
|

|
WebOTX Manual V11.1 (��6��) �ڎ���\�� |
|
|
|
WebOTX Manual V11.1 (��6��) �ڎ���\�� |
�{�߂ł́AKubernetes�A�y��Kubernetes�̏��p�f�B�X�g���r���[�V�����𗘗p���������ɂ����Ă̈�ʓI�ȊĎ��ϓ_�E���@�AWebOTX�𗘗p�����ꍇ�̊Ď��ϓ_�ɂ��Đ������܂��B
WebOTX�̊Ď��ϓ_�͉��\�̂悤�Ȃ��̂��������܂��B
�I���v���~�X���ɂ����āA�e���́A��{�I��WebOTX Application Server���C���X�g�[�����ꂽ�}�V����Ŏ擾���܂��B
| �啪�� | ������ | �擾���@ | �Ď��ړI |
|---|---|---|---|
| ���O�Ď� | WebOTX�̊e�탍�O | �e�L�X�g�G�f�B�^���œ��e���{�����܂��B | WebOTX Application Server�̉ғ���Ԃ�c�����܂��B |
| �A�v���P�[�V�����ŗL�̃��O | �A�v���P�[�V�������̂̉ғ���Ԃ�c�����܂��B | ||
| GC���O | WebOTX Application Server��Java�v���Z�X��GC��c�����AJava�̃q�[�v�������g�p�𑪒肵�܂��B | ||
| �}�V���̃��\�[�X�Ď� | CPU | �^�X�N�}�l�[�W����top�R�}���h�����g�p���A�m�F���܂��B | Kubernetes�m�[�h�̕���Ԃ��Ď����܂��B |
| ������ |
�u2-1. WebOTX�Ƃ��Ă̊Ď��ϓ_�v�ł̓I���v���~�X���ɂ����Ă̏���������Ă��܂����A�R���e�i���̉^�p�ł͒ʏ�A���[�U�[���R���e�i���Œ��ڑ��삷�邱�Ƃ͑z�肵�Ă��܂���B
�{���ł́AKubernetes���ɂ����Ẵ��O�Ď��AKubernetes�m�[�h���\�[�X�Ď����������邽�߂̐��i�A�܂��A�����̗��p���j�ɂ��Đ������܂��B
Kubernetes�����ł̊e���̎擾���@�́A���\�̂悤�ɂȂ�܂��B
| �啪�� | ������ | �擾���@ |
|---|---|---|
| ���O�Ď� | WebOTX�̊e�탍�O | ELK�X�^�b�N���g�p���A���O��~�ρA�{�����܂��B |
| �A�v���P�[�V�����ŗL�̃��O | ||
| GC���O | WebOTX Operator�̃��g���N�X���J�@�\��Prometheus���g�p���A�擾���܂��B | |
| �}�V���̃��\�[�X�Ď� | CPU | Prometheus���g�p���A�e����~�ρA�{�����܂��B |
| ������ |
WebOTX�O�̃T�[�r�X�փ��O���W�A��͂�����j�ɂ��Đ������܂��B
���O�̏W��A��͂ɂ��Ă̊�{�I�ȍl�����́A�ȉ������Q�Ƃ��������B
[�X�^�[�g�A�b�v�K�C�h > �`���[�g���A�� MicroService�� > ���O�̏W��]
[�X�^�[�g�A�b�v�K�C�h > �`���[�g���A�� MicroService�� > ���O�̉��]
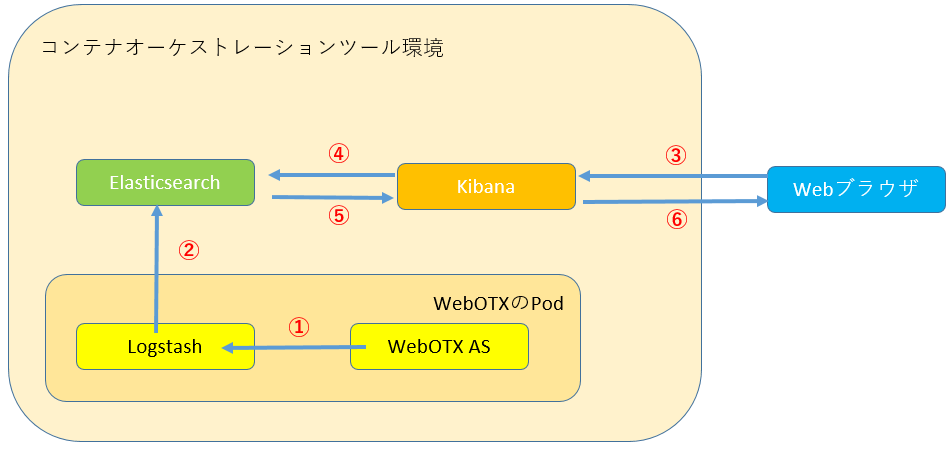
�����Ɏ������j�ł́A���\�̃R���e�i���g�p���܂��B
| �T�[�r�X�� | �@�\���� |
|---|---|
| Logstash | "����Pod���̓���̃e�L�X�g�t�@�C���̍X�V���Ď����A���̓��e�����g�̕W���o�͂�O���ɏo�͂ł���R���e�i�ł��BWebOTX Operator���g�p���AWebOTX Application Server�Ɠ����Pod�Ɋ܂߂邱�Ƃ��ł��܂��B |
| Elasticsearch | �I�[�v���\�[�X�^�̕��U�^�f�[�^�x�[�X�̃R���e�i�ł��B�����ł�Logstash�̏o�͂̊i�[��Ƃ��Ďg�p���܂��B |
| Kibana | Elasticsearch�Ɋi�[���ꂽ�f�[�^��T���A�����A���͂ł���R���e�i�ł��B�u���E�U�o�R�Ń��O�̌����A���ꃍ�O�̃J�E���g��O���t�����s�����Ƃ��ł��܂��B |
Memo
ELK�X�^�b�N�Ƃ́A��L�̃T�[�r�X�̓�������������T�[�r�X�Q���w���܂��B
�ȉ��̂悤�ɂ��āAELK�X�^�b�N�𗘗p�����Ď����������܂��B
Memo
WebOTX�Ƃ��Ă͈̒͂́A�}���́uWebOTX��Pod�v�ł��B
�{���j�Ŏg�p����Ď����i�̃Z�b�g�A�b�v�菇�ɂ��ċL�ڂ��܂��B
WebOTX��Pod�́AWebOTX Operator���g�p���ăC���X�g�[�����Ă�����̂Ƃ��܂��B
ECK Operator���g�p���AElasticsearch���C���X�g�[�����܂��B
