9. 疑难解答¶
本章介绍在使用EXPRESSCLUSTER过程中发生故障时的应对方法。
本章包含以下内容。
9.1. 发生故障时的步骤¶
本节介绍EXPRESSCLUSTER 运行过程中发生故障时的操作步骤。
9.1.1. EXPRESSCLUSTER无法启动/退出¶
安装EXPRESSCLUSTER后重启服务器后,集群系统即开始运行,如果集群系统没有正常运行,请确认以下内容。
集群配置信息的登录状态
需要在生成集群时将集群配置信息登录到所有要构建集群系统的服务器中。如果以下路径下不存在,则可执行尚未执行该操作,请确认。
/opt/nec/ clusterpro/etc/clp.conf
集群配置信息的服务器名,IP地址
请确认服务器名,IP地址是否有效。(# hostname,# ifconfig....)License的注册状态
可执行没有注册License。请在集群中所有服务器上执行如下命令,确认License是否已经注册。
# clplcnsc -l -a
命令的详细信息,请参考本指南的"8.2. EXPRESSCLUSTER命令一览"的"License管理(clplcnsc命令)"。
如果是试用版License或期间定制License,确认注册的License是否在有效期内。
EXPRESSCLUSTER服务的启动设置状态
通过如下命令确认EXPRESSCLUSTER服务的启动设置。
init.d环境时:
# chkconfig --list clusterpro clusterpro 0:off 1: off 2: off 3: on 4: off 5:on 6: off
systemd环境时:
# systemctl is-enabled clusterpro集群进程的生存
请执行以下命令,通过命令的方法确认EXPRESSCLUSTER 进程是否正常运行。
# ps -ef | grep clp root 1669 1 0 00:00 ? 00:00:00 clpmonp -event -a 2 -r 0 -w 0 root 1670 1669 0 00:00 ? 00:00:00 clpevent root 1684 1 0 00:00 ? 00:00:00 clpmonp -trnsv -a 2 -r 0 -w 0 root 1685 1684 0 00:00 ? 00:00:00 clptrnsv root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm root 1796 1795 0 00:00 ? 00:00:00 clprc root 1809 1808 0 00:00 ? 00:00:00 clprm root 1813 1812 0 00:00 ? 00:00:00 clpnm root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1820 1813 0 00:00 ? 00:00:00 clpdiskhb root 1822 1813 0 00:00 ? 00:00:00 clpcomhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb root 1935 1 0 00:00 ? 00:00:00 clpmonp -webmgr -a 2 -o -start -r 0 -w 0 root 1936 1935 0 00:00 ? 00:00:00 clpwebmc -start root 1947 1 0 00:00 ? 00:00:00 clpmonp -webalert -a 2 -r 0 -w 0 root 1948 1947 0 00:00 ? 00:00:00 clpaltd
如果通过ps命令的结果能够确认以下进程的执行状态,则表示EXPRESSCLUSTER运行正常。
事件进程以及数据传送进程
root 1685 1684 0 00:00 ? 00:00:00 clptrnsv root 1669 1 0 00:00 ? 00:00:00 clpmonp -event root 1670 1669 0 00:00 ? 00:00:00 clpevent root 1684 1 0 00:00 ? 00:00:00 clpmonp -trnsv
如果事件进程未启动,则以下的进程管理器不会启动。
进程管理器
root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm
通过启动此进程将进一步生成以下进程,如果查出集群配置信息文件无效等异常,则EXPRESSCLUSTER不会启动。
clprcclprmclpnm资源控制进程
root 1796 1795 0 00:00 ? 00:00:00 clprc
※ 即使组资源未登录仍然可以启动。
资源监视进程
root 1809 1808 0 00:00 ? 00:00:00 clprm
※ 即使监视资源未登录仍然可以启动。
服务器管理进程
root 1813 1812 0 00:00 ? 00:00:00 clpnm
心跳进程
root 1822 1813 0 00:00 ? 00:00:00 clpcomhb root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1820 1813 0 00:00 ? 00:00:00 clpdiskhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb
如果集群配置信息的心跳资源中添加了磁盘心跳资源,则clpdiskhb 将启动,如果添加了COM心跳资源,则clpcomhb 将启动,如果添加了内核模式LAN心跳资源,则clplankhb 将启动。
WebManager 进程
root 1936 1935 0 00:00 ? 00:00:00 clpwebmc -start
Alert 进程
root 1948 1947 0 00:00 ? 00:00:00 clpaltd
上述的ps命令上的显示形式根据信息传送可执行会有所不同。
集群进程的生存 -使用Replicator 时-
请执行以下命令,通过命令的方法确认EXPRESSCLUSTER 进程是否正常运行。
# ps -ef | grep clp root 1669 1 0 00:00 ? 00:00:00 clpmonp - event -a 2 -r 0 -w 0 root 1670 1669 0 00:00 ? 00:00:00 clpevent root 1684 1 0 00:00 ? 00:00:00 clpmonp - trnsv -a 2 -r 0 -w 0 root 1685 1684 0 00:00 ? 00:00:00 clptrnsv root 1696 1 0 00:00 ? 00:00:00 clpmonp - mdagent -a 5 -r 0 -w 30 root 1697 1696 0 00:00 ? 00:00:00 clpmdagent root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm root 1796 1795 0 00:00 ? 00:00:00 clprc root 1809 1808 0 00:00 ? 00:00:00 clprm root 1813 1812 0 00:00 ? 00:00:00 clpnm root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1822 1813 0 00:00 ? 00:00:00 clpcomhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb root 1935 1 0 00:00 ? 00:00:00 clpmonp - webmgr -a 2 -o -start -r 0 -w 0 root 1936 1935 0 00:00 ? 00:00:00 clpwebmc -start root 1947 1 0 00:00 ? 00:00:00 clpmonp - webalert -a 2 -r 0 -w 0 root 1948 1947 0 00:00 ? 00:00:00 clpaltd
如果通过[ps]命令的结果能够确认以下进程的执行状态,则表示EXPRESSCLUSTER运行正常。
事件进程,数据传送进程以及镜像Agent
root 1696 1 0 00:00 ? 00:00:00 clpmonp --mdagent -a 5 -r 0 -w 30 root 1697 1696 0 00:00 ? 00:00:00 clpmdagent
如果事件进程未启动,则以下的进程管理器不会启动。
进程管理器
root 1784 1 0 00:00 ? 00:00:00 /opt/nec/clusterpro/bin/clppm
通过启动此进程将进一步生成以下进程,如果查出集群配置信息文件无效等异常,则EXPRESSCLUSTER不会启动。
clprcclprmclpnm资源控制进程
root 1796 1795 0 00:00 ? 00:00:00 clprc
※ 即使组资源未登录仍然可以启动。
资源监视进程
root 1809 1808 0 00:00 ? 00:00:00 clprm
※ 即使监视资源未登录仍然可以启动。
服务器管理进程
root 1813 1812 0 00:00 ? 00:00:00 clpnm
心跳进程
root 1822 1813 0 00:00 ? 00:00:00 clpcomhb root 1818 1813 0 00:00 ? 00:00:00 clplanhb root 1823 1813 0 00:00 ? 00:00:00 clplankhb
如果集群配置信息的心跳资源中添加了COM心跳资源,则clpcomhb 将启动,如果添加了内核模式LAN心跳资源,则clplankhb 将启动。
WebManager 进程
root 1936 1935 0 00:00 ? 00:00:00 clpwebmc -start
Alert 进程
root 1948 1947 0 00:00 ? 00:00:00 clpaltd
上述的[ps]命令上的显示形式根据传送的信息可执行会有所不同。
镜像驱动程序的载入 -使用Replicator时-
执行[lsmod]命令。通过[lsmod]的执行结果确认以下可载入模块是否已被登录。
liscal
内核模式LAN心跳驱动程序的载入 -使用内核模式LAN心跳资源时-
执行[lsmod]命令。通过[lsmod]的执行结果,确认以下可载入模块是否已登录。
clpkhb
keep alive驱动程序的载入 -使用userw用户空间监视资源(keepalive)资源时-
执行[lsmod]命令。通过[lsmod]的执行结果,确认以下可载入模块是否已登录。
clpka
从[syslog]确认集群正常启动
请查找以下消息,确认EXPRESSCLUSTER进程是否正常启动。
进程管理器的启动确认
<type: pm><event: 1> Starting the cluster daemon...
