1. はじめに¶
1.1. 対象読者と目的¶
『CLUSTERPRO X スタートアップガイド』は、CLUSTERPRO をはじめてご使用になるユーザの皆様を対象に、CLUSTERPRO の製品概要、クラスタシステム導入のロードマップ、他マニュアルの使用方法についてのガイドラインを記載します。また、最新の動作環境情報や制限事項などについても紹介します。
1.2. 本書の構成¶
「2. クラスタシステムとは?」:クラスタシステムおよび CLUSTERPRO の概要について説明します。
「3. CLUSTERPRO の使用方法」:クラスタシステムの使用方法および関連情報について説明します。
「4. CLUSTERPRO の動作環境」:導入前に確認が必要な最新情報について説明します。
1.3. CLUSTERPRO マニュアル体系¶
CLUSTERPRO のマニュアルは、以下の 5 つに分類されます。各ガイドのタイトルと役割を以下に示します。
『CLUSTERPRO X スタートアップガイド』 (Getting Started Guide)
すべてのユーザを対象読者とし、製品概要、動作環境、アップデート情報、既知の問題などについて記載します。
『CLUSTERPRO X インストール&設定ガイド』 (Install and Configuration Guide)
CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアと、クラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO を使用したクラスタシステム導入から運用開始前までに必須の事項について説明します。実際にクラスタシステムを導入する際の順番に則して、CLUSTERPRO を使用したクラスタシステムの設計方法、CLUSTERPRO のインストールと設定手順、設定後の確認、運用開始前の評価方法について説明します。
『CLUSTERPRO X リファレンスガイド』 (Reference Guide)
管理者、および CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアを対象とし、CLUSTERPRO の運用手順、各モジュールの機能説明およびトラブルシューティング情報等を記載します。『CLUSTERPRO X インストール&設定ガイド』を補完する役割を持ちます。
『CLUSTERPRO X メンテナンスガイド』 (Maintenance Guide)
管理者、および CLUSTERPRO を使用したクラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO のメンテナンス関連情報を記載します。
『CLUSTERPRO X ハードウェア連携ガイド』 (Hardware Feature Guide)
管理者、および CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアを対象読者とし、特定ハードウェアと連携する機能について記載します。『CLUSTERPRO X インストール&設定ガイド』を補完する役割を持ちます。
1.4. 本書の表記規則¶
本書では、注意すべき事項、重要な事項および関連情報を以下のように表記します。
注釈
この表記は、重要ではあるがデータ損失やシステムおよび機器の損傷には関連しない情報を表します。
重要
この表記は、データ損失やシステムおよび機器の損傷を回避するために必要な情報を表します。
参考
この表記は、参照先の情報の場所を表します。
また、本書では以下の表記法を使用します。
表記 |
使用方法 |
例 |
|---|---|---|
[ ] 角かっこ |
コマンド名の前後
画面に表示される語(ダイアログボックス、メニューなど)の前後
|
[スタート]をクリックします。
[プロパティ]ダイアログ ボックス
|
コマンドライン中の [ ] 角かっこ |
かっこ内の値の指定が省略可能であることを示します。 |
|
モノスペースフォント |
パス名、コマンドライン、システムからの出力(メッセージ、プロンプトなど)、ディレクトリ、ファイル名、関数、パラメータ |
|
太字 |
ユーザが実際にコマンドプロンプトから入力する値を示します。 |
以下を入力します。
clpcl -s -a
|
|
ユーザが有効な値に置き換えて入力する項目 |
|
 本書の図では、CLUSTERPROを表すために このアイコンを使用します。
本書の図では、CLUSTERPROを表すために このアイコンを使用します。
2. クラスタシステムとは?¶
本章では、クラスタシステムの概要について説明します。
本章で説明する項目は以下のとおりです。
2.1. クラスタシステムの概要¶
現在のコンピュータ社会では、サービスを停止させることなく提供し続けることが成功への重要なカギとなります。例えば、1 台のマシンが故障や過負荷によりダウンしただけで、顧客へのサービスが全面的にストップしてしまうことがあります。そうなると、莫大な損害を引き起こすだけではなく、顧客からの信用を失いかねません。
このような事態に備えるのがクラスタシステムです。クラスタシステムを導入することにより、万一のときのシステム稼働停止時間 (ダウンタイム) を最小限に食い止めたり、負荷を分散させたりすることでシステムダウンを回避することが可能になります。
クラスタとは、「群れ」「房」を意味し、その名の通り、クラスタシステムとは「複数のコンピュータを一群 (または複数群) にまとめて、信頼性や処理性能の向上を狙うシステム」です。クラスタシステムには様々な種類があり、以下の 3 つに分類できます。この中で、CLUSTERPRO は HA(High Availability) クラスタに分類されます。
HA (High Availability) クラスタ
通常時は一方が現用系として業務を提供し、現用系障害発生時に待機系に業務を引き継ぐような形態のクラスタです。高可用性を目的としたクラスタで、データの引継ぎも可能です。共有ディスク型、データミラー型、遠隔クラスタがあります。
負荷分散クラスタ
クライアントからの要求を適切な負荷分散ルールに従って負荷分散ホストに要求を割り当てるクラスタです。高スケーラビリティを目的としたクラスタで、一般的にデータの引継ぎはできません。ロードバランスクラスタ、並列データベースクラスタがあります。
HPC (High Performance Computing) クラスタ
全てのノードの CPU を利用し、単一の業務を実行するためのクラスタです。高性能化を目的としており、あまり汎用性はありません。なお、HPC の 1 つであり、より広域な範囲のノードや計算機クラスタまでを束ねた、グリッドコンピューティングという技術も近年話題に上ることが多くなっています。
2.2. HA (High Availability) クラスタ¶
一般的にシステムの可用性を向上させるには、そのシステムを構成する部品を冗長化し、Single Point of Failure をなくすことが重要であると考えられます。Single Point of Failure とは、コンピュータの構成要素 (ハードウェアの部品) が 1 つしかないために、その箇所で障害が起きると業務が止まってしまう弱点のことを指します。HA クラスタとは、サーバを複数台使用して冗長化することにより、システムの停止時間を最小限に抑え、業務の可用性(availability) を向上させるクラスタシステムをいいます。
システムの停止が許されない基幹業務システムはもちろん、ダウンタイムがビジネスに大きな影響を与えてしまうそのほかのシステムにおいても、HA クラスタの導入が求められています。
HA クラスタは、共有ディスク型とデータミラー型に分けることができます。以下にそれぞれのタイプについて説明します。
2.2.1. 共有ディスク型¶
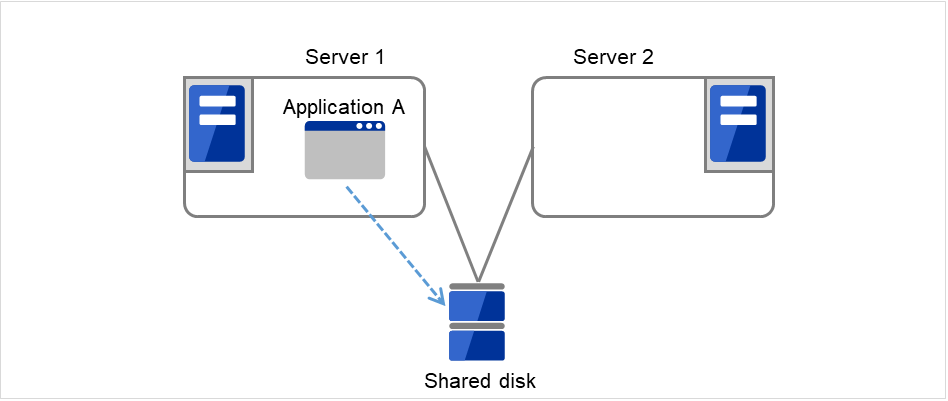
クラスタシステムでは、サーバ間でデータを引き継がなければなりません。このデータを共有ディスク上に置き、ディスクを複数のサーバで利用する形態を共有ディスク型といいます。
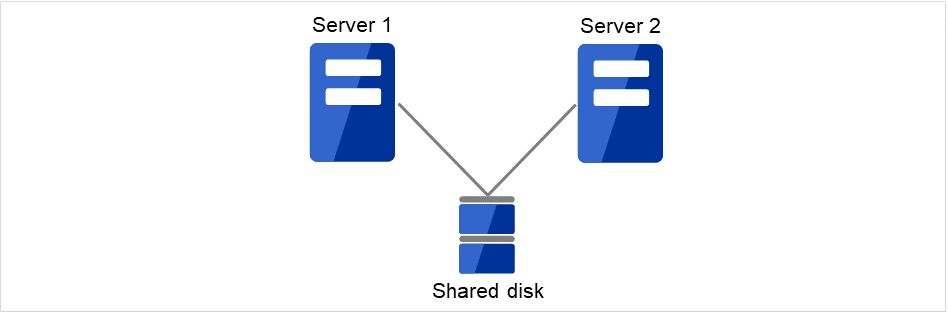
図 2.1 HAクラスタ構成図(共有ディスク型)¶
共有ディスクが必要になるため高価
大規模データを扱うシステム向き
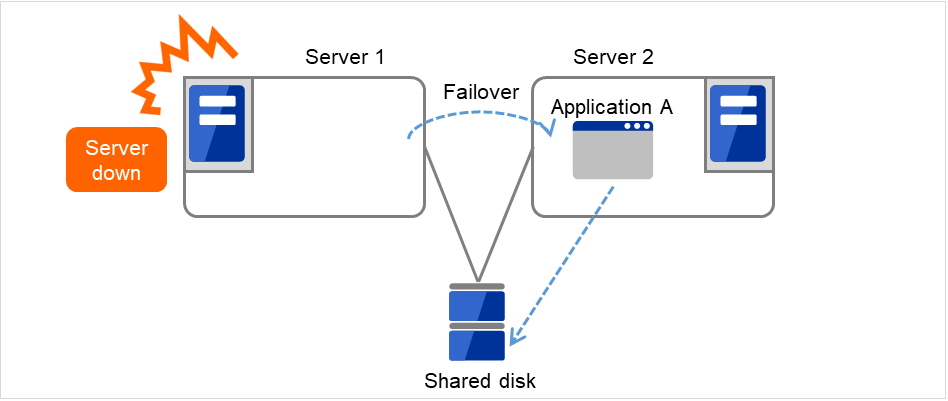
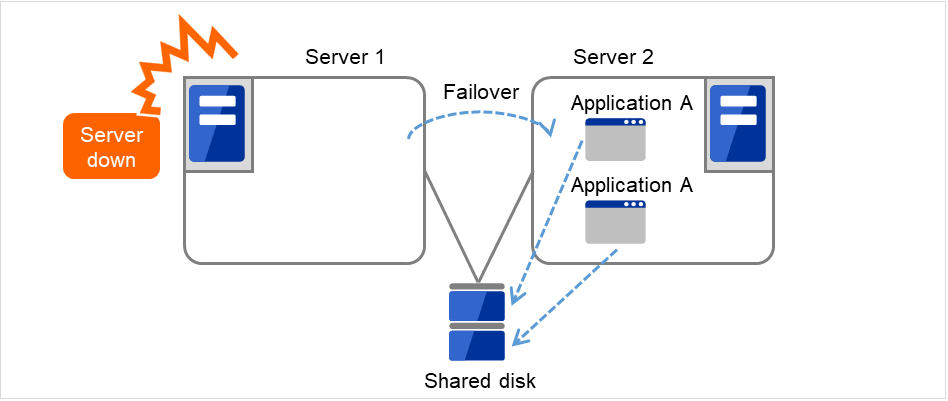
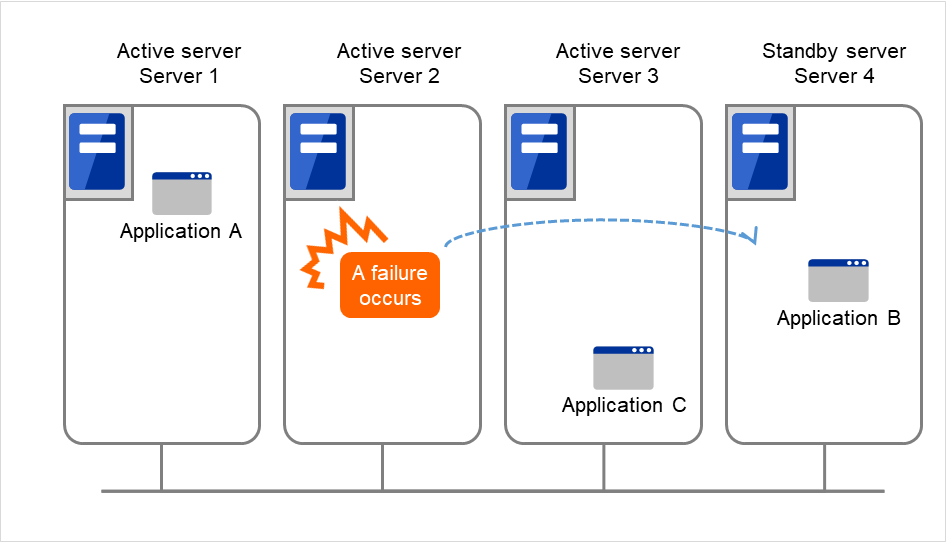
業務アプリケーションを動かしているサーバ(現用系サーバ)で障害が発生した場合、クラスタシステムが障害を検出し、待機系サーバで業務アプリケーションを自動起動させ、業務を引き継がせます。これをフェイルオーバといいます。クラスタシステムによって引き継がれる業務は、ディスク、IP アドレス、アプリケーションなどのリソースと呼ばれるもので構成されています。
クラスタ化されていないシステムでは、アプリケーションをほかのサーバで再起動させると、クライアントは異なる IP アドレスに再接続しなければなりません。しかし、多くのクラスタシステムでは、業務単位に仮想 IP アドレスを割り当てています。このため、クライアントは業務を行っているサーバが現用系か待機系かを意識する必要はなく、まるで同じサーバに接続しているように業務を継続できます。
データを引き継ぐためには、ファイルシステムの整合性をチェックしなければなりません。通常は、ファイルシステムの整合性をチェックするためにチェックコマンド (例えば、Linux の場合は fsck) を実行しますが、ファイルシステムが大きくなるほどチェックにかかる時間が長くなり、その間業務が止まってしまいます。この問題を解決するために、ジャーナリングファイルシステムなどでフェイルオーバ時間を短縮します。
業務アプリケーションは、引き継いだデータの論理チェックをする必要があります。例えば、データベースならばロールバックやロールフォワードの処理が必要になります。これらによって、クライアントは未コミットの SQL 文を再実行するだけで、業務を継続することができます。
障害からの復帰は、障害が検出されたサーバを物理的に切り離して修理後、クラスタシステムに接続すれば待機系として復帰できます。業務の継続性を重視する実際の運用の場合は、ここまでの復帰で十分な状態です。
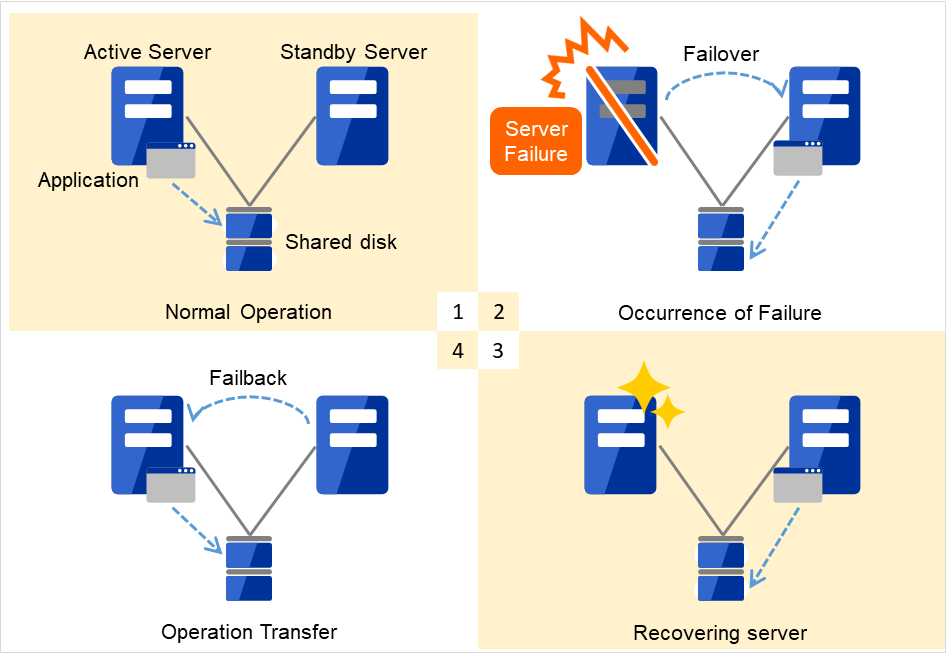
図 2.2 障害発生から復旧までの流れ¶
通常運用
障害発生
サーバ復旧
業務移動
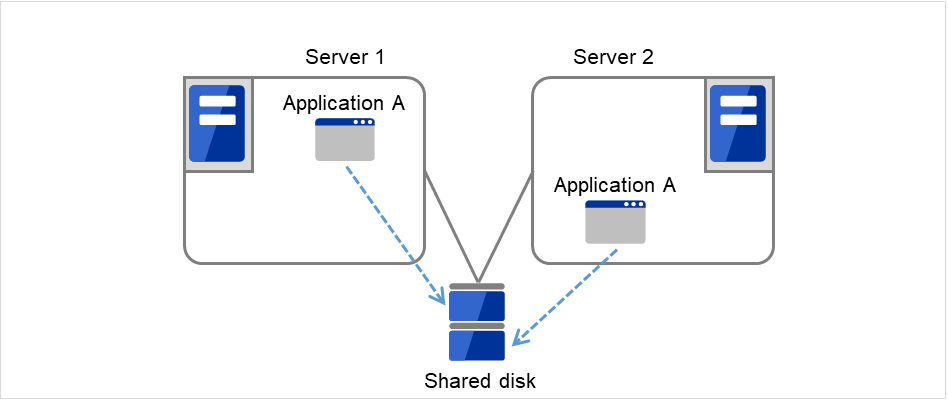
フェイルオーバ先のサーバのスペックが十分でなかったり、双方向スタンバイで過負荷になるなどの理由で元のサーバで業務を行うのが望ましい場合には、元のサーバで業務を再開するためにフェイルバックを行います。
図 2.3 HAクラスタの運用形態(片方向スタンバイ) のように、業務が1つであり、待機系では業務が動作しないスタンバイ形態を片方向スタンバイといいます。
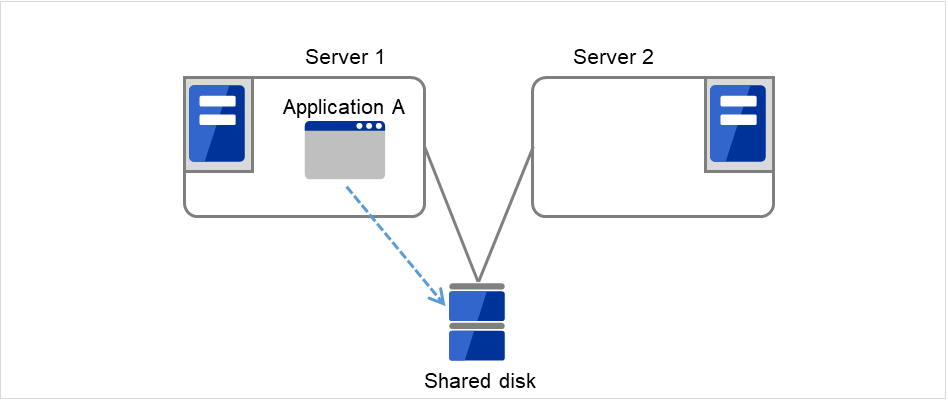
図 2.3 HAクラスタの運用形態(片方向スタンバイ)¶
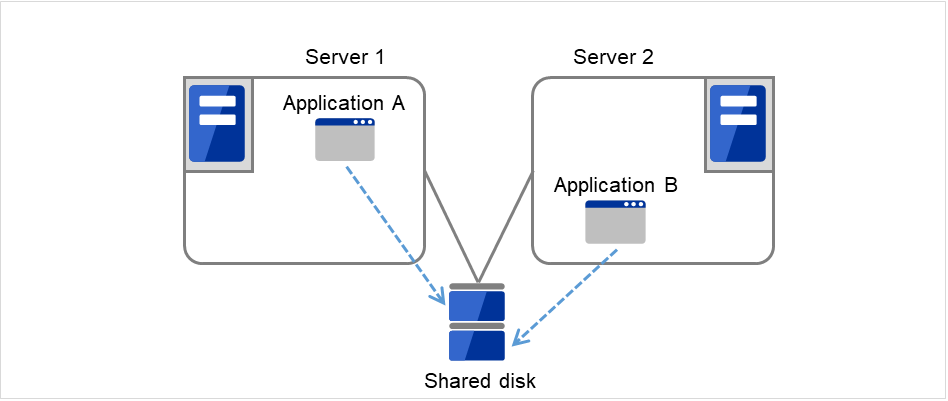
図 2.4 HAクラスタの運用形態(双方向スタンバイ)¶
2.2.2. データミラー型¶
前述の共有ディスク型は大規模なシステムに適していますが、共有ディスクはおおむね高価なためシステム構築のコストが膨らんでしまいます。そこで共有ディスクを使用せず、各サーバのディスクをサーバ間でミラーリングすることにより、同じ機能をより低価格で実現したクラスタシステムをデータミラー型といいます。
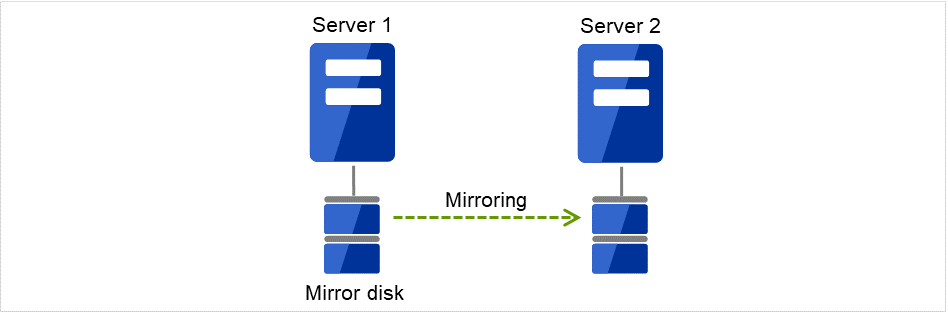
図 2.5 HAクラスタ構成図(データミラー型)¶
共有ディスクが不要なので安価
ミラーリングのためデータ量が多くないシステム向き
しかし、サーバ間でデータをミラーリングする必要があるため、大量のデータを必要とする大規模システムには向きません。
アプリケーションからの Write 要求が発生すると、データミラーエンジンはローカルディスクにデータを書き込むと同時に、インタコネクトを通して待機系サーバにも Write 要求を振り分けます。インタコネクトとは、サーバ間をつなぐネットワークのことで、クラスタシステムではサーバの死活監視のために必要になります。データミラータイプでは死活監視に加えてデータの転送に使用することがあります。待機系のデータミラーエンジンは、受け取ったデータを待機系のローカルディスクに書き込むことで、現用系と待機系間のデータを同期します。
アプリケーションからのRead要求に対しては、単に現用系のディスクから読み出すだけです。
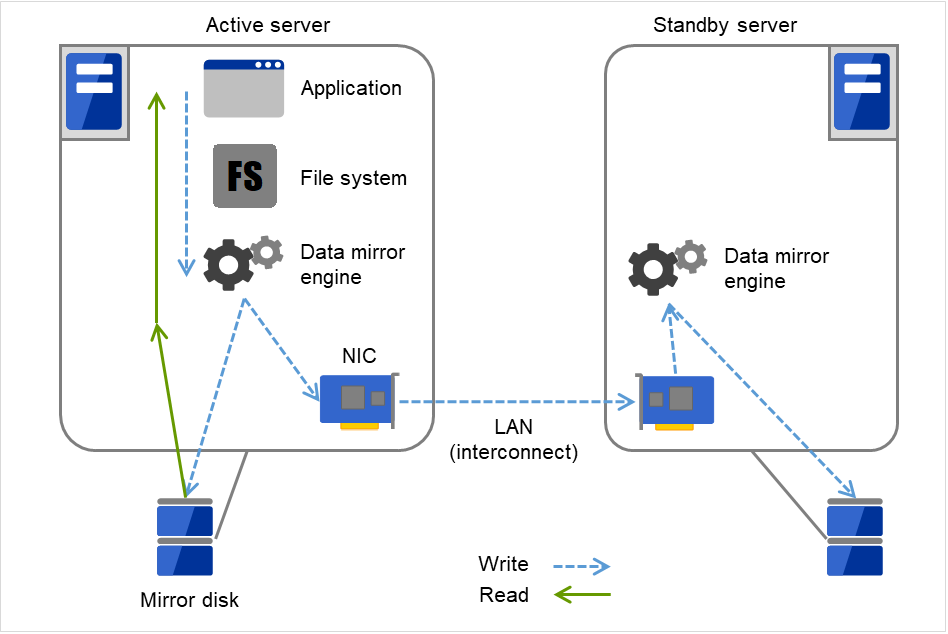
図 2.6 データミラーの仕組み¶
データミラーの応用例として、スナップショットバックアップの利用があります。データミラータイプのクラスタシステムは2カ所に共有のデータを持っているため、待機系のサーバをクラスタから切り離すだけで、バックアップ時間をかけることなくスナップショットバックアップとしてディスクを保存する運用が可能です。
フェイルオーバの仕組みと問題点
ここまで、一口にクラスタシステムといってもフェイルオーバクラスタ、負荷分散クラスタ、HPC (High Performance Computing) クラスタなど、さまざまなクラスタシステムがあることを説明しました。そして、フェイルオーバクラスタはHA (High Availability) クラスタと呼ばれ、サーバそのものを多重化することで、障害発生時に実行していた業務をほかのサーバで引き継ぐことにより、業務の可用性 (Availability) を向上することを目的としたクラスタシステムであることを見てきました。次に、クラスタの実装と問題点について説明します。
2.3. 障害検出のメカニズム¶
クラスタソフトウェアは、業務継続に問題をきたす障害を検出すると業務の引き継ぎ (フェイルオーバ) を実行します。フェイルオーバ処理の具体的な内容に入る前に、簡単にクラスタソフトウェアがどのように障害を検出するか見ておきましょう。
ハートビートとサーバの障害検出
クラスタシステムにおいて、検出すべき最も基本的な障害はクラスタを構成するサーバ全てが停止してしまうものです。サーバの障害には、電源異常やメモリエラーなどのハードウェア障害や OS のパニックなどが含まれます。このような障害を検出するために、サーバの死活監視としてハートビートが使用されます。
ハートビートは、ping の応答を確認するような死活監視だけでもよいのですが、クラスタソフトウェアによっては、自サーバの状態情報などを相乗りさせて送るものもあります。クラスタソフトウェアはハートビートの送受信を行い、ハートビートの応答がない場合はそのサーバの障害とみなしてフェイルオーバ処理を開始します。ただし、サーバの高負荷などによりハートビートの送受信が遅延することも考慮し、サーバ障害と判断するまである程度の猶予時間が必要です。このため、実際に障害が発生した時間とクラスタソフトウェアが障害を検知する時間とにはタイムラグが生じます。
リソースの障害検出
業務の停止要因はクラスタを構成するサーバ全ての停止だけではありません。例えば、業務アプリケーションが使用するディスク装置や NIC の障害、もしくは業務アプリケーションそのものの障害などによっても業務は停止してしまいます。可用性を向上するためには、このようなリソースの障害も検出してフェイルオーバを実行しなければなりません。
リソース異常を検出する手法として、監視対象リソースが物理的なデバイスの場合は、実際にアクセスしてみるという方法が取られます。アプリケーションの監視では、アプリケーションプロセスそのものの死活監視のほか、業務に影響のない範囲でサービスポートを試してみるような手段も考えられます。
2.3.1. 共有ディスク型の諸問題¶
共有ディスク型のフェイルオーバクラスタでは、複数のサーバでディスク装置を物理的に共有します。一般的に、ファイルシステムはサーバ内にデータのキャッシュを保持することで、ディスク装置の物理的な I/O 性能の限界を超えるファイル I/O 性能を引き出しています。
あるファイルシステムを複数のサーバから同時にマウントしてアクセスするとどうなるでしょうか?
