1. Preface¶
1.1. Who Should Use This Guide¶
The EXPRESSCLUSTER® X SingleServerSafe Operation Guide is intended for system administrators who will operate and maintain an introduced system.
1.2. How This Guide Is Organized¶
2. EXPRESSCLUSTER X SingleServerSafe command reference: Provides information on commands available to use in EXPRESSCLUSTER.
3. Notes and restrictions: Provides information on known problems and restrictions.
4. Error messages: Lists and describes error messages you might encounter when operating EXPRESSCLUSTER X SingleServerSafe.
1.3. Terms Used in This Guide¶
EXPRESSCLUSTER X SingleServerSafe, which is described in this guide, uses windows and commands common to those of the clustering software EXPRESSCLUSTER X to ensure high compatibility with EXPRESSCLUSTER X in terms of operation and other aspects. Therefore, cluster-related terms are used in parts of the guide.
The terms used in this guide are defined below.
- Cluster, cluster system
A single server system using EXPRESSCLUSTER X SingleServerSafe
- Cluster shutdown, reboot
Shutdown or reboot of a system using EXPRESSCLUSTER X SingleServerSafe
- Cluster resource
A resource used in EXPRESSCLUSTER X SingleServerSafe
- Cluster object
A resource object used in EXPRESSCLUSTER X SingleServerSafe
- Failover group
A group of group resources (such as applications and services) used in EXPRESSCLUSTER X SingleServerSafe
1.4. EXPRESSCLUSTER X SingleServerSafe Documentation Set¶
The EXPRESSCLUSTER X SingleServerSafe documentation consists of the four guides below. The title and purpose of each guide is described below:
EXPRESSCLUSTER X SingleServerSafe Installation Guide
This guide is intended for system engineers who intend to introduce a system using EXPRESSCLUSTER X SingleServerSafe and describes how to install EXPRESSCLUSTER X SingleServerSafe.
EXPRESSCLUSTER X SingleServerSafe Configuration Guide
This guide is intended for system engineers who intend to introduce a system using EXPRESSCLUSTER X SingleServerSafe and system administrators who will operate and maintain the introduced system. It describes how to set up EXPRESSCLUSTER X SingleServerSafe.
EXPRESSCLUSTER X SingleServerSafe Operation Guide
This guide is intended for system administrators who will operate and maintain an introduced system that uses EXPRESSCLUSTER X SingleServerSafe. It describes how to operate EXPRESSCLUSTER X SingleServerSafe.
EXPRESSCLUSTER X SingleServerSafe Legacy Feature Guide
This guide is intended for system engineers who want to introduce systems using EXPRESSCLUSTER X SingleServerSafe and describes EXPRESSCLUSTER X SingleServerSafe 4.0 WebManager and Builder.
1.5. Conventions¶
In this guide, Note, Important, and See also are used as follows:
Note
Used when the information given is important, but not related to the data loss and damage to the system and machine.
Important
Used when the information given is necessary to avoid the data loss and damage to the system and machine.
See also
Used to describe the location of the information given at the reference destination.
The following conventions are used in this guide.
Convention |
Usage |
Example |
|---|---|---|
Bold |
Indicates graphical objects, such as fields, list boxes, menu selections, buttons, labels, icons, etc. |
In User Name, type your name.
On the File menu, click Open Database.
|
Angled bracket within the command line |
Indicates that the value specified inside of the angled bracket can be omitted. |
|
# |
Prompt to indicate that a Linux user has logged in as root user. |
|
Monospace |
Indicates path names, commands, system output (message, prompt, etc), directory, file names, functions and parameters. |
|
bold
|
Indicates the value that a user actually enters from a command line.
|
Enter the following:
clpcl -s -a
|
italic |
Indicates that users should replace italicized part with values that they are actually working with.
|
rpm -i expressclssss-<version_number> -<release_number>.x86_64.rpm |
 In the figures of this guide, this icon represents EXPRESSCLUSTER X SingleServerSafe.
In the figures of this guide, this icon represents EXPRESSCLUSTER X SingleServerSafe.
1.6. Contacting NEC¶
For the latest product information, visit our website below:
2. EXPRESSCLUSTER X SingleServerSafe command reference¶
This chapter describes the commands available with EXPRESSCLUSTER X SingleServerSafe.
EXPRESSCLUSTER X SingleServerSafe uses commands common to those of the clustering software EXPRESSCLUSTER X to ensure high compatibility with EXPRESSCLUSTER X in terms of operation and other aspects.
This chapter covers:
2.8. Applying and backing up configuration data (clpcfctrl command)
2.17. Requesting processing to cluster servers (clprexec command)
2.20. Estimating the amount of resource usage (clpprer command)
2.22. Displaying the cluster statistics information (clpperfc command)
2.23. Checking the cluster configuration information (clpcfchk command)
2.1. Operating the cluster from the command line¶
EXPRESSCLUSTER X SingleServerSafe provides various commands for performing operations from the command prompt. These commands are useful in such cases as when you are setting up a cluster or cannot use the Cluster WebUI. You can perform a greater number of operations by using the command line than by using the Cluster WebUI.
Note
If the monitor resource detects an error when you have specified a group resource (such as an application resource) as a recovery target in the settings for error detection by a monitor resource, do not perform the following control operations for any service or group by using a command or the Cluster WebUI during recovery (reactivation -> final action).
Stopping or suspending a service
Starting or stopping a group
If you perform the above-mentioned operations while recovery caused by detection of an error by a monitor resource is in progress, other group resources of the group with an error may not stop.However, you can perform them when the final action is completed.
Important
The installation directory contains executable-format files and script files that are not listed in this guide. Do not execute these files by programs or applications other than EXPRESSCLUSTER. Any problems caused by not using EXPRESSCLUSTER will not be supported.
2.2. EXPRESSCLUSTER commands¶
Commands for construction
command
Explanation
Refer to
clpcfctrlDelivers the configuration data created by the Cluster WebUI to servers.Backs up the configuration data to be used by the Cluster WebUI.2.8. Applying and backing up configuration data (clpcfctrl command)
clplcnsc
Manages the product or trial version license of this product.
clpcfchk
Checks cluster configuration data.
2.23. Checking the cluster configuration information (clpcfchk command)
Commands for showing status
command
Explanation
Refer to
clpstat
Displays the status and configuration data of EXPRESSCLUSTER X SingleServerSafe.
clphealthchk
Check the process health.
Commands for operation
command
Explanation
Refer to
clpcl
Starts, stops, suspends, or resumes the daemon.
clpstdn
Stops and shuts down the EXPRESSCLUSTER daemon.
clpgrp
Starts and stops groups.
clptoratio
Extends or displays thetimeout values.
clpmonctrl
Suspends and/or resumes monitor resources on a server.
clpregctrl
Displays and/or initializes reboot count on a single server.
clprsc
Suspends or resumes group resources.
clpcpufreq
Controls CPU frequency.
clptrnreq
Requests a server to execute a process.
clprexec
Requests that an EXPRESSCLUSTER server execute a process from external monitoring.
2.17. Requesting processing to cluster servers (clprexec command)
clpbmccnf
Changes the information on BMC user name and password.
Commands for logs
command
Explanation
Refer to
clplogcc
Collects logs and OS information.
clplogcf
Modifies and displays log level and log output file size.
clpperfc
Displays cluster statistical information on a group or a monitor resource.
2.22. Displaying the cluster statistics information (clpperfc command)
Script-related commands
command
Explanation
Refer to
clplogcmd
Write this command in the EXEC resource script to output messages to any destination.
System monitor-related commands (when the System Resource Agent is used)
command
Explanation
Refer to
clpprer
Estimates the future value from the tendency of the given resource use amount data.
2.20. Estimating the amount of resource usage (clpprer command)
Important
The installation directory contains executable files and script files that are not listed in this guide. Do not execute these files by using any program other than EXPRESSCLUSTER X SingleServerSafe. Any problems caused by not using EXPRESSCLUSTER will not be supported.
2.3. Displaying the status (clpstat command)¶
Displays the status and configuration data of EXPRESSCLUSTER X SingleServerSafe.
-
Command line - clpstat: -s [--long]clpstat: -gclpstat: -mclpstat: -i [--detail]clpstat: --cl [--detail]clpstat: --sv [--detail]clpstat: --grp [group_name] [--detail]clpstat: --rsc [resource_name] [--detail]clpstat: --mon [monitor_name] [--detail]
-
Description Displays the server status and configuration information.
-
Option -
-s¶
-
None¶ Displays the status.
-
--long¶ Displays a name of the cluster name and resource name until the end.
-
-g¶ Displays a group map.
-
-m¶ Displays the status of each monitor resource.
-
-i¶ Displays the configuration data.
-
--cl¶ Displays the configuration data.
-
--sv¶ Displays the server configuration information.
-
--grp[group_name]¶ Displays server group configuration information. By specifying the name of a server group, you can display only the information on the specified server group.
-
--rsc[resource_name]¶ Displays group resource configuration information. By specifying the name of a group resource, you can display only the information on the specified group resource.
-
--mon[monitor_name]¶ Displays monitor resource configuration information. By specifying the name of a monitor resource, you can display only the information on the specified monitor resource.
-
--detail¶ Displays more detailed information on the setting.
-
-
Return Value 0
Success
9
The command was run duplicatedly.
Other than the above
Failure
-
Notes - This command must be executed by a user with the root privilege.This command cannot be double launched.For the language used for this command output, see "Info tab" of "Cluster properties" in "Details of other settings" in "EXPRESSCLUSTER X SingleServerSafe Configuration Guide".When you run the clpstat command with the -s option or without any option, names such as a server name and a resource name are displayed only partway.
-
Error Messages Message
Cause/Solution
Log in as root.
Log on as root user.
Invalid configuration file. Create valid cluster configuration data.
Create valid cluster configuration data by using the Cluster WebUI.
Invalid option.
Specify a valid option.
Could not connect to the server. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Invalid server status.
Check if the cluster daemon is started.
Server is not active. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Invalid server name. Specify a valid server name in the cluster.
Specify the valid name of a server in the cluster.
Invalid heartbeat resource name. Specify a valid heartbeat resource name in the cluster.
Specify the valid name of a heartbeat resource in the cluster.
Invalid network partition resourcename. Specify a valid networkpartition resource name in the cluster.Specify the valid name of a network partition resolution resource in the cluster.Invalid group name. Specify a valid group name in the cluster.
Specify the valid name of a group in the cluster.
Invalid group resource name. Specify a valid group resource name in the cluster.
Specify the valid name of a group resource in the cluster.
Invalid monitor resource name. Specify a valid monitor resource name in the cluster.
Specify the valid name of a monitor resource in the cluster.
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
Check if there is any server on which the cluster daemon has stopped in the cluster.
Invalid parameter.
The value specified as a command parameter may be invalid.
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.A time-out occurred in the EXPRESSCLUSTER internal communication.If time-out keeps occurring, set the internal communication time-out longer.Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
Invalid server group name. Specify a valid server group name in the cluster.
Specify the correct server group name in the cluster.
The cluster is not created.
Create and apply the cluster configuration data.
Could not connect to the server. Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
Cluster is stopped. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Cluster is suspended. To display the cluster status, use --local option.
Cluster is suspended. To display the cluster status, use --local option.
2.4. Operating the EXPRESSCLUSTER daemon (clpcl command)¶
Operates the EXPRESSCLUSTER daemon.
-
Command line - clpcl -sclpcl -t [-w timeout] [--apito timeout]clpcl -r [-w timeout] [--apito timeout]clpcl --suspend [--force] [-w timeout] [--apito timeout]clpcl --resume
-
Description This command starts, stops, suspends, or resumes the EXPRESSCLUSTER daemon.
-
Option -
-s¶ Starts the EXPRESSCLUSTER daemon.
-
-t¶ Stops the EXPRESSCLUSTER daemon.
-
-r¶ Restarts the EXPRESSCLUSTER daemon.
-
--suspend¶ Suspends the EXPRESSCLUSTER daemon.
-
--resume¶ Resumes the EXPRESSCLUSTER daemon.
-
-wtimeout¶ - Specifies the wait time to stop or suspend the cluster daemon to be completed when -t, -r, or --suspend option is used.The unit of time is second.When a timeout is not specified, it waits for unlimited time.When "0" is specified in timeout, it does not wait for the completion of stop or suspension of the EXPRESSCLUSTER daemon.When the -w option is not specified, it waits for the completion of stop or suspension of the EXPRESSCLUSTER daemon for (heartbeat timeout x 2) (seconds).
-
--force¶ When used with the --suspend option, this option forcefully suspends the service regardless of the server status.
-
--apitotimeout¶ - Specify the interval (internal communication timeout) to wait for the EXPRESSCLUSTER daemon start or stop in seconds. A value from 1 to 9999 can be specified.If the --apito option is not specified, waiting for the EXPRESSCLUSTER daemon start or stop is performed according to the value set to the internal communication timeout of the cluster properties.
-
-
Return Value 0
Success
Other than 0
Failure
-
Remarks - When this command is executed with the -s or --resume option specified, it returns control when processing starts on the target server.When this command is executed with the -t or --suspend option specified, it returns control after waiting for the processing to complete.When this command is executed with the -r option specified, it returns control when the EXPRESSCLUSTER daemon restarts on the target server after stopping once.Run the clpstat command to display the started or resumed status of the EXPRESSCLUSTER daemon.
-
Notes - This command must be executed by a user with the root privilege.This command cannot be executed while a group is being started or stopped.Execute the --suspend option when the EXPRESSCLUSTER daemon is active. The --force option forcibly suspends the EXPRESSCLUSTER daemon.When executing the --resume option, make sure that the EXPRESSCLUSTER daemon is not running by the clpstat command.
-
Example Example 1: Activating the EXPRESSCLUSTER daemon in the server
# clpcl -s
Suspend and Resume
When you want to update configuration data or EXPRESSCLUSTER, you can stop the EXPRESSCLUSTER daemon while continuing the operation. This status is called "suspend." Returning from the suspended status to normal status is called "resume."The suspend and resume operations request processing of the server. The EXPRESSCLUSTER daemon of the server must be active when you execute a suspend operation.The following functions stop when the cluster is suspended because the cluster daemon stops while active resources stay active.All monitor resources stop.
You cannot perform operations on groups or group resources (start/stop).
The following commands are disabled;
clpcl options other than --resume
clpstdn
clpgrp
clptoratio
clpmonctrl
-
Error Messages Message
Cause/Solution
Log in as root.
Log on as root user.
Invalid configuration file. Create valid cluster configuration data .
Create valid cluster configuration data using the Cluster WebUI.
Invalid option.
Specify a valid option.
Performed stop processing to the stopped cluster daemon.
The stopping process has been executed on the stopped cluster daemon.
Performed startup processing to the active cluster daemon.
The startup process has been executed on the activated cluster daemon.
Could not connect to the server. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Could not connect to the data transfer server. Check if the server has started up.
Check if the server is running.
Failed to obtain the list of nodes.
Specify a valid server name in the cluster.
Specify the valid name of a server in the cluster.
Failed to obtain the daemon name.
Failed to obtain the cluster name.
Failed to operate the daemon.
Failed to control the cluster.
Resumed the daemon that is not suspended.
Performed the resume process for the HA Cluster daemon that is not suspended.
Invalid server status.
Check that the cluster daemon is started.
Server is busy. Check if this command is already run.
This command may have already been run.
Server is not active. Check if the cluster daemon is active.
Check if the cluster daemon is started.
There is one or more servers of which cluster daemon is active. If you want to perform resume, check if there is any server whose cluster daemon is active in the cluster.
When you execute the command to resume, check if there is no server in the cluster on which the cluster daemon is started.
All servers must be activated. When suspending the server, the cluster daemon need to be active on all servers in the cluster.
When you execute the command to suspend, the cluster daemon must be started in all servers in the cluster.
Resume the server because there is one or more suspended servers in the cluster.
Execute the command to resume because some server(s) in the cluster is in the suspend status.
Invalid server name. Specify a valid server name in the cluster.
Specify the valid name of a sever in the cluster.
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
Check if there is any server on which the cluster daemon is stopped in the cluster.
Invalid parameter.
The value specified as a command parameter may be invalid.
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
A time-out occurred in the HA Cluster internal communication.
If time-out keeps occurring, set the internal communication time-out longer.
Processing failed on some servers. Check the status of failed servers.
If stopping has been executed with all the servers specified, there is one of more server on which the stopping process has failed.
Check the status of the server(s) on which the stopping process has failed.
Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
There is a server that is not suspended in cluster. Check the status of each server.
There is a server that is not suspended in the cluster. Check the status of each server.
Suspend %s : Could not suspend in time.
The server failed to complete the suspending process of the cluster daemon within the time-out period. Check the status of the server.
Stop %s : Could not stop in time.
The server failed to complete the stopping process of the cluster daemon within the time-out period. Check the status of the server.
Stop %s : Server was suspended.
Could not connect to the server. Check if the cluster daemon is active.
The request to stop the cluster daemon was made. However the server was suspended.
Could not connect to the server. Check if the cluster daemon is active.
The request to stop the cluster daemon was made. However connecting to the server failed. Check the status of the server.
Suspend %s : Server already suspended.
Could not connect to the server. Check if the cluster daemon is active.
The request to suspend the cluster daemon was made. However the server was suspended.
Event service is not started.
Event service is not started. Check it.
Mirror Agent is not started.
Mirror Agent is not started. Check it.
Event service and Mirror Agent are not started.
Event service and Mirror Agent are not started. Check them.
Some invalid status. Check the status of cluster.
The status of a group may be changing. Try again after the status change of the group is complete.
2.5. Shutting down the server (clpstdn command)¶
Shuts down the server.
-
Command line clpstdn [-r]
-
Description Stops and shuts down the EXPRESSCLUSTER daemon of the server.
-
Return Value 0
Success
Other than 0
Failure
-
Remarks This command returns control when the group stop processing is completed.
-
Notes - This command must be executed by a user with the root privilege.This command cannot be executed while a group is being started or stopped.
-
Examples Example 1: Shutting down the server
# clpstdn
Example 2: Shutting down and rebooting the server
# clpstdn -r
2.6. Operating groups (clpgrp command)¶
Operates groups.
-
Command line - clpgrp -s [group_name] [--apito timeout]clpgrp -t [group_name] [--apito timeout]
-
Description Starts and stops groups.
-
Option -
-s[group_name]¶ Starts a group. When you specify the name of a group, only the specified group starts up. If no group name is specified, all groups start up.
-
-t[group_name]¶ Stops a group. When you specify the name of a group, only the specified group stops. If no group name is specified, all groups stop.
-
--apitotimeout¶ - Specify the interval (internal communication timeout) to wait for the group resource start or stop in seconds. A value from 1 to 9999 can be specified.If the --apito option is not specified, waiting for the group resource start or stop is performed according to the value set to the internal communication timeout of the cluster properties.
-
-
Return Value 0
Success
Other than 0
Failure
-
Notes - This command must be executed by a user with the root privilege.The EXPRESSCLUSTER daemon must be started on the server that runs this command.
-
Examples The following is a simple example of group operation.
The server has groupA.
-
Error message Message
Cause/Solution
Log in as root.
Log on as root user.
Invalid configuration file. Create valid cluster configuration data.
Create valid cluster configuration data using the Cluster WebUI.
Invalid option.
Specify a valid option.
Could not connect to the server. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Invalid server status.
Check if the cluster daemon is started.
Server is not active. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Invalid server name. Specify a valid server name in the cluster.
Specify the valid name of sever in the cluster.
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
Check if there is any server on which the cluster daemon has stopped in the cluster.
Invalid parameter.
The value specified as a command parameter may be invalid.
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.A time-out occurred in the EXPRESSCLUSTER internal communication.If time-out keeps occurring, set the internal communication time-out longer.Invalid server. Specify a server that can run and stop the group, or a server that can be a target when you move the group.The server that starts/stops the group or to which the group is moved is invalid.Specify a valid server.Could not start the group. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
Start up the group after waiting for the remote server to start up, or after waiting for the time-out of the start-up wait time.
No operable group exists in the server.
Check if there is any group that is operable in the server which requested the process.
The group has already been started on the local server.
Check the status of the group by using the Cluster WebUI or the clpstat command.
The group has already been started on the other server. To start/stop the group on the local server, use -f option.Check the status of the group by using the Cluster WebUI or the clpstat command.If you want to start up or stop a group which was started in a remote server from the local server, move the group or run the command with the -f option.The group has already been started on the other server. To move the group, use "-h <hostname>" option.Check the status of the group by using the Cluster WebUI or clpstat command.If you want to move a group which was started on a remote server, run the command with the "-h <hostname>" option.The group has already been stopped.
Check the status of the group by using the Cluster WebUI or the clpstat command.
Failed to start one or more group resources. Check the status of group
Check the status of group by using Cluster WebUI or the clpstat command.
Failed to stop one or more group resources. Check the status of group
Check the status of group by using the Cluster WebUI or the clpstat command.
The group is busy. Try again later.
Wait for a while and then try again because the group is now being started up or stopped.
An error occurred on one or more groups. Check the status of group
Check the status of the group by using the Cluster WebUI or the clpstat command.
Invalid group name. Specify a valid group name in the cluster.
Specify the valid name of a group in the cluster.
Server is not in a condition to start group or any critical monitor error is detected.Check the status of the server by using the Cluster WebUI or clpstat command.An error is detected in a critical monitor on the server on which an attempt was made to start a group.There is no appropriate destination for the group. Other servers are not in a condition to start group or any critical monitor error is detected.Check the status of the server by using the Cluster WebUI or clpstat command.An error is detected in a critical monitor on all other servers.The group has been started on the other server. To migrate the group, use "-h <hostname>" option.Check the status of the group by using the Cluster WebUI or clpstat command.If you want to move a group which was started on a remote server, run the command with the "-h <hostname>" option.The specified group cannot be migrated.
The specified group cannot be migrated.
The specified group is not vm group.
The specified group is not a virtual machine group.
Migration resource does not exist.Check the status of the group by using the Cluster WebUI or clpstat command.The resource to be migrated is not found.Migration resource is not started.Check the status of the group by using the Cluster WebUI or clpstat command.The resource to be migrated is not started.Some invalid status. Check the status of cluster.
Invalid status for some sort of reason. Check the status of the cluster.
Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
2.7. Collecting logs (clplogcc command)¶
Collects logs.
-
Command line clplogcc [-t collect_type] [-r syslog_rotate_number] [-o path]
-
Description Collects information including logs and the OS information by accessing the data transfer server.
-
Option -
None¶ Logs are collected.
-
-tcollect_type¶ Specifies a log collection pattern. When this option is omitted, a log collection pattern will be type1.
-
-rsyslog_rotate_number¶ Specifies how many generations of syslog will be collected. When this option is omitted, two generations will be collected.
-
-opath¶ Specifies the output destination of collector files. When this option is skipped, logs are output under tmp of the installation path.
-
-
Return Value 0
Success
Other than 0
Failure
-
Remarks Since log files are compressed by tar.gz, add the xzf option to the tar command to decompress them.
-
Notes This command must be executed by a user with the root privilege.
-
Examples Example 1: Collecting logs from the server
# clplogcc Collect Log server1 : Success
Log collection results (server status) of servers on which log collection is executed are displayed.
Process servername: Result (server status)
Execution Result
For this command, the following processes are displayed.
Steps in Process
Explanation
Connect
Displayed when the access fails.
Get Filesize
Displayed when acquiring the file size fails.
Collect Log
Displayed with the file acquisition result.
The following results (server status) are displayed:
Result (server status)
Explanation
Success
Log collection succeeded.
Timeout
Timeout occurred.
Busy
The server is busy.
Not Exist File
The file does not exist.
No Freespace
No free space on the disk.
Failed
Failure caused by other errors.
Error Message
Message
Cause/Solution
Log in as root.
Log in as a root user.
Invalid configuration file. Create valid cluster configuration data.
Create valid configuration data by using the Cluster WebUI.
Invalid option.
Specify the correct option.
Specify a number in a valid range.
Specify a number within a valid range.
Specify a correct number.
Specify a valid number.
Specify correct generation number of syslog.
Specify a valid number for the syslog generation.
Collect type must be specified 'type1' or 'type2' or 'type3' or 'type4' or 'type5' or 'type6'. Incorrect collection type is specified.
Invalid collection type is specified.
Specify an absolute path as the destination of the files to be collected.
Specify an absolute path for the output destination of collected files.
Specifiable number of servers are the max number of servers that can constitute a cluster.
The number of servers that can be specified is the maximum number of servers that can be set up.
Could not connect to the server. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Invalid server status.
Check if the cluster daemon is started.
Server is busy. Check if this command is already run.
This command may be run already. Check them.
Internal error. Check if memory or OS resources are sufficient.
Memory or OS resources may not be sufficient. Check them.
2.7.1. Collecting logs by specifying a type (-t option)¶
To collect only the specified types of logs, run the clplogcc command with the -t option.
Specify a type from 1 thorough 6 for the log collection.
type1
type2
type3
type4
Type 5
Type 6
Default collection information
✓
✓
✓
✓
n/a
n/a
syslog
✓
✓
✓
n/a
n/a
n/a
core
✓
✓
n/a
✓
n/a
n/a
OS information
✓
✓
✓
✓
n/a
n/a
script
✓
✓
n/a
n/a
n/a
n/a
ESMPRO/AC
✓
✓
n/a
n/a
n/a
n/a
HA Logs
n/a
✓
n/a
n/a
n/a
n/a
Mirror Statistics
n/a
n/a
n/a
n/a
n/a
n/a
Cluster Statistics
n/a
n/a
n/a
n/a
n/a
✓
System resource statistical information
✓
✓
✓
✓
n/a
✓
# clplogcc -t type2
When no option is specified, a log type will be type 1.
Information to be collected by default
Logs of each module in the EXPRESSCLUSTER Server
Alert logs
Attribute of each module (ls -l) in the EXPRESSCLUSTER Server
In bin, lib
In alert/bin, webmgr/bin
In ha/jra/bin, ha/sra/bin, ha/jra/lib, ha/sra/lib
In drivers/md
In drivers/khb
- In drivers/ka
All installed packages (rpm -qa execution result)
EXPRESSCLUSTER X SingleServerSafe version (rpm -qi expresscls execution result)
distribution (/etc/*-release)
License Information
Configuration data file
Policy file
Dump files in the shared memory used by EXPRESSCLUSTER X SingleServerSafe
Local node status of EXPRESSCLUSTER (clpstat --local execution results)
Process and thread information (ps execution result)
PCI device information (lspci execution result)
Service information (execution results of the commands such as systemctl, chkconfig, and ls)
Output result of kernel parameter (sysctl -a execution results)
glibc version (rpm -qi glibc execution result)
Kernel loadable module configuration (/etc/modules.conf. /etc/modprobe.conf)
Kernel ring buffer (dmesg execution result)
File system (/etc/fstab)
IPC resource (ipcs execution result)
System (uname -a execution result)
Network statistics (netstat and ss execution result IPv4/IPv6)
ip (execution results of the command ip addr, link, maddr, route or -s l)
All network interfaces (ethtool execution result)
Information collected upon emergency OS shutdown
libxml2 version (rpm -qi libxml2 execution result)
Static host table (/etc/hosts)
File system export table (exportfs -v execution result)
User resource limitations (ulimit -a execution result)
File system exported by kernel-based NFS (/etc/exports)
OS locale
Terminal session environment value (export execution result)
Language locale (/etc/sysconfig/i18n)
Time zone (env - date execution result)
Work area of EXPRESSCLUSTER server
- Monitoring optionsThis information is collected if options are installed.
Collected dump information when the monitor resource timeout occurred
Collected Oracle detailed information when Oracle monitor resource abnormity was detected
syslog
syslog (/var/log/messages)
syslog (/var/log/syslog)
Syslogs for the number of generations specified (/var/log/messages.x)
- journal log (such as files in /var/run/log/journal/)
core file
- core file of EXPRESSCLUSTER moduleStored in /opt/nec/clusterpro/log by the following archive names.
Alert related:
altyyyymmdd_x.tar
Directory for the WebManager server related:
wmyyyymmdd_x.tar
EXPRESSCLUSTER core related:
clsyyyymmdd_x.tar
yyyymmdd indicates the date when the logs are collected. x is a sequence number.
OS information
Kernel mode LAN heartbeat, keep alive
/proc/khb_moninfo
- /proc/ka_moninfo
/proc/devices
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/cpuinfo
/proc/partitions
/proc/pci
/proc/version
/proc/ksyms
/proc/net/bond*
all files of /proc/scsi/ all files in the directory
all files of /proc/ide/ all files in the directory
/etc/fstab
/etc/syslog.conf
/etc/syslog-ng/syslog-ng.conf
/proc/sys/kernel/core_pattern
/proc/sys/kernel/core_uses_pid
/etc/snmp/snmpd.conf
Kernel ring buffer (dmesg execution result)
ifconfig (ifconfig execution result)
iptables (iptables -L execution result)
ipchains (ipchains -L execution result)
df (df execution result)
raw device information (raw -qa execution result)
kernel module load information (lsmod execution result)
host name, domain information (hostname, domainname execution result)
dmidecode (dmidecode execution result)
LVM device information (vgdisplay -v execution result)
snmpd version information (snmpd -v execution result)
- Virtual Infrastructure information (the result of running virt-what)
When you collect logs, you may find the following message on the console. This does not mean failure. The logs are collected normally.
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(Where hd# is the name of the IDE device that exists on the server)- ScriptStart/stop script for a group that was created with the Cluster WebUI.If you specify a user-defined script other than the above (/opt/nec/clusterpro/scripts), it is not included in the log collection information. It must be collected separately.
- ESMPRO/AC Related logsFiles that are collected by running the acupslog command.
HA logs
System resource information
JVM monitor log
System monitor log
- Mirror StatisticsThis version does no collect.
