1. 前言¶
1.1. 读者对象及用途¶
《EXPRESSCLUSTER® X SingleServerSafe设置指南》的读者对象为导入系统的系统工程师以及导入系统后进行维护和操作的系统管理员,说明EXPRESSCLUSTER X SingleServerSafe构建工作的步骤。
1.2. 本手册的构成¶
2. 关于EXPRESSCLUSTER X SingleServerSafe: 对EXPRESSCLUSTER X SingleServerSafe的产品概要进行说明。
3. 创建配置信息: 使用样本的配置示例,对Cluster WebUI / WebManager的启动方法,及创建配置信息的步骤进行说明。
5. 组资源的详细信息: 对在EXPRESSCLUSTER X SingleServerSafe 中作为控制应用程序的单位的组资源的详细信息进行说明。
6. 监视资源的详细信息: 对在EXPRESSCLUSTER X SingleServerSafe中作为执行监视的单位的监视资源的详细信息进行说明。
8. 其他设置的详细信息: 对其他EXPRESSCLUSTER X SingleServerSafe的设置项目的详细信息进行说明。
1.3. 本手册记述的术语¶
本手册说明的EXPRESSCLUSTER X SingleServerSafe为集群链接软件。
为提高与集群软件EXPRESSCLUSTER X 的操作性等方面的兼容性,本手册所介绍的EXPRESSCLUSTERX SingleServerSafe使用了相同的画面及命令。因此,采用了部分集群相关的术语。
请参照下列术语的说明来阅读本手册。
- 集群,集群系统
导入了EXPRESSCLUSTER X SingleServerSafe 的单一服务器的系统
- 集群关闭/重启
导入了EXPRESSCLUSTER X SingleServerSafe 的系统的关闭/重启
- 集群资源
EXPRESSCLUSTER X SingleServerSafe所使用的资源
- 集群对象
EXPRESSCLUSTER X SingleServerSafe所使用的各种资源的对象
- 失效切换组
汇集了EXPRESSCLUSTER X SingleServerSafe所使用的组资源(应用程序,服务等)的组
1.4. EXPRESSCLUSTER X SingleServerSafe 手册体系¶
EXPRESSCLUSTER X SingleServerSafe的手册分为以下 3 类。各指南的标题和用途如下所示。
《 EXPRESSCLUSTER X SingleServerSafe 安装指南》(Install Guide)
本手册的读者对象为导入使用EXPRESSCLUSTER X SingleServerSafe的系统的系统工程师,对EXPRESSCLUSTER X SingleServerSafe的安装步骤进行说明。
《EXPRESSCLUSTER X SingleServerSafe 设置指南》(Configration Guide)
本手册的读者对象为导入使用EXPRESSCLUSTER X SingleServerSafe的集群系统的系统工程师以及导入系统后进行维护和操作的系统管理员,对EXPRESSCLUSTER X SingleServerSafe的构建工作进行说明。
《 EXPRESSCLUSTER X SingleServerSafe 操作指南》(Operation Guide)
本手册的读者对象为使用EXPRESSCLUSTER X SingleServerSafe导入后的进行维护和操作的系统管理员,对EXPRESSCLUSTER X SingleServerSafe的操作方法进行说明。
1.5. 本手册的标记规则¶
在本手册中,需要注意的事项,重要的事项以及相关信息等用如下方法标记。
注解
表示虽然比较重要,但是并不会引起数据损失或系统以及机器损伤的信息。
重要
表示为避免数据损失和系统,机器损坏所必需的信息。
参见
表示参考信息的位置
另外,在手册中使用以下标记法。
标记 |
使用方法 |
例 |
|---|---|---|
[ ] 方括号
|
在命令名的前后,
显示在画面中的字句 (对话框,菜单等) 的前后。
|
点击[开始]。
[属性]对话框
|
命令行中的[ ] 方括号 |
表示括号内的值可以不予指定(可省)。 |
|
# |
表示Linux用户正以root身份登录的提示符。 |
|
等宽字体 |
路径名,命令行,系统输出(消息,提示符等),目录,文件名,函数,参数。 |
|
粗体
|
表示用户在命令提示符后实际输入的值。
|
输入以下内容。
clpcl -s -a
|
斜体 |
用户将其替换为有效值后输入的项目。
|
rpm -i clusterprosss-<版本号>-<发布号>.x86_64.rpm |
 在本手册的图中,为了表示EXPRESSCLUSTER X SingleServerSafe,使用该图标。
在本手册的图中,为了表示EXPRESSCLUSTER X SingleServerSafe,使用该图标。
2. 关于EXPRESSCLUSTER X SingleServerSafe¶
本章中对EXPRESSCLUSTER X SingleServerSafe的功能概要,及可以监视的故障进行了说明。
本章中介绍的内容如下。
2.1. 何谓EXPRESSCLUSTER X SingleServerSafe¶
EXPRESSCLUSTER X SingleServerSafe为可安装到服务器上,来查出服务器上的应用程序及硬件的故障,并可在发生故障时,通过自动重新启动应用程序及服务器,来提高服务器的可用性的产品。
在EXPRESSCLUSTER X SingleServerSafe中,通过指定希望查出异常的应用程序及硬件,自动查出故障,通过自动重新启动应用程序及服务器,进行故障的恢复动作。
注解
上述等硬件的物理性故障,经常在重启服务器后仍无法修复。为防备硬件的物理性故障,请考虑进行硬件的双重化配置或导入集群链接软件等。
2.2. EXPRESSCLUSTER X SingleServerSafe的故障监视原理¶
通过EXPRESSCLUSTER X SingleServerSafe可以进行各种监视,从而能够迅速准确查出故障。下面详细介绍各种监视。
应用程序的生存状态监视
能够使用启动资源(称为应用程序资源,服务资源)启动应用程序,通过监视资源(称为应用程序监视资源,服务监视资源)定期监视进程的生存。在由于业务应用程序异常退出造成业务中断时有效。
注解
如果EXPRESSCLUSTER X SingleServerSafe直接启动的应用程序为启动,结束监视对象的常驻进程的应用程序,则无法查出常驻进程的异常。
注解
无法查出应用程序内部状态的异常(应用程序的停止,结果异常)
由监视选项进行的应用程序/协议的停止/ 结果异常监视
虽然需要另外购买License,但是能够进行数据库应用程序(Oracle,DB2等),协议(FTP,HTTP等),应用程序服务器(WebSphere,WebLogic等)的停止/结果异常监视。有关详情,请参照"6. 监视资源的详细信息"。
资源监视
通过EXPRESSCLUSTER X SingleServerSafe的监视资源能够监视各种资源(应用程序,服务等)和LAN的状态。在由于必须资源异常造成业务中断时有效。
2.2.1. 可监视的故障和无法监视的故障¶
EXPRESSCLUSTER X SingleServerSafe中有可监视的故障和无法监视的故障。在构建和运行集群系统时,需要先了解哪些故障能够监视,而哪些不能监视。
2.2.2. 通过业务监视可以查出的故障和无法查出的故障¶
监视条件:故障应用程序的消失,持续的资源异常,与某网络设备通信的路径中断
可监视故障示例
应用程序的异常退出
LAN NIC的故障
无法监视故障示例
应用程序的停止/结果异常
EXPRESSCLUSTER X SingleServerSafe虽无法直接监视应用程序的停止/结果异常,但是可以监视应用程序,在查出异常时能够创建退出自身的程序,通过EXEC资源启动该程序,由PID监视资源进行监视,从而可以让其进行失效切换。
3. 创建配置信息¶
在EXPRESSCLUSTER X SingleServerSafe中,记述配置内容的数据称为配置信息。使用Cluster WebUI创建配置信息。在本章中,说明了Cluster WebUI的启动方法及创建配置信息的步骤为示例的配置示例。
本章中介绍的内容如下。
3.1. 确认设置值¶
使用Cluster WebUI的编辑模式,实际创建配置信息之前,请确认作为配置信息所设置的值。写出值后,确认信息是否有遗漏。
3.1.1. 环境的示例¶
下面记载了配置信息的参考值。在以后的章节中将逐步介绍以该条件创建配置信息的步骤。实际进行设置时,请替换输入为所创建的配置信息。有关值的决定方法,请参照"5. 组资源的详细信息"和"6. 监视资源的详细信息"。
配置设置例
设置对象 |
设置参数 |
设置值 |
|---|---|---|
服务器的信息 |
服务器名 |
server1 |
监视资源数 |
3 |
|
组 |
类型 |
失效切换 |
组名 |
failover1 |
|
启动服务器 |
server1 |
|
第1个组资源 |
类型 |
EXEC资源 |
组资源名 |
exec1 |
|
常驻类型 |
常驻 |
|
开始路径 |
执行文件的路径 |
|
第1个监视资源
(创建默认值)
|
类型 |
用户空间监视 |
监视 资源名 |
userw1 |
|
第2个监视资源 |
类型 |
IP监视 |
监视资源名 |
ipw1 |
|
监视 IP 地址 |
192.168.0.254(网关) |
|
复归对象 |
- |
|
重新启动次数 |
- |
|
最终动作 |
停止集群Daemon及重新启动OS |
|
第3个监视资源 |
类型 |
PID监视 |
监视资源名 |
pidw1 |
|
对象资源 |
exec1 |
|
复归对象 |
failover1 |
|
重新启动次数 |
3 |
|
最终动作 |
停止集群Daemon及重新启动OS |
注解
第1个监视资源的[用户空间监视]被自动设置。
3.2. 启动Cluster WebUI¶
创建配置信息时,必须访问Cluster WebUI。在此,首先说明Cluster WebUI的概要,之后,访问Cluster WebUI,对创建配置信息的方法进行说明。
3.2.1. 所谓Cluster WebUI¶
所谓Cluster WebUI,就是通过Web 浏览器进行服务器的状态监视,启动/停止服务器/组,以及收集运行日志等的功能。Cluster WebUI的概要如下图所示。
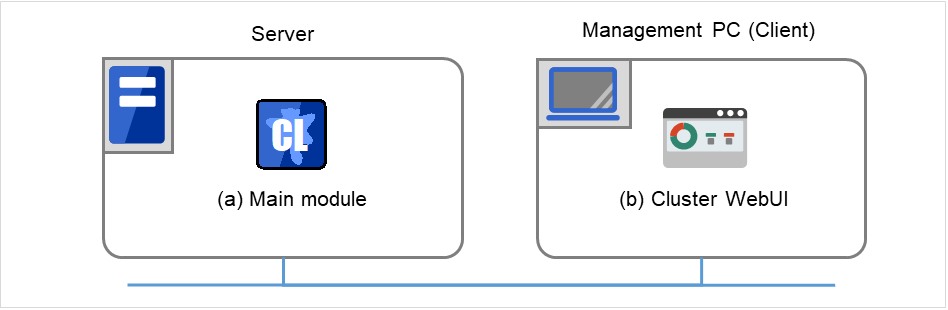
图 3.1 Cluster WebUI¶
3.2.2. 启动Cluster WebUI¶
Cluster WebUI的启动步骤如下所示。
- 启动Web浏览器。在浏览器的地址栏中输入安装了EXPRESSCLUSTER X SingleServerSafe的服务器的IP地址和端口号。
http://ip-address:port/
- ip-address
指定安装了EXPRESSCLUSTER X SingleServerSafe的服务器的IP地址。如是自身服务器,则localhost就可以了。
- port
指定与安装时指定的WebManager的端口号相同的编号(默认值29003)。
- 启动Cluster WebUI。
工具栏的下拉菜单中选择[编辑模式],切换编辑模式。
3.3. 创建配置信息的步骤¶
创建配置信息分为设置服务器,创建组,创建监视资源的3个阶段。新建配置信息时,可使用生成向导。其步骤流程如下所示。
注解
创建的配置信息基本上可使用名称更改功能及属性显示功能,之后进行更改。
-
设置运行EXPRESSCLUSTER X SingleServerSafe的服务器。
-
创建组。通过组控制应用程序的启动及结束。创建所需数量的组。通常需要创建的数量应与想要控制的应用程序数量相当,但在使用[脚本资源]时,也能用1个组控制多个应用程序。
- 添加启动及停止应用程序的资源。
-
监视被指定的监视对象,添加监视资源。创建希望监视的数。
- 添加进行监视的监视资源(IP监视资源)。
- 添加进行监视的监视资源(PID监视资源)。
3.3.1. 1.设置服务器¶
设置服务器。
3.3.1.1. 1-1 设置服务器¶
在安装了EXPRESSCLUSTER X SingleServerSafe之后,可通过重新启动OS来自动创建。Cluster WebUI的操作模式切换至编辑模式画面后,可显示出已经创建的信息。
画面如下所示。
3.3.2. 2.设置组¶
所谓组是指为了执行系统内的某一个独立的业务所必需的服务及流程的集合。
说明添加组的步骤。
3.3.2.1. 2-1 添加组¶
进行组的设置。
点击[组]的[添加组]。
打开[组定义]画面。
请从以下类型中选择。
类型
- 失效切换通常选择此类型。
在[名称]框中输入组名(failover1),然后点击[下一步]。
确认是否选中[所有服务器都可以失效切换] 的复选框,然后点击[下一步]。
组的各个属性的设定画面如下,点击[下一步]设定。
显示[组资源的定义一览],点击[完成]。
3.3.2.2. 2-2 添加组资源(EXEC资源)¶
根据脚本启动/停止应用程序,添加EXEC资源。
点击[failover1]的[添加资源]。
打开[组的资源定义| failover1]画面。在[类型]框中选择组资源的类型(EXEC 资源),在[名称]框中输入组名(exec1)。然后,点击[下一步]。
会显示出依赖关系设置的页面。不作出任何指定,点击[结束]。
显示恢复动作设置。点击[下一步]。
选中[用户应用程序]。此外,在[Start path]上指定执行文件的路径。
点击[调整],打开对话框。在[开始脚本]选中[异步],并点击[确定]。
点击[结束]。
3.3.3. 3.设置监视资源¶
添加监视指定了对象的监视资源。
3.3.3.1. 3-1 添加监视资源(IP 监视资源)¶
点击 [监视]的[添加监视资源]。会显示出[监视资源的定义]。
在[类型]框中选择监视资源的类型(IP监视),在[名称]框中输入监视资源名(ipw1)。然后,点击[下一步]。
注解
由于监视资源作为类型被显示,请选择希望监视的资源。如果选项产品的Licence没有被安装,Licence对应的资源以及监视资源在Cluster WebUI的列表中就不被显示。如果安装过的license无法显示,请点击[获取Licence信息]按钮取得Licence信息。
进入在监视(共通)的设定,这里使用默认值,点击[下一步]。
显示[IP地址列表],然后点击[添加]。
在[Ip地址]框里输入IP地址(192.168.0.254), 点击[确定]。
注解
IP监视资源的监视对象,指定LAN上总是运行的机器(例如,网关)的IP地址。
输入的IP地址在[IP地址列表]里显示,点击[下一步]。
恢复操作设定如下所示,点击[参照],然后选择LocalServer,然后点击完成。
3.3.3.2. 3-2 添加监视资源(PID监视资源)¶
该监视资源可在EXEC开始脚本的类型为[异步]时进行设置。
点击[监视]的[添加监视资源]。
在[类型]框内选择监视资源的类型(PID 监视),在[名称]框内输入监视资源名(pidw1)。点击[下一步]。
输入监视(共通)设置。点击[参照]。
在显示的树形图中选择 [exec1] ,点击[确定] 。将[对象资源] 设为 [exec1] 。点击[下一步] 。
设置复归对象。点击[参照] 。
在显示的树形图中选择 [failover1] ,点击[确定] 。将[复归对象] 设为 [failover1] 。
- 点击[结束]。设置后的画面如下。
3.4. 保存配置信息¶
配置信息分为保存至文件系统上以及保存至外部媒体上的两种方法。在安装了EXPRESSCLUSTER Server的服务器上,可以通过Cluster WebUI反映通过Cluster WebUI保存的信息。
保存配置信息请遵守以下步骤。
从Cluster WebUI的编辑模式中点击[导出配置文件]。
选择存储目标目录,保存。
注解
文件1件(clp.conf)及目录1件(scripts)被保存。不具备所有这些文件及目录时,将不能成功执行命令就结束,所以移动文件时请一定以这2件作为一套。此外,如需更改新建的配置信息,请在上述2件中添加创建clp.conf.bak。
3.6. 反映配置信息¶
如通过Cluster WebUI创建了配置信息,让配置信息反映到服务器中。
反映配置信息时,请遵守以下步骤。
从Cluster WebUI的编辑模式点击[应用配置文件]。
- 根据上传前后配置信息的差异,弹出窗口中将显示上传所需动作相关的确认信息。如动作内容没有问题,点击[确定]。上传成功后,显示"修改已经被成功反映。"的消息。点击[确认]。若上传失败,则请按照显示的消息进行操作。
- Cluster WebUI上显示状态。
 Cluster WebUI的操作和确认方法,可以参考在线手册。点击画面右上的[
Cluster WebUI的操作和确认方法,可以参考在线手册。点击画面右上的[ ]打开在线手册。
]打开在线手册。
4. 确认系统¶
本章中,确认创建的集群系统是否正常启动了。
本章介绍的内容如下。
4.1. 通过Cluster WebUI确认运行¶
要确认设置后的系统,可采用使用Cluster WebUI实施,以及使用命令行实施的方法。本节中对使用Cluster WebUI实施系统确认的方法进行说明。Cluster WebUI在EXPRESSCLUSTER Server的安装阶段就已经被安装了,因此无需重新安装。在此,首先说明Cluster WebUI的概要,之后,访问Cluster WebUI,对确认服务器的方法进行说明。
参见
关于Cluster WebUI 的运行环境,请参阅《安装指南》的"2. 关于EXPRESSCLUSTER X SingleServerSafe "- "确认EXPRESSCLUSTER X SingleServerSafe 的运行环境"-"软件"。
连接Cluster WebUI后,按以下步骤确认运行。
参见
有关Cluster WebUI的操作方法请参考在线版手册。
- 心跳资源确认在Cluster WebUI上服务器的状态为启动完毕。确认服务器的心跳资源的状态为正常。
- 监视资源确认在Cluster WebUI上各监视资源的状态为正常。
- 组的启动启动组。确认在Cluster WebUI上组的状态为启动完毕。
- EXEC 资源在启动了持有EXEC资源的组的服务器上,确认应用程序正在运行。
- 组的停止停止组。确认在Cluster WebUI上组的状态为停止完毕。
- 组的启动启动组。确认在Cluster WebUI上组的状态为启动完毕。
- 服务器关机服务器关机。确认服务器已被正常关机。
4.2. 通过命令确认服务器的运行¶
生成后,使用命令行在配置的服务器上确认状态时,按以下的步骤确认运行。
参见
关于命令的操作方法,请参阅《操作指南》的"EXPRESSCLUSTER X SingleServerSafe命令参考"。
- 心跳资源使用clpstat命令,确认服务器的状态为ONLINE。确认服务器的心跳资源的状态为NORMAL。
- 监视资源使用clpstat命令,确认各监视资源的状态为NORMAL。
- 组的启动使用clpgrp命令, 启动组。使用clpstat命令,确认组的状态为ONLINE。
- EXEC 资源在启动了持有EXEC 资源的组的服务器上,确认应用程序正在运行。
- 组的停止使用clpgrp命令, 停止组。使用clpstat命令,确认组的状态为OFFLINE。
- 组的启动使用clpgrp命令, 启动组。使用clpstat命令,确认组的状态为ONLINE。
- 关机使用clpstdn命令关机。确认服务器已被正常关机。
5. 组资源的详细信息¶
本章中,说明了关于组资源的详细信息。
为提高与集群链接软件EXPRESSCLUSTER X的操作性等方面的兼容性,EXPRESSCLUSTER X SingleServerSafe 使用了相同的画面。
本章介绍的内容如下。
5.2. 设置EXEC资源¶
EXPRESSCLUSTER能够登录由EXPRESSCLUSTER进行管理并在组启动,停止时执行的应用程序及shell脚本。EXEC资源中还能登录用户独有的程序及shell脚本等。Shell脚本与sh的shell脚本格式相同,因此能够记述与各应用程序的情况相应的处理。
5.2.1. EXEC 资源中使用的脚本¶
脚本的种类
EXEC资源中分别备有开始脚本和结束脚本。在需要进行服务器的状态迁移时,EXPRESSCLUSTER将执行各EXEC资源的脚本。需将想要运行的应用程序的启动,停止或复归的步骤写入这些脚本。
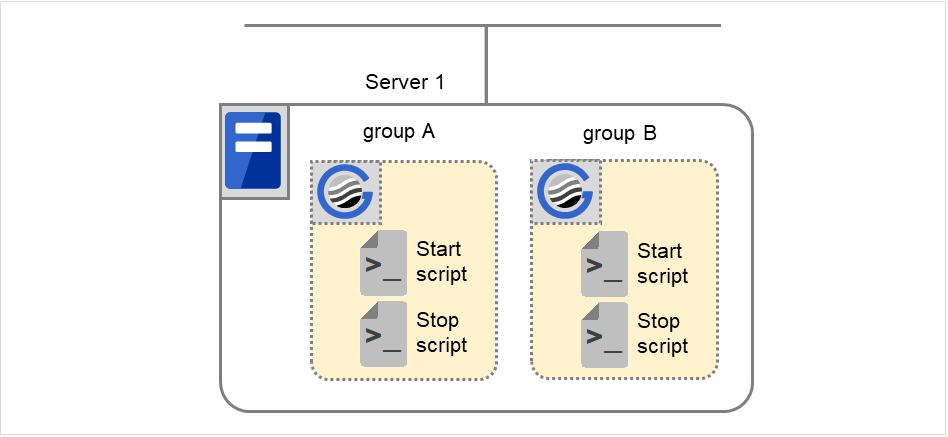
图 5.1 EXEC资源中使用的脚本¶
- Start
开始脚本
- Stop
结束脚本
5.2.2. EXEC资源的脚本中使用的环境变量¶
EXPRESSCLUSTER将执行脚本时的执行状态(脚本执行因素)等设置在环境变量中。
脚本内能够以下图中的环境变量为划分条件,记述符合系统运用情况的处理内容。
结束脚本的环境变量以值的形式返回当前执行的开始脚本的内容。开始脚本中不设置CLP_FACTOR及CLP_PID的环境变量。
仅在CLP_FACTOR的环境变量为CLUSTERSHUTDOWN或SERVERSHUTDOWN时设置CLP_LASTACTION的环境变量。
环境变量 |
环境变量的值 |
意思 |
|---|---|---|
CLP_EVENT
...脚本执行因素
|
START
|
通过启动组被执行时。
由于查出监视资源的异常而重新启动组,而在同一服务器中被执行时。
由于查出监视资源的异常而重新启动组资源,而在同一服务器中被执行时。
|
FAILOVER |
不使用。 |
|
CLP_FACTOR
...组停止因素
|
CLUSTERSHUTDOWN |
通过停止服务器,组被停止时。 |
SERVERSHUTDOWN |
通过停止服务器,组被停止时。 |
|
GROUPSTOP |
通过停止组,组被停止时。 |
|
GROUPMOVE |
不使用。 |
|
GROUPFAILOVER |
不使用。 |
|
GROUPRESTART |
由于查出监视资源的异常而重新启动组资源时。 |
|
RESOURCERESTART |
由于查出监视资源的异常而重新启动组资源时。 |
|
CLP_LASTACTION
...停止后处理
|
REBOOT |
reboot (重新启动) OS时。 |
HALT |
halt (关机) OS时。 |
|
NONE |
无操作。 |
|
CLP_SERVER |
HOME |
不使用。 |
OTHER |
不使用。 |
|
CLP_DISK |
SUCCESS |
不使用。 |
FAILURE |
不使用。 |
|
CLP_PRIORITY |
1~集群内服务器数 |
不使用。 |
CLP_GROUPNAME
...组名
|
组名 |
记载了脚本所属的组名。 |
CLP_RESOURCENAME
...资源名
|
资源名 |
记载了脚本所属的资源名。 |
CLP_PID
...进程ID
|
进程ID |
作为属性开始脚本并非被同步设置时,记载开始脚本的进程ID。开始脚本被同步设置时,本环境变量不持有值。 |
CLP_VERSION_FULL
...EXPRESSCLUSTER完整版
|
EXPRESSCLUSTER完整版 |
表示EXPRESSCLUSTER的完整版。
(例) 5.0.0-1
|
CLP_VERSION_MAJOR
...EXPRESSCLUSTER的主版本
|
EXPRESSCLUSTER主版本 |
表示EXPRESSCLUSTER的主版本。
(例)5
|
CLP_PATH
...EXPRESSCLUSTER安装路径
|
EXPRESSCLUSTER安装路径 |
表示EXPRESSCLUSTER的安装路径。
(例)/opt/nec/clusterpro
|
CLP_OSNAME
...服务器OS名称
|
服务器OS名称 |
表示执行脚本的服务器OS名称。
(例)
①可获取OS名称时:
Red Hat Enterprise Linux Server release 6.8 (Santiago)
②不能获取OS名称时:
Linux
|
CLP_OSVER
...服务器OS版本
|
服务器OS版本 |
表示执行脚本的服务器OS版本。
(例)
①可获取OS名称时:6.8
②不能获取OS名称时:※没有值
|



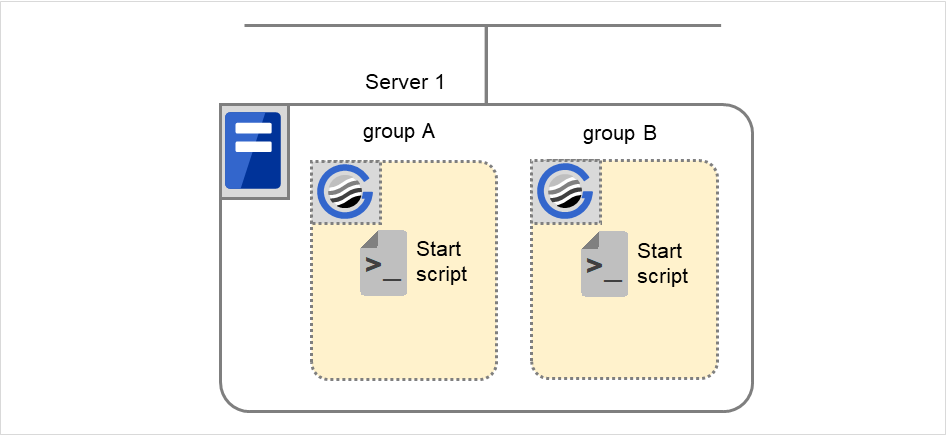
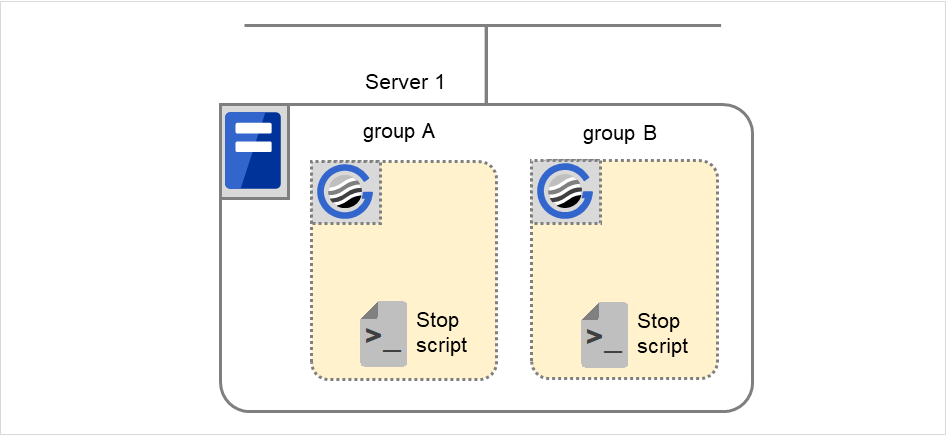
5.2.3. EXEC 资源脚本的记述流程¶
将前面章节中执行脚本的时机与实际的脚本描述联系起来进行介绍。文中的(数字)是指"5.2.2.1. 执行EXEC资源脚本的时机"的各个动作。
组A开始脚本: start.sh的示例
#!/bin/sh # *************************************** # * start.sh * # *************************************** # 参考脚本执行要因的环境变量分配处理。 if ["$CLP_EVENT"="START"] then # 在此记述业务的正常启动处理。 # 该处理在以下时机执行。 # # (1) 正常启动 # else # EXPRESSCLUSTER不运行。 fi # 如果结束代码为0,则判定EXEC资源启动处理成功。 # 记述当脚本内发生错误时,返回0以外的结束代码。 exit 0
A组结束脚本: stop.sh的示例
#!/bin/sh # *************************************** # * stop.sh * # *************************************** # 参考脚本执行要因的环境变量来分配处理。 if ["$CLP_EVENT"="START"] then # 在此记述业务的正常结束处理。在以下时机执行。 # # (2) 正常关机 # else # EXPRESSCLUSTER不运行。 fi exit 0
5.2.4. 创建EXEC 资源脚本的注意事项¶
创建脚本时请注意以下内容。
如果要执行一些需要时间的命令,请在脚本中保留用于表示命令执行完成的跟踪信息。发生故障时,可以使用这些信息来区分故障。保留跟踪信息的方法有以下两种。
- 在脚本中描述echo命令,设置EXEC资源的日志输出目标文件的方法通过echo命令可以标准输出跟踪信息。在此基础上,通过脚本所属资源的属性设置日志输出目标文件。
默认为不输出日志。关于日志输出目标的设置,请参考"详细信息标签页"的"EXEC 资源调整属性"中的"维护标签页"。因为[轮循]复选框未选中时,向设置为日志输出目标的文件中输出日志时没有大小限制,所以请务必注意文件系统的剩余空间。
(例:脚本设置示例)
echo "appstart.." appstart echo "OK"
- 在脚本中描述clplogcmd的方法通过clplogcmd向警报日志或OS的syslog中输出消息。关于clplogcmd,请参考《操作指南》的"EXPRESSCLUSTER X SingleServerSafe 命令参考"的"消息输出命令 (clplogcmd 命令)"。
(例:脚本设置示例)
clplogcmd -m "appstart.." appstart clplogcmd -m "OK"
5.2.5. EXEC资源的注意事项¶
- 关于脚本的日志轮循功能启用脚本日志轮循功能后,将生成调解日志输出(中介进程)的进程。中介进程是从"开始/停止脚本"以及"继承从开始/停止脚本标准输出/标准错误输出中任一或两者的子进程"开始的日志输出到所有停止(文件描述符关闭)为止,一直运行。如果要从日志中排除子进程的输出时,请在从脚本创建进程时重定向标准输出和标准错误输出。
由root用户执行开始脚本/结束脚本。
启动依赖环境变量的应用程序时,应根据需要必须在脚本侧进行环境变量的设置。
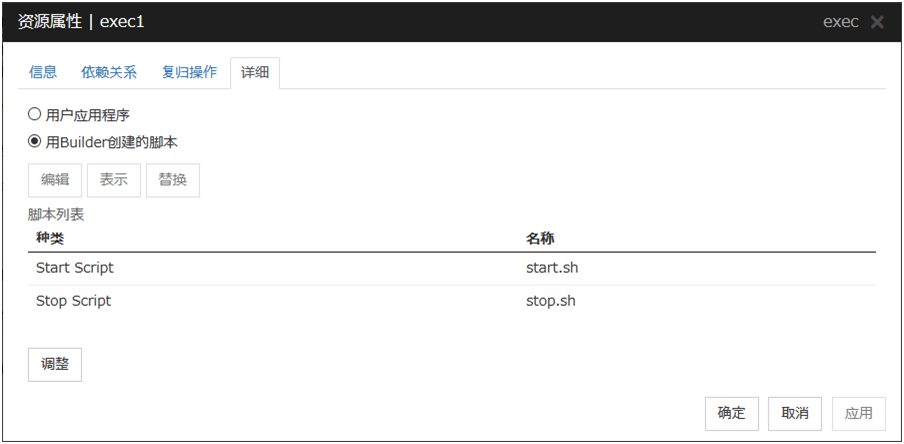
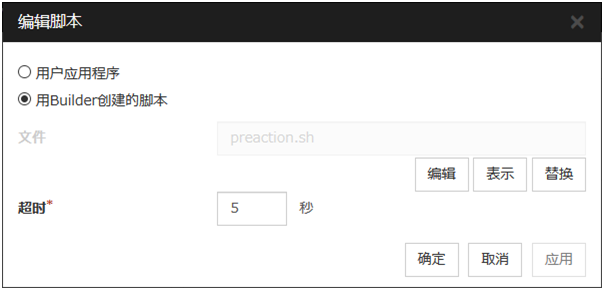
5.2.6. 详细信息标签页¶
用户应用程序
使用可在服务器上执行的文件(可执行的shell脚本或二进制文件)作为脚本。通过服务器上本地磁盘的路径设置各可执行文件的名称。
Cluster WebUI的集群配置信息中也不会包含这些文件。脚本文件不能通过Cluster WebUI进行编辑。
用Cluster WebUI创建的脚本
使用通过Cluster WebUI准备的脚本文件作为脚本。根据需要,可以通过Cluster WebUI编辑脚本文件。脚本文件将被包含到集群配置信息中。
显示
选择[用Cluster WebUI创建的脚本]后,显示选中的脚本文件。
编辑
选择[用Cluster WebUI创建的脚本]后,编辑选中的脚本文件。要反映这些更改请点击[保存]。脚本文件名无法更改。
选择[用户应用程序]时显示[输入应用程序路径]对话框。
输入应用程序路径
设置EXEC资源的可执行文件名。
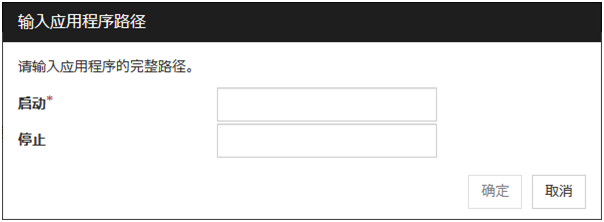
启动 (1023字节以内)
设置EXEC资源开始时的可执行文件名。文件名需要以[/]开头。还可指定参数。
停止 (1023字节以内)
设置EXEC资源停止时的可执行文件名。文件名需要以[/]开头。结束脚本可以省略。可执行文件名需要设置为服务器上的带有以[/]开头的完整路径的文件名。还可指定参数。
替换
选择[用Cluster WebUI创建的脚本]后,显示[选择文件]对话框。
将[资源属性]中选择的脚本文件的内容置换为文件选择对话框中选择的脚本文件的内容。脚本处于正在编辑或正在显示的状态时无法置换。请在此选择脚本文件。请不要选择二进制文件(应用程序等)。
调整
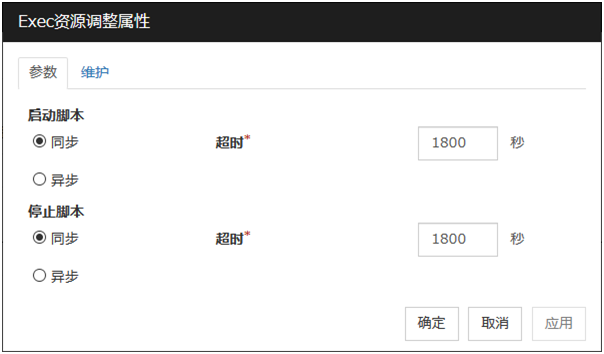
显示EXEC资源调整属性对话框。对EXEC资源进行详细设置。要通过PID监视资源来监视EXEC资源,需要将开始脚本设置为异步。
EXEC 资源调整属性
参数标签页
[启动脚本],[停止脚本]共通内容
同步
执行脚本时等待脚本结束。如果是非常驻(执行后处理立即返回)可执行文件,选择该项。
异步
执行脚本时不等待脚本结束。如果是常驻可执行文件,选择该项。异步执行EXEC资源的开始脚本时,可通过PID监视资源进行监视。超时 (1~9999)
设置执行脚本时等待脚本结束([同步])的情况下的超时时间。仅在选择了[同步]时才可以设置该项。如果脚本没有在设置的时间内结束,则判断为异常。
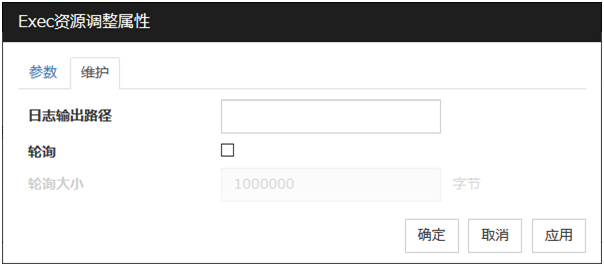
维护标签页
日志输出路径 (1023字节以内)
指定EXEC资源的脚本或可执行文件的标准输出和标准错误输出的重定向目标。如果不指定任何内容,则输出到/dev/null中。需要指定为以[/]开头的值。
[轮询]复选框未选中时,将会无限制的输出到文件中,所以请务必注意文件系统的剩余空间。
[轮询]复选框选中时,输出的日志文件将会转储。并且,还有以下的注意事项。
[日志输出路径]中请记载1009字节以内的日志路径。超过1010字节时,不能进行日志的输出。
日志文件的名称长度请在31字节内记载。超过32字节时,将无法输出日志。
轮询
未选中时,EXEC资源的脚本或可执行文件的执行日志,会以无限制的文件大小输出,选中时则会轮询输出。
轮询大小 (1~999999999)
[轮询]复选框选中时,指定轮询的大小。轮询输出的日志文件配置如下。
文件名
内容
指定[日志输出路径]的文件名
最新的日志。
指定[日志输出路径]的文件名.pre
转储之前的日志。
6. 监视资源的详细信息¶
本章说明在EXPRESSCLUSTER X SingleServerSafe中作为执行监视的单位的监视资源的详细信息。
为提高与集群链接软件EXPRESSCLUSTER X的操作性等方面的兼容性,EXPRESSCLUSTER X SingleServerSafe 使用了相同的画面。
本章中介绍的内容如下。
6.1. 监视资源列表¶
作为监视资源可以定义的资源如下所示。
监视资源名
|
功能
|
监视时机
(粗体为默认值)
|
对象资源
|
|---|---|---|---|
磁盘监视资源 |
监视磁盘设备 |
不间断监视/启动时 |
全部 |
IP监视资源 |
通过ping 命令确认有无响应,从而监视IP地址及通信路径。 |
不间断监视/启动时 |
全部 |
NIC Link Up/Down监视资源 |
取得NIC的Link状态,监视Link的Up/Down。 |
不间断监视/启动时 |
全部 |
PID监视资源 |
监视成功启动的EXEC资源。 |
启动时(固定) |
exec |
用户空间监视资源 |
判断用户空间的stall为异常。 |
不间断监视(固定) |
- |
多目标监视资源 |
通过组合多数的监视资源的状态从而进行监视。 |
启动时(固定) |
全部 |
SoftRAID监视资源 |
监视进行Soft RAID的设备。 |
不间断监视(固定) |
空 |
自定义监视资源 |
通过执行任意的脚本从而进行监视。 |
不间断监视/启动时 |
全部 |
卷管理监视资源 |
提供了多个存储磁盘的监视机制 |
不间断监视/启动时 |
全部 |
消息接收监视资源 |
实现"接收发生异常通知时执行的异常时动作的设置"以及"发生异常通知的Cluster WebUI显示"。 |
不间断监视(固定) |
空 |
进程名监视资源 |
监视任意进程名的进程。 |
不间断监视/启动时 |
全部 |
DB2监视资源 |
提供给IBM DB2数据库的监视机构。 |
启动时(固定) |
全部 |
FTP监视资源 |
提供给FTP服务器的监视机构。 |
不间断监视/启动时 |
全部 |
