| 2. APサーバのチューニング |
Standard/Enterprise EditonにおけるAPサーバのチューニングについて説明します。
| 2.1. アプリケーショングルーピング |
WebOTX Standard/Enterprise Editionではサーバアプリケーションは「アプリケーショングループ」および「プロセスグループ」という単位でグルーピングを行ないます。それぞれどのような観点でグルーピングを行なうべきか説明します。
| 2.1.1. アプリケーショングループ |
アプリケーショングループとは、開始・終了などの運用を共にするアプリケーション群をグルーピングしたものです。例えば、「受発注業務」「在庫数管理業務」といったような業務毎にツリーを分けて管理するといった方法を用います。こうすることで、「受発注業務」は10時から17時まで動作させ、その後は停止させる。「在庫数管理業務」は24時間動作させるなどのアプリケーショングループ単位での独立した運用が行えるようになります。なおアプリケーションに関する設定(例えば、プロセスグループのプロセス数、スレッド数、Java VMオプション等)を変更する場合はアプリケーショングループの再起動が必要となります。
すなわち、業務運用の単位でアプリケーショングループをグルーピングします。
| 2.1.2. プロセスグループ |
プロセスグループとは、ある特定のサービスを提供するプロセス群です。同一のプロセスグループに登録されているコンポーネントは同一のプロセス上でロードされます。 WebOTXはビジネスロジックを記述した1つまたは複数のコンポーネントをプロセスグループに登録し、プロセスとして実行します。
プロセスグループの単位で次の項目が共有されます。
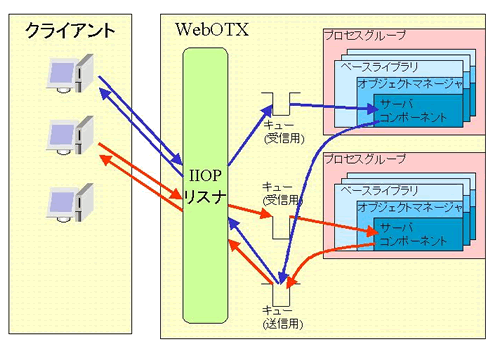
WebOTXではプロセスグループ単位にキューを生成します。同一プロセスグループ上のリクエストはすべてこのキューにキューイングされます。
WebOTXではプロセスグループ単位にJava VMを生成し、配下のコンポーネントをロードします。マルチプロセス構成の場合は同一構成のJava VMが複数生成されます。Java VMに関する設定(ヒープサイズのようなVMオプション等)もプロセスグループ単位での設定となります。
WebOTXではプロセスグループ単位に実行多重度(プロセス、スレッド)を設定します。そのプロセスグループの特性に応じて実行多重度を設定できます。バックエンドサーバへのコネクション
APサーバが利用するバックエンドサーバ(DBやACOSやTPBASE)へのコネクションはプロセスで共有されます。よってプロセスグループを分けたり、マルチプロセスにしたりする場合はその分コネクションが生成されることになります。またVISコネクタの場合、全てのプロセスグループで定義している総スレッド数分のコネクションが生成されます。
| 2.1.3. 処理の流れ |
Standard/Enterprise EditionのサーバAPでの処理の流れについて説明します。
上記で説明したように、プロセスグループ単位でキュー(受信用)が生成されます。クライアント(thinクライアントの構成ではWebサーバ)からの要求はIIOPリスナを経由して、該当プロセスグループのキューにキューイングされます。そのときにプロセスグループ内でアイドル中(フリーな)のスレッドが存在していた場合、即時にそのスレッドでリクエストは実行されます。アイドル中のスレッドが無い場合は、キューで実行待ちとなります。
プロセスグループでキューは共有しますので、例えば実行時間が非常に長い呼び出しが実行された場合、そのリクエストを処理するために1つのスレッドは占有されます。これにより同じプロセスグループ内にある他の呼び出しを実行するスレッドが減少してしまいます。全てのスレッドが長い呼び出しに占有されてしまった場合、そのプロセスグループに対する要求は全てキューイングされることになります。
| 2.1.4. マルチプロセス・マルチスレッド |
プロセスグループを多重実行させる場合、プロセスを多重化させる方法とスレッドを多重化させる方法があります。
各プロセスはシングルスレッドでもマルチスレッドでも動作させることができます。すべてのプロセス上のスレッド群は、単一のキューに対してデータの到着を待ち合わせるので、空きスレッドに効率良くトランザクション要求をディスパッチすることができます。マルチプロセス実行させることにより、アプリケーションの一時的な障害に対してサービスの継続が可能になります。データや環境、タイミングなどの要因でアプリケーション障害が発生しても、そのプロセスだけが異常終了し、他のプロセスは影響を受けません。したがって、システム全体ではサービスを中断させることがありません。
しかしマルチプロセス構成はマルチスレッド構成に比べてより多くのリソースを必要とします。システムで多数のプロセスが起動することによりマシンのリソース不足を招き、サーバ自体が不安定になる恐れがあります。マルチプロセスは予期せぬアプリケーション障害に備えての多重化とし、クライアントからの同時実行に備えての多重化はできるだけマルチスレッドで行う構成が望ましいといえます。ただし、アプリケーションの構成上(スレッド間同期、排他制御)の問題でマルチスレッド動作できないなどの制限がある場合は、マルチプロセス構成で多重度を確保します。
また、システム運用中に発生した想定外の大量のトランザクション要求に対して、動的にアプリケーション多重度(スレッド、プロセス)を増加させることが可能です(注:スレッド数は最初に確保した数以上は増やせません)。これにより、大量のトランザクション要求に対してサーバ側が処理しきれずに要求がキューに滞留しレスポンス悪化することが避けられます。また、負荷が下がったときに安全に実行多重度を元に戻すこともできます。
運用アシスタント機能により、システムの稼働状況に応じて多重度の増減を推奨(または自動変更)することができます。高負荷により設定された応答時間を満たさないと予想される場合は、多重度を増やすよう通知(または自動変更)します。負荷が下がった状態が続くと多重度を減らすように通知(または自動変更)します。詳しくは「運用編(TPモニタの運用操作) 2.40.3 多重度の最適化支援」を参照してください。
