8. 其他设置信息¶
本章对其他监视设置相关信息进行说明。
本章中的说明项目如下所示。
8.1. 关机监视¶
8.1.1. 何谓关机监视¶
8.1.2. 显示/更改关机监视的详细信息¶
- [No]不进行关机监视。
8.1.3. 关机监视的方法¶
关机监视的监视方法如下所示。
- 监视方法 softdog监视方法为softdog时,使用softdog驱动程序设置计时器。
- 监视方法 ipmi监视方法为ipmi时,使用OpenIPMI设置计时器。若未安装OpenIPMI,需要进行安装。关于ipmi,请参考"理解用户空间监视资源"。
- 监视方法 keepalive监视方法为keepalive时,使用EXPRESSCLUSTER的clpkhb和clpka驱动程序设置计时器。
注解
关于clpkhb驱动程序, clpka驱动程序运行的Distribution,kernel版本,请务必确认《开始指南》的"EXPRESSCLUSTER的运行环境"- "软件"- "可运行的Distribution和kernel"。在将Distribution发行的安全升级包应用于已经运行的集群(kernel版本发生变化)时,也请进行确认。
8.1.4. SIGTERM设置¶
监视方法 softdog
关机成功时(选择了监视方法softdog,SIGTERM有效时)
发布命令(clpstdn,clpdown,shutdown,reboot等)。
开始关机监视。
开始关闭OS。
即使在关机处理过程中,OS发布SIGTERM,但是由于已启用SIGTERM,因此关机监视结束。
关闭OS成功。
(d)~(e)中无法查出停止状态。
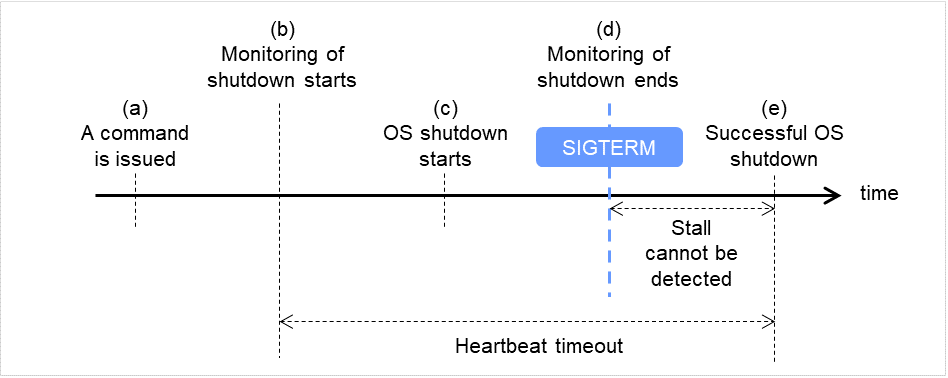
图 8.1 关机成功时(监视方法为softdog, SIGTERM有效时)¶
关机成功时(监视方法为softdog,SIGTERM无效时)
发布命令(clpstdn,clpdown,shutdown,reboot等)。
开始关机监视。
开始关闭OS。
即使在关机处理过程中,OS发布SIGTERM,但是由于SIGTERM被禁用,因此关机监视不会在这个时间点结束。
- 结束关机监视,卸载softdog驱动。关闭OS成功。
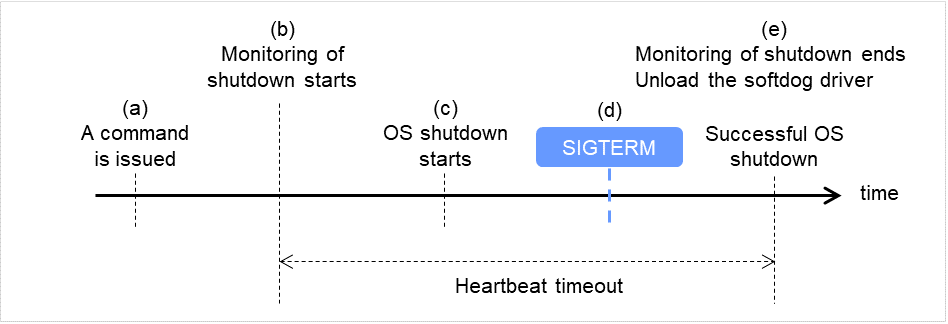
图 8.2 关机成功时(监视方法为softdog,SIGTERM无效时)¶
监视方法 ipmi
关机成功时(监视方法为ipmi, SIGTERM有效时)
发布命令(clpstdn,clpdown,shutdown,reboot等)。
开始关机监视。
开始关闭OS。
即使在关机处理过程中,OS发布SIGTERM,但是由于已启用SIGTERM,因此关机监视结束。
关闭OS成功。
(d)~(e)中无法查出停止状态。
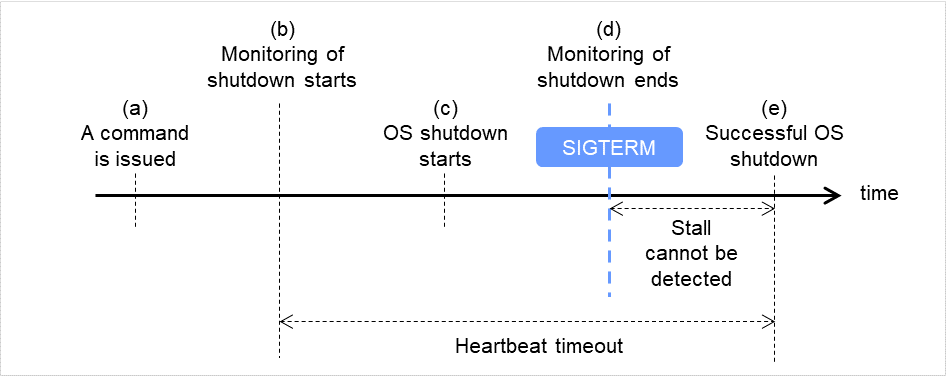
图 8.3 关机成功时(监视方法为 ipmi, SIGTERM 有效时)¶
关机成功时(若监视方法为ipmi,SIGTERM无效时)
发布命令(clpstdn,clpdown,shutdown,reboot等)。
开始关机监视。
开始关闭OS。
即使在关机处理过程中,OS发布SIGTERM,但是由于SIGTERM被禁用,因此关机监视不会在这个时间点结束。
关闭OS成功。
发生重置。
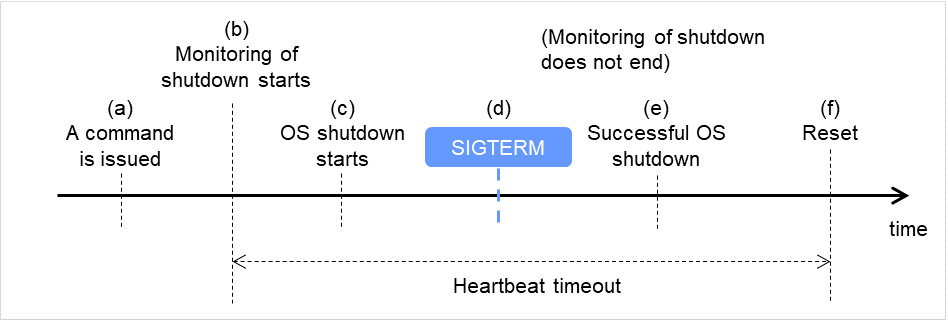
图 8.4 关机成功时 (监视方法为 ipmi,SIGTERM 无效时)¶
即使未发生停止,正常关机的情况下也会因ipmi发生重置。
可以off软件电源的服务器中不会重置。
若监视方法为ipmi,则建议设置SIGTERM为有效。