ECK Operator�̏ڍׁA�y�эŐV�̎菇�́AElastic�����h�L�������g�����Q�Ƃ��������B
https://www.elastic.co/guide/en/cloud-on-k8s/current/index.html
https://www.elastic.co/guide/en/cloud-on-k8s/current/k8s-quickstart.html
�ȉ��̃R�}���h�ŁAECK Operator�̃J�X�^�����\�[�X��`�t�@�C���̓K�p�AECK Operator�̔z�����s���܂��B
ECK Operator�́A"elastic-system"�Ƃ���namespace�z������܂��B
kubectl (oc) apply -f https://download.elastic.co/downloads/eck/1.5.0/all-in-one.yaml
�ȉ��̃R�}���h�ŁAECK Operator���z�����ꂽ���Ƃ��m�F���܂��B
kubectl (oc) get po -n elastic-system
NAME READY STATUS RESTARTS AGE
elastic-operator-0 1/1 Running 0 60s
�ȉ��̃J�X�^�����\�[�X�t�@�C��(elasticsearch.yaml)���쐬���܂��B
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: quickstart
spec:
version: 7.12.1
nodeSets:
- name: default
count: 1
config:
node.store.allow_mmap: false
xpack.security.enabled: false
podTemplate:
spec:
containers:
- name: elasticsearch
env:
- name: READINESS_PROBE_PROTOCOL
value: "http"
Memo
�{���ō쐬����Elasticsearch cluster�́ALogstash�ƘA�g���邽�߁A�Z�L�����e�B�@�\�������Ă��܂��B
�ȉ��̃R�}���h�ŁA�J�X�^�����\�[�X�t�@�C����K�p���܂��B
kubectl (oc) apply -n elastic-system -f elasticsearch.yaml
�ȉ��̃R�}���h�ŁAElasticsearch cluster��Pod (quickstart-es-default) ���z������Ă��邱�Ƃ��m�F���܂��B
kubectl (oc) get po -n elastic-system
NAME READY STATUS RESTARTS AGE
elastic-operator-0 1/1 Running 0 5m
quickstart-es-default-0 1/1 Running 0 60s
�ȉ��̃R�}���h�ŁAElasticsearch�R���e�i��9200�|�[�g�����J����T�[�r�X�����擾���܂��B
�ȉ��̗�ł́A"quickstart-es-http"�ƂȂ�܂��B
kubectl (oc) get svc -n elastic-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elastic-webhook-server ClusterIP 10.100.144.45 <none> 443/TCP 5m
quickstart-es-default ClusterIP None <none> 9200/TCP 60s
quickstart-es-http ClusterIP 10.100.49.2 <none> 9200/TCP 60s
quickstart-es-transport ClusterIP None <none> 9300/TCP 60s
AWS���Kubernetes�N���X�^���\�z���Ă���ꍇ�AAmazonElasticsearch Service�𗘗p���邱�Ƃ��ł��܂��B
�\�z�菇�́A���L�̌����h�L�������g�����Q�Ƃ��������B
WebOTX Application Server�̃J�X�^�����\�[�X��`��ҏW���AElasticsearch�̏����L�����܂��B
- spec.deployment.logstash.elasticsearch: host: <Elasticsearch�̃z�X�g��> port: <Elasticsearch�̃T�[�r�X�̃|�[�g>
[�Ď����i�̃Z�b�g�A�b�v - Elasticsearch]�ɏ]����Elasticsearch���C���X�g�[�������ꍇ�A
Elasticsearch�̃z�X�g��: quickstart-es-http.elastic-system.svc.cluster.local
Elasticsearch�̃T�[�r�X�̃|�[�g: 9200
�ƂȂ�܂��B
�܂��A�ȉ��̂悤��WebOTX�@AS�̃J�X�^�����\�[�X�t�@�C����ҏW���邱�ƂŁA
Logstash���A�v���P�[�V�����ŗL�̃��O�t�@�C�������m���邱�Ƃ��ł��܂�(�����w��\)�B
- spec.webotx application:
logs:
- <�R���e�i���̃��O�t�@�C���@�̃t���p�X>