心跳资源的启动确认
<type: nm><event: 3> Resource lanhb1 of server server1 has started. <type: nm><event: 3> Resource diskhb1 of server server1 has started. <type: nm><event: 1> Server server1 has started. <type: nm><event: 3> Resource diskhb1 of server server2 has started. <type: nm><event: 1> Server server2 has started. <type: nm><event: 3> Resource lanhb1 of server server2 has started.
以上是集群2节点配置下,心跳资源设置如下时的消息。
lanhb1 LAN心跳资源diskhb1 磁盘心跳资源组资源的启动确认
<type: rc><event: 10> Activating group grp1 has started. <type: rc><event: 30> Activating fip1 resource has started. <type: rc><event: 31> Activating fip1 resource has completed. <type: rc><event: 30> Activating disk1 resource has started. <type: rc><event: 31> Activating disk1 resource has completed. <type: rc><event: 11> Activating group grp1 has completed.
以上是组资源grp1在sever1上启动时的消息。组资源的配置信息如下。
fip1 浮动IP资源disk1 共享磁盘资源监视资源的监视开始确认
<type: rm><event: 1> Monitoring userw has started. <type: rm><event: 1> Monitoring ipw1 has started.
以上是监视资源如下设置时的消息。
userw 用户空间监视资源ipw1 IP监视资源License一致性的检查确认
产品版
<type: lcns><event: 1> The number of licenses is 2. (Product name:EXPRESSCLUSTER X)
以上是注册了2CPU的License时的消息。
试用版
<type: lcns><event: 2> The trial license is valid until yyyy/mm/dd. (Product name:EXPRESSCLUSTER X)
- 从syslog 确认集群正常启动 -使用Replicator时-请查找以下消息,从syslog中确认EXPRESSCLUSTER进程是否正常启动。
镜像Agent的启动确认
<type: mdagent><event: 1> Agent has started successfully.
镜像驱动程序的启动确认
<type: liscal><event: 101> Registered blkdev with major=218.
进程管理器的启动确认
<type: pm><event: 1> Starting the cluster daemon...
心跳资源的启动确认
<type: nm><event: 3> Resource lanhb1 of server server1 has started. <type: nm><event: 1> Server server1 has started. <type: nm><event: 3> Resource lanhb1 of server server2 has started. <type: nm><event: 1> Server server2 has started.
以上是集群2节点配置下,心跳资源设置如下时的消息。
lanhb1 LAN心跳资源
组资源的启动确认
<type: rc><event: 10> Activating group grp1 has started. <type: rc><event: 30> Activating fip1 resource has started. <type: rc><event: 31> Activating fip1 resource has completed. <type: rc><event: 30> Activating md1 resource has started. <type: rc><event: 31> Activating md1 resource has completed. <type: rc><event: 11> Activating group grp1 has completed.
以上是组资源 grp1 在 server1 上启动时的消息。组资源的配置信息如下。
fip1 浮动IP资源md1 镜像磁盘资源监视资源的监视开始确认
<type: rm><event: 1> Monitoring userw has started. <type: rm><event: 1> Monitoring ipw1 has started. <type: rm><event: 1> Monitoring mdw1 has started. <type: rm><event: 1> Monitoring mdnw1 has started.
以上是监视资源如下设置时的消息。
userw 用户空间监视资源ipw1 IP监视资源mdw1 镜像磁盘监视资源mdnw1 镜像磁盘连接监视资源License一致性检查确认
产品版
<type: lcns><event: 1> The number of licenses is 2. (Product name:EXPRESSCLUSTER X)
以上是注册了2CPU的License时的消息。
试用版
<type: lcns><event: 2> The trial license is valid until yyyy/mm/dd. (Product name:EXPRESSCLUSTER X)
磁盘的剩余空间状态
请使用[df]等命令确认/opt/nec/clusterpro所属文件系统的剩余空间。EXPRESSCLUSTER Server所使用的磁盘容量请参考《开始指南》的"EXPRESSCLUSTER 的运行环境"。
内存不足或OS资源不足
[top]命令,[free]命令等确认OS的内存使用情况,CPU的使用率。
9.1.2. 组资源启动/停止失败¶
在组资源启动/停止时发现异常时,异常的详细信息将输出到警报,syslog日志中。请根据该信息对异常原因进行分析,并采取相应的处理办法。
9.1.3. 监视资源中发生异常¶
在监视资源中发现异常时,异常的详细信息将输出到警报,syslog中监视资源中。请根据该信息对异常原因进行分析,并采取相应的处理办法。