Cluster Statistics
Cluster Statistics
In perf/cluster
System resource statistics
System resource statistics
In perf/system
2.7.2. syslog generations (-r option)¶
To collect syslogs for the number of generations specified, run the following command.
Example: Collecting logs for the 3 generations
# clplogcc -r 3
The following syslogs are included in the collected logs.
When no option is specified, two generations are collected.
You can collect logs for 0 to 99 generations.
When 0 is specified, all syslogs are collected.
Number of Generation |
Number of generations to be acquired |
|---|---|
0 |
All Generations |
1 |
Current |
2 |
Current + Generation 1 |
3 |
Current + Generation 1 to 2 |
: |
|
x |
Current + Generation 1 to (x - 1) |
2.7.3. Output paths of log files (-o option)¶
Log file is named and be saved as "server name-log.tar.gz".
Since log files are compressed by tar.gz, add the xzf option to the tar command to decompress them.
If not specifying -o option
Logs are output in tmp of installation path.
# clplogcc Collect Log server-name: Success # ls /opt/nec/clusterpro/tmp server-name-log.tar.gz
When the -o option is specified:
If you run the command as follows, logs are located in the specified /home/log directory.
# clplogcc -o /home/log Collect Log server-name: Success # ls /home/log server-name-log.tar.gz
2.7.4. Collecting information when a failure occurs¶
When the following failure occurs, the information for analyzing the failure is collected.
When a server daemon configuring the server abnormally terminates due to interruption by a signal (core dump), an internal status error, or another cause
When a group resource activation error or deactivation error occurs
When monitoring error occurs in a monitor resource
Information to be collected is as follows:
Server information
Some module logs in EXPRESSCLUSTER servers
Dump files in the shared memory used by EXPRESSCLUSTER X SingleServerSafe
Configuration data file
Core files of EXPRESSCLUSTER module
OS information (/proc/*)
/proc/devices
/proc/partitions
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/net/bond*
Information created by running a command
Results of the sysctl -a
Results of the ps
Results of the top
Results of the ipcs
Results of the netstat -i
Results of the ifconfig
Results of the df
Results of the raw -qa
journalctl -e execution result
These are collected by default in the log collection. You do not need to collect them separately.
2.8. Applying and backing up configuration data (clpcfctrl command)¶
2.8.1. Applying configuration data (clpcfctrl --push)¶
Applies the configuration data to servers.
-
Command line clpcfctrl --push -l|-w [-p portnumber] [-x directory] [--nocheck]
-
Description Applies the configuration data created by the Cluster WebUI to servers.
-
Option -
--push¶ - Specify this option when applying the data.This option cannot be omitted.
-
-l¶ - Specify this option when using the configuration data with the data saved by the Cluster WebUI on Linux.You cannot specify -l and -w together.
-
-w¶ - Specify this option when using the configuration data with the data saved by the Cluster WebUI on Windows.You cannot specify both -l and -w together.
-
-p¶ - portnumber Specifies a port number of data transfer port.When this option is omitted, the default value is used. In general, it is not necessary to specify this option.
-
-xdirectory¶ - Specify this option to apply the configuration data in the specified directory.Use this option with either -l or -w.When -l is specified, configuration data saved on the file system by the Cluster WebUI on Linux is used.When -w is specified, configuration data saved by the Cluster WebUI on Windows is used.
-
--nocheck¶ Configuration data is not checked. Use this option only when deleting a server.
-
-
Return Value 0
Success
Other than 0
Failure
-
Notes This command must be executed by a user with the root privilege.
-
Examples Example 1: Delivering configuration data that was saved on the file system using the Cluster WebUI on Linux
# clpcfctrl --push -l -x /mnt/config file delivery to server 127.0.0.1 success. The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
-
Error Message
Message |
Cause/Solution |
|---|---|
Log in as root. |
Log on as a root user. |
This command is already run. |
This command has already been run. |
Invalid option. |
The option is invalid. Check the option. |
Invalid mode.
Check if --push or --pull option is specified.
|
Check if the --push is specified.
|
The target directory does not exist. |
The specified directory does not exist. |
Invalid host name.
Server specified by -h option is not included in the configuration data.
|
The server specified with -h is not included in configuration data. Check if the specified server name or IP address is correct.
|
Canceled. |
This message is displayed when you enter a character other than "y" in response to the command. |
Failed to initialize the xml library.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them. |
Failed to load the configuration file.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them. |
Failed to change the configuration file.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them. |
Failed to load the all.pol file.
Reinstall the RPM.
|
Reinstall the EXPRESSCLUSTER Server RPM.
|
Failed to load the cfctrl.pol file.
Reinstall the RPM.
|
Reinstall the EXPRESSCLUSTER Server RPM.
|
Failed to get the install path.
Reinstall the RPM.
|
Reinstall the EXPRESSCLUSTER Server RPM.
|
Failed to get the cfctrl path.
Reinstall the RPM.
|
Reinstall the EXPRESSCLUSTER Server RPM.
|
Failed to get the list of group. |
Failed to acquire the list of group. |
Failed to get the list of resource. |
Failed to acquire the list of resource. |
Failed to initialize the trncl library.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them.
|
Failed to connect to server %1.
Check if the other server is active and then run the command again.
|
Accessing the server has failed. Check if other server(s) has been started.
Run the command again after the server has started up.
|
Failed to connect to trnsv.
Check if the other server is active.
|
Accessing the server has failed. Check if other server(s) has been started.
|
File delivery failed.
Failed to deliver the configuration data. Check if the other server is active and run the command again.
|
Delivering configuration data has failed. Check if other server(s) has been started.
Run the command again after the server has started up.
|
Multi file delivery failed.
Failed to deliver the configuration data. Check if the other server is active and run the command again.
|
Delivering configuration data has failed. Check if other server(s) has been started.
Run the command again after the server has started up.
|
Failed to deliver the configuration data.
Check if the other server is active and run the command again.
|
Delivering configuration data has failed. Check if other server(s) has been started.
Run the command again after the server has started up.
|
The directory "/work" is not found.
Reinstall the RPM.
|
Reinstall the EXPRESSCLUSTER Server RPM.
|
Failed to make a working directory. |
Memory or OS resources may not be sufficient. Check them. |
The directory does not exist. |
Memory or OS resources may not be sufficient. Check them. |
This is not a directory. |
Memory or OS resources may not be sufficient. Check them. |
The source file does not exist. |
Memory or OS resources may not be sufficient. Check them. |
The source file is a directory. |
Memory or OS resources may not be sufficient. Check them. |
The source directory does not exist. |
Memory or OS resources may not be sufficient. Check them. |
The source file is not a directory. |
Memory or OS resources may not be sufficient. Check them. |
Failed to change the character code set (EUC to SJIS). |
Memory or OS resources may not be sufficient. Check them. |
Failed to change the character code set (SJIS to EUC). |
Memory or OS resources may not be sufficient. Check them. |
Command error. |
Memory or OS resources may not be sufficient. Check them. |
Failed to initialize the cfmgr library.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them.
|
Failed to get size from the cfmgr library.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them.
|
Failed to allocate memory. |
Memory or OS resources may not be sufficient. Check them. |
Failed to change the directory. |
Memory or OS resources may not be sufficient. Check them. |
Failed to run the command. |
Memory or OS resources may not be sufficient. Check them. |
Failed to make a directory. |
Memory or OS resources may not be sufficient. Check them. |
Failed to remove the directory. |
Memory or OS resources may not be sufficient. Check them. |
Failed to remove the file. |
Memory or OS resources may not be sufficient. Check them. |
Failed to open the file. |
Memory or OS resources may not be sufficient. Check them. |
Failed to read the file. |
Memory or OS resources may not be sufficient. Check them. |
Failed to write the file. |
Memory or OS resources may not be sufficient. Check them. |
Internal error.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them.
|
The upload is completed successfully.
To apply the changes you made, shutdown and reboot the cluster.
|
The upload is completed successfully. To apply the changes you made, shut down the server, and then reboot it.
|
The upload was stopped.
To upload the cluster configuration data, stop the cluster.
|
The upload was stopped. To upload the configuration data, stop the server.
|
The upload was stopped.
To upload the cluster configuration data, stop the Mirror Agent.
|
The upload was stopped. To upload the configuration data, stop MirrorAgent.
|
The upload was stopped.
To upload the cluster configuration data, stop the resources to which you made changes.
|
The upload was stopped. To upload the configuration data, stop the resources you changed.
|
The upload was stopped.
To upload the cluster configuration data, stop the groups to which you made changes.
|
The upload was stopped. To upload the configuration data, suspend the server. To upload, stop the group to which you made changes.
|
The upload was stopped.
To upload the cluster configuration data, suspend the cluster.
|
The upload was stopped. To upload the configuration data, suspend the server.
|
The upload is completed successfully.
To apply the changes you made, restart the Alert Sync.
To apply the changes you made, restart the WebManager.
|
The upload is completed successfully. To apply the changes you made, restart the AlertSync service. To apply the changes you made, restart the WebManager service.
|
Internal error.
Check if memory or OS resources are sufficient.
|
Memory or OS resources may not be sufficient. Check them.
|
The upload is completed successfully. |
The upload is completed successfully. |
The upload was stopped.
Failed to deliver the configuration data.
Check if the other server is active and run the command again.
|
The upload was stopped. Delivering configuration data has failed. Check if the other server is active and run the command again.
|
The upload was stopped.
There is one or more servers that cannot be connected to.
To apply cluster configuration information forcibly, run the command again with "--force" option.
|
The upload was stopped. The server that cannot connect exists. To forcibly upload the configuration data, run the command again with the --force option.
|
2.8.2. Backing up the configuration data (clpcfctrl --pull)¶
Backs up the configuration data.
-
Command line clpcfctrl --pull -l|-w [-p portnumber] [-x directory]
-
Description Backs up the configuration data to be used by the Cluster WebUI.
-
Option -
--pull¶ - Specify this option when performing backup.This option cannot be omitted.
-
-l¶ - Specify this option when backing up data as the configuration data that is used for the Cluster WebUI on Linux.You cannot specify both -l and -w together.
-
-w¶ - Specify this option when backing up data as the configuration data that is used for the Cluster WebUI on Windows.You cannot specify both -l and -w together.
-
-p¶ - portnumber Specifies a port number of data transfer port.When this option is omitted, the default value is used. In general, it is not necessary to specify this option.
-
-xdirectory¶ - Specify this option when backing up configuration data in the specified directory.Use this option with either -l or -w.When -l is specified, configuration data is backed up in the format which can be loaded by the Cluster WebUI on Linux.When -w is specified, configuration data is saved in the format which can be loaded by the Cluster WebUI on Windows.
-
-
Return Value 0
Success
Other than 0
Failure
-
Notes This command must be executed by a user with the root privilege.
-
Examples Example 1: Backing up configuration data to the specified directory so that the data can be loaded by the Cluster WebUI on Linux
# clpcfctrl --pull -l -x /mnt/config Command succeeded.(code:0)
-
Error Message Message
Cause/Solution
Log in as root.
Log on as a root user.
This command is already run.
This command has already been run.
Invalid option.
The option is invalid. Check the option.
Invalid mode.Check if --push or --pull option is specified.Check if the --pull is specified.The target directory does not exist.
The specified directory does not exist.
Canceled.
This message is displayed when you enter a character other than "y" in response to the command.
Failed to initialize the xml library.Check if memory or OS resources are sufficient.Memory or OS resources may not be sufficient. Check them.
Failed to load the configuration file.Check if memory or OS resources are sufficient.Memory or OS resources may not be sufficient. Check them.
Failed to change the configuration file.Check if memory or OS resources are sufficient.Memory or OS resources may not be sufficient. Check them.
Failed to load the all.pol file.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to load the cfctrl.pol file.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to get the install path.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to get the cfctrl path.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to initialize the trncl library.Check if memory or OS resources are sufficient.Memory or OS resources may not be sufficient. Check them.Failed to connect to server %1.Check if the other server is active and then run the command again.Accessing the server has failed. Check if other server(s) has been started.Run the command again after the server has started up.Failed to connect to trnsv.Check if the other server is active.Accessing the server has failed. Check if other server(s) has been started.Failed to get configuration data.Check if the other server is active.Acquiring configuration data has failed. Check if other server(s) has been started.The directory "/work" is not found.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to make a working directory.
Memory or OS resources may not be sufficient. Check them.
The directory does not exist.
Memory or OS resources may not be sufficient. Check them.
This is not a drirectory.
Memory or OS resources may not be sufficient. Check them.
The source file does not exist.
Memory or OS resources may not be sufficient. Check them.
The source file is a directory.
Memory or OS resources may not be sufficient. Check them.
The source directory does not exist.
Memory or OS resources may not be sufficient. Check them.
The source file is not a directory.
Memory or OS resources may not be sufficient. Check them.
Failed to change the character code set (EUC to SJIS).
Memory or OS resources may not be sufficient. Check them.
Failed to change the character code set (SJIS to EUC).
Memory or OS resources may not be sufficient. Check them.
Command error.
Memory or OS resources may not be sufficient. Check them.
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.Memory or OS resources may not be sufficient. Check them.Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.Memory or OS resources may not be sufficient. Check them.Failed to allocate memory.
Memory or OS resources may not be sufficient. Check them.
Failed to change the directory.
Memory or OS resources may not be sufficient. Check them.
Failed to run the command.
Memory or OS resources may not be sufficient. Check them.
Failed to make a directory.
Memory or OS resources may not be sufficient. Check them.
Failed to remove the directory.
Memory or OS resources may not be sufficient. Check them.
Failed to remove the file.
Memory or OS resources may not be sufficient. Check them.
Failed to open the file.
Memory or OS resources may not be sufficient. Check them.
Failed to read the file.
Memory or OS resources may not be sufficient. Check them.
Failed to write the file.
Memory or OS resources may not be sufficient. Check them.
Internal error.Check if memory or OS resources are sufficient.Memory or OS resources may not be sufficient. Check them.
2.9. Adjusting time-out temporarily (clptoratio command)¶
Extends or displays the current timeout ratio.
-
Command line - clptoratio -r ratio -t timeclptoratio -iclptoratio -s
-
Description Temporarily extends the following timeout values:
Monitor resource
Heartbeat resource
Alert synchronous service
WebManager service
The current timeout ratio is displayed.
-
Option -
-rratio¶ - Specifies the timeout ratio. Use 1 or larger integer. The maxim timeout ratio is 10,000.If you specify "1," you can return the modified timeout ratio to the original as you can do so when you are using the -i option.
-
-ttime¶ - Specifies the extension period.You can specify minutes for m, hours for h, and days for d. The maximum period of time is 30 days.Example:2m, 3h, 4d
-
-i¶ Sets back the modified timeout ratio.
-
-s¶ Refers to the current timeout ratio.
-
-
Return Value 0
Success
Other than 0
Failure
-
Remarks - When the server is shut down, the timeout ratio you have set will become ineffective. However, if the server is not shut down, the timeout ratio and the extension period that you have set will be maintained.With the -s option, you can only refer to the current timeout ratio. You cannot see other information such as remaining time of extended period.You can see the original timeout value by using the status display command.Heartbeat timeout
# clpstat --cl --detail
Monitor resource timeout# clpstat --mon monitor resource name --detail
-
Notes - This command must be executed by a user with the root privilege.Execute this command when the EXPRESSCLUSTER daemon of the server is active.When you set the timeout ratio, make sure to specify the extension period. However, if you set "1" for the timeout ratio, you cannot specify the extension period.You cannot specify a combination such as "2m3h," for the extension period.
-
Examples Example 1: Doubling the timeout ratio for three days
# clptoratio -r 2 -t 3d
Example 2: Setting back the timeout ratio to original
# clptoratio -i
Example 3: Referring to the current timeout ratio
# clptoratio -s present toratio : 2
The current timeout ratio is set to 2.
-
Error Message Message
Cause/Solution
Log in as root.
Log on as root user.
Invalid configuration file. Create valid cluster configuration data.
Create valid cluster configuration data by using the Cluster WebUI.
Invalid option.
Specify a valid option.
Specify a number in a valid range.
Specify a number within a valid range.
Specify a correct number.
Specify a valid number.
Scale factor must be specified by integer value of 1 or more.
Specify 1 or larger integer for ratio.
Specify scale factor in a range less than the maximum scale factor.
Specify a ratio that is not larger than the maximum ratio.
Set the correct extension period.
Set a valid extension period.
Ex) 2m, 3h, 4d
Set the extension period which does not exceed the maximum ratio.
Set the extension period in a range less than the maximum extension period.
Check if the cluster daemon is started.
Could not connect to the server. Check if the cluster daemon is active.
Check if the cluster daemon is started.
Server is not active. Check if the cluster daemon is active.
Check if there is any server in the cluster with the cluster daemon stopped.
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
Check if there is any server in the cluster with the cluster daemon stopped.
Invalid parameter.
The value specified as a parameter of the command may be invalid.
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
Time-out has occurred in the internal communication of EXPRESSCLUSTER. If it occurs frequently, set the internal communication time-out longer.
Processing failed on some servers. Check the status of failed servers.
There are servers that failed in processing. Check the status of server in the cluster. Operate it while all the servers in the cluster are up and running.
Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
2.10. Modifying the log level and size (clplogcf command)¶
Modifies and displays log level and log output file size.
-
Command line clplogcf -t type -l level -s size
-
Description - Modifies the settings of the log level and log output file size.Displays the currently specified values.
-
Option -
-ttype¶ - Specifies a module type whose settings will be changed.If both -l and -s are omitted, the information set to the specified module will be displayed. See the list of "Types that can be specified to the -t option" for types which can be specified.
-
-llevel¶ - Specifies a log level.You can specify one of the following for a log level.1, 2, 4, 8, 16, 32You can see more detailed information as the log level increases.
-
-s¶ - size Specifies the size of a file for log output.The unit is byte.
-
None¶ Displays the entire configuration information currently set.
-
-
Return Value 0
Success
Other than 0
Failure
-
Remarks Each type of log output by EXPRESSCLUSTER X SingleServerSafe uses four log files. Therefore, it is necessary to have the disk space that is four times larger than what is specified by -s.
-
Notes - This command must be executed by a user with the root privilege.To run this command, the EXPRESSCLUSTER event service must be started.The settings revert to the default values when the server restarts.
-
Examples Example 1: Modifying the pm log level
# clplogcf -t pm -l 8
Example 2: Seeing the pm log level and log file size
# clplogcf -t pm TYPE, LEVEL, SIZE pm, 8, 1000000
Example 3: Displaying the values currently configured
# clplogcf TYPE, LEVEL, SIZE trnsv, 4, 1000000 xml, 4, 1000000 logcf, 4, 1000000
-
Error Message Message
Cause/Solution
Log in as root.
Log on as a root user.
Invalid option.
The option is invalid. Check the option.
Failed to change the configuration. Check if clpevent is running.
clpevent may not be started yet.
Invalid level
The specified level is invalid.
Invalid size
The specified size is invalid.
Failed to load the configuration file. Check if memory or OS resources are sufficient.
The server has not been created.
Failed to initialize the xml library. Check if memory or OS resources are sufficient.
Memory or OS resources may not be sufficient. Check them.
Failed to print the configuration. Check if clpevent is running.
clpevent may not be started yet.
-
Types that can be specified for the -t option (y=yes, n=no) Type:
Module Type
Explanation
The EXPRESSCLUSTER Server
apicl
libclpapicl.so.1.0
API client library
✓
apisv
libclpapisv.so.1.0
API server
✓
bmccnf
clpbmccnf
BMC information update command
✓
cl
clpcl
Server startup and stop command
✓
cfctrl
clpcfctrl
Server generation and server information backup command
✓
cfmgr
libclpcfmgr.so.1.0
Configuration data operation library
✓
cpufreq
clpcpufreq
CPU frequency control command
✓
grp
clpgrp
Group startup and stop command
✓
rsc
clprsc
Group resource startup and stop command
✓
haltp
clpuserw
Shutdown stalling monitoring
✓
healthchk
clphealthchk
Process health check command
✓
ibsv
clpibsv
Information Base server
✓
lcns
libclplcns.so.1.0
License library
✓
lcnsc
clplcnsc
License registration command
✓
logcc
clplogcc
Collect logs command
✓
logcf
clplogcf
Log level and size modification command
✓
logcmd
clplogcmd
Alert producing command
✓
mail
clpmail
Mail Report
✓
mgtmib
libclpmgtmib.so.1.0
SNMP coordination library
✓
monctrl
clpmonctrl
Monitoring control command
✓
nm
clpnm
node map management
✓
pm
clppm
Process management
✓
rc/rc_ex
clprc
Group and group resource management
✓
reg
libclpreg.so.1.0
Reboot count control library
✓
regctrl
clpregctrl
Reboot count control command
✓
rm
clprm
Monitor management
✓
roset
clproset
Disk control
✓
relpath
clprelpath
Process kill command
✓
scrpc
clpscrpc
Script log rotation command
✓
stat
clpstat:
Status display command
✓
stdn
clpstdn
Server shutdown command
✓
toratio
clptoratio
Timeout ratio modification command
✓
trap
clptrap
SNMP trap command
✓
trncl
libclptrncl.so.1.0
Transaction library
✓
rexec
clprexec
External monitoring link processing request command
✓
trnsv
clptrnsv
Transaction server
✓
volmgrc
clpvolmgrc
VxVM disk group import/deport command
✓
alert
clpaltinsert
Alert
✓
webmgr
clpwebmc
WebManager service
✓
webalert
clpaltd
Alert synchronization
✓
exec
clpexec
Exec resource
✓
vm
clpvm
VM resource
✓
diskw
clpdiskw
Disk monitor resource
✓
ipw
clpipw
IP monitor resource
✓
miiw
clpmiiw
NIC Link Up/Down monitor resource
✓
mtw
clpmtw
Multi target monitor resource
✓
pidw
clppidw
PID monitor resource
✓
volmgrw
clpvolmgrw
Volume manager monitor resource
✓
userw
clpuserw
User mode monitor resource
✓
vmw
clpvmw
VM monitor resource
✓
mrw
clpmrw
Message reception monitor resource
✓
snmpmgr
libclp snmpmgr
SNMP trap reception library
✓
lanhb
clplanhb
LAN heartbeat
✓
oraclew
clp_oraclew
Oracle monitor resource
✓
db2w
clp_db2w
DB2 monitor resource
✓
psqlw
clp_psqlw
PostgreSQL monitor resource
✓
mysqlw
clp_mysqlw
MySQL monitor resource
✓
sybasew
clp_sybasew
Sybase monitor resource
✓
odbcw
clp_odbcw
ODBC monitor resource
✓
sqlserverw
clp_sqlserverw
SQL Server monitor resource
✓
sambaw
clp_sambaw
Samba monitor resource
✓
nfsw
clp_nfsw
NFS monitor resource
✓
httpw
clp_httpw
HTTP monitor resource
✓
ftpw
clp_ftpw
FTP monitor resource
✓
smtpw
clp_smtpw
SMTP monitor resource
✓
pop3w
clp_pop3w
POP3 monitor resource
✓
imap4w
clp_imap4w
IMAP4 monitor resource
✓
tuxw
clp_tuxw
Tuxedo monitor resource
✓
wlsw
clp_wlsw
WebLogic monitor resource
✓
wasw
clp_wasw
WebSphere monitor resource
✓
otxw
clp_otxw
WebOTX monitor resource
✓
jraw
clp_jraw
JVM monitor resource
✓
sraw
clp_sraw
System monitor resource
✓
psrw
clp_psrw
Process resource monitor resource
✓
psw
clppsw
Process name monitor resource
✓
vmctrl
libclpvmctrl.so.1.0
VMCtrl library
✓
vmwcmd
clpvmwcmd
VMW command
✓
perfc
clpperfc
Command to display cluster statistical information
✓
cfchk
clpcfchk
Command to check cluster configuration data
✓
2.11. Managing licenses (clplcnsc command)¶
the clplcnsc command manages licenses.
-
Command line - clplcnsc -i [licensefile...]clplcnsc -l [-a]clplcnsc -d serialno [-q]clplcnsc -d -t [-q]clplcnsc -d -a [-q]clplcnsc --reregister licensefile...
-
Description This command registers, refers to and remove the licenses of the product version and trial version of this product.
-
Option -
-i[licensefile...]¶ When a license file is specified, license information is acquired from the file for registration. You can specify multiple licenses. If nothing is specified, you need to enter license information interactively.
-
-l[-a]¶ - References the registered license.The name of displayed items are as follows.
Item
Explanation
Serial No
Serial number (product version only)
User name
User name (trial version only)
Key
License key
Licensed Number of CPU
The number of license (per CPU)
Licensed Number of Computers
The number of license (per node)
Start date
End date
Status
Status of the license
Status
Explanation
valid
valid
invalid
invalid
unknown
unknown
inactive
expired
- 1(1,2,3,4)
Displayed in the case of the fixed term license
- 2(1,2,3,4)
Displayed in the case of the license of trial version
When -a option not specifed, the license status of "invalid", "unknown" and "expired" are not displayed.When specifying -a option, all the licenses are displayed regardless of the license status.
-
-d<param>¶ param
- serialno
Deletes the license with the specified serial number.
- -t
Deletes all the registered licenses of the trial version.
- -a
Deletes all the registered licenses.
-
-q¶ Deletes licenses without displaying a warning message. This is used with -d option.
-
--reregisterlicensefile...¶ Reregisters a fixed-term license. Usually, it is unnecessary to execute the command with this option.
-
-
Return Value 0
Normal termination
1
Cancel
3
Initialization error
5
The option is invalid
8
Other internal error
-
Example of a command entry: for registration
Registering the license interactively
# clplcnsc -i
Product Version/Product Version (Fixed Term)
Select a product division.
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)]...
Enter a serial number.
Enter serial number [ Ex. XXXXXXXX000000]...
Enter a license key.
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX]...
Trial Version
Select a product division.
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)]...
Enter a user name.
Enter user name [ 1 to 63byte ]...
Enter a license key.
Enter license key [Ex. XXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX]...
Specify a license file
# clplcnsc -i /tmp/cpulcns.key
for referring to the license
# clplcnsc -l
Product version
< EXPRESSCLUSTER X SingleServerSafe <PRODUCT> > Seq... 1 Key..... A1234567-B1234567-C1234567-D1234567 Licensed Number of CPU... 2 Status... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Licensed Number of Computers... 1 Status... valid
Product version (fixed term)
< EXPRESSCLUSTER X SingleServerSafe <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Start date..... 2018/01/01 End date...... 2018/01/31 Status........... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Status........... inactive
Trial version
< EXPRESSCLUSTER X SingleServerSafe <TRIAL> > Seq... 1 Key..... A1234567-B1234567-C1234567-D1234567 User name... NEC Start date..... 2018/01/01 End date...... 2018/02/28 Status........... valid
for deleting the license
# clplcnsc -d AAAAAAAA000001 -q
for deleting the license
# clplcnsc -d -t -q
for deleting the license
# clplcnsc -d -a
Deletion confirmation
Are you sure to remove the license? [y/n] ...
-
Notes Run this command as the root user.
Furthermore, when you use -d option and -a option together, all the trial version licenses and product version licenses will be deleted. To delete only the trial license, also specify the -t option. If the licenses including the product license have been deleted, register the product license again.When you refer to a license which includes multiple licenses, all included licenses information are displayed.
-
Error Message Message
Cause/Solution
Processed license num(success : %d, error : %d).The number of processed licenses (success:%d, error:%d)If error is not 0, check if the license information is correct.Command succeeded.
The command ran successfully.
Command failed.
The command did not run successfully.
Log in as root.
You are not authorized to run this command. Log on as the root user.
Invalid cluster configuration data. Check the cluster configuration information.
The cluster configuration data is invalid. Check the cluster configuration data by using the Cluster WebUI.
Initialization error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
The command is already run.
The command is already running. Check the running status by using a command such as the ps command.
The license is not registered.
The license has not been registered yet.
Could not open the license file. Check if the license file exists on the specified path.
Input/Output cannot be done to the license file. Check to see if the license file exists in the specified path.
Could not read the license file. Check if the license file exists on the specified path.
Input/Output cannot be done to the license file. Check to see if the license file exists in the specified path.
The field format of the license file is invalid. The license file may be corrupted. Check the destination from where the file is sent.
The field format of the license file is invalid. The license file may be corrupted. Check it with the file sender.
The cluster configuration data may be invalid or not registered.
The cluster configuration data may be invalid or not registered. Check the configuration data.
Failed to terminate the library. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
Failed to register the license. Check if the entered license information is correct.
Check to see if the entered license information is correct.
Failed to open the license. Check if the entered license information is correct.
Check to see if the entered license information is correct.
Failed to remove the license.
License deletion failed. Parameter error may have occurred or resources (memory or OS) may not be sufficient.
This license is already registered.
This license has already been registered. Check the registered license.
This license is already activated.
This license has already been used. Check the registered license.
This license is unavailable for this product.
This license cannot be used for this product. Check the license.
The maximum number of licenses was reached.
The maximum number of registered licenses has been reached. Delete invalid licenses.
Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
2.12. Outputting messages (clplogcmd command)¶
Registers the specified message with syslog and alert logs, or reports the message by mail.
-
Command line clplogcmd -m message [--syslog] [--alert] [--mail] [-i eventID] [-l level]
Note
Generally, it is not necessary to run this command to set up or operate a server. You need to write the command in the EXEC resource script.
-
Description Write this command in the EXEC resource script and output messages you want to send to the destination.
-
Option -
-mmessage¶ - Specifies a message. This option cannot be omitted. The maximum size of message is 511 bytes. (When syslog is specified as an output destination, the maximum size is 485 bytes.) The message exceeding the maximum size will not be shown.You may use alphabets, numbers, and symbols 3 .