- <�R���e�i���̃��O�t�@�C���A�̃t���p�X>
�ڍׂ́A[�\�z�E�^�p > �R���e�i�^���z�� > Operator > �A�v���P�[�V�������O�̎��W]�����Q�Ƃ��������B
WebOTX Application Server�̃J�X�^�����\�[�X��K�p���܂��B
kubectl (oc) apply -f <�J�X�^�����\�[�Xyaml�t�@�C��> -n <WebOTX��namespace>
ECK Operator���g�p���AKibana���C���X�g�[�����܂��B
�ȉ��̃J�X�^�����\�[�X�t�@�C��(kibana.yaml)���쐬���܂��B
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: quickstart
spec:
version: 7.12.1
count: 1
config:
elasticsearch.hosts:
- http://quickstart-es-http.elastic-system.svc.cluster.local:9200
Memo
�{���ō쐬����Kibana�́A�Z�L�����e�B�@�\��������Elasticsearch�ƘA�g���邽�߁AElasticsearch��URL�ڎw�肵�Ă��܂��B
�ȉ��̃R�}���h�ŁAKibana��yaml�t�@�C����K�p���܂��B
kubectl (oc) apply -n elastic-system -f kibana.yaml
�ȉ��̃R�}���h�ŁAKibana��Pod (quickstart-kb-xxxxx-xxxxx)���N�����Ă��邱�Ƃ��m�F���܂��B
kubectl (oc) get po -n elastic-system
NAME READY STATUS RESTARTS AGE
elastic-operator-0 1/1 Running 0 9m
quickstart-es-default-0 1/1 Running 0 5m
quickstart-kb-54fb494fbd-nv8ms 1/1 Running 0 60s
�u���E�U����A�N�Z�X����ׁA�ȉ��̃R�}���h��Kibana��URL�����J���܂��B
�ȉ��̃R�}���h�ŁALoadBalancer�^�C�v�̃T�[�r�X���쐬���AKibana��URL�����J���܂��B
kubectl expose svc -n elastic-system quickstart-kb-http --target-port 5601 --port 443 --type LoadBalancer --name kibana-url
�ȉ��̃R�}���h�ŁAKibana��URL���擾���܂��B
kubectl get svc kibana-url -n elastic-system NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE quickstart-kb-lb LoadBalancer 10.100.114.185 abcdefghijklmn-123456789.ap-northeast-1.elb.amazonaws.com 443:31700/TCP 125m
URL�́A"https://<EXTERNAL-IP�l>:443"�ƂȂ�܂��B
�ȉ��̃R�}���h�ŁAKibana��URL�����J���܂��B
oc create route passthrough -n elastic-system --service=quickstart-kb-http --port 5601
�ȉ��̃R�}���h�ŁAKibana��URL���擾���܂��B
oc get route quickstart-kb-http -n elastic-system
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
quickstart-kb-http quickstart-kb-http-elastic-system.apps.example.com quickstart-kb-http 5601 passthrough None
URL�́A"https://<HOST/PORT�l>:443"�ƂȂ�܂��B
Kibana��URL�փA�N�Z�X�ł��邱�Ƃ��m�F���܂��B
Kibana�ɂ�郍�O�Ď���@���L�ڂ��܂��B
�ȉ��̎菇�ŁAWebOTX���O�̃C���f�b�N�X�p�^�[����Kibana�ɓo�^���܂��B
�ȉ��̎菇�ŁAKibana����WebOTX�̃��O���擾�ł��邱�Ƃ��m�F���܂��B
message:"* domain1 is alive *"
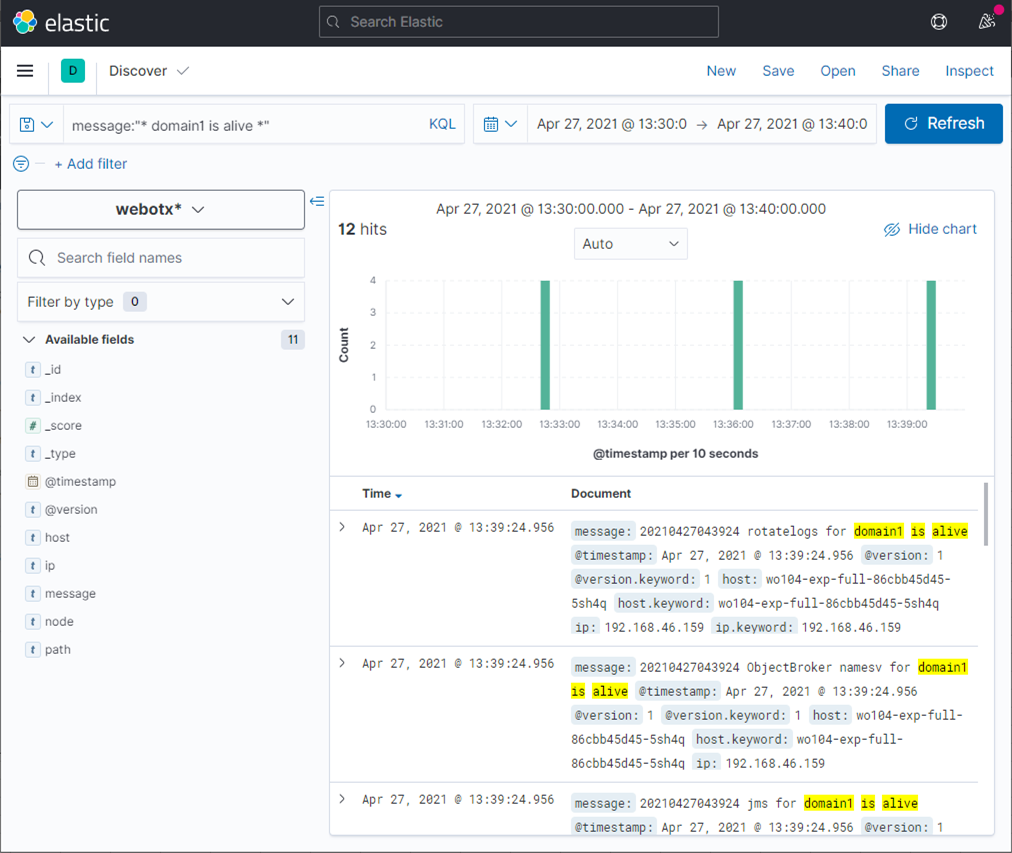
�ȉ��̂悤�ɂ��āA���O�̍i�荞�݂��s�����Ƃ��ł��܂��B
[Search]�e�L�X�g�{�b�N�X�Ɉȉ��̂悤�ɋL�����邱�ƂŁA
���O���x���ɂ��i�荞�݂��s�����Ƃ��ł��܂��B
level.keyword: "WARN" or "ERROR"
��ł́A���O���x��"WARN" �������� "ERROR"�̃��O��\�����Ă��܂��B
�ȉ��̂悤�ɂ��āA���O�̏o�͓����ōi�荞�ނ��Ƃ��ł��܂��B
