9. CLUSTERPRO コマンドリファレンス¶
本章では、CLUSTERPRO で使用可能なコマンドについて説明します。
本章で説明する項目は以下のとおりです。
9.1. コマンドラインからクラスタを操作する¶
CLUSTERPRO では、コマンドラインからクラスタを操作するための多様なコマンドが用意されています。クラスタ構築時や Cluster WebUI が使用できない状況の場合などに便利です。コマンドラインでは、Cluster WebUI で行える以上の種類の操作を行うことができます。
注釈
モニタリソースの異常検出時の設定で回復対象にグループリソース (ディスクリソース、execリソース、...) を指定し、モニタリソースが異常を検出した場合の回復動作遷移中 (再活性化 → フェイルオーバ → 最終動作) には、以下のコマンドまたは、Cluster WebUI からのクラスタおよびグループへの制御は行わないでください。
クラスタの停止/サスペンド
グループの開始/停止/移動
モニタリソース異常による回復動作遷移中に上記の制御を行うと、そのグループの他のグループリソースが停止しないことがあります。
また、モニタリソース異常状態であっても最終動作実行後であれば上記制御を行うことが可能です。
重要
インストールディレクトリ配下に本マニュアルに記載していない実行形式ファイルやスクリプトファイルがありますが、CLUSTERPRO 以外からの実行はしないでください。実行した場合の影響については、サポート対象外とします。
9.2. CLUSTERPRO コマンド一覧¶
クラスタ構築関連
コマンド |
説明 |
参照 |
|---|---|---|
clpcfctrl |
Cluster WebUI で作成した構成情報をサーバに配信します。
Cluster WebUI で使用するためにクラスタ構成情報をバックアップします。
|
|
clplcnsc |
本製品の製品版・試用版ライセンスを管理します。 |
|
clpcfchk |
クラスタ構成情報をチェックします。 |
|
clpcfconv.sh |
クラスタ構成情報ファイルを旧バージョンから現バージョンへ変換します。 |
|
clpcfset
clpcfadm.py
|
クラスタ構成情報ファイルを生成します。 |
|
clpencrypt |
暗号化します。 |
|
clpfwctrl.sh |
ファイアウォールの規則を追加します。 |
状態表示関連
コマンド |
説明 |
参照 |
|---|---|---|
clpstat |
クラスタの状態や、設定情報を表示します。 |
|
clphealthchk |
プロセスの健全性を確認します。 |
クラスタ操作関連
コマンド |
説明 |
参照 |
|---|---|---|
clpcl |
クラスタデーモンの起動、停止、サスペンド、 リジュームなどを実行します。 |
|
clpdown |
CLUSTERPRO デーモンを停止し、サーバをシャットダウンします。 |
|
clpstdn |
クラスタ全体で、CLUSTERPRO デーモンを 停止し、全てのサーバをシャットダウンします。 |
|
clpgrp |
グループの起動、停止、移動を実行します。 |
|
clptoratio |
クラスタ内の全サーバの各種タイムアウト値の延長、表示を行います。 |
|
clproset |
共有ディスクパーティションデバイスの I/O 許可の変更と表示をします。 |
|
clpmonctrl |
モニタリソースの制御を行います。 |
|
clpregctrl |
単一サーバ上で再起動回数の表示/初期化を行います。 |
|
clprsc |
グループリソースの一時停止/再開を行います。 |
|
clprexec |
外部監視から CLUSTERPRO サーバへ処理実行を要求します。 |
|
clpbwctrl |
クラスタ起動同期待ち処理を制御します。 |
ログ関連
コマンド |
説明 |
参照 |
|---|---|---|
clplogcc |
ログ、OS 情報等を収集します。 |
|
clplogcf |
ログレベル、ログ出力ファイルサイズの設定の変更、表示を行います。 |
|
clpperfc |
グループ、モニタリソースに関するクラスタ統計情報を表示します。 |
スクリプト関連
コマンド |
説明 |
参照 |
|---|---|---|
clplogcmd |
EXEC リソースのスクリプトに記述し、任意のメッセージを出力先に出力します。 |
ミラー関連(Replicator を使用している場合のみ)
コマンド |
説明 |
参照 |
|---|---|---|
clpmdstat |
ミラーに関する状態と、設定情報を表示します。 |
|
clpmdctrl |
ミラーディスクリソースの活性/非活性、ミラー復帰など、各種操作を行います。
リクエストキュー最大数の設定表示/変更を行います。
|
|
clpmdinit |
ミラーディスクリソースのクラスタパーティションに対して初期化を行います。
ミラーディスクリソースのデータパーティションに対してファイルシステムを作成します。
|
|
clpbackup.sh |
ミラーリング対象パーティションを、ディスクイメージバックアップ可能な状態にします。 |
|
clprestore.sh |
リストアしたミラーディスクイメージを、利用可能な状態にします。 |
ハイブリッドディスク関連(Replicator DR を使用している場合のみ)
コマンド |
説明 |
参照 |
|---|---|---|
clphdstat |
ハイブリッドディスクに関する状態と、設定情報を表示します。 |
|
clphdctrl |
ハイブリッドディスクリソースの活性/非活性、ミラー復帰など、各種操作を行います。
リクエストキュー最大数の設定表示/変更を行います。
|
|
clphdinit |
ハイブリッドディスクリソースのクラスタパーティションに対して初期化を行います。 |
|
clpbackup.sh |
ミラーリング対象パーティションを、ディスクイメージバックアップ可能な状態にします。 |
|
clprestore.sh |
リストアしたミラーディスクイメージを、利用可能な状態にします。 |
データベース静止点関連
コマンド |
説明 |
参照 |
|---|---|---|
clpdb2still |
DB2の静止点の確保/解放を制御します。 |
|
clpmysqlstill |
MySQLの静止点の確保/解放を制御します。 |
|
clporclstill |
Oracleの静止点の確保/解放を制御します。 |
|
clppsqlstill |
PostgreSQLの静止点の確保/解放を制御します。 |
|
clpmssqlstill |
SQL Serverの静止点の確保/解放を制御します。 |
その他
コマンド |
説明 |
参照 |
|---|---|---|
clplamp |
ネットワーク警告灯を消灯します。 |
9.3. クラスタの状態を表示する (clpstat コマンド)¶
クラスタの状態と、設定情報を表示します。
-
コマンドライン - clpstat -s [--long] [-h hostname]clpstat -g [-h hostname]clpstat -m [-h hostname]clpstat -n [-h hostname]clpstat -f [-h hostname]clpstat -i [--detail] [-h hostname]clpstat --cl [--detail] [-h hostname]clpstat --sv [server_name] [--detail] [-h hostname]clpstat --hb [hb_name] [--detail] [-h hostname]clpstat --fnc [fnc_name] [--detail] [-h hostname]clpstat --svg [servergroup_name] [--detail] [-h hostname]clpstat --grp [group_name] [--detail] [-h hostname]clpstat --rsc [resource_name] [--detail] [-h hostname]clpstat --mon [monitor_name] [--detail] [-h hostname]clpstat --xcl [xclname] [--detail] [-h hostname]clpstat --local
-
説明 クラスタの状態や、設定情報を表示します。
-
オプション -
-s¶
-
オプションなし¶ クラスタの状態を表示します。
-
--long¶ クラスタ名やリソース名などの名前を最後まで表示します。
-
-g¶ クラスタのグループマップを表示します。
-
-m¶ 各サーバ上での各モニタリソースの状態を表示します。
-
-n¶ 各サーバ上での各ハートビートリソースの状態を表示します。
-
-f¶ 各サーバ上でのフェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)の状態を表示します。
-
-i¶ クラスタ全体の設定情報を表示します。
-
--cl¶ クラスタの設定情報を表示します。Replicator, Replicator DR を使用している場合、ミラーエージェントの情報も表示します。
-
--sv[server_name]¶ サーバの設定情報を表示します。サーバ名を指定することによって、指定したサーバ情報のみを表示することができます。
-
--hb[hb_name]¶ ハートビートリソースの設定情報を表示します。ハートビートリソース名を指定することによって、指定したハートビートリソース情報のみを表示できます。
-
--fnc[fnc_name]¶ フェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)の設定情報を表示します。リソース名を指定することによって、指定したネットワークパーティション解決リソースまたは強制停止リソースの情報のみを表示できます。
-
--svg[servergroup_name]¶ サーバグループの設定情報を表示します。サーバグループ名を指定することによって、指定したサーバグループ情報のみを表示できます。
-
--grp[group_name]¶ グループの設定情報を表示します。グループ名を指定することによって、指定したグループ情報のみを表示できます。
-
--rsc[resource_name]¶ グループリソースの設定情報を表示します。グループリソース名を指定することによって、指定したグループリソース情報のみを表示できます。
-
--mon[monitor_name]¶ モニタリソースの設定情報を表示します。モニタリソース名を指定することによって、指定したモニタリソース情報のみを表示できます。
-
--xcl[xclname]¶ 排他ルールの設定情報を表示します。排他ルール名を指定することによって、指定した排他ルール情報のみを表示できます。
-
--detail¶ このオプションを使用することによって、より詳細な設定情報を表示できます。
-
-hhostname¶ hostnameで指定したサーバから情報を取得します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) から情報を取得します。
-
--local¶ クラスタの状態を表示します。-s またはオプションなしと同等の情報を表示しますが、他サーバとの通信は行わずコマンド実行サーバ上の情報のみを表示します。
-
-
戻り値 -s オプションを指定しなかった場合
0
成功
上記以外
異常
-
備考 設定情報表示オプションは組み合わせによって、様々な形式で情報表示をすることができます。
表示結果のサーバ名の横に表示される * は、本コマンドを実行したサーバを表します。
-
注意事項
-
表示例 表示例は次のトピックで説明します。
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Invalid heartbeat resource name. Specify a valid heartbeat resource name in the cluster.
クラスタ内の正しいハートビートリソース名を指定してください。
Invalid network partition resource name. Specify a valid network partition resource name in the cluster.
クラスタ内の正しいネットワークパーティション解決リソース名を指定してください。
Invalid group name. Specify a valid group name in the cluster.
クラスタ内の正しいグループ名を指定してください。
Invalid group resource name. Specify a valid group resource name in the cluster.
クラスタ内の正しいグループリソース名を指定してください。
Invalid monitor resource name. Specify a valid monitor resource name in the cluster.
クラスタ内の正しいモニタリソース名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Invalid server group name. Specify a valid server group name in the cluster.
クラスタ内の正しいサーバグループ名を指定してください。
The cluster is not created.
クラスタ構成情報を作成し、反映してください。
Could not connect to the server. Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Cluster is stopped. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Cluster is suspended. To display the cluster status, use --local option.
クラスタがサスペンド状態です。クラスタの状態を表示するには、 --localオプションを使用してください。
9.3.1. 実行例¶
9.3.2. クラスタの状態を表示する (-s オプション)¶
-s オプションを指定した場合、または、オプションを指定しない場合の例:
-
実行例 # clpstat -s
-
表示例 ===================== CLUSTER STATUS ======================== Cluster : cluster <server> *server1...........: Online server1 lanhb1 : Normal LAN Heartbeat lanhb2 : Normal LAN Heartbeat diskhb1 : Normal DISK Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution pingnp2 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop server2............: Online server2 lanhb1 : Normal LAN Heartbeat lanhb2 : Normal LAN Heartbeat diskhb1 : Normal DISK Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution pingnp2 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop <group> failover1........: Online failover group1 current : server1 disk1 : Online /dev/sdb5 exec1 : Online exec resource1 fip1 : Online 10.0.0.11 failover2........: Online failover group2 current : server2 disk2 : Online /dev/sdb6 exec2 : Online exec resource2 fip2 : Online 10.0.0.12 <monitor> diskw1 : Normal disk monitor1 diskw2 : Normal disk monitor2 ipw1 : Normal ip monitor1 pidw1 : Normal pidw1 userw : Normal usermode monitor sraw : Normal sra monitor ================================================================
各種状態についての説明は、「 各種状態 」で説明します。
9.3.3. グループマップを表示する (-g オプション)¶
グループマップを表示するには、clpstat コマンドに -g オプションを指定して実行します。
-
実行例 # clpstat -g
-
表示例 ================= GROUPMAP INFORMATION ======================== Cluster : cluster *server0 : server1 server1 : server2 ---------------------------------------------------------------- server0 [o] : failover1[o] failover2[o] server1 [o] : failover3[o] ================================================================
停止しているグループは表示されません。
各種状態についての説明は、「 各種状態 」で説明します。
9.3.4. モニタリソースの状態を表示する (-m オプション)¶
モニタリソースの状態を表示するには、clpstat コマンドに -m オプションを指定して実行します。
-
実行例 # clpstat -m
-
表示例 =================== MONITOR RESOURCE STATUS ===================== Cluster : cluster *server0 : server1 server1 : server2 Monitor0 [diskw1 : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor1 [diskw2 : Online] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor2 [ipw1 : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor3 [pidw1 : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Offline Monitor4 [userw : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor5 [sraw : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
9.3.5. ハートビートリソースの状態を表示する (-n オプション)¶
ハートビートリソースの状態を表示するには、clpstat コマンドに -n オプションを指定して実行します。
-
実行例 # clpstat -n
-
表示例 ================== HEARTBEAT RESOURCE STATUS ==================== Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : diskhb1 HB3 : witnesshb1 [on server0 : Online] HB 0 1 2 3 ----------------------------------------------------------------- server0 : o o o o server1 : o o x x [on server1 : Online] HB 0 1 2 3 ----------------------------------------------------------------- server0 : o o x o server1 : o o o o =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
-
表示例の状態についての説明 上の表示例は、ディスクハートビートリソースが断線した場合の、server0、server1 それぞれのサーバから見た全ハートビートリソースの状態を表示しています。
ディスクハートビートリソース diskhb1 は両サーバ間で通信不可の状態になっているので、server0 上では server1 に対して通信不可、server1 上では server0 に対して通信不可になっています。
その他のハートビートリソースは、両サーバともに通信可の状態になっています。
9.3.6. フェンシング機能の状態を表示する (-f オプション)¶
フェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)の状態を表示するには、clpstat コマンドに -f オプションを指定して実行します。
-
実行例 # clpstat -f
-
表示例 ======================== FENCING STATUS ========================== Cluster : cluster *server0 : server1 server1 : server2 NP0 : pingnp1 NP1 : pingnp2 NP2 : httpnp1 FST : forcestop1 [on server0 : Caution] NP/FST 0 1 2 F ----------------------------------------------------------------- server0 : o x o o server1 : o x o - [on server1 : Caution] NP/FST 0 1 2 F ----------------------------------------------------------------- server0 : o x o - server1 : o x o o =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
-
表示例の状態についての説明 上の表示例は、ネットワークパーティション解決リソース pingnp2 の ping 送付先の装置がダウンした場合に、server0、server1 それぞれのサーバから見たネットワークパーティション解決リソースと強制停止リソースの状態を表示しています。
9.3.7. クラスタ設定情報を表示する (--cl オプション)¶
クラスタの設定情報を表示するには、clpstat コマンドに -i オプションもしくは、--cl, --sv, --hb, --svg, --grp, --rsc, --mon, --xcl を指定して実行します。また、--detail オプションを指定すると、より詳細な情報を表示することができます。
設定情報の各項目についての詳細は本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」を参照してください。
クラスタ構成情報を表示するには、clpstat コマンドに --cl オプションを指定して実行します。
-
実行例 # clpstat --cl
-
表示例 ===================== CLUSTER INFORMATION ===================== [クラスタ名 : cluster] コメント : failover cluster =================================================================
9.3.8. 特定のサーバの設定情報のみを表示する (--sv オプション)¶
指定したサーバのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --sv オプションの後に、サーバ名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。サーバ名を指定しない場合は、全てのサーバのクラスタ構成情報を表示します。
-
実行例 # clpstat --sv server1
-
表示例 ===================== CLUSTER INFORMATION ===================== [サーバ0 : server1] コメント : server1 仮想化基盤 : vSphere 製品 : CLUSTERPRO X 5.0 for Linux 内部バージョン : 5.0.0-1 エディション : X プラットフォーム : Linux =================================================================
9.3.9. 特定のハートビートリソース情報のみを表示する (--hb オプション)¶
指定したハートビートリソースのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --hb オプションの後に、ハートビートリソース名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。
-
実行例 LANハートビートリソースの場合
# clpstat --hb lanhb1
-
表示例 ==================== CLUSTER INFORMATION ======================= [HB0 : lanhb1] タイプ : lanhb コメント : LAN Heartbeat =================================================================
-
実行例 ディスクハートビートリソースの場合
# clpstat --hb diskhb
-
表示例 ===================== CLUSTER INFORMATION ===================== [HB2 : diskhb1] タイプ : diskhb コメント : DISK Heartbeat =================================================================
-
実行例 カーネルモード LAN ハートビートリソースの場合
# clpstat --hb lankhb
-
表示例 ===================== CLUSTER INFORMATION ===================== [HB4 : lankhb1] タイプ : lankhb コメント : Kernel Mode LAN Heartbeat =================================================================
-
ヒント --sv オプションと、--hb オプションを同時に用いることによって、次のように表示することもできます。
-
実行例 # clpstat --sv --hb
-
表示例 ===================== CLUSTER INFORMATION ===================== [サーバ0 : server1] コメント : server1 仮想化基盤 : 製品 : CLUSTERPRO X 5.0 for Linux 内部バージョン : 5.0.0-1 エディション : X プラットフォーム : Linux [HB0 : lanhb1] タイプ : lanhb コメント : LAN Heartbeat [HB1 : lanhb2] タイプ : lanhb コメント : LAN Heartbeat [HB2 : diskhb1] タイプ : diskhb コメント : DISK Heartbeat [HB3 : witnesshb] タイプ : witnesshb コメント : Witness Heartbeat [サーバ1 : server2] コメント : server2 仮想化基盤 : 製品 : CLUSTERPRO X 5.0 for Linux 内部バージョン : 5.0.0-1 エディション : X プラットフォーム : Linux [HB0 : lanhb1] タイプ : lanhb コメント : LAN Heartbeat [HB1 : lanhb2] タイプ : lanhb コメント : LAN Heartbeat [HB2 : diskhb1] タイプ : diskhb コメント : DISK Heartbeat [HB3 : witnesshb] タイプ : witnesshb コメント : Witness Heartbeat =================================================================
9.3.10. 特定のフェンシング機能の情報のみを表示する (--fnc オプション)¶
指定したフェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)のみのクラスタ設定情報を表示したい場合は、[clpstat] コマンドで [--fnc] オプションの後に、ネットワークパーティション解決リソース名または強制停止リソース名を指定して実行します。詳細を表示したい場合は、[--detail] オプションを指定します。ネットワークパーティション解決リソース名または強制停止リソース名を指定しない場合は、全てのフェンシング機能のクラスタ構成情報を表示します。
-
実行例 PING ネットワークパーティション解決リソースの場合
# clpstat --fnc pingnp1
-
表示例 ==================== CLUSTER INFORMATION ======================= [NP0 : pingnp1] タイプ : pingnp コメント : ping resolution =================================================================
-
実行例 HTTP ネットワークパーティション解決リソースの場合
# clpstat --fnc httpnp1
-
表示例 ==================== CLUSTER INFORMATION ======================= [NP0 : httpnp1] タイプ : httpnp コメント : http resolution =================================================================
-
実行例 強制停止リソースの場合
# clpstat --fnc forcestop1
-
表示例 ==================== CLUSTER INFORMATION ======================= [FST : forcestop1] タイプ : bmc コメント : Forced stop =================================================================
9.3.11. 特定のサーバグループの情報のみを表示する (--svg オプション)¶
指定したサーバグループのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --svg オプションの後に、サーバグループ名を指定して実行します。サーバグループ名を指定しない場合は、全てのサーバグループのクラスタ構成情報を表示します。
-
実行例 # clpstat --svg servergroup1
-
表示例 ===================== CLUSTER INFORMATION ===================== [サーバグループ0 : servergroup1] サーバ0 : server1 サーバ1 : server2 サーバ2 : server3 =================================================================
9.3.12. 特定のグループの情報のみを表示する (--grp オプション)¶
指定したグループのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --grp オプションの後に、グループ名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。グループ名を指定しない場合は、全てのグループのクラスタ構成情報を表示します。
-
実行例 # clpstat --grp failover1
-
表示例 ===================== CLUSTER INFORMATION ===================== [グループ0 : failover1] タイプ : failover コメント : failover group1 =================================================================