-
--syslog¶
-
--alert¶
-
--mail¶
-
--trap¶ - Specify the output destination from syslog, alert, mail and trap. (You can specify multiple destinations.)This parameter can be omitted. The syslog and alert will be the output destinations when the parameter is omitted.
-
-ieventID¶ - Specify an event ID. Specify event ID. The maximum value of event ID is 10,000.This parameter can be omitted. The default value 1 is set when the parameter is omitted.
-
-llevel¶ - Level of alert to output.Select a level of alert output from ERR, WARN, or INFO. The icon on the alert logs of the Cluster WebUI is determined according to the level you select here.This parameter can be omitted. The default value INFO is set to level when the parameter is omitted.For details, see the online manual.
-
-
Return Value 0
Success
Other than 0
Failure
-
Notes - This command must be executed by a user with the root privilege.When mail is specified as the output destination, you need to make the settings to send mails by using the mail command.
-
Examples - Example 1: When specifying only message (output destinations are syslog and alert):When the following is written in the EXEC resource script, the message is produced in syslog and alert.
clplogcmd -m test1
The following log is the log output in syslog:
Sep 1 14:00:00 server1 clusterpro: <type: logcmd><event: 1> test1
Example 2: When specifying message, output destination, event ID, and level (output destination is mail):When the following is written in the EXEC resource script, the message is sent to the mail address set in the Cluster Properties of the Cluster WebUI.clplogcmd -m test2 --mail -i 100 -l ERR
The following information is sent to the mail destination:Message:test2 Type: logcmd ID: 100 Host: server1 Date: 2018/09/01 14:00:00
Example 3: When specifying a message, output destination, event ID, and level (output destination is trap):When the following is written in the exec resource script, the message is set to the SNMP trap destination set in Cluster Properties of the Cluster WebUI. For more information on the SNMP trap destination settings, see "Cluster properties - Alert Service tab" in "Details of other settings" in "EXPRESSCLUSTER X SingleServerSafe Configuration Guide".clplogcmd -m test3 --trap -i 200 -l ERR
The following information is sent to the SNMP trap destination:
Trap OID: clusterEventErrorAttached data 1: clusterEventMessage = test3Attached data 2: clusterEventID = 200Attached data 3: clusterEventDateTime = 2011/08/01 09:00:00Attached data 4: clusterEventServerName = server1Attached data 5: clusterEventModuleName = logcmd
- 3
Notes on using symbols in the message:
The symbols below must be enclosed in double quotes (""):
# & ' ( ) ~ | ; : * < > , .(For example, if you specify "#" in the message, # is produced.)The symbols below must have a backslash \ in the beginning:
\ ! " & ' ( ) ~ | ; : * < > , .(For example, if you specify \\ in the message, \ is produced.)The symbol that must be enclosed in double quotes ("") and have a backslash \ in the beginning:
`(For example, if you specify "\" in the message, ` is produced.)When there is a space in the message, it must be placed in enclosed in double quotes ("").
The symbol % cannot be used in the message.
2.13. Controlling monitor resources (clpmonctrl command)¶
Controls the monitor resources.
-
Command line - clpmonctrl -s [-m resource_name] [-w wait_time]clpmonctrl -r [-m resource_name] [-w wait_time]clpmonctrl -c [-m resource_name]clpmonctrl -v [-m resource_name]clpmonctrl -e -m resource_nameclpmonctrl -n [-m resource_name]
-
Description Suspends and/or resumes monitor resources.
-
Option -
-s¶ Suspends monitoring.
-
-r¶ Resumes monitoring.
-
-c¶ Resets the times counter of the recovery action.
-
-v¶ Displays the times counter of the recovery action.
-
-e¶ Enables the Dummy Failure. Be sure to specify a monitor resource name with the -m option.
-
-n¶ Disables the Dummy Failure. When a monitor resource name is specified with the -m option, the function is disabled only for the resource. When the -m option is omitted, the function is disabled for all monitor resources.
-
-mresource_name¶ - Specifies a monitor resource to be controlled.This option can be omitted. All monitor resources are controlled when the option is omitted.
-
-wwait_time¶ - Waits for control monitoring on a monitor resource basis. (in seconds)This option can be omitted. The default value 5 is set when the option is omitted.
-
-
Return Value 0
Completed successfully.
1
Privilege for execution is invalid
2
The option is invalid
3
Initialization error
4
The configuration data is invalid.
5
Monitor resource is not registered.
6
The specified monitor resource is invalid
10
EXPRESSCLUSTER is not running.
11
The cluster daemon is suspended
90
Monitoring control wait timeout
128
Duplicated activation
255
Other internal error
-
Examples Example 1: When suspending all monitor resources:
# clpmonctrl -s Command succeeded.
Example 2: When resuming all monitor resources:
# clpmonctrl -r Command succeeded.
-
Remarks If you suspend an already suspended monitor resource or resume an already started one, this command abends without changing the status of the monitor resource.
-
Notes - This command must be executed by a user with the root privilege.Check the status of monitor resource by using the status display command or Cluster WebUI.Before you run this command, use the clpstat command or Cluster WebUI to verify that the status of monitor resources is in either "Online" or "Suspend."When the recovery action of monitor resource uses one of the following settings, "Final Action Count" (which is displayed in the -v option) indicates the number of times to execute a script before the final action.
Execute Script Before Final Action: Enable
Final action: No Operation
-
Error Messages Message
Causes/Solution
Command succeeded.
The command ran successfully.
Log in as root.
You are not authorized to run this command. Log on as root user.
Initialization error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
Invalid cluster configuration data. Check the cluster configuration information.
The cluster configuration data is invalid. Check the cluster configuration data by using the Cluster WebUI.
Monitor resource is not registered.
The monitor resource is not registered.
Specified monitor resource is not registered. Check the cluster configuration information.The specified monitor resource is not registered.Check the cluster configuration data by using the Cluster WebUI.The cluster has been stopped. Check the active status of the cluster daemon by using the command such as ps command.The cluster has been stopped.Check the activation status of the cluster daemon by using a command such as ps command.The cluster has been suspended. The cluster daemon has been suspended. Check activation status of the cluster daemon by using a command such as the ps command.
The cluster daemon has been suspended. Check the activation status of the cluster daemon by using a command such as ps command.
Waiting for synchronization of the cluster. The cluster is waiting for synchronization. Wait for a while and try again.Synchronization of the cluster is awaited.Try again after cluster synchronization is completed.Monitor %1 was unregistered, ignored. The specified monitor resources %1 is not registered, but continue processing. Check the cluster configuration data.There is an unregistered monitor resource in the specified monitor resources but it is ignored and the process is continued.Check the cluster configuration data by using the Cluster WebUI.%1: Monitor resource nameMonitor %1 denied control permission, ignored. but continue processing.The specified monitor resources contain the monitor resource which cannot be controlled, but it does not affect the process.%1: Monitor resource nameThis command is already run.
The command is already running. Check the running status by using a command such as ps command.
Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
-
Monitor resource types that can be specified for the -m option - TypeSuspending/resuming monitoringResetting the times counter of the recovery actionEnabling/disablingDummy Failure
diskw
✓
✓
✓
ipw
✓
✓
✓
miiw
✓
✓
✓
mtw
✓
✓
✓
pidw
✓
✓
✓
volmgrw
✓
✓
✓
userw
✓
✓
n/a
vmw
✓
✓
n/a
mrw
✓
✓
n/a
genw
✓
✓
✓
oraclew
✓
✓
✓
db2w
✓
✓
✓
psqlw
✓
✓
✓
mysqlw
✓
✓
✓
sybasew
✓
✓
✓
odbcw
✓
✓
✓
sqlserverw
✓
✓
✓
sambaw
✓
✓
✓
nfsw
✓
✓
✓
httpw
✓
✓
✓
ftpw
✓
✓
✓
smtpw
✓
✓
✓
pop3w
✓
✓
✓
imap4w
✓
✓
✓
tuxw
✓
✓
✓
wlsw
✓
✓
✓
wasw
✓
✓
✓
otxw
✓
✓
✓
jraw
✓
✓
✓
sraw
✓
✓
✓
psrw
✓
✓
✓
psw
✓
✓
✓
2.14. Controlling group resources (clprsc command)¶
Controls group resources.
-
Command line - clprsc -s resource_name [-f] [--apito timeout]clprsc -t resource_name [-f] [--apito timeout]
-
Description Starts and stops group resources.
-
Option -
-s¶ Starts group resources.
-
-t¶ Stops group resources.
-
-f¶ - When the group resource is online, all group resources that the specified group resource depends starts up.When the group resource is offline, all group resources that the specified group resource depends stop.
-
--apitotimeout¶ - Specify the interval (internal communication timeout) to wait for the group resource start or stop in seconds. A value from 1 to 9999 can be specified.If the --apito option is not specified, waiting for the group resource start or stop is performed according to the value set to the internal communication timeout of the cluster properties.
-
-
Return Value 0
Completed successfully.
Other than 0
Terminated due to a failure.
-
Examples Group resource configuration
# clpstat ========== CLUSTER STATUS ========== Cluster : cluster <server> server1 : Online lanhb1 : Normal lanhb2 : Normal <group> ManagementGroup : Online current : server1 ManagementIP : Online failover1 : Online current : server1 exec1 : Online <monitor> ipw1 : Normal ==================================Example 1: When stopping the resource (exec1) of the group (failover1)
# clprsc -t exec1 Command succeeded. # clpstat ========== CLUSTER STATUS ========== <Abbreviation> <group> ManagementGroup: Online Current: server1 ManagementIP: Online failover1: Online current: server1 exec1: Offline <Abbreviation>
Example 2: When starting the resource (fip1) of the group(failover 1)
# clprsc -s exec1 Command succeeded. # clpstat ========== CLUSTER STATUS ========== <Abbreviation> <group> ManagementGroup: Online Current: server1 ManagementIP: Online failover1: Online current: server1 exec1: Online <Abbreviation>
-
Notes - This command must be executed by a user with the root privilege.Check the status of the group resources by the status display or the Cluster WebUI.
-
Error Messages Message
Causes/Solution
Log in as Administrator.
Run this command as a user with Administrator privileges.
Invalid cluster configuration data. Check the cluster configuration information.
The cluster construction information is not correct. Check the cluster construction information by Cluster WebUI.
Invalid option.
Specify a correct option.
Could not connect server. Check if the cluster service is active.
Check if the EXPRESSCLUSTER is activated.
Invalid server status. Check if the cluster service is active.
Check if the EXPRESSCLUSTER is activated.
Server is not active. Check if the cluster service is active.
Check if the EXPRESSCLUSTER is activated.
Invalid server name. Specify a valid server name in the cluster.
Specify a correct server name in the cluster.
Connection was lost. Check if there is a server where the cluster service is stopped in the cluster.
Check if there is any server with EXPRESSCLUSTER service stopped in the cluster.
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.The group resource is busy. Try again later.Timeout has occurred in internal communication in the EXPRESSCLUSTER.Set the internal communication timeout longer if this error occurs frequently.Because the group resource is in the process of starting or stopping, wait for a while and try again.An error occurred on group resource. Check the status of group resource.
Check the group resource status by using the Cluster WebUI or the clpstat command.
Could not start the group resource. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
Wait until the other server starts or the wait time times out, and then start the group resources.
No operable group resource exists in the server.
Check there is a processable group resource on the specified server.
The group resource has already been started on the local server.
Check the group resource status by using the Cluster WebUI or clpstat command.
The group resource has already been started on the other server.Check the group resource status by using the Cluster WebUI or clpstat command.Stop the group to start the group resources on the local server.The group resource has already been stopped.
Check the group resource status by using the Cluster WebUI or clpstat command.
Failed to start group resource. Check the status of group resource.
Check the group resource status by using the Cluster WebUI or clpstat command.
Failed to stop resource. Check the status of group resource.
Check the group resource status by using the Cluster WebUI or clpstat command.
Depended resource is not offline. Check the status of resource.
Because the status of the depended group resource is not offline, the group resource cannot be stopped. Stop the depended group resource or specify the -f option.
Depending resource is not online. Check the status of resource.
Because the status of the depended group is not online, the group resource cannot be started. Start the depended group resource or specify the -f option.
Invalid group resource name. Specify a valid group resource name in the cluster.
The group resource is not registered.
Server is not in a condition to start resource or any critical monitor error is detected.Check the group resource status by using the Cluster WebUI or clpstat command.An error is detected in a critical monitor on the server on which an attempt to start a group resource was made.Internal error. Check if memory or OS resources are sufficient.
Memory or OS resources may be insufficient. Check them.
2.15. Controlling CPU frequency (clpcpufreq command)¶
Controls CPU frequency.
-
Command line - clpcpufreq --highclpcpufreq --lowclpcpufreq -iclpcpufreq -s
-
Description Enables or disables power-saving mode by CPU frequency control.
-
Option -
--high¶ Sets the highest CPU frequency.
-
--low¶ Sets the lowest CPU frequency to switch to the power-saving mode.
-
-i¶ Passes the CPU frequency control to EXPRESSCLUSTER X SingleServerSafe.
-
-s¶ Displays the current CPU frequency level.
performance: The CPU frequency is at its highest.
powersave: Frequency is lowered and power-saving mode is set.
-
-
Return Value 0
Completed successfully.
Other than 0
Terminated due to a failure.
-
Remarks - If the driver for CPU frequency control is not loaded, an error occurs.If the Use CPU Frequency Control checkbox is not selected in the power saving settings in server properties, this command results in error.
-
Notes - This command must be executed by a user with the root privilege.When you use CPU frequency control, it is required that frequency is changeable in the BIOS settings, and that the CPU supports frequency control by Windows OS power management function.
-
Error Messages Message
Cause/Solution
Log in as root.
Log in as root user.
This command is already run.
This command has already been run.
Invalid option.
Specify a valid option.
Invalid mode.Check if --high or --low or -i or -s option is specified.Check if either of the --high, --low, -I or -s option is specified.Failed to initialize the xml library.Check if memory or OS resources are sufficient.Check to see if the memory or OS resource is sufficient.Failed to load the configuration file.Check if memory or OS resources are sufficient.Check to see if the memory or OS resource is sufficient.Failed to load the all.pol file.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to load the cpufreq.pol file.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to get the install path.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to get the cpufreq path.Reinstall the RPM.Reinstall the EXPRESSCLUSTER Server RPM.Failed to initialize the apicl library.Reinstall the RPM.Check to see if the memory or OS resource is sufficient.Failed to change CPU frequency settings.Check the BIOS settings and the OS settings.Check if the cluster is started.Check if the setting is configured so that CPU frequencycontrol is used.Check the BIOS settings and the OS settings.Check if the cluster service is started.Check if the setting is configured so that CPU frequency control is used.Failed to acquire CPU frequency settings.Check the BIOS settings and the OS settings.Check if the cluster is started.Check if the setting is configured so that CPU frequencycontrol is used.Check the BIOS settings and the OS settings.Check if the cluster service is started.Check if the setting is configured so that CPU frequency control is used.Internal error. Check if memory or OS resources are sufficient.
Check if the memory or OS resource is sufficient.
2.16. Processing inter-cluster linkage (clptrnreq command)¶
The clptrnreq command requests a server to execute a process.
-
Command line clptrnreq -t request_code -h IP [-r resource_name] [-s script_file] [-w timeout]
-
Description The command issues the request to execute specified process to the server in another cluster.
-
Option -
-trequest_code¶ - Specifies the request code of the process to be executed. The following request codes can be specified:GRP_FAILOVER Group failoverEXEC_SCRIPT Execute script
-
-hIP¶ - Specifies the server to issue the request to execute the process with IP address. You can specify more than one server by separating by commas.When you specify group failover for request code, specify the IP addresses of all the servers in the cluster.
-
-rresource_name¶ - Specifies the resource name which belongs to the target group for the request for process when GRP_FAILOVER is specified for request code.If GRP_FAILOVER is specified, -r cannot be omitted.
-
-sscript_file¶ - Specifies the file name of the script to be executed (e.g. batch file or executable file) when EXEC_SCRIPT is specified for request code. The script needs to be created in the worktrnreq folder in the folder where EXPRESSCLUSTER is installed in each server specified with -h.If EXEC_SCRIPT is specified, -s cannot be omitted.
-
-wtimeout¶ - Specifies the timeout value of the command by the second.If the -w option is not specified, the command waits 30 seconds.
-
-
Return Value 0
Completed successfully.
Other than 0
Terminated due to a failure.
-
Notes This command must be executed by a user with the root privilege.
-
Examples Example 1: When performing a failover on the group having the exec1 resource of another cluster
# clptrnreq -t GRP_FAILOVER -h 10.0.0.1,10.0.0.2 -r exec1 Command succeeded.
Example 2: When executing the scrpit1.bat script by the server with IP address 10.0.0.1
# clptrnreq -t EXEC_SCRIPT -h 10.0.0.1 -s script1.sh Command Succeeded.
-
Error Messages Message
Cause/solution
Log in as root.
Log in as root user.
Invalid option.
The command line option is invalid. Specify the correct option.
Could not connect to the data transfer server.Check if the server has started up.Check if the server has started up.Could not connect to all data transfer servers.Check if the servers have started up.Check if all the servers in the cluster have started up.Command timeout.
The cause may be heavy load on OS and so on. Check this.
All servers are busy. Check if this command is already run.
This command may be run already. Check it.
GRP_FAILOVER %s : Group that specified resource(%s) belongs to is offline.
Failover process is not performed because the group to which the specified resource belongs is not started.
EXEC_SCRIPT %s : Specified script(%s) does not exist.The specified script does not exist.Check it.EXEC_SCRIPT %s : Specified script(%s) is not executable.The specified script could not be executed.Check that execution is permitted.%s %s : This server is not permitted to execute clptrnreq.
The server that executed the command does not have permission. Check that the server is registered to the connection restriction IP list of Cluster WebUI.
GRP_FAILOVER %s : Specified resource(%s) does not exist.The specified resource does not exist.Check it.%s %s : %s failed in execute.
request failed in execute.
Internal error. Check if memory or OS resource is sufficient.
Check if the memory or OS resource is sufficient.
2.17. Requesting processing to cluster servers (clprexec command)¶
Issues a processing execution request to another server on which EXPRESSCLUSTER is installed.
-
Command line - clprexec --failover [group_name] -h IP [-r resource_name] [-w timeout] [-p port_number] [-o logfile_path]clprexec --script script_file -h IP [-p port_number] [-w timeout] [-o logfile_path]clprexec --notice [mrw_name] -h IP [-k category[.keyword]] [-p port_number] [-w timeout] [-o logfile_path]clprexec --clear [mrw_name] -h IP [-k category[.keyword]] [-p port_number] [-w timeout] [-o logfile_path]
-
Description This command is an expansion of the existing clptrnreq command and has additional functions such as issuing a processing request (error message) from the external monitor to the EXPRESSCLUSTER server.
-
Option -
--failover¶ - Requests group failover. Specify a group name for group_name.When not specifying the group name, specify the name of a resource that belongs to the group by using the -r option.
-
--scriptscript_name¶ - Requests script execution.For script_name, specify the file name of the script to execute (such as a shell script or executable file).The script must be created in the work/rexec folder, which is in the folder where EXPRESSCLUSTER is installed, on each server specified using -h.
-
--notice¶ - Sends an error message to the EXPRESSCLUSTER server.Specify a message reception monitor resource name for mrw_name.When not specifying the monitor resource name, specify the category and keyword of the message reception monitor resource by using the -k option.
-
--clear¶ - Requests changing the status of the message reception monitor resource from "Abnormal" to "Normal."Specify a message reception monitor resource name for mrw_name.When not specifying the monitor resource name, specify the category and keyword of the message reception monitor resource by using the -k option.
-
-hIP Address¶ - Specify the IP addresses of EXPRESSCLUSTER servers that receive the processing request.Up to 32 IP addresses can be specified by separating them with commas.* If this option is omitted, the processing request is issued to the local server.
-
-rresource_name¶ Specify the name of a resource that belongs to the target group for the processing request when the --failover option is specified.
-
-kcategory[.keyword]¶ - For category, specify the category specified for the message receive monitor when the --notice or --clear option is specified.To specify the keyword of the message receive monitor resource, specify them by separating them with dot after category.
-
-pport_number¶ - Specify the port number.For port_number, specify the data transfer port number specified for the server that receives the processing request.The default value, 29002, is used if this option is omitted.
-
-ologfile_path¶ - In logfile_path, specify the path of the file to which to output the detailed log of this command.The file contains the log of one command execution.* If this option is not specified on a server where EXPRESSCLUSTER is not installed, the log is always output to the standard output.
-
-wtimeout¶ - Specify the command timeout time. The default, 180 seconds, is used if this option is not specified.A value from 5 to MAXINT can be specified.
-
-
Return Value 0
Completed successfully.
Other than 0
Terminated due to a failure.
-
Notes - When issuing error messages by using the clprexec command, the message reception monitor resources for which executing an action when an error occurs is specified in EXPRESSCLUSTER server must be registered and started.The server that has the IP address specified for the -h option must satisfy the following conditions:= EXPRESSCLUSTER X 3.0 or later must be installed.= EXPRESSCLUSTER must be running.(When an option other than --script is used)= mrw must be set up and running.(When the --notice or --clear option is used)When using the Limiting the access by using client IP addresses function, add the IP address of the device in which the clprexec command is executed to the IP Addresses of the Accessible Clients list.For details of the Limiting the access by using client IP addresses function, see "WebManager tab" of "Cluster properties" in "Details of other settings" in the EXPRESSCLUSTER X SingleServerSafe Configuration Guide.
-
Examples Example 1: This example shows how to issue a request to fail over the group failover1 to EXPRESSCLUSTER server 1 (10.0.0.1):
# clprexec --failover failover1 -h 10.0.0.1 -p 29002
Example 2: This example shows how to issue a request to fail over the group to which the group resource (exec1) belongs to EXPRESSCLUSTER server 1 (10.0.0.1):
# clprexec --failover -r exec1 -h 10.0.0.1
Example 3: This example shows how to issue a request to execute the script (script1.sh) on EXPRESSCLUSTER server 1 (10.0.0.1):
# clprexec --script script1.sh -h 10.0.0.1
Example 4: This example shows how to issue an error message to EXPRESSCLUSTER server 1 (10.0.0.1):
* mrw1 set, category: earthquake, keyword: scale3
This example shows how to specify a message receive monitor resource name:
# clprexec --notice mrw1 -h 10.0.0.1 -w 30 -p /tmp/clprexec/ lprexec.log
This example shows how to specify the category and keyword specified for the message receive monitor resource:
# clprexec --notice -h 10.0.0.1 -k earthquake.scale3 -w 30 -p /tmp/clprexec/clprexec.log
Example 5: This example shows how to issue a request to change the monitor status of mrw1 to EXPRESSCLUSTER server 1 (10.0.0.1):
* mrw1 set, category: earthquake, keyword: scale3
This example shows how to specify a message receive monitor resource name:
# clprexec --clear mrw1 -h 10.0.0.1
This example shows how to specify the category and keyword specified for the message receive monitor resource:
# clprexec --clear -h 10.0.0.1 -k earthquake.scale3
-
Error Messages Message
Cause/solution
rexec_ver:%s
-
%s %s : %s succeeded.
-
%s %s : %s will be executed from now.
Check the processing result on the server that received the request.
%s %s : Group Failover did not execute because Group(%s) is offline.
-
%s %s : Group migration did not execute because Group(%s) is offline.
-
Invalid option.
Check the command argument.
Could not connect to the data transfer servers. Check if the servers have started up.
Check whether the specified IP address is correct and whether the server that has the IP address is running.
Command timeout.
Check whether the processing is complete on the server that has the specified IP address.
All servers are busy.Check if this command is already run.
This command might already be running. Check whether this is so.
%s %s : This server is not permitted to execute clprexec.
Check whether the IP address of the server that executes the command is registered in the list of client IP addresses that are not allowed to connect to the Cluster WebUI.
%s %s : Specified monitor resource(%s) does not exist.
Check the command argument.
%s failed in execute.
Check the status of the EXPRESSCLUSTER server that received the request.
2.18. Changing BMC information (clpbmccnf command)¶
Changes the information on BMC user name and password.
-
Command line clpbmccnf [-u username] [-p password]
-
Description Changes the user name/password for the LAN access of the baseboard management controller (BMC) used by EXPRESSCLUSTER.
-
Option -
-uusername¶ - Specifies the user name for BMC LAN access used by EXPRESSCLUSTER. A user name with root privilege needs to be specified.The -u option can be omitted. Upon omission, when the -p option is specified, the value currently set for user name is used. If there is no option specified, it is configured interactively.
-
-ppassword¶ Specifies the password for BMC LAN access used by EXPRESSCLUSTER. The -p option can be omitted. Upon omission, when the -u option is specified, the value currently set for password is used. If there is no option specified, it is configured interactively.
-
-
Return Value 0
Completed successfully.
Other than 0
Terminated due to a failure.
-
Notes - This command must be executed by a user with the root privilege.Execute this command when the server is in normal status.BMC information update by this command is enabled when the server is started/resumed next time.This command does not change the BMC settings. Use a tool attached with the server or other tools in conformity with IPMI standard to check or change the BMC account settings.
-
Examples When you changed the IPMI account password of the BMC in server1 to mypassword, execute the following on server1:
# clpbmccnf -p mypassword
Alternatively, enter the data interactively as follows:
# clpbmccnf New user name: <- If there is no change, press Return to skip New password: ************** Retype new password: ************** Cluster configuration updated successfully.
-
Error Messages Message
Cause/solution
Log in as root
Log in as root user.
Invalid option.
The command line option is invalid. Specify the correct option.
Failed to download the cluster configuration data. Check if the cluster status is normal.
Downloading the cluster configuration data has been failed. Check if the cluster status is normal.
Failed to upload the cluster configuration data. Check if the cluster status is normal.
Uploading the cluster configuration data has been failed. Check if the cluster status is normal.
Invalid configuration file. Create valid cluster configuration data.
The cluster configuration data is invalid. Check the cluster configuration data by using the Cluster WebUI.
Internal error. Check if memory or OS resources are sufficient.
Check if the memory or OS resource is sufficient.
2.19. Controlling reboot count (clpregctrl command)¶
Controls reboot count limitation.
-
Command line - clpregctrl --getclpregctrl -gclpregctrl --clear -t type -r registryclpregctrl -c -t type -r registry
-
Description Displays or initializes the reboot count on a server.
-
Option -
-g,--get¶ Displays reboot count information.
-
-c,--clear¶ Initializes reboot count.
-
-ttype¶ Specifies the type to initialize the reboot count. The type that can be specified is rc or rm.
-
-rregistry¶ Specifies the registry name. The registry name that can be specified is haltcount.
-
-
Return Value 0
Completed successfully.
1
Privilege for execution is invalid
2
Duplicated activation
3
The option is invalid
4
The configuration data is invalid.
10 to 17
Internal Error
20 to 22
Obtaining reboot count information has failed.
90
Allocating memory has failed.
91
Changing the work directory as failed.
-
Examples Display of reboot count information
# clpregctrl -g ****************************** ------------------------- type : rc registry : haltcount comment : halt count kind : int value : 0 default : 0 ------------------------- type : rm registry : haltcount comment : halt count kind : int value : 3 default : 0 ****************************** Command succeeded.(code:0) #
The reboot count is initialized in the following examples.
Example1: When initializing the count of reboots caused by group resource error:
# clpregctrl -c -t rc -r haltcount Command succeeded.(code:0) #
Example2: When initializing the count of reboots caused by monitor resource error:
# clpregctrl -c -t rm -r haltcount Command succeeded.(code:0) #
-
Notes This command must be executed by a user with the root privilege.
-
Error Messages Message
Causes/Solution
Command succeeded.
The command ran successfully.
Log in as root.
You are not authorized to run this command. Log on as root user.
The command is already executed. Check the execution state by using the "ps" command or some other command.
The command is already running. Check the running status by using a command such as ps command.
Invalid option.
Specify a valid option.
Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
2.20. Estimating the amount of resource usage (clpprer command)¶
Estimates the future value from the transition of the resource use amount data listed in the input file, and then outputs the estimate data to a file. Also, the result of threshold judgment on the estimate data can be confirmed.
-
Command line clpprer -i inputfile -o outputfile [-p number] [-t number [-l]]
-
Description Estimates the future value from the tendency of the given resource use amount data.
-
Option -
-iinputfile¶ Specifies the resource data for which a future value is to be obtained.
-
-ooutputfile¶ Specifies the name of the file to which the estimate result is output.
-
-pnumber¶ - Specifies the number of estimate data items.If omitted, 30 items of estimate data are obtained.
-
-tnumber¶ Specifies the threshold to be compared with the estimate data.
-
-l¶ Valid only when the threshold is set with the -t option. Judges the status to be an error when the data value is less than the threshold.
-
-
Return Value 0
Normal end without threshold judgment
1
Error occurrence
2
As a result of threshold judgment, the input data is determined to have exceeded the threshold.
3
As a result of threshold judgment, the estimate data is determined to have exceeded the threshold.
4
As a result of threshold judgment, the data is determined to have not exceeded the threshold.
5
If the number of data items to be analyzed is less than the recommended number of data items to be analyzed (120), the input data is determined to have exceeded the threshold as a result of threshold judgment.
6
If the number of data items to be analyzed is less than the recommended number of data items to be analyzed (120), the estimate data is determined to have exceeded the threshold as a result of threshold judgment.
7
If the number of data items to be analyzed is less than the recommended number of data items to be analyzed (120), the data is determined to have not exceeded the threshold as a result of threshold judgment.
-
Notes - This command can be used only when the license for the system monitor resource (System Resource Agent) is registered. (If the license is registered, you do not have to set up the system monitor resource when configuring a cluster.)The maximum number of input data items of the resource data file specified with the -i option is 500. A certain number of input data items are required to estimate the amount of resource usage. However, if the number of input data items is large, it takes a considerable amount of time to perform the analysis. So, it is recommended that the number of input data items be restricted to about 120. Moreover, the maximum number of output data items that can be specified in option -p is 500.If the time data for the input file is not arranged in ascending order, the estimate will not be appropriate. In the input file, therefore, set the time data arranged in ascending order.