| 2.1.5. グルーピングのポイント |
上記のWebOTXのプロセスグループの特性を考慮してどのようにグルーピングするのが望ましいか説明します。
多重度を確保するにはマルチプロセスとマルチスレッドがありますが、特にマルチプロセス構成にする場合メモリ消費量を考慮する必要があります。以下にWebOTX Java APのメモリ消費量の目安の計算式を示します。
(ヒープサイズ)+(スレッドスタックサイズ)×スレッド数+15(MB)
※1プロセスあたりの計算式です。実際は全てのプロセスの合計値となります
また、 OSによりメモリ消費量は計算式から増減があります。
スレッド数を上げても(スレッドスタックサイズ:既定値1M)分しか増加しないのに比べ、プロセス数を上げると上記の計算式の値全てのサイズ分増加します。メモリ量を考慮すると、多重度はマルチプロセスよりマルチスレッドで行うべきです。
VISコネクタを使用した場合、TPシステムで定義している総スレッド数分コネクションを作成します。VISコネクタのライセンスはコネクション単位ですので、総スレッド数がライセンスを越えることができません。
例えば
WebOTX VISコネクタ実行環境 (4)
WebOTX VISコネクタ実行環境 (+8)
を購入している場合4+8(=12)ライセンスですので、1プロセスグループ1プロセス1スレッド構成にするにしても12個しかプロセスグループを作成することができません。1プロセスグループ2プロセス2スレッド構成の場合は3個(12÷4)のプロセスグループしか作成することができないこととなります。
バックエンドサーバへのコネクション数についても注意が必要となります。マルチプロセス構成とした場合、プロセスの数分、コネクションを生成することとなります。多くのプロセスを生成すると、バックエンドサーバとのコネクション数の制限を越えてしまうことがあります。
上記にも書きましたように、WebOTXはプロセスグループ単位でキューを生成します。ここで作成したコンポーネントを複数のプロセスグループに登録するのと、1プロセスグループに登録するのではどちらがいいのかの考え方について説明します。
複数のプロセスグループに登録する場合は、キューやプロセス空間が他のコンポーネントと完全に独立します。あるコンポーネントに問題があり、ストールやレスポンス悪化、アボートが発生した場合でもその影響をほとんど受けません。あるコンポーネントがストールもしくはレスポンス悪化(もともと正常でも時間がかかる呼び出しでも同様)があった場合、プロセスグループ中のスレッドが、全てストールしてしまう可能性があります。アボートの場合は、Java VM全体でアボートとなり、全てのコンポーネントへの影響が出てきます。このような状態になった場合、そのプロセスグループへの呼び出しは例えその呼び出し自体に問題が無くてもそれ以上処理されなくなりそのプロセスグループ全体がストールしたり、実行プロセスがアボートしてなくなってしまいます。プロセスグループを分けることは、このような現象を未然に予防することができます。
上記で説明したように1プロセスグループに登録する場合ストール、レスポンス悪化、アボートに対して注意が必要になります。対策として、マルチスレッドで多重度を十分に確保することおよびマルチプロセスでアボートしても、プロセス数が0となることを行っておくことがあげられます。複数のプロセスグループの構成より万全ではありませんがある程度問題は回避できます。
| 2.2. チューニングのための事前確認 |
チューニングの方針を立てるためには現在使用中または使用予定のWebOTXのメモリ使用量や性能を正しく把握する必要があります。WebOTXやOSが提供する情報採取方法について説明します。
| 2.2.1. メモリ使用量の確認 |
WebOTXが必要とするメモリ使用量はマニュアルの[セットアップガイド]-[2.リソース]-[2.2メモリ容量]を参照してください。WebOTXのエージェントプロセスが使用するJVMヒープサイズの確認については運用編(ドメインの運用)「4.11.1 Javaプロセスの監視・管理」を、JVMヒープサイズのモニタリングに関しては「運用編(モニタリング) 3.3.1 JVMヒープサイズのモニタリング」を参照してください。アプリケーションプロセスのメモリ使用量の確認については「運用編(TPモニタの運用操作)2.37統計情報の表示」を参照してください。その他のプロセスについてはタスクマネージャ(Windowsの場合)またはtopコマンド(unixの場合)で確認してください。また、OS全体でのメモリ残量はタスクマネージャ(Windowsの場合)またはswapinfoコマンド(unixの場合)で確認できます。
なお、Sun製JDKをご使用の場合はjconsoleを、HP-UXの場合はHPJmeterなどでヒープ使用量を確認することもできます。
| 2.2.2. アプリケーション処理時間の確認 |
実行時間上限設定を適切に行うために、運用アシスタントの実行時間上限の適正値算出機能を利用してください。詳細は「運用編(TPモニタの運用操作) 2.40.4 実行時間上限の適正値算出」を参照してください。
また、プロセス数やスレッド数を適切に設定するためにはキュー滞留数がひとつの目安になります。統合運用管理ツールでのキュー滞留数の確認方法については「運用編(モニタリング) 3.3.3 キューイング数のモニタリング」を参照してください。さらにquewrtコマンドで確認することもできます。「運用編(TPモニタの運用操作) 2.39.5キュー滞留数の確認方法」を参照してください。
| 2.2.3. 多重度の確認 |
クライアント多重度、スレッド多重度がどこまで使われているのかを確認する方法を説明します。
使用中の接続クライアント数については「運用編(モニタリング) 3.3.4 接続クライアント数のモニタリング」を参照してください。
WebOTXは稼動スレッド数などを記録するためにオペレーションジャーナルを採取しています。オペレーションジャーナルを編集することにより、稼動スレッド数を時間毎に調査することができます。「運用編(TPモニタの運用操作) 2.38 オペレーションジャーナルの編集」を参照してください。
| 2.3. リソースチューニング |