�������ʉ�ʂ̏㕔�ɂ́A�����������O�̏o�͉��_�O���t�ŕ\������Ă��܂��B
���̑��AKibana�̊�{�I�ȗ��p���@�ɂ��ẮA�����h�L�������g�����Q�Ƃ��������B
https://www.elastic.co/guide/jp/kibana/current/getting-started.html
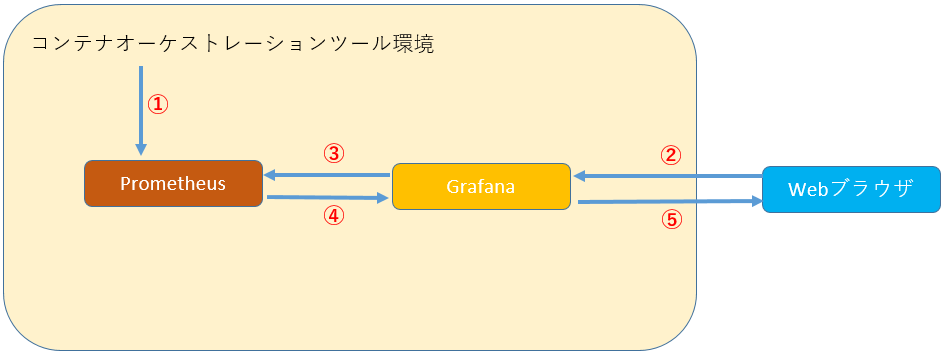
�g�p����T�[�r�X�ꗗ�ƁA���̐������L�ڂ��܂��B
Kuberenetes����l�X�ȏ������W�E�~�ς���f�[�^�x�[�X�ł��B�~�ς������́APromQL�Ƃ����N�G�����g�p�������o�����Ƃ��ł��܂��B
MicroProfile Metrics�@�\���g�p���AWebOTX Application Server�ɔz�������A�v���P�[�V��������C�ӂ̃f�[�^��~�ς��邱�Ƃ��ł��܂��B
�f�[�^�x�[�X�ɕۑ����ꂽ���O��f�[�^�̉����c�[���ł��B���A���^�C���ɃN�G���s���A�u���E�U�o�R�Ńf�[�^���m�F���邱�Ƃ��ł��܂��B
�ȉ��̂悤�ȏ��ŁAKubernetes�m�[�h���\�[�X�Ď����������܂��B
Prometheus��z�����邽�߂�Namespace���쐬���܂��B
kubectl create namespace prometheus
helm���g�p���A�C���X�g�[�����܂��B
helm install prometheus stable/prometheus --namespace prometheus --set alertmanager.persistentVolume.storageClass="gp2",server.persistentVolume.storageClass="gp2"
Prometheus�փu���E�U����A�N�Z�X�ł���悤�AURL�����J���܂��B
kubectl expose deployment prometheus-server -n prometheus --name prometheus --port 80 --target-port 9090 --type LoadBalancer
�쐬����URL�����L�R�}���h�Ŋm�F���A�u���E�U�o�R�ŃA�N�Z�X�ł��邱�Ƃ��m�F���܂��B
kubectl get svc -n prometheus prometheus
OpneShift���ł́A�f�t�H���g�ŃC���X�g�[������Ă���Prometheus���g�p���܂��B
Prometheus��URL�����L�R�}���h�Ŋm�F���A�u���E�U�o�R�ŃA�N�Z�X�ł��邱�Ƃ��m�F���܂��B
oc get route -n openshift-monitoring prometheus-k8s
Prometheus��WebOTX�̃��g���N�X���擾�ł���悤�ɐݒ肵�܂��B
ConfigMap��ҏW���Aprometheus.yml��scrape_configs��WebOTX�̃��g���N�XURL���w�肵�܂��B
scrape_configs:
- job_name: webotx-as
static_configs:
- targets:
- <WebOTX-AS Pod��https�|�[�g���JService��>.<WebOTX-AS Pod�̂���Namespace>.svc.cluster.local:<�|�[�g>
- job_name: webotx-operator
static_configs:
- targets:
- webotx-operator-metrics.webotx.svc.cluster.local:8383
�ڍׂ́A[�\�z�E�^�p > �R���e�i�^���z�� > Operator > Promethues �Ƃ̘A�g]�����Q�Ƃ��������B
Amazon EKS�ւ́AHelm���g�p���A�C���X�g�[�����܂��B
kubectl create ns grafana
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: prometheus
type: prometheus
url: http://prometheus-server.prometheus.svc.cluster.local
access: proxy
isDefault: true
helm install grafana grafana/grafana \ --namespace grafana \ --set persistence.storageClassName="gp2" \ --set persistence.enabled=true \ --set adminPassword='EKS!sAWSome' \ --values grafana.yml \ --set service.type=LoadBalancer
�ȉ��̃R�}���h�ŕҏW�G�f�B�^���J���܂��B
kubectl edit cm grafana -n grafana
�G�f�B�^�ŊJ����ConfigMap�̉��L�K�w�ɒ�`��lj����Ă��������B
data->grafana.ini:
[auth.anonymous]
enabled = true
org_name = Main Org.