通常のファイルシステムは、自分以外のサーバがディスク上のデータを更新するとは考えていないので、キャッシュとディスク上のデータとに矛盾を抱えることとなり、最終的にはデータを破壊します。フェイルオーバクラスタシステムでは、次のネットワークパーティション症状などによる複数サーバからのファイルシステムの同時マウントを防ぐために、ディスク装置の排他制御を行っています。
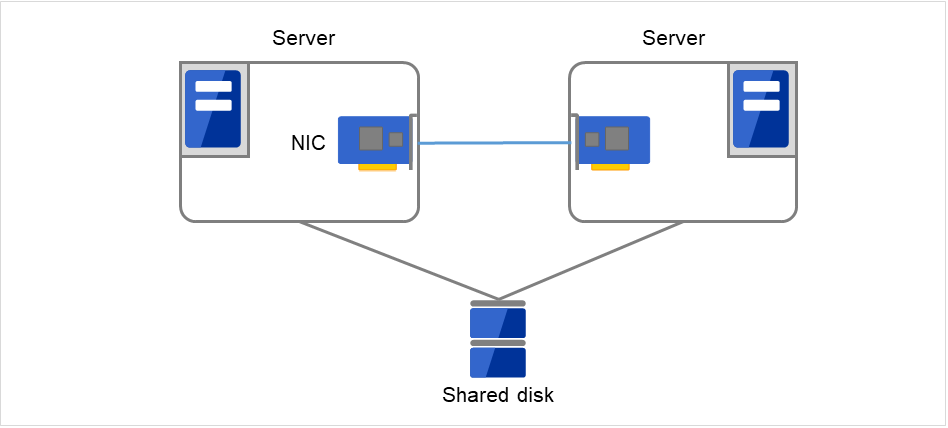
図 2.7 共有ディスクタイプのクラスタ構成¶
2.3.2. ネットワークパーティション症状 (Split-brain-syndrome)¶
サーバ間をつなぐすべてのインタコネクトが切断されると、ハートビートによる死活監視で互いに相手サーバのダウンを検出し、フェイルオーバ処理を実行してしまいます。結果として、複数のサーバでファイルシステムを同時にマウントしてしまい、データ破壊を引き起こします。フェイルオーバクラスタシステムでは異常が発生したときに適切に動作しなければならないことが理解できると思います。
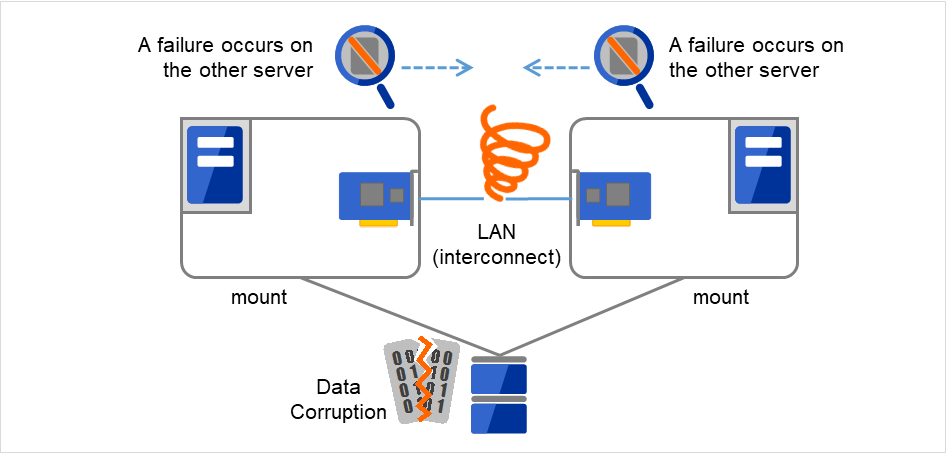
図 2.8 ネットワークパーティション症状¶
このような問題を「ネットワークパーティション症状」またはスプリットブレインシンドローム(Split-brain-syndrome) と呼びます。フェイルオーバクラスタでは、すべてのインタコネクトが切断されたときに、確実に共有ディスク装置の排他制御を実現するためのさまざまな対応策が考えられています。
2.4. クラスタリソースの引き継ぎ¶
クラスタが管理するリソースにはディスク、IP アドレス、アプリケーションなどがあります。これらのクラスタリソースを引き継ぐための、フェイルオーバクラスタシステムの機能について説明します。
2.4.1. データの引き継ぎ¶
クラスタシステムでは、サーバ間で引き継ぐデータは共有ディスク装置上のパーティションに格納します。すなわち、データを引き継ぐとは、アプリケーションが使用するファイルが格納されているファイルシステムを健全なサーバ上でマウントしなおすことにほかなりません。共有ディスク装置は引き継ぐ先のサーバと物理的に接続されているので、クラスタソフトウェアが行うべきことはファイルシステムのマウントだけです。
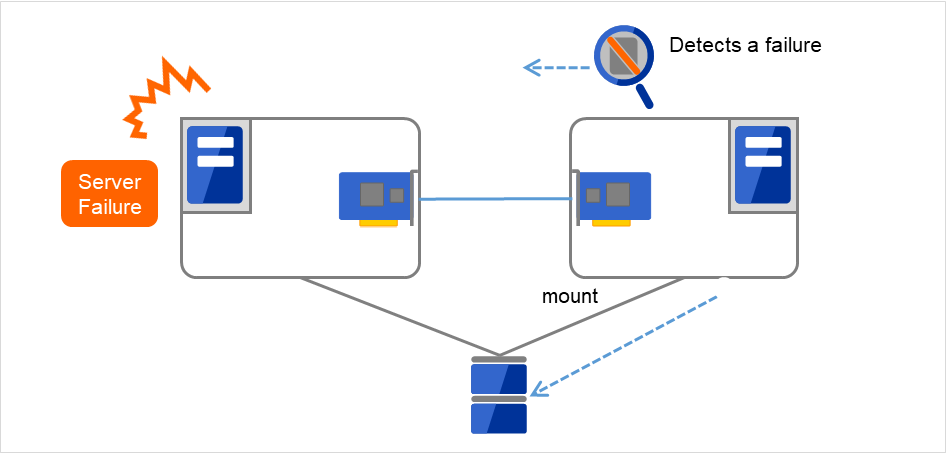
図 2.9 データの引き継ぎ¶
単純な話のようですが、クラスタシステムを設計・構築するうえで注意しなければならない点があります。
1 つは、ファイルシステムの復旧時間の問題です。引き継ごうとしているファイルシステムは、障害が発生する直前までほかのサーバで使用され、もしかしたらまさに更新中であったかもしれません。このため、引き継ぐファイルシステムは通常ダーティであり、ファイルシステムの整合性チェックが必要な状態となっています。ファイルシステムのサイズが大きくなると、整合性チェックに必要な時間は莫大になり、場合によっては数時間もの時間がかかってしまいます。それがそのままフェイルオーバ時間 (業務の引き継ぎ時間) に追加されてしまい、システムの可用性を低下させる要因になります。
もう 1 つは、書き込み保証の問題です。アプリケーションが大切なデータをファイルに書き込んだ場合、同期書き込みなどを利用してディスクへの書き込みを保証しようとします。ここでアプリケーションが書き込んだと思い込んだデータは、フェイルオーバ後にも引き継がれていることが期待されます。例えばメールサーバは、受信したメールをスプールに確実に書き込んだ時点で、クライアントまたはほかのメールサーバに受信完了を応答します。これによってサーバ障害発生後も、スプールされているメールをサーバの再起動後に再配信することができます。クラスタシステムでも同様に、一方のサーバがスプールへ書き込んだメールはフェイルオーバ後にもう一方のサーバが読み込めることを保証しなければなりません。
2.4.2. アプリケーションの引き継ぎ¶
クラスタソフトウェアが業務引き継ぎの最後に行う仕事は、アプリケーションの引き継ぎです。フォールトトレラントコンピュータ (FTC) とは異なり、一般的なフェイルオーバクラスタでは、アプリケーション実行中のメモリ内容を含むプロセス状態などを引き継ぎません。すなわち、障害が発生していたサーバで実行していたアプリケーションを健全なサーバで再実行することでアプリケーションの引き継ぎを行います。
例えば、データベース管理システム (DBMS) のインスタンスを引き継ぐ場合、インスタンスの起動時に自動的にデータベースの復旧 (ロールフォワード / ロールバックなど) が行われます。このデータベース復旧に必要な時間は、DBMS のチェックポイントインターバルの設定などによってある程度の制御ができますが、一般的には数分程度必要となるようです。
多くのアプリケーションは再実行するだけで業務を再開できますが、障害発生後の業務復旧手順が必要なアプリケーションもあります。このようなアプリケーションのためにクラスタソフトウェアは業務復旧手順を記述できるよう、アプリケーションの起動の代わりにスクリプトを起動できるようになっています。スクリプト内には、スクリプトの実行要因や実行サーバなどの情報をもとに、必要に応じて更新途中であったファイルのクリーンアップなどの復旧手順を記述します。

2.5. Single Point of Failureの排除¶
高可用性システムを構築するうえで、求められるもしくは目標とする可用性のレベルを把握することは重要です。これはすなわち、システムの稼働を阻害し得るさまざまな障害に対して、冗長構成をとることで稼働を継続したり、短い時間で稼働状態に復旧したりするなどの施策を費用対効果の面で検討し、システムを設計するということです。
Single Point of Failure (SPOF) とは、システム停止につながる部位を指す言葉であると前述しました。クラスタシステムではサーバの多重化を実現し、システムの SPOF を排除することができますが、共有ディスクなど、サーバ間で共有する部分については SPOF となり得ます。この共有部分を多重化もしくは排除するようシステム設計することが、高可用性システム構築の重要なポイントとなります。
クラスタシステムは可用性を向上させますが、フェイルオーバには数分程度のシステム切り替え時間が必要となります。従って、フェイルオーバ時間は可用性の低下要因の 1 つともいえます。このため、高可用性システムでは、まず単体サーバの可用性を高める ECC メモリや冗長電源などの技術が本来重要なのですが、ここでは単体サーバの可用性向上技術には触れず、クラスタシステムにおいて SPOF となりがちな下記の 3 つについて掘り下げて、どのような対策があるか見ていきたいと思います。
共有ディスク
共有ディスクへのアクセスパス
LAN
2.5.1. 共有ディスク¶
通常、共有ディスクはディスクアレイにより RAID を組むので、ディスクのベアドライブはSPOF となりません。しかし、RAID コントローラを内蔵するため、コントローラが問題となります。多くのクラスタシステムで採用されている共有ディスクではコントローラの二重化が可能になっています。
二重化された RAID コントローラの利点を生かすためには、通常は共有ディスクへのアクセスパスの二重化を行う必要があります。ただし、二重化された複数のコントローラから同時に同一の論理ディスクユニット (LUN) へアクセスできるような共有ディスクの場合、それぞれのコントローラにサーバを1台ずつ接続すればコントローラ異常発生時にノード間フェイルオーバを発生させることで高可用性を実現できます。
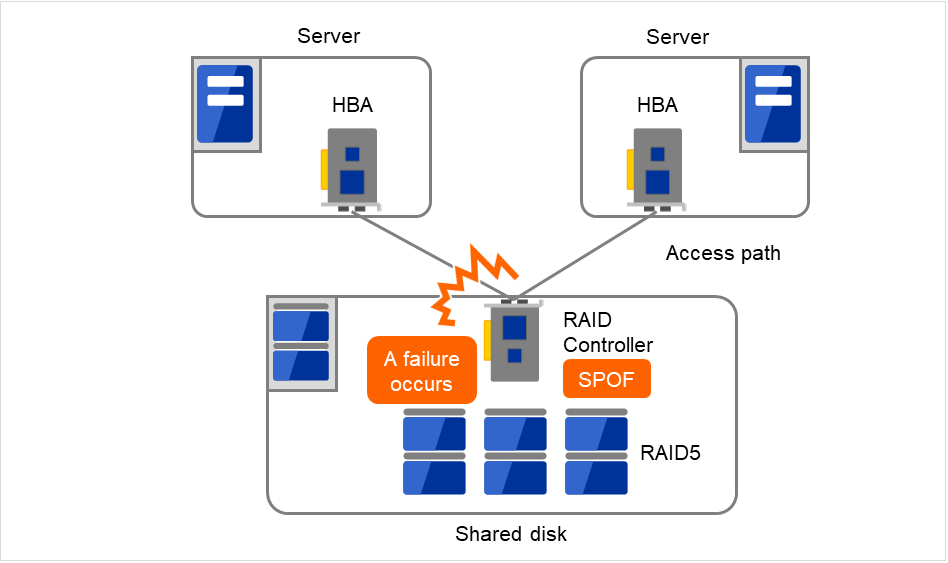
図 2.11 RAIDコントローラとアクセスパスがSPOFとなっている例¶
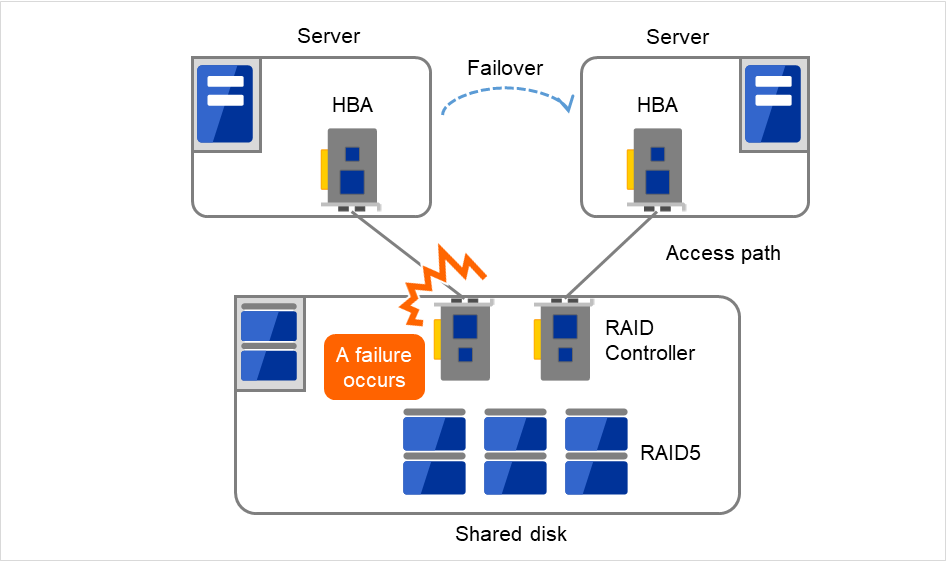
図 2.12 RAIDコントローラとアクセスパスが二重化されている例¶
一方、共有ディスクを使用しないデータミラー型のフェイルオーバクラスタでは、すべてのデータをほかのサーバのディスクにミラーリングするため、SPOF が存在しない理想的なシステム構成を実現できます。ただし、欠点とはいえないまでも、次のような点について考慮する必要があります。
ネットワークを介してデータをミラーリングすることによるディスクI/O性能 (特にwrite性能)
サーバ障害後の復旧における、ミラー再同期中のシステム性能 (ミラーコピーはバックグラウンドで実行される)
ミラー再同期時間 (ミラー再同期が完了するまでクラスタに組み込めない)
すなわち、データの参照が多く、データ容量が多くないシステムにおいては、データミラー型のフェイルオーバクラスタを採用するというのも可用性を向上させるポイントといえます。
2.5.2. 共有ディスクへのアクセスパス¶
共有ディスク型クラスタの一般的な構成では、共有ディスクへのアクセスパスはクラスタを構成する各サーバで共有されます。SCSI を例に取れば、1本の SCSI バス上に 2 台のサーバと共有ディスクを接続するということです。このため、共有ディスクへのアクセスパスの異常はシステム全体の停止要因となり得ます。
対策としては、共有ディスクへのアクセスパスを複数用意することで冗長構成とし、アプリケーションには共有ディスクへのアクセスパスが 1 本であるかのように見せることが考えられます。これを実現するデバイスドライバをパスフェイルオーバドライバなどと呼びます (パスフェイルオーバドライバは共有ディスクベンダーが開発してリリースするケースが多いのですが、Linux版のパスフェイルオーバドライバは開発途上であったりしてリリースされていないようです。現時点では前述のとおり、共有ディスクのアレイコントローラごとにサーバを接続することで共有ディスクへのアクセスパスを分割する手法が Linux クラスタにおいては可用性確保のポイントとなります)。
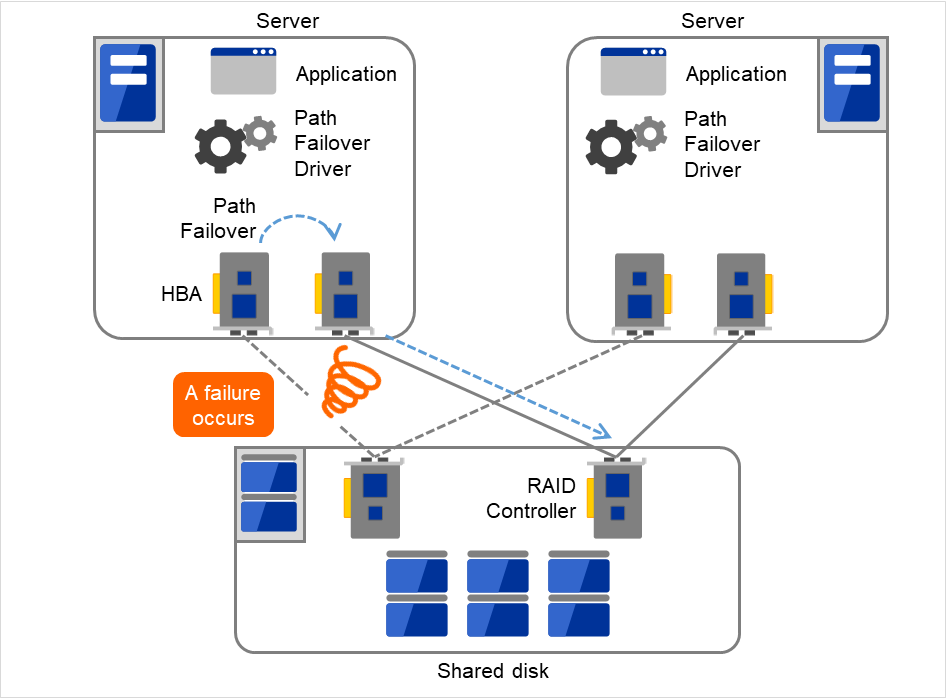
図 2.13 パスフェイルオーバドライバ¶
2.5.3. LAN¶
クラスタシステムに限らず、ネットワーク上で何らかのサービスを実行するシステムでは、LANの障害はシステムの稼働を阻害する大きな要因です。クラスタシステムでは適切な設定を行えば NIC 障害時にノード間でフェイルオーバを発生させて可用性を高めることは可能ですが、クラスタシステムの外側のネットワーク機器が故障した場合はやはりシステムの稼働を阻害します。
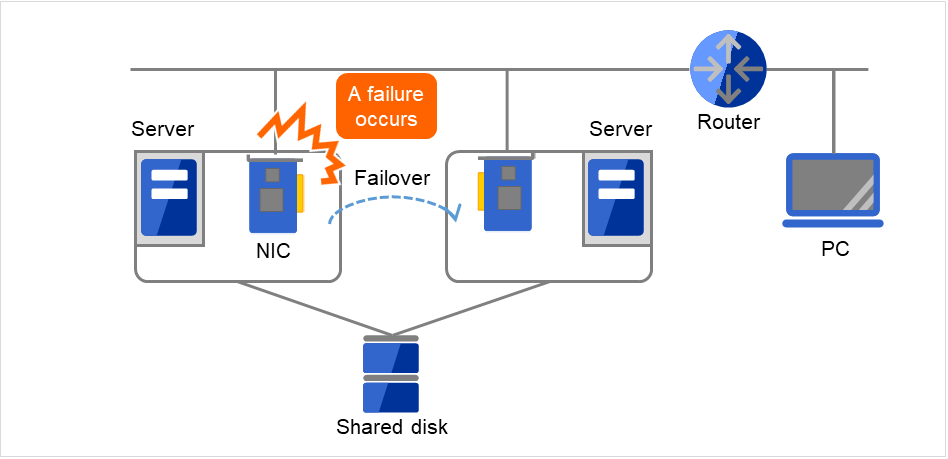
図 2.14 LANにおける障害の例(NIC)¶
この図の場合、Server上のNICが故障してもフェイルオーバすることで、Server上のサービスに対するPCからのアクセスを継続できます。
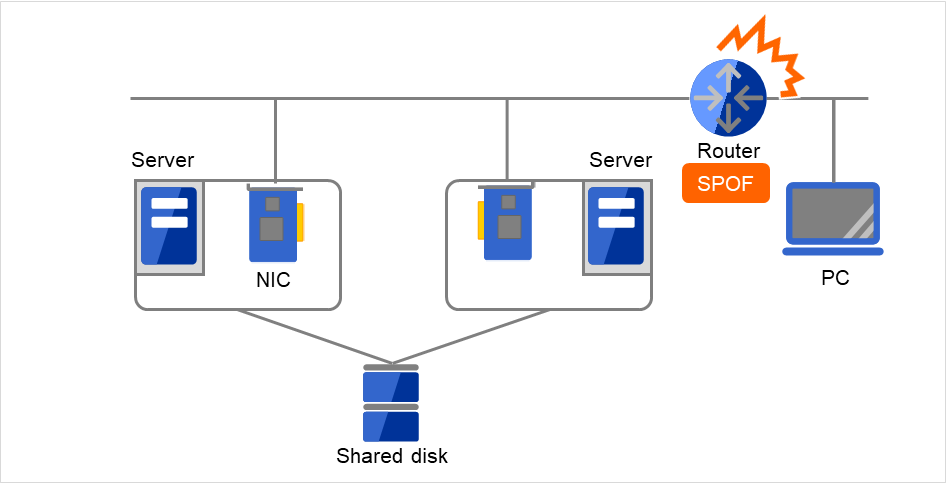
図 2.15 LANにおける障害の例(ルータ)¶
この図の場合、Routerが故障するとServer上のサービスに対するPCからのアクセスを継続できません(RouterがSPOFになっている)。
このようなケースでは、LAN を冗長化することでシステムの可用性を高めます。クラスタシステムにおいても、LAN の可用性向上には単体サーバでの技術がそのまま利用可能です。例えば、予備のネットワーク機器の電源を入れずに準備しておき、故障した場合に手動で入れ替えるといった原始的な手法や、高機能のネットワーク機器を冗長配置してネットワーク経路を多重化することで自動的に経路を切り替える方法が考えられます。また、インテル社の ANS ドライバのようにNICの冗長構成をサポートするドライバを利用するということも考えられます。
ロードバランス装置 (Load Balance Appliance) やファイアウォールサーバ (Firewall Appliance) も SPOF となりやすいネットワーク機器です。これらもまた、標準もしくはオプションソフトウェアを利用することで、フェイルオーバ構成を組めるようになっているのが普通です。同時にこれらの機器は、システム全体の非常に重要な位置に存在するケースが多いため、冗長構成をとることはほぼ必須と考えるべきです。
2.6. 可用性を支える運用¶
2.6.1. 運用前評価¶
システムトラブルの発生要因の多くは、設定ミスや運用保守に起因するものであるともいわれています。このことから考えても、高可用性システムを実現するうえで運用前の評価と障害復旧マニュアルの整備はシステムの安定稼働にとって重要です。評価の観点としては、実運用に合わせて、次のようなことを実践することが可用性向上のポイントとなります。
障害発生箇所を洗い出し、対策を検討し、擬似障害評価を行い実証する
クラスタのライフサイクルを想定した評価を行い、縮退運転時のパフォーマンスなどの検証を行う
これらの評価をもとに、システム運用、障害復旧マニュアルを整備する
クラスタシステムの設計をシンプルにすることは、上記のような検証やマニュアルが単純化でき、システムの可用性向上のポイントとなることが分かると思います。
2.6.2. 障害監視¶
上記のような努力にもかかわらず障害は発生するものです。ハードウェアには経年劣化があり、ソフトウェアにはメモリリークなどの理由や設計当初のキャパシティプラニングを超えた運用をしてしまうことによる障害など、長期間運用を続ければ必ず障害が発生してしまいます。このため、ハードウェア、ソフトウェアの可用性向上と同時に、さらに重要となるのは障害を監視して障害発生時に適切に対処することです。万が一サーバに障害が発生した場合を例に取ると、クラスタシステムを組むことで数分の切り替え時間でシステムの稼働を継続できますが、そのまま放置しておけばシステムは冗長性を失い次の障害発生時にはクラスタシステムは何の意味もなさなくなってしまいます。
このため、障害が発生した場合、すぐさまシステム管理者は次の障害発生に備え、新たに発生した SPOF を取り除くなどの対処をしなければなりません。このようなシステム管理業務をサポートするうえで、リモートメンテナンスや障害の通報といった機能が重要になります。Linuxでは、リモートメンテナンスの面ではいうまでもなく非常に優れていますし、障害を通報する仕組みも整いつつあります。
以上、クラスタシステムを利用して高可用性を実現するうえで必要とされる周辺技術やそのほかのポイントについて説明しました。簡単にまとめると次のような点に注意しましょうということになるかと思います。
Single Point of Failure を排除または把握する
障害に強いシンプルな設計を行い、運用前評価に基づき運用・障害復旧手順のマニュアルを整備する
発生した障害を早期に検出し適切に対処する
3. CLUSTERPRO の使用方法¶
本章では、CLUSTERPRO を構成するコンポーネントの説明と、クラスタシステムの設計から運用手順までの流れについて説明します。
本章で説明する項目は以下のとおりです。
3.1. CLUSTERPRO とは?¶
クラスタについて理解したところで、CLUSTERPRO の紹介を始めましょう。CLUSTERPRO とは、冗長化 (クラスタ化) したシステム構成により、現用系のサーバでの障害が発生した場合に、自動的に待機系のサーバで業務を引き継がせることで、飛躍的にシステムの可用性と拡張性を高めることを可能にするソフトウェアです。
3.2. CLUSTERPRO の製品構成¶
CLUSTERPRO は大きく分けると 2 つのモジュールから構成されています。
- CLUSTERPRO ServerCLUSTERPRO の本体で、サーバの高可用性機能の全てが包含されています。また、Cluster WebUI のサーバ側機能も含まれます。
- Cluster WebUICLUSTERPRO の構成情報の作成や運用管理を行うための管理ツールです。ユーザインターフェイスとして Web ブラウザを利用します。実体は CLUSTERPRO Server に組み込まれていますが、操作は管理端末上の Web ブラウザで行うため、CLUSTERPRO Server 本体とは区別されています。
3.3. CLUSTERPRO のソフトウェア構成¶
CLUSTERPRO のソフトウェア構成は次の図のようになります。Linux サーバ上には「CLUSTERPRO Server (CLUSTERPRO本体)」をインストールします。Cluster WebUI の本体機能は CLUSTERPRO Server に含まれるため、別途インストールする必要がありません。Cluster WebUI は管理 PC 上の Web ブラウザから利用するほか、クラスタを構成する各サーバ上の Web ブラウザでも利用できます。
CLUSTERPRO Server
Cluster WebUI
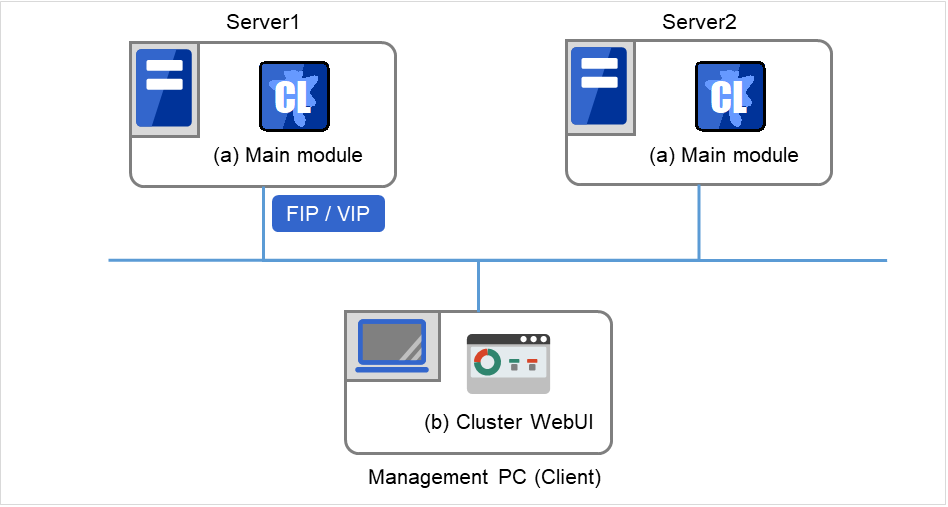
図 3.1 CLUSTERPRO のソフトウェア構成¶
3.3.1. CLUSTERPRO の障害監視のしくみ¶
CLUSTERPRO では、サーバ監視、業務監視、内部監視の 3 つの監視を行うことで、迅速かつ確実な障害検出を実現しています。以下にその監視の詳細を示します。
3.3.2. サーバ監視とは¶
- プライマリインタコネクトフェイルオーバ型クラスタ専用の通信パスで、一般の Ethernet NIC を使用します。ハートビートを行うと同時にサーバ間の情報交換に使用します。
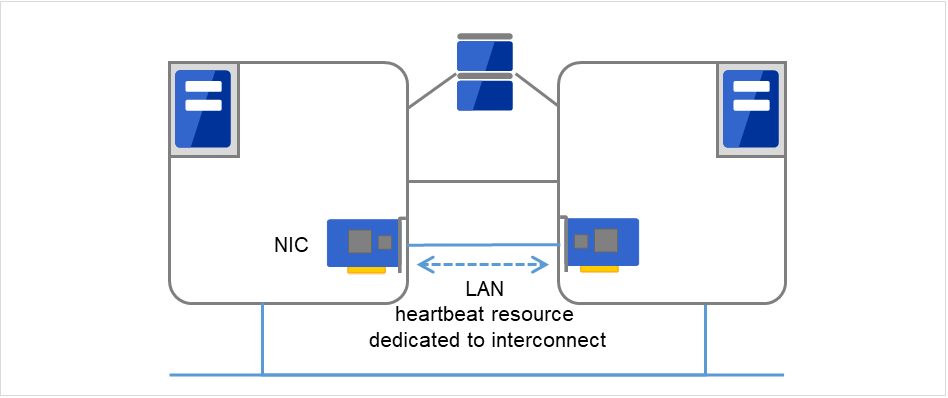
図 3.2 LANハートビート/カーネルモードLANハートビート(プライマリインタコネクト)¶
- セカンダリインタコネクトクライアントとの通信に使用している通信パスを予備のインタコネクトとして使用します。TCP/IP が使用できる NIC であればどのようなものでも構いません。ハートビートを行うと同時にサーバ間の情報交換に使用します。
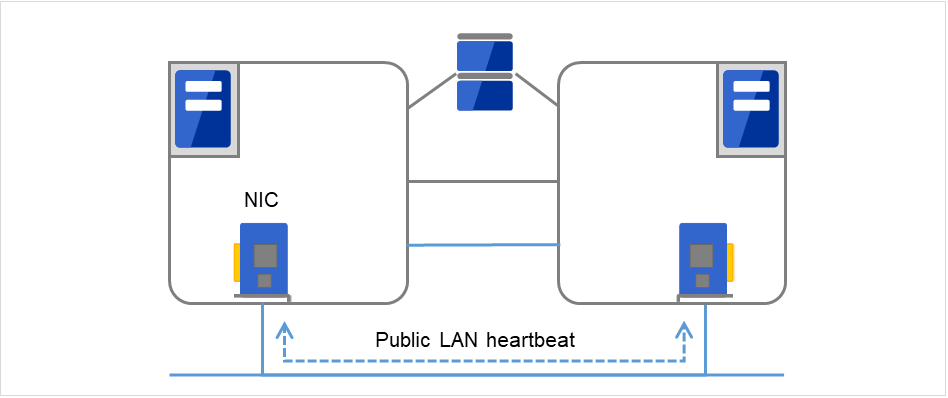
図 3.3 LANハートビート/カーネルモードLANハートビート(セカンダリインタコネクト)¶
- 共有ディスクフェイルオーバ型クラスタを構成する全てのサーバに接続されたディスク上に、CLUSTERPRO 専用のパーティション (CLUSTERパーティション) を作成し、CLUSTER パーティション上でハートビートを行います。
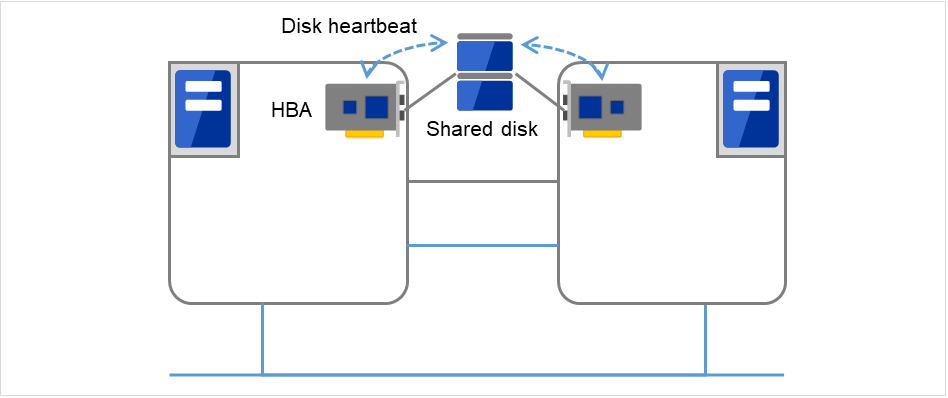
図 3.4 ディスクハートビート¶
- Witnessフェイルオーバ型クラスタを構成する各サーバとWitness サーバサービスが動作している外部サーバ (Witness サーバ) 間で通信を行い、Witness サーバが保持する他サーバとの通信情報から生存を確認します。
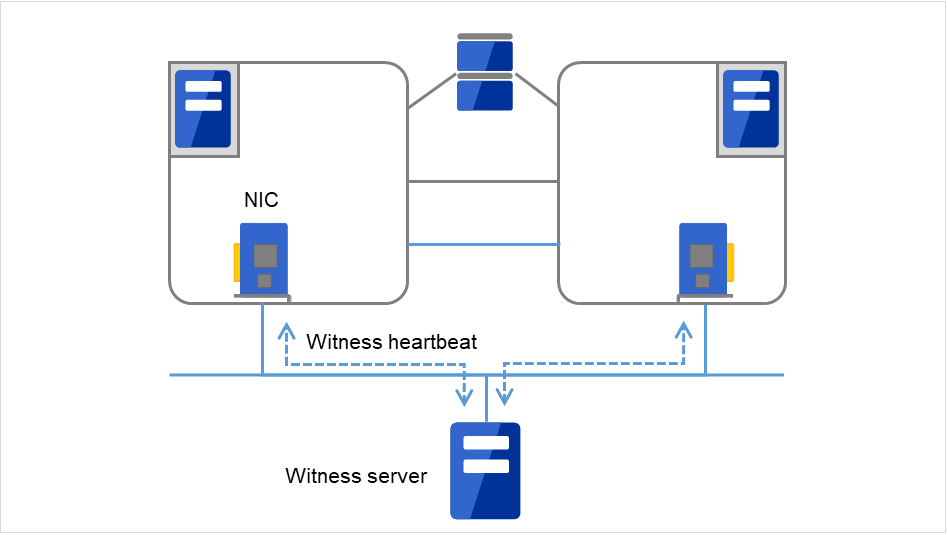
図 3.5 Witnessハートビート¶
注釈
ネットワークパーティション状態について:クラスタサーバ間の全ての通信路に障害が発生しネットワーク的に分断されてしまう状態のことです。ネットワークパーティション状態に対応できていないクラスタシステムでは、通信路の障害とサーバの障害を区別できず、同一資源を複数のサーバからアクセスしデータ破壊を引き起こす場合があります。
3.3.3. 業務監視とは¶
業務監視とは、業務アプリケーションそのものや業務が実行できない状態に陥る障害要因を監視する機能です。
- アプリケーションの死活監視アプリケーションを起動用のリソース (EXEC リソースと呼びます) により起動を行い、監視用のリソース (PID モニタリソースと呼びます) により定期的にプロセスの生存を確認することで実現します。業務停止要因が業務アプリケーションの異常終了である場合に有効です。
注釈
CLUSTERPRO が直接起動したアプリケーションが監視対象の常駐プロセスを起動し終了してしまうようなアプリケーションでは、常駐プロセスの異常を検出することはできません。
アプリケーションの内部状態の異常 (アプリケーションのストールや結果異常) を検出することはできません。
- リソースの監視CLUSTERPRO のモニタリソースによりクラスタリソース (ディスクパーティション、IP アドレスなど) やパブリック LAN の状態を監視することで実現します。業務停止要因が業務に必要なリソースの異常である場合に有効です。
3.3.4. 内部監視とは¶
CLUSTERPRO プロセスの死活監視
3.3.5. 監視できる障害と監視できない障害¶
CLUSTERPRO には、監視できる障害とできない障害があります。クラスタシステム構築時、運用時に、どのような監視が検出可能なのか、または検出できないのかを把握しておくことが重要です。
3.3.6. サーバ監視で検出できる障害とできない障害¶
監視条件: 障害サーバからのハートビートが途絶
監視できる障害の例
ハードウェア障害 (OS が継続動作できないもの)
panic
監視できない障害の例
OS の部分的な機能障害 (マウス/キーボードのみが動作しない等)
3.3.7. 業務監視で検出できる障害とできない障害¶
監視条件: 障害アプリケーションの消滅、 継続的なリソース異常、 あるネットワーク装置への通信路切断
監視できる障害の例
アプリケーションの異常終了
共有ディスクへのアクセス障害 (HBA 1 の故障など)
パブリック LAN NIC の故障
監視できない障害の例
アプリケーションのストール/結果異常
アプリケーションのストール/結果異常を CLUSTERPRO で直接監視することはできませんが、アプリケーションを監視し異常検出時に自分自身を終了するプログラムを作成し、そのプログラムを EXEC リソースで起動、PID モニタリソースで監視することで、フェイルオーバを発生させることは可能です。
- 1
Host Bus Adapterの略で、共有ディスク側ではなく、サーバ本体側のアダプタのことです。
3.4. フェンシング機能¶
CLUSTERPROはフェンシングの仕組みとして「ネットワークパーティション解決」と「強制停止」を備えています。
3.4.1. ネットワークパーティション解決¶
ping 方式
http 方式
参考
ネットワークパーティション解決方法の設定についての詳細は、『リファレンスガイド』の「ネットワークパーティション解決リソースの詳細」を参照してください。
3.4.2. 強制停止¶
サーバ障害を検知したとき、健全なサーバから障害を起こしたサーバに対して停止要求を発行することができます。障害のあるサーバを停止状態へ移行させることにより、業務アプリケーションが複数のサーバで同時に起動する可能性を排除します。強制停止の処理はフェイルオーバが開始される前に実行されます。
参考
強制停止の設定についての詳細は、『リファレンスガイド』の「強制停止リソースの詳細」を参照してください。
3.5. フェイルオーバのしくみ¶
CLUSTERPRO は障害を検出すると、フェイルオーバ開始前に検出した障害がサーバの障害かネットワークパーティション状態かを判別します。この後、健全なサーバ上で各種リソースを活性化し業務アプリケーションを起動することでフェイルオーバを実行します。
このとき、同時に移動するリソースの集まりをフェイルオーバグループと呼びます。フェイルオーバグループは利用者から見た場合、仮想的なコンピュータとみなすことができます。
注釈
クラスタシステムでは、アプリケーションを健全なノードで起動しなおすことでフェイルオーバを実行します。このため、アプリケーションのメモリ上に格納されている実行状態をフェイルオーバすることはできません。
障害発生からフェイルオーバ完了までの時間は数分間必要です。以下にタイムチャートを示します。
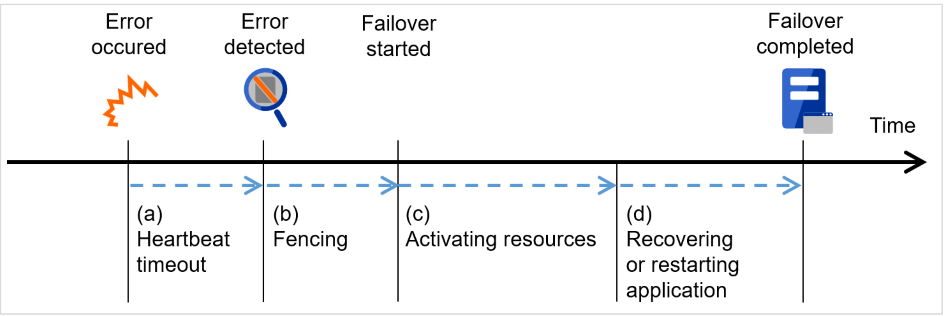
図 3.6 フェイルオーバのタイムチャート¶
ハートビートタイムアウト
業務を実行しているサーバの障害発生後、待機系がその障害を検出するまでの時間です。
フェンシング
ネットワークパーティション解決と強制停止を実施するための時間です。
各種リソース活性化
業務で必要なリソースを活性化するための時間です。
ファイルシステム復旧、ディスク内のデータ引継ぎ、IPアドレスの引継ぎ等を行います。
アプリケーション復旧処理・再起動
業務で使用するアプリケーションの起動に要する時間です。データベースのロールバック/ロールフォワードなどのデータ復旧処理の時間も含まれます。
ロールバック/ロールフォワード時間などはチェックポイントインターバルの調整である程度予測可能です。詳しくは、各ソフトウェア製品のドキュメントを参照してください。
3.5.1. フェイルオーバリソース¶
CLUSTERPRO がフェイルオーバ対象とできる主なリソースは以下のとおりです。
切替パーティション (ディスクリソース、ミラーディスクリソース、ハイブリッドディスクリソースなど)
業務アプリケーションが引き継ぐべきデータを格納するためのディスクパーティションです。
フローティング IP アドレス (フローティング IP リソース)
フローティング IP アドレスを使用して業務へ接続することで、フェイルオーバによる業務の実行位置 (サーバ) の変化をクライアントは気にする必要がなくなります。
パブリック LAN アダプタへの IP アドレス動的割り当てと ARP パケットの送信により実現しています。ほとんどのネットワーク機器からフローティング IP アドレスによる接続が可能です
スクリプト (EXEC リソース)
CLUSTERPRO では、業務アプリケーションをスクリプトから起動します。
共有ディスクにて引き継がれたファイルはファイルシステムとして正常であっても、データとして不完全な状態にある場合があります。スクリプトにはアプリケーションの起動のほか、フェイルオーバ時の業務固有の復旧処理も記述します。
注釈
クラスタシステムでは、アプリケーションを健全なノードで起動しなおすことでフェイルオーバを実行します。このため、アプリケーションのメモリ上に格納されている実行状態をフェイルオーバすることはできません。
3.5.2. フェイルオーバ型クラスタのシステム構成¶
フェイルオーバ型クラスタは、ディスクアレイ装置をクラスタサーバ間で共有します。サーバ障害時には待機系サーバが共有ディスク上のデータを使用し業務を引き継ぎます。
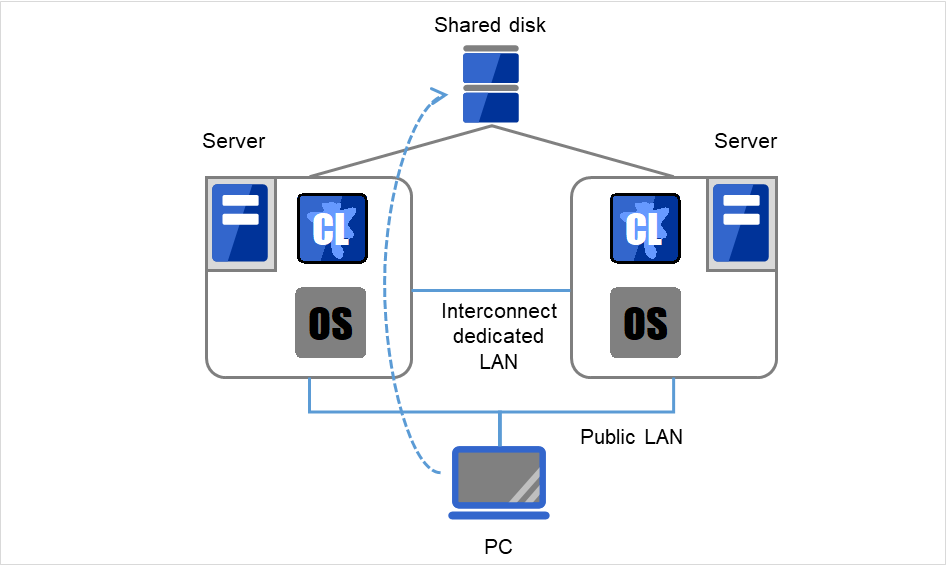
図 3.7 フェイルオーバ型クラスタのシステム構成¶
フェイルオーバ型クラスタでは、運用形態により、次のように分類できます。
片方向スタンバイクラスタ
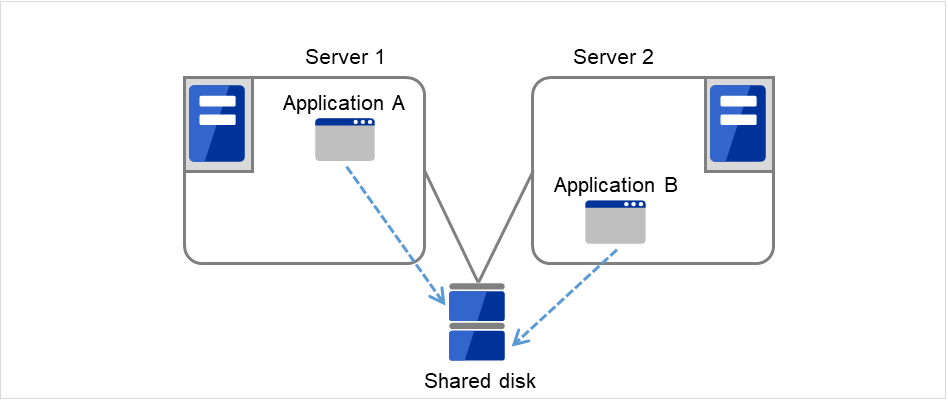
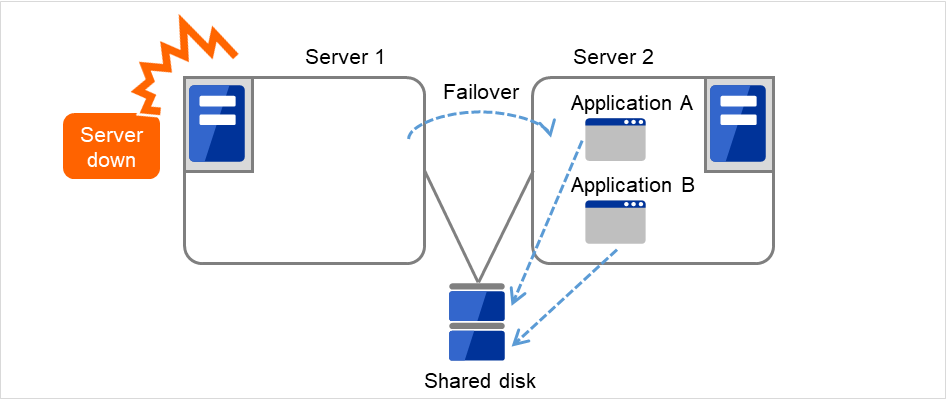
同一アプリケーション双方向スタンバイクラスタ
異種アプリケーション双方向スタンバイクラスタ
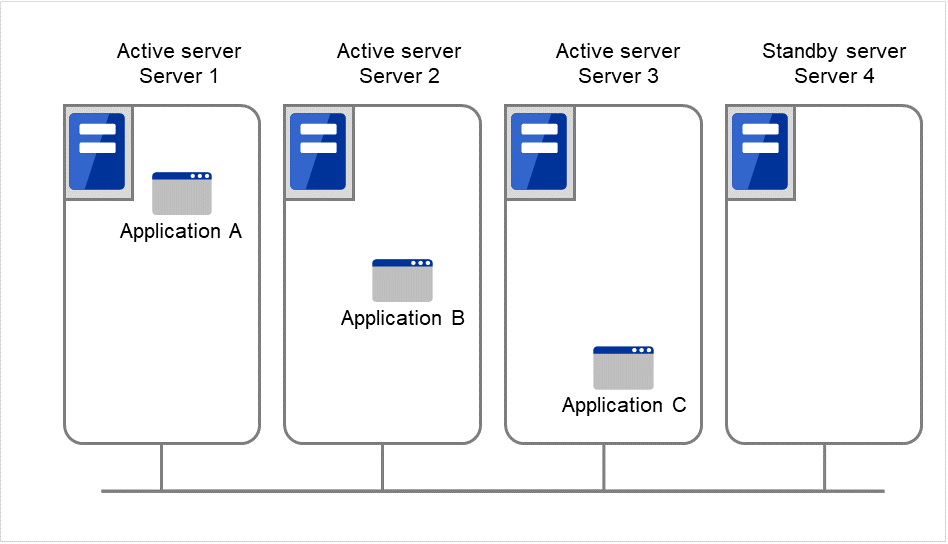
N + N 構成
3.5.3. 共有ディスク型のハードウェア構成¶
共有ディスク構成の CLUSTERPRO の HW 構成は下図のようになります。
サーバ間の通信用に
NIC を 2 枚 (1 枚は外部との通信と流用、1 枚は CLUSTERPRO 専用)
共有ディスクの特定領域
を利用する構成が一般的です。
共有ディスクとの接続インターフェイスは SCSI や Fibre Channel、iSCSI ですが、最近はFibre Channel か iSCSI による接続が一般的です。
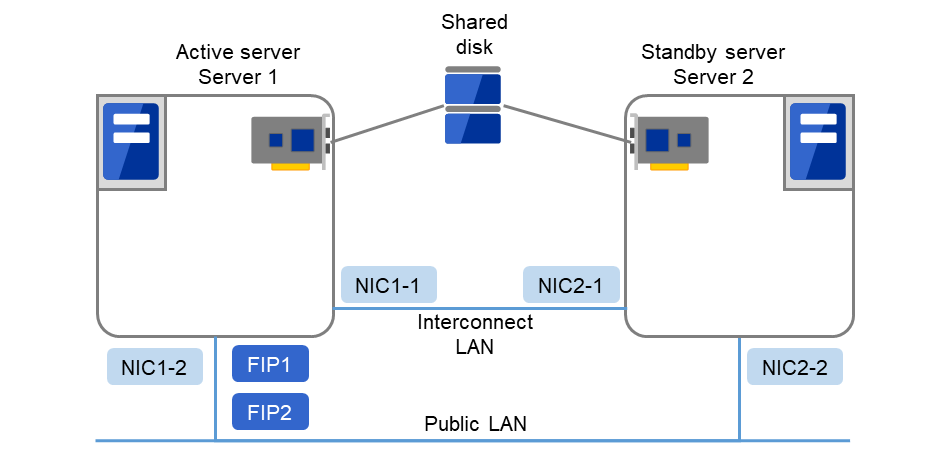
図 3.16 クラスタ構成例(共有ディスク型)¶
FIP1 |
10.0.0.11 (Cluster WebUIクライアントからのアクセス先) |
FIP2 |
10.0.0.12 (業務クライアントからのアクセス先) |
NIC1-1 |
192.168.0.1 |
NIC1-2 |
10.0.0.1 |
NIC2-1 |
192.168.0.2 |
NIC2-2 |
10.0.0.2 |
共有ディスク:
デバイス名
/dev/sdb2
マウントポイント
/mnt/sdb2
ファイルシステム
ext3
3.5.4. ミラーディスク型のハードウェア構成¶
データミラー構成の CLUSTERPRO は、下図のような構成になります。
共有ディスク構成と比べ、ミラーディスクデータコピー用のネットワークが必要となりますが、通常、CLUSTERPRO の内部通信用 NIC と兼用します。
また、ミラーディスクは接続インターフェイス (IDE or SCSI) には依存しません。
ミラーディスク使用時のクラスタ環境のサンプル (OS がインストールされているディスクにクラスタパーティション、データパーティションを確保する場合)
以下の構成では、OSがインストールされているディスクの空きパーティションを、クラスタパーティション、データパーティションとして使用しています。
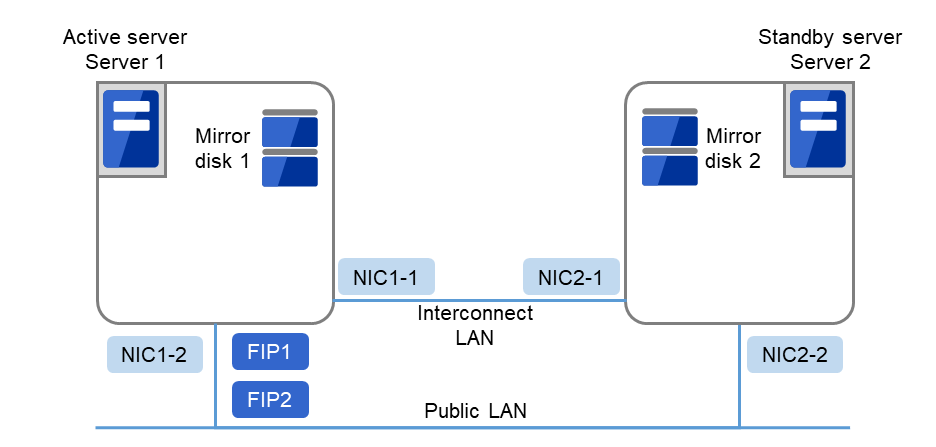
図 3.17 クラスタ構成例(1)(ミラーディスク型)¶
FIP1
10.0.0.11 (Cluster WebUIクライアントからのアクセス先)
FIP2
10.0.0.12 (業務クライアントからのアクセス先)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
OSの/bootデバイス
/dev/sda1
OSのswapデバイス
/dev/sda2
OSの/(root)デバイス
/dev/sda3
クラスタパーティション用デバイス
/dev/sda5
データパーティション用デバイス
/dev/sda6
マウントポイント
/mnt/sda6
ファイルシステム
ext3
ミラーディスク使用時のクラスタ環境のサンプル (クラスタパーティション、データパーティション用のディスクを用意する場合)
以下の構成では、クラスタパーティション、データパーティション用にディスクを用意し、接続しています。
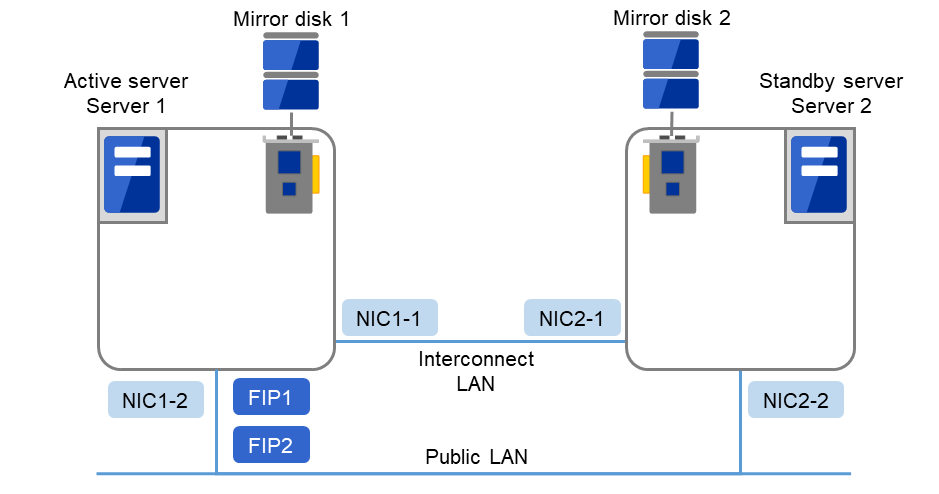
図 3.18 クラスタ構成例(2)(ミラーディスク型)¶
FIP1
10.0.0.11 (Cluster WebUIクライアントからのアクセス先)
FIP2
10.0.0.12 (業務クライアントからのアクセス先)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
OSの/bootデバイス
/dev/sda1
OSのswapデバイス
/dev/sda2
OSの/(root)デバイス
/dev/sda3
クラスタパーティション用デバイス
/dev/sdb1
ミラーリソースディスクデバイス
/dev/sdb2
マウントポイント
/mnt/sdb2
ファイルシステム
ext3
3.5.5. ハイブリッドディスク型のハードウェア構成¶
ハイブリッド構成の CLUSTERPRO は、下図のような構成になります。
共有ディスク構成と比べ、データコピー用のネットワークが必要となりますが、通常、CLUSTERPRO の内部通信用 NIC と兼用します。
また、ディスクは接続インターフェイス (IDE or SCSI) には依存しません。
ハイブリッドディスク使用時のクラスタ環境のサンプル (2 台のサーバで共有ディスクを使用し、3 台目のサーバの通常のディスクへミラーリングする場合)
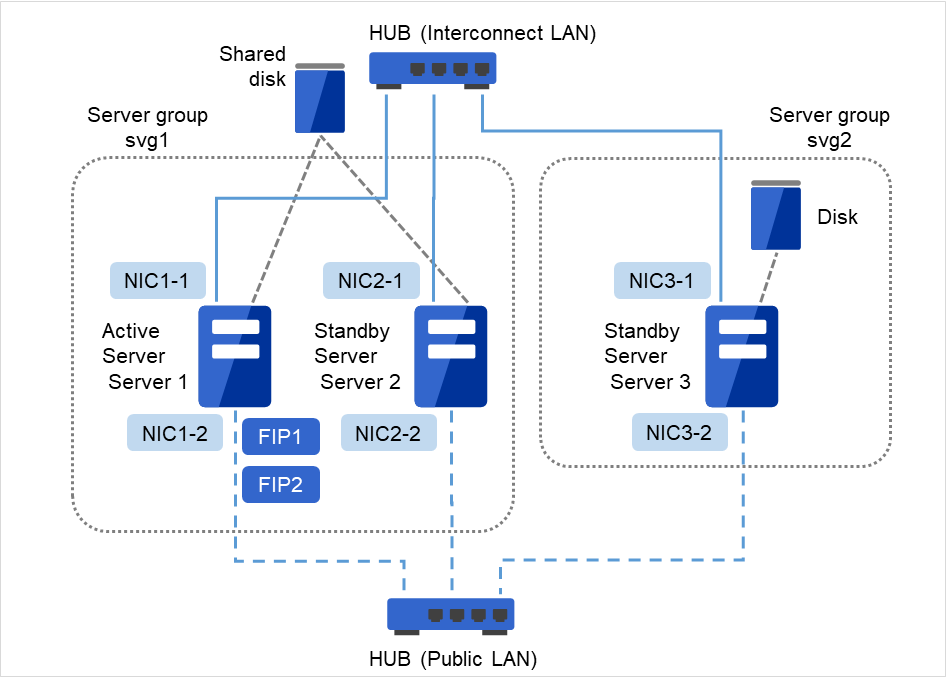
図 3.19 クラスタ構成例(ハイブリッドディスク型)¶
FIP1
10.0.0.11 (Cluster WebUIクライアントからのアクセス先)
FIP2
10.0.0.12 (業務クライアントからのアクセス先)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
NIC3-1
192.168.0.3
NIC3-2
10.0.0.3
共有ディスク
ハイブリッドデバイス
/dev/NMP1
マウントポイント
/mnt/hd1
ファイルシステム
ext3
クラスタパーティション用デバイス
/dev/sdb1
ハイブリッドリソースディスクデバイス
/dev/sdb2
DISKハートビートデバイス名
/dev/sdb3
Rawデバイス名
/dev/raw/raw1
ハイブリッドリソース用ディスク
ハイブリッドデバイス
/dev/NMP1
マウントポイント
/mnt/hd1
ファイルシステム
ext3
クラスタパーティション用デバイス
/dev/sdb1
ハイブリッドリソースディスクデバイス
/dev/sdb2
3.5.6. クラスタオブジェクトとは?¶
CLUSTERPRO では各種リソースを下のような構成で管理しています。
- クラスタオブジェクトクラスタの構成単位となります。
- サーバオブジェクト実体サーバを示すオブジェクトで、クラスタオブジェクトに属します。
- サーバグループオブジェクトサーバを束ねるオブジェクトで、クラスタオブジェクトに属します。
- ハートビートリソースオブジェクト実体サーバの NW 部分を示すオブジェクトで、サーバオブジェクトに属します。
- ネットワークパーティション解決リソースオブジェクトネットワークパーティション解決機構を示すオブジェクトで、サーバオブジェクトに属します。
- グループオブジェクト仮想サーバを示すオブジェクトで、クラスタオブジェクトに属します。
- グループリソースオブジェクト仮想サーバの持つリソース (NW、ディスク) を示すオブジェクトでグループオブジェクトに属します。
- モニタリソースオブジェクト監視機構を示すオブジェクトで、クラスタオブジェクトに属します。
3.6. リソースとは?¶
CLUSTERPRO では、監視する側とされる側の対象をすべてリソースと呼び、分類して管理します。このことにより、より明確に監視/被監視の対象を区別できるほか、クラスタ構築や障害検出時の対応が容易になります。リソースはハートビートリソース、ネットワークパーティション解決リソース、グループリソース、モニタリソースの 4 つに分類されます。以下にその概略を示します。
3.6.1. ハートビートリソース¶
サーバ間で、お互いの生存を確認するためのリソースです。
以下に現在サポートされているハートビートリソースを示します。
- LAN ハートビートリソースEthernet を利用した通信を示します。
- カーネルモード LAN ハートビートリソースEthernet を利用した通信を示します。
- ディスクハートビートリソース共有ディスク上の特定パーティション (ディスクハートビート用パーティション) を利用した通信を示します。共有ディスク構成の場合のみ利用可能です。
- Witness ハートビートリソースWitness サーバサービスが動作している外部サーバから取得した各サーバとの通信状態を示します。
3.6.2. ネットワークパーティション解決リソース¶
ネットワークパーティション状態を解決するためのリソースを示します。
- PING ネットワークパーティション解決リソースPING 方式によるネットワークパーティション解決リソースです。
- HTTP ネットワークパーティション解決リソースHTTP 方式によるネットワークパーティション解決リソースです。
3.6.3. グループリソース¶
フェイルオーバを行う際の単位となる、フェイルオーバグループを構成するリソースです。
以下に現在サポートされているグループリソースを示します。
- フローティング IP リソース (fip)仮想的な IP アドレスを提供します。クライアントからは一般の IP アドレスと同様にアクセス可能です。
- EXEC リソース (exec)業務 (DB、httpd、etc..) を起動/停止するための仕組みを提供します。
- ディスクリソース (disk)共有ディスク上の指定パーティションを提供します。 (共有ディスク) 構成の場合のみ利用可能です。
- ミラーディスクリソース (md)ミラーディスク上の指定パーティションを提供します。 (ミラーディスク) 構成の場合のみ利用可能です。
- ハイブリッドディスクリソース (hd)共有ディスク、またはディスク上の指定パーティションを提供します。(ハイブリッド) 構成の場合のみ利用可能です。
- ボリュームマネージャリソース (volmgr)複数のストレージやディスクを一つの論理的なディスクとして扱います。
- 仮想 IP リソース (vip)仮想的な IP アドレスを提供します。クライアントからは一般の IP アドレスと同様にアクセス可能です。ネットワークアドレスの異なるセグメント間で遠隔クラスタを構成する場合に使用します。
- ダイナミック DNS リソース (ddns)Dynamic DNS サーバに仮想ホスト名と活性サーバの IP アドレスを登録します。
- AWS Elastic IPリソース (awseip)AWS 上で CLUSTERPRO を利用する場合、Elastic IP(以下、EIP)を付与する仕組みを提供します。
- AWS 仮想IPリソース (awsvip)AWS 上で CLUSTERPRO を利用する場合、仮想IP(以下、VIP)を付与する仕組みを提供します。
- AWS セカンダリ IP リソース (awssip)AWS 上で CLUSTERPRO を利用する場合、セカンダリ IP を付与する仕組みを提供します。
- AWS DNS リソース (awsdns)AWS 上で CLUSTERPRO を利用する場合、Amazon Route 53 に仮想ホスト名と活性サーバの IP アドレスを登録します。
- Azure プローブポートリソース (azurepp)Microsoft Azure 上で CLUSTERPRO を利用する場合、業務が稼働するノードで特定のポートを開放する仕組みを提供します。
- Azure DNS リソース (azuredns)Microsoft Azure 上で CLUSTERPRO を利用する場合、Azure DNS に仮想ホスト名と活性サーバの IP アドレスを登録します。
- Google Cloud 仮想 IP リソース (gcvip)Google Cloud Platform 上で CLUSTERPRO を利用する場合、業務が稼働するノードで特定のポートを開放する仕組みを提供します。
- Google Cloud DNS リソース (gcdns)Google Cloud Platform 上で CLUSTERPRO を利用する場合、Cloud DNS に仮想ホスト名と活性サーバの IP アドレスを登録します。
- Oracle Cloud 仮想 IP リソース (ocvip)Oracle Cloud Infrastructure 上で CLUSTERPRO を利用する場合、業務が稼働するノードで特定のポートを開放する仕組みを提供します。
3.6.4. モニタリソース¶
クラスタシステム内で、監視を行う主体であるリソースです。
以下に現在サポートされているモニタリソースを示します。
- フローティング IP モニタリソース (fipw)フローティング IP リソースで起動した IP アドレスの監視機構を提供します。
- IP モニタリソース (ipw)外部の IP アドレスの監視機構を提供します。
- ディスクモニタリソース (diskw)ディスクの監視機構を提供します。共有ディスクの監視にも利用されます。
- ミラーディスクモニタリソース (mdw)ミラーディスクの監視機構を提供します。
- ミラーディスクコネクトモニタリソース (mdnw)ミラーディスクコネクトの監視機構を提供します。
