3. 组资源的详细信息¶
本章将详细说明构成失效切换组的组资源。
关于组的概要内容,请参考《安装&设置指南》的"设计集群系统"。
3.1. 组资源列表和支持的EXPRESSCLUSTER版本¶
各组中可登录的组资源数如下所示。
版本 |
组资源数(平均每组) |
|---|---|
4.0.0-1~ |
256 |
目前支持的组资源如下所示。
组资源名 |
略称 |
功能概要 |
对应版本 |
|---|---|---|---|
EXEC资源 |
exec |
请参考"理解EXEC资源" |
4.0.0-1~ |
磁盘资源 |
disk |
请参考"理解磁盘资源" |
4.0.0-1~ |
浮动IP资源 |
fip |
请参考"理解浮动IP资源" |
4.0.0-1~ |
虚拟IP资源 |
vip |
请参考"理解虚拟IP资源" |
4.0.0-1~ |
镜像磁盘资源 |
md |
请参考"理解镜像磁盘资源" |
4.0.0-1~ |
共享型镜像磁盘资源 |
hd |
请参考"理解共享型镜像磁盘资源" |
4.0.0-1~ |
NAS资源 |
nas |
请参考"理解NAS资源" |
4.0.0-1~ |
卷管理资源 |
volmgr |
请参考"理解卷管理资源" |
4.0.0-1~ |
虚拟机资源 |
vm |
请参考"理解虚拟机资源" |
4.0.0-1~ |
动态域名解析资源 |
ddns |
请参考"理解动态域名解析资源" |
4.0.0-1~ |
AWS Elastic IP资源 |
awseip |
请参考"理解AWS Elastic IP资源" |
4.0.0-1~ |
AWS 虚拟IP资源 |
awsvip |
请参考"理解AWS虚拟IP资源" |
4.0.0-1~ |
AWS DNS资源 |
awsdns |
请参考"理解AWS DNS资源" |
4.0.0-1~ |
Azure 探头端口资源 |
azurepp |
请参考"理解Azure 探头端口资源" |
4.0.0-1~ |
Azure DNS 资源 |
azuredns |
请参考"理解Azure DNS资源" |
4.0.0-1~ |
Google Cloud 虚拟IP资源 |
gcvip |
4.2.0-1~ |
|
Google Cloud DNS资源 |
gcdns |
4.3.0-1~ |
|
Oracle Cloud 虚拟IP资源 |
ocvip |
4.2.0-1~ |
目前支持添加动态资源的组资源如下所示。
组资源名 |
简称 |
功能概要 |
支持版本 |
|---|---|---|---|
EXEC资源 |
exec |
请参考"理解EXEC资源" |
4.0.0-1~ |
磁盘资源 |
disk |
请参考"理解磁盘资源" |
4.0.0-1~ |
浮动IP资源 |
fip |
请参考"理解浮动IP资源" |
4.0.0-1~ |
虚拟IP资源 |
vip |
请参考"理解虚拟IP资源" |
4.0.0-1~ |
卷管理器资源 |
volmgr |
请参考"理解卷管理资源" |
4.0.0-1~ |
3.2. 何谓组¶
所谓组,是指执行失效切换的单位。可以在组中设置与失效切换时的动作相关的规则(失效切换方案)。
3.2.1. 理解组类型¶
组分为"虚拟机组"和"失效切换组"两种类型。
- 虚拟机组以虚拟机为单位执行失效切换(迁移)。在该组中只能登录虚拟机资源,镜像资源,磁盘资源,共享磁盘资源,EXEC资源,NAS资源,卷管理器资源。虚拟机组通过EXPRESSCLUSTER以外的功能,在虚拟机移动到其它服务器时也能够自动跟踪。
- 失效切换组为了继续执行业务,对必要的资源进行了汇总,按业务单位执行失效切换。各组中最多可登录256个组资源。但,不能登录虚拟机资源。
3.2.2. 理解组属性¶
各组可设置的属性如下所示。
- 可启动的服务器从配置集群的服务器中选择可以启动组的服务器,进行设置。此外,在可启动的服务器中设置顺序,设置组启动的优先顺序。
- 组启动属性将组的启动属性设置成自动启动或手动启动。如设置为自动启动,则开始集群时,组会在最优先启动组的服务器上自动启动。如设置为手动启动,则即使服务器启动后,组仍不会启动。请在服务器启动后,使用Cluster WebUI或[clpgrp]命令手动启动组。Cluster WebUI的详细信息,请参考在线手册,[clpgrp]命令的详细信息,请参考本指南的"8. EXPRESSCLUSTER命令参考"的"操作组(clpgrp命令)"。
- 失效切换属性在失效切换属性中设置失效切换的方法。可设置的失效切换属性如下所示。
自动失效切换
心跳超时时,当如组资源及监视资源查出异常时,将趁机自动执行失效切换。
自动失效切换时,可设置以下方法。
- 遵循可启动服务器的设置根据设置为可启动服务器的服务器优先级,确定失效切换目标。
- 执行动态失效切换考虑各服务器的监视器及失效切换组的状态,先确定失效切换目标,再执行失效切换。确定失效切换目标的流程如下。
判定要素
条件
结果
除外列表中登录的监视资源
异常(全部服务器)
没有失效切换目标时,判定禁止目标是否可设为失效切换目标。
正常(仅1台)
将正常的服务器设为失效切换目标。
正常(多台)
比较错误级别。
强行执行失效切换
有设置
忽视除外列表中登录的监视资源,对启动的所有服务器进行比较错误级别的处理。
无设置
不进行失效切换。
错误级别最小的服务器数量
1
将异常程度最小的服务器设为失效切换目标。
2个以上
在异常程度最小的服务器中,比较业务的重要性。
优先使用服务器组中的失效切换方针
有设置
且
与失效切换源相同的服务器组内,存在可进行失效切换的服务器。
将同一服务器组内的服务器设为失效切换目标。
有设置
且
与失效切换源相同的服务器组内,没有可进行失效切换的服务器。
执行smart失效切换的判定处理。
无设置
执行smart失效切换的判定处理。
执行smart失效切换
有设置
且
推荐的失效切换目标服务器数量为1个。
将Smart失效切换推荐的服务器设为失效切换目标。
有设置
且
推荐的失效切换目标服务器数量为2个以上。
对运行级别进行判定处理。
无设置
对运行级别进行判定处理。
运行级别最小的服务器数量
1
将运行级别最小的服务器设为失效切换目标。
2个以上
将已启动的服务器中优先级最高的服务器设为失效切换目标。
注解
除外列表中登录的监视资源从失效切换目标中,除去在监视资源中查出异常的服务器。可以通过Cluster WebUI设置除外监视。错误级别检测异常的监视资源数。Smart失效切换Smart失效切换指的是,根据System Resource Agent收集的系统资源的信息,将负载最小的服务器设为失效切换目标的功能。要启用此功能,需在设置为失效切换目标的所有服务器上注册System Resource Agent的Licence。此外,还需将系统监视资源设置为监视资源。关于系统监视资源,请参照本指南的"4. 监视资源的详细信息"的"理解系统监视资源"。运行级别除管理组,已启动或正在启动的失效切换组数。- 优先使用服务器组中的失效切换方针可失效切换到同一服务器组中的服务器时,优先向该服务器组中的服务器执行失效切换。同一服务器组中没有可执行失效切换的服务器时,将其它服务器组中的服务器设为失效切换目标。
- 在服务器组之间,只启用手动失效切换只有设置上述的[优先使用服务器组中的失效切换方针]时,才可选择。针对同一服务器组中的服务器,自动执行失效切换。同一服务器组中没有可执行失效切换的服务器时,不会自动向其它服务器组中的服务器执行失效切换。将组移动到其它服务器组中的服务器时,需使用Cluster WebUI或[clpgrp]命令移动组。
手动失效切换
心跳超时时,不自动执行失效切换。请使用Cluster WebUI或[clpgrp]命令手动执行失效切换。但是设置为手动失效切换后,在查出组资源及监视资源异常时,也会自动执行失效切换。
注解
在消息接收监视资源的设置中,若设置[向站点外进行失效切换],则动态失效切换和服务组之间的失效切换设置均无效。与失效切换源服务器所属服务器组不同的服务器组中,对其中优先级最高的服务器进行失效切换。
故障恢复属性
设置为自动故障恢复或手动故障恢复。但是,下面的条件下无法设置。
在失效切换组内设有镜像磁盘资源或者共享型镜像磁盘资源
失效切换的属性是 [执行动态失效切换]
设置为自动故障恢复时,失效切换后,优先级最高的服务器启动时,自动执行故障恢复。
设定为手动故障恢复时,即使启动服务器,也不会出现故障恢复。
3.2.3. 理解失效切换策略¶
失效切换策略是指在多台服务器中用来如何确定失效切换目标服务器的优先级。设置时需要注意执行失效切换时不能增加指定服务器的负载。
以下通过可执行失效切换的服务器列表和其中的失效切换优先级举例说明在失效切换策略不同的情况下失效切换操作有何差异。
<图中符号的说明>
服务器状态 |
说明 |
|---|---|
|
正常状态(作为集群正常运行) |
|
停止状态(集群处于停止状态) |
3节点
组 |
服务器的优先顺序 |
||
|---|---|---|---|
优先级1服务器 |
优先级2服务器 |
优先级3服务器 |
|
A |
Server 1 |
Server 3 |
Server 2 |
B |
Server 2 |
Server 3 |
Server 1 |
2节点
组 |
服务器的优先顺序 |
|
|---|---|---|
优先级1服务器 |
优先级2服务器 |
|
A |
Server 1 |
Server 2 |
B |
Server 2 |
Server 1 |
假设A和B的组启动属性为自动启动,故障恢复属性设置为手动故障恢复。
属于互斥属性为「普通互斥」或者「完全互斥」的互斥规则,不能在同一台服务器上启动的多个组,如果要同时在同一台服务器上启动或者失效切换,针对那台服务器,优先级高的组优先。服务器的优先级相同时,以组名称的数字,特殊符号,字母序靠前的一方优先。关于组的互斥属性,请参照"理解组的互斥控制"。
组A和B不属于互斥规则时
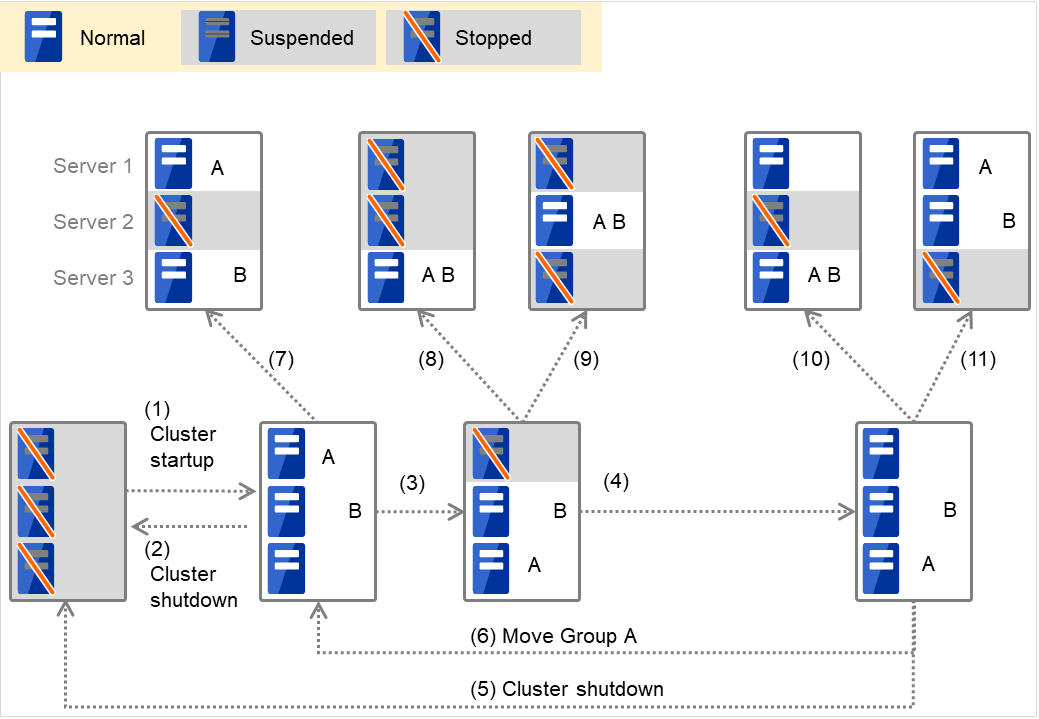
图 3.1 各服务器的状态和Group A,Group B的启动状况¶
集群启动
集群停止
服务器1宕机:接着向优先级高的服务器失效切换
服务器1的电源开启
集群停止
组A移动
服务器2宕机:接着向优先级高的服务器失效切换
服务器2宕机:接着向优先级高的服务器失效切换
服务器3宕机:接着向优先级高的服务器失效切换
服务器2宕机:接着向优先级高的服务器失效切换
服务器3宕机:接着向优先级高的服务器失效切换
组A和B属于互斥属性设置为[普通互斥]的互斥规则时
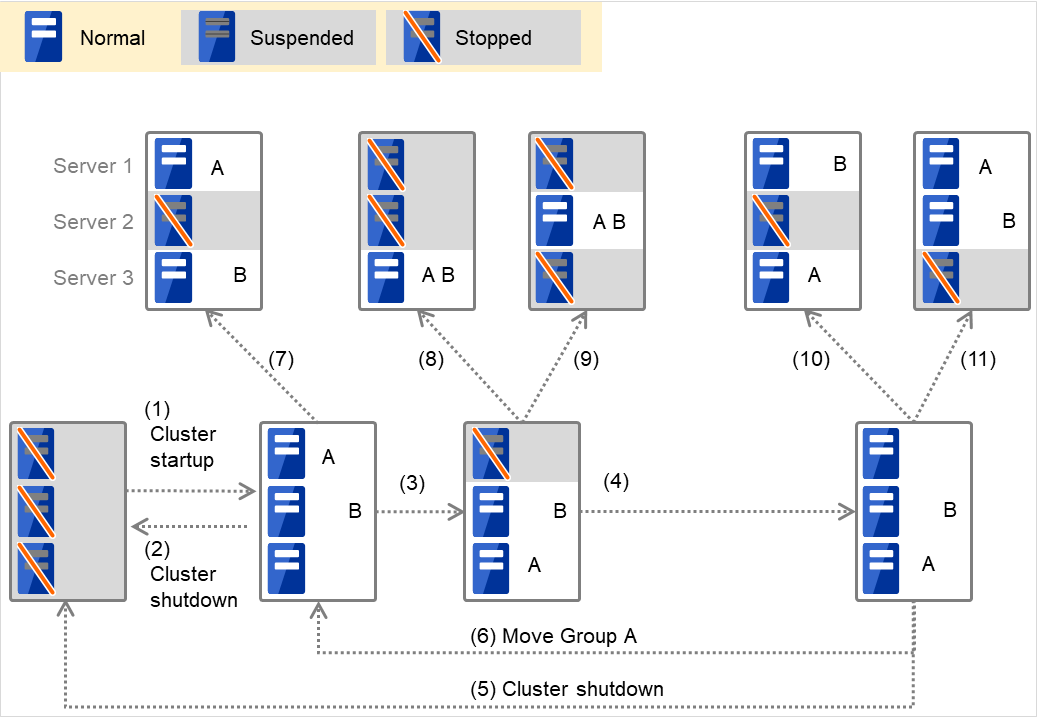
图 3.2 各服务器的状态和Group A,Group B的启动状况(A,B为普通互斥)¶
集群启动
集群停止
服务器1宕机:失效切换至没有启动普通互斥组的服务器
服务器1的电源开启
集群停止
组A移动
服务器2宕机:失效切换至没有启动普通互斥组的服务器
服务器2宕机:不存在没有启动普通互斥组的服务器,但因为存在可以启动的服务器,所以执行失效切换
服务器3宕机:不存在没有启动普通互斥组的服务器,但因为存在可以启动的服务器,所以执行失效切换
服务器2宕机:失效切换至没有启动普通互斥组的服务器
服务器3宕机:失效切换至没有启动普通互斥组的服务器
组A和B属于互斥属性设置为[完全互斥]的互斥规则时
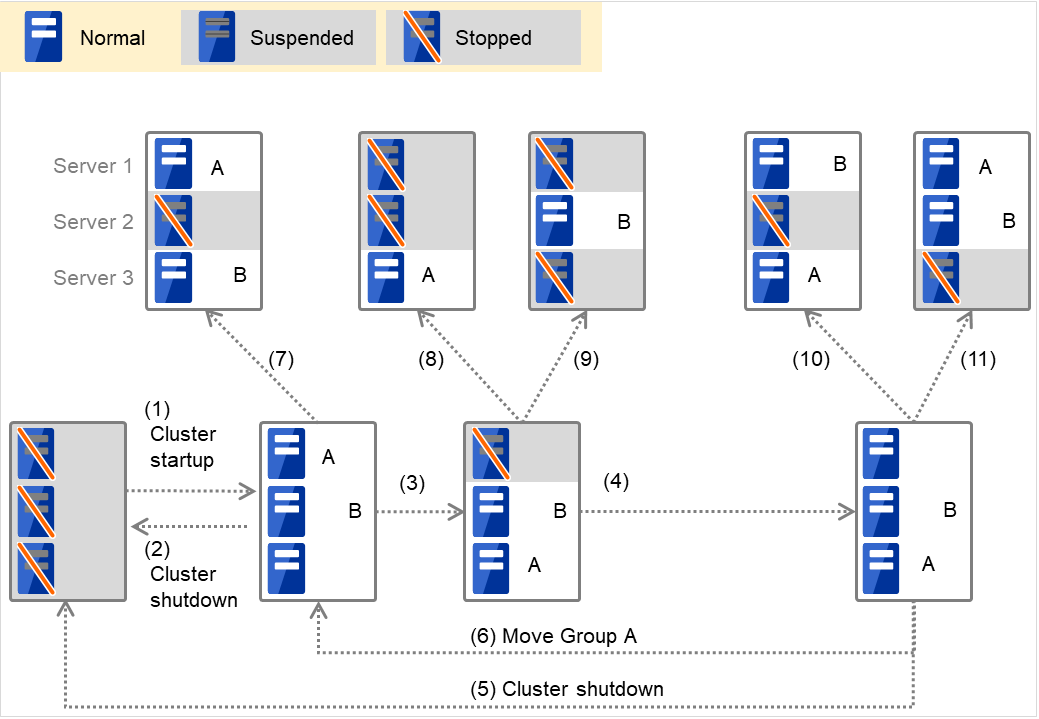
图 3.3 各服务器的状态和Group A,Group B的启动状况(A,B为完全互斥)¶
集群启动
集群停止
服务器1宕机:失效切换至没有启动完全互斥组的服务器
服务器1的电源开启
集群停止
组A移动
服务器2宕机:失效切换至没有启动完全互斥组的服务器
服务器2宕机:不执行失效切换(组B停止)
服务器3宕机:不执行失效切换(组A停止)
服务器2宕机:失效切换至没有启动完全互斥组的服务器
服务器3宕机:失效切换至没有启动完全互斥组的服务器
使用Replicator时(存在2台服务器时)组A和B不属于互斥规则时
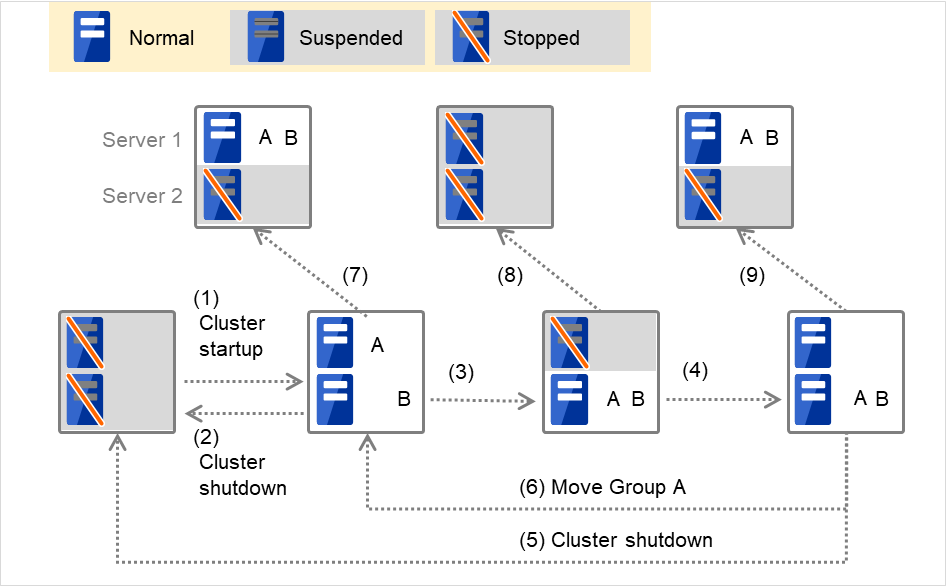
图 3.4 各服务器的状态和Group A,Group B的启动状况(使用Replicator时)¶
集群启动
集群停止
服务器1宕机:失效切换至组A的待机服务器
服务器1的电源开启
集群停止
组A移动
服务器2宕机:失效切换至组B的待机服务器
服务器2宕机
服务器2宕机:失效切换至待机服务器
3.2.4. 查出启动异常,停止异常时的处理¶
查出启动异常,停止异常时进行以下控制。
查出组资源启动异常时的处理流程
启动组资源时如果查出异常,将重试启动操作。
如果按[重试启动次数]中设置的次数重试启动后仍失败,则执行失效切换。
如果按[失效次数]执行失效切换后仍然无法启动,则执行最终运行。
查出组资源停止异常时的处理流程
如果在停止时查出异常,则执行停止重试。
如果按[停止重试启动次数]执行停止重试后仍失败,则执行最终运行。
注解
按照以下设置示例说明查出组资源启动异常时的处理流程。
以下说明上述指定设置时的操作示例。
- 下图中,Server 1 和 Server 2连接到共享磁盘(Shared disk)。失效切换组A(Failover group A)在Server 1上,并且启动了磁盘资源(Disk resource 1)的启动处理(文件系统的Mount处理等)。
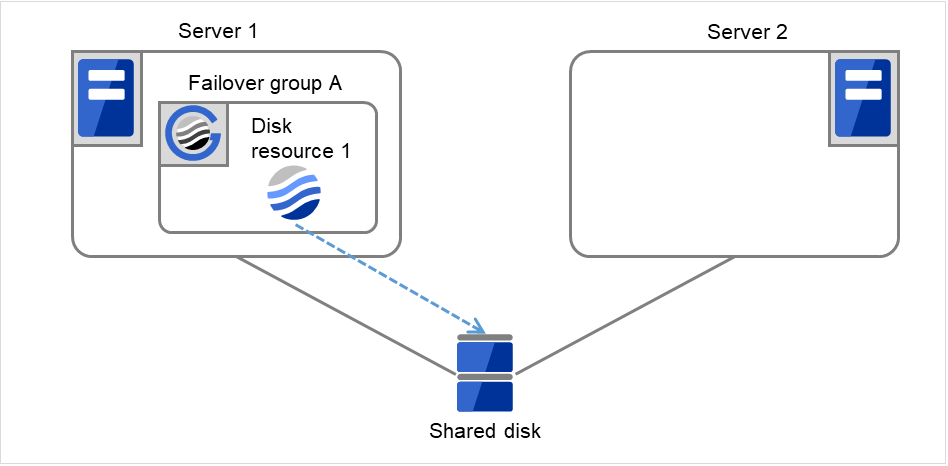
图 3.5 查出组资源启动异常时的流程 (1)¶
Disk resource 1的启动处理异常(fsck异常,mount错误等)。
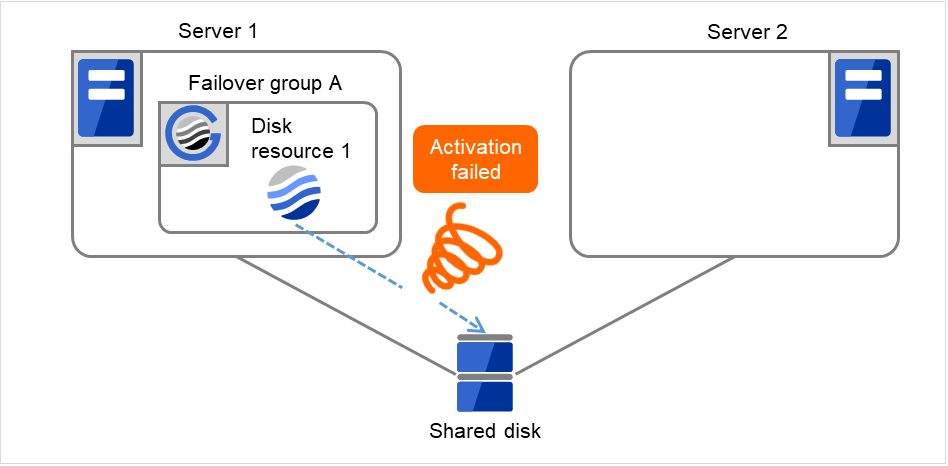
图 3.6 查出组资源启动异常时的流程 (2)¶
重试Disk resource 1的启动处理最多3次(启动重试次数)。
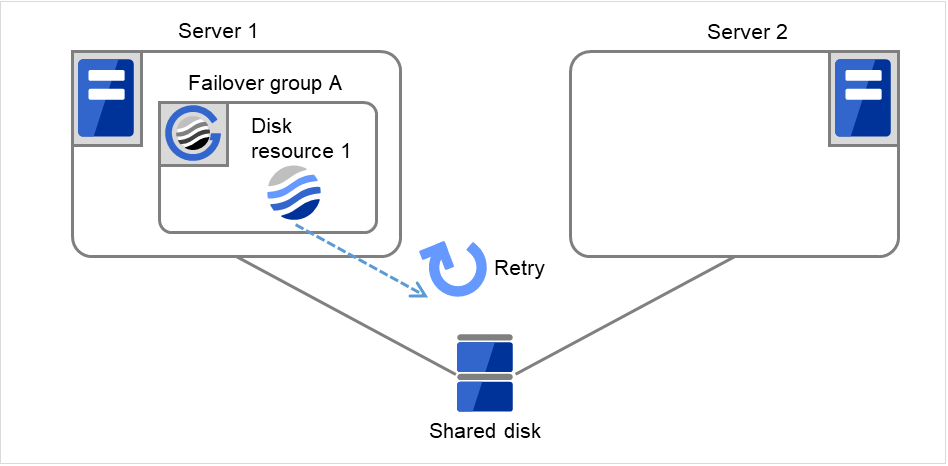
图 3.7 查出组资源启动异常时的流程 (3)¶
- 开始进行Failover group A的失效切换处理。“失效切换界限值”是各服务器上失效切换的次数。换句话说,这是Server 1上第一次失效切换处理。
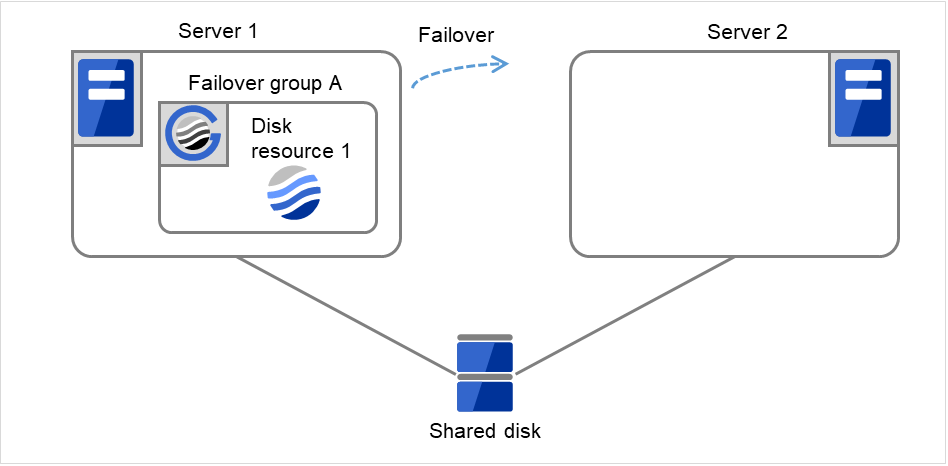
图 3.8 查出组资源启动异常时的流程 (4)¶
- 开始Disk resource 1的启动处理(文件系统的Mount处理等)。如果在Disk resource 1的启动处理中发生异常,则启动处理最多重试3次。
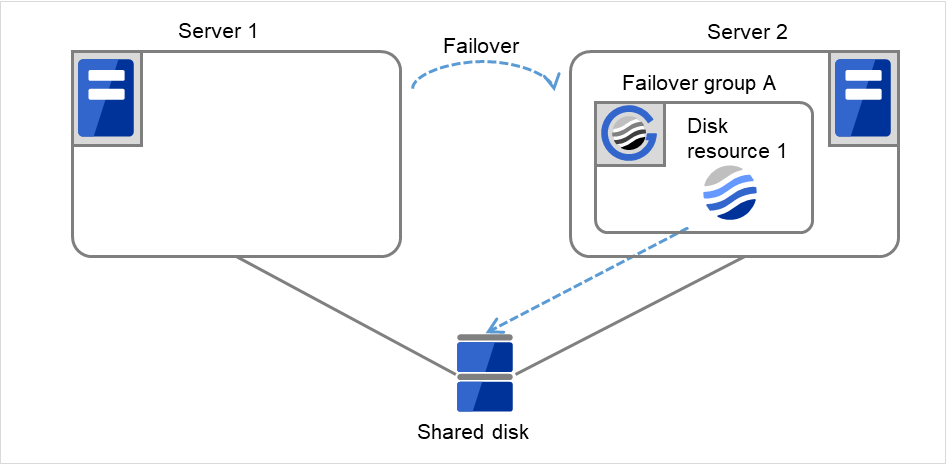
图 3.9 查出组资源启动异常时的流程 (5)¶
- 如果在Server 2上也重试了Disk resource 1的启动处理,则会启动Failover group A的失效切换处理。这是在Server 2上的第一次失效切换处理。
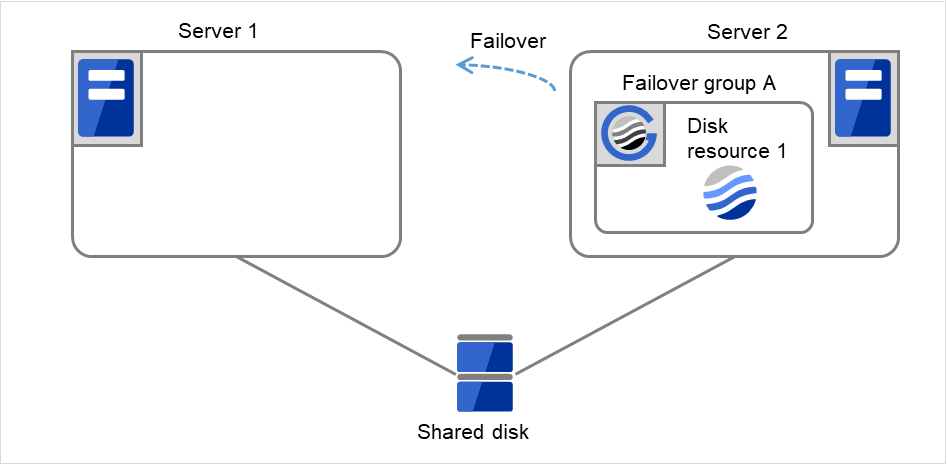
图 3.10 查出组资源启动异常时的流程 (6)¶
在Server 1上开始Disk resource 1的启动处理。如果在Disk resource 1的启动处理中发生异常时,则最多重试3次启动处理。
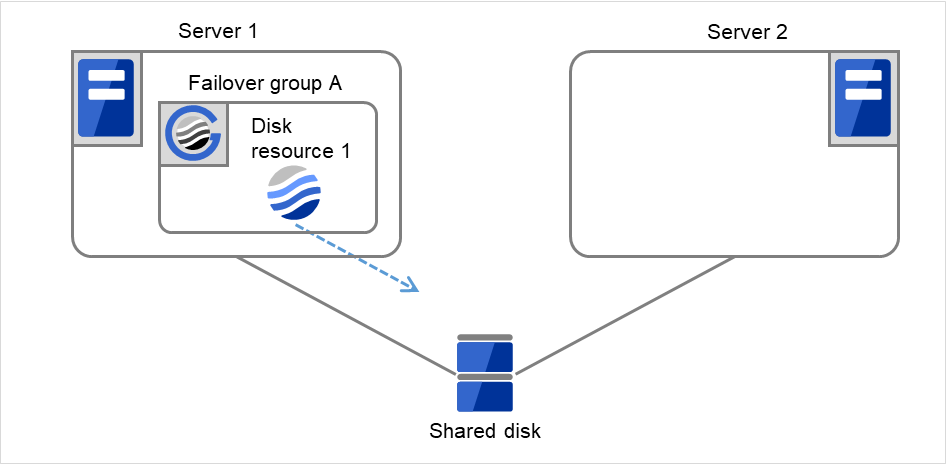
图 3.11 查出组资源启动异常时的流程 (7)¶
- 如果在Server 1上也重试了Disk resource 1的启动处理,则由于失效切换界限值为1,因此不进行失效切换处理,开始设置为“最终动作”的操作。“最终动作”是重试失效切换处理后的操作。在此,开始Failover group A的组停止处理。
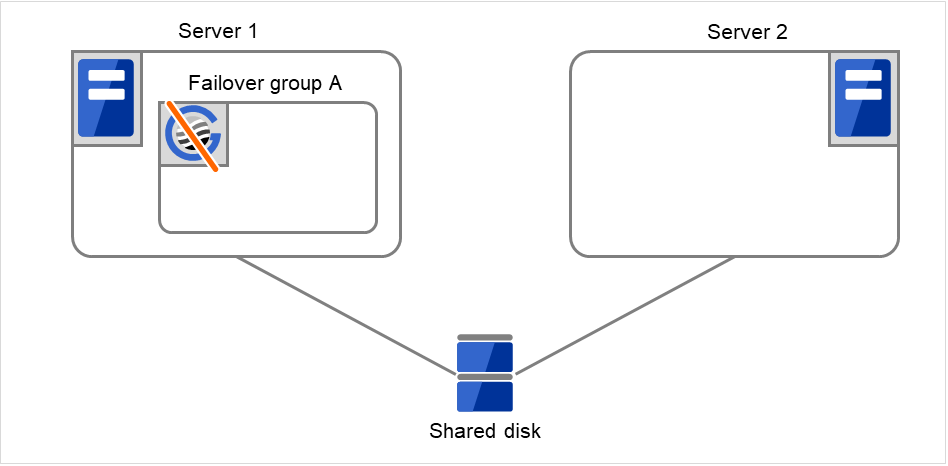
图 3.12 查出组资源启动异常时的流程 (8)¶
3.2.5. 关于最终动作前脚本¶
在检测出组资源的启动异常,停止异常时的最终动作前,可以运行最终动作前脚本。
最终动作前脚本所使用的环境变量
EXPRESSCLUSTER运行脚本时,应将按照何种状态运行 (启动异常时,停止异常时)等的信息设置到环境变量。
在脚本内以下表的环境变量作为分支条件,可记载符合系统运作的处理内容。
环境变量 |
环境变量的值 |
含义 |
|---|---|---|
CLP_TIMING
…运行定时
|
START |
表示因组资源的启动异常而运行最终动作前脚本。 |
STOP |
表示因组资源的停止异常而运行最终动作前脚本。 |
|
CLP_GROUPNAME
…组名
|
组名 |
显示运行最终动作前脚本的原因-检测出异常的组资源所属的组名。 |
CLP_RESOURCENAME
…组资源名
|
组资源名 |
显示运行最终动作前脚本的原因-检测出异常的组资源名。 |
最终动作前脚本的记述流程
就前述标题的环境变量与实际的脚本记述的关联进行说明。
启动异常时的最终动作前脚本的一例
#!/bin/sh # *************************************** # * preactaction.sh # *************************************** ulimit -s unlimited echo "START" # 参考脚本执行要因的环境变量分配处理。 if ["$CLP_TIMING"="START"] then # 这里,记述了启动异常时最终动作前要执行的恢复处理。 # else echo "NO_CLP" fi echo "EXIT" exit 0
制作最终动作前脚本的提示
请注意以下要点制作脚本。
在脚本中,执行运行需要时间的命令时,请保留表示命令执行结束的跟踪记录。此信息可在发生问题时进行故障区分时使用。还备有使用clplogcmd保留跟踪记录的方法。
- 在脚本中使用clplogcmd记述的方法可使用clplogcmd进行Cluster WebUI的警报日志或输出消息至OS的syslog。有关clplogcmd的详情,请参阅本指南的"8. EXPRESSCLUSTER命令参考"的"消息输出(clplogcmd命令)"。
(例:脚本中的范例)
clplogcmd -m "recoverystart.." recoverystart clplogcmd -m "OK"
最终动作前脚本 注意事项
有关从脚本启动的命令和应用程序的堆栈大小
在堆栈大小设定为2MB的状态下运行恢复脚本,恢复动作前脚本。因此,从脚本启动的命令或应用程序需要2MB以上的堆栈大小时,会发生堆栈上溢。发生堆栈上溢时,请在启动命令或应用程序之前设定堆栈大小。有关执行最终动作前脚本的条件
最终动作前脚本是在组资源的启动异常查出时,停止异常查出时的最终动作前被执行的。在最终动作中即使设定了[无任何动作(启动下一个资源/停止)],[无任何动作(不启动下一个资源/停止)]等时,最终动作前脚本也会被执行。最大重起动次数,其他服务器全部停止等情况的最终动作抑制功能导致最终动作没有被执行时,最终动作前脚本也不会被执行。
3.2.6. 关于启动/停止前后脚本¶
可以在组资源的启动/停止前后,执行任意脚本。
在启动/停止前后脚本中使用的环境变量
环境变量 |
环境变量的值 |
含义 |
|---|---|---|
CLP_TIMING
…执行时机
|
PRESTART |
表示组资源启动前执行的脚本。 |
POSTSTART |
表示组资源启动后执行的脚本。 |
|
PRESTOP |
表示组资源停止前执行的脚本。 |
|
POSTSTOP |
表示组资源停止后执行的脚本。 |
|
CLP_GROUPNAME
…组名
|
组名 |
显示脚本所属资源的组名。 |
CLP_RESOURCENAME
…组资源名
|
组资源名 |
显示脚本所属组资源名。 |
启动/停止前后脚本的描述流程
本节结合前面的主题,环境变量和实际的脚本描述进行说明。
启动/停止前后脚本的例子
#!/bin/sh #*********************************************** # rscextent.sh * #*********************************************** ulimit -s unlimited echo "START" if ["$CLP_TIMING"="PRESTART"] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # 在此记述资源启动前要执行的任意处理。 # elif ["$CLP_TIMING"="POSTSTART"] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # 在此记述资源启动后要执行的任意处理。 # elif ["$CLP_TIMING"="PRESTOP"] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # 在此记述资源停止前要执行的任意处理。 # elif ["$CLP_TIMING"="POSTSTOP"] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # 在此记述资源停止后要执行的任意处理。 # fi echo "EXIT" exit 0
做成启动/停止前后脚本的提示
做成脚本时请注意以下几点。
在脚本中,执行运行需要时间的命令时,请保留表示命令执行结束的跟踪记录。此信息可在发生问题时进行故障区分时使用。还备有使用clplogcmd保留跟踪记录的方法。
- 在脚本中使用clplogcmd记述的方法可使用clplogcmd进行Cluster WebUI的警报日志或输出消息至OS的syslog。有关clplogcmd的详情,请参阅本指南的"8. EXPRESSCLUSTER命令参考"的"消息输出(clplogcmd命令)"。
(例:脚本中的范例)
clplogcmd -m "start.." : clplogcmd -m "OK"
启动/停止前后脚本的注意事项
- 有关从脚本启动的命令和应用程序的堆栈大小在堆栈大小设定为2MB的状态下运行启动/停止前后脚本。因此,从脚本启动的命令或应用程序需要2MB以上的堆栈大小时,会发生堆栈上溢。发生堆栈上溢时,请在启动命令或应用程序之前设定堆栈大小。
3.2.7. 重启次数的限制¶
如果将查出启动异常,停止异常时的最终运行,伴随OS再启动设置为重启OS,则可以限制查出启动异常,停止异常时的停止次数或重启次数。
最大重启次数是指各服务器的重启次数的上限值。
注解
重启次数以各台服务器为单位进行记录,所以最大重启次数是指各台服务器中重启次数的上限值。
另外,查出组启动,停止异常时由最终运行引起的重启次数和监视资源异常时最终运行导致的重启次数将会分别记录。
如果将最大重启次数的重置时间设置为0,则不会重置重启次数。重置时需要使用[clpregctrl]命令。关于[clpregctrl]命令,请参考"8. EXPRESSCLUSTER命令参考"的"重启次数控制(clpregctrl命令)"。
按以下设置举例说明重启次数限制的操作流程。
因为最大重启次数设置为1次,所以最终运行[关闭集群服务并重启OS]仅执行一次。
另外,因为将最大重启次数的重置时间设置为10分,所以集群停止后重启时如果组的启动成功,则10分钟过后重置重启次数。
以下说明指定上述设置时的操作示例。
- 下图中,Server 1 和 Server 2连接到共享磁盘(Shared disk)。失效切换组A(Failover group A)在Server 1上,并且启动了磁盘资源(Disk resource 1)的启动处理(文件系统的Mount处理等)。
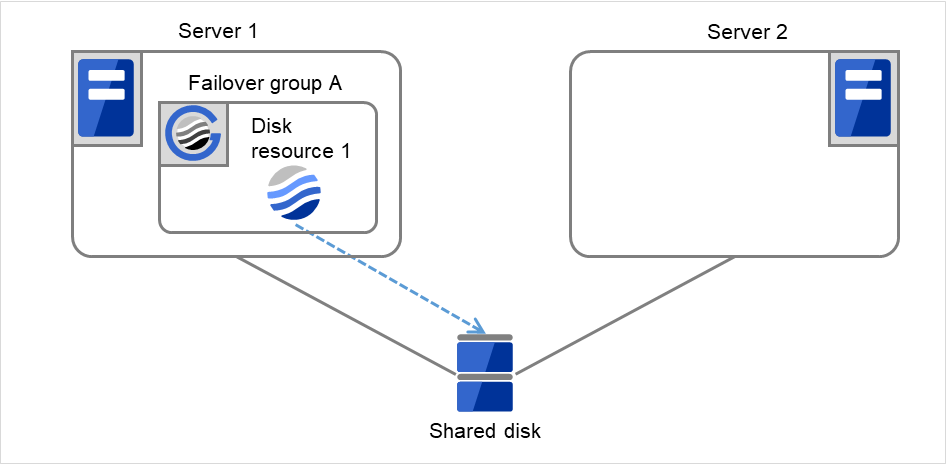
图 3.13 限制重启次数时的处理 (1)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
0次
0次
Disk resource 1的启动处理异常(fsck异常,mount错误等)。
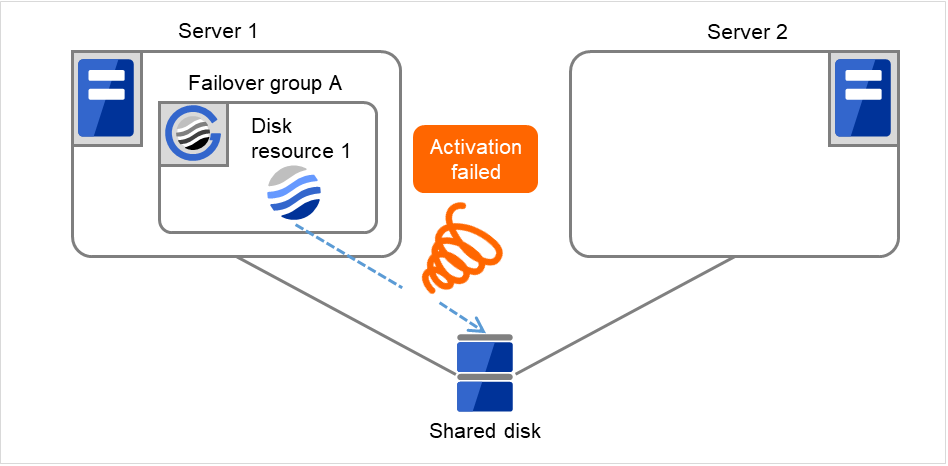
图 3.14 限制重启次数时的处理 (2)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
0次
0次
- 停止集群服务后,重新启动OS。由于“启动重试界限值”,“失效切换界限值”为0,因此将执行最终动作。Server 1中记录重启次数1。
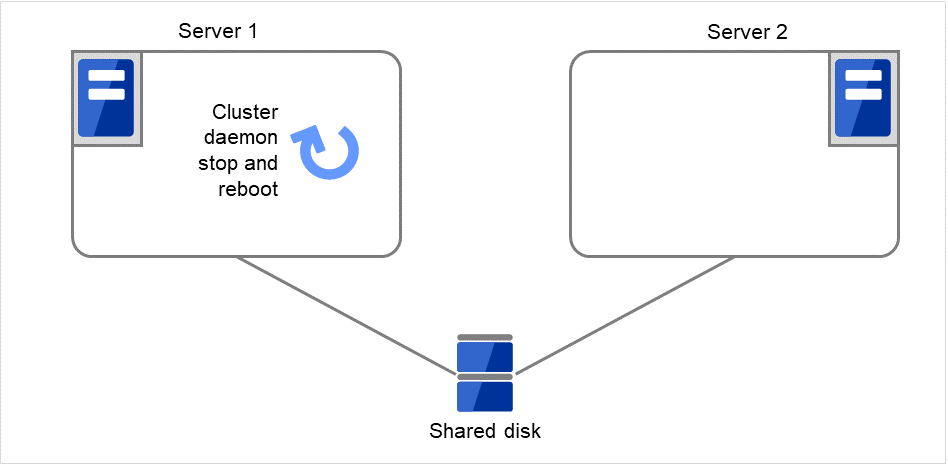
图 3.15 限制重启次数时的处理 (3)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
开始Failover group A的失效切换处理。
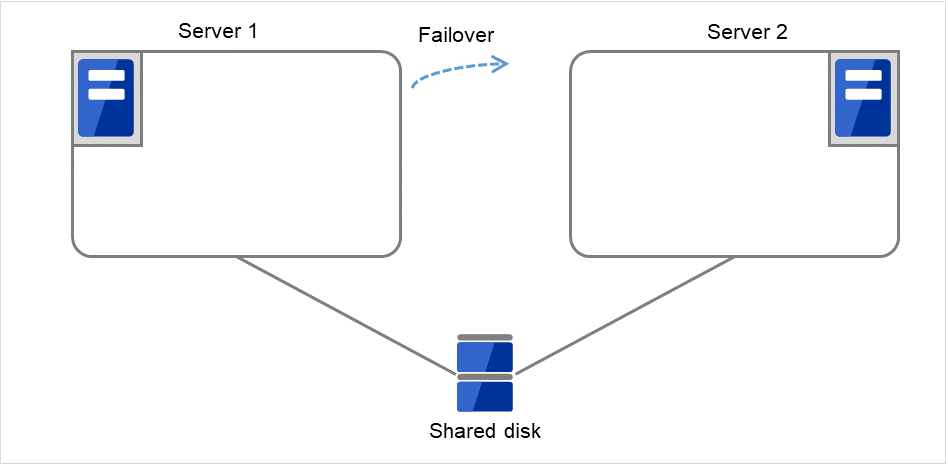
图 3.16 限制重启次数时的处理 (4)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
- 开始Disk resource 1的启动处理(文件系统的Mount处理等)。在Server 2上资源启动成功,在Server 1完成重启。
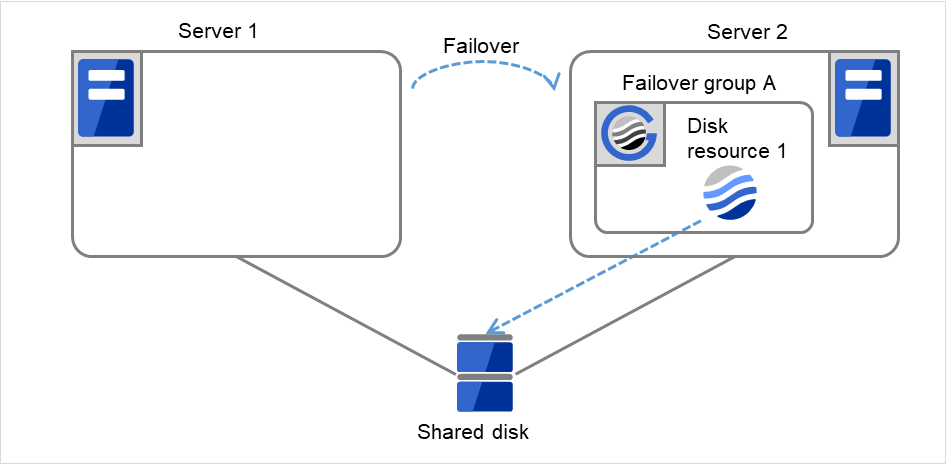
图 3.17 限制重启次数时的处理 (5)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
使用clpgrp命令,Cluster WebUI开始Failover groupA的失效切换处理。
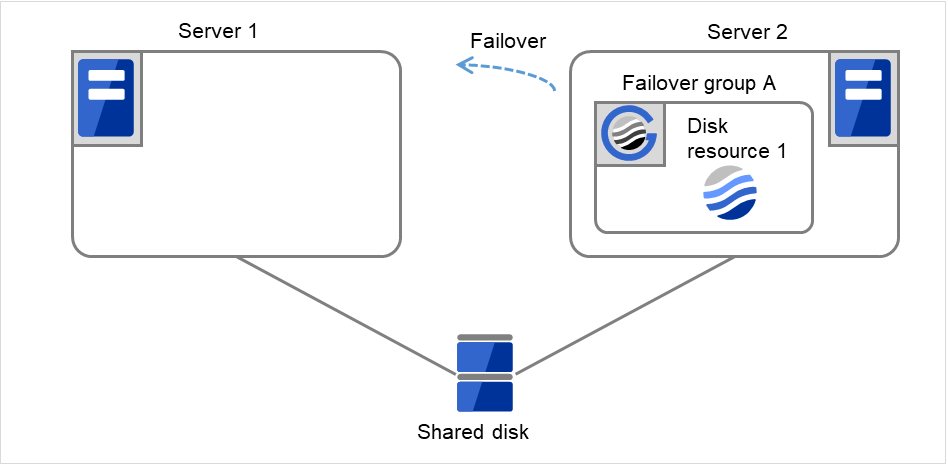
图 3.18 限制重启次数时的处理 (6)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
开始Disk resource 1的启动处理(文件系统的Mount处理等)。
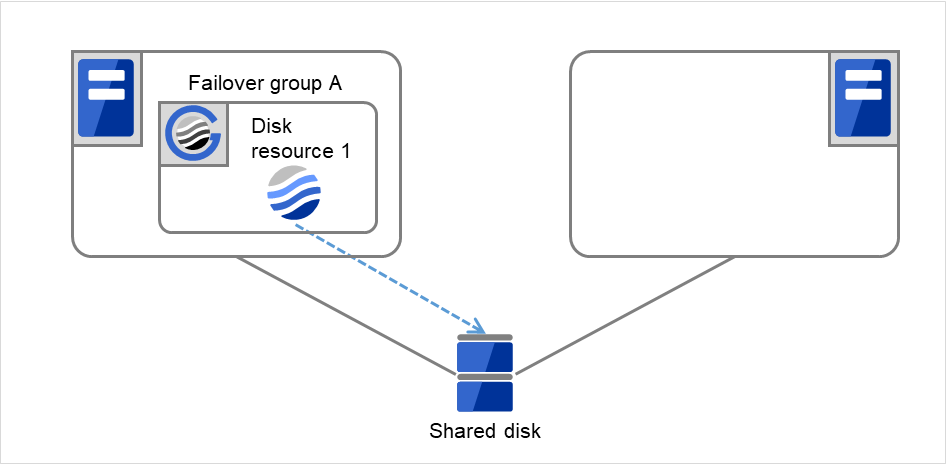
图 3.19 限制重启次数时的处理 (7)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
- Disk resource 1的启动处理异常(fsck异常,mount错误等)。由于已达到最大重启次数,因此不执行最终动作。10分钟后也不会重置重启次数。Failover group A为启动异常状态。
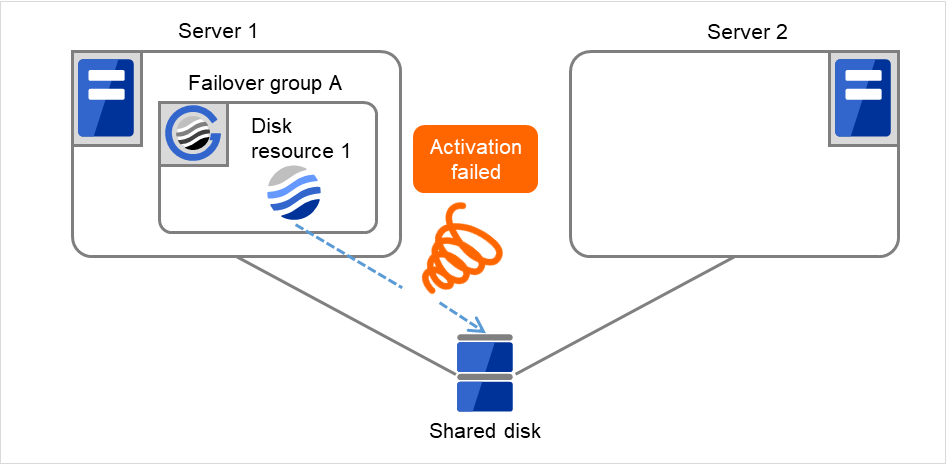
图 3.20 限制重启次数时的处理 (8)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
- 排除导致Disk resource 1启动异常的磁盘异常。然后使用clpstdn命令或Cluster WebUI关闭集群,然后重启。
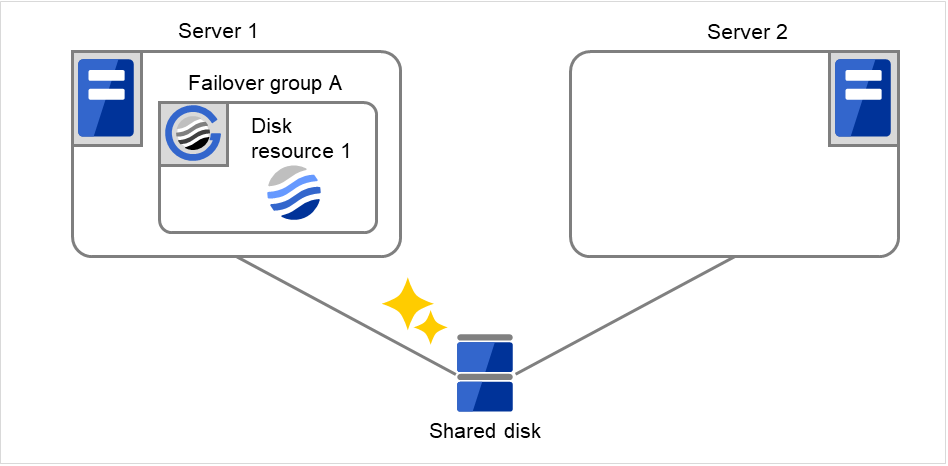
图 3.21 限制重启次数时的处理 (9)¶
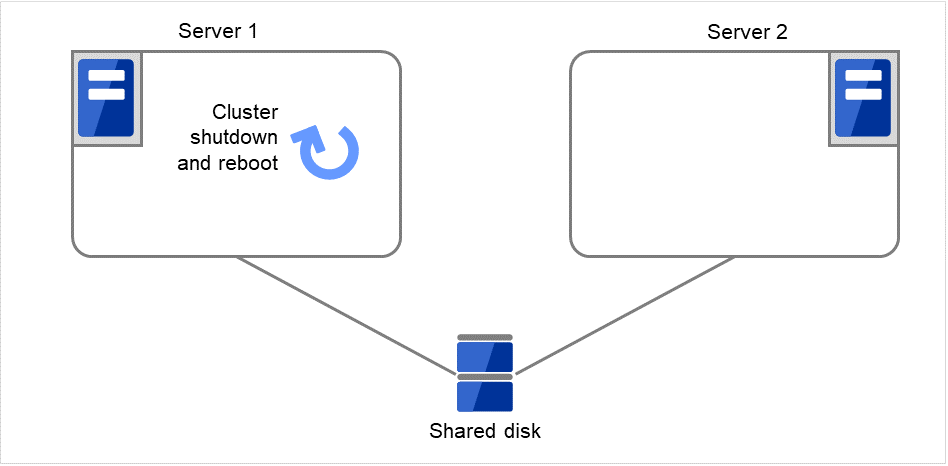
图 3.22 限制重启次数时的处理 (10)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
- Failover group A启动成功。10分钟后重置重启次数。下一次,Failover group A启动时,如果发生 Disk resource 1 启动异常,则将执行最终动作。
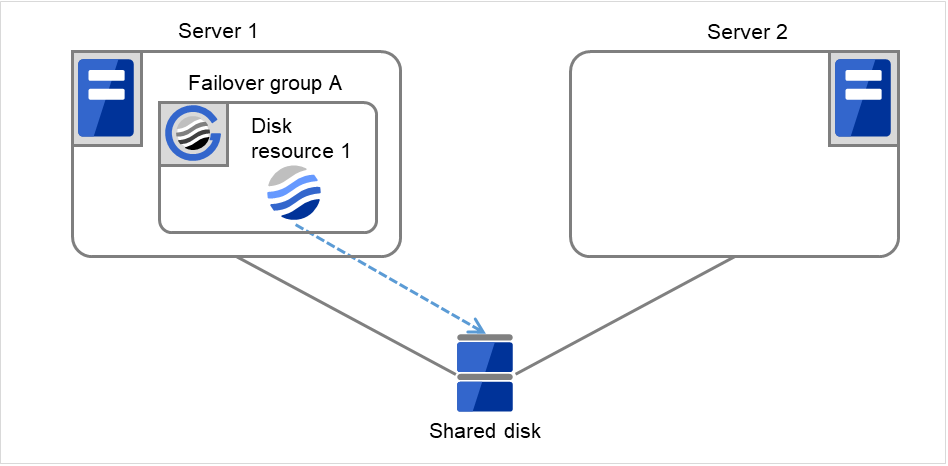
图 3.23 限制重启次数时的处理 (11)¶
Server 1
Server 2
最大重启次数
1次
1次
重启次数
1次
0次
3.2.8. 重启次数的初始化¶
请使用clpregctrl命令初始化重启次数。关于[clpregctrl]命令,请参考本指南的"8. EXPRESSCLUSTER命令参考"的"重启次数控制(clpregctrl命令)"。
3.2.9. 关于进行双重启动检查¶
在启动组时,可以确认是否发生双重启动。
- 判断为没有发生双重启动时开始进行组启动处理。
- 判断发生双重启动时(超时)不开始组的启动处理。在想要启动组的服务器中,组为停止状态。
注解
组为停止状态,执行了资源的单机启动时,进行双重启动检查。但是,在组中有1个资源为启动状态下执行资源的单机启动时,不进行双重启动检查。
选中[执行双重启动检查]复选框的组中,不存在浮动IP资源时,不进行双重启动检查,直接开始启动组。
如果判断发生了双重启动时,组或资源的状态可执行会变为服务器之间不一致。
3.2.10. 理解组的启动,停止等待设置¶
通过设置组的启动,停止等待,可对组的启动,停止等待顺序进行设置。
设置了组的启动等待时:
组启动时,启动等待对象组的启动处理正常完成后,开始本组的启动处理。
组启动时,设置为启动等待的组的等待超时时,组不会启动。
设置了组的停止等待时:
组停止时,停止等待对象组的停止处理正常完成后,开始本组的停止处理。
停止等待处理中如果发生超时时,组将继续停止处理。
停止等待是在Cluster WebUI 中设置的条件下执行的。
若要显示组的启动,停止等待设置,则在Cluster WebUI的编辑模式中点击组的属性,再点击[启动依赖]标签,[停止依赖]标签。
以下通过列表举例说明组的启动依赖深度。
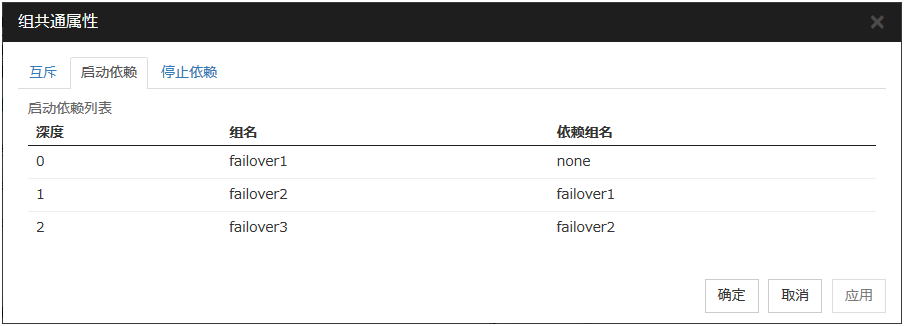

