10. 疑难解答¶
本章介绍使用EXPRESSCLUSTER过程中发生的故障的处理方法。
本章包含以下内容。
10.1. 发生故障时的步骤¶
本节介绍EXPRESSCLUSTER运行过程中发生故障时的操作步骤。
10.1.1. EXPRESSCLUSTER无法启动/退出¶
安装EXPRESSCLUSTER后重启服务器后,集群系统即开始运行,如果集群系统没有正常运行,请确认以下内容。
- 集群配置信息的服务器名,IP地址请确认服务器名,IP地址是否有效。(>hostname,>ipconfig....)
- License的登录状态可执行没有注册License。请在集群中所有服务器上执行License Manager,确认License是否已经登录。如果是试用版License或期间定制版License,确认登录的License是否在有效期内。执行LicenseManger的方法:选择[启动]菜单-[EXPRESSCLUSTER Server]-[License管理]。
- 确认EXPRESSCLUSTER的服务状态启动OS的服务控制管理器,确认以下EXPRESSCLUSTER的服务是否处于启动状态。如果服务均为启动状态,EXPRESSCLUSTER运行正常。执行服务控制管理器的方法:选择[控制面板]-[管理工具] -[服务]。- EXPRESSCLUSTER- EXPRESSCLUSTER Disk Agent- EXPRESSCLUSTER Event- EXPRESSCLUSTER Information Base- EXPRESSCLUSTER API- EXPRESSCLUSTER Manager- EXPRESSCLUSTER Node Manager- EXPRESSCLUSTER Old API Support- EXPRESSCLUSTER Server- EXPRESSCLUSTER Transaction- EXPRESSCLUSTER Web Alert
- 磁盘的可用空间状态执行OS的[磁盘管理],确认<EXPRESSCLUSTER安装路径>所属的磁盘可用空间容量是否够用。EXPRESSCLUSTER所用磁盘容量的相关内容请参考《开始指南》的"EXPRESSCLUSTER的运行环境"。执行[磁盘管理]的方法:选择[控制面板]-[管理工具]-[计算机管理],选择图标树形图中的[服务和应用程序]-[服务]。
- 内存不足或OS资源不足执行OS的任务管理器,确认OS的内存使用情况,CPU的使用率。
10.1.2. 网络分区解决资源启动/停止失败¶
- 主要解决方法原因可执行是内存不足或OS资源不足,请确认。
- PING方法考虑可执行是内存不足或OS的资源不足,请确认。
- DISK方式Cluster WebUI设置错误。请在启动/停止失败的服务器的[服务器属性]->[HBA]标签页中确认磁盘心跳用分区是否设置了过滤。另外,请确认其他资源中(磁盘资源,镜像磁盘资源)是否正在使用磁盘心跳用分区。
10.1.3. 组资源启动/停止失败¶
在组资源启动/停止时发现异常时,异常的详细信息将输出到警报,事件日志中。请使用该信息,参考"组资源启动/停止时的详细信息",分析异常的原因,采取相应的处理办法。
10.1.4. 查出网络分区解决资源异常¶
- 主要解决方法原因可执行是内存不足或OS资源不足,请确认。
- PING方式PING的目标设备没有PING命令的应答。请确认集群服务器到PING的目标设备之间的通信线路是否有问题。
- DISK方式访问磁盘心跳用分区超时,或检测出连接共享磁盘线缆断线。发生超时时,请在[集群的属性]->[NP解决]标签页中选择发生异常的磁盘网络解决资源,然后打开[属性]。在[磁盘NP的属性]对话框中调整[IO等待时间]。如果检测出线缆断线,请确认线缆的连接情况。