- ハイブリッドディスクモニタリソース (hdw)ハイブリッドディスクの監視機構を提供します。
- ハイブリッドディスクコネクトモニタリソース (hdnw)ハイブリッドディスクコネクトの監視機構を提供します。
- PID モニタリソース (pidw)EXEC リソースで起動したプロセスの死活監視機能を提供します。
- ユーザ空間モニタリソース (userw)ユーザ空間のストール監視機構を提供します。
- NIC Link Up/Down モニタリソース (miiw)LAN ケーブルのリンクステータスの監視機構を提供します。
- ボリュームマネージャモニタリソース (volmgrw)複数のストレージやディスクの監視機構を提供します。
- マルチターゲットモニタリソース (mtw)複数のモニタリソースを束ねたステータスを提供します。
- 仮想 IP モニタリソース (vipw)仮想 IP リソースの RIP パケットを送出する機構を提供します。
- ARP モニタリソース (arpw)フローティング IP リソースまたは仮想 IP リソースの ARP パケットを送出する機構を提供します。
- カスタムモニタリソース (genw)監視処理を行うコマンドやスクリプトがある場合に、その動作結果によりシステムを監視する機構を提供します。
- 外部連携モニタリソース (mrw)"異常発生通知受信時に実行する異常時動作の設定" と "異常発生通知のCluster WebUI 表示" を実現するためのモニタリソースです。
- ダイナミック DNS モニタリソース (ddnsw)定期的に Dynamic DNS サーバに仮想ホスト名と活性サーバの IP アドレスを登録します。
- プロセス名モニタリソース (psw)プロセス名を指定することで、任意のプロセスの死活監視機能を提供します。
- DB2 モニタリソース (db2w)IBM DB2 データベースへの監視機構を提供します。
- ftp モニタリソース (ftpw)FTP サーバへの監視機構を提供します。
- http モニタリソース (httpw)HTTP サーバへの監視機構を提供します。
- imap4 モニタリソース (imap4w)IMAP4 サーバへの監視機構を提供します。
- MySQL モニタリソース (mysqlw)MySQL データベースへの監視機構を提供します。
- nfs モニタリソース (nfsw)nfs ファイルサーバへの監視機構を提供します。
- Oracle モニタリソース (oraclew)Oracle データベースへの監視機構を提供します。
- pop3 モニタリソース (pop3w)POP3 サーバへの監視機構を提供します。
- PostgreSQL モニタリソース (psqlw)PostgreSQL データベースへの監視機構を提供します。
- samba モニタリソース (sambaw)samba ファイルサーバへの監視機構を提供します。
- smtp モニタリソース (smtpw)SMTP サーバへの監視機構を提供します。
- Tuxedo モニタリソース (tuxw)Tuxedo アプリケーションサーバへの監視機構を提供します。
- WebSphere モニタリソース (wasw)WebSphere アプリケーションサーバへの監視機構を提供します。
- WebLogic モニタリソース (wlsw)WebLogic アプリケーションサーバへの監視機構を提供します。
- WebOTX モニタリソース (otxw)WebOTX アプリケーションサーバへの監視機構を提供します。
- JVM モニタリソース (jraw)Java VMへの監視機構を提供します。
- システムモニタリソース (sraw)システム全体のリソースへの監視機構を提供します。
- プロセスリソースモニタリソース (psrw)プロセス個別のリソースへの監視機構を提供します。
- AWS Elastic IP モニタリソース (awseipw)AWS Elastic IP リソースで付与した EIP の監視機構を提供します。
- AWS 仮想IPモニタリソース (awsvipw)AWS 仮想IPリソースで付与した VIP の監視機構を提供します。
- AWS セカンダリ IP モニタリソース (awssipw)AWS セカンダリ IP リソースで付与したセカンダリ IP の監視機構を提供します。
- AWS AZ モニタリソース (awsazw)Availability Zone(以下、AZ) の監視機構を提供します。
- AWS DNS モニタリソース (awsdnsw)AWS DNS リソースで付与した仮想ホスト名と IP アドレスの監視機構を提供します。
- Azure プローブポートモニタリソース (azureppw)Azure プローブポートリソースが起動しているノードに対して、プローブポートの監視機構を提供します。
- Azure ロードバランスモニタリソース (azurelbw)Azure プローブポートリソースが起動していないノードに対して、プローブ ポートと同じポート番号が開放されていないかの監視機構を提供します。
- Azure DNS モニタリソース (azurednsw)Azure DNS リソースで付与した仮想ホスト名と IP アドレスの監視機構を提供します。
- Google Cloud 仮想 IP モニタリソース (gcvipw)Google Cloud 仮想 IP リソースが起動しているノードに対して、死活監視のためのポートの監視機構を提供します。
- Google Cloud ロードバランスモニタリソース (gclbw)Google Cloud 仮想 IP リソースが起動していないノードに対して、ヘルスチェック用ポートと同じポート番号が開放されていないかの監視機構を提供します。
- Google Cloud DNS モニタリソース (gcdnsw)Google Cloud DNS リソースで付与した仮想ホスト名と IP アドレスの監視機構を提供します。
- Oracle Cloud 仮想 IP モニタリソース (ocvipw)Oracle Cloud 仮想 IP リソースが起動しているノードに対して、死活監視のためのポートの監視機構を提供します。
- Oracle Cloud ロードバランスモニタリソース (oclbw)Oracle Cloud 仮想 IP リソースが起動していないノードに対して、ヘルスチェック用ポートと同じポート番号が開放されていないかの監視機構を提供します。
3.7. CLUSTERPRO を始めよう!¶
以上で CLUSTERPRO の簡単な説明が終了しました。
以降は、以下の流れに従い、対応するガイドを読み進めながら CLUSTERPRO を使用したクラスタシステムの構築を行ってください。
3.7.2. クラスタシステムの設計¶
『インストール&設定ガイド』の「システム構成を決定する」、「クラスタシステムを設計する」および
『リファレンスガイド 』の「グループリソースの詳細」、「モニタリソースの詳細」、「ハートビートリソースの詳細」、「ネットワークパーティション解決リソースの詳細」、「その他の設定情報」および『ハードウェア連携ガイド』 を参照してください。
3.7.3. クラスタシステムの構築¶
『インストール&設定ガイド』の全編を参照してください。
3.7.4. クラスタシステムの運用開始後の障害対応¶
『メンテナンスガイド』の「保守情報」および『リファレンスガイド』の「トラブルシューティング」、「エラーメッセージ一覧」を参照してください。
4. CLUSTERPRO の動作環境¶
本章では、CLUSTERPRO の動作環境について説明します。
本章で説明する項目は以下の通りです。
4.1. ハードウェア¶
CLUSTERPRO は以下のアーキテクチャのサーバで動作します。
x86_64
IBM POWER LE (Replicator, Replicator DR、並びに、各 Agent は未サポート)
4.1.1. スペック¶
CLUSTERPRO Server で必要なスペックは下記の通りです。
Ethernet ポート 2 つ以上
共有ディスク
ミラー用ディスク または ミラー用空きパーティション
DVD-ROM ドライブ
4.2. ソフトウェア¶
4.2.1. CLUSTERPRO Server の動作環境¶
4.2.2. 動作可能なディストリビューションとkernel¶
注釈
CLUSTERPRO XのCD媒体には、新しいkernelに対応したrpmが含まれていない場合があります。運用環境でのkernelバージョンと本章の「 動作可能なディストリビューションとkernel 」を確認していただき、「CLUSTERPRO Version」に記載されているバージョンに適合したUpdateの適用をお願いいたします。
独自kernelモジュール |
説明 |
|---|---|
カーネルモード LANハートビートドライバ |
カーネルモード LAN ハートビートリソースで使用します。 |
Keepaliveドライバ |
ユーザ空間モニタリソースの監視方法として keepalive を選択した場合に使用します。
シャットダウン監視の監視方法として keepalive を選択した場合に使用します。
|
ミラードライバ |
ミラーディスクリソースで使用します。 |
動作確認済みのディストリビューションと kernel バージョンについては、以下のWebサイトを参照してください。
CLUSTERPRO製品Webサイト→ CLUSTERPRO X→ 動作環境→ Linux 動作環境
注釈
CLUSTERPRO が対応する CentOS のkernelバージョンは、Red Hat Enterprise Linux の対応kernelバージョンを確認してください。
4.2.3. 監視オプションの動作確認済アプリケーション情報¶
モニタリソースの監視対象のアプリケーションのバージョンの情報
x86_64
モニタリソース
備考
Oracle モニタ
Oracle Database 19c (19.3)
5.0.0-1~
DB2 モニタ
DB2 V11.5
5.0.0-1~
PostgreSQL モニタ
PostgreSQL 14.1
5.0.0-1~
PostgreSQL 15.1
5.1.0-1~
PowerGres on Linux 13.5
5.0.0-1~
MySQL モニタ
MySQL 8.0
5.0.0-1~
MySQL 8.0.31
5.1.0-1~
MariaDB 10.5
5.0.0-1~
MariaDB 10.10.2
5.1.0-1~
SQL Server モニタ
SQL Server 2019
5.0.0-1~
SQL Server 2022
5.1.0-1~
samba モニタ
Samba 3.3
4.0.0-1~
Samba 3.6
4.0.0-1~
Samba 4.0
4.0.0-1~
Samba 4.1
4.0.0-1~
Samba 4.2
4.0.0-1~
Samba 4.4
4.0.0-1~
Samba 4.6
4.0.0-1~
Samba 4.7
4.1.0-1~
Samba 4.8
4.1.0-1~
Samba 4.13
4.3.0-1~
nfs モニタ
nfsd 2 (udp)
4.0.0-1~
nfsd 3 (udp)
4.0.0-1~
nfsd 4 (tcp)
4.0.0-1~
mountd 1(tcp)
4.0.0-1~
mountd 2(tcp)
4.0.0-1~
mountd 3(tcp)
4.0.0-1~
http モニタ
バージョン指定無し
4.0.0-1~
smtp モニタ
バージョン指定無し
4.0.0-1~
pop3 モニタ
バージョン指定無し
4.0.0-1~
imap4 モニタ
バージョン指定無し
4.0.0-1~
ftp モニタ
バージョン指定無し
4.0.0-1~
Tuxedo モニタ
Tuxedo 12c Release 2 (12.1.3)
4.0.0-1~
WebLogic モニタ
WebLogic Server 11g R1
4.0.0-1~
WebLogic Server 11g R2
4.0.0-1~
WebLogic Server 12c R2 (12.2.1)
4.0.0-1~
WebLogic Server 14c (14.1.1)
4.2.0-1~
WebSphere モニタ
WebSphere Application Server 8.5
4.0.0-1~
WebSphere Application Server 8.5.5
4.0.0-1~
WebSphere Application Server 9.0
4.0.0-1~
WebOTX モニタ
WebOTX Application Server V9.1
4.0.0-1~
WebOTX Application Server V9.2
4.0.0-1~
WebOTX Application Server V9.3
4.0.0-1~
WebOTX Application Server V9.4
4.0.0-1~
WebOTX Application Server V10.1
4.0.0-1~
WebOTX Application Server V10.3
4.3.0-1~
JVM モニタ
WebLogic Server 11g R1
4.0.0-1~
WebLogic Server 11g R2
4.0.0-1~
WebLogic Server 12c
4.0.0-1~
WebLogic Server 12c R2 (12.2.1)
4.0.0-1~
WebLogic Server 14c (14.1.1)
4.2.0-1~
WebOTX Application Server V9.1
4.0.0-1~
WebOTX Application Server V9.2
4.0.0-1~
プロセスグループ監視にはWebOTX updateが必要
WebOTX Application Server V9.3
4.0.0-1~
WebOTX Application Server V9.4
4.0.0-1~
WebOTX Application Server V10.1
4.0.0-1~
WebOTX Application Server V10.3
4.3.0-1~
WebOTX Enterprise Service Bus V8.4
4.0.0-1~
WebOTX Enterprise Service Bus V8.5
4.0.0-1~
WebOTX Enterprise Service Bus V10.3
4.3.0-1~
JBoss Enterprise Application Platform 7.0
4.0.0-1~
JBoss Enterprise Application Platform 7.3
4.3.2-1~
JBoss Enterprise Application Platform 7.4
5.0.2-1~
Apache Tomcat 8.0
4.0.0-1~
Apache Tomcat 8.5
4.0.0-1~
Apache Tomcat 9.0
4.0.0-1~
Apache Tomcat 10.0
5.0.2-1~
WebSAM SVF for PDF 9.0
4.0.0-1~
WebSAM SVF for PDF 9.1
4.0.0-1~
WebSAM SVF for PDF 9.2
4.0.0-1~
WebSAM SVF PDF Enterprise 10.1
5.1.0-1~
WebSAM Report Director Enterprise 9.0
4.0.0-1~
WebSAM Report Director Enterprise 9.1
4.0.0-1~
WebSAM Report Director Enterprise 9.2
4.0.0-1~
WebSAM RDE SUITE 10.1
5.1.0-1~
WebSAM Universal Connect/X 9.0
4.0.0-1~
WebSAM Universal Connect/X 9.1
4.0.0-1~
WebSAM Universal Connect/X 9.2
4.0.0-1~
WebSAM SVF Connect SUITE Standard 10.1
5.1.0-1~
システムモニタ
バージョン指定無し
4.0.0-1~
プロセスリソースモニタ
バージョン指定無し
4.1.0-1~
注釈
x86_64環境で監視オプションをご利用される場合、監視対象のアプリケーションもx86_64版のアプリケーションをご利用ください。
4.2.4. JVM モニタの動作環境¶
JVMモニタを使用する場合には、Java 実行環境が必要です。また、JBoss Enterprise Application Platformのドメインモードを監視する場合は、Java(TM) SE Development Kitが必要です。
Java(TM) Runtime Environment |
Version 8.0 Update 11 (1.8.0_11) 以降 |
Java(TM) SE Development Kit |
Version 8.0 Update 11 (1.8.0_11) 以降 |
Java(TM) Runtime Environment |
Version 9.0 (9.0.1) 以降 |
Java(TM) SE Development Kit |
Version 9.0 (9.0.1) 以降 |
Java(TM) SE Development Kit |
Version 11.0 (11.0.5) 以降 |
Java(TM) SE Development Kit |
Version 17.0 (17.0.2) 以降 |
Open JDK |
Version 7.0 Update 45 (1.7.0_45) 以降
Version 8.0 (1.8.0) 以降
Version 9.0 (9.0.1) 以降
|
4.2.5. AWS Elastic IP リソース、AWS Elastic IP モニタリソース、AWS AZ モニタリソースの動作環境¶
AWS Elastic IPリソース、AWS Elastic IPモニタリソース、AWS AZモニタリソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.8.0~
2.0.0~
|
|
Python |
2.6.5~
3.5.2~
|
AWS CLI 付属の Python は不可 |
4.2.6. AWS 仮想 IP リソース、AWS 仮想 IP モニタリソースの動作環境¶
AWS 仮想IPリソース、AWS 仮想IPモニタリソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.9.0~
2.0.0~
|
4.2.7. AWS セカンダリ IP リソース、AWS セカンダリ IP モニタリソースの動作環境¶
AWS セカンダリ IP リソース、AWS セカンダリ IP モニタリソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.8.0~
2.0.0~
|
4.2.8. AWS DNS リソース、AWS DNS モニタリソースの動作環境¶
AWS DNS リソース、AWS DNS モニタリソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.11.0~
2.0.0~
|
|
Python (Red Hat Enterprise Linux 6, Cent OS 6, SUSE Linux Enterprise Server 11, Oracle Linux 6 の場合) |
2.6.6~
3.6.5~
|
AWS CLI 付属の Python は不可 |
Python (Red Hat Enterprise Linux 6, Cent OS 6, SUSE Linux Enterprise Server 11, Oracle Linux 6 以外の場合) |
2.7.5~
3.5.2~
|
AWS CLI 付属の Python は不可 |
4.2.9. AWS 強制停止リソースの動作環境¶
AWS 強制停止リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.8.0~
2.0.0~
|
4.2.10. Azure プローブポートリソース、Azure プローブポートモニタリソース、Azure ロードバランスモニタリソースの動作環境¶
Azure プローブポートリソースの動作確認を行った Microsoft Azure 上のデプロイモデルを下記に提示します。ロードバランサーの追加方法は Microsoft のドキュメント(https://azure.microsoft.com/ja-jp/documentation/articles/load-balancer-arm/)を参照してください。
x86_64
デプロイモデル
備考
リソースマネージャー
4.0.0-1~
ロードバランサーの追加が必要
4.2.11. Azure DNS リソース、Azure DNS モニタリソースの動作環境¶
Azure DNS リソース、Azure DNS モニタリソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
Azure CLI (Red Hat Enterprise Linux 6, Cent OS 6, Asianux Server 4, SUSE Linux Enterprise Server 11, Oracle Linux 6 の場合) |
1.0~ |
Python は不要 |
Azure CLI (Red Hat Enterprise Linux 6, Cent OS 6, Asianux Server 4, SUSE Linux Enterprise Server 11, Oracle Linux 6 以外の場合) |
2.0~ |
x86_64
デプロイモデル
備考
リソースマネージャー
4.0.0-1~
Azure DNS の追加が必要
4.2.12. Azure 強制停止リソースの動作環境¶
Azure 強制停止リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
Azure CLI |
2.0~ |
4.2.13. Google Cloud 仮想 IP リソース、Google Cloud 仮想 IP モニタリソース、Google Cloud ロードバランスモニタリソースの動作環境¶
4.2.14. Google Cloud DNS リソース、Google Cloud DNS モニタリソースの動作環境¶
Google Cloud DNS リソース、Google Cloud DNS モニタリソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア
Version
備考
Google Cloud SDK
295.0.0~
4.2.15. Oracle Cloud 仮想 IP リソース、Oracle Cloud 仮想 IP モニタリソース、Oracle Cloud ロードバランスモニタリソースの動作環境¶
4.2.16. OCI 強制停止リソースの動作環境¶
OCI 強制停止リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
OCI CLI |
3.5.3~
|
4.2.17. メール通報機能で暗号化を有効にする場合の動作環境¶
メール通報機能で暗号化を有効にする場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
OpenSSL |
1.1.1~
3.0.0~
|
4.2.18. 必要メモリ容量とディスクサイズ¶
必要メモリサイズ
(ユーザモード)
|
300MB 2
|
|---|---|
必要メモリサイズ
(kernelモード)
|
同期モードの場合
1MB+(リクエストキュー数×I/Oサイズ)+(2MB+差分ビットマップサイズ)×(ミラーディスクリソース、ハイブリッドディスクリソース数)
非同期モードの場合
1MB +{リクエストキュー数}×{I/Oサイズ}
+[3MB
+({I/Oサイズ}×{非同期キュー数})
+({I/Oサイズ}÷ 4KB × 8バイト + 0.5KB)× ({履歴ファイルサイズ制限値}÷{I/Oサイズ}+{非同期キュー数})+{差分ビットマップサイズ}
]×(ミラーディスクリソース、ハイブリッドディスクリソース数)
カーネルモード LAN ハートビートドライバの場合
8MB
キープアライブドライバの場合
8MB
|
必要ディスクサイズ
(インストール直後)
|
300MB
|
必要ディスクサイズ
(運用時)
|
5.0GB + 1.0GB 3
|
注釈
I/O サイズの目安は、以下の様になります。
RHEL9の場合、6MB
RHEL8の場合、2MB
RHEL7の場合、124KB
リクエストキュー数、非同期キュー数の設定値については『リファレンスガイド』の「グループリソースの詳細」の「ミラーディスクリソースを理解する」を参照してください。
ディスクハートビートリソースが使用するパーティションに必要なサイズは「共有ディスクについて」を参照してください。
クラスタパーティションに必要なサイズは「ミラー用のディスクについて」、「ハイブリッドディスクリソース用のディスクについて」を参照してください。
4.3. Cluster WebUI の動作環境¶
4.3.1. 動作確認済 OS、ブラウザ¶
現在の対応状況は下記の通りです。
ブラウザ |
言語 |
|---|---|
Internet Explorer 11 |
日本語/英語/中国語 |
Internet Explorer 10 |
日本語/英語/中国語 |
Firefox |
日本語/英語/中国語 |
Google Chrome |
日本語/英語/中国語 |
Microsoft Edge (Chromium) |
日本語/英語/中国語 |
注釈
IPアドレスで接続する場合、事前に該当のIPアドレスを [ローカル イントラネット] の [サイト] に登録する必要があります。
注釈
Internet Explorer 11 にて Cluster WebUI に接続すると、Internet Explorer が停止することがあります。本事象回避のために、Internet Explorer のアップデート (KB4052978 以降) を適用してください。なお、Windows 8.1/Windows Server 2012R2 に KB4052978 以降を適用するためには、事前に KB2919355 の適用が必要となります。詳細は Microsoft より展開されている情報をご確認ください。
注釈
タブレットやスマートフォンなどのモバイルデバイスには対応していません。
注釈
4.3.2. 必要メモリ容量/ディスク容量¶
必要メモリ容量 500MB 以上
必要ディスク容量 200MB 以上
5. 最新バージョン情報¶
本章では、CLUSTERPROの最新情報について説明します。新しいリリースで強化された点、改善された点などをご紹介します。
5.1. CLUSTERPRO とマニュアルの対応一覧¶
本書では下記のバージョンの CLUSTERPROを前提に説明してあります。CLUSTERPROのバージョンとマニュアルの版数に注意してください。
CLUSTERPROの
内部バージョン
|
マニュアル |
版数 |
備考 |
|---|---|---|---|
5.1.1-1 |
スタートアップガイド |
第 3 版 |
|
インストール&設定ガイド |
第 3 版 |
||
リファレンスガイド |
第 3 版 |
||
メンテナンスガイド |
第 2 版 |
||
ハードウェア連携ガイド |
第 1 版 |
5.2. 機能強化¶
各バージョンにおいて以下の機能強化を実施しています。
項番 |
内部バージョン |
機能強化項目 |
|---|---|---|
1 |
5.0.0-1 |
新しくリリースされた kernel に対応しました。 |
2 |
5.0.0-1 |
Ubuntu 20.04.3 LTS に対応しました。 |
3 |
5.0.0-1 |
SUSE LINUX Enterprise Server 12 SP3 に対応しました。 |
4 |
5.0.0-1 |
メジャーバージョンアップに伴い、いくつかの機能を削除しました。詳細は機能削除一覧を参照してください。 |
5 |
5.0.0-1 |
サーバダウン時の自動フェイルオーバをクラスタ全体で一括して抑止する機能を追加しました。 |
6 |
5.0.0-1 |
グループリソースの活性・非活性異常検出時およびモニタリソースの異常検出時の最終動作によるサーバ再起動の回数がリセットされたときに、アラートログで通知するようにしました。 |
7 |
5.0.0-1 |
ダイナミックフェイルオーバ以外の自動フェイルオーバにおいて、指定したモニタリソースで異常を検出しているサーバをフェイルオーバ先から除外できるようになりました。 |
8 |
5.0.0-1 |
ファイアウォールの規則を追加するコマンド clpfwctrl を追加しました。 |
9 |
5.0.0-1 |
AWS セカンダリ IP リソース、AWS セカンダリ IP モニタリソースを追加しました。 |
10 |
5.0.0-1 |
BMCを利用した強制停止機能をBMC強制停止リソースとして刷新しました。 |
11 |
5.0.0-1 |
仮想マシン強制停止機能をvCenter強制停止リソースとして刷新しました。 |
12 |
5.0.0-1 |
AWS環境の強制停止機能を強制停止リソースに追加しました。 |
13 |
5.0.0-1 |
OCI環境の強制停止機能を強制停止リソースに追加しました。 |
14 |
5.0.0-1 |
強制停止スクリプトをカスタム強制停止リソースとして刷新しました。 |
15 |
5.0.0-1 |
モニタ異常検出時の回復動作等でOSシャットダウンを伴う動作を一括してOSリブートに変更する機能を追加しました。 |
16 |
5.0.0-1 |
グループ間の起動および停止待ち合わせ処理に関するアラートメッセージを改善しました。 |
17 |
5.0.0-1 |
clpstatの設定情報の表示オプションで、リソース起動属性の設定値を表示できるようにしました。 |
18 |
5.0.0-1 |
clpcl/clpstdnコマンドで、自サーバがクラスタ停止状態でも-hオプションを指定できるようにしました。 |
19 |
5.0.0-1 |
実IPアドレス以外で Cluster WebUI に接続して設定モードに切替えた時に警告メッセージを出力するようになりました。 |
20 |
5.0.0-1 |
Cluster WebUI の設定モードでグループリソースを登録している状態でグループの削除が行えるようになりました。 |
21 |
5.0.0-1 |
Cluster WebUI で通信タイムアウトが発生した際のエラーメッセージの内容を変更しました。 |
22 |
5.0.0-1 |
Cluster WebUI のミラーディスク画面でフルコピー等の実行に失敗した際のエラーメッセージの内容を変更しました。 |
23 |
5.0.0-1 |
Cluster WebUI の設定モードで登録したグループ、グループリソース、モニタリソースを複製できる機能を追加しました。 |
24 |
5.0.0-1 |
Cluster WebUI の設定モードで登録したグループリソースを別のグループへ移動できる機能を追加しました。 |
25 |
5.0.0-1 |
Cluster WebUI の設定モードの [グループのプロパティ] のグループリソース一覧から設定を変更できるようになりました。 |
26 |
5.0.0-1 |
Cluster WebUI の設定モードの [モニタ共通のプロパティ] のモニタリソース一覧から設定を変更できるようになりました。 |
27 |
5.0.0-1 |
Cluster WebUI の設定モードでグループリソース非活性時の依存関係が表示されるようになりました。 |
28 |
5.0.0-1 |
Cluster WebUI の設定モードでグループリソース活性時および非活性時の依存関係図を表示する機能を追加しました。 |
29 |
5.0.0-1 |
Cluster WebUI のステータス画面でグループリソース/モニタリソースのタイプやリソース名で表示を絞り込む機能を追加しました。 |
30 |
5.0.0-1 |
ユーザ空間モニタリソース、ダイナミックDNSモニタリソースがクラスタ統計情報機能に対応しました。 |
31 |
5.0.0-1 |
WebManager サービスで通信方式に HTTPS を使用した場合、証明書ファイルとして中間証明書を使用できるようになりました。 |
32 |
5.0.0-1 |
クラスタ構成情報ファイルを旧バージョンから現バージョンへ変換するコマンド clpcfconv.sh を追加しました。 |
33 |
5.0.0-1 |
OS起動時にクラスタサービスの起動を遅延させる機能を追加しました。 |
34 |
5.0.0-1 |
クラスタ構成情報チェック機能のチェック項目を拡充しました。 |
35 |
5.0.0-1 |
Cluster WebUI のクラスタ構成情報チェックのエラー結果において、対処法などの詳細を表示できるようになりました。 |
36 |
5.0.0-1 |
clpcfsetコマンドのcreateオプション指定時にOS種別を指定できるようにしました。 |
37 |
5.0.0-1 |
clpcfsetコマンドにdelオプションを追加し、クラスタ構成情報からリソースやパラメータを削除する機能を追加しました。 |
38 |
5.0.0-1 |
clpcfsetコマンドのインターフェースを強化したclpcfadm.pyコマンドを追加しました。 |
39 |
5.0.0-1 |
AWS DNSリソースの起動完了タイミングをレコードセットがAWS Route53へ伝搬されたことを確認してから起動するように変更しました。 |
40 |
5.0.0-1 |
AWS DNSモニタリソースの監視開始待ち時間の既定値を300秒に変更しました。 |
41 |
5.0.0-1 |
ディスクIO遅延の影響を受けるべきでないモニタリソースについて、監視プロセスがディスク待ち休眠状態(D状態)でタイムアウトした場合に異常ではなく警告と判定するように改善しました。 |
42 |
5.0.0-1 |
clpstatコマンドが二重起動可能となりました。 |
43 |
5.0.0-1 |
Node Managerサービスを追加しました |
44 |
5.0.0-1 |
ハートビート統計情報機能を追加しました。 |
45 |
5.0.0-1 |
HTTP NP解決リソースで、Witnessハートビートリソースを使用しない場合でも Proxyサーバを利用できるようになりました。 |
46 |
5.0.0-1 |
SELinuxのEnforcingモードに対応しました。 |
47 |
5.0.0-1 |
HTTPモニタリソースがDigest認証に対応しました。 |
48 |
5.0.0-1 |
FTPモニタリソースでFTPSを利用するFTPサーバを監視できるようになりました。 |
49 |
5.0.0-1 |
JVMモニタリソースのJBoss EAP ドメインモードがJava9以降で監視できるようになりました。 |
50 |
5.0.2-1 |
JVMモニタリソースが JBoss Enterprise Application Platform 7.4 に対応しました。 |
51 |
5.0.2-1 |
JVMモニタリソースが Apache Tomcat 10.0 に対応しました。 |
52 |
5.1.0-1 |
Ubuntu 22.04.1 LTS に対応しました。 |
53 |
5.1.0-1 |
Ubuntu 20.04.5 LTS に対応しました。 |
54 |
5.1.0-1 |
SUSE LINUX Enterprise Server 15 SP3 に対応しました。 |
55 |
5.1.0-1 |
メール通報機能が SMTPS および STARTTLS に対応しました。 |
56 |
5.1.0-1 |
Azure 環境の強制停止機能を強制停止リソースに追加しました。 |
57 |
5.1.0-1 |
vCenter 強制停止リソースで vSphere Automation API を利用した強制停止機能を追加しました。 |
58 |
5.1.0-1 |
ログファイルを保存する期間を設定できるようになりました。 |
59 |
5.1.0-1 |
構成情報反映時にクラスタ構成情報ファイルのバックアップが作成されるようになりました。 |
60 |
5.1.0-1 |
クラスタ構成情報チェック機能のチェック項目を拡充しました。 |
61 |
5.1.0-1 |
フローティングIPリソースの送信元 IP アドレスを変更できるようになりました。 |
62 |
5.1.0-1 |
マルチターゲットモニタリソースで以下のモニタリソースを登録できるようになりました。
- AWS Elastic IP モニタリソース
- AWS 仮想 IP モニタリソース
- AWS セカンダリ IP モニタリソース
- AWS AZ モニタリソース
- AWS DNS モニタリソース
- Azure プローブポートモニタリソース
- Azure ロードバランスモニタリソース
- Azure DNS モニタリソース
- Google Cloud 仮想 IP モニタリソース
- Google Cloud ロードバランスモニタリソース
- Google Cloud DNS モニタリソース
- Oracle Cloud 仮想 IP モニタリソース
- Oracle Cloud ロードバランスモニタリソース
|
63 |
5.1.0-1 |
カスタムモニタリソースに、設定されたスクリプトの戻り値を警告とする機能を追加しました。 |
64 |
5.1.0-1 |
SQL Server モニタリソースが SQL Server 2022 に対応しました。 |
65 |
5.1.0-1 |
PostgreSQL モニタリソースが PostgreSQL 15.1 に対応しました。 |
66 |
5.1.0-1 |
MySQL モニタリソースが MariaDB 8.0.31 に対応しました。 |
67 |
5.1.0-1 |
MySQL モニタリソースが MariaDB 10.10 に対応しました。 |
68 |
5.1.0-1 |
AWS 環境で、AWS 仮想 IP リソース および AWS 仮想 IP モニタリソースのみを使用する構成では Python が不要になりました。 |
69 |
5.1.0-1 |
AWS 関連機能で実行しているAWS CLI やインスタンスメタデータへのアクセスに環境変数を指定する機能を Cluster WebUI から設定できるようになりました。 |
70 |
5.1.0-1 |
AWS 関連機能で実行しているAWS CLI にコマンドラインオプションを指定する機能を追加しました。 |
71 |
5.1.0-1 |
JVMモニタリソースが WebSAM SVF PDF Enterprise 10.1 に対応しました。 |
72 |
5.1.0-1 |
JVMモニタリソースが WebSAM RDE SUITE 10.1 に対応しました。 |
73 |
5.1.0-1 |
JVMモニタリソースが WebSAM SVF Connect SUITE Standard 10.1 に対応しました。 |
74 |