- 查出用户空间监视资源(监视方法 softdog)的异常时查出"初始化异常"时,请使用系统的[insmod]命令确认softdog驱动程序是否可以载入。此外,发生"服务器重置"时,请确认用户空间的负载状况。其他异常的详细信息请参考"用户空间监视资源"。
- 查出镜像磁盘监视资源的异常时 -使用Replicator时-请确认是否存在磁盘设备,是否预留了集群分区,数据分区。同时,请确认镜像Agent是否已启动。其他异常的详细信息请参考"镜像磁盘监视资源"。
- 查出共享型镜像磁盘监视资源的异常时 -使用Replicator DR时-请确认是否存在磁盘设备,是否预留了集群分区,数据分区。同时,请确认镜像Agent是否已经启动。其他异常的详细信息,请参考"共享型镜像磁盘监视资源"
- 查出共享型镜像磁盘连接监视资源的异常时 -使用Replicator DR时-请确认是否确立镜像磁盘连接。同时,请确认镜像Agent是否已经启动。其他异常的详细信息,请参考"共享型镜像磁盘连接监视资源"。
9.1.4. 发生心跳超时¶
造成服务器之间的心跳超时的原因可执行如下。
原因 |
处理方法 |
|---|---|
LAN/磁盘/COM线缆断线 |
请确认磁盘,COM 线缆的连接状态。
请确认LAN网络通过ping能否发送数据包。
|
由于用户空间负载过高造成心跳超时识别错误 |
如果长时间在OS上执行高负载的应用程序,请事先执行以下命令,延长心跳超时时间。
# clptoratio -r 3 -t 1d在上述的命令中,将心跳超时时间延长了3倍,此设置值保持1天。
|
9.1.5. 发生了网络分区¶
网络分区的含义是服务器之间的通信线路全部中断。以下是发生网络分区时的确认方法。下面以2节点集群结构中,心跳资源内登录了LAN,内核模式LAN,磁盘,COM时的情况为例进行说明。
如果所有心跳资源均为正常状态(即没有发生网络分区),则[clpstat]命令的执行结果如下:
[在server1上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 HB5 : comhb1 [on server0 : Online] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : o o o o o o server1 : o o o o o o [on server1 : Online] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : o o o o o o server1 : o o o o o o =================================================================
[在server2上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster server0 : server1 *server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 HB5 : comhb1 [on server0 : Online] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : o o o o o o server1 : o o o o o o [on server1 : Online] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : o o o o o o server1 : o o o o o o =================================================================
发生了网络分区时,[clpstat]命令的执行结果如下。服务器双方均认为对方服务器已经宕机。
[在server1上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 HB5 : comhb1 [on server0 : Caution] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : o o o o o o server1 : x x x x x x [on server1 : Offline] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : - - - - - - server1 : - - - - - - =================================================================
[在server2上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster server0 : server1 *server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 HB5 : comhb1 [on server0 : Offline] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : - - - - - - server1 : - - - - - - [on server1 : Caution] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : x x x x x x server1 : o o o o o o =================================================================
因此,发生网络分区时请立即关闭两台服务器。之后,确认各心跳资源的如下内容。
LAN心跳资源
LAN线缆的状态
网络接口的状态
内核模式LAN心跳资源
LAN线缆的状态
网络接口的状态
磁盘心跳资源
磁盘线缆的状态
磁盘设备的状态
COM心跳资源
COM线缆的状态
如果私网从发生网络分区的状态中复原,EXPRESSCLUSTER将关闭服务器。
EXPRESSCLUSTER如果发现在多个服务器上启动了同一个组,将关闭启动同一组的所有服务器。
使用Replicator的情况下,服务器重启后的镜像磁盘资源状态可执行根据关闭服务器时间的不同而不同。
根据不同的关闭服务器时间,可执行有"需要强行镜像复归","需要镜像复归","正常状态"等几种状态。
9.1.6. 发生私网整体断线¶
以下是服务器之间私网(LAN心跳资源,内核模式LAN心跳资源)全部中断时的状态确认方法。下面以2节点集群结构中,心跳资源中登录了内核模式LAN,磁盘,COM时的情况为例进行说明。(使用Replicator无法登录磁盘。)
私网全部中断,磁盘和COM正常时,[clpstat]命令的执行结果如下。服务器双方均认为对方服务器正在运行。