10.1.5. 监视资源中发生异常¶
在监视资源中发现异常时,异常的详细信息将输出到警报,事件日志中。请使用该信息,参考"监视资源异常时的详细信息",分析异常的原因,采取相应的处理办法。
10.1.7. 单侧服务器宕机的恢复¶
如果集群的[集群属性]中没有设置自动恢复模式,排除故障重启后服务器将变为"保留(宕机后重启)"状态。使用Cluster WebUI或[clpcl]命令恢复服务器,即可将其恢复为能够作为集群运行的正常状态。
使用Replicator,如果构成镜像组的磁盘之间数据不一致,则可以通过服务器的恢复,自动执行镜像重建,使数据一致。
通过Cluster WebUI恢复服务器的方法请参考在线版手册。
通过[clpcl]命令恢复服务器的方法请参考本指南的"9. EXPRESSCLUSTER命令参考"中的"操作集群(clpcl命令)"。
10.1.8. 两侧服务器宕机的恢复¶
如果集群的[集群属性]->[扩展]标签页中的[自动复归]设置为[关闭],如果由于硬件故障而关闭所有服务器,启动后,所有服务器将与集群分离。请使用Cluster WebUI或[clpcl]命令对所有服务器执行服务器的恢复。
执行服务器的恢复之后,所有的组将处于停止状态。请启动组。使用了Replicator时,启动组后,将自动执行镜像重建,使数据恢复一致。
10.1.9. 发生网络分区¶
网络分区含义是服务器之间的通信线路全部中断。以下是在没有登录网络分区解决资源的状态下发生网络分区时的确认方法。下面以2节点集群结构中,心跳资源中登录了内核模式LAN心跳资源的情况为例进行说明。
如果所有心跳资源均为正常状态(即没有发生网络分区),则[clpstat]命令的执行结果如下:
[在server1上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
*server0 : server1
server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
[on server1 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
=================================================================
[在server2上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
server0 : server1
*server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
[on server1 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
================================================================
发生了网络分区时,[clpstat]命令的执行结果如下。两侧服务器均认为对方服务器已经宕机。
[在server1上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
*server0 : server1
server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Caution]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : x x
[on server1 : Offline]
HB 0 1
-----------------------------------------------------------------
