以指定的类型 类型
模块
说明
alert
clpaltinsert.exe
警报
apicl
clpapicl.dll
API客户端Library
apisv
clpapisv.dll
API服务器
appli
clpappli.dll
应用程序资源
appliw
clpappliw.dll
应用程序监视资源
awsazw
clpawsazw.dll
AWS AZ监视资源
awseip
clpawseip.dll
AWS Elastic IP资源
awsdns
clpawsdns.dll
AWS DNS资源
awsdnsw
clpawsdnsw.dll
AWS DNS监视资源
awseipw
clpawseipw.dll
AWS Elastic IP监视资源
azuredns
clpazuredns.dll
Azure DNS资源
azurednsw
clpazurednsw.dll
Azure DNS监视资源
azurepp
clpazurepp.dll
Azure 探头端口资源
azureppw
clpazureppw.dll
Azure 探头端口监视资源
azurelbw
clpazurelbw.dll
Azure 负载均衡器监视资源
bwctrl
clpbwctrl.exe
集群启动同步等待处理控制命令
cfchk
clpcfchk.exe
集群配置信息检查命令
cfctrl
clpcfctrl.exe
集群生成,集群信息备份命令
cifs
clpcifs.dll
CIFS 资源
cifsw
clpcifsw.dll
CIFS 监视资源
cl
clpcl.exe
集群操作命令
clpdnld
clpdnld.exe
Downloader
clpgetsvcstat
clptrnsv.exe
事务服务器
clpshmstat
clpshmstat.dll
节点状态管理Library
commcl
clpcommcl.dll
通用通信客户端Library
commcl_trace
clpcommcl.dll
通用通信客户端Library
commcl_ws
clpcommcl.dll
通用通信客户端Library
commcl_wsev
clpcommcl.dll
通用通信客户端Library
ddns
clpddns.dll
动态DNS资源
ddnsw
clpddnsw.dll
动态DNS监视资源
diskagcl
clpdiskagcl.dll
磁盘Agent通信客户端
diskagent
clpdiskagent.exe
磁盘Agent
diskfltr
clpdiskfltr.dll
磁盘过滤Library
disknp
clpdisknp.dll
DISK方式网络分区解决资源
diskperf
clpdiskperf.dll
磁盘性能日志输出用库
diskperf_conf
clpdiskperf.dll
磁盘性能日志输出用库
diskperf_trace
clpdiskperf.dll
磁盘性能日志输出用库
diskutil
clpdiskutil.dll
镜像磁盘/磁盘共同Library
diskw
clpdiskw.dll
磁盘RW监视资源
down
clpdown.exe
服务器关闭命令
event
clpevent.dll
事件日志
exping
clpexpng.dll
Ping执行管理
fip
clpfip.dll
浮动IP资源
fipw
clpfipw.dll
浮动IP监视资源
gclbw
clpgclbw.dll
Google Cloud 负载均衡监视资源
gcvip
clpgcvip.dll
Google Cloud 虚拟 IP 资源
gcvipw
clpgcvipw.dll
Google Cloud 虚拟 IP 监视资源
genw
genw.dll
自定义监视资源
grp
clpgrp.exe
组启动,停止,移动
hblog
clplanhb.dll
内核模式LAN心跳资源
hdsnapshot
clphdsnapshot.exe
共享型镜像磁盘快照备份命令
hdtw
clphdtw.dll
共享型镜像磁盘TUR监视资源
healthchk
clphealthchk.exe
进程健全性确认命令
ibsv
clpibsv.exe
Information Base服务
ipw
clpipw.dll
IP监视资源
lankhb
clplanhb.dll
内核模式LAN心跳资源
lcns
clplcns.dll
LicenseLibrary
logc
clplogc.dll
日志收集Library
logcc
clplogcc.exe
日志收集命令
logcf
clplogcf.exe
日志级别,大小更改命令
logcmd
clplogcmd.exe
警报输出命令
mail
clpmail.exe
Mail信息
majonp
clpmajnp.dll
多数决定方式网络化分区解决资源
md
clpmd.dll/clphd.dll
镜像磁盘资源/共享型镜像磁盘资源
mdadmn
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_act
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_copy
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_cr
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_ex
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_flag
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_info
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_trace
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdadmn_z
clpmdadmn.dll
镜像磁盘/共享型镜像磁盘管理库
mdapi
clpmdapi.dll
镜像磁盘/共享型镜像磁盘内部API
mdctrl
clpmdctrl.exe/clphdctrl.exe
镜像磁盘/共享型镜像磁盘控制命令
mddac
clpmddac.dll
镜像磁盘/共享型镜像磁盘控制库
mdfunc
clpmdfunc.dll
镜像磁盘/共享型镜像磁盘功能库
mdfunc_conf
clpmdfunc.dll
镜像磁盘/共享型镜像磁盘功能库
mdfunc_trace
clpmdfunc.dll
镜像磁盘/共享型镜像磁盘功能库
mdnm
clpmdnm.dll
镜像磁盘/共享型镜像磁盘节点管理
mdnm_t
clpmdnm.dll
镜像磁盘/共享型镜像磁盘节点管理
mdstat
clpmdstat.exe/clphdstat.exe
镜像磁盘/共享型镜像磁盘状态显示命令
mdw
clpmdw.dll/clphdw.dll
镜像磁盘/共享型镜像磁盘监视资源
mgtmib
clpmgtmib.dll
SNMP联动库
miiw
clpmiiw.dll
NIC Link Up/Down监视资源
monctrl
clpmonctrl.exe
监视资源控制命令
mrw
clpmrw.dll
消息接收监视资源
mtw
clpmtw.dll
Multi-Target监视资源
nm
clpnm.exe
节点地图管理
oclbw
clpoclbw.dll
Oracle Cloud 负载均衡监视资源
ocvip
clpocvip.dll
Oracle Cloud 虚拟 IP 资源
ocvipw
clpocvipw.dll
Oracle Cloud 虚拟 IP 监视资源
perfc
clpperfc.exe
集群统计信息显示命令
pingnp
clppingnp.dll
Ping方式网络化分区解决资源
pm
Clppm
进程管理
pmsvc
clppmsvc.exe
进程管理
psw
clppsw.dll
进程名监视资源
ptun
clpptun.dll
参数调试
ptunlib
clpptun.dll
参数调试
rc
clprc.exe
组,组资源管理
rc_ex
clprc.exe
组,组资源管理
rd
clprd.exe
智能失效切换用进程
rdl
clprdl.dll
智能失效切换用库
regctrl
clpregctrl.exe
重启次数控制命令
regsync
clpregsync.dll
Registry同步资源
regsyncw
clpregsync.dll
Registry同步监视资源
resdllc
clpresdllc.dll
资源控制Library
rm
clprm.dll
监视器管理
script
clpscript.dll
脚本资源
scrpc
clpscrpc.exe
脚本
scrpl
clpscrpl.exe
脚本
sd
clpsd.dll
磁盘资源
sdadmn
clpsdadmn.dll
磁盘管理Library
sddknp
clpsddknp.dll
磁盘方式网络分区解决Library
sdfunc
clpsdfunc.dll
磁盘功能Library
sdw
clpsdw.dll
磁盘TUR监视资源
sem
clpsem.dll
信号量Library
service
clpservice.dll
服务资源
servicew
clpservicew.dll
服务监视资源
shmcm
clpshmcm.dll
共享内存Library
shmevt
clpshmevt.dll
事件Library
shmnm
clpshmnm.dll
共享内存Library
shmrm
clpshmrm.dll
共享内存Library
snmpmgr
clpsnmpmgr.dll
SNMP Trap接收Library
startup
clpstartup.exe
Startup
stat
clpstat.exe
状态显示命令
stdn
clpstdn.exe
集群关机命令
toratio
clptoratio.exe
超时倍率更改命令
trap
clptrap.exe
SNMP Trap发送命令
trncl
clptrncl.dll
事务Library
rexec
clprexec.exe
外部监视联动处理请求命令
trnsv
clptrnsv.exe
事务服务器
userw
clpuserw.dll
用户空间监视资源
vcom
clpvcom.dll
虚拟计算机名资源
vcomw
clpvcomw.dll
虚拟计算机名监视资源
vip
clpvip.dll
虚拟IP资源
vipw
clpvipw.dll
虚拟IP监视资源
webalert
clpaltd.exe
警报同步
webmgr
clpwebmc.exe
WebManager服务
xml
xlpxml.dll
XMLLibrary
vmctrl
clpvmctrl.dll
VMCTRL Library
volctrl
clpvolctrl.exe
磁盘访问控制命令
-
[-t]选项可指定的监视可选产品的类型 类型
模块
说明
db2w
clp_db2w.dll
DB2监视(Database Agent)
ftpw
clp_ftpw.dll
FTP监视(Internet Server Agent)
httpw
clp_httpw.dll
HTTP监视(Internet Server Agent)
imap4w
clp_imap4w.dll
IMAP4监视(Internet Server Agent)
jra
clpjrasvc.exe
JVM监视资源 (Java Resource Agent)
jraw
clpjraw.dll
JVM监视资源 (Java Resource Agent)
odbcw
clp_odbcw.dll
ODBC监视(Database Agent)
oraclew
clp_oraclew.dll
Oracle监视(Database Agent)
otxw
clp_otxw.dll
WebOTX监视(Application Server Agent)
pop3w
clp_pop3w.dll
POP3监视(Internet Server Agent)
psqlw
clp_psqlw.dll
PostgreSQL监视(Database Agent)
smtpw
clp_smtpw.dll
SMTP监视(Internet Server Agent)
sqlserverw
clp_sqlserverw.dll
SQL Server监视(Database Agent)
sra
clpsraserviceproc.exe
系统监视资源/进程资源监视资源 (System Resource Agent)
sraw
clpsraw.dll
系统监视资源 (System Resource Agent)
psrw
clppsrw.dll
进程资源监视资源(System Resource Agent)
tuxw
clp_tuxw.dll
Tuxedo监视(Application Server Agent)
wasw
clp_wasw.dll
WebSphere监视(Application Server Agent)
wlsw
clp_wlsw.dll
WebLogic监视(Application Server Agent)
9.12. 管理License(clplcnsc命令)¶
进行License的管理。
-
命令行 - clplcnsc -i [licensefile...]clplcnsc -l [-a]clplcnsc -d serialno [-q]clplcnsc -d -t [-q]clplcnsc -d -a [-q]clplcnsc --distributeclplcnsc --reregister licensefile...
-
说明 进行本产品的产品版/试用版License的登录,浏览,删除。
-
选项 -
-i[licensefile...]¶ 如果指定License文件,则通过该文件获取并登录License信息。可以指定多个License文件。也可以指定通配符号。如果不指定,则通过交互方式输入并登录License信息。
-
-l[-a]¶ 浏览已经注册的License。显示内容如下。
项目
说明
Serial No
序列号(仅产品版)
User name
用户名(仅试用版)
Licensed Number of CPU
License的许可数(CPU单位)
Licensed Number of Computers
License许可数(节点单位)
Start date
End date
Status
License的状态
未指定-a选项时,不显示状态为invalid,unknown, expired的License。
指定-a选项时,无论License的状态如何,显示全部的License。
-
-d<param>¶ <param>
- serialno
删除指定序列号的License。
- -t
删除已注册的全部试用版License。
- -a
删除已注册的全部License。
-
-q¶ 删除License时不显示确认信息。请同时指定-d选项。
-
--distribute¶ 将License文件发送至集群内的服务器。一般不需要指定该选项。
-
--reregisterlicensefile...¶ 重新注册期间定制License。一般不需要使用此选项执行命令。
-
-
返回值 0
正常结束
1
取消
2
正常结束(License异步状态)
※是指注册License时,在集群内License同步失败。
该状态的处理方法请参考《安装&设置指南》的"疑难解答"的"License相关的疑难解答"。
3
初始化错误
5
选项错误
8
其它内部错误
-
执行示列 注册
交互方式
# clplcnsc -i
产品版,期间定制版
选择产品区分
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
输入序列号
Enter serial number [ Ex. XXXXXXXX000000 ] ...
输入License key
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
试用版
选择产品区分
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
输入用户名
Enter user name [ 1 to 63byte ] ...
输入License key
Enter license key [Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
指定License文件
clplcnsc -i /tmp/cpulcns.key
参照
# clplcnsc -l
产品版
<EXPRESSCLUSTER X <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Licensed Number of CPU... 2 Status... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Licensed Number of Computers... 1 Status... valid
期间定制版
<EXPRESSCLUSTER X <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Start date..... 2018/01/01 End date...... 2018/01/31 Status........... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Status........... inactive
试用版
<EXPRESSCLUSTER X <TRIAL> > Seq... 1 Key..... A1234567-B1234567-C1234567-D1234567 User name... NEC Start date..... 2018/01/01 End date...... 2018/02/28 Status........... valid
删除
# clplcnsc -d AAAAAAAA000001 -q
删除
# clplcnsc -d -t -q
删除
# clplcnsc -d -a
确认删除
Are you sure to remove the license? [y/n] ...
-
注意事项 请以拥有root权限的用户身份执行该命令。
注册License时,为了进行License同步,请确认数据传输服务器的启动以及集群是否生成。
进行License同步时,按照私网的优先级顺序连接到集群服务器的IP地址,使用成功的路由。
删除License时,只删除执行本命令的服务器上的License信息。不删除其他服务器上的License信息。要删除集群中所有的License信息时,请在所有服务器执行本命令。
另外,使用-d选项时,同时指定-a选项,试用版License和产品版License将被全部删除。仅删除试用版License时,请并用-t选项。已删除包含产品版License在内的信息时,需要重新注册产品版License。
参照License时,如果License中包含多个License,它们将分别显示。
-
错误消息 消息
原因/处理方法
Processed license num(success : %d,error : %d).处理的License数(成功: %d, 失败: %d)失败数不为0时,说明某种原因下处理License失败。请确认License信息是否正确。Command succeeded.
命令成功。
Command failed.
命令失败。
Command succeeded. But the license was not applied to all the servers in the cluster because there are one or more servers that are not started up.
集群中存在宕机的服务器。请在集群内所有服务器执行集群生成步骤。关于集群生成步骤,请参考《安装&设置指南》的"安装EXPRESSCLUSTER"。
Log in as administrator
无执行命令的权限。请用有Administrator权限的用户执行。
Invalid cluster configuration data. Check the cluster configuration information.
集群配置信息无效。请使用Cluster WebUI确认集群配置信息。
Initialization error. Check if memory or OS resources are sufficient.
初始化失败。可执行是内存不足或OS资源不足。请确认。
The command is already run.
命令已经执行。
The license is not registered.
未注册License。
Could not opened the license file. Check if the license file exists on the specified path.或者Could not read the license file. Check if the license file exists on the specified path.无法向License文件进行I/O。请确认License文件是否存在于指定的路径。
The field format of the license file is invalid. The license file may be corrupted. Check the destination from where the file is sent.
License文件的域格式无效。可执行License文件有破损。请确认文件的发送源。
The cluster configuration data may be invalid or not registered.
可执行是集群配置信息无效或未被登录。请确认。
Failed to terminate the library. Check if memory or OS resources are sufficient.
可执行是内存不足或OS资源不足。请确认。
Failed to register the license. Check if the entered license information is correct.或者Failed to open the license. Check if the entered license information is correct.请确认输入的License信息是否正确。
Failed to remove the license.
删除License失败。可执行是参数错误或内存不足或OS资源不足。请确认。
This license is already registered.
此License已经被注册。请确认被注册的License。This license is already activated.
此License已经被使用。请确认被注册的License。This license is unavailable for this product.
此License不适用于本产品。请确认License。The maximum number of licenses was reached.
已经达到可以注册的License最大数。请删除到期的License。Internal error. Check if memory or OS resources are sufficient.
可执行是内存不足或OS资源不足。请确认。
9.13. 镜像相关命令¶
9.13.1. 镜像磁盘状态显示(clpmdstat命令)¶
显示镜像磁盘相关的状态和设置信息。
-
命令行 - clpmdstat {-m|--mirror} mirrordisk-aliasclpmdstat {-a|--active} mirrordisk-aliasclpmdstat {-l|--config}clpmdstat {-c|--connect} mirrordisk-alias
-
说明 - 显示镜像相关的各种状态。显示镜像磁盘资源的设置信息。
-
选项 -
-m,--mirror¶ 显示镜像磁盘资源的状态。
-
-a,--active¶ 显示镜像磁盘资源的启动状态。
-
-l,--config¶ 显示镜像磁盘资源的设置信息。
-
-c,--connect¶ 显示镜像磁盘连接状态。
-
-
参数 -
mirrordisk-alias¶ 指定镜像磁盘资源名。
-
-
返回值 0
成功
0以外
异常
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行命令的机器上镜像磁盘资源为停止状态时,EXPRESSCLUSTER以外的进程访问磁盘的话,执行命令时出现[镜像磁盘切断中]的警告(实际结果没有问题)
-
显示示例 在下个主题中说明显示示例。
-
错误消息 消息
原因/处理方法
Invalid parameter.
参数错误。请确认参数的数值或形式是否错误。
All servers are down.
请确认有对象镜像磁盘资源的服务器至少有1台为启动状态,再次执行命令。
Internal error. The error code is [错误代码].
请重启自身服务器。
-
显示示例 - 镜像磁盘资源状态显示如果指定[--m,--mirror]选项,则显示指定的镜像磁盘资源的状态。根据镜像磁盘资源的状态,镜像磁盘资源状态的显示有2种类型。
镜像磁盘资源的状态为不是镜像复归中时
Status: Abnormal md1 server1 server2 --------------------------------------------------------------- Mirror Color GREEN RED Fast Copy OK OK Lastupdate Time 2021/08/16 18:24:10 -- Break Time 2021/08/16 18:24:01 -- Needed Copy Percent 1% 0% Volume Used Percent 64% --% Volume Size 10240MB 10240MB Server Name DP Error CP Error --------------------------------------------------------------- server1 NO ERROR ERROR server2 NO ERROR ERROR
各项目的说明
项目名
说明
Status
镜像磁盘资源的状态
状态 说明 -------------------------------------------- Normal 正常 Recovering 镜像复归中 Abnormal 异常 No Construction 未进行初始镜像构筑的状态 Uncertain 状态不明或者新旧未确定的状态
Mirror Color
各服务器的镜像磁盘的状态
状态 说明 ---------------------------------- GREEN 正常 YELLOW 镜像复归中 RED 异常 ORANGE 新旧未确定 GRAY 停止中,状态不明 BLUE 启动待机服务器和当前服务器
Fast Copy
差异复制可/不可
状态 说明 ---------------- OK 可复制 NG 不可复制 UNKNOWN 状态不明 -- 不需要差异复制
Lastupdate Time
服务器最后更新数据的时间
Break Time
发生mirror break的时间
Needed CopyPercent再复制需要的百分率
Volume Used Percent
Volume的使用百分率
Volume Size
Volume Size
DP Error
各服务器中的数据分区I/O是否有错
状态 说明 -------------------- OK 正常 ERROR 异常(I/O不可) -- 状态不明
CP Error
各服务器中的集群分区I/O是否有错请参考"DP Error"镜像磁盘资源的状态为镜像复归中时
Status: Recovering md1 server1 server2 --------------------------------------------------------------- Mirror Color YELLOW -> YELLOW 15% Recovery Status --------------------------------------------------------------- Used Time 00:00:21 Remain Time 00:01:59
各项目的说明
项目名
说明
Status
镜像磁盘资源的状态 3
Mirror Color
Used Time
从复制开始经过的时间
Remain Time
预计剩余部门复制完成所需的时间由于根据已复制的速度进行预测并显示,根据双方服务器的负荷情况等,值可执行会增减。
- 显示镜像磁盘资源的启动状态如果指定了[--a,--active]选项,则显示指定镜像磁盘资源的启动状态。
Resource Name: md1 Server Name Active Status --------------------------------------- server1 Active server2 Inactive
各项目的说明
项目名
说明
Resource Name
镜像磁盘资源名
Active Status
启动状态
状态 说明 --------------------- Active 启动 Inactive 停止 Force Acrive 强行启动 -- 状态不明
- 显示镜像磁盘资源设置信息如果指定了[-l,--config]选项,则显示所有的镜像磁盘资源的设置信息。
Resource Name: md1 Syncmode : Sync Config server1 server2 -------------------------------------------------------------- Drive Letter z z Disk Size 10240MB 10240MB
各项目的说明
项目名
说明
Resource Name
镜像磁盘资源名
Syncmode
同步模式
Drive Letter
数据分区盘符
Disk Size
数据分区大小
- 显示镜像磁盘连接的状态指定了[-c,--connect]选项时,显示镜像磁盘连接的状态。下面介绍的是2node的镜像磁盘资源时的例子。
资源在server1中处于启动状态(当前使用的镜像磁盘连接为Priority1,相邻的镜像磁盘连接为Priority2)
Resource Name : md1 Number of Connection: 2 Mirror Disk Connect Priority1 Priority2 ------------------------------------------------------------ server1 Address 10.0.10.11 10.0.20.11 Status Active Standby server2 Address 10.0.10.12 10.0.20.12 Status Active Standby
资源在两个服务器上都处于停止状态(当前使用的镜像磁盘连接为无;相邻的镜像磁盘连接为Priority1)
Resource Name : md1 Number of Connection: 2 Mirror Disk Connect Priority1 Priority2 ------------------------------------------------------------ server1 Address 10.0.10.11 10.0.20.11 Status Standby Standby server2 Address 10.0.10.12 10.0.20.12 Status Standby Standby
镜像磁盘连接只设置1个(资源在server1中处于启动状态)
Resource Name : md1 Number of Connection: 1 Mirror Disk Connect Priority1 Priority2 ------------------------------------------------------------ server1 Address 10.0.10.11 -- Status Active -- server2 Address 10.0.10.12 -- Status Active --
server2已宕机(不能获取server2的镜像磁盘连接状态,资源在server1中处于启动状态)
Resource Name : md1 Number of Connection: 2 Mirror Disk Connect Priority1 Priority2 ------------------------------------------------------------ server1 Address 10.0.10.11 10.0.20.11 Status Error Error server2 Address 10.0.10.12 10.0.20.12 Status Unknown Unknown
各项目的说明
项目名
内容
Resource Name
镜像磁盘资源名
Number of Connection
镜像磁盘连接的个数
Address
镜像磁盘连接(Primary及Secondary)的IP地址参考Cluster WebUI上设置的值Status
镜像磁盘连接(Primary及Secondary)的状态(有无运行状态,断线及连接错误等异常)字符串 镜像磁盘连接的状态 ----------------------------------- Active 正在使用 Standby 未使用且待机中 (未发生故障,可进行通信) Error 未使用且已断线 (发生故障,不可进行通信) Unknown 状态不明 -- 无配置信息
9.13.2. 镜像磁盘资源操作命令(clpmdctrl命令)¶
操作镜像磁盘资源。
-
命令行 - clpmdctrl {-a|--active} mirrordisk-alias [-n|-f]clpmdctrl {-d|--deactive} mirrordisk-aliasclpmdctrl {-b|--break} mirrordisk-alias [-n|-f]clpmdctrl {-f|--force} mirrordisk-aliasclpmdctrl {-r|--recovery} mirrordisk-alias [-a|-f|-vf]clpmdctrl {-c|--cancel} mirrordisk-aliasclpmdctrl {-w|--rwait} mirrordisk-alias [-timeout time] [-rcancel]clpmdctrl {-s|--mdcswitch} mirrordisk-alias [priority-number]clpmdctrl {-p|--compress} [mirrordisk-alias]clpmdctrl {-n|--nocompress} [mirrordisk-alias]clpmdctrl {-z|--resize} mirrordisk-alias partition-size [-force]clpmdctrl --updatekey mirrordisk-alias
注解
使用[--active], [--deactive]选项时请确认EXPRESSCLUSTER服务是否停止。
注解
使用 --resize选项扩展镜像磁盘资源的数据分区时,在数据分区区域之后必须有足够的可用空间。
注解
使用--updatekey选项后更新加密密钥时,按照《维护指南》的"维护信息"的"更新镜像磁盘资源/共享型镜像磁盘资源的加密密钥"中记载的步骤进行。
-
说明 进行镜像磁盘资源的启动/停止、镜像复归等。
-
选项 -
-a,--active¶ - 在自身服务器上启动镜像磁盘资源。镜像磁盘资源的状态正常时进行镜像。镜像磁盘资源的状态不正常时不进行镜像。没有指定[-n]和[-f]中的任何一个时,与指定了[-n]时的运行相同。
-
-n(-a,--active)¶ - 将启动模式指定为普通启动。此选项可省略。指定[-f]的场合不可指定。
-
-f(-a,--active)¶ - 将启动模式指定为强制启动。此选项可省略。指定[-n]的场合不可指定。
-
-d,--deactive¶ 将自身服务器上已启动的镜像磁盘资源停止。
-
-b,--break¶ - 中断镜像磁盘的镜像化,执行指令的服务器上的数据不是最新的数据。到镜像复归为止,即使发生写入镜像磁盘镜像数据也不同步。没有指定[-n]和[-f]中的任何一个时,与指定了[-n]时的运行相同。
-
-n(-b,--break)¶ - 指定退化模式为通常退化。通常退化时,只镜像磁盘被正常镜像化时,中断镜像化后把自身服务器作为非最新。此选项可省略。指定[-f]的场合不可指定。
-
-f(-b,--break)¶ - 指定退化模式为强制退化。强制退化时,镜像化的对方的服务器的状态即使为异常或者不明,也中断镜像化,中断镜像化后把自身服务器作为非最新。此选项可省略。指定[-n]的场合不可指定。
-
-f,--force¶ 对指定的镜像磁盘资源进行强行镜像复归。
-
-r,--recovery¶ - 自身服务器作为复制源,对指定的镜像磁盘资源进行完全镜像复归或差异镜像复归。如果没有指定 [-a]、[-f] 或 [-vf],则操作与指定 [-a] 时相同。
-
-a(-r,--recovery)¶ - 自动选择恢复模式。能够特定差异部位时,执行差异复制。不能确定差异时,与指定了[-f]时的运行相同。此选项可省略。指定了[-f]或[-vf]时,不能进行指定。
-
-f(-r,--recovery)¶ - 能够特定卷的利用空间时,复制所有的利用空间。不能够特定卷的利用空间时,复制卷的所有空间。此选项可省略。指定了[-a]或[-vf]时,不能进行指定。
-
-vf(-r,--recovery)¶ - 不管差异及利用空间,复制卷的全部空间。此选项可省略。指定了[-a]或[-f]时,不能进行指定。
-
-c,--cancel¶ 中止镜像复归。
-
-w,--rwait¶ 等待指定镜像磁盘资源的镜像复归完毕。
-
-timeout(-w,--rwait)¶ - 指定等待镜像复归完毕的超时时间(秒)。这个选项可以省略。省略时不会超时,一直等待镜像复归完毕为止。
-
-rcancel(-w,--rwait)¶ - 等待镜像复归完毕超时时,中断镜像复归。这个选项可以在设置[-timeout]选项时设置。省略时即使超时也继续进行镜像复归。
-
-s,--mdcswitch¶ - 切换用户指定的镜像磁盘资源的镜像磁盘连接的Primary/Secondary。在Priority编号已省略的情况下,执行命令时,只要Primary作为镜像磁盘连接使用,则会切换到Secondary;同样,只要Secondary作为镜像磁盘连接使用,则会切换到Primary。指定Priority编号时,切换到相应Priority的镜像磁盘连接。
-
-p,--compress¶ - 暂时将指定的镜像磁盘资源的镜像数据压缩设置切换到ON。省略镜像磁盘资源名时,暂时将所有镜像磁盘资源的镜像数据压缩设置切换到ON。
-
-n,--nocompress¶ - 暂时将指定的镜像磁盘资源的镜像数据压缩设置切换到OFF。省略镜像磁盘资源名时,暂时将所有镜像磁盘资源的镜像数据压缩设置切换到OFF。
-
-z,--resize¶ - 扩展镜像磁盘资源的数据分区大小。只有镜像磁盘资源的状态正常时才能扩展。
-
-force(-z,--resize)¶ - 不管镜像磁盘资源的状态,强制执行扩展。如果使用该选项,则下次的镜像复归变成全复制。另外,即使使用该选项,镜像复归中也无法扩展。
-
--updatekey¶ - 在不停止资源的情况下更新加密密钥。如果用新服务器替换两台服务器的加密密钥文件,然后执行此选项,则将更新用于加密的密钥。如果在镜像期间执行,镜像将被中断。完成执行后,如有必要,执行镜像复归。
-
-
参数 -
mirrordisk-alias¶ 指定镜像磁盘资源名。
-
time¶ 指定等待镜像复归完毕的超时时间(秒)。
-
priority-number¶ 指定Priority编号(1 或 2)。
-
partition-size¶ - 指定数据分区的新大小。添加以下单位字符之后可以指定。如果指定500G,则扩展500GB。没有添加单位字符时,视作字节处理。
K (Kibi byte)
M (Mibi byte)
G (Gibi byte)
T (Tebi byte)
-
-
返回值 0
成功
101
参数有误
102
状态有误([-w,--rwait]选项指定时,也包括通过[-rcancel]中断镜像复归的情况)
103
从其他服务器对同一资源同时实施操作
104
从自身服务器对同一资源同时实施操作
105
复制目标服务器正在宕机
106
执行指令的服务器没有保留对象资源
107
集群分区或者数据分区上发生I/O错误
109
等待对象镜像磁盘的镜像复归完毕超时(仅限指定[-w,--rwait] [-timeout]选项时)
110
其他错误
111
镜像磁盘的扩展失败(仅限指定[-z,--resize]选项时)
112
加密密钥更新失败(仅限指定[--updatekey]选项时)
113
加密功能为OFF(仅限指定[--updatekey]选项时)
114
加密密钥文件未更新(仅限指定[--updatekey]选项时)
201
切换目标镜像磁盘连接的状态错误(仅限指定[-m,--mdcswitch]选项时)
202
只设置了1个镜像磁盘连接(仅限指定[-m,--mdcswitch]选项时)
203
对方服务器正在宕机
-
备注 本命令在指定的处理的已开始的时机时返回控制。请使用clpmdstat命令来确认处理的状况。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
如果在镜像复归异常结束后再次进行镜像复归,则请将与上次同一个服务器指定为复制源,进行镜像复归。
在镜像复归过程中执行了取消,中断复原后重新开始镜像复归时,请务必使用该命令执行强行镜像复归。
-
执行示例 例1:启动镜像磁盘资源 md1时
# clpmdctrl --active md1 Command succeeded.
例2:停止镜像磁盘资源 md1时
# clpmdctrl --deactive md1 Command succeeded.
例3:镜像复归镜像磁盘资源 md1时
# clpmdctrl --recovery md1 Command succeeded.
-
错误消息 消息
原因/处理方法
Invalid parameter.