WebOTXで消費するメモリについてチューニングする方法について説明します。またディスクサイズを節約する方法について説明します。
| 2.3.1.ドメインエージェントプロセスのヒープサイズの見直し |
ドメインエージェントプロセスのヒープサイズを見直すことにより、ドメインエージェントプロセスの使用メモリをチューニングできます。なおチューニングする値についてはモニタリング情報やJVM統計レポート、GCログを採取するなどして、高負荷時にも耐えられるサイズを見積もる必要があります。少なくしすぎるとOutOfMemoryErrorが発生します。
統合運用管理ツールのドメイン毎に設定
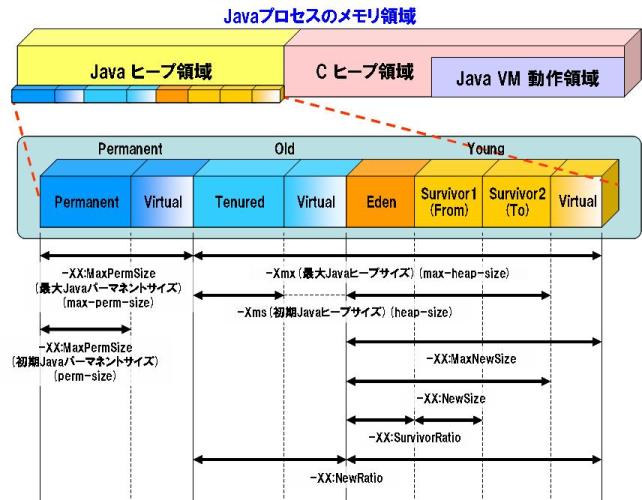
この値は、JVMオプションの一種である -Xmx(下図参照) を指定することと同様の意味を持ちます。
運用管理コマンドの場合は、次のように指定します。
otxadmin> set server.java-config.max-heap-size=<サイズ>
<サイズ>には、-Xmxオプションと同様の指定方法でサイズを指定します。例えば、768Mバイトに指定する場合は "768m" とします。
なお、GC採取時以下のログが出力されていた場合、Javaの通常のヒープとは別のPermanent領域というヒープ領域が足りなくなったことを示しています。
Permanent generation is full...
increase MaxPermSize (current capacity is set to: 67108864 bytes)
ここにはクラスの内部表現が展開されます。アプリケーションによっては非常に多くのクラスをロードするものもあり、Permanent 領域が足りなくなることがあります。このような場合には、Permanent 領域のサイズを変更する必要があります。現在は、デフォルトで128Mバイトに設定されています。
この値は、JVMオプションの一種である -XX:MaxPermSize(下図参照) を指定することと同様の意味を持ちます。
運用管理コマンドの場合は、次のように指定します。
otxadmin> set server.java-config.max-perm-size=<サイズ>
<サイズ>には、-XX:MaxPermSizeオプションと同様の指定方法でサイズを指定します。例えば、256Mバイトに指定する場合は "256m" とします。
いずれも、編集後ドメインを再起動することで設定が反映されます。
なお、それ以外にも、JVMのヒープサイズに関して次のような指定が可能です。
いずれも、編集後ドメインを再起動することで設定が反映されます。
この値は、JVMオプションの一種である -Xms(下図参照) を指定することと同様の意味を持ちます。
運用管理コマンドの場合は、次のように指定します。
otxadmin> set server.java-config.heap-size=<サイズ>
この値は、JVMオプションの一種である -XX:PermSize(下図参照) を指定することと同様の意味を持ちます。
運用管理コマンドの場合は、次のように指定します。
otxadmin> set server.java-config.perm-size=<サイズ>
<サイズ>の部分の指定方法はこれまでと同様です。
なお、これらの設定値が大きすぎると、次のようなエラーが発生してドメインが起動しなくなる場合がありますので注意して下さい。また、実際にこれらのエラーが発生した場合には、OS側でそれ以上のサイズを確保できない状況であることを示していますので、指定した値よりも小さな値を設定するようにしてください。
Error occurred during initialization of VM
Could not reserve enough space for object heap
また、下図にも示すようなこれら以外のJVMオプションによってチューニングを行う場合には、[アプリケーションサーバ]-[JVM構成]-[JVMオプション]に設定値を追加します。
運用管理コマンドの場合は、オプションの形式に応じて次のように指定します。
"-X"で始まるオプション:
otxadmin> create-jvm-options -- -X<JVMオプション名><オプション値>
"-XX"で始まるオプション:
otxadmin> create-jvm-options "-XX\:<JVMオプション名>=<オプション値>"
Young領域(下図参照)の初期サイズを指定します。
運用管理コマンドの場合は、次のように指定します。
otxadmin> create-jvm-options "-XX\:NewSize=<サイズ>"
Young領域(下図参照)の最大サイズを指定します。
運用管理コマンドの場合は、次のように指定します。
otxadmin> create-jvm-options "-XX\:MaxNewSize=<サイズ>"
<サイズ>の部分の指定方法はこれまでと同様です。
Old領域/Young領域 の比(Young : Old = 1 : x)を指定します。
運用管理コマンドの場合は、次のように指定します。
otxadmin> create-jvm-options "-XX\:NewRatio=<x>"
Eden領域/Survivor領域(1つ分)の比(Suvivor : Eden = 1 : x)を指定します。
運用管理コマンドの場合は、次のように指定します。
otxadmin> create-jvm-options "-XX\:SurvivorRatio=<x>"
| 2.3.2. サーバプロセスのヒープサイズ・スタックサイズの見直し |
サーバAPプロセスのヒープサイズ・スタックサイズを見直すことにより、サーバAPプロセスの使用メモリをチューニングできます。GCログを採取するなどして見積もる必要があります。少なくしすぎるとOutOfMemoryErrorが発生します。
統合運用管理ツールのプロセスグループ毎に設定
・ [スレッド制御]-[スレッドスタックサイズ]
・ [JavaVMオプション]-[最大ヒープサイズ]及び[初期ヒープサイズ] (Javaのみ)
| 2.3.3.起動サービスの見直し |
ドメイン作成時の既定値では、既定の状態に従い、サービスの起動設定が行われます。