server0 : - -
server1 : - -
=================================================================
[在server2上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
server0 : server1
*server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Offline]
HB 0 1
-----------------------------------------------------------------
server0 : - -
server1 : - -
[on server1 : Caution]
HB 0 1
-----------------------------------------------------------------
server0 : x x
server1 : o o
=================================================================
因此,发生网络分区时请立即关闭两个服务器。之后,确认各心跳资源的如下内容。
- 内核模式LAN心跳资源- LAN线缆的状态- 网络接口的状态
如果私网从发生网络分区的状态中恢复,EXPRESSCLUSTER将关闭服务器。
EXPRESSCLUSTER如果发现在多个服务器上启动了同一个组,将关闭启动同一组的所有服务器。
用Replicator时,服务器重启后的镜像磁盘资源状态可执行根据关闭服务器时间的不同而不同。
根据不同的关闭服务器时间,可执行有"需要强制镜像复归","需要镜像恢复","正常状态"等几种状态。
10.2. 手动连接镜像磁盘/共享型镜像磁盘¶
EXPRESSCLUSTER由于故障等原因无法启动,需要解除镜像磁盘资源和共享型镜像磁盘资源的数据分区的访问控制时,按以下步骤操作。
10.2.1. 镜像可用的状态下正常连接¶
EXPRESSCLUSTER Server服务无法启动,EXPRESSCLUSTER Disk Agent服务能够启动时,可以按照以下步骤解除访问限制。
在想要连接的服务器上执行以下命令。
镜像磁盘时:
clpmdctrl --active <镜像磁盘资源名 (例:md1)>共享型镜像磁盘时:
clphdctrl --active <共享型镜像磁盘资源名 (例:hd1)>可以访问镜像磁盘资源/共享型镜像磁盘资源。write的数据镜像到另一服务器。
10.2.2. 镜像不可用的状态下强行连接¶
EXPRESSCLUSTER Server服务无法启动,EXPRESSCLUSTER Disk Agent服务也无法启动时保存镜像磁盘/共享型镜像磁盘资源上的数据的步骤如下。
但是前提条件是在此之前镜像应该是正常状态,或者知道哪个服务器拥有最新的数据。
Server 1,Server 2都处于无法启动EXPRESSCLUSTER Server服务的状态。 Server 1有最新的数据。 在有最新数据的服务器中卸载EXPRESSCLUSTER,重新启动服务器。
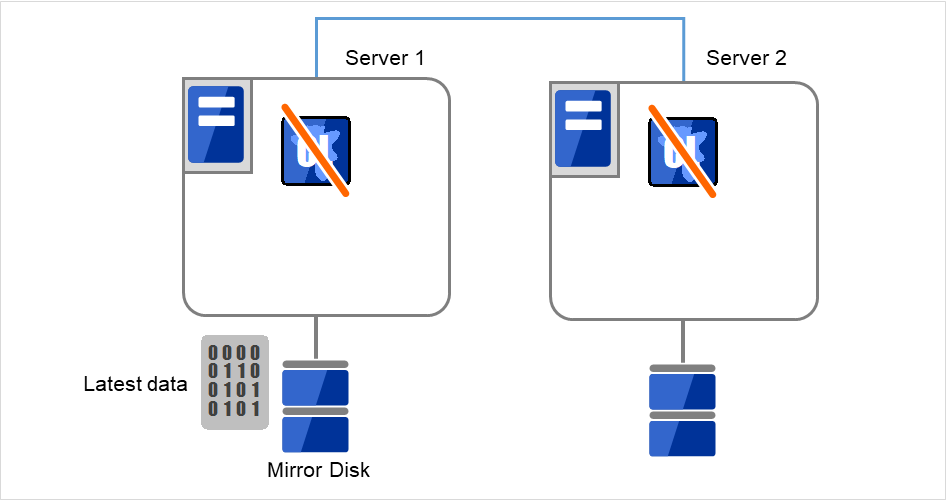
图 10.1 镜像磁盘上的数据保存 (1)¶
将备份设备(Backup device)连接到Server 1,使用backup命令,备份数据分区内的数据。
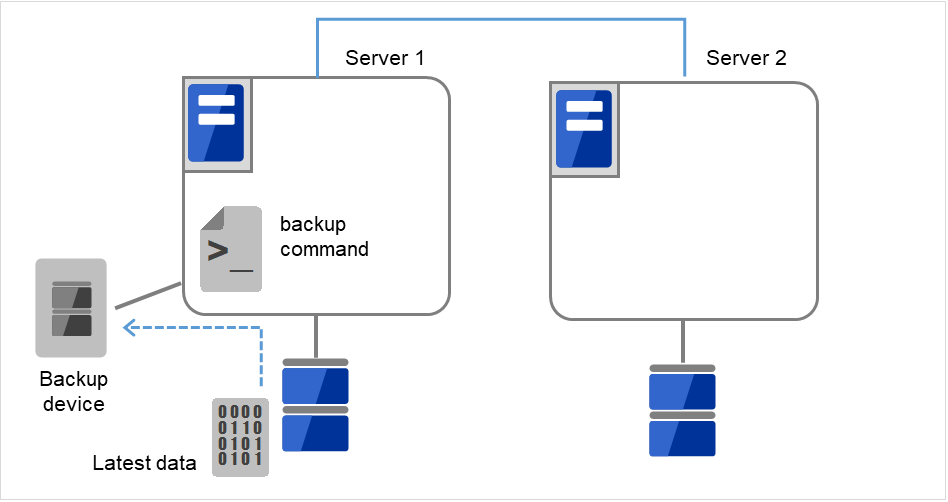
图 10.2 镜像磁盘上的数据保存 (2)¶
对于共享型镜像磁盘资源,在相同服务器组内的其他服务器使用共享磁盘的状态下进行上述处理,因为有可执行破坏共享磁盘上的数据,请务必停止其他服务器,或者在拔去其他服务器电缆的状态下实施。