参数有误。请确认参数的数值和形式是否有误。
The status of [镜像磁盘资源名] is invalid.
请确认状态后,再执行命令。
This command is already run in another server.
请在目前执行中的命令结束后再执行命令。
This command is already run in the local server.
请在目前执行中的命令结束后再执行命令。
[复制目标服务器名] is down.
请启动复制目标服务器,再次执行命令。
[自身服务器名] is not included in Servers that can run the Group of [镜像磁盘资源名].
对象镜像磁盘资源请在可以启动的服务器中执行命令。
Disk error.
请确认在有集群分区或者数据分区的磁盘或者磁盘路径中没有发生HW障碍。
Mirror recovery of [镜像磁盘资源名] is timed out.
请确认超时时间的指定是否妥当,或者是否因高负荷等原因发生磁盘I/O或通信延迟。
Internal error. The error code is [错误代码].
请重启自身服务器。
Standby mirror disk connect has invalid status.
请确认镜像磁盘连接的连接情况。
[镜像磁盘资源名] has only one mirror disk connect.
请确认是否登录有多个镜像磁盘连接。
Other server downed.
请确认服务器的启动状态。
Resize the mirror disk([镜像磁盘资源名]) is failed.
请确认镜像磁盘资源的状态是否正常。请确认当前的数据分区领域上是否有充足的空间。Failed to update the encryption key.
请确认在各服务器上,设置的密钥文件全路径中是否存在密钥文件。
The encryption function is disabled.
由于指定的镜像磁盘资源未启用「加密镜像通信」功能,因此无法更新加密密钥。
The same encryption key is already used.
请更新各服务器的密钥文件,再重新执行。
Automatic mirror recovery is disabled. Its manual resumption is required to resume mirroring.
加密密钥已更新,但镜像已中断。因为自动镜像复归设置为OFF,所以必须手动进行镜像复归。
Failed to resume the automatic mirror recovery. Its manual resumption is required to resume mirroring.
虽然加密密钥已更新,但是镜像已中断。由于自动镜像复归设置为OFF,因此需要手动执行镜像复归。
9.13.3. 分区大小调整命令(clpvolsz命令)¶
确认/缩小磁盘分区的大小。
-
命令行 clpvolsz drive-letter [size]
-
说明 确认通过镜像磁盘资源镜像连接的数据分区的大小,大小不一致时进行调整。
-
返回值 0
大小显示成功
1
大小变更成功
2以上
异常
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
该命令不可以扩展分区大小。
通过该命令缩小分区大小,盘符就被变更为与删除,重新创建分区后一样的状态。分区缩小后必须使用磁盘管理([Control Panel] > [Administrative Tools] > [Computer Management] > [Disk Management])对磁盘再次进行扫描,请确认,重设定/重置盘符。
对象分区已经作为镜像磁盘资源的数据分区/集群分区被登录到集群配置信息中时,在缩小分区大小前一旦删除镜像磁盘资源,请在重设定缩小大小和盘符后再次登录。
分区大小因为在主引导扇区被关联,一般是512Byte的倍数。
-
执行示例 例1:确认Z盘的大小时
# clpvolsz z: Drive <z:> 8,587,160,064
例2:把Z盘的大小缩小为8,587,159,552Byte时
# clpvolsz z: 8587159552 Drive <z:> 8,587,160,064 -> 8,587,159,552 Execute it? [Y/N] ->y SUCCESS
-
错误消息 消息
原因/处理
ERROR:invalid parameter.
参数有误。请确认参数的数值和形式是否有误。
ERROR:larger than partition size.
比当前分区大的值被指定。请指定比当前容量小的值。
ERROR:drive not found.
没有找到指定盘符。请确认盘符指定是否有误。
ERROR:drive open failed.
不能打开指定盘符。请确认盘符是否是允许访问的状态。
ERROR:partition not found.
没有找到指定盘符的分区号码。请确认盘符指定是否有误。
ERROR:partition size zero.
指定盘符的分区大小为0。请确认对象分区是否为MBR形式的BASIC volume。
ERROR:device layout info.
取得磁盘的分区配置信息失败。请确认对象分区是否为MBR形式的BASIC volume。
ERROR:device geometry info.
取得磁盘几何信息失败。请确认磁盘装置是否正常运行。
ERROR:device no info.
取得Device No. / Partition No.失败。请确认对象分区是否为MBR形式的BASIC volume。
ERROR:set device info.
对磁盘的分区信息设定失败。请确认是否禁止对磁盘的写入。
ERROR:memory alloc error.
资源保存失败。请确认是否是内存不足或者OS资源不足。
9.13.4. 磁盘访问控制命令(clpvolctrl命令)¶
进行访问卷的操作。
-
命令行 - clpvolctrl {-o|--open} drive_nameclpvolctrl {-c|--close} drive_nameclpvolctrl {-v|--view} [drive_name]
-
说明 针对设置了过滤链接的HBA下的磁盘卷,进行访问状态的操作。
注解
作为镜像磁盘资源或者共享型镜像磁盘资源注册的卷,不作为通过本命令操作/显示的对象。
-
选项 -
-o,--open¶ - 允许对卷的访问。指定1个允许访问的对象卷的驱动名。
-
-c,--close¶ - 限制对卷的访问。指定1个限制访问的对象卷的驱动名。
-
-v,--view¶ - 显示对卷访问的状态信息。指定1个显示访问状态的对象卷的驱动字符。- 指定了驱动字符时显示指定卷的访问状态。- 未指定驱动字符时(省略时)执行属于命令执行服务器且已连接到已为其设置过滤的HBA的磁盘上所有卷的访问状态显示。
-
-
参数 -
drive_name¶ 指定对象卷的驱动字符。
-
-
返回值 0
命令成功
101
参数错误
102
对象卷已登录资源
103
对象卷已允许访问(仅限使用[-o,--open]选项时)
104
对象卷已限制访问(仅限使用[-c,--close]选项时)
200
其他错误
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
-
执行示例 例1:允许访问卷时
# clpvolctrl --open z Command succeeded.
例2:限制访问卷时
# clpvolctrl --close z Command succeeded.
例3:显示对卷的访问状态的信息时
指定了驱动字符
# clpvolctrl --view z Drive Name Access Status ---------------------------- z open
未指定驱动字符
# clpvolctrl --view Drive Name Access Status ---------------------------- w open x close y close z open
-
错误消息 消息
原因/处理
Invalid parameter.
参数错误。请确认参数数量及格式是否错误。
[驱动器名]: is a volume registered as a resource.
请确认有无使用指定驱动的组资源。
Access to [驱动器名]: is already permitted.
针对已处于可访问状态的驱动,使用[-o,--open]选项执行了命令。
Access to [驱动器名]: is already restricted.
针对已处于禁止访问状态的驱动,使用[-c,--close]选项执行了命令。
Internal error. The error code is [错误代码].
重启自身服务器。
9.13.5. 生成通信加密的密钥文件(clpkeygen命令)¶
创建通信加密的密钥文件。
-
命令行 clpkeygen key-bit-length file-name
-
说明 使用对镜像磁盘连接传输的通信数据进行加密时,创建密钥文件。
-
选项 无
-
返回值 0
命令成功
1
参数不正确
2~12
无法生成加密密钥
13, 14
无法将加密密钥写入文件
-
注意事項 - 本命令为每执行1次就随机生成1个不同的密钥文件。作为加密密钥文件使用时,请将每执行1次生成的文件复制到各服务器中使用。
-
执行示例 例:创建256bit长度的密钥文件。
# clpkeygen 256 keyfile.bin
-
错误消息 消息
原因/处理方法
Invalid option.
参数不正确。请确认引数的数值或格式是否有误。
Internal error.(code=[错误代码]): Check if memory or OS resources are sufficient.
请确认是否存在内存不足或OS资源不足。
Internal error.(code=[错误代码] status=[NTSTATUS])Internal error.(code=[错误代码])OS的内部发生异常。请重启服务器,或者在其他服务器上执行。
Failed to open file.(code=[错误代码] status=[NTSTATUS]): Move or delete file, or Check access right is valid.
请确认是否有写入创建密钥文件的目录中的权限。
Failed to write file.(code=[错误代码] status=[NTSTATUS]): Check if disk space is sufficient.
请确认创建密钥文件的目录是否有充足容量。
9.13.6. 共享型镜像磁盘资源的快照备份操作(clphdsnapshot命令)¶
共享型镜像磁盘资源的快照操作。
-
命令行 - clphdsnapshot {-o|--open} hybriddisk-aliasclphdsnapshot {-c|--close} hybriddisk-alias
-
说明 中断共享型镜像磁盘资源的镜像化,取消数据分区的访问限制,启用快照备份采集。另外,还可以从该状态重新开始镜像化,恢复为通常的状态。
-
选项 -
-o,--open¶ 中断镜像化,取消对执行了命令的服务器上数据分区的访问限制,启用快照备份采集。自动镜像复归设置为启用状态时,该设置会暂时被禁用。
-
-c,--close¶ 对数据分区进行访问限制。自动镜像复归设置为启用状态时,将取消临时被设置的禁用,重新开始进行镜像化。
-
-
参数 -
hybriddisk-alias¶ 指定共享型镜像磁盘资源名。
-
-
返回值 0
命令成功
1
参数错误
2
对象资源没有被镜像化(仅限使用[-o,--open]选项时)
3
对象资源可执行在其他服务器上已经是快照状态,已被强行启动(仅限使用[-o,--open]选项时)
4
对象资源已经是快照状态(仅限使用[-o,--open]选项时)
5
对象资源不是快照状态(仅限使用[-c,--close]选项使用時)
6
对象资源正在镜像复归
7
对象资源在本服务器中不存在
8
已经在当前服务器组中执行了该命令
9
其他错误
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
本命令可以在待机服务器组(作为镜像化的复制目标地址运行的服务器组)的某个服务器上对正常进行镜像化的启动状态的共享型镜
像磁盘资源执行。在当前服务器组的服务器(与资源启动的服务器同一组的服务器)上无法执行。
通过本命令执行的镜像被中断时,根据镜像中断的时机,有可执行无法保证复制目的地数据的NTFS及作为程序数据的完整性。
-
执行示例 在共享型镜像磁盘资源 hd_Z 中采集被镜像化的Z盘的备份时
图 9.7 共享型镜像配置中的备份¶
在待机服务器组的服务器3上执行以下命令
# clphdsnapshot --open hd_Z Command succeeded.
2.在服务器3上使用备份工具采集Z盘的备份
3.在服务器3上执行以下命令
# clphdsnapshot --close hd_Z Command succeeded.
4.如果自动镜像复归设为禁用状态,则通过手动操作恢复镜像
-
错误消息 消息
原因/处理方法
Invalid parameter.
参数错误。请确认参数的数值或形式是否错误。
[共享型镜像磁盘资源名] is not mirroring, or not active.
对于处于停止状态或镜像化中断的共享型镜像磁盘资源无法进行快照备份。请在其他服务器组上启动资源,或在正常的镜像化状态下重新执行快照备份。
[共享型镜像磁盘资源名] is busy on [服务器名].
请确认对象资源是否已经在同一服务器组内的其他服务器处于快照状态或被强行启动。
[共享型镜像磁盘资源名] has already opened.
对已经通过[-o,--open]选项将其置为快照状态的资源重新执行了指定了[-o,--open]选项的命令。请确认执行步骤。
[共享型镜像磁盘资源名] is not open.
对于已经通过[-o,--open]选项没有置为快照状态的资源执行了指定了[-c,--close]选项的命令。请确认指定了[-o,--open]选项的命令是否已经正确执行。
[共享型镜像磁盘资源名] is copying.
对于正在进行镜像复归的共享型镜像磁盘资源不能进行快照备份。请在镜像复归结束后再进行快照备份。
[服务器名] is not available to [共享型镜像磁盘资源名].
在对象资源无法启动的服务器上无法采集快照备份。请在包含该资源的可启动失效切换组的服务器上执行快照备份采集。
Don't execute at active server group.
对于已在同一服务器组内其他服务器上启动的共享型镜像磁盘资源无法进行快照备份。请在待机系服务器组的服务器上执行。
Internal error. The error code is [错误代码]
请确认对象资源的集群分区和数据分区的状态。另外请确认是否有内存不足或OS资源不足。
9.13.7. 共享型镜像磁盘状态显示命令(clphdstat命令)¶
显示共享型镜像磁盘相关的状态和设置信息。
-
命令行 - clphdstat {-m|--mirror} hybriddisk-aliasclphdstat {-a|--active} hybriddisk-aliasclphdstat {-l|--config}clphdstat {-c|--connect} hybriddisk -alias
-
说明 显示与共享型镜像磁盘相关的各种状态。
显示共享型镜像磁盘资源的设置信息。
-
选项 -
-m,--mirror¶ 显示共享型镜像磁盘资源的状态。
-
-a,--active¶ 显示共享型镜像磁盘资源的启动状态。
-
-l,--config¶ 显示共享型镜像磁盘资源的设置信息。
-
-c,--connect¶ 显示镜像磁盘连接状态。
-
-
参数 -
hybriddisk-alias¶ 指定共享型镜像磁盘资源名。
-
-
返回值 0
成功
0 以外
异常
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行命令的机器上共享型镜像磁盘资源为停止状态时,EXPRESSCLUSTER以外的进程使用磁盘的话,执行命令时出现[共享型镜像磁盘中断中]的警告(实际结果没有问题)
-
显示示例 显示示例在下个主题中进行说明。
-
错误消息 消息
原因/处理方法
Invalid parameter.
参数错误。请确认参数的数值或形式是否错误。
All servers are down.
请确认有对象共享型镜像磁盘资源的服务器至少有1台为启动状态,再次执行命令。
Internal error. The error code is [错误代码].
请重启自身服务器。
-
显示示例 - 显示共享型镜像磁盘资源状态如果指定[-m,--mirror]选项,则显示指定的共享型镜像磁盘资源的状态。根据共享型镜像磁盘资源的状态,共享型镜像磁盘资源状态的显示有2种类型。
共享型镜像磁盘资源的状态为不是镜像复归中时
Status: Abnormal hd1 svg01 svg02 ---------------------------------------------------------- Mirror Color GREEN RED Fast Copy OK OK Lastupdate Time 2021/08/17 15:50:27 -- Break Time 2021/08/17 15:44:35 -- Needed Copy Percent 1% 0% Volume Used Percent 67% --% Volume Size 10240MB 10240MB Disk Error NO ERROR ERROR Server Name DP Error CP Error ---------------------------------------------------------- server1 NO ERROR NO ERROR server2 NO ERROR NO ERROR server3 NO ERROR ERROR server4 NO ERROR ERROR
各项目的说明
项目名
说明
Status
共享型镜像磁盘资源的状态
状态 说明 -------------------------------------------- Normal 正常 Recovering 镜像复归中 Abnormal 异常 No Construction 未进行初始镜像构筑的状态 Uncertain 状态不明或者新旧未确定的状态
Mirror Color
各服务器的共享型镜像磁盘的状态
状态 说明 -------------------------------- GREEN 正常 YELLOW 镜像复归中 RED 异常 ORANGE 新旧未确定 GRAY 停止中,状态不明 BLUE 启动待机服务器和当前服务器
Fast Copy
差异复制可/不可
状态 说明 -------------- OK 可复制 NG 不可复制 UNKNOWN 状态不明 -- 不需要差异复制
Lastupdate Time
服务器最后更新数据的时间
Break Time
发生mirror break的时间
Needed CopyPercent再复制需要的百分率
Volume Used Percent
Volume的使用百分率
Volume Size
Volume Size
Disk Error
Disk I/O的状态
状态 说明 -------------------- OK 正常 ERROR 异常(I/O不可) -- 状态不明
DP Error
各服务器中的数据分区I/O是否有错(请参考"Disk Error")CP Error
各服务器中的集群分区I/O是否有错(请参考"Disk Error")共享型镜像磁盘资源的状态为镜像复归中时
Status: Recovering hd1 svg01 svg02 --------------------------------------------------------------- Mirror Color YELLOW -> YELLOW 15% Recovery Status --------------------------------------------------------------- Source Server server1 Destination Server server3 Used Time 00:00:21 Remain Time 00:01:59
各项目的说明
项目名
说明
Status
共享型镜像磁盘资源的状态 4
Mirror Color
Source Server
复制源服务器
Destination Server
复制目标服务器
Used Time
从复制开始经过的时间
Remain Time
预计剩余部分复制完成所需的时间
由于根据已复制的速度进行预测并显示,根据双方服务器的负荷情况等,值可执行会增减。
- 显示共享型镜像磁盘的启动状态如果指定了[-a,--active]选项,则显示指定的共享型镜像磁盘资源的启动状态。
Resource Name: hd1 Server Name Active Status Current Server ----------------------------------------------------------- svg01 server1 Active CURRENT server2 Inactive -- svg02 server3 Force Active CURRENT server4 Inactive --
各项目的说明
项目名
说明
Resource Name
共享型镜像磁盘资源名
Active Status
启动状态
状态 说明 --------------------- Active 启动 Inactive 停止 Force Acrive 强行启动 -- 状态不明
Current Server
当前服务器
状态 说明 -------------------- CURRENT 当前服务器 -- 非当前服务器
- 显示共享型镜像磁盘资源设置信息如果指定了[-l,-- config]选项,则显示所有的共享型镜像磁盘资源的设置信息。
Resource Name: hd1 Syncmode : Sync Config svg01 svg02 ----------------------------------------------------------- Drive Letter z z Disk Size 10240MB 10240MB Server Name server1 server3 server2 server4
各项目的说明
项目名
说明
Resource Name
共享型镜像磁盘资源名
Syncmode
同步模式
Drive Letter
数据分区盘符
Disk Size
数据分区大小
Server Name
各服务器组的组员服务器
- 显示镜像磁盘连接的状态指定了[-c,--connect]选项时,显示镜像磁盘连接的状态。下面介绍的是4node的共享型镜像磁盘资源时的例子。
[集群配置]
服务器:4台 (server1~server4)服务器组:2个 (svg01,svg02)svg01的登录服务器:server1,server2svg02的登录服务器:server3,server4共享型镜像磁盘资源:1个b (hd1)[集群状态]
- 服务器server1中的共享型镜像磁盘资源hd1处于启动状态- 服务器组svg01正在使用优先级1的镜像磁盘连接- 服务器组svg02正在使用优先级2的镜像磁盘连接Resource Name : hd1 Number of Connection: 2 Mirror Disk Connect Priority1 Priority2 ------------------------------------------------------------ <svg01> server1 Address 10.0.10.11 10.0.20.11 Status Active Standby server2 Address 10.0.10.12 10.0.20.12 Status Error Standby <svg02> server3 Address 10.0.10.21 10.0.20.21 Status Standby Active server4 Address 10.0.10.22 10.0.20.22 Status Standby Standby
各项目的说明
项目名
内容
Resource Name
共享型镜像磁盘资源名
Number of Connection
镜像磁盘连接的个数
Address
镜像磁盘连接(Primary及Secondary)的IP地址
参考Cluster WebUI上设置的值
Status
镜像磁盘连接(Primary及Secondary)的状态
(运行状态,有无断线及连接错误等异常)
字符串 镜像磁盘连接的状态 -------------------------------------- Active 正在使用 Standby 未使用且待机中 (未发生故障,可进行通信) Error 未使用且已断线 (发生故障,不可进行通信) Unknown 状态不明 -- 无配置信息
9.13.8. 共享型镜像磁盘资源操作命令(clphdctrl命令)¶
操作共享型镜像磁盘资源。
-
命令行 - clphdctrl {-a|--active} hybriddisk-alias [-n|-f]clphdctrl {-d|--deactive} hybriddisk-aliasclphdctrl {-b|--break} hybriddisk-alias [-n|-f]clphdctrl {-f|--force} hybriddisk-aliasclphdctrl {-r|--recovery} hybriddisk-alias [-a|-f|-vf] [dest-servername]clphdctrl {-c|--cancel} hybriddisk-aliasclphdctrl {-w|--rwait} hybriddisk-alias [-timeout time] [-rcancel]clphdctrl {-s|--mdcswitch} hybriddisk-alias [priority-number]clphdctrl {-p|--compress} [hybriddisk-alias]clphdctrl {-n|--nocompress} [hybriddisk-alias]clphdctrl {-z|--resize} hybriddisk-alias partition-size [-force]clphdctrl --updatekey hybriddisk-alias
注解
使用[--active],[--deactive] 选项时,请确认停止EXPRESSCLUSTER服务。
注解
使用--resize选项执行共享型镜像磁盘资源的数据分区扩展时,按照《维护指南》的"维护信息"的"扩展共享型镜像磁盘的大小"中记载的步骤,必须有序实施两服务器间的扩展。
注解
使用--resize选项后执行共享型镜像磁盘资源的数据分区扩展时,数据分区领域后必须存在充足的空间。
注解
使用--updatekey选项后更新加密密钥时,按照《维护指南》的"维护信息"的"更新镜像磁盘资源/共享型镜像磁盘资源的加密密钥"中记载的步骤进行。
-
说明 进行共享型镜像磁盘资源的启动/停止、镜像复归等。
-
选项 -
-a,--active¶ - 在自身服务器上启动共享型镜像磁盘资源。共享型镜像磁盘资源的状态正常时进行镜像。共享型镜像磁盘资源的状态不正常时不进行镜像。没有指定[-n]和[-f]中的任何一个时,与指定了[-n]时的运行相同。
-
-n(-a,--active)¶ - 将启动模式指定为普通启动。此选项可省略。指定[-f]的场合不可指定。
-
-f(-a,--active)¶ - 将启动模式指定为强制启动。此选项可省略。指定[-n]的场合不可指定。
-
-d,--deactive¶ 将自身服务器上已启动的共享型镜像磁盘资源停止。
-
-b,--break¶ - 中断共享型镜像磁盘资源的镜像化,执行指令的服务器上的数据不是最新的数据。到镜像复归为止,即使发生写入共享型镜像磁盘镜像数据也不同步。没有指定[-n]和[-f]中的任何一个时,与指定了[-n]时的运行相同。
-
-n(-b,--break)¶ - 指定退化模式为通常退化。通常退化时,只共享型镜像磁盘被正常镜像化时,中断镜像化后把自身服务器作为非最新。此选项可省略。指定[-f]的场合不可指定。
-
-f(-b,--break)¶ - 指定退化模式为强制退化。强制退化时,镜像化的对方的服务器或服务器组的状态即使为异常或者不明,也中断镜像化,中断镜像化后把自身服务器作为非最新。此选项可省略。指定[-n]的场合不可指定。
-
-f,--force¶ 对指定的共享型镜像磁盘资源进行强行镜像复归。
-
-r,--recovery¶ - 自身服务器作为复制源,对指定的共享型镜像磁盘资源进行完全镜像复归或差异镜像复归。如果没有指定 [-a]、[-f] 或 [-vf],则操作与指定 [-a] 时相同。
-
-a(-r,--recovery)¶ - 自动选择恢复模式。能够特定差异部位时,执行差异复制。不能确定差异时,与指定了[-f]时的运行相同。此选项可省略。指定了[-f]或[-vf]时,不能进行指定。
-
-f(-r,--recovery)¶ - 能够特定卷的利用空间时,复制所有的利用空间。不能够特定卷的利用空间时,复制卷的所有空间。此选项可省略。指定了[-a]或[-vf]时,不能进行指定。
-
-vf(-r,--recovery)¶ - 不管差异及利用空间,复制卷的全部空间。此选项可省略。指定了[-a]或[-f]时,不能进行指定。
-
-c,--cancel¶ 中止镜像复归。
-
-w,--rwait¶ 等待指定了的共享型镜像磁盘资源的镜像复归完毕。
-
-timeout(-w,--rwait)¶ - 指定等待镜像复归完毕的超时时间(秒)。这个选项可以省略。省略时不会超时,一直等待镜像复归完毕为止。
-
-rcancel(-w,--rwait)¶ - 等待镜像复归完毕超时时,中断镜像复归。这个选项可以在设置[-timeout]选项时设置。省略时即使超时也继续进行镜像复归。
-
-s,--mdcswitch¶ - 切换用户指定的共享型镜像磁盘资源的镜像磁盘连接的Primary/Secondary。在Priority编号已省略的情况下,执行命令时,只要Primary作为镜像磁盘连接使用,则会切换到Secondary;同时,只要Secondary作为镜像磁盘连接使用,则会切换到Primary。指定Priority编号时,切换到相应Priority的镜像磁盘连接。
-
-p,--compress¶ - 暂时将指定的共享型镜像磁盘资源的镜像数据压缩设置切换到ON。省略共享型镜像磁盘资源名时,暂时将所有的共享型镜像磁盘资源的镜像数据压缩设置切换到ON。
-
-n,--nocompress¶ - 暂时将指定的共享型镜像磁盘资源的镜像数据压缩设置切换到OFF。省略共享型镜像磁盘资源名时,暂时将所有的共享型镜像磁盘资源的镜像数据压缩设置切换到OFF。
-
-z,--resize¶ - 扩展共享型镜像磁盘资源的数据分区大小。只在共享型镜像磁盘资源的状态正常时可以扩展。
-
-force(-z,--resize)¶ - 不管共享型镜像磁盘资源的状态,强制执行扩展。使用本选项,则下次镜像复归变成全面复制。另外,即使使用本选项,镜像复归中也无法扩展。
-
--updatekey¶ - 在不停止资源的情况下更新加密密钥。如果用新服务器替换两台服务器的加密密钥文件,然后执行此选项,则将更新用于加密的密钥。如果在镜像期间执行,镜像将被中断。完成执行后,如有必要,执行镜像复归。
-
-
参数 -
hybriddisk-alias¶ 指定共享型镜像磁盘资源名。
-
dest-servername¶ - 指定作为复制源的服务器名。省略时,其他服务器自动判断复制源。
-
time¶ 指定等待镜像复归完毕的超时时间(秒)。
-
priority-number¶ 指定Priority编号(1 或 2)。
-
partition-size¶ - 指定数据分区的新大小。添加以下单位字符之后可以指定。如果指定500G,则扩展500GB。没有添加单位字符时,视作字节处理。
K (Kibi byte)
M (Mibi byte)
G (Gibi byte)
T (Tebi byte)
-
-
返回值 0
成功
101
参数有误
102
状态有误([-w,--rwait]选项指定时,也包括通过[-rcancel]中断镜像复归的情况)
103
从其他服务器对同一资源同时实施操作
104
从自身服务器对同一资源同时实施操作
105
复制目标服务器正在宕机
106
执行指令的服务器没有保留对象资源
107
集群分区或者数据分区上发生I/O错误
109
等待对象共享型镜像磁盘的镜像复归完毕超时(仅限指定[-w,--rwait] [-timeout]选项时)
110
其他错误
111
共享型镜像磁盘的扩展失败(仅限指定[-z, --resize]选项时)
112
加密密钥更新失败(仅限指定[--updatekey]选项时)
113
加密功能为OFF(仅限指定[--updatekey]选项时)
114
加密密钥文件未更新(仅限指定[--updatekey]选项时)
201
切换目标镜像磁盘连接的状态错误(仅限指定[-m,--mdcswitch]选项时)
202
只设置了1个镜像磁盘连接(仅限指定[-m,--mdcswitch]选项时)
203
对方服务器组的全部服务器正在宕机
-
备注 本命令在指定的处理的已开始的时机时返回控制。请使用clphdstat命令来确认处理的状况。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
如果在镜像复归异常结束后再次进行镜像复归,将上次同一个服务器,或将与该服务器相同的服务器组内其他服务器指定为复制源,进行镜像复归。
在镜像复归过程中执行了取消,中断复原后重新开始镜像复归时,请务必使用该命令执行强行镜像复归。
-
执行示例 例1:启动共享型镜像磁盘资源 hd1时
# clphdctrl --active hd1 Command succeeded.
例2:停止共享型镜像磁盘资源 hd1时
# clphdctrl --deactive hd1 Command succeeded.
例3:镜像复归共享型镜像磁盘资源 hd1时
# clphdctrl --recovery hd1 Command succeeded.
-
错误消息 消息
原因/处理方法
Invalid parameter.
