仮想環境では次の図のような障害が考えられます。
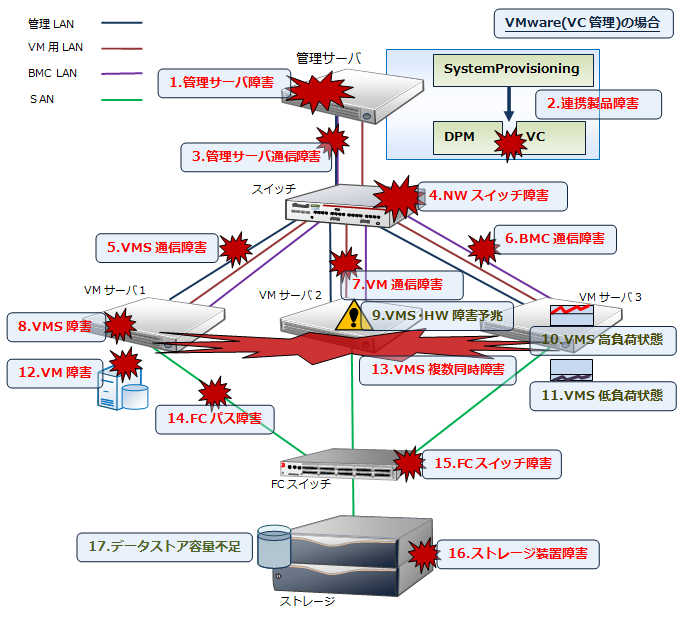
No | 障害 | 障害内容 | 障害の影響 | 復旧作業 | SSCの対応可能な動作 | その他の可用性向上方法など |
|---|---|---|---|---|---|---|
1 | 管理サーバ障害 | 管理サーバのHW/OS/SSC障害 | 管理中全マシンの監視/制御不可 | 管理サーバHW交換、OS再起動など | - | 定期的なバックアップ。クラスタソフトやFTサーバ利用による管理サーバの冗長化 |
2 | 連携製品障害 | VCやDPMなどの障害 | VC:管理中VMS・VMの監視/制御不可、DPM:VM作成不可/パッチ・AP適用不可 | 各製品のサービス再起動など | 連携動作時に障害を検出。
検出時に画面上で通知。 | クラスタソフトによる管理サーバの冗長化 |
3 | 管理サーバ通信障害 | 管理サーバNIC障害/NWケーブル断線 | 管理中全マシンの監視/制御不可 | NIC/ケーブルの交換 | 死活監視で障害を検出。*1
検出時にイベントの通知や画面上で通知を行う。 |
管理サーバの管理LAN ・ NICの冗長化 |
4 | NWスイッチ障害 | NWスイッチのHW障害 | 全業務実行不可。管理中全マシンの監視/制御不可 | NWスイッチHW交換・設定変更など | 死活監視で障害を検出。*1
検出時にイベントの通知や画面上で通知を行う。 | NWスイッチの冗長化 |
5 | VMS通信障害 | VMSの管理LAN・NIC障害/NWケーブル断線 | 障害発生VMSの制御不可。障害発生VMS上のVMに対してMigrationなどほとんどの制御が不可 | NIC/ケーブルを交換する | 死活監視やネットワークパス監視で障害を検出。*1
検出時、別VMSへVM退避を行う。VMSは予備機へ切り替えを行う *2。
また、イベントの通知や画面上で通知を行う。 | VMSの管理LAN ・ NICの冗長化 |
6 | BMC通信障害 | VMSのBMC・ NIC障害/NWケーブル断線 | BMC経由の電源制御/監視/診断不可 | HW障害箇所/ケーブルを交換する | BMC死活監視で障害を検出。*1
検出時にイベントの通知や画面上で通知を行う。 | - |
7 | VM通信障害 | VMSのVM用LAN ・NIC障害/NWケーブル断線 | 障害発生VMS上のVMの業務実行不可。VM作成不可(DPM使用時)/パッチ・AP適用不可 | VMの再起動など | ネットワークパス監視で障害を検出。*1
検出時、別VMSへVM退避を行う。
また、イベントの通知や画面上で通知を行う。 | VMSのVM用 LAN・NICの冗長化 |
8 | VMS障害 | VMSのHW/OS障害 | 障害発生VMS上のVMの業務実行不可 | 障害発生VMS上のVMを別VMSへ移動後、VMSを交換する。OS障害原因を取り除く。 | 死活監視やハードウェア監視で障害を検出。*1
検出時、別VMSへVM退避を行う。VMSは予備機へ切り替えを行う *2。
また、イベントの通知や画面上で通知を行う。 | - |