若OS关闭时发生停止
查出关机停止时
发布命令(clpstdn,clpdown,shutdown,reboot等)。
开始关机监视。
开始关闭OS。
关闭OS过程中发生停止情况。
发生重置。
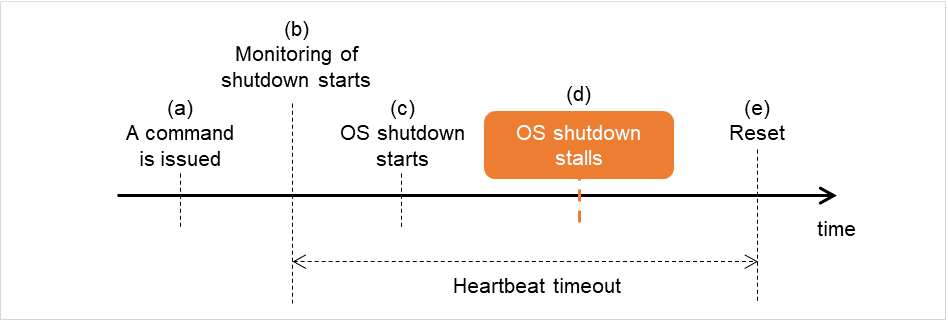
图 8.5 查出关机停止时¶
8.1.5. 使用心跳超时¶
将关机监视的超时值与心跳超时值结合使用。
8.1.6. 超时¶
8.2. bonding¶
8.2.1. 浮动IP资源¶
注意事项:
若将bonding的模式指定为"active-backup",在切换Slave接口时可执行会造成暂时的通信中断。
bonding设置示例
注解
设置私网的IP地址时,请仅设置IP地址。
以下为bondig上使用浮动IP资源时的设置示例。
Device |
Slave |
Mode |
|---|---|---|
bond0 |
eth0
eth1
|
active-backup(1)
balance-tlb(5)
|
bond0 |
eth0
eth1
|
active-backup(1)
balance-tlb(5)
|
图中的 Server 1,Server 2中,从接口 eth0,eth1通过bonding进行组合,构成主接口bond0。 此外,在FIP资源中设置了IP地址以访问Server1,Server2。 与集群服务器位于同一LAN上的主机,远程LAN上的主机都可以使用FIP与集群服务器连接。 无需特殊设置即可在路由器上使用FIP。
FIP资源IP地址: 192.168.1.3
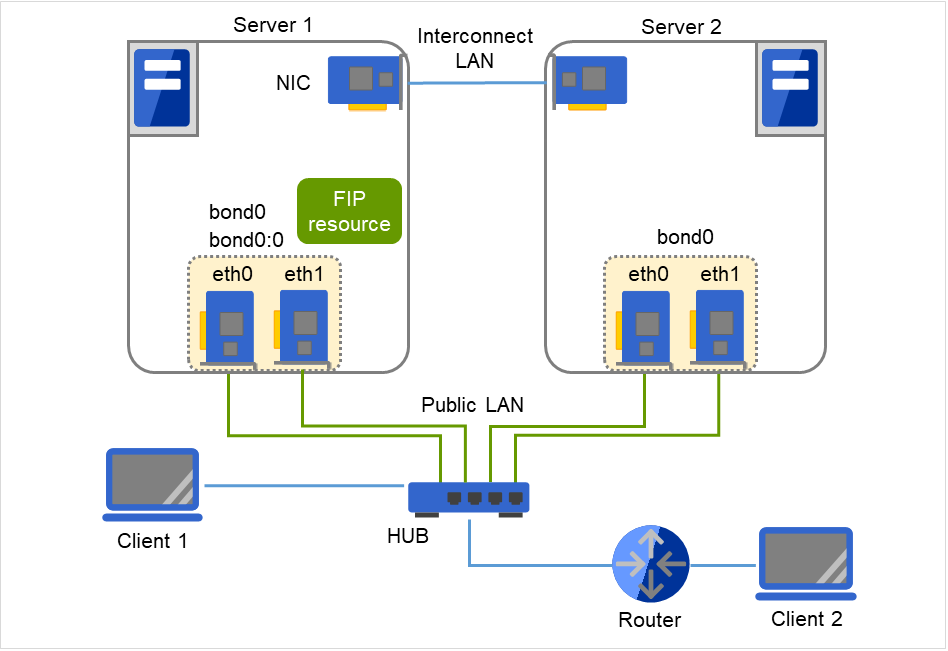
图 8.6 bonding上的浮动IP资源使用示例¶
srv1中通过ifconfig设置的浮动IP资源的启动状态如下所示。(bonding mode指定为"balance-tlb(5)"。)
$ ifconfig
bond0 Link encap:Ethernet HWaddr 00:00:01:02:03:04
inet addr:192.168.1.1 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:6807 errors:0 dropped:0 overruns:0 frame:0
TX packets:2970 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:670032 (654.3 Kb) TX bytes:189616 (185.1 Kb)
bond0:0 Link encap:Ethernet HWaddr 00:00:01:02:03:04
inet addr:192.168.1.3 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:236 errors:0 dropped:0 overruns:0 frame:0
TX packets:2239 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:78522 (76.6 Kb) TX bytes:205590 (200.7 Kb)
eth0 Link encap:Ethernet HWaddr 00:00:01:02:03:04
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:3434 errors:0 dropped:0 overruns:0 frame:0
