10. トラブルシューティング¶
本章では、CLUSTERPRO の使用中に発生した障害に対応する方法について説明します。
本章で説明する項目は以下のとおりです。
10.1. 障害発生時の手順¶
本トピックでは、CLUSTERPRO 運用時に障害が発生した場合の手順について説明します。
10.1.1. CLUSTERPRO が起動しない/終了する¶
CLUSTERPRO インストール後、サーバを再起動するとクラスタシステムの運用が開始されますが、クラスタシステムが正常に動作していない場合は、以下を確認してください。
クラスタ構成情報の登録状態
クラスタ構成情報は、クラスタ生成時にクラスタシステムを構築しようとしている全サーバに登録されている必要があります。以下のパスにクラスタ構成情報が存在しない場合、この手順が未実行の可能性があります。確認してください。
/opt/nec/clusterpro/etc/clp.conf
上記パスにクラスタ構成情報が存在しない場合は、『インストール&設定ガイド』の「クラスタ構成情報を作成する」を実行してください。
クラスタ構成情報のサーバ名、IP アドレス
サーバ名、IP アドレスが正当であるか確認してください。(# hostname、# ifconfig....)ライセンスの登録状態
ライセンスが登録されていない可能性があります。クラスタ内の全サーバで以下のコマンドを実行しライセンスが登録されていることを確認してください。
# clplcnsc -l -a
コマンドの詳細については本ガイドの「9.2. CLUSTERPRO コマンド一覧」の「ライセンスを管理する (clplcnsc コマンド)」を参照してください。
また、試用版ライセンスもしくは期限付きライセンスであれば、登録したライセンスが有効期間内であるか確認してください。
CLUSTERPROサービスの起動設定状態
以下のコマンドで CLUSTERPROサービスの起動設定を確認してください。
init.d環境の場合:
# chkconfig --list clusterpro clusterpro 0:off 1:off 2:off 3:on 4:off 5:on 6:off
systemd環境の場合:
# systemctl is-enabled clusterproクラスタプロセスの生存
CLUSTERPRO プロセスが正常に動作しているかコマンドで確認するには、以下のコマンドを実行してください。
# ps -ef | grep clp root 1669 1 0 00:00 ? 00:00:00 clpmonp - event -a 2 -r 0 -w 0 root 1670 1669 0 00:00 ? 00:00:00 clpevent root 1684 1 0 00:00 ? 00:00:00 clpmonp - trnsv -a 2 -r 0 -w 0 root 1685 1684 0 00:00 ? 00:00:00 clptrnsv root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm root 1796 1795 0 00:00 ? 00:00:00 clprc root 1809 1808 0 00:00 ? 00:00:00 clprm root 1813 1812 0 00:00 ? 00:00:00 clpnm root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1820 1813 0 00:00 ? 00:00:00 clpdiskhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb root 1935 1 0 00:00 ? 00:00:00 clpmonp - webmgr -a 2 -o -start -r 0 -w 0 root 1936 1935 0 00:00 ? 00:00:00 clpwebmc -start root 1947 1 0 00:00 ? 00:00:00 clpmonp - webalert -a 2 -r 0 -w 0 root 1948 1947 0 00:00 ? 00:00:00 clpaltd
[ps] コマンドの結果、以下のプロセスの実行状態が確認できれば正常にCLUSTERPRO が動作しています。
イベントプロセスおよびデータ転送プロセス
root 1685 1684 0 00:00 ? 00:00:00 clptrnsv root 1669 1 0 00:00 ? 00:00:00 clpmonp - event root 1670 1669 0 00:00 ? 00:00:00 clpevent root 1684 1 0 00:00 ? 00:00:00 clpmonp - trnsv
イベントプロセスが未起動状態であれば、次項のプロセスマネージャは起動されません。
プロセスマネージャ
root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm
このプロセスの起動により以下のプロセスが生成されるため、クラスタ構成情報 ファイル不正などの異常を検出すれば、CLUSTERPRO は起動しません。
clprcclprmリソース制御プロセス
root 1796 1795 0 00:00 ? 00:00:00 clprc
※ グループリソースが未登録でも起動します。
リソースモニタプロセス
root 1809 1808 0 00:00 ? 00:00:00 clprm
※ モニタリソースが未登録でも起動します。
サーバ管理プロセス
root 1813 1812 0 00:00 ? 00:00:00 clpnm
ハートビートプロセス
root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1820 1813 0 00:00 ? 00:00:00 clpdiskhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb
クラスタ構成情報のハートビートリソースにディスクハートビートリソースを追加していれば、clpdiskhb が起動され、カーネルモード LAN ハートビートリソースを追加していれば、clplankhb が起動されます。
WebManager プロセス
root 1936 1935 0 00:00 ? 00:00:00 clpwebmc - start
Alert プロセス
root 1948 1947 0 00:00 ? 00:00:00 clpaltd
上記、[ps] コマンドでの表示形式は、ディストリビューションによって異なる場合があります。
クラスタプロセスの生存 -Replicator を使用する場合-
CLUSTERPRO プロセスが正常に動作しているかコマンドで確認するには以下の コマンドを実行してください。
# ps -ef | grep clp root 1669 1 0 00:00 ? 00:00:00 clpmonp - event -a 2 -r 0 -w 0 root 1670 1669 0 00:00 ? 00:00:00 clpevent root 1684 1 0 00:00 ? 00:00:00 clpmonp - trnsv -a 2 -r 0 -w 0 root 1685 1684 0 00:00 ? 00:00:00 clptrnsv root 1696 1 0 00:00 ? 00:00:00 clpmonp - mdagent -a 5 -r 0 -w 30 root 1697 1696 0 00:00 ? 00:00:00 clpmdagent root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm root 1796 1795 0 00:00 ? 00:00:00 clprc root 1809 1808 0 00:00 ? 00:00:00 clprm root 1813 1812 0 00:00 ? 00:00:00 clpnm root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb root 1935 1 0 00:00 ? 00:00:00 clpmonp - webmgr -a 2 -o -start -r 0 -w 0 root 1936 1935 0 00:00 ? 00:00:00 clpwebmc -start root 1947 1 0 00:00 ? 00:00:00 clpmonp - webalert -a 2 -r 0 -w 0 root 1948 1947 0 00:00 ? 00:00:00 clpaltd
[ps] コマンドの結果、以下のプロセスの実行状態が確認できれば正常にCLUSTERPRO が動作しています。
イベントプロセス、データ転送プロセスおよびミラーエージェント
root 1696 1 0 00:00 ? 00:00:00 clpmonp --mdagent -a 5 -r 0 -w 30 root 1697 1696 0 00:00 ? 00:00:00 clpmdagent
イベントプロセスが未起動状態であれば、次項のプロセスマネージャは起動されません。
プロセスマネージャ
root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm
このプロセスの起動により以下のプロセスが生成されるため、クラスタ構成情報ファイル不正などの異常を検出すれば、CLUSTERPRO は起動しません。
clprcclprmリソース制御プロセス
root 1796 1795 0 00:00 ? 00:00:00 clprc
※ グループリソースが未登録でも起動します。
リソースモニタプロセス
root 1809 1808 0 00:00 ? 00:00:00 clprm
※ モニタリソースが未登録でも起動します。
サーバ管理プロセス
root 1813 1812 0 00:00 ? 00:00:00 clpnm
ハートビートプロセス
root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb
クラスタ構成情報のハートビートリソースにカーネルモード LAN ハートビートリソースを追加 していれば、clplankhb が起動されます。
WebManager プロセス
root 1936 1935 0 00:00 ? 00:00:00 clpwebmc -start
Alert プロセス
root 1948 1947 0 00:00 ? 00:00:00 clpaltd
上記、[ps] コマンドでの表示形式は、ディストリビューションによって異なる場合があります。
ミラードライバのロード -Replicator を使用する場合-
[lsmod] コマンドを実行します。[lsmod] の実行結果に以下のローダブルモジュールがエントリされていることを確認します。
liscal
カーネルモード LAN ハートビートドライバのロード -カーネルモード LAN ハートビートリソースを使用する場合-
[lsmod] コマンドを実行します。[lsmod] の実行結果に以下のローダブルモジュールがエントリされていることを確認します。
clpkhb
キープアライブドライバのロード - userw ユーザ空間モニタリソース (keepalive) リソースを使用する場合-
[lsmod] コマンドを実行します。[lsmod] の実行結果に以下のローダブルモジュールがエントリされていることを確認します。
clpka
[syslog] からクラスタ正常起動を確認
CLUSTERPRO プロセスが正常に動作しているか syslog で確認するには以下のメッセージを検索してください。
プロセスマネージャの起動確認
<type: pm><event: 1> Starting the cluster daemon...
ハートビートリソースの活性確認
<type: nm><event: 3> Resource lanhb1 of server server1 has started. <type: nm><event: 3> Resource diskhb1 of server server1 has started. <type: nm><event: 1> Server server1 has started. <type: nm><event: 3> Resource diskhb1 of server server2 has started. <type: nm><event: 1> Server server2 has started. <type: nm><event: 3> Resource lanhb1 of server server2 has started.
上記は、クラスタ 2 ノード構成で、ハートビートリソースに以下を指定した場合の メッセージになります。
lanhb1 LAN ハートビートリソースdiskhb1 ディスクハートビートリソースグループリソースの活性確認
<type: rc><event: 10> Activating group grp1 has started. <type: rc><event: 30> Activating fip1 resource has started. <type: rc><event: 31> Activating fip1 resource has completed. <type: rc><event: 30> Activating disk1 resource has started. <type: rc><event: 31> Activating disk1 resource has completed. <type: rc><event: 11> Activating group grp1 has completed.