-
Input file - The input file format is explained below. Prepare an input file which contains the resource usage data for which to obtain an estimate, in the following format.The input file format is CSV. One piece of data is coded in the form of date and time, numeric value.Moreover, the data and time format is YYYY/MM/DD hh:mm:ss.
File example
2012/06/14 10:00:00,10.0 2012/06/14 10:01:00,10.5 2012/06/14 10:02:00,11.0
-
Examples The estimation of the future value is explained using a simple example.
When an error is detected in the input data:
If the latest value of the input data exceeds the threshold, an error is assumed and a return value of 2 is returned. If the number of input data items is less than the recommended value (=120), a return value of 5 is returned.
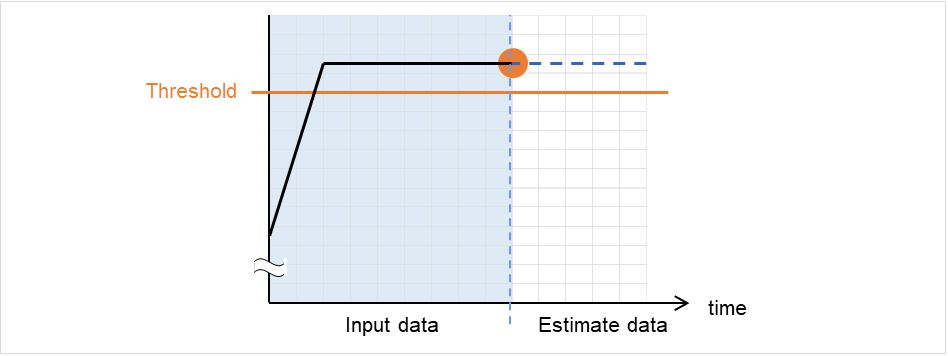
Fig. 2.3 Error detection in the input data¶
When an error is detected in the estimate data:
If the estimate data exceeds the threshold, an error is assumed and a return value of 3 is returned. If the number of input data items is less than the recommended value (=120), a return value of 6 is returned.
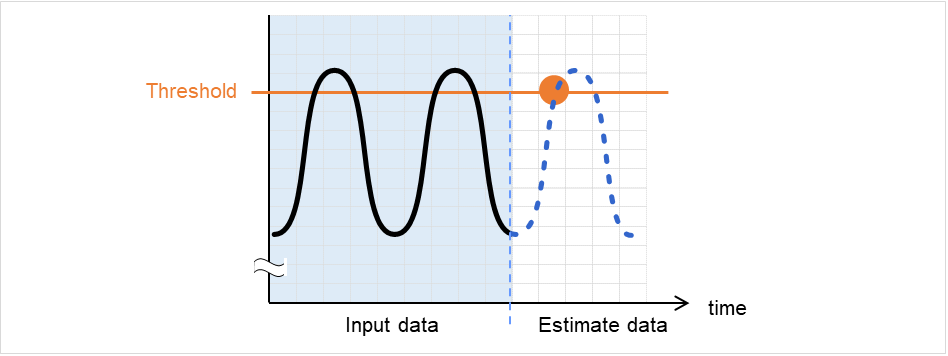
Fig. 2.4 Error detection in the estimate data¶
When no threshold error is detected:
If neither the input data nor the estimate data exceeds the threshold, a return value of 4 is returned. If the number of input data items is less than the recommended value (=120), a return value of 7 is returned.
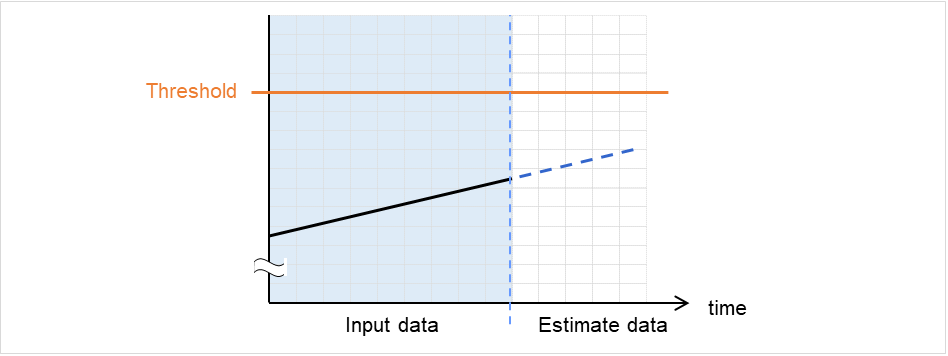
Fig. 2.5 When no threshold error is detected¶
When the -l option is used:
If the -l option is used, an error is assumed when the data is less than the threshold.
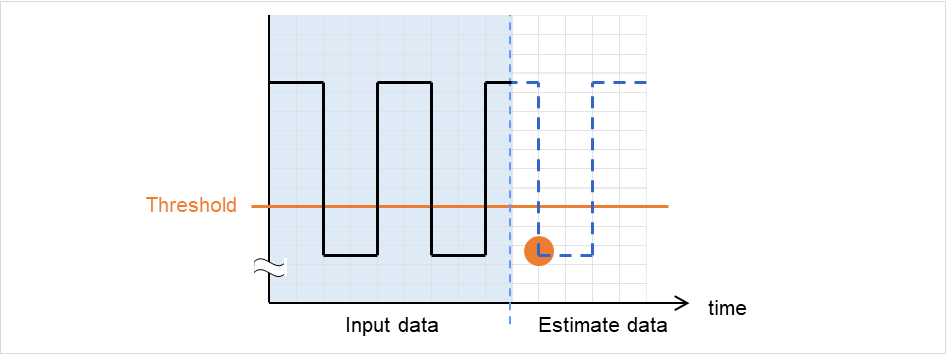
Fig. 2.6 Use of the -l option¶
-
Examples Prepare a file which contains data in the specified format, and then execute the clpprer command. The estimate result can be confirmed as the output file.
Input file: test.csv
2012/06/14 10:00:00,10.0 2012/06/14 10:01:00,10.5 2012/06/14 10:02:00,11.0
# clpprer -i test.csv -o result.csv
Output result: result.csv
2012/06/14 10:03:00,11.5 2012/06/14 10:04:00,12.0 2012/06/14 10:05:00,12.5 2012/06/14 10:06:00,13.0 2012/06/14 10:07:00,13.5 :
Also, by specifying a threshold as an option, you can confirm the threshold judgment result for the estimate at the command prompt.
# clpprer -i test.csv -o result.csv -t 12.5
Execution result
Detect over threshold. datetime = 2012/06/14 10:06:00, data = 13.00, threshold = 12.5
-
Error Messages Message
Causes/Solution
Normal state.
As a result of threshold judgment, no data exceeding the threshold is detected.
Detect over threshold. datetime = %s, data = %s, threshold = %s
As a result of threshold judgment, data exceeding the threshold is detected.
Detect under threshold. datetime = %s, data = %s, threshold = %s
As a result of threshold judgment with the -l option, data less than the threshold is detected.
License is nothing.
The license for the valid System Resource Agent is not registered. Check to see the license.
Inputfile is none.
The specified input data file does not exist.
Inputfile length error.
The path for the specified input data file is too long. Specify no more than 1023 bytes.
Output directory does not exist.
The directory specified with the output file does not exist. Check whether the specified directory exists.
Outputfile length error.
The path for the specified output file is too long. Specify no more than 1023 bytes.
Invalid number of -p.
The value specified in the -p option is invalid.
Invalid number of -t.
The value specified in the -t option is invalid.
Not analyze under threshold(not set -t) .
The -t option is not specified. When using the -I option, also specify the -t option.
File open error [%s]. errno = %s
The file failed to open. The amount of memory or OS resources may be insufficient. Check for any insufficiency.
Inputfile is invalid. cols = %s
The number of input data items is not correct. Set the number of input data items to 2 or more.
Inputfile is invalid. rows = %s
The input data format is incorrect. One line needs to be divided into two rows.
Invalid date format. [expected YYYY/MM/DD HH:MM:SS]
The date of the input data is not of the correct format. Check to see the data.
Invalid date format. Not sorted in ascending order.
Input data is not arranged in ascending order of date and time. Check the data.
File read error.
An invalid value is set in the input data. Check the data.
Too large number of data [%s]. Max number of data is %s.
The number of input data items exceeds the maximum value (500). Reduce the number of data items.
Input number of data is smaller than recommendable number.The number of input data items is less than the recommended number of data items to be analyzed (120).* Data is analyzed even if the recommended number of data items to be analyzed is small.Internal error.
An internal error has occurred.
2.21. Checking the process health (clphealthchk command)¶
Checks the process health.
-
Command line clphealthchk [ -t pm | -t rc | -t rm | -t nm | -h]
Note
This command must be run on the server whose process health is to be checked because this command checks the process health of a single server.
-
Description This command checks the process health of a single server.
-
Option -
None¶ Checks the health of all of pm, rc, rm, and nm.
-
-t<process>¶ process
- pm
Checks the health of pm.
- rc
Checks the health of rc.
- rm
Checks the health of rm.
- nm
Checks the health of nm.
-
-h¶ Displays the usage.
-
-
Return Value
0 |
Normal termination |
1 |
Privilege for execution is invalid |
2 |
Duplicated activation |
3 |
Initialization error |
4 |
The option is invalid |
10 |
The process stall monitoring function has not been enabled. |
11 |
The cluster is not activated (waiting for the cluster to start or the cluster has been stopped.) |
12 |
The cluster daemon is suspended |
100 |
There is a process whose health information has not been updated within a certain period. If the -t option is specified, the health information of the specified process is not updated within a certain period. |
255 |
Other internal error |
-
Examples Example 1: When the processes are healthy
# clphealthchk pm OK rc OK rm OK nm OK
Example 2: When clprc is stalled
# clphealthchk pm OK rc NG rm OK nm OK # clphealthchk -t rc rc NG
Example 3: When the cluster has been stopped
# clphealthchk The cluster has been stopped
-
Remarks If the cluster has been stopped or suspended, the process is also stopped.
-
Notes Run this command as the root user.
-
Error Messages Message
Cause/Solution
Log in as root.
You are not authorized to run this command. Log on as the root user.
Initialization error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
Invalid option.
Specify a valid option.
The function of process stall monitor is disabled.
The process stall monitoring function has not been enabled.
The cluster has been stopped.
The cluster has been stopped.
The cluster has been suspended.
The cluster has been suspended.
This command is already run.
The command has already been started. Check the running status by using a command such as ps command.
Internal error. Check if memory or OS resources are sufficient.
Check to see if the memory or OS resource is sufficient.
2.22. Displaying the cluster statistics information (clpperfc command)¶
the clpperfc command displays the cluster statistics information.
-
Command line - clpperfc --starttime -g group_nameclpperfc --stoptime -g group_nameclpperfc -g [group_name]clpperfc -m monitor_name
-
Description This command displays the median values (millisecond) of the group start time and group stop time.
This command displays the monitoring processing time (millisecond) of the monitor resource.
-
Option -
--starttime-g group_name¶ Displays the median value of the group start time.
-
--stoptime-g group_name¶ Displays the median value of the group stop time.
-
-g[group_name]¶ Displays the each median value of the group start time and group stop time.
If groupname is omitted, it displays the each median value of the start time and stop time of all the groups.
-
-mmonitor_name¶ Displays the last monitor processing time of the monitor resource.
-
-
Return value 0
Normal termination
1
Invalid command option
2
User authentication error
3
Configuration information load error
4
Configuration information load error
5
Initialization error
6
Internal error
7
Internal communication initialization error
8
Internal communication connection error
9
Internal communication processing error
10
Target group check error
12
Timeout error
-
Example of Execution (when displaying the median value of the group start time) # clpperfc --starttime -g failover1 200
-
Example of Execution (when displaying each median value of the start time and stop time of the specific group) # clpperfc -g failover1 start time stop time failover1 200 150
-
Example of Execution (when displaying the monitor processing time of the monitor resource) # clpperfc -m monitor1 100
-
Remarks The time is output in millisecond by this commands.
If the valid start time or stop time of the group was not obtained, - is displayed.
If the valid monitoring time of the monitor resource was not obtained, 0 is displayed.
-
Notes Execute this command as a root user.
-
Error Messages Message
Cause/Solution
Log in as root.
Run this command as the root user.
Invalid option.
The command option is invalid. Check the command option.
Command timeout.
Command execution timed out .
Internal error.
Check if memory or OS resources are sufficient.
2.23. Checking the cluster configuration information (clpcfchk command)¶
This command checks the cluster configuration information.
-
Command line - clpcfchk -o path [-i conf_path]
-
Description This command checks the validness of the setting values based on the cluster configuration information.
-
Option -
-opath¶ Specifies the directory to store the check results.
-
-iconf_path¶ Specifies the directory which stored the configuration information to check.
If this option is omitted, the applied configuration information is checked.
-
-
Return Value 0
Normal termination
Other
than 0 Termination with an error
-
Example of Execution (when checking the applied configuration information) # clpcfchk -o /tmp server1 : PASS
-
Example of Execution (when checking the stored configuration information) # clpcfchk -o /tmp -i /tmp/config server1 : PASS
-
Execution Result For this command, the following check results (total results) are displayed.
Check Results (Total Results)
Description
PASS
No error found.
FAIL
An error found.Check the check results.
-
Remarks Only the total results of each server are displayed.
-
Notes Run this command as a root user.
When checking the configuration information exported through Cluster WebUI, decompress it in advance.
-
Error Messages Message
Cause/Solution
Log in as root.
Log in as a root user.
Invalid option.
Specify a valid option.
Could not opened the configuration file. Check if the configuration file exists on the specified path.
The specified path does not exist. Specify a valid path.
Server is busy. Check if this command is already run.
This command has been already activated.
Failed to obtain properties.
Failed to obtain the properties.
Failed to check validation.
Failed to check the cluster configuration.
Internal error. Check if memory or OS resources are sufficient.
The amount of memory or OS resources may be insufficient. Check for any insufficiency.
3. Notes and restrictions¶
This chapter provides information on known problems and how to troubleshoot the problems.
This chapter covers:
3.1. After starting operating EXPRESSCLUSTER X SingleServerSafe¶
This section provides notes on situations you might encounter after starting to operate EXPRESSCLUSTER.
3.1.1. Messages displayed when the driver is loaded¶
When the clpka driver is loaded, the following message may be displayed in the console or syslog. This symptom is not an error.
kernel: clpka: no version for "struct_module" found: kernel tainted.
kernel: clpka: module license 'unspecified' taints kernel.
3.1.2. ipmi messages¶
If IPMI is used as the user-mode monitor resource, the following many kernel module warning logs are output to syslog:
modprobe: modprobe: Can't locate module char-major-10-173
To avoid this log output, rename /dev/ipmikcs.
3.1.3. Restrictions during recovery operation¶
When you have configured a group resource (EXEC resource, VM resource) as a recovery target in the settings of error detection by a monitor resource, and the monitor resource detects an error, do not perform the following commands or the controls of servers or groups by the Cluster WebUI while recovery (reactivation -> final action) is ongoing.
Stopping or suspending a server
Starting or stopping a group
3.1.4. Executable files and script files not described in the Command Reference¶
The installation directory contains executable files and script files that are not described in "2. EXPRESSCLUSTER X SingleServerSafe command reference" in this guide. Do not execute these files by using any program other than EXPRESSCLUSTER X SingleServerSafe.
Any problems caused by not using EXPRESSCLUSTER will not be supported.
3.1.5. Messages displayed when logs are collected¶
When you collect logs, you may find the following message on the console. This does not mean failure. The logs are collected normally.
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(The name of the IDE device that exists on the server is stored in hd#.)
kernel: Warning: /proc/ide/hd?/settings interface is obsolete, and will be removed soon!
3.1.6. Service start/stop scripts¶
For an init.d environment, the service start and stop scripts output an error in the following cases. An error is not output for a systemd environment.
- Immediately after the EXPRESSCLUSTER Server is installed (for SUSE Linux)When the OS is shut down, the service stop scripts below output an error. This error is output because services are not running and does not indicate an actual problem.
clusterpro_alertsync
clusterpro_webmgr
clusterpro
clusterpro_api
clusterpro_ib
clusterpro_trn
clusterpro_evt
- OS shutdown after manually stopping a service (for SUSE Linux)After a service is stopped using the clpcl command or the Cluster WebUI, the stop script for the service that stopped when the OS shut down outputs an error. This error is output because the service stopped and does not indicate an actual problem.
clusterpro
In the following case, the service stop scripts are executed in the incorrect order:
- OS shutdown after all services are disabled by executing chkconfig --del nameAfter the EXPRESSCLUSTER services are disabled, they are stopped in the incorrect order when the OS shuts down. This occurs because the EXPRESSCLUSTER services disabled when the OS shut down are not stopped.If the server is shut down by the Cluster WebUI or by an EXPRESSCLUSTER command such as the clpstdn command, the EXPRESSCLUSTER services stopping in the incorrect order does not cause a problem.
3.1.7. Checking the service status when systemd is used¶
For a systemd environment, the status of services output by the systemctl command may not reflect the actual status of the cluster.
Use the clpstat command and Cluster WebUI to check the cluster status.
3.1.8. Script files used in EXEC resources¶
The script files used in the EXEC resources are stored in the following directory on the server:
/installation path/scripts/group-name/EXEC resource-name/
If the following changes are made in configuration change, the pre-change script files are not deleted from the server.
When the EXEC resource is deleted or renamed
When a group that belongs to the EXEC resource is deleted or renamed
Old EXEC resource scripts can be deleted when unnecessary.
3.1.9. Monitor resources that monitor active resources¶
When monitor resources that monitoring timing is "Active" have suspended and resumed, the following restriction apply:
In case stopping target resource after suspending monitor resource, monitor resource becomes suspended. As a result, monitoring restart cannot be executed.
In case stopping or starting target resource after suspending monitor resource, monitoring by monitor resource starts when target resource starts.
3.1.10. Notes on the Cluster WebUI¶
If the Cluster WebUI is operated in the state that it cannot communicate with the connection destination, it may take a while until the control returns.
When going through the proxy server, make the settings for the proxy server be able to relay the port number of the Cluster WebUI.
When going through the reverse proxy server, the Cluster WebUI will not operate properly.
When updating EXPRESSCLUSTER X SingleServerSafe, close all running browsers. Clear the browser cache and restart the browser.
Cluster configuration data created using a later version of this product cannot be used with this product.
- Closing the Web browser (by clicking Exit from the menu), the dialog box to confirm to save may be displayed.
 When you continue to edit, click the Stay on this page button.
When you continue to edit, click the Stay on this page button. - Reloading the Web browser (by selecting Refresh button from the menu or tool bar), the dialog box to confirm to save may be displayed.
 When you continue to edit, click the Stay on this page button.
When you continue to edit, click the Stay on this page button. For notes and restrictions of Cluster WebUI other than the above, see the online manual.
3.1.11. System monitor resources,Process resource monitor resource¶
To change a setting, the cluster must be suspended.
System monitor resources do not support a delay warning for monitor resources.
- For the SELinux setting, set permissive or disabled.The enforcing setting may disable the communication needed by EXPRESSCLUSTER.
If the date or time of the OS has been changed while System Resource Agent is running, resource monitoring may operate incorrectly as described below since the timing of analysis which is normally done at 10 minute intervals may differ the first time after the date or time is changed. If either of the following occur, suspend and resume cluster.
No error is detected even after the specified duration for detecting errors has passed.
An error is detected before the specified duration for detecting errors has elapsed.
Up to 64 disks that can be monitored by the disk resource monitoring function of System monitor resources.
3.1.12. JVM monitor resources¶
When restarting the monitoring-target Java VM, suspend or shut down the cluster before restarting the Java VM.
To change a setting, the cluster must be suspended.
JVM monitor resources do not support a delay warning for monitor resources.
When changing the language (for example, from Japanese to Chinese) set to the Cluster WebUI (Cluster Properties - Info tab - Language) after JVM monitor resource registration, delete the registered JVM monitor resource, and then register it again.
3.1.13. HTTP monitor resource¶
The HTTP monitor resource uses any of the following OpenSSL shared library symbolic links:
libssl.so
libssl.so.1.1 (OpenSSL 1.1.1 shared libraly)
libssl.so.10 (OpenSSL 1.0 shared libraly)
libssl.so.6 (OpenSSL 0.9 shared libraly)
The above symbolic links may not exist depending on the OS distribution or version, or the package installation status.If the above symbolic links cannot be found, the following error occurs in the HTTP monitor resource.Detected an error in monitoring<Module Resource Name>. (1 :Can not found library. (libpath=libssl.so, errno=2))
For this reason, if the above error occurred, be sure to check whether the above symbolic links exit in /usr/lib or /usr/lib64.If the above symbolic links do not exit, create the symbolic link libssl.so, as in the command example below.Command example:
cd /usr/lib64 # Move to /usr/lib64. ln -s libssl.so.1.0.1e libssl.so # Create a symbolic link.
4. Error messages¶
This chapter provides information on error messages you might encounter when operating EXPRESSCLUSTER X SingleServerSafe.
This chapter covers:
4.1. Messages reported by syslog, alert, mail, SNMP trap, and Message Topic
4.3. Detailed information on activating and deactivating group resources
4.1. Messages reported by syslog, alert, mail, SNMP trap, and Message Topic¶
The table below lists EXPRESSCLUSTER X SingleServerSafe messages.
Note
Alert mail reporting messages are output to syslog with facility = daemon(0x00000018), identity = "expresscls". Event Type in the table below is equivalent to a syslog log level.
In the table below, each number indicates the following:
[1]alert, [2]syslog, [3]Mail Report, [4]SNMP Trap, [5]Message Topic
Module Type |
Event Type |
Event ID |
Message |
Explanation |
Solution |
1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|---|---|---|---|---|
sss |
Error |
8 |
Failed to update config file. |
The configuration file could not be updated. |
Check the configuration data. |
o |
o |
|||
sss |
Info |
10 |
Updated config file successfully. |
The configuration file has been updated. |
- |
o |
||||
sss |
Error |
12 |
Information in config file is invalid. |
The content of the configuration file is invalid. |
Check the configuration data. |
o |
||||
sss |
Error |
14 |
Failed to obtain server name. |
The server name could not be acquired. |
Memory or OS resources may not be sufficient. Check them. |
o |
||||
sss |
Info |
16 |
Server name is updated. |
The server name has been updated. |
- |
o |
o |
|||
pm |
Info |
1 |
Starting the cluster daemon... |
The EXPRESSCLUSTER daemon has been successfully started. |
- |
o |
o |
|||
pm |
Info |
2 |
Shutting down the cluster daemon... |
The EXPRESSCLUSTER daemon is now being shut down. |
- |
o |
o |
|||
pm |
Info |
3 |
Shutdown monitoring is started... |
Shutdown monitoring has been started. |
- |
o |
o |
|||
pm |
Error |
10 |
The cluster daemon has already started. |
The EXPRESSCLUSTER daemon has already been already started. |
Check the EXPRESSCLUSTER daemon status. |
o |
o |
|||
pm |
Error |
11 |
A critical error occurred in the cluster daemon. |
A critical error occurred in the EXPRESSCLUSTER daemon. |
The user executing the operation does not have root privileges, or there is an insufficiency of memory or OS resources. Check them. |
o |
o |
o |
o |
o |
pm |
Error |
12 |
A problem was detected in XML library. |
A problem was detected in the XML library. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
pm |
Error |
13 |
A problem was detected in cluster configuration data. |
A problem was detected in configuration data. |
Check the configuration data by using the Cluster WebUI. |
o |
o |
o |
o |
o |
pm |
Error |
14 |
No cluster configuration data is found. |
The configuration data does not exist. |
Create a server configuration by using the Cluster WebUI and upload it to the server. |
o |
o |
|||
pm |
Error |
15 |
No information about this server is found in the cluster configuration data. |
This server was not found in the configuration data. |
Check the configuration data by using the Cluster WebUI. |
o |
o |
|||
pm |
Error |
20 |
Process %1 was terminated abnormally. |
Process %1 terminated abnormally. |
Memory or OS resources may not be sufficient. Check them. The abend of the nm process, which does not affect the business operation, prevents you from stopping the cluster. To recover from it, restart the OS by using Cluster WebUI or the clpdown command. |
o |
o |
o |
o |
o |
pm |
Error |
21 |
The system will be stopped because the cluster daemon process terminated abnormally. |
The system will now stop because the EXPRESSCLUSTER daemon process terminated abnormally. |
Deactivation of group resources may be failed. Troubleshoot by following the group resource message. |
o |
o |
|||
pm |
Error |
22 |
An error occurred when initializing process %1.(return code:%2) |
An initialization error occurred in process %1. |
The event process might not be running. |
o |
o |
o |
o |
o |
pm |
Info |
23 |
The system will be stopped. |
The system will now stop. |
- |
o |
o |
|||
pm |
Info |
24 |
The cluster daemon will be stopped. |
Stops the cluster daemon. |
- |
o |
o |
|||
pm |
Info |
25 |
The system will be rebooted. |
System will be rebooted. |
- |
o |
o |
|||
pm |
Info |
26 |
Process %1 will be restarted. |
Process %1 will now be restart. |
- |
o |
o |
|||
pm |
Info |
30 |
Received a request to stop the system from %1. |
A request to stop the system was received from %1. |
- |
o |
o |
|||
pm |
Info |
31 |
Received a request to stop the cluster daemon from %1. |
A request to stop the EXPRESSCLUSTER daemon was received from %1. |
- |
o |
o |
|||
pm |
Info |
32 |
Received a request to reboot the system from %1. |
A request to reboot the system was received from %1. |
- |
o |
o |
|||
pm |
Info |
33 |
Received a request to restart the cluster daemon from %1. |
A request to reboot the EXPRESSCLUSTER daemon was received from %1. |
- |
o |
o |
|||
pm |
Info |
34 |
Received a request to resume the cluster daemon from %1. |
A request to resume the server was received from %1. |
- |
o |
o |
|||
pm |
Info |
35 |
Received a request to suspend the cluster daemon from %1. |
A request to suspend the server was received from %1. |
- |
o |
o |
|||
pm |
Info |
36 |
Received a request to panic by sysrq from %1. |
A request for a panic by sysrq was received from %1. |
- |
o |
o |
|||
pm |
Info |
37 |
Received a request to reset by keepalive driver from %1. |
A request for a reset by the keepalive driver was received from %1. |
- |
o |
o |
|||
pm |
Info |
38 |
Received a request to panic by keepalive driver from %1. |
A request for a panic by the keepalive driver was received from %1. |
- |
o |
o |
|||
pm |
Info |
39 |
Received a request to reset by BMC from %1. |
A request for a reset by BMC was received from %1. |
- |
o |
o |
|||
pm |
Info |
40 |
Received a request to power down by BMC from %1. |
A request for a power down by BMC was received from %1. |
- |
o |
o |
|||
pm |
Info |
41 |
Received a request to power cycle by BMC from %1. |
A request for a power cycle by BMC was received from %1. |
- |
o |
o |
|||
pm |
Info |
42 |
Received a request to send NMI by BMC from %1. |
A request for NMI transmission by BMC was received from %1. |
- |
o |
o |
|||
pm |
Error |
66 |
An attempt to panic by sysrq from %1 failed. |
An attempt to perform a panic by sysrq from %1 failed. |
Check whether the system is set up so that it can be used by sysrq. |
o |
o |
|||
pm |
Error |
67 |
An attempt to reset by keepalive driver from %1 failed. |
An attempt to perform a reset by the keepalive driver from %1 failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
pm |
Error |
68 |
An attempt to panic by keepalive driver from %1 failed. |
An attempt to perform a panic by the keepalive driver from %1 failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
pm |
Error |
69 |
An attempt to reset by BMC from %1 failed. |
An attempt to perform a reset by BMC from %1 failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
pm |
Error |
70 |
An attempt to power down by BMC from %1 failed. |
An attempt to perform a power down by BMC from %1 failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
pm |
Error |
71 |
An attempt to power cycle by BMC from %1 failed. |
An attempt to perform a power cycle by BMC from %1 failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
pm |
Error |
72 |
An attempt to send NMI by BMC from %1 failed. |
An attempt to send NMI by BMC from %1 failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
nm |
Info |
1 |
Server %1 has started. |
Server %1 has started. |
- |
o |
o |
|||
nm |
Info |
2 |
Server %1 has been stopped. |
Server %1 has stopped. |
- |
o |
o |
o |
o |
o |
nm |
Info |
3 |
Resource %1 of server %2 has started. |
Resource %1 of server %2 has started. |
- |
o |
o |
|||
nm |
Info |
4 |
Resource %1 of server %2 has stopped. |
Resource %1 of server %2 has stopped. |
- |
o |
o |
|||
nm |
Info |
5 |
Waiting for all servers to start. |
Waiting for the server to start has started. |
- |
o |
o |
|||
nm |
Info |
6 |
All servers have started. |
The server has started. |
- |
o |
o |
|||
nm |
Info |
7 |
Timeout occurred during the wait for startup of all servers. |
Waiting for all servers to start resulted in a timeout. |
- |
o |
o |
|||
nm |
Error |
8 |
Timeout occurred during the wait for startup of all servers. (Cannot communicate with some servers.) |
Waiting for all servers to start resulted in a timeout. (Internal communication with some servers is not possible.) |
Check that there is no error in the network adapter and the network is correctly connected. |
o |
o |
|||
nm |
Info |
9 |
Waiting for startup of all servers has been canceled. |
Waiting for all servers to start has been canceled. |
- |
o |
o |
|||
nm |
Error |
10 |
Status of resource %1 of server %2 is unknown. |
Resource %1 of Server %2 is unknown. |
Check whether the cable or network settings related to resource %1 are correct. |
o |
o |
o |
o |
o |
nm |
Warning |
11 |
NP resolution process at the cluster startup is disabled. |
The NP resolution process at the cluster startup is disabled. |
The NP resolution process at the cluster startup is disabled. |
o |
o |
|||
nm |
Error |
20 |
Process %1 was terminated abnormally. |
Process %1 terminated abnormally. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
o |
o |
o |
nm |
Info |
21 |
The system will be stopped. |
The system will now stop. |
- |
o |
o |
|||
nm |
Info |
22 |
The cluster daemon will be stopped. |
Stops the cluster daemon. |
- |
o |
o |
|||
nm |
Info |
23 |
The system will be rebooted. |
System will be rebooted. |
- |
o |
o |
|||
nm |
Info |
24 |
Process %1 will be restarted. |
%1 process will be restarted. |
- |
o |
o |
|||
nm |
Error |
30 |
Network partition was detected. Shut down the server %1 to protect data. |
Network partition was detected. Shut down server %1 to protect data. |
All heartbeat resources cannot be used. Check that there is no error in the network adapter and the network is correctly connected.
