1. はじめに¶
1.1. 対象読者と目的¶
『CLUSTERPRO X メンテナンスガイド』は、管理者を対象に、メンテナンス関連情報について記載しています。クラスタ運用時に必要な情報を参照してください。
1.3. CLUSTERPRO マニュアル体系¶
CLUSTERPRO のマニュアルは、以下の 5 つに分類されます。各ガイドのタイトルと役割を以下に示します。
『CLUSTERPRO X スタートアップガイド』 (Getting Started Guide)
すべてのユーザを対象読者とし、製品概要、動作環境、アップデート情報、既知の問題などについて記載します。
『CLUSTERPRO X インストール&設定ガイド』 (Install and Configuration Guide)
CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアと、クラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO を使用したクラスタシステム導入から運用開始前までに必須の事項について説明します。実際にクラスタシステムを導入する際の順番に則して、CLUSTERPRO を使用したクラスタシステムの設計方法、CLUSTERPRO のインストールと設定手順、設定後の確認、運用開始前の評価方法について説明します。
『CLUSTERPRO X リファレンスガイド』 (Reference Guide)
管理者、および CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアを対象とし、CLUSTERPRO の運用手順、各モジュールの機能説明およびトラブルシューティング情報等を記載します。『CLUSTERPRO X インストール&設定ガイド』を補完する役割を持ちます。
『CLUSTERPRO X メンテナンスガイド』 (Maintenance Guide)
管理者、および CLUSTERPRO を使用したクラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO のメンテナンス関連情報を記載します。
『CLUSTERPRO X ハードウェア連携ガイド』 (Hardware Feature Guide)
管理者、および CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアを対象読者とし、特定ハードウェアと連携する機能について記載します。『CLUSTERPRO X インストール&設定ガイド』を補完する役割を持ちます。
1.4. 本書の表記規則¶
本書では、注意すべき事項、重要な事項および関連情報を以下のように表記します。
注釈
この表記は、重要ではあるがデータ損失やシステムおよび機器の損傷には関連しない情報を表します。
重要
この表記は、データ損失やシステムおよび機器の損傷を回避するために必要な情報を表します。
参考
この表記は、参照先の情報の場所を表します。
また、本書では以下の表記法を使用します。
表記 |
使用方法 |
例 |
|---|---|---|
[ ] 角かっこ |
コマンド名の前後
画面に表示される語 (ダイアログボックス、メニューなど) の前後
|
[スタート] をクリックします。
[プロパティ] ダイアログボックス
|
コマンドライン中の [ ] 角かっこ |
かっこ内の値の指定が省略可能であることを示します。 |
|
# |
Linux ユーザが、root でログインしていることを示すプロンプト |
|
モノスペースフォント |
パス名、コマンドライン、システムからの出力 (メッセージ、プロンプトなど)、ディレクトリ、ファイル名、関数、パラメータ |
|
太字 |
ユーザが実際にコマンドラインから入力する値を示します。 |
以下を入力します。
clpcl -s -a
|
|
ユーザが有効な値に置き換えて入力する項目 |
|
 本書の図では、CLUSTERPROを表すために このアイコンを使用します。
本書の図では、CLUSTERPROを表すために このアイコンを使用します。
2. 保守情報¶
本章では、CLUSTERPRO のメンテナンスを行う上で必要な情報について説明します。管理対象となる リソースの詳細について説明します。
本章で説明する項目は以下の通りです。
2.1. CLUSTERPRO のディレクトリ構成¶
注釈
インストールディレクトリ配下に『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」に記載されていない実行形式ファイルやスクリプトファイルがありますが、CLUSTERPRO 以外からは実行しないでください。実行した場合の影響については、サポート対象外とします。
CLUSTERPRO は、以下のディレクトリ構成で構成されます。
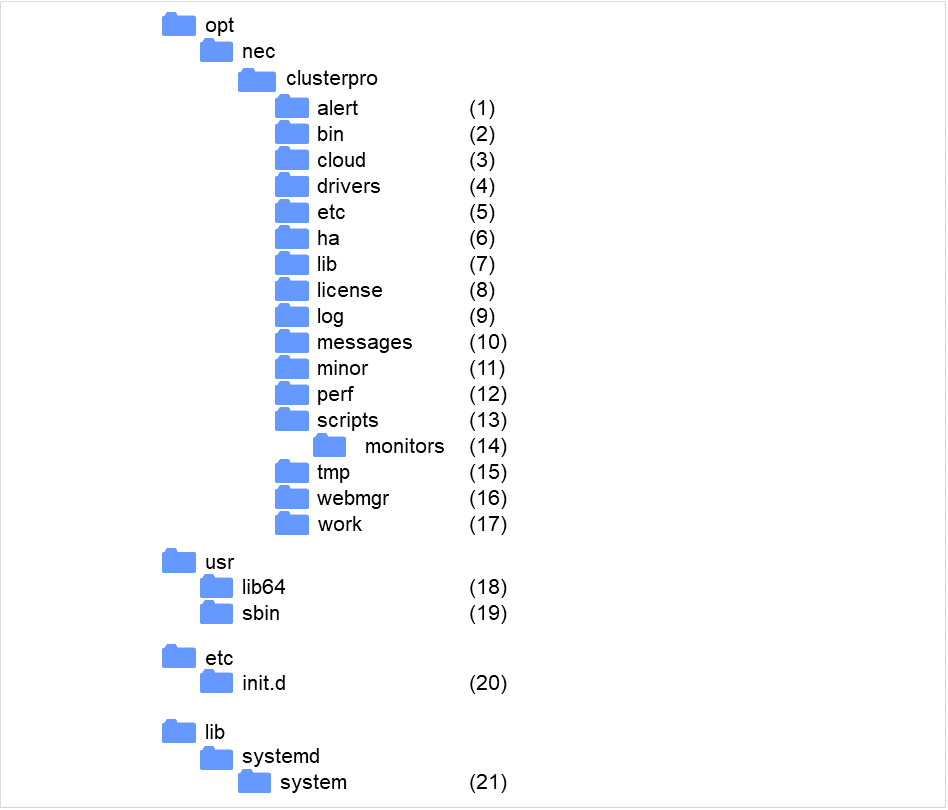
図 2.1 ディレクトリ構成¶
- アラート同期関連CLUSTERPRO アラート同期のモジュールおよび管理ファイルが格納されます。
- クラスタモジュール関連CLUSTERPRO サーバの実行形式ファイルが格納されます。
- クラウド連携製品関連クラウド連携用のスクリプトモジュールなどが格納されます。
クラスタドライバ関連
- ミラードライバデータミラードライバの実行形式ファイルが格納されます。
- カーネルモード LAN ハートビート、キープアライブドライバカーネルモード LAN ハートビート、キープアライブドライバの実行形式ファイルが格納されます。
- クラスタ構成情報関連クラスタ構成情報ファイル、各モジュールのポリシファイルが格納されます。
- HA製品関連Java Resource Agent, System Resource Agentのバイナリ、設定ファイルが格納されています。
- クラスタライブラリ関連CLUSTERPRO サーバのライブラリが格納されます。
- ライセンス関連ライセンス製品のライセンスが格納されます。
- モジュールログ関連各モジュールから出力されるログが格納されます。
- 通報メッセージ (アラート、syslog、mail) 関連各モジュールが アラート、syslog、mail 通報するときのメッセージが格納されます。
- ミラーディスク、ハイブリッドディスク関連ミラーディスク、ハイブリッドディスク用モジュールの実行形式ファイル、ポリシファイルなどが格納されます。
- パフォーマンスログ関連ディスクやシステムのパフォーマンス情報が格納されます。
- グループリソースの EXEC リソーススクリプト関連グループリソースの EXEC リソースのスクリプトが格納されます。
- 回復スクリプト関連モニタリソースの異常検出時にスクリプトの実行が設定されている場合、この機能により実行されるスクリプトが格納されています。
- 一時ファイル関連log 収集時のアーカイブファイルが格納されます。
- WebManager サーバ、Cluster WebUI 関連WebManagerサーバのモジュールおよび管理ファイルが格納されます。
- モジュール作業関連各モジュールの作業用ディレクトリです。
- /usr/lib64CLUSTERPRO サーバのライブラリへのシンボリックリンクが格納されます。
- /usr/sbinCLUSTERPRO サーバの実行形式ファイルへのシンボリックリンクが格納されます。
- /etc/init.dinit.d 環境の場合、CLUSTERPRO サービスの起動/終了スクリプトが格納されます。
- /lib/systemd/system (SUSE Linux の場合は /usr/lib/ systemd/system)systemd 環境の場合、CLUSTERPRO サービスの設定ファイルが格納されます。
2.2. CLUSTERPRO のログ、アラート削除方法¶
CLUSTERPRO のログ、アラートを削除するには下記の手順を実行してください。
クラスタ内の全サーバ上でサービスを無効にします。
clpsvcctrl.sh --disable -a
Cluster WebUI またはclpstdnコマンドでクラスタシャットダウン、リブートを実行し再起動します。
ログを削除するには下記のディレクトリに存在するファイル、ディレクトリを削除します。ログを削除したいサーバ上で実行してください。
/opt/nec/clusterpro/log/
アラートを削除するには下記のディレクトリに存在するファイルを削除します。アラートを削除したいサーバ上で実行してください。
/opt/nec/clusterpro/alert/log/
クラスタ内の全サーバ上でサービスを有効にします。
clpsvcctrl.sh --enable -a
クラスタ内の全サーバ上でrebootコマンドを実行して再起動します。
2.3. ミラー統計情報採取機能¶
Cluster WebUIの設定モードで [クラスタのプロパティ] の [統計情報] タブにある [ミラー統計情報] のチェックボックスにチェックをしていた場合、ミラーの性能に関する情報が採取され、インストールパス/perf/disk配下に以下のファイル名規則で保存されています。以下説明文中では本ファイルをミラー統計情報ファイルとして表記します。
nmpN.cur
nmpN.pre[X]
|
|
|---|---|
cur |
最新の情報出力先であることを示しています。 |
pre |
ローテートされた以前の情報出力先であることを示しています。 |
N |
対象のNMP番号を示しています。 |
[X] |
世代番号を示します。
1世代前の場合は省略されます。
m世代前の場合はXはm-1の値となります。
全世代数がnの場合、一番古いファイルのXはn-2の値となります。
|
採取された情報はミラー統計情報ファイルに保存されます。本ファイルへの統計情報の出力間隔(=サンプリング間隔)は 60 秒です。ファイルのサイズが 16MB でローテートされ、2世代分保存されます。ミラー統計情報ファイルに記録された情報を利用することでミラー機能に関するチューニングの参考にすることが可能です。採取される統計情報には以下のような項目が含まれています。
注釈
採取したミラー統計情報はclplogccコマンドやCluster WebUIによるログ収集で採取されます。
clplogccコマンドでのログ収集時にはtype5を、Cluster WebUIでのログ収集時にはパターン5を指定してください。ログ収集の詳細については、『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ログを収集する (clplogcc コマンド)」または、オンラインマニュアルを参照してください。
統計値名
|
単位
|
説明
|
出力
|
|---|---|---|---|
Write, Total
(Write量)
|
バイト
(MB)
|
ミラーパーティションへWriteしたデータの総量です。
出力される値は、各サンプリングの間にWriteしたデータ量です。
|
LOG,
CMD
(現)
|
Write, Avg
(Write量、平均値)
|
バイト/秒
(MB/s)
|
ミラーパーティションへWriteしたデータの単位時間当たりの量です。
|
LOG,
CMD
(現)
|
Read, Total
(Read量)
|
バイト
(MB)
|
ミラーパーティションからReadしたデータの総量です。
出力される値は、各サンプリングの間にReadしたデータ量です。
|
LOG,
CMD
(現)
|
Read, Avg
(Read量、平均値)
|
バイト/秒
(MB/s)
|
ミラーパーティションからReadしたデータの単位時間当たりの量です。
|
LOG,
CMD
(現)
|
Local Disk Write, Total
(ローカルディスクWrite量)
|
バイト
|
ローカルディスク(データパーティション)へWriteしたデータの総量です。
出力される値は、各サンプリングの間にWriteしたデータ量です。
|
LOG
(両)
|
Local Disk Write, Avg
(ローカルディスク平均Write量)
|
バイト/秒
|
ローカルディスク(データパーティション)へWriteしたデータの単位時間当たりの量です。
|
LOG
(両)
|
Local Disk Read, Total
(ローカルディスクRead量)
|
バイト
|
ローカルディスク(データパーティション)からReadしたデータの総量です。
出力される値は、各サンプリングの間にReadしたデータ量です。
|
LOG
(両)
|
Local Disk Read, Avg
(ローカルディスク平均Read量)
|
バイト/秒
|
ローカルディスク(データパーティション)へReadしたデータの単位時間当たりの量です。
|
LOG
(両)
|
Send, Total
(ミラー通信量、合計値)
|
バイト
(KB)
|
ミラーディスクコネクトで送信したミラー通信総量です。
出力される値は、各サンプリングの間の通信量です。
TCPの制御情報等は含みません。
|
LOG,
CMD
(両)
|
Send, Avg
(ミラー通信量、平均値)
|
バイト/秒
(KB/s)
|
ミラーディスクコネクトで送信した単位時間当たりのミラー通信量です。
|
LOG,
CMD
(両)
|
Compress Ratio
(圧縮率)
|
%
|
ミラーデータ圧縮率です。
(圧縮後サイズ)÷(圧縮前サイズ)
×100
非圧縮の場合には100となります。
出力される値は、各サンプリングの間に行われた通信データをもとに、計算されます。
|
LOG
(現)
|
Sync Time, Max
(ミラー通信時間、最大値)
|
秒/回
|
ミラー同期データを1つ同期するのにかかった時間です。3
出力される値は、そのうち最も時間のかかったミラー同期データの時間です。
通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。
また、出力される値は、各サンプリングの間の通信が対象です。
|
LOG,
CMD
(現)
|
Sync Time, Avg
(ミラー通信時間、平均値)
|
秒/回
|
ミラー同期データを1つ同期するのにかかった時間です。3
出力される値は、通信回数あたりの平均時間です。
通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。
また、出力される値は、各サンプリングの間の通信が対象です。
|
LOG,
CMD
(現)
|
Sync Ack Time, Max
(ミラー同期のACK応答時間、最大値)
|
ミリ秒
|
ミラー同期データを相手サーバへ送信してから、相手サーバからACKを受信するまでにかかった時間です。3
出力される値は、そのうちの最大値です。
ミラーディスクリソースやハイブリッドディスクリソースで設定する、[ミラードライバ] タブの [Ackタイムアウト] を決定するための参考値として使用します。
なお、ACKタイムアウトとなったミラー同期データは、計測の対象外です。
また、出力される値は、ミラーデーモン(ミラーエージェント)が起動してからの値です。
|
LOG
(現)
|
Sync Ack Time, Cur
(ミラー同期のACK応答時間、最新値)
|
ミリ秒
|
LOG
(現)
|
|
Recovery Ack Time, Max
(ミラー復帰のACK応答時間、最大値)
|
ミリ秒
|
ミラー復帰データを相手サーバへ送信してから、相手サーバからACKを受信するまでにかかった時間です。
出力される値は、そのうちの最大値です。
ミラーディスクリソースやハイブリッドディスクリソースで設定する、[ミラードライバ] タブの [Ackタイムアウト] を決定するための参考値として使用します。
なお、ACKタイムアウトとなったミラー同期データは、計測の対象外です。
また、出力される値は、ミラーデーモン(ミラーエージェント)が起動してからの値です。
|
LOG
(現)
|
Recovery Ack Time, Max2
(ミラー復帰のACK応答時間、一定期間中の最大値)
|
ミリ秒
|
ミラー復帰データを相手サーバへ送信してから、相手サーバからACKを受信するまでにかかった時間の最大値です。
出力される値は、1サンプリング期間中の最大値です。
なお、ACKタイムアウトとなったミラー同期データは、計測の対象外です。
|
LOG
(現)
|
Recovery Ack Time, Cur
(ミラー復帰のACK応答時間、最新値)
|
ミリ秒
|
ミラー復帰データを相手サーバへ送信してから、相手サーバからACKを受信するまでにかかった時間です。
出力される値は、最後のACK受信での値です。
なお、ACKタイムアウトとなったミラー同期データは、計測の対象外です。
|
LOG
(現)
|
Sync Diff, Max
(差分量、最大値)
|
バイト
(MB)
|
相手サーバへ同期が完了していないミラー同期データの量です。出力される値は、各サンプリングの間での、最大の値です。
通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。
|
LOG,
CMD
(現)
|
Sync Diff, Cur
(差分量、最新値)
|
バイト
(MB)
|
相手サーバへ同期が完了していないミラー同期データの量です。出力される値は、採取時の最新の値です。
通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。
|
LOG,
CMD
(現)
|
Send Queue, Max
(送信キュー数、最大値)
|
個
|
ミラー同期データを送信するときに使用されるキューの数です。出力される値は、ミラーデーモン(ミラーエージェント)が起動してからの最大値です。
ミラーディスクリソースやハイブリッドディスクリソースで設定する、[非同期] モードの場合の [キューの数] を決定するための参考値として使用します。
|
LOG
(現)
|
Send Queue, Max2
(送信キュー数、一定期間中の最大値)
|
個
|
ミラー同期データを送信するときに使用されるキューの数です。出力される値は、1サンプリング期間内の最大値です。
|
LOG
(現)
|
Send Queue, Cur
(送信キュー数、最新値)
|
個
|
ミラー同期データを送信するときに使用されるキューの数です。出力される値は、採取時の最新の値です。
|
LOG
(現)
|
Request Queue, Max
(リクエストキュー数、最大値)
|
個
|
ミラーパーティションへ送られた、処理中のI/O要求の個数です。出力される値は、ミラーデーモン(ミラーエージェント)が起動してからの最大値です。
クラスタのプロパティの [ミラードライバ] タブの [リクエストキューの最大数] を決定するための参考値として使用します。
|
LOG
(現)
|
Request Queue, Max2
(リクエストキュー数、一定期間中の最大値)
|
個
|
ミラーパーティションへ送られた、処理中のI/O要求の個数です。出力される値は、1サンプリング期間内の最大値です。
|
LOG
(現)
|
Request Queue, Cur
(リクエストキュー数、最新値)
|
個
|
ミラーパーティションへ送られた、処理中のI/O要求の個数です。出力される値は、採取時の最新の値です。
|
LOG
(現)
|
MDC HB Time, Max
(ミラーディスクコネクトのハートビート時間、最大値)
|
秒
|
ミラーディスクコネクトで相手サーバへ ICMP の ECHOを送ってから、相手サーバからICMP の ECHO REPLY を受信するまでの時間です。
出力される値は、ミラーデーモン(ミラーエージェント)が起動してからの最大値です。
|
LOG
(両)
|
MDC HB Time, Max2
(ミラーディスクコネクトのハートビート時間、一定期間中の最大値)
|
秒
|
ミラーディスクコネクトで相手サーバへ ICMP の ECHOを送ってから、相手サーバからICMP の ECHO REPLY を受信するまでの時間です。
出力される値は、1サンプリング期間内の最大値です。
|
LOG
(両)
|
MDC HB Time, Cur
(ミラーディスクコネクトのハートビート時間、最新値)
|
秒
|
ミラーディスクコネクトで相手サーバへ ICMP の ECHOを送ってから、相手サーバからICMP の ECHO REPLY を受信するまでの時間です。
出力される値は、採取時の最新の値です。
|
LOG
(両)
|
Local-Write Waiting Recovery-Read Time, Total
(ミラー同期のI/O排他時間、合計値)
|
秒
|
ミラー復帰中にディスクの同じ領域へWriteが発生した場合、その領域のミラー復帰処理が終わるまでWriteを保留します。
出力される値は、ミラーデーモン(ミラーエージェント)が起動してからのその保留時間の累積値です。
クラスタのプロパティの [ミラーエージェント] タブの [復帰データサイズ] を大きくすると、この保留時間が長くなる可能性があります。これを決定するための参考値として使用します。
|
LOG
(現)
|
Local-Write Waiting Recovery-Read Time, Total2
(ミラー同期のI/O排他時間、一定期間内の累計)
|
秒
|
ミラー復帰中にディスクの同じ領域へ Write が発生した場合、その領域のミラー復帰処理が終わるまでWriteを保留します。
出力される値は、1 サンプリング期間内のその保留時間の累積値です。
|
LOG
(現)
|
Recovery-Read Waiting Local-Write Time, Total
(ミラー復帰のI/O排他時間、合計値)
|
秒
|
ミラーパーティションへの Write 中にディスクの同じ領域へミラー復帰データの Read が発生した場合、その領域への Write 処理が終わるまでミラー復帰データの Read を保留します。
出力される値は、ミラーデーモン(ミラーエージェント)が起動してからのその保留時間の累積値です。
クラスタのプロパティの [ミラーエージェント] タブの [復帰データサイズ] を大きくすると、この保留時間が長くなる可能性があります。これを決定するための参考値として使用します。
|
LOG
(現)
|
Recovery-Read Waiting Local-Write Time, Total2
(ミラー復帰のI/O排他時間、一定期間内の合計値)
|
秒
|
ミラーパーティションへの Write 中にディスクの同じ領域へミラー復帰データの Read が発生した場合、その領域への Write 処理が終わるまでミラー復帰データの Read を保留します。
出力される値は、1 サンプリング期間内のその保留時間の累積値です。
|
LOG
(現)
|
Unmount Time, Max
(アンマウント時間、最大値)
|
秒
|
ミラーディスクリソースやハイブリッドディスクリソースが非活性する時に実行される、umount処理にかかった時間の最大です。
ミラーディスクリソースやハイブリッドディスクリソースで設定する、[アンマウント] タブの [タイムアウト] を決定するための参考値として使用します。
|
LOG
(現)
|
Unmount Time, Last
(アンマウント時間、最新値)