HTTP监视资源 |
提供给HTTP服务器的监视机构。 |
不间断监视/启动时 |
全部 |
IMAP4监视资源 |
提供给IMAP服务器的监视机构。 |
不间断监视/启动时 |
全部 |
MySQL监视资源 |
提供给MySQL数据库的监视机构。 |
启动时(固定) |
全部 |
NFS监视资源 |
提供给NFS的文件服务器的监视机构。 |
不间断监视/启动时 |
全部 |
ODBC监视资源 |
提供给ODBC数据库的监视机构。 |
启动时(固定) |
全部 |
Oracle监视资源 |
提供给Oracle数据库的监视机构。 |
启动时(固定) |
全部 |
POP3监视资源 |
提供给POP服务器的监视机构。 |
不间断监视/启动时 |
全部 |
PostgreSQL监视资源 |
提供给PostgreSQL数据库的监视机构。 |
启动时(固定) |
全部 |
Samba监视资源 |
提供给samba文件服务器的监视机构。 |
不间断监视/启动时 |
全部 |
SMTP监视资源 |
提供给SMTP服务器的监视机构。 |
不间断监视/启动时 |
全部 |
SQL Server监视资源 |
为SQL Server数据库提供监视机制。 |
启动时(固定) |
全部 |
Tuxedo监视资源 |
提供给Tuxedo应用程序服务器的监视机构。 |
不间断监视/启动时 |
全部 |
WebLogic监视资源 |
提供给WebLogic应用程序服务器的监视机构。 |
不间断监视/启动时 |
全部 |
WebSphere监视资源 |
提供给WebSphere应用程序服务器的监视机构。 |
不间断监视/启动时 |
全部 |
WebOTX监视资源 |
提供给WebOTX应用程序服务器的监视机构。 |
不间断监视/启动时 |
全部 |
JVM监视资源 |
进行Java VM的监视。 |
不间断监视/启动时 |
exec |
系统监视资源 |
进行系统资源的监视。 |
不间断监视(固定) |
全部 |
进程资源监视资源 |
进行进程资源的监视。 |
不间断监视(固定) |
全部 |
6.1.1. 监视资源开始监视后的状态¶
消息接收监视资源
自定义监视资源 (仅限监视类型为[异步]时)
DB2监视资源
系统监视资源
进程资源监视资源
JVM监视资源
MySQL监视资源
ODBC监视资源
Oracle监视资源
PostgreSQL监视资源
进程名监视资源
SQL Server监视资源
6.1.2. 监视资源的监视时机¶
监事资源的监视可分为不间断监视及启动时监视2种类型。
可以设置的监视时间根据监视资源而不同。
- 不间断监视监视资源不间断的进行监视。
- 启动时在指定的组资源处于启动状态期间进行监视。在组资源处于停止状态时不进行监视。
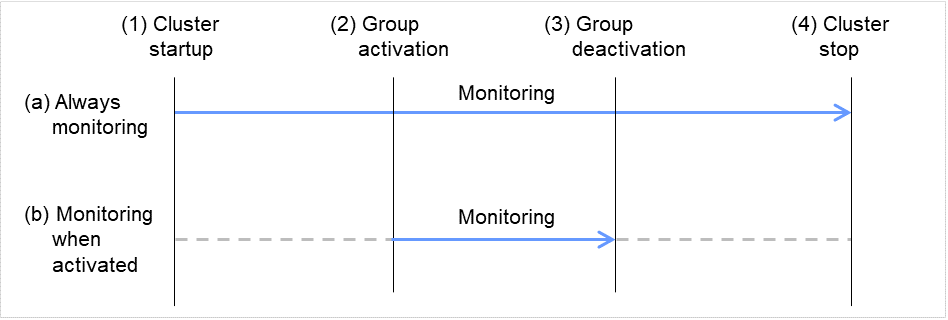
图 6.1 监视资源的不间断监视和启动时监视¶
6.1.3. 暂停/重新启动监视资源¶
通过Cluster WebUI操作
- 通过clpmonctrl命令操作clpmonctrl命令只可以控制执行命令的服务器上的监视资源
并非所有的监视资源都支持暂时停止/重新启动。
监视资源是否可以控制请参考下表。
监视资源 |
可否控制 |
|---|---|
磁盘监视资源 |
可执行 |
IP监视资源 |
可执行 |
用户空间监视资源 |
可执行 |
NIC Link Up/Down监视资源 |
可执行 |
PID监视资源 |
可执行 |
多目标监视资源 |
可执行 |
虚拟IP监视资源 |
可执行 |
自定义监视资源 |
可执行 |
卷管理监视资源 |
可执行 |
SoftRAID监视资源 |
可执行 |
进程名监视资源 |
可执行 |
DB2监视资源 |
可执行 |
FTP监视资源 |
可执行 |
HTTP监视资源 |
可执行 |
IMAP4监视资源 |
可执行 |
MySQL监视资源 |
可执行 |
NFS监视资源 |
可执行 |
ODBC监视资源 |
可执行 |
Oracle监视资源 |
可执行 |
POP3监视资源 |
可执行 |
PostgreSQL监视资源 |
可执行 |
Samba监视资源 |
可执行 |
SMTP监视资源 |
可执行 |
SQL Server监视资源 |
可执行 |
Tuxedo监视资源 |
可执行 |
WebLogic监视资源 |
可执行 |
WebSphere监视资源 |
可执行 |
WebOTX监视资源 |
可执行 |
消息接收监视资源 |
可执行 |
JVM监视资源 |
可执行 |
系统监视资源 |
可执行 |
进程资源监视资源 |
可执行 |
在暂停状态下进行以下操作时,将会解除监视资源暂停状态。
在Cluster WebUI中"重新启动"监视资源
在[clpmonctrl]命令中指定-r选项
集群停止
集群挂起
6.1.4. 发生/解除监视资源的模拟故障¶
监视资源可模拟故障的发生。也可以解除故障。模拟故障发生/解除的方法有以下2种。
- 通过Cluster WebUI(验证模式)操作在Cluster WebUI(验证模式)中,不可控制监视资源的右键菜单无效。
- 通过[clpmonctrl]命令操作控制执行命令的服务器上的监视资源。对不可控制监视资源进行执行时,可成功执行命令,但无法发生模拟故障。
在发生模拟故障的状态下进行以下操作时,将会解除监视资源模拟故障。
在Cluster WebUI(验证模式)中执行监视资源的"解除模拟故障"
将Cluster WebUI模式由验证模式更改到其他模式时,在显示的对话框中选择"是"
在[clpmonctrl]命令中指定-n选项
集群停止
集群挂起
6.1.5. 监视资源的监视优先级¶
为了在OS负载高时能够优先进行监视资源的监视,可以在除用户空间监视资源之外的所有监视资源中设置nice值。
nice值可以指定19(优先级低)~-20(优先级高)范围内的数值。
通过提高nice值的优先级,可以降低监视超时的发生概率。
6.2. 监视资源的属性¶
6.2.2. 监视(共通)标签页¶
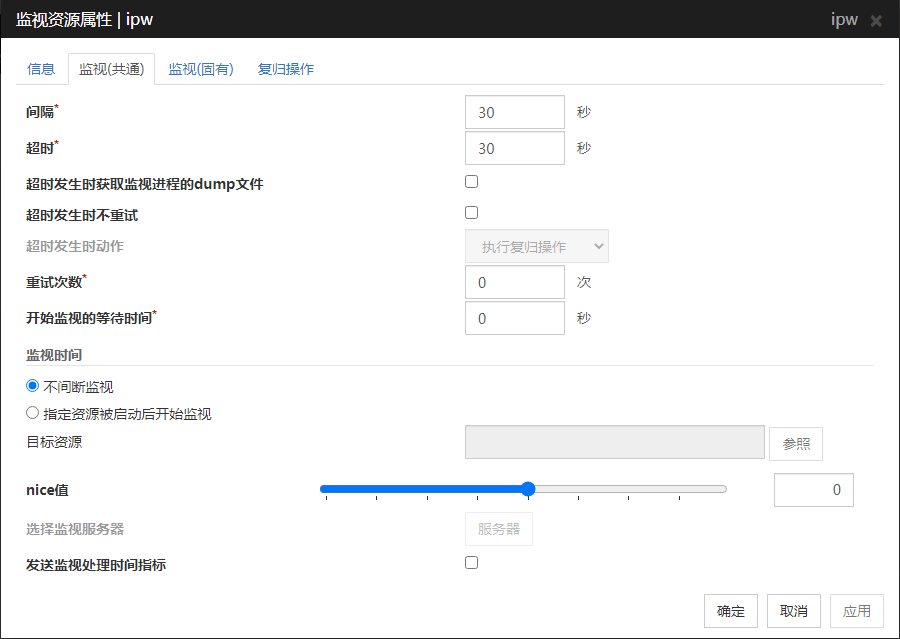
间隔(1~999)
设置确认监视对象状态的时间间隔。
超时(5~999 1)
若在指定时间内没有发现监视对象的正常状态,则判断为异常。
- 1
通过用户空间监视资源设置监视方法为ipmi时,需要设置为255以下的值。
超时发生时获取监视进程的dump文件
选择本功能后,监视资源超时,获取超时的监视资源的dump文件。dump文件最多可取5次。
超时发生时不重试
将本功能设为有效时,若监视资源发生超时则立即执行复归操作。
超时发生时不做回复动作
将本功能设为有效时,若监视资源发生超时则不执行复归操作。仅在将[超时发生时不进行重试]功能设为有效时可以设置。注解
在以下监视资源中,不能设置[超时发生时不重试], [超时发生时不做回复动作]功能。
用户空间监视资源
自定义监视资源 (仅在监视类型为[异步]时)
多目标监视资源
消息接收监视资源
JVM监视资源
系统监视资源
进程资源监视资源
重试次数(0~999)
发现异常状态后,若连续指定次数发现异常,则判断为异常。若指定为0,则在最初发现异常时即判断为异常。
监视开始的等待时间(0~9999)
设置等待监视开始的时间。
监视时间
设置监视的时间。
目标资源
显示进行启动时监视的对象资源。
参照
显示选择对象资源的对话框。树形显示LocalServer和集群中登录的组名,资源名。选择设置的对象资源,点击[确定]。
nice值
设置进程的nice值。
发送监视处理时间指标
设置监视处理时间指标的发送功能。
注解
用户空间监视资源
自定义监视资源(仅限监视类型为[异步]时)
虚拟IP监视资源
消息接收监视资源
动态DNS监视资源
BMC监视资源
Oracle Clusterware同步管理监视资源
JVM监视资源
系统监视资源
进程资源监视资源
6.2.3. 监视(固有)标签页¶
必须根据监视资源设置监视运行时的参数。参数按照各资源说明。
6.2.4. 复归动作标签页¶
设置复归对象和查出异常时的运行。查出异常时可重新启动组,资源和服务器。但是,如果复归对象处于停止状态则不进行复归动作。
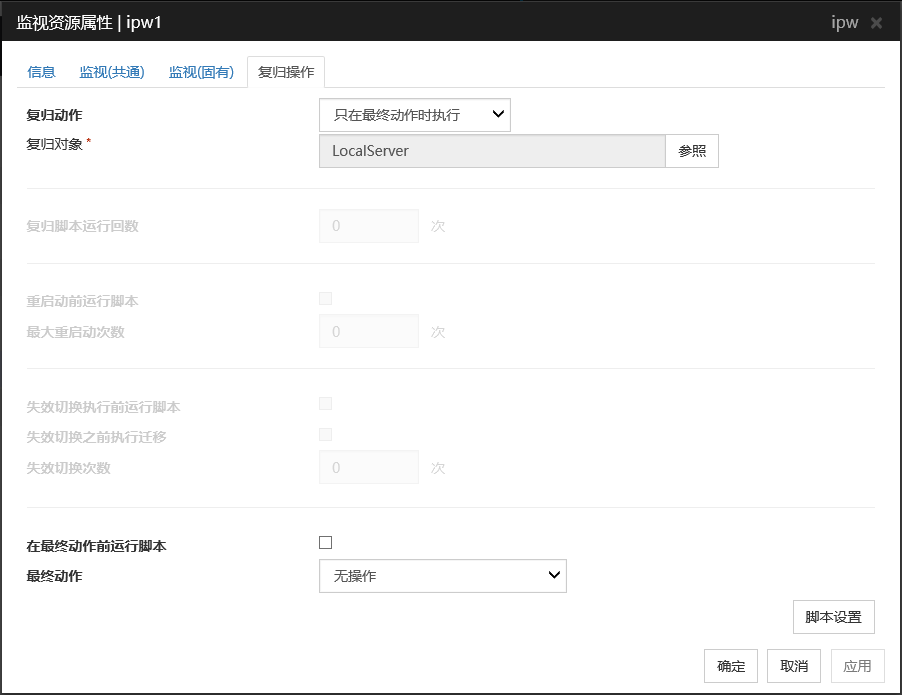
复归动作
选择异常检出时的复归操作。
复归对象
当发现资源异常时,显示要进行恢复的对象。
参照
显示选择复归对象对话框。树形显示LocalServer,All Groups和服务器中登录的组名,资源名。选择要设置的恢复对象,点击[确定]。
复归脚本运行次数 (0~99)
发现异常时,设置[脚本设置]中脚本的运行次数。若设置为0,则不执行脚本。
重启动前运行脚本
重启动次数(0~99)
设置出现异常时进行重新启动的次数。若设置为0,则不重新启动。若选择组或组资源为恢复对象,可进行设置。
失效切换执行前运行脚本
不使用。
失效切换次数 (0~99)
不使用。
在最终动作前运行脚本
指定是否在最终动作前运行脚本。
点击[脚本设置]则显示[编辑脚本]对话框。设置执行的脚本或执行文件后点击[确定]。
脚本设置
显示[编辑脚本]对话框。设置复归脚本,复归动作前执行的脚本/命令。
用户应用程序
使用作为脚本的可在服务器上执行的文件(可执行的批处理文件,执行文件)。在文件名中设置服务器上的本地磁盘绝对路径或者可执行文件名。此外,如果在绝对路径,文件名包含空格时,如下所示,请用双引号(")括起来。
例:
"/tmp/user application/script.sh"各可执行文件不包含在Cluster WebUI的集群配置信息中。由于无法在Cluster WebUI中进行编辑和上传,所以需要在各服务器上准备。
用Cluster WebUI创建的脚本
使用作为脚本的在Cluster WebUI中准备的脚本文件。可以在Cluster WebUI中编辑脚本文件。脚本文件包含在集群配置信息中。
文件 (1023字节内)
选择[用户应用程序]时,设置执行的脚本(可执行的批处理文件,执行文件)。
表示
选择[用Cluster WebUI创建的脚本]时,显示脚本文件。
编辑
选择[用Cluster WebUI创建的脚本]时,编辑脚本文件。如要反映更改时,请点击[保存]。无法更改脚本文件名。
替换
选择[用Cluster WebUI创建的脚本]时,将脚本文件的内容替换为文件选择对话框中选择的脚本文件内容。如脚本已经为显示中或者编辑中时,无法替换。请选择脚本文件。请不要选择二进制文件(应用程序等)。
超时 (1~9999)
指定等待脚本结束的最大时间。规定值为5秒。
最终动作
选择通过重启动复归失败后的复归动作。最终运行有以下选择。
注解
以下情况下请使用[无操作]设置。
暂时控制最终动作时
查出异常后想仅显示警报时
通过多目标监视资源执行实际的最终动作时
注解
sysrq应急措施失败时,关闭OS。
注解
keepalive复位失败时,关闭OS。请不要在没有对应clpkhb驱动,clpka驱动的OS,kernel上进行设置。注解
keepalive应急措施失败时,关闭OS。请不要在没有对应clpkhb驱动,clpka驱动的OS,kernel上进行设置。注解
BMC复位失败时,关闭OS。请不要在没有安装OpenIPMI,或没有运行ipmitool命令的服务器上进行设置。注解
BMC 关闭电源失败时,关闭OS。请不要在未安装OpenIPMI,或没有运行ipmitool命令的服务器上进行设置。注解
BMCPower Cycle失败时,关闭OS。请不要在未安装OpenIPMI,或者未运行ipmitool命令的服务器上进行设置。注解
BMC NMI失败后关闭OS。请不要在未安装OpenIPMI,或者未运行ipmitool命令的服务器上进行设置。
6.3. 磁盘监视资源的设置¶
6.3.1. 监视(固有)标签页¶
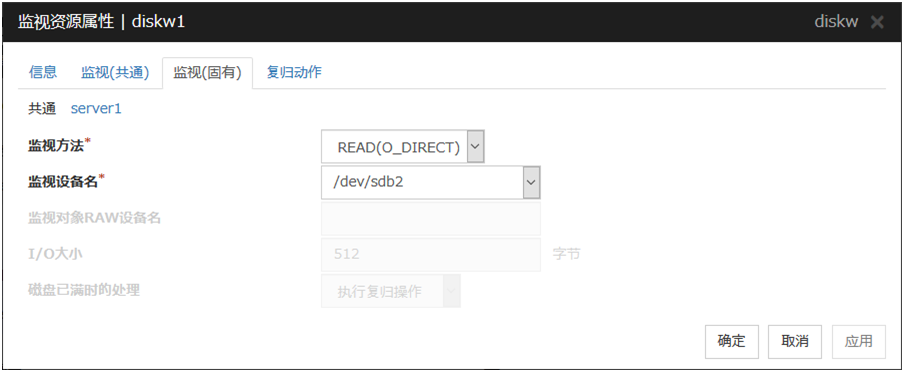
监视方法
从以下选择监视磁盘设备时的监视方法。
TUR
TUR(generic)
TUR(legacy)
READ
READ (O_DIRECT)
WRITE (FILE)
READ (RAW)
监视设备名 (1023字节以内)
监视对象RAW设备名 (1023字节以内)
只有在选择了READ(RAW)监视方法时才可以输入。
I/O 大小(1~99999999)
指定执行read或read/write的大小。
指定为TUR, TUR (generic), TUR (legacy)时,本设置项目被忽视。
磁盘已满时的处理
从下面选择查出磁盘已满(监视的磁盘没有空余容量的状态)时的运行。
指定READ, READ (RAW), READ (O_DIRECT), TUR, TUR (generic), TUR (legacy) 时,查出磁盘已满时的操作项目为灰色不能选择。
如果监视设备名中设置为本地磁盘,则可以执行服务器的本地磁盘监视。
以下是通过READ方式监视本地磁盘[/dev/sda],查出异常时[重启OS]的设置示例
设置项目
设置值
备注
监视设备名
/dev/sdb
第2台SCSI磁盘
监视方法
READ
READ 方式
恢复对象
服务器
-
最终动作
服务器停止,OS重启
OS重启
以下是通过[TUR(generic)方式]监视本地磁盘[/dev/sdb],查出异常时[无操作] (仅在Cluster WebUI中显示警报)的设置示例
设置项目
设置值
备注
监视设备名
/dev/sdb
第2台 SCSI磁盘
监视方法
TUR(generic)
SG_IO方式
最终动作
无操作
6.3.2. 磁盘监视资源的监视方法¶
磁盘监视资源的监视方法主要分为TUR和READ。
TUR的注意事项
- 在不支持SCSI的Test Unit Ready命令及SG_IO命令的磁盘,磁盘接口(HBA)中不能使用。有时虽然硬件支持,而驱动程序不支持,所以也需要确认驱动程序的规格。
LVM逻辑卷(LV)装置有可执行无法正常执行ioctl,因此LV的监视请使用READ。
磁盘接口为IDE的场合,不能使用任何方式的TUR。
S-ATA接口的磁盘中,由于磁盘控制器类型和使用的分配,有时被OS识别为IDE接口的磁盘(hd),也有时被识别为SCSI接口的磁盘(sd)。若被识别为IDE接口,则无法使用任何TUR方式。作为SCSI接口被识别时,可以使用TUR(legacy)。TUR(generic)无法使用。
与Read方式相比,对OS和磁盘的负载小。
使用Test Unit Read,有时无法发现实际媒体的I/O错误。
磁盘上的分区设置为监视对象后不能使用。必须指定whole device (显示磁盘全体的设备)。
- 基于不同的磁盘装置,TUR发行时可执行会根据装置状态,临时返回Unit Attention。虽然临时返回Unit Attention没有问题,但TUR的重试次数设置为0的时,上述情况会被视为错误,并使磁盘监视资源变为异常状态。为了避免无用异常检出,请设置重试次数1次以上。
TUR的监视方法可以选择以下3类。
TUR
对指定的设备按照以下步骤发行ioctl,通过结果进行判断。执行ioctl(SG_GET_VERSION_NUM)命令。根据ioctl的返回值和SG驱动的version进行判断。
- ioctl命令成功,并且SG驱动的version为3.0以上时,执行使用SG驱动的ioctl TUR(SG_IO)。ioctl命令失败或SG驱动的version低于3.0时,执行定义为SCSI命令的ioctl TUR。
TUR(legacy)
使用ioctl(Test Unit Ready)进行监视。向指定的设备发出定义为SCSI命令的Test Unit Ready(TUR)命令,根据结果进行判断。
TUR(generic)
使用ioctl TUR(SG_IO) 进行监视。向指定的设备发出定义为SCSI命令的ioctl(SG_IO)命令,根据结果进行判断。SG_IO即使是SCSI磁盘,根据OS及分配不同,也有可执行不运行。
READ的监视方法如下。
READ
在指定设备(磁盘设备或分区设备)按照指定大小进行READ,根据结果(能够READ的大小)进行判断。
判断能够READ指定的大小。不判断READ的数据正确性。
READ的大小变大后,对OS和磁盘的负载也变大。
关于read大小,请参考"磁盘监视资源中选择READ的I/O大小"进行设置
READ(O_DIRECT) 的监视方法如下。
READ (O_DIRECT)
不要使用缓存(O_DIRECT模式),对指定的设备(磁盘设备或分区设备)上的1扇区或文件进行read,并根据其结果(可read的大小)进行判断。
判断可以read。不判断可以read的数据的正确性。
READ (RAW) 的监视方法如下。
READ (RAW)
与监视方法"READ(O_DIRECT) "一样,不使用OS的缓存,对指定设备的read进行监视。
判断可以read。不判断可以read的数据的正确性。
设置监视方法"READ(RAW)"时,不能监视已mount的分区或可执行会mount的分区。另外,也不能对已mount的分区或可执行会mount的分区的whole device(表示整个磁盘的设备)进行监视。请准备监视专用分区,设置为磁盘监视资源。(请将监视专用分区大小设置为10MB以上)。
WRITE (FILE) 的监视方法如下。
WRITE (FILE)
创建指定路径名的文件,进行写入和删除并进行判断。
不判断写入的数据的正确性。
6.4. 磁盘监视资源中选择了READ(RAW)时的设置示例¶
磁盘监视的设置示例
通过"READ(RAW)"来监视内置HDD)
Disk监视资源 (通过"READ(RAW)"来监视共享磁盘)
下图显示的是服务器和与之相连的磁盘的示例。 在Server 1的内置磁盘中,将/dev/sda3指定为Disk监视器。
注解
请不要指定OS中使用的分区(包括swap)。请不要指定已经mount的分区,可执行会mount的分区,whole device。请确保Disk监视资源的专用分区。此外,在外部连接磁盘(Disk)中,指定/dev/sdb3为Disk监视器。
注解
请不要指定已经mount的分区或者有可执行会mount的分区。此外,请不要指定已经mount的分区或者有可执行会mount的whole device。请确保Disk监视资源的专用分区。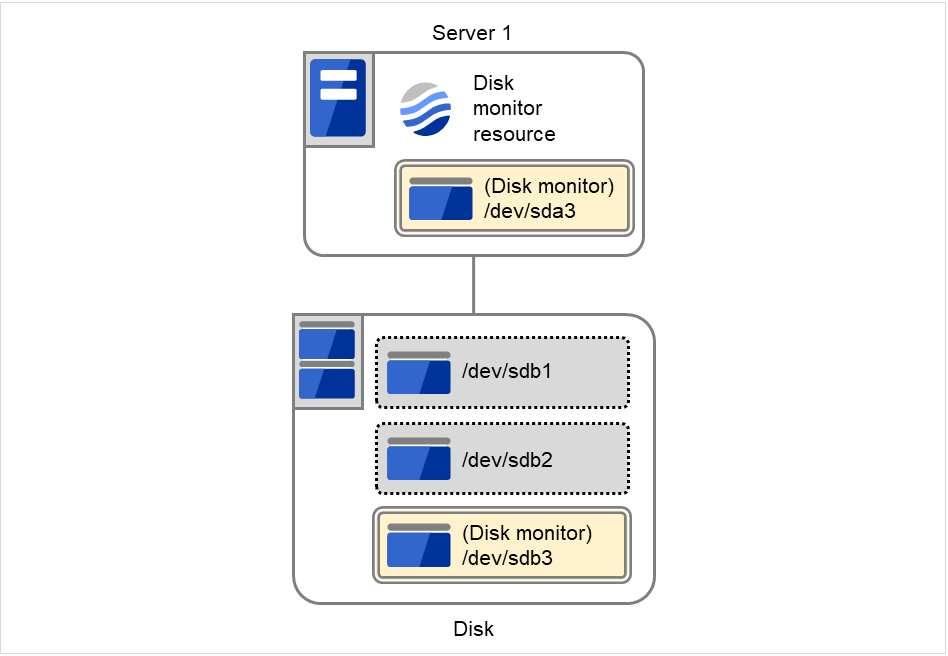
图 6.3 磁盘监视的设置示例¶
6.5. IP监视资源的设置¶
IP 监视资源是指通过ping命令对IP地址进行监视的监视资源。
6.5.1. 监视(固有)标签页¶
在[IP地址列表]中显示监视的IP地址。
添加
添加要监视的IP地址。显示IP地址的输入对话框。
IP地址(255字节以内)
输入进行监视的IP地址或主机名,选择[确定]。请输入可通过公网LAN进行通信的实际IP地址或主机名。设置主机名时,请在OS端进行名称解析的设置(向/etc/hosts添加项目等)。
删除
在监视对象中删除[IP地址列表]中选中的IP地址。
编辑
显示输入IP地址的对话框。显示[IP地址列表]中选中的IP地址,编辑后选择[确定]。
6.5.2. IP监视资源的监视方法¶
使用ping命令对指定IP地址进行监视。若指定IP地址没有任何应答,则判断为异常。
IP地址的应答确认中使用ICMP的packet type 0 (Echo Reply)和8 (Echo Request)。
多个IP地址的情况下,在全部IP地址出现异常时判断为异常时,请在1个IP监视资源中登录所有IP地址。
下图是在1个IP监视资源中注册所有IP地址时的示例。 指定的IP地址即使只有1个是正常的情况下,IP monitor 1都会判断为正常。
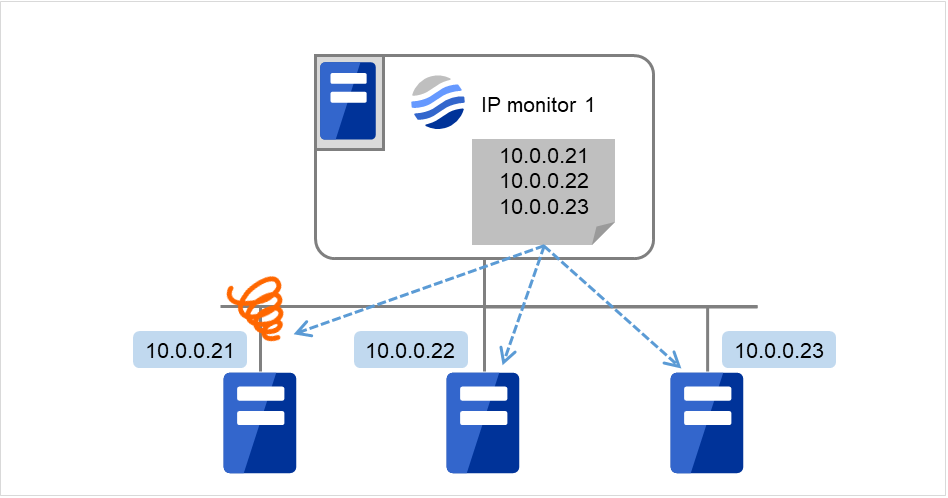
图 6.4 在1个IP监视资源中注册所有IP地址(正常)¶
下图为在1个IP监视资源中注册所有IP地址时的示例。 指定的IP地址全异常时,IP monitor 1判断为异常。
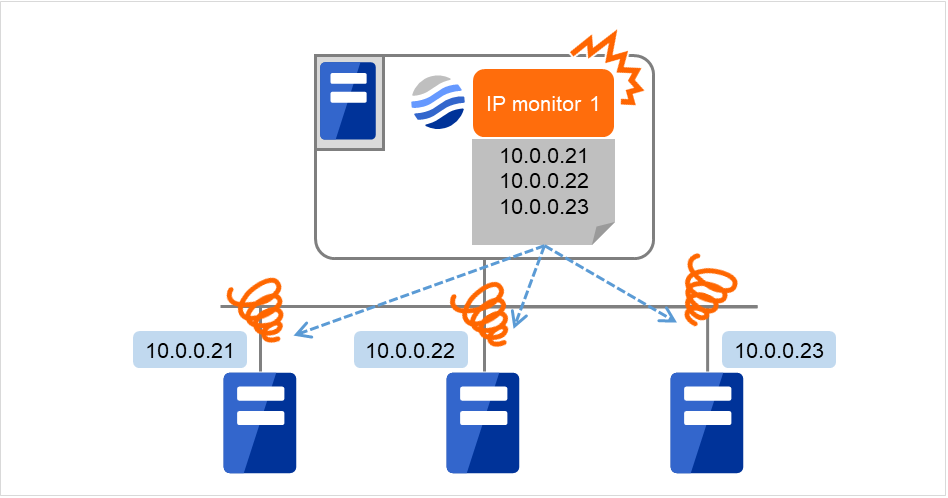
图 6.5 在1个IP监视资源中注册所有IP地址(查出异常)¶
多个IP地址中,若要判断其中某一个为异常时,需要按照各个IP地址,分别创建IP监视资源。
图中显示的是将IP地址一个个注册到各IP监视资源中时的示例。 指定的IP地址查出异常时,IP监视器(图中为IP monitor 1)判断为异常。
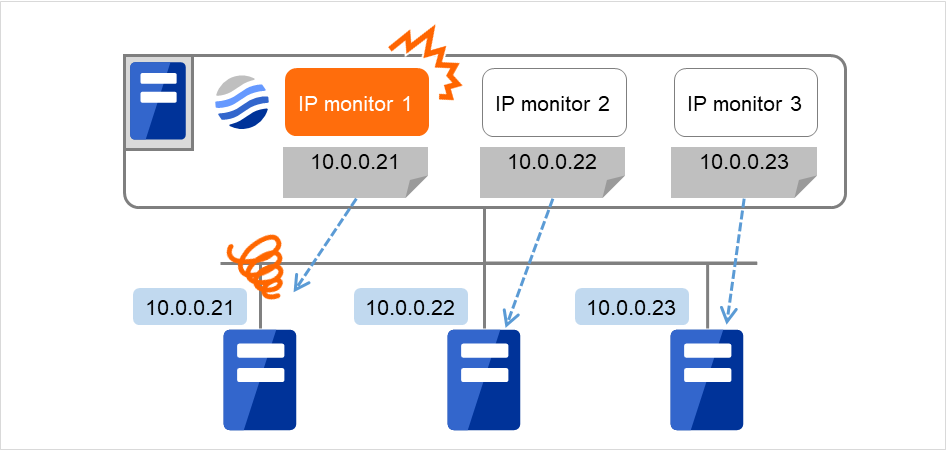
图 6.6 将IP地址一个个注册到各IP监视资源中(查出异常)¶
6.6. NIC Link Up/Down监视资源的设置¶
NIC Link Up/Down 监视资源获取指定的NIC的Link状态,监视Link的Up/Down。
6.6.1. 监视(固有)标签页¶
监视对象(15字节以内)
请设置进行监视的NIC的接口名。bonding设备(例:bond.600)以及team设备(例:team0)也都可以监视。也可以监视VLAN,tagVLAN。(设定例:eth0.8)。
6.6.2. NIC Link UP/Down 监视资源的运行环境¶
支持NIC Link UP/Down监视资源的网络接口
NIC Link UP/Down 监视资源通过以下网络接口进行操作确认。
Ethernet Controller(Chip)
Bus
Driver version
Intel 82557/8/9
PCI
3.5.10-k2-NAPI
Intel 82546EB
PCI
7.2.9
Intel 82573L
PCI
7.3.20-k2-NAPI
Intel 80003ES2LAN
PCI
7.3.20-k2-NAPI
Broadcom BCM5721
PCI
7.3.20-k2-NAPI
6.6.3. NIC Link UP/Down监视资源的注意事项¶
ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: umbg
Wake-on: g
Current message level: 0x00000007 (7)
Link detected: yes
如果ethtool命令的结果中没有显示LAN线缆的链接状况("Link detected: yes")
EXPRESSCLUSTER的NIC Link Up/Down监视资源不能运行的可执行性很高。请使用IP监视资源代替。
如果ethtool命令的结果中显示LAN线缆的链接状况("Link detected: yes")
多数情况下,EXPRESSCLUSTER的NIC Link Up/Down监视资源可以运行,很少情况下可执行无法运行。
尤其是如下所述硬件存在无法运行的情况。请使用IP监视资源替代。
如刀片服务器相同,在LAN连接器NIC芯片之间安装有硬件。
监视对象的NIC为绑定的环境时,请确认MII Polling Interval的设定值是否为0以上。
在实际设备中使用EXPRESSCLUSTER确认NIC Link Up/Down监视资源是否可以使用时,通过以下步骤进行运行确认。
- 在配置信息中登录NIC Link Up/Down监视资源。请将NIC Link Up/Down监视资源的查出异常时的回复动作设置为"无操作"。
请启动集群。
- 请确认NIC Link Up/Down监视资源的状态。LAN线缆的链接状态正常时,如果NIC Link Up/Down监视资源的状态异常,则NIC Link Up/Down监视资源不能运行。
- LAN线缆的链接状态异常(链接断开状态),如果NIC Link Up/Down监视资源的状态异常,则NIC Link Up/Down监视资源可以运行。如果状态正常不变化,则NIC Link Up/Down监视资源无法运行。
6.6.4. NIC Link UP/Down监视配置以及范围¶
有多种因素会导致NIC Link Up/Down监视中发生异常。 如果使用LAN电缆连接服务器和网络设备时发生错误,则服务器侧的电缆可执行已断开。 另外,这时网络设备侧的电缆也可执行会断开。 此外,还有可执行切断网络设备的电源。
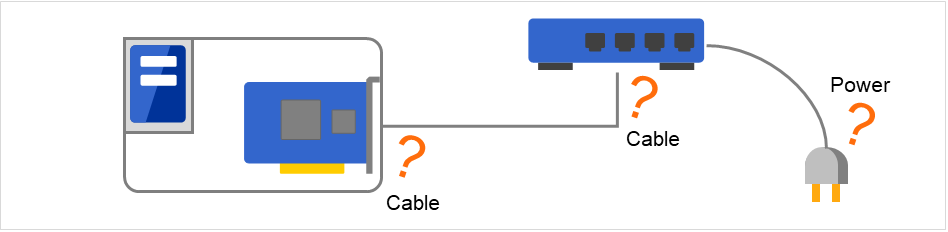
图 6.7 NIC Link Up/Down 监视和异常发生要因¶
- 通过对NIC驱动程序进行ioctl( ),可以查出网络(线缆)的链接确立状态。(IP监视器时,可通过ping指定IP地址后的反应来判断。)
- 监视通过其他服务器和LAN线缆直接连接的NIC时,其他服务器宕机(尚未确立链接)时查出异常。设置监视异常时的恢复操作时,请设置适当值。例如,恢复操作选择为"集群服务停止和OS重启",则会无限反复重启OS。
另外,当对网络进行bondig化时,通过bonding发挥其可用性的情况下,既可以监视下层的副接口(eth0, eth1...),也可以监视主接口(bond0...)。该情况下,建议使用以下设置。
副接口
- 发现异常时的恢复操作:无操作仅有一方网络线缆(eth0)发生异常时,EXPRESSCLUSTER不执行恢复操作,仅输出警告通知。网络的恢复操作由bonding执行。
主接口
- 发现异常时的恢复操作:设置失效切换或关机等所有副接口发生异常时(主接口关闭状态下),EXPRESSCLUSTER执行恢复操作。
下图显示了绑定副接口eth0,eth1,作为主接口bond0时的情况。
当eth0发生故障时,缩小或切换bonding driver。
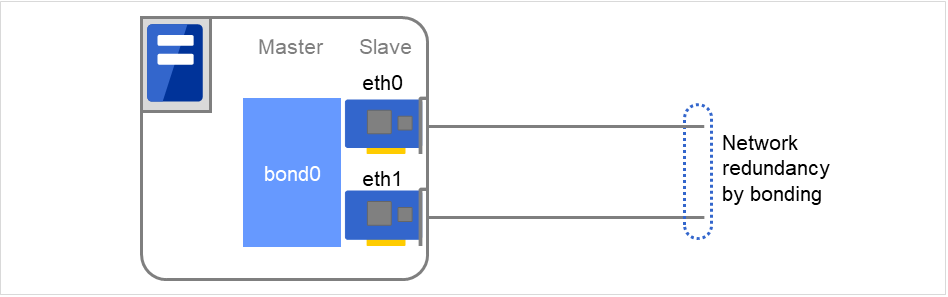
图 6.8 Network bonding的使用示例¶
6.7. PID监视资源的设置¶
对成功启动的EXEC资源进行监视。通过监视进程ID的有无,当进程ID消失时,判断为异常。
进行监视的EXEC资源是在"监视资源的属性"的"目标资源"中设置。只能在启动EXEC资源时的设置为[异步]时进行监视。无法发现进程的停止。
注解
对数据库,samba,apache,sendmail等停止进行监视时,请购买"EXPRESSCLUSTER监视可选产品"。
6.7.1. PID监视资源的注意事项¶
对成功启动EXEC资源进行监视。只能在EXEC资源的开始脚本启动时的设置为[异步]时可以监视。
6.8. 用户空间监视资源的设置¶
6.8.1. 监视(固有)标签页¶
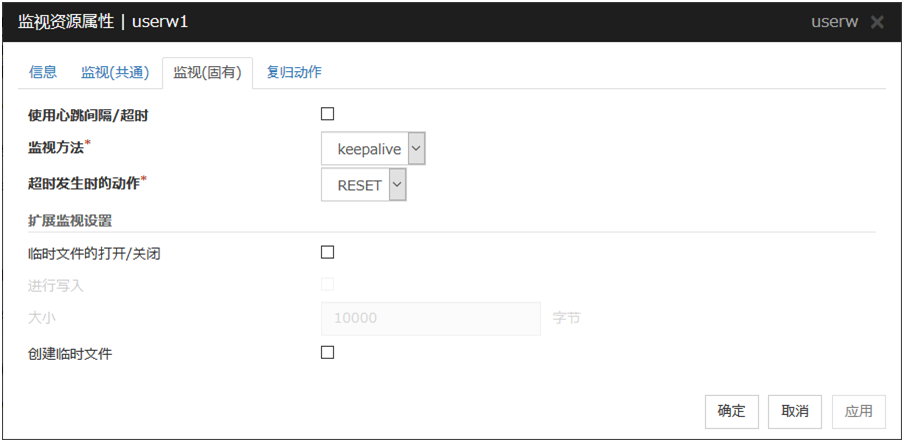
使用心跳间隔/超时
设置监视时间间隔与超时为心跳间隔与超时时选择此选项。
监视方法
在以下选项中选择用户空间监视资源的监视方法。不能选择其他用户空间监视资源中已经采用的方法。
超时发生时的动作
设置最终动作。
临时文件的打开/关闭
进行监视时,设置是否每隔监视时间间隔打开/关闭临时文件。
进行写入
打开/关闭临时文件时,设置是否对临时文件执行写入操作。
大小(1~9999999)
对虚拟文件执行写入操作时,设置写入大小。
创建临时文件
进行监视时,设置是否创建临时文件。
6.8.2. 用户空间监视资源所依赖的驱动程序¶
监视方式 softdog
Softdog
监视方法为softdog时,该驱动程序是必要的。
请形成可加载模块配置。稳定的驱动程序无法运行。
无法使用softdog驱动程序时,不能开始监视。
监视方式 keepalive
clpka
clpkhb
若监视方法为keepalive,需要EXPRESSCLUSTER的clpkhb驱动程序,clpka驱动程序。
clpka驱动程序与clpkhb驱动程序为EXPRESSCLUSTER提供的驱动程序。关于支持范围,请参考《安装指南》的"2. 关于EXPRESSCLUSTER X SingleServerSafe" - "确认EXPRESSCLUSTER X SingleServerSafe的运行环境" - "可以运行的发布版及kernel"。
无法使用clpkhb驱动程序,clpka驱动程序的情况下无法开始监视。
6.8.4. 用户空间监视资源的监视方法¶
用户空间监视资源的监视方法如下所示。
监视方法 softdog
若监视方法为softdog,使用OS的softdog驱动程序。
监视方法 ipmi
若监视方法为ipmi,使用OpenIPMI。未安装OpenIPMI时,需要进行安装。
监视方法 keepalive
若监视方法为 keepalive,则使用clpkhb 驱动程序及clpka驱动程序。
注解
关于clpkhb驱动程序和 clpka驱动程序运行的分配,kernel版本,请务必确认《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"可以运行的分配及kernel"。在将分配器的安全升级包用于已经运行的服务器 (kernel版本发生变化)时,也请进行确认。
监视方法 none
监视方法 none设置用于测试。仅执行用户空间监视资源扩展设置的操作。请不要在实际运行环境中设置此项。
6.8.5. 用户空间监视资源的扩展设置¶
扩展用户空间监视资源需要进行以下设置:创建打开/关闭虚拟文件,写入虚拟文件,创建虚拟线程。若设置失败则无法更新计时器。若在所设超时值或心跳超时时间内各设置连续失败,则重置OS。
打开/关闭虚拟文件
每隔设置的监视間隔,反复执行创建,open,close,删除虚拟文件的操作。
设置该扩展功能时,若磁盘没有空闲容量,open文件失败,计时器不被更新,重置OS。
写入虚拟文件
每隔监视时间间隔,写入所设大小的数据。
当未设置open/close虚拟文件时,无法设置本扩展功能。
创建虚拟线程
每隔监视时间间隔创建虚拟线程。
6.8.6. 用户空间监视资源的逻辑¶
由于监视方法不同而不同的处理内容具有如下特征。关机监视过程中仅采取第1项操作。
监视方法 ipmi
处理概要
反复执行以下2~7步处理。
设置IPMI计时器
open()虚拟文件
write()虚拟文件
虚拟文件fdatasync()
close()虚拟文件
创建虚拟线程
更新IPMI计时器
处理概要2~6是用于设置监视扩展。若不进行各设置,则不执行处理。
- 未超时(正确处理上述2~7)时的操作不执行重置等恢复处理
- 超时时(上述2~7中的某个操作停止或延迟)的操作BMC(服务器本身的管理功能)导致进行重置
优点
由于使用BMC(服务器本身的管理功能),很难被kernel空间故障影响,由此重置成功的可执行性很高。
缺点
在由于依赖于H/W而服务器不支持IPMI,或服务器中未运行OpenIPMI,则无法使用此方法。
使用ESMPRO/ServerAgent的服务器中无法使用此方法。
可执行无法与其他服务器供应商提供的服务器监视软件共用。
监视方法 softdog
处理概要
反复执行以下2~7步处理。
设置softdog
open()虚拟文件
write()虚拟文件
虚拟文件fdatasync()
close()虚拟文件
创建虚拟线程
更新softdog计时器
处理概要2~6是用于设置监视扩展。若不进行各设置,则不执行处理。
- 未超时(正确处理上述2~7)时的操作不执行重置等恢复处理
- 超时时(上述2~7中的某个操作停止或延迟)的操作softdog.ko导致进行重置(machine_restart)
优点
- 由于不依赖于H/W,因此只要有softdog kernel模块,则可采取此方法。(部分版本中默认状态下没有softdog,因此请在设置前确认是否有softdog)
缺点
由于softdog并不依赖于kernel空间的计时器逻辑,因此有时尽管kernel空间发生故障,却不会重置。
监视方法 keepalive
处理概要
反复执行以下2~7处理。
设置keepalive计时器
open()虚拟文件
write()虚拟文件
fdatasync()虚拟文件
close()虚拟文件
创建虚拟线程
更新keepalive计时器
处理概要2~6是用于设置监视扩展。若不进行各设置,则不执行处理。
- 未超时(正确处理上述2~7)时的操作不执行重置等恢复处理
超时时(上述2~7中的某个操作停止或延迟)的操作
通过clpkhb.ko向其它服务器通知[自身服务器重置]
通过执行clpka.ko进行重置(machine_restart)
优点
通过执行clpkhb,向其它服务器通知自身服务器重置 ,可在其它服务器上留下记录(日志)。
缺点
可运行的(提供驱动程序)的Distribution,架构,内核版本受到限制。
由于clpka依赖于kernel空间的计时器逻辑,当kernel空间出现故障时,有时可执行不会重置。
6.8.7. ipmi运行可否的确认方法¶
需要确认服务器本身OpenIPMI的运行状况时,可采取以下操作步骤。
安装OpenIPMI的rpm安装包。
执行/usr/bin/ipmitool。
确认执行结果。
Watchdog Timer Use: SMS/OS (0x04) Watchdog Timer Is: Stopped Watchdog Timer Actions: No action (0x00) Pre-timeout interval: 0 seconds Timer Expiration Flags: 0x00 Initial Countdown: 300 sec Present Countdown: 0 sec可使用OpenIPMI。监视方法可选择ipmi。
6.8.8. 用户空间监视资源的注意事项¶
所有监视方法共通的注意事项
通过Cluster WebUI创建设置信息后,监视方法softdog的用户空间监视资源将自动被创建。
可添加监视方法不同的用户空间监视资源。可删除自动创建的监视方法softdog的用户空间监视资源。
由于OS的softdog驱动程序不存在,或EXPRESSCLUSTER的clpkhb驱动程序,clpka驱动程序不存在,或未安装OpenIPMI的rpm,导致启动用户空间监视资源失败时,Cluster WebUI 的Alert日志中会显示"Monitor userw failed."消息。Cluster WebUI以及clpstat命令显示中资源状态显示为[正常],各服务器的状态为[已启动]。
通过ipmi进行监视的注意事项
6.9. 自定义监视资源的设置¶
自定义监视资源是通过执行任意的脚本对系统进行监视的一种监视资源。
6.9.1. 监视(固有)标签页¶