If DISKHB is being used, check the shared disk status.
If COMHB is being used, check whether the COM cable is correctly connected.
|
o |
o |
|||
nm |
Error |
31 |
An error occurred while confirming the network partition. Shut down the server %1. |
An error occurred in confirming the network partition. Shut down the server %1. |
Check whether an error occurred in the network partition resolution resource. |
o |
o |
|||
nm |
Error |
32 |
Shut down the server %1. (reason:%2) |
Shut down server %1. (Reason: %2) |
No heartbeat can be used. Check that there is no error in the network adapter and the network is correctly connected.
If DISKHB is being used, check the shared disk status.
If COMHB is being used, check whether the COM cable is correctly connected.
|
o |
o |
|||
nm |
Error |
33 |
Cluster service will be stopped. (reason:%1) |
Stop the service. (reason: %1) |
Check the cause following the message. |
o |
o |
|||
nm |
Error |
34 |
The combination of the network partition resources is invalid. (server name:%1) |
The combination of the network partition resources is invalid. (erver name: %1) |
Check the configuration data. |
o |
o |
|||
nm |
Error |
35 |
Failed to start the resource %1. Server name:%2 |
Starting resource %1 failed. (Server name: %2) |
Check whether an error occurred in the network partition resolution resource. |
o |
o |
|||
nm |
Info |
36 |
The network partition %1 of the server %2 has been recovered to the normal status. |
Network partition %1 of server %2 has been recovered to the normal status. |
- |
o |
o |
|||
nm |
Error |
37 |
The network partition %1 of the server %2 has an error. |
The network partition %1 of the server %2 has an error. |
Check whether an error occurred in the network partition resolution resource. |
o |
o |
|||
nm |
Error |
38 |
The resource %1 of the server %2 is unknown. |
The resource %1 of the server %2 is unknown. |
Check the configuration data. |
o |
o |
|||
nm |
Info |
39 |
The server %1 canceled the pending failover. |
The server %1 canceled the pending failover. |
- |
o |
o |
|||
nm |
Error |
80 |
Cannot communicate with server %1. |
Internal communication with server %1 is not possible. |
Check that there is no error in the network adapter and the network is correctly connected. |
o |
o |
|||
nm |
Info |
81 |
Recovered from internal communication error with server %1. |
Internal communication with server %1 has recovered from the abnormal status. |
- |
o |
o |
|||
rc |
Info |
10 |
Activating group %1 has started. |
The activation processing of group %1 has started. |
- |
o |
o |
|||
rc |
Info |
11 |
Activating group %1 has completed. |
The activation processing of group %1 has terminated. |
- |
o |
o |
|||
rc |
Error |
12 |
Activating group %1 has failed. |
The activation processing of group %1 has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
15 |
Waiting for group %1 to start has started. |
Waiting for the group to start has started. |
- |
o |
o |
|||
rc |
Info |
16 |
Waiting for group %1 to start has been completed. |
Waiting for the group to start has been normally completed. |
- |
o |
o |
|||
rc |
Error |
17 |
Group start was canceled because waiting for group %1 to start was timed out. |
Waiting for the group to start has timed out. |
Check the status of the group waiting to start.
If the group has not yet been started, re-perform the group operation after starting that group.
|
o |
o |
|||
rc |
Warning |
18 |
Waiting for group %1 to start has timed out. However, group start continues. |
Waiting for the group to start has timed out. However, group start continues. |
- |
o |
o |
|||
rc |
Info |
20 |
Stopping group %1 has started. |
The stop processing of group %1 has started. |
- |
o |
o |
|||
rc |
Info |
21 |
Stopping group %1 has completed. |
The stop processing of group %1 has terminated. |
- |
o |
o |
|||
rc |
Error |
22 |
Stopping group %1 has failed. |
The stop processing of group %1 has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Warning |
23 |
Server %1 is not in a condition to start group %2. |
Server %1 cannot currently start group %2. |
The server where a complete exclusion group is already active cannot start the group. Stop the complete exclusion group, and then re-execute the operation. |
o |
o |
|||
rc |
Info |
25 |
Waiting for group %1 to stop has started. |
Waiting for the group to stop has started. |
- |
o |
o |
|||
rc |
Info |
26 |
Waiting for group %1 to stop has been completed. |
Waiting for the dependent group to stop has been normally completed. |
- |
o |
o |
|||
rc |
Error |
27 |
Group stop has been canceled because waiting for group %1 to stop has timed out. |
Waiting for the group to stop has timed out. |
Check the status of the group waiting to stop.
If the group has not yet been stopped, re-perform the group operation after stopping that group.
|
o |
o |
|||
rc |
Warning |
28 |
Waiting for group %1 to stop has timed out. However, group stop continues. |
Stop waiting has timed out. However, group stop continues. |
- |
o |
o |
|||
rc |
Info |
30 |
Activating %1 resource has started. |
The activation processing of resource %1 has started. |
- |
o |
||||
rc |
Info |
31 |
Activating %1 resource has completed. |
The activation processing of resource %1 has terminated. |
- |
o |
||||
rc |
Error |
32 |
Activating %1 resource has failed.(%2 : %3) |
The activation processing of resource %1 has failed. |
See "Detailed information on activating and deactivating group resources". |
o |
o |
o |
o |
o |
rc |
Info |
40 |
Stopping %1 resource has started. |
The stop processing of resource %1 has started. |
- |
o |
||||
rc |
Info |
41 |
Stopping %1 resource has completed. |
The stop processing of resource %1 has terminated. |
- |
o |
||||
rc |
Error |
42 |
Stopping %1 resource has failed.(%2 : %3) |
The stop processing of resource %1 has failed. |
See "Detailed information on activating and deactivating group resources". |
o |
o |
o |
o |
o |
rc |
Info |
50 |
Moving group %1 has started. |
The movement processing of group %1 has started. |
- |
o |
o |
|||
rc |
Info |
51 |
Moving group %1 has completed. |
The movement processing of group %1 has terminated. |
- |
o |
o |
|||
rc |
Error |
52 |
Moving group %1 has failed. |
The movement processing of group %1 has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
55 |
Migrating group %1 has started. |
The migration processing of group %1 has started. |
- |
o |
o |
|||
rc |
Info |
56 |
Migrating group %1 has completed. |
The migration processing of group %1 has terminated. |
- |
o |
o |
|||
rc |
Error |
57 |
Migrating group %1 has failed. |
The migration processing of group %1 has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Warning |
58 |
Server %1 is not in a condition to migrate group %2 |
The server %1 is not ready for the migration of the group %2. |
Check the status of the migration destination server.
No server name is output for %1 if there is no migration destination server.
|
o |
o |
|||
rc |
Info |
60 |
Failover group %1 has started. |
The failover processing of group %1 has started. |
- |
o |
o |
|||
rc |
Info |
61 |
Failover group %1 has completed. |
The failover processing of group %1 has terminated. |
- |
o |
o |
|||
rc |
Error |
62 |
Failover group %1 has failed. |
The failover processing of group %1 has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Warning |
63 |
Server %1 is not in a condition to move group %2. |
Server %1 cannot currently move group %2. |
Check the status of the movement destination server.
If the movement destination server does not exist, the server name is not output to %1.
|
o |
o |
|||
rc |
Info |
64 |
Server %1 has been set as the destination for the group %2 (reason: %3). |
Server %1 has been set as the destination for the group %2 (reason: %3). |
- |
o |
o |
|||
rc |
Error |
65 |
There is no appropriate destination for the group %1 (reason: %2). |
There is no appropriate destination for the group %1 (reason: %2). |
Check if any monitor resources detects an error on the other servers. |
o |
o |
|||
rc |
Warning |
66 |
Server %1 is not in a condition to start group %2 (reason: %3). |
Server %1 is not in a condition to start group %2 (reason: %3). |
Check if any monitor resource detects an error on the server. |
o |
o |
|||
rc |
Info |
67 |
Server %1 in the same server group (%2) has been set as the destination for the group %3. |
The destination found in the same server group. |
- |
o |
o |
|||
rc |
Info |
68 |
Server %1 not in the same server group (%2) has been set as the destination for the group %3. |
The destination found in the other server group. |
- |
o |
o |
|||
rc |
Warning |
69 |
Can not failover the group %1 because there is no appropriate destination in the same server group %2. |
The destination not found in the same server group. |
Check if other servers in the same server group are stopped. |
o |
o |
|||
rc |
Info |
70 |
Restarting group %1 has started. |
The restart processing of group %1 has started. |
- |
o |
o |
|||
rc |
Info |
71 |
Restarting group %1 has completed. |
The restart processing of group %1 has terminated. |
- |
o |
o |
|||
rc |
Error |
72 |
Restarting group %1 has failed. |
The restart processing of group %1 has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
74 |
Failback group %1 has started. |
Failback group %1 has started. |
- |
o |
o |
|||
rc |
Info |
75 |
Failback group %1 has completed. |
Failback group %1 has been completed. |
- |
o |
o |
|||
rc |
Error |
76 |
Failback group %1 has failed. |
Failback group %1 has failed. |
Take appropriate action according to the group resource message. |
o |
o |
|||
rc |
Info |
80 |
Restarting resource %1 has started. |
The restart processing of resource %1 has started. |
- |
o |
o |
|||
rc |
Info |
81 |
Restarting resource %1 has completed. |
The restart processing of resource %1 has terminated. |
- |
o |
o |
|||
rc |
Error |
82 |
Restarting resource %1 has failed. |
The restart processing of resource %1 has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
83 |
Starting a single resource %1. |
Resource %1 is being started alone. |
- |
o |
o |
|||
rc |
Info |
84 |
A single resource %1 has been started. |
Starting resource %1 alone has been completed. |
- |
o |
o |
|||
rc |
Error |
85 |
Failed to start a single resource %1. |
Starting resource %1 alone has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Warning |
86 |
Server %1 is not in a condition to start a single resource %2. |
Server %1 cannot currently start resource %2 alone. |
Check the server and group status. |
o |
o |
|||
rc |
Info |
87 |
Stopping a single resource %1. |
Resource %1 is being stopped alone. |
- |
o |
o |
|||
rc |
Info |
88 |
A single resource %1 has been stopped. |
Stopping resource %1 alone has been completed. |
- |
o |
o |
|||
rc |
Error |
89 |
Failed to stop a single resource %1. |
Stopping resource %1 alone has failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
90 |
All the servers in the cluster were shut down. |
All the servers have been shut down. |
- |
o |
o |
|||
rc |
Info |
91 |
The server was shut down. |
All the servers have been shut down. |
- |
o |
o |
|||
rc |
Warning |
100 |
Restart count exceeded the maximum value %1. Final action of resource %2 will not be executed. |
The restart count exceeded the maximum value %1. The final action of resource %2 will not be taken. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
121 |
The CPU frequency has been set to high. |
The CPU frequency has been set to the highest. |
- |
o |
o |
|||
rc |
Info |
122 |
The CPU frequency has been set to low. |
The CPU frequency has been set to the lowest. |
- |
o |
o |
|||
rc |
Info |
124 |
CPU frequency setting has been switched to automatic control by cluster. |
The CPU frequency setting has been switched to automatic control by the server. |
- |
o |
o |
|||
rc |
Error |
140 |
CPU frequency control cannot be used. |
CPU frequency control cannot be used. |
Check BIOS settings and kernel settings. |
o |
o |
|||
rc |
Error |
141 |
Failed to set the CPU frequency to high. |
The CPU frequency could not be set to the highest. |
Check BIOS settings and kernel settings.
Check whether the EXPRESSCLUSTER daemon is running.
Check whether the CPU frequency control function is set to "use".
|
o |
o |
|||
rc |
Error |
142 |
Failed to set the CPU frequency to low. |
The CPU frequency could not be set to the lowest. |
Same as above |
o |
o |
|||
rc |
Error |
144 |
Failed to switch the CPU frequency setting to automatic control by cluster. |
The CPU frequency could not be set to automatic control by the server. |
Check whether the EXPRESSCLUSTER daemon is running.
Check whether the CPU frequency control function is set to "use".
|
o |
o |
|||
rc |
Info |
160 |
Script before final action upon activation failure in resource %1 started. |
The script executed before the final action when an activation failure occurs for resource %1 has been started. |
- |
o |
o |
|||
rc |
Info |
161 |
Script before final action upon activation failure in resource %1 completed. |
The script executed before the final action when an activation failure occurs for resource %1 has been completed. |
- |
o |
o |
|||
rc |
Info |
162 |
Script before final action upon deactivation failure in resource %1 started. |
The script before the final action at deactivation failure in resource (%1) has started. |
- |
o |
o |
|||
rc |
Info |
163 |
Script before final action upon deactivation failure in resource %1 completed. |
The script before the final action at deactivation failure in resource (%1) has been completed. |
- |
o |
o |
|||
rc |
Error |
180 |
Script before final action upon activation failure in resource %1 failed. |
The script executed before the final action when an activation failure occurs for resource %1 has failed. |
Check the cause of the script failure and take measures. |
o |
o |
|||
rc |
Error |
181 |
Script before final action upon deactivation failure in resource %1 failed. |
The script executed before the final action when a deactivation failure occurs for resource %1 has failed. |
Same as above |
o |
o |
|||
rc |
Info |
200 |
Resource(%1) will be reactivated since activating resource(%2) failed. |
Resource %2 will now be reactivated because the activation processing of resource %2 failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
201 |
Group(%1) will be moved to server(%2) since activating resource(%3) failed. |
Group %1 will now be moved to server %2 because resource %3 could not be activated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
202 |
Group(%1) will be stopped since activating resource(%2) failed. |
Group %1 will now be stopped because resource %2 could not be activated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
203 |
Cluster daemon will be stopped since activating resource(%1) failed. |
The EXPRESSCLUSTER server daemon will now be stopped because resource %1 could not be activated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
204 |
System will be halted since activating resource(%1) failed. |
The OS will now be shut down because resource %1 could not be activated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
205 |
System will be rebooted since activating resource(%1) failed. |
The OS will now be rebooted because resource %1 could not be activated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
206 |
Activating group(%1) will be continued since failover process failed. |
The activation processing of group %1 will now be continued because the failover processing failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
220 |
Resource(%1) will be stopping again since stopping resource(%2) failed. |
Resource %1 deactivation will now be retried because the deactivation processing of resource %2 failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
222 |
Group(%1) will be stopped since stopping resource(%2) failed. |
Group %1 will now be stopped because resource %2 could not be deactivated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
223 |
Cluster daemon will be stopped since stopping resource(%1) failed. |
The server daemon will now be stopped because resource %1 could not be deactivated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
224 |
System will be halted since stopping resource(%1) failed. |
The OS will now be shut down because resource %1 could not be deactivated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
225 |
System will be rebooted since stopping resource(%1) failed. |
The OS will now be rebooted because resource %1 could not be deactivated. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
240 |
System panic by sysrq is requested since activating resource(%1) failed. |
A system panic by sysrq has been requested because resource %1 activation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
241 |
System reset by keepalive driver is requested since activating resource(%1) failed. |
A system reset by the keepalive driver has been requested because resource %1 activation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
242 |
System panic by keepalive driver is requested since activating resource(%1) failed. |
A system panic by the keepalive driver has been requested because resource %1 activation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
243 |
System reset by BMC is requested since activating resource(%1) failed. |
A system reset by BMC has been requested because resource %1 activation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
244 |
System power down by BMC is requested since activating resource(%1) failed. |
A system power down by BMC has been requested because resource %1 activation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
245 |
System power cycle by BMC is requested since activating resource(%1) failed. |
A system power cycle by BMC has been requested because resource %1 activation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
246 |
NMI send by BMC is requested since activating resource(%1) failed. |
NMI transmission by BMC has been requested because resource %1 activation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Error |
260 |
An attempt to panic system by sysrq due to failure of resource(%1) activation failed. |
An attempt to panic the system was made by sysrq because resource %1 could not be activated, but this attempt failed. |
Check whether the system is set up so that it can be used by sysrq. |
o |
o |
|||
rc |
Error |
261 |
An attempt to reset system by keepalive driver due to failure of resource(%1) activation failed. |
An attempt to reset the system was made by the keepalive driver because resource %1 could not be activated, but this attempt failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
rc |
Error |
262 |
An attempt to panic system by keepalive driver due to failure of resource(%1) activation failed. |
An attempt to panic the system was made by the keepalive driver because resource %1 could not be activated, but this attempt failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
rc |
Error |
263 |
An attempt to reset system by BMC due to failure of resource(%1) activation failed. |
An attempt to reset the system was made by BMC because resource %1 could not be activated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
264 |
An attempt to power down system by BMC due to failure of resource(%1) activation failed. |
An attempt to power down the system was made by BMC because resource %1 could not be activated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
265 |
An attempt to power cycle system by BMC due to failure of resource(%1) activation failed. |
An attempt to power cycle the system was made by BMC because resource %1 could not be activated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
266 |
An attempt to send NMI by BMC due to failure of resource(%1) activation failed. |
An attempt to send NMI was made by BMC because resource %1 could not be activated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Info |
280 |
System panic by sysrq is requested since deactivating resource(%1) failed. |
A system panic by sysrq has been requested because resource %1 deactivation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
281 |
System reset by keepalive driver is requested since deactivating resource(%1) failed. |
A system reset by the keepalive driver has been requested because resource %1 deactivation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
282 |
System panic by keepalive driver is requested since deactivating resource(%1) failed. |
A system panic by the keepalive driver has been requested because resource %1 deactivation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
283 |
System reset by BMC is requested since deactivating resource(%1) failed. |
A system reset by BMC has been requested because resource %1 deactivation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
284 |
System power down by BMC is requested since deactivating resource(%1) failed. |
A system power down by BMC has been requested because resource %1 deactivation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
285 |
System power cycle by BMC is requested since deactivating resource(%1) failed. |
A system power cycle by BMC has been requested because resource %1 deactivation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Info |
286 |
Sending NMI by BMC is requested since deactivating resource(%1) failed. |
NMI transmission by BMC has been requested because resource %1 deactivation failed. |
Troubleshoot according to the group resource message. |
o |
o |
|||
rc |
Error |
300 |
An attempt to panic system by sysrq due to failure of resource(%1) deactivation failed. |
An attempt to panic the system was made by sysrq because resource %1 could not be deactivated, but this attempt failed. |
Check whether the system is set up so that it can be used by sysrq. |
o |
o |
|||
rc |
Error |
301 |
An attempt to reset system by keepalive driver due to failure of resource(%1) deactivation failed. |
An attempt to reset the system was made by the keepalive driver because resource %1 could not be deactivated, but this attempt failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
rc |
Error |
302 |
An attempt to panic system by keepalive driver due to failure of resource(%1) deactivation failed. |
An attempt to panic the system was made by the keepalive driver because resource %1 could not be deactivated, but this attempt failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
rc |
Error |
303 |
An attempt to reset system by BMC due to failure of resource(%1) deactivation failed. |
An attempt to reset the system was made by BMC because resource %1 could not be deactivated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
304 |
An attempt to power down system by BMC due to failure of resource(%1) deactivation failed. |
An attempt to power down the system was made by BMC because resource %1 could not be deactivated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
305 |
An attempt to power cycle system by BMC due to failure of resource(%1) deactivation failed. |
An attempt to power cycle the system was made by BMC because resource %1 could not be deactivated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
306 |
An attempt to send NMI by BMC due to failure of resource(%1) deactivation failed. |
An attempt to send NMI was made by BMC because resource %1 could not be deactivated, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
340 |
Group start has been canceled because waiting for group %1 to start has failed. |
An error has occurred while waiting for the group to start. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
rc |
Info |
400 |
System power down by BMC is requested. (destination server : %1) |
A system power down by BMC has been requested. (Target server: %1) |
- |
o |
o |
|||
rc |
Info |
401 |
System power cycle by BMC is requested. (destination server : %1) |
A system power cycle by BMC has been requested. (Target server: %1) |
- |
o |
o |
|||
rc |
Info |
402 |
System reset by BMC is requested. (destination server : %1) |
A system reset by BMC has been requested. (Target server: %1) |
- |
o |
o |
|||
rc |
Info |
403 |
Sending NMI by BMC is requested. (destination server : %1) |
NMI sending by BMC has been requested. (Target server: %1) |
- |
o |
o |
|||
rc |
Info |
410 |
Forced stop of virtual machine is requested. (destination server : %s) |
Forced stop of a virtual machine is requested. (Target server: %1) |
- |
o |
o |
|||
rc |
Info |
411 |
Script for forced stop has started. |
Script for forced-stop has started. |
- |
o |
o |
|||
rc |
Info |
412 |
Script for forced stop has completed. |
Script for forced-stop has completed. |
- |
o |
o |
|||
rc |
Error |
420 |
An attempt to power down system by BMC failed. (destination server : %1) |
An attempt to power down the system by BMC has failed. (Target server: %1) |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
421 |
An attempt to power cycle system by BMC failed. (destination server : %1) |
An attempt to power cycle the system by BMC has failed. (Target server: %1) |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
422 |
An attempt to reset system by BMC failed. (destination server : %1) |
An attempt to reset the system by BMC has failed. (Target server: %1) |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
423 |
An attempt to send NMI by BMC failed. (destination server : %1) |
An attempt to send NMI by BMC has failed. (Target server: %1) |
Check whether the ipmitool command can be used. |
o |
o |
|||
rc |
Error |
430 |
An attempt to force stop virtual machine failed. (destination server : %s) |
Forced stop of a virtual machine is requested, but this request failed. (Target server: %1) |
Check whether VMware vSphere CLI can be used. |
o |
o |
|||
rc |
Error |
431 |
Script for forced stop has failed. (%1) |
Script for forced-stop has stopped. |
Check the cause of the script failure and take measures. |
o |
o |
|||
rc |
Error |
432 |
Script for forced stop has timed out. |
Timeout on the-script for forced stop |
Check the cause of the script timeout and take measures. |
o |
o |
|||
rc |
Warning |
441 |
Waiting for group %1 to stop has failed. However, group stop continues. |
An error has occurred while waiting for the group to stop. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
rc |
Warning |
500 |
Since there is no other normally running server, the final action for an activation error of group resource %1 was suppressed. |
Suppression of final action for activation error. |
- |
o |
o |
|||
rc |
Warning |
501 |
Since there is no other normally running server, the final action for a deactivation error of group resource %1 was suppressed. |
Suppression of final action for deactivation error. |
- |
o |
o |
|||
rc |
Warning |
510 |
Cluster action is disabled. |
The cluster action is disabled. |
- |
o |
o |
|||
rc |
Warning |
511 |
Ignored the automatic start of groups because automatic group startup is disabled. |
Being disabled, automatic group startup is ignored. |
- |
o |
o |
|||
rc |
Warning |
512 |
Ignored the recovery action in resource activation because recovery action caused by group resource activation error is disabled. |
Being disabled, the resource recovery action is ignored when a group resource activation error occurs. |
- |
o |
o |
|||
rc |
Warning |
513 |
Ignored the recovery action in resource deactivation because recovery action caused by group resource deactivation error is disabled. |
Being disabled, the resource recovery action is ignored when a group resource deactivation error occurs. |
- |
o |
o |
|||
rc |
Warning |
514 |
Cluster action is set disabled. |
The cluster action is disabled. |
- |
o |
o |
|||
rc |
Warning |
515 |
Cluster action is set enabled. |
The cluster action is enabled. |
- |
o |
o |
|||
rm |
Info |
1 |
Monitoring %1 has started. |
%1 monitoring has started. |
- |
o |
o |
|||
rm |
Info |
2 |
Monitoring %1 has stopped. |
%1 monitoring has stopped. |
- |
o |
o |
|||
rm |
Info |
3 |
%1 is not monitored by this server. |
%1 is not monitored by this server. |
- |
o |
o |
|||
rm |
Warning |
4 |
Warn monitoring %1. (%2 : %3) |
There is a warning about %1 monitoring. |
See "Details about monitor resource errors".
If a monitor resource is preparing for monitoring, the following message may be set in (). No action is required for this message.
(100 : not ready for monitoring.)
|
o |
o |
|||
rm |
Warning |
5 |
The maximum number of monitor resources has been exceeded. (registered resource is %1) |
The maximum number of monitor resources has been exceeded. |
Check the configuration data by using the Cluster WebUI. |
o |
o |
|||
rm |
Warning |
6 |
Monitor configuration of %1 is invalid. (%2 : %3) |
The monitor configuration of %1 is invalid. |
Check the configuration data by using the Cluster WebUI. |
o |
o |
|||
rm |
Error |
7 |
Failed to start monitoring %1. |
%1 monitoring could not be started. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
o |
o |
o |
rm |
Error |
8 |
Failed to stop monitoring %1. |
%1 monitoring could not be stopped. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
rm |
Error |
9 |
Detected an error in monitoring %1. (%2 : %3) |
An error was detected during %1 monitoring. |
See "Details about monitor resource errors".
If a monitoring timeout is detected, the following message is specified in the parentheses:
(99 : Monitor was timeout.)
If Dummy Failure is enabled, the following message is set in (). No action is needed in the latter case.
(201 : Monitor failed for failure verification.)
If no response is returned from a monitor resource for a certain period of time, the following message is set in ().
