1. 前言¶
1.1. 读者对象和用途¶
《EXPRESSCLUSTER X开始指南》以首次使用EXPRESSCLUSTER的用户为对象,介绍了EXPRESSCLUSTER的产品概要,集群系统导入的过程,其他手册的使用方法等。同时还介绍了最新的运行环境信息以及限制事项等。
1.2. 本手册的构成¶
1.3. EXPRESSCLUSTER手册体系¶
EXPRESSCLUSTER 的手册分为以下 6 类。各指南的标题和用途如下所示。
《EXPRESSCLUSTER X 开始指南》(Getting Started Guide)
本手册的读者对象为使用EXPRESSCLUSTER的用户,对产品概要,运行环境,升级信息以及现有的问题等进行了说明。
《EXPRESSCLUSTER X 安装&设置指南》(Install and Configuration Guide)
本手册的读者对象为导入使用EXPRESSCLUSTER的集群系统的系统工程师以及导入集群系统后进行维护和操作的系统管理员。对导入使用了EXPRESSCLUSTER的集群系统后到开始操作前的必备事项进行说明。本手册按照实际导入集群系统时的顺序,对使用EXPRESSCLUSTER的集群系统的设计方法,EXPRESSCLUSTER的安装设置步骤,设置后的确认以及开始操作前的测试方法进行说明。
《EXPRESSCLUSTER X 参考指南》(Reference Guide)
本手册的读者对象为管理员以及导入使用了EXPRESSCLUSTER的集群系统的系统工程师。手册说明了EXPRESSCLUSTER 的操作步骤,各模块的功能以及疑难解答信息等,是对《安装&设置指南》的补充。
《EXPRESSCLUSTER X 维护指南》(Maintenance Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统后进行维护和操作的系统管理员,对EXPRESSCLUSTER的维护的相关信息进行了说明。
《EXPRESSCLUSTER X 硬件整合指南》 (Hardware Feature Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统的系统工程师,对特定的硬件以及与其整合的功能进行说明。是对《安装&设置指南》的补充。
《EXPRESSCLUSTER X 兼容功能指南》(Legacy Feature Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统的系统工程师,对EXPRESSCLUSTER X 4.0 WebManager以及Builder的相关信息等进行了说明。
1.4. 本手册的标记规则¶
在本手册中,需要注意的事项,重要的事项以及相关信息等用如下方法标记。
注解
表示虽然比较重要,但是并不会引起数据损失或系统以及机器的损伤的信息。
重要
表示为避免数据损失和系统,机器损坏所必需的信息。
参见
表示参考信息的位置。
另外在本手册中使用以下标记法。
标记 |
使用方法 |
例 |
|---|---|---|
[ ]方括号
|
在命令名的前后,
显示在画面中的字句 (对话框,菜单等) 的前后。
|
点击[开始]。
[属性]对话框
|
命令行中的[ ]方括号
|
表示括号内的值可以不予指定
(可省)。
|
clpstat -s[-h host_name] |
# |
表示Linux用户正以root身份登录的提示符。 |
|
等宽字体
|
路径名,命令行,系统输出(消息,提示等),目录,文件名,函数,参数。
|
/Linux/4.3/cn/server/
|
粗体
|
表示用户在命令提示符后实际输入的值。
|
输入以下值。
clpcl -s -a
|
斜体 |
用户将其替换为有效值后输入的项目。
|
clpstat -s[-h host_name] |
 在本手册的图中,为了表示EXPRESSCLUSTER,使用该图标。
在本手册的图中,为了表示EXPRESSCLUSTER,使用该图标。
2. 何谓集群系统¶
本章介绍集群系统的概要。
本章介绍以下内容。
2.1. 集群系统的概要¶
在今天的计算机社会中,不中断地持续提供服务是成功的关键所在。例如仅仅由于1台机器因故障或超负荷运行而宕机,从而造成向客户提供的服务全面中断。这样不仅会造成不可估量的损失,还可执行失去客户的信赖。
而集群系统就是避免这种事态发生的系统。导入集群系统后,或者能够将万一发生系统运行停止时的停止时间(DownTime)缩到最短,或者能够通过分散负载的方法回避系统宕机。
所谓集群就是"群""团"的意思,顾名思义,集群系统就是"将多个计算机集合成一个群(或多个群),从而提高可靠性和处理性能的系统"。集群系统有很多种,分为以下3类。其中,EXPRESSCLUSTER属于高可用性集群。
HA (High Availability) 集群
指在正常时将其中一方用作运行服务器,提供业务,运行服务器发生故障时将业务交接给待机服务器的集群形态。该集群主要目的是实现高可用性,可以交接数据。该集群包含共享磁盘型,镜像磁盘型,远程集群型。
负载均衡集群
指能够将客户端发送的请求按照合适的负载均衡原则,分配给各负载均衡主机的集群形态。该集群的主要目的实现高扩展性,一般情况不能进行数据交接。该集群包含负载均衡集群,并列数据库集群。
HPC(High Performance Computing)集群
使用所有节点的CPU,实现单一业务的集群。该集群的主要目的是实现高性能,应用范围不大。另外,该集群是HPC的一种,将更广泛范围内的节点和计算机集群捆绑在一起的网格运算技术也成为近年来关注的焦点。
2.2. HA(High Availability)集群¶
为了提高系统的可用性,普遍认为将系统部件冗余化,排除Single Point of Failure是至关重要的。所谓Single Point of Failure是指因为计算机的配置要素(硬件)只有一个,在这个部件上发生故障时则会造成业务中断这一弱点。HA集群则是通过使用多台服务器使系统冗余化,从而将系统的中断时间限制在最小,提高业务可用性(availability)的集群系统。
绝对不容许系统中断的骨干业务系统自不必说,在系统中断会给业务带来巨大影响的系统中也需要导入HA集群。
HA集群可以分为共享磁盘型和数据镜像型。下面分别介绍两种类型。
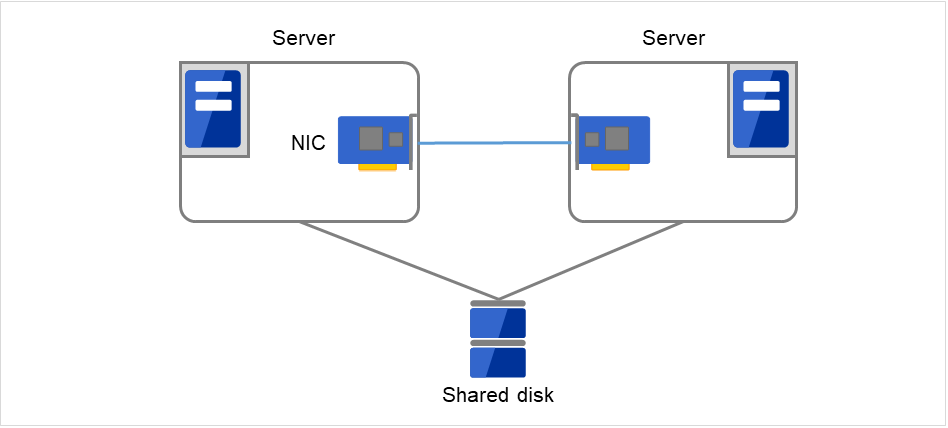
2.2.1. 共享磁盘型¶
在集群系统中,必须在服务器之间进行数据的交接。将这些数据放在共享磁盘上,多个服务器共同使用该磁盘的系统形态称为共享磁盘型。
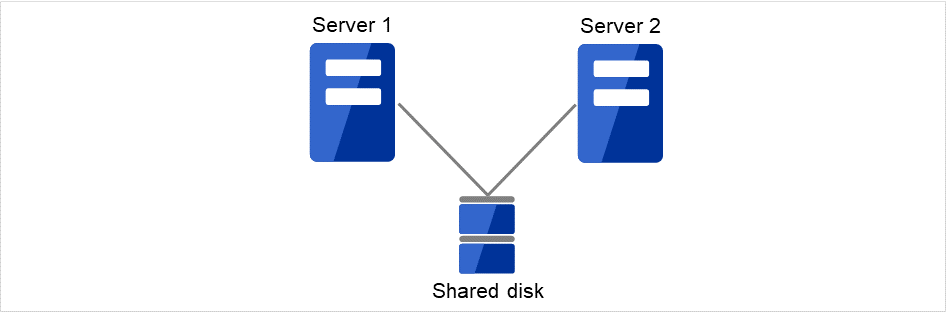
图 2.1 HA集群配置图(共享磁盘型)¶
由于需要共享磁盘而价格高
适用于处理大规模数据的系统
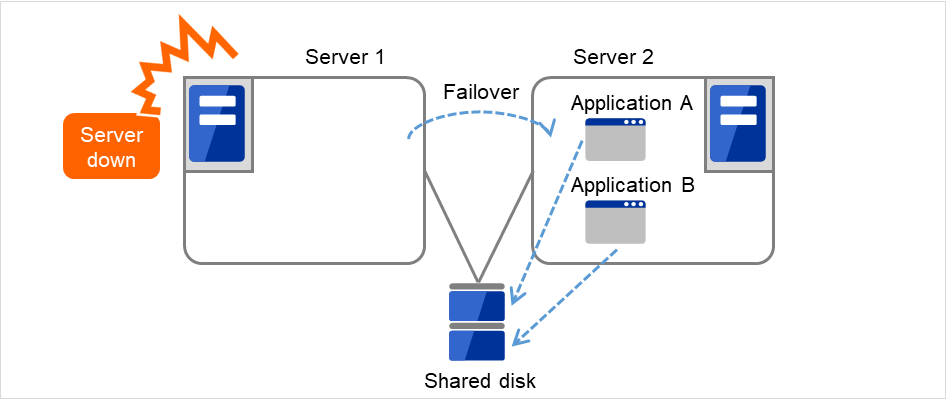
运行业务应用程序的服务器(运行服务器)发生故障时,集群系统能够查出故障,自动启动待机服务器上的业务应用程序,使业务继续进行。该功能称为失效切换。集群系统进行交接的业务由磁盘,IP地址,应用程序等资源配置。
在未进行集群化的系统中,如果在其他服务器上重新启动应用程序,客户端必须重新连接不同的IP地址。但是在多个集群系统中,会以业务为单位分配虚拟IP地址。因此,客户端不必识别现在运行的服务器是运行服务器还是待机服务器,可以完全像连接在同一台服务器上一样继续执行业务。
交接数据时必须检查文件系统的一致性。一般使用检查命令(如在Linux上会使用fsck)检查文件系统的一致性,但是文件系统越大,检查所花的时间越长,检查期间就会造成业务中断。在该系统中为了解决该问题,通过日志文件系统缩短失效切换时间。
业务应用程序需要对交接后的数据进行逻辑检查。如果是数据库,则需要进行回滚或前滚处理。通过该方法,客户端只需要重新执行未提交的SQL文,就可以使业务不中断运行。
恢复故障服务器时,只要将查出故障的服务器进行物理分离,修理之后,重新连接到集群系统上,就可以作为待机服务器恢复了。在重视业务持续性的实际运用过程中,使用这样的恢复方式就足够了。
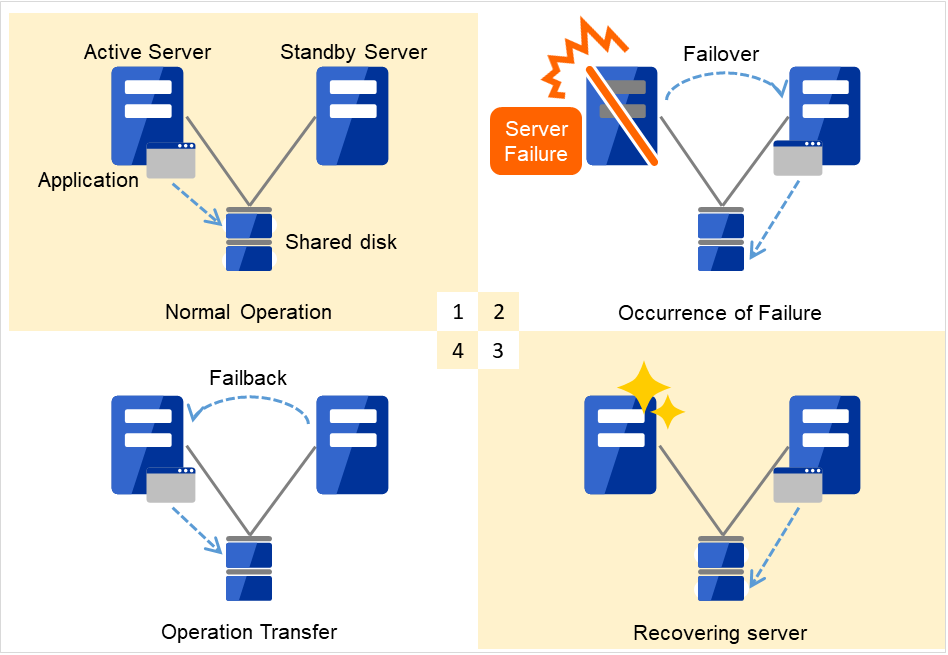
图 2.2 发生故障到服务器恢复的流程¶
一般使用
发生故障
服务器恢复
业务移动
如果失效切换到的服务器配置不够,担心双向待机负荷过大,希望在原来的服务器上运行业务时,可以进行故障恢复,重新在原来的服务器上运行业务。
如 "图 2.3 HA集群的运行形态" 所示,只有一个业务,在待机服务器上没有运行业务的待机形态称为单向待机。
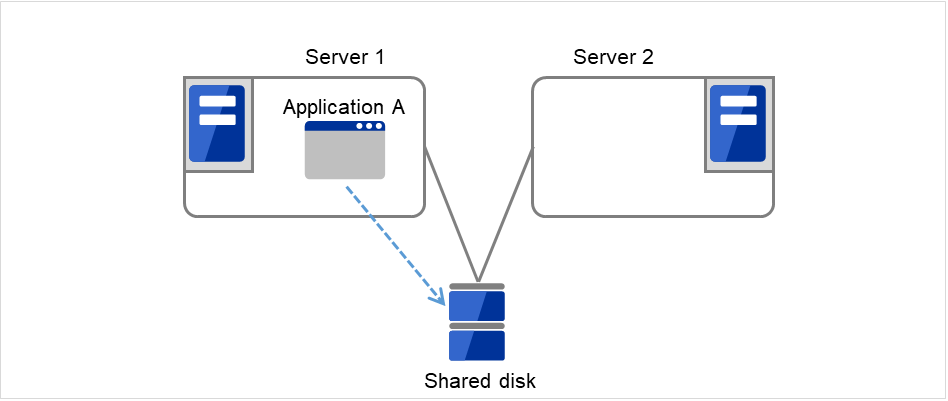
图 2.3 HA集群的运行形态(单向待机)¶
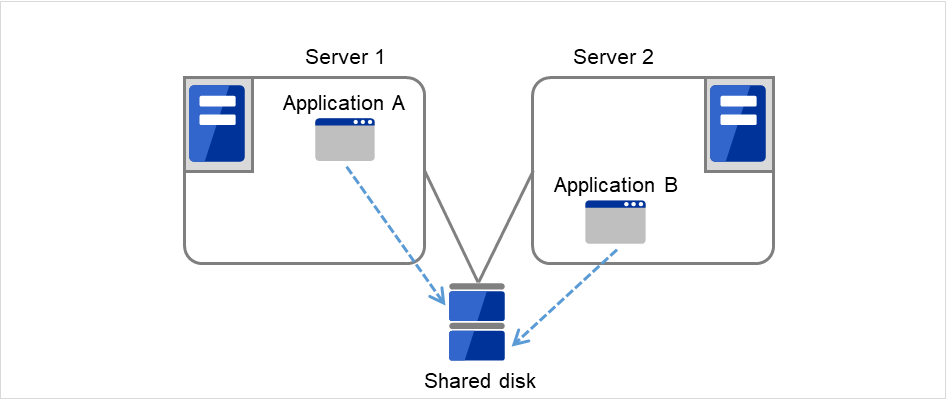
图 2.4 HA集群的运行形态(双向待机)¶
2.2.2. 数据镜像型¶
之前介绍的共享磁盘型适用于大规模系统,但是由于共享磁盘大多很昂贵,所以搭建系统的成本也就随之增加。不使用共享磁盘,在各服务器之间对各服务器上的磁盘进行镜像,通过该方法用低廉的价格实现相同功能的集群系统称为数据镜像型。
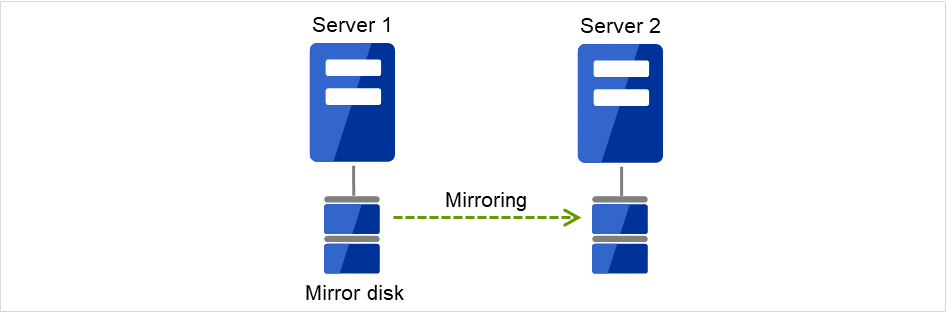
图 2.5 HA集群配置图(数据镜像型)¶
由于不需要共享磁盘而价格便宜
适用于由于镜像而导致数据量不大的系统
但是,因为需要在服务器之间进行数据的镜像,因此不适用于需要大量数据的大规模系统。
应用程序发出write请求时,数据镜像引擎会将数据写入本地磁盘的同时,通过心跳线将write请求同时分发给待机服务器。所谓心跳线是指连接各服务器的网络,在集群系统中需要使用心跳线进行服务器的生存状态监视。在数据镜像类型中,心跳线除了用于生存状态监视,还用于数据传输。待机服务器数据镜像引擎将收到的数据写入待机服务器的本地磁盘,从而实现运行服务器和待机服务器间的数据同步。
应用程序发出Read请求时,则只需单纯从运行服务器的磁盘中读取数据即可。
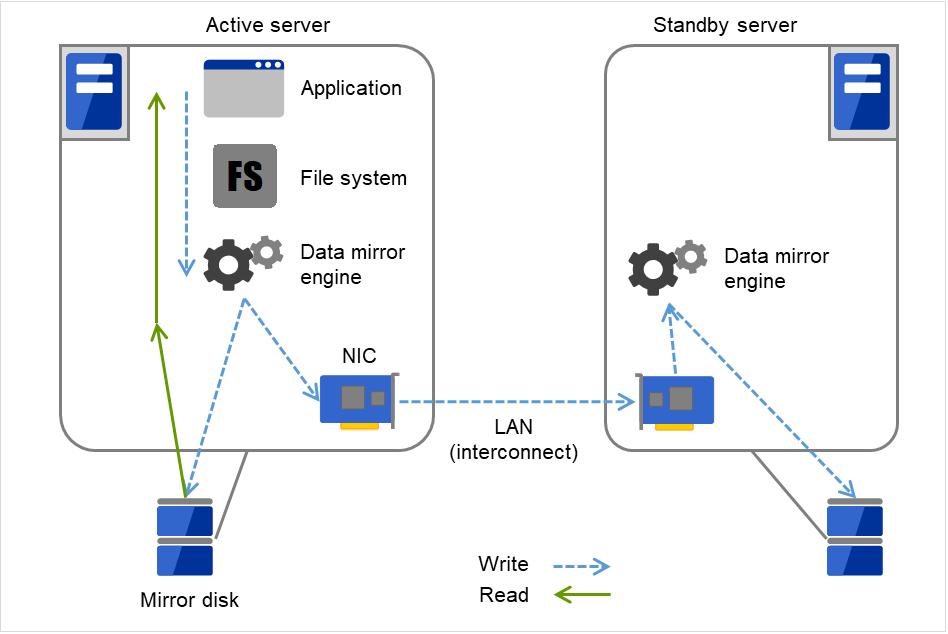
图 2.6 数据镜像的结构¶
作为数据镜像的一个应用示例,可以使用快照备份。数据镜像类型的集群系统由于同时在2处保存共享数据,因此只需将待机服务器从集群中分离开,无需备份,就可以将磁盘作为快照备份保存。
失效切换的机制和问题
至此,我们一口气介绍了包含失效切换集群,负载均衡集群,HPC(High Performance Computing)集群等多种多样的集群系统。我们了解了失效切换集群称为HA(High Availability)集群,其目的是通过将服务器多重化,发生故障时将运行的业务转移到其他服务器上,从而提高业务的可用性(Availability)。下面介绍集群的结构和问题。
2.3. 查出故障的原理¶
集群软件一旦查出影响业务继续运行的故障,就会进行业务的切换(失效切换)。在介绍失效切换处理的详细内容之前,先简单了解一下集群软件是如何检测故障的。
心跳和服务器的故障检测
在集群系统中,应该查出的最基本故障是配置集群的各服务器均停止运行。服务器故障中,包括电源故障,内存错误等硬件故障和OS的panic。要查出该故障,则需要在服务器生存状态监视中使用心跳。
心跳也可以是确认ping应答这样的简单的生存状态监视,但是使用集群软件还能够互相传送本服务器的状态信息。集群软件进行心跳信息的收发信息,没有心跳应答时则认为该服务器发生故障,开始进行失效切换处理。但是考虑到服务器也可执行是因为负载较高,收发心跳信息有延迟,在做出服务器故障判断之前留有一定的缓冲时间。因此,实际发生故障的时间和集群软件查出故障的时间之间有一定时滞。
资源的故障检测
造成业务中断的原因不仅仅是配置集群服务器全部中断,还有可执行是因为业务应用程序使用的磁盘设备或NIC 发生故障,亦或是业务应用程序本身发生故障造成业务中断。为了提高可用性,这些资源故障同样需要查出来并进行失效切换。
作为检测资源故障的方法,如果监视的对象资源是物理设备,则采取实际访问的方法。在应用程序的监视中,除了应用程序进程自身的生存状态监视,还考虑在不影响业务的范围内使用服务端口等手段。
2.4. 集群资源的交接¶
集群管理的资源中有磁盘,IP地址,应用程序等。下面介绍失效切换集群系统中用于交接这些集群资源的功能。
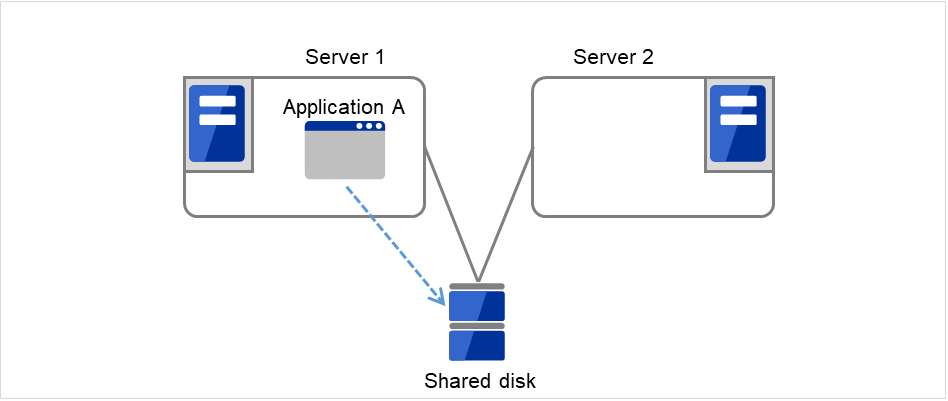
2.4.1. 数据的交接¶
在集群系统中,服务器之间交接的数据存放在共享磁盘设备的分区中。即,所谓的交接数据无非就是将保存有应用程序所使用的文件的文件系统在正常的服务器上重新mount。共享磁盘设备与交接对象服务器物理连接,集群软件需要做的就是文件系统的mount。
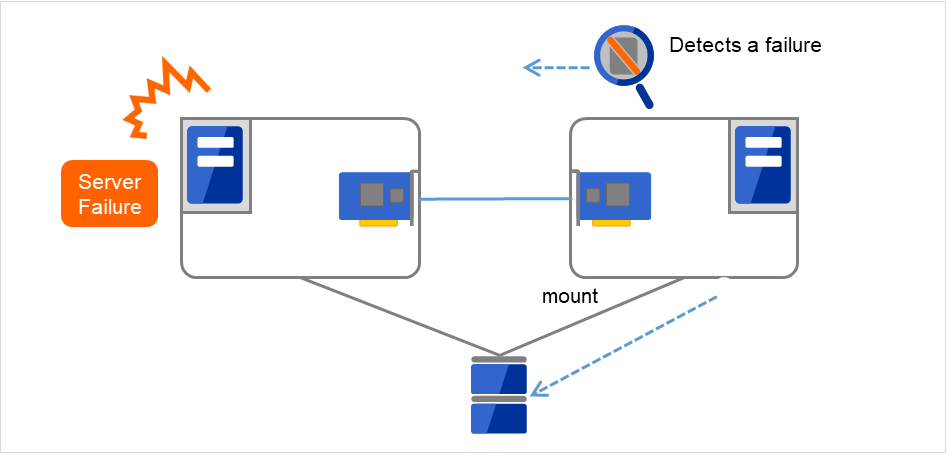
图 2.9 数据的交接¶
虽然这个过程看似简单,但是在设计构建集群系统时还是有很多需要注意的地方。
首先是文件系统的恢复时间问题。要交接的文件系统在发生故障之前可执行正在其他服务器上使用,或者正在更新。所以交接的文件系统一般是会有些垃圾,需要检查文件系统的一致性。文件系统越大,则一致性检查所需的时间就越长,有时甚至需要花几个小时,而这个时间将直接转嫁到失效切换时间(业务的交接时间)中,成为造成系统可用性下降的原因。
还有一个就是写入保证的问题。应用程序将重要的数据写入文件时,要利用同步写入等方法保证在磁盘中也写入该数据。因此,应用程序认为已经写入的数据在失效切换后希望该数据也能够被交接。例如,邮件服务器已经将收到的邮件写入缓冲处理区时,会向客户端或者其他邮件服务器发出收信结束的应答。这样,即使服务器发生故障,在服务器重启后,能够重新传输被缓冲处理的邮件。在集群系统中也一样,必须保证一方服务器写入缓冲处理区的邮件在失效切换后另一个服务器能够读取。
2.4.2. 应用程序的交接¶
集群软件在业务交接的最后工作是交接应用程序。与容错计算机(FTC)不同,在一般的失效切换集群中,不交接包含正在执行应用程序的内存内容的进程状态。即,在发生故障的服务器上运行的应用程序只能通过在正常的服务器上重新执行来完成应用程序的交接。
例如,交接数据库管理系统(DBMS)的实例时,将在启动实例时自动进行数据库的恢复(回滚/前滚等)。数据库恢复所需时间可以通过设置DBMS的Check Point Interval等进行一定的控制,但是一般都需要几分钟。
很多应用程序只要重新执行就可以重新开始运行业务,但是也有些应用程序在发生故障后需要一定的业务恢复步骤。对于这样的应用程序,集群软件将业务恢复步骤写在脚本中,在重启时将不启动应用程序,而是启动该脚本。在脚本中,记载了脚本的执行原因,执行服务器等信息,需要时还会记载尚未更新完毕的文件的整理等恢复步骤。
2.5. Single Point of Failure的排除¶
在构建高可用性系统时,把握所追求的或者说目标的可用性级别是很重要的。即,在设计系统时,必须考虑到对于可执行阻碍系统运行的各种故障应该采取的措施,如通过冗余结构保证系统持续运行,或者能够在短时间恢复到运行状态等,以及这些措施的性价比等。
Single Point of Failure(SPOF)之前已经介绍过,是指可执行造成系统中断的部位。在集群系统中,实现了服务器的多重化,能够排除系统的SPOF,但是共享磁盘等在服务器之间共享的部分可执行造成SPOF。设计系统时将这些共享部分多重化或者排除是构建高可用性系统的关键点。
集群系统虽然提高了可用性,但是失效切换时,还是需要几分钟的系统切换时间的。因此,失效切换时间也是造成可用性下降的原因之一。但是因为在高可用性系统中,ECC内存或冗余电源技术对于提高单体服务器的可用性原本就是很重要的,在本文中我们暂且不谈这些提高单体服务器可用性的技术,在集群系统中,我们挖掘可执行造成SPOF的以下3点原因,看看对此能够采取什么对策。
共享磁盘
共享磁盘的访问路径
LAN
2.5.1. 共享磁盘¶
一般共享磁盘通过磁盘阵列组建RAID,因此磁盘的成对驱动器是不会造成SPOF的。但是由于RAID控制器内置,控制器可执行会发生问题。很多集群系统中所使用的共享磁盘可以实现控制器二重化。
为了发挥二重化RAID控制器优势,一般需要进行共享磁盘访问路径的二重化。如果是二重化的多个控制器能够同时访问同一逻辑磁盘组(LUN)的共享磁盘,可以在每个控制器上分别连接一台服务器,发生控制器故障时可以通过节点间的失效切换实现高可用性。
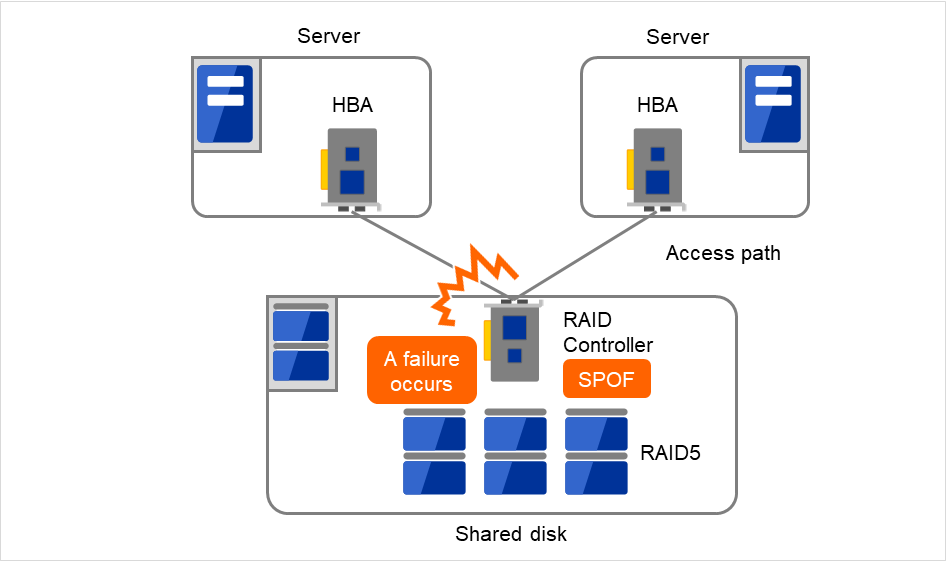
图 2.11 RAID控制器和访问路径为SPOF的示例¶
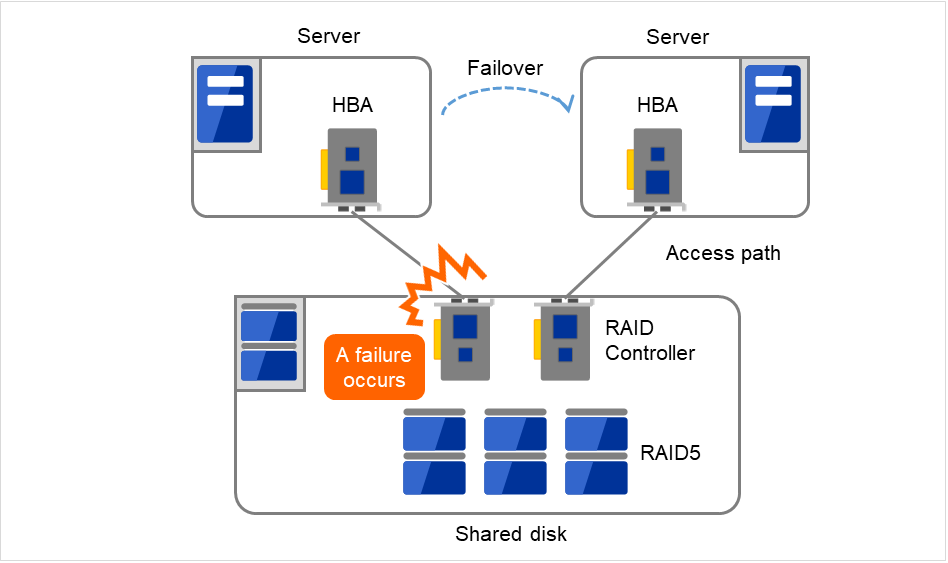
图 2.12 RAID控制器和访问路径二重化的示例¶
另外,在不使用共享磁盘的镜像磁盘型的失效切换集群中,所有的数据都与其他服务器的磁盘镜像化,能够实现没有SPOF的理想系统配置。但是,虽然以下几点不算作缺点,但也需要考虑。
通过网络进行数据镜像化对磁盘I/O性能(特别是write性能)的影响
服务器故障后恢复时,镜像重新同步过程中对系统性能的影响(镜像复制在后台执行)
镜像重新同步的时间(在镜像重新同步完成之前不会嵌入到集群中)
即,在数据引用多,数据容量不大的系统中,使用镜像磁盘型的失效切换集群也可以提高可用性。
2.5.2. 共享磁盘的访问路径¶
在普通的共享磁盘型集群结构中,共享磁盘的访问路径通过配置集群的各服务器共享。以SCSI为例,就是在一条SCSI路径上有2台服务器与共享磁盘连接。因此,共享磁盘访问路径的故障可执行是造成系统整体中断的原因。
作为其对策,可以考虑准备多条共享磁盘的访问路径,配置冗余结构,而从应用程序来看,共享磁盘的访问路径仍然只有1条。实现这一技术的设备驱动程序称为路径失效切换驱动程序(路径失效切换驱动程序多由共享磁盘供应商开发发布,Linux版的路径失效切换驱动程序好像还未开发完毕,尚未发布。现阶段,如前所述,可以通过给每个共享磁盘的阵列控制器连接一个服务器,分割共享磁盘的访问路径,通过此方法可以确保Linux集群的可用性)。
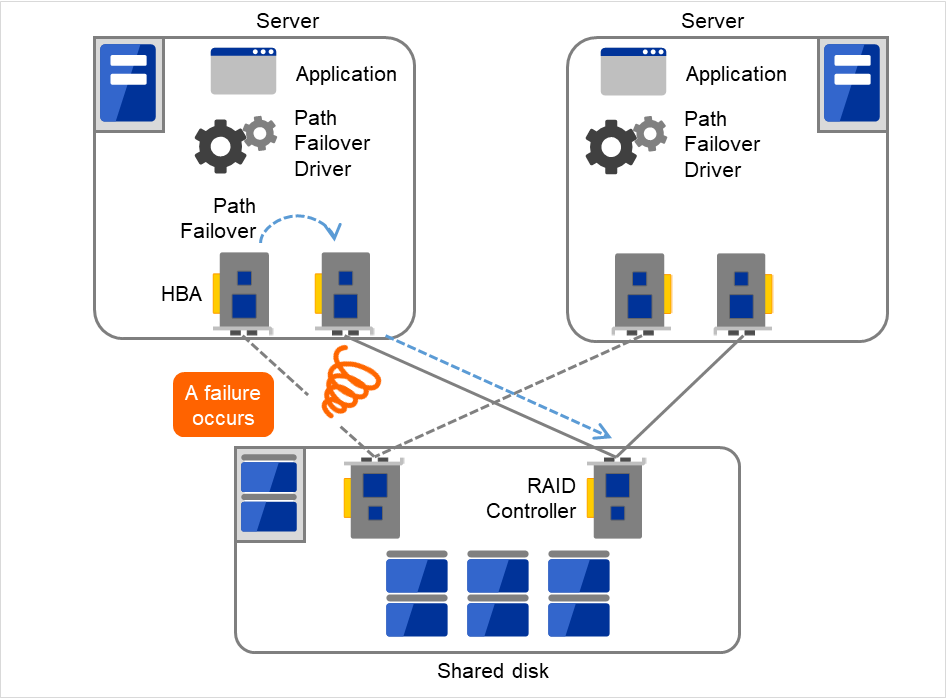
图 2.13 路径失效切换驱动程序¶
2.5.3. LAN¶
不仅仅是集群系统,所有需要在网络上执行某种服务的系统,LAN故障都是阻碍系统运行的重要原因。在集群系统中,如果配置恰当,可以在NIC发生故障时在节点之间进行失效切换,从而提高可用性,但是集群系统外的网络设备如果发生故障仍然会阻碍系统的运行。
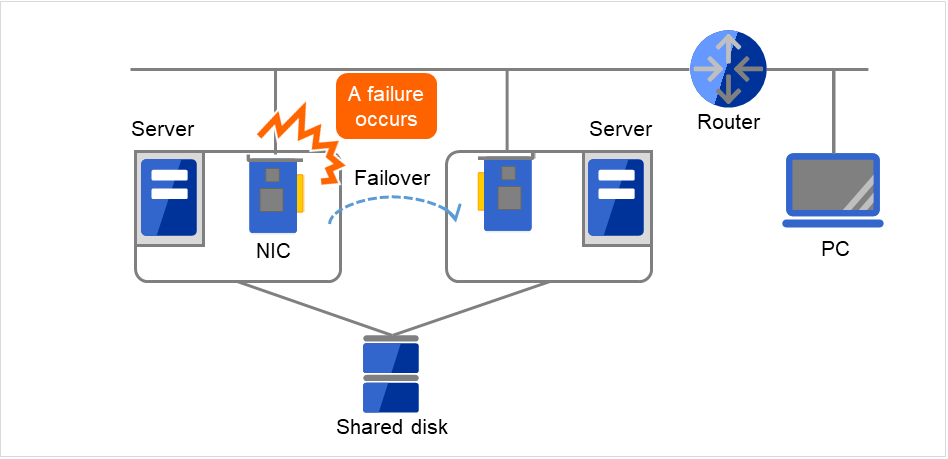
图 2.14 LAN故障的示例(NIC)¶
图中所示的情况,即使服务器上的NIC发生故障,也可以通过失效切换,继续从PC访问服务器上的服务。
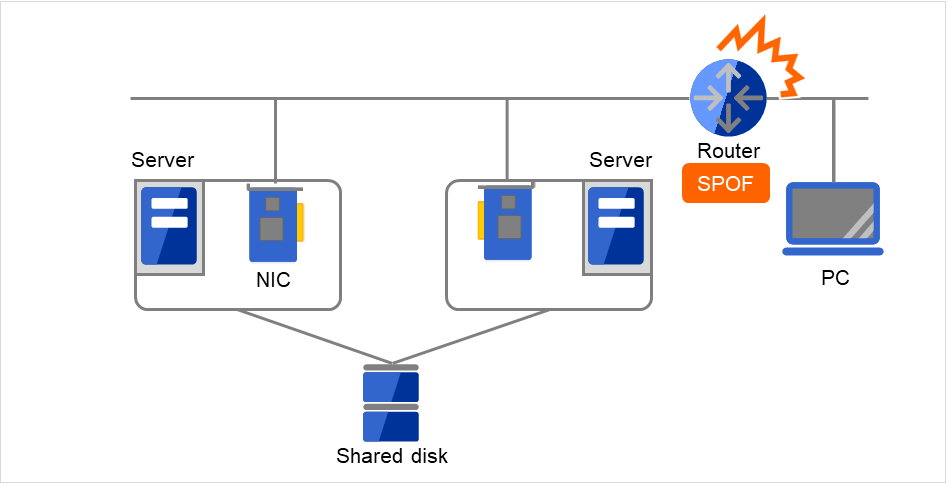
图 2.15 LAN故障的示例(Router)¶
该图所示的情况,如果路由器发生故障,则无法继续从PC访问服务器上的服务(路由器为SPOF)。
在这种情况下,可以通过LAN的冗余化提高系统的可用性。在集群系统中,也可以直接使用单体服务器上的技术提高LAN的可用性。如,一种原始方法是准备好备用的网络设备,先不打开电源,发生故障时手动切换,或者冗余配置高性能的网络设备,通过将网络路径多重化实现路径的自动切换等方法。另外,也可以考虑使用类似于因特尔公司ANS驱动程序的支持NIC冗余结构驱动程序。
负载均衡设备(Load Balance Appliance)和防火墙服务器(Firewall Appliance)都是容易发生SPOF的网络设备。这些可以通过标配或可选的软件,使其能够搭建失效切换结构。同时因为这些设备大多在系统整体中的位置非常重要,所以一般必须配置冗余结构。
2.6. 支持可用性的操作¶
2.6.1. 操作前测试¶
系统问题大多起因于配置错误或操作维护。从这一点来考虑,在实现高可用性系统时,操作前的测试和完善故障恢复手册对系统的稳定运行非常重要。作为测试观点,结合实际操作,进行以下操作可以提高可用性。
筛选故障发生位置,讨论对策,进行模拟故障测试验证
进行假定集群生存周期的测试,验证降级运行时的性能
以这些测试为基础,完善系统操作,故障恢复手册
简化集群系统的设计,能够简化上述的验证操作和手册,提高系统的可用性。
2.6.2. 故障监视¶
虽然我们已经做了上述的努力,可执行还是会发生故障。系统长期持续运行后,必然会发生故障,其原因可执行是硬件老化,软件的内存泄漏,或者操作时超过系统当初设计的承受能力等。因此,在提高硬件,软件可用性的同时,需要进一步监视故障,在发生故障时采取恰当的处理,这一点非常重要。例如,万一服务器发生故障,可以通过搭建集群系统,只需要几分钟的切换时间就可以使系统继续运行,但是如果置之不管,系统失去冗余性,发生下一个故障时集群系统就没有任何意义了。
因此,发生故障时,系统管理员必须要采取措施防范下一故障的发生,排除新发生的SPOF。在支持系统管理业务上,远程维护,故障通知等功能非常重要。勿庸置疑,Linux在远程维护方面非常优秀,故障通告的机制也在逐渐完备。
以上介绍了使用集群系统实现高可用性时所需的周边技术以及其他的一些要点。简单总结一下,就是要注意以下几点:
排除或掌握Single Point of Failure
设计简洁的抵抗故障能力强的系统,在操作前测试的基础上完善操作故障恢复步骤手册
及早查出发生的故障并进行恰当的处理
3. EXPRESSCLUSTER的使用方法¶
本章介绍EXPRESSCLUSTER各个组件的说明,从集群系统的设计到运行步骤之间的流程。
本章将介绍以下内容。
3.1. 何谓EXPRESSCLUSTER¶
现在大家已经了解了集群,下面开始介绍EXPRESSCLUSTER。所谓EXPRESSCLUSTER 就是通过冗余化(集群化)的系统结构,运行服务器发生故障时,自动用待机服务器交接业务的软件,该软件实现了系统可用性和扩展性的飞越性的提高。
3.2. EXPRESSCLUSTER的产品结构¶
EXPRESSCLUSTER大致由2个模块组成。
- EXPRESSCLUSTER ServerEXPRESSCLUSTER主体,包含所有服务器的高可用性功能。还包含Cluster WebUI的服务器一端的功能。
- Cluster WebUI创建EXPRESSCLUSTER的配置信息或者进行操作管理的管理工具。使用Web浏览器作为用户接口。实体嵌入在EXPRESSCLUSTER Server中,通过管理终端上的Web浏览器进行操作,据此与EXPRESSCLUSTER Server主体区分。
3.3. EXPRESSCLUSTER的软件配置¶
EXPRESSCLUSTER的软件配置如下图所示。在Linux服务器上安装"EXPRESSCLUSTER Server(EXPRESSCLUSTER主体)"。Cluster WebUI的主体功能包括在EXPRESSCLUSTER Server内,因此无需另行安装。除了通过管理PC上的Web浏览器以外,Cluster WebUI还能通过构成集群的各服务器上的Web浏览器进行操作。
EXPRESSCLUSTER Server
Cluster WebUI
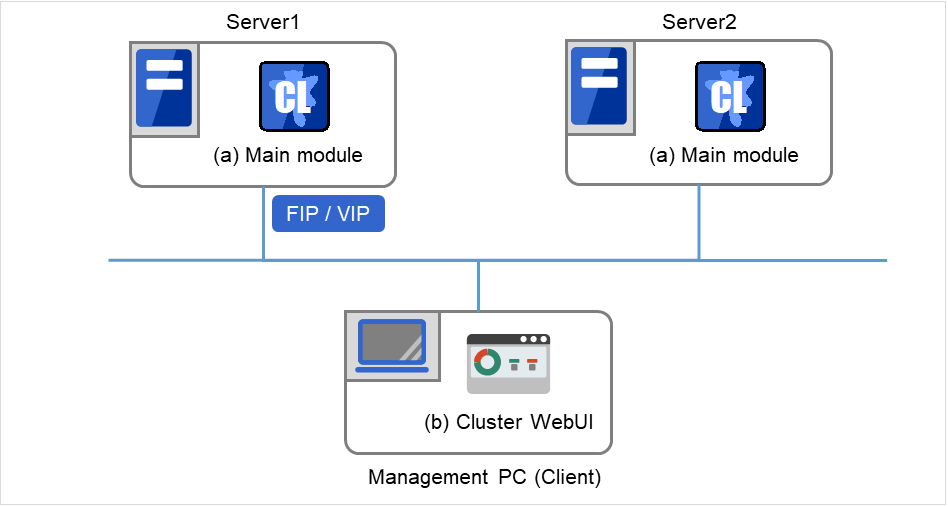
图 3.1 EXPRESSCLUSTER的软件配置¶
3.3.1. EXPRESSCLUSTER的故障监视原理¶
通过EXPRESSCLUSTER可以进行服务器监视,业务监视,内部监视等3种监视,从而能够迅速准确查出故障。下面详细介绍各种监视。
3.3.2. 何谓服务器监视¶
- 私网在失效切换型集群专用的通信线路上,使用普通的Ethernet NIC。除了确认心跳,还可以用于服务器之间的信息交换。
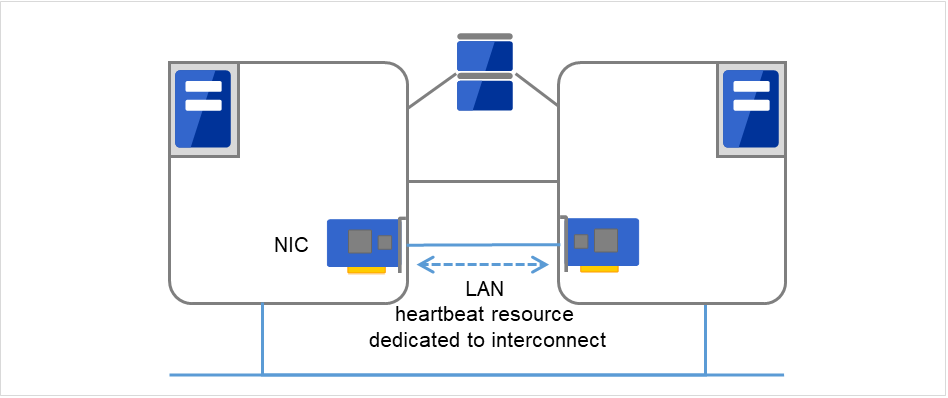
图 3.2 LAN心跳/内核模式LAN心跳(Primary interconnect)¶
- 公网作为备用心跳线,使用与客户端进行通信的通信线路。只要是能够使用TCP/IP的NIC即可。除了确认心跳,还可以用于服务器之间的信息交换。
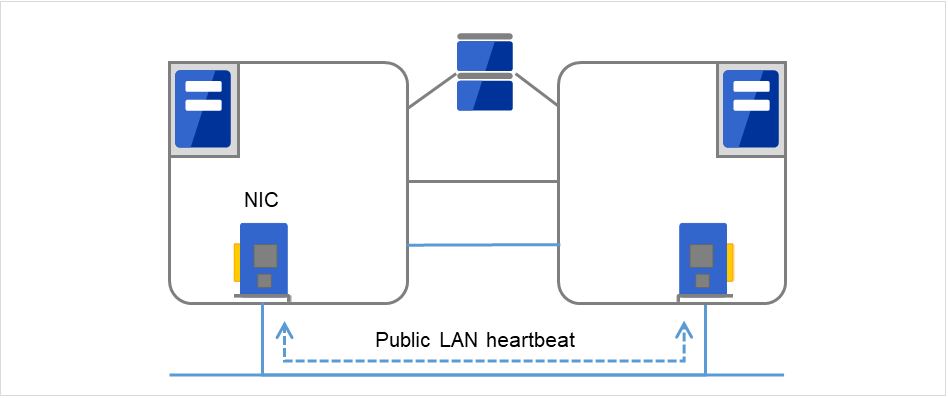
图 3.3 LAN心跳/内核模式LAN心跳(Secondary interconnect)¶
- 共享磁盘在连接到配置失效切换型集群的所有服务器上的磁盘中,创建EXPRESSCLUSTER专用分区(Cluster分区),在Cluster分区上进行心跳确认。
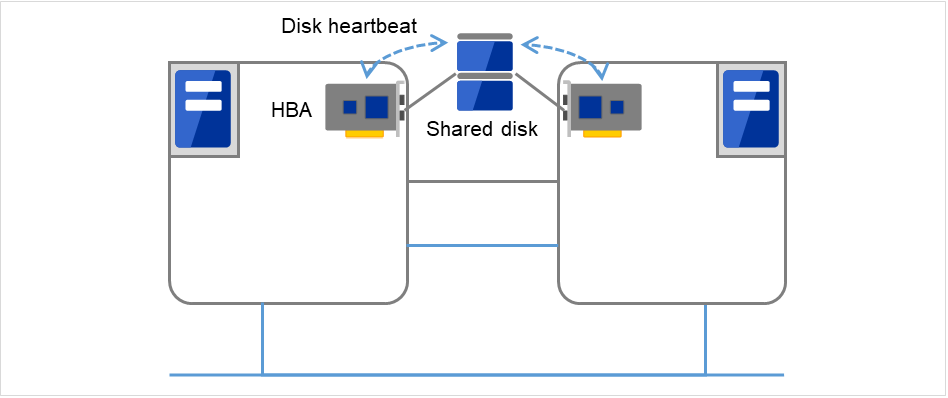
图 3.4 磁盘心跳¶