5.1.0-1 |
プロセスリソース統計情報を出力する機能を追加しました。 |
75 |
5.1.0-1 |
システムモニタリソースで、iノード使用率を監視する機能を追加しました。 |
76 |
5.1.0-1 |
HTTPモニタリソースがクライアント認証に対応しました。 |
77 |
5.1.0-1 |
FTPモニタリソース、HTTPモニタリソースが OpenSSL3.0 に対応しました。 |
78 |
5.1.0-1 |
JVMモニタリソースで、運用ログにリトライ回数に関する情報を出力するようになりました。 |
79 |
5.1.0-1 |
JVMモニタリソースが Java17 に対応しました。 |
80 |
5.1.0-1 |
JVMモニタリソースが Java7 非対応になりました。 |
81 |
5.1.0-1 |
clpbackup.sh、clprestore.sh コマンドにサーバシャットダウンや再起動をおこなわないオプションを追加しました。 |
82 |
5.1.0-1 |
clpcfadm.py コマンドに変更前のクラスタ構成情報のバックアップファイルを作成するオプションを追加しました。 |
83 |
5.1.0-1 |
Cluster WebUI および clplogcc コマンドでプロアクティブ診断用のログを採取できるようになりました。 |
84 |
5.1.0-1 |
Cluster WebUI の操作ログを Cluster WebUI で表示できるようになりました。 |
85 |
5.1.0-1 |
Cluster WebUI が OpenSSL 3.0 に対応しました。 |
86 |
5.1.0-1 |
Cluster WebUI の HTTPS 接続において TLS 1.1 を無効化しました。 |
87 |
5.1.0-1 |
通信可能なサーバのみに対して Cluster WebUI でクラスタ構成情報の反映をおこなう機能を追加しました。 |
88 |
5.1.0-1 |
ユーザ空間モニタリソースとシャットダウン監視の設定で、[監視方法] に 「ipmi」 を選択した際、[タイムアウト発生時動作] に 「NMI」 が設定できるようになりました。 |
89 |
5.1.0-1 |
Cluster WebUI のステータス画面にクラスタの動作が無効化されている設定の一覧を表示する機能を追加しました。 |
90 |
5.1.0-1 |
Cluster WebUI の設定モードで、以下の項目を表示/非表示にする機能およびソートする機能を追加しました。
- [グループのプロパティ] のグループリソース一覧
- [モニタ共通のプロパティ] のモニタリソース一覧
|
91 |
5.1.0-1 |
クラスタプロパティの [接続可能なクライアント台数] の名称を [同時接続セッション数] に変更し、下限値を変更しました。 |
92 |
5.1.0-1 |
Cluster WebUI のアラートログの [受信日時] はデフォルトで非表示になりました。 |
93 |
5.1.0-1 |
Cluster WebUI のステータス画面の [マネージャ再起動] ボタンの説明を 「WebManagerサービス再起動」 に変更しました。 |
94 |
5.1.0-1 |
Cluster WebUI の設定モードから [グループの複製] をおこなう際、グループリソース個別の依存関係も複製できるようになりました。 |
95 |
5.1.0-1 |
Cluster WebUI にて、AWS DNS リソースの設定不備をガードするようにしました。 |
96 |
5.1.0-1 |
Cluster WebUI にて、カスタムモニタリソースの [監視タイプ] に非同期を設定した際の設定不備をガードするようにしました。 |
97 |
5.1.0-1 |
Cluster WebUI にて、Ping NP 解決リソースの設定不備をガードするようにしました。 |
98 |
5.1.0-1 |
クラスタ統計情報で、手動操作によるフェイルオーバか異常検知による自動フェイルオーバの切り分けが可能になりました。 |
99 |
5.1.1-1 |
Red Hat Enterprise Linux 9.0 に対応しました。 |
100 |
5.1.1-1 |
Oracle Linux 9.0 に対応しました。 |
101 |
5.1.1-1 |
MIRACLE LINUX 9.0 に対応しました。 |
102 |
5.1.1-1 |
AlmaLinux 9.0 に対応しました。 |
103 |
5.1.1-1 |
RESTful API が OpenSSL 3.0 に対応しました。 |
104 |
5.1.1-1 |
Witness ハートビートリソースが OpenSSL 3.0 に対応しました。 |
105 |
5.1.1-1 |
HTTP ネットワークパーティション解決リソースが OpenSSL 3.0 に対応しました。 |
5.3. 修正情報¶
各バージョンにおいて以下の修正を実施しています。
項番 |
修正バージョン
/ 発生バージョン
|
修正項目 |
重要度 |
発生条件
発生頻度
|
|---|---|---|---|---|
1 |
5.0.0-1
/ 1.0.0-1 ~ 4.3.2-1
|
グループリソースの単体活性が成功したとき、同じグループ内の他のグループリソースの復旧動作が実行される場合がある。 |
小 |
活性異常状態のグループリソースが存在する状態で、同じグループ内の他のグループリソースを単体活性した場合に発生する。 |
2 |
5.0.0-1
/ 4.1.0-1 ~ 4.3.2-1
|
Cluster WebUI の設定モードでグループリソースの「コメント」を修正したときに、修正内容が更新されない場合がある。 |
小 |
グループリソースの「コメント」を修正して[適用]ボタン押下後、修正前の状態に戻して[OK]ボタンを押下した場合に発生する。 |
3 |
5.0.0-1
/ 4.1.0-1 ~ 4.3.2-1
|
Cluster WebUI の設定モードでモニタリソースの「コメント」を修正したときに、修正内容が更新されない場合がある。 |
小 |
モニタリソースの「コメント」を修正して[適用]ボタン押下後、修正前の状態に戻して[OK]ボタンを押下した場合に発生する。 |
4 |
5.0.0-1
/ 4.0.0-1 ~ 4.3.2-1
|
Cluster WebUI のステータス画面でクラスタの操作を実行した際に、通信タイムアウトが発生すると同一のリクエストを再度発行してしまう。 |
中 |
Cluster WebUI とクラスタサーバ間で通信タイムアウトが発生すると必ず発生する。 |
5 |
5.0.0-1
/ 4.1.0-1 ~ 4.3.2-1
|
Cluster WebUI の設定モードで依存関係を設定した際に、Cluster WebUI がフリーズする場合がある。 |
小 |
2つのグループリソースを互いに依存させた場合に発生する。 |
6 |
5.0.0-1
/ 4.2.0-1 ~ 4.3.2-1
|
clpstatコマンドの応答が遅延することがある。 |
小 |
他のサーバとの通信が切断した場合に発生することがある。 |
7 |
5.0.0-1
/ 3.1.0-1 ~ 4.3.2-1
|
クラスタサービスが停止しないことがある。 |
小 |
クラスタサービスの停止を実行した際にごく稀に発生する。 |
8 |
5.0.0-1
/ 4.0.0-1 ~ 4.3.2-1
|
モニタリソースが監視タイムアウトを誤検出することがある。 |
中 |
モニタリソースの監視処理実行時にごく稀に発生することがある。 |
9 |
5.0.0-1
/ 4.2.0-1 ~ 4.3.2-1
|
clpcfchkコマンドで前回のチェック結果ファイルが存在するディレクトリを"-o"オプションで指定した場合、今回のチェック結果に前回のチェック結果が混入してしまう。 |
小 |
clpcfchkコマンドの"-o"オプションで前回のチェック結果ファイル(cfchk_result.csv)が存在するディレクトリを指定した場合に発生する。 |
10 |
5.0.0-1
/ 4.3.0-1 ~ 4.3.2-1
|
クラスタ構成チェックのfstabに関するチェック処理が失敗することがある。 |
小 |
/etc/fstab のデバイス名、マウントポイントのパスの末尾が"/"の場合に発生する。 |
11 |
5.0.0-1
/ 4.3.0-1 ~ 4.3.2-1
|
clpcfsetコマンドが異常終了することがある。 |
小 |
属性値に空文字列を指定した場合に発生する。 |
12 |
5.0.0-1
/ 4.0.0-1 ~ 4.3.2-1
|
AWS環境で強制停止スクリプトがタイムアウトすることがある。 |
小 |
AWS環境で強制停止スクリプトを実行時に発生することがある。 |
13 |
5.0.0-1
/ 4.2.0-1 ~ 4.3.2-1
|
HTTP方式のNP解決リソースで、ターゲットのレスポンスがステータスコード301だった場合に異常となる。 |
小 |
レスポンスがステータスコード301だった場合に発生する。 |
14 |
5.0.0-1
/ 4.0.0-1 ~ 4.3.2-1
|
WebManager サービスで「クライアントセッションタイムアウト」が機能しないことがある。 |
小 |
「クライアントセッションタイムアウト」が経過するまでに次のリクエストが発行されない場合に発生する。 |
15 |
5.0.0-1
/ 4.0.0-1 ~ 4.3.2-1
|
ハイブリッドディスクリソース利用時、Cluster WebUI のステータス画面とミラーディスク画面のサーバの表示順が一致しない。 |
小 |
ステータス画面のサーバの表示順は優先順位順、ミラーディスク画面のサーバの表示順は所属するサーバグループのサーバグループ名の昇順のため、サーバグループ名に依存して発生する。 |
16 |
5.0.0-1
/ 4.0.0-1 ~ 4.3.2-1
|
モニタリソースの監視処理がタイムアウトした場合、監視異常を検出するまでに時間がかかる場合がある。 |
小 |
モニタリソースの監視処理がタイムアウトした際にごく稀に発生する。 |
17 |
5.0.0-1
/ 1.0.0-1 ~ 4.3.2-1
|
IPモニタリソースやPING NP解決リソースを設定している場合、ICMPパケットが大量に送出されることがある。 |
小 |
ICMPの通信処理で予期せぬパケットを受信した場合に発生する。 |
18 |
5.0.0-1
/ 4.0.0-1 ~ 4.3.2-1
|
プロセスリソースモニタリソースの[メモリ使用量の監視]の[継続時間 (分)]の表記を[最大更新回数 (回)]に修正しました。 |
小 |
Cluster WebUIやclpstatコマンドでプロパティを表示した際に発生する。 |
19 |
5.0.0-1
/ 3.3.2-1 ~ 4.3.2-1
|
ミラーディスクコネクトが切断されている状態で、ミラーディスク関連コマンドの応答が遅くなることがある。 |
小 |
複数のミラーディスクコネクトのうち、優先度の高いものが断線状態の場合に発生する。 |
20 |
5.0.0-1
/ 1.0.0-1 ~ 4.3.2-1
|
ディスクタイプが「raw」のディスクリソースの非活性が失敗することがある。 |
小 |
ディスクリソースのディスクタイプが「raw」で、リソース非活性時にデバイスへアクセスするプロセスが存在している場合に発生する。 |
21 |
5.0.0-1
/ 1.1.0-1 ~ 4.3.2-1
|
ミラーディスクコネクト断線時に、OSが断続的にストールすることがある。 |
小 |
ミラーディスクリソースまたはハイブリッドディスクリソースのモードが「非同期」で、断線発生時にI/Oの負荷が高い状態の場合に、発生することがある。 |
22 |
5.0.0-1
/ 4.2.0-1 ~ 4.3.2-1
|
CLUSTERPRO Information Base サービスが異常終了することがある。 |
小 |
以下のいずれかの操作を行った際にごく稀に発生することがある。
- クラスタ起動
- クラスタ停止
- クラスタサスペンド
- クラスタリジューム
|
23 |
5.0.1-1
/ 5.0.0-1
|
Ubuntu 環境でクラスタ構成情報ファイル変換コマンド clpcfconv.sh が失敗する。 |
小 |
Ubuntu 環境の場合に発生する。 |
24 |
5.0.1-1
/ 5.0.0-1
|
CLUSTERPRO X 3.3 for Linux で作成したクラスタ構成情報ファイルを、クラスタ構成情報ファイル変換コマンドで変換し、クラスタに適用した場合、ミラーエージェントの起動に失敗する。 |
小 |
CLUSTERPRO X 3.3 for Linux からのアップグレードにおいて、ミラーリソース/ハイブリッドディスクリソースを使用している場合に発生する。 |
25 |
5.0.1-1
/ 5.0.0-1
|
clprexecコマンドの--scriptオプションが動作しない |
小 |
--scriptオプションを指定してclprexecコマンドを実行した場合に発生する。 |
26 |
5.0.1-1
/ 5.0.0-1
|
clpcfset コマンドで強制停止リソースを追加した場合、クラスタ起動に失敗する。 |
小 |
clpcfset コマンドで強制停止リソースを追加したクラスタ構成情報を適用したクラスタを起動した場合に発生する。 |
27 |
5.0.1-1
/ 5.0.0-1
|
Amazon Linux 2 環境でカーネルモードLANハートビートが正常に起動しない。 |
中 |
Amazon Linux 2 環境で発生する。 |
28 |
5.0.1-1
/ 4.3.0-1 ~ 4.3.2-1、5.0.0-1
|
ext4ファイルシステムを使用したミラーディスクリソースおよびハイブリッドディスクリソースでフルコピーによるミラー復帰を行うと、コピー先へ正しくデータがコピーされない場合がある。 |
大 |
ext4ファイルシステムを使用したミラーディスクリソースおよびハイブリッドディスクリソースでフルコピーによるミラー復帰を行った場合に発生する。 |
29 |
5.0.1-1
/ 4.3.2-1、5.0.0-1
|
Oracleモニタリソースで、監視タイムアウト発生時にリトライ処理が正常に動作しないことがある。
|
中 |
Oracleモニタリソースで監視処理がタイムアウトした場合に発生する。 |
30 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
Amazon CloudWatch連携機能が動作しないことがある。 |
小 |
Amazon CloudWatch連携機能を設定している場合にごく稀に発生する。 |
31 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
フェイルオーバグループの [起動可能なサーバ] の一覧からサーバを削除した構成情報の設定反映時にグループ停止が要求されない。 |
小 |
フェイルオーバグループの [起動可能なサーバ] の一覧からサーバを削除した構成情報の設定反映時に発生する。 |
32 |
5.0.2-1
/ 4.3.2-1 ~ 5.0.1-1
|
ミラーディスクリソースまたはハイブリットディスクリソースでファイルシステムにXFSを使用していた場合、稀にリソースの活性に失敗する。
|
大 |
Red HatEnterprise Linux 8.4 以降で、ミラーディスクリソースまたはハイブリットディスクリソースでファイルシステムにXFSを使用している場合に発生する。 |
33 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
モニタリソースが監視タイムアウトを誤検知することがある。 |
小 |
モニタリソースの監視処理実行時にごく稀に発生することがある。 |
34 |
5.0.2-1
/ 1.0.0-1 ~ 5.0.1-1
|
keepalive リセット および keepalive パニック が動作しないことがある。
|
小 |
キープアライブドライバで使用しているメジャー番号(10) および マイナー番号(241)が他のドライバで使用されている場合、keepalive リセット および keepalive パニックが失敗する。 |
35 |
5.0.2-1
/ 4.3.0-1 ~ 5.0.1-1
|
Tuxedoモニタリソースの監視プロセスが異常終了し監視異常となる場合がある。 |
中 |
タイミングにより発生する。 |
36 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
複数のサーバに対する強制停止の実行が失敗することがある。 |
小 |
3 台以上のクラスタ構成において、1 台のサーバから複数のサーバに対して強制停止を実行すると稀に発生する。 |
37 |
5.0.2-1
/ 1.0.0-1 ~ 5.0.1-1
|
clpstat コマンドが異常終了することがある。 |
小 |
グループリソースが1つも登録されていないフェイルオーバグループが設定されている環境で発生する。 |
38 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
クラスタサスペンド状態で Cluster WebUI や clpstat コマンドのサーバステータスが停止と表示される場合がある。 |
小 |
クラスタサスペンド状態で以下のサービスを再起動すると発生する。
- clusterpro_nm
- clusterpro_ib
|
39 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
グループリソースやモニタリソースのステータス表示が不正になる場合がある。 |
小 |
OS起動時のクラスタサービスの内部処理で問題が発生した場合に発生する。 |
40 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
Cluster WebUI や clpstat コマンドで強制停止リソースを使用していないサーバのステータスが正しく表示されない。 |
小 |
3 台以上のクラスタ構成において、強制停止を使用しない設定をしたサーバが存在する場合に発生する。 |
41 |
5.0.2-1
/ 5.0.0-1 ~ 5.0.1-1
|
CLUSTERPRO X 5.0 の動作環境に含まれる OS で機能しない高速SSDに関する設定項目が Cluster WebUI で表示される。 |
小 |
ミラーディスクリソースおよびハイブリッドディスクリソースの詳細プロパティに常に表示される。 |
42 |
5.0.2-1
/ 4.3.0-1 ~ 5.0.1-1
|
clpwebmc プロセスが異常終了することがある。 |
小 |
クラスタ運用時にごく稀に発生する。 |
43 |
5.0.2-1
/ 4.3.0-1 ~ 5.0.1-1
|
ディスクリソース、ミラーディスクリソース、ハイブリッドディスクリソースのマウントポイントにスペースが含まれている場合、クラスタ構成情報チェック機能の /etc/fstabのエントリチェック が適切にチェックできない。 |
小 |
スペースを含むマウントポイントを設定し、クラスタ構成情報チェックを実行すると発生する。 |
44 |
5.1.0-1
/ 4.2.0-1 ~ 5.0.2-1
|
CLUSTERPRO Information Base サービスが異常終了することがある。 |
小 |
クラスタシャットダウンを実行した際に稀に発生することがある。 |
45 |
5.1.0-1
/ 4.2.0-1 ~ 5.0.2-1
|
CLUSTERPRO API サービスが異常終了することがある。 |
小 |
タイミングにより発生することがある。 |
46 |
5.1.0-1
/ 4.0.0-1 ~ 5.0.2-1
|
期限付きライセンスの期限終了後、製品版ライセンスではなく期限付きライセンスが優先されて Active になることがある。 |
小 |
期限付きライセンスの期限が終了する際に、未使用の期限付きライセンスと製品版ライセンスが登録されてる場合に発生する。 |
47 |
5.1.0-1
/ 5.0.0-1 ~ 5.0.2-1
|
BMC強制停止リソースのステータスが異常になる。 |
小 |
iLO 共有ネットワークポートを有効にしている場合に発生する。 |
48 |
5.1.0-1
/ 1.0.0-1 ~ 5.0.2-1
|
クラスタリジュームに失敗しクラスタが異常終了することがある。 |
中 |
名前が 1 文字のモニタリソースがあり、それと同じタイプのモニタリソースを複数登録した環境で、クラスタサスペンド・リジュームを繰り返し実行すると発生する。 |
49 |
5.1.0-1
/ 1.0.0-1 ~ 5.0.2-1
|
クラスタ構成情報変更時に適切な反映方法が要求されないことがある。 |
小 |
クラスタ構成情報反映時に稀に発生することがある。 |
50 |
5.1.0-1
/ 3.1.0-1 ~ 5.0.2-1
|
ミラーディスク関連モニタまたはハイブリッドディスク関連モニタのステータスが異常になることがある。 |
中 |
インタコネクトのIPアドレスを変更したクラスタ構成情報を反映後に発生することがある。 |
51 |
5.1.0-1
/ 1.0.0-1 ~ 5.0.2-1
|
非同期ミラーでミラーブレイクした時にサーバが高負荷状態になる場合がある。 |
小 |
未送信キューが大量に滞留している状態でミラーディスクコネクトが断線した時に発生することがある。 |
52 |
5.1.0-1
/ 1.0.0-1 ~ 5.0.2-1
|
現用系サーバの不正ダウン後、復旧手順によっては現用系と待機系でデータの不一致が発生することがある。 |
小 |
現用系サーバの不正ダウン後、ミラーディスクリソースの活性を行わないまま、フルコピーでミラー復帰した場合に発生することがある。 |
53 |
5.1.0-1
/ 4.1.0-1 ~ 5.0.2-1
|
モニタリソースの回復スクリプトが実行されない場合がある。 |
小 |
Cluster WebUI で、[回復動作前にスクリプトを実行する] を ON にした後、スクリプトの編集を行わない場合またはスクリプトの変更と他の変更を同時におこなう場合に発生する。 |
54 |
5.1.0-1
/ 1.0.0-1 ~ 5.0.2-1
|
常時監視に設定したモニタリソースが動作しないことがある。 |
小 |
「監視タイミング」を活性時に設定したモニタリソースを、常時に設定変更した場合に発生する。 |
55 |
5.1.0-1
/ 1.0.0-1 ~ 5.0.2-1
|
カスタムモニタリソース停止時にユーザアプリケーションに対し強制終了シグナルを発行する。 |
中 |
ログローテートを有効にしたカスタムモニタリソースを停止すると発生する。 |
56 |
5.1.0-1
/ 1.0.0-1 ~ 5.0.1-1
|
HTTP モニタリソースの接続可能なホスト名の名前解決に失敗することがある。 |
小 |
接続先にIPアドレスではなくホスト名を指定した場合に発生することがある。 |
57 |
5.1.0-1
/ 4.1.0-1 ~ 5.0.2-1
|
JVM モニタリソースの調整プロパティで[Metaspace]の使用量のしきい値の設定ができない。 |
小 |
常に発生する。 |
58 |
5.1.0-1
/ 3.1.0-1 ~ 5.0.1-1
|
クラスタサスペンドリジューム実行時に JVM モニタリソースの監視に失敗することがある。 |
小 |
クラスタサスペンド時に JVM モニタリソースが停止完了する前にクラスタリジュームを実行した場合に発生する。 |
59 |
5.1.0-1
/ 3.1.0-1 ~ 5.0.1-1
|
JVMモニタリソースのしきい値超過の異常発生後、異常判定しきい値の回数分連続して正常値を計測する前に監視ステータスが正常に戻ることがある。
|
小 |
しきい値超過の異常発生後、次の監視で正常値だった場合に発生する。 |
60 |
5.1.0-1
/ 4.2.0-1 ~ 5.0.2-1
|
clpstat コマンドの表示が実行サーバごとに異なることがある。 |
小 |
クラスタサービスが停止しているサーバ上でコマンドを実行した場合に発生することがある。 |
61 |
5.1.0-1
/ 3.0.0-1 ~ 5.0.2-1
|
clprexec コマンドの実行に失敗することがある。 |
小 |
コマンドを大量に実行した場合に発生することがある。 |
62 |
5.1.0-1
/ 4.3.0-1 ~ 5.0.2-1
|
clpcfset コマンドで作成したクラスタ構成情報のXML属性値が正しくないことがある。 |
小 |
clpcfset コマンドで id 属性ノードを追加した場合に発生する。 |
63 |
5.1.0-1
/ 5.0.0-1 ~ 5.0.2-1
|
clpcfset コマンドで作成したクラスタ構成情報のオブジェクト数が正しくないことがある。 |
小 |
強制停止リソースを含むクラスタ構成情報に対してclpcfset コマンドで追加・削除した場合に発生する。 |
64 |
5.1.0-1
/ 5.0.0-1 ~ 5.0.2-1
|
clpcfadm.py コマンドが正しく実行出来ないことがある。 |
小 |
Cluster WebUI でフェイルオーバグループをすべて削除したクラスタ構成情報に対してclpcfadm.pyコマンドを実行した場合に発生する。 |
65 |
5.1.0-1
/ 5.0.0-1 ~ 5.0.2-1
|
clpcfadm.py コマンドで不正なモニタリソースが設定できることがある。 |
小 |
clpcfadm.py コマンドでモニタリソースを追加する時、モニタリソースタイプに jra と指定すると発生する。 |
66 |
5.1.0-1
/ 5.0.0-1 ~ 5.0.2-1
|
clpcfadm.py コマンドで作成したクラスタ構成情報のリソースの活性・非活性タイムアウト値が正しくないことがある。 |
小 |
clpcfadm.py コマンドでリソースの活性・非活性タイムアウト値の計算を要するパラメータを変更した場合に発生する。 |
67 |
5.1.0-1
/ 4.2.0-1 ~ 5.0.2-1
|
RESTful API を使用したクラスタの状態取得が失敗することがある。 |
小 |
CLUSTERPRO Information Base サービスを再起動した場合に発生することがある。 |
68 |
5.1.0-1
/ 4.2.0-1 ~ 5.0.2-1
|
RESTful API で取得したクラスタのステータスと実際のステータスに不整合が発生することがある。 |
小 |
他サーバとの通信が切断した状態でステータスを取得すると発生することがある。 |
69 |
5.1.0-1
/ 4.2.0-1 ~ 5.0.2-1
|
RESTful API で情報取得ができない場合がある。 |
小 |
操作系の API を実行した直後に情報取得系の API を実行すると稀に発生する。 |
70 |
5.1.0-1
/ 4.2.2-1 ~ 5.0.2-1
|
RESTful API のグループ情報取得にて異常発生時のレスポンスが不正な場合がある。 |
小 |
クラスタサーバで内部エラーが発生した場合に発生することがある。 |
71 |
5.1.0-1
/ 3.1.0-1 ~ 5.0.2-1
|
Cluster WebUI に接続できないことがある。 |
中 |
FIPSモードを有効化した環境で発生することがある。 |
72 |
5.1.0-1
/ 4.0.0-1 ~ 5.0.2-1
|
複数のミラーディスクリソースまたはハイブリッドディスク リソースを登録した構成で Cluster WebUI の表示が遅延することがある。 |
小 |
複数のリソースでミラー復帰が行われる場合に発生することがある。 |
73 |
5.1.0-1
/ 4.0.0-1 ~ 5.0.2-1
|
Cluster WebUI でミラー復帰の中断が失敗することがある。 |
小 |
ミラー復帰を実行した Cluster WebUI とは別のブラウザから接続して中断した場合、または、ミラー復帰実行中にブラウザをリロードした場合に発生する。 |
74 |
5.1.0-1
/ 4.1.0-1 ~ 5.0.2-1
|
Cluster WebUI のクラスタ作成ウィザードでクラスタを生成する際、[管理用IPアドレス] に対応するフローティング IP モニタリソースが自動登録されない。 |
小 |
クラスタ作成ウィザードで [管理用 IP アドレス] を登録した場合に発生する。 |
75 |
5.1.0-1
/ 4.1.0-1 ~ 5.0.2-1
|
Cluster WebUI で ディスクリソースの活性時タイムアウトと非活性時タイムアウトの設定値が変更されない場合がある。 |
小 |
ディスクリソースの[ディスクタイプ]または[ファイルシステム]のみを変更した場合に発生する。 |
76 |
5.1.0-1
/ 4.3.0-1 ~ 5.0.2-1
|
Cluster WebUI によるクラウド環境情報の取得が失敗することがある。 |
小 |
Proxy サーバを経由して Cluster WebUI に接続した場合に発生する。 |
77 |
5.1.0-1
/ 4.0.0-1 ~ 5.0.2-1
|
Cluster WebUI の設定モードで Azure DNS リソースの [TTL] を変更してもレコードに反映されない。 |
小 |
常に発生する。 |
78 |
5.1.0-1
/ 4.2.1-1 ~ 5.0.2-1
|
Cluster WebUI で、プロセス名モニタリソースまたはプロセスリソースモニタリソースに設定するプロセス名の設定が意図せず変わることがある。 |
小 |
プロセス名モニタリソースまたはプロセスリソースモニタリソースのプロセス名に 2バイト以上連続したスペースを設定した状態で、クラスタ構成情報の設定変更をおこなうと発生する。 |
79 |
5.1.0-1
/ 4.1.0-1 ~ 5.0.2-1
|
Cluster WebUI で Ping NP解決リソースのグループを追加する際に、グループ一覧の表示内容が不正になる場合がある。 |
小 |
Ping NP解決リソースのグループ一覧に複数のグループを登録している場合に発生することがある。 |
80 |
5.1.1-1
/ 4.2.0-1 ~ 5.1.0-1
|
構成情報の反映に失敗することがある。 |
小 |
Cluster WebUI を使用して構成情報の反映を繰り返すと発生することがある。 |
81 |
5.1.1-1
/ 4.0.0-1 ~ 5.1.0-1
|
クラスタ起動に失敗することがある。 |
小 |
クラスタ起動時にごく稀に発生することがある。 |
82 |
5.1.1-1
/ 5.0.0-1 ~ 5.1.0-1
|
CLUSTERPRO サービスの起動時にフェイルオーバグループが起動しないことがある。 |
中 |
サーバを 1 台ずつ CLUSTERPRO サービスの停止をおこなった後、CLUSTERPRO サービスの起動をおこなった際に発生することがある。 |
83 |
5.1.1-1
/ 1.0.0-1 ~ 5.1.0-1
|
ミラーディスクリソースまたはハイブリッドディスクリソースにおいて、差分ミラー復帰後にデータ不一致が発生する場合がある。 |
小 |
現用系サーバから待機系サーバに送付したデータの送信完了通知が返ってこない状況で現用系サーバがダウンした場合にごく稀に発生する。 |
84 |
5.1.1-1
/ 3.3.0-1 ~ 5.1.0-1
|
フェイルオーバグループの [起動可能なサーバ] の設定を変更した場合に適切な反映方法が要求されない。 |
小 |
必ず発生する。 |
85 |
5.1.1-1
/ 2.0.0-1 ~ 5.1.0-1
|
カスタムモニタリソースが異常終了することがある。 |
小 |
カスタムモニタリソースの監視処理がタイムアウトした場合に発生することがある。 |
86 |
5.1.1-1
/ 1.0.0-1 ~ 5.1.0-1
|
SQL Server モニタリソースが異常を検出しないことがある。 |
小 |
[監視レベル] を 0 に設定すると発生する。 |
87 |
5.1.1-1
/ 5.1.0-1
|
vCenter 強制停止リソースの定期チェック処理で異常を検出しないことがある。 |
小 |
[強制停止実行方法] に vSphere Automation API を設定し、誤った [仮想マシン名] を設定した場合に発生する。 |
88 |
5.1.1-1
/ 5.1.0-1
|
メール通報機能が動作しないことがある。 |
小 |
X 5.0.2 以前のバージョンでメール通報機能を設定している状態で X 5.1.0 にバージョンアップした場合に発生する。 |
89 |
5.1.1-1
/ 4.2.0-1 ~ 5.1.0-1
|
ハートビートのステータスが不正になることがある。 |
小 |
複数のクラスタサーバに Cluster WebUI を接続している、または、複数のクラスタサーバ上で clpstat コマンドを実行した場合に、発生することがある。 |
90 |
5.1.1-1
/ 5.0.0-1 ~ 5.1.0-1
|
グループリソースのステータスが不正になることがある。 |
小 |
片サーバのみ CLUSTERPRO サービスを再起動した場合に発生することがある。 |
91 |
5.1.1-1
/ 4.3.0-1 ~ 5.1.0-1
|
clpcfset コマンドや clpcfadm コマンドで作成した構成情報の反映に失敗することがある。 |
小 |
clpcfset コマンドや clpcfadm コマンドで作成した構成情報を clpcfctrl コマンドのオプションに --nocheck をつけて反映した場合に発生する。 |
92 |
5.1.1-1
/ 4.3.0-1 ~ 5.1.0-1
|
Cluster WebUIの設定モードで [設定の反映] が実行できない場合がある。 |
小 |
ミラーディスクリソースを登録した構成で [クラスタパーティションI/Oタイムアウト] に [ハートビートタイムアウト] より大きい値を設定した場合に発生する。 |
93 |
5.1.1-1
/ 4.1.0-1 ~ 5.1.0-1
|
ボリュームマネージャモニタリソースの [最大再活性回数] に誤った既定値が設定される。 |
小 |
Cluster WebUI でボリュームマネージャリソースを登録した際に自動追加されるボリュームマネージャモニタリソースで必ず発生する。 |
6. 注意制限事項¶
本章では、注意事項や既知の問題とその回避策について説明します。
本章で説明する項目は以下の通りです。
6.1. システム構成検討時¶
HW の手配、オプション製品ライセンスの手配、システム構成、共有ディスクの構成時に留意すべき事項について説明します。
6.1.1. 機能一覧と必要なライセンス¶
下記オプション製品はサーバ台数分必要となります。
ライセンスが登録されていないリソース・モニタリソースはCluster WebUIの一覧に表示されません。
使用したい機能 |
必要なライセンス |
|---|---|
ミラーディスクリソース |
CLUSTERPRO X Replicator 5.1 4 |
ハイブリッドディスクリソース |
CLUSTERPRO X Replicator DR 5.1 5 |
Oracle モニタリソース |
CLUSTERPRO X Database Agent 5.1 |
DB2 モニタリソース |
CLUSTERPRO X Database Agent 5.1 |
PostgreSQL モニタリソース |
CLUSTERPRO X Database Agent 5.1 |
MySQL モニタリソース |
CLUSTERPRO X Database Agent 5.1 |
SQL Server モニタリソース |
CLUSTERPRO X Database Agent 5.1 |
ODBC モニタリソース |
CLUSTERPRO X Database Agent 5.1 |
Samba モニタリソース |
CLUSTERPRO X File Server Agent 5.1 |
NFS モニタリソース |
CLUSTERPRO X File Server Agent 5.1 |
HTTP モニタリソース |
CLUSTERPRO X Internet Server Agent 5.1 |
SMTP モニタリソース |
CLUSTERPRO X Internet Server Agent 5.1 |
POP3 モニタリソース |
CLUSTERPRO X Internet Server Agent 5.1 |
IMAP4 モニタリソース |
CLUSTERPRO X Internet Server Agent 5.1 |
FTP モニタリソース |
CLUSTERPRO X Internet Server Agent 5.1 |
Tuxedo モニタリソース |
CLUSTERPRO X Application Server Agent 5.1 |
WebLogic モニタリソース |
CLUSTERPRO X Application Server Agent 5.1 |
WebSphere モニタリソース |
CLUSTERPRO X Application Server Agent 5.1 |
WebOTX モニタリソース |
CLUSTERPRO X Application Server Agent 5.1 |
JVM モニタリソース |
CLUSTERPRO X Java Resource Agent 5.1 |
システムモニタリソース |
CLUSTERPRO X System Resource Agent 5.1 |
プロセスリソースモニタリソース |
CLUSTERPRO X System Resource Agent 5.1 |
メール通報機能 |
CLUSTERPRO X Alert Service 5.1 |
ネットワーク警告灯 |
CLUSTERPRO X Alert Service 5.1 |
6.1.2. ミラーディスクの要件について¶
Linux の md によるストライプセット、ボリュームセット、ミラーリング、パリティ付ストライプセットを、ミラーディスクリソースのクラスタパーティションやデータパーティションに使用することはできません。
- Linux の LVM によるボリュームをクラスタパーティションやデータパーティションに使用することは可能です。ただし、SuSEでは、LVM や MultiPath によるボリュームをデータパーティションに使用することはできません。(SuSEでは、それらのボリュームに対する ReadOnly,ReadWrite の制御を CLUSTERPRO が行うことができないため。)
ミラーディスクリソースを、Linux の md や LVM によるストライプセット、ボリュームセット、ミラーリング、パリティ付ストライプセットの対象とすることはできません。
ミラーディスクリソースを使用するにはミラー用のパーティション (データパーティションとクラスタパーティション) が必要です。
ミラー用のパーティションの確保の方法は以下の 2 つがあります。
OS (root パーティションや swap パーティション) と同じディスク上にミラー用のパーティション (クラスタパーティションとデータパーティション) を確保する
OS とは別のディスク (またはLUN) を用意 (追加) してミラー用のパーティションを確保する
以下を参考に上記を選定してください。