|
秒
|
ミラーディスクリソースやハイブリッドディスクリソースが非活性する時に実行される、umount処理にかかった時間です。
出力される値は、umount処理が最後に実行された時の値です。
|
LOG
(現)
|
Fsck Time, Max
(fsck時間、最大値)
|
秒
|
ミラーディスクリソースやハイブリッドディスクリソースが活性する時に実行される、fsck処理にかかった時間の最大です。
ミラーディスクリソースやハイブリッドディスクリソースで設定する、[Fsck] タブの [fsckタイムアウト] を決定するための参考値として使用します。
|
LOG
(現)
|
Fsck Time, Last
(fsck時間、最新値)
|
秒
|
ミラーディスクリソースやハイブリッドディスクリソースが活性する時に実行される、fsck処理にかかった時間です。
出力される値は、fsck処理が最後に実行された時の値です。
|
LOG
(現)
|
- 1
- カッコ内の単位は、コマンドによる表示の場合の単位です。出力時には小数点第2位までの値が出力されます。したがって、小数点第3位以下は切り捨てとなります。換算時に用いられる変換規則は以下です。1KB=1024バイト、1MB=1048576バイト。切り捨てによって0となる場合は、"0.00"を出力します。切り捨てでなくても0の場合は、コマンドでは"None"を、ミラー統計情報ファイルでは"0"を、出力します。
- 2
- CMD … コマンド (clpmdstat, clphdstat) で見ることの出来る情報です。LOG … ミラー統計情報ファイルへ出力される情報です。(現) … 現用系の場合に有効となる値が出力されます。(両) … 現用系/待機系どちらの場合でも有効な値が出力されます。なお、サーバに統計情報として記録される値は、そのサーバの情報のみとなり、他サーバの情報は記録されません。
- 3(1,2,3,4)
- モードが「同期」の場合は、「ミラー同期データを送信してから、相手サーバからACKを受信するまでにかかった時間」です。モードが「非同期」の場合は、「ミラー同期データを同期用のキューに積んでから、相手サーバからACKを受信するまでにかかった時間」です。
「統計情報を採取する」に設定している場合には、一部の情報(上記表の出力列にCMD表記があるもの)をclpmdstat/clphdstatコマンドを使用して採取、表示することができます。コマンドの使用方法については『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ミラー状態を表示する (clpmdstat コマンド)」を参照してください。
コマンドによる表示はCluster WebUI で [クラスタのプロパティ] の [統計情報] タブの [ミラー統計情報] を有効にしている場合のみ利用できます。
2.4. システムリソース統計情報採取機能¶
Cluster WebUI の設定モードで [クラスタのプロパティ] の [統計情報] タブにある [システムリソース統計情報] のチェックボックスにチェックをしていた場合、クラスタにシステムモニタリソースまたはプロセスリソースモニタリソースを追加していた場合、システムリソースに関する情報が採取され、インストールパス/perf/system配下に以下のファイル名規則で保存されています。本ファイルはテキスト形式(CSV)です。以下説明文中では本ファイルをシステムリソース統計情報ファイルとして表記します。
system.cur
system.pre
|
|
|---|---|
cur |
最新の情報出力先であることを示しています。 |
pre |
ローテートされた以前の情報出力先であることを示しています。 |
採取された情報はシステムリソース統計情報ファイルに保存されます。本ファイルへの統計情報の出力間隔(=サンプリング間隔)は 60 秒です。ファイルのサイズが 16MB でローテートされ、2 世代分保存されます。システムリソース統計情報ファイルに記録された情報を利用することでシステムのパフォーマンス解析の参考にすることが可能です。採取される統計情報には以下のような項目が含まれています。
統計値名 |
単位 |
説明 |
|---|---|---|
CPUCount |
個 |
CPU数 |
CPUUtilization |
% |
CPU使用率 |
CPUTotal |
10ミリ秒 |
CPU総時間 |
CPUUser |
10ミリ秒 |
ユーザモードでの消費時間 |
CPUNice |
10ミリ秒 |
優先度の低いユーザモードでの消費時間 |
CPUSystem |
10ミリ秒 |
システムモードでの消費時間 |
CPUIdle |
10ミリ秒 |
タスク待ち消費時間 |
CPUIOWait |
10ミリ秒 |
I/Oの完了待ち時間 |
CPUIntr |
10ミリ秒 |
割り込み処理を行った時間 |
CPUSoftIntr |
10ミリ秒 |
ソフト割り込みを行った時間 |
CPUSteal |
10ミリ秒 |
仮想化環境使用時、他のOSに消費された時間 |
MemoryTotalSize |
バイト(KB) |
総メモリ量 |
MemoryCurrentSize |
バイト(KB) |
メモリ使用量 |
MemoryBufSize |
バイト(KB) |
バッファサイズ |
MemoryCached |
バイト(KB) |
キャッシュメモリサイズ |
MemoryMemFree |
バイト(KB) |
メモリ空き容量 |
MemoryDirty |
バイト(KB) |
ディスク書き込み待機中メモリ |
MemoryActive(file) |
バイト(KB) |
バッファ or ページキャッシュメモリ |
MemoryInactive(file) |
バイト(KB) |
空きバッファ or 空きページキャッシュメモリ |
MemoryShmem |
バイト(KB) |
共有メモリサイズ |
SwapTotalSize |
バイト(KB) |
利用可能なスワップサイズ |
SwapCurrentSize |
バイト(KB) |
使用中のスワップサイズ |
SwapIn |
回 |
スワップインの回数 |
SwapOut |
回 |
スワップアウトの回数 |
ThreadLimitSize |
個 |
スレッド上限値 |
ThreadCurrentSize |
個 |
現在のスレッド数 |
FileLimitSize |
個 |
オープンファイル数の上限 |
FileCurrentSize |
個 |
現在のオープンファイル数 |
FileLimitinode |
個 |
システム全体のinode数 |
FileCurrentinode |
個 |
現在のinode数 |
ProcessCurrentCount |
個 |
現在の総プロセス数 |
出力されるシステムリソース統計情報ファイルの例を記載します。
system.cur
"Date","CPUCount","CPUUtilization","CPUTotal","CPUUser","CPUNice","CPUSystem","CPUIdle","CPUIOWait","CPUIntr","CPUSoftIntr","CPUSteal","MemoryTotalSize","MemoryCurrentSize","MemoryBufSize","MemoryCached","MemoryMemFree","MemoryDirty","MemoryActive(file)","MemoryInactive(file)","MemoryShmem","SwapTotalSize","SwapCurrentSize","SwapIn","SwapOut","ThreadLimitSize","ThreadCurrentSize","FileLimitSize","FileCurrentSize","FileLimitinode","FileCurrentinode","ProcessCurrentCount" "2019/10/31 15:44:50","2","0","34607369","106953","59","23568","34383133","89785","0","3871","0","754236","231664","948","334736","186888","12","111320","167468","50688","839676","0","0","0","5725","183","71371","1696","22626","22219","121" "2019/10/31 15:45:50","2","0","34619340","106987","59","23577","34395028","89816","0","3873","0","754236","231884","948","334744","186660","12","111320","167476","50688","839676","0","0","0","5725","183","71371","1696","22867","22460","121" "2019/10/31 15:46:50","2","0","34631314","107022","59","23586","34406925","89846","0","3876","0","754236","231360","948","334764","187164","4","111348","167468","50688","839676","0","0","0","5725","183","71371","1696","22867","22460","121" :
2.5. プロセスリソース統計情報採取機能¶
Cluster WebUI の設定モードで [クラスタのプロパティ] の [統計情報] タブにある [システムリソース統計情報] のチェックボックスにチェックをしていた場合、クラスタにシステムモニタリソースまたはプロセスリソースモニタリソースを追加していた場合、プロセスリソースに関する情報が採取され、インストールパス/perf/system配下に以下のファイル名規則で保存されています。本ファイルはテキスト形式(CSV)です。以下説明文中では本ファイルをプロセスリソース統計情報ファイルとして表記します。
process.cur
process.pre
|
|
|---|---|
cur |
最新の情報出力先であることを示しています。 |
pre |
ローテートされた以前の情報出力先であることを示しています。 |
採取された情報はプロセスリソース統計情報ファイルに保存されます。本ファイルへの統計情報の出力間隔(=サンプリング間隔)は 60 秒です。ファイルのサイズが 32MB でローテートされ、2 世代分保存されます。プロセスリソース統計情報ファイルに記録された情報を利用することでプロセスのパフォーマンス解析の参考にすることが可能です。採取される統計情報には以下のような項目が含まれています。
統計値名 |
単位 |
説明 |
|---|---|---|
PID |
- |
プロセスID |
CPUUtilization |
% |
CPU使用率 |
MemoryPhysicalSize |
バイト(KB) |
物理メモリ使用量 |
MemoryVirtualSize |
バイト(KB) |
仮想メモリ使用量 |
ThreadCurrentCount |
個 |
スレッド数 |
FileCurrentCount |
個 |
オープンファイル数 |
ProcessName |
- |
プロセス名
※ プロセス名は「"」(ダブルクォーテーション)で括らずに出力します。
|
出力されるプロセスリソース統計情報ファイルの例を記載します。
process.cur
"Date","PID","CPUUtilization","MemoryPhysicalSize","MemoryVirtualSize","ThreadCurrentCount","FileCurrentCount","ProcessName" "2022/09/05 17:08:41","620","0","26384","1132","1","21",/usr/lib/systemd/systemd-logind "2022/09/05 17:08:41","623","0","126384","1096","1","6",/usr/sbin/crond -n "2022/09/05 17:08:41","1023","0","239924","2880","3","12",/usr/sbin/rsyslogd -n :
2.6. クラスタ統計情報採取機能¶
Cluster WebUI の設定モードで [クラスタのプロパティ] の [統計情報] タブにある [クラスタ統計情報] のチェックボックスにチェックをしていた場合、ハートビートリソースの受信間隔やグループのフェイルオーバ、グループリソースの起動、モニタリソースの監視処理等、それぞれの処理の結果や要した時間の情報を採取します。本ファイルはテキスト形式(CSV)です。以下説明文中では本ファイルをクラスタ統計情報ファイルとして表記します。
ハートビートリソースの場合
ハートビートリソースのタイプ毎に同じファイルに出力されます。 カーネルモードLANハートビートリソースおよびユーザモードLANハートビートリソースが対応しています。
[ハートビートリソースタイプ].cur[ハートビートリソースタイプ].precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/heartbeat/
グループの場合
group.curgroup.precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/group/
グループリソースの場合
グループリソースのタイプ毎に同じファイルに出力されます。
[グループリソースタイプ].cur[グループリソースタイプ].precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/group/
モニタリソースの場合
モニタリソースのタイプ毎に同じファイルに出力されます。
[モニタリソースタイプ].cur[モニタリソースタイプ].precur
最新の情報出力先であることを示しています。
pre
ローテートされた以前の情報出力先であることを示しています。
保存先
インストールパス/perf/cluster/monitor/
注釈
クラスタ統計情報ファイルへの統計情報の出力タイミングは以下です。
採取される統計情報には以下の項目が含まれています。
ハートビートリソースの場合
統計値名
説明
Date
統計情報の出力時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000Name
ハートビートリソースの名前です。
Type
ハートビートリソースのタイプ名です。
Local
自サーバのホスト名です。
Remote
相手サーバのホスト名です。
RecvCount
ログ出力間隔以内のハートビート受信回数です。
RecvError
ログ出力間隔以内の受信エラー回数です。
RecvTime(Min)
ログ出力間隔以内のハートビート受信間隔の最小値です。(単位:ミリ秒)
RecvTime(Max)
ログ出力間隔以内のハートビート受信間隔の最大値です。(単位:ミリ秒)
RecvTime(Avg)
ログ出力間隔以内のハートビート受信間隔の平均値です。(単位:ミリ秒)
SendCount
ログ出力間隔以内のハートビート送信回数です。
SendError
ログ出力間隔以内の送信エラー回数です。
SendTime(Min)
ログ出力間隔以内のハートビート送信処理時間の最小値です。(単位:ミリ秒)
SendTime(Max)
ログ出力間隔以内のハートビート送信処理時間の最大値です。(単位:ミリ秒)
SendTime(Avg)
ログ出力間隔以内のハートビート送信処理時間の平均値です。(単位:ミリ秒)
ハートビートリソース以外の場合
統計値名
説明
Date
統計情報の出力時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000Name
グループ / グループリソース / モニタリソースの名前です。
Action
実行した処理の名称です。以下の文字列が出力されます。グループの場合: Start(起動時), Stop(停止時), Move(移動時), Failover(フェイルオーバ時)グループリソースの場合: Start(活性時), Stop(非活性時)モニタリソースの場合: Monitor(監視処理実行時)Result
実行した処理結果の名称です。以下の文字列が出力されます。成功の場合: Success (監視正常, 活性/非活性正常)失敗の場合: Failure (監視異常, 活性/非活性異常)警告の場合: Warning(モニタの場合のみ, 警告の場合)タイムアウトの場合: Timeout (監視タイムアウト)キャンセルの場合: Cancel(処理のキャンセル(グループ起動中のクラスタ停止等))ReturnCode
実行した処理の戻り値です。
StartTime
実行した処理の開始時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000EndTime
実行した処理の終了時刻です。以下の形式で出力されます。(000はミリ秒)YYYY/MM/DD HH:MM:SS.000ResponseTime(ms)
実行した処理の所要時間です。(単位:ミリ秒)ミリ秒表記で出力されます。
下記構成例のグループを起動した場合に出力される統計情報ファイルの例を記載します。
サーバ - ホスト名: server1, server2
ハートビートリソース
- カーネルモードLANハートビートリソースリソース名: lankhb1, lankhb2
グループ
グループ名: failoverA
グループ (failoverA) に属するグループリソース
- execリソースリソース名: exec01, exec02, exec03
lankhb.cur
"Date","Name","Type","Local","Remote","RecvCount","RecvError","RecvTime(Min)","RecvTime(Max)","RecvTime(Avg)","SendCount","SendError","SendTime(Min)","SendTime(Max)","SendTime(Avg)" "2018/12/18 09:35:36.237","lankhb1","lankhb","server1","server1","20","0","3000","3000","3000","20","0","0","0","0" "2018/12/18 09:35:36.237","lankhb1","lankhb","server1","server2","20","0","3000","3000","3000","20","0","0","0","0" "2018/12/18 09:35:36.237","lankhb2","lankhb","server1","server1","20","0","3000","3000","3000","20","0","0","0","0" "2018/12/18 09:35:36.237","lankhb2","lankhb","server1","server2","20","0","3000","3000","3000","20","0","0","0","0" :
group.cur
"Date","Name","Action","Result","ReturnCode","StartTime","EndTime","ResponseTime(ms)" "2018/12/19 09:44:16.925","failoverA","Start","Success",,"2018/12/19 09:44:09.785","2018/12/19 09:44:16.925","7140" :
exec.cur
"Date","Name","Action","Result","ReturnCode","StartTime","EndTime","ResponseTime(ms)" "2018/12/19 09:44:14.845","exec01","Start","Success",,"2018/12/19 09:44:09.807","2018/12/19 09:44:14.845","5040" "2018/12/19 09:44:15.877","exec02","Start","Success",,"2018/12/19 09:44:14.847","2018/12/19 09:44:15.877","1030" "2018/12/19 09:44:16.920","exec03","Start","Success",,"2018/12/19 09:44:15.880","2018/12/19 09:44:16.920","1040" :
2.6.1. クラスタ統計情報ファイルのファイルサイズに関する注意事項¶
クラスタ統計情報ファイルは構成によって生成される数が異なります。構成によっては大量のファイルが生成されるため、構成に合わせてクラスタ統計情報のファイルサイズの設定をご検討ください。クラスタ統計情報ファイルの最大サイズは以下の式で計算します。
クラスタ統計情報のファイルサイズ =([ハートビートリソースのファイルサイズ] x [設定されているハートビートリソースのタイプ数]) x (世代数(2)) +([グループのファイルサイズ]) x (世代数(2)) +([グループリソースのファイルサイズ] x [設定されているグループリソースのタイプ数]) x (世代数(2)) +([モニタリソースのファイルサイズ] x [設定されているモニタリソースのタイプ数]) x (世代数(2))例: 下記構成例の場合に保存されるクラスタ統計情報ファイルの合計最大サイズは 332MB になります。((((50MB) x 1) x 2) + ((1MB) x 2) + ((3MB x 5) x 2) + ((10MB x 10) x 2) = 332MB)
ハートビートリソースタイプ数: 1 (ファイルサイズ: 50MB)
グループ (ファイルサイズ: 1MB)
グループリソースタイプ数: 5 (ファイルサイズ: 3MB)
モニタリソースタイプ数: 10 (ファイルサイズ: 10MB)
2.7. Cluster WebUI 操作ログ出力機能¶
Cluster WebUI の設定モードで [クラスタのプロパティ] の [WebManager] タブにある「Cluster WebUI の操作ログを出力する」のチェックボックスにチェックをしていた場合、Cluster WebUI で操作した情報をログファイルに出力します。本ファイルはテキスト形式(CSV)です。以下説明文中では本ファイルをCluster WebUI 操作ログファイルとして表記します。
cur
最新の情報出力先であることを示しています。
pre<x>
保存先
Cluster WebUI の設定モードで「ログ出力先」に指定したディレクトリ
出力する操作情報には以下の項目が含まれています。
項目名 |
説明 |