- COM端口通过COM端口在配置失效切换型集群的各个服务器之间进行心跳通信,确认其他服务器的生存。
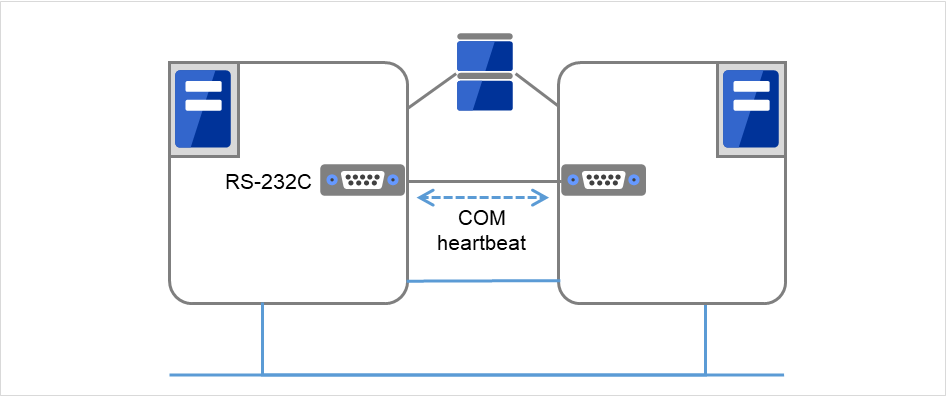
图 3.5 COM心跳¶
- BMC通过BMC在配置失效切换型集群的各个服务器之间进行心跳通信,确认其他服务器的生存。
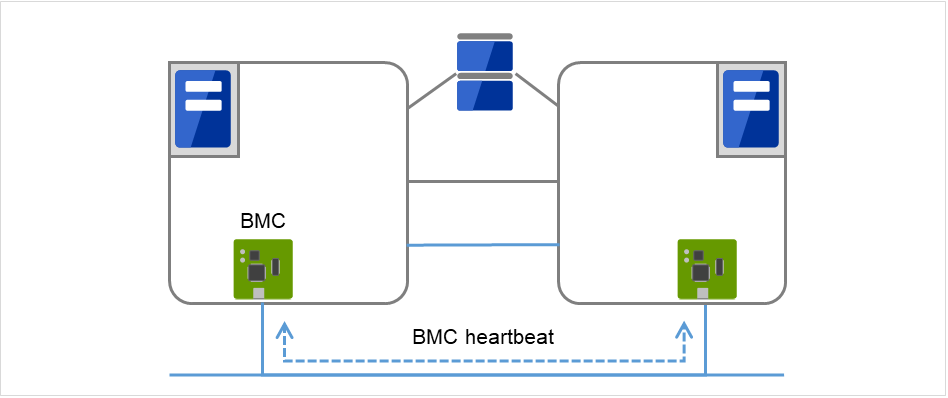
图 3.6 BMC心跳¶
- Witness构成失效切换型集群的各服务器与运行Witness 服务器服务的外部服务器(Witness 服务器)间进行通信,通过与保持Witness 服务器的其他服务器间的通信信息确认生存。

图 3.7 Witness心跳¶
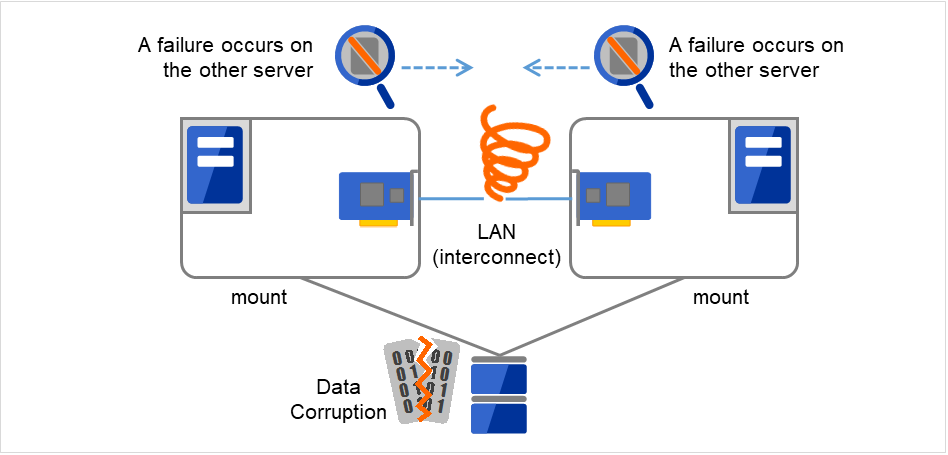
使用这些通信路径能够大幅度提高服务器间通信的可靠性,防止网络分区状态的发生。
注解
网络分区状态:集群服务器之间所有的通信线路均发生故障,造成网络性中断的状态。在不能对应网络分区状态的集群系统中,不能区分通信线路故障和服务器故障,多个服务器同时访问同一资源,就可执行造成数据损坏。
3.3.3. 何谓业务监视¶
业务监视用于监视业务应用程序自身或者造成陷入无法执行业务状态的故障原因。
- 应用程序的生存状态监视能够使用启动资源(称为EXEC资源)启动应用程序,通过监视资源(称为PID监视资源)定期监视进程的生存。在由于业务应用程序异常退出造成业务中断时有效。
注解
如果EXPRESSCLUSTER直接启动的应用程序为启动,结束监视对象的常驻进程的应用程序,则无法查出常驻进程的异常。
无法查出应用程序内部状态的异常(应用程序的停止,结果异常)。
- 资源的监视通过EXPRESSCLUSTER的监视资源能够监视集群资源(磁盘分区,IP地址等)和公网的状态。在由于必须资源异常造成业务中断时有效。
3.3.4. 何谓内部监视¶
EXPRESSCLUSTER进程的生存状态监视
3.3.5. 可监视的故障和无法监视的故障¶
EXPRESSCLUSTER 中有可监视的故障和无法监视的故障。在构建集群系统时,需要先了解哪些故障能够监视,而哪些不能监视。
3.3.6. 通过服务器监视可以查出的故障和无法查出的故障¶
监视条件:故障服务器的心跳中断
可监视的故障示例
硬件故障(OS不能继续运行)
panic
无法监视的故障示例
OS局部功能故障(仅鼠标,键盘等出现故障等)
3.3.7. 通过业务监视可以查出的故障和无法查出的故障¶
监视条件:故障应用程序的消失,持续的资源异常,与某网络设备通信的路径中断
可监视故障示例
应用程序的异常退出
共享磁盘访问故障(HBA [#s1]__的故障等)
公网NIC故障
无法监视故障示例
- 应用程序的停止/结果异常EXPRESSCLUSTER虽无法直接监视应用程序的停止/结果异常,但是可以监视应用程序,在查出异常时能够创建退出自身的程序,通过EXEC资源启动该程序,利用PID监视资源进行监视,从而使其发生失效切换。
- 1
Host Bus Adapter的缩写,不是指共有磁盘一端的适配器,而是指服务器主机一端的适配器。
3.4. 网络分区解决¶
ping方式
http方式
参见
关于网络分区解决方法设置的详细内容,请参考《参考指南》的 "网络分区解决资源的详细信息" 。
3.5. 失效切换的原理¶
EXPRESSCLUSTER查出故障时,在开始失效切换之前会判断查出的故障是服务器的故障还是网络分区状态。之后会在正常的服务器上启动各种资源,启动业务应用程序,执行失效切换。
此时,同时移动的资源集合称为失效切换组。从使用者角度来看,可以把失效切换组看作虚拟的计算机。
注解
在集群系统中,通过在正常的节点上重启应用程序来执行失效切换。因此,在应用程序的内存上保存的执行状态不能进行失效切换。
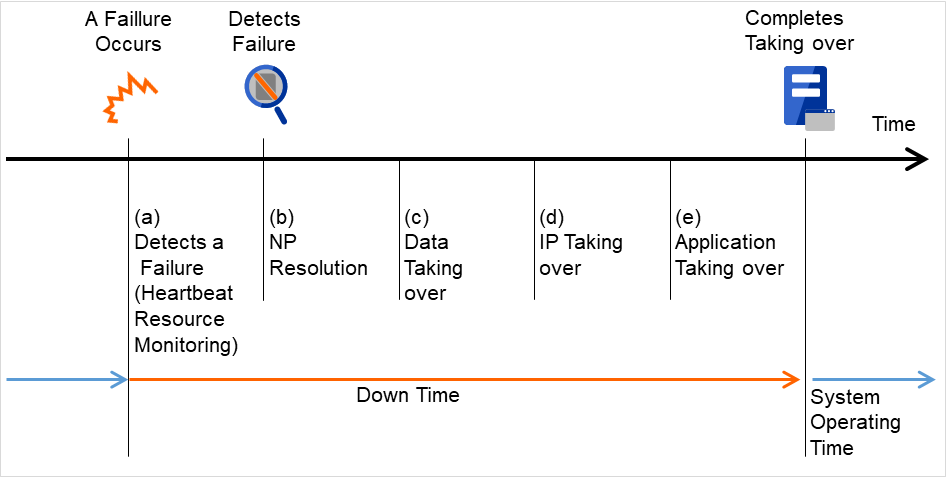
从发生故障到失效切换结束需要几分钟时间。下面是时间图。
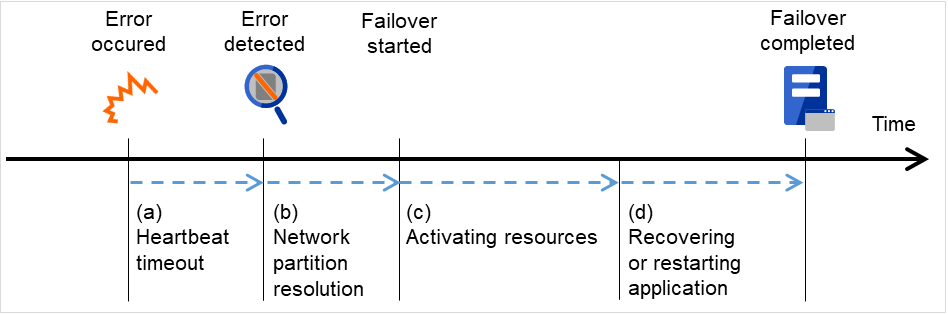
图 3.8 失效切换的时间图¶
心跳确认超时
正在执行业务的服务器发生故障后,到待机服务器查出该故障之间的时间。
- 可以根据业务的负载调整集群属性的设置值。(出厂设置是90秒。)
启动各种资源
启动业务所需资源的时间。
文件系统恢复,磁盘内数据交接,IP地址交接等。
- 一般配置情况下,启动需要几秒,失效切换组中登录的资源种类数量不同,所需时间会相应变化。(具体请参考《安装&设置指南》。)
开始脚本执行时间
数据库的回滚/前滚等数据恢复时间和业务中使用的应用程序的启动时间。
通过调整Check Point Interval时间,可以预测回滚/前滚的时间。详细内容请参考各软件产品的文档。
3.5.1. 失效切换资源¶
EXPRESSCLUSTER能够作为失效切换对象的主要资源如下。
切换分区(磁盘资源等)
保存业务应用程序应该交接的数据的磁盘分区。
浮动IP地址(浮动IP资源)
使用浮动IP地址连接业务,这样客户端可以不必考虑失效切换带来的业务执行位置(服务器)的变化。
浮动IP地址通过向公网适配器动态分配IP地址和发送ARP包来实现。大多数网络设备都能通过浮动IP地址连接。
脚本(EXEC资源)
在EXPRESSCLUSTER中,从脚本启动业务应用程序。
通过共享磁盘交接的文件虽然作为文件系统是正常的,但是作为数据可执行是不完整的。在脚本中,除了启动应用程序,还记载了失效切换时业务特有的恢复处理。
注解
在集群系统中,通过在正常的节点上重启应用程序来执行失效切换。因此,在应用程序的内存上保存的执行状态不能进行失效切换。
3.5.2. 失效切换型集群的系统配置¶
失效切换型集群在集群服务器间共享磁盘阵列设备。服务器发生故障时,待机服务器使用共享磁盘上的数据交接业务。
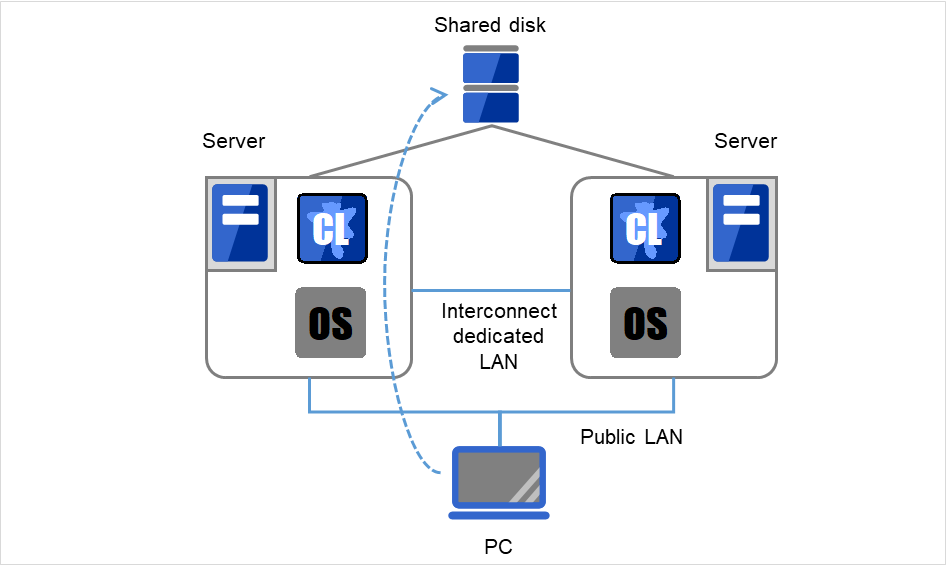
图 3.9 失效切换型集群的系统配置¶
失效切换型集群根据运行形态分为以下几类。
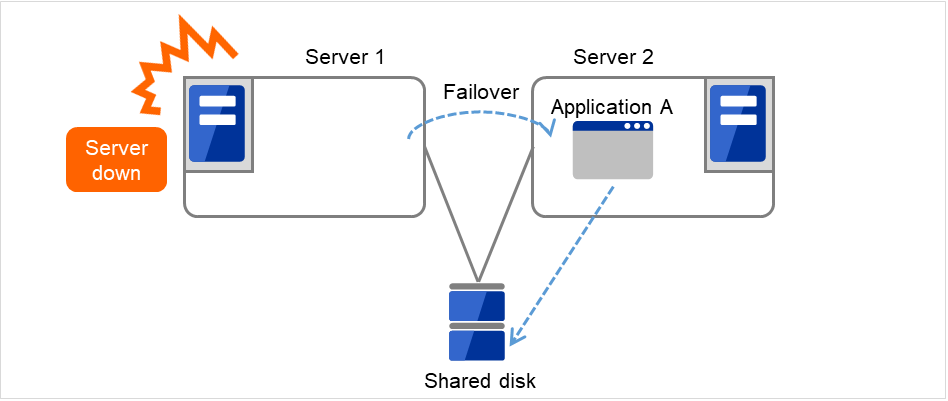
单向待机集群
其中一个服务器作为运行服务器运行业务,另外一个服务器作为待机服务器不运行业务的运行形态。这是最简单的一种运行形态,使用该形态构建的系统失效切换后性能不会降低,可用性高。
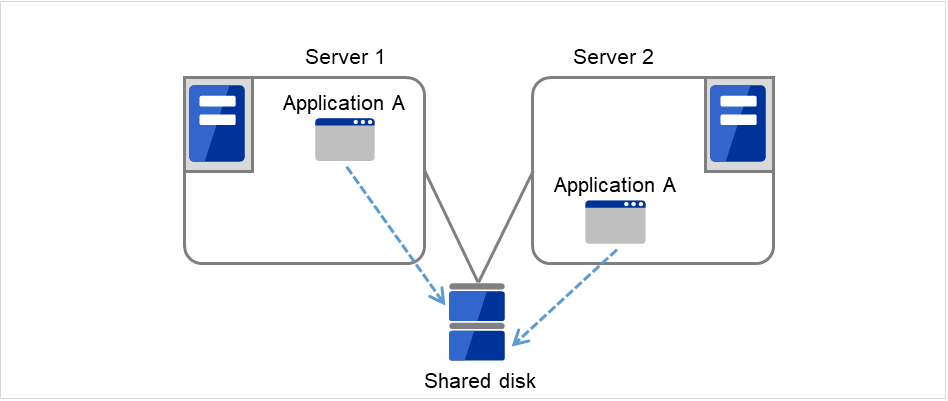
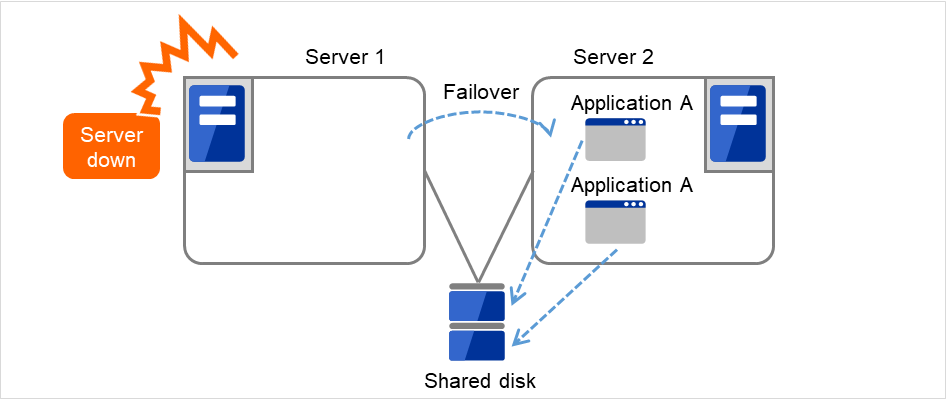
同一应用程序双向待机集群
在多个服务器上同时运行某业务应用程序,互为待机的运行形态。应用程序必须支持双向待机运行。将某业务数据分割成数份时,根据要访问的数据来更改客户端所要连接的目标服务器,可以构建以数据分割为单位的负载均衡系统。
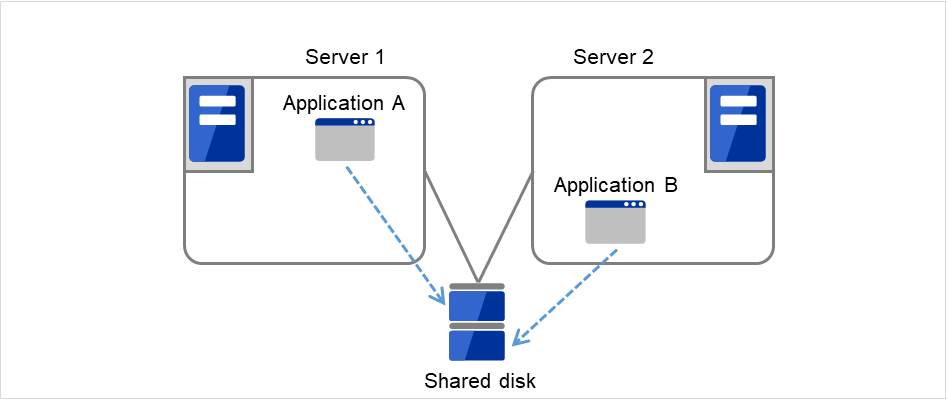
不同应用程序双向待机集群
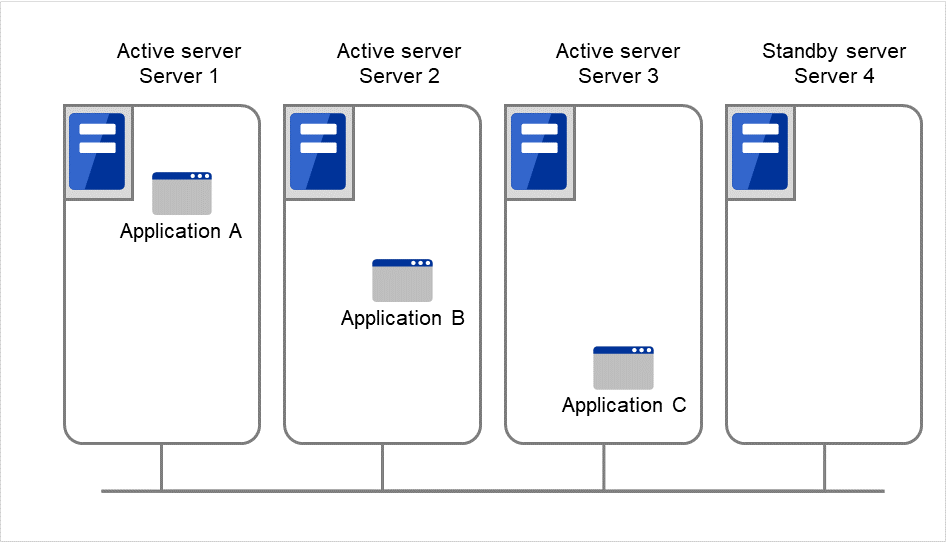
多种业务应用程序分别在不同服务器上运行,互为待机的运行形态。应用程序没有必要一定支持双向待机运行。能够构建以业务为单位的负载均衡系统。
Application A和Application B为不同应用程序。
N + N结构
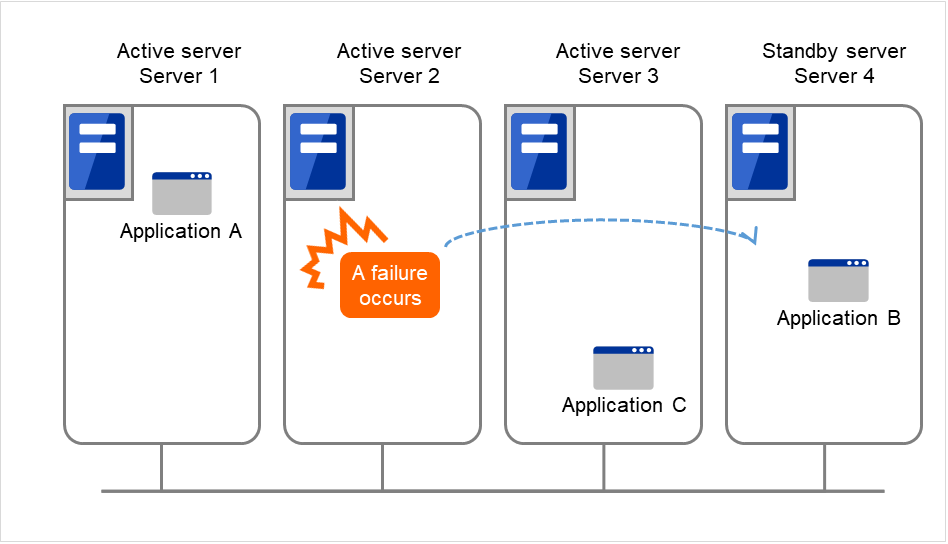
应用前面介绍的结构,可以将系统扩展为使用更多节点的结构。在下图所示的结构中,在3台服务器上执行3种业务,一旦发生问题,将把业务交接给1台待机服务器。在单向待机中,正常时的资源浪费是1/2,在此结构中正常时的资源浪费降低到1/4,而且如果1台发生故障,不会造成系统性能下降。
3.5.3. 共享磁盘型的硬件配置¶
共享磁盘型的EXPRESSCLUSTER的HW配置如下图所示。
服务器之间的通信一般使用以下配置:
2块NIC(1块用于与外部通信,1块为EXPRESSCLUSTER专用)
RS232C cross cable连接的COM端口
共享磁盘的指定区域
与共享磁盘连接的接口可以是SCSI或FibreChannel,但是最近使用FibreChannel进行连接比较普遍。
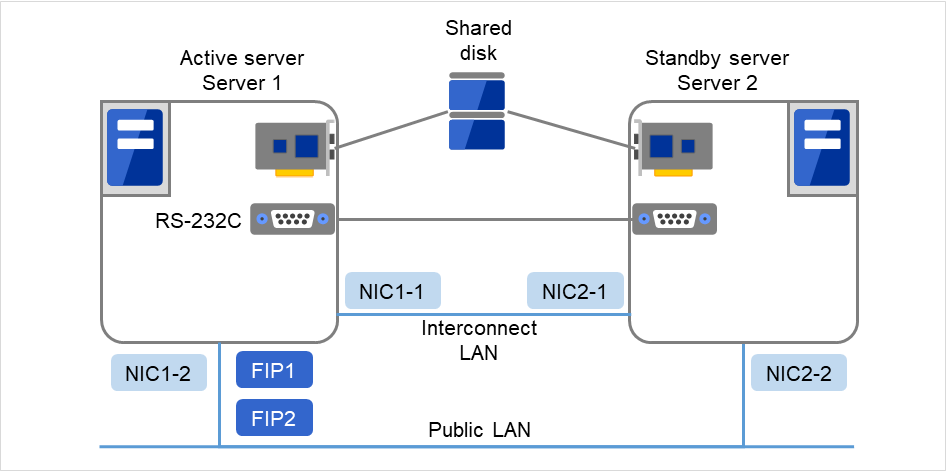
图 3.18 集群配置示例(共享磁盘型)¶
FIP1 |
10.0.0.11 (从Cluster WebUI客户端访问) |
FIP2 |
10.0.0.12 (从业务客户端访问) |
NIC1-1 |
192.168.0.1 |
NIC1-2 |
10.0.0.1 |
NIC2-1 |
192.168.0.2 |
NIC2-2 |
10.0.0.2 |
RS-232C 设备 |
/dev/ttyS0 |
共享磁盘:
设备名
/dev/sdb2
Mount点
/mnt/sdb2
文件系统
ext3
3.5.4. 镜像磁盘型的硬件配置¶
镜像磁盘型的EXPRESSCLUSTER配置如下图所示。
与共享磁盘配置相比,需要配备镜像磁盘数据复制所使用的网络,但是一般是使用EXPRESSCLUSTER的内部通信用NIC代替。
另外,镜像磁盘不依存于连接接口(IDE or SCSI)。
使用镜像磁盘时的集群环境示例(在安装OS的磁盘中确保集群分区和数据分区时)
在以下配置中,将安装了OS的磁盘的空闲分区作为集群分区和数据分区使用。
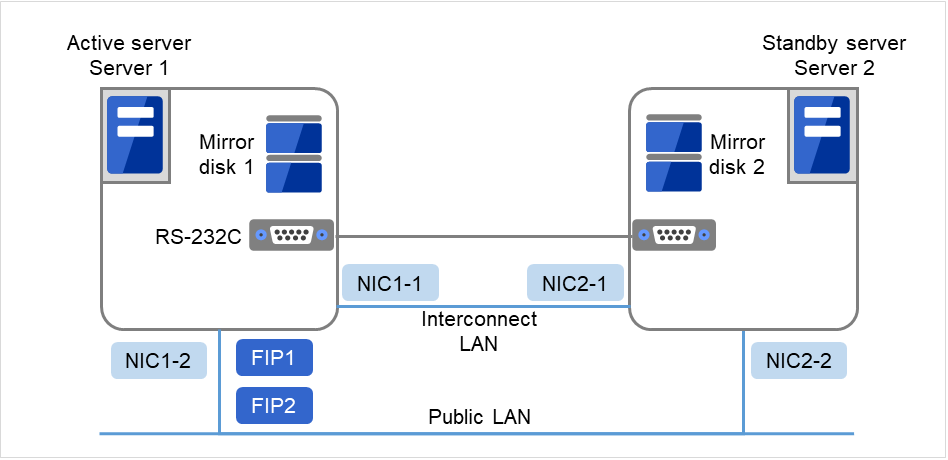
图 3.19 集群配置示例(1)(镜像磁盘型)¶
FIP1
10.0.0.11 (从Cluster WebUI客户端访问)
FIP2
10.0.0.12 (从业务客户端访问)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
RS-232C 设备
/dev/ttyS0
OS的/boot设备
/dev/sda1
OS的swap设备
/dev/sda2
OS的/(root)设备
/dev/sda3
集群分区用设备
/dev/sda5
数据分区用设备
/dev/sda6
Mount点
/mnt/sda6
文件系统
ext3
使用镜像磁盘时的集群环境示例(准备了用于集群分区和数据分区的磁盘时)
在以下配置中,已准备并连接了用于集群分区和数据分区的磁盘。
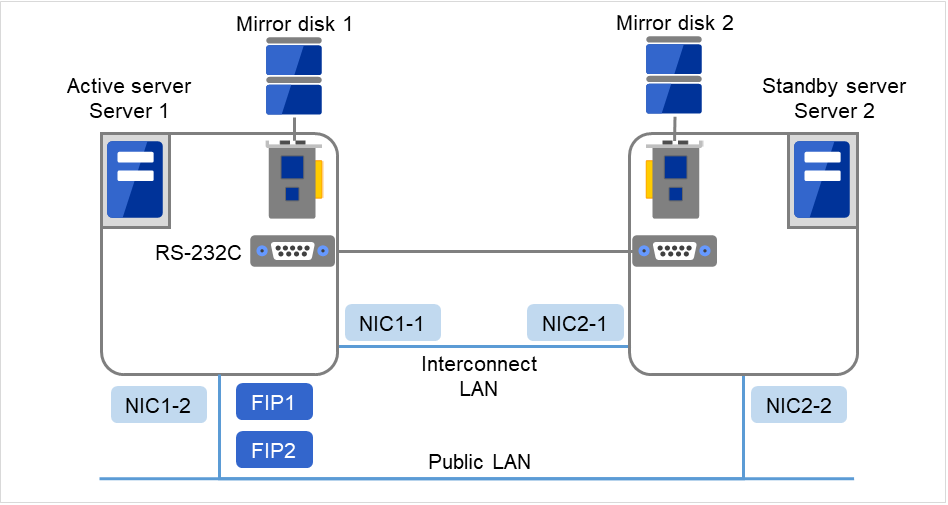
图 3.20 集群配置示例(2)(镜像磁盘型)¶
FIP1
10.0.0.11 (从Cluster WebUI客户端访问)
FIP2
10.0.0.12 (从业务客户端访问)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
RS-232C 设备
/dev/ttyS0
OS的/boot设备
/dev/sda1
OS的swap设备
/dev/sda2
OS的/(root)设备
/dev/sda3
集群分区用设备
/dev/sdb1
镜像资源磁盘设备
/dev/sdb2
Mount点
/mnt/sdb2
文件系统
ext3
3.5.5. 共享型镜像磁盘型的硬件配置¶
共享型配置的EXPRESSCLUSTER配置如下图所示。
与共享磁盘配置相比,需要配备复制数据所使用的网络,但是一般是使用EXPRESSCLUSTER的内部通信用NIC代替。
另外,磁盘不依存于连接接口(IDE or SCSI)。
使用共享型镜像磁盘时的集群环境的示例 (在2台服务器中使用共享磁盘,并镜像第3台服务器的常规磁盘时)
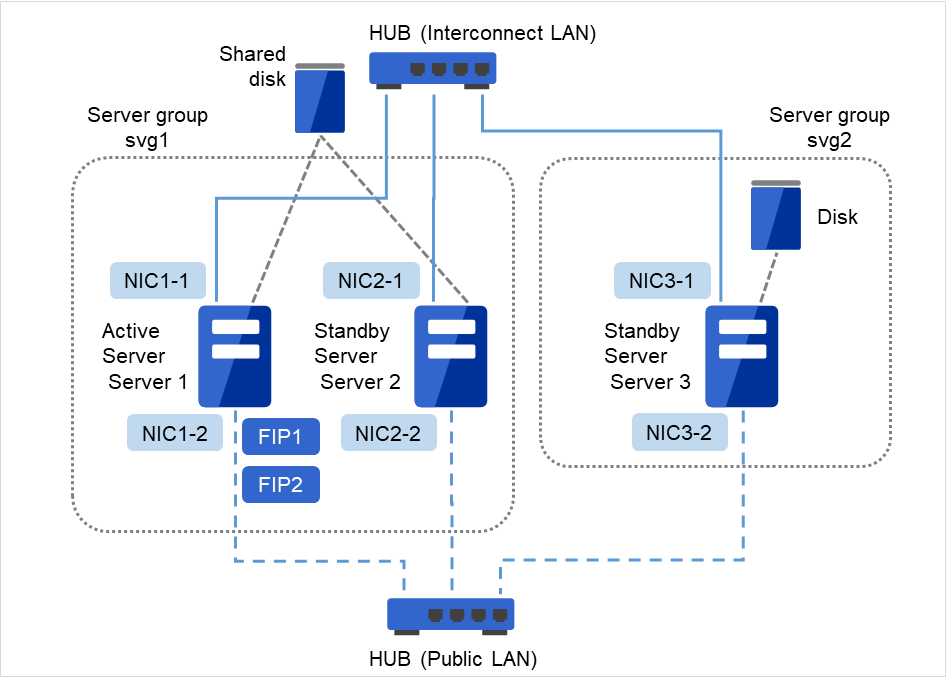
图 3.21 集群配置示例(共享型镜像磁盘型)¶
FIP1
10.0.0.11 (从Cluster WebUI客户端访问)
FIP2
10.0.0.12 (从业务客户端访问)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
NIC3-1
192.168.0.3
NIC3-2
10.0.0.3
共享磁盘
共享型镜像设备
/dev/NMP1
Mount点
/mnt/hd1
文件系统
ext3
集群分区用设备
/dev/sdb1
共享型镜像磁盘资源磁盘设备
/dev/sdb2
DISK心跳设备名
/dev/sdb3
Raw设备名
/dev/raw/raw1
用于共享型镜像磁盘资源的磁盘
共享型镜像设备
/dev/NMP1
Mount点
/mnt/hd1
文件系统
ext3
集群分区用设备
/dev/sdb1
共享型镜像磁盘资源磁盘设备
/dev/sdb2
3.5.6. 何谓集群对象¶
在EXPRESSCLUSTER中,使用以下结构管理各种资源。
- 集群对象配置集群的单位。
- 服务器对象表示实体服务器的对象,属于集群对象。
- 服务器组对象捆绑服务器的对象,属于集群对象。
- 心跳资源对象表示实体服务器的NW部分的对象,属于服务器对象。
- 网络分区解决资源对象表示网络分区解决机构的对象,属于服务器对象。
- 组对象表示虚拟服务器的对象,属于集群对象。
- 组资源对象表示拥有虚拟服务器的资源 (NW,磁盘)的对象,属于组对象。
- 监视资源对象表示监视机构的对象,属于集群对象。
3.6. 何谓资源¶
在EXPRESSCLUSTER中,监视端和被监视端的对象都称为资源,分类进行管理。这样不仅能够明确区分监视/被监视的对象,还能够使构建集群或查出故障时的对应更简便。资源分为心跳资源,网络分区解决资源,组资源和监视资源4类。以下简要介绍各类资源。
3.6.1. 心跳资源¶
在服务器之间互相确认生存状态所使用的资源。
现在支持的心跳资源如下所示:
- LAN心跳资源使用Ethernet的通信。
- 内核模式LAN心跳资源使用Ethernet的通信。
- COM心跳资源使用RS232C(COM)的通信。
- 磁盘心跳资源使用共享磁盘上的特定分区(磁盘心跳分区)的通信。仅限共享磁盘配置时使用。
- BMC心跳资源经由BMC使用Ethernet的通信。仅限在对应BMC的硬件和固件时使用。
- Witness 心跳资源表示从Witness 服务器服务运行的外部服务器中取得的与各服务器间的通信状态。
3.6.3. 组资源¶
组成失效切换的单位——失效切换组的资源。
现在支持的组资源如下所示:
- 浮动IP资源 (fip)提供虚拟IP地址。客户端可以像普通IP地址一样访问。
- EXEC资源 (exec)提供启动/停止业务(DB,httpd,etc..)的机制。
- 磁盘资源 (disk)提供共享磁盘上的指定分区。仅限(共享磁盘)配置时使用。
- 镜像磁盘资源 (md)提供镜像磁盘上的指定分区。仅限(镜像磁盘)配置时使用。
- 共享型镜像磁盘资源 (hd)提供共享磁盘或磁盘上的指定分区。仅限(共享型镜像磁盘)配置时使用。
- 卷管理资源 (volmgr)将多个存储器及磁盘用作一个逻辑磁盘。
- NAS资源 (nas)连接NAS服务器上的共享资源。(集群服务器并不是作为NAS的服务器端运行的资源。)
- 虚拟IP资源 (vip)提供虚拟IP地址。可以像访问客户端的普通IP地址一样访问虚拟IP地址。用于配置网络地址在不同区间的远程集群。
- 虚拟机资源 (vm)进行虚拟机的启动,停止及迁移。
- 动态域名解析资源(ddns)将虚拟主机名及启动服务器的IP地址登录在Dynamic DNS服务器上。
- AWS Elastic IP资源 (awseip)在AWS上利用EXPRESSCLUSTER时,提供可授予Elastic IP(以下称为EIP)的机能。
- AWS虚拟IP资源 (awsvip)在AWS上利用EXPRESSCLUSTER时,提供可授予虚拟IP(以下称为VIP)的机能。
- AWS DNS资源 (awsdns)在AWS上利用EXPRESSCLUSTER时,在Amazon Route 53上登录虚拟主机名和启动服务器的IP地址。
- Azure 探头端口资源 (azurepp)在Microsoft Azure上利用EXPRESSCLUSTER时,提供可在运行业务的节点开放特定的端口的机能。
- Azure DNS资源 (azuredns)Microsoft Azure上利用EXPRESSCLUSTER时,在Azure DNS上登录虚拟主机名和启动服务器的IP地址。
- Google Cloud 虚拟 IP 资源 (gcvip)在Google Cloud Platform上使用ExpressCluster时,提供了一种在业务运行的节点上打开特定端口的机制。
- Google Cloud DNS 资源 (gcdns)Google Cloud Platform上利用EXPRESSCLUSTER时,在Cloud DNS上登录虚拟主机名和启动服务器的IP地址。
- Oracle Cloud 虚拟 IP 资源 (ocvip)在Oracle Cloud Infrastructure上使用ExpressCluster时,提供了一种在业务运行的节点上打开特定端口的机制。
3.6.4. 监视资源¶
是集群系统内进行监视的主体资源。
现在支持的监视资源如下所示:
- 浮动 IP 监视资源 (fipw)提供浮动 IP 资源中启动的 IP 地址的监视机构。
- IP监视资源 (ipw)提供外部IP地址的监视机构。
- 磁盘监视资源 (diskw)提供磁盘的监视机构。也可以用于共享磁盘的监视。
- 镜像磁盘监视资源 (mdw)提供镜像磁盘的监视机构。
- 镜像磁盘接口监视资源 (mdnw)提供镜像磁盘接口的监视机构。
- 共享型镜像磁盘监视资源 (hdw)提供共享型镜像磁盘的监视机构。
- 共享型镜像磁盘接口监视资源 (hdnw)提供共享型镜像磁盘接口的监视机构。
- PID监视资源 (pidw)提供EXEC资源启动的进程的生存状态监视功能。
- 用户空间监视资源 (userw)提供用户空间的停止监视机构。
- NIC Link Up/Down监视资源 (miiw)提供LAN线缆的链接状态的监视机构。
- 卷管理监视资源 (volmgrw)提供多个存储器及磁盘的监视机构。
- Multi-Target监视资源 (mtw)提供捆绑多个监视资源的状态。
- 虚拟IP监视资源 (vipw)提供送出虚拟IP资源RIP包的机构。
- ARP监视资源 (arpw)提供送出浮动IP或虚拟IP资源ARP包的机构。
- 自定义监视资源 (genw)提供有进行监视处理的命令或脚本时,根据其动作结果监视系统的机构。
- 虚拟机监视资源 (vmw)进行虚拟机的生死确认。
- 消息接收监视资源 (mrw)用于实现"设置接收异常发生通知时执行的异常时动作"及"异常发生通知的Cluster WebUI显示"的监视资源。
- 动态域名解析监视资源 (ddnsw)定期将虚拟主机名及启动服务器的IP地址登录在Dynamic DNS服务器上。
- 进程名监视资源 (psw)通过指定进程名,提供任意的进程死活监视功能。
- BMC监视资源 (bmcw)提供配备的BMC的死活监视功能。
- DB2监视资源 (db2w)提供IBM DB2数据库的监视机构。
- ftp监视资源 (ftpw)提供FTP服务器的监视机构。
- http监视资源 (httpw)提供HTTP服务器的监视机构。
- imap4监视资源 (imap4w)提供IMAP4服务器的监视机构。
- MySQL监视资源 (mysqlw)提供MySQL数据库的监视机构。
- nfs监视资源 (nfsw)提供nfs文件服务器的监视机构。
- Oracle监视资源 (oraclew)提供Oracle数据库的监视机构。
- Oracle Clusterware同步管理监视资源(osmw)提供Oracle Clusterware联动进程的监视和成员信息同步功能。
- pop3监视资源(pop3w)提供POP3服务器的监视机构。
- PostgreSQL监视资源 (psqlw)提供PostgreSQL数据库的监视机构。
- samba监视资源 (sambaw)提供samba文件服务器的监视机构。
- smtp监视资源 (smtpw)提供SMTP服务器的监视机构。
- Sybase监视资源 (sybasew)提供Sybase数据库的监视机构。
- Tuxedo监视资源 (tuxw)提供Tuxedo应用程序服务器的监视机构。
- Websphere监视资源 (wasw)提供Websphere应用程序服务器的监视机构。
- Weblogic监视资源 (wlsw)提供Weblogic应用程序服务器的监视机构。
- WebOTX监视资源 (otxw)提供WebOTX应用程序服务器的监视机构。
- JVM 监视资源 (jraw)提供Java VM的监视机构。
- 系统监视资源 (sraw)提供系统整体资源的监视机构。
- 进程资源监视资源(psrw)提供个别进程资源的监视机构。
- AWS Elastic IP监视资源 (awseipw)提供在AWS Elastic IP资源所附加的EIP的监视机构。
- AWS虚拟IP监视资源 (awsvipw)提供在AWS虚拟IP资源所附加的VIP的监视机构。
- AWS AZ监视资源 (awsazw)提供Availability Zone(以下称为AZ)的监视机构。
- AWS DNS监视资源 (awsdnsw)提供在AWS DNS资源授予的虚拟主机名和IP地址的监视机构。
- Azure 探头端口监视资源 (azureppw)针对Azure探头端口资源所启动的节点提供探头端口的监视机构。
- Azure负载均衡监视资源 (azurelbw)针对Azure探头端口资源所启动的节点提供与Probe端口相同的端口号是否被开放的监视机构。
- Azure DNS监视资源 (azurednsw)提供在Azure DNS资源授予的虚拟主机名和IP地址的监视机构。
- Google Cloud 虚拟 IP 监视资源 (gcvipw)对启动了Google Cloud虚拟IP资源的节点,提供用于进行心跳存活监视的端口的监控机制。
- Google Cloud 负载均衡监视资源 (gclbw)对没有启动Google Cloud虚拟IP资源的节点,提供确认是否开放以及用于心跳存活侦测的端口相同的端口号的监控机制。
- Google Cloud DNS监视资源 (gcdnsw)提供在Google Cloud DNS资源授予的虚拟主机名和IP地址的监视机构。
- Oracle Cloud 虚拟 IP 监视资源 (ocvipw)对启动了Oracle Cloud虚拟IP资源的节点,提供用于进行心跳存活监视的端口的监控机制。
- Oracle Cloud 负载均衡监视资源 (oclbw)对没有启动Oracle Cloud虚拟IP资源的节点,提供确认是否开放以及用于心跳存活侦测的端口相同的端口号的监控机制。
4. EXPRESSCLUSTER的运行环境¶
本章介绍EXPRESSCLUSTER的运行环境。
本章介绍的项目如下。
4.1. 硬件¶
EXPRESSCLUSTER在以下架构的服务器上运行。
x86_64
IBM POWER (不支持Replicator,Replicator DR,Database Agent以外的Agent)
IBM POWER LE (不支持Replicator,Replicator DR,各Agent)
4.1.1. 规格¶
EXPRESSCLUSTER Server所需的规格如下所示。
RS-232C板卡 一个(构建3节点以上集群时不需要)
Ethernet板卡 两个以上
共享磁盘
镜像用磁盘或镜像用剩余分区
CD-ROM驱动器
4.1.2. 与Express5800/A1080a,A1040a系列整合相对应的服务器¶
可使用BMC心跳资源和Express5800/A1080a,A1040a系列整合功能的服务器如下所示。此功能仅限以下的服务器可利用。
服务器 |
备注 |
|---|---|
Express5800/A1080a-E |
可执行需要升级最新版的固件。 |
Express5800/A1080a-D |
可执行需要升级最新版的固件。 |
Express5800/A1080a-S |
可执行需要升级最新版的固件。 |
Express5800/A1040a |
可执行需要升级最新版的固件。 |
4.2. 软件¶
4.2.1. EXPRESSCLUSTER Server的运行环境¶
4.2.2. 可运行的Distribution和kernel¶
注解
EXPRESSCLUSTER X的安装光盘,可执行没有对应最新的kernel的rpm安装包。请对比确认运行环境中的kernel版本和本章记载的"可操作的Distribution和Kernel"是否相符,并安装"EXPRESSCLUSTER Version"记载的适当的版本进行升级。
独自的kernel模块 |
说明 |
|---|---|