图 3.24 组的启动顺序¶
通过简单的状态变化示例,对执行组的启动进行说明。
2台结构的服务器上,有3个组时组的失效切换方针
Group A Server 1Group B Server 2Group C Server 1 -> Server 2
组的启动等待设置
Group A 无启动等待设置Group B 无启动等待设置Group C 等待Group A的启动Group C 与Group B在同一服务器中启动时等待
在Server 1中启动Group A和Group C时
在Server 1中,待Group A正常启动后,Group C才会启动。
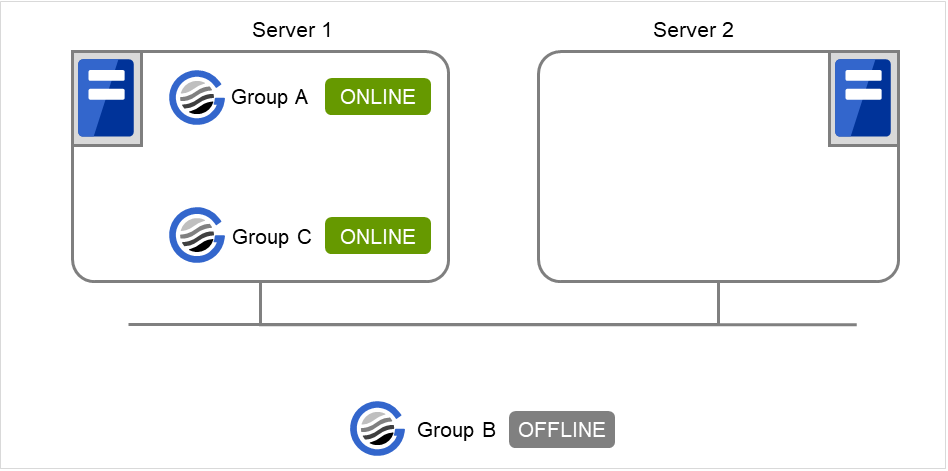
图 3.25 在Server 1 中启动Group A和Group C¶
在Server 1中启动Group A,在Server 2中启动Group C时
在Server 1中,待Group A正常启动后,Group C才会在Server 2中启动。由于未设置"仅在同一台服务器上启动时等待",因此等待其他服务器中Group A的正常启动。
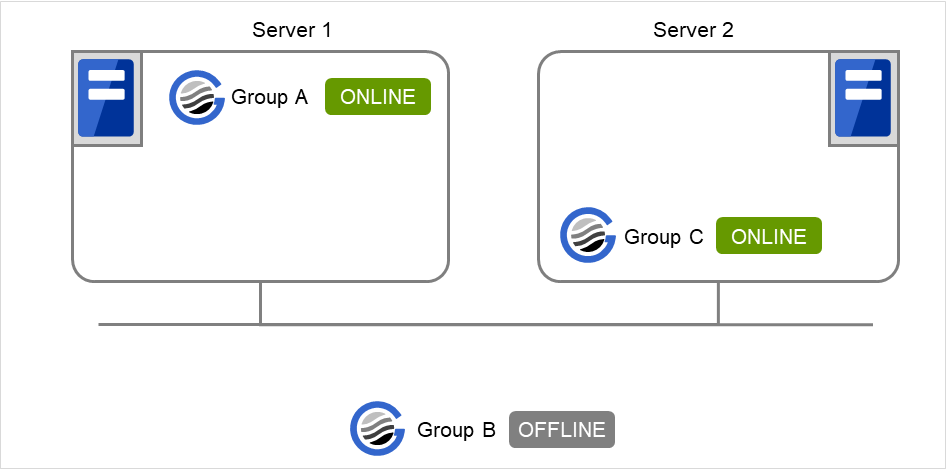
图 3.26 在Server 1中启动Group A,在Server 2中启动Group C¶
在Server 1中启动Group C,在Server 2中启动Group B时
在Server 1中,不等待Group B的正常启动,Group C直接启动。虽设置了仅当Group C和Group B在同一服务器中启动时,Group C等待Group B的启动,但由于还设置了Group B在Server 1中不启动,因此不进行等待。
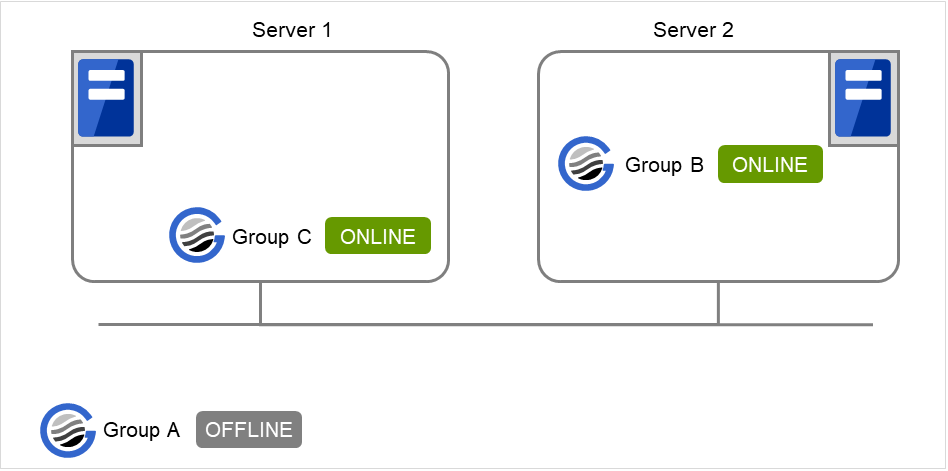
图 3.27 在Server 1 中启动Group C,在Server 2中启动Group B¶
在Server 1中启动Group A和Group C时
Server 1中Group A的启动发生错误时,Group C不启动。
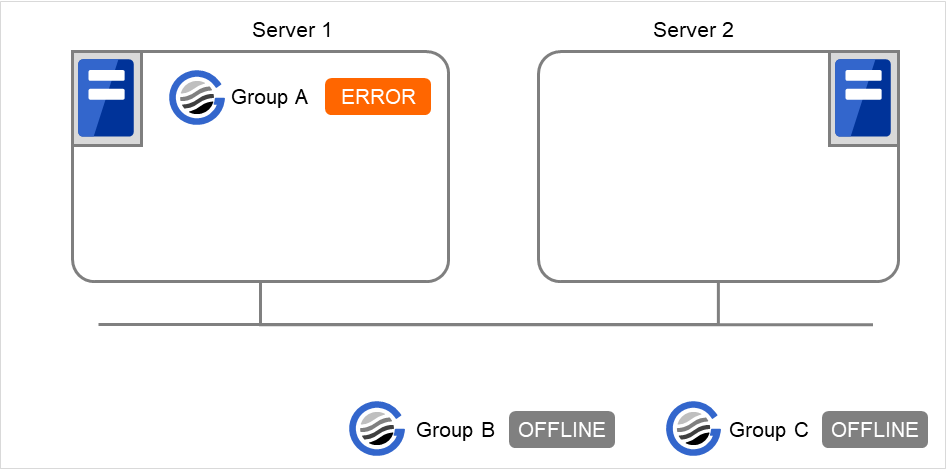
图 3.28 在Server 1中启动Group A出错,Group C不启动¶
在Server 1中启动Group A和Group C时
在Server 1中Group A启动失败,通过Group A的资源复归操作对Server 2进行失效切换时,待Group A在Server 2中启动后,Group C再在Server 1中启动。
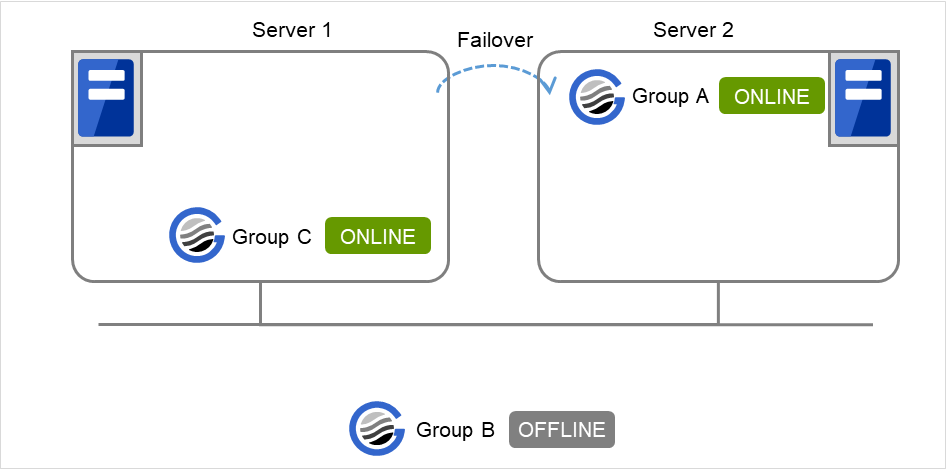
图 3.29 Group A在Server 2中失效切换,在Server 1中启动Group C¶
在Server 1中启动Group A和Group C时
在Server 1中Group A的启动等待超时时,Group C不启动。
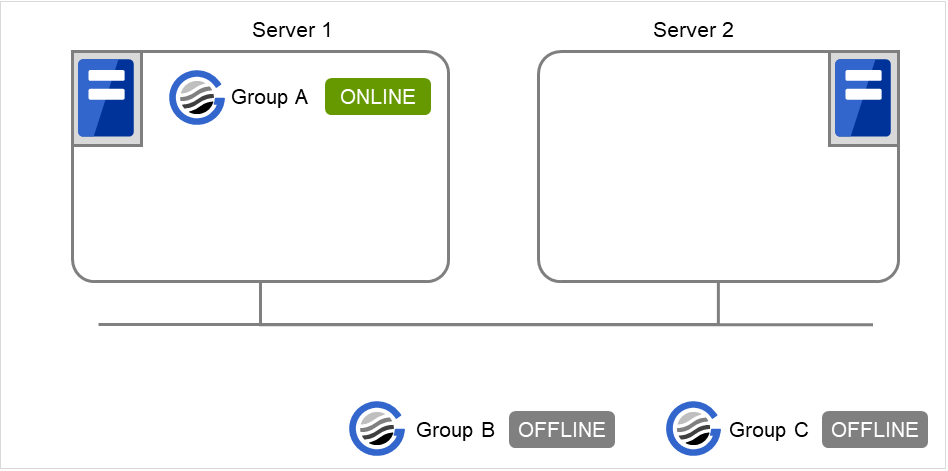
图 3.30 Server 1 中启动Group A¶
在Server 1中仅启动Group C时
由于Server 1中Group A不启动,因此会发生启动等待超时,Group C不启动。
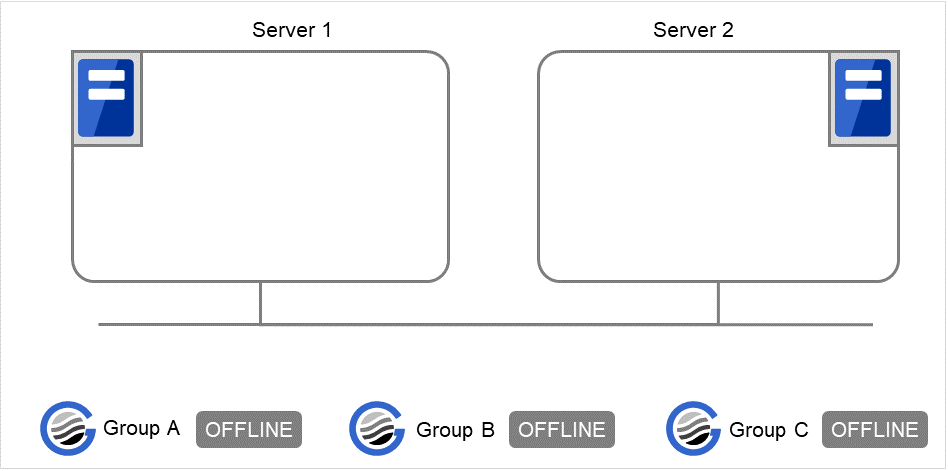
图 3.31 在Server 1中不启动Group A,Group C¶
注解
组启动时,对设置了启动等待的组无自动启动功能。
组启动时,设置了启动等待的组发生等待超时时,组不会启动。
组启动时,设置了启动等待的组启动失败时,组不会启动。
如果启动等待对象的组内存在正常启动的资源和停止的资源时,判断该组已正常启动完毕。
组停止时,对设置了停止等待的组无自动停止功能。
组停止时,对设置了停止等待的组的等待超时时,组的停止处理继续。
组停止时,对设置了停止等待的组停止失败时,组的停止处理继续。
通过Cluster WebUI,clpgrp命令执行组的停止处理和资源的停止处理时,不执行停止等待。要执行停止等待,通过Cluster WebUI中设置的条件(集群停止时,或服务器停止时)来执行。
失效切换时,如果在启动等待处理中发生超时,则失效切换会失败。
3.2.11. 理解组的互斥控制¶
失效切换互斥属性是指设置失效切换时组的互斥属性。但,以下条件时不能设置。
失效切换组的类型是[虚拟机]
失效切换的属性是[执行动态失效切换], [服务器组内失效切换策略优先], [服务器组间仅手动失效切换有效]时
可设置的失效切换互斥属性如下所示。
无互斥
失效切换时,不执行互斥。可进行失效切换的服务器中,优先顺序最高的服务器执行失效切换。
普通互斥
失效切换时,执行互斥。可进行失效切换的服务器中,由其它普通互斥的组没有启动,优先顺序最高的服务器进行失效切换。
但,可进行失效切换的所有服务器中,在其它普通互斥的组已启动时,不执行互斥。可进行失效切换的服务器中,优先顺序最高的服务器执行失效切换。
完全互斥
失效切换时,执行互斥。可进行失效切换的服务器中,由其它完全互斥的组没有启动,优先顺序最高的服务器进行失效切换。
但,可进行失效切换的所有服务器中,在其它完全互斥的组已启动时,不执行失效切换。
3.2.12. 理解服务器组¶
在本节中就服务器组进行说明。
服务器组主要是指在使用共享型镜像磁盘资源时必需的一组服务器群。
在共享磁盘装置上使用共享型镜像磁盘资源时,用同一个共享磁盘装置连接的服务器群作为1个服务器组来设置。
在非共享型磁盘上使用共享型镜像磁盘资源时,也将1台服务器作为1个服务器组来进行设置。
使用共享磁盘上的共享型镜像磁盘资源(镜像源,镜像目标)的服务器,是服务器组内的1台服务器。
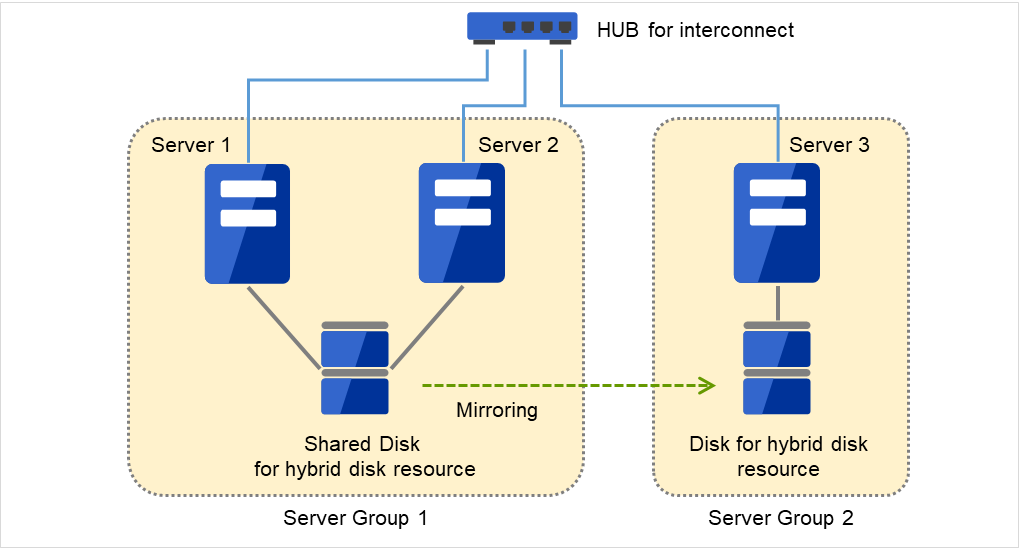
图 3.32 服务器组¶
3.2.13. 理解组资源的依赖关系设置¶
通过设置组资源间的依赖关系,可以设置启动组资源的顺序。
为组资源设置了依赖关系时:
启动时,先启动[依赖资源]后重启动该组资源。
停止时则先执行该组资源,再执行[依赖资源]的停止。
下面以列表形式显示属于某组的资源的依赖深度。


图 3.33 组资源的启动顺序的示例¶

图 3.34 组资源的停止顺序的示例¶
3.2.14. 服务器个别设置组资源¶
组资源的一部分设定值可执行根据服务器不同,设置也不相同。各个服务器中可以设置的资源显示在每个服务器的[详细]标签页。
可以进行服务器个别设置的组资源如下。
组资源名 |
对应版本 |
|---|---|
磁盘资源 |
4.0.0-1~ |
浮动IP资源 |
4.0.0-1~ |
虚拟IP资源 |
4.0.0-1~ |
镜像磁盘资源 |
4.0.0-1~ |
共享型镜像磁盘资源 |
4.0.0-1~ |
动态域名解析资源 |
4.0.0-1~ |
虚拟机资源 |
4.0.0-1~ |
AWS Elastic IP资源 |
4.0.0-1~ |
AWS 虚拟IP资源 |
4.0.0-1~ |
AWS DNS资源 |
4.0.0-1~ |
Azure DNS资源 |
4.0.0-1~ |
注解
虚拟IP资源,AWS Elastic IP资源,AWS 虚拟IP资源,Azure DNS资源中必须有服务器个别设置所需的参数。
可以进行服务器个别设置的参数请参考各组资源的参数说明。可以进行服务器个别设置的参数带有``服务器个别设置``图标。
这里以浮动IP资源为例对服务器个别设置进行说明。

服务器个别设置
在浮动IP资源中显示可以进行服务器个别设置的参数。

个别设置
选择想进行服务器个别设置的服务器名的标签页,并选中复选框,这时可以输入磁盘资源中可以进行服务器个别设置的参数。输入必要参数。
注解
在服务器个别设置中,无法选择[调整]。
3.3. 组的共通属性¶
3.3.1. 互斥标签页¶

添加
添加互斥规则。选择[添加],会显示[互斥规则的定义]对话框。
删除
删除互斥规则。
重命名
显示所选择的更改互斥规则名对话框。
存在下述的输入规则。
最长31个字符(31字节)。
在字符串的开头和结尾不能使用连字符(-)与空格。
字符串不能全部是数字。
在互斥规则中输入唯一(不区分英字母的大小写)的名称。

属性
表示所选择的互斥规则的属性。
互斥规则的定义
设置互斥规则名与互斥属性。互斥属性可以设置普通互斥与完全互斥。只有一个互斥规则可以设置为普通互斥。完全互斥可以设置多个。已经存在设置为普通互斥的互斥规则时不可以选择普通互斥。
名称
显示互斥规则名。
互斥属性
显示互斥规则中设置的互斥属性。
组
显示属于互斥规则的失效切换组名列表。
从[可用组]中选择想登录到互斥规则中的组,点击[添加]按钮。在[互斥对象组]中显示登录到互斥规则中的组。添加到其它互斥规则中的失效切换组不会显示在[可用组]中。



3.4. 组的属性¶

3.4.2. 信息标签页¶

类型
显示组的类型。
使用服务器组设定
名称
显示组名。
注释 (127 字节内)
设置组的注释。只能输入半角英文字母和数字。
3.4.3. 启动服务器标签页¶
启动组的服务器的设置分为启动所有服务器的设置和选择可以启动的服务器或服务器组的设置两种。
使用启动所有服务器的设置时,可以在登录集群的所有服务器上启动组。启动组的服务器的启动顺序和服务器的优先级相等。有关服务器的优先级,请参考本指南的"2. 参数的详细信息" - "Servers属性" - "主服务器标签页"。
使用选择可以启动的服务器和服务器组的设置时,可以从登录集群的服务器或服务器组中任意选择要启动的服务器和服务器组。另外,可以更改启动组的服务器或服务器组的启动顺序。
设置启动失效切换的服务器时

所有服务器都可以失效切换。
指定组启动的服务器。
添加
用于添加可以启动的服务器。从[可用的服务器]中选择要添加的服务器,点击[添加]。该服务器将被添加至可以启动组的服务器列表中。
删除
用于删除可以启动的服务器。从[可以启动组的服务器]中选择要删除的服务器,点击[删除]。该服务器将添加到可用的服务器中。
顺序
用于更改可以启动的服务器的优先级。从[可以启动组的服务器]中选择要更改的服务器,点击箭头。选择的行将上下移动。
使用服务器组设置时
要设置启动包含有共享型镜像磁盘资源的组的服务器,需要设置启动失效切换组的服务器组。

添加
用于在[可以启动的服务器组]中增加服务器组。在[可以使用的服务器组]中选择要添加的服务器组,点击[添加]按钮。服务器组就会添加到[可以启动的服务器组]内。
删除
用于从[可以启动的服务器组]中删除服务器组。从[可以使用的服务器组]中选择要删除的服务器组,点击[删除]按钮。服务器组就会添加到[可以启动的服务器组]内。
顺序
用于更改服务器组的优先顺序。从[可以启动组的服务器]中选择要更改的服务器组,点击箭头。选中的行将会移动。
3.4.4. 属性标签页¶

组启动属性
设置在集群启动时通过EXPRESSCLUSTER自动启动组(自动启动)还是通过Cluster WebUI 或[clpgrp]命令由用户操作来启动(手动启动)。
检测双重启动
确认在组启动前是否发生双重启动。
超时 (1~9999)
指定执行双重启动检查的最大时间。默认为300秒。请注意设置的值要大于在组所属的浮动IP资源的[浮动IP资源调整属性] - [ping超时]中设置的值。
失效切换属性
设置在服务器宕机时是否自动执行失效切换。
故障恢复属性
设置在比启动组的服务器优先级更高的服务器正常启动后是否自动执行故障恢复处理。如果组中包含有镜像磁盘资源或者共享型镜像磁盘资源,请设置为手动故障恢复。
编辑除外监视
在动态失效切换中,检测资源将检测出异常的服务器从失效切换排除。作为失效切换属性选择"执行动态失效切换"时,可以设定用作除外对象的监视资源。
可按监视资源类型,监视资源名来设定除外列表。
添加选择的监视资源类型。
在一个排除的监视资源组中登录多个监视资源时,登录的所有监视资源处于异常状态的服务器将从失效切换目标中排除。
另外,已登录多个排除的监视资源组时,即使任何一个符合条件的服务器将从失效切换目标中排除。
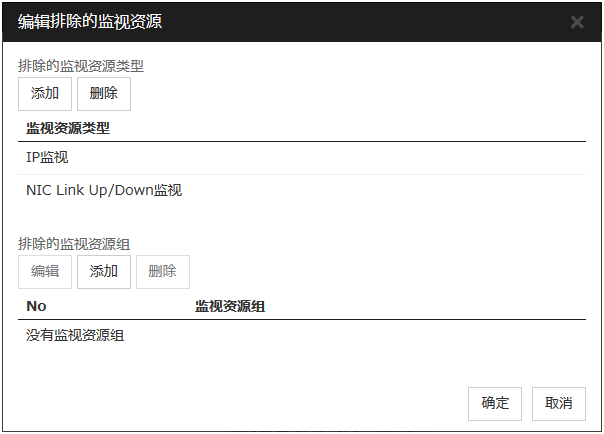


添加
将通过"可用的监视资源一览"选中的监视资源添加到"监视资源一览"。
删除
将通过"监视资源一览"选中的监视资源删除。
注解
下述的监视资源类型不能登录排除的监视资源类型。另外,在排除的监视资源组不能登录资源名。
用户空间监视
ARP监视
虚拟IP监视
镜像磁盘连接监视器
共享型磁盘监视
共享型磁盘连接监视
注解
警告状态的监视资源不判断为异常。但是,镜像磁盘监视资源除外。启动时设定为监视的监视资源,在组启动服务器以外的服务器中不执行监视,因此,不产生异常状态。使用Cluster WebUI,clpmonctrl命令停止的监视资源处于正常状态。没有设定为执行监视资源监视的服务器不执行监视,因此,不发生异常。注解
镜像磁盘监视资源时,通过镜像磁盘资源的可否启动来判断。不依赖于镜像磁盘资源状态。即使镜像磁盘监视资源处于异常状态下,镜像磁盘资源可以正常启动的服务器也不从失效切换目标中排除。即使磁盘监视资源处于正常状态或警告状态下,不能正常启动镜像磁盘资源的服务器将从失效切换目标排除。
3.4.5. 启动依赖标签页¶

添加
将在[可用组]中选择的组添加到[对象组]中。
删除
将在[对象组]中选择的组删除。
依赖组的启动等待时间 (0~9999)
指定对象组的等待正常启动结束的最大时间。默认值为1800 秒。
属性
更改[依赖组]中所选组的属性。

仅在同一台服务器上启动时等待
仅当启动等待组和对象组在同一服务器中启动时,设置是否进行等待。
复选框为ON时
启动进行启动等待的组的服务器不包含在对象组的"启动服务器"中时,不进行等待。
启动进行启动等待的组的非服务器中,如果对象组启动失败,不进行等待。
3.4.6. 停止依赖标签页¶

添加
将[可用组]中选择的组添加到 [依赖组] 。
删除
从[目标组]中删除[目标组]中选择的组。
依赖组的停止等待时间 (0~9999)
指定等待目标组的正常停止结束的最大时间。默认值为 1800 秒。
集群停止时等待依赖组的停止
设定集群停止时是否等待组的停止。
服务器停止时等待依赖组的停止
设定服务器单方停止时是否等待目标组的停止结束。仅目标组中在同一服务器上启动的组等待停止。
组停止时等待目标组的停止
设定组停止操作时是否等待目标组停止结束。仅目标组中在同一服务器上启动的组等待停止。

3.5. 资源的属性¶



3.5.3. 复归操作标签页¶
检测到组资源的启动异常时的流程
如果启动组资源时发生异常,则重试启动操作。
按照[启动重试次数]的设置重试启动失败后,执行失效切换。
按照[失效切换次数]的设置执行失效切换后仍无法启动,执行最终运行。
检测到组资源的停止异常时的流程
如果在停止时查出异常,则重试停止。
按照[停止重试次数]的设置重试停止失败后,执行最终运行。

查出启动异常时的复归操作
启动重试次数 (0~99)
输入查出启动异常时的启动重试次数。如果设置为0,则不会重试启动。
失效切换次数 (0~99)
输入在查出启动异常后按照[[重试启动次数]的指定次数尝试启动失败后执行失效切换的次数。如果设置为0,则不执行失效切换。
最终动作
选择在查出启动异常时按照[重试启动次数]的指定次数尝试启动失败,并且按照[失效切换次数]中的指定次数尝试失效切换也失败后的运行。
最终运行可以选择以下处理。
注解
sysrq应急措施失败时,关闭OS。
注解
keepalive复位失败时,关闭OS。请不要在没有对应clpkhb驱动,clpka驱动的OS,kernel上进行设置。注解
keepalive应急措施失败时,关闭OS。请不要在没有对应clpkhb驱动,clpka驱动的OS,kernel上进行设置。注解
BMC复位失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行[ipmitool]命令的服务器上进行设置。注解
BMC 关闭电源失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行[ipmitool]命令的服务器上进行设置。注解
BMC Power Cycle失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行[ipmitool]命令的服务器上进行设置注解
如果 BMC NMI失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行ipmitool命令的服务器上进行设置注解
I/O Fencing失败的场合,执行操作系统的关闭。
在最终动作前运行脚本
指定是否在执行查出启动异常时的最终动作前运行脚本。
关于脚本设置,请参考"在启动,停止前后运行脚本"的脚本设置说明。
查出停止异常时的复归操作
停止重试次数 (0~99)
输入查出停止异常时重试停止的次数。如果设置为0,则不重试停止。
最终动作
选择查出停止异常时按照[停止重试次数]中指定的次数尝试停止失败后的运行。
最终运行可以选择以下处理。
注解
如果将查出停止异常时的最终运行设置为[无操作],则组将保持停止失败的状态,不会停止。请注意在正式环境中不要设置为[无操作]。
注解
如果将查出停止异常时的最终运行设置为[无操作],则组将保持停止失败的状态,不会停止。请注意在正式环境中不要设置为[无操作]。
注解
sysrq应急措施失败时,关闭OS。
注解
keepalive复位失败时,关闭OS。请不要在没有对应clpkhb驱动,clpka驱动的OS,kernel上进行设置。注解
keepalive应急措施失败时,关闭OS。请不要在没有对应clpkhb驱动,clpka驱动的OS,kernel上进行设置。注解
BMC复位失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行[ipmitool]命令的服务器上进行设置。注解
BMC 关闭电源失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行[ipmitool]命令的服务器上进行设置。注解
BMCPower Cycle失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行[ipmitool]命令的服务器上进行设置。注解
如果BMC NMI失败时,关闭OS。请不要在没有安装OpenIPMI,或者没有运行[ipmitool]命令的服务器上进行设置。注解
I/O Fencing失败的场合,执行操作系统的关闭。
在最终动作前运行脚本
指定是否在执行查出启动异常时的最终动作前运行脚本。
关于脚本设置,请参考"在启动,停止前后运行脚本"的脚本设置说明。
3.5.4. 详细标签页¶
对各个资源中资源固有的参数进行说明。
3.5.5. 扩展标签页¶

资源启动属性
在组启动时,设置其属性,是自动启动资源(自动启动)还是用户通过 Cluster WebUI或者 [clprsc] 命令,操作启动(手动启动)。
在启动,停止前后运行脚本
指定组资源在启动前,启动后,停止前,停止后是否执行脚本,请点击[设置]进行设置。
通过选中复选框,脚本将在指定的时点执行。

执行时点
在启动资源前运行脚本
在启动资源后运行脚本
在停止资源前运行脚本
在停止资源后运行脚本
设置脚本,请点击[设置]。

用户应用程序
使用可在服务器上执行的文件(可执行的Shell Script文件或执行文件)作为脚本。将文件名设置为服务器上本地磁盘的绝对路径或可执行文件名。另外,绝对路径或文件名中包含空白栏时,请按照以下方法,用双引号(")括起来。
例: "/tmp/user application/script.sh"Cluster WebUI的集群配置信息中不会包含各可执行文件。因为不能通过Cluster WebUI进行编辑或上传,需要在各台服务器上准备。
用Cluster WebUI创建的脚本
使用通过Cluster WebUI准备的脚本文件作为脚本。根据需要,可以通过Cluster WebUI编辑脚本文件。脚本文件将被包含到集群配置信息中。
文件 (1023字节以内)
选择了[用户应用程序]时,设置运行的脚本(可执行的Shell Script文件或执行文件)。
显示
选择了[用Cluster WebUI创建的脚本]时,显示脚本文件。通过编辑器编辑并保存的内容不会被反映。
编辑
选择了[用Cluster WebUI创建的脚本]时,编辑脚本文件。要反映这些变更,请点击[保存]。脚本文件名无法更改。
替换
选择了[用Cluster WebUI创建的脚本]时,把脚本文件内容变更为文件选择对话框中所选择的脚本文件内容。脚本处于正在编辑或正在显示的状态时无法置换。请在此选择脚本文件。请不要选择二进制文件(应用程序等)。
超时 (1~9999)
指定等待脚本执行结束的最大时间。在启动前后,停止前后执行的脚本的默认值为30秒。可以通过[查出启动异常时的复归操作] [查出停止异常时的复归操作]的[最终动作前执行脚本]的[设置]按钮设置的超时的默认值为5秒。
3.6. 理解EXEC资源¶
EXPRESSCLUSTER中可以登录由EXPRESSCLUSTER管理的,并且在组启动时,退出时,发生失效切换时以及移动时执行的应用程序或shell脚本。EXEC资源中还可以登录用户特有的程序或shell脚本等。shell脚本与sh的shell脚本格式相同,所以可以针对每个应用程序的实际情况描述其处理。
注解
EXEC资源中执行的应用程序的相同版本必须存在于失效切换策略中的所有服务器中。
3.6.1. EXEC资源的依赖关系¶
默认依存以下组资源类型。
组资源类型 |
|---|
浮动IP资源 |
虚拟IP资源 |
磁盘资源 |
镜像磁盘资源 |
共享型镜像磁盘资源 |
NAS资源 |
虚拟机资源 |
卷管理资源 |
动态域名解析资源 |
AWS Elastic IP资源 |
AWS 虚拟IP资源 |
AWS DNS资源 |
Azure 探头端口资源 |
Azure DNS资源 |
3.6.2. 有关EXEC资源的启动/停止处理结果的判定方法¶
3.6.3. EXEC资源中使用的脚本¶
脚本的类型
EXEC资源中分别准备有开始脚本和结束脚本。EXPRESSCLUSTER在需要切换集群状态时会执行每个EXEC资源的脚本。需要在这些脚本中说明在集群环境下运行的应用程序的启动,退出或者恢复的步骤。
3.6.4. EXEC资源的脚本中使用的环境变量¶
EXPRESSCLUSTER在执行脚本时,需要在环境变量中设置脚本执行时的状态(脚本执行原因)等信息。
在脚本内可以以下图中的环境变量为分支条件说明与系统操作相符的处理内容。
结束脚本在环境变量中将之前执行的开始脚本的内容作为返回值。在开始脚本中不会设置CLP_FACTOR以及CLP_PID环境变量。
CLP_LASTACTION环境变量仅在CLP_FACTOR环境变量为CLUSTERSHUTDOWN或者SERVERSHUTDOWN时设置。
环境变量 |
环境变量的值 |
含义 |
|---|---|---|
CLP_EVENT
…脚本执行起因
|
START |
因为集群启动而执行。
因为组的启动而执行。
因为组的移动,在移动目标服务器中执行。
因为查出监视资源的异常而重启组时,在同一服务器中执行。
因为查出监视资源的异常而重启组资源时,在同一服务器中执行。
|
FAILOVER |
因为服务器宕机,在失效切换目标服务器中执行。
因为查出监视资源的异常,在失效切换目标服务器中执行。
因为启动组资源失败,在失效切换目标服务器中执行。
|
|
CLP_FACTOR
…组停止原因
|
CLUSTERSHUTDOWN |
因为集群停止导致组被停止。 |
SERVERSHUTDOWN |
因为服务器停止导致组被停止。 |
|
GROUPSTOP |
因为执行组停止处理,导致组被停止。 |
|
GROUPMOVE |
因为执行组移动处理,导致组被移动。 |
|
GROUPFAILOVER |
因为查出监视资源的异常,执行组的失效切换。
因为启动组资源失败,执行组的失效切换。
|
|
GROUPRESTART |
因为查出监视资源的异常而重启组。 |
|
RESOURCERESTART |
因为查出监视资源的异常而重启组资源。 |
|
CLP_LASTACTION
…集群停止后的处理
|
REBOOT |
Reboot(重启)OS。 |
HALT |
Halt(关闭)OS。 |
|
NONE |
不执行任何操作。 |
|
CLP_SERVER
…执行脚本的服务器
|
HOME |
在组的主服务器中执行。 |
OTHER |
在组的主服务器之外的服务器中执行。 |
|
CLP_DISK 1
…共享磁盘或镜像磁盘上的分区连接信息
|
SUCCESS |
不存在连接失败的分区。 |
FAILURE |
存在连接失败的分区。 |
|
CLP_PRIORITY
…执行脚本的服务器在失效切换策略中的顺序
|
1~集群内的服务器数 |
显示执行的服务器的优先级。值为从1开始的数字。数字越小,服务器优先级越高。
CLP_PRIORITY为1时,表示在主服务器中执行。
|
CLP_GROUPNAME
…组名
|
组名 |
脚本所属的组名。 |
CLP_RESOURCENAME
…资源名
|
资源名 |
脚本所属的资源名。 |
CLP_PID
…进程ID
|
进程ID |
在属性中将开始脚本设置为异步时,该值表示开始脚本的进程ID。如果将开始脚本设置为同步,则该环境变量没有值。 |
CLP_VERSION_FULL
…EXPRESSCLUSTER完整版
|
EXPRESSCLUSTER完整版 |
表示EXPRESSCLUSTER的完整版。(例) 4.3.0-1
|
CLP_VERSION_MAJOR
…EXPRESSCLUSTER的主版本
|
EXPRESSCLUSTER主版本 |
表示EXPRESSCLUSTER的主版本。(例)4
|
CLP_PATH
…EXPRESSCLUSTER安装路径
|
EXPRESSCLUSTER安装路径 |
表示EXPRESSCLUSTER的安装路径。(例)/opt/nec/clusterpro
|
CLP_OSNAME
…服务器OS名称
|
服务器OS名称 |
表示执行脚本的服务器OS名称。
(例) 1. 可以获取OS名称时:Red Hat Enterprise Linux Server release 6.8 (Santiago)
2. 不能获取OS名称时:Linux
|
CLP_OSVER
…服务器OS版本
|
服务器OS版本 |
表示执行脚本的服务器OS版本。
(例) 1. 可以获取OS版本时:6.8
2. 不能获取OS版本时:没有值
|
- 1
磁盘资源,镜像磁盘资源,共享型磁盘资源,卷管理资源列为对象范围内。
设置[EXEC资源调整属性]的 [待机服务器中执行] 为有效,在待机服务器上执行脚本时,在环境变量中设置的信息如下图所示。
环境变量 |
环境变量的值 |
含义 |
|---|---|---|
CLP_EVENT
…脚本执行起因
|
STANDBY |
在待机服务器上执行时。
|
CLP_SERVER
……脚本的执行服务器
|
HOME |
在主服务器执行组。 |
OTHER |
在主服务器以外执行组。 |
|
CLP_PRIORITY
…已执行脚本的服务器
失效切换政策的顺序
|
1~集群内的服务器数 |
显示被执行的服务器的优先权。以1开头的服务器,数字越小,优先级越高。
如果CLP_PRIORITY为1,则表示该命令已在主服务器上执行。
|
CLP_GROUPNAME
…组名
|
组名 |
表示脚本所属的组名。 |
CLP_RESOURCENAME
…资源名
|
资源名 |
表示脚本所属的资源名。 |
CLP_VERSION_FULL
…EXPRESSCLUSTER完整版
|
EXPRESSCLUSTER完整版 |
表示EXPRESSCLUSTER的完整版。(例) 4.3.0-1
|
CLP_VERSION_MAJOR
…EXPRESSCLUSTER的主版本
|
EXPRESSCLUSTER主版本 |
表示EXPRESSCLUSTER的主版本。(例)4
|
CLP_PATH
…EXPRESSCLUSTER安装路径
|
EXPRESSCLUSTER安装路径 |
表示EXPRESSCLUSTER的安装路径。(例)/opt/nec/clusterpro
|
CLP_OSNAME
…服务器OS名称
|
服务器OS名称 |
表示执行脚本的服务器OS名称。
(例) 1. 可以获取OS名称时:Red Hat Enterprise Linux Server release 6.8 (Santiago)
2. 不能获取OS名称时:Linux
|
CLP_OSVER
…服务器OS版本
|
服务器OS版本 |
表示执行脚本的服务器OS版本。
(例) 1. 可以获取OS版本时:6.8
2. 不能获取OS版本时:没有值
|
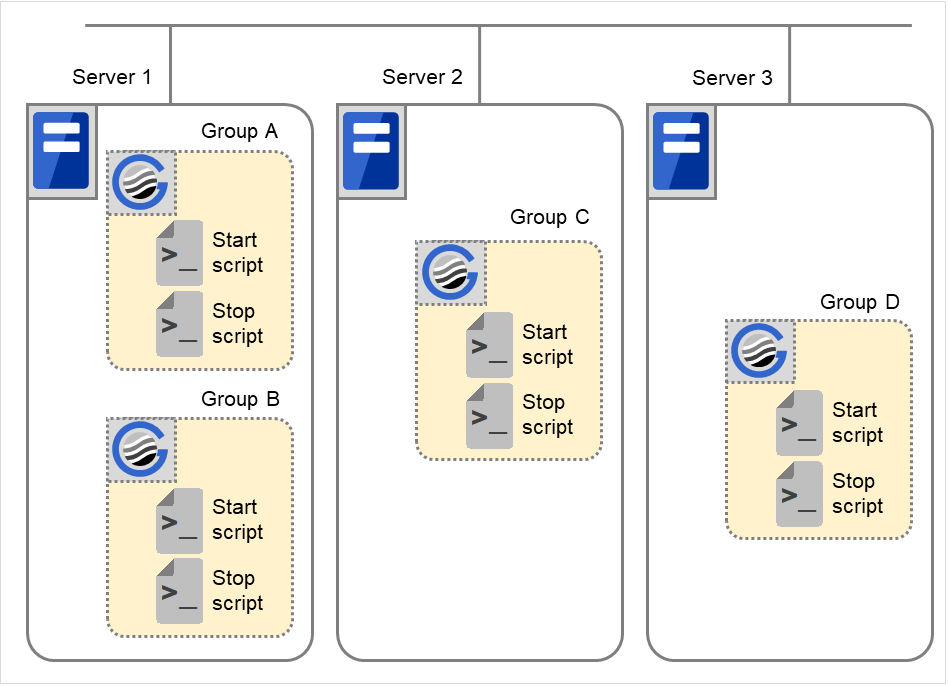
3.6.5. EXEC资源脚本的执行时机¶
以下通过集群状态变化图说明开始脚本,结束脚本的执行时机与环境变量的关系。
- 简单起见,以由2台服务器构成的集群为例说明。关于3台以上服务器构成的集群中可执行发生的执行时机和环境变量的关系,将以补充的形式进行说明。
图中的服务器显示以下状态。
服务器
服务器状态