(202: couldn't receive reply from monitor resource in time.)
|
o |
o |
o |
o |
o |
rm |
Info |
10 |
%1 is not monitored. |
%1 is not being monitored. |
- |
o |
o |
|||
rm / mm |
Info |
12 |
Recovery target %1 has stopped because an error was detected in monitoring %2. |
Recovery target %1 has been stopped because an error was detected during %2 monitoring. |
- |
o |
o |
|||
rm / mm |
Info |
13 |
Recovery target %1 has restarted because an error was detected in monitoring %2. |
Recovery target %1 has been restarted because an error was detected during %2 monitoring. |
- |
o |
o |
|||
rm / mm |
Info |
14 |
Recovery target %1 failed over because an error was detected in monitoring %2. |
Recovery target %1 has been failed over because an error was detected during %2 monitoring. |
- |
o |
o |
|||
rm / mm |
Info |
15 |
Stopping the cluster has been required because an error was detected in monitoring %1. |
Stopping the server has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Info |
16 |
Stopping the system has been required because an error was detected in monitoring %1. |
Stopping the system has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Info |
17 |
Rebooting the system has been required because an error was detected in monitoring %1. |
Rebooting the system has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Error |
18 |
Attempted to stop the recovery target %1 due to the error detected in monitoring %2, but failed. |
An attempt to stop recovery target %1 was made because an error was detected during %2 monitoring, but this attempt failed. |
Check the status of resource %1. |
o |
o |
|||
rm / mm |
Error |
19 |
Attempted to restart the recovery target %1 due to the error detected in monitoring %2, but failed. |
An attempt to restart recovery target %1 was made because an error was detected during %2 monitoring, but this attempt failed. |
Check the status of resource %1. |
o |
o |
|||
rm / mm |
Error |
20 |
Attempted to fail over %1 due to the error detected in monitoring %2, but failed. |
An attempt to fail over recovery target %1 was made because an error was detected during %2 monitoring, but this attempt failed. |
Check the status of resource %1. |
o |
o |
|||
rm / mm |
Error |
21 |
Attempted to stop the cluster due to the error detected in monitoring %1, but failed. |
An attempt to stop the server was made because an error was detected during %1 monitoring, but this attempt failed. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
rm / mm |
Error |
22 |
Attempted to stop the system due to the error detected in monitoring %1, but failed. |
An attempt to stop the system was made because an error was detected during %1 monitoring, but this attempt failed. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
rm / mm |
Error |
23 |
Attempted to reboot the system due to the error detected in monitoring %1, but failed. |
An attempt to reboot the system was made because an error was detected during %1 monitoring, but this attempt failed. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
rm |
Error |
24 |
The group of %1 resource is unknown. |
The group of resource %1 is unknown. |
The configuration data may be incorrect. Check them. |
o |
o |
|||
rm / mm |
Warning |
25 |
Recovery will not be executed since the recovery target %1 is not active. |
Recovery will not be performed because recovery target %1 is inactive. |
- |
o |
o |
|||
rm / mm |
Info |
26 |
%1 status changed from error to normal. |
%1 monitoring has changed from "error" to "normal". |
- |
o |
o |
|||
rm / mm |
Info |
27 |
%1 status changed from error or normal to unknown. |
%1 monitoring has changed from "error" or "normal" to "unknown". |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
rm |
Error |
28 |
Initialization error of monitor process. (%1 : %2) |
A monitor process initialization error occurred. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
rm |
Info |
29 |
Monitoring %1 was suspended. |
%1 monitoring has been suspended. |
- |
o |
o |
|||
rm |
Info |
30 |
Monitoring %1 was resumed. |
%1 monitoring has been resumed. |
- |
o |
o |
|||
rm |
Info |
31 |
All monitors were suspended. |
All monitors were suspended. |
- |
o |
o |
|||
rm |
Info |
32 |
All monitors were resumed. |
All monitors were resumed. |
- |
o |
o |
|||
rm / mm |
Info |
35 |
System panic by sysrq has been required because an error was detected in monitoring %1. |
A system panic by sysrq has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Error |
36 |
Attempted to panic system by sysrq due to the error detected in monitoring %1, but failed. |
An attempt to panic the system was made by sysrq because an error was detected during %1 monitoring, but this attempt failed. |
Check whether the system is set up so that it can be used by sysrq. |
o |
o |
|||
rm / mm |
Info |
37 |
System reset by keepalive driver has been required because an error was detected in monitoring %1. |
A system reset by the keepalive driver has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Error |
38 |
Attempted to reset system by keepalive driver due to the error detected in monitoring %1, but failed. |
An attempt to reset the system was made by the keepalive driver because an error was detected during %1 monitoring, but this attempt failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
rm / mm |
Info |
39 |
System panic by keepalive driver has been required because an error was detected in monitoring %1. |
A system panic by the keepalive driver has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Error |
40 |
Attempted to panic system by keepalive driver due to the error detected in monitoring %1, but failed. |
An attempt to panic the system was made by the keepalive driver because an error was detected during %1 monitoring, but this attempt failed. |
Check whether the keepalive driver can be used in this environment. |
o |
o |
|||
rm / mm |
Info |
41 |
System reset by BMC has been required because an error was detected in monitoring %1. |
A system reset by BMC has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Error |
42 |
Attempted to reset system by BMC due to the error detected in monitoring %1, but failed. |
An attempt to reset the system was made by BMC because an error was detected during %1 monitoring, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rm / mm |
Info |
43 |
System power down by BMC has been required because an error was detected in monitoring %1. |
A system power down by BMC has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Error |
44 |
Attempted to power down system by BMC due to the error detected in monitoring %1, but failed. |
An attempt to power down the system was made by BMC because an error was detected during %1 monitoring, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rm / mm |
Info |
45 |
System power cycle by BMC has been required because an error was detected in monitoring %1. |
A system power cycle by BMC has been requested because an error was detected during %1 monitoring. |
- |
o |
o |
|||
rm / mm |
Error |
46 |
Attempted to power cycle system by BMC due to the error detected in monitoring %1, but failed. |
An attempt to power cycle the system was made by BMC because an error was detected during %1 monitoring, but this attempt failed. |
Check whether the ipmitool command can be used. |
o |
o |
|||
rm / mm |
Info |
47 |
NMI send by BMC has been required because an error was detected in monitoring %1. |
NMI of the system by BMC has been required because an error was detected in monitoring %1. |
- |
o |
o |
|||
rm / mm |
Error |
48 |
Attempted to send NMI by BMC due to the error detected in monitoring %1, but failed. |
Attempted to NMI of the system by BMC due to the error detected in monitoring %1, but failed. |
Check if the ipmitool command can be used. |
o |
o |
|||
rm |
Info |
49 |
%1 status changed from warning to normal. |
%1 monitoring has changed from "warning" to "normal". |
- |
o |
o |
|||
rm |
Error |
57 |
Stopping the cluster is required since license (%1) is invalid. |
Stopping the server has been requested because the license is invalid. |
Register a valid license. |
o |
o |
o |
o |
o |
rm |
Error |
58 |
Stopping the cluster due to invalid license (%1) failed. |
The server could not be stopped because the license is invalid. |
Register a valid license. |
o |
o |
|||
rm |
Warning |
71 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
A monitoring delay was detected during %1 monitoring. The current timeout value is %2 (seconds) x %3 (ticks per second). The actual measurement value at delay detection has reached %4 (ticks), exceeding the delay warning rate %5 (%). |
Check the load on the server where monitoring delay was detected and reduce the load.
If monitoring timeouts are detected, the monitoring timeout time must be extended.
|
o |
o |
|||
rm |
Warning |
72 |
%1 could not Monitoring. |
%1 could not perform monitoring. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
rm / mm |
Info |
81 |
Script before %1 upon failure in monitor resource %2 started. |
The script before %1 in monitor resource %2 has been started. |
- |
o |
o |
|||
rm / mm |
Info |
82 |
Script before %1 upon failure in monitor resource %2 completed. |
The script before %1 in monitor resource %2 has been complete. |
- |
o |
o |
|||
rm / mm |
Error |
83 |
Script before %1 upon failure in monitor resource %2 failed. |
The script before %1 in monitor resource %2 has failed. |
Check the cause of the script failure and take measures. |
o |
o |
|||
rm |
Warning |
100 |
Restart count exceeded the maximum of %1. Final action of monitoring %2 will not be executed. |
The final action of %2 has not been executed because restart count exceeded the maximum value %1. |
- |
o |
o |
|||
rm |
Warning |
120 |
The virtual machine (%1) has been migrated by an external operation. |
The virtual machine managed by the resource %1 has been migrated by an external operation. |
- |
o |
o |
|||
rm |
Warning |
121 |
The virtual machine (%1) has been started by an external operation. |
The virtual machine managed by the resource %1 has been started by an external operation. |
- |
o |
o |
|||
rm |
Info |
130 |
Collecting detailed information was triggered by error detection when monitoring monitor resource $1. |
Collecting detailed information was triggered by error detection when monitoring monitor resource $1. The timeout time is %2 seconds. |
- |
o |
o |
|||
rm |
Info |
131 |
The collection of detailed information triggered by error detection when monitoring monitor resource $1 has completed. |
The collection of detailed information triggered by error detection when monitoring monitor resource $1 has completed. |
- |
o |
o |
|||
rm |
Warning |
132 |
The collection of detailed information triggered by error detection when monitoring monitor resource $1 has failed. |
The collection of detailed information triggered by error detection when monitoring monitor resource $1 has failed. |
- |
o |
o |
|||
rm |
Info |
140 |
Process %1 has started. |
Process %1 has started. |
- |
o |
o |
|||
rm |
Warning |
141 |
Process %1 has restarted. |
Process %1 has restarted. |
- |
o |
o |
|||
rm |
Warning |
142 |
Process %1 does not exist. |
Process %1 does not exist. |
- |
o |
o |
|||
rm |
Error |
143 |
Process %1 was restarted %2 times, but terminated abnormally. |
Process %1 was restarted %2 times, but terminated abnormally. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
rm |
Error |
150 |
The cluster is stopped since process %1 was terminated abnormally. |
The cluster is stopped since process %1 was terminated abnormally. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
rm |
Error |
151 |
The server is shut down since process %1 was terminated abnormally. |
The server is shut down since process %1 was terminated abnormally. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
rm |
Error |
152 |
The server is restarted since process %1 was terminated abnormally. |
The server is restarted since process %1 was terminated abnormally. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
rm |
Error |
160 |
Monitor resource %1 cannot be controlled since the license is invalid. |
Monitor resource %1 cannot be controlled since the license is invalid. |
Register a valid license. |
o |
o |
|||
rm |
Info |
170 |
Recovery script has been executed since an error was detected in monitoring %1. |
Recovery script has been executed since an error was detected in monitoring %1. |
- |
o |
o |
|||
rm |
Error |
171 |
An attempt was made to execute the recovery script due to a %1 monitoring failure, but failed. |
An attempt was made to execute the recovery script due to a %1 monitoring failure, but failed. |
Check the cause of the recovery script failure and take appropriate action. |
o |
o |
|||
rm |
Info |
180 |
Dummy Failure of monitor resource %1 is enabled. |
Dummy Failure of monitor resource %1 is enabled. |
- |
o |
o |
|||
rm |
Info |
181 |
Dummy Failure of monitor resource %1 is disabled. |
Dummy Failure of monitor resource %1 is disabled. |
- |
o |
o |
|||
rm |
Info |
182 |
Dummy Failure of all monitor will be enabled. |
Dummy Failure of all monitor will be enabled. |
- |
o |
o |
|||
rm |
Info |
183 |
Dummy Failure of all monitor will be disabled. |
Dummy Failure of all monitor will be disabled. |
- |
o |
o |
|||
rm |
Warning |
184 |
An attempt was made to enable Dummy Failure of monitor resource %1, but failed. |
An attempt was made to enable Dummy Failure of monitor resource %1, but failed. |
Check whether monitor resource %1 corresponds to Dummy Failure. |
o |
o |
|||
rm |
Warning |
185 |
An attempt was made to disable Dummy Failure of monitor resource %1, but failed. |
An attempt was made to disable Dummy Failure of monitor resource %1, but failed. |
Check whether monitor resource %1 corresponds to Dummy Failure. |
o |
o |
|||
rm |
Info |
190 |
Recovery action caused by monitor resource error is disabled. |
Recovery action caused by monitor resource error is disabled. |
- |
o |
o |
|||
rm |
Info |
191 |
Recovery action caused by monitor resource error is enabled. |
Recovery action caused by monitor resource error is enabled. |
- |
o |
o |
|||
rm |
Warning |
192 |
Ignored the recovery action in monitoring %1 because recovery action caused by monitor resource error is disabled. |
Ignored the recovery action in monitoring %1 because recovery action caused by monitor resource error is disabled. |
- |
o |
o |
|||
rm |
Warning |
193 |
Recovery action at timeout occurrence was disabled, so the recovery action of monitor %1 was not executed. |
o |
o |
|||||
rm |
Warning |
200 |
Since there is no other normally running server, the final action(%1) for the error detection of monitor resource %2 was suppressed. |
Suppression of final action for error detection. |
- |
o |
o |
|||
rm |
Warning |
220 |
Recovery will not be executed since any recovery target is not active. |
Recovery will not be executed since any recovery target is not active. |
- |
o |
o |
|||
rm |
Warning |
221 |
Recovery will not be executed because the group that is set for the recovery target is not active. |
Recovery will not be executed because the group that is set for the recovery target is not active. |
- |
o |
o |
|||
mm |
Info |
901 |
Message monitor has been started. |
Message monitor (external linkage monitor module) has been started. |
- |
o |
o |
|||
mm |
Error |
902 |
Failed to initialize message monitor. (%1 : %2) |
Message monitor (external linkage monitor module) could not be initialized. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
mm |
Warning |
903 |
An error of %1 type and %2 device has been detected. (%3) |
External error %3 of category %1 and keyword %2 has been received. |
- |
o |
o |
|||
mm |
Error |
905 |
An error has been detected in monitoring %1. (%2) |
An error was detected in monitor resource %1 monitoring. |
Take appropriate action according to the %2 message. |
o |
o |
o |
o |
o |
mm |
Error |
906 |
Message monitor was terminated abnormally. |
Message monitor (external linkage monitor module) has been terminated abnormally. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
mm |
Error |
907 |
Failed to execute action. (%1) |
Executing recovery action has failed. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
o |
|||
mm |
Info |
908 |
The system will be stopped. |
The OS will be shut down. |
- |
o |
o |
|||
mm |
Info |
909 |
The cluster daemon will be stopped. |
The cluster will be stopped. |
- |
o |
o |
|||
mm |
Info |
910 |
The system will be rebooted. |
The OS will be rebooted. |
- |
o |
o |
|||
mm |
Info |
911 |
Message monitor will be restarted. |
Message monitor (external linkage monitor module) will be restarted. |
- |
o |
o |
|||
mm |
Info |
912 |
Received a message by SNMP Trap from external. (%1 : %2) |
Received a message by SNMP Trap from external. |
- |
o |
o |
|||
trnsv |
Error |
1 |
There was a notification from external (IP=%1), but it was denied. |
The notification from %1 was received, but it was denied. |
- |
o |
o |
|||
trnsv |
Info |
10 |
There was a notification (%1) from external (IP=%2). |
The notification (%1) from %2 was received. |
- |
o |
o |
|||
trnsv |
Info |
20 |
Recovery action (%1) of monitoring %2 has been executed because a notification arrived from external. |
Recovery action when an error is detected (%1) of the monitor resource %2 has been executed due to an notification from external arrived. |
- |
o |
o |
|||
trnsv |
Info |
21 |
Recovery action (%1) of monitoring %2 has been completed. |
Execution of recovery action when an error is detected (%1) of the monitor resource %2 succeeded. |
- |
o |
o |
|||
trnsv |
Error |
22 |
Attempted to recovery action (%1) of monitoring %2, but it failed. |
Executed recovery action when an error is detected (%1) of the monitor resource %2, but it failed. |
Check if recovery action when an error is detected is executable. |
o |
o |
|||
trnsv |
Info |
30 |
Action (%1) has been completed. |
Execution of action (%1) succeeded. |
- |
o |
o |
|||
trnsv |
Error |
31 |
Attempted to execute action (%1), but it failed. |
Executed action (%1), but it failed. |
Check if recovery action when an error is detected is executable. |
o |
o |
|||
trnsv |
Info |
40 |
Script before action of monitoring %1 has been executed. |
Script before action when an error is detected of the monitor resource (%1) has been executed. |
- |
o |
||||
trnsv |
Info |
41 |
Script before action of monitoring %1 has been completed. |
Execution of script before action when an error is detected of the monitor resource (%1) succeeded. |
- |
o |
||||
trnsv |
Error |
42 |
Attempted to execute script before action of monitoring %1, but it failed. |
Executed script before action when an error is detected of the monitor resource (%1), but it failed. |
Check if script before action when an error is detected is executable. |
o |
||||
lanhb |
Warning |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred in the heartbeat from HB resource %1 of server %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on server %2 and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
o |
o |
|||
lanhb |
Warning |
72 |
Heartbeats sent from HB resource %1 are delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred during the heartbeat transmission of HB resource %1. The transmission destination server is %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on the server to which the delay warning was issued and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
|||||
lanhb |
Warning |
73 |
Heartbeats received by HB resource %1 are delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred during the heartbeat reception of HB resource %1. The transmission source server is %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on the server to which the delay warning was issued and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
|||||
lankhb |
Warning |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred in the heartbeat from HB resource %1 of server %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on server %2 and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
o |
o |
|||
lankhb |
Warning |
73 |
Heartbeats received from HB resource %1 is delayed.(timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
A delay occurred during the heartbeat reception of HB resource %1. The transmission source server is %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on the server to which the delay warning was issued and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
|||||
diskhb |
Error |
10 |
Device(%1) of resource(%2) does not exist. |
The specified device does not exist. |
Check the configuration data. |
o |
o |
|||
diskhb |
Error |
11 |
Device(%1) of resource(%2) is not a block device. |
The specified device does not exist. |
Check the configuration data. |
o |
o |
|||
diskhb |
Error |
12 |
Raw device(%1) of resource(%2) does not exist. |
The specified device does not exist. |
Check the configuration data. |
o |
o |
|||
diskhb |
Error |
13 |
Binding device(%1) of resource(%2) to raw device(%3) failed. |
The specified device does not exist. |
Check the configuration data. |
o |
o |
|||
diskhb |
Error |
14 |
Raw device(%1) of resource(%2) has already been bound to other device. |
Raw device %1 of resource %2 is bound to another device. |
Specify an unused raw device. |
o |
o |
|||
diskhb |
Error |
15 |
File system exists on device(%1) of resource(%2). |
A file system exists in device %1 of resource %2. |
To use device %1, delete the file system. |
o |
o |
|||
diskhb |
Info |
20 |
Resource %1 recovered from initialization error. |
Resource %1 has recovered from the initialization error. |
- |
o |
o |
|||
diskhb |
Warning |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred in the heartbeat from HB resource %1 of server %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on server %2 and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
o |
o |
|||
diskhb |
Warning |
72 |
Heartbeat write of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6). |
A delay occurred during the heartbeat write of HB resource %1. The write destination server is %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on the server to which the delay warning was issued and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
|||||
diskhb |
Warning |
73 |
Heartbeat read of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred during the heartbeat read of HB resource %1. The read source server is %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on the server to which the delay warning was issued and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
|||||
comhb |
Info |
1 |
Device (%1) does not exist. |
The specified device does not exist. |
Check the configuration data. |
o |
o |
|||
comhb |
Info |
2 |
Failed to open the device (%1). |
The specified device could not be opened. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
comhb |
Warning |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred in the heartbeat from HB resource %1 of server %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on server %2 and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
o |
o |
|||
comhb |
Warning |
72 |
Heartbeat write of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6). |
A delay occurred during the heartbeat write of HB resource %1. The transmission destination server is %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on the server to which the delay warning was issued and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
|||||
comhb |
Warning |
73 |
Heartbeat read of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
A delay occurred during the heartbeat read of HB resource %1. The transmission source server is %2. The current timeout value is "%3 (seconds) x %4 (ticks per second)". The actual measurement value when the delay occurred became %5 (ticks), exceeding the delay warning percentage %6 (%). |
Check the load on the server to which the delay warning was issued and reduce the load.
If an HB timeout occurs, the HB timeout time must be extended.
|
|||||
bmchb |
Error |
10 |
Failed to initialize to BMC. |
BMC initialization failed. |
Check whether the hardware can use the BMC linkage function. |
o |
o |
|||
bmchb |
Warning |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
Heartbeats from HB resource %1 of server %2 are delayed. The current timeout value is %3 (second) x %4 (tick count per second). The actual measurement value at delay generation is %5 (tick count) and exceeded the delay warning rate %6 (%). |
Check the load status of the server %2 and remove the load.
If an HB timeout occurs, extend it.
|
o |
o |
|||
monp |
Error |
1 |
An error occurred when initializing monitored process %1. (status=%2) |
An initialization error occurred in monitored process %1. |
Memory or OS resources might not be sufficient, or the configuration data might be inconsistent. Check them.
If the configuration data is not registered, the process message below is output. This message output, however, does not indicate a problem.
+ mdagnt
+ webmgr
+ webalert
|
o |
o |
|||
monp |
Error |
2 |
Monitor target process %1 terminated abnormally. (status=%2) |
Monitor target process %1 terminated abnormally. |
Memory or OS resources may not be sufficient. Check them. |
o |
o |
|||
monp |
Info |
3 |
Monitor target process %1 will be restarted. |
Monitor target process %1 will now be restarted. |
- |
o |
o |
|||
monp |
Info |
4 |
The cluster daemon will be stopped since the monitor target process %1 terminated abnormally. |
The server will now be stopped because monitor target process %1 terminated abnormally. |
- |
o |
o |
|||
monp |
Error |
5 |
Attempted to stop the cluster daemon, but failed. |
Stopping the server has failed. |
The server might not be running or memory or OS resources might not be sufficient. Check them. |
o |
o |
|||
monp |
Info |
6 |
The system will be stopped since the monitor target process %1 terminated abnormally. |
The system will now stop because monitor target process %1 terminated abnormally. |
- |
o |
o |
|||
monp |
Error |
7 |
Attempted to stop the system, but failed. (status=%#x) |
Stopping the system has failed. |
The server might not be running or memory or OS resources might not be sufficient. Check them. |
o |
o |
|||
monp |
Info |
8 |
System will be rebooted since monitor target process %1 terminated abnormally. |
The system will now be rebooted because monitor target process %1 terminated abnormally. |
- |
o |
o |
|||
monp |
Error |
9 |
Attempted to reboot the system, but failed. (status=%#x) |
Rebooting the system has failed. |
The server might not be running or memory or OS resources might not be sufficient. Check them. |
o |
o |
|||
cl |
Info |
1 |
There was a request to start %1 from the %2. |
A request to start %1 has been issued from %2. |
- |
o |
o |
|||
cl |
Info |
2 |
There was a request to stop %1 from the %2. |
A request to stop %1 has been issued from %2. |
- |
o |
o |
|||
cl |
Info |
3 |
There was a request to suspend %1 from the %2. |
A request to suspend %1 has been issued from %2. |
- |
o |
o |
|||
cl |
Info |
4 |
There was a request to resume %s from the %s. |
A request to resume %1 has been issued from %2. |
- |
o |
o |
|||
cl |
Error |
11 |
A request to start %1 failed(%2). |
A request to start %1 has failed. |
Check the server status. |
o |
o |
|||
cl |
Error |
12 |
A request to stop %1 failed(%2). |
A request to stop %1 has failed. |
Check the server status. |
o |
o |
|||
cl |
Error |
13 |
A request to suspend %1 failed(%2). |
A request to suspend %1 has failed. |
Check the server status. |
o |
o |
|||
cl |
Error |
14 |
A request to resume %1 failed(%2). |
A request to resume %1 has failed. |
Check the server status. |
o |
o |
|||
cl |
Error |
15 |
A request to %1 cluster failed on some servers(%2). |
Request %1 has failed on some servers. |
Check the server statuses. |
o |
o |
|||
cl |
Error |
16 |
A request to start %1 failed on some servers(%2). |
Starting %1 failed on some servers. |
Check the status of %1. |
o |
o |
|||
cl |
Error |
17 |
A request to stop %1 failed on some servers(%2). |
Stopping %1 failed on some servers. |
Check the status of %1. |
o |
o |
|||
cl |
Warning |
18 |
Automatic start is suspended because the cluster service was not stopped according to the normal procedure. |
Automatic start has been suspended since Automatic startup after the system down was not set. |
To start the cluster service, use the Cluster WebUI or clpcl command. |
o |
o |
|||
cl |
Warning |
20 |
A request to start %1 failed because cluster is running(%2). |
Starting %1 has failed since the cluster is running. |
Check the status of the cluster. |
o |
o |
|||
cl |
Warning |
21 |
A request to stop %1 failed because cluster is running(%2). |
Stopping %1 has failed since the cluster is running. |
Check the status of the cluster. |
o |
o |
|||
Error |
1 |
The license is not registered. (%1) |
Purchase and register the license. |
- |
o |
o |
||||
Error |
2 |
The trial license has expired in %1. (%2) |
Register a valid license. |
- |
o |
o |
||||
Error |
3 |
The registered license is invalid. (%1) |
Register a valid license. |
- |
o |
o |
||||
Error |
4 |
The registered license is unknown. (%1) |
Register a valid license. |
- |
o |
o |
||||
Error |
5 |
mail failed(%s).(SMTP server: %s) |
Mail reporting has failed. |
Check if an error has occurred on the SMTP server, or a trouble occurred in communicating with the SMTP server. |
o |
o |
||||
Info |
6 |
mail successed.(SMTP server: %s) |
mail succeed. |
- |
o |
o |
||||
userw |
Warning |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
A monitoring delay was detected during %1 monitoring. The current timeout value is "%2 (seconds) x %3 (ticks per second)". The actual measurement value when the delay was detected became %4 (ticks), exceeding the delay warning percentage %5 (%). |
- |
o |
o |
|||
vipw |
Warning |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
A monitoring delay was detected during %1 monitoring. The current timeout value is "%2 (seconds) x %3 (ticks per second)". The actual measurement value when the delay was detected became %4 (ticks), exceeding the delay warning percentage %5 (%). |
- |
o |
o |
|||
ddnsw |
Warning |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
A monitoring delay was detected during %1 monitoring. The current timeout value is "%2 (seconds) x %3 (ticks per second)". The actual measurement value when the delay was detected became %4 (ticks), exceeding the delay warning percentage %5 (%). |
- |
o |
o |
|||
vmw |
Warning |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
A monitoring delay was detected during %1 monitoring. The current timeout value is "%2 (seconds) x %3 (ticks per second)". The actual measurement value when the delay was detected became %4 (ticks), exceeding the delay warning percentage %5 (%). |
- |
o |
o |
|||
apisv |
Info |
1 |
There was a request to stop cluster from the %1(IP=%2). |
A request to stop the server has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
2 |
There was a request to shutdown cluster from the %1(IP=%2). |
A request to shut down the server has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
3 |
There was a request to reboot cluster from the %1(IP=%2). |
A request to reboot the server has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
4 |
There was a request to suspend cluster from the %1(IP=%2). |
A request to suspend the server has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
10 |
There was a request to stop server from the %1(IP=%2). |
A request to stop the server has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
11 |
There was a request to shutdown server from the %1(IP=%2). |
A request to shut down the server has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
12 |
There was a request to reboot server from the %1(IP=%2). |
A request to reboot the server has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
30 |
There was a request to start group(%1) from the %2(IP=%3). |
A request to start group %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
31 |
There was a request to start all groups from the %1(IP=%2). |
A request to start all groups has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
32 |
There was a request to stop group(%1) from the %2(IP=%3). |
A request to stop group %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
33 |
There was a request to stop all groups from the %1(IP=%2). |
A request to stop all groups has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
34 |
There was a request to restart group(%1) from the %2(IP=%3). |
A request to restart group %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
35 |
There was a request to restart all groups from the %1(IP=%2). |
A request to restart all groups has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
36 |
There was a request to move group(%1) from the %2(IP=%3). |
A request to move group %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
37 |
There was a request to move group from the %1(IP=%2). |
A request to move a group has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
38 |
There was a request to failover group(%1) from the %2(IP=%3). |
A request to fail over group %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
39 |
There was a request to failover group from the %1(IP=%2). |
A request to fail over a group has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
40 |
There was a request to migrate group(%1) from the %2(IP=%3). |
A request to migrate group %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
41 |
There was a request to migrate group from the %1(IP=%2). |
A request to migrate a group has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
42 |
There was a request to failover all groups from the %1(IP=%2). |
A request to provide failover for all groups was issued from %2. |
- |
o |
o |
|||
apisv |
Info |
43 |
There was a request to cancel waiting for the dependence destination group of group the %1 was issued from %2. |
A request to cancel waiting for the dependence destination group of group %1 was issued from %2. |
- |
o |
o |
|||
apisv |
Info |
50 |
There was a request to start resource(%1) from the %2(IP=%3). |
A request to start resource %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
51 |
There was a request to start all resources from the %1(IP=%2). |
A request to start all resources has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
52 |
There was a request to stop resource(%1) from the %2(IP=%3). |
A request to stop resource %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
53 |
There was a request to stop all resources from the %1(IP=%2). |
A request to stop all resources has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
54 |
There was a request to restart resource(%1) from the %2(IP=%3). |
A request to restart resource %1 has been issued from %2. |
- |
o |
o |
|||
apisv |
Info |
55 |
There was a request to restart all resources from the %1(IP=%2). |
A request to restart all resources has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
60 |
There was a request to suspend monitor resources from the %1(IP=%2). |
A request to suspend monitor resources has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
61 |
There was a request to resume monitor resources from the %1(IP=%2). |
A request to resume monitor resources has been issued from %1. |
- |
o |
o |
|||
apisv |
Info |
62 |
There was a request to enable Dummy Failure of monitor resources from the %1(IP=%2). |
A request to enable Dummy Failure of monitor resource was issued from %1. |
- |
o |
o |
|||
apisv |
Info |
63 |
There was a request to disable Dummy Failure of monitor resources from the %1(IP=%2). |
A request to disable Dummy Failure of monitor resource was issued from %1. |
- |
o |
o |
|||
apisv |
Info |
70 |
There was a request to set CPU frequency level from the %1(IP=%2). |
A request to set a CPU frequency level has been issued from %1. |
- |
o |
o |
|||
apisv |
Error |
101 |
A request to stop cluster was failed(0x%08x). |
A request to stop the server has failed. |
Check the server status. |
o |
o |
|||
apisv |
Error |
102 |
A request to shutdown cluster was failed(0x%08x). |
A request to shut down the server has failed. |
Check the server status. |
o |
o |
|||
apisv |
Error |
103 |
A request to reboot cluster was failed(0x%08x). |
A request to reboot the server has failed. |
Check the server status. |
o |
o |
|||
apisv |
Error |
104 |
A request to suspend cluster was failed(0x%08x). |
A request to suspend the server has failed. |
Check the server status. |
o |
o |
|||
apisv |
Error |
110 |
A request to stop server was failed(0x%08x). |
A request to stop the server has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
111 |
A request to shutdown server was failed(0x%08x). |
A request to shut down the server has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
112 |
A request to reboot server was failed(0x%08x). |
A request to reboot the server has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
113 |
A request to server panic was failed(0x%08x). |
Server panic has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
114 |
A request to server reset was failed(0x%08x). |
Server reset has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
115 |
A request to server sysrq was failed(0x%08x). |
SYSRQ panic has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
116 |
A request to KA RESET was failed(0x%08x). |
Keepalive reset has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
117 |
A request to KA PANIC was failed(0x%08x). |
Keepalive panic has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
118 |
A request to BMC RESET was failed(0x%08x). |
BMC reset has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
119 |
A request to BMC PowerOff was failed(0x%08x). |
BMC power-off has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
120 |
A request to BMC PowerCycle was failed(0x%08x). |
BMC power cycle has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
121 |
A request to BMC NMI was failed(0x%08x). |
BMC NMI has failed. |
Check the status of the server. |
o |
o |
|||
apisv |
Error |
130 |
A request to start group(%1) was failed(0x%08x). |
A request to start group %1 has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful group start. |
o |
o |
|||
apisv |
Error |
131 |
A request to start all groups was failed(0x%08x). |
A request to start all groups has failed. |
Same as above |
o |
o |
|||
apisv |
Error |
132 |
A request to stop group(%1) was failed(0x%08x). |
A request to stop group %1 has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful group stop. |
o |
o |
|||
apisv |
Error |
133 |
A request to stop all groups was failed(0x%08x). |
A request to stop all groups has failed. |
Same as above |
o |
o |
|||
apisv |
Error |
134 |
A request to restart group(%1) was failed(0x%08x). |
Restarting group (%1) has failed. |
Take appropriate action according to the group stop failure message issued by rc. |
o |
o |
|||
apisv |
Error |
135 |
A request to restart all groups was failed(0x%08x). |
Restarting all groups has failed. |
Same as above. |
o |
o |
|||
apisv |
Error |
136 |
A request to move group(%1) was failed(0x%08x). |
A request to move group %1 has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful group movement. |
o |
o |
|||
apisv |
Error |
137 |
A request to move all groups was failed(0x%08x). |
Moving all groups has failed. |
Same as above. |
o |
o |
|||
apisv |
Error |
138 |
A request to failover group(%1) was failed(0x%08x). |
A request to fail over group %1 has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful group failover. |
o |
o |
|||
apisv |
Error |
139 |
A request to failover group was failed(0x%08x). |
A request to fail over all groups has failed. |
Same as above |
o |
o |
|||
apisv |
Error |
140 |
A request to migrate group(%1) was failed(0x%08x). |
Migration of group (%1) has failed. |
Take appropriate action according to the group failover failure message issued by rc. |
o |
o |
|||
apisv |
Error |
141 |
A request to migrate all groups was failed(0x%08x). |
Migration of all groups has failed. |
Same as above. |
o |
o |
|||
apisv |
Error |
142 |
A request to failover all groups was failed(0x%08x). |
Failover for all groups has failed. |
Same as above. |
o |
o |
|||
apisv |
Error |
143 |
A request to cancel waiting for the dependency destination group of group %1 has failed(0x%08x). |
Canceling waiting for the dependency destination group of group %1 has failed. |
Same as above. |
o |
o |
|||
apisv |
Error |
150 |
A request to start resource(%1) was failed(0x%08x). |
A request to start resource %1 has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful resource start. |
o |
o |
|||
apisv |
Error |
152 |
A request to stop resource(%1) was failed(0x%08x). |
A request to stop resource %1 has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful resource stop. |
o |
o |
|||
apisv |
Error |
154 |
A request to restart resource(%1) was failed(0x%08x). |
A request to restart resource %1 has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful resource restart. |
o |
o |
|||
apisv |
Error |
155 |
A request to restart all resources was failed(0x%08x). |
A request to start all resources has failed. |
Same as above |
o |
o |
|||
apisv |
Error |
160 |
A request to suspend monitor resource was failed(0x%08x). |
A request to suspend the monitor resources has failed. |
Check the status of the monitor resources. |
o |
o |
|||
apisv |
Error |
161 |
A request to resume monitor resource was failed(0x%08x). |
A request to resume the monitor resources has failed. |
Same as above |
o |
o |
|||
apisv |
Error |
162 |
A request to enable Dummy Failure of monitor resource was failed(0x%08x). |
The monitor resource failed to start Dummy Failure. |
Check the status of the monitor resource. |
o |
o |
|||
apisv |
Error |
163 |
A request to disable Dummy Failure of monitor resource was failed(0x%08x). |
The monitor resource failed to stop Dummy Failure. |
Same as above. |
o |
o |
|||
apisv |
Error |
170 |
A request to set CPU frequency was failed(0x%08x). |
A request to specify the CPU frequency has failed. |
Take appropriate action according to the message output by rc indicating the unsuccessful CPU frequency specification. |
o |
o |
|||
cfmgr |
Info |
1 |
The cluster configuration data has been uploaded by %1. |
The configuration data has been uploaded. |
- |
o |
o |
|||
sra |
Error |
1 |
system monitor closed because reading the SG file failed. |
An error occurred in reading the SG file. |
Check the message separately issued. |
o |
||||
sra |
Error |
2 |
Opening an ignore file failed. file name = %1, errno = %2.
