1. はじめに¶
1.1. 対象読者と目的¶
『CLUSTERPRO X SingleServerSafe 操作ガイド』は、システム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO X SingleServerSafe の操作方法について説明します。
1.2. 本書の構成¶
「2. CLUSTERPRO X SingleServerSafe コマンドリファレンス」:CLUSTERPRO X SingleServerSafeで使用可能なコマンドについて説明します。
「4. エラーメッセージ一覧」:CLUSTERPRO X SingleServerSafe 運用中に表示されるエラーメッセージの一覧について説明します。
1.3. 本書で記述される用語¶
本書で説明する CLUSTERPRO X SingleServerSafe は、クラスタリングソフトウェアである CLUSTERPRO X との操作性などにおける親和性を高めるために、共通の画面・コマンドを使用しています。そのため、一部、クラスタとしての用語が使用されています。
以下ように用語の意味を解釈して本書を読み進めてください。
- クラスタ、クラスタシステム
CLUSTERPRO X SingleServerSafe を導入した単サーバのシステム
- クラスタシャットダウン/リブート
CLUSTERPRO X SingleServerSafe を導入したシステムのシャットダウン、リブート
- クラスタリソース
CLUSTERPRO X SingleServerSafe で使用されるリソース
- クラスタオブジェクト
CLUSTERPRO X SingleServerSafe で使用される各種リソースのオブジェクト
- フェイルオーバグループ
CLUSTERPRO X SingleServerSafe で使用されるグループリソース(アプリケーション、サービスなど)をまとめたグループ
1.4. CLUSTERPRO X SingleServerSafe マニュアル体系¶
CLUSTERPRO X SingleServerSafeのマニュアルは、以下の 4 つに分類されます。各ガイドのタイトルと役割を以下に示します。
『CLUSTERPRO X SingleServerSafe for Linux インストールガイド』 (Install Guide)
CLUSTERPRO X SingleServerSafeを使用したシステムの導入を行うシステムエンジニアを対象読者とし、CLUSTERPRO X SingleServerSafeのインストール作業の手順について説明します。
『CLUSTERPRO X SingleServerSafe for Linux 設定ガイド』 (Configuration Guide)
CLUSTERPRO X SingleServerSafeを使用したシステムの導入を行うシステムエンジニアと、システム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO X SingleServerSafeの構築作業の手順について説明します。
『CLUSTERPRO X SingleServerSafe for Linux 操作ガイド』 (Operation Guide)
CLUSTERPRO X SingleServerSafe を使用したシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO X SingleServerSafe の操作方法について説明します。
『CLUSTERPRO X SingleServerSafe for Linux 互換機能ガイド』 (Legacy Feature Guide)
CLUSTERPRO X SingleServerSafe を使用したシステムの導入を行うシステムエンジニアを対象読者とし、CLUSTERPRO X SingleServerSafe 4.0 WebManager および Builder について説明します。
1.5. 本書の表記規則¶
本書では、注意すべき事項、重要な事項および関連情報を以下のように表記します。
注釈
この表記は、重要ではあるがデータ損失やシステムおよび機器の損傷には関連しない情報を表します。
重要
この表記は、データ損失やシステムおよび機器の損傷を回避するために必要な情報を表します。
参考
この表記は、参照先の情報の場所を表します。
また、本書では以下の表記法を使用します。
表記 |
使用方法 |
例 |
|---|---|---|
[ ] 角かっこ |
コマンド名の前後
画面に表示される語 (ダイアログボックス、メニューなど) の前後
|
[スタート] をクリックします。
[プロパティ] ダイアログ ボックス
|
コマンドライン中の [ ] 角かっこ |
かっこ内の値の指定が省略可能であることを示します。 |
|
# |
Linux ユーザが、root でログインしていることを示すプロンプト |
|
モノスペースフォント |
パス名、コマンドライン、システムからの出力 (メッセージ、プロンプトなど)、ディレクトリ、ファイル名、関数、パラメータ |
|
太字 |
ユーザが実際にコマンドラインから入力する値を示します。 |
以下を入力します。
# clpcl -s -a
|
|
ユーザが有効な値に置き換えて入力する項目 |
|
 本書の図では、CLUSTERPRO X SingleServerSafe を表すために このアイコンを使用します。
本書の図では、CLUSTERPRO X SingleServerSafe を表すために このアイコンを使用します。
2. CLUSTERPRO X SingleServerSafe コマンドリファレンス¶
本章では、CLUSTERPRO X SingleServerSafe で使用可能なコマンドについて説明します。
CLUSTERPRO X SingleServerSafe は、クラスタリングソフトウェアである CLUSTERPRO X との操作性などにおける親和性を高めるために、共通のコマンドを使用しています。
本章で説明する項目は以下のとおりです。
2.1. コマンドラインから操作する¶
CLUSTERPRO X SingleServerSafe では、コマンドプロンプトから操作するための多様なコマンドが用意されています。構築時やCluster WebUI が使用できない状況の場合などに便利です。コマンドラインでは、Cluster WebUI で行える以上の種類の操作を行うことができます。
注釈
モニタリソースの異常検出時の設定で回復対象にグループリソース(アプリケーションリソース、...)を指定し、モニタリソースが異常を検出した場合の回復動作遷移中(再活性化 → 最終動作)には、以下のコマンドまたは、Cluster WebUI からのサービスおよびグループへの制御は行わないでください。
サービスの停止/サスペンド
グループの開始/停止
モニタリソース異常による回復動作遷移中に上記の制御を行うと、そのグループの他のグループリソースが停止しないことがあります。また、モニタリソース異常状態であっても最終動作実行後であれば上記制御を行うことが可能です。
重要
インストールディレクトリ配下に本マニュアルに記載していない実行形式ファイルやスクリプトファイルがありますが、CLUSTERPRO X SingleServerSafe以外からの実行はしないでください。実行した場合の影響については、サポート対象外とします。
2.2. コマンド一覧¶
構築関連
コマンド
説明
関連
clpcfctrl
Cluster WebUI で作成した構成情報をサーバに配信します。Cluster WebUI で使用するために構成情報をバックアップします。clplcnsc
本製品の製品版・試用版ライセンスを管理します。
clpcfchk
クラスタ構成情報をチェックします。
状態表示関連
コマンド
説明
関連
clpstat
CLUSTERPRO X SingleServerSafeの状態や、設定情報を表示します。
clphealthchk
プロセスの健全性を確認します。
操作関連
コマンド
説明
関連
clpcl
デーモンの起動、停止、サスペンド、リジュームなどを実行します。
clpstdn
CLUSTERPROデーモンを停止し、サーバをシャットダウンします。
clpgrp
グループの起動、停止を実行します。
clptoratio
各種タイムアウト値の延長、表示を行います。
clpmonctrl
単一サーバ上でのモニタリソースの一時停止/再開を行います。
clpregctrl
単一サーバ上で再起動回数の表示/初期化を行います。
clprsc
グループリソースの一時停止/再開を行います。
clpcpufreq
CPUクロックの制御を行います。
clptrnreq
サーバへ処理実行を要求します。
clprexec
外部監視からCLUSTERPROサーバへ処理実行を要求します。
clpbmccnf
BMCユーザ名・パスワード情報を変更します。
ログ関連
コマンド
説明
関連
clplogcc
ログ、OS情報等を収集します。
clplogcf
ログレベル、ログ出力ファイルサイズの設定の変更、表示を行います。
clpperfc
グループ、モニタリソースに関するクラスタ統計情報を表示します。
スクリプト関連
コマンド
説明
関連
clplogcmd
EXECリソースのスクリプトに記述し、任意のメッセージを出力先に出力します。
システムモニタ関連 (System Resorce Agentを使用している場合のみ)
コマンド
説明
関連
clpprer
与えられたリソース使用量データの傾向から将来値を予測します。
重要
インストールディレクトリ配下に本マニュアルに記載していない実行形式ファイルやスクリプトファイルがありますが、CLUSTERPRO X SingleServerSafe以外からの実行はしないでください。実行した場合の影響については、サポート対象外とします。
2.3. 状態を表示する (clpstat コマンド)¶
CLUSTERPRO X SingleServerSafe の状態と、設定情報を表示します。
-
コマンドライン - clpstat -s [--long]clpstat -gclpstat -mclpstat -i [--detail]clpstat --cl [--detail]clpstat --sv [--detail]clpstat --grp [group_name] [--detail]clpstat --rsc [resource_name] [--detail]clpstat --mon [monitor_name] [--detail]
-
説明 サーバの状態や、設定情報を表示します。
-
パラメータ -
-s¶
-
オプションなし¶ 状態を表示します。
-
--long¶ クラスタ名やリソース名などの名前を最後まで表示します。
-
-g¶ グループマップを表示します。
-
-m¶ 各モニタリソースの状態を表示します。
-
-i¶ 設定情報を表示します。
-
--cl¶ 設定情報を表示します。
-
--sv¶ サーバの設定情報を表示します。
-
--grp[group_name]¶ グループの設定情報を表示します。グループ名を指定することによって、指定したグループ情報のみを表示できます。
-
--rsc[resource_name]¶ グループリソースの設定情報を表示します。グループリソース名を指定することによって、指定したグループリソース情報のみを表示できます。
-
--mon[monitor_name]¶ モニタリソースの設定情報を表示します。モニタリソース名を指定することによって、指定したモニタリソース情報のみを表示できます。
-
--detail¶ このオプションを使用することによって、より詳細な設定情報を表示できます。
-
-
戻り値 0
成功
9
二重起動
上記以外
異常
-
注意事項
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Invalid heartbeat resource name. Specify a valid heartbeat resource name in the cluster.
クラスタ内の正しいハートビートリソース名を指定してください。
Invalid network partition resource name. Specify a valid network partition resource name in the cluster.クラスタ内の正しいネットワークパーティション解決リソース名を指定してください。
Invalid group name. Specify a valid group name in the cluster.
クラスタ内の正しいグループ名を指定してください。
Invalid group resource name. Specify a valid group resource name in the cluster.
クラスタ内の正しいグループリソース名を指定してください。
Invalid monitor resource name. Specify a valid monitor resource name in the cluster.
クラスタ内の正しいモニタリソース名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Invalid server group name. Specify a valid server group name in the cluster.
クラスタ内の正しいサーバグループ名を指定してください。
This command is already run.
本コマンドは既に実行されています。本コマンドは二重起動できません。
The cluster is not created.
クラスタ構成情報を作成し、反映してください。
Could not connect to the server. Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Cluster is stopped. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Cluster is suspended. To display the cluster status, use --local option.
クラスタがサスペンド状態です。クラスタの状態を表示するには、 --localオプションを使用してください。
2.4. CLUSTERPRO デーモンを操作する (clpcl コマンド)¶
CLUSTERPROデーモンを操作します。
-
コマンドライン - clpcl -sclpcl -t [-w timeout] [--apito timeout]clpcl -r [-w timeout] [--apito timeout]clpcl --suspend [--force] [-w timeout] [--apito timeout]clpcl --resume
-
説明 CLUSTERPROデーモンの起動、停止、サスペンド、リジュームなどを実行します。
-
パラメータ -
-s¶ CLUSTERPROデーモンを起動します。
-
-t¶ CLUSTERPROデーモンを停止します。
-
-r¶ CLUSTERPROデーモンを再起動します。
-
--suspend¶ CLUSTERPROデーモンをサスペンドします。
-
--resume¶ CLUSTERPROデーモンをリジュームします。
-
-wtimeout¶ - -t, -r, --suspendオプションの場合にのみclpclコマンドがCLUSTERPROデーモンの停止またはサスペンドの完了を待ち合わせる時間を指定します。単位は秒です。timeoutの指定がない場合、無限に待ち合わせします。timeoutに"0"を指定した場合、待ち合わせしません。-wオプションを指定しない場合、(ハートビートタイムアウト×2)秒待ち合わせします。
-
--force¶ --suspend オプションと一緒に用いることで、サーバの状態に関わらず強制的にサスペンドを実行します。
-
--apitotimeout¶ - CLUSTERPRO デーモンの停止、再起動、サスペンドを待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999 の値が指定できます。[--apito] オプション指定しない場合は、クラスタプロパティの内部通信タイムアウトに設定された値に従い、待ち合わせを行います。
-
-
戻り値 0
成功
0 以外
異常
-
備考 - 本コマンドを -s または --resume オプションで実行した場合、対象のサーバで処理が開始したタイミングで制御を戻します。-t または --suspend オプションで実行した場合、処理の完了を待ち合わせてから制御を戻します。-r オプションで実行した場合、対象のサーバでCLUSTERPROデーモンが一度停止し、起動を開始したタイミングで制御を戻します。CLUSTERPROデーモンの起動またはリジュームの状況はclpstatコマンドで確認してください。
-
注意事項 - 本コマンドは、root権限を持つユーザで実行してください。本コマンドはグループの起動処理中、停止処理中に実行できません。サスペンドを実行する場合は、CLUSTERPROデーモンが起動した状態で実行してください。--forceオプションを用いると、強制的にサスペンドを実行します。リジュームを実行する場合は、clpstatコマンドを用いてCLUSTERPROデーモンが起動していないかを確認してください。
-
実行例 例1:サーバのCLUSTERPROデーモンを起動させる場合
# clpcl -s
-
サスペンド・リジュームについて - 構成情報の更新、CLUSTERPROのアップデートなどを行いたい場合に、業務を継続したまま、CLUSTERPROデーモンを停止させることができます。この状態をサスペンドといいます。サスペンド状態から通常の業務状態に戻ることをリジュームといいます。サスペンド・リジュームはサーバに対して処理を要求します。サスペンドは、サーバのCLUSTERPROデーモンが起動した状態で実行してください。サスペンド状態では、活性していたリソースはそのまま活性した状態でCLUSTERPROデーモンが停止するため以下の機能が停止します。
全てのモニタリソースが停止します。
グループまたはグループリソースの操作ができなくなります。(起動、停止)
以下のコマンドが使用不可となります。
clpcl の --resume以外のオプション
clpstdn
clpgrp
clptoratio
clpmonctrl
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Performed stop processing to the stopped cluster daemon.
停止している CLUSTERPRO デーモンに対して停止処理を実行しました。
Performed startup processing to the active cluster daemon.
起動している CLUSTERPRO デーモンに対して起動処理を実行しました。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Could not connect to the data transferserver. Check if the server has startedup.
サーバが起動しているか確認してください。
Failed to obtain the list of nodes.Specify a valid server name in thecluster.
クラスタ内の正しいサーバ名を指定してください。
Failed to obtain the daemon name.
クラスタ名の取得に失敗しました。
Failed to operate the daemon.
クラスタの制御に失敗しました。
Resumed the daemon that is not suspended.
サスペンド状態ではない CLUSTERPROデーモンに対して、リジューム処理を実行しました。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is busy. Check if this command is already run.
既に本コマンドを実行している可能性があります。確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
There is one or more servers of which cluster daemon is active. If you want to perform resume, check if there is any server whose cluster daemon is active in the cluster.
リジュームを実行する場合、クラスタ内にCLUSTERPRO デーモンが起動しているサーバがないか確認してください。
All servers must be activated. When suspending the server, the cluster daemon need to be active on all servers in the cluster.
サスペンドを実行する場合、クラスタ内の全てのサーバで、CLUSTERPRO デーモンが起動している必要があります。
Resume the server because there is one or more suspended servers in the cluster.
クラスタ内にサスペンドしているサーバがあるので、リジュームを実行してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内にCLUSTERPROデーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してみてください。Processing failed on some servers. Check the status of failed servers.
全サーバ指定で停止処理を実行した場合、処理に失敗したサーバが存在します。処理に失敗したサーバの状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
There is a server that is not suspended in cluster. Check the status of each server.
クラスタ内にサスペンド状態でないサーバが存在します。各サーバの状態を確認してください。Suspend %s : Could not suspend in time.
サーバはタイムアウト時間内にCLUSTERPROデーモンのサスペンド処理が完了しませんでした。サーバの状態を確認してください。
Stop %s : Could not stop in time.
サーバはタイムアウト時間内にCLUSTERPROデーモンの停止処理が完了しませんでした。サーバの状態を確認してください。
Stop %s : Server was suspended.Could not connect to the server. Check if the cluster daemon is active..CLUSTERPRO デーモンの停止要求をしましたが、サーバはサスペンド状態でした。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンの停止要求をしましたが、サーバに接続できませんでした。サーバの状態を確認してください。Suspend %s : Server already suspended.Could not connect to the server. Check if the cluster daemon is active.CLUSTERPRO デーモンのサスペンド要求をしましたが、サーバはサスペンド状態でした。
Event service is not started.
イベントサービスが起動していません。確認してください。Mirror Agent is not started.
ミラーエージェントが起動していません。確認してください。Event service and Mirror Agent are not started.
イベントサービスとミラーエージェントが起動していません。確認してください。
Some invalid status. Check the status of cluster.
遷移中のグループが存在する可能性があります。グループの遷移が終了してから、再度実行してください。
2.5. サーバをシャットダウンする (clpstdn コマンド)¶
サーバをシャットダウンします。
-
コマンドライン clpstdn [-r]
-
説明 サーバのCLUSTERPRO デーモンを停止し、シャットダウンします。
-
戻り値 0
成功
0 以外
異常
-
備考 本コマンドは、グループ停止処理が完了したタイミングで制御を戻します。
-
注意事項 - 本コマンドは、root権限を持つユーザで実行してください。本コマンドはグループの起動処理中、停止処理中に実行できません。
-
実行例 例1: サーバシャットダウンを行う場合
# clpstdn
例2: サーバシャットダウンリブートを行う場合
# clpstdn -r
2.6. グループを操作する (clpgrp コマンド)¶
グループを操作します。
-
コマンドライン - clpgrp -s [group_name] [--apito timeout]clpgrp -t [group_name] [--apito timeout]
-
説明 グループの起動、停止を実行します。
-
パラメータ -
-s[group_name]¶ グループを起動します。グループ名を指定すると、指定されたグループのみ起動します。グループ名の指定がない場合は、全てのグループが起動されます。
-
-t[group_name]¶ グループを停止します。グループ名を指定すると、指定されたグループのみ停止します。グループ名の指定がない場合は、全てのグループが停止されます。
-
--apitotimeout¶ - グループの起動、停止を待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999の値が指定できます。[--apito] オプション指定しない場合は、クラスタプロパティの内部通信タイムアウトに設定された値に従い、待ち合わせを行います。
-
-
戻り値 0
成功
0 以外
異常
-
注意事項 - 本コマンドは、root権限を持つユーザで実行してください。本コマンドを実行するサーバはCLUSTERPROデーモンが起動している必要があります。
-
実行例 グループ操作の実行を、簡単な例で説明します。
サーバで、「groupA」を持っている場合
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか 確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内にCLUSTERPROデーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が 設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。Invalid server. Specify a server that can run and stop the group, or a server that can be a target when you move the group.
グループを起動、停止、移動する先のサーバが不正です。正しいサーバを指定してください。Could not start the group. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
他サーバが起動するのを待つか、起動待ち 時間がタイムアウトするのを待って、グループを起動させてください。
No operable group exists in the server.
処理を要求したサーバに処理可能なグループが存在するか確認してください。
The group has already been started on the local server.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
The group has already been started on the other server. To start/stop the group on the local server, use -f option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを自サーバで起動/停止させたい場合は、グループの移動を 実行するか、-f オプションを加えて実行してください。The group has already been started on the other server. To move the group, use "-h <hostname>" option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを移動したい場合は、"-h <hostname>" オプションを加えて実行してください。The group has already been stopped.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Failed to start one or more group resources. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Failed to stop one or more group resources. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
The group is busy. Try again later.
グループが起動処理中、もしくは停止処理中なので、しばらく待ってから実行してください。
An error occurred on one or more groups. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Invalid group name. Specify a valid group name in the cluster.
クラスタ内の正しいグループ名を指定してください。
Server is not in a condition to start group or any critical monitor error is detected.
Cluster WebUI や、clpstat コマンドでサーバの状態を確認してください。グループを起動しようとしたサーバで除外モニタに含まれるモニタの異常が検出されています。There is no appropriate destination for the group. Other servers are not in a condition to start group or any critical monitor error is detected.
Cluster WebUI や、clpstat コマンドでサーバの状態を確認してください。他の全てのサーバで除外モニタに含まれるモニタの異常が検出されています。The group has been started on the other server. To migrate the group, use "-h <hostname>" option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを移動したい場合は、"-h <hostname>" オプションを加えて実行してください。The specified group cannot be migrated.
指定されたグループはマイグレーションできません。
The specified group is not vm group.
指定されたグループは仮想マシングループではありません。
Migration resource does not exist.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。マイグレーション対象のリソースが存在しません。Migration resource is not started.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。マイグレーション対象のリソースが起動していません。Some invalid status. Check the status of cluster.
何らかの不正な状態です。クラスタの状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
2.7. ログを収集する (clplogcc コマンド)¶
ログを収集します。
-
コマンドライン clplogcc [-t collect_type] [-r syslog_rotate_number] [-o path]
-
説明 データ転送サーバに接続し、ログ、OS情報等を収集します。
-
パラメータ -
なし¶ ログを収集します。
-
-tcollect_type¶ ログ収集パターンを指定します。省略した場合のログ収集パターンは type1 です。
-
-rsyslog_rotate_number¶ syslog の収集する世代数を指定します。省略した場合は、2世代収集します。
-
-opath¶ 収集ファイルの出力先を指定します。省略した場合は、インストールパスの tmp 配下にログが出力されます。
-
-
戻り値 0
成功
0 以外
異常
-
備考 ログファイルは tar.gz で圧縮されているので、tarコマンドに、xzf オプションを付けて解凍してください。
-
注意事項 本コマンドは、root権限を持つユーザで実行してください。
-
実行例 例1: サーバからログを収集する場合
# clplogcc Collect Log server1 : Success
ログ収集を実行したサーバの実行結果(サーバ状態)が表示されます。
処理過程 サーバ名 : 実行結果(サーバ状態)
実行結果
本コマンドの結果で表示される処理過程は以下になります。
処理過程
説明
Connect
接続に失敗した場合に表示します。
Get Filesize
ファイルサイズ取得に失敗した場合に表示します。
Collect Log
ファイル取得の結果を表示します。
実行結果(サーバ状態)については以下になります。
実行結果(サーバ状態)
説明
Success
成功です。
Timeout
タイムアウトしました。
Busy
サーバがビジー状態です。
Not Exist File
ファイルが存在しません。
No Freespace
ディスクに空き容量がありません。
Failed
その他のエラーによる失敗です。
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しい構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Specify a number in a valid range.
正しい範囲で数字を指定してください。
Specify a correct number.
正しい数字で指定してください。
Specify correct generation number of syslog.
正しいsyslogの世代数を指定してください。
Collect type must be specified 'type1' or 'type2' or 'type3' or 'type4' or 'type5' or 'type6'. Incorrect collection type is specified.
収集タイプの指定が間違っています。
Specify an absolute path as the destination of the files to be collected.
収集ファイルの出力先は絶対パスで指定してください。
Specifiable number of servers are the max number of servers that can constitute a cluster.
指定可能なサーバ数は、構成可能な最大サーバ数です。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is busy. Check if this command is already run.
既に本コマンドを実行している可能性があります。確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.7.1. タイプを指定したログの収集 (-t オプション)¶
type1 |
type2 |
type3 |
type4 |
type5 |
type6 |
|
|---|---|---|---|---|---|---|
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
|
✓ |
✓ |
✓ |
n/a |
n/a |
n/a |
|
✓ |
✓ |
n/a |
✓ |
n/a |
n/a |
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
|
n/a |
✓ |
n/a |
n/a |
n/a |
n/a |
|
n/a |
n/a |
n/a |
n/a |
n/a |
n/a |
|
n/a |
n/a |
n/a |
n/a |
n/a |
✓ |
|
✓ |
✓ |
✓ |
✓ |
n/a |
✓ |
# clplogcc -t type2
オプションを指定しない場合のログ収集タイプは type1 です。
デフォルト収集情報
CLUSTERPROサーバの各モジュールログ
アラートログ
CLUSTERPROサーバの各モジュールの属性情報(ls -l)
bin、lib配下
alert/bin、webmgr/bin配下
ha/jra/bin、ha/sra/bin、ha/jra/lib、ha/sra/lib配下
drivers/md配下
drivers/khb配下
- drivers/ka配下
インストール済の全パッケージ情報(rpm -qa の実行結果)
CLUSTERPRO X SingleServerSafeのバージョン情報(rpm -qi clusterpro の実行結果)
distribution情報(/etc/*-release)
ライセンス情報
構成情報ファイル
ポリシファイル
CLUSTERPRO X SingleServerSafeが使用している共有メモリのダンプ
CLUSTERPRO のステータス状態(clpstat --localの実行結果)
プロセス、スレッド情報(ps の実行結果)
PCIデバイス情報(lspci の実行結果)
サービス情報 (systemctl、chkconfig、ls コマンド等の実行結果)
kernelパラメータの出力結果(sysctl -a の実行結果)
glibcバージョン(rpm -qi glibc の実行結果)
カーネルローダブルモジュール設定情報(/etc/modules.conf、/etc/modprobe.conf)
カーネルのリングバッファ情報(dmesg の実行結果)
ファイルシステム情報(/etc/fstab)
IPCリソース情報(ipcs の実行結果)
システム情報(uname -a の実行結果)
ネットワーク統計情報(netstat, ss の実行結果IPv4/IPv6)
ip (ip addr,link,maddr,route,-s l の実行結果)
全ネットワークインターフェイス情報(ethtool の実行結果)
緊急OSシャットダウン時の採取情報
libxml2バージョン(rpm -qi libxml2 の実行結果)
静的ホストテーブル(/etc/hosts)
ファイルシステムのエクスポートテーブル(exportfs -v の実行結果)
ユーザリソース制限情報(ulimit -a の実行結果)
カーネルベースのNFSでエクスポートされるファイルシステム(/etc/exports)
OSのロケール(locale)
ターミナルセッションの環境変数(export の実行結果)
言語ロケール(/etc/sysconfig/i18n)
タイムゾーン(env - date の実行結果)
CLUSTERPROサーバのワーク領域情報
- 各監視オプション製品に関する情報監視オプション製品をインストールされていれば収集されます
モニタリソースのタイムアウト発生時に採取したダンプ情報
- Oracle モニタリソース異常検出時に採取した Oracle 詳細情報
syslog
syslog (/var/log/messages)
syslog (/var/log/syslog)
指定された世代数の syslog (/var/log/messages.x)
- journal ログ(/var/run/log/journal/ 配下のファイルなど)
coreファイル
- CLUSTERPROモジュールのcoreファイル/opt/nec/clusterpro/log配下に以下のアーカイブ名で格納されます。
アラート関連
altyyyymmdd_x.tar
WebManager サーバ関連
wmyyyymmdd_x.tar
CLUSTERPROコア関連
clsyyyymmdd_x.tar srayyyymmdd_x.tar jrayyyymmdd_x.tar
yyyymmdd はログの収集日付、 x はシーケンシャル番号になります。
OS情報
カーネルモードLANハートビート、キープアライブ情報
/proc/khb_moninfo
/proc/ka_moninfo
/proc/devices
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/cpuinfo
/proc/partitions
/proc/pci
/proc/version
/proc/ksyms
/proc/net/bond*
/proc/scsi/ ディレクトリ内の全ファイル
/proc/ide/ ディレクトリ内の全ファイル
/etc/fstab
/etc/rc*.d
/etc/syslog.conf
/etc/syslog-ng/syslog-ng.conf
/proc/sys/kernel/core_pattern
/proc/sys/kernel/core_uses_pid
/etc/snmp/snmpd.conf
カーネルのリングバッファ情報(dmesg の実行結果)
ifconfig (ifconfig の実行結果)
iptables (iptables -L の実行結果)
ipchains (ipchains -L の実行結果)
df (df の実行結果)
rawデバイス情報 (raw -qa の実行結果)
カーネルモジュールロード情報 (lsmod の実行結果)
ホスト名、ドメイン名情報 (hostname、domainname の実行結果)
dmidecode (dmidecode の実行結果)
LVM デバイス情報 (vgdisplay -v の実行結果)
snmpd バージョン情報 (snmpd -v の実行結果)
仮想化基盤情報 (virt-what の実行結果)
ログ収集を実行した場合、コンソールに以下のメッセージが表示されることがありますが、異常ではありません。ログは正常に収集されています。
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(hd#にはサーバ上に存在するIDEのデバイス名が入ります)- スクリプトCluster WebUI で作成されたグループ起動/停止スクリプト上記以外のユーザ定義スクリプト(/opt/nec/clusterpro/scripts以外)を指定した場合は、ログ収集の採取情報に含まれないため、別途採取する必要があります。
- ESMPRO/AC関連ログacupslogコマンドの実行により収集されるファイル
HA ログ
システムリソース情報
JVM モニタログ
- システムモニタログ
- ミラー統計情報このバージョンでは収集されません。
クラスタ統計情報
クラスタ統計情報
- /perf/cluster 配下
システムリソース統計情報
システムリソース統計情報
/perf/system 配下
2.7.2. syslog の世代 (-r オプション)¶
syslogを、指定した世代分収集するには以下のように実行します。
例)世代数 3 でログ収集を行う場合
# clplogcc -r 3
収集したログには以下の syslog が含まれています。
オプションを指定しない場合は、2世代収集されます。
指定できる世代数は、0~99 です。
0 を指定した場合は、全ての syslog を収集します。
世代数 |
取得する世代 |
|---|---|
0 |
全世代 |
1 |
カレント |
2 |
カレント + 世代1 |
3 |
カレント + 世代1~2 |
: |
|
x |
カレント + 世代1~(x-1) |
2.7.3. ログファイルの出力先 (-o オプション)¶
ファイル名は、「サーバ名-log.tar.gz」で保存されます。
ログファイルは tar.gz で圧縮されているので、tarコマンドに、xzf オプションを付けて解凍してください。
-o オプションを指定しない場合
インストールパスの tmp 配下にログが出力されます。
# clplogcc Collect Log サーバ名: Success # ls /opt/nec/clusterpro/tmp サーバ名-log.tar.gz
-o オプションを指定する場合
以下のようにコマンドを実行すると、指定したディレクトリ /home/log 配下にログが出力されます。
# clplogcc -o /home/log Collect Log サーバ名: Success # ls /home/log サーバ名-log.tar.gz
2.7.4. 異常発生時の情報採取¶
以下の異常発生時に、障害解析のための情報を採取します。
構成するサーバデーモンが、シグナルの割り込みによる終了(core dump)、内部ステータス異常による終了などで異常終了した場合
グループリソースの活性異常、非活性異常が発生した場合
モニタリソースの監視異常が発生した場合
採取する情報は以下です。
情報
CLUSTERPROサーバの一部のモジュールログ
CLUSTERPRO X SingleServerSafeが使用している共有メモリのダンプ
構成情報ファイル
CLUSTERPROモジュールのcoreファイル
OS情報(/proc/*)
/proc/devices
/proc/partitions
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/net/bond*
コマンド実行による情報
sysctl -a の結果
ps の結果
top の結果
ipcs の結果
netstat -in の結果
netstat -apn の結果
netstat -gn の結果
netstat -rn の結果
ifconfig の結果
ip addr の結果
ip -s l の結果
df の結果
raw -qa の結果
journalctl -e の結果
この情報はログ収集のデフォルト収集情報として採取されるため、別途採取する必要はありません。
2.8. 構成情報の反映、バックアップを実行する (clpcfctrl コマンド)¶
2.8.1. 構成情報を反映する(clpcfctrl --push)¶
構成情報をサーバに反映します。
-
コマンドライン clpcfctrl --push -l|-w [-p portnumber] [-x directory] [--nocheck]
-
説明 Cluster WebUI で作成した構成情報をサーバに反映します。
-
パラメータ -
--push¶ - 反映時に指定します。省略できません。
-
-l¶ - Linux上で Cluster WebUI を使用して保存した構成情報を使用する場合に指定します。-wと同時には指定できません。
-
-w¶ - Windows上で Cluster WebUI を使用して保存した構成情報を使用する場合に指定します。-lと同時に指定することはできません。
-
-pportnumber¶ - データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
-
-xdirectory¶ - 指定したディレクトリにある構成情報を反映する場合に指定します。-lまたは-wと共に使用します。-lを指定した場合は、Linux上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を使用します。-wを指定した場合は、Windows上でCluster WebUI を使用して保存した構成情報を使用します。
-
--nocheck¶ 構成情報のチェックを実行しません。サーバ削除時のみ使用します。通常は使用しないでください。
-
-
戻り値 0
成功
0以外
異常
-
注意事項 本コマンドはroot権限をもつユーザで実行してください。
-
実行例 例1: Linux上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を配信する場合
# clpcfctrl --push -l -x /mnt/config file delivery to server 127.0.0.1 success. The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
rootユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。
Invalid mode.Check if --push or --pull option is specified.--pushを指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Invalid host name.Server specified by -h option is not included in the configuration data.-hで指定したサーバが構成情報に含まれていません。指定したサーバ名またはIPアドレスが正しいか確認してください。
Canceled.