org_role = Viewer
kubectl delete po <grafana��Pod��> -n grafana
Red Hat OpenShift Container Platform�ł́APROMETHEUS�N���X�^�[���j�^�����O�@�\�Ƃ��āAGrafana���W������Ă��܂����A����̃_�b�V���{�[�h�������p�ł��܂���B
�{���ł́A�W���Ƃ͕ʂ̃l�[���X�y�[�X��Grafana���C���X�g�[������菇�ɂ��Đ������܂��B
Red Hat OpenShift Container Platform������A�N���X�^�[���j�^�����O�̋@�\�𗘗p�ł��邱�ƁB
�ڍׂɂ��ẮA�ȉ���OpenShift�����}�j���A�������Q�Ƃ��������B
https://access.redhat.com/documentation/ja-jp/openshift_container_platform/4.7/html/monitoring/
oc create ns grafana
Name�Fgrafana
Installed Namespace�Fgrafana
Name�Fgrafana Anonymous�Ftrue
Binding Type�FCluster-wide Role Binding�iClusterRoleBinding) Role Binding - Name�Fcluster-monitoring-view Role - Role Name�Fcluster-monitoring-view Subject�FService Account Subject - Subject Namespace�Fgrafana Subject - Subject Name�Fgrafana-serviceaccount
Name�Fprometheus-grafanadatasource Name�Fprometheus-grafanadatasource.yaml
caution
��ʂł́A����"Name"�̐ݒ荀�ڂ��\������܂����A��҂�yaml�t�@�C�������w�肵�܂��B
�G�f�B�^�ŊJ���ꂽGrafanaDataSource�̉��L�K�w�̒�`��ύX���Ă��������B
<Grafana�T�[�r�X�A�J�E���g�̃g�[�N��>�ɂ́A�O�̎菇�Ŏ擾�������̂��w�肵�܂�
spec->datasources:
- access: proxy
editable: true
isDefault: true
jsonData:
timeInterval: 5s
name: Prometheus
type: prometheus
url: 'http://prometheus-service:9090'
version: 1
spec->datasources:
- access: proxy
editable: true
isDefault: true
jsonData:
httpHeaderName1: 'Authorization'
timeInterval: 5s
tlsSkipVerify: true
name: prometheus
secureJsonData:
httpHeaderValue1: 'Bearer <Grafana�T�[�r�X�A�J�E���g�̃g�[�N��>'
type: prometheus
url: 'https://prometheus-k8s.openshift-monitoring.svc.cluster.local:9091'
�ʂ�Grafana�_�b�V���{�[�h�쐬�ɂ��ẮAGrafana�����h�L�������g�����Q�Ƃ��������B
���L�R�}���h��Prometheus��URL���擾���A�u���E�U�o�R�ŃA�N�Z�X���܂��B
kubectl get svc -n prometheus
oc get route -n openshift-monitoring
Prometheus�̃y�[�W���APromQL�����s���܂��B
�Ď��Ŏg�p����ePromQL�̗���ȉ��ɋL�ڂ��܂��B
Caution
Kubernetes�₻�̑������W�T�[�r�X�̃o�[�W�����ɂ��A�g�p�ł���N�G�����ς�邱�Ƃ�����܂��B
| ����� | �N�G���� | ���� |
|---|---|---|
| CPU�g�p�� | sum by(cpu) (rate(container_cpu_usage_seconds_total{image!="",container!="POD",pod="<�C�ӂ�Pod��>"}[2m] ) ) * 100 | �C�ӂ�Pod���R���e�i��CPU�g�p�ʂ̓��A[�R���e�i�C���[�W����������, POD���̂��̂łȂ�����]�����O����2���ӂ�̑����ʂ̕��ς̍��v(�g�p��)���ACPU�R�A���ɎZ�o���܂��B |
| �������g�p�� | sum (container_memory_usage_bytes{pod="<�C�ӂ�Pod��>",container!="", container!="POD"}) / sum(node_memory_MemTotal_bytes{kubernetes_node=~"<Pod���z������Ă���m�[�h��>"}) * 100 | �C�ӂ�Pod���R���e�i�̃������g�p���̓��A[�R���e�i������������, POD���̂��̂łȂ�����]�����v���A�����Pod���z������Ă���m�[�h�̃������ő�ʂŊ����ĎZ�o���܂��B |
| ����� | �N�G���� | ���� |
|---|---|---|
| CPU�g�p�� | sum by(cpu) (rate(container_cpu_usage_seconds_total{image!="",container_name!="POD",pod_name="<�C�ӂ�Pod��>"}[2m] ) ) * 100 | �C�ӂ�Pod���R���e�i��CPU�g�p�ʂ̓��A[�R���e�i�C���[�W����������, POD���̂��̂łȂ�����]�����O����2���ӂ�̑����ʂ̕��ς̍��v(�g�p��)���ACPU�R�A���ɎZ�o���܂��B |
| �������g�p�� | sum (container_memory_usage_bytes{pod_name="<�C�ӂ�Pod��>",container_name!="", container_name!="POD"}) / sum(node_memory_MemTotal_bytes{instance=~"<Pod���z������Ă���m�[�h��IP�A�h���X>:.*"}) * 100 | �C�ӂ�Pod���R���e�i�̃������g�p���̓��A[�R���e�i������������, POD���̂��̂łȂ�����]�����v���A�����Pod���z������Ă���m�[�h�̃������ő�ʂŊ����ĎZ�o���܂��B |
| ����� | �N�G���� | ���� |
|---|---|---|
| CPU�g�p�� | sum by(cpu) (rate(container_cpu_usage_seconds_total{image!="",container!="POD",pod="<�C�ӂ�Pod��>"}[2m] ) ) * 100 | �C�ӂ�Pod���R���e�i��CPU�g�p�ʂ̓��A[�R���e�i�C���[�W����������, POD���̂��̂łȂ�����]�����O����2���ӂ�̑����ʂ̕��ς̍��v(�g�p��)���ACPU�R�A���ɎZ�o���܂��B |