10.3. 镜像中断状态的恢复¶
自动镜像复归可用时,无需进行特殊操作,镜像恢复将自动执行。
如果需要强制镜像复归,则需要通过命令或Cluster WebUI执行强制镜像恢复操作。
自动镜像复归禁用时,需要通过命令或Cluster WebUI执行镜像恢复操作。
在以下情况下,差分镜像恢复功能无效,执行全面复制。
- 因为更换磁盘等而更改了镜像磁盘资源/共享型镜像磁盘资源的分区设置时
- 在镜像磁盘资源正常启动的状态下两侧服务器同时宕机时
- 在共享型镜像磁盘资源正常启动的状态下两侧服务器组的当前服务器(在服务器组内进行磁盘更新/管理的服务器)同时宕机时
- 因为磁盘故障等不能正常记录差分信息时
10.3.1. 自动复原镜像¶
自动镜像复归启用时,在以下条件下将执行自动镜像复归。
在以下条件下不执行自动镜像复归。
镜像恢复的执行状态确认请参考"通过命令确认镜像恢复的执行状态"以及"使用Cluster WebUI确认镜像恢复的执行状态"。
10.3.2. 使用命令确认镜像中断状态¶
如果是镜像磁盘资源,执行以下命令可以确认镜像中断状态。
clpmdstat --mirror <镜像磁盘资源名 (例:md1)>
执行[clpmdstat]命令后即显示镜像磁盘资源的状态。
正常时
Status: Normal md1 server1 server2 --------------------------------------------------------------- Mirror Color GREEN GREEN Fast Copy -- -- Lastupdate Time -- -- Break Time -- -- Needed Copy Percent 0% 0% Volume Used Percent 64% 64% Volume Size 10240MB 10240MB Server Name DP Error CP Error --------------------------------------------------------------- server1 NO ERROR NO ERROR server2 NO ERROR NO ERROR
需要镜像恢复时
Status: Abnormal md1 server1 server2 --------------------------------------------------------------- Mirror Color GREEN RED Fast Copy OK OK Lastupdate Time 2021/08/16 18:24:10 -- Break Time 2021/08/16 18:24:01 -- Needed Copy Percent 1% 0% Volume Used Percent 64% --% Volume Size 10240MB 10240MB Server Name DP Error CP Error --------------------------------------------------------------- server1 NO ERROR NO ERROR server2 NO ERROR NO ERROR
需要强制镜像复归时