上記は、グループリソース grp1 が server1 で活性した時のメッセージになります。グループリソースの構成情報は以下になります。
fip1 フローティング IP リソースdisk1 共有ディスクリソースモニタリソースの監視開始確認
<type: rm><event: 1> Monitoring userw has started. <type: rm><event: 1> Monitoring ipw1 has started.
上記は、モニタリソースに以下を指定した場合のメッセージになります。
userw ユーザ空間モニタリソースipw1 IP モニタリソースライセンス整合性チェック確認
製品版
<type: lcns><event: 1> The number of licenses is 2. (Product name:CLUSTERPRO X)
上記は、2CPU のライセンスが登録されている場合のメッセージになります。
試用版
<type: lcns><event: 2> The trial license is valid until yyyy/mm/dd. (Product name:CLUSTERPRO X)
- syslog からクラスタ正常起動を確認 -Replicator を使用する場合-CLUSTERPRO プロセスが正常に動作しているか syslog で確認するには以下のメッセージを検索してください。
ミラーエージェントの起動確認
<type: mdagent><event: 1> Agent has started successfully.
ミラードライバの起動確認
<type: liscal><event: 101> Registered blkdev with major=218.
プロセスマネージャの起動確認
<type: pm><event: 1> Starting the cluster daemon...
ハートビートリソースの活性確認
<type: nm><event: 3> Resource lanhb1 of server server1 has started. <type: nm><event: 1> Server server1 has started. <type: nm><event: 3> Resource lanhb1 of server server2 has started. <type: nm><event: 1> Server server2 has started.
上記は、クラスタ 2 ノード構成で、ハートビートリソースに以下を指定した場合の メッセージになります。
lanhb1 LAN ハートビートリソース
グループリソースの活性確認
<type: rc><event: 10> Activating group grp1 has started. <type: rc><event: 30> Activating fip1 resource has started. <type: rc><event: 31> Activating fip1 resource has completed. <type: rc><event: 30> Activating md1 resource has started. <type: rc><event: 31> Activating md1 resource has completed. <type: rc><event: 11> Activating group grp1 has completed.
上記は、グループリソース grp1 が server1 で活性した時のメッセージになります。グループリソース の構成情報は以下になります。
fip1 フローティング IP リソースmd1 ミラーディスクリソースモニタリソースの監視開始確認
<type: rm><event: 1> Monitoring userw has started. <type: rm><event: 1> Monitoring ipw1 has started. <type: rm><event: 1> Monitoring mdw1 has started. <type: rm><event: 1> Monitoring mdnw1 has started.
上記は、モニタリソースに以下を指定した場合のメッセージになります。
userw ユーザ空間モニタリソースipw1 IP モニタリソースmdw1 ミラーディスクモニタリソースmdnw1 ミラーディスクコネクトモニタリソースライセンス整合性チェック確認
製品版
<type: lcns><event: 1> The number of licenses is 2. (Product name:CLUSTERPRO X)
上記は、2CPU のライセンスが登録されている場合のメッセージになります。
試用版
<type: lcns><event: 2> The trial license is valid until yyyy/mm/dd. (Product name:CLUSTERPRO X)
ディスクの空き容量状態
/opt/nec/clusterpro が属するファイルシステムの空き容量を確認するには、[df] コマンドなどで確認してください。CLUSTERPRO サーバが使用するディスク容量については、『スタートアップガイド』の「CLUSTERPRO の動作環境」を参照してください。
メモリ不足または、OS リソース不足
[top] コマンド、[free] コマンドなどで、OS のメモリ使用状況、CPU 使用率を確認してください。
10.1.2. グループリソース活性/非活性に失敗する¶
グループリソースの活性/非活性時に異常を検出した場合、異常の詳細情報をアラート、syslog に出力します。その情報から異常に対する原因を解析し、対処してください。
- フローティング IP リソース指定した IP アドレスが既にネットワーク上で使用されていないか、間違ったネットワークセグメントの IP アドレスを指定していないか確認してください。その他の異常の詳細情報については、「フローティングIPリソース」を 参照してください。
- ミラーディスクリソース -Replicator を使用する場合-ディスクデバイス、マウントポイントが存在するか、クラスタパーティション、データパーティションが確保されているか確認してください。また、ミラーディスクリソースに指定したファイルシステムが使用可能か確認してください。その他の異常の詳細情報については、「ミラーディスクリソース」を参照してください。
- ハイブリッドディスクリソース -Replicator DR を使用する場合-ディスクデバイス、マウントポイントが存在するか、クラスタパーティション、データパーティションが確保されているか確認してください。また、ハイブリッドディスクリソースに指定したファイルシステムが使用可能か確認してください。その他の異常の詳細情報については、「ハイブリッドディスクリソース」を参照してください。
10.1.3. モニタリソースで異常が発生した¶
モニタリソースにより異常を検出した場合、異常の詳細情報をアラート、syslog に出力します。その情報から異常に対する原因を解析し、対処してください。
- IP モニタリソースによる異常検出時[ping] コマンドによるパケット送信が可能か、別ネットワークセグメントであればルーティングされているか確認してください。その他の異常の詳細情報については、「IP モニタリソース」を参照してください。
- ディスクモニタリソースによる異常検出時ディスクデバイスが存在するか、共有ディスクであれば SCSI ケーブル、Fibre ケーブルが断線していないか確認してください。その他の異常の詳細情報については、「ディスクモニタリソース」を参照してください。
- PID モニタリソースによる異常検出時監視対象であるプロセスが存在するか [ps] コマンドなどで確認してください。その他の異常の詳細情報については、「PID モニタリソース」を参照してください。
- ユーザ空間モニタリソース(監視方法 softdog)による異常検出時"初期化異常" を検出した場合、OSの [insmod] コマンドを使用して、softdog ドライバをロード可能か確認してください。また"サーバリセット"が発生した場合は、ユーザ空間の負荷状況を確認してください。その他の異常の詳細情報については、「ユーザ空間モニタリソース」を参照してください。
- ミラーディスクモニタリソースによる異常検出時-Replicator を使用する場合-ディスクデバイスが存在するか、クラスタパーティション、データパーティションが確保されているか確認してください。またミラーエージェントが起動しているか確認してください。その他の異常の詳細情報については、「ミラーディスクモニタリソース」を参照してください。
- ミラーディスクコネクトモニタリソースによる異常検出時-Replicator を使用する場合-ミラーディスクコネクトが接続されているか確認してください。またミラーエージェントが起動しているか確認してください。その他の異常の詳細情報については、「ミラーディスクコネクトモニタリソース」を参照してください。