正常状态(作为集群正常运行)

停止状态(集群处于停止状态)
(例) 在处于正常状态的服务器中组A正在运行。
在已启动的服务器中优先级别最高的服务器上启动各组。
集群中定义的组有A,B,C三个,它们各自的失效切换策略如下。
组
优先级1服务器
优先级2服务器
A
Server 1
Server 2
B
Server 2
Server 1
C
Server 1
Server 2
【集群状态变化图】
以下说明有代表性的集群状态变化。
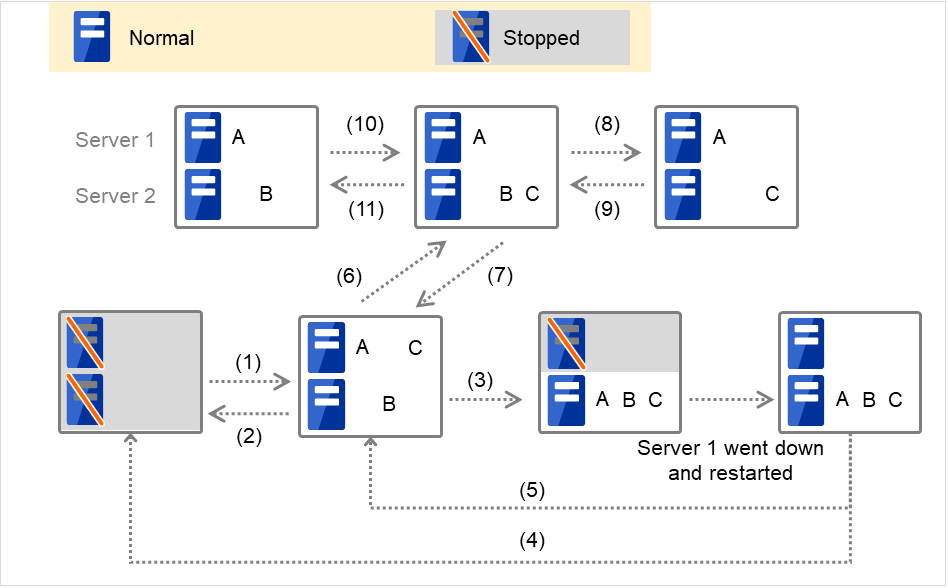
图 3.36 集群状态变化的示例(概要)¶
以下逐一说明图中1.~11.的含义。
正常启动
此处的正常启动是指在主服务器中正常执行开始脚本。
在已启动的服务器中优先级别最高的服务器上分别启动各组。
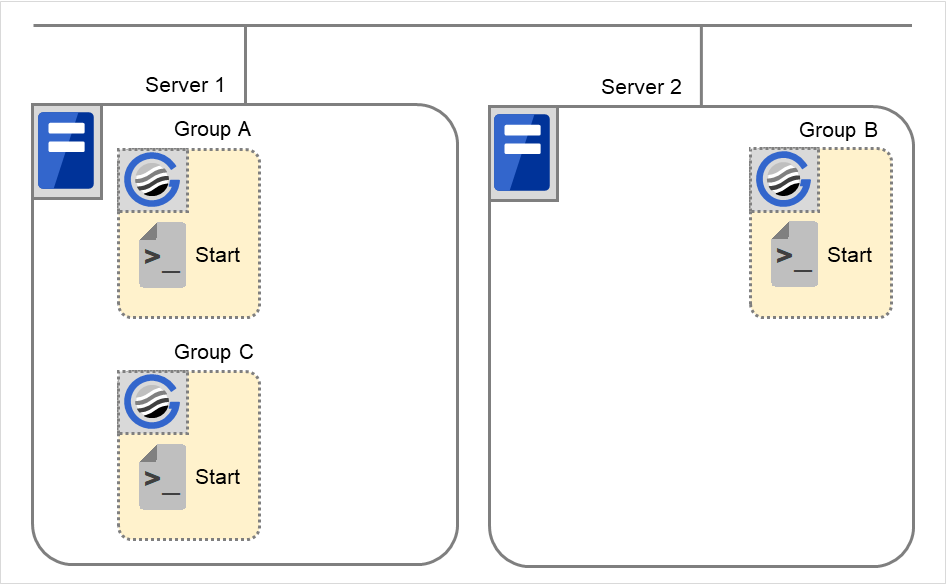
图 3.37 状态和脚本执行(正常启动)¶
Start的对应环境变量
Group A
Group B
Group C
CLP_EVENT
START
START
START
CLP_SERVER
HOME
HOME
HOME
正常停止
此处的正常停止是指在正常启动或因为组的移动(在线故障恢复)执行结束脚本所对应的开始脚本后,集群立即停止的情况。
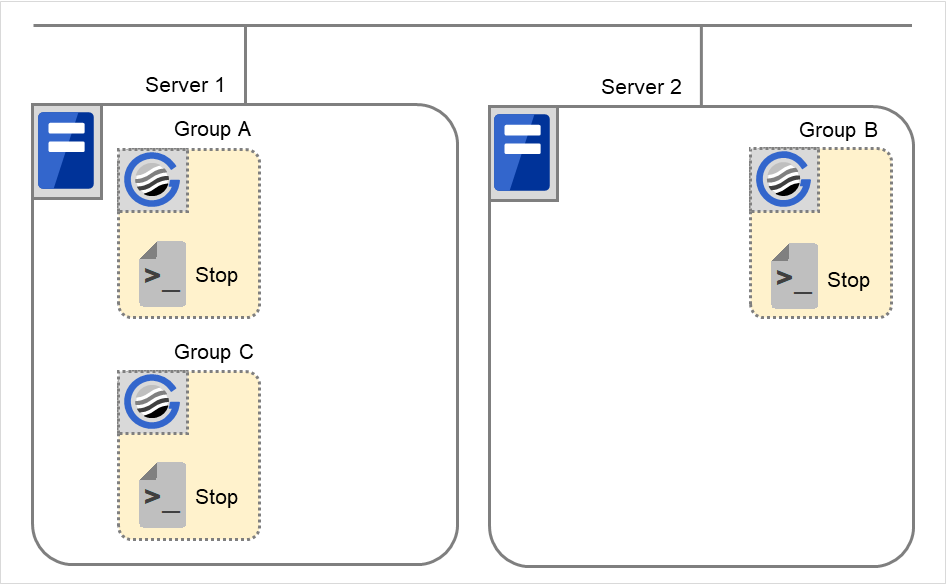
图 3.38 状态和脚本执行(正常停止)¶
Stop对应的环境变量
Group A
Group B
Group C
CLP_EVENT
START
START
START
CLP_SERVER
HOME
HOME
HOME
因为服务器1宕机执行失效切换
因为发生故障,以服务器1为主服务器的组的开始脚本在下一优先级的服务器(服务器2)上执行。在开始脚本中,需要事先以CLP_EVENT(=FAILOVER)为分支条件,描述业务的启动,恢复处理(例如数据库的回滚处理等)。
如果部分处理仅想在主服务器以外的服务器上执行,需要以CLP_SERVER(=OTHER)作为分支条件在脚本中进行描述。
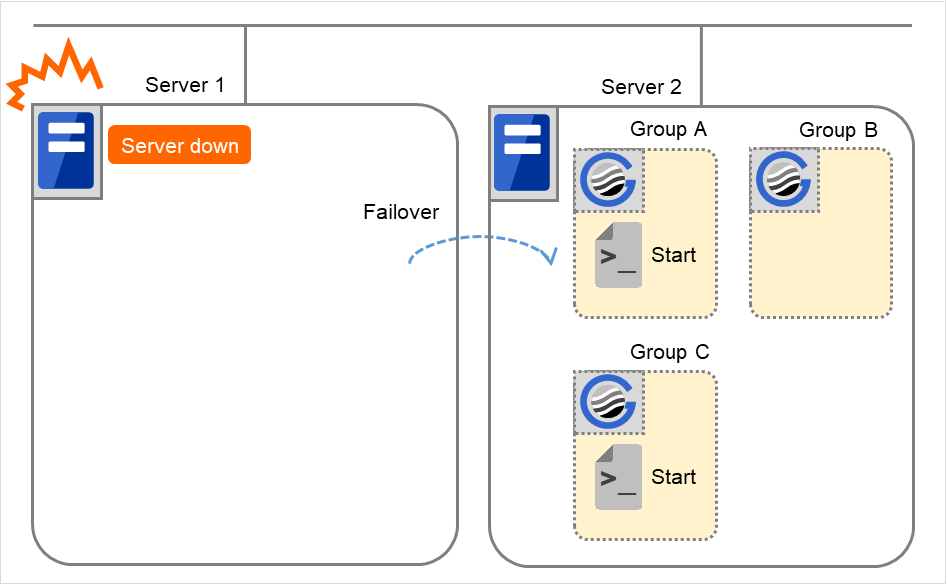
图 3.39 状态和脚本执行(因为服务器宕机执行失效切换)¶
Start对应的环境变量
Group A
Group C
CLP_EVENT
FAILOVER
FAILOVER
CLP_SERVER
OTHER
OTHER
服务器1失效切换后集群停止
在失效切换目标服务器2中执行组A和C的结束脚本(通过正常停止执行组B的结束脚本)。
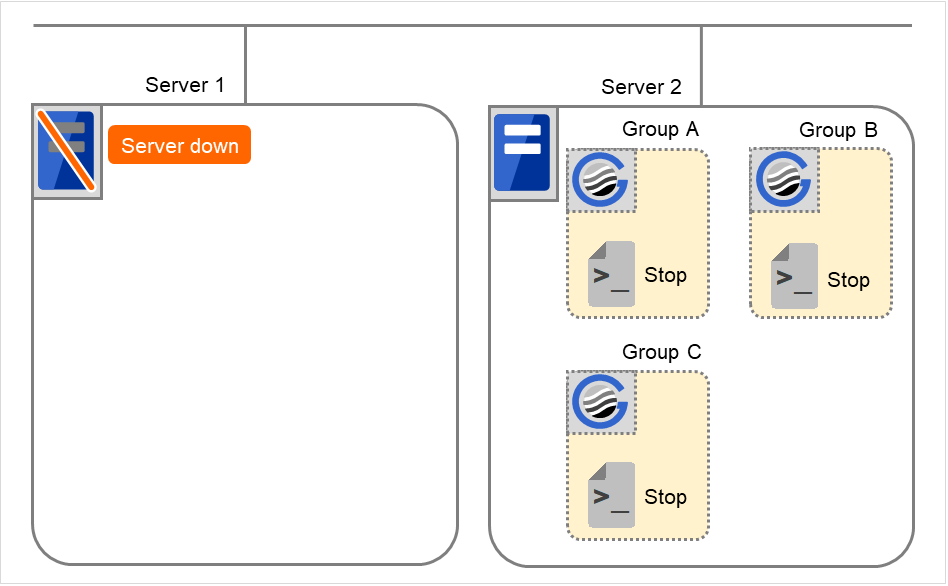
图 3.40 状态和脚本执行(失效切换后集群停止)¶
Stop对应的环境变量
Group A
Group B
Group C
CLP_EVENT
FAILOVER
START
FAILOVER
CLP_SERVER
OTHER
HOME
OTHER
组A和组C的移动
在失效切换目标服务器2中执行组A和组C的结束脚本后,在服务器1中执行开始脚本。
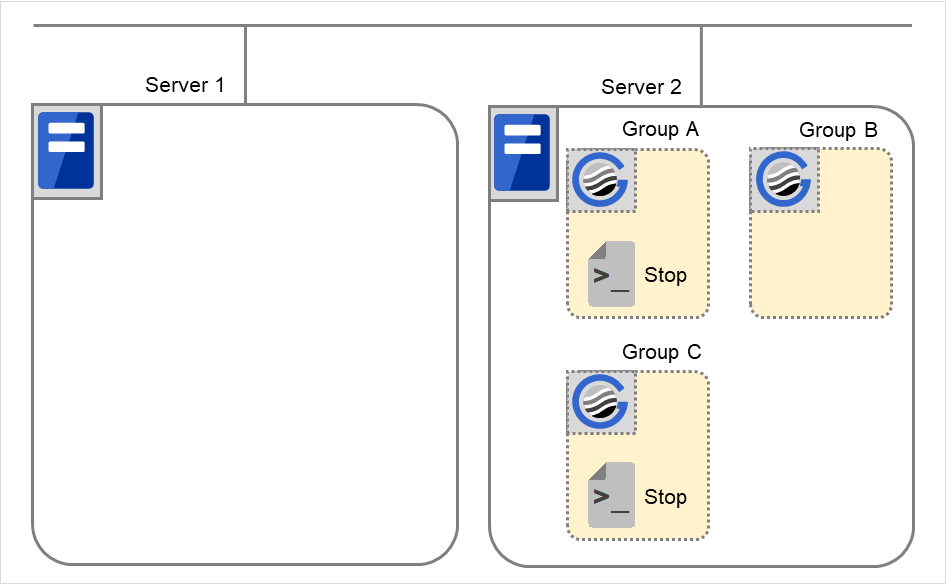
图 3.41 状态和脚本执行(Group A,Group C的移动)(1)¶
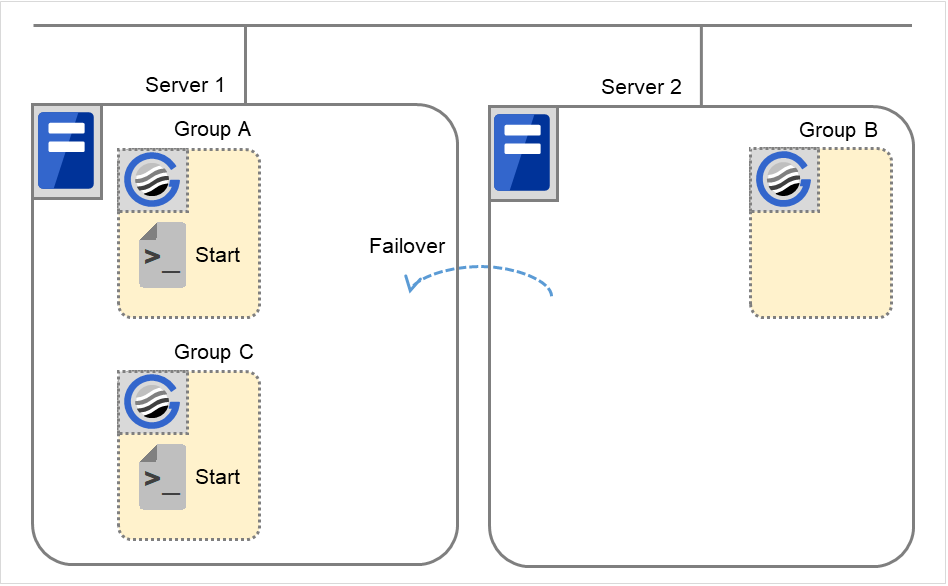
图 3.42 状态和脚本执行(Group A,Group C的移动)(2)¶
Stop对应的环境变量
Group A
Group C
CLP_EVENT
FAILOVER 2
FAILOVER
CLP_SERVER
OTHER
OTHER
Start对应的环境变量
Group A
Group C
CLP_EVENT
START
START
CLP_SERVER
HOME
HOME
- 2
- 结束脚本的环境变量的值为之前执行的开始脚本的环境变量的值。"5. 组A和组C的移动"中,因为之前没有发生集群停止,所以值为FAILOVER。但如果在"5. 组A和组C的移动"之前集群停止,则值应为START。
组C的故障,失效切换
组C中发生故障后,在服务器1中执行组C的结束脚本,在服务器2中执行组C的开始脚本。
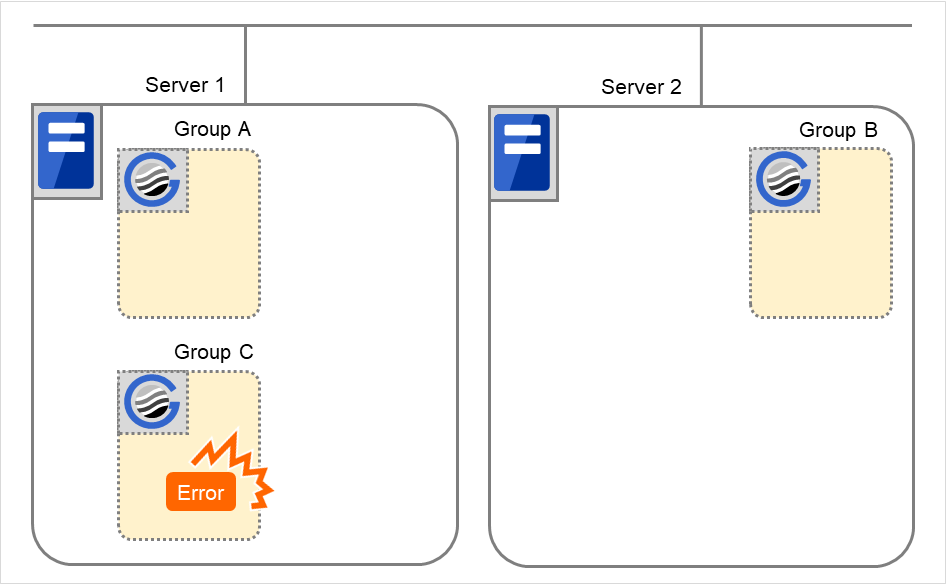
图 3.43 状态和脚本执行(Group C的故障,失效切换)(1)¶
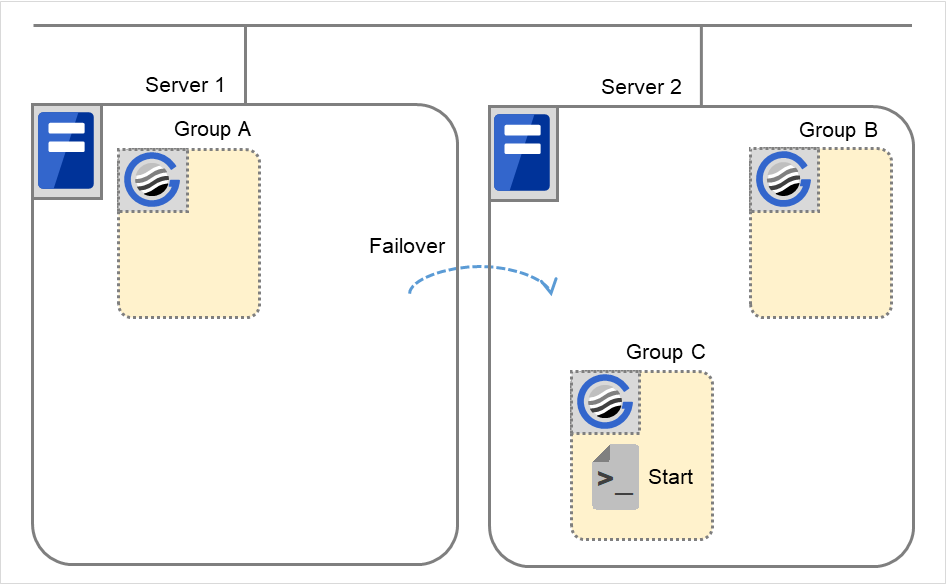
图 3.44 状态和脚本执行(Group C的故障,失效切换)(2)¶
对应Server 1Stop的环境变量
Group C
CLP_EVENT
START
CLP_SERVER
HOME
对应Server 2Start的环境变量
Group C
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
组C的移动
将在6.中因失效切换移动至服务器2的组C从服务器2移动至服务器1。在服务器2中执行结束脚本后,在服务器1中执行开始脚本。
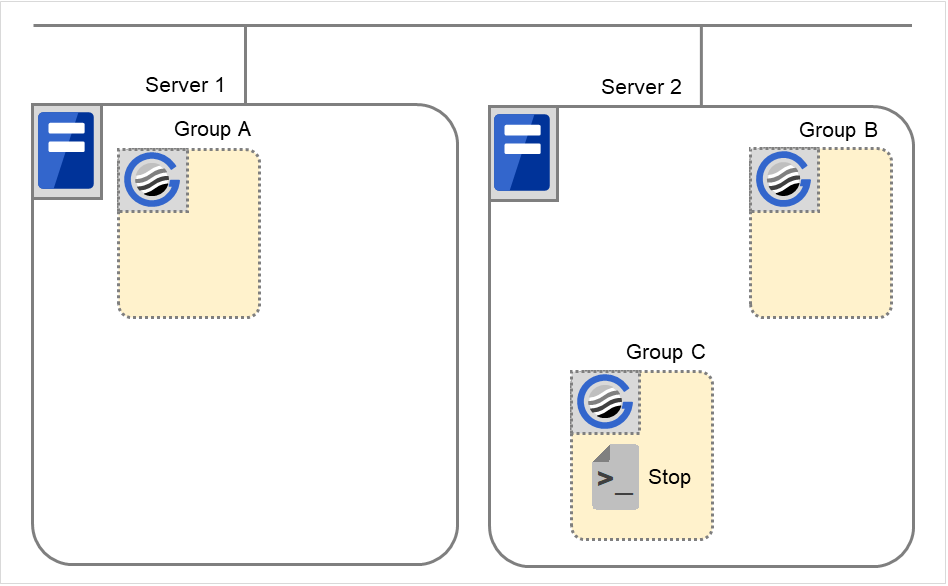
图 3.45 状态和脚本执行(Group C的移动)(1)¶
Stop(因为在6. 中执行失效切换)
Group C
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
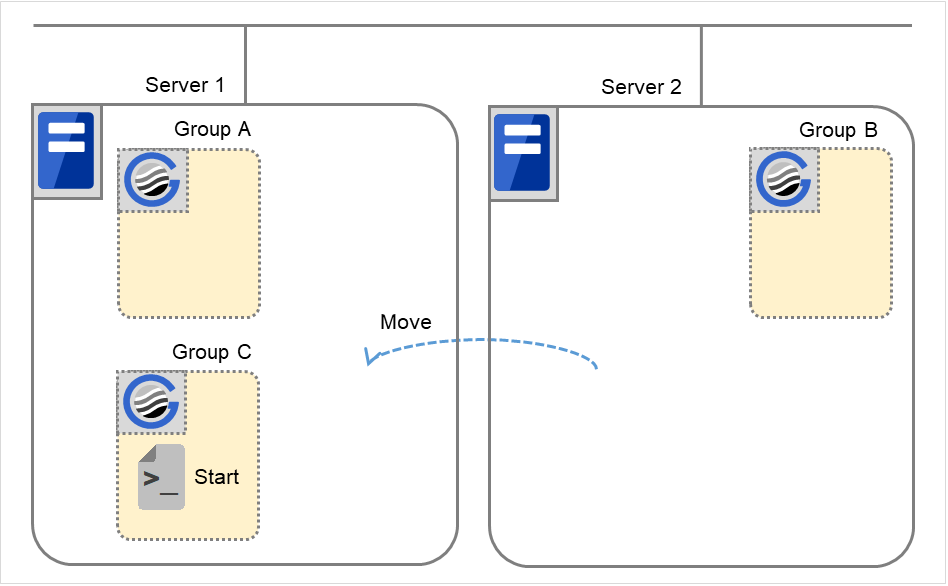
图 3.46 状态和脚本执行(Group C的移动)(2)¶
Start
Group C
CLP_EVENT
START
CLP_SERVER
HOME
组B的停止
在服务器2中执行组B的结束脚本。
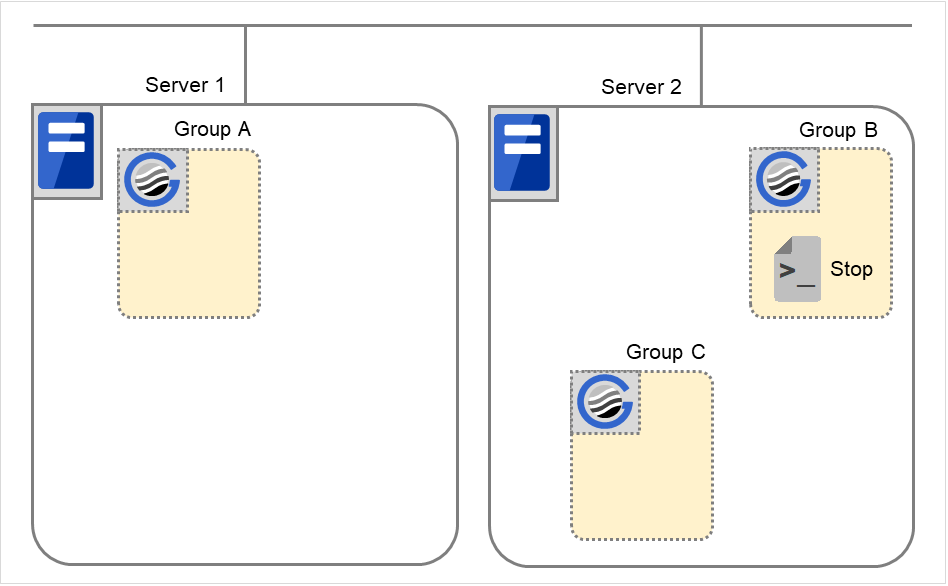
图 3.47 状态和脚本执行(Group B的停止)¶
Stop
Group B
CLP_EVENT
START
CLP_SERVER
HOME
组B的启动
在服务器2中执行组B的开始脚本。
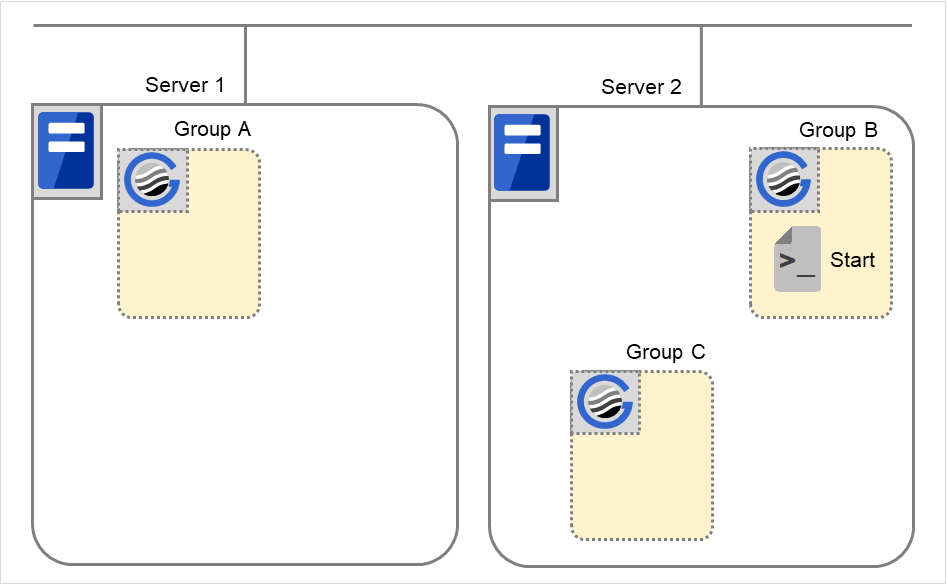
图 3.48 状态和脚本执行(Group B的启动)¶
Start
Group B
CLP_EVENT
START
CLP_SERVER
HOME
组C的停止
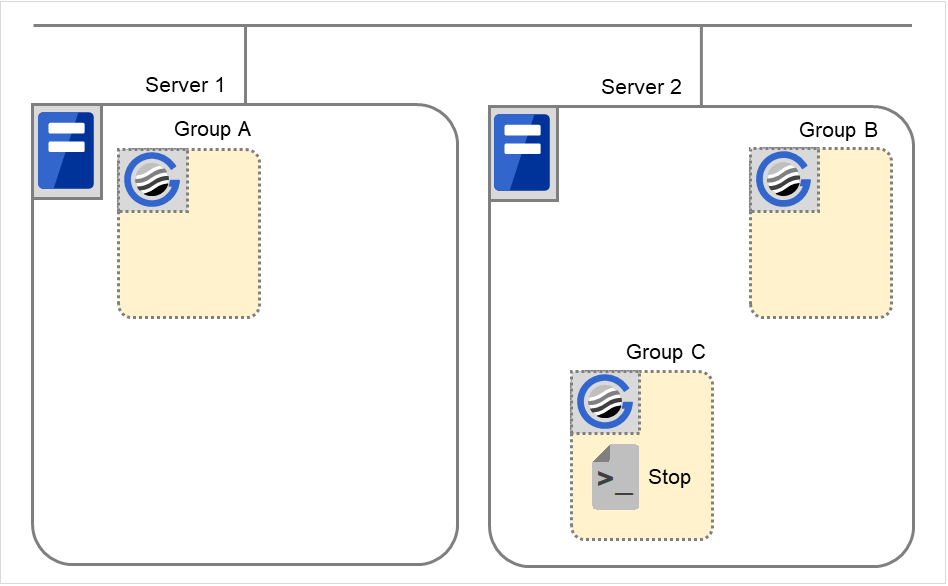
组C的启动
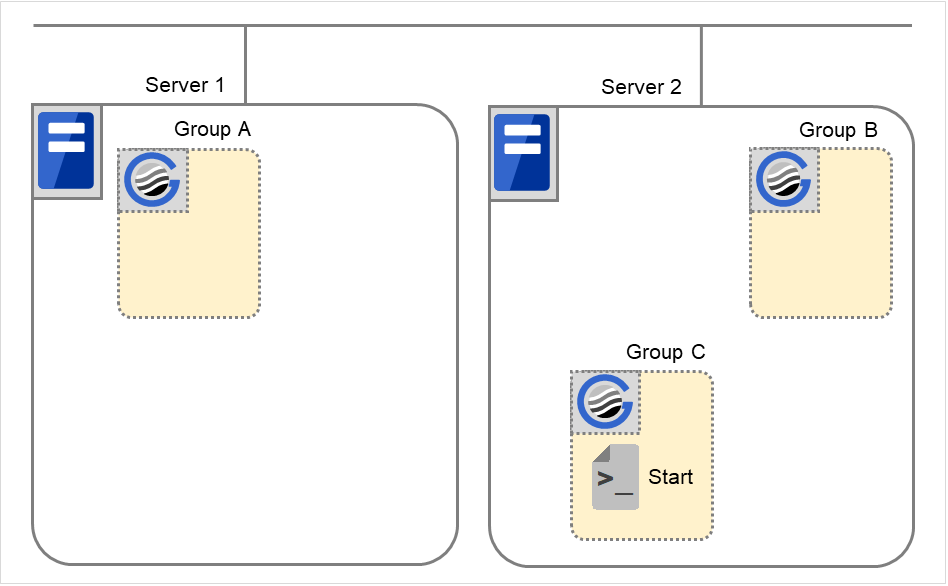
【补充1】
组的失效切换策略中设置的服务器为3台或更多时,如果主服务器以外的服务器中的运行不同,则使用CLP_PRIORITY代替CLP_SERVER(HOME/OTHER)。
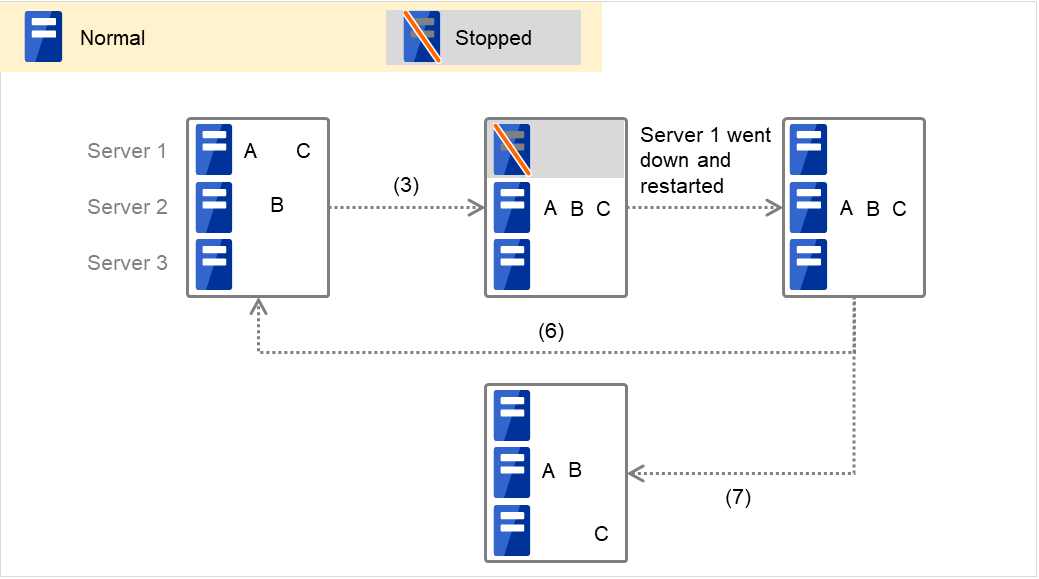
图 3.51 集群状态变化的示例(因为服务器宕机执行失效切换)¶
(例1)集群状态变化图为"3. 因为服务器1宕机执行失效切换"时
因为发生故障,以服务器1为主服务器的组的开始脚本在拥有下一优先级的失效切换策略的服务器2中执行。在开始脚本中,需要事先以CLP_EVENT(=FAILOVER)为分支条件描述业务的启动,恢复处理(例如数据库的回滚处理等)。
如果部分处理仅想在失效切换策略优先级为第2的服务器中执行,则需要在脚本中以CLP_PRIORITY(=2)为分支条件描述。
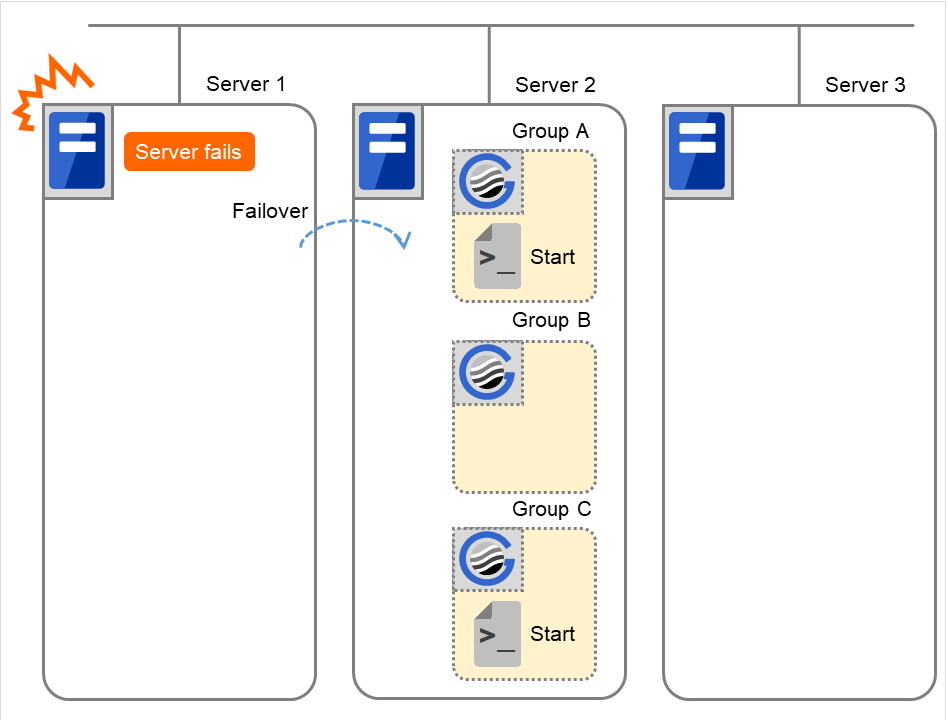
图 3.52 状态和脚本执行(Group A,Group C的启动)¶
Start对应的环境变量
Group A
Group C
CLP_EVENT
FAILOVER
FAILOVER
CLP_SERVER
OTHER
OTHER
CLP_PRIORITY
2
2
(例2) 集群状态变化图为"7. 组C的移动"时
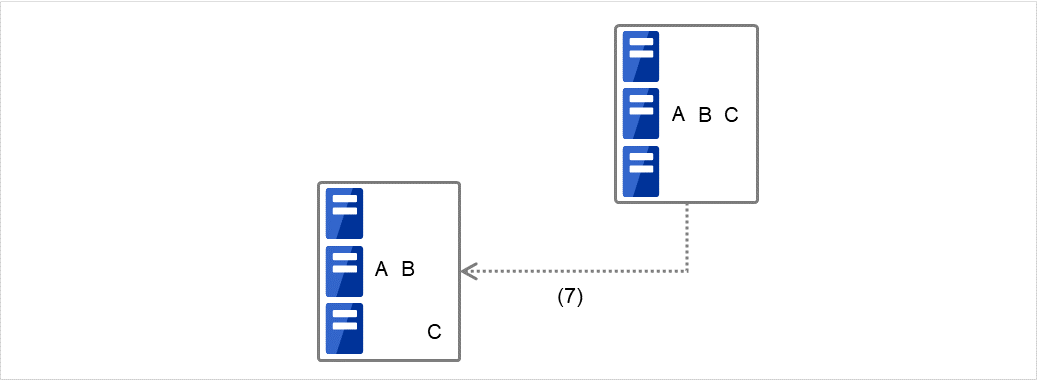
图 3.53 集群状态变化的示例(Group C的移动)¶
在执行失效切换的服务器2中执行组C的结束脚本后,在服务器3中执行开始脚本。
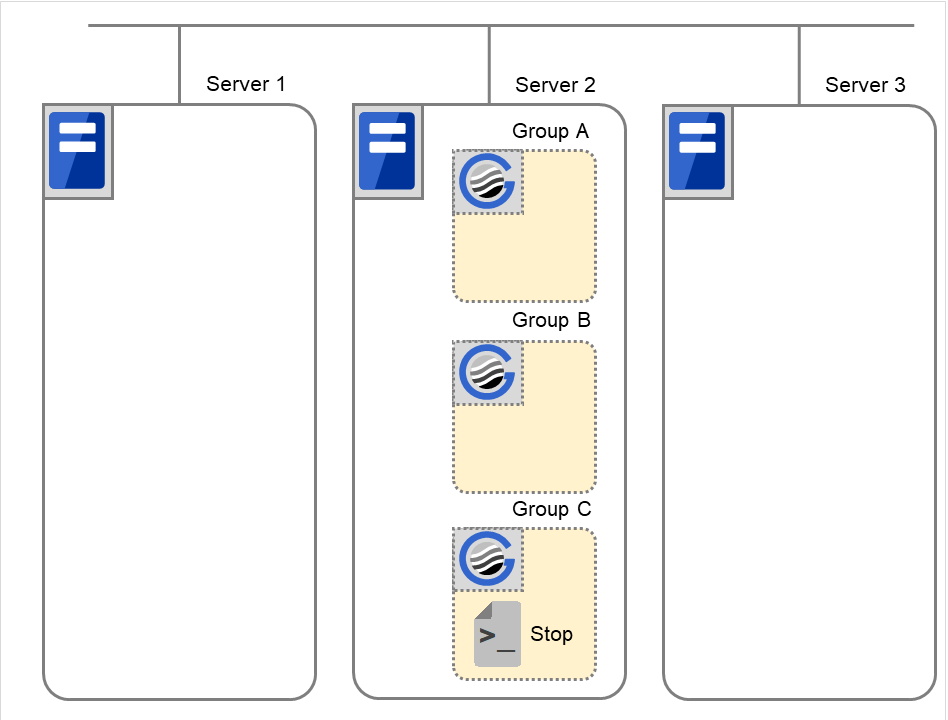
图 3.54 状态和脚本执行(Group C的移动)(1)¶
Stop对应的环境变量
Group C
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
CLP_PRIORITY
2
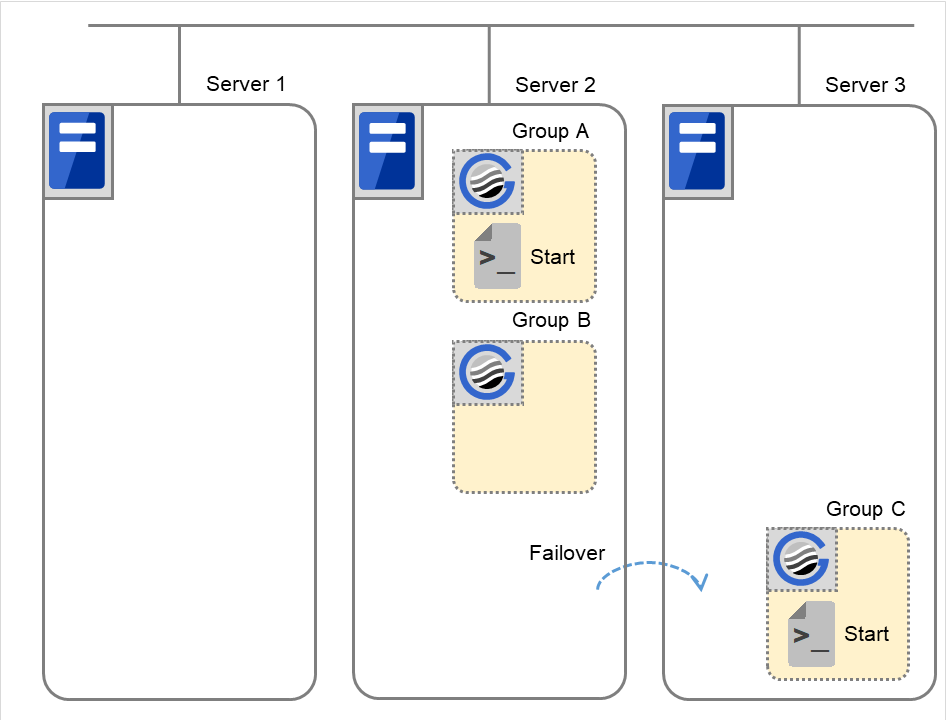
图 3.55 状态和脚本执行(Group C的移动)(2)¶
Start对应的环境变量
Group C
CLP_EVENT
START
CLP_SERVER
OTHER
CLP_PRIORITY
3
【补充2】
资源监视器(重新)启动脚本时
资源监视器发现应用程序的异常(重新)启动脚本时的环境变量如下。
(例1) 资源监视器查出服务器1中启动的应用程序的异常退出,在服务器1中重启组A时
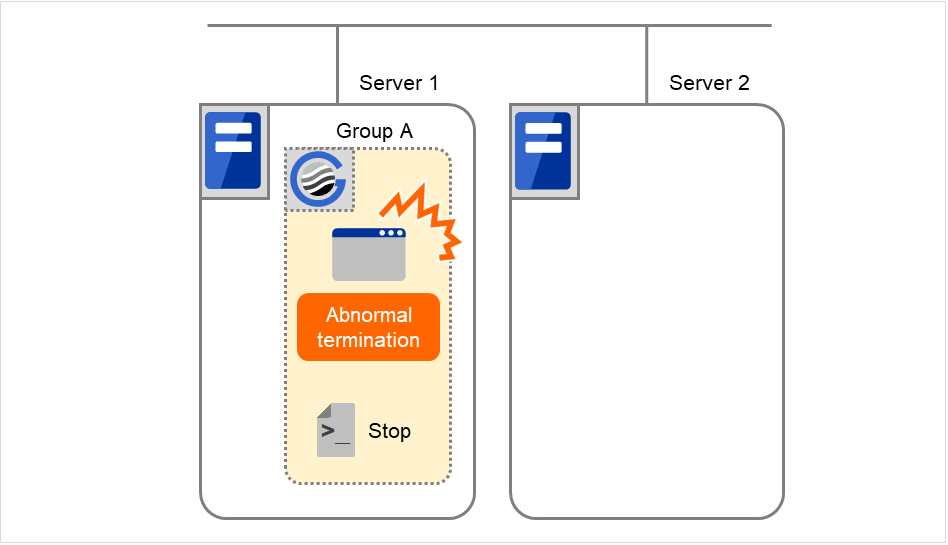
图 3.56 状态和脚本执行(Group A的重启)(1)¶
Stop对应的环境变量
Group A |
|
|---|---|
CLP_EVENT |
与执行Start时的值相同 |
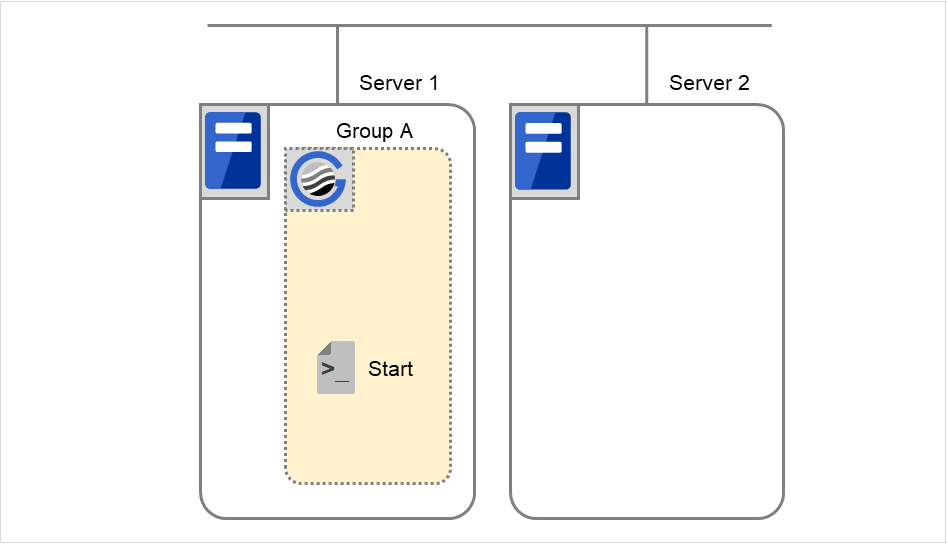
图 3.57 状态和脚本执行(Group A的重启)(2)¶
Start对应的环境变量
Group A
CLP_EVENT
START
(例2) 资源监视器查出服务器1中启动的应用程序的异常退出,失效切换至服务器2,在服务器2中启动组A时
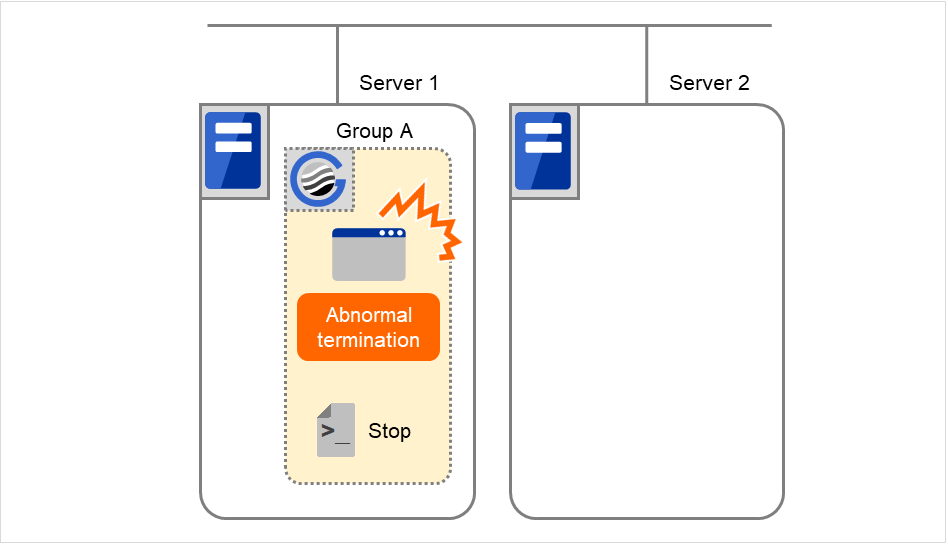
图 3.58 状态和脚本执行(Group A的失效切换)(1)¶
Stop对应的环境变量
Group A
CLP_EVENT
与执行Start时的值相同
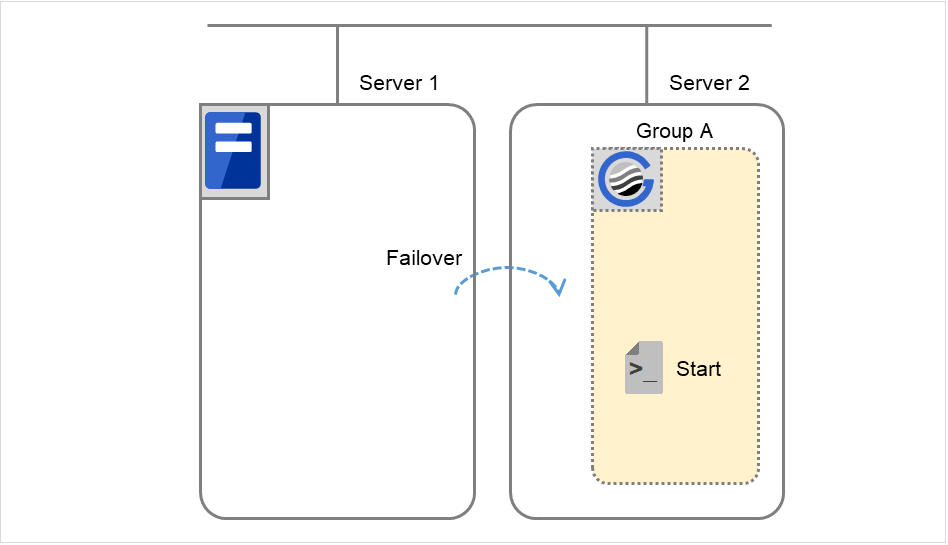
图 3.59 状态和脚本执行(Group A的失效切换)(2)¶
Start对应的环境变量
Group A |
|
|---|---|
CLP_EVENT |
FAILOVER |
【补充3】
如果启用了[EXEC资源调整属性]中的[在待机服务器上执行], 根据在启动组的服务器(=运行服务器)上执行开始脚本和结束脚本的时间, 该脚本可以在尚未启动该组的其他服务器(=待机服务器)上执行。
与运行服务器上的脚本执行相比,待机服务器上的脚本执行具有以下特征。
脚本的执行结果(错误代码)不影响组资源的状态。
不执行启动前后脚本或停止前后脚本。
不启动,不停止启动时监视器。
被设置的环境变量的种类,值不同(请参考前一项" EXEC资源的脚本中使用的环境变量 ")。
参考集群状态迁移图来说明待机服务器上脚本执行的时间与环境变量之间的关系。
【集群状态迁移图】
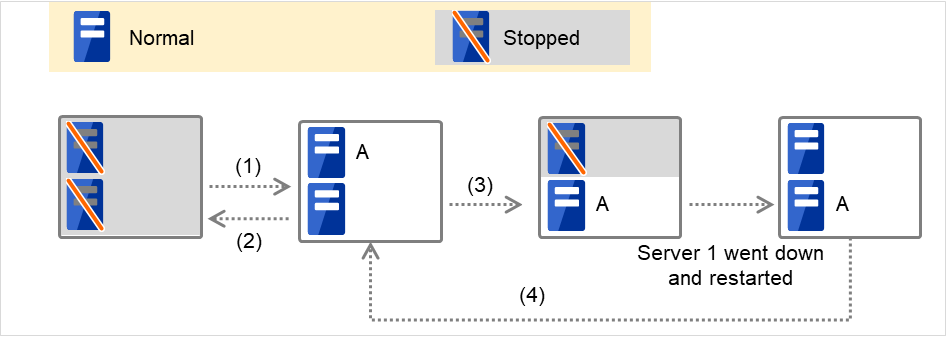
图 3.60 集群状态变化的示例(因为服务器宕机执行失效切换)¶
图中的 1. ~ 4.对应以下说明。
正常启动
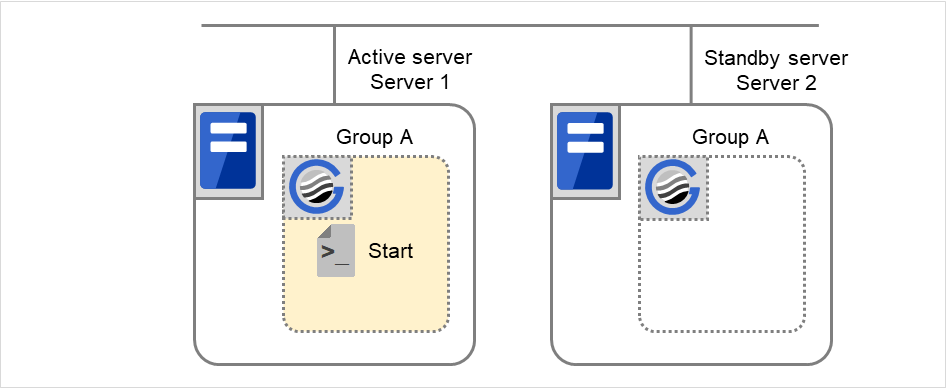
图 3.61 状态和脚本执行(Group A的正常启动)(1)¶
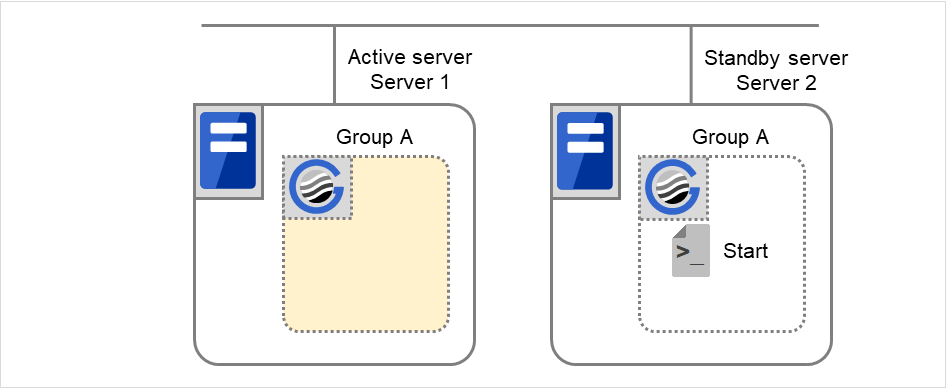
图 3.62 状态和脚本执行(Group A的正常启动)(2)¶
Start对应的环境变量
Server 1
Server 2
CLP_EVENT
START
STANDBY
CLP_SERVER
HOME
OTHER
正常停止
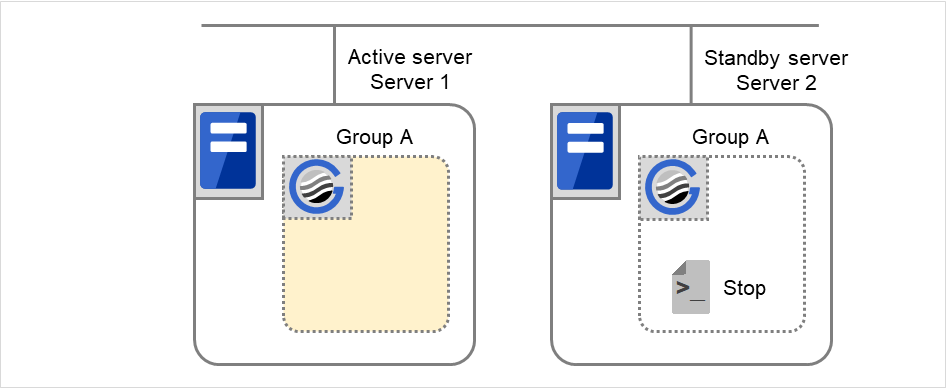
图 3.63 状态和脚本执行(Group A的正常停止)(1)¶
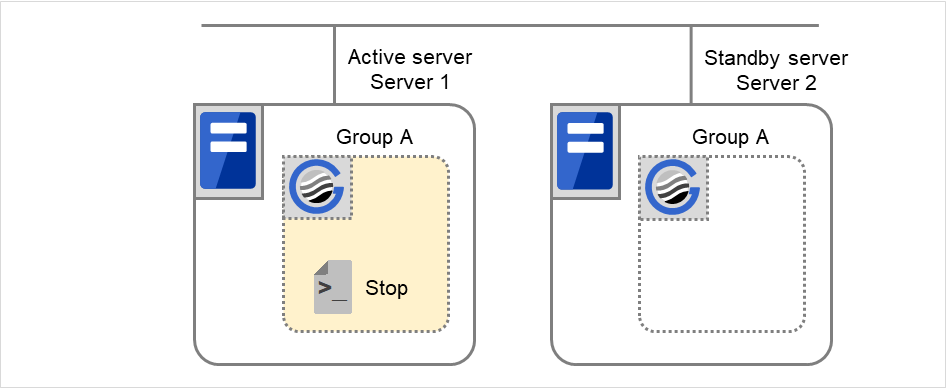
图 3.64 状态和脚本执行(Group A的正常停止)(2)¶
Stop 对应的环境变量
Server 1
Server 2
CLP_EVENT
START
STANDBY
CLP_SERVER
HOME
OTHER
因服务器1宕机的失效切换
因为服务器1宕机,作为待机服务器无法执行开始脚本。
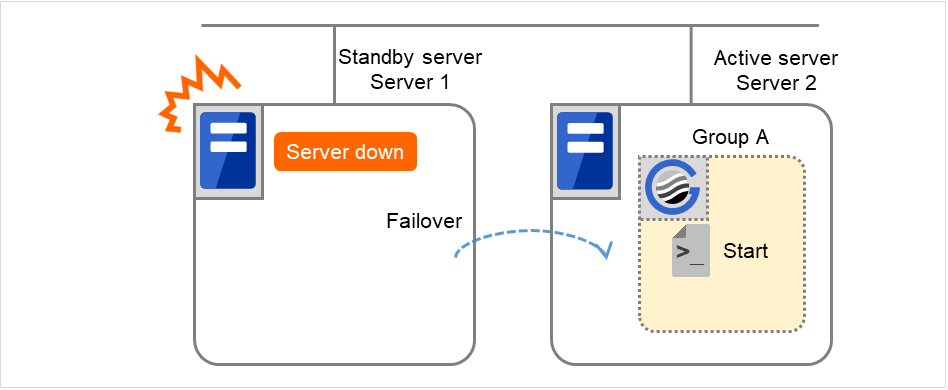
图 3.65 集群状态变化的示例(因为服务器宕机执行失效切换)¶
Start 对应的环境变量
Server 2
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
组A的移动
在服务器1(=待机服务器)和服务器2(=运行服务器)上执行组A的结束脚本之后, 在服务器1(=运行服务器)和服务器2(=待机服务器)上执行开始脚本。
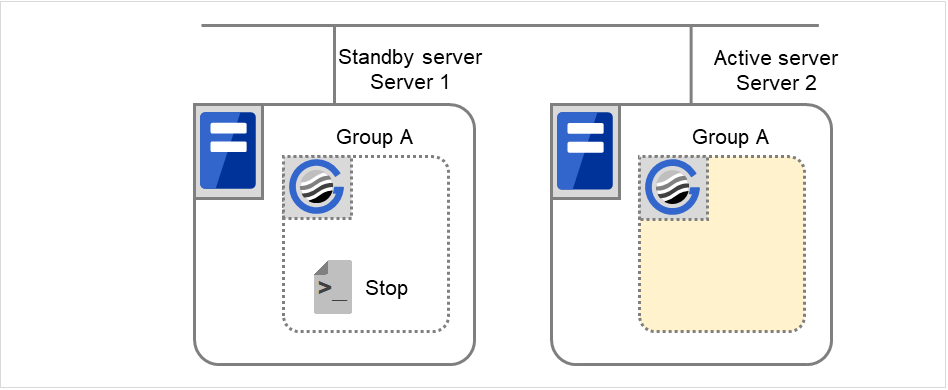
图 3.66 状态和脚本执行(Group A的移动)(1)¶
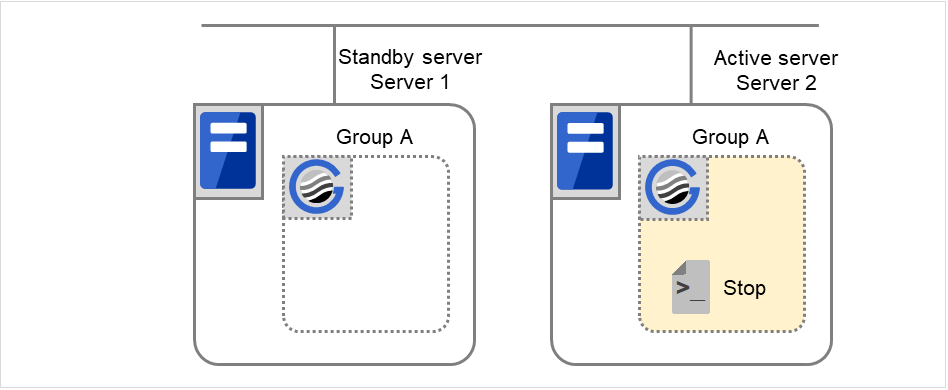
图 3.67 状态和脚本执行(Group A的移动)(2)¶
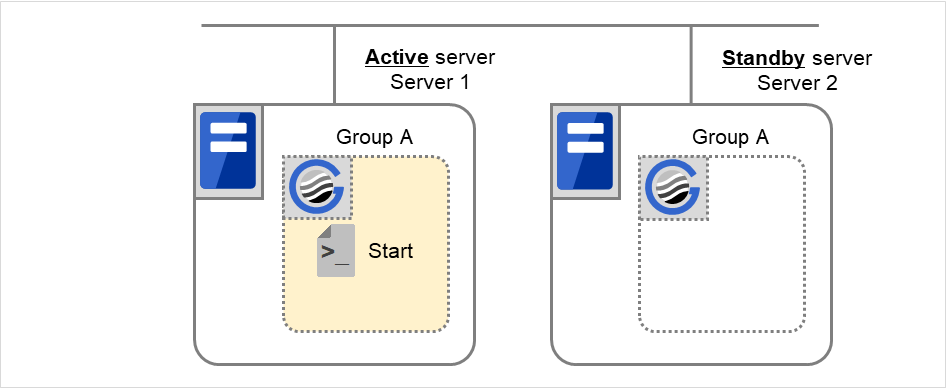
图 3.68 状态和脚本执行(Group A的移动)(3)¶
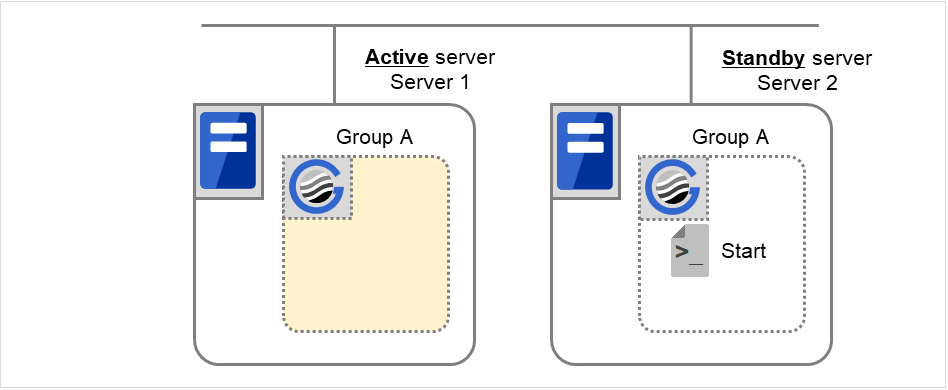
图 3.69 状态和脚本执行(Group A的移动)(4)¶
3.6.6. EXEC资源脚本的描述流程¶
本节说明了上节中说明的脚本执行时机与实际脚本描述之间的关系。文中的(数字)指155页" EXEC资源脚本的执行时机 "中的各种操作。
组A开始脚本:s tart.sh的示例
#!/bin/sh
# ***************************************
# * start.sh *
# ***************************************
# 参考脚本执行要因的环境变量来分配处理。
if ["$CLP_EVENT"="START"]
then
# 参考DISK连接信息环境变量来判定是否要进行错误处理。
if ["$CLP_DISK"="SUCCESS"]
then
# 在此记述业务的正常启动处理。
# 该处理在以下时机执行。
#
# (1) 正常启动
# (5) Group A 和 Group C的移动
#
# 参考执行服务器环境变量来分配处理。
if ["$CLP_SERVER"="HOME"]
then
# 在此记述仅在主服务器中正常启动业务时要进行的处理。
# 该处理在以下时机执行。
#
# (1) 正常启动
# (5) Group A 和 Group C的移动
#
else
# 在此记述仅在除主服务器以外,正常启动业务时要进行的处理。
#
fi
else
# 在此记述磁盘相关错误的处理。
#
fi
elif ["$CLP_EVENT"="FAILOVER"]
then
# 参考DISK连接信息环境变量来判定是否要进行错误处理。
if ["$CLP_DISK"="SUCCESS"]
then
# 在此记述业务的正常启动处理。
# 该处理在以下时机执行。
#
# (3) 因为Server 1宕机执行时效切换
#
# 参考执行服务器环境变量来分配处理。
if ["$CLP_SERVER"="HOME"]
then
# 在此记述仅在失效切换后,在主服务器中启动业务时要进行的处理。
#
else
# 在此记述仅在失效切换后,在非主服务器中启动业务时要进行的处理。
# 该处理在以下时机执行。
#
# (3) 因为Server 1宕机执行失效切换
#
fi
else
# 在此记述磁盘相关错误的处理。
#
fi
else
# EXPRESSCLUSTER不运行。
fi
# 如果结束代码为0,则判定EXEC资源启动处理成功。
# 记述当脚本内发生错误时,返回0以外的结束代码。
exit 0
组A结束脚本:stop.sh的示例
#!/bin/sh
# ***************************************
# * stop.sh *
# ***************************************
# 参考脚本执行要因的环境变量来分配处理。
if ["$CLP_EVENT"="START"]
then
if ["$CLP_DISK"="SUCCESS"]
then
# 在此记述业务的正常启动处理。在以下时机执行。
#
# (2) 正常停止
#
# 参考执行服务器环境变量来分配处理。
if ["$CLP_SERVER"="HOME"]
then
# 在此记述仅在失效切换后,在主服务器中正常停止业务时要进行的处理。
# 该处理在以下时机执行。
#
# (2) 正常停止
#
else
# 在此记述仅在除主服务器以外,正常停止业务时要进行的处理。
#
fi
else
# 在此记述磁盘相关错误的处理。
#
fi
elif ["$CLP_EVENT"="FAILOVER"]
then
# 参考DISK连接信息环境变量来判定是否要进行错误处理。
if ["$CLP_DISK"="SUCCESS"]
then
# 在此记述失效切换后的正常结束处理。
# 该处理在以下时机执行。
#
# (4) Server 1失效切换后,集群关闭
# (5) Group A 和 Group C的移动
#
# 参考执行服务器环境变量来分配处理。
if ["$CLP_SERVER"="HOME"]
then
# 在此记述仅在失效切换后,在主服务器中停止业务时要进行的处理。
#
else
# 在此记述仅在失效切换后,在非主服务器中停止业务时要进行的处理。
# 该处理在以下时机执行。
#
# (4) Server 1失效切换后,集群关闭
# (5) Group A 和 Group C的移动
#
fi
else
# 在此记述磁盘相关错误。
#
fi
else
# EXPRESSCLUSTER不运行。
fi
# 如果结束代码为0,则判定EXEC资源停止处理成功。
# 记述当脚本内发生错误时,返回0以外的结束代码。
exit 0
3.6.7. 创建EXEC资源脚本时的注意事项¶
创建脚本时请注意以下内容。
如果要执行一些需要时间的命令,请在脚本中保留用于表示命令执行完成的跟踪信息。发生故障时,可以使用这些信息来区分故障。保留跟踪信息的方法有以下两种。
- 在脚本中描述[echo]命令,设置EXEC资源的日志输出目标文件的方法通过[echo]命令可以标准输出跟踪信息。在此基础上,通过脚本所属资源的属性设置日志输出目标文件。默认为不输出日志。关于日志输出目标的设置,请参考"详细标签页"的"EXEC资源调整属性"中的"维护标签页"。因为[轮询]复选框未选中时,向设置为日志输出目标的文件中输出日志时没有大小限制,所以请务必注意文件系统的剩余空间。
(例:脚本设置示例)
echo "appstart.." appstart echo "OK"
- 在脚本中描述clplogcmd的方法通过clplogcmd向Cluster WebUI的警报日志或OS的syslog中输出消息。关于clplogcmd,请参考本指南的"8. EXPRESSCLUSTER命令参考"的"消息输出(clplogcmd命令)"。
(例:脚本设置示例)
clplogcmd -m "appstart.." appstart clplogcmd -m "OK"
3.6.8. EXEC资源的注意事项¶
关于脚本轮询功能
启用脚本日志轮询功能后,将生成调解日志输出(中介进程)的进程。中介进程是从"开始/停止脚本"和"继承从开始/停止脚本标准输出/标准错误输出中任一或两者的子进程"开始的日志输出到所有停止(文件描述符关闭)为止,一直运行的。如果要从日志中排除子进程的输出时,请在从脚本创建进程时重定向标准输出和标准错误输出。
开始脚本/结束脚本应由root用户执行。
启动依赖环境变量的应用程序时,必须根据所需,需要在脚本侧进行环境变量的设置。
3.6.9. 详细标签页¶

