9. CLUSTERPRO コマンドリファレンス
本章では、CLUSTERPRO で使用可能なコマンドについて説明します。
本章で説明する項目は以下のとおりです。
9.1. コマンドラインからクラスタを操作する
CLUSTERPRO では、コマンドラインからクラスタを操作するための多様なコマンドが用意されています。クラスタ構築時や Cluster WebUI が使用できない状況の場合などに便利です。コマンドラインでは、Cluster WebUI で行える以上の種類の操作を行うことができます。
注釈
モニタリソースの異常検出時の設定で回復対象にグループリソース (ディスクリソース、EXEC リソースなど) を指定し、モニタリソースが異常を検出した場合の回復動作遷移中 (再活性化 → フェイルオーバ → 最終動作) には、Cluster WebUI やコマンドによる以下の操作は行わないでください。
クラスタの停止/サスペンド
グループの起動/停止/移動
モニタリソース異常による回復動作遷移中に上記の制御を行うと、そのグループの他のグループリソースが停止しないことがあります。
また、モニタリソース異常状態であっても最終動作実行後であれば上記制御を行うことが可能です。
重要
インストールディレクトリ配下に本マニュアルに記載していない実行形式ファイルやスクリプトファイルがありますが、CLUSTERPRO 以外からの実行はしないでください。実行した場合の影響については、サポート対象外とします。
9.2. CLUSTERPRO コマンド一覧
クラスタ構築関連
コマンド |
説明 |
参照 |
|---|---|---|
clpcfctrl |
Cluster WebUI で作成した構成情報をサーバに配信します。
Cluster WebUI で使用するためにクラスタ構成情報をバックアップします。
|
|
clplcnsc |
本製品の製品版・試用版ライセンスを管理します。 |
|
clpcfchk |
クラスタ構成情報をチェックします。 |
|
clpsvportchk.sh |
通信ポートの接続可否をチェックします。 |
|
clpcfconv.sh |
クラスタ構成情報ファイルを旧バージョンから現バージョンへ変換します。 |
|
clpfwctrl.sh |
ファイアウォールの規則を追加します。 |
|
clpselctrl.sh |
SELinux 用の設定をおこないます。 |
|
clpsvcctrl.sh |
サービスの自動起動の種類を変更します。 |
状態表示関連
コマンド |
説明 |
参照 |
|---|---|---|
clpstat |
クラスタの状態や、設定情報を表示します。 |
|
clphealthchk |
プロセスの健全性を確認します。 |
クラスタ操作関連
コマンド |
説明 |
参照 |
|---|---|---|
clpcl |
クラスタデーモンの起動、停止、サスペンド、 リジュームなどを実行します。 |
|
clpdown |
CLUSTERPRO デーモンを停止し、サーバをシャットダウンします。 |
|
clpstdn |
クラスタ全体で、CLUSTERPRO デーモンを 停止し、全てのサーバをシャットダウンします。 |
|
clpgrp |
グループの起動、停止、移動を実行します。 |
|
clptoratio |
クラスタ内の全サーバの各種タイムアウト値の延長、表示を行います。 |
|
clproset |
共有ディスクパーティションデバイスの I/O 許可の変更と表示をします。 |
|
clpmonctrl |
モニタリソースの制御を行います。 |
|
clpregctrl |
単一サーバ上で再起動回数の表示/初期化を行います。 |
|
clprsc |
グループリソースの一時停止/再開を行います。 |
|
clprexec |
外部監視から CLUSTERPRO サーバへ処理実行を要求します。 |
|
clpbwctrl |
クラスタ起動同期待ち処理を制御します。 |
|
clpswctrl.sh |
サービス起動遅延時間の待ち合わせ処理を制御します。 |
ログ関連
コマンド |
説明 |
参照 |
|---|---|---|
clplogcc |
ログ、OS 情報等を収集します。 |
|
clplogcf |
ログレベル、ログ出力ファイルサイズの設定の変更、表示を行います。 |
|
clpperfc |
グループ、モニタリソースに関するクラスタ統計情報を表示します。 |
|
clpalttrace |
サーバ別アラートログファイルを出力します。 |
スクリプト関連
コマンド |
説明 |
参照 |
|---|---|---|
clplogcmd |
EXEC リソースのスクリプトに記述し、任意のメッセージを出力先に出力します。 |
ミラー関連(Replicator を使用している場合のみ)
コマンド |
説明 |
参照 |
|---|---|---|
clpmdstat |
ミラーに関する状態と、設定情報を表示します。 |
|
clpmdctrl |
ミラーディスクリソースの活性/非活性、ミラー復帰など、各種操作を行います。
リクエストキュー最大数の設定表示/変更を行います。
|
|
clpmdinit |
ミラーディスクリソースのクラスタパーティションに対して初期化を行います。
ミラーディスクリソースのデータパーティションに対してファイルシステムを作成します。
|
|
clpbackup.sh |
ミラーリング対象パーティションを、ディスクイメージバックアップ可能な状態にします。 |
|
clprestore.sh |
リストアしたミラーディスクイメージを、利用可能な状態にします。 |
ハイブリッドディスク関連(Replicator DR を使用している場合のみ)
コマンド |
説明 |
参照 |
|---|---|---|
clphdstat |
ハイブリッドディスクに関する状態と、設定情報を表示します。 |
|
clphdctrl |
ハイブリッドディスクリソースの活性/非活性、ミラー復帰など、各種操作を行います。
リクエストキュー最大数の設定表示/変更を行います。
|
|
clphdinit |
ハイブリッドディスクリソースのクラスタパーティションに対して初期化を行います。 |
|
clpbackup.sh |
ミラーリング対象パーティションを、ディスクイメージバックアップ可能な状態にします。 |
|
clprestore.sh |
リストアしたミラーディスクイメージを、利用可能な状態にします。 |
データベース静止点関連
コマンド |
説明 |
参照 |
|---|---|---|
clpdb2still |
DB2の静止点の確保/解放を制御します。 |
|
clpmysqlstill |
MySQLの静止点の確保/解放を制御します。 |
|
clporclstill |
Oracleの静止点の確保/解放を制御します。 |
|
clpmssqlstill |
SQL Serverの静止点の確保/解放を制御します。 |
その他
コマンド |
説明 |
参照 |
|---|---|---|
clplamp |
ネットワーク警告灯を消灯します。 |
9.3. クラスタの状態を表示する (clpstat コマンド)
クラスタの状態と、設定情報を表示します。
- コマンドライン
- clpstat [--long] [-h hostname]clpstat -s [--long] [-h hostname]clpstat -s [--cl | --sv | --sv <srvname> | --hb <hbname> | --grp | --grp <grpname> | --rsc <rscname> | --mon | --mon <monname>]clpstat -s [--hb <hbname> | --grp <grpname> | --rsc <rscname> |--mon <monname>] [--sv <srvname>]clpstat -g [-h hostname]clpstat -m [-h hostname]clpstat -n [-h hostname]clpstat -f [-h hostname]clpstat -i [--detail] [-h hostname]clpstat --cl [--detail] [-h hostname]clpstat --sv [server_name] [--detail] [-h hostname]clpstat --hb [hb_name] [--detail] [-h hostname]clpstat --fnc [fnc_name] [--detail] [-h hostname]clpstat --svg [servergroup_name] [--detail] [-h hostname]clpstat --grp [group_name] [--detail] [-h hostname]clpstat --rsc [resource_name] [--detail] [-h hostname]clpstat --mon [monitor_name] [--detail] [-h hostname]clpstat --xcl [xclname] [--detail] [-h hostname]clpstat --local
- 説明
クラスタの状態や、設定情報を表示します。
- オプション
- -s,オプションなし
クラスタの状態を表示します。
- -s {--cl | --sv | --sv <srvname> | --hb <hbname> | --grp | --grp <grpname> | --rsc <rscname>
- | --mon | --mon <monname>}
指定したコンポーネントの状態に応じた値を返却します。 詳細については「 -s オプションを使用した戻り値の詳細 」で説明します。
- -s {--hb <hbname> | --grp <grpname> | --rsc <rscname> | --mon <monname>} --sv <srvname>
--sv オプションで指定したサーバのコンポーネントの状態に応じた値を返却します。 詳細については「 -s オプションを使用した戻り値の詳細 」で説明します。
- --long
クラスタ名やリソース名などの名前を最後まで表示します。
- -g
クラスタのグループマップを表示します。
- -m
各サーバ上での各モニタリソースの状態を表示します。
- -n
各サーバ上での各ハートビートリソースの状態を表示します。
- -f
各サーバ上でのフェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)の状態を表示します。
- -i
クラスタ全体の設定情報を表示します。
- --cl
クラスタの設定情報を表示します。Replicator, Replicator DR を使用している場合、ミラーエージェントの情報も表示します。
- --sv [server_name]
サーバの設定情報を表示します。サーバ名を指定することによって、指定したサーバ情報のみを表示することができます。
- --hb [hb_name]
ハートビートリソースの設定情報を表示します。ハートビートリソース名を指定することによって、指定したハートビートリソース情報のみを表示できます。
- --fnc [fnc_name]
フェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)の設定情報を表示します。リソース名を指定することによって、指定したネットワークパーティション解決リソースまたは強制停止リソースの情報のみを表示できます。
- --svg [servergroup_name]
サーバグループの設定情報を表示します。サーバグループ名を指定することによって、指定したサーバグループ情報のみを表示できます。
- --grp [group_name]
グループの設定情報を表示します。グループ名を指定することによって、指定したグループ情報のみを表示できます。
- --rsc [resource_name]
グループリソースの設定情報を表示します。グループリソース名を指定することによって、指定したグループリソース情報のみを表示できます。
- --mon [monitor_name]
モニタリソースの設定情報を表示します。モニタリソース名を指定することによって、指定したモニタリソース情報のみを表示できます。
- --xcl [xclname]
排他ルールの設定情報を表示します。排他ルール名を指定することによって、指定した排他ルール情報のみを表示できます。
- --detail
このオプションを使用することによって、より詳細な設定情報を表示できます。
- -h hostname
hostnameで指定したサーバから情報を取得します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) から情報を取得します。
- --local
クラスタの状態を表示します。-s またはオプションなしと同等の情報を表示しますが、他サーバとの通信は行わずコマンド実行サーバ上の情報のみを表示します。
- 戻り値
-s オプションを指定しなかった場合
0
成功
0以外
失敗
- 備考
設定情報表示オプションは組み合わせによって、様々な形式で情報表示をすることができます。
表示結果のサーバ名の横に表示される * は、本コマンドを実行したサーバを表します。
- 注意事項
- 表示例
表示例は次のトピックで説明します。
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO Information Base サービスが起動しているか確認してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Invalid heartbeat resource name. Specify a valid heartbeat resource name in the cluster.
クラスタ内の正しいハートビートリソース名を指定してください。
Invalid network partition resource name. Specify a valid network partition resource name in the cluster.
クラスタ内の正しいネットワークパーティション解決リソース名を指定してください。
Invalid group name. Specify a valid group name in the cluster.
クラスタ内の正しいグループ名を指定してください。
Invalid group resource name. Specify a valid group resource name in the cluster.
クラスタ内の正しいグループリソース名を指定してください。
Invalid monitor resource name. Specify a valid monitor resource name in the cluster.
クラスタ内の正しいモニタリソース名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Invalid server group name. Specify a valid server group name in the cluster.
クラスタ内の正しいサーバグループ名を指定してください。
The cluster is not created.
クラスタ構成情報を作成し、反映してください。
Could not connect to the server. Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Cluster is stopped. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Cluster is suspended. To display the cluster status, use --local option.
クラスタがサスペンド状態です。クラスタの状態を表示するには、 --localオプションを使用してください。
9.3.1. クラスタの状態を表示する (-s オプション)
-s オプションを指定した場合、または、オプションを指定しない場合の例:
- 実行例
# clpstat -s
- 表示例
===================== CLUSTER STATUS ======================== Cluster : cluster <server> *server1...........: Online server1 lanhb1 : Normal LAN Heartbeat lanhb2 : Normal LAN Heartbeat diskhb1 : Normal DISK Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution pingnp2 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop server2............: Online server2 lanhb1 : Normal LAN Heartbeat lanhb2 : Normal LAN Heartbeat diskhb1 : Normal DISK Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution pingnp2 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop <group> failover1........: Online failover group1 current : server1 disk1 : Online /dev/disk/by-id/scsi-222850001557d9443-part5 exec1 : Online exec resource1 fip1 : Online 10.0.0.11 failover2........: Online failover group2 current : server2 disk2 : Online /dev/disk/by-id/scsi-222850001557d9443-part6 exec2 : Online exec resource2 fip2 : Online 10.0.0.12 <monitor> diskw1 : Normal disk monitor1 diskw2 : Normal disk monitor2 ipw1 : Normal ip monitor1 pidw1 : Normal pidw1 userw : Normal usermode monitor sraw : Normal sra monitor ================================================================
各種状態についての説明は、「 各種状態 」で説明します。
9.3.2. グループマップを表示する (-g オプション)
グループマップを表示するには、clpstat コマンドに -g オプションを指定して実行します。
- 実行例
# clpstat -g
- 表示例
================= GROUPMAP INFORMATION ======================== Cluster : cluster *server0 : server1 server1 : server2 ---------------------------------------------------------------- server0 [o] : failover1[o] failover2[o] server1 [o] : failover3[o] ================================================================
停止しているグループは表示されません。
各種状態についての説明は、「 各種状態 」で説明します。
9.3.3. モニタリソースの状態を表示する (-m オプション)
モニタリソースの状態を表示するには、clpstat コマンドに -m オプションを指定して実行します。
- 実行例
# clpstat -m
- 表示例
=================== MONITOR RESOURCE STATUS ===================== Cluster : cluster *server0 : server1 server1 : server2 Monitor0 [diskw1 : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor1 [diskw2 : Online] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor2 [ipw1 : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor3 [pidw1 : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Offline Monitor4 [userw : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online Monitor5 [sraw : Normal] ----------------------------------------------------------------- server0 [o] : Online server1 [o] : Online =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
9.3.4. ハートビートリソースの状態を表示する (-n オプション)
ハートビートリソースの状態を表示するには、clpstat コマンドに -n オプションを指定して実行します。
- 実行例
# clpstat -n
- 表示例
================== HEARTBEAT RESOURCE STATUS ==================== Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : diskhb1 HB3 : witnesshb1 [on server0 : Online] HB 0 1 2 3 ----------------------------------------------------------------- server0 : o o o o server1 : o o x x [on server1 : Online] HB 0 1 2 3 ----------------------------------------------------------------- server0 : o o x o server1 : o o o o =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
- 表示例の状態についての説明
上の表示例は、ディスクハートビートリソースが断線した場合の、server0、server1 それぞれのサーバから見た全ハートビートリソースの状態を表示しています。
ディスクハートビートリソース diskhb1 は両サーバ間で通信不可の状態になっているので、server0 上では server1 に対して通信不可、server1 上では server0 に対して通信不可になっています。
その他のハートビートリソースは、両サーバともに通信可の状態になっています。
9.3.5. フェンシング機能の状態を表示する (-f オプション)
フェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)の状態を表示するには、clpstat コマンドに -f オプションを指定して実行します。
- 実行例
# clpstat -f
- 表示例
======================== FENCING STATUS ========================== Cluster : cluster *server0 : server1 server1 : server2 NP0 : pingnp1 NP1 : pingnp2 NP2 : httpnp1 FST : forcestop1 [on server0 : Caution] NP/FST 0 1 2 F ----------------------------------------------------------------- server0 : o x o o server1 : o x o - [on server1 : Caution] NP/FST 0 1 2 F ----------------------------------------------------------------- server0 : o x o - server1 : o x o o =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
- 表示例の状態についての説明
上の表示例は、ネットワークパーティション解決リソース pingnp2 の ping 送付先の装置がダウンした場合に、server0、server1 それぞれのサーバから見たネットワークパーティション解決リソースと強制停止リソースの状態を表示しています。
9.3.6. クラスタ設定情報を表示する (--cl オプション)
クラスタの設定情報を表示するには、clpstat コマンドに -i オプションもしくは、--cl, --sv, --hb, --svg, --grp, --rsc, --mon, --xcl を指定して実行します。また、--detail オプションを指定すると、より詳細な情報を表示することができます。
設定情報の各項目についての詳細は本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」を参照してください。
クラスタ構成情報を表示するには、clpstat コマンドに --cl オプションを指定して実行します。
- 実行例
# clpstat --cl
- 表示例
===================== CLUSTER INFORMATION ===================== [クラスタ名 : cluster] コメント : failover cluster =================================================================
9.3.7. 特定のサーバの設定情報のみを表示する (--sv オプション)
指定したサーバのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --sv オプションの後に、サーバ名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。サーバ名を指定しない場合は、全てのサーバのクラスタ構成情報を表示します。
- 実行例
# clpstat --sv server1
- 表示例
===================== CLUSTER INFORMATION ===================== [サーバ0 : server1] コメント : server1 仮想化基盤 : vSphere 製品 : CLUSTERPRO X 6.0 for Linux 内部バージョン : 6.0.0-1 エディション : X プラットフォーム : Linux =================================================================
9.3.8. 特定のハートビートリソース情報のみを表示する (--hb オプション)
指定したハートビートリソースのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --hb オプションの後に、ハートビートリソース名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。
- 実行例
LANハートビートリソースの場合
# clpstat --hb lanhb1
- 表示例
==================== CLUSTER INFORMATION ======================= [HB0 : lanhb1] タイプ : lanhb コメント : LAN Heartbeat =================================================================
- 実行例
ディスクハートビートリソースの場合
# clpstat --hb diskhb
- 表示例
===================== CLUSTER INFORMATION ===================== [HB2 : diskhb1] タイプ : diskhb コメント : DISK Heartbeat =================================================================
- 実行例
カーネルモード LAN ハートビートリソースの場合
# clpstat --hb lankhb
- 表示例
===================== CLUSTER INFORMATION ===================== [HB4 : lankhb1] タイプ : lankhb コメント : Kernel Mode LAN Heartbeat =================================================================
- ヒント
--sv オプションと、--hb オプションを同時に用いることによって、次のように表示することもできます。
- 実行例
# clpstat --sv --hb
- 表示例
===================== CLUSTER INFORMATION ===================== [サーバ0 : server1] コメント : server1 仮想化基盤 : 製品 : CLUSTERPRO X 6.0 for Linux 内部バージョン : 6.0.0-1 エディション : X プラットフォーム : Linux [HB0 : lanhb1] タイプ : lanhb コメント : LAN Heartbeat [HB1 : lanhb2] タイプ : lanhb コメント : LAN Heartbeat [HB2 : diskhb1] タイプ : diskhb コメント : DISK Heartbeat [HB3 : witnesshb] タイプ : witnesshb コメント : Witness Heartbeat [サーバ1 : server2] コメント : server2 仮想化基盤 : 製品 : CLUSTERPRO X 6.0 for Linux 内部バージョン : 6.0.0-1 エディション : X プラットフォーム : Linux [HB0 : lanhb1] タイプ : lanhb コメント : LAN Heartbeat [HB1 : lanhb2] タイプ : lanhb コメント : LAN Heartbeat [HB2 : diskhb1] タイプ : diskhb コメント : DISK Heartbeat [HB3 : witnesshb] タイプ : witnesshb コメント : Witness Heartbeat =================================================================
9.3.9. 特定のフェンシング機能の情報のみを表示する (--fnc オプション)
指定したフェンシング機能(ネットワークパーティション解決リソースおよび強制停止リソース)のみのクラスタ設定情報を表示したい場合は、[clpstat] コマンドで [--fnc] オプションの後に、ネットワークパーティション解決リソース名または強制停止リソース名を指定して実行します。詳細を表示したい場合は、[--detail] オプションを指定します。ネットワークパーティション解決リソース名または強制停止リソース名を指定しない場合は、全てのフェンシング機能のクラスタ構成情報を表示します。
- 実行例
PING ネットワークパーティション解決リソースの場合
# clpstat --fnc pingnp1
- 表示例
==================== CLUSTER INFORMATION ======================= [NP0 : pingnp1] タイプ : pingnp コメント : ping resolution =================================================================
- 実行例
HTTP ネットワークパーティション解決リソースの場合
# clpstat --fnc httpnp1
- 表示例
==================== CLUSTER INFORMATION ======================= [NP0 : httpnp1] タイプ : httpnp コメント : http resolution =================================================================
- 実行例
強制停止リソースの場合
# clpstat --fnc forcestop1
- 表示例
==================== CLUSTER INFORMATION ======================= [FST : forcestop1] タイプ : bmc コメント : Forced stop =================================================================
9.3.10. 特定のサーバグループの情報のみを表示する (--svg オプション)
指定したサーバグループのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --svg オプションの後に、サーバグループ名を指定して実行します。サーバグループ名を指定しない場合は、全てのサーバグループのクラスタ構成情報を表示します。
- 実行例
# clpstat --svg servergroup1
- 表示例
===================== CLUSTER INFORMATION ===================== [サーバグループ0 : servergroup1] サーバ0 : server1 サーバ1 : server2 サーバ2 : server3 =================================================================
9.3.11. 特定のグループの情報のみを表示する (--grp オプション)
指定したグループのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --grp オプションの後に、グループ名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。グループ名を指定しない場合は、全てのグループのクラスタ構成情報を表示します。
- 実行例
# clpstat --grp failover1
- 表示例
===================== CLUSTER INFORMATION ===================== [グループ0 : failover1] タイプ : failover コメント : failover group1 =================================================================
9.3.12. 特定のグループリソースの情報のみを表示する (--rsc オプション)
指定したグループリソースのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --rsc オプションの後に、グループリソースを指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。グループリソース名を指定しない場合は、全てのグループリソースのクラスタ構成情報を表示します。
- 実行例
フローティング IP リソースの場合
# clpstat --rsc fip1
- 表示例
===================== CLUSTER INFORMATION ===================== [リソース2 : fip1] タイプ : fip コメント : 10.0.0.11 IPアドレス : 10.0.0.11 =================================================================
- ヒント
--grp オプションと、--rsc オプションを同時に用いることによって、次のように表示することもできます。
- 実行例
# clpstat --grp --rsc
- 表示例
===================== CLUSTER INFORMATION ===================== [グループ0 : failover1] タイプ : failover コメント : failover group1 [リソース0 : disk1] タイプ : disk コメント : /dev/disk/by-id/scsi-222850001557d9443-part5 ディスクタイプ : disk ファイルシステム : ext3 デバイス名 : /dev/disk/by-id/scsi-222850001557d9443-part5 マウントポイント : /mnt/sd1 [リソース1 : exec1] タイプ : exec コメント : exec resource1 開始スクリプトパス : /opt/userpp/start1.sh 終了スクリプトパス : /opt/userpp/stop1.sh [リソース2 : fip1] タイプ : fip コメント : 10.0.0.11 IPアドレス : 10.0.0.11 [グループ1 : failover2] タイプ : failover コメント : failover group2 [リソース0 : disk2] タイプ : disk コメント : /dev/disk/by-id/scsi-222850001557d9443-part6 ディスクタイプ : disk ファイルシステム : ext3 デバイス名 : /dev/disk/by-id/scsi-222850001557d9443-part6 マウントポイント : /mnt/sd2 [リソース1 : exec2] タイプ : exec コメント : exec resource2 開始スクリプトパス : /opt/userpp/start2.sh 終了スクリプトパス : /opt/userpp/stop2.sh [リソース2 : fip2] タイプ : fip コメント : 10.0.0.12 IPアドレス : 10.0.0.12 =================================================================
9.3.13. 特定のモニタリソースの情報のみを表示する (--mon オプション)
指定したモニタリソースのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --mon オプションの後に、モニタリソース名を指定して実行します。詳細を表示したい場合は、--detail オプションを指定します。モニタリソース名を指定しない場合は、全てのモニタリソースのクラスタ構成情報を表示します。
- 実行例
フローティング IP モニタリソース
# clpstat --mon fipw1
- 表示例
===================== CLUSTER INFORMATION ===================== [モニタ2 : fipw1] タイプ : fipw コメント : fip monitor1 =================================================================
9.3.14. サーバ個別設定したリソース情報を表示する (--rsc または --mon オプション)
サーバ別に設定したリソース情報を表示したい場合は、clpstat コマンドで --rsc または --mon オプションの後に、リソース名を指定して実行すると各サーバの設定値が表示されます。
- 実行例
IP モニタリソースの監視対象 IP アドレスをサーバ個別設定した場合
# clpstat --mon ipw1
- 表示例
===================== CLUSTER INFORMATION ===================== [モニタ2 : ipw1] タイプ : ipw コメント : ip monitor1 IPアドレスリスト : 各サーバの設定を参照 <server1> IPアドレス : 10.0.0.253 : 10.0.0.254 <server2> IPアドレス : 10.0.1.253 : 10.0.1.254 =================================================================
9.3.15. 特定の排他ルールの設定情報のみを表示する (--xcl オプション)
指定した排他ルールのみのクラスタ設定情報を表示したい場合は、clpstat コマンドで --xcl オプションの後に、排他ルール名を指定して実行します。
- 実行例
# clpstat --xcl excl1
- 表示例
===================== CLUSTER INFORMATION ===================== [排他ルール0 : excl1] 排他属性 : 通常排他 グループ0 : failover1 グループ1 : failover2 =================================================================
9.3.16. すべてのクラスタ情報を表示する (-i オプション)
-i オプションを指定すると、--cl、--sv、--hb、--svg、--grp、--rsc、--mon、--xcl オプションが全て指定された設定情報を表示することができます。
--detail オプションをつけて実行すると、全てのクラスタ設定情報の詳細を表示できます。
このオプションは一度に表示する情報量が多いので、実際に使用する場合は、パイプを用いて less コマンドなどを使用して表示させるか、あるいはリダイレクトを用いてファイルに出力するなどして、参照してください。
- ヒント
-i オプションの指定はコンソールに全ての情報が表示されます。ある一部の情報を表示したい場合は、--cl、--sv、--hb、--svg、--grp、--rsc、--mon オプションを組み合わせて使うと便利です。たとえば、以下のような使い方もできます。
- 実行例
サーバ名 server0 の情報と、グループ名 failover1 の情報と、その指定したグループに存在する全てのグループリソースの情報を、詳細に表示したい場合
# clpstat --sv server0 --grp failover1 --rsc --detail
9.3.17. クラスタの状態を表示する (--local オプション)
--local オプションを指定すると、他サーバとの通信処理は行わずコマンド実行サーバ上の情報のみを表示することができます。
- 実行例
# clpstat --local
- 表示例
===================== CLUSTER STATUS ======================== Cluster : cluster cluster ........: Start cluster <server> *server1 ........: Online server1 lanhb1 : Normal LAN Heartbeat lanhb2 : Normal LAN Heartbeat diskhb1 : Normal DISK Heartbeat witnesshb1 : Normal Witness Heartbeat pingnp1 : Normal ping resolution pingnp2 : Normal ping resolution httpnp1 : Normal http resolution forcestop1 : Normal Forced stop server2 .........: Online server2 lanhb1 : - LAN Heartbeat lanhb2 : - LAN Heartbeat diskhb1 : - DISK Heartbeat witnesshb1 : - Witness Heartbeat pingnp1 : - ping resolution pingnp2 : - ping resolution httpnp1 : - http resolution forcestop1 : - Forced stop <group> failover1 .......: Online failover group1 current : server1 disk1 : Online /dev/disk/by-id/scsi-222850001557d9443-part5 exec1 : Online exec resource1 fip1 : Online 10.0.0.11 failover2 .......: - failover group2 current : server2 disk2 : - /dev/disk/by-id/scsi-222850001557d9443-part6 exec2 : - exec resource2 fip2 : - 10.0.0.12 <monitor> diskw1 : Online disk monitor1 diskw2 : Online disk monitor2 ipw1 : Online ip monitor1 pidw1 : Online pidw1 userw : Online usermode monitor sraw : Online sra monitor =================================================================
各種状態についての説明は、「 各種状態 」で説明します。
9.3.18. 各種状態
- クラスタ
機能
状態
説明
状態表示 (--local)
Start
起動中
〃
Suspend
サスペンド中
〃
Stop
停止中
〃
Unknown
状態不明
- サーバ
機能
状態
説明
状態表示ハートビートリソース状態表示Online
起動済
〃
Offline
停止済
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Caution
ハートビートリソースが異常
〃
Suspend
サスペンド中
〃
Unknown
状態不明
〃
Online (Dummy Failure)
起動済(擬似障害)
〃
Offline (Dummy Failure)
停止済(擬似障害)
〃
Online Pending (Dummy Failure)
起動処理中(擬似障害)
〃
Offline Pending (Dummy Failure)
停止処理中(擬似障害)
〃
Caution (Dummy Failure)
ハートビートリソースが異常(擬似障害)
〃
-
状態不明
グループマップ表示モニタリソース状態表示o
起動済
〃
x
停止済
〃
-
状態不明
- ハートビートリソース
機能
状態
説明
状態表示
Normal
正常
〃
Caution
異常 (一部)
〃
Error
異常 (全部)
〃
Unused
未使用
〃
Unknown
状態不明
〃
-
状態不明
ハートビートリソース状態表示
o
通信可
〃
x
通信不可
〃
-
未使用、状態不明
- ネットワークパーティション解決リソース および 強制停止リソース
機能
状態
説明
状態表示
Normal
正常
〃
Error
異常
〃
Unused
未使用
〃
Unknown
状態不明
〃
-
状態不明
ネットワークパーティション解決リソース・強制停止リソース状態表示o
通信可
〃
x
通信不可
〃
-
未使用、状態不明
- グループ
機能
状態
説明
状態表示
Online
起動済
〃
Offline
停止済
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Error
異常
〃
Unknown
状態不明
〃
-
状態不明
グループマップ表示
o
起動済
〃
e
異常
〃
p
起動処理中、停止処理中
- グループリソース
機能
状態
説明
状態表示
Online
起動済
〃
Offline
停止済
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Online Failure
起動失敗
〃
Offline Failure
停止失敗
〃
Unknown
状態不明
〃
-
状態不明
- モニタリソース
機能
状態
説明
状態表示
Normal
成功
〃
Caution
異常 (一部)
〃
Error
異常 (全部)
〃
Unknown
状態不明
〃
Normal (Dummy failure)
正常 (擬似障害)
〃
Caution (Dummy failure)
異常 (一部) (擬似障害)
〃
Error (Dummy failure)
異常 (全部) (擬似障害)
状態表示 (--local)モニタリソース状態表示Online
起動済かつ正常
〃
Offline
停止済
〃
Caution
警告
〃
Suspend
一時停止
〃
Online Pending
起動処理中
〃
Offline Pending
停止処理中
〃
Online Failure
異常
〃
Offline Failure
停止失敗
〃
Unknown
状態不明
〃
Online (Dummy failure)
起動済 (擬似障害)
〃
Offline (Dummy failure)
停止済 (擬似障害)
〃
Caution (Dummy failure)
警告 (擬似障害)
〃
Suspend (Dummy failure)
一時停止 (擬似障害)
〃
Online Pending (Dummy failure)
起動処理中 (擬似障害)
〃
Offline Pending (Dummy failure)
停止処理中 (擬似障害)
〃
Online Failure (Dummy failure)
起動失敗 (擬似障害)
〃
Offline Failure (Dummy failure)
停止失敗 (擬似障害)
〃
-
状態不明
9.3.19. -s オプションを使用した戻り値の詳細
クラスタの状態を表示する (-s --cl)
クラスタの状態に応じた値を返却します。
- 実行例
# clpstat -s --cl
- 表示例
Cluster : Normal Servers : Normal Groups : Normal Monitors : Normal
- 戻り値と状態一覧
戻り値
状態
説明
0
Normal
成功
2
Offline
停止済
3
Caution
異常 (一部)
9
Unknown
状態不明
10
Suspend
サスペンド中
上記以外
-
内部エラー
全てのサーバの状態を表示する (-s --sv)
全てのサーバの状態に応じた値を返却します。
- 実行例
# clpstat -s --sv
- 表示例
Servers : Normal
- 戻り値と状態一覧
戻り値
状態
説明
0
Normal
成功
2
Offline
停止済
3
Caution
異常 (一部)
9
Unknown
状態不明
10
Suspend
サスペンド中
-
(Dummy failure) [1]
擬似障害
上記以外
-
内部エラー
特定のサーバの状態を表示する (-s --sv <srvname>)
指定したサーバの状態に応じた値を返却します。[--sv] オプションの後にサーバ名を指定して実行します。
- 実行例
# clpstat -s --sv server1
- 表示例
Server server1 : Online
- 戻り値と状態一覧
戻り値
状態
説明
1
Online
起動済
2
Offline
停止済
3
Caution
ハートビートリソース又はフェンシング機能が異常
7
Online Pending
起動処理中
8
Offline Pending
停止処理中
10
Suspend
サスペンド中
-
(Dummy failure) [2]
擬似障害
上記以外
-
内部エラー
特定のハートビートリソースの状態を表示する (-s --hb <hbname>)
指定したハートビートリソースの状態に応じた値を返却します。[--hb] オプションの後にハートビートリソース名を指定して実行します。
- 実行例
# clpstat -s --hb lankhb1
- 表示例
HB lankhb1 : Normal
- 戻り値と状態一覧
サーバ指定なしの場合
戻り値
状態
説明
0
Normal
成功
2
Offline
停止済
3
Caution
異常 (一部)
4
Error
異常 (全部)
15
Unused
未使用
上記以外
-
内部エラー
サーバ指定ありの場合
戻り値
状態
説明
1
Online
起動済
2
Offline
停止済
9
Unknown
状態不明
15
Unused
未使用
上記以外
-
内部エラー
全てのグループの状態を表示する (-s --grp)
全てのグループの状態に応じた値を返却します。
- 実行例
# clpstat -s --grp
- 表示例
Groups : Normal
- 戻り値と状態一覧
戻り値
状態
説明
0
Normal
成功
3
Caution
異常 (一部)
4
Error
異常 (全部)
上記以外
-
内部エラー
特定のグループの状態を表示する (-s --grp <grpname>)
指定したグループの状態に応じた値を返却します。[--grp] オプションの後にグループ名を指定して実行します。
- 実行例
# clpstat -s --grp failover1
- 表示例
Group failover1 : Online (current server1)
- 戻り値と状態一覧
戻り値
状態
説明
1
Online
起動済
2
Offline
停止済
4
Error
異常
7
Online Pending
起動処理中
8
Offline Pending
停止処理中
9
Unknown
状態不明
上記以外
-
内部エラー
特定のグループリソースの状態を表示する (-s --rsc <rscname>)
指定したグループリソースの状態に応じた値を返却します。[--rsc] オプションの後にグループリソース名を指定して実行します。
- 実行例
# clpstat -s --rsc fip1
- 表示例
Resource fip1 : Online (current server1)
- 戻り値と状態一覧
戻り値
状態
説明
1
Online
起動済
2
Offline
停止済
5
Online Failure
起動失敗
6
Offline Failure
停止失敗
7
Online Pending
起動処理中
8
Offline Pending
停止処理中
9
Unknown
状態不明
上記以外
-
内部エラー
全てのモニタの状態を表示する (-s --mon)
全てのモニタの状態に応じた値を返却します。
- 実行例
# clpstat -s --mon
- 表示例
Monitors : Normal
- 戻り値と状態一覧
戻り値
状態
説明
0
Normal
成功
2
Offline
停止済
3
Caution
警告
4
Error
異常 (全部)
9
Unknown
状態不明
-
(Failure Verification) [3]
擬似障害
-
(Failure Verification/Recovery Action Disabled) [3]
擬似障害/異常検出による回復動作無効
-
(Recovery Action Disabled) [3]
異常検出による回復動作無効
上記以外
-
内部エラー
特定のモニタリソースの状態を表示する (-s --mon <monname>)
指定したモニタリソースの状態に応じた値を返却します。[--mon] オプションの後にモニタリソース名を指定して実行します。
- 実行例
# clpstat -s --mon fipw1
- 表示例
Monitor fipw1 : Normal
- 戻り値と状態一覧
サーバ指定なしの場合
戻り値
状態
説明
0
Normal
成功
2
Offline
停止済
3
Caution
警告
4
Error
異常 (全部)
9
Unknown
状態不明
10
Suspend
一時停止
-
(Dummy failure) [4]
擬似障害
上記以外
-
内部エラー
サーバ指定ありの場合
戻り値
状態
説明
1
Online
起動済
2
Offline
停止済
3
Caution
警告
5
Online Failure
異常
6
Offline Failure
停止失敗
7
Online Pending
起動処理中
8
Offline Pending
停止処理中
9
Unknown
状態不明
10
Suspend
一時停止
-
(Dummy failure) [4]
擬似障害
上記以外
-
内部エラー
9.4. クラスタを操作する (clpcl コマンド)
クラスタを操作します。
- コマンドライン
- clpcl -s [-a] [-h hostname]clpcl -t [-a] [-h hostname] [-w timeout] [--apito timeout]clpcl -r [-a] [-h hostname] [-w timeout] [--apito timeout]clpcl --suspend [--force] [-w timeout] [--apito timeout]clpcl --resume
- 説明
CLUSTERPRO デーモンの起動、停止、サスペンド、リジュームなどを実行します。
- オプション
- -s
CLUSTERPRO デーモンを起動します。
- -t
CLUSTERPRO デーモンを停止します。
- -r
CLUSTERPRO デーモンを再起動します。
- -w timeout
-t, -r, --suspendオプションの場合にのみclpclコマンドがCLUSTERPROデーモンの停止またはサスペンドの完了を待ち合わせる時間を指定します。
単位は秒です。
timeout の指定がない場合、無限に待ち合わせします。
timeout に "0" を指定した場合、待ち合わせしません。
-w オプションを指定しない場合、(ハートビートタイムアウト×2) 秒待ち合わせします。
- --suspend
クラスタ全体をサスペンドします。
- --resume
クラスタ全体をリジュームします。リジュームしたクラスタは、サスペンド時のグループおよびグループリソースの状態が保持されています。
- -a
全てのサーバで実行されます。
- -h hostname
hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
- --force
--suspend オプションと一緒に用いることで、クラスタ内のサーバの状態に関わらず強制的にサスペンドを実行します。
- --apito timeout
- CLUSTERPRO デーモンの停止、再起動、サスペンドを待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999 の値が指定できます。[--apito] オプションを指定しない場合は、3600 秒待ち合わせを行います。
- 戻り値
0
成功
0以外
失敗
- 備考
- 本コマンドを -s または --resume オプションで実行した場合、対象のサーバで処理が開始したタイミングで制御を戻します。-t または --suspend オプションで実行した場合、処理の完了を待ち合わせてから制御を戻します。-r オプションで実行した場合、対象のサーバでCLUSTERPROデーモンが一度停止し、起動を開始したタイミングで制御を戻します。
CLUSTERPROデーモンの起動またはリジュームの状況はclpstatコマンドで確認してください。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドはグループの起動処理中、停止処理中に実行できません。
-hオプションのサーバ名は、クラスタ内のサーバ名を指定してください。
サスペンドを実行する場合は、クラスタ内の全サーバのCLUSTERPRO デーモンが起動した状態で実行してください。--forceオプションを用いると、クラスタ内に停止しているサーバが存在しても強制的にサスペンドを実行します。
クラスタ起動時およびリジューム時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
リジュームを実行する場合は、clpstat コマンドを用いてクラスタ内に起動しているサーバがないか確認してください。
本コマンドは、CLUSTERPRO デーモンのみの起動/停止等をおこないます。ミラーエージェントなどの起動/停止まではおこなわれません。
- 実行例
例1: 自サーバの CLUSTERPRO デーモンを起動させる場合
# clpcl -s
例2: server0 から server1 の CLUSTERPRO デーモンを起動させる場合
# clpcl -s -h server1 Start server1 : Command succeeded.
サーバ名指定の場合は、上記のように表示されます。
Start サーバ名 : 実行結果 (失敗した場合はその原因)
例3: 全サーバの CLUSTERPRO デーモンを起動させる場合
# clpcl -s -a Start server0 : Command succeeded. Start server1 : Performed startup processing to the active cluster daemon.
全サーバ起動の場合は、上記のように表示されます。
Start サーバ名 : 実行結果 (失敗した場合はその原因)
例4: 全サーバの CLUSTERPRO デーモンを停止させる場合
# clpcl -t -a
全サーバ停止の場合、各サーバの CLUSTERPRO デーモンの停止を待ち合わせします。
エラーの場合はエラーメッセージが表示されます。
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Performed stop processing to the stopped cluster daemon.
停止している CLUSTERPRO デーモンに対して停止処理を実行しました。
Performed startup processing to the active cluster daemon.
起動している CLUSTERPRO デーモンに対して起動処理を実行しました。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Could not connect to the data transfer server. Check if the server has started up.
サーバが起動しているか確認してください。
Failed to obtain the list of nodes.Specify a valid server name in the cluster.クラスタ内の正しいサーバ名を指定してください。
Failed to obtain the daemon name.
クラスタ名の取得に失敗しました。
Failed to operate the daemon.