9.3.13. 特定のグループリソースの情報のみを表示する (--rsc オプション)¶
指定したグループリソースのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --rsc オプションの後に、グループリソースを指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。グループリソース名を指定しない場合は、全てのグループリソースのクラスタ構成情報を表示します。
-
実行例 フローティング IP リソースの場合
# clpstat --rsc fip1
-
表示例 ===================== CLUSTER INFORMATION ===================== [リソース2 : fip1] タイプ : fip コメント : 10.0.0.11 IPアドレス : 10.0.0.11 =================================================================
-
ヒント --grp オプションと、--rsc オプションを同時に用いることによって、次のように表示することもできます。
-
実行例 # clpstat --grp --rsc
-
表示例 ===================== CLUSTER INFORMATION ===================== [グループ0 : failover1] タイプ : failover コメント : failover group1 [リソース0 : disk1] タイプ : disk コメント : /dev/sdb5 ディスクタイプ : disk ファイルシステム : ext2 デバイス名 : /dev/sdb5 RAWデバイス名 : マウントポイント : /mnt/sdb5 [リソース1 : exec1] タイプ : exec コメント : exec resource1 開始スクリプトパス : /opt/userpp/start1.sh 終了スクリプトパス : /opt/userpp/stop1.sh [リソース2 : fip1] タイプ : fip コメント : 10.0.0.11 IPアドレス : 10.0.0.11 [グループ1 : failover2] タイプ : failover コメント : failover group2 [リソース0 : disk2] タイプ : disk コメント : /dev/sdb6 ディスクタイプ : disk ファイルシステム : ext2 デバイス名 : /dev/sdb6 RAWデバイス名 : マウントポイント : /mnt/sdb6 [リソース1 : exec2] タイプ : exec コメント : exec resource2 開始スクリプトパス : /opt/userpp/start2.sh 終了スクリプトパス : /opt/userpp/stop2.sh [リソース2 : fip2] タイプ : fip コメント : 10.0.0.12 IPアドレス : 10.0.0.12 =================================================================
9.3.14. 特定のモニタリソースの情報のみを表示する (--mon オプション)¶
指定したモニタリソースのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --mon オプションの後に、モニタリソース名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。モニタリソース名を指定しない場合は、全てのモニタリソースのクラスタ構成情報を表示します。
-
実行例 フローティング IP モニタリソース
# clpstat --mon fipw1
-
表示例 ===================== CLUSTER INFORMATION ===================== [モニタ2 : fipw1] タイプ : fipw コメント : fip monitor1 =================================================================
9.3.15. サーバ個別設定したリソース情報を表示する (--rsc または --mon オプション)¶
サーバ別に設定したリソース情報を表示したい場合は、clpstat コマンドで --rsc または --mon オプションの後に、リソース名を指定して実行すると各サーバの設定値が表示されます。
-
実行例 IP モニタリソースの監視対象 IP アドレスをサーバ個別設定した場合
# clpstat --mon ipw1
-
表示例 ===================== CLUSTER INFORMATION ===================== [モニタ2 : ipw1] タイプ : ipw コメント : ip monitor1 IPアドレスリスト : 各サーバの設定を参照 <server1> IPアドレス : 10.0.0.253 : 10.0.0.254 <server2> IPアドレス : 10.0.1.253 : 10.0.1.254 =================================================================
9.3.16. 特定の排他ルールの設定情報のみを表示する (--xcl オプション)¶
指定した排他ルールのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --xcl オプションの後に、排他ルール名を指定して実行します。
-
実行例 # clpstat --xcl excl1
-
表示例 ===================== CLUSTER INFORMATION ===================== [排他ルール0 : excl1] 排他属性 : 通常排他 グループ0 : failover1 グループ1 : failover2 =================================================================
9.3.17. すべてのクラスタ情報を表示する (-i オプション)¶
-i オプションを指定すると、--cl、--sv、--hb、--svg、--grp、--rsc、--mon、--xcl オプションが全て指定された設定情報を表示することができます。
--detail オプションをつけて実行すると、全てのクラスタ設定情報の詳細を表示できます。
このオプションは一度に表示する情報量が多いので、実際に使用する場合は、パイプを用いて less コマンドなどを使用して表示させるか、あるいはリダイレクトを用いてファイルに出力するなどして、参照してください。
-
ヒント -i オプションの指定はコンソールに全ての情報が表示されます。ある一部の情報を表示したい場合は、--cl、--sv、--hb、--svg、--grp、--rsc、--mon オプションを組み合わせて使うと便利です。たとえば、以下のような使い方もできます。
-
実行例 サーバ名 server0 の情報と、グループ名 failover1 の情報と、その指定したグループに存在する全てのグループリソースの情報を、詳細に表示したい場合
# clpstat --sv server0 --grp failover1 --rsc --detail
9.3.18. クラスタの状態を表示する (--local オプション)¶
--local オプションを指定すると、他サーバとの通信処理は行わずコマンド実行サーバ上の情報のみを表示することができます。
-
実行例 # clpstat --local
-
表示例 ===================== CLUSTER STATUS ======================== Cluster : cluster cluster ........: Start cluster <server> *server1 ........: Online server1 lanhb1 : Normal LAN Heartbeat lanhb2 : Normal LAN Heartbeat diskhb1 : Normal DISK Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution pingnp2 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop server2 .........: Online server2 lanhb1 : - LAN Heartbeat lanhb2 : - LAN Heartbeat diskhb1 : - DISK Heartbeat witnesshb1 : - Witness Heartbeat pingnp1 : - ping resolution pingnp2 : - ping resolution httpnp1 : - http resolution forcestop1 : - Forced stop <group> failover1 .......: Online failover group1 current : server1 disk1 : Online /dev/sdb5 exec1 : Online exec resource1 fip1 : Online 10.0.0.11 failover2 .......: - failover group2 current : server2 disk2 : - /dev/sdb6 exec2 : - exec resource2 fip2 : - 10.0.0.12 <monitor> diskw1 : Online disk monitor1 diskw2 : Online disk monitor2 ipw1 : Online ip monitor1 pidw1 : Online pidw1 userw : Online usermode monitor sraw : Online sra monitor =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
9.3.19. 各種状態¶
-
クラスタ 機能
状態
説明
状態表示 (--local)
Start
起動中
〃
Suspend
サスペンド中
〃
Stop
停止中
〃
Unknown
状態不明
-
サーバ 機能
状態
説明
状態表示ハートビートリソース状態表示Online
起動中
〃
Offline
停止中
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Caution
ハートビートリソースが異常
〃
Unknown
状態不明
〃
-
状態不明
グループマップ表示モニタリソース状態表示o
起動中
〃
x
停止中
〃
-
状態不明
-
ハートビートリソース 機能
状態
説明
状態表示
Normal
正常
〃
Caution
異常 (一部)
〃
Error
異常 (全部)
〃
Unused
未使用
〃
Unknown
状態不明
〃
-
状態不明
ハートビートリソース状態表示
o
通信可
〃
x
通信不可
〃
-
未使用、状態不明
-
ネットワークパーティション解決リソース および 強制停止リソース 機能
状態
説明
状態表示
Normal
正常
〃
Error
異常
〃
Unused
未使用
〃
Unknown
状態不明
〃
-
状態不明
ネットワークパーティション解決リソース・強制停止リソース状態表示o
通信可
〃
x
通信不可
〃
-
未使用、状態不明
-
グループ 機能
状態
説明
状態表示
Online
起動済
〃
Offline
停止済
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Error
異常
〃
Unknown
状態不明
〃
-
状態不明
グループマップ表示
o
起動済
〃
e
異常
〃
p
起動処理中、停止処理中
-
グループリソース 機能
状態
説明
状態表示
Online
起動済
〃
Offline
停止済
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Online Failure
起動失敗
〃
Offline Failure
停止失敗
〃
Unknown
状態不明
〃
-
状態不明
-
モニタリソース 機能
状態
説明
状態表示
Normal
正常
〃
Caution
異常 (一部)
〃
Error
異常 (全部)
〃
Unused
未使用
〃
Unknown
状態不明
状態表示 (--local)モニタリソース状態表示Online
起動済かつ正常
〃
Offline
停止済
〃
Caution
警告
〃
Suspend
一時停止
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Online Failure
異常
〃
Offline Failure
停止失敗
〃
Unused
未使用
〃
Unknown
状態不明
〃
-
状態不明
9.4. クラスタを操作する (clpcl コマンド)¶
クラスタを操作します。
-
コマンドライン - clpcl -s [-a] [-h hostname]clpcl -t [-a] [-h hostname] [-w timeout] [--apito timeout]clpcl -r [-a] [-h hostname] [-w timeout] [--apito timeout]clpcl --suspend [--force] [-w timeout] [--apito timeout]clpcl --resume
-
説明 CLUSTERPRO デーモンの起動、停止、サスペンド、リジュームなどを実行します。
-
オプション -
-s¶ CLUSTERPRO デーモンを起動します。
-
-t¶ CLUSTERPRO デーモンを停止します。
-
-r¶ CLUSTERPRO デーモンを再起動します。
-
-wtimeout¶ -t, -r, --suspendオプションの場合にのみclpclコマンドがCLUSTERPROデーモンの停止またはサスペンドの完了を待ち合わせる時間を指定します。
単位は秒です。
timeout の指定がない場合、無限に待ち合わせします。
timeout に "0" を指定した場合、待ち合わせしません。
-w オプションを指定しない場合、(ハートビートタイムアウト×2) 秒待ち合わせします。
-
--suspend¶ クラスタ全体をサスペンドします。
-
--resume¶ クラスタ全体をリジュームします。リジュームしたクラスタは、サスペンド時のグループおよびグループリソースの状態が保持されています。
-
-a¶ 全てのサーバで実行されます。
-
-hhostname¶ hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
-
--force¶ --suspend オプションと一緒に用いることで、クラスタ内のサーバの状態に関わらず強制的にサスペンドを実行します。
-
--apitotimeout¶ - CLUSTERPRO デーモンの停止、再起動、サスペンドを待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999の値が指定できます。[--apito] オプション指定しない場合は、クラスタプロパティの内部通信タイムアウトに設定された値に従い、待ち合わせを行います。
-
-
戻り値 0
成功
0 以外
異常
-
備考 - 本コマンドを -s または --resume オプションで実行した場合、対象のサーバで処理が開始したタイミングで制御を戻します。-t または --suspend オプションで実行した場合、処理の完了を待ち合わせてから制御を戻します。-r オプションで実行した場合、対象のサーバでCLUSTERPROデーモンが一度停止し、起動を開始したタイミングで制御を戻します。
CLUSTERPROデーモンの起動またはリジュームの状況はclpstatコマンドで確認してください。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
本コマンドはグループの起動処理中、停止処理中に実行できません。
-hオプションのサーバ名は、クラスタ内のサーバ名を指定してください。
サスペンドを実行する場合は、クラスタ内の全サーバのCLUSTERPRO デーモンが起動した状態で実行してください。--forceオプションを用いると、クラスタ内に停止しているサーバが存在しても強制的にサスペンドを実行します。
クラスタ起動時およびリジューム時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
リジュームを実行する場合は、clpstat コマンドを用いてクラスタ内に起動しているサーバがないか確認してください。
本コマンドは、CLUSTERPRO デーモンのみの起動/停止等をおこないます。ミラーエージェントなどの起動/停止まではおこなわれません。
-
実行例 例1: 自サーバの CLUSTERPRO デーモンを起動させる場合
# clpcl -s
例2: server0 から server1 の CLUSTERPRO デーモンを起動させる場合
# clpcl -s -h server1 Start server1 : Command succeeded.
サーバ名指定の場合は、上記のように表示されます。
Start サーバ名 : 実行結果 (失敗した場合はその原因)
例3: 全サーバの CLUSTERPRO デーモンを起動させる場合
# clpcl -s -a Start server0 : Command succeeded. Start server1 : Performed startup processing to the active cluster daemon.
全サーバ起動の場合は、上記のように表示されます。
Start サーバ名 : 実行結果 (失敗した場合はその原因)
例4: 全サーバの CLUSTERPRO デーモンを停止させる場合
# clpcl -t -a
全サーバ停止の場合、各サーバの CLUSTERPRO デーモンの停止を待ち合わせします。
エラーの場合はエラーメッセージが表示されます。
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Performed stop processing to the stopped cluster daemon.
停止している CLUSTERPRO デーモンに対して停止処理を実行しました。
Performed startup processing to the active cluster daemon.
起動している CLUSTERPRO デーモンに対して起動処理を実行しました。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Could not connect to the data transfer server. Check if the server has started up.
サーバが起動しているか確認してください。
Failed to obtain the list of nodes.Specify a valid server name in the cluster.クラスタ内の正しいサーバ名を指定してください。
Failed to obtain the daemon name.
クラスタ名の取得に失敗しました。
Failed to operate the daemon.
クラスタの制御に失敗しました。
Resumed the daemon that is not suspended.
サスペンド状態ではない CLUSTERPROデーモンに対して、リジューム処理を実行しました。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is busy. Check if this command is already run.
既に本コマンドを実行している可能性があります。確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
There is one or more servers of which cluster daemon is active. If you want to perform resume, check if there is any server whose cluster daemon is active in the cluster.
リジュームを実行する場合、クラスタ内にCLUSTERPRO デーモンが起動しているサーバがないか確認してください。
All servers must be activated. When suspending the server, the cluster daemon need to be active on all servers in the cluster.
サスペンドを実行する場合、クラスタ内の全てのサーバで、CLUSTERPRO デーモンが起動している必要があります。
Resume the server because there is one or more suspended servers in the cluster.
クラスタ内にサスペンドしているサーバがあるので、リジュームを実行してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内にCLUSTERPROデーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してみてください。Processing failed on some servers. Check the status of failed servers.
全サーバ指定で停止処理を実行した場合、処理に失敗したサーバが存在します。処理に失敗したサーバの状態を確認してください。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
There is a server that is not suspended in cluster. Check the status of each server.
クラスタ内にサスペンド状態でないサーバが存在します。各サーバの状態を確認してください。Suspend %s : Could not suspend in time.
サーバはタイムアウト時間内にCLUSTERPROデーモンのサスペンド処理が完了しませんでした。サーバの状態を確認してください。
Stop %s : Could not stop in time.
サーバはタイムアウト時間内にCLUSTERPROデーモンの停止処理が完了しませんでした。サーバの状態を確認してください。
Stop %s : Server was suspended.Could not connect to the server. Check if the cluster daemon is active.CLUSTERPRO デーモンの停止要求をしましたが、サーバはサスペンド状態でした。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンの停止要求をしましたが、サーバに接続できませんでした。サーバの状態を確認してください。Suspend %s : Server already suspended.Could not connect to the server. Check if the cluster daemon is active.CLUSTERPRO デーモンのサスペンド要求をしましたが、サーバはサスペンド状態でした。
Event service is not started.
イベントサービスが起動していません。確認してください。
Mirror Agent is not started.
ミラーエージェントが起動していません。確認してください。
Event service and Mirror Agent are not started.
イベントサービスとミラーエージェントが起動していません。確認してください。
Some invalid status. Check the status of cluster.
遷移中のグループが存在する可能性があります。グループの遷移が終了してから、再度実行してください。
Failed to shutdown the server.
サーバのシャットダウンまたは、リブートに失敗しました。
9.5. 指定したサーバをシャットダウンする (clpdown コマンド)¶
指定したサーバをシャットダウンします。
-
コマンドライン clpdown [-r] [-h hostname]
-
説明 CLUSTERPRO デーモンを停止し、サーバをシャットダウンします。
-
オプション -
オプションなし¶ サーバをシャットダウンします。
-
-r¶ サーバを再起動します。
-
-hhostname¶ hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
-
-
戻り値 0
成功
0 以外
異常
-
備考 - 本コマンドは、CLUSTERPRO デーモンを停止後、内部的に以下の コマンドを実行しています。オプション指定なしの場合 shutdown-r オプション指定の場合 reboot
本コマンドは、グループ停止処理が完了したタイミングで制御を戻します。
本コマンドは、CLUSTERPRO デーモンが停止状態でもサーバをシャットダウンします。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
本コマンドはグループの起動処理中、停止処理中に実行できません。
-h オプションのサーバ名は、クラスタ内のサーバを指定してください。
-
実行例 例1 : 自サーバの CLUSTERPRO デーモンを停止し、シャットダウンする場合
# clpdown
例2 server0 から server1 をシャットダウンリブートさせる場合
# clpdown -r -h server1
-
エラーメッセージ 「クラスタを操作する (clpcl コマンド)」を参照してください。
9.6. クラスタ全体をシャットダウンする (clpstdn コマンド)¶
クラスタ全体をシャットダウンします。
-
コマンドライン clpstdn [-r] [-h hostname]
-
説明 クラスタ全体で、CLUSTERPRO デーモンを停止し、全てのサーバをシャットダウンします。
-
オプション -
オプションなし¶ クラスタシャットダウンを実行します。
-
-r¶ クラスタシャットダウンリブートを実行します。
-
-hhostname¶ hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
-
-
戻り値 0
成功
0 以外
異常
-
備考 本コマンドは、グループ停止処理が完了したタイミングで制御を戻します。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
本コマンドはグループの起動処理中、停止処理中に実行できません。
-h オプションのサーバ名は、クラスタ内のサーバを指定してください。
コマンドを実行したサーバから通信不能なサーバ (全ての LAN ハートビートリソースがOfflineのサーバ) はシャットダウンされません。
-
実行例 例1 : クラスタシャットダウンを行う場合
# clpstdn
例2 : クラスタシャットダウンリブートを行う場合
# clpstdn -r
-
エラーメッセージ 「クラスタを操作する (clpcl コマンド)」を参照してください。
9.7. グループを操作する (clpgrp コマンド)¶
グループを操作します。
-
コマンドライン - clpgrp -s [group_name] [-h hostname] [-f] [--apito timeout]clpgrp -t [group_name] [-h hostname] [-f] [--apito timeout]clpgrp -m [group_name] [-h hostname] [-a hostname] [--apito timeout]clpgrp -n group_name
-
説明 グループの起動、停止、移動を実行します。
-
オプション -
-s[group_name]¶ グループを起動します。グループ名を指定すると、指定されたグループのみ起動します。グループ名の指定がない場合は、全てのグループが起動されます。
-
-t[group_name]¶ グループを停止します。グループ名を指定すると、指定されたグループのみ停止します。グループ名の指定がない場合は、全てのグループが停止されます。
-
-m[group_name]¶ 指定されたグループを移動します。グループ名指定しない場合、全てのグループを移動します。移動したグループのグループリソースの状態は保持されます。
-
-hhostname¶ hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
-
-ahostname¶ hostname で指定したサーバをグループの移動先サーバとします。-a オプションを省略した場合は、グループの移動先はフェイルオーバポリシーに従います。
-
-f¶ - 他サーバで起動しているグループに対して、-s オプションと使うと強制的に処理を要求したサーバで起動します。-t オプションと使うと強制的に停止します。
-
-ngroup_name¶ グループの起動済サーバ名を表示します。
-
--apitotimeout¶ - グループの起動、停止、移動を待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999の値が指定できます。[--apito] オプション指定しない場合は、クラスタプロパティの内部通信タイムアウトに設定された値に従い、待ち合わせを行います。
-
-
戻り値 0
成功
0 以外
異常
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
本コマンドを実行するサーバは CLUSTERPRO デーモンが起動している必要があります。
-h、-a オプションのサーバ名は、クラスタ内のサーバを指定してください。
-m オプションの場合は必ずグループ名を指定してください。
-m オプションでグループ移動を行った場合、移動先サーバでグループの起動処理を開始した時点で正常と判断します。本コマンドが成功していても移動先サーバでリソースの活性に失敗している場合がありますので注意してください。戻り値でグループの起動完了を確認したい場合は# clpgrp -s [group_name] [-h hostname] -fを実行して下さい。排他属性が「通常排他」に設定されている排他ルールに所属するグループを、[-m] オプションでグループを移動する際は、[-a] オプションで明示的に移動先サーバを指定してください。
[-a]オプション省略時に、移動可能な全てのサーバで、排他属性が「通常排他」に設定されている排他ルールに所属するグループが起動している場合は、グループ移動に失敗します。
-
実行例 グループ操作の実行を、簡単な状態遷移の例で説明します。
2 台構成のサーバで、グループを 2 つ持っている場合
グループのフェイルオーバポリシー
groupA server1 → server2groupB server2 → server1グループが 2 つとも停止している状態。
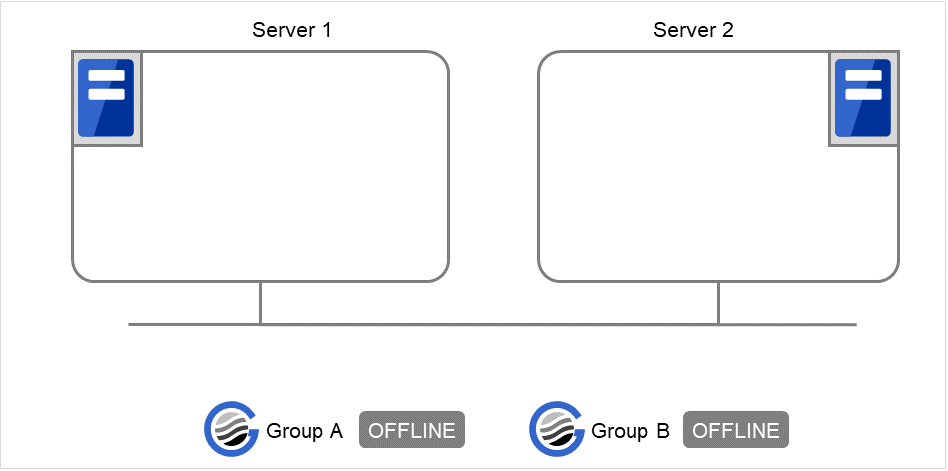
図 9.1 clpgrp実行時状態 (1)¶
server1 で以下のコマンドを実行します。
# clpgrp -s groupA
server1 で、groupA が起動します。
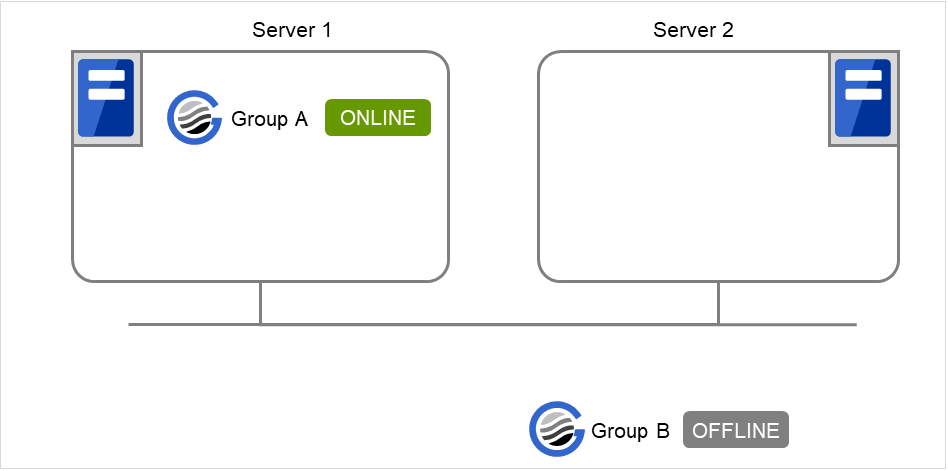
図 9.2 clpgrp実行時状態 (2)¶
server2 で以下のコマンドを実行します。
# clpgrp -s
現在停止している起動可能な全てのグループが server2 で起動します。
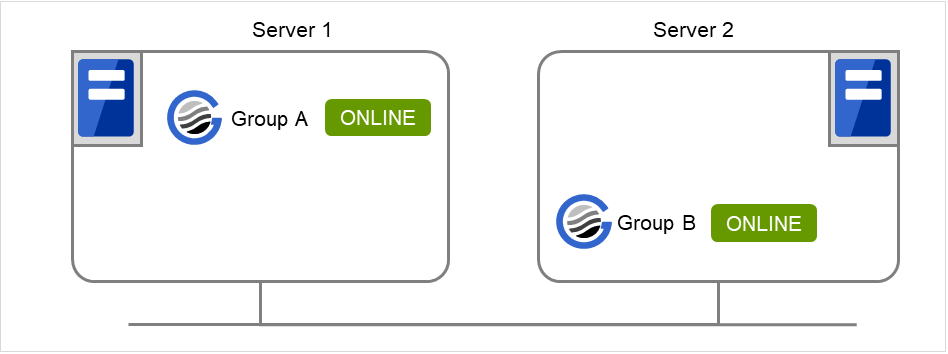
図 9.3 clpgrp実行時状態 (3)¶
server1 で以下のコマンドを実行します。
server1 で以下のコマンドを実行します。
server1 で以下のコマンドを実行します。
# clpgrp -t Command Succeeded.
コマンドを実行すると、server1 で動作しているグループは存在しないので、「Command Succeeded.」が表示されます。
server1 で、6 で実行したコマンドに -f を付けて実行します。
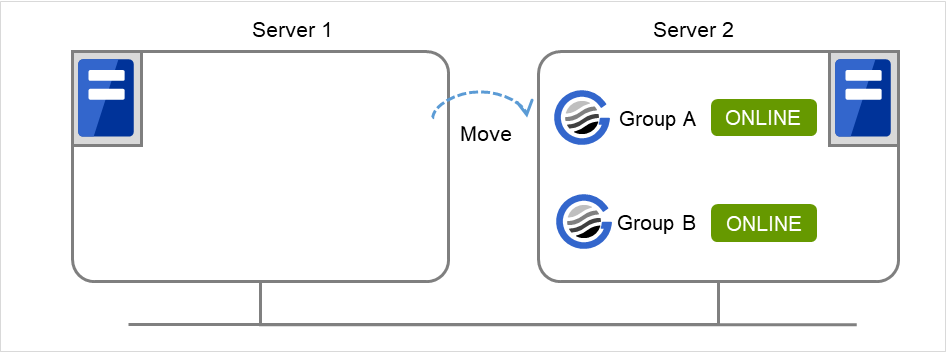
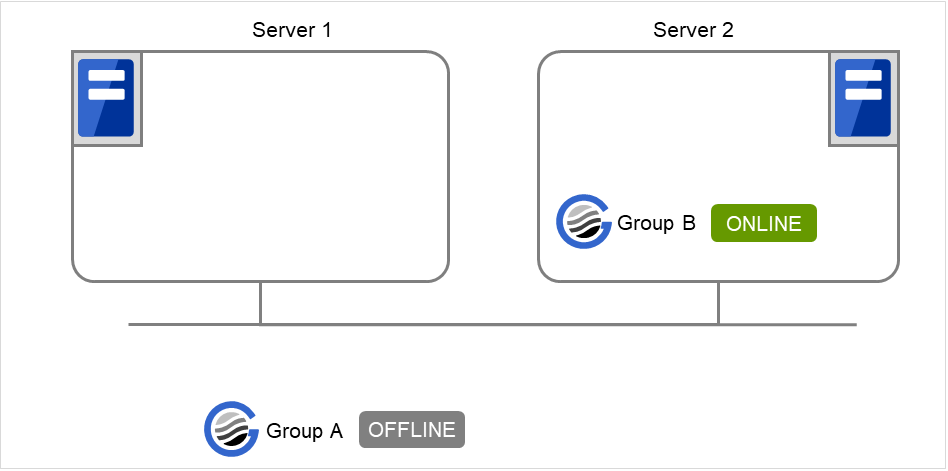
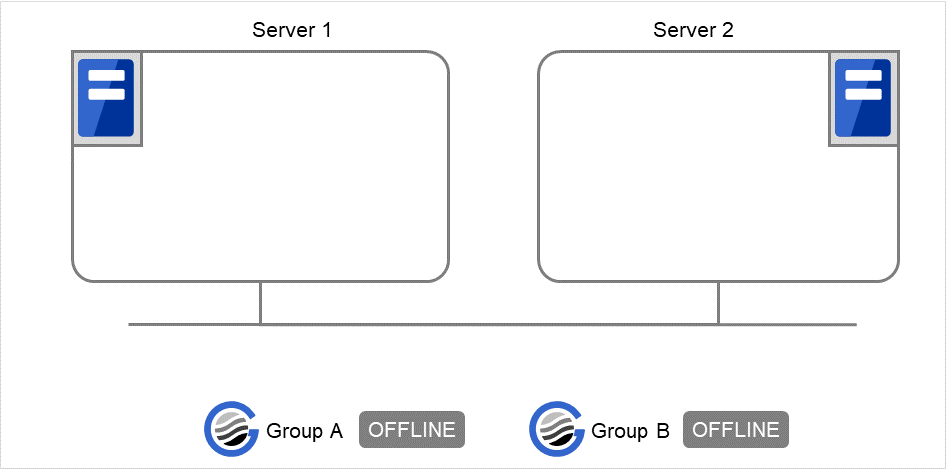
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか 確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内にCLUSTERPROデーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。Invalid server. Specify a server that can run and stop the group, or a server that can be a target when you move the group.