Kernel模式LAN心跳驱动程序 |
使用Kernel模式LAN心跳资源。 |
Keepalive驱动程序
|
当用户空间监视资源的监视方法选择keepalive时使用。
当关机监视的监视方法选择keepalive时使用。
|
镜像驱动程序 |
使用镜像磁盘资源。 |
关于运行确认完毕的发布版和kernel版本信息,请参照以下的Web站点。
EXPRESSCLUSTER的Web站点-> System Requirements-> EXPRESSCLUSTER X for Linux
注解
EXPRESSCLUSTER支持的CentOS的内核版本请确认Red Hat Enterprise Linux的支持内核版本。
4.2.3. 运行确认完毕的监视选项应用程序信息¶
监视资源的监视对象的应用程序版本信息
x86_64
Oracle监视
Oracle Database 12c Release1 (12.1)
4.0.0-1~
Oracle Database 12c Release 2 (12.2)
4.0.0-1~
Oracle Database 18c (18.3)
4.1.0-1~
Oracle Database 19c (19.3)
4.1.0-1~
DB2监视
DB2 V10.5
4.0.0-1~
DB2 V11.1
4.0.0-1~
DB2 V11.5
4.2.0-1~
PostgreSQL监视
PostgreSQL 9.3
4.0.0-1~
PostgreSQL 9.4
4.0.0-1~
PostgreSQL 9.5
4.0.0-1~
PostgreSQL 9.6
4.0.0-1~
PostgreSQL 10
4.0.0-1~
PostgreSQL 11
4.1.0-1~
PostgreSQL 12
4.2.2-1~
PowerGres on Linux 9.1
4.0.0-1~
PowerGres on Linux 9.4
4.0.0-1~
PowerGres on Linux 9.6
4.0.0-1~
PowerGres on Linux 11
4.1.0-1~
MySQL监视
MySQL 5.5
4.0.0-1~
MySQL 5.6
4.0.0-1~
MySQL 5.7
4.0.0-1~
MySQL 8.0
4.1.0-1~
MariaDB 5.5
4.0.0-1~
MariaDB 10.0
4.0.0-1~
MariaDB 10.1
4.0.0-1~
MariaDB 10.2
4.0.0-1~
MariaDB 10.4
4.2.0-1~
MariaDB 10.3
4.1.0-1~
Sybase监视
Sybase ASE 15.5
4.0.0-1~
Sybase ASE 15.7
4.0.0-1~
Sybase ASE 16.0
4.0.0-1~
SQL Server监视
SQL Server 2017
4.0.0-1~
SQL Server 2019
4.2.0-1~
samba监视
Samba 3.3
4.0.0-1~
Samba 3.6
4.0.0-1~
Samba 4.0
4.0.0-1~
Samba 4.1
4.0.0-1~
Samba 4.2
4.0.0-1~
Samba 4.4
4.0.0-1~
Samba 4.6
4.0.0-1~
Samba 4.7
4.1.0-1~
Samba 4.8
4.1.0-1~
Samba 4.13
4.3.0-1~
nfs监视
nfsd 2 (udp)
4.0.0-1~
nfsd 3 (udp)
4.0.0-1~
nfsd 4 (tcp)
4.0.0-1~
mountd 1(tcp)
4.0.0-1~
mountd 2(tcp)
4.0.0-1~
mountd 3(tcp)
4.0.0-1~
http监视
未指定版本
4.0.0-1~
smtp监视
未指定版本
4.0.0-1~
pop3监视
未指定版本
4.0.0-1~
imap4监视
未指定版本
4.0.0-1~
ftp监视
未指定版本
4.0.0-1~
Tuxedo监视
Tuxedo 12c Release 2 (12.1.3)
4.0.0-1~
Weblogic监视
WebLogic Server 11g R1
4.0.0-1~
WebLogic Server 11g R2
4.0.0-1~
WebLogic Server 12c R2 (12.2.1)
4.0.0-1~
WebLogic Server 14c (14.1.1)
4.2.0-1~
Websphere监视
WebSphere Application Server 8.5
4.0.0-1~
WebSphere Application Server 8.5.5
4.0.0-1~
WebSphere Application Server 9.0
4.0.0-1~
WebOTX监视
WebOTX Application Server V9.1
4.0.0-1~
WebOTX Application Server V9.2
4.0.0-1~
WebOTX Application Server V9.3
4.0.0-1~
WebOTX Application Server V9.4
4.0.0-1~
WebOTX Application Server V10.1
4.0.0-1~
WebOTX Application Server V10.3
4.3.0-1~
JVM监视
WebLogic Server 11g R1
4.0.0-1~
WebLogic Server 11g R2
4.0.0-1~
WebLogic Server 12c
4.0.0-1~
WebLogic Server 12c R2 (12.2.1)
4.0.0-1~
WebLogic Server 14c (14.1.1)
4.2.0-1~
WebOTX Application Server V9.1
4.0.0-1~
WebOTX Application Server V9.2
4.0.0-1~
进程组监视需要进行WebOTX update
WebOTX Application Server V9.3
4.0.0-1~
WebOTX Application Server V9.4
4.0.0-1~
WebOTX Application Server V10.1
4.0.0-1~
WebOTX Application Server V10.3
4.3.0-1~
WebOTX Enterprise Service Bus V8.4
4.0.0-1~
WebOTX Enterprise Service Bus V8.5
4.0.0-1~
WebOTX Enterprise Service Bus V10.3
4.3.0-1~
JBoss Enterprise Application Platform 7.0
4.0.0-1~
Apache Tomcat 8.0
4.0.0-1~
Apache Tomcat 8.5
4.0.0-1~
Apache Tomcat 9.0
4.0.0-1~
WebSAM SVF for PDF 9.0
4.0.0-1~
WebSAM SVF for PDF 9.1
4.0.0-1~
WebSAM SVF for PDF 9.2
4.0.0-1~
WebSAM Report Director Enterprise 9.0
4.0.0-1~
WebSAM Report Director Enterprise 9.1
4.0.0-1~
WebSAM Report Director Enterprise 9.2
4.0.0-1~
WebSAM Universal Connect/X 9.0
4.0.0-1~
WebSAM Universal Connect/X 9.1
4.0.0-1~
WebSAM Universal Connect/X 9.2
4.0.0-1~
系统监视
未指定版本
4.0.0-1~
进程资源监视
未指定版本
4.1.0-1~
注解
x86_64环境中使用监视选项时,监视对象的应用程序也请使用x86_64版的应用程序。
IBM POWER
DB2监视
DB2 V10.5
4.0.0-1~
PostgreSQL监视
PostgreSQL 9.3
4.0.0-1~
PostgreSQL 9.4
4.0.0-1~
PostgreSQL 9.5
4.0.0-1~
PostgreSQL 9.6
4.0.0-1~
PostgreSQL 10
4.0.0-1~
PostgreSQL 11
4.1.0-1~
注解
IBM POWER环境中使用监视选项时,监视对象的应用程序也请使用IBM POWER版的应用程序。
4.2.4. 虚拟机资源的运行环境¶
进行虚拟机资源运行确认的虚拟基础架构的版本信息如下所示。
虚拟基础架构
|
版本
|
EXPRESSCLUSTER
Version
|
备注
|
|---|---|---|---|
vSphere |
5.5 |
4.0.0-1~ |
需要管理用OS |
6.5 |
4.0.0-1~ |
需要管理用OS |
|
XenServer |
6.5 (x86_64) |
4.0.0-1~ |
|
KVM |
Red Hat Enterprise Linux 6.9 (x86_64) |
4.0.0-1~ |
|
Red Hat Enterprise Linux 7.4 (x86_64) |
4.0.0-1~ |
注解
在XenServer 上使用EXPRESSCLUSTER时,下面的功能不能使用。
内核模式 LAN心跳资源
镜像磁盘资源/共享型镜像磁盘资源
用户空间监视资源 (keepalive/softdog 方式)
关机监视 (keepalive/softdog 方式)
4.2.5. JVM监视器的运行环境¶
使用JVM监视器时,需要可Java 的执行环境。此外,监视JBoss Enterprise Application Platform 的domain 模式时,需要安装Java(TM) SE Development Kit。
Java(TM) Runtime Environment |
Version 7.0 Update 6 (1.7.0_6) 以上 |
Java(TM) SE Development Kit |
Version 7.0 Update 1 (1.7.0_1) 以上 |
Java(TM) Runtime Environment |
Version 8.0 Update 11 (1.8.0_11) 以上 |
Java(TM) SE Development Kit |
Version 8.0 Update 11 (1.8.0_11) 以上 |
Java(TM) Runtime Environment |
Version 9.0 (9.0.1) 以上 |
Java(TM) SE Development Kit |
Version 9.0 (9.0.1) 以上 |
Java(TM) SE Development Kit |
Version 11.0 (11.0.5) 以上 |
Open JDK |
Version 7.0 Update 45 (1.7.0_45) 以上
Version 8.0 (1.8.0) 以上
Version 9.0 (9.0.1) 以上
|
进行JVM监视器的负载均衡器联动功能的运行确认的负载均衡器如下所示。
x86_64
Express5800/LB400h以上
4.0.0-1~
InterSec/LB400i以上
4.0.0-1~
BIG-IP v11
4.0.0-1~
CoyotePoint Equalizer
4.0.0-1~
4.2.6. AWS Elastic IP资源,AWS虚拟IP资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源的运行环境¶
想使用AWS Elastic IP资源,AWS虚拟IP资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源时,需要以下的软件。
软件 |
Version |
备注 |
|---|---|---|
AWS CLI |
1.6.0~ |
|
Python
|
2.6.5~
2.7.5~
3.5.2~
3.6.8~
3.8.1~
3.8.3~
|
AWS CLI 附带的 Python 不可以
|
x86_64
Red Hat Enterprise Linux 6.8
4.0.0-1~
Red Hat Enterprise Linux 6.9
4.0.0-1~
Red Hat Enterprise Linux 6.10
4.1.0-1~
Red Hat Enterprise Linux 7.3
4.0.0-1~
Red Hat Enterprise Linux 7.4
4.0.0-1~
Red Hat Enterprise Linux 7.5
4.1.0-1~
Red Hat Enterprise Linux 7.6
4.1.0-1~
Red Hat Enterprise Linux 7.7
4.2.0-1~
Red Hat Enterprise Linux 7.8
4.3.0-1~
Red Hat Enterprise Linux 8.2
4.3.0-1~
Cent OS 6.8
4.0.0-1~
Cent OS 6.9
4.0.0-1~
Cent OS 6.10
4.2.0-1~
Cent OS 7.3
4.0.0-1~
Cent OS 7.4
4.0.0-1~
Cent OS 7.5
4.1.0-1~
Cent OS 7.6
4.2.0-1~
SUSE Linux Enterprise Server 11 SP3
4.0.0-1~
SUSE Linux Enterprise Server 11 SP4
4.0.0-1~
SUSE Linux Enterprise Server 12 SP1
4.0.0-1~
SUSE Linux Enterprise Server 12 SP2
4.1.0-1~
SUSE Linux Enterprise Server 12 SP4
4.2.0-1~
SUSE Linux Enterprise Server 15 SP1
4.2.0-1~
Oracle Linux 6.6
4.0.0-1~
Oracle Linux 7.3
4.0.0-1~
Oracle Linux 7.6
4.2.0-1~
Ubuntu 14.04.LTS
4.0.0-1~
Ubuntu 16.04.3 LTS
4.0.0-1~
Ubuntu 18.04.3 LTS
4.2.0-1~
Amazon Linux 2
4.1.0-1~
4.2.7. AWS DNS资源,AWS DNS监视资源的运行环境¶
想使用AWS DNS资源,AWS DNS监视资源时,需要以下的软件。
软件 |
Version |
备注 |
|---|---|---|
AWS CLI |
1.11.0~ |
|
Python (Red Hat Enterprise Linux 6, Cent OS 6, SUSE Linux Enterprise Server 11, Oracle Linux 6的场合)
|
2.6.6~
3.6.5~
3.8.1~
|
AWS CLI 附带的 Python 不可以
|
Python (Red Hat Enterprise Linux 6, Cent OS 6, SUSE Linux Enterprise Server 11, Oracle Linux 6 以外的场合)
|
2.7.5~
3.5.2~
3.6.8~
3.8.1~
3.8.3~
|
AWS CLI 附带的 Python 不可以
|
x86_64
Red Hat Enterprise Linux 6.8
4.0.0-1~
Red Hat Enterprise Linux 6.9
4.0.0-1~
Red Hat Enterprise Linux 6.10
4.1.0-1~
Red Hat Enterprise Linux 7.3
4.0.0-1~
Red Hat Enterprise Linux 7.4
4.0.0-1~
Red Hat Enterprise Linux 7.5
4.1.0-1~
Red Hat Enterprise Linux 7.6
4.1.0-1~
Red Hat Enterprise Linux 7.7
4.2.0-1~
Red Hat Enterprise Linux 7.8
4.3.0-1~
Red Hat Enterprise Linux 8.2
4.3.0-1~
Cent OS 6.8
4.0.0-1~
Cent OS 6.9
4.0.0-1~
Cent OS 6.10
4.2.0-1~
Cent OS 7.3
4.0.0-1~
Cent OS 7.4
4.0.0-1~
Cent OS 7.5
4.1.0-1~
Cent OS 7.6
4.2.0-1~
SUSE Linux Enterprise Server 11 SP3
4.0.0-1~
SUSE Linux Enterprise Server 11 SP4
4.0.0-1~
SUSE Linux Enterprise Server 12 SP1
4.0.0-1~
SUSE Linux Enterprise Server 12 SP2
4.1.0-1~
SUSE Linux Enterprise Server 12 SP4
4.2.0-1~
SUSE Linux Enterprise Server 15 SP1
4.2.0-1~
Oracle Linux 6.6
4.0.0-1~
Oracle Linux 7.3
4.0.0-1~
Oracle Linux 7.6
4.2.0-1~
Ubuntu 14.04.LTS
4.0.0-1~
Ubuntu 16.04.3 LTS
4.0.0-1~
Ubuntu 18.04.3 LTS
4.2.0-1~
Amazon Linux 2
4.1.0-1~
4.2.8. Azure 探头端口资源,Azure 探头端口监视资源,Azure负载均衡监视资源的运行环境¶
x86_64
Red Hat Enterprise Linux 6.8
4.0.0-1~
Red Hat Enterprise Linux 6.9
4.0.0-1~
Red Hat Enterprise Linux 6.10
4.1.0-1~
Red Hat Enterprise Linux 7.3
4.0.0-1~
Red Hat Enterprise Linux 7.4
4.0.0-1~
Red Hat Enterprise Linux 7.5
4.1.0-1~
Red Hat Enterprise Linux 7.6
4.1.0-1~
Red Hat Enterprise Linux 7.7
4.2.0-1~
Red Hat Enterprise Linux 7.8
4.3.0-1~
Red Hat Enterprise Linux 8.2
4.3.0-1~
CentOS 6.8
4.0.0-1~
CentOS 6.9
4.0.0-1~
CentOS 6.10
4.1.0-1~
CentOS 7.3
4.0.0-1~
CentOS 7.4
4.0.0-1~
CentOS 7.5
4.1.0-1~
CentOS 7.6
4.1.0-1~
Asianux Server 4 SP6
4.0.0-1~
Asianux Server 4 SP7
4.0.0-1~
Asianux Server 7 SP1
4.0.0-1~
Asianux Server 7 SP2
4.0.0-1~
Asianux Server 7 SP3
4.2.0-1~
SUSE Linux Enterprise Server 11 SP3
4.0.0-1~
SUSE Linux Enterprise Server 11 SP4
4.0.0-1~
SUSE Linux Enterprise Server 12 SP1
4.0.0-1~
SUSE Linux Enterprise Server 12 SP2
4.1.0-1~
SUSE Linux Enterprise Server 12 SP4
4.2.0-1~
SUSE Linux Enterprise Server 15 SP1
4.2.0-1~
Oracle Linux 6.6
4.0.0-1~
Oracle Linux 7.3
4.0.0-1~
Oracle Linux 7.5
4.1.0-1~
Oracle Linux 7.7
4.2.0-1~
Ubuntu 14.04.LTS
4.0.0-1~
Ubuntu 16.04.3 LTS
4.0.0-1~
Ubuntu 18.04.3 LTS
4.2.0-1~
x86_64
部署模型
备注
资源管理器
4.0.0-1~
需要追加负载均衡器
4.2.9. Azure DNS资源,Azure DNS监视资源的运行环境¶
想使用Azure DNS资源,Azure DNS监视资源时,需要以下的软件。
软件 |
版本 |
备注 |
|---|---|---|
Azure CLI (Red Hat Enterprise Linux 6, Cent OS 6, Asianux Server 4, SUSE Linux Enterprise Server 11, Oracle Linux 6 的情况) |
1.0~ |
不需要Python |
Azure CLI (Red Hat Enterprise Linux 6, Cent OS 6, Asianux Server 4, SUSE Linux Enterprise Server 11, Oracle Linux 6 以外的情况) |
2.0~ |
x86_64
Red Hat Enterprise Linux 6.8
4.0.0-1~
Red Hat Enterprise Linux 6.9
4.0.0-1~
Red Hat Enterprise Linux 6.10
4.1.0-1~
Red Hat Enterprise Linux 7.3
4.0.0-1~
Red Hat Enterprise Linux 7.4
4.0.0-1~
Red Hat Enterprise Linux 7.5
4.1.0-1~
Red Hat Enterprise Linux 7.6
4.1.0-1~
Red Hat Enterprise Linux 7.7
4.2.0-1~
Red Hat Enterprise Linux 7.8
4.3.0-1~
Red Hat Enterprise Linux 8.2
4.3.0-1~
CentOS 6.8
4.0.0-1~
CentOS 6.9
4.0.0-1~
CentOS 6.10
4.1.0-1~
CentOS 7.3
4.0.0-1~
CentOS 7.4
4.0.0-1~
CentOS 7.5
4.1.0-1~
CentOS 7.6
4.1.0-1~
Asianux Server 4 SP6
4.0.0-1~
Asianux Server 4 SP7
4.0.0-1~
Asianux Server 7 SP1
4.0.0-1~
Asianux Server 7 SP2
4.0.0-1~
Asianux Server 7 SP3
4.2.0-1~
SUSE Linux Enterprise Server 11 SP3
4.0.0-1~
SUSE Linux Enterprise Server 11 SP4
4.0.0-1~
SUSE Linux Enterprise Server 12 SP1
4.0.0-1~
SUSE Linux Enterprise Server 12 SP2
4.1.0-1~
SUSE Linux Enterprise Server 12 SP4
4.2.0-1~
SUSE Linux Enterprise Server 15 SP1
4.2.0-1~
Oracle Linux 6.6
4.0.0-1~
Oracle Linux 7.3
4.0.0-1~
Oracle Linux 7.5
4.1.0-1~
Oracle Linux 7.7
4.2.0-1~
Ubuntu 14.04.LTS
4.0.0-1~
Ubuntu 16.04.3 LTS
4.0.0-1~
Ubuntu 18.04.3 LTS
4.2.0-1~
执行了Azure DNS资源,Azure DNS监视资源运行确认的Microsoft Azure上的部署模型如下所示。Azure DNS的设置方法请参考《EXPRESSCLUSTER X Mircosoft Azure的HA Cluster构筑指南 (Linux版)》。