クラスタの制御に失敗しました。
Resumed the daemon that is not suspended.
サスペンド状態ではない CLUSTERPROデーモンに対して、リジューム処理を実行しました。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is busy. Check if this command is already run.
既に本コマンドを実行している可能性があります。確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
There is one or more servers of which cluster daemon is active. If you want to perform resume, check if there is any server whose cluster daemon is active in the cluster.
リジュームを実行する場合、クラスタ内にCLUSTERPRO デーモンが起動しているサーバがないか確認してください。
All servers must be activated. When suspending the server, the cluster daemon need to be active on all servers in the cluster.
サスペンドを実行する場合、クラスタ内の全てのサーバで、CLUSTERPRO デーモンが起動している必要があります。
Resume the server because there is one or more suspended servers in the cluster.
クラスタ内にサスペンドしているサーバがあるので、リジュームを実行してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内にCLUSTERPROデーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してみてください。Processing failed on some servers. Check the status of failed servers.
全サーバ指定で停止処理を実行した場合、処理に失敗したサーバが存在します。処理に失敗したサーバの状態を確認してください。Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
There is a server that is not suspended in cluster. Check the status of each server.
クラスタ内にサスペンド状態でないサーバが存在します。各サーバの状態を確認してください。Suspend %s : Could not suspend in time.
サーバはタイムアウト時間内にCLUSTERPROデーモンのサスペンド処理が完了しませんでした。サーバの状態を確認してください。
Stop %s : Could not stop in time.
サーバはタイムアウト時間内にCLUSTERPROデーモンの停止処理が完了しませんでした。サーバの状態を確認してください。
Stop %s : Server was suspended.Could not connect to the server. Check if the cluster daemon is active.CLUSTERPRO デーモンの停止要求をしましたが、サーバはサスペンド状態でした。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンの停止要求をしましたが、サーバに接続できませんでした。サーバの状態を確認してください。Suspend %s : Server already suspended.Could not connect to the server. Check if the cluster daemon is active.CLUSTERPRO デーモンのサスペンド要求をしましたが、サーバはサスペンド状態でした。
Event service is not started.
イベントサービスが起動していません。確認してください。
Mirror Agent is not started.
ミラーエージェントが起動していません。確認してください。
Event service and Mirror Agent are not started.
イベントサービスとミラーエージェントが起動していません。確認してください。
Some invalid status. Check the status of cluster.
遷移中のグループが存在する可能性があります。グループの遷移が終了してから、再度実行してください。
Failed to shutdown the server.
サーバのシャットダウンまたは、リブートに失敗しました。
9.5. 指定したサーバをシャットダウンする (clpdown コマンド)
指定したサーバをシャットダウンします。
- コマンドライン
clpdown [-r] [-h hostname]
- 説明
CLUSTERPRO デーモンを停止し、サーバをシャットダウンします。
- オプション
- オプションなし
サーバをシャットダウンします。
- -r
サーバを再起動します。
- -h hostname
hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
- 戻り値
0
成功
0以外
失敗
- 備考
- 本コマンドは、CLUSTERPRO デーモンを停止後、内部的に以下の コマンドを実行しています。オプション指定なしの場合 shutdown-r オプション指定の場合 reboot
本コマンドは、グループ停止処理が完了したタイミングで制御を戻します。
本コマンドは、CLUSTERPRO デーモンが停止状態でもサーバをシャットダウンします。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドはグループの起動処理中、停止処理中に実行できません。
本コマンドは、クラスタサスペンド状態では実行しないでください。
-h オプションのサーバ名は、クラスタ内のサーバを指定してください。
- 実行例
例1 : 自サーバの CLUSTERPRO デーモンを停止し、シャットダウンする場合
# clpdown
例2 server0 から server1 をシャットダウンリブートさせる場合
# clpdown -r -h server1
- エラーメッセージ
「クラスタを操作する (clpcl コマンド)」を参照してください。
9.6. クラスタ全体をシャットダウンする (clpstdn コマンド)
クラスタ全体をシャットダウンします。
- コマンドライン
clpstdn [-r] [-h hostname]
- 説明
クラスタ全体で、CLUSTERPRO デーモンを停止し、全てのサーバをシャットダウンします。
- オプション
- オプションなし
クラスタシャットダウンを実行します。
- -r
クラスタシャットダウンリブートを実行します。
- -h hostname
hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
- 戻り値
0
成功
0以外
失敗
- 備考
本コマンドは、グループ停止処理が完了したタイミングで制御を戻します。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドはグループの起動処理中、停止処理中に実行できません。
-h オプションのサーバ名は、クラスタ内のサーバを指定してください。
コマンドを実行したサーバから通信不能なサーバ (全ての LAN ハートビートリソースがOfflineのサーバ) はシャットダウンされません。
- 実行例
例1 : クラスタシャットダウンを行う場合
# clpstdn
例2 : クラスタシャットダウンリブートを行う場合
# clpstdn -r
- エラーメッセージ
「クラスタを操作する (clpcl コマンド)」を参照してください。
9.7. グループを操作する (clpgrp コマンド)
グループを操作します。
- コマンドライン
- clpgrp -s [group_name] [-h hostname] [-f] [--apito timeout]clpgrp -t [group_name] [-h hostname] [-f] [--apito timeout]clpgrp -m [group_name] [-h hostname] [-a hostname] [--apito timeout]clpgrp -n group_nameclpgrp --move-svg --from srcsvgname --to destsvgname
- 説明
グループの起動、停止、移動を実行します。
- オプション
- -s [group_name]
グループを起動します。グループ名を指定すると、指定されたグループのみ起動します。グループ名の指定がない場合は、全てのグループが起動されます。
- -t [group_name]
グループを停止します。グループ名を指定すると、指定されたグループのみ停止します。グループ名の指定がない場合は、全てのグループが停止されます。
- -m [group_name]
指定されたグループを移動します。グループ名指定しない場合、全てのグループを移動します。移動したグループのグループリソースの状態は保持されます。
- -h hostname
hostname で指定したサーバに処理を要求します。-h オプションを省略した場合は、コマンド実行サーバ (自サーバ) に処理を要求します。
- -a hostname
hostname で指定したサーバをグループの移動先サーバとします。-a オプションを省略した場合は、グループの移動先はフェイルオーバポリシーに従います。
- -f
- 他サーバで起動しているグループに対して、-s オプションと使うと強制的に処理を要求したサーバで起動します。-t オプションと使うと強制的に停止します。
- -n group_name
グループの起動済サーバ名を表示します。
- --apito timeout
- グループの起動、停止、移動を待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999 の値が指定できます。[--apito] オプションを指定しない場合は、3600 秒待ち合わせを行います。
- --move-svg
- サーバグループ間で全グループを移動します。[--move-svg] オプションを指定した場合は、[--from] オプション、[--to] オプションの指定が必要です。
- --from srcsvgname
- 移動元サーバグループ名を指定します。未指定または複数のサーバグループ名を指定することはできません。
- --to destsvgname
- 移動先サーバグループ名を指定します。未指定または複数のサーバグループ名を指定することはできません。
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドを実行するサーバは CLUSTERPRO デーモンが起動している必要があります。
-h、-a オプションのサーバ名は、クラスタ内のサーバを指定してください。
-m オプションの場合は必ずグループ名を指定してください。
[-m] オプションまたは [--move-svg] オプションでグループ移動を行った場合、移動先サーバでグループの起動処理を開始した時点で成功(戻り値:0)と判断します。本コマンドが成功していても移動先サーバでリソースの活性に失敗している場合がありますので注意してください。移動先サーバでのグループ起動処理の結果を戻り値で判断する場合は、下記のコマンドを使用してグループ移動を実行してください。# clpgrp -s [group_name] [-h hostname] -f
排他属性が「通常排他」に設定されている排他ルールに所属するグループを、[-m] オプションでグループを移動する際は、[-a] オプションで明示的に移動先サーバを指定してください。
[-a]オプション省略時に、移動可能な全てのサーバで、排他属性が「通常排他」に設定されている排他ルールに所属するグループが起動している場合は、グループ移動に失敗します。
[--move-svg] オプションでサーバグループ間の全グループ移動を行う場合、CLUSTERPRO の設定として以下の条件を満たしている必要があります。
クラスタサーバは複数のサーバグループに所属していないこと
グループには起動可能なサーバグループが設定されていること
サーバグループ間の全グループ移動では、サーバグループ内のサーバ優先順位に従ってグループ移動します。
- 実行例
グループ操作の実行を、簡単な状態遷移の例で説明します。
2 台構成のサーバで、グループを 2 つ持っている場合
グループのフェイルオーバポリシー
groupA server1 → server2groupB server2 → server1グループが 2 つとも停止している状態。
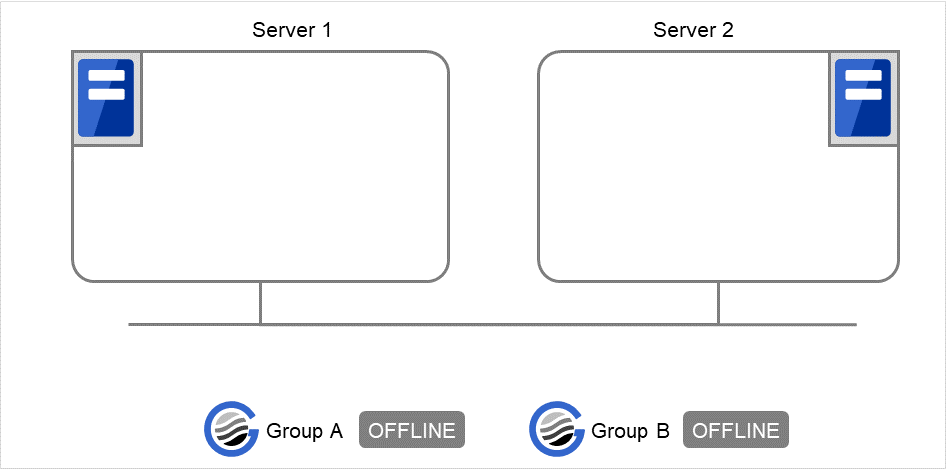
図 9.1 clpgrp実行時状態 (1)
server1 で以下のコマンドを実行します。
# clpgrp -s groupA
server1 で、groupA が起動します。
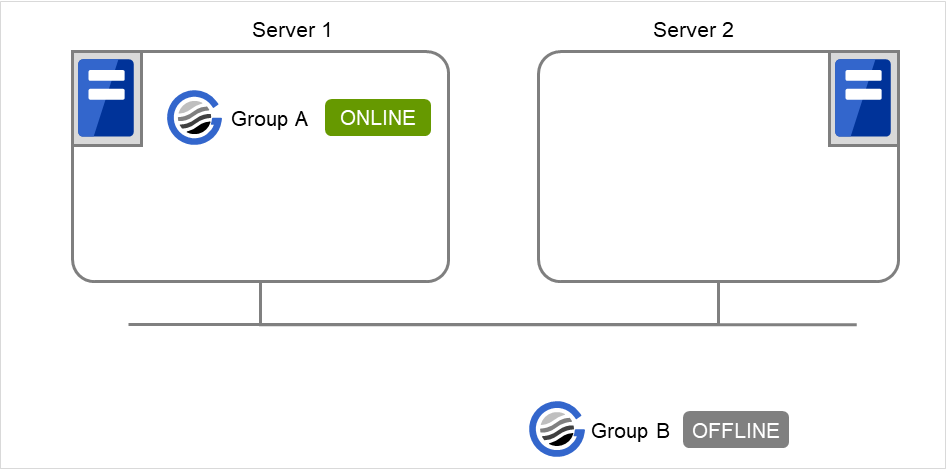
図 9.2 clpgrp実行時状態 (2)
server1 で以下のコマンドを実行します。
# clpgrp -n groupA server1
コマンドを実行すると、groupA は server1 で起動しているため、「server1」が表示されます。
server2 で以下のコマンドを実行します。
# clpgrp -s
現在停止している起動可能な全てのグループが server2 で起動します。
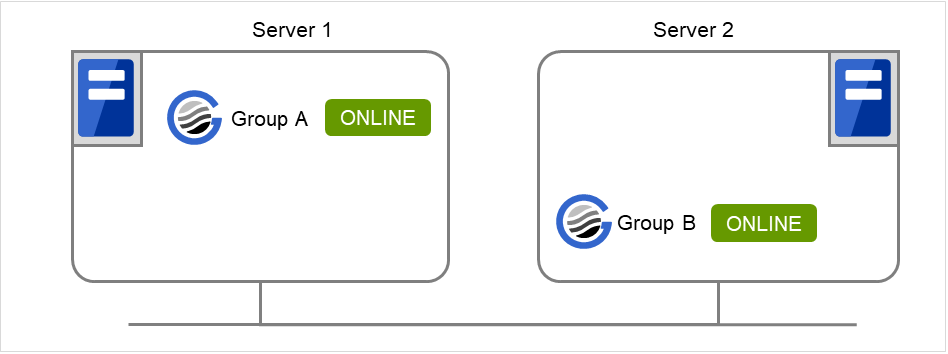
図 9.3 clpgrp実行時状態 (3)
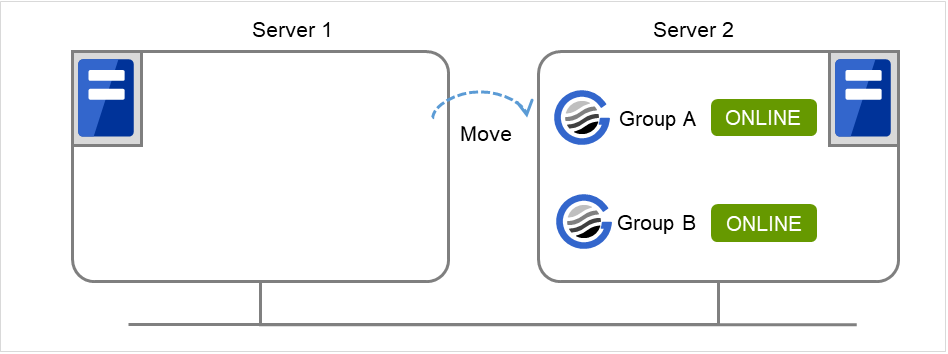
server1 で以下のコマンドを実行します。
server1 で以下のコマンドを実行します。
server1 で以下のコマンドを実行します。
# clpgrp -t Command Succeeded.
コマンドを実行すると、server1 で動作しているグループは存在しないので、「Command Succeeded.」が表示されます。
server1 で、7 で実行したコマンドに -f を付けて実行します。
3 台構成のサーバで、グループを 3 つ持っている場合
グループはすべてのサーバグループで起動可能とする
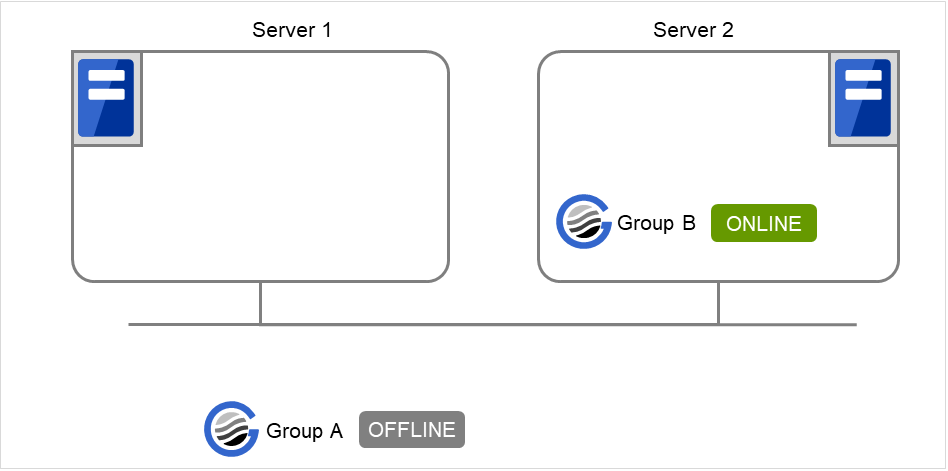
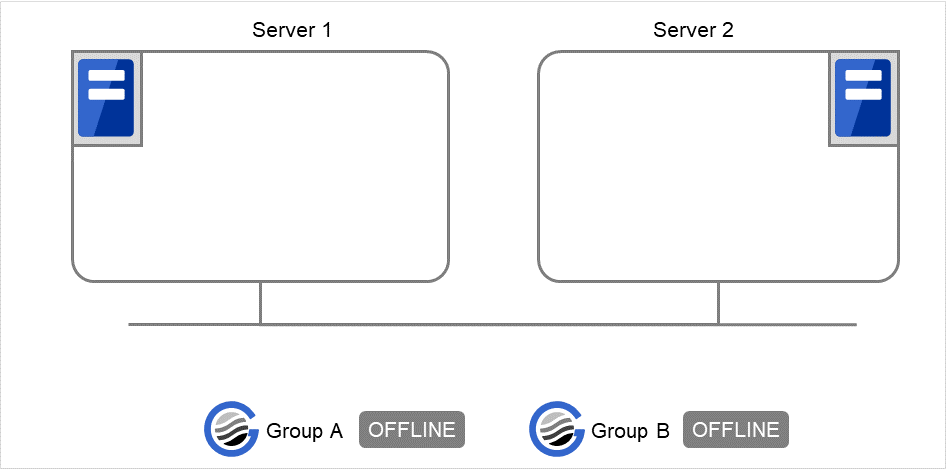
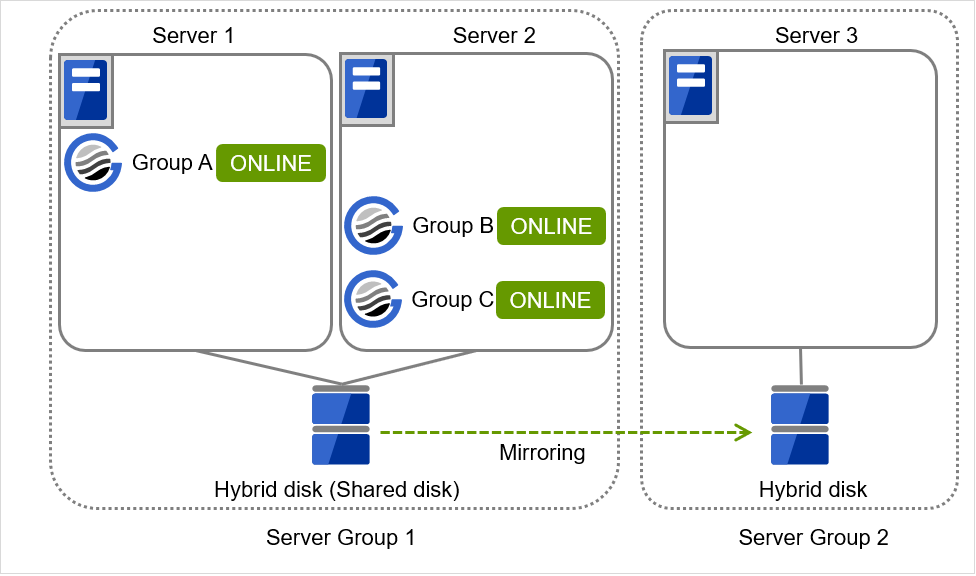
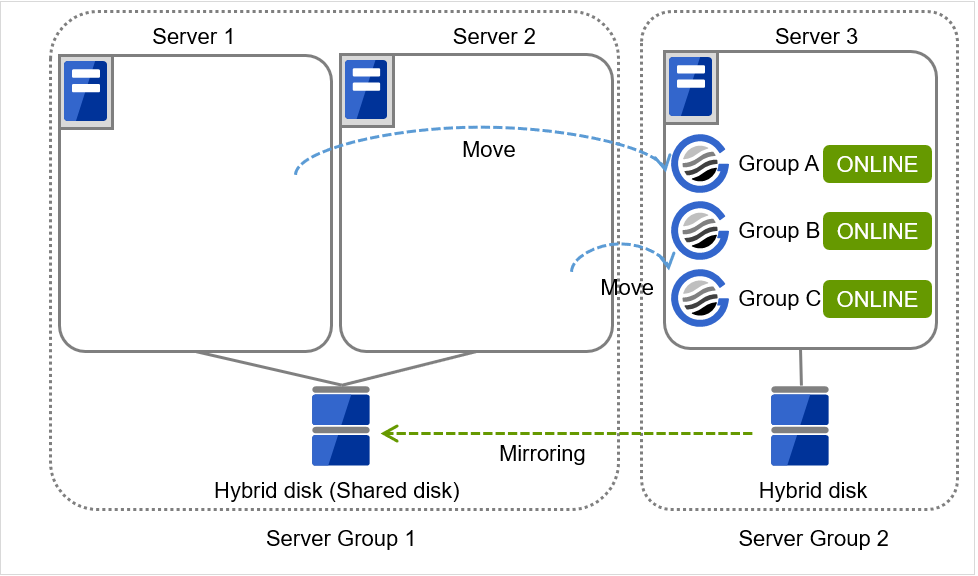
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか 確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost. Check if there is a server where the cluster daemon is stopped in the cluster.
クラスタ内にCLUSTERPROデーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が設定されている可能性があります。
Internal communication timeout has occurred in the cluster server. If it occurs frequently, set the longer timeout.
CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。Invalid server. Specify a server that can run and stop the group, or a server that can be a target when you move the group.
グループを起動、停止、移動する先のサーバが不正です。正しいサーバを指定してください。Could not start the group. Try it again after the other server is started, or after the Wait Synchronization time is timed out.
他サーバが起動するのを待つか、起動待ち 時間がタイムアウトするのを待って、グループを起動させてください。
No operable group exists in the server.
処理を要求したサーバに処理可能なグループが存在するか確認してください。
The group has already been started on the local server.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
The group has already been started on the other server. To start/stop the group on the local server, use -f option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを自サーバで起動/停止させたい場合は、グループの移動を 実行するか、-f オプションを加えて実行してください。The group has already been started on the other server. To move the group, use "-h <hostname>" option.
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。他サーバで起動しているグループを移動したい場合は、"-h <hostname>" オプションを加えて実行してください。Failed to start one or more group resources. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Failed to stop one or more group resources. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
The group is busy. Try again later.
グループが起動処理中、もしくは停止処理中なので、しばらく待ってから実行してください。
An error occurred on one or more groups. Check the status of group
Cluster WebUI や、clpstat コマンドでグループの状態を確認してください。
Invalid group name. Specify a valid group name in the cluster.
クラスタ内の正しいグループ名を指定してください。
Server is not in a condition to start group or any critical monitor error is detected.
Cluster WebUI や、clpstat コマンドでサーバの状態を確認してください。グループを起動しようとしたサーバで「フェイルオーバ先サーバの除外に使用するモニタリソース」に含まれるモニタの異常が検出されています。There is no appropriate destination for the group. Other servers are not in a condition to start group or any critical monitor error is detected.
Cluster WebUI や、clpstat コマンドでサーバの状態を確認してください。他の全てのサーバで「フェイルオーバ先サーバの除外に使用するモニタリソース」に含まれるモニタの異常が検出されています。Some invalid status. Check the status of cluster.
何らかの不正な状態です。クラスタの状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
9.8. ログを収集する (clplogcc コマンド)
ログを収集します。
- コマンドライン
clplogcc [ [-h hostname] | [-n targetnode1 -n targetnode2 ......] ] [-t collect_type] [-r syslog_rotate_number] [-o path] [-l]
- 説明
データ転送サーバに接続し、ログ、OS 情報等を収集します。
- オプション
- なし
クラスタ内のログを収集します。
- -h hostname
クラスタノード情報取得時の接続先サーバ名を指定します。
- -t collect_type
ログ収集パターンを指定します。省略した場合のログ収集パターンは type1 です。ログ収集タイプについての説明は、「 タイプを指定したログの収集 (-t オプション) 」 で説明します。
- -r syslog_rotate _number
syslog の収集する世代数を指定します。省略した場合は、2 世代収集します。
- -o path
収集ファイルの出力先を指定します。省略した場合は、インストールパスの tmp 配下にログが出力されます。
- -n targetnode
ログを収集するサーバ名を指定します。この場合は、クラスタ全体のログを収集するのではなく、指定したサーバのみログを収集することができます。
- -l
- データ転送サーバを経由せずにローカルサーバのログを収集します。-h,-n オプションと同時に指定することはできません。
- 戻り値
0
成功
0以外
失敗
- 備考
ログファイルは tar.gz で圧縮されているので、tar コマンドに、xzf オプションを付けて解凍してください。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
-h オプションのサーバ名は、名前解決できるクラスタ内のサーバ名を指定してください。
-n オプションのサーバ名は、名前解決できるサーバ名を指定してください。名前解決できない場合は、インタコネクトもしくはパブリック LANアドレスを指定してください。
本コマンド実行時、インタコネクトの優先度順でクラスタサーバのIPアドレスに接続し、成功した経路を使用します。
tar コマンドの圧縮フォーマットが pax 形式の Linux OS にて収集したログファイルをgnutar 形式の tar コマンドで展開した場合、PaxHeaders.X フォルダが生成されますが、動作上の問題はありません。
- 実行例
例1: クラスタ内の全てのサーバからログを収集する場合
# clplogcc Collect Log server1 : Success Collect Log server2 : Success
ログ収集を実行したサーバの実行結果 (サーバ状態) が表示されます。
処理過程 サーバ名 : 実行結果 (サーバ状態)
- 実行結果
本コマンドの結果で表示される処理過程は以下になります。
処理過程
説明
Connect
接続に失敗した場合に表示します。
Get Filesize
ファイルサイズ取得に失敗した場合に表示します。
Collect Log
ファイル取得の結果を表示します。
実行結果 (サーバ状態) については以下になります。
実行結果(サーバ状態)
説明
Success
成功です。
Timeout
タイムアウトしました。
Busy
サーバがビジー状態です。
Not Exist File
ファイルが存在しません。
No Freespace
ディスクに空き容量がありません。
Failed
その他のエラーによる失敗です。
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file. Create valid cluster configuration data.
Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Specify a number in a valid range.
正しい範囲で数字を指定してください。
Specify a correct number.
正しい数字で指定してください。
Specify correct generation number of syslog.
正しい syslog の世代数を指定してください。
Collect type must be specified 'type1' or 'type2' or 'type3'' or 'type4' or 'type5' or 'type6'. Incorrect collection type is specified.
収集タイプの指定が間違っています。
The specified output-path does not exist.
-o オプションで指定したパスが存在しません。正しいパスを指定してください。Specify an absolute path as the destination of the files to be collected.
収集ファイルの出力先は絶対パスで指定してください。
Specifiable number of servers are the max number of servers that can constitute a cluster.
指定可能なサーバ数は、クラスタ構成可能な最大サーバ数です。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Failed to obtain the list of nodes.Specify a valid server name in the cluster.クラスタ内の正しいサーバ名を指定してください。
Invalid server status.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is busy. Check if this command is already run.
既に本コマンドを実行している可能性があります。確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
9.8.1. タイプを指定したログの収集 (-t オプション)
指定したタイプのログのみを収集したい場合は、clplogcc コマンドで -t オプションを指定して実行します。
ログの収集タイプは type1 ~ 6、proactdiag を指定します。
type1 |
type2 |
type3 |
type4 |
type5 |
type6 |
proactdiag |
|
|---|---|---|---|---|---|---|---|
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
✓ |
|
✓ |
✓ |
✓ |
n/a |
n/a |
n/a |
✓ |
|
✓ |
✓ |
n/a |
✓ |
n/a |
n/a |
n/a |
|
✓ |
✓ |
✓ |
✓ |
n/a |
n/a |
✓ |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
✓ |
|
✓ |
✓ |
n/a |
n/a |
n/a |
n/a |
n/a |
|
n/a |
✓ |
n/a |
n/a |
n/a |
n/a |
n/a |
|
n/a |
n/a |
n/a |
n/a |
✓ |
n/a |
✓ |
|
n/a |
n/a |
n/a |
n/a |
n/a |
✓ |
✓ |
|
✓ |
✓ |
✓ |
✓ |
n/a |
✓ |
✓ |
|
n/a |
n/a |
n/a |
n/a |
n/a |
n/a |
✓ |
コマンドラインからは以下のように実行します。
実行例:収集タイプ type2 でログ収集を行う場合。
# clplogcc -t type2
オプションを指定しない場合のログ収集タイプは type1 です。
デフォルト収集情報
CLUSTERPRO サーバの各モジュールログ
アラートログ
CLUSTERPRO サーバの各モジュールの属性情報 (ls -l)
bin、lib 配下
cloud 配下
alert/bin、webmgr/bin 配下
ha/jra/bin、ha/sra/bin、ha/jra/lib、ha/sra/lib 配下
drivers/md 配下
drivers/khb 配下
drivers/ka 配下
CLUSTERPRO のモジュールに対する SELinux コンテキストの適用規則 (clpselctrl.sh --list の実行結果)
CLUSTERPRO インストールパス配下の SELinux コンテキスト情報 (ls -ZR の実行結果)
インストール済の全パッケージ情報 (rpm -qa の実行結果など)
CLUSTERPRO のバージョン情報 (rpm -qi clusterpro の実行結果など)
distribution 情報 (/etc/*-release)
ライセンス情報
クラスタ構成情報ファイル
ポリシーファイル
クラウド環境設定ディレクトリ
CLUSTERPRO が使用している共有メモリのダンプ
CLUSTERPRO の自ノードステータス (clpstat --local の実行結果)
プロセス、スレッド情報 (ps、top の実行結果)
PCI デバイス情報 (lspci の実行結果)
サービス情報 (systemctl、chkconfig、ls コマンド等の実行結果)
サービス起動順序・依存関係情報 (systemctl、systemd-analyze コマンドの実行結果)
kernel パラメータの出力結果 (sysctl -a の実行結果)
glibc バージョン (rpm -qi glibc の実行結果など)
カーネルローダブルモジュール設定情報 (/etc/modules.conf、/etc/modprobe.conf)
カーネルのリングバッファ情報 (dmesg の実行結果)
ファイルシステム情報 (/etc/fstab)
IPC リソース情報 (ipcs の実行結果)
システム情報 (uname -a の実行結果)
ネットワーク統計情報 (netstat, ss の実行結果IPv4/IPv6)
ip (ip addr,link,maddr,route,-s l の実行結果)
全ネットワークインターフェイス情報 (ethtool の実行結果)
緊急 OS シャットダウン時の採取情報 (「異常発生時の情報採取」を参照)
libxml2 バージョン (rpm -qi libxml2 の実行結果など)
静的ホストテーブル (/etc/hosts)
ファイルシステムのエクスポートテーブル (exportfs -v の実行結果)
ユーザリソース制限情報 (ulimit -a の実行結果)
カーネルベースの NFS でエクスポートされるファイルシステム (/etc/exports)
OS のロケール (locale)
ターミナルセッションの環境変数 (export の実行結果)
言語ロケール (/etc/sysconfig/i18n)
タイムゾーン (env - date の実行結果)
CLUSTERPRO サーバのワーク領域情報
- 各監視オプション製品に関する情報監視オプション製品をインストールされていれば収集されます。
モニタリソースのタイムアウト発生時に採取したダンプ情報
Oracle モニタリソース異常検出時に採取した Oracle 詳細情報
Cluster WebUI の操作ログ (『メンテナンスガイド』 - 「保守情報」 - 「Cluster WebUI 操作ログ出力機能」を参照)
API サービスの操作ログ (『メンテナンスガイド』 - 「保守情報」 - 「API サービス操作ログ出力機能」を参照)
AWS 関連の情報
以下のコマンドの実行結果
which aws
aws --version
aws configure list
aws configure get output
aws ec2 describe-network-interfaces
aws ec2 describe-instance-attribute --attribute disableApiStop
以下のインスタンスメタデータ
ami-id
instance-type
availability-zone
region
OCI 関連の情報
以下のインスタンスメタデータ
image
shape
availabilityDomain
region
Google Cloud 関連の情報
以下のインスタンスメタデータ
image
vmSize
zone
Azure 関連の情報
以下のインスタンスメタデータ
imageReference
location
vmSize
zone
syslog
syslog (/var/log/messages)
syslog (/var/log/syslog)
指定された世代数の syslog (/var/log/messages.x)
journal ログ(/var/run/log/journal/ 配下のファイルなど)
core ファイル
- CLUSTERPRO モジュールの core ファイル/opt/nec/clusterpro/log 配下に以下のアーカイブ名で格納されます。
アラート関連
alt yyyymmdd_x.tar
WebManagerサーバ関連
wm yyyymmdd_x.tar
CLUSTERPRO コア関連
cls yyyymmdd_x.tar
sra yyyymmdd_x.tar
jra yyyymmdd_x.tar
yyyymmdd はログの収集日付、 x はシーケンシャル番号になります。
OS 情報
カーネルモード LAN ハートビート、キープアライブ情報
/proc/khb_moninfo
/proc/ka_moninfo
/dev
/proc/devices
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/cpuinfo
/proc/partitions
/proc/pci
/proc/version
/proc/ksyms
/proc/net/bond*
/proc/scsi/ ディレクトリ内の全ファイル
/proc/ide/ ディレクトリ内の全ファイル
/etc/fstab
/etc/rc*.d
/etc/syslog.conf
/etc/syslog-ng/syslog-ng.conf
/etc/snmp/snmpd.conf
カーネルのリングバッファ情報 (dmesg の実行結果)
ifconfig (ifconfig の実行結果)
iptables (iptables -L の実行結果)
ipchains (ipchains -L の実行結果)
df (df の実行結果)
カーネルモジュールロード情報 (lsmod の実行結果)
ホスト名、ドメイン名情報 (hostname、domainname の実行結果)
dmidecode (dmidecode の実行結果)
LVM デバイス情報 (vgdisplay -v の実行結果)
snmpd バージョン情報 (snmpd -v の実行結果)
仮想化基盤情報 (virt-what の実行結果)
blockdev (blockdev --report の実行結果)
lsblk (lsblk -i の実行結果)
getenforce (getenforce の実行結果)
ログ収集を実行した場合、コンソールに以下のメッセージが表示されることがありますが、異常ではありません。ログは正常に収集されています。
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(hd#にはサーバ上に存在する IDE のデバイス名が入ります)
スクリプト
Cluster WebUI で作成されたグループ起動/停止スクリプト
上記以外のユーザ定義スクリプト (/opt/nec/clusterpro/scripts以外) を指定した場合は、ログ収集の採取情報に含まれないため、別途採取する必要があります。
ESMPRO/AC 関連ログ
acupslog コマンドの実行により収集されるファイル
HA ログ
システムリソース情報
JVM モニタログ
システムモニタログ
ミラー統計情報
ミラー統計情報
ミラー復帰性能情報
perf/disk 配下
クラスタ統計情報
クラスタ統計情報
perf/cluster 配下
システムリソース統計情報
システムリソース統計情報
perf/system 配下
プロアクティブ診断ログ
追加ログ採取ツールの実行により収集されるファイル
9.8.2. syslog の世代 (-r オプション)
syslog を、指定した世代分収集するには以下のように実行します。
例)世代数 3 でログ収集を行う場合
# clplogcc -r 3
収集したログには以下の syslog が含まれています。
オプションを指定しない場合は、2 世代収集されます。
指定できる世代数は、0~99 です。
0 を指定した場合は、全ての syslog を収集します。
世代数 |
取得する世代 |
|---|---|
0 |
全世代 |
1 |
カレント |
2 |
カレント + 世代1 |
3 |
カレント + 世代1~2 |
: |
|
: |
|
x |
カレント + 世代1~ (x-1) |
9.8.3. ログファイルの出力先 (-o オプション)
ファイル名は、「サーバ名-log.tar.gz」で保存されます。
-n オプションで IP アドレスを指定した場合、ファイル名は、「IP アドレス-log.tar.gz」で保存されます。
ログファイルは tar.gz で圧縮されているので、tar コマンドに、xzf オプションを付けて解凍してください。
-o オプションを指定しない場合
インストールパスの tmp 配下にログが出力されます。
# clplogcc Collect Log サーバ名: Success # ls /opt/nec/clusterpro/tmp サーバ名-log.tar.gz
-o オプションを指定する場合
以下のようにコマンドを実行すると、指定したディレクトリ /home/log 配下にログが出力されます。
# clplogcc -o /home/log Collect Log サーバ名: Success # ls /home/log サーバ名-log.tar.gz
9.8.4. ログ収集サーバ指定 (-n オプション)
-n オプションを用いることによって、指定したサーバのみログを収集することができます。
例)クラスタ内の Server1 と Server3 のログを収集する場合
# clplogcc -n Server1 -n Server3
同じクラスタ内のサーバを指定してください。
指定可能なサーバ数は、クラスタ構成可能な最大サーバ数です。
9.8.5. 異常発生時の情報採取
以下の異常発生時に、障害解析のための情報を採取します。
クラスタを構成するクラスタデーモンが、シグナルの割り込みによる終了 (core dump)、内部ステータス異常による終了などで異常終了した場合
グループリソースの活性異常、非活性異常が発生した場合
モニタリソースの監視異常が発生した場合
採取する情報は以下です。
クラスタ情報
CLUSTERPRO サーバの一部のモジュールログ
CLUSTERPRO が使用している共有メモリのダンプ
クラスタ構成情報ファイル
OS 情報 (/proc/*)
/proc/devices
/proc/partitions
/proc/mdstat
/proc/modules
/proc/mounts
/proc/meminfo
/proc/net/bond*
コマンド実行による情報
sysctl -a の結果
ps の結果
top の結果
ipcs の結果
netstat -in の結果
netstat -apn の結果
netstat -gn の結果
netstat -rn の結果
ifconfig の結果
ip -s l の結果
df の結果
systemctl -t service の結果
pldd <CLUSTERPRO プロセスID> の結果
uptime の結果
journalctl -e の結果
tail -500 <syslog ファイル> の結果
この情報はログ収集のデフォルト収集情報として採取されるため、別途採取する必要はありません。
9.9. クラスタ構成情報変更、クラスタ構成情報バックアップ、クラスタ構成情報チェックを実行する (clpcfctrl コマンド)
9.9.1. クラスタを生成する、クラスタ構成情報を変更する
クラスタ構成情報をサーバに配信します。
- コマンドライン
clpcfctrl --push [-h hostname | IP ] [-p portnumber] [-x directory] [--force] [--nocheck]
- 説明
Cluster WebUI で作成した構成情報をサーバに配信します。
- オプション
- --push
配信時に指定します。省略できません。
- -h hostname | IP
- 構成情報を配信するサーバを指定します。ホスト名または IP アドレスを指定します。省略時は構成情報にある全サーバに配信します。
- -p portnumber
- データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
- -x directory
- 指定したディレクトリにある構成情報を配信する場合に指定します。
- --force
起動していないサーバが存在する場合でも、強制的にクラスタ構成情報を配信します。
- --nocheck
変更をクラスタに反映させるために必要な操作のチェックを行わずに配信します。配信した構成情報をクラスタに反映させるためには必要に応じた操作を手動で実行する必要があります。
- 戻り値
0
成功
0以外
失敗
- 備考
Cluster WebUIでエクスポートしたクラスタ構成情報ファイルを、clpcfctrl --push コマンドでクラスタサーバーへ配信するには以下の手順に従ってください。
Cluster WebUIを起動し、[設定モード]に切り替えます。
必要に応じて、Cluster WebUIからクラスタ構成を変更します。
Cluster WebUIから、[設定のエクスポート]を選択し、任意のフォルダへクラスタ構成情報ファイル(zip形式)を保存します。
Cluster WebUIのエクスポートしたクラスタ構成情報ファイル(zip形式)を、クラスタサーバーから参照可能な任意のフォルダに展開します。
クラスタ内のいずれかのクラスタサーバーのコマンドプロンプトから、clpcfctrl --push を実行します。
- 注意事項
本コマンドは root 権限をもつユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
クラスタから一部サーバを削除した構成情報をアップロードする際は、削除するサーバの CLUSTERPRO サーバをアンインストールしてください。
--nocheck オプションは保守手順などの特別な用途においてのみ使用します。通常の操作では使用しないでください。
- 実行例
例1 : Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を配信する場合
# clpcfctrl --push -x /mnt/config file delivery to server 10.0.0.11 success. file delivery to server 10.0.0.12 success. The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
例2: 再インストール したサーバに構成情報を配信する場合
# clpcfctrl --push -h server2 The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。Invalid mode.Check if --push or --pull option is specified.--push を指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Invalid host name.Server specified by -h option is not included in the configuration data.-h で指定したサーバが構成情報に含まれていません。指定したサーバ名または IP アドレスが正しいか確認してください。Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the list of group.
グループ一覧の取得に失敗しました。
Failed to get the list of resource.
リソース一覧の取得に失敗しました。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active and then run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the collect size.
収集ファイルのサイズの取得に失敗しました。他のサーバが起動しているか確認してください。Failed to collect the file.
ファイル収集に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the list of node.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
Failed to check server property.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
File delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Multi file delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。The directory "work" is not found. Reinstall the RPM.
CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
クラスタ構成情報のパスが正しいか確認してください。
This is not a directory.