グループを起動、停止、移動する先のサーバが不正です。正しいサーバを指定してください。Could not start the group. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
他サーバが起動するのを待つか、起動待ち 時間がタイムアウトするのを待って、グループを起動させてください。
No operable group exists in the server.
処理を要求したサーバに処理可能なグループが存在するか確認してください。
The group has already been started on the local server.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
The group has already been started on the other server. To start/stop the group on the local server, use -f option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを自サーバで起動/停止させたい場合は、グループの移動を 実行するか、-f オプションを加えて実行してください。The group has already been started on the other server. To move the group, use "-h <hostname>" option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを移動したい場合は、"-h <hostname>" オプションを加えて実行してください。The group has already been stopped.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Failed to start one or more group resources. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Failed to stop one or more group resources. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
The group is busy. Try again later.
グループが起動処理中、もしくは停止処理中なので、しばらく待ってから実行してください。
An error occurred on one or more groups. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Invalid group name. Specify a valid group name in the cluster.
クラスタ内の正しいグループ名を指定してください。
Server is not in a condition to start group or any critical monitor error is detected.
Cluster WebUI や、clpstat コマンドでサーバの状態を確認してください。グループを起動しようとしたサーバで「フェイルオーバ先サーバの除外に使用するモニタリソース」に含まれるモニタの異常が検出されています。There is no appropriate destination for the group. Other servers are not in a condition to start group or any critical monitor error is detected.
Cluster WebUI や、clpstat コマンドでサーバの状態を確認してください。他の全てのサーバで「フェイルオーバ先サーバの除外に使用するモニタリソース」に含まれるモニタの異常が検出されています。The group has been started on the other server. To migrate the group, use "-h <hostname>" option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを移動したい場合は、"-h <hostname> オプションを加えて実行してください。Some invalid status. Check the status of cluster.
何らかの不正な状態です。クラスタの状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
9.8. ログを収集する (clplogcc コマンド)¶
ログを収集します。
-
コマンドライン clplogcc [ [-h hostname] | [-n targetnode1 -n targetnode2 ......] ] [-t collect_type] [-r syslog_rotate_number] [-o path] [-l]
-
説明 データ転送サーバに接続し、ログ、OS 情報等を収集します。
-
オプション -
なし¶ クラスタ内のログを収集します。
-
-hhostname¶ クラスタノード情報取得時の接続先サーバ名を指定します。
-
-tcollect_type¶ ログ収集パターンを指定します。省略した場合のログ収集パターンは type1 です。ログ収集タイプについての説明は、「 タイプを指定したログの収集 (-t オプション) 」 で説明します。
-
-rsyslog_rotate _number¶ syslog の収集する世代数を指定します。省略した場合は、2 世代収集します。
-
-opath¶ 収集ファイルの出力先を指定します。省略した場合は、インストールパスの tmp 配下にログが出力されます。
-
-ntargetnode¶ ログを収集するサーバ名を指定します。この場合は、クラスタ全体のログを収集するのではなく、指定したサーバのみログを収集することができます。
-
-l¶ - データ転送サーバを経由せずにローカルサーバのログを収集します。-h,-n オプションと同時に指定することはできません。
-
-
戻り値 0
成功
0 以外
異常
-
備考 ログファイルは tar.gz で圧縮されているので、tar コマンドに、xzf オプションを付けて解凍してください。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-h オプションのサーバ名は、名前解決できるクラスタ内のサーバ名を指定してください。
-n オプションのサーバ名は、名前解決できるサーバ名を指定してください。名前解決できない場合は、インタコネクトもしくはパブリック LANアドレスを指定してください。
本コマンド実行時、インタコネクトの優先度順でクラスタサーバのIPアドレスに接続し、成功した経路を使用します。
tar コマンドの圧縮フォーマットが pax 形式の Linux OS にて収集したログファイルをgnutar 形式の tar コマンドで展開した場合、PaxHeaders.X フォルダが生成されますが、動作上の問題はありません。
-
実行例 例1: クラスタ内の全てのサーバからログを収集する場合
# clplogcc Collect Log server1 : Success Collect Log server2 : Success
ログ収集を実行したサーバの実行結果 (サーバ状態) が表示されます。
処理過程 サーバ名 : 実行結果 (サーバ状態)
-
実行結果 本コマンドの結果で表示される処理過程は以下になります。
処理過程
説明
Connect
接続に失敗した場合に表示します。
Get Filesize
ファイルサイズ取得に失敗した場合に表示します。
Collect Log
ファイル取得の結果を表示します。
実行結果 (サーバ状態) については以下になります。
実行結果(サーバ状態)
説明
Success
成功です。
Timeout
タイムアウトしました。
Busy
サーバがビジー状態です。
Not Exist File
ファイルが存在しません。
No Freespace
ディスクに空き容量がありません。
Failed
その他のエラーによる失敗です。
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Specify a number in a valid range.
正しい範囲で数字を指定してください。
Specify a correct number.
正しい数字で指定してください。
Specify correct generation number of syslog.
正しい syslog の世代数を指定してください。
Collect type must be specified 'type1' or 'type2' or 'type3'' or 'type4' or 'type5' or 'type6'. Incorrect collection type is specified.
収集タイプの指定が間違っています。
Specify an absolute path as the destination of the files to be collected.
収集ファイルの出力先は絶対パスで指定してください。
Specifiable number of servers are the max number of servers that can constitute a cluster.
指定可能なサーバ数は、クラスタ構成可能な最大サーバ数です。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Failed to obtain the list of nodes.Specify a valid server name in the cluster.クラスタ内の正しいサーバ名を指定してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is busy. Check if this command is already run.
既に本コマンドを実行している可能性があります。確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
9.8.1. タイプを指定したログの収集 (-t オプション)¶
指定したタイプのログのみを収集したい場合は、clplogcc コマンドで -t オプションを指定して実行します。
ログの収集タイプは type1 ~ 6 までを指定します。
type1 |
type2 |
type3 |
type4 |
type5 |
type6 |
|
|---|---|---|---|---|---|---|
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
|
✓ |
✓ |
✓ |
n/a |
n/a |
n/a |
|
✓ |
✓ |
n/a |
✓ |
n/a |
n/a |
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
|
n/a |
✓ |
n/a |
n/a |
n/a |
n/a |
|
n/a |
n/a |
n/a |
n/a |
✓ |
n/a |
|
n/a |
n/a |
n/a |
n/a |
n/a |
✓ |
|
✓ |
✓ |
✓ |
✓ |
n/a |
✓ |
コマンドラインからは以下のように実行します。
実行例:収集タイプ type2 でログ収集を行う場合。
# clplogcc -t type2
オプションを指定しない場合のログ収集タイプは type1 です。
デフォルト収集情報
CLUSTERPRO サーバの各モジュールログ
アラートログ
CLUSTERPRO サーバの各モジュールの属性情報 (ls -l)
bin、lib 配下
cloud 配下
alert/bin、webmgr/bin 配下
ha/jra/bin、ha/sra/bin、ha/jra/lib、ha/sra/lib 配下
drivers/md 配下
drivers/khb 配下
drivers/ka 配下
インストール済の全パッケージ情報 (rpm -qa の実行結果など)
CLUSTERPRO のバージョン情報 (rpm -qi clusterpro の実行結果など)
distribution 情報 (/etc/*-release)
ライセンス情報
クラスタ構成情報ファイル
ポリシーファイル
クラウド環境設定ディレクトリ
CLUSTERPRO が使用している共有メモリのダンプ
CLUSTERPRO の自ノードステータス(clpstat --localの実行結果)
プロセス、スレッド情報 (ps の実行結果)
PCI デバイス情報 (lspci の実行結果)
サービス情報 (systemctl、chkconfig、ls コマンド等の実行結果)
kernel パラメータの出力結果 (sysctl -a の実行結果)
glibc バージョン (rpm -qi glibc の実行結果など)
カーネルローダブルモジュール設定情報 (/etc/modules.conf、/etc/modprobe.conf)
カーネルのリングバッファ情報 (dmesg の実行結果)
ファイルシステム情報 (/etc/fstab)
IPC リソース情報 (ipcs の実行結果)
システム情報 (uname -a の実行結果)
ネットワーク統計情報 (netstat, ss の実行結果IPv4/IPv6)
ip (ip addr,link,maddr,route,-s l の実行結果)
全ネットワークインターフェイス情報 (ethtool の実行結果)
緊急 OS シャットダウン時の採取情報 (「異常発生時の情報採取」を参照)
libxml2 バージョン (rpm -qi libxml2 の実行結果など)
静的ホストテーブル (/etc/hosts)
ファイルシステムのエクスポートテーブル (exportfs -v の実行結果)
ユーザリソース制限情報 (ulimit -a の実行結果)
カーネルベースの NFS でエクスポートされるファイルシステム (/etc/exports)
OS のロケール (locale)
ターミナルセッションの環境変数 (export の実行結果)
言語ロケール (/etc/sysconfig/i18n)
タイムゾーン (env - date の実行結果)
CLUSTERPRO サーバのワーク領域情報
- 各監視オプション製品に関する情報監視オプション製品をインストールされていれば収集されます。
モニタリソースのタイムアウト発生時に採取したダンプ情報
Oracle モニタリソース異常検出時に採取した Oracle 詳細情報
syslog
syslog (/var/log/messages)
syslog (/var/log/syslog)
指定された世代数の syslog (/var/log/messages.x)
journal ログ(/var/run/log/journal/ 配下のファイルなど)
core ファイル
- CLUSTERPRO モジュールの core ファイル/opt/nec/clusterpro/log 配下に以下のアーカイブ名で格納されます。
アラート関連
alt yyyymmdd_x.tar
WebManagerサーバ関連
wm yyyymmdd_x.tar
CLUSTERPRO コア関連
cls yyyymmdd_x.tar
sra yyyymmdd_x.tar
jra yyyymmdd_x.tar
yyyymmdd はログの収集日付、 x はシーケンシャル番号になります。
OS 情報
カーネルモード LAN ハートビート、キープアライブ情報
/proc/khb_moninfo
/proc/ka_moninfo
/proc/devices
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/cpuinfo
/proc/partitions
/proc/pci
/proc/version
/proc/ksyms
/proc/net/bond*
/proc/scsi/ ディレクトリ内の全ファイル
/proc/ide/ ディレクトリ内の全ファイル
/etc/fstab
/etc/rc*.d
/etc/syslog.conf
/etc/syslog-ng/syslog-ng.conf
/etc/snmp/snmpd.conf
カーネルのリングバッファ情報 (dmesg の実行結果)
ifconfig (ifconfig の実行結果)
iptables (iptables -L の実行結果)
ipchains (ipchains -L の実行結果)
df (df の実行結果)
raw デバイス情報 (raw -qa の実行結果)
カーネルモジュールロード情報 (lsmod の実行結果)
ホスト名、ドメイン名情報 (hostname、domainname の実行結果)
dmidecode (dmidecode の実行結果)
LVM デバイス情報 (vgdisplay -v の実行結果)
snmpd バージョン情報 (snmpd -v の実行結果)
仮想化基盤情報 (virt-what の実行結果)
blockdev (blockdev --report の実行結果)
ログ収集を実行した場合、コンソールに以下のメッセージが表示されることがありますが、異常ではありません。ログは正常に収集されています。
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(hd#にはサーバ上に存在する IDE のデバイス名が入ります)
スクリプト
Cluster WebUI で作成されたグループ起動/停止スクリプト
上記以外のユーザ定義スクリプト (/opt/nec/clusterpro/scripts以外) を指定した場合は、ログ収集の採取情報に含まれないため、別途採取する必要があります。
ESMPRO/AC 関連ログ
acupslog コマンドの実行により収集されるファイル
HA ログ
システムリソース情報
JVM モニタログ
システムモニタログ
ミラー統計情報
ミラー統計情報
perf/disk 配下
クラスタ統計情報
クラスタ統計情報
perf/cluster 配下
システムリソース統計情報
システムリソース統計情報
perf/system 配下
9.8.2. syslog の世代 (-r オプション)¶
syslog を、指定した世代分収集するには以下のように実行します。
例)世代数 3 でログ収集を行う場合
# clplogcc -r 3
収集したログには以下の syslog が含まれています。
オプションを指定しない場合は、2 世代収集されます。
指定できる世代数は、0~99 です。
0 を指定した場合は、全ての syslog を収集します。
世代数 |
取得する世代 |
|---|---|
0 |
全世代 |
1 |
カレント |
2 |
カレント + 世代1 |
3 |
カレント + 世代1~2 |
: |
|
: |
|
x |
カレント + 世代1~ (x-1) |
9.8.3. ログファイルの出力先 (-o オプション)¶
ファイル名は、「サーバ名-log.tar.gz」で保存されます。
-n オプションで IP アドレスを指定した場合、ファイル名は、「IP アドレス-log.tar.gz」で保存されます。
ログファイルは tar.gz で圧縮されているので、tar コマンドに、xzf オプションを付けて解凍してください。
-o オプションを指定しない場合
インストールパスの tmp 配下にログが出力されます。
# clplogcc Collect Log サーバ名: Success # ls /opt/nec/clusterpro/tmp サーバ名-log.tar.gz
-o オプションを指定する場合
以下のようにコマンドを実行すると、指定したディレクトリ /home/log 配下にログが出力されます。
# clplogcc -o /home/log Collect Log サーバ名: Success # ls /home/log サーバ名-log.tar.gz
9.8.4. ログ収集サーバ指定 (-n オプション)¶
-n オプションを用いることによって、指定したサーバのみログを収集することができます。
例)クラスタ内の Server1 と Server3 のログを収集する場合
# clplogcc -n Server1 -n Server3
同じクラスタ内のサーバを指定してください。
指定可能なサーバ数は、クラスタ構成可能な最大サーバ数です。
9.8.5. 異常発生時の情報採取¶
以下の異常発生時に、障害解析のための情報を採取します。
クラスタを構成するクラスタデーモンが、シグナルの割り込みによる終了 (core dump)、内部ステータス異常による終了などで異常終了した場合
グループリソースの活性異常、非活性異常が発生した場合
モニタリソースの監視異常が発生した場合
採取する情報は以下です。
クラスタ情報
CLUSTERPRO サーバの一部のモジュールログ
CLUSTERPRO が使用している共有メモリのダンプ
クラスタ構成情報ファイル
OS 情報 (/proc/*)
/proc/devices
/proc/partitions
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/net/bond*
コマンド実行による情報
sysctl -a の結果
ps の結果
top の結果
ipcs の結果
netstat -in の結果
netstat -apn の結果
netstat -gn の結果
netstat -rn の結果
ifconfig の結果
ip addr の結果
ip -s l の結果
df の結果
raw -qa の結果
journalctl -e の結果
この情報はログ収集のデフォルト収集情報として採取されるため、別途採取する必要はありません。
9.9. クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)¶
9.9.1. クラスタを生成する、クラスタ構成情報を変更する¶
クラスタ構成情報をサーバに配信します。
-
コマンドライン clpcfctrl --push [-h hostname | IP ] [-p portnumber] [-x directory] [--force] [--nocheck]
-
説明 Cluster WebUI で作成した構成情報をサーバに配信します。
-
オプション -
--push¶ 配信時に指定します。省略できません。
-
-hhostname | IP¶ - 構成情報を配信するサーバを指定します。ホスト名または IP アドレスを指定します。省略時は構成情報にある全サーバに配信します。
-
-pportnumber¶ - データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
-
-xdirectory¶ - 指定したディレクトリにある構成情報を配信する場合に指定します。-l または -w と共に使用します。-l を指定した場合は、Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を使用します。-w を指定した場合は、Windows 上で Cluster WebUI を使用して保存した構成情報を使用します。
-
--force¶ 起動していないサーバが存在する場合でも、強制的にクラスタ構成情報を配信します。
-
--nocheck¶ クラスタ構成情報のチェックを実行しません。通常は使用しないでください。
-
-
戻り値 0
成功
0以外
異常
-
注意事項 本コマンドは root 権限をもつユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
-
実行例 例1 : Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を配信する場合
# clpcfctrl --push -x /mnt/config file delivery to server 10.0.0.11 success. file delivery to server 10.0.0.12 success. The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
例2: 再インストール したサーバに構成情報を配信する場合
# clpcfctrl --push -h server2 The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。Invalid mode.Check if --push or --pull option is specified.--push を指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Invalid host name.Server specified by -h option is not included in the configuration data.-h で指定したサーバが構成情報に含まれていません。指定したサーバ名または IP アドレスが正しいか確認してください。Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the list of group.
グループ一覧の取得に失敗しました。
Failed to get the list of resource.
リソース一覧の取得に失敗しました。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active and then run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the collect size.
収集ファイルのサイズの取得に失敗しました。他のサーバが起動しているか確認してください。Failed to collect the file.
ファイル収集に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the list of node.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
Failed to check server property.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
File delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Multi file delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。The directory "work" is not found. Reinstall the RPM.
CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
〃
This is not a directory.
〃
The source file does not exist.
〃
The source file is a directory.
〃
The source directory does not exist.
〃
The source file is not a directory.
〃
Failed to change the character code set (EUC to SJIS).
〃
Failed to change the character code set (SJIS to EUC).
〃
Command error.
〃
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
〃
Failed to run the command.
〃
Failed to make a directory.
〃
Failed to remove the directory.
〃
Failed to remove the file.
〃
Failed to open the file.
〃
Failed to read the file.
〃
Failed to write the file.
〃
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
The upload is completed successfully.To start the cluster, refer to "How to create a cluster"in the Installation and Configration Guide.The upload is completed successfully.To apply the changes you made, shutdown and reboot the cluster.アップロードは成功しました。変更を反映するためにクラスタシャットダウン、再起動を実行してください。The upload was stopped.To upload the cluster configuration data, stop the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタを停止してください。The upload was stopped.To upload the cluster configuration data, stop the Mirror Agent.アップロードは停止しました。クラスタ構成情報をアップロードするためにはMirrorAgentを停止してください。The upload was stopped.To upload the cluster configuration data,stop the resources to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためには変更を加えたリソースを停止してください。The upload was stopped.To upload the cluster configuration data,stop the groups to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドする必要があります。アップロードするためには変更を加えたグループを停止してください。The upload was stopped.To upload the cluster configuration data, suspend the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドしてください。The upload is completed successfully.To apply the changes you made, restart the Alert Sync service.To apply the changes you made, restart the WebManager service.アップロードは成功しました。クラスタ構成情報を反映させるために AlertSync サービスを 再起動してください。クラスタ構成情報を反映させるために WebManager サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Information Base service.アップロードは成功しました。クラスタ構成情報を反映させるために Information Base サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the API service.アップロードは成功しました。クラスタ構成情報を反映させるために API サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Node Manager service.アップロードは成功しました。クラスタ構成情報を反映させるために Node Manager サービスを再起動 してください。The upload is completed successfully.
アップロードは成功しました。
The upload was stopped.Failed to deliver the configuration data.Check if the other server is active and run the command again.アップロードは停止しました。クラスタ構成情報の配信に失敗しました。他のサーバの起動状態を確認し、コマンドを再実行してください。The upload was stopped.There is one or more servers that cannot be connected to.To apply cluster configuration information forcibly,run the command again with "--force" option.アップロードは停止しました。接続できないサーバが存在します。クラスタ構成情報を強制的にアップロードするためには --force オプションを指定してコマンドを再実行してください。
9.9.2. クラスタ構成情報をバックアップする¶
クラスタ構成情報をバックアップします。
-
コマンドライン clpcfctrl --pull -l|-w [-h hostname | IP ] [-p portnumber] [-x directory]
-
説明 Cluster WebUI で使用するためにクラスタ構成情報をバックアップします。
-
オプション -
--pull¶ バックアップ時に指定します。省略できません。
-
-l¶ - Linux 上の Cluster WebUI で使用する構成情報としてバックアップする場合に指定します。-w と同時に指定することはできません。
-
-w¶ - Windows 上の Cluster WebUI で使用する構成情報としてバックアップする場合に指定します。-l と同時に指定することはできません。
-
-hhostname | IP¶ - バックアップ元サーバを指定します。ホスト名または IP アドレスを指定します。省略時はコマンド実行サーバの構成情報を使用します。
-
-pportnumber¶ - データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
-
-xdirectory¶ - 指定したディレクトリに構成情報をバックアップします。-l または -w と共に使用します。-l を指定した場合は、Linux 上の Cluster WebUI で読み込むことができる構成情報としてバックアップします。-w を指定した場合は、Windows 上のCluster WebUI で読み込むことができる構成情報として保存します。
-
-
戻り値 0
成功
0以外
異常
-
注意事項 本コマンドは root 権限を持つユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
-
実行例 例1 : Linux 上の Cluster WebUI で読み込むための構成情報を指定ディレクトリにバックアップする場合
# clpcfctrl --pull -l -x /mnt/config Command succeeded.(code:0)
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
すでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。
Invalid mode.Check if --push or --pull option is specified.--push を指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active andthen run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。Failed to get configuration data.Check if the other server is active.構成情報の取得に失敗しました。他のサーバが起動しているか確認してください。The directory "work" is not found.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
〃
This is not a directory.
〃
The source file does not exist.
〃
The source file is a directory.
〃
The source directory does not exist.