用户应用程序
使用可在服务器上执行的文件(可执行的shell脚本或二进制文件)作为脚本。通过服务器上本地磁盘的路径设置各可执行文件的名称。
各可执行文件不会发布到各服务器上,需要在各台服务器上准备。Cluster WebUI的集群配置信息中也不会包含这些文件。脚本文件不能通过Cluster WebUI进行编辑。
用Cluster WebUI创建的脚本
使用通过Cluster WebUI准备的脚本文件作为脚本。根据需要,可以通过Cluster WebUI编辑脚本文件。脚本文件将被包含到集群配置信息中。
显示
选择[用Cluster WebUI创建的脚本]时,显示脚本文件。
编辑
选择[用Cluster WebUI创建的脚本]时,编辑脚本文件。要反映这些变更,请点击[保存]。脚本文件名无法更改。
选择[用户应用程序]时显示[输入应用程序路径]对话框。
输入应用程序路径
设置EXEC资源的可执行文件名。

启动 (1023字节以内)
设置EXEC资源启动时的可执行文件名。文件名需要以[/]开头。还可指定参数。
停止 (1023字节以内)
设置EXEC资源停止时的可执行文件名。文件名需要以[/]开头。结束脚本可以省略。
可执行文件名需要设置为集群服务器上的带有以[/]开头的完整路径的文件名。还可指定参数。
替换
选择[用Cluster WebUI创建的脚本]时,显示[文件选择]对话框。
将[资源属性]中选择的脚本文件的内容置换为[文件选择]对话框中选择的脚本文件的内容。脚本处于正在编辑或正在显示的状态时无法置换。请在此选择脚本文件。请不要选择二进制文件(应用程序等)。
调整
显示EXEC资源调整属性对话框。对EXEC资源进行详细设置。要通过PID监视资源来监视EXEC资源,需要将开始脚本设置为异步。
EXEC资源调整属性
参数标签页

[启动脚本],[停止脚本]共通内容
同步
执行脚本时等待脚本结束。如果是非常驻(执行后处理立即返回)可执行文件,选择该项。
异步
执行脚本时不等待脚本结束。如果是常驻可执行文件,选择该项。异步执行EXEC资源的开始脚本时,可通过PID监视资源进行监视。
超时 (1~9999)
设置执行脚本时等待脚本结束([同步])的情况下的超时时间。仅在选择了[同步]时才可以设置该项。如果脚本没有在设置的时间内结束,则判断为异常。
待机服务器上执行
设置是否在待机服务器上执行脚本。启用此参数时,可以设置在待机服务器上执行时的超时时间(1~9999)。
维护标签页

日志输出路径 (1023字节以内)
指定EXEC资源的脚本或可执行文件的标准输出和标准错误输出的重定向目标。如果不指定任何内容,则输出到/dev/null中。需要指定为以[/]开头的值。[轮询]复选框未选中时,将会无限制的输出到文件中,所以请务必注意文件系统的剩余空间。[轮询]复选框选中时,输出的日志文件将会轮询。并且,还有以下的注意事项。[日志的输出路径]中请记载1009字节以内的日志路径。超过1010字节时,不能进行日志的输出。日志文件的名称长度请在31字节内记载。超过32字节时,文件名会在达到31字节时切断。超过32字节时,不能输出日志。多个EXEC资源中进行日志Rotate时,即使路径名不一样,如果日志文件名称一样时,有时不能正确反映Rotate大小(ex. /home/foo01/log/exec.log, /home/foo02/log/exec.log)。
轮询
未选中时,EXEC资源的脚本或可执行文件的执行日志,会以无限制的文件大小输出,选中时则会轮询输出。
轮询大小 (1~999999999)[轮询]复选框选中时,指定轮询的大小。轮询输出的日志文件配置如下。
文件名
内容
指定[日志输出路径]的文件名
最新的日志。
指定[日志输出路径]的文件名.pre
轮询之前的日志。
3.7. 理解磁盘资源¶
3.7.1. 磁盘资源的依赖关系¶
默认依存以下的组资源类型。
组资源类型 |
|---|
动态域名解析资源 |
浮动IP资源 |
虚拟IP资源 |
卷管理资源 |
AWS Elastic IP资源 |
AWS 虚拟IP资源 |
AWS DNS资源 |
Azure 探头端口资源 |
Azure DNS资源 |
3.7.2. 何谓切换分区?¶
切换分区是指连接到构成集群的多台服务器的共享磁盘上的分区。
按照失效切换策略,以失效切换组为单位进行切换。通过将业务所需的数据保存到切换分区中,在执行失效切换或移动失效切换组等操作时,可以自动继承这些数据。
注解
磁盘型"raw"通过EXPRESSCLUSTER将切换分区map (bind)到OS的raw磁盘上来实现。另外,磁盘资源调整属性的 [运行未绑定]复选框为ON时,磁盘资源停止时执行未绑定处理。
切换分区不可以在所有服务器中以同一设备名访问时,请进行服务器个别设置。
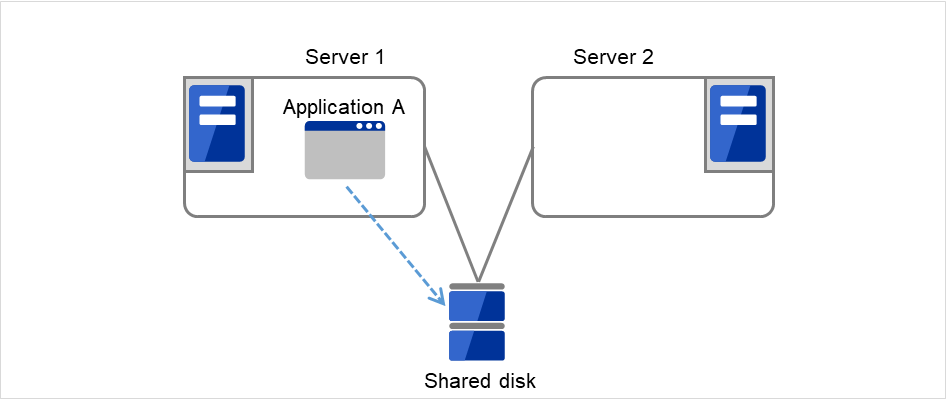
图 3.70 切换分区 (1)¶
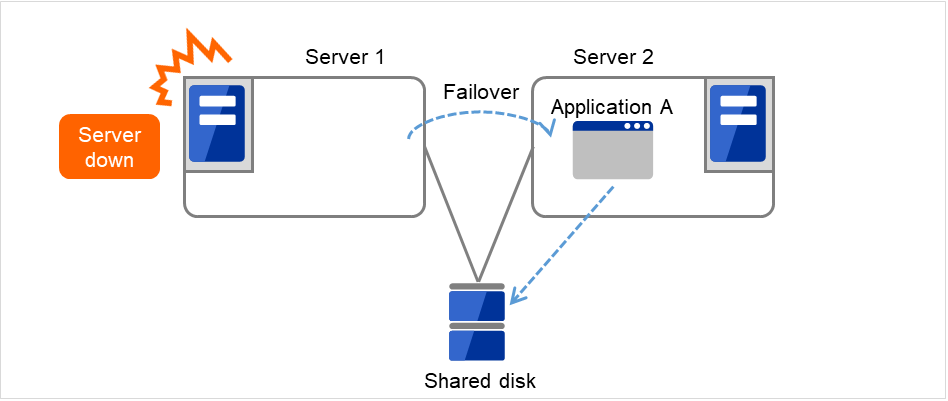
图 3.71 切换分区 (2)¶
3.7.3. 磁盘资源控制下的设备空间扩展方法¶
对象设备的空间扩展,请按以下的步骤设定。并且,以下的步骤必须在对象磁盘资源启动的服务器上执行。
执行clpgrp命令等停止对象磁盘资源所属的组。
用mount命令或者df命令确认磁盘没有被挂载。
- 根据对象磁盘资源的类型,执行以下的命令,将磁盘的状态从Read Only改成Read Write。#clproset -w -d (设备名)
实施设备的空间扩展
- 根据对象磁盘资源的类型,执行以下的命令,将磁盘的状态从Read Write改成Read Only。#clproset -o -d (设备名)
执行clpgrp命令等启动对象磁盘资源所属的组。
3.7.4. 磁盘资源的相关注意事项¶
<磁盘资源整体>
文件系统的访问控制(mount/unmount)由EXPRESSCLUSTER实现,所以请不要设置为在OS中执行mount/unmount。此外,不要将共享磁盘的文件系统作为条目加入到/etc/fstab中。(需要向/etc/fstab添加条目时,不要使用ignore参数,使用noauto参数)
磁盘资源中设置的分区设备名在集群内的所有服务器上都是只读状态。在启动组的服务器中,在启动时解除只读状态。
如果在集群属性的[扩展]标签页内,选中[Mount/Umount命令互斥]时,则磁盘资源,NAS资源,镜像资源的mount/unmount在同一服务器内互斥运行,所以磁盘资源的启动/停止可执行花费较长的时间。
- 在mount点中指定包含符号链接的路径时,查出异常时的运行即使选择[强制结束进程]也不能强行停止。此外,同样指定了包含「//」在内的路径时,也不能进行强制结束。
为了防止在OS启动时更改设备顺序, 请将udev设备设置为设备名(例:/dev/disk/by-id/[设备名])。
<利用磁盘类型[LVM]时>
使用本设置时,推荐同时使用卷管理资源,执行对卷组的控制。具体请参考"理解卷管理资源"。
卷的定义不在EXPRESSCLUSTER端进行。
文件系统请不要指定[zfs]。
<利用磁盘类型[VXVM]]时>
使用本设置时,请一并参考"理解卷管理资源"。
卷的定义不在EXPRESSCLUSTER端进行。
导入磁盘组,只使用卷启动状态下可以访问的raw磁盘(/dev/vx/rdsk/[磁盘组名]/[卷名])时(不在卷上构筑文件系统而进行raw访问时),不需要磁盘资源。
文件系统请不要指定[zfs]。
3.7.5. 详细标签页¶

磁盘类型 服务器个别设置
指定磁盘的类型。从以下类型中选择。
disk
raw
lvm
vxvm
文件系统 (15字节以内) 服务器个别设置
指定磁盘设备上创建的文件系统的类型。可选择的类型如下。也可以直接输入。[磁盘类型]为[raw]以外时需要设置。
ext3
ext4
xfs
reiserfs
vxfs
zfs
设备名 (1023字节以内) 服务器个别设置
选择作为磁盘资源使用的磁盘设备名。也能够直接输入。[文件系统]为[zfs]以外时,需要以[/]开头。[文件系统]为[zfs]时,指定ZFS数据组名。
Raw设备名 (1023字节以内) 服务器个别设置
设置作为磁盘资源使用的RAW磁盘设备名。[磁盘类型]为[raw]或[vxvm]时需要设置。
Mount点 (1023字节以内) 服务器个别设置
设置mount磁盘设备的目录。需要设置为以[/]开头的值。[磁盘类型]为[raw]以外时需要设置。
调整
显示[磁盘资源调整属性]对话框。设置磁盘资源的详细信息。[磁盘类型]是[raw]以外时可以设置。
磁盘资源属性([disk类型]为[raw]以外的场合)
Mount标签页
显示与mount有关的详细设置。

Mount选项 (1023字节以内)
设置mount磁盘设备上的文件系统时传给[mount]命令的参数。使用",(逗号)"分隔多个参数。
mount参数示例
设置项目
设置值
设备名
/dev/sdb5
Mount点
/mnt/sdb5
文件系统
ext3
Mount选项
rw,data=journal
上述设置时执行的[mount]命令
mount -t ext3 -o rw,data=journal /dev/sdb5 /mnt/sdb5
超时 (1~999)
设置mount磁盘设备上的文件系统时等待[mount]命令结束的超时时间。如果文件系统容量大,则花费的时间可执行较长。请注意不要设置过小的值。
重试次数 (0~999)
设置[mount]磁盘设备上的文件系统失败时的[mount]重试次数。如果设置为0,则不进行重试。
默认值
点击[默认值]后,所有项目将设置为默认值。
Unmount标签页
显示与unmount有关的详细设置。

超时 (1~999)
设置unmount磁盘设备上的文件系统时等待[umount]命令结束的超时时间。
重试次数 (0~999)
设置unmount磁盘设备上的文件系统失败时的unmount重试次数。如果设置为0,则不进行重试。
重试间隔 (0~999)
设置unmount磁盘设备上的文件系统失败时到执行下次重试的间隔。
查出异常时的强制动作
设置unmount失败后重试unmount时执行的操作。
默认值
点击[默认值]后,所有项目将设置为默认值。
Fsck标签页
显示与[fsck]相关的详细设置。在文件系统中指定为[xfs]以外时可以显示。文件系统指定为[zfs]时无效。

fsck 选项 (1023字节以内)
指定检查磁盘设备上的文件系统时传给[fsck]命令的选项。请使用空格分割多个参数。此处指定参数时请注意不要使[fsck]命令变为交互形式。如果[fsck]命令成为交互形式,则经过[fsck 超时]时间后,资源启动将出错。文件系统在[reiserfs]时,fsck命令会变为交互形式,但通过由EXPRESSCLUSTER向[reiserfsck]传递"Yes"可以避免这个现象。
fsck超时 (1~9999)
指定检查磁盘设备上的文件系统时等待[fsck]命令结束的超时时间。如果文件系统容量大,则花费的时间可执行较长。请注意不要设置过小的值。
Mount执行前的fsck操作
从以下操作中选择mount磁盘设备上的文件系统之前[fsck]的运行。
注解
[fsck]的指定次数与文件系统管理的检查间隔没有关系。
Mount失败时的fsck操作
设置mount磁盘设备上的文件系统失败时[fsck]的运行。在[重试次数]的设置值为0以外的情况下设置有效。
注解
不建议同时将[Mount执行前的fsck操作]设置为[不执行]。如果这样设置,磁盘资源不会执行[fsck],所以如果切换分区发生通过[fsck]可以恢复的异常时,无法对磁盘资源进行失效切换。
reiserfs的再次构建
指定发生[reiserfsck]可以修复的错误时的运行。
默认值
点击[默认值]后,所有项目将设置为默认值。
xfs_repair标签页
显示与[xfs_repair]相关的详细设置。仅在文件系统中指定为[xfs]时可以显示。

xfs_repair选项 (1023字节以内)
检查磁盘设备上的文件系统时,请指定传递给[xfs_repair]命令的参数。设置多个参数时,请用空格区分开。
xfs_repair超时(1~9999)
检查磁盘设备上的文件系统时,指定等待[xfs_repair]命令结束的超时时间。文件系统的容量较大时,有可执行比较费时。因此请注意所设置的值不要太小。
Mount失败时的xfs_repair操作
设置Mount磁盘设备上的文件系统失败时[xfs_repair]的动作。此设置仅在[Mount重试次数] 的设置值为0以外时有效。
默认值
点击[默认值]后,所有项目将设置为默认值。
磁盘资源调整属性([磁盘类型]为[raw]的场合)
未绑定标签页
显示与未绑定有关的详细设置。

运行未绑定
指定RAW磁盘设备的未绑定执行有无。
超时 (1~999)
[执行未绑定]复选框为ON时,设定RAW磁盘设备的等待unmount处理结束的超时时间。
重试次数 (1~999)
[执行未绑定] 复选框为ON时,RAW磁盘设备的unmount处理失败的情况下,指定unmount重试次数。
默认值
点击[默认值]后,所有项目将设置为默认值。
3.8. 理解浮动IP资源¶
3.8.1. 浮动IP资源的依赖关系¶
默认情况下,没有依存的组资源类型。
3.8.2. 何谓浮动IP?¶
客户端应用程序可以使用浮动IP地址连接集群服务器。通过使用浮动IP地址,即使发生"失效切换"或者"移动组",客户端也无需考虑连接目标服务器的切换。
浮动IP地址既可以在同一LAN上使用也可以从远程LAN使用。
执行[ifconfig]命令或API,给OS分配IP地址。 [ifconfig]命令或API中执行哪一个,浮动IP资源自动判断。
[ifconfig]命令为以下格式以外时,执行API。
eth0 Link encap:Ethernet HWaddr 00:50:56:B7:1B:C0
inet addr:192.168.1.113 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::250:56ff:feb7:1bc0/64 Scope:Link
(以下略)
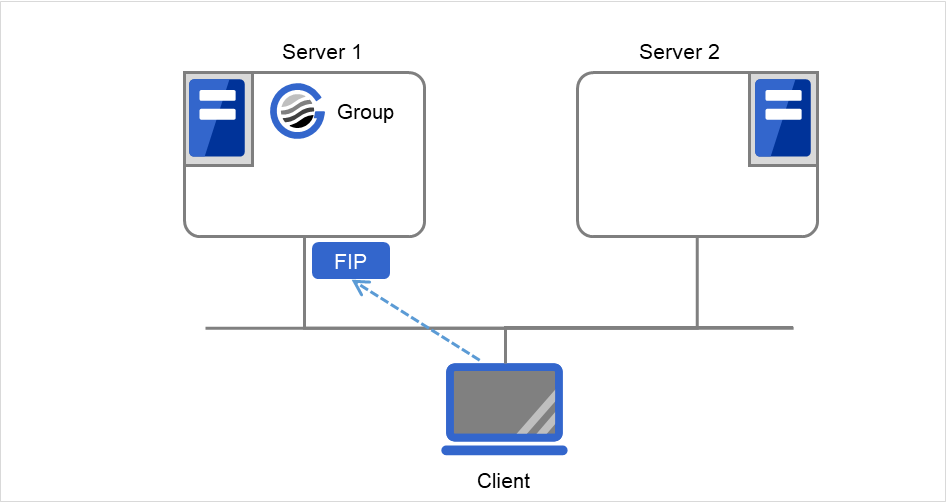
Client通过浮动IP(FIP)访问 Server 1。
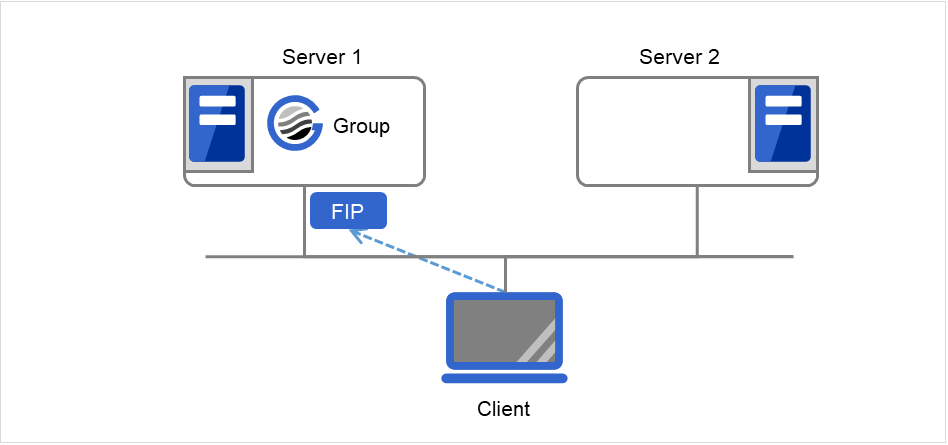
图 3.72 通过浮动IP访问 (1)¶
即使从Server 1到Server 2发生失效切换,由于Client的连接目标是FIP,因此无需知道连接目标服务器已更改。
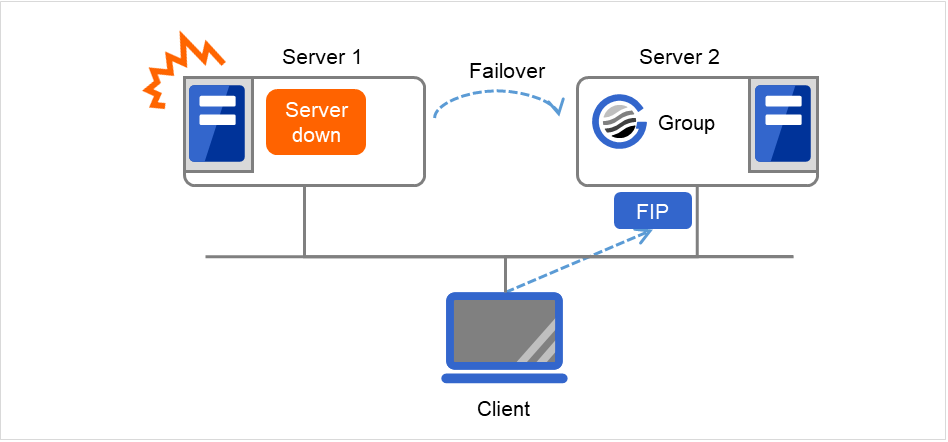
图 3.73 通过浮动IP访问 (2)¶
分配地址
分配给浮动IP地址的地址需要满足以下条件。
与集群服务器所属的LAN在同一网络地址内但尚未使用的主机地址
请在该条件下分配所需数量(一般等于失效切换组数)的IP地址。由于该IP地址与一般的主机地址相同,所以也可以从互联网等的全局IP地址中分配。
切换方式的结构
IPv4时,通过从FIP资源启动的服务器发送ARP广播,ARP表上的MAC地址会进行切换。
IPv6时,不发送ARP广播。
EXPRESSCLUSTER发送的ARP广播包的内容如下。

图 3.74 EXPRESSCLUSTER发送的ARP广播数据包¶
路径控制
不需要设置路由表。
使用条件
可以从以下机器访问浮动IP地址。
集群服务器本身
同一集群内的其他服务器,其他集群系统内的服务器
与集群服务器在同一LAN内以及远程LAN的客户端
如果满足以下条件,则上述机器以外的其他机器也可以使用浮动IP地址。但是,不能保证所有机器都能进行Architecture的连接。请事先进行充分的测试。
通信协议是TCP/IP通信协议或者是SCTP/IP
支持ARP协议
即使是由交换集线器构成的LAN,浮动IP地址的机制也可以正常运行。
服务器宕机时,已连接的TCP/IP连接会断开。
3.8.3. 浮动IP资源的相关注意事项¶
请不要在浮动 IP 资源启动的服务器中执行网络的重新启动。重新启动网络后,浮动 IP 资源添加的 IP 地址就会被删除。
- 关于[ifconfig]命令的Time-lag导致的IP地址重复。浮动IP资源设置如下时,资源的失效切换有可执行会失败。
[启动重试次数]中设置的值小于默认值
未设置[Ping重试次数],[Ping间隔]
出现该现象的原因如下。
在失效切换源服务器上对浮动IP地址进行停止后,根据[ifconfig]命令的规范释放IP地址有时候会比较耗费时间。
在失效切换目标服务器上对浮动IP地址进行启动时,对为防止冗余启动而预定启动的浮动IP地址执行[ping]命令后,由于上述原因可以ping到,资源启动异常。
该现象可以通过以下设置来避免。
- 关于OS停止时的IP地址重复在已启动浮动IP地址的状态下发生OS停止时,如果设置如下则资源的失效切换有时会失败。
[Ping超时]指定为0以外的值
[FIP强制启动]为Off
出现该现象的原因如下。
在已启动浮动IP地址的状态下出现如下OS部分停止的现象
网络模块运行,能够对其他节点发出的ping作出反应
用户空间监视资源无法查出停止
在失效切换目标服务器上启动浮动IP地址时,对为防止冗余启动而预定启动的浮动IP地址执行[ping]命令后,由于上述原因可以ping到,资源启动异常。
在该现象频发的机器环境下,通过进行以下设置可以避免该问题的发生。但是,请注意失效切换后,根据停止的状况有时会发生两组启动,并且根据时机的不同有时会导致服务器关机。关于双重启动的详细信息,请参考《维护指南》的"维护信息"的"服务器宕机的发生条件"的"从网络分区恢复"。
- [Ping超时]设置为0不对浮动IP地址进行重复确认。
- [FIP强制启动]设置为On即使浮动IP地址在其他服务器上使用,也强行启动浮动IP地址。
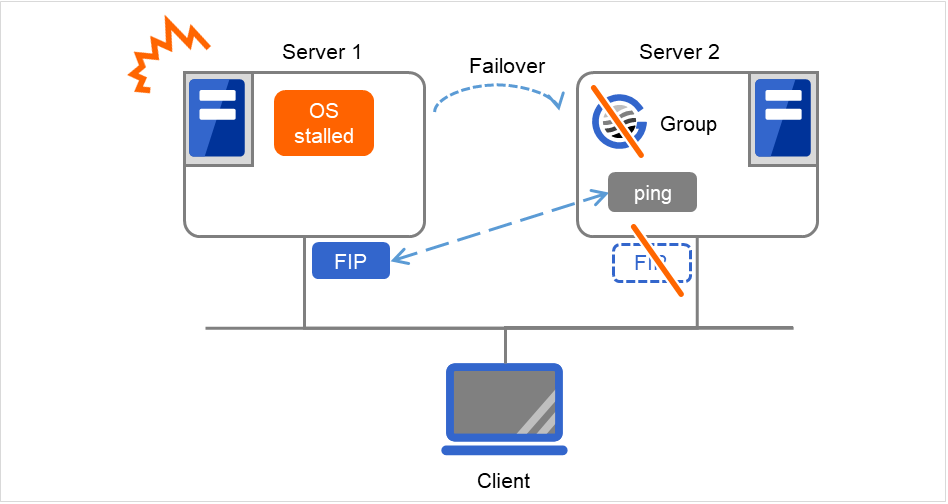
ping超时的设置为0以外,且FIP强制启动为OFF时
由于Server 1的OS已停滞,因此在FIP为启动状态下发生失效切换。 但是,之后立即对在Server 2中启动FIP前执行的ping命令返回响应。 因此,为了防止发生双重启动,Server 2上的FIP启动失败。
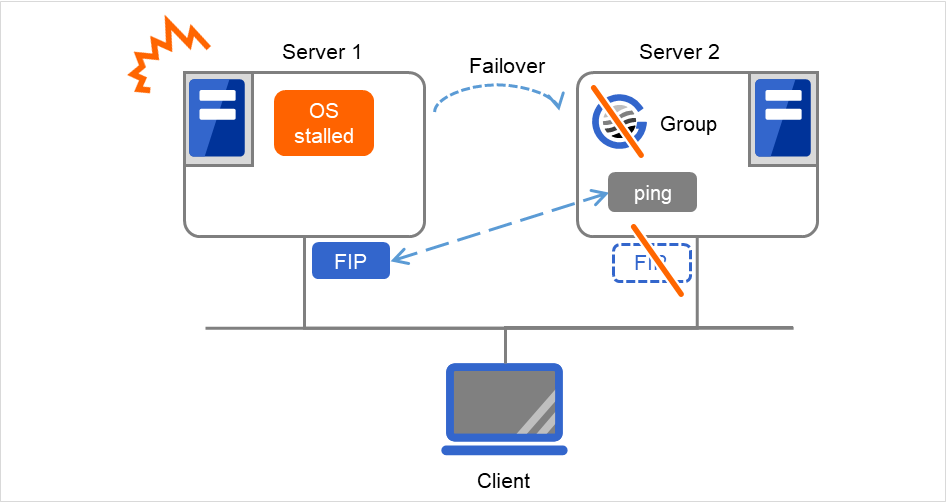
图 3.77 ping超时的设置为0以外,且FIP强制启动为OFF时¶
ping超时为0时
由于Server 1的OS已停滞,因此在FIP为启动状态下发生失效切换。 Server 2中不对FIP执行ping命令,Server 2中的FIP启动成功。
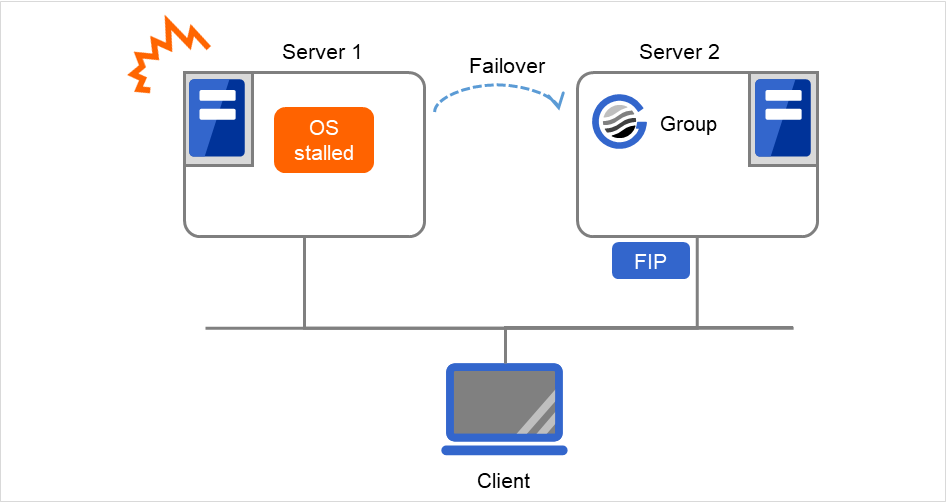
图 3.78 ping超时为0时¶
ping超时的设置为0以外,且FIP强制启动为ON时
由于Server 1的OS已停滞,因此在FIP为启动状态下发生失效切换。 Server 2中对FIP执行ping命令,但是不管结果如何,Server 2中的FIP启动都会强制成功。
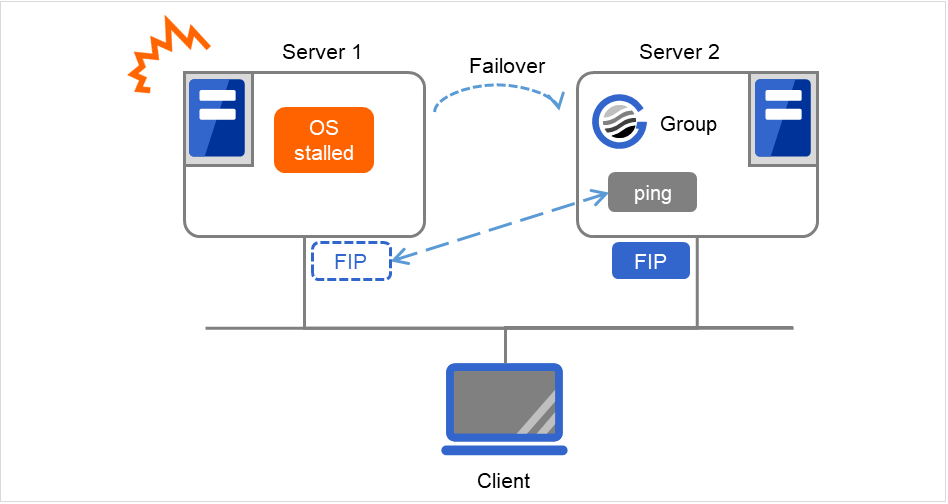
图 3.79 ping超时的设置为0以外,且FIP强制启动为ON时¶
- 关于分配浮动IP的虚拟NIC的MAC地址分配浮动IP的虚拟NIC的MAC地址是实际NIC的MAC地址。因此,浮动IP资源发生失效切换,对应的MAC地址会发生改变。
- 关于资源启动时,来自当前服务器的IP通信的资源地址即使浮动IP资源启动,来自服务器的IP通信的源发信地址也是实际服务器的实际IP。如果想将源发信地址设置为浮动IP时,需要在应用方面进行设置。
将FIP强制启动设定为On时,如果在启动浮动IP地址后,从同一网络段的机器连接浮动IP地址,则有可执行连接到更早存在的IP地址的机器。
浮动IP资源不支持在OpenVPN启动的环境中运行。
在浮动IP资源中添加IP地址的NIC名(网络接口名,例:eth0)的长度上限是15个字符。超过15个字符时会启动异常。此时,需修改NIC名(网络接口名)。
浮动IP资源在启动前,为了检查是否存在重复的IP地址,会执行[ping]命令。因此,如果已经设置此IP地址的网络设备通过防火墙设定拒绝接受ICMP报文,会导致[ping]命令不能确认重复IP地址,所以浮动IP地址可执行会重复。
3.8.4. 浮动IP资源停止等待处理¶
通过[ifconfig]命令执行浮动IP地址的停止后,进行以下处理。
通过[ifconfig]命令进行等待处理
执行[ifconfig]命令或API,取得分配给OS的IP地址一览。 [ifconfig]命令和API中执行哪一个,由浮动IP资源自动判断。如果IP地址一览中不存在浮动IP地址则判断为停止。
如果IP地址一览中存在浮动IP地址,则等待1秒钟。等待时间不能通过Cluster WebUI更改。
上述处理最多重复4次。该次数不能通过Cluster WebUI更改。
该结果异常时,是否将浮动IP资源作为停止异常,可以在浮动IP资源的停止确认标签页的[I/F删除确认]的[查出异常时的状态]中更改。
通过[ping]命令进行停止确认处理
执行[ping]命令,在浮动IP地址中确认有无应答。如果浮动IP地址没有应答则判断为停止。
如果浮动IP地址有应答,则等待1秒钟。等待时间不能通过Cluster WebUI更改。
上述处理最多重复4次。此次数不同通过Cluster WebUI更改。
[ping]命令在超时时间1秒设置下执行。该超时时间不能通过Cluster WebUI更改。
该结果异常时,可以在浮动IP资源的停止确认标签页的[I/F应答确认]的[查出异常时的状态]中更改。
注解
3.8.5. 详细标签页¶