クラスタ構成情報のパスが正しいか確認してください。
The source file does not exist.
クラスタ構成情報のパスが正しいか確認してください。
The source file is a directory.
クラスタ構成情報のパスが正しいか確認してください。
The source directory does not exist.
クラスタ構成情報のパスが正しいか確認してください。
The source file is not a directory.
クラスタ構成情報のパスが正しいか確認してください。
Failed to change the character code set (EUC to SJIS).
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to change the character code set (SJIS to EUC).
メモリ不足または OS のリソース不足が考えられます。確認してください。
Command error.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to run the command.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to make a directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to remove the directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to remove the file.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to open the file.
クラスタ構成情報のパスが正しいか確認してください。
Failed to read the file.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to write the file.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
The upload is completed successfully.To start the cluster, refer to "How to create a cluster"in the Installation and Configuration Guide.The upload is completed successfully.To apply the changes you made, shutdown and reboot the cluster.アップロードは成功しました。変更を反映するためにクラスタシャットダウン、再起動を実行してください。The upload was stopped.To upload the cluster configuration data, stop the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタを停止してください。The upload was stopped.To upload the cluster configuration data, stop the Mirror Agent.アップロードは停止しました。クラスタ構成情報をアップロードするためにはMirrorAgent(clusterpro_md) を停止してください。The upload was stopped.To upload the cluster configuration data,stop the resources to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためには変更を加えたリソースを停止してください。The upload was stopped.To upload the cluster configuration data,stop the groups to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドする必要があります。アップロードするためには変更を加えたグループを停止してください。The upload was stopped.To upload the cluster configuration data, suspend the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドしてください。The upload is completed successfully.To apply the changes you made, restart the Alert Sync service.To apply the changes you made, restart the WebManager service.アップロードは成功しました。クラスタ構成情報を反映させるために AlertSync サービス(clusterpro_alertsync) を 再起動してください。クラスタ構成情報を反映させるために WebManager サービス(clusterpro_webmgr) を再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Information Base service.アップロードは成功しました。クラスタ構成情報を反映させるために Information Base サービス(clusterpro_ib) を再起動 してください。The upload is completed successfully.To apply the changes you made, restart the API service.アップロードは成功しました。クラスタ構成情報を反映させるために API サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Node Manager service.アップロードは成功しました。クラスタ構成情報を反映させるために Node Manager サービスを再起動 してください。The upload is completed successfully.
アップロードは成功しました。
The upload was stopped.Failed to deliver the configuration data.Check if the other server is active and run the command again.アップロードは停止しました。クラスタ構成情報の配信に失敗しました。他のサーバの起動状態を確認し、コマンドを再実行してください。The upload was stopped.There is one or more servers that cannot be connected to.To apply cluster configuration information forcibly,run the command again with "--force" option.アップロードは停止しました。接続できないサーバが存在します。クラスタ構成情報を強制的にアップロードするためには --force オプションを指定してコマンドを再実行してください。
9.9.2. クラスタ構成情報をバックアップする
クラスタ構成情報をバックアップします。
- コマンドライン
clpcfctrl --pull -l|-w [-h hostname | IP ] [-p portnumber] [-x directory]
- 説明
Cluster WebUI で使用するためにクラスタ構成情報をバックアップします。
- オプション
- --pull
バックアップ時に指定します。省略できません。
- -l
- Linux 上の Cluster WebUI で使用する構成情報としてバックアップする場合に指定します。-w と同時に指定することはできません。
- -w
- Windows 上の Cluster WebUI で使用する構成情報としてバックアップする場合に指定します。-l と同時に指定することはできません。
- -h hostname | IP
- バックアップ元サーバを指定します。ホスト名または IP アドレスを指定します。省略時はコマンド実行サーバの構成情報を使用します。
- -p portnumber
- データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
- -x directory
- 指定したディレクトリに構成情報をバックアップします。-l または -w と共に使用します。-l を指定した場合は、Linux 上の Cluster WebUI で読み込むことができる構成情報としてバックアップします。-w を指定した場合は、Windows 上のCluster WebUI で読み込むことができる構成情報として保存します。
- 戻り値
0
成功
0以外
失敗
- 備考
clpcfctrl --pull コマンドで取得したクラスタ構成情報ファイルを、Cluster WebUI でクラスタサーバーへ配信するには以下の手順に従ってください。
clpcfctrl --pull コマンドを実行し、任意のフォルダへクラスタ構成情報ファイルを保存します。
の clp.conf と scripts を選択し、zip 形式で圧縮したファイルを作成します (ファイル名は任意)。
Cluster WebUI の設定モードから [設定のインポート] をクリックし、保存したファイル (zip 形式) を読み込みます。
必要に応じて、Cluster WebUI からクラスタ構成を変更し、[設定の反映] をクリックする。
- 注意事項
本コマンドは root 権限を持つユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
- 実行例
例1 : Linux 上の Cluster WebUI で読み込むための構成情報を指定ディレクトリにバックアップする場合
# clpcfctrl --pull -l -x /mnt/config Command succeeded.(code:0)
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
すでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。
Invalid mode.Check if --push or --pull option is specified.--push を指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active andthen run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。Failed to get configuration data.Check if the other server is active.構成情報の取得に失敗しました。他のサーバが起動しているか確認してください。The directory "work" is not found.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
〃
This is not a directory.
〃
The source file does not exist.
〃
The source file is a directory.
〃
The source directory does not exist.
〃
The source file is not a directory.
〃
Failed to change the character code set (EUC to SJIS).
〃
Failed to change the character code set (SJIS to EUC).
〃
Command error.
〃
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
〃
Failed to run the command.
〃
Failed to make a directory.
〃
Failed to remove the directory.
〃
Failed to remove the file.
〃
Failed to open the file.
〃
Failed to read the file.
〃
Failed to write the file.
〃
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.9.3. グループ無停止でリソースを追加する
グループ無停止でリソースを追加します。
- コマンドライン
clpcfctrl --dpush [-p portnumber] [-x directory] [--force]
- 説明
グループ無停止でリソースを動的に追加します。
- オプション
- --dpush
動的リソース追加時に指定します。省略できません。
- -p portnumber
- データ転送ポートのポート番号を指定します。省略時は初期値を使用します。通常は指定の必要はありません。
- -x directory
- 指定したディレクトリにある構成情報を配信する場合に指定します。
- --force
起動していないサーバが存在する場合でも、強制的にクラスタ構成情報を配信します。
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは root 権限をもつユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
動的リソース追加に対応したリソースに関しては『メンテナンスガイド』の「保守情報」の「グループ無停止でリソースを追加する手順」を参照してください。
本オプションを利用する際は、クラスタ内のすべてのノードがCLUSTERPROの内部バージョン3.2.1-1以降である必要があります。
動的リソース追加コマンド実施中はリジュームしないでください。クラスタの構成情報に不整合が生じクラスタ停止・またはサーバシャットダウンする事があります。
動的リソース追加コマンドを途中で終了させた場合、追加対象のリソースの活性状態が不定となる可能性があります。再度実行し完了させるか手動でクラスタリブートしてください。
- 実行例
例1 : Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報を使用して動的リソース追加する場合
# clpcfctrl --dpush -x /mnt/config file delivery to server 10.0.0.11 success. file delivery to server 10.0.0.12 success. The upload is completed successfully.(cfmgr:0) Command succeeded.(code:0)
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。Invalid mode.Check if --push or --pull option is specified.--push を指定しているか確認してください。
The target directory does not exist.
指定されたディレクトリは存在しません。
Invalid host name.Server specified by -h option is not includedin the configuration data.-h で指定したサーバが構成情報に含まれていません。指定したサーバ名または IP アドレスが正しいか確認してください。Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the list of group.
グループ一覧の取得に失敗しました。
Failed to get the list of resource.
リソース一覧の取得に失敗しました。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active andthen run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the collect size.
収集ファイルのサイズの取得に失敗しました。他のサーバが起動しているか確認してください。Failed to collect the file.
ファイル収集に失敗しました。他のサーバが起動しているか確認してください。
Failed to check server property.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
File delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Multi file delivery failed.Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。The directory "work" is not found. Reinstall the RPM.
CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
〃
This is not a directory.
〃
The source file does not exist.
〃
The source file is a directory.
〃
The source directory does not exist.
〃
The source file is not a directory.
〃
Failed to change the character code set (EUC to SJIS).
〃
Failed to change the character code set (SJIS to EUC).
〃
Command error.
〃
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
〃
Failed to run the command.
〃
Failed to make a directory.
〃
Failed to remove the directory.
〃
Failed to remove the file.
〃
Failed to open the file.
〃
Failed to read the file.
〃
Failed to write the file.
〃
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
The upload is completed successfully.To start the cluster, refer to "How to create a cluster"in the Installation and Configuration Guide.The upload is completed successfully.To apply the changes you made, shutdown and reboot the cluster.アップロードは成功しました。変更を反映するためにクラスタシャットダウン、再起動を実行してください。The upload was stopped.To upload the cluster configuration data, stop the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタを停止してください。The upload was stopped.To upload the cluster configuration data, stop the Mirror Agent.アップロードは停止しました。クラスタ構成情報をアップロードするためにはMirrorAgentを停止してください。The upload was stopped.To upload the cluster configuration data,stop the resources to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためには変更を加えたリソースを停止してください。The upload was stopped.To upload the cluster configuration data,stop the groups to which you made changes.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドする必要があります。アップロードするためには変更を加えたグループを停止してください。The upload was stopped.To upload the cluster configuration data, suspend the cluster.アップロードは停止しました。クラスタ構成情報をアップロードするためにはクラスタをサスペンドしてください。The upload is completed successfully.To apply the changes you made, restart the Alert Sync service.To apply the changes you made, restart the WebManager service.アップロードは成功しました。クラスタ構成情報を反映させるために AlertSync サービスを 再起動してください。クラスタ構成情報を反映させるために WebManager サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Information Base service.アップロードは成功しました。クラスタ構成情報を反映させるために Information Base サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the API service.アップロードは成功しました。クラスタ構成情報を反映させるために API サービスを再起動 してください。The upload is completed successfully.To apply the changes you made, restart the Node Manager service.アップロードは成功しました。クラスタ構成情報を反映させるために Node Manager サービスを再起動 してください。The upload is completed successfully.
アップロードは成功しました。
The upload was stopped.Failed to deliver the configuration data.Check if the other server is active and run the command again.アップロードは停止しました。クラスタ構成情報の配信に失敗しました。他のサーバの起動状態を確認し、コマンドを再実行してください。The upload was stopped.There is one or more servers that cannot be connected to.To apply cluster configuration information forcibly,run the command again with "--force" option.アップロードは停止しました。接続できないサーバが存在します。クラスタ構成情報を強制的にアップロードするためには--force オプションを指定してコマンドを再実行してください。The upload was stopped.Failed to active resource.Please check the setting of resource.アップロードは停止しました。リソースの活性に失敗しました。リソースの設定を確認してください。
9.9.4. グループリソース動的追加時にクラスタ構成情報をチェックする
グループリソース動的追加時にクラスタ構成情報をチェックします。
- コマンドライン
clpcfctrl --compcheck [-x directory]
- 説明
グループ無停止でリソースを動的に追加する際に、クラスタ構成情報に問題がないかを確認します。
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは root 権限をもつユーザで実行してください。
本コマンド実行時、クラスタサーバへの接続は以下の順で行い接続が成功した経路を使用します。
インタコネクト LAN 側の IP アドレス
パブリック LAN 側の IP アドレス
本コマンドは新しい構成情報と既存の構成情報との差分を取り、追加部分のリソースの構成情報についてチェックします。
- 実行例
例1 : Linux 上で Cluster WebUI を使用してファイルシステム上に保存した構成情報をチェックする場合
# clpcfctrl --compcheck -x /mnt/config The check is completed successfully.(cfmgr:0) Command succeeded.(code:0)
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
This command is already run.
本コマンドはすでに起動されています。
Invalid option.
オプションが不正です。オプションを確認してください。The target directory does not exist.
指定されたディレクトリは存在しません。
Canceled.
コマンドの問い合わせに "y" 以外を入力した場合に表示されます。
Failed to initialize the xml library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to load the configuration file.Check if memory or OS resources are sufficient.〃
Failed to change the configuration file.Check if memory or OS resources are sufficient.〃
Failed to load the all. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to load the cfctrl. pol file.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the install path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the cfctrl path.Reinstall the RPM.CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to get the list of group.
グループ一覧の取得に失敗しました。
Failed to get the list of resource.
リソース一覧の取得に失敗しました。
Failed to initialize the trncl library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to connect to server %1.Check if the other server is active and then run the command againサーバとの接続に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to connect to trnsv.Check if the other server is active.サーバとの接続に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the collect size.
収集ファイルのサイズの取得に失敗しました。他のサーバが起動しているか確認してください。Failed to collect the file.
ファイル収集に失敗しました。他のサーバが起動しているか確認してください。
Failed to get the list of node.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
Failed to check server property.Check if the server name or ip addresses are correct.構成情報のサーバ名と IP アドレスが正しく設定されているか確認してください。
File delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Multi file delivery failed. Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。Failed to deliver the configuration data.Check if the other server is active and run the command again.構成情報の配信に失敗しました。他のサーバが起動しているか確認してください。サーバ起動後、再度コマンドを実行してください。The directory "work" is not found. Reinstall the RPM.
CLUSTERPRO サーバ RPM を再インストールしてください。
Failed to make a working directory.
メモリ不足または OS のリソース不足が考えられます。確認してください。
The directory does not exist.
〃
This is not a directory.
〃
The source file does not exist.
〃
The source file is a directory.
〃
The source directory does not exist.
〃
The source file is not a directory.
〃
Failed to change the character code set (EUC to SJIS).
〃
Failed to change the character code set (SJIS to EUC).
〃
Command error.
〃
Failed to initialize the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to get size from the cfmgr library.Check if memory or OS resources are sufficient.メモリ不足または、OS のリソース不足が考えられます。確認してください。
Failed to allocate memory
メモリ不足またはOS のリソース不足が考えられます。確認してください。
Failed to change the directory.
〃
Failed to run the command.
〃
Failed to make a directory.
〃
Failed to remove the directory.
〃
Failed to remove the file.
〃
Failed to open the file.
〃
Failed to read the file.
〃
Failed to write the file.
〃
Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.10. タイムアウトを一時調整する (clptoratio コマンド)
現在のタイムアウト倍率の延長、表示を行います。
- コマンドライン
- clptoratio -r ratio -t timeclptoratio -iclptoratio -s
- 説明
クラスタ内の全サーバで以下の各種タイムアウト値を一時的に延長や、現在のタイムアウト倍率を表示します。
モニタリソース
ハートビートリソース
ミラーエージェント
ミラードライバ
アラート同期サービス
WebManagerサービス
- オプション
- -r ratio
- タイムアウト倍率を指定します。1 以上の整数値で設定してください。最大タイムアウト倍率は10000 倍です。「1」を指定した場合、-i オプションと同様に、変更したタイムアウト倍率を元に戻すことができます。
- -t time
- 延長期間を指定します。分m、時間h、日d が指定できます。最大延長期間は 30 日です。例)2m、3h、4d
- -i
変更したタイムアウト倍率を元に戻します。
- -s
現在のタイムアウト倍率を参照します。
- 戻り値
0
成功
0以外
失敗
- 備考
クラスタシャットダウンを実行すると、設定したタイムアウト倍率は無効になります。クラスタ内のサーバが 1 台でもシャットダウンされていなければ、設定したタイムアウト倍率、延長期間は保たれます。
-s オプションで参照できるのは、現在のタイムアウト倍率のみです。延長期間の残り時間などは参照できません。
状態表示コマンドを用いて、元のタイムアウト値を参照できます。
ハートビートタイムアウト
# clpstat --cl --detail
モニタリソースタイムアウト
# clpstat --mon モニタリソース名 --detail
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
クラスタ内の全サーバの CLUSTERPRO デーモンが起動した状態で実行してください。
タイムアウト倍率を設定する場合、延長期間の指定は必ず行ってください。しかし、タイムアウト倍率指定に「1」を指定した場合は、延長期間を指定することはできません。
延長期間指定に、「2m3h」などの組み合わせはできません。
倍率延長期間内にサーバを再起動すると、延長期間を過ぎてもタイムアウト倍率が元に戻りません。この場合、タイムアウト倍率を元に戻すには clptoratio -i コマンドを実施してください。
本コマンドは、強制停止リソースの各種タイムアウト値には対応していません。
- 実行例
例1 : タイムアウト倍率を 3 日間 2 倍にする場合
# clptoratio -r 2 -t 3d
例2 : タイムアウト倍率を元に戻す場合
# clptoratio -i
例3 : 現在のタイムアウト倍率を参照する場合
# clptoratio -s present toratio : 2
現在のタイムアウト倍率は 2 で設定されていることが分かります。
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
Invalid configuration file.Create valid cluster configuration data.Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
Specify a number in a valid range.
正しい範囲で数字を指定してください。
Specify a correct number.
正しい数字で指定してください。
Scale factor must be specified by integer value of 1 or more.
倍率は 1 以上の整数値で指定してください。
Specify scale factor in a range less than the maximum scale factor.
最大倍率を超えない範囲で倍率を指定してください。
Set the correct extension period.
正しい延長期間の設定をしてください。
Ex) 2m, 3h, 4d
最大延長期間を超えない範囲で延長期間を設定してください。
Set the extension period in a range less than the maximum extension period.
CLUSTERPRO デーモンが起動しているか確認してください。
Could not connect to the server. Check if the cluster daemon is active.
CLUSTERPRO デーモンが起動しているか確認してください。
Server is not active.Check if the cluster daemon is active.クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Connection was lost.Check if there is a server where the cluster daemon is stopped in the cluster.クラスタ内に CLUSTERPRO デーモンが停止しているサーバがないか確認してください。
Invalid parameter.
コマンドの引数に指定した値に不正な値が 設定されている可能性があります。
Internal communication timeout has occurred in the cluster server.If it occurs frequently, set the longer timeout.CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してみてください。Processing failed on some servers.Check the status of failed servers.処理に失敗したサーバが存在します。クラスタ内のサーバの状態を確認してください。クラスタ内の全てのサーバが起動した状態で実行してください。Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.11. ログレベル/サイズを変更する (clplogcf コマンド)
ログレベル、ログ出力ファイルサイズの設定の変更、表示を行います。
- コマンドライン
clplogcf -t type -l level -s size
- 説明
- ログレベル、ログ出力ファイルサイズの設定を変更します。現在の設定値を表示します。
- オプション
- -t type
- 設定を変更するモジュールタイプを指定します。指定可能なタイプには、オプション指定なしで実行した際に出力される情報(TYPE列)を参照してください。
- -l level
- ログレベルを指定します。指定可能なログレベルは以下のいずれかです。1、2、4、8、16、32数値が大きいほど詳細なログが出力されます。
- -s size
- ログを出力するファイルのサイズを指定します。単位は byte です。
- なし
現在設定されている全情報を表示します。
- 戻り値
0
成功
0以外
失敗
- 備考
CLUSTERPRO が出力するログは、各タイプで 4 つのログファイルを使用します。このため -s で指定したサイズの4倍のディスク容量が必要です。
- 注意事項
本コマンドは root 権限をもつユーザで実行してください。
本コマンドの実行には CLUSTERPRO イベントサービスが動作している必要があります。
設定変更は、本コマンドを実行したサーバのみで有効となります。また、サーバを再起動すると設定は元に戻ります。
- 実行例
例1 : pm のログレベルを変更する場合
# clplogcf -t pm -l 8
例2 : pm のログレベル、ログファイルサイズを参照する場合
# clplogcf -t pm TYPE, LEVEL, SIZE pm, 8, 1000000
例3 : 現在の設定値を表示する場合
# clplogcf TYPE, LEVEL, SIZE trnsv, 4, 1000000 xml, 4, 1000000 logcf, 4, 1000000
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root ユーザで実行してください。
Invalid option.
オプションが不正です。オプションを確認してください。
Failed to change the configuration. Check if clpevent is running.
clpevent が起動されていない可能性があります。
Invalid level
指定したレベルが不正です。
Invalid size
指定したサイズが不正です。
Failed to load the configuration file. Check if memory or OS resources are sufficient.
クラスタ生成されていないサーバです。
Failed to initialize the xml library. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Failed to print the configuration. Check if clpevent is running.
clpevent が起動されていない可能性があります。
9.12. ライセンスを管理する (clplcnsc コマンド)
ライセンスの管理を行います。
- コマンドライン
- clplcnsc -i [licensefile…]clplcnsc -l [-a]clplcnsc -d serialno [-q]clplcnsc -d -t [-q]clplcnsc -d -a [-q]clplcnsc --distributeclplcnsc --reregister licensefile...
- 説明
本製品の製品版・試用版ライセンスの登録、参照、削除を行います。
- オプション
- -i [licensefile…]
ライセンスファイルを指定すると、そのファイルよりライセンス情報を取得し、登録します。ライセンスファイルは複数指定することができます。ワイルドカードの指定も可能です。指定しなければ、対話形式によりライセンス情報を入力し登録します。
- -l [-a]
登録されているライセンスを参照します。表示する項目を以下に示します。
項目名
説明
Serial No
シリアルナンバー (製品版のみ)
User name
ユーザ名 (試用版のみ)
Key
ライセンスキー
Licensed Number of CPU
ライセンス許諾数(CPU単位)
Licensed Number of Computers
ライセンス許諾数(ノード単位)
Start date
End date
Status
ライセンスの状態
状態
説明
valid
有効
invalid
無効
unknown
不明
inactive
expired
-a オプションを指定しない場合は、ライセンスの状態が invalid, unknown, expired であるライセンスは表示しません。
-a オプションを指定した場合は、ライセンスの状態に関わらず、全てのライセンスを表示します。
- -d <param>
param
serialno
指定したシリアルナンバーのライセンスを削除します。
-t
登録されている全ての試用版ライセンスを削除します。
-a
登録されている全てのライセンスを削除します。
- -q
ライセンスを削除する時の確認メッセージを表示せずに削除します。-dオプションと一緒に指定してください。
- --distribute
ライセンスファイルをクラスタ内のサーバに配信します。通常、このオプションでコマンドを実行する必要はありません。
- --reregister licensefile…
期限付きライセンスを使用している環境で、クラスタ内の一部のサーバのみ再インストールする場合に使用するオプションとなります。通常、このオプションは使用しません。
- 戻り値
0
成功
1
キャンセル
2
成功 (ライセンス非同期状態)
※ ライセンス登録時、クラスタ内でライセンスの同期が失敗したことを意味します。
この状態での対処方法は、『インストール&設定ガイド』の「トラブルシューティング」の「ライセンス関連」を参照してください。
3
初期化エラー
5
オプション不正
8
その他内部エラー
- 実行例
登録
対話形式
# clplcnsc -i
製品版、製品版(期限付き)
製品区分選択
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
シリアルナンバー入力
Enter serial number [ Ex. XXXXXXXX000000 ] ...
ライセンスキー入力
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
試用版
製品区分選択
Selection of License Version 1. Product Version 2. Trial Version e. Exit Select License Version. [1, 2, or e (default:1)] ...
ユーザ名入力
Enter user name [ 1 to 63byte ] ...
ライセンスキー入力
Enter license key [ Ex. XXXXXXXX-XXXXXXXX-XXXXXXXX-XXXXXXXX] ...
ライセンスファイル指定
# clplcnsc -i /tmp/cpulcns.key
参照
# clplcnsc -l
製品版
< CLUSTERPRO X <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Licensed Number of CPU... 2 Status... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Licensed Number of Computers... 1 Status... valid
製品版(期限付き)
< CLUSTERPRO X <PRODUCT> > Seq... 1 Serial No..... AAAAAAAA000001 Key..... A1234567-B1234567-C1234567-D1234567 Start date..... 2018/01/01 End date...... 2018/01/31 Status........... valid Seq... 2 Serial No..... AAAAAAAA000002 Key..... E1234567-F1234567-G1234567-H1234567 Status........... inactive
試用版
< CLUSTERPRO X <TRIAL> > Seq... 1 Key..... A1234567-B1234567-C1234567-D1234567 User name... NEC Start date..... 2018/01/01 End date...... 2018/02/28 Status........... valid
削除
# clplcnsc -d AAAAAAAA000001 -q
削除
# clplcnsc -d -t -q
削除
# clplcnsc -d -a
削除確認
Are you sure to remove the license? [y/n] ...
- 注意事項
ライセンス登録時はライセンス同期を行うため、データ転送サーバの起動、クラスタ生成が行われていることを確認してください。
ライセンス同期する際、インタコネクトの優先度順でクラスタサーバのIPアドレスに接続し、成功した経路を使用します。
ライセンス削除時は、本コマンドを実行したサーバ上のライセンス情報のみが削除されます。他のサーバ上のライセンス情報は削除されません。クラスタ内のライセンス情報を全て削除する場合は、全てのサーバで本コマンドを実行してください。
また、-d オプション利用時に -aオプションを併用した場合、全ての試用版ライセンスおよび製品版ライセンスが削除されます。試用版ライセンスのみ削除する場合は -t オプションを併用してください。製品版ライセンスも含めて削除してしまった場合は製品版ライセンスの再登録をしてください。
ライセンス参照時は、あるライセンスに複数のライセンスが包含されている場合、それぞれ個別に表示されます。
ダウンしているサーバが存在する場合、本コマンドの実行に時間がかかる場合がありますが、動作上の問題はありません。
- エラーメッセージ
メッセージ
原因/対処法
Processed license num(success: %d, error: %d).処理したライセンス数(成功: %d, 失敗: %d)失敗が 0 でない場合は、何らかの理由でライセンス処理が失敗しています。ライセンス情報が正しいか確認してください。Command succeeded.
コマンドは成功しました。
Command failed.
コマンドは失敗しました。
Command succeeded.But the license was not applied to all the servers in the clusterbecause there are one or more servers that are not started up.クラスタ内にダウンしているサーバが存在します。クラスタ内の全サーバでクラスタ生成手順を実行してください。クラスタ生成手順については、『インストール&設定ガイド』の「CLUSTERPRO をインストールする」を参照してくださいLog in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。Initialization error.Check if memory or OS resources are sufficient.クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。Initialization error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
The command is already run.
コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。The license is not registered.
ライセンスが未登録状態です。
Could not opened the license file.Check if the license file exists on the specified path.ライセンスファイルへの I/O ができません。ライセンスファイルが指定されたパスに存在するか確認してください。Could not read the license file.Check if the license file exists on the specified path.〃
The field format of the license file is invalid.The license file may be corrupted.Check the destination from where the file is sent.ライセンスファイルのフィールド形式が不正です。ライセンスファイルが壊れている可能性があります。ファイルの送付元に確認してください。The cluster configuration data may be invalid or not registered.
クラスタ構成情報が不正または、未登録状態が考えられます。確認してください。Failed to terminate the library.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。Failed to register the license.Check if the entered license information is correct.入力したライセンス情報が正しいか確認してください。
Failed to open the license.Check if the entered license information is correct.〃
Failed to remove the license.
ライセンスの削除に失敗しました。パラメータ誤り、メモリ不足、または OS のリソース不足が考えられます。確認してください。This license is already registered.
このライセンスはすでに登録されています。登録されているライセンスを確認してください。This license is already activated.
このライセンスはすでに使用されています。登録されているライセンスを確認してください。This license is unavailable for this product.
このライセンスはこの製品では使用できません。ライセンスを確認してください。The maximum number of licenses was reached.
登録可能なライセンスの最大数に達しました。期限切れのライセンスを削除してください。Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.13. ディスク I/O を閉塞する (clproset コマンド)
パーティションデバイスの I/O 許可の変更と表示をします。
- コマンドライン
- clproset -o [-d device_name | -r resource_name -t resource_type | -a]clproset -w [-d device_name | -r resource_name -t resource_type | -a]clproset -s [-d device_name | -r resource_name -t resource_type | -a]
- 説明
共有ディスクのパーティションデバイスの I/O 許可を ReadOnly / ReadWrite 可能 に設定します。
設定されているパーティションデバイスの I/O 許可の状態を表示します。
- オプション
- -o
パーティションデバイスの I/O を ReadOnly に設定します。ReadOnly に設定すると、設定したパーティションデバイスに対して、書き込みができなくなります。
- -w
パーティションデバイスの I/O を ReadWrite 可能 に設定します。ReadWrite に設定すると、設定したパーティションデバイスに対して、読み書きが可能になります。
- -s
パーティションデバイスの I/O 許可の状態を表示します。
- -d device_name
パーティションデバイスを指定します。
- -r resource_name
ディスクリソース名を指定します。
- -t resource_type
グループリソースタイプを指定します。現バージョンでは、グループリソースタイプには必ず「disk」を指定してください。
- -a
全てのディスクリソースに対して実行します。
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドは共有ディスクリソースのみに有効なコマンドです。ミラーディスクリソース、ハイブリッドディスクリソースには使用できません。
リソース名で指定する場合は必ずグループリソースタイプも指定してください。
- 実行例
例1 : ディスクリソース名 disk1 の I/O を RW にする場合
# clproset -w -r disk1 -t disk /dev/disk/by-id/scsi-222850001557d9443-part5 : succeeded (disk1)
例2 : 全てのリソースの I/O 情報を取得する場合
# clproset -s -a /dev/disk/by-id/scsi-222850001557d9443-part5 : rw (disk) /dev/disk/by-id/scsi-222850001557d9443-part6 : ro (disk)
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid configuration file.Create valid cluster configuration data.Cluster WebUI で正しいクラスタ構成情報を作成してください。
Invalid option.
正しいオプションを指定してください。
The -t option must be specified for the -r option.
-r オプションの場合は、必ず -t オプションを指定してください。
Specify 'disk' to specify a group resource.
グループリソースタイプには、「disk」を指定してください。
Invalid group resource name.Specify a valid group resource name in the cluster.正しいグループリソース名を指定してください。
invalid device name.
正しいデバイス名を指定してください。
command timeout.
OSに負荷がかかっているなどの原因が考えられます。確認してください。Internal error.Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。注釈
『インストール&設定ガイド』の「動作チェックを行う」に記載されている用途以外に本コマンドを使用しないでください。CLUSTERPRO デーモンが起動している場合に本コマンドを実行すると、ファイルシステムを壊す恐れがあります。
9.14. ミラー状態を表示する (clpmdstat コマンド)
ミラーに関する状態と、設定情報を表示します。
- コマンドライン
- clpmdstat {--connect | -c} mirrordisk-aliasclpmdstat {--mirror | -m} mirrordisk-aliasclpmdstat {--active | -a} mirrordisk-aliasclpmdstat {--detail | -d} mirrordisk-aliasclpmdstat {--list | -l}clpmdstat {--perf | -p} [interval [count]] mirrordisk-alias
- 説明
ミラーに関する各種状態を表示します。
ミラーディスクリソースの設定情報を表示します。
- オプション
- --connect, -c
ミラーディスクコネクトの状態を表示します。
- --mirror, -m
ミラーディスクリソースの状態を表示します。
- --active, -a
ミラーディスクリソースの活性状態を表示します。
- --detail, -d
ミラーディスクリソースの設定情報を表示します。
- --list, -l
ミラーディスクリソースの一覧を表示します。
- --perf
ミラーディスクリソースの統計情報を表示します。
- パラメータ
- mirrordisk-alias
ミラーディスクリソース名を指定します。
- interval
- 統計情報をサンプリングする時間間隔を指定します。何も指定されない場合にはデフォルトとして60秒が指定されます。1から9999までの値が指定可能です。
- count
- 統計情報を表示する回数を指定します。interval値とともに使用します。1から9999までの値が指定可能です。interval値を指定し、count値を省略した場合には無限に表示します。表示を停止する場合には[Ctrl] + [C]で停止してください。interval値、count値ともに省略した場合にはinterval値60、count値1が指定されたものとして動作します。
- 戻り値
--connect, -c
--mirror, -m
戻り値
区分
コマンド実行サーバ(自サーバ)のミラーディスクの状態 [8]他サーバのミラーディスクの状態 [8]
0
成功
BLACK
BLACK
1
BLACK
GREEN
4
BLACK
RED
5
BLACK
BLUE
6
BLACK
GRAY
16
GREEN
BLACK
17
GREEN
GREEN
20
GREEN
RED
21
GREEN
BLUE
22
GREEN
GRAY
34
YELLOW
YELLOW
64
RED
BLACK
65
RED
GREEN
68
RED
RED
69
RED
BLUE
70
RED
GRAY
80
BLUE
BLACK
81
BLUE
GREEN
84
BLUE
RED
85
BLUE
BLUE
86
BLUE
GRAY
96
GRAY
BLACK
97
GRAY
GREEN
100
GRAY
RED
101
GRAY
BLUE
102
GRAY
GRAY
上記以外
失敗
-
-
--active, -a
戻り値
区分
コマンド実行サーバ(自サーバ)のミラーディスクリソースの活性状態 [9]他サーバのミラーディスクリソースの活性状態 [9]
17
成功
Inactive
Inactive
18
Inactive
Active(活性)
19
Inactive
Active(アクセス制限解除状態)
20
Inactive
停止中、通信エラー
33
Active(活性)
Inactive
34
Active(活性)
Active(活性)
35
Active(活性)
Active(アクセス制限解除状態)
36
Active(活性)
停止中、通信エラー
49
Active(アクセス制限解除状態)
Inactive
50
Active(アクセス制限解除状態)
Active(活性)
51
Active(アクセス制限解除状態)
Active(アクセス制限解除状態)
52
Active(アクセス制限解除状態)
停止中、通信エラー
65
停止中、通信エラー
Inactive
66
停止中、通信エラー
Active(活性)
67
停止中、通信エラー
Active(アクセス制限解除状態)
上記以外
失敗
-
-
--detail, -d
戻り値
区分
0
成功
0以外
失敗
--list, -l
戻り値
区分
0
成功
0以外
失敗
--perf
戻り値
区分
0
成功
0以外
失敗
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
- 表示例
表示例は次のトピックで説明します。
- エラーメッセージ
メッセージ
原因/対処法
Error: Log in as root.
root 権限を持つユーザで実行してください。
Error: Failed to read the configuration file.Check if it exists or is configured properly.設定ファイルの読み込みに失敗しました。設定ファイルが存在するか、正しく設定されているか確認してください。Error: Failed to acquire mirror disk resource name.Check if the Mirror Agent is operating normally.ミラーディスクリソース名の取得に失敗しました。ミラーエージェントが正常に動作しているか確認してください。Error: Specified mirror disk resource was not found.Specify a valid mirror disk resource name.指定したミラーディスクリソースが見つかりませんでした。正しいミラーディスクリソース名を指定してください。Error: Invalid mirror-alias.Specify a valid mirror disk resource name.正しいミラーディスクリソース名を指定してください。
Error: Failed to get the server name.Check if the configuration file is correct and the Mirror Agent is operating normally.サーバ名の取得に失敗しました。設定ファイルが正しいか、ミラーエージェントが正常に動作しているか確認してください。Error: Failed to communicate with other servers.Check if the Mirror Agent of the other server is operating normallyand the interconnect LAN is connected.相手サーバとの通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。Error: Mirror disks of the remote server may be down.Check if the Mirror Agent of the remote server is operating normallyand the interconnect LAN is connected.相手サーバとの通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。Error: Failed to get the mirror disk status.Check if the Mirror Agent on the local server is operating normally.ミラーディスク状態の取得に失敗しました。自サーバのミラーエージェントが正常に動作しているか確認してください。Error: Failed to acquire the mirror index.Check if the Mirror Agent is operating normally.ミラーエージェントが正常に動作しているか確認してください。
Error: mirror agent is not runningCheck if the Mirror Agent is active.ミラーエージェントが起動していません。モジュールタイプ mdagent の syslog またはアラートメッセージを確認して対処してください。Error: Failed to acquire the active status of the Mirror Agent of the local server.Shut down the cluster and reboot both servers.自サーバのミラーディスクリソース活性状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: Failed to acquire the active status of the Mirror Agent of the other server.Shut down the cluster and reboot both servers.相手サーバのミラーディスクリソース活性状態取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: Failed to acquire mirror recovery status.Reboot the local server.ミラー復帰状態の取得に失敗しました。自サーバを再起動してください。Error: Failed to acquire the list of mirror disks.Reboot the local server.ミラーディスクリストの取得に失敗しました。自サーバを再起動してください。Error: Failed to acquire the mirror configuration information.Check if the Mirror Agent is operating normally.ミラー設定情報の取得に失敗しました。ミラーエージェントが正常に動作しているか確認してください。Error: Failed to acquire the mirror disk configuration information of both servers.Shut down the cluster and reboot both servers.両サーバのミラーディスク設定情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: The number of the bits of the bitmap is invalid.The mirror difference information of the cluster partition is invalid.Shut down the cluster. If it fails again, replace the disk.For procedure to replace the disk, see the Reference Guideクラスタパーティションにおけるミラー差分情報の取得に失敗しました。クラスタシャットダウンを実行してください。再度このエラーが発生するようであれば、ディスクを交換してください。Error: Failed to get bitmap information.Failed to acquire the mirror difference information of the local server.Reboot the local server.クラスタパーティションにおけるミラー差分情報が不正です。クラスタシャットダウンを実行してください。再度このエラーが発生するようであれば、ディスクを交換してください。Error: Failed to read the mirror difference information of the local server.Reboot the local server.自サーバのミラー差分情報の読取に失敗しました。自サーバを再起動してください。Error: Failed to acquire semaphore.Reboot the local server.セマフォ取得に失敗しました。自サーバを再起動してください。Error: A malloc error.Failed to reserve the memory space.Reboot the local server.メモリ確保に失敗しました。自サーバを再起動してください。Error: Mirror driver of the local server is not loaded.Refer to the Reference Guide to load the driver.自サーバのミラードライバがロードされていません。本ガイドの「10. トラブルシューティング」を参照して確認してください。Error: Internal error (errorcode: 0xxxx).Shut down the cluster and reboot the server.クラスタシャットダウンを実行し、サーバを再起動してください。
Error: Failed to communicate with server %1 and %2.Check if both Mirror Agents of the two servers are operating normallyand the interconnect LANs are connected.表示されている両サーバとの通信に失敗しました。両サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入ります。Error: Failed to communicate with server %1.Check if Mirror Agent of the server is operating normallyand the interconnect LAN is connected.Failed to acquire the mirror disk detail information of the server %2.Shut down the cluster and reboot both servers.サーバ %1 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。サーバ %2 のミラーディスクの詳細情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。Error:Failed to acquire the mirror disk detail information of the server %1.Shut down the cluster and reboot both servers.Failed to communicate with server %2.Check if Mirror Agent of the server is operating normallyand the interconnect LAN is connected.サーバ %1 のミラーディスク詳細情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。サーバ %2 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入りますError:Failed to acquire the mirror disk detail information of the server %1 and server %2.Shut down the cluster and reboot both servers.両サーバのミラーディスクの詳細情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。Error:Failed to communicate with server %1 .Check if Mirror Agent of the server is operating normallyand the interconnect LAN is connected.Failed to acquire mirror disk %3 net interface status of the server %2.Shut down the cluster and reboot both servers.サーバ %1 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。サーバ %2 のミラーディスクリソース %3 のミラーディスクコネクト状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはミラーリソース名が入ります。Error:Failed to acquire mirror disk %3 net interface status of the server %1.Shut down the cluster and reboot both servers.Failed to communicate with server %2 .Check if Mirror Agent of the server is operating normallyand the interconnect LAN is connected.サーバ %1 のミラーディスクリソース %3 のミラーディスクコネクト状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。サーバ %2 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入ります。%3 にはミラーリソース名が入ります。Error:Failed to acquire mirror disk %3 net interface status of the server %1 and server %2.Shut down the cluster and reboot both servers.両サーバのミラーディスクコネクト状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはミラーリソース名が入ります。Error:Failed to communicate with server %1 .Check if Mirror Agent of the server is operating normallyand the interconnect LAN is connected.Failed to acquire mirror disk %3 net interface status of the server %2.Shut down the cluster and reboot both servers.サーバ %1 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。サーバ %2 のミラーディスクリソース %3 のミラーディスクコネクト状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはミラーリソース名が入ります。Error:Failed to acquire the active status of the Mirror disk %3 of the server %1.Shut down the cluster and reboot both servers.Failed to communicate with server %2 .Check if Mirror Agent of the server is operating normally and the interconnect LAN is connected.サーバ %1 の指定したミラーディスクリソース %3 の活性状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。サーバ %2 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入ります。%3 にはミラーリソース名が入ります。Error:Failed to acquire the active status of the Mirror disk %3 of the server %1 and server %2.Shut down the cluster and reboot both servers.両サーバのミラーディスクリソースの状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはミラーリソース名が入ります。Error:Failed to get all server names.Check if the configuration file is correct and the Mirror Agent is operating normally.サーバ名の取得に失敗しました。クラスタ構成情報のファイルが正しいか、ミラーエージェントが正常に動作しているか確認してください。The disk alias does not match the command.