参数有误。请确认参数的数值和形式是否有误。
The status of [共享型镜像磁盘资源名] is invalid.
请确认状态后,再执行命令。
This command is already run in another server.
请在目前执行中的命令结束后再执行命令。
This command is already run in the local server.
请在目前执行中的命令结束后再执行命令。
[复制目标服务器名] is down.
在复制源中启动指定的服务器,或者在复制源中指定其他服务器再执行命令。
[自身服务器名] is not included in Servers that can run the Group of [共享型镜像磁盘资源名].
对象共享型镜像磁盘资源请在可以启动的服务器中执行命令。
Disk error.
请确认在有集群分区或者数据分区的磁盘或者磁盘路径中没有发生HW障碍。
Mirror recovery of [共享型镜像磁盘资源名] is timed out.
请确认超时时间的指定是否妥当,或者是否因高负荷等原因发生磁盘I/O或通信延迟。
Internal error. The error code is [错误代码].
请重启自身服务器。
Standby mirror disk connect has invalid status.
请确认镜像磁盘连接的连接情况。
[共享型镜像磁盘资源名] has only one mirror disk connect.
请确认是否登录有多个镜像磁盘连接。
All of other server group downed.
请确认服务器的启动状态。
Resize the hybrid disk([共享型镜像磁盘资源名]) is failed.
请确认共享型镜像磁盘资源的状态是否正常。请确认当前的数据分区领域上是否有充足的空间。Failed to update the encryption key.
请确认在各服务器上,设置的密钥文件全路径中是否存在密钥文件。
The encryption function is disabled.
由于指定的镜像磁盘资源未启用「加密镜像通信」功能,因此无法更新加密密钥。
The same encryption key is already used.
请更新各服务器的密钥文件,再重新执行。
Automatic mirror recovery is disabled. Its manual resumption is required to resume mirroring.
加密密钥已更新,但镜像已中断。因为自动镜像复归设置为OFF,所以必须手动进行镜像复归。
Failed to resume the automatic mirror recovery. Its manual resumption is required to resume mirroring.
虽然加密密钥已更新,但是镜像已中断。由于自动镜像复归设置为OFF,因此需要手动执行镜像复归。
9.13.9. 准备磁盘映像备份(clpbackup命令)¶
镜像对象分区处于可以磁盘映像备份的状态。
-
命令行 - clpbackup --preclpbackup --pre --no-shutdownclpbackup --pre --only-shutdownclpbackup --postclpbackup --post --no-rebootclpbackup --post --only-rebootclpbackup --help
-
说明 - 在将服务器上的镜像磁盘(集群分区和数据分区)进行磁盘映像备份时,或将其所在的服务器的系统磁盘进行磁盘映像备份时,请执行此命令。此命令按照以下流程执行。1. 执行clpbackup --pre。通过这个,镜像变成备份模式,服务器关机。2. 备份磁盘映像。3. 执行clpbackup --post。通过这个,从备份模式返回一般模式,服务器重启。4. 服务器启动后,通过执行镜像复归,同步备份中产生的镜像差异。另外,恢复已备份的磁盘映像时,请使用clprestore命令。
-
选项 -
--pre¶ - 将镜像对象分区备份为磁盘映像时,或者将它们所在的服务器的系统磁盘进行磁盘映像备份时使用。请在备份之前指定此选项并执行。指定此选项并执行,则服务器上的所有集群分区和数据分区(镜像对象分区)变成备份模式,服务器关机。关机后,即使启动服务器EXPRESSCLUSTER服务也无法自动启动。备份模式的镜像变为非最新(状态为红色),必须通过全面复制进行镜像复归。另外,无法进行自动镜像复归。
-
--post¶ - 指定这选项并执行,则通过--pre选项设置的备份模式被解除,返回到一般模式,服务器重启。重启后,EXPRESSCLUSTER服务自动启动。磁盘映像备份完成后,请指定此选项并执行。
-
--no-shutdown¶ - 添加并指定此选项,则会导致命令退出而不关闭服务器。EXPRESSCLUSTER 服务将停止,而不是关闭服务器。不想关闭服务器时指定。
-
--no-reboot¶ - 添加并指定此选项,则省略服务器重启。将启动EXPRESSCLUSTER 服务,而不是重新启动服务器。不想重新启动服务器时,或者想节约重启时间时指定。
-
--only-shutdown¶ - 在有共享型镜像磁盘资源的环境中的服务器组中,有多个服务器时使用。在服务器组内第一台服务器中执行clpbackup --pre,完成后请在该服务器组中其他的服务器上运行clpbackup --pre --only-shutdown。
-
--only-reboot¶ - 在有共享型镜像磁盘资源的环境中的服务器组中,有多个服务器时使用。在服务器组内第一台服务器中执行clpbackup --post,完成后请在该服务器组中其他的服务器上运行clpbackup --post --only-reboot。
-
--help¶ 显示Usage。
-
-
返回值 0
成功
1
异常
-
备注 备份模式下,镜像为非最新(状态为红色),不进行自动镜像复归,如果进行镜像复归则不是差异复制而是全面复制。
本命令不适用于基于文件的备份/还原,而是用于磁盘映像备份/还原。从启动状态的镜像磁盘或者共享型镜像磁盘备份文件的步骤,或者解除限制访问待机系统的镜像磁盘或者共享型镜像磁盘备份文件的步骤,与使用本命令的步骤不同。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行本命令,则服务器上的所有镜像磁盘资源和共享型镜像磁盘资源为处理对象。
进行备份/恢复时,请备份/恢复集群分区和数据分区。
执行此命令,则服务器关机或者重启。
在包含安装了4.3版之前的EXPRESSCLUSTER的服务器的集群环境中,不支持此功能。
-
错误消息 消息
原因/处理方法
Invalid option.
请指定正确的选项。
Log in as administrator.
请以拥有Administrator权限的用户身份执行该命令。
Internal error.
内存不足或OS的资源不足。请确认。
Internal error (setlocal command).
内存不足或OS的资源不足。请确认。
Log directory is not found.
可执行未正确安装,或者没有执行权限。
Command failed.
此命令失败。请确认此错误消息之前显示的错误消息。
-
执行示例 例1:执行备份前是备份模式时
C:\> clpbackup --pre clpbackup.bat : Beginning backup-mode. Command succeeded. clpbackup.bat : Changing the setting of cluster services to Manual Startup. clpbackup.bat : Shutting down... Command succeeded. clpbackup.bat : Command succeeded.
例2:备份完成后返回原来的模式时
C:\> clpbackup --post clpbackup.bat : Ending backup-mode. Command succeeded. clpbackup.bat : Changing the setting of cluster services to Auto Startup. clpbackup.bat : Rebooting... Command succeeded. clpbackup.bat : Command succeeded.
9.13.10. 磁盘映像恢复后的处理(clprestore命令)¶
已恢复的镜像磁盘映像处于可使用状态。
-
命令行 - clprestore --preclprestore --pre --only-shutdownclprestore --postclprestore --post --only-rebootclprestore --post --skip-copyclprestore --help
-
说明 - 恢复集群分区和数据分区的磁盘映像时,或者恢复存在那些的服务器的系统磁盘的磁盘映像时,请执行这命令。这个命令按照以下流程执行。1. 执行clprestore --pre。通过执行此命令,EXPRESSCLUSTER服务的自动启动关闭,服务器关机。2. 恢复磁盘映像。3. 启动Cluster WebUI,设置为编辑模式。确认/修改各镜像磁盘资源/共享型镜像磁盘资源的设置后,反映设置。4. 执行clprestore --post。通过执行此命令,EXPRESSCLUSTER服务的自动启动打开,服务器重启。5. 服务器重启后,通过Cluster WebUI或者命令,实施镜像复归。进行全面复制镜像处于同步状态。(指定--skip-copy时不需要全面复制。)
-
选项 -
--pre¶ - 指定此选项并执行,则EXPRESSCLUSTER服务的自动启动关闭,服务器关机。然后,下次服务器启动时,EXPRESSCLUSTER服务无法自动启动。请在恢复磁盘映像前,关闭服务器时执行。如果服务器未启动,或者要还原(包含系统磁盘)时,在恢复前无需执行本命令。
-
--post¶ - 指定此选项并执行,则EXPRESSCLUSTER服务的自动启动打开,服务器重启。请在恢复磁盘映像后执行。
-
--skip-copy¶ - 此选项和--post选项一起指定。此选项只在当前系统和待机系统中恢复同一磁盘映像时可以指定。镜像复归时不需要全面复制。指定此选项并执行时,必须事先关闭镜像磁盘资源或共享型镜像磁盘资源的"进行初始镜像构建"。
-
--only-shutdown¶ - 在有共享型镜像磁盘资源的环境中的服务器组中,有多个服务器时使用。在服务器组内第一台服务器中执行clprestore --pre,完成后请在该服务器组中其他的服务器上运行clprestore --pre --only-shutdown。此选项可省略。
-
--only-reboot¶ - 在有共享型镜像磁盘资源的环境中的服务器组中,有多个服务器时使用。在服务器组内第一台服务器中执行clprestore --post,完成后请在该服务器组中其他的服务器上运行clprestore --post --only-reboot。在服务器组内第一台服务器中执行clprestore --post --skip-copy,完成后请在该服务器组中其他的服务器上运行clprestore --post --only-reboot。
-
--help¶ 显示Usage。
-
-
返回值 0
成功
1
异常
-
备注 - 本命令不适用于基于文件的备份/还原,而是用于磁盘映像备份/还原。从启动状态的镜像磁盘或者共享型镜像磁盘备份文件的步骤,或者解除限制访问待机系统的镜像磁盘或者共享型镜像磁盘备份文件的步骤,与使用本命令的步骤不同。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
执行本命令,则服务器上的所有镜像磁盘资源和共享型镜像磁盘资源为处理对象。
进行备份/恢复时,请备份/恢复集群分区和数据分区。
执行此命令,则服务器关机或者重启。
在包含安装了4.3版之前的EXPRESSCLUSTER的服务器的集群环境中,不支持此功能。
-
错误消息 消息
原因/处理方法
Invalid option.
请指定正确的选项。
Log in as administrator.
请以拥有Administrator权限的用户身份执行该命令。
Internal error.
内存不足或OS的资源不足。请确认。
Internal error (setlocal command).
内存不足或OS的资源不足。请确认。
Set "Initial Mirror Construction" parameter of md/hd resource to off by using Cluster WebUI.
指定--skip-copy选项时,必须关闭md/hd资源的"进行初始镜像构建"。命令执行前,在Cluster WebUI的编辑模式下,请更改设置为关闭。Log directory is not found.
可执行未正确安装,或者没有执行权限。
Command failed.
此命令失败。请确认此错误消息之前显示的错误消息。
-
执行示例 例1:实施恢复前关机时
C:\> clprestore --pre clprestore.bat : Changing the setting of cluster services to Manual Startup. clprestore.bat : Shutting down... Command succeeded. clprestore.bat : Command succeeded.
例2:恢复后,配置信息再次反映后,启动集群时
C:\> clprestore --post clprestore.bat : Beginning backup-mode. Command succeeded. clprestore.bat : Changing the setting of cluster services to Auto Startup. clprestore.bat : Rebooting... Command succeeded. clprestore.bat : Command succeeded.
例3:将同一映像恢复到两服务器后,配置信息再次反映后,启动集群时
C:\> clprestore --post --skip-copy Command succeeded. clprestore.bat : Changing the setting of cluster services to Auto Startup. clprestore.bat : Rebooting... Command succeeded. clprestore.bat : Command succeeded.
9.14. 消息输出命令(clplogcmd命令)¶
将指定消息登录到警报日志中的命令。
-
命令行 clplogcmd -m message [--alert] [--mail] [-i ID] [-l level]
注解
通常在构筑和操作集群时不需要执行该命令。在脚本资源的脚本中进行描述和使用的命令。
-
说明 在脚本资源的脚本中描述,将任意消息输出到输出目标中。
以下列形式输出消息。
[ID] message
-
选项 -
-
-alert¶ 从alert,mail中指定输出目标(可指定多数)。
-
--mail¶ - 该参数可以省略。省略时alert为输出目标。
-
-iID¶ - 指定事件ID。该参数可以省略。省略时ID设置为1。
-
-llevel¶ - 输出的警报的级别。可指定为ERR,WARN,INFO中的任何一种。根据该级别指定Cluster WebUI中的警报日志的图标。
该参数可以省略。省略时level设置为INFO。
具体内容请参考在线版手册。
- 5
消息中含有符号时,要注意以下几点。
需要用""括起来的符号
& | < >(例 如果在消息中指定"&",则输出&。)需要在前面加上\ 的符号\(例 如果在消息中指定\\ ,则输出 \。)如果消息中含有空格,则需要以""括起来。
-
-
返回值 0
成功
0以外
异常
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
[-i] 选项的设计与Linux版不同。Windows版中输出到警报的事件ID是固定的,无法更改。
-
执行示例 例1:指定了消息,事件ID,级别时
如果在脚本资源的脚本中做了如下描述,则在警报日志中输出消息。
clplogcmd -m test1 -i 100 -l ERR
例2: 指定消息,输出目标,事件ID,级别时(输出目标 mail)
脚本资源的脚本中进行了以下描述时,消息被发送到Cluster WebUI的集群属性中设置的邮件地址。关于邮件地址的详细设置请参考本指南的"2. 参数的详细信息"-"集群属性" -"Alert服务标签页"
clplogcmd -m test2 --mail -i 100 -l ERR
以下内容的邮件被发送到mail的发送目标。
Message:test2 Type:ogcmd ID: 100 Host: server1 Date: 2019/04/10 10:00:00
9.15. 控制监视资源(clpmonctrl命令)¶
进行监视资源的控制。
-
命令行 - clpmonctrl -s [-h <hostname>] [-m resource name] [-w wait time]clpmonctrl -r [-h <hostname>] [-m resource name] [-w wait time]clpmonctrl -c [-m resource name]clpmonctrl -v [-m resource name]clpmonctrl -e [-h <hostname>] -m resource_nameclpmonctrl -n [-h <hostname>] [-m resource_name]
注解
由于-c以及-v在单个服务器上进行监视资源控制,因此需要在进行控制的所有服务器上执行该命令。在集群中的所有服务器上暂停/重启监视资源时,建议从Cluster WebUI执行。当[失效切换次数计算单位]的设置是"集群"时,如果只在一部分服务器上执行-c, --clear选项,有可执行出现服务器间的复归动作的次数计数器不一致,之后复归动作不能正确被执行的情况。
-
说明 暂时停止/重新开始监视资源,或恢复操作的回数的表示/重置,或故障验证功能的有效/无效。
-
选项 -
-s,--suspend¶ 暂时停止监视。
-
-r,--resume¶ 重新开始监视。
-
-c,--clear¶ 重置回复操作回数。
-
-v,--view¶ 表示回复操作回数。
-
-e¶ 将故障验证功能设为有效。请务必使用-m选项指定监视资源名。
-
-n¶ 将故障验证功能设为无效。请务必使用-m选项指定监视资源名,此时只有该资源属于对象。省略-m选项时,所有监视资源属于对象。
-
-m,--monitor¶ - 指定要控制的监视资源。可以省略。若省略则对所有的监视资源进行控制。
-
-w,--wait¶ - 以监视资源为单位等待监视控制。(秒)可以省略,省略时设为5秒。
-
-h¶ 对Hostname指定的服务器请求处理。如果省略了[-h]选项,则对命令执行服务器(自身服务器)请求处理。-c以及-v时无法指定。
-
-
返回值 0
正常结束
1
执行权限有误
2
选项有误
3
初始化错误
4
集群配置信息有误
5
未登录监视资源
6
指定监视资源有误
10
集群未启动状态
11
EXPRESSCLUSTER服务挂起状态
12
集群同步等待状态
90
监视控制等待超时
128
二重启动
200
服务器连接错误
201
状态不正确
202
服务器名不正确
255
其他内部错误
-
执行示例 例1:暂时停止所有监视资源时
# clpmonctrl -s Command succeeded.
例2:重新开始监视资源时
# clpmonctrl -r Command succeeded.
-
备注 对已经处于暂时停止状态的监视资源执行暂时停止时,或对处于已启动状态的监视资源执行重新开始时,该命令异常结束,不更改监视资源状态。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
请以状态显示命令或Cluster WebUI确认监视资源的状态。
请通过[clpstat]命令或Cluster WebUI确认监视资源的状态为"已启动"或"暂时停止"后,再执行命令。
如果监视资源的复归运行设置为以下,则-v选项中显示的"FinalAction Count" 会显示「最终运行前脚本」的执行次数。- 最终运行前执行脚本: 有效- 最终运行: "不操作"
-
错误消息 消息
原因/处理
Command succeeded.
命令成功。
You are not authorized to run the command. Log in as Administrator.
没有命令的执行权。请以拥有Administrator权限的用户身份执行命令。
Initialization error. Check if memory or OS resources are sufficient.
内存不足或OS资源不足。请确认。
Invalid cluster configuration data. Check the cluster configuration information.
集群配置信息有误。请通过Cluster WebUI确认集群配置信息。
Monitor resource is not registered.
未登录监视资源。
Specified monitor resource is not registered. Check the cluster configuration information.
未登录指定的监视资源。请通过Cluster WebUI确认集群配置信息。The cluster has been stopped. Check the active status of the cluster service by using the command such as ps command.
集群处于停止状态。请使用管理工具的[service]确认EXPRESSCLUSTER Server的启动状态。The cluster has been suspended. The cluster service has been suspended. Check activation status of the cluster service by using a command such as the ps command.
集群处于挂起状态。请使用管理工具的[service]确认EXPRESSCLUSTER Server的启动状态。
Waiting for synchronization of the cluster... The cluster is waiting for synchronization. Wait for a while and try again.
集群处于同步等待状态。请在集群同步等待结束后再次执行命令。Monitor %1 was unregistered, ignored. The specified monitor resources %1is not registered, but continue processing. Check the cluster configuration data.
指定的监视资源中有未登录的监视资源,忽略,继续处理。请通过Cluster WebUI确认集群配置信息。%1:监视资源名The command is already executed. Check the execution state by using the "ps" command or some other command.
已经执行命令。请使用task manager等确认执行状态。
Internal error. Check if memory or OS resources are sufficient.
内存不足或OS资源不足。请确认。
Could not connect to the server.Check if the cluster service is active.请确认集群服务是否启动。
Some invalid status. Check the status of cluster.
出现某种错误的状态。请确认集群的状态。
Invalid server name. Specify a valid server name in the cluster.
请指定集群中正确的服务器名。
-
可指定-m选项的监视资源类型 类型
暂时停止/重新启动监视资源
复原操作次数的计数器的表示/复位
故障验证功能的有效化/无效化appliw
✓
✓
✓
diskw
✓
✓
✓
fipw
✓
✓
✓
ipw
✓
✓
✓
mdw
✓
✓
n/a
miiw
✓
✓
✓
mtw
✓
✓
✓
regsyncw
✓
✓
✓
sdw
✓
✓
✓
servicew
✓
✓
✓
vcomw
✓
✓
✓
vipw
n/a
✓
✓
cifsw
✓
✓
✓
hdw
✓
✓
n/a
hdtw
✓
✓
✓
genw
✓
✓
✓
mrw
✓
✓
n/a
db2w
✓
✓
✓
ftpw
✓
✓
✓
httpw
✓
✓
✓
imap4w
✓
✓
✓
odbcw
✓
✓
✓
oraclew
✓
✓
✓
pop3w
✓
✓
✓
psqlw
✓
✓
✓
smtpw
✓
✓
✓
sqlserverw
✓
✓
✓
tuxw
✓
✓
✓
userw
✓
✓
✓
wasw
✓
✓
✓
wlsw
✓
✓
✓
otxw
✓
✓
✓
jraw
✓
✓
✓
sraw
✓
✓
✓
psrw
✓
✓
✓
psw
✓
✓
✓
ddnsw
n/a
✓
n/a
awsazw
✓
✓
✓
awsdnsw
✓
✓
✓
awseipw
✓
✓
✓
awssipw
✓
✓
✓
awsvipw
✓
✓
✓
azurednsw
✓
✓
✓
azurelbw
✓
✓
✓
azureppw
✓
✓
✓
gcdnsw
✓
✓
✓
gclbw
✓
✓
✓
gcvipw
✓
✓
✓
oclbw
✓
✓
✓
ocvipw
✓
✓
✓
9.16. 控制组资源(clprsc命令)¶
控制组资源。
-
命令行 - clprsc -s resource_name [-h hostname] [-f] [--apito timeout]clprsc -t resource_name [-h hostname] [-f] [--apito timeout]clprsc -n resource_nameclprsc -v resource_name
-
说明 启动/停止组资源。
-
选项 -
-s¶ 启动组资源。
-
-t¶ 停止组资源。
-
-h¶ 要求使用hostname对指定服务器进行处理。
省略[-h]选项时,要求对以下服务器进行处理。
组停止完毕时,命令执行服务器(自身服务器)
组启动完毕时,组启动着的服务器
-
-f¶ - 组资源启动时,启动依赖指定组资源的所有组资源。组资源停止时,停止依赖指定组资源的所有组资源。
-
-n¶ 显示组资源的已启动服务器名。
-
--apito¶ - 可以秒为单位指定组资源的启动,停止的等待时间(内部通信超时)。可指定为1-9999的值。不指定[--apito]选项时,请按照集群属性的内部通信超时所设置的值,进行等待。
-
-v¶ 显示组资源的失效切换次数计数器。
-
-
返回值 0
正常结束
0以外
异常结束
-
执行示例 组资源配置
# clpstat ========== CLUSTER STATUS ========== Cluster : cluster <server> *server1.............: Online lankhb1 : Normal lankhb2 : Normal pingnp1 : Normal server2 .............: Online lankhb1 : Normal lankhb2 : Normal pingnp1 : Normal <group> ManagementGroup ....: Online current : server1 ManagementIP : Online failover1...........: Online current : server1 fip1 : Online md1 : Online script1 : Online failover2...........: Online current : server2 fip2 : Online md2 : Online script1 : Online <monitor> fipw1 : Normal fipw2 : Normal ipw1 : Normal mdw1 : Normal mdw2 : Normal =========================================例1:停止组failover1的资源fip1时
# clprsc -t fip1 Command succeeded.
# clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup.....: Online current : server1 ManagementIP : Online failover1 ..........: Online current : server1 fip1 : Offline md1 : Online script1 : Online failover2...........: Online current : server2 fip2 : Online md2 : Online script1 : Online <省略>例2:启动组failover1的资源fip1时
# clprsc -s fip1 Command succeeded.
# clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup.........: Online current : server1 ManagementIP : Online failover1...............: Online current : server1 fip1 : Online md1 : Online script1 : Online failover2 ..............: Online current : server2 fip2 : Online md2 : Online script1 : Online <省略>
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
组资源的状态请以状态显示命令或Cluster WebUI确认。
在组内有启动完毕的组资源时,在不同服务器上不可以启动停止完毕的组资源。
-
错误消息 消息
原因/处理
Log in as Administrator.
请以拥有Administrator权限的用户身份执行命令。
Invalid cluster configuration data. Check the cluster configuration information.
集群配置信息有误。请通过Cluster WebUI确认集群配置信息。
Invalid option.
请指定正确的选项。
Could not connect server. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Invalid server status. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Server is not active. Check if the cluster service is active.
请确认是否启动了EXPRESSCLUSTER服务。
Invalid server name. Specify a valid server name in the cluster.
请指定集群中正确的服务器名。
Connection was lost. Check if there is a server where the cluster service is stopped in the cluster.
请确认集群中是否有停止了EXPRESSCLUSTER服务的服务器。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
EXPRESSCLUSTER的内部通信超时。如果频繁出现该现象,请将内部通信超时设为更长的时间。The group resource is busy. Try again later.
因为组资源启动处理中或停止处理中,请稍候执行。
An error occurred on group resource. Check the status of group resource.
请通过Cluster WebUI或[clpstat]命令确认组资源的状态。
Could not start the group resource. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
请等待其它服务器启动或等待启动等待时间超时,启动组资源。
No operable group resource exists in the server.
请确认请求处理的服务器中是否存在可处理的组资源。
The group resource has already been started on the local server.
请通过Cluster WebUI或[clpstat]命令确认组资源的状态。
The group resource has already been started on the other server. To start the group resource on the local server, stop the group resource.
请通过Cluster WebUI或[clpstat]命令确认组资源的状态。在本地服务器启动组资源时,请停止组。The group resource has already been stopped.
请通过Cluster WebUI或[clpstat]命令确认组资源的状态。
Failed to start group resource. Check the status of group resource.
请通过Cluster WebUI或[clpstat]命令确认组资源的状态。
Failed to stop resource. Check the status of group resource.
请通过Cluster WebUI或[clpstat]命令确认组资源的状态。
Depending resource is not offline. Check the status of resource.
因为依赖的组资源的状态不是停止完毕,不可以停止组资源。请停止依赖的组资源或者指定[-f]选项。
Depending resource is not online. Check the status of resource.
因为依赖的组资源的状态不是启动完毕,不可以启动组资源。请停止依赖的组资源或者指定[-f]选项。
Invalid group resource name. Specify a valid group resource name in the cluster.
组资源未登录。
Server is isolated.
服务器处于保留(宕机后重启)状态。
Internal error. Check if memory or OS resources are sufficient.
内存不足或OS的资源不足。请确认。
Server is not in a condition to start resource. Critical monitor error is detected.