TX packets:1494 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:332303 (324.5 Kb) TX bytes:94113 (91.9 Kb)
Interrupt:18 Base address:0x2800 Memory:fc041000-fc041038
eth1 Link encap:Ethernet HWaddr 00:00:05:06:07:08
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:215 errors:0 dropped:0 overruns:0 frame:0
TX packets:1627 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:77162 (75.3 Kb) TX bytes:141394 (138.0 Kb)
Interrupt:19 Base address:0x2840 Memory:fc042000-fc042038
eth2 Link encap:Ethernet HWaddr 00:00:09:10:11:12
inet addr:192.168.2.1 Bcast:192.168.2.255 Mask: 255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:47 errors:0 dropped:0 overruns:0 frame:0
TX packets:1525 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2820 (2.7 Kb) TX bytes:110113 (107.5 Kb)
Interrupt:24 Base address:0x3000 Memory:fc500000-fc500038
以上是"bond0"的block绑定了eth0,eth1的设备信息。 使用Public LAN和第二个私网的设备。
"bond0:0" block 显示在"bond0"上启动的浮动IP地址的信息。
"eth2"是在第一个私网中使用的设备。
8.2.2. 镜像磁盘连接¶
注意事项:
bonding上使用镜像磁盘连接,在切换Slave接口时可执行会造成暂时的通信中断。根据镜像处理的时间不同,有时候在bonding切换处理完成后会执行复原。
bonding设置示例
以下将对bondig上使用镜像磁盘连接的设置示例进行说明。
Cluster Server |
Device |
Slave |
Mode |
|---|---|---|---|
srv1 |
bond0 |
eth1
eth2
|
balance-rr(0)
active-backup(1)
balance-tlb(5)
|
srv2 |
bond0 |
eth1
eth2
|
balance-rr(0)
active-backup(1)
balance-tlb(5)
|
8.3. 警报服务¶
8.3.1. 何谓警报服务?¶
EXPRESSCLUSTER警报服务能够将EXPRESSCLUSTER上发生的业务异常通知给远程的管理员。
通知方法有以下三种。通知方法不同,所通知的现象也不同。
- 电子邮件通报在Cluster WebUI显示警报消息时,通过邮件通报警报内容。
- 网络警告灯通报服务器启动时和服务器宕机时通过网络警告灯通报,显示服务器的状态。如果服务器正常停止,网络警告灯将熄灭。电子邮件通报和网络警告灯通报功能互相独立运行。
- SNMP Trap发送在Cluster WebUI显示警报消息时,通过SNMP Trap发送警报内容。
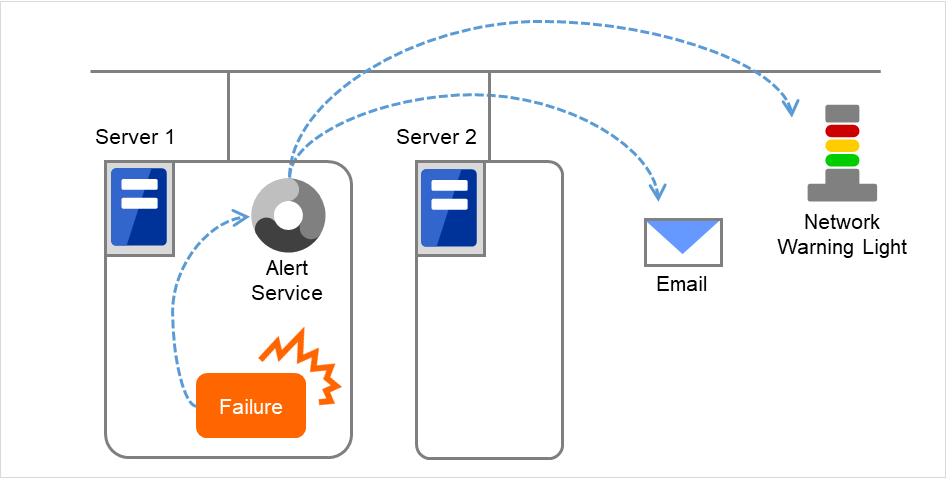