コマンドの問い合わせに"y"以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the configuration file.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to load the all.pol file.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to load the cfctrl.pol file.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to get the install path.
CLUSTERPROサーバRPMを再インストールしてください。
Reinstall the RPM.
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to get the list of group.
グループ一覧の取得に失敗しました。
Failed to get the list of resource.
リソース一覧の取得に失敗しました。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active and then run the command again.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
File delivery failed.Failed to deliver the configuration data. Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Multi file delivery failed.Failed to deliver the configuration data. Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。The directory "/work" is not found.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to make a working directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The directory does not exist.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
This is not a directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source file does not exist.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source file is a directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source directory does not exist.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source file is not a directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the character code set (EUC to SJIS).
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the character code set (SJIS to EUC).
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Command error.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OSのリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OSのリソース不足が考えられます。確認してください。
Failed to allocate memory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to run the command.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to make a directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to remove the directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to remove the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to open the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to read the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to write the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Internal error.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
The upload is completed successfully.To apply the changes you made, shutdown and reboot the cluster.アップロードは成功しました。変更を反映するためにサーバシャットダウン、再起動を実行してください。
The upload was stopped.To upload the cluster configuration data, stop the cluster.アップロードは停止しました。構成情報をアップロードするためにはサーバを停止してください。
The upload was stopped.To upload the cluster configuration data, stop the Mirror Agent.アップロードは停止しました。構成情報をアップロードするためにはMirrorAgentを停止してください。
The upload was stopped.To upload the cluster configuration data, stop the resources to which you made changes.アップロードは停止しました。構成情報をアップロードするためには変更を加えたリソースを停止してください。
The upload was stopped.To upload the cluster configuration data, stop the groups to which you made changes.アップロードは停止しました。構成情報をアップロードするためにはサーバをサスペンドする必要があります。アップロードするためには変更を加えたグループを停止してください。
The upload was stopped.To upload the cluster configuration data, suspend the cluster.アップロードは停止しました。構成情報をアップロードするためにはサーバをサスペンドしてください。
The upload is completed successfully.To apply the changes you made, restart the Alert Sync service.To apply the changes you made, restart the WebManager service.アップロードは成功しました。構成情報を反映させるためにAlertSyncサービスを再起動してください。構成情報を反映させるためにWebManager サービスを再起動してください。
The upload is completed successfully.To apply the changes you made, restart the Information Base service.アップロードは成功しました。クラスタ構成情報を反映させるために Information Base サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the API service.アップロードは成功しました。クラスタ構成情報を反映させるために API サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Node Manager service.アップロードは成功しました。クラスタ構成情報を反映させるために Node Manager サービスを再起動 してください。Internal error.Check if memory or OS resources are sufficient.メモリ不足または、OSのリソース不足が考えられます。確認してください。
The upload is completed successfully.
アップロードは成功しました。
The upload was stopped.Failed to deliver the configuration data.Check if the other server is active and run the command again.アップロードは停止しました。構成情報の配信に失敗しました。他のサーバの起動状態を確認し、コマンドを再実行してください。
The upload was stopped.There is one or more servers that cannot be connected to.To apply cluster configuration information forcibly, run the command again with "--force" option.アップロードは停止しました。接続できないサーバが存在します。構成情報を強制的にアップロードするためには--forceオプションを指定してコマンドを再実行してください。
2.8.2. 構成情報をバックアップする (clpcfctrl --pull)¶
構成情報をバックアップします。
-
コマンドライン clpcfctrl --pull -l|-w [-p portnumber] [-x directory]
-
説明 Cluster WebUI で使用するために構成情報をバックアップします。
-
パラメータ -
--pull¶ - バックアップ時に指定します。省略できません。
-
-l¶ - Linux上の Cluster WebUI で使用する構成情報としてバックアップする場合に指定します。-wと同時に指定することはできません。
-
-w¶ - Windows上の Cluster WebUI で使用する構成情報としてバックアップする場合に指定します。-lと同時に指定することはできません。
-
-pportnumber¶ - データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
-
-xdirectory¶ - 指定したディレクトリに構成情報をバックアップします。-lまたは-wと共に使用します。-lを指定した場合は、Linux上の Cluster WebUI で読み込むことができる構成情報としてバックアップします。-wを指定した場合は、Windows上のCluster WebUI で読み込むことができる構成情報として保存します。
-
-
戻り値 0
成功
0以外
異常
-
注意事項 本コマンドはroot権限を持つユーザで実行してください。
-
実行例 例1: Linux上の Cluster WebUI で読み込むための構成情報を指定ディレクトリにバックアップする場合
# clpcfctrl --pull -l -x /mnt/config Command succeeded.(code:0)
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
rootユーザで実行してください。
This command is already run.
すでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。
Invalid mode.Check if --push or --pull option is specified.--pullを指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Canceled.
コマンドの問い合わせに"y"以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the configuration file.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to load the all.pol file.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to load the cfctrl.pol file.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active and then run the command again.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
Failed to get configuration data.Check if the other server is active.構成情報の取得に失敗しました。他のサーバが起動しているか確認してください。
The directory "/work" is not found.Reinstall the RPM.CLUSTERPROサーバRPMを再インストールしてください。
Failed to make a working directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The directory does not exist.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
This is not a drirectory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source file does not exist.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source file is a directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source directory does not exist.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
The source file is not a directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the character code set (EUC to SJIS).
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the character code set (SJIS to EUC).
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Command error.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OSのリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OSのリソース不足が考えられます。確認してください。
Failed to allocate memory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to change the directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to run the command.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to make a directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to remove the directory.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to remove the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to open the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to read the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to write the file.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Internal error.Check if memory or OS resources are sufficient.メモリ不足またはOSのリソース不足が考えられます。確認してください。
2.9. タイムアウトを一時調整する(clptoratio コマンド)¶
現在のタイムアウト倍率の延長、表示を行います。
-
コマンドライン - clptoratio -r ratio -t timeclptoratio -iclptoratio -s
-
説明 以下の各種タイムアウト値を一時的に延長します。
モニタリソース
ハートビートリソース
アラート同期サービス
WebManager サービス
現在のタイムアウト倍率を表示します。
-
パラメータ -
-rratio¶ - タイムアウト倍率を指定します。1 以上の整数値で設定してください。最大タイムアウト倍率は10000倍です。「1」を指定した場合、-i オプションと同様に、変更したタイムアウト倍率を元に戻すことができます。
-
-ttime¶ - 延長期間を指定します。分m、時間h、日d が指定できます。最大延長期間は30日です。例)2m、3h、4d
-
-i¶ 変更したタイムアウト倍率を元に戻します。
-
-s¶ 現在のタイムアウト倍率を参照します。
-
-
戻り値 0
成功
0 以外
異常
-
備考 - サーバシャットダウンを実行すると、設定したタイムアウト倍率は無効になります。サーバがシャットダウンされていなければ、設定したタイムアウト倍率、延長期間は保たれます。-s オプションで参照できるのは、現在のタイムアウト倍率のみです。延長期間の残り時間などは参照できません。状態表示コマンドを用いて、元のタイムアウト値を参照できます。ハートビートタイムアウト
# clpstat --cl --detail
モニタリソースタイムアウト# clpstat --mon モニタリソース名 --detail
-
注意事項 - 本コマンドは、root 権限を持つユーザで実行してください。サーバのCLUSTERPRO デーモンが起動した状態で実行してください。タイムアウト倍率を設定する場合、延長期間の指定は必ず行ってください。しかし、タイムアウト倍率指定に「1」を指定した場合は、延長期間を指定することはできません。延長期間指定に、「2m3h」などの組み合わせはできません。
-
実行例 例1: タイムアウト倍率を3日間2倍にする場合
# clptoratio -r 2 -t 3d
例2: タイムアウト倍率を元に戻す場合
# clptoratio -i
例3: 現在のタイムアウト倍率を参照する場合
# clptoratio -s present toratio : 2
現在のタイムアウト倍率は 2 で設定されていることが分かります。
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Specify a number in a valid range.
正しい範囲で数字を指定してください。
Specify a correct number.
正しい数字で指定してください。
Scale factor must be specified by integer value of 1 or more.
倍率は 1 以上の整数値で指定してください。
Specify scale factor in a range less than the maximum scale factor.
最大倍率を超えない範囲で倍率を指定してください。
Set the correct extension period.
正しい延長期間の設定をしてください。
Ex) 2m, 3h, 4d
最大延長期間を超えない範囲で延長期間を設定してください。
Set the extension period in a range less than the maximum extension period.
CLUSTERPRO デーモンが起動しているか確認してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active. Check if the cluster daemon is active.
クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してみてください。
Processing failed on some servers. Check the status of failed servers.
処理に失敗したサーバが存在します。クラスタ内のサーバの状態を確認してください。クラスタ内の全てのサーバが起動した状態で実行してください。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.10. ログレベル/サイズを変更する(clplogcf コマンド)¶
ログレベル、ログ出力ファイルサイズの設定の変更、表示を行います。
-
コマンドライン clplogcf -t type -l level -s size
-
説明 - ログレベル、ログ出力ファイルサイズの設定を変更します。現在の設定値を表示します。
-
パラメータ -
-ttype¶ - 設定を変更するモジュールタイプを指定します。-l と -s のいずれも省略した場合は、指定したモジュールタイプに設定されている情報を表示します。指定可能なタイプは「-tオプションに指定可能なタイプ」の表を参照してください。
-
-llevel¶ - ログレベルを指定します。指定可能なログレベルは以下のいずれかです。1、2、4、8、16、32数値が大きいほど詳細なログが出力されます。
-
-ssize¶ - ログを出力するファイルのサイズを指定します。単位は byte です。
-
なし¶ 現在設定されている全情報を表示します。
-
-
戻り値 0
成功
0以外
異常
-
備考 CLUSTERPRO X SingleServerSafeが出力するログは、各タイプで 4 つのログファイルを使用します。このため-sで指定したサイズの4倍のディスク容量が必要です。
-
注意事項 - 本コマンドはroot権限をもつユーザで実行してください。本コマンドの実行にはCLUSTERPROイベントサービスが動作している必要があります。サーバを再起動すると設定は元に戻ります。
-
実行例 例1: pmのログレベルを変更する場合
# clplogcf -t pm -l 8
例2: pmのログレベル、ログファイルサイズを参照する場合
# clplogcf -t pm TYPE, LEVEL, SIZE pm, 8, 1000000
例3: 現在の設定値を表示する場合
# clplogcf TYPE, LEVEL, SIZE trnsv, 4, 1000000 xml, 4, 1000000 logcf, 4, 1000000
-
エラーメッセージ メッセージ
原因/対処法
Log in as root.
rootユーザで実行してください。
Invalid option.
オプションが不正です。オプションを確認してください。
Failed to change the configuration. Check if clpevent is running.
clpeventが起動されていない可能性があります。
Invalid level
指定したレベルが不正です。
Invalid size
指定したサイズが不正です。
Failed to load the configuration file. Check if memory or OS resources are sufficient.
生成されていないサーバです。
Failed to initialize the xml library. Check if memory or OS resources are sufficient.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Failed to print the configuration. Check if clpevent is running.
clpeventが起動されていない可能性があります。
-
-tオプションに指定可能なタイプ タイプ
モジュール
説明
本体
apicl
libclpapicl.so.1.0
APIクライアントライブラリ
✓
apisv
libclpapisv.so.1.0
APIサーバ
✓
bmccnf
clpbmccnf
BMC情報更新コマンド
✓
cl
clpcl
サーバ起動、停止コマンド
✓
cfctrl
clpcfctrl
サーバ生成、サーバ情報バックアップコマンド
✓
cfmgr
libclpcfmgr.so.1.0
構成情報操作ライブラリ
✓
cpufreq
clpcpufreq
CPUクロック制御コマンド
✓
grp
clpgrp
グループ起動、停止、コマンド
✓
rsc
clprsc
グループリソース起動、停止コマンド
✓
haltp
clpuserw
シャットダウンストール監視
✓
healthchk
clphealthchk
プロセス健全性確認コマンド
✓
ibsv
clpibsv
Information Base サーバ
✓
lcns
libclplcns.so.1.0
ライセンスライブラリ
✓
lcnsc
clplcnsc
ライセンス登録コマンド
✓
logcc
clplogcc
ログ収集コマンド
✓
logcf
clplogcf
ログレベル、サイズ変更コマンド
✓
logcmd
clplogcmd
アラート出力コマンド
✓
mail
clpmail
Mail通報
✓
mgtmib
libclpmgtmib.so.1.0
SNMP 連携ライブラリ
✓
monctrl
clpmonctrl
監視制御コマンド
✓
nm
clpnm
ノードマップ管理
✓
pm
clppm
プロセス管理
✓
rc/rc_ex
clprc
グループ、グループリソース管理
✓
reg
libclpreg.so.1.0
再起動回数制御ライブラリ
✓
regctrl
clpregctrl
再起動回数制御コマンド
✓
rm
clprm
モニタ管理
✓
roset
clproset
ディスク制御
✓
relpath
clprelpath
プロセス強制終了コマンド
✓
scrpc
clpscrpc
スクリプトログローテート実行コマンド
✓
stat
clpstat
ステータス表示コマンド
✓
stdn
clpstdn
サーバシャットダウンコマンド
✓
toratio
clptoratio
タイムアウト倍率変更コマンド
✓
trap
clptrap
SNMP トラップ送信コマンド
✓
trncl
libclptrncl.so.1.0
トランザクションライブラリ
✓
rexec
clprexec
外部監視連動処理要求コマンド
✓
trnsv
clptrnsv
トランザクションサーバ
✓
volmgrc
clpvolmgrc
VxVMディスクグループ import/deportコマンド
✓
alert
clpaltinsert
アラート
✓
webmgr
clpwebmc
WebManager サービス
✓
webalert
clpaltd
アラート同期
✓
exec
clpexec
EXECリソース
✓
vm
clpvm
仮想マシンリソース
✓
diskw
clpdiskw
ディスクモニタリソース
✓
ipw
clpipw
IPモニタリソース
✓
miiw
clpmiiw
NIC Link Up/Downモニタリソース
✓
mtw
clpmtw
マルチターゲットモニタリソース
✓
pidw
clppidw
PIDモニタリソース
✓
volmgrw
clpvolmgrw
ボリュームマネージャモニタリソース
✓
userw
clpuserw
ユーザ空間モニタリソース
✓
vmw
clpvmw
仮想マシンモニタリソース
✓
mrw
clpmrw
メッセージ受信モニタリソース
✓
snmpmgr
libclp snmpmgr
SNMP トラップ受信ライブラリ
✓
lanhb
clplanhb
LANハートビート
✓
oraclew
clp_oraclew
Oracleモニタリソース
✓
db2w
clp_db2w
DB2モニタリソース
✓
psqlw
clp_psqlw
PostgreSQLモニタリソース
✓
mysqlw
clp_mysqlw
MySQLモニタリソース
✓
sybasew
clp_sybasew
Sybaseモニタリソース
✓
odbcw
clp_odbcw
ODBCモニタリソース
✓
sqlserverw
clp_sqlserverw
SQL Serverモニタリソース
✓
sambaw
clp_sambaw
Sambaモニタリソース
✓
nfsw
clp_nfsw
NFSモニタリソース
✓
httpw
clp_httpw
HTTPモニタリソース
✓
ftpw
clp_ftpw
FTPモニタリソース
✓
smtpw
clp_smtpw
SMTPモニタリソース
✓
pop3w
clp_pop3w
POP3モニタリソース
✓
imap4w
clp_imap4w
IMAP4モニタリソース
✓
tuxw
clp_tuxw
Tuxedoモニタリソース
✓
wlsw
clp_wlsw
WebLogicモニタリソース
✓
wasw
clp_wasw
WebSphereモニタリソース
✓
otxw
clp_otxw
WebOTXモニタリソース
✓
jraw
clp_jraw
JVM モニタリソース
✓
sraw
clp_sraw
システムモニタリソース
✓
psrw
clp_psrw
プロセスリソースモニタリソース
✓
psw
clppsw
プロセス名モニタリソース
✓
vmctrl
libclpvmctrl.so.1.0
VMCTRL ライブラリ
✓
vmwcmd
clpvmwcmd
VMW コマンド
✓
perfc
clpperfc
クラスタ統計情報表示コマンド
✓
cfchk
clpcfchk
クラスタ構成情報チェックコマンド
✓
2.11. ライセンスを管理する(clplcnsc コマンド)¶
ライセンスの管理を行います。
-
コマンドライン - clplcnsc -i [licensefile…]clplcnsc -l [-a]clplcnsc -d serialno [-q]clplcnsc -d -t [-q]clplcnsc -d -a [-q]clplcnsc --reregister licensefile...
-
説明 本製品の製品版・試用版ライセンスの登録、参照、削除を行います。
-
パラメータ -
-i[licensefile…]¶ ライセンスファイルを指定すると、そのファイルよりライセンス情報を取得し、登録します。ライセンスファイルは複数指定することができます。ワイルドカードの指定も可能です。指定しなければ、対話形式によりライセンス情報を入力し登録します。
-
-l[-a]¶ 登録されているライセンスを参照します。表示する項目を以下に示します。
項目名
説明
Serial No
シリアルナンバー (製品版のみ)
User name
ユーザ名 (試用版のみ)
Key
ライセンスキー
Licensed Number of CPU
ライセンス許諾数(CPU単位)
Licensed Number of Computers
ライセンス許諾数(ノード単位)
Start date
End date
Status
ライセンスの状態
状態
説明
valid
有効
invalid
無効
unknown
不明
inactive
expired
-a オプションを指定しない場合は、ライセンスの状態が invalid, unknown, expired であるライセンスは表示しません。-a オプションを指定した場合は、ライセンスの状態に関わらず、全てのライセンスを表示します。
-
-d<param>¶ param
- serialno
指定したシリアルナンバーのライセンスを削除します。
- -t
登録されている全ての試用版ライセンスを削除します。
- -a
登録されている全てのライセンスを削除します。
-
-q¶ ライセンスを削除する時の確認メッセージを表示せずに削除します。-dオプションと一緒に指定してください。
-
--reregisterlicensefile…¶ 期限付きライセンスを再登録します。通常、このオプションでコマンドを実行する必要はありません。
-
-
戻り値 0
正常終了
1
キャンセル
3
初期化エラー
5
オプション不正
8
その他内部エラー
-
実行例 登録
対話形式
# clplcnsc -i
製品版、製品版(期限付き)
製品区分選択
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
シリアルナンバー入力
Enter serial number [ Ex. XXXXXXXX000000 ] ...
ライセンスキー入力
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
試用版
製品区分選択
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
ユーザ名入力
Enter user name [ 1 to 63byte ] ...
ライセンスキー入力
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
ライセンスファイル指定
# clplcnsc -i /tmp/cpulcns.key
参照
# clplcnsc -l
製品版
< CLUSTERPRO X SingleServerSafe <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Licensed Number of CPU... 2 Status... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Licensed Number of Computers... 1 Status... valid
製品版(期限付き)
< CLUSTERPRO X SingleServerSafe <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Start date..... 2018/01/01 End date...... 2018/01/31 Status........... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Status........... inactive
試用版
< CLUSTERPRO X SingleServerSafe <TRIAL> > Seq... 1 Key..... A1234567-B1234567-C1234567-D1234567 User name... NEC Start date..... 2018/01/01 End date...... 2018/02/28 Status........... valid
削除
# clplcnsc -d AAAAAAAA000001 -q
削除
# clplcnsc -d -t -q
削除
# clplcnsc -d -a
削除確認
Are you sure to remove the license? [y/n] ...
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-d オプション利用時に -aオプションを併用した場合、全ての試用版ライセンスおよび製品版ライセンスが削除されます。試用版ライセンスのみ削除する場合は -t オプションを併用してください。製品版ライセンスも含めて削除してしまった場合は製品版ライセンスの再登録をしてください。ライセンス参照時は、あるライセンスに複数のライセンスが包含されている場合、それぞれ個別に表示されます。
-
エラーメッセージ メッセージ
原因/対処法
Processed license num(success: %d, error : %d).処理したライセンス数(成功: %d, 失敗: %d)失敗が 0 でない場合は、何らかの理由でライセンス処理が失敗しています。ライセンス情報が正しいか確認してください。Command succeeded.
コマンドは成功しました。
Command failed.
コマンドは失敗しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Invalid cluster configuration data. Check the cluster configuration information.
クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The command is already run.
コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。The license is not registered.
ライセンスが未登録状態です。
Could not opened the license file. Check if the license file exists on the specified path.
ライセンスファイルへの I/O ができません。ライセンスファイルが指定されたパスに存在するか確認してください。
Could not read the license file. Check if the license file exists on the specified path.
ライセンスファイルへの I/O ができません。ライセンスファイルが指定されたパスに存在するか確認してください。
The field format of the license file is invalid. The license file may be corrupted. Check the destination from where the file is sent.
ライセンスファイルのフィールド形式が不正です。ライセンスファイルが壊れている可能性があります。ファイルの送付元に確認してください。
The cluster configuration data may be invalid or not registered.
クラスタ構成情報が不正または、未登録状態が考えられます。確認してください。Failed to terminate the library. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to register the license. Check if the entered license information is correct.
入力したライセンス情報が正しいか確認してください。
Failed to open the license. Check if the entered license information is correct.
入力したライセンス情報が正しいか確認してください。
Failed to remove the license.
ライセンスの削除に失敗しました。パラメータ誤り、メモリ不足、または OS のリソース不足が考えられます。確認してください。
This license is already registered.
このライセンスはすでに登録されています。登録されているライセンスを確認してください。This license is already activated.
このライセンスはすでに使用されています。登録されているライセンスを確認してください。This license is unavailable for this product.
このライセンスはこの製品では使用できません。ライセンスを確認してください。The maximum number of licenses was reached.
登録可能なライセンスの最大数に達しました。期限切れのライセンスを削除してください。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.12. メッセージを出力する (clplogcmd コマンド)¶
指定したメッセージをsyslog,アラートログに登録する、またはmail通報するコマンドです。
-
コマンドライン clplogcmd -m message [--syslog] [--alert] [--mail] [-i eventID] [-l level]
注釈
通常、サーバの構築や運用ではこのコマンドの実行は不要です。EXECリソースのスクリプトに記述して使用するコマンドです。
-
説明 EXECリソースのスクリプトに記述し、任意のメッセージを出力先に出力します。
-
パラメータ -
-mmessage¶ - 出力するメッセージを指定します。省略できません。メッセージの最大サイズは511バイトです。(出力先にsyslogを指定した場合は485バイトです。) 最大サイズ以降のメッセージは表示されません。メッセージには英語、数字、記号 3 が使用可能です。
-
--syslog¶
-
--alert¶
-
--mail¶
-
--trap¶ - syslog、alert、mail、trapの中から出力先を指定します (複数指定可能です。)。このパラメータは省略可能です。省略時にはsyslogとalertが出力先になります。
-
-ieventID¶ - イベントIDを指定します。イベントIDの最大値は10000です。このパラメータは省略可能です。省略時にはeventIDに1が設定されます。
-
-llevel¶ - 出力するアラートのレベルです。ERR、WARN、INFOのいずれかを指定します。このレベルによってCluster WebUI でのアラートログのアイコンを指定します。このパラメータは省略可能です。省略時にはlevelにINFOが設定されます。詳細はオンラインマニュアルを参照してください。
-
-
戻り値 0
成功
0 以外
異常
-
注意事項 - 本コマンドは、root権限を持つユーザで実行してください。出力先にmailを指定する場合、mailコマンドでmail送信ができる設定を行ってください。
-
実行例 - 例1: メッセージのみ指定する場合(出力先 syslog,alert)EXECリソースのスクリプトに下記を記述した場合、syslog、alertにメッセージを出力します。
clplogcmd -m test1
syslogには、下記のログが出力されます。
Sep 1 14:00:00 server1 clusterpro: <type: logcmd><event: 1> test1
例2: メッセージ、出力先、イベントID、レベルを指定する場合(出力先 mail)EXECリソースのスクリプトに下記を記述した場合、Cluster WebUI のクラスタのプロパティで設定したメールアドレスにメッセージが送信されます。clplogcmd -m test2 --mail -i 100 -l ERR
mailの送信先には、下記の内容のメールが送信されます。Message:test2 Type: logcmd ID: 100 Host: server1 Date: 2018/09/01 14:00:00
例3: メッセージ、出力先、イベント ID、レベルを指定する場合 (出力先 trap)EXEC リソースのスクリプトに下記を記述した場合、Cluster WebUI のクラスタのプロパティで設定したSNMP トラップ送信先にメッセージが送信されます。clplogcmd -m test3 --trap -i 200 -l ERR
SNMP トラップの送信先には、下記の内容の SNMP トラップが送信されます。
Trap OID: clusterEventError添付データ1: clusterEventMessage = test3添付データ2: clusterEventID = 200添付データ3: clusterEventDateTime = 2011/08/01 09:00:00添付データ4: clusterEventServerName = server1添付データ5: clusterEventModuleName = logcmd
- 3
メッセージに記号を含む場合の注意点は以下のとおりです。
"" で囲む必要がある記号
# & ' ( ) ~ | ; : * < > , .
(例 "#"をメッセージに指定すると、 #が出力されます。)\ を前につける必要がある記号
\ ! " & ' ( ) ~ | ; : * < > , .
(例 \をメッセージに指定すると、 \が出力されます。)で囲む必要がありかつを前につける必要がある記号
`
(例 "`"をメッセージに指定すると、 `が出力されます。)メッセージにスペースを含む場合、""で囲む必要があります。
メッセージに % は使用できません。
2.13. モニタリソースを制御する (clpmonctrl コマンド)¶
モニタリソースの制御を行います。
-
コマンドライン - clpmonctrl -s [-m resource_name] [-w wait_time]clpmonctrl -r [-m resource_name] [-w wait_time]clpmonctrl -c [-m resource_name]clpmonctrl -v [-m resource_name]clpmonctrl -e -m resource_nameclpmonctrl -n [-m resource_name]
-
説明 モニタリソースの一時停止/再開を行います。
-
パラメータ -
-s¶ 監視を一時停止します。
-
-r¶ 監視を再開します。
-
-c¶ 回復動作の回数カウンタをリセットします。
-
-v¶ 回復動作の回数カウンタを表示します。
-
-e¶ 障害検証機能を有効にします。必ず-mオプションでモニタリソース名を指定してください。
-
-n¶ 障害検証機能を無効にします。-mオプションでモニタリソース名を指定した場合は、そのリソースのみが対象となります。-mオプションを省略した場合は、全モニタリソースが対象となります。
-
-mresource_name¶ - 制御するモニタリソースを指定します。省略可能で、省略時は全てのモニタリソースに対して制御を行います。
-
-wwait_time¶ - モニタリソース単位で監視制御を待合わせます。(秒)省略可能で、省略時は5秒が設定されます。
-
-
戻り値 0
正常終了
1
実行権限不正
2
オプション不正
3
初期化エラー
4
構成情報不正
5
モニタリソース未登録
6
指定モニタリソース不正
10
CLUSTERPRO未起動状態
11
CLUSTERPROデーモンサスペンド状態
90
監視制御待ちタイムアウト
128
二重起動
255
その他内部エラー
-
実行例 例1: 全モニタリソースを一時停止する場合
# clpmonctrl -s Command succeeded.
例2: 全モニタリソースを再開する場合
# clpmonctrl -r Command succeeded.
-
備考 既に一時停止状態にあるモニタリソースに一時停止を行った場合や既に起動済状態にあるモニタリソースに再開を行った場合は、本コマンドはエラー終了し、モニタリソース状態は変更しません。
-
注意事項 - 本コマンドは、root権限を持つユーザで実行してください。モニタリソースの状態は、状態表示コマンドまたは Cluster WebUI で確認してください。clpstatコマンドまたは、Cluster WebUI でモニタリソースの状態が"起動済"または、"一時停止"であることを確認後、実行してください。モニタリソースの回復動作が下記のように設定されている場合、-vオプションで表示される "FinalAction Count" には 「最終動作前スクリプト」の実行回数が表示されます。
最終動作前にスクリプトを実行する: 有効
最終動作: "何もしない"
-
エラーメッセージ メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が 考えられます。確認してください。
Invalid cluster configuration data. Check the cluster configuration information.
クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。
Monitor resource is not registered.
モニタリソースが登録されていません。
Specified monitor resource is not registered. Check the cluster configuration information.
指定されたモニタリソースは、登録されていません。Cluster WebUI でクラスタ構成情報を確認してください。The cluster has been stopped. Check the active status of the cluster daemon by using the command such as ps command.
クラスタは、停止状態です。ps コマンドなどで CLUSTERPRO デーモンの起動状態を確認してください。The cluster has been suspended. The cluster daemon has been suspended. Check activation status of the cluster daemon by using a command such as the ps command.
CLUSTERPRO デーモンは、サスペンド状態です。ps コマンドなどで CLUSTERPRO デーモンの起動状態を確認してください。
Waiting for synchronization of the cluster... The cluster is waiting for synchronization. Wait for a while and try again.
クラスタは、同期待ち状態です。クラスタ同期待ち完了後、再度実行して ください。Monitor %1 was unregistered, ignored. The specified monitor resources %1is not registered, but continue processing. Check the cluster configuration data.
指定されたモニタリソース中に登録されていないモニタリソースありますが、無視して処理を継続します。Cluster WebUI でクラスタ構成情報を確認してください。%1 :モニタリソース名Monitor %1 denied control permission, ignored. but continue processing.
指定されたモニタリソース中に制御できないモニタリソースがありますが、無視して処理を継続します。%1 :モニタリソース名This command is already run.
コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が 考えられます。確認してください。
-
-m オプションに指定可能なモニタリソースタイプ - タイプ監視の一時停止/再開回復動作の回数カウンタ/リセット障害検証機能の有効化/無効化
diskw
✓
✓
✓
ipw
✓
✓
✓
miiw
✓
✓
✓
mtw
✓
✓
✓
pidw
✓
✓
✓
volmgrw
✓
✓
✓
userw
✓
✓
n/a
vmw
✓
✓
n/a
mrw
✓
✓
n/a
genw
✓
✓
✓
oraclew
✓
✓
✓
db2w
✓
✓
✓
psqlw
✓
✓
✓
mysqlw
✓
✓
✓
sybasew
✓
✓
✓
odbcw
✓
✓
✓
sqlserverw
✓
✓
✓
sambaw
✓
✓
✓
nfsw
✓
✓
✓
httpw
✓
✓
✓
ftpw
✓
✓
✓
smtpw
✓
✓
✓
pop3w
✓
✓
✓
imap4w
✓
✓
✓
tuxw
✓
✓
✓
wlsw
✓
✓
✓
wasw
✓
✓
✓
otxw
✓
✓
✓
jraw
✓
✓
✓
sraw
✓
✓
✓
psrw
✓
✓
✓
psw
✓
✓
✓
2.14. グループリソースを制御する (clprscコマンド)¶
グループリソースの制御を行います。
-
コマンドライン - clprsc -s resource_name [-f] [--apito timeout]clprsc -t resource_name [-f] [--apito timeout]
-
説明 グループリソースを起動/停止します。
-
パラメータ -
-s¶ グループリソースを起動します。
-
-t¶ グループリソースを停止します。
-
-f¶ - グループリソース起動時は、指定したグループリソースが依存する全グループリソースを起動します。グループリソース停止時は、指定したグループリソースに依存している全グループリソースを停止します。
-
--apito¶ - グループリソースの起動、停止を待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999の値が指定できます。[--apito] オプション指定しない場合は、クラスタプロパティの内部通信タイムアウトに設定された値に従い、待ち合わせを行います。
-
-
戻り値 0
正常終了
0以外
異常終了
-
実行例 グループリソース構成
# clpstat ========== CLUSTER STATUS ========== Cluster : cluster <server> server1 : Online lanhb1 : Normal lanhb2 : Normal <group> ManagementGroup : Online current : server1 ManagementIP : Online failover1 : Online current : server1 exec1 : Online <monitor> ipw1 : Normal ==================================例1:グループfailover1のリソースexec1を停止する場合
# clprsc -t exec1 Command succeeded. # clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup : Online current : server1 ManagementIP : Online failover1 : Online current : server1 exec1 : Offline <省略>例2:グループfailover1のリソースexec1を起動する場合
# clprsc -s exec1 Command succeeded. # clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup : Online current : server1 ManagementIP : Online failover1 : Online current : server1 exec1 : Online <省略>
-
注意事項 - 本コマンドは、root権限を持つユーザで実行してください。グループリソースの状態は、状態表示コマンドまたは Cluster WebUI で確認してください。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid cluster configuration data. Check the cluster configuration information.
クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。
Invalid option.
正しいオプションを指定してください。
Could not connect server. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Invalid server status. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Server is not active. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost. Check if there is a server where the cluster service is stopped in the cluster.
クラスタ内に CLUSTERPRO サービスが停止しているサーバがないか確認してください。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。The group resource is busy. Try again later.
グループリソースが起動処理中、もしくは停止処理中のため、しばらく待ってから実行してください。
An error occurred on group resource. Check the status of group resource.
Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。
Could not start the group resource. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
他サーバが起動するのを待つか、起動待ち時間が タイムアウトするのを待って、グループリソースを起動させてください。
No operable group resource exists in the server.
処理を要求したサーバに処理可能なグループリソースが存在するか確認してください。
The group resource has already been started on the local server.
Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。
The group resource has already been started on the other server.
Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。グループリソースをローカルサーバで起動するには、グループを停止してください。The group resource has already been stopped.
Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。
Failed to start group resource. Check the status of group resource.
Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。
Failed to stop resource. Check the status of group resource.
Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。
Depended resource is not offline. Check the status of resource.
依存しているグループリソースの状態が停止済でないため、グループリソースを停止できません。依存しているグループリソースを停止するか、-f オプションを指定してください。Depending resource is not online. Check the status of resource.
依存しているグループリソースの状態が起動済でないため、グループリソースを起動できません。依存しているグループリソースを起動するか、-f オプションを指定してください。Invalid group resource name. Specify a valid group resource name in the cluster.
グループリソースが登録されていません。
Server is not in a condition to start resource or any critical monitor error is detected.
Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。グループリソースを起動しようとしたサーバで除外モニタに含まれるモニタの異常が検出されています。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.15. CPU クロックを制御する (clpcpufreq コマンド)¶
CPUクロックの制御を行います。
-
コマンドライン - clpcpufreq --highclpcpufreq --lowclpcpufreq -iclpcpufreq -s
-
説明 CPUクロック制御による省電力モードの有効化/無効化を制御します。
-
パラメータ -
--high¶ CPUクロック数を最大にします。
-
--low¶ CPUクロック数を下げて省電力モードにします。
-
-i¶ CPUクロックの制御をCLUSTERPRO X SingleServerSafe に戻します。
-
-s¶ 現在の設定状態を表示します。
performance クロック数を最大にしています。
powersave クロック数を下げて省電力モードにしています。
-
-
戻り値 0
正常終了
0以外
異常終了
-
備考 - CPUクロック制御用ドライバがロードされていない場合にはエラーとなります。サーバのプロパティの省電力の設定で、「CPUクロック制御機能を使用する」にチェックを入れていない場合、本コマンドを実行するとエラーとなります。
-
注意事項 - 本コマンドは、root権限を持つユーザで実行してください。CPUクロック制御機能を使用する場合、BIOSの設定でクロックの変更が可能になっていることと、CPUがOSの電源管理機能によるクロック制御をサポートしていることと、カーネルが対応していることが必要となります。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
正しいオプションを指定してください。
Invalid mode.Check if --high or --low or -i or -s option is spedified.--high, --low, -I, -s いずれかのオプションが指定されているか確認してください。Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the all.pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。Failed to load the cpufreq.pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。Failed to get the cpufreq path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。Failed to initialize the apicl library.Reinstall the RPM.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to change CPU frequency settings.Check the BIOS settings and the OS settings.Check if the cluster is started.Check if the setting is configured so that CPU frequencycontrol is used.BIOS の設定、OS の設定を確認してください。CLUSTERPRO サービスが起動しているか確認してください。CPU クロック制御機能を使用する設定になっているか確認してください。Failed to acquire CPU frequency settings.Check the BIOS settings and the OS settings.Check if the cluster is started.Check if the setting is configured so that CPU frequencycontrol is used.BIOS の設定、OS の設定を確認してください。CLUSTERPRO サービスが起動しているか確認してください。CPU クロック制御機能を使用する設定になっているか確認してください。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.16. クラスタ間連携を行う (clptrnreq コマンド)¶
サーバへ処理実行を要求します。
-
コマンドライン clptrnreq -t request_code -h IP [-r resource_name] [-s script_file] [-w timeout]
-
説明 指定した処理実行要求を他クラスタのサーバに発行します。
-
パラメータ -
-trequest_code¶ - 実行する処理のリクエストコードを指定します。以下のリクエストコードを指定することができます。GRP_FAILOVER グループフェイルオーバEXEC_SCRIPT スクリプトの実行
-
-hIP¶ - 処理実行要求を発行するサーバをIPアドレスで指定します。カンマ区切りで複数指定することが可能です。指定可能なIPアドレスの最大数は32です。リクエストコードにグループフェイルオーバを指定する場合、クラスタ内の全てのサーバのIPアドレスを指定してください。
-
-rresource_name¶ - リクエストコードにGRP_FAILOVERを指定した場合に、処理要求の対象となるグループに属するリソース名を指定します。GRP_FAILOVERを指定した場合、-rは省略できません。
-
-sscript_file¶ - リクエストコードにEXEC_SCRIPTを指定した場合に、実行するスクリプト(シェルスクリプトや実行可能ファイル等)のファイル名を指定します。スクリプトは-hで指定した各サーバのCLUSTERPROインストールディレクトリ配下のwork/trnreqディレクトリに作成しておく必要があります。EXEC_SCRIPTを指定した場合、-sは省略できません。
-
-wtimeout¶ - コマンドのタイムアウト値を秒単位で指定します。タイムアウト値で指定可能な最小値は5秒です。-wオプションを指定しない場合、30秒待ち合わせます。
-
-
戻り値 0
正常終了
0以外
異常終了
-
注意事項 本コマンドは、root権限を持つユーザで実行してください。
-
実行例 例1: 他クラスタのexec1リソースを持つグループをフェイルオーバさせる場合
# clptrnreq -t GRP_FAILOVER -h 10.0.0.1,10.0.0.2 -r exec1 Command succeeded.
例2: IPアドレス10.0.0.1のサーバにスクリプトscrpit1.shを実行させる場合
# clptrnreq -t EXEC_SCRIPT -h 10.0.0.1 -s script1.sh Command Succeeded.
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root権限を持つユーザで実行してください。
Invalid option.
コマンドラインオプションが不正です。正しいオプションを指定してください。
Could not connect to the data transfer servers.Check if the servers have started up.サーバが起動しているか確認してください。
Could not connect to all data transfer server.Check if the servers have started up.クラスタ内の全てのサーバが起動しているか確認してください。
Command timeout.
OSに負荷がかかっているなどの原因が考えられます。確認してください。
All servers are busy. Check if this command is already run.
既に本コマンドを実行している可能性があります。確認してください。
GRP_FAILOVER %s : Group that specified resource(%s) belongs to is offline.
指定されたリソースが属するグループは停止状態のため、フェイルオーバ処理は行われませんでした。
EXEC_SCRIPT %s : Specified script(%s) does not exist.
指定したスクリプトが存在しません。確認してください。
EXEC_SCRIPT %s : Specified script(%s) does not executable.
指定したスクリプトが実行できませんでした。実行権限があるか確認してください。
%s %s : This server is not permitted to execute clptrnreq.
コマンドを実行したサーバに実行権限がありません。Cluster WebUI の接続制限のIP一覧に登録されているか確認してください。
GRP_FAILOVER %s : Specified resource(%s) does not exist.
指定したリソースが存在しません。確認してください。
%s %s : %s failed in execute..
指定された処理実行に失敗しました。
2.17. クラスタサーバに処理を要求する(clprexec コマンド)¶
CLUSTERPROがインストールされた他サーバへ処理実行を要求します。
-
コマンドライン - clprexec --failover [group_name] -h IP [-r resource_name] [-w timeout] [-p port_number] [-o logfile_path]clprexec --script script_file -h IP [-p port_number] [-w timeout] [-o logfile_path]clprexec --notice [mrw_name] -h IP [-k category[.keyword]] [-p port_number] [-w timeout] [-o logfile_path]clprexec --clear [mrw_name] -h IP [-k category[.keyword]] [-p port_number] [-w timeout] [-o logfile_path]
-
説明 従来のclptrnreqコマンドに外部監視からCLUSTERPROサーバへ処理要求を発行する機能(異常発生通知)などを追加したコマンドです。
-
パラメータ -
--failover¶ - グループフェイルオーバ要求を行います。group_nameにはグループ名を指定してください。グループ名を省略する場合は、-rオプションによりグループに属するリソース名を指定してください。
-
--scriptscript_name¶ - スクリプト実行要求を行います。scirpt_nameには、実行するスクリプト(シェルスクリプトや実行可能ファイル等)のファイル名を指定します。スクリプトは-h で指定した各サーバのCLUSTERPRO インストールディレクトリ配下のwork/rexec ディレクトリ配下に作成しておく必要があります。
-
--notice¶ - CLUSTERPROサーバへ異常発生通知を行います。mrw_nameにはメッセージ受信モニタリソース名を指定してください。モニタリソース名を省略する場合、-kオプションでメッセージ受信モニタリソースのカテゴリ, キーワードを指定してください。
-
--clear¶ - メッセージ受信モニタリソースのステータスを"異常"から"正常"へ変更する要求を行います。mrw_nameにはメッセージ受信モニタリソース名を指定してください。モニタリソース名を省略する場合、-kオプションでメッセージ受信モニタリソースのカテゴリ, キーワードを指定してください。
-
-hIP Address¶ - 処理要求発行先のCLUSTERPROサーバのIPアドレスを指定してください。カンマ区切りで複数指定可能、指定可能なIPアドレス数は32個です。※ 本オプションを省略する場合、処理要求発行先は自サーバになります。
-
-rresource_name¶ --failoverオプションを指定する場合に、処理要求の対象となるグループに属するリソース名を指定します。
-
-kcategory[.keyword]¶ - --noticeまたは--clearオプションを指定する場合、categoryに外部連携モニタリソースに設定しているカテゴリを指定してください。外部連携モニタリソースのキーワードを指定する場合は、catergoryのあとにドット区切りで指定してください。
-
-pport_number¶ - ポート番号を指定します。port_numberに処理要求発行先サーバに設定されているデータ転送ポート番号を指定してください。本オプションを省略した場合、デフォルト29002を使用します。
-
-ologfile_path¶ - logfile_pathには、本コマンドの詳細ログを出力するファイルpathを指定します。ファイルにはコマンド1回分のログが保存されます。※ CLUSTERPROがインストールされていないサーバで本オプションを指定しない場合、標準出力のみとなります。
-
-wtimeout¶ - コマンドのタイムアウトを指定します。指定しない場合は、デフォルト180秒です。5~MAXINTまで指定可能です。
-
-
戻り値 0
正常終了
0以外
異常終了
-
注意事項 - [clprexec] コマンドを使って異常発生通知を発行する場合、CLUSTERPRO サーバ側で実行させたい異常時動作を設定したメッセージ受信モニタリソースを登録/起動しておく必要がある。-h オプションで指定する IP アドレスを持つサーバは、下記の条件を満たす必要がある。= CLUSTERPRO X 3.0以降がインストールされていること= CLUSTERPRO が起動していること( --script オプション以外の場合)= mrwが設定/起動されていること( --notice, --clear オプションの場合)[クライアント IP アドレスによる接続制限] が有効の場合、[clprexec] コマンドを実行する装置の IP アドレスを追加しておくこと。
-
実行例 例1: CLUSTERPROサーバ1(10.0.0.1)に対して、グループfailover1のフェイルオーバ要求を発行する場合
# clprexec --failover failover1 -h 10.0.0.1 -p 29002
例2: CLUSTERPROサーバ1(10.0.0.1)に対して、グループリソース(exec1)が属するグループのフェイルオーバ要求を発行する場合
# clprexec --failover -r exec1 -h 10.0.0.1
例3: CLUSTERPROサーバ1(10.0.0.1)に対して、スクリプト(script1.sh)実行要求を発行する場合
# clprexec --script script1.sh -h 10.0.0.1
例4: CLUSTERPROサーバ1(10.0.0.1)に対して異常発生通知を発行する
※ mrw1設定 カテゴリ:earthquake、キーワード:scale3
外部連携モニタリソース名を指定する場合
# clprexec --notice mrw1 -h 10.0.0.1 -w 30 -p /tmp/clprexec/ lprexec.log
外部連携モニタリソースに設定されているカテゴリとキーワードを指定する場合
# clprexec --notice -h 10.0.0.1 -k earthquake.scale3 -w 30 -p /tmp/clprexec/clprexec.log
例5: CLUSTERPROサーバ1(10.0.0.1)に対してmrw1のモニタステータス変更要求を発行する
※ mrw1の設定 カテゴリ:earthquake、キーワード:scale3
外部連携モニタリソース名を指定する場合
# clprexec --clear mrw1 -h 10.0.0.1
外部連携モニタリソースに設定されているカテゴリとキーワードを指定する場合
# clprexec --clear -h 10.0.0.1 -k earthquake.scale3
-
エラーメッセージ メッセージ
原因/対処
rexec_ver:%s
-
%s %s : %s succeeded.
-
%s %s : %s will be executed from now.
要求発行先のサーバで処理結果を確認してください。
%s %s : Group Failover did not execute because Group(%s) is offline.
-
%s %s : Group migration did not execute because Group(%s) is offline.
-
Invalid option.
コマンドの引数を確認してください。
Could not connect to the data transfer servers. Check if the servers have started up.
指定した IP アドレスが正しいかまたは IP アドレスを持つサーバが起動しているか確認してください。
Command timeout.
指定した IP アドレスを持つサーバで処理が完了しているか確認してください。
All servers are busy.Check if this command is already run.
既に本コマンドが実行されている可能性があります。確認してください。
%s %s : This server is not permitted to execute clprexec.
Cluster WebUI 接続制限のクライアント IP アドレス一覧にコマンドを実行するサーバの IP アドレスが 登録されているか確認してください。
%s %s : Specified monitor resource(%s) does not exist.
コマンドの引数を確認してください。
%s failed in execute.
要求発行先の CLUSTERPRO サーバの状態を確認してください。
2.18. BMC 情報を変更する(clpbmccnf コマンド)¶
BMCユーザ名・パスワード情報を変更します。
-
コマンドライン clpbmccnf [-u username] [-p password]
-
説明 CLUSTERPROが使用するベースボード管理コントローラー(BMC)のLANアクセス用のユーザ名/パスワードを変更します。
-
パラメータ -
-uusername¶ - CLUSTERPROが使用するBMC LANアクセス用のユーザ名を指定します。root権限を持つユーザ名を指定する必要があります。-uオプションは省略可能です。省略時に-pオプションが指定されている場合、ユーザ名は現在設定されている値を使用します。オプション指定がない場合は対話形式で設定します。
-
-ppassword¶ CLUSTERPROが使用するBMC LANアクセス用のパスワードを指定します。-pオプションは省略可能です。省略時に-uオプションが指定されている場合、パスワードは現在設定されている値を使用します。オプション指定がない場合は対話形式で設定します。
-
-
戻り値 0
正常終了
0以外
異常終了
-
注意事項 - 本コマンドは、root 権限を持つユーザで実行してください。本コマンドはサーバが正常な状態で実行してください。本コマンドによる BMC 情報の更新は、次回サーバ起動時/リジューム時に有効になります。本コマンドは BMC の設定を変更するものではありません。BMC のアカウント設定の確認・変更にはサーバ付属のツールか IPMI 規格に準拠した他のツールを使用してください。
-
実行例 server1 の BMC の IPMI アカウントのパスワードを mypassword に変更した場合、server1 上で下記を実行します。
# clpbmccnf -p mypassword
または、以下のように対話形式で入力します。
# clpbmccnf New user name: ←変更がない場合はリターンキーを押下してスキップ New password: ********** Retype new password: ********** Cluster configuration updated successfully.
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
コマンドラインオプションが不正です。正しいオプションを指定してください。Failed to download the cluster configuration data. Check if the cluster status is normal.
クラスタ構成情報のダウンロードに失敗しました。クラスタの状態が正常か確認してください。Failed to upload the cluster configuration data. Check if the cluster status is normal.
クラスタ構成情報のアップロードに失敗しました。クラスタの状態が正常か確認してください。Invalid configuration file. Create valid cluster configuration data.
クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.19. 再起動回数を制御する(clpregctrl コマンド)¶
再起動回数制限の制御を行います。
-
コマンドライン - clpregctrl --getclpregctrl -gclpregctrl --clear -t type -r registryclpregctrl -c -t type -r registry
-
説明 サーバ上で再起動回数の表示/初期化を行います。
-
パラメータ -
-g,--get¶ 再起動回数情報を表示します。
-
-c,--clear¶ 再起動回数を初期化します。
-
-ttype¶ 再起動回数を初期化するタイプを指定します。指定可能なタイプはrcまたはrmです。
-
-rregistry¶ レジストリ名を指定します。指定可能なレジストリ名はhaltcountです。
-
-
戻り値 0
正常終了
1
実行権限不正
2
二重起動
3
オプション不正
4
構成情報不正
10~17
内部エラー
20~22
再起動回数情報取得失敗
90
メモリアロケート失敗
91
ワークディレクトリ変更失敗
-
実行例 再起動回数情報表示
# clpregctrl -g ****************************** ------------------------- type : rc registry : haltcount comment : halt count kind : int value : 0 default : 0 ------------------------- type : rm registry : haltcount comment : halt count kind : int value : 3 default : 0 ****************************** Command succeeded.(code:0) #
例1、2は、再起動回数を初期化します。
例1:グループリソース異常による再起動回数を初期化する場合
# clpregctrl -c -t rc -r haltcount Command succeeded.(code:0) #
例2:モニタリソース異常による再起動回数を初期化する場合
# clpregctrl -c -t rm -r haltcount Command succeeded.(code:0) #
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-
エラーメッセージ メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。The command is already executed. Check the execution state by using the "ps" command or some other command.
コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。Invalid option.
オプションが不正です。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.20. リソース使用量を予測する (clpprerコマンド)¶
入力ファイルに記載されているリソース使用量データの推移より、将来的な値の推移を予測し、予測結果をファイルに出力します。また、予測したデータのしきい値判定結果を確認することもできます。
-
コマンドライン clpprer -i <inputfile> -o <outputfile> [-p <number>] [-t <number> [-l]]
-
説明 与えられたリソース使用量データの傾向から将来値を予測します。
-
パラメータ -
-i<inputfile>¶ 将来の値を求めたいリソースデータを指定します。
-
-o<outputfile>¶ 予測結果を出力するファイル名を指定します。
-
-p<number>¶ 予測データ数を指定します。指定がない場合は、30件の予測データを求めます。
-
-t<number>¶ 予測データと比較するしきい値を指定します。
-
-l¶ [-t] オプションでしきい値の設定を行った場合のみ有効になるオプションです。しきい値を下回った場合を異常と判定します。
-
-
戻り値 0
しきい値判定を行わず正常終了した場合
1
異常が発生した場合
2
入力データがしきい値判定の結果、しきい値を超えたと判断した場合
3
予測データがしきい値判定の結果、しきい値を超えたと判断した場合
4
しきい値判定の結果、しきい値を超えていないと判断した場合
5
分析対象データ数が分析推奨データ数 (120) に足りていない場合に、入力データがしきい値判定の結果、しきい値を超えたと判断した場合
6
分析対象データ数が分析推奨データ数 (120) に足りていない場合に、予測データがしきい値判定の結果、しきい値を超えたと判断した場合
7
分析対象データ数が分析推奨データ数 (120) に足りていない場合に、しきい値判定の結果、しきい値を超えていないと判断した場合
-
注意事項 - 本コマンドは、システムモニタリソース(System Resource Agent)のライセンスを登録している場合のみ利用することができます。(ライセンスが登録されていればクラスタ構成にシステムモニタリソースを設定いただく必要はありません。)オプション -i で指定するリソースデータファイルの入力データ数は最大で 500 件となります。リソース使用量の予測にはある程度の入力データ数が必要となります。ただし、入力データ数が多い場合は分析に要する処理時間も長くなるため、入力データ数は 120 件程度を推奨します。また、オプション -p に指定可能な出力データ数も最大で500 件となります。入力ファイルの時刻データが昇順に並んでいない場合は正しく予測を行うことができません。入力ファイルには昇順に並んでいる時刻データを設定してください。
-
入力ファイル 入力ファイルのフォーマットについて説明します。入力ファイルは予測結果を取得したいリソース使用量について、下記のフォーマット通り記載したファイルをご用意ください。
入力ファイルはCSV 形式で、1個のデータを [日時,数値] の形で記載します。また、日時のフォーマットは YYYY/MM/DD hh:mm:ss です。ファイル例
2012/06/14 10:00:00,10.0 2012/06/14 10:01:00,10.5 2012/06/14 10:02:00,11.0
-
実行例 将来の値の予測を簡単な例で説明します。
入力データで異常を検出した場合
入力データの最新の値がしきい値を超えていた場合は、異常と判断して戻り値 2を返却します。入力データ数が推奨値(=120)未満の場合は戻り値5を返却します。
図 2.3 入力データで異常を検出¶
予測データで異常を検出
予測データがしきい値を超えていた場合は、異常と判断して戻り値 3を返却します。入力データ数が推奨値(=120)未満の場合は戻り値6を返却します。
図 2.4 予測データで異常を検出¶
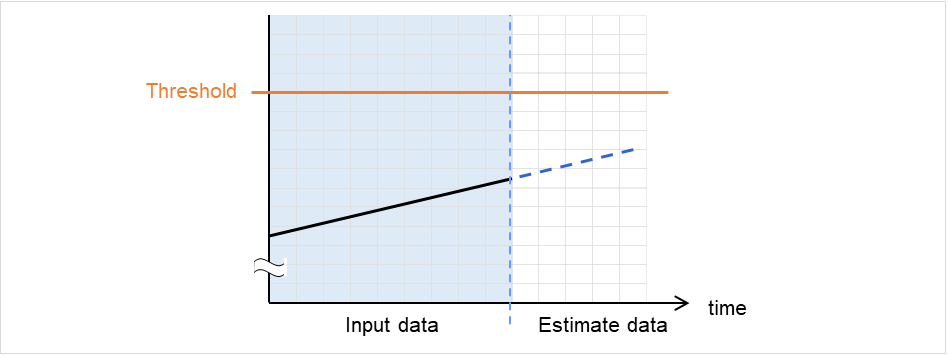
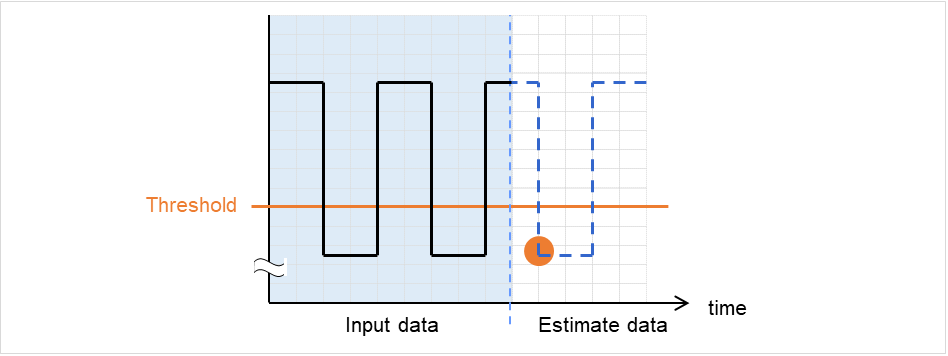
-
実行例 フォーマットに指定された形式で記載されたファイルを準備し、clpprer コマンドを実行いただくことで予測結果を出力ファイルとして確認いただくことができます。
入力ファイル test.csv
2012/06/14 10:00:00,10.0 2012/06/14 10:01:00,10.5 2012/06/14 10:02:00,11.0
# clpprer -i test.csv -o result.csv
出力結果 result.csv
2012/06/14 10:03:00,11.5 2012/06/14 10:04:00,12.0 2012/06/14 10:05:00,12.5 2012/06/14 10:06:00,13.0 2012/06/14 10:07:00,13.5 :また、オプションにしきい値を設定することで予測値のしきい値判定結果をコマンドプロンプト上で確認することができます。
# clpprer -i test.csv -o result.csv -t 12.5
実行結果
Detect over threshold. datetime = 2012/06/14 10:06:00, data = 13.00, threshold = 12.5
-
エラーメッセージ メッセージ
原因/対処法
Normal state.
しきい値判定の結果、しきい値を超えるデータはありませんでした。
Detect over threshold. datetime = %s, data = %s, threshold = %s
しきい値判定の結果、しきい値を超えるデータを検出しました。
Detect under threshold. datetime = %s, data = %s, threshold = %s
-l オプションによるしきい値判定の結果、しきい値を下回るデータを検出しました。
License is nothing.
有効なSystem Resrouce Agentのライセンスが登録されていません。ライセンスを確認してください。
Inputfile is none.
指定した入力データファイルが存在しません。
Inputfile length error.
指定した入力データファイルのパスが長すぎます。1023 バイト以下で指定してください。
Output directory does not exist.
出力ファイルで指定されているディレクトリが存在しません。指定したディレクトリが存在するか確認してください。
Outputfile length error.
指定した出力ファイルのパスが長すぎます。1023 バイト以下で指定してください。
Invalid number of -p.
-p オプションに指定した値が不正です。
Invalid number of -t.
-t オプションに指定した値が不正です。
Not analyze under threshold(not set -t).
-t オプションが指定されていません。-l オプションを使用する場合 -t オプションも指定してください。
File open error [%s]. errno = %s
ファイルオープンに失敗しました。メモリ不足やOSのリソース不足が考えられます。確認してください。
Inputfile is invalid. cols = %s
入力データ数が正しくありません。入力データ数は2件以上に設定してください。
Inputfile is invalid. rows = %s
入力データのフォーマットが正しくありません。1行は2列にする必要があります。
Invalid date format. [expected YYYY/MM/DD HH:MM:SS]
入力データの日付が不正なフォーマットになっています。データを確認してください。
Invalid date format. Not sorted in ascending order.