- ハイブリッドディスクモニタリソースによる異常検出時-Replicator DR を使用する場合-ディスクデバイスが存在するか、クラスタパーティション、データパーティションが確保されているか確認してください。またミラーエージェントが起動しているか確認してください。その他の異常の詳細情報については、「ハイブリッドディスクモニタリソース」を参照してください。
- ハイブリッドディスクコネクトモニタリソースによる異常検出時-Replicator DR を使用 する場合-ミラーディスクコネクトが接続されているか確認してください。またミラーエージェントが起動しているか確認してください。その他の異常の詳細情報については、「ハイブリッドディスクコネクトモニタリソース」を参照してください。
- NIC Link Up/Down モニタリソースによる異常検出時ネットワーク機器とのリンク状態を確認してください。その他の異常の詳細については、「NIC Link Up/Down モニタリソース」を参照してください。
10.1.4. ハートビートのタイムアウトが発生した¶
サーバ間のハートビートでタイムアウトが発生する原因は、以下のことが考えられます。
原因 |
対処 |
|---|---|
LAN/ディスクケーブルの断線 |
ディスクについては、ケーブルの接続状態を確認してください。
LAN については、ping によるパケット送信が可能か確認してください。
|
ユーザ空間の高負荷状態による誤認 |
長時間 OS に負荷をかけるアプリケーションを実行する場合は、あらかじめ以下のコマンドを実行し、ハートビートタイムアウトを延長してください。
# clptoratio -r 3 -t 1d上記コマンドは、ハートビートタイムアウト値を 3倍に延長し、その値を 1 日間保持します。
|
10.1.5. ネットワークパーティションが発生した¶
ネットワークパーティションは、サーバ間の通信経路が全て遮断されたことを意味します。ここではネットワークパーティションが発生した場合の確認方法を示します。以下の説明では、クラスタ 2 ノード構成でハートビートリソースに LAN、カーネルモード LAN、ディスクを登録した場合の例で説明します。
全ハートビートリソースが正常な状態である (つまりネットワークパーティションが発生していない) 場合、[clpstat] コマンドの実行結果は以下のとおりです。
[server1でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 [on server0 : Online] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : o o o o o server1 : o o o o o [on server1 : Online] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : o o o o o server1 : o o o o o =================================================================
[server2でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster server0 : server1 *server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 [on server0 : Online] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : o o o o o server1 : o o o o o [on server1 : Online] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : o o o o o server1 : o o o o o =================================================================
ネットワークパーティションが発生している場合、[clpstat] コマンドの実行結果は以下のとおりです。両サーバとも相手サーバがダウンした状態であると認識しています。
[server1でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 [on server0 : Caution] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : o o o o o server1 : x x x x x [on server1 : Offline] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : - - - - - server1 : - - - - - =================================================================
[server2でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster server0 : server1 *server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 [on server0 : Offline] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : - - - - - server1 : - - - - - [on server1 : Caution] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : x x x x x server1 : o o o o o =================================================================
このように、ネットワークパーティションが発生している場合、ただちに両サーバをシャットダウンしてください。その上で、各ハートビートリソースについて、以下のことを確認してください。
LAN ハートビートリソース
LAN ケーブルの状態
ネットワークインターフェイスの状態
カーネルモード LAN ハートビートリソース
LAN ケーブルの状態
ネットワークインターフェイスの状態
ディスクハートビートリソース
ディスクケーブルの状態
ディスクデバイスの状態
ネットワークパーティションが発生した状態から、インタコネクト LAN が復帰した場合、CLUSTERPRO はサーバをシャットダウンさせます。
CLUSTERPRO は、複数のサーバで同じグループが活性しているのを検出するとサーバをシャットダウンさせます。同じグループを活性している全てのサーバがシャットダウンします。
Replicator の場合、サーバをシャットダウンさせるときのタイミングにより、サーバ再起動後にミラーディスクリソースの状態が異なる場合があります。
サーバをシャットダウンさせるときのタイミングによって、強制ミラー復帰が必要な状態、ミラー復帰が必要な状態、正常状態の場合があります。
10.1.6. 全インタコネクト LAN 断線が発生した¶
両サーバ間の全てのインタコネクト (LAN ハートビートリソース、カーネルモード LAN ハートビートリソース) が切断された場合のステータスの確認方法を示します。以下の説明では、クラスタ 2 ノード構成でハートビートリソースに LAN、ディスクを登録した場合の例で説明します。(Replicator ではディスクは登録できません。)
全てのインタコネクトが切断され、ディスクが正常な場合、[clpstat] コマンドの実行結果は以下のとおりです。両サーバとも相手サーバが動作中であると認識しています。
[server1でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 [on server0 : Caution] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : o o o o o server1 : x x x x o [on server1 : Caution] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : - - - - - server1 : - - - - - =================================================================