〃
The source file is not a directory.
〃
Failed to change the character code set (EUC to SJIS).
〃
Failed to change the character code set (SJIS to EUC).
〃
Command error.
〃
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
〃
Failed to run the command.
〃
Failed to make a directory.
〃
Failed to remove the directory.
〃
Failed to remove the file.
〃
Failed to open the file.
〃
Failed to read the file.
〃
Failed to write the file.
〃
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.9.3. グループ無停止でリソースを追加する¶
グループ無停止でリソースを追加します。
-
コマンドライン clpcfctrl --dpush [-p portnumber] [-x directory] [--force]
-
説明 グループ無停止でリソースを動的に追加します。
-
オプション -
--dpush¶ 動的リソース追加時に指定します。省略できません。
-
-pportnumber¶ - データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
-
-xdirectory¶ - 指定したディレクトリにある構成情報を配信する場合に指定します。-l または -w と共に使用します。-l を指定した場合は、Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を使用します。-w を指定した場合は、Windows 上で Cluster WebUI を使用して保存した構成情報を使用します。
-
--force¶ 起動していないサーバが存在する場合でも、強制的にクラスタ構成情報を配信します。
-
-
戻り値 0
成功
0以外
異常
-
注意事項 本コマンドは root 権限をもつユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
動的リソース追加に対応したリソースに関しては『メンテナンスガイド』の「保守情報」の「グループ無停止でリソースを追加する手順」を参照してください。
本オプションを利用する際は、クラスタ内のすべてのノードがCLUSTERPROの内部バージョン3.2.1-1以降である必要があります。
動的リソース追加コマンド実施中はリジュームしないでください。クラスタの構成情報に不整合が生じクラスタ停止・またはサーバシャットダウンする事があります。
動的リソース追加コマンドを途中で終了させた場合、追加対象のリソースの活性状態が不定となる可能性があります。再度実行し完了させるか手動でクラスタリブートしてください。
-
実行例 例1 : Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を使用して動的リソース追加する場合
# clpcfctrl --dpush -x /mnt/config file delivery to server 10.0.0.11 success. file delivery to server 10.0.0.12 success. The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。Invalid mode.Check if --push or --pull option is specified.--push を指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Invalid host name.Server specified by -h option is not includedin the configuration data.-h で指定したサーバが構成情報に含まれていません。指定したサーバ名または IP アドレスが正しいか確認してください。Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the list of group.
グループ一覧の取得に失敗しました。
Failed to get the list of resource.
リソース一覧の取得に失敗しました。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active andthen run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the collect size.
収集ファイルのサイズの取得に失敗しました。他のサーバが起動しているか確認してください。Failed to collect the file.
ファイル収集に失敗しました。他のサーバが起動しているか確認してください。
Failed to check server property.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
File delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Multi file delivery failed.Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。The directory "work" is not found. Reinstall the RPM.
CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
〃
This is not a directory.
〃
The source file does not exist.
〃
The source file is a directory.
〃
The source directory does not exist.
〃
The source file is not a directory.
〃
Failed to change the character code set (EUC to SJIS).
〃
Failed to change the character code set (SJIS to EUC).
〃
Command error.
〃
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
〃
Failed to run the command.
〃
Failed to make a directory.
〃
Failed to remove the directory.
〃
Failed to remove the file.
〃
Failed to open the file.
〃
Failed to read the file.
〃
Failed to write the file.
〃
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
The upload is completed successfully.To start the cluster, refer to "How to create a cluster"in the Installation and Configration Guide.The upload is completed successfully.To apply the changes you made, shutdown and reboot the cluster.アップロードは成功しました。変更を反映するためにクラスタシャットダウン、再起動を実行してください。The upload was stopped.To upload the cluster configuration data, stop the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタを停止してください。The upload was stopped.To upload the cluster configuration data, stop the Mirror Agent.アップロードは停止しました。クラスタ構成情報をアップロードするためにはMirrorAgentを停止してください。The upload was stopped.To upload the cluster configuration data,stop the resources to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためには変更を加えたリソースを停止してください。The upload was stopped.To upload the cluster configuration data,stop the groups to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドする必要があります。アップロードするためには変更を加えたグループを停止してください。The upload was stopped.To upload the cluster configuration data, suspend the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドしてください。The upload is completed successfully.To apply the changes you made, restart the Alert Sync service.To apply the changes you made, restart the WebManager service.アップロードは成功しました。クラスタ構成情報を反映させるために AlertSync サービスを 再起動してください。クラスタ構成情報を反映させるために WebManager サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Information Base service.アップロードは成功しました。クラスタ構成情報を反映させるために Information Base サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the API service.アップロードは成功しました。クラスタ構成情報を反映させるために API サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Node Manager service.アップロードは成功しました。クラスタ構成情報を反映させるために Node Manager サービスを再起動 してください。The upload is completed successfully.
アップロードは成功しました。
The upload was stopped.Failed to deliver the configuration data.Check if the other server is active and run the command again.アップロードは停止しました。クラスタ構成情報の配信に失敗しました。他のサーバの起動状態を確認し、コマンドを再実行してください。The upload was stopped.There is one or more servers that cannot be connected to.To apply cluster configuration information forcibly,run the command again with "--force" option.アップロードは停止しました。接続できないサーバが存在します。クラスタ構成情報を強制的にアップロードするためには--force オプションを指定してコマンドを再実行してください。The upload was stopped.Failed to active resource.Please check the setting of resource.アップロードは停止しました。リソースの活性に失敗しました。リソースの設定を確認してください。
9.9.4. グループリソース動的追加時にクラスタ構成情報をチェックする¶
グループリソース動的追加時にクラスタ構成情報をチェックします。
-
コマンドライン clpcfctrl --compcheck [-x directory]
-
説明 グループ無停止でリソースを動的に追加する際に、クラスタ構成情報に問題がないかを確認します。
-
オプション -
--compcheck¶ - 構成情報チェック時に指定します。省略できません。
-
-xdirectory¶ - 指定したディレクトリにある構成情報を配信する場合に指定します。-l または -w と共に使用します。-l を指定した場合は、Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を使用します。-w を指定した場合は、Windows 上で Cluster WebUI を使用して保存した構成情報を使用します。
-
-
戻り値 0
成功
0以外
異常
-
注意事項 本コマンドは root 権限をもつユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
本コマンドは新しい構成情報と既存の構成情報との差分を取り、追加部分のリソースの構成情報についてチェックします。
-
実行例 例1 : Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報をチェックする場合
# clpcfctrl --compcheck -x /mnt/config The check is completed successfully.(cfmgr:0) Command succeeded.(code:0)
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。The target directory does not exist.
指定されたディレクトリは存在しません。
Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the list of group.
グループ一覧の取得に失敗しました。
Failed to get the list of resource.
リソース一覧の取得に失敗しました。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active and then run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the collect size.
収集ファイルのサイズの取得に失敗しました。他のサーバが起動しているか確認してください。Failed to collect the file.
ファイル収集に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the list of node.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
Failed to check server property.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
File delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Multi file delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。The directory "work" is not found. Reinstall the RPM.
CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
〃
This is not a directory.
〃
The source file does not exist.
〃
The source file is a directory.
〃
The source directory does not exist.
〃
The source file is not a directory.
〃
Failed to change the character code set (EUC to SJIS).
〃
Failed to change the character code set (SJIS to EUC).
〃
Command error.
〃
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
〃
Failed to run the command.
〃
Failed to make a directory.
〃
Failed to remove the directory.
〃
Failed to remove the file.
〃
Failed to open the file.
〃
Failed to read the file.
〃
Failed to write the file.
〃
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.10. タイムアウトを一時調整する (clptoratio コマンド)¶
現在のタイムアウト倍率の延長、表示を行います。
-
コマンドライン - clptoratio -r ratio -t timeclptoratio -iclptoratio -s
-
説明 クラスタ内の全サーバで以下の各種タイムアウト値を一時的に延長や、現在のタイムアウト倍率を表示します。
モニタリソース
ハートビートリソース
ミラーエージェント
ミラードライバ
アラート同期サービス
WebManagerサービス
-
オプション -
-rratio¶ - タイムアウト倍率を指定します。1 以上の整数値で設定してください。最大タイムアウト倍率は10000 倍です。「1」を指定した場合、-i オプションと同様に、変更したタイムアウト倍率を元に戻すことができます。
-
-ttime¶ - 延長期間を指定します。分m、時間h、日d が指定できます。最大延長期間は 30 日です。例)2m、3h、4d
-
-i¶ 変更したタイムアウト倍率を元に戻します。
-
-s¶ 現在のタイムアウト倍率を参照します。
-
-
戻り値 0
成功
0 以外
異常
-
備考 クラスタシャットダウンを実行すると、設定したタイムアウト倍率は無効になります。クラスタ内のサーバが 1 台でもシャットダウンされていなければ、設定したタイムアウト倍率、延長期間は保たれます。
-s オプションで参照できるのは、現在のタイムアウト倍率のみです。延長期間の残り時間などは参照できません。
状態表示コマンドを用いて、元のタイムアウト値を参照できます。
ハートビートタイムアウト
# clpstat --cl --detail
モニタリソースタイムアウト
# clpstat --mon モニタリソース名 --detail
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
クラスタ内の全サーバの CLUSTERPRO デーモンが起動した状態で実行してください。
タイムアウト倍率を設定する場合、延長期間の指定は必ず行ってください。しかし、タイムアウト倍率指定に「1」を指定した場合は、延長期間を指定することはできません。
延長期間指定に、「2m3h」などの組み合わせはできません。
倍率延長期間内にサーバを再起動すると、延長期間を過ぎてもタイムアウト倍率が元に戻りません。この場合、タイムアウト倍率を元に戻すには clptoratio -i コマンドを実施してください。
本コマンドは、強制停止リソースの各種タイムアウト値には対応していません。
-
実行例 例1 : タイムアウト倍率を 3 日間 2 倍にする場合
# clptoratio -r 2 -t 3d
例2 : タイムアウト倍率を元に戻す場合
# clptoratio -i
例3 : 現在のタイムアウト倍率を参照する場合
# clptoratio -s present toratio : 2
現在のタイムアウト倍率は 2 で設定されていることが分かります。
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
Invalid configuration file.Create valid cluster configuration data.Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Specify a number in a valid range.
正しい範囲で数字を指定してください。
Specify a correct number.
正しい数字で指定してください。
Scale factor must be specified by integer value of 1 or more.
倍率は 1 以上の整数値で指定してください。
Specify scale factor in a range less than the maximum scale factor.
最大倍率を超えない範囲で倍率を指定してください。
Set the correct extension period.
正しい延長期間の設定をしてください。
Ex) 2m, 3h, 4d
最大延長期間を超えない範囲で延長期間を設定してください。
Set the extension period in a range less than the maximum extension period.
CLUSTERPRO デーモンが起動しているか確認してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active.Check if the cluster daemon is active.クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Connection was lost.Check if there is a server where the cluster daemon is stopped in the cluster.クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が 設定されている可能性があります。
Internal communication timeout has occurred in the cluster server.If it occurs frequently, set the longer timeout.CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してみてください。Processing failed on some servers.Check the status of failed servers.処理に失敗したサーバが存在します。クラスタ内のサーバの状態を確認してください。クラスタ内の全てのサーバが起動した状態で実行してください。Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.11. ログレベル/サイズを変更する (clplogcf コマンド)¶
ログレベル、ログ出力ファイルサイズの設定の変更、表示を行います。
-
コマンドライン clplogcf -t type -l level -s size
-
説明 - ログレベル、ログ出力ファイルサイズの設定を変更します。現在の設定値を表示します。
-
オプション -
-ttype¶ - 設定を変更するモジュールタイプを指定します。-l と -s のいずれも省略した場合は、指定したモジュールタイプに設定されている情報を表示します。指定可能なタイプは「-t オプションに指定可能なタイプ」の表を参照してください。
-
-llevel¶ - ログレベルを指定します。指定可能なログレベルは以下のいずれかです。1、2、4、8、16、32数値が大きいほど詳細なログが出力されます。
-
-ssize¶ - ログを出力するファイルのサイズを指定します。単位は byte です。
-
なし¶ 現在設定されている全情報を表示します。
-
-
戻り値 0
成功
0以外
異常
-
備考 CLUSTERPRO が出力するログは、各タイプで 4 つのログファイルを使用します。このため -s で指定したサイズの4倍のディスク容量が必要です。
-
注意事項 本コマンドは root 権限をもつユーザで実行してください。
本コマンドの実行には CLUSTERPRO イベントサービスが動作している必要があります。
設定変更は、本コマンドを実行したサーバのみで有効となります。また、サーバを再起動すると設定は元に戻ります。
-
実行例 例1 : pm のログレベルを変更する場合
# clplogcf -t pm -l 8
例2 : pm のログレベル、ログファイルサイズを参照する場合
# clplogcf -t pm TYPE, LEVEL, SIZE pm, 8, 1000000
例3 : 現在の設定値を表示する場合
# clplogcf TYPE, LEVEL, SIZE trnsv, 4, 1000000 xml, 4, 1000000 logcf, 4, 1000000
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
Invalid option.
オプションが不正です。オプションを確認してください。
Failed to change the configuration. Check if clpevent is running.
clpevent が起動されていない可能性があります。
Invalid level
指定したレベルが不正です。
Invalid size
指定したサイズが不正です。
Failed to load the configuration file. Check if memory or OS resources are sufficient.
クラスタ生成されていないサーバです。
Failed to initialize the xml library. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to print the configuration. Check if clpevent is running.
clpevent が起動されていない可能性があります。
-
-t オプションに指定可能なタイプ タイプ
モジュール
説明
本体
Replicator を使用している場合
Replicator DR を使用している場合
apicl
libclpapicl.so.1.0
API クライアントライブラリ
✓
✓
✓
apisv
libclpapisv.so.1.0
API サーバ
✓
✓
✓
cl
clpcl
クラスタ起動、停止コマンド
✓
✓
✓
cfctrl
clpcfctrl
クラスタ生成、クラスタ情報バックアップコマンド
✓
✓
✓
cfmgr
libclpcfmgr.so.1.0
クラスタ構成情報操作ライブラリ
✓
✓
✓
down
clpdown
サーバ停止コマンド
✓
✓
✓
grp
clpgrp
グループ起動、停止、移動コマンド
✓
✓
✓
rsc
clprsc
グループリソース起動、停止コマンド
✓
✓
✓
haltp
clpuserw
シャットダウン監視
✓
✓
✓
healthchk
clphealthchk
プロセス健全性確認コマンド
✓
✓
✓
ibsv
clpibsv
Information Base サーバ
✓
✓
✓
lcns
libclplcns.so.1.0
ライセンスライブラリ
✓
✓
✓
lcnsc
clplcnsc
ライセンス登録コマンド
✓
✓
✓
logcc
clplogcc
ログ収集コマンド
✓
✓
✓
logcf
clplogcf
ログレベル、サイズ変更コマンド
✓
✓
✓
logcmd
clplogcmd
アラート出力コマンド
✓
✓
✓
mail
clpmail
Mail 通報
✓
✓
✓
mgtmib
libclpmgtmib.so.1.0
SNMP 連携ライブラリ
✓
✓
✓
mm
libclpmm.so.1.0
外部監視連動処理ライブラリ
✓
✓
✓
monctrl
clpmonctrl
監視制御コマンド
✓
✓
✓
nm
clpnm
ノードマップ管理
✓
✓
✓
pm
clppm
プロセス管理
✓
✓
✓
rc/rc_ex
clprc
グループ、グループリソース管理
✓
✓
✓
reg
libclpreg.so.1.0
再起動回数制御ライブラリ
✓
✓
✓
regctrl
clpregctrl
再起動回数制御コマンド
✓
✓
✓
rm
clprm
モニタ管理
✓
✓
✓
roset
clproset
ディスク制御
✓
✓
✓
relpath
clprelpath
プロセス強制終了コマンド
✓
✓
✓
scrpc
clpscrpc
スクリプトログローテート実行コマンド
✓
✓
✓
stat
clpstat
ステータス表示コマンド
✓
✓
✓
stdn
clpstdn
クラスタシャットダウンコマンド
✓
✓
✓
toratio
clptoratio
タイムアウト倍率変更コマンド
✓
✓
✓
trap
clptrap
SNMP トラップ送信コマンド
✓
✓
✓
trncl
libclptrncl.so.1.0
トランザクションライブラリ
✓
✓
✓
rexec
clprexec
外部監視連動処理要求コマンド
✓
✓
✓
bwctrl
clpbwctrl
クラスタ起動同期待ち処理制御コマンド
✓
✓
✓
trnsv
clptrnsv
トランザクションサーバ
✓
✓
✓
alert
clpaltinsert
アラート
✓
✓
✓
webmgr
clpwebmc
WebManager サーバ
✓
✓
✓
webalert
clpaltd
アラート同期
✓
✓
✓
rd
clprd
スマートフェイルオーバ用プロセス
✓
✓
✓
rdl
libclprdl.so.1.0
スマートフェイルオーバ用ライブラリ
✓
✓
✓
disk
clpdisk
ディスクリソース
✓
✓
✓
disk_fsck
clpdisk
ディスクリソース
✓
✓
✓
exec
clpexec
EXEC リソース
✓
✓
✓
fip
clpfip
フローティング IP リソース
✓
✓
✓
fipw
clpfipw
フローティングIPモニタリソース
✓
✓
✓
nas
clpnas
NAS リソース
✓
✓
✓
volmgr
clpvolmgr
ボリュームマネージャリソース
✓
✓
✓
vip
clpvip
仮想 IP リソース
✓
✓
✓
ddns
clpddns
ダイナミック DNS リソース
✓
✓
✓
arpw
clparpw
ARP モニタリソース
✓
✓
✓
diskw
clpdiskw
ディスクモニタリソース
✓
✓
✓
ipw
clpipw
IP モニタリソース
✓
✓
✓
miiw
clpmiiw
NIC Link Up/Down モニタリソース
✓
✓
✓
mtw
clpmtw
マルチターゲットモニタリソース
✓
✓
✓
pidw
clppidw
PID モニタリソース
✓
✓
✓
volmgrw
clpvolmgrw
ボリュームマネージャモニタリソース
✓
✓
✓
userw
clpuserw
ユーザ空間モニタリソース
✓
✓
✓
vipw
clpvipw
仮想 IP モニタリソース
✓
✓
✓
ddnsw
clpddnsw
ダイナミック DNS モニタ リソース
✓
✓
✓
mrw
clpmrw
外部連携モニタリソース
✓
✓
✓
genw
clpgenw
カスタムモニタリソース
✓
✓
✓
snmpmgr
libclp snmpmgr
SNMP トラップ受信ライブラリ
✓
✓
✓
diskhb
clpdiskhb
ディスクハートビート
✓
✓
✓
lanhb
clplanhb
LAN ハートビート
✓
✓
✓
lankhb
clplankhb
カーネルモード LAN ハート ビート
✓
✓
✓
pingnp
libclppingnp.so.1.0
PING ネットワークパーティション解決
✓
✓
✓
exping
libclppingnp.so.1.0
PING ネットワークパーティション解決
✓
✓
✓
mdadmn
libclpmdadmn.so.1.0
ミラーディスクアドミンライブラリ
n/a
✓
✓
mdfunc
libclpmdfunc.so.1.0
ミラーディスクファンクション ライブラリ
n/a
✓
✓
mdagent
clpmdagent
ミラーエージェント
n/a
✓
✓
mdctrl
clpmdctrl
ミラーディスクリソース操作 コマンド
n/a
✓
n/a
mdinit
clpmdinit
ミラーディスク初期化コマンド
n/a
✓
n/a
mdstat
clpmdstat
ミラー状態表示コマンド
n/a
✓
n/a
hdctrl
clphdctrl
ハイブリッドディスクリソース操作コマンド
n/a
n/a
✓
hdinit
clphdinit
ハイブリッドディスク初期化 コマンド
n/a
n/a
✓
hdstat
clphdstat
ハイブリッド状態表示コマンド
n/a
n/a
✓
md
clpmd
ミラーディスクリソース
n/a
✓
n/a
md_fsck
clpmd
ミラーディスクリソース
n/a
✓
n/a
mdw
clpmdw
ミラーディスクモニタリソース
n/a
✓
n/a
mdnw
clpmdnw
ミラーディスクコネクトモニタリソース
n/a
✓
n/a
hd
clphd
ハイブリッドディスクリソース
n/a
n/a
✓
hd_fsck
clphd
ハイブリッドディスクリソース
n/a
n/a
✓
hdw
clphdw
ハイブリッドディスクモニタリソース
n/a
n/a
✓
hdnw
clphdnw
ハイブリッドディスクコネクトモニタリソース
n/a
n/a
✓
oraclew
clp_oraclew
Oracle モニタリソース
✓
✓
✓
db2w
clp_db2w
DB2 モニタリソース
✓
✓
✓
psqlw
clp_psqlw
PostgreSQL モニタリソース
✓
✓
✓
mysqlw
clp_mysqlw
MySQL モニタリソース
✓
✓
✓
odbcw
clp_odbcw
ODBC モニタリソース
✓
✓
✓
sqlserverw
clp_sqlserverw
SQL Server モニタリソース
✓
✓
✓
sambaw
clp_sambaw
Samba モニタリソース
✓
✓
✓
nfsw
clp_nfsw
NFS モニタリソース
✓
✓
✓
httpw
clp_httpw
HTTP モニタリソース
✓
✓
✓
ftpw
clp_ftpw
FTP モニタリソース
✓
✓
✓
smtpw
clp_smtpw
SMTP モニタリソース
✓
✓
✓
pop3w
clp_pop3w
POP3 モニタリソース
✓
✓
✓
imap4w
clp_imap4w
IMAP4 モニタリソース
✓
✓
✓
tuxw
clp_tuxw
Tuxedo モニタリソース
✓
✓
✓
wlsw
clp_wlsw
WebLogic モニタリソース
✓
✓
✓
wasw
clp_wasw
WebSphere モニタリソース
✓
✓
✓
otxw
clp_otxw
WebOTX モニタリソース
✓
✓
✓
jraw
clp_jraw
JVM モニタリソース
✓
✓
✓
sraw
clp_sraw
システムモニタリソース
✓
✓
✓
psrw
clp_psrw
プロセスリソースモニタリソース
✓
✓
✓
psw
clppsw
プロセス名モニタリソース
✓
✓
✓
mdperf
clpmdperf
統計情報採取
n/a
✓
✓
vmctrl
libclpvmctrl.so.1.0
VMCTRL ライブラリ
✓
✓
✓
awseip
clpawseip
AWS Elastic IP リソース
✓
✓
✓
awsvip
clpawsvip
AWS 仮想 IP リソース
✓
✓
✓
awsdns
clpawsdns
AWS DNS リソース
✓
✓
✓
awseipw
clpawseipw
AWS Elastic IP モニタリソース
✓
✓
✓
awsvipw
clpawsvipw
AWS 仮想 IP モニタリソース
✓
✓
✓
awsazw
clpawsazw
AWS AZ モニタリソース
✓
✓
✓
awsdnsw
clpawsdnsw
AWS DNS モニタリソース
✓
✓
✓
azurepp
clpazurepp
Azure プローブポートリソース
✓
✓
✓
azuredns
clpazuredns
Azure DNS リソース
✓
✓
✓
azureppw
clpazureppw
Azure プローブポートモニタリソース
✓
✓
✓
azurelbw
clpazurelbw
Azure ロードバランスモニタリソース
✓
✓
✓
azurednsw
clpazurednsw
Azure DNS モニタリソース
✓
✓
✓
gcvip
clpgcvip
Google Cloud 仮想 IP リソース
✓
✓
✓
gcvipw
clpgcvipw
Google Cloud 仮想 IP モニタリソース
✓
✓
✓
gclbw
clpgclbw
Google Cloud ロードバランスモニタリソース
✓
✓
✓
ocvip
clpocvip
Oracle Cloud 仮想 IP リソース
✓
✓
✓
ocvipw
clpocvipw
Oracle Cloud 仮想 IP モニタリソース
✓
✓
✓
oclbw
clpoclbw
Oracle Cloud ロードバランスモニタリソース
✓
✓
✓
perfc
clpperfc
クラスタ統計情報表示コマンド
✓
✓
✓
cfchk
clpcfchk
クラスタ構成情報チェックコマンド
✓
✓
✓
9.12. ライセンスを管理する (clplcnsc コマンド)¶
ライセンスの管理を行います。
-
コマンドライン - clplcnsc -i [licensefile…]clplcnsc -l [-a]clplcnsc -d serialno [-q]clplcnsc -d -t [-q]clplcnsc -d -a [-q]clplcnsc --distributeclplcnsc --reregister licensefile...