x86_64
资源管理器
4.0.0-1~
需要追加Azure DNS
4.2.10. Google Cloud 虚拟 IP 资源,Google Cloud 虚拟 IP 监视资源,Google Cloud 负载均衡监视资源的运行环境¶
x86_64
发行版本
备注
Red Hat Enterprise Linux 6.10
4.2.0-1~
Red Hat Enterprise Linux 7.7
4.2.0-1~
SUSE Linux Enterprise Server 15 SP1
4.2.0-1~
Ubuntu 16.04.3 LTS
4.2.0-1~
Ubuntu 18.04.3 LTS
4.2.0-1~
4.2.11. Google Cloud DNS 资源,Google Cloud DNS 监视资源的运行环境¶
想使用Google Cloud DNS资源,Google Cloud DNS监视资源时,需要以下的软件。
软件
版本
备注
Google Cloud SDK
295.0.0~
x86_64
Red Hat Enterprise Linux 8.2
4.3.0-1~
4.2.12. Oracle Cloud 虚拟 IP 资源,Oracle Cloud 虚拟 IP 监视资源,Oracle Cloud 负载均衡监视资源的运行环境¶
x86_64
发行版本
备注
Oracle Linux 6.10
4.2.0-1~
Oracle Linux 7.7
4.2.0-1~
Ubuntu 16.04.3 LTS
4.2.0-1~
Ubuntu 18.04.3 LTS
4.2.0-1~
4.2.13. 所需内存容量和磁盘容量¶
所需内存容量
(用户模式)
|
200MB 2
|
|---|---|
所需内存容量
(内核模式)
|
同步模式时
1MB +(请求队列数×I/O大小)+
(2MB+差分Bitmap大小)×(镜像磁盘资源,共享型镜像磁盘资源数)
异步模式时
1MB +{请求队列数}×{I/O大小}
+[3MB
+({I/O大小}×{异步队列数})
+({I/O大小}÷ 4KB × 8字节 + 0.5KB)× ({历史文件大小限制值}÷{I/O大小}+{异步队列数})
+{差分Bitmap大小}
]×(镜像磁盘资源,共享型镜像磁盘资源数)
内核模式 LAN心跳驱动程序时
8MB
KeepAlive驱动程序时
8MB
|
所需磁盘容量
(安装后)
|
300MB
|
所需磁盘容量
(运行时)
|
5.0GB
|
- 2
除Option类
注解
I/O大小的标准如下所示。
关于请求队列数,异步队列数的设置值,请参考《参考指南》的"组资源的详细信息"的"理解镜像磁盘资源"。
关于磁盘心跳资源使用的分区所需的大小,请参考"关于共享磁盘"。
关于集群分区所需的大小请参考"关于镜像用磁盘","关于共享型镜像磁盘资源用磁盘"。
4.3. Cluster WebUI 的运行环境¶
4.3.1. 运行确认完毕的OS,浏览器¶
现在的支持情况如下。
浏览器 |
语言 |
|---|---|
Internet Explorer 11 |
日文/英文/中文 |
Internet Explorer 10 |
日文/英文/中文 |
Firefox |
日文/英文/中文 |
Google Chrome |
日文/英文/中文 |
Microsoft Edge (Chromium) |
日文/英文/中文 |
注解
通过IP地址连接时,需要事先将该IP地址登录到 [本地Intranet] 的 [站点] 中。
注解
用 Internet Explorer11连接Cluster WebUI时,Internet Explorer可执行会停止。为了避免发生,请更新Internet Explorer(KB4052978或更高版本)。此外,为了在Windows 8.1/Windows Server 2012R2中应用KB4052978以上的版本,请提前应用KB2919355。相关信息请参考Microsoft部署的信息。
注解
不支持平板电脑和智能手机等移动设备。
4.3.2. 所需内存容量/磁盘容量¶
所需内存容量 500MB以上
所需磁盘容量 200MB以上
5. 最新版本信息¶
在本章中对EXPRESSCLUSTER的最新信息进行说明。为您介绍新发布版本中强化和改善的内容。
5.1. EXPRESSCLUSTER和手册的对应表¶
本手册中以下列版本的EXPRESSCLUSTER为前提进行说明。请注意EXPRESSCLUSTER的版本和手册的版本。
EXPRESSCLUSTER内部版本 |
手册 |
版本数 |
备注 |
|---|---|---|---|
4.3.0-1 |
开始指南 |
第1版 |
|
第1版 |
|||
第1版 |
|||
第1版 |
|||
第1版 |
|||
第2版 |
5.2. 功能强化¶
对于各个版本,分别进行了以下的功能强化。
No |
内部版本 |
功能强化项目 |
|---|---|---|
1 |
4.0.0-1 |
安装了新设计的管理GUI (Cluster WebUI)。 |
2 |
4.0.0-1 |
WebManager支持了HTTPS协议。 |
3 |
4.0.0-1 |
能够使用期间定制License。 |
4 |
4.0.0-1 |
扩大了镜像磁盘资源,共享型镜像磁盘资源的最大值。 |
5 |
4.0.0-1 |
卷管理资源,卷管理监视资源对应了ZFS存储池。 |
6 |
4.0.0-1 |
增加了支持的OS。 |
7 |
4.0.0-1 |
支持了systemd。 |
8 |
4.0.0-1 |
Oracle监视资源支持了Oracle 12c R2。 |
9 |
4.0.0-1 |
MySQL监视资源支持了MariaDB 10.2。 |
10 |
4.0.0-1 |
PostgreSQL监视资源支持了PowerGres on Linux 9.6。 |
11 |
4.0.0-1 |
添加了SQL Server监视资源。 |
12 |
4.0.0-1 |
添加了ODBC监视资源。 |
13 |
4.0.0-1 |
WebOTX监视资源支持了WebOTX V10.1。 |
14 |
4.0.0-1 |
JVM监视资源支持了Apache Tomcat 9.0。 |
15 |
4.0.0-1 |
JVM监视资源支持了WebOTX V10.1。 |
16 |
4.0.0-1 |
JVM监视资源可以进行以下的监视。
|
17 |
4.0.0-1 |
添加了AWS DNS资源,AWS DNS监视资源。 |
18 |
4.0.0-1 |
添加了Azure DNS资源,Azure DNS监视资源。 |
19 |
4.0.0-1 |
改善了监视资源错误判定以及超时判定的精度。 |
20 |
4.0.0-1 |
添加了在组资源启动/停止的前后,可以执行任意脚本的功能。 |
21 |
4.0.0-1 |
在发生两机双活时可以选择要存活的服务器组。 |
22 |
4.0.0-1 |
失效切换属性设定为[完全互斥]的组,可以做互斥对象的组合设定。 |
23 |
4.0.0-1 |
减少内部进程间通信消耗的TCP端口数量。 |
24 |
4.0.0-1 |
强化了日志收集的收集项目。 |
25 |
4.0.0-1 |
可以设置镜像磁盘资源,共享型镜像磁盘资源的差分Bitmap大小。 |
26 |
4.0.1-1 |
支持新发布的kernel。 |
27 |
4.0.1-1 |
在WebManager中如果因为设置不佳导致无法使用HTTPS时,消息将输出到syslog以及警告日志中。 |
28 |
4.1.0-1 |
支持新发布的kernel。 |
29 |
4.1.0-1 |
支持Red Hat Enterprise Linux 7.6。 |
30 |
4.1.0-1 |
支持SUSE Linux Enterprise Server 12 SP2。 |
31 |
4.1.0-1 |
支持Amazon Linux 2。 |
32 |
4.1.0-1 |
支持Oracle Linux 7.5。 |
33 |
4.1.0-1 |
Oracle 监视资源支持Oracle Database 18c。 |
34 |
4.1.0-1 |
Oracle 监视资源支持Oracle Database 19c。 |
35 |
4.1.0-1 |
PostgreSQL 监视资源支持PostgreSQL11。 |
36 |
4.1.0-1 |
PostgreSQL 监视资源支持PowerGres V11。 |
37 |
4.1.0-1 |
MySQL 监视资源支持MySQL8.0。 |
38 |
4.1.0-1 |
MySQL 监视资源支持MariaDB10.3。 |
39 |
4.1.0-1 |
以下资源/ 监视资源支持Python3。
|
40 |
4.1.0-1 |
用于SAP NetWeaver 的SAP 联动连接器支持以下的OS。
|
41 |
4.1.0-1 |
用于SAP NetWeaver 的SAP 联动连接器支持以下的SAP NetWeaver。
|
42 |
4.1.0-1 |
用于SAP NetWeaver 的SAP联动连接器/示例脚本支持以下。
|
43 |
4.1.0-1 |
Samba 监视资源支持如下。
|
44 |
4.1.0-1 |
可在Cluster WebUI 中进行集群构成,配置更改。 |
45 |
4.1.0-1 |
镜像磁盘资源/共享型镜像磁盘资源支持RAW分区。 |
46 |
4.1.0-1 |
镜像的设置项目中添加"镜像复归 I/O 大小",可以调整镜像复归性能。 |
47 |
4.1.0-1 |
改善共享型镜像磁盘资源(异步模式)的服务器组内的失效切换处理时间。 |
48 |
4.1.0-1 |
共享型镜像磁盘资源的镜像复归中可以进行服务器组内的失效切换。 |
49 |
4.1.0-1 |
改善镜像异步模式的未发送邮件数据的缓冲机构。 |
50 |
4.1.0-1 |
添加用于DB2 的 DB 静止点命令。 |
51 |
4.1.0-1 |
添加用于PostgreSQL 的 DB 静止点命令。 |
52 |
4.1.0-1 |
添加用于Sybase的 DB 静止点命令。 |
53 |
4.1.0-1 |
添加用于SQL Server的 DB 静止点命令。 |
54 |
4.1.0-1 |
MySQL的DB静止点命令支持MariaDB。 |
55 |
4.1.0-1 |
添加了Witness 心跳资源。 |
56 |
4.1.0-1 |
添加了HTTP 网络分区解决资源。 |
57 |
4.1.0-1 |
扩充了在更改集群配置时,不需要停止业务就能反映更改的设置项目。 |
58 |
4.1.0-1 |
添加了在启动失效切换组时,重复检查浮动IP地址的功能。 |
59 |
4.1.0-1 |
在远程集群配置中,添加了即使检测出服务器组间的心跳超时,也仅在设置好的时间内暂停自动失效切换的功能。 |
60 |
4.1.0-1 |
扩充了可以在EXEC资源的开始/结束脚本中使用的环境变量。 |
61 |
4.1.0-1 |
添加了一项功能实现依据"强制停止"脚本的执行结果来制止故障转移。 |
62 |
4.1.0-1 |
可以编辑在强制停止功能以及机箱ID联动功能中执行的IPMI命令。 |
63 |
4.1.0-1 |
添加了进程资源监视资源,集中系统监视资源的进程资源监视功能。 |
64 |
4.1.0-1 |
镜像统计信息中添加了新的统计值。 |
65 |
4.1.0-1 |
添加了系统资源统计信息采集功能。 |
66 |
4.1.0-1 |
添加了将失效切换组,组资源,监视资源的运行状况作为集群统计信息保存的功能。 |
67 |
4.1.0-1 |
在日志收集模式中添加了镜像统计信息和集群统计信息。 |
68 |
4.1.0-1 |
添加了用户监视资源中,等待异步脚本的监视开始的功能。 |
69 |
4.1.0-1 |
添加了执行集群停止时,在组资源停止前等待用户监视资源停止结束的设置。 |
70 |
4.1.0-1 |
添加了用于指定clpmonctrl命令请求处理的服务器的参数。 |
71 |
4.1.0-1 |
已在与WebManager服务器的HTTPS连接中禁用SSL和TLS 1.0。 |
72 |
4.1.0-1 |
添加了到可以使用共享磁盘为止的等待启动集群的功能。 |
73 |
4.1.0-1 |
关机监视的默认值从"始终执行"更改为"只在组停止处理失败时执行"。 |
74 |
4.1.1-1 |
支持了Asianux 7 SP3。 |
75 |
4.1.1-1 |
改善了Cluster WebUI的表示和相关操作。 |
76 |
4.1.2-1 |
支持新发布的 kernel 。 |
77 |
4.1.2-1 |
Cluster WebUI 以及 HTTP 监视资源支持 OpenSSL 1.1.1。 |
78 |
4.2.0-1 |
添加了可以操作集群并获取状态的RESTful API。 |
79 |
4.2.0-1 |
改善了Cluster WebUI和通过命令获取集群信息的处理。 |
80 |
4.2.0-1 |
添加了检查集群配置信息的功能。 |
81 |
4.2.0-1 |
增强了当查出异常执行OS panic时,记录到待机服务器的消息内容。 |
82 |
4.2.0-1 |
添加了禁用组的自动启动和启动/停止异常时的复归动作的功能。 |
83 |
4.2.0-1 |
使用License管理命令,删除集群节点时可以重新配置期间定制License。 |
84 |
4.2.0-1 |
可以用OS的用户帐户登录到Cluster WebUI。 |
85 |
4.2.0-1 |
在EXEC资源中,执行和结合运行服务器上的开始·结束脚本,在待机服务器上也可以执行脚本。 |
86 |
4.2.0-1 |
可以在不停止操作的情况下添加·删除集群节点。 |
87 |
4.2.0-1 |
扩充了组的停止等待的设置条件。 |
88 |
4.2.0-1 |
添加了在Cluster WebUI 中显示组启动停止预测时间的功能。 |
89 |
4.2.0-1 |
支持新发布的kernel。 |
90 |
4.2.0-1 |
支持Red Hat Enterprise Linux 7.7。 |
91 |
4.2.0-1 |
支持SUSE LINUX Enterprise Server 15。 |
92 |
4.2.0-1 |
支持SUSE LINUX Enterprise Server 15 SP1。 |
93 |
4.2.0-1 |
支持SUSE LINUX Enterprise Server 12 SP4。 |
94 |
4.2.0-1 |
支持Oracle Linux 7.7。 |
95 |
4.2.0-1 |
支持Ubuntu 18.04.3 LTS。 |
96 |
4.2.0-1 |
可以通过以下功能使用Proxy服务器。
|
97 |
4.2.0-1 |
使用Cluster WebUI和clpstat命令改善了集群停止状态和集群挂起状态的显示内容。 |
98 |
4.2.0-1 |
在日志收集模式中添加了系统统计信息。 |
99 |
4.2.0-1 |
添加用于显示组启动停止预测时间以及监视资源的监视所用时间的命令。 |
100 |
4.2.0-1 |
更改系统资源统计信息的输出目标。 |
101 |
4.2.0-1 |
扩充了系统资源统计信息的收集信息。 |
102 |
4.2.0-1 |
HTTP监视资源支持BASIC认证。 |
103 |
4.2.0-1 |
AWS AZ监视资源的状态在可用区中为information 或者 impaired时,从异常更改为警告。 |
104 |
4.2.0-1 |
添加了Google Cloud 虚拟IP资源,Google Cloud 虚拟IP监视资源。 |
105 |
4.2.0-1 |
添加了Oracle Cloud 虚拟IP资源,Oracle Cloud 虚拟IP监视资源。 |
106 |
4.2.0-1 |
对于以下监视资源,AWS CLI命令响应获取失败操作的默认值已从"不执行复归动作(显示警告)"更改为“不执行复归动作(不显示警告)"。
|
107 |
4.2.0-1 |
DB2监视资源支持DB2 v11.5。 |
108 |
4.2.0-1 |
MySQL监视资源支持MariaDB 10.4。 |
109 |
4.2.0-1 |
SQL Server监视资源支持SQL Server 2019。 |
110 |
4.2.0-1 |
添加了不间断扩展镜像磁盘资源的数据分区大小的功能。 |
111 |
4.2.0-1 |
改善了发生磁盘监视资源超时时警报日志的输出信息。 |
112 |
4.2.2-1 |
支持新发布的 kernel。 |
113 |
4.2.2-1 |
支持Red Hat Enterprise Linux 7.8。 |
114 |
4.2.2-1 |
支持Red Hat Enterprise Linux 8.1。 |
115 |
4.2.2-1 |
支持MIRACLE LINUX 8 Asianux Inside。 |
116 |
4.2.2-1 |
扩展了可以通过RESTful API获取的资源状态信息。 |
117 |
4.2.2-1 |
PostgreSQL监视资源支持PostgreSQL12。 |
118 |
4.3.0-1 |
支持新发布的kernel。 |
119 |
4.3.0-1 |
支持Red Hat Enterprise Linux 7.9。 |
120 |
4.3.0-1 |
支持Red Hat Enterprise Linux 8.2。 |
121 |
4.3.0-1 |
支持Ubuntu 20.04.1 LTS。 |
122 |
4.3.0-1 |
支持SUSE LINUX Enterprise Server 12 SP5。 |
123 |
4.3.0-1 |
支持SUSE LINUX Enterprise Server 15 SP2。 |
124 |
4.3.0-1 |
通过RESTful API,可以操作/参考用于监视资源和心跳的超时放大率。 |
125 |
4.3.0-1 |
通过RESTful API扩充了相当于clprexec命令的功能 。 |
126 |
4.3.0-1 |
通过RESTful API可以为每个用户组/IP地址设置权限(操作/参考)。 |
127 |
4.3.0-1 |
改善了在Cluster WebUI中添加资源时只根据系统环境显示资源类型的功能。 |
128 |
4.3.0-1 |
添加了在Cluster WebUI中自动获取AWS相关资源设置的功能。 |
129 |
4.3.0-1 |
更改了期间定制License已过期时的集群操作。 |
130 |
4.3.0-1 |
心跳超时时间内重启服务器时,消息将输出到syslog以及警告日志中。 |
131 |
4.3.0-1 |
添加了失效切换组启动时不自动启动组资源的功能。 |
132 |
4.3.0-1 |
改善了查出双重启动时的关机操作。 |
133 |
4.3.0-1 |
在clpbwctrl命令中添加了集群启动时禁用NP解决的功能。 |
134 |
4.3.0-1 |
服务器的最大重启次数的默认值变更为3次,重启时间变更为60分钟。 |
135 |
4.3.0-1 |
添加了在查出异常时因操作而进行服务器重启,panic时无需等待心跳超时时间就可以进行失效切换的功能。 |
136 |
4.3.0-1 |
增加了使用clpgrp/clprsc/clpdown/clpstdn/clpcl命令的内部通信超时的默认值。 |
137 |
4.3.0-1 |
在警报服务中添加了向Amazon SNS发送消息的功能。 |
138 |
4.3.0-1 |
可以把监视资源的监视处理时间作为指标发送到Amazon CloudWatch。 |
139 |
4.3.0-1 |
支持fluentd等的日志数据收集工具。 |
140 |
4.3.0-1 |
可以把监视资源的监视处理时间作为指标发送到StatsD。 |
141 |
4.3.0-1 |
扩充了集群配置信息检查功能的检查项目。 |
142 |
4.3.0-1 |
添加了简化映像备份还原的命令clpbackup.sh, clprestore.sh。 |
143 |
4.3.0-1 |
添加了Google Cloud DNS资源,Google Cloud DNS监视资源。 |
144 |
4.3.0-1 |
改善了根据HTTP网络分区解决资源查出网络分区时的警报消息。 |
145 |
4.3.0-1 |
可以把Cluster WebUI的操作日志输出到服务器端。 |
146 |
4.3.0-1 |
查出监视超时时可以获取内存转储。 |
147 |
4.3.0-1 |
可以从Cluster WebUI确认警报日志的详细(处理方法等)。 |
148 |
4.3.0-1 |
可以管理在Witness服务器里具有相同集群名的多个集群。 |
149 |
4.3.0-1 |
添加了集群配置信息创建命令clpcfset。 |
150 |
4.3.0-1 |
可以从Cluster WebUI的编辑模式的[组的属性]确认组资源列表。 |
151 |
4.3.0-1 |
可以从Cluster WebUI的编辑模式的[监视共通属性]确认监视资源列表。 |
152 |
4.3.0-1 |
Cluster WebUI支持Microsoft Edge(Chromium版)。 |
153 |
4.3.0-1 |
向Cluster WebUI的警报日志的详细筛选对象中添加了消息。 |
154 |
4.3.0-1 |
改善了监视资源的延迟警报消息。 |
155 |
4.3.0-1 |
改善了启动时监视对象的组启动处理中查出监视异常时的消息。 |
156 |
4.3.0-1 |
添加了命令clpcfreset以重置设置,例如Cluster Web UI的密码。 |
157 |
4.3.0-1 |
改善了Cluster WebUI的[状态]画面的操作图标的布局。 |
158 |
4.3.0-1 |
扩充了可以设置服务器组间的失效切换时的犹豫时间的上限值。 |
159 |
4.3.0-1 |
浏览器重启后也保持Cluster WebUI的[仪表盘]的用户自定义设置。 |
160 |
4.3.0-1 |
可以登录多个系统监视资源。 |
161 |
4.3.0-1 |
可以登录多个进程资源监视资源。 |
162 |
4.3.0-1 |
在进程资源监视资源中添加了只把特定进程作为监视对象的功能。 |
163 |
4.3.0-1 |
HTTP监视资源支持GET请求的监视。 |
164 |
4.3.0-1 |
在Weblogic监视资源的监视方法中添加了REST API。 |
165 |
4.3.0-1 |
当收集系统资源信息所需的zip和unzip软件包不足时,将输出警告消息。 |
166 |
4.3.0-1 |
把NFS监视资源的NFS版本的默认值变更为v4。 |
167 |
4.3.0-1 |
WebOTX监视资源支持WebOTX V10.3。 |
168 |
4.3.0-1 |
JVM监视资源支持WebOTX V10.3。 |
169 |
4.2.0-1 |
Weblogic监视资源支持Oracle WebLogic Server 14c (14.1.1)。 |
170 |
4.2.0-1 |
JVM监视资源支持Oracle WebLogic Server 14c (14.1.1)。 |
171 |
4.3.0-1 |
Samba监视资源支持Samba 4.13。 |
172 |
4.3.0-1 |
JVM监视资源支持Java11。 |
173 |
4.3.0-1 |
支持镜像磁盘资源和共享型镜像磁盘资源中使用的镜像数据的通信进行加密。 |
174 |
4.3.0-1 |
镜像磁盘资源和共享型镜像磁盘资源支持ext4文件系统的64bit feature,uninit_bg feature。 |
175 |
4.3.0-1 |
无中断扩展镜像磁盘资源的数据分区大小的功能支持ext2,ext3,ext4文件系统。 |
176 |
4.3.0-1 |
添加了无中断扩展共享型镜像磁盘资源的数据分区大小的功能。 |
177 |
4.3.0-1 |
改善了使用xfs文件系统时的初始镜像构筑和全复制的所需时间。 |
178 |
4.3.0-1 |
改善了镜像复归的速度。 |
179 |
4.3.0-1 |
以下资源支持AWS CLI v2。
|
5.3. 修改信息¶
各版本做了以下修改。
No.