请使用Cluster WebUI或[clpstat]命令确认组资源状态。在准备启动组资源的服务器上检测出排除列表中包含的监视异常。
9.17. 关闭网络警告灯命令(clplamp命令)¶
关闭网络警告灯。
-
命令行 clplamp -h host_name
-
说明 关闭指定的服务器用的网络警告灯。
设置音频文件回放时,停止音频文件的回放。
-
选项 -
-hhost_name¶ - 指定要关闭网络警告灯的服务器。必须设置。
-
-
返回值 0
正常结束
0以外
异常结束
-
执行例 例1:执行server1相对应的警告灯熄灭,音频警告停止时
# clplamp -h server1 Command succeeded.
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
9.18. 外部监视联动处理请求命令(clprexec命令)¶
要求服务器执行处理。
-
命令行 - clprexec --failover [group_name] -h IP [-r resource_name] [-w timeout] [-p port_number] [-o logfile_path]clprexec --script script_file -h IP [-p port_number] [-w timeout] [-o logfile_path]clprexec --notice [mrw_name] -h IP [-k category[.keyword]] [-p port_number] [-w timeout] [-o logfile_path]clprexec --clear [mrw_name] -h IP [-k category[.keyword]] [-p port_number] [-w timeout] [-o logfile_path]
-
说明 向其他集群的服务器发送指定的处理执行请求。
-
选项 -
--failover¶ - 请求执行组失效切换。请在[group_name]中指定组名。省略组名时,请使用[-r]选项指定组所属资源名。
-
--scriptscript_name¶ - 请求执行脚本。在[scirpt_name]中指定要执行脚本(批处理文件及可执行文件等)的文件名。需事先在以[-h]指定的各服务器上的EXPRESSCLUSTER安装目录下的work\trnreq子目录下创建脚本。
-
--notice¶ - 向EXPRESSCLUSTER服务器发送异常发生通知。请在[mrw_name]中指定消息接收监视资源名。省略监视资源名时,请使用[-k]选项指定消息接收监视资源的监视类型,监视对象。
-
--clear¶ - 请求将消息接收监视资源的状态从异常更改为正常。请在[mrw_name]中指定消息接收监视资源名。省略监视资源名时,请使用[-k]选项指定消息接收监视资源的监视类型,监视对象。
-
-hIP Address¶ - 请指定发出处理请求的EXPRESSCLUSTER服务器的IP地址。使用逗号可指定多个IP地址,最多可指定32个IP地址。※ 如省略本选项,则处理请求发行目标变成自身服务器。
-
-rresource_name¶ 指定[--failover]选项时,指定成为处理请求对象的组所属的资源名。
-
-kcategory[.keyword]¶ - 指定[--notice]或[--clear]选项时,请在[category]中指定消息接收监视器上设定的监视类型。指定消息接收监视资源的关键字时,请在[category]的后面通过逗号隔开进行指定。
-
-pport_number¶ - 指定端口号。请在[port_number]中指定处理请求发行目标服务器中设定的数据传送端口号。省略本选项时,使用默认值29002。
-
-ologfile_path¶ - 在[logfile_path]中指定输出本命令详细日志的文件路径。文件会保存1次命令的日志。※在未安装EXPRESSCLUSTER的服务器中不指定本选项时,则只变成为标准输出。
-
-wtimeout¶ - 指定命令的超时时间。不指定时,默认值为180秒。最大可指定为5~999。
-
-
返回值 0
正常结束
0以外
异常结束
-
注意事项 使用[clprexec]命令发行异常发生通知时,需预先登录/启动设定了在EXPRESSCLUSTER服务器侧要执行异常时动作的消息接收监视资源。
拥有-h选项指定的IP地址的服务器需满足以下条件。=安装有EXPRESSCLUSTER X3.0以上版本= EXPRESSCLUSTER已启动( 除--script选项以外时)=已设置/启动mrw( --notice, --clear选项时)当[通过客户端IP地址控制连接]启用时,需要添加执行[clprexec]命令的设备的IP地址。
[根据客户端IP地址限制连接]的详细信息,请参考本指南的"2. 参数的详细信息"-"集群属性"-"Web管理器标签页"。
-
执行示例 例1:向EXPRESSCLUSTER服务器1(10.0.0.1)发行组failover1的失效切换请求时
# clprexec --failover failover1 -h 10.0.0.1 -p 29002
例2:向EXPRESSCLUSTER服务器1(10.0.0.1)发行组资源(exec1)所在组的失效切换请求时
# clprexec --failover -r exec1 -h 10.0.0.1
例3:向EXPRESSCLUSTER服务器1(10.0.0.1)发行脚本(script1.bat)执行请求时
# clprexec --script script1.bat -h 10.0.0.1
例4:向EXPRESSCLUSTER服务器1(10.0.0.1)发行异常发生通知
※ mrw1设置 监视类型:earthquake,监视对象:scale3
指定消息接收监视资源名时
# clprexec --notice mrw1 -h 10.0.0.1 -w 30 -o /tmp/clprexec/ lprexec.log
指定消息接收监视资源中设定的监视类型和监视对象时
# clprexec --notice -h 10.0.0.1 -k earthquake.scale3 -w 30 -o /tmp/clprexec/clprexec.log
例5: 向EXPRESSCLUSTER服务器1(10.0.0.1)发行mrw1的监视状态变更请求
※ mrw1设置 监视类型:earthquake,监视对象:scale3
指定消息接收监视资源名时
# clprexec --clear mrw1 -h 10.0.0.1
指定消息接收监视资源中设定的监视类型和监视对象时
# clprexec --clear -h 10.0.0.1 -k earthquake.scale3
-
错误消息 消息
原因/处理方法
success
-
Invalid option.
请确认命令的参数。
Could not connect to the data transfer servers. Check if the servers have started up.
请确认指定IP地址是否正确或拥有IP地址的服务器是否已启动。
Could not connect to all data transfer server.
请确认指定的IP地址是否正确,或使用此IP地址的服务器是否已启动。
Command timeout.
请确认拥有指定IP地址的服务器是否已完成处理。
All servers are busy.Check if this command is already run.
可执行已经执行本命令。请确认。
Group (%s) is offline.
请确认在发出处理请求的服务器中组是否已启动。
Group that specified resource(%s) belongs to is offline.
请确认指定资源所在组是否启动在处理要求的服务器上。
Specified script(%s) does not exist.
指定的脚本不存在。
%s %s : Specified resource(%s) is not exist.
指定的资源或者监视资源不存在。
%s %s : Specified resource(Category:%s, Keyword:%s) is not exist.
指定的资源或者监视资源不存在。
Specified group(%s) does not exist.
指定的组不存在。
This server is not permitted to execute clprexec.
请确认执行命令的服务器的IP地址是否已注册到限制Cluster WebUI连接的客户端IP地址列表中。
%s failed in execute.
请确认发行请求的目标EXPRESSCLUSTER服务器的状态。
9.19. 控制集群启动同步等待处理的命令(clpbwctrl命令)¶
控制集群启动同步等待处理。
-
命令行 - clpbwctrl -cclpbwctrl --np [on|off]clpbwctrl -h
注解
由于--np选项在单个服务器上进行控制,因此必须在所有控制服务器上执行。
-
说明 - 跳过在集群内所有服务器的集群服务停止的状态下启动服务器时出现的集群启动同步等待时间。单个服务器上指定集群启动时是否进行网络分区解决处理。
-
选项 -
-c,--cancel¶ 取消集群启动同步等待处理。
-
--np[on|off]¶ - 指定集群启动时是否进行网络分区解决处理。指定on则进行网络分区解决处理。指定off则不进行。默认指定为on。[on|off]可以省略。省略时,显示当前的设置。
-
-h,--help¶ 显示Usage
-
-
返回值 0
正常结束
0以外
异常结束
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
-
执行示例 取消集群启动同步等待处理时
#clpbwctrl -c Command succeeded.
集群启动时不进行网络分区解决处理时
#clpbwctrl --np off Command succeeded. #clpbwctrl --np Resolve network partition on startup : off
-
错误消息 消息
原因/处理方法
Log in as Administrator.
请以拥有Administrator权限的用户身份执行。
Invalid option.
命令行选项错误。请指定正确的选项。
Cluster service has already been started.
集群已经启动。集群不在启动等待状态。
The cluster is not waiting for synchronization.
全部集群都不在启动等待状态。请确认是否集群服务停止状态。
Command Timeout.
命令执行超时。
Internal error.
发生内部错误。
9.20. 重启次数控制命令(clpregctrl命令)¶
控制重启次数限制。
-
命令行 - clpregctrl --getclpregctrl -gclpregctrl --clear -t type -r registryclpregctrl -c -t type -r registry
注解
由于是在单个服务器上控制重启次数限制,因此,需要在实施控制的所有服务器上运行本命令。
-
说明 显示/初始化单个服务器上的重启次数。
-
选项 -
-g,--get¶ 显示重启次数信息。
-
-c,--clear¶ 初始化重启次数。
-
-ttype¶ 指定重启次数初始化格式。可指定的格式为[rc]或[rm]。
-
-rregistry¶ 指定注册表名。可指定的注册表名为[haltcount]。
-
-
返回值 0
正常结束
1
执行权限错误
2
双重启动
3
选项错误
4
集群配置信息错误
10~17
内部错误
20~22
获取重启次数信息失败
90
内存分配失败
-
执行示例 显示重启次数信息
# clpregctrl -g ************************** ------------------------- type : rc registry : haltcount comment : halt count kind : int value : 0 default : 0 ------------------------- type : rm registry : haltcount comment : halt count kind : int value : 3 default : 0 ************************** success.(code:0) #
例1,2为重启次数的初始化。
由于重启次数在各台服务器中进行记录,因此,请在控制实际的重启次数的服务器上执行本命令。
例1:组资源异常导致重启次数的初始化时
# clpregctrl -c -t rc -r haltcount success.(code:0) #
例2:监视资源异常导致重启次数的初始化时
# clpregctrl -c -t rm -r haltcount success.(code:0) #
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
-
错误消息 消息
原因/处理方法
Command succeeded.
命令成功。
Log in as Administrator.
没有命令的执行权限。请以拥有Administrator权限的用户身份执行。
The command is already executed.
命令已执行。
Invalid option.
选项错误。
Internal error. Check if memory or OS resources are sufficient.
可执行是内存不足或者OS资源不足。请确认。
9.21. 确认进程的健全性 (clphealthchk 命令)¶
确认进程的健全性。
-
命令行 clphealthchk [ -t pm | -t rc | -t rm | -t nm | -h]
注解
本命令在单一服务器上确认进程的健全性。请在要确认健全性的服务器上执行。
-
说明 确认单一服务器上的进程健全性。
-
选项 -
无¶ 确认pm/rc/rm/nm的健全性。
-
-t<process>¶ process
- pm
确认pm的健全性。
- rc
确认rc的健全性。
- rm
确认rm的健全性。
- nm
确认nm的健全性。
-
-h¶ 显示Usage。
-
-
返回值
0 |
正常结束 |
1 |
执行权限非法 |
2 |
二重启动 |
3 |
初始化错误 |
4 |
选项无效 |
10 |
进程失控监视功能未设置 |
11 |
集群未启动状态(包含集群启动处理中,集群停止处理中) |
12 |
集群挂起状态 |
100 |
存在一定时间内没有更新健全性信息的进程
-t选项指定时,指定进程的健全性信息一定时间内未更新
|
255 |
其他内部错误 |
-
执行示例 例1:健全时
# clphealthchk pm OK rc OK rm OK nm OK
例2:clprc失控时
# clphealthchk pm OK rc NG rm OK nm OK # clphealthchk -t rc rc NG
例3:集群停止时
# clphealthchk The cluster has been stopped
-
备注 集群停止或挂起时进程是停止的。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
-
错误消息 消息
原因/处理方法
Log in as Administrator.
无执行命令的权限。请用有Administrator权限的用户执行。
Initialization error. Check if memory or OS resources are sufficient.
可执行是内存不足或OS资源不足。请确认。
Invalid option.
请指定正确的选项。
The function of process stall monitor is disabled.
进程失控监视功能无效。
The cluster has been stopped.
集群处于停止状态。
The cluster has been suspended.
集群处于挂起状态。
This command is already run.
本命令已被执行。
Internal error. Check if memory or OS resources are sufficient.
可执行是内存不足或OS资源不足。请确认。
9.22. 设定从集群外实行关闭操作系统时的动作 (clpstdncnf命令)¶
设定从集群外执行关闭操作系统时的动作。
-
命令行 - clpstdncnf -e [time]clpstdncnf -dclpstdncnf -v
注解
此命令设置在单个服务器上通过集群外部的操作关闭OS时的操作,必须在想要配置的所有服务器上执行。
-
说明 设定从集群外执行关机时的动作。
-
选项 -
-e[time]¶
实行关闭操作系统时,time指定集群服务停止的等待时间。Time以分钟单位,可指定为1-1440的值。第2次以后可以不指定time。不指定时使用当前的设定值。-
-d¶ 实行关闭操作系统时,不等待集群服务停止。
-
-v¶ 确认设定内容。
-
-
返回值 0
正常结束
0以外
异常结束
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
云等虚拟环境下,由虚拟化基础架构侧实行关闭客户机操作系统时,如果关闭客户机操作系统需要时间,则虚拟化基础架构侧可以强制停止虚拟机电源。
-
执行示例 例1:集群服务停止的等待时间为最长30分钟时
# clpstdncnf -e 30 Command succeeded. # clpstdncnf -v Mode : wait Timeout : 30 min
例2:不等待集群服务停止时
# clpstdncnf -d Command succeeded. # clpstdncnf -v Mode : no wait Timeout : 30 min
9.23. 控制DB2的静止点 (clpdb2still 命令)¶
控制DB2的静止点。
-
命令行 - clpdb2still -d databasename -u username -sclpdb2still -d databasename -u username -r
-
说明 控制确保/释放DB2的静止点。
-
返回值 0
成功
2
命令选项不正确
4
指定为-u 选项的用户认证错误
5
确保静止点失败
6
释放静止点失败
99
内部错误
-
注意事项 - 请以拥有Administrator 权限的用户身份执行该命令。指定为-u 选项的用户名和密码需要事先在EXPRESSCLUSTER的编辑模式下从集群的[属性] -> [账户]标签页设置。指定为-u 选项的用户必须具有可以执行DB2的SET WRITE命令的权限。
-
执行示例 # clpdb2still -d sample -u db2admin -s Database Connection Information Database server = DB2/NT64 11.1.0 SQL authorization ID = DB2ADMIN Local database alias = SAMPLE DB20000I The SET WRITE command completed successfully. DB20000I The SQL command completed successfully. DB20000I The SQL DISCONNECT command completed successfully.
# clpdb2still -d sample -u db2admin -r Database Connection Information Database server = DB2/NT64 11.1.0 SQL authorization ID = DB2ADMIN Local database alias = SAMPLE DB20000I The SET WRITE command completed successfully. DB20000I The SQL command completed successfully. DB20000I The SQL DISCONNECT command completed successfully. Command succeed.
-
错误消息 消息
原因/处理方法
Invalid command option.
命令选项不正确。请确认命令选项。Username or password is not correct.
用户认证失败。请确认用户名以及密码。Suspend database failed.
确保静止点失败。db2 命令的错误消息输出时,请进行相应错误内容的处理。Resume database failed.
释放静止点失败。db2 命令的错误消息输出时,请进行相应错误内容的处理。Internal error.
发生内部错误。
9.24. 控制Oracle的静止点(clporclstill 命令)¶
控制Oracle的静止点。
-
命令行 - clporclstill -d connectionstring [-u username] -sclporclstill -d connectionstring -r
-
说明 控制确保/释放Oracle的静止点。
-
选项 -
-dconnectionstring¶ 指定连接到控制静止点的对象的数据库的字符串。
-
-uusername¶ 指定执行控制静止点的数据库用户名。只指定为-s 选项时可以指定。省略时使用OS认证。
-
-s¶ 确保静止点。
-
-r¶ 释放静止点。
-
-
返回值 0
成功
2
命令选项不正确
3
DB连接错误
4
用户认证错误
5
静止点确保失败
6
静止点释放失败
99
内部错误
-
注意事项 请以拥有Administrator 权限的用户身份执行该命令。
不指定-u 选项使用OS认证时,执行该命令的用户为了得到Oracle的管理员权限需要归属于ORA_DBA组。
指定为-u 选项的用户名和密码需要事先在EXPRESSCLUSTER的编辑模式下从集群的[属性] -> [账户]标签页设置。
指定为-u 选项的用户必须具有Oracle的管理员权限。
通过-s 选项指定确保静止点命令之后确保静止点成功时,该确保静止点命令仍然驻留,不会返回控制。其他进程中通过 -r 选项执行静止点开放命令,驻留的确保静止点命令结束后返回控制。
执行本命令时,需要事先把Oracle设置为ARCHIVELOG模式。
使用本命令后在进行确保静止点状态下获得的Oracle数据文件处于备份模式。恢复数据文件后使用时需要在Oracle上解除备份模式。
-
执行示例 # clporclstill -d orcl -u oracle -s Command succeed.
# clporclstill -d orcl -r Command succeed.
-
错误消息 消息
原因/处理方法
Invalid command option.
命令选项不正确。请确认命令选项。Cannot connect to database.
无法连接到数据库。请确认数据库名以及数据库的状态。Username or password is not correct.
用户认证失败。请确认用户名以及密码。Suspend database failed.
确保静止点失败。请确认用户权限以及数据库的设置。Resume database failed.
释放静止点失败。请确认用户权限以及数据库的设置。Internal error.
发生内部错误。
9.25. 控制PostgreSQL的静止点(clppsqlstill 命令)¶
控制PostgreSQL的静止点。
-
命令行 - clppsqlstill -d databasename -u username -sclppsqlstill -d databasename -r
-
说明 控制确保/释放PostgreSQL的静止点。
-
返回值 0
成功
2
命令选项不正确
3
DB连接错误
4
指定为-u 选项的用户认证错误
5
静止点确保失败
6
静止点释放失败
99
内部错误
-
注意事项 请以拥有Administrator 权限的用户身份执行该命令。
如果连接到PostgreSQL的端口号与默认的5432不同,请在环境变量PQPORT中设置端口号。
自定为-u 选项的用户必须具有PostgreSQL的超级用户权限。
执行本命令时,需要事先启用PostgreSQL的WAL存档。
通过-s 选项指定确保静止点命令之后确保静止点成功时,该确保静止点命令仍然驻留,不会返回控制。其他进程中通过 -r 选项执行静止点开放命令,驻留的确保静止点命令结束后返回控制。
-
执行示例 # clppsqlstill -d postgres -u postgres-s Command succeeded. # clppsqlstill -d postgres -r Command succeeded.
-
错误消息 消息
原因/处理方法
Invalid command option.
命令选项不正确。请确认命令选项。Cannot connect to database.
无法连接到数据库。请确认数据库名以及数据库的状态。Username or password is not correct.
用户认证失败。请确认用户名以及密码。Suspend database failed.
确保静止点失败。请确认用户权限以及数据库的设置。Resume database failed.
释放静止点失败。请确认用户权限以及数据库的设置。Internal error.
发生内部错误。
9.26. 控制SQL Server的静止点(clpmssqlstill 命令)¶
控制SQL Server的静止点。
-
命令行 - clpmssqlstill -d databasename [-u username] -sclpmssqlstill -d databasename -r
-
说明 控制确保/释放SQL Server的静止点。
-
选项 -
-ddatabasename¶ 指定成为控制静止点对象的数据库名。
-
-uusername¶ 指定执行控制静止点的数据库用户名。只指定为-s 选项时可以指定。省略时使用OS认证。
-
-s¶ 确保静止点。
-
-r¶ 释放静止点。
-
-
返回值 0
成功
2
命令选项不正确
3
DB连接错误
4
用户认证错误
5
静止点确保失败
6
静止点释放失败
99
内部错误
-
注意事项 请以拥有Administrator 权限的用户身份执行该命令。
不指定-u 选项使用OS认证时,执行该命令的用户必须具有SQL Server的管理员权限。
指定为-u 选项的用户名和密码需要事先在EXPRESSCLUSTER的编辑模式下从集群的[属性] -> [账户]标签页设置。
指定为-u 选项的用户必须具有执行SQL Server的BACKUP DATABASE声明的权限。
通过-s 选项指定确保静止点命令之后确保静止点成功时,该确保静止点命令仍然驻留,不会返回控制。其他进程中通过 -r 选项执行静止点开放命令,驻留的确保静止点命令结束后返回控制。
-
执行示例 # clpmssqlstill -d userdb -u sa -s Command succeeded.
# clpmssqlstill -d userdb -r Command succeeded.
-
错误消息 消息
原因/处理方法
Invalid command option.
命令选项不正确。请确认命令选项。Cannot connect to database.
无法连接到数据库。请确认数据库名以及数据库的状态。Username or password is not correct.
用户认证失败。请确认用户名以及密码。Suspend database failed.
确保静止点失败。请确认用户权限以及数据库的设置。Resume database failed.
释放静止点失败。请确认用户权限以及数据库的设置。Internal error.
发生内部错误。
9.27. 显示集群统计信息(clpperfc命令)¶
显示集群统计信息。
-
命令行 - clpperfc --starttime -g group_nameclpperfc --stoptime -g group_nameclpperfc -g [group_name]clpperfc -m monitor_name
-
说明 显示组的启动,停止时间的中位数(毫秒)。
显示监视资源的监视处理时间(毫秒)。
-
选项 -
--starttime-g group_name¶ 显示组的启动时间的中位数。
-
--stoptime-g group_name¶ 显示组的停止时间的中位数。
-
-g[group_name]¶ 显示组的启动,停止时间的中位数。
省略了groupname时,显示全组的启动,停止时间的中位数。
-
-mmonitor_name¶ 显示最新的监视资源的监视处理时间。
-
-
返回值 0
正常结束
1
命令选项不正确
2
用户认证错误
3
配置信息加载错误
4
配置信息加载错误
5
初始化错误
6
内部错误
7
内部通信初始化错误
8
内部通信连接错误
9
内部通信处理错误
10
对象组检查错误
12
超时错误
-
执行示例 (显示组的启动时间的中位数时) # clpperfc --starttime -g failover1 200
-
执行示例 (显示特定组的启动,停止时间的中位数时) # clpperfc -g failover1 start time stop time failover1 200 150
-
执行示例 (显示监视资源的监视处理时间时) # clpperfc -m monitor1 100
-
备注 通过该命令输出的时间单位为毫秒。
有效的组的启动,停止时间无法获取时,显示 - 。
有效的监视资源的监视时间无法获取时,显示0。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
-
错误消息 消息
原因/处理方法
Log in as Administrator.
请具有Administrator权限的用户执行。
Invalid option.
命令选项不正确。请确认命令选项。
Command timeout.
执行命令超时了。
Internal error.
考虑到内存不足或者OS的资源不足。请确认。
9.28. 检查集群配置信息(clpcfchk命令)¶
检查集群配置信息。
-
命令行 - clpcfchk -o path [-i conf_path]
-
说明 确认以集群配置信息为基础的设定值的妥当性。
-
返回值 0
正常结束
0以外
异常结束
-
执行示例 (检查反映完毕的配置信息时) # clpcfchk -o /tmp server1 : PASS server2 : PASS
-
执行示例 (检查已保存的配置信息时) # clpcfchk -o /tmp -i /tmp/config server1 : PASS server2 : FAIL
-
执行结果 该命令的结果中显示的检查结果(综合结果)如下。
检查结果(综合结果)
说明
PASS
没有问题。
FAIL
有问题。请确认检查结果。
-
备注 只显示各服务器的综合结果。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
检查通过Cluster WebUI导出的配置信息时,请事先对其进行解压缩。
-
错误消息 消息
原因/处理方法
Log in as Administrator.
请具有Administrator权限的用户执行。
Invalid option.
请指定正确的选项。
Could not opened the configuration file. Check if the configuration file exists on the specified path.
指定的路径不存在。请指定正确的路径。
Server is busy. Check if this command is already run.
该命令已经启动。
Failed to obtain properties.
获取属性失败。
Failed to check validation.
集群配置检查失败。
Internal error. Check if memory or OS resources are sufficient.
考虑到内存不足或者OS的资源不足。请确认。
9.29. 更换集群配置信息文件(clpcfconv命令)¶
进行集群配置信息文件的更换。
-
命令行 - clpcfconv -i <input-path> [-o <output-path>]
-
说明 集群配置信息文件从旧版本更换到现在版本中。
-
选项 -
-i<input-path>¶ 指定存在旧版本的配置信息文件的目录。
-
-o<output-path>¶ - 指定更换后的配置信息文件的输出目录。如果省略该选项,则更换后的配置信息文件将输出到当前目录。
-
-
返回值 0
正常结束
0以外
异常结束
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
该命令只更换集群配置信息文件中的clp.conf。
该命令在<安装目标目录>\etc下无法执行。
该命令不支持使用早于 EXPRESSCLUSTER X 3.3 for Windows(内部版本 11.35)的版本创建的集群配置信息文件。
-
执行示例 更换成功时
# clpcfconv -i C:\temp\config_x430 -o C:\temp\config_new Command succeeded.
更换成功,且密码被清除时
# clpcfconv -i C:\temp\config_x430 -o C:\temp\config_new Command succeeded. Password for Operation has been initialized. Password for Reference has been initialized. Please set the password again by using Cluster WebUI.
-
错误消息 消息
原因/处理方法
Command succeeded.
命令成功。
Password for Operation has been initialized.
清除了集群密码方式的操作用密码。
Password for Reference has been initialized.
清除了集群密码方式的参考用密码。
Please set the password again by using Cluster WebUI.
请使用Cluster WebUI再次设置已清除的密码。
Log in as administrator.
请具有Administrator权限的用户执行。
Failed to get etc directory path.
可执行未正确安装,或者没有执行权限。
Not available in this directory.
在<安装目标目录>\etc下无法执行。将当前目录更改为 <安装目标目录>\etc等以外的其他目录。Could not opened the configuration file. Check if the configuration file exists on the specified path.
在使用-i选项指定的路径中不存在集群配置信息文件(clp.conf)。请确认集群配置信息文件在指定的路径中是否存在。The specified output-path does not exist.
通过-o选项指定的路径不存在。请指定正确的路径。Invalid configuration file.
集群配置信息文件不正确。请确认集群配置信息文件。The version of this configuration data file is not supported. Convert it with Builder for offline use (internal version 11.35), then retry.
这是该命令不支持的版本的集群配置信息文件。请在内部版本11.35的离线版Builder中更换后,再次执行。%1 : Command failed. code:%2
命令%1失败了。请确认命令的返回值 (%2) 或在此错误消息之前显示的错误消息。Command failed.