[在server1上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster *server0 : server1 server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 HB5 : comhb1 [on server0 : Caution] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : o o o o o o server1 : x x x x o o [on server1 : Caution] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : - - - - - - server1 : - - - - - - =================================================================
[在server2上执行命令的结果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS ================= Cluster : cluster server0 : server1 *server1 : server2 HB0 : lanhb1 HB1 : lanhb2 HB2 : lankhb1 HB3 : lankhb2 HB4 : diskhb1 HB5 : comhb1 [on server0 : Caution] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : - - - - - - server1 : - - - - - - [on server1 : Caution] HB 0 1 2 3 4 5 ----------------------------------------------------------------- server0 : x x x x o o server1 : o o o o o o =================================================================
如果私网全部中断,因为能够使用磁盘心跳,COM心跳进行通信,因此将不发生失效切换。
但是如果使用私网进行通信的命令无法使用,则需要尽快复原私网。
请确认各心跳资源的如下内容。
LAN心跳资源
LAN线缆的状态
网络接口的状态
内核模式LAN心跳资源
LAN线缆的状态
网络接口的状态
在Replicator中,同时使用私网和镜像磁盘连接时,私网(镜像磁盘连接)中断可执行造成镜像中断。复原私网后,请执行镜像复归。
9.1.8. 手动mount镜像磁盘¶
EXPRESSCLUSTER由于故障等原因无法启动时,需要手动mount镜像磁盘时,按以下步骤操作。
9.1.9. 镜像可用的状态下正常mount¶
EXPRESSCLUSTER Daemon无法启动,镜像Agent(EXPRESSCLUSTER数据镜像Daemon)可以启动时的操作步骤如下。
在想要mount的服务器上执行以下命令。
clpmdctrl --active <镜像磁盘资源名 (例:md1)>
可以访问镜像磁盘资源的Mount点。write的数据将在对方服务器组上建立镜像。
9.1.10. 镜像不可用的状态下强行mount¶
EXPRESSCLUSTER Daemon无法启动,镜像Agent(EXPRESSCLUSTER数据镜像Daemon)也无法启动时,为了保存镜像磁盘上的数据,按以下步骤操作。
但是前提条件是在此之前镜像应该是正常状态,或者知道哪个服务器拥有最新的数据。
- Server 1,Server 2都处于无法启动EXPRESSCLUSTER Daemon的状态。Server 1有最新的数据。在各服务器中执行以下命令,设置不启动EXPRESSCLUSTER服务。
clpsvcctrl.sh --disable -a
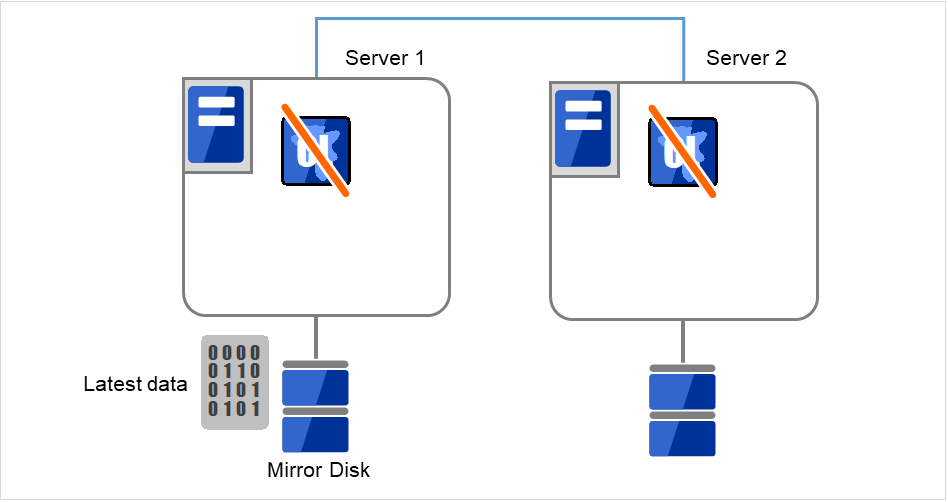
图 9.1 镜像磁盘上的数据保存 (1)¶
使用[reboot]命令重启持有最新数据的服务器或最后启动镜像磁盘资源的服务器。使用[shutdown]命令关闭另一侧的服务器。
在这里,重新启动有最新数据的Server 1,关闭没有最新数据的Server 2。
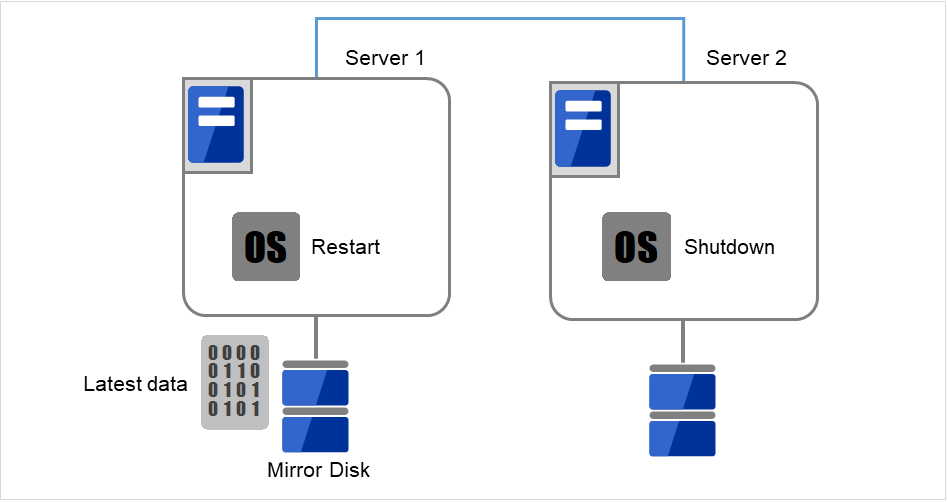
图 9.2 镜像磁盘上的数据保存 (2)¶
执行[mount]命令,用read-only的方式mount镜像磁盘上的数据分区。
(例) mount -r -t ext3 /dev/sdb5 /mnt
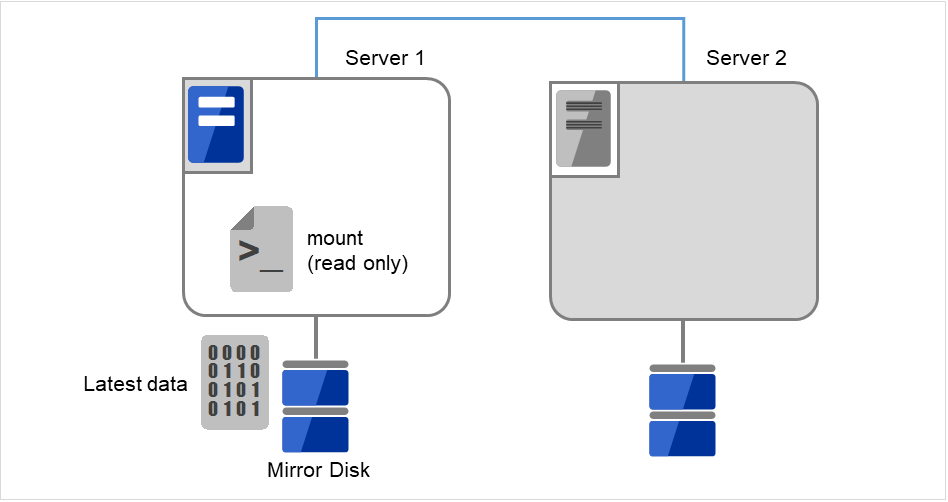
图 9.3 镜像磁盘上的数据保存 (3)¶
将数据分区内的数据备份到磁带等设备中。
将备份设备(Backup device)连接到Server 1,使用tar和cpio等命令,备份数据分区内的数据。
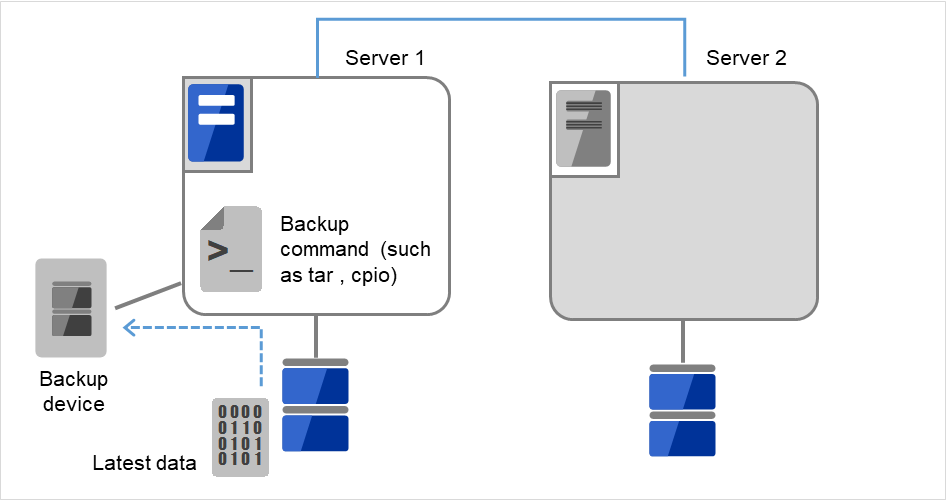
图 9.4 镜像磁盘上的数据保存 (4)¶
unmount已mount的数据分区。
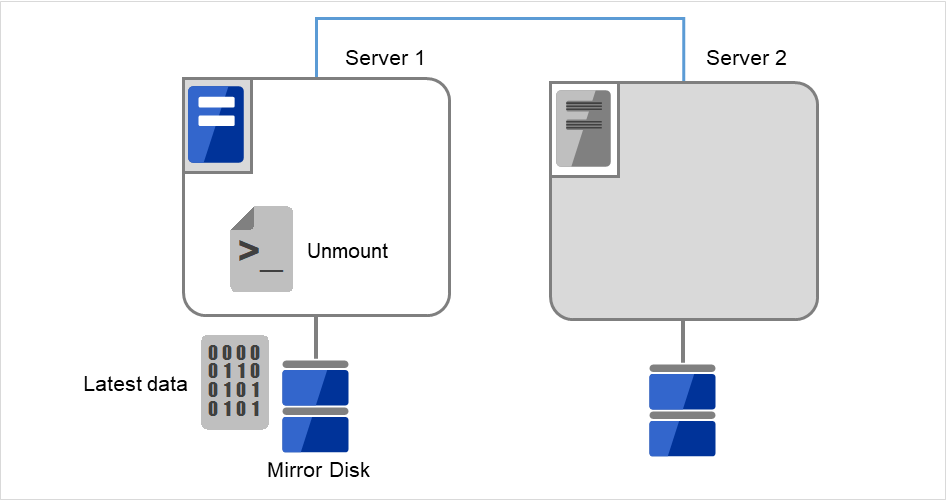
图 9.5 镜像磁盘上的数据保存 (5)¶
9.1.11. 手动mount共享型镜像磁盘¶
如果EXPRESSCLUSTER因为故障等原因不能启动时,按照以下步骤手动mount共享型镜像磁盘。
9.1.12. 镜像可用的状态下正常mount¶
EXPRESSCLUSTER Daemon无法启动,镜像Agent(EXPRESSCLUSTER数据镜像Daemon)可以启动时的操作步骤如下。
在想要mount的服务器上执行以下命令。
clphdctrl --active <共享型镜像磁盘资源名(例:hd1)>
可以访问共享型镜像磁盘资源的Mount点。write的数据将在对方服务器组上建立镜像。
9.1.13. 镜像不可用的状态下强行mount¶
EXPRESSCLUSTER Daemon无法启动,镜像Agent(EXPRESSCLUSTER数据镜像Daemon)也无法启动时,为了保存共享型镜像磁盘上的数据,按以下步骤操作。
但是前提条件是在此之前镜像应该是正常状态,或者知道哪个服务器持有最新的数据。
- 无法在任何服务器上启动EXPRESSCLUSTER Daemon。Server 1有最新的数据。在各服务器中执行命令,设置不启动EXPRESSCLUSTER服务。
clpsvcctrl.sh --disable -a
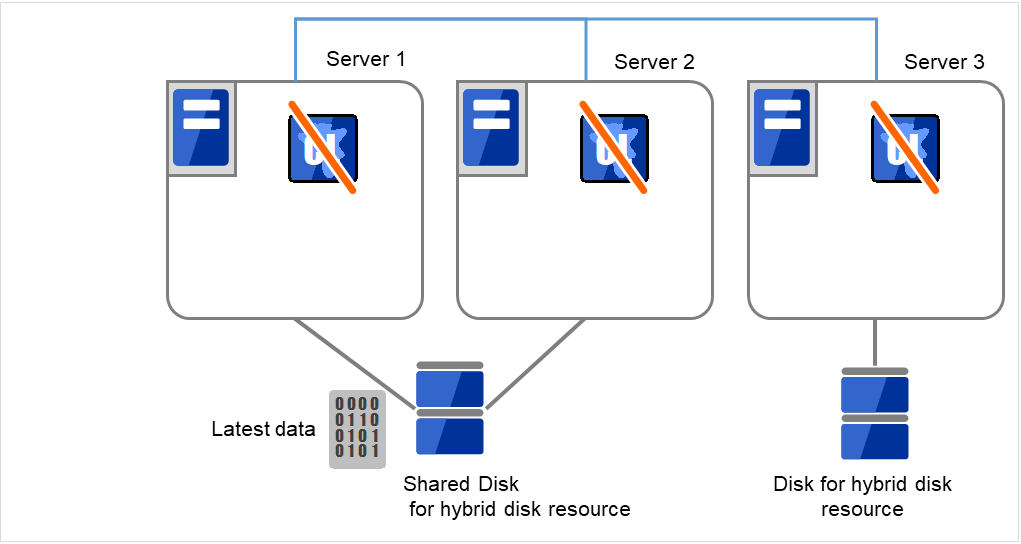
图 9.6 共享型镜像磁盘上的数据保存 (1)¶
使用[reboot]命令重启持有最新数据的服务器或最后启动共享型镜像磁盘资源的服务器上。使用[shutdown]命令关闭其他服务器。
在这里,重新启动有最新数据的Server 1,关闭没有最新数据的Server 2和Server 3。
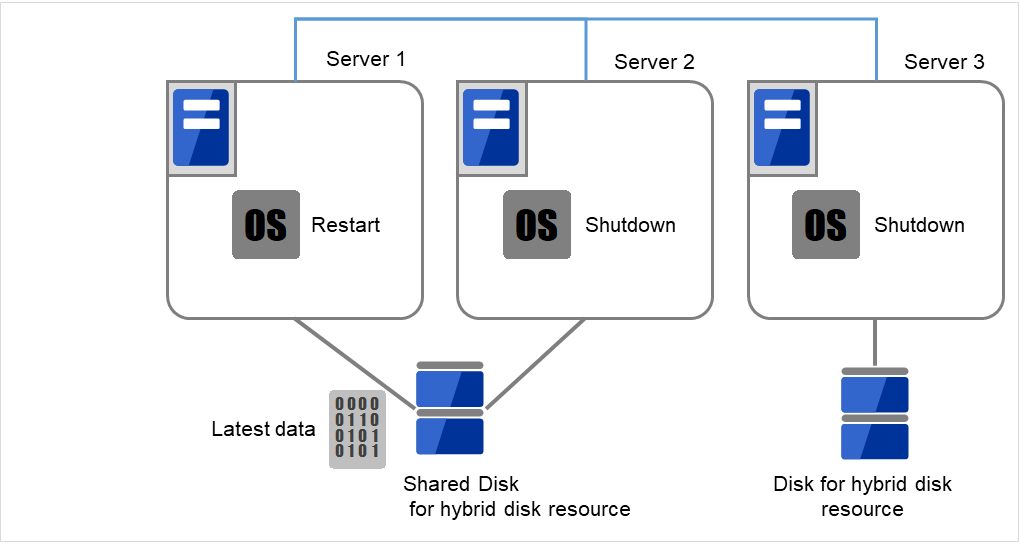