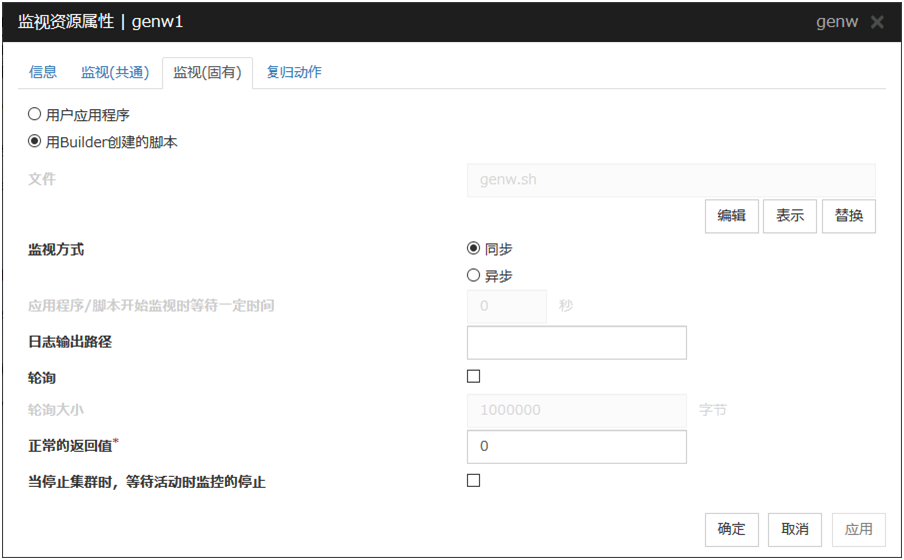
用户应用程序
使用可在服务器上执行的文件(可执行的Shell Script文件或执行文件)作为脚本。通过服务器上本地磁盘的绝对路径设置各可执行文件的名称。
Cluster WebUI的配置信息中不会包含各可执行文件。因为不能通过Cluster WebUI进行编辑或上传,需要在各台服务器上准备。
用Cluster WebUI创建的脚本
使用通过Cluster WebUI准备的脚本文件作为脚本。根据需要,可以通过Cluster WebUI编辑脚本文件。脚本文件将被包含到配置信息中。
文件(1023字节以内)
选择了[用户应用程序]时,通过服务器上本地磁盘的绝对路径设置运行的脚本(可执行的Shell Script文件或执行文件)。
表示
选择了[用Cluster WebUI创建的脚本]时,显示脚本文件。
编辑
选择了[用Cluster WebUI创建的脚本]时,编辑脚本文件。要反映这些更改,请点击[保存]。脚本文件名无法更改。
替换
选择了[用Cluster WebUI创建的脚本]时,把脚本文件内容更改为文件选择对话框中所选择的脚本文件内容。脚本处于正在编辑或正在显示的状态时无法置换。请在此选择脚本文件。请不要选择二进制文件(应用程序等)。
监视方式
选择监视方法。
等待固定时间以启动应用程序/脚本监视(0~9999)
监视类型为[异步]时设置从启动应用程序/脚本到开始监视的等待时间。该等待时间应小于通过[监视(共通)]标签页设置的超时值。
注解
此设置在下次启动监视时生效。
默认值 :0
日志输出路径(1023字节以内)
设置脚本内输出的log输出目标。未选中[轮询]复选框时,将会无限制的输出,所以请务必注意文件系统的剩余空间。选中[轮询]复选框时,将轮询输出的日志文件。此外,请注意如下的注意事项。
请将[日志输出路径]中记录的日志路径控制在1009字节以内。超过1010字节后,日志将无法输出。
请将日志文件的名称控制在31字节以内。超过32字节后,无法输出日志。
在多个自定义监视资源上运行日志转储,若路径名不同但日志文件名相同时,(ex. /home/foo01/log/genw.log, /home/foo02/log/genw.log)转储大小可执行无法正确反映。
轮询
脚本或可执行文件的执行日志关闭时,以无限制的文件大小方式输出,开启时转储输出。
轮询大小 (1~999999999)
选中[轮询]复选框时,会指定轮询的大小。
轮询输出的日志文件构成如下。
文件名
内容
[日志输出路径]指定的文件名
此为最新日志。
[日志输出路径]指定的文件名.pre
此为转储前的日志。
正常的返回值(1023字节以内)
监视类型为[同步]时,对于脚本的错误代码是什么值时判断为正常进行设置。有多个值时,像0,2,3这样用逗号分隔开,或者像0-3这样用连字号指定数值范围
默认值 : 0
等待停止集群时停止启动时监视
等待群集停止时停止自定义监视资源。仅当为监视时序设置[启动时]时,此设置才有效。
6.9.2. 自定义监视资源的注意事项¶
6.9.3. 自定义监视资源的监视方法¶
6.10. 卷管理监视资源的设置¶
卷管理监视资源是对由卷管理器管理的逻辑磁盘执行监视的监视资源。
6.10.1. 监视(固有)标签页¶
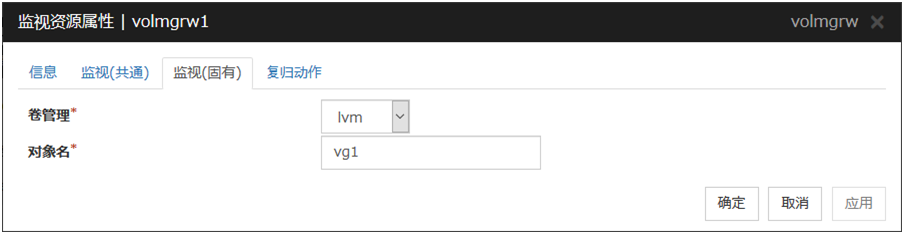
卷管理
设置管理作为监视对象的逻辑磁盘的卷管理器的种类。对应完毕的卷管理器如下。
lvm (LVM卷组)
zfspool (ZFS 存储池)
对象名(1023字节以内)
设置作为监视对象名称。卷管理为[lvm]时,可以进行多个卷的统合控制。控制多个卷时,卷名用半角空格区分设定。
6.10.2. 卷管理监视资源的注意事项¶
6.10.3. 卷管理监视资源的监视方法¶
lvm (LVM卷组)
zfspool (ZFS 存储池)
6.11. 多目标监视资源的设置¶
多目标监视资源对多个监视资源进行监视。
6.11.1. 监视(固有)标签页¶
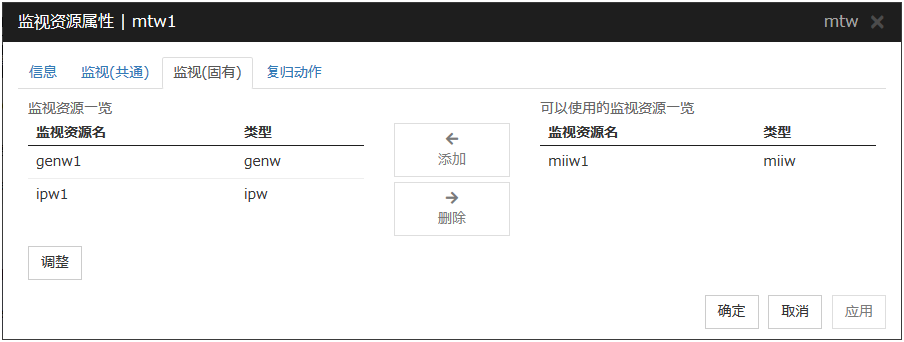
添加
将选中监视资源添加到[监视资源列表]中。
删除
在[监视资源列表]中删除选中的监视资源。
调整
显示[多目标监视资源调整属性]对话框。进行多目标监视资源的详细设置。
多目标监视资源调整属性
参数标签页
显示参数相关的详细设置。
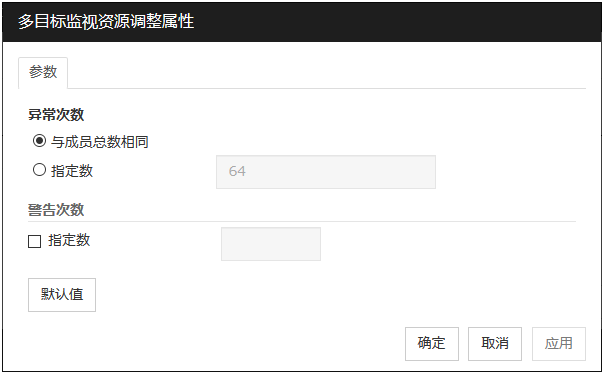
异常次数
选择多目标监视器处于异常的条件。
警告次数
默认值
用于需要恢复至默认值时。点击[默认值]按钮,则所有项目都被设置为默认值。
6.11.2. 多目标监视资源的注意事项¶
多目标监视资源会把登录中的监视资源的状态"已停止(offline)"视作异常处理。因此登录了启动时监视的监视资源时,有监视资源没有检出异常,多目标监视资源却检出异常的情况。请不要登录启动时监视的监视资源。
6.11.3. 多目标监视资源的状态¶
已登录的监视资源数 2异常界限值 2警告界限值 1
多目标监视资源的状态如下所示。
多目标监视资源状态
|
监视资源1状态
正常
(normal)
|
监视资源1状态
异常
(error)
|
监视资源1状态
已停止
(offline)
|
|---|---|---|---|
监视资源2状态
正常
(normal)
|
正常
(normal)
|
警告
(caution)
|
警告
(caution)
|
监视资源2状态
异常
(error)
|
警告
(caution)
|
异常
(error)
|
异常
(error)
|
监视资源2状态
已停止
(offline)
|
警告
(caution)
|
异常
(error)
|
正常
(normal)
|
- 多目标监视资源对已登录的监视资源状态进行监视。若处于异常(error)状态的监视资源个数超过异常次数,则多目标监视资源出现异常(error)。若处于异常(error)状态的监视资源个数超过警告次数,则多目标监视资源为警告(caution)状态。若所有登录的监视资源状态都已停止(offline),多目标监视资源的状态将为正常(normal)。除了所有登录的监视资源状态均已停止(offline)的情况之外,多目标监视资源将已登录的监视资源状态处于已停止(offline)的情况判断为异常(error)。
- 即便已登录的监视资源状态为异常(error),也不会执行该监视资源出现异常时的操作。仅在多目标监视资源出现异常(error)时,才会执行多目标监视资源出现异常时的操作。
6.12. 多目标监视资源的设置示例¶
- Disk总线冗余配置驱动程序的使用示例只有磁盘设备(/dev/sdb, /dev/sdc等)同时也出现异常的情况下,才需要视为异常(error)。下图显示了使用两个HBA和Disk路径双重化驱动,使路径双重化的配置。启动一侧的HBA故障时,缩小或切换Disk路径双重化驱动。
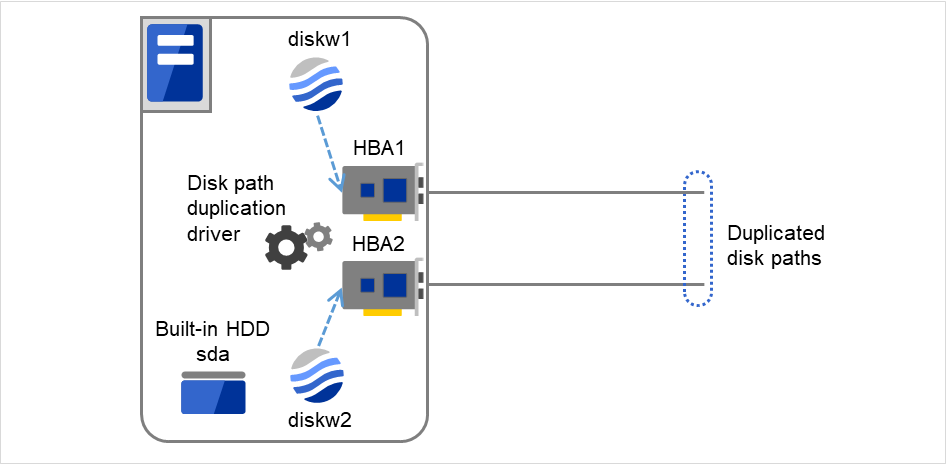
图 6.9 Disk路径双重化驱动的使用示例¶
多目标监视资源(mtw1)中登录的监视资源
diskw1
diskw2
多目标监视资源(mtw1)的异常次数,警告次数
异常次数 2
警告次数 0
多目标监视资源(mtw1)中登录的监视资源的详细设置
- 磁盘监视资源(diskw1)监视设备名 /dev/sdb启动界限值 0失效切换界限值 0最终动作 无操作
- 磁盘监视资源(diskw2)监视设备名 /dev/sdc启动界限值 0失效切换界限值 0最终动作 无操作
上述设置中,即便发现多目标监视资源的监视资源中登录的diskw1和diskw2中一侧发生异常,也不对出现异常的监视资源执行异常时操作。
若diskw1与diskw2都出现异常,而2个监视资源状态为异常(error)和已停止(offline)时,执行多目标监视资源中设置的异常时操作。
6.13. 软件RAID监视资源的设置¶
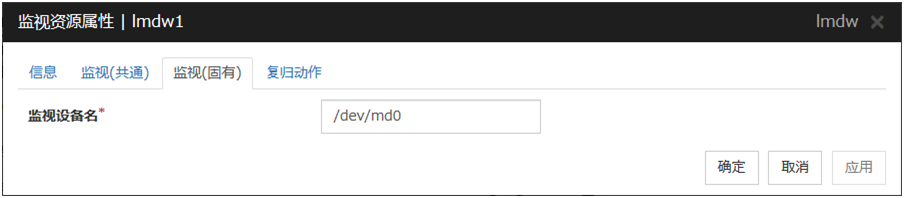
软件RAID监视资源是对进行软件RAID的设备进行监视的监视资源。
6.13.1. 软件RAID监视资源的监视方法¶
软件RAID监视资源可利用md驱动程序对进行软件RAID的设备进行监视。一方DISK异常且软件RAID结束时,发出WARNING通知。
注解
双方磁盘异常时,由于无法查出异常,因此请在发出结束通知时进行DISK的复归操作。
6.14. 消息接收监视资源的设置¶
6.14.1. 监视(固有)标签页¶
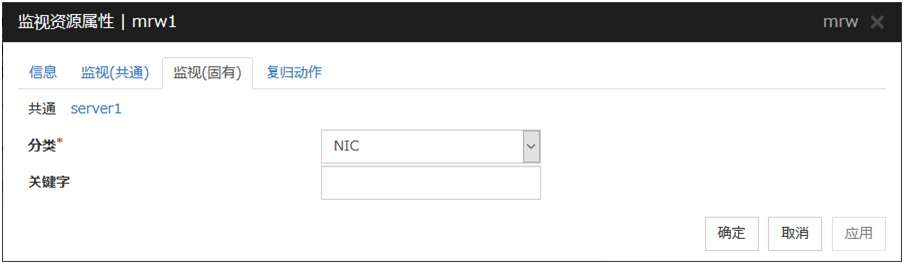
在监视类型和监视对象中使用clprexec命令参数-k设置要传递的关键词。可以省略监视对象。
分类(32字节以内)
clprexec命令参数-k指定监视类型。可选择列表框中的已有字符串或指定任意字符串。
关键字(1023字节以内)
clprexec命令参数-k设置要传递的关键词。
6.14.2. 复归动作标签页¶
设置复归对象和查出异常时的动作。消息接收监视资源时,查出异常时的动作选择[重启复归对象],[对复归对象执行失效切换]或[最终动作]的任一1个。但是,复归对象若为停止状态则不执行复归动作。
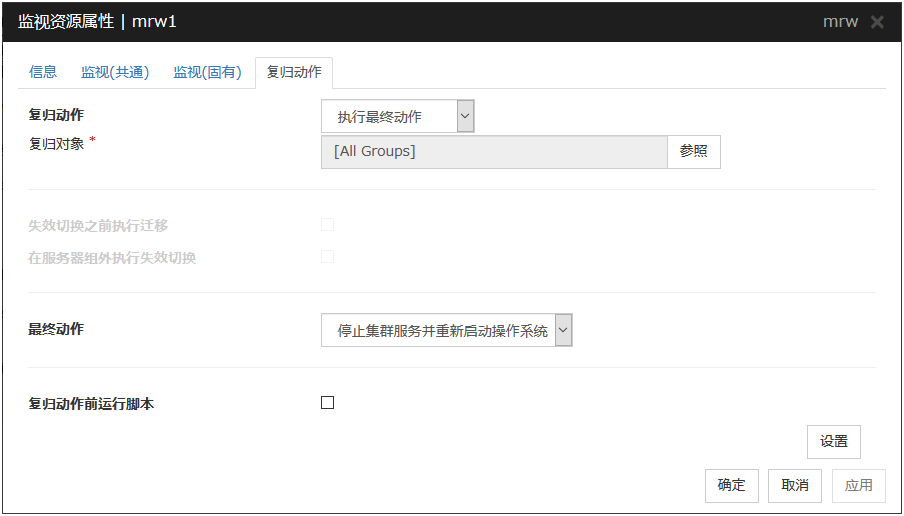
复归动作
选择查出监视异常时执行的动作。
复归动作前运行脚本
在执行复归动作中选择的查出异常时的动作前,指定是否执行脚本。
6.14.3. 消息接收监视资源的监视方法¶
- 接收到外部的异常发生通知时,执行已设置了已通知监视类型和监视对象(可省略监视对象)的消息接收监视资源在异常发生时的恢复动作。有多个设置了已通知监视类型,监视对象的消息接收监视资源时,执行各监视资源的恢复动作。
下图为使用消息接收监视资源的配置示例。 从clprexec命令接收到异常发生通知的Server2的消息接收监视资源,执行查出自身状态更改和异常时的复归动作。
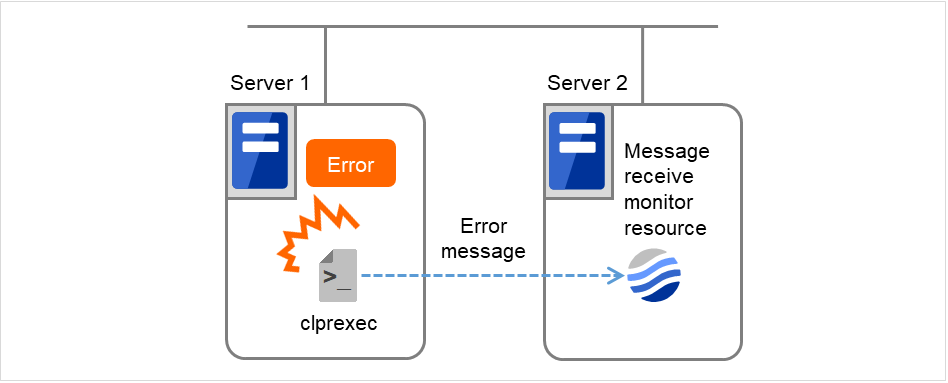
图 6.10 使用消息接收监视资源的配置¶
6.14.4. 与消息接收监视资源相关的注意事项¶
在消息接收监视资源处于暂停状态下接收到外部的异常发生通知时,不执行异常时动作。
接收到外部的异常发生通知时,消息接收监视资源的状态变成"异常"。变成"异常"的消息接收监视资源的状态不会自动恢复到"正常"。如要恢复状态为"正常",请使用clprexec命令。关于clprexec命令,请参考《操作指南》的"EXPRESSCLUSTER X SingleServerSafe 命令参考"。
在接收到外部的异常发生通知后,消息接收监视资源的状态变成"异常"的状态下,接收到异常发生通知时,不执行异常发生时的恢复动作。
6.15. 进程名监视资源的设置¶
进程名监视资源是可以监视任意进程名进程的监视资源。
6.15.1. 监视(固有)标签页¶
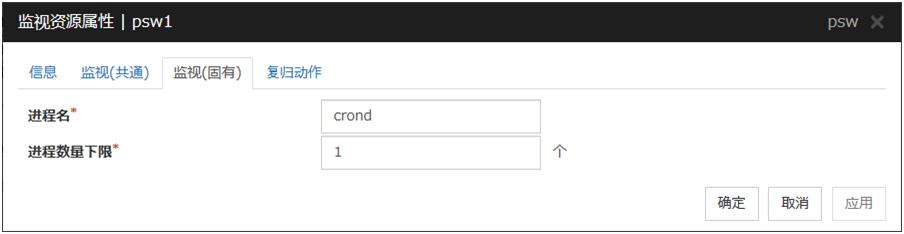
进程名 (1023字节以内)
设置监视对象进程的进程名。进程名通过ps(1)命令的输出结果等来确认。此外,以下3种情况也可指定进程名的通配符。除此之外无法指定。
【前方一致】 <程名所包含的字符串>*
【后方一致】 *<程名所包含的的字符串>
【部分一致】 *<程名所包含的字符串>*
进程数量下限(1~999)
设置作为监视对象的进程的监视个数。如果进程名中设置的监视对象的进程的个数低于设置值时,判断为异常。
6.15.2. 进程名监视资源的注意事项¶
存在多个指定为监视对象的进程名之进程时,按以下条件选择一个进程作为监视对象,并进行监视。
进程间存在主从关系时,监视主进程。
进程间无主从关系时,监视启动时间最早的进程。
若进程间无主从关系,且启动时间也相同,则监视进程ID最小的进程。
同一名称的进程多个存在时,根据进程的启动个数进行监视时,设置监视进程数下限值的个数。低于同一名称进程的设置个数时判断为异常发生。进程数的下限值的个数可指定为1到999之间。进程数下限值设置为1时,选择一个进程作为监视对象,并进行监视。
可指定为监视对象的进程名最多为1023字节。若指定超过1023字节的进程名之进程为监视对象时,使用通配符号(*)进行指定。
监视对象进程的进程名超过1023字节时,可识别的进程名只有前1023字节。使用通配符(*)指定时,请指定小于1023字节的字符串。
若监视对象的进程名过长,则输出到日志中的进程名信息将省略后半部分。
受监视进程的进程名中含有「"」(双引号)或「,」(逗号)时,警报消息可执行无法正确显示进程名。
请使用ps(1)等命令确认实际工作中的进程的进程名后对监视对象进程名进行设置。
执行结果实例
# ps -eaf UID PID PPID C STIME TTY TIME CMD root 1 0 0 Sep12 ? 00:00:00 init [5] : root 5314 1 0 Sep12 ? 00:00:00 /usr/sbin/acpid root 5325 1 0 Sep12 ? 00:00:00 /usr/sbin/sshd htt 5481 1 0 Sep12 ? 00:00:00 /usr/sbin/htt -retryonerror 0
根据以上的命令执行结果,监视/usr/sbin/htt时,指定 /usr/sbin/htt -retryonerror 0为监视对象进程名。
在监视对象进程名中,进程的参数为进程名的一部分来作为监视对象进程的特别指定。指定监视对象进程名时,请指定包括参数在内的进程名。仅监视不含参数的进程名时,请使用通配符号(*)来指定不含参数的前方一致或部分一致。
6.15.3. 进程名监视资源的监视方法¶
指定进程名的进程。进程数的下限值为1时,根据进程名确定进程ID,进程ID消失则判断为异常。无法检测出进程的停止。
进程数的下限值设置为大于1的数值时,根据个数对设置的进程名的进程进行监视。并根据进程名计算出监视对象进程的个数,低于下限值时判断为异常。不能查出进程的停止。
6.16. DB2监视资源的设置¶
DB2监视资源用来监视服务器上运行的DB2数据库。
6.16.1. 监视(固有)标签页¶
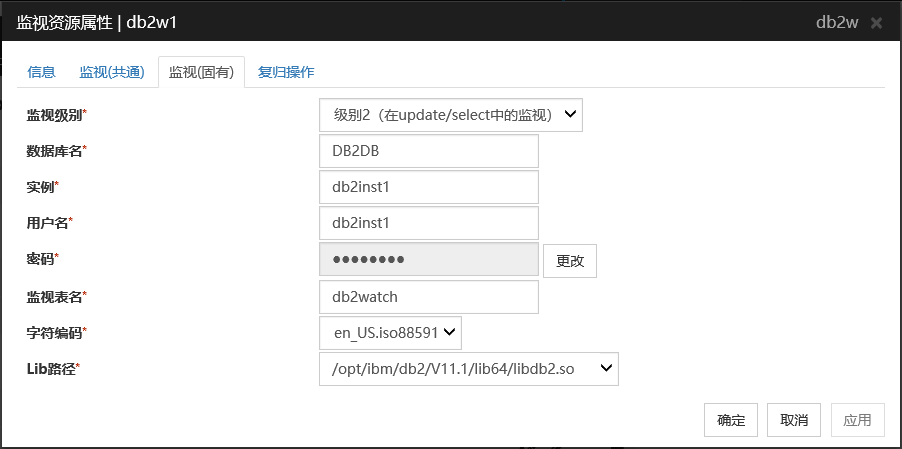
监视级别
从以下选项中选择一项。请务必进行设置。
默认值 :级别2(在update/select中的监视)
数据库名 (255字节以内)
设置要监视的数据库名。请务必设置。
默认值 : 无
实例(255字节以内)
设置要监视的数据库的实例名。请务必设置。
默认值 : db2inst1
用户名 (255字节以内)
设置登录数据库时使用的用户名。请务必设置。请指定可以访问指定数据库的DB2用户。默认值 : db2inst1
密码 (255字节以内)
设置登录数据库时使用的密码。请务必设置。
默认值 :无
监视表名 (255字节以内)
设置在数据库上创建的用于监视的表名。请务必设置。因为该表需要创建和删除,请注意不要与业务用表重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。默认值 : db2watch
字符编码
设置DB2的字符集。请务必设置。
默认值 : 无
Lib路径(1023字节以内)
设置DB2的主页路径。请务必设置。
默认值: /opt/ibm/db2/V11.1/lib64/libdb2.so
6.16.2. DB2监视资源的注意事项¶
有关运行确认完毕的DB2版本,请参考《安装指南》的"2. 关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
本监视资源利用DB2的CLI library,进行DB2的监视。本监视资源若为异常时,请确认指定的DB2的CLI library路径是否存在。
通过参数指定的数据库名/实例/用户名/密码等的值和进行监视的DB2环境不同时,不能进行DB2监视。请根据显示的错误信息确认环境。
以下"6.16.3. DB2监视资源的监视方法"中说明的监视级别中,请注意以下几点。
选择"级别1",且监视开始时没有监视表格,则监视发生错误。请创建以下监视表格。
选择"级别2",且监视开始时没有监视表格,EXPRESSCLUSTER将自动生成监视表格。这时,Cluster WebUI的Alert日志中显示没有监视表格的消息。
选择"级别3"监视时,每次都要创建/删除监视表格,因此监视负载比"级别1""级别2"高。
选择的监视级别 |
事先创建监视表格 |
|---|---|
级别1(在select中的监视) |
有必要 |
级别2(在update/select中的监视) |
无必要 |
级别3(每次都进行create/drop) |
无必要 |
可按以下步骤创建监视表格。
使用SQL语句生成时(以监视表格名为db2watch时为例)
sql> create table <用户名>.db2watch (num int not null primary key) sql> insert into db2watch values(0) sql> commit
使用EXPRESSCLUSTER的命令时
前提条件是,必须完成监视资源设置。
clp_db2w --createtable -n <DB2监视资源名>手动删除创建的监视表格时,请执行以下命令:
clp_db2w --deletetable -n <DB2监视资源名>
6.16.3. DB2监视资源的监视方法¶
DB2监视资源按从以下监视级别中选择的级别进行监视。
级别1(在select中的监视)
该监视只对监视表格进行参照。对监视表格执行的SQL语句为(select )。作为监视结果,如果出现以下情况则视为异常。数据库连接或SQL语句响应中通知异常时
级别2(在update/select中的监视)
该监视还对监视表格进行更新。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(update / select )。监视开始时自动创建监视表格的场合,对监视表格执行的SQL语句为(create/insert)。作为监视结果,如果出现以下情况则视为异常。数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
级别3(每次都进行create/drop)
每次都对监视表格进行更新及创建和删除。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(create / insert / select / drop )。
作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
6.17. FTP监视资源的设置¶
FTP监视资源监视服务器上运行的FTP服务。它监视FTP协议,而不是监视特定的应用程序。因此,可以监视实现了FTP协议的各种应用程序。
6.17.1. 监视(固有)标签页¶
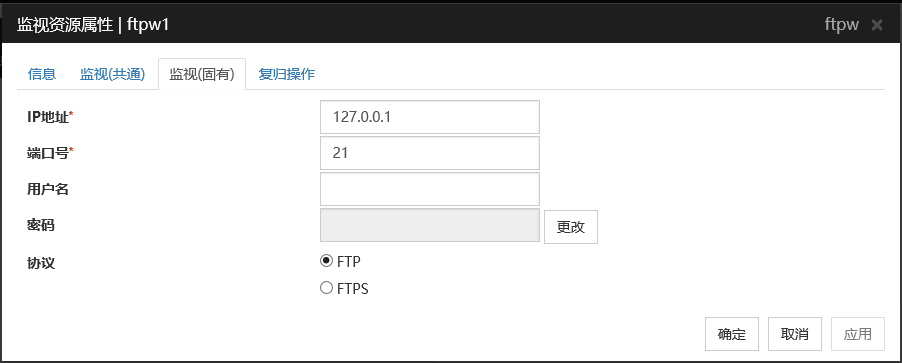
IP地址 (79字节以内)
设置监视的FTP服务器的IP地址。请务必进行设置。
一般情况下连接到在自身服务器中运行的FTP服务器上,因此设置回环地址(127.0.0.1)。但在由于设置了FTP服务器而限制了能够连接的地址时,设置可连接的地址(浮动IP地址等)。
默认值 : 127.0.0.1
端口号 (1~65535)
设置监视的FTP的端口号。请务必进行设置。
默认值 : 21
用户名 (255字节以内)
设置登录FTP时的用户名。
默认值: 无
密码 (255字节以内)
设置登录FTP时的密码。
默认值 :无
协议
设置用于与 FTP 服务器通信的协议。 通常选择 FTP,但如果需要通过 FTP over SSL / TLS 进行连接,请选择 FTPS。
默认值 : FTP
注解
使用 FTPS 需要 OpenSSL 库。
6.17.2. FTP监视资源的注意事项¶
请在监视对象资源中指定启动FTP的exec资源等。在启动对象资源后开始监视。但如果对象资源启动后FTP不能立即运行或其他情况下,请通过[开始监视的等待时间]进行调整。
针对每个监视动作,FTP服务本身会输出运行日志等,请通过FTP侧的设置进行适当控制。
将FTP服务器的FTP消息(横幅,欢迎访问FTP服务器消息等)从既定的设置变更时,有可执行被视为监视异常。
6.17.3. FTP监视资源的监视方法¶
连接FTP服务失败
对FTP命令的响应中通知有异常
6.18. HTTP监视资源的设置¶
HTTP监视资源监视服务器上运行的HTTP Daemon。
6.18.1. 监视(固有)标签页¶
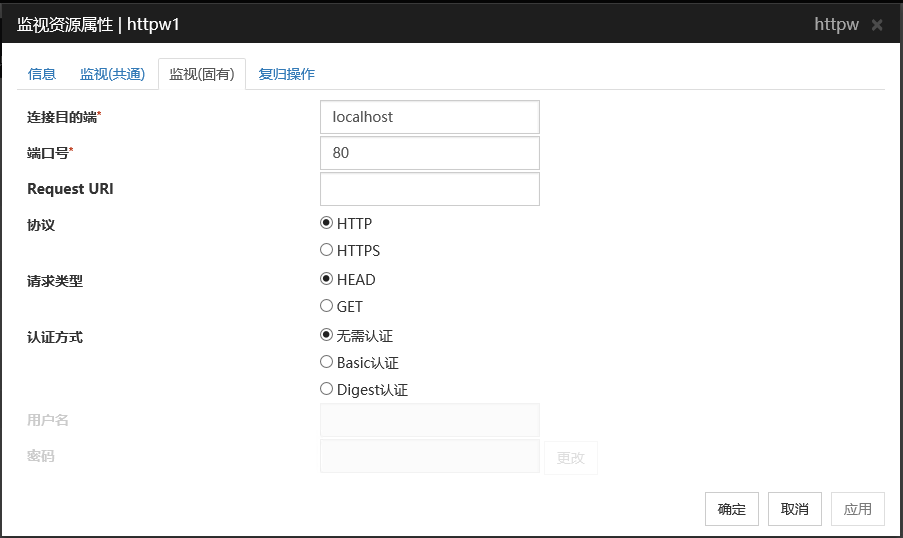
连接目的端(255字节以内)
设置监视的HTTP服务器名。请务必设置。一般情况下连接到在自身服务器中运行的HTTP服务器上,因此设置回环地址(127.0.0.1)。但在由于设置了HTTP服务器而限制了能够连接的地址时,设置可连接的地址(浮动IP地址等)。默认值 : localhost
端口号(1~65535)
设置连接到HTTP服务器时的端口号。请务必设置。
默认值 : 80 (HTTP时)443 (HTTPS时)
Request URI(255字节以内)
设置Request URI(例:"/index.html")。
默认值 : 无
协议
设定与HTTP服务器通信使用的协议。通常选择HTTP,但是需要通过HTTP over SSL连接时选择HTTPS。
默认值 : HTTP
以下,項目追加
注解
要使用HTTPS,需要OpenSSL库。
Request类型
设置连接到HTTP服务器时的HTTP Request的类型。请务必进行设置。
默认值 : HEAD
认证方式
设置连接到 HTTP 服务器时的认证方法。
默认值 : 无需认证
用户名(255字节以内)
设置登录HTTP时的用户名。
默认值 : 无
密码(255字节以内)
设置登录HTTP时的密码。
默认值 : 无
6.18.2. HTTP监视资源的注意事项¶
有关运行确认完毕的HTTP版本,请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
HTTP监视资源不支持客户端验证。
可用于 HTTP 监视资源的 DIGEST 认证的算法是 MD5。
6.18.3. HTTP监视资源的监视方法¶
HTTP监视资源进行以下监视。
连接HTTP daemon时通知异常
应答HTTP request的信息不是以" HTTP/"开头
应答HTTP request的状态代码为400,500时(Request URI指定默认值以外的URI时)
6.19. IMAP4监视资源的设置¶
IMAP4监视资源监视服务器上运行的服务。它监视IMAP4协议,而不是监视特定的应用程序。因此,可以监视实现了IMAP4协议的各种应用程序。
6.19.1. 监视(固有)标签页¶
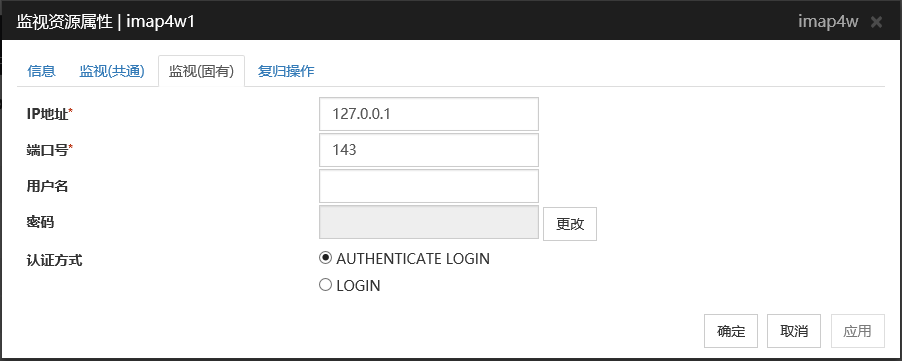
IP地址 (79字节以内)
设置监视的IMAP4服务器的IP地址。请务必进行设置。
一般情况下连接到在自身服务器中运行的IMAP4服务器上,因此设置回环地址(127.0.0.1)。但在由于设置了IMAP4服务器而限制了能够连接的地址时,设置可连接的地址(浮动IP地址等)。
默认值 : 127.0.0.1
端口号 (1~65535)
设置监视的IMAP4的端口号。请务必进行设置。
默认值 : 143
用户名 (255字节以内)
设置登录IMAP4时的用户名。
默认值 : 无
密码 (189字节以内)
设置登录IMAP4时的密码。点击[变更]按钮后,显示密码指定对话框进行设置。
默认值 : 无
认证方式
设置登录IMAP4时的认证方式。需要符合使用的IMAP4的设置。
6.19.2. IMAP4监视资源的注意事项¶
请在监视对象资源中指定启动IMAP4服务器的exec资源等。虽然在启动对象资源后开始进行监视,但如果对象资源启动后IMAP4服务器不能立即运行或其他情况下,请通过[监视开始等待时间]进行调整。
针对每个监视动作,IMAP4服务本身会输出运行日志等,请通过IMAP4服务器侧的设置进行适当控制。
6.19.3. IMAP4监视资源的监视方法¶
连接IMAP4服务失败
对IMAP4命令的响应中通知有异常
6.20. MySQL监视资源的设置¶
MySQL监视资源是监视在服务器上运行的MySQL数据库的监视资源。
6.20.1. 监视(固有)标签页¶
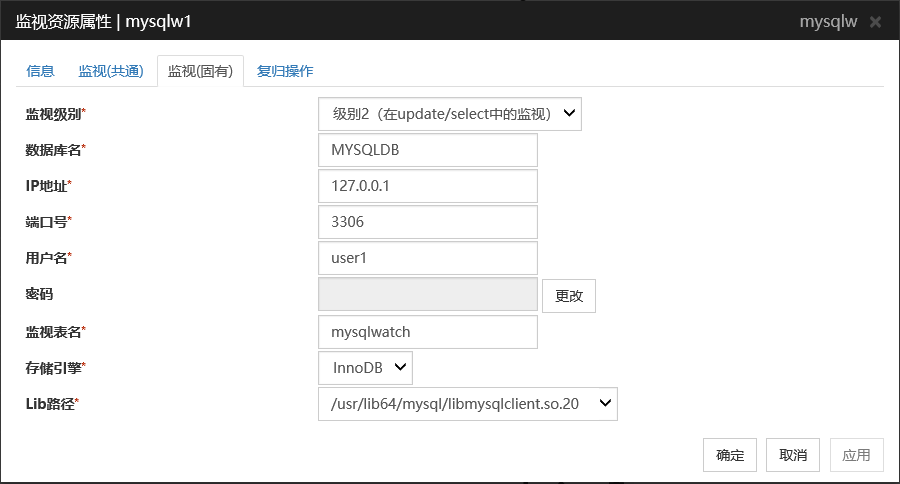
监视级别
从以下选项中选择一项。请务必进行设置。
默认值 :级别2(在update/select中的监视)
数据库名 (255字节以内)
设置要监视的数据库名。请务必设置。
默认值 : 无
IP地址 (79字节以内)
设置连接服务器的IP地址。请务必设置。
默认值 : 127.0.0.1
端口号 (1~65535)
设置连接时的端口号。请务必设置。
默认值: 3306
用户名 (255字节以内)
设置登录数据库时使用的用户名。请务必设置。
请设置可以访问指定数据库的MySQL用户。
默认值 : 无
密码 (255字节以内)
设置登录数据库时使用的密码。
默认值 : 无
监视表名 (255字节以内)
设置在数据库上创建的用于监视的表名。请务必设置。
因为该表需要创建和删除,请注意不要与业务用表重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。默认值: mysqlwatch
存储引擎
设置用于创建监视用表的存储引擎。请务必设置。
默认值: InnoDB
Lib路径 (1023字节以内)
设置MySQL的库路径。请务必设置。
默认值: /usr/lib64/mysql/libmysqlclient.so.20
6.20.2. MySQL监视资源的注意事项¶
有关运行确认完毕的MySQL版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
参数指定值和进行监视的MySQL环境不同时,请根据Cluster WebUI的Alert日志中显示错误信息确认环境。
以下"6.20.3. MySQL监视资源的监视方法"中说明的监视级别中,请注意以下几点。
选择"级别1"且监视开始时没有监视表格,则监视发生错误。请创建以下监视表格。
选择"级别2"且监视开始时没有监视表格,则EXPRESSCLUSTER自动创建监视表格。这时,Cluster WebUI的Alert日志中显示没有监视表格的消息。
选择"级别3"监视时,每次都要创建/删除监视表格,因此监视负载比"级别1""级别2"高。
选择的监视级别 |
事先创建监视表格 |
|---|---|
级别1(在select中的监视) |
有必要 |
级别2(在update/select中的监视) |
无必要 |
级别3(每次都进行create/drop) |
无必要 |
可按以下步骤创建监视表格。
使用SQL语句生成时(以监视表格名为mysqlwatch时为例)
sql> create table mysqlwatch (num int not null primary key) ENGINE=<引擎>; sql> insert into mysqlwatch values(0); sql> commit;
使用EXPRESSCLUSTER的命令时
前提条件是,必须完成监视资源设置。
clp_mysqlw --createtable -n <MySQL监视资源名>手动删除创建的监视表格时,请执行以下命令:
clp_mysqlw --deletetable -n <MySQL监视资源名>
6.20.3. MySQL监视资源的监视方法¶
MySQL监视资源按从以下监视级别中选择的级别进行监视。
- 级别1(在select中的监视)该监视只对监视表格进行参照。对监视表格执行的SQL语句为(select )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
- 级别2(在update/select中的监视)该监视还对监视表格进行更新。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(update / select )。监视开始时自动创建监视表格的场合,对监视表格执行的SQL语句为(create/insert)。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
- 级别3(每次都进行create/drop)每次都对监视表格进行更新及创建和删除。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为( create / insert / select / drop )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
6.21. NFS监视资源的设置¶
NFS监视资源是监视在服务器上运行的NFS的数据库的监视资源。
6.21.1. 监视(固有)标签页¶
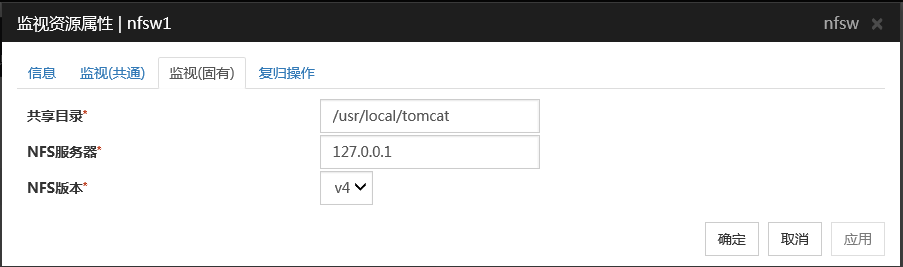
共享目录 (1023字节以内)
设置文件共享目录。请务必设置。
默认值 : 无
NFS服务器 (255字节以内)
设置进行NFS监视的服务器的IP地址。请务必设置。
默认值: 127.0.0.1
NFS版本
从选择项中选择一个执行NFS监视的NFS版本。请务必设置。RHEL 7不支持NFS版本v2。
默认值:v4
6.21.3. NFS监视资源的注意事项¶
有关运行确认完毕的NFS版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
有关监视的共享目录,为了可以从自身服务器连接请设置exports文件。
"监视(固有)"tab - "NFS版本"中指定的版本的nfsd,或者nfsd对应的mountd被检出消失时,被视作发生异常。nfsd对应的mountd如下。
nfsd版本 |
mountd版本 |
|---|---|
v2 (udp) |
v1 (tcp) 或 v2 (tcp) |
v3 (udp) |
v3 (tcp) |
v4 (tcp) |
- |
6.21.4. NFS监视资源的监视方法¶
NFS服务的要求的应答结果异常时
mountd 失效时 (NFS v4除外)
nfsd失效时
rpcbind服务停止时
export的领域失效时 (NFS v4除外)
6.22. ODBC监视资源的设置¶
ODBC监视资源是监视在服务器上运行的ODBC数据库的监视资源。
6.22.1. 监视(固有)标签页¶
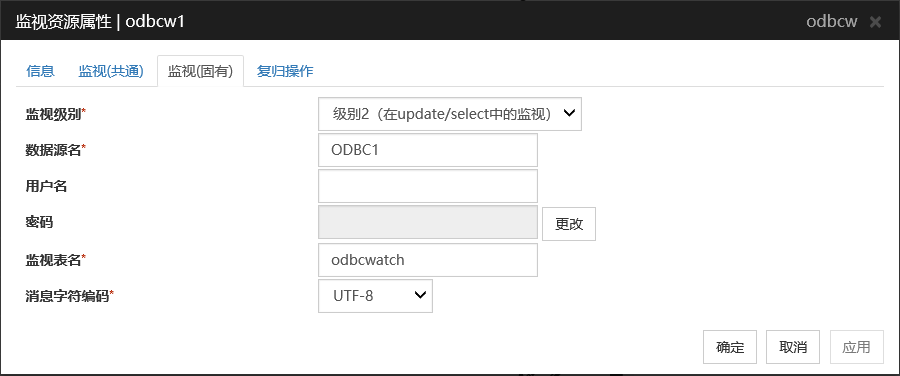
监视级别
从以下选项中选择一项。请务必进行设置。
默认值 :级别2(在update/select中的监视)
数据源名 (255字节以内)
设置要监视的数据源名。请务必设置。
默认值 : 无
用户名 (255字节以内)
设置登录数据库时使用的用户名。在odbc.ini中设置了用户名的场合,这里不需要指定。默认值 : 无
密码 (255字节以内)
设置登录数据库时使用的密码。
默认值 : 无
监视表名 (255字节以内)
设置在数据库上创建的用于监视的表名。请务必设置。
因为该表需要创建和删除,请注意不要与业务用表重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。默认值: odbcwatch
消息字符编码
设置数据库的消息字符编码。
默认值 : UTF-8
6.22.2. ODBC监视资源的注意事项¶
由于监控进程使用unixODBC驱动程序管理器,请事先安装要监控的数据库的ODBC驱动程序,并将数据源的设定设置到odbc.ini中。
参数指定值和进行监视的数据库环境不同时,请根据Cluster WebUI的Alert日志中显示错误信息确认环境。
以下"6.22.3. ODBC监视资源的监视方法"中说明的监视级别中,请注意以下几点。
选择"级别1"且监视开始时没有监视表格,则监视发生错误。请创建以下监视表格。
选择"级别2"且监视开始时没有监视表格,则EXPRESSCLUSTER自动创建监视表格。这时,Cluster WebUI的Alert日志中显示没有监视表格的消息。
选择"级别3"监视时,每次都要创建/删除监视表格,因此监视负载比"级别1""级别2"高。
选择的监视级别 |
事先创建监视表格 |
|---|---|
级别1(在select中的监视) |
有必要 |
级别2(在update/select中的监视) |
无必要 |
级别3(每次都进行create/drop) |
无必要 |
可按以下步骤创建监视表格。
监视表格名可以指定英文数字,部分符号(下划线等)。
(以监视表格名为odbcwatch时为例)
sql> create table odbcwatch (num int not null primary key); sql> insert into odbcwatch values(0); sql> commit;
使用EXPRESSCLUSTER的命令时
前提条件是,必须完成监视资源设置。
clp_odbcw --createtable -n <ODBC监视资源名>手动删除创建的监视表格时,请执行以下命令:
clp_odbcw --deletetable -n <ODBC监视资源名>
6.22.3. ODBC监视资源的监视方法¶
ODBC监视资源按从以下监视级别中选择的级别进行监视。
- 级别1(在select中的监视)该监视只对监视表格进行参照。对监视表格执行的SQL语句为(select )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
- 级别2(在update/select中的监视)该监视还对监视表格进行更新。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(update / select )。监视开始时自动创建监视表格的场合,对监视表格执行的SQL语句为(create/insert)。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