[server2でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster server0 : server1 *server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 [on server0 : Caution] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : - - - - - server1 : - - - - - [on server1 : Caution] HB 0 1 2 3 4 ----------------------------------------------------------------- server0 : x x x x o server1 : o o o o o =================================================================
このように、全てのインタコネクトが切断されている場合、ディスクハートビートでの通信ができるため、フェイルオーバは発生しません。
しかし、インタコネクトを使用して通信するコマンドは使用できなくなるため、インタコネクトの 早急な復旧が必要となります。
各ハートビートリソースについて、以下のことを確認してください。
LAN ハートビートリソース
LAN ケーブルの状態
ネットワークインターフェイスの状態
カーネルモード LAN ハートビートリソース
LAN ケーブルの状態
ネットワークインターフェイスの状態
Replicator でインタコネクトとミラーディスクコネクトが兼用されている場合、インタコネクト (ミラーディスクコネクト) が切断されることによりミラーブレイクが発生します。インタコネクト復旧後、ミラー復帰を実行してください。
10.1.8. ミラーディスクを手動で mount する¶
CLUSTERPRO が障害などで起動できない場合に、ミラーディスクを手動で mount する場合には以下の手順を実行します。
10.1.9. ミラーリング可能な状態で正常に mount するには¶
CLUSTERPRO デーモンが起動不可能で、ミラーエージェント(CLUSTERPRO データミラーデーモン)が起動可能な場合の手順です。
mount したいサーバ上で以下のコマンドを実行します。
clpmdctrl --active <ミラーディスクリソース名(例:md1)>
ミラーディスクリソースのマウントポイントへのアクセスが可能になります。write したデータは相手サーバにミラーリングされます。
10.1.10. ミラーリング不可能な状態で強制的に mount するには¶
CLUSTERPRO デーモンが起動不可能で、ミラーエージェント(CLUSTERPRO データミラーデーモン)も起動不可能な場合に、ミラーディスク上のデータを保存するための手順です。
ただし、そうなる直前までミラーが正常状態にあったか、またはどちらのサーバが最新のデータを持っているかがわかっていることが条件となります。
- Server 1、Server 2ともにCLUSTERPROデーモンが起動できない状態です。Server 1が最新データをもっていることが分かっています。各サーバで以下のコマンドを実行し、CLUSTERPROサービスが起動しないように設定します。
clpsvcctrl.sh --disable -a
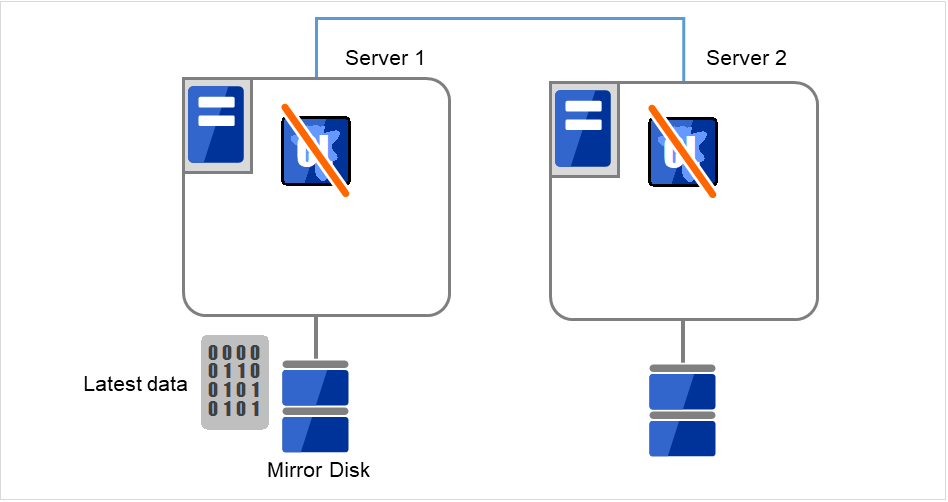
図 10.1 ミラーディスク上のデータ保存 (1)¶
最新のデータを持っているサーバ、または最後にミラーディスクリソースを活性したサーバ上で、[reboot] コマンドを使用して再起動します。もう一方のサーバは [shutdown] コマンドを使用してシャットダウンします。
ここでは、最新データをもっているServer 1を再起動、そうでないServer 2をシャットダウンします。
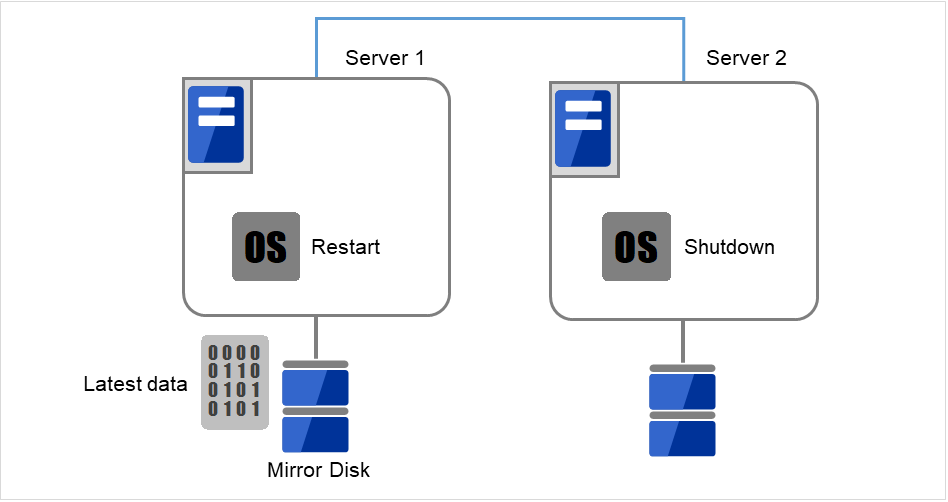
図 10.2 ミラーディスク上のデータ保存 (2)¶
[mount] コマンドを実行して、ミラーディスク上のデータパーティションを read-only でマウントします。
(例) mount -r -t ext3 /dev/sdb5 /mnt
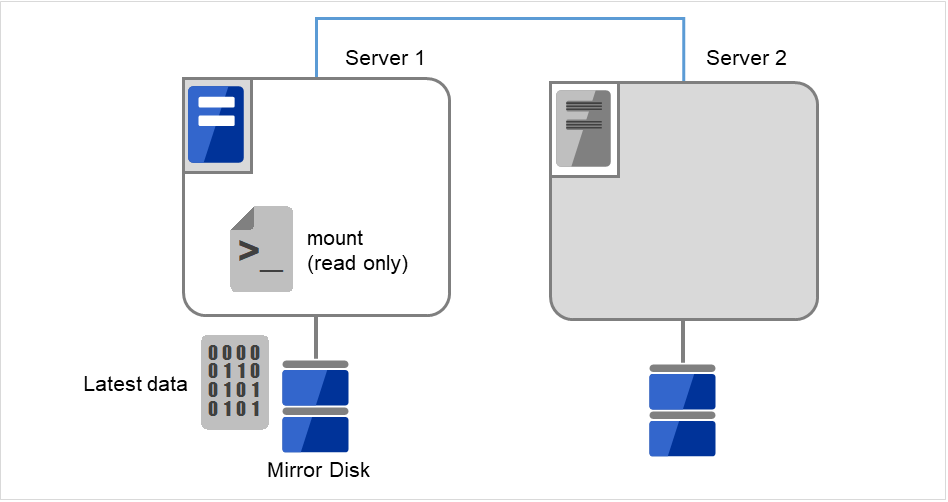
図 10.3 ミラーディスク上のデータ保存 (3)¶
データパーティション内のデータをテープなどにバックアップします。
Server 1にバックアップ装置(Backup device)を接続し、tarやcpioなどのコマンドを使って、データパーティション内のデータをバックアップします。
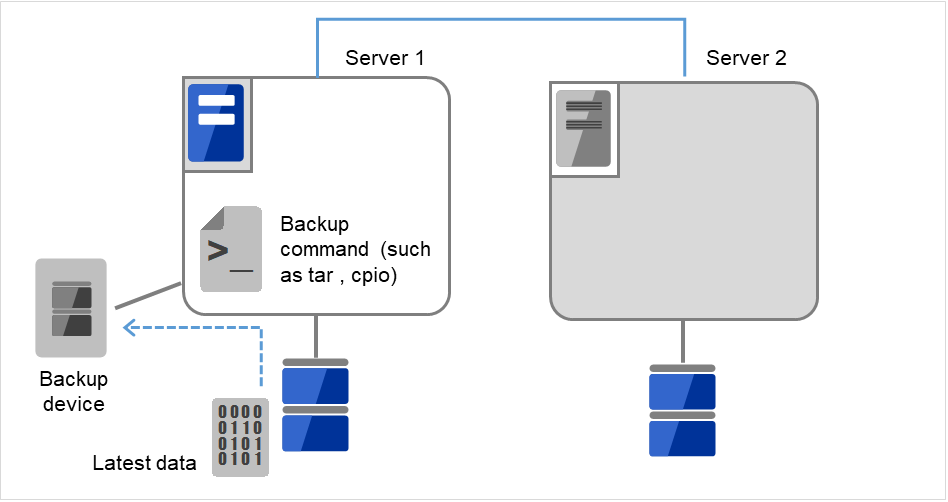
図 10.4 ミラーディスク上のデータ保存 (4)¶
マウントしたデータパーティションをアンマウントします。
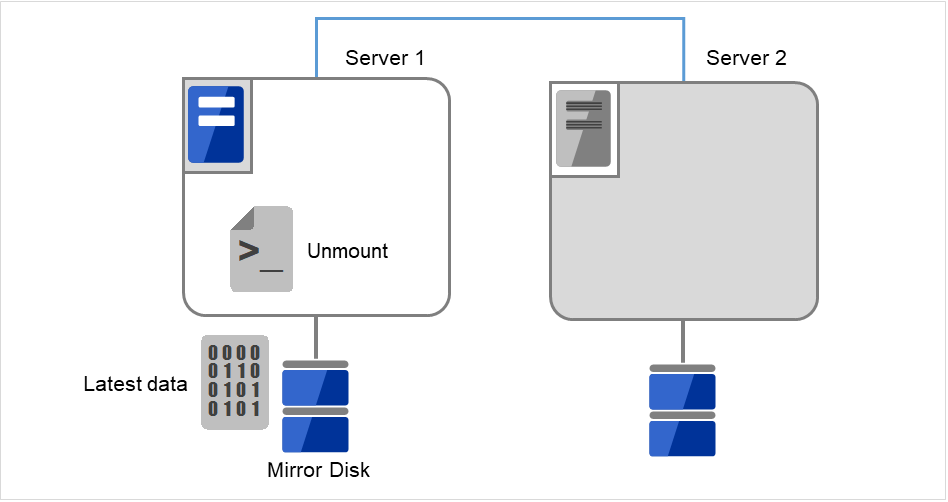
図 10.5 ミラーディスク上のデータ保存 (5)¶
10.1.11. ハイブリッドディスクを手動で mount する¶
CLUSTERPROが障害などで起動できない場合に、ハイブリッドディスクを手動でmountする場合には以下の手順を実行します。
10.1.12. ミラーリング可能な状態で正常に mount するには¶
CLUSTERPRO デーモンが起動不可能で、ミラーエージェント(CLUSTERPRO データミラーデーモン)が起動可能な場合の手順です。
mount したいサーバ上で以下のコマンドを実行します。
clphdctrl --active <ハイブリッドディスクリソース名(例:hd1)>
ハイブリッドディスクリソースのマウントポイントへのアクセスが可能になります。write したデータは相手サーバグループにミラーリングされます。
10.1.13. ミラーリング不可能な状態で強制的に mount するには¶
CLUSTERPRO デーモンが起動不可能で、ミラーエージェント(CLUSTERPRO データミラーデーモン)も起動不可能な場合に、ハイブリッドディスク上のデータを保存するための手順です。
ただし、そうなる直前までミラーが正常状態にあったか、またはどちらのサーバが最新のデータを持っているかがわかっていることが条件となります。
- いずれのサーバもCLUSTERPROデーモンが起動できない状態です。Server 1が最新データをもっていることが分かっています。各サーバでコマンドを実行し、CLUSTERPROサービスが起動しないように設定します。
clpsvcctrl.sh --disable -a
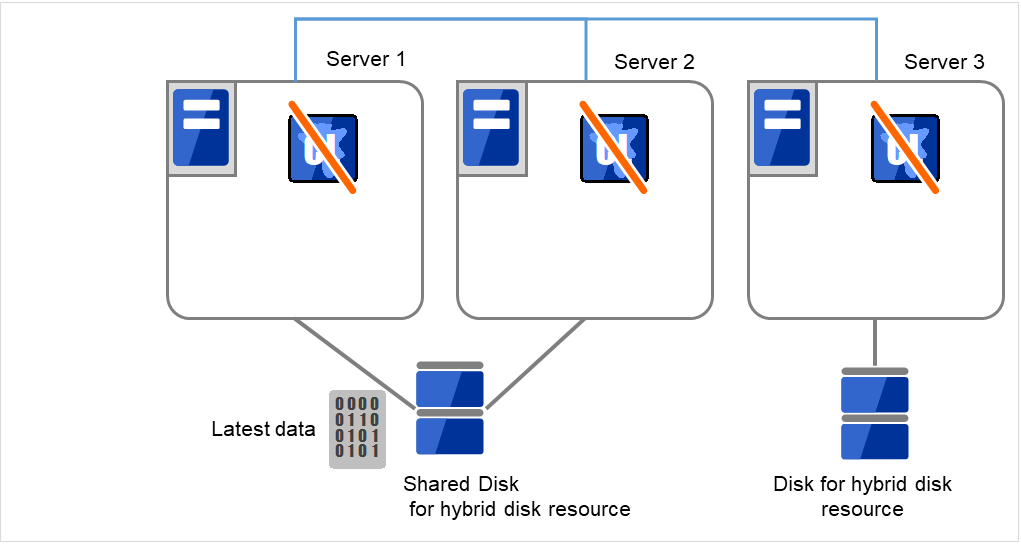
図 10.6 ハイブリッドディスク上のデータ保存 (1)¶
- 最新のデータを持っているサーバ、または最後にハイブリッドディスクリソースを活性したサーバ上で、[reboot] コマンドを使用して再起動します。他のサーバは [shutdown] コマンドを使用してシャットダウンします。
ここでは、最新データをもっているServer 1を再起動、そうでないServer 2およびServer 3をシャットダウンします。
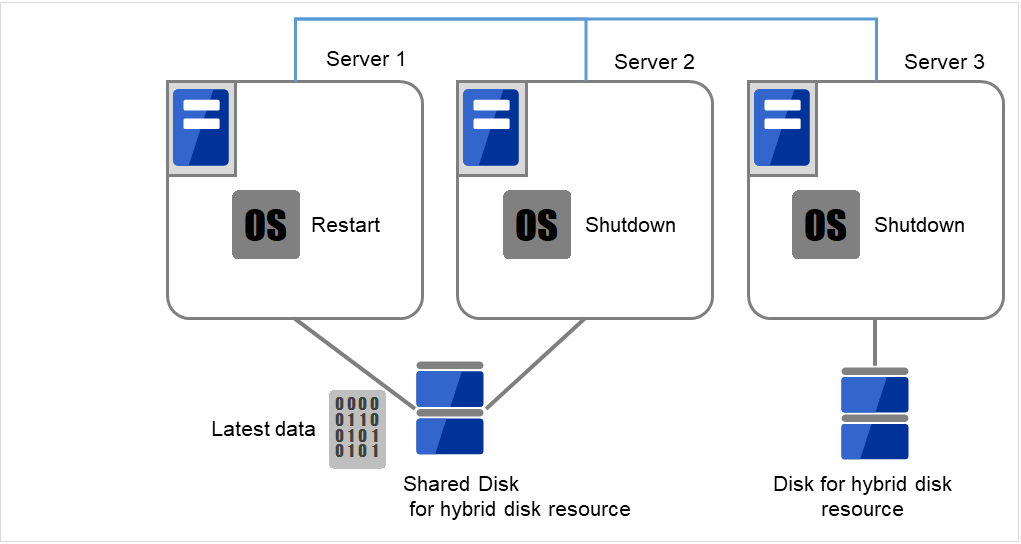
図 10.7 ハイブリッドディスク上のデータ保存 (2)¶
[mount] コマンドを実行して、ハイブリッドディスク上のデータパーティションを read-onlyでマウントします。
(例)
mount -r -t ext3 /dev/sdb5 /mnt
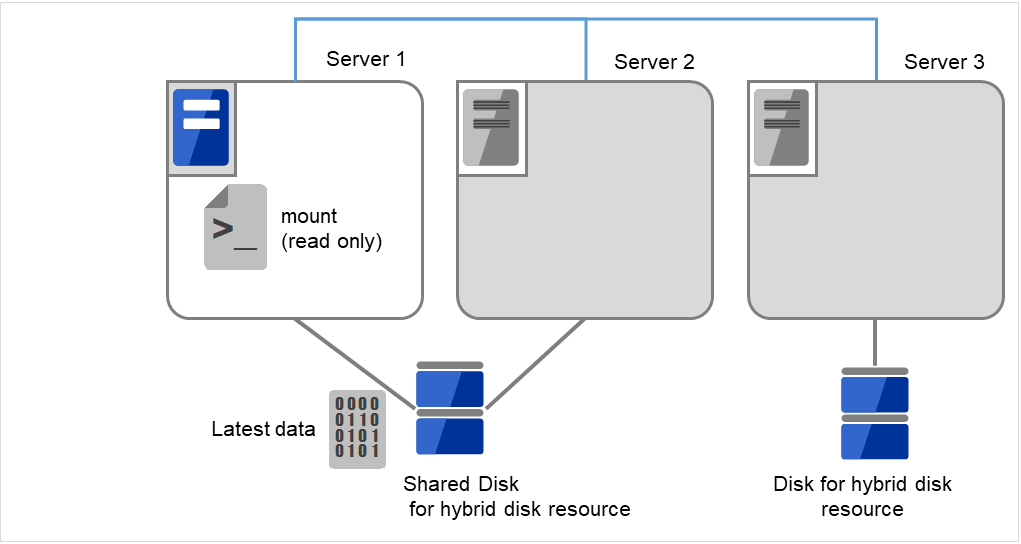
図 10.8 ハイブリッドディスク上のデータ保存 (3)¶
データパーティション内のデータをテープなどにバックアップします。
Server 1にバックアップ装置(Backup device)を接続し、tarやcpioなどのコマンドを使って、データパーティション内のデータをバックアップします。
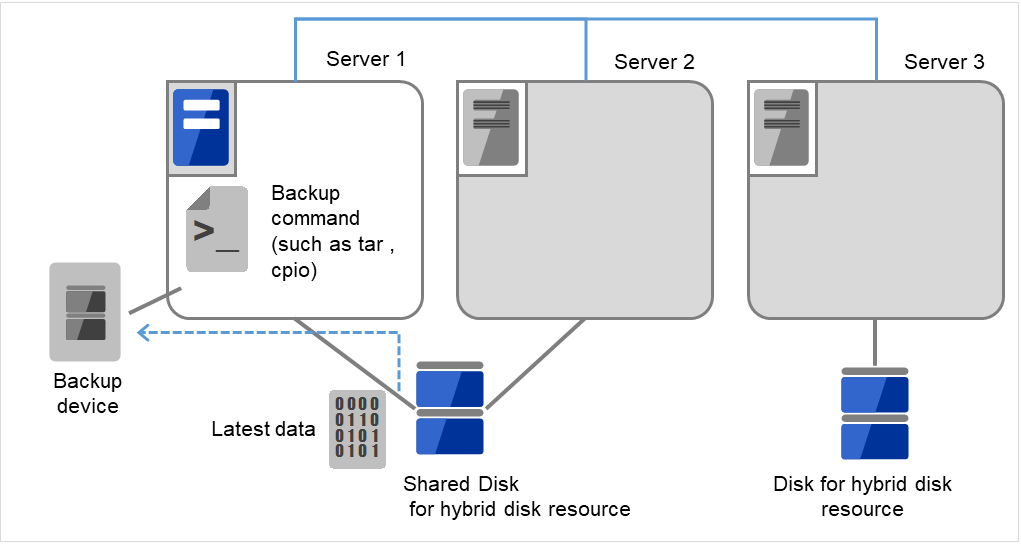
図 10.9 ハイブリッドディスク上のデータ保存 (4)¶
マウントしたデータパーティションをアンマウントします。
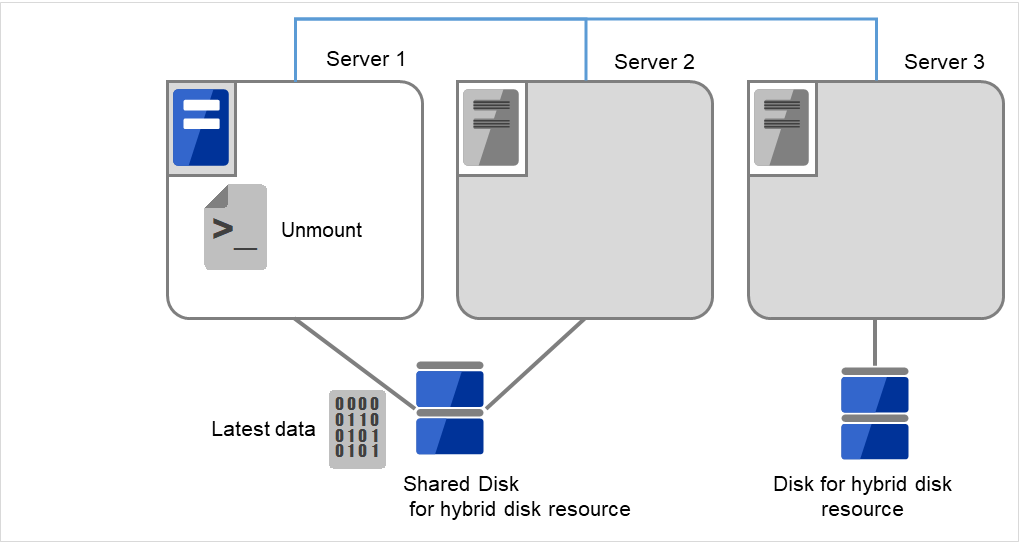
図 10.10 ハイブリッドディスク上のデータ保存 (5)¶
10.1.14. ミラーディスク、ハイブリッドディスクを手動で mkfs するには¶
クラスタ構成、ミラー構成を変更せず、ミラーパーティションのファイルシステムを再作成したい場合には、以下の手順を実行します。
クラスタが正常状態であることを確認します。
データのバックアップが必要な場合は、『インストール&設定ガイド』の「動作チェックを行う」の「バックアップ手順を確認する」、「リストア手順を確認する」を参照して、バックアップを実行します。
mkfs したいミラーディスクリソースを持つグループを停止します。
mkfs を実行するサーバ上で以下のコマンドを実行します。
ミラーディスクの場合
clpmdctrl --active -nomount <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --active -nomount <ハイブリッドディスクリソース名 (例:hd1)>
- mkfs コマンドを使用してファイルシステムを構築します。ディスクがミラーリングされるため相手サーバのディスクも mkfs されます。