此命令失败。请确认此错误消息之前显示的错误消息。
9.30. 生成集群配置信息文件(clpcfset, clpcfadm.py命令)¶
9.30.1. clpcfset命令¶
生成集群配置信息文件。
-
命令行 - clpcfset {create|--create} clustername charset [encode] [serveros]clpcfset {add|--add} clsparam tagname parameterclpcfset {add|--add} srv servername priorityclpcfset {add|--add} hba servername id portnumber deviceid instanceidclpcfset {add|--add} device servername type id info [extend]clpcfset {add|--add} forcestop envclpcfset {add|--add} hb lankhb deviceid priorityclpcfset {add|--add} hb witnesshb deviceid priority hostclpcfset {add|--add} np disknp deviceid priorityclpcfset {add|--add} np pingnp deviceid priority groupid listid ipadressclpcfset {add|--add} np httpnp deviceid priority [host]clpcfset {add|--add} np majonp deviceid priorityclpcfset {add|--add} grp grouptype groupnameclpcfset {add|--add} grpparam groupname tagname parameterclpcfset {add|--add} rsc groupname resourcetype resourcenameclpcfset {add|--add} rscparam resourcetype resourcename tagname parameterclpcfset {add|--add} rscdep resourcetype resourcename dependresourcenameclpcfset {add|--add} mon monitortype resourcenameclpcfset {add|--add} monparam monitortype resourcename tagname parameterclpcfset {del|--del} clsparam tagnameclpcfset {del|--del} srv servernameclpcfset {del|--del} device servername idclpcfset {del|--del} forcestopclpcfset {del|--del} hb lankhb deviceidclpcfset {del|--del} hb lanhb deviceidclpcfset {del|--del} hb diskhb deviceidclpcfset {del|--del} hb witnesshb deviceidclpcfset {del|--del} np pingnp deviceidclpcfset {del|--del} np httpnp deviceidclpcfset {del|--del} grp groupnameclpcfset {del|--del} grpparam groupname tagnameclpcfset {del|--del} rsc groupname resourcetype resourcenameclpcfset {del|--del} rscparam resourcetype resourcename tagnameclpcfset {del|--del} rscdep resourcetype resourcename [dependresourcename]clpcfset {del|--del} mon monitortype resourcenameclpcfset {del|--del} monparam monitortype resourcename tagname
-
说明 输出生成本产品的集群配置信息的文件。
-
选项 -
{create|--create}clustername charset [encode] [serveros]¶ 指定集群名,encode后新建集群。
对于clustername,指定集群名称,对于charset,为EXPRESSCLUSTER的语言指定日语的SJIS,英语的ASCII和中文的GB2312。
encode是在使用WebUI创建配置信息时,根据运行WebUI的服务器的OS和EXPRESSCLUSTER的语言确定的参数。 省略时,和charset做相同的设置。
OS为Windows时: SJIS
OS为Linux且为日语时: EUC-JP
OS为Linux且为英语时: ASCII
OS为Linux且为中文时: GB2312
serveros 在为 Linux 环境创建集群配置信息时指定"linux"。省略时设置为"windows"。创建Linux环境的集群配置信息时请参考"EXPRESSCLUSTER X for Linux 参考指南"。
-
{add|--add}<param>¶ param
- clsparam tagname parameter
- 指定标签页名和参数设置集群属性。关于tagname,parameter请参考"参数一览(clpcfset, clpcfadm.py命令)"。
- srv servername priority
- 指定服务器名,优先级添加服务器。servername中指定服务器名。对于priority,主服务器为0。之后每递增1。
- hba servername id portnumber deviceid instanceid
- 指定服务器名和ID添加HBA。id从0开始指定。之后每递增1。portnumber,deviceid,instanceid的值通过其他命令clpdiskctrl可以获取。
- device servername type id info [extend]
- 指定服务器名,类型添加设备。type从lan, mdc, witness, disknp, ping, http, majo中指定。对于id,每个type从0开始指定。之后每递增1。对于lan, mdc,在info中指定IP地址。对于witness,info中未使用:0/使用:1,extend中指定连接目标的Witness服务器的主机地址和端口(地址:端口)。disknp在info中指定卷ID,在extend中指定设备路径。关于卷ID和设备路径可以通过其他命令clpdiskctrl获取。ping, http, majo在info中指定未使用:0/使用:1。
- forcestop env
- 指定环境类型,添加强制停止资源。env指定bmc, vcenter, aws, oci或custom中任意一个。
- hb lankhb deviceid priority
- 指定设备ID,优先级添加内核模式心跳。对于deviceid,指定通过add device指定的ID。心跳的priority从0开始指定。之后每递增1。
- hb witnesshb deviceid priority host
- 指定设备ID,优先级,目标主机添加Witness心跳。对于deviceid,指定通过add device指定的ID。心跳的priority从0开始指定。之后每递增1。对于host,指定连接目标的Witness服务器的主机地址和端口(地址:端口)。
- np disknp deviceid priority
- 指定优先级,设备ID,添加DISK方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。NP解决资源的priority从0开始指定。之后每递增1。
- np pingnp deviceid priority groupid listid ipadress
- 指定优先级,设备ID,组ID,列表ID,IP地址,添加PING方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。priority,groupid,listid从0开始指定。之后每递增1。对于ipadress,指定NP解决资源中使用的IP地址。
- np httpnp priority deviceid [host]
- 指定设备ID,优先级,目标主机,添加HTTP方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。NP解决资源的priority从0开始指定。之后每递增1。[host]指定连接目标的Witness服务器的主机地址和端口(地址:端口)。省略[host]时,使用Witness HB资源的设置。
- np majonp deviceid priority
- 指定优先级,设备ID,添加多数决定方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。NP解决资源的priority从0开始指定。之后每递增1。
- grp grouptype groupname
- 指定组类型,组名添加组。对于grouptype,指定failover或ManagementGroup。
- grpparam groupname tagname parameter
- 指定组名,标签页名和参数设置组的属性。关于tagname,parameter请参考"参数一览(clpcfset, clpcfadm.py命令)"。
- rsc groupname resourcetype resourcenam
- 指定组名,资源类型,资源名添加资源。
- rscparam resourcetype resourcename tagname paramter
- 指定资源类型,资源名,标签页名和参数设置资源的属性。关于tagname,parameter请参考"参数一览(clpcfset, clpcfadm.py命令)"。
- rscdep resourcetype resourcename dependresourcename
- 指定资源名添加资源的依赖关系。resourcetype,resourcename中设置资源类型和资源名,dependresourcename中指定依赖的资源名。组资源中设置依赖关系时,启动时dependresourcename的启动完成后,resourcename中指定的组资源开始启动。停止时resourcename中指定的组资源的停止完成后,dependresourcename开始停止。作为示例,在列表中显示属于当前组的资源所依赖的深度。

图 9.8 组资源启动顺序的示例¶

图 9.9 组资源停止顺序的示例¶
- mon monitortype monitorresource
- 指定监视资源类型名,监视资源名添加监视资源。
- monparam monitortype monitorresource tagname paramter
- 指定监视资源类型,监视资源名,标签页名和参数设置监视资源的属性。关于tagname,parameter请参考"参数一览(clpcfset, clpcfadm.py命令)"。
-
{del|--del}<param>¶ param
- clsparam tagname
- 指定标签页名,删除集群的属性。tagname请参考"参数一览(clpcfset, clpcfadm.py命令)"。
- srv servername
- 删除服务器名、指定的服务器。
- hba servername id
- 指定服务器名、ID,删除HBA。
- device servername id
- 指定服务器名、设备ID删除设备。6
- forcestop
- 删除强制停止资源。
- hb lankhb deviceid
- 指定设备ID,删除内核模式LAN心跳。6
- hb witnesshb deviceid
- 指定设备ID,删除witness心跳。6
- np disknp deviceid
- 指定设备ID,删除DISK方式的网络分区解决资源。6
- np pingnp deviceid
- 指定设备ID,删除PING方式的网络分区解决资源。6
- np httpnp deviceid
- 指定设备ID,删除HTTP方式的网络分区解决资源。6
- np majonp deviceid
- 指定设备ID,删除多数决定方式的网络分区解决资源。6
- grp groupname
- 指定组名,删除组。
- grpparam groupname tagname
- 指定组名、标签页名,删除组的属性。tagname请参考"参数一览(clpcfset, clpcfadm.py命令)"。
- rsc groupname resourcetype resourcename
- 指定组名、组资源类型、组资源名,删除组资源。
- rscparam resourcetype resourcename tagname
- 指定组资源类型、组资源名、标签页名,删除组资源的属性。tagname请参考"参数一览(clpcfset, clpcfadm.py命令)"。
- rscdep resourcetype resourcename [dependresourcename]
- 指定组资源类型、组资源名、依赖的组资源名,删除组资源的依赖关系。resourcetype、resourcename中设置组资源类型和组资源名,dependresourcename中指定依赖的组资源名。省略dependresourcena时,删除所有的依赖关系并更改为默认的依赖关系。
- mon monitortype monitorresource
- 指定监视资源类型、监视资源名,删除监视资源。
- monparam monitortype monitorresource tagname
- 指定监视资源类型、监视资源名、标签页名,删除监视资源的属性。tagname请参考"参数一览(clpcfset, clpcfadm.py命令)"
-
- 6(1,2,3,4,5,6,7)
- 删除时的设备ID指定在集群配置信息中设置的值。通过该命令的add device选项指定的设备ID,根据设备类型添加并设置以下的值。
lan
-
mdc
400
witness
700
disknp
10100
ping
10200
http
10700
majo
10300
-
返回值 0
正常结束
0以外
异常结束
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
关于各参数可以输入的字符串和禁用字符串,请参考"本指南的各章节"。
本命令在集群配置信息文件里只创建clp.conf。在脚本资源、自定义监视资源等中使用的脚本文件必须手动创建。
请在当前目录中已配置集群配置信息文件(clp.conf)的状态下执行该命令。
- 例
配置失效切换组failover1所属的SCRIPT资源script1和自定义监视资源genw1的脚本时。
scripts ├─failover1 │ └─script1 │ start.bat │ stop.bat │ └─monitor.s └─genw1 genw.bat
-
执行示例 添加集群
# clpcfset create cluster GB2312 SJIS
# clpcfset create cluster GB2312 linux
添加/更改集群属性的参数
# clpcfset add clsparam pm/exec0/recover 7 # clpcfset add clsparam pm/exec1/recover 7
删除集群属性的参数
# clpcfset del clsparam pm/exec0/recover # clpcfset del clsparam pm/exec1/recover
添加服务器
# clpcfset add srv server1 0
删除服务器
# clpcfset del srv server1
添加HBA
# clpcfset add hba server1 0 1 VMBUS\{ba6163d9-04a1-4d29-b605-72e2ffb1dc7f} {9637c0f4-2a65-41ed-b884-a59d0e12f731}删除HBA
# clpcfset del hba server1 0
添加内核模式LAN心跳
# clpcfset add device server1 lan 0 192.168.137.71 # clpcfset add hb lankhb 0 0
删除内核模式LAN心跳
# clpcfset del device server1 0 # clpcfset del hb lankhb 0
添加Witness心跳
# clpcfset add device server1 witness 0 1 192.168.2.1:49152 # clpcfset add hb witnesshb 0 3 192.168.2.1:49152
删除witness心跳
# clpcfset del device server1 700 # clpcfset del hb witnesshb 700
添加DISK方式的网络分区解决资源
# clpcfset add device server1 disknp 0 07081c5e-b794-4826-9a7b-48a9664c42c9 R # clpcfset add np disknp 0 0
删除DISK方式的网络分区解决资源
# clpcfset del device server1 10100 # clpcfset del np disknp 10100
添加PING方式的网络分区解决资源
# clpcfset add device server1 ping 0 1 # clpcfset add np pingnp 0 1 0 0 192.168.1.1
删除PING方式的网络分区解决资源
# clpcfset del device server1 10200 # clpcfset del np pingnp 10200
添加HTTP方式的网络分区解决资源
使用Witness HB资源的设置时
# clpcfset add device server1 http 0 1 # clpcfset add np httpnp 0 2
添加HTTP方式的网络分区解决资源
未使用Witness HB资源的设置时
# clpcfset add device server1 http 0 1 # clpcfset add np httpnp 0 2 192.168.2.2:49152
删除HTTP方式的网络分区解决资源
# clpcfset del device server1 10700 # clpcfset del np httpnp 10700
添加多数决定方式的网络分区解决资源
# clpcfset add device server1 majo 0 1 # clpcfset add np majonp 0 3
删除多数决定方式的网络分区解决资源
# clpcfset del device server1 10300 # clpcfset del np majonp 10300
添加强制停止资源(bmc时)
# clpcfset add forcestop bmc
删除强制停止资源
# clpcfset del forcestop
添加组
# clpcfset add grp failover failover1
添加/更改组属性的参数
# clpcfset add grpparam failover1 policy@server1/order 0 # clpcfset add grpparam failover1 policy@server2/order 1
删除组属性的参数
# clpcfset del grpparam failover1 policy@server1/order # clpcfset del grpparam failover1 policy@server2/order
删除组
# clpcfset del grp failover1
添加资源
# clpcfset add rsc failover1 fip fip1
添加/更改组资源属性的参数
# clpcfset add rscparam fip fip1 parameters/ip 192.168.137.171
删除组资源属性的参数
# clpcfset del rscparam fip fip1 parameters/ip
删除组资源
# clpcfset del rsc failover1 fip fip1
添加资源的依赖关系
# clpcfset add rscdep fip fip1 ddns1
删除组资源的依赖关系
删除个别的依赖关系时
# clpcfset del rscdep fip fip1 ddns1
删除组资源的依赖关系
删除所有的依赖关系返回到默认的依赖关系时
# clpcfset del rscdep fip fip1
添加监视资源
# clpcfset add mon fipw fipw1
添加/更改监视资源属性的参数
# clpcfset add monparam fipw fipw1 target fip1
删除监视资源属性的参数
# clpcfset del monparam fipw fipw1 target
删除监视资源
# clpcfset del mon fipw fipw1
-
错误消息 消息
原因/处理方法
Log in as administrator.
请由具有Administrator权限的用户执行。
Invalid option.
请指定正确的选项。
Invalid configuration file. Use the create option.
请执行本命令的create选项。
Invalid parameter.
参数有误。请确认参数的数值和形式是否有误。
Parameter length error.
命令的引数中指定的字符串过长。
Specify a number in a valid range.
请指定正确范围内的数字。
The specified path does not exist.
请指定正确的路径。
Failed to save the configuration file.
考虑到内存不足或者OS的资源不足。请确认。
Internal error. Check if memory or OS resources are sufficient.
考虑到内存不足或者OS的资源不足。请确认。
9.30.2. clpcfadm.py命令¶
-
命令行 - clpcfadm.py {create} clustername charset [-e encode] [-s serveros]clpcfadm.py {add} srv servername priorityclpcfadm.py {add} device servername type id info [extend]clpcfadm.py {add} forcestop envclpcfadm.py {add} hb lankhb deviceid priorityclpcfadm.py {add} hb lanhb deviceid priorityclpcfadm.py {add} hb diskhb deviceid priorityclpcfadm.py {add} hb witnesshb deviceid priority hostclpcfadm.py {add} np pingnp deviceid priority groupid listid ipadressclpcfadm.py {add} np httpnp deviceid priority [--host host]clpcfadm.py {add} grp grouptype groupnameclpcfadm.py {add} rsc groupname resourcetype resourcenameclpcfadm.py {add} rscdep resourcetype resourcename dependresourcenameclpcfadm.py {add} mon monitortype resourcenameclpcfadm.py {del} srv servernameclpcfadm.py {del} device servername idclpcfadm.py {del} forcestopclpcfadm.py {del} hb lankhb deviceidclpcfadm.py {del} hb lanhb deviceidclpcfadm.py {del} hb diskhb deviceidclpcfadm.py {del} hb witnesshb deviceidclpcfadm.py {del} np pingnp deviceidclpcfadm.py {del} np httpnp deviceidclpcfadm.py {del} grp groupnameclpcfadm.py {del} rsc groupname resourcetype resourcenameclpcfadm.py {del} rscdep resourcetype resourcenameclpcfadm.py {del} mon monitortype resourcenameclpcfadm.py {mod} -t [tagname] [--set parameter] [--delete] [--nocheck]
-
说明 输出生成本产品的集群配置信息的文件。
命令行中显示可以指定的标签页名列表。
-
选项 -
{create|--create}clustername charset [-e encode] [-s serveros]¶ 指定集群名,encode后新建集群。
对于clustername,指定集群名称,对于charset,为EXPRESSCLUSTER的语言指定日语的SJIS,英语的ASCII和中文的GB2312。
encode是在使用WebUI创建配置信息时,根据运行WebUI的服务器的OS和EXPRESSCLUSTER的语言确定的参数。 省略时,和charset做相同的设置。
OS为Windows时: SJIS
OS为Linux且为日语时: EUC-JP
OS为Linux且为英语时: ASCII
OS为Linux且为中文时: GB2312
serveros 在为 Linux 环境创建集群配置信息时指定"linux"。省略时设置为"windows"。创建Linux环境的集群配置信息时请参考"EXPRESSCLUSTER X for Linux 参考指南"。
-
{add|--add}<param>¶ param
- srv servername priority
- 指定服务器名,优先级添加服务器。servername中指定服务器名。对于priority,主服务器为0。之后每递增1。
- hba servername id portnumber deviceid instanceid
- 指定服务器名和ID添加HBA。id从0开始指定。之后每递增1。portnumber,deviceid,instanceid的值通过其他命令clpdiskctrl可以获取。
- device servername type id info [extend]
- 指定服务器名,类型添加设备。type从lan, mdc, witness, disknp, ping, http, majo中指定。对于id,每个type从0开始指定。之后每递增1。对于lan, mdc,在info中指定IP地址。对于witness,info中未使用:0/使用:1,extend中指定连接目标的Witness服务器的主机地址和端口(地址:端口)。disknp在info中指定卷ID,在extend中指定设备路径。关于卷ID和设备路径可以通过其他命令clpdiskctrl获取。ping, http, majo在info中指定未使用:0/使用:1。
- forcestop env
- 指定环境类型,添加强制停止资源。env指定bmc, vcenter, aws, oci或custom中任意一个。
- hb lankhb deviceid priority
- 指定设备ID,优先级添加内核模式心跳。对于deviceid,指定通过add device指定的ID。心跳的priority从0开始指定。之后每递增1。
- hb witnesshb deviceid priority host
- 指定设备ID,优先级,目标主机添加Witness心跳。对于deviceid,指定通过add device指定的ID。心跳的priority从0开始指定。之后每递增1。对于host,指定连接目标的Witness服务器的主机地址和端口(地址:端口)。
- np disknp deviceid priority
- 指定优先级,设备ID,添加DISK方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。NP解决资源的priority从0开始指定。之后每递增1。
- np pingnp deviceid priority groupid listid ipadress
- 指定优先级,设备ID,组ID,列表ID,IP地址,添加PING方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。priority,groupid,listid从0开始指定。之后每递增1。对于ipadress,指定NP解决资源中使用的IP地址。
- np httpnp priority deviceid [--host host]
- 指定设备ID,优先级,目标主机,添加HTTP方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。NP解决资源的priority从0开始指定。之后每递增1。[host]指定连接目标的Witness服务器的主机地址和端口(地址:端口)。省略[host]时,使用Witness HB资源的设置。
- np majonp deviceid priority
- 指定优先级,设备ID,添加多数决定方式的网络分区解决资源。对于deviceid,指定通过add device指定的ID。NP解决资源的priority从0开始指定。之后每递增1。
- grp grouptype groupname
- 指定组类型,组名添加组。对于grouptype,指定failover或ManagementGroup。
- rsc groupname resourcetype resourcename
- 指定组名,资源类型,资源名添加资源。
- rscdep resourcetype resourcename dependresourcename
- 指定资源名添加资源的依赖关系。resourcetype,resourcename中设置资源类型和资源名,dependresourcename中指定依赖的资源名。组资源中设置依赖关系时,启动时dependresourcename的启动完成后,resourcename中指定的组资源开始启动。停止时resourcename中指定的组资源的停止完成后,dependresourcename开始停止。作为示例,在列表中显示属于当前组的资源所依赖的深度。
图 9.10 组资源启动顺序的示例¶
图 9.11 组资源停止顺序的示例¶
- mon monitortype monitorresource
- 指定监视资源类型名,监视资源名添加监视资源。
-
{del|--del}<param>¶ param
- srv servername
- 删除服务器名、指定的服务器。
- hba servername id
- 指定服务器名、ID,删除HBA。
- device servername id
- 指定服务器名、设备ID删除设备。7
- forcestop
- 删除强制停止资源。
- hb lankhb deviceid
- 指定设备ID,删除内核模式LAN心跳。7
- hb witnesshb deviceid
- 指定设备ID,删除witness心跳。7
- np disknp deviceid
- 指定设备ID,删除DISK方式的网络分区解决资源。7
- np pingnp deviceid
- 指定设备ID,删除PING方式的网络分区解决资源。7
- np httpnp deviceid
- 指定设备ID,删除HTTP方式的网络分区解决资源。7
- np majonp deviceid
- 指定设备ID,删除多数决定方式的网络分区解决资源。7
- grp groupname
- 指定组名,删除组。
- rsc groupname resourcetype resourcename
- 指定组名、组资源类型、组资源名,删除组资源。
- rscdep resourcetype resourcename
- 指定组资源类型、组资源名,删除组资源的所有依赖关系,更改为默认的依赖关系。在resourcetype、resourcename中指定组资源类型和组资源名。
- mon monitortype monitorresource
- 指定监视资源类型、监视资源名,删除监视资源。
-
{mod}-t [tagname] [--set param] [--delete] [--nocheck]¶ - -t [tagname]
- 是必选项。请在tagname中指定标签页名。省略时root要素被指定。--set或者--delete选项未指定时,显示tagname的子要素列表。指定--set且指定子要素中不存在的tagname时,请指定--nocheck选项。tagname请参考"参数一览(clpcfset, clpcfadm.py命令)"。
- [--set param]
进行参数的更改。请在param上指定tagname的设置值。
- [--delete]
从集群配置信息里删除tagname。
- [--nocheck]
是和--set同时使用的选项。如果tagname不存在,则不会发生错误。
-
- 7(1,2,3,4,5,6,7)
- 删除时的设备ID指定在集群配置信息中设置的值。通过该命令的add device选项指定的设备ID,根据设备类型添加并设置以下的值。
lan
-
mdc
400
witness
700
disknp
10100
ping
10200
http
10700
majo
10300
-
返回值 0
正常结束
0以外
异常结束
-
运行环境 请参阅《开始指南》的"EXPRESSCLUSTER Server的运行环境" - "clpcfadm.py命令的运行环境"。
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
关于各参数可以输入的字符串和禁用字符串,请参考"本指南的各章节"。
本命令在集群配置信息文件里只创建clp.conf。在脚本资源/EXEC资源,自定义监视资源等中使用的脚本文件必须手动创建。
请在当前目录中已配置集群配置信息文件(clp.conf)的状态下执行该命令。
- 例
配置失效切换组failover1所属的SCRIPT资源script1和自定义监视资源genw1的脚本时。
scripts ├─failover1 │ └─script1 │ start.bat │ stop.bat │ └─monitor.s └─genw1 genw.bat
-
执行示例 显示标签名的列表(显示/root的子要素列表)
# clpcfadm.py mod -t 显示示例 # all # cluster # messages # pm # rm # webalert # webmgr
显示标签名的列表(显示/root/pm/exec0子要素列表)
# clpcfadm.py mod -t pm/exec0 显示示例([]内是当前的设置值) # recover [5] # retry [5] # type [rc] # wait [1800]
添加集群
# clpcfadm.py create cluster ASCII -e SJIS
# clpcfadm.py create cluster ASCII -s linux
添加/更改集群属性的参数
# clpcfadm.py mod -t pm/exec0/recover --set 7 # clpcfadm.py mod -t pm/exec1/recover --set 7
删除集群属性的参数
# clpcfadm.py mod -t pm/exec0/recover --delete # clpcfadm.py mod -t pm/exec1/recover --delete
添加服务器
# clpcfadm.py add srv server1 0
删除服务器
# clpcfadm.py del srv server1
添加HBA
# clpcfadm.py add hba server1 0 1 VMBUS\{ba6163d9-04a1-4d29-b605-72e2ffb1dc7f} {9637c0f4-2a65-41ed-b884-a59d0e12f731}删除HBA
# clpcfadm.py del hba server1 0
添加内核模式LAN心跳
# clpcfadm.py add device server1 lan 0 192.168.137.71 # clpcfadm.py add hb lankhb 0 0
删除内核模式LAN心跳
# clpcfadm.py del device server1 0 # clpcfadm.py del hb lankhb 0
添加Witness心跳
# clpcfadm.py add device server1 witness 0 1 192.168.2.1:49152 # clpcfadm.py add hb witnesshb 0 3 192.168.2.1:49152
删除witness心跳
# clpcfadm.py del device server1 700 # clpcfadm.py del hb witnesshb 700
添加DISK方式的网络分区解决资源
# clpcfadm.py add device server1 disknp 0 07081c5e-b794-4826-9a7b-48a9664c42c9 R # clpcfadm.py add np disknp 0 0
删除DISK方式的网络分区解决资源
# clpcfadm.py del device server1 10100 # clpcfadm.py del np disknp 10100
添加PING方式的网络分区解决资源
# clpcfadm.py add device server1 ping 0 1 # clpcfadm.py add np pingnp 0 1 0 0 192.168.1.1
删除PING方式的网络分区解决资源
# clpcfadm.py del device server1 10200 # clpcfadm.py del np pingnp 10200
添加HTTP方式的网络分区解决资源
使用Witness HB资源的设置时
# clpcfadm.py add device server1 http 0 1 # clpcfadm.py add np httpnp 0 2
添加HTTP方式的网络分区解决资源
未使用Witness HB资源的设置时
# clpcfadm.py add device server1 http 0 1 # clpcfadm.py add np httpnp 0 2 --host 192.168.2.2:49152
删除HTTP方式的网络分区解决资源
# clpcfadm.py del device server1 10700 # clpcfadm.py del np httpnp 10700
添加多数决定方式的网络分区解决资源
# clpcfadm.py add device server1 majo 0 1 # clpcfadm.py add np majonp 0 3
删除多数决定方式的网络分区解决资源
# clpcfadm.py del device server1 10300 # clpcfadm.py del np majonp 10300
添加强制停止资源(bmc时)
# clpcfadm.py add forcestop bmc
删除强制停止资源
# clpcfadm.py del forcestop
添加组
# clpcfadm.py add grp failover failover1
添加/更改组属性的参数
# clpcfadm.py mod -t group@failover1/start --set 0
删除组属性的参数
# clpcfadm.py mod -t group@failover1/start --delete
删除组
# clpcfadm.py del grp failover1
添加资源
# clpcfadm.py add rsc failover1 fip fip1
添加/更改组资源属性的参数
# clpcfadm.py mod -t resource/fip@fip1/parameters/ip --set 192.168.137.171
删除组资源属性的参数
# clpcfadm.py mod -t resource/fip@fip1/parameters/ip --delete
删除组资源
# clpcfadm.py del rsc failover1 fip fip1
添加资源的依赖关系
# clpcfadm.py add rscdep fip fip1 ddns1
删除组资源的依赖关系
删除个别的依赖关系时
# clpcfadm.py mod -t resource/fip@fip1/depend@ddns1 --delete
删除组资源的依赖关系
删除所有的依赖关系返回到默认的依赖关系时
# clpcfadm.py del rscdep fip fip1
添加监视资源
# clpcfadm.py add mon fipw fipw1
添加/更改监视资源属性的参数
# clpcfadm.py mod -t monitor/fipw@fipw1/target --set fip1
删除监视资源属性的参数
# clpcfadm.py mod -t monitor/fipw@fipw1/target --delete
删除监视资源
# clpcfadm.py del mon fipw fipw1
添加使用了--nocheck选项的参数
# clpcfadm.py mod -t webmgr/security/clientlist/ip --set 127.0.0.1 --nocheck
# clpcfadm.py mod -t group@failover1/policy@server1/order --set 0 --nocheck
# clpcfadm.py mod -t resource/fip@fip1/server@server1/parameters/ip --set 127.0.0.1 --nocheck
# clpcfadm.py mod -t monitor/fipw@fipw1/relation/name --set LocalServer --nocheck
-
错误消息 消息
原因/处理方法
Log in as administrator.
请由具有Administrator权限的用户执行。
'%1' is not found.
没有发现文件%1。
The specified object does not exist. '%1'
指定的对象%1不存在。
The specified element '%1' does not exist in '%2'.
指定的要素%1在%2中不存在。
The specified path does not exist in a config file.
指定的路径在集群配置信息里不存在。
Invalid config file. Use the 'create' option.
请执行该命令的create选项。
The config file already exists.
集群配置信息已经存在。
Non-configurable elements specified.
不是可以设置的标签页名。
Invalid value specified. Specify as follows: <resource type>@<resource name>
请按照<组资源类型>@<组资源名>的格式指定。
Invalid path specified.
指定了无效的路径。
Cannot register a '%1' any more.
%1达到注册上限。
The following arguments are required :%1
请指定%1。
Argument %1: allowed only with argument '%2'
%1只在%2时为有效的选项。
Argument %1: invalid choice: '%2' (choose from %3)
%1中指定的%2为无效的值。请从%3的选项里指定。
Argument %1: invalid value: '%2' (The value must be in the range [%3, %4])
%1中指定的%2为无效的值。请从%3至%4的范围中指定数值。
Argument %1: invalid value: '%2' (The length must be less than %3)
%1中指定的%2的字符串过长。请设置为%3以内的长度。
Argument %1: '%2' already exists.
%1中已经存在%2。
Argument %1: '%2' does not exist.
%1中不存在%2。
Argument %1: cannot specify a dependency to the same object.
%1指定了对同一对象的依赖关系。请指定不同的对象。
Argument %1: does not appear to be an IPv4.