- 级别3(每次都进行create/drop)每次都对监视表格进行更新及创建和删除。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为( create / insert / select / drop )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
6.23. Oracle监视资源的设置¶
Oracle监视资源用来监视服务器上运行的Oracle数据库。
6.23.1. 监视(固有)标签页¶
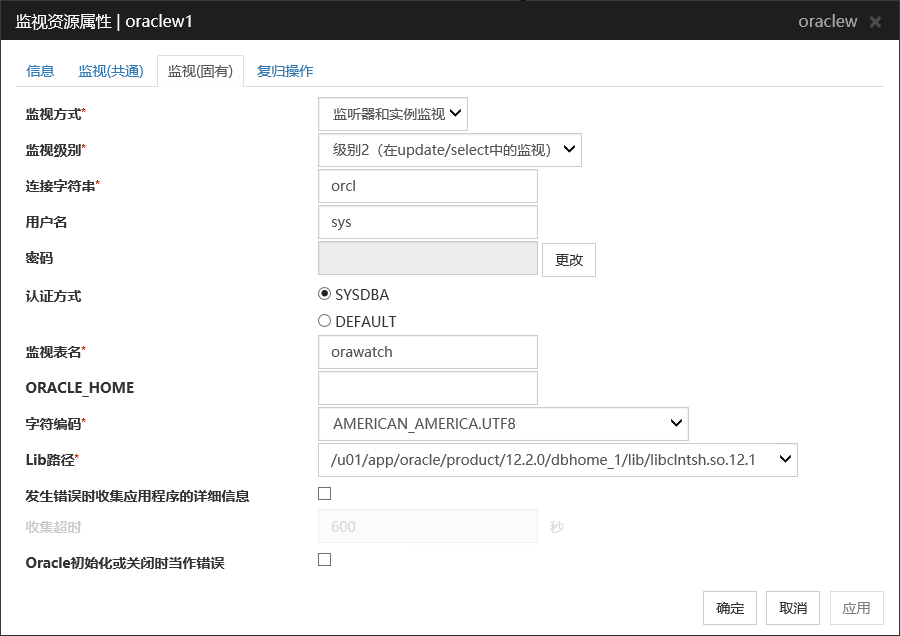
监视方式
选择作为监视对象的Oracle功能。
监视级别
从以下选项中选择一项。监视方式为"只监视监听器"时,会忽略本设置。
默认值 :级别2(在update/select中的监视)
连接字符串 (255字节以内)
设置要监视的数据库的连接字符串。请务必设置。监视方式为"只监视实例"时,设置ORACLE_SID。
监视方式
ORACLE_HOME
连接字符串
监视级别
监视监听器和实例
不输入
指定连接字符串
按设置的级别监视
只监视监听器
已输入时,使用Oracle的命令监视
指定连接字符串
按设置的级别监视
未输入时,确认经由监听器的实例连接
指定连接字符串
忽略级别设置
只监视实例
已输入时,通过BEQ连接确认实例
指定ORACLE_SID
按设置的级别监视
未输入时,确认经由监听器的实例
指定连接字符串
按设置的级别监视
默认值 :无连接字符串的默认值
用户名 (255字节以内)
指定登录数据库时使用的用户名。请务必设置。请指定可以访问指定数据库的Oracle用户。默认值 : sys
密码 (255字节以内)
设置登录数据库时使用的密码。
默认值 :无
认证方式
设置数据库认证方式。
默认值 : SYSDBA
监视表名 (255字节以内)
设置在数据库上创建的用于监视的表名。请务必设置。因为该表需要创建和删除,请注意不要与业务用表重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。默认值 : orawatch
ORACLE_HOME(255字节以内)
指定ORACLE_HOME设置的路径名。 需要以[/] 开头。监视方式选择了「只监视监听器」「只监视实例」时使用。
默认值:无
字符编码
设置Oracle的字符集。请务必设置。
默认值 : JAPANESE_JAPAN.JA16EUC
Lib路径 (1023字节以内)
设置Oracle Call Interface(OCI)的库路径。请务必设置。
默认值 : /u01/app/oracle/product/12.2.0/dbhome_1/lib/libclntsh.so.12.1
发生错误时收集应用程序的详细信息
本功能设为有效的情况下,Oracle监视资源检出异常时,Oracle的详细信息将被采集。详细信息最多采集5次。
注解
在采集过程中,如果发生由集群停止所导致的Oracle服务的终止,有可执行无法采集到正确的信息。
默认值 : 无效
收集超时
设置收集详细信息时的超时时间。
默认值: 600
Oracle初始化或关闭时当做错误
使用本功能的时候,Oracle的初始化或关闭中的状态被检出时,直接被视作监视错误。当使用Oracle Clusterware等联动功能,使Oracle在运行过程中自动重启的场合,请关闭此功能。这样Oracle在初始化或关闭的状态下监视变为正常。但是Oracle的初始化或关闭的状态持续1小时以上时,监视变为错误。默认值:无效
6.23.2. Oracle监视资源的注意事项¶
有关运行确认完毕的Oracle版本,请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
本监视资源利用Oracle的接口(Oracle Call Interface),进行Oracle的监视。因此,必须在进行监视的服务器上安装用于接口的库(libclntsh.so)。
通过参数指定的连接字符串/用户名/密码等的值和进行监视的Oracle环境不同时,不能进行Oracle监视。请根据各错误信息确认环境。
指定为参数用户名的用户默认为sys,但另外创建用于监视的用户时,各监视级别需授予以下访问权限。(不授予sysdba权限时)
选择的监视级别 |
事先创建监视表格 |
|---|---|
级别0(数据库状态) |
无必要 |
级别1(在select中的监视) |
有必要 |
级别2(在update/select中的监视) |
无必要 |
级别3(每次都进行create/drop) |
无必要 |
用户名指定为 sys 时,可执行输出 Oracle 的监察日志。如果不想大量输出监察日志时,请指定为 sys 以外的用户名。
"字符编码"的设置不影响Oracle自身的运行。
EXPRESSCLUSTER向OS的messages(syslog)登录1字节以外(ANK字符除外)的字符时,通常以EUC编码登录。因此,根据使用的Distribution不同,非EUC的messages(syslog)字符编码可执行会出现乱码,无法正确显示。
(Cluster WebUI的警报日志并没有问题。)
为防止出现乱码,请选择将"字符编码"设为AMERICAN_AMERICA.US7ASCII或AMERICAN_AMERICA.UTF8(使用ANK字符的语言)。
设置示例:
- 希望用日语表示时请选择以JAPANESE_JAPAN开始的字符集。
- 希望用英语表示时请选择以AMERICAN_AMERICA开始的字符集。
以下"6.23.3. Oracle监视资源的监视方法"中说明的监视级别中,请注意以下几点。
选择"级别1",且监视开始时没有监视表格,则监视发生错误。请创建以下监视表格。
选择"级别2",且监视开始时没有监视表格,EXPRESSCLUSTER将自动生成监视表格。这时,Cluster WebUI的Alert日志中显示没有监视表格的消息。
选择"级别3"监视时,每次都要创建/删除监视表格,因此监视负载比"级别1""级别2"高。又因为Oracle的资源使用量持续增加,所以除了定期重启Oracle实例的运用外,不建议设置"级别3"的监视。
选择的监视级别 |
事先创建监视表格 |
|---|---|
级别0(数据库状态) |
无必要 |
级别1(在select中的监视) |
有必要 |
级别2(在update/select中的监视) |
无必要 |
级别3(每次都进行create/drop) |
无必要 |
可按以下步骤创建监视表格。
使用SQL语句创建时
sql> create table orawatch (num number(11,0) primary key); sql> insert into orawatch values(0); sql> commit;※请创建指定为参数用户名的用户架构
利用EXPRESSCLUSTER的命令时
前提条件是,必须完成监视资源设置。
clp_oraclew --createtable -n <Oracle监视资源名>※在参数的用户名中指定的用户是sys以外没有授予sysdba权限的用户时,需要CREATE TABLE权限。手动删除作成的监视表格,请执行以下命令:clp_oraclew --deletetable -n <Oracle监视资源名>
6.23.3. Oracle监视资源的监视方法¶
Oracle监视资源按从以下监视级别中选择的级别进行监视。
- 级别0(数据库状态)参考Oracle的管理表格(V$INSTANCE表格),确认DB的状态(实例的状态)。该监视为简单监视,不对监视表格执行SQL语句。作为监视结果,如果出现以下情况则视为异常。
Oracle 的管理表( V$INSTANCE 表)的状态( status )为未启动状态( MOUNTED,STARTED )时
Oracle 的管理表( V$INSTANCE 表)的数据库状态( database_status )为未启动状态( SUSPENDED,INSTANCE RECOVERY )时
- 级别1(在select中的监视)该监视只对监视表格进行参照。对监视表格执行的SQL语句为(select )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
- 级别2(在update/select中的监视)该监视还对监视表格进行更新。通过SQL语句,对最大为5位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(update / select )。监视开始时自动创建监视表格的场合,对监视表格执行的SQL语句为(create/insert)。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
- 级别3(每次都进行create/drop)每次都对监视表格进行更新及创建和删除。通过SQL语句,对最大为5位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(create / insert / select / drop )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
6.24. POP3监视资源的设置¶
POP3监视资源用来监视服务器上运行的POP3服务。它监视POP3协议,而不是监视特定的应用程序。因此,可以用来监视实现了POP3协议的各种应用程序。
6.24.1. 监视(固有)标签页¶
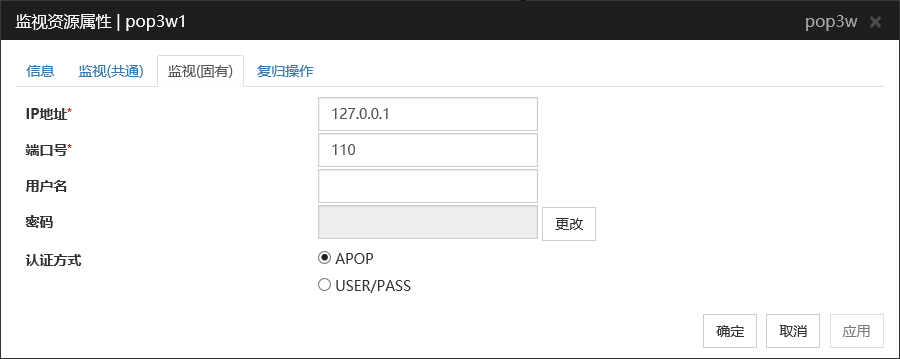
IP地址 (79字节以内)
设置监视的POP3服务器的IP地址。请务必进行设置。
一般情况下连接到在自身服务器中工作的POP3服务器上,因此设置回环地址(127.0.0.1)。但在由于设置了POP3服务器而限制了能够连接的地址时,设置可连接的地址(浮动IP地址等)。
默认值: 127.0.0.1
端口号 (1~65535)
设置监视的POP3的端口号。请务必进行设置。
默认值 : 110
用户名 (255字节以内)
设置登录POP3时的用户名。
默认值 : 无
密码 (255字节以内)
设置登录POP3时的密码。点击[更改]按钮后,显示密码指定对话框进行设置。
默认值 : 无
认证方式
选择登录POP3时的认证方式。需要结合使用的POP3的设置。
6.24.2. POP3监视资源的注意事项¶
请在监视对象资源中指定启动POP3的exec资源等。在启动对象资源后开始监视。但如果对象资源启动后POP3不能立即运行或其他情况下,请通过[监视开始等待时间]进行调整。
针对每个监视动作,POP3服务本身会输出运行日志等,请通过POP3侧的设置进行适当控制。
6.24.3. POP3监视资源的监视方法¶
连接POP3服务器失败
对命令的响应中通知有异常
6.25. PostgreSQL监视资源的设置¶
PostgreSQL监视资源用来监视服务器上运行的PostgreSQL数据库。
6.25.1. 监视(固有)标签页¶
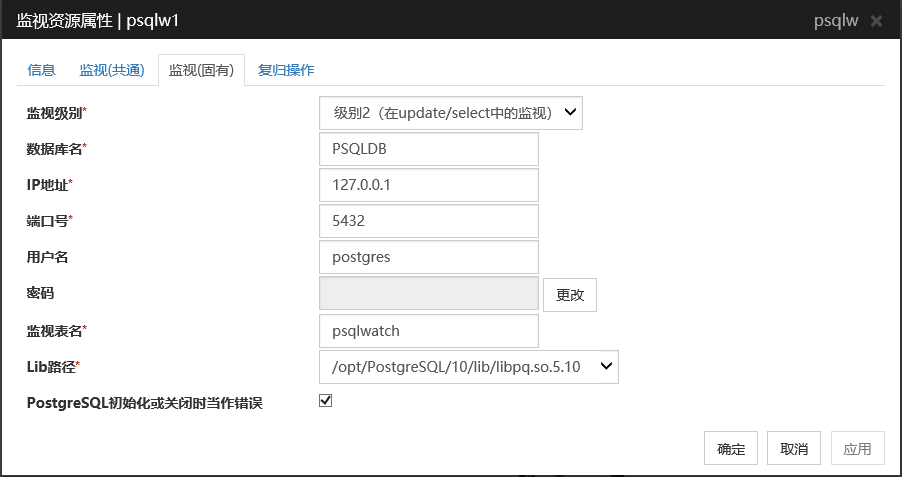
监视级别
从以下选项中选择一项。请务必进行设置。
默认值 :级别2(在update/select中的监视)
数据库名 (255字节以内)
设置要监视的数据库名。请务必设置。
默认值 : 无
IP地址 (79字节以内)
设置连接服务器的IP地址。请务必设置。
默认值: 127.0.0.1
端口号 (1~65535)
设置连接时的端口号。请务必设置。
默认值 : 5432
用户名 (255字节以内)
设置登录数据库时使用的用户名。请务必设置。请指定可以访问指定数据库的PostgreSQL用户。默认值 : postgres
密码 (255字节以内)
设置登录数据库时使用的密码。
默认值 : 无
监视表名 (255字节以内)
设置在数据库上创建的用于监视的表名。请务必设置。
因为该表需要创建和删除,请注意不要与业务用表重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。默认值 : psqlwatch
Lib路径 (1023字节以内)
设置PostgreSQL的库路径。请务必设置。
默认值 : /opt/PostgreSQL/10/lib/libpq.so.5.10
在PostgreSQL的初始化或关闭时当作错误
将本功能设为有效时,若检测出PostgreSQL 的初始化中或关机中的状态,则马上变为监视错误。将本功能设为无效时,即使检测出PostgreSQL 的初始化中或关机中的状态,也变为监视正常。但若经过1小时以上,PostgreSQL的初始化中或关机中的状态依然持续,则变为监视错误。默认值 : 有效
6.25.2. PostgreSQL监视资源的注意事项¶
有关运行确认完毕的PostgreSQL版本,请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
参数指定值和进行监视的PostgreSQL环境不同时,请根据Cluster WebUI的警报日志中显示错误信息确认环境。
YYYY-MM-DD hh:mm:ss JST moodle moodle LOG: statement: DROP TABLE psqlwatch YYYY-MM-DD hh:mm:ss JST moodle moodle ERROR: table "psqlwatch" does not exist YYYY-MM-DD hh:mm:ss JST moodle moodle STATEMENT: DROP TABLE psqlwatch YYYY-MM-DD hh:mm:ss JST moodle moodle LOG: statement: CREATE TABLE psqlwatch (num INTEGER NOT NULL PRIMARY KEY) YYYY-MM-DD hh:mm:ss JST moodle moodle NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "psqlwatch_pkey" for table "psql watch" YYYY-MM-DD hh:mm:ss JST moodle moodle LOG: statement: DROP TABLE psqlwatch
选择的监视级别 |
事先创建监视表格 |
|---|---|
级别1(在select中的监视) |
有必要 |
级别2(在update/select中的监视) |
无必要 |
级别3(每次都进行create/drop) |
无必要 |
可按以下步骤创建监视表格。
使用SQL语句生成时(以监视表格名为psqlwatch时为例)
sql> CREATE TABLE psqlwatch ( num INTEGER NOT NULL PRIMARY KEY); sql> INSERT INTO psqlwatch VALUES(0) ; sql> COMMIT;
使用EXPRESSCLUSTER的命令时
前提条件是,必须完成监视资源设置。
clp_psqlw --createtable -n <PostgreSQL监视资源名>手动删除创建的监视表格时,请执行以下命令:
clp_psqlw --deletetable -n <PostgreSQL监视资源名>
6.25.3. PostgreSQL监视资源的监视方法¶
PostgreSQL监视资源按从以下监视级别中选择的级别进行监视。
- 级别1(在select中的监视)该监视只对监视表格进行参照。对监视表格执行的SQL语句为(select )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
- 级别2(在update/select中的监视)该监视还对监视表格进行更新。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(update / select / reindex / vacuum)。监视开始时自动创建监视表格的场合,对监视表格执行的SQL语句为(create/insert)。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
- 级别3(每次都进行create/drop)每次都对监视表格进行更新及创建和删除。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(create / insert / select / reindex / drop / vacuum)。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
6.26. Samba监视资源的设置¶
Samba监视资源是监视在服务器上运行的Samba文件服务器的监视资源。
6.26.1. 监视(固有)标签页¶
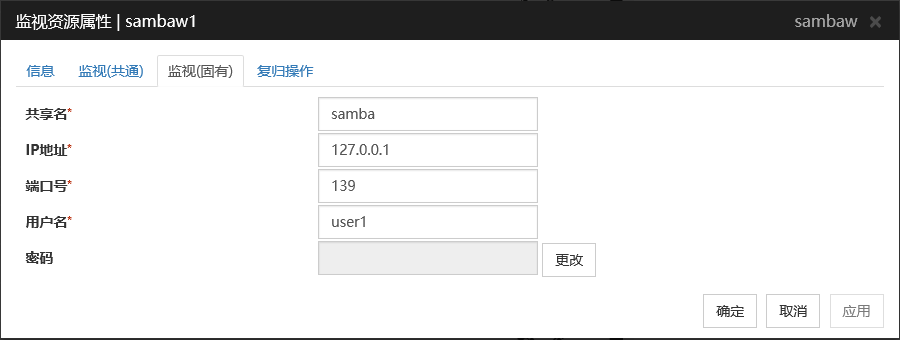
共享名 (255字节以内)
设置进行监视的Samba服务器的共享名。请务必设置。
默认值 : 无
IP地址 (79字节以内)
设置Samba服务器的IP地址。请务必设置。
端口号 (1~65535)
设置Samba daemon使用的端口号。请务必设置。libsmbclient的版本是3 以下时(例.RHEL 6 与 libsmbclient.so捆绑),[端口号]只能指定139或445。smb.conf 的 smb ports 也请指定相同的值。
默认值: 139
用户名 (255字节以内)
设置登录Samba服务时的用户名。请务必设置。
默认值 : 无
密码 (255字节以内)
设置登录Samba服务时的密码。
默认值 : 无
6.26.2. Samba监视资源的注意事项¶
有关运行确认完毕的Samba版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
本监视资源异常时,可执行参数的设置值和Samba环境不一致,请确认环境。
有关监视共享名,请将smb.conf设置为可以从自身服务器连接。另外,smb.conf文件的security参数为share时,请将guest connection设置为有效。
不监视有关文件共享,打印机共享以外的Samba功能。
Samba的认证模式为Domain或Server时,在监视服务器上执行smbmount,有时因本监视资源的参数指定的用户名而被mount。
6.26.3. Samba监视资源的监视方法¶
对于Samba服务的要求的应答内容不正确时
6.27. SMTP监视资源的设置¶
SMTP监视资源是监视在服务器上运行的SMTP Daemon的监视资源。
6.27.1. 监视(固有)标签页¶
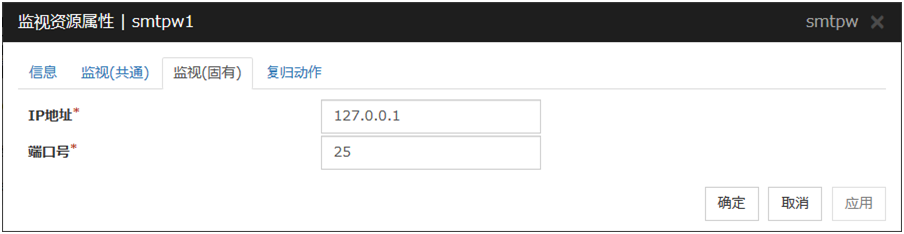
IP地址 (79字节以内)
设置监视的SMTP服务器的IP地址。请务必设置。
默认值: 127.0.0.1
端口号 (1~65535)
设置连接SMTP服务器时的端口号。请务必设置。
默认值 : 25
6.27.2. SMTP监视资源的注意事项¶
有关运行确认完毕的SMTP版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
平均负载超过sendmail.def文件中设置的RefuseLA值时的状态持续一定时间,本监视资源视为异常,进行失效切换。
6.27.3. SMTP监视资源的监视方法¶
SMTP daemon的连接或NOOP命令的响应中通知异常时
6.28. SQL Server监视资源的设置¶
SQL Server监视资源是监视在服务器上运行的SQL Server数据库的监视资源。
6.28.1. 监视(固有)标签页¶
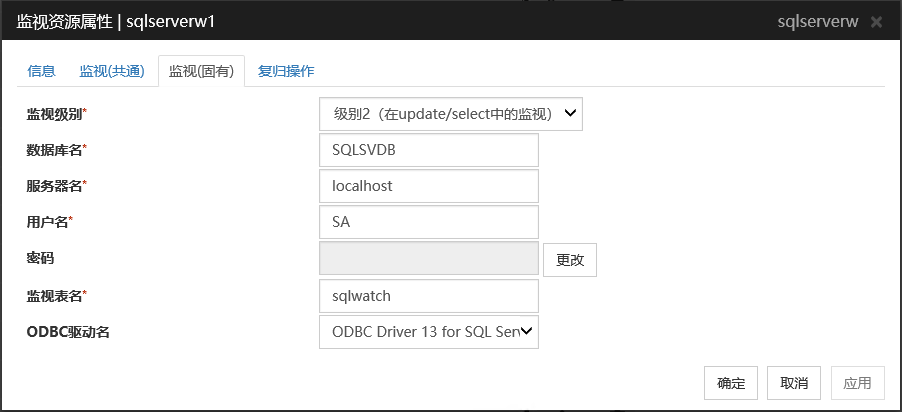
监视级别
从以下选项中选择一项。请务必进行设置。
默认值 :级别2(在update/select中的监视)
数据库名 (255字节以内)
设置要监视的数据库名。请务必设置。
默认值 : 无
服务器名 (255字节以内)
设置要监视的数据库的服务器名。请务必设置。
默认值 : localhost
用户名 (255字节以内)
设置登录数据库时使用的用户名。请务必设置。请设置可以访问指定数据库的SQL Server用户。默认值 : SA
密码 (255字节以内)
设置登录数据库时使用的密码。请务必设置。
默认值 : 无
监视表名 (255字节以内)
设置在数据库上创建的用于监视的表名。请务必设置。因为该表需要创建和删除,请注意不要与业务用表重名。另外,还需要注意不要与SQL语句的保留字重复。根据数据库的式样,监视的表名有不能设置的字符。详细请确认数据库的式样。默认值: sqlwatch
ODBC驱动名(255字节以内)
设置SQL Server的ODBC驱动的名称。请务必设置。
默认值: ODBC Driver 13 for SQL Server
6.28.2. SQL Server监视资源的注意事项¶
有关运行确认完毕的SQL Server版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
本监视资源利用Microsoft ODBC Driver for SQL Server,进行SQL Server监视。
参数指定值和进行监视的SQL Server环境不同时,请根据Cluster WebUI的警报日志中显示错误信息确认环境。
选择的监视级别 |
事先创建监视表格 |
|---|---|
级别0(数据库状态) |
无必要 |
级别1(在select中的监视) |
有必要 |
级别2(在update/select中的监视) |
无必要 |
级别3(每次都进行create/drop) |
无必要 |
可按以下步骤创建监视表格。
监视表格名可以指定英文数字,部分符号(下划线等)。
使用SQL语句生成时(以监视表格名为sqlwatch时为例)
SET IMPLICIT_TRANSACTIONS打开时
sql> CREATE TABLE sqlwatch (num INT NOT NULL PRIMARY KEY) sql> GO sql> INSERT INTO sqlwatch VALUES(0) sql> GO
SET IMPLICIT_TRANSACTIONS关闭时
sql> CREATE TABLE sqlwatch (num INT NOT NULL PRIMARY KEY) sql> GO sql> INSERT INTO sqlwatch VALUES(0) sql> GO sql> COMMIT sql> GO
使用EXPRESSCLUSTER的命令时
前提条件是,必须完成监视资源设置。
clp_sqlserverw --createtable -n <SQL Server监视资源名>手动删除创建的监视表格时,请执行以下命令:
clp_sqlserverw --deletetable -n <SQL Server监视资源名>
6.28.3. SQL Server监视资源的监视方法¶
SQL Server监视资源按从以下监视级别中选择的级别进行监视。
- 级别0(数据库状态)参考SQL Server的管理表格,确认DB的状态。该监视为简单监视,不对监视表格执行SQL语句。作为监视结果,如果出现以下情况则视为异常。
数据库状态不是online时
- 级别1(在select中的监视)该监视只对监视表格进行参照。对监视表格执行的SQL语句为(select )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
- 级别2(在update/select中的监视)该监视还对监视表格进行更新。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为(update / select )。监视开始时自动创建监视表格的场合,对监视表格执行的SQL语句为(create/insert)。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
- 级别3(每次都进行create/drop)每次都对监视表格进行更新及创建和删除。通过SQL语句,对最大为10位的数值数据进行写入和读入操作。对监视表格执行的SQL语句为( create / insert / select / drop )。作为监视结果,如果出现以下情况则视为异常。
数据库连接或SQL语句响应中通知异常时
写入和读入的数据不一致时
6.29. Tuxedo监视资源的设置¶
Tuxedo监视资源是监视在服务器上运行的Tuxedo的监视资源。
6.29.1. 监视(固有)标签页¶
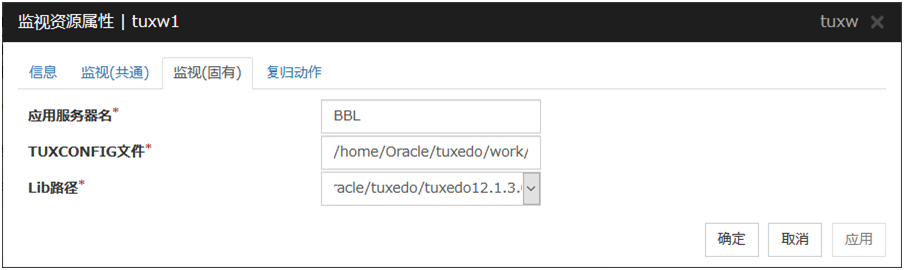
应用服务器名 (255字节以内)
设置监视的应用程序服务器名。请务必设置。
默认值: BBL
TUXCONFIG文件名 (1023字节以内)
设置Tuxedo的配置文件名。请务必设置。
默认值: 无
Lib路径 (1023字节以内)
设置Tuxedo的库路径。请务必设置。
默认值: /home/Oracle/tuxedo/tuxedo12.1.3.0.0/lib/libtux.so
6.29.2. Tuxedo监视资源的注意事项¶
有关运行确认完毕的Tuxedo版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
Tuxedo的库(libtux.so等)不存在时,不能进行监视。
6.29.3. Tuxedo监视资源的监视方法¶
(1)连接应用程序服务器或对状态取得的应答中通知异常时
6.30. WebLogic监视资源的设置¶
WebLogic监视资源是监视在服务器上运行的WebLogic的监视资源。
6.30.1. 监视(固有)标签页¶
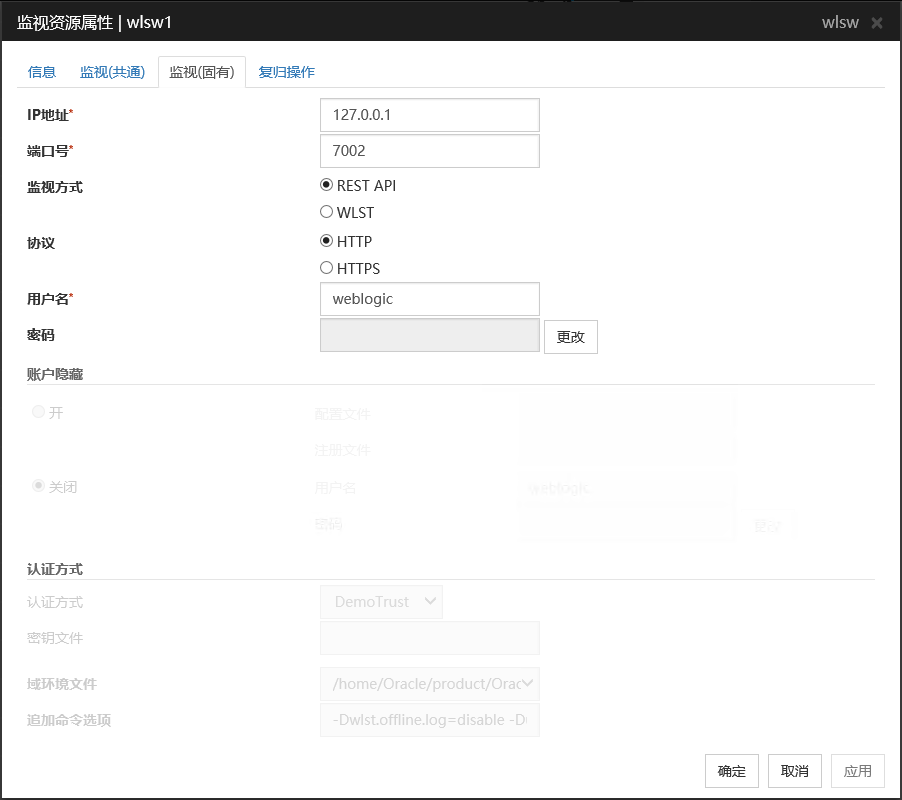
IP地址 (79字节以内)
设置监视的WebLogic服务器的IP地址。请务必设置。
默认值: 127.0.0.1
端口号 (1~65535)
设置连接服务器时的端口号。请务必设置。
默认值 : 7002
监视方式
设置服务器的监视方式。请务必设置。
默认值 : RESTful API
协议
设置要监视的服务器的协议。[监视方式]中选择RESTful API时,请务必选择。
默认值 : HTTP
注解
请在RHEL8环境中设置HTTP。
用户名 (255字节以内)
设置WebLogic的用户名。[监视方式]中选择RESTful API时,请务必输入。
默认值 : weblogic
密码 (255字节以内)
设置WebLogic的密码。[监视方式]中选择RESTful API时,如有必要请输入。
默认值 : 无
帐户隐藏
直接设置用户名和密码时为[关闭],记述到文件内时为[开]。请务必设置。
默认值 : 关闭
配置文件 (1023字节以内)
设置保存用户信息的文件名。帐户Shadow为 [开]时,请务必设置。
默认值 : 无
注册文件 (1023字节以内)
将保存用于访问配置文件路径的密码的文件名以全路径设置。帐户Shadow 为[开]时,请务必设置。
默认值 : 无
用户名 (255字节以内)
设置WebLogic的用户名。帐户Shadow为 [关闭]时,请务必设置。
默认值 :weblogic
密码 (255字节以内)
设置WebLogic的密码。
默认值 : 无
认证方式
设置连接应用程序服务器时的认证方式。请务必设置。如果想使用SSL通信进行监视时,[认证方式]请指定为[DemoTrust]或[CustomTrust]。是否选择[DemoTrust]或[CustomTrust]取决于WebLogic Administraion Console上的设置。如果WebLogic Administraion Console的[Keystore]是[Demo Identity and Demo Trust],请指定[DemoTrust]。在这种情况下,不必设置[密钥文件]。如果WebLogic Administraion Console的[Keystore]是[Custom Identity and Custom Trust],请指定[CustomTrust]。在这种情况下,必须设置[密钥文件]。默认值 : DemoTrust
密钥文件 (1023字节以内)
设置SSL认证时的认证文件。认证方式为[CustomTrust]时,请务必设置。请设置WebLogic Administraion Console上的[Custom Identity Keystore]处指定的文件。默认值 : 无
域环境文件 (1023字节以内)
设置WebLogic的域环境文件名。请务必设置。
默认值 :/home/Oracle/product/Oracle_Home/user_projects/domains/base_domain/bin/setDomainEnv.sh
追加命令选项(1023字节以内)
变更向[webLogic.WLST] 命令的传递选项时设置。
默认值: -Dwlst.offline.log=disable -Duser.language=en_US
6.30.2. WebLogic监视资源的注意事项¶
有关运行确认完毕的WebLogic版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
在本监视资源中选择 [WLST] 为监视方式时,为了进行监视必须具备Java环境。因为应用程序服务器系统利用了Java的功能,有时发生Java的死机时也视为异常。
由于WebLogic启动时若无法立即运行则视作异常,请通过[监视开始等待时间]进行调整。或者请先启动WebLogic(例:在监视的对象资源上指定启动WebLogic的EXEC资源)。
在RHEL8 环境下,如果监视方法选择[RESTful API],请将协议设置为[HTTP]。
6.30.3. WebLogic监视资源的监视方法¶
WebLogic监视资源进行以下监视。
监视方式:选择RESTful API 时
WebLogic提供了称为WebLogic RESTful管理服务的RESTful API。
通过此RESTful API执行应用程序服务器监视。
作为监视结果,当以下应答通知异常时都视为异常。
RESTful API 的应答中通知异常时
注解
监视方式:与WLST相比,可以减少监视时应用程序服务器的CPU负荷。
监视方式:选择WLST时
利用[weblogic.Admin]命令或[weblogic.WLST]命令执行connect,执行应用程序服务器监视。[weblogic.Admin]命令可执行时,执行[weblogic.Admin]命令。[weblogic.Admin]命令不可执行时,执行[weblogic.WLST]命令。
作为监视结果,如果出现以下情况则视为异常。
connect应答中通知异常时
根据不同的[认证方式]执行以下的动作。
DemoTrust: 使用WebLogic的Demo用认证文件的SSL认证方式
CustomTrust: 使用用户做成的认证文件的SSL认证方式
Not Use SSL: 不执行SSL认证
6.31. WebSphere监视资源的设置¶
WebSphere监视资源是监视在服务器上运行的WebSphere的监视资源。
6.31.1. 监视(固有)标签页¶
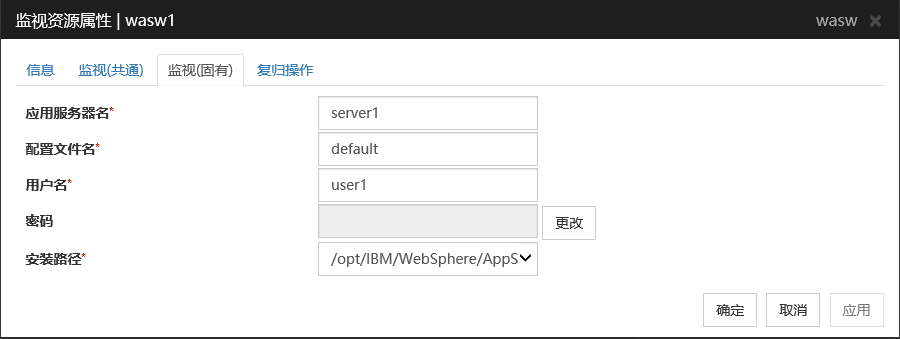
应用服务器名 (255字节以内)
设置监视的应用程序服务器名。请务必设置。
默认值 : server1
配置文件名 (1023字节以内)
设置监视的应用程序服务器的配置文件名。请务必设置。
默认值 : default
用户名 (255字节以内)
设置WebSphere的用户名。请务必设置。
默认值 :无
密码 (255字节以内)
设置WebSphere的密码。
默认值 : 无
安装路径 (1023字节以内)
设置WebSphere的安装路径。请务必设置。
默认值 : /opt/IBM/WebSphere/AppServer
6.31.2. WebSphere监视资源的注意事项¶
有关运行确认完毕的WebSphere版本请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
为了通过本监视资源进行监视,必须JAVA环境。因为应用程序服务器系统利用了JAVA的功能,有时发生JAVA的死机时也视为异常。
6.31.3. WebSphere监视资源的监视方法¶
WebSphere监视资源进行以下监视。
利用WebSphere的serverStatus.sh命令,执行应用程序服务器的监视。
作为监视结果,如果出现以下情况则视为异常。
取得的应用程序服务器的状态中通知异常时
6.32. WebOTX监视资源的设置¶
WebOTX监视资源监视服务器上运行的WebOTX。
6.32.1. 监视(固有)标签页¶
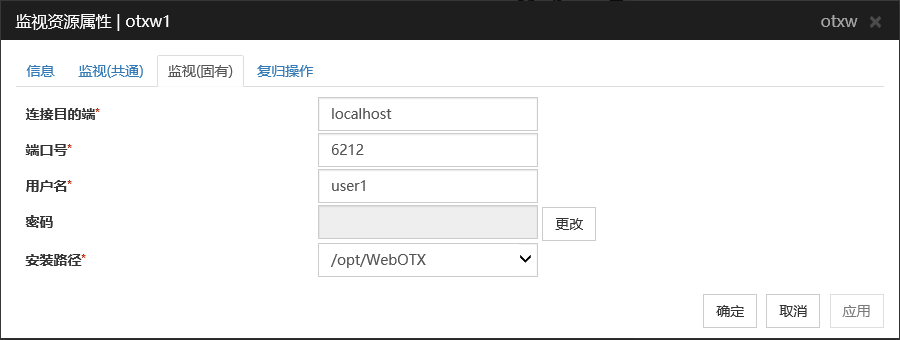
连接目的端 (255字节以内)
设置监视的服务器的名称。请务必进行设置。
默认值: localhost
端口号 (1~65535)
设置与服务器连接时的端口号。请务必进行设置。监视WebOTX用户域时,请设置WebOTX域的管理端口号。管理端口号为创建域时<域名>.properties的domain.admin.port处设置的端口号。关于<域名>.properties 的详细请参考WebOTX的文档。默认值 : 6212
用户名 (255字节以内)
设置WebOTX的用户名。请务必进行设置。监视WebOTX用户域时,请设置WebOTX域的登录用户名默认值 :无
密码 (255字节以内)
设置WebOTX的密码。
默认值 :无
安装路径 (1023字节以内)