- 障害時の保守性、性能を重視する場合- OS とは別にミラー用のディスクを用意することを推奨します。
- H/W Raid の仕様の制限で LUN の追加ができない場合H/W Raid のプリインストールモデルで LUN 構成変更が困難な場合- OS と同じディスクにミラー用のパーティションを確保します。
- ミラーディスクリソースを複数使用する場合には、さらにミラーディスクリソース毎に個別のディスクを用意(追加) することを推奨します。同一のディスク上に複数のミラーディスクリソースを確保すると性能の低下やミラー復帰に時間がかかることがあります。これらの現象は Linux OS のディスクアクセスの性能に起因するものです。
ミラー用のディスクとして使用するにはディスクをサーバ間で同じにする必要があります。
ディスクのインターフェイス
両サーバのミラーディスクまたは、ミラー用のパーティションを確保するディスクは、ディスクのインターフェイスを同じにしてください。
例)
組み合わせ
サーバ1
サーバ2
OK
SCSI
SCSI
OK
IDE
IDE
NG
IDE
SCSI
ディスクのタイプ
両サーバのミラーディスクまたは、ミラー用のパーティションを確保するディスクは、ディスクのタイプを同じにしてください。
例)
組み合わせ
サーバ1
サーバ2
OK
HDD
HDD
OK
SSD
SSD
NG
HDD
SSD
ディスクのセクタサイズ
両サーバのミラーディスクまたは、ミラー用のパーティションを確保するディスクは、ディスクの論理セクタサイズを同じにしてください。
例)
組み合わせ
サーバ1
サーバ2
OK
論理セクタ512B
論理セクタ512B
OK
論理セクタ4KB
論理セクタ4KB
NG
論理セクタ512B
論理セクタ4KB
ミラー用のディスクとして使用するディスクのジオメトリがサーバ間で異なる場合の注意
fdisk コマンドなどで確保したパーティションサイズはシリンダあたりのブロック (ユニット) 数でアラインされます。
データパーティションのサイズと初期ミラー構築の方向の関係が以下になるようにデータパーティションを確保してください。
コピー元のサーバ ≦ コピー先のサーバ
コピー元のサーバとは、ミラーディスクリソースが所属するフェイルオーバグループのフェイルオーバポリシーが高いサーバを指します。コピー先のサーバとは、ミラーディスクリソースが所属するフェイルオーバグループのフェイルオーバポリシーが低いサーバを指します。
また、データパーティションのサイズは、コピー元側とコピー先側とで 32GiB, 64GiB, 96GiB, … (32GiBの倍数) を跨がないように注意してください。32GiBの倍数を跨ぐサイズの場合、初期ミラー構築に失敗することがあります。データパーティションは同程度のサイズで確保するようにしてください。
例)
組み合わせ
データパーティションのサイズ
説明
サーバ1側
サーバ2側
OK
30GiB
31GiB
両方とも0~32GiB未満の範囲内にあるのでOK
OK
50GiB
60GiB
両方とも32GiB以上~64GiB未満の範囲内にあるのでOK
NG
30GiB
39GiB
32GiBを跨いでいるのでNG
NG
60GiB
70GiB
64GiBを跨いでいるのでNG
6.1.4. ハイブリッドディスクとして使用するディスクの要件について¶
Linux の md によるストライプセット、ボリュームセット、ミラーリング、パリティ付ストライプセットを、ハイブリッドディスクリソースのクラスタパーティションやデータパーティションに使用することはできません。
- Linux の LVM によるボリュームをクラスタパーティションやデータパーティションに使用することは可能です。ただし、SuSEでは、LVM や MultiPath によるボリュームをデータパーティションに使用することはできません。(SuSEでは、それらのボリュームに対する ReadOnly,ReadWrite の制御を CLUSTERPRO が行うことができないため。)
ハイブリッドディスクリソースを、Linux の md や LVM によるストライプセット、ボリュームセット、ミラーリング、パリティ付ストライプセットの対象とすることはできません。
ハイブリッドディスクリソースを使用するにはハイブリッドディスク用のパーティション (データパーティションとクラスタパーティション) が必要です。
さらにハイブリッドディスク用のディスクを共有ディスク装置で確保する場合には、共有ディスク装置を共有するサーバ間のディスクハートビートリソース用のパーティションが必要です。
ハイブリッドディスク用のディスクを共有ディスク装置でないディスクから確保する場合、パーティションの確保の方法は以下の 2 つがあります。
OS (rootパーティションやswapパーティション) と同じディスク上にハイブリッドディスク用のパーティション (クラスタパーティションとデータパーティション) を確保する
OS とは別のディスク (またはLUN) を用意 (追加) してハイブリッドディスク用のパーティションを確保する
以下を参考に上記を選定してください。
- 障害時の保守性、性能を重視する場合- OS とは別にハイブリッドディスク用のディスクを用意することを推奨します。
- H/W Raid の仕様の制限で LUN の追加ができない場合H/W Raid のプリインストールモデルで LUN 構成変更が困難な場合- OS と同じディスクにハイブリッドディスク用のパーティションを確保します。
ハイブリッドディスクリソースを確保する装置
必要なパーティション
共有ディスク装置
共有型でないディスク装置
データパーティション
必要
必要
クラスタパーティション
必要
必要
ディスクハートビート用パーティション
必要
不要
OSと同じディスク(LUN)上での確保
-
可能
- ハイブリッドディスクリソースを複数使用する場合には、さらにハイブリッドディスクリソース毎に個別の LUN を用意 (追加) することを推奨します。同一のディスク上に複数のハイブリッドディスクリソースを確保すると性能の低下やミラー復帰に時間がかかることがあります。これらの現象は Linux OS のディスクアクセスの性能に起因するものです。
ハイブリッドディスク用のディスクとして使用するディスクのタイプやジオメトリがサーバ間で異なる場合の注意
データパーティションのサイズと初期ミラー構築の方向の関係が以下になるようにデータパーティションを確保してください。
コピー元のサーバ ≦ コピー先のサーバ
コピー元のサーバとは、ハイブリッドディスクリソースが所属するフェイルオーバグループのフェイルオーバポリシーが高いサーバを指します。コピー先のサーバとは、ハイブリッドディスクリソースが所属するフェイルオーバグループのフェイルオーバポリシーが低いサーバを指します。
また、データパーティションのサイズは、コピー元側とコピー先側とで 32GiB, 64GiB, 96GiB, … (32GiBの倍数) を跨がないように注意してください。32GiBの倍数を跨ぐサイズの場合、初期ミラー構築に失敗することがあります。データパーティションは同程度のサイズで確保するようにしてください。
例)
組み合わせ
データパーティションのサイズ
説明
サーバ1側
サーバ2側
OK
30GiB
31GiB
両方とも0~32GiB未満の範囲内にあるのでOK
OK
50GiB
60GiB
両方とも32GiB以上~64GiB未満の範囲内にあるのでOK
NG
30GiB
39GiB
32GiBを跨いでいるのでNG
NG
60GiB
70GiB
64GiBを跨いでいるのでNG
6.1.5. IPv6 環境について¶
下記の機能はIPv6環境では使用できません。
AWS Elastic IP リソース
AWS 仮想 IP リソース
AWS セカンダリ IP リソース
AWS DNS リソース
Azure プローブポートリソース
Azure DNS リソース
Google Cloud 仮想 IP リソース
Google Cloud DNS リソース
Oracle Cloud 仮想 IP リソース
AWS Elastic IP モニタリソース
AWS 仮想 IP モニタリソース
AWS セカンダリ IP モニタリソース
AWS AZ モニタリソース
AWS DNS モニタリソース
Azure プローブポートモニタリソース
Azure ロードバランスモニタリソース
Azure DNS モニタリソース
Google Cloud 仮想 IP モニタリソース
Google Cloud ロードバランスモニタリソース
Google Cloud DNS モニタリソース
Oracle Cloud 仮想 IP モニタリソース
Oracle Cloud ロードバランスモニタリソース
下記の機能はリンクローカルアドレスを使用できません。
LAN ハートビートリソース
カーネルモード LAN ハートビートリソース
ミラーディスクコネクト
PING ネットワークパーティション解決リソース
FIP リソース
VIP リソース
6.1.6. ネットワーク構成について¶
NAT環境等のように、自サーバのIPアドレスおよび相手サーバのIPアドレスが、各サーバで異なるような構成においては、クラスタ構成を構築/運用できません。
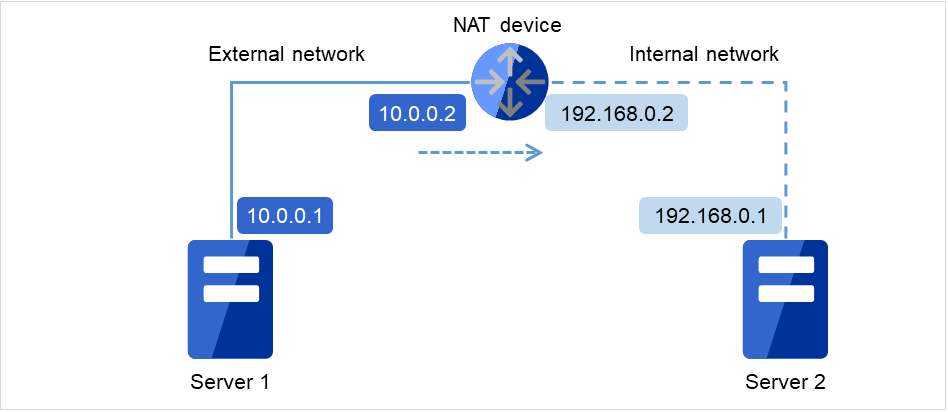
図 6.1 クラスタを構成できない環境の例¶
Server 1でのクラスタ設定
自サーバ: 10.0.0.1
相手サーバ: 10.0.0.2
Server 2でのクラスタ設定
自サーバ: 192.168.0.1
相手サーバ: 10.0.0.1
6.1.7. モニタリソース回復動作の「最終動作前にスクリプトを実行する」について¶
6.1.8. NIC Link Up/Down モニタリソース¶
ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: umbg
Wake-on: g
Current message level: 0x00000007 (7)
Link detected: yes
ethtool コマンドの結果で LAN ケーブルのリンク状況 ("Link detected: yes") が表示されない場合
CLUSTERPRO の NIC Link Up/Down モニタリソースが動作不可能な可能性が高いです。IP モニタリソースで代替してください。
ethtool コマンドの結果で LAN ケーブルのリンク状況 ("Link detected: yes") が表示される場合
多くの場合 CLUSTERPRO の NIC Link Up/Down モニタリソースが 動作可能ですが、希に動作不可能な場合があります。
特に以下のようなハードウェアでは動作不可能な場合があります。IP モニタリソースで代替してください。
ブレードサーバのように実際の LAN のコネクタと NIC のチップとの間にハードウェアが実装されている場合
監視対象のNICがBonding環境の場合、MII Polling Interval の設定値が0以上に設定されているか確認してください。
実機で CLUSTERPRO を使用して NIC Link Up/Down モニタリソースの使用可否を確認する場合には以下の手順で動作確認を行ってください。
- NIC Link Up/Down モニタリソースを構成情報に登録してください。NIC Link Up/Down モニタリソースの異常検出時回復動作の設定は「何もしない」を選択してください。
- クラスタを起動してください。
- NIC Link Up/Down モニタリソースのステータスを確認してください。LAN ケーブルのリンク状態が正常状態時に NIC Link Up/Down モニタリソースのステータスが異常となった場合、NIC Link Up/Down モニタリソースは動作不可です。
- LAN ケーブルのリンク状態を異常状態 (リンクダウン状態) にしたときに NIC Link Up/Down モニタリソースのステータスが異常となった場合、NIC Link Up/Down モニタリソースは動作可能です。ステータスが正常のまま変化しない場合、NIC Link Up/Down モニタリソースは動作不可です。
6.1.9. ミラーディスクリソース、ハイブリッドディスクリソースの write 性能について¶
ミラーディスクリソース/ハイブリッドディスクリソースのディスクミラーリングには同期ミラーと非同期ミラーの 2 種類の方式があります。
同期ミラーの場合、ミラーリング対象のデータパーティションへの書き込み要求毎に、両サーバのディスクへの書き込みを実施し、その完了を待ち合わせます。各サーバへの書き込みは並行して実施されますが、他サーバのディスクへの書き込みはネットワークを介して実施されるため、ミラーリングしない通常のローカルディスクに比べ書き込み性能が低下します。特にネットワークの通信速度が低く遅延が大きい遠隔クラスタ構成などの場合は大幅に性能が低下することになります。
非同期ミラーの場合、自サーバへの書き出しは即時実行しますが、他サーバへの書き出しは一旦ローカルキューに保存し、バックグラウンドで書き出します。非同期ミラーの場合も書き込み要求毎に更新データをキューに保存するため、ミラーリングしない通常のローカルディスクや共有ディスクに比べると、書き込み性能が低下します。このため、ディスクへの書き込み処理に高いスループットが要求されるシステム(更新系が多いデータベースシステムなど) には共有ディスクの使用を推奨します。
また、非同期ミラーの場合、書き込み順序は保証されますが、現用系サーバがダウンした場合に最新の更新分が失われる可能性があります。このため、障害発生直前の情報を確実に引き継ぐ必要がある場合は、同期ミラーか共有ディスクを用いる必要があります。
6.1.10. 非同期ミラーの履歴ファイルについて¶
非同期モードのミラーディスク/ハイブリッドディスクでは、メモリ上のキューに記録しきれない書き込みデータは、履歴ファイル格納フォルダとして指定されたフォルダに履歴ファイルとして一時的に記録されます。この履歴ファイルは、履歴ファイルのサイズ制限を設定していない場合、指定されたフォルダに制限なく書き出されます。このような設定の場合、回線速度が業務アプリケーションのディスク更新量に比べて低すぎると、リモートサーバへの書き込み処理がディスク更新に追いつかず、履歴ファイルでディスクが溢れてしまいます。このため、遠隔クラスタ構成でも業務 AP のディスク更新量に合わせて十分な速度の通信回線を確保する必要があります。
また、長時間の通信遅延や、ディスク更新の連続発生などにより、履歴ファイル格納ディレクトリが溢れた場合に備え、履歴ファイルの書き出し先に指定するディレクトリには十分な空き容量を確保し、履歴ファイルサイズ制限を設定するか、システムディスクとは別のディスク上のディレクトリを指定する必要があります。
6.1.11. ミラーディスクリソース、ハイブリッドディスクリソースを syslog の出力先にしない¶
ミラーディスクコネクトのパス冗長化の方法として、bonding を利用する。
ユーザ空間監視のタイムアウト値やミラー関連のタイムアウト値を調整する。
6.1.12. ミラーディスクリソース、ハイブリッドディスクリソース終了時の注意点¶
- ミラーディスクリソースやハイブリッドディスクリソースをマウントしたディレクトリやサブディレクトリやファイルへアクセスするプロセスがある場合は、シャットダウン時やフェイルオーバ時など各ディスクリソースが非活性になる際に、終了スクリプト等を使って各ディスクリソースへのアクセスを終了した状態にしてください。各ディスクリソースの設定によっては、アンマウント時の異常検出時動作 (各ディスクリソースにアクセスしたままのプロセスを強制終了する) が行われたり、アンマウントが失敗して非活性異常時の復旧動作 (OSシャットダウン等) が行われたりすることがあります。
- ミラーディスクリソースやハイブリッドディスクリソースをマウントしたディレクトリやサブディレクトリやファイルに対して大量のアクセスを行った場合、ディスクリソース非活性時のアンマウントにて、ファイルシステムのキャッシュがディスクへ書き出されるのに長い時間がかかることがあります。このような場合には、ディスクへの書き出しが正常に完了するよう、アンマウントのタイムアウト時間を余裕を持った設定にしてください。
- 上記の設定については、『リファレンスガイド』の「グループリソースの詳細」に記載されている、[復旧動作] タブや、[詳細] タブの [調整] プロパティ [アンマウント] タブを、参照してください。
6.1.13. 複数の非同期ミラー間のデータ整合性について¶
6.1.14. ミラー同期を中断した場合の同期先のミラーデータ参照について¶
6.1.15. ミラーディスク、ハイブリッドディスクリソースに対する O_DIRECT について¶
6.1.16. ミラーディスク、ハイブリッドディスクリソースに対する初期ミラー構築時間について¶
ext2/ext3/ext4/xfs と、その他のファイルシステムとでは、初期ミラー構築や全面ミラー復帰にかかる時間が異なります。
注釈
xfsの場合は、リソース非活性時の方が所要時間が短くなります。
6.1.17. ミラーディスク、ハイブリッドディスクコネクトについて¶
ミラーディスク、ハイブリッドディスクコネクトを冗長化する場合には両方のIPアドレスのバージョンをそろえてください。
ミラーディスクコネクトのIPアドレスはすべて、IPv4またはIPv6のどちらかにそろえてください。
6.1.18. JVM モニタリソースについて¶
同時に監視可能なJava VMは最大25個です。同時に監視可能なJava VMとはCluster WebUI ([監視(固有)]タブ-[識別名])で一意に識別するJava VM数のことです。
Java VMとJava Resource Agent間のコネクションはSSLには対応していません。
スレッドのデッドロックは検出できない場合があります。これは、Java VMの既知で発生している不具合です。詳細は、OracleのBug Databaseの「Bug ID: 6380127 」を参照してください。
JVMモニタリソースが監視できるJava VMは、JVMモニタリソースが動作中のサーバと同じサーバ内のみです。
JVMモニタリソースが監視できるJBoss のサーバインスタンスは、1 サーバに1 つまでです。
Cluster WebUI (クラスタプロパティ-[JVM監視]タブ-[Javaインストールパス])で設定したJavaインストールパスは、クラスタ内のサーバにおいて、共通の設定となります。JVM監視が使用するJava VMのバージョンおよびアップデートは、クラスタ内のサーバにおいて、同じものにしてください。
Cluster WebUI (クラスタプロパティ-[JVM監視]タブ-[接続設定]ダイアログ-[管理ポート番号])で設定した管理ポート番号は、クラスタ内のサーバにおいて、共通の設定となります。
x86_64版OS上においてIA32版の監視対象のアプリケーションを動作させている場合、監視を行うことはできません。
Cluster WebUI (クラスタプロパティ-[JVM監視]タブ-[最大Javaヒープサイズ])で設定した最大Javaヒープサイズを3000など大きな値に設定すると、JVMモニタリソースが起動に失敗します。システム環境に依存するため、システムのメモリ搭載量を元に決定してください。
- 監視対象Java VMの起動オプションに「-XX:+UseG1GC」が付加されている場合、Java 7以前ではJVMモニタリソースの[プロパティ]-[監視(固有)] タブ-[調整]プロパティ-[メモリ]タブ内の設定項目は監視できません。Java 8以降ではJVMモニタリソースの[プロパティ]-[監視(固有)] タブ- [JVM種別]に[Oracle Java(usage monitoring)]を選択すれば監視可能です。
6.1.19. ネットワーク警告灯の要件について¶
「警子ちゃんミニ」、「警子ちゃん 4G」を使用する場合、警告灯にパスワードを設定しないで下さい。
- 音声ファイルの再生による警告を行う場合、あらかじめ音声ファイル再生に対応したネットワーク警告灯に音声ファイルを登録しておく必要があります。音声ファイルの登録に関しては、各ネットワーク警告灯の取扱説明書を参照して下さい。
ネットワーク警告灯にクラスタ内のサーバからの rsh コマンド実行を許可するように設定してください。
6.2. OS インストール前、OS インストール時¶
OS をインストールするときに決定するパラメータ、リソースの確保、ネーミングルールなどで留意して頂きたいことです。
6.2.1. ミラー用のディスクについて¶
ディスクのパーティション
(例) 両サーバに 1つの SCSI ディスクを増設して 1つのミラーディスクのペアにする場合
図では、2台のサーバそれぞれにSCSIディスクを増設しています。ディスク内はクラスタパーティション(Cluster partition)とデータパーティション(Data partition)に分かれています。このパーティションの組はミラーディスクリソースのフェイルオーバの単位であり、ミラーパーティションデバイスと呼ばれます。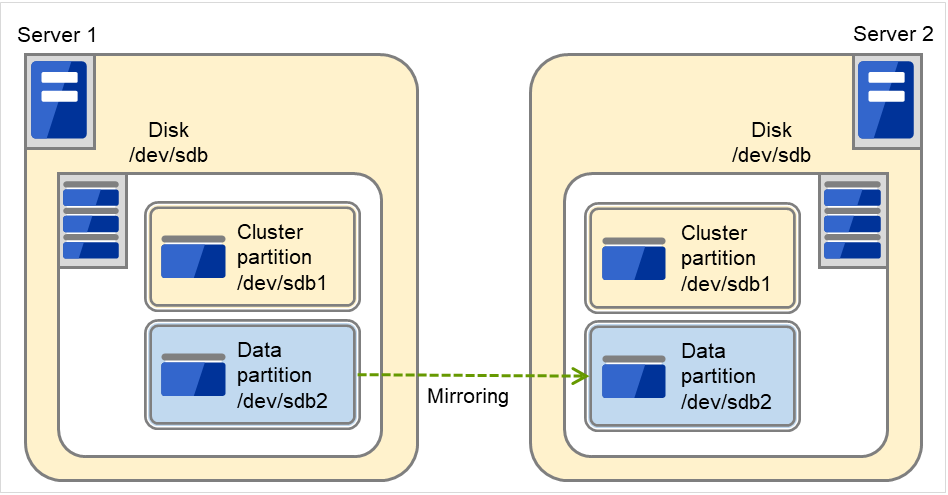
図 6.2 ディスクとパーティション構成(SCSIディスク増設時)¶
(例) 両サーバの OS が格納されている IDE ディスクの空き領域を使用してミラーディスクのペアにする場合
図では、内蔵ディスクのOS等が使用していない領域をミラーパーティションデバイス(クラスタパーティション、データパーティション)として使用しています。
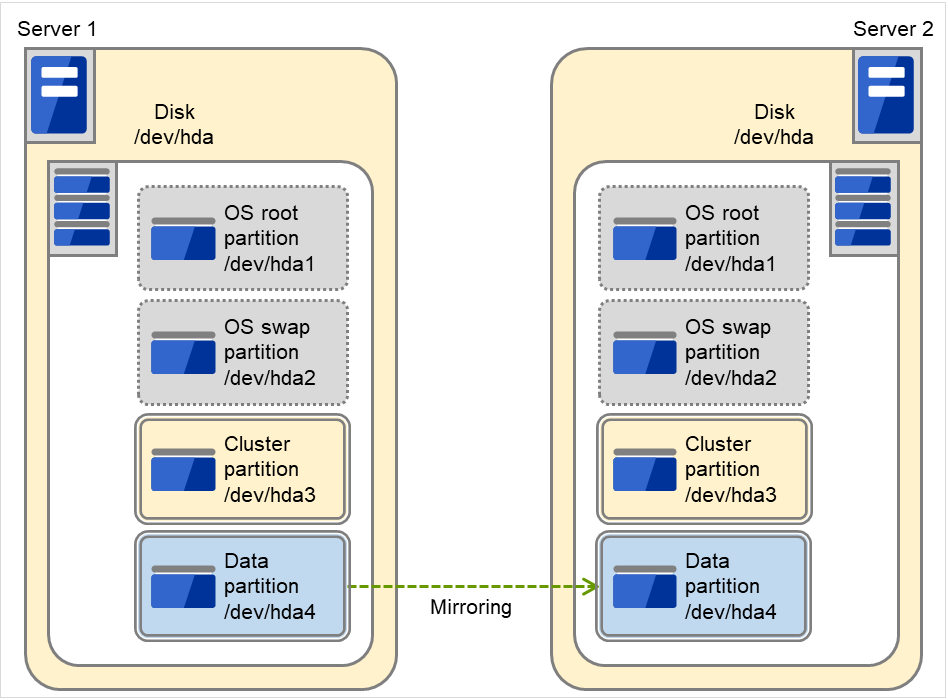
図 6.3 ディスクとパーティション構成(既存ディスクの空き領域使用時)¶
ミラーパーティションデバイスは CLUSTERPRO のミラーリングドライバが上位に提供するデバイスです。
クラスタパーティションとデータパーティションの 2 つのパーティションをペアで確保してください。
OS (root パーティションや swap パーティション) と同じディスク上にミラーパーティション (クラスタパーティション、データパーティション) を確保することも可能です。
- 障害時の保守性、性能を重視する場合OS (root パーティションや swap パーティション) と別にミラー用のディスクを用意することを推奨します。
- H/W Raid の仕様の制限で LUN の追加ができない場合H/W Raid のプリインストールモデルで LUN 構成変更が困難な場合
OS (rootパーティションやswapパーティション) と同じディスクにミラーパーティション(クラスタパーティション、データパーティション)を確保することも可能です。
ディスクの配置
ミラーディスクとして複数のディスクを使用することができます。
また 1 つのディスクに複数のミラーパーティションデバイスを割り当てて使用することができます。
(例) 両サーバに2つの SCSI ディスクを増設して2つのミラーディスクのペアにする場合。
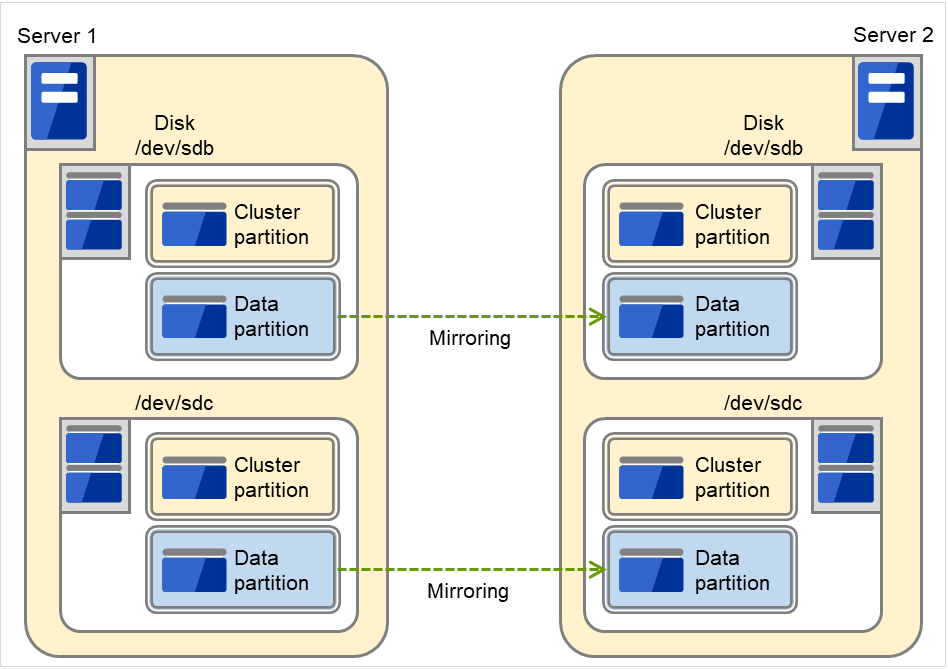
図 6.4 複数のディスクそれぞれをミラーパーティションとして使用¶
1 つのディスク上にクラスタパーティションとデータパーティションをペアで確保してください。
データパーティションを 1 つ目のディスク、クラスタパーティションを 2 つ目のディスクとするような使い方はできません。
(例) 両サーバに 1つの SCSI ディスクを増設して 2つのミラーパーティションにする場合
図は、1つのディスク内にミラーパーティションを2つ確保した場合を示しています。
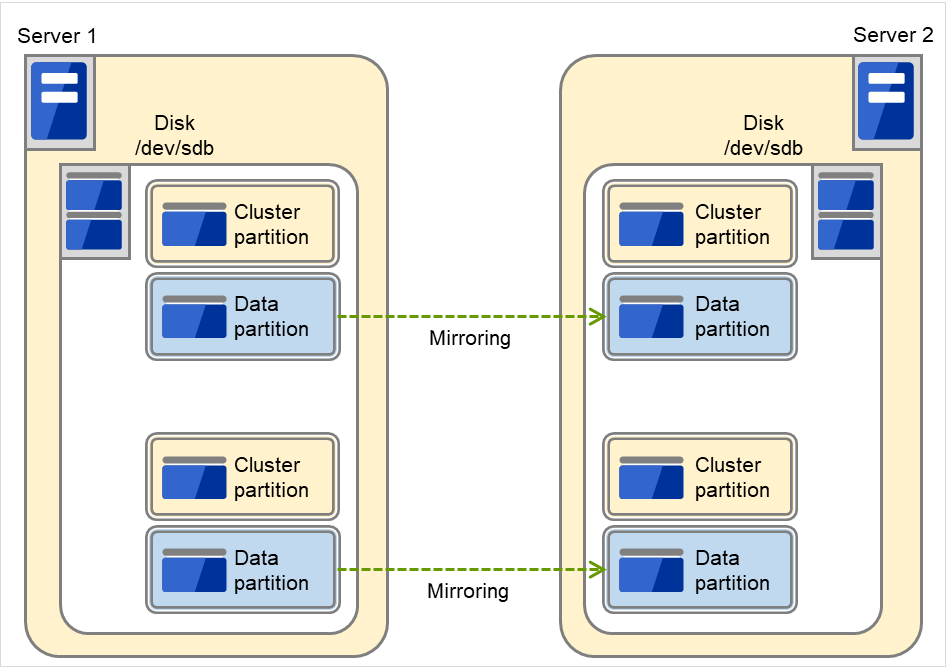
図 6.5 ディスク内の複数領域をミラーパーティションとして使用¶
ディスクに対して Linux の md によるストライプセット、ボリュームセット、ミラーリング、パリティ付きストライプセットの機能はサポートしていません。
6.2.2. ハイブリッドディスクリソース用のディスクについて¶
ディスクのパーティション
共有ディスクまたは共有型でないディスク (サーバ内蔵、サーバ間で共有していない外付型ディスク筐体など) を使用することができます。
(例) 2 台のサーバで共有ディスクを使用し 3 台目のサーバでサーバに内蔵したディスクを使用する場合
図は、Server 3の内蔵ディスクをミラーパーティションデバイスとして使用しています。
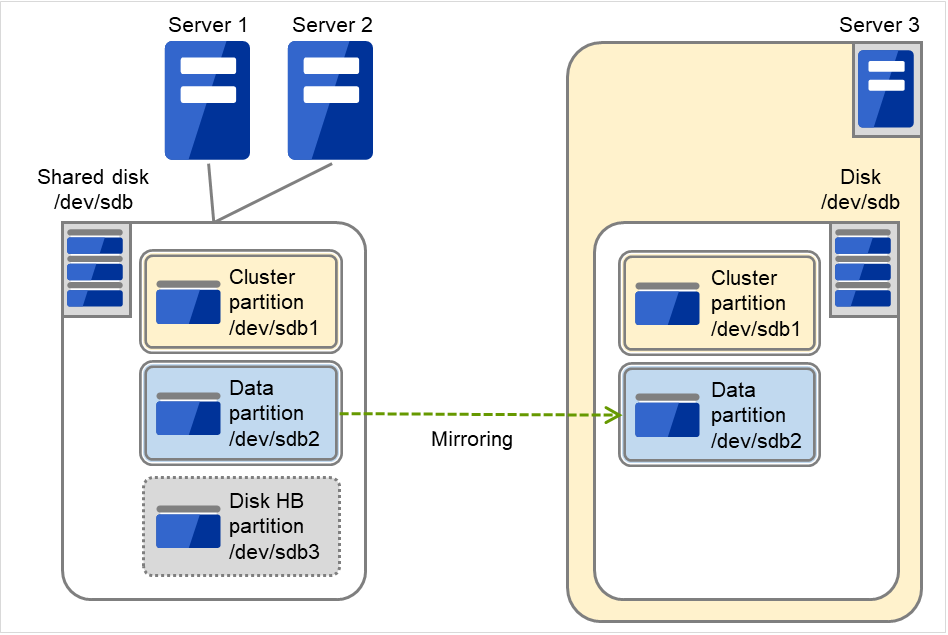
図 6.6 ディスクとパーティション構成(共有ディスクと内蔵ディスク使用時)¶
ミラーパーティションデバイスは CLUSTERPRO のミラーリングドライバが上位に提供するデバイスです。
クラスタパーティションとデータパーティションの 2 つのパーティションをペアで確保してください。
共有型でないディスク (サーバ内蔵、サーバ間で共有していない外付型ディスク筐体など) を使用する場合には OS (rootパーティションや swap パーティション) と同じディスク上にミラーパーティション (クラスタパーティション、データパーティション) を確保することも可能です。
- 障害時の保守性、性能を重視する場合OS (root パーティションや swap パーティション) と別にミラー用のディスクを用意することを推奨します。
- H/W Raid の仕様の制限で LUN の追加ができない場合H/W Raid のプリインストールモデルで LUN 構成変更が困難な場合OS (rootパーティションやswapパーティション) と同じディスクにミラーパーティション(クラスタパーティション、データパーティション)を確保することも可能です。
さらにハイブリッドディスク用のディスクを共有ディスク装置で確保する場合には、共有ディスク装置を共有するサーバ間のディスクハートビートリソース用のパーティションを確保してください。
ディスクに対して Linux の md によるストライプセット、ボリュームセット、ミラーリング、パリティ付きストライプセットの機能はサポートしていません。
6.2.4. 依存するドライバ¶
softdog
ユーザ空間モニタリソースの監視方法が softdog の場合、このドライバが必要です。
ローダブルモジュール構成にしてください。スタティックドライバでは動作しません。
6.2.6. ミラードライバのメジャー番号¶
- ミラードライバはメジャー番号 218 を使用します。他のデバイスドライバでは、メジャー番号の 218 を使用しないでください。
6.2.7. カーネルモード LAN ハートビートドライバ、キープアライブドライバのメジャー番号¶
カーネルモード LAN ハートビートドライバは、メジャー番号 10、マイナー番号 253 を使用します。
キープアライブドライバは、メジャー番号 10、マイナー番号 254 を使用します。
他のドライバが上記のメジャー及びマイナー番号を使用していないことを確認してください。
6.2.8. ディスクモニタリソースの RAW 監視用のパーティション確保¶
ディスクモニタリソースの RAW 監視を設定する場合、監視専用のパーティションを用意してください。パーティションサイズは 10MB 確保してください。
6.2.9. SELinuxの設定¶
enforcing に設定している状態で CLUSTERPRO のドライバをロード可能にするには、 『インストール&設定ガイド』 - 「SELinuxに関する設定をおこなう (必須)」 に記載の手順を実施してください。
6.2.10. NetworkManagerの設定¶
Red Hat Enterprise Linux 6 環境で NetworkManager サービスが動作している場合、ネットワークの切断時に意図しない動作(通信経路の迂回、ネットワークインターフェイスの消失など)となる場合があるため、NetworkManager サービスを停止する設定を推奨します。
6.2.11. LVM メタデータデーモンの設定¶
- Red Hat Enterprise Linux 7 系の環境で、ボリュームマネージャリソース、およびボリュームマネージャモニタリソースにて LVM の制御/監視を行う場合、LVM メタデータデーモンを無効にする必要があります。メタデータデーモンを無効化する手順は以下の通りです。
以下のコマンドにて LVM メタデータデーモンを停止してください。
# systemctl stop lvm2-lvmetad.service
/etc/lvm/lvm.conf を編集し、use_lvmetad の値を 0 に設定してください。
6.2.12. セキュアブートの設定¶
セキュアブートの設定は無効化してください。
6.3. OS インストール後、CLUSTERPRO インストール前¶
OS のインストールが完了した後、OS やディスクの設定をポート番号の変更について行うときに留意して頂きたいことです。
6.3.1. 通信ポート番号¶
CLUSTERPRO インストール後にclpfwctrlコマンドでファイアウォールの設定を行うことができます。詳細は『リファレンスガイド』 - 「CLUSTERPRO コマンドリファレンス」 - 「ファイアウォールの規則を追加する (clpfwctrlコマンド)」を参照してください。 また、clpfwctrlコマンドで設定を行うポートについては、以下の表のclpfwctrl欄に ✓ が記載されているポートとなります。
クラウド環境の場合は、インスタンス側のファイアウォール設定の他に、クラウド基盤側のセキュリティ設定においても、下記のポート番号にアクセスできるようにしてください。
[サーバ・サーバ間] [サーバ内ループバック]
From
To
備考
clpfwctrl
サーバ
自動割り当て 6
サーバ
29001/TCP
内部通信
✓
サーバ
自動割り当て
サーバ
29002/TCP
データ転送
✓
サーバ
自動割り当て
サーバ
29002/UDP
ハートビート
✓
サーバ
自動割り当て
サーバ
29003/UDP
アラート同期
✓
サーバ
自動割り当て
サーバ
29004/TCP
ミラーエージェント間通信
✓
サーバ
自動割り当て
サーバ
29006/UDP
ハートビート(カーネルモード)
✓
サーバ
自動割り当て
サーバ
29008/TCP
クラスタ情報管理
✓
サーバ
自動割り当て
サーバ
29010/TCP
Restful API 内部通信
✓
サーバ
自動割り当て
サーバ
XXXX 7 /TCP
ミラーディスクリソースデータ同期
✓
サーバ
自動割り当て
サーバ
XXXX 8 /TCP
ミラードライバ間通信
✓
サーバ
自動割り当て
サーバ
XXXX 9 /TCP
ミラードライバ間通信
✓
サーバ
icmp
サーバ
icmp
ミラードライバ間キープアライブ、FIP/VIPリソースの重複確認、ミラーエージェントサーバ
自動割り当て
サーバ
XXXX 10 /UDP
内部ログ用通信
✓
[サーバ・クライアント間]
From
To
備考
clpfwctrl
Restful API クライアント
自動割り当て
サーバ
29009/TCP
http通信
✓
[サーバ・Cluster WebUI 間]
From
To
備考
clpfwctrl
Cluster WebUI
自動割り当て
サーバ
29003/TCP
http通信
✓
[その他]
From
To
備考
clpfwctrl
サーバ
自動割り当て
ネットワーク警告灯
各製品のマニュアルを参照
ネットワーク警告灯制御
サーバ
自動割り当て
サーバのBMCのマネージメントLAN
623/UDP
BMC制御 (強制停止)
サーバ
自動割り当て
Witness サーバ
Cluster WebUI で設定した通信ポート番号
Witness ハートビートリソースの接続先ホスト
サーバ
icmp
監視先
icmp
IPモニタ
サーバ
icmp
監視先
icmp
Ping方式ネットワークパーティション解決リソースの監視先
サーバ
自動割り当て
監視先
Cluster WebUI で設定した通信ポート番号
HTTP方式ネットワークパーティション解決リソースの監視先
サーバ
自動割り当て
サーバ
Cluster WebUI で設定した管理ポート番号 11
JVMモニタ
✓
サーバ
自動割り当て
監視先
Cluster WebUIで設定した接続ポート番号 11
JVMモニタ
サーバ
自動割り当て
サーバ
Cluster WebUIで設定したプローブ ポート番号 12
Azure プローブポートリソース
✓
サーバ
自動割り当て
AWS リージョンエンドポイント
443/tcp 13
AWS Elastic IP リソースAWS 仮想 IP リソースAWS セカンダリ IP リソースAWS DNS リソースAWS Elastic IP モニタリソースAWS 仮想 IP モニタリソースAWS セカンダリ IP モニタリソースAWS AZ モニタリソースAWS DNS モニタリソースAWS 強制停止リソースサーバ
自動割り当て
Azure エンドポイント
443/tcp 14
Azure DNS リソース
サーバ
自動割り当て
Azure の権威DNSサーバ
53/udp
Azure DNS モニタリソース
サーバ
自動割り当て
サーバ
Cluster WebUIで設定したポート番号 12
Google Cloud 仮想 IP リソース
✓
サーバ
自動割り当て
サーバ
Cluster WebUIで設定したポート番号 12
Oracle Cloud 仮想 IP リソース
✓
- 6
自動割り当てでは、その時点で使用されていないポート番号が割り当てられます。
- 7
- ミラーディスク、ハイブリッドディスクリソースごとに使用するポート番号です。ミラーディスクリソース、ハイブリッドディスク作成時に設定します。初期値として 29051 が設定されます。また、ミラーディスクリソース、ハイブリッドディスクの追加ごとに 1 を加えた値が自動的に設定されます。変更する場合は、Cluster WebUI の [ミラーディスクリソースプロパティ] - [詳細] タブ、[ハイブリッドディスクリソースプロパティ] - [詳細] タブで設定します。詳細については『リファレンスガイド』の「グループリソースの詳細」を参照してください。
- 8
- ミラーディスクリソース、ハイブリッドディスクごとに使用するポート番号です。ミラーディスクリソース、ハイブリッドディスク作成時に設定します。初期値として 29031 が設定されます。また、ミラーディスクリソース、ハイブリッドディスクの追加ごとに 1 を加えた値が自動的に設定されます。変更する場合は、Cluster WebUI の [ミラーディスクリソースプロパティ] - [詳細] タブ、[ハイブリッドディスクリソースプロパティ] - [詳細] タブで設定します。詳細については『リファレンスガイド』の「グループリソースの詳細」を参照してください。
- 9
- ミラーディスクリソース、ハイブリッドディスクごとに使用するポート番号です。ミラーディスクリソース、ハイブリッドディスク作成時に設定します。初期値として 29071 が設定されます。また、ミラーディスクリソース、ハイブリッドディスクの追加ごとに 1 を加えた値が自動的に設定されます。変更する場合は、Cluster WebUI の [ミラーディスクリソースプロパティ] - [詳細] タブ、[ハイブリッドディスクリソースプロパティ] - [詳細] タブで設定します。詳細については『リファレンスガイド』の「グループリソースの詳細」を参照してください。
- 10
[クラスタプロパティ] - [ポート番号 (ログ)] タブでログの通信方法に [UDP] を選択し、ポート番号で設定したポート番号を使用します。デフォルトのログの通信方法 [UNIXドメイン] では通信ポートは使用しません。
- 11(1,2)
JVMモニタリソースでは以下の2つのポート番号を使用します。
管理ポート番号はJVMモニタリソースが内部で使用するためのポート番号です。Cluster WebUIの [クラスタプロパティ]-[JVM監視] タブ-[接続設定] ダイアログで設定します。詳細については『リファレンスガイド』の「パラメータの詳細」を参照してください。
接続ポート番号は監視先(WebLogic Server, WebOTX)のJava VMと接続するためのポート番号です。Cluster WebUI の該当するJVMモニタリソース名の[プロパティ]-[監視(固有)]タブで設定します。詳細については『リファレンスガイド』の「モニタリソースの詳細」を参照してください。
- 12(1,2,3)
ロードバランサが、各サーバの死活監視に使用するポート番号です。
- 13
以下のAWS関連リソースはAWS CLI を実行します。AWS CLI では上記のポート番号を使用します。
AWS Elastic IP リソース
AWS 仮想 IP リソース
AWS セカンダリ IP リソース
AWS DNS リソース
AWS Elastic IP モニタリソース
AWS 仮想 IP モニタリソース
AWS セカンダリ IP モニタリソース
AWS AZ モニタリソース
AWS DNS モニタリソース
AWS 強制停止リソース
- 14
Azure DNS リソースでは、Azure CLI を実行します。Azure CLI では上記のポート番号を使用します。
6.3.2. 通信ポート番号の自動割り当て範囲の変更¶
OS が管理している通信ポート番号の自動割り当ての範囲と CLUSTERPRO が使用する通信ポート番号と重複する場合があります。
通信ポート番号の自動割り当ての範囲と CLUSTERPRO が使用する通信ポート番号が重複する場合には、重複しないように OS の設定を変更してください。
OS の設定状態の確認例/表示例
通信ポート番号の自動割り当ての範囲はディストリビューションに依存します。
# cat /proc/sys/net/ipv4/ip_local_port_range 1024 65000これは、アプリケーションが OS へ通信ポート番号の自動割り当てを要求した場合、1024 ~ 65000 の範囲でアサインされる状態です。
# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000これは、アプリケーションが OS へ通信ポート番号の自動割り当てを要求した場合、32768 ~ 61000 の範囲でアサインされる状態です。
OS の設定の変更例
/etc/sysctl.conf に以下の行を追加します。(30000 ~ 65000 に変更する場合)
net.ipv4.ip_local_port_range = 30000 65000この設定はOS再起動後に有効になります。
/etc/sysctl.confを修正後、下記のコマンドを実行することで即時反映することができます。
# sysctl -p
6.3.3. ポート数不足を回避する設定について¶
6.3.4. 時刻同期の設定¶
クラスタシステムでは、複数のサーバの時刻を定期的に同期する運用を推奨します。ntp などを使用してサーバの時刻を同期させてください。
6.3.5. NIC デバイス名について¶
ifconfig コマンドの仕様により、NIC デバイス名が短縮される場合、CLUSTERPRO で扱えるNIC デバイス名の長さもそれに依存します。
6.3.7. ミラー用のディスクについて¶