9 | VMS・HW 障害予兆 | 致命的でないVMSのHW障害 | 症状が悪化した場合、VMS障害が発生する可能性がある | 障害箇所HW交換。VMS本体を交換する場合は、VMS上のVMを別VMSへ移動が必要 | ハードウェア監視で障害を検出。
検出時、別VMSへVM退避を行う。VMSは予備機へ切り替えを行う *2。
また、イベントの通知や画面上で通知を行う。 | - |
10 | VMS高負荷状態 | VMSが高負荷状態になる | 高負荷による業務遅延 | - | 性能監視で障害を検出。
検出時、VM最適配置による負荷分散を行う。 | - |
11 | VMS低負荷状態 | VMSが低負荷状態になる | VMS利用効率の低下 | - | 性能監視で障害を検出。
検出時、VM最適配置による省電力を行う。
| - |
12 | VM障害 | VMのHW/OS障害 | 障害発生VMの業務実行不可 | VMの再起動など | 死活監視で障害を検出。*1
検出時にイベントの通知や画面上で通知を行う。 | クラスタソフトによるVMの冗長化 |
13 | VMS複数同時障害 | 電源などの共有装置障害(ブレードの場合)や停電による複数VMSの停止 | 停止したVMS上の業務実行不可 | 電源などの共有装置を交換、停電復旧後に起動 | 死活監視で障害を検出。*1
検出時にイベントの通知や画面上で通知を行う。 | 電源装置の冗長化、UPSの導入 |
14 | FCパス障害 | VMSのHBA障害/FCケーブル断線 | 障害発生VMS上のVMの業務実行不可 | HBA/FCケーブルの交換 | ストレージパス監視で検出。*1
検出時にイベントの通知や画面上で通知を行う。 | HBA冗長化 |
15 | FCスイッチ障害 | FCスイッチ障害 | 全業務実行不可 | FCスイッチの交換 | ストレージパス監視で検出。*1
検出時にイベントの通知や画面上で通知を行う。 | FCスイッチ冗長化 |
16 | ストレージ装置障害 | ストレージのポート/コントローラ/ディスク障害 | 全業務実行不可 | ストレージ障害箇所の交換。データが無くなった場合はシステム再構築が必要 | ストレージパス監視で検出。*1
検出時にイベントの通知や画面上で通知を行う。 | ポート/コントローラの冗長化。ディスクを冗長性のあるRAIDレベルで構成する |
17 | データストア容量不足 | データストアの容量不足 | 新規VM作成不可、VMのディスク拡張不可 | データストア追加、容量拡張 | データストアの監視で検出。
検出時にイベントの通知や画面上で通知を行う。
| - |
*1 死活監視やストレージパス監視、ネットワークパス監視では、該当箇所の障害の影響により発生する現象を障害として検出します。そのため、該当箇所の障害を明示的に特定して検出することはできません。各監視機能の詳細については、「2.4.1. 管理対象の種類別の利用可能な監視機能について」を参照してください。
*2 VMSの予備機へ切り替えは、ブートコンフィグ(vIO)置換の設定が必要です。ブートコンフィグ(vIO)置換は、Express5800/SIGMABLADEでのみ利用可能です。「4.8.3. ブートコンフィグ(vIO)置換による仮想マシンサーバのN+1リカバリ」を参照してください。
各障害の具体的な検出動作や復旧動作詳細について、仮想化基盤全体で共通部分もありますが、仮想化基盤別に異なる部分も多くあります。