%1:File name
%2:errno
|
The SG file (%1) failed to be opened. |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
3 |
Reading a configuration file failed. |
An error occurred in reading the SG file. |
Check the message separately issued. |
o |
||||
sra |
Error |
4 |
Trace log initialization failed. |
The internal log file could not be initialized. |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
5 |
Creating a daemon process failed. |
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Error |
6 |
Reading a service configuration file failed. |
An error occurred in reading the SG file. |
Check the message separately issued. |
o |
||||
sra |
Error |
7 |
mlock() failed. |
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Error |
8 |
A daemon process could not be created. |
SystemResourceAgent has failed to start (turning the process into a daemon). |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Error |
9 |
stdio and stderr could not be closed. |
SystemResourceAgent has failed to start (closing the standard I/O). |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Error |
10 |
A signal mask could not be set up. |
SystemResourceAgent has failed to start (setting the signal mask). |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Error |
11 |
A configuration file error occurred. (1) [line = %1, %2]
%1:Line
%2:Setting value
|
SystemResourceAgent has failed to start (reading the SG file). |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
12 |
A configuration file error occurred. (2) [line=%1, %2]
%1:Line
%2:Setting value
|
SystemResourceAgent has failed to start (reading the SG file). |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
13 |
A plugin event configuration file error occurred. The DLL pointer was not found. [line = %1, %2]
%1:Line
%2:Setting value
|
SystemResourceAgent has failed to start (registering the plugin event). |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
14 |
malloc failed. [event structure] |
SystemResourceAgent has failed to start (registering the plugin event). |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
15 |
A service configuration file error occurred due to an invalid event. [%1]
%1:Setting value
|
SystemResourceAgent has failed to start (reading the service file). |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
16 |
A plugin event configuration file
error occurred due to %1.
%1:Cause of error
|
SystemResourceAgent has failed to start (reading the plugin event file). |
Restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Error |
17 |
Internal error occurred. |
A shared memory access error has occurred. |
- |
o |
||||
sra |
Warning |
101 |
Opening an SG file failed. file name = %1, errno = %2
%1:File name
%2:errno
|
The SG file (%1) failed to be opened. |
Recreate the SG file and restart the cluster, or execute the suspend and resume. |
o |
||||
sra |
Warning |
102 |
malloc(3) fail(1) . [%1]
%1:Function name
|
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Warning |
103 |
malloc(3) fail(2). [%1]
%1:Function name
|
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Warning |
104 |
An internal error occurred. rename(2) error (errno = %1)
%1:errno
|
This product has terminated abnormally. |
See the most recently issued system log message. |
o |
||||
sra |
Warning |
105 |
realloc(3) fail. [%1].
%1:Function name
|
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Warning |
106 |
A script timed out. (%1 %2)
%1:Script file name
%2:Argument
|
An external error has occurred. |
Check the load status of the server and remove the load. |
o |
||||
sra |
Warning |
107 |
[%1] execvp(2) fail (%2).
%1:Script file name
%2:errno
|
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Warning |
108 |
[%1] fork fail (%2). Suspended.
%1:Script file name
%2:errno
|
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Warning |
109 |
malloc(3) fail. [%1]
%1:Function name
|
An external error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
o |
||||
sra |
Info |
201 |
A script was executed. (%1)
%1:Script name
|
Script (%1) has been executed. |
- |
o |
||||
sra |
Info |
202 |
Running a script finished. (%1)
%1:Script name
|
Script has ended normally. |
- |
o |
||||
sra |
Info |
203 |
An %1 event succeeded.
%1:Executed event type
|
The operation management command has been executed.
The executed event type (boot, shutdown, stop, start, or flush) is output.
|
- |
o |
||||
sra |
Error |
301 |
A process resource error was detected. (%1, type = cpu, pid = %2, %3)
%1:Monitor resource name
%2:Process ID
%3:Process name
|
An error was detected in monitoring the CPU usage rates of specific processes. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
301 |
A process resource error was detected. (%1, type = memory leak, pid = %2, %3)
%1:Monitor resource name
%2:Process ID
%3:Process name
|
An error was detected in monitoring the memory usage of specific processes. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
301 |
A process resource error was detected. (%1, type = file leak, pid = %2, %3)
%1:Monitor resource name
%2:Process ID
%3:Process name
|
An error was detected in monitoring the number (maximum) of open files of specific processes. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
301 |
A process resource error was detected. (%1, type = open file, pid = %2, %3)
%1:Monitor resource name
%2:Process ID
%3:Process name
|
An error was detected in monitoring the number (upper kernel limit) of open files of specific processes. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
301 |
A process resource error was detected. (%1, type = thread leak, pid = %2, %3)
%1:Monitor resource name
%2:Process ID
%3:Process name
|
An error was detected in monitoring the number of threads of specific processes. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
301 |
A process resource error was detected. (%1, type = defunct, pid = %2, %3)
%1:Monitor resource name
%2:Process ID
%3:Process name
|
An error was detected in monitoring the zombie processes. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
301 |
A process resource error was detected. (%1, type = same name process, pid = %2, %3)
%1:Monitor resource name
%2:Process ID
%3:Process name
|
An error was detected in monitoring the same-name processes. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
302 |
A system resource error was detected. (%1, type = cpu)
%1:Monitor resource name
|
An error was detected in monitoring the CPU usage rates of the system. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
302 |
A system resource error was detected. (%1, type = memory)
%1:Monitor resource name
|
An error was detected in monitoring the total usage of memory of the system. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
302 |
A system resource error was detected. (%1, type = swap)
%1:Monitor resource name
|
An error was detected in monitoring the total usage of virtual memory of the system. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
302 |
A system resource error was detected. (%1, type = file)
%1:Monitor resource name
|
An error was detected in monitoring the total number of open files of the system. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
302 |
A system resource error was detected. (%1, type = thread)
%1:Monitor resource name
|
An error was detected in monitoring the total number of threads of the system. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
303 |
A system resource error was detected. (%1, type = number of process, user name = %2)
%1:Monitor resource name
%2:User name
|
An error was detected in monitoring the number of running processes for each user of the system. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
304 |
A disk resource error was detected. (%1, type = used rate, level = NOTICE, %2)
%1:Monitor resource name
%2:mount point
|
A notice level error was detected in monitoring the disk usage rates. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
304 |
A disk resource error was detected. (%1, type = used rate, level = WARNING, %2)
%1:Monitor resource name
%2:mount point
|
A warning level error was detected in monitoring the disk usage rates. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
304 |
A disk resource error was detected. (%1, type = free space, level = NOTICE, %2)
%1:Monitor resource name
%2:mount point
|
A notice level error was detected in monitoring the free disk space. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Error |
304 |
A disk resource error was detected. (%1, type = free space, level = WARNING, %2)
%1:Monitor resource name
%2:mount point
|
A warning level error was detected in monitoring the free disk space. |
Check the possible causes of the monitoring failure. |
o |
o |
|||
sra |
Warning |
401 |
zip/unzip package is not installed. |
The compression of statistical information collected by System Resource Agent failed. |
Check if a zip (unzip) package has been installed in the system. |
o |
o |
|||
lcns |
Info |
1 |
The number of licenses is %1. (Product name:%2) |
The number of cluster licenses is %1.
%1: Number of licenses
%2: Product name
|
- |
o |
o |
|||
lcns |
Info |
2 |
The trial license is valid until %1. (Product name:%2) |
The trial license is effective until %1.
%1: Trial end date
%2: Product name
|
- |
o |
o |
|||
lcns |
Warning |
3 |
The number of licenses is insufficient. The number of insufficient licenses is %1. (Product name:%2) |
The number of licenses is insufficient. The number of insufficient licenses is %1.
%1: Required number of licenses
%2: Product name
|
Purchase the required number of licenses and then register them. |
o |
o |
|||
lcns |
Error |
4 |
The license is not registered. (Product name:%1) |
The license is not registered.
%1: Product name
|
Purchase the license and then register it. |
o |
o |
|||
lcns |
Error |
5 |
The trial license has expired in %1. (Product name:%2) |
The validity term of the trial license has expired.
%1: Trial end date
%2: Product name
|
Register a valid license. |
o |
o |
|||
lcns |
Error |
6 |
The registered license is invalid. (Product name:%1, Serial No:%2) |
The registered license is invalid.
%1: Product name
%2: Serial number
|
Register a valid license. |
o |
o |
|||
lcns |
Error |
7 |
The registered license is unknown. (Product name:%1) |
The registered license is unknown.
%1: Product name
|
Register a valid license. |
o |
o |
|||
lcns |
Error |
8 |
The trial license is valid from %1. (Product name:%2) |
The validity term of the trial license is not reached.
%1: Trial start date
%2: Product name
|
Register a valid license. |
o |
o |
|||
lcns |
Info |
9 |
The fixed term license is valid until %1. (Product name:%2) |
The validity term of the fixed-term license is effective until %1.
%1:End date of validity term
%2: Product name
|
- |
o |
o |
|||
lcns |
Error |
10 |
The fixed term license has expired in %1. (Product name:%2) |
The validity term of the fixed-term license has expired.
%1: End date of validity term
%2: Product name
|
Register a valid license. |
o |
o |
|||
webmgr |
Warning |
21 |
HTTPS configuration isn't correct, HTTPS mode doesn't work. Please access WebManager by HTTP mode. |
HTTPS configuration isn't correct, HTTPS mode doesn't work. Please access WebManager by HTTP mode. |
- |
o |
o |
4.2. Driver syslog messages¶
4.2.1. Kernel mode LAN heartbeat driver¶
Module Type |
Event type |
Event ID |
Message |
Description |
Solution |
|---|---|---|---|---|---|
clpkhb |
Info |
101 |
Kernel Heartbeat was initialized successfully. (major=%1, minor=%2) |
The clpkhb driver was successfully loaded. |
- |
clpkhb |
Info |
102 |
Kernel Heartbeat was released successfully. |
The clpkhb driver was successfully unloaded. |
- |
clpkhb |
Error |
103 |
Can not register miscdev on minor=%1. (err=%2) |
Failed to load the clpkhb driver. |
- |
clpkhb |
Error |
104 |
Can not deregister miscdev on minor=%1. (err=%2) |
Failed to unload the clpkhb driver. |
- |
clpkhb |
Info |
105 |
Kernel Heartbeat was initialized by %1. |
The clpkhb driver was successfully initialized by [%1] module. |
- |
clpkhb |
Info |
106 |
Kernel Heartbeat was terminated by %1. |
The clpkhb driver was successfully terminated by [%1] module. |
- |
clpkhb |
Error |
107 |
Can not register Kernel Heartbeat proc file! |
Failed to create proc file for the clpkhb driver. |
- |
clpkhb |
Error |
108 |
Version error. |
The inside version information of the clpkhb driver is invalid. |
Reinstall EXPRESSCLUSTER. |
clpkhb |
Info |
110 |
The send thread has been created. (PID=%1) |
The send thread of the clpkhb driver was successfully created. The process ID is [%1]. |
- |
clpkhb |
Info |
110 |
The recv thread has been created. (PID=%1) |
The receive thread of the clpkhb driver was successfully created. The process ID is [%1]. |
- |
clpkhb |
Error |
111 |
Failed to create send thread. (err=%1) |
Failed to create the send thread of the clpkhb driver due to the error [%1]. |
- |
clpkhb |
Error |
111 |
Failed to create recv thread. (err=%1) |
Failed to create the receive thread of the clpkhb driver due to the error [%1]. |
- |
clpkhb |
Info |
112 |
Killed the send thread successfully. |
The send thread of clpkhb driver was successfully stopped. |
- |
clpkhb |
Info |
112 |
Killed the recv thread successfully. |
The receive thread of clpkhb driver was successfully stopped. |
- |
clpkhb |
Info |
113 |
Killed the recv thread successfully. |
Killing the clpkhb driver. |
- |
clpkhb |
Info |
114 |
Killed the recv thread successfully. |
Killing the clpkhb driver. |
- |
clpkhb |
Info |
115 |
Kernel Heartbeat has been stopped |
The clpkhb driver successfully stopped. |
- |
clpkhb |
Error |
120 |
Failed to create socket to send %1 packet. (err=%2) |
Failed to create the socket for sending the [%1] (HB/DOWN/KA) packet due to the error [%2]. |
- |
clpkhb |
Error |
120 |
Failed to create socket to receive packet. (err=%2) |
Failed to create the socket for receiving the packet due to the error [%2]. |
- |
clpkhb |
Error |
121 |
Failed to create sending %1 socket address. (err=%2) |
Failed to set the socket for sending the [%1] (HB/DOWN/KA) packet. |
The physical memory may be running out. Add physical memories, or terminate unnecessary applications. |
clpkhb |
Error |
122 |
Failed to create %1 socket address. (err=%2) |
Failed to set the socket for sending the [%1] (HB/DOWN/KA) packet. |
The physical memory may be running out. Add physical memories, or terminate unnecessary applications. |
clpkhb |
Error |
123 |
Failed to bind %1 socket. (err=%2) |
Failed to bind the socket for [%1] (HB/DOWN/KA). |
Check the status of the operating system.
The communication port for clpkhb may be used already by other applications or others. Check the usage status of the communication port.
Check the cluster configuration information server property if the IP address set for the interconnect LAN I/F is correct.
|
clpkhb |
Error |
125 |
Failed to send %1 data to %2. (err=%3) |
Failed to send [%1] (HB/DOWN/KA) data to [%2]. |
Check the status of the network for the clpkhb communication.
Check the status of the remote server.
Check that the setting information is correct.
|
clpkhb |
Error |
126 |
Failed to receive data. (err=%3) |
Failed to receive data. |
The remote server may be down. Check if the server is active.
If the server is not down, check the status of the network for clpkhb.
|
clpkhb |
Info |
127 |
|
|
Other applications may be sending the data to the port for clpkhb. Check the usage status of the port. |
clpkhb |
Error |
128 |
|
|
Same as above. |
clpkhb |
Info |
129 |
Receiving operation was interrupted by ending signal! |
The receive thread ends by termination signal. |
- |
clpkhb |
Info |
130 |
|
|
Check the status of the server where the reset occurred. |
clpkhb |
Info |
131 |
|
|
Check the status of the server where the panic occurred. |
clpkhb |
Error |
140 |
Reference an inaccessible memory area! |
Failed to pass data to an application by ioctl(). |
Check the status of the operating system. |
clpkhb |
Error |
141 |
Failed to allocate memory! |
Failed to allocate memory. |
The physical memory may be running out. Add physical memories, or terminate unnecessary applications. |
clpkhb |
Error |
142 |
Invalid argument, %1! |
The parameter passed to the clpkhb driver is not correct. |
Check if the settings are correct. |
clpkhb |
Warning |
143 |
Local node has nothing with current resource. |
The heartbeat resource information passed to the clpkhb driver is not correct. |
Same as above. |
4.2.2. Keepalive driver¶
Module Type |
Event type |
Event ID |
Message |
Description |
Solution |
|---|---|---|---|---|---|
clpka |
Info |
101 |
Kernel Keepalive was initialized successfully.
(major=%1, minor=%2)
|
The clpka driver was successfully loaded. |
- |
clpka |
Info |
102 |
Kernel Keepalive was released successfully. |
The clpka driver was successfully unloaded. |
- |
clpka |
Error |
103 |
Can not register miscdev on minor=%1. (err=%2) |
Failed to load the clpka driver. |
Check the distribution and kernel support the kernel mode LAN heartbeat. |
clpka |
Info |
105 |
Kernel Keepalive was Initialized by %1. |
The clpka driver was successfully initialized. |
- |
clpka |
Error |
107 |
Can not register Kernel Keepalive proc file! |
Failed to create proc file for the clpka driver. |
The kernel may not be running normally because of lack of memory or other reasons. Add physical memories, or terminate unnecessary applications. |
clpka |
Error |
108 |
Version error. |
The version of the clpka driver is invalid. |
Check if the installed clpka driver is legitimate. |
clpka |
Error |
111 |
Failed to create notify thread. (err=%1) |
Failed to create the thread of the clpka driver. |
The kernel may not be running normally because of lack of memory or other reasons. Add physical memories, or terminate unnecessary applications. |
clpka |
Info |
130 |
Reboot tried. |
In keeping with the settings, the clpka driver tried to restart the machine. |
- |
clpka |
Info |
132 |
Kernel do nothing. |
In keeping with the settings, the clpka driver did nothing. |
- |
clpka |
Error |
140 |
Reference an inaccessible memory area! |
Failed to pass the version information of the clpka driver to the cluster main body. |
Check if the installed clpka driver is legitimate. |
clpka |
Error |
141 |
Failed to allocate memory! |
The size of physical memory is not sufficient. |
The physical memory is running out. Add physical memories, or terminate unnecessary applications. |
clpka |
Error |
142 |
Invalid argument, %1! |
Invalid information was passed from the cluster main body to the clpka driver. |
Check if the installed clpka driver is legitimate. |
clpka |
Error |
144 |
Process (PID=%1) is not set. |
A process other than cluster main body tried operation to the clpka driver. |
Check if there is any application trying to access to the clpka driver erroneously. |
4.3. Detailed information on activating and deactivating group resources¶
4.3.1. EXEC resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
exec |
Error |
1 |
Termination code %1 was returned. |
A termination code other than 0 has been returned as the execution result of a synchronous script or application. |
If this message appears for a script, the contents of the script might be incorrect. Check whether the script is correctly specified.
If this message appears for an application, the application might have terminated abnormally. Check the application operation.
|
exec |
Error |
1 |
Command was not completed within %1 seconds. |
Execution of a synchronous script or application has not terminated within the specified time. |
If this message appears for a script, the contents of the script might be incorrect. Check whether the script is correctly described.
If this message appears for an application, the application might have stalled. Check the application operation.
The cause of this error might be identifiable from the logs. For details about log output settings, refer to "Details of other settings" in the "EXPRESSCLUSTER X SingleServerSafe Configuration Guide".
|
exec |
Error |
1 |
Command was aborted. |
A synchronous script or application has been aborted. |
If this message appears for an application, the application might have been aborted. Check the application operation.
Memory or OS resources may not be sufficient. Check them.
|
exec |
Error |
1 |
Command was not found. (error=%1) |
The application was not found. |
The application path might be incorrect. Check the path of the application in the configuration data. |
exec |
Error |
1 |
Command string was invalid. |
The application path is invalid. |
Check the path of the application in the configuration data. |
exec |
Error |
1 |
Log string was invalid. |
The path of the log output destination is incorrect. |
Check the path of the data log output destination in the configuration data. |
exec |
Error |
1 |
Internal error. (status=%1) |
Another internal error occurred. |
Memory or OS resources may not be sufficient. Check them. |
4.3.2. VM resources¶
Module Type |
Type |
Return value |
Message |
Description |
Solution |
|---|---|---|---|---|---|
vm |
Error |
1 to 6,8 |
Initialize error occured. |
An error was detected while initialization. |
Check if the cluster configuration information is correct. |
vm |
Error |
7 |
Parameter is invalid. |
The parameter is invalid. |
Check if the cluster configuration information is correct. |
vm |
Error |
9 to 13 |
Failed to %s virtual machine %s. |
Failed to control the virtual machine. |
Check the status of the virtual machine. |
vm |
Error |
22 |
Datastore must be setted. |
Datastore name must be setted in the Cluster WebUI. |
Click the [Details] tab of VM Resources Properties in the Cluster WebUI, enter the name of data store containing the virtual machine configuration information to [Data Store Name]. And then click [Apply the Configuration File]. |
vm |
Error |
23 |
VM configuration file path must be setted. |
VM configuration file path must be setted in the Cluster WebUI. |
Click the [Details] tab of VM Resources Properties in the Cluster WebUI, enter the path where the virtual machine configuration information is stored to [VM Configuration File Path]. And then click [Apply the Configuration File]. |
vm |
Error |
Other |
Internal error occured. |
Another internal error occurred. |
Memory or OS resources may not be sufficient. Check them. |
4.4. Details about monitor resource errors¶
4.4.1. Software RAID monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
lmdw |
Warning |
101 |
Device=(%1): Bad disks(%2) are detected in mirror disk. |
Some physical disks under the mirror disk are damaged and now have the [caution] status. |
The mirror disk can be used but the damaged physical disks must be replaced. |
lmdw |
Warning |
102
190
|
Internal error.err=%1 |
An internal error occurred. |
There might not be enough memory space or OS resources. Check them. |
lmdw |
Warning |
102
190
|
Config file error.(err=%1) |
The contents of the configuration data are incorrect. |
Check whether the configuration data is correct. |
lmdw |
Warning |
190 |
Soft RAID module has a problem. (err=%1) |
The kernel module related to software RAID is faulty. |
- |
lmdw |
Warning |
190 |
Options or parameters are invalid. |
A command parameter error occurred. |
Check whether the configuration data is correct. |
lmdw |
Warning |
190 |
Failed to read config file.(err=%1) |
The configuration file could not be read. |
Check whether the configuration data is correct. |
lmdw |
Warning |
191 |
Device=(%1): Mirror disk is in recovery process (%2). |
The mirror disk is now in the [recovery] process. |
- |
4.4.2. IP monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
ipw |
Error |
5 |
Ping was failed by timeout. IP=%s... |
The ping command has failed due to a timeout. |
The system may be under high load, or memory or OS resources may not be sufficient. Check them. |
ipw |
Error |
31 |
Ping cannot reach. (ret=%1) IP=%2... |
The packet transmitted by the ping command has not arrived. |
Check whether the ping command to the corresponding IP address succeeds. If the command fails, check the status of the device that has the IP address or status of the network interface. |
ipw |
Warning |
102 |
Ping was failed. (ret=%1) IP=%2... |
The ping command has failed. |
Memory or OS resources may not be sufficient. Check them. |
ipw |
Warning |
106
108 to 121
|
Internal error. (status=%1) |
Another internal error occurred. |
Memory or OS resources may not be sufficient. Check them. |
ipw |
Warning |
189 |
Internal error. (status=%1) |
Monitoring of the IP monitor resource failed by time out. |
Memory or OS resources may not be sufficient. Check them. |
4.4.3. Disk monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
diskw |
Error |
12 |
Ioctl was failed. (err=%1) Device=%2 |
Failed to control the device. |
Check if the monitoring target disk is connected properly, the disk is powered on, or no other errors are occurred on the disk. |
diskw |
Error |
14 |
Open was failed. (err=%1) File=%2 |
The file could not be opened. |
Check whether a directory that has the same name as the file exists, the monitoring target disk is connected properly, the disk is on, or other errors occurred on the disk.
Memory or OS resources may not be sufficient. Check them.
|
diskw |
Error |
14 |
Open was failed.
(err=%1) Device=%2
|
Opening the device
failed.
|
Check whether a directory that has the same name as the file exists, the monitoring target disk is connected properly, the disk is on, or other errors occurred on the disk.
Memory or OS resources may not be sufficient. Check them.
|
diskw |
Error |
16 |
Read was failed. (err=%1) Device=%2 |
Reading from the device has failed. |
Check if the monitoring target disk is connected properly, the disk is powered on, or no other errors are occurred on the disk.
Memory or OS resources may not be sufficient. Check them.
|
diskw |
Error |
18 |
Write was failed. (err=%1) File=%2 |
Writing to the file has failed. |
Check if the monitoring target disk is connected properly, the disk is powered on, or no other errors are occurred on the disk. |
Memory or OS resources may not be sufficient. Check them. |
|||||
diskw |
Error |
41 |
SG_IO failed. (sg_io_hdr_t info:%1 SG_INFO_OK_MASK: %2) |
SG_IO has failed. |
Check if the monitoring target disk is connected properly, the disk is powered on, or no other errors are occurred on the disk. |
diskw |
Error |
49 |
Already bound for other. Rawdevice=%1 Device=%2 |
The RAW device has already been bound by another real device. |
The set RAW device has already been bound by another real device. Change the RAW device name on the Cluster WebUI. |
diskw |
Error |
55 |
Bind was failed. Rawdevice=%1 Device=%2 |
Bind failed. |
Bind failed. Check the RAW device name on the Cluster WebUI. |
diskw |
Error |
56 |
Lseek was failed by timeout. Device=%1 |
Lseek failed. |
The possible cause is the heavily loaded system, insufficient memory, or insufficient OS resources. Check if any of these exists. |
diskw |
Error |
57 |
Fdatasync was failed by timeout. Device=%1 |
Fdatasync failed. |
Check if the disk as a monitoring target is appropriately connected, is turned on, or has anything abnormal.
The possible cause is the heavily loaded system, insufficient memory, or insufficient OS resources. Check if any of these exists.
|
diskw |
Warning |
101 |
Ioctl was failed by timeout. Device=%1 |
The device control failed due to timeout. |
Check the disk to be monitored is properly connected, powered on, or does not have any problem.