图 9.7 共享型镜像磁盘上的数据保存 (2)¶
执行[mount]命令,用read-only的方式mount共享型镜像磁盘上的数据分区。
(例) mount -r -t ext3 /dev/sdb5 /mnt
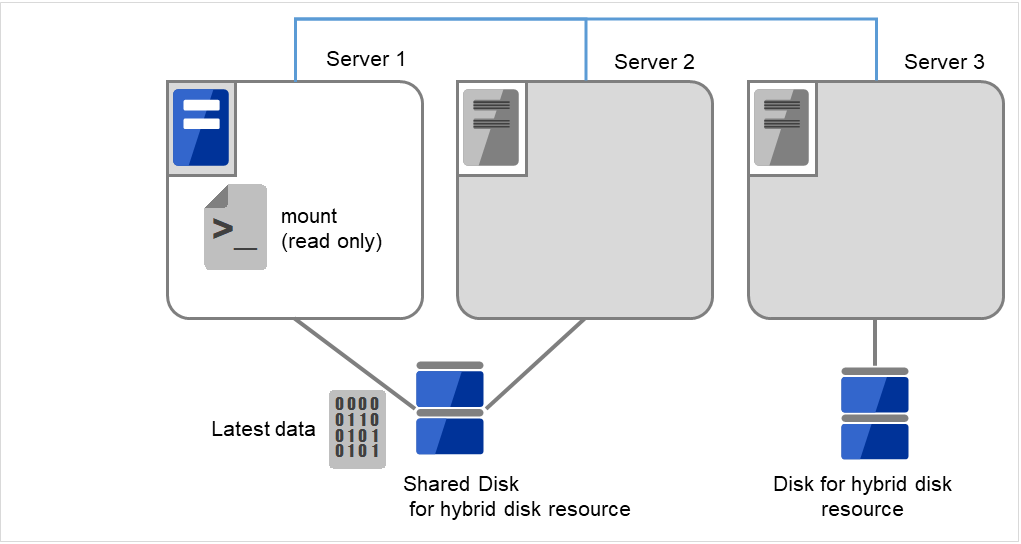
图 9.8 共享型镜像磁盘上的数据保存 (3)¶
将数据分区内的数据备份到磁带等媒体中。
将备份设备(Backup device)连接到Server 1,使用tar和cpio等命令,备份数据分区内的数据。
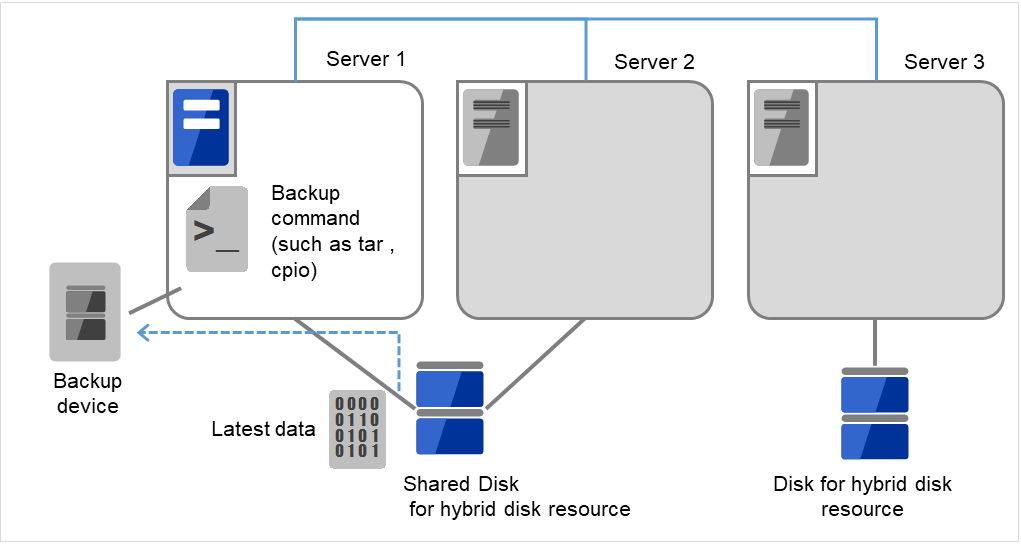
图 9.9 共享型镜像磁盘上的数据保存 (4)¶
卸载已经挂载的数据分区。
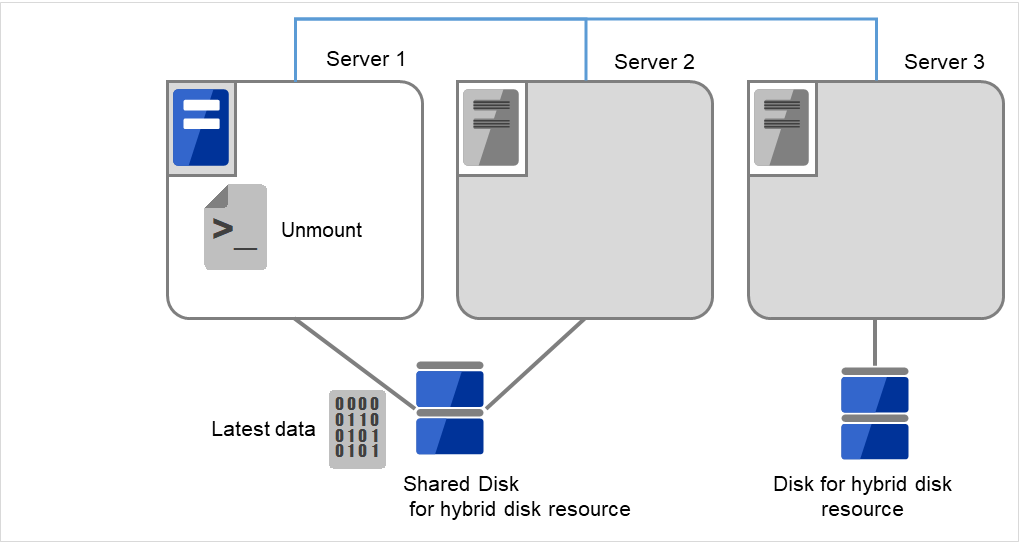
图 9.10 共享型镜像磁盘上的数据保存 (5)¶
9.1.14. 手动mkfs镜像磁盘和共享型镜像磁盘¶
需要在不更改集群配置,镜像配置的状态下重新创建镜像分区的文件系统时,按以下步骤操作。
确认集群状态正常。
停止持有想要mkfs的镜像磁盘资源的组。
在要执行mkfs的服务器上执行以下命令。
如果是镜像磁盘
clpmdctrl --active -nomount <镜像磁盘资源名(例:md1)>
如果是共享型镜像磁盘
clphdctrl --active -nomount <共享型镜像磁盘资源名(例:hd1)>
- 使用mkfs命令构建文件系统。由于磁盘镜像,所以对方服务器的磁盘也将被mkfs。
(例) mkfs -t ext3 <镜像分区设备名 (例:/dev/NMP1)>
确认文件系统创建完毕后,执行以下命令。
如果是镜像磁盘
clpmdctrl --deactive <镜像磁盘资源名(例:md1)>
如果是共享型镜像磁盘
clphdctrl --deactive <共享型镜像磁盘资源名(例:hd1)>
9.1.15. 镜像中断状态的复原¶
如果启用了自动镜像复归,则无需进行特殊操作,镜像复归将自动执行。
如果需要强行镜像复归,则需要通过命令或Cluster WebUI执行强制镜像复归操作。
在强制镜像复归中,差异镜像复归功能可执行会禁用,将执行全面复制。
禁用自动镜像复归时,需要通过命令或Cluster WebUI执行镜像复归操作。
9.1.16. 自动复原镜像¶
自动镜像复归启用时,在以下条件下将执行自动镜像复归。
镜像磁盘资源或共享型镜像磁盘资源启动
镜像磁盘资源或共享型镜像磁盘资源启动的服务器上有最新数据
集群中的服务器状态正常,且能够确认镜像状态
服务器之间的数据有不同
在以下条件下不执行自动镜像复归。
其中一方服务器未启动
- 无法确认其他服务器的镜像状态(不能进行通信,或其他服务器的集群停止等情况。)
没有镜像状态正常的服务器
镜像状态为保留时(仅限于共享型镜像磁盘资源)
- 手动停止镜像同步时(使用clpmdctrl,clphdctrl命令执行--break参数来停止同步,或在Cluster WebUI的镜像磁盘列表中,将GREEN-GREEN状态更改为GREEN-RED状态时。但是,停止同步后重启服务器,或手动重新开始同步的情况除外。)
- 停止镜像磁盘监视资源,共享型镜像磁盘监视资源时(使用clpmonctrl命令,或在Cluster WebUI中暂停该监视资源时。)
镜像复归的执行状态确认请参考"通过命令确认镜像复归的执行状态"以及"使用Cluster WebUI确认镜像复归的执行状态"。
9.1.17. 使用命令确认镜像中断状态¶
如果是镜像磁盘
clpmdstat --mirror <镜像磁盘资源名(例:md1)>
如果是共享型镜像磁盘
clphdstat --mirror <共享型镜像磁盘资源名(例:hd1)>
执行clpmdstat命令,clphdstat命令后,显示镜像磁盘资源和共享型镜像磁盘资源的状态。
正常时
Mirror Status: Normal md1 server1 server2 -------------------------------------------------------- Mirror Color GREEN GREEN
需要镜像复归时
Mirror Status: Abnormal Total Difference: 1% md1 server1 server2 ------------------------------------------------------------ Mirror Color GREEN RED Lastupdate Time 2018/03/04 17:30:05 -- Break Time 2018/03/04 17:30:05 -- Disk Error OK OK Difference Persent 1% --
需要强行镜像复归时
Mirror Status: Abnormal Total Difference: 1% md1 server1 server2 ---------------------------------------------------------------- Mirror Color RED RED Lastupdate Time 2018/03/09 14:07:10 2004/03/09 13:41:34 Break Time 2018/03/09 14:06:21 2004/03/09 13:41:34 Disk Error OK OK Difference Persent 1% 1%
正在进行镜像复归时
请参考"通过命令确认镜像复归的执行状态"。
9.1.18. 通过命令确认镜像复归的执行状态¶
执行以下命令确认镜像复归的执行状态。
如果是镜像磁盘资源
clpmdstat --mirror <镜像磁盘资源名(例:md1)>
如果是共享型镜像磁盘资源
clphdstat --mirror <共享型镜像磁盘资源名(例:hd1)>
镜像复归正在进行则显示如下信息。
Mirror Status: Recovering
md1 server1 server2
---------------------------------------------------
Mirror Color YELLOW YELLOW
Recovery Status Value
-------------------------------------
Status: Recovering
Direction: src server1
dst server2
Percent: 7%
Used Time: 00:00:09
Remain Time: 00:01:59
Iteration Times: 1/1
镜像复归完成则显示如下信息。
Mirror Status: Normal
md1 server1 server2
--------------------------------------------------------
Mirror Color GREEN GREEN
9.1.19. 通过命令进行镜像复归的方法¶
执行以下命令开始复原镜像。
如果是镜像磁盘