设置WebOTX的安装路径。请务必进行设置。
默认值 : /opt/WebOTX
6.32.2. WebOTX监视资源的注意事项¶
有关运行确认完毕的WebOTX版本,请参考《安装指南》的"关于EXPRESSCLUSTER X SingleServerSafe"的"已进行运行确认的监视选项的应用程序信息"。
要通过本监视资源进行监视,需要JAVA环境。因为应用程序服务器系统使用JAVA的功能,有时发生JAVA的死机等时也会被视为异常。
6.32.3. WebOTX监视资源的监视方法¶
获取的应用服务器的状态通知有异常
6.33. JVM监视资源设置¶
JVM监视资源监视在服务器上操作的Java VM,或监视应用程序服务器使用的资源利用信息。
6.33.1. 监视(固有)标签页¶
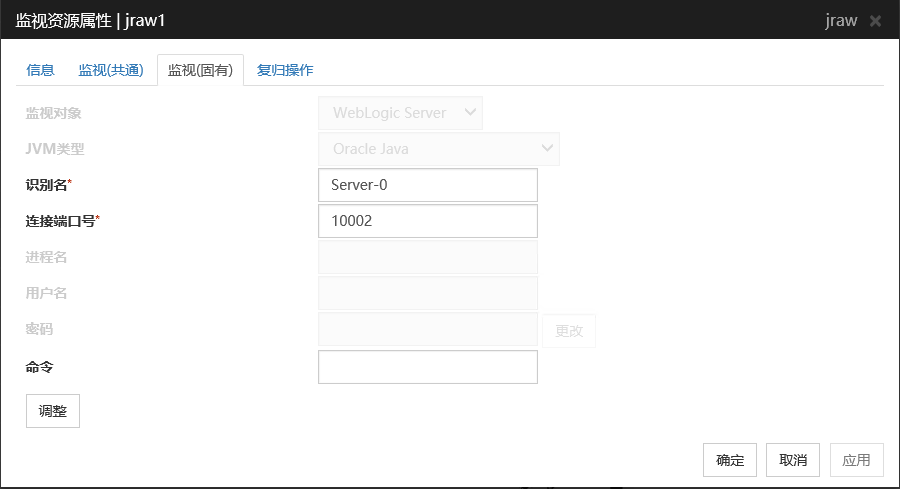
监视对象
从列表中选择监视对象。监视WebSAM SVF for PDF,WebSAM Report Director Enterprise和WevSAM Universal Connect/X 时,请选择[WebSAM SVF]。监视自己制造的Java应用程序时,请选择[Java应用程序]。监视JBoss Enterprise Application Platform的单机模式时选择 [JBoss],监视JBoss Enterprise Application Platform的域模式时选择「JBoss 域模式」。默认值 : 无
JVM类型
从列表中选择监视对象应用程序操作的Java VM。Java 8以及OpenJDK 8以上时,请选择[Oracle Java(usage monitoring)]。在Java 8则有如下的规格更改。
无法获取在非堆区域下的各内存的最大值。
Perm Gen被更改为Metaspace。
追加了Compressed Class Space。
因此,在Java 8[内存]标签页的监视项目更改如下。
使用率监视更改为使用量监视。
不能监视[Perm Gen],Perm Gen[shared-ro],Perm Gen[shared-rw]。请将复选框设定为Off。
可监视[Metaspace],[Compressed Class Space]。
在Java 9中存在以下的设计变更。
Code Cache被分割。
因此,在Java 9中[内存]标签页的监视项目变更为以下。
不能监视[Code Cache]。请将复选框设定为Off。
可以监视[CodeHeap non-nmethods],[CodeHeap profiled],[CodeHeap non-profiled]。
各监视对象可按如下进行指定。
默认值 : 无
识别名(255字节以内)
识别名是在JVM监视资源的JVM运用log中输出监视对象信息时,为了与其它JVM监视资源区别而设置的。因此,设置识别名时请设置JVM监视资源见唯一的字符串。请务必进行设置。
默认值 : 无
连接端口号 (1024~65535)
JVM监视资源设置监视对象Java VM和JMX连接时使用的端口号。JVM监视资源通过连接监视对象Java VM和JMX获取信息。因此,登录JVM监视资源时,需要对监视资源Java VM开放JMX的连接端口。请务必进行设置。不建议设置42424~61000。
默认值 : 无
进程名(1024字节以内)
进程名是JVM监视资源在监视对象Java VM和JMX进行连接时,为了区别于别的JVM监视资源而设定的。因此请设定可以唯一标识JVM监视资源的字符串。
默认值 : 无
用户名(255字节以内)
设置连接监视对象Java VM的管理员名称。
默认值 :无
密码 (255字节以内)
设置连接监视对象Java VM的管理员密码。
默认值 : 无
命令(255字节)
查出监视对象的Java VM异常时,设置要执行的命令。可指定根据不同异常原因执行的命令和参数。请指定绝对路径。另外,请用双引号("")将执行文件名括起来。例)"/usr/local/bin/command" arg1 arg2此处无法连接监视对象Java VM或获取使用资源量时查出异常时,设置要执行的命令。请同时参考"6.33.17. 查出异常时按照不同故障原因执行命令"。默认值: 无
点击[调整]后,弹出的对话框中会显示以下内容。根据以下说明进行详细设置。
6.33.2. 内存标签(在[JVM类型]选择[Oracle Java],[OpenJDK]时)¶
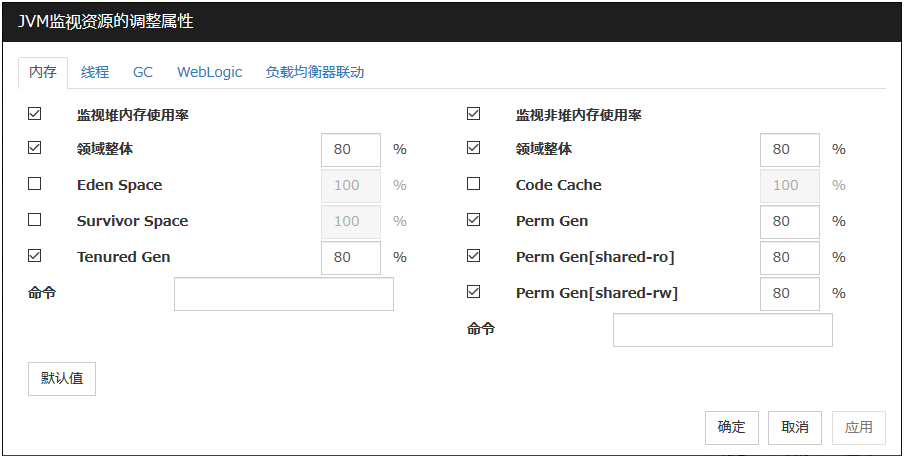
监视堆内存使用率
对监视对象Java VM使用的Java堆空间使用率进行监视设置。
领域整体 (1~100)
设置监视对象Java VM使用的Java堆空间使用率之界限值。
默认值 : 80[%]
Eden Space (1~100)
设置监视对象Java VM使用的Java Eden Space使用率之界限值。作为GC方式指定为G1 GC时,请换读为G1 Eden Space。
默认值 : 100[%]
Survivor Space (1~100)
设置监视对象Java VM使用的Java Survivor Space使用率之界限值。作为GC方式指定为G1 GC时,请换读为G1 Survivor Space。
默认值 : 100[%]
Tenured Gen (1~100)
设置监视对象Java VM使用的JJava Tenured(Old) Gen空间使用率之界限值。作为GC方式指定为G1 GC时,请换读为G1 Old Gen。
默认值 : 80[%]
监视非堆内存使用率
对监视对象Java VM使用的Java非堆空间之使用率进行监视设置。
领域整体 (1~100)
设置监视对象Java VM使用的Java非堆空间使用率之界限值。
默认值 : 80[%]
Code Cache (1~100)
设置监视对象Java VM使用的Java Code Cache空间使用率之界限值。
默认值 : 100[%]
Perm Gen (1~100)
设置监视对象Java VM使用的Java Perm Gen空间使用率之界限值。
默认值 : 80[%]
Perm Gen[shared-ro] (1~100)
设置监视对象Java VM使用的Java Perm Gen [shared-ro]空间使用率之界限值。Java Perm Gen [shared-ro] 空间使用率范围,是其监视对象Java VM启动选项 -client -Xshare:on -XX:+UseSerialGC 启动时设置的使用范围。默认值 : 80[%]
Perm Gen[shared-rw] (1~100)
设置监视对象Java VM使用的Java Perm Gen [shared-rw]空间使用率之界限值。Java Perm Gen [shared-rw] 空间使用率范围,是其监视对象Java VM启动选项 -client -Xshare:on -XX:+UseSerialGC 启动时设置的使用范围。默认值 : 80[%]
命令(255字节以内)
查出监视对象的Java VM异常时,设置要执行的命令。可指定根据不同异常原因执行的命令和参数。请指定绝对路径。另外,请用双引号("")将执行文件名括起来。例)"/usr/local/bin/command" arg1 arg2此处在监视对象的Java VM的Java堆内存区域,Java非堆内存区域上查出异常时,设置要执行的命令。请同时参考"6.33.17. 查出异常时按照不同故障原因执行命令"。默认值: 无
默认值
点击[默认值]按钮后,所有项目将设置为默认值。
6.33.3. 内存标签 (在[JVM类型]选择[Oracle Java(usage monitoring)]时)¶
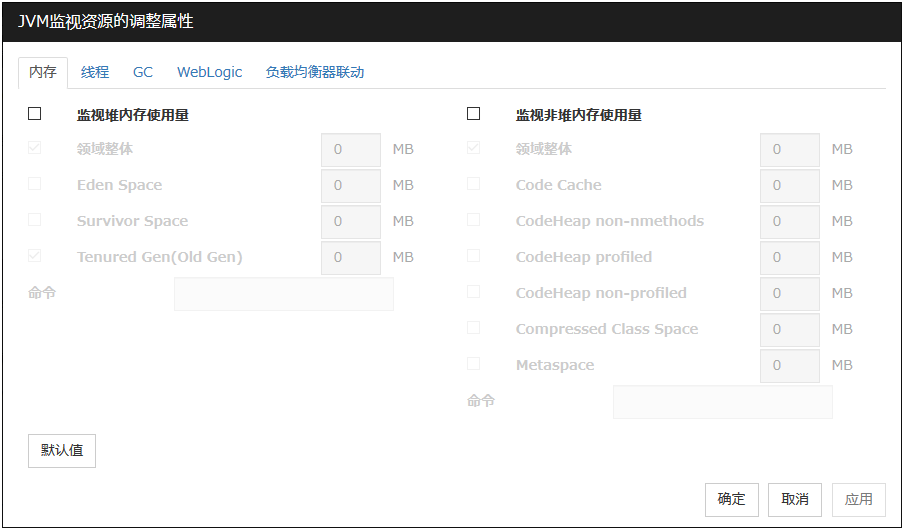
监视堆内存使用量
对监视对象Java VM使用的Java堆空间使用量进行监视设置。
领域整体 (0~102400)
设置监视对象Java VM使用的Java堆空间使用量之界限值。设置为0的时候,不监视。
默认值 :0[MB]
Eden Space (0~102400)
设置监视对象Java VM使用的Java Eden Space使用量之界限值。设置为0的时候,不监视。作为GC方式指定为G1 GC时,请换读为G1 Eden Space。
默认值 :0[MB]
Survivor Space (0~102400)
设置监视对象Java VM使用的Java Survivor Space使用量之界限值。设置为0的时候,不监视。作为GC方式指定为G1 GC时,请换读为G1 Survivor Space。
默认值 :0[MB]
Tenured Gen (0~102400)
设置监视对象Java VM使用的JJava Tenured(Old) Gen空间使用量之界限值。设置为0的时候,不监视。作为GC方式指定为G1 GC时,请换读为G1 Old Gen。
默认值 : 0[MB]
监视非堆内存使用量
对监视对象Java VM使用的Java非堆空间之使用量进行监视设置。
领域整体 (0~102400)
设置监视对象Java VM使用的Java非堆空间使用量之界限值。设置为0的时候,不监视。
默认值 :0[MB]
Code Cache (0~102400)
设置监视对象Java VM使用的Java Code Cache空间使用量之界限值。设置为0的时候,不监视。
默认值 :0[MB]
CodeHeap non-nmethods(0~102400)
设置监视对象Java VM使用的Java CodeHeap non-nmethods空间使用量的界限值。设置为0的时候,不监视。
默认值 :0[MB]
CodeHeap profiled(0~102400)
设置监视对象Java VM使用的Java CodeHeap profiled nmethods空间使用量的界限值。设置为0的时候,不监视。
默认值 :0[MB]
CodeHeap non-profiled (0~102400)
设置监视对象Java VM使用的Java CodeHeap non-profiled nmethods空间使用量的界限值。设置为0的时候,不监视。
默认值 :0[MB]
Compressed Class Space(0~102400)
设置监视对象Java VM使用的Compressed Class Space空间使用量的界限值。设置为0的时候,不监视。
默认值 :0[MB]
Metaspace (0~102400)
设置监视对象Java VM使用的Metaspace空间使用量之界限值。设置为0的时候,不监视。
默认值 :0[MB]
命令(255字节以内)
查出监视对象的Java VM异常时,设置要执行的命令。可指定根据不同异常原因执行的命令和参数。请指定绝对路径。另外,请用双引号("")将执行文件名括起来。例)"/usr/local/bin/command" arg1 arg2此处在监视对象的Java VM的Java堆内存区域,Java非堆内存区域上查出异常时,设置要执行的命令。请同时参考"6.33.17. 查出异常时按照不同故障原因执行命令"。默认值: 无
默认值
点击[默认值]按钮后,所有项目将设置为默认值。
6.33.4. 内存标签(选择Oracle JRockit时)¶
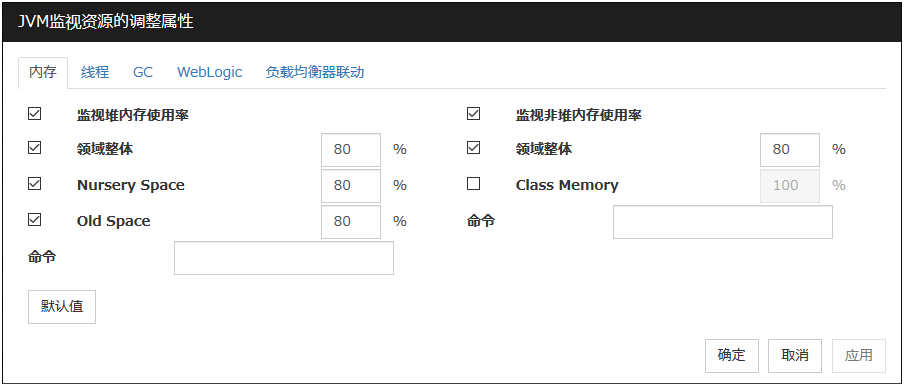
仅在[JVM类型]中选择[JRockit]时显示。
监视堆内存使用率
对监视对象Java VM使用的Java堆空间使用率进行监视设置。
领域整体 (1~100)
设置监视对象Java VM使用的Java堆空间使用率之界限值。
默认值 : 80[%]
Nursery Space (1~100)
设置监视对象JRockit JVM使用的Java Nursery Space使用率之界限值。
默认值 : 80[%]
Old Space (1~100)
设置监视对象JRockit JVM使用的Java Old Space使用率之界限值。
默认值 : 80[%]
监视非堆内存使用率
对监视对象Java VM使用的Java非堆空间之使用率进行监视设置。
领域整体 (1~100)
设置监视对象Java VM使用的Java堆空间使用率之界限值。
默认值 : 80[%]
Class Memory (1~100)
设置监视对象JRockit JVM使用的Java Class Memory使用率之界限值。
默认值 : 100[%]
命令 (255字节以内)
查出监视对象的Java VM异常时,设置要执行的命令。可指定根据不同异常原因执行的命令和参数。请指定绝对路径。另外,请用双引号("")将执行文件名括起来。例)"/usr/local/bin/command" arg1 arg2此处在监视对象的Java VM的Java堆内存区域,Java非堆内存区域上查出异常时,设置要执行的命令。请同时参考"6.33.17. 查出异常时按照不同故障原因执行命令"。默认值: 无
默认值
点击[默认值]按钮后,所有项目将设置为默认值。
6.33.5. 线程标签¶
监视动作中的线程数 (1~65535)
设置监视对象Java VM中正在运行的线程上限值。
默认值 : 65535[线程]
命令 (255字节以内)
查出监视对象的Java VM异常时,设置要执行的命令。可指定根据不同异常原因执行的命令和参数。请指定绝对路径。另外,请用双引号("")将执行文件名括起来。例)"/usr/local/bin/command" arg1 arg2此处在监视对象Java VM中当前运行的线程数上查出异常时,设置要执行的命令。请同时参考"6.33.17. 查出异常时按照不同故障原因执行命令"。默认值: 无
默认值
点击[默认值]按钮后,所有项目将设置为默认值。
6.33.6. GC标签¶
监视Full GC执行时间 (1~65535)
在监视对象Java VM中,设置前一次测量后的Full GC执行时间之界限值。Full GC执行时间指的是,除以前一次测量后Full GC发生次数而得出的平均值。
若希望将Full GC执行时间3000毫秒,Full GC发生次数3次的情况判定为异常,则请将前一次测量后的Full GC执行时间设置为1000毫秒以下。
默认值 : 65535[毫秒]
监视Full GC发生次数 (1~65535)
在监视对象Java VM中,设置前一次测量后的Full GC发生次数之界限值。
默认值 : 1(次)
命令 (255字节以内)
查出监视对象的Java VM异常时,设置要执行的命令。可指定根据不同异常原因执行的命令和参数。请指定绝对路径。另外,请用双引号("")将执行文件名括起来。例)"/usr/local/bin/command" arg1 arg2此处在监视对象Java VM的Full GC执行时间和Full GC发生次数上查出异常时,设置要执行的命令。请同时参考"6.33.17. 查出异常时按照不同故障原因执行命令"。默认值: 无
默认值
点击[默认值]按钮后,所有项目将设置为默认值。
6.33.7. WebLogic标签¶
仅在[监视对象]中选择[WebLogic Server]时显示。
监视Work Manager的请求
在WebLogic Server中,对Work Manager的待机请求状态进行监视设置。
监视对象Work Manager
对监视对象的WebLogic Server,设置监视目标应用程序的Work Manager名称。执行Work Manager监视时,请务必设置。
App1[WM1,WM2,...];App2[WM1,WM2,...];...
在App和WM中可指定的字符为ASCII字符。(不包括Shift_JIS 编码0x005C 和0x00A1~0x00DF )
若应用程序中包含存档的版本,请在App中指定"应用程序名#版本"。
若应用程序名中包含"["或"]",请在其前面添加"¥¥"。
(例如)应用程序名为app[2]时,则为app¥¥[2¥¥]
默认值 : 无
请求数 (1~65535)
在监视对象WebLogic Server的Work Manager中,设置待机请求数的界限值。
默认值 : 65535
平均值 (1~65535)
在监视对象WebLogic Server的Work Manager中,设置待机请求数平均值的界限值。
默认值 : 65535
相比上一次测量值的增加率 (1~1024)
在监视对象WebLogic Server的Work Manager中,设置上一次测量后待机请求数增量的界限值。
默认值 : 80[%]
监视线程Pool的请求
在监视对象WebLogic Server的线程Pool中,对待机请求数,执行请求数进行监视设定。所谓的请求数,它包括WebLogic Server内部的等待处理,执行的HTTP请求数,EJB的调用,WebLogic Serve内部处理的请求数等。但是,即使增加了也不能判断异常状态。请在JVM统计日志收集的时指定。
待机请求 请求数 (1~65535)
设置待机请求数的界限值。
默认值 : 65535
待机请求 平均值 (1~65535)
设置待机请求数平均值的界限值。
默认值 : 65535
待机请求 相比上一次测量值的增加率 (1~1024)
设置上一次测量后,待机请求数增量的界限值。
默认值 : 80[%]
执行请求 请求数 (1~65535)
设置单位时间内执行请求数的界限值。
默认值 : 65535
执行请求 平均值 (1~65535)
设置单位时间内执行的请求数平均值之界限值。
默认值 : 65535
执行请求 相比上一次测量值的增加率 (1~1024)
设置上一次测量后,单位时间内执行的请求数增量之界限值。
默认值 : 80[%]
命令 (255字节以内)
查出监视对象的Java VM异常时,设置要执行的命令。可指定根据不同异常原因执行的命令和参数。请指定绝对路径。另外,请用双引号("")将执行文件名括起来。例)"/usr/local/bin/command" arg1 arg2此处在WebLogic Server的任务管理器的请求和线程池的请求中查出异常时,设置要执行的命令。请同时参考"6.33.17. 查出异常时按照不同故障原因执行命令"。默认值: 无
默认值
点击[默认值]按钮后,所有项目将设置为默认值。
6.33.8. JVM监视资源的注意事项¶
创建JVM监视资源前需要事先设置[集群的属性]的[JVM监视]标签页的[Java安装路径]。
请指定WebLogic Server或WebOTX等在Java VM上操作的应用程序服务器作为监视对象的资源。虽然启动JVM监视资源后Java Resource Agent会开始监视,但当刚刚启动JVM监视资源后,监视对象(WebLogic Server或WebOTX)无法立即运行时,请调整[监视开始等待时间]。
[监视(共通)] - [重试次数]设置无效。如果你想延迟查出异常时,请更改[集群的属性] - [JVM监视]标签页 - [资源测量设置] - [共通] - [重试次数]的设置。
6.33.9. JVM监视资源的监视方法¶
无法连接监视对象的Java VM或应用程序服务器时
获取的Java VM或应用程序服务器的资源使用量规定次数(异常判定次数)超出客户定义的界限值时
出现以下监视结果则视为恢复正常。
复归动作后再次打开监视时低于界限值时
注解
Cluster WebUI的[收集集群日志]不收集监视对象(WebLogic Server和WebOTX)的设置文件及日志文件。
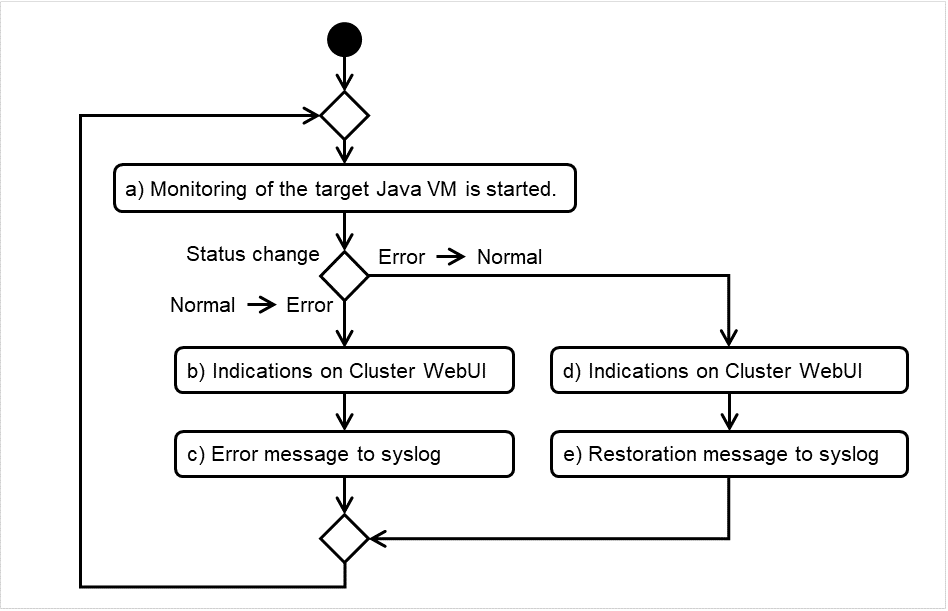
图 6.11 通过JVM监视资源进行监视的流程¶
超过基本界限值时的操作如下。
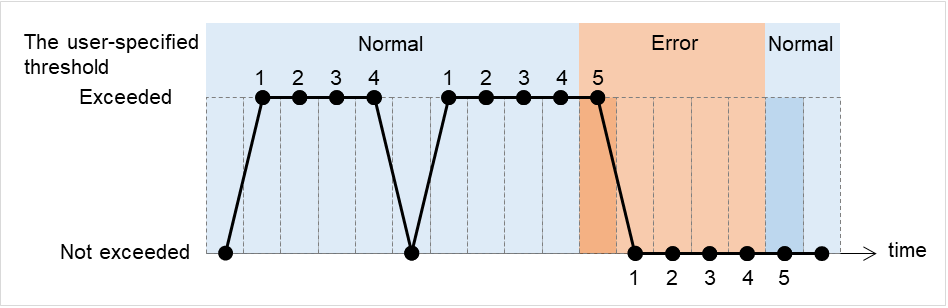
图 6.12 超过界限值时的操作¶
连续发生异常时情况如下
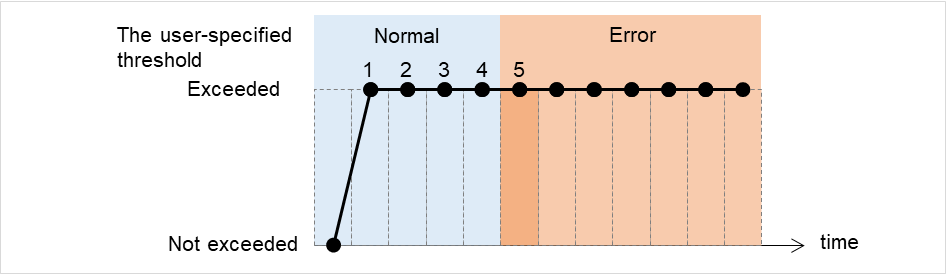
图 6.13 连续发生异常时的动作¶
以监视Full GC(Garbage Collection)为例进行说明。
图中水平轴表示时间经过。 图的上面部分显示的是各监视时间是否查出GC发生,下面部分显示在每个时间点连续多少次查出Full GC。 当异常判定界限值Full GC连续发生,则JVM监视资源会检测到监视器异常。 由于异常判定界限值设置为5次,因此当查出Full GC达到5次时会检测到监视器异常。
Full GC对系统的影响很大,因此建议将异常判定界限值设为1次。
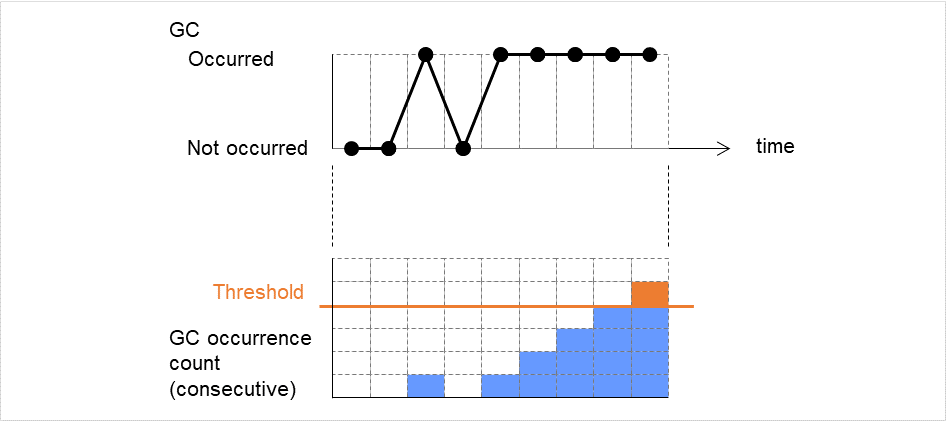
图 6.14 监视图(设置异常判定界限值为5次时)¶
6.33.10. 何谓JVM统计日志¶
保存JVM监视资源收集的监视对象Java VM的统计信息的文件就是JVM统计日志。文件格式为csv格式。目标位置如下所示。
<EXPRESSCLUSTER安装路径>/log/ha/jra/*.stat
下述的"监视项目"表示JVM监视资源的[属性]-[监视(固有)]标签页内的设置项目。
关于各监视项目,选中[监视],并且设置了阈值时,收集统计信息,输出信息到JVM统计日志。不选中[监视],以及选中[监视]但不设置阈值时,信息不会输出至JVM统计日志。
与监视项目对应的JVM统计日志如下所示。
监视项目 |
对应的JVM统计日志 |
|---|---|
[内存]标签页-[监视堆内存使用率]
[内存]标签页-[监视非堆内存使用率]
[内存]标签页-[监视堆内存使用量]
[内存]标签页-[监视非堆内存使用量]
|
jramemory.stat |
[线程]标签页-[监视运行中的线程数] |
jrathread.stat |
[GC]标签页-[监视Full GC执行时间]
[GC]标签页-[监视Full GC发生次数]
|
jragc.stat |
[WebLogic]标签页-[监视任务管理器的请求]
[WebLogic]标签页-[监视线程池的请求]
以上任意一个检查时,wlworkmanager.stat和wlthreadpool.stat两个输出。
|
wlworkmanager.stat
wlthreadpool.stat
|
6.33.11. 确认监视对象Java VM的Java内存区域的使用量(jramemory.stat)¶
记录监视对象Java VM的Java内存区域使用量的日志文件。通过日志输出设置的循环方式,文件名会变为以下其中之一。
选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[文件大小]时:
jramemory<从0开始的整数>.stat选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[时间]时:
jramemory<YYYYMMDDhhmm>.stat格式如下所示。
No |
格式 |
描述 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
显示记录日志的日期时间。 |
2 |
半字节英文数字符号 |
显示监视对象Java VM的名称。通过JVM监视资源的[属性]-[监视固有]标签页-[识别名称]设置的值。 |
3 |
半字节英文数字符号 |
Java内存池的名称。详细内容请参考"
关于Java内存池名称"。
|
4 |
半字节英文数字符号 |
Java内存池的类型。
Heap,Non-Heap
|
5 |
半字节数字 |
Java VM启动时OS上要求的内存量。单位为字节。(init)
监视对象Java VM启动时,可在以下Java VM启动时通过选项指定大小。
・HEAP:-Xms
・NON_HEAP 永久区域(Perm Gen):-XX:PermSize
・NON_HEAP 代码缓存区域(Code Cache):-XX:InitialCodeCacheSize
|
6 |
半字节数字 |
Java VM当前使用的内存量。单位为字节。(used) |
7 |
半字节数字 |
保证Java VM当前使用的内存量。单位为字节。(committed)
会根据内存的使用状况有所增减,但一定是大于used,小于max。
|
8 |
半字节数字 |
Java VM可使用的最大内存量。单位为字节。(max)
可在以下Java VM启动时通过选项指定大小。
・HEAP:-Xmx
・NON_HEAP 永久区域(Perm Gen):-XX:MaxPermSize
・NON_HEAP 代码缓存区域(Code Cache):-XX:ReservedCodeCacheSize
例)
java -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=128m javaAP
上例中NON_HEAP的max变为128m+128m=256m。
(注意)
若在-Xms和-Xmx上指定相同值,则可执行变为(init)>(max)。这是因为HEAP的max显示从-Xmx指定确保的区域空间中减少Survivor Space一半大小之后的空间。
|
9 |
半字节数字 |
测量对象的Java VM在启动后使用的内存量的峰值。Java内存池的名称为HEAP,NON_HEAP时,与Java VM当前使用的内存量(used)相同。单位为字节。 |
10 |
半字节数字 |
[JVM类型]处选择[Oracle Java(usage monitoring)]选项时,请忽略该项目。
[JVM类型]处选择[Oracle Java(usage monitoring)]以外的选项时,Java内存池的类型(No.4的域)为HEAP时,max(No.8的域)×边界值(%)的内存量。单位为字节。
Java内存池的类型为HEAP时,0固定。
|
6.33.12. 确认监视对象Java VM的线程运行状态(jrathread.stat)¶
记录监视对象Java VM的线程运行状态的日志文件。通过日志输出设置的循环方式,文件名会变为以下其中之一。
选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[文件大小]时:
jrathread<从0开始的整数>.stat选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[时间]时:
jrathread<YYYYMMDDhhmm>.stat格式如下所示。
No |
格式 |
描述 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
显示记录日志的日期时间。 |
2 |
半字节英文数字符号 |
显示监视对象Java VM的名称。通过JVM监视资源的[属性]-[监视固有]标签页-[识别名称]设置的值。 |
3 |
半字节英文数字符号 |
显示监视对象Java VM中当前在执行的线程数。 |
4 |
[半字节数字: 半字节数字:...] |
显示监视对象Java VM中死锁的线程ID。反复死锁数ID。 |
5 |
半字节英文数字符号 |
显示监视对象Java VM中死锁的线程的详细信息。死锁数按照以下形式反复。
线程名,线程ID,线程状态 UserTime, CpuTime, WaitedCount, WaitedTime, isInNative, isSuspended <换行>
stacktrace<换行>
:
stacktrace<换行>
stacktrace=ClassName, FileName, LineNumber, MethodName, isNativeMethod
|
6.33.13. 确认监视对象Java VM的GC运行状态(jragc.stat)¶
记录监视对象Java VM的GC运行状态的日志文件。通过日志输出设置的循环方式,文件名会变为以下其中之一。
选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[文件大小]时:
jragc<从0开始的整数>.stat选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[时间]时:
jragc<YYYYMMDDhhmm>.stat在JVM监视资源中输出复制GC和Full GC这2种GC信息。
在JVM监视资源中,对于Oracle Java情况下的以下GC,计算作为Full GC发生次数的增量。
MarksweepCompact
MarkSweepCompact
PS Marksweep
ConcurrentMarkSweep
格式如下所示。
No |
格式 |
描述 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
显示记录日志的日期时间。 |
2 |
半字节英文数字符号 |
显示监视对象Java VM的名称。通过JVM监视资源的[属性]-[监视固有]标签页-[识别名称]设置的值。 |
3 |
半字节英文数字符号 |
显示监视对象Java VM的GC名称。
监视对象Java VM为Oracle Java时
具有如下内容。
Copy
MarksweepCompact
MarkSweepCompact
PS Scavenge
PS Marksweep
ParNew
ConcurrentMarkSweep
监视对象Java VM为Oracle JRockit时
具有如下内容。
Garbage collection optimized for throughput Old Collector
Garbage collection optimized for short pausetimes Old Collector
Garbage collection optimized for deterministic pausetimes Old Collector
Static Collector
Static Old Collector
Garbage collection optimized for throughput Young Collector
|
4 |
半字节数字 |
显示监视对象Java VM在启动后到测量时间为止的GC发生次数。JVM监视资源在开始监视前发生的GC的发生次数也包含在值内。 |
5 |
半字节数字 |
显示监视对象Java VM在启动后到测量时间为止的GC总执行时间。单位为毫秒。JVM监视资源在开始监视前发生的GC的执行时间也包含在值内。 |
6.33.14. 确认WebLogic Server的任务管理器的运行状态(wlworkmanager.stat)¶
记录WebLogic Server的任务管理器的运行状态的日志文件。通过日志输出设置的循环方式,文件名会变为以下其中之一。
选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[轮循方式]-[文件大小]时:
wlworkmanager<从0开始的整数>.stat选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[轮循方式]-[时间]时:
wlworkmanager<YYYYMMDDhhmm>.stat
格式如下所示。
No |
格式 |
描述 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
显示记录日志的日期时间。 |
2 |
半字节英文数字符号 |
显示监视对象Java VM的名称。通过JVM监视资源的[属性]-[监视固有]标签页-[识别名称]设置的值。 |
3 |
半字节英文数字符号 |
显示应用程序名称。 |
4 |
半字节英文数字符号 |
显示任务管理器名称。 |
5 |
半字节数字 |
显示执行的请求数量。 |
6 |
半字节数字 |
显示待机的请求数量。 |
6.33.15. 确认WebLogic Server的线程池的运行状态(wlthreadpool.stat)¶
记录WebLogic Server的线程池的运行状态的日志文件。通过日志输出设置的循环方式,文件名会变为以下其中之一。
选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[文件大小]时:
wlthreadpool<从0开始的整数>.stat选择[集群的属性]-[监视JVM]标签页-[日志输出设置]-[循环方式]-[时间]时:
wlthreadpool<YYYYMMDDhhmm>.stat
格式如下所示。
No |
格式 |
描述 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
显示记录日志的日期时间。 |
2 |
半字节英文数字符号 |
显示监视对象Java VM的名称。通过JVM监视资源的[属性]-[监视固有]标签页-[识别名称]设置的值。 |
3 |
半字节数字 |
显示执行的请求总数。 |
4 |
半字节数字 |
显示待处理的请求数量。 |
5 |
半字节数字 |
显示每个单位时间(秒)的请求处理数量。 |
6 |
半字节数字 |
显示用于执行应用程序的线程的总数。 |
7 |
半字节数字 |
显示空闲状态的线程数。 |
8 |
半字节数字 |
显示执行中的线程数。 |
9 |
半字节数字 |
显示待机状态的线程数。 |
6.33.16. 关于Java内存池名称¶
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用率]-[领域整体] |
HEAP |
[监视堆内存使用率]-[Eden Space] |
Eden Space |
[监视堆内存使用率]-[Survivor Space] |
Survivor Space |
[监视堆内存使用率]-[Tenured Gen] |
Tenured Gen |
[监视非堆内存使用率]-[领域整体] |
NON_HEAP |
[监视非堆内存使用率]-[Code Cache] |
Code Cache |
[监视非堆内存使用率]-[Perm Gen] |
Perm Gen |
[监视非堆内存使用率]-[Perm Gen[shared-ro]] |
Perm Gen [shared-ro] |
[监视非堆内存使用率]-[Perm Gen[shared-rw]] |
Perm Gen [shared-rw] |
