ミッションクリティカルな業務システムを設計する上での考え方について説明します。
今日のミッションクリティカルな業務システムは、計画、非計画に関わらずシステム全体の停止が許されず、24 時間365 日のサービス提供が求められるます。このような可用性に対する厳しい要求に対しては障害など予期せぬ事象による影響を最小限としシステム全体が停止すること(非計画停止)を防ぐこと、およびあらかじめ計画して行うパッチ適用やサーバ増強などを行うためにシステム停止(計画停止)を行う場合の、システムへの影響を最小化することが必要です。
-
非計画停止の極小化
システム構成を設計する時点で、費用に応じてできるだけ構成を多重化、冗長化し障害時のシステム全体の停止を防止します。また障害が発生した場合、障害の早期検出と迅速な復旧が重要となります。またシステムのバックアップ管理も必要となってきます。また障害発生後復旧までの間、性能劣化が許されるのかという点も考慮しなければなりません。例えば複数サーバ(n台)での負荷分散運用を行っている場合、あるノードで障害が発生するとそのノードはシステムから切り離され縮退運転を行うことになりますが、このときn-1台での構成となってしまうためシステムの処理能力が通常時よりダウンすることとなります。これに対応するためにはm台の待機サーバをあらかじめ用意しておきノード障害時に、障害ノードの運用を引き継ぐなどの対応を行うこととなります。
-
計画停止の最小化
ユーザに提供しているサービスを停止することなく、システムのメンテナンス(動的メンテナンス)や拡張(動的拡張)を行えることが重要となります。動的に可能かは、メンテナンスまたは拡張する要素(サーバ、メモリ、CPU 、ディスク、アプリケーションなど)によっても変わります。サービスを停止せざるを得ない場合は停止時間が最小となる構成を考える必要があります。
システムの処理能力の拡張を行うための手法については以下に説明する「スケールアップ」、「スケールアウト」の考え方があります。システムの特性に応じて適切な拡張を行う必要があります。
-
スケールアップ
CPU、メモリ、ディスクなどサーバマシン内のリソースを拡張し処理能力を向上する方法
-
スケールアウト
同様な構成のサーバマシンを追加することにより処理能力を向上する方法
一般的にスケールアウトによる拡張が有効となるのは、全く同様なアプリケーションが複数のサーバで同時に動作し負荷分散が行える場合です。さらにサーバ間の連携が必要ない場合は、n台構成にすることにより1台の場合のほぼn倍の性能を実現することが可能となります。ただし、複数サーバ構成とした時、処理を依頼するクライアントがアクセスするサーバを意識することは好ましくありません。よって、単一のサーバもしくは装置が全クライアントからのリクエストを受け、複数のサーバに処理を振り分ける仕組みが必要となります。データベースサーバのように全く同様なアプリケーションが複数のサーバで同時に実行できない場合などはスケールアップで拡張を行います。
システムを拡張する場合の要件としては以下の要件が挙げられます。システム設計時にこれらの要件が満たされるかどうか検証を行う必要があります。
-
アプリケーションを変更することなく拡張可能なこと
システム運用中に予期しないタイミングでシステムの拡張を行わなければならないことがあります。このときにアプリケーションをいちいち変更していたのでは迅速な対応ができません。アプリケーションに影響を与えることなくシステムの拡張ができることが重要になります。
-
現在動作しているシステムを停止しないでもしくは非常に短い時間で拡張可能なこと
24時間365日連続運転しているシステムにとって、システム拡張を行うために現在運用しているサービスを停止させることがあってはいけません。
スケールアウトによりシステム拡張ができる場合、負荷分散を行うための装置やソフトウェアを利用する構成が一般的になっています。
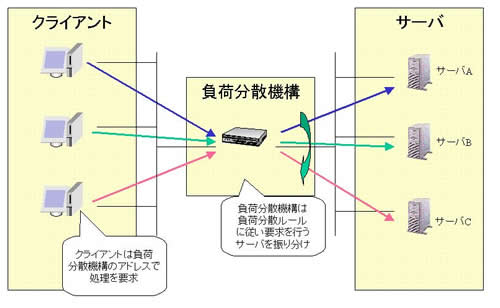
負荷分散機構を用いた代表的な構成は図のようになっています。処理を割り振るルールにはいくつかの方式がありますが、ここではもっとも単純なラウンドロビン方式の例をあげます。クライアントは負荷分散機構に処理をリクエストします。負荷分散機構は、最初のリクエストはサーバA にその次はサーバB に、その次はサーバC にというように、順番にリクエストを割り振ります。これによりクライアントから個別のサーバを隠蔽し、仮想的な巨大なサーバを実現することが可能となります。ただし、負荷分散機構の割り振り先のサーバは同一の処理を行う必要があります。またサーバ間で排他が必要な処理はオーバーヘッドにより負荷分散を用いた処理の処理能力に制限を設けますので、できるだけ避ける必要があります。
次に負荷分散の実現方式について以下に挙げます。
-