IP地址 服务器个别设置
输入要使用的浮动IP地址。设置bonding时,请用"%"分隔指定bonding的I/F名。详细信息请参考本指南的"7. 其他设置信息"的"bonding"。
设置bonding时的示例:10.0.0.12%bond0
有关浮动 IP资源的默认值,IPv4时屏蔽位数为24bit,IPv6时屏蔽位数为128bit,检索与本地计算机上的子网屏蔽一致的地址,对相应的网络接口赋予别名,并添加浮动IP地址。
明确指定屏蔽位数时,请在地址之后指定[/屏蔽位数] 。
(IPv6地址时必须指定[/屏蔽位数])
例) fe80::1/8
明确指定网络接口时,请在地址之后指定[%接口名]。
例) fe80::1/8%eth1
在上述的例子中,在网络接口eth1 添加了屏蔽位数8的浮动IP地址。
设定tagVLAN时,用"%"分隔指定tagVLAN的I/F名。
设定tagVLAN时的例子: 10.0.0.12%eth0.1
IPv6地址并且[ifconfig]命令能使用的环境的场合,因为区分大小写,ifconfig输出格式和浮动IP的地址格式请保持一致。
调整
显示[浮动IP资源调整属性]对话框。进行浮动IP资源的详细信息设置。
浮动IP资源调整属性
参数标签页
显示浮动IP资源参数相关的详细设置。

ifconfig
获取IP地址一览以及进行浮动IP资源的启动/停止各处理中执行的[ifconfig]命令相关的详细设置。
ping
在启动浮动IP资源之前,为检查是否存在重复的IP地址而发出的[ping]命令相关的详细设置。
ARP发送次数 (0~999)
设置启动浮动IP资源时发送的ARP包的发送次数。设置为0则不发送ARP包。
判断NIC Link Down异常
启动浮动IP资源之前,设置是否执行NIC Link Down确认。由于NIC 板卡,驱动程序的不同,有时不支持所需的ioctl( )。NIC Link Up/Down 监视器能否运行,可以使用各个Distributor 提供的 [ethtool]命令进行确认。关于使用[ethtool]命令的确认方法,请参照本指南的"理解NIC Link Up/Down监视资源" - "NIC Link UP/Down监视资源的注意事项"。
bonding设备的情况下,启动时构成bonding的所有NIC为Link Down状态时,判定为异常。
默认值
点击[默认值]后,所有项目将设置为默认值。
停止确认标签页
显示浮动IP资源的停止确认相关的详细设置。

I/F删除确认
I/F 应答确认
3.9. 理解虚拟IP资源¶
3.9.1. 虚拟IP资源的依赖关系¶
默认情况下没有依存的组资源类型。
3.9.2. 何谓虚拟IP资源?¶
客户端应用程序可以使用虚拟IP地址连接集群服务器。另外,服务器之间也可以使用虚拟IP地址进行连接。通过使用虚拟IP地址,即使发生失效切换/失效切换组移动,客户端也无需考虑连接目标服务器的切换。
IP地址一览的取得以及虚拟IP资源的启动/停止的各处理是通过执行[ifconfig]命令或API。执行[ifconfig]命令或API的哪一个,虚拟IP资源自动判断。以下示例。
RHEL 7 以上(包括RHEL 7 兼容的OS) [ifconfig]命令不能使用的环境:执行API。
RHEL 7 以上(包括RHEL 7 兼容的OS) 通过net-tools包[ifconfig]命令能使用的环境:执行API。这是因为[ifconfig]命令的输出方式和RHEL 6 以下版本没有兼容性。
RHEL 6 [ifconfig]命令能使用的环境:执行[ifconfig]命令。
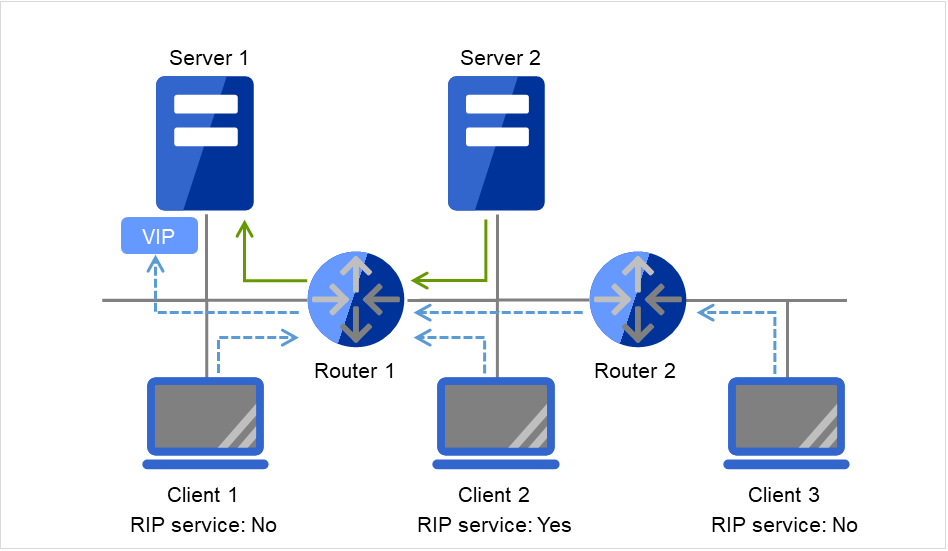
图 3.80 使用虚拟IP的配置 (1)¶
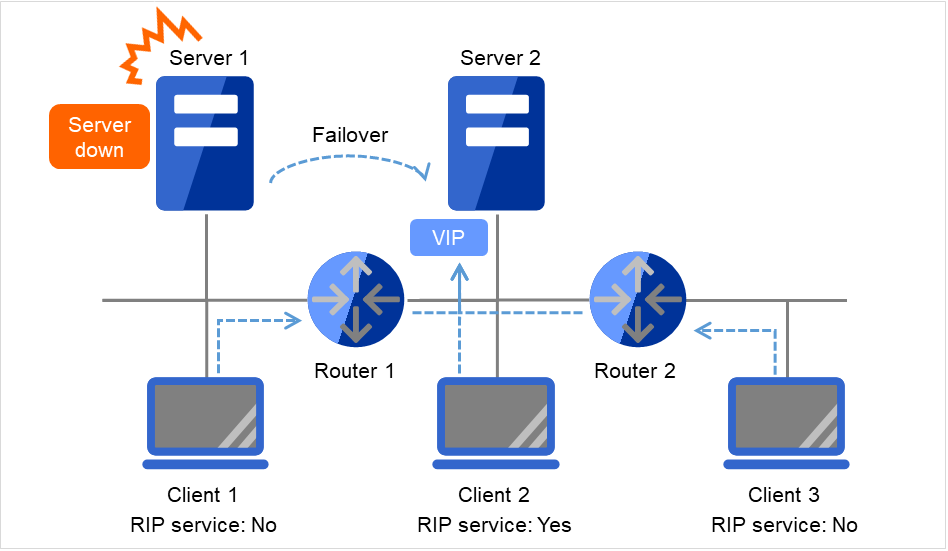
图 3.81 使用虚拟IP的配置 (2)¶
3.9.3. 虚拟IP地址的探讨¶
分配给虚拟IP地址的IP地址需要满足以下条件。
在集群服务器所属LAN的网络地址范围之外
不与现有网络地址冲突
要满足这两个条件,请选择以下2种分配方法中的一种。
重新获取合法的网络IP地址作为虚拟IP地址,由此处分配虚拟IP地址。
从私有IP地址空间选择合适的网络IP地址,由此处分配各自的虚拟IP地址。下面举例说明具体步骤。
从网络地址192.168.0 ~ 192.168.255中选择1个用作虚拟IP地址。
从上面选择的网络地址中分配64个字符以内的主机IP地址用作虚拟IP地址。(譬如选择网络地址192.168.10,从其中分配192.168.10.1和192.168.10.254两个地址作作为主机IP地址。)
虚拟IP地址的子网掩码设置为255.255.255.0。
设置多个虚拟IP资源时,必须有虚设用的虚拟IP地址。详细信息请参考"使用虚拟IP资源时的事先准备"。
另外还需要注意以下几点。
私有IP地址是用于组织内封闭网络的地址,所以不能在因特网供应商之外的组织使用虚拟IP地址。
私有IP地址相关的路径信息不能泄漏到组织外。
为了避免私有IP地址冲突,需要在组织内部进行调整。
3.9.4. 使用虚拟IP资源时的事先准备¶
集群配置符合下列条件时,各服务器上必须设置与虚拟IP地址相同网络地址的伪虚拟IP地址。
存在多个虚拟IP资源
存在网络地址和NIC别名相同的资源
注解
不能设置伪虚拟IP地址时,任意的虚拟IP资源停止时 设定了相同的NIC别名的其它虚拟IP地址有时也会被OS删除。
伪虚拟IP地址必须满足以下条件。
是与虚拟IP资源的IP地址相同的网络地址,是固有IP地址
可以准备用于构成集群的各服务器的伪虚拟IP地址
每个NIC别名都准备
以下设置示例时,必须在各服务器上设置伪虚拟IP地址。
- 虚拟IP资源1IP地址 10.0.1.11/24NIC别名 eth1
- 虚拟IP资源2IP地址 10.0.1.12/24NIC别名 eth1
作为示例设置如下伪虚拟IP地址。
- 服务器1的伪虚拟IP资源IP地址 10.0.1.100/24NIC别名 eth1:0
- 服务器2的伪虚拟IP资源IP地址 10.0.1.101/24NIC别名 eth1:0
为了使伪虚拟IP地址在OS启动时有效,请按照以下步骤对OS进行设置。
以下步骤是在服务器1的eth1上设置10.0.1.100/24。
对每个distribution进行如下设置。
- SUSE LINUX Enterprise Server时编辑下述路径文件,添加设置内容的斜体部分。
路径
/etc/sysconfig/network/ifcfg-eth1-"MAC_address_of_eth1"
设置内容
BOOTPROTO='static' BROADCAST='10.0.0.255' IPADDR='10.0.0.1' MTU='' NETMASK='255.255.255.0' NETWORK='10.0.0.0' IPADDR_1='10.0.1.100' NETMASK_1='255.255.255.0' NETWORK_1='10.0.1.0' LABEL_1=1 REMOTE_IPADDR='' STARTMODE='onboot' UNIQUE='xxxx' _nm_name='xxxx'
- SUSE LINUX Enterprise Server 以外时作成下述路径的文件,添加设置内容。
路径
/etc/sysconfig/network-scripts/ifcfg-eth1:0
设置内容
DEVICE=eth1:0 BOOTPROTO=static BROADCAST=10.0.1.255 HWADDR=eth1的MAC地址 IPADDR=10.0.1.100 NETMASK_1='255.255.255.0' NETWORK=10.0.1.0 ONBOOT=yes TYPE=Ethernet
重启OS。
OS重启后伪虚拟IP地址有效。请对服务器2也作相同设置。
由于集群的配置更改必须进行上述的设置时,请按照以下步骤进行。
停止集群。步骤请参考《安装&设置指南》的"操作前的准备工作"-"暂停EXPRESSCLUSTER" - "停止EXPRESSCLUSTER 后台程序"。
禁用集群daemon。步骤请参考《安装&设置指南》的"操作前的准备工作"-"暂停EXPRESSCLUSTER"- "禁用EXPRESSCLUSTER 后台程序"。
更改上述设置。
重启OS,确认设置是否有所反映。
使集群daemon有效。步骤请参考《安装&设置指南》的"操作前的准备工作" - "暂停EXPRESSCLUSTER"-"启用被禁用的EXPRESSCLUSTER 后台程序"。
3.9.5. 路径控制¶
要从远程LAN访问虚拟IP地址,到远程LAN和集群服务器的LAN的路径上的所有路由器中都必须将虚拟IP地址的路由信息设置为有效。
具体需要以下设置。
集群服务器的LAN上的路由器解析主机RIP。
从集群服务器到远程服务器的路径上的路由器全部设置为动态路由控制或者虚拟IP地址的路由相关信息设置为静态路由信息。
3.9.6. 虚拟IP地址的使用条件¶
可以使用虚拟IP地址的环境
可以从以下机器正确访问虚拟IP地址。即使是使用交换机的LAN,虚拟IP地址机制也可以正常运行。
但是,服务器宕机时已连接的TCP/IP连接会被断开。
在不能设置接收主机形式的RIP以及创建主机形式的路由表的交换机上使用虚拟IP地址时,需要重新申请1个网络地址,并将各个服务器的虚拟IP地址设置为属于各自的网络地址的虚拟IP地址。
与启动虚拟IP的服务器属于同一LAN的集群服务器
如果满足以下条件,则可以使用虚拟IP地址。
能通过接收RIP包进行路径更改的机器
能通过路由器进行虚拟IP地址路径信息解析的机器
与启动虚拟IP的服务器属于不同LAN的集群服务器
如果满足以下访问条件,则可以使用虚拟IP地址。
能通过访问路由器进行虚拟IP地址路径信息解析的机器
与集群服务器属于同一LAN的客户端
如果满足以下条件,则可以使用虚拟IP地址。
能通过接收RIP包进行路径更改的机器
能通过访问路由器进行虚拟IP地址路径信息解析的机器
远程LAN上的客户端
如果满足以下条件,则可以使用虚拟IP地址。
能通过访问路由器进行虚拟IP地址路径信息解析的机器
3.9.7. 虚拟IP资源相关注意事项¶
请不要在虚拟 IP 资源启动的服务器中执行网络的重新启动。重新启动网络后,虚拟 IP 资源添加的 IP 地址就会被删除。
虚拟IP地址有以下规则。
关于分配虚拟IP的虚拟NIC的MAC地址
分配虚拟IP的虚拟NIC的MAC地址是实际NIC的MAC地址。因此,虚拟IP资源进行失效切换,对应的MAC地址也会被更改。
关于资源启动时,来自当前服务器的IP通信资源地址
即使是在虚拟IP资源启动时,来自当前服务器的IP通信的源发信地址也基本是服务器的实际IP。如果想将源发信端的地址更改为虚拟IP,需要在应用端进行设置。
使用的路由协议
将使用的路由协议设置为「RIPver2」时,发送的RIP包内的子网掩码为「255.255.255.255」。
3.9.8. 详细标签页¶

IP地址 服务器个别设置
输入要使用的虚拟IP地址。明确指定屏蔽位数时,请在地址后面指定[/屏蔽位数]。(IPv6地址时必须指定[/屏蔽位数])
NIC别名 服务器个别设置
输入启动时要使用的虚拟IP地址的NIC接口名。
目标IP地址 服务器个别设置
输入RIP包的发送目标IP地址。IPv4指定广播地址,IPv6指定路由器的IPv6地址。
发送源IP地址 服务器个别设置
输入RIP包发送时绑定的IP地址。在启动虚拟IP地址的NIC中指定启动的实际IP地址。
使用IPv6地址时,请指定发送源IP地址为本地链路地址。
注解
发送间隔 (1~30) 服务器个别设置
输入RIP包的发送间隔。
使用路由协议 服务器个别设置
输入要使用的RIP版本。IPv4环境下从RIPver1,RIPver2选择。IPv6环境下从RIPngver1,RIPngver2,RIPngver3选择。也可以选择多个路由协议。
调整
显示[虚拟IP资源的调整属性]对话框。进行虚拟IP资源的详细设置。
虚拟IP资源调整属性
参数标签页
显示与虚IP资源的参数相关的详细设置。

ifconfig
通过IP地址一览的取得以及在虚拟IP资源的启动/停止的各处理中执行的[ifconfig]命令相关详细设置。
ping
为了在启动虚拟IP资源之前检查是否已存在重复的IP地址而发出的[ping]命令,此命令相关的详细设置如下。
ARP发送次数 (0~999)
设置启动虚拟IP资源时ARP包的发送次数。设置为0不发送ARP包。
判断NIC Link Down异常
启动浮动IP资源之前,设置是否执行NIC Link Down确认。由于NIC 板卡,驱动程序的不同,有时不支持所需的ioctl( )。NIC Link Up/Down 监视器能否运行,可以使用各个Distributor 提供的 [ethtool]命令进行确认。关于使用[ethtool]命令的确认方法,请参照本手册的"理解NIC Link Up/Down监视资源"-"NIC Link UP/Down监视资源的注意事项"。
默认值
点击[默认值]后,所有项目将设置为默认值。
停止确认标签页
显示虚拟IP资源的停止确认相关的详细设置。

I/F的删除确认
I/F 应答确认
RIP标签页
显示虚拟IP资源的RIP相关详细设置。

下一跳IP地址
输入RIP的下个中继地址(下个路由器的地址)。下个中继 IP 地址可以省略。只有RIPver2时可以指定。不可以指定netmask或prefix。
度量值 (1~15)
输入RIP的度量值。度量是为了到达目的地的RIP的中继计数。
端口
在[端口号]中显示RIP发送使用的通信端口号一览。
添加
添加RIP发送使用的端口号。显示[输入端口号]对话框。

端口号
请输入RIP发送使用的端口号,选择[确定]。
编辑
显示[输入端口号]对话框。显示在[端口号]选择的端口号,编辑后选择[OK]。
删除
从列表中删除在[端口号]选择的端口号。
RIPng标签页
显示虚拟IP资源的RIPng相关详细设置。

度量值 (1~15)
输入RIPng的度量值。度量是为了到达目的地的RIPng的中继计数。
端口
在[端口号]中显示RIPng发送使用的通信端口号一览。
添加
添加RIPng发送使用的端口号。显示[输入端口号]对话框。