[JVM类型]选择了[Oracle Java],并且监视对象Java VM的启动选项上添加了"-XX:+UseParallelGC","-XX:+UseParallelOldGC"时,jramemory.stat中的No3的Java内存池名称如下所示。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用率]-[领域整体] |
HEAP |
[监视堆内存使用率]-[Eden Space] |
PS Eden Space |
[监视堆内存使用率]-[Survivor Space] |
PS Survivor Space |
[监视堆内存使用率]-[Tenured Gen] |
PS Old Gen |
[监视非堆内存使用率]-[领域整体] |
NON_HEAP |
[监视非堆内存使用率]-[Code Cache] |
Code Cache |
[监视非堆内存使用率]-[Perm Gen] |
PS Perm Gen |
[监视非堆内存使用率]-[Perm Gen[shared-ro]] |
Perm Gen [shared-ro] |
[监视非堆内存使用率]-[Perm Gen[shared-rw]] |
Perm Gen [shared-rw] |
[JVM类型]选择了[Oracle Java],并且监视对象Java VM的启动选项上添加了"-XX:+UseConcMarkSweepGC"时,jramemory.stat中的No3的Java内存池名称如下所示。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用率]-[领域整体] |
HEAP |
[监视堆内存使用率]-[Eden Space] |
Par Eden Space |
[监视堆内存使用率]-[Survivor Space] |
Par Survivor Space |
[监视堆内存使用率]-[Tenured Gen] |
CMS Old Gen |
[监视非堆内存使用率]-[领域整体] |
NON_HEAP |
[监视非堆内存使用率]-[Code Cache] |
Code Cache |
[监视非堆内存使用率]-[Perm Gen] |
CMS Perm Gen |
[监视非堆内存使用率]-[Perm Gen[shared-ro]] |
Perm Gen [shared-ro] |
[监视非堆内存使用率]-[Perm Gen[shared-rw]] |
Perm Gen [shared-rw] |
在[JVM类型]选择[Oracle Java(usage monitoring)],并且在Java VM的启动选项添加「-XX:+UseSerialGC」时,jramemory.stat中的No3的Java内存池名称如下所示。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用量]-[领域整体] |
HEAP |
[监视堆内存使用量]-[Eden Space] |
Eden Space |
[监视堆内存使用量]-[Survivor Space] |
Survivor Space |
[监视堆内存使用量]-[Tenured Gen] |
Tenured Gen |
[监视非堆内存使用量]-[领域整体] |
NON_HEAP |
[监视非堆内存使用量]-[Code Cache] |
Code Cache(Java 9以上时,没有输出) |
[监视非堆内存使用量]-[Metaspace] |
Metaspace |
[监视非堆内存使用量]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[监视非堆内存使用量]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[监视非堆内存使用量]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[监视非堆内存使用量]-[Compressed Class Space] |
Compressed Class Space |
在[JVM类型]选择[Oracle Java(usage monitoring)],并且在Java VM的启动选项添加「-XX:+UseParallelGC」,「-XX:+UseParallelOldGC」时,jramemory.stat中的No3的Java内存池名称如下所示。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用量]-[领域整体] |
HEAP |
[监视堆内存使用量]-[Eden Space] |
PS Eden Space |
[监视堆内存使用量]-[Survivor Space] |
PS Survivor Space |
[监视堆内存使用量]-[Tenured Gen] |
PS Old Gen |
[监视非堆内存使用量]-[领域整体] |
NON_HEAP |
[监视非堆内存使用量]-[Code Cache] |
Code Cache(Java 9以上时,没有输出) |
[监视非堆内存使用量]-[Metaspace] |
Metaspace |
[监视非堆内存使用量]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[监视非堆内存使用量]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[监视非堆内存使用量]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[监视非堆内存使用量]-[Compressed Class Space] |
Compressed Class Space |
在[JVM类型]选择[Oracle Java(usage monitoring)],并且在Java VM的启动选项添加「-XX:+UseConcMarkSweepGC」时,jramemory.stat中的No3的Java内存池名称如下所示。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用量]-[领域整体] |
HEAP |
[监视堆内存使用量]-[Eden Space] |
Par Eden Space |
[监视堆内存使用量]-[Survivor Space] |
Par Survivor Space |
[监视堆内存使用量]-[Tenured Gen] |
CMS Old Gen |
[监视非堆内存使用量]-[领域整体] |
NON_HEAP |
[监视非堆内存使用量]-[Code Cache] |
Code Cache(Java 9以上时,没有输出) |
[监视非堆内存使用量]-[Metaspace] |
Metaspace |
[监视非堆内存使用量]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[监视非堆内存使用量]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[监视非堆内存使用量]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[监视非堆内存使用量]-[Compressed Class Space] |
Compressed Class Space |
在[JVM类型]选择[Oracle Java(usage monitoring)],并且在监视对象Java VM的启动选项添加「-XX:+UseParNewGC」时,jramemory.stat中的No3的Java内存池名称如下所示。Java 9以上时,如果附加了「-XX:+UseParNewGC」,监视对象Java VM不能起动。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用量]-[领域整体] |
HEAP |
[监视堆内存使用量]-[Eden Space] |
Par Eden Space |
[监视堆内存使用量]-[Survivor Space] |
Par Survivor Space |
[监视堆内存使用量]-[Tenured Gen] |
Tenured Gen |
[监视非堆内存使用量]-[领域整体] |
NON_HEAP |
[监视非堆内存使用量]-[Code Cache] |
Code Cache |
[监视非堆内存使用量]-[Metaspace] |
Metaspace |
[监视非堆内存使用量]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[监视非堆内存使用量]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[监视非堆内存使用量]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[监视非堆内存使用量]-[Compressed Class Space] |
Compressed Class Space |
在[JVM类型]选择[Oracle Java(usage monitoring)] ,并且在监视对象Java VM的启动选项添加「-XX::+UseG1GC」时,jramemory.stat中的No3的Java内存池名称如下所示。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用量]-[领域整体] |
HEAP |
[监视堆内存使用量]-[Eden Space] |
G1 Eden Space |
[监视堆内存使用量]-[Survivor Space] |
G1 Survivor Space |
[监视堆内存使用量]-[Tenured Gen(Old Gen)] |
G1 Old Gen |
[监视非堆内存使用量]-[领域整体] |
NON_HEAP |
[监视非堆内存使用量]-[Code Cache] |
Code Cache(Java 9以上时,没有输出) |
[监视非堆内存使用量]-[Metaspace] |
Metaspace |
[监视非堆内存使用量]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[监视非堆内存使用量]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[监视非堆内存使用量]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[监视非堆内存使用量]-[Compressed Class Space] |
Compressed Class Space |
监视对象Java VM为Oracle JRockit时(在[JVM类型]中选择[JRockit]时),jramemory.stat中的No3的Java内存池名称如下所示。
监视项目 |
作为memory_name输出的字符串 |
|---|---|
[监视堆内存使用率]-[领域整体] |
HEAP memory |
[监视堆内存使用率]-[Nursery Space] |
Nursery |
[监视堆内存使用率]-[Old Space] |
Old Space |
[监视非堆内存使用率]-[领域整体] |
NON_HEAP |
[监视非堆内存使用率]-[Class Memory] |
Class Memory |
JVM统计日志jramemory.stat中的Java内存池名称和Java VM内存空间的关系如下所示。
Oracle Java 7时
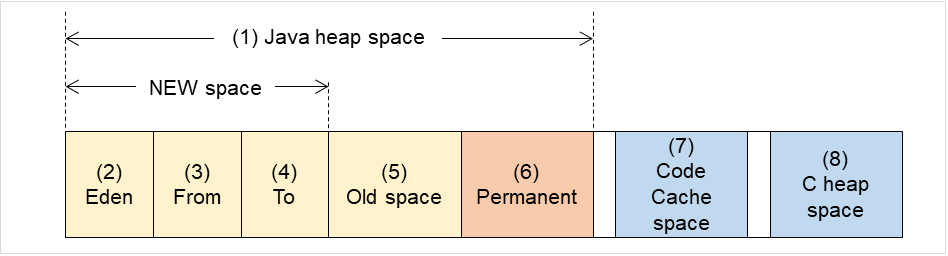
图 6.15 Java VM内存空间(Oracle Java 7)¶
图中的No
监视项目
jramemory.stat的Java内存池名称。
(1)
[监视堆内存使用率]-[领域整体]
HEAP
(2)
[监视堆内存使用率]-[Eden Space]EdenSpacePS Eden SpacePar Eden Space(3)+(4)[监视堆内存使用率]-[Survivor Space]Survivor SpacePS Survivor SpacePar Survivor Space(5)
[监视堆内存使用率]-[Tenured Gen]
Tenured GenPS Old GenCMS Old Gen(6)
[监视非堆内存使用率]-[Perm Gen][监视非堆内存使用率]-[Perm Gen[shared-ro]][监视非堆内存使用率]-[Perm Gen[shared-rw]]Perm GenPerm Gen [shared-ro]Perm Gen [shared-rw]PS Perm GenCMS Perm Gen(7)
[监视非堆内存使用率]-[Code Cache]
Code Cache
(8)
-
-
(6)+(7)
[监视非堆内存使用率]-[领域整体]
NON_HEAP※不包含堆栈轨迹Oracle Java 8/Oracle Java 9/Oracle Java 11时
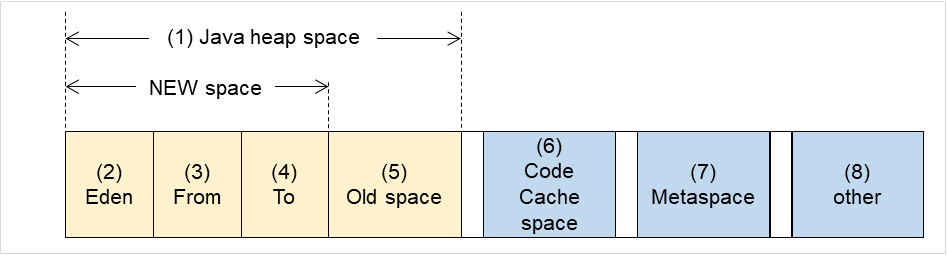
图 6.16 Java VM内存空间(Oracle Java 8/Oracle Java 9/Oracle Java 11)¶
图中的No
监视项目
jramemory.stat的Java内存池名称。
(1)
[监视堆内存使用量]-[领域整体]
HEAP
(2)
[监视堆内存使用量]-[Eden Space]EdenSpacePS Eden SpacePar Eden SpaceG1 Eden Space(3)+(4)
[监视堆内存使用量]-[Survivor Space]
Survivor SpacePS Survivor SpacePar Survivor SpaceSurvivor Space(5)
[监视堆内存使用量]-[Tenured Gen]
Tenured GenPS Old GenCMS Old GenG1 Old Gen(6)
[监视非堆内存使用量]-[Code Cache]
Code Cache(Java 9以上时,没有输出)
(6)
[监视非堆内存使用量]-[CodeHeap non-nmethods]
CodeHeap non-nmethods(仅Java 9以上时输出)
(6)
[监视非堆内存使用量]-[CodeHeap profiled]
CodeHeap profiled nmethods(仅Java 9以上时输出)
(6)
[监视非堆内存使用量]-[CodeHeap non-profiled]
CodeHeap non-profiled nmethods(仅Java 9以上时输出)
(7)
[监视非堆内存使用量]-[Metaspace]
Metaspace
(8)
[监视非堆内存使用量]-[Compressed Class Space]
Compressed Class Space
(6)+(7)+(8)
[监视非堆内存使用量]-[领域整体]
NON_HEAP
Oracle JRockit时
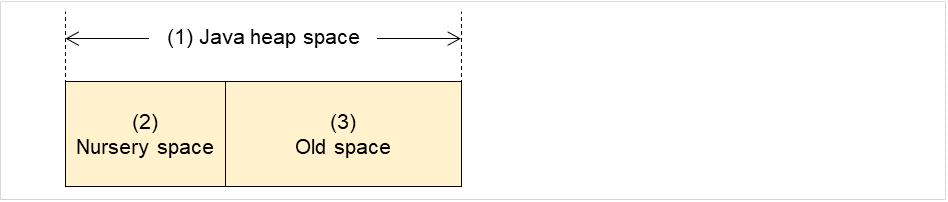
图 6.17 Java VM内存空间(Oracle JRockit)¶
图中的No
监视项目
jramemory.stat的Java内存池名称。
(1)
[监视堆内存使用率]-[领域整体]
HEAP memory
(2)
[监视堆内存使用率]-[Nursery Space]
Nursery
(3) 2
[监视堆内存使用率]-[Old Space]
Old Space
-
[监视非堆内存使用率]-[领域整体]
NON_HEAP
-
[监视非堆内存使用率]-[Class Memory]
Class Memory
- 2
关于jramemory.stat的Java内存池名称"Old Space",并非HEAP内的old区域的值,与"HEAP memory"全体为同值。无法只进行(3)的测量。
6.33.17. 查出异常时按照不同故障原因执行命令¶
故障原因 |
设置项目 |
|---|---|
・连接监视对象的Java VM失败
・资源测量失败
|
[监视(固有)]标签页-[命令] |
・堆内存使用率
・非堆内存使用率
・堆内存使用量
・非堆内存使用量
|
[监视(固有)]标签页-[调整]属性-[内存]标签页-[命令] |
・运行中的线程数 |
[监视(固有)]标签页-[调整]属性-[线程]标签页-[命令] |
・Full GC执行时间
・Full GC发生次数
|
[监视(固有)]标签页-[调整]属性-[GC]标签页-[命令] |
・WebLogic的任务管理器的请求
・WebLogic的线程池的请求
|
[监视(固有)]标签页-[调整]属性-[WebLogic]标签页-[命令] |
[命令]将故障原因的详情作为命令的参数传递。参数与结合[命令]的最后进行传递。通过自身创建脚本等向[命令]设置,可执行特别针对故障原因的运行。作为参数传递的字符串如下所示。
已记载多个作为参数传递的字符串时,按照监视对象Java VM的GC方式来传递其中一种。差异的详细内容请参考"
关于Java内存池名称"。
记载为(Oracle Java时)(Oracle JRockit时)时,根据JVM类型有所不同。无记载时,JVM类型不会造成区别。
故障原因的详细信息 |
作为参数传递的字符串 |
|---|---|
・连接监视对象的Java VM失败
・资源测量失败
|
无 |
[监视(固有)]标签页-[调整]属性-[内存]标签页-[监视堆内存使用率]-[领域整体]
(Oracle Java时)
|
HEAP |
[内存]标签页-[监视堆内存使用率]-[Eden Space]
(Oracle Java时)
|
EdenSpace
PSEdenSpace
ParEdenSpace
|
[内存]标签页-[监视堆内存使用率]-[Survivor
Space]
(Oracle Java时)
|
SurvivorSpace
PSSurvivorSpace
ParSurvivorSpace
|
[内存]标签页-[监视堆内存使用率]-[Tenured Gen]
(Oracle Java时)
|
TenuredGen
PSOldGen
CMSOldGen
|
[内存]标签页-[监视非堆内存使用率]-[领域整体]
(Oracle Java时)
|
NON_HEAP
|
[内存]标签页-[监视非堆内存使用率]-[Code Cache]
(Oracle Java时)
|
CodeCache
|
[内存]标签页-[监视非堆内存使用率]-[Perm Gen]
(Oracle Java时)
|
PermGen
PSPermGen
CMSPermGen
|
[内存]标签页-[监视非堆内存使用率]-[Perm Gen[shared-ro]]
(Oracle Java时)
|
PermGen[shared-ro]
|
[内存]标签页-[监视非堆内存使用率]-[Perm Gen[shared-rw]]
(Oracle Java时)
|
PermGen[shared-rw]
|
[内存]标签页-监视堆内存使用量]-[领域整体](Oracle Java(usage monitoring)时) |
HEAP |
[内存]标签页-监视堆内存使用量]-[Eden Space](Oracle Java(usage monitoring)时)
|
EdenSpace
PSEdenSpace
ParEdenSpace
G1EdenSpace
|
[内存]标签页-监视堆内存使用量]-[Survivor Space](Oracle Java(usage monitoring)时)
|
SurvivorSpace
PSSurvivorSpace
ParSurvivorSpace
G1SurvivorSpace
|
[内存]标签页-监视堆内存使用量]-[Tenured Gen](Oracle Java(usage monitoring)时)
|
TenuredGen
PSOldGen
CMSOldGen
G1OldGen
|
[内存]标签页-[监视非堆内存使用量]-[领域整体](Oracle Java(usage monitoring)时) |
NON_HEAP |
[内存]标签页-[监视非堆内存使用量]-[Code Cache](Oracle Java(usage monitoring)时) |
CodeCache |
[内存]标签页-[监视非堆内存使用量]-[Metaspace](Oracle Java(usage monitoring)时) |
Metaspace |
[内存]标签页-[监视非堆内存使用量]-[CodeHeap non-nmethods](Oracle Java(usage monitoring)的场合) |
non-nmethods |
[内存]标签页-[监视非堆内存使用量]-[CodeHeap profiled](Oracle Java(usage monitoring)的场合) |
profilednmethods |
[内存]标签页-[监视非堆内存使用量]-[CodeHeap non-profiled](Oracle Java(usage monitoring)的场合) |
non-profilednmethods |
[内存]标签页-[监视非堆内存使用量]-[Compressed Class Space](Oracle Java(usage monitoring)的场合) |
CompressedClassSpace |
[内存]标签页-[监视堆内存使用率]-[领域整体]
(Oracle JRockit时)
|
HEAP
Heap
|
[内存]标签页-[监视堆内存使用率]-[Nursery Space]
(Oracle JRockit时)
|
Nursery
|
[内存]标签页-[监视堆内存使用率]-[Old Space]
(Oracle JRockit时)
|
OldSpace
|
[内存]标签页-[监视非堆内存使用率]-[领域整体]
(Oracle JRockit时)
|
NON_HEAP
|
[内存]标签页-[监视非堆内存使用率]-[Class Memory]
(Oracle JRockit时)
|
ClassMemory
|
[线程]标签页-[监视运行中的线程数] |
Count |
[GC]标签页-[监视Full GC执行时间] |
Time |
[GC]标签页-[监视Full GC发生次数] |
Count |
[WebLogic]标签页-[监视任务管理器的请求]-[待机请求 请求数] |
WorkManager_PendingRequests |
[WebLogic]标签页-[监视线程池的请求]-[待机请求 请求数] |
ThreadPool_PendingUserRequestCount |
[WebLogic]标签页-[监视线程池的请求]-[执行请求 请求数] |
ThreadPool_Throughput |
以下显示执行示例。
例1)
设置项目 |
设置内容 |
|---|---|
[监视(固有)]标签页-[调整]属性-[GC]标签页-[命令] |
/usr/local/bin/downcmd |
[监视(固有)]标签页-[调整]属性-[GC]标签页-[监视Full GC发生次数] |
1 |
[集群]属性-[JVM监视]标签页-[资源测量设置]-[共同]标签页-[异常判断边界值] |
3 |
如果连续发生异常判断边界值次数(3次)并且发生Full GC,则JVM监视资源会查出监视异常,将"/usr/local/bin/downcmd Cont"作为命令执行。
例2)
设置项目 |
设置内容 |
|---|---|
[监视(固有)]标签页-[调整]属性-[GC]标签页-[命令] |
"/usr/local/bin/downcmd" GC |
[监视(固有)]标签页-[调整]属性-[GC]标签页-[监视Full GC执行时间] |
65536 |
[集群]属性-[JVM监视]标签页-[资源测量设置]-[共同]标签页-[异常判断边界值] |
3 |
如果连续发生异常判断边界值次数(3次)并且Full GC执行时间超过65535毫秒,则JVM监视资源会查出监视异常,将"/usr/local/bin/downcmd GC Time"作为命令执行。
例3)
设置项目 |
设置内容 |
|---|---|
[监视(固有)]标签页-[调整]属性-[内存]标签页-[命令] |
"/usr/local/bin/downcmd" memory |
[监视(固有)]标签页-[调整]属性-[内存]标签页-[监视堆内存使用率] |
on |
[监视(固有)]标签页-[调整]属性-[内存]标签页-[Eden Space] |
80 |
[监视(固有)]标签页-[调整]属性-[内存]标签页-[Survivor Space] |
80 |
[集群]属性-[JVM监视]标签页-[资源测量设置]-[共同]标签页-[异常判断边界值] |
3 |
如果连续发生异常判断边界值次数(3次)并且Java Eden Space的使用率和Java Survivor Space的使用率超过80%,则JVM监视资源会查出监视异常,将"/usr/local/bin/downcmd memory EdenSpace SurvivorSpace"作为命令执行。
[命令]中设置的等待命令结束的超时(秒),在[集群的属性]-[JVM监视]-[命令超时]中进行设置。这适用于上述各标签页的[命令]中的相同值。无法在各[命令]中设置。
如果超时,无法执行强制结束[命令]进程之类的处理。请客户执行[命令]进程的后处理(例:强制结束)。如果超时,将以下消息输出至JVM运用日志中。
action thread execution did not finish. action is alive = <指令>
注意事项如下所示。
查出Java VM正常复归时(异常->正常时)无法执行[命令]。
[命令]以查出Java VM异常时(边界值的超过连续数次发生异常判断时)为契机执行。不在每个边界值超出上执行。
在多个标签页上设置[命令]后,同时发生故障时执行多个[命令]。因此,请注意系统负载。
同时监视[监视(固有)]标签页-[调整]属性-[WebLogic]标签页-[监视任务管理器的请求],[监视(固有)]标签页-[调整]属性-[WebLogic]标签页-[监视任务管理器的请求]-[待机请求 平均值]时,可执行会同时执行2次[命令]。
这是由于[集群]属性-[JVM监视]标签页-[资源测量设置]-[WebLogic]标签页--[间隔 请求数]和[集群]属性-[JVM监视]标签页-[资源测量设置]-[WebLogic]标签页--[间隔 平均值]的异常查出可执行同时发生。请设置成仅监视其中一方作为回避方法。以下监视项目的组合也一样。
[监视(固有)]标签页-[调整]属性-[WebLogic]标签页-[监视线程池的请求]-[待机请求 请求数]和[监视(固有)]标签页-[调整]属性-[WebLogic]标签页-[监视线程池的请求]-[待机请求 平均值]
[监视(固有)]标签页-[调整]属性-[WebLogic]标签页-[监视线程池的请求]-[待机请求 请求数]和[监视(固有)]标签页-[调整]属性-[WebLogic]标签页-[监视线程池的请求]-[执行请求 平均值]
6.33.18. 监视WebLogic Server¶
- 启动WebLogic Server Administration Console。启动方法请参考WebLogic Server使用说明书的"Administration Console的概要"。选择 域设置-域-设置-整体。在这里请先确认"启用管理端口"复选框为未选中状态
在域设置-服务器中选择监视对象的服务器名。选择的服务器名设置为Cluster WebUI的编辑模式中[属性]-[监视(固有)]标签的识别名。请参考EXPRESSCLUSTER X 的《参考指南》 - "监视资源的详细信息" - "理解JVM监视资源"。
在监视对象服务器的设置-整体中,确认"监听端口"中管理连接的端口号。
停止WebLogic Server。停止方法请参考WebLogic Server使用说明书的"WebLogic Server的启动和停止"。
打开WebLogic Server的启动脚本。
在打开的脚本中记载以下内容。
监视对象为WebLogic Server的管理服务器时
JAVA_OPTIONS="${JAVA_OPTIONS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djavax.management.builder.initial=weblogic.management.jmx.mbeanserver.WLSMBeanServerBuilder"
※在实际操作中请将上述内容记载为1行。
监视对象为WebLogic Server的管理对象服务器时
if [ "${SERVER_NAME}" = "SERVER_NAME" ]; then JAVA_OPTIONS="${JAVA_OPTIONS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djavax.management.builder.initial=weblogic.management.jmx.mbeanserver.WLSMBeanServerBuilder" fi
※在实际操作中,请将if语句记载为1行。
注解
n用来指定监视时使用的端口号。指定的端口号请指定为与监视对象Java VM的监听端口号不同的号码。此外,同一设备有多个监视对象的WebLogic Server时,请指定不同于监听端口号和其他应用程序端口号的号码。
注解
SERVER_NAME指定为"选择监视对象服务器"中确认的监视对象服务器名。存在多个监视对象服务器时,按照同样的设置(1~10行)更改服务器名,重复设置。
注解
上述内容中添加的部分请放在以下记载的前面。
${JAVA_HOME}/bin/java ${JAVA_VM} ${MEM_ARGS} ${JAVA_OPTIONS} -Dweblogic.Name=${SERVER_NAME} -Djava.security.policy=${WL_HOME}/server/lib/weblogic.policy ${PROXY_SETTINGS} ${SERVER_CLASS}
※在实际操作中请将上述内容记载为1行
※因WebLogic的版本而异,上述的java引数的内容有可执行不同,在执行java之前,若已记载了JAVA_OPTIONS,则没有问题。
注解
监视[内存标签]的[Perm Gen[shared-ro]]或[Perm Gen[shared-rw]]时,添加以下内容。
-client -Xshare:on -XX:+UseSerialGC
- 监视任务管理器或线程池的请求时,请进行如下设置。启动监视对象WebLogic Server的WLST(wlst.sh)。请在显示的控制台画面上执行以下命令。
> connect('USERNAME','PASSWORD','t3://SERVER_ADDRESS:SERVER_PORT') > edit() > startEdit() > cd('JMX/DOMAIN_NAME') > set('PlatformMBeanServerUsed','true') > activate() > exit()请将上述USERNAME,PASSWORD,SERVER_ADDRESS,SERVER_PORT,DOMAIN_NAME替换为符合域环境的值
重启监视对象WebLogic Server
6.33.19. 监视WebOTX¶
6.33.20. 监视WebOTX域代理的Java进程¶
不需要本操作。
6.33.21. 监视WebOTX进程组的Java进程¶
通过集成操作管理工具连接域。
在树形图中选择[<域名>]-[TP系统]-[应用程序组]-[<应用程序组名>]-[进程组]-[<进程组名>]。
在右侧显示的[JVM选项]标签内的[其他参数]属性中,用1行指定下一个Java选项。n用来指定端口号。若同一设备有多个监视对象Java VM存在,请指定不同的端口号。这里指定的端口号在Cluster WebUI([监视资源的属性]->[监视(固有)]标签页->[连接端口号])中也会设置。
-Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djavax.management.builder.initial=com.nec.webotx.jmx.mbeanserver.JmxMBeanServerBuilder
※在WebOTX V9.2不需要进行-Djavax.management.builder.initial的指定。
- 完成设置后点击[更新]。完成设置后,重启进程组。本设置也可在WebOTX集成操作管理工具[Java系统属性]标签内的[Java系统属性]中进行指定。此时,"-D"为不指定,"="之前的字符串指定为"名称","="之后的字符串指定为"值"。
设置标签名
项目名
设置值
监视(共通)
监视时机
不间断
复归操作
复归操作
仅执行最终操作
复归操作
最终操作
不操作
注解
使用WebOTX 进程组的功能设置进程故障时的重启时,如果在EXPRESSCLUSTER的恢复操作中执行进程组的重启,则WebOTX 进程组的功能有可执行不能正常运行。因此,监视WebOTX 进程组时,请从Cluster WebUI对JVM监视资源进行以下的设置。
6.33.22. 接收WebOTX notification通知¶
通过登录特定的监听器类,当WebOTX查出故障时就发行notification。JVM监视资源接收到该notification,就会向JVM运行日志发出以下的通知。
%1$s:Notification received. %2$s.