|---|---|
Date |
操作情報の出力時刻です。
以下の形式で出力されます。(000はミリ秒)
YYYY/MM/DD HH:MM:SS.000
|
Operation |
Cluster WebUI で実行した操作です。 |
Request |
Cluster WebUI から WebManager サーバへ発行したリクエスト URL です。 |
IP |
Cluster WebUI を操作したクライアントの IP アドレスです。 |
UserName |
操作を実行したユーザ名です。
Cluster WebUI にログインする方法として「OS 認証方式」を利用している場合に Cluster WebUI にログインしたユーザ名が出力されます。
|
HTTP-Status |
HTTPステータスコードです。
200 : 成功
200以外 : 失敗
|
ErrorCode |
実行した操作の戻り値です。 |
ResponseTime(ms) |
実行した操作の所要時間です。(単位:ミリ秒)
ミリ秒表記で出力されます。
|
ServerName |
操作対象のサーバ名です。
サーバ名、または、IP アドレスが出力されます。
操作対象としてサーバ名が指定された操作の場合に出力されます。
|
GroupName |
操作対象のグループ名です。
操作対象としてグループ名が指定された操作の場合に出力されます。
|
ResourceName |
操作対象のリソース名です。
ハートビートリソース名/ネットワークパーティション解決リソース名/グループリソース名/モニタリソース名が出力されます。
操作対象としてリソース名が指定された操作の場合に出力されます。
|
ResourceType |
操作対象のリソースタイプです。
操作対象としてリソースタイプが指定された操作の場合に出力されます。
|
Parameters… |
操作固有のパラメータです。 |
出力される Cluster WebUI 操作ログファイルの例を記載します。
"Date","Operation","Request","IP","UserName","HTTP-Status","ErrorCode","ResponseTime(ms)","ServerName","GroupName","ResourceName","ResourceType","Parameters..." "2020/08/14 17:08:39.902","Cluster properties","/GetClusterproInfo.js","10.0.0.15","user1",200,0,141,,,, "2020/08/14 17:08:46.659","Monitor properties","/GetMonitorResourceProperty.js","10.0.0.15","user1",200,0,47,,,"fipw1","fipw" "2020/08/14 17:15:31.093","Resource properties","/GetGroupResourceProperty.js","10.0.0.15","user1",200,0,47,,"failoverA","fip1","fip" "2020/08/14 17:15:45.309","Start group","/GroupStart.js","10.0.0.15","user1",200,0,0,"server1","failoverA",, "2020/08/14 17:16:23.862","Suspend all monitors","/AllMonitorSuspend.js","10.0.0.15","user1",200,0,453,"server1",,,,"server2" :
認証失敗時に出力される Cluster WebUI 操作ログファイルの例です。
クラスタパスワード方式の場合
"Date","Operation","Request","IP","UserName","HTTP-Status","ErrorCode","ResponseTime(ms)","ServerName","GroupName","ResourceName","ResourceType","Parameters..." "2020/11/20 09:29:59.710","Login","/Login.js","10.0.0.15","",403,,0,,,,
OS認証方式の場合
"Date","Operation","Request","IP","UserName","HTTP-Status","ErrorCode","ResponseTime(ms)","ServerName","GroupName","ResourceName","ResourceType","Parameters..." "2020/11/20 09:29:59.710","Login User","/LoginUser.js","10.0.0.15","user1",401,,0,,,,
2.8. 通信ポート情報¶
CLUSTERPRO はいくつかのポート番号を使用します。ファイアウォールの設定を変更してCLUSTERPRO がポート番号を使用できるように設定してください。
クラウド環境の場合は、インスタンス側のファイアウォール設定の他に、クラウド基盤側のセキュリティ設定においても、下記のポート番号にアクセスできるようにしてください。
CLUSTERPRO が使用するポート番号については、『スタートアップガイド』 -「注意制限事項」-「通信ポート番号」を参照してください。
2.9. クラスタドライバデバイス情報¶
ミラードライバは、メジャー番号として 218 をおもに使用します。他のドライバがこのメジャー番号を使用していないことを確認してください。ただし、システムの制約上どうしても 218 以外で動作させたいときは、メジャー番号の変更が可能です。
カーネルモード LAN ハートビートドライバは、メジャー番号 10、マイナー番号 253 をおもに使用します。他のドライバがこのメジャーおよびマイナー番号を使用していないことを確認してください。
キープアライブドライバは、メジャー番号 10、マイナー番号 254 をおもに使用します。他のドライバがこのメジャーおよびマイナー番号を使用していないことを確認してください。
2.10. サーバダウンの発生条件¶
CLUSTERPRO では、以下の異常が発生した場合、リソースなどを保護することを目的とし、サーバのシャットダウン、リセット、パニック等を発生させます。
2.10.1. リソース活性/非活性異常時の最終動作¶
リソース活性/非活性異常時の最終動作に以下が設定されている場合
最終動作 |
挙動 |
|---|---|
クラスタサービス停止と OS シャットダウン |
グループリソース停止後、通常のシャットダウンを発生させます。 |
クラスタサービス停止と OS 再起動 |
グループリソース停止後、通常のリブートを発生させます。 |
sysrq パニック |
グループリソース活性/非活性異常時に、パニックを発生させます。 |
keepalive リセット |
グループリソース活性/非活性異常時に、リセットを発生させます。 |
keepalive パニック |
グループリソース活性/非活性異常時に、パニックを発生させます。 |
BMC リセット |
グループリソース活性/非活性異常時に、リセットを発生させます。 |
BMC パワーオフ |
グループリソース活性/非活性異常時に、パワーオフを発生させます。 |
BMC パワーサイクル |
グループリソース活性/非活性異常時に、パワーサイクルを発生させます。 |
BMC NMI |
グループリソース活性/非活性異常時に、NMI を発生させます。 |
2.10.2. リソース活性/非活性ストール発生時の動作¶
リソースの活性/非活性ストール発生時動作に以下が設定されていて、リソース活性/非活性処理で想定以上の時間がかかった場合
ストール発生時動作 |
挙動 |
|---|---|
クラスタサービス停止と OS シャットダウン |
グループリソース活性/非活性ストール発生時に、グループリソース停止後、通常のシャットダウンを発生させます。 |
クラスタサービス停止と OS 再起動 |
グループリソース活性/非活性ストール発生時に、グループリソース停止後、通常のリブートを発生させます。 |
sysrq パニック |
グループリソース活性/非活性ストール発生時に、パニックを発生させます。 |
keepalive リセット |
グループリソース活性/非活性ストール発生時に、リセットを発生させます。 |
keepalive パニック |
グループリソース活性/非活性ストール発生時に、パニックを発生させます。 |
BMC リセット |
グループリソース活性/非活性ストール発生時に、リセットを発生させます。 |
BMC パワーオフ |
グループリソース活性/非活性ストール発生時に、パワーオフを発生させます。 |
BMC パワーサイクル |
グループリソース活性/非活性ストール発生時に、パワーサイクルを発生させます。 |
BMC NMI |
グループリソース活性/非活性ストール発生時に、NMI を発生させます。 |
リソース活性ストールが発生した場合、アラートおよびsyslogに下記のメッセージが出力されます。
モジュールタイプ : rc
イベントID : 32
メッセージ : Activating %1 resource has failed.(99 : command is timeout)
説明 : %1リソースの起動処理が失敗しました。
リソース非活性ストールが発生した場合、アラートおよびsyslogに下記のメッセージが出力されます。
モジュールタイプ : rc
イベントID : 42
メッセージ : Stopping %1 resource has failed.(99 : command is timeout)
説明 : %1リソースの停止処理が失敗しました。
2.10.3. モニタリソース異常検出時の最終動作¶
モニタリソース監視異常時の最終動作に以下が設定されている場合
最終動作 |
挙動 |
|---|---|
クラスタサービス停止と OS シャットダウン |
グループリソース停止後、シャットダウンを発生させます。 |
クラスタサービス停止と OS リブート |
グループリソース停止後、リブートを発生させます。 |
Sysrq パニック |
モニタリソース異常検出時に、パニックを発生させます。 |
Keepalive リセット |
モニタリソース異常検出時に、リセットを発生させます。 |
Keepalive パニック |
モニタリソース異常検出時に、パニックを発生させます。 |
BMC リセット |
モニタリソース異常検出時に、リセットを発生させます。 |
BMC パワーオフ |
モニタリソース異常検出時に、パワーオフを発生させます。 |
BMC パワーサイクル |
モニタリソース異常検出時に、パワーサイクルを発生させます。 |
BMC NMI |
モニタリソース異常検出時に、NMI を発生させます。 |
2.10.4. 強制停止動作¶
強制停止のタイプが [BMC] に設定されている場合
強制停止アクション |
挙動 |
|---|---|
BMC リセット |
フェイルオーバグループが存在していたダウン サーバでリセットを発生させます。 |
BMC パワーオフ |
フェイルオーバグループが存在していたダウン サーバでパワーオフを発生させます。 |
BMC パワーサイクル |
フェイルオーバグループが存在していたダウン サーバでパワーサイクルを発生させます。 |
BMC NMI |
フェイルオーバグループが存在していたダウン サーバで NMI を発生させます。 |
強制停止のタイプが [vCenter] に設定されている場合
強制停止アクション |
挙動 |
|---|---|
パワーオフ |
フェイルオーバグループが存在していたダウン サーバでパワーオフを発生させます。 |
リセット |
フェイルオーバグループが存在していたダウン サーバでリセットを発生させます。 |
強制停止のタイプが [AWS]、[Azure] または [OCI] に設定されている場合
強制停止アクション |
挙動 |
|---|---|
stop |
フェイルオーバグループが存在していたダウン サーバのインスタンスを停止します。 |
reboot |
フェイルオーバグループが存在していたダウン サーバのインスタンスを再起動します。 |
2.10.5. 緊急サーバシャットダウン、緊急サーバリブート¶
以下のプロセスの異常終了検出時、シャットダウンまたはリブートを発生させます。シャットダウンまたはリブートのいずれになるかは [クラスタサービスのプロセス異常時動作] の設定によります。
clprc
clprm
2.10.6. CLUSTERPRO デーモン停止時のリソース非活性異常¶
CLUSTERPRO デーモン停止処理でリソースの非活性に失敗した場合、[クラスタサービスのプロセス異常時動作] で設定された処理が実行されます。
2.10.7. ユーザ空間でのストール検出¶
タイムアウト時間以上のストール発生時に OS のハードウェアリセットまたはパニックを発生させます。ハードウェアリセットまたはパニックのいずれになるかはユーザ空間モニタリソースの [タイムアウト発生時動作] の設定によります。
2.10.8. シャットダウン中のストール検出¶
OS シャットダウンの延長でストール発生時に OS のハードウェアリセットまたはパニックを発生させます。ハードウェアリセットまたはパニックのいずれになるかはシャットダウン監視の [タイムアウト発生時動作] の設定によります。
2.10.9. ネットワークパーティションからの復帰¶
ネットワークパーティション解決リソースが設定されていない場合、全てのハートビートが遮断された場合 (ネットワークパーティション) に両サーバがお互いにフェイルオーバを行います。その結果、両サーバでグループが活性化されます。ネットワークパーティション解決リソースが設定されている場合でも両サーバでグループが活性化されることがあります。
この状態からインタコネクトが復旧した場合に、両サーバ、またはいずれかのサーバでシャットダウンを発生させます。
ネットワークパーティションについては『リファレンスガイド』の「トラブルシューティング」の「ネットワークパーティションが発生した」を参照してください。
2.10.10. ネットワークパーティション解決¶
ネットワークパーティション解決リソースが設定されている場合、全てのハートビートが遮断された場合 (ネットワークパーティション) にネットワークパーティション解決を行います。ネットワークパーティション状態と判定した場合には、いずれかのサーバ、あるいは全てのサーバでシャットダウンまたはサービス停止を発生させます。シャットダウンまたはサービス停止のいずれになるかは [NP 発生時動作] の設定によります。
ネットワークパーティション解決については『リファレンスガイド』の「ネットワークパーティション解決リソースの詳細」を参照してください。
2.10.11. ミラーディスク異常 -Replicator を使用している場合-¶
ミラーディスクに異常が発生した場合、ミラーエージェントが reset を発生させます。
2.10.12. ハイブリッドディスク異常 -Replicator DR を使用している場合-¶
ハイブリッドディスクに異常が発生した場合、ミラーエージェントが reset を発生させます。
2.10.13. クラスタサスペンド・リジューム失敗時¶
クラスタサスペンド・リジュームに失敗したサーバはシャットダウンします。
2.11. 一時的にフェイルオーバを実行させないように設定するには¶
サーバダウンによるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
- タイムアウトの一時調整タイムアウトを一時的に調整することで、サーバダウンによるフェイルオーバを抑止することができます。タイムアウトの一時調整には、[clptoratio] コマンドを使用します。クラスタ内のいずれかのサーバ上で [clptoratio] コマンドを実行してください。
例) HBタイムアウトが90秒のときに、1時間、HBタイムアウトを3600秒に延長する場合
clptoratio -r 40 -t 1h
[clptoratio] コマンドの詳細に関しては『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「タイムアウトを一時調整する (clptoratio コマンド)」を参照してください。 - タイムアウトの一時調整の解除タイムアウトの一時調整を解除します。クラスタ内のいずれかのサーバ上で [clptoratio] コマンドを実行してください。
clptoratio -i
[clptoratio] コマンドの詳細に関しては『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「タイムアウトを一時調整する (clptoratio コマンド)」を参照してください。
モニタリソースの監視を一時停止することにより監視異常によるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
- モニタリソースの監視一時停止監視を一時停止することで、監視によるフェイルオーバの発生を抑止することができます。監視の一時停止には、[clpmonctrl] コマンドを使用します。クラスタ内の全てのサーバで [clpmonctrl] コマンドを実行してください。または、クラスタ内の任意のサーバで -hオプションを使い全てのサーバに [clpmonctrl] コマンドを実行してください。
例) コマンド実行サーバ上の全ての監視を停止する場合
clpmonctrl -s
例) -hオプションにて指定したサーバ上の全ての監視を停止する場合
clpmonctrl -s -h < サーバ名 >
[clpmonctrl] コマンドの詳細に関しては『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「モニタリソースを制御する (clpmonctrl コマンド)」を参照してください。 - モニタリソースの監視再開監視を再開させます。クラスタ内の全てのサーバで [clpmonctrl] コマンドを実行してください。または、クラスタ内の任意のサーバで -hオプションを使い全てのサーバに [clpmonctrl] コマンドを実行してください。
例) コマンド実行サーバ上の全ての監視を再開する場合
clpmonctrl -r
例) -hオプションにて指定したサーバ上の全ての監視を再開する場合
clpmonctrl -r -h < サーバ名 >
[clpmonctrl] コマンドの詳細に関しては『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「モニタリソースを制御する (clpmonctrl コマンド)」を参照してください。
モニタリソース異常時の回復動作を無効化することにより監視異常によるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
- モニタリソース異常時の回復動作を無効化するモニタリソース異常時の回復動作を無効化する設定になっていると、モニタリソースが異常を検出しても回復動作を行わなくなります。この機能を設定するには、Cluster WebUI の設定モードから [クラスタのプロパティ] の [拡張] タブの [クラスタ動作の無効化] にある [モニタリソースの異常検出時の回復動作] にチェックを入れ、設定を反映してください。
- モニタリソース異常時の回復動作を無効化しないモニタリソース異常時の回復動作を無効化する設定を解除します。Cluster WebUI の設定モードから [クラスタのプロパティ] の [拡張] タブの [クラスタ動作の無効化] にある [モニタリソースの異常検出時の回復動作] のチェックを外し、設定を反映してください。
グループリソース活性異常時の復旧動作を無効化することにより活性異常によるフェイルオーバを一時的に抑止する場合には、以下の手順を実行してください。
- グループリソース活性異常時の復旧動作を無効化するグループリソース活性異常時の復旧動作を無効化する設定になっていると、グループリソースが活性異常を検出しても復旧動作を行わなくなります。この機能を設定するには、Cluster WebUI の設定モードから [クラスタのプロパティ] の [拡張] タブの [クラスタ動作の無効化] にある [グループリソースの活性異常検出時の復旧動作] にチェックを入れ、設定を反映してください。
- グループリソース活性異常時の復旧動作を無効化しないグループリソース活性異常時の復旧動作を無効化する設定を解除します。Cluster WebUI の設定モードから [クラスタのプロパティ] の [拡張] タブの [クラスタ動作の無効化] にある [グループリソースの活性異常検出時の復旧動作] のチェックを外し、設定を反映してください。
2.12. ミラーディスクの交換手順¶
ミラーディスク故障時等、運用開始後にミラーディスクの交換を行う場合、以下の手順を実行してください。
参考
デーモンの停止、および開始の詳細については、『インストール&設定ガイド』の「運用開始前の準備を行う」の「CLUSTERPRO を一時停止する」を参照してください。
2.12.1. 単体のディスクで構成される (非RAID) ミラーディスクを交換する場合¶
ミラーディスクを交換する側のサーバを終了します。
注釈
サーバ終了前に『インストール&設定ガイド』の「CLUSTERPRO デーモンの無効化」を行っておくことを推奨します。デーモンを無効化するサーバ上で、以下のコマンドを実行して、デーモンを無効にします。clpsvcctrl.sh --disable core mgr
ハイブリッドディスク故障の場合、交換対象のディスクに接続されている全てのサーバを終了してください。
新しいディスクをサーバ内に設置します。
新しいディスクを設置したサーバを起動します。このとき、CLUSTERPRO サービスを起動しないようにします。手順1. で CLUSTERPRO デーモンの無効化を行っていない場合、OS 起動時にランレベル 1 で起動します。
新しいディスクに対し、fdisk コマンドを用いて、元と同じパーティションを区切った状態を作ります。
注釈
ハイブリッドディスクで共有ストレージ側を交換する場合、その共有ストレージに接続されているどこか1台のサーバでパーティションの作成とファイルシステムの作成を行ってください。
過去に CLUSTERPRO のミラーディスクやハイブリッドディスクとして使用していたディスクを、データを破棄して流用する場合には、クラスタパーティションの初期化を行ってください。
クラスタパーティション(CLUSTERパーティション)の初期化については、『インストール&設定ガイド』の「システム構成を決定する」の「ハードウェア構成後の設定」内の各該当項目(「ハイブリッドディスクリソース用の共有ディスクを設定する (Replicator DR 使用時は必須)」、「ハイブリッドディスクリソース用のパーティションを設定する (Replicator DR 使用時は必須)」、「ミラーディスクリソース用のパーティションを設定する (Replicator 使用時は必須)」)を参照してください。