| �������g�p�� | sum (container_memory_usage_bytes{pod="<�C�ӂ�Pod��>",container!="", container!="POD"}) / sum(node_memory_MemTotal_bytes{instance=~"<Pod���z������Ă���m�[�h��>"}) * 100 | �C�ӂ�Pod���R���e�i�̃������g�p���̓��A[�R���e�i������������, POD���̂��̂łȂ�����]�����v���A�����Pod���z������Ă���m�[�h�̃������ő�ʂŊ����ĎZ�o���܂��B |
| ����� | �N�G���� | ���� |
|---|---|---|
| CPU�g�p�� | sum by (cpu) (rate(node_cpu_seconds_total{mode!="<�C�ӂ̃m�[�h��>", mode!="<�C�ӂ̃m�[�h��>", kubernetes_node=~"<�C�ӂ̃m�[�h��>"}[2m])) * 100 | �C�ӂ̃m�[�h��CPU�g�p�ʂ̓��A�ғ����[�h��"idle", "steal"�łȂ����̂�2��������̕��ϑ����ʂ�CPU�R�A���ɎZ�o���܂��B |
| �������g�p�� | ((node_memory_MemTotal_bytes{kubernetes_node=~"<�C�ӂ̃m�[�h��>"} - node_memory_MemFree_bytes{kubernetes_node=~"<�C�ӂ̃m�[�h��>"} - node_memory_Cached_bytes{kubernetes_node=~"<�C�ӂ̃m�[�h��>"} - node_memory_Buffers_bytes{kubernetes_node=~"<�C�ӂ̃m�[�h��>"}) / node_memory_MemTotal_bytes{kubernetes_node=~"<�C�ӂ̃m�[�h��>"}) * 100 | �C�ӂ̃m�[�h�̃������ő�l����[�e��, �L���b�V��, �o�b�t�@]�����������̂��A�ēx�ő�l�Ŋ����ĎZ�o���܂��B |
| �f�B�X�N�g�p�� | sum(rate(node_disk_io_time_seconds_total{kubernetes_node=~"<�C�ӂ̃m�[�h��>"}[2m])) by (device) *100 | �C�ӂ̃m�[�h�̃f�B�X�N�g�p���Ԃ�2���ӂ�̕��ϑ����ʂ̍��v(=�g�p��)���A�f�B�X�N���ɎZ�o���܂��B |
| �l�b�g���[�N��M�� | sum(rate(container_network_receive_bytes_total{instance=~"<�C�ӂ̃m�[�h��>"}[2m])) by (interface) | �C�ӂ̃m�[�h�̃l�b�g���[�N��M / ���M�ʂ�2���ӂ�̑����ʂ̍��v(�g�p��)���A�l�b�g���[�N�C���^�[�t�F�[�X���ɎZ�o���܂��B |
| �l�b�g���[�N���M�� | sum(rate(container_network_transmit_bytes_total{instance=~"<�C�ӂ̃m�[�h��>"}[2m])) by (interface) |
| ����� | �N�G���� | ���� |
|---|---|---|
| CPU�g�p�� | sum by (cpu) (rate (node_cpu_seconds_total{mode!="idle", mode!="steal", instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>"}[2m])) * 100 | �C�ӂ̃m�[�h��CPU�g�p�ʂ̓��A�ғ����[�h��"idle", "steal"�łȂ����̂�2��������̕��ϑ����ʂ�CPU�R�A���ɎZ�o���܂��B |
| �������g�p�� | ((node_memory_MemTotal_bytes{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>.*"} - node_memory_MemFree_bytes{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>:.*"} - node_memory_Cached_bytes{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>:.*"} - node_memory_Buffers_bytes{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>:.*"}) / node_memory_MemTotal_bytes{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>:.*"}) * 100 | �C�ӂ̃m�[�h�̃������ő�l����[�e��, �L���b�V��, �o�b�t�@]�����������̂��A�ēx�ő�l�Ŋ����ĎZ�o���܂��B |
| �f�B�X�N�g�p�� | sum(rate(node_disk_io_time_seconds_total{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>:.*"}[2m])) by (device) *100 | �C�ӂ̃m�[�h�̃f�B�X�N�g�p���Ԃ�2���ӂ�̕��ϑ����ʂ̍��v(=�g�p��)���A�f�B�X�N���ɎZ�o���܂��B |
| �l�b�g���[�N�g�p�� | sum(rate(container_network_receive_bytes_total{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>:.*"}[2m])) by (interface) | �C�ӂ̃m�[�h�̃l�b�g���[�N��M / ���M�ʂ�2���ӂ�̑����ʂ̍��v(�g�p��)���A�l�b�g���[�N�C���^�[�t�F�[�X���ɎZ�o���܂��B |
| �l�b�g���[�N���M�� | sum(rate(container_network_transmit_bytes_total{instance=~"<�C�ӂ̃m�[�h��IP�A�h���X>:.*"}[2m])) by (interface) |
| ����� | �N�G���� | ���� |
|---|---|---|
| CPU�g�p�� | sum by (cpu) (rate(node_cpu_seconds_total{mode!="idle", mode!="steal", instance=~"<�C�ӂ̃m�[�h��>"}[2m])) * 100 | �C�ӂ̃m�[�h��CPU�g�p�ʂ̓��A�ғ����[�h��"idle", "steal"�łȂ����̂�2��������̕��ϑ����ʂ�CPU�R�A���ɎZ�o���܂��B |
| �������g�p�� | ((node_memory_MemTotal_bytes{instance=~"<�C�ӂ̃m�[�h��>"} - node_memory_MemFree_bytes{instance=~"<�C�ӂ̃m�[�h��>"} - node_memory_Cached_bytes{instance=~"<�C�ӂ̃m�[�h��>"} - node_memory_Buffers_bytes{instance=~"<�C�ӂ̃m�[�h��>"}) / node_memory_MemTotal_bytes{instance=~"<�C�ӂ̃m�[�h��>"}) * 100 | �C�ӂ̃m�[�h�̃������ő�l����[�e��, �L���b�V��, �o�b�t�@]�����������̂��A�ēx�ő�l�Ŋ����ĎZ�o���܂��B |