%1为无效值。请按照IPv4格式指定。
Invalid value: '%1' (The value must be greater than 0)
%1为无效值。请指定大于0的数值。
9.30.3. 参数一览 (clpcfset, clpcfadm.py命令)¶
| 集群 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 集群属性 | |||||||||||
| 信息标签页 | |||||||||||
| 集群名 | - | ||||||||||
| 注释 | - | ||||||||||
| 语言 | 英语 | ||||||||||
| 私网签页 | |||||||||||
| 优先级 | - | ||||||||||
| 添加, 删除 | - | ||||||||||
| [种类]列 | |||||||||||
| [镜像磁盘连接]]列 | |||||||||||
| [服务器]列 内核模式 | - | ||||||||||
| [服务器]列 使用Witness HB | |||||||||||
| [服务器]列 镜像通信专用 | |||||||||||
| [服务器]列 镜像磁盘连接]使用 | |||||||||||
| 服务器宕机通知 | ON | ||||||||||
| 服务器重置通知 | OFF | ||||||||||
| 执行服务器生存确认 | OFF | ||||||||||
| 超时 | 1 [秒] | ||||||||||
| Witness心跳的属性 | |||||||||||
| 对象主机 | |||||||||||
| 服务端口号 | 80 | ||||||||||
| 使用SSL | OFF | ||||||||||
| 使用Proxy | OFF | ||||||||||
| HTTP超时 | 10[秒] | ||||||||||
| Fencing 标签页 | |||||||||||
| 追加,删除 | - | ||||||||||
| [种类]列 | DISK | ||||||||||
| Ping对象 | - | ||||||||||
| [服务器]列 | - | ||||||||||
| 磁盘NP的属性 | |||||||||||
| IO等待时间 | 80 [秒] | ||||||||||
| 监视 间隔 | 60 [秒] | ||||||||||
| 监视 超时 | 300 [秒] | ||||||||||
| 监视 重试次数 | 0 [次] | ||||||||||
| Ping NP的属性 | |||||||||||
| 接口标签页 | |||||||||||
| 组列表 序号 | |||||||||||
| 组列表 IP地址列表 | |||||||||||
| IP地址列表 IP地址 | |||||||||||
| 详细设定 间隔 | 5 [秒] | ||||||||||
| 详细设定 超时 | 3 [秒] | ||||||||||
| 详细设定 重试次数 | 3 [次] | ||||||||||
| HTTP NP 的属性 | |||||||||||
| 使用Witness HB的设置 | - | ||||||||||
| 对象主机 | |||||||||||
| 服务端口号 | 80 | ||||||||||
| 使用SSL | OFF | ||||||||||
| 使用Proxy | OFF | ||||||||||
| 间隔 | 5[秒] | ||||||||||
| 超时 | 20[秒] | ||||||||||
| HTTP超时 | 10[秒] | ||||||||||
| 网络分区解决调整属性 | |||||||||||
| NP发生时动作 | 紧急关机 | cluster/networkpartition/npaction | 1~6 | parameter中可以指定的值如下所示。 1:停止集群服务 2:停止集群服务并关闭操作系统 3:停止集群服务并重新启动操作系统 4:紧急关机 5:生成主动停止错误 6:HW重设 |
|||||||
| 强制停止 类型 | 不使用 | ||||||||||
| BMC强制停止的属性 | |||||||||||
| 服务器列表签页 | |||||||||||
| 服务器 (添加, 删除, 编辑) | - | forcestop/bmc/server@<服务器名>/use | 0, 1 | 在XPATH中指定服务器名。 parameter中可以指定的值如下所示。 0: 不使用 1: 使用 |
|||||||
| BMC输入 | |||||||||||
| IP地址 | - | forcestop/bmc/server@<服务器名>/parameters/ip | 字符串 | 在XPATH中指定服务器名。 在parameter中指定IP地址。 |
|||||||
| 用户名 | - | forcestop/bmc/server@<服务器名>/parameters/user | 字符串 | 在XPATH中指定服务器名。 在parameter中指定用户名。 |
|||||||
| 密码 | - | forcestop/bmc/server@<服务器名>/parameters/password | 字符串 | 在XPATH中指定服务器名。 在parameter中指定密码。 |
|||||||
| 强制停止签页 | |||||||||||
| 强制停止动作 | BMC Power Off | forcestop/bmc/parameters/action | 字符串 | parameter中可以指定的值如下所示。 poweroff: BMC Power Off powercycle: BMC Power Cycle reset: BMC Reset nmi: BMC NMI |
|||||||
| 强制停止超时 | 15[秒] | forcestop/bmc/exec/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 停止结束等待时间 | 15[秒] | forcestop/bmc/wait/timeout | 5~999 | 在parameter中指定待时间[秒]。 | |||||||
| 停止请求后直到失效切换开始为止的宽限时间 | 15[秒] | forcestop/bmc/wait/fodelay | 5~999 | 在parameter中指定宽限时间[秒]。 | |||||||
| 抑制运行失败时的失效切换 | OFF | forcestop/bmc/suppression | 0, 1 | parameter中可以指定的值如下所示。 0: OFF 1: ON |
|||||||
| vCenter强制停止的属性 | |||||||||||
| 服务器列表签页 | |||||||||||
| 服务器 (添加, 删除, 编辑) | - | forcestop/vcenter/server@<服务器名>/use | 0, 1 | 在XPATH中指定服务器名。 parameter中可以指定的值如下所示。 0: 不使用 1: 使用 |
|||||||
| 虚拟机名输入 | |||||||||||
| 虚拟机名 | - | forcestop/vcenter/server@<服务器名>/parameters/vmname | 字符串 | 在XPATH中指定服务器名。 在parameter中指定虚拟机名。 |
|||||||
| 数据中心名 | - | forcestop/vcenter/server@<服务器名>/parameters/datacenter | 字符串 | 在XPATH中指定服务器名。 在parameter中指定数据中心名。 |
|||||||
| 强制停止签页 | |||||||||||
| 强制停止动作 | Power Off | forcestop/vcenter/parameters/action | 字符串 | parameter中可以指定的值如下所示。 poweroff: Power Off reset: Reset |
|||||||
| 强制停止超时 | 10[秒] | forcestop/vcenter/exec/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 停止结束等待时间 | 10[秒] | forcestop/vcenter/wait/timeout | 5~999 | 在parameter中指定待时间[秒]。 | |||||||
| 停止请求后直到失效切换开始为止的宽限时间 | 10[秒] | forcestop/vcenter/wait/fodelay | 5~999 | 在parameter中指定宽限时间[秒]。 | |||||||
| 抑制运行失败时的失效切换 | OFF | forcestop/vcenter/suppression | 0, 1 | parameter中可以指定的值如下所示。 0: OFF 1: ON |
|||||||
| vCenter签页 | |||||||||||
| 强制停止执行方法 | vSphere Automation API | forcestop/vcenter/parameters/method | 字符串 | parameter中可以指定的值如下所示。 restapi: vSphere Automation API vcli: VMware vSphere CLI |
|||||||
| VMware vSphere CLI 安装路径 | C:\Program Files
(x86)\VMware\VMware vSphere CLI |
forcestop/vcenter/server@<服务器名>/parameters/commandpath | 字符串 | 在XPATH中指定服务器名。 在parameter中指定VMware vSphere CLI安装路径。 |
|||||||
| 主机名 | - | forcestop/vcenter/parameters/ip | 字符串 | 在parameter中指定IP地址。 | |||||||
| 用户名 | - | forcestop/vcenter/parameters/user | 字符串 | 在parameter中指定用户名。 | |||||||
| 密码 | - | forcestop/vcenter/parameters/password | 字符串 | 在parameter中指定密码。 | |||||||
| Perl路径 | - | forcestop/vcenter/server@<服务器名>/parameters/perlpath | 字符串 | 在XPATH中指定服务器名。 在parameter中指定Perl路径。 |
|||||||
| AWS强制停止的属性 | |||||||||||
| 服务器列表签页 | |||||||||||
| 服务器 (添加, 删除, 编辑) | - | forcestop/aws/server@<服务器名>/use | 0, 1 | 在XPATH中指定服务器名。 parameter中可以指定的值如下所示。 0: 不使用 1: 使用 |
|||||||
| 输入实例 | |||||||||||
| 实例ID | - | forcestop/aws/server@<服务器名>/parameters/id | 字符串 | 在XPATH中指定服务器名。 在parameter中指定实例ID。 |
|||||||
| 强制停止签页 | |||||||||||
| 强制停止动作 | stop | forcestop/aws/parameters/action | 字符串 | parameter中可以指定的值如下所示。 stop: stop reboot: reboot |
|||||||
| 强制停止超时 | 10[秒] | forcestopaws/exec/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 停止结束等待时间 | 180[秒] | forcestopaws/wait/timeout | 5~999 | 在parameter中指定待时间[秒]。 | |||||||
| 停止请求后直到失效切换开始为止的宽限时间 | 120[秒] | forcestop/aws/wait/fodelay | 5~999 | 在parameter中指定宽限时间[秒]。 | |||||||
| 抑制运行失败时的失效切换 | OFF | forcestop/aws/suppression | 0, 1 | parameter中可以指定的值如下所示。 0: OFF 1: ON |
|||||||
| Azure强制停止的属性 | |||||||||||
| 服务器列表签页 | |||||||||||
| 服务器 (添加, 删除, 编辑) | - | forcestop/azure/server@<服务器名>/use | 0, 1 | 在XPATH中指定服务器名。 parameter中可以指定的值如下所示。 0: 不使用 1: 使用 |
|||||||
| 虚拟机名输入 | |||||||||||
| 虚拟机名 | - | forcestop/azure/server@<服务器名>/parameters/vmname | 字符串 | 在XPATH中指定服务器名。 在parameter中指定虚拟机名。 |
|||||||
| 强制停止签页 | |||||||||||
| 强制停止动作 | stop | forcestop/azure/parameters/action | 字符串 | parameter中可以指定的值如下所示。 stop: stop reboot: reboot |
|||||||
| 强制停止超时 | 10[秒] | forcestop/azure/exec/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 停止结束等待时间 | 180[秒] | forcestop/azure/wait/timeout | 5~999 | 在parameter中指定待时间[秒]。 | |||||||
| 停止请求后直到失效切换开始为止的宽限时间 | 120[秒] | forcestop/azure/wait/fodelay | 5~999 | 在parameter中指定宽限时间[秒]。 | |||||||
| 抑制运行失败时的失效切换 | OFF | forcestop/azure/suppression | 0, 1 | parameter中可以指定的值如下所示。 0: OFF 1: ON |
|||||||
| Azure签页 | |||||||||||
| 用户URI | - | forcestop/azure/server@服务器名>/parameters/useruri | 字符串 | 在parameter中指定用户URI。 | |||||||
| 租户ID | - | forcestop/azure/server@服务器名>/parameters/tenantid | 字符串 | 在parameter中指定租户ID。 | |||||||
| 服务主体的文件路径 | - | forcestop/azure/server@服务器名>/parameters/certfile | 字符串 | 在parameter中指定服务主体的文件路径。 | |||||||
| 资源组名 | - | forcestop/azure/server@服务器名>/parameters/rscgrp | 字符串 | 在parameter中指定资源组名。 | |||||||
| OCI强制停止的属性 | |||||||||||
| 服务器列表签页 | |||||||||||
| 服务器 (添加, 删除, 编辑) | - | forcestop/oci/server@<服务器名>/use | 0, 1 | 在XPATH中指定服务器名。 parameter中可以指定的值如下所示。 0: 不使用 1: 使用 |
|||||||
| 输入实例 | |||||||||||
| 实例ID | - | forcestop/oci/server@<服务器名>/parameters/id | 字符串 | 在XPATH中指定服务器名。 在parameter中指定实例ID。 |
|||||||
| 强制停止签页 | |||||||||||
| 强制停止动作 | stop | forcestop/oci/parameters/action | 字符串 | parameter中可以指定的值如下所示。 stop: stop reboot: reboot |
|||||||
| 强制停止超时 | 15[秒] | forcestop/oci/exec/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 停止结束等待时间 | 180[秒] | forcestop/oci/wait/timeout | 5~999 | 在parameter中指定待时间[秒]。 | |||||||
| 停止请求后直到失效切换开始为止的宽限时间 | 120[秒] | forcestop/oci/wait/fodelay | 5~999 | 在parameter中指定宽限时间[秒]。 | |||||||
| 抑制运行失败时的失效切换 | OFF | forcestop/oci/suppression | 0, 1 | parameter中可以指定的值如下所示。 0: OFF 1: ON |
|||||||
| 自定义强制停止的属性 | |||||||||||
| 服务器列表签页 | |||||||||||
| 服务器 (添加, 删除) | - | forcestop/custom/server@<服务器名>/use | 0, 1 | 在XPATH中指定服务器名。 parameter中可以指定的值如下所示。 0: 不使用 1: 使用 |
|||||||
| 强制停止签页 | |||||||||||
| 强制停止超时 | 10[秒] | forcestop/custom/exec/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 抑制运行失败时的失效切换 | OFF | forcestop/custom/suppression | 0, 1 | parameter中可以指定的值如下所示。 0: OFF 1: ON |
|||||||
| 脚本签页 | |||||||||||
| 选择用户应用程序时 输入应用程序路径(编辑) |
- | ||||||||||
| 选择用Builder创建的脚本时 添加,删除,编辑,替换 |
forcestop.bat | forcestop/custom/parameters/path | 字符串 | 在parameter中指定脚本(forcestop.bat)。 | |||||||
| 执行用户 | - | ||||||||||
| 超时标签页 | |||||||||||
| 服务启动延迟时间 | 0 [秒] | ||||||||||
| 网络初始化结束等待时间 | 3 [分] | ||||||||||
| 同步等待时间 | 5 [分] | ||||||||||
| 心跳线 间隔 | 3 [秒] | cluster/heartbeat/interval | 1000~99000 | 在parameter中指定间隔[毫秒]。 | |||||||
| 心跳线 超时 | 30 [秒] | cluster/heartbeat/timeout | 20000~99990000 | 在parameter中指定超时[毫秒]。 需要大于间隔的值。 |
|||||||
| 内部通信超时 | 180 [秒] | ||||||||||
| 端口号标签页 | |||||||||||
| 内部通信端口号 | 29001 | ||||||||||
| Information Base端口号 | 29008 | ||||||||||
| 数据传送端口号 | 29002 | ||||||||||
| WebManager HTTP端口号 | 29003 | ||||||||||
| API HTTP端口号 | 29009 | ||||||||||
| API内部通信端口号 | 29010 | ||||||||||
| 磁盘 Agent 端口号 | 29004 | ||||||||||
| 镜像驱动端口号 | 29005 | ||||||||||
| 内核模式心跳端口号 | 29106 | ||||||||||
| Alert 同步端口号 | 29003 | ||||||||||
| 复归标签页 | |||||||||||
| 集群服务的进程异常时动作 | 紧急关机 | pm/exec0/recover pm/exec1/recover pm/exec2/recover |
5, 6, 7 | 所有路径的parameter中指定相同的值。 在parameter中可以指定的值如下所示。 5:紧急关机 6:生成主动停止错误 7:HW重设 |
|||||||
| HA进程异常时动作 | |||||||||||
| 进程再启动次数 | 3 [次] | ||||||||||
| 重试次数超出设置值时的操作 | 无操作 | ||||||||||
| 发生组资源的启动/停止失控时的动作 | 紧急关机 | cluster/rsctimeout/rsctoaction | 0, 5, 6 | 在parameter中可以指定的值如下所示。 0:不进行任何操作(作为启动/停止异常来处理) 5:紧急关机 6:产生了故意停止错误 |
|||||||
| 随查出异常时OS的停止,控制最终动作 | |||||||||||
| 查出组资源启动异常时 | Off | ||||||||||
| 查出组资源停止异常时 | Off | ||||||||||
| 查出监视资源异常时 | Off | ||||||||||
| 查出双启动时的控制关机 | |||||||||||
| 查出双启动时不关闭的服务器组 | - | ||||||||||
| 查出双启动时不关闭的服务器 | - | ||||||||||
| Alert服务标签页 | - | ||||||||||
| 使Alert通报设置生效 | 不使用 | ||||||||||
| Alert发送地址的变更标签页 | |||||||||||
| 消息列表 (添加, 删除, 编辑) | - | ||||||||||
| 消息标签页 | |||||||||||
| 分类 | Process | ||||||||||
| 模块类型 | apisv | ||||||||||
| 事件 ID | - | ||||||||||
| Destination Alert Logs | 不使用 | ||||||||||
| Destination Alert Extension | 不使用 | ||||||||||
| Destination Mail Report | 不使用 | ||||||||||
| Destination SNMP Trap | 不使用 | ||||||||||
| Destination Message Topic | 不使用 | ||||||||||
| Destination Event Log(DisableOnly) | 不使用 | ||||||||||
| 命令(添加, 删除, 编辑) | - | ||||||||||
| 邮件地址 | 空白(功能关闭) | ||||||||||
| 主题 | - | ||||||||||
| 邮件发送方式 | SMTP | ||||||||||
| SMTP设置 | |||||||||||
| 动作标签页 | |||||||||||
| 邮件发送文书的字符编码 | - | ||||||||||
| 通信应答等候时间 | 30 [秒] | ||||||||||
| 主题的编码 | 不使用 | ||||||||||
| 优先级 | - | ||||||||||
| SMTP 服务器(添加, 删除) | - | ||||||||||
| 输入SMTP服务器 | |||||||||||
| SMTP服务器标签页 | |||||||||||
| SMTP 服务器 | - | ||||||||||
| 使用SSL | Off | ||||||||||
| 连接方式 | SMTPS | ||||||||||
| SMTP 端口号 | 25 | ||||||||||
| 发信人邮件地址 | - | ||||||||||
| SMTP认证有效 | 不使用 | ||||||||||
| 认证方式 | LOGIN | ||||||||||
| 用户名 | - | ||||||||||
| 密码 | - | ||||||||||
| 使用网络警告灯 | 不使用 | ||||||||||
| 动作标签页 | |||||||||||
| 发送地址一览 | - | ||||||||||
| 发送地址标签页 | |||||||||||
| 发送地址服务器 | - | ||||||||||
| SNMP 端口号 | 162 | ||||||||||
| SNMP版本 | v2c | ||||||||||
| SNMP 团体名 | public | ||||||||||
| WebManager标签页 | |||||||||||
| 使WebManager服务有效 | 使用 | ||||||||||
| 通信方式 | HTTP | ||||||||||
| 同时连接会话数 | 64 | ||||||||||
| 密码设置 | |||||||||||
| 集群密码方式 / OS认证方式 | 集群密码方式 | ||||||||||
| 集群密码方式 | |||||||||||
| 操作用密码 | - | ||||||||||
| 参照用密码 | - | ||||||||||
| OS认证方式 | |||||||||||
| 没有授权组 | - | ||||||||||
| (添加, 删除, 编辑) | |||||||||||
| 操作权 | On | ||||||||||
| 登录会话的有效时间 | 1440 [分] | ||||||||||
| 自动退出登录时间 | 60 [分] | ||||||||||
| 锁定阈值 | 0 [次] | ||||||||||
| 锁定期间 | 10 [分] | ||||||||||
| 通过客户端IP地址控制连接 | 不使用 | webmgr/security/clientlist/iprest | 0, 1 | 在parameter中可以指定的值如下所示。 0:不选中复选框 1:选中复选框 |
|||||||
| 客户端IP地址限制连接列表 | - | webmgr/security/clientlist/ip@<IP地址> | "" | 在XPATH中指定允许连接的客户端IP地址。 - IP地址时:10.0.0.21 - 网络地址时:10.0.1.0/24 在parameter中指定空白字符""。 |
|||||||
| (添加, 删除, 编辑) | |||||||||||
| 调整 | 使用 | ||||||||||
| Cluster WebUI操作日志 | |||||||||||
| 导出Cluster WebUI的操作日志 | 使用 | ||||||||||
| 日志输出路径 | - | ||||||||||
| 文件大小 | 1[MB] | ||||||||||
| 统合WebManager用的IP地址 | |||||||||||
| 优先级 | - | ||||||||||
| [种类]列(添加, 删除) | - | ||||||||||
| WebManager调整属性 | |||||||||||
| 动作标签页 | |||||||||||
| 客户端会话超时 | 30 [秒] | ||||||||||
| 画面数据更新间隔 | 90 [秒] | ||||||||||
| 镜像 Agent 超时 | 150 [秒] | ||||||||||
| 日志文件的有效期限 | 600 [秒] | ||||||||||
| 使用时钟信息显示功能 | On | ||||||||||
| API标签页 | |||||||||||
| 使API服务生效 | 不使用 | ||||||||||
| 通信方式 | HTTP | ||||||||||
| 通过客户端IP地址控制连接 | 不使用 | ||||||||||
| 没有客户端IP地址 | - | ||||||||||
| (添加, 删除, 编辑) | |||||||||||
| API调整属性 | |||||||||||
| 认证锁定的阈值 | 3 [次] | ||||||||||
| HTTP服务器启动重试次数 | 3 [次] | ||||||||||
| HTTP服务器启动间隔 | 5 [秒] | ||||||||||
| 加密标签页 | |||||||||||
| 证书文件 | - | ||||||||||
| 私钥文件 | - | ||||||||||
| SSL链接库 | - | ||||||||||
| Crypto链接库 | - | ||||||||||
| Alert日志标签页 | |||||||||||
| 使用Alert服务有效 | 使用 | ||||||||||
| 保存最大Alert记录数 | 10000 | ||||||||||
| Alert 同步 方法 | Unicast(固定) | ||||||||||
| Alert 同步 通信超时 | 30 [秒] | ||||||||||
| 延迟警告标签页 | |||||||||||
| 心跳延迟警告 | 使用80 [%] | ||||||||||
| 监视延迟警告 | 使用80 [%] | ||||||||||
| 磁盘标签页 | |||||||||||
| 切断磁盘连接失败时 重试间隔 | 3 [秒] | ||||||||||
| 切断磁盘连接失败时 重试次数 | 指定次数 | ||||||||||
| 切断磁盘连接失败时 次数 | 10 [次] | ||||||||||
| 切断磁盘连接失败时 超时 | 1800 [秒] | ||||||||||
| 切断磁盘连接失败时 最终动作 | 强制切断连接 | ||||||||||
| 镜像磁盘标签页 | |||||||||||
| 自动镜像初始构建 | 使用 | ||||||||||
| 自动镜像复归 | 使用 | ||||||||||
| 差分Bitmap大小 | 1 | ||||||||||
| 异步时历史记录区大小 | 100 | ||||||||||
| 给镜像中断状态下的失效切换留出一段指定的宽容时间 | 不使用 | ||||||||||
| 超时 | 30 [秒] | ||||||||||
| 切断磁盘连接失败时 重试间隔 | 3 [秒] | ||||||||||
| 切断磁盘连接失败时 重试次数 | 指定次数 | ||||||||||
| 切断磁盘连接失败时 次数 | 10 [次] | ||||||||||
| 切断磁盘连接失败时 超时 | 1800 [秒] | ||||||||||
| 切断磁盘连接失败时 最终动作 | 强制切断连接 | ||||||||||
| 账户标签页 | |||||||||||
| 账户列表(添加, 删除, 编辑) | - | ||||||||||
| RIP(互换)标签页 | |||||||||||
| 网络地址列表 | - | ||||||||||
| (添加, 删除, 编辑) | |||||||||||
| 子网掩码 | |||||||||||
| JVM监视标签页 | |||||||||||
| Java安装路径 | - | ||||||||||
| 最大Java内存大小 | 16[MB] | ||||||||||
| Java VM追加选项 | - | ||||||||||
| 命令超时 | 60[秒] | ||||||||||
| 日志输出设置 | |||||||||||
| 日志等级 | INFO | ||||||||||
| 保持的版本数 | 10[版本] | ||||||||||
| Rotation方式 | 文件大小 | ||||||||||
| Rotation方式文件大小 最大容量 | 3072[KB] | ||||||||||
| Rotation方式 时间 开始时刻 | 0:00 | ||||||||||
| Rotation方式 时间 间隔 | 24[小时] | ||||||||||
| 资源监测设置[共通] | |||||||||||
| 重试次数 | 10[次] | ||||||||||
| 异常判断限度值 | 5[次] | ||||||||||
| 间隔 储存器使用量・工作线程数 | 60[秒] | ||||||||||
| 间隔 Full GC发生次数・执行时间 | 120[秒] | ||||||||||
| 资源监测设置[WebLogic] | |||||||||||
| 重试次数 | 3[次] | ||||||||||
| 异常判断限度值 | 5[次] | ||||||||||
| 间隔要求数 | 60[秒] | ||||||||||
| 间隔平均值 | 300[秒] | ||||||||||
| 连接设置 | |||||||||||
| 管理端口号 | 25500 | ||||||||||
| 重试次数 | 3[次] | ||||||||||
| 到下一次连接前的等待时间 | 60[秒] | ||||||||||
| 云签页 | |||||||||||
| 启用Amazon SNS联动功能 | 不使用 | ||||||||||
| TopicArn | - | ||||||||||
| 启用Amazon CloudWatch联动功能 | 不使用 | ||||||||||
| Namespace | - | ||||||||||
| 发送指标的间隔 | 60 [秒] | ||||||||||
| 执行 AWS 相关功能时的环境变量 | |||||||||||
| 名称 | - | ||||||||||
| 值 | - | ||||||||||
| AWS CLI 命令行选项 | |||||||||||
| aws cloudwatch | - | ||||||||||
| aws ec2 | - | ||||||||||
| aws route53 | - | ||||||||||
| aws sns | - | ||||||||||
| 统计信息标签页 | |||||||||||
| 集群统计信息 心跳资源 | On | ||||||||||
| 集群统计信息 文件大小 | 50[MB] | ||||||||||
| 集群统计信息 组 | On | ||||||||||
| 集群统计信息 文件大小 | 1[MB] | ||||||||||
| 集群统计信息 组资源 | On | ||||||||||
| 集群统计信息 文件大小 | 1[MB] | ||||||||||
| 集群统计信息 监视资源 | On | ||||||||||
| 集群统计信息 文件大小 | 10[MB] | ||||||||||
| 镜像统计信息 收集统计信息 | On | ||||||||||
| 系统资源统计信息 收集统计信息 | Off | ||||||||||
| 扩展签页 | |||||||||||
| 最大再启动次数 | 3 [次] | ||||||||||
| 重置最大再启动次数的时间 | 60 [分] | ||||||||||
| 自动复归 | On | ||||||||||
| 失效切换次数计算单位 | 服务器 | ||||||||||
| 服务器间的失效切换时的宽限时间 | 0[秒] | ||||||||||
| 将 OS 停止操作更改为 OS 重启操作 | 不使用 | ||||||||||
| 禁用集群动作 | |||||||||||
| 组自动启动 | Off | ||||||||||
| 检测到组资源的启动异常时的复归动作 | Off | ||||||||||
| 检测到组资源的停止异常时的复归动作 | Off | ||||||||||
| 检测到监视资源的异常时的复归动作 | Off | ||||||||||
| 服务器宕机时的失效切换 | Off | ||||||||||
| Servers | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 服务器共通属性 | |||||||||||
| 主服务器 | |||||||||||
| 顺序 | 服务器添加顺序 | ||||||||||
| 服务器组标签页 | |||||||||||
| 添加 | 通过指定服务器组的设置顺序进行添加。 | ||||||||||
| 删除 | |||||||||||
| 重命名 | |||||||||||
| 服务器组的设置 | |||||||||||
| 名称 | failover | 通过指定顺序进行添加。 | |||||||||
| 注释 | - | ||||||||||
| 顺序 | [可以启动的服务器]添加顺序 | servergroup@<服务器组名>/policy@<服务器名>/order | 0, 1, 2, ... | 在XPATH中指定服务器组名和添加的服务器名。 在parameter中指定优先级。优先级最高为0,之后每递增1 。 |
|||||||
| 添加 | - | 通过指定顺序进行添加。 | |||||||||
| 删除 | - | ||||||||||
| 服务器 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 添加服务器 [1] | |||||||||||
| 删除服务器 [2] | |||||||||||
| 服务器属性 | |||||||||||
| 信息标签页 | |||||||||||
| 名称 [3] | - | ||||||||||
| 注释 | - | ||||||||||
| 警告灯标签页 | |||||||||||
| 序号(添加, 删除) | 添加I/F的顺序 | ||||||||||
| IP地址(编辑) | - | ||||||||||
| 警告灯的类型 | DN-1000S / DN-1000R / DN-1300GL | ||||||||||
| 用户名 | - | ||||||||||
| 密码 | - | ||||||||||
| 指定rsh命令执行文件路径 | Off | ||||||||||
| 文件路径 | - | ||||||||||
| 服务器开始运行时声音提示 | Off | ||||||||||
| 服务器终止运行时声音提示 | Off | ||||||||||
| 声音文件编号 | - | ||||||||||
| 声音文件编号 | - | ||||||||||
| HBA标签页 | |||||||||||
| 集群管理的HBA列表 | - | ||||||||||
| 不被集群系统管理的分区 | - | ||||||||||
| Proxy标签页 | |||||||||||
| Proxy方案 | None | ||||||||||
| Proxy服务器 | - | ||||||||||
| Proxy端口 | - | ||||||||||
| [1] 关于服务器的添加,删除的步骤请参考《维护指南》。 | |||||||||||
| [2] 关于服务器的添加,删除的步骤请参考《维护指南》。 | |||||||||||
| [3] 更改服务器主机名或IP地址时需要注意。关于主机名或IP地址的更改步骤,参考《维护指南》。 | |||||||||||
| Groups | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 组的共通属性 | |||||||||||
| 互斥标签页 | |||||||||||
| 互斥规则一览 | |||||||||||
| 添加 | - | ||||||||||
| 删除 | - | ||||||||||
| 名称変更 | - | ||||||||||
| 属性 | - | ||||||||||
| 互斥规则属性 | |||||||||||
| 注释 | - | ||||||||||
| 添加 | - | ||||||||||
| 删除 | - | ||||||||||
| 组 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 添加组 | |||||||||||
| 删除组 | - | ||||||||||
| 组属性 | |||||||||||
| 信息标签页 | |||||||||||
| 类型 | 失效切换 | ||||||||||
| 使用服务器组设定 | 不使用 | svgpolicy@<ID>/order svgpolicy@<ID>/svgname |
0, 1, 2, ... 字符串 |
在XPATH中指定ID。在parameter中指定与指定的优先级相同的数值。 在parameter中指定优先级。优先级最高为0,之后每次递增1。 在XPATH中指定ID。指定和优先级相同的数值。 在parameter中指定添加的服务器组名。 |
|||||||
| 名称 | - | ||||||||||
| 注释 | - | ||||||||||
| 启动的服务器标签页 | |||||||||||
| 在所有的服务器上进行失效切换 | 使用 | 通过添加服务器将其关闭。 | |||||||||
| 服务(追加,削除) | - | policy@<服务器名>/order | 0, 1, 2, ... | 在XPATH中指定可启动的服务器名。 在parameter中指定优先级。优先级最高为0,之后每递增1。 使用服务器组设置时在服务器组中添加已添加的服务器。 |
|||||||
| 属性标签页 | |||||||||||
| 组启动属性 | 自动启动 | start | 0, 1 | 在parameter中可以指定的值如下所示。 0:手动启动 1:自动启动 |
|||||||
| 进行双重启动检查 | Off | ||||||||||
| 超时 | 300[秒] | ||||||||||
| 失效切换属性 | 自动失效切换 | failover | 0, 1 | 在parameter中可以指定的值如下所示。 0:手动失效切换 1:自动失效切换 |
|||||||
| 自动失效切换 | 遵从自动失效切换的设置 | failover | 1, 100, 200, 201 | 在parameter中可以指定的值如下所示。 1:遵循可用服务器的设定 100:动态确定失效切换目标 200:优先使用服务器组中的失效切换方案 201:在服务器组之间,只启用手动失效切换 |
|||||||
| 优先服务器组内的失效切换策略 | 不使用 | autonomic/functype/srvgrp/use | 0, 1 | 在parameter中可以指定的值如下所示。 0:Off 1:On |
|||||||
| 进行智能失效切换 | 不使用 | ||||||||||
| 服务器组间仅手动进行失效切换有效 | 不使用 | failover | 200, 201 | 请参考自动失效切换的说明。 | |||||||
| 从失效切换目标中排除在指定的监视资源中检测到异常的服务器 | 不使用 | ||||||||||
| 在所有服务器中都检测到异常时,忽略异常并进行失效切换 | 不使用 | ||||||||||
| 故障恢复属性 | 手动故障恢复 | failback | 0, 1 | 在parameter中可以指定的值如下所示。 0:手动故障恢复 1:自动故障恢复 |
|||||||
| 用于排除失效切换目标服务器的监视资源 | IP监视 | ||||||||||
| NIC Link Up/Down监视 | |||||||||||
| 逻辑服务标签页 | |||||||||||
| 逻辑服务名称 (添加, 删除) | - | ||||||||||
| 启动等待标签页 | |||||||||||
| 对象组 | - | ||||||||||
| 对象组的启动等待时间 | 1800[秒] | ||||||||||
| 对象组的属性 | |||||||||||
| 仅在同一服务器内启动时等待 | 不使用 | ||||||||||
| 停止等待标签页 | |||||||||||
| 对象组 | - | ||||||||||
| 对象组的停止等待时间 | 1800[秒] | ||||||||||
| 集群停止时等待目标组的停止 | On | ||||||||||
| 服务器停止时等待目标组的停止 | Off | ||||||||||
| 组停止时等待依赖组的停止 | Off | ||||||||||
| 组资源共通 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 添加组资源 | |||||||||||
| 删除组资源 | - | ||||||||||
| 组资源的共通属性 | |||||||||||
| 信息标签页 | |||||||||||
| 名称 | 每个资源的固定值 | ||||||||||
| 注释 | - | ||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| 依赖资源 (添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 在启动,停止前后运行脚本 | |||||||||||
| 在启动资源前运行脚本 | Off | ||||||||||
| 在停止资源前运行脚本 | Off | ||||||||||
| 在启动资源后运行脚本 | Off | ||||||||||
| 在停止资源后运行脚本 | Off | ||||||||||
| 脚本的编辑 | |||||||||||
| 用户应用程序 | |||||||||||
| 用Builder创建的脚本 | |||||||||||
| 文件 | rscextent.bat | ||||||||||
| 超时 | 30[秒] | ||||||||||
| 执行用户 | - | ||||||||||
| 重启动次数 | 0 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试。在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 脚本的编辑 | |||||||||||
| 用户应用程序 | |||||||||||
| 用Cluster WebUIr创建的脚本 | |||||||||||
| 文件 | preactaction.bat | ||||||||||
| 超时 | 5 [秒] | ||||||||||
| 执行用户 | - | ||||||||||
| 停止重试次数 | 0 [次] | ||||||||||
| 最终动作 | 停止集群服务并关闭操作系统. | deact/retry | 0~99 | 在parameter中指定查出停止异常时进行停止重试的次数。设置为0则不进行停止重试。 | |||||||
| 在最终动作前运行脚本 | 不使用 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 脚本的编辑 | |||||||||||
| 用户应用程序 | |||||||||||
| 用Builder创建的脚本 | |||||||||||
| 文件 | preactaction.bat | ||||||||||
| 超时 | 5 [秒] | ||||||||||
| 执行用户 | - | ||||||||||
| 应用程序资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 应用程序资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| ・浮动IP资源 | |||||||||||
| ・虚拟IP资源 | |||||||||||
| ・虚拟主机名资源 | |||||||||||
| ・磁盘资源 | |||||||||||
| ・共享型磁盘镜像资源 | |||||||||||
| ・镜像磁盘资源 | |||||||||||
| ・注册表同步资源 | |||||||||||
| ・CIFS 资源 | |||||||||||
| ・AWS Elastic IP资源 | |||||||||||
| ・AWS 虚拟IP资源 | |||||||||||
| ・AWS 辅助IP资源 | |||||||||||
| ・AWS DNS资源 | |||||||||||
| ・Azure探头端口资源 | |||||||||||
| ・Azure DNS资源 | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 0[次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定动作服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 对应服务器数 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 最终动作前运行脚本 | 关闭 | ||||||||||
| 停止重试次数 | 0[次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 集群服务停止后,关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 最终动作前运行脚本 | 关闭 | ||||||||||
| 详细标签页 | |||||||||||
| 常驻类型 | 常驻 | ||||||||||
| 起始路径 | - | ||||||||||
| 结束路径 | - | ||||||||||
| 应用程序资源的调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 开始 同步,异步 | 同步 | ||||||||||
| 开始 超时 | 1800 [秒] | ||||||||||
| 开始 正常的返回值 | - | ||||||||||
| 结束 同步,异步 | 同步 | ||||||||||
| 结束 超时 | 1800 [秒] | ||||||||||
| 结束 正常的返回值 | - | ||||||||||
| 对象虚拟主机资源名 | - | ||||||||||
| 允许桌面对话 | 不使用 | ||||||||||
| 结束时,应强制终止应用程序 | 不使用 | ||||||||||
| 执行用户 | 个别设定 | ||||||||||
| 启动标签页 | |||||||||||
| 当前目录 | - | ||||||||||
| 选项参数 | - | ||||||||||
| 窗口大小 | 隐藏 | ||||||||||
| 执行用户 域 | - | ||||||||||
| 执行用户 账户 | - | ||||||||||
| 执行用户 口令 | - | ||||||||||
| 从命令窗口执行 | 不使用 | ||||||||||
| 停止标签页 | |||||||||||
| 当前目录 | - | ||||||||||
| 选项参数 | - | ||||||||||
| 窗口大小 | 隐藏 | ||||||||||
| 执行用户 域 | - | ||||||||||
| 执行用户 账户 | - | ||||||||||
| 执行用户 口令 | - | ||||||||||
| 从命令窗口执行 | 不使用 | ||||||||||
| 浮动IP资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 浮动IP资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 (没有默认值) | ||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| IP 地址 | - | parameters/ip | 字符串 | 在parameter中指定使用中的浮动IP地址。 | |||||||
| 浮动IP资源的调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 执行 ping | 使用 | ||||||||||
| ping 间隔 | 1 [秒] | ||||||||||
| ping 超时 | 1000 [毫秒] | ||||||||||
| ping 重试次数 | 5 [次] | ||||||||||
| ping FIP强制启动 | 不使用 | ||||||||||
| 判定NIC Link Down为异常 | 不使用 | ||||||||||
| 镜像磁盘资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 镜像磁盘资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 (没有默认值) | ||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 3 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 镜像磁盘号. | 1 | parameters/nmpindex | 1~22 | 在parameter中指定分配镜像分区的镜像磁盘号。此编号不能和其他的共享型镜像磁盘资源或镜像磁盘资源相同。 | |||||||