图 8.7 警报服务¶
通过电子邮件通报,即便管理终端在异地,也可以在发生故障后尽快察知。
邮件通报接收方可以设置为手机。
通过网络警告灯的点亮,可以从视觉上判断故障的发生。
通过网络警告灯的音频文件回放,可以从声音判断故障。
SNMP Trap可向设置的通报接收服务器发送故障内容。
通过电子邮件通报时,使用以下格式通报Alert内容。
邮件名
EXPRESSCLUSTER正文
Message: Server [已宕机服务器名] has been stopped. Type: nm ID: 2 Host: [发件人 服务器名] Date: [发送时间戳]
8.3.2. 警报服务的注意事项¶
要使用邮件通报和网络警告灯通报功能,需要EXPRESSCLUSTER X Alert Service 5.1 for Linux。
本功能的目的是通报故障的发生,不能对EXPRESSCLUSTER的故障进行调查并查找原因。发生故障后,需要通过EXPRESSCLUSTER的日志和syslog等其他手段判断详细的故障原因。
在Linux中使用网络警告灯功能时,需要安装rsh包。
8.3.3. 邮件通报处理¶
通过邮件通报与Cluster WebUI的警报消息相同的内容。关于具体什么样的警报消息会通过邮件通报,请参考本指南的"11. 错误消息一览表"的"syslog,警告,邮件通告消息,SNMP Trap消息,Message Topic"部分的说明。
邮件通报的警报可以更改。详细内容请参考本指南的"2. 参数的详细信息"- "集群属性" - "Alert服务标签页"部分的说明。
8.3.4. 网络警告灯通报处理¶
网络警告灯执行如下各种操作。
- 服务器启动时服务器正常启动时,绿灯点亮。
- 服务器停止时服务器正常停止时,指示灯熄灭。
- 服务器宕机时服务器宕机时,红灯点亮。正常服务器会检测到其他异常服务器的状态并进行通报,所以如果所有的服务器都宕机时,则最后宕机的服务器的网络警告灯无法通知故障。
网络警告灯一旦点亮或闪烁,则除非集群关机时将不会熄灭。如果要熄灭指示灯,请执行[clplamp]命令。关于[clplamp]命令,请参照本指南的"9.2. EXPRESSCLUSTER命令一览"的"熄灭网络警告灯(clplamp命令)"。
音频文件回放对应的网络警告灯(本公司指定产品)时,可以设置音频文件回放与灯亮和灯灭连动。
8.3.5. SNMP Trap发送动作¶
通过SNMP Trap发送与Cluster WebUI的警报消息相同的内容。具体什么样的警报消息会通过SNMP Trap发送,请参考本指南的"11. 错误消息一览表" - "syslog,警告,邮件通告消息,SNMP Trap消息,Message Topic"的说明。
SNMP Trap发送的Alert可以更改。详情请参照本指南的"2. 参数的详细信息" - "集群属性" - "Alert服务标签页"。
关于SNMP Trap的详情请参照"何谓SNMP Trap发送?"。
8.4. SNMP 联动¶
8.4.1. 何谓SNMP联动?¶
SNMP联动基于EXPRESSCLUSTER MIB定义,可通过EXPRESSCLUSTER的SMNP Trap发送,以及来自SNMP Manager的SNMP获取信息。
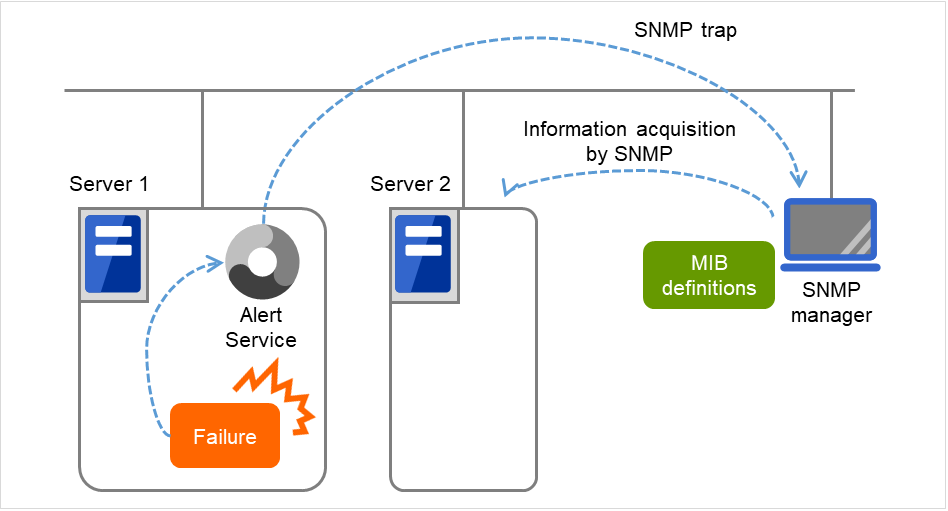
图 8.8 SNMP联动¶
8.4.2. 何谓EXPRESSCLUSTER MIB的定义?¶
从SNMP联动获取的信息汇总为MIB定义文件。
在使用后面提到的SNMP Trap发送以及从SNMP获取信息的功能时,都需要MIB定义文件。