この際、運用上必要のないサービスを起動させない設定にすることによりメモリを削減することができます。サービスを停止する場合、下記の表に記載されている停止条件を確認し、停止条件に全て合致しているか確認を行った後、設定を変更してください。
統合運用管理ツールのドメイン毎に設定
・ [アプリケーションサーバ]-[内部ライフサイクルモジュール]-[(各サービス)]-[設定項目(Configurations)]-[起動の可否]
表示されていないサービスを表示させるためには、統合運用管理ツールの[システム]-[システム設定]-[画面表示]において、管理対象の表示レベルと属性の表示レベルを詳細レベルの情報を表示するように変更してください。
これらのサービスのうち、以下のサービスについては設定を変更しないで下さい。次回以降、ドメインが正常に起動できなくなる可能性があります。
| ライフサイクル名 (英語名) |
既定状態 | 停止への変更 | 停止条件 | 備考 |
| 管理サービス (AdminService) |
起動 | 不可 | ||
| アプリケーションサービス (ApplicationService) |
起動 | 不可 | ||
| データベースコントローラ (DBControllerService) |
起動 | 可 | データベースコントローラを使用してデータベースの起動を行わない場合 |
JavaSE6で、テスト用サーバをインストールした場合、自動的にJavaDB(Derby)の自動起動設定を行います。 |
| ライフサイクルイベントサービス (DeclarativeLifecycleEventService) |
停止 | 可 | ライフサイクルモジュール(Lifecycle Module)」と呼ばれるユーザ定義のスタートアップクラスを使用(定義)していない場合 | |
| ダウンローダ管理サービス (DownloaderManagerService) |
インストール時の選択によって異なる | 可 | ダウンローダ環境を使用しない場合 | ダウンローダ環境をインストールしない場合、既定では停止になっています。 |
| JavaEEサーバ (JavaEEServer) |
起動 | 不可 | ||
| JMSプロバイダ (JmsProvider) |
起動 | 可 | 業務アプリケーションでJMSを使用していな場合 | |
| JNDIサービス (JNDIService) |
起動 | 可 | セッションレプリケーションを使用していない場合 WebOTXのJNDIを使用していない場合 |
|
| ライフサイクルモジュールサービス (LifecycleModuleService) |
起動 | 可 | ライフサイクルモジュール(Lifecycle Module)」と呼ばれるユーザ定義のスタートアップクラスを使用(定義)していない場合 | |
| ObjectBrokerサービス (ObjectBrokerService) |
起動 | 可 | Webコンテナサービスを使用しない場合 EJBを使用しない場合 JNDIサービスを使用しない場合 |
|
| 永続マネージャサービス (PersistenceManagerService) |
起動 | 可 | CMP タイプの EJB Timer Bean を使用していない場合 | |
| リモートJMXコネクタ (RemoteJmxConnector) |
起動 | 不可 | ||
| WSRMサービス (RmServiceLifecycle) |
停止 | 可 | WSRMサービスを使用していない場合 Webサービスを使用していない場合 |
|
| セキュリティサービス (SecurityService) |
起動 | 不可 | ||
| 自己管理サービス (SelfManagementService) |
停止 | 可 | ライフサイクルモジュール(Lifecycle Module)」と呼ばれるユーザ定義のスタートアップクラスを使用(定義)していない場合 | |
| システムアプリケーションサービス (SystemApplicationService) |
起動 | 可 | EJB タイマーサービス を使用していない場合 | |
| TPモニタマネージャサービス (TPMonitorManagerService) |
Editionにより異なる | 不可 | Expressインストール時には停止状態となっており、使用することができません。 | |
| Transactionサービス (TransactionService) |
起動 | 不可 | ||
| Webサービス管理 (WSMgmtService) |
起動 | 可 | Webサービスを使用していない場合 | |
| Webコンテナサービス (WebContainerService) |
起動 | 可 | Webアプリケーションを使用していない場合 統合運用管理コンソールを使用しない場合 |
|
| Webサーバサービス (WebServerService) |
インストール時の選択によって異なる | 可 | WebOTX Webサーバを使用していない場合 インストール時にアドバンスドモードを選択している場合 (別マシンのWebサーバを利用しない限り、必要となります。) |
| 2.3.4. プロセス数・スレッド数の見直し |
サーバAPプロセスのプロセス数およびスレッド数を減らすことによりシステム全体のメモリを削減することが出来ます。それ以上にメモリの節約を必要とする場合はコンポーネントの集約を行うことによりメモリを削減できます。ただし、障害の局所化か難しくなるなどのデメリットもあるので注意が必要です。
・ 統合運用管理ツールのプロセスグループの[プロセス制御]-[プロセス数]
・ 統合運用管理ツールのプロセスグループの[スレッド制御]-[スレッド数]
| 2.3.5.ディスクサイズの節約 |
ディスクサイズを節約するためにアプリケーションログのファイルサイズを制限したり、プロセス終了により退避されたアプリケーションログを削除したりすることができます。例えば削除可能なアプリケーションログについては「運用編(ロギング) 2.4.1 サーバアプリケーショントレース採取」に記述しているsaveディレクトリがあります。但し、ログの削除は障害発生時のプロセスの異常終了の原因究明に支障が出る可能性があるため注意が必要です。