-
説明 本製品の製品版・試用版ライセンスの登録、参照、削除を行います。
-
オプション -
-i[licensefile…]¶ ライセンスファイルを指定すると、そのファイルよりライセンス情報を取得し、登録します。ライセンスファイルは複数指定することができます。ワイルドカードの指定も可能です。指定しなければ、対話形式によりライセンス情報を入力し登録します。
-
-l[-a]¶ 登録されているライセンスを参照します。表示する項目を以下に示します。
項目名
説明
Serial No
シリアルナンバー (製品版のみ)
User name
ユーザ名 (試用版のみ)
Key
ライセンスキー
Licensed Number of CPU
ライセンス許諾数(CPU単位)
Licensed Number of Computers
ライセンス許諾数(ノード単位)
Start date
End date
Status
ライセンスの状態
-a オプションを指定しない場合は、ライセンスの状態が invalid, unknown, expired であるライセンスは表示しません。
-a オプションを指定した場合は、ライセンスの状態に関わらず、全てのライセンスを表示します。
-
-d<param>¶ param
- serialno
指定したシリアルナンバーのライセンスを削除します。
- -t
登録されている全ての試用版ライセンスを削除します。
- -a
登録されている全てのライセンスを削除します。
-
-q¶ ライセンスを削除する時の確認メッセージを表示せずに削除します。-dオプションと一緒に指定してください。
-
--distribute¶ ライセンスファイルをクラスタ内のサーバに配信します。通常、このオプションでコマンドを実行する必要はありません。
-
--reregisterlicensefile…¶ 期限付きライセンスを再登録します。通常、このオプションでコマンドを実行する必要はありません。
-
-
戻り値 0
正常終了
1
キャンセル
2
正常終了 (ライセンス非同期状態)
※ ライセンス登録時、クラスタ内でライセンスの同期が失敗したことを意味します。
この状態での対処方法は、『インストール&設定ガイド』の「トラブルシューティング」の「ライセンス関連」を参照してください。
3
初期化エラー
5
オプション不正
8
その他内部エラー
-
実行例 登録
対話形式
# clplcnsc -i
製品版、製品版(期限付き)
製品区分選択
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
シリアルナンバー入力
Enter serial number [ Ex. XXXXXXXX000000 ] ...
ライセンスキー入力
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
試用版
製品区分選択
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
ユーザ名入力
Enter user name [ 1 to 63byte ] ...
ライセンスキー入力
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
ライセンスファイル指定
# clplcnsc -i /tmp/cpulcns.key
参照
# clplcnsc -l
製品版
< CLUSTERPRO X <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Licensed Number of CPU... 2 Status... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Licensed Number of Computers... 1 Status... valid
製品版(期限付き)
< CLUSTERPRO X <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Start date..... 2018/01/01 End date...... 2018/01/31 Status........... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Status........... inactive
試用版
< CLUSTERPRO X <TRIAL> > Seq... 1 Key..... A1234567-B1234567-C1234567-D1234567 User name... NEC Start date..... 2018/01/01 End date...... 2018/02/28 Status........... valid
削除
# clplcnsc -d AAAAAAAA000001 -q
削除
# clplcnsc -d -t -q
削除
# clplcnsc -d -a
削除確認
Are you sure to remove the license? [y/n] ...
-
注意事項 ライセンス登録時はライセンス同期を行うため、データ転送サーバの起動、クラスタ生成が行われていることを確認してください。
ライセンス同期する際、インタコネクトの優先度順でクラスタサーバのIPアドレスに接続し、成功した経路を使用します。
ライセンス削除時は、本コマンドを実行したサーバ上のライセンス情報のみが削除されます。他のサーバ上のライセンス情報は削除されません。クラスタ内のライセンス情報を全て削除する場合は、全てのサーバで本コマンドを実行してください。
また、-d オプション利用時に -aオプションを併用した場合、全ての試用版ライセンスおよび製品版ライセンスが削除されます。試用版ライセンスのみ削除する場合は -t オプションを併用してください。製品版ライセンスも含めて削除してしまった場合は製品版ライセンスの再登録をしてください。
ライセンス参照時は、あるライセンスに複数のライセンスが包含されている場合、それぞれ個別に表示されます。
ダウンしているサーバが存在する場合、本コマンドの実行に時間がかかる場合がありますが、動作上の問題はありません。
-
エラーメッセージ メッセージ
原因/対処法
Processed license num(success: %d, error: %d).処理したライセンス数(成功: %d, 失敗: %d)失敗が 0 でない場合は、何らかの理由でライセンス処理が失敗しています。ライセンス情報が正しいか確認してください。Command succeeded.
コマンドは成功しました。
Command failed.
コマンドは失敗しました。
Command succeeded.But the license was not applied to all the servers in the clusterbecause there are one or more servers that are not started up.クラスタ内にダウンしているサーバが存在します。クラスタ内の全サーバでクラスタ生成手順を実行してください。クラスタ生成手順については、『インストール&設定ガイド』の「CLUSTERPRO をインストールする」を参照してくださいLog in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。Initialization error.Check if memory or OS resources are sufficient.クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。Initialization error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
The command is already run.
コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。The license is not registered.
ライセンスが未登録状態です。
Could not opened the license file.Check if the license file exists on the specified path.ライセンスファイルへの I/O ができません。ライセンスファイルが指定されたパスに存在するか確認してください。Could not read the license file.Check if the license file exists on the specified path.〃
The field format of the license file is invalid.The license file may be corrupted.Check the destination from where the file is sent.ライセンスファイルのフィールド形式が不正です。ライセンスファイルが壊れている可能性があります。ファイルの送付元に確認してください。The cluster configuration data may be invalid or not registered.
クラスタ構成情報が不正または、未登録状態が考えられます。確認してください。Failed to terminate the library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。Failed to register the license.Check if the entered license information is correct.入力したライセンス情報が正しいか確認してください。
Failed to open the license.Check if the entered license information is correct.〃
Failed to remove the license.
ライセンスの削除に失敗しました。パラメータ誤り、メモリ不足、または OS のリソース不足が考えられます。確認してください。This license is already registered.
このライセンスはすでに登録されています。登録されているライセンスを確認してください。This license is already activated.
このライセンスはすでに使用されています。登録されているライセンスを確認してください。This license is unavailable for this product.
このライセンスはこの製品では使用できません。ライセンスを確認してください。The maximum number of licenses was reached.
登録可能なライセンスの最大数に達しました。期限切れのライセンスを削除してください。Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.13. ディスク I/O を閉塞する (clproset コマンド)¶
パーティションデバイスの I/O 許可の変更と表示をします。
-
コマンドライン - clproset -o [-d device_name | -r resource_name -t resource_type | -a]clproset -w [-d device_name | -r resource_name -t resource_type | -a]clproset -s [-d device_name | -r resource_name -t resource_type | -a]
-
説明 共有ディスクのパーティションデバイスの I/O 許可を ReadOnly / ReadWrite 可能 に設定します。
設定されているパーティションデバイスの I/O 許可の状態を表示します。
-
オプション -
-o¶ パーティションデバイスの I/O を ReadOnly に設定します。ReadOnly に設定すると、設定したパーティションデバイスに対して、書き込みができなくなります。
-
-w¶ パーティションデバイスの I/O を ReadWrite 可能 に設定します。ReadWrite に設定すると、設定したパーティションデバイスに対して、読み書きが可能になります。
-
-s¶ パーティションデバイスの I/O 許可の状態を表示します。
-
-ddevice_name¶ パーティションデバイスを指定します。
-
-rresource_name¶ ディスクリソース名を指定します。
-
-tresource_type¶ グループリソースタイプを指定します。現バージョンでは、グループリソースタイプには必ず「disk」を指定してください。
-
-a¶ 全てのディスクリソースに対して実行します。
-
-
戻り値 0
成功
0 以外
異常
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
本コマンドは共有ディスクリソースのみに有効なコマンドです。ミラーディスクリソース、ハイブリッドディスクリソースには使用できません。
リソース名で指定する場合は必ずグループリソースタイプも指定してください。
-
実行例 例1 : ディスクリソース名 disk1 の I/O を RW にする場合
# clproset -w -r disk1 -t disk /dev/sdb5 : succeeded (disk1)
例2 : 全てのリソースの I/O 情報を取得する場合
# clproset -s -a /dev/sdb5 : rw (disk) /dev/sdb6 : ro (raw)
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file.Create valid cluster configuration data.Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
The -t option must be specified for the -r option.
-r オプションの場合は、必ず -t オプションを指定してください。
Specify 'disk' or 'raw to specify a group resource.
グループリソースタイプの指定は、「disk」または「raw」を指定してください。
Invalid group resource name.Specify a valid group resource name in the cluster.グループリソースタイプの指定は、「disk」または「raw」を指定してください。
Invalid group resource name.Specify a valid group resource name in the cluster.正しいグループリソース名を指定してください。
invalid device name.
正しいデバイス名を指定してください。
command timeout.
OSに負荷がかかっているなどの原因が考えられます。確認してください。Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。注釈
『インストール&設定ガイド』の「動作チェックを行う」に記載されている用途以外に本コマンドを使用しないでください。CLUSTERPRO デーモンが起動している場合に本コマンドを実行すると、ファイルシステムを壊す恐れがあります。
9.16. メッセージを出力する (clplogcmd コマンド)¶
指定したメッセージを syslog,alert に登録する、mail 通報する、または SNMP トラップ送信するコマンドです。
-
コマンドライン clplogcmd -m message [--syslog] [--alert] [--mail] [--trap] [-i eventID] [-l level]
注釈
通常、クラスタの構築や運用ではこのコマンドの実行は不要です。EXEC リソースの スクリプトに記述して使用するコマンドです。
-
説明 EXEC リソースのスクリプトに記述し、任意のメッセージを出力先に出力します。
-
オプション -
-mmessage¶ - 出力するメッセージを指定します。省略できません。メッセージの最大サイズは511バイトです。(出力先に syslog を指定した場合は 485 バイトです。) 最大サイズ以降のメッセージは表示されません。
メッセージには英語、数字、記号 7 が使用可能です。
-
--syslog¶
-
--alert¶
-
--mail¶
-
--trap¶ syslog、alert、mail、trap の中から出力先を指定します (複数指定可能です)。
このパラメータは省略可能です。省略時にはsyslog と alert が出力先になります。
出力先についての詳細は『メンテナンスガイド』の「保守情報」の「CLUSTERPRO のディレクトリ構成」を参照してください。
-
-ieventID¶ イベント ID を指定します。イベント ID の最大値は 10000 です。
このパラメータは省略可能です。省略時にはeventID に 1 が設定されます。
-
-llevel¶ - 出力するアラートのレベルです。ERR、WARN、INFO のいずれかを指定します。このレベルによって Cluster WebUI でのアラートログのアイコンを指定します。
このパラメータは省略可能です。省略時にはlevel に INFO が設定されます。
詳細はオンラインマニュアルを参照してください。
- 7
メッセージに記号を含む場合の注意点は以下のとおりです。
"" で囲む必要がある記号
# & ' ( ) ~ | ; : * < > , .(例 "#" をメッセージに指定すると、 #が出力されます。)\ を前につける必要がある記号
\ ! " & ' ( ) ~ | ; : * < > , .(例 \\ をメッセージに指定すると、 \が出力されます。)"" で囲む必要があり かつ \ を前につける必要がある記号
`(例 "\`" をメッセージに指定すると、 `が出力されます。)メッセージにスペースを含む場合、"" で囲む必要があります。
メッセージに % は使用できません。
-
-
戻り値 0
成功
0 以外
異常
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
出力先に mail を指定する場合、mail コマンドで mail 送信ができる設定を行ってください。
-
実行例 例1: メッセージのみ指定する場合 (出力先 syslog,alert)
EXEC リソースのスクリプトに下記を記述した場合、syslog、alert にメッセージを出力します。
# clplogcmd -m test1
syslog には、下記のログが出力されます。
Sep 1 14:00:00 server1 clusterpro: <type: logcmd><event: 1> test1
例2: メッセージ、出力先、イベント ID、レベルを指定する場合 (出力先 mail)
EXEC リソースのスクリプトに下記を記述した場合、Cluster WebUI のクラスタプロパティで設定したメールアドレスにメッセージが送信されます。メールアドレスの設定についての詳細は本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「アラートサービスタブ」を参照してください。
# clplogcmd -m test2 --mail -i 100 -l ERR
mail の送信先には、下記の内容のメールが送信されます。
Message:test2Type: logcmdID: 100Host: server1Date: 2004/09/01 14:00:00例3: メッセージ、出力先、イベント ID、レベルを指定する場合 (出力先 trap)
EXEC リソースのスクリプトに下記を記述した場合、Cluster WebUI のクラスタのプロパティで設定したSNMP トラップ送信先にメッセージが送信されます。SNMP トラップ送信先の設定についての詳細は本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「アラートサービスタブ」を参照してください。
# clplogcmd -m test3 --trap -i 200 -l ERR
SNMP トラップの送信先には、下記の内容の SNMP トラップが送信されます。
Trap OID: clusterEventError添付データ1: clusterEventMessage = test3添付データ2: clusterEventID = 200添付データ3: clusterEventDateTime = 2011/08/01 09:00:00添付データ4: clusterEventServerName = server1添付データ5: clusterEventModuleName = logcmd
9.17. モニタリソースを制御する (clpmonctrl コマンド)¶
モニタリソースの制御を行います。
-
コマンドライン - clpmonctrl -s [-h <hostname>] [-m resource name] [-w wait time]clpmonctrl -r [-h <hostname>] [-m resource name] [-w wait time]clpmonctrl -c [-m resource_name]clpmonctrl -v [-m resource_name]clpmonctrl -e [-h <hostname>] -m resource_nameclpmonctrl -n [-h <hostname>] [-m resource_name]
注釈
-cおよび-vは、単一サーバ上でモニタリソースの制御を行うため、制御を行う全サーバ上で実行する必要があります。クラスタ内の全サーバ上のモニタリソースの一時停止/再開を行う場合には、Cluster WebUI から実行されることを推奨します。
-
説明 モニタリソースの一時停止/再開、または回復動作の回数カウンタの表示/リセット、障害検証機能の有効/無効を行います。
-
オプション -
-s¶ 監視を一時停止します。
-
-r¶ 監視を再開します。
-
-c¶ 回復動作の回数カウンタをリセットします。
-
-v¶ 回復動作の回数カウンタを表示します。
-
-e¶ 障害検証機能を有効にします。必ず-mオプションでモニタリソース名を指定してください。
-
-n¶ 障害検証機能を無効にします。-mオプションでモニタリソース名を指定した場合は、そのリソースのみが対象となります。-mオプションを省略した場合は、全モニタリソースが対象となります。
-
-mresource_name¶ - 制御するモニタリソースを指定します。省略可能で、省略時は全てのモニタリソースに対して制御を行います。
-
-wwait_time¶ - モニタリソース単位で監視制御を待合わせます。(秒)省略可能で、省略時は 5 秒が設定されます。
-
-h¶ hostname で指定したサーバに処理を要求します。[-h] オプションを省略した場合は、コマンド 実行サーバ (自サーバ) に処理を要求します。-cおよび-vの場合は指定できません。
-
-
戻り値 0
正常終了
1
実行権限不正
2
オプション不正
3
初期化エラー
4
クラスタ構成情報不正
5
モニタリソース未登録
6
指定モニタリソース不正
10
クラスタ未起動状態
11
CLUSTERPRO デーモンサスペンド状態
12
クラスタ同期待ち状態
90
監視制御待ちタイムアウト
128
二重起動
200
サーバ接続エラー
201
ステータス不正
202
サーバ名不正
255
その他内部エラー
-
実行例 例1: 全モニタリソースを一時停止する場合
# clpmonctrl -s Command succeeded.
例2: 全モニタリソースを再開する場合
# clpmonctrl -r Command succeeded.
-
備考 既に一時停止状態にあるモニタリソースに一時停止を行った場合や既に起動済状態にあるモニタリソースに再開を行った場合は、本コマンドはエラー終了し、モニタリソース状態は変更しません。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
モニタリソースの状態は、clpstat コマンドまたは Cluster WebUI で確認してください。
モニタリソースの一時停止/再開を行う場合は、clpstat コマンドまたはCluster WebUI でモニタリソースの状態が "起動済" または、"一時停止" であることを確認して実行してください。
モニタリソースの回復動作が下記のように設定されている場合、-vオプションで表示される "FinalAction Count" には 「最終動作前スクリプト」の実行回数が表示されます。
最終動作前にスクリプトを実行する: 有効
最終動作: "何もしない"
-
エラーメッセージ メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Invalid cluster configuration data.Check the cluster configuration information.クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。
Monitor resource is not registered.
モニタリソースが登録されていません。
Specified monitor resource is not registered.Check the cluster configuration information.指定されたモニタリソースは、登録されていません。Cluster WebUI でクラスタ構成情報を確認してください。The cluster has been suspended. The cluster daemon has been suspended.Check activation status of the cluster daemon by using a command such as the ps command.CLUSTERPRO デーモンは、サスペンド状態です。ps コマンドなどで CLUSTERPRO デーモンの起動状態を確認してください。Waiting for synchronization of the cluster... The cluster is waiting for synchronization.Wait for a while and try again.クラスタは、同期待ち状態です。クラスタ同期待ち完了後、再度実行してください。Monitor %1 was unregistered, ignored.The specified monitor resources %1is not registered, but continue processing.Check the cluster configuration data.指定されたモニタリソース中に登録されていないモニタリソースありますが、無視して処理を継続します。Cluster WebUI でクラスタ構成情報を確認してください。%1 :モニタリソース名Monitor %1 denied control permission, ignored. but continue processing.指定されたモニタリソース中に制御できないモニタリソースがありますが、無視して処理を継続します。%1 :モニタリソース名This command is already run.コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。Internal error. Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。Could not connect to the server.クラスタサービスが起動しているか確認してください。Check if the cluster service is active. Some invalid status.何らかの不正な状態です。クラスタの状態を確認してください。Check the status of cluster. Invalid server name. Specify a valid server name in the cluster.クラスタ内の正しいサーバ名を指定してください。
-
-m オプションに指定可能なモニタリソースタイプ タイプ
監視の一時停止/再開
回復動作の回数カウンタ/リセット障害検証機能の有効化/無効化arpw
n/a
✓
n/a
diskw
✓
✓
✓
fipw
✓
✓
✓
ipw
✓
✓
✓
miiw
✓
✓
✓
mtw
✓
✓
✓
pidw
✓
✓
✓
volmgrw
✓
✓
✓
userw
✓
✓
n/a
vipw
n/a
✓
n/a
ddnsw
n/a
✓
n/a
mrw
✓
✓
n/a
genw
✓
✓
✓
mdw
✓
✓
n/a
mdnw
✓
✓
n/a
hdw
✓
✓
n/a
hdnw
✓
✓
n/a
oraclew
✓
✓
✓
osmw
✓
✓
✓
db2w
✓
✓
✓
psqlw
✓
✓
✓
mysqlw
✓
✓
✓
odbcw
✓
✓
✓
sqlserverw
✓
✓
✓
sambaw
✓
✓
✓
nfsw
✓
✓
✓
httpw
✓
✓
✓
ftpw
✓
✓
✓
smtpw
✓
✓
✓
pop3w
✓
✓
✓
imap4w
✓
✓
✓
tuxw
✓
✓
✓
wlsw
✓
✓
✓
wasw
✓
✓
✓
otxw
✓
✓
✓
jraw
✓
✓
✓
sraw
✓
✓
✓
psrw
✓
✓
✓
psw
✓
✓
✓
awsazw
✓
✓
✓
awsdnsw
✓
✓
✓
awseipw
✓
✓
✓
awssipw
✓
✓
✓
awsvipw
✓
✓
✓
azurednsw
✓
✓
✓
azurelbw
✓
✓
✓
azureppw
✓
✓
✓
gcdnsw
✓
✓
✓
gclbw
✓
✓
✓
gcvipw
✓
✓
✓
oclbw
✓
✓
✓
ocvipw
✓
✓
✓
9.18. グループリソースを制御する (clprscコマンド)¶
グループリソースの制御を行います。
-
コマンドライン - clprsc -s resource_name [-h hostname] [-f] [--apito timeout]clprsc -t resource_name [-h hostname] [-f] [--apito timeout]clprsc -n resource_nameclprsc -v resource_name
-
説明 グループリソースを起動/停止します。
-
オプション -
-s¶ グループリソースを起動します。
-
-t¶ グループリソースを停止します。
-
-h¶ hostname で指定されたサーバに処理を要求します。
-h オプションを省略した場合は、以下のサーバへ処理を要求します。
グループが停止済の場合、コマンド実行サーバ(自サーバ)
グループが起動済の場合、グループが起動しているサーバ
-
-f¶ グループリソース起動時は、指定したグループリソースが依存する全グループリソースを起動します。
グループリソース停止時は、指定したグループリソースに依存している全グループリソースを停止します。
-
-n¶ グループリソースの起動済サーバを表示します。
-
--apitotimeout¶ グループリソースの起動、停止を待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999の値が指定できます。
[--apito] オプション指定しない場合は、クラスタプロパティの内部通信タイムアウトに設定された値に従い、待ち合わせを行います。
-
-v¶ グループリソースのフェイルオーバ回数カウンタを表示します。
-
-
戻り値 0
正常終了
0以外
異常終了
-
実行例 グループリソース構成
# clpstat =========== CLUSTER STATUS =========== Cluster : cluster <server> *server1..................: Online lanhb1 : Normal lanhb2 : Normal pingnp1 : Normal server2..................: Online lanhb1 : Normal lanhb2 : Normal pingnp1 : Normal <group> ManagementGroup........: Online current : server1 ManagementIP : Online failover1..............: Online current : server1 fip1 : Online md1 : Online exec1 : Online failover2..............: Online current : server2 fip2 : Online md2 : Online exec2 : Online <monitor> ipw1 : Normal mdnw1 : Normal mdnw2 : Normal mdw1 : Normal mdw2 : Normal ======================================例1:グループ failover1 のリソース fip1 を停止する場合
# clprsc -t fip1 Command succeeded.
#clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup........: Online current : server1 ManagementIP : Online failover1..............:Online current : server1 fip1 : Offline md1 : Online exec1 : Online failover2..............: Online current : server2 fip2 : Online md2 : Online exec2 : Online <省略>
例2:グループ failover1 のリソース fip1 を起動する場合
# clprsc -s fip1 Command succeeded.
# clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup.......: Online current : server1 ManagementIP : Online failover1.............: Online current : server1 fip1 : Online md1 : Online exect1 : Online failover2.............: Online current : server2 fip2 : Online md2 : Online exec2 : Online <省略>
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
グループリソースの状態は、状態表示コマンドまたは Cluster WebUI で確認してください。
グループ内に起動済グループリソースがある場合は、停止済グループリソースを異なるサーバで起動することはできません。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid cluster configuration data.Check the cluster configuration information.クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。Invalid option.