ネットワークアドレス変換方式
クライアントは負荷分散装置のIPアドレスに対してリクエストを行い、リクエストを受け取った負荷分散装置が受け取ったパケットのIPアドレスもしくはMACアドレスを負荷分散を行う各サーバのアドレスに書き換え、各サーバに処理要求を行う方式です。この方式は多くの負荷分散装置で実装され特にWebサーバ層の負荷分散方式として用いられます。
-
DNS方式
クライアントはDNSサーバに対して仮想のサーバ名を元にIPアドレスの変換を要求します。DNSサーバで負荷分散機構を有しており、仮想のサーバ名が指定された場合、変換するIPアドレスを振り分けることで負荷分散を実現します。この方式もWebサーバ層の負荷分散として用いられますが障害対策の面で不十分なためこの構成による負荷分散は推奨しません。
-
分散オブジェクト方式
CORBAなどオブジェクトを通してクライアント、サーバ間のリクエスト処理を実装する方式では、クライアントが利用するオブジェクトリファレンス内にリクエストを処理するサーバの情報(サーバ名、ポート番号)が埋め込まれており、クライアントがリクエストを要求した場合、オブジェクト内で指定されているサーバに要求が行われます。クライアントがオブジェクト取得を要求したときに返却するオブジェクトリファレンス内に埋め込まれているサーバ名をラウンドロビンで変更したり、あらかじめ複数のサーバ名が指定されており、クライアントリクエスト要求毎に、要求先のサーバ情報をそのオブジェクト内で指定されているサーバ情報よりラウンドロビンに取得することにより負荷分散を実現します。この機能については主にアプリケーションサーバで用いられます。WebOTXでもアプリケーションサーバの負荷分散にはこの方式を採用しています。
また、負荷分散機構を検討する上で重要なポイントとしては障害時の縮退機能と負荷分散のポリシーです。次に負荷分散のポリシーについて説明します。
-
ラウンドロビン
負荷分散対象のサーバを順々に振り分ける方式です。サーバの処理能力や負荷状態などを考慮しないため、同一構成で個々のサーバの処理能力に差がない場合に用います。
-
重み付けラウンドロビン
あらかじめ予定した割合(重み付け)でサーバに処理を割り振る方式です。個々のサーバの処理能力に差がある場合、処理能力に応じ適切な重み付けを行うことによりサーバ資源を有効に活用することが可能です。
-
動的負荷分散
各サーバの現在の処理状況を判断し、最も処理能力に余裕があるサーバに処理を振り分ける方式です。主に以下の状態を判断材料とします。
-
TCPコネクション数による振り分け
最も少ないコネクションのサーバに処理を要求します。
-
サーバレスポンス時間による振り分け
各サーバにpingなどでレスポンスを取得し、最もレスポンスの短いサーバに処理を要求します。
-
サーバリソース(メモリ、CPU)による振り分け
サーバのリソース使用状況(空きメモリ、CPU使用率)を取得し、最も負荷の少ないサーバに処理を要求します。
負荷分散機構を提供する装置やソフトウェアによって選択できる負荷分散方式やポリシーが異なりますので各製品でどのような負荷分散ができるのか考慮する必要があります。WebOTXのアプリケーションサーバはラウンドロビン、重み付けラウンドロビンの負荷分散を提供しています。
サーバが障害発生時においてもシステムを継続して運用させるためには、サーバを複数台にで構成(クラスタ構成)し、障害のあったサーバの業務を他のサーバで引き継がせる必要があります。クラスタ構成においては次の仕組みが必要となっています。障害を検出する仕組みと、障害発生後、どのようにして業務運用を続行させるかを考慮する必要があります。
-
障害検出
サーバで発生した障害を検出する仕組み
-
フェイルオーバ
稼動系サーバと待機系サーバとで構成されており、稼動系サーバで障害が発生した場合は処理を待機系サーバで引き継ぎ業務運用を続行する
-
縮退運転
障害が発生した場合、該当サーバをシステムから切り離して業務運用を続行する
フェイルオーバを利用したクラスタ構成で、クラスタソフトウェアと連携させることにより実現できます。フェイルオーバ型クラスタでは、ハートビートを利用したサーバ間の相互監視によるサーバマシン自体の障害検出、強制サーバ停止によるシステムの切り替え、グループ管理による、アプリケーションごとのフェイルオーバの3 つの機能により高可用を実現しており、従来から高度な可用性が要求されるシステムで一般的に採用される構成です。
クラスタソフトウェアについて
クラスタソフトウェアと連携したフェイルオーバ型クラスタ構成の一般的な特徴について説明します。詳しくは個々のクラスタソフトウェアの機能を確認してください。
-
フェイルオーバするサービスグループの管理