指定されたリソース名 (ミラーエイリアス名) のリソースタイプが不正です。md リソースには clpmdstat を使ってください。hd リソースには clphdstat を使ってください。Invalid command name. clpmdstat
コマンド名が無効です。コマンドのファイル名を変更しないでください。The function of collecting statistics is disabled.
統計情報採取機能が有効ではありません。Cluster WebUI で [クラスタのプロパティ] の [統計情報] タブにある [ミラー統計情報] の設定を確認してください。Collecting mirror statistics failed. Please retry in a few seconds later.
一時的な高負荷等により、統計情報の採取に失敗しました。時間をおいて再度実行してください。再度表示される場合にはミラーエージェントが正常に動作しているか確認してください。
9.14.1. 表示例
ミラーディスクコネクトの状態表示
--connect オプションを指定した場合、ミラーディスクコネクトの状態を表示します。
Mirror Disk Name : md1 [Server : server1] 192.168.0.1 : Using [Server : server2] 192.168.0.2 : Using
各項目の説明
項目名
説明
Mirror Disk Name
ミラーディスクリソース名
Server Name
サーバ名
IP Address
ミラーディスクコネクトに指定された IP アドレス
Status
ミラーディスクコネクトの状態
状態 説明 --------------------- Using 使用中 Free 未使用 Error 異常 -- 状態不明
ミラーディスクリソースの状態表示
--mirror オプションを指定した場合、指定したミラーディスクリソースの状態を表示します。
ミラーディスクリソース状態表示は、ミラーディスクリソースの状態によって、3 種類の表示があります。
ミラーディスクリソースの状態が正常の場合
Mirror Status: Normal md1 server1 server2 ------------------------------------------------------------ Mirror Color GREEN GREEN
各項目の説明
項目名
説明
Mirror Status
ミラーディスクリソースの状態
状態 説明 ---------------------------------- Normal 正常 Recovering ミラー復帰中 Abnormal 異常 No Construction 初期ミラー構築 されていない状態
Mirror Color
各サーバのミラーディスクの状態
状態 説明 ---------------------------------------------- GREEN 正常 YELLOW ミラー復帰中 RED 異常 BLUE 両系活性 GRAY 停止中、状態不明 BLACK クラスタパーティション未初期化、 クラスタパーティションデータ異常などミラーディスクリソースの状態が異常の場合
Mirror Status: Abnormal md1 server1 server2 ------------------------------------------------------------ Mirror Color GREEN RED Lastupdate Time 2018/03/05 04:02:39 -- Break Time 2018/03/05 19:27:28 -- Disk Error OK OK Difference Percent 25% 0%
各項目の説明
項目名
説明
Mirror Status
ミラーディスクリソースの状態 [10]
Mirror Color
各サーバのミラーディスクの状態 [10]
Lastupdate Time
サーバ上でデータが最後に更新された時刻
Break Time
ミラーブレイクが発生した時刻
Disk Error
Disk I/O の状態
状態 説明 ---------------------- OK 正常 Error 異常 (I/O不可) -- 状態不明
Difference Percent
各サーバ上の差分データのパーセンテージ括弧表記の場合は、差分データ量計算処理中の未確定値。ミラー復帰中の場合
Mirror Status: Recovering md1 server1 server2 ------------------------------------------------------------ Mirror Color YELLOW YELLOW Recovery Status Value ---------------------------------------- Status: Recovering Direction: src server1 dst server2 Percent: 3% Used Time: 00:00:01 Remain Time: 00:00:32 Iteration Times: 1/1
各項目の説明
項目名
説明
Mirror Status
ミラーディスクリソースの状態 [11]
Mirror Color
各サーバのミラーディスクの状態 [11]
Status
ミラー復帰の状態
状態 説明 ---------------------------------------------------- Preparing コピー前の準備中 復帰中にリソースが起動していて I/O 負荷が 高い場合には、この状態が長く続く場合があります Recovering コピー中 Completing コピー後処理中 Nothing 復帰停止中Direction
src : コピー元サーバdst : コピー先サーバPercent
コピーが必要な容量に対する、コピー済の割合
Used Time
コピーを開始してからの経過時間
Remain Time
残りのコピー完了までに必要な予測時間
コピー済の速度から予測して表示するので、両サーバの負荷状況などにより値が増減する場合があります。
Iteration Times
運用モードが非同期モードのときのミラー復帰の現在の繰り返し回数と設定値
ミラーディスクリソースの活性状態表示
--active オプションを指定した場合、指定したミラーディスクリソースの活性状態を表示します。
md1 server1 server2 -------------------------------------------- Active Status Active Inactive
各項目の説明
Active Status
説明
Inactive
非活性
Active
活性(または、アクセス制限解除状態)
--
状態不明
ミラーディスクリソース情報表示
--detail オプションを指定した場合、指定したミラーディスクリソースの設定情報を表示します。
Mirror Disk Name : md1 Sync Switch : On Sync Mode : Sync Diff Recovery : Enable Compress : Sync Data : Off Recovery Data : Off [Server : server1] NMP/Disk Size(MB) : 95378/95378 DP Device : /dev/disk/by-id/scsi-222850001557d9443-part2 CP Device : /dev/disk/by-id/scsi-222850001557d9443-part1 [Server : server2] NMP/Disk Size(MB) : 95378/95378 DP Device : /dev/disk/by-id/scsi-2222400015526436d-part2 CP Device : /dev/disk/by-id/scsi-2222400015526436d-part1
各項目の説明
項目名
説明
Mirror Disk Name
ミラーディスクリソース名
Sync Switch
データを同期する/しない
Sync Mode
同期モード/非同期モード
Diff Recovery
差分復帰の可否
Compress
Sync Data
ミラー同期データを圧縮する/しない
Recovery Data
ミラー復帰データを圧縮する/しない
Server Name
サーバ名
NMP/Disk Size(MB)
NMP
両サーバのデータパーティションサイズのうち小さい方のサイズ
Disk Size
実際のデータパーティションのサイズ
DP Device
データパーティションデバイス名
CP Device
クラスタパーティションデバイス名
ミラーディスクリソース一覧表示
--list オプションを指定した場合、ミラーディスクリソースの一覧を表示します。
[Replicator Option] server1 : Installed server2 : Installed server3 : Installed [Servers Which Can Be Started] <md1> server1 server3 <md2> server2 server3
各項目の説明
項目名
説明
Replicator Option
Replicatorのライセンス登録状態
Servers Which Can Be Started
ミラーディスクリソースの起動可能なサーバ
統計情報表示
--perfオプションを指定した場合、ミラーリング機能に関する性能を表示します。
md1 ---Write(MB)---- ---Read(MB)---- ---Send(MB)---- --SyncTime(s)-- -SyncDiff(MB) Total Avg Total Avg Total Avg Max Avg Max Cur 0.14 0.00 0.10 0.00 0.02 0.00 0.04 0.02 0.07 None
各項目の説明
項目名
説明
Write (Total)
ミラーパーティションへWriteしたデータの総量です。単位はMBです。出力される値は、各サンプリングの間にWriteしたデータ量です。Write (Avg)
ミラーパーティションへWriteしたデータの単位時間当たりの量です。単位はMB/sです。
Read (Total)
ミラーパーティションからReadしたデータの総量です。単位はMBです。出力される値は、各サンプリングの間にReadしたデータ量です。Read (Avg)
ミラーパーティションからReadしたデータの単位時間当たりの量です。単位はMB/sです。
Send (Total)
ミラーディスクコネクトで送信したミラー通信総量です。単位はMBです。出力される値は、各サンプリングの間の通信量です。TCPの制御情報等は含みません。Send (Avg)
ミラーディスクコネクトで送信した単位時間当たりのミラー通信量です。単位はMB/sです。
SyncTime (Max)
ミラー同期データを1つ同期するのにかかった時間です。出力される値は、そのうち最も時間のかかったミラー同期データの時間です。単位は秒/回です。通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。また、出力される値は、各サンプリングの間の通信が対象です。SyncTime (Avg)
ミラー同期データを1つ同期するのにかかった時間です。出力される値は、通信回数あたりの平均時間です。単位は秒/回です。通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。また、出力される値は、各サンプリングの間の通信が対象です。SyncDiff (Max)
相手サーバへ同期が完了していないミラー同期データの量です。出力される値は、各サンプリングの間での、最大の値です。単位はMBです。通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。SyncDiff (Cur)
相手サーバへ同期が完了していないミラー同期データの量です。出力される値は、採取時の最新の値です。単位はMBです。通信不可等によって同期できなかった(ミラーブレイクとなった)ミラー同期データは対象外です。clpmdstatコマンドによる統計情報表示は小数点第2位までの表示となっています。実際に採取されたデータを適切な単位に換算し、表示する過程において小数点第3位以下は切り捨てとなっています。換算時に用いられた変換規則は以下です。
1KB = 1024byte, 1MB = 1048576byte
切り捨てによって0となる場合には"0.00"と表示します。切り捨てではなく実際に0の場合には"None"と表示されます。
出力される値はコマンドを実行したサーバでの情報となります。Write (Total), Write(Avg), Read(Total), Read(Avg), SyncTime(Max), SyncTime(Avg), SyncDiff(Max), SyncDiff(Cur)については現用系でのみ有効な値が出力されます。待機系では値が保持または"None"となります。Send(Total), Send(Avg)は現用系、待機系どちらでも有効な値が出力されます。
9.15. ミラーディスクリソースを操作する (clpmdctrl コマンド)
ミラーディスクリソースを操作します。
- コマンドライン
- clpmdctrl {--active | -a} mirrordisk-aliasclpmdctrl {--active | -a} -nomount mirrordisk-aliasclpmdctrl {--active | -a} -force [-ro] mirrordisk-aliasclpmdctrl {--active | -a} -force -nomount mirrordisk-aliasclpmdctrl {--deactive | -d} mirrordisk-aliasclpmdctrl {--break | -b} mirrordisk-aliasclpmdctrl {--recovery | -r} mirrordisk-aliasclpmdctrl {--force | -f} [-v] recovery-source-servername mirrordisk-aliasclpmdctrl {--force | -f} mirrordisk-aliasclpmdctrl {--cancel | -c} mirrordisk-aliasclpmdctrl {--rwait | -w} [-timeout time [-rcancel]] mirrordisk-aliasclpmdctrl --getreqclpmdctrl --setreq request-countclpmdctrl --sync [mirrordisk-alias]clpmdctrl --nosync [mirrordisk-alias]clpmdctrl {--compress | -p} [mirrordisk-alias]clpmdctrl {--nocompress | -n} [mirrordisk-alias]clpmdctrl {--mdcswitch | -s} [mdc-priority] mirrordisk-aliasclpmdctrl {--resize | -z} [-force] partition-size mirrordisk-aliasclpmdctrl --updatekey mirrordisk-alias
重要
--activeでアクセス制限解除を実行した場合は、必ず--deactiveでアクセス制限を元に戻してください。また、活性状態のリソースに対して--deactiveを実行しないでください。そのままの状態でリソースの起動や停止が発生すると、ファイルシステムが壊れる可能性があります。注釈
--resize オプションを使用してミラーディスクリソースのデータパーティション拡張を実行する場合は、『メンテナンスガイド』の「保守情報」の「ミラーディスクリソースのパーティションのオフセットやサイズを変更する」に記載の手順に従って、両サーバの拡張を順次実施する必要があります。
注釈
--resize オプションを使用してミラーディスクリソースのデータパーティション拡張を実行する場合は、データパーティションがLVMで構成されており、かつボリュームグループの未使用PE(Physical Extent)量が十分であることが必要です。
注釈
--updatekeyオプションを使用して暗号化鍵を更新する場合、『メンテナンスガイド』の「保守情報」の「ミラーディスクリソース/ハイブリッドディスクリソースの暗号鍵を更新する」に記載の手順に従ってください。
- 説明
ミラーディスクリソースのアクセス制限解除(強制活性)、アクセス制限を行います。
ミラーディスクの切り離し(ミラー同期の中断)を行います。
ミラー復帰、強制ミラー復帰、ミラー復帰のキャンセル、ミラー復帰の完了待ちを行います。
リクエストキュー最大数の設定表示/変更を行います。
ミラーデータの同期の有無を切り換えます。
ミラーデータの圧縮有無を切り換えます。
使用する通信経路(ミラーディスクコネクト)を切り換えます。
データパーティションサイズを拡張します。
暗号化鍵を更新します。
- オプション
- --active, -a
- 自サーバでミラーディスクリソースをアクセス制限解除します。ミラーディスクリソースの状態が正常な場合はミラーリングします。ミラーディスクリソースの状態が正常な場合以外はミラーリングしません。
- -force(--active,-a指定時)
- --active オプションとともに使用します。異常状態(RED)のミラーディスクリソースをアクセス制限解除します。(強制活性)ミラーリングが停止しているサーバで実行可能です。
- -nomount
- --active オプションとともに使用します。ファイルシステムをマウントせずに、ミラーパーティションデバイスのアクセスを可能にします。ファイルシステムにnoneを指定している場合、このオプションは意味を持ちません。
- -ro
- --active --force オプションとともに使用します。読み取り専用で、ミラーディスクリソースをアクセス制限解除(強制活性)します。
- --deactive, -d
自サーバでアクセス制限解除されているミラーディスクリソースをアクセス制限状態にします。
- --break, -b
- コマンドを実行したサーバ上で mirrordisk-alias で指定されたミラーディスクリソースを強制的に切り離します。(ミラー同期を中断します。)コマンドを実行したサーバのミラーディスクの状態は異常状態(RED) になります。コマンドを実行していないサーバのミラーディスクの状態は変わりません。ミラーディスクに書き込みが発生してもミラーデータは同期されません。ミラー復帰を行い正常に完了すると、切り離しは解除されます。ミラー復帰完了による切り離し解除、または、リブートをおこなうまで、自動ミラー復帰は自動的に開始されません。
- --recovery, -r
- 指定したミラーディスクリソースを全面ミラー復帰もしくは、差分ミラー復帰します。全面ミラー復帰、差分ミラー復帰の判断は自動的に行われます。
- --force, -f
- 指定したミラーディスクリソースを強制ミラー復帰します。mirrordisk-alias のみを指定した場合には、コマンドを実行したサーバのミラーディスクの状態を強制的に 異常状態(RED)から正常状態 (GREEN) に変更します。ミラーの再同期の処理は行われません。recovery-source-servername と mirrordisk-alias を指定した場合には、 recovery-source-servername をコピー元として全面ミラー復帰を行います。全面ミラー復帰が完了した後にミラーディスクのステータスが正常状態になります。
- -v
- --force オプションとともに使用します。ファイルシステムが使用していない領域も含め、全面ミラー復帰を行います。
- --cancel, -c
- ミラー復帰を中止します。自動ミラー復帰が ON に設定されていて、ミラーディスクモニタリソースが動作している場合、ミラー復帰を中止後しばらくすると自動的にミラー復帰が再開されます。その場合には、Cluster WebUI または clpmonctrl コマンドでミラーディスクモニタリソースを一時停止状態にしてから、ミラー復帰の中止を実行してください。
- --rwait, -w
指定したミラーディスクリソースのミラー復帰完了を待ちます。
- -timeout
- --rwait オプションとともに使用します。ミラー復帰完了待ちのタイムアウト時間(秒) を指定します。このオプションは省略可能です。省略時はタイムアウトを行わず、ミラー復帰が完了するまで待ち続けます。
- -rcancel
- --rwait -timeout オプションとともに使用します。ミラー復帰完了待ちがタイムアウトした場合に、ミラー復帰を中断します。このオプションは -timeout オプションを設定した場合に設定できます。省略時はタイムアウトしてもミラー復帰を続行します。
- --getreq
現在のリクエストキュー最大数を表示します。
- --setreq
- リクエストキュー最大数を設定します。この設定は、サーバをシャットダウンした場合には、クラスタ構成情報で設定している値に戻ります。クラスタ構成情報を変更したい場合は、Cluster WebUI を用いて変更してください。詳しくは本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「ミラードライバタブ -Replicator / Replicator DR を使用している場合-」を参照してください。コマンドを実行したサーバに対してのみ有効です。
- --sync
- ミラーデータを同期する動作に切り換えます。ミラーディスクリソース名を指定しない場合には、すべてのミラーリソースに対してミラーデータを同期する動作に切り換えます。
- --nosync
- ミラーデータを同期しない動作に切り換えます。ミラーディスクリソース名を指定しない場合には、すべてのミラーリソースに対してミラーデータを同期しない動作に切り換えます。ただし、ミラー復帰中に発生したディスクの更新は待機系へ同期されます。自動ミラー復帰が ON に設定されていて、ミラーディスクモニタリソースが動作している場合、自動ミラー復帰は動作します。ミラー復帰完了後でも、同期しない動作のままとなります。解除するには、--sync オプション指定によるコマンド実行をおこないます。サーバをシャットダウンすると、クラスタ構成情報で設定している同期の動作の状態に戻ります。クラスタ構成情報を変更したい場合は、Cluster WebUI を用いて変更してください。詳しくは本ガイドの「3. グループリソースの詳細」 - 「ミラーディスクリソースを理解する」 - 「詳細タブ」 - 「ミラーディスクリソース調整プロパティ」 - 「ミラータブ」を参照してください。
- --compress, -p
- ミラー同期/復帰データを転送するときに、一時的に、圧縮して転送します。同期モードが同期の場合には、ミラー復帰データのみ、圧縮します。同期モードが非同期の場合には、ミラー同期/復帰データ両方を圧縮します。ミラーディスクリソース名を指定しない場合には、すべてのミラーディスクリソースに対して圧縮転送する動作に切り換えます。
- --nocompress, -n
- ミラー同期/復帰データを転送するときに、一時的に、圧縮しないで転送します。ミラーディスクリソース名を指定しない場合には、すべてのミラーディスクリソースに対して圧縮転送しない動作に切り換えます。
- --mdcswitch, -s
- 指定された優先順位のミラーディスクコネクト (mdc) を使用するように、通信を切り換えます。優先順位 mdc-priority の指定が省略された場合は、現在使用されている mdcの次の優先順位の mdc へ切り換えます。一番低い優先順位の mdc を使用していた場合には、優先順位が一番高い mdc へ切り換えます。切り換え先の mdc への接続に失敗した場合は、次に有効な mdc へ接続を試みます。切り換え先として既に現在使用しているmdc が指定された場合には、通信を切り換えずに終了します。
- --resize, -z
- ミラーディスクリソースのデータパーティションサイズを拡張します。ミラーディスクリソースの状態が正常である場合のみ、拡張が可能です。
- -force(--resize,-z指定時)
- --resizeオプションとともに使用します。ミラーディスクリソースの状態に関わらず、強制的に拡張を実行します。本オプションを使用すると、次回のミラー復帰がフルコピーとなります。また、本オプションを使用しても、ミラー復帰中は拡張することができません。
- --updatekey
- 暗号化鍵を、リソースを停止することなく更新します。両サーバの暗号化鍵ファイルを新しいものに置き換えたうえで本オプションを実行すると、暗号化に使用する鍵が更新されます。ミラーリング中に実行した場合はミラーリングが中断されます。実行完了後に必要に応じてミラー復帰を実行してください。
- パラメータ
- recovery-source-servername
コピー元となるサーバ名を指定します。
- mirrordisk-alias
ミラーディスクリソース名を指定します。
- request-count
- リクエストキュー最大数を指定します。指定可能な範囲は、2048~65535 です。
- time
ミラー復帰完了待ちのタイムアウト時間(秒) を指定します。
- mdc-priority
- ミラーディスクコネクト (mdc) の優先順位を指定します。優先順位は、クラスタ全体での番号ではなく、対象のミラーディスクリソースに対して設定した mdc 順位を、1 または 2 で指定します。
- partition-size
- データパーティションの新しいサイズを指定します。以下の単位文字を付加して指定することができます。"500G"と指定すると、500ギビバイトに拡張されます。単位文字が付加されない場合は、バイト単位として扱われます。
K (Kibi byte)
M (Mebi byte)
G (Gibi byte)
T (Tebi byte)
- 戻り値
0
成功
255 (-1)
失敗
254 (-2)
対象ミラーディスクがミラーブレイク状態か、ミラー構築が途中で失敗した (--rwait オプション指定時のみ。-rcancel でミラー復帰を中断した場合も含む)
253 (-3)
対象ミラーディスクのミラー復帰完了待ちがタイムアウト (--rwait -timeout オプション指定時のみ)
- 備考
--getreq オプションで表示される request-count は、clpstat コマンドで表示される「Request Queue Maximum Number」と同じです。
# clpstat --cl --detail
本コマンドは、指定した処理が開始したタイミングで制御を戻します。処理の状況はclpmdstatコマンドで確認してください。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
ミラー復帰の異常終了後に再度ミラー復帰を行う場合、前回と同じサーバをコピー元として指定し、ミラー復帰をしてください。
3node 以上の構成のときにコマンドを実行するサーバがミラーディスクリソースを含むグループの起動サーバに含まれていない場合は、本コマンドはエラーになります。グループの起動サーバに含まれていない場合は本コマンドを実行しないでください。
ミラー同期途中に --break (-b) や --nosync オプションでミラー同期を中断した場合や、ミラー復帰途中にミラー復帰を中断した場合には、強制活性や強制ミラー復帰をおこなって同期先のミラーディスクにアクセス可能にしても、ファイルシステムやアプリケーションデータが異常になっている場合があります。詳細については『スタートアップガイド』 - 「注意制限事項」 - 「ミラー同期を中断した場合の同期先のミラーデータ参照について」を参照してください。
- 実行例
例1 : 正常状態の ミラーディスクリソース md1 をアクセス制限解除する場合
# clpmdctrl --active md1 <md1@server1>: active successfully
例2 : ミラーディスクリソース md1 をアクセス制限状態にする場合
# clpmdctrl --deactive md1 <md1@server1>: deactive successfully
例3 : ミラーディスクリソース md1 のミラーディスクを切り離す場合
# clpmdctrl --break md1 md1: isolate successfully
例4 : 両サーバのミラーディスクの状態が異常状態で、リソース md1 を使用する業務 (グループ名 failover1) の復旧を急ぐ場合
# clpmdctrl --force md1 The data of mirror disk in local server maybe is not latest. Do you still want to continue? (Y/N) md1: Force recovery successful. # clpgrp -s failover1 Command succeeded.
自動ミラー復帰が 「する」 の場合には このタイミングでミラー復帰が実行されます。自動ミラー復帰が 「しない」 の場合には以下のコマンドを実行します。
# clpmdctrl --recovery md1
例5 : ミラーディスクリソース md1 をミラー復帰する場合
# clpmdctrl --recovery md1
例6 : リクエストキュー最大数を 2048 に設定する場合
# clpmdctrl --setreq 2048 current I/O request count <2048>
例7 : ミラーディスクリソース md1 をデータ同期しない設定にする場合
# clpmdctrl --nosync md1
- エラーメッセージ
メッセージ
原因/対処法
Error: Log in as root.
root 権限を持つユーザで実行してください。
Error: Failed to read the configuration file.Check if it exists or is configured properly.設定ファイルの読み込みに失敗しました。設定ファイルが存在するか、正しく設定されているか確認してください。Error: Specified mirror disk resource was not found.Specify a valid mirror disk resource name.指定したミラーディスクリソースが見つかりませんでした。正しいミラーディスクリソース名を指定してください。Error: Invalid mirror-alias.Specify a valid mirror disk resource name.正しいミラーディスクリソース名を指定してください。
Error: Failed to get the server name.Check if the configuration file is correct and the Mirror Agent is operating normally.指定したサーバ名が見つかりませんでした。入力したサーバ名が設定ファイルに存在するか確認してください。Error: Invalid server name.Specify a valid server name.正しいサーバ名を指定してください。
Error: Failed to communicate with other servers.Check if the Mirror Agent of the other server is operating normallyand the mirror disk connect is connected.相手サーバとの通信に失敗しました。相手サーバのミラーエージェントが動作しているか、ミラーディスクコネクトが接続されているか確認してください。Error: Failed to get the mirror disk status.Check if the Mirror Agent on the local server is operating normally.ミラーディスク状態の取得に失敗しました。自サーバのミラーエージェントが正常に動作 しているか確認してください。Error: Failed to get the mirror index.Check if the Mirror Agent is operating normally.ミラーエージェントが正常に動作しているか確認してください。
Error: The status of mirror disk resource of the local server is abnormal.
自サーバのミラーディスクリソースの状態が異常です。
Error: Specified mirror disk resource is already active.Check active status of mirror disk resource by running the following command:clpmdstat --active <alias>指定したミラーディスクリソースは既に活性化しています。以下のコマンドを用いてミラーディスクリソースの活性状態を確認してください。clpmdstat --active <alias>Error: A hardware error has occurred on the disk.Check the disk.ディスクに H/W エラーが発生しました。ディスクを確認してください。Error: The sizes of data partition of the servers do not match.
両サーバのデータパーティションのサイズが一致していません。
Error: Specified mirror disk is not active.Check the active status of mirror disk resource.指定したミラーディスクリソースは活性化していません。ミラーディスクリソースの活性状態を確認してください。Error: There is no recovering mirror disk resource.
ミラー復帰中のミラーディスクリソースがありません。
Error: Mirror disk resource is recovering.Wait until mirror recovery completes.ミラーディスクリソースがミラー復帰中です。ミラー復帰が終わるまで待ってください。Error: Failed to cancel the mirror recovery.The system may be highly loaded.Wait for a while and try again.ミラー復帰の中止に失敗しました。システムが高負荷の可能性があります。しばらく待ってからリトライしてください。Error: Performed mirror recovery to the mirror disk resource that is not necessary to recover the mirror.Run the clpmdctrl--force command if you want to perform forced mirror recovery.正常状態のミラー復帰が不要なミラーディスクリソースに対してミラー復帰をしました。強制ミラー復帰を実行したい場合、"clpmdctrl --force" を用いて実行してください。Error: Specification of the server that is copied from is incorrect.When executing mirror recovery again after a failure end of mirror recovery,specify the same server as the previous one.コピー元サーバの指定が間違っています。ミラー復帰の異常終了後に再度ミラー復帰を行う場合、前回と同じサーバをコピー元として指定し、ミラー復帰を実行してください。Error: Forced mirror recovery is required.Run the clpmdctrl --force command to perform the recovery.強制ミラー復帰が必要な状態です。"clpmdctrl --force" を用いて実行してください。Error: Server with old data is specified as the server which is copied from.Specify a correct recovery direction.古いデータを持つサーバをコピー元サーバとして指定しています。正しい復帰方向を指定してくださいError: Failed to acquire mirror recovery status.Reboot the local server.ミラー復帰状態の取得に失敗しました。自サーバを再起動してください。Error: Both of the mirrors are not constructed.Initial mirror configuration of the mirror disks by running the clpmdctrl --force command is necessary.ミラーディスクの初期ミラー構築が必要な状態です。"clpmdctrl --force" を用いて初期ミラー構築をしてください。Error: Initial mirror configuration of mirror disk of local server is necessary.Specify the other server as the one that is copied from by using the clpmdctrl --force commandto configure an initial mirror.自サーバのミラーディスクの初期ミラー構築が必要な状態です。"clpmdctrl --force" を用いて相手サーバをコピー元として指定し、初期ミラー構築をしてください。Error: Initial mirror configuration of mirror disk of the other server is necessary.Specify the local server as the one that is copied from by using the clpmdctrl--force commandto configure an initial mirror.相手サーバのミラーディスクの初期ミラー構築が必要な状態です。"clpmdctrl --force" を用いて自サーバをコピー元として指定し、初期ミラー構築をしてください。Error: Mirror flag error. Use "clpmdinit" to construct the mirror.The status of cluster partition of the mirror disk resource is abnormal.When the server with the error has the latest data, backup the data, initialize the cluster partition,and replace the same disk by using the same disk.If the error persists, change the disk to new one.ミラーディスクリソースのクラスタパーティションの状態が異常です。エラーが発生したサーバが最新データを保持している場合は、『インストール&設定ガイド』の「動作チェックを行う」を参照してデータのバックアップをとり、クラスタパーティションを初期化し、と同じ手順を実行してください。再度発生するようであれば、エラーの発生するディスクを新しいディスクに交換してください。Error: Both local and remote mirrors are active.Shut down the cluster and execute forced mirror recovery after rebooting the server.両系活性になっています。クラスタシャットダウンを実行し、サーバを再起動後に、強制ミラー復帰を実行してください。Error: Mirror Agent is not running.Check if the Mirror Agent is active.ミラーエージェントは起動していません。ミラーエージェントが起動しているか確認してください。Error: System call error.Failed to run the system command when active and/or inactive.Check if the search path is set to an environment variable.活性化/非活性化時のシステムコマンド実行に失敗しました。サーチパスが環境変数に設定されているか確認してください。Error: Failed to create a mount point.The disk space may not be sufficient.マウントポイントの作成に失敗しました。ディスクの容量不足が考えられます。確認してください。Error: Timeout has occurred on active fsck.When it is not journaling file system, it may take time to run fsck if the size of data partition of mirror disk is large.Set timeout of fsck longer.活性化の fsck でタイムアウトが発生しています。ジャーナリングファイルシステムではない場合、ミラーディスクのデータパーティションのサイズが大きいと fsck に時間がかかることがあります。Cluster WebUI を用いて fsck タイムアウトの設定を長くしてください。Error: Timeout occurs at activation mount. Set mount timeout longer.
活性化時のファイルシステムのマウントでタイムアウトが発生しています。Cluster WebUI を用いてマウントタイムアウトの設定を長くしてください。Error: Timeout occurs at deactivation mount.Set unmount timeout longer.非活性化時のファイルシステムのアンマウントでタイムアウトが発生しています。Cluster WebUI を用いてアンマウントタイムアウトの設定を長くしてください。Error: fsck failed. Check if file system type of data partition does not match configuration file,fsck option is incorrect or partition is incorrect.fsck に失敗しました。データパーティションのファイルシステムタイプが設定ファイルと一致しない、fsck オプションが間違っている、パーティションが壊れている、などが考えられます。確認してください。Error: Failed to mount when active.The file system type of the data partition does not match the settings of the configuration file, or the partition may be corrupted活性化時のマウントに失敗しました。データパーティションのファイルシステムタイプが設定ファイルにおける設定と一致しない、またはパーティションが壊れていることが考えられます。確認してください。Error: Failed to unmount when inactive.Check if the file system on the data partition is busy.非活性化時のアンマウントに失敗しました。データパーティション上のファイルシステムがビジー状態ではないことを確認してください。Error: Mirror disk resource is on process of activation.Execute after activation is completed.ミラーディスクリソースが活性化処理中です。活性化完了後に実行してください。Error: Failed to perform forced mirror recovery or activate a single server.Check if any hardware error has occurred on the disk.単体サーバの強制ミラー復帰、または活性化に失敗しました。ディスクに H/W エラーが発生していないか確認してください。Error: Entered incorrect maximum number of request queues.Check the specifiable range.不正なリクエストキュー最大数を入力しました。指定可能な数値範囲を確認してください。Error: Failed to set the maximum number of request queues.Reboot the local server.リクエストキュー最大数の設定に失敗しました。自サーバを再起動してください。Error: Failed to acquire the maximum number of request queues.Reboot the local server.リクエストキュー最大数の取得に失敗しました。自サーバを再起動してください。Mirror disk resource was not found on local server.Cannot perform this action.ミラーディスクリソースが自サーバで定義されていません。リクエストキュー最大数の設定はできませんでした。確認してください。Error: Failed to get the NMP path.Check if the Mirror Agent is operating normally.Reboot the local server.ミラーエージェントが正常に動作しているか確認してください。自サーバを再起動してください。Error: Failed to acquire the mirror configuration information.Check if the Mirror Agent is operating normally.ミラー設定情報の取得に失敗しました。ミラーエージェントが正常に動作しているか確認してください。Error: Failed to acquire the mirror disk configuration information.Reboot the local server.ミラーディスク設定情報の取得に失敗しました。自サーバを再起動してください。Error: Failed to acquire the mirror disk configuration information of both local and remote servers.Shut down the cluster and reboot both servers.両サーバのミラーディスク設定情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: Failed to get the number of bits of the bitmap due to the errors occurredwhen acquiring the mirror difference information of the cluster partition.Shut down the cluster.If it fails again, replace the disk. For procedure to replace the disk, see the Reference Guide.Error: The number of the bits in the bitmap is invalid. The mirror difference information of the cluster partition is invalid.Shut down the cluster. If it fails again, replace the disk.For procedure to replace the disk, see Reference Guide.Error: Failed to read the mirror difference information of the local server.Reboot the local server.自サーバのミラー差分情報の読取に失敗しました。自サーバを再起動してください。Error: Failed to read the mirror difference information of the other server.Reboot the other server.相手サーバのミラー差分情報の読取に失敗しました。相手サーバを再起動してください。Error: Failed to get the bitmap information of the local server due to the errors occurredwhen acquiring the mirror difference information of the local server.Reboot the local server.自サーバのミラー差分情報の取得に失敗しました。自サーバを再起動してください。Error: Failed to read the disk space.Shut down the cluster and reboot the server.ディスク容量の取得に失敗しました。クラスタシャットダウンを実行し、サーバを再起動してください。Error: Failed to acquire the disk space of the other server.Shut down the cluster and reboot both servers.相手サーバのディスク容量の取得に失敗しました。クラスタシャットダウンを実行し、サーバを再起動してください。Error: Setting of cluster partition failed.Restart local server.クラスタパーティションの設定に失敗しました。自サーバを再起動してください。Error: Error occurred on the settings of the mirror disk resource.Reboot the local server.ミラーディスクリソースの状態設定にエラーが発生しました。自サーバを再起動してください。Error: Failed to create a thread.Reboot the local server.スレッドの作成に失敗しました。自サーバを再起動してください。Error: Internal error. Failed to create process.Reboot the local serverプロセスの作成に失敗しました。自サーバを再起動してください。Error: Failed to acquire semaphore.Reboot the local server.セマフォ取得に失敗しました。自サーバを再起動してください。Error: A malloc error. Failed to reserve the memory space.Reboot the local server.メモリ確保に失敗しました。自サーバを再起動してください。Error: Mirror driver of the local server is not loaded.Confirm kernel version.自サーバのミラードライバがロードされていません。カーネルバージョンを確認してください。Error: Mirror recovery cannot be executed as NMP size of mirror recovery destination is smallerthan the size of where the mirror is recovered from. Change the recovery destination and try again.ミラー復帰先の NMP サイズがミラー復帰元より小さいので、ミラー復帰を実行できません。ミラー復帰方向を変更し、再度実行してください。Error: NMP size of local server is bigger, cannot active.Initial mirror configuration is not completed.Execute mirror recovery from server of smaller NMP size to that of larger one.初期ミラー構築が完了していません。NMP サイズの小さいサーバから大きいサーバへ強制ミラー復帰を実行してください。Local and remote recovery mode do not match. Reboot a server other than the master server to keepthe same contents of configuration file among servers.Note that a failover may occur at server reboot.両サーバの復帰モードに相違があります。復帰は実行しません。サーバ間で情報ファイルの内容を同一のものにするためマスタサーバ以外のサーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Failed to get remote recovery mode. Recovery will not be interrupted.Check the communication status of mirror connect.相手サーバの復帰モードが取得できません。復帰処理は中断しません。ミラーコネクトの通信状態を確認してください。Failed to get local recovery mode. Recovery will not be interrupted.Note that a failover may occur at server reboot.自サーバの復帰モードが取得できません。復帰処理は中断しません。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Local or remote mirror is forced actived.Cannot to perform this action.ミラーディスクが強制活性状態です。ミラー復帰はできませんでした。確認してください。The recovery destination of mirror disk is activated.Cannot perform this action.ミラー復帰先が活性状態です。ミラー復帰はできませんでした。確認してください。Mirror disk connection is disconnected.Cannot perform this action.ミラーディスクコネクトの通信状態が異常です。ミラー復帰はできませんでした。確認してください。Failed to get mirror disk list and failed to set all NMP sync flag.Reboot the local server.Note that a failover may occur at server reboot.ミラーディスクのリストの取得に失敗したため、すべてのミラーディスクに対する 「データ同期する」の設定はエラーとなりました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Failed to get mirror disk list and failed to set all NMP sync flag to OFF.Reboot the local server.Note that a failover may occur at server reboot.ミラーディスクのリストの取得に失敗したため、すべてのミラーディスクに対する「データ同期しない」の設定はエラーとなりました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Failed to set sync flag on both servers.Shut down a cluster and reboot server.「データ同期する」の設定は両方のサーバで失敗しました。クラスタシャットダウンと再起動を行ってください。Failed to set sync flag to OFF on both servers.Shut down a cluster and reboot server.「データ同期しない」の設定は両方のサーバで失敗しました。クラスタシャットダウンと再起動を行ってください。%1:Succeeded to set sync flag ON on %2 Failed to set sync flag ON on %3Check the communication status of mirror connect%1 の「データ同期する」の設定はサーバ %2 で成功、サーバ%3 で失敗しました。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください。%1 にはミラーリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。%1:Succeeded to set sync flag OFF on %2Failed to set sync flag OFF on %3Check the communication status of mirror connect%1 の「データ同期しない」の設定はサーバ %2 で成功、サーバ%3 で失敗しました。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください。%1 にはミラーリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。Succeeded to set sync flag on remote server and failed on local server.Note that a failover may occur at server reboot.「データ同期する」の設定は自サーバで失敗、相手サーバで成功しました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Succeeded to set sync flag to OFF on remote server and failed on local server.Note that a failover may occur at server reboot.「データ同期しない」の設定は自サーバで失敗、相手サーバで成功しました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Cannot change the settings of sync status during mirror recovery.Change the settings after mirror recovery is completed.ミラー復帰中には「データ同期」の設定の変更はできません。ミラー復帰が完了してから設定を変更してください。Mirror disk resource was not found on local server.Cannot perform this action.ミラーディスクリソースが自サーバで定義されていません。「データ同期」の設定の変更はできません。The status of the mirror disk does not satisfy the conditions to perform this action.A probable cause:1. Local mirror disk is not initialized or is already force activated.2. Local mirror disk is not RED or remote is GREEN or remote is already activated.ミラーのステータスが不正です。強制復帰はできません。The data of mirror disk in the local server may not be the latest.Do you still want to continue? (Y/N)自サーバのデータは最新ではない可能性があります。相手サーバのミラーディスクのステータスが確認できない状態です。片サーバでの強制復帰を継続しますか?Forced recovery has completed successfully.
強制ミラー復帰が正常に終了しました。
The status of mirror disk in local server is not GREEN or is already activated.Cannot perform this action.ミラーのステータスが不正です。ミラーの切り離しはできません。Failed to set an isolate flag in the local server.
ミラー切り離しのフラグを更新できませんでした。
Isolated completed successfully.
ミラーの切り離しの操作が正常に終了しました。
The status of the mirror disk does not satisfy the conditions to perform this action.A probable cause:1. Mirror disk is not initialized or is not RED.2. Mirror disk is already activated.ミラーのステータスが不正です。強制活性はできません。sync flag of %1 is successfully set to ON.
%1 が「データ同期する」に設定されました。%1 にはミラーディスクリソース名が入ります。Failed to set sync flag of %1 on both servers.Shut down the cluster and reboot server.両方のサーバでデータ同期フラグの設定に失敗しました。%1 にはミラーディスクリソース名が入ります。%3:Succeeded to set sync flag ON on %1Failed to set sync flag ON on %2Check the communication status of mirror connect.片方のサーバでデータ同期フラグの設定に失敗しました。ミラーディスクコネクトが正常に通信できるか確認してください。%1 には設定に成功したサーバ名が入ります。%2 には設定に失敗したサーバ名が入ります。%3 にはミラーディスクリソース名が入ります。%1:Cannot change the settings of sync status during mirror recovery.Change the settings after mirror recovery is completed.ミラー復帰中なので、データ同期フラグの変更ができません。復帰完了した後、再度実行してください。%1 にはミラーディスクリソース名が入ります。sync flag of %1 is successfully set to OFF.
%1 が「データ同期しない」に設定されました。%1 にはミラーディスクリソース名が入ります。%3:Succeeded to set sync flag OFF on %1Failed to set sync flag OFF on %2Check the communication status of mirror connect.片方のサーバでデータ同期フラグの設定に失敗しました。ミラーディスクコネクトが正常に通信できるか確認してください。%1 には設定に成功したサーバ名が入ります。%2 には設定に失敗したサーバ名が入ります。%3 にはミラーディスクリソース名が入ります。The specified mirror disk is not defined on this server.
指定されたミラーディスクが自サーバで定義されていません。
Failed to acquire the path of mirror device.Check if the Mirror Agent is operating normally.Reboot the local server.ミラーデバイスのデバイス名の取得に失敗しました。ミラーエージェントが動作しているかを確認してください。The disk alias does not match the command.
指定されたリソース名のリソースタイプが不正です。ミラーディスクリソースに対しては clpmdctrl コマンドを使ってください。ハイブリッドディスクリソースに対しては clphdctrl コマンドを使ってください。Invalid command name.
コマンド名が無効です。clpmdctrl コマンドのファイル名を変更しないでください。
Failed to get host name.