正しいオプションを指定してください。
Could not connect server. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Invalid server status. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Server is not active. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost.Check if there is a server where the cluster service is stopped in the cluster.クラスタ内に CLUSTERPRO サービスが停止しているサーバがないか確認してください。Internal communication timeout has occurred in the cluster server.If it occurs frequently, set the longer timeout.CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。The group resource is busy. Try again later.グループリソースが起動処理中、もしくは停止処理中のため、しばらく待ってから実行してください。An error occurred on group resource. Check the status of group resource.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Could not start the group resource.Try it again after the other server is started, or after the Wait Synchronization time is timed out.他サーバが起動するのを待つか、起動待ち時間が タイムアウトするのを待って、グループリソースを起動させてください。No operable group resource exists in the server.処理を要求したサーバに処理可能なグループリソースが存在するか確認してください。The group resource has already been started on the local server.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。The group resource has already been started on the other server.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。グループリソースをローカルサーバで起動するには、グループを停止してください。The group resource has already been stopped.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Failed to start group resource. Check the status of group resource.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Failed to stop resource. Check the status of group resource.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Depended resource is not offline. Check the status of resource.依存しているグループリソースの状態が停止済でないため、グループリソースを停止できません。依存しているグループリソースを停止するか、-f オプションを指定してください。Depending resource is not online. Check the status of resource.依存しているグループリソースの状態が起動済でないため、グループリソースを起動できません。依存しているグループリソースを起動するか、-f オプションを指定してください。Invalid group resource name. Specify a valid group resource name in the cluster.グループリソースが登録されていません。Server is not in a condition to start resource or any critical monitor error is detected.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。グループリソースを起動しようとしたサーバで「フェイルオーバ先サーバの除外に使用するモニタリソース」に含まれるモニタの異常が検出されています。Internal error. Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.19. 再起動回数を制御する (clpregctrl コマンド)¶
再起動回数制限の制御を行います。
-
コマンドライン - clpregctrl --getclpregctrl -gclpregctrl --clear -t type -r registryclpregctrl -c -t type -r registry
注釈
本コマンドは、単一サーバ上で再起動回数制限の制御を行うため、制御を行う全サーバ上で実行する必要があります。
-
説明 単一サーバ上で再起動回数の表示/初期化を行います。
-
オプション -
-g,--get¶ 再起動回数情報を表示します。
-
-c,--clear¶ 再起動回数を初期化します。
-
-ttype¶ 再起動回数を初期化するタイプを指定します。指定可能なタイプは rc または rm です。
-
-rregistry¶ レジストリ名を指定します。指定可能なレジストリ名はhaltcount です。
-
-
戻り値 0
正常終了
1
実行権限不正
2
二重起動
3
オプション不正
4
クラスタ構成情報不正
10~17
内部エラー
20~22
再起動回数情報取得失敗
90
メモリアロケート失敗
91
ワークディレクトリ変更失敗
-
実行例 再起動回数情報表示
# clpregctrl -g
****************************** ------------------------- type : rc registry : haltcount comment : halt count kind : int value : 0 default : 0 ------------------------- type : rm registry : haltcount comment : halt count kind : int value : 3 default : 0 ****************************** Command succeeded.(code:0) #
例1 、2 は、再起動回数を初期化します。
server2 の再起動回数を制御する場合は、server2 で本コマンドを実行してください。
例1:グループリソース異常による再起動回数を初期化する場合
# clpregctrl -c -t rc -r haltcount Command succeeded.(code:0)
例2:モニタリソース異常による再起動回数を初期化する場合
# clpregctrl -c -t rm -r haltcount Command succeeded.(code:0)
-
備考 再起動回数制限に関しては本ガイドの「3. グループリソースの詳細」 - 「グループとは?」 - 「再起動回数制限について」を参照してください。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-
エラーメッセージ メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。The command is already executed. Check the execution state by using the "ps" command or some other command.
コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。Invalid option.
オプションが不正です。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
9.20. ネットワーク警告灯を消灯する (clplamp コマンド)¶
ネットワーク警告灯を消灯します。
-
コマンドライン clplamp -h hostname
-
説明 指定したサーバ用のネットワーク警告灯を消灯します。
音声ファイルの再生を設定していた場合、音声ファイルの再生を停止します。
-
オプション -
-hhostname¶ 消灯したいネットワーク警告灯のサーバを指定します。
-
-
戻り値 0
正常終了
0以外
異常終了
-
実行例 例1: server1 に対応する警告灯の消灯、音声警告の停止を行う場合
# clplamp -h server1 Command succeeded.
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
9.21. クラスタサーバに処理を要求する (clprexec コマンド)¶
サーバへ処理実行を要求します。
-
コマンドライン - clprexec --failover ( [group_name] | [-r resource_name] ) -h IP [-w timeout] [-p port_number] [-o logfile_path]clprexec --script script_file -h IP [-p port_number] [-w timeout] [-o logfile_path]clprexec --notice ( [mrw_name] | [-k category[. keyword]] ) -h IP [-p port_number] [-w timeout] [-o logfile_path]clprexec --clear ( [mrw_name] | [-k category[. keyword]] ) -h IP [-p port_number] [-w timeout] [-o logfile_path]
-
説明 指定した処理実行要求を他クラスタのサーバに発行します。
-
オプション -
--failover¶ グループフェイルオーバ要求を行います。group_name にはグループ名を指定してください。
グループ名を省略する場合は、-r オプションによりグループに属するリソース名を指定してください。
-
--scriptscript_name¶ スクリプト実行要求を行います。
scirpt_name には、実行するスクリプト (シェルスクリプトや実行可能ファイル等) のファイル名を指定します。
スクリプトは -h で指定した各サーバのCLUSTERPRO インストールディレクトリ配下の work/rexec ディレクトリ配下に作成しておく必要があります。
-
--notice¶ CLUSTERPRO サーバへ異常発生通知を行います。
mrw_name には外部連携モニタリソース名を指定してください。
モニタリソース名を省略する場合、-k オプションで外部連携モニタリソースのカテゴリ,キーワードを指定してください。
-
--clear¶ 外部連携モニタリソースのステータスを "異常"から "正常" へ変更する要求を行います。
mrw_name には外部連携モニタリソース名を指定してください。
モニタリソース名を省略する場合、-k オプションで外部連携モニタリソースのカテゴリ,キーワードを指定してください。
-
-hIP Address¶ 処理要求発行先の CLUSTERPRO サーバのIP アドレスを指定してください。
カンマ区切りで複数指定可能、指定可能な IPアドレス数は 32 個です。
※ 本オプションを省略する場合、処理要求発行先は自サーバになります。
-
-rresource_name¶ --failover オプションを指定する場合に、処理要求の対象となるグループに属するリソース名を指定します。
-
-kcategory[.keyword]¶ --notice または --clear オプションを指定する場合、category にメッセージ受信モニタに設定しているカテゴリを指定してください。
外部連携モニタリソースのキーワードを指定する場合は、category のあとにドット区切りで指定してください。
-
-pport_number¶ ポート番号を指定します。
port_number に処理要求発行先サーバに設定されているデータ転送ポート番号を指定してください。
本オプションを省略した場合、デフォルト 29002を使用します。
-
-ologfile_path¶ logfile_path には、本コマンドの詳細ログを出力するファイル path を指定します。
ファイルにはコマンド 1 回分のログが保存されます。
※ CLUSTERPRO がインストールされていないサーバで本オプションを指定しない場合、標準出力のみとなります。
-
-wtimeout¶ コマンドのタイムアウトを指定します。指定しない場合は、デフォルト 180 秒です。
5 ~ MAXINT まで指定可能です。
-
-
戻り値 0
正常終了
0 以外
異常終了
-
注意事項 [clprexec] コマンドを使って異常発生通知を発行する場合、CLUSTERPRO サーバ側で実行させたい異常時動作を設定した外部連携モニタリソースを登録/起動しておく必要があります。
-h オプションで指定する IP アドレスを持つサーバは、下記の条件を満たす必要があります。
CLUSTERPRO X 3.0 以降がインストールされていること
- CLUSTERPRO が起動していること( --script オプション以外の場合)
- mrw が設定/起動されていること( --notice, --clear オプションの場合)
[クライアント IP アドレスによって接続を制御する] が有効の場合、[clprexec] コマンドを実行する装置の IP アドレスを追加しておく必要があります。
[クライアント IP アドレスによって接続を制御する] は、本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「WebManagerタブ」を参照してください。
-
実行例 例1: CLUSTERPRO サーバ1 (10.0.0.1) に対して、グループ failover1 のフェイルオーバ要求を発行する場合
# clprexec --failover failover1 -h 10.0.0.1 -p 29002
例2: CLUSTERPROサーバ1 (10.0.0.1) に対して、グループリソース (exec1) が属するグループのフェイルオーバ要求を発行する場合
# clprexec --failover -r exec1 -h 10.0.0.1
例3: CLUSTERPROサーバ 1 (10.0.0.1) に対して、スクリプト(script1.sh) 実行要求を発行する場合
# clprexec --script script1.sh -h 10.0.0.1
例4: CLUSTERPROサーバ 1 (10.0.0.1) に対して異常発生通知を発行する
※ mrw1 設定 カテゴリ:earthquake、キーワード:scale3
外部連携モニタリソース名を指定する場合
# clprexec --notice mrw1 -h 10.0.0.1 -w 30 -p /tmp/clprexec/clprexec.log
外部連携モニタリソースに設定されているカテゴリとキーワードを指定する場合
# clprexec --notice -k earthquake.scale3 -h 10.0.0.1 -w 30 -p /tmp/clprexec/clprexec.log
例5: CLUSTERPRO サーバ 1 (10.0.0.1) に対して mrw1 のモニタステータス変更要求を発行する
※ mrw1 の設定 カテゴリ:earthquake、キーワード:scale3
外部連携モニタリソース名を指定する場合
# clprexec --clear mrw1 -h 10.0.0.1
外部連携モニタリソースに設定されているカテゴリとキーワードを指定する場合
# clprexec --clear -k earthquake.scale3 -h 10.0.0.1
-
エラーメッセージ メッセージ
原因/対処
rexec_ver:%s
-
%s %s : %s succeeded.
-
%s %s : %s will be executed from now.
要求発行先のサーバで処理結果を確認してください。
%s %s : Group Failover did not execute because Group(%s) is offline.
-
%s %s : Group migration did not execute because Group(%s) is offline.
-
Invalid option.
コマンドの引数を確認してください。
Could not connect to the data transfer servers. Check if the servers have started up.
指定した IP アドレスが正しいかまたは IP アドレスを持つサーバが起動しているか確認してください。
Command timeout.
指定した IP アドレスを持つサーバで処理が完了しているか確認してください。
All servers are busy. Check if this command is already run.
既に本コマンドが実行されている可能性があります。確認してください。
%s %s : This server is not permitted to execute clprexec.
Cluster WebUI 接続制限のクライアント IP アドレス一覧にコマンドを実行するサーバの IP アドレスが 登録されているか確認してください。
%s %s : Specified monitor resource(%s) does not exist.
コマンドの引数を確認してください。
%s %s : Specified resource(Category:%s, Keyword:%s) does not exist.
コマンドの引数を確認してください。
%s failed in execute.
要求発行先の CLUSTERPRO サーバの状態を確認してください。
9.22. クラスタ起動同期待ち処理を制御する (clpbwctrl コマンド)¶
クラスタ起動同期待ち処理を制御します。
-
コマンドライン - clpbwctrl -cclpbwctrl --np [on|off]clpbwctrl -h
注釈
--npオプションは、単一サーバ上で制御を行うため、制御を行う全サーバ上で実行する必要があります。
-
説明 - クラスタ内の全サーバのクラスタサービスが停止している状態からサーバを起動したときに発生する、クラスタ起動同期待ち時間をスキップします。単一サーバ上でクラスタ起動時にネットワークパーティション解決処理を行うか行わないかを指定します。
-
オプション -
-c,--cancel¶ クラスタ起動同期待ち処理をキャンセルします。
-
--np[on|off]¶ - クラスタ起動時にネットワークパーティション解決処理を行うか行わないかを指定します。onを指定するとネットワークパーティション解決処理を行います。offを指定すると行いません。既定ではonが指定されています。[on|off]は省略可能です。省略した場合、現在の設定を表示します。
-
-h,--help¶ Usage を表示
-
-
戻り値 0
正常終了
0以外
異常終了
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-
実行例 クラスタ起動同期待ち処理をキャンセルする場合
# clpbwctrl -c Command succeeded.
クラスタ起動時にネットワークパーティション解決処理を行わない場合
# clpbwctrl --np off Command succeeded. # clpbwctrl --np Resolve network partition on startup : off
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
コマンドラインオプションが不正です。正しいオプションを指定してください。
Cluster service has already been started.
すでにクラスタは起動しています。起動同期待ち状態ではありません。
The cluster is not waiting for synchronization.
起動同期待ち処理中ではありませんでした。クラスタサービスが停止している等の原因が考えられます。
Command Timeout.
コマンドの実行がタイムアウトしました。
Internal error.
内部エラーが発生しました。
9.23. プロセスの健全性を確認する (clphealthchk コマンド)¶
プロセスの健全性を確認します。
-
コマンドライン clphealthchk [ -t pm | -t rc | -t rm | -t nm | -h]
注釈
本コマンドは、単一サーバ上でプロセスの健全性を確認します。健全性を確認したいサーバ上で実行する必要があります。
-
説明 単一サーバ上でのプロセスの健全性を確認します。
-
オプション -
なし¶ pm/rc/rm/nm の健全性を確認します。
-
-t<process>¶ process
- pm
pm の健全性を確認します。
- rc
rc の健全性を確認します。
- rm
rm の健全性を確認します。
- nm
nm の健全性を確認します。
-
-h¶ Usageを出力します。
-
-
戻り値 0
正常終了
1
実行権限不正
2
二重起動
3
初期化エラー
4
オプション不正
10
プロセスストール監視機能未設定
11
クラスタ未起動状態(クラスタ起動待ち合わせ中、クラスタ停止処理中を含む)
12
クラスタサスペンド状態
100
健全性情報が一定時間更新されていないプロセスが存在する
-t オプション指定時は、指定プロセスの健全性情報が一定時間更新されていない
255
その他内部エラー
-
実行例 例1: 健全な場合
# clphealthchk pm OK rc OK rm OK nm OK
例2: clprc: がストールしている場合
# clphealthchk pm OK rc NG rm OK nm OK
# clphealthchk -t rc rc NG
例3: クラスタが停止している場合
# clphealthchk The cluster has been stopped
-
備考 クラスタが停止している場合や、サスペンドしている場合にはプロセスは停止しています。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Invalid option.
正しいオプションを指定してください。
The function of process stall monitor is disabled.
プロセスストール監視機能が有効ではありません。
The function of process stall monitor is disabled.
クラスタは停止状態です。
The cluster has been suspended.
クラスタはサスペンド状態です。
This command is already run.
コマンドは既に実行されています。ps コマンドなどで実行状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
9.24. DB2 の静止点を制御する (clpdb2still コマンド)¶
DB2の静止点の制御を行います。
-
コマンドライン - clpdb2still -d databasename -u username -sclpdb2still -d databasename -u username -r
-
説明 DB2の静止点の確保/解放を制御します。
-
オプション -
-ddatabasename¶ 静止点制御の対象となるデータベース名を指定します。
-
-uusername¶ 静止点制御を実行するユーザ名を指定します。
-
-s¶ 静止点の確保を行います。
-
-r¶ 静止点の解放を行います。
-
-
戻り値 0
正常終了
2
コマンドオプション不正
5
静止点確保失敗
6
静止点解放失敗
-
実行例 # clpdb2still -d sample -u db2inst1 -s データベース接続情報 データベース・サーバー = DB2/LINUXX8664 11.1.0 SQL 許可 ID = DB2INST1 ローカル・データベース別名 = SAMPLE DB20000I SET WRITE コマンドが正常に完了しました。 DB20000I SQL コマンドが正常に完了しました。 DB20000I SQL DISCONNECT コマンドが正常に完了しました。
# clpdb2still -d sample -u db2inst1 -r データベース接続情報 データベース・サーバー = DB2/LINUXX8664 11.1.0 SQL 許可 ID = DB2INST1 ローカル・データベース別名 = SAMPLE DB20000I SET WRITE コマンドが正常に完了しました。 DB20000I SQL コマンドが正常に完了しました。 DB20000I SQL DISCONNECT コマンドが正常に完了しました。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-u オプションに指定するユーザには、DB2のSET WRITEコマンドを実行できる権限が必要です。
-
エラーメッセージ メッセージ
原因/対処
invalid database name
データーベース名が不正です。データーベース名を確認してください。
invalid user name
ユーザ名が不正です。ユーザ名を確認してください。
missing database name
データーベース名が指定されていません。データーベース名を指定してください。
missing user name
ユーザ名が指定されていません。ユーザ名を指定してください。
missing operation '-s' or '-r'
静止点の確保/解放が指定されていません。静止点の確保または解放のいずれかを指定してください。
suspend command return code = n
静止点確保で失敗しました。直前に su コマンドのエラーメッセージが出力されている場合は、ユーザ名とパスワードを確認してください。また、db2 コマンドのエラーメッセージが出力されている場合は、エラー内容に応じた対処をしてください。resume command return code = n
静止点解放で失敗しました。直前に su コマンドのエラーメッセージが出力されている場合は、ユーザ名とパスワードを確認してください。db2 コマンドのエラーメッセージが出力されている場合は、エラー内容に応じた対処をしてください。
9.25. MySQL の静止点を制御する (clpmysqlstill コマンド)¶
MySQLの静止点の制御を行います。
-
コマンドライン - clpmysqlstill -d databasename [-u username] -sclmypsqlstill -d databasename -r
-
説明 MySQLの静止点の確保/解放を制御します。
-
オプション -
-ddatabasename¶ 静止点制御の対象となるデータベース名を指定します。
-
-uusername¶ 静止点制御を実行するデーターベースユーザ名を指定します。-s オプションを指定した場合のみ指定可能です。省略した場合はデフォルトユーザとしてrootが設定されます。
-
-s¶ 静止点の確保を行います。
-
-r¶ 静止点の解放を行います。
-
-
戻り値 0
正常終了
2
コマンドオプション不正
3
DB接続エラー
4
-u オプションに指定したユーザの認証エラー
5
静止点確保失敗
6
静止点解放失敗
99
内部エラー
-
実行例 # clpmysqlstill -d mysql -u root -s Command succeeded.
# clpmysqlstill -d mysql -r Command succeeded.
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。また環境変数LD_LIBRARY_PATHにMySQLのクライアントライブラリlibmysqlclient.soの存在するディレクトリを設定してください。
-u オプションに指定するユーザのパスワードは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ユーザ名:パスワード:」の形式で設定してください。行の最後にはコロン「:」を付けてください。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
パスワード設定の例: root:password:
-u オプションに指定するユーザにはMySQLの FLUSH TABLES WITH READ LOCKステートメントを実行できる権限が必要です。
-s オプションで静止点確保コマンドを実行して静止点確保に成功した場合、その静止点確保コマンドは常駐したまま制御を戻しません。別プロセスにて -r オプションで静止点開放コマンドを実行することにより、常駐していた静止点確保コマンドが終了して制御が戻ります。
-
エラーメッセージ メッセージ
原因/対処
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Cannot connect to database.
データーベースに接続できません。データーベース名及びデータベースの状態を確認してください。
Username or password is not correct.
ユーザ認証で失敗しました。ユーザ名及びパスワード確認してください。
Suspend database failed.
静止点確保で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Resume database failed.
静止点解放で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Internal error.
内部エラーが発生しました。
9.26. Oracle の静止点を制御する (clporclstill コマンド)¶
Oracleの静止点の制御を行います。
-
コマンドライン - clporclstill -d connectionstring [-u username] -sclporclstill -d connectionstring -r
-
説明 Oracleの静止点の確保/解放を制御します。
-
オプション -
-dconnectionstring¶ 静止点制御の対象となるデータベースへの接続文字列を指定します。
-
-uusername¶ 静止点制御を実行するデーターベースユーザ名を指定します。-s オプションを指定した場合のみ指定可能です。省略した場合はOS認証が使用されます。
-
-s¶ 静止点の確保を行います。
-
-r¶ 静止点の解放を行います。
-
-
戻り値 0
正常終了
2
コマンドオプション不正
3
DB接続エラー
4
ユーザ認証エラー
5
静止点確保失敗
6
静止点解放失敗
99
内部エラー
-
実行例 # clporclstill -d orcl -u oracle -s Command succeeded.
# clporclstill -d orcl -r Command succeeded.
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。また環境変数LD_LIBRARY_PATHにOracleのクライアントライブラリlibclntsh.soの存在するディレクトリを設定してください。さらに環境変数ORACLE_HOMEにOracleのホームディレクトリを設定してください。
-u オプションを指定せずOS認証を使用する場合、本コマンドを実行するユーザはOracleの管理者権限を得るためにdbaグループに所属している必要があります。
-u オプションに指定するユーザのパスワードは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ユーザ名:パスワード:」の形式で設定してください。行の最後にはコロン「:」を付けてください。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
パスワード設定の例: oracle:password:
-u オプションに指定するユーザにはOracleの管理者権限が必要です。
-s オプションで静止点確保コマンドを実行して静止点確保に成功した場合、その静止点確保コマンドは常駐したまま制御を戻しません。別プロセスにて -r オプションで静止点開放コマンドを実行することにより、常駐していた静止点確保コマンドが終了して制御が戻ります。
本コマンドを実行する場合、事前にOracleをARCHIVELOGモードに設定しておく必要があります。
本コマンドを使用して静止点確保を行った状態で取得したOracleのデータファイルはバックアップモードになっています。データファイルをリストアして利用する場合はOracle上でバックアップモードを解除する必要があります。
-
エラーメッセージ メッセージ
原因/対処
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Cannot connect to database.
データーベースに接続できません。データーベース名及びデータベースの状態を確認してください。
Username or password is not correct.
ユーザ認証で失敗しました。ユーザ名及びパスワード確認してください。
Suspend database failed.
静止点確保で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Resume database failed.
静止点解放で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Internal error.
内部エラーが発生しました。
9.27. PostgreSQL の静止点を制御する (clppsqlstill コマンド)¶
PostgreSQLの静止点の制御を行います。
-
コマンドライン - clppsqlstill -d databasename -u username -sclppsqlstill -d databasename -r
-
説明 PostgreSQLの静止点の確保/解放を制御します。
-
オプション -
-ddatabasename¶ 静止点制御の対象となるデータベース名を指定します。
-
-uusername¶ 静止点制御を実行するデーターベースユーザ名を指定します。
-
-s¶ 静止点の確保を行います。
-
-r¶ 静止点の解放を行います。
-
-
戻り値 0
正常終了
2
コマンドオプション不正
3
DB接続エラー
4
-u オプションに指定したユーザの認証エラー
5
静止点確保失敗
6
静止点解放失敗
99
内部エラー
-
実行例 # clppsqlstill -d postgres -u postgres -s Command succeeded.