自動で初期ミラー構築がおこなわれないようにします。
ミラーディスクを交換しない側のサーバ上で業務を稼働した状態で (ミラーディスクリソースを含むグループが活性している状態で)、並行してディスクのコピー(初期ミラー構築)を行いたい場合には、初期ミラー構築が自動的におこなわれないようにする必要は、ありません。
ディスクのコピーが完了するまで業務を停止してもよい場合 (グループを非活性にしてもよい場合)には、そのミラーディスクリソースを含むグループを非活性状態にしてください。
注釈
- 手順(A) では、ファイルシステムの種類によってはディスク使用量分のコピーを行いますので、コピー時間がディスク使用量に依存する場合があります。また、業務の稼働とコピー処理とが並行して行われるため、場合によっては高負荷になったり、コピーに時間がかかったりすることがあります。
業務を停止した状態で(グループが非活性の状態で)ディスクをコピーする場合の手順(B) では、ファイルシステムによってはディスク使用量分のコピーを行いますので、コピー時間がディスク使用量に依存する場合があります。業務の開始(グループの活性)は、コピー完了後に行うことができます。
新しいディスクを設置した側のサーバで、CLUSTERPRO デーモンの有効化を行い、サーバを再起動させます。
注釈
- サーバ終了前に『インストール&設定ガイド』の「CLUSTERPRO デーモンの無効化」を行った場合、ここで CLUSTERPRO デーモンを有効化しておきます。デーモンを有効化するサーバ上で、以下のコマンドを実行して、デーモンを有効にします。
clpsvcctrl.sh --enable core mgr
以下のコマンドで初期ミラー構築(ディスクのコピー)を開始してください。
- ミラーディスクを交換しない側のサーバ上で業務を稼働している場合自動で初期ミラー構築(ディスクのコピー)が開始されます。もし、「初期ミラー構築を行う」を「オフ」に設定している場合には、自動では開始されませんので、ミラーディスクリストまたは下記のコマンドで、手動で開始してください。
【ミラーディスクの場合】
clpmdctrl --force <コピー元サーバ名> <ミラーディスクリソース名>
【ハイブリッドディスクの場合】
clphdctrl --force <コピー元サーバ名> <ハイブリッドディスクリソース名>
- 業務を停止していて、ディスクのコピーが完了した後に、業務を開始する場合(ミラーディスクリソースを含むグループが非活性の状態でコピーする場合)
【ミラーディスクの場合】
clpmdctrl --force <コピー元サーバ名> <ミラーディスクリソース名>
【ハイブリッドディスクの場合】
clphdctrl --force <コピー元サーバ名> <ハイブリッドディスクリソース名>
- 業務を停止している状態(非活性状態)で初期ミラー構築を開始した場合 (B) は、初期ミラー構築完了後(ディスクのコピー完了後)に、業務を開始(グループを活性)することができます。ミラー復帰を中断した場合には、グループを活性せずに再度初期ミラー構築を開始してください。
2.12.2. 複数のディスクで構成される (RAID) ミラーディスクを交換する場合¶
ミラーディスクを交換する側のサーバを終了します。
注釈
- サーバ終了前に『インストール&設定ガイド』の「CLUSTERPRO デーモンの無効化」を行っておくことを推奨します。デーモンを無効化するサーバ上で、以下のコマンドを実行して、デーモンを無効にします。
clpsvcctrl.sh --disable core mgr
ハイブリッドディスク故障の場合、交換対象のディスクに接続されている全てのサーバを終了してください。
新しいディスクをサーバ内に設置します。
新しいディスクを設置しサーバを起動します。
OS 起動前に RAID の再構築を行います。
- OS 起動時、CLUSTERPRO サービスを起動しないようにします。手順1.でCLUSTERPRO デーモンの無効化を行っていない場合、OS 起動時にランレベル 1 で起動し、CLUSTERPRO デーモンの無効化を行ってからランレベル 3 で起動してください。必要に応じて、データパーティションからデータのバックアップを取ってください。
LUNが初期化されている場合には、新しいディスクに対し、fdiskコマンドを用いて、クラスタパーティションとデータパーティションを作成します。
注釈
ハイブリッドディスクで共有ストレージ側を交換する場合、その共有ストレージに接続されているどこか1台のサーバでパーティションとファイルシステムを作成してください。
root でログインし、以下のいずれかの方法でクラスタパーティションを初期化します。
ddコマンドを使わない方法
【ミラーディスクの場合】
clpmdinit --create force <ミラーディスクリソース名>
【ハイブリッドディスクの場合】
clphdinit --create force <ハイブリッドディスクリソース名>
注釈
- ミラーディスクの場合で、ミラーディスクリソースの設定で「初期mkfsを行う」を「オン」にしている場合には、このコマンドの実行時に mkfs が実行され、ファイルシステムが初期化されます。なお、大容量ディスクの場合には mkfs に時間がかかることがあります。(mkfsが実行されると、データパーティションに保存されているデータは消えます。コマンド実行前に必要に応じてデータパーティションからデータのバックアップを取ってください。)ミラーのデータは、後述の初期ミラー構築により相手サーバ側からコピーされます。
ddコマンドを使う方法
【ミラーディスクの場合】
dd if=/dev/zero of=<クラスタパーティションのデバイス名(例:/dev/sdb1)> clpmdinit --create quick <ミラーディスクリソース名>
【ハイブリッドディスクの場合】
dd if=/dev/zero of=<クラスタパーティションのデバイス名(例:/dev/sdb1)> clphdinit --create quick <ハイブリッドディスクリソース名>
注釈
dd コマンドを実行すると of= で指定したパーティションのデータは初期化されます。パーティションデバイス名に間違いがないか十分に確認してから dd コマンドを実行してください。
dd コマンドを実行したときに以下のメッセージが表示されることがありますが、異常ではありません。
dd: writing to <CLUSTERパーティションのデバイス名>: No space left on device
ミラーのデータは、後述の初期ミラー構築により相手サーバ側からコピーされます。コマンド実行前に必要に応じてデータパーティションからデータのバックアップを取ってください。
自動で初期ミラー構築がおこなわれないようにします。
- ミラーディスクを交換しない側 のサーバ上で業務を稼働した状態 (ミラーディスクリソースを含むグループが活性している状態)で、並行してディスクのコピー(初期ミラー構築)を行いたい場合には、初期ミラー構築が自動的におこなわれないようにする必要は、ありません。
ディスクのコピーが完了するまで業務を停止してもよい場合 (グループを非活性にしてもよい場合)には、そのミラーディスクリソースを含むグループを非活性状態にしてください。
注釈
- 手順(A) では、ファイルシステムの種類によってはディスク使用量分のコピーを行いますので、コピー時間がディスク使用量に依存する場合があります。また、業務の稼働とコピー処理とが並行して行われるため、場合によっては高負荷になったり、コピーに時間がかかったりすることがあります。
業務を停止した状態で(グループが非活性の状態で)ディスクをコピーする場合の手順(B) では、ファイルシステムによってはディスク使用量分のコピーを行いますので、コピー時間がディスク使用量に依存する場合があります。業務の開始(グループの活性)は、コピー完了後に行うことができます。
ディスクを交換した側のサーバで、CLUSTERPRO デーモンの有効化を行い、サーバを再起動させます。
注釈
- サーバ終了前に『インストール&設定ガイド』の「CLUSTERPRO デーモンの無効化」を行った場合、ここで CLUSTERPRO デーモンを有効化しておきます。デーモンを有効化するサーバ上で、以下のコマンドを実行して、デーモンを有効にします。
clpsvcctrl.sh --enable core mgr
以下のコマンドで初期ミラー構築(ディスクのコピー)を開始してください。
- ミラーディスクを交換しない側のサーバ上で業務を稼働している場合自動で初期ミラー構築(ディスクのコピー)が開始されます。もし、「初期ミラー構築を行う」を「オフ」に設定している場合には、自動では開始されませんので、ミラーディスクリストまたは下記のコマンドで、手動で開始してください。
【ミラーディスクの場合】
clpmdctrl --force <コピー元サーバ名> <ミラーディスクリソース名>
【ハイブリッドディスクの場合】
clphdctrl --force <コピー元サーバ名> <ハイブリッドディスクリソース名>
- 業務を停止していてディスクのコピーが完了した後に開始する場合(ミラーディスクリソースを含むグループが非活性の状態でコピーする場合)
【ミラーディスクの場合】
clpmdctrl --force <コピー元サーバ名> <ミラーディスクリソース名>
【ハイブリッドディスクの場合】
clphdctrl --force <コピー元サーバ名> <ハイブリッドディスクリソース名>
- 業務を停止している状態(非活性状態)で初期ミラー構築を開始した場合 (B) は、初期ミラー構築完了後(ディスクのコピー完了後)に、業務を開始(グループを活性)することができます。ミラー復帰を中断した場合には、グループを活性せずに再度初期ミラー構築を開始してください。
2.12.3. 両系のミラーディスクを交換する場合¶
注釈
両系のミラーディスクを交換した場合、ミラーディスク内のデータは失われます。必要に応じてディスク交換後、バックアップデータ等から復旧してください。
両サーバとも終了します。
注釈
- 両サーバともサーバ終了前に『インストール&設定ガイド』の「CLUSTERPRO デーモンの無効化」を行っておくことを推奨します。デーモンを無効化するサーバ上で、以下のコマンドを実行して、デーモンを無効にします。
clpsvcctrl.sh --disable core mgr
両サーバとも新しいディスクをサーバ内に設置します。
両サーバを起動します。このとき、CLUSTERPRO サービスを起動しないようにします。手順1. で CLUSTERPRO デーモンの無効化を行っていない場合、OS 起動時にランレベル 1 で起動します。
両サーバの新しいディスクに対し、fdisk コマンドを用いて、元と同じパーティションを区切った状態を作ります。
注釈
ハイブリッドディスクで共有ストレージ側を交換する場合、その共有ストレージに接続されているどこか1台のサーバでパーティションの作成とファイルシステムの作成を行ってください。
過去に CLUSTERPRO のミラーディスクやハイブリッドディスクとして使用していたディスクを、データを破棄して流用する場合には、クラスタパーティションの初期化を行ってください。データパーティションのファイルシステムの初期化も、必要に応じて行ってください。
クラスタパーティション(CLUSTERパーティション)の初期化、および、ファイルシステムの作成とその要否については、『インストール&設定ガイド』の「システム構成を決定する」の「ハードウェア構成後の設定」内の各該当項目(「ハイブリッドディスクリソース用の共有ディスクを設定する (Replicator DR 使用時は必須)」、「ハイブリッドディスクリソース用のパーティションを設定する (Replicator DR 使用時は必須)」、「ミラーディスクリソース用のパーティションを設定する (Replicator 使用時は必須)」)を参照してください。
両サーバを再起動させます。
注釈
- サーバ終了前に『インストール&設定ガイド』の「CLUSTERPRO デーモンの無効化」を行った場合、ここで CLUSTERPRO デーモンを有効化しておきます。デーモンを有効化するサーバ上で、以下のコマンドを実行して、デーモンを有効にします。
clpsvcctrl.sh --enable core mgr
- 再起動すると、自動で初期ミラー構築(全面ミラー復帰)が開始されます。「初期ミラー構築を行う」を「オフ」に設定している場合には、自動的に開始されずにそのまま正常状態になります。従ってこの場合には必ず、Cluster WebUI のミラーディスクリスト または clpmdctrl, clphdctrlコマンドで、手動で全面ミラー復帰を開始してください。
必要に応じて全面ミラー復帰完了後に、バックアップデータ等からデータを復旧してください。
2.14. サーバを交換するには -ミラーディスクの場合-¶
2.14.1. ミラーディスクも交換する場合¶
管理 IP アドレスで Cluster WebUI に接続します。管理 IP アドレスがない場合は、交換しないサーバの IP アドレスで Cluster WebUI を接続します。
障害が発生したサーバマシンとディスクを交換します。交換前のサーバと同じ IP アドレス、ホスト名を設定します。
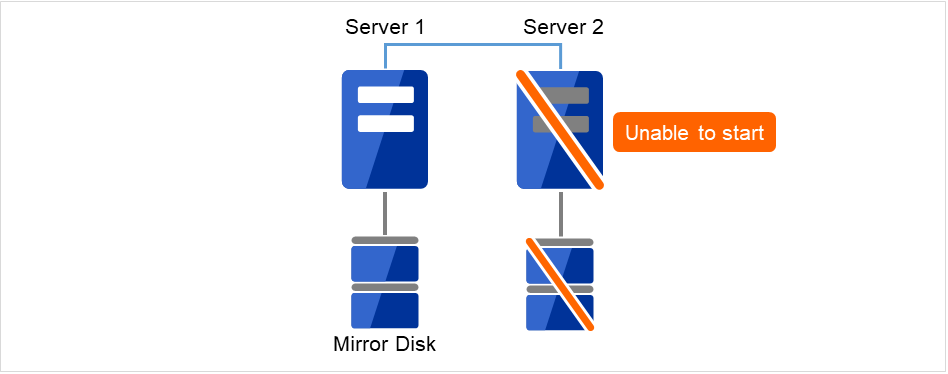
図 2.2 Server2が起動できず、ディスクも使用できない¶
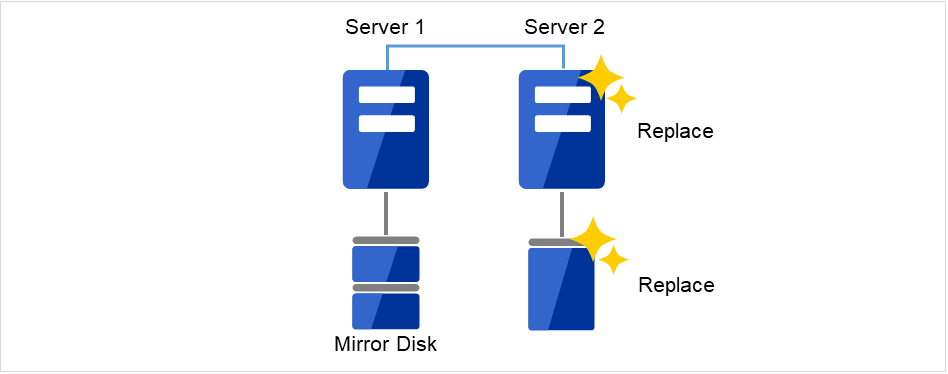
図 2.3 Server2を新しいサーバと新しいディスクに交換¶
[fdisk] コマンドを使用してディスクのパーティションを確保します。
交換したサーバに CLUSTERPRO サーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」の「CLUSTERPRO Server のセットアップ」を参照してください。CLUSTERPRO サーバをインストールしたサーバはインストール後、再起動しておく必要があります。
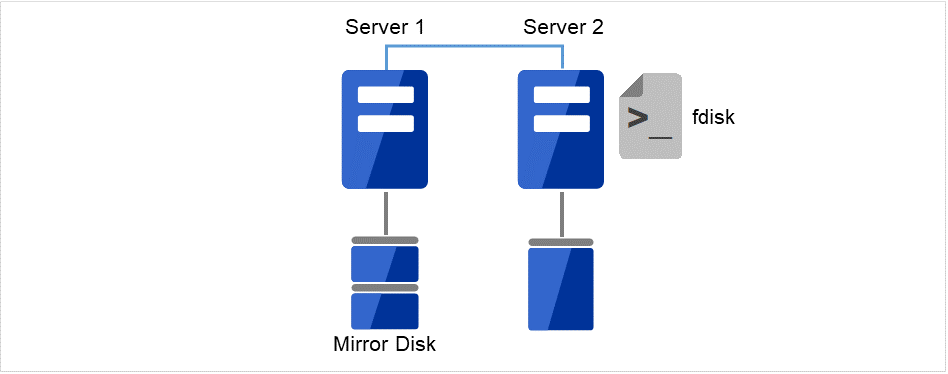
図 2.4 新しいディスクにパーティションを確保¶
以前、ミラーディスクとして使用したことがあるディスクを流用する場合は、クラスタパーティションの初期化を行ってください。
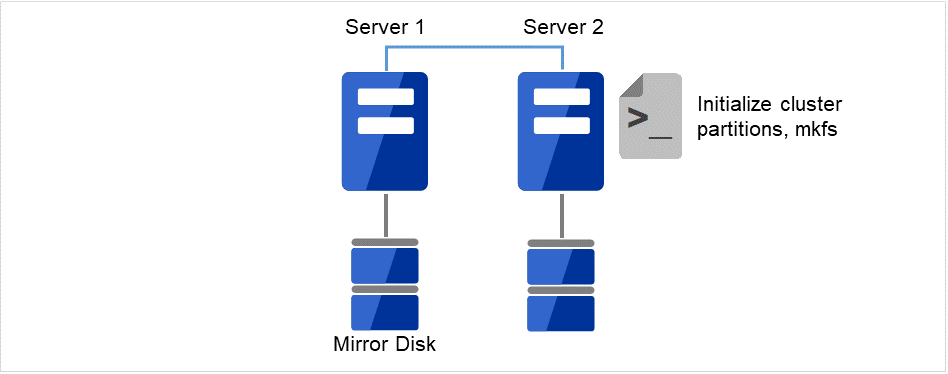
図 2.5 新しいディスクのパーティション設定を実行¶
- 接続した Cluster WebUI の設定モードから、クラスタ構成情報をアップロードします。期限付きライセンスを使用している場合は、以下のコマンドを実行します。
clplcnsc --reregister <ライセンスファイル格納フォルダのパス>
アップロード後、交換したサーバを再起動してください。 - 再起動後、交換したディスクのクラスタパーティションの初期化、データパーティションのファイルシステム作成が実行されます。初期ミラー構築を行う設定にしている場合は、その後、ミラー復帰が実行されます。初期ミラー構築を行う設定にしていない場合は、手動でミラー復帰を実行する必要があります。ミラー復帰は全面コピーとなります。以下のコマンドを実行してミラー復帰の完了を確認するか、Cluster WebUI を使用してミラー復帰の完了を確認します。詳細は『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ミラー関連コマンド」を参照してください。
clpmdstat --mirror <ミラーディスクリソース名(例:md1)>
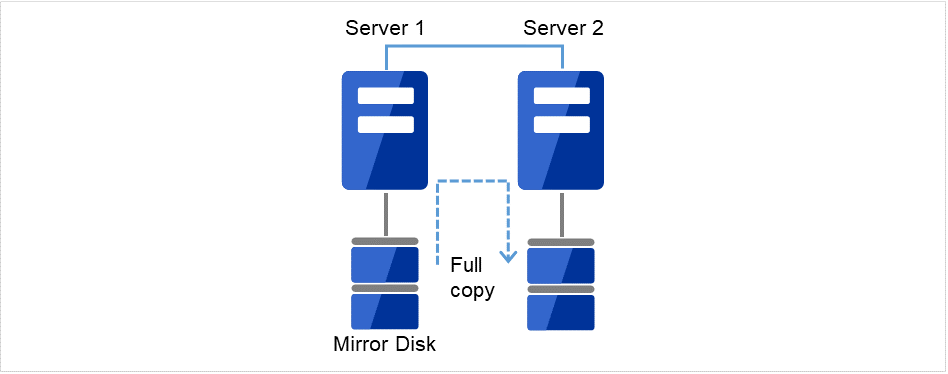
図 2.6 Server1よりミラー復帰開始(全面コピー)¶
2.14.2. ミラーディスクを流用する場合¶
管理 IP で Cluster WebUI に接続します。管理 IP がない場合は、交換しないサーバの実 IP で Cluster WebUI を接続します。
障害が発生したサーバマシンを交換し、ミラーディスクを流用します。交換前のサーバと同じ IP アドレス、ホスト名を設定します。
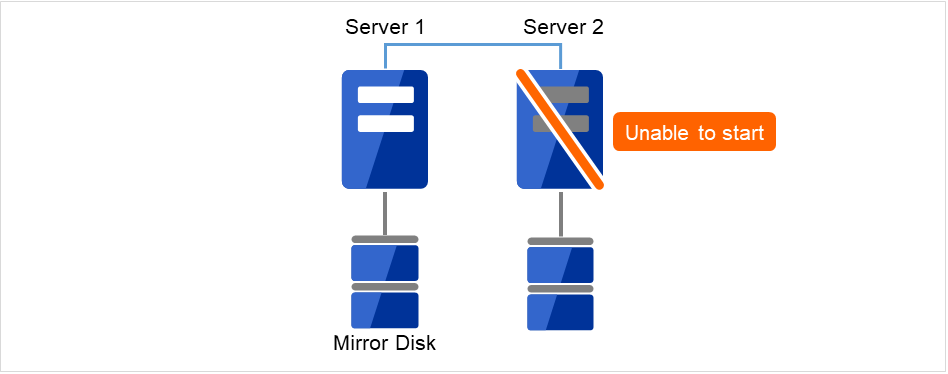
図 2.7 Server2が起動できない¶
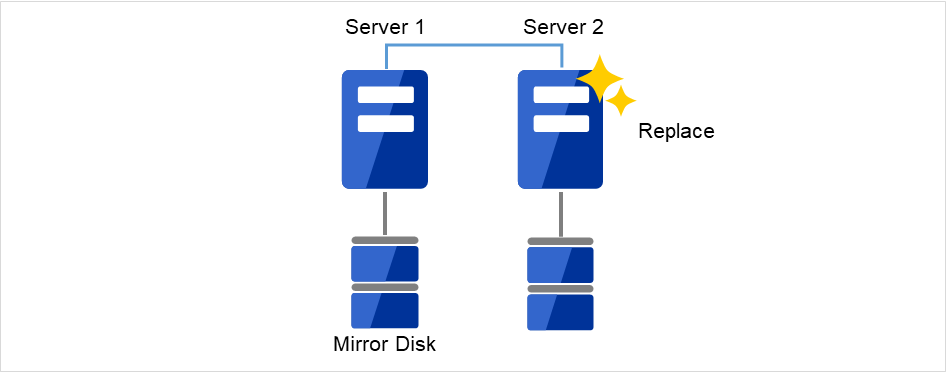
図 2.8 Server2を新しいサーバに交換¶
交換したサーバに CLUSTERPROサーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」の「CLUSTERPRO Server のセットアップ」を参照してください。CLUSTERPRO サーバをインストールしたサーバはインストール後、再起動しておく必要があります。
- 接続した Cluster WebUI の設定モードから、クラスタ構成情報をアップロードします。期限付きライセンスを使用している場合は、以下のコマンドを実行します。
clplcnsc --reregister <ライセンスファイル格納フォルダのパス>
アップロード後、交換したサーバを再起動してください。 - 再起動後、差分がない場合はこのまま運用を開始することができます。再起動後、ミラーディスクに差分がある場合はミラー復帰操作が必要です。自動ミラー復帰が有効な場合はミラー復帰が実行されます。自動ミラー復帰が無効な場合は手動でミラー復帰を実行する必要があります。以下のコマンドを実行してミラー復帰の完了を確認するか、Cluster WebUI を使用してミラー復帰の完了を確認します。詳細は『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ミラー関連コマンド」を参照してください。
clpmdstat --mirror <ミラーディスクリソース名(例:md1)>
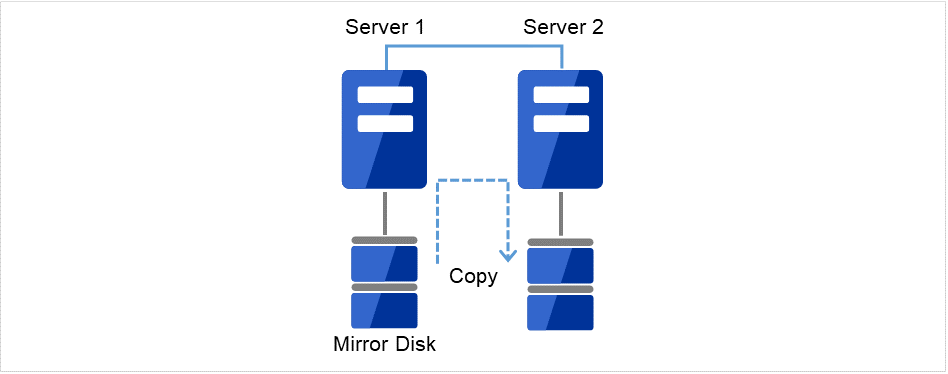
図 2.9 Server1よりミラー復帰開始(差分コピー)¶
2.15. サーバを交換するには -ハイブリッドディスクの場合-¶
2.15.1. 共有ディスクでないハイブリッドディスクも交換する場合¶
管理 IP アドレスで Cluster WebUI に接続します。管理 IP アドレスがない場合は、交換しないサーバの IP アドレスで Cluster WebUI を接続します。
障害が発生したサーバマシンとディスクを交換します。交換前のサーバと同じ IP アドレス、ホスト名を設定します。
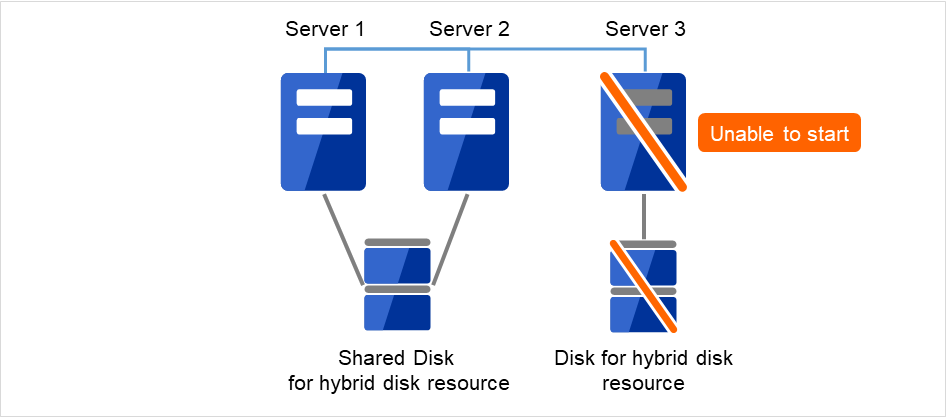
図 2.10 Server3が起動できず、ディスクも使用できない¶
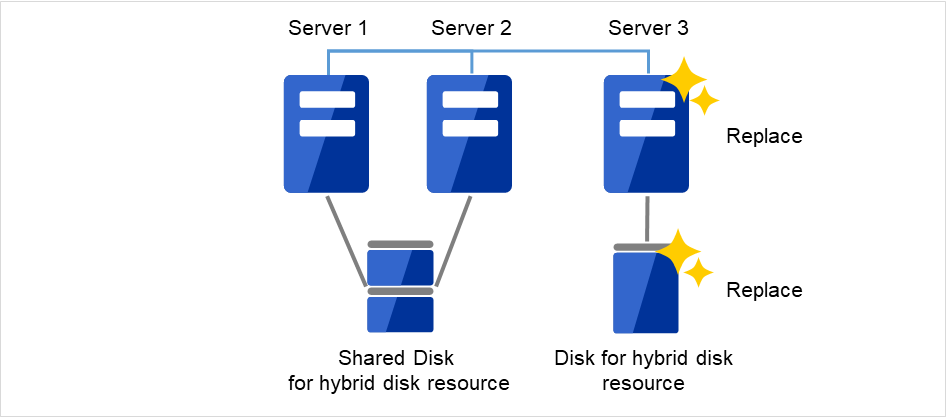
図 2.11 新しいサーバと新しいディスクに交換¶
[fdisk] コマンドを使用してディスクのパーティションを確保します。
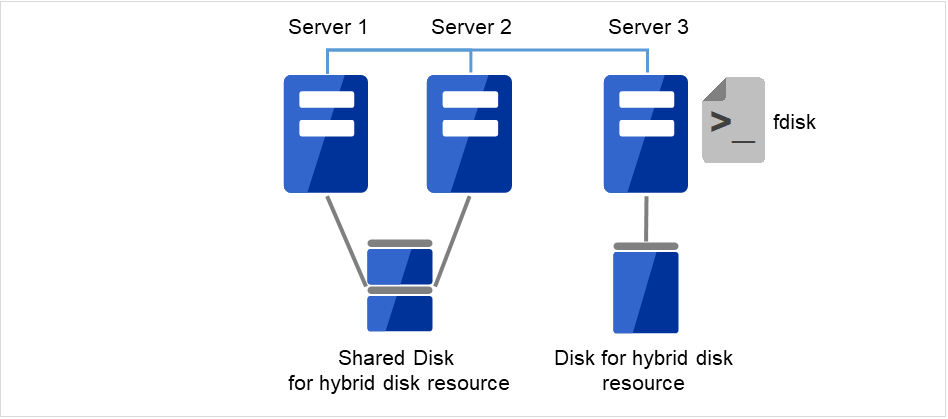
図 2.12 Server3の新しいディスクにパーティションを確保¶
交換したサーバに CLUSTERPRO サーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」 - 「CLUSTERPRO Server のセットアップ」を参照してください。CLUSTERPRO サーバをインストールしたサーバはインストール後、再起動しておく必要があります。
- 接続した Cluster WebUI の設定モードから、クラスタ構成情報をアップロードします。期限付きライセンスを使用している場合は、以下のコマンドを実行します。
clplcnsc --reregister <ライセンスファイル格納フォルダのパス>
交換したサーバで [clphdinit] コマンドを実行します。
# clphdinit --create force <ハイブリッドディスクリソース名(例:hd1)>
交換したサーバを再起動してください。
- 再起動後、初期ミラー構築を行う設定にしている場合は、ミラー復帰が実行されます。初期ミラー構築を行う設定にしていない場合は、手動でミラー復帰を実行する必要があります。ミラー復帰は全面コピーとなります。以下のコマンドを実行してミラー復帰の完了を確認するか、Cluster WebUI を使用してミラー復帰の完了を確認します。詳細は『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」 - 「ハイブリッドディスク関連コマンド」を参照してください。
clphdstat --mirror {<ハイブリッドディスクリソース名(例:hd1)>}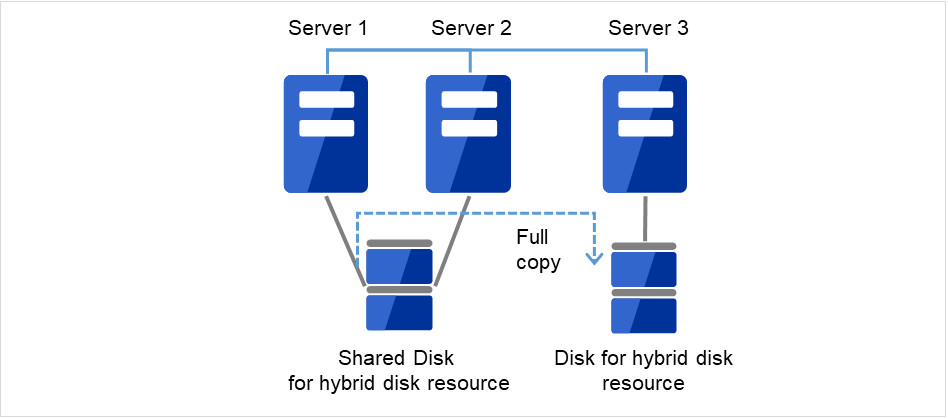
図 2.13 Server1よりミラー復帰開始(全面コピー)¶
2.15.2. 共有ディスクのハイブリッドディスクも交換する場合¶
管理 IP アドレスで Cluster WebUI に接続します。管理 IP アドレスがない場合は、交換しないサーバの IP アドレスで Cluster WebUI を接続します。
障害が発生したサーバと共有ディスクで接続されていたサーバで CLUSTERPRO サービスが起動しないように設定します。
clpsvcctrl.sh --disable core
- 障害が発生したサーバと共有ディスクで接続されていたサーバを OS のシャットダウン コマンドなどでシャットダウンします。交換中も業務を継続したい場合にはサーバ 3 にグループを移動してください。
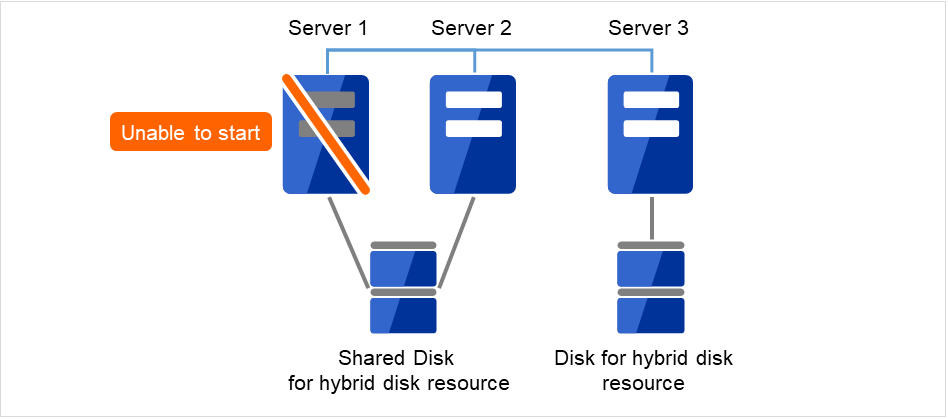
図 2.14 Server1が起動できず、共有ディスクも使用できない¶
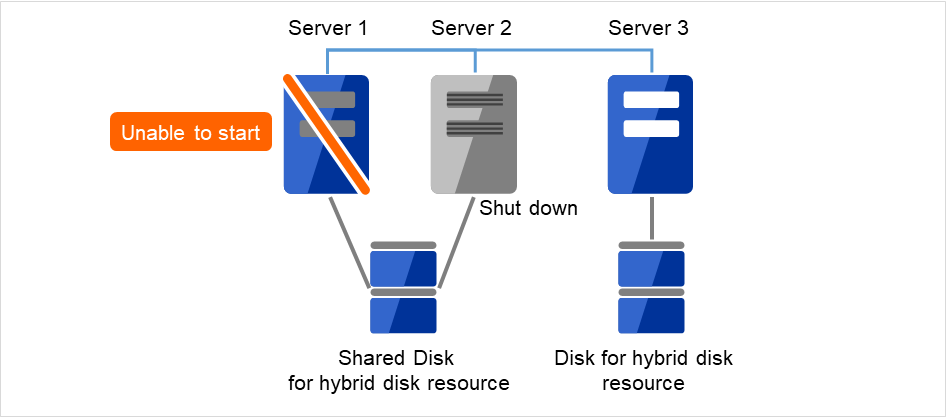
図 2.15 Server2をシャットダウン¶
障害が発生したサーバマシンと共有ディスクを交換します。交換前のサーバと同じ IP アドレス、ホスト名を設定します。
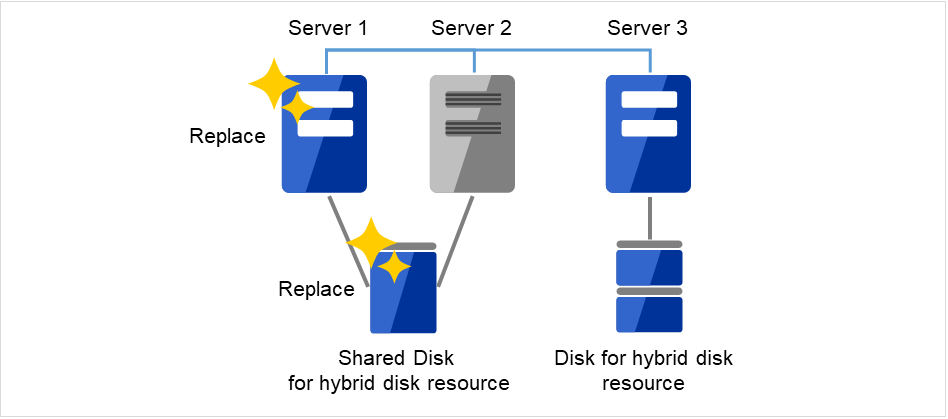
図 2.16 新しいサーバと新しいディスクに交換¶
交換したサーバから [fdisk] コマンドを使用してディスクのパーティションを確保します。
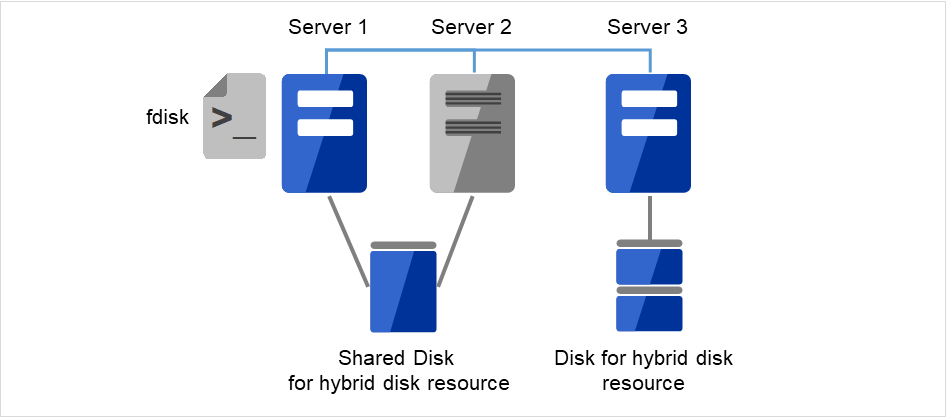
図 2.17 Server1に接続された新しい共有ディスクにパーティションを確保¶
- 交換したサーバに CLUSTERPRO サーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」 - 「CLUSTERPRO Server のセットアップ」を参照してください。CLUSTERPROサーバをインストールしたサーバはインストール後、再起動しておく必要があります。障害が発生したサーバと共有ディスクで接続されていたサーバを起動します。共有ディスクに接続されたサーバのうち、交換していない方のサーバでは、CLUSTERPROを起動しない状態です。