サーバ名の取得に失敗しました。
<%1>: mirror broken
%1 のステータスが不正です。ミラーディスクがミラーブレイク状態か、ミラー構築が途中で失敗しました。%1 にはミラーディスクリソース名が入ります。<%1>: recovery timeout
%1 のミラー復帰がタイムアウトしました。タイムアウト時間の指定が妥当か、または、高負荷等によりディスク I/O や通信の遅延が発生していないか確認してください。%1 にはミラーディスクリソース名が入ります。Cannot perform this action.(Device: %1).Check if the Cluster Partition or Data Partition is OK.操作しようとしたミラーディスクリソースは、クラスタパーティションまたはデータパーティションに異常があり、稼働していません。そのため操作を行えませんでした。<%1> : Succeeded to set compress flag ON.
リソース %1 のミラー転送データの圧縮をONに設定しました。%1 にはミラーディスクリソース名が入ります。<%1> : Succeeded to set compress flag OFF.
リソース %1 のミラー転送データの圧縮をOFF に設定しました。%1 にはミラーディスクリソース名が入ります。<%1> : Failed to set compress flag ON.
リソース %1 のミラー転送データの圧縮のON 設定に失敗しました。%1 にはミラーディスクリソース名が入ります。<%1> : Failed to set compress flag OFF.
リソース %1 のミラー転送データの圧縮のOFF 設定に失敗しました。%1 にはミラーディスクリソース名が入ります。<%1> : Failed to set compress flag ON on %2.
サーバ %2 で、リソース %1 のミラー転送データの圧縮を ON にできませんでした。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください。%1 にはミラーディスクリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。<%1> : Failed to set compress flag OFF on %2.
サーバ %2 で、リソース %1 のミラー転送データの圧縮を OFF にできませんでした。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください。%1 にはミラーディスクリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。<%1>: Succeeded to switch mirror disk connection.Now using mdc <priority:%2>.リソース %1 の優先順位 %2 のミラーディスクコネクトへ切り換えました。%1 にはミラーディスクリソース名が入ります。%2 には新たに使用するミラーディスクコネクトについての優先順位の番号が入ります。Error: There is no need to switch mirror disk connection.
指定されたミラーディスクコネクトを既に現在使用しており、切り換える必要がないため、切り換えませんでした。
Error: Failed to switch mirror disk connection.The specified mirror disk connection is ERROR.指定されたミラーディスクコネクトは ERRORの状態であるため、切り換えませんでした。
Error: Failed to switch mirror disk connection.The other mirror disk connections are ERROR.他のミラーディスクコネクトが全て ERROR の状態であるため、切り換えませんでした。Error: Failed to switch mirror disk connection.
ミラーディスクコネクトの切り換えに失敗しました。
Error: Specified mdc priority does not exist.
指定された優先順位のミラーディスクコネクトは、存在しません。構成情報に定義されていません。<%1>: Succeeded to resize data partition. <new size:%2>.
リソース %1 のデータパーティションサイズの拡張に成功しました。%1 にはミラーディスクリソース名が入ります。%2 には拡張後のデータパーティションサイズがバイト単位で入ります。Error: Failed to resize data partition.
データパーティションサイズの拡張に失敗しました。データパーティションがLVMで構成されているか確認してください。ボリュームグループの未使用PE量が十分であることを確認してください。Error: NMP sizes of both servers are different. Cannot perform this action.
ミラーディスクリソースのデータサイズ情報が両サーバで異なるため、ミラー復帰ができません。ミラー拡張手順の実行途中でのミラー復帰ではないか、確認してください。Error: The status of mirror disk resource is abnormal.
ミラーディスクリソースの状態が正常ではないため、処理が実行できません。
<%1>: Updated the encryption key successfully.%2: %3%2: %3リソース %1 の暗号化鍵の更新に成功しました。%1 にはミラーディスクリソース名が入ります。%2 にはサーバ名が入ります。%3 には更新結果として、更新成功時は Success が、同一の暗号化鍵が既に使用されている場合は Same key が入ります。Error: Failed to update the encryption key.
暗号化鍵の更新に失敗しました。各サーバ上で、設定した鍵ファイルフルパスに鍵ファイルが存在するか確認してください。Error: The encryption function is disabled.
指定したミラーディスクリソースは「ミラー通信を暗号化する」機能が有効ではないため、暗号化鍵の更新はできません。
Error: The same encryption key is already used.
同一の暗号化鍵が既に使用されています。各サーバの鍵ファイルを新しいものに更新して、再度実行してください。Error: Failed to set value on shared memory.Reboot the local server.設定情報の取得に失敗しました。サーバを再起動してください。Automatic mirror recovery is disabled.Its manual resumption is required to resume mirroring.ミラーリングは中断されています。自動ミラー復帰がOFFであるため、手動でミラー復帰を行う必要があります。Failed to resume the automatic mirror recovery.Its manual resumption is required to resume mirroring.ミラーリングは中断されています。手動でミラー復帰を行う必要があります。
9.16. ミラーディスクを初期化する (clpmdinit コマンド)
ミラーディスクの初期化を行います。
- コマンドライン
- clpmdinit {--create | -c} normal [mirrordisk-alias]clpmdinit {--create | -c} quick [mirrordisk-alias]clpmdinit {--create | -c} force [mirrordisk-alias]
重要
通常、クラスタの構築や運用ではこのコマンドの実行は不要です。データ用に使用していたパーティションを初期化しますので、使用する場合には十分注意をしてください。
- 説明
ミラーディスクリソースのクラスタパーティションに対して初期化を行います。
ミラーディスクリソースのデータパーティションに対してファイルシステムを作成します(ファイルシステムにnoneを指定している場合を除く)。
- オプション
- {--create, -c} <mode>
mode
- normal
- クラスタパーティションの初期化、データパーティションのファイルシステムの作成を必要があれば実行します。 [12]必要の有無は、クラスタパーティション上にCLUSTERPRO が設定するマジックナンバーで判断します。通常、このオプションでコマンドを実行する必要はありません。
- quick
- クラスタパーティションの初期化を必要があれば実行します。必要の有無は、クラスタパーティション上にCLUSTERPRO が設定するマジックナンバーで判断します。通常、このオプションでコマンドを実行する必要はありません。
- force
- force クラスタパーティションの初期化、データパーティションのファイルシステムの作成を強制的に実行します。 [12]このオプションは CLUSTERPRO のミラーディスクとして一旦使用したディスクを再度使用する場合に使用します。
- パラメータ
- mirrordisk-alias
- ミラーディスクリソース名を指定します。指定しない場合は全てのミラーディスクリソースに対して処理を行います。
- 戻り値
0
成功
0以外
失敗
- 注意事項
- 本コマンドを実行すると、ミラーディスクが初期化されます。使用する場合には十分注意をしてください。
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドが制御を戻すまで、他のコマンドを実行しないでください。
本コマンドを実行する場合、クラスタ内の全サーバで、ミラーエージェントが停止していることを確認してください。
確認方法
# ps -e | grep clpmdagent
3node以上の構成のときにコマンドを実行するサーバがミラーディスクリソースを含むグループの起動サーバに含まれていない場合は、本コマンドはエラーになります。グループの起動サーバに含まれていない場合は本コマンドを実行しないでください。
- 実行例
例1 : ミラーディスクリソース md1 に使用するディスクが、以前CLUSTERPRO のミラーディスクとして使用していたので強制的にクラスタパーティションを初期化する場合
# clpmdinit --create force md1 mirror info will be set as default the main handle on initializing mirror disk <md1> success initializing mirror disk complete
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Stop the Mirror Agent.
ミラーエージェントを停止してください。
The clpmdinit command is currently running.Execute after it is completed.本コマンドは実行中です。完了してから実行してください。Invalid mirror-alias. Specify a valid mirror disk resource name.
正しいミラーディスクリソース名を指定してください。
The mirror disk resource was not found.Set the mirror disk resource properly.ミラーディスクリソースが見つかりませんでした。ミラーディスクリソースを正しく設定してください。Specified mirror disk resource <%1> was not found.Specify a valid mirror disk resource name.指定したミラーディスクリソースが見つかりませんでした。正しいミラーディスク リソース名を指定してください。The partition does not exist .Check if the cluster partition of specified mirror disk resource exists (<%1>).指定したミラーディスクリソースのクラスタパーティションが存在するか確認してください。
Check if the cluster partition size of specified mirror disk resource is larger than 1GB. <%1>
指定したミラーディスクリソースのクラスタパーティションのサイズが 1GB 以上であるか確認してください。
Internal error (open error <%1>).The cluster partition of the mirror disk resource may not exist or the OS resource may be insufficient.指定したミラーディスクリソースのクラスタパーティションが存在しない、または OS の リソース不足が考えられます。確認してください。Internal error (<%1> cluster partition: unknown error).Failed to initialize the cluster partition.Check if any hardware error has occurred on the disk.クラスタパーティションの初期化に失敗しました。ディスクに H/W エラーが発生していないか確認してください。確認してください。The data partition does not exist (<%1>).Check if the data partition of the specified mirror disk resource exists. Data Partition is: %2指定したミラーディスクリソースのデータパーティションが存在するか確認してください。
Failed to initialize the cluster partition <%1>.The data partition of the specified mirror disk resource may not exist,hardware error may have occurred on the disk, or specified file system may not be supported by OS.Check them. mirror<%2>: fstype<%3>データパーティションの初期化に失敗しました。指定したミラーディスクリソースのデータパーティションが存在しない、またはディスクの H/W エラー、OS がサポートしていないファイルシステムを指定した、などの原因が考えられます。確認してください。Unknown error occurred when formatting mirror-disk<%1>.The data partition of the specified mirror disk resource may not exist or hardware errormay have occurred on the disk. Check them.データパーティションの初期化に失敗しました。指定したミラーディスクリソースのデータパーティションが存在しない、またはディスクの H/W エラーが考えられます。確認してください。Internal error (Failed to open the data partition:<%1>).Failed to initialize the data partition.The data partition of the specified mirror disk resource may not exist or OS resource may not be sufficient.Data Partition is: %2データパーティションの初期化に失敗しました。指定したミラーディスクリソースのデータパーティションが存在しない、または OS のリソース不足が考えられます。確認してください。Internal error (data partition check error---<%1>).Failed to initialize the data partition.Check if any hardware error has occurred on the disk.データパーティションの初期化に失敗しました。ディスクに H/W エラーが発生していないか確認してください。Failed to acquire mirror disk list information. Reboot the local server.
ミラーディスクリストの取得に失敗しました。自サーバを再起動してください。
Internal error (PID write failed).Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
Internal error (initialization failed) Failed to read the configuration file, or failed to initialize the shared memory or semaphore.Check if the file is configured properly and reboot the local server.設定ファイルの読み込みに失敗、または共有メモリ、セマフォの初期化に失敗しました。設定ファイルが正しいことを確認して、自サーバを再起動してください。Internal error (termination failed) Failed to release the shared memory.Check if any system error has occurred while running the program.共有メモリの解放に失敗しました。プログラムの実行中にシステムの異常が発生していないか確認してください。A malloc error. Failed to reserve the memory space. Reboot the local server..メモリの確保に失敗しました。自サーバを再起動してください。An error has occurred when the data partition is set to writable mode. <Device:%1>.Reboot the local server.データパーティションを書込可能に設定するときにエラーが発生しました。自サーバを再起動してください。An error has occurred when the data partition is set to read-only mode.<Device:%1>.Reboot the local server.データパーティションをリードオンリーに設定するときにエラーが発生しました。自サーバを再起動してください。Cluster Partition or Data Partition does not exist.
クラスタパーティションまたはデータパーティションがありません。パーティションを作成していることを確認してください。Failed to upgrade the cluster partition of <%s>.
クラスタパーティションのアップグレードに失敗しました。ディスクに異常がないか確認してください。Specified mirror disk resource was not found on local server. Cannot perform this action.
ミラーディスクリソースが自サーバで定義されていません。初期化操作はできませんでした。確認してください。The disk alias does not match the command.
指定されたリソース名 (ミラーエイリアス名) のリソースタイプが不正です。md リソースには clpmdinit を使ってください。hd リソースには clphdinit を使ってください。Invalid command name.
コマンド名が無効です。clpmdinit コマンドのファイル名を変更しないでください。
Initializing mirror disk of %1 failed.Check if the Cluster Partition or Data Partition is OK.初期化しようとしたミラーディスクリソースは、クラスタパーティションまたはデータパーティションに異常があり、初期化できませんでした。
9.17. ディスクイメージバックアップの準備をする (clpbackup.sh コマンド)
ミラーリング対象パーティションを、ディスクイメージバックアップ可能な状態にします。
- コマンドライン
- clpbackup.sh --preclpbackup.sh --pre --no-shutdownclpbackup.sh --pre --only-shutdownclpbackup.sh --pre --onlineclpbackup.sh --postclpbackup.sh --post --no-rebootclpbackup.sh --post --only-rebootclpbackup.sh --post --onlineclpbackup.sh --help
- 説明
- サーバ上にあるミラー用ディスク(クラスタパーティションとデータパーティション)をディスクイメージバックアップする際には、このコマンドを実行してください。
このコマンドは、下記の流れで実行します。
clpbackup.sh --pre を実行します。これにより、ミラーがバックアップモードになります。
ディスクイメージをバックアップします。
clpbackup.sh --post を実行します。これにより、バックアップモードから通常のモードへ戻ります。
ミラー復帰の実行により、バックアップ中に生じたミラーの差分を同期します。
なお、バックアップしたディスクイメージをリストアする際には、clprestore.shコマンドを利用してください。このコマンドを使ったディスクイメージバックアップの手順については、 『メンテナンスガイド』の 「保守情報」の 「ミラー/ハイブリッドディスクをディスクイメージでバックアップするには」 を参照してください。また、--online オプション指定時の手順については、 『メンテナンスガイド』の 「保守情報」の 「業務稼働状態でミラーディスクのスナップショットバックアップを作成するには」 を参照してください。
- オプション
- --pre
- ミラーリング対象パーティションをディスクイメージのままバックアップする際に使用します。バックアップする直前にこのオプションを指定して実行してください。このオプションを指定して実行すると、そのサーバ上のすべてのクラスタパーティションとデータパーティション(ミラーリング対象パーティション)がバックアップモードになり、サーバがシャットダウンします。シャットダウン後は、サーバを起動してもCLUSTERPROサービスは自動起動しません。バックアップモードのミラーは、非最新(ステータスが赤)となり、フルコピーによるミラー復帰が必要となります。また、自動ミラー復帰がおこなわれません。
- --post
- このオプションを指定して実行すると、--preオプションで設定したバックアップモードが解除されて通常のモードに戻り、サーバが再起動します。再起動後は、CLUSTERPROサービスが自動起動します。ディスクイメージバックアップが完了した後に、このオプションを指定して実行してください。
- --no-shutdown
- このオプションを追加で指定すると、サーバのシャットダウンをおこなわずにコマンドが終了します。サーバシャットダウンする代わりに、CLUSTERPROサービスとミラーエージェントが、停止します。サーバをシャットダウンしたくない場合に、指定します。
- --no-reboot
- このオプションを追加で指定すると、サーバ再起動が省略されます。サーバ再起動する代わりに、ミラーエージェントとCLUSTERPROサービスが、起動します。サーバを再起動したくない場合や、再起動にかかる時間を節約したい場合に、指定します。
- --only-shutdown
- ハイブリッドディスクリソースがある環境で、サーバグループにサーバが複数ある場合に、使用します。サーバグループ内の1つめのサーバで clpbackup.sh --pre を実行したら、 それが完了した後に、そのサーバグループ内の残りのサーバで clpbackup.sh --pre --only-shutdown を実行してください。
- --only-reboot
- ハイブリッドディスクリソースがある環境で、サーバグループにサーバが複数ある場合に、使用します。サーバグループ内の1つめのサーバで clpbackup.sh --post を実行したら、 それが完了した後に、そのサーバグループ内の残りのサーバで clpbackup.sh --post --only-reboot を実行してください。
- --online
- このオプションは、ミラーディスクリソースが活性している状態のままでバックアップを採取する場合に指定します。clpbackup.sh --pre --online を実行した場合は、クラスタがサスペンド状態になり監視機能が一時停止します。 実行したサーバ上では、ミラーディスクへの書き込みのキャッシュがディスクへ書き出され、以降のミラーディスクへの書き込み要求は一時停止状態になります。 また、そのサーバ上のすべてのクラスタパーティションとデータパーティションがバックアップモードになります。 CLUSTERPROサービスの自動起動と、フェイルオーバグループの自動起動は、オフになります。clpbackup.sh --post --online を実行した場合は、バックアップモードが解除されて通常のモードに戻ります。 ミラーディスクへの書き込み一時停止状態は解除され、書き込みが再開されます。 CLUSTERPROサービスの自動起動と、フェイルオーバグループの自動起動は、オンに戻ります。 サスペンド状態だったクラスタは通常状態に戻り監視が再開します。このオプションを指定すると、ミラーディスクに対して、fsfreeze コマンドが実行されます。 そのため、全てのミラーディスクのファイルシステムが、fsfreeze コマンドがサポートするファイルシステムである必要があります。
- --help
Usageを表示します。
- 戻り値
0
成功
1
失敗
- 備考
- バックアップモードでは、ミラーは非最新(ステータスが赤)となり、自動ミラー復帰は行われず、ミラー復帰をおこなうと差分コピーではなくフルコピーとなります。
- 本コマンドは、ファイル単位でのバックアップ/リストアではなく、ディスクイメージでのバックアップ/リストアが対象です。活性状態のミラーディスクやハイブリッドディスクからファイルをバックアップする手順や、待機系のミラーディスクやハイブリッドディスクをアクセス制限解除してファイルをバックアップする手順は、本コマンドを使う手順とは別の手順となります。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドを実行すると、そのサーバ上のすべてのミラーディスクリソースとハイブリッドディスクリソースが、処理の対象になります。
バックアップ/リストアをおこなう際は、クラスタパーティションとデータパーティションの両方を、バックアップ/リストアしてください。
このコマンドを実行すると、サーバがシャットダウンまたは再起動する場合があります。
X 4.3よりも前の CLUSTERPRO がインストールされたサーバが含まれるクラスタ環境では、この機能はサポートされません。
- エラーメッセージ
メッセージ
原因/対処法
Invalid option.
正しいオプションを指定してください。
Log in as root.
root 権限を持つユーザで実行してください。
Internal error.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Log directory is not found.
正しくインストールされていないか、実行権限がない可能性があります。
Command failed.
このコマンドが失敗しました。このエラーメッセージの直前に表示されたエラーメッセージを確認してください。
- 実行例
例1: バックアップ実施前にバックアップモードにする場合
# clpbackup.sh --pre clpbackup.sh : Beginning backup-mode. All backup flags have set to <ON>. clpbackup.sh : Changing the setting of cluster services to Manual Startup. clpbackup.sh : Shutting down... Command succeeded. clpbackup.sh : Command succeeded.
例2: バックアップ完了後に元のモードに戻す場合
# clpbackup.sh --post clpbackup.sh : Starting Mirror Agent. Command succeeded. clpbackup.sh : Ending backup-mode. All backup flags have set to <OFF>. clpbackup.sh : Changing the setting of cluster services to Auto Startup. clpbackup.sh : Stopping Mirror Agent. Command succeeded. clpbackup.sh : Rebooting... Reboot server1 : Command succeeded. clpbackup.sh : Command succeeded.
9.18. ディスクイメージリストア後の処理をする (clprestore.sh コマンド)
リストアしたミラーディスクイメージを、利用可能な状態にします。
- コマンドライン
- clprestore.sh --preclprestore.sh --pre --no-shutdownclprestore.sh --pre --only-shutdownclprestore.sh --postclprestore.sh --post --no-rebootclprestore.sh --post --only-rebootclprestore.sh --post --skip-copyclprestore.sh --post --skip-copy --no-rebootclprestore.sh --post --onlineclprestore.sh --post --online --skip-copyclprestore.sh --help
- 説明
- クラスタパーティションおよびデータパーティションのディスクイメージをリストアする際には、このコマンドを実行してください。
このコマンドは、下記の流れで実行します。
clprestore.sh --pre を実行します。これにより、CLUSTERPROサービスの自動起動がオフになり、サーバがシャットダウンします。
ディスクイメージをリストアします。
クラスタパーティションおよびデータパーティションのパスを確認します。パスが変わっている場合は、対応するミラーディスクリソース/ハイブリッドディスクリソースの設定を、Cluster WebUI で変更します。
clprestore.sh --post を実行します。これにより、CLUSTERPROサービスの自動起動がオンになり、サーバが再起動します。
サーバ再起動後、Cluster WebUIまたはコマンドで、ミラー復帰を実行します。フルコピーがおこなわれてミラーが同期状態になります。(--skip-copy指定の場合はフルコピーは不要です。)
なお、ディスクイメージをバックアップする際には、clpbackup.shコマンドを実行してください。また、--online オプション指定時の手順については、 『メンテナンスガイド』の 「保守情報」の 「業務稼働状態で作成したミラーディスクのスナップショットからリストアするには」 を参照してください。
- オプション
- --pre
- このオプションを指定して実行すると、CLUSTERPROサービスの自動起動がオフになり、サーバがシャットダウンします。従って、次回サーバ起動時には CLUSTERPROサービスは自動起動しません。ディスクイメージをリストアする前に、サーバをシャットダウンする時に、実行してください。サーバが起動しない場合や、システムディスクを含めてリストアする場合には、リストア前に本コマンドを実行する必要はありません。
- --post
- このオプションを指定して実行すると、CLUSTERPROサービスの自動起動がオンになり、サーバが再起動します。ディスクイメージをリストアした後に、実行してください。
- --skip-copy
- このオプションは、--postオプションと一緒に指定します。このオプションは、現用系側と待機系側の両方に同一のディスクイメージをリストアした場合にのみ、指定可能です。ミラー復帰時のフルコピーが不要となります。このオプションを指定して実行する場合には、あらかじめミラーディスクリソースやハイブリッドディスクリソースの [初期ミラー構築を行う] をオフに設定しておく必要があります。
- --no-shutdown
- このオプションを追加で指定すると、サーバのシャットダウンをおこなわずにコマンドが終了します。サーバシャットダウンする代わりに、CLUSTERPROサービスとミラーエージェントが、停止します。サーバをシャットダウンしたくない場合に、指定します。
- --no-reboot
- このオプションを追加で指定すると、サーバ再起動が省略されます。サーバ再起動する代わりに、ミラーエージェントとCLUSTERPROサービスが、起動します。サーバを再起動したくない場合や、再起動にかかる時間を節約したい場合に、指定します。
- --only-shutdown
- ハイブリッドディスクリソースがあるで、サーバグループにサーバが複数ある場合に、使用します。サーバグループ内の1つめのサーバで clprestore.sh --pre を実行したら、 それが完了した後に、そのサーバグループ内の残りのサーバで clprestore.sh --pre --only-shutdown を実行してください。このオプションは、省略可能です。
- --only-reboot
- ハイブリッドディスクリソースがあるで、サーバグループにサーバが複数ある場合に、使用します。サーバグループ内の1つめのサーバで clprestore.sh --post または clprestore.sh --post --skip-copy を実行したら、 それが完了した後に、そのサーバグループ内の残りのサーバで clprestore.sh --post --only-reboot を実行してください。このオプションは、省略可能です。
- --online
- このオプションは、clpbackup.sh --pre --online を実行してバックアップしたミラーディスクを、リストアした際に指定します。CLUSTERPROサービスの自動起動と、フェイルオーバグループの自動起動が、オンに戻ります。
- --help
Usageを表示します。
- 戻り値
0
成功
1
失敗
- 備考
- 本コマンドは、ファイル単位でのバックアップ/リストアではなく、ディスクイメージでのバックアップ/リストアが対象です。活性状態のミラーディスクやハイブリッドディスクからファイルをバックアップする手順や、待機系のミラーディスクやハイブリッドディスクをアクセス制限解除してファイルをバックアップする手順は、本コマンドを使う手順とは別の手順となります。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドを実行すると、そのサーバ上のすべてのミラーディスクリソースとハイブリッドディスクリソースが、処理の対象になります。
バックアップ/リストアをおこなう際は、クラスタパーティションとデータパーティションの両方を、バックアップ/リストアしてください。
このコマンドを実行すると、サーバがシャットダウンまたは再起動する場合があります。
X 4.3よりも前の CLUSTERPRO がインストールされたサーバが含まれるクラスタ環境では、この機能はサポートされません。
- エラーメッセージ
メッセージ
原因/対処法
Invalid option.
正しいオプションを指定してください。
Log in as root.
root 権限を持つユーザで実行してください。
Internal error.
メモリ不足または、OS のリソース不足が考えられます。確認してください。
Set "Initial Mirror Construction" parameter and "Initial mkfs" parameter of md/hd resource to off by using Cluster WebUI.
--skip-copyオプション指定時には、md/hdリソースの [初期ミラー構築を行う] をオフに設定する必要があります。コマンド実行前に、Cluster WebUIの設定モードで、設定を一旦オフに変更してください。Log directory is not found.
正しくインストールされていないか、実行権限がない可能性があります。
Command failed.
このコマンドが失敗しました。このエラーメッセージの直前に表示されたエラーメッセージを確認してください。
- 実行例
例1: リストア実施前にシャットダウンする場合
# clprestore.sh --pre clprestore.sh : Changing the setting of cluster services to Manual Startup. clprestore.sh : Shutting down... Command succeeded. clprestore.sh : Command succeeded.
例2: リストア後、クラスタを起動する場合
# clprestore.sh --post clprestore.sh : Changing the setting of cluster services to Auto Startup. clprestore.sh : Rebooting... Reboot server1 : Command succeeded. clprestore.sh : Command succeeded.
例3: 同一イメージを両サーバへ同時にリストア後、クラスタを起動する場合(※)
# clprestore.sh --post --skip-copy Mirror info will be set as default. The main handle on initializing mirror disk <md1> success. Initializing mirror disk complete. clprestore.sh : Changing the setting of cluster services to Auto Startup. clprestore.sh : Rebooting... Reboot server1 : Command succeeded. clprestore.sh : Command succeeded.
(※途中でミラーディスク初期化のメッセージが出ますが、データパーティションは初期化されません。)
9.19. ハイブリッドディスク状態を表示する (clphdstat コマンド)
ハイブリッドディスクに関する状態と、設定情報を表示します。
- コマンドライン
- clphdstat {--connect | -c} hybriddisk-aliasclphdstat {--mirror | -m} hybriddisk-aliasclphdstat {--active | -a} hybriddisk-aliasclphdstat {--detail | -d} hybriddisk-aliasclphdstat {--list | -l}clphdstat {--perf | -p} [interval [count]] hybriddisk-alias
- 説明
ハイブリッドディスクのミラーリング状況に関する各種状態を 表示します。
ハイブリッドディスクリソースの設定情報を表示します。
- オプション
- --connect, -c
ミラーディスクコネクトの状態を表示します。
- --mirror, -m
ハイブリッドディスクリソースの状態を表示します。
- --active, -a
ハイブリッドディスクリソースの活性状態を表示します。
- --detail, -d
ハイブリッドディスクリソースの設定情報を表示します。
- --list, -l
ハイブリッドディスクリソースの一覧を表示します。
- --perf
ハイブリッドディスクリソースの統計情報を表示します。
- パラメータ
- hybriddisk-alias
ハイブリッドディスクのリソース名を指定します。
- interval
- 統計情報をサンプリングする時間間隔を指定します。何も指定されない場合にはデフォルトとして60秒が指定されます。1から9999までの値が指定可能です。
- count
- 統計情報を表示する回数を指定します。interval値とともに使用します。1から9999までの値が指定可能です。interval値を指定し、count値を省略した場合には無限に表示します。表示を停止する場合には[Ctrl] + [C]で停止してください。interval値、count値ともに省略した場合にはinterval値60、count値1が指定されたものとして動作します。
- 戻り値
--mirror, -m
戻り値
区分
コマンド実行サーバグループ(自サーバグループ)のハイブリッドディスクの状態 [13]他サーバグループのハイブリッドディスクの状態 [13]
0
成功
BLACK
BLACK
1
BLACK
GREEN
3
BLACK
ORANGE
4
BLACK
RED
5
BLACK
BLUE
6
BLACK
GRAY
16
GREEN
BLACK
17
GREEN
GREEN
19
GREEN
ORANGE
20
GREEN
RED
21
GREEN
BLUE
22
GREEN
GRAY
34
YELLOW
YELLOW
48
ORANGE
BLACK
49
ORANGE
GREEN
51
ORANGE
ORANGE
52
ORANGE
RED
53
ORANGE
BLUE
54
ORANGE
GRAY
64
RED
BLACK
65
RED
GREEN
67
RED
ORANGE
68
RED
RED
69
RED
BLUE
70
RED
GRAY
80
BLUE
BLACK
81
BLUE
GREEN
83
BLUE
ORANGE
84
BLUE
RED
85
BLUE
BLUE
86
BLUE
GRAY
96
GRAY
BLACK
97
GRAY
GREEN
99
GRAY
ORANGE
100
GRAY
RED
101
GRAY
BLUE
102
GRAY
GRAY
上記以外
失敗
-
-
--active, -a
戻り値
区分
コマンド実行サーバグループ(自サーバグループ)のハイブリッドディスクリソースの活性状態 [14]他サーバグループのハイブリッドディスクリソースの活性状態 [14]
17
成功
Inactive
Inactive
18
Inactive
Active(活性)
19
Inactive
Active(アクセス制限解除状態)
20
Inactive
停止中、通信エラー
33
Active(活性)
Inactive
34
Active(活性)
Active(活性)
35
Active(活性)
Active(アクセス制限解除状態)
36
Active(活性)
停止中、通信エラー
49
Active(アクセス制限解除状態)
Inactive
50
Active(アクセス制限解除状態)
Active(活性)
51
Active(アクセス制限解除状態)
Active(アクセス制限解除状態)
52
Active(アクセス制限解除状態)
停止中、通信エラー
65
停止中、通信エラー
Inactive
66
停止中、通信エラー
Active(活性)
67
停止中、通信エラー
Active(アクセス制限解除状態)
上記以外
失敗
-
-
上記以外の戻り値は、「ミラー状態を表示する (clpmdstat コマンド)」の「戻り値」を参照してください。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドは、サーバグループ内にカレントサーバがない場合、サーバグループ内でミラーエージェントが正常に稼働しているサーバがカレントサーバになります。
サーバグループのプロパティのサーバのプライオリティで最も高プライオリティのサーバが選択されます。
- 表示例
表示例は次のトピックで説明します。
- エラーメッセージ
メッセージ
原因/対処法
Error: Log in as root.
root 権限を持つユーザで実行してください。
Error: Failed to read the configuration file.Check if it exists or is configured properly.設定ファイルの読み込みに失敗しました。設定ファイルが存在するか、正しく設定されているか確認してください。Error: Failed to acquire hybrid disk resource name.Check if the Mirror Agent is operating normally.ハイブリッドディスクリソース名の取得に失敗しました。ミラーエージェントが正常に動作しているか確認してください。Error: Specified hybrid disk resource was not found.Specify a valid hybrid disk resource name.指定したハイブリッドディスクリソースが見つかりませんでした。正しいハイブリッドディスクリソース名を指定してください。Error: Invalid hybrid-alias.Specify a valid hybrid disk resource name.正しいハイブリッドディスクリソース名を指定してください。
Error: Failed to get the server name.Check if the configuration file is correct and the Mirror Agent is operating normally.サーバ名の取得に失敗しました。設定ファイルが正しいか、ミラーエージェントが正常に動作しているか確認してください。Error: Failed to communicate with other servers.Check if the Mirror Agent of the other server is operating normally相手サーバとの通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。Error: Failed to get the hybrid disk status.Check if the Mirror Agent on the local server is operating normally.ハイブリッドディスク状態の取得に失敗しました。自サーバのミラーエージェントが正常に動作しているか確認してください。Error: Failed to acquire the mirror index.Check if the Mirror Agent is operating normally.ミラーエージェントが正常に動作しているか確認してください。
Error: mirror agent is not running Check if the Mirror Agent is active.ミラーエージェントが起動していません。モジュールタイプ mdagent の syslog またはアラートメッセージを確認して対処してください。Error: Failed to acquire the active status of the Mirror Agent of the local server.Shut down the cluster and reboot both servers.自サーバのミラーディスクリソース活性状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: Failed to acquire the active status of the Mirror Agent of the other server.Shut down the cluster and reboot both servers.相手サーバのミラーディスクリソース活性状態取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: Failed to acquire mirror recovery status.Reboot the local server.ミラー復帰状態の取得に失敗しました。自サーバを再起動してください。Error: Failed to acquire the list of hybrid disks.Reboot the local server.ハイブリッドディスクリストの取得に失敗しました。自サーバを再起動してください。Error: Failed to acquire the mirror configuration information.Check if the Mirror Agent is operating normally.ミラー設定情報の取得に失敗しました。ミラーエージェントが正常に動作しているか確認してください。Error: Failed to acquire the hybrid disk configuration information of both servers.Shut down the cluster and reboot both servers両サーバのハイブリッドディスク設定情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: The number of the bits of the bitmap is invalid.The mirror difference information of the cluster partition is invalid.Shut down the cluster. If it fails again, replace the disk.For procedure to replace the disk, see the Reference Guide.クラスタパーティションにおけるミラー差分情報の取得に失敗しました。クラスタシャットダウンを実行してください。再度このエラーが発生するようであれば、ディスクを交換してください。Error: Failed to get bitmap information.Failed to acquire the mirror difference information of the local server.Reboot the local server.クラスタパーティションにおけるミラー差分情報が不正です。クラスタシャットダウンを実行してください。再度このエラーが発生するようであれば、ディスクを交換してください。Error: Failed to get bitmap information.Failed to acquire the mirror difference information of the local server.Reboot the local server.自サーバのミラー差分情報の取得に失敗しました。自サーバを再起動してください。Error: Failed to read the mirror difference information of the local server.Reboot the local server.自サーバのミラー差分情報の読取に失敗しました。自サーバを再起動してください。Error: Failed to acquire semaphore.Reboot the local server.セマフォ取得に失敗しました。自サーバを再起動してください。Error: A malloc error. Failed to reserve the memory space.Reboot the local server.メモリ確保に失敗しました。自サーバを再起動してください。Error: Mirror driver of the local server is not loaded.Refer to the Reference Guide to load the driver.自サーバのミラードライバがロードされていません。本ガイドの「10. トラブルシューティング」を参照して確認してください。Error: Internal error (errorcode: 0xxxx).Shut down the cluster and reboot the server.クラスタシャットダウンを実行し、サーバを再起動してください。
Error: Failed to communicate with server %1 and %2.Check if both Mirror Agents of the two servers are operating normally and the interconnect LANs are connected.表示されている両サーバとの通信に失敗しました。両サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入ります。Error: Failed to communicate with server %1.Check if Mirror Agent of the server is operating normally and the interconnect LAN is connected.Failed to acquire the hybrid disk detail information of the server %2.Shut down the cluster and reboot both servers.サーバ %1 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。サーバ %2 のハイブリッドディスクの詳細情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。Error:Failed to acquire the hybrid disk detail information of the server %1.Shut down the cluster and reboot both servers.Failed to communicate with server %2.Check if Mirror Agent of the server is operating normally and the interconnect LAN is connected.サーバ %1 のハイブリッドディスク詳細情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。サーバ %2 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入ります。Error:Failed to acquire the hybrid disk detail information of the server %1 and server %2.Shut down the cluster and reboot both servers."両サーバのハイブリッドディスクの詳細情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。Error:Failed to communicate with server %1 .Check if Mirror Agent of the server is operating normally and the interconnect LAN is connected.Failed to acquire hybrid disk %3 net interface status of the server %2.Shut down the cluster and reboot both servers.サーバ %1 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。サーバ %2 のミラーディスクリソース %3 のミラーディスクコネクト状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはハイブリッドディスクリソース名が入ります。Error:Failed to acquire hybrid disk %3 net interface status of the server %1.Shut down the cluster and reboot both servers.Failed to communicate with server %2 .Check if Mirror Agent of the server is operating normally and the interconnect LAN is connected.サーバ %1 のハイブリッドディスクリソース %3 のミラーディスクコネクト状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。サーバ %2 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入ります。%3 にはハイブリッドディスクリソース名が入ります。Error:Failed to acquire hybrid disk %3 net interface status of the server %1 and server %2.Shut down the cluster and reboot both servers.両サーバのハイブリッドディスクコネクト状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはハイブリッドディスクリソース名が入ります。Error:Failed to communicate with server %1 .Check if Mirror Agent of the server is operating normally and the interconnect LAN is connected.Failed to acquire the active status of the Hybrid disk %3 of the server %2.Shut down the cluster and reboot both servers.サーバ %1 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。サーバ %2 のハイブリッドディスクリソース %3 の活性状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはハイブリッドディスクリソース名が入ります。Error:Failed to acquire the active status of the Hybrid disk %3 of the server %1.Shut down the cluster and reboot both servers.Failed to communicate with server %2 .Check if Mirror Agent of the server is operating normally and the interconnect LAN is connected.サーバ %1 の指定したハイブリッドディスクリソース %3 の活性状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。サーバ %2 との通信に失敗しました。相手サーバのミラーエージェントが動作しているか、インタコネクトが接続されているか確認してください。%1,%2 にはサーバ名が入ります。%3 にはハイブリッドディスクリソース名が入ります。Error:Failed to acquire the active status of the Hybrid disk %3 of the server %1 and server %2.Shut down the cluster and reboot both servers.両サーバのハイブリッドディスクリソースの状態の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。%1,%2 にはサーバ名が入ります。%3 にはハイブリッドディスクリソース名が入ります。Error:Failed to get all server names.Check if the configuration file is correct and the Mirror Agent is operating normally.サーバ名の取得に失敗しました。クラスタ構成情報のファイルが正しいか、ミラーエージェントが正常に動作しているか確認してください。The disk alias does not match the command.
指定されたリソース名 (ミラーエイリアス名) のリソースタイプが不正です。md リソースには clpmdstat を使ってください。hd リソースには clphdstat を使ってください。This server is not current server. Cannot perform this action.カレントサーバでないため、コマンドは実行できません。
Hybrid disk internal error.
内部エラーが発生しました。
The function of collecting statistics is disabled.