端口号
请输入RIPng发送使用的端口号,选择[确认]。
编辑
显示[输入端口号]对话框。显示在[端口号]选择的端口号,编辑后选择[OK]。
删除
从列表中删除在[端口号]选择的端口号。
3.10. 理解镜像磁盘资源¶
3.10.1. 镜像磁盘资源的依赖关系¶
默认情况下,依存以下组资源类型。
组资源类型 |
|---|
浮动IP资源 |
虚拟IP资源 |
AWS Elastic IP资源 |
AWS 虚拟IP资源 |
AWS DNS资源 |
Azure 探头端口资源 |
Azure DNS资源 |
3.10.2. 何谓镜像磁盘?¶
镜像磁盘是指在构成集群的2台服务器之间进行磁盘数据镜像的磁盘对。
在下图中,连接到Server 1的Mirror disk 1 以及连接到Server 2的Mirror disk 2,成对进行磁盘数据的镜像。
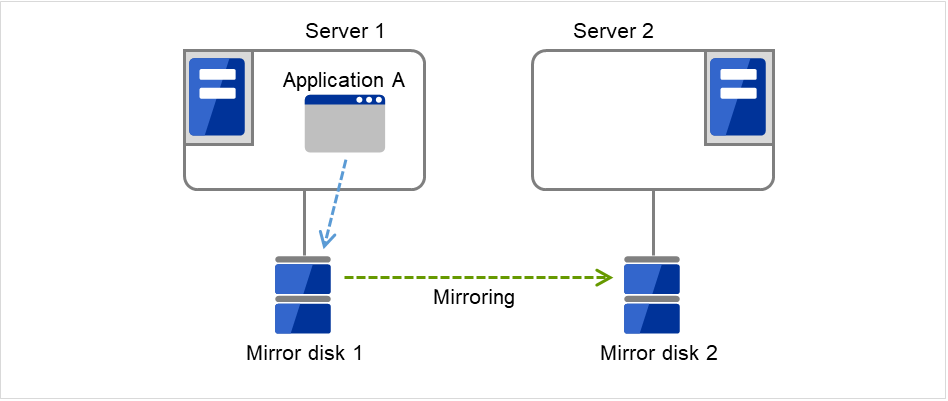
图 3.82 镜像磁盘配置 (1)¶
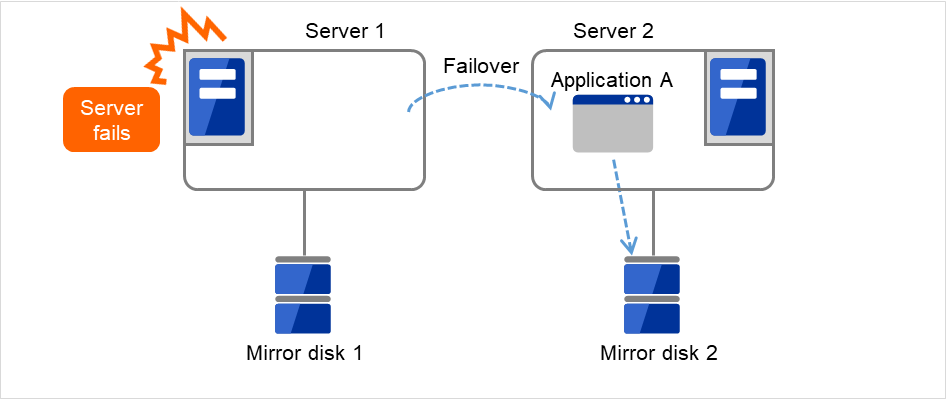
图 3.83 镜像磁盘配置 (2)¶
数据分区
保存镜像的数据(业务数据等)的分区称作数据分区。
请按照以下方式分配数据分区。
- 数据分区大小请确保1GB以上,不到1TB的分区。※从数据配置时间,复归的时间的观点来看,建议使用不满1TB的大小。
- 分区ID83(Linux)
- 如果镜像资源的mkfs的设置为[构建初始文件系统],则在生成集群时将自动构建文件系统。
- 文件系统的访问控制(mount/umount)由EXPRESSCLUSTER进行,所以请不要在OS端对数据分区的mount/umount进行设置。
集群分区
EXPRESSCLUSTER用于控制镜像分区而使用的专用分区称为集群分区。
请按照以下方式分配集群分区。
- 集群分区大小请最低保证1024MB。根据磁盘几何配置信息,有时可执行为1024MB以上。即使1024MB以上也没有任何问题。
- 分区ID83(Linux)
- 集群分区需要与数据镜像所用数据分区成对进行分配。
- 集群分区中请不要构建文件系统。
- 关于文件系统的访问控制(mount/umount),EXPRESSCLUSTER将镜像分区设备作为挂载设备进行管理,所以请不要在OS端对集群分区的mount/umount进行设置。
镜像分区设备(/dev/NMPx)
1个镜像磁盘资源中将1个镜像分区设备提供给文件系统。作为镜像磁盘资源登录后,只能从1台服务器(通常为资源组的主用端服务器)进行访问。
通常情况下,用户(AP)通过文件系统进行I/O,所以不需要意识到镜像分区设备(dev/NMPx)。通过Cluster WebUI创建信息时,分配不重复的设备名。
- 文件系统的访问控制(mount/umount)由EXPRESSCLUSTER进行,所以请不要在OS侧对镜像分区设备进行mount/umount。关于从业务应用程序等是否可以访问镜像分区(镜像磁盘资源)的考虑方法,与使用共享磁盘的切换分区(磁盘资源)相同。
镜像分区的切换依照失效切换组各自的失效切换策略进行。
镜像磁盘连接
每个镜像磁盘资源最多可以登录两个镜像磁盘连接。
如果登录两个镜像磁盘连接,则切换时的处理等如下所示。
可以将镜像数据同步所使用的路径双重化。如果某个镜像磁盘连接因为短线等原因导致不能使用时,还可以实现镜像数据的同步。
镜像的速度没有变化。
如果在数据写入过程中切换镜像磁盘连接,则可执行暂时变成镜像中断状态,在镜像磁盘连接切换完成后执行差分镜像恢复。
如果在镜像恢复过程中切换镜像磁盘连接,则会发生镜像恢复中断。如果设置为自动执行镜像恢复,则在镜像磁盘连接切换完成后,自动开始镜像恢复。如果没有设置自动镜像恢复,则在镜像磁盘连接切换完成后,需要再次执行镜像恢复。
关于镜像磁盘连接的设置,请参考本指南的"2. 参数的详细信息" - "集群属性" - "私网标签页"。
磁盘分区
在与OS(root分区和swap分区)同一个磁盘上,也可以确保镜像分区(集群分区,数据分区)。
- 需要保证故障时的维护性时建议您使用与OS(root分区和swap分区)不同的磁盘用于镜像。
- 因为H/W RAID的规格限制,不能增加LUN时在H/W RAID的预安装模式中,很难更改LUN配置时在与OS(root分区和swap分区)同一个磁盘上,也可以确保镜像分区(集群分区,数据分区)。
在两台服务器上增设1个SCSI磁盘作为1个镜像磁盘对时
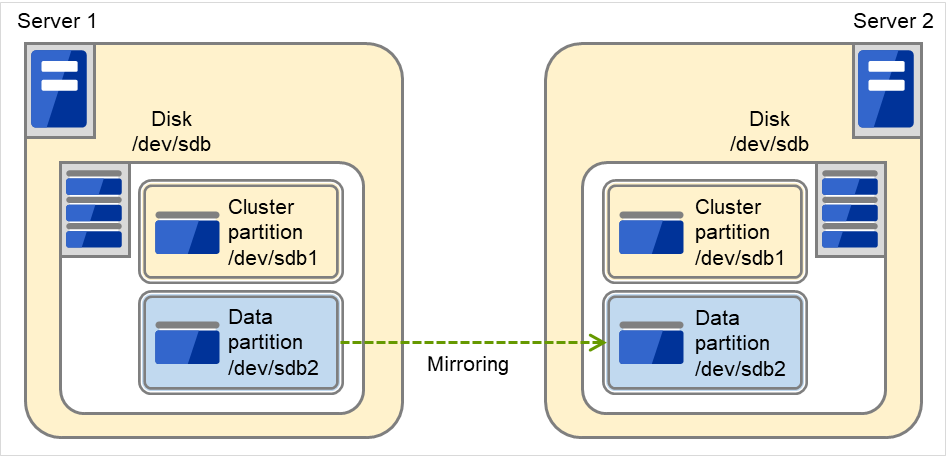
图 3.84 将增设的1个磁盘作为镜像分区时¶
使用两台服务器的OS所存储的IDE磁盘的剩余空间设置镜像磁盘对时
下图中,磁盘的OS等未使用的区域被用作镜像分区设备(集群分区,数据分区)。
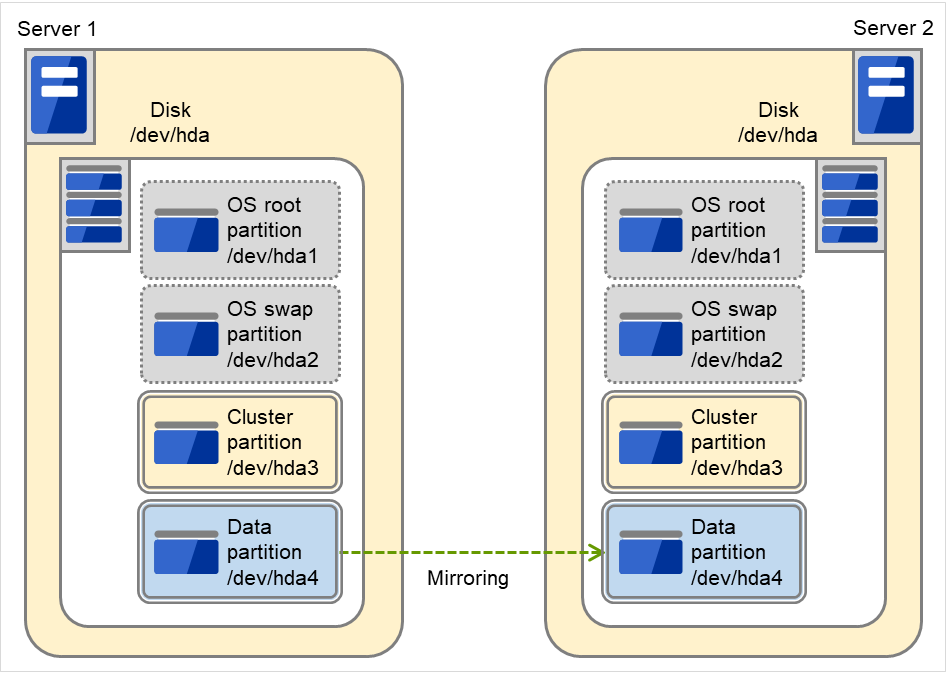
图 3.85 将磁盘可用空间作为镜像分区时¶
- 磁盘配置镜像磁盘可以使用多个磁盘。另外,可以在1个磁盘中分配多个镜像分区磁盘。
在两台服务器中加装2个SCSI磁盘并使2个镜像磁盘成对时
下图显示了将有相同大小分区的两对磁盘用作镜像分区时的情况。
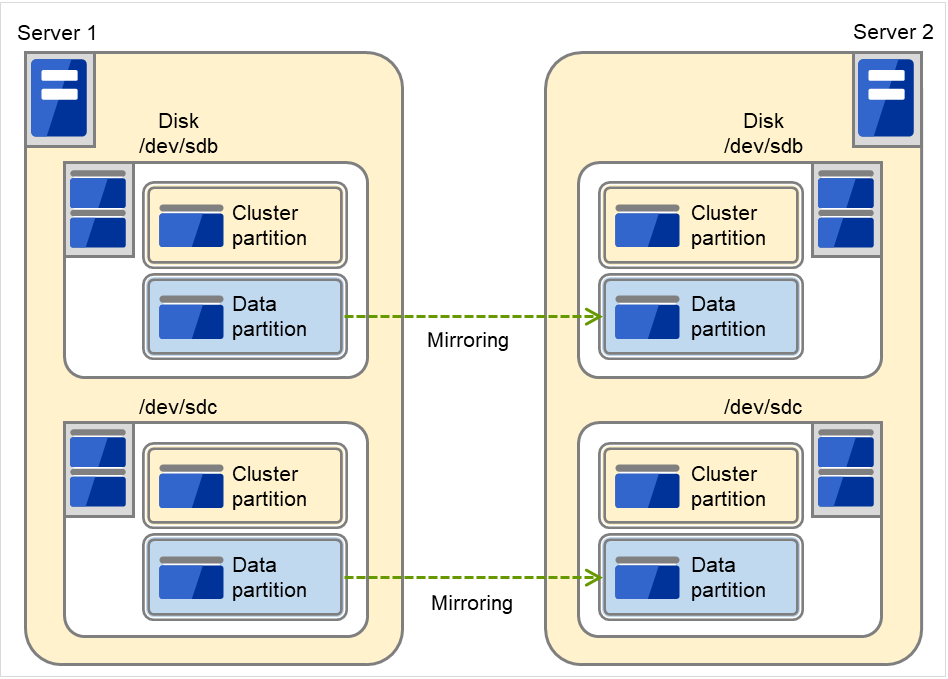
图 3.86 将各磁盘作为镜像分区时¶
在两台服务器上加装1个SCSI磁盘并设置2个镜像分区时
图中显示了在各磁盘中,除了集群分区外,还保留有相同大小的两个分区,并将它们用作数据分区时的情况。
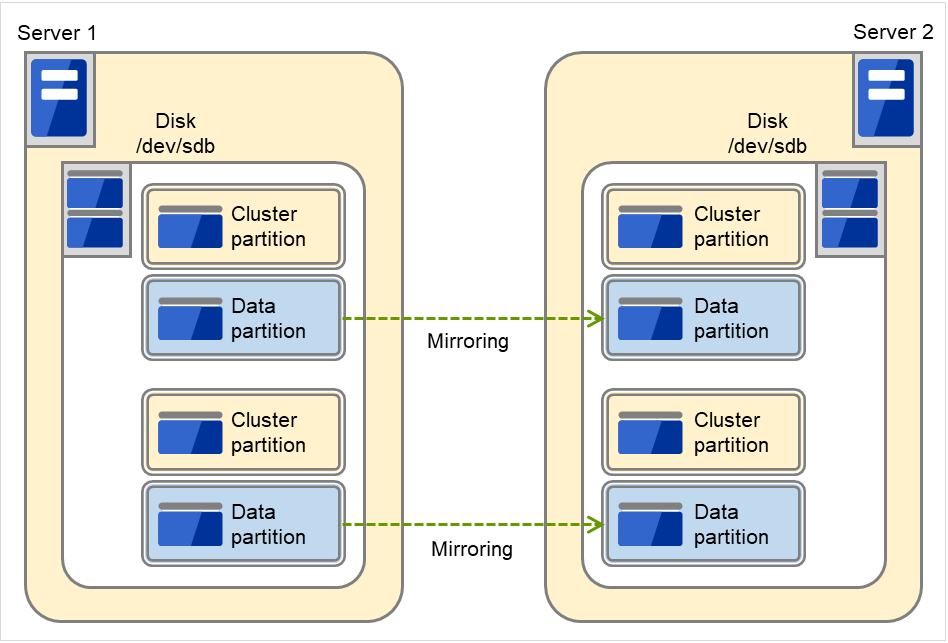
图 3.87 将磁盘内多个空间作为镜像分区时¶
3.10.3. 镜像参数设置的考虑方法¶
镜像磁盘端口号
设置镜像驱动之间收发镜像数据的TCP端口号。需要针对每个镜像磁盘资源分别进行设置。
在Cluster WebUI中追加镜像磁盘资源时,在以下条件下显示初始值。
29051之后的端口号,未使用并且最小的端口号
心跳端口号
设置镜像驱动之间收发控制用数据的TCP端口号。需要针对镜像磁盘资源分别进行设置。
在Cluster WebUI中追加镜像磁盘资源时,在以下条件下显示初始值。
29031之后的端口号,未使用并且最小的端口号
ACK2端口号
设置镜像驱动之间收发控制用数据的TCP端口号。需要针对镜像磁盘资源分别进行设置。
在Cluster WebUI中追加镜像磁盘资源时,在以下条件下显示初始值。
29071之后的端口号,未使用并且最小的端口号
请求队列的最大数
镜像磁盘驱动程序从上层发出I/O要(写入要求)编入队列而设置队列个数。数值越大则写入的性能越高但物理内存消耗较大。
请按照如下方式设置。
在下述条件下,增大数值可以期待提高性能。
服务器中存在较多物理内存且剩余内存空间充足。
连接超时
镜像复归及数据同步时,等待服务器之间通信连接成功的超时。
发送超时
该超时用于以下情况。
镜像复归及数据同步时,从当前服务器向待机服务器开始发送write数据起至发送完成为止的等待超时
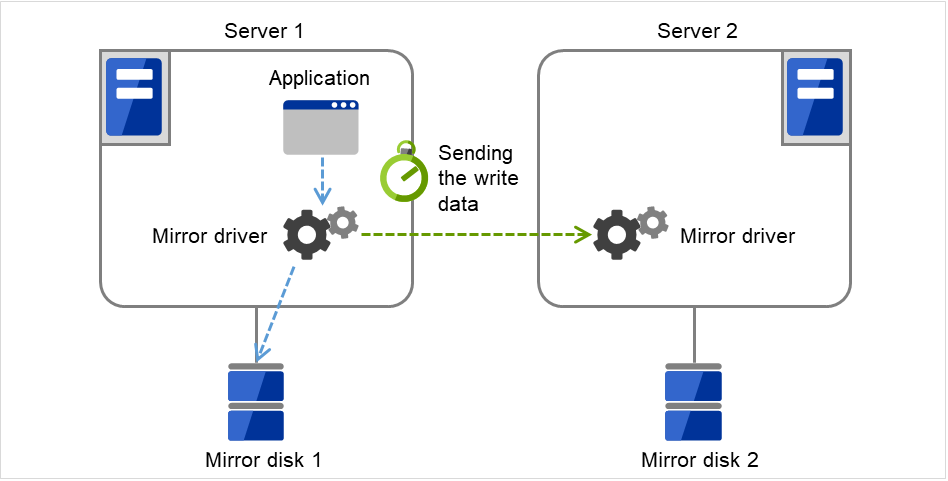
图 3.88 发送超时(write数据)¶
※具体内容是从向网络(TCP)的发送缓存器开始存储发送数据起,至存储完成为止的等待超时。当TCP的缓存期变满,没有空闲空间时发生等待超时。
确认是否需要发送ACK的时间间隔,当当前服务器向待机服务器发送通知write完成的处理中,是否存在发送的ACK。
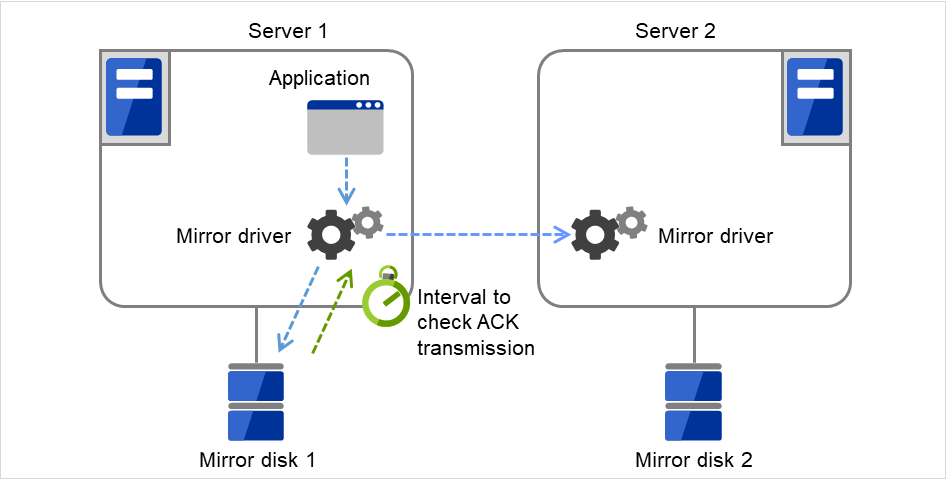
图 3.89 发送超时(ACK发送检查)¶
接收超时
该超时用于以下情况。
待机服务器从开始接收当前服务器发出的write数据起至接收完成为止的等待超时
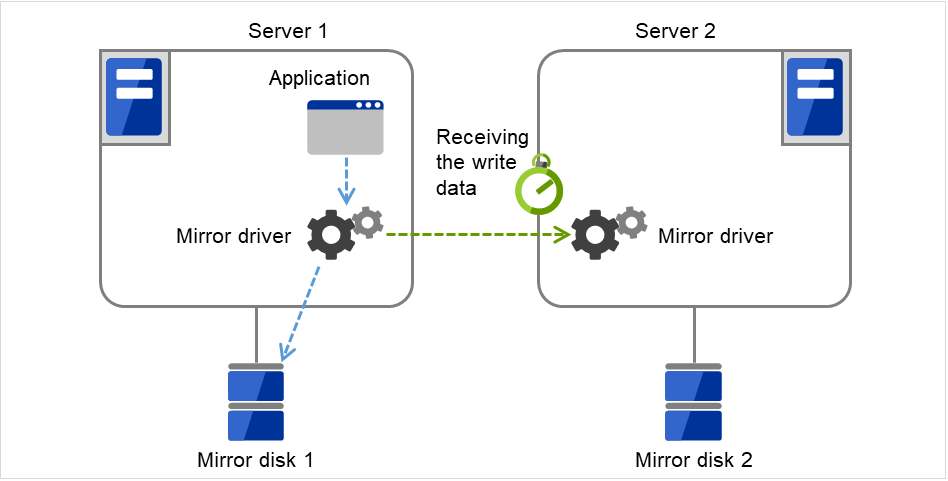
图 3.90 接收超时¶
Ack超时
该超时用于以下情况。
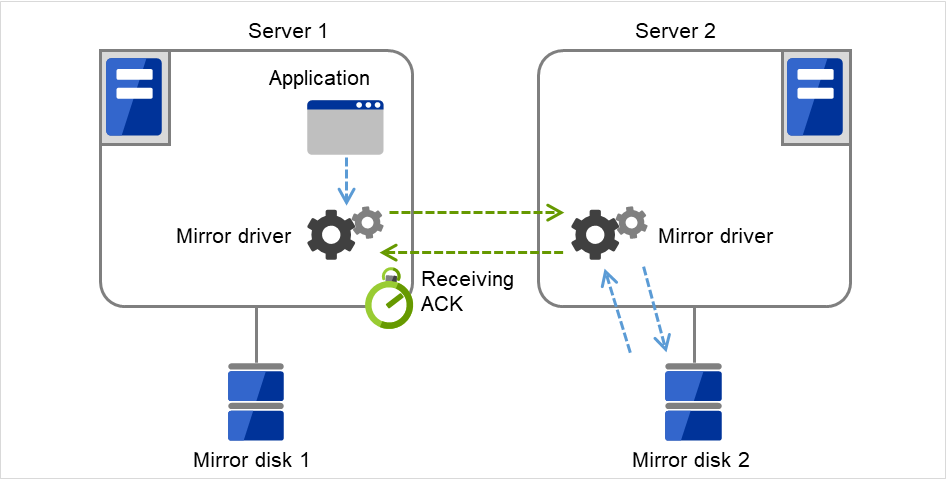
图 3.91 ACK超时(从待机服务器接收ACK)¶
※当模式设置为同步模式时,向应用程序的应答等待至ACK接收或者ACK接收超时为止。 当模式设置为异步模式时,向应用程序的应答在写入当前服务器后,不需等待ACK就执行反馈。
- 从待机服务器向当前服务器发送完通知write完成的ACK至收到当前服务器的ACK为止的等待超时。超时时间内如果收不到当前服务器的ACK,则将差异信息积累到待机服务器端的差异Bitmap。
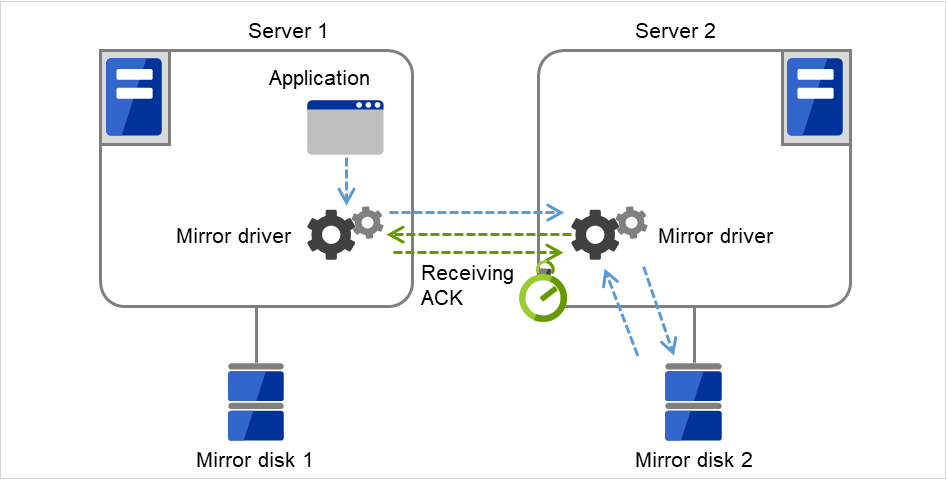
图 3.92 ACK超时(从当前服务器接收ACK)¶
镜像复归时,从复制源服务器开始发送复原数据起至等待收到复制目标服务器发出的接收完成通知ACK为止的超时
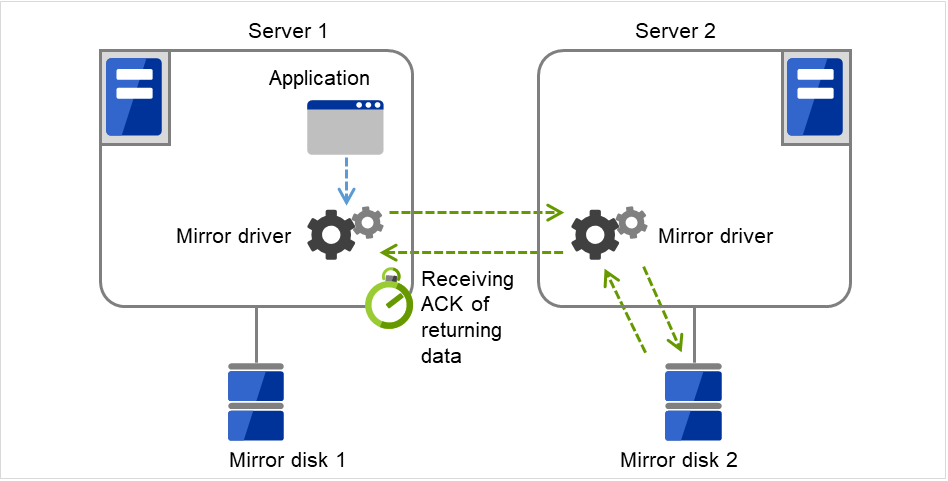
图 3.93 ACK超时(复归数据接收ACK)¶
※当复原数据的发送量达到「复原数据大小」的量时,反馈1个ACK。 因此,复原数据大小越大,则效率越高,但是发生ACK超时时,需要重新发送的数据量也会增多。
心跳间隔(1~600)
在2台服务器的镜像驱动之间,为了确认镜像磁盘连接的健全性而执行心跳的间隔(秒)。通常请在默认状态下使用。
ICMP Echo Reply接收超时(1~100)
在2台服务器的镜像驱动之间,为了确认镜像磁盘连接的健全性而执行心跳时所利用的值。发送ICMP Echo Request后,从对方服务器接收到ICMP Echo Reply的最长等待时间。若经过此超时值,也没有接收到ICMP Echo Reply时,最多可以重复后述的ICMP重试次数。通常请在默认状态下使用。
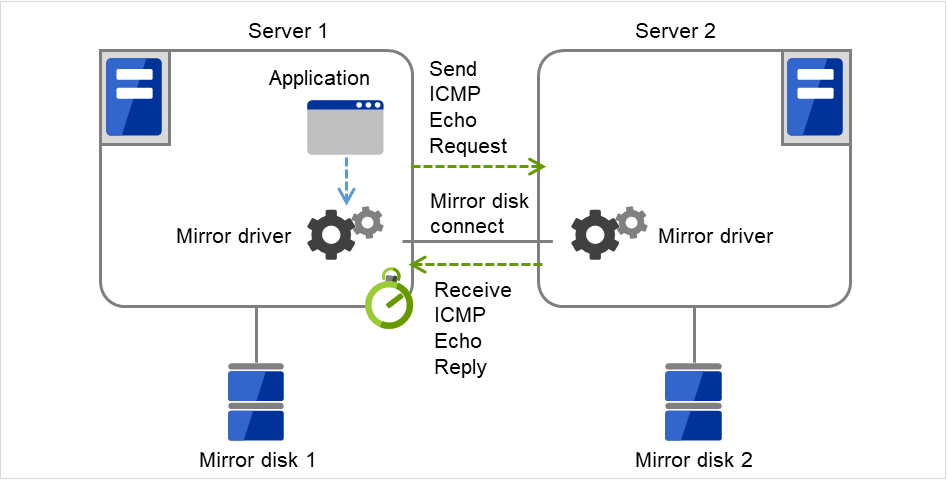
图 3.94 ICMP Echo Reply 接收超时¶
ICMP Echo Request重试次数(1~50)
从对应ICMP Echo Request的对方服务器的ICMP Echo Reply在前述的ICMP Reply接收超时为止没能接收时的ICMP Echo Request发送的最多重试次数。通常请在默认状态下使用。
通过调整ICMP Echo Reply接收超时和ICMP Echo Request重试次数,可以进行判断镜像磁盘连接断线的灵敏度调整。
增加重试次数
发生远地的网络延迟时
发生网络暂时故障时
减少重试次数
缩短网络故障检测所需时间时
差分Bitmap更新间隔
写入差异位图的信息暂时保存在内存上,定期写出集群分区。通过待机服务器确认有无输出信息的时间间隔。
差分Bitmap大小
指定差分Bitmap的大小。
数据分区的容量大时,设置更大的差分Bitmap大小,可以提高差分备份的效率。
但是,因为会降低内存效率,一般请使用默认值。
另外,这个设定要在集群中做成镜像磁盘资源和共享型镜像磁盘资源前设定。这些资源在集群内存在时,无法变更此设定。
初始镜像构筑
对构筑集群后首次启动时是否进行初始镜像构筑进行设置。
- 构建初始镜像构筑集群后首次启动时进行初始镜像构筑。在ext2/ext3/ext4/xfs和其他的文件系统中,构建初始镜像时间是不同的。
- 不构筑初始镜像构筑集群后首次启动时不进行初始镜像构筑。集群构筑前需要通过EXPRESSCLUSTER以外的方式完全统一镜像磁盘的数据分区内容。
初始mkfs
对构筑集群后首次启动时是否对镜像磁盘的数据分区进行mkfs进行设置。
- 构建初始文件系统构筑集群后首次启动时对镜像磁盘的数据分区进行mkfs。
- 不构筑初始初始文件系统构筑集群后首次启动时不对镜像磁盘的数据分区进行mkfs。镜像磁盘的数据分区中已经构筑有文件系统,已经存在要冗余化的数据,但不需要通过mkfs构建或初始化文件系统的情况下,可设置为不执行初始mkfs。用于镜像磁盘的分区构成需要满足镜像磁盘资源的条件。 4 对单一服务器进行集群化时需予以注意。
- 4
镜像磁盘中必须有集群分区。将单一服务器的磁盘作为镜像对象时如果无法分配集群分区,则暂时进行备份然后重新申请分区。
选择了[不构筑初始镜像]时,无法选择[构建初始文件系统] (分别对当前使用和待机的数据分区进行mkfs,mkfs刚结束后,在当前运行的数据分区和待机的数据分区内将产生差异。因此,要执行初始mkfs时,必须进行初始镜像构筑(复制当前运行的数据分区和待机数据分区)。因此,选择[执行初始镜像构筑]后,才可选择[执行初始mkfs]。)
队列数
注解
通信带宽限制
注解
历史文件保存目录
历史文件大小限制
模式为[异步]时,指定历史文件的累积量上限。如果历史文件达到上限,则变为镜像中断的状态。
数据压缩
指定压缩并发送的镜像同步数据([异步]模式)或镜像复归数据。使用低速网络时,通过压缩发送数据,可以减轻发送量。
注解
因压缩处理,发送数据时会出现CPU负荷增高的情况。
在低速网络中,压缩使发送量减少,会比非压缩的节省时间。相反,在高速网络中,与节省的传送时间相比,则明显增加了压缩处理时间和负荷,因此,会花费更多时间。
压缩效率高数据较多时,压缩使发送量减少,会比非压缩的节省时间。压缩效率低数据较多时,不但没有减少发送量,却又增加了压缩处理时间和负荷,因此,会花费更多时间。
镜像Agent发送超时
从镜像Agent向目标服务器发送处理请求至收到处理结果为止的等待超时。
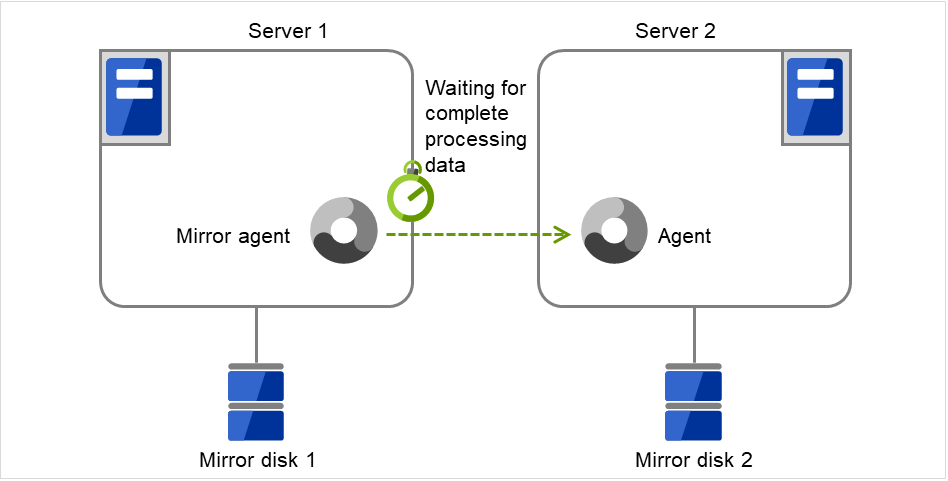
图 3.95 镜像Agent发送超时¶
镜像Agent接收超时
从镜像Agent创建与目标服务器之间的通信socket至开始接收为止的等待超时。
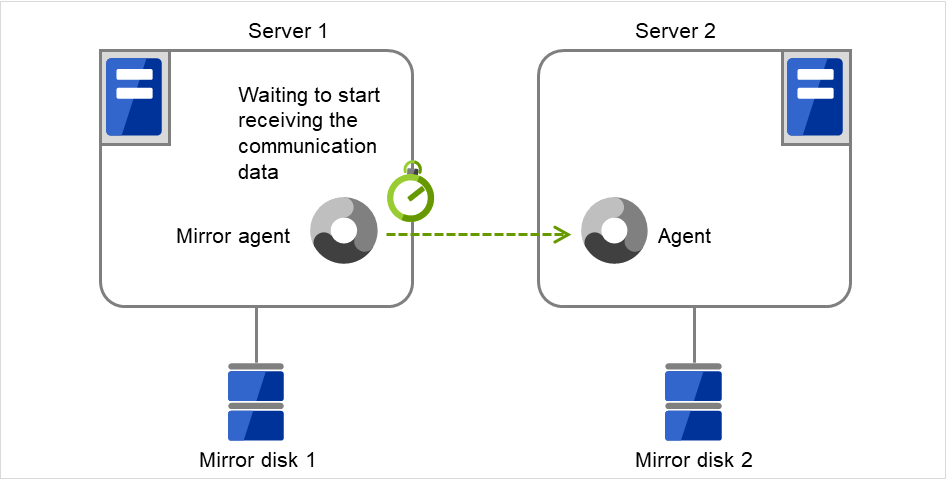
图 3.96 镜像Agent接收超时¶
复原数据大小 (64~32768)
指定镜像复归每次处理中2台服务器之间交换的数据大小。一般使用默认值。
增大值
服务器之间交换数据的次数变少,因此处理全部镜像复归的时间也变短。
- 镜像复归过程中,对磁盘性能可执行下降。(镜像复归数据的磁盘读取范围与从文件系统写入磁盘的范围相重合时,独占访问,后一访问需要等待前一访结束后才能进行。)在网络较慢的环境中,该恢复数据大小的值越大,进行1次镜像恢复的数据传输所需时间越长。如果对镜像的正常磁盘访问与该镜像恢复传输中的范围重合,则磁盘访问将等待该传输完成后再进行访问。这样可执行会导致磁盘性能低下。因此,尤其是在网络较慢的环境下,请尽量缩小此值。)
减小值
镜像复归过程中2台服务器之间收发的数据被细化,因此,网络速度慢或服务器高负荷时的超时发生概率降低。
因服务器之间处理次数增加,尤其在发生网络延迟的环境下,镜像复归处理需要的时间延长。
加密镜像通信
3.10.4. 镜像磁盘的构筑示例¶
如果沿用过去用作镜像磁盘的磁盘,则集群分区上会残留以前的数据,所以需要进行初始化。关于集群分区的初始化,请参《安装&设置指南》。
- 进行初始镜像构筑进行初始mkfs
首先,安装EXPRESSCLUSTER并进行设置。 然后,在分别连接到Server 1,Server 2的磁盘上运行初始mkfs。
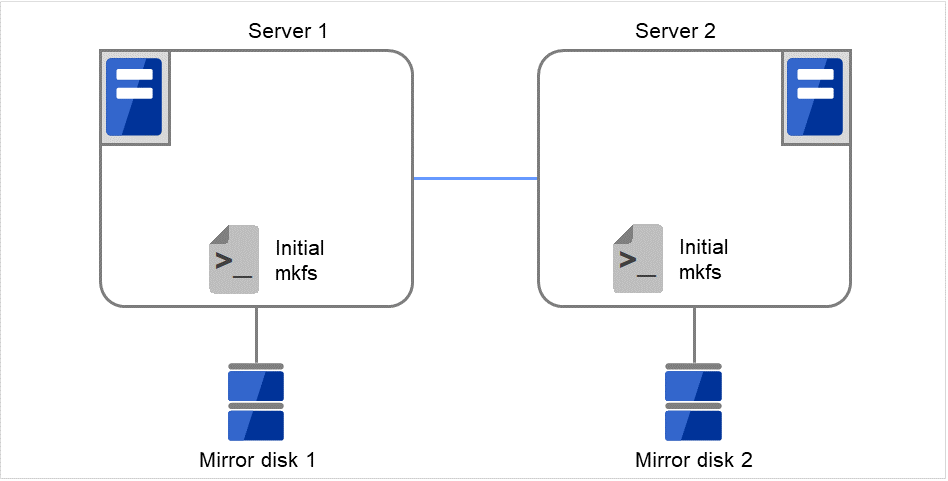
图 3.97 镜像磁盘构筑示例(进行初始镜像构筑和初始mkfs)(1)¶
接着开始进行初始镜像构筑。 从Server 1的 Mirror disk 1完全复制到 Server 2的 Mirror disk 2。
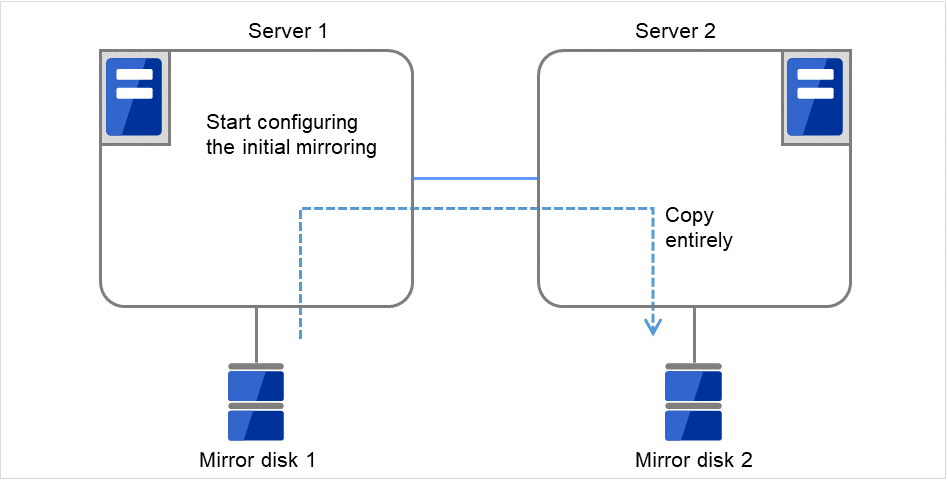
图 3.98 镜像磁盘构筑示例(进行初始镜像构筑和初始mkfs)(2)¶
- 进行初始镜像构筑不进行初始mkfs
首先,如果可以在构建集群之前准备双重化的 Application数据,请先在当前运行的镜像磁盘(Mirror disk 1)的数据分区中进行创建(ex.数据库的初始DB等)。 关于分区构筑,请参考 "3.10.2. 何谓镜像磁盘?" 。 接着,分别在Server 1,Server 2上安装EXPRESSCLUSTER并进行设置。
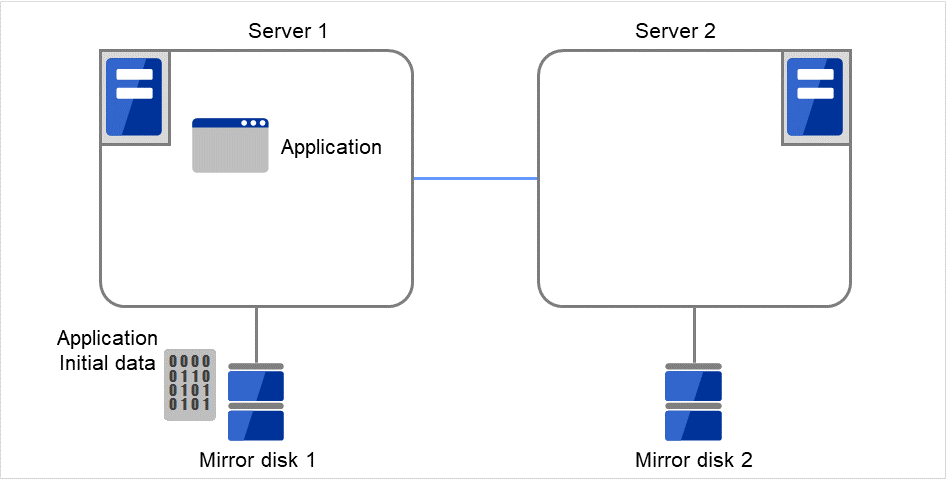
图 3.99 镜像磁盘构筑示例(仅进行初始镜像构筑)(1)¶
接着开始进行初始镜像构筑。 从Server 1的 Mirror disk 1完全复制到 Server 2的 Mirror disk 2。
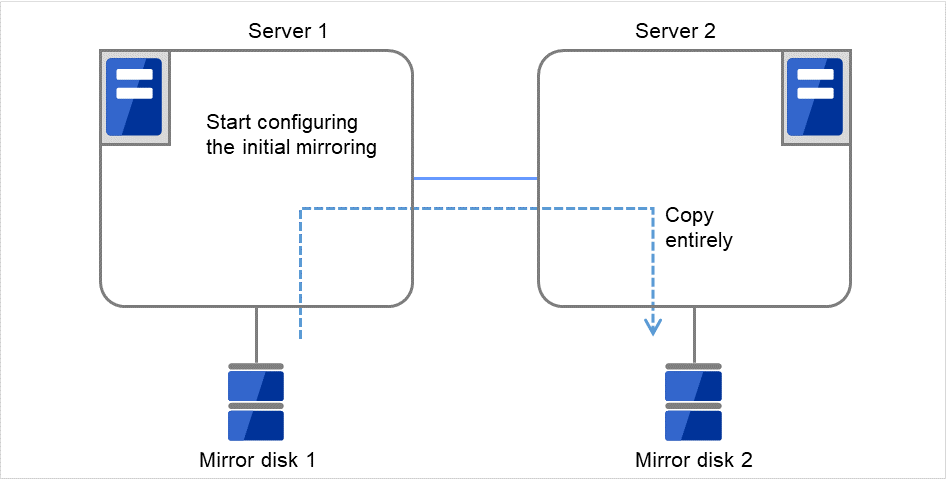
图 3.100 镜像磁盘构筑示例(仅进行初始镜像构筑)(2)¶
- 不进行初始镜像构筑不进行初始mkfs
例如通过以下方法可以统一两台服务器的镜像磁盘的内容。(构筑集群后则不能使用。请务必在构筑集群之前实施。)
例1
复制磁盘分区映像的方法
首先,如果可以在构建集群之前准备双重化的 Application数据,请先在当前运行的镜像磁盘(Mirror disk 1)的数据分区中进行创建(ex.数据库的初始DB等)。 关于分区构筑,请参考 "3.10.2. 何谓镜像磁盘?" 。
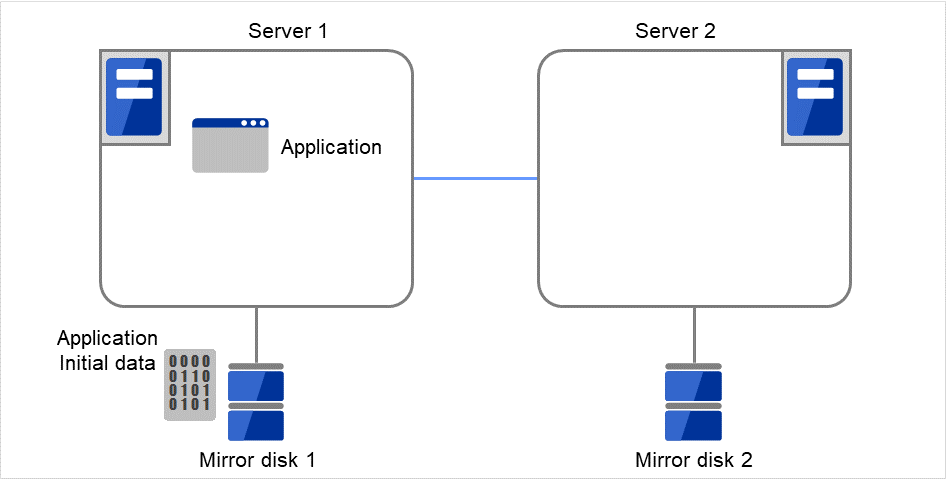
图 3.101 镜像磁盘构筑示例(复制分区映像)(1)¶
取下待机服务器(Server 2)的镜像磁盘(Mirror disk 2),连接到当前服务器(Server 1)。
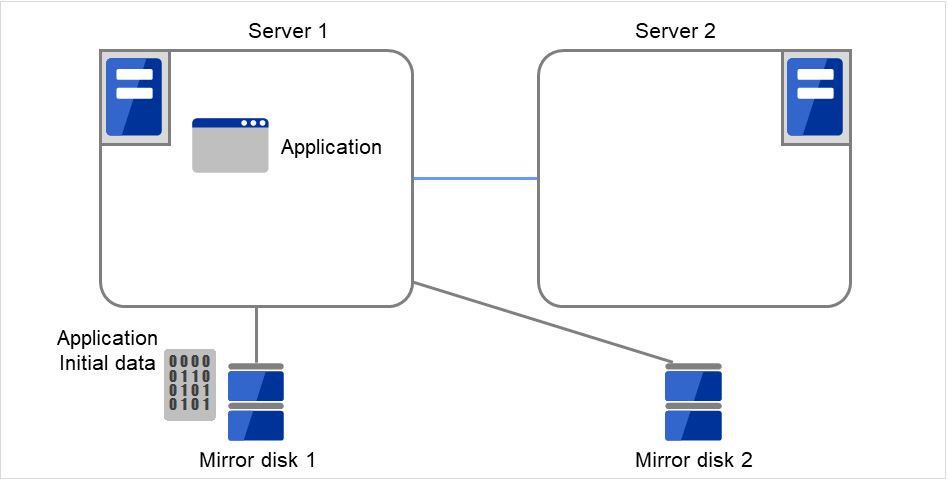
图 3.102 镜像磁盘构筑示例(复制分区映像)(2)¶
Mirror disk 1(当前运行的镜像磁盘)为Unmount状态,使用dd命令等将 整个Mirror disk 1的数据分区复制到Mirror disk 2的数据分区中。请注意,通过文件系统复制时,分区映像将不相同。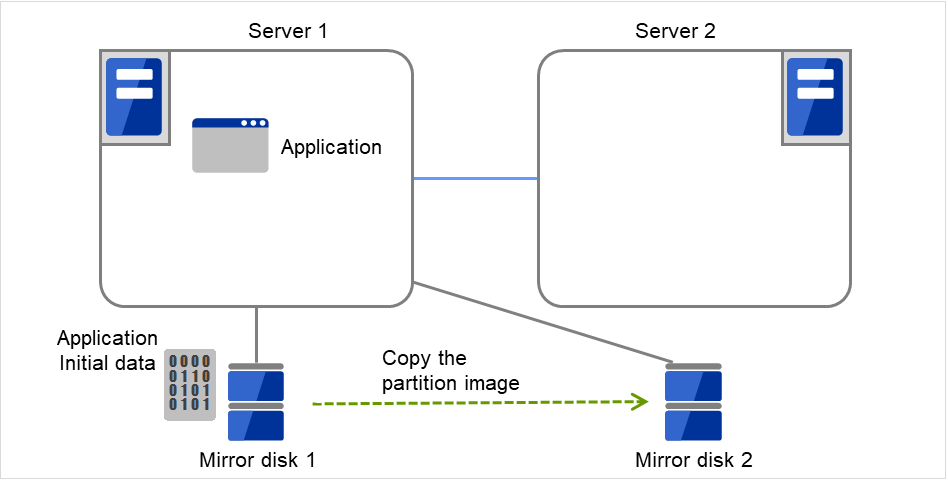
图 3.103 镜像磁盘构筑示例(复制分区映像)(3)¶
将已连接到当前服务器(Server 1)的待机镜像磁盘(Mirror disk 2)返回到待机服务器(Server 2)。此外,安装EXPRESSCLUSTER并进行设置。之后,通过“不进行初始mkfs·不进行初始镜像构筑”时的设置,构建集群。不执行镜像分区的初始构筑(初始同步)。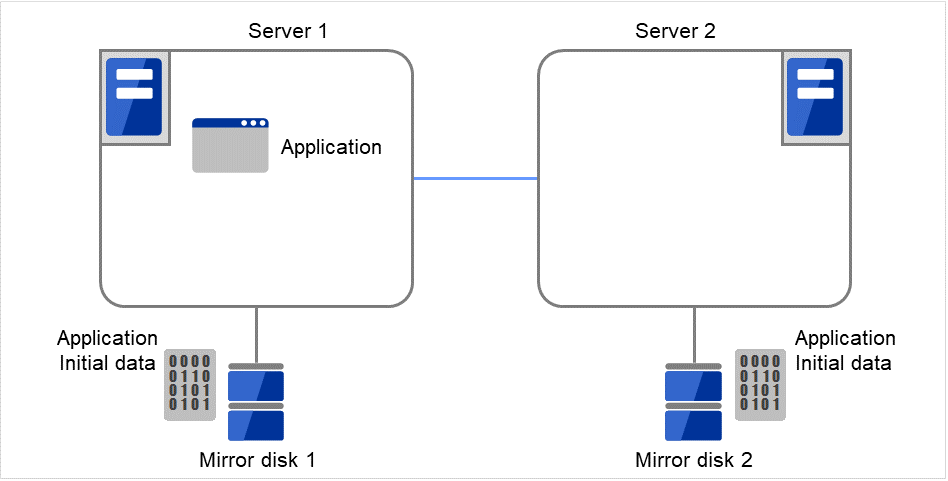
图 3.104 镜像磁盘构筑示例(复制分区映像)(4)¶
例2
通过备份设备进行复制的方法
首先,如果可以在构建集群之前准备双重化的 Application数据,请先在当前运行的镜像磁盘(Mirror disk 1)的数据分区中进行创建(ex.数据库的初始DB等)。
图 3.105 镜像磁盘构筑示例(使用备份设备)(1)¶
将备份设备(Backup device)连接到当前服务器(Server 1)。使用诸如dd命令等在分区映像中备份的命令,备份镜像磁盘(Mirror disk 1)的数据分区的数据。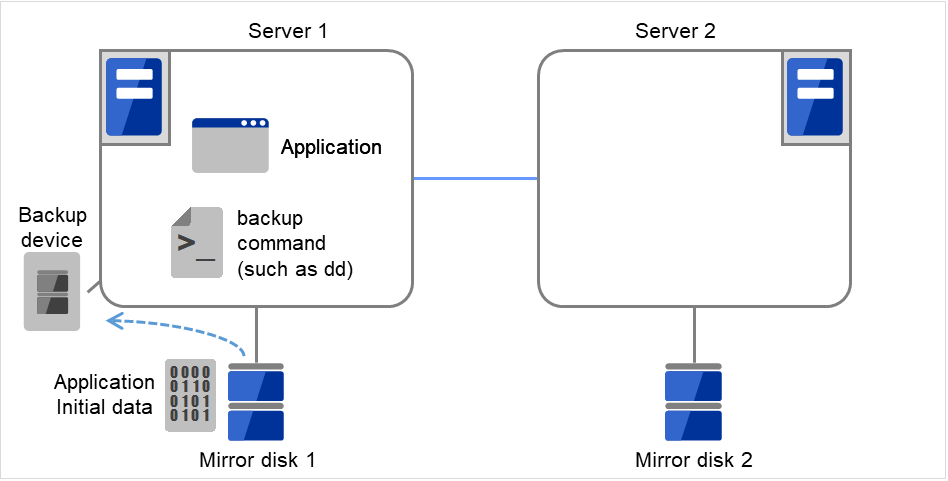
图 3.106 镜像磁盘构筑示例(使用备份设备)(2)¶
将备份设备(Backup device)连接到待机服务器(Server 2)中,并将在当前服务器(Server 1)中备份数据时的媒介移动到Server 2的备份设备中。
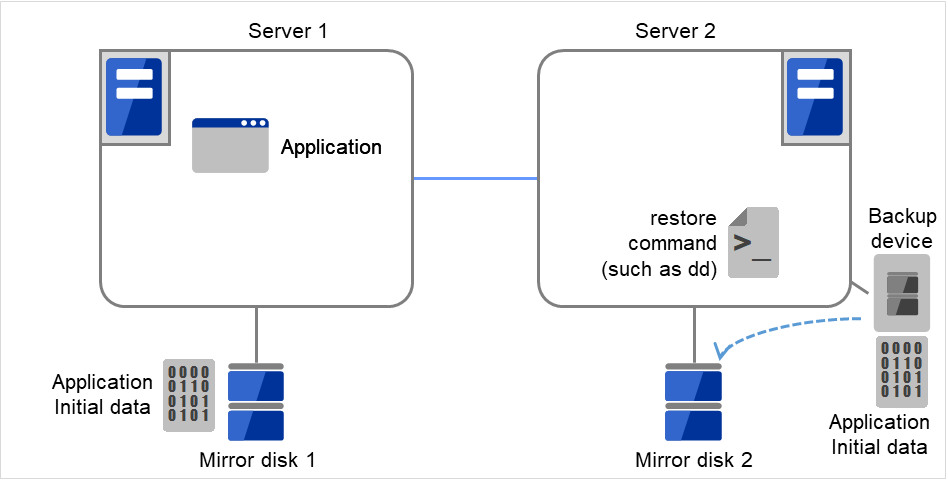
图 3.107 镜像磁盘构筑示例(使用备份设备)(3)¶
安装EXPRESSCLUSTER并进行设置。之后,通过“不进行初始mkfs·不进行初始镜像构筑”时的设置,构建集群。不执行镜像分区的初始构筑(初始同步)。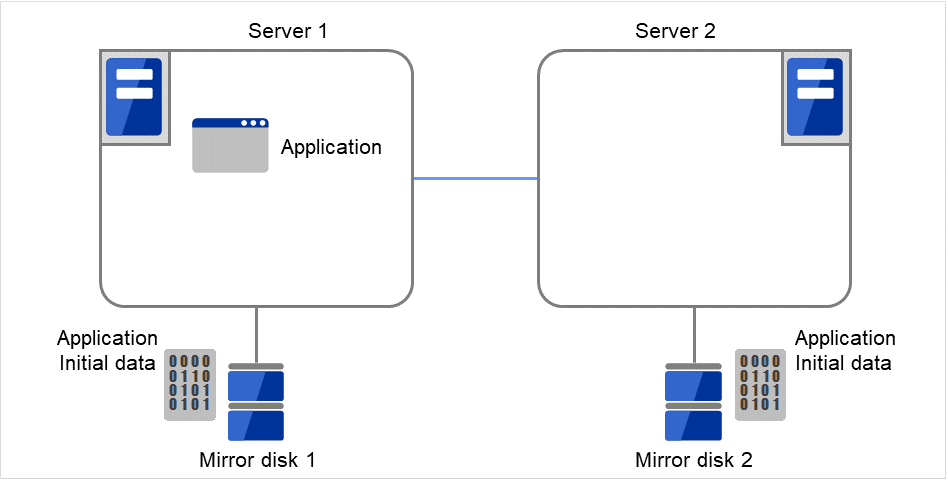
图 3.108 镜像磁盘构筑示例(使用备份设备)(4)¶
3.10.5. 镜像磁盘资源的相关注意事项¶
两台服务器中,不可以使用相同设备名访问时,请进行服务器个别设置。
在集群属性的[扩展]标签页中选中[Mount/Umount命令互斥]时,则磁盘资源,NAS资源,镜像资源的mount/umount在同一服务器内互斥运行,所以镜像资源的启动/停止有时候较费时间。
在mount点中指定包含符号链接的路径,查出异常时的运行即使选择[强制结束进程]也不能强行停止。
此外,同样指定了包含「//」在内的路径时,也不能进行强制结束。
不能将由Linux的md实现的带区集,卷集,镜像,带奇偶性的带区集的磁盘指定为集群分区或数据分区。
- 可以在集群分区或数据分区中指定由Linux的LVM实现的卷。另外,有关SuSE Linux,不能在集群分区或数据分区中使用由LVM及MultiPath实现的卷。
镜像磁盘资源(镜像分区设备)不能作为由Linux的md实现的带区集,卷集,镜像,带奇偶性的带区集的对象。
如果服务器间作为镜像磁盘的磁盘几何信息不同时:
通过[fdisk]命令等申请的分区大小根据每个柱面的Block(单元)数来分配。
分配数据分区时,请确保数据分区的大小及初始镜像构筑方向的关系如下。
复制源服务器 ≤ 复制目标服务器
复制源服务器是指镜像资源所属的失效切换组的失效切换策略较高的服务器。复制目标服务器是指镜像资源所属的失效切换组的失效切换策略较低的服务器。另外,请确保数据分区为相同程度的大小。请注意数据分区的大小在复制源服务器侧和复制目标服务器侧不要超过32GiB, 64GiB, 96GiB, ... (32GiB的倍数)。若超过32GiB的倍数,则有可执行出现初始镜像构筑失败。例)
组合
数据分区的大小
说明
服务器1侧
服务器2侧
OK
30GiB
31GiB
由于双方均在0~32GiB不足的范围内,因此OK
OK
50GiB
60GiB
由于双方均在32GiB以上~64GiB不足的范围内,因此OK
NG
30GiB
39GiB
由于超过了32GiB,因此NG
NG
60GiB
70GiB
由于超过了64GiB,因此NG
- 针对镜像磁盘资源中使用的文件,请不要使用open()system call的O_DIRECT标识。如,Oracle设置参数中的filesystemio_options = setall 等相当于这种情况。
请不要将(/dev/NMP1等)指定为DISK监视的READ(O_DIRECT)方式的监视目标。
有关镜像磁盘资源的数据分区及集群分区,请在所有的服务器上使用相同逻辑扇区大小的磁盘设备。若使用不同逻辑扇区大小的设备,则不能正常运作。另外,数据分区与集群分区之间,即使逻辑扇区大小不同也可正常运作。
例)
组合
分区的逻辑扇区大小
说明
服务器1侧
服务器1侧
服务器2侧
服务器2侧
数据分区
集群分区
数据分区
集群分区
OK
512B
512B
512B
512B
逻辑扇区大小统一
OK
4KB
512B
4KB
512B
数据分区统一为4KB,集群分区统一为512B
NG
4KB
512B
512B
512B
数据分区的逻辑扇区大小没有统一
NG
4KB
4KB
4KB
512B
集群分区的逻辑扇区大小没有统一
有关作为镜像磁盘资源的数据分区及集群分区所使用的磁盘,请不要将HDD和SSD混合在一起使用。若混合在一起则无法获得最佳的性能。另外,数据分区与集群分区之间,即使磁盘类型不同也可正常运作。
例)
组合
分区的磁盘类型
说明
服务器1侧
服务器1侧
服务器2侧
服务器2侧
数据分区
集群分区
数据分区
集群分区
OK
HDD
HDD
HDD
HDD
磁盘类型统一
OK
SSD
HDD
SSD
HDD
数据分区统一为SSD,集群分区统一为HDD
NG
SSD
HDD
HDD
HDD
在数据分区,HDD/SSD混合在一起
NG
SSD
SSD
SSD
HDD
在集群分区,HDD/SSD混合在一起
3.10.6. Mount前后处理的流程¶
按照以下步骤执行镜像磁盘资源启动时的mount处理。
文件系统中指定none时,不进行mount处理。
已事先挂载?
已经挂载时 -> 参见×
挂载前已进行执行fsck的设置?
为执行fsck 的时机 -> 向设备执行 fsck
挂载设备
挂载成功 -> 参见○
进行挂载的重试设置?
不进行重试设置时 -> 参见×
挂载失败时执行 fsck(xfs_repair)的设置时
2.中执行fsck成功时 -> 参见6.
3.中因为超时失败时 -> 参见6.
上述以外的情况 -> 向设备执行fsck(xfs_repair)
重新尝试设备的挂载
挂载成功 -> 参见○
是否在挂载的重试次数以内?
重试次数以内时 -> 参见6.
超过重试次数时 -> 参见×
○ 启动资源(挂载成功)
× 启动资源失败(没有被挂载)
3.10.7. Umount前后处理的流程¶
按照以下步骤执行镜像磁盘资源停止时的Umount处理。
文件系统中指定none时,不进行umount处理。
已事先卸载?
已经卸载时 -> 参见×
卸载设备
卸载成功 -> 参见○
进行卸载的重试设置?
不进行重试设置时 -> 参见×
仍在挂载码?(从挂载列表中删除挂载点,镜像设备是否也处于未使用状态?)
不挂载时 -> 参见○
尝试使用Mount点的进程的KILL
重新尝试设备的卸载
卸载成功 -> 参见○
不是卸载时间超时,而是否从挂载列表中已删除挂载点?
挂载点已被删除 -> 等到镜像设备不能使用为止(至少等待卸载超时的时间为止)是否在卸载的重试次数以内?
重试次数以内时 -> 参见4.
超过重试次数时 -> 参见×
○ 资源停止(卸载成功)
× 资源停止失败(处在挂载状态,或者已被卸载)
3.10.8. 镜像的状态变为异常的条件¶
以镜像磁盘资源的状态从正常(GREEN)状态变为异常(RED)状态为例,主要原因如下所示。
- 因通信(镜像磁盘连接)的断线或待机服务器停止等,导致运行服务器与待机侧服务器不能进行镜像同步,产生差异。因待机侧服务器没有保持最新数据,因此变为异常(RED)状态。
- 设定为镜像数据不同步,当运行服务器与待机侧服务器之间产生差异时。因待机侧服务器没有保持最新数据,因此变为异常(RED)状态。
- 进行断开镜像磁盘(中断镜像链接断)操作时。待机侧服务器变为异常(RED)状态。
- 镜像复归中(镜像的再同步中)中断镜像复归时。因待机侧服务器尚未复制结束,因此变为异常(RED)状态。
- 运行服务器因服务器宕机等,不能正常进行集群关机时。(已启动的镜像磁盘资源没有迁移为停止而停止时。)此服务器的镜像磁盘在服务器启动后变为异常(RED)状态。
- 仅一方的服务器启动,启动镜像磁盘后,不进行镜像同步就停止此服务器,另一方的服务器启动,启动镜像磁盘时。由于两方的服务器的镜像磁盘各自进行更新,因此两方服务器的镜像磁盘均变为异常(RED)状态。如上所示,两方服务器的镜像磁盘各自进行更新时,由于不能自动地判断将哪一方的服务器的镜像磁盘作为复制源,因此无法进行自动镜像复归。而需要执行强制镜像复归。
- 因通信(镜像磁盘连接)的断线或待机服务器重启等,致运行服务器与待机侧服务器不能进行镜像同步,产生差异。接着,因运行服务器发生服务器宕机等无法正常进行集群关机时。在这种情况下,之后即使正常地失效切换到待机侧服务器,两方服务器启动后均变为异常(RED)状态。此时,也无法进行自动镜像复归。而需要执行强制镜像复归。
有关镜像状态的参照方法,请参阅如下的章节。
在线手册
-
-
-
显示镜像磁盘资源状态
-
-
此外,有关镜像复归,强制镜像复归的步骤,请参阅如下的章节。
3.10.9. 详细标签页¶

镜像分区设备名
选择与镜像分区相关联的镜像分区设备名。
镜像磁盘资源和共享型镜像磁盘资源中已经设置的设备名不会在列表内显示。
Mount点 (1023字节以内) 服务器个别设置
设置要mount镜像分区磁盘的目录。需要用[/]开头。
数据分区设备名 (1023字节以内) 服务器个别设置
设置用作磁盘资源的数据分区设备名。需要用[/]开头。
集群分区设备名 (1023字节以内) 服务器个别设置
设置与数据分区成对的的集群分区设备名。需要用[/]开头。
文件系统 服务器个别设置
指定镜像分区上使用的文件系统类型。从以下类型中选择。也可以直接输入。
ext2
ext3
ext4
xfs
jfs
reiserfs
none(无文件系统)
镜像磁盘连接

添加
添加镜像磁盘连接时使用。请从[可用镜像磁盘连接]中选择想添加的I/F编号,点击[添加]按钮。添加的I/F编号就在[镜像磁盘连接列表]中显示。
删除
用于删除使用的镜像磁盘连接时。请从[镜像磁盘连接列表]中选择要删除的I/F编号,点击[删除]按钮。删除的I/F编号就在[可用镜像磁盘连接] 中显示。
顺序
用于更改使用的镜像磁盘连接优先级时。请从[镜像磁盘连接列表]中选择要更改的I/F编号,点击箭头按钮。移动选择的行。
调整
显示[镜像磁盘资源调整属性]对话框。进行镜像磁盘资源的详细设置。
镜像磁盘资源调整属性
Mount标签页
显示Mount相关的详细设置。
[镜像磁盘资源详细]标签页的文件系统中指定none时不显示。

Mount选项 (1023字节以内)
设置mount镜像分区设备上的文件系统时传递给[mount]命令的参数。多个参数使用", (逗号)"隔开。
Mount选项示例
设置项
设置值
镜像分区设备名
/dev/NMP5
镜像Mount点
/mnt/sdb5
文件系统
ext3
Mount选项
rw,data=journal
进行上述设置时执行的[mount]命令
mount -t ext3 -o rw,data=journal /dev/NMP5 /mnt/sdb5
超时 (1~999)
设置mount镜像分区设备上的文件系统时等待[mount]命令结束的超时时间。文件系统的容量较大则有时比较耗费时间。请注意所设置的值。
重试次数 (0~999)
设置镜像分区设备上的文件系统mount失败时的mount重试次数。设置为0则不执行重试。
默认值
点击[默认值]后,所有项目将设置为默认值。
Unmount标签页
显示unmount相关的详细设置。
[镜像磁盘资源详细]标签页的文件系统中指定none时不显示。

超时 (1~999)
设置unmount镜像分区设备上的文件系统时等待[umount]命令结束的超时时间。
重试次数 (0~999)
设置镜像分区磁盘上的文件系统unmount失败时的unmount重试次数。设置为0则不进行重试。
重试间隔 (0~999)
设置镜像分区设备上的文件系统unmount失败时到执行下次重试的间隔。
查出异常时的强制动作
从下列操作中选择Unmount失败后进行unmount重试时执行的操作。
默认值
点击[默认值]后,所有项目将设置为默认值。
Fsck标签页
显示[fsck]相关的详细设置。
[镜像磁盘资源详细]标签页中,文件系统中指定xfs或者none时不显示。

Fsck选项 (1023字节以内)
指定检查镜像分区设备上的文件系统时传递给[fsck]命令的参数。多个参数请用空格隔开设置。此处请指定不会使[fsck]命令变成交互形式的参数。如果[fsck]命令变为交互形式,则[fsck超时]时间过后资源启动会出错。
Fsck超时 (1~9999)
指定检查镜像分区设备上的文件系统时等待fsck命令结束的超时时间。文件系统的容量较大则有时比较耗费时间。请注意设置的值。
Mount执行前的fsck操作
从以下操作中选择mount镜像分区设备上的文件系统之前的[fsck]操作。
注解
[fsck]的指定次数与文件系统所管理的检查间隔没有关系。
Mount失败时的fsck操作
设置镜像分区设备上的文件系统mount失败时的[fsck]操作。该设置在[重试次数]的设置值不为0时有效。
注解
不推荐[mount执行前的fsck动作]为[不执行]的组合。该设置下镜像资源不执行[fsck],所以镜像分区中存在可以通过[fsck]修复的异常时,无法对镜像资源进行失效切换。
Reiserfs的再次构建
指定当发生[reiserfsck]可修复的错误时的处理。
默认值
点击[默认值]按钮后,在所有项目中设定默认值。
xfs_repair标签页
显示与[xfs_repair]相关的详细设置。仅在文件系统中指定为[xfs]时可以显示。

xfs_repair选项 (1023字节以内)
检查磁盘设备上的文件系统时,请指定传递给[xfs_repair]命令的参数。设置多个参数时,请用空格区分开。
xfs_repair超时(1~9999)
检查磁盘设备上的文件系统时,指定等待[xfs_repair]命令结束的超时时间。文件系统的容量较大时,有可执行比较费时。因此请注意所设置的值不要太小。
Mount失败时的xfs_repair操作
设置Mount磁盘设备上的文件系统失败时[xfs_repair]的动作。此设置仅在[Mount重试次数] 的设置值为0以外时有效。
默认值
点击[默认值]后,所有项目将设置为默认值。
镜像标签页
显示镜像磁盘相关的详细设置。

初始镜像构建
执行构筑集群时是否进行初始镜像构筑。
在ext2/ext3/ext4和其他的文件系统中,构建初始镜像的时间不同。
构建初始文件系统
指定构筑集群时是否进行初始mkfs。只有进行初始镜像构筑时才可以指定。
如果是共享型镜像磁盘资源,则不是集群构建时的初始mkfs,而是[clphdinit]命令的处理。
数据同步
指定镜像磁盘资源启动时是否进行镜像数据的同步。
模式
指定镜像数据的同步模式。
选择[异步]时,可勾选[通信带宽限制]复选框。
选择[异步]后,可以编辑[历史文件保存目录]中的文本框。设置队列超过时,保存文件的目录。没有指定时,在(EXPRESSCLUSTER安装目录)/work下生成文件。
选择[异步]后,可以编辑[历史文件大小限制]的文本框。历史文件的总计达到该大小时,变为镜像中断状态。指定0或者无指定时,没有大小限制。
此外,选择了[异步]后,可勾选[压缩数据]复选框。
复归时压缩数据
设置是否压缩镜像复归的通信数据。
加密镜像通信
设置是否加密流经镜像磁盘连接的通信数据。它同时影响镜像同步的通信数据和镜像复归的通信数据。
密钥文件全路径 (1023 字节以内)
指定用于加密流经镜像磁盘连接的通信数据的密钥文件的全路径。如果要进行加密,必须要指定。
注解
密钥文件使用通过OS的openssl命令生成的文件。以下是RHEL7系列的执行示例。由于每个distribution的openssl命令的选项系统不一样,因此请在执行前进行确认。# openssl rand 16 -out (密钥文件名) 生成密钥长度为128bit(16字节)的加密密钥 # openssl rand 24 -out (密钥文件名) 生成密钥长度为192bit(24字节)的加密密钥 # openssl rand 32 -out (密钥文件名) 生成密钥长度为256bit(32字节)的加密密钥密钥长度可以是128bit,192bit或256bit。
重要
请务必在可以启动镜像磁盘资源的所有服务器中使用相同的密钥文件。如果密钥文件不同,则无法正常镜像。
默认值
点击[默认值]后,所有项目将设置为默认值。
镜像驱动标签页
镜像驱动相关的详细设置显示。

镜像数据端口号 (1~65535 5 )
设置镜像驱动在服务器间发送接收磁盘数据时使用的TCP端口号。最初作成的镜像磁盘资源或共享型镜像磁盘资源中默认设置为[29051]。第2个之后的镜像磁盘资源或共享型镜像磁盘资源的设置值在默认情况下依次加1[29052,29053,…]。
- 5
不推荐使用Well-known Port,特别是1~1023号的Reserved Port。
心跳端口号 (1~65535 6 )
设置镜像驱动在服务器间进行控制用数据通信的TCP端口号。最初作成的镜像磁盘资源或共享型镜像磁盘资源中默认设置为[29031]。第2个之后的镜像磁盘资源或共享型镜像磁盘资源的设置值在默认情况下依次加1 [29032,29033,…]。
- 6
不推荐使用Well-known Port,特别是1~1023号的Reserved Port。
ACK2端口号 (1~65535 7 )
设置镜像驱动在服务器间进行控制用数据通信的TCP端口号。最初作成的镜像磁盘资源或共享型镜像磁盘资源中默认设置为[29071]。第2个之后的镜像磁盘资源或共享型镜像磁盘资源的设置值在默认情况下依次加1 [29072,29073,…]。
- 7
不推荐使用Well-known Port,特别是1~1023号的Reserved Port。
发送超时 (10~99)
设置写入数据的发送超时时间。
连接超时 (5~99)
设置连接超时时间。
Ack超时 (1~600)
设置镜像复归,数据同步时等待Ack应答的超时时间。
收信超时 (1~600)
设置接收等待写入确认的超时时间。
心跳间隔(1~600)
通过镜像驱动来设置镜像磁盘连接之间的心跳间隔。
ICMP Echo Reply接收超时(1~100)
通过镜像驱动来设置镜像磁盘连接之间的心跳超时。在此设定的时间内出现无应答一直持续到ICMP Echo Request重试次数时,则判定为镜像磁盘连接断线。
ICMP Echo Request重试次数 (1~50)
通过镜像驱动来设置镜像磁盘连接之间的心跳重试次数。ICMP Echo Reply接收超时的同时,关系到镜像连接断线的判定灵敏度。
默认值
点击[默认值]按钮,则以下项目均被设置为默认值。
发送超时
连接超时
Ack超时
接收超时
心跳间隔
ICMP Echo Reply接收超时
ICMP Echo Request重试次数
注解
[镜像数据端口号],[心跳端口号]和[ACK2端口号]必须在每个资源中设置不同的端口号。另外,这些端口号不能与集群中使用的其他端口号重复。因此,即使点击[默认值]按钮也不会设置为默认值。
高速SSD标签页
在镜像磁盘资源显示有关高速SSD使用的详细设置。