Status: Abnormal md1 server1 server2 --------------------------------------------------------------- Mirror Color RED RED Fast Copy NG NG Lastupdate Time 2021/08/16 18:24:10 2021/08/16 18:50:33 Break Time 2021/08/16 18:24:01 2021/08/16 18:24:01 Needed Copy Percent 1% 1% Volume Used Percent 64% --% Volume Size 10240MB 10240MB Server Name DP Error CP Error --------------------------------------------------------------- server1 NO ERROR NO ERROR server2 NO ERROR NO ERROR
正在进行镜像恢复时
请参考"通过命令确认镜像恢复的执行状态"。
如果是镜像磁盘资源,执行以下命令可以确认镜像中断状态。
clphdstat --mirror <共享型镜像磁盘资源名 (例:hd1)>
详细请参照本指南的"9. EXPRESSCLUSTER命令参考"的"共享型镜像磁盘状态显示命令(clphdstat命令)"。
10.3.3. 通过命令确认镜像恢复的执行状态¶
在镜像磁盘资源中,执行以下命令能够确认镜像恢复的执行状态。
clpmdstat --mirror <镜像磁盘资源名 (例:md1)>
镜像恢复正在进行则显示如下信息。
Status: Recovering
md1 server1 server2
---------------------------------------------------------------
Mirror Color YELLOW -> YELLOW
15%
Recovery Status
---------------------------------------------------------------
Used Time 00:00:21
Remain Time 00:01:59
镜像恢复完成则显示如下信息。
Status: Normal
md1 server1 server2
---------------------------------------------------------------
Mirror Color GREEN GREEN
Fast Copy -- --
Lastupdate Time -- --
Break Time -- --
Needed Copy Percent 0% 0%
Volume Used Percent 64% 64%
Volume Size 10240MB 10240MB
Server Name DP Error CP Error
---------------------------------------------------------------
server1 NO ERROR NO ERROR
server2 NO ERROR NO ERROR
如果是镜像磁盘资源,执行以下命令可以确认镜像中断状态。
clphdstat --mirror <共享型镜像磁盘资源名 (例:hd1)>
详细请参照本指南的"9. EXPRESSCLUSTER命令参考"的"共享型镜像磁盘状态显示命令(clphdstat命令)"。
10.3.4. 用命令执行镜像恢复¶
执行以下命令开始恢复镜像。
镜像磁盘时:
clpmdctrl --recovery <镜像磁盘资源名 (例:md1)>
共享型镜像磁盘时:
clphdctrl --recovery <共享型镜像磁盘资源名 (例:hd1)>
可以进行局部镜像恢复时,使用不同信息进行恢复(FastSync技术)。
命令在开始执行镜像恢复后,将立刻返回控制。镜像恢复的状态请参考"通过命令确认镜像恢复的执行状态"以及"使用Cluster WebUI确认镜像恢复的执行状态"进行确认。
10.3.5. 通过命令强制镜像复归¶