需要用SNMP Manager接收来自EXPRESSCLUSTER的SNMP Trap,或用SNMP Manager获取集群状态时,请在SNMP Manager中嵌入EXPRESSCLUSTER MIB定义文件。
关于如何在SNMP Manager中嵌入MIB定义文件,请参照各SNMP Manager的使用手册。
EXPRESSCLUSTER MIB定义文件位于EXPRESSCLUSTER X DVD-ROM下。
<EXPRESSCLUSTER X DVD-ROM>Common<版本编号>mib
各MIB定义文件有以下几种含义。
No. |
MIB定义文件 |
描述 |
|---|---|---|
NEC-CLUSTER-SMI.mib |
EXPRESSCLUSTER MIB树的根路径已定义。 |
|
NEC-CLUSTER-EVENT-MIB.mib |
与EXPRESSCLUSTER的SNMP Trap发送功能关联的Trap 定义或MIB已定义。 |
|
NEC-CLUSTER-MANAGEMENT-MIB.mib |
与EXPRESSCLUSTER的以下信息关联的MIB已定义。
|
SNMP Manager嵌入的文件不同,可利用的功能也不同。
接收来自的EXPRESSCLUSTER的SNMP Trap时
1. NEC-CLUSTER-SMI.mib2. NEC-CLUSTER-EVENT-MIB.mib
利用SNMP获取信息时
1. NEC-CLUSTER-SMI.mib2. NEC-CLUSTER-MANAGEMENT-MIB.mib
8.4.3. 何谓SNMP Trap发送?¶
SNMP Trap发送是指将与Cluster WebUI的警报消息相同的内容发送至SNMP Manager的功能。
为了实现Trap送信,必须要另外设定SNMP Trap的发送地址。请参照本指南的"2. 参数的详细信息" - "集群属性" - "Alert服务标签页"的"SNMP Trap 发送地址设置"。
发送的Trap用NEC-CLUSTER-EVENT-MIB定义。
已用NEC-CLUSTER-EVENT-MIB定义的各MIB对象如下所示。
clusterEventNotifications组
已定义发送Trap的组。此处已定义的各MIB对象的含义如下。
No. |
SNMP TRAP OID |
描述 |
|---|---|---|
clusterEventInformation |
表示信息级别Alert的Trap。
添加clusterEvent组的MIB对象。
|
|
clusterEventWarning |
表示警报级别Alert的Trap。
添加clusterEvent组的MIB对象。
|
|
clusterEventError |
表示异常级别Alert的Trap。
添加clusterEvent组的MIB对象。
|
clusterEvent组
已定义向Trap添加信息的组。此处已定义的各MIB对象的含义如下。
No. |
SNMP OID |
描述 |
|---|---|---|
clusterEventMessage |
表示Alert信息。 |
|
clusterEventID |
表示事件ID。 |
|
clusterEventDateTime |
表示Alert的发送时间。 |
|
clusterEventServerName |
表示Alert的发送来源服务器。 |
|
clusterEventModuleName |
表示Alert的发送来源模块。 |
8.4.4. 何谓用SNMP获取信息?¶
利用SNMP协议,可获取部分EXPRESSCLUSTER的配置信息,状态信息。但是,EXPRESSCLUSTER本身并不具备SNMP代理功能。需另行安装Net-SNMP snmpd Daemon作为SNMP代理。
何谓SNMP代理?