| �f�B�X�N�g�p�� | sum(rate(node_disk_io_time_seconds_total{instance=~"<�C�ӂ̃m�[�h��>"}[2m])) by (device) *100 | �C�ӂ̃m�[�h�̃f�B�X�N�g�p���Ԃ�2���ӂ�̕��ϑ����ʂ̍��v(=�g�p��)���A�f�B�X�N���ɎZ�o���܂��B |
| �l�b�g���[�N�g�p�� | sum(rate(container_network_receive_bytes_total{node=~"<�C�ӂ̃m�[�h��>"}[2m])) by (interface) | �C�ӂ̃m�[�h�̃l�b�g���[�N��M / ���M�ʂ�2���ӂ�̑����ʂ̍��v(�g�p��)���A�l�b�g���[�N�C���^�[�t�F�[�X���ɎZ�o���܂��B |
| �l�b�g���[�N���M�� | sum(rate(container_network_transmit_bytes_total{node=~"<�C�ӂ̃m�[�h��>"}[2m])) by (interface) |
WebOTX Application Server��MicroProfile Metrics�@�\���o�͂�����(���g���N�X)��Prometheus�Ŏ擾����菇�ɂ��āA�������܂��B
MicroProfile Metrics���g�p�����A�v���P�[�V�����쐬�ɂ��ẮA[�A�v���P�[�V�����J���K�C�h > ���̑��̃A�v���P�[�V���� > �}�C�N���T�[�r�X�A�v���P�[�V�����̊J�� > MicroProfile Metrics]�����Q�Ƃ��������B
WebOTX Application Server��MicroProfile Metrics�@�\���o�͂��郁�g���N�X�ꗗ���A���LURL�Ŏ擾���邱�Ƃ��ł��܂��B
https://<WebOTX Application Server��URL>:<WebOTX Application Server�̃|�[�g>/metrics
# HELP base:classloader_total_loaded_class_count Display the total number of classed that have been loaded since the JVM has started execution. # TYPE base:classloader_total_loaded_class_count counter base:classloader_total_loaded_class_count 13555.0 # HELP base:cpu_system_load_average # TYPE base:cpu_system_load_average gauge base:cpu_system_load_average 4.2 # HELP base:thread_count Display the current number of live threads including both daemon and non-daemon threads. # TYPE base:thread_count counter base:thread_count 67.0 # HELP base:gc_mark_sweep_compact_count Display the total number of collections that have occured. This attribute display -1 if the collection count is undefined for this collector. # TYPE base:gc_mark_sweep_compact_count counter base:gc_mark_sweep_compact_count 4.0 # HELP base:classloader_current_loaded_class_count Display the number of classes that are currently loaded in the JVM. # TYPE base:classloader_current_loaded_class_count counter base:classloader_current_loaded_class_count 13556.0 # HELP base:gc_copy_count Display the total number of collections that have occured. This attribute display -1 if the collection count is undefined for this collector. # TYPE base:gc_copy_count counter base:gc_copy_count 126.0 # HELP base:jvm_uptime_seconds Display the start time of the JVM. # TYPE base:jvm_uptime_seconds gauge base:jvm_uptime_seconds 84.705 # HELP base:gc_copy_time_seconds Display the approximate occumulated collection elapsed time. # TYPE base:gc_copy_time_seconds counter base:gc_copy_time_seconds 1.32 # HELP base:memory_committed_heap_bytes Display the amount of memory that is committed for the JVM to use. # TYPE base:memory_committed_heap_bytes gauge base:memory_committed_heap_bytes 2.00704E8 # HELP base:thread_max_count Display the peak live thread count since the JVM started or peak was reset. This includes daemon and non-daemon threads. # TYPE base:thread_max_count counter base:thread_max_count 68.0 # HELP base:cpu_available_processors Di # TYPE base:cpu_available_processors gauge base:cpu_available_processors 1.0 # HELP base:thread_daemon_count Display the current number of live daemon threads. # TYPE base:thread_daemon_count counter base:thread_daemon_count 64.0 # HELP base:gc_mark_sweep_compact_time_seconds Display the approximate occumulated collection elapsed time. # TYPE base:gc_mark_sweep_compact_time_seconds counter base:gc_mark_sweep_compact_time_seconds 