(例) mkfs -t ext3 <ミラーパーティションデバイス名 (例:/dev/NMP1)>
バックアップしたデータのリストアが必要な場合は、『インストール&設定ガイド』の「動作チェックを行う」の「バックアップ手順を確認する」、「リストア手順を確認する」を参照して、リストアを実行します。
ファイルシステム作成の完了を確認後、以下のコマンドを実行します。
ミラーディスクの場合
clpmdctrl --deactive <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --deactive <ハイブリッドディスクリソース名 (例:hd1)>
10.1.15. ミラーブレイク状態からの復旧を行う¶
自動ミラー復帰が有効になっている場合には、特別な手順は必要ありません。自動的にミラー復帰が実行されます。
ただし、強制ミラー復帰が必要な場合には、コマンドまたは Cluster WebUI から強制ミラー復帰操作が必要です。
強制ミラー復帰では、差分ミラー復帰機能は無効になり、全面コピーとなります。
自動ミラー復帰が無効になっている場合には、コマンドまたは Cluster WebUI からミラー復帰操作が必要です。
10.1.16. 自動でミラーを復帰するには¶
自動ミラー復帰が有効になっている場合には、自動ミラー復帰は以下の条件の場合に実行されます。
ミラーディスクリソース、ハイブリッドディスクリソースを活性化していること
ミラーディスクリソース、ハイブリッドディスクリソースを活性化しているサーバが最新のデータを保持していること
クラスタ内のサーバが正常状態で、かつミラー状態の確認ができること
サーバ間でデータの差分があること
自動ミラー復帰は以下の条件の場合には実行されません。
いずれかのサーバが起動していない
- 他サーバのミラー状態が確認できない(通信できない場合や、相手サーバのクラスタが停止している場合など)
ミラー状態が正常のサーバが存在しない
ミラー状態が保留状態の場合(ハイブリッドディスクリソースのみ)
- 手動でミラーの同期を停止している場合(clpmdctrl, clphdctrl コマンドで--breakオプションを実行して同期を停止している場合や、Cluster WebUI のミラーディスクリストで GREEN-GREEN の状態から GREEN-RED の状態に変更している場合。ただし、同期を停止させた後にサーバを再起動した場合や、同期を手動で再開させた場合を、除く。)
- ミラーディスクモニタリソース、ハイブリッドディスクモニタリソースを停止している場合(clpmonctrlコマンドやCluster WebUI で、該当するモニタリソースを一時停止にしている場合。)
ミラー復帰の実行状態の確認は「コマンドによるミラー復帰中に実行状態を確認するには」および 「Cluster WebUI でミラー復帰中の実行状態を確認するには」を参照してください。
10.1.17. コマンドでミラーブレイク状態を確認するには¶
以下のコマンドを実行してミラーブレイク状態を確認します。
ミラーディスクの場合
clpmdstat --mirror <ミラーディスクリソース名(例:md1)>
ハイブリッドディスクの場合
clphdstat --mirror <ハイブリッドディスクリソース名(例:hd1)>
clpmdstat コマンド、clphdstat コマンドを実行するとミラーディスクリソース、ハイブリッドディスクリソースの状態が表示されます。
正常な場合
Mirror Status: Normal md1 server1 server2 -------------------------------------------------------- Mirror Color GREEN GREEN
ミラー復帰が必要な場合
Mirror Status: Abnormal Total Difference: 1% md1 server1 server2 ------------------------------------------------------------ Mirror Color GREEN RED Lastupdate Time 2018/03/04 17:30:05 -- Break Time 2018/03/04 17:30:05 -- Disk Error OK OK Difference Persent 1% --
強制ミラー復帰が必要な場合
Mirror Status: Abnormal Total Difference: 1% md1 server1 server2 ---------------------------------------------------------------- Mirror Color RED RED Lastupdate Time 2018/03/09 14:07:10 2004/03/09 13:41:34 Break Time 2018/03/09 14:06:21 2004/03/09 13:41:34 Disk Error OK OK Difference Persent 1% 1%
ミラー復帰処理中の場合
「コマンドによるミラー復帰中に実行状態を確認するには」を参照してください。
10.1.18. コマンドによるミラー復帰中に実行状態を確認するには¶
以下のコマンドを実行してミラー復帰処理の実行状態を確認します。
ミラーディスクの場合
clpmdstat --mirror <ミラーディスクリソース名(例:md1)>
ハイブリッドディスクの場合
clphdstat --mirror <ハイブリッドディスクリソース名(例:hd1)>
ミラー復帰処理中は以下の情報が表示されます。
Mirror Status: Recovering
md1 server1 server2
---------------------------------------------------
Mirror Color YELLOW YELLOW
Recovery Status Value
-------------------------------------
Status: Recovering
Direction: src server1
dst server2
Percent: 7%
Used Time: 00:00:09
Remain Time: 00:01:59
Iteration Times: 1/1
ミラー復帰処理が完了すると以下の情報が表示されます。
Mirror Status: Normal
md1 server1 server2
--------------------------------------------------------
Mirror Color GREEN GREEN
10.1.19. コマンドでミラー復帰を行うには¶
以下のコマンドを実行してミラー復帰を開始します。
ミラーディスクの場合
clpmdctrl --recovery <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --recovery <ハイブリッドディスクリソース名 (例:hd1)>
差分ミラー復帰が可能な場合には差分情報を使用して復帰を行います。差分ミラー復帰の場合には復帰時間が短縮されます(FastSyncテクノロジー)。
このコマンドはミラー復帰の実行を開始すると、すぐに制御を戻します。ミラー復帰の状態は「コマンドによるミラー復帰中に実行状態を確認するには」および「Cluster WebUI でミラー復帰中の実行状態を確認するには」を参照して確認してください。
10.1.20. コマンドによる強制ミラー復帰を行うには¶
CLUSTERPRO がどちらのサーバが最新データを保持しているか判断できない場合には、強制ミラー復帰が必要となります。
このような場合は、最新のデータを保持しているサーバを手動で特定し、強制ミラー復帰を実行する必要があります。
以下のいずれかの方法で、最新データを保持しているサーバを特定してください。
Cluster WebUI のミラーディスクリストによる確認
Cluster WebUIのミラーディスクリストから、確認したいミラーディスクリソースをクリックします。
[詳細情報] アイコンをクリックします。
最終データ更新時刻 (Last Data Update Time) を確認し、最新のデータを持つサーバを特定します。ただし、最終データ更新時刻は OS に設定されている時刻に依存します。
clpmdstat コマンド、clphdstat コマンドによる確認
Cluster WebUI のミラーディスクリストによる確認と同様の方法です。異なる部分はコマンドを使用することです。
以下のコマンドを実行します。
ミラーディスクの場合
clpmdstat --mirror <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdstat --mirror <ハイブリッドディスクリソース名 (例:hd1)>
最終データ更新時刻 (Lastupdate Time) を確認し、最新のデータを持つサーバを特定します。ただし、最終データ更新時刻は OS に設定されている時刻に依存します。