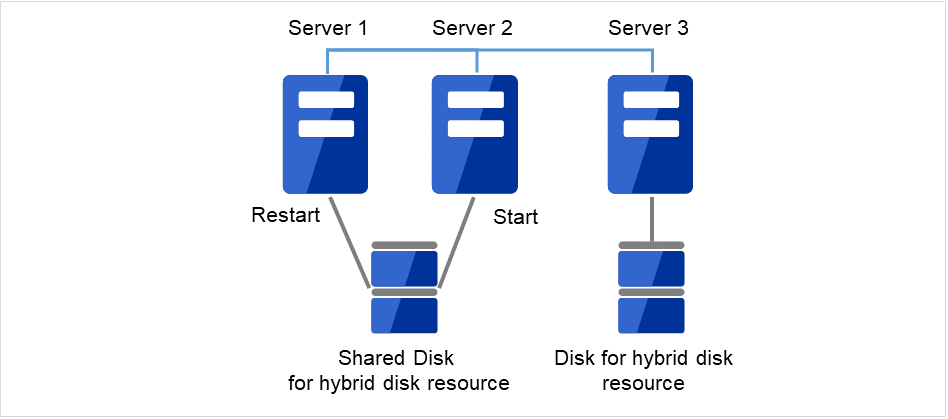
図 2.18 Server1にCLUSTERPROをインストールし、Server2も起動¶
- 接続した Cluster WebUI の設定モードから、クラスタ構成情報をアップロードします。期限付きライセンスを使用している場合は、以下のコマンドを実行します。
clplcnsc --reregister <ライセンスファイル格納フォルダのパス>
交換したサーバで [clphdinit] コマンドを実行します。
# clphdinit --create force <ハイブリッドディスクリソース名(例:hd1)>
障害が発生したサーバと共有ディスクで接続されていたサーバで CLUSTERPRO サービスが起動するように設定します。
clpsvcctrl.sh --enable core
交換したサーバを再起動してください。障害が発生したサーバと共有ディスクで接続されていたサーバも再起動してください。
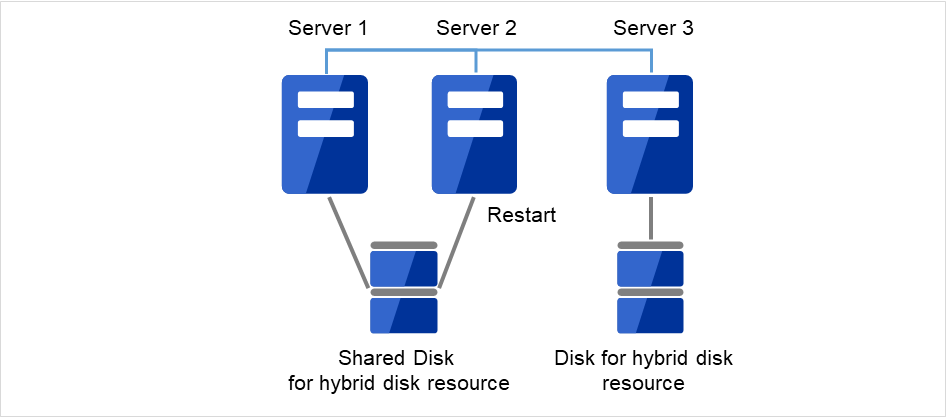
図 2.19 交換したサーバ、および共有ディスクに接続されたサーバを再起動¶
- 再起動後、初期ミラー構築を行う設定にしている場合は、ミラー復帰が実行されます。初期ミラー構築を行う設定にしていない場合は、手動でミラー復帰を実行する必要があります。ミラー先のサーバは共有ディスクが接続されているサーバグループのカレントサーバになります。(図の例は サーバ 1 がカレントサーバの場合です)ミラー復帰は全面コピーとなります。以下のコマンドを実行してミラー復帰の完了を確認するか、Cluster WebUI を使用してミラー復帰の完了を確認します。詳細は『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ハイブリッドディスク関連コマンド」を参照してください。
clphdstat --mirror <ハイブリッドディスクリソース名(例:hd1)>
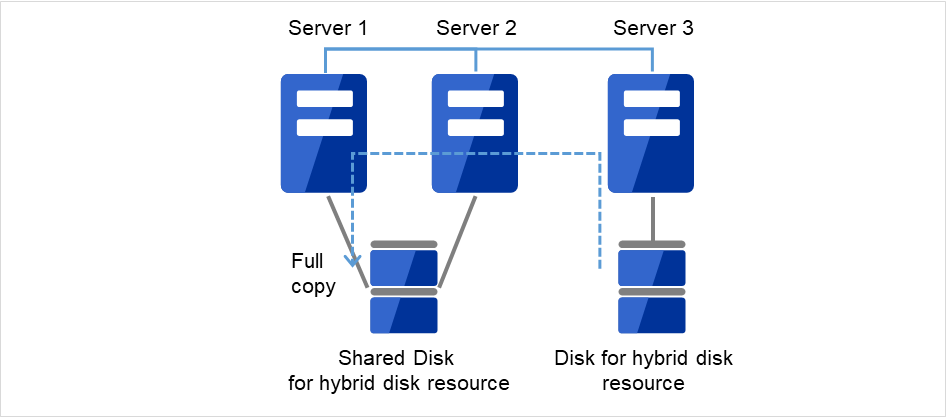
図 2.20 ミラー復帰開始(全面コピー)¶
2.15.3. ディスクを流用する場合¶
管理 IP で Cluster WebUI に接続します。管理 IP がない場合は、交換しないサーバの実 IP で Cluster WebUI を接続します。
障害が発生したサーバマシンを交換し、ミラーディスクを流用します。交換前のサーバと同じ IP アドレス、ホスト名を設定します。
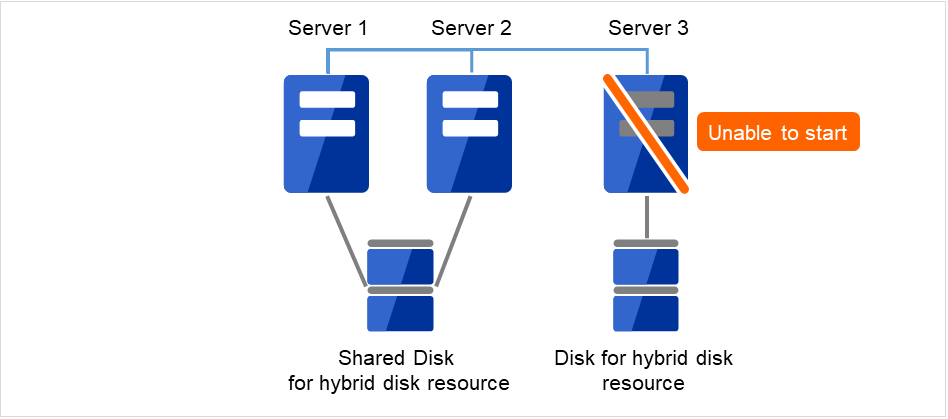
図 2.21 Server1が起動できず、共有ディスクも使用できない¶
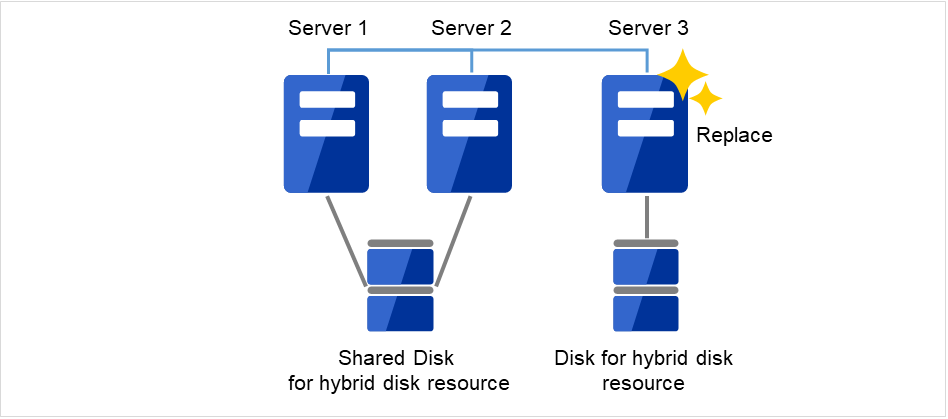
図 2.22 Server3を新しいサーバに交換¶
交換したサーバに CLUSTERPRO サーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」 - 「CLUSTERPRO Server のセットアップ」を参照してください。CLUSTERPRO サーバをインストールしたサーバはインストール後、再起動しておく必要があります。
- 接続した Cluster WebUI の設定モードから、クラスタ構成情報をアップロードします。期限付きライセンスを使用している場合は、以下のコマンドを実行します。
clplcnsc --reregister <ライセンスファイル格納フォルダのパス>
アップロード後、交換したサーバを再起動してください。 - 再起動後、差分がない場合はこのまま運用を開始することができます。再起動後、ミラーディスクに差分がある場合はミラー復帰操作が必要です。自動ミラー復帰が有効な場合はミラー復帰が実行されます。自動ミラー復帰が無効な場合は手動でミラー復帰を実行する必要があります。以下のコマンドを実行してミラー復帰の完了を確認するか、Cluster WebUI を使用してミラー復帰の完了を確認します。詳細は『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「ハイブリッドディスク関連コマンド」を参照してください。
clphdstat --mirror <ハイブリッドディスクリソース名(例:hd1)>
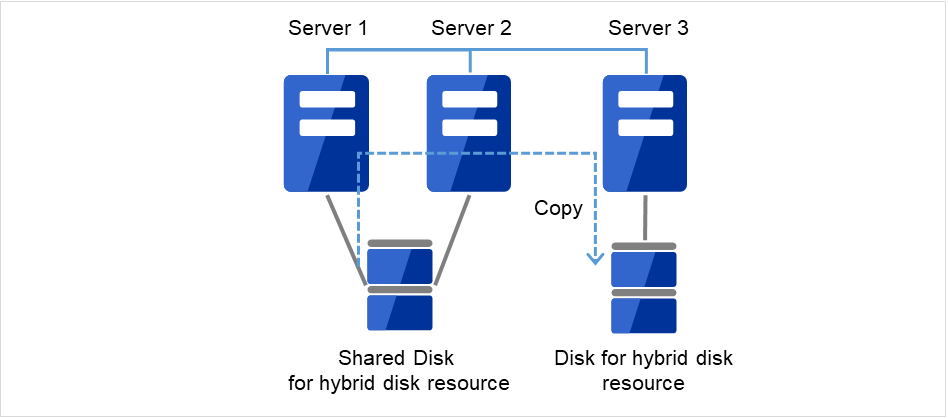
図 2.23 Server1よりミラー復帰開始(差分コピー)¶
2.15.4. 共有ディスクが接続されたサーバを交換する場合¶
管理 IP アドレスで Cluster WebUI に接続します。管理 IP アドレスがない場合は、交換しないサーバの IP アドレスで Cluster WebUI を接続します。
障害が発生したサーバマシンと共有ディスクを交換します。交換前のサーバと同じ IP アドレス、ホスト名を設定します。
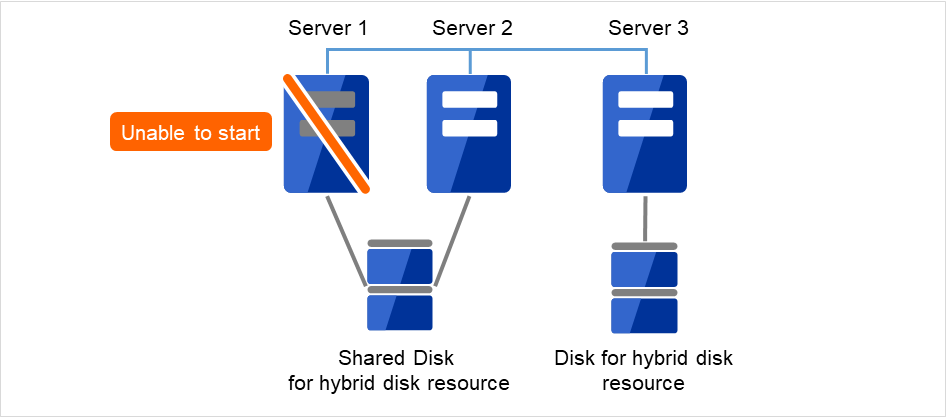
図 2.24 Server1が起動できない¶
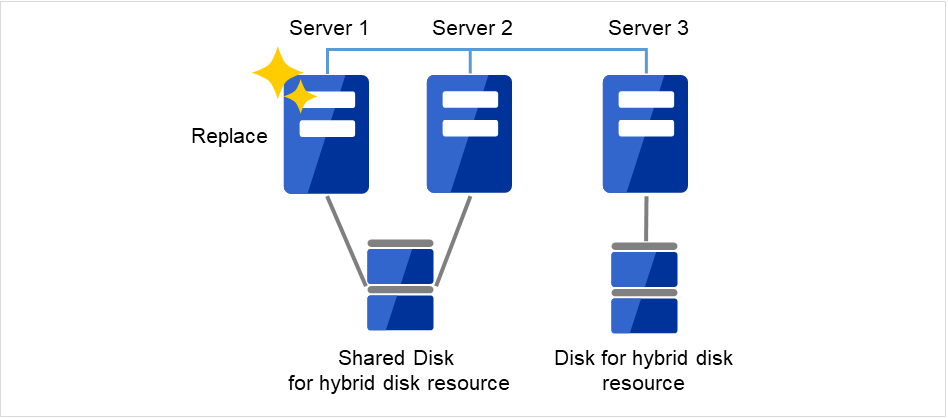
図 2.25 Server1を新しいサーバに交換¶
交換したサーバに CLUSTERPRO サーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」 - 「CLUSTERPRO Server のセットアップ」を参照してください。CLUSTERPRO サーバをインストールしたサーバはインストール後、再起動しておく必要があります。
- 接続した Cluster WebUI の設定モードから、クラスタ構成情報をアップロードします。期限付きライセンスを使用している場合は、以下のコマンドを実行します。
clplcnsc --reregister <ライセンスファイル格納フォルダのパス>
アップロード後、交換したサーバを再起動してください。
2.16. 仮想マシンをリストアするには -ミラーディスクの場合-¶
仮想環境上のサーバのシステムディスクに異常が発生した場合、 以下の手順でディスクを交換し、バックアップデータからのリストアを行ってください。
注釈
clpbackup.sh --pre --no-shutdownを実行するよう記述していますが、代わりにclpbackup.sh --preを実行してサーバがシャットダウンした状態にしてからバックアップを採取するようにしてください。 システムディスクのバックアップを採取する場合、システムディスクが静止した状態にしておくことが推奨されるためです。
システムディスクをリストアするサーバ (以下、対象サーバ) で起動しているグループがあれば、 グループの移動を行ってください。グループの移動が完了した後、 各グループリソースが正常に起動していることを確認してください。
自動ミラー復帰が動作しないようにするために、 Cluster WebUI または [clpmonctrl] コマンドを使用して、 リストアしないサーバにおける全てのミラーディスクモニタリソースを一時停止してください。
clpmonctrl -s -h <サーバ名> -m <モニタリソース名>
[clprestore.sh] コマンドを実行して対象サーバをシャットダウンしてください。
clprestore.sh --pre
対象サーバのバックアップイメージを使用して新しい仮想ハードディスクを作成してください。
対象サーバの仮想ハードディスクがシステムディスク用のものとミラーディスク用のもの に分かれている場合は、それぞれのバックアップイメージを使用して 新しい仮想ハードディスクを作成してください。
- 対象サーバの仮想ハードディスクを交換してください。交換方法の詳細については、仮想化基盤やクラウド環境のマニュアルや ガイドを参照してください。
対象サーバを起動してください。
注釈
バックアップを採取する際にclpbackup.sh --preを実行した状態であるため、 クラスタサービスの自動起動はオフに設定されています。 そのため、対象サーバが起動してもクラスタサービスは自動起動しません。リストアしたサーバでディスクのデバイスファイル名がリストア前と変わっていないことを確認します。 デバイスファイル名が変わっている場合は元通りに設定してください。 また、OS の日付/時刻がクラスタ内の他のサーバと同じであることを確認してください。
[clprestore.sh] コマンドを実行して対象サーバを再起動してください。
clprestore.sh --post
Cluster WebUI のミラーディスクリストから、 すべてのミラーディスクリソースのミラー復帰 (フルコピー) を行います。
注釈
最新としたいデータを持つサーバ側がコピー元になるようにしてください。また、リストアの過程で差分情報が不正になっている可能性があるため、 差分コピーではなくフルコピーを指定してください。Cluster WebUI または [clpmonctrl] コマンドを使用して、 リストアしていないサーバにおけるミラーディスクモニタリソースを再開してください。
clpmonctrl -r -h <サーバ名> -m <モニタリソース名>
ミラーが正常に同期できていることを、 Cluster WebUI または [clpmdstat] コマンドを使って確認してください。
clpmdstat --mirror <mdリソース名>
注釈
両方のサーバでミラーのステータスが GREEN であれば、 ミラーは正常に同期されています。
2.17. ミラー/ハイブリッドディスクをディスクイメージでバックアップするには¶
ミラーディスク/ハイブリッドディスク用のパーティション(クラスタパーティションとデータパーティション)を ディスクイメージでバックアップする場合は、以下の該当するいずれかの手順でおこなってください。
注釈
clpbackup.sh --preまたはclpbackup.sh --postを実行して、 次にサーバグループ内の残りのサーバでclpbackup.sh --pre --only-shutdownまたはclpbackup.sh --post --only-rebootを実行するよう、記述しています。手順の中では、前者のサーバの目安として、サーバグループ内のカレントサーバを記述していますが、 サーバグループ内で最初にコマンドを実行する1つめのサーバは必ずしもカレントサーバでなくても問題ありません。なお、サーバグループにサーバが1つしかない場合には、 後者のサーバグループ内の残りのサーバでおこなうclpbackup.sh --pre --only-shutdownやclpbackup.sh --post --only-rebootの作業は必要ありません。※ カレントサーバとは、サーバグループ内のサーバのうち、ミラーデータの送受信やディスクへの書き込み処理を、 その時点で受け持っているサーバのことを示します。現用系側では、ハイブリッドディスクリソースが起動しているサーバが、カレントサーバです。その現用系側のカレントサーバから送られて来るミラーデータを受信して、待機系側のミラーディスクに書き込むのが、待機系側のカレントサーバです。Some invalid status. Check the status of cluster.などのエラーが表示されてサーバがシャットダウンしない場合は、 しばらく待ってから、再度 [clpbackup.sh] コマンドを実行してください。clpbackup.sh --postを実行時に、ミラーエージェントの起動がタイムアウトしてエラーとなる場合があります。その場合は、しばらく待ってから、再度 [clpbackup.sh] コマンドを実行してください。参考
clpbackup.sh に関しては『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「ディスクイメージバックアップの準備をする (clpbackup.sh コマンド)」 を参照してください。
2.17.1. 現用系/待機系のミラーディスクを両方同時にバックアップする場合¶
ミラーが正常に同期できていることを、Cluster WebUI の [ミラーディスク] タブ、または [clpmdstat] / [clphdstat] コマンドを使って、確認してください。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名>
注釈
両方のサーバまたはサーバグループでミラーのステータスが GREEN であれば、 ミラーは正常に同期されています。ハイブリッドディスクリソースの場合は、現用系側/待機系側の両サーバグループのカレントサーバが、 それぞれどのサーバになっているかについても、確認してください。フェイルオーバグループ(業務)が起動している場合は、Cluster WebUI または [clpgrp] コマンドを使って、フェイルオーバグループを停止してください。
[clpbackup.sh] コマンドを使って、ミラーディスクをバックアップモードに変更してください。
ミラーディスクリソースの場合:
現用系側/待機系側の両サーバにて、下記コマンドを実行してください。
clpbackup.sh --pre --no-shutdown
ハイブリッドディスクリソースの場合:
両サーバグループ内の1つのサーバにて、下記コマンドを実行してください。
clpbackup.sh --pre
注釈
実行すると、ミラーの状態がバックアップ用に変更され、クラスタサービスの自動起動がオフに設定されます。ミラーディスクリソースの場合、これらの動作の完了後にクラスタサービスが停止します。ハイブリッドディスクリソースの場合、これらの動作の完了後にサーバがシャットダウンします。- ハイブリッドディスクリソースの場合は、[clpbackup.sh] コマンドを実行したサーバのシャットダウン後に、残りのサーバで、それぞれ下記コマンドを実行してください。
clpbackup.sh --pre --only-shutdown
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
現用系側/待機系側の両サーバにて、バックアップを実行してください。
バックアップ作業が完了したら、ミラーディスクをバックアップモードから通常のモードに戻してください。
ミラーディスクリソースの場合:
現用系側/待機系側の両サーバにて、下記コマンドを実行してください。
clpbackup.sh --post --no-reboot
ハイブリッドディスクリソースの場合:
全サーバを起動してください。その後、両サーバグループ内の1つのサーバにて、下記コマンドを実行してください。clpbackup.sh --post
注釈
実行すると、ミラーの状態が通常用に戻り、クラスタサービスの自動起動がオンに設定されます。ミラーディスクリソースの場合、これらの動作の完了後にクラスタサービスが起動します。ハイブリッドディスクリソースの場合、これらの動作の完了後にサーバがリブートします。ハイブリッドディスクの場合は、先の [clpbackup.sh] コマンドを実行したサーバがリブートを開始したら、残りの全サーバで、それぞれ下記コマンドを実行してください。
clpbackup.sh --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
両系の全サーバでクラスタサービスが起動したら、 ミラーが正常に同期できていることを、 Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。
2.17.2. 現用系/待機系のミラーディスクを片サーバずつバックアップする場合¶
下記の手順で、「待機系側のミラーディスクをバックアップする場合」を参照して、交互にバックアップをおこなってください。
待機系側のディスクのバックアップ作業を、「待機系側のミラーディスクをバックアップする場合」を参照しておこなってください。
バックアップ作業完了後、ミラー復帰が完了して現用系と待機系のミラーディスクが同期状態になったら、 現用系から待機系へフェイルオーバグループの移動をおこなってください。
元現用系のディスクのバックアップ作業を、「待機系側のミラーディスクをバックアップする場合」を参照しておこなってください。
バックアップ作業完了後、ミラー復帰が完了して現用系と待機系のミラーディスクが同期状態になったら、 必要に応じてフェイルオーバグループの移動をおこなってください。
2.17.3. 待機系側のミラーディスクをバックアップする場合¶
ミラーが正常に同期できていることを、Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名>
注釈
両方のサーバまたはサーバグループでミラーのステータスが GREEN であれば、 ミラーは正常に同期されています。ハイブリッドディスクリソースの場合は、待機系側のサーバグループのカレントサーバが、 どのサーバになっているかについても、確認してください。ミラー領域に書き込んでいるデータの静止点を確保するために、 Cluster WebUI または [clpgrp] コマンドを使って、 ミラーディスクリソースやハイブリッドディスクリソースを含むフェイルオーバグループ(業務)を、停止してください。
注釈
フェイルオーバグループを停止することによって、データが書き込み途中の状態でバックアップされることや、 キャッシュによりデータがミラー領域に書き込まれずにバックアップされないことを、防ぎます。
自動ミラー復帰が動作しないようにするために、Cluster WebUI または [clpmonctrl] コマンドで、 現用系/待機系両方の全てのミラーディスクモニタリソース/ハイブリッドディスクモニタリソースを、一時停止してください。
clpmonctrl -s -h <サーバ名> -m <モニタリソース名>
[clpbackup.sh] コマンドを使って、ミラーディスクをバックアップモードに変更してください。
ミラーディスクリソースの場合:
待機系側(バックアップする側)のサーバにて、下記コマンドを実行してください。
clpbackup.sh --pre --no-shutdown
ハイブリッドディスクリソースの場合:
待機系側サーバグループ内の1つのサーバにて、下記コマンドを実行してください。
clpbackup.sh --pre
注釈
実行すると、ミラーの状態がバックアップ用に変更され、クラスタサービスの自動起動がオフに設定されます。ミラーディスクリソースの場合、これらの動作の完了後にクラスタサービスが停止します。ハイブリッドディスクリソースの場合、これらの動作の完了後にサーバがシャットダウンします。ハイブリッドディスクの場合は、[clpbackup.sh] コマンドを実行したサーバのシャットダウン後に、待機系側サーバグループ内の残りの全サーバで、下記コマンドを実行してください。
clpbackup.sh --pre --only-shutdown
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
業務をすぐに再開したい場合は、Cluster WebUI または [clpgrp] コマンドを使って、 現用系側(バックアップしない側)のサーバでフェイルオーバグループ(業務)を起動してください。
待機系側サーバにて、ディスクイメージでのバックアップをおこなってください。
バックアップ作業が完了したら、ミラーディスクをバックアップモードから通常のモードに戻してください。
ミラーディスクリソースの場合:
待機系側のサーバにて、下記コマンドを実行してください。
clpbackup.sh --post --no-reboot
ハイブリッドディスクリソースの場合:
待機系側サーバグループの全サーバを起動してください。その後、待機系側サーバグループ内の1つのサーバにて、下記コマンドを実行してください。clpbackup.sh --post
注釈
実行すると、ミラーの状態が通常用に戻り、クラスタサービスの自動起動がオンに設定されます。ミラーディスクリソースの場合、これらの動作の完了後にクラスタサービスが起動します。ハイブリッドディスクリソースの場合、これらの動作の完了後にサーバがリブートします。ハイブリッドディスクの場合は、待機系側のサーバグループ内の残りの全サーバで、下記コマンドを実行してください。
clpbackup.sh --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
- 待機系側サーバでクラスタサービスが起動します。ミラーディスクモニタリソース/ハイブリッドディスクモニタリソースが一時停止のままになっている場合は、 Cluster WebUI または [clpmonctrl] コマンドで、再開してください。
clpmonctrl -r -h <サーバ名> -m <モニタリソース名>
もしも、フェイルオーバグループ(業務)を停止したままにしていた場合は(先の手順ですぐに再開しなかった場合には)、 現用系側のサーバで、フェイルオーバグループ(業務)を起動可能です。
- 自動ミラー復帰が有効な場合には、バックアップ作業中に現用系と待機系との間に生じたミラー差分が、自動で同期されて、ミラーが正常な状態になります。自動ミラー復帰がおこなわれずに、正常な状態にならない場合には、Cluster WebUI の [ミラーディスク] タブで [差分コピー] 操作 または [clpmdctrl] / [clphdctrl] コマンドを実行して、 ミラー復帰をおこなってください。
ミラーディスクリソースの場合:
clpmdctrl --recovery <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --recovery <hdリソース名>
注釈
ハイブリッドディスクリソースの場合、カレントサーバ上で実行してください。
2.17.4. 片系のみで動作しているミラーディスクをバックアップする場合¶
相手サーバが停止していてミラー同期していない状態で、片系だけで現用系として稼働しているサーバやサーバグループの ミラーディスクをバックアップする場合の手順については、 「現用系/待機系のミラーディスクを両方同時にバックアップする場合」を参照して、 「両系」「両サーバ」を意味する部分を、「片系」「片側のサーバ」に読み替えて、実施してください。
参考
サーバ起動時に、他のサーバが起動するのを待たずに、すぐにフェイルオーバグループ(業務)を起動したい場合には、 サーバ起動時に下記コマンドを実行することで、クラスタ起動同期待ちを解除することができます。※ なお、まだ起動同期待ちではない場合や、既に起動同期待ちがタイムアウトした場合には、コマンドがエラーになります。clpbwctrl -cclpbwctrl コマンドに関しては 『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「クラスタ起動同期待ち処理を制御する (clpbwctrl コマンド)」 を参照してください。
2.18. ミラー/ハイブリッドディスクにディスクイメージをリストアするには¶
ミラーディスク/ハイブリッドディスク用のパーティション(クラスタパーティションとデータパーティション)に、 「ミラー/ハイブリッドディスクをディスクイメージでバックアップするには」でバックアップしたディスクイメージをリストアする場合は、 以下のいずれかの手順でおこなってください。