入力データの日時が昇順に並んでいません。データを確認してください。
File read error.
入力データに不正な値が設定されています。データを確認してください。
Too large number of data [%s]. Max number of data is %s.
入力データ数が最大値(500)を超えています。データ数を減らしてください。
Input number of data is smaller than recommendable number.
入力データ数が分析推奨データ数(120)より少ないです。※分析推奨データが少ない場合でも、分析は行われます。Internal error.
内部エラーが発生しました。
2.21. プロセスの健全性を確認する (clphealthchk コマンド)¶
プロセスの健全性を確認します。
-
コマンドライン clphealthchk [ -t pm | -t rc | -t rm | -t nm | -h]
注釈
本コマンドは、単一サーバ上でプロセスの健全性を確認します。健全性を確認したいサーバ上で実行する必要があります。
-
説明 単一サーバ上でのプロセスの健全性を確認します。
-
パラメータ -
なし¶ pm/rc/rm/nm の健全性を確認します。
-
-t<process>¶ process
- pm
pm の健全性を確認します。
- rc
rc の健全性を確認します。
- rm
rm の健全性を確認します。
- nm
nm の健全性を確認します。
-
-h¶ Usageを出力します。
-
-
戻り値 0
正常終了
1
実行権限不正
2
二重起動
3
初期化エラー
4
オプション不正
10
プロセスストール監視機能未設定
11
クラスタ未起動状態(クラスタ起動待ち合わせ中、クラスタ停止処理中を含む)
12
クラスタサスペンド状態
100
健全性情報が一定時間更新されていないプロセスが存在する
-t オプション指定時は、指定プロセスの健全性情報が一定時間更新されていない
255
その他内部エラー
-
実行例 例1: 健全な場合
# clphealthchk pm OK rc OK rm OK nm OK
例2: clprc がストールしている場合
# clphealthchk pm OK rc NG rm OK nm OK # clphealthchk -t rc rc NG
例3: クラスタが停止している場合
# clphealthchk The cluster has been stopped
-
備考 クラスタが停止している場合や、サスペンドしている場合にはプロセスは停止しています。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Invalid option.
正しいオプションを指定してください。
The function of process stall monitor is disabled.
プロセスストール監視機能が有効ではありません。
The cluster has been stopped.
クラスタは停止状態です。
The cluster has been suspended.
クラスタはサスペンド状態です。
This command is already run.
コマンドは既に実行されています。ps コマンドなどで実行状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
2.22. クラスタ統計情報を表示する(clpperfc コマンド)¶
クラスタ統計情報を表示します。
-
コマンドライン - clpperfc --starttime -g group_nameclpperfc --stoptime -g group_nameclpperfc -g [group_name]clpperfc -m monitor_name
-
説明 グループの起動、停止時間の中央値(ミリ秒)を表示します。
モニタリソースの監視処理時間(ミリ秒)を表示します。
-
オプション -
--starttime-g group_name¶ グループの起動時間の中央値を表示します。
-
--stoptime-g group_name¶ グループの停止時間の中央値を表示します。
-
-g[group_name]¶ グループの起動、停止時間の中央値を表示します。
groupnameを省略した場合は、全グループの起動、停止時間の中央値を表示します。
-
-mmonitor_name¶ 直近のモニタリソースの監視処理時間を表示します。
-
-
戻り値 0
正常終了
1
コマンドオプション不正
2
ユーザ認証エラー
3
構成情報ロードエラー
4
構成情報ロードエラー
5
初期化エラー
6
内部エラー
7
内部通信初期化エラー
8
内部通信接続エラー
9
内部通信処理エラー
10
対象グループチェックエラー
12
タイムアウトエラー
-
実行例 グループの起動時間の中央値を表示する場合
# clpperfc --starttime -g failover1 200
特定グループの起動、停止時間の中央値を表示する場合
# clpperfc -g failover1 start time stop time failover1 200 150モニタリソースの監視処理時間を表示する場合
# clpperfc -m monitor1 100
-
備考 本コマンドで出力する時間の単位はミリ秒です。
有効なグループの起動時間、停止時間が取得できなかった場合は - が表示されます。
有効なモニタリソースの監視時間が取得できなかった場合は 0 が表示されます。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Command timeout.
コマンドの実行がタイムアウトしました。
Internal error.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
2.23. クラスタ構成情報をチェックする (clpcfchk コマンド)¶
クラスタ構成情報をチェックします。
-
コマンドライン - clpcfchk -o path [-i conf_path]
-
説明 クラスタ構成情報を基に設定値の妥当性を確認します。
-
オプション -
-opath¶ チェック結果を保存するディレクトリを指定します。
-
-iconf_path¶ チェックする構成情報を保存したディレクトリを指定します。
省略した場合は、反映済みの構成情報をチェックします。
-
-
戻り値 0
正常終了
0以外
エラー終了
-
実行例 反映済みの構成情報をチェックする場合
# clpcfchk -o /tmp server1 : PASS
保存した構成情報をチェックする場合
# clpcfchk -o /tmp -i /tmp/config server1 : PASS
-
実行結果 本コマンドの結果で表示されるチェック結果 (総合結果)は以下になります。
チェック結果(総合結果)
説明
PASS
問題がありません。
FAIL
問題があります。チェック結果を確認してください。
-
備考 各サーバの総合結果のみを表示します。
-
注意事項 本コマンドは、root 権限を持つユーザで実行してください。
Cluster WebUI でエクスポートした構成情報をチェックする場合、事前に解凍してください。
-
エラーメッセージ メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
Could not opened the configuration file. Check if the configuration file exists on the specified path.
指定されたパスが存在しません。正しいパスを指定してください。
Server is busy. Check if this command is already run.
本コマンドはすでに起動されています。
Failed to obtain properties.
プロパティの取得に失敗しました。
Failed to check validation.
クラスタ構成チェックに失敗しました。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
3. 注意制限事項¶
本章では、注意事項や既知の問題とその回避策について説明します。
本章で説明する項目は以下の通りです。
3.1. CLUSTERPRO X SingleServerSafe 運用後¶
運用を開始した後に発生する事象で留意して頂きたい事項です。
3.1.1. ドライバロード時のメッセージについて¶
clpkaドライバをloadした際に、以下のメッセージがコンソール、syslogに表示されることがあります。この現象は異常ではありません。
kernel: clpka: no version for "struct_module" found: kernel tainted.
kernel: clpka: module license 'unspecified' taints kernel.
3.1.2. ipmi のメッセージについて¶
ユーザ空間モニタリソースにIPMIを使用する場合、syslogに下記のkernelモジュール警告ログが多数出力されます。
modprobe: modprobe: Can't locate module char-major-10-173
このログ出力を回避したい場合は、/dev/ipmikcsをrenameしてください。
3.1.3. 回復動作中の操作制限¶
モニタリソースの異常検出時の設定で回復対象にグループリソース(EXECリソース、仮想マシンリソース)を指定し、モニタリソースが異常を検出した場合の回復動作遷移中(再活性化 → 最終動作)には、以下のコマンドまたは、Cluster WebUI からのサーバ及びグループへの制御は行わないでください。
サーバの停止 / サスペンド
グループの開始 / 停止
3.1.4. コマンドリファレンスに記載されていない実行形式ファイルやスクリプトファイルについて¶
3.1.5. ログ収集時のメッセージ¶
ログ収集を実行した場合、コンソールに以下のメッセージが表示されることがありますが、異常ではありません。ログは正常に収集されています。
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(hd#にはサーバ上に存在するIDEのデバイス名が入ります)
kernel: Warning: /proc/ide/hd?/settings interface is obsolete, and will be removed soon!
3.1.6. サービス起動/停止用スクリプトについて¶
init.d 環境では以下の場合に、サービスの起動/停止スクリプトでエラーが出力されます。systemd環境ではエラーは出力されません。
- CLUSTERPRO Server インストール直後(SUSE Linux の場合)OSシャットダウン時に下記のサービス停止スクリプトでエラーが出力されます。各サービスが起動されていないことが原因で出力されるエラーのため問題はありません。
clusterpro_alertsync
clusterpro_webmgr
clusterpro
clusterpro_api
clusterpro_ib
clusterpro_trn
clusterpro_evt
- サービスの手動停止後のOSシャットダウン(SUSE Linux の場合)clpcl コマンドや Cluster WebUI からサービスを停止後、OS シャットダウン時に停止したサービスの停止スクリプトでエラーが出力されます。サービスが停止していることが原因で出力されるエラーのため問題はありません。
clusterpro
以下の場合に、サービスの停止スクリプトが不正な順序で実行されます。
- chkconfig --del name を実行し全サービスを無効化した後の OS シャットダウンCLUSTERPRO のサービスを無効化した後、OS シャットダウン時に CLUSTERPRO のサービスが不正な順序で停止されます。OS シャットダウン時に無効化したCLUSTERPRO のサービスが停止されないことが原因で発生します。Cluster WebUI から実行するサーバシャットダウンや、clpstdn コマンドなど CLUSTERPRO のコマンドを使用してのサーバシャットダウンの場合は不正な順序で停止されても問題ありません。
3.1.7. systemd 環境でのサービス状態確認について¶
systemd 環境ではsystemctl コマンドによるサービスの状態表示と、実際のクラスタの状態とは一致しない場合があります。
クラスタの状態の確認には clpstat コマンド、Cluster WebUI を使用してください。
3.1.8. EXEC リソースで使用するスクリプトファイルについて¶
EXEC リソースで使用するスクリプトファイルはサーバ上の下記のディレクトリに配置されます。
/インストールパス/scripts/グループ名/EXECリソース名/
構成変更時に下記の変更を行った場合、変更前のスクリプトファイルはサーバ上からは削除されません。
EXEC リソースを削除した場合や EXEC リソース名を変更した場合
EXEC リソースが所属するグループを削除した場合やグループ名を変更した場合
変更前のスクリプトファイルが必要ない場合は、削除しても問題ありません。
3.1.9. 活性時監視設定のモニタリソースについて¶
活性時監視設定のモニタリソースの一時停止/再開には下記の制限事項があります。
モニタリソースの一時停止後、監視対象リソースを停止させた場合モニタリソースは停止状態となります。そのため、監視の再開はできません。
モニタリソースを一時停止後、監視対象リソースを停止/起動させた場合、監視対象リソースが起動したタイミングで、モニタリソースによる監視が開始されます。
3.1.10. Cluster WebUI について¶
接続先と通信できない状態で操作を行うと、制御が戻ってくるまでしばらく時間が必要な場合があります。
Proxy サーバを経由する場合は、Cluster WebUI のポート番号を中継できるように、Proxy サーバの設定をしてください。
- Reverse Proxy サーバを経由する場合、Cluster WebUI は正常に動作しません。CLUSTERPRO X SingleServerSafe のアップデートを行った場合、起動している全てのブラウザを一旦終了してください。ブラウザ側のキャッシュをクリアして、ブラウザを起動してください。
本製品より新しいバージョンで作成されたクラスタ構成情報は、本製品で利用することはできません。
- Web ブラウザを終了すると (ウィンドウフレームの [X] 等)、確認ダイアログが表示される場合があります。
 設定を続行する場合は [ページに留まる] を選択してください。
設定を続行する場合は [ページに留まる] を選択してください。 - Web ブラウザをリロードすると (メニューの [最新の情報に更新] やツールバーの [現在のページを再読み込み] 等) 、確認ダイアログが表示される場合があります。
 設定を続行する場合は [ページに留まる] を選択してください。
設定を続行する場合は [ページに留まる] を選択してください。 上記以外の Cluster WebUI の注意制限事項についてはオンラインマニュアルを参照してください。
3.1.11. システムモニタリソース、プロセスリソースモニタリソースについて¶
設定内容の変更時にはクラスタサスペンドを行う必要があります。
モニタリソースの遅延警告には対応していません。
- SELinux の設定は permissive または disabled にしてください。enforcing に設定すると CLUSTERPRO で必要な通信が行えない場合があります。
動作中に OS の日付/時刻を変更した場合、10分間隔で行っている解析処理のタイミングが日付/時刻変更後の最初の一回だけずれてしまいます。以下のようなことが発生するため、必要に応じてクラスタのサスペンド・リジュームを行ってください。
異常として検出する経過時間を過ぎても、異常検出が行われない。
異常として検出する経過時間前に、異常検出が行われる。
システムモニタリソースのディスクリソース監視機能で同時に監視できる最大のディスク数は64台です。
3.1.12. JVM モニタリソースについて¶
監視対象のJava VMを再起動する場合はクラスタサスペンドするか、クラスタ停止を行った後に行ってください。
設定内容の変更時にはクラスタサスペンドを行う必要があります。
モニタリソースの遅延警告には対応していません。
JVMモニタリソースを登録後にCluster WebUI の言語(クラスタプロパティ→情報タブ→言語)を変更する場合(例:日本語→中国語)、JVMモニタリソースを一旦削除し、再度JVMモニタリソースを登録してください。
3.1.13. HTTP モニタリソースについて¶
HTTPモニタリソースでは以下いずれかのOpenSSLの共有ライブラリのシンボリックリンクを利用しています。
libssl.so
libssl.so.1.1 (OpenSSL 1.1.1 の共有ライブラリ)
libssl.so.10 (OpenSSL 1.0の共有ライブラリ)
libssl.so.6 (OpenSSL 0.9の共有ライブラリ)
OSのディストリビューションやバージョン、およびパッケージのインストール状況によっては、上記のシンボリックリンクが存在しない場合があります。HTTP モニタリソースでは、上記のシンボリックリンクが見つけられない場合は、以下のようなエラーが発生します。Detected an error in monitoring <Monitor Resource Name>. (1 :Can not found library. (libpath=libssl.so, errno=2))
このため、上記のエラーが発生した場合は、/usr/lib または /usr/lib64 配下などに上記のシンボリックリンクが存在しているか確認をお願いします。また、上記のシンボリックリンクが存在しない場合は、下記のコマンド例のようにシンボリックリンク libssl.so を作成頂きますようお願いします。コマンド例:
cd /usr/lib64 # /usr/lib64 へ移動 ln -s libssl.so.1.0.1e libssl.so # シンボリックリンクの作成
4. エラーメッセージ一覧¶
本章では、CLUSTERPRO X SingleServerSafe 運用中に表示されるエラーメッセージの一覧について説明します。
本章で説明する項目は以下の通りです。
4.1. syslog、アラート、メール通報、SNMP トラップメッセージ、Message Topic¶
注釈
syslogに facility = daemon(0x00000018), identity = "clusterpro" で出力します。以下の表の「イベント分類」がsyslogのログレベルに相当します。
下表で使用する記号は以下を表します。
[1]alert, [2]syslog, [3]Mail Report, [4]SNMP Trap, [5]Message Topic
モジュールタイプ |
イベント分類 |
イベントID |
メッセージ |
説明 |
対処 |
1 |
2 |
3 |
4 |
5 |
|---|---|---|---|---|---|---|---|---|---|---|
sss |
エラー |
8 |
Failed to update config file. |
コンフィグファイルの更新が失敗しました。 |
構成情報を確認してください。 |
● |
● |
|||
sss |
情報 |
10 |
Updated config file successfully. |
コンフィグファイルが更新されました。 |
- |
● |
||||
sss |
エラー |
12 |
Information in config file is invalid. |
コンフィグファイルの内容が不正です。 |
構成情報を確認してください。 |
● |
||||
sss |
エラー |
14 |
Failed to obtain server name. |
サーバ名の取得が失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sss |
情報 |
16 |
Server name is updated. |
サーバ名が更新されました。 |
- |
● |
● |
|||
pm |
情報 |
1 |
Starting the cluster daemon… |
CLUSTERPROデーモンが正常に起動されました。 |
- |
● |
● |
|||
pm |
情報 |
2 |
Shutting down the cluster daemon… |
CLUSTERPROデーモンを停止しています。 |
- |
● |
● |
|||
pm |
情報 |
3 |
Shutdown monitoring is started… |
シャットダウン監視が開始されました。 |
- |
● |
● |
|||
pm |
エラー |
10 |
The cluster daemon has already started. |
CLUSTERPROデーモンは、既に起動されています。 |
CLUSTERPROデーモンの状態を確認してください。 |
● |
● |
|||
pm |
エラー |
11 |
A critical error occurred in the cluster daemon. |
CLUSTERPROデーモンで重大なエラーが発生しました。 |
実行ユーザが root権限を持っていないか或いは、メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
● |
● |
● |
pm |
エラー |
12 |
A problem was detected in XML library. |
XML ライブラリ内で問題が検出されました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
pm |
エラー |
13 |
A problem was detected in cluster configuration data. |
構成情報で問題が検出されました。 |
Cluster WebUI で構成情報を確認してください。 |
● |
● |
● |
● |
● |
pm |
エラー |
14 |
No cluster configuration data is found. |
構成情報が存在しません。 |
Cluster WebUI でサーバ構成を作成し、サーバにアップロードしてください。 |
● |
● |
|||
pm |
エラー |
15 |
No information about this server is found in the cluster configuration data. |
自サーバが構成情報に存在しません。 |
Cluster WebUI で構成情報を確認してください。 |
● |
● |
|||
pm |
エラー |
20 |
Process %1 was terminated abnormally. |
%1 プロセスが異常終了しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 nm プロセスが異常終了した場合でも業務影響はありませんが、クラスタ停止操作を行うことができなくなります。 回復するには、Cluster WebUI や clpdown コマンドにて OS 再起動を実施してください。 |
● |
● |
● |
● |
● |
pm |
エラー |
21 |
The system will be stopped because the cluster daemon process terminated abnormally. |
CLUSTERPROデーモンのプロセスが異常終了したため、システムを停止します。 |
グループリソースの非活性失敗が考えられます。グループリソースのメッセージに従って対処を行ってください。 |
● |
● |
|||
pm |
エラー |
22 |
An error occurred when initializing process %1.(return code:%2) |
%1 プロセスの初期化エラーです。 |
イベントプロセスが起動されていない事が考えられます。 |
● |
● |
● |
● |
● |
pm |
情報 |
23 |
The system will be stopped. |
システムを停止します。 |
- |
● |
● |
|||
pm |
情報 |
24 |
The cluster daemon will be stopped. |
CLUSTERPROデーモンを停止します。 |
- |
● |
● |
|||
pm |
情報 |
25 |
The system will be rebooted. |
システムを再起動します。 |
- |
● |
● |
|||
pm |
情報 |
26 |
Process %1 will be restarted. |
%1 プロセスを再起動します。 |
- |
● |
● |
|||
pm |
情報 |
30 |
Received a request to stop the system from %1. |
%1 からシステム停止要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
31 |
Received a request to stop the cluster daemon from %1. |
%1 からCLUSTERPROデーモン停止要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
32 |
Received a request to reboot the system from %1. |
%1 からシステム再起動要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
33 |
Received a request to restart the cluster daemon from %1. |
%1 からCLUSTERPROデーモン再起動要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
34 |
Received a request to resume the cluster daemon from %1. |
%1 からサーバリジューム要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
35 |
Received a request to suspend the cluster daemon from %1. |
%1 からサーバサスペンド要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
36 |
Received a request to panic by sysrq from %1. |
%1 からsysrqによるパニック要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
37 |
Received a request to reset by keepalive driver from %1. |
%1 からkeepaliveドライバによるリセット要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
38 |
Received a request to panic by keepalive driver from %1. |
%1 からkeepaliveドライバによるパニック要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
39 |
Received a request to reset by BMC from %1. |
%1 からBMCによるリセット要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
40 |
Received a request to power down by BMC from %1. |
%1 からBMCによるパワーダウン要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
41 |
Received a request to power cycle by BMC from %1. |
%1 からBMCによるパワーサイクル要求を受け取りました。 |
- |
● |
● |
|||
pm |
情報 |
42 |
Received a request to send NMI by BMC from %1. |
%1 からBMCによるNMI送信要求を受け取りました。 |
- |
● |
● |
|||
pm |
エラー |
66 |
An attempt to panic by sysrq from %1 failed. |
%1 からのsysrqによるパニックをしようとしましたが、失敗しました。 |
sysrqが使用できるようにシステムが構成されているか確認してください。 |
● |
● |
|||
pm |
エラー |
67 |
An attempt to reset by keepalive driver from %1 failed. |
%1 からのkeepaliveドライバによるリセットをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
pm |
エラー |
68 |
An attempt to panic by keepalive driver from %1 failed. |
%1 からのkeepaliveドライバによるパニックをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
pm |
エラー |
69 |
An attempt to reset by BMC from %1 failed. |
%1 からのBMCによるリセットをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
pm |
エラー |
70 |
An attempt to power down by BMC from %1 failed. |
%1 からのBMCによるパワーダウンをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
pm |
エラー |
71 |
An attempt to power cycle by BMC from %1 failed. |
%1 からのBMCによるパワーサイクルをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
pm |
エラー |
72 |
An attempt to send NMI by BMC from %1 failed. |
%1 からのBMCによるNMI送信をしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
nm |
情報 |
1 |
Server %1 has started. |
サーバ %1 が起動しました。 |
- |
● |
● |
|||
nm |
情報 |
2 |
Server %1 has been stopped. |
サーバ %1 が停止しました。 |
- |
● |
● |
● |
● |
● |
nm |
情報 |
3 |
Resource %1 of server %2 has started. |
サーバ %2 の %1 リソースが起動しました。 |
- |
● |
● |
|||
nm |
情報 |
4 |
Resource %1 of server %2 has stopped. |
サーバ %2 の %1 リソースが停止しました。 |
- |
● |
● |
|||
nm |
情報 |
5 |
Waiting for all servers to start. |
サーバの起動待ち合わせを開始しました。 |
- |
● |
● |
|||
nm |
情報 |
6 |
All servers have started. |
サーバが起動しました。 |
- |
● |
● |
|||
nm |
情報 |
7 |
Timeout occurred during the wait for startup of all servers. |
全サーバの起動待ち合わせがタイムアウトしました。 |
- |
● |
● |
|||
nm |
エラー |
8 |
Timeout occurred during the wait for startup of all servers. (Cannot communicate with some servers.) |
全サーバの起動待ち合わせがタイムアウトしました。(いくつかのサーバとの内部通信ができない状態です。) |
ネットワークアダプタでエラーが発生していないか、あるいはネットワークが正しく接続されているか確認してください。 |
● |
● |
|||
nm |
情報 |
9 |
Waiting for startup of all servers has been canceled. |
サーバの起動待ち合わせをキャンセルしました。 |
- |
● |
● |
|||
nm |
エラー |
10 |
Status of resource %1 of server %2 is unknown. |
サーバ %2 の %1 リソースの状態が不明です。 |
%1 リソースに関するケーブルまたは、ネットワークの設定が正しいか確認してください。 |
● |
● |
● |
● |
● |
nm |
警告 |
11 |
NP resolution process at the cluster startup is disabled. |
クラスタ起動時のネットワークパーティション解決処理が無効になっています。 |
クラスタ起動時のネットワークパーティション解決処理が無効になっています。 |
● |
● |
|||
nm |
エラー |
20 |
Process %1 was terminated abnormally. |
%1 プロセスが異常終了しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
● |
● |
● |
nm |
情報 |
21 |
The system will be stopped. |
システムを停止します。 |
- |
● |
● |
|||
nm |
情報 |
22 |
The cluster daemon will be stopped. |
CLUSTERPROデーモンを停止します。 |
- |
● |
● |
|||
nm |
情報 |
23 |
The system will be rebooted. |
システムを再起動します。 |
- |
● |
● |
|||
nm |
情報 |
24 |
Process %1 will be restarted. |
%1 プロセスを再起動します。 |
- |
● |
● |
|||
nm |
エラー |
30 |
Network partition was detected. Shut down the server %1 to protect data. |
ネットワークパーティションを検出しました。データ保護のためサーバ%1をシャットダウンします。 |
全てのハートビートが使用できない状態です。ネットワークアダプタでエラーが発生していないか、あるいはネットワークが正しく接続されているか確認してください。
DISKHBを使用している場合には共有ディスクの状態を確認してください。
COMHBを使用している場合にはCOMケーブルが正しく接続されているか確認してください。
|
● |
● |
|||
nm |
エラー |
31 |
An error occurred while confirming the network partition. Shut down the server %1. |
ネットワークパーティションの確認時に問題が発生しました。データ保護のためサーバ%1をシャットダウンします。 |
ネットワークパーティション解決リソースでエラーが発生していないか確認してください。 |
● |
● |
|||
nm |
エラー |
32 |
Shut down the server %1. (reason:%2) |
サーバ%1をシャットダウンします。(理由:%2) |
全てのハートビートが使用できない状態です。ネットワークアダプタでエラーが発生していないか、あるいはネットワークが正しく接続されているか確認してください。
DISKHBを使用している場合には共有ディスクの状態を確認してください。
COMHBを使用している場合にはCOMケーブルが正しく接続されているか確認してください。
|
● |
● |
|||
nm |
エラー |
33 |
Cluster service will be stopped. (reason:%1) |
サービスを停止します。(理由:%1) |
理由に示す要因を取り除いてください。 |
● |
● |
|||
nm |
エラー |
34 |
The combination of the network partition resources is invalid. (server name:%1) |
ネットワークパーティション解決リソースの組み合わせが不正です。(サーバ名:%1) |
構成情報を確認してください。 |
● |
● |
|||
nm |
エラー |
35 |
Failed to start the resource %1. Server name:%2 |
リソース%1の起動に失敗しました。(サーバ名:%2) |
ネットワークパーティション解決リソースでエラーが発生していないか確認してください。 |
● |
● |
|||
nm |
情報 |
36 |
The network partition %1 of the server %2 has been recovered to the normal status. |
サーバ%2のネットワークパーティション%1が正常状態に復帰しました。 |
- |
● |
● |
|||
nm |
エラー |
37 |
The network partition %1 of the server %2 has an error. |
サーバ%2のネットワークパーティション%1が異常です。 |
ネットワークパーティション解決リソースでエラーが発生していないか確認してください。 |
● |
● |
|||
nm |
エラー |
38 |
The resource %1 of the server %2 is unknown. |
サーバ%2のリソース%1が不明です。 |
構成情報を確認してください。 |
● |
● |
|||
nm |
情報 |
39 |
The server %1 canceled the pending failover. |
サーバ%1がフェイルオーバをキャンセルしました。 |
- |
● |
● |
|||
nm |
エラー |
80 |
Cannot communicate with server %1. |
サーバ%1との内部通信ができない状態です。 |
ネットワークアダプタでエラーが発生していないか、あるいはネットワークが正しく接続されているか確認してください。 |
● |
● |
|||
nm |
情報 |
81 |
Recovered from internal communication error with server %1. |
サーバ%1との内部通信が異常状態から復帰しました。 |
- |
● |
● |
|||
rc |
情報 |
10 |
Activating group %1 has started. |
%1 グループの起動処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
11 |
Activating group %1 has completed. |
%1 グループの起動処理が終了しました。 |
- |
● |
● |
|||
rc |
エラー |
12 |
Activating group %1 has failed. |
%1 グループの起動処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
15 |
Waiting for group %1 to start has started. |
グループの起動待ち合わせ処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
16 |
Waiting for group %1 to start has been completed. |
グループの起動待ち合わせ処理が正常に完了しました。 |
- |
● |
● |
|||
rc |
エラー |
17 |
Group start has been canceled because waiting for group %1 to start has timed out. |
グループの起動待ち合わせ処理でタイムアウトが発生しました。 |
起動待ち合わせ先グループの状態を確認してください。
グループが起動されていない場合は、そのグループを起動後に再度グループ操作を実行してください。
|
● |
● |
|||
rc |
警告 |
18 |
Waiting for group %1 to start has timed out. However, group start continues. |
グループの起動待ち合わせ処理でタイムアウトが発生しましたが、グループの起動を継続します。 |
- |
● |
● |
|||
rc |
情報 |
20 |
Stopping group %1 has started. |
%1 グループの停止処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
21 |
Stopping group %1 has completed. |
%1 グループの停止処理が終了しました。 |
- |
● |
● |
|||
rc |
エラー |
22 |
Stopping group %1 has failed. |
%1 グループの停止処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
警告 |
23 |
Server %1 is not in a condition to start group %2. |
サーバ%1は グループ%2を起動できる状態ではありません。 |
すでに完全排他グループが起動しているサーバでは完全排他グループを起動することはできません。完全排他グループを停止して再度実行してください。 |
● |
● |
|||
rc |
情報 |
25 |
Waiting for group %1 to stop has started. |
グループの停止待ち合わせ処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
26 |
Waiting for group %1 to stop has been completed. |
依存しているグループの停止待ち合わせ処理が正常に完了しました。 |
- |
● |
● |
|||
rc |
エラー |
27 |
Group stop has been canceled because waiting for group %1 to stop has timed out. |
グループの停止待ち合わせ処理でタイムアウトが発生しました。 |
停止待ち合わせ先グループの状態を確認してください。
グループが停止されていない場合は、そのグループを停止後に再度グループ操作を実行してください。