无法确定哪个服务器持有最新数据时,或者EXPRESSCLUSTER无法自动判断时,则需要进行强制镜像复归。
此时,需要手动确定持有最新数据的服务器,执行强制镜像复归。
注解
在强制镜像复归中的镜像复制有可执行是全面复制,而不是差分复制。
请使用下述某种方法确定持有最新数据的服务器。
通过Cluster WebUI的Mirror Disk 列表确认
1. 从Cluster WebUI的镜像磁盘列表中,点击想确认的镜像磁盘资源/共享型镜像磁盘资源。2. 点击[详细信息]图标。3. 确认最终数据更新时间(Last data updated time),确定持有最新数据的服务器。但是,此最终数据更新时间将取决于OS所设置的时间。
通过[clpmdstat]/[clphdstat]命令进行确认。
可以通过以下命令进行确认。
执行以下命令。
镜像磁盘时:
clpmdstat --mirror <镜像磁盘资源名 (例:md1)>共享型镜像磁盘时:
clphdstat --mirror <共享型镜像磁盘资源名 (例:hd1)>确认最终数据更新时间(Last data updated time),确定持有最新数据的服务器。但是,此最终数据更新时间将取决于OS所设置的时间。
通过磁盘上的数据进行确认
注解
如果弄错操作步骤,可执行会造成数据损坏,因此请尽量使用上述的「通过Cluster WebUI的Mirror Disk List进行确认」或者「通过[clpmdstat] / [clphdstat] 命令进行确认」的步骤。
镜像磁盘时:
确认所有的组均已停止。
执行以下命令,连接镜像磁盘资源。
clpmdctrl --active <镜像磁盘资源名 (例:md1)> -f逻辑验证连接目标服务器上的数据。
执行以下命令,断开镜像磁盘资源。
clpmdctrl --deactive <镜像磁盘资源名 (例:md1)>共享型镜像磁盘的场合:
确认所有的组均已停止。
执行以下命令,连接镜像磁盘资源。
clphdctrl --active <共享型镜像磁盘资源名 (例:hd1)> -f逻辑验证连接目标服务器上的数据。
执行以下命令,断开共享型镜像磁盘资源。
clphdctrl --deactive <共享型镜像磁盘资源名 (例:hd1)>
确定了持有最新数据的服务器后,执行以下命令,开始强制镜像复归。
镜像磁盘时(在保存最新数据的服务器上执行):
clpmdctrl --force <镜像磁盘资源名 (例:md1)>
共享型镜像磁盘时(在保存最新数据的服务器上执行):
clphdctrl --force <共享型镜像磁盘资源名 (例:hd1)>
注解
[clpmdctrl --force] 和 [clphdctrl --force]命令把执行的服务器侧的数据更新为最新数据。执行此步骤后,当自动镜像复归禁用时请手动进行镜像复归。
[clpmdctrl]/[clphdctrl]命令在开始执行强制镜像复归后,将立刻返回控制。强制镜像复归的状态请参考"通过命令确认镜像恢复的执行状态"以及"使用Cluster WebUI确认镜像恢复的执行状态"进行确认。
确认强制镜像复归完成后,就可以启动组使用镜像磁盘了。
10.3.6. 通过命令只在一台服务器上进行强制镜像复归¶
有时,可执行其中某台服务器因为H/W或OS故障无法启动,而可以启动的服务器上又不是最新的数据。
如果想只在能够启动的服务器上启动业务,则可以对能够启动的服务器进行强制镜像复归。
执行该操作后,执行了命令的服务器将强行拥有最新数据。因此,目前无法启动的服务器能够启动之后,其数据将不再是最新数据。
了解这一点之后,请执行以下操作。
针对镜像磁盘资源,在一台服务器上进行强制复归执行使用Cluster WebUI的步骤。请参阅"使用Cluster WebUI仅对一台服务器进行强制镜像复归"的步骤。