統計情報採取機能が有効ではありません。Cluster WebUI で [クラスタのプロパティ] の [統計情報] タブにある [ミラー統計情報] の設定を確認してください。Collecting mirror statistics failed.Please retry in a few seconds later.一時的な高負荷等により、統計情報の採取に失敗しました。時間をおいて再度実行してください。再度表示される場合にはミラーエージェントが正常に動作しているか確認してください。
9.19.1. 表示例
ミラーディスクコネクトの状態表示
--connect オプションを指定した場合、ハイブリッドディスクが使用するミラーディスクコネクトの状態を表示します。
Hybrid Disk Name : hd1 [Server : server1] 192.168.0.1 : Using [Server : server2] 192.168.0.2 : Using
各項目の説明
項目名
説明
Hybrid Disk Name
ハイブリッドディスクリソース名
Server Name
サーバ名
IP Address
ミラーディスクコネクトに指定された IP アドレス
Status
ミラーディスクコネクトの状態
状態 説明 --------------------- Using 使用中 Free 未使用 Error 異常 -- 状態不明
ハイブリッドディスクリソースの状態表示
--mirror オプションを指定した場合、指定したハイブリッドディスクリソースの状態を表示します。
ハイブリッドディスクリソースの状態が正常の場合
Mirror Status: Normal hd1 server1 server2 ------------------------------------------------------------------ Mirror Color GREEN GREEN
各項目の説明
項目名
説明
Mirror Status
ハイブリッドディスクリソースの状態
状態 説明 ---------------------------------- Normal 正常 Recovering ミラー復帰中 Abnormal 異常 No Construction 初期ミラー構築 されていない状態
Mirror Color
各サーバのハイブリッドディスクの状態
状態 説明 ---------------------------------------------- GREEN 正常 YELLOW ミラー復帰中 ORANGE 保留 (どちらのサーバが最新データを保持 しているか決められない状態) RED 異常 BLUE 両系活性 GRAY 停止中、状態不明 BLACK クラスタパーティション未初期化、 クラスタパーティションデータ異常などハイブリッドディスクリソースの状態が異常の場合
Mirror Status: Abnormal hd1 server1 server2 ------------------------------------------------------------ Mirror Color GREEN RED Lastupdate Time 2018/03/24 15:41:07 -- Break Time 2018/03/24 15:40:38 -- Disk Error OK OK Difference Percent 1% --
各項目の説明
項目名
説明
Mirror Status
ハイブリッドディスクリソースの状態 [15]
Mirror Color
各サーバのハイブリッドディスクの状態 [15]
Lastupdate Time
サーバ上でデータが最後に更新された時刻
ハイブリッドディスクの状態が保留の場合には表示されません
Break Time
ミラーブレイクが発生した時刻
ハイブリッドディスクの状態が保留の場合には表示されません
Disk Error
Disk I/O の状態
状態 説明 ---------------------- OK 正常 Error 異常 (I/O不可) -- 状態不明
ハイブリッドディスクの状態が保留の場合には表示されません
Difference Percent
各サーバ上の差分データのパーセンテージ括弧表記の場合は、差分データ量計算処理中の未確定値。ハイブリッドディスクの状態が保留の場合には表示されませんミラー復帰中の場合
Mirror Status: Recovering hd1 server1 server2 ------------------------------------------------------------ Mirror Color YELLOW YELLOW Recovery Status Value ---------------------------------------- Status: Recovering Direction: src server1 dst server2 Percent: 3% Used Time: 00:00:01 Remain Time: 00:00:32 Iteration Times: 1/1
各項目の説明
「ミラー状態を表示する (clpmdstat コマンド)」の「各項目の説明」を参照してください。
ハイブリッドディスクリソースの活性状態表示
--active オプションを指定した場合、指定したハイブリッドディスクリソースの活性状態を表示します。
hd1 server1 server2 ---------------------------------------------------------------- Active Status Active Inactive
各項目の説明
「ミラー状態を表示する (clpmdstat コマンド)」の「各項目の説明」を参照してください。
ハイブリッドディスクリソース情報表示
--detail オプションを指定した場合、指定したハイブリッドディスクリソースの設定情報を表示します。
Hybrid Disk Name : hd1 Sync Switch : On Sync Mode : Sync Diff Recovery : Disable Compress : Sync Data : Off Recovery Data : Off [Server : server1] NMP/Disk Size(MB) : 2447/2447 DP Device : /dev/disk/by-id/scsi-222850001557d9443-part2 CP Device : /dev/disk/by-id/scsi-222850001557d9443-part1 [Server : server2] NMP/Disk Size(MB) : 2447/2447 DP Device : /dev/disk/by-id/scsi-2222400015526436d-part2 CP Device : /dev/disk/by-id/scsi-2222400015526436d-part1
各項目の説明
項目名
説明
Hybrid Disk Name
ハイブリッドディスクリソース名
Sync Switch
データを同期する
Sync Mode
同期モード
Diff Recovery
差分復帰の可否
Server Name
カレントサーバ名
NMP/Disk Size(MB)
NMP:両サーバのデータパーティションサイズのうち小さい方のサイズDisk Size:実際のデータパーティションサイズDP Device
データパーティションデバイス名
CP Device
クラスタパーティションデバイス名
ハイブリッドディスクリソース一覧表示
--list オプションを指定した場合、ハイブリッドディスクリソースの一覧を表示します。
[HybridDisk Option] server1 : Installed server2 : Installed server3 : Installed [Servers Which Can Be Started] <hd1> [ServerGroup0 : server_group1] *server1 server2 [ServerGroup1 : server_group2] *server3 <hd2> [ServerGroup0 : server_group1] server1 *server2 [ServerGroup1 : server_group2] *server3
各項目の説明
項目名
説明
HybridDisk Option
Replicator DR のライセンス登録状態
Servers Which Can Be Started
ハイブリッドディスクリソースのサーバグループと起動可能なサーバ
*
各サーバグループ内のカレントサーバ
統計情報表示
「ミラー状態を表示する (clpmdstat コマンド)」の「統計情報表示」を参照してください。
9.20. ハイブリッドディスクリソースを操作する (clphdctrl コマンド)
ハイブリッドディスクリソースを操作します。
- コマンドライン
- clphdctrl {--active | -a} hybriddisk-aliasclphdctrl {--active | -a} -nomount hybriddisk-aliasclphdctrl {--active | -a} -force [-ro] hybriddisk-aliasclphdctrl {--active | -a} -force -nomount hybriddisk-aliasclphdctrl {--deactive | -d} hybriddisk-aliasclphdctrl {--break | -b} hybriddisk-aliasclphdctrl {--force | -f} [-v] recovery-source-servername hybriddisk-aliasclphdctrl {--force | -f} hybriddisk-aliasclphdctrl {--recovery | -r} hybriddisk-aliasclphdctrl {--cancel | -c} hybriddisk-aliasclphdctrl {--rwait | -w} [-timeout time [-rcancel]] hybriddisk-aliasclphdctrl --getreqclphdctrl --setreq request-countclphdctrl --sync [hybriddisk-alias]clphdctrl --nosync [hybriddisk-alias]clphdctrl --setcur hybriddisk-aliasclphdctrl {--compress | -p} [hybriddisk-alias]clphdctrl {--nocompress | -n} [hybriddisk-alias]clphdctrl {--mdcswitch | -s} [mdc-priority] hybriddisk-aliasclphdctrl {--resize | -z} [-force] partition-size hybriddisk-aliasclphdctrl --updatekey hybriddisk-alias
重要
--activeでアクセス制限解除を実行した場合は、必ず--deactiveでアクセス制限を元に戻してください。また、活性状態のリソースに対して--deactiveを実行しないでください。そのままの状態でリソースの起動や停止が発生すると、ファイルシステムが壊れる可能性があります。注釈
--resize オプションを使用してハイブリッドディスクリソースのデータパーティション拡張を実行する場合は、『メンテナンスガイド』の「保守情報」の「ハイブリッドディスクリソースのパーティションのオフセットやサイズを変更する」に記載の手順に従って、両サーバの拡張を順次実施する必要があります。
注釈
--resize オプションを使用してハイブリッドディスクリソースのデータパーティション拡張を実行する場合は、データパーティションがLVMで構成されており、かつボリュームグループの未使用PE(Physical Extent)量が十分であることが必要です。
注釈
--updatekeyオプションを使用して暗号化鍵を更新する場合、『メンテナンスガイド』の「保守情報」の「ミラーディスクリソース/ハイブリッドディスクリソースの暗号鍵を更新する」に記載の手順に従ってください。
- 説明
ハイブリッドディスクリソースのアクセス制限解除(強制活性)、アクセス制限を行います。
ハイブリッドディスクの切り離し(ミラー同期の中断)を行います。
ミラー復帰、 強制ミラー復帰、ミラー復帰のキャンセル、ミラー復帰の完了待ちを行います。
リクエストキュー最大数の設定表示/変更を行います。
ミラーデータの同期の有無を切り換えます。
ハイブリッドディスクリソースのカレント権を取得します。
ミラーデータの圧縮有無を切り換えます。
使用する通信経路(ミラーディスクコネクト)を切り換えます。
データパーティションサイズを拡張します。
暗号化鍵を更新します。
- オプション
- --active, -a
- 自サーバでハイブリッドディスクリソースをアクセス制限解除します。ハイブリッドディスクリソースの状態が正常な場合はミラーリングします。ハイブリッドディスクリソースの状態が正常な場合以外はミラーリングしません。
- -force(-a,--active指定時)
- --active オプションとともに使用します。異常状態のハイブリッドディスクリソースをアクセス制限解除します。(強制活性)ミラーリングが停止しているサーバで実行可能です。
- -nomount
- --active オプションとともに使用します。ファイルシステムをマウントせずに、ハイブリッドパーティションデバイスのアクセスを可能にします。ファイルシステムにnoneを指定している場合、このオプションは意味を持ちません。
- -ro
- --active -force オプションとともに使用します。読み取り専用で、ハイブリッドディスクリソースをアクセス制限解除(強制活性)します。
- --deactive, -d
自サーバでアクセス制限解除されているハイブリッドディスクリソースをアクセス制限状態にします。
- --break, -b
- コマンドを実行したサーバ上で hybriddisk-alias で指定されたハイブリッドディスクリソースを強制的に切り離します。(ミラー同期を中断します。)コマンドを実行したサーバのハイブリッドディスクの状態は異常状態 (RED) になります。コマンドを実行していないサーバのハイブリッドディスクの状態は変わりません。ハイブリッドディスクに書き込みが発生してもデータは同期されません。ミラー復帰を行い正常に完了すると、切り離しは解除されます。ミラー復帰完了による切り離し解除、または、リブートをおこなうまで、自動ミラー復帰は自動的に開始されません。
- --recovery, -r
- 指定したハイブリッドディスクリソースを全面ミラー復帰もしくは、差分ミラー復帰します。全面ミラー復帰、差分ミラー復帰の判断は自動的に行われます。
- --force, -f
- 指定したハイブリッドディスクリソースを強制ミラー復帰します。hybriddisk-alias のみを指定した場合には、コマンドを実行したサーバのハイブリッドディスクの状態を強制的に異常状態(RED)から正常状態 (GREEN) に変更します。ミラーの再同期の処理は行われません。recovery-source-servername と hybriddisk-alias を指定した場合には、 recovery-source-servername をコピー元として全面ミラー復帰を行います。全面ミラー復帰が完了した後にハイブリッドディスクのステータスが正常状態になります。
- -v
- --force オプションとともに使用します。ファイルシステムが使用していない領域も含め、全面ミラー復帰を行います。
- --cancel, -c
- ミラー復帰を中止します。自動ミラー復帰が ON に設定されていて、ハイブリッドディスクモニタリソースが動作している場合、ミラー復帰を中止後しばらくすると自動的にミラー復帰が再開されます。その場合には、Cluster WebUI または clpmonctrl コマンドでハイブリッドディスクモニタリソースを一時停止状態にしてから、ミラー復帰の中止を実行してください。
- --rwait, -w
指定したハイブリッドディスクリソースのミラー復帰完了を待ちます。
- -timeout
- --rwait オプションとともに使用します。ミラー復帰完了待ちのタイムアウト時間(秒) を指定します。このオプションは省略可能です。省略時はタイムアウトを行わず、ミラー復帰が完了するまで待ち続けます。
- -rcancel
- --rwait -timeout オプションとともに使用します。ミラー復帰完了待ちがタイムアウトした場合に、ミラー復帰を中断します。このオプションは -timeout オプションを設定した場合に設定できます。省略時はタイムアウトしてもミラー復帰を続行します。
- --getreq
現在のリクエストキュー最大数を表示します。
- --setreq
- リクエストキュー最大数を設定します。この設定は、サーバをシャットダウンした場合には、クラスタ構成情報で設定している値に戻ります。クラスタ構成情報を変更したい場合は、Cluster WebUI を用いて変更してください。詳しくは「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「ミラードライバタブ -Replicator / Replicator DR を使用している場合-」を 参照してください。コマンドを実行したサーバに対してのみ有効です。
- --sync
- ミラーデータを同期する動作に切り換えます。ハイブリッドディスクリソース名を指定しない場合には、すべてのハイブリッドリソースに対してミラーデータを同期する動作に切り換えます。
- --nosync
- ミラーデータを同期しない動作に切り換えます。ハイブリッドディスクリソース名を指定しない場合には、すべてのハイブリッドリソースに対してミラーデータを同期しない動作に切り換えます。ただし、ミラー復帰中に発生したディスクの更新は待機系へ同期されます。自動ミラー復帰が ON に設定されていて、ハイブリッドディスクモニタリソースが動作している場合、自動ミラー復帰は動作します。ミラー復帰完了後でも、同期しない動作のままとなります。解除するには、--sync オプション指定によるコマンド実行をおこないます。サーバをシャットダウンすると、クラスタ構成情報で設定している同期の動作の状態に戻ります。クラスタ構成情報を変更したい場合は、Cluster WebUI を用いて変更してください。詳しくは本ガイドの「3. グループリソースの詳細」 - 「ミラーディスクリソースを理解する」 - 「詳細タブ」 - 「ミラーディスクリソース調整プロパティ」 - 「ミラータブ」を参照してください。
- --setcur
hybriddisk-alias で指定されたハイブリッドディスクリソースのカレント権をコマンドを実行したサーバで取得します。
- --compress, -p
- ミラー同期/復帰データを転送するときに、一時的に、圧縮して転送します。同期モードが同期の場合には、ミラー復帰データのみ、圧縮します。同期モードが非同期の場合には、ミラー同期/復帰データ両方を圧縮します。ハイブリッドディスクリソース名を指定しない場合には、すべてのハイブリッドディスクリソースに対して圧縮転送する動作に切り換えます。
- --nocompress, -n
- ミラー同期/復帰データを転送するときに、一時的に、圧縮しないで転送します。ハイブリッドディスクリソース名を指定しない場合には、すべてのハイブリッドディスクリソースに対して圧縮転送しない動作に切り換えます。
- --mdcswitch, -s
- 指定された優先順位のミラーディスクコネクト (mdc) を使用するように、通信を切り換えます。優先順位 mdc-priority の指定が省略された場合は、現在使用されている mdcの次の優先順位の mdc へ切り換えます。一番低い優先順位の mdc を使用していた場合には、優先順位が一番高い mdc へ切り換えます。切り換え先の mdc への接続に失敗した場合は、次に有効な mdc へ接続を試みます。切り換え先として既に現在使用しているmdc が指定された場合には、通信を切り換えずに終了します。
- --resize, -z
- ハイブリッドディスクリソースのデータパーティションサイズを拡張します。ハイブリッドディスクリソースの状態が正常である場合のみ、拡張が可能です。
- -force(--resize,-z指定時)
- --resizeオプションとともに使用します。ハイブリッドディスクリソースの状態に関わらず、強制的に拡張を実行します。本オプションを使用すると、次回のミラー復帰がフルコピーとなります。また、本オプションを使用しても、ミラー復帰中は拡張することができません。
- --updatekey
- 暗号化鍵を、リソースを停止することなく更新します。両サーバグループのカレントサーバの暗号化鍵ファイルを新しいものに置き換えたうえで本オプションを実行すると、暗号化に使用する鍵が更新されます。ミラーリング中に実行した場合はミラーリングが中断されます。実行完了後に必要に応じてミラー復帰を実行してください。
- パラメータ
- recovery-source-servername
コピー元となるサーバ名を指定します。
- hybriddisk-alias
ハイブリッドディスクリソース名を指定します。
- request-count
リクエストキュー最大数を指定します。指定可能な範囲は、2048~65535 です。
- time
ミラー復帰完了待ちのタイムアウト時間(秒) を指定します。
- mdc-priority
- ミラーディスクコネクト (mdc) の優先順位を指定します。優先順位は、クラスタ全体での番号ではなく、対象のハイブリッドディスクリソースに対して設定した mdc 順位を、1 または 2で指定します。
- partition-size
- データパーティションの新しいサイズを指定します。以下の単位文字を付加して指定することができます。"500G"と指定すると、500ギビバイトに拡張されます。単位文字が付加されない場合は、バイト単位として扱われます。
K (Kibi byte)
M (Mebi byte)
G (Gibi byte)
T (Tebi byte)
- 戻り値
0
成功
255 (-1)
失敗
254 (-2)
対象ハイブリッドディスクがミラーブレイク状態か、ミラー構築が途中で失敗した (--rwait オプション指定時のみ。-rcancel でミラー復帰を中断した場合も含む)
253 (-3)
対象ハイブリッドディスクのミラー復帰完了待ちがタイムアウト (--rwait -timeout オプション指定時のみ)
- 備考
--getreq オプションで表示される request-count は、clpstat コマンドで表示される [Request Queue Maximum Number] と同じです。
# clpstat --cl --detail
本コマンドは、指定した処理が開始したタイミングで制御を戻します。処理の状況はclphdstatコマンドで確認してください。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
--active/--force (強制ミラー復帰) /--setcur はカレント権を持っているサーバまたはカレント権が取得できるサーバで実行できます。
--recovery、--force (recovery-source-servernameを指定した全面ミラー復帰) は以下の状態で実行できます。
コピー元サーバがカレント権を持っている状態、またはカレント権が取得できる状態
- コピー先サーバがカレント権を持っている状態、またはカレント権が取得できる状態(共有ディスク上にハイブリッドディスクリソースを設定している構成で、カレント権を持っていないサーバではミラー復帰はできません)
--break/--cancel/--setreq/--sync/--nosync/--setreq/--updatekey はカレント権を持っているサーバで実行できます。
本コマンドでカレントサーバが変更される条件について、詳しくは「カレントサーバが変更される操作一覧」を参照して下さい。
ミラー復帰の異常終了後に再度ミラー復帰を行う場合、前回と同じサーバをコピー元として指定し、ミラー復帰をしてください。
コマンドを実行するサーバがハイブリッドディスクリソースを含むグループの起動サーバに含まれていない場合は、本コマンドはエラーになります。グループの起動サーバに含まれていない場合は本コマンドを実行しないでください。
ミラー同期途中に --break (-b) や --nosync オプションでミラー同期を中断した場合や、ミラー復帰途中にミラー復帰を中断した場合には、強制活性や強制ミラー復帰をおこなって同期先のハイブリッドディスクにアクセス可能にしても、ファイルシステムやアプリケーションデータが異常になっている場合があります。詳細については『スタートアップガイド』の「注意制限事項」 - 「ミラー同期を中断した場合の同期先のミラーデータ参照について」を参照してください。
- 実行例
例1 : 正常状態の ハイブリッドディスクリソース hd1 をアクセス制限解除する場合
# clphdctrl --active hd1 < hd1@server1>: active successfully
例2 : ハイブリッドディスクリソース hd1 をアクセス制限状態にする場合
# clphdctrl --deactive hd1 < hd1@server1>: deactive successfully
例3 : ハイブリッドディスクリソース hd1 のハイブリッドディスクを切り離す場合
# clphdctrl --break hd1 hd1: isolate successfully
例4 : 両サーバのハイブリッドディスクの状態が異常状態で、リソース hd1 を使用する業務 (グループ名 failover1) の復旧を急ぐ場合
# clphdctrl --force hd1 The data of mirror disk in local server maybe is not latest. Do you still want to continue? (Y/N) hd1: Force recovery successful. # clpgrp -s failover1 Command succeeded.
自動ミラー復帰が 「する」 の場合には このタイミングでミラー復帰が実行されます。自動ミラー復帰が 「しない」 の場合には以下のコマンドを実行します。
# clphdctrl --recovery hd1
例5 : ハイブリッドディスクリソース hd1 をミラー復帰する場合
# clphdctrl --recovery hd1
例6 : リクエストキュー最大数を 2048 に設定する場合
# clphdctrl --setreq 2048 current I/O request count <2048>
例7 : ハイブリッドディスクリソース hd1 をデータ同期しない設定にする場合
# clphdctrl --nosync hd1
- エラーメッセージ
メッセージ
原因/対処法
Error: Log in as root.
root 権限を持つユーザで実行してください。
Error: Failed to read the configuration file.Check if it exists or is configured properly.設定ファイルの読み込みに失敗しました。設定ファイルが存在するか、正しく設定されているか確認してください。Error: Specified hybrid disk resource was not found.Specify a valid mirror disk resource name.指定したハイブリッドディスクリソースが見つかりませんでした。正しいハイブリッドディスクリソース名を指定してください。Error: Invalid hybrid-alias.Specify a valid mirror disk resource name.正しいハイブリッドディスクリソース名を指定してください。
Error:Failed to get the server name.Check if the configuration file is correct and the Mirror Agent is operating normally.サーバ名の取得に失敗しました。設定ファイルが正しいか、ミラーエージェントが正常に動作しているか確認してください。Error: Specified server name was not found.Check if the server name exists in the configuration file.指定したサーバ名が見つかりませんでした。入力したサーバ名が設定ファイルに存在するか確認してください。Error: Invalid server name. Specify a valid server name.
正しいサーバ名を指定してください。
Error: Failed to communicate with other servers.Check if the Mirror Agent of the other server is operating normally and the mirror disk connect is connected.相手サーバとの通信に失敗しました。相手サーバのミラーエージェントが動作しているか、ミラーディスクコネクトが接続されているか確認してください。Error: Failed to get the hybrid disk status.Check if the Mirror Agent on the local server is operating normally.ハイブリッドディスク状態の取得に失敗しました。自サーバのミラーエージェントが正常に動作しているか確認してください。Error: Failed to get the mirror index.Check if the Mirror Agent is operating normally.ミラーエージェントが正常に動作しているか確認してください。
Error: The status of hybrid disk resource of the local server is abnormal.
自サーバのハイブリッドディスクリソースの状態が異常です。
Error: Specified hybrid disk resource is already active.Check active status of hybrid disk resource by running the following command: clphdstat --active <alias>指定したハイブリッドディスクリソースは既に活性化しています。以下のコマンドを用いてハイブリッドディスクリソースの活性状態を確認してください。clphdstat --active <alias>Error: A hardware error has occurred on the disk. Check the disk.
ディスクに H/W エラーが発生しました。ディスクを確認してください。
Error: The sizes of data partition of the servers do not match.
両サーバのデータパーティションのサイズが一致していません。
Error: Specified hybrid disk is not active.Check the active status of hybrid disk resource.指定したハイブリッドディスクリソースは活性化していません。ハイブリッドディスクリソースの活性状態を確認してください。Error: There is no recovering hybrid disk resource.
ミラー復帰中のハイブリッドディスクリソースがありません。
Error: Mirror hybrid resource is recovering.Wait until mirror recovery completes.ハイブリッドディスクリソースがミラー復帰中です。ミラー復帰が終わるまで待ってください。Error: Failed to cancel the mirror recovery.The system may be highly loaded. Wait for a while and try again.ミラー復帰の中止に失敗しました。システムが高負荷の可能性があります。しばらく待って からリトライしてください。Error: Performed mirror recovery to the hybrid disk resource that is not necessary to recover the mirror.Run the clphdctrl--force command if you want to perform forced mirror recovery.正常状態のミラー復帰が不要なハイブリッドディスクリソースに対してミラー復帰をしました。強制ミラー復帰を実行したい場合、"clphdctrl --force" を用いて実行してください。Error: Specification of the server that is copied from is incorrect.When executing mirror recovery again after a failure end of mirror recovery, specify the same server as the previous one.コピー元サーバの指定が間違っています。ミラー復帰の異常終了後に再度ミラー復帰を行う場合、前回と同じサーバをコピー元として指定し、ミラー復帰を実行してください。Error: Forced mirror recovery is required. Run the clphdctrl --force command to perform the recovery.強制ミラー復帰が必要な状態です。"clphdctrl --force" を用いて実行してください。Error: Server with old data is specified as the server which is copied from.Specify a correct recovery direction.古いデータを持つサーバをコピー元サーバとして指定しています。正しい復帰方向を指定してください。Error: Failed to acquire mirror recovery status.Reboot the local server.ミラー復帰状態の取得に失敗しました。自サーバを再起動してください。Error: Both of the mirrors are not constructed.Initial mirror configuration of the hybrid disks by running the clpmdctrl --force command is necessary.ハイブリッドディスクの初期ミラー構築が必要な状態です。"clphdctrl --force" を用いて初期ミラー構築をしてください。Error: Initial mirror configuration of mirror disk of local server is necessary.Specify the other server as the one that is copied from by using the clphdctrl --force command to configure an initial mirror.自サーバのハイブリッドディスクの初期ミラー構築が必要な状態です。"clphdctrl --force" を用いて相手サーバをコピー元として指定し、初期ミラー構築をしてください。Error: Initial mirror configuration of mirror disk of the other server is necessary.Specify the local server as the one that is copied from by using the clphdctr l--force command to configure an initial mirror.相手サーバのハイブリッドディスクの初期ミラー構築が必要な状態です。"clphdctrl --force" を用いて自サーバをコピー元として指定し、初期ミラー構築をしてください。Error: Mirror flag error. Use "clphdinit" to construct the mirror.The status of cluster partition of the hybrid disk resource is abnormal.When the server with the error has the latest data, backup the data, initialize the cluster partition, and replace the same disk by using the same disk.If the error persists, change the disk to new one.ハイブリッドディスクリソースのクラスタパーティションの状態が異常です。エラーが発生したサーバが最新データを保持している場合は、『インストール&設定ガイド』の「動作チェックを行う」を参照してデータのバックアップをとり、クラスタパーティションを初期化し、再度発生するようであれば、エラーの発生するディスクを新しいディスクに交換してください。Error: Both local and remote mirrors are active.Shut down the cluster and execute forced mirror recovery after rebooting the server.両系活性になっています。クラスタシャットダウンを実行し、サーバを再起動後に、強制ミラー復帰を実行してください。Error: Mirror Agent is not running.Check if the Mirror Agent is active.ミラーエージェントは起動していません。ミラーエージェントが起動しているか確認してください。Error: System call error. Failed to run the system command when active and/or inactive.Check if the search path is set to an environment variable.活性化/非活性化時のシステムコマンド実行に失敗しました。サーチパスが環境変数に設定されているか確認してください。Error: Failed to create a mount point.The disk space may not be sufficient.マウントポイントの作成に失敗しました。ディスクの容量不足が考えられます。 確認してください。Error: Timeout has occurred on active fsck. When it is not journaling file system,it may take time to run fsck if the size of data partition of hybrid disk is large.Set timeout of fsck longer.活性化の fsck でタイムアウトが発生しています。ジャーナリングファイルシステムではない場合、ハイブリッドディスクのデータパーティションのサイズが大きいと fsck に時間がかかることがあります。Cluster WebUI を用いて fsck タイムアウトの設定を長くしてください。Error: Timeout occurs at activation mount.Set mount timeout longer.活性化時のファイルシステムのマウントでタイムアウトが発生しています。Cluster WebUI を用いてマウントタイムアウトの設定を長くしてください。Error: Timeout occurs at deactivation mount.Set unmount timeout longer.非活性化時のファイルシステムのアンマウントでタイムアウトが発生しています。Cluster WebUI を用いてアンマウントタイムアウトの設定を長くしてください。Error: fsck failed. Check if file system type of data partition does not match configuration file,fsck option is incorrect or partition is incorrect.fsck に失敗しました。データパーティションのファイルシステムタイプが設定ファイルと一致しない、fsck オプションが間違っている、パーティションが壊れている、などが考えられます。確認してください。Error: Failed to mount when active. The file system type of the data partition does not matchthe settings of the configuration file, or the partition may be corrupted.活性化時のマウントに失敗しました。データパーティションのファイルシステムタイプが設定ファイルにおける設定と一致しない、またはパーティションが壊れていることが考えられます。確認してください。Error: Failed to unmount when inactive.Check if the file system on the data partition is busy.非活性化時のアンマウントに失敗しました。データパーティション上のファイルシステムがビジー状態ではないことを確認してください。Error: Hybrid disk resource is on process of activation.Execute after activation is completed.ハイブリッドディスクリソースが活性化処理中です。活性化完了後に実行してください。Error: Failed to perform forced mirror recovery or activate a single server.Check if any hardware error has occurred on the disk.単体サーバの強制ミラー復帰、または活性化に失敗しました。ディスクに H/W エラーが発生していないか確認してください。Error: Entered incorrect maximum number of request queues. Check the specifiable range.不正なリクエストキュー最大数を入力しました。指定可能な数値範囲を確認してください。Error: Failed to set the maximum number of request queues. Reboot the local server..リクエストキュー最大数の設定に失敗しました。自サーバを再起動してください。Error: Failed to acquire the maximum number of request queues. Reboot the local server.リクエストキュー最大数の取得に失敗しました。自サーバを再起動してください。Hybrid disk resource was not found on local server. Cannot perform this action.ハイブリッドディスクリソースが自サーバで定義されていません。リクエストキュー最大数の設定はできませんでした。確認してください。Error: Failed to get the NMP path. Check if the Mirror Agent is operating normally.Reboot the local server.ミラーエージェントが正常に動作しているか確認してください。自サーバを再起動してください。Error: Failed to acquire the mirror configuration information.Check if the Mirror Agent is operating normally.ミラー設定情報の取得に失敗しました。ミラーエージェントが正常に動作しているか確認してください。Error: Failed to acquire the hybrid disk configuration information. Reboot the local server.ハイブリッドディスク設定情報の取得に失敗しました。自サーバを再起動してください。Error: Failed to acquire the hybrid disk configuration information of both local and remote servers.Shut down the cluster and reboot both servers両サーバのハイブリッドディスク設定情報の取得に失敗しました。クラスタシャットダウンを実行し、両サーバを再起動してください。Error: Failed to get the number of bits of the bitmap due to the errors occurredwhen acquiring the mirror difference information of the cluster partition. Shut down the cluster.If it fails again, replace the disk. For procedure to replace the disk, see the Reference Guide.Error: The number of the bits in the bitmap is invalid.The mirror difference information of the cluster partition is invalid. Shut down the cluster.If it fails again, replace the disk. For procedure to replace the disk, see Reference Guide.Error: The number of the bits in the bitmap is invalid.The mirror difference information of the cluster partition is invalid. Shut down the cluster.If it fails again, replace the disk. For procedure to replace the disk, see Reference Guide.クラスタパーティションにおけるミラー差分情報が不正です。クラスタシャットダウンを実行してください。再度このエラーが発生するようであれば、ディスクを交換してください。Error: Failed to read the mirror difference information of the local server.Reboot the local server.自サーバのミラー差分情報の読取に失敗しました。自サーバを再起動してください。Error: Failed to read the mirror difference information of the local server.Reboot the local server.相手サーバのミラー差分情報の読取に失敗しました。相手サーバを再起動してください。Error: Failed to get the bitmap information of the local server due to the errors occurredwhen acquiring the mirror difference information of the local server. Reboot the local server.自サーバのミラー差分情報の取得に失敗しました。自サーバを再起動してください。Error: Failed to read the disk space. Shut down the cluster and reboot the server.ディスク容量の取得に失敗しました。クラスタシャットダウンを実行し、サーバを再起動してください。Error: Failed to acquire the disk space of the other server.Shut down the cluster and reboot both servers.相手サーバのディスク容量の取得に失敗しました。クラスタシャットダウンを実行し、サーバを再起動してください。Error: Setting of cluster partition failed. Restart local server.クラスタパーティションの設定に失敗しました。自サーバを再起動してください。Error: Error occurred on the settings of the hybrid disk resource.Reboot the local server.ハイブリッドディスクリソースの状態設定でエラーが発生しました。自サーバを再起動してください。Error: Failed to create a thread. Reboot the local server.スレッドの作成に失敗しました。自サーバを再起動してください。Error: Internal error. Failed to create process. Reboot the local server.プロセスの作成に失敗しました。自サーバを再起動してください。Error: Failed to acquire semaphore. Reboot the local server.セマフォ取得に失敗しました。自サーバを再起動してください。Error: A malloc error. Failed to reserve the memory space.Reboot the local server.メモリ確保に失敗しました。自サーバを再起動してください。Error: Mirror driver of the local server is not loaded.Confirm kernel version.自サーバのミラードライバがロードされていません。カーネルバージョンを確認してください。Error: Mirror recovery cannot be executed as NMP size of mirror recovery destination is smaller thanthe size of where the mirror is recovered from. Change the recovery destination and try again.ミラー復帰先の NMP サイズがミラー復帰元よりも小さいので、ミラー復帰を実行出来ません。ミラー復帰方向を変更し、再度実行してください。Error: NMP size of local server is bigger, cannot active.Initial mirror configuration is not completed. Execute mirror recovery from server of smaller NMP sizeto that of larger one.初期ミラー構築が完了していません。NMP サイズの小さいサーバから大きいサーバへ強制ミラー復帰を実行してください。Local and remote recovery mode do not match. Reboot a server other than the master serverto keep the same contents of configuration file among servers.Note that a failover may occur at server reboot.両サーバの復帰モードに相違があります。復帰は実行しません。サーバ間で情報ファイルの内容を同一のものにするためマスタサーバ以外のサーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Failed to get remote recovery mode. Recovery will not be interrupted.Check the communication status of mirror connect.相手サーバの復帰モードが取得できません。復帰処理は中断しません。ミラーコネクトの通信状態を確認してください。Failed to get local recovery mode. Recovery will not be interrupted.Note that a failover may occur at server reboot.自サーバの復帰モードが取得できません。復帰処理は中断しません。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Local or remote mirror is forced actived. Cannot to perform this action.ハイブリッドディスクが強制活性状態です。ミラー復帰はできませんでした。確認してください。The recovery destination of hybrid disk is activated.Cannot perform this action.ハイブリッドディスクコネクトの通信状態が異常です。ミラー復帰はできませんでした。確認してください。Failed to get hybrid disk list and failed to set all NMP sync flag. Reboot the local server.Note that a failover may occur at server reboot.ハイブリッドディスクのリストの取得に失敗したため、データ同期の設定がすべてのハイブリッドディスクに対してエラーとなりました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Failed to get hybrid disk list and failed to set all NMP sync flag to OFF. Reboot the local server.Note that a failover may occur at server reboot.ハイブリッドディスクのリストの取得に失敗したため、データ同期しない設定がすべてのハイブリッドディスクに対してエラーとなりました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Failed to set sync flag on both servers. Shut down a cluster and reboot server.データ同期の設定が両方のサーバで失敗しました。クラスタシャットダウンと再起動を行ってください。Failed to set sync flag to OFF on both servers. Shut down a cluster and reboot server.データ同期しない設定が両方のサーバで失敗しました。クラスタシャットダウンと再起動を行ってください。%1:Succeeded to set sync flag ON on %2Failed to set sync flag ON on %3Check the communication status of mirror connect%1 の「データ同期する」の設定はサーバ %2 で成功、サーバ %3 で失敗しました。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください。%1 にはリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。%1:Succeeded to set sync flag OFF on %2Failed to set sync flag OFF on %3Check the communication status of mirror connect.%1 の「データ同期しない」の設定はサーバ %2 で成功、サーバ %3 で失敗しました。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください。%1 にはリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。Succeeded to set sync flag on remote server and failed on local server.Note that a failover may occur at server reboot.データ同期の設定が、自サーバで失敗、相手サーバで成功しました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Succeeded to set sync flag to OFF on remote server and failed on local server.Note that a failover may occur at server reboot.データ同期しない設定が、自サーバで失敗、相手サーバで成功しました。自サーバを再起動してください。サーバの再起動時にフェイルオーバが発生することがあるので注意してください。Cannot change the settings of sync status during mirror recovery.Change the settings after mirror recovery is completed.ミラー復帰中には「データ同期」の設定の変更はできません。ミラー復帰が完了してから設定を変更してください。Hybrid disk resource was not found on local server.Cannot perform this action.ハイブリッドディスクリソースが自サーバで定義されていません。「データ同期」の設定の変更はできません。The status of the hybrid disk does not satisfy the conditions to perform this action.A probable cause:1. Local hybrid disk is not initialized or is already force activated.2. Local hybrid disk is not RED or remote is GREEN or remote is already activated.ミラーのステータスが不正です。強制復帰はできません。The data of hybrid disk in the local server may not be the latest.Do you still want to continue? (Y/N)自サーバのデータは最新ではない可能性があります。相手サーバのハイブリッドディスクのステータスが確認できない状態です。Forced recovery has completed successfully.強制ミラー復帰が正常に終了しました。The status of hybrid disk in local server is not GREEN or is already activated.Cannot perform this action.ミラーのステータスが不正です。ミラーの切り離しはできません。Failed to set an isolate flag in the local server.ミラー切り離しのフラグを更新できませんでした。Isolated completed successfully.ミラーの切り離しの操作が正常に終了しました。The status of the hybrid disk does not satisfy the conditions to perform this action.A probable cause:1. Hybrid disk is not initialized or is not RED.2. Hybrid disk is already activated.ミラーのステータスが不正です。強制活性はできません。sync flag of %1 is successfully set to ON.%1 が「データ同期する」に設定されました。%1 にはリソース名が入ります。Failed to set sync flag of %1 on both servers.Shut down the cluster and reboot server.両方のサーバでデータ同期フラグの設定に失敗しました。%1 にはリソース名が入ります。%3:Succeeded to set sync flag ON on %1Failed to set sync flag ON on %2Check the communication status of mirror connect.片方のサーバでデータ同期フラグの設定に失敗しました。ミラーディスクコネクトが正常に通信できるか確認してください。%1 には設定に成功したサーバ名が入ります。%2 には設定に失敗したサーバ名が入ります。%3 にはリソース名が入ります。%1:Cannot change the settings of sync status during mirror recovery.Change the settings after mirror recovery is completed.ミラー復帰中なので、データ同期フラグの変更ができません。復帰完了した後、再度実行してください。%1 にはリソース名が入ります。sync flag of %1 is successfully set to OFF.%1 が「データ同期しない」に設定されました。%1 にはリソース名が入ります。%3:Succeeded to set sync flag OFF on %1Failed to set sync flag OFF on %2Check the communication status of mirror connect.片方のサーバでデータ同期フラグの設定に失敗しました。ミラーディスクコネクトが正常に通信できるか確認してください。%1 には設定に成功したサーバ名が入ります。%2 には設定に失敗したサーバ名が入ります。%3 にはリソース名が入ります。The specified hybrid disk is not defined on this server.指定されたハイブリッドディスクが自サーバで定義されていません。Failed to acquire the path of mirror device.Check if the Mirror Agent is operating normally.Reboot the local server.ミラーデバイスのデバイス名の取得に失敗しました。ミラーエージェントが動作しているかを確認してください。The disk alias does not match the command.指定されたリソース名のリソースタイプが不正です。ミラーディスクリソースに対してはclpmdctrl コマンドを使ってください。ハイブリッドディスクリソースに対してはclphdctrl コマンドを使ってください。Invalid command name.コマンド名が無効です。clphdctrl コマンドのファイル名を変更しないでください。There is an error when the server gets current priority.カレント権限を取得する時にエラーが発生しました。Data synchronizing. Cannot perform this action.データ同期中は、この操作は実行できません。The other server is already active. Cannot perform this action.他のサーバでリソースを活性しているため、この操作は実行できません。Cannot judge which side has the nearest data.Cannot perform this action. Reboot or execute force recovery.どちらのサーバが最新データを持っているかを判断できません。この操作は実行できません。強制ミラー復帰を実行してください。Failed to get host name.サーバ名の取得に失敗しました。This server is not current server. Cannot perform this action.カレントサーバでないため、コマンドは実行できません。Hybrid disk internal error.内部エラーが発生しました。The current server is being forced to actived,cannot release current right.カレント権限を持っているサーバでリソースを強制活性している間は、カレント権限を解放できません。The current server is changing. Cannot perform this action.カレントサーバがカレント権を変更中なので、コマンドは実行できません。<%1>: mirror broken%1 のステータスが不正です。ハイブリッドディスクがミラーブレイク状態か、または、ミラー構築が途中で失敗しました。%1 にはリソース名が入ります。<%1>: recovery timeout%1 のミラー復帰がタイムアウトしました。タイムアウト時間の指定が妥当か、また、高負荷等によりディスク I/O や通信の遅延が発生していないか確認してください。%1 にはリソース名が入ります。Cannot perform this action.(Device: %1).Check if the Cluster Partition or Data Partition is OK.操作しようとしたハイブリッドディスクリソースは、クラスタパーティションまたはデータパーティションに異常があり、稼働していません。そのため操作を行えませんでした。<%1> : Succeeded to set compress flag ON.リソース %1 のミラー転送データの圧縮を ON に設定しました。%1 にはリソース名が入ります。<%1> : Succeeded to set compress flag OFF.リソース %1 のミラー転送データの圧縮を OFF に設定しました。%1 にはリソース名が入ります。<%1> : Failed to set compress flag ON.リソース %1 のミラー転送データの圧縮のON 設定に失敗しました。%1 にはリソース名が入ります。<%1> : Failed to set compress flag OFF.リソース %1 のミラー転送データの圧縮の OFF 設定に失敗しました。%1 にはリソース名が入ります。<%1> : Failed to set compress flag ON on %2.サーバ %2 で、リソース %1 のミラー転送データの圧縮を ON にできませんでした。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください%1 にはリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。<%1> : Failed to set compress flag OFF on %2.サーバ %2 で、リソース %1 のミラー転送データの圧縮を OFF にできませんでした。サーバの動作状態やミラーディスクコネクトの通信状態を確認してください。%1 にはリソース名が入ります。%2 には設定に失敗したサーバ名が入ります。<%1>: Succeeded to switch mirror disk connection.Now using mdc <priority:%2>.リソース %1 の優先順位 %2 のミラーディスクコネクトへ切り換えました。%1 にはリソース名が入ります。%2 には新たに使用するミラーディスクコネクトについての優先順位の番号が入ります。Error: There is no need to switch mirror disk connection.指定されたミラーディスクコネクトを既に現在使用しており、切り換える必要がないため、切り換えませんでした。Error: Failed to switch mirror disk connection. The specified mirror disk connection is ERROR.指定されたミラーディスクコネクトは ERRORの状態であるため、切り換えませんでした。Error: Failed to switch mirror disk connection. The other mirror disk connections are ERROR.他のミラーディスクコネクトが全て ERROR の状態であるため、切り換えませんでした。Error: Failed to switch mirror disk connection.ミラーディスクコネクトの切り換えに失敗しました。Error: Specified mdc priority does not exist.指定された優先順位のミラーディスクコネクトは、存在しません。構成情報に定義されていません。<%1>: Succeeded to resize data partition. <new size:%2>.
リソース %1 のデータパーティションサイズの拡張に成功しました。%1 にはリソース名が入ります。%2 には拡張後のデータパーティションサイズがバイト単位で入ります。Error: Failed to resize data partition.
データパーティションサイズの拡張に失敗しました。データパーティションがLVMで構成されているか確認してください。ボリュームグループの未使用PE量が十分であることを確認してください。<%1>: Succeeded to update nmp size.