|
● |
● |
|||
rc |
警告 |
28 |
Waiting for group %1 to stop has timed out. However, group stop continues. |
停止待ち合わせ処理でタイムアウトが発生しましたが、グループの停止を継続します。 |
- |
● |
● |
|||
rc |
情報 |
30 |
Activating %1 resource has started. |
%1 リソースの起動処理を開始しました。 |
- |
● |
||||
rc |
情報 |
31 |
Activating %1 resource has completed. |
%1 リソースの起動処理が終了しました。 |
- |
● |
||||
rc |
エラー |
32 |
Activating %1 resource has failed.(%2 : %3) |
%1 リソースの起動処理が失敗しました。 |
「グループリソース活性/非活性時の詳細情報」を参照してください。
起動処理でストールが発生した場合にはActivating %1 resource has failed.(99 : command is timeout)が出力されます。
|
● |
● |
● |
● |
● |
rc |
情報 |
40 |
Stopping %1 resource has started. |
%1 リソースの停止処理を開始しました。 |
- |
● |
||||
rc |
情報 |
41 |
Stopping %1 resource has completed. |
%1 リソースの停止処理が終了しました。 |
- |
● |
||||
rc |
エラー |
42 |
Stopping %1 resource has failed.(%2 : %3) |
%1 リソースの停止処理が失敗しました。 |
「グループリソース活性/非活性時の詳細情報」を参照してください。
停止処理でストールが発生した場合にはStopping %1 resource has failed.(99 : command is timeout)が出力されます。
|
● |
● |
● |
● |
● |
rc |
情報 |
50 |
Moving group %1 has started. |
%1 グループの移動処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
51 |
Moving group %1 has completed. |
%1 グループの移動処理が終了しました。 |
- |
● |
● |
|||
rc |
エラー |
52 |
Moving group %1 has failed. |
%1 グループの移動処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
55 |
Migrating group %1 has started. |
%1 グループのマイグレーション処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
56 |
Migrating group %1 has completed. |
%1 グループのマイグレーション処理が終了しました。 |
- |
● |
● |
|||
rc |
エラー |
57 |
Migrating group %1 has failed. |
%1 グループのマイグレーション処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
警告 |
58 |
Server %1 is not in a condition to migrate group %2. |
サーバ%1 はグループ%2 をマイグレーションできる状態ではありません。 |
マイグレーション先サーバの状態を確認してください。
マイグレーション先サーバが存在しない場合には%1 にサーバ名は出力されません。
|
● |
● |
|||
rc |
情報 |
60 |
Failover group %1 has started. |
%1 グループのフェイルオーバ処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
61 |
Failover group %1 has completed. |
%1 グループのフェイルオーバ処理が終了しました。 |
- |
● |
● |
|||
rc |
エラー |
62 |
Failover group %1 has failed. |
%1 グループのフェイルオーバ処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
警告 |
63 |
Server %1 is not in a condition to move group %2. |
サーバ%1は グループ%2を移動できる状態ではありません。 |
移動先サーバの状態を確認してください。
移動先サーバが存在しない場合には%1にサーバ名は出力されません。
|
● |
● |
|||
rc |
情報 |
64 |
Server %1 has been set as the destination for the group %2 (reason: %3). |
サーバ%1を グループ%2のフェイルオーバ先に設定しました。(理由: %3) |
- |
● |
● |
|||
rc |
エラー |
65 |
There is no appropriate destination for the group %1 (reason: %2). |
グループ%1の適切なフェイルオーバ先がありません。(理由: %2) |
フェイルオーバ可能なサーバがありません。
サーバが停止しているか、フェイルオーバができないモニタリソース異常が発生しています。
サーバを起動するか、モニタリソース異常の原因を取り除くか、異常を検出しているモニタリソースを停止してください。
|
● |
● |
|||
rc |
警告 |
66 |
Server %1 is not in a condition to start group %2 (reason: %3). |
サーバ%1はグループ%2を起動できる状態ではありません。(理由: %2) |
グループの起動ができないモニタリソース異常が発生しています。
モニタリソース異常の原因を取り除くか、異常を検出しているモニタリソースを停止してください。
|
● |
● |
|||
rc |
情報 |
67 |
Server %1 in the same server group (%2) has been set as the destination for the group %3. |
同じサーバグループ%2内のサーバ%1を グループ%3のフェイルオーバ先に設定しました。 |
- |
● |
● |
|||
rc |
情報 |
68 |
Server %1 not in the same server group (%2) has been set as the destination for the group %3. |
サーバグループ%2とは別のサーバグループ内のサーバ%1を グループ%3のフェイルオーバ先に設定しました。 |
- |
● |
● |
|||
rc |
警告 |
69 |
Can not failover the group %1 because there is no appropriate destination in the same server group %2. |
サーバグループ%2内にグループ%1をフェイルオーバできるサーバがありません。 |
サーバグループ内のサーバを起動してからグループを起動するか、別のサーバグループ内のサーバでグループを起動してください。 |
● |
● |
|||
rc |
情報 |
70 |
Restarting group %1 has started. |
%1 グループの再起動処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
71 |
Restarting group %1 has completed. |
%1 グループの再起動処理が終了しました。 |
- |
● |
● |
|||
rc |
エラー |
72 |
Restarting group %1 has failed. |
%1 グループの再起動処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
74 |
Failback group %s has started. |
%1 グループのフェイルバック処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
75 |
Failback group %s has completed. |
%1 グループのフェイルバック処理が終了しました。 |
- |
● |
● |
|||
rc |
情報 |
76 |
Failback group %s has failed. |
%1 グループのフェイルバック処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
80 |
Restarting resource %1 has started. |
%1 リソースの再起動処理を開始しました。 |
- |
● |
● |
|||
rc |
情報 |
81 |
Restarting resource %1 has completed. |
%1 リソースの再起動処理が終了しました。 |
- |
● |
● |
|||
rc |
エラー |
82 |
Restarting resource %1 has failed. |
%1 リソースの再起動処理が失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
83 |
Starting a single resource %1. |
リソース%1 を単体起動しています。 |
- |
● |
● |
|||
rc |
情報 |
84 |
A single resource %1 has been started. |
リソース%1 の単体起動が完了しました。 |
- |
● |
● |
|||
rc |
エラー |
85 |
Failed to start a single resource %1. |
リソース%1 の単体起動に失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
警告 |
86 |
Server %1 is not in a condition to start a single resource %2. |
サーバ%1 はリソース%2を単体起動できる状態ではありません。 |
サーバおよびグループの状態を確認してください。 |
● |
● |
|||
rc |
情報 |
87 |
Stopping a single resource %1. |
リソース%1 を単体停止しています。 |
- |
● |
● |
|||
rc |
情報 |
88 |
A single resource %1 has been stopped. |
リソース%1 の単体停止が完了しました。 |
- |
● |
● |
|||
rc |
エラー |
89 |
Failed to stop a single resource %1. |
リソース%1 の単体停止に失敗しました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
90 |
All the servers in the cluster were shut down. |
サーバを停止しました。 |
- |
● |
● |
|||
rc |
情報 |
91 |
The server was shut down. |
サーバを停止しました。 |
- |
● |
● |
|||
rc |
警告 |
100 |
Restart count exceeded the maximum value %1. Final action of resource %2 will not be executed. |
再起動回数が最大値 %1 を超えました。リソース %2 の最終アクションは実行されません。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
121 |
The CPU frequency has been set to high. |
CPUクロックレベルを最高に設定しました。 |
- |
● |
● |
|||
rc |
情報 |
122 |
The CPU frequency has been set to low. |
CPUクロックレベルを最低に設定しました。 |
- |
● |
● |
|||
rc |
情報 |
124 |
CPU frequency setting has been switched to automatic control by cluster. |
CPUクロック設定をサーバによる自動制御に切り替えました。 |
- |
● |
● |
|||
rc |
エラー |
140 |
CPU frequency control cannot be used. |
CPUクロック制御機能は使用できません。 |
BIOSの設定、カーネルの設定を確認してください。 |
● |
● |
|||
rc |
エラー |
141 |
Failed to set the CPU frequency to high. |
CPUクロックレベルを最高に設定できませんでした。 |
BIOSの設定、カーネルの設定を確認してください。
CLUSTERPROデーモンが起動しているか確認してください。
CPUクロック制御機能を使用する設定になっているか確認してください。
|
● |
● |
|||
rc |
エラー |
142 |
Failed to set the CPU frequency to low. |
CPUクロックレベルを最低に設定できませんでした。 |
同上 |
● |
● |
|||
rc |
エラー |
144 |
Failed to switch the CPU frequency setting to automatic control by cluster. |
CPUクロック設定をサーバによる自動制御に切り替えられませんでした。 |
CLUSTERPROデーモンが起動しているか確認してください。
CPUクロック制御機能を使用する設定になっているか確認してください。
|
● |
● |
|||
rc |
情報 |
160 |
Script before final action upon deactivation failure in resource %1 started. |
リソース(%1)の非活性異常時最終動作前スクリプトを開始しました。 |
- |
● |
● |
|||
rc |
情報 |
161 |
Script before final action upon deactivation failure in resource %1 completed. |
リソース(%1)の非活性異常時最終動作前スクリプトが完了しました。 |
- |
● |
● |
|||
rc |
情報 |
162 |
Script before final action upon deactivation failure in resource %1 started. |
リソース(%1)の非活性異常時最終動作前スクリプトを開始しました。 |
- |
● |
● |
|||
rc |
情報 |
163 |
Script before final action upon deactivation failure in resource %1 completed. |
リソース(%1)の非活性異常時最終動作前スクリプトが完了しました。 |
- |
● |
● |
|||
rc |
エラー |
180 |
Script before final action upon activation failure in resource %1 failed. |
リソース(%1)の活性異常時最終動作前スクリプトが失敗しました。 |
スクリプトが失敗した原因を確認し、対処を行ってください。 |
● |
● |
|||
rc |
エラー |
181 |
Script before final action upon deactivation failure in resource %1 failed. |
リソース(%1)の非活性異常時最終動作前スクリプトが失敗しました。 |
同上 |
● |
● |
|||
rc |
情報 |
200 |
Resource(%1) will be reactivated since activating resource(%2) failed. |
リソース %1 の活性処理失敗によりリソース %2 を再活性します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
201 |
Group(%1) will be moved to server(%2) since activating resource(%3) failed. |
リソース %3 の活性処理失敗によりグループ %1 をサーバ %2 に移動します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
202 |
Group(%1) will be stopped since activating resource(%2) failed. |
リソース %2 の活性処理失敗によりグループ %1 を停止します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
203 |
Cluster daemon will be stopped since activating resource(%1) failed. |
リソース %1 の活性処理失敗によりCLUSTERPROサーバデーモンを停止します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
204 |
System will be halted since activating resource(%1) failed. |
リソース %1 の活性処理失敗により OS をシャットダウンします。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
205 |
System will be rebooted since activating resource(%1) failed. |
リソース %1 の活性処理失敗により OS を再起動します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
206 |
Activating group(%1) will be continued since failover process failed. |
フェイルオーバに失敗しため、グループ %1 の起動処理を継続します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
220 |
Resource(%1) will be stopping again since stopping resource(%2) failed. |
リソース %2 の非活性処理失敗によりリソース %1 の非活性をリトライします。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
222 |
Group(%1) will be stopped since stopping resource(%2) failed. |
リソース %2 の非活性処理失敗によりグループ %1 を停止します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
223 |
Cluster daemon will be stopped since stopping resource(%1) failed. |
リソース %1 の非活性処理失敗によりサーバデーモンを停止します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
224 |
System will be halted since stopping resource(%1) failed. |
リソース %1 の非活性処理失敗により OS を停止します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
225 |
System will be rebooted since stopping resource(%1) failed. |
リソース %1 の非活性処理失敗により OS を再起動します。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
240 |
System panic by sysrq is requested since activating resource(%1) failed. |
リソース%1 の活性異常によりsysrqによるシステムのパニックが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
241 |
System reset by keepalive driver is requested since activating resource(%1) failed. |
リソース%1 の活性異常によりkeepaliveドライバによるシステムのリセットが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
242 |
System panic by keepalive driver is requested since activating resource(%1) failed. |
リソース%1 の活性異常によりkeepaliveドライバによるシステムのパニックが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
243 |
System reset by BMC is requested since activating resource(%1) failed. |
リソース%1 の活性異常によりBMCによるシステムのリセットが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
244 |
System power down by BMC is requested since activating resource(%1) failed. |
リソース%1 の活性異常によりBMCによるシステムのパワーダウンが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
245 |
System power cycle by BMC is requested since activating resource(%1) failed. |
リソース%1 の活性異常によりBMCによるシステムのパワーサイクルが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
246 |
NMI send by BMC is requested since activating resource(%1) failed. |
リソース%1 の活性異常によりBMCによるNMI送信が要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
エラー |
260 |
An attempt to panic system by sysrq due to failure of resource(%1) activation failed. |
リソース%1 の活性異常によりsysrqによるシステムのパニックをしようとしましたが、失敗しました。 |
sysrqが使用できるようにシステムが構成されているか確認してください。 |
● |
● |
|||
rc |
エラー |
261 |
An attempt to reset system by keepalive driver due to failure of resource(%1) activation failed. |
リソース%1 の活性異常によりkeepaliveドライバによるシステムのリセットをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
rc |
エラー |
262 |
An attempt to panic system by keepalive driver due to failure of resource(%1) activation failed. |
リソース%1 の活性異常によりkeepaliveドライバによるシステムのパニックをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
rc |
エラー |
263 |
An attempt to reset system by BMC due to failure of resource(%1) activation failed. |
リソース%1 の活性異常によりBMCによるシステムのリセットをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
264 |
An attempt to power down system by BMC due to failure of resource(%1) activation failed. |
リソース%1 の活性異常によりBMCによるシステムのパワーダウンをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
265 |
An attempt to power cycle system by BMC due to failure of resource(%1) activation failed. |
リソース%1 の活性異常によりBMCによるシステムのパワーサイクルをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
266 |
An attempt to send NMI by BMC due to failure of resource(%1) activation failed. |
リソース%1 の活性異常によりBMCによるNMI送信をしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
情報 |
280 |
System panic by sysrq is requested since deactivating resource(%1) failed. |
リソース%1 の非活性異常によりsysrqによるシステムのパニックが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
281 |
System reset by keepalive driver is requested since deactivating resource(%1) failed. |
リソース%1 の非活性異常によりkeepaliveドライバによるシステムのリセットが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
282 |
System panic by keepalive driver is requested since deactivating resource(%1) failed. |
リソース%1 の非活性異常によりkeepaliveドライバによるシステムのパニックが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
283 |
System reset by BMC is requested since deactivating resource(%1) failed. |
リソース%1 の非活性異常によりBMCによるシステムのリセットが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
284 |
System power down by BMC is requested since deactivating resource(%1) failed. |
リソース%1 の非活性異常によりBMCによるシステムのパワーダウンが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
285 |
System power cycle by BMC is requested since deactivating resource(%1) failed. |
リソース%1 の非活性異常によりBMCによるシステムのパワーサイクルが要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
情報 |
286 |
Sending NMI by BMC is requested since deactivating resource(%1) failed. |
リソース%1 の非活性異常によりBMCによるNMI送信が要求されました。 |
グループリソースのメッセージに従った対処を行ってください。 |
● |
● |
|||
rc |
エラー |
300 |
An attempt to panic system by sysrq due to failure of resource(%1) deactivation failed. |
リソース%1 の非活性異常によりsysrqによるシステムのパニックをしようとしましたが、失敗しました。 |
sysrqが使用できるようにシステムが構成されているか確認してください。 |
● |
● |
|||
rc |
エラー |
301 |
An attempt to reset system by keepalive driver due to failure of resource(%1) deactivation failed. |
リソース%1 の非活性異常によりkeepaliveドライバによるシステムのリセットをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
rc |
エラー |
302 |
An attempt to panic system by keepalive driver due to failure of resource(%1) deactivation failed. |
リソース%1 の非活性異常によりkeepaliveドライバによるシステムのパニックをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
rc |
エラー |
303 |
An attempt to reset system by BMC due to failure of resource(%1) deactivation failed. |
リソース%1 の非活性異常によりBMCによるシステムのリセットをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
304 |
An attempt to power down system by BMC due to failure of resource(%1) deactivation failed. |
リソース%1 の非活性異常によりBMCによるシステムのパワーダウンをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
305 |
An attempt to power cycle system by BMC due to failure of resource(%1) deactivation failed. |
リソース%1 の非活性異常によりBMCによるシステムのパワーサイクルをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
306 |
An attempt to send NMI by BMC due to failure of resource(%1) deactivation failed. |
リソース%1 の非活性異常によりBMCによるNMI送信をしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
340 |
Group start has been canceled because waiting for group %1 to start has failed. |
グループの起動待ち合わせ処理でエラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rc |
情報 |
400 |
System power down by BMC is requested. (destination server : %1) |
BMCによるシステムのパワーダウンを要求しました。(対象サーバ : %1) |
- |
● |
● |
|||
rc |
情報 |
401 |
System power cycle by BMC is requested. (destination server : %1) |
BMCによるシステムのパワーサイクルを要求しました。(対象サーバ : %1) |
- |
● |
● |
|||
rc |
情報 |
402 |
System reset by BMC is requested. (destination server : %1) |
BMCによるシステムのリセットを要求しました。(対象サーバ : %1) |
- |
● |
● |
|||
rc |
情報 |
403 |
Sending NMI by BMC is requested. (destination server : %1) |
BMCによるNMI送信が要求されました。(対象サーバ : %1) |
- |
● |
● |
|||
rc |
情報 |
410 |
Forced stop of virtual machine is requested. (destination server : %s) |
仮想マシンの強制停止を要求しました。(対象サーバ : %1) |
- |
● |
● |
|||
rc |
情報 |
411 |
Script for forced stop has started. |
強制停止スクリプトを開始しました。 |
- |
● |
● |
|||
rc |
情報 |
412 |
Script for forced stop has completed. |
強制停止スクリプトが完了しました。 |
- |
● |
● |
|||
rc |
エラー |
420 |
An attempt to power down system by BMC failed. (destination server : %1) |
BMCによるシステムのパワーダウンを要求しましたが、失敗しました。(対象サーバ : %1) |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
421 |
An attempt to power cycle system by BMC failed. (destination server : %1) |
BMCによるシステムのパワーサイクルを要求しましたが、失敗しました。(対象サーバ : %1) |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
422 |
An attempt to reset system by BMC failed. (destination server : %1) |
BMCによるシステムのリセットを要求しましたが、失敗しました。(対象サーバ : %1) |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
423 |
An attempt to send NMI by BMC failed. (destination server : %1) |
BMCによるNMI送信を要求しましたが、失敗しました。(対象サーバ : %1) |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
430 |
An attempt to force stop virtual machine failed. (destination server : %s) |
仮想マシンの強制停止を要求しましたが、失敗しました。(対象サーバ : %1) |
VMware vSphere CLI が使用可能であるか確認してください。 |
● |
● |
|||
rc |
エラー |
431 |
Script for forced stop has failed. (%1) |
強制停止スクリプトが失敗しました。(%1) |
スクリプトが失敗した原因を確認し、対処を行ってください。 |
● |
● |
|||
rc |
エラー |
432 |
Script for forced stop has timed out. |
強制停止スクリプトでタイムアウトが発生しました。 |
スクリプトがタイムアウトした原因を確認し、対処を行ってください。 |
● |
● |
|||
rc |
警告 |
441 |
Waiting for group %1 to stop has failed. However, group stop continues. |
グループの停止待ち合わせ処理でエラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rc |
警告 |
500 |
Since there is no other normally running server, the final action for an activation error of group resource %1 was suppressed. |
正常に稼動しているサーバが他に存在しないためグループリソース %1 の活性異常の最終動作を抑制しました。 |
- |
● |
● |
|||
rc |
警告 |
501 |
Since there is no other normally running server, the final action for a deactivation error of group resource %1 was suppressed. |
正常に稼動しているサーバが他に存在しないためグループリソース %1 の非活性異常の最終動作を抑制しました。 |
- |
● |
● |
|||
rc |
警告 |
510 |
Cluster action is disabled. |
クラスタ動作が無効化されています。 |
- |
● |
● |
|||
rc |
警告 |
511 |
Ignored the automatic start of groups because automatic group startup is disabled. |
グループの自動起動が無効になっているため、グループの自動起動は無視されました。 |
- |
● |
● |
|||
rc |
警告 |
512 |
Ignored the recovery action in resource activation because recovery action caused by group resource activation error is disabled. |
グループリソース活性異常時の復旧動作が無効になっているため、リソースの復旧動作は無視されました。 |
- |
● |
● |
|||
rc |
警告 |
513 |
Ignored the recovery action in resource deactivation because recovery action caused by group resource deactivation error is disabled. |
グループリソース非活性異常時の復旧動作が無効になっているため、リソースの復旧動作は無視されました。 |
- |
● |
● |
|||
rc |
情報 |
514 |
Cluster action is set disabled. |
クラスタ動作を無効にしました。 |
- |
● |
● |
|||
rc |
情報 |
515 |
Cluster action is set enabled. |
クラスタ動作を有効にしました。 |
- |
● |
● |
|||
rm |
情報 |
1 |
Monitoring %1 has started. |
%1 の監視を開始しました。 |
- |
● |
● |
|||
rm |
情報 |
2 |
Monitoring %1 has stopped. |
%1 の監視を停止しました。 |
- |
● |
● |
|||
rm |
情報 |
3 |
%1 is not monitored by this server. |
%1 の監視は、当サーバでは行いません。 |
- |
● |
● |
|||
rm |
警告 |
4 |
Warn monitoring %1. (%2 : %3) |
%1 の監視を警告します。 |
「モニタリソース異常時の詳細情報」を参照してください。
モニタリソースが監視準備中の場合、()内は以下のメッセージが設定されることがあります。このメッセージに対する対処は必要ありません。
(100 : not ready for monitoring.)
|
● |
● |
|||
rm |
警告 |
5 |
The maximum number of monitor resources has been exceeded. (registered resource is %1) |
最大モニタリソース数を超えています。 |
Cluster WebUI で構成情報を確認してください。 |
● |
● |
|||
rm |
警告 |
6 |
Monitor configuration of %1 is invalid. (%2 : %3) |
%1 のモニタ構成が不正です。 |
Cluster WebUI で構成情報を確認してください。 |
● |
● |
|||
rm |
エラー |
7 |
Failed to start monitoring %1. |
%1 の監視の開始に失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
● |
● |
● |
rm |
エラー |
8 |
Failed to stop monitoring %1. |
%1 の監視の停止に失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
エラー |
9 |
Detected an error in monitoring %1. (%2 : %3) |
%1 の監視で異常を検出しました。 |
「モニタリソース異常時の詳細情報」を参照してください。
監視タイムアウトを検出した場合、()内は以下のメッセージが設定されます。
(99 : Monitor was timeout.)
擬似障害発生中の場合、()内は以下のメッセージが設定されます。この場合の対処は必要ありません。
(201: Monitor failed for failure verification.)
モニタリソースから一定時間応答がなかった場合、()内は以下のメッセージが設定されます。
(202: couldn't receive reply from monitor resource in time.)