数据分区
在镜像磁盘资源的数据分区使用高速SSD时,请选中复选框。在所有的节点上,数据分区所使用的磁盘设备请统一为HDD或SSD。若两者混合在一起,则无法发挥出最佳的性能。
集群分区
在镜像磁盘资源的集群分区使用高速SSD时,请选中复选框。在所有的节点上,集群分区所使用的磁盘设备请统一为HDD或SSD。若两者混合在一起,则无法发挥出最佳的性能。
3.11. 理解共享型镜像磁盘资源¶
3.11.1. 共享型镜像磁盘资源的依赖关系¶
默认情况下,依存以下组资源类型。
组资源类型 |
|---|
浮动IP资源 |
虚拟IP资源 |
AWS Elastic IP资源 |
AWS 虚拟IP资源 |
AWS DNS资源 |
Azure 探头端口资源 |
Azure DNS资源 |
3.11.2. 何谓共享型镜像磁盘?¶
共享型镜像磁盘是指在两个服务器组之间进行数据镜像的资源。服务器组由1台或者2台服务器构成。服务器组由2台服务器构成的情况下使用共享磁盘。服务器组由1台服务器构成时,使用非共享型的磁盘(服务器内置,在服务器之间不共享的外置型磁盘等)。
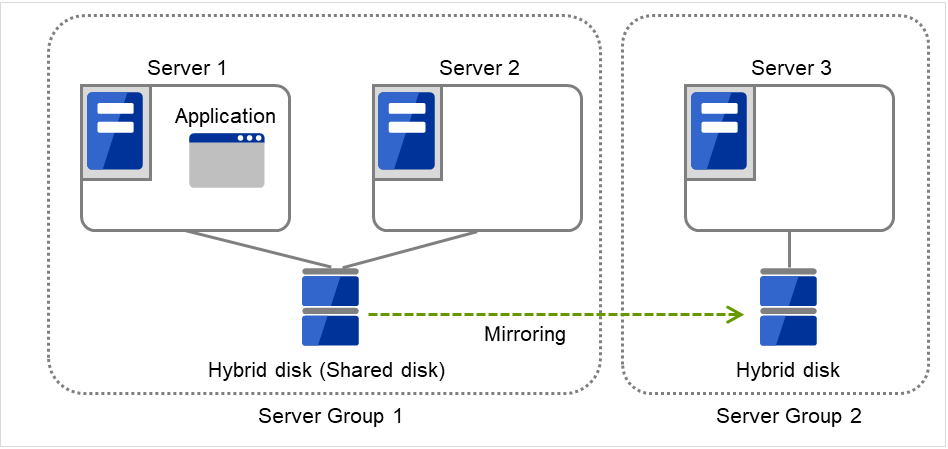
图 3.109 共享型镜像磁盘配置 (1)(通常时)¶
Server 1宕机,Application在 Server 2中进行失效切换。
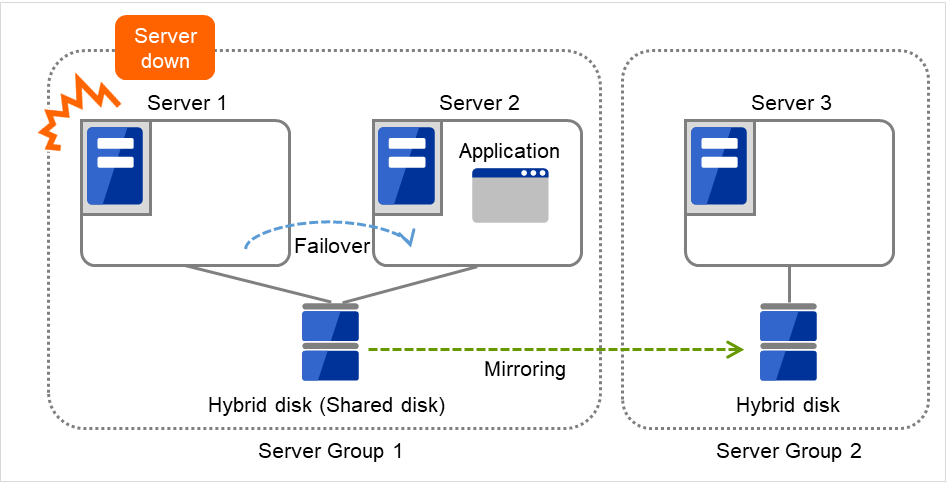
图 3.110 共享型镜像磁盘配置 (2)(Server 1宕机)¶
Server 2宕机,Application在Server 3中进行失效切换。
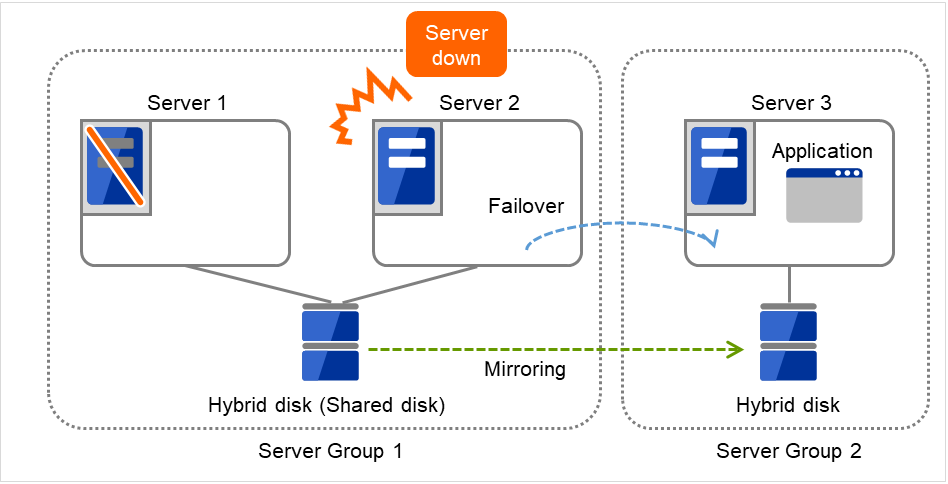
图 3.111 共享型镜像磁盘配置 (3)(Server 2宕机)¶
数据分区
保存镜像的数据(业务数据等)的分区称作数据分区。
请按照以下方式分配数据分区。
- 数据分区大小请确保1GB以上,不到1TB的分区。※数据的配置时间,复归时间的观点来看,建议使用不满1TB的大小。
- 分区ID83(Linux)
- 在本版本的共享镜像磁盘资源中文件系统是不会被自动生成。需要根据需求手动进行生成文件系统。
- 文件系统的访问控制(mount/umount)由EXPRESSCLUSTER进行,所以请不要在OS端对数据分区的mount/umount进行设置。
集群分区
EXPRESSCLUSTER用于控制共享型镜像磁盘而使用的专用分区称为集群分区。
请按照以下方式分配集群分区。
- 集群分区大小请最低保证1024MB。根据磁盘几何配置信息,有时可执行为1024MB以上。即使1024MB以上也没有任何问题。
- 分区ID83(Linux)
- 集群分区需要与数据镜像所用数据分区成对进行分配。
- 集群分区中请不要构建文件系统。
镜像分区设备(/dev/NMPx)
1个共享型镜像磁盘资源中将1个镜像分区设备提供给文件系统。作为共享型镜像磁盘资源登录后,只能从1台服务器(通常为资源组的主用端服务器)进行访问。
通常情况下,用户(AP)通过文件系统进行I/O,所以不需要意识到镜像分区设备(dev/NMPx)。通过Cluster WebUI创建信息时,分配不重复的设备名。
- 文件系统的访问控制(mount/umount)由EXPRESSCLUSTER进行,所以请不要在OS侧对镜像分区设备进行mount/umount。关于从业务应用程序等是否可以访问镜像分区(共享型镜像磁盘资源)的考虑方法,与使用共享磁盘的切换分区(磁盘资源)相同。
镜像分区的切换依照失效切换组各自的失效切换策略进行。
镜像分区的特殊设备名使用/dev/NMPx(x代表数字1~8)。请不要在其他设备驱动中使用/dev/NMPx。
镜像分区使用主编号218。请不要在其他设备驱动中使用主编号218。
例1) 2台服务器使用共享磁盘,第3台服务器使用服务器内置的磁盘时
图为共享型镜像磁盘配置的示例。Server 1和Server 2共享一个 Shared disk,Shared disk的 Cluster partition,以及 Data partition的内容镜像到连接Server 3的Disk中。该Cluster partition 以及Data partition是共享型镜像磁盘资源中失效切换的单元,是镜像分区设备。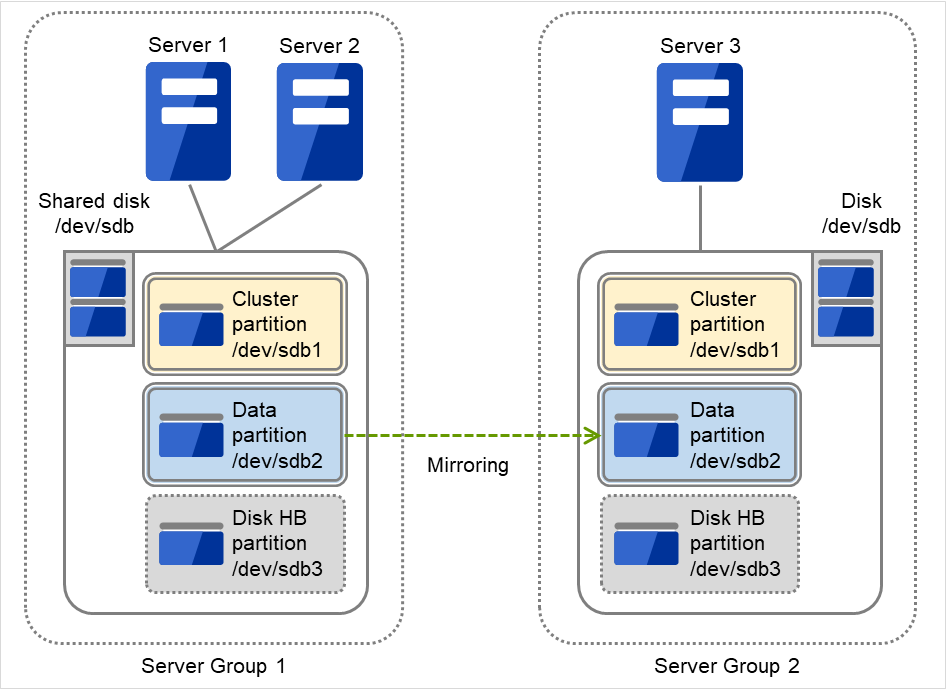
图 3.112 共享型镜像磁盘配置中的分区¶
使用非共享型的磁盘时(在服务器组内有1台服务器时),可以在与OS(root分区和swap分区) 同一个磁盘上确保共享型镜像磁盘资源用分区(集群分区,数据分区)。
- 需要保证故障时的维护性时建议您使用与OS(root分区和swap分区)不同的磁盘用于镜像。
- 由于H/W RAID的规格限制,不能增加LUN时在H/W RAID的预安装模式中,很难更改LUN配置时
在与OS(root分区和swap分区)同一个磁盘上,也可以确保共享型镜像磁盘资源分区(集群分区,数据分区)。
镜像磁盘连接
请参考镜像磁盘资源的"镜像磁盘连接"。
3.11.3. 镜像参数设置的考虑方法¶
以下的参数与镜像磁盘资源相同。请参考镜像磁盘资源。
镜像磁盘端口号
心跳端口号
ACK2端口号
请求队列的最大数
连接超时
发送超时
接收超时
Ack超时
差分Bitmap更新间隔 (集群属性)
差分Bitmap大小 (集群属性)
镜像Agent发送超时(集群属性)
镜像Agent接收超时(集群属性)
复原数据大小(集群属性)
初始镜像构建
队列数
通信带域限制
历史文件保存目录
历史文件大小限制
心跳间隔
ICMP Echo Reply接收超时
ICMP Echo Request重试次数
密钥文件全路径
以下参数与镜像磁盘资源不同。
- 初始mkfs在本版本的共享镜像磁盘资源中,不会自动进行mkfs,请根据需要提前手动进行。
3.11.4. 共享型镜像磁盘资源的相关注意事项¶
服务器间设定为集群分区或者数据分区的设备名不同时,请进行服务器个别设置。但是,属于同一服务器组的服务器间设备名不同时,请在设备名中设定by-id。
在集群属性的[扩展]标签页中选中[Mount/Umount命令互斥]时,则磁盘资源,NAS资源,镜像资源,共享型镜像磁盘资源的mount/unmount在同一服务器内互斥运行,所以共享型镜像磁盘资源的启动/停止有时候较费时间。
在mount点中指定包含符号链接的路径,查出异常时的运行即使选择[强制结束进程]也不能强行停止。
此外,同样指定了包含「//」在内的路径时,也不能进行强制结束。
不能将由Linux的md实现的带区集,卷集,镜像,带奇偶性的带区集的磁盘指定为集群分区或数据分区。
- 可以在集群分区或数据分区中指定由Linux的LVM实现的卷。另外,有关SuSE Linux,不能在集群分区或数据分区中使用由LVM及MultiPath实现的卷。
共享型镜像磁盘资源(镜像分区设备)不能作为由Linux的md和LVM实现的带区集,卷集,镜像,带奇偶性的带区集的对象。
如果服务器间作为共享型镜像磁盘的磁盘几何信息不同时:
通过[fdisk]命令等申请的分区大小根据每个柱面的Block(单元)数来分配。
分配数据分区时,请确保数据分区的大小及初始镜像构筑方向的关系如下。复制源服务器 ≤ 复制目标服务器复制源服务器是指共享型镜像磁盘资源所属的失效切换组的服务器组中优先级别较高的服务器组。复制目标服务器是指共享型镜像磁盘资源所属的失效切换组的服务器组中优先级别较低的服务器组。另外,请确保数据分区为相同程度的大小。请注意数据分区的大小在复制源服务器侧和复制目标服务器侧不要超过32GiB, 64GiB, 96GiB, ... (32GiB的倍数)。若超过32GiB的倍数,则有可执行出现初始镜像构筑失败。例)
组合
数据分区的大小
说明
服务器1侧
服务器2侧
OK
30GiB
31GiB
由于双方均在0~32GiB不足的范围内,因此OK
OK
50GiB
60GiB
由于双方均在32GiB以上~64GiB不足的范围内,因此OK
NG
30GiB
39GiB
由于超过了32GiB,因此NG
NG
60GiB
70GiB
由于超过了64GiB,因此NG
- 针对共享型磁盘资源中使用的文件,请不要使用open()system call的O_DIRECT标识。如,Oracle设定参数中的filesystemio_options = setall等相当于这种情况。
请不要将镜像分区设备(/dev/NMP1等)指定为DISK监视的READ(O_DIRECT)方式的监视目标。
在使用共享型镜像磁盘的集群配置中,请不要将监视资源的最终动作设置为[停止集群服务]。
有关共享型磁盘资源的数据分区及集群分区,请在所有的服务器上使用相同逻辑扇区大小的磁盘设备。若使用不同逻辑扇区大小的设备,则不能正常运作。另外,数据分区与集群分区之间,即使逻辑扇区大小不同也可正常运作。
例)
组合
分区的逻辑扇区大小
说明
服务器1侧
服务器1侧
服务器2侧
服务器2侧
数据分区
集群分区
数据分区
集群分区
OK
512B
512B
512B
512B
逻辑扇区大小统一
OK
4KB
512B
4KB
512B
数据分区统一为4KB,集群分区统一为512B
NG
4KB
512B
512B
512B
数据分区的逻辑扇区大小没有统一
NG
4KB
4KB
4KB
512B
集群分区的逻辑扇区大小没有统一
有关作为共享型磁盘资源的数据分区及集群分区所使用的磁盘,请不要将HDD和SSD混合在一起使用。若混合在一起则无法获得最佳的性能。另外,数据分区与集群分区之间,即使磁盘类型不同也可正常运作。
例)
组合
分区的磁盘类型
说明
服务器1侧
服务器1侧
服务器2侧
服务器2侧
数据分区
集群分区
数据分区
集群分区
OK
HDD
HDD
HDD
HDD
磁盘类型统一
OK
SSD
HDD
SSD
HDD
数据分区统一为SSD,集群分区统一为HDD
NG
SSD
HDD
HDD
HDD
在数据分区,HDD/SSD混合在一起
NG
SSD
SSD
SSD
HDD
在集群分区,HDD/SSD混合在一起
关于当前服务器异常宕机后的镜像恢复的处理
如果当前运行的服务器发生异常宕机,则根据宕机时间,分为全面镜像恢复和差分镜像恢复两种情况。
在通过共享磁盘连接的服务器(同一服务器组内的服务器)中启动资源时
图为共享型镜像磁盘配置的示例。Server 1和Server 2共享一个 Shared disk,Shared disk的 Cluster partition,以及 Data partition的内容镜像到连接Server 3的Disk中。
图 3.113 共享型镜像磁盘配置 (1)(同一服务器组内启动资源, 通常时)¶
Server 1宕机,Hybrid Disk Resource在Server 2中失效切换。
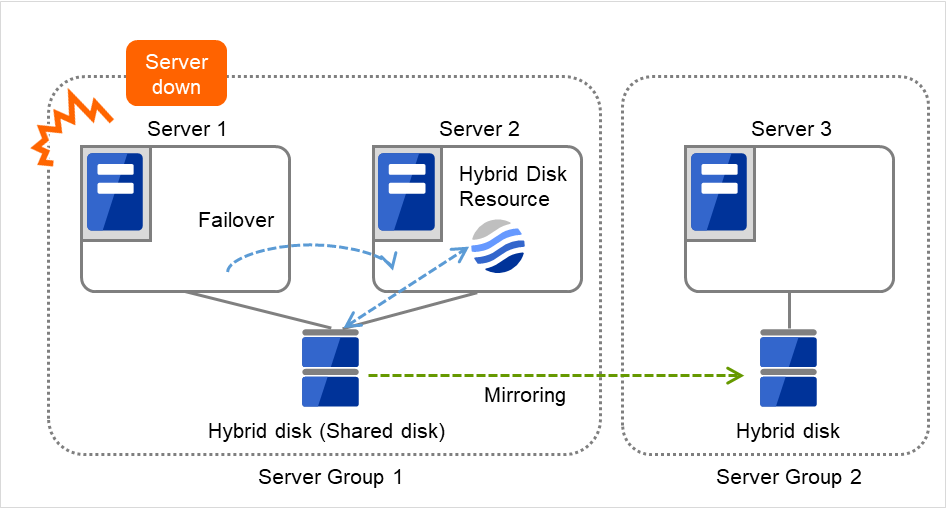
图 3.114 共享型镜像磁盘配置 (2)(同一服务器组内启动资源, Server 1宕机)¶
如果要在Shared disk 和连接到 Server 3 的Disk之间进行镜像恢复处理时,则根据Server 1宕机的时机不同,处理内容也会不同。
- Server 1(当前服务器)宕机前,Server 1中识别到向Server 3(待机服务器)发送数据失败/ACK1接收错误,可以将它们记录到集群分区中时判断与已宕机的Server 1相同的服务器组所属的服务器(Server 2)具有最新的数据,执行从Server 2到Server 3的全面镜像恢复。
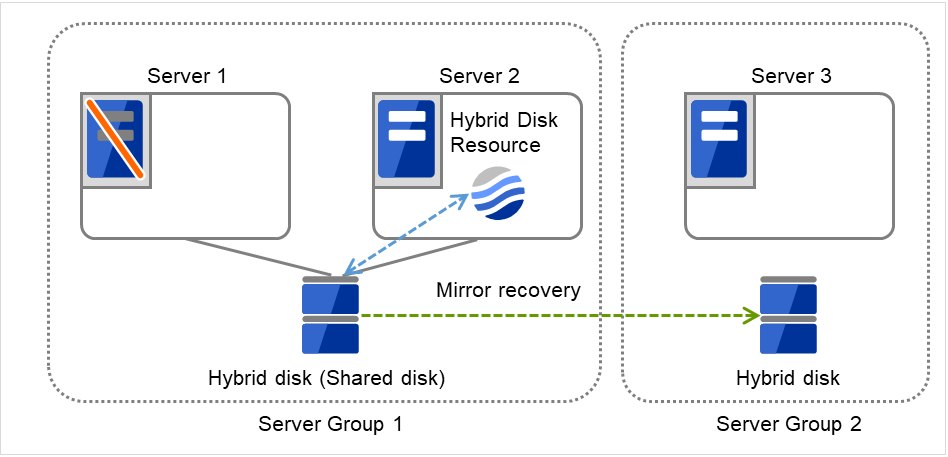
图 3.115 共享型镜像磁盘配置 (3)(同一服务器组内启动资源, Server 1宕机后的镜像恢复)¶
- 其他场合由于无法判断Server 2和Server 3哪个服务器具有最新的数据,因此镜像为保留状态。失效切换组的失效切换属性为"自动失效切换"时,由于资源是在下一个优先级服务器上启动的,因此通过保留状态启动资源。失效切换组的失效切换属性为手动时,镜像为保留状态。
在对方服务器组的服务器中启动资源时
图为共享型镜像磁盘配置的示例。 Server 1和Server 2共享一个 Shared disk,Shared disk的 Cluster partition,以及 Data partition的内容镜像到连接Server 3的Disk中。
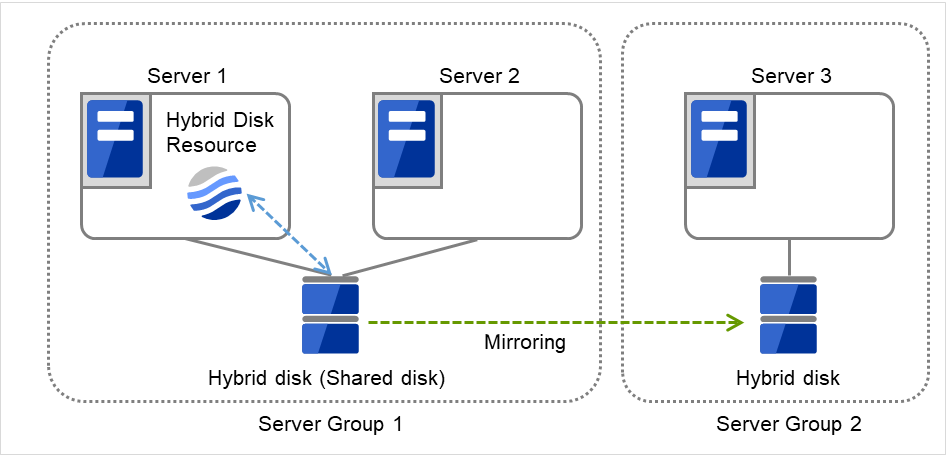
图 3.116 共享型镜像磁盘配置 (1)(在目标服务器组内启动资源,通常时)¶
Server 1宕机,Hybrid Disk Resource在Server 3中失效切换。
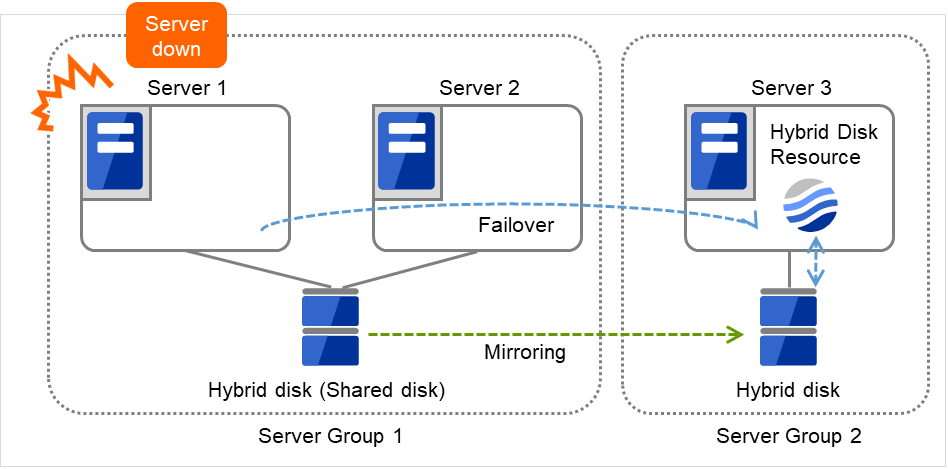
图 3.117 共享型镜像磁盘配置 (2)(在目标服务器组内启动资源, Server 1宕机)¶
- Server 1宕机前,Server 1识别到向Server 3发送数据失败/ACK1接收错误,可以将它们记录到集群分区中时判断Server group 1是否具有最新数据,在Server 3中包含共享型镜像磁盘资源的组启动失败。
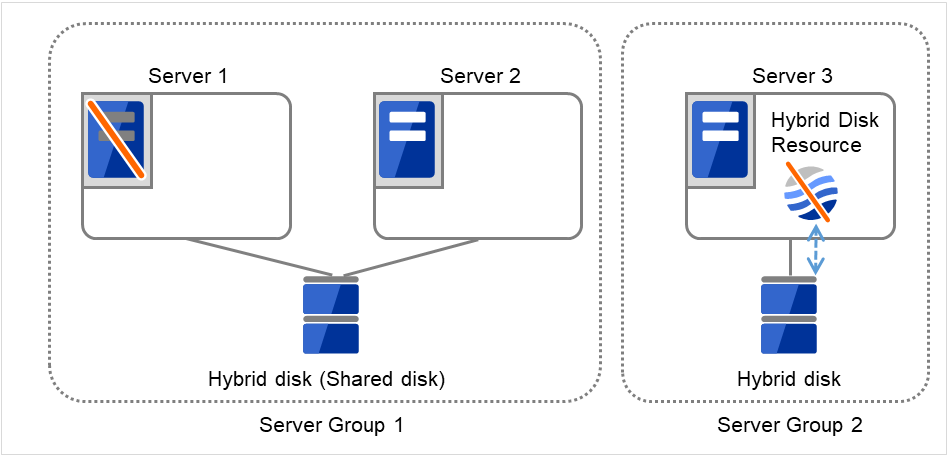
图 3.118 共享型镜像磁盘配置 (3)(在目标服务器组内启动资源, Server 1宕机后的镜像恢复)¶
- 其他场合由于无法判断Server 2和Server 3哪个服务器具有最新的数据,因此镜像为保留状态。失效切换组的失效切换属性为"自动失效切换"时,由于资源是在下一个优先级服务器上启动的,因此通过保留状态启动资源。失效切换组的失效切换属性为手动时,镜像为保留状态。
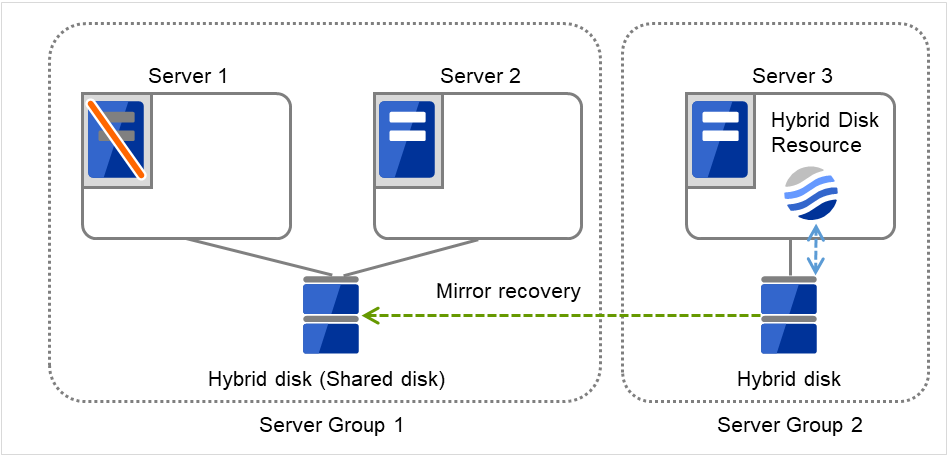
图 3.119 共享型镜像磁盘配置 (4)(在目标服务器组内启动资源, Server 1宕机后的镜像恢复)¶
3.11.5. Mount前后处理的流程¶
按照以下步骤执行共享型镜像磁盘资源启动时的mount处理。
文件系统中指定none时不进行mount处理。
已事先挂载?
已经挂载时 -> 参见×
挂载前已进行执行fsck的设置?
为执行fsck 的时机 -> 向设备执行 fsck
挂载设备
挂载成功 -> 参见○
进行挂载的重试设置?
不进行重试设置时 -> 参见×
挂载失败时执行 fsck(xfs_repair)的设置时
2.中执行fsck成功时 -> 参见6.
3.中因为超时失败时 -> 参见6.
上述以外的情况 -> 向设备执行fsck(xfs_repair)
重新尝试设备的挂载
挂载成功 -> 参见○
是否在挂载的重试次数以内?
重试次数以内时 -> 参见6.
超过重试次数时 -> 参见×
○ 启动资源(挂载成功)
× 启动资源失败(没有被挂载)
3.11.6. Umount前后处理的流程¶
按照以下步骤执行共享型镜像磁盘资源停止时的Umount处理。
文件系统中指定none时,不进行umount处理。
已事先卸载?
已经卸载时 -> 参见×
卸载设备
卸载成功 -> 参见○
进行卸载的重试设置?
不进行重试设置时 -> 参见×
仍旧挂载?(即使从挂载列表中删除挂载点,镜像设备也处于未使用状态)
已不挂载 -> 参见○
尝试使用Mount点的进程的KILL
重新尝试设备的卸载
卸载成功 -> 参见○
不是卸载超时,而是否从挂载列表中已删除挂载点?
挂载点已被删除 -> 等到镜像设备不能使用为止(至少等待卸载超时的时间为止)是否在卸载的重试次数以内?
重试次数以内时 -> 参见4.
超过重试次数时 -> 参见×
○ 资源停止(卸载成功)
× 资源停止失败(处在挂载状态,或者已被卸载)
3.11.7. 详细标签页¶
以下镜像磁盘资源相同。请参考镜像磁盘资源的相关内容。
共享型镜像磁盘详细标签页 (参考镜像磁盘[详细]标签页)
镜像磁盘连接的选择
共享型镜像磁盘调整属性 (参考镜像磁盘调整属性)
Mount标签页
Unmount标签页
Fsck标签页
xfs_repair标签页
镜像标签页(执行初始mkfs之外的参数)
镜像驱动标签页
高速SSD标签页
以下标签页与镜像磁盘资源不同。
共享型镜像磁盘调优属性的镜像签页[执行初始mkfs]
进行初始mkfs
在本版本的共享镜像磁盘资源中,无论什么设置,在构建集群时都不会自动执行初始mkfs。
3.12. 理解NAS资源¶
3.12.1. NAS资源的依赖关系¶
默认依存以下组资源类型。
组资源类型 |
|---|
动态域名解析资源 |
浮动IP资源 |
虚拟IP资源 |
AWS Elastic IP资源 |
AWS 虚拟IP资源 |
AWS DNS资源 |
Azure 探头端口资源 |
Azure DNS资源 |
3.12.2. 何谓NAS资源?¶
NAS资源控制NFS服务器上的资源。
通过将业务所需的数据保存到NFS服务器上,在执行失效切换,失效切换组移动等操作时可以自动继承这些数据。
图 3.120 NAS资源 (1)¶
图 3.121 NAS资源 (2)¶
3.12.3. NAS资源相关的注意事项¶
文件系统的访问控制(mount/unmount)由EXPRESSCLUSTER实现,所以请不要设置为在OS中执行mount/unmount。
在NFS服务器上,需要设置对构成集群的服务器的NFS资源访问许可。
请在EXPRESSCLUSTER服务器端设置为启动portmap服务。
在NAS服务器名中指定主机名时,请设置为可以名称解析。
如果在集群的属性的[扩展]标签页内选中[Mount/Umount命令互斥]时,则磁盘资源,NAS资源,镜像资源的mount/unmount在同一服务器内互斥运行,所以NAS资源的启动/停止可执行花费较长的时间。
在mount点中指定包含符号链接的路径,查出异常时的运行即使选择[强制结束进程]也不能强行停止。 此外,同样指定了包含「//」在内的路径时,也不能进行强制结束。
3.12.4. 详细标签页¶

服务器名称 (255字节以内)
设置NFS服务器的IP地址或者主机名。如果设置主机名,请在OS端设置名称解析(向/etc/hosts添加目录等)。
共享名 (1023字节以内)
设置NFS服务器上的共享名称。
Mount点 (1023字节以内)
设置NFS资源的mount目录。需要以[/]开头。
文件系统 (15字节以内)
设置NFS资源的文件系统的类型。也可直接输入。
nfs
调整
显示[Nas资源调整属性]对话框。对NAS资源进行详细设置。
Nas 资源调整属性
Mount标签页
显示mount相关的详细设置。

Mount选项 (1023字节以内)
设置mount文件系统时传递[mount]命令的参数。使用",(逗号)"分隔多个参数。
Mount选项示例
设置项目
设置值
服务器名称
nfsserver
共享名
/share1
Mount点
/mnt/nas1
文件系统
nfs
Mount选项
rw
上述设置时执行的[mount]命令
mount -t nfs -o rw nfsserver1:/share1 /mnt/nas1
超时 (1~999)
设置mount文件系统时等待[mount]命令结束的超时时间。根据网络负载大小,可执行花费的时间较长。请注意设置的值。
重试次数 (0~999)
设置mount文件系统失败时的mount重试次数。
如果设置为0,则不进行重试。
默认值
点击[默认值]后,所有项目将设置为默认值。
Unmount标签页
显示与unmount有关的详细设置。

超时 (1~999)
设置unmount文件系统时等待[umount]命令结束的超时时间。
重试次数 (0~999)
设置unmount文件系统失败时的unmount重试次数。
如果设置为0,则不进行重试。
重试间隔 (0~999)
设置unmount文件系统失败时到执行下次重试的间隔。
查出异常时的强制动作
从以下操作中选择unmount失败后重试unmount时执行的操作。
默认值
点击[默认值]后,所有项目将设置为默认值。
Nas标签页
显示NAS相关的详细设置。

Ping超时 (0~999)
设置执行NAS资源启动和停止时用于确认与NFS服务器的连接而执行的[ping]命令的超时时间。如果设置为0,则不会执行[ping]命令。
默认值
点击[默认值]后,所有项目将设置为默认值。
3.13. 理解卷管理资源¶
3.13.1. 卷管理资源的依赖关系¶
默认值依赖以下组资源类型。
组资源类型 |
|---|
动态域名解析资源 |
浮动IP资源 |
虚拟IP资源 |
AWS Elastic IP资源 |
AWS 虚拟IP资源 |
AWS DNS资源 |
Azure 探头端口资源 |
Azure DNS资源 |
3.13.2. 何谓卷管理资源?¶
所谓卷管理,是将多个存储器和磁盘作为1个逻辑磁盘使用的用于磁盘管理的软件。
卷管理资源对通过卷管理所管理的逻辑磁盘进行控制。
通过将业务所需的数据保存到逻辑磁盘上,在执行失效切换,失效切换组移动等操作时,可以自动继承这些数据。
图 3.122 卷管理资源 (1)¶
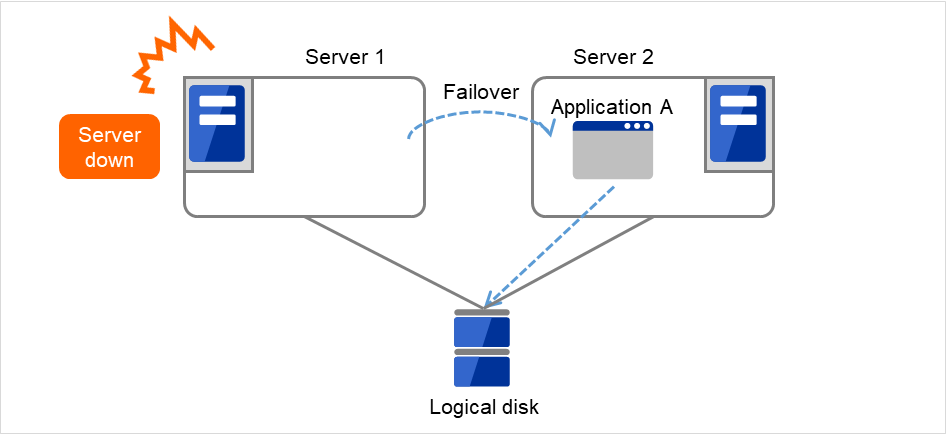
图 3.123 卷管理资源 (2)¶
3.13.3. 卷管理资源的相关注意事项¶
<卷管理资源整体>
请不要将镜像磁盘设为卷管理资源的管理对象。
通过磁盘资源控制各个卷。
逻辑磁盘的访问控制(import/export)由EXPRESSCLUSTER实施,因此,请不要设置为在OS侧执行import/export。
<利用卷管理器[lvm]时>
不在EXPRESSCLUSTER侧定义卷组。
由于必须控制各卷,因此,最少需要1个磁盘资源。
EXPRESSCLUSTER的设置信息中包含的卷组在OS启动时自动进行导出处理。
EXPRESSCLUSTER的设置信息中不包含的卷组则不进行导出。
指定通过共享磁盘配置的VG为对象卷时,依据LVM的设计,VG的import/export状态会被记录到共享磁盘上,在当前服务器上进行启动(import),停止(export)时,在备用服务器上也可以看到同样的状态。
在Red Hat Enterprise Linux 7以后的环境中,在卷管理资源中执行LVM的控制时,需要将LVM元数据服务设定为无效。
启动资源时执行以下命令。
命令
参数
使用的时机
vgs
-P
确认卷组的状态时
--noheadings
确认卷组的状态时
-o vg_attr,vg_name
确认卷组的状态时
vgimport
(无)
导入卷组时
vgscan
(无)
启动卷组时
vgchange
-ay
启动卷组时
资源启动时顺序如下所示
图 3.124 资源启动时的顺序(lvm)¶
执行确认卷状态的命令。执行失败,则启动失败。
vgs -P --noheadings -o vg_attr, vg_name VG名
执行导入卷的命令。执行失败,则启动失败。
vgimport VG名
执行卷扫描命令。
vgscan执行启动卷的命令。执行成功则启动成功,执行失败则启动失败。
vgchange -ay VG名
停止资源时执行以下命令。
命令
参数
使用的时机
vgs
-P
确认卷组的状态时
--noheadings
确认卷组的状态时
-o vg_attr,vg_name
确认卷组的状态时
vgchange
-an
卷组停止时
vgexport
(无)
导出卷组时
不启动资源时的顺序如下所示
图 3.125 停止资源时的顺序(lvm)¶
- 执行确认卷状态的命令。执行失败,则停止失败。执行成功时,如果对象VG为导出状态,则停止成功。
vgs -P --noheadings -o vg_attr, vg_name VG名
执行卷停止命令。执行失败,则停止失败。
vgchange -an VG名
执行卷导出命令。如果成功则停止成功,如果失败则停止失败。
vgexport VG名
<利用卷管理器[vxvm]时>
不在EXPRESSCLUSTER侧定义磁盘组。
EXPRESSCLUSTER的设置信息中包含的磁盘组在OS启动时自动进行逐出处理。
EXPRESSCLUSTER的设置信息中不包含的磁盘组则不逐出。
如果无法在失效切换源服务器上正常逐出磁盘组,则在失效切换目标服务器上,根据VxVM的规格,清除主机ID的选项为OFF时,将无法导入磁盘组。
发生导入超时时,实际上有时导入已经成功。如果导入参数中设置了清除主机ID或者强行导入参数则进行导入重试,可以避免该现象。
启动资源时执行以下命令。
命令
参数
使用的时机
vxdg
import
磁盘组导入时
-t
磁盘组导入时
-C
导入磁盘组失败,清除主机ID选项ON时
-f
导入磁盘组失败,强行启动选项ON时
vxrecover
-g
启动指定的磁盘组的卷时
-sb
启动指定的磁盘组的卷时
启动资源时的顺序如下所示。
图 3.126 启动资源时的顺序(vxvm)¶
执行导入命令。执行失败,则启动失败。
vxdg -t import DG名
执行下面的命令。
vxdg -t -C import DG名
执行下面的命令。
vxdg -t -f import DG名
执行下面的命令。
vxdg -t -C -f import DG名
停止资源时执行以下命令。
命令
参数
使用的时机
vxdg
deport
磁盘组逐出时
flush
刷新时
vxvol
-g
指定了的磁盘组的卷停止时
stopall
指定了的磁盘组的卷停止时
停止资源时的顺序如下所示。
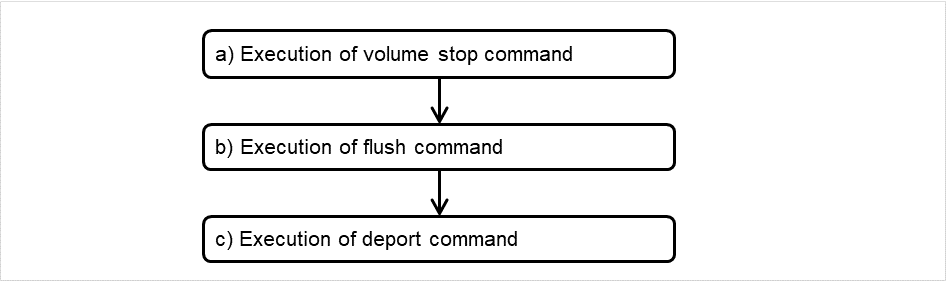
图 3.127 停止资源时的顺序(vxvm)¶
执行卷停止命令。
执行Flash命令
执行导出命令。
<利用卷管理器[zfspool]时>
在iSCSI环境利用ZFS存储池时, 一旦发生iSCSI连接断线,对ZFS的export处理会有大的延迟(OS的限制)。ZFS的iSCSI断线时的动作用ZFS的属性值"failmode"规定,EXPRESSCLUSTER推荐"failmode=panic" 。"failmode=panic"时,iSCSI断线后,在一定时间内OS会自动执行panic动作。
ZFS的属性值"mountpoint"设置为legacy的数据集仅在导入存储池时文件系统不mount。此时卷管理资源以外,有必要使用磁盘资源执行ZFS文件系统的mount/unmount。
- Ubuntu16.04以上时,根据OS启动时机,可执行会发生双重启动。请注意在OS启动时,即使自动导入存储池,也要确保文件系统没有自动mount。
抑制自动mount的方法可参考以下任意一种。
将ZFS的值"mountpoint"设置为"legacy"。
将ZFC的值"canmount"设置为"noauto"。
通过此设置,在OS启动时,即使自动导入也会抑制自动mount,可以防止双重启动。这时,需要使用磁盘资源,进行ZFS文件系统的mount/unmount。
3.13.4. 详细标签页¶

卷管理器
指定要利用的卷管理器。可选择下面的卷管理器。
lvm (lvm卷组控制)
vxvm (vxvm磁盘组控制)
zfspool (ZFS 存储池控制)
对象名 (1023个字节以内)
以<VG名>的形式(只有目标名)设置卷名。
组合框的选项会从所有服务器中获取卷组信息,并显示1台以上的服务器中存在的全部卷组。
卷管理为[lvm]时,可以进行多个卷的统合控制。控制多个卷时,使用半角空格来区分卷名。
调整
显示[卷管理资源调整属性]对话框。详细设置卷管理资源。
卷管理资源调整属性([卷管理器]为[zfspool]以外时)
导入标签页
显示导入相关的详细设置。

导入超时 (1~9999)
设置导入卷时等待命令结束的超时时间。
卷启动超时 (1~9999)
设置启动命令的超时时间。
卷状态确认超时 (1~999)
设定状态确认命令的超时时间。
卷管理设置为 [lvm] 时可用。
清除主机ID
一般导入失败时,设置成建立主机ID的清除标识进行重试。选中复选框时,清除主机ID。
卷管理器为[vxvm]时,可以使用。
强制导入
导入失败时,设置是否尝试强制导入。选中复选框时,执行强制导入。
卷管理器为[vxvm]时,可以使用。
默认值
点击[默认值]后,所有项目将设置为默认值。
导出标签页
显示导出相关的详细设置。

卷停止超时 (1~9999)
设置不启动卷命令的超时时间。
Flush超时 (1~9999)
设置刷新命令的超时时间。
卷管理器为[vxvm]时,可以使用。
导出超时 (1~9999)
设置导出/逐出命令的超时时间。
卷状态确认超时 (1~999)
设置状态确认命令的超时时间。
卷管理设置为 [lvm]的场合可用。
默认值
点击[默认值]后,所有项目将设置为默认值。
卷管理资源调整属性([卷管理器]为[zfspool]时)
导入标签页
显示导入相关的详细设置。

导入超时 (1~9999)
设置导入卷时等待命令结束的超时时间。
强制导入
导入失败时,设置是否尝试强制导入。选中复选框时,执行强制导入。
执行ping检查
仅在强制导入为ON时可以设定为有效。
由于[在其它主机导入完成]而导致导入失败时,在执行强制导入之前,通过ping设定经完成导入主机的活动状况监视。执行活动状况监视后,如果已完成导入主机正在运行,则不需要执行强制启动。从而避免多个主机同时导入同一个pool。选择为ON时执行活动状况监视。
注解
本设定为有效时,如果从EXPRESSCLUSTER停止到OS关闭为止花费时间较长,则失效切换可执行失败。例如,监视资源检测到异常而且当前服务器关机时,如果在当前服务器停止前待机服务器的卷管理被启动,则通过ping检查使启动失败。
默认值
点击[默认值]后,所有项目将设置为默认值。
导出标签页
显示导出相关的详细设置。

导出超时 (1~9999)
导出卷时,设置等待命令结束的超时时间。
强制导出
导出失败时,设置是否尝试强制导出。选中复选框时,执行强制导出。
默认值
点击[默认值]后,所有项目将设置为默认值。
3.14. 理解虚拟机资源¶
3.14.1. 虚拟机资源的依赖关系¶
在默认值中,没有依赖的组资源类型。
3.14.2. 何谓虚拟机资源?¶
此资源可控制虚拟化基础架构上的虚拟机(客机OS)。
在安装EXPRESSCLUSTER的管理用OS中启动,停止虚拟机。vSphere的情况下,将EXPRESSCLUSTER安装到管理用虚拟机的客机OS上,即可使用。
也可执行虚拟机的迁移操作。但是,使用vSphere时需要进行vCenter的使用设置。
图 3.128 安装EXPRESSCLUSTER到虚拟化基础架构的管理OS时的配置图¶
图 3.129 安装EXPRESSCLUSTER到管理用虚拟机上的OS时的配置图(仅限vSphere)¶
3.14.3. 虚拟机资源相关的注意事项¶
若虚拟化基础架构的类型为XenServer或KVM,仅当EXPRESSCLUSTER安装到虚拟化基础架构的主机OS上时,虚拟机资源才有效。
若虚拟化基础架构的类型为vSphere,将EXPRESSCLUSTER安装到客机OS上也可使用虚拟机资源,但此时需使用vCenter。
虚拟机资源只能登录到组类型为虚拟机的组。
1个虚拟机资源只能登录到1个组
若虚拟化基础架构的类型选择为vSphere,则执行迁移操作时需选中[使用vCenter]。
- 确认控制虚拟机资源的虚拟机 (客机 OS)的启动时间,务必设定 [虚拟机资源调整属性] 的 [虚拟机启动等待时间]。由于[虚拟机启动等待时间] 的缺省值为0秒,因此不进行更改时,虚拟机监视资源有可执行误检测出监视异常。
3.14.4. 详细标签页¶
vSphere时

虚拟机类型
指定虚拟化基础架构的种类。
集群服务安装路径
指定安装EXPRESSCLUSTER的OS类型。选择客机OS后,则使用vCenter的复选框会自动选中。
虚拟机名 (255字节以内)
请输入虚拟机名。输入VM配置文件路径时,不需要设置。此外,在虚拟化基础架构侧可执行更改虚拟机名时,请设置VM配置文件的路径名称。
数据保存名 (255字节以内)
请指定存储虚拟机设置信息的数据保存名。
虚拟机配置文件路径 (1023字节以内)
请指定存储虚拟机设置信息的路径。
主机IP地址 服务器个别设置
请指定主机的管理IP地址。需使用服务器个别设置,对每个服务器进行指定。
用户名 (255字节以内) 服务器个别设置
请指定启动虚拟机时使用的用户名。
密码 (255字节以内) 服务器个别设置
请指定启动虚拟机时使用的密码。
使用vCenter
请指定是否使用vCenter。利用迁移功能时,需使用vCenter。
vCenter的主机名 (1023字节以内)
请指定vCenter的主机名。
vCenter的用户名 (255字节以内)
请指定连接到vCenter时的用户名。
vCenter的密码 (255字节以内)
请指定连接到vCenter时的密码。
资源池名 (255字节以内) 服务器个别设置
请指定启动虚拟机的资源池名。
XenServer时

虚拟机类型
指定虚拟化基础架构的类型。
虚拟机名 (255字节以内)
请输入虚拟机名。设置UUID时不需要。此外,在虚拟化基础架构侧可执行更改虚拟机名时,请设置UUID。
UUID
请指定识别虚拟机的UUID(Universally Unique Identifier)。
库路径 (1023字节以内)
请指定控制XenServer时使用的库的路径。
用户名 (255字节以内)
请指定启动虚拟机时使用的用户名。
密码 (255字节以内)
请指定启动虚拟机时使用的密码。
KVM时

虚拟机类型
指定虚拟化基础架构的类型。
虚拟机名 (255字节以内)
请输入虚拟机名。设置UUID时不需要。
UUID
请指定识别虚拟机的UUID(Universally Unique Identifier)。
库路径 (1023字节以内)
请指定控制KVM时使用的库的路径。
调整
显示[虚拟机资源调整属性]对话框。对虚拟机资源进行详细设置。
虚拟机资源调整属性