| 数据分区驱动器盘符 | - | parameters/volumemountpoint | 字符串 | 在parameter中指定数据分区的驱动器盘符 (A:\~Z:\)。 | |||||||
| 集群分区驱动器盘符 | - | parameters/cpvolumemountpoint | 字符串 | 在parameter中指定集群分区的驱动器盘符 (A:\~Z:\)。 | |||||||
| 集群分区的偏移索引 | 0 | parameters/cpvolumeoffsetindex | 0~7 | 在parameter中指定集群分区内使用区域的索引编号。使用多个共享型镜像磁盘时,为了不使集群分区内使用的区域重叠,请给每个共享型镜像磁盘分配不同的索引编号。 | |||||||
| 选择镜像磁盘连接 | |||||||||||
| 镜像磁盘连接标签页 | |||||||||||
| 顺序 | 镜像磁盘连接顺序 | parameters/netdev@<ID>/priority | 0, 1, 2, ... | 在XPATH中指定ID。指定和顺序相同的数值。 在parameter指定顺序。顺序最高为0,之后每递增1。 |
|||||||
| MDC(添加,删除) | 在集群中登录的镜像磁盘连接的上位2个 | parameters/netdev@<ID>/device parameters/netdev@<ID>/mdcname |
0~16 字符串 |
在XPATH中指定ID。指定和顺序相同的数值。 在parameter中指定设备ID。设备ID指定为MDC设置时指定的ID。 在XPATH中指定ID。指定和顺序相同的数值。 在parameter中指定添加的MDC名。 |
|||||||
| 可以启动组的服务器 (添加, 删除) | - | 通过指定数据分区和集群分区进行添加。 | |||||||||
| 数据分区 (编辑) | - | server@<服务器名>/parameters/volumeguid | 字符串 | 在XPATH中指定服务器名。 在parameter中指定数据分区中使用的分区GUID。 使用clpdiskctrl命令取得GUID 。 |
|||||||
| 集群分区 (编辑) | - | server@<服务器名>/parameters/cpvolumeguid | 字符串 | 在XPATH中指定服务器名。 在parameter中指定在集群分区中使用的分区GUID。 使用clpdiskctrl命令取得GUID。 |
|||||||
| 镜像磁盘资源的调整属性 | |||||||||||
| 镜像标签页 | |||||||||||
| 镜像磁盘初次复归 | 使用 | ||||||||||
| 镜像连接超时 | 20 [秒] | ||||||||||
| 请求队列最大数 | 2048 [KB] | ||||||||||
| 模式 | 同步 | ||||||||||
| 内核队列大小 | 2048 [KB] | ||||||||||
| 应用程序队列大小 | 2048 [KB] | ||||||||||
| 线程超时 | 30 [秒] | ||||||||||
| 镜像连接宽带限制 | 无限制 | ||||||||||
| 历史文件路径 | - | ||||||||||
| 历史文件的大小限制 | 无限制 | ||||||||||
| 压缩数据 | 不使用 | ||||||||||
| 复归时压缩数据 | 不使用 | ||||||||||
| 注册表同步资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 注册表同步资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 | ||||||||||
| ・CIFS资源 | |||||||||||
| ・磁盘资源 | |||||||||||
| ・共享型磁盘镜像资源 | |||||||||||
| ・浮动IP资源 | |||||||||||
| ・镜像磁盘资源 | |||||||||||
| ・虚拟IP资源 | |||||||||||
| ・虚拟主机名资源 | |||||||||||
| ・AWS Elastic IP资源 | |||||||||||
| ・AWS 虚拟IP资源 | |||||||||||
| ・AWS 辅助IP资源 | |||||||||||
| ・AWS DNS资源 | |||||||||||
| ・Azure探头端口资源 | |||||||||||
| ・Azure DNS资源 | |||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 0 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 注册表列表(添加,删除,编辑) | 1 | ||||||||||
| 注册表同步资源的调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 发送间隔 | 1[秒] | ||||||||||
| 脚本资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 脚本资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 | ||||||||||
| ・CIFS资源 | |||||||||||
| ・磁盘资源 | |||||||||||
| ・共享型磁盘镜像资源 | |||||||||||
| ・浮动IP资源 | |||||||||||
| ・镜像磁盘资源 | |||||||||||
| ・虚拟IP资源 | |||||||||||
| ・虚拟主机名资源 | |||||||||||
| ・AWS Elastic IP资源 | |||||||||||
| ・AWS 虚拟IP资源 | |||||||||||
| ・AWS 辅助IP资源 | |||||||||||
| ・AWS DNS资源 | |||||||||||
| ・Azure探头端口资源 | |||||||||||
| ・Azure DNS资源 | |||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 0 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 脚本内容(添加,删除,编辑,替换) | - | ||||||||||
| 脚本资源的调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 开始 同步,异步 | 同步 | ||||||||||
| 开始 超时 | 1800 [秒] | parameters/acttimeout | 1~9999 | 在parameter中指定执行脚本时等待结束的场合 ([同步])的超时。只在选择[同步]时可以输入。 | |||||||
| 开始 正常的返回值 | 忽略返回值 | ||||||||||
| 开始 在备用服务器上执行 | Off | ||||||||||
| 开始 超时(在备用服务器) | 10[秒] | ||||||||||
| 执行复归处理 | Off | ||||||||||
| 结束 同步,异步 | 同步 | ||||||||||
| 结束 超时 | 1800[秒] | parameters/deacttimeout | 1~9999 | 在parameter中指定执行脚本时等待结束时([同步])的超时。只在选择[同步]时可以输入。 | |||||||
| 结束 正常的返回值 | 忽略返回值 | ||||||||||
| 结束 在备用服务器上执行 | Off | ||||||||||
| 结束 超时(在备用服务器) | 10[秒] | ||||||||||
| 对象VCOM资源名 | - | ||||||||||
| 允许桌面对话 | 不使用 | ||||||||||
| 执行用户 | - | ||||||||||
| 磁盘资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 磁盘资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 (没有默认设置) | ||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 3 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定的服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源). | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务器并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 驱动器盘符 | - | parameters/volumemountpoint | 字符串 | 在parameter中指定使用中的磁盘驱动器盘符(A:\~Z:\)。 | |||||||
| 可启动组的服务器 (添加, 删除) | - | ||||||||||
| GUID (编辑) | - | server@<服务器名>/parameters/volumeguid | 字符串 | 在XPATH中指定服务器名。 在parameter中指定使用中的分区GUID。 使用clpdiskctrl命令取得GUID。 |
|||||||
| 服务资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 服务资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 | ||||||||||
| ・CIFS 资源 | |||||||||||
| ・磁盘资源 | |||||||||||
| ・共享型磁盘镜像资源 | |||||||||||
| ・浮动IP资源 | |||||||||||
| ・镜像磁盘资源 | |||||||||||
| ・注册表同步资源 | |||||||||||
| ・虚拟IP资源 | |||||||||||
| ・虚拟主机名资源 | |||||||||||
| ・AWS Elastic IP资源 | |||||||||||
| ・AWS 虚拟IP资源 | |||||||||||
| ・AWS 辅助IP资源 | |||||||||||
| ・AWS DNS资源 | |||||||||||
| ・Azure探头端口资源 | |||||||||||
| ・Azure DNS资源 | |||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 1 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 服务名 | - | parameters/name | 字符串 | 在parameter中指定在服务资源中使用的服务名或者服务显示名。 | |||||||
| 服务资源的调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 开始 同步 不同步 | 同步 | ||||||||||
| 开始 超时 | 1800 [秒] | ||||||||||
| 结束 同步 不同步 | 同步 | ||||||||||
| 结束 超时 | 1800 [秒] | ||||||||||
| 对象VCOM资源名 | - | ||||||||||
| 服务标签页 | |||||||||||
| 开始参数 | - | ||||||||||
| 在服务已经启动的场合下,不产生错误 | 不使用 | ||||||||||
| 服务开始后的等待 | 0 [秒] | ||||||||||
| 服务停止后的等待 | 0 [秒] | ||||||||||
| 虚拟计算机名资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 虚拟计算机名资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 | ||||||||||
| ・浮动IP资源 | |||||||||||
| ・虚拟IP资源 | |||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 虚拟主机名 | - | ||||||||||
| 对象FIP资源名 | - | ||||||||||
| 虚拟主机名资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 动态登录至DNS | 不使用 | ||||||||||
| 关联IP地址 | FIP | ||||||||||
| 编辑 | - | ||||||||||
| 虚拟IP资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 虚拟IP资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 (没有默认值) | ||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| IP 地址 | - | ||||||||||
| Net Mask | - | ||||||||||
| 目的地IP地址 | - | ||||||||||
| 源IP地址 | - | ||||||||||
| 发送时间间隔 | 30 [秒] | ||||||||||
| 使用路由协议 | RIPver1 | ||||||||||
| 虚拟IP资源的调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 执行 ping | 使用 | ||||||||||
| 间隔 | 1 [秒] | ||||||||||
| 超时 | 1000 [毫秒] | ||||||||||
| 重试次数 | 5 [次] | ||||||||||
| VIP强制启动 | 不使用 | ||||||||||
| 判定NIC Link Down为异常 | 不使用 | ||||||||||
| RIP标签页 | |||||||||||
| 度量值 | 3 | ||||||||||
| 使用端口号 | 520 | ||||||||||
| RIPng标签页 | |||||||||||
| 度量值 | 1 | ||||||||||
| 使用端口号 | 521 | ||||||||||
| CIFS资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| CIFS资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有依赖关系 | 使用 | ||||||||||
| ・磁盘资源 | |||||||||||
| ・镜像磁盘资源 | |||||||||||
| ・共享型磁盘镜像资源 | |||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 0 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 执行驱动器共享设置的自动保存 | Off | ||||||||||
| 对象驱动器 | - | ||||||||||
| 共享设置文件 | - | ||||||||||
| 还原共享设置时的失败判定为启动异常 | 不使用 | ||||||||||
| 共享名 | - | ||||||||||
| 文件夹 | - | ||||||||||
| 注释 | - | ||||||||||
| 文件夹已经共享时不作为启动异常 | 使用 | ||||||||||
| CIFS资源的调整属性 | |||||||||||
| 缓存标签页 | |||||||||||
| 允许缓存 | 使用 | ||||||||||
| 缓冲存储器 | 自动缓存 | ||||||||||
| 用户标签页 | |||||||||||
| 限制用户数 | 无限制 | ||||||||||
| 最大 | - | ||||||||||
| 允许访问 | Everyone 只读 | ||||||||||
| 共享型镜像磁盘监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 共享型镜像磁盘资源属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 开启(没有依赖资源) | ||||||||||
| 依赖资源(添加, 删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 重启动次数 | 3 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 停止集群服务并关闭操作系统. | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 共享型镜像硬盘号 | 2 | parameters/hdindex | 1~22 | 在parameter中指定分配共享型镜像磁盘资源的磁盘编号。此编号不能和其他的共享型镜像磁盘资源或镜像磁盘资源相同。 | |||||||
| 数据分区驱动器盘符 | - | parameters/volumemountpoint | 字符串 | 在parameter中指定数据分区的驱动器盘符(A:\~Z:\)。 | |||||||
| 集群分区驱动器盘符 | - | parameters/cpvolumemountpoint | 字符串 | 在parameter中指定集群分区的驱动器盘符(A:\~Z:\)。 | |||||||
| 集群分区的偏移索引 | 0 | parameters/cpvolumeoffsetindex | 0~7 | 在parameter中指定集群分区中使用领域的索引编号。使用多个共享型镜像磁盘时,为了不使集群分区内使用的区域重叠,请给每个共享型镜像磁盘分配不同的索引编号。 | |||||||
| 选择镜像磁盘连接 | |||||||||||
| 镜像磁盘连接标签页 | |||||||||||
| 顺序 | 镜像磁盘连接顺序 | parameters/netdev@<ID>/priority | 0, 1, 2, ... | 在XPATH中指定ID。指定和顺序相同的数值。 在parameter中指定顺序。优先级最高为0,之后每递增1。 |
|||||||
| MDC(添加,删除) | 在集群中登录的镜像磁盘连接的上位2个 | parameters/netdev@<ID>/device parameters/netdev@<ID>/mdcname |
0~16 字符串 |
在XPATH中指定ID。指定和顺序相同的数值。 在parameter中指定设备ID。设备ID指定为MDC设置时已指定的ID。 在XPATH中指定ID。指定和顺序相同的数值。 在parameter中指定添加的MDC名。 |
|||||||
| 共享型镜像磁盘资源调整属性 | |||||||||||
| 镜像标签页 | |||||||||||
| 镜像磁盘初次复归 | 开启 | ||||||||||
| 镜像连接超时 | 20 [秒] | ||||||||||
| 请求队列最大数 | 2048 [KB] | ||||||||||
| 模式 | 同步 | ||||||||||
| 内核队列的大小 | 2048 [KB] | ||||||||||
| 应用程序队列的大小 | 2048 [KB] | ||||||||||
| 线程超时 | 30 [秒] | ||||||||||
| 镜像连接的带宽限制 | 无限制 | ||||||||||
| 历史文件路径 | - | ||||||||||
| 历史文件的大小限制 | 无限制 | ||||||||||
| 数据压缩 | 不压缩 | ||||||||||
| 虚拟机资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 虚拟机资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 开启 | ||||||||||
| ・共享型镜像磁盘资源 | |||||||||||
| ・磁盘资源 | |||||||||||
| ・镜像磁盘资源 | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无操作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 集群服务停止和OS关机 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 虚拟机类型 | Hyper-V | ||||||||||
| 虚拟机名 | - | ||||||||||
| 虚拟机配置文件路径 | - | ||||||||||
| 虚拟机资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 请求超时 | 180 [秒] | ||||||||||
| 虚拟机启动等待时间 | 0 [秒] | ||||||||||
| 虚拟机停止等待时间 | 60 [秒] | ||||||||||
| 动态DNS资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 动态DNS资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| ・浮动IP资源 | |||||||||||
| ・虚拟IP资源 | |||||||||||
| ・AWS Elastic IP资源 | |||||||||||
| ・AWS虚拟IP资源 | |||||||||||
| ・AWS 辅助IP资源 | |||||||||||
| ・Azure探头端口资源 | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 0[次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 指定次数0[次] | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 查出启动异常时的最终动作 | 无操作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 查出停止异常时的最终动作 | 集群服务停止和OS关机 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 虚拟主机名 | - | ||||||||||
| IP地址 | - | ||||||||||
| DDNS服务器 | - | ||||||||||
| 端口号 | 53 | ||||||||||
| 缓存的TTL | 0 [秒] | ||||||||||
| 定期执行动态更新 | 使用 | ||||||||||
| 更新间隔 | 60 [分] | ||||||||||
| 删除已注册的IP地址 | 使用 | ||||||||||
| Kerberos认证 | 不使用 | ||||||||||
| AWS Elastic IP资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS Elastic IP资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| EIP ALLOCATION ID | - | ||||||||||
| ENI ID | - | ||||||||||
| AWS Elastic IP资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| AWS CLI 超时 | 100 [秒] | ||||||||||
| AWS 虚拟IP资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS 虚拟IP资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| IP地址 | - | parameters/ip | 字符串 | 在parameter中指定使用中的IP地址。作为VIP地址,需要指定不属于VPC的CIDR的IP地址。 | |||||||
| VPC ID | - | parameters/vpcid 进行服务器个别设置时 server@<服务器名>/parameters/vpcid |
字符串 | 在parameter中指定服务器所属的VPC ID。 进行服务器个别设置时在XPATH中指定服务器名。对于共通XPATH请指定任意服务器的VPCID。 |
|||||||
| ENI ID | - | parameters/eniid 进行服务器个别设置时 server@<服务器名>/parameters/eniid |
字符串 | 在parameter中指定作为VIP的路径目标的ENI ID。 进行服务器个别设置时在XPATH中指定服务器名。对于共通XPATH请指定任意服务器的ENI ID。 |
|||||||
| AWS 虚拟IP资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 启动超时 | 300 [秒] | ||||||||||
| 停止超时 | 60 [秒] | ||||||||||
| AWS 辅助IP资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS 辅助IP资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| IP地址 | - | ||||||||||
| ENI ID | - | ||||||||||
| AWS 辅助IP资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 启动超时 | 180 [秒] | ||||||||||
| 停止超时 | 180 [秒] | ||||||||||
| AWS DNS 资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS DNS资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 宿主区 ID | - | parameters/hostedzoneid | 字符串 | 在parameter中指定Amazon Route 53 的 Hosted Zone ID 。 | |||||||
| 资源记录集名 | - | parameters/recordset | 字符串 | 在parameter中指定DNS A 记录名。请在记录名的末尾添加一个点(.)。如果[资源记录集名]中包含转义码,则为监视异常。请设置不含转义码的[资源记录集名]。请以小写字符指定[资源记录集名]。 | |||||||
| IP地址 | - | parameters/ip 进行服务器个别设置时 server@<服务器名>/parameters/ip |
字符串 | 在parameter中指定与虚拟主机名(DNS 名)对应的IP地址(IPv4)。 进行服务器个别设置时在XPATH中指定服务器名。对于共通XPATH请指定任意服务器的IP地址。 |
|||||||
| TTL | 300[秒] | ||||||||||
| 停止时删除资源记录集 | 不使用 | ||||||||||
| Azure DNS资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| AWS CLI 超时 | 100 [秒] | ||||||||||
| Azure 探头端口资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Azure 探头端口资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| Probe端口 | - | ||||||||||
| Azure 探头端口资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| Probe等待的超时 | 30 [秒] | ||||||||||
| Azure DNS 资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Azure DNS资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 记录集名 | - | ||||||||||
| 区名 | - | ||||||||||
| IP地址 | - | ||||||||||
| TTL | 300[秒] | ||||||||||
| 资源组名 | - | ||||||||||
| 用户URI | - | ||||||||||
| 租户ID | - | ||||||||||
| 服务主体的文件路径 | - | ||||||||||
| Azure CLI文件路径 | - | ||||||||||
| 停止时删除记录集 | 使用 | ||||||||||
| Azure DNS资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| AWS CLI 超时 | 100 [秒] | ||||||||||
| Google Cloud 虚拟 IP 资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Google Cloud 虚拟 IP 资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 端口号 | - | ||||||||||
| Google Cloud 虚拟 IP 资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 健康检查超时 | 30 [秒] | ||||||||||
| Oracle Cloud 虚拟 IP 资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Oracle Cloud 虚拟 IP 资源的属性 | |||||||||||
| 依赖关系标签页 | |||||||||||
| 遵循原有的依赖关系 | 使用 | ||||||||||
| (无原有的依赖关系) | |||||||||||
| 依赖资源(添加,删除) | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 启动化重试次数 | 5 [次] | act/retry | 0~99 | 在parameter中指定查出启动异常时进行启动重试的次数。设置为0则不重试启动。 | |||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | act/fo2 | 0~99 | 在parameter中指定查出启动异常时进行启动重试在[启动重试阈值]中已指定次数都失败后进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | act/fo | 0~99 | 在失效切换阈值中指定次数时,在parameter中指定进行失效切换的次数。设置为0则不进行失效切换。 | |||||||
| 检测到组资源的启动异常时的最终动作 | 无任何动作(不启动下一个资源) | act/action | 0~6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (启动下一个资源) 1:无任何动作 (不启动下一个资源) 2:组停止 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 停止重试次数 | 0 [次] | deact/retry | 0~99 | 在parameter中指定查出停止异常时停止重试次数。设置为0则不进行停止重试。 | |||||||
| 检测到组资源的停止出异常时的最终动作 | 停止集群服务并关闭操作系统 | deact/action | 0, 1, 4, 5, 6 | 在parameter中可以指定的值如下所示。 0:无任何动作 (停止下一个资源) 1:无任何动作 (不停止下一个资源) 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 |
|||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 详细标签页 | |||||||||||
| 端口号 | - | ||||||||||
| Oracle Cloud 虚拟 IP 资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 健康检查超时 | 30 [秒] | ||||||||||
| 监视资源 共通 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 添加监视资源 | - | ||||||||||
| 删除监视资源 | - | ||||||||||
| 监视资源属性 | |||||||||||
| 信息标签页 | |||||||||||
| 名称 | - | ||||||||||
| 注释 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 脚本的编辑 | |||||||||||
| 用户应用程序 | - | ||||||||||
| 用Cluster WebUIr创建的脚本 | - | ||||||||||
| 超时 | 5 [秒] | ||||||||||
| 执行用户 | - | ||||||||||
| 应用程序监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 应用程序监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 3 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时机 | 启动时(固定) | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定成为对象的应用程序资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 最大重启动次数 | 3 [次] (如果复归对象不是集群) | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 最终动作 | 无操作 | ||||||||||
| 磁盘RW监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 磁盘RW监视资源属性 | |||||||||||
| 监视(固有)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 300 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 0 [次] | ||||||||||
| 开始监视的等待时间 | 0 [秒] | ||||||||||
| 监视时间 | 指定资源被启动后开始监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 文件名 | - | parameters/file | 字符串 | 在parameter中指定要访问的文件名。 | |||||||
| I/O 大小 | 2000000 [字节] | ||||||||||
| 查出Stall异常时的动作 | 生成主动停止错误 | ||||||||||
| 磁盘已满时的处理 | 执行复归操作 | ||||||||||
| 使Write Through方式有效 | 无效 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 最大重启动次数 | 0 [次] (如果复归对象不是集群) | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 浮动IP监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 浮动IP监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的浮动IP资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视NIC Link Up/Down | 关闭 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] (如果复归对象不是集群) | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| IP监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| IP监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| IP地址列表 (添加, 删除, 编辑) | - | parameters/list@<ID>/ip | 字符串 | 在XPATH中指定ID。ID从1开始指定,之后每递增1。 在parameter中指定进行监视的IP地址。请输入可通过公网LAN进行通信的实际IP地址。 |
|||||||
| Ping超时 | 5000 [毫秒] | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最多次数 | 3 [次] (如果复归对象不是集群) | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 镜像磁盘监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 镜像磁盘监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 999 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 10 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 镜像磁盘资源 | - | parameters/object | 字符串 | 在parameter中指定进行监视的镜像磁盘资源名。 | |||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类rsc。 在parameter中指定复归对象的镜像磁盘资源名。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | ||||||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | ||||||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | ||||||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | ||||||||||
| NIC Link Up/Down监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| NIC Link Up/Down监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 个别设置服务器 (添加, 删除, 编辑) | - | server@<服务器名>/parameters/object | 字符串 | 在XPATH中指定服务器名。 在parameter中指定进行监视的NIC的IP地址。 |
|||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 多目标监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 多目标监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视资源列表 (添加, 删除) | - | ||||||||||
| 多目标监视资源调整属性 | |||||||||||
| 参数标签页 | |||||||||||
| 异常次数 | 与成员总数相同 | ||||||||||
| 指定数字 | 64 | ||||||||||
| 警告次数 | 不使用 | ||||||||||
| 指定数字 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 注册表同步监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 注册表同步监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 磁盘TUR监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 磁盘TUR监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 300 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 磁盘资源 | - | parameters/object | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 服务监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 服务监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 3 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 启动时 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的服务资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 服务名 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 虚拟计算机名监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 虚拟计算机名监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的虚拟计算机名资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 集群服务停止和OS关机 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 虚拟IP监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 虚拟IP监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的虚拟IP资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| CIFS 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| CIFS监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的 CIFS 资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 检查帐户 | 无操作 | ||||||||||
| 路径 | - | ||||||||||
| 检查 | 读取 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 共享型镜像磁盘监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 共享型镜像磁盘资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 999 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 10 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 共享型镜像磁盘资源 | - | parameters/object | 字符串 | 在parameter中指定共享型镜像磁盘资源名。 | |||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类rsc。 在parameter中指定复归对象的共享型镜像磁盘资源名。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | ||||||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | ||||||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | ||||||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | ||||||||||
| 共享型镜像磁盘TUR监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 共享型镜像磁盘TUR监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 300 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 共享型镜像磁盘资源 | parameters/object | 字符串 | 在parameter中指定作为监视对象的磁盘资源名。 | ||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类rsc。 在parameter中指定复归对象的共享型镜像磁盘资源名。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | ||||||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | ||||||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | ||||||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | ||||||||||
| 自定义监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 自定义监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 3 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视脚本路径种别 | 用Builder创建的脚本 | parameters/default | 0, 1 | 在parameter中可以指定的值如下所示。 0:用户应用程序 1:用Builder创建的脚本 |
|||||||
| 文件 | genw.bat | parameters/path | 字符串 | 在parameter中通过服务器上的本地磁盘的绝对路径指定执行的脚本(可执行的批处理文件或者执行文件)。 只是,脚本后不能指定参数。 |
|||||||
| 监视方式 | 同步 | ||||||||||
| 正常的返回值 | 0 | ||||||||||
| 警告的返回值 | - | ||||||||||
| 结束时,应强制终止应用程序 | 不使用 | ||||||||||
| 当停止集群时,等待启动时监控的停止 | Off | ||||||||||
| 执行用户 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 消息接收监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 消息接收监视源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 10 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 重试次数 | 0 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时机 | 不间断监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 对象资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可启动的服务器(添加,删除) | - | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 分类 | - | ||||||||||
| 关键字 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 对复归对象进行失效切换 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| 对其他服务器组进行失效切换 | OFF | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 在复归动作前运行脚本 | 不使用 | ||||||||||
| VM 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 虚拟机监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时机 | 启动时(固定) | ||||||||||
| 对象资源 | - | target | 字符串 | 在parameter中指定作为对象的虚拟机资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 虚拟机资源 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| DB2 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| DB2监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视级别 | 级别2(在update/select中的监视) | ||||||||||
| 数据库名 | - | ||||||||||
| 接口名 | DB2 | ||||||||||
| 用户名 | db2admin | ||||||||||
| 口令 | - | ||||||||||
| 监视表名 | DB2WATCH | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| FTP 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| FTP监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 3 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| IP地址 | 127.0.0.1 | ||||||||||
| 端口号 | 21 | ||||||||||
| 用户名 | - | ||||||||||
| 口令 | - | ||||||||||