如果使用共享型镜像磁盘资源,在对象服务器上执行以下命令,开始强制镜像复归。
镜像磁盘时:
clpmdctrl --force <镜像磁盘资源名 (例:md1)>
共享型镜像磁盘时:
clphdctrl --force <共享型镜像磁盘资源名 (例:hd1)>
执行命令后,就可以启动组使用共享型镜像磁盘了。
10.3.7. 使用Cluster WebUI确认镜像中断状态¶
从Cluster WebUI启动镜像磁盘列表,可以确认镜像中断状态。
正常时

需要镜像恢复时

需要强制镜像复归时

正在进行镜像恢复处理时
请参考"使用Cluster WebUI确认镜像恢复的执行状态 "。
10.3.8. 使用Cluster WebUI确认镜像恢复的执行状态¶
从Cluster WebUI的镜像磁盘列表确认镜像恢复的执行状态。
镜像恢复正在进行则显示如下信息。

镜像恢复已经完成则显示如下信息。

10.3.9. 使用Cluster WebUI进行镜像复归¶
从Cluster WebUI的镜像磁盘列表中点击需要复归的镜像磁盘名,则变为下图。

点击需要复归的服务器的[差量复制]或[全复制],点击[执行]则执行镜像复归。
可进行局部镜像恢复时使用不同信息进行恢复(FastSync技术)。局部镜像恢复与强制镜像复归相比,会节省恢复时间。
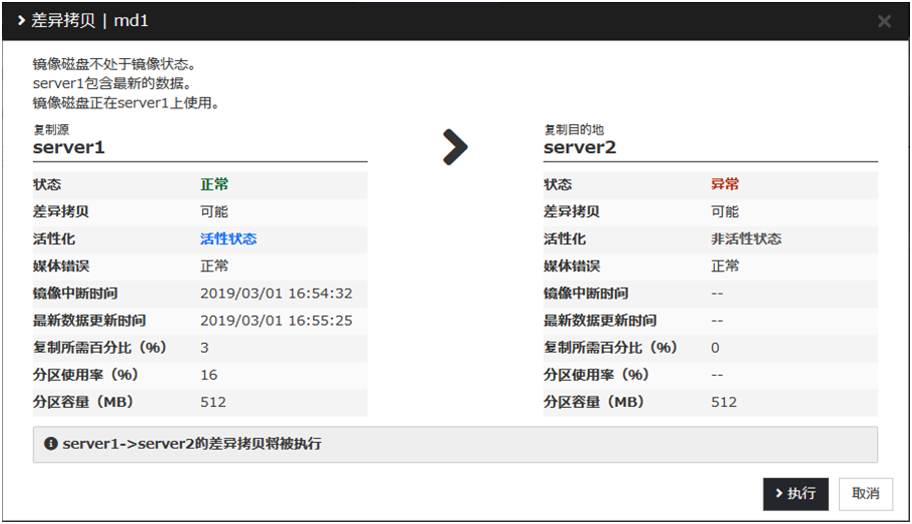
镜像恢复的状态请参考"通过命令确认镜像恢复的执行状态"以及"使用Cluster WebUI确认镜像恢复的执行状态"确认。
10.3.10. 使用Cluster WebUI进行强制镜像复归¶
EXPRESSCLUSTER无法确定哪个服务器持有最新数据时,则需要进行强制镜像复归。
此时,需要手动确定持有最新数据的服务器,执行强制镜像复归。
在强制镜像复归中,镜像恢复功能可执行会禁用,将进行全面复制。
请使用下述某种方法确定持有最新数据的服务器。
通过Cluster WebUI的镜像磁盘列表确认
1. 从Cluster WebUI的镜像磁盘列表中显示想确认的镜像磁盘资源的详细信息。2. 点击[详细信息]图标。3. 确认最终数据更新时间,确定持有最新数据的服务器。但是,此最终数据更新时间将取决于OS所设置的时间。
点击持有最新数据的服务器的[强制镜像复归],则变为下图。点击[执行]则开始镜像恢复。
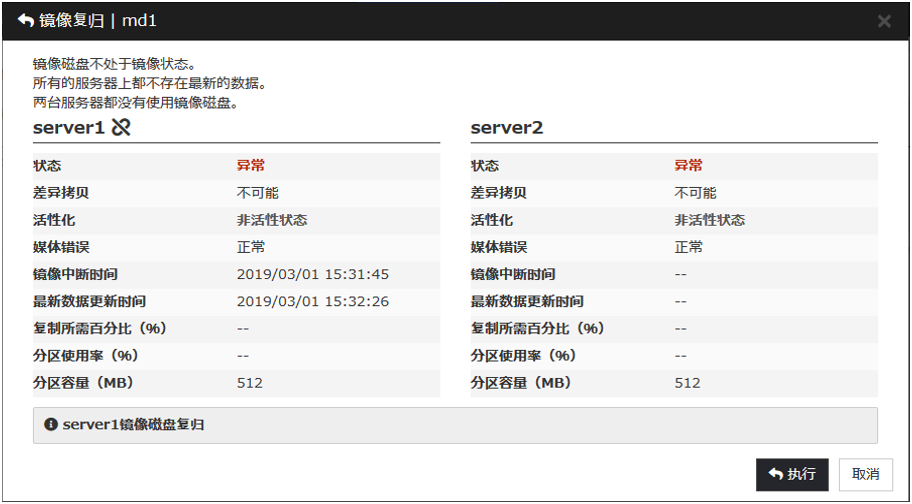
强制镜像复归的状态请参考"通过命令确认镜像恢复的执行状态"以及"使用Cluster WebUI确认镜像恢复的执行状态"确认。
确认强制镜像复归完成后,就可以启动组使用镜像磁盘。
10.3.11. 使用Cluster WebUI仅对一台服务器进行强制镜像复归¶
有时,可执行其中某一台服务器因为H/W或OS故障无法启动,而可以启动的服务器上又不是最新的数据。
如果想仅在能够启动的服务器上开始业务,则可以对能够启动的服务器进行强制镜像复归。
执行该操作后,执行了命令的服务器将强行拥有最新数据。因此,目前无法启动的服务器能够启动之后,其数据将不再是最新数据。了解这一点之后,请执行以下操作。
从Cluster WebUI的镜像磁盘列表中执行强制镜像复归。点击强制镜像复归的服务器的[镜像复归]则变为下图。点击[执行]则开始强制镜像复归。
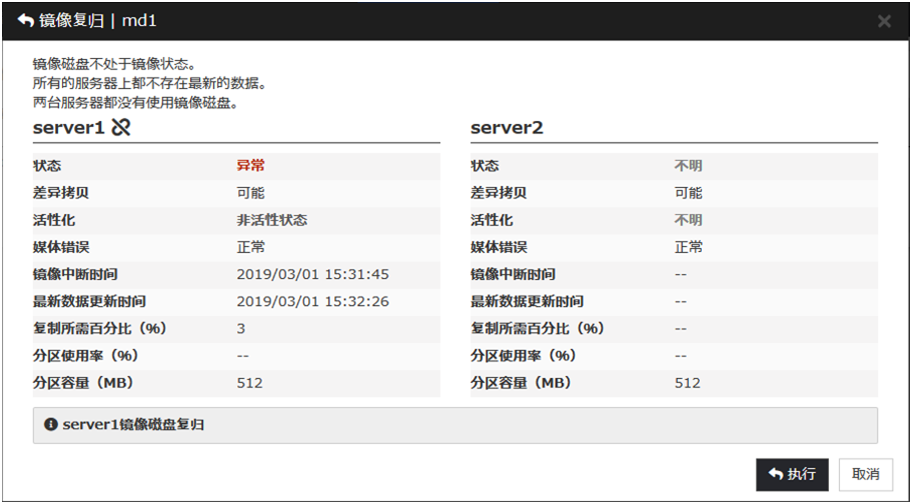
执行强制镜像复归后,就可以启动组使用镜像磁盘了。
10.3.12. 媒介感知功能无效¶
所谓媒介感知功能是指能够检测出网络线缆断线的OS功能,在检测出该故障时,TCP/IP能够收到媒介感知功能发出的通知,使分配给断线网卡的IP地址等信息在断线期间不可用。如果运行过程中IP地址等信息无效,则EXPRESSCLUSTER无法正常运行,因此安装时会禁用媒介感知功能。