请求超时
指定等待虚拟机启动/停止等请求结束的时间。
在指定时间内请求未完成时,视为超时,资源启动或停止失败。
虚拟机启动等待时间
在发出虚拟机的启动请求后,务必等待的时间。
虚拟机停止等待时间
等待虚拟机停止的最长时间。在确认虚拟机已停止时,完成停止。
3.15. 理解动态域名解析资源¶
3.15.2. 何谓动态域名解析资源?¶
动态域名解析资源将虚拟主机名和启动服务器的IP地址登录到Dynamic DNS服务器。客户端应用程序可以使用虚拟主机名连接集群服务器。通过使用虚拟主机名,即使发生"失效切换"或"组移动",客户端也无需考虑连接目标的服务器的切换。
下图显示了动态DNS服务器(DDNS服务器),Server 1和Server 2以及Client。 Server 1向DDNS服务器注册虚拟主机名和IP地址。
图 3.130 使用动态DNS服务器的配置 (1)¶
Client向DDNS服务器查询作为访问目标的虚拟主机名所对应的IP地址。 DDNS服务器用虚拟主机名所对应的Server 1的IP地址来回应查询。 Client连接到虚拟主机名的IP地址。
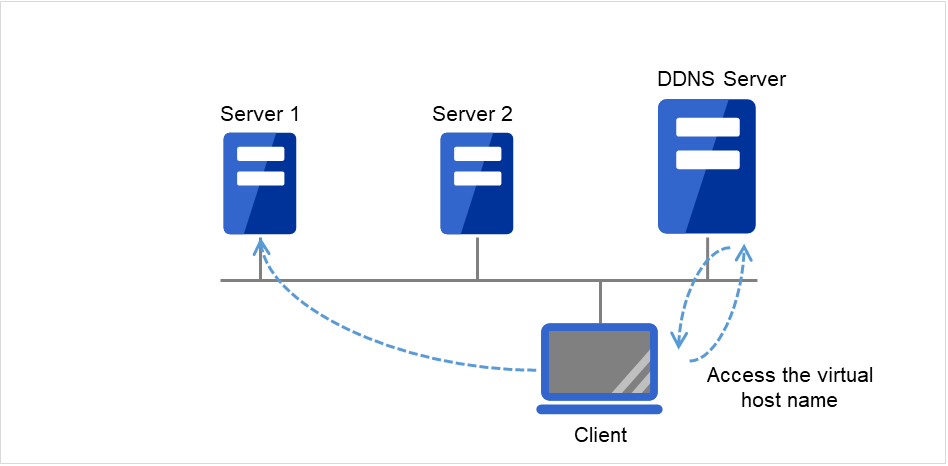
图 3.131 使用动态DNS服务器的配置 (2)¶
Server 1宕机,向Server 2发生失效切换。
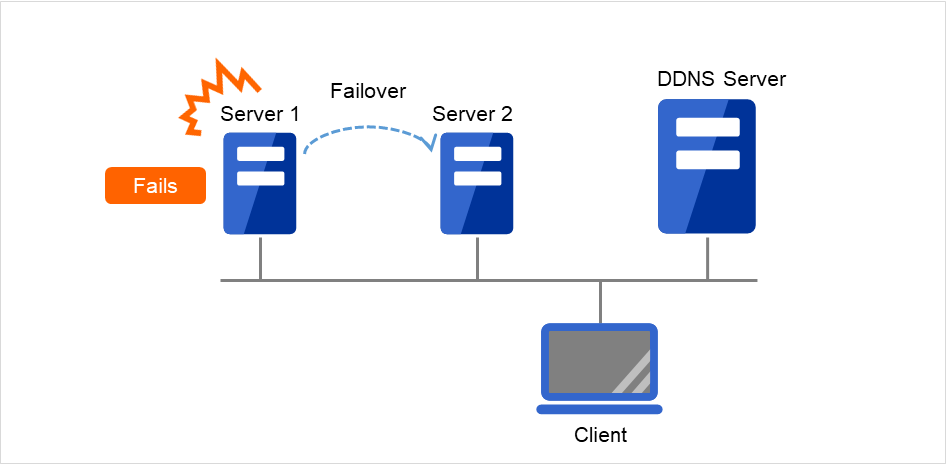
图 3.132 使用动态DNS服务器的配置 (3)¶
Server 2向DDNS服务器注册虚拟主机名和IP地址。
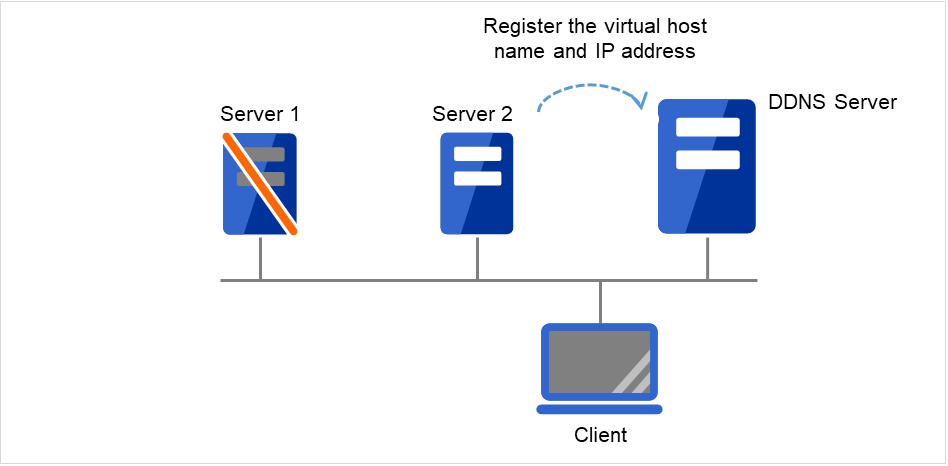
图 3.133 使用动态DNS服务器的配置 (4)¶
Client向DDNS服务器查询作为访问目标的虚拟主机名所对应的IP地址。 DDNS服务器用虚拟主机名所对应的Server 2的IP地址来回应查询。 Client连接到虚拟主机名的IP地址。
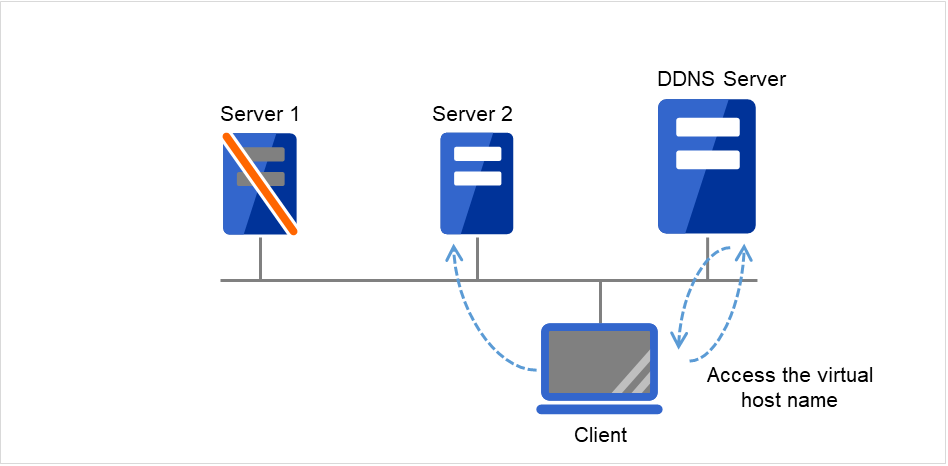
图 3.134 使用动态DNS服务器的配置 (5)¶
3.15.3. 使用动态域名解析资源时的事先准备¶
使用动态域名解析资源之前,需要构建DDNS服务器。
下面以BIND9为例进行介绍。
根据动态域名解析资源的使用方式构建DDNS服务器时,/etc/named.conf的设置分为以下2种。请以要使用的方式来设置DDNS服务器中的/etc/named.conf。
以要认证的方式使用动态域名解析资源时
在BIND9服务器上使用[dnssec-keygen]命令创建共享键。设定为在/etc/named.conf中追加共享键,允许更新Zone File。
添加动态域名解析资源时,在认证键名中填写共享键名,在认证键值中填写共享健值。
注解
关于DDNS服务器的构建方法,[dnssec-keygen]命令的使用方法,allow-update以外的设置方法等,请参考BIND手册。
设置示例:
- 生成共享键。#dnssec-keygen -a HMAC-MD5 -b 256 -n HOST exampleexample是共享键名。
执行[dnssec-keygen]命令后,生成以下2个文件。由于是共享键,所以2个文件的Key相同。
Kexample.+157+09088.keyKexample.+157+09088.private下面的named.conf设置中,从Kexample.+157+09088.key提取共享键,与使用Kexample.+157+09088.private的结果相同。Kexample.+157+09088.key的共享键值为下面带下划线部分的字符串。# cat Kexample.+157+09088.keyexample. IN KEY 512 3 157 iuBgSUEIBjQUKNJ36NocAgaB /etc/named.conf中补记共享键信息。
key " example " { algorithm hmac-md5; secret " iuBgSUEIBjQUKNJ36NocAgaB"; };
在/etc/named.conf中,将共享键的信息补记到zone语句。
zone "example.jp" { : allow-update{ key example; }; : };
通过Cluster WebUI添加动态域名解析资源时,请在认证键名中填写共享键名(example),再在认证键值中填写共享键值(iuBgSUEIBjQUKNJ36NocAgaB)。
以无认证的方式使用动态域名解析资源时
作为可更新ZONE file的IP范围[allow-update {xxx.xxx.xxx.xxx}],请务必在/etc/named.conf中设置集群中所有服务器的IP。
设置示例:
集群中服务器1的IP:192.168.10.110集群中服务器2的IP:192.168.10.111在/etc/named.conf的zone语句中补记允许更新的IP范围。
zone "example.jp" { : //可更新的IP范围 allow-update { 192.168.10.0/24; }; : };
或
zone "example.jp" { : //可更新的IP范围 allow-update { 192.168.10.110; 192.168.10.111; }; : };
添加动态域名解析资源时,请不要在认证键名和认证键值中填写任何内容。
3.15.4. 动态域名解析资源相关的注意事项¶
使用动态域名解析资源时,在各个服务器上都需要安装了bind-utils包。
需要在各服务器的/etc/resolv.conf中设置使用的动态DNS服务器的信息。
各服务器IP属于不同网段时,不能将FIP设置为动态域名解析资源的IP。
将各服务器的IP地址登录到DDNS服务器时,请通过服务器个别设置进行设置各服务器的IP。
从客户端使用虚拟主机名连接时,如果拥有动态域名解析资源的组发生失效切换,需要重新进行连接。(重启浏览器等)
本资源的有认证方式只支持使用BIND9构建的DDNS服务器。使用无认证方式时,请不要在动态域名解析资源的认证键名和认证键值中填写任何内容。
关于经由虚拟主机名的Cluster WebUI连接动作
- 按不同服务器,在动态域名解析资源中设置各服务器的IP地址时客户端使用虚拟主机名连接Cluster WebUI时,如果出现拥有动态域名解析资源的组失效切换,则Cluster WebUI连接不会自动切换。需重启浏览器,再次连接Cluster WebUI。
- 动态域名解析资源中已设定FIP地址时客户端使用虚拟主机名连接Cluster WebUI时,如果出现拥有动态域名解析资源的组失效切换,则Cluster WebUI连接自动切换。
- 要认证方式使用动态域名解析资源时,需要集群中各服务器的时间和DDNS服务器的时间差小于5分钟。时间差大于5分钟时,虚拟主机名不能登录到DDNS服务器。
3.15.5. 详细标签页¶

虚拟主机名
向DDNS服务器输入要登录的虚拟主机名。
IP地址 服务器个别设置
在虚拟主机名中填写对应的IP地址。
与FIP资源同时使用时,在[通用]标签页中输入FIP资源的IP地址。使用各服务器的IP地址时,请使用各服务器的标签页输入IP地址。
DDNS服务器
输入DDNS服务器的IP地址。
端口号
填写DDNS服务器的端口号。默认值为53。
认证键名
输入使用[dnssec-keygen]命令生成共享键时的共享键名。
认证键值
输入使用[dnssec-keygen]命令生成的共享键值。
3.16. 理解AWS Elastic IP资源¶
3.16.1. AWS Elastic IP资源的依赖关系¶
默认值没有依赖的组资源类型。
3.16.2. 何谓AWS Elastic IP资源?¶
客户端应用程序对于Amazon Web Services(以下AWS)环境的Amazon Virtual Private Cloud(以下,VPC),能使用Elastic IP(以下,EIP)地址来连接集群服务器。通过使用EIP地址,即使发生"失效切换"或"组移动",客户端也不需要关心连接地址VPC的切换。
可以结合使用AWS Elastic IP资源,AWS虚拟IP资源和AWS DNS资源。
通过EIP控制的HA集群
将实例配置在Public的Subnet上(将业务向VPC的外部公开)时使用。
集群化的实例配置在各Availability Zone(以下,AZ)的Public的Subnet上,假定各个实例为可经由互联网网关访问互联网的构成。
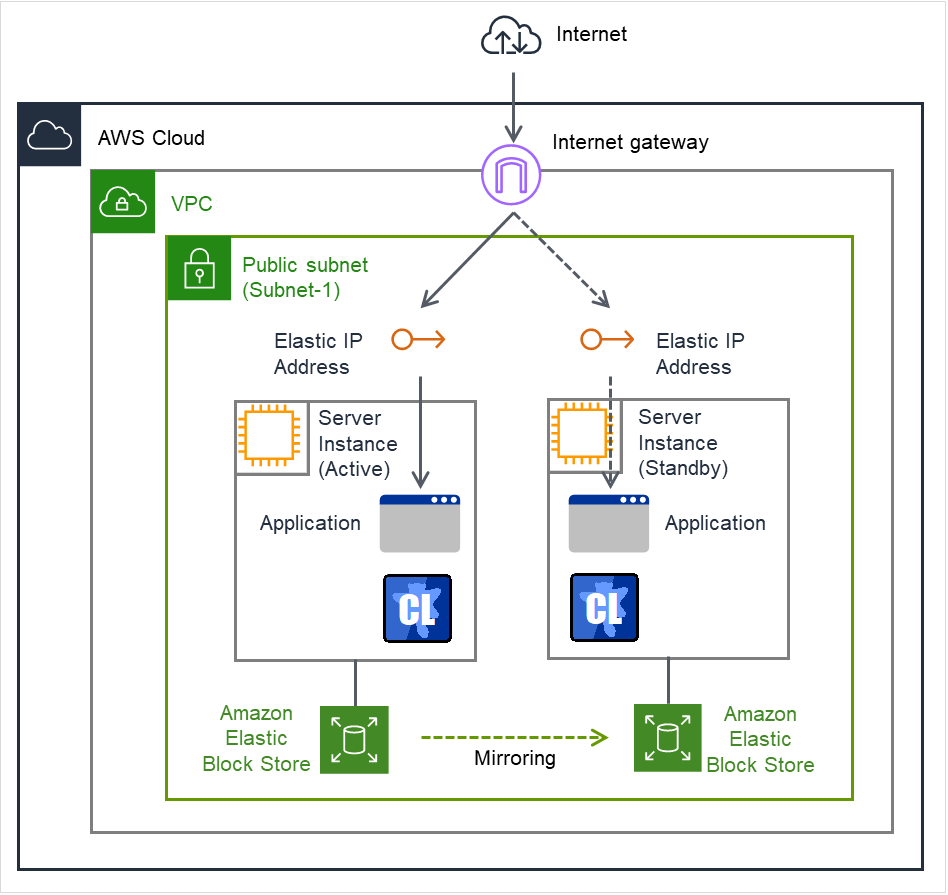
图 3.135 使用AWS Elastic IP 资源的配置¶
3.16.3. AWS Elastic IP资源相关的注意事项¶
请参阅《开始指南》的"注意限制事项" - "创建EXPRESSCLUSTER的信息时"- "关于AWS Elastic IP资源的设置"。
3.16.4. 使环境变量反映到AWS Elastic IP资源执行的AWS CLI中¶
通过在环境变量设置文件中指定环境变量的方式,可以将环境变量反映到AWS Elastic IP资源,AWS虚拟IP资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源执行的AWS CLI中。
AWS环境中,使用代理服务器等场合时有效。
环境变量设置文件的配置如下所示。
<EXPRESSCLUSTER安装路径>/cloud/aws/clpaws_setting.conf
环境变量设置文件的格式如下所示。
环境变量名= 值
指定例)
[ENVIRONMENT] HTTP_PROXY = http://10.0.0.1:3128 HTTPS_PROXY = http://10.0.0.1:3128
参数设置多个值时,请以逗号分隔(,)列出。除了环境变量NO_PROXY之外指定多个连接目标时的记载示例如下所示。
指定例)
NO_PROXY = 169.254.169.254,ec2.ap-northeast-1.amazonaws.com
环境变量设置文件的式样如下所示。
第一行请务必指定为[ENVIRONMENT]。不指定时,不设置环境变量。
环境变量设置文件不存在时,以及没有读取权限时忽略。不会导致启动异常和监视异常。
已设置了同名的环境变量时,会覆盖原有的值。
可设置多个环境变量。设置多个环境变量时,一行请只设置一个环境变量。
=两侧的空格的有无不影响设置是否有效。
环境变量名的前面存在空格或者标签时,以及=的两侧存在标签时,设置无效。
环境变量区分大小写。
值中含有空格时,不需要使用""(双引号)括起来。
环境变量设置文件中设置的环境变量是只在从AWS Elastic IP资源,AWS 虚拟IP资源,AWS DNS 资源,AWS Elastic IP监视资源,AWS 虚拟IP监视资源,AWS DNS监视资源,AWS AZ监视资源执行的 AWS CLI 中反映。因此,除此之外的脚本(例.最终动作前脚本,启动/停止前后脚本,从EXEC 资源执行的脚本)中不反映。除此之外的脚本内执行 AWS CLI 时,必要的环境变量请在当前脚本内设置。
3.16.5. 详细标签页¶

EIP ALLOCATION ID (45 字节以内)
EIP控制时,指定替换对象的EIP的ID。
ENI ID (45 字节以内) 服务器可个别设置
EIP控制时,指定分配EIP的ENI ID。各个服务器必须进行个别设置。
[共通]标签页上,指定任意服务器的ENI ID,各个服务器必须进行个别设置。
AWS Elastic IP资源调整属性
参数标签页
超时 (1~999)
设置在AWS Elastic IP资源的启动/停止的各种处理中所执行的[AWS CLI]命令的超时。

3.17. 理解AWS虚拟IP资源¶
3.17.1. AWS 虚拟IP资源的依赖关系¶
默认值没有依赖的组资源类型。
3.17.2. 何谓AWS虚拟IP资源?¶
客户端应用程序对于AWS环境的VPC,能使用虚拟IP(以下,VIP)地址来连接集群服务器。通过使用VIP地址,即使发生"失效切换"或"组移动",客户端也不需要关心连接地址VPC的切换。AWS虚拟IP资源在启动时执行AWS CLI,进行route table的更新处理。
可以结合使用AWS Elastic IP资源,AWS虚拟IP资源和AWS DNS资源。
通过VIP控制的HA集群
将实例配置在Private的Subnet上(将业务向VPC的外部公开)时使用。
集群化的实例以及访问此实例的实例群配置在各Availability Zone(以下,AZ)的Private的Subnet上,假定各个实例为可经由互联网网关访问互联网的构成。
图 3.136 使用AWS 虚拟 IP 资源的配置¶
3.17.3. AWS虚拟IP资源相关的注意事项¶
请参阅《开始指南》的"注意限制事项" - "创建EXPRESSCLUSTER的信息时"-"关于AWS 虚拟IP资源的设置"。
3.17.4. 使环境变量反映到AWS虚拟IP资源执行的AWS CLI中¶
通过在环境变量设置文件中指定环境变量的方式,可以将环境变量反映到AWS Elastic IP资源,AWS虚拟IP资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源执行的AWS CLI中。
AWS环境中,使用代理服务器等场合时有效。
环境变量设置文件的配置如下所示。
<EXPRESSCLUSTER安装路径>/cloud/aws/clpaws_setting.conf
环境变量设置文件的格式如下所示。
环境变量名= 值
指定例)
[ENVIRONMENT] HTTP_PROXY = http://10.0.0.1:3128 HTTPS_PROXY = http://10.0.0.1:3128
参数设置多个值时,请以逗号分隔(,)列出。除了环境变量NO_PROXY之外指定多个连接目标时的记载示例如下所示。
指定例)
NO_PROXY = 169.254.169.254,ec2.ap-northeast-1.amazonaws.com
环境变量设置文件的式样如下所示。
第一行请务必指定为[ENVIRONMENT]。不指定时,不设置环境变量。
环境变量设置文件不存在时,以及没有读取权限时忽略。不会导致启动异常和监视异常。
已设置了同名的环境变量时,会覆盖原有的值。
可设置多个环境变量。设置多个环境变量时,一行请只设置一个环境变量。
=两侧的空格的有无不影响设置是否有效。
环境变量名的前面存在空格或者标签时,以及=的两侧存在标签时,设置无效。
环境变量区分大小写。
值中含有空格时,不需要使用""(双引号)括起来。
环境变量设置文件中设置的环境变量是只在从AWS Elastic IP资源,AWS 虚拟IP资源,AWS DNS 资源,AWS Elastic IP监视资源,AWS 虚拟IP监视资源,AWS DNS监视资源,AWS AZ监视资源执行的 AWS CLI 中反映。因此,除此之外的脚本(例.最终动作前脚本,启动/停止前后脚本,从EXEC 资源执行的脚本)中不反映。除此之外的脚本内执行 AWS CLI 时,必要的环境变量请在当前脚本内设置。
3.17.5. 详细标签页¶

IP地址 (45 字节以内)
VIP控制时,指定所使用的VIP地址。作为VIP地址需要指定为不属于VPC的CIDR的IP地址。
VPC ID (45 字节以内) 服务器可个别设置
VIP控制时,指定服务器所属的VPC ID。进行服务器个别设置时,[共通]标签页上,指定任意一台服务器的VPC ID,各个服务器请进行个别设置。路径的设置方法,请参考以下。
《EXPRESSCLUSTER X 面向Amazon Web Services的HA集群构筑指南(Linux版)》-"4-1.VPC环境的设置"
ENI ID (45 字节以内) 服务器可个别设置
VIP控制时,指定VIP的路径控制目标的ENI ID。指定的ENI ID需要将Source/Dest. Check 设为disabled。各个服务器必须进行个别设置。
进行服务器个别设置时,[共通]标签页上,指定任意一台服务器的ENI ID,各个服务器请进行个别设置。
AWS 虚拟 IP资源调整属性
参数标签页

超时 (1~999)
设置在AWS 虚拟IP资源的启动/停止的各种处理中所执行的[AWS CLI]命令的超时。
3.18. 理解AWS DNS资源¶
3.18.1. AWS DNS 资源的依赖关系¶
默认值没有依赖的组资源类型。
3.18.2. 何谓AWS DNS资源?¶
图 3.137 使用AWS DNS资源的配置¶
对应于Amazon Web Services(以下简称AWS)使用的虚拟主机名(DNS名)的IP地址在启动时通过执行AWS CLI进行登录,在停止时通过执行AWS CLI进行删除。
客户端可以使用虚拟主机名访问失效切换组启动的节点。
利用AWS DNS资源,即使在AWS上,客户端也不需要意识到所连接的目标节点通过失效切换或组的移动的进行了切换。
可以结合使用AWS Elastic IP资源,AWS虚拟IP资源和AWS DNS资源。
利用AWS DNS资源时,在构建集群之前,需要进行以下准备工作。
创建Amazon Route 53的宿主区
安装AWS CLI
3.18.3. AWS DNS 资源相关的注意事项¶
如果使用虚拟主机名(DNS名)从客户端进行连接,在添加AWS DNS资源的失效切换组时发生失效切换,则可执行需要重新连接。
请参阅《开始指南》的"注意限制事项"-"创建EXPRESSCLUSTER的信息时"-"关于AWS DNS资源的设置"。
3.18.4. 使环境变量反映到AWS DNS 资源执行的AWS CLI中¶
通过在环境变量设置文件中指定环境变量的方式,可以将环境变量反映到AWS Elastic IP资源,AWS虚拟IP资源,AWS DNS 资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源,AWS DNS监视资源执行的AWS CLI中。
AWS环境中,使用代理服务器等场合时有效。
环境变量设置文件的配置如下所示。
<EXPRESSCLUSTER安装路径>/cloud/aws/clpaws_setting.conf
环境变量设置文件的格式如下所示。
环境变量名= 值
指定例)
[ENVIRONMENT] HTTP_PROXY = http://10.0.0.1:3128 HTTPS_PROXY = http://10.0.0.1:3128
参数设置多个值时,请以逗号分隔(,)列出。除了环境变量NO_PROXY之外指定多个连接目标时的记载示例如下所示。
指定例)
NO_PROXY = 169.254.169.254,ec2.ap-northeast-1.amazonaws.com
环境变量设置文件的式样如下所示。
第一行请务必指定为[ENVIRONMENT]。不指定时,不设置环境变量。
环境变量设置文件不存在时,以及没有读取权限时忽略。不会导致启动异常和监视异常。
已设置了同名的环境变量时,会覆盖原有的值。
可设置多个环境变量。设置多个环境变量时,一行请只设置一个环境变量。
=两侧的空格的有无不影响设置是否有效。
环境变量名的前面存在空格或者标签时,以及=的两侧存在标签时,设置无效。
环境变量区分大小写。
值中含有空格时,不需要使用""(双引号)括起来。
环境变量设置文件中设置的环境变量是只在从AWS Elastic IP资源,AWS 虚拟IP资源,AWS DNS 资源,AWS Elastic IP监视资源,AWS 虚拟IP监视资源,AWS DNS监视资源,AWS AZ监视资源执行的 AWS CLI 中反映。因此,除此之外的脚本(例.最终动作前脚本,启动/停止前后脚本,从EXEC 资源执行的脚本)中不反映。除此之外的脚本内执行 AWS CLI 时,必要的环境变量请在当前脚本内设置。
3.18.5. 详细标签页¶

宿主区ID (255字节以内)
输入Amazon Route 53的宿主区 ID。
资源记录集名 (255字节以内)
输入DNS A记录名。请在记录名的末尾添加一个点(.)。如果[资源记录集名]中包含转义码,则为监视异常。请设置不含转义码的[资源记录集名]。请以小写字符指定[资源记录设置名]。
IP地址 (39字节以内) 服务器个别设置
输入与虚拟主机名(DNS名)对应的IP地址(IPv4)。 要使用每台服务器的IP地址,请在每台服务器的标签页上输入IP地址。 当为每个服务器设置时,请在[共通]标签页上指定任意服务器的IP地址,并为其他服务器进行个别设置。
TTL (0~2147483647)
输入缓存的生存期(TTL=Time To Live)。
停止时删除资源记录集
调整
会显示出[AWS DNS资源调整属性]对话框。进行AWS DNS资源的详细信息设置。
AWS DNS资源调整属性
参数标签页

超时 (1~999)
设置在AWS DNS资源的启动/停止的各种处理中所执行的[AWS CLI]命令的超时。
3.19. 理解Azure 探头端口资源¶
3.19.1. Azure 探头端口资源的依赖关系¶
默认值没有依赖的组资源类型。
3.19.2. 何谓Azure 探头端口资源?¶
客户端应用程序对于Microsoft Azure环境里可用性套件上虚拟机,能使用公用虚拟IP(以下,VIP)地址来连接集群服务器。通过使用VIP地址,即使发生"失效切换"或"组移动",客户端也不需要关心虚拟机的切换。
图 3.138 使用Azure 探头端口资源的配置¶
上图中构建在Microsoft Azure 环境上的集群,是通过指定称作VIP的公有IP地址和从外部进行通信的端点,或DNS名和从外部进行通信的端点来进行访问的。集群的运行服务器与待机侧服务器,通过EXPRESSCLUSTER控制Microsoft Azure的负载均衡器(上述图中的Load Balancer)来进行切换。进行控制时利用Health Check。
启动时,启动用于等待Microsoft Azure负载均衡器的死活监视(访问探头端口)的探头端口控制进程。
停止时,停止用于等待死活监视(访问探头端口)的探头端口控制进程。
Azure 探头端口资源也可以对应Microsoft Azure的内部负载分散(Internal Load Balancing)。进行内部负载分散时,VIP变为Azure的私有IP地址。
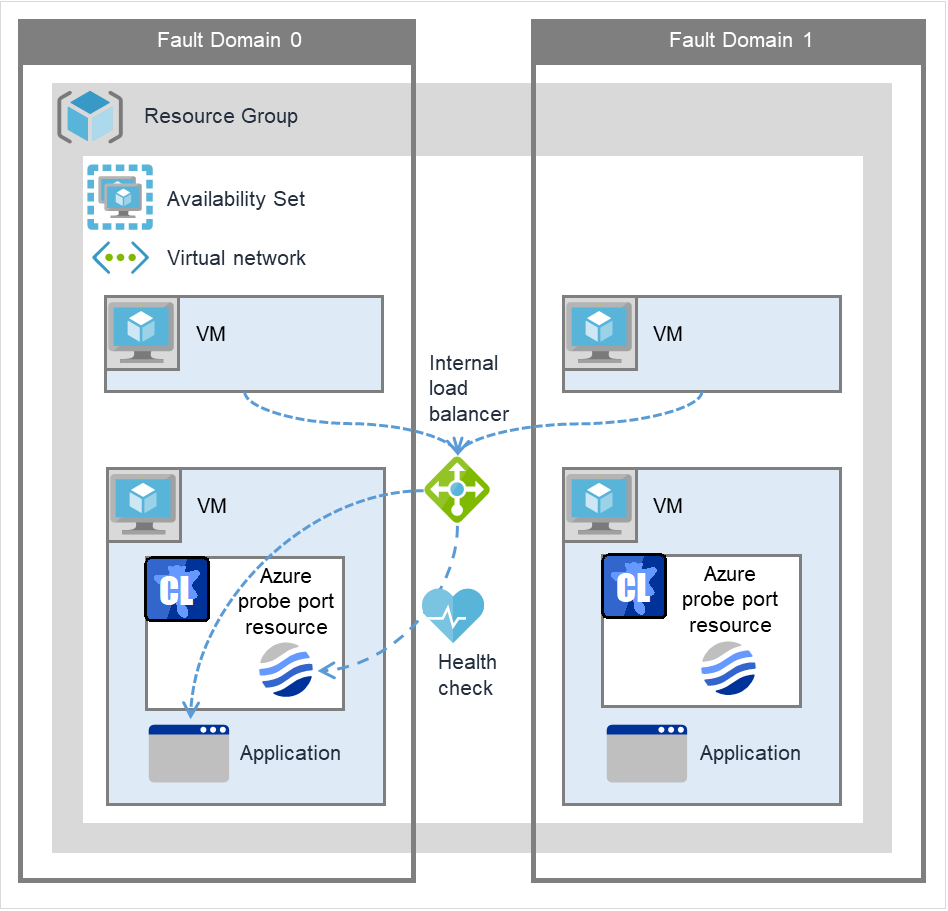
图 3.139 使用Azure 探头端口资源的配置(内部负荷分配)¶
3.19.3. Azure 探头端口资源相关的注意事项¶
私人端口与Probe端口相同时,不需要添加Azure 探头端口资源和Azure 探头端口监视资源。
请参阅《开始指南》的"注意限制事项"-"创建EXPRESSCLUSTER的信息时"-"关于Azure 探头端口资源的设置"。
3.19.4. 详细标签页¶

Probe端口 (1~65535)
Microsoft Azure的负载均衡器指定监视各服务器的死活所使用的端口号。新建端点时请指定 ProbePort所指定的值。Probe通信协议请指定TCP。
调整
显示[Azurepp资源调整属性]对话框。进行Azure Probe端口资源的详细设置。
AWS 探头端口资源调整属性
参数标签页

等待Probe的超时 (5~999999999)
指定从Microsoft Azure的负载均衡器的等待死活监视的超时时间。可确认是否从Azure的负载均衡器定期进行死活监视。
3.20. 理解Azure DNS资源¶
3.20.1. Azure DNS 资源的依赖关系¶
默认值没有依赖的组资源类型。
3.20.2. 何谓Azure DNS资源?¶
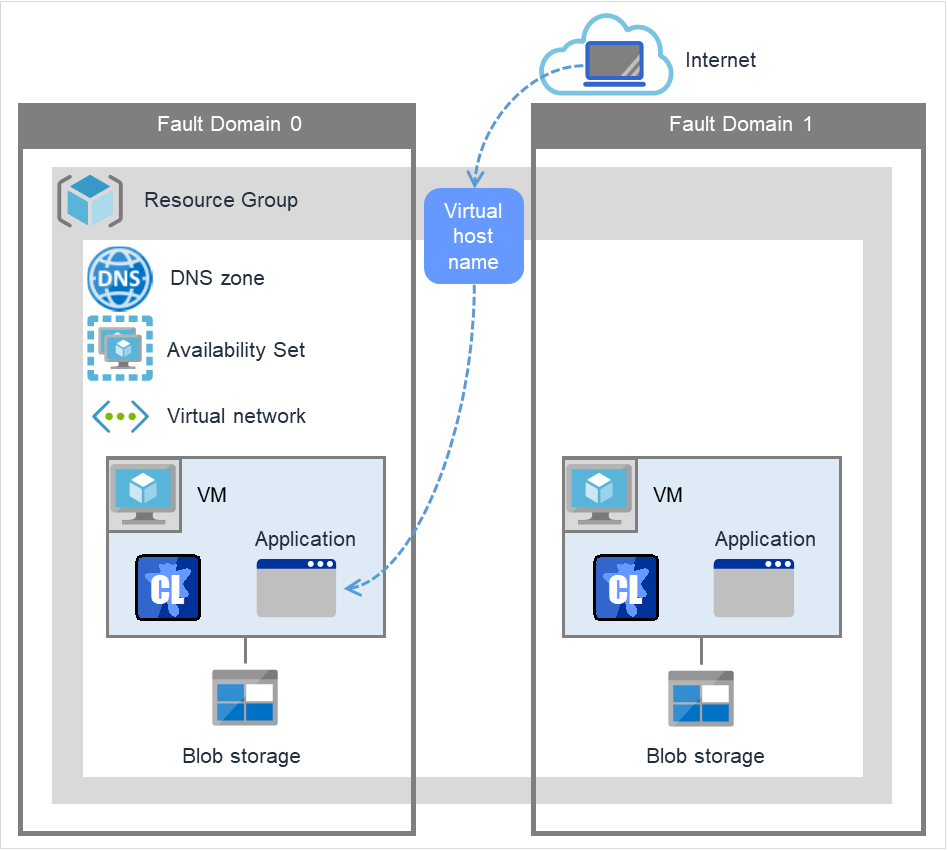
图 3.140 使用Azure DNS资源的配置¶
Azure DNS资源从虚拟主机名(DNS名)获取设置的IP地址,来控制Azure DNS记录集和DNS A记录。
客户端可以使用虚拟主机名(DNS名)访问失效切换组启动的节点。
利用Azure DNS资源,即使在Microsoft Azure上,客户端也不需要意识到所连接的目标节点通过失效切换或组的移动进行了切换。
利用Azure DNS资源时,在构建集群之前,需要进行以下准备工作。详细请参考《EXPRESSCLUSTER X 面向Microsoft Azure 的HA集群构筑指南(Linux 版)》
Microsoft Azure的资源组,创建DNS区域
安装Azure CLI
Red Hat Enterprise Linux 6 和兼容的OS时, Azure CLI要使用Azure CLI 1.0。
Red Hat Enterprise Linux 7 和兼容的OS时, Azure CLI要使用Azure CLI 2.0。
安装Python(仅使用Azure CLI 2.0时)
3.20.3. Azure DNS资源相关的注意事项¶
如果使用虚拟主机名(DNS名)从客户端进行连接,在添加Azure DNS资源的失效切换组时发生失效切换,则可执行需要重新连接。
请参阅《开始指南》的"注意限制事项"-"创建EXPRESSCLUSTER的信息时" - "关于Azure DNS资源的设置"。
请参阅《开始指南》的"注意限制事项"-"安装OS后,安装EXPRESSCLUSTER前"- "关于Azure DNS资源"。
3.20.4. 详细标签页¶

记录集名 (253字节以内)
输入记录集名以注册Azure DNS 的 A记录。
区名 (253字节以内)
输入Azure DNS记录集所属的DNS区域名。
IP地址 (39字节以内) 服务器个别设置
输入与虚拟主机名(DNS名)对应的IP地址(IPv4)。 要使用每台服务器的IP地址,请在每台服务器的标签页上输入IP地址。 当为每个服务器设置时,请在[共通]标签页上指定任意服务器的IP地址,并为其他服务器进行个别设置。
TTL (0~2147483647)
输入缓存的生存期(TTL=Time To Live)。
资源组名 (180字节以内)
输入DNS区域所属的Microsoft Azure的资源组名。
用户URI (2083字节以内)
输入Microsoft Azure登录的用户URI。
租户ID (36字节以内)
输入Microsoft Azure登录用的tenantId。
服务主体的文件路径 (1023字节以内)
输入Microsoft Azure登录用的服务主体文件名(证书的文件名)。 请指定绝对路径。
服务主体的指纹 (256字节以内)
Microsoft Azure日志登录用的服务主体(证明书)的指纹。请仅在使用Azure CLI 1.0时输入。
Azure CLI 文件路径 (1023字节以内)
输入Azure CLI的安装路径和文件名。 请指定绝对路径。
停止时删除记录集
调整
会显示出[Azure DNS资源调整属性]对话框。进行Azure DNS资源的详细信息设置。
Azure DNS资源调整属性
参数标签页

超时 (1~999)
设置在Azure DNS资源的启动/停止的各种处理中所执行的[Azure CLI]命令的超时。
3.21. 理解Google Cloud 虚拟 IP 资源¶
3.21.1. Google Cloud 虚拟 IP 资源的依存关系¶
默认值中没有依存的组资源类型。
3.21.2. 所谓Google Cloud 虚拟 IP 资源?¶
客户端应用程序对于Google Cloud Platform 环境的虚拟机,使用公共虚拟 IP 地址(以下称为VIP)可以连接到构成集群的节点。通过使用VIP 地址,即使失效切换或者发生组的移动,客户也不需要进行虚拟机的切换。
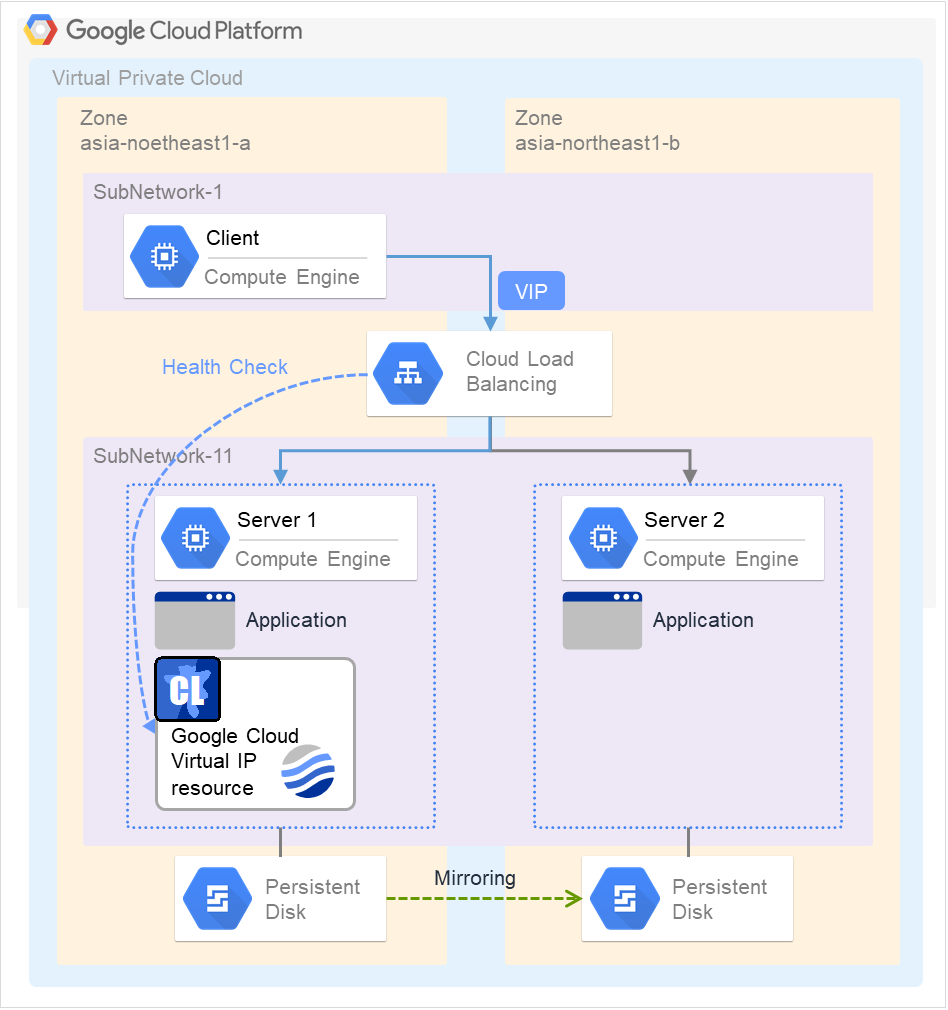
图 3.141 使用 Google Cloud Platform 虚拟IP资源的配置¶
通过指定一个称为VIP的全局IP地址和一个用于外部通信的端口,或一个DNS名称和一个用于外部通信的端口,来访问在上述图中的Google Cloud Platform环境上构建的集群。通过控制EXPRESSCLUSTER的Google Cloud Platform负载均衡器(上图中的负载均衡器),可以切换集群的运行和待机。使用上图的Health Check进行控制。
启动控制进程以等待启动时从Google Cloud Platform负载平衡器进行存活侦测,打开[端口号]中指定的端口。
停止时因为等待存活侦测停止控制进程,关闭[端口号]中指定的端口。
Google Cloud 虚拟 IP 资源还支持 Google Cloud Platform 的内部负荷平衡。
3.21.3. Google Cloud 虚拟 IP 资源的注意事项¶
- 根据 Google Cloud Platform 规范,外部TCP网络负载平衡需要使用HTTP协议进行传统的存货侦测。Google Cloud 虚拟 IP 资源仅支持使用TCP协议的存活侦测,因此无法响应来自外部TCP网络负载均衡器的存活侦测。因此,无法使用通过外部TCP网络负载均衡器使用Google Cloud 虚拟 IP 资源的HA集群。请使用内部TCP负载均衡器。请参考以下内容。存活侦测的概念:
如果专用端口和存活侦测的端口相同,则无需添加Google Cloud 虚拟 IP资源和Google Cloud 虚拟IP监视资源。
请参考《开始指南》的"注意限制事项" - "创建EXPRESSCLUSTER的信息时" - "关于Google Cloud虚拟IP资源的设置"。
3.21.4. 详细标签页¶

端口号 (1~65535)
Google Cloud Platform的负载均衡器指定使用各节点的存活侦测的端口号。请在负载均衡器的存活侦测设定时指定已指定端口号的值。负载均衡器请指定[TCP 负荷平衡]。
调整
显示[Google Cloud 虚拟 IP资源调整属性]对话框。 进行Google Cloud 虚拟 IP 资源的详细设定。
Google Cloud 虚拟 IP资源调整属性

存活侦测超时 (5~999999999)
指定从Google Cloud Platform 的负载均衡器等待存活侦测的超时时间。确认是否从Google Cloud Platform 的负载均衡器进行定期存活侦测。
3.22. 理解Google Cloud DNS 资源¶
3.22.1. Google Cloud DNS 资源的依存关系¶
默认值中没有依存的组资源类型。
3.22.2. 所谓Google Cloud DNS 资源?¶
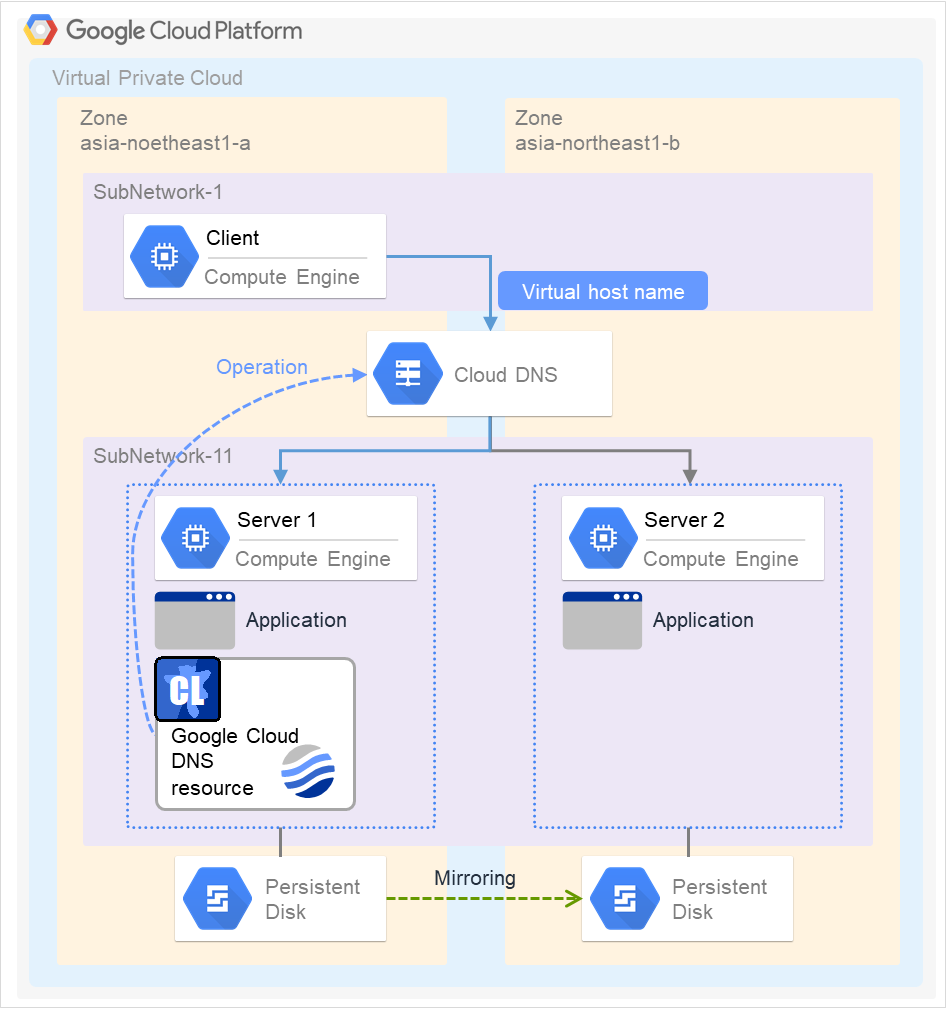
Google Cloud DNS资源从虚拟主机名(DNS名)获取设置的IP地址,来控制Google Cloud DNS记录集和DNS A记录。
客户端可以使用虚拟主机名(DNS名)访问失效切换组启动的节点。
利用Google Cloud DNS资源,即使在Google Cloud Platform上,客户端也不需要意识到所连接的目标节点通过失效切换或组的移动进行了切换。
3.22.3. Google Cloud DNS资源相关的注意事项¶
请参阅《开始指南》的"注意限制事项"-"创建EXPRESSCLUSTER的信息时" - "关于Google Cloud DNS资源的设置"。
请参阅《开始指南》的"注意限制事项"-"安装OS后,安装EXPRESSCLUSTER前"- "关于Google Cloud DNS资源"。
3.22.4. 详细标签页¶


区名 (63字节以内)
输入Google Cloud DNS记录集所属的DNS区域名。
DNS名 (253字节以内)
输入Google Cloud DNS中注册的A记录的DNS名。
IP地址 (39字节以内) 服务器个别设置
输入与虚拟主机名(DNS名)对应的IP地址(IPv4)。 要使用每台服务器的IP地址,请在每台服务器的标签页上输入IP地址。 当为每个服务器设置时,请在[共通]标签页上指定任意服务器的IP地址,并为其他服务器进行个别设置。
TTL (0~2147483647)
输入缓存的生存期(TTL=Time To Live)。
停止时删除记录集
3.23. 理解Oracle Cloud 虚拟 IP 资源¶
3.23.1. Oracle Cloud 虚拟 IP 资源的依存关系¶
默认值中没有依存的组资源类型。
3.23.2. 所谓Oracle Cloud 虚拟 IP 资源?¶
客户端应用程序对于Oracle Cloud Infrastructure 环境的虚拟机,使用公共虚拟 IP 地址(以下称为VIP)可以连接到构成集群的节点。通过使用VIP 地址,即使失效切换或者发生组的移动,客户也不需要进行虚拟机的切换。
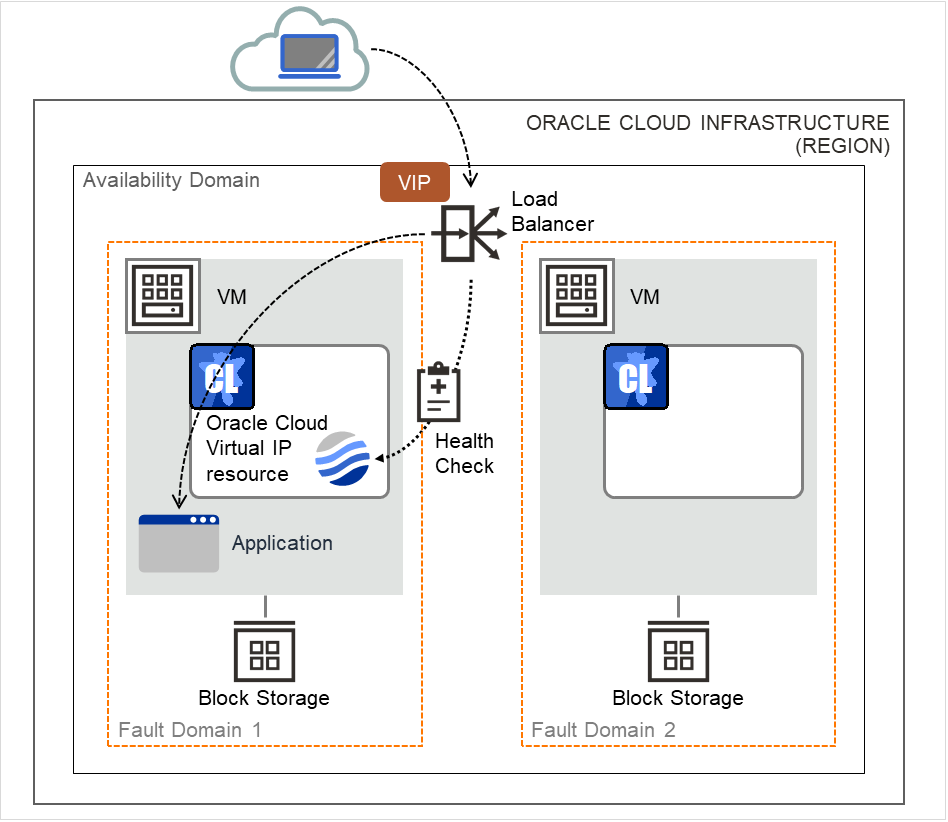
图 3.143 使用Oracle Cloud 虚拟IP资源的配置¶
通过指定一个称为VIP的全局IP地址和一个用于外部通信的端口,或一个DNS名称和一个用于外部通信的端口,来访问在上述图中的Oracle Cloud Platform环境上构建的集群。通过控制EXPRESSCLUSTER的Oracle Cloud Platform负载均衡器(上图中的负载均衡器),可以切换集群的运行和待机。使用上图的Health Check进行控制。
启动控制进程以等待启动时从Oracle Cloud Platform负载平衡器进行存活侦测,打开[端口号]中指定的端口。
停止时因为等待存活侦测停止控制进程,关闭[端口号]中指定的端口。
Oracle Cloud 虚拟 IP 资源还支持 Oracle Cloud Infrastructure 的专用负载均衡器。专用负载均衡器时,VIP 是 Oracle Cloud Platform 的专用 IP 地址。
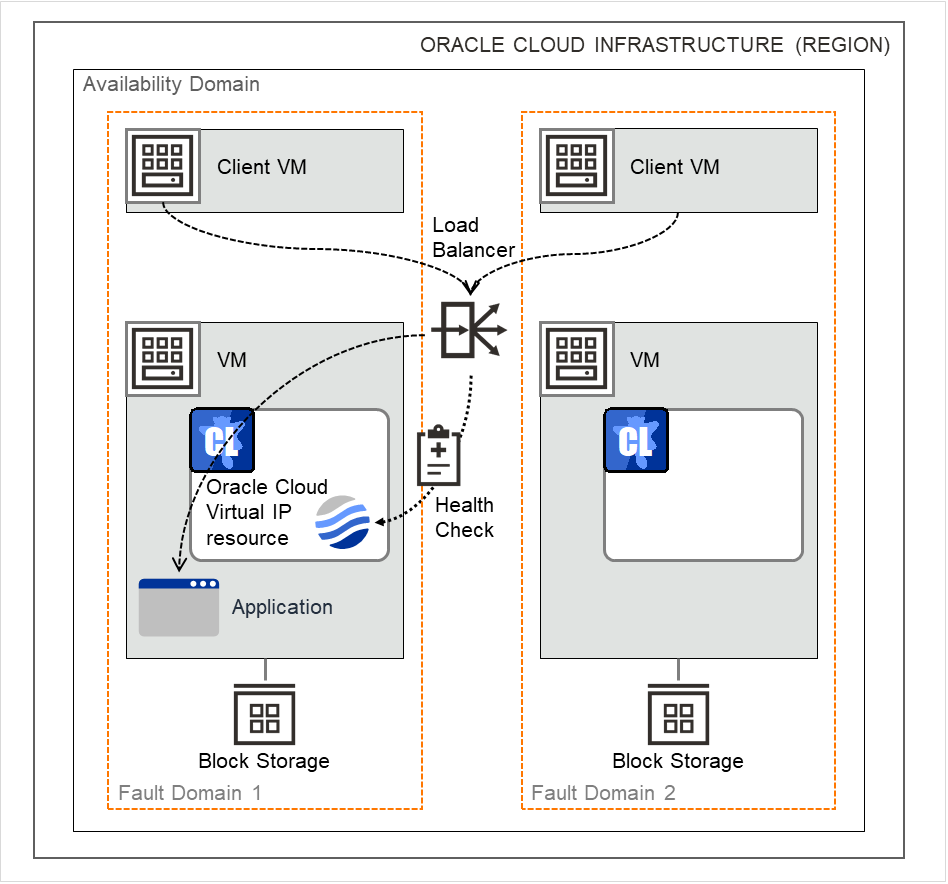
图 3.144 使用Oracle Cloud 虚拟IP资源的配置(专用负载均衡器)¶
3.23.3. Oracle Cloud 虚拟 IP 资源的注意事项¶
如果专用端口和存活侦测的端口相同,则无需添加Oracle Cloud 虚拟 IP资源和Oracle Cloud 虚拟IP监视资源。
请参考《开始指南》的"注意限制事项" - "创建EXPRESSCLUSTER的信息时" - "关于Oracle Cloud虚拟IP资源的设置"。
3.23.4. 详细标签页¶

端口号(1~65535)
Oracle Cloud Platform的负载均衡器指定使用各节点的存活侦测的端口号。请在负载均衡器的存活侦测设定时指定已指定端口号的值。存活侦测请指定TCP。
调整
显示[Oracle Cloud 虚拟 IP资源调整属性]对话框。 进行Oracle Cloud 虚拟 IP 资源的详细设定。
Oracle Cloud 虚拟 IP资源调整属性

存活侦测超时 (5~999999999)
指定从Oracle Cloud Platform 的负载均衡器等待存活侦测的超时时间。确认是否从Oracle Cloud Platform 的负载均衡器进行定期存活侦测。