注釈
clprestore.sh --postまたはclprestore.sh --post --skip-copyを実行して、 次にサーバグループ内の残りのサーバでclprestore.sh --post --only-rebootを実行するよう、記述しています。手順の中では、前者のサーバの例として、サーバグループ内のカレントサーバを記述していますが、 サーバグループ内で最初にコマンドを実行する1つめのサーバは必ずしもカレントサーバでなくても問題ありません。なお、サーバグループにサーバが1つしかない場合には、 後者のサーバグループ内の残りのサーバでおこなうclprestore.sh --post --only-rebootの作業は必要ありません。※ カレントサーバとは、サーバグループ内のサーバのうち、ミラーデータの送受信やディスクへの書き込み処理を、 その時点で受け持っているサーバのことを示します。現用系側では、ハイブリッドディスクリソースが起動しているサーバが、カレントサーバです。その現用系側のカレントサーバから送られて来るミラーデータを受信して、待機系側のミラーディスクに書き込むのが、待機系側のカレントサーバです。Some invalid status. Check the status of cluster.などのエラーが表示されてサーバがシャットダウンしない場合は、 しばらく待ってから、再度 [clprestore.sh] コマンドを実行してください。Invalid configuration file.などのエラーが表示されて再起動しない場合は、 構成情報が登録されているか、また、CLUSTERPROのインストールやファイアウォールの設定等に問題がないか、 確認してください。参考
clprestore.sh に関しては『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「ディスクイメージリストア後の処理をする (clprestore.sh コマンド)」 を参照してください。
2.18.1. 現用系/待機系の両サーバに同一のミラーディスクイメージを同時にリストアする場合¶
重要
本手順では、ミラーディスクリソース/ハイブリッドディスクリソースの設定にて、[初期ミラー構築を行う] をあらかじめオフにしておく必要があります。[初期ミラー構築を行う] や [初期mkfsを行う] がオンになっている場合は、エラーとなりますので、Cluster WebUI を使ってオフに設定してください。
フェイルオーバグループ(業務)が起動している場合は、Cluster WebUI または [clpgrp] コマンドを使って、フェイルオーバグループを停止してください。
- 現用系/待機系の全サーバにて、それぞれ下記コマンドを実行してください。※ OSが起動できず、OSやCLUSTERPROの再インストールやリストアをおこなう必要がある場合には、そのサーバでは、その作業をおこなった後にて、下記コマンドを実行してください。
clprestore.sh --pre
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
- 現用系/待機系の両方のサーバにて、クラスタパーティションおよびデータパーティションのリストアをおこなってください。※ 現用系と待機系に同一のディスクイメージをリストアしてください。
現用系/待機系の両方のリストア作業が完了したら、全サーバを起動してください。
- サーバ起動後、リストアしたクラスタパーティションやデータパーティションのパスを確認してください。パスが変わっている場合は、Cluster WebUI を起動して [設定モード] にして、 ミラーディスクリソース/ハイブリッドディスクリソースのプロパティの [詳細] タブで、各パスの設定を変更して、 [設定の反映] をおこなってください。
重要
パスの設定が間違っていると、ミラーの起動に失敗したり、パーティションを破壊したりする可能性があります。充分に注意して設定してください。もしも、パスの設定誤りによって後の手順にてミラーの起動に失敗した場合には、手順1からやり直してください。 - 現用系側/待機系側の両サーバにて、それぞれ下記コマンドを実行してください。※ ハイブリッドディスクの場合は、現用系側/待機系側の各サーバグループ内の1つのサーバにて(例えば各サーバグループのカレントサーバにて)、それぞれ実行してください。
clprestore.sh --post --skip-copy
注釈
実行すると、全クラスタパーティションが初期化され、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
注釈
ミラーディスクリソース/ハイブリッドディスクリソースの設定で、[初期ミラー構築を行う] がオンになっている場合は、コマンドがエラーとなります。その場合は、Cluster WebUI を使って [初期ミラー構築を行う] をオフに変更して [設定の反映] をおこなってから、再度コマンドを実行してください。もしも、停止しているサーバが存在していて、それが原因で Cluster WebUI で [設定の反映] に失敗する場合は、一旦 [設定のエクスポート] で構成情報をディスク上に保存してください。クラスタに属するいずれかのサーバからアクセスできるディスク上にその構成情報ファイルを展開した後、展開した構成情報ファイルを [clpcfctrl] コマンドで強制的にサーバに配信してください。clpcfctrl --push -x <展開した構成情報ファイルclp.confがあるディレクトリのパス> --force
※ 配信完了後、保存した圧縮形式ファイルや、それを展開して取得した構成情報ファイルは、削除可能です。※ なお、もしも、停止していて配信できなかったサーバがある場合には、構成情報の不整合が発生しない様、必ず後でそのサーバへも配信してください。参考
[clpcfctrl] コマンドに関しては、『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」 を参照してください。注釈
もしも、ミラーエージェントが起動している場合には、クラスタパーティション初期化処理にてコマンドがエラーとなります。その場合は、clprestore.sh --preを実行後、サーバを起動して、再度clprestore.sh --post --skip-copyコマンドを実行してください。 - ハイブリッドディスクの場合は、前述の手順6のコマンドを実行したサーバがリブートを開始したら、 サーバグループ内の残りの全サーバにて、それぞれ下記コマンドを実行してください。
clprestore.sh --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
- 現用系/待機系の両方の全サーバが起動したら、各ミラーの状態を、Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。現用系/待機系の両方のミラーのステータスが、"正常" (GREEN) となります。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名>
- [初期ミラー構築を行う] の設定を変更した場合は、必要に応じて、Cluster WebUI を使って設定を元に戻してください。なお、設定を反映する際に、クラスタの停止が必要となります。
2.18.2. 現用系/待機系の両サーバにミラーディスクイメージをそれぞれ同時にリストアする場合¶
参考
現用系/待機系の両系のミラーディスクに同一イメージをリストアする手順については、「現用系/待機系の両サーバに同一のミラーディスクイメージを同時にリストアする場合」を参照してください。
フェイルオーバグループ(業務)が起動している場合は、Cluster WebUI または [clpgrp] コマンドを使って、フェイルオーバグループを停止してください。
- 現用系/待機系の全サーバにて、それぞれ下記コマンドを実行してください。※ OSが起動できず、OSやCLUSTERPROの再インストールやリストアをおこなう必要がある場合には、そのサーバでは、その作業をおこなった後にて、下記コマンドを実行してください。
clprestore.sh --pre
注釈
実行すると、クラスタサービスの自動起動がオフに設定され、サーバがシャットダウンします。
現用系/待機系の両方のサーバにて、クラスタパーティションおよびデータパーティションのリストアをおこなってください。
現用系/待機系の両方のリストア作業が完了したら、全サーバを起動してください。
- サーバ起動後、リストアしたクラスタパーティションやデータパーティションのパスを確認してください。パスが変わっている場合は、Cluster WebUI を起動して [設定モード] にして、 ミラーディスクリソース/ハイブリッドディスクリソースのプロパティの [詳細] タブで、各パスの設定を変更して、 [設定の反映] をおこなってください。
重要
パスの設定が間違っていると、ミラーの起動に失敗したり、パーティションを破壊したりする可能性があります。充分に注意して設定してください。もしも、パスの設定誤りによって後の手順にてミラーの起動に失敗した場合には、手順1からやり直してください。注釈
もしも、停止しているサーバが存在していて、それが原因で Cluster WebUI で [設定の反映] に失敗する場合は、一旦 [設定のエクスポート] で構成情報をディスク上に保存してください。クラスタに属するいずれかのサーバからアクセスできるディスク上にその構成情報ファイルを展開した後、展開した構成情報ファイルを [clpcfctrl] コマンドで強制的にサーバに配信してください。clpcfctrl --push -x <展開した構成情報ファイルclp.confがあるディレクトリのパス> --force
※ 配信完了後、保存した圧縮形式ファイルや、それを展開して取得した構成情報ファイルは、削除可能です。※ なお、停止していて配信できなかったサーバがある場合には、構成情報の不整合が発生しない様、必ず後でそのサーバへも配信してください。参考
[clpcfctrl] コマンドに関しては、『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」 を参照してください。 - 現用系側/待機系側の両サーバにて、それぞれ下記コマンドを実行してください。※ ハイブリッドディスクリソースの場合は、現用系側/待機系側の各サーバグループ内の1つのサーバにて(例えば各サーバグループのカレントサーバにて)、それぞれ実行してください。
clprestore.sh --post
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
- ハイブリッドディスクの場合は、前述の手順6のコマンドを実行したサーバがリブートを開始したら、 サーバグループ内の残りの全サーバにて、それぞれ下記コマンドを実行してください。
clprestore.sh --post --only-reboot
注釈
実行すると、クラスタサービスの自動起動がオンに設定され、サーバがリブートします。
- 現用系/待機系の両方の全サーバが起動したら、各ミラーの状態を、Cluster WebUI または [clpmdstat] / [clphdstat] コマンドを使って確認してください。現用系/待機系の両方のミラーのステータスが、"異常" (RED) となります。
ミラーディスクリソースの場合:
clpmdstat --mirror <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdstat --mirror <hdリソース名>
フェイルオーバグループの状態を、Cluster WebUI または [clpstat] コマンドを使って確認してください。
起動に失敗しているフェイルオーバグループがあったら、Cluster WebUI または [clpgrp] コマンドを使って、そのフェイルオーバグループを停止してください。
- Cluster WebUI の [ミラーディスク] タブでの [強制ミラー復帰] 操作、または [clpmdctrl] / [clphdctrl] コマンド(--forceオプション)を使って、 最新としたい側のミラーのステータスを "正常" (GREEN) に変更してください。※ コマンドで実行する場合は、ステータスを "正常" (GREEN) にしたい側のサーバ上で実行します。
ミラーディスクリソースの場合:
clpmdctrl --force <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --force <hdリソース名>
フェイルオーバグループを、Cluster WebUI または [clpgrp] コマンドを使って、最新とした側のサーバで起動してください。
フェイルオーバグループ起動後、Cluster WebUI の [ミラーディスク] タブでの [フルコピー] 操作、 または [clpmdctrl] / [clphdctrl] コマンドを使って、 ミラー復帰をおこなってください。
ミラーディスクリソースの場合:
clpmdctrl --recovery <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --recovery <hdリソース名>
注釈
ハイブリッドディスクリソースの場合、カレントサーバ上で実行してください。
注釈
フェイルオーバグループを起動する前に、Cluster WebUI や [clpmdctrl] / [clphdctrl] コマンドを使ってミラー復帰を開始することも可能です。なお、その場合には、ミラー復帰(フルコピー)が完了するかキャンセルするまで、フェイルオーバグループは起動できません。ミラーディスクリソースの場合:
clpmdctrl --force <コピー元サーバ名> <mdリソース名>
ハイブリッドディスクリソースの場合:
clphdctrl --force <コピー元サーバ名> <hdリソース名>
参考
[clpmdctrl] / [clphdctrl] コマンドに関しては、『リファレンスガイド』の 「CLUSTERPRO コマンドリファレンス」の 「ミラーディスクリソースを操作する (clpmdctrl コマンド)」 「ハイブリッドディスクリソースを操作する (clphdctrl コマンド)」 を参照してください。なお、--forceオプション(コピー元サーバを指定しない方法:強制ミラー復帰)を指定して実行する場合には、ステータスを "正常" (GREEN) にしたい側のサーバ上にて、 コマンドを実行します。実行後、ステータスを "正常" (GREEN) にしたサーバで、フェイルオーバグループを起動(業務を開始)できます。また、--forceオプション(コピー元サーバを指定する方法:フルコピー)を指定して実行する場合には、どのサーバ上でも実行可能です。 実行すると、ミラー復帰(フルコピー)が始まります。なお、ミラー復帰が始まると、ミラー復帰が完了するか中断するまで、 フェイルオーバグループを起動できません(業務を開始できません)。
2.18.3. 片系のみでミラーディスクイメージをリストアする場合¶
現用系サーバが起動している状態で、待機系サーバのミラーディスクのみをリストアする手順については、 「仮想マシンをリストアするには -ミラーディスクの場合-」を参照して、 「システムディスクをリストアするサーバ」を「ミラーディスクをリストアするサーバ」に読み替えて、 手順1(フェイルオーバグループの移動)から手順11(ミラーが正常に同期できていることの確認)までを 実施してください。 その際、手順4と手順5においてミラーディスク用の仮想ハードディスクのみを作成・交換するように してください。
リストア対象外のサーバやサーバグループが停止した状態で、 現用系サーバやサーバグループのミラーディスクを単機(片側)のみでリストアする手順については、 「現用系/待機系の両サーバにミラーディスクイメージをそれぞれ同時にリストアする場合」を参照して、 「両系」「両サーバ」を意味する部分を、「片系」「片側のサーバ」に読み替えて、 手順1(フェイルオーバグループの停止)から手順12(フェイルオーバグループの開始)までを 実施してください。
重要
参考
サーバ起動時に、他サーバの起動を待たずに、すぐにクラスタサービスを起動したい場合には、 サーバ起動時に下記コマンドを実行することで、クラスタ起動同期待ちを解除することができます。※ なお、まだ起動同期待ちではない場合や、既に起動同期待ちがタイムアウトした場合には、コマンドがエラーになります。clpbwctrl -cclpbwctrl コマンドに関しては『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」の「クラスタ起動同期待ち処理を制御する (clpbwctrl コマンド)」を参照してください。
2.19. クラスタ起動同期待ち時間について¶
クラスタ内の全てのサーバで同時に電源を投入したとしても CLUSTERPRO が同時に起動されるとは限りません。クラスタのシャットダウン後再起動を実行した場合も同様に CLUSTERPRO が同時に起動されるとは限りません。
このため、CLUSTERPRO では、あるサーバが起動されるとクラスタ内の他のサーバの起動を待ち合わるようになっています。
初期設定値として 5 分が設定されます。この待ち合わせ時間は、Cluster WebUI の [クラスタのプロパティ]-[タイムアウト] タブの [同期待ち時間] で変更することができます。
詳細については『リファレンスガイド』の「パラメータの詳細」 - 「クラスタプロパティ」 - 「タイムアウトタブ」を参照してください。
2.20. ディスクリソースのファイルシステムを変更する¶
管理 IP で Cluster WebUI に接続します。管理 IP がない場合は、いずれかのサーバの実IP で Cluster WebUI を接続します。
ディスクリソースのファイルシステムを変更したい場合、以下の手順で行ってください。
Cluster WebUI の操作モードから [クラスタ停止] を実行します。
- 以下のコマンドを実行します。例) ディスクリソースのパーティションデバイスが /dev/sdb5 の場合
# clproset -w -d /dev/sdb5これにより、CLUSTERPRO の動作に関わりなく、ディスクリソースのディスクパーティションが読み書き可能になります。注釈
ここに記載されている用途以外にこのコマンドを使用しないでください。CLUSTERPRO デーモンが起動している場合にこのコマンドを使用すると、ファイルシステムを壊す恐れがあります。
パーティションデバイスにファイルシステムを作成します。
- 以下のコマンドを実行し、ディスクリソースのパーティションを ReadOnly に設定します。例) ディスクリソースのパーティションデバイスが /dev/sdb5 の場合
# clproset -o -d /dev/sdb5 Cluster WebUI の設定モードから、ディスクリソースのファイルシステムの設定情報を変更します。
Cluster WebUI の設定モードから、更新したクラスタ構成情報をアップロードします。
Cluster WebUI の操作モードから [クラスタ開始] を実行します。
以上で、設定が有効になります。
2.21. ミラーディスクリソースのパーティションのオフセットやサイズを変更する¶
運用を開始した後で、ミラーディスクリソースに設定しているデータパーティションやクラスタパーティションのオフセット (位置) やサイズを変更したい場合、以下の手順で行ってください。
注釈
必ず以下の手順で行ってください。データパーティションやクラスタパーティションに指定しているパーティションを fdisk で変更するだけでは、ミラーディスクリソースは正常に動作しなくなります。
2.21.1. データパーティションをLVMで構成している場合¶
データパーティションをLVMで構成している場合、使用しているファイルシステムによっては、リソースを再作成することなく、または業務を停止することなくデータパーティションを拡張することができます。
データパーティションのファイルシステム |
リソースの再作成 |
業務停止 |
参照 |
|---|---|---|---|
xfs, ext2, ext3, ext4, ファイルシステムなし(none) |
不要 |
不要 |
2.21.1.1. 使用しているファイルシステムがext系かxfs、またはファイルシステムを使用していない場合のデータパーティション拡張 |
上記以外 |
要 |
要 |
注釈
この方法では拡張のみ可能です。縮小する場合は、下記「2.21.2. データパーティションをLVM以外で構成している場合」記載の手順を実行してください。
注釈
下記の手順でデータパーティションを拡張する場合は、データパーティションがLVMで構成されており、かつボリュームグループの未使用PE(Physical Extent)量が十分確保されている必要があります。
2.21.1.1. 使用しているファイルシステムがext系かxfs、またはファイルシステムを使用していない場合のデータパーティション拡張¶
サイズを変更したいミラーディスクリソースの名称を [clpstat] コマンドまたはCluster WebUI で確認します。
予期せぬ事態に備え、サイズを変更したいミラーディスクリソースを持つグループが活性しているサーバで、パーティション内のデータをテープなどにバックアップします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。 ミラーディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
以下を確認してください。
ミラーディスクリソースの状態が正常であること
両サーバで、データパーティションが所属するボリュームグループの未使用PE(Physical Extent)量が十分であること。
Cluster WebUIの操作モードからミラーディスクモニタリソースをすべて「一時停止」にし、自動でミラー復帰が行われない状態にします。
ミラーディスクリソースが活性していない側のサーバで、以下の[clpmdctrl]コマンドを実行します。どちらのサーバでもリソースが活性してない場合は、どちらから実行しても構いません。以下は、md01のデータパーティションを500ギビバイトに拡張する場合の例です。
# clpmdctrl --resize 500G md01
重要
もう一方のサーバで、同様に[clpmdctrl]コマンドを実行します。以下は、md01のデータパーティションを500ギビバイトに拡張する場合の例です。
# clpmdctrl --resize 500G md01データパーティションにxfsまたはext系ファイルシステムを構築している場合、ミラーディスクリソースが活性している側のサーバでコマンドを実行して、ファイルシステムの対象領域を広げます。
<xfsの場合># xfs_growfs /mnt/nmp1(/mnt/nmp1はミラーディスクリソースのマウントポイントに応じて変更する)