根据SNMP Manager(网络管理软件)提出的获取信息要求(GetRequest, GetNextRequest) ,反馈(GetResponse)各种配置信息,状态信息的功能。
注解
利用SNMP获取信息时,请务必执行《安装&设置指南》中的"如何设置SNMP联动功能"。
8.4.5. 关于可通过SNMP联动获取的MIB¶
可通过SNMP联动功能获取的MIB用NEC-CLUSTER-MANAGEMENT-MIB定义。
已用NEC-MANAGEMENT-MIB定义的各MIB对象如下所示。
clusterGeneral组
可获取集群联动信息的组。此处已定义的各MIB对象的含义如下。
No. |
SNMP OID |
描述 |
|---|---|---|
clusterName |
表示集群名。 |
|
clusterComment |
表示集群的注释。 |
|
clusterStatus |
表示目前集群的状态。 以下是MIB的获取值与Cluster WebUI状态的对应。 MIB值 状态
----------------
normal [正常]
caution [警告]
Error [异常]
unknown \-
|
clusterServer组
可获取服务器联动信息的组。获取clusterServerTable时的索引按服务器优先顺序排列。此处已定义的各MIB对象的含义如下。
No. |
SNMP OID |
描述 |
|---|---|---|
clusterServerLocalServerIndex |
表示目前接受SNMP信息获取要求的服务器索引(clusterServerIndex)。 |
|
clusterServerTable |
表示服务器信息表。 |
|
clusterServerEntry |
表示服务器的信息列表。 此列表的索引是clusterServerIndex。 |
|
clusterServerIndex |
表示唯一一个能识别各服务器的索引。 |
|
clusterServerName |
表示服务器名。 |
|
clusterServerComment |
表示服务器的注释。 |
|
clusterServerStatus |
表示目前的服务器状态。 以下是MIB的获取值与Cluster WebUI状态的对应。 MIB值 状态
--------------------
Online [已启动]
Offline [已停止]
unknown [不明]
|
|
clusterServerPriority |
表示服务器的优先顺序。 |
|
clusterServerProductName |
表示服务器中已安装的EXPRESSCLUSTER产品名称。 |
|
clusterServerProductVersion |
表示服务器中已安装的EXPRESSCLUSTER产品版本。 |
|
clusterServerProductInstallPath |
表示服务器已安装的EXPRESSCLUSTER之安装路径。 |
|
clusterServerPlatformName |
表示服务器的平台名称。 |
clusterGroup组
可获取组联动信息的组。此处已定义的各MIB对象的含义如下。
No. |
SNMP OID |
描述 |
|---|---|---|
clusterGroupTable |
表示组信息表。 |
|
clusterGroupEntry |
表示服务器的信息列表。 此列表的索引是clusterGroupIndex。 |
|
clusterGroupIndex |
表示唯一一个能识别各组的索引。 |
|
clusterGroupName |
表示组名。 |
|
clusterGroupComment |
表示组的注释。 |
|
clusterGroupType |
表示组的类型。 以下是MIB的获取值与组类型的对应。 MIB值 组的类型
---------------------------
failover 失效切换组
Cluster 管理组
|
|
clusterGroupStatus |
表示目前的组状态。 以下是MIB的获取值与Cluster WebUI状态的对应。 MIB值 状态
--------------------------
Online [已启动]
onlineFailure [启动失败]
offlineFailure [停止失败]
Offline [已停止]
unknown [不明]
onlinePending [启动中]
offlinePending [停止中]
|
|
clusterGroupCurrentServerIndex |
表示目前组正在启动的服务器索引 (clusterServerIndex)。 组停止时,返回值为"-1"。 |
8.5. 禁止自动启动非正常停止后的集群服务¶
8.5.1. 何谓禁止自动启动集群服务?¶