clpmdctrl --recovery <镜像磁盘资源名 (例:md1)>
如果是共享型镜像磁盘
clphdctrl --recovery <共享型镜像磁盘资源名 (例:hd1)>
可以进行差异镜像复归时,使用差异信息进行复原。差异镜像复归的复原时间会缩短(FastSync技术)。
此命令在开始执行镜像复归后,将立刻返回控制。镜像复归的状态请参考"通过命令确认镜像复归的执行状态"以及"使用Cluster WebUI确认镜像复归的执行状态"进行确认。
9.1.20. 通过命令强行执行镜像复归¶
EXPRESSCLUSTER无法确定哪个服务器持有最新数据时,则需要进行强行镜像复归。
此时,需要手动确定持有最新数据的服务器,执行强行镜像复归。
请使用下述某种方法确定持有最新数据的服务器。
通过Cluster WebUI的镜像磁盘列表确认
从Cluster WebUI的镜像磁盘列表中,点击想要确认的镜像磁盘资源。
点击[详细信息]图标。
确认最终数据更新时间(Last up date Time),确定持有最新数据的服务器。但是,此最终数据更新时间将取决于OS所设置的时间。
通过[clpmdstat]命令和[clpmdstat]命令进行确认
与用Cluster WebUI的镜像磁盘列表进行确认的方法相同。不同的是使用命令。
执行以下命令。
如果是镜像磁盘
clpmdstat --mirror <镜像磁盘资源名(例:md1)>
如果是共享型镜像磁盘
clphdstat --mirror <共享型镜像磁盘资源名(例:hd1)>
确认最终数据更新时间(Lastupdate Time),确定持有最新数据的服务器。但是,此最终数据更新时间将取决于OS所设置的时间。
- 通过镜像磁盘上的数据进行确认如果弄错操作步骤,可执行会造成数据损坏,因此不推荐使用本方法。可以在双方服务器上执行以下操作,确定拥有最新数据的服务器。1. 确定所有的组均已停止。2. 参考"镜像不可用的状态下强行mount",用read only方式mount数据分区。3. 逻辑验证Mount Point中的数据。4. Unmount数据分区。
确定了保存有最新数据的服务器后,采取以下任意方法,开始强制镜像复归。
- 方法(1) 保持启动的状态进行全面复制的方法采用此方法进行强制镜像复归时,差异镜像复归功能会禁用,将进行全面复制。在强制镜像复归中一旦停止组时,到强制镜像复归完成为止,无法启动组。确认强制镜像复归完成后,就可以通过启动组使用镜像磁盘。由于在组启动的状态下同时执行强制镜像复归,因此系统的负载可执行会升高。组包含多个镜像磁盘资源或共享型镜像磁盘资源时,这些资源需全部在同一服务器上保存最新数据。
- 执行clpmdctrl,clphdctrl命令,开始全面复制。(指定命令的函数的参数中的保存有最新数据的服务器和资源名。)
镜像磁盘
clpmdctrl --force <保存有最新数据的服务器> <镜像磁盘资源名(例:md1)>
共享型磁盘
clphdctrl --force <保存有最新数据的服务器> <共享型磁盘资源名(例:hd1)>
利用命令开始镜像复归后,命令会立即恢复控制。确认镜像复归的状态,并等待其完成。
没有启动组时,确认镜像复归完成后,启动组。
- 方法(2) 在停止状态下进行全面复制的方法利用此方法进行强制镜像复归时,差异镜像复归功能变为无效,而进行全面复制。因文件系统的种类或磁盘使用量的不同,有可执行与方法(1)或方法(3)的启动状态下进行的步骤相比,复制时间变短。在停止组的状态下进行。到强制镜像复归完成为止,无法启动组。确认强制镜像复归完成后,就可以通过启动组使用镜像磁盘。组包含多个镜像磁盘资源或共享型镜像磁盘资源时,这些资源需全部在同一服务器上保存最新数据。
已启动组时,暂时停止组。
- 执行clpmdctrl, clphdctrl命令,进行全面复制。(将保存有最新数据的服务器名和资源名指定为命令的参数。)
镜像磁盘时
clpmdctrl --force <保存有最新数据的服务器> <镜像磁盘资源名(例:md1)>
共享型镜像磁盘时
clphdctrl --force <保存有最新数据的服务器> <共享型镜像磁盘资源名(例:hd1)>
利用命令开始镜像复归后,命令会立即恢复控制。确认镜像复归的状态,并等待镜像复归完成。
确认镜像复归完成后,启动组。
- 方法(3) 从停止状态转为启动状态,进行全面复制的方法利用此方法进行强制镜像复归时,差异镜像复归功能变为无效,而进行全面复制。在强制镜像复归中暂时停止组时,到强制镜像复归完成为止,无法启动组。确认强制镜像复归完成后,就可以通过启动组使用镜像磁盘。由于在组启动的状态下同时执行强制镜像复归,因此系统的负载可执行会升高。组包含多个镜像磁盘资源或共享型镜像磁盘资源时,这些资源需全部在同一服务器上保存最新数据。
- 在不启动组的状态下,暂时停止监视镜像磁盘资源或共享型镜像磁盘资源的镜像磁盘监视资源或共享型镜像磁盘监视资源。在各服务器上执行下述的命令。此时,自动镜像复归会暂时无法动作。
clpmonctrl -s -m <该监视资源名 (例:mdw1)>
(不用命令而使用Cluster WebUI暂时停止监视资源时,执行该镜像磁盘监视资源或共享型镜像磁盘监视资源的"暂时停止监视"。通过在确认画面上选择[暂停],该监视资源变为"暂时停止"的状态。)
- 在保存有最新数据的服务器上,执行clpmdctrl, clphdctrl命令,将该服务器侧的镜像磁盘更改为最新状态。(不能将保存有最新数据的服务器名指定为命令的参数。)
镜像磁盘时
clpmdctrl --force <镜像磁盘资源名 (例:md1)>
共享型镜像磁盘时
clphdctrl --force <共享型镜像磁盘资源名 (例:hd1)>
- 通过Cluster WebUI的镜像磁盘列表,或执行clpmdstat, clphdstat命令确认该镜像磁盘资源,共享型镜像磁盘资源已变为最新状态(正常)。确认后,执行clpgrp命令或使用Cluster WebUI,在保存有最新数据的服务器上启动相应的组。
- 启动组后,执行clpmdctrl, clphdctrl命令,开始进行全面复制。(指定命令的函数的参数中的保存有最新数据的服务器和资源名。)镜像磁盘
clpmdctrl --force <保存有最新数据的服务器> <镜像磁盘资源名 (例:md1)>
共享型磁盘
clphdctrl --force <保存有最新数据的服务器> <共享型磁盘资源名 (例:hd1)>
- 利用命令开始镜像复归后,命令会立即恢复控制。接着,暂时停止的监视资源会恢复原状。在各服务器上执行下述命令。
clpmonctrl -r -m <该监视资源名 (例:mdw1)>
(不用命令而使用Cluster WebUI使监视资源重新开始时,请执行该镜像磁盘监视资源或共享型镜像磁盘监视资源的[重新开始监视]。通过在确认画面上选择[重新开始],该监视资源重新开始。)
- 方法(4) 使用自动镜像复归,差异镜像复归的方法可进行差异镜像复归时,使用差异信息进行复归。由于在组启动的状态下同时执行镜像复归,因此系统的负载可执行会升高。
组包含多个镜像磁盘资源或共享型镜像磁盘资源时,这些资源需全部在同一服务器上保存最新数据。