リソース %1 のデータパーティションサイズ情報の更新に成功しました。%1 にはリソース名が入ります。Error: Failed to update nmp size.
データパーティションサイズ情報の更新に失敗しました。コマンド実行サーバを再起動してください。<%1>: Succeeded to resize data partition. <new size:%2>.Failed to update nmp size on local server.データパーティションサイズの拡張に成功しましたが、コマンド実行サーバのデータパーティションサイズ情報の更新に失敗しました。コマンド実行サーバを再起動してください。%1 にはリソース名が入ります。%2 には拡張後のデータパーティションサイズがバイト単位で入ります。Error: NMP sizes of both servers are different. Cannot perform this action.
ハイブリッドディスクリソースのデータサイズ情報が両サーバで異なるため、ミラー復帰ができません。ミラー拡張手順の実行途中でのミラー復帰ではないか、確認してください。Error: The status of mirror disk resource is abnormal.
ハイブリッドディスクリソースの状態が正常ではないため、処理が実行できません。Error: Failed to update the encryption key.
暗号化鍵の更新に失敗しました。各サーバ上で、設定した鍵ファイルフルパスに鍵ファイルが存在するか確認してください。<%1>: Updated the encryption key successfully.%2: %3%2: %3リソース %1 の暗号化鍵の更新に成功しました。%1 にはミラーディスクリソース名が入ります。%2 にはサーバ名が入ります。%3 には更新結果として、更新成功時は Success が、同一の暗号化鍵が既に使用されている場合は Same key が入ります。Error: The encryption function is disabled.
指定したハイブリッドディスクリソースは「ミラー通信を暗号化する」機能が有効ではないため、暗号化鍵の更新はできません。
Error: The same encryption key is already used.
同一の暗号化鍵が既に使用されています。各サーバの鍵ファイルを新しいものに更新して、再度実行してください。Error: Failed to set value on shared memory.Reboot the local server.設定情報の取得に失敗しました。サーバを再起動してください。Automatic mirror recovery is disabled.Its manual resumption is required to resume mirroring.ミラーリングは中断されています。自動ミラー復帰がOFFであるため、ミラーリングの再開には手動でのミラー復帰が必要です。Failed to resume the automatic mirror recovery.Its manual resumption is required to resume mirroring.ミラーリングは中断されています。手動でミラー復帰を行う必要があります。
9.20.1. カレントサーバが変更される操作一覧
カレントサーバは本コマンドで下記の操作を行った場合にも変更されます。
ハイブリッドディスクのステータス |
カレントサーバ変更可否 |
可能な操作 |
|||
|---|---|---|---|---|---|
サーバグループ1 |
サーバグループ2 |
サーバグループ1 |
サーバグループ2 |
サーバグループ1 |
サーバグループ2 |
正常/非活性 |
正常/非活性 |
可能 |
可能 |
1 |
1 |
正常/非活性 |
異常/非活性 |
可能 |
可能 |
1 |
1,3 |
正常/活性 |
異常/非活性 |
不可能 |
可能 |
- |
1,3 |
異常/非活性 |
異常/非活性 |
可能 |
可能 |
1,2,3 |
1,2,3 |
異常/非活性 |
異常/強制活性 |
可能 |
不可能 |
2,3 |
- |
異常/非活性 |
不明 |
可能 |
不可能 |
2,3 |
- |
保留/非活性 |
保留/非活性 |
可能 |
可能 |
1 |
1 |
保留/非活性 |
不明 |
可能 |
不可能 |
2 |
- |
1 |
ミラー復帰 (差分、全面) |
2 |
片サーバのみ強制ミラー復帰 |
3 |
アクセス制限解除 (強制活性) |
4 |
ミラーディスク切り離し |
注釈
Cluster WebUI で同様の操作を行う場合はオンラインマニュアルを参照してください。
9.21. ハイブリッドディスクを初期化する (clphdinit コマンド)
ハイブリッドディスクの初期化を行います。
- コマンドライン
- clphdinit {--create | -c} normal [hybriddisk-alias]clphdinit {--create | -c} quick [hybriddisk-alias]clphdinit {--create | -c} force [hybriddisk-alias]
重要
通常、クラスタの構築や運用ではこのコマンドの実行は不要です。データ用に使用していたパーティションを初期化しますので、使用する場合には十分注意をしてください。
- 説明
ハイブリッドディスクリソースのクラスタパーティションに対して初期化を行います。
ハイブリッドディスクリソースのデータパーティションに対しては、本バージョンでは自動ではファイルシステムを作成しませんので、必要に応じてあらかじめ作成してください。
- オプション
- {--create, -c} <mode>
mode
- normal
- クラスタパーティションの初期化を必要があれば実行します。必要の有無は、クラスタパーティション上にCLUSTERPRO が設定するマジックナンバーで判断します。通常、このオプションでコマンドを実行する必要はありません。
- quick
- クラスタパーティションの初期化を必要があれば実行します。必要の有無は、クラスタパーティション上にCLUSTERPRO が設定するマジックナンバーで判断します。通常、このオプションでコマンドを実行する必要はありません。
- force
- クラスタパーティションの初期化を強制的に実行します。このオプションは CLUSTERPRO のハイブリッドディスクとして一旦使用したディスクを再度使用する場合に使用します。
- パラメータ
- hybriddisk-alias
ハイブリッドディスクリソース名を指定します。指定しない場合は全てのハイブリッドディスクリソースに対して処理を行います。
- 戻り値
0
成功
0以外
失敗
- 注意事項
- 本コマンドを実行すると、ハイブリッドディスクが初期化されます。使用する場合には十分注意をしてください。
1つのサーバグループ内に複数のサーバがある場合には、同一サーバグループ内で何れか 1 台のサーバで実行すればクラスタパーティションの初期化は完了します。
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドが制御を戻すまで、他のコマンドを実行しないでください。
本コマンドを実行する場合、クラスタ内の全サーバで、ミラーエージェントが停止していることを確認してください。
確認方法
# ps -e | grep clpmdagent
3node以上の構成のときにコマンドを実行するサーバがハイブリッドディスクリソースを含むグループの起動サーバに含まれていない場合は、本コマンドはエラーになります。グループの起動サーバに含まれていない場合は本コマンドを実行しないでください。
- 実行例
例1 : ハイブリッドディスクリソース hd1 に使用するディスクが、以前CLUSTERPRO のハイブリッドディスクとして使用していたので強制的にクラスタパーティションを初期化する場合
# clphdinit --create force hd1 mirror info will be set as default the main handle on initializing hybrid disk < hd1> success initializing hybrid disk complete
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Stop the Mirror Agent.
ミラーエージェントを停止してください。
The clphdinit command is currently running. Execute after it is completed.
本コマンドは実行中です。完了してから実行してください。
Invalid hybrid-alias. Specify a valid mirror disk resource name.
正しいハイブリッドディスクリソース名を指定してください。
The mirror hybrid resource was not found.Set the hybrid disk resource properly.ハイブリッドディスクリソースが見つかりませんでした。ハイブリッドディスクリソースを正しく設定してください。Specified hybrid disk resource <%1> was not found.Specify a valid hybrid disk resource name.指定したハイブリッドディスクリソースが見つかりませんでした。正しいハイブリッドディスクリソース名を指定してください。The partition does not exist .Check if the cluster partition of specified hybrid disk resource exists (<%1>).指定したハイブリッドディスクリソースのクラスタパーティションが存在するか確認してください。Check if the cluster partition size of specified hybrid disk resource is larger than 1GB. <%1>指定したハイブリッドディスクリソースのクラスタパーティションのサイズが 1GB 以上であるか確認してください。Internal error (open error <%1>).The cluster partition of the hybrid disk resource may not exist or the OS resource may be insufficient.指定したハイブリッドディスクリソースのクラスタパーティションが存在しない、または OS のリソース不足が考えられます。確認してください。Internal error (<%1> cluster partition: unknown error).Failed to initialize the cluster partition.Check if any hardware error has occurred on the disk.クラスタパーティションの初期化に失敗しました。ディスクに H/W エラーが発生していないか確認してください。Internal error (<%1> cluster partition: %2).Check if the size of cluster partition is sufficient and if there is any hardware error on the disk.クラスタパーティションの設定に失敗しました。クラスタパーティションの容量不足、またはディスクの H/W エラーが考えられます。確認してください。The data partition does not exist (<%1>).Check if the data partition of the specified hybrid disk resource exists. Data Partition is: %2指定したハイブリッドディスクリソースのデータパーティションが存在するか確認してください。Failed to initialize the cluster partition <%1>.The data partition of the specified hybrid disk resource may not exist, hardware error may have occurred on the disk,or specified file system may not be supported by OS. Check them. mirror<%2>: fstype<%3>データパーティションの初期化に失敗しました。指定したハイブリッドディスクリソースのデータパーティションが存在しない、またはディスクの H/W エラー、OS がサポートしていないファイルシステムを指定した、などの原因が考えられます。確認してください。Unknown error occurred when formatting mirror-disk<%1>.The data partition of the specified hybrid disk resource may not exist or hardware error may have occurred on the disk. Check them.データパーティションの初期化に失敗しました。指定したハイブリッドディスクリソースのデータパーティションが存在しない、またはディスクの H/W エラーが考えられます。Internal error (Failed to open the data partition:<%1>).Failed to initialize the data partition.The data partition of the specified hybrid disk resource may not exist or OS resource may not be sufficient.Data Partition is: %2データパーティションの初期化に失敗しました。指定したハイブリッドディスクリソースのデータパーティションが存在しない、または OS のリソース不足が考えられます。確認してください。Internal error (data partition check error---<%1>).Failed to initialize the data partition. Check if any hardware error has occurred on the disk.データパーティションの初期化に失敗しました。ディスクに H/W エラーが発生していないか確認してください。Failed to acquire hybrid disk list information. Reboot the local server.ハイブリッドディスクリストの取得に失敗しました。自サーバを再起動してください。Internal error (PID write failed). Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。Internal error (initialization failed)Failed to read the configuration file, or failed to initialize the shared memory or semaphore.Check if the file is configured properly and reboot the local server.設定ファイルの読み込みに失敗、または共有メモリ、セマフォの初期化に失敗しました。設定ファイルが正しいことを確認して、自サーバを再起動してください。Internal error (termination failed) Failed to release the shared memory.Check if any system error has occurred while running the program.共有メモリの解放に失敗しました。プログラムの実行中にシステムの異常が発生していないか確認してください。A malloc error. Failed to reserve the memory space. Reboot the local server..メモリの確保に失敗しました。自サーバを再起動してください。An error has occurred when the data partition is set to writable mode. <Device:%1>. Reboot the local server.データパーティションを書込可能に設定するときにエラーが発生しました。自サーバを再起動してください。An error has occurred when the data partition is set to read-only mode.<Device:%1>. Reboot the local server.データパーティションをリードオンリーに設定するときにエラーが発生しました。自サーバを再起動してください。Cluster Partition or Data Partition does not exist.クラスタパーティションまたはデータパーティションがありません。パーティションを作成していることを確認してください。Failed to upgrade the cluster partition of <%s>.クラスタパーティションのアップグレードに失敗しました。ディスクに異常がないか確認してください。Specified hybrid disk resource was not found on local server.Cannot perform this action.ハイブリッドディスクリソースが自サーバで定義されていません。初期化操作はできませんでした。確認してください。The disk alias does not match the command.指定されたリソース名 (ミラーエイリアス名) のリソースタイプが不正です。md リソースには clpmdinit を使ってください。hd リソースには clphdinit を使ってください。Invalid command name.コマンド名が無効です。 clphdinit コマンドのファイル名を変更しないでください。Initializing hybrid disk of %1 failed.Check if the Cluster Partition or Data Partition is OK.初期化しようとしたハイブリッドディスクリソースは、クラスタパーティションまたはデータパーティションに異常があり、初期化できませんでした。
9.22. ディスクイメージバックアップの準備をする (clpbackup.sh コマンド)
9.17. 「ディスクイメージバックアップの準備をする (clpbackup.sh コマンド)」を参照して下さい。
9.23. ディスクイメージリストア後の処理をする (clprestore.sh コマンド)
9.18. 「ディスクイメージリストア後の処理をする (clprestore.sh コマンド)」を参照して下さい。
9.24. メッセージを出力する (clplogcmd コマンド)
指定したメッセージを syslog,alert に登録する、mail 通報する、または SNMP トラップ送信するコマンドです。
- コマンドライン
clplogcmd -m message [--syslog] [--alert] [--mail] [--trap] [-i eventID] [-l level]
注釈
通常、クラスタの構築や運用ではこのコマンドの実行は不要です。EXEC リソースの スクリプトに記述して使用するコマンドです。
- 説明
EXEC リソースのスクリプトに記述し、任意のメッセージを出力先に出力します。
- オプション
- -m message
- 出力するメッセージを指定します。省略できません。メッセージの最大サイズは511バイトです。(出力先に syslog を指定した場合は 485 バイトです。) 最大サイズ以降のメッセージは表示されません。
メッセージには英語、数字、記号 [16] が使用可能です。
- --syslog
- --alert
- --mail
- --trap
syslog、alert、mail、trap の中から出力先を指定します (複数指定可能です)。
このパラメータは省略可能です。省略時にはsyslog と alert が出力先になります。
出力先についての詳細は『メンテナンスガイド』の「保守情報」の「CLUSTERPRO のディレクトリ構成」を参照してください。
- -i eventID
イベント ID を指定します。イベント ID の最大値は 10000 です。
このパラメータは省略可能です。省略時にはeventID に 1 が設定されます。
- -l level
- 出力するアラートのレベルです。ERR、WARN、INFO のいずれかを指定します。このレベルによって Cluster WebUI でのアラートログのアイコンを指定します。
このパラメータは省略可能です。省略時にはlevel に INFO が設定されます。
詳細はオンラインマニュアルを参照してください。
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
出力先に mail を指定する場合、mail コマンドで mail 送信ができる設定を行ってください。
- 実行例
例1: メッセージのみ指定する場合 (出力先 syslog,alert)
EXEC リソースのスクリプトに下記を記述した場合、syslog、alert にメッセージを出力します。
# clplogcmd -m test1
syslog には、下記のログが出力されます。
Sep 1 14:00:00 server1 clusterpro: <type: logcmd><event: 1> test1
例2: メッセージ、出力先、イベント ID、レベルを指定する場合 (出力先 mail)
EXEC リソースのスクリプトに下記を記述した場合、Cluster WebUI のクラスタプロパティで設定したメールアドレスにメッセージが送信されます。メールアドレスの設定についての詳細は本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「アラートサービスタブ」を参照してください。
# clplogcmd -m test2 --mail -i 100 -l ERR
mail の送信先には、下記の内容のメールが送信されます。
Message:test2Type: logcmdID: 100Host: server1Date: 2004/09/01 14:00:00例3: メッセージ、出力先、イベント ID、レベルを指定する場合 (出力先 trap)
EXEC リソースのスクリプトに下記を記述した場合、Cluster WebUI のクラスタのプロパティで設定したSNMP トラップ送信先にメッセージが送信されます。SNMP トラップ送信先の設定についての詳細は本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「アラートサービスタブ」を参照してください。
# clplogcmd -m test3 --trap -i 200 -l ERR
SNMP トラップの送信先には、下記の内容の SNMP トラップが送信されます。
Trap OID: clusterEventError添付データ1: clusterEventMessage = test3添付データ2: clusterEventID = 200添付データ3: clusterEventDateTime = 2011/08/01 09:00:00添付データ4: clusterEventServerName = server1添付データ5: clusterEventModuleName = logcmd
9.25. モニタリソースを制御する (clpmonctrl コマンド)
モニタリソースの制御を行います。
- コマンドライン
- clpmonctrl -s [-h <hostname>] [-m resource name] [-w wait time]clpmonctrl -r [-h <hostname>] [-m resource name] [-w wait time]clpmonctrl -c [-m resource_name]clpmonctrl -v [-m resource_name]clpmonctrl -e [-h <hostname>] -m resource_nameclpmonctrl -n [-h <hostname>] [-m resource_name]
注釈
-cおよび-vは、単一サーバ上でモニタリソースの制御を行うため、制御を行う全サーバ上で実行する必要があります。クラスタ内の全サーバ上のモニタリソースの一時停止/再開を行う場合には、Cluster WebUI から実行されることを推奨します。
- 説明
モニタリソースの一時停止/再開、または回復動作の回数カウンタの表示/リセット、障害検証機能の有効/無効を行います。
- オプション
- -s
監視を一時停止します。
- -r
監視を再開します。
- -c
回復動作の回数カウンタをリセットします。
- -v
回復動作の回数カウンタを表示します。
- -e
障害検証機能を有効にします。必ず-mオプションでモニタリソース名を指定してください。
- -n
障害検証機能を無効にします。-mオプションでモニタリソース名を指定した場合は、そのリソースのみが対象となります。-mオプションを省略した場合は、全モニタリソースが対象となります。
- -m resource_name
- 制御するモニタリソースを指定します。省略可能で、省略時は全てのモニタリソースに対して制御を行います。
- -w wait_time
- モニタリソース単位で監視制御を待合わせます。(秒)省略可能で、省略時は 5 秒が設定されます。
- -h
hostname で指定したサーバに処理を要求します。[-h] オプションを省略した場合は、コマンド 実行サーバ (自サーバ) に処理を要求します。-cおよび-vの場合は指定できません。
- 戻り値
0
成功
1
実行権限不正
2
オプション不正
3
初期化エラー
4
クラスタ構成情報不正
5
モニタリソース未登録
6
指定モニタリソース不正
10
クラスタ未起動状態
11
CLUSTERPRO デーモンサスペンド状態
12
クラスタ同期待ち状態
90
監視制御待ちタイムアウト
128
二重起動
200
サーバ接続エラー
201
ステータス不正
202
サーバ名不正
255
その他内部エラー
- 実行例
例1: 全モニタリソースを一時停止する場合
# clpmonctrl -s Command succeeded.
例2: 全モニタリソースを再開する場合
# clpmonctrl -r Command succeeded.
- 備考
既に一時停止状態にあるモニタリソースに一時停止を行った場合や既に起動済状態にあるモニタリソースに再開を行った場合は、本コマンドはエラー終了し、モニタリソース状態は変更しません。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
モニタリソースの状態は、clpstat コマンドまたは Cluster WebUI で確認してください。
モニタリソースの一時停止/再開を行う場合は、clpstat コマンドまたはCluster WebUI でモニタリソースの状態が "起動済" または、"一時停止" であることを確認して実行してください。
モニタリソースの回復動作が下記のように設定されている場合、-vオプションで表示される "FinalAction Count" には 「最終動作前スクリプト」の実行回数が表示されます。
最終動作前にスクリプトを実行する: 有効
最終動作: "何もしない"
- エラーメッセージ
メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Invalid cluster configuration data.Check the cluster configuration information.クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。
Monitor resource is not registered.
モニタリソースが登録されていません。
Specified monitor resource is not registered.Check the cluster configuration information.指定されたモニタリソースは、登録されていません。Cluster WebUI でクラスタ構成情報を確認してください。The cluster has been suspended. The cluster daemon has been suspended.Check activation status of the cluster daemon by using a command such as the ps command.CLUSTERPRO デーモンは、サスペンド状態です。ps コマンドなどで CLUSTERPRO デーモンの起動状態を確認してください。Waiting for synchronization of the cluster... The cluster is waiting for synchronization.Wait for a while and try again.クラスタは、同期待ち状態です。クラスタ同期待ち完了後、再度実行してください。Monitor %1 was unregistered, ignored.The specified monitor resources %1is not registered, but continue processing.Check the cluster configuration data.指定されたモニタリソース中に登録されていないモニタリソースありますが、無視して処理を継続します。Cluster WebUI でクラスタ構成情報を確認してください。%1 :モニタリソース名Monitor %1 denied control permission, ignored. but continue processing.指定されたモニタリソース中に制御できないモニタリソースがありますが、無視して処理を継続します。%1 :モニタリソース名This command is already run.コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。Internal error. Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。Could not connect to the server.Check if the cluster service is active.クラスタサービスが起動しているか確認してください。Some invalid status.Check the status of cluster.何らかの不正な状態です。クラスタの状態を確認してください。Invalid server name. Specify a valid server name in the cluster.クラスタ内の正しいサーバ名を指定してください。
- -m オプションに指定可能なモニタリソースタイプ
タイプ
監視の一時停止/再開
回復動作の回数カウンタ/リセット障害検証機能の有効化/無効化arpw
n/a
✓
n/a
diskw
✓
✓
✓
fipw
✓
✓
✓
ipw
✓
✓
✓
miiw
✓
✓
✓
mtw
✓
✓
✓
pidw
✓
✓
✓
volmgrw
✓
✓
✓
userw
✓
✓
n/a
vipw
n/a
✓
n/a
ddnsw
n/a
✓
n/a
mrw
✓
✓
n/a
genw
✓
✓
✓
mdw
✓
✓
n/a
mdnw
✓
✓
n/a
hdw
✓
✓
n/a
hdnw
✓
✓
n/a
oraclew
✓
✓
✓
db2w
✓
✓
✓
psqlw
✓
✓
✓
mysqlw
✓
✓
✓
odbcw
✓
✓
✓
sqlserverw
✓
✓
✓
sambaw
✓
✓
✓
nfsw
✓
✓
✓
httpw
✓
✓
✓
ftpw
✓
✓
✓
smtpw
✓
✓
✓
pop3w
✓
✓
✓
imap4w
✓
✓
✓
tuxw
✓
✓
✓
wlsw
✓
✓
✓
wasw
✓
✓
✓
otxw
✓
✓
✓
jraw
✓
✓
✓
sraw
✓
✓
✓
psrw
✓
✓
✓
psw
✓
✓
✓
awsazw
✓
✓
✓
awsdnsw
✓
✓
✓
awseipw
✓
✓
✓
awssipw
✓
✓
✓
awsvipw
✓
✓
✓
azurednsw
✓
✓
✓
gcdnsw
✓
✓
✓
ocdnsw
✓
✓
✓
ocsipw
✓
✓
✓
9.26. グループリソースを制御する (clprscコマンド)
グループリソースの制御を行います。
- コマンドライン
- clprsc -s resource_name [-h hostname] [-f] [--apito timeout]clprsc -t resource_name [-h hostname] [-f] [--apito timeout]clprsc -n resource_nameclprsc -v resource_name
- 説明
グループリソースを起動/停止します。
- オプション
- -s
グループリソースを起動します。
- -t
グループリソースを停止します。
- -h
hostname で指定されたサーバに処理を要求します。
-h オプションを省略した場合は、以下のサーバへ処理を要求します。
グループが停止済の場合、コマンド実行サーバ(自サーバ)
グループが起動済の場合、グループが起動しているサーバ
- -f
グループリソース起動時は、指定したグループリソースが依存する全グループリソースを起動します。
グループリソース停止時は、指定したグループリソースに依存している全グループリソースを停止します。
- -n
グループリソースの起動済サーバを表示します。
- --apito timeout
グループリソースの起動、停止を待ち合わせる時間(内部通信タイムアウト)を秒単位で指定します。1-9999 の値が指定できます。
[--apito] オプションを指定しない場合は、3600 秒待ち合わせを行います。
- -v
グループリソースのフェイルオーバ回数カウンタを表示します。
- 戻り値
0
成功
0以外
失敗
- 実行例
グループリソース構成
# clpstat =========== CLUSTER STATUS =========== Cluster : cluster <server> *server1..................: Online lanhb1 : Normal lanhb2 : Normal pingnp1 : Normal server2..................: Online lanhb1 : Normal lanhb2 : Normal pingnp1 : Normal <group> ManagementGroup........: Online current : server1 ManagementIP : Online failover1..............: Online current : server1 fip1 : Online md1 : Online exec1 : Online failover2..............: Online current : server2 fip2 : Online md2 : Online exec2 : Online <monitor> ipw1 : Normal mdnw1 : Normal mdnw2 : Normal mdw1 : Normal mdw2 : Normal ======================================例1:グループ failover1 のリソース fip1 を停止する場合
# clprsc -t fip1 Command succeeded.
#clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup........: Online current : server1 ManagementIP : Online failover1..............:Online current : server1 fip1 : Offline md1 : Online exec1 : Online failover2..............: Online current : server2 fip2 : Online md2 : Online exec2 : Online <省略>
例2:グループ failover1 のリソース fip1 を起動する場合
# clprsc -s fip1 Command succeeded.
# clpstat ========== CLUSTER STATUS ========== <省略> <group> ManagementGroup.......: Online current : server1 ManagementIP : Online failover1.............: Online current : server1 fip1 : Online md1 : Online exec1 : Online failover2.............: Online current : server2 fip2 : Online md2 : Online exec2 : Online <省略>
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
グループリソースの状態は、状態表示コマンドまたは Cluster WebUI で確認してください。
グループ内に起動済グループリソースがある場合は、停止済グループリソースを異なるサーバで起動することはできません。
- エラーメッセージ
メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid cluster configuration data.Check the cluster configuration information.クラスタ構成情報が不正です。Cluster WebUI でクラスタ構成情報を確認してください。Invalid option.
正しいオプションを指定してください。
Could not connect server. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Invalid server status. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Server is not active. Check if the cluster service is active.
CLUSTERPRO サービスが起動しているか確認してください。
Invalid server name. Specify a valid server name in the cluster.
クラスタ内の正しいサーバ名を指定してください。
Connection was lost.Check if there is a server where the cluster service is stopped in the cluster.クラスタ内に CLUSTERPRO サービスが停止しているサーバがないか確認してください。Internal communication timeout has occurred in the cluster server.If it occurs frequently, set the longer timeout.CLUSTERPRO の内部通信でタイムアウトが発生しています。頻出するようであれば、内部通信タイムアウトを長めに設定してください。The group resource is busy. Try again later.グループリソースが起動処理中、もしくは停止処理中のため、しばらく待ってから実行してください。An error occurred on group resource. Check the status of group resource.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Could not start the group resource.Try it again after the other server is started, or after the Wait Synchronization time is timed out.他サーバが起動するのを待つか、起動待ち時間が タイムアウトするのを待って、グループリソースを起動させてください。No operable group resource exists in the server.処理を要求したサーバに処理可能なグループリソースが存在するか確認してください。The group resource has already been started.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Failed to start group resource. Check the status of group resource.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Failed to stop resource. Check the status of group resource.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。Depended resource is not offline. Check the status of resource.依存しているグループリソースの状態が停止済でないため、グループリソースを停止できません。依存しているグループリソースを停止するか、-f オプションを指定してください。Depending resource is not online. Check the status of resource.依存しているグループリソースの状態が起動済でないため、グループリソースを起動できません。依存しているグループリソースを起動するか、-f オプションを指定してください。Invalid group resource name. Specify a valid group resource name in the cluster.グループリソースが登録されていません。Server is not in a condition to start resource or any critical monitor error is detected.Cluster WebUI や、clpstat コマンドでグループリソースの状態を確認してください。グループリソースを起動しようとしたサーバで「フェイルオーバ先サーバの除外に使用するモニタリソース」に含まれるモニタの異常が検出されています。Internal error. Check if memory or OS resources are sufficient.メモリ不足または OS のリソース不足が考えられます。確認してください。
9.27. 再起動回数を制御する (clpregctrl コマンド)
再起動回数制限の制御を行います。
- コマンドライン
- clpregctrl --getclpregctrl -gclpregctrl --clear -t type -r registryclpregctrl -c -t type -r registry
注釈
本コマンドは、単一サーバ上で再起動回数制限の制御を行うため、制御を行う全サーバ上で実行する必要があります。
- 説明
単一サーバ上で再起動回数の表示/初期化を行います。
- オプション
- -g, --get
再起動回数情報を表示します。
- -c, --clear
再起動回数を初期化します。
- -t type
再起動回数を初期化するタイプを指定します。指定可能なタイプは rc または rm です。
- -r registry
レジストリ名を指定します。指定可能なレジストリ名はhaltcount です。
- 戻り値
0
成功
1
実行権限不正
2
二重起動
3
オプション不正
4
クラスタ構成情報不正
10~17
内部エラー
20~22
再起動回数情報取得失敗
90
メモリアロケート失敗
91
ワークディレクトリ変更失敗
- 実行例
再起動回数情報表示
# clpregctrl -g
****************************** ------------------------- type : rc registry : haltcount comment : halt count kind : int value : 0 default : 0 ------------------------- type : rm registry : haltcount comment : halt count kind : int value : 3 default : 0 ****************************** Command succeeded.(code:0) #
例1 、2 は、再起動回数を初期化します。
server2 の再起動回数を制御する場合は、server2 で本コマンドを実行してください。
例1:グループリソース異常による再起動回数を初期化する場合
# clpregctrl -c -t rc -r haltcount Command succeeded.(code:0)
例2:モニタリソース異常による再起動回数を初期化する場合
# clpregctrl -c -t rm -r haltcount Command succeeded.(code:0)
- 備考
再起動回数制限に関しては本ガイドの「3. グループリソースの詳細」 - 「グループとは?」 - 「再起動回数制限について」を参照してください。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
- エラーメッセージ
メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。The command is already executed. Check the execution state by using the "ps" command or some other command.
コマンドは、既に実行されています。ps コマンドなどで実行状態を確認してください。Invalid option.
オプションが不正です。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
9.28. ネットワーク警告灯を消灯する (clplamp コマンド)
ネットワーク警告灯を消灯します。
- コマンドライン
clplamp -h hostname
- 説明
指定したサーバ用のネットワーク警告灯を消灯します。
音声ファイルの再生を設定していた場合、音声ファイルの再生を停止します。
- オプション
- -h hostname
消灯したいネットワーク警告灯のサーバを指定します。
- 戻り値
0
成功
0以外
失敗
- 実行例
例1: server1 に対応する警告灯の消灯、音声警告の停止を行う場合
# clplamp -h server1 Command succeeded.
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
9.29. クラスタサーバに処理を要求する (clprexec コマンド)
サーバへ処理実行を要求します。
- コマンドライン
- clprexec --failover {[group_name] | [-r resource_name]} -h IP [-w timeout] [-p port_number] [-o logfile_path]clprexec --script script_file -h IP [-p port_number] [-w timeout] [-o logfile_path]clprexec --notice {[mrw_name] | [-k category[. keyword]]} -h IP [-p port_number] [-w timeout] [-o logfile_path]clprexec --clear {[mrw_name] | [-k category[. keyword]]} -h IP [-p port_number] [-w timeout] [-o logfile_path]
- 説明
指定した処理実行要求を他クラスタのサーバに発行します。
- オプション
- --failover
グループフェイルオーバ要求を行います。group_name にはグループ名を指定してください。
グループ名を省略する場合は、-r オプションによりグループに属するリソース名を指定してください。
- --script script_name
スクリプト実行要求を行います。
script_name には、実行するスクリプト (シェルスクリプトや実行可能ファイル等) のファイル名を指定します。
スクリプトは -h で指定した各サーバのCLUSTERPRO インストールディレクトリ配下の work/rexec ディレクトリ配下に作成しておく必要があります。
※ スクリプト名は以下の使用可能文字からなる文字列で指定してください。
使用可能文字
詳細
英数字
a-z, A-Z, 0-9
"-"
ハイフン
"_"
アンダースコア
"."
ドット
- --notice
CLUSTERPRO サーバへ異常発生通知を行います。
mrw_name には外部連携モニタリソース名を指定してください。
モニタリソース名を省略する場合、-k オプションで外部連携モニタリソースのカテゴリ,キーワードを指定してください。
- --clear
外部連携モニタリソースのステータスを "異常"から "正常" へ変更する要求を行います。
mrw_name には外部連携モニタリソース名を指定してください。
モニタリソース名を省略する場合、-k オプションで外部連携モニタリソースのカテゴリ,キーワードを指定してください。
- -h IP Address
処理要求発行先の CLUSTERPRO サーバのIP アドレスを指定してください。
カンマ区切りで複数指定可能、指定可能な IPアドレス数は 32 個です。
注釈
本オプションを省略する場合、処理要求発行先は自サーバになります。
- -r resource_name
--failover オプションを指定する場合に、処理要求の対象となるグループに属するリソース名を指定します。
- -k category[.keyword]
--notice または --clear オプションを指定する場合、category にメッセージ受信モニタに設定しているカテゴリを指定してください。
外部連携モニタリソースのキーワードを指定する場合は、category のあとにドット区切りで指定してください。
- -p port_number
ポート番号を指定します。
port_number に処理要求発行先サーバに設定されているデータ転送ポート番号を指定してください。
本オプションを省略した場合、デフォルト 29002を使用します。
- -o logfile_path
logfile_path には、本コマンドの詳細ログを出力するファイル path を指定します。
ファイルにはコマンド 1 回分のログが保存されます。
注釈
CLUSTERPRO がインストールされていないサーバで本オプションを指定しない場合、標準出力のみとなります。
- -w timeout
コマンドのタイムアウトを指定します。指定しない場合は、デフォルト 180 秒です。
5 ~ MAXINT まで指定可能です。
- 戻り値
0
成功
0以外
失敗
- 注意事項
[clprexec] コマンドを使って異常発生通知を発行する場合、CLUSTERPRO サーバ側で実行させたい異常時動作を設定した外部連携モニタリソースを登録/起動しておく必要があります。
-h オプションで指定する IP アドレスを持つサーバは、下記の条件を満たす必要があります。
CLUSTERPRO X 3.0 以降がインストールされていること
- CLUSTERPRO が起動していること( --script オプション以外の場合)
- mrw が設定/起動されていること( --notice, --clear オプションの場合)
[クライアント IP アドレスによって接続を制御する] が有効の場合、[clprexec] コマンドを実行する装置の IP アドレスを追加しておく必要があります。
[クライアント IP アドレスによって接続を制御する] は、本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「WebManagerタブ」を参照してください。
- 実行例
例1: CLUSTERPRO サーバ1 (10.0.0.1) に対して、グループ failover1 のフェイルオーバ要求を発行する場合
# clprexec --failover failover1 -h 10.0.0.1 -p 29002
例2: CLUSTERPROサーバ1 (10.0.0.1) に対して、グループリソース (exec1) が属するグループのフェイルオーバ要求を発行する場合
# clprexec --failover -r exec1 -h 10.0.0.1
例3: CLUSTERPROサーバ 1 (10.0.0.1) に対して、スクリプト(script1.sh) 実行要求を発行する場合
# clprexec --script script1.sh -h 10.0.0.1
例4: CLUSTERPROサーバ 1 (10.0.0.1) に対して異常発生通知を発行する
※ mrw1 設定 カテゴリ:earthquake、キーワード:scale3
外部連携モニタリソース名を指定する場合
# clprexec --notice mrw1 -h 10.0.0.1 -w 30 -p /tmp/clprexec/clprexec.log
外部連携モニタリソースに設定されているカテゴリとキーワードを指定する場合
# clprexec --notice -k earthquake.scale3 -h 10.0.0.1 -w 30 -p /tmp/clprexec/clprexec.log
例5: CLUSTERPRO サーバ 1 (10.0.0.1) に対して mrw1 のモニタステータス変更要求を発行する
※ mrw1 の設定 カテゴリ:earthquake、キーワード:scale3
外部連携モニタリソース名を指定する場合
# clprexec --clear mrw1 -h 10.0.0.1
外部連携モニタリソースに設定されているカテゴリとキーワードを指定する場合
# clprexec --clear -k earthquake.scale3 -h 10.0.0.1
- 備考
clprexec コマンドを実行する環境と、処理要求発行先の環境が異なる OS でも動作可能です。
例: Linux 環境の CLUSTERPRO サーバに対して、Windows 環境上の clprexec コマンドから処理を要求する。
- エラーメッセージ
メッセージ
原因/対処
rexec_ver:%s
-
%s %s : %s succeeded.
-
%s %s : %s will be executed from now.
要求発行先のサーバで処理結果を確認してください。
%s %s : Group Failover did not execute because Group(%s) is offline.
-
%s %s : Group migration did not execute because Group(%s) is offline.
-
Invalid option.
コマンドの引数を確認してください。
Could not connect to the data transfer servers. Check if the servers have started up.
指定した IP アドレスが正しいかまたは IP アドレスを持つサーバが起動しているか確認してください。
Command timeout.
指定した IP アドレスを持つサーバで処理が完了しているか確認してください。
All servers are busy. Check if this command is already run.
既に本コマンドが実行されている可能性があります。確認してください。
%s %s : This server is not permitted to execute clprexec.
Cluster WebUI 接続制限のクライアント IP アドレス一覧にコマンドを実行するサーバの IP アドレスが 登録されているか確認してください。
%s %s : Specified monitor resource(%s) does not exist.
コマンドの引数を確認してください。
%s %s : Specified resource(Category:%s, Keyword:%s) does not exist.
コマンドの引数を確認してください。
%s failed in execute.
要求発行先の CLUSTERPRO サーバの状態を確認してください。
9.30. クラスタ起動同期待ち処理を制御する (clpbwctrl コマンド)
クラスタ起動同期待ち処理を制御します。
- コマンドライン
- clpbwctrl -cclpbwctrl --np [on|off]clpbwctrl -h
注釈
--npオプションは、単一サーバ上で制御を行うため、制御を行う全サーバ上で実行する必要があります。
- 説明
- クラスタ内の全サーバのクラスタサービスが停止している状態からサーバを起動したときに発生する、クラスタ起動同期待ち時間をスキップします。単一サーバ上でクラスタ起動時にネットワークパーティション解決処理を行うか行わないかを指定します。
- オプション
- -c,--cancel
クラスタ起動同期待ち処理をキャンセルします。
- --np [on|off]
- クラスタ起動時にネットワークパーティション解決処理を行うか行わないかを指定します。onを指定するとネットワークパーティション解決処理を行います。offを指定すると行いません。既定ではonが指定されています。[on|off]は省略可能です。省略した場合、現在の設定を表示します。
- -h,--help
Usage を表示
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
- 実行例
クラスタ起動同期待ち処理をキャンセルする場合
# clpbwctrl -c Command succeeded.
クラスタ起動時にネットワークパーティション解決処理を行わない場合
# clpbwctrl --np off Command succeeded. # clpbwctrl --np Resolve network partition on startup : off
- エラーメッセージ
メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
コマンドラインオプションが不正です。正しいオプションを指定してください。
Cluster service has already been started.
すでにクラスタは起動しています。起動同期待ち状態ではありません。
The cluster is not waiting for synchronization.
起動同期待ち処理中ではありませんでした。クラスタサービスが停止している等の原因が考えられます。
Command Timeout.
コマンドの実行がタイムアウトしました。
Internal error.
内部エラーが発生しました。
9.31. プロセスの健全性を確認する (clphealthchk コマンド)
プロセスの健全性を確認します。
- コマンドライン
clphealthchk [ -t pm | -t rc | -t rm | -t nm | -h]
注釈
本コマンドは、単一サーバ上でプロセスの健全性を確認します。健全性を確認したいサーバ上で実行する必要があります。
- 説明
単一サーバ上でのプロセスの健全性を確認します。
- オプション
- なし
clppm/clprc/clprm/clpnm の健全性を確認します。
- -t <process>
process
- pm
clppm の健全性を確認します。
- rc
clprc の健全性を確認します。
- rm
clprm の健全性を確認します。
- nm
clpnm の健全性を確認します。
- -h
Usageを出力します。
- 戻り値
0
成功
1
実行権限不正
2
二重起動
3
初期化エラー
4
オプション不正
10
プロセスストール監視機能未設定
11
クラスタ未起動状態(クラスタ起動待ち合わせ中、クラスタ停止処理中を含む)
12
クラスタサスペンド状態
100
健全性情報が一定時間更新されていないプロセスが存在する
-t オプション指定時は、指定プロセスの健全性情報が一定時間更新されていない
255
その他内部エラー
- 実行例
例1: 健全な場合
# clphealthchk pm OK rc OK rm OK nm OK
例2: clprc: がストールしている場合
# clphealthchk pm OK rc NG rm OK nm OK
# clphealthchk -t rc rc NG
例3: クラスタが停止している場合
# clphealthchk The cluster has been stopped
- 備考
クラスタが停止している場合や、サスペンドしている場合にはプロセスは停止しています。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
- エラーメッセージ
メッセージ
原因/対処
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
Invalid option.
正しいオプションを指定してください。
The function of process stall monitor is disabled.
プロセスストール監視機能が有効ではありません。
The function of process stall monitor is disabled.
クラスタは停止状態です。
The cluster has been suspended.
クラスタはサスペンド状態です。
This command is already run.