クラスタソフトウェアはフェイルオーバを行うサービスをグルーピングして管理を行います。同じ管理グループに属するサービスは常に同一のサーバ上で実行されます(管理グループ内のサービスが動作しているサーバがそのグループの稼動系となります)。例えばサービスAとサービスBが同一の管理グループに属する場合、最初はその管理グループの稼動系のサーバで両サービスとも動作することになります。サービスAが異常終了しフェイルオーバする場合、サービスBも一緒にフェイルオーバすることになります。よってフェイルオーバ後は両サービスとも待機系のサーバで動作することになります。またこの管理グループ単位で以下に説明する仮想ホスト名、仮想IPアドレス、 共有ディスクなど、マルチサーバで利用できる共有リソースを使用することができます。クラスタソフトウェアを利用する場合、どのようにサービスをグルーピングするのかを考慮する必要があります。
-
仮想ホスト名、仮想IPアドレス
マルチサーバクラスタ構成において、クライアントがサーバにアクセスするために使用するホスト名もしくはIPアドレスについて、実際に処理を要求するサーバが異なってもそれを意識させない仕組みが必要となります。クラスタソフトウェアでは管理グループ単位で仮想ホスト名、仮想IPアドレスを設定できます。仮想ホスト名、仮想IPアドレスを利用してサーバに要求を行うと、その管理グループが現在動作しているサーバに対して要求が行われます。仮想ホスト名、仮想IPアドレスを利用していると、最初は稼動系のサーバに要求が行われますがフェイルオーバが発生すると、仮想ホスト名、仮想IPアドレスは待機系のサーバに引き継がれます。よってフェイルオーバ後は仮想ホスト名、仮想IPアドレスを利用した要求は待機系のサーバで処理されることになります。
-
共有ディスク
フェイルオーバ型のクラスタ構成において、フェイルオーバ発生時に稼動系から待機系に状態や構成の引き継ぎを行う場合、引き継ぐための情報を格納するためのディスクを提供しています。共有ディスクは管理グループ単位で利用ができ、一般的には稼動系のサーバでアクセス(参照、更新)が行えるようになっています。例えばサービスAの設定ファイルを共有ディスク上に構築することにより、サービスAがフェイルオーバしたとき、待機系ノードでサービスが開始することになりますが、このときに共有ディスク上にある構成情報を参照することにより、稼動系ノードと同じ設定でサービスを開始させることが可能となります。
-
フェイルオーバ制御を行う各種スクリプト
サービスの開始や停止フェイルオーバの発生時などのタイミングでそのサービスに応じた処理を行うためにクラスタソフトウェアではさまざまなタイミングで呼び出される各種スクリプトを提供しています。スクリプトの種類については各クラスタソフトウェアに依存しますが、一般的に提供されているスクリプトについて説明します。
-
開始スクリプト
管理グループがクラスタシステムで開始されるとき、およびフェイルオーバによりフェイルオーバ先のノードでグループが開始に呼び出されます。ここで管理グループに属するサービスの起動などの処理を行います。
-
終了スクリプト
管理グループがクラスタシステムで終了するとき、およびフェイルオーバによりフェイルオーバ元のノードでグループが終了するときに呼び出されます。ここで管理グループに属するサービスの停止などの処理を行います。終了メソッドについてはサーバダウンによるフェイルオーバなどでは呼び出されません。よって必ず終了メソッドが呼ばれることを前提とした作りにしてはいけません。
-
障害監視機能
クラスタソフトウェアはクラスタ管理グループに属するサービスに異常が発生しているかどうかを監視する仕組みを提供しています。障害監視機能の提供する機能についてはクラスタソフトウェアに依存しますが、一般的には定期的にサービス異常が発生していないかチェックし(どのようにチェックを行うかは作り込みとなります)異常が発生した場合どのような処置を行うかを指定します。
-
対象となるサービスをそのノード内で再起動させる
異常が発生したサービスを再起動させることにより運用を続行させます。何回再起動させるかの指定もでき、何回再起動しても復旧しない場合はフェイルオーバさせることができます。
-
管理グループをフェイルオーバさせる
異常が発生したためフェイルオーバによりノード切り替えを行い処理を続行します。
同一処理を行う複数台のマシンの前に負荷分散機構を置く構成です。拡張性を確保するには、できるだけ複数サーバ間の連携をなくす必要があります。負荷分散型クラスタ構成では、高可用で拡張性の高い業務システムが効率的に実現できます。処理要求はフロントの負荷分散機構に対して行われ、負荷分散機構は管理するノードにその処理を割り振ります。障害時には、負荷分散機構が障害が発生したノードを検知し、処理の割り振り先から外します。つまりノードの縮退により可用性を確保しています。この時の障害検知方法は負荷分散機構の機能に依存します。