このsaveディレクトリを定期的に削除したい場合はタスクスケジューラ(Windowsの場合)やcron(unixの場合)を利用する方法があります。
タスクスケジューラは[コントロールパネル]-[タスク]-[スケジュールされたタスクの追加]で使用できます。saveディレクトリ削除(退避)用バッチを作成してタスクスケジューラに登録してください。
cronはcrontabファイルの命令に従って実行されます。HP-UXの場合、crontabファイルは実行ユーザ名と同じで、/usr/lib/cron/cron.allowファイルに該当する名前がある場合にcrontabを実行できます。他OSではディレクトリやファイル名が異なる場合がありますが、基本的には使い方は同じです。詳細はmanコマンドで確認してください。
| 2.3.6.配備時のエージェントプロセスメモリ節約 |
Standard/Enterprise Editionで動作するTP モニタは、オペレーション毎にトランザクション等の実行時情報を管理する機能を備えています。あるモジュールが配備されると、TP モニタでは個々のオペレーションを識別するために番号を付与して、内部管理テーブルと状態情報との関連付けを行います。EJB モジュールの場合には、オペレーションがリモートインタフェースのメソッドに該当します。
メソッド識別情報の割り当て範囲を限定することにより、配備処理中に行われる識別情報の生成数を削減し、エージェントプロセスでのメモリ消費量の削減が可能です。
詳しくは、運用編マニュアル”アプリケーションの配備”中「9.1 EJB のメソッド識別情報の割り当て抑止」を参照してください。
| 2.4. 性能チューニング |
サーバAPの性能チューニングについて説明します。
| 2.4.1. 多重度のチューニング |
プロセスグループの適正な多重度を算出するための方法について説明します。
待ち行列理論を用いた計算により理論値を算出する方法について説明します。まずは以下の値について要件を整理します。
単位時間のトランザクション処理件数の逆数です。既存システムもしくはユーザ要件から算出してください。
サーバでのその処理の実行時間です。既存システムもしくはユーザ要件から算出してください。
クライアントからみた応答時間です(サービス時間+待ち時間)。既存システムもしくはユーザ要件から算出してください。
プロセスグループの多重度です。
これらを待ち行列理論で計算して必要な多重度Nを求めます。
N=RTs/Ta(R-Ts)
例えば
Ta=0.1 (10件/秒)
Ts=0.2
R=0.5
とすると
N=0.5*0.2/0.1*(0.5-0.1)=2.5
となり要求を満たすには3多重必要ということになります。
本番運用を想定したプロトタイプを動作させ多重度を求める方法について説明します。プロトタイプを用いた測定のほうがより実運用に即した値を求めることが出来ます。
単体評価で算出
平均サービス時間:Tsを1多重で1つのクライアントからアクセスして時間を求めます。その他の値は既存システムもしくはユーザ要件から算出した値を用いて多重度を求めることが出来ます。
負荷評価で確認
実際に平均到着間隔:Taだけの負荷をかけて多重度を変えながらレスポンス時間を確認します。
運用アシスタントにより多重度の適正を診断することができます。多重度が多すぎる/少なすぎる場合は統合運用管理ツールなどを通して通知されます。
また運用アシスタントの多重度自動変更機能を利用することにより、システムの稼働状況に合わせて多重度を自動的に変更させることができます。詳しくは「運用編(TPモニタの運用操作) 2.40.3 多重度の最適化支援」を参照してください。
| 2.4.2. CPU使用率の確認 |
応答時間が長い場合はその時のCPU使用率を確認してください。応答時間が長い場合はその時のCPU使用率を確認してください。プロセスグループの「動作情報」タブの「プロセス情報」で確認できます。CPU情報はオペレーションジャーナルに記録され、統計的に解析することが可能です。
CPU使用率が高い場合はプロセス数やスレッド数を増やしても性能がよくなるとは限らないため、CPU使用率を減らすなどの対策が必要です。
| 2.4.3.重要な処理を優先的に実行したい場合の設定 |
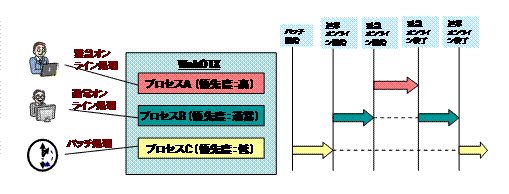
多重度を増やす等の対処をおこなっても、他のプロセスが動作中でCPU時間がなかなか割り当てられない場合などはレスポンス時間が大きくなってしまいます。プロセスの優先度を指定することにより、高優先度の処理は他のプロセスより優先されるため、CPU負荷が高い状況でも処理投入後即開始することが可能となります。
例えば、以下のように業務特性に合わせた最適な優先度設定が可能です。(※)
処理 |
優先度 |
緊急オンライン処理 |
高 |
通常オンライン処理 |
通常(未設定) |
バッチ処理 |
低 |
さらに、呼び出し処理単位の優先度設定(オペレーション優先度)と組合せて、よりきめ細かな設定が可能です。
プロセス優先度の設定はプロセスグループ単位で行います。具体的な設定方法は「運用編(TPモニタの運用操作)」の「2.22 サーバアプリケーション制御のための設定」を参照してください。
オペレーション優先度の設定はオペレーション単位で行います。具体的な設定方法は「運用編(TPモニタの運用操作)」の「2.24 オペレーション制御のための設定」を参照してください。
(※)優先度を維持するためには優先度を固定化する必要があります。またLinux OSでは優先度を固定することが出来ません。優先度を高く設定しても、実行を続けると優先度が落ちる場合があります。
| 2.4.4. 性能ネック箇所の特定 |
性能測定を行なった結果、性能が想定していたより出ない場合、どの部分に問題があるのか特定する方法について説明します。
実際にどれくらいの実行時間で運用しているかを確認する方法について説明します。レスポンス時間の把握により問題のあるオペレーションを特定することが出来ます。
オペレーションの性能情報は[統計情報]-[ドメイン名]-[アプリケーション]-[アプリケーション名]-[モジュール名]-[インタフェース名]-[オペレーション名]を参照して下さい。