|
● |
● |
● |
● |
● |
rm |
情報 |
10 |
%1 is not monitored. |
%1 を監視していません。 |
- |
● |
● |
|||
rm / mm |
情報 |
12 |
Recovery target %1 has stopped because an error was detected in monitoring %2. |
%2 の監視で異常を検出したため、回復対象 %1 が停止されました。 |
- |
● |
● |
|||
rm / mm |
情報 |
13 |
Recovery target %1 has restarted because an error was detected in monitoring %2. |
%2 の監視で異常を検出したため、回復対象 %1 が再起動されました。 |
- |
● |
● |
|||
rm / mm |
情報 |
14 |
Recovery target %1 failed over because an error was detected in monitoring %2. |
%2 の監視で異常を検出したため、回復対象 %1 がフェイルオーバされました。 |
- |
● |
● |
|||
rm / mm |
情報 |
15 |
Stopping the cluster has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、サーバの停止が要求されました。 |
- |
● |
● |
|||
rm / mm |
情報 |
16 |
Stopping the system has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、システムの停止が要求されました。 |
- |
● |
● |
|||
rm / mm |
情報 |
17 |
Rebooting the system has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、システムの再起動が要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
18 |
Attempted to stop the recovery target %1 due to the error detected in monitoring %2, but failed. |
%2 の監視異常により回復対象 %1 を停止しようとしましたが、失敗しました。 |
%1 リソースの状態を確認してください。 |
● |
● |
|||
rm / mm |
エラー |
19 |
Attempted to restart the recovery target %1 due to the error detected in monitoring %2, but failed. |
%2 の監視異常により回復対象 %1 を再起動しましたが、失敗しました。 |
%1 リソースの状態を確認してください。 |
● |
● |
|||
rm / mm |
エラー |
20 |
Attempted to fail over %1 due to the error detected in monitoring %2, but failed. |
%2 の監視異常により回復対象 %1 をフェイルオーバしようとしましたが、失敗しました。 |
%1 リソースの状態を確認してください。 |
● |
● |
|||
rm / mm |
エラー |
21 |
Attempted to stop the cluster due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりサーバを停止しようとしましたが、失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm / mm |
エラー |
22 |
Attempted to stop the system due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりシステムを停止しようとしましたが、失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm / mm |
エラー |
23 |
Attempted to reboot the system due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりシステムを再起動しようとしましたが、失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
エラー |
24 |
The group of %1 resource is unknown. |
%1 リソースが所属するグループが不明です。 |
構成情報が不整合である可能性があります。確認してください。 |
● |
● |
|||
rm / mm |
警告 |
25 |
Recovery will not be executed since the recovery target %1 is not active. |
回復対象%1が非活性のため回復動作を行いません。 |
- |
● |
● |
|||
rm / mm |
情報 |
26 |
%1 status changed from error to normal. |
%1 の監視が異常から正常に復帰しました。 |
- |
● |
● |
|||
rm / mm |
情報 |
27 |
%1 status changed from error or normal to unknown. |
%1 の監視が異常または、正常から不明になりました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
エラー |
28 |
Initialization error of monitor process. (%1 : %2) |
モニタプロセスの初期化エラーです。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
情報 |
29 |
Monitoring %1 was suspended. |
%1 の監視を一時停止しました。 |
- |
● |
● |
|||
rm |
情報 |
30 |
Monitoring %1 was resumed. |
%1 の監視を再開しました。 |
- |
● |
● |
|||
rm |
情報 |
31 |
All monitors were suspended. |
全ての監視を一時停止しました。 |
- |
● |
● |
|||
rm |
情報 |
32 |
All monitors were resumed. |
全ての監視を再開しました。 |
- |
● |
● |
|||
rm / mm |
情報 |
35 |
System panic by sysrq has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、sysrqによるシステムのパニックが要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
36 |
Attempted to panic system by sysrq due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりsysrqによるシステムのパニックを
しようとしましたが、失敗しました。
|
sysrqが使用できるようにシステムが構成されているか確認してください。 |
● |
● |
|||
rm / mm |
情報 |
37 |
System reset by keepalive driver has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、keepaliveドライバによるシステムのリセットが要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
38 |
Attempted to reset system by keepalive driver due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりkeepaliveドライバによるシステムのリセットをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
rm / mm |
情報 |
39 |
System panic by keepalive driver has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、keepaliveドライバによるシステムのパニックが要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
40 |
Attempted to panic system by keepalive driver due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりkeepaliveドライバによるシステムのパニックをしようとしましたが、失敗しました。 |
keepaliveドライバが使用可能な環境であるか確認してください。 |
● |
● |
|||
rm / mm |
情報 |
41 |
System reset by BMC has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、BMCによるシステムのリセットが要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
42 |
Attempted to reset system by BMC due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりBMCによるシステムのリセットをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rm / mm |
情報 |
43 |
System power down by BMC has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、BMCによるシステムのパワーダウンが要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
44 |
Attempted to power down system by BMC due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりBMCによるシステムのパワーダウンをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rm / mm |
情報 |
45 |
System power cycle by BMC has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、BMCによるシステムのパワーサイクルが要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
46 |
Attempted to power cycle system by BMC due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりBMCによるシステムのパワーダウンをしようとしましたが、失敗しました。 |
ipmitoolコマンドが使用可能であるか確認してください。 |
● |
● |
|||
rm / mm |
情報 |
47 |
NMI send by BMC has been required because an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、BMCによるシステムのNMIが要求されました。 |
- |
● |
● |
|||
rm / mm |
エラー |
48 |
Attempted to send NMI by BMC due to the error detected in monitoring %1, but failed. |
%1 の監視異常によりBMCによるシステムのNMIをしようとしましたが、失敗しました。 |
ipmitool コマンドが使用可能であるか確認してください。 |
● |
● |
|||
rm |
情報 |
49 |
%1 status changed from warning to normal. |
%1 の監視が警告から正常に復帰しました。 |
- |
● |
● |
|||
rm |
エラー |
57 |
Stopping the cluster is required since license (%1) is invalid. |
ライセンス不正により、サーバ停止が要求されました。 |
有効なライセンスを登録してください。 |
● |
● |
● |
● |
● |
rm |
エラー |
58 |
Stopping the cluster due to invalid license (%1) failed. |
ライセンス不正によるサーバ停止が成功しませんでした。 |
有効なライセンスを登録してください。 |
● |
● |
|||
rm |
警告 |
71 |
Detected a monitor delay in monitoring %1. (timeout=%2 actual-time=%3 delay warning rate=%4) |
%1 の監視で監視遅延を検出しました。現在のタイムアウト値は %2(tick count)です。
遅延検出時の実測値が %3(tick count)となり、遅延警告割合 %4(%)を超えました。
|
監視遅延を検出したサーバの負荷状況を確認し、負荷を取り除いてください。
監視タイムアウトを検出するようであれば、監視タイムアウトの延長が必要となります。
|
● |
● |
|||
rm |
警告 |
72 |
%1 could not Monitoring. |
%1 は監視処理が実行できませんでした。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm / mm |
情報 |
81 |
Script before %1 upon failure in monitor resource %2 started. |
%2モニタリソースの%1前スクリプトを開始しました。 |
- |
● |
● |
|||
rm / mm |
情報 |
82 |
Script before %1 upon failure in monitor resource %2 completed. |
%2モニタリソースの %1 前スクリプトが完了しました。 |
- |
● |
● |
|||
rm / mm |
エラー |
83 |
Script before %1 upon failure in monitor resource %2 failed. |
%2モニタリソースの %1 前スクリプトが失敗しました。 |
スクリプトが失敗した原因を確認し、対処を行ってください。 |
● |
● |
|||
rm |
警告 |
100 |
Restart count exceeded the maximum of %1. Final action of monitoring %2 will not be executed. |
再起動回数が最大値%1を超えたので、%2の最終動作は実行されませんでした。 |
- |
● |
● |
|||
rm |
警告 |
120 |
The virtual machine (%1) has been migrated to %2 by an external operation. |
%1リソースが管理している仮想マシンが外部操作によりサーバ%2へマイグレーションされました。 |
- |
● |
● |
|||
rm |
警告 |
121 |
The virtual machine (%1) has been started by an external operation. |
%1リソースが管理している仮想マシンが外部操作により起動されました。 |
- |
● |
● |
|||
rm |
情報 |
130 |
The collecting of detailed information triggered by monitor resource %1 error has been started (timeout=%2). |
モニタリソース$1の監視の異常検出を契機とした詳細情報の採取を開始しました。タイムアウトは%2秒です。 |
- |
● |
● |
|||
rm |
情報 |
131 |
The collection of detailed information triggered by monitor resource %1 error has been completed. |
モニタリソース%1の監視の異常検出を契機とした詳細情報の採取が完了しました。 |
- |
● |
● |
|||
rm |
警告 |
132 |
The collection of detailed information triggered by monitor resource %1 error has been failed (%2). |
モニタリソース%1の監視の異常検出を契機とした詳細情報の採取が失敗しました。 |
- |
● |
● |
|||
rm |
情報 |
140 |
Process %1 has started. |
プロセス%1を起動しました。 |
- |
● |
● |
|||
rm |
警告 |
141 |
Process %1 has restarted. |
プロセス%1を再起動しました。 |
- |
● |
● |
|||
rm |
警告 |
142 |
Process %1 does not exist. |
プロセス%1が消滅しました。 |
- |
● |
● |
|||
rm |
エラー |
143 |
Process %1 was restarted %2 times, but terminated abnormally. |
プロセス%1を%2回再起動しましたが、異常終了しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
エラー |
150 |
The cluster is stopped since process %1 was terminated abnormally. |
プロセス%1が異常終了したので、クラスタを停止します。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
エラー |
151 |
The server is shut down since process %1 was terminated abnormally. |
プロセス%1が異常終了したので、サーバをシャットダウンします。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
エラー |
152 |
The server is restarted since process %1 was terminated abnormally. |
プロセス%1が異常終了したので、サーバを再起動します。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
rm |
エラー |
160 |
Monitor resource %1 cannot be controlled since the license is invalid. |
ライセンスが有効でないため、モニタリソース%1を制御できません。 |
有効なライセンスを登録してください。 |
● |
● |
|||
rm |
情報 |
170 |
Recovery script has been executed since an error was detected in monitoring %1. |
%1 の監視で異常を検出したため、回復スクリプトが実行されました。 |
- |
● |
● |
|||
rm |
エラー |
171 |
An attempt was made to execute the recovery script due to a %1 monitoring failure, but failed. |
%1 の監視異常により回復スクリプトを実行しましたが、失敗しました。 |
回復スクリプトが失敗した原因を確認し、対処を行ってください。 |
● |
● |
|||
rm |
情報 |
180 |
Dummy Failure of monitor resource %1 is enabled. |
モニタリソース%1の擬似障害を開始しました。 |
- |
● |
● |
|||
rm |
情報 |
181 |
Dummy Failure of monitor resource %1 is disabled. |
モニタリソース%1の擬似障害を停止しました。 |
- |
● |
● |
|||
rm |
情報 |
182 |
Dummy Failure of all monitor will be enabled. |
全モニタリソースの擬似障害を開始します。 |
- |
● |
● |
|||
rm |
情報 |
183 |
Dummy Failure of all monitor will be disabled. |
全モニタリソースの擬似障害を停止します。 |
- |
● |
● |
|||
rm |
警告 |
184 |
An attempt was made to enable Dummy Failure of monitor resource %1, but failed. |
モニタリソース%1の擬似障害の開始に失敗しました。 |
モニタリソース%1が擬似障害に対応しているか確認してください。 |
● |
● |
|||
rm |
警告 |
185 |
An attempt was made to disable Dummy Failure of monitor resource %1, but failed. |
モニタリソース%1の擬似障害の停止に失敗しました。 |
モニタリソース%1が擬似障害に対応しているか確認してください。 |
● |
● |
|||
rm |
情報 |
190 |
Recovery action caused by monitor resource error is disabled. |
モニタリソース異常時の回復動作を無効にしました。 |
- |
● |
● |
|||
rm |
情報 |
191 |
Recovery action caused by monitor resource error is enabled. |
モニタリソース異常時の回復動作を有効にしました。 |
- |
● |
● |
|||
rm |
警告 |
192 |
Ignored the recovery action in monitoring %1 because recovery action caused by monitor resource error is disabled. |
モニタ異常時の回復動作が無効になっているため、モニタリソース%1の回復動作が無視されました。 |
- |
● |
● |
|||
rm |
警告 |
193 |
Recovery action at timeout occurrence was disabled, so the recovery action of monitor %s was not executed. |
タイムアウト発生時の回復動作が無効であるため、監視 %1 の回復動作は実行されませんでした。 |
- |
● |
● |
|||
rm |
警告 |
200 |
Since there is no other normally running server, the final action(%1) for the error detection of monitor resource %2 was suppressed. |
正常に稼動しているサーバが他に存在しないためモニタリソース %2 の異常検出による最終動作(%1)を抑制しました。 |
- |
● |
● |
|||
rm |
警告 |
220 |
Recovery will not be executed since any recovery target is not active. |
いずれの回復対象も起動状態ではないため、回復動作は実行されません。 |
- |
● |
● |
|||
rm |
警告 |
221 |
Recovery will not be executed because the group that is set for the recovery target is not active. |
回復対象に設定されたグループリソースの属するフェイルオーバグループが非活性状態のため回復動作を行いません。 |
- |
● |
● |
|||
mm |
情報 |
901 |
Message monitor has been started. |
メッセージモニタ (外部連携モニタの関連モジュール) が開始されました。 |
- |
● |
● |
|||
mm |
エラー |
902 |
Failed to initialize message monitor. (%1 : %2) |
メッセージモニタ (外部連携モニタの関連モジュール) の初期化に失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
mm |
警告 |
903 |
An error of %1 type and %2 device has been detected. (%3) |
カテゴリ %1、キーワード %2 の外部エラー %3 を受信しました。 |
- |
● |
● |
|||
mm |
エラー |
905 |
An error has been detected in monitoring %1. (%2) |
モニタリソース %1 の監視で異常を検出しました。 |
%2 のメッセージに従った対処を実施してください。 |
● |
● |
● |
● |
● |
mm |
エラー |
906 |
Message monitor was terminated abnormally. |
メッセージモニタ (外部連携モニタの関連モジュール) が異常終了しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
mm |
エラー |
907 |
Failed to execute action. (%1) |
回復動作の実行に失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
mm |
情報 |
908 |
The system will be stopped. |
OS のシャットダウンが実行されます。 |
- |
● |
● |
|||
mm |
情報 |
909 |
The cluter daemon will be stopped. |
クラスタ停止が実行されます。 |
- |
● |
● |
|||
mm |
情報 |
910 |
The system will be rebooted. |
OS のリブートが実行されます。 |
- |
● |
● |
|||
mm |
情報 |
911 |
Message monitor will be restarted. |
メッセージモニタ (外部連携モニタの関連モジュール) が再起動されます。 |
- |
● |
● |
|||
mm |
情報 |
912 |
Received a message by SNMP Trap from external. (%1 : %2) |
SNMP Trap のメッセージを受信しました。メッセージは、項目 (%1) の情報 (%2) を含みます。 |
- |
● |
● |
|||
trnsv |
エラー |
1 |
There was a notification from external (IP=%1), but it was denied. |
%1から通知を受付ましたが、許可されませんでした。 |
- |
● |
● |
|||
trnsv |
情報 |
10 |
There was a notification (%1) from external (IP=%2). |
%2から通知(%1)を受け付けました。 |
- |
● |
● |
|||
trnsv |
情報 |
20 |
Recovery action (%1) of monitoring %2 has been executed because a notification arrived from external. |
外部通知によりモニタリソース%2の異常時動作(%1)の実行を開始しました。 |
- |
● |
● |
|||
trnsv |
情報 |
21 |
Recovery action (%1) of monitoring %2 has been completed. |
モニタリソース%2の異常時動作(%1)が成功しました。 |
- |
● |
● |
|||
trnsv |
エラー |
22 |
Attempted to recovery action (%1) of monitoring %2, but it failed. |
モニタリソース%2の異常時動作(%1)を実行しましたが、失敗しました。 |
異常時動作が実行可能な環境か確認してください。 |
● |
● |
|||
trnsv |
情報 |
30 |
Action (%1) has been completed. |
動作(%1)の実行に成功しました。 |
- |
● |
● |
|||
trnsv |
エラー |
31 |
Attempted to execute action (%1), but it failed. |
動作(%1)を実行を実行しましたが、失敗しました。 |
動作が実行可能な環境か確認してください。 |
● |
● |
|||
trnsv |
情報 |
40 |
Script before action of monitoring %1 has been executed. |
モニタリソース(%1)の異常時動作前スクリプトを実行しました。 |
- |
● |
||||
trnsv |
情報 |
41 |
Script before action of monitoring %1 has been completed. |
モニタリソース(%1)の異常時動作前スクリプトの実行に成功しました。 |
- |
● |
||||
trnsv |
エラー |
42 |
Attempted to execute script before action of monitoring %1, but it failed. |
モニタリソース(%1)の異常時動作前スクリプトの実行に失敗しました。 |
異常時動作前スクリプトが実行可能かどうか確認してください。 |
● |
||||
lanhb |
警告 |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
サーバ %2 のHBリソース %1 からのハートビートに遅延が発生しました。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
サーバ %2 の負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
● |
● |
|||
lanhb |
警告 |
72 |
Heartbeats sent from HB resource %1 are delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
HBリソース %1 のハートビート送信で遅延が発生しました。送信先サーバは %2 です。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
遅延が警告されたサーバの負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
|||||
lanhb |
警告 |
73 |
Heartbeats received by HB resource %1 are delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
HBリソース %1 のハートビート受信で遅延が発生しました。送信元サーバは %2 です。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
遅延が警告されたサーバの負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
|||||
lankhb |
警告 |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
サーバ %2 のHBリソース %1 からのハートビートに遅延が発生しました。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
サーバ %2 の負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
● |
● |
|||
lankhb |
警告 |
73 |
Heartbeats received from HB resource %1 is delayed.(timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
HBリソース %1 のハートビート受信で遅延が発生しました。送信元サーバは %2 です。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
遅延が警告されたサーバの負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
|||||
diskhb |
エラー |
10 |
Device(%1) of resource(%2) does not exist. |
デバイスが存在しません。 |
構成情報を確認してください。 |
● |
● |
|||
diskhb |
エラー |
11 |
Device(%1) of resource(%2) is not a block device. |
デバイスが存在しません。 |
構成情報を確認してください。 |
● |
● |
|||
diskhb |
エラー |
12 |
Raw device(%1) of resource(%2) does not exist. |
デバイスが存在しません。 |
構成情報を確認してください。 |
● |
● |
|||
diskhb |
エラー |
13 |
Binding device(%1) of resource(%2) to raw device(%3) failed. |
デバイスが存在しません。 |
構成情報を確認してください。 |
● |
● |
|||
diskhb |
エラー |
14 |
Raw device(%1) of resource(%2) has already been bound to other device. |
リソース %2 のrawデバイス %1 は別のデバイスにバインドされています。 |
使用していないrawデバイスを設定してください。 |
● |
● |
|||
diskhb |
エラー |
15 |
File system exists on device(%1) of resource(%2). |
リソース %2 のデバイス %1 にはファイルシステムが存在します。 |
デバイス %1 を使用する場合はファイルシステムを削除してください。 |
● |
● |
|||
diskhb |
情報 |
20 |
Resource %1 recovered from initialization error. |
リソース%1 が初期化エラーから復帰しました。 |
- |
● |
● |
|||
diskhb |
警告 |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
サーバ %2 のHBリソース %1 からのハートビートに遅延が発生しました。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
サーバ %2 の負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
● |
● |
|||
diskhb |
警告 |
72 |
Heartbeat write of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6). |
HBリソース %1 のハートビート書き込みで遅延が発生しました。書き込み先サーバは %2 です。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
遅延が警告されたサーバの負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
|||||
diskhb |
警告 |
73 |
Heartbeat read of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
HBリソース %1 のハートビート読み込みで遅延が発生しました。読み込み元サーバは %2 です。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
遅延が警告されたサーバの負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
|||||
comhb |
情報 |
1 |
Device (%1) does not exist. |
デバイスが存在しません。 |
構成情報を確認してください。 |
● |
● |
|||
comhb |
情報 |
2 |
Failed to open the device (%1). |
デバイスのオープンに失敗しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
comhb |
警告 |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
サーバ %2 のHBリソース %1 からのハートビートに遅延が発生しました。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
サーバ %2 の負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
● |
● |
|||
comhb |
警告 |
72 |
Heartbeat write of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6). |
HBリソース %1 のハートビート書き込みで遅延が発生しました。送信先サーバは %2 です。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
遅延が警告されたサーバの負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
|||||
comhb |
警告 |
73 |
Heartbeat read of HB resource %1 is delayed.(server=%2 timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
HBリソース %1 のハートビート読み込みで遅延が発生しました。送信元サーバは %2 です。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
遅延が警告されたサーバの負荷状況を確認し、負荷を取り除いてください。
HBタイムアウトが発生するようであれば、HBタイムアウトの延長が必要となります。
|
|||||
bmchb |
エラー |
10 |
Failed to initialize to BMC. |
BMCの初期化に失敗しました。 |
ハードウェアが BMC 連携機能を使用可能か確認してください。 |
● |
● |
|||
bmchb |
警告 |
71 |
Heartbeats sent from HB resource %1 of server %2 are delayed.(timeout=%3*%4 actual-time=%5 delay warning rate=%6) |
サーバ %2 のHBリソース %1 からのハートビートに遅延が発生しました。現在のタイムアウト値は %3(秒) x %4(1秒あたりのtick count)です。遅延発生時の実測値が %5(tick count)となり、遅延警告割合 %6(%)を超えました。 |
サーバ %2 の負荷状況を確認し、負荷を取り除いてください。 |
● |
● |
|||
monp |
エラー |
1 |
An error occurred when initializing monitored process %1. (status=%2) |
監視対象プロセス %1 の初期化エラーです。 |
メモリ不足、OSのリソース不足、または、構成情報が不整合である可能性が考えられます。確認してください。
構成情報が未登録状態であれば、以下のプロセスのメッセージが出力されますが、問題ありません。
+ mdagnt
+ webmgr
+ webalert
|
● |
● |
|||
monp |
エラー |
2 |
Monitor target process %1 terminated abnormally. (status=%2) |
監視対象プロセス %1 が異常終了しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
monp |
情報 |
3 |
Monitor target process %1 will be restarted. |
監視対象プロセス %1 を再起動します。 |
- |
● |
● |
|||
monp |
情報 |
4 |
The cluster daemon will be stopped since the monitor target process %1 terminated abnormally. |
監視対象プロセス %1 の異常終了により、サーバを停止します。 |
- |
● |
● |
|||
monp |
エラー |
5 |
Attempted to stop the cluster daemon, but failed. |
サーバを停止しようとしましたが、失敗しました。 |
サーバが未起動状態、メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
monp |
情報 |
6 |
The system will be stopped since the monitor target process %1 terminated abnormally. |
監視対象プロセス %1 の異常終了により、システムを停止します。 |
- |
● |
● |
|||
monp |
エラー |
7 |
Attempted to stop the system, but failed. (status=%#x) |
システムを停止しようとしましたが、失敗しました。 |
サーバが未起動状態、メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
monp |
情報 |
8 |
System will be rebooted since monitor target process %1 terminated abnormally. |
監視対象プロセス %1 の異常終了により、システムを再起動します。 |
- |
● |
● |
|||
monp |
エラー |
9 |
Attempted to reboot the system, but failed. (status=%#x) |
システムを再起動しようとしましたが、失敗しました。 |
サーバが未起動状態、メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
● |
|||
cl |
情報 |
1 |
There was a request to start %1 from the %2. |
%2から%1の起動要求がありました。 |
- |
● |
● |
|||
cl |
情報 |
2 |
There was a request to stop %1 from the %2. |
%2から%1の停止要求がありました。 |
- |
● |
● |
|||
cl |
情報 |
3 |
There was a request to suspend %1 from the %2. |
%2から%1のサスペンド要求がありました。 |
- |
● |
● |
|||
cl |
情報 |
4 |
There was a request to resume %s from the %s. |
%2から%1のリジューム要求がありました。 |
- |
● |
● |
|||
cl |
エラー |
11 |
A request to start %1 failed(%2). |
%1の起動要求に失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
cl |
エラー |
12 |
A request to stop %1 failed(%2). |
%1の停止要求に失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
cl |
エラー |
13 |
A request to suspend %1 failed(%2). |
%1のサスペンド要求に失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
cl |
エラー |
14 |
A request to resume %1 failed(%2). |
%1のリジューム要求に失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
cl |
エラー |
15 |
A request to %1 cluster failed on some servers(%2). |
サーバの%1要求がいくつかのサーバで失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
cl |
エラー |
16 |
A request to start %1 failed on some servers(%2). |
%1の起動が失敗したサーバがあります。 |
%1の状態を確認してください。 |
● |
● |
|||
cl |
エラー |
17 |
A request to stop %1 failed on some servers(%2). |
%1の停止が失敗したサーバがあります。 |
%1の状態を確認してください。 |
● |
● |
|||
cl |
警告 |
18 |
Automatic start is suspended because the cluster service was not stopped according to the normal procedure. |
「ダウン後自動起動する」が設定されていないため自動起動を中止しました。 |
クラスタサービスを起動するためにはCluster WebUI またはclpclコマンドでクラスタサービスを起動してください。 |
● |
● |
|||
cl |
警告 |
20 |
A request to start %1 failed because cluster is running(%2). |
クラスタが起動しているため、%1の起動に失敗しました。 |
クラスタの状態を確認してください。 |
● |
● |
|||
cl |
警告 |
21 |
A request to stop %1 failed because cluster is running(%2). |
クラスタが起動しているため、%1の停止に失敗しました。 |
クラスタの状態を確認してください。 |
● |
● |
|||
エラー |
1 |
The license is not registered. (%1) |
ライセンスを購入して登録してください。 |
- |
● |
● |
||||
エラー |
2 |
The trial license has expired in %1. (%2) |
有効なライセンスを登録してください。 |
- |
● |
● |
||||
エラー |
3 |
The registered license is invalid. (%1) |
有効なライセンスを登録してください。 |
- |
● |
● |
||||
エラー |
4 |
The registered license is unknown. (%1) |
有効なライセンスを登録してください。 |
- |
● |
● |
||||
エラー |
5 |
mail failed(%s).(SMTP server: %s) |
メール通報が失敗しました。 |
SMTPサーバにエラーが発生していないか、あるいはSMTPサーバとの通信に問題がないか確認してください。 |
● |
● |
||||
情報 |
6 |
mail successed.(SMTP server: %s) |
メール通報が成功しました。 |
- |
● |
● |
||||
userw |
警告 |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
%1 の監視で監視遅延を検出しました。現在のタイムアウト値は %2(秒) x %3(1秒あたりのtick count)です。遅延検出時の実測値が %4(tick count)となり、遅延警告割合 %5(%)を超えました。 |
監視遅延を検出したサーバの負荷状況を確認し、負荷を取り除いてください。
監視タイムアウトを検出するようであれば、監視タイムアウトの延長が必要となります。
|
● |
● |
|||
vipw |
警告 |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
%1 の監視で監視遅延を検出しました。現在のタイムアウト値は %2(秒) x %3(1秒あたりのtick count)です。遅延検出時の実測値が %4(tick count)となり、遅延警告割合 %5(%)を超えました。 |
監視遅延を検出したサーバの負荷状況を確認し、負荷を取り除いてください。
監視タイムアウトを検出するようであれば、監視タイムアウトの延長が必要となります。
|
● |
● |
|||
ddnsw |
警告 |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
%1 の監視で監視遅延を検出しました。現在のタイムアウト値は %2(秒) x %3(1秒あたりのtick count)です。遅延検出時の実測値が %4(tick count)となり、遅延警告割合 %5(%)を超えました。 |
監視遅延を検出したサーバの負荷状況を確認し、負荷を取り除いてください。
監視タイムアウトを検出するようであれば、監視タイムアウトの延長が必要となります。
|
● |
● |
|||
vmw |
警告 |
1 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
%1 の監視で監視遅延を検出しました。現在のタイムアウト値は %2(秒) x %3(1秒あたりのtick count)です。遅延検出時の実測値が %4(tick count)となり、遅延警告割合 %5(%)を超えました。 |
監視遅延を検出したサーバの負荷状況を確認し、負荷を取り除いてください。
監視タイムアウトを検出するようであれば、監視タイムアウトの延長が必要となります。
|
● |
● |
|||
apisv |
情報 |
1 |
There was a request to stop cluster from the %1(IP=%2). |
%1からサーバ停止の要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
2 |
There was a request to shutdown cluster from the %1(IP=%2). |
%1からサーバシャットダウンの要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
3 |
There was a request to reboot cluster from the %1(IP=%2). |
%1からサーバリブートの要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
4 |
There was a request to suspend cluster from the %1(IP=%2). |
%1からサーバサスペンドの要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
10 |
There was a request to stop server from the %1(IP=%2). |
%1からサーバ停止の要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
11 |
There was a request to shutdown server from the %1(IP=%2). |
%1からサーバシャットダウンの要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
12 |
There was a request to reboot server from the %1(IP=%2). |
%1からサーバリブートの要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
30 |
There was a request to start group(%1) from the %2(IP=%3). |
%2からグループ%1の起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
31 |
There was a request to start all groups from the %1(IP=%2). |
%1から全グループの起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
32 |
There was a request to stop group(%1) from the %2(IP=%3). |
%2からグループ%1の停止要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
33 |
There was a request to stop all groups from the %1(IP=%2). |
%1から全グループの停止要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
34 |
There was a request to restart group(%1) from the %2(IP=%3). |
%2からグループ%1の再起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
35 |
There was a request to restart all groups from the %1(IP=%2). |
%1から全グループの再起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
36 |
There was a request to move group(%1) from the %2(IP=%3). |
%2からグループ%1の移動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
37 |
There was a request to move group from the %1(IP=%2). |
%1からグループの移動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
38 |
There was a request to failover group(%1) from the %2(IP=%3). |
%2からグループ%1のフェイルオーバ要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
39 |
There was a request to failover group from the %1(IP=%2). |
%1からグループのフェイルオーバ要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
40 |
There was a request to migrate group(%1) from the %2(IP=%3). |
%2からグループ%1のマイグレーション要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
41 |
There was a request to migrate group from the %1(IP=%2). |
%2からグループのマイグレーション要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
42 |
There was a request to failover all groups from the %1(IP=%2). |
%2から全グループのフェイルオーバ要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
43 |
There was a request to cancel waiting for the dependence destination group of group the %1 was issued from %2. |
%2からグループ%1の依存先グループ待ち合わせ処理のキャンセル要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
50 |
There was a request to start resource(%1) from the %2(IP=%3). |
%2からリソース%1の起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
51 |
There was a request to start all resources from the %1(IP=%2). |
%1から全リソースの起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
52 |
There was a request to stop resource(%1) from the %2(IP=%3). |
%2からリソース%1の停止要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
53 |
There was a request to stop all resources from the %1(IP=%2). |
%1から全リソースの停止要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
54 |
There was a request to restart resource(%1) from the %2(IP=%3). |
%2からリソース%1の再起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
55 |
There was a request to restart all resources from the %1(IP=%2). |
%1から全リソースの再起動要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
60 |
There was a request to suspend monitor resources from the %1(IP=%2). |
%1からモニタリソースのサスペンド要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
61 |
There was a request to resume monitor resources from the %1(IP=%2). |
%1からモニタリソースのリジューム要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
62 |
There was a request to enable Dummy Failure of monitor resources from the %1(IP=%2). |
%1からモニタリソースの擬似障害の開始要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
63 |
There was a request to disable Dummy Failure of monitor resources from the %1(IP=%2). |
%1からモニタリソースの擬似障害の停止要求がありました。 |
- |
● |
● |
|||
apisv |
情報 |
70 |
There was a request to set CPU frequency level from the %1(IP=%2). |
%1からCPUクロックの設定要求がありました。 |
- |
● |
● |
|||
apisv |
エラー |
101 |
A request to stop cluster was failed(0x%08x). |
サーバ停止に失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
102 |
A request to shutdown cluster was failed(0x%08x). |
サーバシャットダウンに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
103 |
A request to reboot cluster was failed(0x%08x). |
サーバリブートに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
104 |
A request to suspend cluster was failed(0x%08x). |
サーバサスペンドに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
110 |
A request to stop server was failed(0x%08x). |
サーバ停止に失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
111 |
A request to shutdown server was failed(0x%08x). |
サーバシャットダウンに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
112 |
A request to reboot server was failed(0x%08x). |
サーバリブートに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
113 |
A request to server panic was failed(0x%08x). |
サーバパニックに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
114 |
A request to server reset was failed(0x%08x). |
サーバリセットに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
115 |
A request to server sysrq was failed(0x%08x). |
SYSRQパニックに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
116 |
A request to KA RESET was failed(0x%08x). |
Keepaliveリセットに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
117 |
A request to KA PANIC was failed(0x%08x). |
Keepaliveパニックに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
118 |
A request to BMC RESET was failed(0x%08x). |
BMCリセットに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
119 |
A request to BMC PowerOff was failed(0x%08x). |
BMCパワーオフに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
120 |
A request to BMC PowerCycle was failed(0x%08x). |
BMCパワーサイクルに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
121 |
A request to BMC NMI was failed(0x%08x). |
BMC NMIに失敗しました。 |
サーバの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
130 |
A request to start group(%1) was failed(0x%08x). |
グループ(%1)の起動に失敗しました。 |
rcが出力するグループ起動失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
131 |
A request to start all groups was failed(0x%08x). |
全グループの起動に失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
132 |
A request to stop group(%1) was failed(0x%08x). |
グループ(%1)の停止に失敗しました。 |
rcが出力するグループ停止失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
133 |
A request to stop all groups was failed(0x%08x). |
全グループの停止に失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
134 |
A request to restart group(%1) was failed(0x%08x). |
グループ(%1)の再起動に失敗しました。 |
rcが出力するグループ停止失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
135 |
A request to restart all groups was failed(0x%08x). |
全グループの再起動に失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
136 |
A request to move group(%1) was failed(0x%08x). |
グループ(%1)の移動に失敗しました。 |
rcが出力するグループ移動失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
137 |
A request to move all groups was failed(0x%08x). |
全グループの移動に失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
138 |
A request to failover group(%1) was failed(0x%08x). |
グループ(%1)のフェイルオーバに失敗しました。 |
rcが出力するグループフェイルオーバ失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
139 |
A request to failover group was failed(0x%08x). |
全グループのフェイルオーバに失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
140 |
A request to migrate group(%1) was failed(0x%08x). |
グループ(%1)のマイグレーションに失敗しました。 |
rcが出力するグループフェイルオーバ失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
141 |
A request to migrate all groups was failed(0x%08x). |
全グループのマイグレーションに失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
142 |
A request to failover all groups was failed(0x%08x). |
全グループのフェイルオーバに失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
143 |
A request to cancel waiting for the dependency destination group of group %1 has failed(0x%08x). |
グループ%1の依存先グループ待ち合わせ処理のキャンセルに失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
150 |
A request to start resource(%1) was failed(0x%08x). |
リソース(%1)の起動に失敗しました。 |
rcが出力するリソース起動失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
152 |
A request to stop resource(%1) was failed(0x%08x). |
リソース(%1)の停止に失敗しました。 |
rcが出力するリソース停止失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
154 |
A request to restart resource(%1) was failed(0x%08x). |
リソース(%1)の再起動に失敗しました。 |
rcが出力するリソース再起動失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
apisv |
エラー |
155 |
A request to restart all resources was failed(0x%08x). |
全リソースの再起動に失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
160 |
A request to suspend monitor resource was failed(0x%08x). |
モニタリソースのサスペンドに失敗しました。 |
モニタリソースの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
161 |
A request to resume monitor resource was failed(0x%08x). |
モニタリソースのリジュームに失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
162 |
A request to enable Dummy Failure of monitor resource was failed(0x%08x). |
モニタリソースの擬似障害の開始に失敗しました。 |
モニタリソースの状態を確認してください。 |
● |
● |
|||
apisv |
エラー |
163 |
A request to disable Dummy Failure of monitor resource was failed(0x%08x). |
モニタリソースの擬似障害の停止に失敗しました。 |
同上 |
● |
● |
|||
apisv |
エラー |
170 |
A request to set CPU frequency was failed(0x%08x). |
CPUクロックレベルの設定に失敗しました。 |
rcが出力するCPUクロックレベル設定失敗のメッセージに従った対処を行ってください。 |
● |
● |
|||
cfmgr |
情報 |
1 |
The cluster configuration data has been uploaded by %1. |
構成情報がアップロードされました。 |
- |
● |
● |
|||
sra |
エラー |
1 |
system monitor closed because reading the SG file failed. |
SG ファイルの読み込み処理で異常がありました。 |
別途出力されているメッセージを確認してください。 |
● |
||||
sra |
エラー |
2 |
Opening an ignore file failed. file name = %1, errno = %2.
%1:ファイル名
%2:errno
|
SGファイル(%1)をオープンできませんでした。 |
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
3 |
Reading a configuration file failed. |
SG ファイルの読み込み処理で異常がありました。 |
別途出力されているメッセージを確認してください。 |
● |
||||
sra |
エラー |
4 |
Trace log initialization failed. |
内部ログファイルの初期化に失敗しました。 |
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
5 |
Creating a daemon process failed. |
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
エラー |
6 |
Reading a service configuration file failed. |
SG ファイルの読み込み処理で異常がありました。 |
別途出力されているメッセージを確認してください。 |
● |
||||
sra |
エラー |
7 |
mlock() failed. |
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
エラー |
8 |
A daemon process could not be created. |
SystemResource
Agentの起動(プロセスのデーモン化)に失敗しました。
|
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
エラー |
9 |
stdio and stderr could not be closed. |
SystemResource
Agent の起動(標準入出力のclose)に失敗しました。
|
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
エラー |
10 |
A signal mask could not be set up. |
SystemResource
Agent の起動(シグナルマスクの設定)に失敗しました。
|
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
エラー |
11 |
A configuration file error occurred. (1) [line = %1, %2]
%1:行
%2:設定値
|
SystemResource
Agentの起動(SG ファイルの読み込み)に失敗しました。
|
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
12 |
A configuration file error occurred. (2) [line=%1, %2]
%1:行
%2:設定値
|
SystemResource
Agentの起動(SG ファイルの読み込み)に失敗しました。
|
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
13 |
A plugin event configuration file error occurred. The DLL pointer was not found. [line = %1, %2]
%1:行
%2:設定値
|
SystemResource
Agentの起動(プラグインイベント登録)に失敗しました。
|
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
14 |
malloc failed. [event structure] |
SystemResource
Agentの起動(プラグインイベント登録)に失敗しました。
|
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
15 |
A service configuration file error occurred due to an invalid event. [%1]
%1:設定値
|
SystemResource
Agentの起動(サービスファイルの読み込み)に失敗しました。
|
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
16 |
A plugin event configuration file
error occurred due to %1.