- ミラーディスク上のデータによる確認この方法は手順を誤るとデータ破壊を引き起こす可能性があるため推奨できません。以下の手順を両サーバで実行して最新のデータを持つサーバを特定します。1. 全てのグループが停止していることを確認します。2. 「ミラーリング不可能な状態で強制的に mount するには」を参照して、データパーティションを read only でマウントします。3. マウントポイントに存在するデータを論理的に確認、検証します。4. データパーティションをアンマウントします。
最新のデータを保持しているサーバを特定できたら、以下のいずれかの方法で強制ミラー復帰を開始します。
- 方法(1) 活性したままの状態で全面コピーを行う方法この方法による強制ミラー復帰では、差分ミラー復帰機能は無効になり、全面コピーとなります。強制ミラー復帰中にグループを一旦停止した場合には、強制ミラー復帰が完了するまで、グループを起動することはできません。その場合には、強制ミラー復帰の完了を確認後にグループを起動することでミラーディスクを使用することが可能になります。グループを起動したままの状態で強制ミラー復帰が並行して行われるため、システムの負荷が高くなる可能性があります。グループが複数のミラーディスクリソースやハイブリッドディスクリソースを含んでいる場合、それらのリソース全てが同じサーバ上で最新データを保持している必要があります。
- clpmdctrl, clphdctrlコマンドを実行して、全面コピーを開始します。(コマンドの引数に最新データ保持サーバ名とリソース名を指定します。)
ミラーディスクの場合
clpmdctrl --force <最新データ保持サーバ名> <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --force <最新データ保持サーバ名> <ハイブリッドディスクリソース名 (例:hd1)>
コマンドによってミラー復帰を開始すると、コマンドはすぐに制御を戻します。ミラー復帰の状態を確認して、ミラー復帰が完了するのを待ちます。
もしグループを停止した場合には、ミラー復帰が完了したことを確認後に、グループを起動します。
- 方法(2) 非活性状態にて全面コピーを行う方法この方法による強制ミラー復帰では、差分ミラー復帰機能は無効になり、全面コピーとなります。ファイルシステムの種類やディスク使用量や負荷状況によっては、方法(1)や方法(3)の活性状態で行う手順よりも、コピー時間は短くなります。グループを停止した状態でおこないます。強制ミラー復帰が完了するまで、グループを起動することはできません。強制ミラー復帰の完了確認後に、グループを起動することでミラーディスクを使用することが可能になります。グループが複数のミラーディスクリソースやハイブリッドディスクリソースを含んでいる場合、それらのリソース全てが同じサーバ上で最新データを保持している必要があります。
グループが起動している場合には、一旦グループを停止します。
- clpmdctrl, clphdctrlコマンドを実行して、全面コピーを開始します。(コマンドの引数に最新データ保持サーバ名とリソース名を指定します。)
ミラーディスクの場合
clpmdctrl --force <最新データ保持サーバ名> <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --force <最新データ保持サーバ名> <ハイブリッドディスクリソース名 (例:hd1)>
コマンドによってミラー復帰を開始すると、コマンドはすぐに制御を戻します。ミラー復帰の状態を確認して、ミラー復帰が完了するのを待ちます。
ミラー復帰が完了したことを確認後、グループを起動します。
- 方法(3) 非活性状態から活性状態にして全面コピーを行う方法この方法による強制ミラー復帰では、差分ミラー復帰機能は無効になり、全面コピーとなります。強制ミラー復帰中にグループを一旦停止した場合には、強制ミラー復帰が完了するまで、グループを起動することはできません。その場合には、強制ミラー復帰の完了を確認後にグループを起動することでミラーディスクを使用することが可能になります。グループを起動したままの状態で強制ミラー復帰が並行して行われるため、システムの負荷が高くなる可能性があります。グループが複数のミラーディスクリソースやハイブリッドディスクリソースを含んでいる場合、それらのリソース全てが同じサーバ上で最新データを保持している必要があります。
- グループが起動していない状態にて、ミラーディスクリソースやハイブリッドディスクリソースを監視している、ミラーディスクモニタリソースやハイブリッドディスクモニタリソースを、一時停止します。各サーバにて下記コマンドを実行してください。これにより、自動ミラー復帰が一時的に動作しなくなります。
clpmonctrl -s -m <該当モニタリソース名 (例:mdw1)>
(コマンドの代わりに Cluster WebUI を使ってモニタリソースを一時停止する場合には、該当のミラーディスクモニタリソースやハイブリッドディスクモニタリソースの「モニタ一時停止」を実行してください。確認画面で「一時停止」を選択すると、そのモニタが「一時停止」の状態になります。)
- 最新のデータを保持しているサーバ上にて、clpmdctrl, clphdctrlコマンドを実行して、該当サーバ側のミラーディスクを最新状態に変更します。(コマンドの引数には最新データ保持サーバ名は指定しません。)
ミラーディスクの場合
clpmdctrl --force <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --force <ハイブリッドディスクリソース名 (例:hd1)>
- 該当するミラーディスクリソース、ハイブリッドディスクリソースが最新状態 (正常) になったことを、Cluster WebUI のミラーディスクリスト、または、clpmdstat, clphdstat コマンドで確認します。確認後、clpgrp コマンドや Cluster WebUI を使い、最新のデータを保持しているサーバで該当グループを起動させます。
- グループの起動完了後、clpmdctrl, clphdctrl コマンドを実行して、全面コピーを開始します。(コマンドの引数に最新データ保持サーバ名とリソース名を指定します。)
ミラーディスクの場合
clpmdctrl --force <最新データ保持サーバ名> <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --force <最新データ保持サーバ名> <ハイブリッドディスクリソース名 (例:hd1)>
- コマンドによってミラー復帰を開始すると、コマンドはすぐに制御を戻します。次に、一時停止したモニタリソースを元に戻します。各サーバにて下記コマンドを実行してください。
clpmonctrl -r -m <該当モニタリソース名 (例:mdw1)>
(コマンドの代わりに Cluster WebUI を使ってモニタリソースを再開させる場合には、該当のミラーディスクモニタリソースやハイブリッドディスクモニタリソースの「モニタ再開」を実行してください。確認画面で「再開」を選択すると、そのモニタが再開します。)
- 方法(4) 自動ミラー復帰、差分ミラー復帰を利用する方法差分ミラー復帰が可能な場合には差分情報を使用して復帰を行います。グループを起動した状態でミラー復帰が並行して行われるため、システムの負荷が高くなる可能性があります。グループが複数のミラーディスクリソースやハイブリッドディスクリソースを含んでいる場合、それらのリソース全てが同じサーバ上で最新データを保持している必要があります。
- 最新のデータを保持しているサーバ上にて、clpmdctrl, clphdctrl コマンドを実行して、該当サーバ側のミラーディスクを最新状態に変更します。(コマンドの引数には最新データ保持サーバ名を指定しません。)
ミラーディスクの場合
clpmdctrl --force <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --force <ハイブリッドディスクリソース名 (例:hd1)>
- グループが起動していない場合は、該当するミラーディスクリソース、ハイブリッドディスクリソースが最新状態 (正常) になったことを、Cluster WebUI のミラーディスクリスト、または、clpmdstat, clphdstat コマンドで確認します。確認後、clpgrpコマンドや Cluster WebUI を使い、最新のデータを保持しているサーバで該当グループを起動させます。
- グループが起動していなかった場合には、該当グループが起動後(活性後)、自動ミラー復帰が始まります。グループが起動していた場合には、1. の操作後に、自動ミラー復帰が始まります。自動ミラー復帰をOFFに設定している場合等、自動ミラー復帰が開始されない場合には、clpmdctrl, clphdctrl コマンドやミラーディスクリストを使って、手動でミラー復帰を開始してください。
ミラーディスクの場合