0.702 # HELP base:classloader_total_unloaded_class_count Display the total number of classed that have been unloaded since the JVM has started execution. # TYPE base:classloader_total_unloaded_class_count counter base:classloader_total_unloaded_class_count 0.0 # HELP base:memory_max_heap_bytes Display the maximum amount of heap memory. This attribute displays -1 if the maximum heap memory size is undefined. # TYPE base:memory_max_heap_bytes gauge base:memory_max_heap_bytes 8.73791488E8 # HELP base:memory_used_heap_bytes Display the amount of used heap memory. # TYPE base:memory_used_heap_bytes gauge base:memory_used_heap_bytes 1.29386776E8 # HELP vendor:machine_disk_free_disk_space_bytes Represents the amount of free disk space. (Unit: Bytes) # TYPE vendor:machine_disk_free_disk_space_bytes gauge vendor:machine_disk_free_disk_space_bytes 8.130185216E10 # HELP vendor:machine_disk_usable_free_disk_space_bytes Represents the amount of free disk space available. (Unit: Bytes) # TYPE vendor:machine_disk_usable_free_disk_space_bytes gauge vendor:machine_disk_usable_free_disk_space_bytes 8.130185216E10 # HELP vendor:license_code Represents a registered product code. # TYPE vendor:license_code gauge vendor:license_code 0.0 # HELP vendor:license_count Represents the number of licenses registered. # TYPE vendor:license_count counter vendor:license_count 1.0 # HELP vendor:license_available_cores Represents the number of CPU cores that Java virtual machine can use. # TYPE vendor:license_available_cores gauge vendor:license_available_cores 1.0 # HELP vendor:machine_disk_disk_used_rate_ratio Represents the utilization of a disk. (Unit: %) # TYPE vendor:machine_disk_disk_used_rate_ratio gauge vendor:machine_disk_disk_used_rate_ratio 5.0 # HELP vendor:machine_disk_total_disk_space_bytes Represents the total capacity of the disk. (Unit: Bytes) # TYPE vendor:machine_disk_total_disk_space_bytes gauge vendor:machine_disk_total_disk_space_bytes 8.5886742528E10 # HELP vendor:machine_os_available_processors The number of processors available to the Java virtual machine. This method is equivalent to the Runtime.availableProcessors() method. This value may change during a particular invocation of the virtual machine. # TYPE vendor:machine_os_available_processors counter vendor:machine_os_available_processors 1.0 # HELP vendor:java_vm_memory_all_application_server_physical_mem_size_bytes Represents the amount of physical memory used by the application server. (Unit: Kilobytes) # TYPE vendor:java_vm_memory_all_application_server_physical_mem_size_bytes gauge vendor:java_vm_memory_all_application_server_physical_mem_size_bytes 3.615468E9 # HELP vendor:java_vm_memory_all_application_server_virtual_mem_size_bytes Represents the amount of virtual memory used by the application server. (Unit: Kilobytes) # TYPE vendor:java_vm_memory_all_application_server_virtual_mem_size_bytes gauge vendor:java_vm_memory_all_application_server_virtual_mem_size_bytes 0.0
WebOTX Application Server �t���v���t�@�C���ŃR���e�i�́AEclipse MicroProfile Metrics�ɂ�郁�g���N�X�p�G���h�|�C���g�̗L�����ɂ��ẮA�ȉ������Q�Ƃ��������B
[�\�z�E�^�p > �R���e�i�^���z�� > WebOTX Application Server�̃R���e�i�C���[�W > 1.1.3. �lj��\��]
�܂��AWebOTX Operator���g�p�������[�^�����O�@�\�ɂ��ẮA�ȉ������Q�Ƃ��������B
[�\�z�E�^�p > �R���e�i�^���z�� > Operator > 2.1.5. ���[�^�����O�@�\�̗��p]
| �擾��� | PromQL | ���s���ʗ� |
|---|---|---|
| �X���b�h�J�E���^ | base:thread_count | 75.0 (threads) |
| JVM�̃������q�[�v�ő�l | base:memory_max_heap_bytes | 1.761738752E9 (bytes) |
| JVM�̃������q�[�v�g�p�� | base]memory_used_heap_bytes | 1.30548032E8 (bytes) |