|
修改版本
/ 发生版本
|
修改项目
|
重要性
|
发生条件
发生频率
|
|---|---|---|---|---|
1
|
4.0.1-1
/ 4.0.0-1
|
可以启动同一个产品的两个限时许可证。
|
小
|
当证书到期,同时进行自动启动库存未使用证书的处理和用证书注册命令进行新证书注册操作处理时,偶尔会发生。
|
2
|
4.0.1-1
/ 4.0.0-1
|
通过clpgrp命令启动组时失败。
|
小
|
在互斥规则已被设定的配置中,不指定启动对象的组名执行clpgrp命令时会发生。
|
3
|
4.0.1-1
/ 4.0.0-1
|
在混合了CPU证书和VM节点证书的配置中,会出现提示CPU证书不足的警告消息。
|
小
|
CPU证书和VM节点证书混合时会发生。
|
4
|
4.0.1-1
/ 4.0.0-1
|
在Azure DNS监视资源中,即使Azure上的DNS服务器正常运行,也会异常。
|
小
|
以下条件都满足时一定会发生。
・选中[确认域名解析]时
・Azure CLI 的版本为2.0.30 ~ 2.0.32 时 (2.0.29 以下,2.0.33 以上时不会发生)
|
5
|
4.0.1-1
/ 4.0.0-1
|
在Azure DNS监视资源中,即使一部分Azure上的DNS服务器正常运行,也会异常。
|
小
|
以下条件都满足时一定会发生。
・选中[确认域名解析]时
・通过Azure CLI获取的DNS服务器列表中显示在第一个的DNS服务器没有正常运行时(第二个之后的DNS服务器正常运行)
|
6
|
4.0.1-1
/ 4.0.0-1
|
Azure DNS监视资源中,Azure上的DNS服务器列表获取失败时也不作为异常。
|
小
|
以下条件都满足时一定会发生。
・选中[确认域名解析]时
・通过Azure CLI获取DNS服务器列表失败时
|
7
|
4.0.1-1
/ 4.0.0-1
|
使用JVM监视资源时,监视对象Java VM中会发生内存泄露。
|
中
|
满足以下条件时会发生。
・选中[监视 (固有)]标签页-[调整]属性-[线程]标签页-[监视运行中的线程数]时
|
8
|
4.0.1-1
/ 4.0.0-1
|
JVM监视资源的Java进程中,发生内存泄露。
|
中
|
满足以下条件时会发生。
・[监视 (固有)]标签页-[调整]属性中的设置全选中
・多次创建JVM 监视资源时
|
9
|
4.0.1-1
/ 4.0.0-1
|
JVM监视资源中,即使关闭以下参数,JVM统计日志(jramemory.stat)还是会被输出。
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视堆使用量]
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视非堆使用量]
|
小
|
满足以下条件时一定会发生。
・[监视 (固有)]标签页-[JVM 种别]为[Oracle Java(usage monitoring)]时
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视堆使用量]关闭时
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视非堆使用量]关闭时
|
10
|
4.1.0-1
/ 4.0.0-1
|
使用SAP NetWeaver示例脚本的自定义监视资源被检测到故障时,SAP服务的停止处理过程中会进行SAP服务的开始处理。
|
小
|
当SAP服务的停止处理需要花费时间时会发生。
|
11
|
4.1.0-1
/ 4.0.0-1
|
如果AWS使用的标签页内容中包含了非ASCII字符,则启动AWS虚拟IP资源会失败。
|
小
|
如果AWS使用的标签页内容中包含了非ASCII字符时,一定会发生。
|
12
|
4.1.0-1
/ 4.0.0-1
|
EXPRESSCLUSTER语言设置选择"英文"以外时,SAP NetWeaver 的 SAP联动连接无法正常运行。
|
小
|
选择除"英文"以外时一定会发生。
|
13
|
4.1.0-1
/ 4.0.0-1
|
SQLServer监视中,DB缓存中存在SQL文,可执行会导致性能上的问题。
|
小
|
监视级别2时会发生。
|
14
|
4.1.0-1
/ 4.0.0-1
|
SQLServer 监视中,监视用户名不正确时,应该是警告的情况却变成了监视异常。
|
小
|
监视参数中存在设置错误时发生。
|
15
|
4.1.0-1
/ 4.0.0-1
|
ODBC监视中监视用户名不正确时,应该是警告的情况却变成了监视异常。
|
小
|
监视参数中存在设置错误时发生。
|
16
|
4.1.0-1
/ 4.0.0-1
|
Database Agent 中监视异常时的复归操作推迟30秒执行。
|
小
|
复归操作执行时一定会发生。
|
17
|
4.1.0-1
/ 4.0.0-1
|
Database Agent 中,通过clptoratio 命令设置超时倍率无效。
|
小
|
一定会发生。
|
18
|
4.1.0-1
/ 4.0.0-1
|
集群挂起时会发生超时。
|
中
|
集群复原处理中执行集群挂起操作时,很少会发生。
|
19
|
4.1.0-1
/ 4.0.0-1
|
设置为手动启动的失效切换组在失效切换时,在失效切换源中未被启动的组资源,在失效切换目标中被启动了。
|
小
|
下述的状态转变时会发生。
1. 集群停止
2. 集群启动
3. 设置为手动启动的失效切换组的一部分组资源单一启动
4. 关闭了启动了组资源的服务器
|
20
|
4.1.0-1
/ 4.0.0-1
|
用clpstat命令,集群停止处理中的状态未正确显示。
|
小
|
从集群停止执行后到集群停止结束之间,执行clpstat命令时会发生。
|
21
|
4.1.0-1
/ 4.0.0-1
|
没有结束停止处理的组资源的状态显示为停止状态。
|
中
|
对于停止处理失败状态下的组资源,在进行下述操作时会发生。
・启动操作
・停止操作
|
22
|
4.1.0-1
/ 4.0.0-1
|
因为关机监视,失效切换会在服务器重置之前开始。
|
大
|
由于系统高负荷,关机监视运行延迟时,偶尔会发生。
|
23
|
4.1.0-1
/ 4.0.0-1
|
更改强制停止功能设置时,有时会没有执行恰当反映方法(集群挂起/恢复)。
|
小
|
虚拟机强制停止设置初次反映时发生。
|
24
|
4.1.0-1
/ 4.0.0-1
|
有时会无法反映更改集群属性的"日志通信方法"的设置。
|
小
|
集群初次构筑时,把"日志通信发法"更改为除"UNIX域"以外时发生。
|
25
|
4.1.0-1
/ 4.0.0-1
|
exec 资源,用户监视资源的脚本日志中发生以下问题。
・异步脚本的日志输出时刻为所有进程完成时刻。
・有时留有日志的临时保存文件。
|
小
|
脚本的日志轮循功能启用时发生。
|
26
|
4.1.0-1
/ 4.0.0-1
|
创建镜像磁盘资源以及共享型镜像磁盘资源时指定"不进行初始镜像构筑"则首次的镜像复归一定会全复制。
|
小
|
指定"不进行初始镜像构筑"一定会发生。
|
27
|
4.1.0-1
/ 4.0.0-1
|
镜像磁盘/共享型镜像磁盘的启动/停止/监视处理时发生延迟。
|
小
|
镜像磁盘资源/共享型镜像磁盘资源数的合计约16个以上时发生。
|
28
|
4.1.0-1
/ 4.0.0-1
|
磁盘监视资源中,即使查出超时未提示异常而是警告。
|
中
|
磁盘监视资源中查出超时时发生。
|
29
|
4.1.1-1
/ 4.1.0-1
|
切换到Cluster WebUI的编辑模式失败。
|
小
|
从特定浏览器通过HTTPS访问Cluster WebUI时发生。
|
30
|
4.1.1-1
/ 4.1.0-1
|
当镜像磁盘资源或共享型镜像磁盘资源在异步模式下,主服务器宕机并导致执行差量复制的主服务器与备份服务器的数据不一致。
|
大
|
当主服务器宕机并执行差量复制时发生。
|
31
|
4.1.1-1
/ 4.1.0-1
|
当指定LVM逻辑卷为镜像磁盘资源或共享型镜像磁盘资源的数据分区时,初始镜像构筑和镜像复归将无法完成。
|
大
|
当指定LVM逻辑卷为数据分区时发生。
|
32
|
4.1.2-1
/ 4.1.0-1
|
设置网络警告灯时,以下项目的设置值未保存在配置信息中。
- 使用网络警告灯
- 服务器启动时播放音频文件
- 音频文件编号
- 服务器停止时播放音频文件
- 音频文件编号
|
小
|
设置网络警告灯时总是会发生。
|
33
|
4.2.2-1
/ 4.0.0-1~4.2.0-1
|
镜像重建期间可执行无法正确显示剩余时间。 |
小 |
当镜像重建期间的剩余时间超过一小时时发生。 |
34 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
镜像恢复期间,镜像磁盘监视资源/共享型镜像磁盘监视资源的状态不会变为警告。
|
小
|
镜像磁盘监视资源/共享型镜像磁盘监视资源的状态从异常状态到开始镜像恢复时发生。
|
35 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
用clpstat命令可执行会显示以下错误消息。
Could not connect to the server.
Internal error.Check if memory or OS resources are sufficient.
|
小 |
启动集群后立即执行clpstat命令时很少会发生。 |
36 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
应用配置信息时,可执行会显示不必要的操作(WebManager服务器重新启动)。 |
小 |
设置配置信息的时候,只有在满足同时修改 [关闭·重启集群]和[重启webmanager]两者所需要的设定信息的时候才会发生。 |
37 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
组以及组资源的当前服务器信息可执行不一致。 |
中 |
设置手动失效切换时,心跳线断线恢复后很少会发生。 |
38 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
反映配置信息时,可执行需要不必要的操作(挂起/恢复)。 |
小 |
参考自动注册的监视资源的属性时,可执行会发生。 |
39 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
多目标监视资源中,可执行无法按照异常阈值以及警告阈值的设置方式进行操作。 |
小 |
|
40 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
动态DNS资源的启动可执行会失败。 |
中 |
资源名称和主机名称的总和超过124个字节时,很少发生。 |
41 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
Cluster WebUI中镜像磁盘操作可执行无法正常工作。 |
小 |
更改镜像代理端口号时发生。 |
42 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
用clpstat命令可执行会显示不正确的项目名称。
|
小 |
在存在磁盘心跳资源的环境下执行clpstat --hb --detail时会发生。 |
43 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
rpcbind服务可执行会意外启动。 |
小 |
在收集日志时会发生。 |
44 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
clusterpro_evt服务可执行在nfs之前启动。 |
小 |
发生在init.d环境中。 |
45 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
EXPRESSCLUSTER Web Alert服务可执行会异常终止。 |
小 |
不管具体条件如何,这种情况很少发生。 |
46 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
虚拟机强制停止功能的超时设置可执行不起作用。 |
中 |
在使用虚拟机强制停止功能并且强制停止过程需要时间时发生。 |
47 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
重新启动集群时,该组可执行无法启动。 |
中 |
重启集群时,在运行组停止处理中,较早地重新启动待机服务器时很少会发生。 |
48 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
服务器停止处理可执行需要很长时间。 |
小 |
集群停止时很少发生。 |
49 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
即使组或资源的停用失败,也可执行会输出指示停用成功的警报。 |
小 |
在紧急关机时发生。 |
50 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
查出服务器关闭时,组可执行不会进行失效切换。 |
中 |
在服务器启动时内部信息的同步处理期间检测到服务器关闭时会发生这种情况。 |
51 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
在PID监视资源中,如果要监视的进程已消失,则可执行不会检测到错误。 |
小 |
在监视间隔期间,用与已经消失的进程相同的进程ID启动新的进程时。 |
52 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
监视进程资源监视资源的打开文件数(内核上限值)不会根据设置值检测到错误。 |
小 |
选中[打开文件数(内核上限值)的监视]时一定会发生。 |
53 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
EXEC资源停止时,会强制结束其他进程。 |
中 |
当EXEC资源中满足以下所有条件时会发生。
|
54 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
镜像磁盘资源和共享型镜像磁盘资源中,启动的服务器的镜像磁盘状态变为异常。 |
大 |
执行以下跳转时发生。
|
55 |
4.2.0-1
/ 4.0.0-1~4.1.2-1
|
当卷管理器监视资源的监视目标是LVM镜像时,LVM镜像的降级状态变为监视异常。
|
小 |
当LVM镜像处于降级状态时发生。 |
56 |
4.2.2-1
/ 4.1.0-1~4.2.0-1
|
无法更改镜像通信专用私网的IP地址。 |
小 |
在配置集群时,在高优先级服务器之前添加低优先级服务器时发生。 |
57 |
4.2.2-1
/ 4.2.0-1
|
集群配置信息检查功能,不能正确对端口号的特定范围进行确认。 |
小 |
检查对象的端口号为以下范围时发生。
临时端口最大值<对象端口号<=端口号最大值(65535)
|
58 |
4.2.2-1
/ 4.2.0-1
|
通过集群配置信息检查功能检查AWSCLI命令失败。 |
小 |
在设置了以下组资源的环境中执行集群配置信息检查时发生。
・AWS Elastic IP资源
・AWS 虚拟IP资源
・AWS DNS 资源
|
59 |
4.2.2-1
/ 4.2.0-1
|
启动集群后执行集群配置信息检查时,检查浮动IP资源和虚拟IP资源失败。 |
小 |
在浮动IP资源和虚拟IP资源为启动状态下执行集群配置信息检查时发生。 |
60 |
4.2.2-1
/ 4.1.0-1~4.2.0-1
|
不启动Oracle Clusterware 同步管理监视资源。 |
小 |
设置Oracle Clusterware同步管理监视资源时,未从默认值更改复归操作时发生。 |
61 |
4.3.0-1
/ 4.0.0-1~4.2.2-1
|
警报发送目标设定的[Alert Extension]无法使用。 |
小 |
在警报发送目标设定中选择了[Alert Extension]时,一定发生。 |
62 |
4.3.0-1
/ 4.2.0-1~4.2.2-1
|
在没有启动失效切换组的服务器上,进行其组相关的集群配置检查。 |
小 |
启动服务器的设置中,设置了没有启动失效切换的服务器时会发生。 |
63 |
4.3.0-1
/ 1.0.0-1~4.2.2-1
|
不必要的数据包发送到未使用的服务器设定的内核模式LAN心跳。 |
小 |
在内核模式LAN心跳上设置未使用服务器时一定发生。 |
64 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
当服务器关闭时,可执行会不必要地执行通过关闭停止监视进行的重置。 |
小 |
在通过组资源停止失败或者NP解决处理执行服务器关闭的场合时会发生。 |
65 |
4.3.0-1
/ 4.2.0-1~4.2.2-1
|
EXPRESSCLUSTER Information Base服务会异常结束。 |
小 |
在OS资源不足时偶尔发生。 |
66 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
不必要的数据传输包发送到设置了未使用的服务器的私网中。 |
小 |
当在私网中设置了未使用的服务器时一定会发生。 |
67 |
4.3.0-1
/ 4.2.0-1~4.2.2-1
|
Cluster WebUI中无法迁移到编辑模式。 |
小 |
当通过OS认证方法设置了密码并且该设置仅反映在没有操作权限的组中时,会发生这种情况。 |
68 |
4.3.0-1
/ 4.2.0-1~4.2.2-1
|
Cluster WebUI的[状态]画面中的[服务器服务开始]按钮未启用。 |
小 |
连接Cluster WebUI的服务器的服务停止时会发生。 |
69 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
Cluster WebUI的编辑模式的[资源的属性]-[依赖关系]标签页中删除依赖的资源时会显示不正确。 |
小 |
删除依赖的资源时会发生。 |
70 |
4.3.0-1
/ 4.0.0-1~4.2.2-1
|
在Cluster WebUI的[镜像磁盘]画面中点击镜像磁盘资源时,仍会显示加载图标。 |
小 |
点击镜像磁盘资源时获取镜像信息的通信失败时会发生。 |
71 |
4.3.0-1
/ 4.0.0-1~4.2.2-1
|
Cluster WebUI中[仪表盘]画面的警报日志和[镜像磁盘]画面没有显示。 |
小 |
共享型镜像磁盘资源的信息获取失败时会发生。 |
72 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
在Cluster WebUI中添加组资源和监视资源时编辑的脚本文件没有保存在正确的路径中。 |
小 |
在添加组资源和监视资源的画面中编辑脚本文件后返回到前个画面,更改组资源名和监视资源名时会发生。 |
73 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
将服务器添加到Cluster WebUI中BMC设置的集群时,会生产错误的集群配置信息。 |
小 |
设置BMC的集群中添加服务器时会发生。 |
74 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
当Cluster WebUI的[组的属性]-[信息]标签页上的[使用服务器组设置]从打开更改为关闭时,[属性]标签页的显示内容不正确。 |
小 |
把[属性]标签页的失效切换属性设置为"在服务器组内首选失效切换策略"的状态下,"使用服器组设置"从打开更改为关闭时会发生。 |
75 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
在Cluster WebUI的[监视资源的属性]-[监视(共通)]标签页中,[监视时机]-[对象资源]的[参考]按钮无法点击。 |
小 |
[监视时机]从不间断监视更改为启动时监视之后登录的监视资源的[监视资源的属性]打开时会发生。 |
76 |
4.3.0-1
/ 4.2.0-1~4.2.2-1
|
Cluster WebUI Offline中点击[服务器]-[添加服务器]按钮时,显示错误消息的服务器无法添加。 |
小 |
点击[服务器]-[添加服务器]按钮时会发生。 |
77 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
Cluster WebUI的编辑模式下,在错误的时间里输出废弃当前集群配置的消息。 |
小 |
在不更改配置信息的情况下进行以下操作后,点击设置的导入按钮或获取按钮时会发生。
・设置的导出
・中途取消设置反映
・集群配置信息检查
|
78 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
Cluster WebUI的编辑模式下进行不必要的设定值检查。 |
小 |
在没有设置镜像磁盘资源/共享型镜像磁盘资源的环境下,[HB超时]比[CPIO超时]短时会发生。 |
79 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
设置警告灯的环境中添加服务器时,配置信息中保存不必要的信息。 |
小 |
设置警告灯的环境中添加服务器时会发生。 |
80 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
在系统监视资源中,指定了9个字符以上的监视资源名,不会查出监视异常。 |
小 |
指定9个字符及以上的监视资源名时一定发生。 |
81 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
进程资源监视资源中,指定了9个字符及以上的监视资源名不会查出监视异常。 |
小 |
指定9个字符及以上的监视资源名时一定发生。 |
82 |
4.3.0-1
/ 2.1.0-1~4.2.2-1
|
Cluster WebUI的[状态]画面中,HTTP监视资源的高级属性显示的[协议]不正确。 |
小 |
一定发生。 |
83 |
4.3.0-1
/ 4.1.0-1~4.2.2-1
|
Witness心跳资源的超时检测可执行会延迟。 |
中 |
在与Witness服务器通信中断的服务器上发生。 |
84 |
4.3.0-1
/ 4.2.0-1~4.2.2-1
|
如果在禁用组自动启动的环境中检测到服务器关闭,则可执行会意外启动已停止的失效切换组。 |
小 |
在集群启动后存在从未启动的失效切换组时会发生。 |
6. 注意限制事项¶
本章将阐述注意事项,现有问题及其避免方法。
本章阐述事项如下。
6.1. 研究系统配置时¶
下文将阐述准备HW,可选产品License,构筑系统和配置共享磁盘时的注意事项。
6.1.1. 功能列表与所需License¶
下述可选产品需要同服务器个数相当的license。
没有进行License登录的资源,监视器资源不会显示在Cluster WebUI的一览表中。
想要使用的功能 |
所需License |
|---|---|
镜像磁盘资源 |
EXPRESSCLUSTER X Replicator 4.3 3 |
共享型镜像磁盘资源 |
EXPRESSCLUSTER X Replicator DR 4.3 4 |
Oracle监视器资源 |
EXPRESSCLUSTER X Database Agent 4.3 |
DB2监视器资源 |
EXPRESSCLUSTER X Database Agent 4.3 |
PostgreSQL监视器资源 |
EXPRESSCLUSTER X Database Agent 4.3 |
MySQL监视器资源 |
EXPRESSCLUSTER X Database Agent 4.3 |
Sybase监视器资源 |
EXPRESSCLUSTER X Database Agent 4.3 |
SQL Server监视器资源 |
EXPRESSCLUSTER X Database Agent 4.3 |
ODBC监视器资源 |
EXPRESSCLUSTER X Database Agent 4.3 |
Samba监视器资源 |
EXPRESSCLUSTER X File Server Agent 4.3 |
nfs监视器资源 |
EXPRESSCLUSTER X File Server Agent 4.3 |
http监视器资源 |
EXPRESSCLUSTER X Internet Server Agent 4.3 |
smtp监视器资源 |
EXPRESSCLUSTER X Internet Server Agent 4.3 |
pop3监视器资源 |
EXPRESSCLUSTER X Internet Server Agent 4.3 |
imap4监视器资源 |
EXPRESSCLUSTER X Internet Server Agent 4.3 |
ftp监视器资源 |
EXPRESSCLUSTER X Internet Server Agent 4.3 |
Tuxedo监视器资源 |
EXPRESSCLUSTER X Application Server Agent 4.3 |
Weblogic监视器资源 |
EXPRESSCLUSTER X Application Server Agent 4.3 |
Websphere监视器资源 |
EXPRESSCLUSTER X Application Server Agent 4.3 |
WebOTX监视器资源 |
EXPRESSCLUSTER X Application Server Agent 4.3 |
JVM监视器资源 |
EXPRESSCLUSTER X Java Resource Agent 4.3 |
系统监视器资源 |
EXPRESSCLUSTER X System Resource Agent 4.3 |
进程资源监视资源 |
EXPRESSCLUSTER X System Resource Agent 4.3 |
邮件通报功能 |
EXPRESSCLUSTER X Alert Service 4.3 |
网络警告灯 |
EXPRESSCLUSTER X Alert Service 4.3 |
6.1.2. 关于镜像磁盘的需求¶
通过Linux的md设定的等量磁盘组,卷组,镜像链接,带奇偶校验的等量磁盘组,不能作为镜像磁盘资源的集群分区或数据分区来使用。
- 通过Linux的 LVM,可将卷作为集群分区或数据分区来使用。但是,在SuSE上不能通过LVM或MultiPath将卷作为集群分区或数据分区来使用。(这是因为在SuSE上,针对这些卷,EXPRESSCLUSTER无法进行ReadOnly,ReadWrite的控制。)
作为镜像磁盘资源使用的磁盘不支持基于Linux的md的Stripe Set,Volume Set,磁盘镜像建立,带校验的Stripe Set的功能。
使用镜像磁盘资源时需要镜像用的分区(数据分区和集群分区)。
确保镜像用分区有以下2个方法:
和OS(root分区或swap分区)在同一磁盘上确保镜像用的分区(集群分区和数据分区)
和OS准备(添加)其他磁盘(或者LUN)确保镜像用的分区
可以参考以下条目来选择上面的某种方法。
- 重视故障维护,性能时- 建议在OS之外另外准备镜像用磁盘。
- 受H/W Raid规格的限制无法添加LUN时用H/W Raid的预装模式难于更改LUN的配置时- 在同一OS上确保磁盘的镜像用分区。
- 使用多个镜像磁盘资源时,建议为每个镜像磁盘资源准备(添加)磁盘。在同一磁盘上确保使用多个镜像磁盘资源时,可执行出现性能低下或镜像恢复时间较长现象。这与访问Linux OS磁盘的性能相关。
将磁盘作为镜像用磁盘使用时,需要在各服务器间使用相同磁盘。
磁盘接口
请统一用于确保双方服务器镜像磁盘或镜像用分区的磁盘的接口。
例)
组合
服务器1
服务器2
OK
SCSI
SCSI
OK
IDE
IDE
NG
IDE
SCSI
磁盘类型
请统一用于确保双方服务器镜像磁盘或镜像用分区的磁盘的类型。
例)
组合
服务器1
服务器2
OK
HDD
HDD
OK
SSD
SSD
NG
HDD
SSD
磁盘的扇区大小
请统一用于确保双方服务器镜像磁盘或镜像用分区的磁盘的逻辑扇区大小。
例)
组合
服务器1
服务器2
OK
逻辑扇区512B
逻辑扇区512B
OK
逻辑扇区4KB
逻辑扇区4KB
NG
逻辑扇区512B
逻辑扇区4KB
各服务器间作为镜像用磁盘使用的磁盘几何数据不同时,请注意以下事项:
用fdisk等命令确保的分区容量按照柱面附近的块(单元)数分配。请确保数据分区,以使数据分区容量和初始镜像构筑方向形成如下关系。复制来源服务器 ≦ 复制目标服务器
复制来源服务器是指镜像磁盘资源所属的失效切换组中失效切换原则较高的服务器。复制目标服务器是指镜像磁盘资源所属的失效切换组中失效切换原则较低的服务器。
另外,数据分区的大小在复制源和复制目标处差别较大时,有时会出现初始镜像构筑失败。请确保数据分区为相同程度的大小。
另外,请注意数据分区的大小在复制来源端和复制目标端上不要超过32GiB, 64GiB, 96GiB, ... (32GiB的倍数)。若数据分区的大小超过32GiB的倍数时,构建初始镜像时有可执行会失败。请确保数据分区的大小为相同程度。
例)
组合
数据分区的大小
说明
服务器1侧
服务器2侧
OK
30GiB
31GiB
由于双方均在0~32GiB不足的范围内,因此OK
OK
50GiB
60GiB
由于双方均在2GiB以上~64GiB不足的范围内,因此OK
NG
30GiB
39GiB
由于超过了32GiB,因此NG
NG
60GiB
70GiB
由于超过了64GiB,因此NG
6.1.3. 关于共享磁盘的需求¶
在共享磁盘中使用基于Linux的LVM的Stripe Set,Volume Set,镜像化,带校验的Stripe Set的功能时,磁盘资源中所设分区的ReadOnly,ReadWrite无法由EXPRESSCLUSTER进行控制。
使用VxVM时,在用于EXPRESSCLUSTER磁盘心跳的共享磁盘上需要不受VxVM控制的LUN。在设置共享磁盘LUN时请留意。
使用LVM功能时,请使用磁盘资源(磁盘类型"lvm")与卷管理资源。
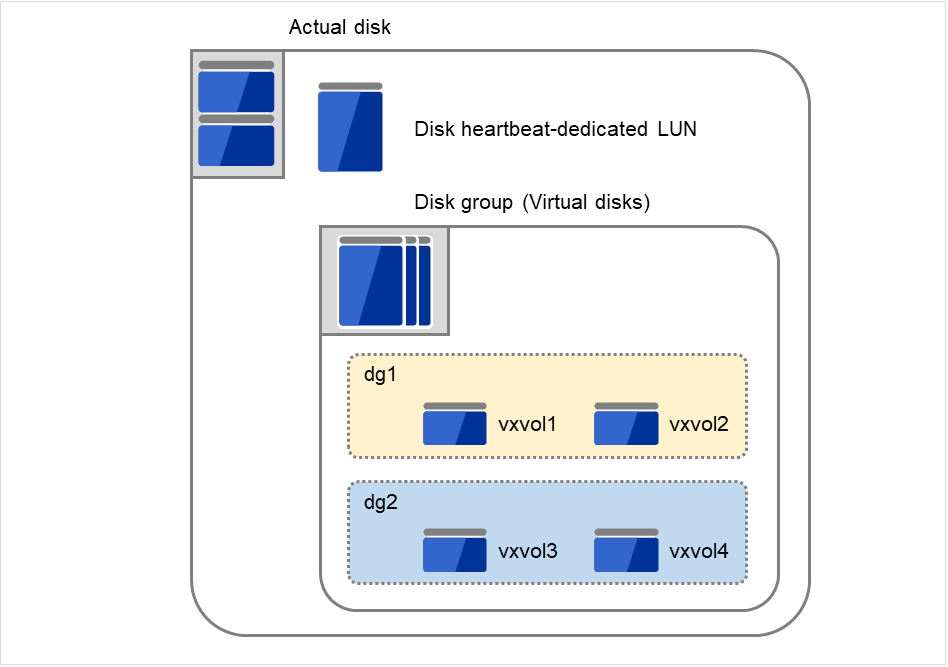
图 6.1 磁盘配置¶
6.1.4. 关于作为共享型镜像磁盘使用的磁盘的需求¶
作为共享型镜像磁盘资源使用的磁盘不支持基于Linux的md的Stripe Set,Volume Set,镜像化,带校验的Stripe Set的功能。
- 通过Linux的 LVM,可将卷作为集群分区或数据分区来使用。但是,在SuSE上不能通过LVM或MultiPath将卷作为集群分区或数据分区来使用。(这是因为在SuSE上,针对这些卷,EXPRESSCLUSTER无法进行ReadOnly,ReadWrite的控制。)
使用共享型镜像磁盘资源时需要共享型镜像磁盘用的分区(数据分区和集群分区)。
使用共享磁盘装置确保共享型镜像磁盘用的磁盘时,需要有通用共享磁盘装置的服务器之间的磁盘心跳资源用的分区。
从非共享磁盘装置确保共享型镜像磁盘用的磁盘时,分区的确保方法有以下2种。
在同一OS(root分区或swap分区)中的磁盘上确保共享型镜像磁盘用分区(集群分区和数据分区)
准备(添加)不在同一OS上的磁盘(或者LUN),确保共享型镜像磁盘用的分区
可以参考以下条目来选择上面的某种方法。
- 重视故障维护,性能时- 建议在OS之外另外准备共享型镜像磁盘用磁盘。
- 受H/W Raid规格的限制无法添加LUN时用H/W Raid的预装模式难于更改LUN的配置时- 在同一OS上确保磁盘的共享型镜像磁盘用分区。
确保共享型镜像磁盘资源的装置
必要的分区的种类
共享磁盘装置
非共享型磁盘装置
数据分区
必要
必要
集群分区
必要
必要
磁盘心跳用分区
必要
不要
确保和OS同一磁盘(LUN)
-
可执行
- 使用多个共享型镜像磁盘资源时,建议为每个共享型镜像磁盘资源单独准备(添加)LUN。在同一磁盘上确保使用多个共享型镜像磁盘资源时,可执行出现性能低下或镜像恢复时间较长的现象。这与访问Linux OS磁盘的性能相关。
各服务器间作为共享型镜像磁盘用磁盘所使用的磁盘的种类及几何数据不同时,请注意以下事项:
请确保数据分区的容量和初始镜像构筑方向形成如下关系
复制来源服务器 ≦ 复制目标服务器
复制来源服务器是指共享型镜像磁盘资源所属的失效切换组中失效切换原则较高的服务器。复制目标服务器是指共享型镜像磁盘资源所属的失效切换组中失效切换原则较低的服务器
另外,数据分区的大小在复制源和复制目标处差别较大时,有时会出现初始镜像构筑失败。请确保数据分区为相同程度的大小。
另外,请注意数据分区的大小在复制来源端和复制目标端上不要超过32GiB, 64GiB, 96GiB, ... (32GiB的倍数)。若数据分区的大小超过32GiB的倍数时,构建初始镜像时有可执行会失败。请确保数据分区的大小为相同程度。
例)
组合
数据分区的大小
说明
服务器1侧
服务器2侧
OK
30GiB
31GiB
由于双方均在0~32GiB不足的范围内,因此OK
OK
50GiB
60GiB
由于双方均在2GiB以上~64GiB不足的范围内,因此OK
NG
30GiB
39GiB
由于超过了32GiB,因此NG
NG
60GiB
70GiB
由于超过了64GiB,因此NG
6.1.5. 关于IPv6环境¶
在IPv6环境下,不能使用以下功能。
BMC心跳资源
AWS Elastic IP 资源
AWS 虚拟 IP资源
AWS DNS资源
Azure 探头端口资源
Azure DNS资源
Google Cloud 虚拟 IP 资源
Google Cloud DNS 资源
Oracle Cloud 虚拟 IP 资源
AWS Elastic IP 监视资源
AWS 虚拟 IP监视资源
AWS AZ监视资源
AWS DNS监视资源
Azure 探头端口监视资源
Azure 负载均衡监视资源
Azure DNS监视资源
Google Cloud 虚拟 IP 监视资源
Google Cloud 负载均衡监视资源
Google Cloud DNS 监视资源
Oracle Cloud 虚拟 IP 监视资源
Oracle Cloud 负载均衡监视资源
以下功能不能使用本地链路地址。
LAN心跳资源
内核模式LAN心跳资源
镜像磁盘连接
PING网络分区解决资源
FIP资源
VIP资源
6.1.6. 关于网络设置¶
在NAT环境等自身服务器的IP地址和对方服务器的IP地址在不同服务器上形成不同的配置时,不能构筑/运用集群。
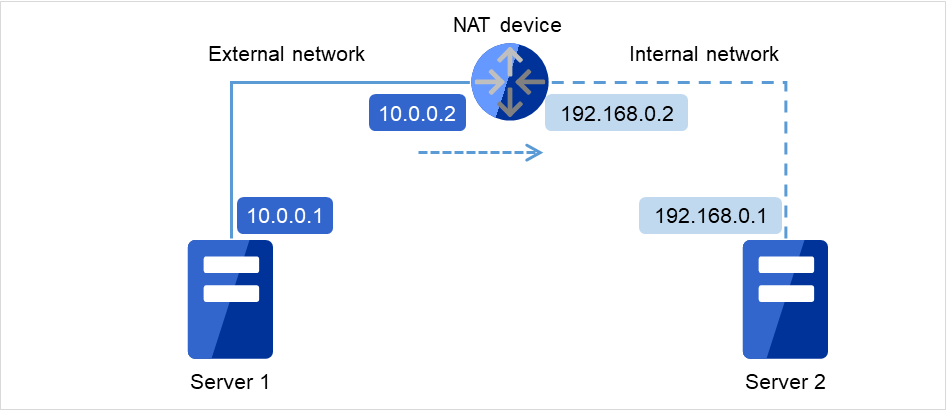
图 6.2 无法配置集群的环境的示例¶
Server 1中的集群设置
自身服务器: 10.0.0.1
对方服务器: 10.0.0.2
Server 2中的集群设置
自身服务器: 192.168.0.1
对方服务器: 10.0.0.1
6.1.7. 关于监视器资源恢复工作的"最终工作前执行脚本"¶
6.1.8. NIC Link Up/Down监视资源¶
ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: umbg
Wake-on: g