ミラーディスクリソース管理用パーティション (クラスタパーティション) とミラーディスクリソースで使用するパーティション (データパーティション) を設定します。
- ミラーディスク上のファイルシステムは CLUSTERPRO が制御します。ミラーディスクのファイルシステムを OS の /etc/fstab にエントリしないでください。(ミラーパーティションデバイスやミラーのマウントポイント、クラスタパーティションやデータパーティションを、OS の /etc/fstab にエントリしないでください。)(ignore オプション付きでも /etc/fstab へのエントリは行わないでください。ignore でエントリした場合、mount の実行時にはエントリが無視されますが、fsck 実行時にはエラーが発生することがあります。)(また、noauto オプションでの /etc/fstab へのエントリも、誤って手動でマウントしてしまう場合や、何らかのアプリケーションがマウントしてしまう可能性もないとは言えず、おすすめできません。)
クラスタパーティションは 1024MiB 以上確保してください。(1024MB ちょうどを指定しても、ディスクのジオメトリの違いにより実際には 1024MB より大きなサイズが確保されますが、問題ありません)。また、クラスタパーティションにはファイルシステムを構築しないでください。
ミラー用ディスクの設定手順は『インストール&設定ガイド』を参照してください。
6.3.8. ハイブリッドディスクリソース用のディスクについて¶
ハイブリッドディスクリソースの管理用パーティション (クラスタパーティション) とハイブリッドディスクリソースで使用するパーティション (データパーティション) を設定します。
さらにハイブリッドディスク用のディスクを共有ディスク装置で確保する場合には、共有ディスク装置を共有するサーバ間のディスクハートビートリソース用のパーティションを確保します。
- ハイブリッドディスク上のファイルシステムは CLUSTERPRO が制御します。ハイブリッドディスクのファイルシステムを OS の /etc/fstab にエントリしないでください。(ミラーパーティションデバイスやミラーのマウントポイント、クラスタパーティションやデータパーティションを、OS の /etc/fstab にエントリしないでください。)(ignore オプション付きでの /etc/fstab へのエントリも行わないでください。ignore でエントリした場合、mount の実行時にはエントリが無視されますが、fsck 実行時にはエラーが発生することがあります。)(また、noauto オプションでの /etc/fstab へのエントリも、誤って手動でマウントしてしまう場合や、何らかのアプリケーションがマウントしてしまう可能性もないとは言えず、おすすめできません。)
クラスタパーティションは 1024MiB 以上確保してください。(1024MB ちょうどを指定しても、ディスクのジオメトリの違いにより実際には 1024MB より大きなサイズが確保されますが、問題ありません)。また、クラスタパーティションにはファイルシステムを構築しないでください。
ハイブリッドディスク用ディスクの設定手順は『インストール&設定ガイド』を参照してください。
本バージョンでは、ハイブリッドディスクリソースで使用するデータパーティションにファイルシステムを手動で作成する必要があります。作成し忘れた場合の手順については、『インストール&設定ガイド』の「システム構成を決定する」の「ハードウェア構成後の設定」を参照してください。
6.3.9. ミラーディスクリソース、ハイブリッドディスクリソースで ext3またはext4 を使用する場合¶
6.3.9.1. Block sizeについて¶
ミラーディスクリソース、またはハイブリッドディスクリソースのデータパーティションに対し、mkfsコマンドを手動で実行してext3またはext4ファイルシステムを構築する場合、Block sizeを1024に指定しないでください。
ミラーディスクリソースおよびハイブリッドディスクリソースはBlock size 1024に対応しておりません。明示的にBlock sizeを指定する場合は、2048か4096を指定してください。
6.3.10. OS 起動時間の調整¶
電源が投入されてから、OS が起動するまでの時間が、下記の 2 つの時間より長くなるように調整してください。
共有ディスクを使用する場合に、ディスクの電源が投入されてから使用可能になるまでの時間
ハートビートタイムアウト時間
設定手順は『インストール&設定ガイド』を参照してください。
6.3.11. ネットワークの確認¶
インタコネクトやミラーディスクコネクトで使用するネットワークの確認をします。クラスタ内のすべてのサーバで確認します。
設定手順は『インストール&設定ガイド』を参照してください。
6.3.12. OpenIPMI について¶
以下の機能で OpenIPMI を使用します。
グループリソースの活性異常時/非活性異常時の最終アクション
モニタリソースの異常時アクション
ユーザ空間モニタリソース
シャットダウン監視
物理マシンの強制停止機能
CLUSTERPRO に OpenIPMI は添付しておりません。ユーザ様ご自身で別途OpenIPMI の rpm ファイルをインストールしてください。
ご使用予定のサーバ (ハードウェア) の OpenIPMI 対応可否についてはユーザ様にて事前に確認ください。
ハードウェアとして IPMI 規格に準拠している場合でも実際には OpenIPMI が動作しない場合がありますので、ご注意ください。
- サーバベンダが提供するサーバ監視ソフトウェアを使用する場合には ユーザ空間モニタリソースとシャットダウンストール監視の監視方法に IPMI を選択しないでください。これらのサーバ監視ソフトウェアと OpenIPMI は共にサーバ上の BMC (Baseboard Management Controller) を使用するため競合が発生して正しく監視が行うことができなくなります。
6.3.13. ユーザ空間モニタリソース、シャットダウン監視 (監視方法softdog) について¶
- 監視方法に softdog を設定する場合、softdogドライバを使用します。CLUSTERPRO以外でsoftdogドライバを使用する機能を動作しない設定にしてください。例えば、以下のような機能が該当することが確認されています。
OS 標準添付の heartbeat
i8xx_tco ドライバ
iTCO_WDT ドライバ
- systemd の watchdog機能, シャットダウン監視機能
監視方法に softdog を設定する場合、OS 標準添付の heartbeat を動作しない設定にしてください。
SUSE LINUX 11 では監視方法に softdog を設定する場合、i8xx_tco ドライバと同時に使用することができません。i8xx_tco ドライバを使用しない場合は、i8xx_tco をロードしない設定にしてください。
Red Hat Enterprise Linux 6 では監視方法に softdog を設定する場合、iTCO_WDT ドライバと同時に使用することができません。iTCO_WDT ドライバを使用しない場合は、iTCO_WDT をロードしない設定にしてください。
6.3.14. ログ収集について¶
- SUSE LINUX では CLUSTERPRO のログ収集機能で OS の syslog を採取する場合、ローテートされた syslog (message) ファイルのサフィックスが異なるため syslog の世代の指定機能が動作しません。ログ収集機能の syslog の世代の指定を行うためには syslog のローテートの設定を下記のように変更して運用する必要があります。
/etc/logrotate.d/syslog ファイルの compress と dateext をコメントアウトする
各サーバでログの総サイズが2GBを超えた場合、ログ収集が失敗することがあります。
6.3.15. nsupdate,nslookup について¶
以下の機能で nsupdate と nslookup を使用します。
グループリソースのダイナミック DNS リソース (ddns)
モニタリソースのダイナミック DNS モニタリソース (ddnsw)
CLUSTERPRO に nsupdate と nslookup は添付しておりません。ユーザ様ご自身で別途 nsupdate と nslookup の rpm ファイルをインストールしてください。
nsupdate、nslookup に関する以下の事項について、弊社は対応いたしません。ユーザ様の判断、責任にてご使用ください。
nsupdate、nslookup 自体に関するお問い合わせ
nsupdate、nslookup の動作保証
nsupdate、nslookup の不具合対応、不具合が原因の障害
各サーバの nsupdate、nslookup の対応状況のお問い合わせ
6.3.16. FTP モニタリソースについて¶
FTPサーバに登録するバナーメッセージや接続時のメッセージが長い文字列または複数行の場合、監視異常となる場合があります。FTPモニタリソースで監視する場合は、バナーメッセージや接続時のメッセージを登録しないようにしてください。
6.3.17. Red Hat Enterprise Linux 7 以降利用時の注意事項¶
メール通報機能では OS 提供の [mail] コマンドを利用しています。最小構成では [mail] コマンドがインストールされないため、以下のいずれかを実施してください
クラスタプロパティの[アラートサービス]タブで[メール送信方法]に[SMTP] を選択。
mailx をインストール。
6.3.18. Ubuntu 利用時の注意事項¶
CLUSTERPRO 関連コマンドを実行する時は root ユーザで実行してください。
Application Server AgentはWebSphereモニタのみ動作可能です。これは他のアプリケーションサーバがUbuntuをサポートしていないためです。
メール通報機能では OS 提供の [mail] コマンドを利用しています。最小構成では [mail] コマンドがインストールされないため、以下のいずれかを実施してください
クラスタプロパティの[アラートサービス]タブで[メール送信方法]に[SMTP] を選択。
mailutils をインストール。
SNMP による情報取得機能は動作しません。
6.3.19. AWS 環境における時刻同期¶
6.3.20. AWS環境におけるIAMの設定について¶
IAMの設定手順は次の通りです。
まずIAMポリシーを作成します。後述の「IAMポリシーの作成」を参照してください。
- 次にインスタンスの設定を行います。IAMロールを使用する場合、後述の「インスタンスの設定 - IAMロールを使用する」を参照してください。IAMユーザを使用する場合、後述の「インスタンスの設定 - IAMユーザを使用する」を参照してください。
IAMポリシーの作成
AWS の EC2 や S3 などのサービスへのアクションに対するアクセス許可を記述したポリシーを作成します。CLUSTERPRO の AWS 関連リソースおよびモニタリソースが AWS CLI を実行するために許可が必要なアクションは以下のとおりです。
必要なポリシーは将来変更される可能性があります。
AWS 仮想IPリソース/AWS 仮想IPモニタリソース
アクション
説明
VPC、ルートテーブル、ネットワークインタフェースの情報を取得する時に必要です。
ec2:ReplaceRoute
ルートテーブルを更新する時に必要です。
AWS Elastic IPリソース/AWS Elastic IPモニタリソース
アクション
説明
EIP、ネットワークインタフェースの情報を取得する時に必要です。
ec2:AssociateAddress
EIPをENIに割り当てる際に必要です。
ec2:DisassociateAddress
EIPをENIから切り離す際に必要です。
AWS セカンダリ IP リソース/AWS セカンダリ IP モニタリソース
アクション
説明
ネットワークインタフェース、サブネットの情報を取得する時に必要です。
ec2:AssignPrivateIpAddresses
セカンダリIPアドレスの割り当てをする時に必要です。
ec2:UnassignPrivateIpAddresses
セカンダリIPアドレスの割り当て解除をする時に必要です。
AWS AZモニタリソース
アクション
説明
ec2:DescribeAvailabilityZones
アベイラビリティゾーンの情報を取得する時に必要です。
AWS DNS リソース/AWS DNS モニタリソース
アクション
説明
route53:ChangeResourceRecordSets
リソースレコードセットの追加、削除、設定内容の更新をする時に必要です。
route53:GetChange
リソースレコードセットの追加、設定内容の更新する時に必要です。
route53:ListResourceRecordSets
リソースレコードセット の情報を取得する時に必要です。
AWS 強制停止リソース
アクション
説明
ec2:DescribeInstances
インスタンスの情報を取得する時に必要です。
ec2:StopInstances
インスタンスの停止をする時に必要です。
ec2:RebootInstances
インスタンスの再起動をする時に必要です。
ec2:DescribeInstanceAttribute
インスタンスの属性を取得するときに必要です。
モニタリソースの監視処理時間を Amazon CloudWatch に送信する機能
アクション
説明
cloudwatch:PutMetricData
カスタムメトリクスを送信する時に必要です。
アラートサービスのメッセージを Amazon SNS に送信する機能
アクション
説明
sns:Publish
メッセージを送信する時に必要です。
以下のカスタムポリシーの例では全てのAWS 関連リソースおよびモニタリソースが使用するアクションを許可しています。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:Describe*", "ec2:ReplaceRoute", "ec2:AssociateAddress", "ec2:DisassociateAddress", "ec2:AssignPrivateIpAddresses", "ec2:UnassignPrivateIpAddresses", "ec2:StopInstances", "ec2:RebootInstances", "route53:ChangeResourceRecordSets", "route53:GetChange", "route53:ListResourceRecordSets" ], "Effect": "Allow", "Resource": "*" } ] }IAM Management Console の [Policies] - [Create Policy] で カスタムポリシーを作成できます。
インスタンスの設定 - IAMロールを使用する
IAM ロールを作成し、インスタンスに付与することでAWS CLIを実行可能にする方法です。
図 6.7 IAMロールを使用したインスタンスの設定¶
インスタンス作成時に、「IAM Role」に作成した IAM ロールを指定します。
インスタンスにログオンします。
/sbin、/bin、/usr/sbin、/usr/bin
Python3のみインストールされており /usr/bin/python が存在しない場合、/usr/bin/python3.x (xはバージョン) もしくは /usr/bin/python3 に対し /usr/bin/python のシンボリックリンクを作成してください。AWS CLI をインストールします。
AWS CLI のインストールパスは、以下のいずれかにする必要があります。/sbin、/bin、/usr/sbin、/usr/bin、/usr/local/binAWS CLI のセットアップ方法に関する詳細は下記を参照してください。(PythonまたはAWS CLIのインストールを行った時点ですでにCLUSTERPROがインストール済の場合は、OSを再起動してからCLUSTERPROの操作を行ってください。)
シェルから以下のコマンドを実行します。
$ sudo aws configure質問に対して AWS CLI の実行に必要な情報を入力します。AWS アクセスキー ID、AWS シークレットアクセスキーは入力しないことに注意してください。
AWS Access Key ID [None]: (Enterのみ) AWS Secret Access Key [None]: (Enterのみ) Default region name [None]: <既定のリージョン名> Default output format [None]: text"Default output format"は、"text" 以外を指定することも可能です。もし誤った内容を設定してしまった場合は、/root/.aws をディレクトリごと消去してから上記操作をやり直してください。
インスタンスの設定 - IAMユーザを使用する
図 6.8 IAMユーザを使用したインスタンスの設定¶
IAM ユーザを作成し、そのアクセスキーID、シークレットアクセスキーをインスタンス内に保存することでAWS CLIを実行可能にする方法です。インスタンス作成時の IAM ロールの付与は不要です。
インスタンスにログインします。
Python3のみインストールされており /usr/bin/python が存在しない場合、/usr/bin/python3.x (xはバージョン) もしくは /usr/bin/python3 に対し/usr/bin/python のシンボリックリンクを作成してください。
AWS CLI をインストールします。
AWS CLI のインストールパスは、以下のいずれかにする必要があります。/sbin、/bin、/usr/sbin、/usr/bin、/usr/local/binAWS CLI のセットアップ方法に関する詳細は下記を参照してください。(PythonまたはAWS CLIのインストールを行った時点ですでにCLUSTERPROがインストール済の場合は、OSを再起動してからCLUSTERPROの操作を行ってください。)シェルから以下のコマンドを実行します。
$ sudo aws configure質問に対して AWS CLI の実行に必要な情報を入力します。AWS アクセスキー ID、AWS シークレットアクセスキーは作成した IAM ユーザの詳細情報画面から取得したものを入力します。
AWS Access Key ID [None]: <AWS アクセスキー> AWS Secret Access Key [None]: <AWS シークレットアクセスキー> Default region name [None]: <既定のリージョン名> Default output format [None]: text"Default output format"は、"text"以外を指定することも可能です。もし誤った内容を設定してしまった場合は、/root/.aws をディレクトリごと消去してから上記操作をやり直してください。
6.3.21. AWS CLIのインストールパスについて¶
6.3.22. Azure DNS リソースについて¶
Azure CLI のインストール、サービス プリンシパルの作成の手順は、『CLUSTERPRO X Microsoft Azure 向け HAクラスタ 構築ガイド』を参照してください。
Azure DNS リソースが利用するため、Azure CLI および Python のインストールが必要です。Python は、Redhat Enterprise Linux/Cent OS など OS に同梱されています。Azure CLI の詳細については、以下のWeb サイトを参照してください。
Microsoft Azure のドキュメント:Azure DNS リソースが利用するため、Azure DNS のサービスが必要です。Azure DNS の詳細については、以下のWeb サイトを参照してください。
CLUSTERPRO が Microsoft Azure と連携するためには、Microsoft Azure の組織アカウントが必要となります。組織アカウント以外のアカウントは Azure CLI 実行時に対話形式でのログインが必要となるため使用できません。
- Azure CLI を使用して、サービス プリンシパルを作成する必要があります。Azure DNS リソースは Microsoft Azure にログインし、DNS ゾーンへの登録を実行します。Microsoft Azure へのログイン時、サービス プリンシパルによる Azure ログインを利用します。サービスプリンシパルや詳細な手順については、以下のWeb サイトを参照してください。Azure CLI 2.0 を使用してログインする:Azure CLI 2.0 で Azure サービス プリンシパルを作成する:作成されたサービスプリンシパルのロールを既定のContributor(共同作成者)から別のロールに変更する場合、Actions プロパティとして以下のすべての操作へのアクセス権を持つロールを選択してください。この条件を満たさないロールに変更した場合、Azure DNS リソースの起動がエラーにより失敗します。
Azure CLI 1.0の場合
Microsoft.Network/dnsZones/readMicrosoft.Network/dnsZones/A/writeMicrosoft.Network/dnsZones/A/readMicrosoft.Network/dnsZones/A/deleteMicrosoft.Network/dnsZones/NS/readAzure CLI 2.0の場合
Microsoft.Network/dnsZones/A/writeMicrosoft.Network/dnsZones/A/deleteMicrosoft.Network/dnsZones/NS/read Azure プライベート DNS には未対応です。
6.3.23. Google Cloud DNS リソースについて¶
Google Cloud の Cloud DNS を使用します。Cloud DNS の詳細については、以下の Web サイトを参照してください。
Cloud DNSCloud DNS の操作に使用するため、Cloud SDK のインストールが必要です。Cloud SDK の詳細については、以下のサイトを参照してください。
Cloud SDK以下の権限を持ったアカウントで Cloud SDK を承認する必要があります。
dns.changes.createdns.changes.getdns.managedZones.getdns.resourceRecordSets.createdns.resourceRecordSets.deletedns.resourceRecordSets.listdns.resourceRecordSets.updateCloud SDK の承認については、以下の Web サイトを参照してください。
Cloud SDK ツールの承認
6.3.24. Samba モニタリソースについて¶
Samba モニタリソースはSMBプロトコルバージョン 2.0以降やNTLM認証やSMB署名に対応するために内部バージョン 4.1.0-1 より共有ライブラリの libsmbclient.so.0 を利用しています。libsmbclient.so.0 は libsmbclient パッケージに含まれるため、インストールされているか確認してください。
libsmbclient のバージョンが 3 以下の場合(例.RHEL 6 に同梱の libsmbclient)、[ポート番号]は139もしくは445しか指定できません。smb.conf の smb ports に含まれるポート番号を指定してください。
Samba モニタリソースがサポートするSMBプロトコルのバージョンはインストールされている libsmbclient に依存します。libsmbclient でのサポート可否は、各ディストリビュータが提供する smbclient コマンドで監視対象の共有への接続を試行することで確認することができます。
6.3.25. HTTP ネットワークパーティション解決リソース、Witness ハートビートリソースについて¶
- HTTP ネットワークパーティション解決リソース、Witness ハートビートリソースでは、SSLを使用する場合に OpenSSL 1.0/1.1 を使用します。既定の設定で使用するライブラリは以下の通りです。
libssl.so.10 (CLUSTERPRO の rpm パッケージをインストールした場合)
libssl.so.1.0.0 (CLUSTERPRO の deb パッケージをインストールした場合)
使用するライブラリを変更する場合は、クラスタプロパティの暗号化タブで [SSLライブラリ] および [Cryptoライブラリ] を設定してください。
6.3.26. OCI 環境における CLI の設定について¶
6.3.27. OCI 強制停止リソースの設定について¶
<CLUSTERPROインストールパス>/cloud/oci/clpociforcestop.sh ・OCI CLI コマンドのインストールディレクトリに応じて変更するパラメータ export PATH=$PATH:[OCI CLIコマンドのインストールディレクトリ] <例> export PATH=$PATH:/root/bin ・OCI構成ファイルの格納場所に応じて変更するパラメータ OCI_Path="[OCI構成ファイルのパス]" <例> OCI_Path="/root/.oci/config"
6.3.28. OCI 環境におけるポリシーの設定について¶
ポリシーの設定
CLUSTERPRO の OCI 関連機能が OCI CLI を実行するために必要なポリシーは以下の通りです。
必要なポリシーは将来変更される可能性があります。
OCI 強制停止リソース
ポリシー構文
説明
Allow <subject> to use instance-family in <location>
インスタンスの停止、再起動、情報を取得する時に必要です。
<subject>、 <location> は環境に応じた値を入れてください。
6.4. CLUSTERPRO の情報作成時¶
CLUSTERPRO の構成情報の設計、作成前にシステムの構成に依存して確認、留意が必要な事項です。
6.4.1. CLUSTERPRO インストールパス配下のディレクトリ、ファイルについて¶
6.4.2. 環境変数¶
環境変数が 256 個以上設定されている環境では、下記の処理を実行できません。下記の機能またはリソースを使用する場合は、環境変数を 255 個以下に設定してください。
グループの起動/停止処理
exec リソースが活性/非活性時に実行する開始/停止スクリプト
カスタムモニタリソースが監視時に実行するスクリプト
グループリソース、モニタリソース異常検出後の最終動作実行前スクリプト
グループリソースの活性/非活性前後スクリプト
強制停止スクリプト
注釈
システムに設定されている環境変数とCLUSTERPROで設定される環境変数を合わせて255個以下になるように設定してください。CLUSTERPROが設定する環境変数は約30個です。
6.4.3. シャットダウン監視について¶
Red Hat Enterprise Linux 8 系 OS 以降の場合、監視方法によらず[SIGTERM を有効にする]をONに設定してください。
6.4.4. サーバのリセット、パニック、パワーオフ¶
CLUSTERPROが「サーバのリセット」または「サーバのパニック」、または「サーバのパワーオフ」を行う場合、サーバが正常にシャットダウンされません。そのため下記のリスクがあります。
マウント中のファイルシステムへのダメージ
保存していないデータの消失
OS のダンプ採取の中断
「サーバのリセット」または「サーバのパニック」が発生する設定は下記です。
グループリソース活性時/非活性時異常時の動作
sysrq パニック
keepalive リセット
keepalive パニック
BMC リセット
BMC パワーオフ
BMC サイクル
BMC NMI
モニタリソース異常検出時の最終動作
sysrq パニック
keepalive リセット
keepalive パニック
BMC リセット
BMC パワーオフ
BMC サイクル
BMC NMI
ユーザ空間監視のタイムアウト検出時動作
監視方法 softdog
監視方法 ipmi
- 監視方法 keepalive
注釈
「サーバのパニック」は監視方法が keepalive の場合のみ設定可能です。
シャットダウンストール監視
監視方法 softdog
監視方法 ipmi
- 監視方法 keepalive
注釈
「サーバのパニック」は監視方法が keepalive の場合のみ設定可能です。
強制停止機能の動作
BMC リセット
BMC パワーオフ
BMC サイクル
BMC NMI
- VMware vSphere パワーオフ
6.4.5. グループリソースの非活性異常時の最終アクション¶
6.4.6. ミラーディスクのファイルシステムの選択について¶
現在動作確認を完了しているファイルシステムは下記の通りです。
ext3
ext4
xfs
reiserfs
jfs
vxfs
none(ファイルシステムなし)
6.4.7. ハイブリッドディスクのファイルシステムの選択について¶
現在動作確認を完了しているファイルシステムは下記の通りです。
ext3
ext4
xfs
reiserfs
none(ファイルシステムなし)
6.4.8. ミラーディスクを多く定義した場合の単体サーバ起動時間について¶
6.4.9. ディスクモニタリソースの RAW 監視について¶
ディスクモニタリソースの RAW 監視を設定する場合、既に mount しているパーティションまたは mount する可能性のあるパーティションの監視はできません。また、既にmount しているパーティションまたは mount する可能性のあるパーティションのwhole device(ディスク全体を示すデバイス)をデバイス名に設定して監視することもできません。
監視専用のパーティションを用意してディスクモニタリソースの RAW 監視に設定してください。
6.4.10. 遅延警告割合¶
遅延警告割合を 0 または、100 に設定すれば以下のようなことを行うことが可能です。
- 遅延警告割合に 0 を設定した場合監視毎に遅延警告がアラート通報されます。この機能を利用し、サーバが高負荷状態での監視リソースへのポーリング時間を算出し、監視リソースの監視タイムアウト時間を決定することができます。
- 遅延警告割合に 100 を設定した場合遅延警告の通報を行いません。テスト運用以外で、0% 等の低い値を設定しないように注意してください。
6.4.11. ディスクモニタリソースの監視方法 TUR について¶
- SCSI の Test Unit Ready コマンドや SG_IO コマンドをサポートしていないディスク、ディスクインターフェイス (HBA) では使用できません。ハードウェアがサポートしている場合でもドライバがサポートしていない場合があるのでドライバの仕様も合わせて確認してください。
- S-ATA インターフェイスのディスクの場合には、ディスクコントローラのタイプや使用するディストリビューションにより、OS に IDE インターフェイスのディスク (hd) として認識される場合と SCSI インターフェイスのディスク (sd) として認識される場合があります。IDE インターフェイスとして認識される場合には、すべての TUR 方式は使用できません。SCSI インターフェイスとして認識される場合には、TUR (legacy) が使用できます。TUR (generic) は使用できません。
Read 方式に比べて OS やディスクへの負荷は小さくなります。
Test Unit Ready では、実際のメディアへの I/Oエラーは検出できない場合があります。
6.4.12. LAN ハートビートの設定/カーネルモード LAN ハートビートの設定について¶
優先度が一番高いインタコネクトには、全サーバ間で通信可能な LAN ハートビートまたはカーネルモード LAN ハートビートを設定してください。
カーネルモード LAN ハートビートリソースを 2 つ以上設定することを推奨します(クラウド環境や遠隔クラスタ環境のようにネットワークの追加が難しい場合はその限りではありません)。
インタコネクト専用の LAN を LAN ハートビートリソースとして登録し、さらにパブリックLAN も LAN ハートビートリソースとして登録することを推奨します。
カーネルモード LAN ハートビートが使用できるディストリビューション,カーネルの場合には カーネルモード LAN ハートビートの利用を推奨します。
6.4.13. スクリプトのコメントなどで取り扱える 2 バイト系文字コードについて¶
CLUSTERPRO では、Linux 環境で編集されたスクリプトは EUC、Windows 環境で編集されたスクリプトは Shift-JIS として扱われます。その他の文字コードを利用した場合、環境によっては文字化けが発生する可能性があります。
6.4.14. スクリプトの文字コードと改行コードについて¶
Cluster WebUI 以外で作成したスクリプトを clpcfctrl コマンドで設定反映する場合、構成情報ファイル(clp.conf)とスクリプトの文字コードと改行コードが同じであることを確認してから設定反映してください。文字コードまたは改行コードが異なる場合、スクリプトが正常に動作しない可能性があります。
6.4.15. システムモニタリソースの設定について¶
- リソース監視の検出パターンSystem Resource Agent では、「しきい値」、「監視継続時間」という2つのパラメータを組み合わせて検出を行います。各システムリソース(オープンファイル数、ユーザプロセス数、スレッド数、メモリ使用量、CPU 使用率、仮想メモリ使用量)を継続して収集し、一定時間(継続時間として指定した時間)しきい値を超えていた場合に異常を検出します。
6.4.16. 外部連携モニタリソースの設定について¶
外部連携モニタリソースに異常を通知するには、[clprexec] コマンドを用いる方法、サーバ管理基盤連携機能を用いる方法の二つ方法があります。
[clprexec] コマンドを用いる場合は CLUSTERPRO CD に同梱されているファイルを利用します。通知元サーバの OS やアーキテクチャに合わせて利用してください。また、通知元サーバと通知先サーバの通信が可能である必要があります。
サーバ管理基盤連携機能については、『ハードウェア連携ガイド』の「サーバ管理基盤との連携」を参照してください。
6.4.17. JVM 監視の設定について¶
監視対象がWebLogic Serverの場合、JVMモニタリソースの以下の設定値については、システム環境(メモリ搭載量など)により、設定範囲の上限に制限がかかることがあります。
[ワークマネージャのリクエストを監視する]-[リクエスト数]
[ワークマネージャのリクエストを監視する]-[平均値]
[スレッドプールのリクエストを監視する]-[待機リクエスト リクエスト数]
[スレッドプールのリクエストを監視する]-[待機リクエスト 平均値]
[スレッドプールのリクエストを監視する]-[実行リクエスト リクエスト数]
[スレッドプールのリクエストを監視する]-[実行リクエスト 平均値]
監視対象のJRockit JVM が64bit 版の場合、JRockit JVMから取得した各最大メモリ量がマイナスとなり使用率が計算できないため、以下のパラメータが監視できません。
[ヒープ使用率を監視する]- [領域全体]
[ヒープ使用率を監視する]- [Nursery Space]
[ヒープ使用率を監視する]- [Old Space]
[非ヒープ使用率を監視する]- [領域全体]
[非ヒープ使用率を監視する]- [ClassMemory]
JVMモニタリソースを使用するには、「4. CLUSTERPRO の動作環境」の「4.2.4. JVM モニタの動作環境」に記載しているJRE(Java Runtime Environment)をインストールしてください。監視対象(WebLogic ServerやWebOTX)が使用するJREと同じ物件を使用することも、別の物件を使用することも可能です。
モニタリソース名に空白を含まないでください。
6.4.18. ボリュームマネージャリソース利用時の CLUSTERPRO 起動処理について¶
CLUSTERPRO起動時に、ボリュームマネージャがlvmの場合はvgchangeコマンドによる非活性処理を行うため、システムの起動に時間がかかることがあります。本件が問題となる場合は、下記のようにCLUSTERPRO本体の起動/停止スクリプトを編集してください。
init.d 環境の場合、/etc/init.d/clusterproを下記のように編集してください。
#!/bin/sh # # Startup script for the CLUSTERPRO daemon # : : # See how we were called. case "$1" in start) : : # export all volmgr resource # clp_logwrite "$1" "clpvolmgrc start." init_main # ./clpvolmgrc -d > /dev/null 2>&1 # retvolmgrc=$? # clp_logwrite "$1" "clpvolmgrc end.("$retvolmgrc")" init_main : :
systemd 環境の場合/opt/nec/clusterpro/etc/systemd/clusterpro.shを下記のように編集してください。
#!/bin/sh # # Startup script for the CLUSTERPRO daemon # : : # See how we were called. case "$1" in start) : : # export all volmgr resource # clp_logwrite "$1" "clpvolmgrc start." init_main # ./clpvolmgrc -d > /dev/null 2>&1 # retvolmgrc=$? # clp_logwrite "$1" "clpvolmgrc end.("$retvolmgrc")" init_main
6.4.19. AWS CLI コマンドラインオプション¶
AWS 関連機能では AWS CLI を実行しています。
複数のコマンドラインオプションを指定する場合はスペースで区切りで指定してください。
aws cloudwatch
Amazon CloudWatch 連携
aws ec2
AWS Elastic IP リソース
AWS 仮想 IP リソース
AWS セカンダリ IP リソース
AWS Elastic IP モニタリソース
AWS 仮想 IP モニタリソース