また、レスポンス時間(キュー待ち時間を含む応答時間)の他に、実行時間(キュー待ち時間を含まない処理時間)とCPU時間を確認することで性能ネック箇所を切り分けることができます。性能ネック箇所として疑わしいのは以下の箇所となります。
レスポンス時間 >> 実行時間 であれば多重度不足
実行時間 >> CPU時間 であればDBやネットワークなどのバックエンド問題
実行時間 ≒ CPU時間 であれば業務AP内でのループ
キュー滞留が発生しているかを確認する方法について説明します。キュー滞留が発生している場合、多重度が不足しておりレスポンス悪化になっている可能性が考えられます。
キュー滞留数の確認方法については「運用編(TPモニタの運用操作)」の「2.39 障害解析」を参照ください。
オペレーション単位でオペレーションの処理状況(平均時間、最大時間、最小時間、呼び出し回数、平均CPU使用時間(ユーザモード/カーネルモード)、最大CPU使用時間(ユーザモード/カーネルモード)、最小CPU使用時間(ユーザモード/カーネルモード))を確認することができます。これによりより問題のあるオペレーションを特定することが出来ます。
オペレーションジャーナルの確認方法については「運用編(TPモニタの運用操作)」の「2.38 オペレーションジャーナルの編集」を参照ください。
イベントジャーナルを採取してオペレーションの処理の流れを詳細に調べることができます。
イベントジャーナルについては「運用編(TPモニタの運用操作)」の「2.39 障害解析」を参照ください。
Javaアプリケーションの場合プロファイリングを行なうことにより、より詳細に問題箇所を特定することが出来ます。
| 2.5. その他チューニングに関する設定 |
高負荷になりレスポンスが悪化した場合などに考慮が必要なタイムアウト値や、プロセス起動・停止に必要なタイムアウト値などに関する設定、その他上限設定について説明します。
| 2.5.1. 起動・停止タイムアウト(メッセージ表示) |
プロセスの起動操作、停止操作の完了を待ち合わせる時間を設定します。
タイムアウトした場合はエラーメッセージが表示されます。但し、プロセスの起動処理自体は実行され続けます。
設定項目 |
説明 |
既定値 |
設定値範囲 |
補足事項 |
1.システム起動タイムアウト |
システムの起動処理に関するタイムアウトの設定をします。 |
120秒 |
1以上の整数で秒単位 |
内部プロセスの電文応答待ち時間である70秒よりも長い値を指定してください |
2.システム停止タイムアウト |
システムの停止処理に関するタイムアウトの設定をします。 |
120秒 |
1以上の整数で秒単位 |
内部プロセスの電文応答待ち時間である70秒よりも長い値を指定してください |
3.アプリケーショングループ起動タイムアウト |
アプリケーショングループの起動処理に関するタイムアウトの設定をします。 |
120秒 |
1以上の整数で秒単位 |
内部プロセスの電文応答待ち時間である70秒よりも長い値を指定してください |
4.アプリケーショングループ停止タイムアウト |
アプリケーショングループの停止処理に関するタイムアウトの設定をします。 |
120秒 |
1以上の整数で秒単位 |
内部プロセスの電文応答待ち時間である70秒よりも長い値を指定してください |
5.プロセスグループ起動タイムアウト |
プロセスグループの起動処理に関するタイムアウトの設定をします。 |
120秒 |
1以上の整数で秒単位 |
内部プロセスの電文応答待ち時間である70秒よりも長い値を指定してください |
6.プロセスグループ停止タイムアウト |
プロセスグループの停止処理に関するタイムアウトの設定をします。 |
120秒 |
1以上の整数で秒単位 |
内部プロセスの電文応答待ち時間である70秒よりも長い値を指定してください |
設定方法
1. otxadmin> set tpsystem.startTimeOut=120
2. otxadmin> set tpsystem.stopTimeOut=120
3. otxadmin> set tpsystem.applicationGroups.アプリケーショングループ名.startTimeOut=120
4. otxadmin> set tpsystem.applicationGroups.アプリケーショングループ名.stopTimeOut=120
5. otxadmin> set tpsystem.applicationGroups.アプリケーショングループ名.processGroups.プロセスグループ名.startTimeOut=120
6. otxadmin> set tpsystem.applicationGroups.アプリケーショングループ名.processGroups.プロセスグループ名.stopTimeOut=120
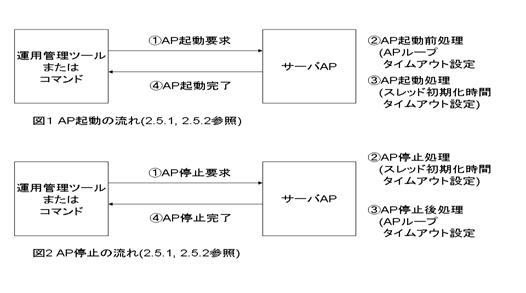
| 2.5.2. 起動・停止タイムアウト(プロセス終了) |
アプリケーションプロセスの起動または停止に長い時間がかかる場合はタイムアウトを検出して異常終了することがあります。この場合、処理時間が妥当か検証し、妥当でないなら処理を見直し、妥当ならタイマ値を見直す必要があります。
設定項目 |
説明 |
既定値 |
設定値範囲 |
1. スレッド初期化時間 |
スレッド初期化にかかる時間のタイムアウト値を設定します。 |
600秒 |
1-2147483647で秒単位 |
2. APループ |
スレッド初期化前及びスレッド終了後にかかる時間のタイムアウト値を設定します。 |
600秒 |
1以上の整数で秒単位 |
スレッド初期化時間のタイムアウト値は以下の場所で時間のかかる処理を行っている場合に考慮が必要です。
コンストラクタ・デストラクタ(アパートメントの場合)
常駐オブジェクトのコンストラクタ・デストラクタ
設定を反映させるためにはアプリケーショングループを再起動してください。
また、APループのタイムアウト値は以下の場所で時間のかかる処理を行っている場合に考慮が必要です。
コンストラクタ・デストラクタ(ステートレスフリーの場合)
コンポーネント初期化インタフェース
実装情報の定義関数
プロセス起動および終了時のコールバック関数