- 在保存有最新数据的服务器上,执行clpmdctrl,clphdctrl命令,将该服务器的镜像磁盘更改到最新状态。(不指定保存有最新数据的服务器名为命令的参数。)
如果是镜像磁盘
clpmdctrl --force <镜像磁盘资源名 (例:md1)>
如果是共享型镜像磁盘
clphdctrl --force <共享型镜像磁盘资源名 (例:hd1)>
- 没有启动组时,通过Cluster WebUI的镜像磁盘列表,或使用clpmdstat,clphdstat命令,确认该镜像磁盘资源,共享型镜像磁盘资源为最新状态(正常)。确认后,使用clpgrp命令或Cluster WebUI,在保存有最新数据的服务器中启动该组。
- 没有启动组时,该组启动后(启动后),开始自动镜像复归。启动组时,在1的操作后,开始自动镜像复归。
自动镜像复归设置为OFF,镜像磁盘不能自动复归时,请使用clpmdctrl,clphdctrl命令或镜像磁盘列表,手动开始镜像复归。
如果是镜像磁盘
clpmdctrl --recovery <镜像磁盘资源名 (例:md1)>
如果是共享型镜像磁盘
clphdctrl --recovery <共享型镜像磁盘资源名 (例:hd1)>
执行[clpmdctrl],[clphdctrl]命令启动镜像复归后,立即返回控制。镜像复归的进展状态请参考"通过命令确认镜像复归的执行状态"和"使用Cluster WebUI确认镜像复归的执行状态"来确认。
9.1.21. 通过命令只在一台服务器上进行强行镜像复归¶
有时,可执行其中某台服务器因为H/W或OS故障无法启动,而可以启动的服务器上又不持有最新的数据。
如果想只在能够启动的服务器上启动业务,则可以对能够启动的服务器进行强行镜像复归。
执行该操作后,执行了命令的服务器将强行拥有最新数据。因此,目前无法启动的服务器能够启动之后,其数据将不再是最新数据。
请在了解这一点的基础上执行以下操作。
执行以下命令,开始强行镜像复归。
如果是镜像磁盘
clpmdctrl --force <镜像磁盘资源名 (例:md1)>
如果是共享型镜像磁盘
clphdctrl --force <共享型镜像磁盘资源名 (例:hd1)>
执行命令后,启动组后,即可使用镜像磁盘和共享型镜像磁盘。
9.1.22. 使用Cluster WebUI确认镜像中断状态¶
正常时

需要镜像复归时

需要强行镜像复归时

正在进行镜像复归时
9.1.23. 使用Cluster WebUI确认镜像复归的执行状态¶
从Cluster WebUI的镜像磁盘列表,确认镜像复归的执行状态。
(以下是镜像磁盘资源的示例。共享型镜像磁盘资源的画面显示与此不同,但是状态的含义,描述都相同。)
镜像复归正在进行则显示如下信息。

镜像复归已经完成则显示如下信息。

9.1.24. 通过Cluster WebUI进行镜像复归的方法¶
有关Cluster WebUI的镜像磁盘列表,请参考在线手册。
镜像复归的状态请参考"通过命令确认镜像复归的执行状态"以及"使用Cluster WebUI确认镜像复归的执行状态"进行确认。
9.1.25. 使用Cluster WebUI进行强行镜像复归¶
EXPRESSCLUSTER无法确定哪个服务器持有最新数据时,则需要进行强行镜像复归。
此时,需要手动确定持有最新数据的服务器,执行强行镜像复归。
请使用下述某种方法确定持有最新数据的服务器。
通过Cluster WebUI的镜像磁盘列表确认
在Cluster WebUI的镜像磁盘列表中,显示想确认的镜像磁盘资源的详细信息。
点击[详细信息]图标。
确认最终数据更新时间(Last Data Update Time),确定持有最新数据的服务器。但是,此最终数据更新时间将取决于OS所设置的时间。
通过[clpmdstat]和[clphdstat]命令进行确认
与用Cluster WebUI的镜像磁盘列表进行确认的方法相同。不同的是使用命令。
执行以下命令。
如果是镜像磁盘
clpmdstat --mirror <镜像磁盘资源名 (例:md1)>
如果是共享型镜像磁盘
clphdstat --mirror <共享型镜像磁盘资源名 (例:hd1)>
确认最终数据更新时间(Last Data Update Time),确定持有最新数据的服务器。但是,此最终数据更新时间将取决于OS所设置的时间。
- 通过镜像磁盘上的数据进行确认如果弄错操作步骤,可执行会造成数据损坏,因此不推荐使用本方法。可以在两个服务器上执行以下操作,确定拥有最新数据的服务器。
确定所有的组均已停止。
参考"镜像不可用的状态下强行mount",用read only方式mount数据分区。
逻辑确认,验证Mount点中的数据。
Unmount数据分区。
确定了持有最新数据的服务器后,从Cluster WebUI的镜像磁盘列表执行强行镜像复归。有关镜像磁盘列表,请参考在线手册。
使用以下任一方法开始强制镜像复归。
- 方法(1) 实施全面复制的方法采用此方法进行强制镜像复归时,差异镜像复归功能会禁用,将进行全面复制。并且,强制镜像复归完成后,将无法启动组。确认强制镜像复归完成后,就可以通过启动组使用镜像磁盘。
- 在镜像磁盘列表中,从保存有最新数据的服务器向复制目标服务器执行[全面复制],开始镜像复归。(已启动组时,在镜像磁盘列表中,不能操作选择[全面复制]。此时,可暂时停止组,或者使用命令进行强制镜像复归。)
确认镜像复归完成后,在保存有最新数据的服务器中启动组。
- 方法(2) 使用自动镜像复归,差异镜像复归的方法可进行差异镜像复归时,使用差异信息进行复归。差异镜像复归与强行镜像复归相比,复归时间缩短(FastSync技术)。由于在组启动的状态下同时执行镜像复归,因此系统的负载可执行会升高。组包含多个镜像磁盘资源或共享型镜像磁盘资源时,这些资源需全部在同一服务器上保存最新数据。
- 使用镜像磁盘列表,将保存有最新数据的服务器之镜像磁盘从异常更改为正常。(已启动组时,使用镜像磁盘列表,不能操作选择Full Copy。此时,可暂时停止组,或者使用命令进行强制镜像复归。)
- 确认该镜像磁盘资源,共享型镜像磁盘资源为最新状态(正常)。确认后,在保存有最新数据的服务器上启动该组。
- 该组启动(启动)后,开始自动镜像复归。可差异镜像复归时,执行差异镜像复归。不可差异镜像复归时,执行Full Copy。没有将自动镜像复归设置为ON,镜像磁盘不能自动开始时,使用镜像磁盘列表,手动开始镜像复归。
镜像复归的状态请参考"通过命令确认镜像复归的执行状态"以及"使用Cluster WebUI确认镜像复归的执行状态"确认。
9.1.26. 通过Cluster WebUI只在一台服务器上进行强行镜像复归¶
有时,可执行其中某台服务器因为H/W或OS故障无法启动,而可以启动的服务器上又不是最新的数据。
如果想只在能够启动的服务器上启动业务,则可以对能够启动的服务器进行强行镜像复归。
执行该操作后,服务器将强行保存最新数据。因此,目前无法启动的服务器能够启动之后,其数据将不再是最新数据。请在了解这一点的基础上执行以下操作。
从Cluster WebUI的镜像磁盘列表,执行强行镜像复归。有关镜像磁盘列表,请参考在线手册。
执行强行镜像复归后启动组,即可使用镜像磁盘。
9.1.27. 更改共享型镜像磁盘的当前服务器¶