# clppsqlstill -d postgres -r Command succeeded.
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。また、環境変数LD_LIBRARY_PATHにPostgreSQLのクライアントライブラリlibpq.soの存在するディレクトリを設定してください。PostgreSQLに接続するポート番号がデフォルトの5432と異なる場合は環境変数PQPORTにポート番号を設定してください。
-u オプションに指定するユーザのパスワードは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ユーザ名:パスワード:」の形式で設定してください。行の最後にはコロン「:」を付けてください。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
パスワード設定の例: postgres:password:
-u オプションに指定するユーザにはPostgreSQLのスーパーユーザ権限が必要です。
本コマンドを実行する場合、事前にPostgreSQLのWALアーカイブを有効にしておく必要があります。
-s オプションで静止点確保コマンドを実行して静止点確保に成功した場合、その静止点確保コマンドは常駐したまま制御を戻しません。別プロセスにて -r オプションで静止点開放コマンドを実行することにより、常駐していた静止点確保コマンドが終了して制御が戻ります。
-
エラーメッセージ メッセージ
原因/対処
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Cannot connect to database.
データーベースに接続できません。データーベース名及びデータベースの状態を確認してください。
Username or password is not correct.
ユーザ認証で失敗しました。ユーザ名及びパスワード確認してください。
Suspend database failed.
静止点確保で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Resume database failed.
静止点解放で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Internal error.
内部エラーが発生しました。
9.28. SQL Server の静止点を制御する (clpmssqlstill コマンド)¶
SQL Serverの静止点の制御を行います。
-
コマンドライン - clpmssqlstill -d databasename -u username -v vdiusername -sclpmssqlstill -d databasename -v vdiusername -r
-
説明 SQL Serverの静止点の確保/解放を制御します。
-
オプション -
-ddatabasename¶ 静止点制御の対象となるデータベース名を指定します。
-
-uusername¶ 静止点制御を実行するデーターベースユーザ名を指定します。
-
-vvdiusername¶ vdiを実行するOSユーザ名を指定します。
-
-s¶ 静止点の確保を行います。
-
-r¶ 静止点の解放を行います。
-
-
戻り値 0
正常終了
2
コマンドオプション不正
3
DB接続エラー
4
-u オプションに指定したユーザの認証エラー
5
静止点確保失敗
6
静止点解放失敗
7
タイムアウトエラー
99
内部エラー
-
実行例
実行例
# clpmssqlstill -d userdb -u sa -v mssql -s Command succeeded.# clpmssqlstill -d userdb -v mssql -r Command succeeded.
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。また環境変数LD_LIBRARY_PATHにSQL ServerのVDIクライアントライブラリlibsqlvdi.soの存在するディレクトリとODBCライブラリlibodbc.soの存在するディレクトリを設定してください。
-u オプションに指定するユーザのパスワードは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ユーザ名:パスワード:」の形式で設定してください。行の最後にはコロン「:」を付けてください。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
パスワード設定の例: sa:password:
-u オプションに指定するユーザにはSQL ServerのBACKUP DATABASEステートメントを実行できる権限が必要です。
-v オプションに指定するOSユーザには、VDIクライアントの実行権限が必要です。
本コマンドのタイムアウトは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「タイムアウト名:秒数:」の形式で設定してください。行の最後にはコロン「:」を付けてください。設定しない場合は下記の例に記載の値が既定値として使用されます。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
タイムアウト(GetConfiguration)設定の例:cfgtimeout:1:
タイムアウト(GetCommand)設定の例:cmdtimeout:90:
タイムアウト(SQL)設定の例:sqltimeout:60:
データベース操作で使用するODBCドライバは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ODBCドライバ:使用するODBCドライバ名:」の形式で設定してください。行の最後にはコロン「:」を付けてください。設定しない場合は下記の例に記載の値が既定値として使用されます。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
ODBCドライバの例:odbcdriver:ODBC Driver 13 for SQL Server:
-s オプションで静止点確保コマンドを実行して静止点確保に成功した場合、その静止点確保コマンドは常駐したまま制御を戻しません。別プロセスにて -r オプションで静止点開放コマンドを実行することにより、常駐していた静止点確保コマンドが終了して制御が戻ります。
-
エラーメッセージ メッセージ
原因/対処
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Cannot connect to database.
データーベースに接続できません。データーベース名及びデータベースの状態を確認してください。
Username or password is not correct.
ユーザ認証で失敗しました。ユーザ名及びパスワード確認してください。
Suspend database failed.
静止点確保で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Resume database failed.
静止点解放で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Timeout.
コマンドがタイムアウトしました。
Internal error.
内部エラーが発生しました。
9.29. クラスタ統計情報を表示する(clpperfc コマンド)¶
クラスタ統計情報を表示します。
-
コマンドライン - clpperfc --starttime -g group_nameclpperfc --stoptime -g group_nameclpperfc -g [group_name]clpperfc -m monitor_name
-
説明 グループの起動、停止時間の中央値(ミリ秒)を表示します。
モニタリソースの監視処理時間(ミリ秒)を表示します。
-
オプション -
--starttime-g group_name¶ グループの起動時間の中央値を表示します。
-
--stoptime-g group_name¶ グループの停止時間の中央値を表示します。
-
-g[group_name]¶ グループの起動、停止時間の中央値を表示します。
groupnameを省略した場合は、全グループの起動、停止時間の中央値を表示します。
-
-mmonitor_name¶ 直近のモニタリソースの監視処理時間を表示します。
-
-
戻り値 0
正常終了
1
コマンドオプション不正
2
ユーザ認証エラー
3
構成情報ロードエラー
4
構成情報ロードエラー
5
初期化エラー
6
内部エラー
7
内部通信初期化エラー
8
内部通信接続エラー
9
内部通信処理エラー
10
対象グループチェックエラー
12
タイムアウトエラー
-
実行例 グループの起動時間の中央値を表示する場合
# clpperfc --starttime -g failover1 200
特定グループの起動、停止時間の中央値を表示する場合
# clpperfc -g failover1 start time stop time failover1 200 150モニタリソースの監視処理時間を表示する場合
# clpperfc -m monitor1 100
-
備考 本コマンドで出力する時間の単位はミリ秒です。
有効なグループの起動時間、停止時間が取得できなかった場合は - が表示されます。
有効なモニタリソースの監視時間が取得できなかった場合は 0 が表示されます。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Command timeout.
コマンドの実行がタイムアウトしました。
Internal error.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
9.30. クラスタ構成情報をチェックする (clpcfchk コマンド)¶
クラスタ構成情報をチェックします。
-
コマンドライン - clpcfchk -o path [-i conf_path]
-
説明 クラスタ構成情報を基に設定値の妥当性を確認します。
-
オプション -
-opath¶ チェック結果を保存するディレクトリを指定します。
-
-iconf_path¶ チェックする構成情報を保存したディレクトリを指定します。
省略した場合は、反映済みの構成情報をチェックします。
-
-
戻り値 0
正常終了
0以外
エラー終了
-
実行例 反映済みの構成情報をチェックする場合
# clpcfchk -o /tmp server1 : PASS server2 : PASS
保存した構成情報をチェックする場合
# clpcfchk -o /tmp -i /tmp/config server1 : PASS server2 : FAIL
-
実行結果 本コマンドの結果で表示されるチェック結果 (総合結果)は以下になります。
チェック結果(総合結果)
説明
PASS
問題がありません。
FAIL
問題があります。チェック結果を確認してください。
-
備考 各サーバの総合結果のみを表示します。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
Cluster WebUI でエクスポートした構成情報をチェックする場合、事前に解凍してください。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
Could not opened the configuration file. Check if the configuration file exists on the specified path.
指定されたパスが存在しません。正しいパスを指定してください。
Server is busy. Check if this command is already run.
本コマンドはすでに起動されています。
Failed to obtain properties.
プロパティの取得に失敗しました。
Failed to check validation.
クラスタ構成チェックに失敗しました。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
9.31. クラスタ構成情報ファイルを変換する (clpcfconv.sh コマンド)¶
クラスタ構成情報ファイルの変換を行います。
-
コマンドライン - clpcfconv.sh -i <input-path> [-o <output-path>]
-
説明 クラスタ構成情報ファイルを旧バージョンから現バージョンへ変換します。
-
オプション -
-i<input-path>¶ 旧バージョンの構成情報ファイルが存在するディレクトリを指定します。
-
-o<output-path>¶ - 変換後の構成情報ファイルを出力するディレクトリを指定します。本オプションを省略した場合、カレントディレクトリに変換後の構成情報ファイルが出力されます。
-
-
戻り値 0
正常終了
0以外
異常終了
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
本コマンドは、クラスタ構成情報ファイルのうち、clp.conf のみを変換します。
本コマンドは、<インストール先ディレクトリ>/etc 直下では実行できません。
本コマンドは、CLUSTERPRO X 3.3 for Linux(内部バージョン 3.3.5-1)より古いバージョンで作成したクラスタ構成情報ファイルには対応していません。
CLUSTERPRO X 5.0 for Linux より古いバージョンでクラスタパスワード方式のパスワードを設定していた場合、本コマンドでクラスタ構成情報ファイルを変換するとパスワードがクリアされます。変換後のクラスタ構成情報を反映後、Cluster WebUI を使用してパスワードを再設定してください。
-
実行例 変換が成功した場合
# clpcfconv.sh -i /tmp/config_x430 -o /tmp/config_new Command succeeded.
変換が成功し、パスワードがクリアされた場合
# clpcfconv.sh -i /tmp/config_x430 -o /tmp/config_new Command succeeded. Password for Operation has been initialized. Password for Reference has been initialized. Please set the password again by using Cluster WebUI.
-
エラーメッセージ メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Password for Operation has been initialized.
クラスタパスワード方式の操作用パスワードをクリアしました。
Password for Reference has been initialized.
クラスタパスワード方式の参照用パスワードをクリアしました。
Please set the password again by using Cluster WebUI.
Cluster WebUI を使用してクリアされたパスワードを再設定してください。
Log in as root.
root 権限を持つユーザで実行してください。
Not available in this directory.
<インストール先ディレクトリ>/etc 直下では実行できません。カレントディレクトリを <インストール先ディレクトリ>/etc 以外に変更してください。Could not opened the configuration file. Check if the configuration file exists on the specified path.
-i オプションで指定したパスにクラスタ構成情報ファイル(clp.conf)が存在しません。クラスタ構成情報ファイルが指定されたパスに存在するか確認してください。The specified output-path does not exist.
-o オプションで指定したパスが存在しません。正しいパスを指定してください。Invalid configuration file.
クラスタ構成情報ファイルが不正です。クラスタ構成情報ファイルを確認してください。The version of this configuration data file is not supported. Convert it with Builder for offline use (internal version 3.3.5-1), then retry.
本コマンドがサポートしていないバージョンのクラスタ構成情報ファイルです。内部バージョン 3.3.5-1 のオフライン版 Builder で変換後、もう一度実行してください。%1 : Command failed. code:%2
コマンド %1 が失敗しました。コマンドの戻り値(%2)、または、このエラーメッセージの直前に表示されたエラーメッセージを確認してください。Command failed.
このコマンドが失敗しました。このエラーメッセージの直前に表示されたエラーメッセージを確認してください。
9.32. クラスタ構成情報ファイルを生成する (clpcfset, clpcfadm.py コマンド)¶
9.32.1. clpcfset コマンド¶
クラスタ構成情報ファイルの生成を行います。
-
コマンドライン - clpcfset {create|--create} clustername charset [encode] [serveros]clpcfset {add|--add} clsparam tagname parameterclpcfset {add|--add} srv servername priorityclpcfset {add|--add} device servername type id info [extend]clpcfset {add|--add} forcestop envclpcfset {add|--add} hb lankhb deviceid priorityclpcfset {add|--add} hb lanhb deviceid priorityclpcfset {add|--add} hb diskhb deviceid priorityclpcfset {add|--add} hb witnesshb deviceid priority hostclpcfset {add|--add} np pingnp deviceid priority groupid listid ipadressclpcfset {add|--add} np httpnp deviceid priority [host]clpcfset {add|--add} grp grouptype groupnameclpcfset {add|--add} grpparam groupname tagname parameterclpcfset {add|--add} rsc groupname resourcetype resourcenameclpcfset {add|--add} rscparam resourcetype resourcename tagname parameterclpcfset {add|--add} rscdep resourcetype resourcename dependresourcenameclpcfset {add|--add} mon monitortype resourcenameclpcfset {add|--add} monparam monitortype resourcename tagname parameterclpcfset {del|--del} clsparam tagnameclpcfset {del|--del} srv servernameclpcfset {del|--del} device servername idclpcfset {del|--del} forcestopclpcfset {del|--del} hb lankhb deviceidclpcfset {del|--del} hb lanhb deviceidclpcfset {del|--del} hb diskhb deviceidclpcfset {del|--del} hb witnesshb deviceidclpcfset {del|--del} np pingnp deviceidclpcfset {del|--del} np httpnp deviceidclpcfset {del|--del} grp groupnameclpcfset {del|--del} grpparam groupname tagnameclpcfset {del|--del} rsc groupname resourcetype resourcenameclpcfset {del|--del} rscparam resourcetype resourcename tagnameclpcfset {del|--del} rscdep resourcetype resourcename [dependresourcename]clpcfset {del|--del} mon monitortype resourcenameclpcfset {del|--del} monparam monitortype resourcename tagname
-
説明 本製品のクラスタ構成情報を生成しファイルに出力します。
-
オプション -
{create|--create}clustername charset [encode] [serveros]¶ クラスタ名、エンコードを指定して新規クラスタを作成します。
clusternameにはクラスタ名、charsetはCLUSTERPROの言語に応じて、日本語ならEUC-JP、英語ならASCII、中国語ならGB2312を指定します。
encodeはWebUIで構成情報を作成した場合に、WebUIが動作するサーバのOSとCLUSTERPROの言語により決定されるパラメータです。省略した場合は、charsetと同様の設定となります。
OSがWindowsの場合: SJIS
OSがLinuxかつ日本語の場合: EUC-JP
OSがLinuxかつ英語の場合: ASCII
OSがLinuxかつ中国語の場合: GB2312
serverosはWindows環境のクラスタ構成情報を作成する場合に"windows"を指定します。省略した場合は"linux"が設定されます。Windows環境のクラスタ構成情報を作成する場合は「 CLUSTERPRO X for Windows リファレンスガイド 」を参照してください。
-
{add|--add}<param>¶ param
- clsparam tagname parameter
- クラスタのプロパティをタグ名とパラメータを指定して設定します。tagname、parameterは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
- srv servername priority
- サーバ名、優先順位を指定してサーバを追加します。servernameにはサーバ名を指定します。priorityはマスタサーバが0になります。以降は1ずつインクリメントします。
- device servername type id info [extend]
- サーバ名、種別を指定してデバイスを追加します。typeはlan, mdc, disk, witness, ping, httpの中から指定します。idはtype毎に0から指定します。以降は 1 ずつインクリメントします。lan, mdcはinfoにIPアドレスを指定します。diskはinfoにデバイスのパスを指定します。witnessはinfoに使用しない:0/使用する:1、extendに接続先のWitnessサーバのホストアドレスとポート(アドレス:ポート)を指定します。ping, httpはinfoに使用しない:0/使用する:1を指定します。
- forcestop env
- 環境種別を指定して強制停止リソースを追加します。envはbmc, vcenter, aws, ociまたはcustomのいずれかを指定します。
- hb lankhb deviceid priority
- デバイスID、優先順位を指定してカーネルモードLANハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は 1 ずつインクリメントします。
- hb lanhb deviceid priority
- デバイスID、優先順位を指定してユーザモードLANハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は 1 ずつインクリメントします。
- hb diskhb deviceid priority
- デバイスID、優先順位を指定してディスクハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は 1 ずつインクリメントします。
- hb witnesshb deviceid priority host
- デバイスID、優先順位、ターゲットホストを指定してWitnessハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は1ずつインクリメントします。hostは接続先のWitnessサーバのホストアドレスとポート(アドレス:ポート)を指定します。
- np pingnp deviceid priority groupid listid ipadress
- 優先順位、デバイスID、グループID、リストID、IPアドレスを指定してPING方式によるネットワークパーティション解決リソースを追加します。deviceidはadd deviceで指定したIDを指定します。priority、groupid、listidは0から指定します。以降は1ずつインクリメントします。ipadressはNP解決リソースで用いるIPアドレスを指定します。
- np httpnp priority deviceid [host]
- デバイスID、優先順位、ターゲットホストを指定してHTTP方式によるネットワークパーティション解決リソースを追加します。deviceidはadd deviceで指定したIDを指定します。NP解決リソースのpriorityは0から指定します。以降は1ずつインクリメントします。[host]は接続先のWitnessサーバのホストアドレスとポート(アドレス:ポート)を指定します。[host]を省略した場合は、Witness HBリソースの設定を使用します。
- grp grouptype groupname
- グループタイプ、グループ名を指定してグループを追加します。grouptypeはfailoverまたはManagementGroupを指定します。
- grpparam groupname tagname parameter
- グループのプロパティをグループ名、タグ名とパラメータを指定して設定します。tagname、parameterは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
- rsc groupname resourcetype resourcename
- グループ名、グループリソースタイプ、グループリソース名を指定してグループリソースを追加します。
- rscparam resourcetype resourcename tagname paramter
- グループリソースのプロパティをグループリソースタイプ、グループリソース名、タグ名とパラメータを指定して設定します。tagname、parameterは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
- rscdep resourcetype resourcename dependresourcename
- グループリソース名を指定してグループリソースの依存関係を追加します。resourcetype、resourcenameにグループリソースタイプとグループリソース名を設定し、dependresourcenameに依存するグループリソース名を指定します。グループリソースに依存関係を設定した場合、活性時はdependresourcenameの活性化が完了してから、resourcenameに指定したグループリソースの活性化が開始されます。非活性時はresourcenameに指定したグループリソースの非活性化が完了してから、dependresourcenameの非活性化が開始されます。例として該当グループに所属するグループリソースの依存する深度を一覧で表示します。


図 9.7 活性順序¶

図 9.8 非活性順序¶
- mon monitortype monitorresource
- モニタリソースタイプ、モニタリソース名を指定してモニタリソースを追加します。
- monparam monitortype monitorresource tagname paramter
- モニタリソースのプロパティをモニタリソースタイプ、モニタリソース名、タグ名とパラメータを指定して設定します。tagname、parameterは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
-
{del|--del}<param>¶ param
- clsparam tagname
- クラスタのプロパティをタグ名を指定して削除します。tagnameは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
- srv servername
- サーバ名を指定してサーバを削除します。
- device servername id
- サーバ名、デバイスIDを指定してデバイスを削除します。8
- forcestop
- 強制停止リソースを削除します。
- hb lankhb deviceid
- デバイスIDを指定してカーネルモードLANハートビートを削除します。8
- hb lanhb deviceid
- デバイスIDを指定してユーザモードLANハートビートを削除します。8
- hb diskhb deviceid
- デバイスIDを指定してディスクハートビートを削除します。8
- hb witnesshb deviceid
- デバイスIDを指定してWitnessハートビートを削除します。8
- np pingnp deviceid
- デバイスIDを指定してPING方式によるネットワークパーティション解決リソースを削除します。8
- np httpnp deviceid
- デバイスIDを指定してHTTP方式によるネットワークパーティション解決リソースを削除します。8
- grp groupname
- グループ名を指定してグループを削除します。
- grpparam groupname tagname
- グループのプロパティをグループ名、タグ名を指定して削除します。tagnameは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
- rsc groupname resourcetype resourcename
- グループ名、グループリソースタイプ、グループリソース名を指定してリソースを削除します。
- rscparam resourcetype resourcename tagname
- グループリソースのプロパティをグループリソースタイプ、グループリソース名、タグ名を指定して削除します。tagnameは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
- rscdep resourcetype resourcename [dependresourcename]
- グループリソースタイプ、グループリソース名、依存するグループリソース名を指定してグループリソースの依存関係を削除します。resourcetype、resourcenameにグループリソースタイプとグループリソース名を設定し、dependresourcenameに依存するグループリソース名を指定します。dependresourcenameを省略した場合は、全ての依存関係を削除し既定の依存関係に変更します。
- mon monitortype monitorresource
- モニタリソースタイプ、モニタリソース名を指定してモニタリソースを削除します。
- monparam monitortype monitorresource tagname
- モニタリソースのプロパティをモニタリソースタイプ、モニタリソース名、タグ名を指定して削除します。tagnameは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
-
-
戻り値 0
成功
0 以外
異常
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
各パラメータに入力可能な文字列や禁則文字列については、『本ガイドの各章』を参照してください。
本コマンドはクラスタ構成情報ファイルのうち、clp.confのみを作成します。EXECリソース、カスタムモニタリソースなどで使用するスクリプトファイルについては手動で作成する必要があります。
カレントディレクトリにクラスタ構成情報ファイル(clp.conf)を配置した状態で本コマンドを実行してください。
- 例
フェイルオーバグループ failover1 に所属するEXECリソース exec1、および カスタムモニタリソース genw1 のスクリプトを配置する場合。
scripts ├─failover1 │ └─exec1 │ start.sh │ stop.sh │ └─monitor.s └─genw1 genw.sh
本コマンドで作成したclp.confを整形するにはxmllintを利用してください。環境によってxmllintをインストールする必要があります。
XML文章を整形し、ファイルに出力する場合の使用例は以下になります。
xmllint --format --output <整形後clp.confのファイルパス> <整形前clp.confのファイルパス>
-
実行例 クラスタ追加
# clpcfset create cluster EUC-JP SJIS
# clpcfset create cluster SJIS windows
クラスタプロパティの追加・変更
# clpcfset add clsparam pm/exec0/recover 7 # clpcfset add clsparam pm/exec1/recover 7 # clpcfset add clsparam pm/exec2/recover 7
クラスタプロパティの削除
# clpcfset del clsparam pm/exec0/recover # clpcfset del clsparam pm/exec1/recover # clpcfset del clsparam pm/exec2/recover
サーバの追加
# clpcfset add srv server1 0
サーバの削除
# clpcfset del srv server1
カーネルモードLANハートビートの追加
# clpcfset add device server1 lan 0 192.168.137.71 # clpcfset add hb lankhb 0 0
カーネルモードLANハートビートの削除
# clpcfset del device server1 0 # clpcfset del hb lankhb 0
ユーザモードLANハートビートの追加
# clpcfset add device server1 lan 0 192.168.138.71 # clpcfset add hb lanhb 0 1
ユーザモードLANハートビートの削除
# clpcfset del device server1 0 # clpcfset del hb lanhb 0
ディスクハートビートの追加
# clpcfset add device server1 disk 0 /dev/sdc1 # clpcfset add hb diskhb 0 2
ディスクハートビートの削除
# clpcfset del device server1 300 # clpcfset del hb diskhb 300
Witnessハートビートの追加
# clpcfset add device server1 witness 0 1 192.168.2.1:49152 # clpcfset add hb witnesshb 0 3 192.168.2.1:49152
Witnessハートビートの削除
# clpcfset del device server1 700 # clpcfset del hb witnesshb 700
PNG方式によるネットワークパーティション解決リソースの追加
# clpcfset add device server1 ping 0 1 # clpcfset add np pingnp 0 1 0 0 192.168.1.1
PNG方式によるネットワークパーティション解決リソースの削除
# clpcfset del device server1 10200 # clpcfset del np pingnp 10200
HTTP方式によるネットワークパーティション解決リソースの追加
Witness HBリソースの設定を使用する場合
# clpcfset add device server1 http 0 1 # clpcfset add np httpnp 0 2
HTTP方式によるネットワークパーティション解決リソースの追加
Witness HBリソースの設定を使用しない場合
# clpcfset add device server1 http 0 1 # clpcfset add np httpnp 0 2 192.168.2.2:49152
HTTP方式によるネットワークパーティション解決リソースの削除
# clpcfset del device server1 10700 # clpcfset del np httpnp 10700
強制停止リソースの追加(bmcの場合)
# clpcfset add forcestop bmc
強制停止リソースの削除
# clpcfset del forcestop
グループの追加
# clpcfset add grp failover failover1
グループプロパティの追加・変更
# clpcfset add grpparam failover1 policy@server1/order 0 # clpcfset add grpparam failover1 policy@server2/order 1
グループプロパティの削除
# clpcfset del grpparam failover1 policy@server1/order # clpcfset del grpparam failover1 policy@server2/order
グループの削除
# clpcfset del grp failover1
グループリソースの追加
# clpcfset add rsc failover1 fip fip1
グループリソースプロパティの追加・変更
# clpcfset add rscparam fip fip1 parameters/ip 192.168.137.171
グループリソースプロパティの削除
# clpcfset del rscparam fip fip1 parameters/ip
グループリソースの削除
# clpcfset del rsc failover1 fip fip1
グループリソースの依存関係の追加
# clpcfset add rscdep fip fip1 ddns1
グループリソースの依存関係の削除
個別の依存関係を削除する場合
# clpcfset del rscdep fip fip1 ddns1
グループリソースの依存関係の削除
全ての依存関係を削除し既定の依存関係に戻す場合
# clpcfset del rscdep fip fip1
モニタリソースの追加
# clpcfset add mon fipw fipw1
モニタリソースプロパティの追加・変更
# clpcfset add monparam fipw fipw1 target fip1
モニタリソースプロパティの削除
# clpcfset del monparam fipw fipw1 target
モニタリソースの削除
# clpcfset del mon fipw fipw1
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
Invalid configuration file. Use the create option.