コマンドは既に実行されています。ps コマンドなどで実行状態を確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
9.32. DB2 の静止点を制御する (clpdb2still コマンド)
DB2の静止点の制御を行います。
- コマンドライン
- clpdb2still -d databasename -u username -sclpdb2still -d databasename -u username -r
- 説明
DB2の静止点の確保/解放を制御します。
- オプション
- -d databasename
静止点制御の対象となるデータベース名を指定します。
- -u username
静止点制御を実行するユーザ名を指定します。
- -s
静止点の確保を行います。
- -r
静止点の解放を行います。
- 戻り値
0
成功
2
コマンドオプション不正
5
静止点確保失敗
6
静止点解放失敗
- 実行例
# clpdb2still -d sample -u db2inst1 -s データベース接続情報 データベース・サーバー = DB2/LINUXX8664 11.1.0 SQL 許可 ID = DB2INST1 ローカル・データベース別名 = SAMPLE DB20000I SET WRITE コマンドが正常に完了しました。 DB20000I SQL コマンドが正常に完了しました。 DB20000I SQL DISCONNECT コマンドが正常に完了しました。
# clpdb2still -d sample -u db2inst1 -r データベース接続情報 データベース・サーバー = DB2/LINUXX8664 11.1.0 SQL 許可 ID = DB2INST1 ローカル・データベース別名 = SAMPLE DB20000I SET WRITE コマンドが正常に完了しました。 DB20000I SQL コマンドが正常に完了しました。 DB20000I SQL DISCONNECT コマンドが正常に完了しました。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
-u オプションに指定するユーザには、DB2のSET WRITEコマンドを実行できる権限が必要です。
- エラーメッセージ
メッセージ
原因/対処
invalid database name
データーベース名が不正です。データーベース名を確認してください。
invalid user name
ユーザ名が不正です。ユーザ名を確認してください。
missing database name
データーベース名が指定されていません。データーベース名を指定してください。
missing user name
ユーザ名が指定されていません。ユーザ名を指定してください。
missing operation '-s' or '-r'
静止点の確保/解放が指定されていません。静止点の確保または解放のいずれかを指定してください。
suspend command return code = n
静止点確保で失敗しました。直前に su コマンドのエラーメッセージが出力されている場合は、ユーザ名とパスワードを確認してください。また、db2 コマンドのエラーメッセージが出力されている場合は、エラー内容に応じた対処をしてください。resume command return code = n
静止点解放で失敗しました。直前に su コマンドのエラーメッセージが出力されている場合は、ユーザ名とパスワードを確認してください。db2 コマンドのエラーメッセージが出力されている場合は、エラー内容に応じた対処をしてください。
9.33. MySQL の静止点を制御する (clpmysqlstill コマンド)
MySQLの静止点の制御を行います。
- コマンドライン
- clpmysqlstill -d databasename [-u username] -sclpmysqlstill -d databasename -r
- 説明
MySQLの静止点の確保/解放を制御します。
- オプション
- -d databasename
静止点制御の対象となるデータベース名を指定します。
- -u username
静止点制御を実行するデーターベースユーザ名を指定します。-s オプションを指定した場合のみ指定可能です。省略した場合はデフォルトユーザとしてrootが設定されます。
- -s
静止点の確保を行います。
- -r
静止点の解放を行います。
- 戻り値
0
成功
2
コマンドオプション不正
3
DB接続エラー
4
-u オプションに指定したユーザの認証エラー
5
静止点確保失敗
6
静止点解放失敗
99
内部エラー
- 実行例
# clpmysqlstill -d mysql -u root -s Command succeeded.
# clpmysqlstill -d mysql -r Command succeeded.
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。また環境変数LD_LIBRARY_PATHにMySQLのクライアントライブラリlibmysqlclient.soの存在するディレクトリを設定してください。
-u オプションに指定するユーザのパスワードは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ユーザ名:パスワード:」の形式で設定してください。行の最後にはコロン「:」を付けてください。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
パスワード設定の例: root:password:
-u オプションに指定するユーザにはMySQLの FLUSH TABLES WITH READ LOCKステートメントを実行できる権限が必要です。
-s オプションで静止点確保コマンドを実行して静止点確保に成功した場合、その静止点確保コマンドは常駐したまま制御を戻しません。別プロセスにて -r オプションで静止点開放コマンドを実行することにより、常駐していた静止点確保コマンドが終了して制御が戻ります。
- エラーメッセージ
メッセージ
原因/対処
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Cannot connect to database.
データーベースに接続できません。データーベース名及びデータベースの状態を確認してください。
Username or password is not correct.
ユーザ認証で失敗しました。ユーザ名及びパスワード確認してください。
Suspend database failed.
静止点確保で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Resume database failed.
静止点解放で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Internal error.
内部エラーが発生しました。
9.34. Oracle の静止点を制御する (clporclstill コマンド)
Oracleの静止点の制御を行います。
- コマンドライン
- clporclstill -d connectionstring [-u username] -sclporclstill -d connectionstring -r
- 説明
Oracleの静止点の確保/解放を制御します。
- オプション
- -d connectionstring
静止点制御の対象となるデータベースへの接続文字列を指定します。
- -u username
静止点制御を実行するデーターベースユーザ名を指定します。-s オプションを指定した場合のみ指定可能です。省略した場合はOS認証が使用されます。
- -s
静止点の確保を行います。
- -r
静止点の解放を行います。
- 戻り値
0
成功
2
コマンドオプション不正
3
DB接続エラー
4
ユーザ認証エラー
5
静止点確保失敗
6
静止点解放失敗
99
内部エラー
- 実行例
# clporclstill -d orcl -u oracle -s Command succeeded.
# clporclstill -d orcl -r Command succeeded.
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。また環境変数LD_LIBRARY_PATHにOracleのクライアントライブラリlibclntsh.soの存在するディレクトリを設定してください。さらに環境変数ORACLE_HOMEにOracleのホームディレクトリを設定してください。
-u オプションを指定せずOS認証を使用する場合、本コマンドを実行するユーザはOracleの管理者権限を得るためにdbaグループに所属している必要があります。
-u オプションに指定するユーザのパスワードは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ユーザ名:パスワード:」の形式で設定してください。行の最後にはコロン「:」を付けてください。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
パスワード設定の例: oracle:password:
-u オプションに指定するユーザにはOracleの管理者権限が必要です。
-s オプションで静止点確保コマンドを実行して静止点確保に成功した場合、その静止点確保コマンドは常駐したまま制御を戻しません。別プロセスにて -r オプションで静止点開放コマンドを実行することにより、常駐していた静止点確保コマンドが終了して制御が戻ります。
本コマンドを実行する場合、事前にOracleをARCHIVELOGモードに設定しておく必要があります。
本コマンドを使用して静止点確保を行った状態で取得したOracleのデータファイルはバックアップモードになっています。データファイルをリストアして利用する場合はOracle上でバックアップモードを解除する必要があります。
- エラーメッセージ
メッセージ
原因/対処
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Cannot connect to database.
データーベースに接続できません。データーベース名及びデータベースの状態を確認してください。
Username or password is not correct.
ユーザ認証で失敗しました。ユーザ名及びパスワード確認してください。
Suspend database failed.
静止点確保で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Resume database failed.
静止点解放で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Internal error.
内部エラーが発生しました。
9.35. SQL Server の静止点を制御する (clpmssqlstill コマンド)
SQL Serverの静止点の制御を行います。
- コマンドライン
- clpmssqlstill -d databasename -u username -v vdiusername -sclpmssqlstill -d databasename -v vdiusername -r
- 説明
SQL Serverの静止点の確保/解放を制御します。
- オプション
- -d databasename
静止点制御の対象となるデータベース名を指定します。
- -u username
静止点制御を実行するデーターベースユーザ名を指定します。
- -v vdiusername
vdiを実行するOSユーザ名を指定します。
- -s
静止点の確保を行います。
- -r
静止点の解放を行います。
- 戻り値
0
成功
2
コマンドオプション不正
3
DB接続エラー
4
-u オプションに指定したユーザの認証エラー
5
静止点確保失敗
6
静止点解放失敗
7
タイムアウトエラー
99
内部エラー
- 実行例
実行例
# clpmssqlstill -d userdb -u sa -v mssql -s Command succeeded.# clpmssqlstill -d userdb -v mssql -r Command succeeded.
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。また環境変数LD_LIBRARY_PATHにSQL ServerのVDIクライアントライブラリlibsqlvdi.soの存在するディレクトリとODBCライブラリlibodbc.soの存在するディレクトリを設定してください。
-u オプションに指定するユーザのパスワードは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ユーザ名:パスワード:」の形式で設定してください。行の最後にはコロン「:」を付けてください。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
パスワード設定の例: sa:password:
-u オプションに指定するユーザにはSQL ServerのBACKUP DATABASEステートメントを実行できる権限が必要です。
-v オプションに指定するOSユーザには、VDIクライアントの実行権限が必要です。
本コマンドのタイムアウトは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「タイムアウト名:秒数:」の形式で設定してください。行の最後にはコロン「:」を付けてください。設定しない場合は下記の例に記載の値が既定値として使用されます。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
タイムアウト(GetConfiguration)設定の例:cfgtimeout:1:
タイムアウト(GetCommand)設定の例:cmdtimeout:90:
タイムアウト(SQL)設定の例:sqltimeout:60:
データベース操作で使用するODBCドライバは事前にCLUSTERPROインストールディレクトリ下のetcディレクトリのstillpoint.confファイル内で、「ODBCドライバ:使用するODBCドライバ名:」の形式で設定してください。行の最後にはコロン「:」を付けてください。設定しない場合は下記の例に記載の値が既定値として使用されます。
ファイルパスの例: /opt/nec/clusterpro/etc/stillpoint.conf
ODBCドライバの例:odbcdriver:ODBC Driver 13 for SQL Server:
-s オプションで静止点確保コマンドを実行して静止点確保に成功した場合、その静止点確保コマンドは常駐したまま制御を戻しません。別プロセスにて -r オプションで静止点開放コマンドを実行することにより、常駐していた静止点確保コマンドが終了して制御が戻ります。
本コマンドを実行する場合は、CLUSTERPROの一部ディレクトリおよびファイルのパーミッションを以下のとおりに変更してください。なお、インストールパスを既定から変更している場合は、適宜読み替えて実施してください。
例)既定のインストールパス:/opt/nec/clusterproの場合
# chmod 755 /opt/nec/clusterpro # chmod 755 /opt/nec/clusterpro/bin # chmod 555 /opt/nec/clusterpro/bin/clpmssqlstillsub # chmod 755 /opt/nec/clusterpro/lib # chmod 555 /opt/nec/clusterpro/lib/libclpxml.so.1.0 # chmod 555 /opt/nec/clusterpro/lib/libclplog.so.1.0 # chmod 555 /opt/nec/clusterpro/lib/libclpstatsd.so.1.0
また、変更したパーミッションを元に戻す場合は以下のとおりに実施してください。
# chmod 700 /opt/nec/clusterpro # chmod 700 /opt/nec/clusterpro/bin # chmod 500 /opt/nec/clusterpro/bin/clpmssqlstillsub # chmod 700 /opt/nec/clusterpro/lib # chmod 500 /opt/nec/clusterpro/lib/libclpxml.so.1.0 # chmod 500 /opt/nec/clusterpro/lib/libclplog.so.1.0 # chmod 500 /opt/nec/clusterpro/lib/libclpstatsd.so.1.0
- エラーメッセージ
メッセージ
原因/対処
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Cannot connect to database.
データーベースに接続できません。データーベース名及びデータベースの状態を確認してください。
Username or password is not correct.
ユーザ認証で失敗しました。ユーザ名及びパスワード確認してください。
Suspend database failed.
静止点確保で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Resume database failed.
静止点解放で失敗しました。ユーザ権限及びデータベースの設定を確認してください。
Timeout.
コマンドがタイムアウトしました。
Internal error.
内部エラーが発生しました。
9.36. クラスタ統計情報を表示する(clpperfc コマンド)
クラスタ統計情報を表示します。
- コマンドライン
- clpperfc --starttime -g group_nameclpperfc --stoptime -g group_nameclpperfc -g [group_name]clpperfc -m monitor_name
- 説明
グループの起動、停止時間の中央値(ミリ秒)を表示します。
モニタリソースの監視処理時間(ミリ秒)を表示します。
- オプション
- --starttime -g group_name
グループの起動時間の中央値を表示します。
- --stoptime -g group_name
グループの停止時間の中央値を表示します。
- -g [group_name]
グループの起動、停止時間の中央値を表示します。
groupnameを省略した場合は、全グループの起動、停止時間の中央値を表示します。
- -m monitor_name
直近のモニタリソースの監視処理時間を表示します。
- 戻り値
0
成功
1
コマンドオプション不正
2
ユーザ認証エラー
3
構成情報ロードエラー
4
構成情報ロードエラー
5
初期化エラー
6
内部エラー
7
内部通信初期化エラー
8
内部通信接続エラー
9
内部通信処理エラー
10
対象グループチェックエラー
12
タイムアウトエラー
- 実行例
グループの起動時間の中央値を表示する場合
# clpperfc --starttime -g failover1 200
特定グループの起動、停止時間の中央値を表示する場合
# clpperfc -g failover1 start time stop time failover1 200 150モニタリソースの監視処理時間を表示する場合
# clpperfc -m monitor1 100
- 備考
本コマンドで出力する時間の単位はミリ秒です。
有効なグループの起動時間、停止時間が取得できなかった場合は - が表示されます。
有効なモニタリソースの監視時間が取得できなかった場合は 0 が表示されます。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
- エラーメッセージ
メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
コマンドオプションが不正です。コマンドオプションを確認してください。
Command timeout.
コマンドの実行がタイムアウトしました。
Internal error.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
9.37. クラスタ構成情報をチェックする (clpcfchk コマンド)
クラスタ構成情報をチェックします。
- コマンドライン
- clpcfchk -o path [-i conf_path]
- 説明
クラスタ構成情報を基に設定値の妥当性を確認します。
- オプション
- -o path
チェック結果を保存するディレクトリを指定します。
- -i conf_path
チェックする構成情報を保存したディレクトリを指定します。
省略した場合は、反映済みの構成情報をチェックします。
- 戻り値
0
成功
0以外
失敗
- 実行例
反映済みの構成情報をチェックする場合
# clpcfchk -o /tmp server1 : PASS server2 : PASS
保存した構成情報をチェックする場合
# clpcfchk -o /tmp -i /tmp/config server1 : PASS server2 : FAIL
- 実行結果
本コマンドの結果で表示されるチェック結果 (総合結果)は以下になります。
チェック結果(総合結果)
説明
PASS
問題がありません。
FAIL
問題があります。チェック結果を確認してください。
- 備考
各サーバの総合結果のみを表示します。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
Cluster WebUI でエクスポートした構成情報をチェックする場合、事前に解凍してください。
- エラーメッセージ
メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
Could not opened the configuration file. Check if the configuration file exists on the specified path.
指定されたパスが存在しません。正しいパスを指定してください。
Server is busy. Check if this command is already run.
本コマンドはすでに起動されています。
Failed to obtain properties.
プロパティの取得に失敗しました。
Failed to check validation.
クラスタ構成チェックに失敗しました。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足またはOSのリソース不足が考えられます。確認してください。
9.38. 通信ポートの接続可否をチェックする (clpsvportchk.sh コマンド)
通信ポートの接続可否をチェックします。
- コマンドライン
- clpsvportchk [-h server_name]
- 説明
クラスタ構成情報をもとに利用ポートの接続可否を確認します。
- オプション
- -h server_name
チェックする対象サーバのホスト名を指定します。
省略した場合は、コマンド実行中のサーバをチェックします。
- 戻り値
0
成功(すべてのポートが解放)
1
成功(閉じているポートが存在)
2
タイムアウト
3
コマンドオプション不正
4
内部エラー
- 実行例
対象サーバ上でポートの接続可否をチェックする場合
# clpsvportchk.sh - 29001 / Internal communication: OK - 29002 / Data transfer: OK - 29003 / Alert synchronization: NG - 29008 / Cluster information management: OK
対象サーバを指定してポートの接続可否をチェックする場合
# clpsvportchk.sh -h server1 - 29001 / Internal communication: OK - 29002 / Data transfer: OK - 29003 / Alert synchronization: NG - 29008 / Cluster information management: OK
- 備考
使用するポートをデフォルトから変更する場合は、構成情報反映後に実行してください。
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
- エラーメッセージ
メッセージ
原因/対処
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
9.39. クラスタ構成情報ファイルを変換する (clpcfconv.sh コマンド)
クラスタ構成情報ファイルの変換を行います。
- コマンドライン
- clpcfconv.sh -i <input-path> [-o <output-path>]
- 説明
クラスタ構成情報ファイルを旧バージョンから現バージョンへ変換します。
- オプション
- -i <input-path>
旧バージョンの構成情報ファイルが存在するディレクトリを指定します。
- -o <output-path>
- 変換後の構成情報ファイルを出力するディレクトリを指定します。本オプションを省略した場合、カレントディレクトリに変換後の構成情報ファイルが出力されます。
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは、root 権限を持つユーザで実行してください。
本コマンドは、クラスタ構成情報ファイルのうち、clp.conf のみを変換します。
本コマンドは、<インストール先ディレクトリ>/etc 直下では実行できません。
本コマンドは、CLUSTERPRO X 3.3 for Linux(内部バージョン 3.3.5-1)より古いバージョンで作成したクラスタ構成情報ファイルには対応していません。
CLUSTERPRO X 6.0 より古いバージョンでクラスタパスワード方式のパスワードを設定していた場合、本コマンドでクラスタ構成情報ファイルを変換するとパスワードが次のように設定されます。
- CLUSTERPRO X 5.0 より古いバージョンの場合変換後、すべてのパスワードがクリアされます。変換後のクラスタ構成情報を反映後、Cluster WebUI を使用して [操作・設定用パスワード]、[操作用パスワード]、[参照用パスワード] を再設定してください。
- CLUSTERPRO X 5.0 以降、 CLUSTERPRO X 6.0 より古いバージョンの場合旧バージョンの [操作用パスワード] は、[操作・設定用パスワード] と [操作用パスワード] 両方に設定されます。旧バージョンの [参照用パスワード] は、[参照用パスワード] として引き継がれます。[操作・設定用パスワード] と [操作用パスワード] を異なる値に設定したい場合は、変換後のクラスタ構成情報を反映後、Cluster WebUI を使用して変更してください。
パスワードの設定方法は、本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「WebManagerタブ」を参照してください。
- 実行例
変換が成功した場合
# clpcfconv.sh -i /tmp/config_x430 -o /tmp/config_new Command succeeded.
変換が成功し、パスワードがクリアされた場合
# clpcfconv.sh -i /tmp/config_x430 -o /tmp/config_new Command succeeded. Password for Operation/Configuration has been initialized. Password for Reference has been initialized. Please set the password again by using Cluster WebUI.
本コマンドで変換できない設定が存在する場合
# clpcfconv.sh -i /tmp/config_x520 -o /tmp/config_new Command succeeded. Warning: This command cannot convert the following settings in the Cloud tab of Cluster Properties. For already configured items, use Cluster WebUI to set them again in the Environment Variable tab of Server Properties. - Environment variables at the time of performing AWS-related features Warning: This command cannot convert the following settings. For already configured items, use Cluster WebUI to set each of them again to HTTP_PROXY or HTTPS_PROXY in the Environment Variable tab of Server Properties. - Server Properties - Proxy tab - Oracle Cloud DNS Resource Properties: Use Proxy [Targets] Server: - server1 - server2 Oracle Cloud DNS Resource: - ocdns1
- エラーメッセージ
メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Password for Operation/Configuration has been initialized.
クラスタパスワード方式の操作・設定用パスワードをクリアしました。
Password for Reference has been initialized.
クラスタパスワード方式の参照用パスワードをクリアしました。
Please set the password again by using Cluster WebUI.
Cluster WebUI を使用してクリアされたパスワードを再設定してください。
Warning: This command cannot convert the following settings in the Cloud tab of Cluster Properties.For already configured items, use Cluster WebUI to set them again in the Environment Variable tab of Server Properties.- AWS CLI Command line options- Environment variables at the time of performing AWS-related features[クラスタのプロパティ] - [クラウド] タブの下記設定は、本コマンドで変換できません。Cluster WebUI を使用して [サーバプロパティ] - [環境変数] タブに再設定してください。・AWS CLI コマンドラインオプション・AWS関連機能実行時の環境変数なお、上記各設定はそれぞれ該当する設定が行われている場合のみ出力します。Warning: This command cannot convert the following settings.For already configured items, use Cluster WebUI to set each of them again to HTTP_PROXY or HTTPS_PROXY in the Environment Variable tab of Server Properties.- Server Properties - Proxy tab- Witness HeartBeat Properties: Use Proxy- HTTP NP Properties: Use Proxy- Oracle Cloud DNS Resource Properties: Use Proxy下記の Proxy 関連の設定は本コマンドで変換できません。Cluster WebUI を使用して [サーバプロパティ] - [環境変数] タブに HTTP_PROXY または HTTPS_PROXY として再設定してください。・サーバプロパティ - [Proxy] タブ・Witnessハートビートプロパティ「Proxyを使用する」・HTTP NPプロパティ「Proxyを使用する」・Oracle Cloud DNSリソースプロパティ「Proxyを使用する」なお、上記各設定は、それぞれ該当する設定が行われている場合のみ出力し、[Targets] に設定が行われているサーバ名、または、リソース名が出力されます。[Targets]%1:- %2再設定が必要な Proxy 関連の設定が行われているサーバ名、または、リソース名です。%1 :設定対象%2 :サーバ名、または、リソース名Log in as root.
root 権限を持つユーザで実行してください。
Not available in this directory.
<インストール先ディレクトリ>/etc 直下では実行できません。カレントディレクトリを <インストール先ディレクトリ>/etc 以外に変更してください。Could not opened the configuration file. Check if the configuration file exists on the specified path.
-i オプションで指定したパスにクラスタ構成情報ファイル(clp.conf)が存在しません。クラスタ構成情報ファイルが指定されたパスに存在するか確認してください。The specified output-path does not exist.
-o オプションで指定したパスが存在しません。正しいパスを指定してください。Invalid configuration file.
クラスタ構成情報ファイルが不正です。クラスタ構成情報ファイルを確認してください。The version of this configuration data file is not supported. Convert it with Builder for offline use (internal version 3.3.5-1), then retry.
本コマンドがサポートしていないバージョンのクラスタ構成情報ファイルです。内部バージョン 3.3.5-1 のオフライン版 Builder で変換後、もう一度実行してください。%1 : Command failed. code:%2
コマンド %1 が失敗しました。コマンドの戻り値(%2)、または、このエラーメッセージの直前に表示されたエラーメッセージを確認してください。Command failed.
このコマンドが失敗しました。このエラーメッセージの直前に表示されたエラーメッセージを確認してください。
9.40. ファイアウォールの規則を追加する (clpfwctrl.sh コマンド)
CLUSTERPRO で使用するサーバのファイアウォールのゾーンに「ルール」の追加、削除を行います。
- コマンドライン
- clpfwctrl.sh --add [--zone=<ZONE>]clpfwctrl.sh --removeclpfwctrl.sh --help
- 説明
注釈
本コマンドは サーバのファイアウォールサービスを起動した状態で実行してください。
注釈
本コマンドは、単一サーバ上での、ファイアウォールのゾーンに「ルール」の追加、削除を行います。追加、削除を行いたい全てのサーバで実行する必要があります。
注釈
本コマンドは CLUSTERPRO インストール直後と構成情報反映直後に実行してください。
注釈
本コマンドは firewall-cmd、firewall-offline-cmd コマンドが使用できる環境のみ対応しています。
CLUSTERPROで使用するポート番号にアクセスできるようにするため、ファイアウォールのゾーンに「ルール」を追加します。また、追加した「ルール」を削除します。本コマンドで設定するポート番号、プロトコルの詳細については『スタートアップガイド』 -「注意制限事項」 - 「OS インストール後、CLUSTERPRO インストール前」 - 「通信ポート番号」を参照してください。ファイアウォールのゾーンにCLUSTERPROで使用する「ルール」を以下の名前で追加します。既に同じルール名が追加されている場合は、一度削除を行った後、追加を行います。ルール名の変更はしないでください。ルール名
clusterpro
- オプション
- --add [--zone=<ZONE>]
ファイアウォールの「ルール」を追加します。ゾーン名を指定すると、指定されたゾーンに対して「ルール」を追加します。 ゾーン名の指定がない場合は、デフォルトゾーンに対して「ルール」を追加します。
- --remove
追加したファイアウォールの「ルール」を削除します。
- --help
Usageを表示します。
- 戻り値
0
成功
0以外
失敗
- 注意事項
- 本コマンドは root 権限をもつユーザで実行してください。本コマンドはアウトバウンドについては追加を行いません。必要であれば別途追加をしてください。JVMモニタリソースを1度でも登録すると、本コマンドはJVMモニタリソースの管理ポート番号を必ず許可します。本コマンド実行時に、メモリ上に一時的に設定しているファイアウォールの設定については破棄されます。
- 実行例
デフォルトゾーンに「ルール」を追加する場合
# clpfwctrl.sh --add Command succeeded.
- 実行例
ゾーン「home」に「ルール」を追加する場合
# clpfwctrl.sh --add --zone=home Command succeeded.
- 実行例
設定した「ルール」を削除する場合
# clpfwctrl.sh --remove Command succeeded.
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
Failed to register rule(CLUSTERPRO). Invalid port.
構成情報に不正なポート番号が設定されています。構成情報を確認してください。
Failed to register rule(CLUSTERPRO). Invalid zone.
ゾーン名が不正です。ゾーン名を確認してください。
Unsupported environment.
サポート対象外のOSです。
Could not read xmlpath. Check if xmlpath exists on the specified path. (%1)
xml パスが構成情報に存在するか確認してください。%1 :xml パスCould not opened the configuration file. Check if the configuration file exists on the specified path. (%1)
構成情報が存在するか確認してください。%1 :xml パスCould not read type. Check if type exists on the policy file. (%1)
ポリシーファイルが存在しているか確認してください。%1 :xml パスnot exist xmlpath. (%1)
xml パスが構成情報に存在するか確認してください。%1 :xml パスFailed to obtain properties. (%1)
xml パスが構成情報に存在するか確認してください。%1 :xml パスNot exist java install path. (%1)
Java インストールパスが存在するか確認してください。%1 :Java インストールパスInternal error. Check if memory or OS resources are sufficient. (%1)
メモリ不足またはOSのリソース不足が考えられます。確認してください。%1 :xml パス
9.41. SELinux 用の設定をおこなう (clpselctrl.sh コマンド)
CLUSTERPRO 用の SELinux コンテキストのルールを追加して、SELinux が有効な状態でもクラスタが動作するようにします。
- コマンドライン
- clpselctrl.sh --addclpselctrl.sh --deleteclpselctrl.sh --listclpselctrl.sh --checkclpselctrl.sh --help
- 説明
- CLUSTERPRO 用の SELinux コンテキストのルールを追加します。SELinux が有効な状態で本コマンドを実行しなかった場合、CLUSTERPRO のサービスの起動や、ドライバのロードに、失敗することがあります。これらを回避するために、CLUSTERPRO インストール直後や、SELinux の設定を Enforcing へ変更する前に、本コマンドを実行してください。
注釈
SELinux が Enforcing の状態で CLUSTERPRO をインストールする場合は、CLUSTERPRO インストール直後に OSを再起動するよりも前に
clpselctrl.sh --addを実行してください。CLUSTERPRO をインストールした後に SELinux を Enforcing へ変更する場合は、 SELinux を Enforcing へ変更する前に
clpselctrl.sh --addを実行してください。CLUSTERPRO をアンインストールする場合は、
clpselctrl.sh --addで設定した情報が不要になりますので、 CLUSTERPRO をアンインストールする直前に、clpselctrl.sh --deleteを実行して削除してください。
注釈
clpselctrl.sh コマンド使用時の手順に関しては、『インストール&設定ガイド』の 「CLUSTERPRO をインストールする」 - 「CLUSTERPRO Server のセットアップ」 - 「SELinux 用の設定」を参照してください。
CLUSTERPRO アンインストール時の手順に関しては、『インストール&設定ガイド』の 「CLUSTERPRO をアンインストール/再インストールする」 - 「アンインストール手順」 - 「CLUSTERPRO Server のアンインストール」を参照してください。
注釈
過去に CLUSTERPRO のドライバをロードできるようにするために semodule -i コマンドを使って clpka.pp clpkhb.pp liscal.pp のインストールをおこなった場合には、 clpselctrl.sh --add コマンドを実行することにより、そのインストールした情報が不要になりますので、下記を実行してそれらの情報を削除してください。
# semodule -r clpka clpkhb liscal
- オプション
- -a, --add
CLUSTERPRO 用の SELinux コンテキストのルールを追加します。
- -d, --delete
--add オプションで追加した SELinux コンテキストのルールを削除します。
- -l, --list
CLUSTERPRO 用の SELinux コンテキストのルールの一覧を表示します。
- -c, --check
- CLUSTERPRO 用の SELinux コンテキストのルールが追加されているかを確認します。結果は「OK」または「NG」で表示されます。
- -h, --help
Usageを表示します。
- 戻り値
0
成功
0
OK(--checkオプションの場合)
1
失敗
1
NG(--checkオプションの場合)
2
内部エラー
3
オプション指定誤り
4
grepコマンドエラー
5
コマンドの実行権限がない
6
必要なコマンドがない
その他
その他のエラー
- 注意事項
- 本コマンドは root 権限をもつユーザで実行してください。本コマンドは、semanage コマンドと restorecon コマンドを使用します。 semanage コマンドや restorecon コマンドがインストールされていない場合には、事前にインストールをおこなってください。
# dnf -y install policycoreutils-python-utils
本コマンドでルールの追加/削除を実行するとValueErrorが表示されることがありますが、 最後にclpselctrl.sh : Command succeeded.が表示されていれば問題ありません。
- 実行例
SELinux コンテキストの設定をおこなう場合
# clpselctrl.sh --add clpselctrl.sh : Command succeeded.
- 実行例
過去に semodule -i で CLUSTERPRO のドライバ用の clpka.pp clpkhb.pp liscal.pp をインストールしていた場合
# clpselctrl.sh --add clpselctrl.sh : Please execute 'semodule -r clpka clpkhb liscal' to remove these SELinux policy packages. clpselctrl.sh : Command succeeded. # semodule -r clpka clpkhb liscal libsemanage.semanage_direct_remove_key: Removing last clpka module (no other clpka module exists at another priority). libsemanage.semanage_direct_remove_key: Removing last clpkhb module (no other clpkhb module exists at another priority). libsemanage.semanage_direct_remove_key: Removing last liscal module (no other liscal module exists at another priority).
- 実行例
設定済みの時に、チェックと一覧表示を実行した場合
# clpselctrl.sh --check OK # clpselctrl.sh --list /opt/nec/clusterpro/drivers(/.*)? /opt/nec/clusterpro/etc/init.d/.* /opt/nec/clusterpro/etc/systemd/.*\.service /opt/nec/clusterpro/etc/systemd/.*\.sh
- エラーメッセージ
メッセージ
戻り値
原因/対処法
Command succeeded.
0
設定または削除に成功した。もしくは既に設定や削除がおこなわれていた。Command failed.
1
設定または削除に失敗した。
OK
0
既に設定済み。(--checkオプションの場合)
NG
1
未設定、または、削除済み。(--checkオプションの場合)
Internal error.
2
メモリ不足またはOSのリソース不足が考えられます。確認してください。
Invalid option.
3
正しいオプションを指定してください。
grep command failed.
4
grep コマンドでエラーが発生しました。
Log in as root.
5
root 権限を持つユーザで実行してください。
'semanage' and 'restorecon' commands are required.
6
semanageコマンドやrestoreconコマンドが見つかりません。インストールしてください。
Please execute 'semodule -r clpka clpkhb liscal' to remove these SELinux policy packages.
--
古い設定があります。表示されたコマンドを実行して古い設定を削除してください。
9.42. サーバ別アラートログファイルを出力する (clpalttrace コマンド)
サーバ別アラートログファイルを出力するコマンドです。
- コマンドライン
- clpalttrace [-o csv_path] [ -m max_alert_count ] [-r] [-c server1_ms:server2_ms:...]
- 説明
- サーバ毎にメッセージが別れたアラートログの情報を CSV ファイルに出力します。CSV ファイルは <インストールパス>/log/alttrace.csv に出力します。CSV ファイルの形式は、『メンテナンスガイド』の「サーバ別アラートログ出力機能」を参照してください。
- オプション
- -o csv_path
- 出力する CSV ファイルのパスを指定します。相対パスまたは絶対パスでの指定が可能です。出力先ディレクトリの実体は、以下のいずれかのディレクトリ配下である必要があります。
ディレクトリ
パスの指定例
実行ユーザのホームディレクトリ
/root/cluster-logs/alttrace.csv
OS の一時ディレクトリ
/tmp/alttrace.csv
パスは中間ディレクトリを含め全て ASCII 文字で指定します。指定したパスに既存のファイルが存在する場合は、そのファイルを上書きします。-o オプションを省略した場合は、<インストールパス>/log/alttrace.csv に出力します。
- -m max_alert_count
- CSV ファイルに出力する最大のアラートログ件数を指定します。max_alert_count には、1 ~ [クラスタのプロパティ] - [アラートログ] タブ - [保存最大アラートレコード数] の件数の範囲で指定可能です。省略した場合は、アラートログ件数は 1,000 件になります。
- -r
- ログの順番を降順 (Time の降順) で出力します。省略した場合は、昇順 (Time の昇順) で出力します。
- -c server1_ms:server2_ms:...
- 各サーバのログの発生日時を全て補正します。補正前の日時が CSV 内の RawTime に設定され、補正後の日時が CSV 内の Time に設定されます。各サーバの補正値を server1_ms:server2_ms:... に指定します。server1_ms:server2_ms:... の形式は以下のとおりです。- 各サーバの補正値 (単位:ミリ秒) をコロン (:) で分かち書きします。(例:0:1234:-5678)- コロン (:) の左右に空白を含むことはできません。- 左から右へサーバの優先順位が高いサーバから低いサーバの順に補正値を指定します。- 全てのサーバの補正値を指定する必要があります。- 対象サーバの発生日時を進めたい場合、補正値として 正の自然数 を指定します。最大値は 2,147,483,647 です。(例:1234)- 対象サーバの発生日時を戻したい場合、補正値として 負の自然数 を指定します。最小値は -2,147,483,648 です。(例:-5678)- 対象サーバの発生日時を補正しない場合、補正値として 0 を指定します。-c オプションを省略した場合、発生日時の補正は行いません。CSV 内の RawTime, Time には同じ日時が設定されます。
- 戻り値
0
成功
0以外
失敗
- ヒント
- 本コマンドで出力されるアラートメッセージは、Cluster WebUI のアラートログと共通です。既定で出力されるアラートメッセージは、『リファレンスガイド』の「syslog、アラート、userlog、メール通報、SNMP トラップメッセージ、Message Topic」に記載のメッセージ一覧の表から alert に●印のあるメッセージが該当します。出力したいアラートメッセージが、既定で出力されるか否か上記のメッセージ一覧の表から確認することをおすすめします。例えば、グループリソースの起動・停止のアラートメッセージは既定では出力されません。既定の出力から変更したい場合、『リファレンスガイド』の「アラートサービスタブ」- [アラート通報先を変更する] からカスタマイズすることができます。
- 注意事項
本コマンドは root 権限をもつユーザで実行してください。
本コマンドを同時刻に複数起動することはできません。
Cluster WebUI のアラートログの表示と異なる場合があります。Cluster WebUI のアラートログで表示可能な受信日時は本コマンドでは出力されません。
各サーバの時刻がずれている場合、アラートログファイル内の日時もずれたまま出力されます。このため、クラスタ内のすべてのサーバの時刻を定期的に同期する運用を推奨します。(-c オプションを使用して固定値によるアラートログファイル内の日時の補正も可能です)
-m オプションで大きな件数を指定した場合、本コマンドの実行完了までに時間がかかる場合があります。
-c オプションはサマータイムを考慮した補正には対応していません。サマータイムが切り替わる前後 1 時間における補正後の日時の順序は、実際の順序とは一致しません。
- 実行例
例1 : サーバ別アラートログファイルを出力する場合
# clpalttrace Command succeeded.
例2 : /root/cluster-logs/alttrace.csv に出力する場合
# clpalttrace -o /root/cluster-logs/alttrace.csv Command succeeded.
例3 : 最大 2,000 件のアラートログを出力する場合
# clpalttrace -m 2000 Command succeeded.
例4 : ログを降順にして出力する場合
# clpalttrace -r Command succeeded.
例5 : サーバ3台構成において、server1 の発生日時は補正なし、server2 の全発生日時を 2345 ミリ秒進める, server3 の全発生日時を -3456 ミリ秒戻す補正を行って出力する場合
# clpalttrace -c 0:2345:-3456 [Time correction] server1: +0 ms server2: +2345 ms server3: -3456 ms Command succeeded.
- エラーメッセージ
メッセージ
原因/対処
Command succeeded.
コマンドは成功しました。
Log in as root.
コマンドの実行権がありません。root 権限を持つユーザで実行してください。
Invalid option.
正しいオプションを指定してください。
Initialization error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
This command is already run.
本コマンドはすでに起動されています。
Failed to get alert logs.
アラートログの取得に失敗しました。アラートサービスが起動しているか確認してください。
Failed to get data for time correction.
時刻補正用情報の取得に失敗しました。
Failed to export the CSV file.
CSV の出力に失敗しました。ファイルが既に開かれている、または、メモリ不足、OS のリソース不足が考えられます。確認してください。
Internal error. Check if memory or OS resources are sufficient.
メモリ不足または OS のリソース不足が考えられます。確認してください。
9.43. サービス起動遅延時間の待ち合わせ処理を制御する (clpswctrl.sh コマンド)
サービス起動遅延時間の待ち合わせ処理を制御します。
- コマンドライン
- clpswctrl.sh -cclpswctrl.sh -h
- 説明
- CLUSTERPROのサービスが起動するまでの時間を遅延するために待機する時間をスキップします。
- オプション
- -c, --cancel
- サービスの起動遅延時間の待ち合わせ処理をキャンセルします。本オプションは、サービスの起動遅延時間の待ち合わせ処理中にのみ有効です。
- -h, --help
Usage を表示します。
- 戻り値
0
成功
0以外
失敗
- 注意事項
- 本コマンドは root 権限をもつユーザで実行してください。本コマンドはサービスの起動遅延時間の待ち合わせ処理中にのみ有効です。
- 実行例
- サービスの起動遅延時間の待ち合わせ処理をキャンセルする場合
# clpswctrl.sh -c Command succeeded.
- エラーメッセージ
メッセージ
原因/対処法
Log in as root.
root 権限を持つユーザで実行してください。
Invalid option.
コマンドラインオプションが不正です。正しいオプションを指定してください。
Cluster service has already been started.
すでにクラスタは起動しています。
Cancel process has failed.
キャンセル処理に失敗しました。
9.44. サービスの自動起動を有効/無効化する (clpsvcctrl コマンド)
CLUSTERPRO で使用するサービスの自動起動を有効または無効に変更します。
- コマンドライン
- clpsvcctrl.sh --enable {-a | base | core | mgr | <service_name>}clpsvcctrl.sh --disable {-a | base | core | mgr | <service_name>}clpsvcctrl.sh --listclpsvcctrl.sh --help
- 説明
CLUSTERPRO で使用するサービスの自動起動を有効または無効に変更します。
- オプション
- --enable {-a | base | core | mgr | <service_name>}
- --disable {-a | base | core | mgr | <service_name>}
- サービスの自動起動を有効または無効に変更します。-a を指定すると、CLUSTERPRO 全てのサービスの自動起動を有効または無効に変更します。<service_name> を指定すると、指定したサービスの自動起動を有効または無効に変更します。base, core, mgr のいずれかを指定すると、オプションに対応したサービスの自動起動を有効または無効に変更します。詳細については以下の「サービス、オプション一覧」を確認してください。※ ✓ はオプションに対応したサービスが含まれます。n/a はオプションに対応したサービスは含まれません。
- サービス、オプション一覧
サービス名
-a
base
core
mgr
clusterpro_evt
✓
✓
n/a
n/a
clusterpro_nm
✓
✓
n/a
n/a
clusterpro_trn
✓
✓
n/a
n/a
clusterpro_ib
✓
✓
n/a
n/a
clusterpro_api
✓
n/a
n/a
n/a
clusterpro_md
✓
n/a
✓
n/a
clusterpro
✓
n/a
✓
n/a
clusterpro_webmgr
✓
n/a
n/a
✓
clusterpro_alertsync
✓
n/a
n/a
✓
- --list
CLUSTERPRO で使用するサービスの一覧と自動起動の設定を確認します。
- --help
Usage を表示します。
- 戻り値
0
成功
0以外
失敗
- 注意事項
本コマンドは root 権限をもつユーザで実行してください。
- 実行例
CLUSTERPRO の全てのサービスの自動起動を有効に変更する場合
# clpsvcctrl.sh --enable -a
- 実行例
CLUSTERPRO の core の自動起動を有効に変更する場合
# clpsvcctrl.sh --enable core
- 実行例
CLUSTERPRO の全てのサービスの自動起動を無効に変更する場合
# clpsvcctrl.sh --disable -a
- エラーメッセージ
メッセージ
原因/対処法
Invalid option.
正しいオプションを指定してください。