WO_ObjectListener (JavaAPでフリースレッドモデルの場合のみ)
BindingHooks (ステートレスフリーで名前サーバへの登録方法が一時的の場合のみ)
設定を反映させるためにはTPシステムを再起動してください。
スレッド初期化時間
統合運用管理ツールのプロセスグループの[スレッド制御]-[スレッド初期化時間]
APループ
ファイル(unixの場合) : /opt/WebOTX/domains/<domain名>/config/tpsystem/tpbase.cnf
修正前 : APLOOP 600
修正後 : APLOOP xxx
(注: xxxにプロセス起動または停止に必要な時間以上の値を秒単位で入れてください)
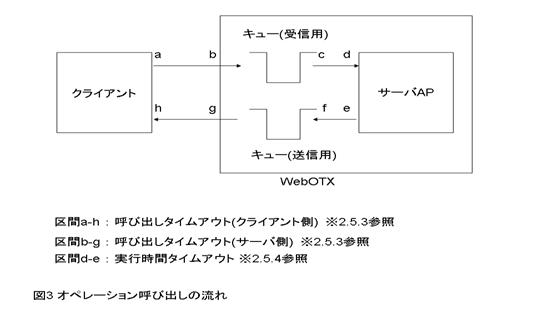
| 2.5.3. 呼び出しタイムアウト |
クライアント側で設定する場合
クライアント側でオペレーション実行要求を出してからその応答をもらうまでのタイムアウト値を設定します。このタイムアウト値を設定することで、クライアントが無応答となることを抑止します。このタイムアウト値はサーバでの実行時間のほかに通信に要する時間およびキュー待ち時間を考慮して設定します。
設定項目 |
説明 |
既定値 |
設定値範囲 |
1. Javaクライアントからのオペレーション呼び出しタイムアウト時間 |
EJB、JNDIなどRMI-IIOP通信を使用する呼び出しのタイムアウト時間です。 |
30秒 |
0以上 ※0を指定した場合は無制限 |
2. Javaクライアントでの無通信監視タイムアウト時間 |
クライアント側で一定時間送受信要求のないコネクションをクローズするまでのタイムアウト時間です。 |
無制限 |
0以上 ※0を指定した場合は無制限 |
3. オペレーション呼び出しのタイムアウト時間 |
CORBA通信を使用する呼び出しのタイムアウト時間です。 |
30秒 |
0以上 ※0を指定した場合は無制限 |
4. コネクションラウンドロビンでのオペレーション呼び出しのタイムアウト時間 |
多重化オブジェクトによるコネクションラウンドロビン機能を利用する場合に有効になります。個々のサーバへのオペレーション呼び出しのタイムアウト時間です。 |
オペレーション呼び出しのタイムアウト時間の値 |
0以上 ※0を指定した場合は無制限 |
1. Javaクライアントからのオペレーション呼び出しタイムアウト時間
Javaコマンドラインで指定する場合
以下の形式でシステムプロパティを指定
-Djp.co.nec.orb.RequestTimeout=<タイムアウト時間(秒)>
J2EEサーバ(Webコンテナ、JNDIサーバ)に指定する場合
統合運用管理ツールのserver.java-configの「JVMオプション」に以下の形式でシステムプロパティを追加
-Djp.co.nec.orb.RequestTimeout=<タイムアウト時間(秒)>
プロセスグループ(EJBコンテナ)に指定する場合:
統合運用管理ツールのtpsystem.applicationGroups.<アプリケーショングループ名>.processGroups.<プロセスグループ名>の「Javaシステムプロパティ」で行の追加を実行し、1列に「jp.co.nec.orb.RequestTimeout」、2列に秒数を指定
2. Javaクライアントでの無通信監視タイムアウト時間
Javaコマンドラインで指定する場合
以下の形式でシステムプロパティを指定
-Djp.co.nec.orb.ClientAutoTimeout=<タイムアウト時間(秒)>
J2EEサーバ(Webコンテナ、JNDIサーバ)に指定する場合
統合運用管理ツールのserver.java-configの「JVMオプション」に以下の形式でシステムプロパティを追加
-Djp.co.nec.orb.ClientAutoTimeout=<タイムアウト時間(秒)>
プロセスグループ(EJBコンテナ)に指定する場合
統合運用管理ツールのtpsystem.applicationGroups.<アプリケーショングループ名>.processGroups.<プロセスグループ名>の「Javaシステムプロパティ」で行の追加を実行し、1列に「jp.co.nec.orb.ClientAutoTimeout」、2列に秒数を指定
3. オペレーション呼び出しのタイムアウト時間
統合運用管理ツールで指定する場合
server.objectbrokerconfigの「共通」タブの「リクエスト呼び出しのタイムアウト時間」に秒数を指定
コマンドで指定する場合
otxadmin> set server.objectbrokerconfig.RequestTimeout=<設定値>
【注意】
Javaクライアントの場合、上記の「Javaクライアントからのオペレーション呼び出しタイムアウト時間」が設定されていれば、そちらが本設定よりも優先されます
4. コネクションラウンドロビンでのオペレーション呼び出しのタイムアウト時間
統合運用管理ツールで指定する場合
server.objectbrokerconfig.の「Cpp」タブの「多重化使用時の最大待ち時間」に秒数を指定
コマンドで指定する場合
otxadmin> set server.objectbrokerconfig.ConnectionRoundRobinTimeout=<設定値>
サーバ側で設定する場合(AP応答監視タイマ)
オペレーション実行要求をサーバが受け付けてからその応答を返すまでのタイムアウト値を設定します(既定値:上限なし)。このタイムアウト値を設定することで、クライアントが無応答となることを抑止します。このタイムアウト値はサーバでの実行時間のほかに通信に要する時間およびキュー待ち時間を考慮して設定します。各オペレーションの実行時間(予測値)の最大値よりは大きな値を設定する必要があります。設定を反映させるためにはアプリケーショングループの再起動が必要です。
なお、AP応答監視タイマを超過した場合、クライアントにエラーは返りますがサーバAPは処理を継続したままなのでサーバAPの無応答状態が改善するわけではありません。サーバAPの無応答状態を改善させるためには[2.5.4 実行時間タイムアウト]を設定してください。