本コマンドのcreateオプションを実行してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Parameter length error.
コマンドの引数に指定した文字列が長すぎます。
Specify a number in a valid range.
正しい範囲で数字を指定してください。
The specified path does not exist.
正しいパスを指定してください。
Failed to save the configuration file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
9.32.2. clpcfadm.py コマンド¶
-
コマンドライン - clpcfadm.py {create} clustername charset [-e encode] [-s serveros]clpcfadm.py {add} srv servername priorityclpcfadm.py {add} device servername type id info [extend]clpcfadm.py {add} forcestop envclpcfadm.py {add} hb lankhb deviceid priorityclpcfadm.py {add} hb lanhb deviceid priorityclpcfadm.py {add} hb diskhb deviceid priorityclpcfadm.py {add} hb witnesshb deviceid priority hostclpcfadm.py {add} np pingnp deviceid priority groupid listid ipadressclpcfadm.py {add} np httpnp deviceid priority [--host host]clpcfadm.py {add} grp grouptype groupnameclpcfadm.py {add} rsc groupname resourcetype resourcenameclpcfadm.py {add} rscdep resourcetype resourcename dependresourcenameclpcfadm.py {add} mon monitortype resourcenameclpcfadm.py {del} srv servernameclpcfadm.py {del} device servername idclpcfadm.py {del} forcestopclpcfadm.py {del} hb lankhb deviceidclpcfadm.py {del} hb lanhb deviceidclpcfadm.py {del} hb diskhb deviceidclpcfadm.py {del} hb witnesshb deviceidclpcfadm.py {del} np pingnp deviceidclpcfadm.py {del} np httpnp deviceidclpcfadm.py {del} grp groupnameclpcfadm.py {del} rsc groupname resourcetype resourcenameclpcfadm.py {del} rscdep resourcetype resourcenameclpcfadm.py {del} mon monitortype resourcenameclpcfadm.py {mod} -t [tagname] [--set parameter] [--delete] [--nocheck]
-
説明 本製品のクラスタ構成情報を生成しファイルに出力します。
コマンドラインに指定可能なタグ名一覧を表示します。
-
オプション -
{create|--create}clustername charset [-e encode] [-s serveros]¶ クラスタ名、エンコードを指定して新規クラスタを作成します。
clusternameにはクラスタ名、charsetはCLUSTERPROの言語に応じて、日本語ならEUC-JP、英語ならASCII、中国語ならGB2312を指定します。
encodeはWebUIで構成情報を作成した場合に、WebUIが動作するサーバのOSとCLUSTERPROの言語により決定されるパラメータです。省略した場合は、charsetと同様の設定となります。
OSがWindowsの場合: SJIS
OSがLinuxかつ日本語の場合: EUC-JP
OSがLinuxかつ英語の場合: ASCII
OSがLinuxかつ中国語の場合: GB2312
serverosはWindows環境のクラスタ構成情報を作成する場合に"windows"を指定します。省略した場合は"linux"が設定されます。Windows環境のクラスタ構成情報を作成する場合は「 CLUSTERPRO X for Windows リファレンスガイド 」を参照してください。
-
{add|--add}<param>¶ param
- srv servername priority
- サーバ名、優先順位を指定してサーバを追加します。servernameにはサーバ名を指定します。priorityはマスタサーバが0になります。以降は1ずつインクリメントします。
- device servername type id info [extend]
- サーバ名、種別を指定してデバイスを追加します。typeはlan, mdc, disk, witness, ping, httpの中から指定します。idはtype毎に0から指定します。以降は 1 ずつインクリメントします。lan, mdcはinfoにIPアドレスを指定します。diskはinfoにデバイスのパスを指定します。witnessはinfoに使用しない:0/使用する:1、extendに接続先のWitnessサーバのホストアドレスとポート(アドレス:ポート)を指定します。ping, httpはinfoに使用しない:0/使用する:1を指定します。
- forcestop env
- 環境種別を指定して強制停止リソースを追加します。envはbmc, vcenter, aws, ociまたはcustomのいずれかを指定します。
- hb lankhb deviceid priority
- デバイスID、優先順位を指定してカーネルモードLANハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は 1 ずつインクリメントします。
- hb lanhb deviceid priority
- デバイスID、優先順位を指定してユーザモードLANハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は 1 ずつインクリメントします。
- hb diskhb deviceid priority
- デバイスID、優先順位を指定してディスクハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は 1 ずつインクリメントします。
- hb witnesshb deviceid priority host
- デバイスID、優先順位、ターゲットホストを指定してWitnessハートビートを追加します。deviceidはadd deviceで指定したIDを指定します。ハートビートのpriorityは0から指定します。以降は1ずつインクリメントします。hostは接続先のWitnessサーバのホストアドレスとポート(アドレス:ポート)を指定します。
- np pingnp deviceid priority groupid listid ipadress
- 優先順位、デバイスID、グループID、リストID、IPアドレスを指定してPING方式によるネットワークパーティション解決リソースを追加します。deviceidはadd deviceで指定したIDを指定します。priority、groupid、listidは0から指定します。以降は1ずつインクリメントします。ipadressはNP解決リソースで用いるIPアドレスを指定します。
- np httpnp priority deviceid [--host host]
- デバイスID、優先順位、ターゲットホストを指定してHTTP方式によるネットワークパーティション解決リソースを追加します。deviceidはadd deviceで指定したIDを指定します。NP解決リソースのpriorityは0から指定します。以降は1ずつインクリメントします。[host]は接続先のWitnessサーバのホストアドレスとポート(アドレス:ポート)を指定します。[host]を省略した場合は、Witness HBリソースの設定を使用します。
- grp grouptype groupname
- グループタイプ、グループ名を指定してグループを追加します。grouptypeはfailoverまたはManagementGroupを指定します。
- rsc groupname resourcetype resourcename
- グループ名、グループリソースタイプ、グループリソース名を指定してグループリソースを追加します。
- rscdep resourcetype resourcename dependresourcename
- グループリソース名を指定してグループリソースの依存関係を追加します。resourcetype、resourcenameにグループリソースタイプとグループリソース名を設定し、dependresourcenameに依存するグループリソース名を指定します。グループリソースに依存関係を設定した場合、活性時はdependresourcenameの活性化が完了してから、resourcenameに指定したグループリソースの活性化が開始されます。非活性時はresourcenameに指定したグループリソースの非活性化が完了してから、dependresourcenameの非活性化が開始されます。例として該当グループに所属するグループリソースの依存する深度を一覧で表示します。
図 9.9 活性順序¶
図 9.10 非活性順序¶
- mon monitortype monitorresource
- モニタリソースタイプ、モニタリソース名を指定してモニタリソースを追加します。
-
{del|--del}<param>¶ param
- srv servername
- サーバ名を指定してサーバを削除します。
- device servername id
- サーバ名、デバイスIDを指定してデバイスを削除します。9
- forcestop
- 強制停止リソースを削除します。
- hb lankhb deviceid
- デバイスIDを指定してカーネルモードLANハートビートを削除します。9
- hb lanhb deviceid
- デバイスIDを指定してユーザモードLANハートビートを削除します。9
- hb diskhb deviceid
- デバイスIDを指定してディスクハートビートを削除します。9
- hb witnesshb deviceid
- デバイスIDを指定してWitnessハートビートを削除します。9
- np pingnp deviceid
- デバイスIDを指定してPING方式によるネットワークパーティション解決リソースを削除します。9
- np httpnp deviceid
- デバイスIDを指定してHTTP方式によるネットワークパーティション解決リソースを削除します。9
- grp groupname
- グループ名を指定してグループを削除します。
- rsc groupname resourcetype resourcename
- グループ名、グループリソースタイプ、グループリソース名を指定してグループリソースを削除します。
- rscdep resourcetype resourcename
- グループリソースタイプ、グループリソース名を指定してグループリソースの全ての依存関係を削除し既定の依存関係に変更します。resourcetype、resourcenameにグループリソースタイプとグループリソース名を指定します。
- mon monitortype monitorresource
- モニタリソースタイプ、モニタリソース名を指定してモニタリソースを削除します。
-
{mod}-t [tagname] [--set param] [--delete] [--nocheck]¶ - -t [tagname]
- 必須オプションです。tagnameにはタグ名を指定してください。省略した場合はroot要素が指定されます。--setまたは、--deleteオプションが指定されなかった場合はtagnameの子要素を一覧表示します。--setを指定かつ子要素に存在しないtagnameを指定する場合は--nocheckオプションを指定してください。tagnameは「パラメータ一覧 (clpcfset, clpcfadm.py コマンド)」を参照してください。
- [--set param]
パラメータの変更を行います。paramにはtagnameの設定値を指定してください。
- [--delete]
クラスタ構成情報からtagnameを削除します。
- [--nocheck]
--setと同時に使用するオプションです。tagnameが存在しない場合にエラーとしません。
-
- 9(1,2,3,4,5,6,7)
- 削除時のデバイスIDはクラスタ構成情報に設定された値を指定します。本コマンドのadd deviceオプションで指定したデバイスIDは、デバイス種別に応じた以下の値をプラスして設定しています。
lan
-
mdc
400
disk
300
witness
700
ping
10200
http
10700
-
戻り値 0
成功
0 以外
異常
-
動作環境 『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「ソフトウェア」 - 「clpcfadm.py コマンドの動作環境」を参照してください。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
各パラメータに入力可能な文字列や禁則文字列については、『本ガイドの各章』を参照してください。
本コマンドはクラスタ構成情報ファイルのうち、clp.confのみを作成します。EXECリソース、カスタムモニタリソースなどで使用するスクリプトファイルについては手動で作成する必要があります。
カレントディレクトリにクラスタ構成情報ファイル(clp.conf)を配置した状態で本コマンドを実行してください。
- 例
フェイルオーバグループ failover1 に所属するEXECリソース exec1、および カスタムモニタリソース genw1 のスクリプトを配置する場合。
scripts ├─failover1 │ └─exec1 │ start.sh │ stop.sh │ └─monitor.s └─genw1 genw.sh
本コマンドで作成したclp.confを整形するにはxmllintを利用してください。環境によってxmllintをインストールする必要があります。
XML文章を整形し、ファイルに出力する場合の使用例は以下になります。
xmllint --format --output <整形後clp.confのファイルパス> <整形前clp.confのファイルパス>
-
実行例 タグ名の一覧表示(/rootの子要素一覧を表示)
# clpcfadm.py mod -t 表示例 # all # cluster # messages # pm # rm # webalert # webmgr
タグ名の一覧表示(/root/pm/exec0の子要素一覧を表示)
# clpcfadm.py mod -t pm/exec0 表示例 ([] 内は現在の設定値) # recover [5] # retry [5] # type [rc] # wait [1800]
クラスタ追加
# clpcfadm.py create cluster EUC-JP -e SJIS
# clpcfadm.py create cluster SJIS -s windows
クラスタプロパティの追加・変更
# clpcfadm.py mod -t pm/exec0/recover --set 7 # clpcfadm.py mod -t pm/exec1/recover --set 7 # clpcfadm.py mod -t pm/exec2/recover --set 7
クラスタプロパティの削除
# clpcfadm.py mod -t pm/exec0/recover --delete # clpcfadm.py mod -t pm/exec1/recover --delete # clpcfadm.py mod -t pm/exec2/recover --delete
サーバの追加
# clpcfadm.py add srv server1 0
サーバの削除
# clpcfadm.py del srv server1
カーネルモードLANハートビートの追加
# clpcfadm.py add device server1 lan 0 192.168.137.71 # clpcfadm.py add hb lankhb 0 0
カーネルモードLANハートビートの削除
# clpcfadm.py del device server1 0 # clpcfadm.py del hb lankhb 0
ユーザモードLANハートビートの追加
# clpcfadm.py add device server1 lan 0 192.168.138.71 # clpcfadm.py add hb lanhb 0 1
ユーザモードLANハートビートの削除
# clpcfadm.py del device server1 0 # clpcfadm.py del hb lanhb 0
ディスクハートビートの追加
# clpcfadm.py add device server1 disk 0 /dev/sdc1 # clpcfadm.py add hb diskhb 0 2
ディスクハートビートの削除
# clpcfadm.py del device server1 300 # clpcfadm.py del hb diskhb 300
Witnessハートビートの追加
# clpcfadm.py add device server1 witness 0 1 192.168.2.1:49152 # clpcfadm.py add hb witnesshb 0 3 192.168.2.1:49152
Witnessハートビートの削除
# clpcfadm.py del device server1 700 # clpcfadm.py del hb witnesshb 700
PNG方式によるネットワークパーティション解決リソースの追加
# clpcfadm.py add device server1 ping 0 1 # clpcfadm.py add np pingnp 0 1 0 0 192.168.1.1
PNG方式によるネットワークパーティション解決リソースの削除
# clpcfadm.py del device server1 10200 # clpcfadm.py del np pingnp 10200
HTTP方式によるネットワークパーティション解決リソースの追加
Witness HBリソースの設定を使用する場合
# clpcfadm.py add device server1 http 0 1 # clpcfadm.py add np httpnp 0 2
HTTP方式によるネットワークパーティション解決リソースの追加
Witness HBリソースの設定を使用しない場合
# clpcfadm.py add device server1 http 0 1 # clpcfadm.py add np httpnp 0 2 --host 192.168.2.2:49152
HTTP方式によるネットワークパーティション解決リソースの削除
# clpcfadm.py del device server1 10700 # clpcfadm.py del np httpnp 10700
強制停止リソースの追加(bmcの場合)
# clpcfadm.py add forcestop bmc
強制停止リソースの削除
# clpcfadm.py del forcestop
グループの追加
# clpcfadm.py add grp failover failover1
グループプロパティの追加・変更
# clpcfadm.py mod -t group@failover1/start --set 0
グループプロパティの削除
# clpcfadm.py mod -t group@failover1/start --delete
グループの削除
# clpcfadm.py del grp failover1
グループリソースの追加
# clpcfadm.py add rsc failover1 fip fip1
グループリソースプロパティの追加・変更
# clpcfadm.py mod -t resource/fip@fip1/parameters/ip --set 192.168.137.171
グループリソースプロパティの削除
# clpcfadm.py mod -t resource/fip@fip1/parameters/ip --delete
グループリソースの削除
# clpcfadm.py del rsc failover1 fip fip1
グループリソースの依存関係の追加
# clpcfadm.py add rscdep fip fip1 ddns1
グループリソースの依存関係の削除
個別の依存関係を削除する場合
# clpcfadm.py mod -t resource/fip@fip1/depend@ddns1 --delete
グループリソースの依存関係の削除
全ての依存関係を削除し既定の依存関係に戻す場合
# clpcfadm.py del rscdep fip fip1
モニタリソースの追加
# clpcfadm.py add mon fipw fipw1
モニタリソースプロパティの追加・変更
# clpcfadm.py mod -t monitor/fipw@fipw1/target --set fip1
モニタリソースプロパティの削除
# clpcfadm.py mod -t monitor/fipw@fipw1/target --delete
モニタリソースの削除
# clpcfadm.py del mon fipw fipw1
--nocheckオプションを使用したパラメータ追加
# clpcfadm.py mod -t webmgr/security/clientlist/ip --set 127.0.0.1 --nocheck
# clpcfadm.py mod -t group@failover1/policy@server1/order --set 0 --nocheck
# clpcfadm.py mod -t resource/fip@fip1/server@server1/parameters/ip --set 127.0.0.1 --nocheck
# clpcfadm.py mod -t monitor/fipw@fipw1/relation/name --set LocalServer --nocheck
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
'%1' is not found.
ファイル %1 が見つかりません。
The specified object does not exist. '%1'
指定したオブジェクト %1 は存在しません。
The specified element '%1' does not exist in '%2'.
指定した要素 %1 は %2 に存在しません。
The specified path does not exist in a config file.
指定したパスはクラスタ構成情報に存在しません。
Invalid config file. Use the 'create' option.
本コマンドのcreateオプションを実行してください。
The config file already exists.
クラスタ構成情報は既に存在しています。
Non-configurable elements specified.
設定可能なタグ名ではありません。
Invalid value specified. Specify as follows: <resource type>@<resource name>
<グループリソースタイプ>@<グループリソース名>の形式で指定してください。
Invalid path specified.
無効なパスが指定されています。
Cannot register a '%1' any more.
%1 は登録上限に達しています。
The following arguments are required :%1
%1 を指定してください。
Argument %1: allowed only with argument '%2'
%1 は %2 の時のみ有効なオプションです。
Argument %1: invalid choice: '%2' (choose from %3)
%1 に指定した %2 は無効な値です。%3 の選択肢から指定してください。
Argument %1: invalid value: '%2' (The value must be in the range [%3, %4])
%1 に指定した %2 は無効な値です。 %3 から %4 の範囲の数値を指定してください。
Argument %1: invalid value: '%2' (The length must be less than %3)
%1 に指定した %2 は文字列が長すぎます。 %3 以下の長さにしてください。
Argument %1: '%2' already exists.
%1 に %2 は既に存在しています。
Argument %1: '%2' does not exist.
%1 に %2 が存在しません。
Argument %1: cannot specify a dependency to the same object.
%1 は同じオブジェクトへの依存関係を指定しています。異なるオブジェクトを指定してください。
Argument %1: does not appear to be an IPv4.
%1 は無効な値です。IPv4形式で指定してください。
Invalid value: '%1' (The value must be greater than 0)
%1 は無効な値です。0以上の数値を指定してください。
9.32.3. パラメータ一覧 (clpcfset, clpcfadm.py コマンド)¶
9.33. 暗号化する (clpencryptコマンド)¶
文字列を暗号化します。
-
コマンドライン clpencrypt password
-
説明 クラスタ構成情報でパスワード等の必要な値を暗号化する。
-
パラメータ -
password¶ 暗号化する文字列を指定します。
-
-
戻り値 0
成功
0 以外
異常
-
実行例 # clpencrypt password
-
表示例 20220001111abaabdbb35c04
-
エラーメッセージ メッセージ
原因/対処法
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
9.34. ファイアウォールの規則を追加する (clpfwctrlコマンド)¶
CLUSTERPRO で使用するサーバのファイアウォールのゾーンに「ルール」の追加、削除を行います。
-
コマンドライン - clpfwctrl --add [--zone=<ZONE>]clpfwctrl --removeclpfwctrl --help
-
説明 注釈
本コマンドは サーバのファイアウォールを有効にしている場合に実行してください。
注釈
本コマンドは、単一サーバ上での、ファイアウォールのゾーンに「ルール」の追加、削除を行います。追加、削除を行いたい全てのサーバで実行する必要があります。
注釈
本コマンドは CLUSTERPRO インストール直後と構成情報反映直後に実行してください。
注釈
本コマンドは firewall-cmd、firewall-offline-cmd コマンドが使用できる環境のみ対応しています。
CLUSTERPROで使用するポート番号にアクセスできるようにするため、ファイアウォールのゾーンに「ルール」を追加します。また、追加した「ルール」を削除します。本コマンドで設定するポート番号、プロトコルの詳細については『スタートアップガイド』 -「注意制限事項」 - 「OS インストール後、CLUSTERPRO インストール前」 - 「通信ポート番号」を参照してください。ファイアウォールのゾーンにCLUSTERPROで使用する「ルール」を以下の名前で追加します。既に同じルール名が追加されている場合は、一度削除を行った後、追加を行います。ルール名の変更はしないでください。ルール名
clusterpro
-
オプション -
--add[--zone=<ZONE>]¶ ファイアウォールの「ルール」を追加します。ゾーン名を指定すると、指定されたゾーンに対して「ルール」を追加します。 ゾーン名の指定がない場合は、デフォルトゾーンに対して「ルール」を追加します。
-
--remove¶ 追加したファイアウォールの「ルール」を削除します。
-
--help¶ Usageを表示します。
-
-
戻り値 0
成功
0 以外
異常
-
注意事項 - 本コマンドは root 権限をもつユーザで実行してください。本コマンドはアウトバウンドについては追加を行いません。必要であれば別途追加をしてください。JVMモニタリソースを1度でも登録すると、本コマンドはJVMモニタリソースの管理ポート番号を必ず許可します。本コマンド実行時に、メモリ上に一時的に設定しているファイアウォールの設定については破棄されます。
-
実行例 デフォルトゾーンに「ルール」を追加する場合
# clpfwctrl.sh --add Command succeeded.
-
実行例 ゾーン「home」に「ルール」を追加する場合
# clpfwctrl.sh --add --zone=home Command succeeded.
-
実行例 設定した「ルール」を削除をする場合
# clpfwctrl.sh --remove Command succeeded.
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
Failed to register rule(CLUSTERPRO). Invalid port.
構成情報に不正なポート番号が設定されています。構成情報を確認してください。
Failed to register rule(CLUSTERPRO). Invalid zone.
ゾーン名が不正です。ゾーン名を確認してください。
Unsupported environment.
サポート対象外のOSです。
Could not read xmlpath. Check if xmlpath exists on the specified path. (%1)
xml パスが構成情報に存在するか確認してください。%1 :xml パスCould not opened the configuration file. Check if the configuration file exists on the specified path. (%1)
構成情報が存在するか確認してください。%1 :xml パスCould not read type. Check if type exists on the policy file. (%1)
ポリシーファイルが存在しているか確認してください。%1 :xml パスnot exist xmlpath. (%1)
xml パスが構成情報に存在するか確認してください。%1 :xml パスFailed to obtain properties. (%1)
xml パスが構成情報に存在するか確認してください。%1 :xml パスNot exist java install path. (%1)
Java インストールパスが存在するか確認してください。%1 :Java インストールパスInternal error. Check if memory or OS resources are sufficient. (%1)
メモリ不足またはOSのリソース不足が考えられます。確認してください。%1 :xml パス