通过Cluster WebUI的集群关机/集群重启/集群停止,[clpstdn]命令,[clpcl -t -a]命令以外的方法停止EXPRESSCLUSTER处理时,下次启动OS时,将禁止EXPRESSCLUSTER服务自动启动的功能。
设置为禁止自动启动时,以OS关机命令或通过Cluster WebUI的集群关机/集群重启/集群停止,[clpstdn]命令,[clpcl -t -a]命令等停止EXPRESSCLUSTER时,下次启动服务器,EXPRESSCLUSTER服务不会自动启动。
执行集群关机或停止集群,停止处理EXPRESSCLUSTER服务导致发生异常及因OS重置或电源断开而未执行停止处理时,下次启动OS时,EXPRESSCLUSTER服务不会自动启动。
8.5.2. 显示/更改禁止自动启动¶
- [关机后自动启动]不禁止自动启动。
- [关机后不禁止自动启动]以集群关机或停止集群以外的方法停止服务器,或集群关机和停止集群非正常结束时,下次启动OS时,将禁止自动启动集群服务。
8.5.3. 禁止自动启动的条件¶
禁止自动启动的条件如下。
以集群关机或停止集群以外的方法停止集群时
由于OS的重置,Panic,电源断开等没有执行集群服务停止处理时
由于对集群关机或集群停止处理的集群服务进行停止处理,导致组的停止处理失败时
构成集群的一部分服务器做了集群单体停止时
8.5.4. 禁止自动启动的注意事项¶
若OS启动时EXPRESSCLUSTER服务没有自动启动,请使用Cluster WebUI或[clpcl]命令启动EXPRESSCLUSTER服务。
若OS启动时EXPRESSCLUSTER服务没有自动启动,将会输出Cluster WebUI上的Alert信息和syslog信息。
8.6. 服务器组间自动失效切换时的等待宽限时间¶
8.6.1. 何谓等待宽限时间?¶
服务器间的自动失效切换时,只在指定的时间内等待失效切换的开始。从检测到服务器宕机开始,到过了宽限时间后,开始执行失效切换。
8.6.2. 等待宽限时间条件¶
等待下述设定的组的失效切换
选中[信息]标签页- [使用服务器组设置]
在[启动服务器]标签页- [可启动的服务器组]中多个服务器组被指定
选中[属性]标签页- [失效切换属性] - [自动失效切换] - [优先服务器组内的失效切换政策],且选中[在服务器组之间只有手动失效切换有效]
在以下场合,不进行宽限时间的等待。
对同一个服务器组中的服务器进行失效切换时
通过服务器宕机通知查出服务器宕机时
强制停止类型设置为[不使用]以外,执行强制停止成功时,以及满足不执行强制停止条件时
NP 解决资源被设置时
8.6.4. 等待宽限时间的注意事项¶
在宽限时间等待中,对失效切换对象的组进行操作时,取消宽限时间等待,不执行失效切换。
在宽限时间等待中,在可以确认宕机的服务器的生存时,取消宽限时间等待,不执行失效切换。
在宽限时间等待中,失效切换目标服务器宕机时,失效切换开始可执行会比等待宽限时间长。
8.7. Witness 服务器服务¶
8.7.1. 何谓Witness 服务器服务?¶
从集群内的各服务器接收Witness 心跳,将各服务器的心跳接收状况作为应答发送的服务。从集群外的服务器中安装使用。
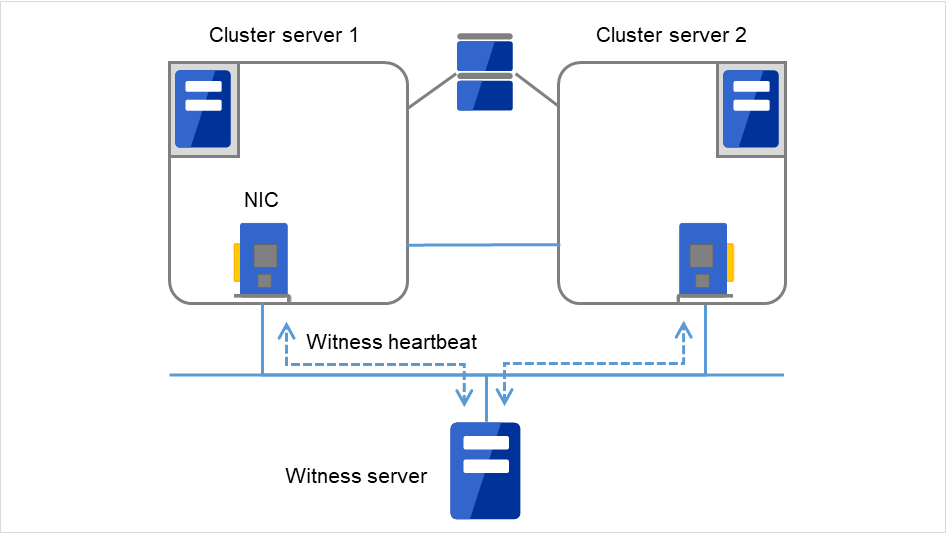
图 8.9 Witness 服务器服务¶
8.7.2. Witness 服务器服务相关的注意事项¶
Witness 服务器服务在Node.js 环境中运行。因此在安装Witness服务器服务之前,需要先安装Node.js。
请参阅《开始指南》的"EXPRESSCLUSTER的运行环境" - "Witness服务器的运行环境"。
8.7.3. 安装Witness 服务器服务的方法¶
使用Node.js 环境的npm 命令进行安装。将Witness 服务器服务模块存放在任意的文件夹内,执行以下命令。
> npm install --global clpwitnessd-<version>.tgz
请从安装盘 DVD-ROM中的以下路径获取Witness服务器的服务模块。
Common/<version>/common/tools/witnessd/clpwitnessd-<version>.tgz
8.7.4. Witness 服务器的设置方法¶
要更改Witness服务器服务设置时,直接编辑设置文件。打开以下命令执行结果的第1行中显示的文件夹。
> npm list --global clpwitnessd
(执行结果示例)
C:\Users\Administrator\AppData\Roaming\npm
\`-- clpwitnessd@4.1.0
请将保存在打开的文件夹下的node_modules\clpwitnessd中的clpwitnessd.conf.js用记事本等文本编辑器进行编辑。
设置项目如下。
项目 |
默认值 |
说明 |