clpmdctrl --recovery <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --recovery <ハイブリッドディスクリソース名 (例:hd1)>
clpmdctrl コマンド、clphdctrl コマンドはミラー復帰の実行を開始すると、すぐに制御を戻します。ミラー復帰の進捗状態は「コマンドによるミラー復帰中に実行状態を確認するには」および「Cluster WebUI でミラー復帰中の実行状態を確認するには」を参照して確認してください。
10.1.21. コマンドによるサーバ 1 台のみの強制ミラー復帰を行うには¶
いずれかのサーバが H/W や OS の障害により起動できない状態となり、起動可能なサーバも最新データを保持している保障がない場合があります。
起動できるサーバだけでも業務を開始したい場合には起動できるサーバを強制ミラー復帰することができます。
この操作を実行すると、コマンドを実行したサーバが強制的に最新データを保持することになります。このため、起動できない状態にあったサーバが起動できるようになった場合でも、そのサーバのデータを最新として扱うことはできなくなります。
この点を理解したうえで以下の手順を実行してください。
以下のコマンドを実行して、強制ミラー復帰を開始します。
ミラーディスクの場合
clpmdctrl --force <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdctrl --force <ハイブリッドディスクリソース名 (例:hd1)>
コマンド実行後、グループを起動してミラーディスク、ハイブリッドディスクを使用することが可能になります。
10.1.22. Cluster WebUI でミラーブレイク状態を確認するには¶
正常な場合

ミラー復帰が必要な場合

強制ミラー復帰が必要な場合

ミラー復帰処理中の場合
「Cluster WebUI でミラー復帰中の実行状態を確認するには」を参照してください。
10.1.23. Cluster WebUI でミラー復帰中の実行状態を確認するには¶
Cluster WebUI のミラーディスクリストからミラー復帰処理の実行状態を確認します。(下記の例はミラーディスクリソースの場合です。ハイブリッドディスクリソースの場合には、画面の表示が異なりますが、ステータスの意味、説明は同じです。)
ミラー復帰処理中は以下の情報が表示されます。
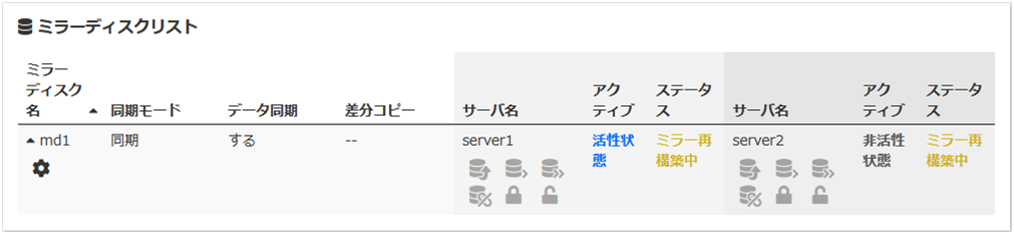
ミラー復帰処理が完了すると以下の情報が表示されます。
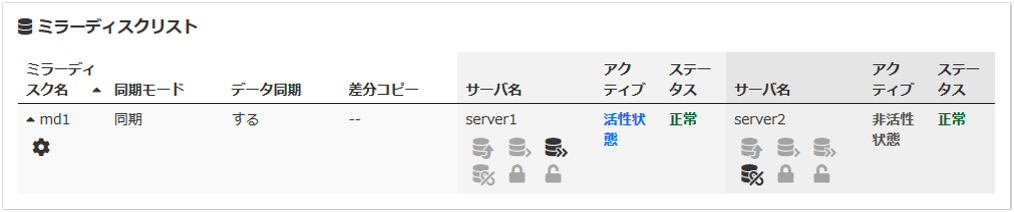
10.1.24. Cluster WebUI でミラー復帰を行うには¶
Cluster WebUI のミラーディスクリストに関してはオンラインマニュアルを参照してください。
ミラー復帰の状態は「コマンドによるミラー復帰中に実行状態を確認するには」および「Cluster WebUI でミラー復帰中の実行状態を確認するには」を参照して確認してください。
10.1.25. Cluster WebUI で強制ミラー復帰を行うには¶
CLUSTERPRO がどちらのサーバが最新データを保持しているか判断できない場合には強制ミラー復帰が必要となります。
このような場合は、最新のデータを保持しているサーバを手動で特定し、強制ミラー復帰を実行する必要があります。
以下のいずれかの方法で、最新データを保持しているサーバを特定してください。
Cluster WebUI のミラーディスクリストによる確認
Cluster WebUIのミラーディスクリストから、確認したいミラーディスクリソースの詳細情報を表示します。
[詳細情報] アイコンをクリックします。
最終データ更新時刻 (Last Data Update Time) を確認し、最新のデータを持つサーバを特定します。ただし、最終データ更新時刻は OS に設定されている時刻に依存します。
clpmdstat コマンド、clphdstat コマンドによる確認
Cluster WebUI のミラーディスクリストによる確認と同様の方法です。異なる部分はコマンドを使用することです。
以下のコマンドを実行します。
ミラーディスクの場合
clpmdstat --mirror <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合
clphdstat --mirror <ハイブリッドディスクリソース名 (例:hd1)>
最終データ更新時刻 (Lastupdate Time) を確認し、最新のデータを持つサーバを特定します。ただし、最終データ更新時刻は OS に設定されている時刻に依存します。
- ミラーディスク上のデータによる確認この方法は手順を誤るとデータ破壊を引き起こす可能性があるため推奨できません。以下の手順を両サーバで実行して最新のデータを持つサーバを特定します。
全てのグループが停止していることを確認します。
「ミラーリング不可能な状態で強制的に mount するには」を参照して、データパーティションを read only でマウントします。
マウントポイントに存在するデータを論理的に確認、検証します。
データパーティションをアンマウントします。
最新のデータを保持しているサーバを特定できたら、Cluster WebUI のミラーディスクリストから強制ミラー復帰を実行します。ミラーディスクリストに関してはオンラインマニュアルを参照してください。
以下のいずれかの方法で強制ミラー復帰を開始します。
- 方法(1) 全面コピーを行う方法この方法による強制ミラー復帰では、差分ミラー復帰機能は無効になり、全面コピーとなります。また、強制ミラー復帰が完了するまで、グループを起動することができません。強制ミラー復帰の完了を確認後に、グループを起動することでミラーディスクを使用することが可能になります。
- ミラーディスクリストから、最新データを保持しているサーバ側からコピー先サーバ側へ [フルコピー] を実行してミラー復帰を開始します。(グループが既に起動済みの場合には、ミラーディスクリストにて [フルコピー] を操作選択することができません。そのような場合には、一旦グループを停止するか、または、コマンドによる強制ミラー復帰の方法を行ってください。)
ミラー復帰が完了したことを確認後、グループを起動します。
- 方法(2) 自動ミラー復帰、差分ミラー復帰を利用する方法差分ミラー復帰が可能な場合には差分情報を使用して復帰を行います。差分ミラー復帰は 強制ミラー復帰と比較して復帰時間が短縮されます(FastSyncテクノロジー)。グループを起動した状態でミラー復帰が並行して行われるため、システムの負荷が高くなる可能性があります。グループが複数のミラーディスクリソースやハイブリッドディスクリソースを含んでいる場合、それらのリソース全てが同じサーバ上で最新データを保持している必要があります。
- ミラーディスクリストを使って最新データを保持しているサーバ側のミラーディスクを、異常から正常へ変更します。(グループが既に起動済みの場合には、ミラーディスクリストにてこの操作を行うことができません。そのような場合には、一旦グループを停止するか、または、コマンドによる強制ミラー復帰の方法を行ってください。)
- 該当するミラーディスクリソース、ハイブリッドディスクリソースが最新状態(正常)になったことを、確認します。確認後、最新のデータを保持しているサーバで該当グループを起動させます。
- 該当グループが起動(活性)後、自動ミラー復帰が始まります。差分ミラー復帰が可能な場合には差分ミラー復帰が行われます。差分ミラー復帰が不可能な場合には全面コピーが行われます。自動ミラー復帰をONに設定していない等、自動ミラー復帰が開始されない場合には、ミラーディスクリストを使って手動でミラー復帰を開始してください。
ミラー復帰の状態は「コマンドによるミラー復帰中に実行状態を確認するには」および「Cluster WebUI でミラー復帰中の実行状態を確認するには」を参照して確認してください。
10.1.26. Cluster WebUI でサーバ 1 台のみの強制ミラー復帰を行うには¶
いずれかのサーバが H/W や OS の障害により起動できない状態となり、起動可能なサーバも最新データを保持している保障がない場合があります。
起動できるサーバだけでも業務を開始したい場合には、起動できるサーバを強制ミラー復帰 することができます。
この操作を実行すると、そのサーバが強制的に最新データを保持することになります。このため、起動できない状態にあったサーバが起動できるようになった場合でも、そのサーバのデータを最新として扱えなくなります。この点を理解したうえで以下の手順を実行してください。
Cluster WebUI のミラーディスクリストから強制ミラー復帰を実行します。ミラーディスクリストに関してはオンラインマニュアルを参照してください。
強制ミラー復帰の実行後、グループを起動してミラーディスクを使用することが可能になります。
10.1.27. ハイブリッドディスクのカレントサーバを変更するには¶
カレントサーバを変更可能な条件は以下の場合です。