%1:エラー原因
|
SystemResource
Agentの起動(プラグインイベントファイルの読み込み)に失敗しました。
|
クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
エラー |
17 |
Internal error occurred. |
共有メモリアクセスエラーが発生しました。 |
- |
● |
||||
sra |
警告 |
101 |
Opening an SG file failed. file name = %1, errno = %2
%1:ファイル名
%2:errno
|
SGファイル (%1) をオープンできませんでした。 |
SGファイルを再作成し、クラスタを再起動するかサスペンド・リジュームを実行してください。 |
● |
||||
sra |
警告 |
102 |
malloc(3) fail(1) . [%1]
%1:関数名
|
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
警告 |
103 |
malloc(3) fail(2). [%1]
%1:関数名
|
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
警告 |
104 |
An internal error occurred. rename(2) error (errno = %1)
%1:errno
|
本製品が異常終了しました。 |
直前に出力されているシステムログメッセージを参照してください。 |
● |
||||
sra |
警告 |
105 |
realloc(3) fail. [%1].
%1:関数名
|
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
警告 |
106 |
A script timed out. (%1 %2)
%1:スクリプトファイル名
%2:引数
|
内部エラーが発生しました。 |
サーバの負荷状況を確認し、負荷を取り除いてください。 |
● |
||||
sra |
警告 |
107 |
[%1] execvp(2) fail (%2).
%1:スクリプト名
%2:errno
|
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
警告 |
108 |
[%1] fork fail (%2). Suspended.
%1:スクリプト名
%2:errno
|
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
警告 |
109 |
malloc(3) fail. [%1]
%1:関数名
|
内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
● |
||||
sra |
情報 |
201 |
A script was executed. (%1)
%1:スクリプト名
|
スクリプト (%1) を実行しました。 |
- |
● |
||||
sra |
情報 |
202 |
Running a script finished. (%1)
%1:スクリプト名
|
スクリプトが正常に終了しました。 |
- |
● |
||||
sra |
情報 |
203 |
An %1 event succeeded.
%1:実行したイベント種別
|
運用管理コマンドを実行しました。
%1 は実行したイベント種別(boot, shutdown, stop, start, flush)が出力されます。
|
- |
● |
||||
sra |
エラー |
301 |
A process resource error was detected. (%1, type = cpu, pid = %2, %3)
%1:モニタリソース名
%2:プロセスID
%3:プロセス名
|
特定プロセスのCPU使用率監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
301 |
A process resource error was detected. (%1, type = memory leak, pid = %2, %3)
%1:モニタリソース名
%2:プロセスID
%3:プロセス名
|
特定プロセスのメモリ使用量監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
301 |
A process resource error was detected. (%1, type = file leak, pid = %2, %3)
%1:モニタリソース名
%2:プロセスID
%3:プロセス名
|
特定プロセスのオープンファイル数(最大値)監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
301 |
A process resource error was detected. (%1, type = open file, pid = %2, %3)
%1:モニタリソース名
%2:プロセスID
%3:プロセス名
|
特定プロセスのオープンファイル数(カーネル上限値)監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
301 |
A process resource error was detected. (%1, type = thread leak, pid = %2, %3)
%1:モニタリソース名
%2:プロセスID
%3:プロセス名
|
特定プロセスのスレッド数監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
301 |
A process resource error was detected. (%1, type = defunct, pid = %2, %3)
%1:モニタリソース名
%2:プロセスID
%3:プロセス名
|
ゾンビプロセス監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
301 |
A process resource error was detected. (%1, type = same name process, pid = %2, %3)
%1:モニタリソース名
%2:プロセスID
%3:プロセス名
|
同一名プロセス監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
302 |
A system resource error was detected. (%1, type = cpu)
%1:モニタリソース名
|
システムのCPU使用率監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
302 |
A system resource error was detected. (%1, type = memory)
%1:モニタリソース名
|
システムの総メモリ使用量監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
302 |
A system resource error was detected. (%1, type = swap)
%1:モニタリソース名
|
システムの総仮想メモリ使用量監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
302 |
A system resource error was detected. (%1, type = file)
%1:モニタリソース名
|
システムの総オープンファイル数監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
302 |
A system resource error was detected. (%1, type = thread)
%1:モニタリソース名
|
システムの総スレッド数監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
303 |
A system resource error was detected. (%1, type = number of process, user name = %2)
%1:モニタリソース名
%2:ユーザ名
|
システムのユーザごとの起動プロセス数監視で異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
304 |
A disk resource error was detected. (%1, type = used rate, level = NOTICE, %2)
%1:モニタリソース名
%2:マウントポイント
|
ディスク使用率監視で通知レベルの異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
304 |
A disk resource error was detected. (%1, type = used rate, level = WARNING, %2)
%1:モニタリソース名
%2:マウントポイント
|
ディスク使用率監視で警告レベルの異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
304 |
A disk resource error was detected. (%1, type = free space, level = NOTICE, %2)
%1:モニタリソース名
%2:マウントポイント
|
ディスク空き容量監視で通知レベルの異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
エラー |
304 |
A disk resource error was detected. (%1, type = free space, level = WARNING, %2)
%1:モニタリソース名
%2:マウントポイント
|
ディスク空き容量監視で警告レベルの異常を検出しました。 |
監視異常の原因を確認してください。 |
● |
● |
|||
sra |
警告 |
401 |
zip/unzip package is not installed. |
System Resource Agentが収集した統計情報の圧縮に失敗しました。 |
システムに zip または unzip のパッケージがインストールされているか確認してください。 |
● |
● |
|||
lcns |
情報 |
1 |
The number of licenses is %1. (Product name:%2) |
クラスタのライセンス数は%1 です。
%1:ライセンス数
%2:製品名
|
- |
● |
● |
|||
lcns |
情報 |
2 |
The trial license is valid until %1. (Product name:%2) |
試用版ライセンスの有効期間は%1 までです。
%1:試用終了日
%2:製品名
|
- |
● |
● |
|||
lcns |
警告 |
3 |
The number of licenses is insufficient. The number of insufficient licenses is %1. (Product name:%2) |
ライセンスが不足しています。不足ライセンス数は%1です。
%1:ライセンス不足数
%2:製品名
|
不足数分のライセンスを購入して登録してください。 |
● |
● |
|||
lcns |
エラー |
4 |
The license is not registered. (Product name:%1) |
ライセンスが登録されていません。
%1:製品名
|
ライセンスを購入して登録してください。 |
● |
● |
|||
lcns |
エラー |
5 |
The trial license has expired in %1. (Product name:%2) |
試用版ライセンスの有効期限切れです。
%1:試用終了日
%2:製品名
|
有効なライセンスを登録してください。 |
● |
● |
|||
lcns |
エラー |
6 |
The registered license is invalid. (Product name:%1, Serial No:%2) |
登録されているライセンスが無効な状態です。
%1:製品名
%2:シリアルナンバー
|
有効なライセンスを登録してください。 |
● |
● |
|||
lcns |
エラー |
7 |
The registered license is unknown. (Product name:%1) |
登録されているライセンスが不明な状態です。
%1:製品名
|
有効なライセンスを登録してください。 |
● |
● |
|||
lcns |
エラー |
8 |
The trial license is valid from %1. (Product name:%2) |
試用版ライセンスの有効期間に到達していません。
%1:試用開始日
%2:製品名
|
有効なライセンスを登録してください。 |
● |
● |
|||
lcns |
情報 |
9 |
The fixed term license is valid until %1. (Product name:%2) |
期限付きライセンスの有効期間は%1までです。
%1:有効期間終了日
%2:製品名
|
- |
● |
● |
|||
lcns |
エラー |
10 |
The fixed term license has expired in %1. (Product name:%2) |
期限付きライセンスの有効期限切れです。
%1:有効期間終了日
%2:製品名
|
有効なライセンスを登録してください。 |
● |
● |
|||
webmgr |
警告 |
21 |
HTTPS configuration isn't correct, HTTPS mode doesn't work. Please access WebManager by HTTP mode. |
HTTPS の設定が正しくないため、HTTPS で WebManager を利用できません。WebManager へは HTTP で接続してください。 |
- |
● |
● |
4.2. ドライバの syslog メッセージ¶
4.2.1. カーネルモード LAN ハートビートドライバ¶
モジュール
タイプ
|
イベント
分類
|
イベントID |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
clpkhb |
情報 |
101 |
Kernel Heartbeat was initialized successfully. (major=%1, minor=%2) |
clpkhbドライバのロードが成功しました。 |
- |
clpkhb |
情報 |
102 |
Kernel Heartbeat was released successfully. |
clpkhbドライバのアンロードが成功しました。 |
- |
clpkhb |
エラー |
103 |
Can not register miscdev on minor=%1. (err=%2) |
clpkhbドライバのロードに失敗しました。 |
- |
clpkhb |
エラー |
104 |
Can not deregister miscdev on minor=%1. (err=%2) |
clpkhbドライバのアンロードに失敗しました。 |
- |
clpkhb |
情報 |
105 |
Kernel Heartbeat was initialized by %1. |
clpkhbドライバは[%1]モジュールにより正常に初期化されました。 |
- |
clpkhb |
情報 |
106 |
Kernel Heartbeat was terminated by %1. |
clpkhbドライバは[%1]モジュールにより正常に終了されました。 |
- |
clpkhb |
エラー |
107 |
Can not register Kernel Heartbeat proc file! |
clpkhbドライバ用のprocファイルの作成に失敗しました。 |
- |
clpkhb |
エラー |
108 |
Version error. |
clpkhbドライバの内部バージョン情報が不正です。 |
CLUSTERPROを再インストールしてください。 |
clpkhb |
情報 |
110 |
The send thread has been created. (PID=%1) |
clpkhbドライバの送信スレッドは正常に作成されました。
プロセスIDは[%1]です。
|
- |
clpkhb |
情報 |
110 |
The recv thread has been created. (PID=%1) |
clpkhbドライバの受信スレッドは正常に作成されました。
プロセスIDは[%1]です。
|
- |
clpkhb |
エラー |
111 |
Failed to create send thread. (err=%1) |
エラー[%1]により、clpkhbドライバの送信スレッドの作成に失敗しました。 |
- |
clpkhb |
エラー |
111 |
Failed to create recv thread. (err=%1) |
エラー[%1]により、clpkhbドライバの受信スレッドの作成に失敗しました。 |
- |
clpkhb |
情報 |
112 |
Killed the send thread successfully. |
clpkhbドライバの送信スレッドは正常に停止されました。 |
- |
clpkhb |
情報 |
112 |
Killed the recv thread successfully. |
clpkhbドライバの受信スレッドは正常に停止されました。 |
- |
clpkhb |
情報 |
113 |
Killed the recv thread successfully. |
clpkhbドライバを終了しています。 |
- |
clpkhb |
情報 |
114 |
Killed the recv thread successfully. |
clpkhbドライバを停止しています。 |
- |
clpkhb |
情報 |
115 |
Kernel Heartbeat has been stopped| |
clpkhbドライバは正常に停止しました。 |
- |
clpkhb |
エラー |
120 |
Failed to create socket to send %1 packet. (err=%2) |
エラー[%2]により、[%1](HB/DOWN/KA)パケット送信用のソケットの作成に失敗しました。 |
- |
clpkhb |
エラー |
120 |
Failed to create socket to receive packet. (err=%2) |
エラー[%2]により、パケット受信用のソケットの作成に失敗しました。 |
- |
clpkhb |
エラー |
121 |
Failed to create sending %1 socket address. (err=%2) |
[%1](HB/DOWN/KA)送信用ソケットの設定に失敗しました。 |
物理メモリが不足している可能性があります。
物理メモリを増設するか、余分なアプリケーションを終了してください。
|
clpkhb |
エラー |
122 |
Failed to create %1 socket address. (err=%2) |
[%1](HB/DOWN/KA)送信用ソケットの設定に失敗しました。 |
物理メモリが不足している可能性があります。
物理メモリを増設するか、余分なアプリケーションを終了してください。
|
clpkhb |
エラー |
123 |
Failed to bind %1 socket. (err=%2) |
[%1](HB/DOWN/KA/recv)用ソケットのバインドに失敗しました。 |
OSの状態を確認してください。
clpkhb用の通信ポートが既に他のアプリケーション等により利用されている可能性があります。通信ポートの使用状況を確認してください。
インタコネクトLAN I/Fに設定したIPアドレスに誤りがないか、クラスタ構成情報のサーバのプロパティを確認してください。
|
clpkhb |
エラー |
125 |
Failed to send %1 data to %2. (err=%3) |
[%1](HB/DOWN/KA)データを[%2]へ送信できませんでした。 |
clpkhb通信用のネットワークの状態を確認してください。
相手サーバの状態を確認してください。
設定情報に問題がないか、確認してください。
|
clpkhb |
エラー |
126 |
Failed to receive data. (err=%3) |
データ受信に失敗しました。 |
相手サーバがダウンしている可能性があります。確認してください。
相手サーバがダウンしていない場合には、clpkhb用のネットワークの状態を確認してください。
|
clpkhb |
情報 |
127 |
|
|
別のアプリケーションが、clpkhb用のポートにデータを送信している可能性があります。ポートの使用状況を確認してください。 |
clpkhb |
エラー |
128 |
|
|
同上。 |
clpkhb |
情報 |
129 |
Receiving operation was interrupted by ending signal! |
受信スレッドは終了シグナルにより終了します。 |
- |
clpkhb |
情報 |
130 |
|
|
リセットが発生したサーバの状態を確認してください。 |
clpkhb |
情報 |
131 |
|
|
パニックが発生したサーバの状態を確認してください。 |
clpkhb |
エラー |
140 |
Reference an inaccessible memory area! |
ioctl()によるアプリケーションとのデータの受け渡しに失敗しました。 |
OSの状態を確認してください。 |
clpkhb |
エラー |
141 |
Failed to allocate memory! |
メモリの確保に失敗しました。 |
物理メモリが不足している可能性があります。物理メモリを増設するか、余分なアプリケーションを終了してください。 |
clpkhb |
エラー |
142 |
Invalid argument, %1! |
clpkhbドライバに渡されたパラメータが正しくありません。 |
設定が正しく行われているか、確認してください。 |
clpkhb |
警告 |
143 |
Local node has nothing with current resource. |
clpkhbドライバに渡されたハートビートリソース情報が正しくありません。 |
同上。 |
4.2.2. キープアライブドライバ¶
モジュール
タイプ
|
イベント
分類
|
イベント ID |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
clpka |
情報 |
101 |
Kernel Keepalive was initialized successfully. (major=%1, minor=%2) |
clpkaドライバは正常にロードされました。 |
- |
clpka |
情報 |
102 |
Kernel Keepalive was released successfully. |
clpkaドライバは正常にアンロードされました。 |
- |
clpka |
エラー |
103 |
Can not register miscdev on minor=%1. (err=%2) |
clpkaドライバのロードに失敗しました。 |
カーネルモードLANハートビートが対応しているディストリビューション、カーネルであるか確認してください。 |
clpka |
情報 |
105 |
Kernel Keepalive was initialized by %1. |
clpkaドライバは正常に初期化されました。 |
- |
clpka |
エラー |
107 |
Can not register Kernel Keepalive proc file! |
clpkaドライバ用のprocファイルの作成に失敗しました。 |
メモリ不足等によってカーネルが正常に動作していない可能性があります。物理メモリを増設するか、余分なアプリケーションを終了してください。 |
clpka |
エラー |
108 |
Version error. |
clpkaドライバのバージョンが不正です。 |
インストールされているclpkaドライバが正規のものか確認してください。 |
clpka |
エラー |
111 |
Failed to create notify thread. (err=%1) |
clpkaドライバのスレッドの生成に失敗しました。 |
メモリ不足等によってカーネルが正常に動作していない可能性があります。物理メモリを増設するか、余分なアプリケーションを終了してください。 |
clpka |
情報 |
130 |
Reboot tried. |
設定に従い、clpkaドライバがマシンの再起動を試みました。 |
- |
clpka |
情報 |
132 |
Kernel do nothing. |
設定に従い、clpkaドライバは何も行いませんでした。 |
- |
clpka |
エラー |
140 |
Reference an inaccessible memory area! |
clpkaドライバのバージョン情報をクラスタ本体へ渡せませんでした。 |
インストールされているclpkaドライバが正規のものか確認してください。 |
clpka |
エラー |
141 |
Failed to allocate memory! |
物理メモリが不足しています。 |
物理メモリが不足しています。物理メモリを増設するか、余分なアプリケーションを終了してください。 |
clpka |
エラー |
142 |
Invalid argument, %1! |
clpkaドライバへクラスタ本体から不正な情報が渡されました。 |
インストールされているclpkaドライバが正規のものか確認してください。 |
clpka |
エラー |
144 |
Process (PID=%1) is not set. |
clpkaドライバへクラスタ本体 以外のプロセス(%1)から操作が行われようとしました。 |
clpkaドライバへ誤ってアクセスしようとしたアプリケーション(%1)がないか確認してください。 |
4.3. グループリソース活性/非活性時の詳細情報¶
4.3.1. EXEC リソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
exec |
エラー |
1 |
Termination code %1 was returned. |
同期型のスクリプトまたはアプリケーションの実行結果として0以外の終了コードが戻されました。 |
スクリプトの場合、スクリプトの内容に問題がある可能性があります。スクリプトが正しく記述されているか確認してください。
アプリケーションの場合、アプリケーションが異常終了した可能性があります。アプリケーションの動作を確認してください。
|
exec |
エラー |
1 |
Command was not completed within %1 seconds. |
同期型のスクリプトまたはアプリケーションの実行が指定時間以内に正常終了しませんでした。 |
スクリプトの場合、スクリプトの内容に問題がある可能性があります。スクリプトが正しく記述されているか確認してください。
アプリケーションの場合、アプリケーションがストールした可能性があります。アプリケーションの動作を確認してください。
それぞれ、ログから原因を特定できる可能性があります。
|
exec |
エラー |
1 |
Command was aborted. |
同期型のスクリプトまたはアプリケーションが異常終了しました。 |
アプリケーションの場合、アプリケーションが異常終了した可能性があります。アプリケーションの動作を確認してください。
メモリ不足またはOSのリソース不足が考えられます。確認してください。
|
exec |
エラー |
1 |
Command was not found. (error=%1) |
アプリケーションが存在しませんでした。 |
アプリケーションのパスが不正な可能性があります。構成情報のアプリケーションのパスを確認してください。 |
exec |
エラー |
1 |
Command string was invalid. |
アプリケーションのパスが不正です。 |
構成情報のアプリケーションのパスを確認してください。 |
exec |
エラー |
1 |
Log string was invalid. |
ログ出力先のパスが不正です。 |
構成情報のログ出力先のパスを確認してください。 |
exec |
エラー |
1 |
Internal error. (status=%1) |
その他内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
4.3.2. 仮想マシンリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
vm |
エラー |
1~6,8 |
Initialize error occured. |
初期化中に異常を検出しました。 |
クラスタ構成情報が正しいか確認してください。 |
vm |
エラー |
7 |
Parameter is invalid. |
パラメータが不正です。 |
クラスタ構成情報が正しいか確認してください。 |
vm |
エラー |
9~13 |
Failed to %s virtual machine %s. |
仮想マシンの制御に失敗しました。 |
仮想マシンの状態を確認してください。 |
vm |
エラー |
22 |
Datastore must be setted. |
Cluster WebUI でデータストア名の記入が必要です。 |
Cluster WebUI の仮想マシンリソースのプロパティの詳細タブで、[データストア名]に仮想マシンの設定情報を格納しているデータストア名を記入して、[設定の反映]を実施してください。 |
vm |
エラー |
23 |
VM configuration file path must be setted. |
Cluster WebUI でVM構成ファイルのパスの記入が必要です。 |
Cluster WebUI の仮想マシンリソースのプロパティの詳細タブで、[VM構成ファイルのパス]に仮想マシンの設定情報を格納しているパスを記入して、[設定の反映]を実施してください。 |
vm |
エラー |
その他 |
Internal error occured. |
その他内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
4.4. モニタリソース異常時の詳細情報¶
4.4.1. ソフト RAID モニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
lmdw |
警告 |
101 |
Device=(%1): Bad disks(%2) are detected in mirror disk. |
ミラーディスクの配下の物理ディスクは一部壊れて、[警告]のステータスです。 |
ミラーディスク自身は使用可能ですが、壊れた物理ディスクの取替えを行う必要があります。 |
lmdw |
警告 |
102 |
Internal error.err=%1 |
内部エラーが発生したことを示します。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
lmdw |
警告 |
190 |
Internal error.err=%1 |
内部エラーが発生したことを示します。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
lmdw |
警告 |
102 |
Config file error.(err=%1) |
構成情報の内容が異常であることを示します。 |
構成情報が正しいか確認してください。 |
lmdw |
警告 |
190 |
Config file error.(err=%1) |
構成情報の内容が異常であることを示します。 |
構成情報が正しいか確認してください。 |
lmdw |
警告 |
190 |
Soft RAID module has a problem. (err=%1) |
Soft RAID関連のカーネルモジュールは異常である。 |
- |
lmdw |
警告 |
190 |
Options or parameters are invalid. |
コマンドパラメータエラーが発生したことを示します。 |
構成情報が正しいか確認してください。 |
lmdw |
警告 |
190 |
Failed to read config file.(err=%1) |
構成ファイルの読み取りに失敗したことを示します。 |
構成情報が存在するか確認してください。 |
lmdw |
警告 |
191 |
Device=(%1): Mirror disk is in recovery process (%2). |
ミラーディスクは[復帰中]です。 |
- |
4.4.2. IP モニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
ipw |
エラー |
5 |
Ping was failed by timeout. IP=%s... |
pingコマンドがタイムアウトにより失敗しました。 |
システム高負荷、メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
ipw |
エラー |
31 |
Ping cannot reach. (ret=%1) IP=%2... |
pingコマンドによるパケットが届きませんでした。 |
該当IPアドレスへの pingコマンドが成功するか確認してください。pingコマンドが失敗した場合は、該当IPアドレスをもつ機器の状態、あるいはネットワークインターフェイスの状態を確認してください。 |
ipw |
警告 |
102 |
Ping was failed. (ret=%1) IP=%2... |
pingコマンドが失敗しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
ipw |
警告 |
106 |
Internal error. (status=%1) |
その他内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
ipw |
警告 |
108~121 |
Internal error. (status=%1) |
その他内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
ipw |
警告 |
189 |
Internal error. (status=%1) |
IPモニタリソースの監視処理がタイムアウトにより失敗しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
4.4.3. ディスクモニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
diskw |
エラー |
12 |
Ioctl was failed. (err=%1) Device=%2 |
デバイスの制御に失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。 |
diskw |
エラー |
14 |
Open was failed. (err=%1) File=%2 |
ファイルのオープンに失敗しました。 |
ファイル名と同じようなディレクトリが存在しているか、監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
メモリ不足またはOSのリソース不足が考えられます。確認してください。
|
diskw |
エラー |
14 |
Open was failed. (err=%1) Device=%2 |
デバイスのオープンに失敗しました。 |
ファイル名と同じようなディレクトリが存在しているか、監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
メモリ不足またはOSのリソース不足が考えられます。確認してください。
|
diskw |
エラー |
16 |
Read was failed. (err=%1) Device=%2 |
デバイスからの読み込みに失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
メモリ不足またはOSのリソース不足が考えられます。確認してください。
|
diskw |
エラー |
18 |
Write was failed. (err=%1) File=%2 |
ファイルの書き込みに失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
メモリ不足またはOSのリソース不足が考えられます。確認してください。
|
diskw |
エラー |
41 |
SG_IO failed. (sg_io_hdr_t info:%1 SG_INFO_OK_MASK: %2) |
SG_IOに失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。 |
diskw |
エラー |
49 |
Already bound for other. Rawdevice=%1 Device=%2 |
RAWデバイスは既に他の実デバイスにバインドされています。 |
設定したRAWデバイスは既に他の実デバイスにバインドされています。Cluster WebUI でRAWデバイス名を変更してください |
diskw |
エラー |
55 |
Bind was failed. Rawdevice=%1 Device=%2 |
バインドに失敗しました。 |
バインドに失敗しました。Cluster WebUI でRAWデバイス名を確認してください。 |
diskw |
エラー |
56 |
Lseek was failed by timeout. Device=%1 |
lseekに失敗しました。 |
システム高負荷、メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
diskw |
エラー |
57 |
Fdatasync was failed by timeout. Device=%1 |
fdatasyncに失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
システム高負荷、メモリ不足または、OSのリソース不足が考えられます。確認してください。
|
diskw |
警告 |
101 |
Ioctl was failed by timeout. Device=%1 |
デバイスの制御がタイムアウトにより失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
システム高負荷、メモリ不足または、OSのリソース不足が考えられます。確認してください。
|
diskw |
警告 |
101 |
Open was failed by timeout. File=%1 |
ファイルのオープンがタイムアウトにより失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
システム高負荷、メモリ不足、またはOSのリソース不足が考えられます。確認してください。
|
diskw |
警告 |
101 |
Open was failed by timeout. Device=%1 |
デバイスのオープンがタイムアウトにより失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
システム高負荷、メモリ不足、またはOSのリソース不足が考えられます。確認してください。
|
diskw |
警告 |
101 |
Read was failed by timeout. Device=%1 |
デバイスからの読み込みがタイムアウトにより失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
システム高負荷、メモリ不足または、OSのリソース不足が考えられます。確認してください。
|
diskw |
警告 |
101 |
Write was failed by timeout. File=%1 |
ファイルの書き込みがタイムアウトにより失敗しました。 |
監視対象ディスクが正しく接続されているか、監視対象ディスクの電源がONになっているか、あるいは監視対象ディスクにその他の異常が発生していないか確認してください。
システム高負荷、メモリ不足、またはOSのリソース不足が考えられます。確認してください。
|
diskw |
警告 |
101 |
Bind was failed. Rawdevice=%1 Device=%2 |
バインドに失敗しました。 |
バインドに失敗しました。Cluster WebUI でRAWデバイス名を確認してください。 |
diskw |
警告 |
101 |
Stat was failed. (err=%1) Device=%2 |
statに失敗しました。 |
statに失敗しました。Cluster WebUI でデバイス名を確認してください。 |
diskw |
警告 |
101 |
Popen was failed. (err=%1) |
popenに失敗しました。 |
popenに失敗しました。メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
diskw |
警告 |
101 |
Option was invalid. |
パラメータが不正です。 |
クラスタ構成情報が正しいか確認してください。 |
diskw |
警告 |
190 |
Option was invalid. |
パラメータが不正です。 |
クラスタ構成情報が正しいか確認してください。 |
diskw |
警告 |
101 |
Internal error. (status=%1) |
内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
diskw |
警告 |
190 |
Internal error. (status=%1) |
内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
diskw |
警告 |
190 |
Parameter was invalid. File=%1 |
指定されたファイル名が不正です。 |
/devで始まるデバイスファイルは指定しないでください。通常のファイルを指定してください。 |
diskw |
警告 |
190 |
Device was invalid. Device=%1 |
指定された実デバイスが不正です。 |
Cluster WebUI でディスクモニタリソースのデバイス名を確認してください。 |
diskw |
警告 |
191 |
Ignored disk full error. |
ディスクフルエラーを無視しました。 |
デバイスの使用状況を確認してください。 |
4.4.4. PID モニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
pidw |
エラー |
1 |
Process does not exist. (pid=%1) |
プロセスが存在しません。 |
監視対象プロセスが何らかの原因により消滅しました。確認してください。 |
pidw |
警告 |
100 |
Resource %1 was not found. |
リソースが見つかりませんでした。 |
Cluster WebUI でクラスタ構成情報を確認してください。 |
pidw |
警告 |
100 |
Internal error. (status=%1) |
その他内部エラーが発生しました。 |
メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
4.4.5. ユーザ空間モニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
userw |
エラー |
1 |
Initialize error. (%1) |
プロセスの初期化中に異常を検出しました。 |
ユーザ空間モニタリソースが依存するドライバが存在するか、またはrpmがインストールされているかどうか確認してください。依存するドライバまたはrpmは監視方法によって異なります。 |
4.4.6. カスタムモニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
genw |
エラー |
1 |
Initialize error. (status=%d) |
初期化中に異常を検出しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
genw |
エラー |
2 |
Termination code %d was returned. |
意図しない戻り値が返されました。 |
クラスタ構成情報が正しいか確認してください。 |
genw |
エラー |
3 |
User was not superuser. |
rootユーザではありません。 |
rootユーザでログインしてください。 |
genw |
エラー |
4 |
Getting of config was failed. |
クラスタ構成情報の取得に失敗しました。 |
クラスタ構成情報が存在するか確認してください。 |
genw |
エラー |
5 |
Parameter was invalid. |
パラメータが不正です。 |
クラスタ構成情報が正しいか確認してください。 |
genw |
エラー |
6 |
Option was invalid. |
パラメータが不正です。 |
クラスタ構成情報が正しいか確認してください。 |
genw |
エラー |
7 |
Monitor Resource %s was not found. |
リソースが見つかりませんでした。 |
クラスタ構成情報が正しいか確認してください。 |
genw |
エラー |
8 |
Create process failed. |
プロセスの生成に失敗しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
genw |
エラー |
9 |
Process does not exist. (pid=%d) |
プロセスが存在していませんでした。 |
プロセスの有無を確認してください。 |
genw |
エラー |
10 |
Process aborted. (pid=%d) |
プロセスが存在していませんでした。 |
プロセスの有無を確認してください。 |
genw |
エラー |
11 |
Asynchronous process does not exist. (pid=%d) |
プロセスが存在していませんでした。 |
プロセスの有無を確認してください。 |
genw |
エラー |
12 |
Asynchronous process aborted. (pid=%d) |
プロセスが存在していませんでした。 |
プロセスの有無を確認してください。 |
genw |
エラー |
13 |
Monitor path was invalid. |
パスが不正です。 |
クラスタ構成情報が正しいか確認してください。 |
genw |
エラー |
その他 |
Internal error. (status=%d) |
その他内部エラーが発生しました。 |
- |
4.4.7. マルチターゲットモニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
mtw |
エラー |
1 |
Option was invalid. |
パラメータが不正です。 |
クラスタ構成情報が正しいか確認してください。 |
mtw |
エラー |
2 |
User was not superuser. |
rootユーザではありません。 |
rootユーザでログインしてください。 |
mtw |
エラー |
3 |
Internal error. (status=%d) |
その他内部エラーが発生しました。 |