AWS セカンダリ IP モニタリソース
AWS AZ モニタリソース
AWS 強制停止リソース
Cluster WebUI によるクラウド環境情報の取得
aws route53
AWS DNS リソース
AWS DNS モニタリソース
aws sns
Amazon SNS 連携
AWS CLI のコマンドラインオプションの詳細についてはAWSのドキュメントをご参照ください。
注釈
6.4.20. AWS 関連機能実行時の環境変数¶
AWS 関連機能では AWS CLI やインスタンスメタデータへのアクセスを実行します。
クラスタプロパティのクラウドタブで [AWS関連機能実行時の環境変数] を設定することで、これらの処理に反映する環境変数を指定することができます。 AWS環境にてプロキシサーバを利用する場合や、AWS CLI の設定ファイルや認証情報ファイルを指定する場合などに有効です。
[AWS関連機能実行時の環境変数] の設定が有効になる機能は以下の通りです。
AWS Elastic IP リソース
AWS 仮想 IP リソース
AWS セカンダリ IP リソース
AWS DNS リソース
AWS Elastic IP モニタリソース
AWS 仮想 IP モニタリソース
AWS セカンダリ IP モニタリソース
AWS AZ モニタリソース
AWS DNS モニタリソース
AWS 強制停止リソース
Amazon SNS 連携
Amazon CloudWatch 連携
Cluster WebUI によるクラウド環境情報の取得
また、環境変数設定ファイルを使用することで環境変数を指定することもできます。 この場合、[AWS関連機能実行時の環境変数] は設定しないでください。[AWS関連機能実行時の環境変数] を設定した場合は環境変数設定ファイルは使用できません。
注釈
環境変数設定ファイルは旧バージョンとの互換性維持のための機能です。 環境変数の設定には [AWS関連機能実行時の環境変数] の使用を推奨します。
環境変数設定ファイルは、以下に配置しています。
<CLUSTERPROインストールパス>/cloud/aws/clpaws_setting.conf
環境変数設定ファイルのフォーマットは、以下のとおりです。
環境変数名 = 値
記載例)
[ENVIRONMENT] HTTP_PROXY = http://10.0.0.1:3128 HTTPS_PROXY = http://10.0.0.1:3128 NO_PROXY = 169.254.169.254,ec2.ap-northeast-1.amazonaws.com
環境変数設定ファイルの仕様は、以下のとおりです。
一行目は [ENVIRONMENT] を記載してください。記載がない場合は環境変数が設定されないことがあります。
環境変数設定ファイルが存在しない場合や読み取り権限がない場合は無視します。活性異常や監視異常にはなりません。
同名の環境変数が既に設定されている場合、値を上書きします。
環境変数名の前にスペースやタブがある場合または = の両側にタブがある場合、設定が反映されないことがあります。
環境変数名は大文字・小文字を区別します。
値にスペースが入る場合、""(ダブルクォート)で括る必要はありません。
環境変数はグループリソースやモニタリソースの共通スクリプト (例.最終動作前スクリプト、活性/非活性前後スクリプト) には反映されません。
6.4.21. AWS 関連機能実行時に使用する設定ファイルと認証情報ファイルについて¶
AWS 関連機能から実行されるAWS CLIは以下のフォルダに保存されている設定ファイルと認証情報ファイルを使用しています。
/root/.aws
AWS_CONFIG_FILE AWS_SHARED_CREDENTIALS_FILE
AWS CLIの環境変数の詳細についてはAWSのドキュメントをご参照ください。
6.4.22. AWS Elastic IP リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
AWS Elastic IPリソースはASCII文字以外の文字に対応していません。下記のコマンドの実行結果にASCII文字以外の文字が含まれないことを確認してください。
aws ec2 describe-addresses --allocation-ids <EIP ALLOCATION ID>
AWS Elastic IP リソースはENIのプライマリプライベートIPアドレスにEIPを関連付けます。セカンダリプライベートIPアドレスに関連付けはできません。
6.4.23. AWS 仮想 IP リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
AWS 仮想 IP リソースとAWS セカンダリ IP リソースは組み合わせて使用できません。
- AWS 仮想 IPリソースはASCII文字以外の文字に対応していません。下記のコマンドの実行結果にASCII文字以外の文字が含まれないことを確認してください。
aws ec2 describe-vpcs --vpc-ids <VPC ID> aws ec2 describe-route-tables --filters Name=vpc-id,Values=<VPC ID> aws ec2 describe-network-interfaces --network-interface-ids <ENI ID>
AWS 仮想IPリソースは、VPC ピアリング接続を経由してのアクセスが必要な場合では利用することができません。これは、VIP として使用する IP アドレスが VPC の範囲外であることを前提としており、このような IP アドレスは VPC ピアリング接続では無効とみなされるためです。VPC ピアリング接続を経由してのアクセスが必要な場合は、Amazon Route 53 を利用する AWS DNS リソースを使用してください。
インスタンスが使用するルートテーブルに、仮想IPが使用するIPアドレスのルートが存在しない場合でもAWS仮想IPリソースは正常に起動します。この動作は仕様どおりです。AWS 仮想 IP リソースは活性化時において、指定されたIPアドレスのエントリが存在するルートテーブルに対してのみその内容を更新します。ルートテーブルが一つも見つからなかった場合でも更新対象なしとして正常と判断します。どのルートテーブルにエントリが存在する必要があるかはシステムの構成で決まるため、AWS 仮想 IP リソースとしては正常性の判断対象とはしていません。
6.4.24. AWS セカンダリ IP リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
AWS 仮想 IP リソースとAWS セカンダリ IP リソースは組み合わせて使用できません。
- AWS セカンダリ IP リソースはASCII文字以外の文字に対応していません。下記のコマンドの実行結果にASCII文字以外の文字が含まれないことを確認してください。
aws ec2 describe-network-interfaces --network-interface-ids <ENI ID> aws ec2 describe-subnets --subnet-ids <SUBNET_ID>
AWS セカンダリ IP リソースはサブネットが異なる構成では利用できません。
- AWS セカンダリ IP リソースで割り当てられるセカンダリ IP アドレスはインスタンスタイプごとに上限があります。詳細は下記を参照してください。
6.4.25. AWS DNS リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
[リソースレコードセット名] にエスケープコードを含む場合、監視が異常になります。エスケープコードを含まない [リソースレコードセット名] を設定してください。
AWS DNS リソースの活性時、DNS 設定の変更がすべての Amazon Route 53 DNS サーバーに伝播済みとなるまでは待ち合わせません。これは Route 53 の仕様上、リソースレコードセットの変更が全体に適用されるまでに時間が掛かるためです。「AWS DNS モニタリソースの設定について」も参照してください。
AWS DNS リソースはアカウントに紐づいています。そのため、複数のアカウントやAWS アクセスキーID、AWS シークレットアクセスキーを使い分ける運用はできません。その場合は、EXECリソースなどで AWS CLI を実行するスクリプトによる運用を検討してください。
6.4.26. AWS DNS モニタリソースの設定について¶
AWS DNS モニタリソースは、監視時に AWS CLI を実行します。実行する AWS CLI のタイムアウトは、AWS DNS リソースで設定した [AWS CLI タイムアウト] を利用します。
AWS DNS リソースの活性直後、以下の事象により AWS DNS モニタリソースによる監視が失敗する可能性があります。この場合、AWS DNS モニタリソースの [監視開始待ち時間] を Amazon Route 53 における DNS 設定の変更が反映される時間より長く設定してください(https://aws.amazon.com/jp/route53/faqs/)。
AWS DNS リソースの活性時、リソースレコードセットの追加や更新をする。
Amazon Route 53 における DNS 設定の変更が反映される前に、AWS DNS モニタリソースが監視を実行すると名前解決ができないため監視に失敗する。DNS リゾルバキャッシュが有効な間は、その後も AWS DNS モニタリソースは監視に失敗する。
Amazon Route 53 における DNS 設定の変更が反映される。
AWS DNS リソースの [TTL] の有効期間が経過すると名前解決に成功するため、AWS DNS モニタリソースの監視が成功する。
6.4.27. Azure プローブポートリソースの設定について¶
IPv6はサポートしていません。
Microsoft Azure 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
6.4.28. Azure ロードバランスモニタリソースの設定について¶
Azure ロードバランスモニタリソースが異常を検知した場合、Azureのロードバランサからの現用系と待機系の切り替えが正しく行われない可能性があります。そのため、Azure ロードバランスモニタリソースの[最終動作]には[クラスタサービス停止と OS シャットダウン]を選択することを推奨とします。
6.4.29. Azure DNS リソースの設定について¶
IPv6はサポートしていません。
Microsoft Azure 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
6.4.30. Google Cloud 仮想 IP リソースの設定について¶
IPv6はサポートしていません。
6.4.31. Google Cloud ロードバランスモニタリソースの設定について¶
Google Cloud ロードバランスモニタリソースが異常を検知した場合、ロードバランサからの現用系と待機系の切り替えが正しく行われない可能性があります。そのため、Google Cloud ロードバランスモニタリソースの [最終動作] には [クラスタサービス停止と OS シャットダウン] を選択することを推奨します。
6.4.32. Google Cloud DNS リソースの設定について¶
IPv6はサポートしていません。
Google Cloud Platform 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
複数のGoogle Cloud DNSリソースの活性・非活性処理が同時に実行されるとエラーが発生することがあります。そのため、クラスタ内で複数のGoogle Cloud DNSリソースを使用する場合は、リソースの依存関係やグループの起動・停止待ち合わせ等で活性・非活性処理が同時に実行されないように設定する必要があります。
6.4.33. Oracle Cloud 仮想 IP リソースの設定について¶
IPv6はサポートしていません。
6.4.34. Oracle Cloud ロードバランスモニタリソースの設定について¶
Oracle Cloud ロードバランスモニタリソースが異常を検知した場合、ロードバランサからの現用系と待機系の切り替えが正しく行われない可能性があります。そのため、Oracle Cloud ロードバランスモニタリソースの [最終動作] には [クラスタサービス停止と OS シャットダウン] を選択することを推奨します。
6.4.35. リソース追加ウィザード画面に表示されるリソースタイプ一覧について¶
6.4.36. ミラーディスクリソースとハイブリッドディスクリソースの共存について¶
同一のフェイルオーバーグループにミラーディスクリソースとハイブリッドディスクリソースを混在させることはできません。
6.5. CLUSTERPRO 運用後¶
クラスタとして運用を開始した後に発生する事象で留意して頂きたい事項です。
6.5.1. udev 環境等でのミラードライバロード時のエラーメッセージについて¶
udev 環境等でミラードライバのロード時に、以下のようなログが messages ファイルにエントリされることがあります。
kernel: [I] <type: liscal><event: 141> NMPx device does not exist. (liscal_make_request) kernel: [I] <type: liscal><event: 141> - This message can be recorded on udev environment when liscal is initializing NMPx. kernel: [I] <type: liscal><event: 141> - Ignore this and following messages 'Buffer I/O error on device NMPx' on udev environment. kernel: Buffer I/O error on device NMPx, logical block xxxx
kernel: <liscal liscal_make_request> NMPx device does not exist. kernel: Buffer I/O error on device NMPx, logical block xxxx
ファイル名:50-liscal-udev.rules
ACTION=="add", DEVPATH=="/block/NMP*", OPTIONS+="ignore_device"
ACTION=="add", DEVPATH=="/devices/virtual/block/NMP*", OPTIONS+="ignore_device"
6.5.2. ミラーパーティションデバイスに対するバッファ I/O エラーのログについて¶
ミラーディスクリソースやハイブリッドディスクリソースが非活性の状態の時に、ミラーパーティションデバイスがアクセスされると、以下のようなログがmessagesファイルに記録されます。
kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=xxxxx) kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. : kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=xxxx) : kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=xxxx)
kernel: <liscal liscal_make_request> NMPx I/O port is close, mount(0), io(0). kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
(x や xxxx には数字が入ります)
udev環境によるもの
この場合は、ミラードライバのロード時に『kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx』のメッセージとともに『kernel: [I] <type: liscal><event: 141>』のメッセージが記録されます。
本メッセージは異常を示すものではなく、CLUSTERPRO の動作には影響ありません。
- この詳細については、『6.5.1. udev 環境等でのミラードライバロード時のエラーメッセージについて』を参照してください。
OS の情報収集コマンド(sosreport, sysreport, blkid コマンド等)が実行された時とき
この場合は、本メッセージは異常を示すものではなく、CLUSTERPRO の動作には影響ありません。
OS が提供する情報収集コマンドが実行されると、OS が認識しているデバイスへのアクセスが行われます。この時、非活性状態のミラーディスクにもアクセスが行われ、その結果として、上記のメッセージが記録されます。
- このメッセージをCLUSTERPROの設定等で抑止する方法はありません。
ミラーディスクのアンマウントがタイムアウトしたとき
この場合は、ミラーディスクリソースのアンマウントがタイムアウトしたことを示すメッセージとともに、本メッセージが記録されます。
CLUSTERPRO の動作としては、ミラーディスクリソースの『非活性異常検出の復旧動作』がおこなわれます。また、ファイルシステムに不整合が発生している可能性があります。
- この詳細については、『6.5.3. 大量 I/O によるキャッシュ増大』を参照してください。
ミラーディスク非活性時にマウントされたままの状態となっている場合
この場合は、以下の流れの後に、上記のメッセージが記録されます。
ミラーディスクリソースが活性状態になった後、ユーザやアプリケーション(NFSなど)により、ミラーパーティションのデバイス(/dev/NMPx)やミラーディスクリソースのマウントポイント内に対して、追加でマウントを行った。
その後、1で追加されたマウントポイントをアンマウントしないまま、ミラーディスクリソースを非活性にした。
CLUSTERPRO の動作には影響ありませんが、ファイルシステムに不整合が発生している可能性があります。
- この詳細については、『6.5.4. ミラーディスクリソース等に複数のマウントをおこなった場合』を参照してください。
複数のミラーディスクリソースを設定している場合
2つ以上のミラーディスクリソースを設定している場合、活性時に、一部のディストリビューションにて fsck の挙動によって、上記のメッセージが出力されることがあります。
- この詳細については、『6.5.5. 複数のミラーディスクリソース、ハイブリッドディスクリソース使用時のsyslog メッセージについて』を参照してください。
その他、何らかのアプリケーションによりアクセスされたとき
上記以外のケースの場合、何らかのアプリケーションが非活性状態のミラーディスクリソースにアクセスしようとしたことが考えられます。
ミラーディスクリソースが活性していない状態であれば、CLUSTERPRO の動作には影響ありません。
6.5.3. 大量 I/O によるキャッシュ増大¶
- ミラーディスクリソースやハイブリッドディスクリソースに対してディスクの性能を上回る大量の書き込みを行うと、ミラーの通信が切断等されていないにもかかわらず、書き込みから制御が戻らないことや、メモリの確保エラーが発生することがあります。処理性能を上回る I/O 要求が大量にある場合、ファイルシステムがキャッシュを大量に確保して、キャッシュやユーザー空間用のメモリ (HIGHMEMゾーン) が不足すると、カーネル空間用のメモリ (NORMALゾーン) も使用されることがあります。このような場合には、下記のカーネルパラメータを変更して、カーネル空間用のメモリがキャッシュに利用されるのを抑制してください。sysctl コマンド等を使用して OS 起動時にパラメータが変更されるように設定してください。
/proc/sys/vm/lowmem_reserve_ratio
- ミラーディスクリソースやハイブリッドディスクリソースに対して大量のアクセスを行った場合、ディスクリソース非活性時のアンマウントにて、ファイルシステムのキャッシュがディスクへ書き出されるのに長い時間がかかることがあります。また、このとき、ファイルシステムからディスクへの書き出しが完了する前に、アンマウントタイムアウトが発生すると、下記の様な、I/Oエラーのメッセージや、アンマウント失敗のメッセージが記録されることがあります。このような場合には、ディスクへの書き出しが正常に完了するよう、該当ディスクリソースのアンマウントのタイムアウト時間を余裕を持った値に設定してください。
≪例1≫
clusterpro: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 193> NMPx close I/O port OK. kernel: [I] <type: liscal><event: 195> NMPx close mount port OK. kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device NMPx, logical block xxxxkernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: Buffer I/O error on device NMPx, logical block xxxx :
≪例2≫
clusterpro: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 148> NMPx holder 1. (before umount) clusterpro: [E] <type: md><event: 46> umount timeout. Make sure that the length of Unmount Timeout is appropriate. (Device:mdx) : clusterpro: [E] <type: md><event: 4> Failed to deactivate mirror disk. Umount operation failed.(Device:mdx) kernel: [I] <type: liscal><event: 148> NMPx holder 1. (after umount) clusterpro: [E] <type: rc><event: 42> Stopping mdx resource has failed.(83 : System command timeout (umount, timeout=xxx)) :
6.5.4. ミラーディスクリソース等に複数のマウントをおこなった場合¶
- ミラーディスクリソースやハイブリッドディスクリソースが活性した後に、そのミラーパーティションデバイス(/dev/NMPx)やマウントポイント(のファイル階層の一部)に対して、mount コマンドで別の場所にも追加でマウントした場合には、そのディスクリソースが非活性になる前に、必ずその追加したマウントポイントをアンマウントしてください。もしも、追加したマウントポイントをアンマウントしないままで非活性がおこなわれると、メモリ上に残っているファイルシステムのデータがディスクに完全には書き出されないことがあるため、ディスク上のデータが不完全な状態のままディスクへのI/Oが閉ざされ非活性が完了してしまいます。また、このとき、非活性後もファイルシステムがディスクへ書き込みをおこない続けようとするため、下記の様なI/Oエラーのメッセージが記録されることがあります。また、その後のサーバ停止時などで、ミラーエージェント停止の際にミラードライバを終了できずにミラーエージェントの停止に失敗して、サーバが再起動することがあります。
≪例≫
clusterpro: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 148> NMP1 holder 1. (before umount) kernel: [I] <type: liscal><event: 148> NMP1 holder 1. (after umount) kernel: [I] <type: liscal><event: 193> NMPx close I/O port OK. kernel: [I] <type: liscal><event: 195> NMPx close mount port OK. clusterpro: [I] <type: rc><event: 41> Stopping mdx resource has completed. kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device NMPx, logical block xxxxx kernel: lost page write due to I/O error on NMPx kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: Buffer I/O error on device NMPx, logical block xxxxx kernel: lost page write due to I/O error on NMPx :
6.5.5. 複数のミラーディスクリソース、ハイブリッドディスクリソース使用時のsyslog メッセージについて¶
kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
kernel: <liscal liscal_make_request> NMPx I/O port is close, mount(0), io(0). kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
CLUSTERPRO としては問題はありません。messages ファイルを圧迫するなどの問題がある場合にはミラーディスクリソース、ハイブリッドディスクリソースの以下の設定を変更してください。
Mount 実行前の fsck アクションを「実行しない」
Mount 失敗時の fsck アクションを「実行する」
6.5.6. ドライバロード時のメッセージについて¶
ミラードライバを load した際に、以下のようなメッセージがコンソール、syslog に表示されることがあります。この現象は異常ではありません。
kernel: liscal: no version for "xxxxx" found: kernel tainted. kernel: liscal: module license 'unspecified' taints kernel.
(xxxxx には文字列が入ります)
同様に、clpka ドライバ, clpkhb ドライバを load した際に、以下のようなメッセージがコンソール、syslog に表示されることがあります。この現象は異常ではありません。
kernel: clpkhb: no version for "xxxxx" found: kernel tainted. kernel: clpkhb: module license 'unspecified' taints kernel.
kernel: clpka: no version for "xxxxx" found: kernel tainted. kernel: clpka: module license 'unspecified' taints kernel.
(xxxxx には文字列が入ります)
6.5.7. ミラーディスクリソース、ハイブリッドディスクリソースへの最初の I/O 時のメッセージについて¶
ミラーディスクリソースやハイブリッドディスクリソースをマウント後の最初の read/write の際に、以下のようなメッセージがコンソール、syslog に表示されることがあります。この現象は異常ではありません。
kernel: JBD: barrier-based sync failed on NMPx - disabling barriers (x には数字が入ります)
6.5.8. X-Window 上のファイル操作ユーティリティについて¶
X-Window 上で動作する一部のファイル操作ユーティリティ (GUI でファイルやディレクトリのコピーや移動などの操作を行うもの) に以下の挙動をするものがあります。
ブロックデバイスが使用可能であるかサーチする
サーチの結果、マウントが可能なファイルシステムがあればマウントする
6.5.9. ipmi のメッセージについて¶
ユーザ空間モニタリソースに IPMI を使用する場合、syslog に下記の kernel モジュール警告ログが多数出力されます。
modprobe: modprobe: Can't locate module char-major-10-173
このログ出力を回避したい場合は、/dev/ipmikcs を rename してください。
6.5.10. 回復動作中の操作制限¶
モニタリソースの異常検出時の設定で回復対象にグループリソース (ディスクリソース、EXECリソース、...) を指定し、モニタリソースが異常を検出した場合の回復動作遷移中 (再活性化 → フェイルオーバ → 最終動作) には、以下のコマンドまたは、Cluster WebUI からのクラスタ及びグループへの制御は行わないでください。
クラスタの停止 / サスペンド
グループの開始 / 停止 / 移動
6.5.11. コマンド編に記載されていない実行形式ファイルやスクリプトファイルについて¶
6.5.12. fsck の実行について¶
- ディスクリソース/ミラーディスクリソース/ハイブリッドディスクリソースの活性時に fsckを実行するよう設定している場合、ext2/ext3/ext4 ファイルシステムを mount する際に、設定に応じて fsck が実行されます。しかし、ファイルシステムのサイズや使用量、実行状況によっては、fsck に時間がかかり、fsck のタイムアウトを超過してマウントが失敗することがあります。これは、fsck の実行に下記の様なパターンがあるためです。
- ジャーナルのチェックのみを簡易的に行うパターン。短時間で完了します。
- ファイルシステム全体の整合性チェックを行うパターン。OS で保持している情報「180 日以上チェックしていない」や「30 回 (前後の)マウント後に行う」に該当した場合。ファイルシステムのサイズや使用量などによっては長い時間を要します。
このような場合には、タイムアウトが発生しないよう、該当するディスクリソースの fsck タイムアウト時間を余裕を持った設定にしてください。 ディスクリソース/ミラーディスクリソース/ハイブリッドディスクリソースの活性時に fsckを実行しないよう設定している場合、ext2/ext3/ext4 ファイルシステムを mount する際に、OSで保持している fsck 実行推奨 mount 回数等を超過すると、システムログやコンソールに以下の警告が出力されることがあります。
EXT3-fs warning: xxxxx, running e2fsck is recommended (注) xxxxx の部分は複数のパターンがあります。
この警告が出力された場合、ファイルシステムに対してfsckを実行することを推奨します。
fsck を手動で実行する場合は、以下の手順で行ってください。なお、以下の手順は必ず、該当ディスクリソースが活性しているサーバ上にて実行してください。該当ディスクリソースが所属するグループを、clpgrp コマンド等で非活性にしてください。
ディスクが mount されていないことを、mount コマンドや df コマンドを使用して確認します。
該当ディスクリソースの種類に応じて、以下の該当するコマンドを実行してディスクを Read Only から Read Write の状態にします。
(ディスクリソースの場合の例) デバイス名が /dev/sdb5 の場合
# clproset -w -d /dev/sdb5 /dev/sdb5 : success
(ミラーディスクリソースの場合の例) リソース名が md1 の場合
# clpmdctrl --active -nomount md1 <md1@server1>: active successfully
(ハイブリッドディスクリソースの場合の例) リソース名が hd1 の場合
# clphdctrl --active -nomount hd1 <hd1@server1>: active successfully
- fsck を実行します。(ミラーディスクリソースやハイブリッドディスクリソースの場合、fsckにデバイス名を指定する場合には、そのリソースに対応するミラーパーティションデバイス名(/dev/NMPx)を指定してください。)
該当ディスクリソースの種類に応じて、以下の該当するコマンドを実行して、ディスクを Read Write から Read Only の状態にします。
(ディスクリソースの場合の例) デバイス名が /dev/sdb5 の場合
# clproset -o -d /dev/sdb5 /dev/sdb5 : success
(ミラーディスクリソースの場合の例) リソース名が md1 の場合
# clpmdctrl --deactive md1 <md1@server1>: deactive successfully
(ハイブリッドディスクリソースの場合の例) リソース名が hd1 の場合
# clphdctrl --deactive hd1 <hd1@server1>: deactive successfully
該当ディスクリソースが所属するグループを、clpgrp コマンド等で活性にしてください。
もしも、fsck を実行することなしに警告を出力しないようにする必要がある場合には、ext2, ext3,ext4 の場合、最大 mount 回数の変更を tune2fs コマンドを使用して、該当ディスクリソースが活性しているサーバ上にて実行してください。
以下のコマンドを実行してください。
(ディスクリソースの場合の例) デバイス名が /dev/sdb5 の場合
# tune2fs -c -1 /dev/sdb5 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
(ミラーディスクリソースの場合の例) ミラーパーティションデバイス名が /dev/NMP1 の場合
# tune2fs -c -1 /dev/NMP1 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
(ハイブリッドディスクリソースの場合の例) ミラーパーティションデバイス名が /dev/NMP1 の場合
# tune2fs -c -1 /dev/NMP1 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
最大 mount 回数が変更されたことを確認してください。
(例) デバイス名が /dev/sdb5 の場合
# tune2fs -l /dev/sdb5 tune2fs 1.42.9 (28-Dec-2013) Filesystem volume name: <none> : Maximum mount count: -1 :
6.5.13. xfs_repair の実行について¶
xfsを使用しているディスクリソース/ミラーディスクリソース/ハイブリッドディスクリソースの活性時に、xfsに関する警告がコンソールに出力される場合は、xfs_repairを実行してファイルシステムを修復することを推奨します。
xfs_repiarは、以下の手順で実行してください。
リソースが活性していないことを確認してください。活性している場合は、Cluster WebUIなどで非活性状態にしてください。
デバイスを書き込み可能にします。
(ディスクリソースの例) デバイス名が /dev/sdb1である場合
# clproset -w -d /dev/sdb1 /dev/sdb1 : success(ミラーディスクリソースの例) リソース名がmd1の場合
# clpmdctrl --active -nomount md1 <md1@server1>: active successfully(ハイブリッドディスクリソースの例) リソース名がhd1の場合
# clphdctrl --active -nomount hd1 <hd1@server1>: active successfullyデバイスをマウントします。
(ディスクリソースの例) デバイス名が /dev/sdb1である場合
# mount /dev/sdb1 /mnt(ミラーディスクリソース/ハイブリッドディスクリソースの例) ミラーパーティションデバイス名が /dev/NMP1 の場合
# mount /dev/NMP1 /mntデバイスをアンマウントします。
# umount /mnt注釈
xfs_repair ユーティリティは、ダーティログを持つファイルシステムを修復できません。ログをクリアするために、一度マウントしてアンマウントする処置が必要となります。
xfs_repair を実行します。
(ディスクリソースの例) デバイス名が /dev/sdb1である場合
# xfs_repair /dev/sdb1(ミラーディスクリソース/ハイブリッドディスクリソースの例) ミラーパーティションデバイス名が /dev/NMP1 の場合
# xfs_repair /dev/NMP1デバイスを書き込み禁止にします。
(ディスクリソースの例) デバイス名が /dev/sdb1である場合
# clproset -o -d /dev/sdb1 /dev/sdb1 : success(ミラーディスクリソースの例) リソース名がmd1の場合
# clpmdctrl --deactive md1 <md1@server1>: deactive successfully(ハイブリッドディスクリソースの例) リソース名がhd1の場合
# clphdctrl --deactive hd1 <hd1@server1>: deactive successfully
以上で、xfsファイルシステムの修復は終了です。
6.5.14. ログ収集時のメッセージ¶
ログ収集を実行した場合、コンソールに以下のメッセージが表示されることがありますが、異常ではありません。ログは正常に収集されています。なお、以下のメッセージはiptables コマンドが出力しているものでありCLUSTERPROから抑制することはできません。
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(hd# にはサーバ上に存在する IDE のデバイス名が入ります)
kernel: Warning: /proc/ide/hd?/settings interface is obsolete, and will be removed soon!