ハイブリッドディスクのステータス |
カレントサーバ変更可否 |
||
|---|---|---|---|
サーバグループ1 |
サーバグループ2 |
サーバグループ1 |
サーバグループ2 |
異常/非活性 |
異常/非活性 |
可能 |
可能 |
正常/非活性 |
異常/非活性 |
可能 |
可能 |
異常/非活性 |
正常/非活性 |
可能 |
可能 |
正常/非活性 |
正常/非活性 |
可能 |
可能 |
正常/活性 |
異常/非活性 |
不可能 |
可能 |
異常/非活性 |
正常/活性 |
可能 |
不可能 |
正常/活性 |
正常/非活性 |
不可能 |
不可能 |
保留/非活性 |
保留/非活性 |
可能 |
可能 |
10.1.28. コマンドでカレントサーバを変更するには¶
カレントサーバにしたいサーバ上で以下のコマンドを実行してハイブリッドディスクのカレントサーバを変更します。
clphdctrl --setcur <ハイブリッドディスクリソース名 (例:hd1)>
10.1.29. Cluster WebUI でカレントサーバを変更するには¶
Cluster WebUI のミラーディスクリストに関してはオンラインマニュアルを参照してください。
10.2. VERITAS Volume Manager の障害時の処理¶
このトピックでは、VERITAS Volume Manager 使用時の障害発生時の対応手順について説明します。
10.2.1. VERITAS Volume Manager の構成を変更するには¶
VERITAS Volume Manager の構成変更に OS の再起動が必要であるか、必要でないかによって、構成変更手順が異なります。
構成変更に OS の再起動が不要な場合 → 「VERITAS Volume Manager の構成変更に OS の再起動が不要な場合」を参照してください。
構成変更に OS の再起動が必要な場合 → 「VERITAS Volume Manager の構成変更に OS の再起動が必要な場合」を参照してください。
VERITAS Volume Manager の構成変更に OS の再起動が不要な場合
管理 IP で Cluster WebUI に接続します。管理 IP がない場合は、いずれかのサーバの実 IP で Cluster WebUI を接続します。
Cluster WebUI から [クラスタ停止] を実行します。
VERITAS Volume Manager の構成を変更します。
Cluster WebUI の設定モードから、リソースの設定情報を変更します。
Cluster WebUI の設定モードから、更新したクラスタ構成情報をアップロードします。
Cluster WebUI の操作モードから [クラスタ開始] を実行します。
以上で、設定が有効になります。
VERITAS Volume Manager の構成変更に OS の再起動が必要な場合
クラスタ構成情報をバックアップします。Cluster WebUI を使用する OS の種類によって以下のいずれかの手順になります。
Linux の Web ブラウザで動作する Cluster WebUI 用にバックアップする場合は以下のコマンドを実行します。
clpcfctrl --pull -l -x <構成情報のパス>
Windows の Web ブラウザで動作する Cluster WebUI 用にバックアップする場合は以下のコマンドを実行します。
clpcfctrl --pull -w -x <構成情報のパス>
[clpcfctrl] のトラブルシューティングについては本ガイドの「9.2. CLUSTERPRO コマンド一覧」の「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」を参照してください。
全サーバで CLUSTERPRO サービスが起動しないように設定します。
clpsvcctrl.sh --disable core
CLUSTERPRO デーモンを停止します。
clpcl -t -a
VERITAS Volume Manager の構成を変更します。(この段階で OS の再起動を実行します)
Cluster WebUI の設定モードから、リソースの設定情報を変更します。
Cluster WebUI の設定モードから、更新したクラスタ構成情報をアップロードします。
全サーバで CLUSTERPRO サービスが起動するように設定します。
clpsvcctrl.sh --enable core
全サーバを再起動します。
以上で、次回 OS 起動時に設定が有効になります。
10.2.2. VERITAS Volume Manager 障害時における CLUSTERPRO の運用¶
VERITAS Volume Manager に何らかの障害が発生し、ディスクリソースおよびボリュームマネージャリソースが異常を検出した場合でも、グループのフェイルオーバや最終動作を実行したくない場合は「クラスタ構成情報を変更する場合」の手順を参照してください。
VERITAS Volume Manager の障害を回復し、再度 CLUSTERPRO で制御する場合は 「クラスタ構成情報を元に戻す場合」の手順を参照してください。
クラスタ構成情報を変更する場合
全サーバをランレベル 1 で起動します。
全サーバで CLUSTERPRO サービスが起動しないように設定します。
clpsvcctrl.sh --disable core
全サーバを再起動します。
クラスタ構成情報をバックアップします。Cluster WebUI を使用する OS の種類によって以下のいずれかの手順になります。
Linux の Web ブラウザで動作する Cluster WebUI 用にバックアップする場合は以下のコマンドを実行します。
clpcfctrl --pull -l -x <構成情報のパス>
Windows の Web ブラウザで動作する Cluster WebUI 用にバックアップする場合は以下のコマンドを実行します。
clpcfctrl --pull -w -x <構成情報のパス>
[clpcfctrl] のトラブルシューティングについては本ガイドの「9.2. CLUSTERPRO コマンド一覧」の「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」を参照してください。
Cluster WebUI の設定モードから、リソースの設定情報を変更します。
ディスクリソース
ボリュームマネージャリソース
上記グループリソースの場合、[リソースのプロパティ] ダイアログボックスの [復旧動作] タブで以下のように設定してください。
- 活性異常検出時の復旧動作活性リトライしきい値 0 回フェイルオーバしきい値 0 回最終動作 何もしない (次のリソースを活性する)
- 非活性異常検出時の復旧動作非活性リトライしきい値 0 回最終動作 何もしない (次のリソースを非活性する)
ボリュームマネージャモニタリソース
ディスクモニタリソース
上記モニタリソースの場合、[モニタリソースのプロパティ] ダイアログボックスの [回復動作] タブで以下のように設定してください。
- 異常検出時回復動作 最終動作のみ実行最終動作 何もしない
Cluster WebUI の設定モードから、更新したクラスタ構成情報をアップロードします。
全サーバで CLUSTERPRO サービスが起動するように設定します。
clpsvcctrl.sh --enable core
全サーバを再起動します。
以上で、次回 OS 起動時に設定が有効になります。
クラスタ構成情報を元に戻す場合
CLUSTERPRO デーモンが動作している場合は以下のコマンドを使用して、CLUSTERPRO デーモンを停止します。
clpcl -t -a
「クラスタ構成情報を変更する場合」の手順 5 で作成し保存しておいた構成情報をサーバに配信します。
clpcfctrl --push -x <構成情報のパス>
[clpcfctrl] のトラブルシューティングについては本ガイドの「9.2. CLUSTERPRO コマンド一覧」の「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」を参照してください。
以上で、次回 CLUSTERPRO デーモン起動時に設定が有効になります。
10.3. fsck / xfs_repair コマンドの進捗状況を確認するには¶
ディスクリソース、ミラーディスクリソース、ハイブリッドディスクリソースの活性時に実行されるfsck / xfs_repairは、パーティションのサイズやファイルシステムの状態によって、完了までに長時間を要することがあります。
ディスクリソース、ミラーディスクリソース、ハイブリッドディスクリソースが発行したfsck / xfs_repair コマンドの進捗状況は、以下のログファイルを参照して確認することができます。
リソース |
ログファイル |
|---|---|
ディスクリソース |
disk_fsck.log.cur |
ミラーディスクリソース |
md_fsck.log.cur |
ハイブリッドディスクリソース |
hd_fsck.log.cur |