Current message level: 0x00000007 (7)
Link detected: yes
在ethtool命令的执行结果中,没有显示LAN网线状况("Link detected: yes")时
EXPRESSCLUSTER的NIC Link Up/Down监视资源不可运行的可执行性很高。请使用IP监视资源代替。
在ethtool命令的执行结果中,显示LAN网线状况("Link detected: yes")时
大多数情况下 EXPRESSCLUSTER的NIC Link Up/Down监视资源可以运行,但也有时无法运行。
尤其是在以下硬件下可执行无法运行。请使用IP监视资源代替。
如同刀片服务器一样,硬件位于LAN连接器和NIC芯片之间。
监视对象的NIC处于Bonding环境时,请确认MII Polling Interval的设置值已设置为0以上。
在实际的机器上使用EXPRESSCLUSTER确认能否使用NIC Link Up/Down监视资源时,请按照以下步骤进行运行确认。
- 请在配置信息中注册NIC Link Up/Down监视资源。在NIC Link Up/Down监视资源的查出异常时的复归操作的设置中,选择"无操作"。
启动集群。
- 请确认NIC Link Up/Down监视资源的状态。LAN网线的链接状态是正常状态时, NIC Link Up/Down监视资源的状态为异常的情况下, NIC Link Up/Down监视资源不可运行。
- LAN网线的连接状态是异常状态(链接断开状态) 时,NIC Link Up/Down监视资源的状态为异常的情况下,NIC Link Up/Down监视资源可以运行。状态保持正常不做变化时,NIC Link Up/Down监视资源不可运行。
6.1.9. 关于镜像磁盘资源,共享型镜像磁盘资源的write性能¶
镜像磁盘,共享型镜像磁盘资源的write处理是通过网络向对方和己方服务器磁盘进行write。而read处理只从己方服务器的磁盘进行read。
- 基于上述原因,其write性能没有尚未集群化的单个服务器的性能优良。如果是要求write具有与单个服务器相同的高吞吐量的系统 (更新用服务器多的数据库系统等),建议使用共享磁盘。
6.1.10. 勿将镜像磁盘资源,共享型镜像磁盘资源作为syslog的输出目的地¶
使用bonding作为镜像磁盘连接的路径二重化方法。
调整用户空间监视的超时值和镜像相关的超时值。
6.1.11. 镜像磁盘资源,共享型镜像磁盘资源终止时的注意事项¶
- 若有对加载了镜像磁盘资源和共享型磁盘资源的目录和子目录,文件进行访问的进程,在关机或失效切换等各磁盘资源处于停止状态时,请使用结束脚本等终止对各磁盘资源的访问。根据各磁盘资源的设置,有时会发生当卸载时查出异常而进行的操作(强行终止访问了磁盘资源的进程),卸载失败停止异常时的复归操作(OS关机等)。
- 若对加载了镜像磁盘资源和共享型磁盘资源的目录和子目录,文件进行了大量访问,当对磁盘资源执行停止卸载时,将文件系统缓存写入磁盘时可执行耗费很长时间。此时,为了保证对磁盘的写能正常终止,在设置卸载超时时间时,请留出足够的富余。
6.1.12. 多个异步镜像之间的数据一致性¶
6.1.13. 关于中断了镜像同步时的参照同步方的镜像数据¶
6.1.14. 关于O_DIRECT在镜像磁盘,共享型镜像磁盘资源上的使用¶
6.1.15. 关于镜像磁盘,共享型镜像磁盘初始化构筑的时间¶
在ext2/ext3/ext4/xfs与其他文件系统中,初始化镜像以及全面镜像所需的时间各异。
注解
xfs时,资源停止时所需的时间将更短。
6.1.16. 关于镜像磁盘,共享型镜像磁盘连接¶
对镜像磁盘,共享型镜像磁盘连接进行冗余化处理时,需要两个IP地址使用同一版本。
请将所有镜像磁盘连接的IP地址设置为IPv4或者IPv6的其中一方。
6.1.17. 关于JVM监视资源¶
可同时进行监视的Java VM最多是25个。可同时监视的Java VM指,通过Cluster WebUI ([监视(固有)]标签->[识别名])可进行唯一识别的Java VM的数量。
Java VM和Java Resource Agent之间的回收不支持SSL。
有时可执行不能检测出线程死锁。这是已经确认的来自JavaVM的缺陷。详细内容请参考Oracle的Bug Database的"Bug ID: 6380127 "。(2011年10月现在)。
JVM监视资源可监视的Java VM需与JVM监视器资源工作时的服务器在同一服务器内。
JVM监视资源可监视的JBoss的服务器实例1个服务器上最多只有一个实例。
通过Cluster WebUI (集群属性->[JVM监视]标签页->[Java安装路径])进行设定的Java安装路径在集群内的服务器内属于共通设定。关于JVM监视中使用的Java VM的版本以及升级版本,请在集群内服务器上使用同一版本。
通过Cluster WebUI (集群属性->[JVM监视]标签页->[连接设定]对话框->[管理端口号])进行设定的管理端口号在集群内的服务器内属于共通设定。
x86_64版OS上运行IA32版的监视对象的应用程序时,不能进行监视。
如果将通过Cluster WebUI (集群属性->[JVM监视]标签页->[最大Java堆大小])设置的最大Java堆大小值设置为3000等大数值,则JVM监视资源会启动失败。由于依赖于系统环境,请根据系统的内存搭载容量来决定。
使用负载均衡联动的监视对象Java VM的负载算出功能时,建议在SingleServerSafe中使用。另外,仅限在Red Hat Enterprise Linux环境下可以运行。
- 在监视对象Java VM的启动选项添加了「-XX:+UseG1GC」时,在Java 7以前则不能监视JVM监视资源的[属性]-[监视(固有)]标签页-[调整]属性-[内存]标签内的设置项目。在Java 8以上则可通过在JVM监视资源的[属性]-[监视(固有)]标签页- [JVM类型]选择[Oracle Java(usage monitoring)]来进行监视。
6.1.18. 关于邮件通知¶
不提供STARTTLS和SSL的邮件通知功能。
6.1.19. 关于网络警告灯的要求¶
使用"DN-1000S","DN-1500GL"时,请勿设置警告灯密码。
- 因回放音频文件而出现警告时,应将音频文件重新登录到"音频文件回放对应的网络警告灯"上。有关音频文件登录,请参阅"各网络警告灯"使用说明书。
在网络警告灯里请设置允许来自集群内的服务器的rsh命令执行。
6.2. 安装OS前,安装OS时¶
请在安装OS时注意即将决定的参数,资源确保,命名规则等。
6.2.1. 关于镜像用磁盘¶
磁盘分区
例)在双方服务器上增加1个SCSI磁盘,创建1个镜像磁盘Pair时
图中的2台服务器中都添加了SCSI磁盘。磁盘被分为集群分区(Cluster partition)和数据分区(Data partition)。这个分区的组是镜像磁盘资源的失效切换单位,被称为镜像分区设备。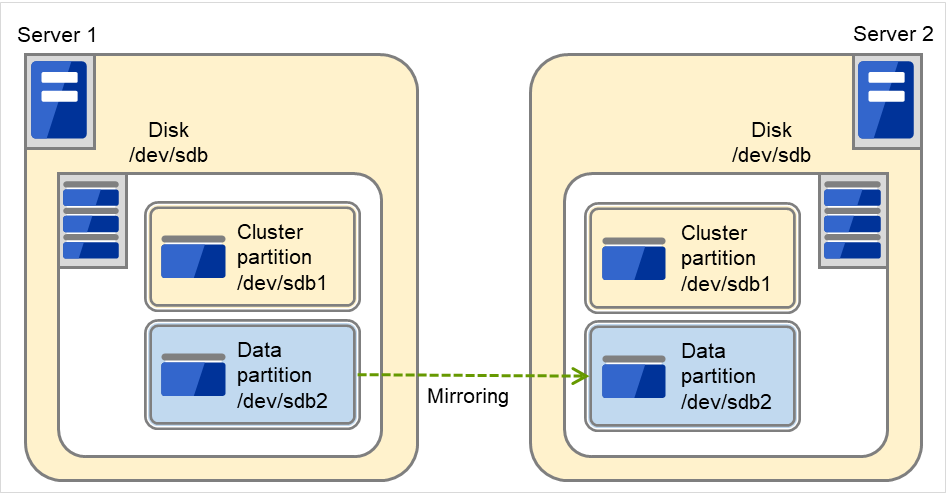
图 6.3 磁盘和分区配置(添加SCSI磁盘时)¶
例)使用存储双方服务器OS的IDE磁盘剩余容量创建镜像磁盘Pair时
在该图中,内置磁盘的OS未使用的区域被用作镜像分区设备(集群分区,数据分区)。
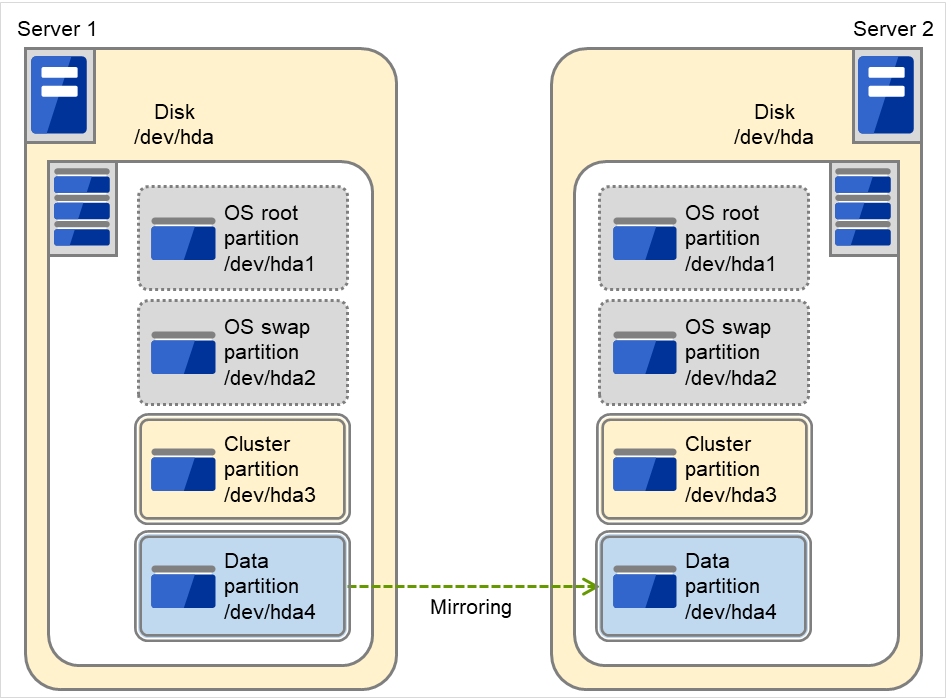
图 6.4 磁盘和分区配置(使用现有磁盘的可用空间时)¶
镜像分区设备是EXPRESSCLUSTER磁盘镜像驱动程序向上层提供的设备。
确保集群分区和数据分区的2个分区为Pair。
可以在处于和OS(root分区或swap分区)相同的磁盘上确保镜像分区(集群分区,数据分区)。
- 重视故障维护,性能时建议准备OS(root分区或swap分区)之外的镜像用磁盘。
- 受H/W Raid规格的限制无法添加LUN时用H/W Raid的预装模式难于更改LUN的配置时
可以在处于OS(root分区或swap分区)内的磁盘上确保镜像分区(集群分区,数据分区)。
磁盘配置
可以将多个磁盘用作镜像磁盘。
另外,可以在1个磁盘中分配多个镜像分区设备加以利用。
例)在双方服务器上增设2个SCSI磁盘,创建2个镜像磁盘Pair时。
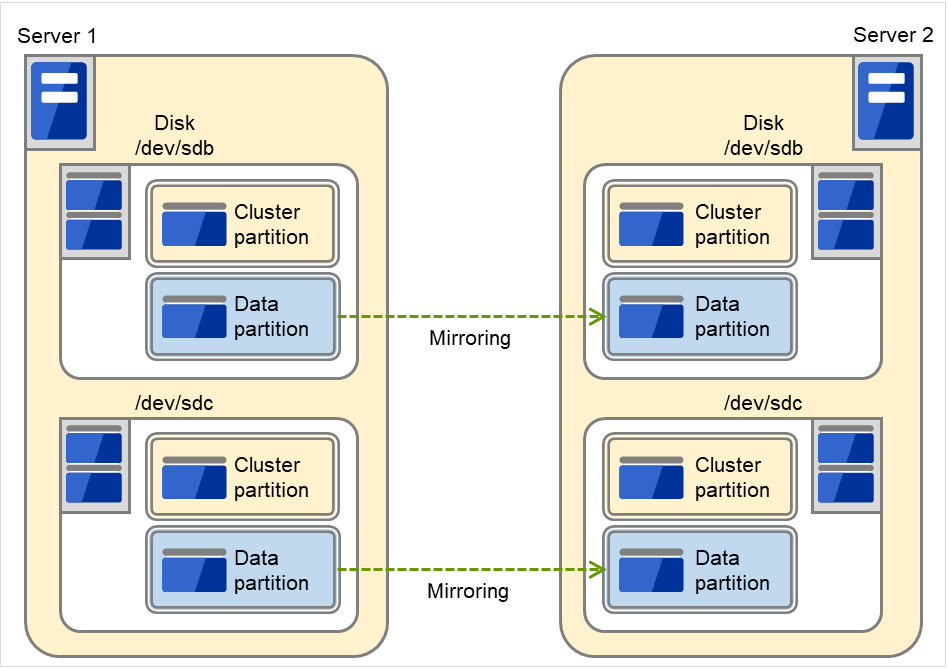
图 6.5 多个磁盘被用作镜像分区¶
请在1个磁盘上用Pair确保集群分区和数据分区。
不能将数据分区作为第1个磁盘,集群分区作为第2个磁盘使用。
例)在双方服务器上增设1个SCSI磁盘,创建2个镜像分区时
该图显示了在1个磁盘内保留2个镜像分区时的情况。
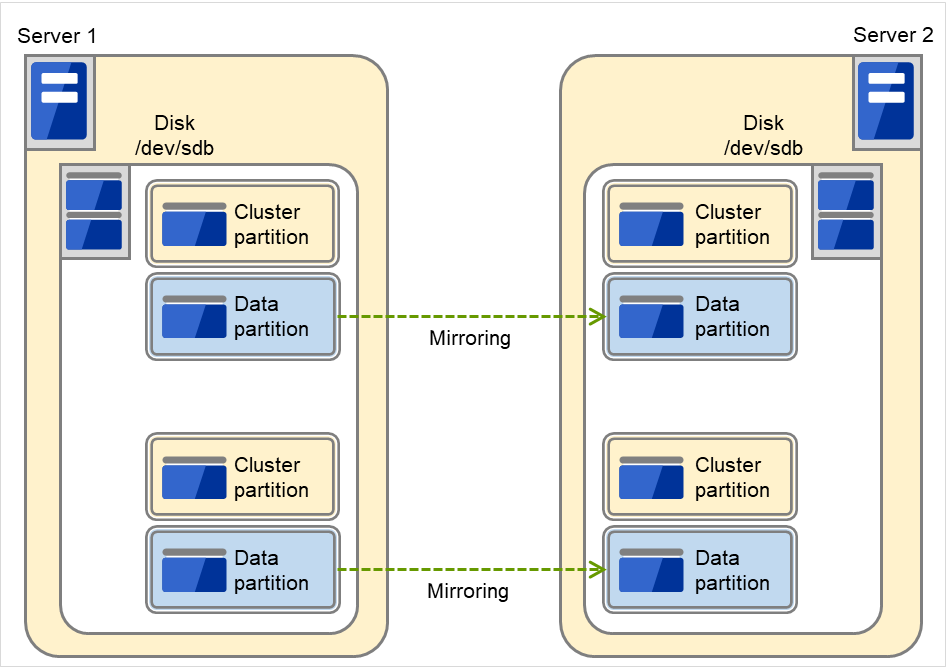
图 6.6 将磁盘内的多个区域用作镜像分区¶
磁盘不支持基于Linux的md的Stripe Set,Volume Set,磁盘镜像建立,带校验的Stripe Set的功能。
6.2.2. 关于共享型镜像磁盘资源用磁盘¶
磁盘分区
可以使用共享磁盘或非共享型磁盘(服务器内置,服务器间不共享的外置型磁盘机箱等)。
例)在2台服务器上使用共享磁盘,并在第3台服务器上使用服务器的内置磁盘时
该图显示的是,将Server 3的内置磁盘用作镜像分区设备。
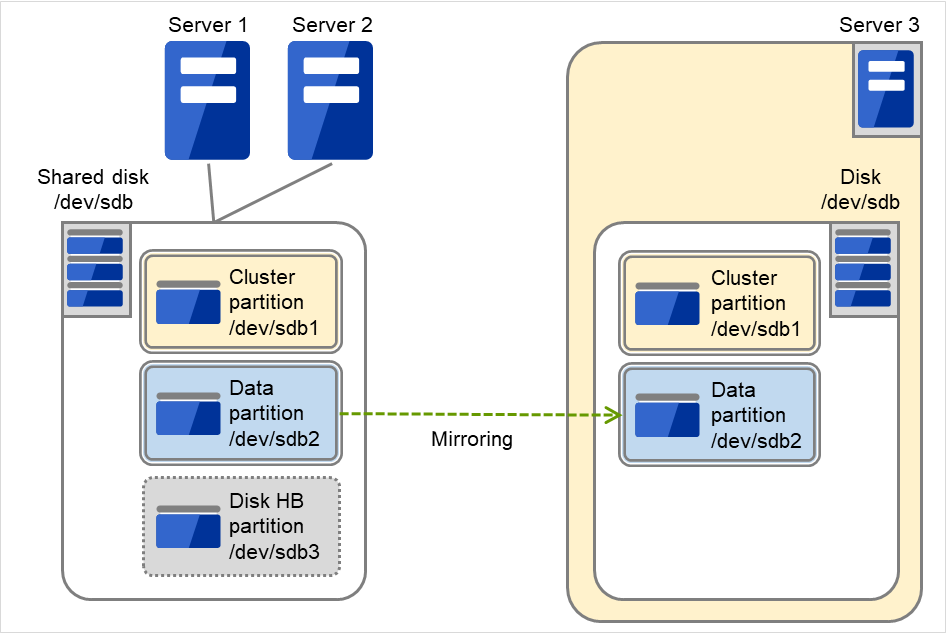
图 6.7 磁盘和分区配置(使用共享磁盘和内置磁盘时)¶
镜像分区设备是EXPRESSCLUSTER磁盘镜像驱动程序向上层提供的设备。
确保集群分区和数据分区的2个分区为Pair。
使用非共享型磁盘(服务器内置,服务器间不共享的外置型磁盘机箱等)时,可以在处于OS(root分区或swap分区)内的磁盘上确保镜像分区(集群分区,数据分区)。
可以在OS(root分区或swap分区)所在的磁盘上确保镜像分区(集群分区,数据分区)。
使用共享磁盘装置确保共享型镜像磁盘用的磁盘时,需要有通用共享磁盘装置的服务器之间的磁盘心跳资源用的分区。
不支持基于Linux的md的Stripe Set,Volume Set,磁盘镜像建立,带校验的Stripe Set的功能。
6.2.3. 依存库¶
libxml2
请在安装OS时安装libxml2。
6.2.4. 依存驱动程序¶
softdog
在用户空间监视资源的监视方法softdog时,需要该驱动程序。
请构筑Loadable模块。不能在静态驱动程序上运行。
6.2.5. 所需的数据包¶
tar
安装OS时请安装tar。
6.2.6. 镜像驱动程序的主编号¶
6.2.7. 内核模式LAN心跳驱动程序,KeepAlive驱动程序的主编号¶
内核模式LAN心跳驱动程序使用主编号10,副编号240。
KeepAlive驱动程序使用主编号10,副编号241。
请确保不要在其他驱动程序上使用上述主,副编号。
6.2.8. 确保磁盘监视资源用于RAW监视的分区¶
请在设置磁盘监视资源的RAW监视时准备监视专用的分区。请确保分区大小为10MB。
6.2.9. 设置SELinux¶
SELinux请设置为permissive 或 disabled。
如果设为enforcinfg,则有时无法用EXPRESSCLUSTER进行必要的通信。
6.2.10. 设置NetworkManager¶
在Red Hat Enterprise Linux 6环境中运行NetworkManager服务的情况下,网络切断时会出现意外动作(通信径路迂回,网络接口消失等),建议进行停止NetworkManager 的设置。
6.2.11. LVM 元数据服务的配置¶
- 在Red Hat Enterprise Linux 7以后的环境中,卷管理资源以及卷管理监视资源执行LVM的控制/监视时,需要将LVM元数据服务设定为无效。将元数据服务变为无效的步骤如下。
通过以下的命令,请停止LVM元数据服务。
# systemctl stop lvm2-lvmetad.service
编辑/etc/lvm/lvm.conf,将use_lvmetad的值设定为0。
6.3. 安装OS后,安装EXPRESSCLUSTER前¶
OS安装结束后,请注意OS和磁盘的设置。
6.3.1. 通信端口号¶
[服务器/服务器间] [服务器内循环]
From
To
备注
服务器
自动分配 5
服务器
29001/TCP
内部通信
服务器
自动分配
服务器
29002/TCP
数据发送
服务器
自动分配
服务器
29002/UDP
心跳
服务器
自动分配
服务器
29003/UDP
警告同步
服务器
自动分配
服务器
29004/TCP
镜像代理间通信
服务器
自动分配
服务器
29006/UDP
心跳(内核模式)
服务器
自动分配
服务器
29008/TCP
集群信息管理
服务器
自动分配
服务器
29010/TCP
Restful API 内部通信
服务器
自动分配
服务器
XXXX 6 /TCP
镜像磁盘资源数据同步
服务器
自动分配
服务器
XXXX 7 /TCP
镜像驱动程序间通信
服务器
自动分配
服务器
XXXX 8 /TCP
镜像驱动程序间通信
服务器icmp服务器icmp镜像驱动程序间KeepAliveFIP/VIP资源的重复确认镜像代理服务器
自动分配
服务器
XXXX 9 /UDP
内部日志用通信
[服务器・客户端之间]
From
To
备注
Restful API 客户端
自动分配
服务器
29009/TCP
http通信
[服务器・Cluster WebUI之间]
From
To
备注
Cluster WebUI
自动分配
服务器
29003/TCP
http通信
[其他]
From
To
备注
服务器
自动分配
网络警告灯
请参照各产品的手册
控制网络警告灯
服务器
自动分配
服务器的BMC的管理LAN
623/UDP
控制BMC (强制停止/机箱指示灯联动)
服务器的BMC的管理器LAN
自动分配
服务器
162/UDP
设定为BMC 联动用的消息接收监视器的监视对象
服务器的BMC的管理器LAN
自动分配
服务器的BMC的管理器LAN
5570/UDP
BMC HB通信
服务器
自动分配
Witness 服务器
通过Cluster WebUI中设定的通信端口号
Witness 心跳资源的连接目标主机
服务器
icmp
监视对象
icmp
IP监视
服务器
icmp
NFS服务器
icmp
NAS资源的NFS服务器生存状态确认
服务器
icmp
监视对象
icmp
Ping方式网络分区解决资源的监视对象
服务器
自动分配
监视目标
通过Cluster WebUI 设定的通信端口号
HTTP 方式网络分区解决资源的监视目标
服务器
自动分配
服务器
通过Cluster WebUI设定的管理端口号 10
JVM监视器
服务器
自动分配
监视对象
通过Cluster WebUI设定的管理端口号 10
JVM监视器
服务器
自动分配
监视对象
使用Cluster WebUI进行设定的负载均衡器联动管理端口号 10
JVM监视器
服务器
自动分配
BIG-IP LTM
通过Cluster WebUI设定的管理端口号 10
JVM监视器
服务器
自动分配
服务器
通过Cluster WebUI设定的Probe端口 11
Azure 探头端口资源
服务器自动分配AWS区域端点443/tcp 12AWS Elastic IP资源AWS虚拟IP资源AWS DNS资源AWS Elastic IP监视资源AWS虚拟IP监视资源AWS AZ监视资源AWS DNS监视资源服务器
自动分配
Azure端点
443/tcp 13
Azure DNS资源
服务器
自动分配
Azure的权威DNS服务器
53/udp
Azure DNS监视资源
服务器
自动分配
服务器
在Cluster WebUI中设置的端口号 11
Google Cloud 虚拟 IP 资源
服务器
自动分配
服务器
在Cluster WebUI中设置的端口号 11
Oracle Cloud 虚拟 IP 资源
- 5
自动分配是指该时刻未使用的端口号将被分配。
- 6
即每个镜像磁盘资源,共享型镜像磁盘资源使用的端口号。在创建镜像磁盘资源,共享型镜像磁盘资源时设置。初始值设置为29051。此外,每添加1个镜像磁盘资源,共享型镜像磁盘资源,值就会自动加1。更改时,用Cluster WebUI的 [镜像磁盘资源属性]-[详细],[共享型镜像磁盘资源属性]-[详细]标签页设置。详细内容请参考《参考指南》的"组资源的详细信息"。
- 7
即每个镜像磁盘资源,共享型镜像磁盘资源使用的端口号。在创建镜像磁盘资源,共享型镜像磁盘资源时设置。初始值设置为29031。此外,每添加1个镜像磁盘资源,共享型镜像磁盘资源,值就会自动加1。更改时,用Cluster WebUI的 [镜像磁盘资源属性]-[详细],[共享型镜像磁盘资源属性]-[详细]标签页设置。详细内容请参考《参考指南》的"组资源的详细信息"。
- 8
即每个镜像磁盘资源,共享型镜像磁盘资源使用的端口号。在创建镜像磁盘资源,共享型镜像磁盘资源时设置。初始值设置为29071。此外,每添加1个镜像磁盘资源,共享型镜像磁盘资源,值就会自动加1。更改时,用Cluster WebUI的 [镜像磁盘资源属性]-[详细],[共享型镜像磁盘资源属性]-[详细]标签页设置。详细内容请参考《参考指南》的"组资源的详细信息"。
- 9
在集群属性, 端口号(日志)的标签中,将[日志的通信方式]选为 [UDP],使用在端口号中设定的端口号。日志的通信方法[UNIX Domain] 默认为不使用通信端口。
- 10(1,2,3,4)
JVM监视资源使用以下的4个端口号。
管理端口号为JVM监视资源内部用的端口号。可在Cluster WebUI的[集群属性]-[JVM监视]标签页[连接设置] 对话框上进行设置。有关详情,请参阅《参考指南》的"参数的详细信息"。
连接端口号为与监视目标(WebLogic Server, WebOTX)的Java VM建立连接的端口号。可在Cluster WebUI的相应的JVM监视资源名的[属性]-[监视(固有)]标签页上进行设置。有关详情,请参阅《参考指南》的"监视资源的详细信息"。
负载均衡器联动管理端口号为进行负载均衡器联动时使用的端口号。不使用负载均衡器联动时,不需要进行设置。可在Cluster WebUI的[集群属性]-[JVM监视]标签页[负载均衡器联动設定] 对话框上进行设置。有关详情,请参阅《参考指南》的"参数的详细信息"。
通信端口号为通过BIG-IP LTM进行负载均衡器联动时使用的端口号。不使用负载均衡器联动时,不需要进行设置。可在Cluster WebUI的[集群属性]-[JVM监视]标签页[负载均衡器联动設定] 对话框上进行设置。有关详情,请参阅《参考指南》的"参数的详细信息"。
- 11(1,2,3)
负载均衡器进行各服务器的死活监视时所使用的端口号。
- 12
对于AWS Elastic IP资源,AWS虚拟IP资源,AWS DNS资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源,AWS DNS监视资源,执行AWS CLI。AWS CLI中使用上述端口。
- 13
对于Azure DNS 资源,执行Azure CLI。Azure CLI中使用上述端口。
6.3.2. 更改通信端口号的自动分配的范围¶
OS所管理的通信端口号的自动分配的范围有可执行与EXPRESSCLUSTER所使用的通信端口号重复。
通信端口号的自动分配的范围与EXPRESSCLUSTER所使用的通信端口号重复时,请更改OS的设置使通信端口号不重复。
OS的设置状态的确认例/显示例
通信端口号的自动分配的范围需依靠Distribution。
# cat /proc/sys/net/ipv4/ip_local_port_range 1024 65000如上是应用程序向OS请求通信端口号的自动分配时,被分配到1024~65000的范围内的状态。
# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000如上是应用程序向OS请求通信端口号的自动分配时,被分配到32768~61000的范围内的状态。
更改OS设置例
在/etc/sysctl.conf 增加如下所示的一行。(更改为30000~65000时)
net.ipv4.ip_local_port_range = 30000 65000此设置要在OS重启后才能变为有效。
修改/etc/sysctl.conf之后,通过执行以下的命令可以实现即时反映。
# sysctl -p
6.3.3. 关于避免端口数不足的设置¶
6.3.4. 时钟同步的设置¶
建议在集群系统上定期进行多个服务器的时钟同步。请使用ntp等同步服务器的时间。
6.3.5. 关于NIC设备名¶
根据ifconfig命令的规则,若NIC设备名被缩短,则EXPRESSCLUSTER所处理的NIC设备名的长短也需要相应变更。
6.3.7. 关于镜像用磁盘¶
设置镜像磁盘资源管理用分区(集群分区)和镜像磁盘资源使用的分区(数据分区)。
- 镜像磁盘上的文件系统由EXPRESSCLUSTER控制。请不要将镜像磁盘的文件系统登录到OS的/etc/fstab中。(请不要将镜像分区设备以及镜像的mount point,镜像分区以及数据分区登录到OS 的/etc/fstab。)(也不要登录到带ignore参数的 /etc/fstab中。在ignore登录时,mount的执行时登录会被忽视,在fsck执行时有可执行发生错误。)
(此外,在noauto 参数登录到/etc/fstab时,也有可执行错误地进行手动mount,或不能排除因某种应用程序而进行mount的可执行性,因此不推荐这种操作方法。)
请为集群分区至少保留1024MB (1024*1024*1024 字节)。(即使精确指定1024MB,由于磁盘的几何数据差异,实际上将保留大于1024BM的大小,但这并不是问题)。此外,请勿在集群分区上构筑文件系统。
镜像磁盘的设置步骤请参考《安装&设置指南》。
6.3.8. 关于共享型镜像磁盘资源用磁盘¶
设置共享型镜像磁盘资源管理用分区(集群分区)和共享型镜像磁盘资源使用的分区(数据分区)。
使用共享磁盘装置确保共享型镜像磁盘时,确保通用共享磁盘装置的服务器间的磁盘心跳资源用分区。
- 共享型镜像磁盘上的文件系统由EXPRESSCLUSTER控制。请不要将共享型镜像磁盘的文件系统登录到OS的/etc/fstab中。(请不要将镜像分区设备以及镜像的mount point,镜像分区以及数据分区登录到OS 的/etc/fstab。)(也不要登录到带ignore参数的 /etc/fstab中。在ignore登录时,mount的执行时登录会被忽视,在fsck执行时有可执行发生错误。)(此外,在noauto 参数登录到/etc/fstab时,也有可执行错误地进行手动mount,或不能排除因某种应用程序而进行mount的可执行性,因此不推荐这种操作方法。)
请为集群分区至少保留1024MB (1024*1024*1024 字节)。(即使精确指定1024MB,由于磁盘的几何数据差异,实际上将保留大于1024BM的大小,但这并不是问题)。此外,请勿在集群分区上构筑文件系统。
共享型镜像磁盘用磁盘的设置步骤请参考《安装&设置指南》。
在本系统内,必须手动在共享型镜像磁盘所使用的数据分区上设置文件系统。忘记设置时,请参照《安装&设置指南》的"确定系统配置 配置硬件后的设置"。
6.3.9. 在镜像磁盘资源,共享型磁盘资源使用ext3或者ext4时¶
6.3.9.1. 关于Block size¶
对于镜像磁盘资源或者共享性磁盘资源的数据分区,手动执行mkfs命令,构建ext3或者ext4文件系统时,请不要将Block size指定为1024。
镜像磁盘资源以及共享型磁盘资源不支持Block size 1024。要明确指定Block size时,请指定2048或者4096。
6.3.10. OS启动时间的调整¶
请将从开启电源到OS启动为止的时间,调整为超过如下2种时间的长度。
使用共享磁盘时,从接通磁盘的电源到可以使用的时间
心跳超时时间
设置步骤请参考《安装&设置指南》。
6.3.12. 关于OpenIPMI¶
在以下功能中使用OpenIPMI。
组资源启动异常时/停止异常时的最终运行
监视资源异常时的运行
用户空间监视资源
关机监视
物理机的强制停止功能
机箱ID指示灯联动
在EXPRESSCLUSTER中没有附加OpenIPMI。用户请另行自行安装OpenIPMI的 rpm 文件。
对于能否支持已经预定要使用的服务器(硬件)的OpenIPMI的问题,请用户提前进行确认。
即使在作为硬件依据IPMI规格标准时,由于实际上OpenIPMI有时不运行,因此请多加注意。
- 使用服务器厂商所提供的服务器监视软件时,请不要选择IPMI作为用户空间监视资源和Shutdownstall监视的监视方法。由于这些服务器监视软件和OpenIPMI共同使用服务器上的BMC(Baseboard Management Controller),因此会发生冲突,令监视无法正常进行。
6.3.13. 关于用户空间监视资源,关机监视(监视方法softdog)¶
- 监视方法中设置为softdog时,请使用softdog驱动。在EXPRESSCLUSTER以外使用softdog驱动的功能请设置为不运行。例如:确认了相应的以下那样的功能。
OS标准附带的heartbeat
i8xx_tco驱动
iTCO_WDT驱动
systemd 的watchdog功能,关机监视功能。
监视方法中设置为softdog时,请设置为不运行OS标准附带的heartbeat。
在SUSE LINUX 11中,监视方法设为softdog时,无法与i8xx_tco驱动同时使用。不使用i8xx_tco驱动时,请设置为不装载i8xx_tco。
Red Hat Enterprise Linux 6时,监视方法里设置了softdog的场合,不能同时使用iTCO_WDT驱动。不使用iTCO_WDT时,请设定为不Load iTCO_WDT。
6.3.14. 关于收集日志¶
在SUSE LINUX 10/11中,使用EXPRESSCLUSTER的日志收集功能获取OS的syslog时,由于被rotate了的syslog(message)文件的suffiies不同,因此syslog的世代的指定功能无法运行。若要指定日志收集功能的syslog的世代,则需要将syslog的rotate的设置作如下修改在进行应用。
注释掉 /etc/logrotate.d/syslog文件的compress和dateext
各服务器中日志的总大小超出2GB时,有时会导致日志收集失败。
6.3.15. 关于nsupdate,nslookup¶
下列功能使用nsupdate和nslookup。
组资源的动态域名解析资源 (ddns)
监视资源的动态域名解析监视资源 (ddnsw)
EXPRESSCLUSTER中未附带nsupdate及nslookup。请用户另行自行安装nsupdate及nslookup的 rpm 文件。
本公司不负责与nsupdate,nslookup相关的以下事项。请用户在自行判断,自负责任的基础上再予以使用。
对nsupdate,nslookup 本身的相关咨询
nsupdate,nslookup的运行保证
nsupdate,nslookup的问题解决及由此引发的故障
对各服务器的nsupdate,nslookup的支持情况的咨询
6.3.16. 关于FTP监视资源¶
FTP服务器上登录的横幅通知,连接时的通知的文字列过长或者为复数行时,有可执行出现监视异常。使用FTP监视资源监视时,请不要登录横幅通知,连接时的通知。
6.3.17. 使用Red Hat Enterprise Linux 7时的注意事项¶
邮件通报功能使用操作系统提供的[mail]命令。最小构成中由于未安装[mail]命令,请执行以下任意一项
集群属性的[Alert服务]页中,[邮件发送方法]项设置为[SMTP]。
安装mailx
6.3.18. 使用Ubuntu时的注意事项¶
执行EXPRESSCLUSTER相关命令时,请由root用户执行。
Application Server Agent只支持Websphere监视。因为其他应用服务器不支持Ubuntu
邮件通报功能使用操作系统提供的[mail]命令。最小构成中由于未安装[mail]命令,请执行以下任意一项
集群属性的[Alert服务]页中,[邮件发送方法]项设置为[SMTP]。
安装mailx
不执行根据SNMP取得信息功能
6.3.19. AWS环境中的时刻同步¶
6.3.20. 关于AWS环境中IAM的设置¶
IAM的设置步骤如下所示。
首先请创建IAM policy。请参考后面的"IAM policy的创建"。
- 接下来进行实例设置。使用IAM角色时,请参考后面的“实例的设置-使用IAM角色”。使用IAM用户时,请参考后面的“实例的设置-使用IAM用户”。
IAM policy的创建
创建policy,该policy记载了针对AWS的EC2和S3等的服务的动作的访问许可。EXPRESSCLUSTER的AWS关联资源以及监视资源执行AWS CLI所允许的必要的动作如下所示。
必要的policy有可执行将来被变更。
AWS虚拟IP资源/AWS虚拟IP监视资源
动作
说明
取得VPC,路由表,网络接口的信息时必需。
ec2:ReplaceRoute
更新路由表时必需。
AWS Elastic IP资源/AWS Elastic IP监视资源
动作
说明
取得EIP,网络接口的信息时必需。
ec2:AssociateAddress
将EIP分配到ENI时必需。
ec2:DisassociateAddress
将EIP从ENI分离时必需。
AWS AZ监视资源
动作
说明
ec2:DescribeAvailabilityZones
取得可用区的信息时必需。
AWS DNS资源/AWS DNS监视资源
动作
说明
route53:ChangeResourceRecordSets
追加,删除资源记录集,更新设置内容时必需。
route53:ListResourceRecordSets
取得资源记录集信息时必需。
向Amazon CloudWatch发送监视资源的监视处理时间的功能
动作
说明
cloudwatch:PutMetricData
发送自定义指标时所需。
向 Amazon SNS发送警报服务消息的功能
动作
说明
sns:Publish
发送消息时所需。
以下的自定义policy的例子是许可全部AWS关联资源以及监视资源所使用的动作。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:Describe*", "ec2:ReplaceRoute", "ec2:AssociateAddress", "ec2:DisassociateAddress", "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets" ], "Effect": "Allow", "Resource": "*" } ] }通过IAM Management Console的[Policies] - [Create Policy]可创建自定义policy。
实例的设置-使用IAM角色
通过创建IAM角色并赋给实例从而使AWS CLI可执行的方法。
图 6.8 设置使用IAM角色的实例¶
创建IAM角色。在创建的角色上附加IAM policy。
通过IAM Management Console的[Roles] - [Create New Role]可创建IAM角色。
创建实例时,指定[IAM Role]上做成的IAM角色。
登录实例。
/sbin,/bin,/usr/sbin,/usr/bin
只安装了Python3, /usr/bin/python 不存在时,请对于/usr/bin/python3.x (x为版本)或者 /usr/bin/python3 创建 /usr/bin/python 的符号链接。从shell执行pip命令,安装AWS CLI。
$ pip install awscli关于pip命令的详细信息请参考如下。AWS CLI的安装路径必须为以下之一。/sbin,/bin,/usr/sbin,/usr/bin,/usr/local/bin关于AWS CLI的更新方法详情请参考如下。(安装Python或AWS CLI时已经安装了EXPRESSCLUSTER时,请重启OS再执行EXPRESSCLUSTER的操作。)
从shell执行以下的命令。
$ sudo aws configure针对提问输入执行AWS CLI所必需的信息。请注意不要输入AWS Access ID,AWS Secret Access Key。
AWS Access Key ID [None]: (只按Enter键) AWS Secret Access Key [None]: (只按Enter键) Default region name [None]: <默认的区域名> Default output format [None]: text"Default output format"可以指定为"text"之外的格式。如果内容设置错误时,删除/root/.aws目录后,再重新执行上述操作。
实例的设置-使用IAM用户
创建IAM用户,通过将Access ID,Secret Access Key保存在实例内部使AWS CLI能够执行的方法。实例创建时不需要IAM角色的授予。
图 6.9 设置使用IAM用户的实例¶
登录实例。
/sbin,/bin,/usr/sbin,/usr/bin
只安装了Python3, /usr/bin/python 不存在时,请对于/usr/bin/python3.x (x为版本)或者 /usr/bin/python3 创建 /usr/bin/python 的符号链接。从shell执行pip命令,安装AWS CLI。
$ pip install awscli关于pip命令的详细信息请参考如下。AWS CLI的安装路径必须为以下之一。/sbin,/bin,/usr/sbin,/usr/bin,/usr/local/bin关于AWS CLI 的安装方法,详情请参考下述。(安装Python或AWS CLI时已经安装了EXPRESSCLUSTER时,请重启OS再执行EXPRESSCLUSTER的操作。)
从shell执行以下的命令。
$ sudo aws configure针对提问输入执行AWS CLI所必需的信息。AWS Access ID,AWS Secret Access Key处输入从已创建的IAM用户的详细信息画面取得的内容。
AWS Access Key ID [None]: <AWS Access Key > AWS Secret Access Key [None]: <AWS Secret Access Key > Default region name [None]: <默认的区域名> Default output format [None]: text"Default output format"可以指定为"text"之外的格式。如果内容设置错误时,请将/root/.aws目录删除后再重新执行上述操作。
6.3.21. 关于Azure DNS资源¶
安装Azure CLI,服务主体创建的步骤请参考《EXPRESSCLUTER X Microsoft Azure HA 集群构筑指南 (Linux 版)》。
为了利用Azure DNS资源,需要安装Azure CLI和Python。Python与Redhat Enterprise Linux/Cent OS等操作系统是捆绑在一起的。关于Azure CLI的具体内容,请参考以下Web站点。
Microsoft Azure的文档:为了利用Azure DNS资源,需要Azure DNS的服务。关于Azure DNS的具体内容,请参考以下Web站点。