%1$s,%2$s的意思如下。
%1$s: 监视对象Java VM
%2$s: notification的通知 (ObjectName=,type=,message=)
现在,可监视的资源的Mbean的详细信息如下表所述。
ObjectName |
[domainname]:j2eeType=J2EEDomain,name=[domainname],category=runtime |
|---|---|
Notification类型 |
nec.webotx.monitor.alivecheck.not-alive |
消息 |
failed |
6.33.23. 监视JBoss¶
单机模式
停止JBoss,(JBoss安装路径)从编辑器打开/bin/standalone.conf。
保存上述设置后,启动JBoss。
请在Cluster WebUI(JVM监视资源名称->[属性]-[监视(固有)]标签页-[识别名称])上设置与其他监视对象不重复的任意字符串(例:JBoss)。
域模式
请在Cluster WebUI(JVM监视资源名称->[属性]-[监视(固有)]标签页-[识别名称])上设置与其他监视对象不重复的任意字符串(例:JBoss)。另外,请在Cluster WebUI(JVM监视资源名称->[属性]->[监视(固有)]标签页-[进程名称])中设置Java VM启动时的全部选项以特定唯一性。
6.33.24. 监视Tomcat¶
本章将介绍JVM监视资源的监视对象Tomcat的设置步骤。
使用rpm包安装了Tomcat时,停止Tomcat,打开/etc/sysconfig/tomcat6 或者/etc/sysconfig/tomcat。使用rpm包未安装Tomcat时,停止Tomcat,创建(Tomcat安装路径)/bin/setenv.sh 。
- 打开后,在设置文件的Java选项中,用1行记载以下内容。n用来指定端口号。若同一设备有多个监视对象Java VM存在,请指定不同的端口号。这里指定的端口号在Cluster WebUI([监视资源的属性]->[监视(固有)]标签页->[连接端口号])中也会设置。
CATALINA_OPTS="${CATALINA_OPTS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
保存上述设置后,启动Tomcat。
请在Cluster WebUI(JVM监视资源名->[属性]->[监视(固有)]标签->[识别名称])中,设置与监视对象不同的任意字符串(例如:tomcat)。
6.33.25. 监视SVF¶
对JVM监视资源中,监视对象的SVF 的设置进行说明。
监视对象为Tomcat时:
请按照如下更改OS的 SVF 用户的环境变量。n指定端口号。同一设备上存在多个监视对象的Java VM时,请指定不重复的端口号。此处指定的端口号也可通过Cluster WebUI([监视资源属性]->[监视(固有)]标签页->[连接端口号])进行设置。
JAVA_OPTS="-Xms512m -Xmx512m -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false" export JAVA_OPTS
监视对象为Tomcat以外时:
从下表中选择监视对象,从编辑器打开该当的脚本。
监视对象
编辑的脚本
Simple Httpd Service(8.x时)
<SVF安装路径>/bin/SimpleHttpd
Simple Httpd Service(9.x时)
<SVF安装路径>/bin/UCXServer
RDE Service
<SVF安装路径>/rdjava/rdserver/rd_server_startup.sh
<SVF安装路径>/rdjava/rdserver/svf_server_startup.sh
RD Spool Balancer
<SVF安装路径>/rdjava/rdbalancer/rd_balancer_startup.sh
SVF Print Spooler Service
<SVF安装路径>/bin/spooler
- 在Java选项指定处用1行来记述以下的内容。n 用来指定端口编号。如果同一机器中存在多个监视对象的Java VM,则需要指定不重复的端口编号。此处指定的端口编号也可通过Cluster WebUI([监视资源的属性]->[监视(固有)]标签页->[连接端口号])来设置。
JAVA_OPTIONS="${JAVA_OPTIONS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
监视对象为RDE Service时,在以下的启动路径中和rd_balancer_startup.sh中追加${JAVA_OPTIONS}。
java -Xmx256m -Xms256m -Djava.awt.headless=true ${JAVA_OPTIONS} -classpath $CLASSPATH jp.co.fit.vfreport.RdSpoolPlayerServer &
6.33.26. 监视自制的Java 应用程序¶
对JVM监视资源中,监视对象的Java应用程序的设置进行说明。监视对象的Java应用程序为停止状态,在Java应用程序的启动时选项中,将下面的Java选项指定为1行。n用来指定为监视所用的端口号。如果同一机器中存在多个监视对象的Java VM,则需要指定不重复的端口编号。此处指定的端口编号也可通过Cluster WebUI([监视资源属性]->[监视(固有)]标签页->[连接端口号])来设置。
-Dcom.sun.management.jmxremote.port=n
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
通过Java应用程序添加以下时也需要指定。
-Djavax.management.builder.initial=<MBeanServerBuilder 的类名>
6.34. 系统监视资源的设置¶
系统监视资源可持续收集系统资源统计信息,并根据一定的知识信息进行解析处理。通过解析结果,可尽早发现资源枯竭。
6.34.1. 监视(固有)标签页¶

CPU使用率的监视
设置是否进行CPU使用率的监视。
使用率 (1~100)
设置查出CPU使用率异常的阈值。
持续时间 (1~1440)
设置查出CPU使用率异常的时间。若持续高于阈值的时间超过指定时间,将会查出异常。
总内存使用量的监视
设置是否进行总内存使用量的监视。
使用量 (1~100)
设置查出内存使用量异常的阈值(占系统内存量百分比)。
持续时间 (1~1440)
设置查出总内存使用量异常的时间。若持续高于阈值的时间超过指定时间,将会查出异常。
总虚拟内存使用量的监视
设置是否进行总虚拟内存使用量的监视。
使用量 (1~100)
设置查出虚拟内存使用量异常的阈值。
持续时间 (1~1440)
设置查出总虚拟内存使用量异常的时间。超过阈值的持续时间在所指定的时间以上时,查出异常。
总打开文件数的监视
设置是否进行总打开文件数的监视。
打开文件总数(相对系统上限值的比率) (1~100)
设置查出总打开文件异常的阀值(对系统上限值的比率)。
持续时间 (1~1440)
设置查出总打开文件异常的时间超过阈值的持续时间在所指定的时间以上时,查出异常。
总线程数的监视
设置是否进行总线程数的监视。
总线程数 (0~100)
设置查出总启动线程数异常的阀值(对系统上限值的比率)。
持续时间 (1~1440)
设置查出总线程数异常的时间超过阈值的持续时间在所指定的时间以上时,查出异常。
每个用户的启动进程数的监视
设置是否进行各用户的启动进程数的监视。
各用户启动进程数 (0~100)
设置查出各用户启动进程数异常的阀值(对系统上限值的比率)。
持续时间 (1~1440)
设置查出各用户的启动进程数异常的时间超过阈值的持续时间在所指定的时间以上时,查出异常。
添加
添加要监视的磁盘。会显示出[输入监视条件]对话框。按照[输入监视条件]对话框的说明,进行判定为异常的监视条件的详细设置。
删除
从监视对象中删除在[磁盘列表]上选择的磁盘。
编辑
会显示出[输入监视条件]对话框。由于会显示出在[磁盘列表]上选择的磁盘的监视条件,因此可进行编辑,然后选择[OK]。
Mount点 (1024字节以内)
设置进行监视的挂载点。需要以[/]开头。
使用率
设置是否进行磁盘使用率的监视。
警告级别 (1~100)
设置检测磁盘使用率警報级别异常的阈值。
通知级别 (1~100)
设置检测磁盘使用率通知级别异常的阈值。
持续时间 (1~43200)
设置检测磁盘使用率通知级别异常的时间。在指定时间以上持续超过阈值时,检测为异常。
剩余容量
设置是否进行磁盘空余容量的监视。
警告级别 (1~4294967295)
设置检测磁盘空余容量警報级别异常的容量(MB)。
通知级别 (1~4294967295)
设置检测磁盘空余容量通知级别异常的容量(MB)。
持续时间 (1~43200)
设置检测磁盘空余容量通知级别异常的时间。在指定时间以上持续超过阈值时,检测为异常。
6.34.2. 系统监视资源的注意事项¶
在系统全体资源监视下,反复在阈值上下增减时
动作中如果更改了OS的日期和时间时,每隔10分钟执行的解析处理的时机只在日期/时刻变更后的第一次发生偏离。为了发生如下所示,必要时请挂起和恢复集群操作。
即使过了异常检出的经过时间,也不执行异常的检出。
异常检出经过时间前,执行异常的检出。
进行集群的挂起/复原时,从其启动的瞬间即开始收集信息。
系统资源使用量的解析每10分钟进行一次。因此,持续监视时间最多可执行经过10分钟后才会查出异常。
磁盘资源使用量的解析每60分钟进行一次。因此,持续监视时间最多可执行经过60分钟后才会查出异常。
磁盘资源的剩余容量监视中指定的磁盘容量,请指定为比实际磁盘容量小的数值。如果指定为较大值,将被认为剩余容量不足,查出异常。
交换正在监视中的磁盘时,如果交换前和交换后的磁盘在以下项目有差异,需要清除之前的解析信息。
磁盘的总容量
文件系统
请在没有获得Swap领域的机器中,不要选中系统的总虚拟内存使用量的监视。
磁盘资源监视功能,不能对固定磁盘以外的磁盘进行监视。
系统资源监视中收集的磁盘使用率由磁盘总容量与磁盘可用容量算出的。与df(1)命令表示的磁盘使用率的计算方法不同,数值会稍有偏差。
磁盘资源监视功能的同时可监视最大磁盘数为64台。
- 系统资源的统计信息路径: <data路径>/hasrm_monitor_list.xml.YYYYMMDDhhmmss.zip最大个数: 1500 个
- 系统资源的解析信息路径: <data路径>/hasrm_analyze_list.xml.YYYYMMDDhhmmss.zip最大个数: 3 个
- 磁盘资源的统计信息路径: <data路径>/hasrm_diskcapacity_monitor_list.xml.YYYYMMDDhhmmss.zip最大个数: 10 个
- 磁盘资源的解析信息路径: <data路径>/hasrm_diskcapacity_analyze_list.xml.YYYYMMDDhhmmss.zip最大个数: 3 个
6.34.3. 系统监视资源的监视方法¶
利用默认值进行系统资源监视时,如资源的使用量达到90%以上的状态持续,则在60分钟后通知资源监视的异常。
查出利用默认值进行系统资源监视时的总内存使用量的异常的示例如下所示。
若总内存使用量一直持续超过总内存使用量阈值状态,达到一定时间即会超出阈值。
下图中,总内存使用量持续超过阈值(90%),并且连续超过监视持续时间(60分钟),因此查出总内存使用量异常。
图 6.18 若超过总内存使用量阈值的状态持续一定时间时(查出异常)¶
若总内存使用率持续在总内存使用阈值上下浮动,则不会超出总内存使用量阈值。
下图中,总内存使用量暂时超过总内存使用量的阈值(90%)。 但是,由于超过该阈值的状态不会持续监视持续时间(60分钟),因此不会查出总内存使用量异常。
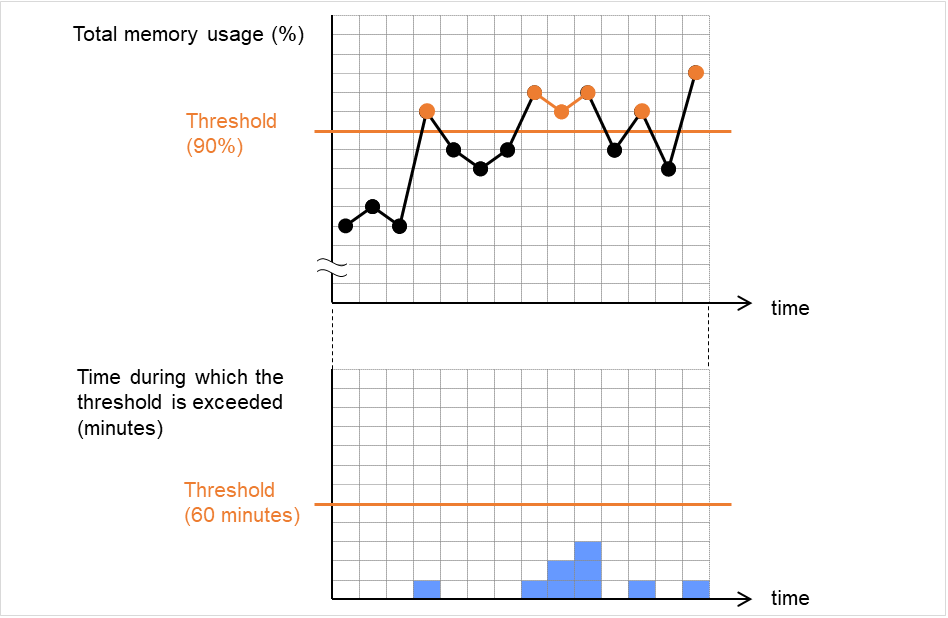
图 6.19 若超过总内存使用量阈值的状态不持续一定时间时(不查出异常)¶
警告级别的磁盘容量监视
通知级别的磁盘容量监视
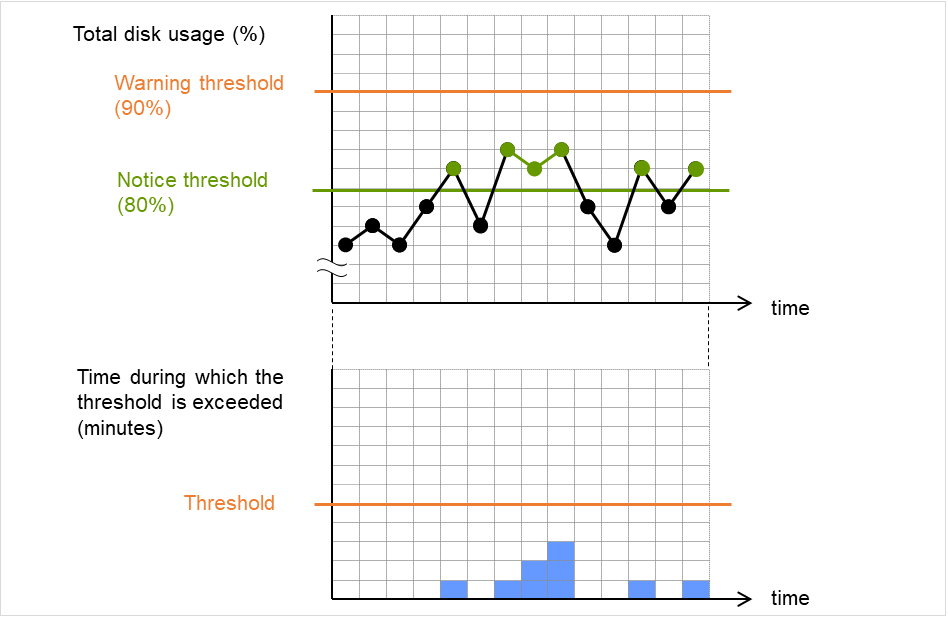
6.35. 进程资源监视资源的设置¶
进程资源监视资源,是不断收集使用进程的资源的统计信息,并根据一定的知识信息进行分析。从分析结果中可以较早的发现发生资源耗尽的情况。
6.35.1. 监视(固有)标签页¶
进程名 (1023字节以内)
设置监视对象进程的进程名。不设置进程名时,启动中的所有进程都作为监视对象。
此外,以下3种情况也可指定进程名的通配符。除此之外无法指定。
【前方一致】 <进程名所包含的字符串>*
【后方一致】 *<进程名所包含的的字符串>
【部分一致】 *<进程名所包含的字符串>*
可指定为监视对象的进程名最多为1023字节。若指定超过1023字节的进程名之进程为监视对象时,使用通配符号(*)进行指定。
监视对象进程的进程名超过1023字节时,可识别的进程名只有前1023字节。使用通配符(*)指定时,请指定小于1023字节的字符串。
请通过ps(1)命令等确认实际运行进程的进程名后,设定监视对象进程名。
执行结果实例
UID PID PPID C STIME TTY TIME CMD root 1 0 0 Sep12 ? 00:00:00 init [5] : root 5314 1 0 Sep12 ? 00:00:00 /usr/sbin/acpid root 5325 1 0 Sep12 ? 00:00:00 /usr/sbin/sshd htt 5481 1 0 Sep12 ? 00:00:00 /usr/sbin/htt -retryonerror 0在 /usr/sbin/htt 监视情况 执行上述命令,得出以上结果指定监视对象进程名为 /usr/sbin/htt -retryonerror 0。在监视对象进程名中,进程的参数为进程名的一部分来作为监视对象进程的特别指定。指定监视对象进程名时,请指定包括参数在内的进程名。仅监视不含参数的进程名时,请使用通配符号(*)来指定不含参数的前方一致或部分一致。
CPU使用率的监视
设置是否进行CPU使用率的监视。
使用率 (1~100)
设置查出CPU使用率异常的阈值。
持续时间 (1~129600)
设置查出CPU使用率异常的时间。若持续高于阈值的时间超过指定时间,将会查出异常。
总内存使用量的监视
设置是否进行内存使用量的监视。
相比初次监视的增加率(1~1000)
设置查出内存使用量异常的阈值。
最大更新次数(1~129600)
设置查出内存使用量异常的更新次数。如果在指定的更新次数或更多时间内持续超过阈值,则会查出异常。
打开文件数的监视(最大值)
设置是否进行打开文件数的监视(最大值)。
刷新次数(1~1024)
设置查出打开文件数异常的刷新次数。打开文件数的最大值超过指定次数更新时,查出异常。
打开文件数的监视(内核上限值)
设置是否进行打开文件数的监视(内核上限值)。
比率(1~100)
设置查出打开文件数的异常的阈值(对于内核上限值的比率)。
线程数的监视
设置是否进行线程数的监视。
持续时间(1~129600)
设置查出线程数异常的时间。如果有线程数增加,且超过指定时间以上的进程,则查出异常。
监视僵死程序
设置是否进行僵死程序的监视。
持续时间(1~129600)
设置查出总线程数异常的时间。如果有成为总线程且超过指定时间以上的进程,则查出异常。
监视同一名称的进程
设置是否进行同一名称进程的监视。
个数(1~10000)
设置查出同一名称进程异常的个数。同一名称进程超过指定个数时,查出异常。
6.35.2. 进程资源监视资源的注意事项¶
使用进程资源监视资源时,需要zip以及unzip的包。
关于进程资源监视资源的设定值,推荐使用默认值。
换出的进程不作为资源异常检测对象。
正在运行时若更改OS的日期或时间,会导致每10分钟进行一次的解析处理时刻在日期或时间更改后的第一次有偏差。由于可执行会发生以下问题,请进行挂起集群和恢复集群操作。
已经到了异常查出时间,却没有查出异常。
还没到异常查出时间,却查出异常。
- 进程资源的统计信息路径: <data路径>/hasrm_monitor_list.xml.YYYYMMDDhhmmss.zip最大个数: 1500 个
- 进程资源的解析信息路径: <data路径>/hasrm_analyze_list.xml.YYYYMMDDhhmmss.zip最大个数: 3 个
要使进程资源监视资源的状态从异常回到正常状态,请执行以下任意一种处理。
集群的挂起/复原
集群的停止/开始
6.35.3. 进程资源监视资源的监视方法¶
查出进程资源监视的内存使用量异常的示例如下所示。
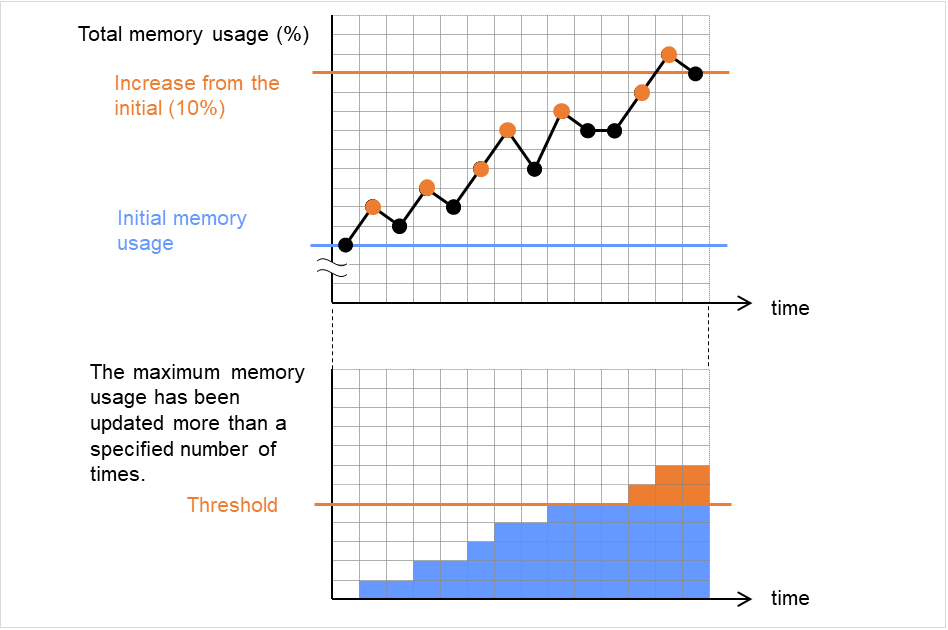
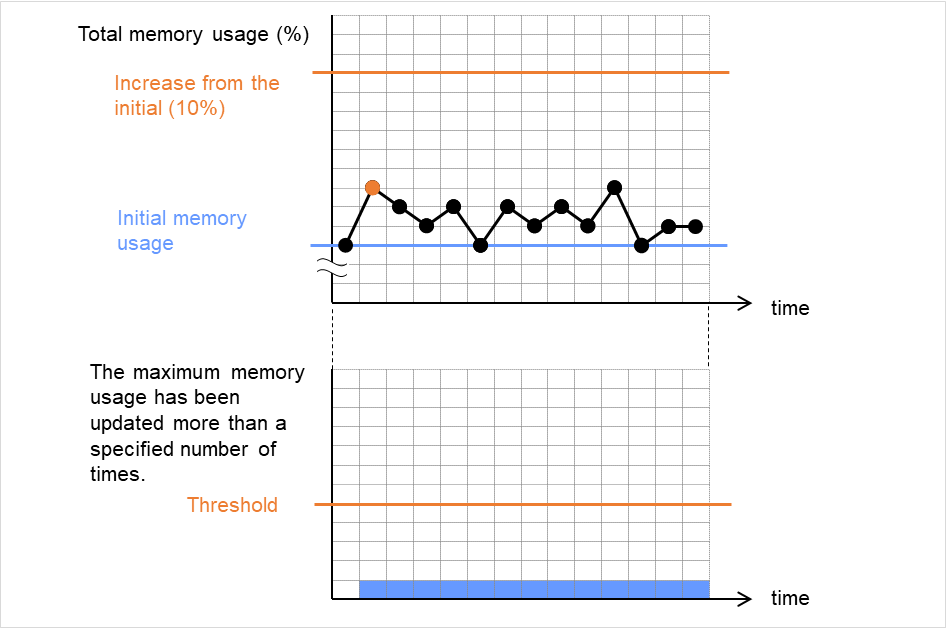
7. 心跳资源的详细信息¶
本章说明心跳资源的详细内容。
为提高与集群链接软件EXPRESSCLUSTER X的操作性等方面的兼容性,EXPRESSCLUSTER X SingleServerSafe 使用了相同的画面。
本章中介绍的内容如下。
7.1. 心跳资源列表¶
进行服务器的死活监视。心跳设备包括以下几种。
心跳资源名 |
简称 |
功能概要 |
|---|---|---|
LAN心跳资源
|
lanhb
|
使用LAN对服务器进行死活监视
也用于集群内通信。
|
LAN心跳需要设置1个。
8. 其他设置的详细信息¶
本章对EXPRESSCLUSTER X SingleServerSafe的其他项目的详细信息进行说明。
为提高与集群链接软件EXPRESSCLUSTER X的操作性等方面的兼容性,EXPRESSCLUSTER X SingleServerSafe 使用了相同的画面。
本章介绍的内容如下。
8.1. 集群属性¶
在[集群的属性]中,可以显示EXPRESSCLUSTER X SingleServerSafe的详细信息及更改设置。
8.1.1. 信息标签页¶
显示集群名,登录,更改注释。
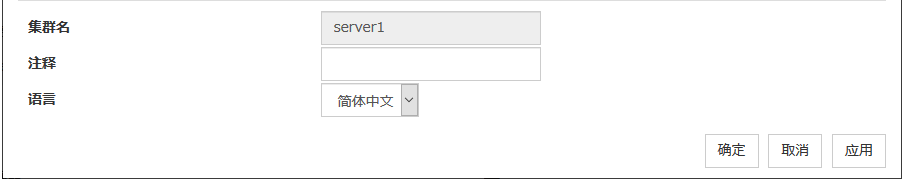
集群名
显示集群名。此处不能更改名称。
注释 (127字节以内)
设置注释。只可输入半角英文数字。
语言
从下列语言中选择显示语言。请设置运行Cluster WebUI的OS的语言(区域设置)。
英语
日语
简体中文
8.1.2. 私网标签页¶
不使用
8.1.3. Fencing 标签页¶
不使用
8.1.4. 超时标签页¶
设置超时等值。
服务启动延迟时间 (0~9999)
OS启动时延迟集群服务启动的时间。
同步等待时间 (0~99)
服务器启动时等待其他服务器启动的时间。
心跳线
心跳间隔及心跳超时。
- 间隔(1~99)心跳间隔。
- 超时(2~9999)心跳超时。如果在此处设置的时间内持续无应答,则视为服务器宕机。
需要大于间隔的值。
关机监视(参考"监视标签页")时,包含应用程序在内,需要设为比OS关机时间长的时间。
内部通信超时(1~9999)
在执行EXPRESSCLUSTER的命令或Cluster WebUI上的操作,显示画面时等所执行的EXPRESSCLUSTER服务器的内部通信中使用的超时值。
默认值
返回默认值时使用。点击[默认值]则所有的项目都被设置为默认值。
8.1.5. 端口号标签页¶
设置TCP端口号,UDP端口号。
TCP
TCP的各端口号不能重复。
UDP
默认值
用于返回到默认值。若点击[默认值]按钮,则所有的项目都设为默认值。
8.1.6. 端口号(镜像)标签页¶
不使用。
8.1.7. 端口号(日志)标签页¶
设置日志的通信方法。
日志的通信方式
端口号 (1~65535)
日志的通信方法选择了UDP时使用的端口号。不能与端口号标签页的UDP的各端口号重复。
默认值
用于返回到默认值。点击[默认值],则所有的项目都设为默认值。
8.1.8. 监视标签页¶
设置监视相关的项目。
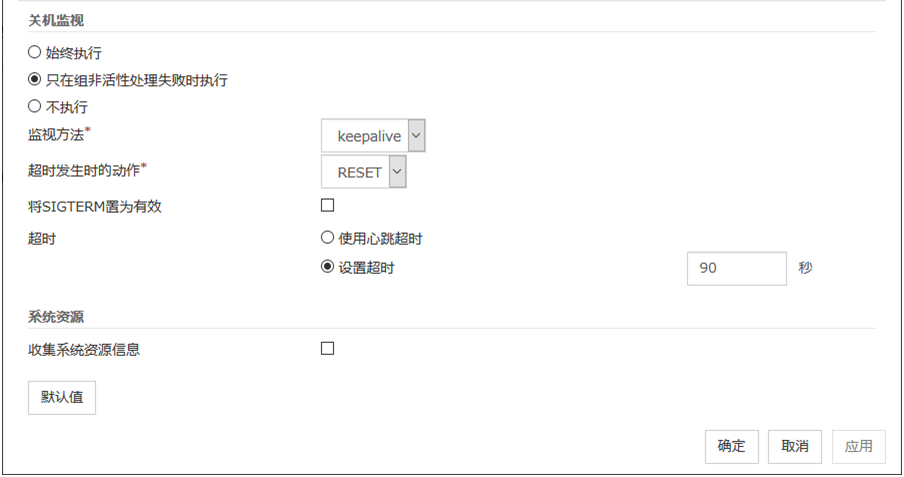
关机监视
在通过EXPRESSCLUSTER的命令执行了服务器关机时,监视OS是否停止。若集群服务判断OS停止,则强行复位,或者做应急措施。服务器的应急措施只有在监视方法keepalive时才能进行设定。
监视方法
从下列选项中选择进行关机监视时的监视方法。
softdog
ipmi
keepalive
超时发生时的动作
在下述两种方法中选择当判断OS 停止时的动作。只有在监视方法选择为keepalive才可以设定。
将SIGTERM设置为有效
设置进行关机监视时是否将SIGTERM设为有效。
注解
如果在[监视方法]中选择了ipmi,撤消了[将SIGTERM置为有效]的选中状态,则即使OS关机正常结束,也不会复位。
使用心跳的超时
使关机监视的超时值与心跳超时值结合使用。
设置超时(2~9999)
如果不将心跳超时值用作关机监视的超时值,则指定超时值。
系统资源
设置系统资源信息的收集/不收集。为提高运行性能,定期收集系统资源信息。系统资源情报对EXPRESSCLUSTER的动作状况的调查有帮助,使得调查因为系统资源部不足引起的错误变得容易。
8.1.9. 复归标签页¶
进行复原相关设置。
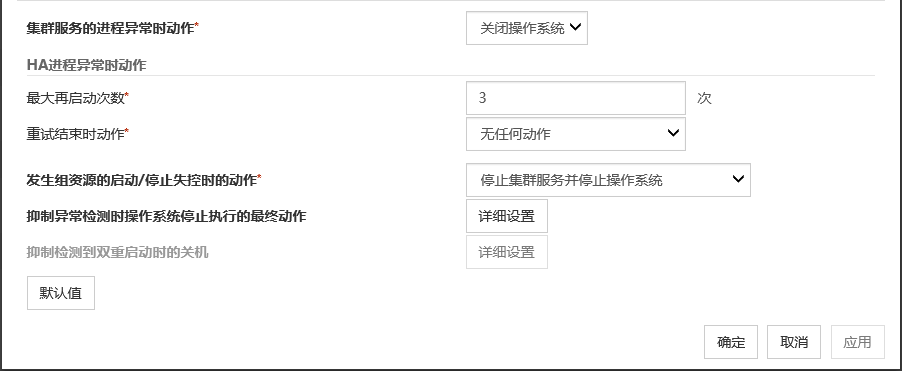
集群服务的进程异常时动作
指定集群服务的进程异常时的动作。
HA进程异常时工作
注解
HA进程是在系统监视资源或进程资源监视资源,JVM监视资源,系统资源信息收集功能中使用的进程。
发生组资源的启动/停止失控时的动作
指定组资源的启动/停止发生宕机时的动作。
注解
指定为"不进行任何操作(作为启动/停止异常来处理) ",在发生宕机时,对组资源的影响变为不确定,因此不建议将设定更改为"不进行任何操作(作为启动/停止异常来处理) "。
指定为"不进行任何操作(作为启动/停止异常来处理) "时,检测出组资源的启动/停止异常时的复归动作的设定如下所示。
启动/停止重试次数 : 0次
失效切换次数 : 0次
最终动作 : 伴随OS停止的动作
抑制异常检测时操作系统停止执行的最终动作
点击[详细设置],设置随异常检测而OS停止时的最终动作控制。
注解
外部联动监视资源不属于查出异常时控制操作的对象。
因查出组资源启动/停止时的最终动作,或者查出监视资源异常时的最终动作,而使 OS停止会发生如下情况。
集群服务停止和OS关机
集群服务停止和OS重启
sysrq错误
keepalive复位
keepalive错误
BMC复位
BMC断电
BMC断电
BMC NMI
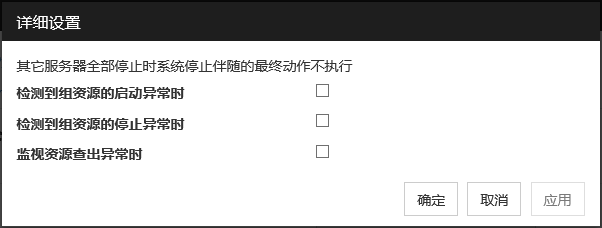
控制检测出双启动时的关机
不使用。
8.1.10. Alert服务标签页¶
设置邮件通告功能。
使用邮件通告功能时,请登录Alert Service的License。
注解
要使用邮件通告功能,网络警告灯,请购买EXPRESSCLUSTER X Alert Service 5.0 for Linux。
使Alert通报设置生效
设置是否将警报通告目的地从默认设置更改为其他设置。如果要更改,请点击[编辑]并设置输出目的地。如果不选中此处的复选框,则可将更改后的输出目的地暂时恢复到默认值。关于默认通报目的地,请参考《操作指南》的"错误消息一览表"的"syslog,警报,邮件通告消息,SNMP Trap消息,Message Topic"。
邮件地址 (255字节以内)
输入通告目标邮件地址。如果要设置多个邮件地址,请用分号分隔邮件地址。
主题 (127字节以内)
请输入邮件名。
邮件发送方法
设置邮件发送方法。
输出日志级别到系统日志
在EXPRESSCLUSTER X SingleServerSafe运行时输出的syslog的消息中添加级别。
使用网络警告灯
不使用。
更改警报发送地址
点击[编辑]按钮,显示Alert发送地址的变更对话框。
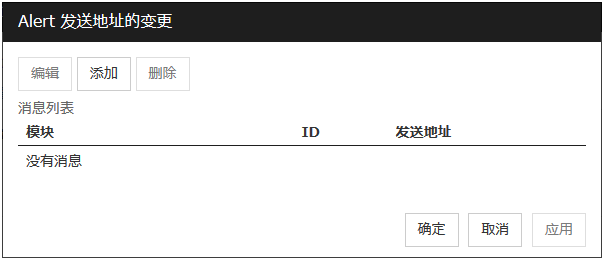
添加
追加要定制通报接收方的模块类型和事件ID。点击[添加]按钮后,显示消息输入对话框。
分类
选择模块类型的大分类。
模块类型 (31字节以内)
选择要更改发送地址的模块类型名。
事件ID
发送地址
选择通报接收方。
添加
追加警报扩展功能的命令。点击[添加]后,显示输入命令的对话框。针对1个事件ID,最多可以输入4个命令。
删除
删除警报扩展功能的命令时使用。选择命令,请点击[删除]。
编辑
编辑警报扩展功能的命令时使用。选择命令,请点击[编辑]。
命令 (511字节以内)
输入SNMP trap等执行通报的命令。请指定绝对路径。不能浏览指定的命令的执行结果。
设置示例:
/usr/local/bin/snmptrap -v1 -c HOME 10.0.0.2 0 10.0.0.1 1 0 '' 1 s "%%MSG%%"
SMTP设置
点击[SMTP设置]后,显示通过邮件通报使用的[SMTP设置]对话框。
邮件发送文书的字符编码 (127字节以内)
设置通过邮件通报时发送邮件的字符编码。
通信应答的等候时间 (1~999)
设置与SMTP服务器之间的通信超时。
主题的编码
设置是否对邮件主题进行编码。
SMTP服务器列表
显示已经设置的SMTP服务器。该版本中可以设置的SMTP服务器为4台。
添加
添加SMTP服务器。点击该按钮后,显示SMTP的输入对话框。
删除
用于删除SMTP服务器的设定。
编辑
用于变更SMTP服务器的设定。
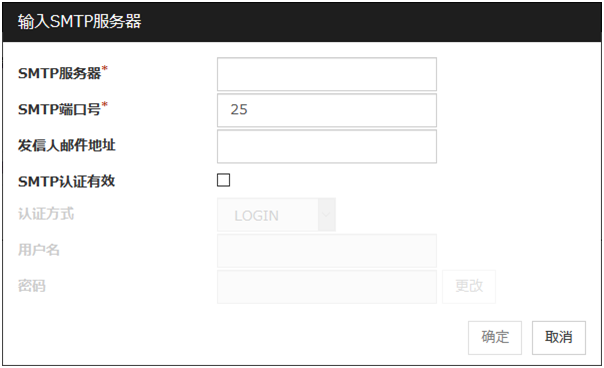
SMTP服务器 (255字节以内)
设置SMTP服务器的IP地址或者主机名。
SMTP端口号 (1~65535)
设置SMTP服务器的端口编号。
发信人邮件地址 (255字节以内)
设置邮件通报发送的邮件的发送方地址。
SMTP认证有效
设置是否将进行SMTP认证。
认证方式
选择SMTP认证方式。
用户名 (255字节以内)
设置SMTP认证使用的用户名。
密码 (255字节以内)
设置SMTP认证使用的密码。
发送地址一览表
显示设定的SNMP Trap发送地址。本版本中可设定的SNMP Trap发送地址最多为32件。
添加
添加SNMP Trap发送地址。点击[添加],显示发送地址的输入对话框。
删除
删除SNMP Trap发送地址的设置时使用。
编辑
改变SNMP Trap发送地址的设置时使用。
发送地址服务器 (255 字节以内)
设置SNMP Trap发送目的地的服务器名。
SNMP 端口号 (1-65535)
设置SNMP Trap发送目的地的端口号。
SNMP版本
设置SNMP Trap发送目的地的SNMP版本。
SNMP团体名(255字节以内)
设置SNMP Trap发送目的地的SNMP团体名。
8.1.11. WebManager标签页¶
设置WebManager服务器。
使WebManager服务有效
将WebManager服务器设为有效。
通信方式
可连接的客户端台数 (1~999)
设置可连接的客户端台数。
由密码来控制连接
点击[设置]按钮,则显示[密码]对话框。
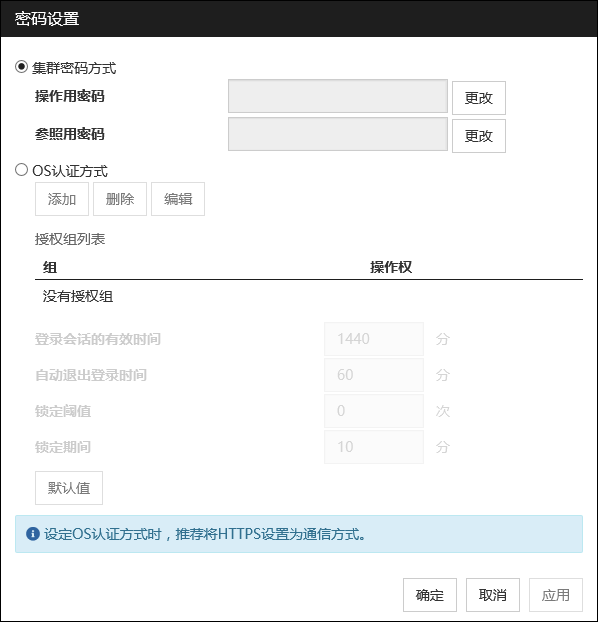
集群密码方式/OS认证方式
从以下选择登录到Cluster WebUI的方法。
集群密码方式
OS认证方式
登录Cluster WebUI的用户必须预先在服务器中注册。此外,由于为每个组设置了集群的操作权限,因此需要在服务器上注册该组并使用户属于该组。
添加
在将组添加到[授权的组列表]中时使用。点击[添加],显示[组名]对话框。选中[操作权限]复选框的状态下添加新组。
删除
从[授权的组列表]中删除组时使用。从[授权的组列表]中选择要删除的组,点击[删除]。
编辑
编辑组时使用。从[授权的组列表]中选择要编辑的组,点击[编辑]。被选中的组,显示输入[组名]的对话框。编辑后的组的操作权限不变。
操作权限
设置[授权的组列表]中注册的组的操作权限。
登录会话的有效时间(0~525600)
登录会话的有效时间。如果设置为0则不会过期。
自动注销时间 (0~99999)
Cluster WebUI和WebManager服务器之间没有通信时,自动注销的时间。设置为0时不会自动注销。
锁定阈值 (0~999)
用于锁定连续登陆失败的客户端IP地址的阈值。被锁定的客户端IP地址,在锁定期结束之前都无法登陆。设置为0时客户端IP地址不会被锁定。
锁定时间 (1~99999)
锁定的客户端IP地址自动解锁之前的时间。
默认值
返回默认值时使用。点击[默认值],则 登录会话的有效时间,自动注销时间,锁定阈值,锁定时间 都被设置为默认值。
通过客户端IP地址控制连接
通过客户端IP地址控制连接。
添加
用于在[允许连接的客户端IP地址列表]中添加IP地址。点击[添加]按钮,则显示IP地址的输入对话框。新添加的IP地址拥有操作权。
IP地址时的示例 : 10.0.0.21
网络地址时的示例 : 10.0.1.0/24
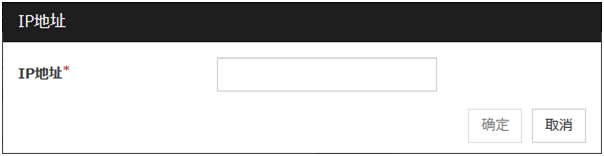
删除
用于从[允许连接的客户端IP地址列表]中删除IP地址。请选择要从[允许连接的客户端IP地址列表]删除的IP地址,点击[删除]。
编辑
用于编辑IP地址。在[允许连接的客户端IP地址列表]中选择要编辑的IP地址,点击[编辑]。显示输入了所选IP地址的IP地址的输入对话框。已编辑的IP地址的操作权不变。
注解
允许该连接的客户端IP地址也可用于限制基于clprexec的外部操作连接。
操作权
对[允许连接的客户端IP地址列表]中登录的IP地址设置操作权。
导出Cluster WebUI的操作日志
输出Cluster WebUI的操作日志。
日志输出路径 (255 字节内)
指定Cluster WebUI操作日志的输出目录。请指定绝对路径和ASCII字符。
文件大小 (1~10)
指定Cluster WebUI操作日志的大小。当达到指定的文件大小时,将进行轮询。最多可以保存5代日志文件。
连接用IP地址
点击[设置],会显示集成WebManager用的IP地址对话框。
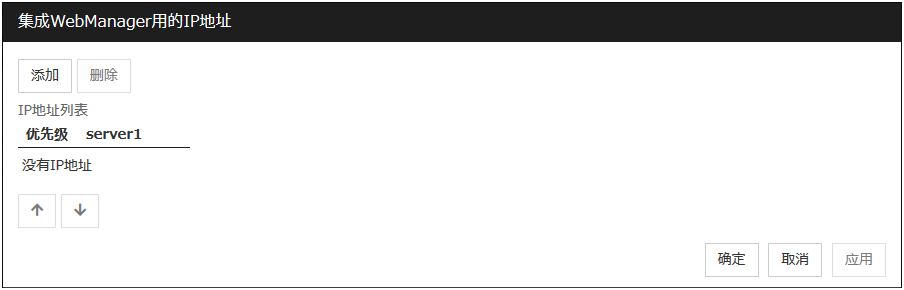
调整
用于调整WebManager服务器。点击[调整]则显示[Web管理器调整属性]对话框。
8.1.12. API 标签页¶
设置API服务。
启用API服务
启用API服务。