<ext系の場合># resize2fs -p /dev/NMP1(NMP1はミラーパーティションデバイス名に応じて変更する)
データパーティションにファイルシステムを使用していない場合(none)、この手順は必要ありません。
手順4で「一時停止」にしたミラーディスクモニタリソースを、Cluster WebUI の操作モードからすべて「再開」します。
重要
# clpmdctrl --resize -force 500G md01
注釈
# clpmdctrl --resize 1022M md01 と指定すると、データパーティションのサイズは1024M、ファイルシステム拡張の上限が1022Mとなります。注釈
2.21.1.2. その他のファイルシステムを使用している場合のデータパーティション拡張¶
基本的な手順は「2.21.2. データパーティションをLVM以外で構成している場合」と同じです。
ただし、[fdisk]でパーティションのサイズを変更する箇所は、代わりに[lvextend]コマンドを使用して拡張を行ってください。
2.21.2. データパーティションをLVM以外で構成している場合¶
2.21.2.1. ミラーディスクリソースのパーティションのデバイス名を変更しない場合¶
サイズを変更したいミラーディスクリソースの名称を [clpstat] コマンドまたはCluster WebUI で確認します。
- サイズを変更したいミラーディスクリソースを持つグループが活性しているサーバで、パーティション内のデータをテープなどにバックアップします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ミラーディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
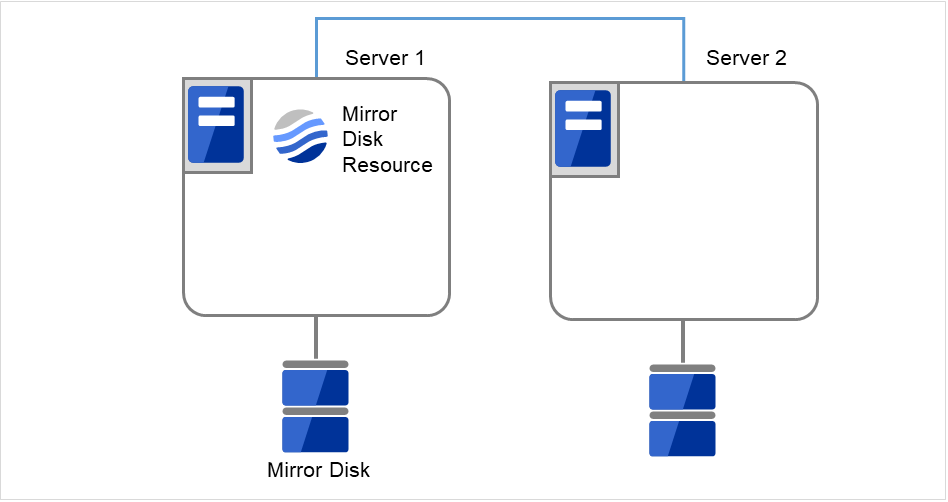
図 2.26 Server1ではミラーディスクリソースが活性状態¶
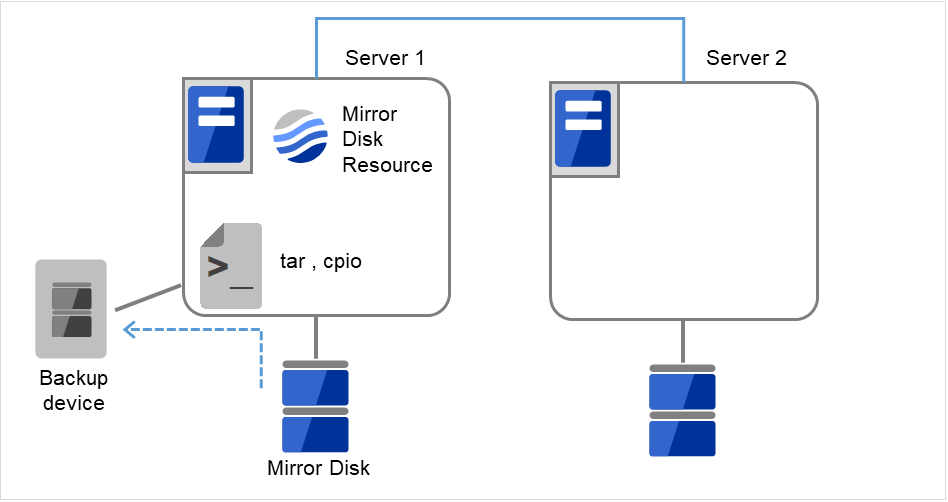
図 2.27 Server1でデータをバックアップ¶
両サーバで CLUSTERPRO サービスが起動しないように設定します。
clpsvcctrl.sh --disable core
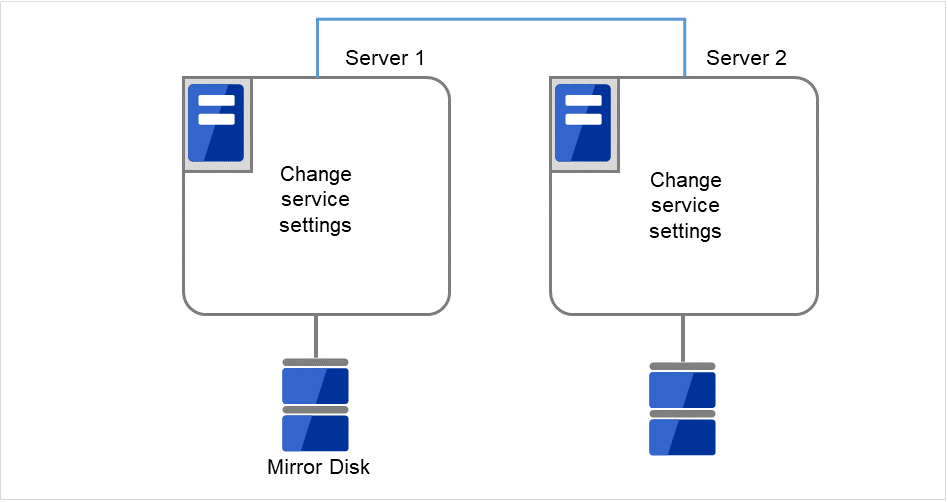
図 2.28 CLUSTERPRO サービスが起動しないよう設定変更¶
- クラスタのシャットダウンと、OS の再起動をおこないます。いずれかのサーバで [clpstdn] コマンドを使用してクラスタシャットダウンリブートを実行するか、またはCluster WebUI からクラスタシャットダウンリブートを実行します。
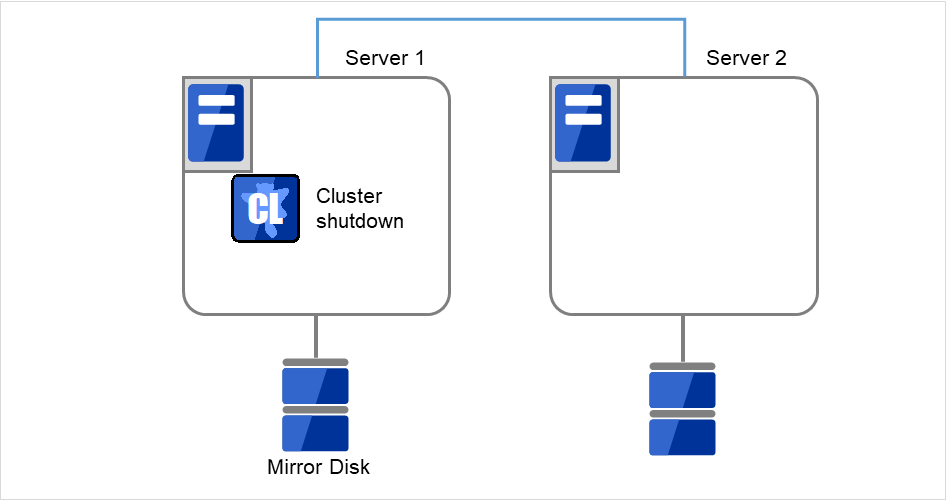
図 2.29 いずれかのサーバでクラスタシャットダウンを実行¶
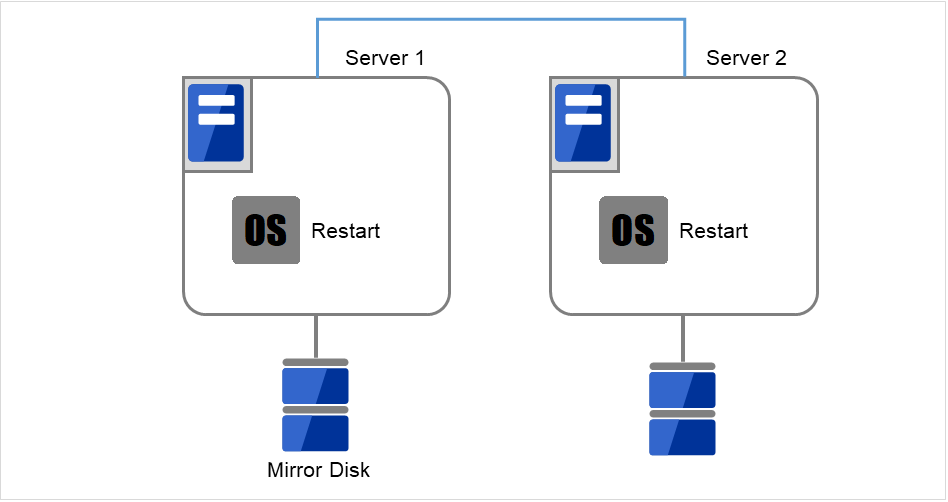
図 2.30 OSを再起動¶
両サーバで [fdisk] コマンドを使用してパーティションのオフセットやサイズを変更します。
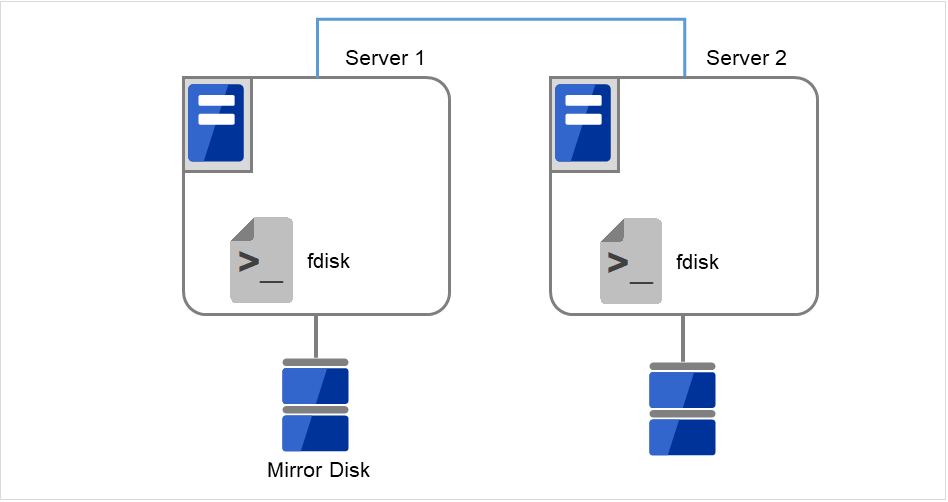
図 2.31 パーティションサイズを変更¶
両サーバで以下のコマンドを実行します。
# clpmdinit --create force <ミラーディスクリソース名>
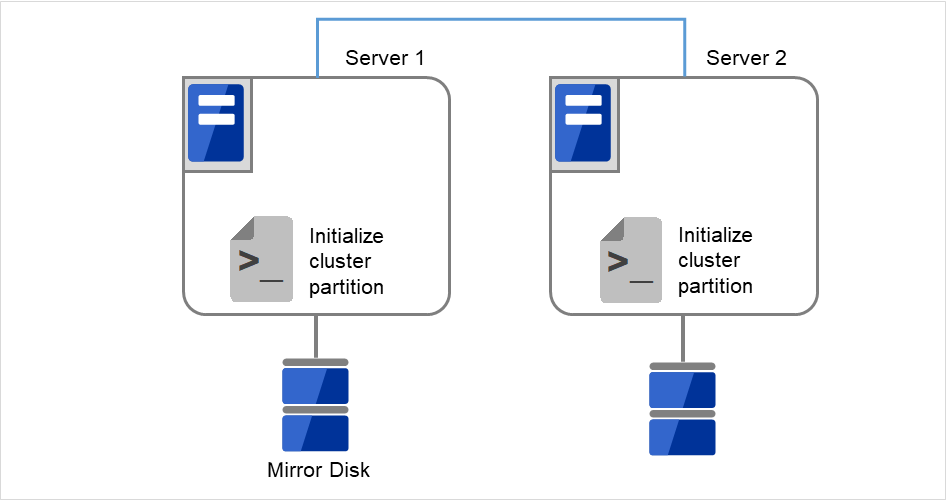
図 2.32 クラスタパーティションを初期化¶
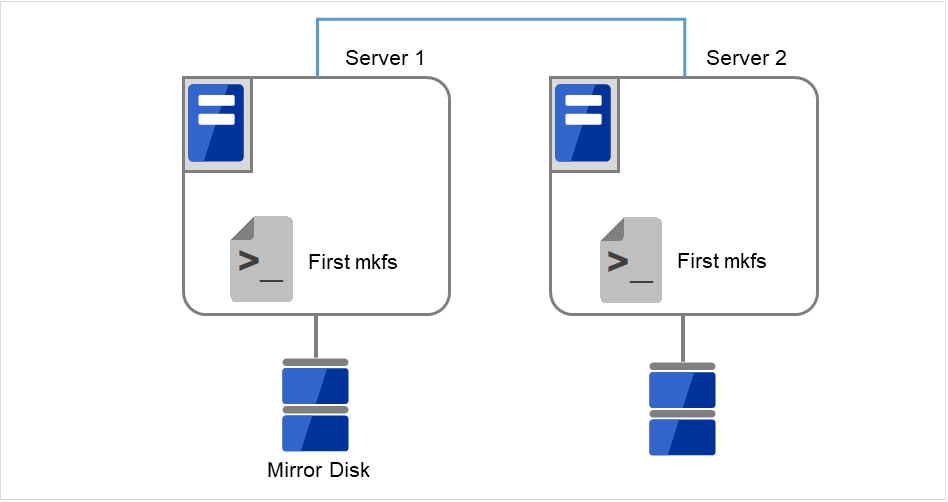
図 2.33 初回のmkfsを実行し、ファイルシステムを作成¶
注釈
ミラーディスクリソースの設定で [初期 mkfs を行う] をオフに設定した場合には、mkfs が自動では行われませんので、手動で mkfs をデータパーティションに対して実行してください。
両サーバで CLUSTERPRO サービスが起動するように設定します。
clpsvcctrl.sh --enable core
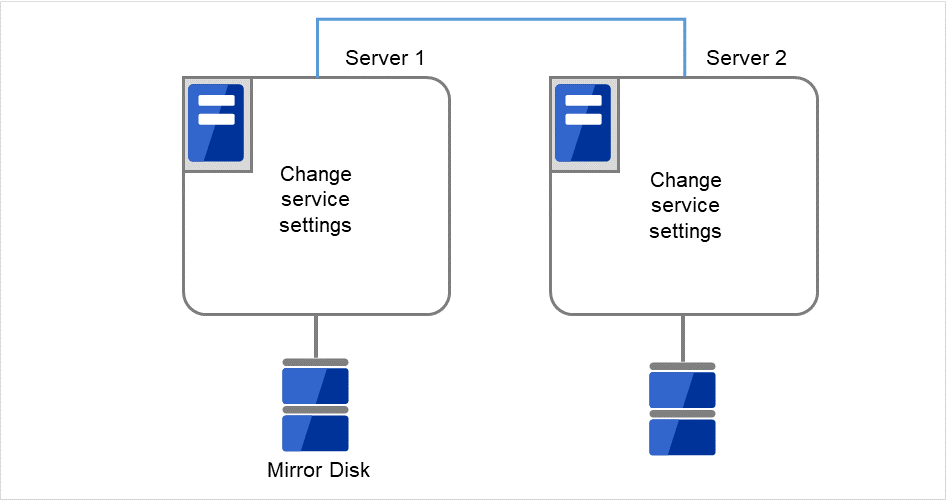
図 2.34 CLUSTERPRO サービスが起動するよう設定変更¶
[reboot] コマンドを使用して両サーバを再起動します。クラスタとして起動します。
クラスタ起動時にクラスタ生成後の初期ミラー構築と同じ処理が実行されますので、以下のコマンドを実行して初期ミラー構築の完了を確認するか、Cluster WebUI を使用して初期ミラー構築の完了を確認します。
# clpmdstat --mirror <ミラーディスクリソース名>
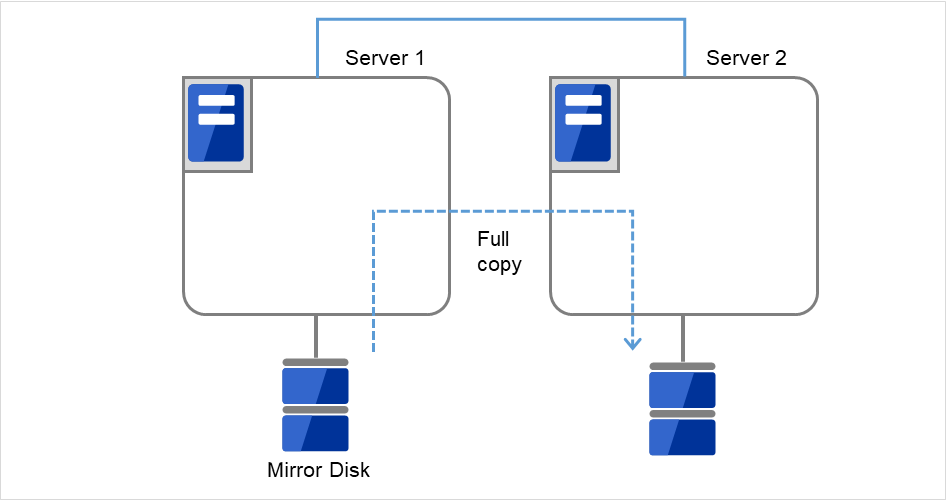
図 2.35 Server1よりミラー復帰開始¶
初期ミラー構築が完了してフェイルオーバグループが起動するとミラーディスクリソースが活性状態になります。
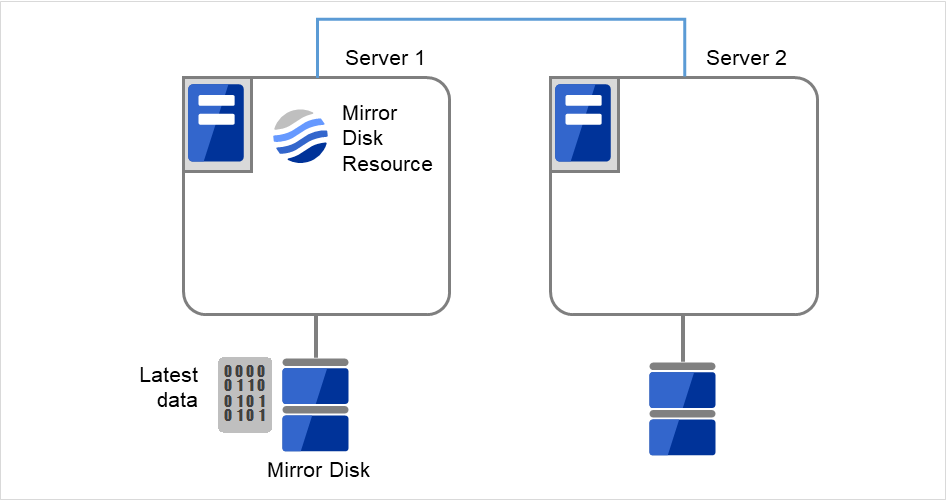
図 2.36 初期ミラー構築完了¶
- サイズを変更したミラーパーティションを持つグループが活性しているサーバで、バックアップしていたデータをリストアします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ミラーディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
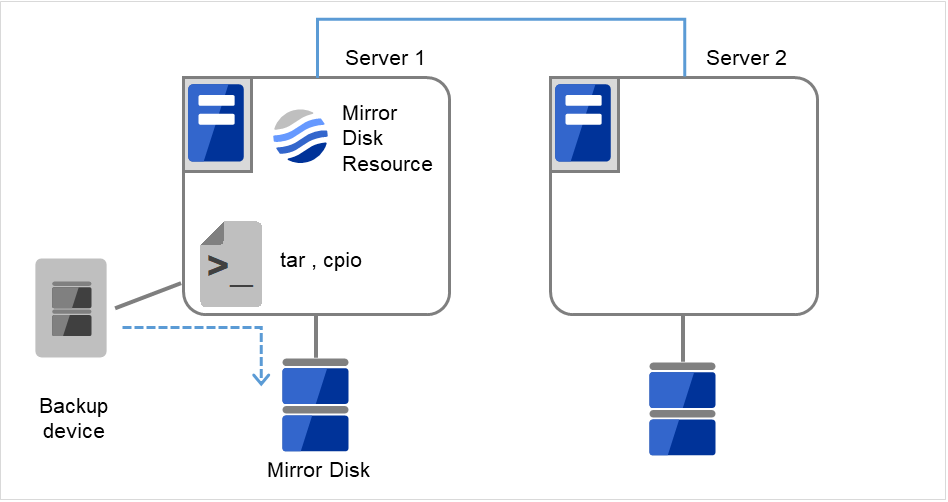
図 2.37 バックアップしていたデータをリストア¶
2.21.2.2. ミラーディスクリソースのパーティションのデバイス名を変更する場合¶
サイズを変更したいミラーディスクリソースの名称を [clpstat] コマンドまたはCluster WebUI で確認します。
- サイズを変更したいミラーディスクリソースを持つグループが活性しているサーバで、パーティション内のデータをテープなどにバックアップします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ミラーディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
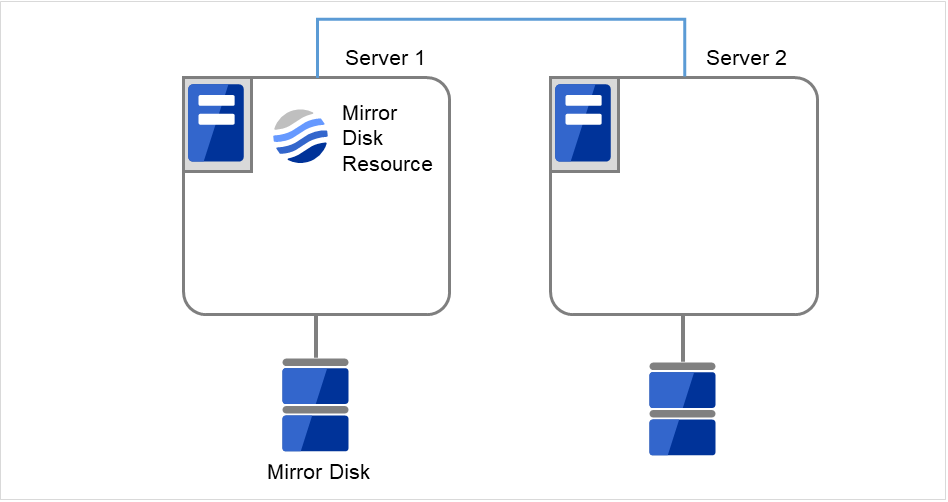
図 2.38 Server1ではミラーディスクリソースが活性状態¶
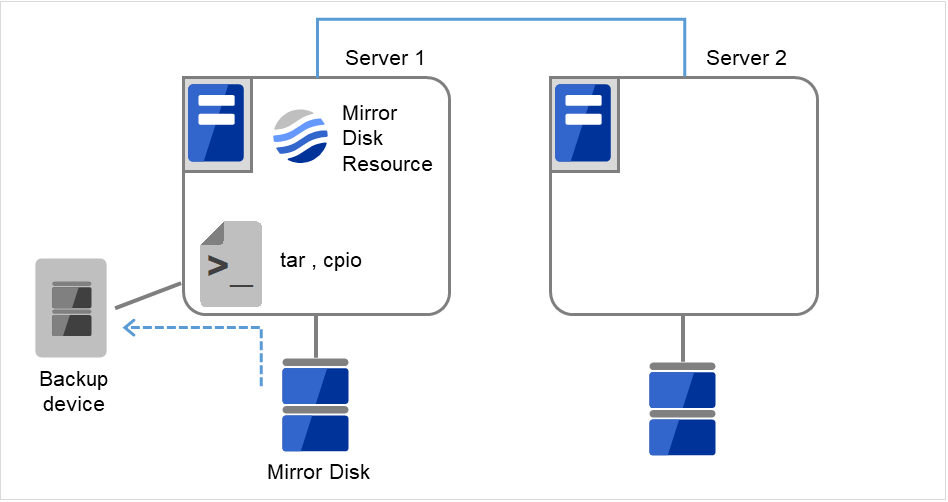
図 2.39 Server1でデータをバックアップ¶
両サーバで CLUSTERPRO サービスが起動しないように設定します。
clpsvcctrl.sh --disable core
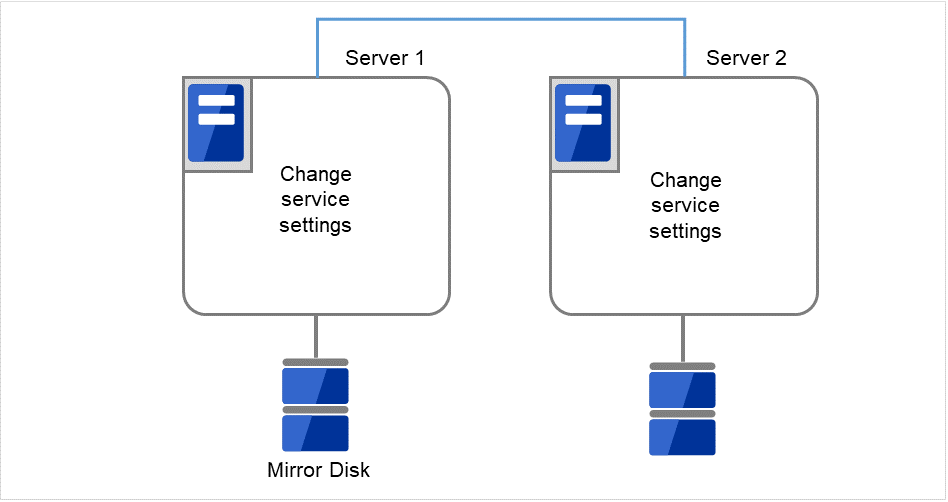
図 2.40 CLUSTERPRO サービスが起動しないよう設定変更¶
- クラスタのシャットダウンと、OS の再起動を行います。いずれかのサーバで [clpstdn] コマンドを使用してクラスタシャットダウンリブートを実行するか、または Cluster WebUI からクラスタシャットダウンリブートを実行します。
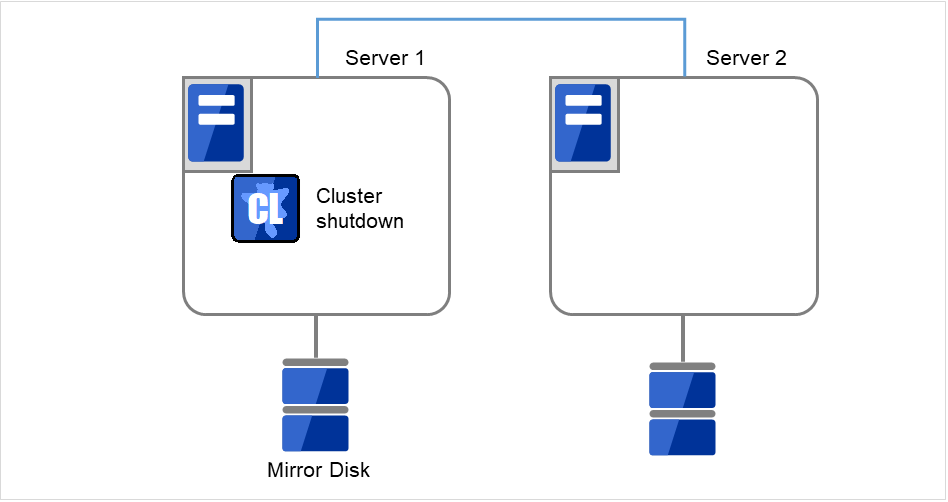
図 2.41 いずれかのサーバでクラスタシャットダウンを実行¶
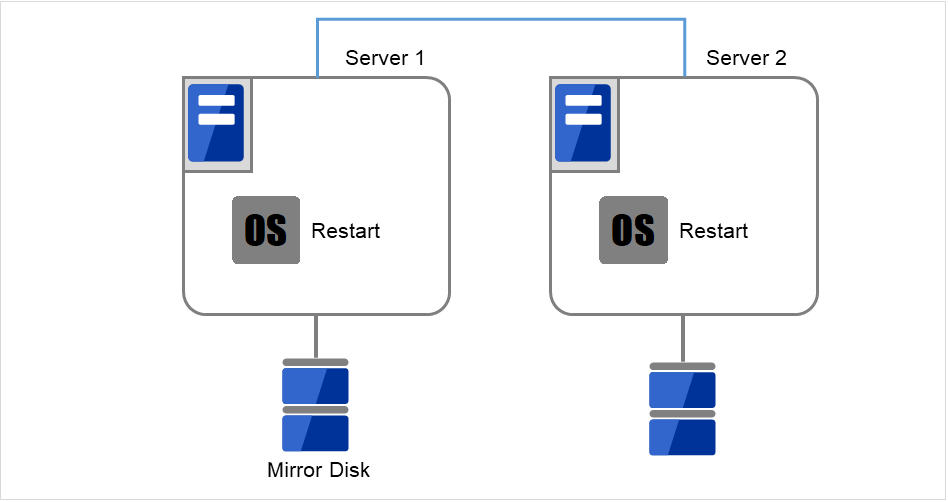
図 2.42 OSを再起動¶
両サーバで [fdisk] コマンドを使用してパーティションのオフセットやサイズを変更します。
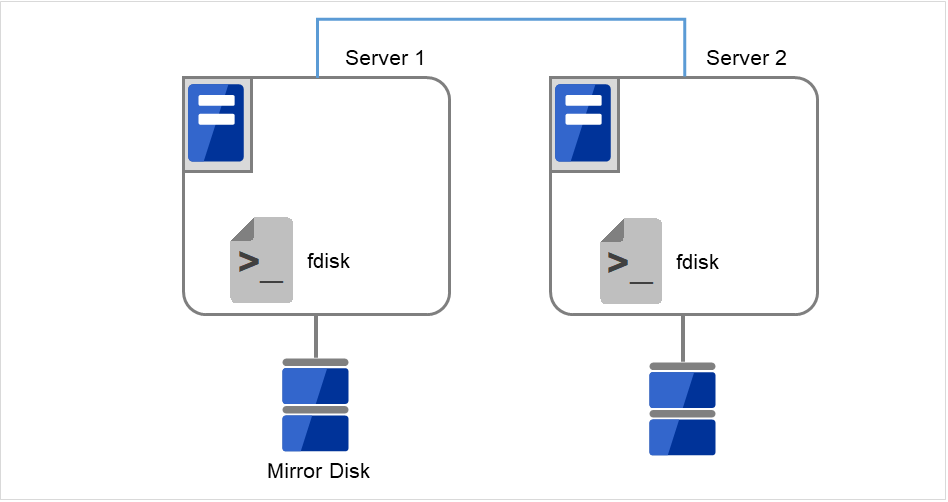
図 2.43 パーティションサイズを変更¶
クラスタ構成情報を変更、アップロードします。『インストール&設定ガイド』の「クラスタ構成情報を変更する」の「Cluster WebUI を使用してクラスタ構成情報を変更する」を参照してミラーディスクリソースの変更を行います。
両サーバで以下のコマンドを実行します。
# clpmdinit --create force <ミラーディスクリソース名>
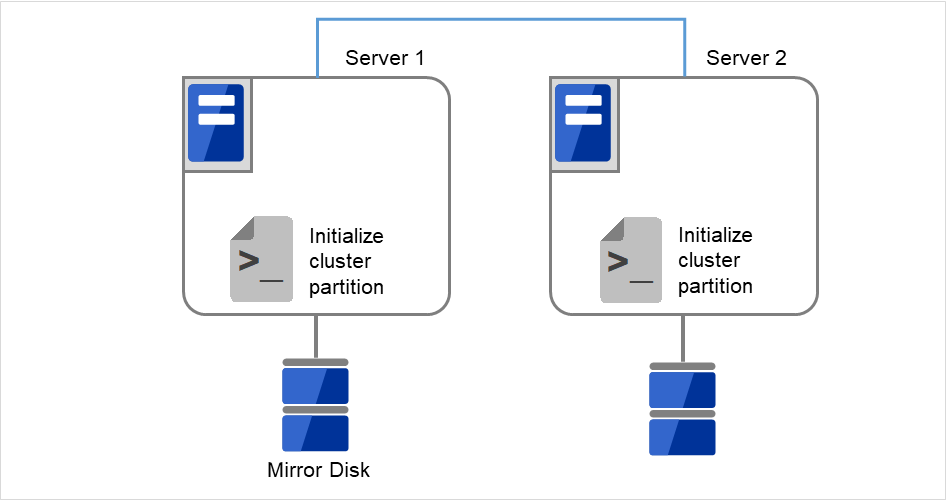
図 2.44 クラスタパーティションを初期化¶
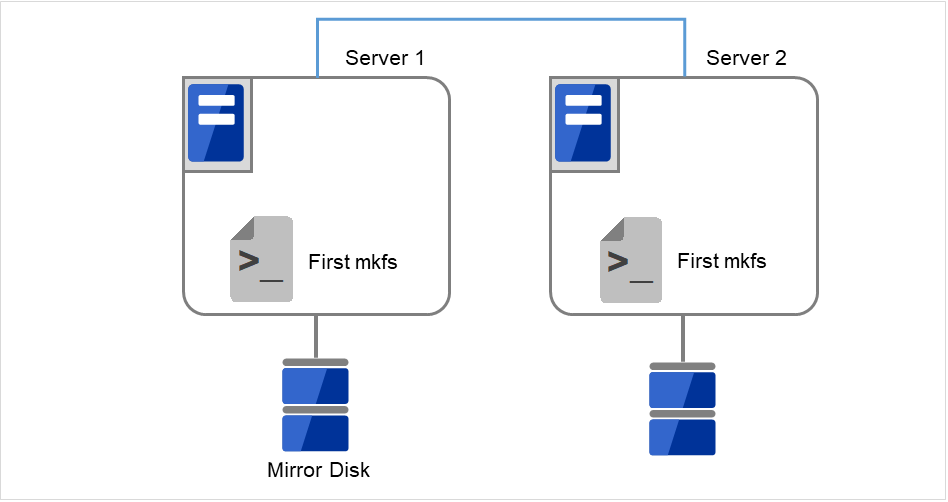
図 2.45 初回のmkfsを実行し、ファイルシステムを作成¶
注釈
ミラーディスクリソースの設定で [初期 mkfs を行う] をオフに設定した場合には、mkfs が自動では行われませんので、手動で mkfs をデータパーティションに対して実行してください。
両サーバで CLUSTERPRO サービスが起動するように設定します。
clpsvcctrl.sh --enable core
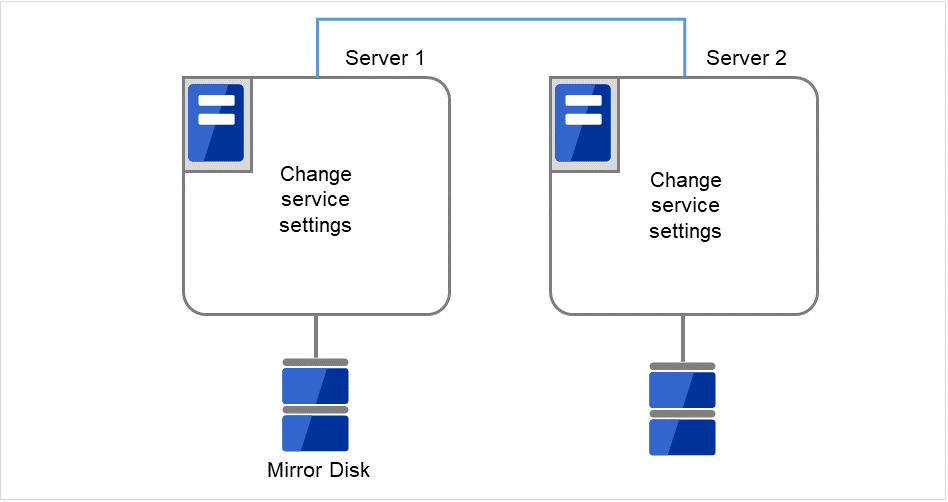
図 2.46 CLUSTERPRO サービスが起動するよう設定変更¶
[reboot] コマンドを使用して両サーバを再起動します。クラスタとして起動します。
クラスタ起動時にクラスタ生成後の初期ミラー構築と同じ処理が実行されますので、以下のコマンドを実行して初期ミラー構築の完了を確認するか、Cluster WebUI を使用して初期ミラー構築の完了を確認します。
# clpmdstat --mirror <ミラーディスクリソース名>
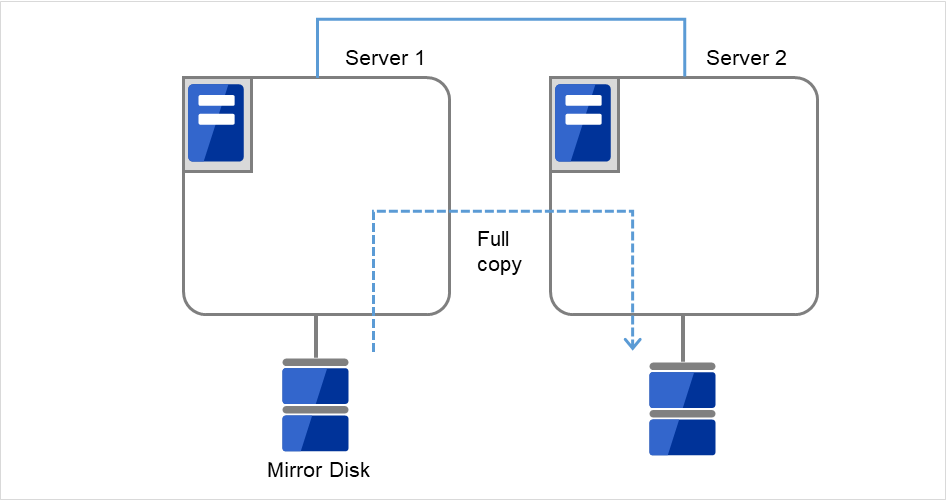
図 2.47 Server1よりミラー復帰開始¶
初期ミラー構築が完了してフェイルオーバグループが起動するとミラーディスクリソースが活性状態になります。
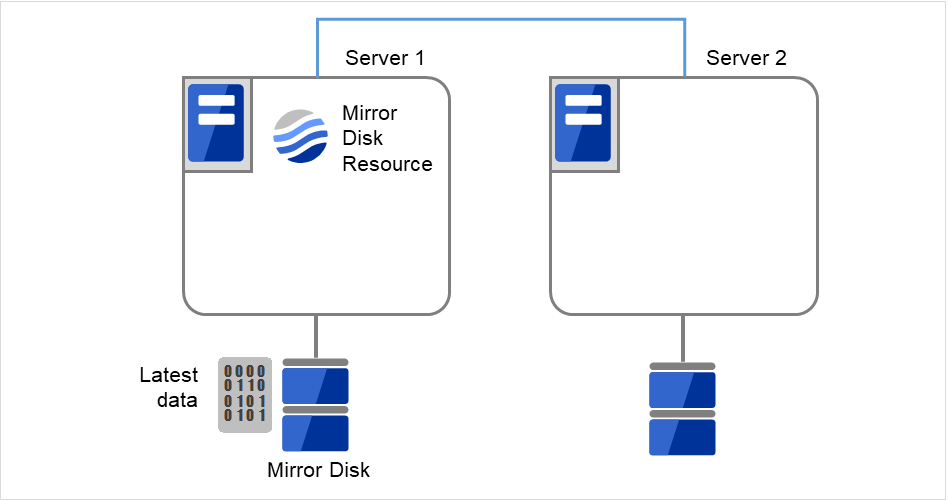
図 2.48 初期ミラー構築完了¶
- サイズを変更したミラーパーティションを持つグループが活性しているサーバで、バックアップしていたデータをリストアします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ミラーディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
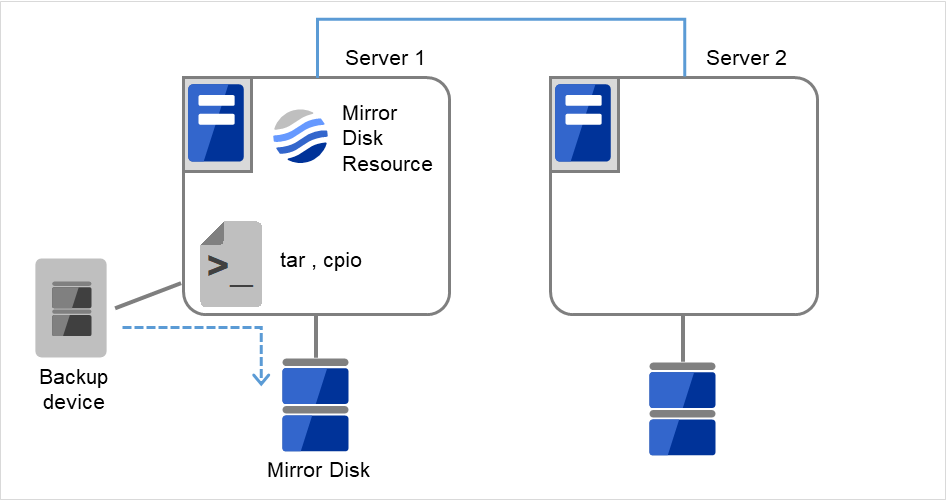
図 2.49 バックアップしていたデータをリストア¶
2.22. ハイブリッドディスクリソースのパーティションのオフセットやサイズを変更する¶
運用を開始した後で、ハイブリッドディスクリソースに設定しているデータパーティションやクラスタパーティションのオフセット (位置) やサイズを変更したい場合、以下の手順で行ってください。
注釈
必ず以下の手順で行ってください。データパーティションやクラスタパーティションに指定しているパーティションを fdisk で変更するだけでは、ハイブリッドディスクリソースは正常に動作しなくなります。
2.22.1. データパーティションをLVMで構成している場合¶
データパーティションをLVMで構成している場合、使用しているファイルシステムによっては、リソースを再作成することなく、または業務を停止することなくデータパーティションを拡張することができます。
データパーティションのファイルシステム |
リソースの再作成 |
業務停止 |
参照 |
|---|---|---|---|
xfs, ext2, ext3, ext4, ファイルシステムなし(none) |
不要 |
不要 |
2.22.1.1. 使用しているファイルシステムがext系かxfs、またはファイルシステムを使用していない場合のデータパーティション拡張 |
上記以外 |
要 |
要 |
注釈
この方法では拡張のみ可能です。縮小する場合は、下記「2.22.2. データパーティションをLVM以外で構成している場合」記載の手順を実行してください。
注釈
下記の手順でデータパーティションを拡張する場合は、データパーティションがLVMで構成されており、かつボリュームグループの未使用PE(Physical Extent)量が十分確保されている必要があります。
2.22.1.1. 使用しているファイルシステムがext系かxfs、またはファイルシステムを使用していない場合のデータパーティション拡張¶
サイズを変更したいハイブリッドディスクリソースの名称を [clpstat] コマンドまたはCluster WebUI で確認します。
予期せぬ事態に備え、サイズを変更したいハイブリッドディスクリソースを持つグループが活性しているサーバで、パーティション内のデータをテープなどにバックアップします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。 ハイブリッドディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
以下を確認してください。
ハイブリッドディスクリソースの状態が正常であること
両サーバで、データパーティションが所属するボリュームグループの未使用PE(Physical Extent)量が十分であること。
Cluster WebUIの操作モードからハイブリッドディスクモニタリソースをすべて「一時停止」にし、自動でミラー復帰が行われない状態にします。
各サーバグループのカレントサーバのみを残し、他のサーバをすべてシャットダウンしてください。カレントサーバはclphdstatの-aオプションで確認できます。以下は、リソースhd01のカレントサーバを確認する場合の例です。
clphdstat -a hd01
ハイブリッドディスクリソースが活性していない側のサーバグループ上のカレントサーバで、以下の[clphdctrl]コマンドを実行します。 | どちらのサーバグループでもリソースが活性してない場合は、どちらから実行しても構いません。以下は、hd01のデータパーティションを500ギビバイトに拡張する場合の例です。
# clphdctrl --resize 500G hd01
重要
ハイブリッドディスクリソースがいずれかのサーバで活性中の場合は、必ず活性してない方のサーバグループから実行してください。活性している側のサーバグループから実行すると、ミラーブレイク発生の原因となります。
- もう一方のサーバグループ上のカレントサーバで、同様に以下のclphdctrlコマンドを実行します。以下は、hd01のデータパーティションを500ギビバイトに拡張する場合の例です。
# clphdctrl --resize 500G hd01 データパーティションにxfsまたはext系ファイルシステムを構築している場合、ハイブリッドディスクリソースが活性しているサーバでコマンドを実行して、ファイルシステムの対象領域を広げます。
<xfsの場合># xfs_growfs /mnt/nmp1(/mnt/nmp1はハイブリッドディスクリソースのマウントポイントに応じて変更する)<ext系の場合># resize2fs -p /dev/NMP1
(NMP1はミラーパーティションデバイス名に応じて変更する)データパーティションにファイルシステムを使用していない場合(none)、この手順は必要ありません。
手順4で「一時停止」にしたハイブリッドディスクモニタリソースを、Cluster WebUI の操作モードからすべて「再開」します。
手順5でシャットダウンしていたサーバをすべて起動します。
重要
# clphdctrl --resize -force 500G hd01
注釈
# clphdctrl --resize 1022M hd01 と指定すると、データパーティションのサイズは1024M、ファイルシステム拡張の上限が1022Mとなります。注釈
xfs_growfsおよびresize2fs の実行中は大量の書き込みが発生するため、業務I/Oの性能が低下することがあります。負荷の高い時間帯を避けて実行することを推奨します。
2.22.1.2. その他のファイルシステムを使用している場合のデータパーティション拡張¶
基本的な手順は「2.22.2. データパーティションをLVM以外で構成している場合」と同じです。
ただし、[fdisk]でパーティションのサイズを変更する箇所は、代わりに[lvextend]コマンドを使用して拡張を行ってください。
2.22.2. データパーティションをLVM以外で構成している場合¶
2.22.2.1. ハイブリッドディスクリソースのパーティションのデバイス名を変更しない場合¶
サイズを変更したいハイブリッドディスクリソースの名称を [clpstat] コマンドまたはCluster WebUI で確認します。
- サイズを変更したいハイブリッドディスクリソースを持つグループが活性しているサーバで、パーティション内のデータをテープなどにバックアップします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ハイブリッドディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
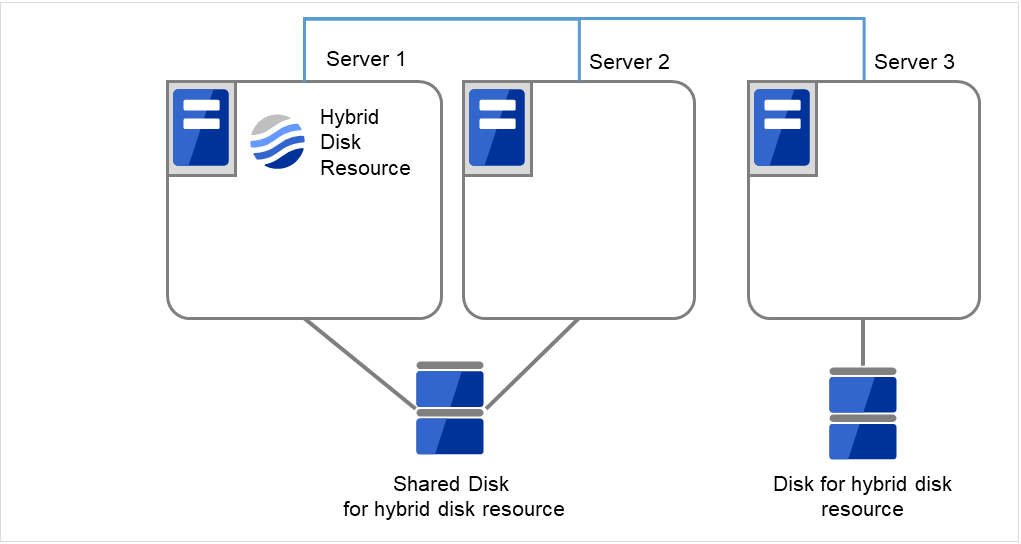
図 2.50 Server1ではハイブリッドディスクリソースをもつグループが活性状態¶
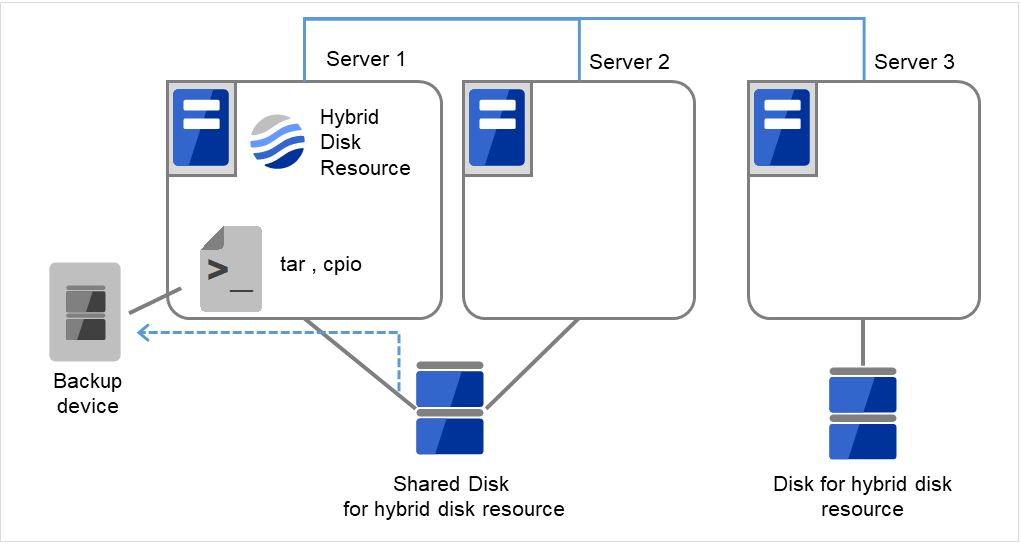
図 2.51 Server1でデータをバックアップ¶
全てのサーバで CLUSTERPRO サービスが起動しないように設定します。
clpsvcctrl.sh --disable core
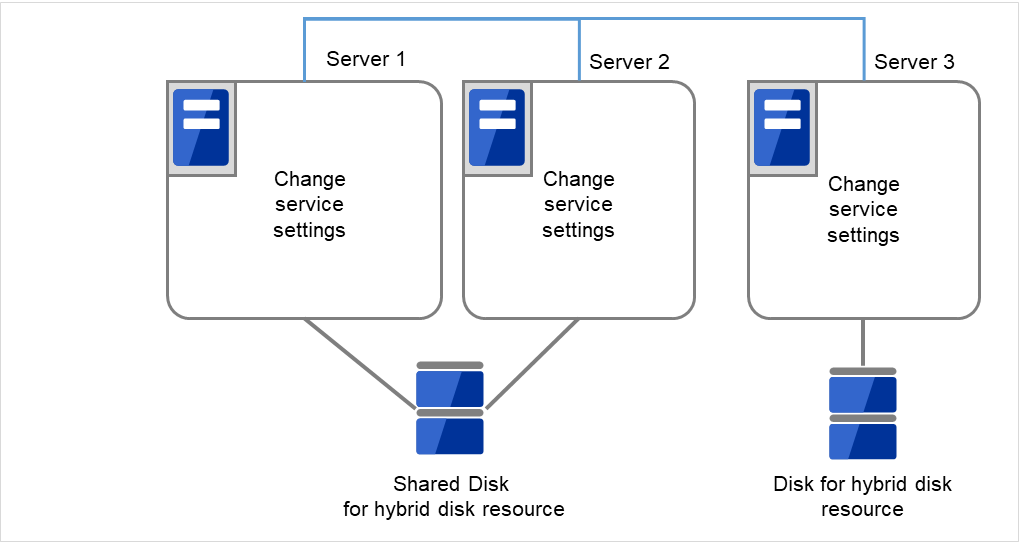
図 2.52 CLUSTERPRO サービスが起動しないよう設定変更¶
- クラスタのシャットダウンと、OS の再起動を行います。いずれかのサーバで [clpstdn] コマンドを使用してクラスタシャットダウンリブートを実行するか、または Cluster WebUI からクラスタシャットダウンリブートを実行します。
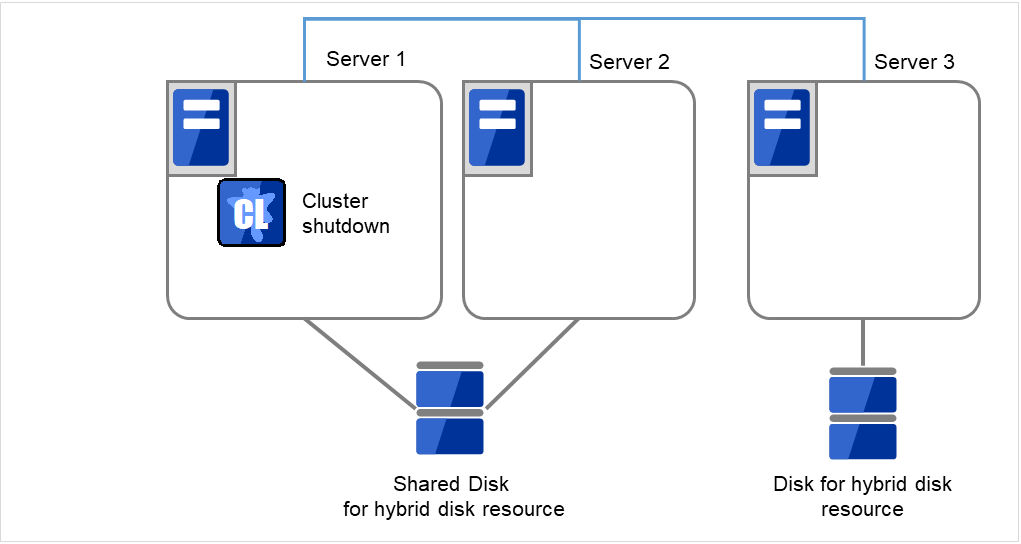
図 2.53 いずれかのサーバでクラスタシャットダウンを実行¶
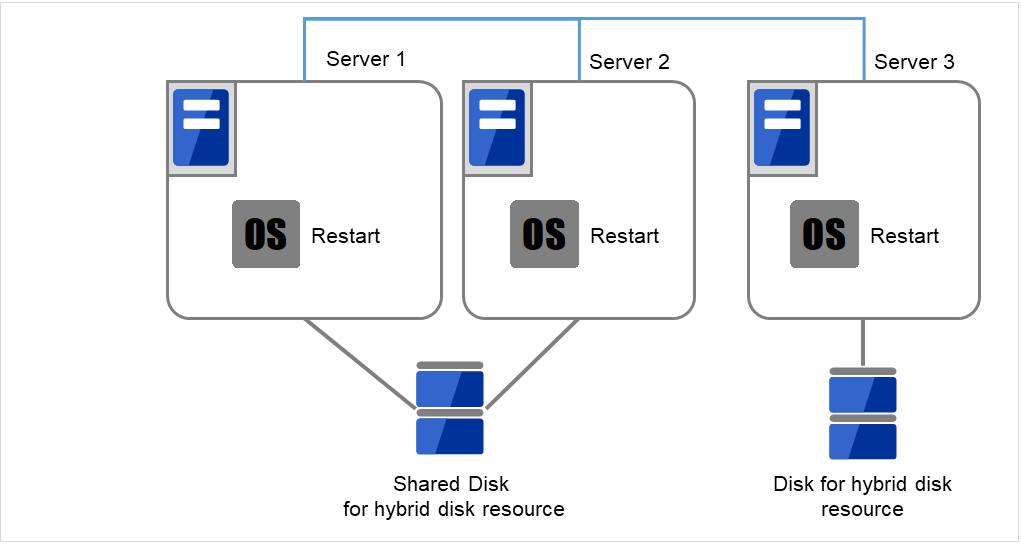
図 2.54 OSを再起動¶
- サーバで [fdisk] コマンドを使用してパーティションのオフセットやサイズを変更します。共有ディスクを接続しているサーバでは、どちらか片方のサーバから [fdisk] コマンドを実行して変更します。
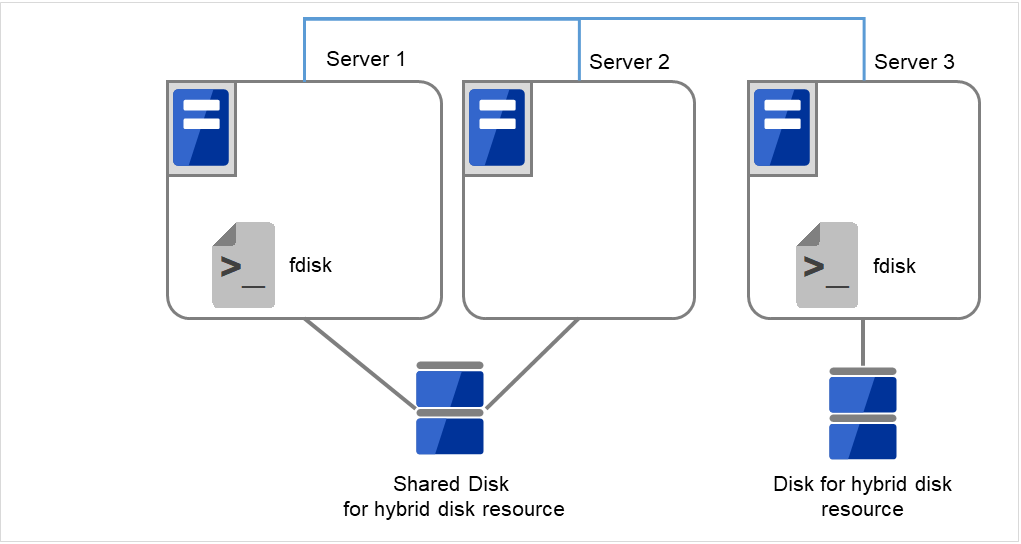
図 2.55 パーティションサイズを変更¶
- サーバで以下のコマンドを実行します。共有ディスクを接続しているサーバでは、上記の手順を実行したサーバからコマンドを 実行します。
# clphdinit --create force <ハイブリッドディスクリソース名>
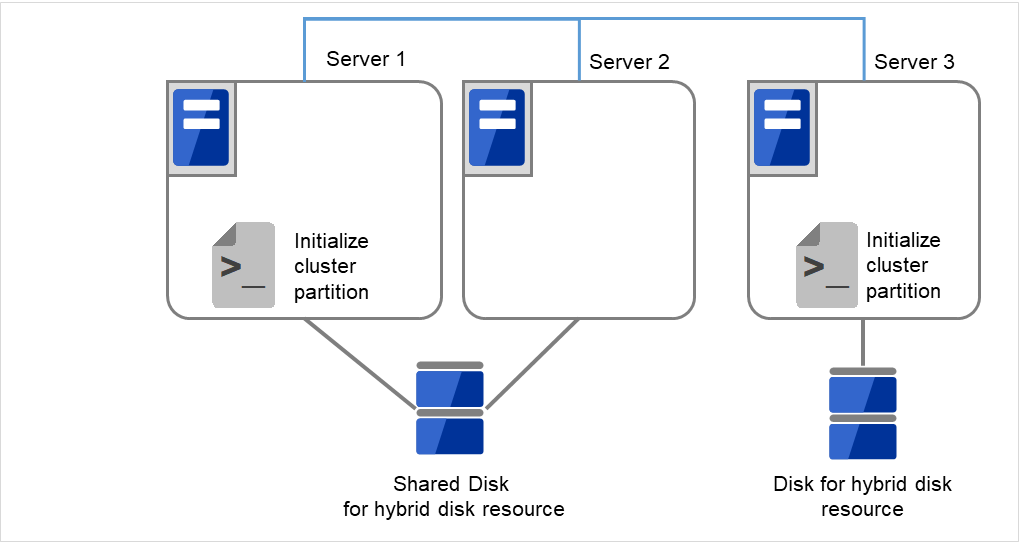
図 2.56 クラスタパーティションを初期化¶
- mkfsを実行します。共有ディスクを接続しているサーバでは、上記の手順を実行したサーバから mkfs コマンドを 実行します。
# mkfs -t <ファイルシステム種別>* <データパーティション>
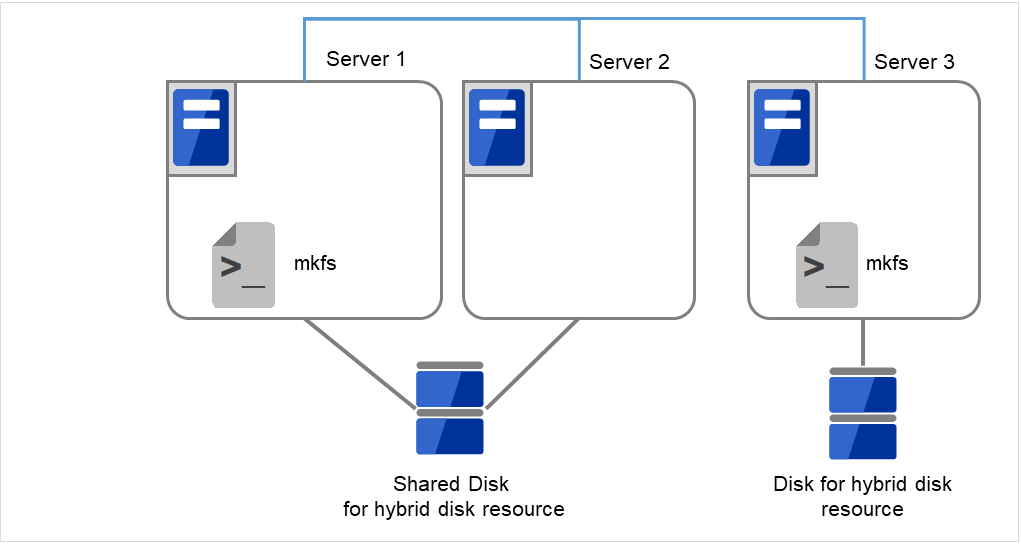
図 2.57 初回のmkfsを実行し、ファイルシステムを作成¶
全てのサーバで CLUSTERPRO サービスが起動するように設定します。
clpsvcctrl.sh --enable core
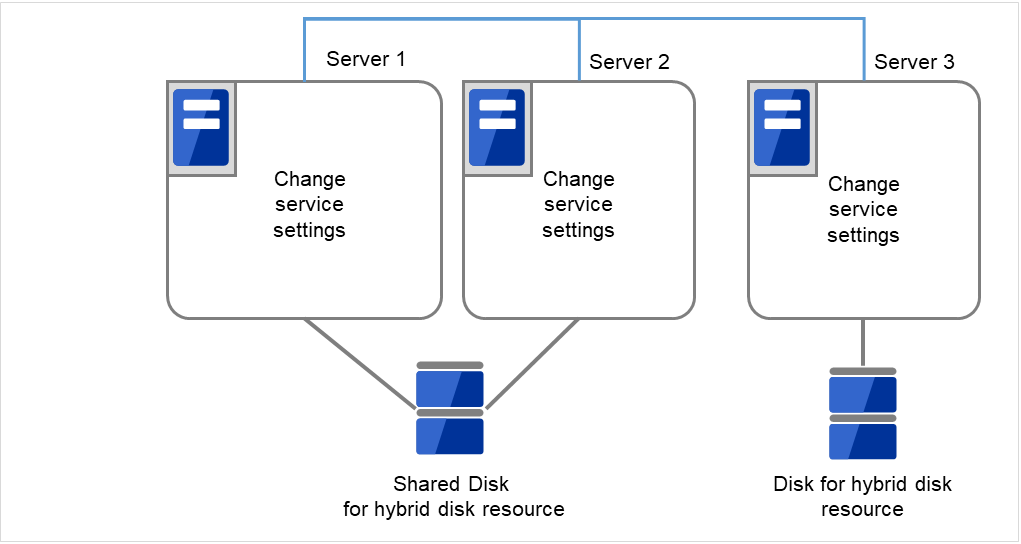
図 2.58 CLUSTERPRO サービスが起動するよう設定変更¶
[reboot] コマンドを使用して全サーバを再起動します。クラスタとして起動します。
クラスタ起動時にクラスタ生成後の初期ミラー構築と同じ処理が実行されますので、以下のコマンドを実行して初期ミラー構築の完了を確認するか、Cluster WebUI を使用して初期ミラー構築の完了を確認します。
# clphdstat --mirror <ハイブリッドディスクリソース名>
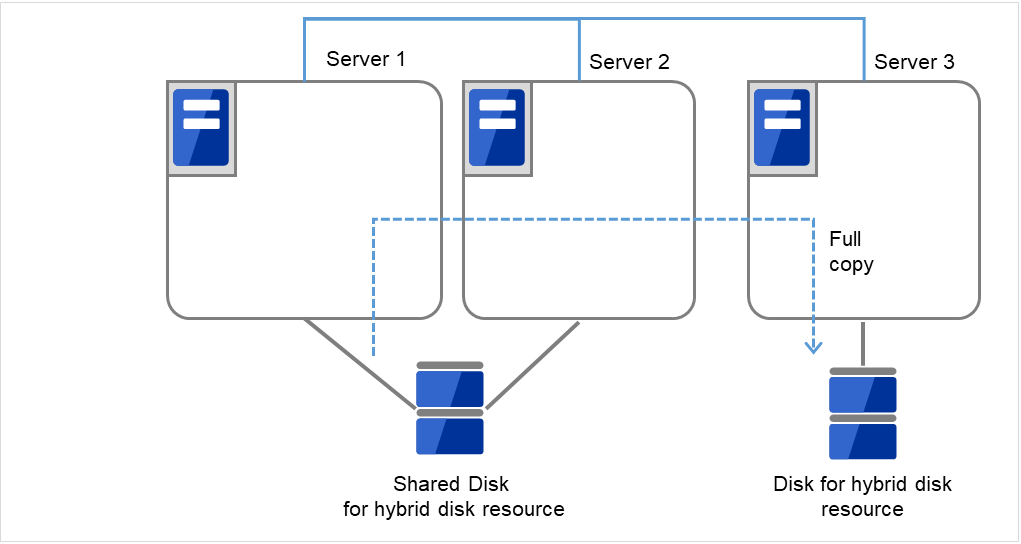
図 2.59 Server1よりミラー復帰開始¶
初期ミラー構築が完了してフェイルオーバグループが起動するとハイブリッドディスクリソースが活性状態になります。
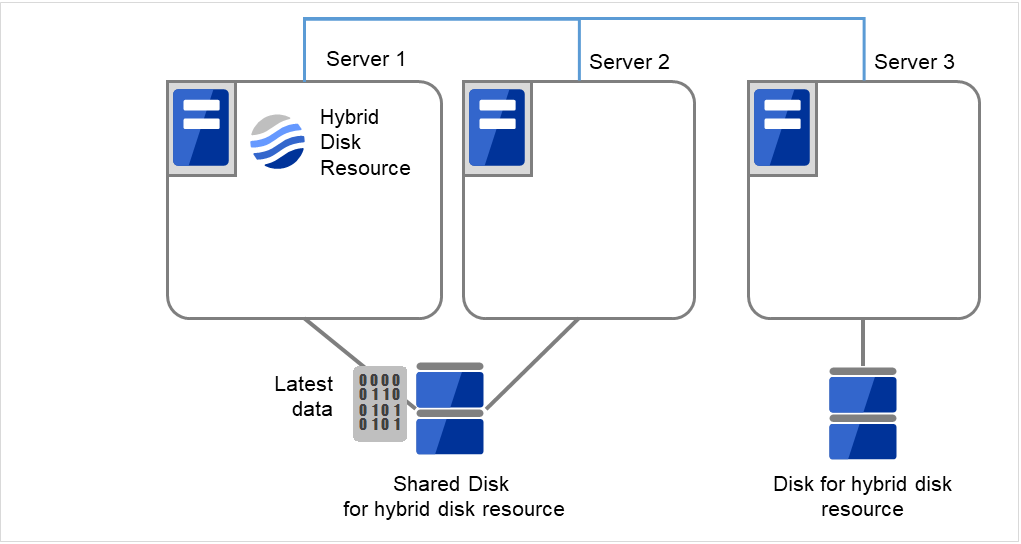
図 2.60 初期ミラー構築完了¶
- サイズを変更したパーティションを持つグループが活性しているサーバで、バックアップしていたデータをリストアします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ハイブリッドディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
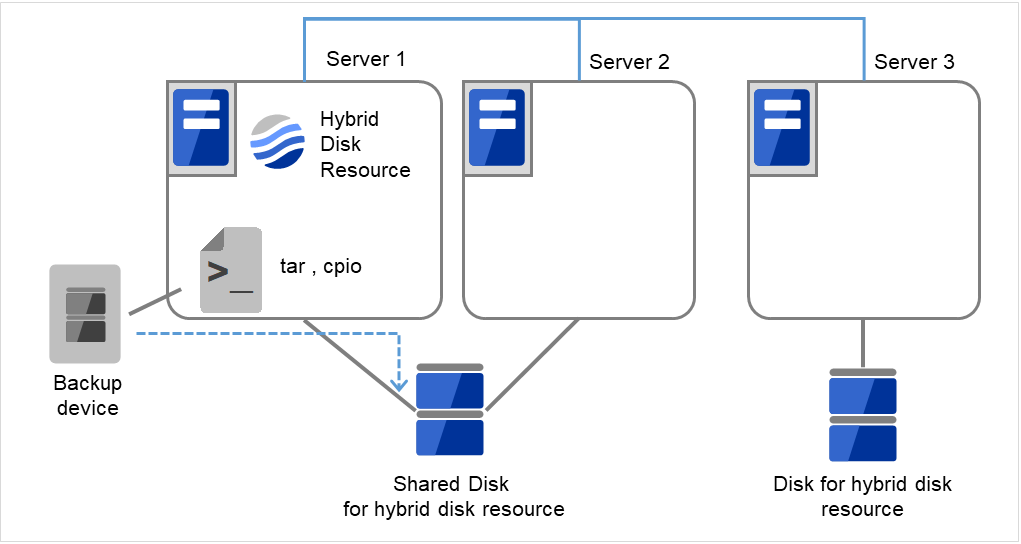
図 2.61 バックアップしていたデータをリストア¶
2.22.2.2. ハイブリッドディスクリソースのパーティションのデバイス名を変更する 場合¶
サイズを変更したいハイブリッドディスクリソースの名称を [clpstat] コマンドまたはCluster WebUI で確認します。
- サイズを変更したいハイブリッドディスクリソースを持つグループが活性しているサーバで、パーティション内のデータをテープなどにバックアップします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ハイブリッドディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
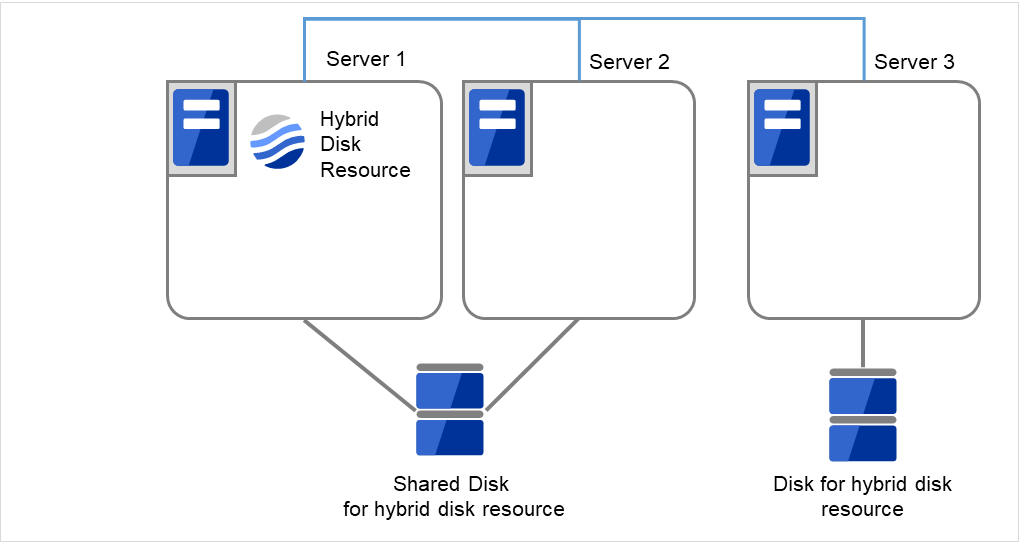
図 2.62 Server1ではハイブリッドディスクリソースをもつグループが活性状態¶
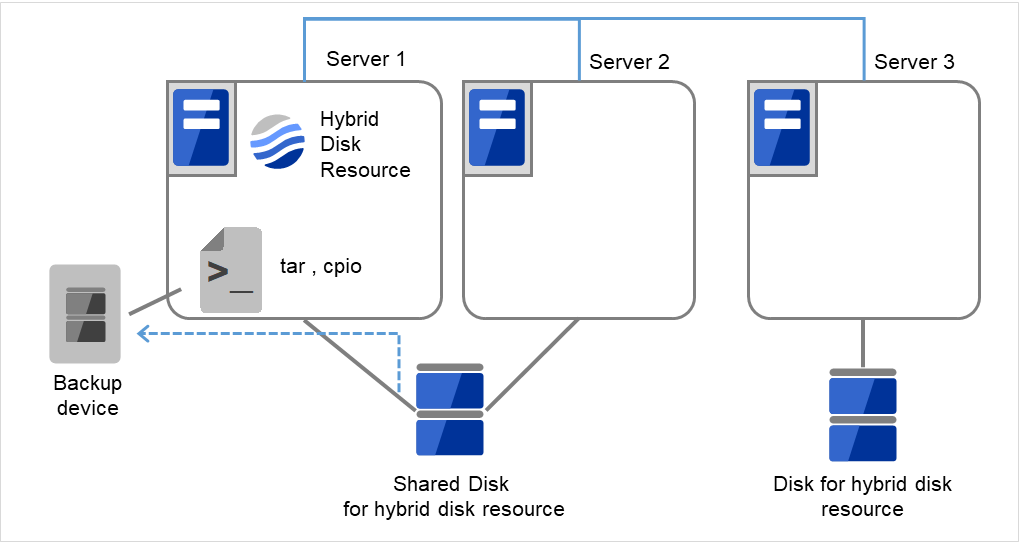
図 2.63 Server1でデータをバックアップ¶
全てのサーバで CLUSTERPRO サービスが起動しないように設定します。
clpsvcctrl.sh --disable core
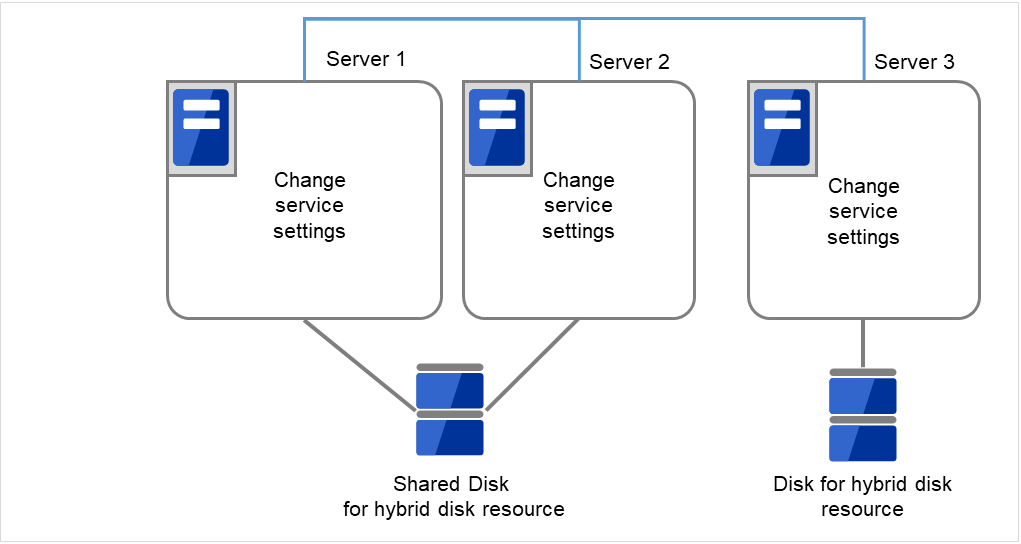
図 2.64 CLUSTERPRO サービスが起動しないよう設定変更¶
- クラスタのシャットダウンと、OS の再起動を行います。いずれかのサーバで [clpstdn] コマンドを使用してクラスタシャットダウンリブートを実行するか、または Cluster WebUI からクラスタシャットダウンリブートを実行します。
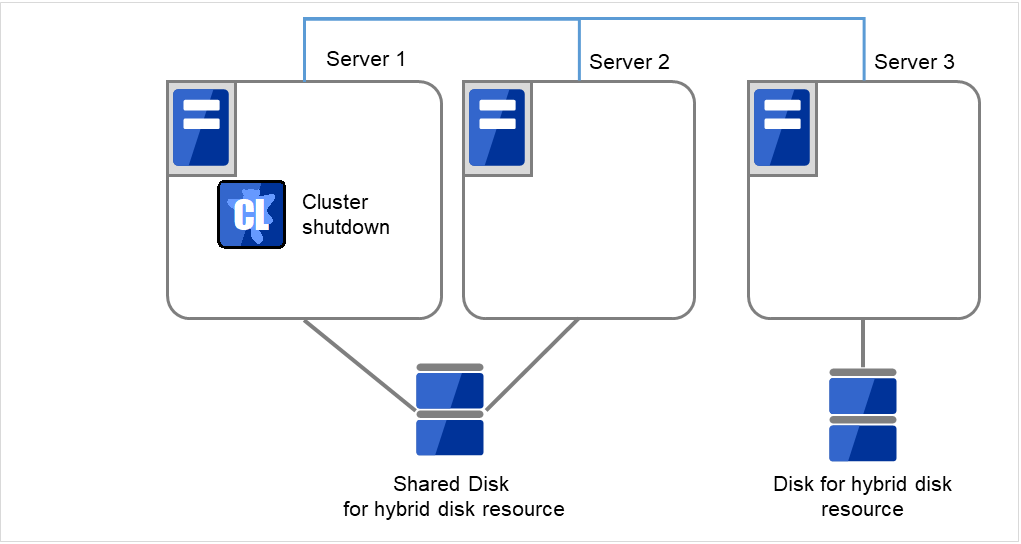
図 2.65 いずれかのサーバでクラスタシャットダウンを実行¶
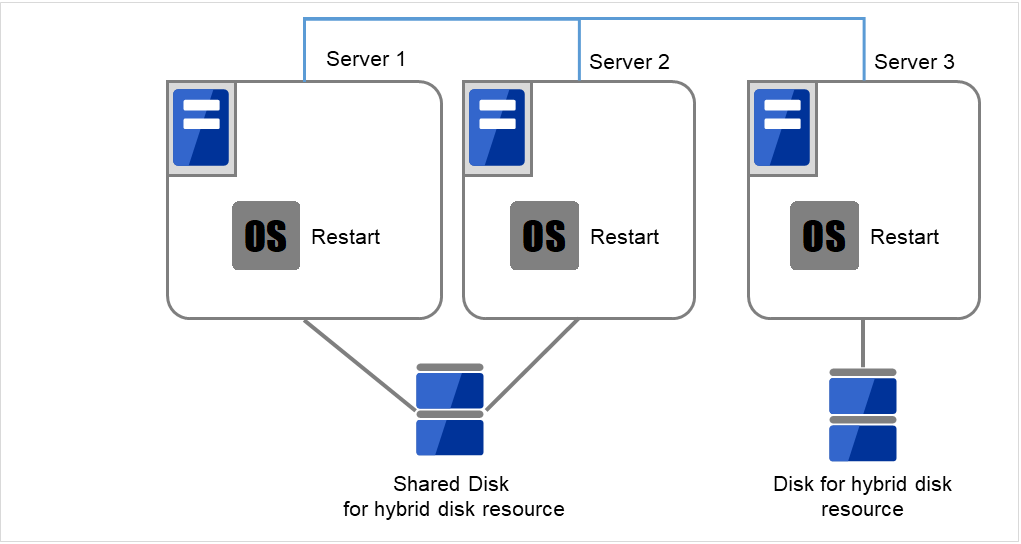
図 2.66 OSを再起動¶