EXPRESSCLUTER为了和Microsoft Azure联动,需要Microsoft Azure的组织账户。组织账户以外的账户在Azure CLI运行时需要对话形式的登录,因此不能使用。
- 使用Azure CLI,需要创建服务主体。Azure DNS资源是登录到Microsoft Azure,执行对DNS区域的登记。登录到Microsoft Azure时,利用通过服务主体的Azure登录。关于服务主体和具体步骤,请参考以下的Web站点。使用Azure CLI 2.0进行登录:在Azure CLI 2.0 上创建 Azure 服务主体:创建出服务主体的角色由默认的Contributor(共同创造者)改为别的角色时,作为Actions 属性,请选择拥有以下的全部操作的访问权的角色。如果改变为不满足该条件的角色时,启动Azure DNS 资源就会发生错误而失败。
Azure CLI 1.0时
Microsoft.Network/dnsZones/readMicrosoft.Network/dnsZones/A/writeMicrosoft.Network/dnsZones/A/readMicrosoft.Network/dnsZones/A/deleteMicrosoft.Network/dnsZones/NS/readAzure CLI 2.0 时
Microsoft.Network/dnsZones/A/writeMicrosoft.Network/dnsZones/A/deleteMicrosoft.Network/dnsZones/NS/read 不支持Azure私有DNS。
6.3.22. 关于Google Cloud DNS资源¶
使用Google Cloud的Cloud DNS。关于Cloud DNS的详细信息,请参考以下Web网站。
Cloud DNS要使用Cloud DNS操作,需要安装Cloud SDK。关于Cloud SDK的详细信息,请参考以下网站。
Cloud SDK需要用具有以下权限的帐户批准Cloud SDK。
dns.changes.createdns.changes.getdns.managedZones.getdns.resourceRecordSets.createdns.resourceRecordSets.deletedns.resourceRecordSets.listdns.resourceRecordSets.update关于批准Cloud SDK,请参考以下Web网站。
Cloud SDK工具批准
6.3.23. 关于Samba监视资源¶
Samba监视资源为了支持SMB协议版本2.0以上的版本,支持NTLM认证,支持SMB署名,使用内部版本4.1.0-1共享库的libsmbclient.so.0。由于libsmbclient.so.0包含在libsmbclient 包中,所以请确认是否已安装。
Libsmbclient的版本为3以下时(例.捆绑在RHEL 6中的libsmbclient.so),[端口号]只能指定139或者445。请指定包含在smb.conf的smb ports中的端口号。
Samba监视资源支持的SMB协议的版本依赖于已安装的libsmbclient中。可以尝试用各Distributor提供的smbclient命令连接共享监视对象,来确认libsmbclient是否支持。
6.3.24. 关于HTTP网络分区解决资源,Witness心跳资源¶
- 在HTTP 网络分区解决资源,Witness 心跳资源中使用SSL时,使用OpenSSL 1.0/1.1。默认使用的库如下。
libssl.so.10 (安装ExpressCluster rpm数据包时)
libssl.so.1.0.0 (安装EXPRESSCLUSTER deb数据包后)
要更改要使用的库时,请在集群属性的加密标签页中设置[SSL库]和[Crypto库]。
6.4. 创建EXPRESSCLUSTER的信息时¶
下文将阐述设计和创建EXPRESSCLUSTER构筑信息之前,需要依照系统构筑确认和注意的事项。
6.4.1. 有关EXPRESSCLUSTER安装路径下的目录,文件¶
6.4.2. 环境变量¶
在环境变量被设为大于256个的环境中,无法执行下列处理。若使用下列功能或资源,请将环境变量设为小于255个。
组启动/停止处理
Exec资源启动/停止时执行的开始/停止脚本
自定义监视器资源在监视时执行的脚本
组资源,监视器资源异常被查出时最终操作执行前脚本
组资源的启动/停止前后执行的脚本
强制停止脚本
注解
请将系统设定的环境变量和EXPRESSCLUSTER设定的环境变量之总和设定在255个以下。EXPRESSCLUSTER设定的环境变量约为30个。
6.4.3. 强制停止功能和机体ID指示灯的联动¶
使用强制停止功能和机体ID指示灯联动时,必须设置各服务器的BMC IP地址,用户名,密码。用户名请务必设置登录了密码的用户名。
6.4.4. 服务器的Reset,Panic,Power off¶
EXPRESSCLUSTER执行"Server reset"或"Server panic"或"Server power off"时,服务器不能被正常关闭。所以会有以下风险。
对mount中的文件系统造成损坏
丢失未保存的数据
OS dump 收集中断
发生"Server reset"或"Server panic"的设置如下。
组资源启动时/停止时异常的处理
sysrq panic
keepalive reset
keepalive panic
BMC reset
BMC poweroff
BMC cycle
BMC NMI
I/O Fencing(High-End Server Option)
监视资源查出异常的最终运行
sysrq panic
keepalive reset
keepalive panic
BMC reset
BMC poweroff
BMC cycle
BMC NMI
I/O Fencing(High-End Server Option)
用户空间监视查出超时的处理
监视方法 softdog
监视方法 ipmi
监视方法 ipmi(High-End Server Option)
监视方法 keepalive
注解
"Server panic"仅在监视方法为KeepAlive时才可以设置。
Shutdown stall监视
监视方法 softdog
监视方法 ipmi
监视方法 ipmi(High-End Server Option)
监视方法 keepalive
注解
"Server panic"仅在监视方法为keepalive时才可以设置。
强制停止功能的操作
BMC reset
BMC poweroff
BMC cycle
BMC NMI
VMware vSphere poweroff
6.4.5. 组资源停止异常时的最终运行¶
查出停止异常时,对最终运行选择[无操作],则组将在启动失败的状态下停止。在正式的运行环境下,请不要设置为[无操作]。
6.4.6. 确认VxVM使用的RAW设备¶
请提前调查卷RAW设备的物理RAW设备。
在安装EXPRESSCLUSTER前,导入在单方服务器上可以启动的所有磁盘组,将所有卷调整到启动状态。
- 执行如下命令。在以下的输出示例中,
/dev/raw/raw2,/dev/raw/raw3是RAW设备名。此外,major ..., minor ...的部分是主/副编号。# raw -qa /dev/raw/raw2: bound to major 199, minor 2 /dev/raw/raw3: bound to major 199, minor 3
例)磁盘组名和卷名分别为如下情况时
磁盘组名为dg1
dg1目录下的卷名为 vol1,vol2
- 执行如下命令。在以下的输出示例中,
199, 2,199, 3的部分是主/副编号。# ls -l /dev/vx/dsk/dg1/ brw------- 1 root root 199, 2 May 15 22:13 vol1 brw------- 1 root root 199, 3 May 15 22:13 vol2
确保 2) 和 3) 的主/副编号相同。
切勿在EXPRESSCLUSTER的磁盘心跳资源,Disk类型为“VxVM”以外的磁盘资源,监视方法为READ (VxVM) 以外的磁盘监视资源中设置在1中确认的RAW设备。
6.4.9. 关于多定义镜像磁盘时的单体服务器的启动时间¶
多定义镜像磁盘资源的个数,将「启动服务器时等待其他服务器启动的时间」设置的比较短时,如果启动单体服务器,启动镜像代理就可执行花费较多的时间,且镜像磁盘资源,镜像磁盘服务器的监视资源等可执行不能正常启动。
如果启动单体服务器时进入上述的状态,请将同步等待监视([集群属性] - [超时] 标签页 - [同步等待时间] 中设置)的值替换为较大的值进行设置变更。
6.4.10. 关于磁盘监视资源的RAW监视¶
设置磁盘监视资源的RAW监视时,无法监视已经mount的分区或可以mount的分区。另外,不能将设备名设置为已经mount的分区或可以mount的分区的whole device(显示磁盘整体的设备)进行监视。
请准备监视专用的分区,将其设置到磁盘监视资源的RAW监视内。
6.4.11. 迟延警告比例¶
将迟延警告比例设置为0或100时,可以进行如下操作。
- 将迟延警告比例设置为0时每次执行监视都会通报迟延警告。可利用该功能计算出服务器在高负荷状态下监视资源的监视时间,从而决定监视资源的监视超时时间。
- 将迟延警告比例设置为100时迟延警告将不发出通报。
除了测试运行以外,请不要将值设置为诸如0%之类的低值。
6.4.12. 关于磁盘监视资源的监视方法TUR¶
- 不能在不支持SCSI的Test Unit Ready命令或SG_IO命令的磁盘,磁盘接口(HBA)上使用。有时硬件支持但驱动程序不支持,所以请结合驱动程序的规格进行确认。
- 根据磁盘控制器的类型或使用版本的不同,OS可执行将S-ATA接口磁盘视为IDE接口的磁盘(hd),也可执行视为SCSI接口的磁盘(sd)。被视为IDE接口时,所有TUR方式将无法使用。被视为SCSI接口时,TUR(legacy)和TUR(generic)不能使用。
与read方式相比,对OS和磁盘的负荷较小。
有时用Test Unit Ready不能查出物理媒介的I/O错误。
6.4.13. 关于LAN心跳的设置¶
至少需要设置1个LAN心跳资源或1个内核模式LAN心跳资源。
建议将心跳线专用LAN作为LAN心跳资源登录,进而将公网也作为LAN心跳资源登录(建议设置2个以上LAN心跳资源)。
在使用共享型镜像磁盘资源的情况下请不要使用服务器宕机通知
6.4.14. 关于内核模式LAN心跳的设置¶
至少需要设置1个LAN心跳资源或1个内核模式LAN心跳资源。
建议对内核模式LAN心跳可用版本的内核并用内核模式LAN心跳。
6.4.15. 关于COM心跳的设置¶
为防止网络中断时双方机器都被启动,建议在可以使用COM的环境下使用COM心跳资源。
6.4.16. 关于BMC心跳的设置¶
BMC的硬件和固件需要对应BMC心跳。
6.4.17. 关于BMC监视器资源的设置¶
BMC的硬件和固件需要对应BMC心跳。
6.4.18. 关于能用于脚本注释等的2字节系字符编码¶
在EXPRESSCLUSTER中,Linux环境下编辑的脚本作为EUC使用,而Windows环境下编辑的脚本则作为Shift-JIS使用。如使用其他字符编码,可执行因环境不同而出现乱码的情况。
6.4.19. 关于虚拟机组的失效切换互斥属性的设置¶
请不要向排他规则里追加设置在虚拟机组内的组。
6.4.20. 关于系统监视器资源的设置¶
- 资源监视器的监测模式System Resource Agent通过「最多次数」和「监视持续时间」两个参数的组合进行检测。通过继续收集各系统资源(打开文件数,用户访问数,线程数,内存使用量,CPU 使用率,虚拟内存使用量),当一定时间内(指定为持续时间的时间)超过最多次数时,就会检测出异常。
6.4.21. 关于消息接收监视器资源的设定¶
向消息接收监视器资源通知异常时有3个方法。使用[clprexec] 命令的方法,使用BMC 联动功能的方法和使用服务器管理平台整合功能的方法。
使用[clprexec]命令时,请使用与EXPRESSCLUSTER CD同箱捆包的文件。请根据通知源的服务器的OS和架构来适当使用。并且,通知源服务器和通知目标服务器要处于可通信状态。
使用BMC联动功能时,需要BMC的硬件和固件可支持此功能。并且,需要将从BMC的管理用IP地址到OS 的IP地址保持一个可以通信的状态。
关于服务器管理平台整合功能,请参考《硬件整合指南》的"与服务器管理基础设施的整合"。
6.4.22. 关于JVM监视器的设定¶
监视目标为WebLogic Server时,对于JVM监视器资源的设定值,由于系统环境(内存搭载量等)的原因,设定范围的上限值可执行会受到限制。
[监视Work Manager的要求]-[要求数]
[监视Work Manager的要求]-[平均值]
[监视线程Pool的要求]-[待机要求 要求数]
[监视线程Pool的要求]-[待机要求 平均值]
[监视线程Pool的要求]-[执行要求 要求数]
[监视线程Pool的要求]-[执行要求 平均值]
监视目标的JRockit JVM 为64bit 版时,从JRockit JVM获取的各最大储存量会减少,致使不能计算出使用率,因此不能对以下的参数进行监视。
[监视堆使用率]- [领域整体]
[监视堆使用率]- [Nursery Space]
[监视堆使用率]- [Old Space]
[监视非堆使用率]- [领域整体]
[监视非堆使用率]- [ClassMemory]
要使用JVM监视资源,请安装"4. EXPRESSCLUSTER的运行环境"的"JVM监视的运行环境"中记载的JRE(Java Runtime Environment)。可与使用监视对象(WebLogic Server和WebOTX)的JRE在相同的项目中使用,也可使用在其他项目。
监视资源名中不要含空白字符。
检测出异常时,不能并用为了按照故障原因而执行命令的[命令]和负载均衡器联动功能。
6.4.23. 关于使用卷管理器资源时的EXPRESSCLUSTER的启动处理¶
EXPRESSCLUSTER启动时,卷管理器为lvm时通过vgchange命令进行停止处理,为vxvm时进行deport处理,因此系统的启动有可执行比较费时。如有问题时,可按照如下对EXPRESSCLUSTER本体的启动/停止脚本进行编辑。
init.d环境时,请将/etc/init.d/clusterpro按照如下进行编辑。
#!/bin/sh # # Startup script for the EXPRESSCLUSTER daemon # : : # See how we were called. case "$1" in start) : : # export all volmgr resource # clp_logwrite "$1" "clpvolmgrc start." init_main # ./clpvolmgrc -d > /dev/null 2>&1 # retvolmgrc=$? # clp_logwrite "$1" "clpvolmgrc end.("$retvolmgrc")" init_main : :
systemd环境时,请将/opt/nec/clusterpro/etc/systemd/clusterpro.sh按照如下进行编辑。
#!/bin/sh # # Startup script for the EXPRESSCLUSTER daemon # : : # See how we were called. case "$1" in start) : : # export all volmgr resource # clp_logwrite "$1" "clpvolmgrc start." init_main # ./clpvolmgrc -d > /dev/null 2>&1 # retvolmgrc=$? # clp_logwrite "$1" "clpvolmgrc end.("$retvolmgrc")" init_main
6.4.24. 关于AWS Elastic IP资源的设置¶
不支持IPv6。
在AWS环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源和虚拟IP监视资源。
AWS Elastic IP资源不支持ASCII字符以外的字符。请确认以下命令的执行结果中不包含ASCII字符以外的字符。
aws ec2 describe-addresses --allocation-ids <EIP ALLOCATION ID>
6.4.25. 关于AWS虚拟IP资源的设置¶
不支持IPv6。
在AWS环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源和虚拟IP监视资源。
AWS虚拟IP资源不支持ASCII字符以外的字符。请确认以下命令的执行结果中不包含ASCII字符以外的字符。
aws ec2 describe-vpcs --vpc-ids <VPC ID> aws ec2 describe-route-tables --filters Name=vpc-id,Values=<VPC ID> aws ec2 describe-network-interfaces --network-interface-ids <ENI ID>
在需要经由VPC-Peering连接的访问时,不能利用AWS虚拟IP资源。这是因为作为VIP使用的IP地址是在VPC范围之外的前提,这样的IP地址在VPC-Peering连接中被视为无效。需要经由VPC-Peering连接的访问时,请使用利用了Amazon Route 53的AWS DNS资源。
在使用实例的路由表中,即使没有定义使用虚拟IP的IP地址和ENI,AWS虚拟IP资源也能正常启动。这是规定好的。在启动AWS虚拟IP资源时,仅更新存在指定IP地址条目的路由表内容。即使没有找到任何一个路由表,也会因为没有更新目标而被判断为正常。由于该条目是否必须要存在于哪个路由表,是由系统配置决定的,因此,不作为检查AWS虚拟IP资源正常性的目标。
6.4.26. 关于AWS DNS资源的设置¶
不支持IPv6。
在AWS 环境下,不能利用浮动 IP 资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源。
如果[资源记录集名称]中包含转义码,则为监视异常。请设置不含转义码的[资源记录集名称]。
启动AWS DNS资源后,它不会等待DNS配置更改传播到所有Amazon Route 53 DNS服务器。 这是因为,根据Route 53的规范,将资源记录集更改应用于整个过程需要花费时间。请参考"关于AWS DNS监视资源的设置"。
由于AWS DNS资源绑定在一个账户上,因此,无法使用多个帐户,AWS访问ID,AWS秘密访问密钥。在这种情况下,请考虑使用通过EXEC资源执行AWS CLI的脚本。
6.4.27. 关于AWS DNS监视资源的设置¶
AWS DNS监视资源在监视时执行AWS CLI。执行AWS CLI的超时是利用在AWS DNS资源上设置的[AWS CLI超时]。
AWS DNS资源的启动后,根据以下的情况,AWS DNS监视资源的监视可执行会失败。这时,请将AWS DNS监视资源的 [开始监视等待时间] 设置为比Amazon Route 53中DNS设定改变反映的时间更长的时间(https://aws.amazon.com/jp/route53/faqs/)。
启动AWS DNS 资源时,追加和更新记录集合。
反映Amazon Route 53中的DNS设置改变前,监视AWS DNS监视资源时就会由于不能进行域名解析而失败。在DNS解析器缓存有效的期间内,之后,监视AWS DNS监视资源也会失败。
反映Amazon Route 53中的DNS设置改变。
经过AWS DNS资源的 [TTL] 有效期,由于域名解析成功,监视AWS DNS监视资源成功。
6.4.28. 关于Azure 探头端口资源的设置¶
不支持IPv6。
在Microsoft Azure环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源和虚拟IP监视资源。
6.4.29. 关于Azure负载均衡监视资源的设置¶
Azure负载均衡监视资源检测出异常时,Azure的负载均衡器的主服务器和备份服务器转换可执行不能正确被执行。因此,建议设置Azure负载均衡监视资源的[最终动作]为[停止集群服务并关闭操作系统]。
6.4.30. 关于Azure DNS资源的设置¶
不支持IPv6。
在Microsoft Azure 环境下,不能利用浮动 IP 资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源。
6.4.31. 关于Google Cloud 虚拟 IP 资源的设置¶
不支持IPv6。
6.4.32. 关于Google Cloud 负载均衡监视资源的设置¶
如果Google Cloud负载均衡监视资源检测到异常,则可执行无法正确地从负载均衡器在运行系统和待机系统之间进行切换。因此,建议在Google Cloud负载均衡监视资源的[最终动作]中选择[停止集群服务停止和关闭操作系统]。
6.4.33. 关于Google Cloud DNS资源的设置¶
不支持IPv6。
在Google Cloud Platform 环境下,不能利用浮动 IP 资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源。
如果同时执行多个Google Cloud DNS资源的启动/停止处理,可执行会发生错误。因此,在集群中使用多个Google Cloud DNS资源时,需要进行设置,以便由于资源的依赖关系和组的启动/停止等待而不能同时执行启动/停止处理。
6.4.34. 关于Oracle Cloud 虚拟 IP 资源的设置¶
不支持IPv6。
6.4.35. 关于Oracle Cloud 负载均衡监视资源的设置¶
如果Oracle Cloud负载均衡监视资源检测到异常,则可执行无法正确地从负载均衡器在运行系统和待机系统之间进行切换。因此,建议在Oracle Cloud负载均衡监视资源的[最终动作]中选择[停止集群服务停止和关闭操作系统]。
6.4.36. 使用集群资源iSCSI设备时的注意点¶
- iSCSI服务启动后,到iSCSI设备能使用为止需要花费时间的环境时,有在iSCSI设备可使用前集群已启动的现象。这时,请在镜像代理的启动/停止脚本里追加如下的sleep。只有在init.d环境的情况下,追加如下的修正。systemd环境的情况下不需要追加。
例)iSCSI服务启动后,到iSCSI设备能使用为止需要花费30秒时的修改例
请在/etc/init.d/clusterpro_md里追加sleep 30。
: : case "$1" in start) sleep 30 clp_filedel "$1" init_md : :
6.4.37. 反映设置磁盘I/O闭塞时的注意点¶
新建集群时,或者更改配置时更改磁盘I/O闭塞的设置之后执行配置信息的上传时,作为反映方法有时不显示"重启OS"。当更改了磁盘I/O闭塞的设置,为了使配置信息生效,请重启OS。
6.5. 操作EXPRESSCLUSTER后¶
请注意集群操作开始后的现象。
6.5.1. 关于udev等环境下的镜像驱动程序加载时的错误信息¶
在udev环境下加载镜像驱动程序时,messages文件有时会登入以下日志。
kernel: [I] <type: liscal><event: 141> NMP1 device does not exist. (liscal_make_request) kernel: [I] <type: liscal><event: 141> - This message can be recorded on udev environment when liscal is initializing NMPx. kernel: [I] <type: liscal><event: 141> - Ignore this and following messages 'Buffer I/O error on device NMPx' on udev environment. kernel: Buffer I/O error on device NMP1, logical block 0
kernel: <liscal liscal_make_request> NMP1 device does not exist. kernel: Buffer I/O error on device NMP1, logical block 112
文件名:50-liscal-udev.rules
ACTION=="add", DEVPATH=="/block/NMP*",OPTIONS+="ignore_device"
ACTION=="add", DEVPATH=="/devices/virtual/block/NMP*", OPTIONS+="ignore_device"
6.5.2. 关于针对镜像分区设备的缓存I/O错误的日志¶
镜像磁盘资源或共享磁盘资源处于停止的状态时,若访问镜像分区设备,则如下所示的日志会被记录到messages文件。
kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=*xxxxx*) kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. : kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=*xxxx*) : kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=*xxxx*)
kernel: <liscal liscal_make_request> NMPx I/O port is close, mount(0), io(0). kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
(x或 xxxx中填入字符串)
因udev环境而导致的
在这种情况下,在镜像驱动程序加载时,与"kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx"的消息一起,"kernel: [I] <type: liscal><event: 141>"的消息也会被记录。
本消息并不表示属于异常,也不会影响到EXPRESSCLUSTER的运作。
有关详情,请参阅本章的"关于udev等环境下的镜像驱动程序加载时的错误信息"。
运行OS的信息收集命令(sosreport, sysreport, blkid 命令等)时
在这种情况下,本消息并不表示属于异常,也不会影响到EXPRESSCLUSTER的运作。
若运行OS所提供的信息收集命令,则访问OS所识别的设备。此时,也会访问停止状态的镜像磁盘,其结果,上述的消息也会被记录。
没有通过EXPRESSCLUSTER的设置等抑制此消息的方法。
镜像磁盘的Unmount超时时
在这种情况下,与提示镜像磁盘资源的Unmount超时的消息一起,此消息也会被记录。
EXPRESSCLUSTER会进行镜像磁盘资源的"查出停止异常的恢复动作"。此外,文件系统有可执行发生不一致。
有关详情,请参阅本章的"因大量I/O而导致的缓存增大"。
在镜像磁盘停止食变为被Mount的状态的情况下
在这种情况下,在以下的流程后,上述的消息会被记录。
镜像磁盘资源变为启动状态后,可通过用户或应用程序(NFS等),针对镜像分区的设备(/dev/NMPx)或镜像磁盘资源的Mount point内,会添加进行Mount。
之后,保持不Unmount在(1)所添加的Mount point的状态,将镜像磁盘资源置为停止。
虽不影响到EXPRESSCLUSTER的运作,但文件系统有可执行发生不一致。
有关详情,请参阅本章的"在镜像磁盘资源等进行复数的Mount时"。
设置复数个镜像磁盘资源时
设置2个以上的镜像磁盘资源时,因启动时的一部分分配的fsck的行为的不同,有可执行输出上述的消息。
有关详情,请参阅本章的"关于使用复数个镜像磁盘资源,共享型磁盘资源时的syslog消息"。
其他,因被某种应用程序访问时
上述以外的情形时,可想象某种应用程序想访问停止状态的镜像磁盘资源。
镜像磁盘资源处于未启动的状态下,不会影响到EXPRESSCLUSTER的运作。
6.5.3. 因大量I/O而导致的缓存增大¶
- 若针对镜像磁盘资源或共享型磁盘资源进行超过磁盘性能的大量写入工作,即使镜像的通信尚未被切断等,但不能控制从写入工作中返回,或有可执行发生不能确保内存的错误。有大量超过处理性能的I/O要求时,文件系统需确保大量的缓存,若缓存或用户空间用的内存(HIGHMEM区)不足,则也有可执行使用内核空间用的内存(NORMAL区)。在这种情况下,请更改下述的内核参数,来抑制内核空间用的内存被利用为缓存。使用sysctl 命令等,设置在OS启动时可以更改参数。
/proc/sys/vm/lowmem_reserve_ratio
- 针对镜像磁盘资源或共享型磁盘资源进行大量的访问时,在磁盘资源停止时的Unmount,文件系统的缓存的内容写入到磁盘有可执行需要花费较长的时间。此时,若在从文件系统写入磁盘的工作结束之前,发生Unmount超时,则如下述所示的I/O错误的消息,Unmount失败的消息有可执行会被记录。在这种情况下,为了保证写入到磁盘的工作能够正常结束,请将相应磁盘资源的Unmount的超时时间设置为留有余力的值。
≪例1≫
clusterpro: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 193> NMPx close I/O port OK. kernel: [I] <type: liscal><event: 195> NMPx close mount port OK. kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device NMPx, logical block xxxx kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: Buffer I/O error on device NMPx, logical block xxxx :
≪例2≫
clusterpro: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 148> NMPx holder 1. (before umount) clusterpro: [E] <type: md><event: 46> umount timeout. Make sure that the length of Unmount Timeout is appropriate. (Device:mdx) : clusterpro: [E] <type: md><event: 4> Failed to deactivate mirror disk. Umount operation failed.(Device:mdx) kernel: [I] <type: liscal><event: 148> NMPx holder 1. (after umount) clusterpro: [E] <type: rc><event: 42> Stopping mdx resource has failed.(83 : System command timeout (umount, timeout=xxx)) :
6.5.4. 在镜像磁盘资源等进行复数的Mount时¶
- 在镜像磁盘资源或共享型磁盘资源启动后,针对镜像分区设备(/dev/NMPx)或Mount point(的文件阶层的一部分),想通过mount 命令添加到其他的位置,也进行Mount时,在磁盘资源变为停止之前,请务必将添加的Mount point进行Unmount。如果,不对添加的Mount point进行Unmount而进行停止,则内存上所残留的文件系统的数据有可执行不能完全写入到磁盘,因此磁盘上的数据保持为不完全的状态,向磁盘的I/O被切断,从而结束停止。此外,在这种情况下,由于停止后也想继续进行从文件系统写入到磁盘的工作,因此如下述所示的I/O错误的消息有可执行被记录。此外,在之后的服务器停止时等情况下,停止镜像Agent之际有可执行因无法结束镜像驱动程序,而导致停止镜像Agent失败,服务器重启。
≪例≫
clusterpro: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 148> NMP1 holder 1. (before umount) kernel: [I] <type: liscal><event: 148> NMP1 holder 1. (after umount) kernel: [I] <type: liscal><event: 193> NMPx close I/O port OK. kernel: [I] <type: liscal><event: 195> NMPx close mount port OK. clusterpro: [I] <type: rc><event: 41> Stopping mdx resource has completed. kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device NMPx, logical block xxxxx kernel: lost page write due to I/O error on NMPx kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: Buffer I/O error on device NMPx, logical block xxxxx kernel: lost page write due to I/O error on NMPx :
6.5.5. 关于使用复数个镜像磁盘资源,共享型磁盘资源时的syslog消息¶
设置2个以上的镜像磁盘资源,共享型磁盘资源时,在镜像磁盘资源,共享型磁盘资源的启动时,则以下的消息有可执行会被登录到OS的messages文件。
这种现象,有可执行是因为一部分的分配的fsck命令的行为 (访问原来不属于fsck对象的块设备的行为)而导致的。
kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
kernel: <liscal liscal_make_request> NMPx I/O port is close, mount(0), io(0). kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
相对EXPRESSCLUSTER而言并不存在问题。但若发生压迫messages文件等问题时,请更改镜像磁盘资源,共享型磁盘资源的以下设置。
将执行Mount前的fsck动作更改为「不执行」
将Mount失败时的fsck动作更改为「执行」
6.5.6. 关于驱动程序加载时的消息¶
加载镜像驱动程序时,如下消息有时显示在控制台和syslog上,此现象不属于异常。
kernel: liscal: no version for "xxxxx" found: kernel tainted. kernel: liscal: module license 'unspecified' taints kernel.