在以下情况下可以更改当前服务器。
共享型镜像磁盘的状态 |
当前服务器变更可否 |
||
|---|---|---|---|
服务器组1 |
服务器组2 |
服务器组1 |
服务器组2 |
异常/停止 |
异常/停止 |
可以 |
可以 |
正常/停止 |
异常/停止 |
可以 |
可以 |
异常/停止 |
正常/停止 |
可以 |
可以 |
正常/停止 |
正常/停止 |
可以 |
可以 |
正常/启动 |
异常/停止 |
不可以 |
可以 |
异常/停止 |
正常/启动 |
可以 |
不可以 |
正常/启动 |
正常/停止 |
不可以 |
不可以 |
保留/停止 |
保留/停止 |
可以 |
可以 |
9.1.29. 通过Cluster WebUI更改当前服务器¶
有关Cluster WebUI的镜像磁盘列表,请参考在线手册。
9.2. VERITAS卷管理器发生故障时的处理¶
本节介绍使用VERITAS卷管理器发生故障时的对应方法。
9.2.1. 更改VERITAS卷管理器的配置¶
更改VERITAS卷管理器的配置时,其操作步骤根据是否需要重启OS会有所不同。
更改配置时不需要重启OS时 -> 请参考"更改VERITAS卷管理器的配置不需要重启OS时"。
更改配置时需要重启OS时 -> 请参考"更改VERITAS卷管理器的配置需要重启OS时"。
更改VERITAS卷管理器的配置不需要重启OS时
使用管理IP地址连接到Cluster WebUI。如果没有管理IP地址,请使用任意服务器的物理IP地址连接到Cluster WebUI。
使用Cluster WebUI执行[停止集群]。
更改VERITAS卷管理器的配置。
从Cluster WebUI的编辑模式更改资源设置信息。
从Cluster WebUI的编辑模式上传集群配置信息。
从Cluster WebUI的操作模式执行[启动集群]。
配置更改完毕,配置开始生效。
更改VERITAS卷管理器的配置需要重启OS时
将集群配置信息备份。请根据使用Cluster WebUI的OS的种类,选择相应的操作步骤。
如果为在Linux的Web浏览器上运行的Cluster WebUI备份,则执行以下命令。
clpcfctrl --pull -l -x <配置信息的路径>
如果为在Windows的Web浏览器上运行的Cluster WebUI备份,则执行以下命令。
clpcfctrl --pull -w -x <配置信息的路径>
有关[clpcfctrl]的疑难解答,请参考本指南的"8.2. EXPRESSCLUSTER命令一览" 的 "更改集群配置信息,备份集群配置信息,检查集群配置信息(clpcfctrl命令)"。
设置在所有服务器中不启动EXPRESSCLUSTER服务。
clpsvcctrl.sh --disable core
停止EXPRESSCLUSTER Daemon。
clpcl -t -a
更改VERITAS卷管理器的配置。(在此步执行OS重启)
从Cluster WebUI的编辑模式,更改资源的设置信息。
从Cluster WebUI的编辑模式上传更新的集群配置信息。
设置在所有服务器中启动EXPRESSCLUSTER服务。
clpsvcctrl.sh --enable core
重启所有服务器。
配置更改完毕,下次启动组时配置开始生效。
9.2.2. VERITAS卷管理器发生故障时的EXPRESSCLUSTER的操作¶
如果在VERITAS卷管理器上发生了某种故障,磁盘资源以及卷管理器资源中查出异常,但不想执行组的失效切换或最终动作时,请参考"更改集群配置信息时"。
要将VERITAS卷管理器从故障中复原,重新通过EXPRESSCLUSTER来控制时,请参考"复原集群配置信息"的步骤。
更改集群配置信息时
使用Run Level1启动所有服务器。
设置在所有服务器中不启动EXPRESSCLUSTER服务。
clpsvcctrl.sh --disable core
重启所有服务器。
将集群配置信息备份。请根据使用Cluster WebUI的OS的种类,选择相应的操作步骤。
如果为在Linux的Web浏览器上运行的Cluster WebUI备份,则执行以下命令。
clpcfctrl --pull -l -x <配置信息的路径>
如果为在Windows的Web浏览器上运行的Cluster WebUI备份,则执行以下命令。
clpcfctrl --pull -w -x <配置信息的路径>
有关[clpcfctrl]的疑难解答,请参考本指南的"8.2. EXPRESSCLUSTER命令一览"的"更改集群配置信息,备份集群配置信息,检查集群配置信息(clpcfctrl命令)"。
从Cluster WebUI的编辑模式,更改资源的设置信息。
磁盘资源
卷管理器资源
在上述组资源的情况下,请在[资源属性]对话框中的[复归操作] 标签页上进行如下设置。
- 检测到组资源的启动异常时的复归操作重试启动次数 0次效切换次数 0次最终动作 无任何动作(启动下一个资源)
- 检测到组资源的停止异常时的复归操作停止重试次数 0次最终动作 无任何动作(不启动下一个资源)
卷管理器监视资源
磁盘监视资源
在上述监视资源的情况下,请在[监视资源属性]对话框的[复归操作]标签页上进行如下设置。
- 查出异常时复归动作 只在最终动作时执行最终动作 无操作
从Cluster WebUI的编辑模式上传更新的集群配置信息。
设置在所有服务器中启动EXPRESSCLUSTER服务。
clpsvcctrl.sh --enable core
重启所有服务器。
这样,在下次启动OS后,配置即可生效。
复原集群配置信息
EXPRESSCLUSTER Daemon运行时,使用以下命令,停止EXPRESSCLUSTER Daemon。
clpcl -t -a
将使用"更改集群配置信息时"的步骤5 中创建保存好的配置信息传送给服务器。根据备份的配置信息的种类,选择以下相应的操作步骤。
使用Linux用的备份配置信息时执行以下命令。
clpcfctrl --push -l -x <配置信息的路径>
使用Windows用的备份配置信息时执行以下命令。
clpcfctrl --push -w -x <配置信息的路径>
有关[clpcfctrl]的疑难解答,请参考本指南的"8.2. EXPRESSCLUSTER命令一览"的"更改集群配置信息,备份集群配置信息,检查集群配置信息(clpcfctrl命令)"。
至此,在下一次启动EXPRESSCLUSTER Daemon时配置即生效。
9.3. 确认fsck / xfs_repair命令的进度状况¶
在磁盘资源,镜像磁盘资源,共享型镜像磁盘资源启动时执行fsck / xfs_repair命令,根据分区的大小以及文件系统的状态,到命令执行完毕有可执行需要较长的时间。
参照以下的日志文件能够确认磁盘资源,镜像磁盘资源,共享型镜像磁盘资源执行fsck / xfs_repair命令的进度状况。
资源 |
日志文件 |
|---|---|
磁盘资源 |
disk_fsck.log.cur |
镜像磁盘资源 |
md_fsck.log.cur |
共享型磁盘资源 |
hd_fsck.log.cur |