The system may be heavily loaded, memory or OS resources may not be sufficient. Check them.
|
diskw |
Warning |
101 |
Open was failed by timeout. File=%1 |
Opening the file failed due to timeout. |
Check the disk to be monitored is properly connected, powered on, or does not have any problem. |
diskw |
Warning |
101 |
Open was failed by timeout. Device=%1 |
Opening the device failed due to timeout. |
The system may be heavily loaded, memory or OS resources may not be sufficient. Check them. |
diskw |
Warning |
101 |
Read was failed by timeout. Device=%1 |
Failed to read from the device due to timeout. |
Check the disk to be monitored is properly connected, powered on, or does not have any problem. |
The system may be heavily loaded, memory or OS resources may not be sufficient. Check them. |
|||||
diskw |
Warning |
101 |
Write was failed by timeout. File=%1 |
Writing to the file failed due to timeout. |
Check the disk to be monitored is properly connected, powered on, or does not have any problem. |
The system may be heavily loaded, memory or OS resources may not be sufficient. Check them. |
|||||
diskw |
Warning |
101 |
Bind was failed. Rawdevice=%1 Device=%2 |
Bind failed. |
Bind failed. Check the RAW device name on the Cluster WebUI. |
diskw |
Warning |
101 |
Stat was failed. (err=%1) Device=%2 |
Stat failed. |
Stat failed. Check the device name on the Cluster WebUI. |
diskw |
Warning |
101 |
Popen was failed. (err=%1) |
Popen failed. |
Popen failed. Memory or OS resources may not be sufficient. Check them. |
diskw |
Warning |
101
190
|
Option was invalid. |
The option is invalid. |
Check the cluster configuration data. |
diskw |
Warning |
101
190
|
Internal error. (status=%1) |
An error other than the errors mentioned above has occurred. |
Memory or OS resources may not be sufficient. Check them. |
diskw |
Warning |
190 |
Parameter was invalid. File=%1 |
The specified file name is invalid. |
Do not specify the file whose name starts with /dev. Specify a normal file. |
diskw |
Warning |
190 |
Device was invalid. Device=%1 |
The specified real device is invalid. |
Check the device name of the disk monitor resource on the Cluster WebUI. |
diskw |
Warning |
191 |
Ignored disk full error. |
A disk full error has been ignored. |
Check the usage of the device. |
4.4.4. PID monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
pidw |
Error |
1 |
Process does not exist. (pid=%1) |
The process does not exist. |
Process of the monitoring target was cleared due to some error. Check them. |
pidw |
Warning |
100 |
Resource %1 was not found. |
The resource is not found. |
Check the cluster configuration data by using the Cluster WebUI. |
pidw |
Warning |
100 |
Internal error. (status=%1) |
Another internal error occurred. |
Memory or OS resources may not be sufficient. Check them. |
4.4.5. User space monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
userw |
Error |
1 |
Initialize error. (%1) |
An error was detected during process initialization. |
Check if the driver depended on by the user mode monitor resources exists, or the rpm is installed. The driver or rpm differ depending on the monitor method. |
4.4.6. Custom monitor resource¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
genw |
Error |
1 |
Initialize error. (status=%d) |
An error was detected while initialization. |
Memory or OS resources may not be sufficient. Check them. |
genw |
Error |
2 |
Termination code %d was returned. |
An unexpected value was returned. |
Check if the cluster configuration information is correct. |
genw |
Error |
3 |
User was not superuser. |
User was not root user. |
Log in as root user. |
genw |
Error |
4 |
Getting of config was failed. |
Failed to get the cluster configuration information. |
Check if the cluster configuration information exists. |
genw |
Error |
5 |
Parameter was invalid. |
The parameter is invalid. |
Check if the cluster configuration information is correct. |
genw |
Error |
6 |
Option was invalid. |
The parameter is invalid. |
Check if the cluster configuration information is correct. |
genw |
Error |
7 |
Monitor Resource %s was not found. |
The resoruce was not found. |
Check if the cluster configuration information is correct. |
genw |
Error |
8 |
Create process failed. |
Create process failed. |
Memory or OS resources may not be sufficient. Check them. |
genw |
Error |
9 |
Process does not exist. (pid=%d) |
The process did not exist. |
Check if the process exists. |
genw |
Error |
10 |
Process aborted. (pid=%d) |
The process did not exist. |
Check if the process exists. |
genw |
Error |
11 |
Asynchronous process does not exist. (pid=%d) |
The process did not exist. |
Check if the process exists. |
genw |
Error |
12 |
Asynchronous process aborted. (pid=%d) |
The process did not exist. |
Check if the process exists. |
genw |
Error |
13 |
Monitor path was invalid. |
The path is invalid. |
Check if the cluster configuration information is correct. |
genw |
Error |
others |
Internal error. (status=%d) |
Another internal error occurred. |
- |
4.4.7. Multi target monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
mtw |
Error |
1 |
Option was invalid. |
The parameter is invalid. |
Check if the cluster configuration information is correct. |
mtw |
Error |
2 |
User was not superuser. |
User was not root user. |
Log in as root user. |
mtw |
Error |
3 |
Internal error. (status=%d) |
Another internal error occurred. |
- |
4.4.8. JVM monitor resources¶
Module Type |
Type |
Return value |
Message |
Description |
Solution |
|---|---|---|---|---|---|
jraw |
Error |
11 |
An error was detected in accessing the monitor target. |
Java VM to be monitored cannot be connected. |
Check that the Java VM to be monitored is running. |
jraw |
Error |
12 |
JVM status changed to abnormal. cause = %1. |
An error was detected in monitoring Java VM.
%1: Error generation cause
GarbageCollection
JavaMemoryPool
Thread
WorkManagerQueue
WebOTXStall
|
Based on the message, check the Java application that is running on Java VM to be monitored. |
jraw |
Warning |
189 |
Internal error occurred. |
An internal error has occurred. |
Execute cluster suspend and cluster resume. |
4.4.9. System monitor resources¶
Module Type |
Type |
Return value |
Message |
Description |
Solution |
|---|---|---|---|---|---|
sraw |
Error |
11 |
Detected an error in monitoring system resource |
An error was detected when monitoring system resources. |
There may be an error with the resources. Check them. |
4.4.10. Process resource monitor resource¶
Module Type |
Type |
Return value |
Message |
Description |
Solution |
|---|---|---|---|---|---|
psrw |
Error |
11 |
Detected an error in monitoring process resource |
An error was detected when monitoring Process resources. |
There may be an error with the resources. Check them. |
4.4.11. NIC Link Up/Down monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
miiw |
Error |
20 |
NIC %1 link was down. |
The NIC link has gone down. |
Check whether the LAN cable is connected properly. |
miiw |
Warning |
110 |
Get address information was failed. (err=%1) |
The socket address of the IPv4 or IPv6 address family could not be obtained. |
Check whether the kernel configuration supports TCP/IP networking (IPv4 or IPv6). |
miiw |
Warning |
111 |
Socket creation was failed. (err=%1) |
The socket could not be created. |
Memory or OS resources may not be sufficient. Check them. |
miiw |
Warning |
112 |
ioctl was failed. (err=%1) Device=%2 Request=%3 |
The control request to the network driver has failed. |
Check whether the network driver supports control request %3.
For details about the verified NIC and network driver, see "Monitor resource details" in the "EXPRESSCLUSTER X SingleServerSafe Configuration Guide".
|
miiw |
Warning |
113 |
MII was not supported or no such device. Device=%1 |
MII is not supported by NIC or the monitored object does not exist. |
For details about the verified NIC and network driver, see "Monitor resource details" in the "EXPRESSCLUSTER X SingleServerSafe Configuration Guide".
If the monitored target does not exist, check the network interface name, such as by using ifconfig.
|
miiw |
Warning |
189 |
Internal error. (status=%d) |
Another internal error occurred. |
- |
miiw |
Warning |
190 |
Option was invalid. |
The option is invalid. |
Check the configuration data by using the Cluster WebUI. |
miiw |
Warning |
190 |
Config was invalid. (err=%1) %2 |
The configuration data is invalid. |
Check the configuration data by using the Cluster WebUI. |
4.4.12. VM monitor resources¶
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
vmw |
Error |
1 |
initialize error occured. |
An error was detected while initialization. |
Memory or OS resources may not be sufficient. Check them. |
vmw |
Error |
11 |
monitor success, virtual machine is not running. |
Stop of the virtual machine was detected. |
Check the status of the virtual machine. |
vmw |
Error |
12 |
failed to get virtual machine status. |
Failed to get the status of the virtual machine. |
Check if the virtual machine exists. |
vmw |
Error |
13 |
timeout occured. |
The monitoring timed out. |
The OS may be highly loaded. Check it. |
4.4.13. Volume manager monitor resources¶
Module Type |
Type |
Return value |
Message |
Description |
Solution |
|---|---|---|---|---|---|
volmgrw |
Error |
21 |
Command was failed. (cmd=%1, ret=%2) |
%1 command failed. The return value is %2. |
The command failed. Check the action status of the volume manager. |
volmgrw |
Error |
22
23
|
Internal error. (status=%1) |
Another internal error occurred. |
- |
volmgrw |
Warning |
190 |
Option was invalid. |
The option is invalid. |
Check the cluster configuration information on the Cluster WebUI. |
volmgrw |
Warning |
191 |
%1 %2 is %3 ! |
The status of the target (%2) of the volume manager (%1) transferred to %3. |
Check the status of the volume manager target. |
volmgrw |
Warning |
Others |
Internal error. (status=%1) |
Another internal error occurred. |
- |
4.4.14. Process name monitor resources¶
Module Type |
Type |
Return value |
Message |
Description |
Solution |
|---|---|---|---|---|---|
psw |
Error |
11 |
Process[%1 (pid=%2)]
Down
|
Deletion of a monitored process has been detected. |
Check whether the monitored process is running normally. |
psw |
Error |
12 |
The number of processes is less than the specified minimum process count. %1/%2 (%3) |
The number of started processes for the monitor target process is less than the specified minimum count. |
Check whether the monitored process is running normally. |
psw |
Warning |
100 |
Monitoring timeout |
Monitoring has timed out. |
The OS may be highly loaded. Check that. |
psw |
Warning |
101
190
|
Internal error |
An internal error has occurred. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
psw |
Warning |
190 |
Initialize error |
An error has been detected during initialization. |
Check the following possible causes: memory shortage or OS resource insufficiency. |
4.4.15. Monitoring option monitor resources¶
The monitoring option monitor resources use common messages. Module types differ per monitoring option monitor resource.
Monitoring Option Monitor Resource |
Module Type |
|---|---|
DB2 monitor resource |
db2w |
FTP monitor resource |
ftpw |
HTTP monitor resource |
httpw |
IMAP4 monitor resource |
imap4w |
MySQL monitor resource |
mysqlw |
NFS monitor resource |
nfsw |
ODBC monitor resource |
odbcw |
Oracle monitor resource |
oraclew |
POP3 monitor resource |
pop3w |
PostgreSQL monitor resource |
psqlw |
Samba monitor resource |
sambaw |
SMTP monitor resource |
smtpw |
SQL Server monitor resource |
sqlserverw |
Sybase monitor resource |
sybasew |
Tuxedo monitor resource |
tuxw |
WebLogic monitor resource |
wlsw |
WebSphere monitor resource |
wasw |
WebOTX monitor resource |
otxw |
Module Type |
Type |
Return Value |
Message |
Explanation |
Solution |
|---|---|---|---|---|---|
(see the list above) |
Error |
5 |
Failed to connect to %1 server. [ret=%2] |
Connecting to the monitoring target has failed.
The application name is displayed in place of %1.
|
Check the status of the monitoring target. |
(see the list above) |
Error |
7 |
Failed to execute SQL statement (%1). [ret=%2] |
The SQL statement could not be executed.
The monitoring target is displayed in place of %1.
|
Check the configuration data by using the Cluster WebUI. |
(see the list above) |
Error |
8 |
Failed to access with %1. |
Data access with the monitoring target has failed.
The monitoring target is displayed in place of %1.
|
Check the status of the monitoring target. |
(see the list above) |
Error |
9 |
Detected error in %1. |
The monitoring target is abnormal.
The monitoring target is displayed in place of %1.
|
Check the status of the monitoring target. |
(see the list above) |
Warning |
104 |
Detected function exception. [%1, ret=%2] |
An error was detected.
The monitoring target is displayed in place of %1.
|
Check the configuration data by using the Cluster WebUI.
The OS might be heavily loaded. Check them.
|
(see the list above) |
Warning |
106 |
Detected authority error. |
User authentication has failed. |
Check the user name, password, and access permissions. |
(see the list above) |
Warning |
111 |
Detected timeout error. |
Communication with the monitoring target timed out. |
The OS might be heavily loaded. Check them. |
(see the list above) |
Warning |
112 |
Can not found install path. (install path=%1) |
The install path could not be loaded from the specified location.
The install path is displayed in place of %1.
|
Check the install path location. |
(see the list above) |
Warning |
113 |
Can not found library. (libpath=%1, errno=%2) |
The library could not be loaded from the specified location.
The library path is displayed in place of %1.
|
Check the library location. |
(see the list above) |
Warning |
171 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
A monitoring delay was detected in monitoring %1. The current timeout value is %2 (second) x %3 (tick count per second). The actual measurement value at delay detection is %4 (tick count) and exceeded the delay warning rate %5 (%). |
Check the load status of the server on which a monitoring delay was detected and remove the load.
If a monitoring timeout is detected, extend it.
|
(see the list above) |
Info |
181 |
The collecting of detailed information triggered by monitor resource %1 error has been started (timeout=%2). |
Collecting of detailed information triggered by the detection of a monitor resource $1 monitoring error has started. The timeout is %2 seconds. |
- |
(see the list above) |
Info |
182 |
The collection of detailed information triggered by monitor resource %1 error has been completed. |
Collecting of detailed information triggered by the detection of a monitor resource %1 monitoring error has been completed. |
- |
(see the list above) |
Warning |
183 |
The collection of detailed information triggered by monitor resource %1 error has been failed (%2). |
Collecting of detailed information triggered by the detection of a monitor resource %1 monitoring error has failed. (%2) |
- |
(see the list above) |
Warning |
189 |
Internal error. (status=%1) |
Internal error. |
- |
(see the list above) |
Warning |
190 |
Init error. [%1, ret=%2] |
An error was detected during initialization.
license, library, XML, share memory, or log is displayed where %1 is represented.
|
The OS might be heavily loaded. Check them. |
(see the list above) |
Warning |
190 |
Get config information error. [ret=%1] |
Failed to obtain the configuration data. |
Check the configuration data by using the Cluster WebUI. |
(see the list above) |
Warning |
190 |
Invalid parameter. |
The configuration data of the Config or Policy file is invalid.
The command parameter is invalid.
|
Check the configuration data by using the Cluster WebUI. |
(see the list above) |
Warning |
190 |
Init function error. [%1, ret=%2] |
Initialize error occurred in the function.
The executive function name is displayed in %1.
|
OS may be heavily loaded. Check the status of OS. |
(see the list above) |
Warning |
190 |
User was not superuser. |
The user does not have root privileges. |
The user executing the operation might not have root privileges, or the memory or OS resources might be insufficient. Check them. |
(see the list above) |
Warning |
190 |
The license is not registered. |
The license is not registered. |
Check whether the correct license is registered. |
(see the list above) |
Warning |
190 |
The registration license overlaps. |
The license you are attempting to register already exists. |
Check whether the correct license is registered. |
(see the list above) |
Warning |
190 |
The license is invalid. |
The license is invalid. |
Check whether the correct license is registered. |
(see the list above) |
Warning |
190 |
The license of trial expired by %1. |
The trial license has expired.
The expiration date is displayed in place of %1.
|
- |
(see the list above) |
Warning |
190 |
The license of trial effective from %1. |
The date is not the starting date of the trial license.
The starting date of the trial license is displayed in place of %1.
|
- |
4.5. JVM monitor resource log output messages¶
The following messages belong to the JVM operation and JVM load balancer linkage log files that are specific to the JVM monitor resources.
4.5.1. JVM operation log¶
Message |
Cause of generation |
Action |
|---|---|---|
Failed to write the %1$s.stat. |
Writing to the JVM statistics log has failed.
%1$s.stat: JVM statistics log file name
|
Check whether there is sufficient free disk space. |
%1$s: analyze finish[%4$s]. state = %2$s, cause = %3$s |
(When the status of the Java VM to be monitored is abnormal) the resource use amount has exceeded the threshold in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Status of Java VM to be monitored
(1=normal, 0=abnormal)
%3$s: Error generation location at abnormality occurrence
%4$s: Measurement thread name
|
Review the Java application that runs on the Java VM to be monitored. |
thread stopped by UncaughtException. |
The thread of the JVM monitor resource has stopped. |
Execute cluster suspend/cluster resume and then restart the JVM monitor resource. |
thread wait stopped by Exception. |
The thread of the JVM monitor resource has stopped. |
Execute cluster suspend/cluster resume and then restart the JVM monitor resource. |
%1$s: monitor thread can't connect to JVM. |
The Java VM to be monitored could not be connected.
%1$s: Name of the Java VM to be monitored
|
Check that the Java VM to be monitored is running. |
%1$s: monitor thread can't get the JVM state. |
The resource use amount could not be acquired from Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check that the Java VM to be monitored is running. |
%1$s: JVM state is changed [abnormal -> normal]. |
The status of the Java VM to be monitored has changed from abnormal to normal.
%1$s: Name of the Java VM to be monitored
|
- |
%1$s: JVM state is changed [normal -> abnormal]. |
The status of the Java VM to be monitored has changed from normal to abnormal.
%1$s: Name of the Java VM to be monitored
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: Failed to connect to JVM. |
The Java VM to be monitored could not be connected.
%1$s: Name of the Java VM to be monitored
|
Check that the Java VM to be monitored is running. |
Failed to write exit code. |
The JVM monitor resource failed to write data to the file for recording the exit code. |
Check whether there is sufficient free disk space. |
Failed to be started JVM Monitor. |
Starting of the JVM monitor resource has failed. |
Check the JVM operation log, remove the cause preventing the start, execute cluster suspend/cluster resume, and then restart the JVM monitor resource. |
JVM Monitor already started. |
The JVM monitor resource has already been started. |
Execute cluster suspend/cluster resume and then restart the JVM monitor resource. |
%1$s: GARBAGE_COLLECTOR_MXBEAN_DOMAIN_TYPE is invalid. |
GC information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: GarbageCollectorMXBean is invalid. |
GC information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: Failed to measure the GC stat. |
GC information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: GC stat is invalid. last.getCount = %2$s, last.getTime = %3$s, now.getCount = %4$s, now.getTime = %5$s. |
The GC generation count and GC execution time could not be measured for the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: GC generation count at last measurement
%3$s: Total GC execution time at last measurement
%4$s: GC generation count at this measurement
%5$s: Total GC execution time at this measurement
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: GC average time is too long. av = %6$s, last.getCount = %2$s, last.getTime = %3$s, now.getCount = %4$s, now.getTime = %5$s. |
The average GC execution time has exceeded the threshold in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: GC
generation count at last
measurement
%3$s: Total GC execution time at last measurement
%4$s: GC generation count at this measurement
%5$s: Total GC execution time at this measurement
%6$s: Average of the GC execution time used from the last measurement to this measurement
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: GC average time is too long compared with the last connection. av = %6$s, last.getCount = %2$s, last.getTime = %3$s, now.getCount = %4$s, now.getTime = %5$s. |
After the Java VM to be monitored was reconnected, the average of the GC execution time has exceeded the threshold in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: GC
generation count at last
measurement
%3$s: Total GC execution time at last measurement
%4$s: GC generation count at this measurement
%5$s: Total GC execution time at this measurement
%6$s: Average of the GC execution time used from the last measurement to this measurement
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: GC count is too frequently. count = %4$s last.getCount = %2$s, now.getCount = %3$s. |
The GC generation count has exceeded the threshold in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: GC
generation count at last
measurement
%3$s: GC generation count at this measurement
%4$s: GC generation count from the last measurement to this measurement
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: GC count is too frequently compared with the last connection. count = %4$s last.getCount = %2$s, now.getCount = %3$s. |
After the Java VM to be monitored was reconnected, the GC generation count has exceeded the threshold in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: GC
generation count at last
measurement
%3$s: GC generation count at this measurement
%4$s: GC generation count from the last measurement to this measurement
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: RuntimeMXBean is invalid. |
Information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: Failed to measure the runtime stat. |
Information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct.
Check whether the processing load is high in the Java VM to be monitored.
|
%1$s: MEMORY_MXBEAN_NAME is invalid. %2$s, %3$s. |
Memory information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Memory pool name
%3$s: Memory name
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: MemoryMXBean is invalid. |
Memory information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: Failed to measure the memory stat. |
Memory information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct.
Check whether the processing load is high in the Java VM to be monitored.
|
%1$s: MemoryPool name is undefined. memory_name = %2$s. |
Memory information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Name of the Java memory pool to be measured
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: MemoryPool capacity is too little. memory_name = %2$s, used = %3$s, max = %4$s, ratio = %5$s%. |
The Java memory pool free space has fallen below the threshold in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Name of the Java memory pool to be measured
%3$s: Use amount of the Java memory pool
%4$s: Maximum usable amount of the Java memory pool
%5$s: Use rate of the Java memory pool
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: THREAD_MXBEAN_NAME is invalid. |
Thread information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: ThreadMXBean is invalid. |
Thread information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: Failed to measure the thread stat. |
Thread information could not be acquired from Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: Detect Deadlock. threads = %2$s. |
Thread deadlock has occurred in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: ID of the deadlock thread
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: Thread count is too much(%2$s). |
The number of activated threads has exceeded the threshold in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of activated threads at measurement
|
Review the Java application that runs on the Java VM to be monitored. |
%1$s: ThreadInfo is null.Thread count = %2$s. |
Thread information could not be acquired in the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of activated threads at measurement
|
Check whether the operating environment of the version of the Java VM to be monitored is correct. |
%1$s: Failed to disconnect. |
Disconnection from the Java VM to be monitored has failed.
%1$s: Name of the Java VM to be monitored
|
- |
%1$s: Failed to connect to WebLogicServer. |
WebLogic Server to be monitored could not be connected.
%1$s: Name of the Java VM to be monitored
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: Failed to connect to Sun JVM. |
Java VM and WebOTX to be monitored could not be connected.
%1$s: Name of the Java VM to be monitored
|
Review the Java application that runs on the Java VM and WebOTX to be monitored. |
Failed to open the %1$s. |
The JVM statistics log could not be output.
%1$s: Name of the HA/JVMSaverJVM statistics log file
|
Check whether the disk has sufficient free space or whether the number of open files has exceeded the upper limit. |
%1$s: Can't find monitor file. |
No monitoring
%1$s: Name of the Java VM to be monitored
|
- |
%1$s: Can't find monitor file, monitor stopped[thread:%2$s]. |
Monitoring stops.
%1$s: Name of the Java VM to be monitored
%2$s: Type of the measurement thread
|
- |
%1$s: Failed to create monitor status file. |
An internal file could not be created.
%1$s: Name of the Java VM to be monitored
|
Check whether the disk free space and the maximum number of volume files are sufficient. |
%1$s: Failed to delete monitor status file. |
An internal file could not be deleted.
%1$s: Name of the Java VM to be monitored
|
Check whether there is a problem with the hard disk. |
%1$s: com.bea:Type=ServerRuntime is invalid. |
Information could not be acquired from the Java VM to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the Java VM to be monitored is correct. |
%1$s: WorkManagerRuntimeMBean or ThreadPoolRuntimeMBean is invalid. |
Information could not be acquired from the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the WebLogic Server to be monitored is correct. |
%1$s: Failed to measure the WorkManager or ThreadPool stat. |
Information could not be acquired from the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
|
Check whether the operating environment of the WebLogic Server to be monitored is correct. |
%1$s: ThreadPool stat is invalid. last.pending = %2$s, now.pending = %3$s. |
The number of waiting requests could not be measured in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s:Number of waiting requests at last measurement
%3$s:Number of waiting requests at this measurement
|
Check whether the operating environment of the version of the WebLogic Server to be monitored is correct. |
%1$s: WorkManager stat is invalid. last.pending = %2$s, now.pending = %3$s. |
The number of waiting requests could not be measured in the work manager of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of waiting requests at last measurement
%3$s: Number of waiting requests at this measurement
|
Check whether the operating environment of the version of the WebLogic Server to be monitored is correct. |
%1$s: PendingRequest count is too much. count = %2$s. |
The number of waiting requests has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of waiting requests at this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: PendingRequest increment is too much. increment = %4$s%%, last.pending = %2$s, now.pending = %3$s. |
The increment of the number of waiting requests has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of waiting requests at last measurement
%3$s: Number of waiting requests at this measurement
%4$s: Increment of the number of waiting requests from the last measurement to this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: PendingRequest increment is too much compared with the last connection. increment = %4$s, last.pending = %2$s, now.pending = %3$s. |
After the WebLogic Server to be monitored was reconnected, the increment of the number of waiting requests has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of waiting requests at last measurement
%3$s: Number of waiting requests at this measurement
%4$s: Increment of the number of waiting requests from the last measurement to this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: Throughput count is too much. count = %2$s. |
The number of requests executed per unit time has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of requests executed per unit time at this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: Throughput increment is too much. increment = %4$s, last.throughput = %2$s, now.throughput = %3$s. |
The increment of the number of requests executed per unit time has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of requests executed per unit time at last measurement
%3$s: Number of requests executed per unit time at this measurement
%4$s: Increment of the number of requests executed per unit time from the last measurement to this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: Throughput increment is too much compared with the last connection. increment = %4$s, last.throughput = %2$s, now.throughput = %3$s. |
After the WebLogic Server to be monitored was reconnected, the increment of the number of requests executed per unit time has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of requests executed per unit time at last measurement
%3$s: Number of requests executed per unit time at this measurement
%4$s: Increment of the number of requests executed per unit time from the last measurement to this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: PendingRequest count is too much. appName = %2$s, name = %3$s, count = %4$s. |
The number of waiting requests has exceeded the threshold in the work manager of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Application name
%3$s: Work manager name
%4$s: Number of waiting requests
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: PendingRequest increment is too much. appName = %2$s, name = %3$s, increment = %6$s%%, last.pending = %4$s, now.pending = %5$s. |
The increment of the number of waiting requests has exceeded the threshold in the work manager of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Application name
%3$s: Work manager name
%4$s: Number of waiting requests at last measurement
%5$s: Number of waiting requests at this measurement
%6$s: Increment of the number of waiting requests from the last measurement to this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: PendingRequest increment is too much compared with the last connection. AppName = %2$s, Name = %3$s, increment = %6$s, last.pending = %4$s, now.pending = %5$s. |
After the WebLogic Server to be monitored was reconnected, the increment of the number of waiting requests has exceeded the threshold in the work manager of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Application name
%3$s: Work manager name
%4$s: Number of waiting requests at last measurement
%5$s: Number of waiting requests at this measurement
%6$s: Increment of the number of waiting requests from the last measurement to this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: Can't find WorkManager. appName = %2$s, name = %3$s. |
The work manager which was set could not be acquired from the WebLogic Server.
%1$s: Name of the Java VM to be monitored
%2$s: Application name
%3$s: Work manager name
|
Review the setting of Target WebLogic Work Managers. |
%1$s: analyze of average start[%2$s]. |
Analyzing of the average value has started.
%1$s: Name of the Java VM to be monitored
%2$s: Thread name
|
- |
%1$s: analyze of average finish[%2$s].state = %3$s. |
Analyzing of the average value has been completed.
%1$s: Name of the Java VM to be monitored
%2$s: Thread name
%3$s: Status of the target to be monitored
|
- |
%1$s: Average of PendingRequest count is too much. count = %2$s. |
The average of the number of waiting requests has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of waiting requests at this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: Average of Throughput count is too much. count = %2$s. |
The average of the number of requests executed per unit time has exceeded the threshold in the thread pool of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Number of requests executed per unit time at this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored. |
%1$s: Average of PendingRequest count is too much. AppName = %2$s, Name = %3$s, count = %4$s. |
The average of the number of waiting requests has exceeded the threshold in the work manager of the WebLogic Server to be monitored.
%1$s: Name of the Java VM to be monitored
%2$s: Application name
%3$s: Work manager name
%4$s: Number of waiting requests at this measurement
|
Review the Java application that runs on the WebLogic Server to be monitored.
|
Error: Failed to operate clpjra_bigip.[%1$s] |
%1$s: Error code |
Review the setting. |
action thread execution did not finish. action is alive = %1$s. |
Execution of Command has timed out.
%1$s: Executable file name specified by Command
|
Forcibly terminate Command.
Review Command timeout.
Remove the cause of the timeout, such as a high load.
|
%1$s: Failed to connect to Local JVM. cause = %2$s. |
Failed to establish connection to JBoss.
%1$s: Monitor target name
%2$s: Detailed cause of the failure
The detailed cause is one of the following.
- Failed to found tool.jar, please set jdk's path for the java path.
- Load tool.jar exception
- Get Local JVM url path exception
- Failed to get process name
- Failed to connect to JBoss JVM.
|
Review Java Installation Path and Process Name.
Specify JDK, instead of JRE, as Java Installation Path.
Check whether JBoss has started.
|
4.5.2. JVM load balancer linkage log¶
Message |
Cause of generation |
Action |
|---|---|---|
lbadmin command start. |
Execution of the load balancer linkage command has started. |
- |
lbadmin command finish. |
Execution of the load balancer linkage command has been completed. |
- |
Into HealthCheck mode. |
The health check function is enabled. |
- |
Into Weight mode. |
The load calculation function of the Java VM to be monitored is valid. |
- |
The PID of lbadmin.jar is "%1". |
ID of the process relating to the load balancer linkage
%1: Process ID of lbadmin.jar
|
- |
Thread wait stopped by Exception |
Waiting for down judgment has been stopped. |
- |
Rename Command succeeded. |
Renaming of the HTML file has been successful. |
- |
Rename Command failed. |
Renaming of the HTML file has failed. |
Check the HTML file name and HTML rename destination file name. |
%1 doesn't exist. |
The rename source HTML file does not exist.
%1: HTML file name
|
Check the HTML file name. |
%1 already exists. |
The rename destination HTML file already exists.
%1: HTML rename destination file name
|
Check the HTML rename destination file name. |
Can't rename file:%1. |
Renaming of the HTML file has failed.
%1: HTML file name
|
Check the HTML rename destination file name. |
The number of retries exceeded the limit. |
The retry count for renaming the HTML file has exceeded the upper limit. |
Check the HTML rename destination file name. |
The percent of the load is "%1". |
Load calculation for the Java VM to be monitored has been successful.
%1: Load of Java VM to be monitored
|
- |
stat log (%1) doesn't exist. |
There is no JVM statistics log file.
%1: JVM statistics log file name
|
Execute cluster suspend/cluster resume and then restart the JVM monitor resource. |
stat log(%1:) cannot be opened for reading. |
The JVM statistics log file could not be opened.
%1: JVM statistics log file name
|
Execute cluster suspend/cluster resume and then restart the JVM monitor resource. |
format of stat log (%1) is wrong. |
The contents of the JVM statistics log file are invalid.
%1: JVM statistics log file name
|
After deleting the JVM statistics log file, execute cluster suspend/cluster resume and then restart the JVM monitor resource. |
Failed to get load of application server. |
Data for load calculation could not be acquired from the JVM statistics log file. |
Review whether the load calculation setting of the Java VM to be monitored is correct. |
Can't find lock file(%1s*.stat.lck), maybe HA/JVMSaver did not start yet. |
JVM monitor resource has not yet started.
%1: Internal file name
|
Start the JVM monitor resource. |