| 协议 | FTP | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| HTTP 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| HTTP监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 3 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 连接目的端 | 127.0.0.1 | ||||||||||
| 端口号 | 80 | ||||||||||
| 监视URI | - | ||||||||||
| 协议 | HTTP | ||||||||||
| 请求类型 | HEAD | ||||||||||
| 认证方式 | 无需认证 | ||||||||||
| 用户名 | - | ||||||||||
| 密码 | - | ||||||||||
| 客户端验证 | 不使用 | ||||||||||
| 客户端证书主体名称 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| IMAP4 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| IMAP4监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 3 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| IP地址 | 127.0.0.1 | ||||||||||
| 端口号 | 143 | ||||||||||
| 用户名 | - | ||||||||||
| 口令 | - | ||||||||||
| 认证方式 | AUTHENTICATELOGIN | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| ODBC 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| ODBC监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视级别 | 级别2(在update/select中的监视) | ||||||||||
| 数据源名 | - | ||||||||||
| 用户名 | - | ||||||||||
| 口令 | - | ||||||||||
| 监视表名 | ODBCWATCH | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Oracle 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Oracle监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时获取监视进程的dump文件 | 不获取 | ||||||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视方式 | 监听器和实例都监视 | ||||||||||
| 监视级别 | 级别2(在update/select中的监视) | ||||||||||
| 连接字符串 | - | agentparam/dbname | 字符串 | 在parameter中指定数据库的连接字符串。请务必设置。 监视方式为"只监视实例"时,设置ORACLE_SID。 |
|||||||
| 用户名 | Sys | agentparam/username | 字符串 | 在parameter中指定登录到数据库时的用户名。 | |||||||
| 口令 | - | agentparam/password | 字符串 | 在parameter中指定登录到数据库时的密码。 | |||||||
| 操作系统认证 | Off | agentparam/os | 0, 1 | 指定登录Oracle时的认证方式。需要与Oracle的设置保持一致。 在parameter中可以指定的值如下所示。 0:复选框没有选中(默认值) 1:复选框被选中 |
|||||||
| SYSDBA/DEFAULT | SYSDBA | agentparam/certificate | 0, 1 | 指定登录Oracle时的用户权限。需要与指定的用户名的权限保持一致。 在parameter中可以指定的值如下所示。 0:SYSDBA 1:DEFAULT |
|||||||
| 监视表名 | ORAWATCH | agentparam/tablename | 字符串 | 在parameter中指定在数据库上创建的监视用表的名称。请务必设置。因为该表需要创建和删除,请注意不要与运行时用到的表格重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。 | |||||||
| ORACLE_HOME | - | agentparam/oraclehome | 字符串 | 在parameter中指定在ORACLE_HOME中设置的路径名。需要设置为[/]开头的名字。当监视方式为"只监视监听器","只监视实例"时使用。 | |||||||
| 字符编码 | (Following the setting of the application) | ||||||||||
| 发生错误时收集应用程序的详细信息 | 不使用 | ||||||||||
| 收集超时 | 600 [秒] | ||||||||||
| Oracle初始化或关机中出现错误 | 关闭 | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| POP3 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| POP3监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 3 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| IP 地址 | 127.0.0.1 | ||||||||||
| 端口号 | 110 | ||||||||||
| 用户名 | - | ||||||||||
| 口令 | - | ||||||||||
| 认证方式 | APOP | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| PostgreSQL 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| PostgreSQL 监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视级别 | 级别2(在update/select中的监视) | ||||||||||
| 数据库名 | - | ||||||||||
| IP地址 | 127.0.0.1 | ||||||||||
| 端口号 | 5432 | ||||||||||
| 用户名 | postgres | ||||||||||
| 口令 | - | ||||||||||
| 监视表名 | PSQLWATCH | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| SMTP 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| SMTP监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 3 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| IP地址 | 127.0.0.1 | ||||||||||
| 端口号 | 25 | ||||||||||
| 用户名 | - | ||||||||||
| 口令 | - | ||||||||||
| 认证方式 | CRAM-MD5 | ||||||||||
| 邮件地址 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| SQL Server监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| SQL Server监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视级别 | 级别2(在update/select中的监视) | ||||||||||
| 数据库名 | - | agentparam/dbname | 字符串 | 在parameter中指定受监视的数据库名。请务必进行设置。 | |||||||
| 接口名 | MSSQLSERVER | agentparam/instance | 字符串 | 在parameter中指定受监视的数据库接口名。请务必设置。 | |||||||
| 用户名 | SA | agentparam/username | 字符串 | 在parameter中指定登录到数据库时的用户名请务必设置。 在通过虚拟机资源进行控制的虚拟机的客户机OS上对运行的SQL Server数据库进行监视时,也需要以[服务器名\实例名]的格式指定虚拟机的服务器名。 |
|||||||
| 口令 | - | agentparam/password | 字符串 | 在parameter中指定登录到数据库时的密码。 | |||||||
| 监视表名 | SQLWATCH | agentparam/tablename | 字符串 | 在parameter中指定在数据库上创建的监视用表的名称。请务必设置。因为该表需要创建和删除,请注意不要与运行时用到的表格重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。 | |||||||
| ODBC驱动名 | ODBC Driver 13 for SQL Server | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Tuxedo 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Tuxedo监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 应用服务器名 | BBL | ||||||||||
| TUXCONFIG文件 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| WebSphere 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| WebSphere监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 应用服务器名 | server1 | ||||||||||
| 配置文件名 | Default | ||||||||||
| 用户名 | - | ||||||||||
| 口令 | - | ||||||||||
| 安装路径 | C:\Program Files\IBM\WebSphere\AppServer | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| WebLogic 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| WebLogic监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 2 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| IP地址 | 127.0.0.1 | ||||||||||
| 端口号 | 7002 | ||||||||||
| 监视方式 | RESTful API | ||||||||||
| 协议 | HTTP | ||||||||||
| 用户名 | weblogic | ||||||||||
| 密码 | - | ||||||||||
| 添加命令选项 | -Dwlst.offline.log=disable | ||||||||||
| -Duser.language=en_US | |||||||||||
| 账户隐藏 | 关闭 | ||||||||||
| 开 配置文件 | - | ||||||||||
| 开 注册文件 | - | ||||||||||
| 关闭 用户名 | Weblogic | ||||||||||
| 关闭 口令 | - | ||||||||||
| 认证方式 | DemoTrust | ||||||||||
| 密匙文件 | - | ||||||||||
| 安装路径 | C:\Oracle\Middleware\Oracle_Home\wlserver | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| WebOTX 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| WebOTX监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 连接目的 | localhost | ||||||||||
| 端口号 | 6212 | ||||||||||
| 用户名 | - | ||||||||||
| 密码 | - | ||||||||||
| 安装路径 | - | ||||||||||
| 复归操作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 停止集群服务并关闭操作系统. | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| JVM 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| JVM监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60[秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180[秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 0[次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0[秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视 | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视目标 | - | ||||||||||
| JVM种类 | - | ||||||||||
| 识别名 | - | ||||||||||
| 连接端口号 | - | ||||||||||
| 进程名 | - | ||||||||||
| 用户名 | - | ||||||||||
| 密码 | - | ||||||||||
| 命令 | - | ||||||||||
| 内存标签页([JVM类型]选择[Oracle Java]时) | |||||||||||
| 监视堆使用率 | On | ||||||||||
| 区域整体 | 80[%] | ||||||||||
| Eden Space | 100[%] | ||||||||||
| Survivor Space | 100[%] | ||||||||||
| Tenured Gen | 80[%] | ||||||||||
| 监视非堆使用率 | On | ||||||||||
| 区域整体 | 80[%] | ||||||||||
| Code Cache | 100[%] | ||||||||||
| Perm Gen | 80[%] | ||||||||||
| Perm Gen[shared-ro] | 80[%] | ||||||||||
| Perm Gen[shared-rw] | 80[%] | ||||||||||
| 命令 | - | ||||||||||
| 内存标签页([JVM类型]选择[Oracle Java(usage monitoring]时) | |||||||||||
| 监视堆内存使用量 | Off | ||||||||||
| 领域整体 | 0[兆字节] | ||||||||||
| Eden Space | 0[兆字节] | ||||||||||
| Survivor Space | 0[兆字节] | ||||||||||
| Tenured Gen(Old Gen) | 0[兆字节] | ||||||||||
| 监视非堆内存使用量 | Off | ||||||||||
| 领域整体 | 0[兆字节] | ||||||||||
| Code Cache | 0[兆字节] | ||||||||||
| CodeHeap non-nmethods | 0[兆字节] | ||||||||||
| CodeHeap profiled | 0[兆字节] | ||||||||||
| CodeHeap non- profiled | 0[兆字节] | ||||||||||
| Compressed Class Space | 0[兆字节] | ||||||||||
| Metaspace | 0[兆字节] | ||||||||||
| 命令 | - | ||||||||||
| 线程标签页 | |||||||||||
| 监视工作中的线程数 | 65535[线程] | ||||||||||
| 命令 | - | ||||||||||
| GC标签页 | |||||||||||
| 监视Full GC执行时间 | 65535[毫秒] | ||||||||||
| 监视Full GC发生次数 | 1[次] | ||||||||||
| 命令 | - | ||||||||||
| WebLogic标签页 | |||||||||||
| 监视工作管理器的要求 | Off | ||||||||||
| 监视目标工作管理器 | - | ||||||||||
| 要求数 | 65535 | ||||||||||
| 平均值 | 65535 | ||||||||||
| 上次测量后的增加率 | 80[%] | ||||||||||
| 监视线程Poor的要求 | Off | ||||||||||
| 待机要求 要求数 | 65535 | ||||||||||
| 待机要求 平均値 | 65535 | ||||||||||
| 待机要求 上次测量后的增加率 | 80[%] | ||||||||||
| 执行要求 要求数 | 65535 | ||||||||||
| 执行要求 平均值 | 65535 | ||||||||||
| 执行要求 上次测量后的增加率 | 80[%] | ||||||||||
| 命令 | - | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换前执行迁移 | Off | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 最终动作前执行脚本 | Off | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 系统监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 系统监视资源属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30[秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60[秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 0[次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0[秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有的服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| CPU使用率的监视 | On | ||||||||||
| CPU使用率 | 90[%] | ||||||||||
| 持续时间 | 60[分] | ||||||||||
| 总内存使用量的监视 | On | ||||||||||
| 总内存使用量 | 90[%] | ||||||||||
| 持续时间 | 60[分] | ||||||||||
| 总虚拟内存使用量的监视 | On | ||||||||||
| 总虚拟内存使用量 | 90[%] | ||||||||||
| 持续时间 | 60[分] | ||||||||||
| 逻辑驱动 | |||||||||||
| 使用率 | On | ||||||||||
| 警报等级 | 90[%] | ||||||||||
| 通知等级 | 80[%] | ||||||||||
| 持续时间 | 1440[分] | ||||||||||
| 剩余容量 | On | ||||||||||
| 警报等级 | 500[MB] | ||||||||||
| 通知等级 | 1000[MB] | ||||||||||
| 持续时间 | 1440[分] | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不执行 | ||||||||||
| 重启动最大次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不执行 | ||||||||||
| 失效切换前执行迁移 | Off | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 进程资源监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 进程资源监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30[秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60[秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 重试次数 | 0[次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 监视开始等待时间 | 0[秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 | ||||||||||
| 对象资源 | - | ||||||||||
| 異异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 进程名 | - | ||||||||||
| CPU使用率的监视 | On | ||||||||||
| 使用率 | 90[%] | ||||||||||
| 持续时间 | 1440[分] | ||||||||||
| 内存使用量的监视 | On | ||||||||||
| 第一次监视时的增加率 | 10[%] | ||||||||||
| 最大更新次数 | 1440[次] | ||||||||||
| 打开文件数的监视(最大值) | Off | ||||||||||
| 更新次数 | 1440[次] | ||||||||||
| 线程数的监视 | On | ||||||||||
| 持续时间 | 1440[分] | ||||||||||
| 同一名称进程的监视 | Off | ||||||||||
| 个数 | 100[个] | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 执行复归脚本的次数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | Off | ||||||||||
| 最大重启动次数 | 0[次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | Off | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 最大失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 最终动作前执行脚本 | Off | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 用户空间监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 用户空间监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 30 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 300 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有的服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 使用心跳的间隔/超时 | 使用 | ||||||||||
| 监视方法 | keepalive | ||||||||||
| 超时发生时的动作 | 发生故意停止错误 | parameters/stallaction | 0, 1, 2 | 在parameter中可以指定的值如下所示。 0:无操作 1:HW重置 2:发生停止错误 |
|||||||
| 创建虚拟线程 | 使用 | ||||||||||
| 动态DNS监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 动态DNS监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时机 | 启动时 (固定) | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的动态DNS资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有的服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 执行域名解析检查 | 使用 | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不使用 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不使用 | ||||||||||
| 失效切换前执行迁移 | 不使用 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 最终动作前执行脚本 | 不使用 | ||||||||||
| 复归动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| 进程名监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| 进程名监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 5[秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 60 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | On | ||||||||||
| 超时发生时不做回复动作 | On | ||||||||||
| 重试次数 | 0 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 3 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时机 | 启动时 (固定) | polling/timing | 0, 1 | 在parameter中可以指定的值如下所示。 0:不间断监视 1:指定资源被启动后开始监视 |
|||||||
| 目标资源 | - | target | 字符串 | 如需进行启动时监视,在parameter中指定作为对象的资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有的服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 进程名 | - | parameters/processname | 字符串 | 在parameter中指定受监视的进程名。请务必进行设置。 此外,可使用下述的3种模式指定进程名的通配符号。其它模式不可指定。 【前方一致】 <包含进程名中的字符串>* 【后方一致】 *<包含进程名中的字符串> 【部分一致】 *<包含进程名中的字符串>* |
|||||||
| 进程数量下线 | 1 [个] | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本执行次数 | 0 [次] | ||||||||||
| 重启动前执行脚本 | 不使用 | ||||||||||
| 重启动最大次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 执行失效切换前执行脚本 | 不使用 | ||||||||||
| 失效切换前执行迁移 | 不使用 | ||||||||||
| 失效切换目标服务器 | 稳定运行服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 最终动作前执行脚本 | Off | ||||||||||
| 复归动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| AWS Elastic IP监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS Elastic IP监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视(固定) | ||||||||||
| 目标资源 | awseip | target | 字符串 | 在parameter中指定作为对象的 AWS Elastic IP 资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| AWS CLI命令未得到应答时的动作 | 不运行复归动作(不显示警告) | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| AWS虚拟IP监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS 虚拟IP监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视(固定) | ||||||||||
| 目标资源 | awsvip | target | 字符串 | 在parameter中指定作为对象的 AWS虚拟IP资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| AWS CLI命令未得到应答时的动作 | 不运行复归动作(不显示警告) | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| AWS辅助IP监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS 辅助IP监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 120 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 3 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视(固定) | ||||||||||
| 目标资源 | awssip | target | 字符串 | 在parameter中指定作为对象的 AWS虚拟IP资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| AWS CLI命令未得到应答时的动作 | 不运行复归动作(不显示警告) | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| AWS AZ监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS AZ监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 (固定) | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 可用性区域 | - | ||||||||||
| AWS CLI命令未得到应答时的动作 | 不运行复归动作(不显示警告) | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| AWS DNS监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| AWS DNS监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 (固定) | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的 AWS DNS资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 监视资源记录集 | 使用 | ||||||||||
| AWS CLI命令未得到应答时的动作 | 不运行复归动作(不显示警告) | ||||||||||
| 执行域名解析检查 | 使用 | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Azure 探头端口监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Azure 探头端口监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视(固定) | ||||||||||
| 目标资源 | azurepp | target | 字符串 | 在parameter中指定作为对象的 Azure 探头端口资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| Probe端口等待超时时动作 | 不运行复归动作(显示警告) | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Azure负载均衡器监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Azure负载均衡器监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 (固定) | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 目标资源 | - | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 仅执行最终运行 | ||||||||||
| 复归对象 | LocalServer | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | - | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 0 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 指定次数0 [次] | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Azure DNS监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Azure DNS监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 (固定) | ||||||||||
| 目标资源 | - | target | 字符串 | 在parameter中指定作为对象的 Azure DNS资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 执行域名解析检查 | 使用 | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 仅执行最终运行 | ||||||||||
| 复归对象 | LocalServer | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | - | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Google Cloud 虚拟 IP 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Google Cloud 虚拟 IP 监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视(固定) | ||||||||||
| 目标资源 | gcvip | target | 字符串 | 在parameter中指定作为对象的 Google Cloud 虚拟 IP 资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 健康检查超时时动作 | 不运行复归动作(不显示警告) | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Google Cloud 负载均衡监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Google Cloud 负载均衡监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 (固定) | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 目标资源 | - | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 仅执行最终运行 | ||||||||||
| 复归对象 | LocalServer | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | - | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 0 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 指定次数0 [次] | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Oracle Cloud 虚拟 IP 监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Oracle Cloud 虚拟 IP 监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 指定资源被启动后开始监视(固定) | ||||||||||
| 目标资源 | ocvip | target | 字符串 | 在parameter中指定作为对象的 Oracle Cloud 虚拟 IP 资源名。 | |||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 健康检查超时时动作 | 不运行复归动作(不显示警告) | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 自定义设置 | ||||||||||
| 复归对象 | - | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 3 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | 状态稳定服务器 | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 1 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 与服务器数目相同 | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
| Oracle Cloud 负载均衡监视资源 | |||||||||||
| 参数 | 默认值 | XPATH | parameter 設定値 |
説明 | |||||||
| Oracle Cloud 负载均衡监视资源的属性 | |||||||||||
| 监视(共通)标签页 | |||||||||||
| 间隔 | 60 [秒] | polling/interval | 1~999 | 在parameter中指定确认监视对象状态的间隔[秒]。 | |||||||
| 超时 | 180 [秒] | polling/timeout | 5~999 | 在parameter中指定超时[秒]。 | |||||||
| 超时发生时不重试 | 使用 | ||||||||||
| 超时发生时不做回复动作 | 使用 | ||||||||||
| 重试次数 | 1 [次] | polling/reconfirmation | 0~999 | 在parameter中指定重试次数。 若指定为0,则在最初发现异常时即判断为异常。 |
|||||||
| 开始监视的等待时间 | 0 [秒] | firstmonwait | 0~9999 | 在parameter中指定开始监视为止的等待时间[秒]。 | |||||||
| 监视时间 | 不间断监视 (固定) | ||||||||||
| 目标资源 | - | ||||||||||
| 异常检出服务器 | |||||||||||
| 异常检出服务器 | 所有服务器 | ||||||||||
| 可以启动组的服务器 (添加, 删除) | - | ||||||||||
| 发送监视处理时间指标 | 不使用 | ||||||||||
| 监视(固有)标签页 | |||||||||||
| 目标资源 | - | ||||||||||
| 复归动作标签页 | |||||||||||
| 复归动作 | 仅执行最终运行 | ||||||||||
| 复归对象 | LocalServer | relation/type relation/name |
字符串 | 在parameter中指定复归对象的种类。 rsc:资源 grp:组 cls:LocalServer 在parameter中指定复归对象的名称。rsc时指定资源名。 grp时指定组名。设置[ALL Groups]时指定空白字符""。 cls时指定LocalServer。 |
|||||||
| 复归脚本运行回数 | 0 [次] | ||||||||||
| 重启动前运行脚本 | 不使用 | ||||||||||
| 重启动次数 | 0 [次] | emergency/threshold/restart | 0~99 | 在parameter中指定查出异常时进行重启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。 | |||||||
| 失效切换执行前运行脚本 | 不使用 | ||||||||||
| 失效切换目标服务器 | - | ||||||||||
| [失效切换次数计算单位]选择[服务器]时 | |||||||||||
| 失效切换次数 | 0 [次] | emergency/threshold/fo2 | 0~99 | 在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| [失效切换次数计算单位]选择[集群]时 | |||||||||||
| 最大失效切换次数 | 指定次数0 [次] | emergency/threshold/fo | 0~99 | 指定最大失效切换次数时在parameter中指定进行失效切换的次数。若设置为0,则不执行失效切换。若设置为0,则不执行失效切换。当选择组或组资源或All Groups为恢复对象时,可进行设置。 | |||||||
| 在最终动作前运行脚本 | 不使用 | ||||||||||
| 最终动作 | 无操作 | emergency/action | 0, 2, 3, 4, 5, 6, 16 | 在parameter中可以指定的值如下所示。 0:无操作 2:停止组 3:停止集群服务 4:停止集群服务并关闭操作系统 5:停止集群服务并操作系统重启 6:生成主动停止错误 16:停止资源 |
|||||||
9.31. 加密(clpencrypt命令)¶
加密字符串。
-
命令行 clpencrypt password
-
说明 加密集群配置信息中密码等必要的值。
-
参数 -
password¶ 指定加密的字符串。
-
-
返回值 0
正常结束
0以外
异常结束
-
执行示例 # clpencrypt password
-
显示示例 20220001111abaabdbb35c04
-
错误消息 消息
原因/处理方法
Invalid parameter.
参数有误。请确认参数的数值和形式是否有误。
9.32. 操作驱动的GUID和HBA信息(clpdiskctrl命令)¶
设置,获取驱动的GUID和HBA。
-
命令行 - clpdiskctrl {set|--set} filter driveclpdiskctrl {get|--get} guid driveclpdiskctrl {get|--get} hba drive
-
说明 在集群配置信息中获取必需的驱动GUID和HBA信息。
-
选项 -
{set|--set}filter drive¶ - 设置驱动指定的HBA的过滤器。drive中指定驱动字符。
-
{get|--get}<param>¶ param
- guid drive
- 指定驱动获取GUID。drive中指定驱动字符。
- hba drive
- 指定驱动获取HBA信息。drive中指定驱动字符。
-
-
返回值 0
正常结束
0以外
异常结束
-
注意事项 请以拥有Administrator权限的用户身份执行该命令。
-
执行示例 设置HBA的过滤器
# clpdiskctrl.exe set filter R
-
执行示例 获取GUID
# clpdiskctrl.exe get guid R
-
显示示例 019056a3-a7ad-4de3-9ed8-d5e752e501ea
-
执行示例 获取HBA信息
# clpdiskctrl.exe get hba R
-
显示示例 4 ROOT\ISCSIPRT 0000
-
错误消息 消息
原因/处理方法
Log in as administrator.
请由具有Administrator权限的用户执行。
Invalid option.
请指定正确的选项。
Invalid parameter.
参数有误。请确认参数的数值和形式是否有误。
Drive not found.
没有找到指定盘符。请确认盘符指定是否有误。
Device no info.
设备信息获取失败。请确认磁盘装置是否正常运行。
Specify the data drive.
请指定除Windows的系统驱动(一般为C: )以外的驱动。
Failed to set filter.
设置过滤器失败。
Internal error. Check if memory or OS resources are sufficient.
考虑到内存不足或者OS的资源不足。请确认。
9.33. 添加防火墙的规则(clpfwctrl命令)¶
添加、删除在EXPRESSCLUSTER中使用的服务器的防火墙的"入站规则"。
-
命令行 - clpfwctrl --add [--profile public | private | domain]clpfwctrl --removeclpfwctrl --help
-
说明 注解
该命令请在启用服务器的防火墙时执行。
注解
该命令在单个服务器上添加、删除防火墙的"入站规则"。需要在想添加、删除的所有服务器上执行。
注解
请在安装 EXPRESSCLUSTER 后和在反映配置信息后立即执行该命令。
为了能访问在 EXPRESSCLUSTER使用的端口号,添加防火墙的"入站规则"。另外,删除已添加的"入站规则"。将 EXPRESSCLUSTER 使用的规则添加到具有以下组名和名称的"入站规则"中。相同组名已经添加时,删除一次后,再进行添加。请不要更改组名。组名
EXPRESSCLUSTER
名称
EXPRESSCLUSTER (TCP-In)
EXPRESSCLUSTER (UDP-In)
EXPRESSCLUSTER (ICMPv4-In)
EXPRESSCLUSTER (ICMPv6-In)
-
选项 -
--add[--profile public | private | domain]¶ 添加防火墙的"入站规则"。如果指定profile名,则添加已指定的profile。 profile名未指定时,指定"全部"。
-
--remove¶ 删除已添加的防火墙的"入站规则"。
-
--help¶ 显示Usage。
-
-
返回值 0
成功
0 以外
异常
-
注意事项 - 请具有Administrator权限的用户执行该命令。该命令不进行"入站规则"的添加。如有需要请另行添加。如果只注册了一次JVM监视资源,则该命令必须允许JVM监视资源的管理端口号。
-
执行示例 在profile中指定"全部"后添加"入站规则"时
# clpfwctrl.bat --add Command succeeded.
-
执行示例 在profile中指定"域"和"个人"后添加"入站规则"时
# clpfwctrl.bat --profile domain private Command succeeded.
-
执行示例 删除已添加的"入站规则"时
# clpfwctrl.bat --remove Command succeeded.
-
错误消息 消息
原因/处理方法
Log in as Administrator.
请由具有Administrator权限的用户执行。
Invalid option.
请指定正确的选项。
Log directory is not found.
可能没有正确安装,或者没有执行权限。
Failed to register rule(CLUSTERPRO). Invalid port.
配置信息中设置了不正确的端口号。请确认配置信息。
Unsupported environment.
是不支持的OS环境。
Could not read xmlpath. Check if xmlpath exists on the specified path. (%1)
请确认xml路径是否在配置信息中存在。%1:xml路径Could not opened the configuration file. Check if the configuration file exists on the specified path. (%1)
请确认配置信息是否存在。%1:xml路径Could not read type. Check if type exists on the policy file. (%1)
请确认政策(policy)文件是否存在。%1:xml路径not exist xmlpath. (%1)
请确认xml路径是否在配置信息中存在。%1:xml路径Failed to obtain properties. (%1)
请确认xml路径是否在配置信息中存在。%1:xml路径Not exist java install path. (%1)
请确认Java安装路径是否存在。%1 :Java安装路径Internal error. Check if memory or OS resources are sufficient. (%1)
可能内存不足或者OS的资源不足。请确认。%1:xml路径