(xxxxx 中填入字符串)
除了加载clpka驱动程序和clpkhb驱动程序外,控制台和syslog上将可执行显示下述消息,此现象不属于异常。
kernel: clpkhb: no version for "xxxxx" found: kernel tainted. kernel: clpkhb: module license 'unspecified' taints kernel.
kernel: clpka: no version for "xxxxx" found: kernel tainted. kernel: clpka: module license 'unspecified' taints kernel. (xxxxx 中填入字符串)
6.5.7. 关于使用多个镜像磁盘资源,共享型镜像磁盘资源时的最初I/O信息¶
Mount镜像磁盘资源,共享型镜像磁盘资源后的最初read/write时,Consol将会出现以下信息,Syslog中也会出现。此现象非异常情况。
kernel: JBD: barrier-based sync failed on NMPx - disabling barriers (xxxxx 中填入字符串)
6.5.8. 关于ipmi的消息¶
在用户空间监视资源中使用IPMI时,将向syslog输出许多下述kernel模块警告日志。
modprobe: modprobe: Can't locate module char-major-10-173
要避免该日志的输出,请为/dev/ipmikcs重命名。
6.5.9. 恢复运行中的操作限制¶
使用查出监视资源异常时的设置,为复归对象指定组资源(磁盘资源,EXEC资源......),请不要在查出监视资源异常,正在恢复运行时(重新启动 -> 失效切换 -> 最终运行),控制如下命令或者来源于Cluster WebUI的集群和组。
集群的停止/挂起
组的开始/停止/移动
如果在监视资源异常,正在恢复运行时执行上述控制,该组的其他组资源可执行不会停止。然而,监视资源异常时,如果执行了最终运行,则可以进行上述的控制。
6.5.11. 关于执行fsck¶
- 启动磁盘资源/镜像磁盘资源/共享型磁盘资源时设定为执行fsck的情况下,将ext2/ext3/ext4文件系统进行Mount时,根据设定来执行fsck。然而,根据文件系统大小,使用量,实际状况fsck会比较费时,超出fsck超时时,则认为Mount失败。此处,fsck运行时会出下以下各种情况。
- 只对整体的简易检查。短时间内完成。
- 运行对文件系统全体的联动性检查。检查符合OS保存的信息[180天以上的不检查]或[30回(前后的)mount后执行]的场合。根据文件系统的大小和使用量等信息,所花费时间较长。
此时为了不发生超时,设置磁盘资源的fsck超时时间时请留出足够的富余。
启动磁盘资源/镜像磁盘资源/共享型磁盘资源时设定为不执行fsck的情况下, ext2/ext3/ext4文件系统进行Mount时,超出OS保持的fsck实行mount次数时,系统日志或Console输出以下警告信息。
EXT3-fs warning: xxxxx, running e2fsck is recommended (注)xxxxx 中填入字符串。
出现该警告的场合,建议针对文件系统执行fsck。
手动执行fsck时,请按照以下指南执行。并且,以下指南必须在该磁盘资源启动的服务器上执行。通过clpgrp等命令,将该磁盘资源所属的组失效。
磁盘为被mount时,使用mount或者fd等命令来确认。
- 根据磁盘资源种类,通过执行以下命令将磁盘装从Read Only改为Read Write。
(磁盘资源的场合) 磁盘名为/dev/sdb5时
# clproset -w -d /dev/sdb5 /dev/sdb5 : success
(镜像磁盘资源的场合) 资源名为md1时
# clpmdctrl --active -nomount md1 <md1@server1>: active successfully
(共享型镜像磁盘资源的场合) 资源名为hd1时
# clphdctrl --active -nomount hd1 <hd1@server1>: active successfully
- 执行fsck。(镜像磁盘资源或共享磁盘资源的情况下,在fsck指定设备名时,请指定对应其资源的镜像分区设备名(/dev/NMPx))
- 根据磁盘资源种类,通过执行以下命令将磁盘装从Read Only改为Read Write。
(磁盘资源的场合) 磁盘名为/dev/sdb5时
# clproset -o -d /dev/sdb5 /dev/sdb5 : success
(镜像磁盘资源的场合) 资源名为md1时
# clpmdctrl --deactive md1 <md1@server1>: deactive successfully
(共享型镜像磁盘资源的场合) 资源名为hd1时
# clphdctrl --deactive hd1 <hd1@server1>: deactive successfully
通过clpgrp等命令,将该磁盘资源所属的组启动。
如没有执行fsck而不期望出现警告信息时,ext2/ext3/ext4的情况下,通过tune2fs命令变更最大mount次数,请在该磁盘资源被启动的服务器上执行。
- 请执行以下命令。
(磁盘资源的场合)磁盘名为/dev/sdb5时
# tune2fs -c -1 /dev/sdb5 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
(镜像磁盘资源的场合) 镜像分区设备名为/dev/NMP1时
# tune2fs -c -1 /dev/NMP1 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
(共享型镜像磁盘资源的场合)镜像分区设备名为/dev/NMP1时
# tune2fs -c -1 /dev/NMP1 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
- 请确认最大mount回数被更改。(例) 设备名为/dev/sdb5时
# tune2fs -l /dev/sdb5 tune2fs 1.42.9 (28-Dec-2013) Filesystem volume name: <none> : Maximum mount count: -1 :
6.5.12. 关于执行xfs_repair¶
如果在启动使用xfs的磁盘资源/镜像磁盘资源/共享型镜像磁盘资源时向控制台输出有关xfs的警告,建议执行xfs_repair修复文件系统。
请按照以下步骤执行xfs_repiar。
请确认资源是否未启动。 如果处于启动状态,请使用Cluster WebUI等将其停用。
使设备可写入。
(磁盘资源示例)设备名称为/ dev / sdb1时
# clproset -w -d /dev/sdb1 /dev/sdb1 : success(镜像磁盘示例) 资源名为md1时
# clpmdctrl --active -nomount md1 <md1@server1>: active successfully(共享型磁盘资源示例) 资源名为hd1时
# clphdctrl --active -nomount hd1 <hd1@server1>: active successfullymount设备。
(磁盘资源示例) 设备名为 /dev/sdb1时
# mount /dev/sdb1 /mnt(镜像磁盘资源/共享型镜像磁盘资源的示例) 镜像分区设备名为 /dev/NMP1 时
# mount /dev/NMP1 /mntumount设备。
# umount /mnt注解
xfs_repair实用程序无法修复带有脏日志的文件系统。 为了清除日志,有必要mount和unmount一次。
执行xfs_repair 。
(磁盘资源示例) 设备名为 /dev/sdb1时
# xfs_repair /dev/sdb1(镜像磁盘资源/共享型镜像磁盘资源的示例) 镜像分区设备名为 /dev/NMP1 时
# xfs_repair /dev/NMP1禁止写入设备。
(磁盘资源示例) 设备名为 /dev/sdb1时
# clproset -o -d /dev/sdb1 /dev/sdb1 : success(镜像磁盘示例) 资源名为md1时
# clpmdctrl --deactive md1 <md1@server1>: deactive successfully(共享型磁盘资源示例) 资源名为hd1时
# clphdctrl --deactive hd1 <hd1@server1>: deactive successfully
这样就完成了xfs文件系统的修复。
6.5.13. 收集日志时的消息¶
执行日志收集时,控制台上可执行显示下列消息,不属于异常。日志在正常收集。
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
(在hd#内有存在于服务器IDE的设备名)
kernel: Warning: /proc/ide/hd?/settings interface is obsolete, and will be removed soon!
6.5.14. 关于镜像恢复中的失效切换或启动¶
- 镜像磁盘资源或共享磁盘资源处于镜像恢复状态下,不能启动停止状态下的镜像磁盘资源或共享磁盘资源。镜像恢复状态下,不能移动含有此磁盘资源的失效切换组。镜像恢复状态下,发生失效切换时,失效切换将失败。镜像恢复状态下,因复制目标服务器不能保持最新状态,对复制目标服务器或复制目标服务器组的失效切换将失败。另外,因检测出监视资源异常时的操作等,共享磁盘资源向同一服务器组执行失效转换的情况下,没有移动当前全值却失效切换失败。但是,失效切换,移动或启动中,恰好镜像恢复结束时,失效切换就会成功。
- 登录构成信息后第一次启动镜像时,或由于发生故障等更换镜像用的磁盘后第一次启动镜像时,会进行初期镜像构建。初期镜像构建时,会从镜像启动后的运行服务器侧开始,然后到备用服务器侧的镜像用磁盘,最后进行磁盘的复制(全面镜像恢复)。到此初期镜像构建(全面镜像恢复)结束,镜像处于正常的同步状态为止,请不要失效切换到备用,或向备用移动组。若在磁盘的复制途中进行失效切换或组移动,备用的镜像磁盘会保持不完全的状态下而启动备用,未复制到备用的数据有可执行会丢失,文件系统有可执行会发生数据不一致。
6.5.15. 集群关机,集群重启(镜像磁盘资源,共享磁盘资源)¶
6.5.16. 特定服务器的关机,特定服务器的重启(镜像磁盘资源,共享型磁盘资源)¶
6.5.17. 关于服务启动/停止用脚本¶
init.d环境中,在下列情况下,服务器启动/停止脚本中输出错误。systemd环境中不输出错误。
- 构筑集群前启动OS时下列服务启动脚本中输出错误。由于出错原因为集群尚未构筑,因此没有问题。
clusterpro_md
- 下列情况下,服务的停止脚本执行的顺序有误。关闭禁用服务后的OSEXPRESSCLUSTER的服务设置为无效后关闭OS时,EXPRESSCLUSTER的服务由于顺序错误而停止。这是由于关闭OS时失效的EXPRESSCLUSTER服务没有被停止所造成的。从Cluster WebUI执行的集群关闭或使用clpstdn命令等EXPRESSCLUSTER命令关闭集群时,即使由于错误顺序造成服务停止也没有问题。
6.5.18. 关于服务启动时间¶
根据启动时有无等待处理的不同,EXPRESSCLUSTER的各服务器有时需要耗费较长的时间。
- clusterpro _evt除主服务器以外,其他服务器下载主服务器配置信息的处理过程最长需要等待2分钟。如主服务器已启动,则通常只需几秒钟即可完成。主服务器无需等待此项处理。
- clusterpro _trn无特别的等待处理。通常只需几秒钟即可完成。
- clusterpro_ib无特别的等待处理。通常只需几秒钟即可完成。
- clusterpro_api无特别的等待处理。通常只需几秒钟即可完成。
- clusterpro _md只有存在镜像磁盘资源或共享型镜像磁盘资源时,本服务才会启动。镜像代理正常启动最长需要等待1分钟。通常只需几秒钟即可完成。
- clusterpro无特别的等待处理,但是EXPRESSCLUSTER的启动耗时有时需要数十秒钟。通常只需几秒钟即可完成。
- clusterpro _webmgr无特别的等待处理。通常只需几秒钟即可完成。
- clusterpro _alertsync无特别的等待处理。通常只需几秒钟即可完成。
此外,EXPRESSCLUSTER Daemon启动后,需要进行集群同步启动等待处理,默认设置的等待时间为5分钟。
此项内容的相关信息请参考《维护指南》的"维护信息"的"集群启动同步等待时间"。
6.5.19. 关于systemd环境中的服务状态确认¶
6.5.20. 关于在EXEC资源中使用的脚本文件¶
在EXEC资源中使用的脚本文件保存于各服务器的以下路径中。
/安装路径/scripts/组名/EXEC资源名/
更改集群配置时进行以下更改的情况下,更改前的脚本文件不会从服务器上删除。
删除EXEC资源时或更改EXEC资源名时
EXEC资源所在的组被删除或组名被更改时
若不需要更改前的脚本文件时,可以删除。
6.5.21. 关于启动时监视设置的监视资源¶
启动时监视设置的监视资源的暂停/继续有以下限制事项。
暂停监视资源后,停止了监视对象资源时,监视器资源变为停止状态。因此无法重启监视。
暂停监视资源后,停止/启动了监视对象资源时,在监视对象资源启动时,启动基于监视器资源的监视。
6.5.22. 关于Cluster WebUI¶
如果不能与访问地址通信,需要等待控制恢复。
需要通过Proxy服务器时,请将Proxy服务器设置为可以继续使用Cluster WebUI端口号的状态。
经由Reverse Proxy服务器时,Cluster WebUI不能正常运行。
- 已经执行EXPRESSCLUSTER升级后,请关掉所有启动的浏览器。清除浏览器侧的缓存,启动浏览器。
使用比本产品更新的版本创建的集群配置信息,不能在本产品中使用。
- 关掉Web浏览器(窗口框的[X]等),有时会显示确认对话框。
 想要继续设置时,点击[留在此页]。
想要继续设置时,点击[留在此页]。 - 重新加载Web浏览器(菜单的[刷新]和工具条的[重新读取现有的网页]等),有时会显示确认对话框。
 想要继续设置时,点击[留在此页]。
想要继续设置时,点击[留在此页]。 有关上记以外的Cluster WebUI的注意限制事项请参考在线版手册。
6.5.23. 关于镜像磁盘,共享型镜像磁盘资源的分区大小变化¶
如果想要在开始运行之后更改镜像分区的容量,请参考《维护指南》的"维护信息"的"更改镜像磁盘资源分区的位移或大小"。
6.5.24. 关于更改内核转储设置¶
- 在Red Hat Enterprise Linux 6等环境中,运行集群状态下,更改[内核转储设置] (system-config-kdump)的kdump设置并使其[应用]时,会出现以下错误信息。在这种情况下,请停止集群(正在使用镜像磁盘资源或共享型磁盘时,停止集群和镜像代理)后,执行内核转储设置。※ 下面的{驱动器名}部分可以是clpka, clpkhb和liscal中的任何一个。
No module {驱动器名} found for kernel {内核版}, aborting
6.5.25. 关于浮动 IP,虚拟 IP 资源¶
设置了浮动 IP 资源或者虚拟 IP 资源时,请不要在这些资源启动的服务器上执行网络的重新启动。如果重新启动网络,各资源添加的 IP 地址就会被删除。
6.5.26. 关于系统监视资源,进程资源监视资源¶
改变设定内容时,需要进行集群的挂起。
不对应监视资源的延迟警告。
请将SELinux 设定为permissive或 disabled。
设定为enforcinfg时,EXPRESSCLUSTER中有可执行不能进行所需的通信。
若运行中改变OS的日期/时间,则每隔10分钟执行的解析处理仅在日期或时间更改后的最初时序出现一次错位。出现以下两种问题时,请根据需要执行集群挂起·复归。
即使异常检测时间间隔经过之后,也不执行异常检测。
异常检测时间间隔经过之前,执行异常检测。
在系统监视资源的磁盘资源监视功能中可以同时监视的最大磁盘数为64台。
6.5.27. 关于JVM监视资源¶
需要重新启动监视对象的Java VM时,请进行集群挂起后或停止集群后再进行。
改变设定内容时,请进行集群的挂起。
不对应监视资源的延迟警告。
6.5.28. 关于HTTP监视资源¶
HTTP监视资源使用了以下其中的一个OpenSSL共享库的符号链接。
libssl.so
libssl.so.1.1 (OpenSSL 1.1.1 的共享库)
libssl.so.10 (OpenSSL 1.0的共享库)
libssl.so.6 (OpenSSL 0.9的共享库)
根据OS的发布,版本以及软件包的安装状况,上述的符号链接可执行不存在。HTTP监视资源找不到上述的符号链接时会发生以下错误。Detected an error in monitoring <Monitor Resource Name>. (1 :Can not found library. (libpath=libssl.so, errno=2))
因此,发生上述错误时,请确认/usr/lib或者/usr/lib64等目录下是否存在上诉的符号链接。另外,上诉的符号链接不存在时,请像下面的命令例那样做成符号链接libssl.so。命令例:cd /usr/lib64 #/usr/lib64目录移动 ln -s libssl.so.1.0.1e libssl.so #符号链接作成
6.5.29. 关于AWS环境的AMI的恢复¶
在AWS虚拟IP资源,AWS Elastic IP资源的ENI ID中设定为主网卡的[ENI ID]时,从AMI等恢复时,需要变更AWS虚拟IP资源,AWS Elastic IP资源的设定。此外,设定为备用网卡的ENI ID时,从AMI等恢复时根据分离/连接处理,由于同一个ENI ID可执行被继续使用,不需要变更AWS虚拟IP资源,AWS Elastic IP资源的设定。
6.6. 更改EXPRESSCLUSTER的配置时¶
开始集群运行后,如果对配置进行更改时,需要对发生的事项留意。
6.6.1. 关于组共通属性的互斥规则¶
6.6.2. 关于资源属性的依存关系¶
6.6.3. 关于组资源的添加,删除¶
例) 浮动IP资源fip1从组failover1移动到别的组failover2时
从组failover1中删除fip1。
执行设定的反映。
向组failover2中添加fip1。
执行设定的反映。
6.6.5. 关于消息接收监视资源的集群统计信息的设置¶
在更改监视资源的集群统计信息设置时,即使执行了挂起/复原,也无法使集群统计信息的设置在消息接收监视资源中生效。如果要使集群统计信息的设置在消息接收监视资源中生效,请重启OS。
6.7. EXPRESSCLUSTER版本升级时¶
作为集群开始操作后,进行EXPRESSCLUSTER 的版本升级时需要注意的事项。
6.7.1. 功能更改一览¶
各版本中更改的功能如下所示。
内部版本 4.0.0-1
内部版本 4.1.0-1
历史文件存储目录
历史文件大小限制
※更新后,这些设置立即为空白。在这种情况下,"历史文件存储目录"被视为安装了ExpressCluster的目录,"历史文件大小限制"被视为无限制。
内部版本 4.2.0-1
内部版本 4.3.0-1
- 关于Weblogic 监视资源添加作为新监视方式的REST API。从此版本开始REST API将作为默认的监视方式。升级版本时,请重新设置监视方式。更改密码的默认值。如果使用的是以前的默认值weblogic,请重新设置。
6.7.3. 参数删除一览¶
在通过Cluster WebUI可以设定的参数中,有关各版本中被删除的参数如下表所示。
内部版本 4.0.0-1
集群
参数
默认值
集群属性
Alert服务标签页
使用Alert扩展机能
Off
Web管理器标签页
允许接入WebManager Mobile
Off
WebManager Mobile用密码
操作用密码
-
参照用密码
-
JVM监视资源
参数
默认值
JVM监视资源属性
监视(固有)标签页
内存标签页 ([JVM类型]处选择 [Oracle Java]时)
监视虚拟内存使用量
2048 [MB]
内存标签页 ([JVM类型]处选择[Oracle JRockit]时)
监视虚拟内存使用量
2048 [MB]
内存标签页 ([JVM类型]处选择[Oracle Java(usage monitoring)]时)
监视虚拟内存使用量
2048 [MB]
内部版本 4.1.0-1
集群
参数
默认值
集群属性
Web管理器标签页
Web管理器调整属性
动作标签页
警示框最大记录数
300
客户端数据更新方法
Real Time
6.7.4. 默认值更改一览¶
在通过Cluster WebUI可以设置的参数中,各版本中被更改的默认值如下表所示。
版本升级后,想要继续设置[更改前的默认值]时,在版本升级后请重新设置该值。
在设置了[更改前的默认值]以外的值时,版本升级后会保留之前的设定值。不需要重新设置。
内部版本 4.0.0-1
集群
参数
更改前的默认值
更改后的默认值
集群属性
监视标签页
监视方法
softdog
keepalive
JVM监视 标签页
最大Java堆内存大小
7 [MB]
16 [MB]
EXEC资源
参数
更改前的默认值
更改后的默认值
EXEC资源属性
依赖关系 标签页
遵循原有的依赖关系
磁盘资源
参数
更改前的默认值
更改后的默认值
磁盘资源属性
依赖关系 标签页
遵循原有的依赖关系
详细 标签页
磁盘资源调整属性
Mount 标签页
超时
60 [秒]
180 [秒]
xfs_repair 标签页([文件系统]处选择[xfs]时)
On
Off
NAS资源
参数
更改前的默认值
更改后的默认值
NAS资源属性
依赖关系 标签页
遵循原有的依赖关系
镜像磁盘资源
参数
更改前的默认值
更改后的默认值
镜像磁盘资源属性
依赖关系 标签页
遵循原有的依赖关系
详细 标签页
镜像磁盘资源调整属性
xfs_repair 标签页([文件系统]处选择[xfs]时)
On
Off
共享型镜像磁盘资源
参数
更改前的默认值
更改后的默认值
共享型镜像磁盘资源属性
依赖关系 标签页
遵循原有的依赖关系
详细 标签页
共享型镜像磁盘资源调整属性
xfs_repair 标签页([文件系统]处选择[xfs]时)
On
Off
卷管理资源
参数
更改前的默认值
更改后的默认值
卷管理资源属性
依赖关系 标签页
遵循原有的依赖关系
虚拟IP监视资源
参数
更改前的默认值
更改后的默认值
虚拟IP监视资源属性
监视 (共通) 标签页
超时
30 [秒]
180 [秒]
PID监视资源
参数
更改前的默认值
更改后的默认值
PID监视资源属性
监视 (共通) 标签页
开始监视的等待时间
0 [秒]
3 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
用户空间监视资源
参数
更改前的默认值
更改后的默认值
用户空间监视资源属性
监视 (固有) 标签页
监视方法
softdog
keepalive
NIC Link Up/Down监视资源
参数
更改前的默认值
更改后的默认值
NIC Link Up/Down 监视资源属性
监视 (共通) 标签页
超时
60 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
ARP监视资源
参数
更改前的默认值
更改后的默认值
ARP 监视资源属性
监视 (共通) 标签页
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
动态域名解析监视资源
参数
更改前的默认值
更改后的默认值
动态域名解析监视资源属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
进程名监视器资源
参数
更改前的默认值
更改后的默认值
进程名监视器资源属性
监视 (共通) 标签页
开始监视的等待时间
0 [秒]
3 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
DB2监视资源
参数
更改前的默认值
更改后的默认值
DB2 监视资源属性
监视 (固有) 标签页
密码
ibmdb2
-
Lib路径
/opt/IBM/db2/V8.2/lib/libdb2.so
/opt/ibm/db2/V11.1/lib64/libdb2.soMySQL监视资源
参数
更改前的默认值
更改后的默认值
MySQL 监视资源属性
监视 (固有) 标签页
存储引擎
MyISAM
InnoDB
Lib路径
/usr/lib/mysql/libmysqlclient.so.15
/usr/lib64/mysql/libmysqlclient.so.20Oracle监视资源
参数
更改前的默认值
更改后的默认值
Oracle 监视资源属性
监视 (固有) 标签页
密码
change_on_install
-
Lib路径
/opt/app/oracle/product/10.2.0/db_1/lib/libclntsh.so.10.1
/u01/app/oracle/product/12.2.0/dbhome_1/lib/libclntsh.so.12.1PostgreSQL监视资源
参数
更改前的默认值
更改后的默认值
PostgreSQL 监视资源属性
监视 (固有) 标签页
Lib路径
/usr/lib/libpq.so.3.0
/opt/PostgreSQL/10/lib/libpq.so.5.10Sybase监视资源
参数
更改前的默认值
更改后的默认值
Sybase 监视资源属性
监视 (固有) 标签页
Lib路径
/opt/sybase/OCS-12_5/lib/libsybdb.so
/opt/sap/OCS-16_0/lib/libsybdb64.soTuxedo监视资源
参数
更改前的默认值
更改后的默认值
Tuxedo 监视资源属性
监视 (固有) 标签页
Lib路径
/opt/bea/tuxedo8.1/lib/libtux.so
/home/Oracle/tuxedo/tuxedo12.1.3.0.0/lib/libtux.soWeblogic监视资源
参数
更改前的默认值
更改后的默认值
Weblogic 监视资源属性
监视 (固有) 标签页
域环境文件
/opt/bea/weblogic81/samples/domains/examples/setExamplesEnv.sh
home/Oracle/product/Oracle_Home/user_projects/domains/base_domain/bin/setDomainEnv.shJVM监视资源
参数
更改前的默认值
更改后的默认值
JVM监视资源属性
监视 (共通) 标签页
超时
120 [秒]
180 [秒]
浮动IP监视资源
参数
更改前的默认值
更改后的默认值
浮动IP监视资源属性
监视 (共通) 标签页
超时
60 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
AWS Elastic IP监视资源
参数
更改前的默认值
更改后的默认值
AWS Elastic IP监视资源属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
AWS虚拟IP监视资源
参数
更改前的默认值
更改后的默认值
AWS 虚拟IP监视资源属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
AWS AZ监视资源
参数
更改前的默认值
更改后的默认值
AWS AZ监视资源属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
Azure探头端口监视资源
参数
更改前的默认值
更改后的默认值
Azure 探头端口监视资源属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
Azure负载均衡监视资源
参数
更改前的默认值
更改后的默认值
Azure 负载均衡监视资源属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
内部版本 4.1.0-1
集群
参数
更改前的默认值
更改后的默认值
集群属性
监视标签页
关机监视
始终执行
只在组停止处理失败时执行
内部版本 4.2.0-1
AWS Elastic IP 监视资源
参数
更改前的默认值
更改后的默认值
AWS Elastic IP监视资源的属性
监视 (固有) 标签页
AWS CLI命令响应获取失败操作
不运行恢复动作(显示警告)
不运行恢复动作(不显示警告)
AWS 虚拟 IP 监视资源
参数
更改前的默认值
更改后的默认值
AWS 虚拟 IP监视资源的属性
监视 (固有) 标签页
AWS CLI命令响应获取失败操作
不运行恢复动作(显示警告)
不运行恢复动作(不显示警告)
AWS AZ 监视资源
参数
更改前的默认值
更改后的默认值
AWS AZ监视资源的属性
监视 (固有) 标签页
AWS CLI命令响应获取失败操作
不运行恢复动作(显示警告)
不运行恢复动作(不显示警告)
AWS DNS 监视资源
参数
更改前的默认值
更改后的默认值
AWS DNS 监视资源的属性
监视 (固有) 标签页
AWS CLI命令响应获取失败操作
不运行恢复动作(显示警告)
不运行恢复动作(不显示警告)
内部版本 4.3.0-1
集群
参数
更改前的默认值
更改后的默认值
集群属性
扩展标签页
最大再启动次数
0 [次]
3 [次]
重置最大再启动次数的时间
0 [分]
60 [分]
NFS 监视资源
参数
更改前的默认值
更改后的默认值
NFS 监视资源的属性
监视 (固有) 标签页
NFS 版本
v2
v4
Weblogic监视资源
参数
更改前的默认值
更改后的默认值
Weblogic 监视资源属性
监视 (固有) 标签页
密码
weblogic
无
6.7.5. 参数移动一览¶
在通过Cluster WebUI可以设定的参数中,各版本设定位置存在更改的参数如下表所示
更改前的设置位置 |
更改后的设置位置 |
|---|---|
[集群属性]-[复归标签页]-[最大再启动次数] |
[集群属性]-[扩展标签页]-[最大再启动次数] |
[集群属性]-[复归标签页]-[重置最大再启动次数的时间] |
[集群属性]-[扩展标签页]-[重置最大再启动次数的时间] |
[集群属性]-[复归标签页]-[使用强制停止功能] |
[集群属性]-[扩展标签页]-[使用强制停止功能] |
[集群属性]-[复归标签页]-[强制停止操作] |
[集群属性]-[扩展标签页]-[强制停止操作] |
[集群属性]-[复归标签页]-[强制停止超时] |
[集群属性]-[扩展标签页]-[强制停止超时] |
[集群属性]-[复归标签页]-[虚拟机强制停止设定] |
[集群属性]-[扩展标签页]-[虚拟机强制停止设定] |
[集群属性]-[复归标签页]-[运行强制停止脚本] |
[集群属性]-[扩展标签页]-[运行强制停止脚本] |
[集群属性]-[节能标签页]-[使用CPU频率控制功能] |
[集群属性]-[扩展标签页]-[使用CPU频率控制功能] |
[集群属性]-[复归标签页]-[宕机后自动启动] |
[集群属性]-[扩展标签页]-[宕机后自动启动] |
[集群属性]-[排他标签页]-[mount/umount命令互斥] |
[集群属性]-[扩展标签页]-[Mount/Umount命令互斥] |
[集群属性]-[复归标签页]-[抑制监视资源异常时的复归动作] |
[集群属性]-[扩展标签页]-[禁用集群操作]-[监视资源异常时的复归动作] |
[组属性]-[属性标签页]-[失效切换互斥属性] |
[组共通属性]-[互斥标签页] |
7. 升级步骤¶
本章将阐述EXPRESSCLUSTER 的升级步骤。
本章将阐述的项目如下。
参见
从X4.0/4.1/4.2 升级到 X 4.3 的步骤请参考《升级步骤说明书》。
7.1. EXPRESSCLUSTER X的升级步骤¶
7.1.1. 从X 3.0/3.1/3.2/3.3升级到X 4.3¶
首先请确认以下注意事项。
使用镜像磁盘资源/共享型镜像磁盘资源时,集群分区空间的大小要在1024MB以上。此外,需要镜像磁盘资源/共享型镜像磁盘资源的全复制。
使用镜像磁盘资源/共享型镜像磁盘资源时,推荐事前做数据的备份。关于备份请参考《安装&设置指南》的"进行运行检查"的"确认备份步骤","确认恢复步骤"。
请在root用户上升级EXPRESSCLUSTER Server。
以下,就有关从Linux版EXPRESSCLUSTER X 3.0/3.1/3.2/3.3进行升级的步骤进行说明。
开始升级前,请使用WebManager或命令确认正在运行集群的各服务器的状态以及所有资源的状态是否正常。
备份集群配置信息。集群配置信息除了在做成时通过Builder保存外,通过clpcfctrl命令也可以做成备份。详细请参考《参考指南》的"EXPRESSCLUSTER命令参考"-"更改集群配置信息,备份集群配置信息,检查集群配置信息(clpcfctrl命令)"-"备份集群配置信息"。
在构成集群的所有服务器上,卸载EXPRESSCLUSTER。卸载步骤请参照《安装&设置指南》的"卸载/重装EXPRESSCLUSTER"-"卸载步骤"-"卸载EXPRESSCLUSTER Server"。
在构成集群的所有服务器上,新安装EXPRESSCLUSTER。新安装步骤请参照《安装&设置指南》的"安装EXPRESSCLUSTER"以及"注册License"。
使用镜像磁盘资源/共享型镜像磁盘资源时,要准备1024MB以上的分区作为集群分区。
- 访问以下地址启动WebManager。http://安装了服务器的实际IP地址 :29003/main.htm导入集群配置信息,读取备份的配置信息。镜像磁盘资源/共享型镜像磁盘资源使用的集群分区和配置信息不一致的场合,修改配置信息。另外,镜像磁盘资源/共享型镜像磁盘资源所属的组的[属性]的[属性]标签页的[组启动属性]是自动启动的场合,设置成手动启动。
使用镜像磁盘资源时,对各镜像磁盘资源执行以下的步骤。
打开资源的[属性]的[详细]标签页,点击[调整]按钮,显示[镜像磁盘资源调整属性]对话框。
打开[镜像磁盘资源调整属性]的[镜像]标签页,将[构建初始文件系统]设置为Off。
应用配置信息。
使用期间定制License时,请执行以下命令。# clplcnsc --distribute
使用镜像磁盘资源/共享型镜像磁盘资源时,对各镜像磁盘资源/共享型镜像磁盘资源,请在所有的服务器上执行以下的命令。初始化集群分区。(镜像磁盘资源的场合)# clpmdinit --create force <镜像磁盘资源名>
(共享型镜像磁盘资源的场合)# clphdinit --create force <共享型镜像磁盘资源名>
启动Cluster WebUI,开始集群。
使用镜像磁盘资源/共享型镜像磁盘资源时,从镜像磁盘列表持有最新信息的服务器作为复制源,执行全复制。
启动组,确认各资源正常启动。
步骤6以及步骤7中,[组启动属性]以及[构建初始文件系统]的设置变更场合,通过Cluster WebUI将设置复原,点击[应用配置文件],将集群配置信息反映到集群。
至此EXPRESSCLUSTER Server升级完毕。启动集群,通过使用Cluster WebUI 或clpstat指令,请确认各服务器作为集群是否正常运行。
8. 词汇表¶
- 心跳线
- 集群服务器之间的通信路径。(相关) 私网,公网
- 虚拟IP地址
构筑远程集群时使用的资源(IP地址)。
- 管理客户端
已启动Cluster WebUI的机器。
- 启动属性
- 集群启动时,决定是自动还是手动启动失效切换组的失效切换组的属性。可在管理客户端进行设置。
- 共享磁盘
可从多台服务器访问的磁盘。
- 共享磁盘型集群
使用共享磁盘的集群系统。
- 切换分区
- 连接到多台计算机的,可切换使用的磁盘分区。(相关)磁盘心跳用分区
- 集群系统
通过LAN等连接多台计算机,并作为1个系统进行操作的系统形态。
- 集群关机
关闭整个集群系统(构筑集群的所有服务器)。
- 集群分区
- 设在镜像磁盘,共享型镜像磁盘上的分区。用于管理镜像磁盘,共享型镜像磁盘。(相关)磁盘心跳用分区
- 运行服务器
- 对某一业务装置来说,正在运行业务的服务器。(相关) 待机服务器
- 从服务器 (服务器)
- 一般使用时,失效切换组进行失效切换的目标服务器。(相关) 主服务器
- 待机服务器
- 非运行服务器。(相关) 运行服务器
- 磁盘心跳用分区
共享磁盘型集群中用于心跳通信的分区。
- 数据分区
- 可与共享磁盘的切换分区一样进行使用的本地磁盘镜像磁盘,共享型镜像磁盘中设置的数据用的分区。(相关) 集群分区
- 网络分区解决资源
- 指所有的心跳中断。(相关) 心跳线,心跳
- 节点
在集群系统中,指构筑集群的服务器。在网络用语中,指可以传输,接收和处理信号的,包括计算机和路由器在内的设备。
- 心跳
- 指为了监视服务器而在服务器之间定期进行相互间的通信。(相关) 心跳线,网络分区解决资源
- 公网
- 服务器/客户端之间的通信路径。(相关) 心跳线,私网
- 失效切换
指由于查出故障,待机服务器继承运行服务器上的业务应用程序。
- 故障恢复
将某台服务器上已启动的业务应用程序通过失效切换交接给其他服务器后,再把业务返回到已启动业务应用程序的服务器。
- 失效切换组
执行业务所需的集群资源,属性的集合。
- 失效切换移动组
指用户故意将业务应用程序从运行服务器移动到待机服务器。
- 失效切换策略
可进行失效切换的服务器列表及其列表中具有失效切换优先顺序的属性。
- 私网
- 指仅连接构筑集群的服务器的LAN。(相关) 心跳线,公网
- 主服务器 (服务器)
- 失效切换组中作为基准的主服务器。(相关) 从服务器 (服务器)
- 浮动IP地址
- 发生了失效切换时,可忽视客户端的应用程序所连接服务器发生切换而使用的IP地址。在与集群服务器所属的LAN相同的网络地址中,分配其他未使用的主机地址。
- 主服务器(Master Server)
Cluster WebUI的[服务器共通properties]-[Master Server]中显示在最前面的服务器。
- 镜像磁盘连接
镜像磁盘,共享型镜像磁盘集群中用于进行数据镜像的LAN。可通过和内部主网的通用进行设置。
- 镜像磁盘系统
- 不使用共享磁盘的集群系统。在服务器之间镜像服务器的本地磁盘。