- サーバで [fdisk] コマンドを使用してパーティションのオフセットやサイズを変更します。共有ディスクを接続しているサーバでは、どちらか片方のサーバから [fdisk] コマンドを実行して変更します。
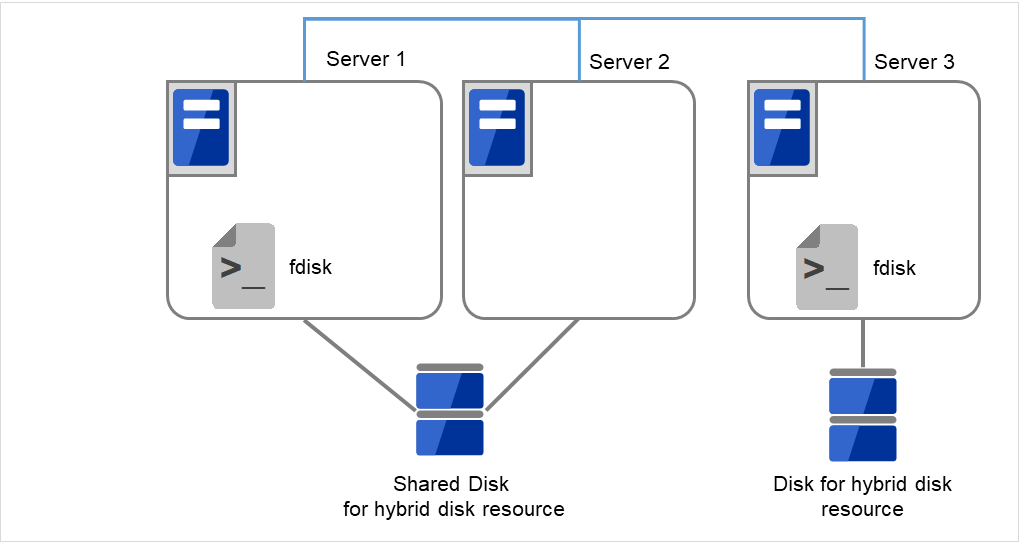
図 2.67 パーティションサイズを変更¶
クラスタ構成情報を変更、アップロードします。『インストール&設定ガイド』の「クラスタ構成情報を変更する」の「Cluster WebUI を使用してクラスタ構成情報を変更する」を参照してハイブリッドディスクリソースの変更を行います。
- サーバで以下のコマンドを実行します。共有ディスクを接続しているサーバでは、上記の手順を実行したサーバからコマンドを実行します。
# clphdinit --create force <ハイブリッドディスクリソース名>
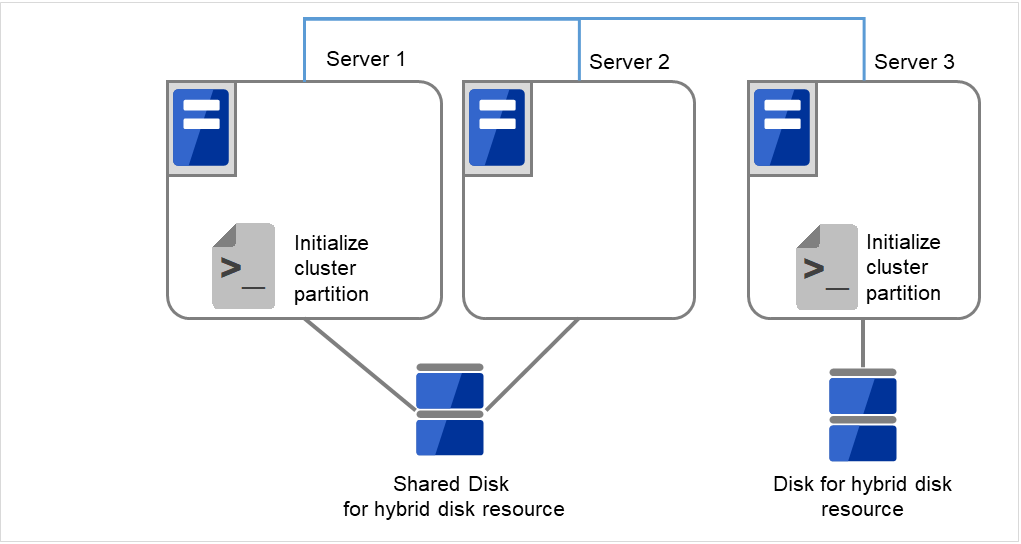
図 2.68 クラスタパーティションを初期化¶
- サーバで mkfs コマンドを実行します。共有ディスクを接続しているサーバでは、上記の手順を実行したサーバから mkfs コマンドを実行します。
# mkfs -t <ファイルシステム種別> <データパーティション>
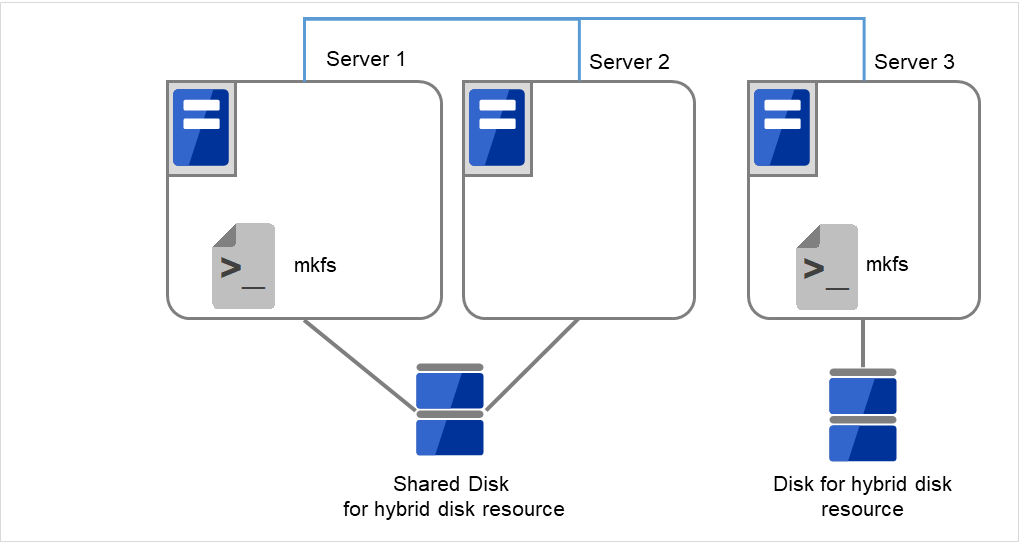
図 2.69 初回のmkfsを実行し、ファイルシステムを作成¶
全てのサーバで CLUSTERPRO サービスが起動するように設定します。
clpsvcctrl.sh --enable core
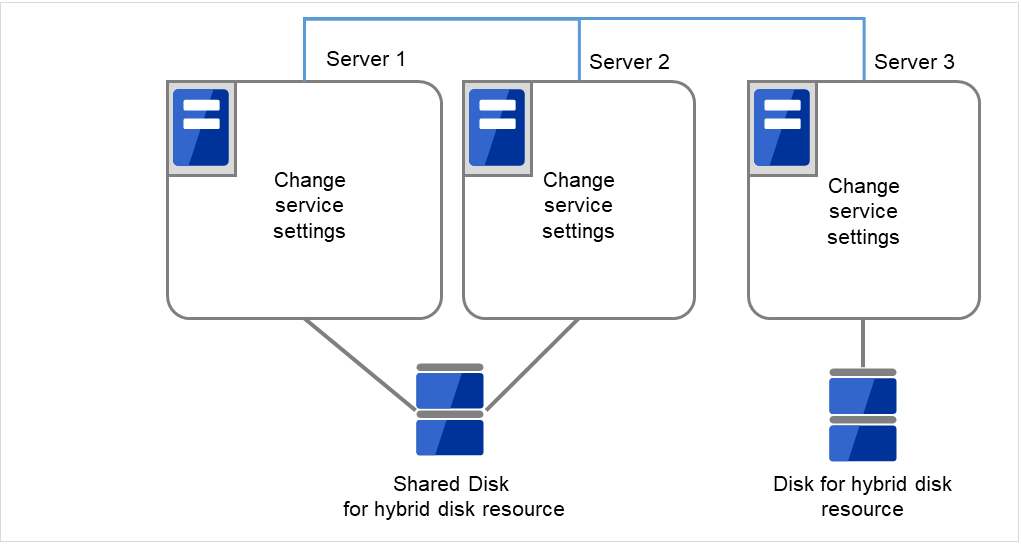
図 2.70 CLUSTERPRO サービスが起動するよう設定変更¶
[reboot] コマンドを使用して全サーバを再起動します。クラスタとして起動します。
クラスタ起動時にクラスタ生成後の初期ミラー構築と同じ処理が実行されますので、以下のコマンドを実行して初期ミラー構築の完了を確認するか、Cluster WebUI を使用して初期ミラー構築の完了を確認します。
# clphdstat --mirror <ハイブリッドディスクリソース名>
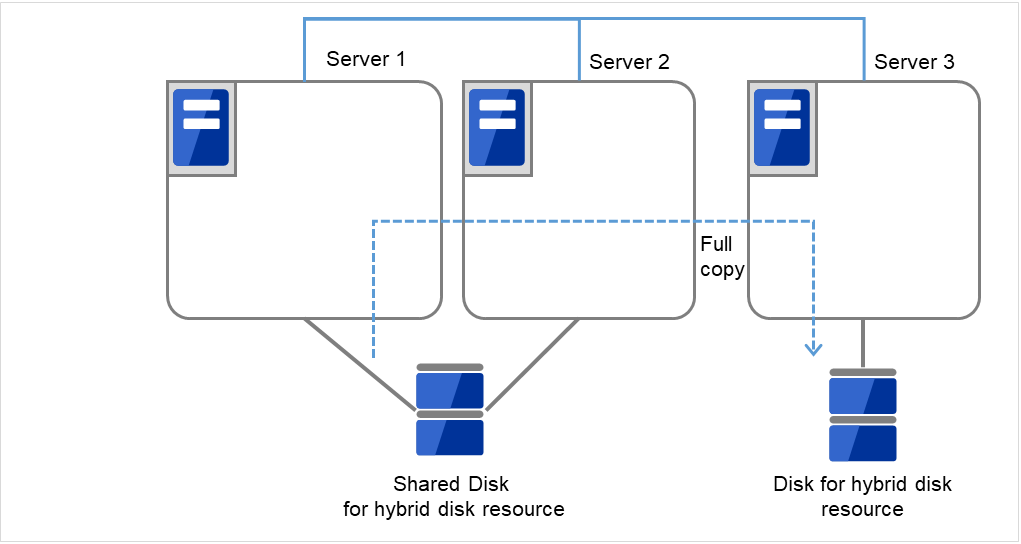
図 2.71 Server1よりミラー復帰開始¶
初期ミラー構築が完了してフェイルオーバグループが起動するとハイブリッドディスクリソースが活性状態になります。
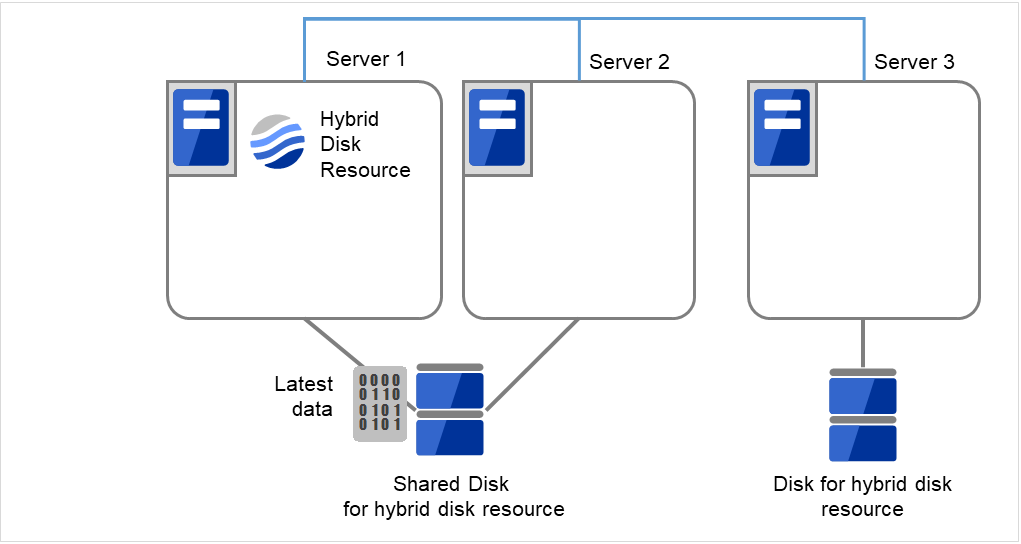
図 2.72 初期ミラー構築完了¶
- サイズを変更したパーティションを持つグループが活性しているサーバで、バックアップしていたデータをリストアします。ただし、パーティションデバイスを直接アクセスするバックアップコマンドはサポートしていません。ハイブリッドディスクリソース上のデータを破棄しても問題ない場合には、この手順は必要ありません。
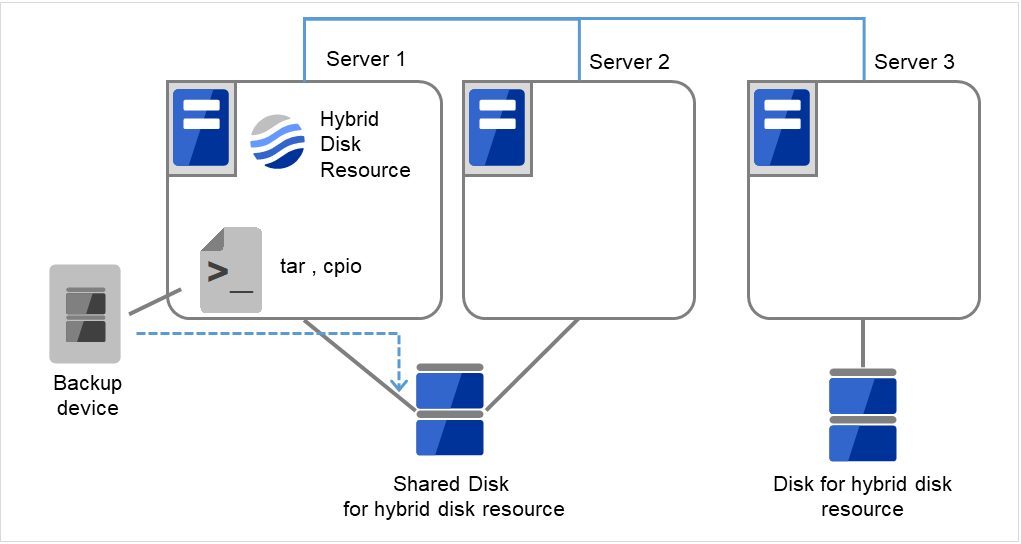
図 2.73 バックアップしていたデータをリストア¶
2.23. サーバ構成の変更 (追加、削除)¶
2.23.1. サーバ追加(ミラーディスク、ハイブリッドディスクを使用していない環境の場合)¶
サーバの追加を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの追加を行う場合、その他の変更 (グループリソースの追加等) は行わないでください。
クラスタの状態を正常状態にします。
追加するサーバに CLUSTERPRO サーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」 - 「CLUSTERPRO Server のセットアップ」 - 「 CLUSTERPRO RPM をインストールするには」を参照してください。CLUSTERPRO サーバをインストールしたサーバはインストール後、再起動しておく必要があります。
クラスタ内の他サーバに Web ブラウザで接続して Cluster WebUI の設定モードの [サーバの追加] をクリックします。
Cluster WebUI の設定モードから追加サーバの以下の情報を再設定します。
仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの送信元 IP アドレスの情報 (仮想 IP リソースを使用する場合)
AWS Elastic IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS Elastic IP リソースを使用する場合)
AWS 仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS 仮想 IP リソースを使用する場合)
AWS セカンダリ IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS セカンダリ IP リソースを使用する場合)
Azure DNS リソースの [プロパティ]→[詳細] タブにある追加サーバの IP アドレス の情報 (Azure DNS リソースを使用する場合)
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
反映動作の実行を問う画面が表示されます。画面に従って反映してください。
Cluster WebUI の操作モードから追加したサーバの [サーバサービス開始] を実行します。
Cluster WebUI の操作モードで [最新情報を取得] をクリックし、表示された情報でクラスタが正常になっていることを確認します。
2.23.2. サーバ追加(ミラーディスク、ハイブリッドディスクを使用している環境の場合)¶
サーバの追加を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの追加を行う場合、その他の変更 (グループリソースの追加等) は行わないでください。
クラスタの状態を正常状態にします。
追加するサーバに CLUSTERPRO サーバをインストールします。詳細は『インストール&設定ガイド』の「CLUSTERPRO をインストールする」 - 「CLUSTERPRO Server のセットアップ」 - 「 CLUSTERPRO RPM をインストールするには」を参照してください。CLUSTERPRO サーバをインストールしたサーバはインストール後、再起動しておく必要があります。
Cluster WebUI の操作モードから [クラスタ停止] を実行します。
Cluster WebUI の操作モードから [ミラーエージェント停止] を実行します。
クラスタ内の他サーバに Web ブラウザで接続して Cluster WebUI の設定モードの [サーバの追加] をクリックします。
Cluster WebUI の設定モードから追加サーバの以下の情報を再設定します。
仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの送信元 IP アドレスの情報 (仮想 IP リソースを使用する場合)
AWS Elastic IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS Elastic IP リソースを使用する場合)
AWS 仮想 IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS 仮想 IP リソースを使用する場合)
AWS セカンダリ IP リソースの [プロパティ]→[詳細] タブにある追加サーバの ENI ID の情報 (AWS セカンダリ IP リソースを使用する場合)
Azure DNS リソースの [プロパティ]→[詳細] タブにある追加サーバの IP アドレス の情報 (Azure DNS リソースを使用する場合)
- 追加サーバでハイブリッドディスクリソースを使用する場合、Cluster WebUI の設定モードの [サーバ] の [プロパティ] をクリックします。 [サーバグループ] タブから起動可能なサーバに追加します。起動可能なサーバの追加は必要なサーバグループにのみ行ってください。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。サービスを再起動するダイアログが表示されますので、[OK] を選択します。
Cluster WebUI の操作モードから [ミラーエージェント開始] を実行します。
Cluster WebUI の操作モードから [クラスタ開始] を実行します。
Cluster WebUI の操作モードで [最新情報を取得] をクリックし、表示された情報でクラスタが正常になっていることを確認します。
2.23.3. サーバ削除(ミラーディスク、ハイブリッドディスクを使用していない環境の場合)¶
サーバの削除を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの削除を行う場合、その他の変更 (グループリソースの追加等) は行わないでください。
削除するサーバに登録したライセンスに関しては以下を参照してください。
CPUライセンスは対処不要です。
期限付きライセンスは対処不要です。未開始のライセンスがあれば自動で回収し他サーバに配布されます。
クラスタの状態を正常状態にします。削除するサーバでグループが活性している場合には他のサーバにグループを移動してください。
削除するサーバがサーバグループに登録されている場合は、Cluster WebUI の設定モードの [サーバ] の [プロパティ] をクリックします。 [サーバグループ] タブで起動可能なサーバから対象サーバを削除します。
Cluster WebUI の設定モードで削除するサーバの [サーバの削除] をクリックします。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
反映動作の実行を問う画面が表示されます。画面に従って反映してください。
Cluster WebUI の操作モードで [最新情報を取得] をクリックし、表示された情報でクラスタが正常になっていることを確認します。
- 削除したサーバは、クラスタ未構築状態になります。削除するサーバの CLUSTERPRO サーバをアンインストールする場合、『インストール&設定ガイド』の「CLUSTERPRO をアンインストール/再インストールする」 - 「アンインストール手順」 - 「 CLUSTERPRO Server のアンインストール」を参照してください。なお、上記アンインストール手順に含まれるサーバ再起動は、削除したサーバにて OS からリブートするよう読み替えて実施してください。
2.23.4. サーバ削除(ミラーディスク、ハイブリッドディスクを使用している環境の場合)¶
サーバの削除を行う場合、以下の手順で行ってください。
重要
クラスタ構成変更でサーバの削除を行う場合、後述の手順以外の設定変更 (グループリソースの追加等) は行わないでください。
削除するサーバに登録したライセンスに関しては以下を参照してください。
CPUライセンスは対処不要です。
期限付きライセンスは対処不要です。未開始のライセンスがあれば自動で回収し他サーバに配布されます。
クラスタの状態を正常状態にします。削除するサーバでグループが活性している場合には他のサーバにグループを移動してください。
Cluster WebUI の操作モードから [クラスタ停止] を実行します。
Cluster WebUI の操作モードから [ミラーエージェント停止] を実行します。
Cluster WebUI の設定モードでミラーディスクリソース、ハイブリッドディスクリソースの [リソースの削除] をクリックします。
削除するサーバがサーバグループに登録されている場合は、Cluster WebUI の設定モードの [サーバ] の [プロパティ] をクリックします。 [サーバグループ] タブで起動可能なサーバから対象サーバを削除します。
Cluster WebUI の設定モードで削除するサーバの [サーバの削除] をクリックします。
Cluster WebUI の設定モードの [設定の反映] をクリックし、クラスタ構成情報をクラスタに反映します。
Cluster WebUI の操作モードから「ミラーエージェント開始」、[クラスタ開始] を実行します。
Cluster WebUI の操作モードで [最新情報を取得] をクリックし、表示された情報でクラスタが正常になっていることを確認します。
- 削除したサーバは、クラスタ未構築状態になります。削除するサーバの CLUSTERPRO サーバをアンインストールする場合、『インストール&設定ガイド』の「CLUSTERPRO をアンインストール/再インストールする」 - 「アンインストール手順」 - 「 CLUSTERPRO Server のアンインストール」を参照してください。なお、上記アンインストール手順に含まれるサーバ再起動は、削除したサーバにて OS からリブートするよう読み替えて実施してください。
2.24. サーバ IP アドレスの変更手順¶
運用を開始した後で、サーバの IP アドレスを変更したい場合、以下の手順で行ってください。
2.24.1. インタコネクト IP アドレス/ミラーディスクコネクト IP アドレス変更手順¶
クラスタ内の全てのサーバが正常であることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
- クラスタ構成情報をバックアップします。[clpcfctrl] コマンドを使用してバックアップを作成します。クラスタ生成時の構成情報がある場合は、その構成情報を使用します。
Cluster WebUI の設定モードで、バックアップしたクラスタ構成情報をもとにサーバの IP アドレスを変更後、保存します。
クラスタ内の全てのサーバで CLUSTERPRO デーモンの起動設定を無効にします。 詳細については、『インストール&設定ガイド』の「運用開始前の準備を行う」 - 「CLUSTERPRO を一時停止する」 - 「CLUSTERPRO デーモンの無効化」を参照してください。
[clpstdn] コマンド、またはCluster WebUI の操作モードからクラスタをシャットダウン後、全てのサーバを再起動します。
IP アドレスを変更します。IP アドレス変更後、サーバの再起動が必要であれば IP アドレスを変更したサーバ上で [reboot] コマンド等を使用して再起動してください。
変更した IP アドレスが有効であることを [ping] コマンド等により確認します。
クラスタ構成情報を全サーバに配信します。[clpcfctrl] コマンドを使用して配信します。
クラスタ内の全てのサーバで CLUSTERPRO デーモンの起動設定を有効にします。
クラスタ内の全てのサーバ上で [reboot] コマンド等を使用して再起動します。
クラスタ内の全てのサーバが正常であることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
2.24.2. インタコネクト IP アドレスのサブネットマスクのみを変更する¶
クラスタ内の全てのサーバが正常であることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
- クラスタ構成情報をバックアップします。[clpcfctrl] コマンドを使用してバックアップを作成します。クラスタ生成時の構成情報がある場合は、その構成情報を使用します。
Cluster WebUI の設定モードで、クラスタ構成情報をもとにサーバの IP アドレスを変更後、保存します。
クラスタ内の全てのサーバで CLUSTERPRO デーモンの起動設定を無効にします。
[clpstdn] コマンド、または Cluster WebUI の操作モードからクラスタをシャットダウン後、全てのサーバを再起動します。
IP アドレスのサブネットマスクを変更します。IP アドレスのサブネットマスクを変更後、サーバの再起動が必要であれば IPアドレスのサブネットマスクを変更したサーバ上で[reboot] コマンド等を使用して再起動してください。
変更した IP アドレスが有効であることを [ping] コマンド等により確認します。
クラスタ構成情報を全サーバに配信します。[clpcfctrl] コマンドを使用して配信します。
クラスタ内の全てのサーバで CLUSTERPRO デーモンの起動設定を有効にします。
クラスタ内の全てのサーバ上で [reboot] コマンド等を使用して再起動します。
クラスタ内の全てのサーバが正常であることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
2.25. ホスト名の変更手順¶
運用を開始した後で、サーバのホスト名を変更したい場合、以下の手順で行ってください。
2.25.1. ホスト名変更手順¶
クラスタ内の全てのサーバが正常であることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
- クラスタ構成情報をバックアップします。[clpcfctrl] コマンドを使用してバックアップを作成します。クラスタ生成時の構成情報がある場合は、その構成情報を使用します。
Cluster WebUI の設定モードで、バックアップしたクラスタ構成情報をもとにサーバのホスト名を変更後、保存します。
- クラスタ内の全てのサーバで CLUSTERPRO デーモンの起動設定を無効にします。
[clpstdn] コマンド、または Cluster WebUI の操作モードからクラスタをシャットダウン後、全てのサーバを再起動します。
ホスト名を変更します。ホスト名変更後、サーバの再起動が必要であればホスト名を変更したサーバ上で [reboot] コマンド等を使用して再起動してください。
変更したホスト名が有効であることを [ping] コマンド等により確認します。
クラスタ構成情報を全サーバに配信します。[clpcfctrl] コマンドを使用して配信します。[clpcfctrl]コマンドの実行には、--nocheckオプションが必要です。
注釈
クラスタ構成情報チェックを行う場合、クラスタ構成情報配信前に行ってください。
クラスタ内の全てのサーバで CLUSTERPRO デーモンの起動設定を有効にします。
クラスタ内の全てのサーバ上で [reboot] コマンド等を使用して再起動します。
クラスタ内の全てのサーバが正常であることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
参考
[clpcfctrl] のトラブルシューティングについては『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス 」 - 「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」を参照してください。
デーモンの停止、および開始の詳細については、「インストール&設定ガイド」の「運用開始前の準備を行う」 - 「CLUSTERPRO を一時停止する」を参照してください。
2.26. グループ無停止でリソースを追加する手順¶
動的リソース追加に対応したリソースに関しては運用を開始した後で、グループ無停止でグループにリソースを追加することが可能です。
現在、動的リソース追加に対応しているリソースは以下のとおりです。
グループリソース名 |
略称 |
対応バージョン |
|---|---|---|
EXEC リソース |
exec |
4.0.0-1~ |
ディスクリソース |
disk |
4.0.0-1~ |
フローティング IP リソース |
fip |
4.0.0-1~ |
仮想 IP リソース |
vip |
4.0.0-1~ |
ボリュームマネージャリソース |
volmgr |
4.0.0-1~ |
参考
運用を開始した後で、動的リソース追加を行う場合には以下の手順で行ってください。
2.26.1. 動的リソース追加手順¶
クラスタ内の全てのサーバが正常であることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
リソースを追加するグループ内の全てのリソースが正常に起動していることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
Cluster WebUI の設定モードを使用して、グループにリソースを追加後、保存します。
[clpcl --suspend] コマンド、または Cluster WebUI の操作モードからクラスタをサスペンドします。
クラスタ構成情報を全サーバに配信します。[clpcfctrl] コマンドを使用して配信します。下記のコマンドを実行して動的リソース追加を行います。
clpcfctrl --dpush -x <構成情報のパス>
[clpcl --resume] コマンド、または Cluster WebUI の操作モードからクラスタをリジュームします。
リソースが追加されていることを [clpstat] コマンド、または Cluster WebUI を使用して確認します。
参考
[clpcfctrl] のトラブルシューティングについては『リファレンスガイド』の「CLUSTERPRO コマンドリファレンス」 - 「クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)」を参照してください。
2.27. ミラーディスクリソース/ハイブリッドディスクリソースの暗号鍵を更新する¶
ミラーディスクリソースおよびハイブリッドディスクリソースのミラー通信暗号化に使用する暗号鍵を更新する場合は、以下の手順で実施します。
注釈
下記手順は、ミラーディスクリソースおよびハイブリッドディスクリソースが活性した状態のまま実行可能です。ただし、ミラーリング中の場合は、ミラーリングが中断しますので、手順完了後にミラー復帰を実行してください。
opensslコマンドを使用し、新しく暗号鍵ファイルを生成します。
openssl rand 32 -out newkeyfile.bin
ミラーディスクリソースまたはハイブリッドディスクリソースが活性可能な全サーバの暗号鍵ファイルを、手順1で生成したファイルで上書きします(ファイル名は元のままにする)。
clpmdctrlまたはclphdctrlの--updatekeyオプションを実行してください。
ミラーディスクリソースの場合:
clpmdctrl --updatekey md01
ハイブリッドディスクリソースの場合:
clphdctrl --updatekey hd01
ミラーディスクリソースの場合は任意のサーバ上で、ハイブリッドディスクリソースの場合は、いずれかのカレントサーバ上で1度実行するのみで、更新が必要な全サーバの鍵情報を更新します。この時、ミラーリング中の場合は、ミラーリングが中断されます。暗号鍵情報の更新が完了します。以後、新しい暗号鍵を使用してミラー通信の暗号化および復号が実施されます。
必要に応じて、ミラー復帰を実行してミラーリングを再開してください。