- |
4.4.8. JVM モニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
jraw |
エラー |
11 |
An error was detected in accessing the monitor target. |
監視対象のJava VMに接続できません。 |
監視対象のJava VMが起動されていることを確認してください。 |
jraw |
エラー |
12 |
JVM status changed to abnormal. cause = %1. |
Java VMの監視で異常を検出しました。
%1:異常発生原因
GarbageCollection
JavaMemoryPool
Thread
WorkManagerQueue
WebOTXStall
|
メッセージを元に監視対象のJava VM上で動作しているJavaアプリケーションを確認してください。 |
jraw |
警告 |
189 |
Internal error occurred. |
内部エラーが発生しました。 |
クラスタサスペンドおよびクラスタリジュームを実行してください。 |
4.4.9. システムモニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
sraw |
エラー |
11 |
Detected an error in monitoring system resource |
システムリソースの監視で異常を検出しました。 |
リソースに関する何らかの異常が考えられます。確認してください。 |
4.4.10. プロセスリソースモニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
psrw |
エラー |
11 |
Detected an error in monitoring process resource |
プロセスリソースの監視で異常を検出しました。 |
リソースに関する何らかの異常が考えられます。確認してください。 |
4.4.11. NIC Link Up/Down モニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
miiw |
エラー |
20 |
NIC %1 link was down. |
NICのLinkがDownしました。 |
LANケーブルが正し接続されているか確認してください。 |
miiw |
警告 |
110 |
Get address information was failed. (err=%1) |
IPv4または、IPv6アドレスファミリーのソケットアドレスの取得に失敗しました。 |
カーネルのコンフィグレーションがTCP/IPネットワーキング(IPv4または、IPv6)をサポートしているか確認してください。 |
miiw |
警告 |
111 |
Socket creation was failed. (err=%1) |
ソケットの作成に失敗しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
miiw |
警告 |
112 |
ioctl was failed. (err=%1) Device=%2 Request=%3 |
ネットワークドライバへの制御リクエストが失敗しました。 |
ネットワークドライバが %3 の制御リクエストをサポートしているか確認してください。 |
miiw |
警告 |
113 |
MII was not supported or no such device. Device=%1 |
NICにMIIがサポートされていないかあるいは、監視対象が存在しません。 |
監視対象が存在しない場合は、ifconfig等でネットワークインターフェイス名を確認してください。 |
miiw |
警告 |
189 |
Internal error. (status=%d) |
その他内部エラーが発生しました。 |
- |
miiw |
警告 |
190 |
Option was invalid. |
オプションが不正です。 |
Cluster WebUI で構成情報を確認してください。 |
miiw |
警告 |
190 |
Config was invalid. (err=%1) %2 |
構成情報が不正です。 |
Cluster WebUI で構成情報を確認してください。 |
4.4.12. 仮想マシンモニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
vmw |
エラー |
1 |
initialize error occured. |
初期化中に異常を検出しました。 |
メモリ不足またはOSのリソース不足、仮想化環境の問題が考えられます。確認してください。 |
vmw |
エラー |
11 |
monitor success, virtual machine is not running. |
仮想マシンの停止を検出しました。 |
仮想マシンの状態を確認してください。 |
vmw |
エラー |
12 |
failed to get virtual machine status. |
仮想マシンの状態の取得に失敗しました。 |
仮想マシンが存在しているか確認してください。 |
vmw |
エラー |
13 |
timeout occured. |
監視はタイムアウトしました。 |
OSが高負荷状態の可能性があります。確認してください。 |
4.4.13. ボリュームマネージャモニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
volmgrw |
エラー |
21 |
Command was failed. (cmd=%1, ret=%2) |
%1のコマンドが失敗しました。コマンドの戻り値は%2です。 |
コマンドが失敗しました。ボリュームマネージャの動作状況を確認してください。 |
volmgrw |
エラー |
22 |
Internal error. (status=%1) |
その他の内部エラーが発生しました。 |
- |
volmgrw |
エラー |
23 |
Internal error. (status=%1) |
その他の内部エラーが発生しました。 |
- |
volmgrw |
警告 |
190 |
Option was invalid. |
オプションが不正です。 |
Cluster WebUI でクラスタ構成情報を確認してください。 |
volmgrw |
警告 |
191 |
%1 %2 is %3 ! |
ボリュームマネージャ(%1)のターゲット(%2)のステータスが%3に遷移しました。 |
ボリュームマネージャターゲットの状態を確認してください。 |
volmgrw |
警告 |
その他 |
Internal error. (status=%1) |
その他の内部エラーが発生しました。 |
- |
4.4.14. プロセス名モニタリソース¶
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
psw |
エラー |
11 |
Process[%1 (pid=%2)]
Down
|
監視対象プロセスの消滅を検出しました。 |
監視対象プロセスが正しく動作しているか確認してください。 |
psw |
エラー |
12 |
The number of processes is less than the specified minimum process count. %1/%2 (%3) |
監視対象プロセスの起動プロセス数が指定された下限値未満になっています。 |
監視対象プロセスが正しく動作しているか確認してください。 |
psw |
警告 |
100 |
Monitoring timeout |
監視はタイムアウトしました。 |
OSが高負荷状態の可能性があります。確認してください。 |
psw |
警告 |
101 |
Internal error |
内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
psw |
警告 |
190 |
Internal error |
内部エラーが発生しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
psw |
警告 |
190 |
Initialize error |
初期化中に異常を検出しました。 |
メモリ不足またはOSのリソース不足が考えられます。確認してください。 |
4.4.15. 監視オプションモニタリソース¶
監視オプションモニタリソースは共通のメッセージを使用します。モジュールタイプは監視オプションモニタリソースごとに異なります。
監視オプションモニタリソース |
モジュールタイプ |
|---|---|
DB2モニタリソース |
db2w |
FTPモニタリソース |
ftpw |
HTTPモニタリソース |
httpw |
IMAP4モニタリソース |
imap4w |
MySQLモニタリソース |
mysqlw |
NFSモニタリソース |
nfsw |
ODBCモニタリソース |
odbcw |
Oracleモニタリソース |
oraclew |
POP3モニタリソース |
pop3w |
PostgreSQLモニタリソース |
psqlw |
Sambaモニタリソース |
sambaw |
SMTPモニタリソース |
smtpw |
SQL Serverモニタリソース |
sqlserverw |
Sybaseモニタリソース |
sybasew |
Tuxedoモニタリソース |
tuxw |
WebLogicモニタリソース |
wlsw |
WebSphereモニタリソース |
wasw |
WebOTXモニタリソース |
otxw |
モジュール
タイプ
|
分類 |
返値 |
メッセージ |
説明 |
対処 |
|---|---|---|---|---|---|
(別表) |
エラー |
5 |
Failed to connect to %1 server. [ret=%2] |
監視対象への接続に失敗しました。
%1には、アプリケーション名が入ります。
|
監視対象の状態を確認してください。 |
(別表) |
エラー |
7 |
Failed to execute SQL statement (%1). [ret=%2] |
SQL文の実行に失敗しました。
%1には、監視対象が入ります。
|
Cluster WebUI で構成情報を確認してください。 |
(別表) |
エラー |
8 |
Failed to access with %1. |
監視対象とのデータアクセスが失敗しました。
%1には、監視対象が入ります。
|
監視対象の状態を確認してください。 |
(別表) |
エラー |
9 |
Detected error in %1. |
監視対象が異常です。
%1には、監視対象が入ります。
|
監視対象の状態を確認してください。 |
(別表) |
警告 |
104 |
Detected function exception. [%1, ret=%2] |
異常を検出しました。
%1には監視対象が入ります。
|
Cluster WebUI でクラスタ構成情報を確認してください。
OSが高負荷状態の可能性があります。確認してください。
|
(別表) |
警告 |
106 |
Detected authority error. |
ユーザ認証が失敗しました。 |
ユーザ名・パスワード・アクセス権を確認してください。 |
(別表) |
警告 |
111 |
Detected timeout error. |
監視対象と通信タイムアウトになりました。 |
OSが高負荷状態の可能性があります。確認してください。 |
(別表) |
警告 |
112 |
Can not found install path. (install path=%1) |
インストールパスが見つかりません。
%1にはインストールパスが入ります。
|
インストールパスの場所を確認してください。 |
(別表) |
警告 |
113 |
Can not found library. (libpath=%1, errno=%2) |
指定した場所からライブラリをロードすることができませんでした。
%1にはライブラリのパスが入ります。
|
ライブラリの場所を確認してください。 |
(別表) |
警告 |
171 |
Detected a monitor delay in monitoring %1. (timeout=%2*%3 actual-time=%4 delay warning rate=%5) |
%1 の監視で監視遅延を検出しました。現在のタイムアウト値は %2(秒) x %3(1秒あたりのtick count)です。遅延検出時の実測値が %4(tick count)となり、遅延警告割合 %5(%)を超えました。 |
監視遅延を検出したサーバの負荷状況を確認し、負荷を取り除いてください。
監視タイムアウトを検出するようであれば、監視タイムアウトの延長が必要となります。
|
(別表) |
情報 |
181 |
The collecting of detailed information triggered by monitor resource %1 error has been started (timeout=%2). |
モニタリソース$1の監視の異常検出を契機とした詳細情報の採取を開始しました。タイムアウトは%2秒です。 |
- |
(別表) |
情報 |
182 |
The collection of detailed information triggered by monitor resource %1 error has been completed. |
モニタリソース%1の監視の異常検出を契機とした詳細情報の採取が完了しました。 |
- |
(別表) |
警告 |
183 |
The collection of detailed information triggered by monitor resource %1 error has been failed (%2). |
モニタリソース%1の監視の異常検出を契機とした詳細情報の採取が失敗しました。(%2) |
- |
(別表) |
警告 |
189 |
Internal error. (status=%1) |
内部エラーを検出しました。 |
- |
(別表) |
警告 |
190 |
Init error. [%1, ret=%2] |
初期化中に異常を検出しました。
%1にはlicense, library, XML, share memory, log の一つが入ります。
|
OSが高負荷状態の可能性があります。確認してください。 |
(別表) |
警告 |
190 |
Get config information error. [ret=%1] |
設定情報の取得に失敗しました。 |
Cluster WebUI でクラスタ構成情報を確認してください。 |
(別表) |
警告 |
190 |
Invalid parameter. |
Configファイル/Policyファイルの設定情報が不正です。
コマンドのパラメータが不正です。
|
Cluster WebUI でクラスタ構成情報を確認してください。 |
(別表) |
警告 |
190 |
Init function error. [%1, ret=%2] |
初期化中に関数の異常を検出しました。
%1には実行関数名が入ります。
|
OSが高負荷状態の可能性があります。確認してください。 |
(別表) |
警告 |
190 |
User was not superuser. |
ユーザはRoot権限を持っていません。 |
実行ユーザが root権限を持っていないか或いは、メモリ不足または、OSのリソース不足が考えられます。確認してください。 |
(別表) |
警告 |
190 |
The license is not registered. |
ライセンスが登録されていません。 |
正しいライセンスが登録されているか確認してください。 |
(別表) |
警告 |
190 |
The registration license overlaps. |
登録したライセンスが重複しています。 |
正しいライセンスが登録されているか確認してください。 |
(別表) |
警告 |
190 |
The license is invalid. |
ライセンスが不正です。 |
正しいライセンスが登録されているか確認してください。 |
(別表) |
警告 |
190 |
The license of trial expired by %1. |
試用版ライセンスの試用期限が切れています。
%1には使用期限が入ります。
|
- |
(別表) |
警告 |
190 |
The license of trial effective from %1. |
試用版ライセンスの試用開始期限になっていません。
%1には使用期限が入ります。
|
- |
4.5. JVM モニタリソースのログ出力メッセージ¶
以下のメッセージはJVM モニタリソース独自のログファイルであるJVM運用ログ、JVMロードバランサ連携ログのメッセージ一覧です。
4.5.1. JVM 運用ログ¶
メッセージ |
発生原因 |
対処方法 |
|---|---|---|
Failed to write the %1$s.stat. |
JVM統計ログの書き込みに失敗しました。
%1$s.stat:JVM統計ログファイル名
|
ディスク空き容量が十分か確認してください。 |
%1$s: analyze finish[%4$s]. state = %2$s, cause = %3$s
|
(監視対象のJava VMの状態が異常時)監視対象のJava VMでリソース使用量がしきい値を超えました。
%1$s:監視対象のJava VM名称
%2$s:監視対象のJava VMの状態
(1=正常,0=異常)
%3$s:異常発生時のエラー発生箇所
%4$s:計測スレッド名
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
thread stopped by UncaughtException. |
JVMモニタリソースのスレッドが停止しました。 |
クラスタサスペンド/クラスタレジュームを実行し、JVMモニタリソースを再起動してください。 |
thread wait stopped by Exception. |
JVMモニタリソースのスレッドが停止しました。 |
クラスタサスペンド/クラスタレジュームを実行し、JVMモニタリソースを再起動してください。 |
%1$s: monitor thread can't connect to JVM.
|
監視対象のJava VMへ接続できませんでした。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMが起動されていることを確認してください。
|
%1$s: monitor thread can't get the JVM state.
|
監視対象のJava VMからリソース使用量が取得できませんでした。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMが起動されていることを確認してください。
|
%1$s: JVM state is changed [abnormal -> normal].
|
監視対象のJava VMの状態が異常から正常へ変化しました。
%1$s:監視対象のJava VM名称
|
-
|
%1$s: JVM state is changed [normal -> abnormal].
|
監視対象のJava VMの状態が正常から異常へ変化しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: Failed to connect to JVM.
|
監視対象のJava VMへ接続できませんでした。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMが起動されていることを確認してください。
|
Failed to write exit code. |
JVMモニタリソースが終了コードを記録するファイルに書き込みできませんでした。 |
ディスク空き容量が十分か確認してください。 |
Failed to be started JVM Monitor. |
JVMモニタリソースの起動に失敗しました。 |
JVM運用ログを確認して開始できない原因を取り除いてから、クラスタサスペンド/クラスタレジュームを実行し、JVMモニタリソースを再起動してください。 |
JVM Monitor already started. |
JVMモニタリソースはすでに起動しています。 |
クラスタサスペンド/クラスタレジュームを実行し、JVMモニタリソースを再起動してください。 |
%1$s: GARBAGE_COLLECTOR
_MXBEAN_DOMAIN_TYPE is invalid.
|
監視対象のJava VMからGC情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: GarbageCollectorMXBean is invalid.
|
監視対象のJava VMからGC情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの作環境が正しいか確認してください。
|
%1$s: Failed to measure the GC stat.
|
監視対象のJava VMからGC情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: GC stat is invalid. last.getCount = %2$s, last.getTime = %3$s, now.getCount = %4$s, now.getTime = %5$s.
|
監視対象のJava VMからGC発生回数、GC実行時間の計測に失敗しました。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点のGC発生回数
%3$s:前回計測時点のGC総実行時間
%4$s:今回計測時点のGC発生回数
%5$s:今回計測時点のGC総実行時間
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: GC average time is too long. av = %6$s, last.getCount = %2$s, last.getTime = %3$s, now.getCount = %4$s, now.getTime = %5$s.
|
監視対象のJava VMでGC実行時間の平均がしきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点のGC発生回数
%3$s:前回計測時点のGC総実行時間
%4$s:今回計測時点のGC発生回数
%5$s:今回計測時点のGC総実行時間
%6$s:前回計測時点から今回計測時点までに実行されたGC実行時間の平均
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: GC average time is too long compared with the last connection. av = %6$s, last.getCount = %2$s, last.getTime = %3$s, now.getCount = %4$s, now.getTime = %5$s.
|
監視対象のJava VMへ再接続した後、監視対象のJava VMでGC実行時間の平均がしきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点のGC発生回数
%3$s:前回計測時点のGC総実行時間
%4$s:今回計測時点のGC発生回数
%5$s:今回計測時点のGC総実行時間
%6$s:前回計測時点から今回計測時点までに実行されたGC実行時間の平均
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: GC count is too frequently. count = %4$s last.getCount = %2$s, now.getCount = %3$s.
|
監視対象のJava VMでGC発生回数がしきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点のGC発生回数
%3$s:今回計測時点のGC発生回数
%4$s:前回計測時点から今回計測時点までのGC発生回数
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: GC count is too frequently compared with the last connection. count = %4$s last.getCount = %2$s, now.getCount = %3$s.
|
監視対象のJava VMへ再接続した後、監視対象のJava VMでGC発生回数がしきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点のGC発生回数
%3$s:今回計測時点のGC発生回数
%4$s:前回計測時点から今回計測時点までのGC発生回数
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: RuntimeMXBean is invalid.
|
監視対象のJava VMから情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: Failed to measure the runtime stat.
|
監視対象のJava VMから情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
監視対象のJava VMで処理負荷が高くなっていないかを確認してください。
|
%1$s: MEMORY_MXBEAN_NAME is invalid. %2$s, %3$s.
|
監視対象のJava VMからメモリ情報取得に失敗しました。
%1$s:監視対象のJava VM名称
%2$s:メモリプールの名称
%3$s:メモリの名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: MemoryMXBean is invalid.
|
監視対象のJava VMからメモリ情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: Failed to measure the memory stat.
|
監視対象のJava VMからメモリ情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
監視対象のJava VMで処理負荷が高くなっていないかを確認してください。
|
%1$s: MemoryPool name is undefined. memory_name = %2$s.
|
監視対象のJava VMからメモリ情報取得に失敗しました。
%1$s:監視対象のJava VM名称
%2$s:計測対象のJavaメモリプール名
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: MemoryPool capacity is too little. memory_name = %2$s, used = %3$s, max = %4$s, ratio = %5$s%.
|
監視対象のJava VMのJavaメモリプールの空き容量がしきい値を下回りました。
%1$s:監視対象のJava VM名称
%2$s:計測対象のJavaメモリプール名
%3$s:Javaメモリプールの使用量
%4$s:Javaメモリプールの使用可能な最大量
%5$s:Javaメモリプールの利用率
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: THREAD_MXBEAN_NAME is invalid.
|
監視対象のJava VMからスレッド情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: ThreadMXBean is invalid.
|
監視対象のJava VMからスレッド情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: Failed to measure the thread stat.
|
監視対象のJava VMからスレッド情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: Detect Deadlock. threads = %2$s.
|
監視対象のJava VMでスレッドのデッドロックが発生しました。
%1$s:監視対象のJava VM名称
%2$s:デッドロックしたスレッドのID
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: Thread count is too much(%2$s).
|
監視対象のJava VMでスレッドの起動数がしきい値を超えました。
%1$s:監視対象のJava VM名称
%2$s:計測時点でのスレッド起動数
|
監視対象のJava VM上で動作するJavaアプリケーションを見直してください。
|
%1$s: ThreadInfo is null.Thread count = %2$s.
|
監視対象のJava VMでスレッドの情報取得に失敗しました。
%1$s:監視対象のJava VM名称
%2$s:計測時点でのスレッド起動数
|
監視対象のJava VMのバージョンの動作環境が正しいか確認してください
|
%1$s: Failed to disconnect.
|
監視対象のJava VMからの切断に失敗しました。
%1$s:監視対象のJava VM名称
|
-
|
%1$s: Failed to connect to WebLogicServer.
|
監視対象のWebLogic Serverの接続に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: Failed to connect to Sun JVM.
|
監視対象のJava VM、WebOTXの接続に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VM、WebOTX上で動作するJavaアプリケーションを見直してください。
|
Failed to open the %1$s.
|
JVM統計ログの出力に失敗しました。
%1$s:HA/JVMSaverJVM統計ログファイル名称
|
ディスク空き容量が十分か、オープン済みのファイル数が上限を超えていないか確認してください。
|
%1$s: Can't find monitor file.
|
監視をしません。
%1$s:監視対象のJava VM名称
|
-
|
%1$s: Can't find monitor file, monitor stopped[thread:%2$s].
|
監視を停止します。
%1$s:監視対象のJava VM名称
%2$s:計測スレッドの種類
|
-
|
%1$s: Failed to create monitor status file.
|
内部ファイルの作成に失敗しました。
%1$s:監視対象のJava VM名称
|
ディスク空き容量やボリュームのファイル最大数が十分か確認してください。
|
%1$s: Failed to delete monitor status file.
|
内部ファイルの削除に失敗しました。
%1$s:監視対象のJava VM名称
|
ハードディスクに問題がないか確認してください。
|
%1$s: com.bea:Type=ServerRuntime is invalid.
|
監視対象のJava VMから情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のJava VMの動作環境が正しいか確認してください。
|
%1$s: WorkManagerRuntimeMBean or ThreadPoolRuntimeMBean is invalid.
|
監視対象のWebLogic Server から情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のWebLogic Server の動作環境が正しいか確認してください。
|
%1$s: Failed to measure the WorkManager or ThreadPool stat.
|
監視対象のWebLogic Serverから情報取得に失敗しました。
%1$s:監視対象のJava VM名称
|
監視対象のWebLogic Server の動作環境が正しいか確認してください。
|
%1$s: ThreadPool stat is invalid. last.pending = %2$s, now.pending = %3$s.
|
監視対象のWebLogic Serverのスレッドプールで待機リクエスト数の計測に失敗しました。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点の待機リクエスト数
%3$s:今回計測時点の待機リクエスト数
|
監視対象のWebLogic Server のバージョンの動作環境が正しいか確認してください。
|
%1$s: WorkManager stat is invalid. last.pending = %2$s, now.pending = %3$s.
|
監視対象のWebLogic Serverのワークマネージャで待機リクエスト数の計測に失敗しました。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点の待機リクエスト数
%3$s:今回計測時点の待機リクエスト数
|
監視対象のWebLogic Server のバージョンの動作環境が正しいか確認してください。
|
%1$s: PendingRequest count is too much. count = %2$s.
|
監視対象のWebLogic Serverのスレッドプールで待機リクエスト数が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:今回計測時点の待機リクエスト数
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: PendingRequest increment is too much. increment = %4$s%%, last.pending = %2$s, now.pending = %3$s.
|
監視対象のWebLogic Serverのスレッドプールで待機リクエスト数の増分が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点の待機リクエスト数
%3$s:今回計測時点の待機リクエスト数
%4$s:前回計測時点から今回計測時点までの待機リクエスト数の増分
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: PendingRequest increment is too much compared with the last connection. increment = %4$s, last.pending = %2$s, now.pending = %3$s.
|
監視対象のWebLogic Serverへ再接続した後、監視対象のWebLogic Serverのスレッドプールで待機リクエスト数の増分が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点の待機リクエスト数
%3$s:今回計測時点の待機リクエスト数
%4$s:前回計測時点から今回計測時点までの待機リクエスト数の増分
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: Throughput count is too much. count = %2$s.
|
監視対象のWebLogic Serverのスレッドプールで単位時間あたりに実行したリクエスト数が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:今回計測時点の単位時間あたりに実行したリクエスト数
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: Throughput increment is too much. increment = %4$s, last.throughput = %2$s, now.throughput = %3$s.
|
監視対象のWebLogic Serverのスレッドプールで単位時間あたりに実行したリクエスト数の増分が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点の単位時間あたりに実行したリクエスト数
%3$s:今回計測時点の単位時間あたりに実行したリクエスト数
%4$s:前回計測時点から今回計測時点までの単位時間あたりに実行したリクエスト数の増分
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: Throughput increment is too much compared with the last connection. increment = %4$s, last.throughput = %2$s, now.throughput = %3$s.
|
監視対象のWebLogic Serverへ再接続した後、監視対象のWebLogic Serverのスレッドプールで単位時間あたりに実行したリクエスト数の増分が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:前回計測時点の単位時間あたりに実行したリクエスト数
%3$s:今回計測時点の単位時間あたりに実行したリクエスト数
%4$s:前回計測時点から今回計測時点までの単位時間あたりに実行したリクエスト数の増分
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: PendingRequest count is too much. appName = %2$s, name = %3$s, count = %4$s.
|
監視対象のWebLogic Serverのワークマネージャで待機リクエスト数が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:アプリケーション名
%3$s:ワークマネージャ名
%4$s:待機リクエスト数
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: PendingRequest increment is too much. appName = %2$s, name = %3$s, increment = %6$s%%, last.pending = %4$s, now.pending = %5$s.
|
監視対象のWebLogic Serverのワークマネージャで待機リクエストの数の増分が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:アプリケーション名
%3$s:ワークマネージャ名
%4$s:前回計測時点の待機リクエスト数
%5$s:今回計測時点の待機リクエスト数
%6$s:前回計測時点から今回計測時点までの待機リクエスト数の増分
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: PendingRequest increment is too much compared with the last connection. AppName = %2$s, Name = %3$s, increment = %6$s, last.pending = %4$s, now.pending = %5$s.
|
監視対象のWebLogic Serverへ再接続した後、監視対象のWebLogic Serverのワークマネージャで待機リクエスト数の増分が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:アプリケーション名
%3$s:ワークマネージャ名
%4$s:前回計測時点の待機リクエストの数
%5$s:今回計測時点の待機リクエストの数
%6$s:前回計測時点から今回計測時点までの待機リクエスト数の増分
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: Can't find WorkManager. appName = %2$s, name = %3$s.
|
設定したワークマネージャがWebLogic Serverから取得できません。
%1$s:監視対象のJava VM名称
%2$s:アプリケーション名
%3$s:ワークマネージャ名
|
[監視対象のWebLogicワークマネージャ]の設定を見直してください。
|
%1$s: analyze of average start[%2$s].
|
平均値の分析を開始しました。
%1$s:監視対象のJava VM名称
%2$s:スレッド名
|
-
|
%1$s: analyze of average finish[%2$s].state = %3$s.
|
平均値の分析が終了しました。
%1$s:監視対象のJava VM名称
%2$s:スレッド名
%3$s:監視対象の状態
|
-
|
%1$s: Average of PendingRequest count is too much. count = %2$s.
|
監視対象のWebLogic Serverのスレッドプールで待機リクエスト数の平均値が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:今回計測時点の待機リクエスト数
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: Average of Throughput count is too much. count = %2$s.
|
監視対象のWebLogic Serverのスレッドプールで単位時間あたりに実行したリクエスト数の平均値が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:今回計測時点の単位時間あたりに実行したリクエスト数
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
%1$s: Average of PendingRequest count is too much. AppName = %2$s, Name = %3$s, count = %4$s.
|
監視対象のWebLogic Serverのワークマネージャで待機リクエスト数の平均値が、しきい値を超えています。
%1$s:監視対象のJava VM名称
%2$s:アプリケーション名
%3$s:ワークマネージャ名
%4$s:今回計測時点の待機リクエスト数
|
監視対象のWebLogic Server上で動作するJavaアプリケーションを見直してください。
|
Error: Failed to operate clpjra_bigip.[%1$s] |
%1$s:エラーコード |
設定内容を見直してください。 |
action thread execution did not finish. action is alive = %1$s.
|
[コマンド]がタイムアウトしました。
%1$s:[コマンド]で設定した実行ファイル名
|
[コマンド]を強制終了させてください。
[コマンドタイムアウト]を見直してください。
高負荷などタイムアウトした原因を取り除いてください。
|
%1$s: Failed to connect to Local JVM. cause = %2$s.
|
JBossへの接続に失敗しました。
%1$s:監視対象名
%2$s:失敗の詳細原因
詳細原因は以下のいずれかです。
・Failed to found tool.jar, please set jdk's path for the java path.
・Load tool.jar exception
・Get Local JVM url path exception
・Failed to get process name
・Failed to connect to JBoss JVM.
|
[Javaインストールパス]、[プロセス名]を見直してください。
[Javaインストールパス]にはJREではなく、JDKを設定してください。
JBossが起動しているか確認してください。
|
4.5.2. JVM ロードバランサ連携ログ¶
メッセージ |
発生原因 |
対処方法 |
|---|---|---|
lbadmin command start. |
ロードバランサ連携のコマンドの実行を開始しました。 |
- |
lbadmin command finish. |
ロードバランサ連携のコマンドの実行が終了しました。 |
- |
Into HealthCheck mode. |
ヘルスチェック機能が有効です。 |
- |
Into Weight mode. |
監視対象Java VMの負荷算出機能が有効です。 |
- |
The PID of lbadmin.jar is "%1". |
ロードバランサ連携関連のプロセスのプロセスIDです。
%1:lbadmin.jarのプロセスID
|
- |
Thread wait stopped by Exception |
ダウン判定の待機を中止しました。 |
- |
Rename Command succeeded. |
HTMLファイルのリネーム処理が成功しました。 |
- |
Rename Command failed. |
HTMLファイルのリネーム処理が失敗しました。 |
HTMLファイル名とHTMLリネーム先ファイル名を確認してください。 |
%1 doesn't exist.
|
リネーム元のHTMLファイルが存在しません。
%1:HTMLファイル名
|
HTMLファイル名を確認してください。
|
%1 already exists.
|
リネーム先のHTMLファイルが既に存在します。
%1:HTMLリネーム先ファイル名
|
HTMLリネーム先ファイル名を確認してください。
|
Can't rename file:%1.
|
HTMLファイルのリネーム処理に失敗しました。
%1:HTMLファイル名
|
HTMLリネーム先ファイル名を確認してください
|
The number of retries exceeded the limit. |
HTMLファイルリネーム処理のリトライ回数が上限を超えました。 |
HTMLリネーム先ファイル名を確認してください。 |
The percent of the load is "%1".
|
監視対象Java VMの負荷算出に成功しました。
%1:監視対象Java VMの負荷
|
-
|
stat log (%1) doesn't exist.
|
JVM統計ログファイルがありません。
%1:JVM統計ログファイル名
|
クラスタサスペンド/クラスタレジュームを実行し、JVMモニタリソースを再起動してください。
|
stat log(%1:) cannot be opened for reading.
|
JVM統計ログファイルのオープンに失敗しました。
%1:JVM統計ログファイル名
|
クラスタサスペンド/クラスタレジュームを実行し、JVMモニタリソースを再起動してください。
|
format of stat log (%1) is wrong.
|
JVM統計ログファイルの中身が不正です。
%1:JVM統計ログファイル名
|
JVM統計ログファイルを削除した後、クラスタサスペンド/クラスタレジュームを実行し、JVMモニタリソースを再起動してください。
|
Failed to get load of application server. |
JVM統計ログファイルから負荷算出のためのデータ取得に失敗しました。 |
監視対象Java VMの負荷算出設定が正しいか見直してください。 |
Can't find lock file(%1s*.stat.lck), maybe HA/JVMSaver did not start yet.
|
JVMモニタリソースが起動していません。
%1:内部ファイル名
|
JVMモニタリソースを起動してください。
|