6.5.15. ミラー復帰中のフェイルオーバや活性について¶
- ミラーディスクリソースやハイブリッドディスクリソースがミラー復帰中の状態の時には、非活性状態のミラーディスクリソースやハイブリッドディスクリソースを活性できません。ミラー復帰中に、該当ディスクリソースを含むフェイルオーバグループの移動はできません。ミラー復帰中に、フェイルオーバが発生した場合、コピー先のサーバが最新の状態を保持していないため、コピー先サーバやコピー先サーバグループへのフェイルオーバに失敗します。また、モニタリソース異常検出時の動作等によって、ハイブリッドディスクリソースが同じサーバグループ内のサーバへフェイルオーバする場合も、カレント権が移動せずフェイルオーバに失敗します。なお、タイミングによってフェイルオーバ中や移動中や活性中にミラー復帰が終了した場合には、成功することがあります。
- 構成情報登録後の最初のミラー起動時や、障害発生等でミラー用のディスクを交換した後の最初のミラー起動時には、初期ミラー構築がおこなわれます。初期ミラー構築では、ミラー活性直後に現用系サーバ側から、待機系サーバ側のミラー用ディスクへ、ディスクのコピー(全面ミラー復帰)がおこなわれます。この初期ミラー構築(全面ミラー復帰)が完了してミラーが正常な同期状態になるまでは、待機系へのフェイルオーバや待機系へのグループ移動をおこなわないでください。このディスクのコピー途中でフェイルオーバやグループ移動を行うと、待機系のミラーディスクが不完全な状態のままで待機系で活性してしまい、待機系へコピーされていないデータが失われたり、ファイルシステムに不整合が発生したりする可能性があります。
6.5.16. クラスタシャットダウン・クラスタシャットダウンリブート(ミラーディスクリソース、ハイブリッドディスクリソース)¶
6.5.17. 特定サーバのシャットダウン、リブート (ミラーディスクリソース、ハイブリッドディスクリソース)¶
6.5.18. サービス起動/停止用スクリプトについて¶
init.d 環境では以下の場合に、サービスの起動/停止スクリプトでエラーが出力されます。systemd環境ではエラーは出力されません。
- クラスタ構築前OS 起動時に下記のサービス起動スクリプトでエラーが出力されます。クラスタ未構築が原因で出力されるエラーのため問題はありません。
clusterpro_md
- 以下の場合に、サービスの停止スクリプトが不正な順序で実行されます。サービスを無効化した後の OS シャットダウンCLUSTERPRO のサービスを無効化した後、OS シャットダウン時に CLUSTERPROのサービスが不正な順序で停止されます。OS シャットダウン時に無効化したCLUSTERPRO のサービスが停止されないことが原因で発生します。Cluster WebUI から実行するクラスタシャットダウンや、clpstdn コマンドなどCLUSTERPRO のコマンドを使用してのクラスタシャットダウンの場合は不正な順序で停止されても問題ありません。
6.5.19. サービス起動時間について¶
CLUSTERPRO の各サービスは、起動時の待ち合わせ処理の有無により時間がかかる場合があります。
- clusterpro_evtマスタサーバ以外のサーバは、マスタサーバの構成情報をダウンロードする処理を最大 2 分間待ち合わせます。マスタサーバが起動済みの場合、通常数秒以内に終了します。マスタサーバはこの処理で待ち合わせは発生しません。
- clusterpro_nm特に待ち合わせ処理はありません。通常数秒以内に終了します。
- clusterpro_trn特に待ち合わせ処理はありません。通常数秒以内に終了します。
- clusterpro_ib特に待ち合わせ処理はありません。通常数秒以内に終了します。
- clusterpro_api特に待ち合わせ処理はありません。通常数秒以内に終了します。
- clusterpro_mdミラーディスクリソースもしくはハイブリッドディスクリソースが存在する場合のみ、本サービスが起動します。ミラーエージェントが正常に起動するのを最長 1 分間待ち合わせます。通常数秒以内に終了します。
- clusterpro特に待ち合わせ処理はありませんが、CLUSTERPRO の起動に時間がかかる場合数十秒かかります。通常数秒以内に終了します。
- clusterpro_webmgr特に待ち合わせ処理はありません。通常数秒以内に終了します。
- clusterpro_alertsync特に待ち合わせ処理はありません。通常数秒以内に終了します。
6.5.20. systemd 環境でのサービス状態確認について¶
6.5.21. EXEC リソースで使用するスクリプトファイルについて¶
EXEC リソースで使用するスクリプトファイルは各サーバ上の下記のディレクトリに配置されます。
/インストールパス/scripts/グループ名/EXECリソース名/
クラスタ構成変更時に下記の変更を行った場合、変更前のスクリプトファイルはサーバ上からは削除されません。
EXEC リソースを削除した場合や EXEC リソース名を変更した場合
EXEC リソースが所属するグループを削除した場合やグループ名を変更した場合
変更前のスクリプトファイルが必要ない場合は、削除しても問題ありません。
6.5.22. 活性時監視設定のモニタリソースについて¶
活性時監視設定のモニタリソースの一時停止/再開には下記の制限事項があります。
モニタリソースの一時停止後、監視対象リソースを停止させた場合モニタリソースは 停止状態となります。そのため、監視の再開はできません。
モニタリソースを一時停止後、監視対象リソースを停止/起動させた場合、監視対象リソースが起動したタイミングで、モニタリソースによる監視が開始されます。
6.5.23. Cluster WebUI について¶
接続先と通信できない状態で操作を行うと、制御が戻ってくるまでしばらく時間が必要な場合があります。
Proxy サーバを経由する場合は、Cluster WebUI のポート番号を中継できるように、Proxy サーバの設定をしてください。
Reverse Proxy サーバを経由する場合、Cluster WebUI は正常に動作しません。
- CLUSTERPRO のアップデートを行った場合、起動している全てのブラウザを一旦終了してください。ブラウザ側のキャッシュをクリアして、ブラウザを起動してください。
本製品より新しいバージョンで作成されたクラスタ構成情報は、本製品で利用することはできません。
Web ブラウザを終了すると (ウィンドウフレームの [X] 等)、確認ダイアログが表示される場合があります。
設定を続行する場合は [ページに留まる] を選択してください。
Web ブラウザをリロードすると (メニューの [最新の情報に更新] やツールバーの [現在のページを再読み込み] 等)、確認ダイアログが表示される場合があります。
設定を続行する場合は [ページに留まる] を選択してください。
上記以外の Cluster WebUI の注意制限事項についてはオンラインマニュアルを参照してください。
6.5.24. ミラーディスク、ハイブリッドディスクリソースのパーティションサイズ変更¶
運用を開始した後で、ミラーパーティションのサイズを変更したい場合は、『メンテナンスガイド』の「保守情報」の「ミラーディスクリソースのパーティションのオフセットやサイズを変更する」を参照してください。
6.5.25. カーネルダンプの設定変更について¶
- Red Hat Enterprise Linux 6 等にて、クラスタが稼働している状態で、「カーネルダンプの設定」 (system-config-kdump) で kdump の設定を変更して「適用」しようとすると、以下の様なエラーメッセージが出る場合があります。この様な場合は一旦、クラスタの停止(ミラーディスクリソースやハイブリッドディスクリソースを使用している場合には、クラスタの停止とミラーエージェントの停止)をおこなってから、カーネルダンプの設定を実行してください。※ 下記の {ドライバ名} の部分は、clpka, clpkhb, liscal のいずれかになります。
No module {ドライバ名} found for kernel {カーネルバージョン}, aborting
6.5.26. フローティング IP、仮想 IP リソースについて¶
フローティング IP リソースまたは仮想 IP リソースを設定している場合、これらのリソースが活性しているサーバでネットワーク再起動は実行しないでください。ネットワークを再起動すると各リソースによって追加された IP アドレスが削除されます。
6.5.27. システムモニタリソース、プロセスリソースモニタリソースについて¶
設定内容の変更時にはクラスタサスペンドを行う必要があります。
モニタリソースの遅延警告には対応していません。
動作中に OS の日付/時刻を変更した場合、10分間隔で行っている解析処理のタイミングが日付/時刻変更後の最初の一回だけずれてしまいます。以下のようなことが発生するため、必要に応じてクラスタのサスペンド・リジュームを行ってください。
異常として検出する経過時間を過ぎても、異常検出が行われない。
異常として検出する経過時間前に、異常検出が行われる。
システムモニタリソースのディスクリソース監視機能で同時に監視できる最大のディスク数は64台です。
6.5.28. JVM モニタリソースについて¶
監視対象のJava VMを再起動する場合はクラスタサスペンドするか、クラスタ停止を行った後に行ってください。
設定内容の変更時にはクラスタサスペンドを行う必要があります。
モニタリソースの遅延警告には対応していません。
6.5.29. HTTP モニタリソースについて¶
HTTPモニタリソースでは以下いずれかのOpenSSLの共有ライブラリのシンボリックリンクを利用しています。
libssl.so
libssl.so.1.1 (OpenSSL 1.1.1 の共有ライブラリ)
libssl.so.10 (OpenSSL 1.0の共有ライブラリ)
- libssl.so.6 (OpenSSL 0.9の共有ライブラリ)
OSのディストリビューションやバージョン、およびパッケージのインストール状況によっては、上記のシンボリックリンクが存在しない場合があります。HTTP モニタリソースでは、上記のシンボリックリンクが見つけられない場合は、以下のようなエラーが発生します。Detected an error in monitoring <Monitor Resource Name>. (1 :Can not found library. (libpath=libssl.so, errno=2))
このため、上記のエラーが発生した場合は、/usr/lib または /usr/lib64 配下などに上記のシンボリックリンクが存在しているか確認をお願いします。また、上記のシンボリックリンクが存在しない場合は、下記のコマンド例のようにシンボリックリンク libssl.so を作成頂きますようお願いします。
コマンド例:cd /usr/lib64 # /usr/lib64 へ移動 ln -s libssl.so.1.0.1e libssl.so # シンボリックリンクの作成
6.5.30. AWS 環境における AMI のリストアについて¶
AWS 仮想 IP リソースや AWS Elastic IP リソースやAWS セカンダリ IP リソースの [ENI ID] にプライマリネットワークインターフェイスの ENI ID を設定している場合、AMI などからのリストア時には、AWS 仮想 IP リソースや AWS Elastic IP リソースやAWS セカンダリ IP リソースの設定を変更する必要があります。なお、セカンダリネットワークインターフェイスの ENI ID を設定している場合、AMI などからのリストア時にはデタッチ/アタッチ処理によって同一 ENI ID の引き継ぎが可能なため、AWS 仮想 IP リソースや AWS Elastic IP リソースやAWS セカンダリ IP リソースの再設定は不要です。
6.6. CLUSTERPROの構成変更時¶
クラスタとして運用を開始した後に構成を変更する場合に発生する事象で留意して頂きたい事項です。
6.6.1. グループ共通プロパティの排他ルールについて¶
6.6.2. リソースプロパティの依存関係について¶
6.6.3. ディスクリソースの削除について¶
ディスクリソースを削除した場合、該当デバイスが Read Only となることがあります。
clprosetコマンドを使用して該当デバイスを Read Write の状態にしてください。
6.6.4. 外部連携モニタリソースのクラスタ統計情報の設定について¶
モニタリソースのクラスタ統計情報の設定を変更した場合、サスペンド・リジュームを実行しても外部連携モニタリソースにはクラスタ統計情報の設定が反映されません。外部連携モニタリソースにもクラスタ統計情報の設定を反映させる場合は、OS の再起動を行ってください。
6.6.5. ポート番号の変更について¶
サーバのファイアウォールを有効にしており、ポート番号を変更した場合、ファイアウォールの設定の変更が必要です。clpfwctrlコマンドでファイアウォールの設定を行うことができます。詳細は『リファレンスガイド』 - 「CLUSTERPRO コマンドリファレンス」 - 「ファイアウォールの規則を追加する (clpfwctrlコマンド)」を参照してください。
6.7. CLUSTERPROバージョンアップ時¶
クラスタとして運用を開始した後にCLUSTERPRO をバージョンアップ(アップグレードまたはアップデート)する際に留意して頂きたい事項です。
6.7.1. 機能変更一覧¶
各バージョンで変更された機能について、以下に示します。
内部バージョン 4.0.0-1
内部バージョン 4.1.0-1
履歴ファイル格納ディレクトリ
履歴ファイルサイズ制限
※アップデート直後はこれらの設定値は空白となっています。この場合、「履歴ファイル格納ディレクトリ」はCLUSTERPROをインストールしたディレクトリ、「履歴ファイルサイズ制限」は無制限として取り扱います。
本設定値については『リファレンスガイド』の「グループリソースの詳細」、「ミラーディスクリソースを理解する」を参照してください。
システムモニタリソースについて
システムモニタリソース内で設定していた「System Resource Agent プロセス設定」 部分を新規モニタリソースとして分離しました。「System Resource Agent プロセス設定」で監視設定を行っている場合、本監視の設定は無効となります。アップデート後も本監視を継続する場合は、アップデート後に新規にプロセスリソースモニタリソースを登録し、監視設定を行ってください。プロセスリソースモニタリソースの監視設定の詳細は『リファレンスガイド』の「モニタリソースの詳細」、「プロセスリソースモニタリソースを理解する」を参照してください。
内部バージョン 4.2.0-1
内部バージョン 4.3.0-1
内部バージョン 5.0.0-1
内部バージョン 5.1.0-1
6.7.2. 機能削除一覧¶
各バージョンで削除された機能について、以下に示します。
重要
内部バージョン 4.0.0-1
機能
対処
WebManager Mobile
OracleASモニタリソース
内部バージョン 5.0.0-1
機能
対処
WebManager/Builder
COMハートビートリソース
[クラスタプロパティ] - [インタコネクトタブ] を開き、タイプが [不明] と表示されているハートビート I/F を削除してください。
仮想マシングループを含んだ「ホストクラスタ用の構成情報」は移行できません。
BMC連携機能
関連する外部連携モニタリソースを削除してください。
High-End Server Option
回復動作「IO Fencing(High-End Server Option)」
監視方法「ipmi(High-End Server Option)」
BMC モニタリソース
Oracle Clusterware 同期管理モニタリソース
High-End Server Option の機能を使用した構成情報は移行できません。
-
-
-
-
-
ディスク I/O 閉塞デバイス
-
DISK ハートビート RAW デバイス
-
IBM POWER、IBM POWER LE は対応していません。
NASリソース
-
Sybaseモニタリソース
-
VXVM連携機能
ディスクリソース - ディスクタイプ(VXVM)ボリュームマネージャリソース - ボリュームマネージャ(VXVM)ディスクモニタリソース - 監視方法 (READ (VXVM))ボリュームマネージャモニタリソース - ボリュームマネージャ(VXVM)VxVM 連携機能を利用した構成情報は移行できません。
6.7.3. パラメータ削除一覧¶
Cluster WebUI で設定可能なパラメータのうち、各バージョンで削除されたものについて、以下の表に示します。
内部バージョン 4.0.0-1
クラスタ
パラメータ
既定値
クラスタのプロパティ
アラートサービスタブ
アラート拡張機能を使用する
オフ
WebManager タブ
WebManager Mobile の接続を許可する
オフ
WebManager Mobile 用パスワード
操作用パスワード
-
参照用パスワード
-
JVM モニタリソース
パラメータ
既定値
JVMモニタリソースのプロパティ
監視 (固有) タブ
メモリタブ ([JVM種別]に [Oracle Java]選択時)
仮想メモリ使用量を監視する
2048 [MB]
メモリタブ ([JVM種別]に [Oracle JRockit]選択時)
仮想メモリ使用量を監視する
2048 [MB]
メモリタブ ([JVM種別]に [Oracle Java(usage monitoring)]選択時)
仮想メモリ使用量を監視する
2048 [MB]
内部バージョン 4.1.0-1
クラスタ
パラメータ
既定値
クラスタのプロパティ
WebManager タブ
WebManager 調整プロパティ
動作タブ
アラートビューア最大レコード数
300
クライアントデータ更新方法
Real Time
内部バージョン 5.0.0-1
クラスタ
パラメータ
既定値
クラスタのプロパティ
インタコネクトタブ
[サーバ] 列 COM デバイス
DISK ハートビートのプロパティ
Raw デバイス
アラートサービスタブ
筐体 ID ランプ連携を使用する
オフ
筐体 ID ランプ点滅コマンド
-
インターバル
-
拡張タブ
仮想マシン強制停止設定 仮想マシン管理ツール
vCenter
仮想マシン強制停止設定 コマンド
/usr/lib/vmware-vcli/apps/vm/vmcontrol.pl
強制停止スクリプトを使用する
オフ
サーバのプロパティ
情報タブ
仮想マシン
オフ
種類
vSphere
BMCタブ
強制停止コマンドライン
-
筐体IDランプ 点滅 / 消灯
-
BMC (High-End Server Option) タブ
IPアドレス
-
ディスクI/O閉塞 タブ
I/F 番号 (追加、削除)
I/F 追加順
デバイス (編集)
-
PCIスロット閉塞 (High-End Server Option) タブ
PCIスロット1 - PCIスロット16
オフ
内部バージョン 5.0.2-1
ミラーディスクリソース
パラメータ
既定値
ミラーディスクリソースのプロパティ
詳細タブ
ミラーディスクリソース調整プロパティ
高速 SSD タブ
データパーティション
オフ
クラスタパーティション
オフ
ハイブリッドディスクリソース
パラメータ
既定値
ハイブリッドディスクリソースのプロパティ
詳細タブ
ハイブリッドディスクリソース調整プロパティ
高速 SSD タブ
データパーティション
オフ
クラスタパーティション
オフ
内部バージョン 5.1.0-1
仮想 IP リソース
パラメータ
既定値
仮想 IP リソースのプロパティ
詳細タブ
仮想 IP リソース調整プロパティ
RIP タブ
ネクストホップ IP アドレス
-
6.7.4. 既定値変更一覧¶
Cluster WebUI で設定可能なパラメータのうち、各バージョンで既定値が変更されたものについて、以下の表に示します。
バージョンアップ後も [変更前の既定値] の設定を継続したい場合は、バージョンアップ後に改めてその値に再設定してください。
[変更前の既定値] 以外の値を設定していた場合、バージョンアップ後もそれ以前の設定値が継承されます。再設定の必要はありません。
内部バージョン 4.0.0-1
クラスタ
パラメータ
変更前の既定値
変更後の既定値
クラスタのプロパティ
監視タブ
監視方法
softdog
keepalive
JVM監視タブ
最大Javaヒープサイズ
7 [MB]
16 [MB]
Execリソース
パラメータ
変更前の既定値
変更後の既定値
Exec リソースのプロパティ
依存関係タブ
既定の依存関係に従う
ディスクリソース
パラメータ
変更前の既定値
変更後の既定値
ディスクリソースのプロパティ
依存関係タブ
既定の依存関係に従う
詳細タブ
ディスクリソース調整プロパティ
マウントタブ
タイムアウト
60 [秒]
180 [秒]
xfs_repair タブ([ファイルシステム]に[xfs]選択時)
オン
オフ
NAS リソース
パラメータ
変更前の既定値
変更後の既定値
NAS リソースのプロパティ
依存関係タブ
既定の依存関係に従う
ミラーディスクリソース
パラメータ
変更前の既定値
変更後の既定値
ミラーディスクリソースのプロパティ
依存関係タブ
既定の依存関係に従う
詳細タブ
ミラーディスクリソース調整プロパティ
xfs_repair タブ([ファイルシステム]に[xfs]選択時)
オン
オフ
ハイブリッドディスクリソース
パラメータ
変更前の既定値
変更後の既定値
ハイブリッドディスクリソースのプロパティ
依存関係タブ
既定の依存関係に従う
詳細タブ
ハイブリッドディスクリソース調整プロパティ
xfs_repair タブ([ファイルシステム]に[xfs]選択時)
オン
オフ
ボリュームマネージャリソース
パラメータ
変更前の既定値
変更後の既定値
ボリュームマネージャリソースのプロパティ
依存関係タブ
既定の依存関係に従う
仮想IPモニタリソース
パラメータ
変更前の既定値
変更後の既定値
仮想 IP モニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
30 [秒]
180 [秒]
PIDモニタリソース
パラメータ
変更前の既定値
変更後の既定値
PIDモニタリソースのプロパティ
監視 (共通) タブ
監視開始待ち時間
0 [秒]
3 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
ユーザ空間モニタリソース
パラメータ
変更前の既定値
変更後の既定値
ユーザ空間モニタリソースのプロパティ
監視 (固有) タブ
監視方法
softdog
keepalive
NIC Link Up/Downモニタリソース
パラメータ
変更前の既定値
変更後の既定値
NIC Link Up/Down モニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
60 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
ARPモニタリソース
パラメータ
変更前の既定値
変更後の既定値
ARP モニタリソースのプロパティ
監視 (共通) タブ
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
ダイナミック DNS モニタリソース
パラメータ
変更前の既定値
変更後の既定値
ダイナミックDNSモニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
プロセス名モニタリソース
パラメータ
変更前の既定値
変更後の既定値
プロセス名モニタリソースのプロパティ
監視 (共通) タブ
監視開始待ち時間
0 [秒]
3 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
DB2モニタリソース
パラメータ
変更前の既定値
変更後の既定値
DB2 モニタリソースのプロパティ
監視 (固有) タブ
パスワード
ibmdb2
-
ライブラリパス
/opt/IBM/db2/V8.2/lib/libdb2.so
/opt/ibm/db2/V11.1/lib64/libdb2.soMySQL モニタリソース
パラメータ
変更前の既定値
変更後の既定値
MySQL モニタリソースのプロパティ
監視 (固有) タブ
ストレージエンジン
MyISAM
InnoDB
ライブラリパス
/usr/lib/mysql/libmysqlclient.so.15
/usr/lib64/mysql/libmysqlclient.so.20Oracle モニタリソース
パラメータ
変更前の既定値
変更後の既定値
Oracle モニタリソースのプロパティ
監視 (固有) タブ
パスワード
change_on_install
-
ライブラリパス
/opt/app/oracle/product/10.2.0/db_1/lib/libclntsh.so.10.1
/u01/app/oracle/product/12.2.0/dbhome_1/lib/libclntsh.so.12.1PostgreSQL モニタリソース
パラメータ
変更前の既定値
変更後の既定値
PostgreSQL モニタリソースのプロパティ
監視 (固有) タブ
ライブラリパス
/usr/lib/libpq.so.3.0
/opt/PostgreSQL/10/lib/libpq.so.5.10Tuxedoモニタリソース
パラメータ
変更前の既定値
変更後の既定値
Tuxedo モニタリソースのプロパティ
監視 (固有) タブ
ライブラリパス
/opt/bea/tuxedo8.1/lib/libtux.so
/home/Oracle/tuxedo/tuxedo12.1.3.0.0/lib/libtux.soWebLogic モニタリソース
パラメータ
変更前の既定値
変更後の既定値
WebLogic モニタリソースのプロパティ
監視 (固有) タブ
ドメイン環境ファイル
/opt/bea/weblogic81/samples/domains/examples/setExamplesEnv.sh
/home/Oracle/product/Oracle_Home/user_projects/domains/base_domain/bin/setDomainEnv.shJVM モニタリソース
パラメータ
変更前の既定値
変更後の既定値
JVMモニタリソースのプロパティ
監視 (共通)タブ
タイムアウト
120 [秒]
180 [秒]
フローティングIP モニタリソース
パラメータ
変更前の既定値
変更後の既定値
フローティングIP モニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
60 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
AWS Elastic IP モニタリソース
パラメータ
変更前の既定値
変更後の既定値
AWS Elastic IPモニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
AWS 仮想 IP モニタリソース
パラメータ
変更前の既定値
変更後の既定値
AWS 仮想IPモニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
AWS AZ モニタリソース
パラメータ
変更前の既定値
変更後の既定値
AWS AZモニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
Azure プローブポートモニタリソース
パラメータ
変更前の既定値
変更後の既定値
Azure プローブポートモニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
Azure ロードバランスモニタリソース
パラメータ
変更前の既定値
変更後の既定値
Azure ロードバランスモニタリソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
内部バージョン 4.1.0-1
クラスタ
パラメータ
変更前の既定値
変更後の既定値
クラスタのプロパティ
監視タブ
シャットダウン監視
常に実行する
グループ非活性処理に失敗した場合のみ実行する
内部バージョン 4.2.0-1
AWS Elastic IP モニタリソース
パラメータ
変更前の既定値
変更後の既定値
AWS Elastic IPモニタリソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
AWS 仮想 IP モニタリソース
パラメータ
変更前の既定値
変更後の既定値
AWS 仮想 IPモニタリソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
AWS AZ モニタリソース
パラメータ
変更前の既定値
変更後の既定値
AWS AZモニタリソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
AWS DNS モニタリソース
パラメータ
変更前の既定値
変更後の既定値
AWS DNS モニタリソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
内部バージョン 4.3.0-1
クラスタ
パラメータ
変更前の既定値
変更後の既定値
クラスタのプロパティ
拡張タブ
最大再起動回数
0 [回]
3 [回]
最大再起動回数をリセットする時間
0 [分]
60 [分]
API タブ
通信方式
HTTP
HTTPS
NFS モニタリソース
パラメータ
変更前の既定値
変更後の既定値
NFSモニタリソースのプロパティ
監視 (固有) タブ
NFSバージョン
v2
v4
WebLogic モニタリソース
パラメータ
変更前の既定値
変更後の既定値
WebLogic モニタリソースのプロパティ
監視 (固有) タブ
パスワード
weblogic
なし
内部バージョン 4.3.2-1
ミラーディスクリソース
パラメータ
変更前の既定値
変更後の既定値
ミラーディスクリソースのプロパティ
詳細 タブ
ミラーディスクリソース調整プロパティ
ミラー タブ
初期mkfsを行う
オン
オフ
AWS DNS リソース
パラメータ
変更前の規定値
変更後の規定値
AWS DNS リソースのプロパティ
詳細 タブ
非活性時にリソースレコードセットを削除する
オン
オフ
内部バージョン 5.0.0-1
クラスタ
パラメータ
変更前の既定値
変更後の既定値
クラスタのプロパティ
監視タブ
SIGTERMを有効にする
オフ
オン
Execリソース
パラメータ
変更前の既定値
変更後の既定値
Exec リソースのプロパティ
依存関係タブ
既定の依存関係に従う
ディスクリソース
パラメータ
変更前の既定値
変更後の既定値
ディスクリソースのプロパティ
依存関係タブ
既定の依存関係に従う
ミラーディスクリソース
パラメータ
変更前の既定値
変更後の既定値
ミラーディスクリソースのプロパティ
依存関係タブ
既定の依存関係に従う
ハイブリッドディスクリソース
パラメータ
変更前の既定値
変更後の既定値
ハイブリッドディスクリソースのプロパティ
依存関係タブ
既定の依存関係に従う
ボリュームマネージャリソース
パラメータ
変更前の既定値
変更後の既定値
ボリュームマネージャリソースのプロパティ
依存関係タブ
既定の依存関係に従う
ダイナミック DNS リソース
パラメータ
変更前の既定値
変更後の既定値
ダイナミック DNS リソースのプロパティ
依存関係タブ
既定の依存関係に従う
内部バージョン 5.1.0-1
クラスタ
パラメータ
変更前の既定値
変更後の既定値
クラスタのプロパティ
WebManager タブ
Cluster WebUI の操作ログを出力する
オフ
オン
6.7.5. パラメータ移動一覧¶
Cluster WebUI で設定可能なパラメータのうち、各バージョンで設定箇所が変更されたものについて、以下の表に示します。
内部バージョン 4.0.0-1
変更前の設定箇所
変更後の設定箇所
[クラスタのプロパティ]-[リカバリタブ]-[最大再起動回数]
[クラスタのプロパティ]-[拡張タブ]-[最大再起動回数]
[クラスタのプロパティ]-[リカバリタブ]-[最大再起動回数をリセットする時間]
[クラスタのプロパティ]-[拡張タブ]-[最大再起動回数をリセットする時間]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止機能を使用する]
[クラスタのプロパティ]-[拡張タブ]-[強制停止機能を使用する]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止アクション]
[クラスタのプロパティ]-[拡張タブ]-[強制停止アクション]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[拡張タブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[リカバリタブ]-[仮想マシン強制停止設定]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止スクリプトを実行する]
[クラスタのプロパティ]-[拡張タブ]-[強制停止スクリプトを実行する]
[クラスタのプロパティ]-[リカバリタブ]-[ダウン後自動起動する]
[クラスタのプロパティ]-[拡張タブ]-[ダウン後自動起動する]
[クラスタのプロパティ]-[排他タブ]-[マウント、アンマウントコマンド排他]
[クラスタのプロパティ]-[拡張タブ]-[マウント、アンマウントコマンドを排他する]]
[クラスタのプロパティ]-[リカバリタブ]-[モニタリソース異常時の回復動作を抑制する]
[クラスタのプロパティ]-[拡張タブ]-[クラスタ動作の無効化]-[モニタリソースの異常時の回復動作]
[グループのプロパティ]-[属性タブ]- [フェイルオーバ排他属性]
[グループ共通のプロパティ] -[排他タブ]
内部バージョン 5.0.0-1
変更前の設定箇所
変更後の設定箇所
[クラスタのプロパティ]-[拡張タブ]-[強制停止機能を使用する]
[クラスタのプロパティ]-[フェンシングタブ]-[強制停止]-[タイプ]
[クラスタのプロパティ]-[拡張タブ]-[強制停止アクション]
[BMC強制停止のプロパティ]-[強制停止タブ]-[強制停止アクション]
[クラスタのプロパティ]-[拡張タブ]-[強制停止タイムアウト]
[BMC強制停止のプロパティ]-[強制停止タブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[アクション]
[vCenter強制停止のプロパティ]-[強制停止タブ]-[強制停止アクション]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[タイムアウト]
[vCenter強制停止のプロパティ]-[強制停止タブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[ホスト名]
[vCenter強制停止のプロパティ]-[vCenterタブ]-[ホスト名]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[ユーザ名]
[vCenter強制停止のプロパティ]-[vCenterタブ]-[ユーザ名]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[パスワード]
[vCenter強制停止のプロパティ]-[vCenterタブ]-[パスワード]
[サーバのプロパティ]-[BMCタブ]-[IPアドレス]
[BMC強制停止のプロパティ]-[サーバ一覧タブ]-[BMCの入力]-[IPアドレス]
[サーバのプロパティ]-[BMCタブ]-[ユーザ名]
[BMC強制停止のプロパティ]-[サーバ一覧タブ]-[BMCの入力]-[ユーザ名]
[サーバのプロパティ]-[BMCタブ]-[パスワード]
[BMC強制停止のプロパティ]-[サーバ一覧タブ]-[BMCの入力]-[パスワード]
内部バージョン 5.1.0-1
変更前の設定箇所
変更後の設定箇所
[クラスタのプロパティ]-[監視タブ]-[システムリソース]
[クラスタのプロパティ]-[統計情報タブ]-[システムリソース統計情報]
[クラスタのプロパティ]-[ミラーエージェントタブ]-[統計情報を採取する]
[クラスタのプロパティ]-[統計情報タブ]-[ミラー統計情報]
[クラスタのプロパティ]-[拡張タブ]-[クラスタ統計情報]
[クラスタのプロパティ]-[統計情報タブ]-[クラスタ統計情報]
7. アップグレード手順¶
本章では、CLUSTERPRO のアップデート手順について説明します。
本章で説明する項目は以下の通りです。
7.1. CLUSTERPRO X のアップグレード手順¶
7.1.1. X 3.3/4.x から X 5.1 へのアップグレード¶
まず、以下の注意事項をご確認ください。
本アップグレード手順は CLUSTERPRO X 3.3 for Linux の内部バージョン 3.3.5-1 以降より可能です。
CLUSTERPRO X 4.2 for Linux 以降、CLUSTERPRO が使用するポート番号が追加されました。CLUSTERPRO X 4.1 for Linux 以前のバージョンからアップグレードする場合、事前に必要なポート番号にアクセスできるようにしてください。 CLUSTERPRO が使用するポート番号は、「6.3.1. 通信ポート番号」を参照してください。
ミラーディスクリソース/ハイブリッドディスクリソースを使用している場合、クラスタパーティションのサイズとして 1024MiB 以上の領域が必要になります。また、ミラーディスクリソース/ハイブリッドディスクリソースのフルコピーが必要となります。
ミラーディスクリソース/ハイブリッドディスクリソースを使用している場合、事前にデータのバックアップを取ることを推奨します。バックアップ手順については『インストール&設定ガイド』の「動作チェックを行う」の「バックアップ手順を確認する」、「バックアップ手順を確認する」を参照してください。
CLUSTERPRO Server は rootユーザでアップデートしてください。
参考
同一メジャーバージョン間のアップデート手順は、『アップデート手順書』を参照してください。
以下、CLUSTERPRO X 3.3/4.x for Linux からアップグレードする場合の手順について説明します。
アップデートを開始する前に、クラスタ運用中の各サーバの状態、および全リソースの状態が正常状態であることを Cluster WebUI、WebManager またはコマンドから確認してください。
クラスタ構成情報をバックアップします。クラスタ構成情報は作成時に Cluster WebUI、Builder で保存する他に、clpcfctrl コマンドでバックアップを作成することもできます。詳細は『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」- 「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」 - 「クラスタ構成情報をバックアップする」を参照してください。
クラスタを構成する全サーバで CLUSTERPRO をアンインストールします。アンインストール手順は『インストール&設定ガイド』の「CLUSTERPRO をアンインストール/再インストールする」 - 「アンインストール手順」 - 「CLUSTERPRO Server のアンインストール」を参照してください。
クラスタを構成するサーバで CLUSTERPROを新規インストールします。新規インストール手順は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」および「ライセンスを登録する」を参照してください。
新規インストールしたいずれかのサーバでクラスタ構成情報変換コマンドを実行します。
クラスタ構成情報変換コマンドを実行する作業ディレクトリ(例: /tmp 等) に移動します。
- 移動した作業ディレクトリ配下に、手順 2. でバックアップしたクラスタ構成情報をコピーして配置します。clp.conf および scripts ディレクトを配置してください。
注釈
Cluster WebUI でバックアップした場合、クラスタ構成情報は zip 圧縮されています。zip を解凍すると clp.conf および scripts ディレクトが展開されます。 以下のコマンドを実行し、クラスタ構成情報を変換します。
# clpcfconv.sh -i .
作業ディレクトリ配下にあるクラスタ構成情報(clp.conf) と scripts ディレクトリを zip で圧縮します。
注釈
zipファイルを展開するとclp.confファイルとscriptsディレクトリが解凍されるよう配置してください。
- Cluster WebUI の設定モードを開き、「設定のインポート」をクリックします。手順 5. で生成したクラスタ構成情報(zip) をインポートしてください。
X 3.3 からのアップグレードで、かつ、ミラーリソース/ハイブリッドディスクリソースを使用している場合は、以下を実施してください。
クラスタパーティションとして 1024MiB 以上のサイズのパーティションを準備します。
- ミラーディスクリソース/ハイブリッドディスクリソース用のクラスタパーティションが構成情報と異なる場合は、構成情報を変更します。また、ミラーディスクリソース/ハイブリッドディスクリソースが所属するグループの [プロパティ] の [属性] タブにある [グループ起動属性] が自動起動となっている場合には手動起動に設定します。
ミラーディスクリソースを使用している場合は、各ミラーディスクリソースに対して以下の手順を実行します。
リソースの [プロパティ] の [詳細] タブを開き、[調整] ボタンをクリックして [ミラーディスクリソース調整プロパティ] を表示させます。
[ミラーディスクリソース調整プロパティ] の [ミラー] タブを開き、[初期mkfsを行う] のチェックをオフにします。
強制停止機能または強制停止スクリプトを使用している場合は、以下を実施してください。
- [クラスタのプロパティ] - [フェンシング] タブ - [強制停止] - [タイプ] を設定します。強制停止スクリプトを使用している場合は [カスタム] を選択してください。強制停止スクリプトを使用しておらず、CLUSTERPRO が物理マシン上で動作する場合は [BMC] を、仮想マシン上で動作する場合は [vCenter] を選択してください。
[プロパティ] をクリックして強制停止リソースのプロパティ画面を表示し、各パラメータを設定してください。
Cluster WebUI の「設定の反映」をクリックして構成情報を反映します。
期限付きライセンスを使用している場合は、以下のコマンドを実行します。# clplcnsc --distribute
X 3.3 からのアップグレードで、かつ、ミラーリソース/ハイブリッドディスクリソースを使用している場合は、以下を実施してください。
各ミラーディスクリソース/ハイブリッドディスクリソースに対して、全てのサーバ上で以下のコマンドを実行してください。クラスタパーティションが初期化されます。(ミラーディスクリソースの場合)
# clpmdinit --create force <ミラーディスクリソース名>
(ハイブリッドディスクリソースの場合)
# clphdinit --create force <ハイブリッドディスクリソース名>
Cluster WebUI の操作モードを開き、クラスタを開始します。
X 3.3 からのアップグレードで、かつ、ミラーリソース/ハイブリッドディスクリソースを使用している場合は、以下を実施してください。
ミラーディスクリストから最新情報を保有しているサーバをコピー元として、フルコピーを行います。
グループを起動し、各リソースが正常に起動することを確認します。
手順 8. で [グループ起動属性] の設定を変更した場合は、Cluster WebUI を起動して設定を戻し、[設定の反映] をクリックして クラスタ構成情報をクラスタに反映します。
以上で CLUSTERPRO Server のアップデートは完了です。Cluster WebUI またはclpstat コマンドで、各サーバが、クラスタとして正常に動作していることを確認してください。
8. 用語集¶
- インタコネクト
- クラスタ サーバ間の通信パス(関連) プライベート LAN、パブリック LAN
- 仮想 IP アドレス
遠隔地クラスタを構築する場合に使用するリソース(IP アドレス)
- 管理クライアント
Cluster WebUI が起動されているマシン
- 起動属性
- クラスタ起動時、自動的にフェイルオーバグループを起動するか、手動で起動するかを決定するフェイル オーバ グループの属性管理クライアントより設定が可能
- 共有ディスク
複数サーバよりアクセス可能なディスク
- 共有ディスク型クラスタ
共有ディスクを使用するクラスタシステム
- 切替パーティション
- 複数のコンピュータに接続され、切り替えながら使用可能なディスクパーティション(関連) ディスクハートビート用パーティション
- クラスタシステム
複数のコンピュータを LAN などでつないで、1 つのシステムのように振る舞わせるシステム形態
- クラスタシャットダウン
クラスタシステム全体 (クラスタを構成する全サーバ)をシャットダウンさせること
- クラスタパーティション
- ミラーディスク、ハイブリッドディスクに設定するパーティション。ミラーディスク、ハイブリッドディスクの管理に使用する。(関連) ディスクハートビート用パーティション
- 現用系
- ある 1 つの業務セットについて、業務が動作しているサーバ(関連) 待機系
- セカンダリ (サーバ)
- 通常運用時、フェイルオーバグループがフェイルオーバする先のサーバ(関連) プライマリ (サーバ)
- 待機系
- 現用系ではない方のサーバ(関連) 現用系
- ディスクハートビート用パーティション
共有ディスク型クラスタで、ハートビート通信に使用するためのパーティション
- データパーティション
- 共有ディスクの切替パーティションのように使用することが可能なローカルディスクミラーディスク、ハイブリッドディスクに設定するデータ用のパーティション(関連) クラスタパーティション
- ネットワークパーティション
- 全てのハートビートが途切れてしまうこと(関連) インタコネクト、ハートビート
- ノード
クラスタシステムでは、クラスタを構成するサーバを指す。ネットワーク用語では、データを他の機器に経由することのできる、コンピュータやルータなどの機器を指す。
- ハートビート
- サーバの監視のために、サーバ間で定期的にお互いに通信を行うこと(関連) インタコネクト、ネットワークパーティション
- パブリック LAN
- サーバ / クライアント間通信パスのこと(関連) インタコネクト、プライベート LAN
- フェイルオーバ
障害検出により待機系が、現用系上の業務アプリケーションを引き継ぐこと
- フェイルバック
- あるサーバで起動していた業務アプリケーションがフェイルオーバにより他のサーバに引き継がれた後、業務アプリケーションを起動していたサーバに再び業務を戻すこと
- フェイルオーバグループ
業務を実行するのに必要なクラスタリソース、属性の集合
- フェイルオーバグループの移動
ユーザが意図的に業務アプリケーションを現用系から待機系に移動させること
- フェイルオーバポリシー
フェイルオーバ可能なサーバリストとその中でのフェイルオーバ優先順位を持つ属性
- プライベート LAN
- クラスタを構成するサーバのみが接続された LAN(関連) インタコネクト、パブリック LAN
- プライマリ (サーバ)
- フェイルオーバグループでの基準で主となるサーバ(関連) セカンダリ (サーバ)
- フローティング IP アドレス
- フェイルオーバが発生したとき、クライアントのアプリケーションが接続先サーバの切り替えを意識することなく使用できる IP アドレスクラスタサーバが所属する LAN と同一のネットワークアドレス内で、他に使用されていないホストアドレスを割り当てる
- マスタサーバ
Cluster WebUI の [サーバ共通のプロパティ]-[マスタサーバ] で先頭に表示されているサーバ
- ミラーディスクコネクト
ミラーディスク、ハイブリッドディスクでデータのミラーリングを行うために使用する LAN。プライマリインタコネクトと兼用で設定することが可能。
- ミラーディスクシステム
- 共有ディスクを使用しないクラスタシステムサーバのローカルディスクをサーバ間でミラーリングする