統合運用管理ツールのプロセスグループの[上限設定]-[AP応答監視タイマ]
| 2.5.4. 実行時間タイムアウト |
サーバ側でオペレーション実行を行なってから実行完了までのタイムアウト値を設定します(既定値:上限なし)。この値はサーバでの実行時間のみ考慮して設定します(キュー待ち時間は含みません)。
実行時間上限設定を適切に行うために、運用アシスタントの実行時間上限の適正値算出機能を利用してください。詳細は「運用編(TPモニタの運用操作) 2.40.4 実行時間上限の適正値算出」を参照してください。
なお、実行時間タイムアウト値を超過した場合、APは終了します。APを再起動させるためには再起動回数(統合運用管理ツールのTPシステムの[上限設定]-[プロセス障害時の再起動回数])を2以上にする必要があります。推奨はデフォルトの5です。プロセス障害時の再起動回数が1でAPが終了した場合、プロセスは終了したままで再起動しませんので注意してください。
統合運用管理ツールのオペレーションの[オペレーションの自動活性]-[実行時間上限]
| 2.5.5. クライアント無通信監視間隔 |
サーバとクライアントの間の無通信状態を監視します(既定値:上限なし)。本タイマ値以上無通信状態(具体的には要求も応答も流れない状態)が続いた場合はコネクションを切断します。設定を反映させるためにはTPシステムの再起動が必要です。
統合運用管理ツールの[IIOPListener]-[クライアント制御]-[クライアント無通信監視を行う]及び[クライアント無通信監視間隔]
| 2.5.6. キューイング数上限 |
サーバアプリケーションすべてのスレッドがクライアントからのリクエスト処理を行なっている場合、新たな要求はキューイングされ実行待ちとなります。既定値ではメモリの許す限りキューイングされてしまい、クライアントから見るとキュー数が増えれば増えるほど無応答時間が長くなります。ある程度以上のキューイングを抑制することによりクライアントのレスポンスを保証することが出来ます。
(平均待ち時間)=(平均サービス時間)*{(キュー数)+1}
統合運用管理ツールでTPシステム毎、アプリケーショングループ毎、プロセスグループ毎(後者ほど設定優先度高)に設定できます。
TPシステムの[上限設定]-[キューの最大数]
アプリケーショングループの[キューの最大数]-[キューの最大数]
プロセスグループの[キューの最大数]-[キューの最大数]及び[アプリケーショングループと同様の最大数とする]
| 2.5.7. 接続クライアント数上限 |
richクライアントの場合、想定以上の接続を受けるとサーバ側資源(主にメモリとファイルディスクリプタ)を余分に使います。接続数に上限を設けることにより設定以上のクライアントから要求を受け付けなくすることが出来ます。ただし接続クライアント数をぎりぎりに設定してしまうとゴーストセッションが残っている場合、接続できなくなる可能性がありますので、ゴーストセッションの対策をとった上である程度の余裕を持たせてください。ゴーストセッションの対策については運用編「トラブルシューティング(障害解析) クライアント接続数オーバへの対応」を参照してください。
統合運用管理ツールの[TPシステム]-[IIOPリスナ]-[上限設定]-[利用可能な同時接続クライアント数]
| 2.5.8. 1セッションあたりの同時実行数 |
thinクライアント構成の場合、Webサーバから1つのセッションを通して多重にリクエスト要求が発行されます。クライアント数やトランザクション処理件数に応じた1セッションあたりの同時実行数を設ける必要があります。
統合運用管理ツールの[TPシステム]-[IIOPリスナ]-[クライアント制御]-[1プロセス当たりの多重度]
| 2.5.9. 電文長の長いメッセージの送受信 |
サーバ側の送受信の上限は設定の有無にかかわらず9,999,998バイト(10M)となります。
また、クライアントがVBまたはC++の場合、電文の受信最大サイズは8,388,608バイト(8M)となります。クライアント側での受信電文長を10Mまで増やしたい場合はクライアントマシンのレジストリ変更が必要です。
レジストリの名前:HKEY_LOCAL_MACHINE\SOFTWARE\NEC\ObjectSpinner\1\MaxMessageSize
属性:文字列属性(REG_SZ)
値 :0〜4294967295(単位:バイト)
意味:受信可能とする最大サイズを指定します。
補足:送信には関係ありません。
| 2.5.10. 接続要求最大保留数 |
クライアントから瞬時に大量の接続要求が来た場合、WebOTX側での接続処理が間に合わずクライアントへエラーが返ってしまうことがあります。このような場合には本パラメータの値を大きくすることにより、接続要求をサーバ側で保留することができます。
統合運用管理ツールの[TPシステム]-[IIOPリスナ]-[クライアント制御]-[接続要求最大保留数]
| 2.5.11. メモリプールサイズ |
クライアントからのCORBAリクエストはメモリプールとして事前に確保した共有メモリ上に受信されます。また、サーバからのCORBA応答もメモリプールに展開された後に送信を行います。これらの領域は、クライアントへの送信が完了した時点で解放されます。
このような管理方式にすることで、外因によらず迅速で確実なバッファ取得ができることになりますが、一方で、このサイズを適当な値に設定する必要があります。
バッファ使用区間はCORBAリクエストの受信から送信までですので、サーバ側でのオペレーションの同時実行数が上がるほどバッファが必要になります(キューイングされているものも含む)。また、リクエストや応答のメッセージサイズが大きいほどバッファが必要になります。
なお、本用途に使用されるバッファ領域はメモリプールサイズ×0.9となります。
必要なメモリプールサイズの最大値は次の通り計算できます。
(メモリプールサイズの最大値) = (メモリブロック数) * (ブロックサイズ)
(メモリブロック数) = {もっとも大きい電文のサイズ/(ブロックサイズ) + 1} *
(WebOTXで同時に処理するオペレーション数)
(ブロックサイズ) = 4704 bytes
統合運用管理ツールの[TPシステム]-[システムパラメータ/動的情報]-[メモリプールサイズ]