|---|---|---|
http.enable |
True |
指定是否执行HTTP服务器。
true: 执行
false: 不执行
|
http.port |
80 |
指定HTTP服务器的备用端口号。 |
http.keepalive |
10000 |
指定HTTP服务器的keepalive时间。
[毫秒]
|
https.enable |
False |
指定是否执行HTTPS服务器。
true: 执行
false: 不执行
|
https.port |
443 |
指定HTTPS服务器的备用端口号。 |
https.keepalive |
10000 |
指定HTTPS服务器的keepalive时间。
[毫秒]
|
https.ssl.key |
server_key.pem |
指定在HTTPS服务器中使用的秘钥文件。 |
https.ssl.crt |
server_crt.pem |
指定在HTTPS服务器中使用的证书文件。 |
log.directory |
. |
指定日志输出目标文件夹。 |
log.level |
info |
指定日志输出级别。
error: 只进行错误日志输出
warn: 输出error + 警告日志
info: 输出warn + 信息日志
debug:输出 info + 详细日志
|
log.size |
1024 * 1024 * 512 |
指定日志的轮循大小。
[字节]
|
data.available |
10000 |
指定集群服务器的通信状况数据的默认有效期限。
[毫秒]
|
8.7.5. Witness 服务器服务的执行方法¶
执行以下命令,在前台启动Witness服务器服务。Windows服务或者作为Linux后台的执行方法请参考下面"Witness 服务器服务的OS服务化"。
> clpwitnessd
8.7.6. Witness 服务器服务的OS服务化¶
想要在OS启动时开始Witness 服务器服务,需要作为OS服务进行注册。
Witness 服务器服务作为OS服务的注册方法(Windows 服务控制管理器,Linux systemd 时) 如示例所示。此外,OS服务的注册方法因环境不同而不同,因此请根据使用的环境参考以下信息进行设置。
Windows 服务控制管理器的注册
以下是使用npm packagewinser 进行注册的步骤。
使用npm 命令,安装winser。执行以下命令, winser package从npm存储库中下载后,进行安装。
> npm install --global winser
在任意的场所创建执行服务用的文件夹。在默认设置中,该文件夹用于保存日志文件,SSL秘钥文件,SSL证书文件。
在用于执行服务的文件夹下,创建一个使用winser的用于服务注册用的package.json 文件。路径的分隔符中请输入两个 \ 。此外,虽然会因字符数的原因被换行,但是 "start" 中指定的路径实际上是1行。
{ "name": "clpwitnessd-service", "version": "1.0.0", "license": "UNLICENSED", "private": true, "scripts": { "start": "C:\\Users\\Administrator\\AppData\\Roaming\\npm\\clpwitnessd.cmd" } }
执行winser命令,注册和启动服务。
> winser -i -a
从[控制面板]-[管理工具]-[服务]中确认在package.json的"name"里指定名称的服务(ex. clpwitnessd-service)已被注册。
Linux systemd 的注册
创建systemd 的Unit文件,进行注册的步骤如下。
- 在任意的场所创建执行服务用的目录。在默认设置中,该文件夹用于保存日志文件,SSL秘钥文件,SSL证书文件。(ex. /opt/clpwitnessd)
- /etc/systemd/system 中创建 Witness服务器服务的 Unit 文件。(ex. clpwitnessd.service)
[Unit] Description=EXPRESSCLUSTER Witness Server After=syslog.target network.target [Service] Type=simple ExecStart=/usr/bin/clpwitnessd WorkingDirectory=/opt/clpwitnessd KillMode=process Restart=always [Install] WantedBy=multi-user.target
执行systemctl 命令,注册,启动服务。
# systemctl enable clpwitnessd # systemctl start clpwitnessd