通信方式
以组为单位设置权限
为每个组设置和控制集群的搜查权限。
登录到发出请求的服务器的用户必须事先在服务器中注册。此外,由于为每个组设置了集群的操作权限,因此有必要在服务器中注册组,并且用户要属于该组。
添加
在[授权组列表]中添加组时使用。点击[添加]显示[组名]对话框。在[操作权限]为ON的状态下添加新的组。
删除
从[授权组列表]中删除组时使用。请从[授权组列表]中选择要删除的组,点击[删除]。
编辑
编辑组时使用。从[授权组列表]中选择要编辑的组,点击[编辑]。显示已输入选择组的[组名]对话框。已编辑的组的操作权限不会改变。
操作权限
设置[授权组列表]中注册的组的操作权限。
通过客户端IP地址控制连接
通过客户端IP地址控制连接。
添加
用于在[允许连接的客户端IP地址列表]中添加IP地址。点击[添加]按钮,则显示IP地址的输入对话框。新添加的IP地址拥有操作权。
IP地址(80字节以内)
输入允许连接的客户端IP地址。
IP地址示例 : 10.0.0.21
网络地址示例 : 10.0.1.0/24
删除
用于从[允许连接的客户端IP地址列表]中删除IP地址。请选择要从[允许连接的客户端IP地址列表]删除的IP地址,点击[删除]。
编辑
用于编辑IP地址。在[允许连接的客户端IP地址列表]中选择要编辑的IP地址,点击[编辑]。显示输入了所选IP地址的IP地址的输入对话框。
操作权
对[通过客户端IP地址控制连接]中登录的IP地址设置操作权。
调整
调整API服务时使用。点击[调整],显示[API 调整属性]对话框。
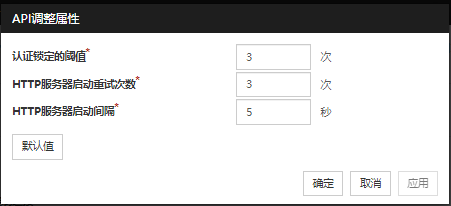
8.1.13. 加密 标签页¶
设置集群相关服务加密时使用的文件及库。
证书文件
设置与客户端通信时使用的服务器证书文件。服务器证书文件需要单独准备。
私钥文件
设置与客户端通信时使用的私钥文件。私钥文件需要单独准备。
SSL链接库
设置加密用的SSL链接库。请指定OpenSSL所提供的SSL链接库。请根据安装目录等环境不同而设定。
Crypto链接库
设置加密用的Crypto链接库。请指定OpenSSL所提同的Crypto链接库。请根据安装目录等环境不同而设定。
注解
OpenSSL是HTTPS所必需的。不支持OpenSSL 1.1.0或更高版本。
8.1.14. Alert日志标签页¶
设置警报日志。
使Alert服务有效
设置是否启动警报服务。
保存最大Alert记录数 (1~99999)
服务器的警报服务可保存的最大警报消息数。
Alert同步:方法
不使用。
Alert同步:通信超时(1~300)
不使用。
默认值
用于返回到默认值。点击[默认值],则所有的项目都设为默认值。
8.1.15. 延迟警告标签页¶
设置延迟警告。关于延迟警告的详细信息,请参考"9. 监视运行的详细信息"的"监视资源延迟警告"。

心跳延迟警告 (0~100)
设置心跳延迟警告的比例。如果在此处指定的心跳超时时间的比例所示的时间内没有心跳的应答,则警报日志中显示警告。如果设为100则不显示警告。
监视器延迟警告 (0~100)
设置监视器的延迟警告的比例。如果在此处指定的监视器超时时间的比例所示的时间内没有监视器的应答,则在警报日志中显示警告。如果设为100则不显示警告。
注解
8.1.16. 镜像Agent标签页¶
不使用。
8.1.17. 镜像驱动标签页¶
不使用。
8.1.18. JVM监视标签页¶
设置JVM监视中使用的详细参数。
注解
为了显示Cluster WebUI的JVM监视标签页,需要执行注册了Java Resource Agent的License的[更新服务器信息]。
Java安装路径 (255字节以内)
设置JVM监视中使用的Java VM的安装路径。请指定为绝对路径和ASCII文字。末尾不要添加"/"。指定例:/usr/java/jdk-9
最大Java堆大小 (7~4096)
JVM监视中使用的Java VM的最大堆大小使用兆字节来设定(相当于Java VM启动时的选项-Xmx)。
Java VM追加选项 (1024字节以内)
设定JVM监控所使用的Java VM启动时选项。但请在[最大Java堆大小]中指定-Xmx。指定示例:-XX:+UseSerialGC
日志输出设定
点击[设置]按钮后,显示输入命令的对话框。
资源测量设定
点击[设置]按钮,显示输入资源测量设置的对话框。
连接设定
点击[设置]按钮,显示输入连接设置的对话框。
日志输出设定
点击[设置]按钮时,会显示输入日志输出设置的对话框。
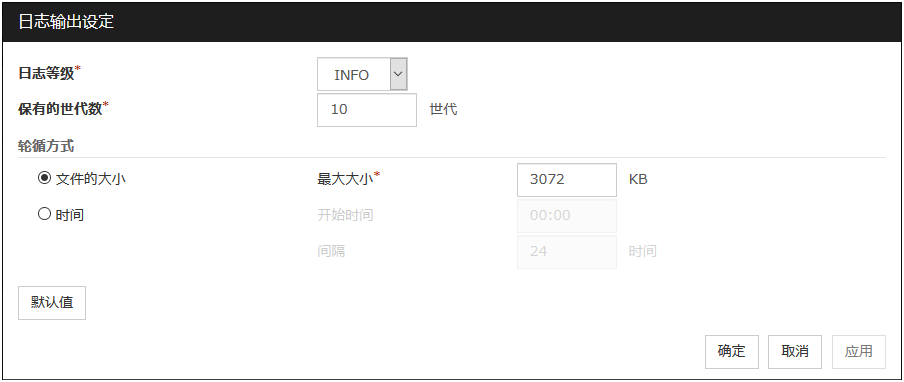
日志等级
选择JVM监视输出的日志的日志等级。
保有的时代数 (2~100)
对JVM监视输出的日志,进行保持版本数的设置。[轮循方式]中指定[时间]时,因为执行了集群挂起就重置轮循次数,所以请注意每次挂起< EXPRESSCLUSTER安装路径>\log\ha\jra 下的日志文件都会增加。
轮循方式
选择JVM监视输出的日志的Rotation方式。根据文件大小进行Rotation时,将JVM运用日志等每一个日志文件的最大容量设置为千字节(范围为200~2097151)。根据时间进行Rotation时,则将日志Rotation的开始时刻设置为"hh:mm"形式(hh:指定为0~23小时,mm:指定为0~59分),将Rotation间隔设置为小时(范围为1~8784)。
默认值
将日志等级,保持版本数和Rotataion方式设置为返回默认值。
资源测量设定[共通]
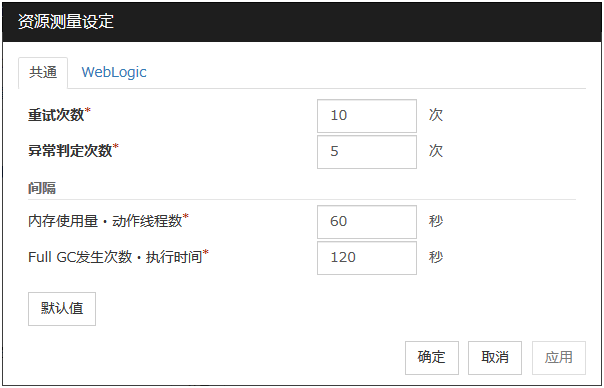
重试次数 (1~1440)
设置JVM中的资源监测失败时资源监测的重试次数。
异常判判定次数(1~10)
当JVM中通过资源监测获得的Java VM,应用程序服务器的资源使用量连续超出客户定义的限度值时,判断为异常的设置次数。
间隔 内存使用量・动作线程数 (15~600)
设置JVM中的监测储存器使用量和工作线程数之间的间隔。
间隔 Full GC发生次数・执行时间 (15~600)
设置JVM中的监测Full GC发生次数和发生时间之间的间隔。
默认值
将重试次数,异常判断限度值和间隔的设置返回默认值。
资源测量设定[WebLogic]
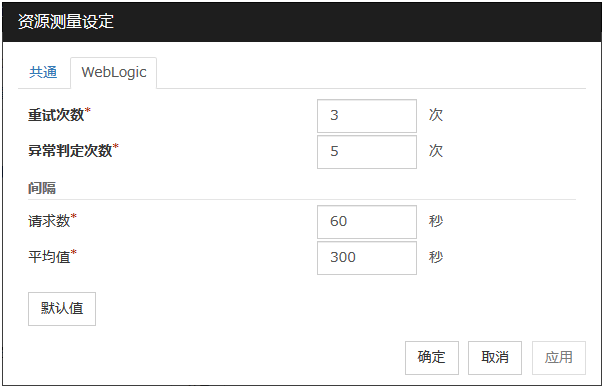
重试次数 (1~5)
设置JVM中的资源监测失败时资源监测的重试次数。
异常判定够次数(1~10)
当JVM中通过资源监测获得的Java VM,应用程序服务器的资源使用量连续超出客户定义的限度值时,判断为异常的设置次数。
间隔 请求数 (15~600)
设置JVM中的WebLogic监视中监测工作管理器和线程Poor的要求数之间的间隔。
间隔 平均值 (15~600)
设置JVM中的WebLogic监视中监测工作管理器和线程Poor的要求数平均值之间的间隔。请将此数值设置为间隔 要求数中设定数值的整数倍数。
默认值
将重试次数,异常判断限度值和间隔的设置返回默认值。
连接设定
点击[设置]按钮,显示连接监视目标的Java VM的设置输入对话框。
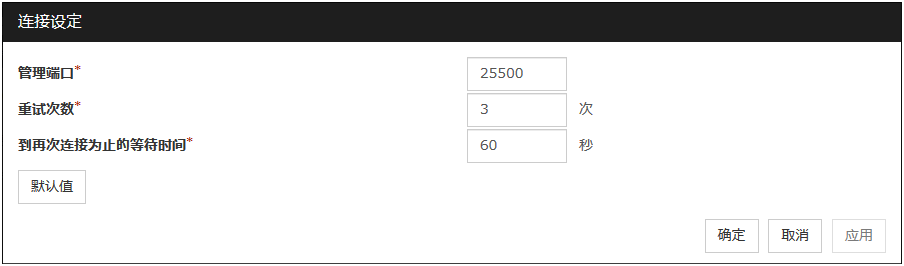
管理端口号 (1~65535)
设置JVM监视资源内部使用的端口号。请不要覆盖其他端口号。设置连接到监视对象的Java VM的端口号。不推荐使用32768~61000号。
重试次数 (1~5)
设置连接监视对象的Java VM失败时的重试次数。
到再次连接为止的等待时间 (15~60)
设置连接监视对象的Java VM失败时,到下一次连接前的间隔时间。
默认值
将管理端口号,重试次数,下一次连接前的等待时间的设置返回默认值。
8.1.19. 云标签页¶
设置在云环境中使用的功能。
启用Amazon SNS联动功能
设置Amazon SNS联动功能。
TopicArn
设置要在Amazon SNS联动功能中使用的TopicArn。
启用Amazon CloudWatch联动功能
设置Amazon CloudWatch联动功能。
注解
使用Amazon CloudWatch联动功能时,必须选中[将Amazon CloudWatch联动功能设置为有效],并将对象监视资源的[监视(共通)]标签页-[发送监视处理时间度量]设置为有效。
Namespace
设置Amazon CloudWatch联动功能中使用的Namespace。
度量的发送间隔
设置将监视资源的监视处理时间发送到Amazon CloudWatch的频率。
8.1.20. 扩展标签页¶
设置集群的其它功能。
再启动限制
伴随着将OS重启设置为组资源和监视资源查出异常时的最终运行,可执行出现永远反复重启的情况。通过设置重启次数,可限制反复重启。
注解
[重置最大再启动次数的时间]设为0时,不能重置再启动次数。重置再启动次数时,请使用clpregctrl命令。
宕机后自动启动
如果使用集群关机,集群停止以外的方法停止服务器时,或者集群关机,集群停止时不能正常结束时,设定下次OS启动时是否自动启动集群的服务。
Mount/Umount命令互斥
不使用。
服务器组间失效切换的宽限时间(0~99999)
不使用。
将 OS 停止操作更改为 OS 重启操作
将所有OS停止操作更改为OS重启操作。
注解
以下的监视资源不作为操作更改的对象。
消息接收监视资源
用户空间监视资源
禁用集群动作
注解
禁用监视资源异常检出时的复归操作,则用户空间监视资源无效。消息接收监视器资源不能成为禁用监视资源异常检出时的复归操作的对象。
集群统计信息
默认值
用于返回到默认值。点击[默认值]按钮,则所有的项目都设为默认值。

8.3. 最大登录数量列表¶
Version |
最大登录数量 |
|
|---|---|---|
服务器 |
4.0.0-1以上 |
1 |
组 |
4.0.0-1以上 |
128 |
组资源
(每1 个组)
|
4.0.0-1以上 |
256 |
监视资源 |
4.0.0-1以上 |
512 |
9. 监视运行的详细信息¶
为分析如何设置监视时的监视间隔,监视超时,监视重试次数,本章按几种故障模式详细介绍了查出故障的方法。
本章介绍的内容如下。
9.1. 关于不间断监视及启动时监视¶
Server startup: 服务器启动
Group activation: 组启动
Group deactivation: 组停止
Server stops: 服务器停止
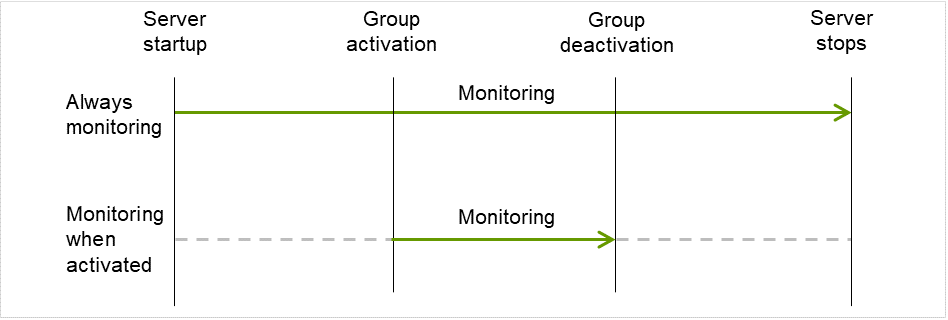
图 9.1 监视资源的不间断监视和启动时监视¶
9.2. 监视资源的监视间隔机制¶
所有监视资源按照监视间隔进行监视。
下面通过时序来说明根据该监视间隔时间的设置进行正常监视或者异常时对监视资源进行监视的流程。
发现监视正常执行时
图中显示在服务器启动后开始监视或者重启时的动作。 主监视进程(Main monitoring process)收到监视结果后,在监视间隔(Monitor interval)后将重复启动监视。
设置值如下所示时的运行示例:
<监视>监视间隔 30秒监视超时 60秒监视重试次数 0次
图 9.2 监视间隔(发现监视正常执行时)¶
发现监视出现异常时(未进行监视重试设置)
图中显示了监视对象(Monitor target)发生了异常,在发现异常后的动作。 主监视进程(Main monitoring process)收到监视结果(异常)后,对恢复对象组执行失效切换。
发现监视异常后,在下次监视时会查出监视异常,然后对恢复对象执行重新启动。
设置值如下所示时的运行示例:
<监视>监视间隔 30秒监视超时 60秒监视重试次数 0次<发现异常>恢复动作 复归对象重新启动恢复对象 组恢复脚本执行次数 0次重新启动次数 1次最终动作 不进行任何操作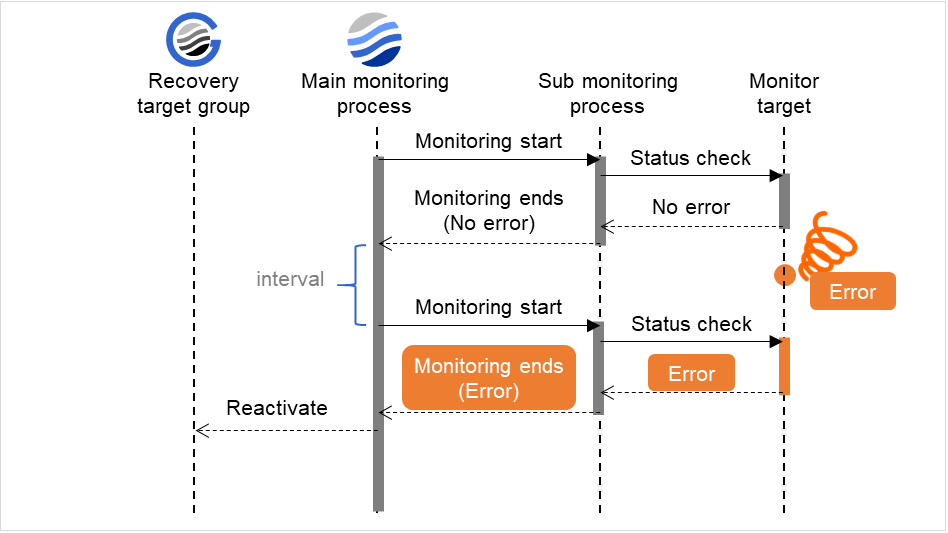
图 9.3 监视间隔(发现监视出现异常时 ・未进行监视重试设置)¶
查出监视异常时(对监视重试进行设置)
图中显示了监视对象(Monitor target)发生了异常,在发现异常后的动作。 主监视进程(Main monitoring process)收到监视结果(异常)后,执行监视操作达到设置的监视重试次数为止。如果监视对象仍然无法恢复时,对恢复对象组执行失效切换。
发生监视异常后,会在下次监视时查出监视异常。若在重试监视次数内无法恢复,则对恢复对象执行重新启动。
设置值如下所示时的运行示例:
<监视>监视间隔 30秒监视超时 60秒监视重试次数 2次<查出异常>恢复动作 复归对象重新启动恢复对象 组恢复脚本执行次数 0次重新启动次数 1次最终动作 不进行任何操作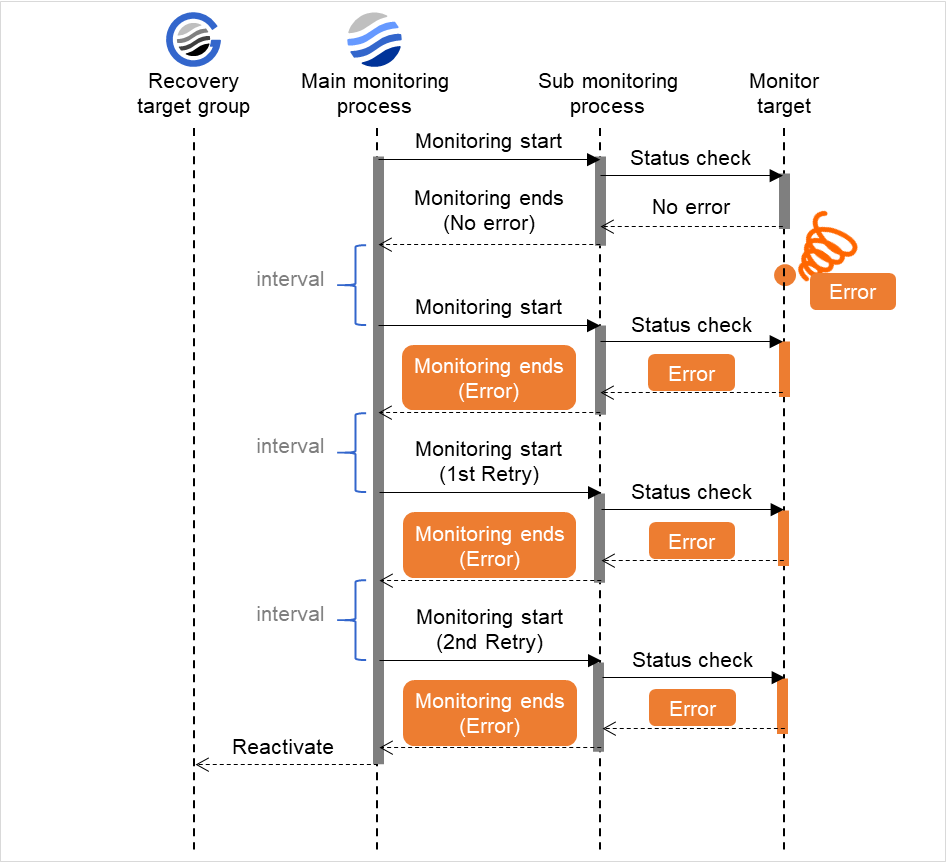
图 9.4 监视间隔(查出监视异常时 ・对监视重试进行设置)¶
查出监视超时时(未进行监视重试设置)
图中显示在设置的时间内没有结束监视处理时的动作。 主监视进程(Main monitoring process)在启动监视后,如果在监视超时中设置的时间内无法取得监视结果,则对恢复对象组进行失效切换。
发生监视超时后,会立即对针对恢复对象执行的恢复操作执行重新启动。
设置值如下所示时的运行示例:
<监视>监视间隔 30秒监视超时 60秒监视重试次数 0次<查出异常>恢复动作 复归对象重新启动恢复对象 组恢复脚本执行次数 0次重新启动次数 1次最终动作 不进行任何操作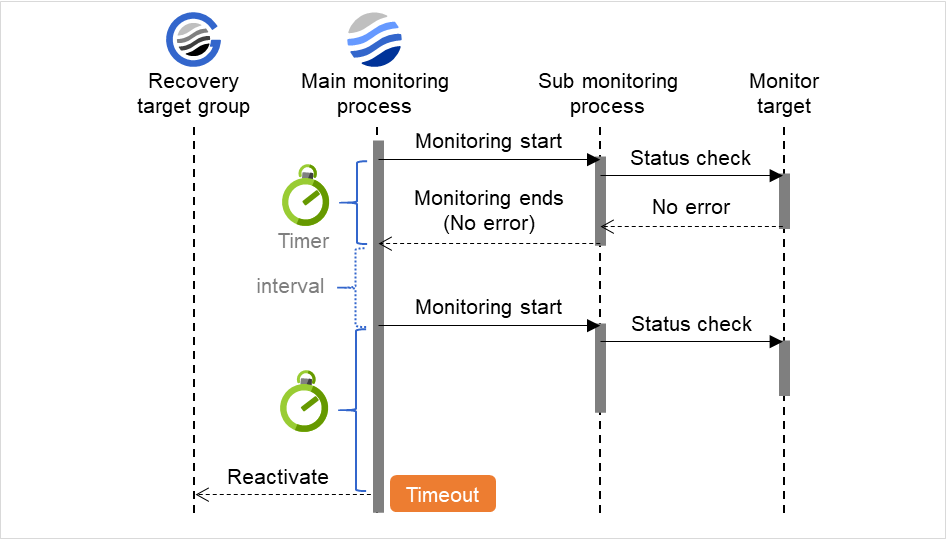
图 9.5 监视间隔(查出监视超时时 ・未进行监视重试设置)¶
查出监视超时时(对监视重试进行了设置)
图中显示在设置的时间内没有结束监视处理时的动作。 主监视进程(Main monitoring process)在启动监视后,如果在监视超时中设置的时间内无法取得监视结果,则执行监视操作达到设置的监视重试次数为止。如果仍然无法取得监视结果,则对恢复对象组进行失效切换。
监视超时发生后,进行监视重试,对恢复对象执行重新启动。
设置值如下所示时的运行示例:
<监视>监视间隔 30秒监视超时 60秒监视重试次数 1次<发现异常>恢复动作 复归对象重新启动恢复对象 组恢复脚本执行次数 0次重新启动次数 1次最终动作 不进行任何操作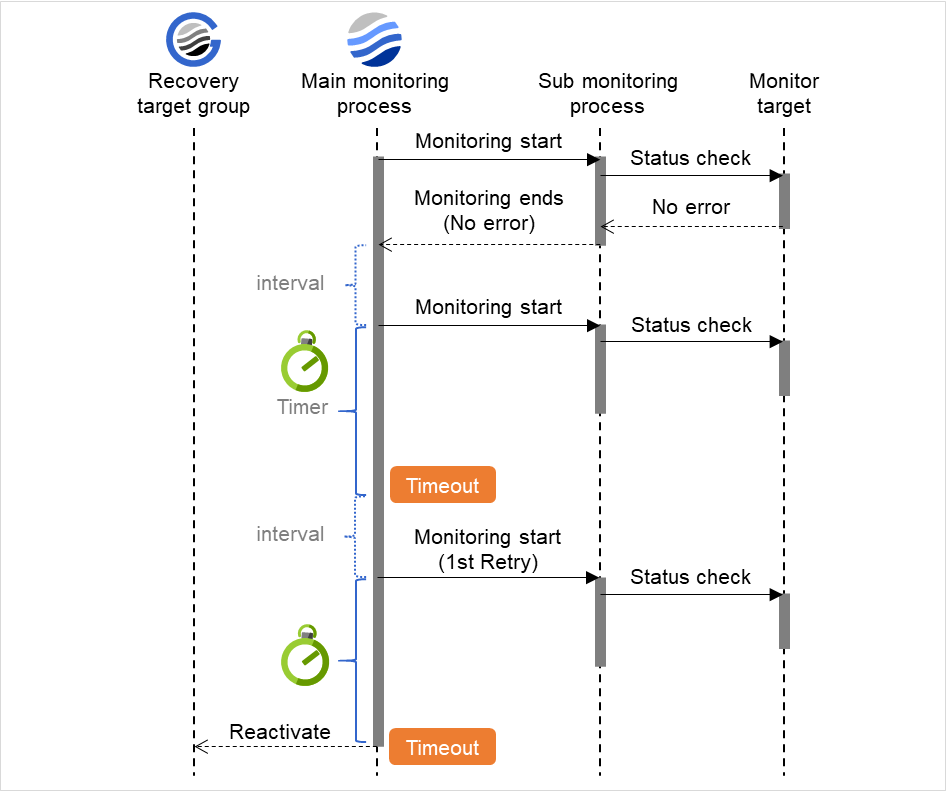
图 9.6 监视间隔(查出监视超时时 ・对监视重试进行了设置)¶
9.3. 监视资源发现异常时的操作¶
发现异常时对恢复对象执行的恢复操作如下所示。
若发现监视对象出现异常,则重新启动恢复对象(恢复操作为[只执行最终动作]时,及[自定义设置]中重新启动界限值设置为0时不执行重新启动)。
重新启动失败时,或者即使执行重新启动也发现异常时,进行最终操作。 [自定义设置]中设置的重新启动次数的最大值大于2时,连指定次数都要再次进行重新启动。
按照重新启动界限值重新启动后仍失败,则执行失效切换。若设置有失效切换前执行脚本,则执行脚本后再进行失效切换。
按照失效切换界限值的设置执行失效切换后仍然查出异常,则执行最终动作。若设置有最终动作前执行脚本,则执行脚本后再执行最终动作。
复归操作针对的复归对象必须处于以下状态。
恢复对想 |
状态 |
重新启动 4 |
最终操作 5 |
|---|---|---|---|
组/
组资源
|
已停止 |
No |
No |
正在启动或停止 |
No |
No |
|
已启动 |
Yes |
Yes |
|
异常 |
Yes |
Yes |
|
无 |
- |
- |
Yes |
Yes:执行恢复运行 No:不执行恢复运行
注解
在设置查出监视资源异常的情况下将恢复对象指定为组资源(例: EXEC资源),而监视资源发现异常时,处于恢复操作过渡(重新启动 ->最终动作) 的状态下,请不要执行以下命令或在Cluster WebUI中执行以下操作。
停止 / 暂停服务器
开始 / 停止组
请注意,即便恢复操作失败,重新启动恢复操作的次数均为1次。
9.4. 监视状态由异常恢复(正常)¶
若发现监视异常,恢复操作过渡过程或全部恢复操作结束发现监视资源恢复,则该监视资源所保留的以下界限值的计数器被重置。但是,若恢复对象指定为组资源,组时,只在被指定的同一个恢复对象的所有的监视资源的状态都变为正常状态时,计数器被重置。
重新启动界限值
重启动次数
最终动作的是否执行将被重置。
9.5. 恢复操作时启动/停止恢复对象出现异常¶
当监视资源的监视目标与恢复对象的组资源为同一设备,发现监视异常时,可执行会在执行恢复操作过程中查出启动/停止组资源异常。
9.6. 关于复归脚本,复归操作前的脚本¶
复归脚本,复归操作前脚本使用的环境变量
EXPRESSCLUSTER在执行脚本时,需要在环境变量中设置脚本执行时的状态(复归操作类型)等信息。在脚本内可以以下图中的环境变量为分支条件说明与系统操作相符的处理内容。
环境变量
环境变量的值
含义
RECOVERY
作为复归脚本执行时。
RESTART
重新启动前执行时。
FINALACTION
最终动作前执行时。
复归脚本执行次数
显示第几次执行复归脚本。
重新启动次数
显示第几次重新启动。
失效切换次数
显示第几次失效切换。
复归脚本,复归操作前脚本的描述流程
本节讲解了上节中说明的环境变量与实际脚本描述之间的关系。
复归脚本,复归操作前脚本的例子
#!/bin/sh # *************************************** # * preactaction.sh # *************************************** # 参考脚本执行要因的环境变量分配处理。 if ["$CLP_ACTION"="RECOVERY"] then # 在这里记述了复归处理。 # 该处理在以下时机执行。 # # 复归动作: 复归脚本 elif ["$CLP_ACTION"="RESTART"] then # 在这里记述了重启动前处理。 # 该处理在以下时机执行。 # # 复归动作: 重启动 elif ["$CLP_ACTION"="FINALACTION"] then # 在这里记述了复归处理。 # 该处理在以下时机执行。 # # 复归动作: 最终动作 fi exit 0
创建复归脚本,复归操作前脚本时的注意事项
创建脚本时请注意以下内容。
如果要执行一些需要时间的命令,请在脚本中保留用于表示命令执行完成的跟踪信息。发生故障时,可以使用这些信息来区分故障。可使用clplogcmd保留跟踪信息。
(例:脚本设置示例)
clplogcmd -m "recoverystart.." recoverystart clplogcmd -m "OK"
复归脚本,复归操作前脚本的注意事项
9.7. 监视资源延迟警告¶
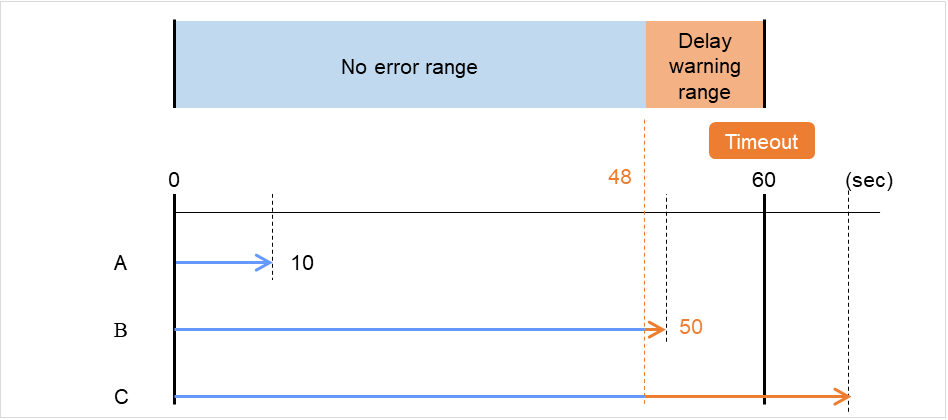
图 9.7 监视轮询时间和延迟警告¶
- 监视处理时间为10秒,监视资源处于正常状态。此时不发出警告。
- 监视处理时间为50秒,发现监视延迟,监视资源处于正常状态。此时,由于超过延迟警告比率80%,所以发警告通知。
- 监视轮询时间超过监视超时时间,即60秒,发生监视超时,监视资源处于异常状态。此时不发出警告。
另外,若将延迟警告比例设置为0或100,可进行以下操作。
- 将延迟警告比例设置为0每次监视都发延迟警告通知。利用此功能,可计算出服务器在高负载状态下对监视资源的监视处理时间,由此确定监视资源的监视超时时间
- 将延迟警告比例设置为100不发出延迟警告通知。
注解
除测试运行的情况之外,请不要设置0%等较低的值。
参见
监视资源的延迟警告是通过[集群的属性]->[延迟警告]标签页的[监视延迟警告]进行设置。
9.8. 监视资源的监视开始等待¶
如果监视开始等待时间为0秒,则在启动服务器或重新启动监视之后开始监视资源轮询。
[监视资源配置]

图 9.8 监视资源的监视开始等待(监视开始等待时间0秒)¶
如果监视开始等待时间为30秒,则在启动服务器或者重新启动监视后等待30秒之后开始监视资源轮询。
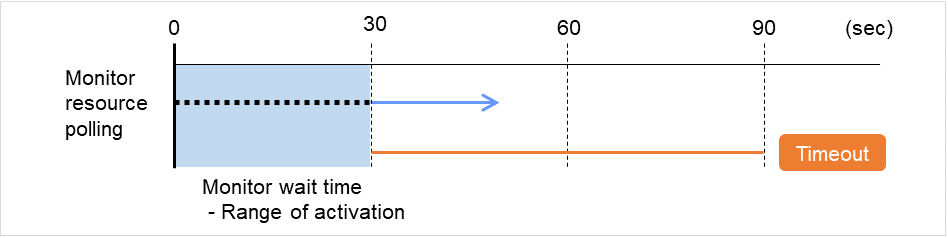
图 9.9 监视资源的监视开始等待(监视开始等待时间30秒)¶
注解
使用监视控制命令,暂时停止/重新启动监视资源时也是在指定的等待监视开始时间经过后进行。
在与监视PID监视资源的EXEC资源一样,因为应用程序的设置错误等导致监视开始后可执行立刻结束,并且无法重新启动的情况下,使用等待监视开始时间。
例如下列情况中,若将等待监视开始时间设置为0,可执行会出现无限重复执行恢复操作的情况。
这种情况下,应用程序将启动一次。 此外,开始通过PID监视器进行监视,由PID监视器进行的轮询会正常结束。 但是随后,由于某种原因,应用程序会异常结束。
[PID监视资源配置]
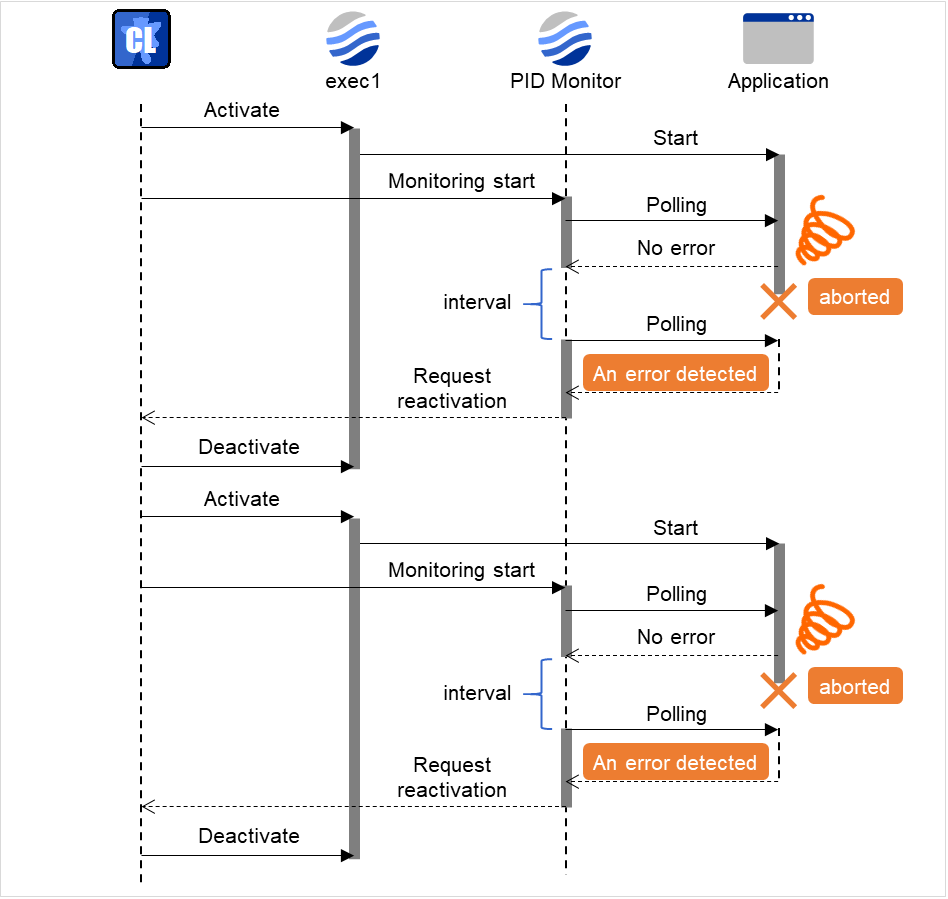
图 9.10 监视资源的监视开始等待(监视开始等待时间0秒)¶
该恢复操作无限重复进行的原因是由于第一次监视轮询正常结束。监视资源恢复操作的当前次数当监视资源处于正常状态时被重置。因此,当前次数总被重置为0,重新启动的恢复操作就会无限重复进行。
通过设置等待监视开始时间,可以避免以上现象的发生。
等待监视开始时间设置为应用程序启动后可执行结束的时间,默认设置为60秒。
这种情况下,应用程序将启动一次。 之后,在设定的开始监视等待时间之后,开始由PID监视器进行监视。 随后,虽然由于某种原因,应用程序异常结束,但是这是由PID监视器的首次轮询检测到的。
[PID监视资源配置]
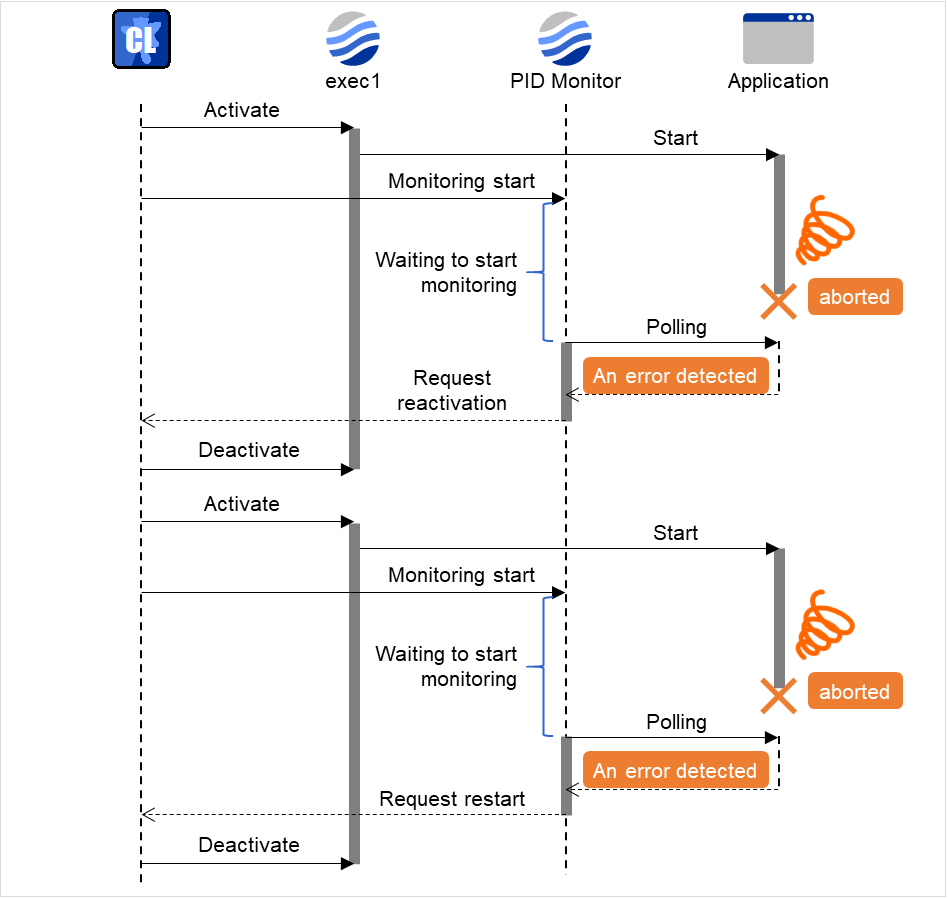
图 9.11 监视资源的监视开始等待(监视开始等待时间60秒)¶
9.9. 关于重启次数限制¶
将[停止集群Daemon并关闭操作系统] 或[停止集群Daemon并重启操作系统] 作为启动异常,检测到组资源的停止异常时的最终动作或监视资源查出异常时的最终动作与重启OS同时执行时,能够限制查出监视资源异常导致的关机次数或重启次数。
注解
由于再启动次数记录在各个服务器上,因此最大再启动次数为各个服务器的再启动次数上限。
10. 注意限制事项¶
10.1. 研究系统配置时¶
对系统配置时的注意事项进行说明。
10.1.1. 关于JVM监视资源¶
可同时进行监视的Java VM最多是25个。可同时监视的Java VM指,通过Cluster WebUI ([监视(固有)]标签页->[识别名])可进行唯一识别的Java VM的数量。
Java VM和JVM监视器资源之间的连接不支持SSL。
有时可执行不能检测出线程死锁。这是已经确认的来自JavaVM的缺陷。详细内容请参考Oracle的Bug Database的"Bug ID: 6380127 "。(2011年10月现在)。
JVM监视器资源可监视的Java VM需与JVM监视器资源工作时的服务器在同一服务器内。
JVM监视器资源可监视的JBoss的服务器实例1个服务器上最多只有一个实例。
x86_64版OS上运行IA32版的监视对象的应用程序时,不能进行监视。
如果将通过Cluster WebUI ([集群的属性]->[JVM监视]标签页->[最大Java堆大小])设置的最大Java堆大小值设置为3000等大数值,则JVM监视器资源会启动失败。由于依赖于系统环境,请根据系统的内存搭载容量来决定。
- 在监视对象Java VM的启动选项添加「-XX:+UseG1GC」时,在Java 7以前则不能监视JVM监视资源的[属性]-[监视(固有)]标签页-[调整]属性-[内存]标签页内的设置项目。在Java 8以后,可通过在JVM监视资源的[属性]-[监视(固有)]标签页--[JVM类型]选择[Oracle Java(usage monitoring)]来进行监视。
10.1.2. 关于邮件通知¶
不提供STARTTLS和SSL的邮件通知功能。
10.2. 创建EXPRESSCLUSTER X SingleServerSafe配置信息时¶
依赖于配置信息的设计,创建前系统的配置,必须确认及注意的事项。
10.2.1. 有关安装路径下的目录,文件¶
10.2.2. 环境变量¶
在环境变量被设为大于256个的环境中,无法执行下列脚本。若使用下列功能或资源,请将环境变量设为小于255个。
Exec资源启动/停止时执行的开始/停止脚本
自定义监视器资源在监视时执行的脚本
组资源,监视器资源异常被查出时最终操作执行前脚本
10.2.3. 服务器的Reset,Panic,Power Off¶
EXPRESSCLUSTER X SingleServerSafe 进行"重置服务器","panic服务器"或"关闭服务器"时,服务器无法正常关机。因此存在以下风险。
Mount中的文件系统损坏
未保存的数据丢失
发生"重置服务器"或"panic服务器"的设置如下所示。
组资源启动时/停止时异常的运行
sysrq Panic
keepalive Reset
keepalive Panic
BMC Reset
BMC Power Off
BMC Cycle
BMC NMI
查出监视资源异常时的最终动作
sysrq Panic
keepalive Reset
keepalive Panic
BMC Reset
BMC Power Off
BMC Cycle
BMC NMI
查出用户空间监视的超时时的运行
监视方法 softdog
监视方法 ipmi
监视方法 keepalive
注解
"panic服务器"仅在监视方法为keepalive时才能设置。
Shutdownstall监视
监视方法 softdog
监视方法 ipmi
监视方法 keepalive
注解
"panic服务器"仅在监视方法为keepalive时才能设置。
10.2.4. 组资源查出停止异常时的最终操作¶
查出停止异常时,对最终运行选择[无操作],则组将在启动失败的状态下停止。在正式的运行环境下,请不要设置为[无操作]。
10.2.5. 延迟警告比例¶
将延迟警告比例设置为0或100时,可以进行如下操作。
- 将延迟警告比例设置为0时每次执行监视都会通报延迟警告。可利用该功能计算出服务器在高负载状态下监视资源的监视时间,从而决定监视资源的监视超时时间
- 将延迟警告比例设置为100时延迟警告将不发出通报。
除了测试运行以外,请不要将值设置为诸如0%之类的低值。
10.2.6. 关于磁盘监视资源的监视方法TUR¶
- 不能在不支持SCSI的Test Unit Ready命令或SG_IO命令的磁盘,磁盘接口(HBA)上使用。有时硬件支持但驱动程序不支持,所以请结合驱动程序的规格进行确认。
- 根据磁盘控制器的类型或使用的分配的不同,OS可执行将S-ATA接口磁盘视为IDE接口的磁盘(hd),也可执行视为SCSI接口的磁盘(sd)。被视为IDE接口时,所有TUR方式将无法使用。被视为SCSI接口时,TUR(legacy)和TUR(generic)不能使用。
与read方式相比,对OS和磁盘的负载较小。
有时用Test Unit Ready不能查出物理媒体的I/O错误。
10.2.7. 关于能用于脚本注释等的双字节系字符编码¶
在EXPRESSCLUSTER中,Linux环境下编辑的脚本作为EUC使用,而Windows环境下编辑的脚本则作为Shift-JIS使用。如使用其他字符编码,可执行出现因环境不同而出现乱码的情况。
10.2.8. 关于脚本字符代码和换行代码¶
使用 clpcfctrl 命令设置反映用非 Cluster WebUI 创建的脚本时,请确保配置信息文件 (clp.conf) 和脚本的字符代码和换行代码在设置反映之前相同。如果字符代码或换行代码不同,脚本可能无法正常工作。
10.2.9. 关于系统监视器资源的设置¶
- 资源监视器的监测模式System Resource Agent通过「最多次数」和「监视持续时间」两个参数的组合进行检测。通过继续收集各系统资源(打开文件数,用户访问数,线程数,内存使用量,CPU 使用率,虚拟内存使用量),当一定时间内(指定为持续时间的时间)超过最多次数时,就会检测出异常。
10.2.10. 关于消息接收监视器资源的设置¶
向消息接收监视器资源通知异常时,使用[clprexec] 命令的方法。
使用[clprexec]命令时,请使用与EXPRESSCLUSTER CD同箱捆包的文件。请根据通知源的服务器的OS和架构来适当使用。并且,通知源服务器和通知目标服务器要处于可通信状态。
10.2.11. 关于JVM监视器的设置¶
监视目标为WebLogic Server时,对于JVM监视器资源的设定值,由于系统环境(内存搭载量等)的原因,设定范围的上限值可执行会受到限制。
[监视Work Manager的要求]-[要求数]
[监视Work Manager的要求]-[平均值]
[监视线程Pool的要求]-[待机要求 要求数]
[监视线程Pool的要求]-[待机要求 平均值]
[监视线程Pool的要求]-[执行要求 要求数]
[监视线程Pool的要求]-[执行要求 平均值]
监视目标的JRockit JVM 为64bit 版时,从JRockit JVM获取的各最大储存量会减少,致使不能计算出使用率,因此不能对以下的参数进行监视。
[监视堆使用率]- [领域整体]
[监视堆使用率]- [Nursery Space]
[监视堆使用率]- [Old Space]
[监视非堆使用率]- [领域整体]
[监视非堆使用率]- [ClassMemory]
使用Java Resource Agent请按照《安装指南》的[JVM监视器的运行环境]中记载的JRE(Java Runtime Environment)进行安装。可与使用监视对象(WebLogic Server和WebOTX)的JRE在相同的项目中使用,也可使用在其他项目。
监视资源名中不要包含空格。
10.3. 更改ExpressCluster X SingleServerSafe的配置时¶
开始集群运行后如果对配置进行变更时,需要对发生的事项留意。
10.3.1. 关于资源属性的依存关系¶
10.3.2. 关于消息接收监视资源的集群统计信息的设置¶
在更改监视资源的集群统计信息设置时,即使执行了挂起/复原,也无法在消息接收监视资源中反映集群统计信息的设置。如果要在消息接收资源中也反映集群统计信息,请重启操作系统。
10.3.3. 关于端口号的更改¶
启用服务器的防火墙,更改端口号时需要更改防火墙的设置。使用clpfwctrl命令可以进行防火墙的设置。详细内容请参考《操作指南》的"EXPRESSCLUSTER X SingleServerSafe命令参考"的"添加防火墙的规则(clpfwctrl命令)"。