8. その他の設定情報¶
本章では、その他の監視設定や通報設定に関する情報について記載します。
本章で説明する項目は以下の通りです。
8.1. シャットダウン監視¶
8.1.1. シャットダウン監視とは?¶
8.1.2. シャットダウン監視を表示/変更するには¶
- [常に実行する]シャットダウン監視をします。ハートビートタイムアウト (「5. ハートビートリソースの詳細」を参照してください。) を、アプリケーションの終了時間を含めて OS がシャットダウンする時間より長い時間に設定する必要があります。
- [グループ非活性処理に失敗した場合のみ実行する]グループの非活性処理に失敗した場合のみシャットダウン監視をします。ハートビートタイムアウト (「5. ハートビートリソースの詳細」を参照してください。) を、アプリケーションの終了時間を含めて OS がシャットダウンする時間より長い時間に設定する必要があります。共有ディスク、ミラーディスク、ハイブリッドディスクを使用する場合は [グループ非活性処理に失敗した場合のみ実行する] を選択することを推奨します。
- [実行しない]シャットダウン監視をしません。
8.1.3. シャットダウン監視の方法¶
シャットダウン監視の監視方法は以下のとおりです。
- 監視方法 softdog監視方法が softdog の場合、softdog ドライバを使ってタイマを設定します。
- 監視方法 ipmi監視方法が ipmi の場合、OpenIPMI を使ってタイマを設定します。OpenIPMI がインストールされていない場合、インストールする必要があります。ipmi については「ユーザ空間モニタリソースを理解する」を参照してください。
- 監視方法 keepalive監視方法が keepalive の場合、CLUSTERPRO の clpkhb ドライバと clpka ドライバを使ってタイマを設定します。
注釈
clpkhb ドライバ、clpka ドライバが動作するディストリビューション、kernel バージョンについては必ず『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「ソフトウェア」 - 「動作可能なディストリビューションと kernel」で確認してください。ディストリビュータがリリースするセキュリティパッチを既に運用中のクラスタへ適用する場合(kernelバージョンが変わる場合) にも確認してください。
8.1.4. SIGTERM の設定¶
監視方法 softdog
シャットダウン成功時 (監視方法が softdog、SIGTERM が有効の場合)
コマンド(clpstdn、clpdown、shutdown、rebootなど)を発行します。
シャットダウン監視を開始します。
OSシャットダウンが開始されます。
シャットダウン処理の途中でOSがSIGTERMを発行すると、SIGTERMが有効になっているため、シャットダウン監視が終了します。
OSシャットダウンが成功します。
(d)~(e)の間、ストールを検出することができません。
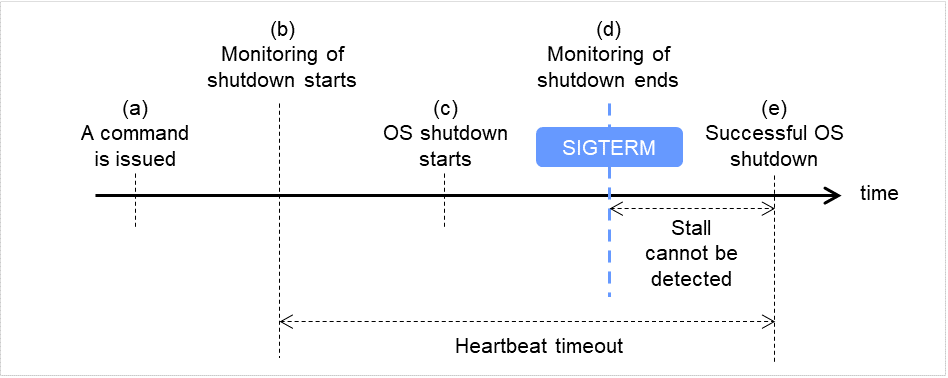
図 8.1 シャットダウン成功時(監視方法が softdog、SIGTERM が有効の場合)¶
シャットダウン成功時 (監視方法が softdog、SIGTERM が有効でない場合)
コマンド(clpstdn、clpdown、shutdown、rebootなど)を発行します。
シャットダウン監視を開始します。
OSシャットダウンが開始されます。
シャットダウン処理の途中でOSがSIGTERMを発行しても、SIGTERMが無効になっているため、シャットダウン監視はこの時点で終了しません。
- シャットダウン監視は終了し、softdogドライバがアンロードされます。OSシャットダウンが成功します。
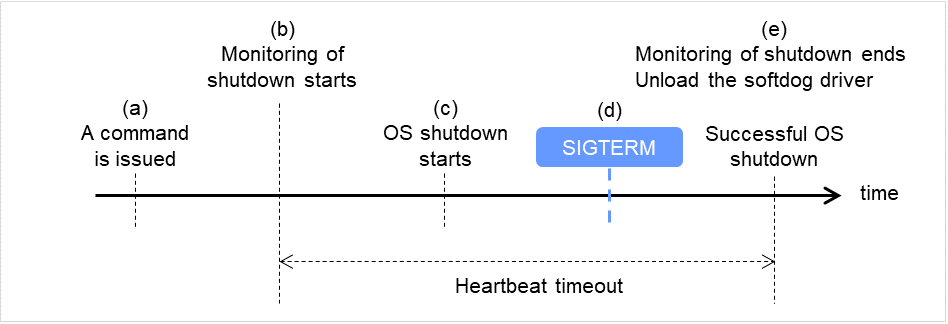
図 8.2 シャットダウン成功時(監視方法が softdog、SIGTERM が有効でない場合)¶
監視方法 ipmi
シャットダウン成功時 (監視方法が ipmi, SIGTERM が有効の場合)
コマンド(clpstdn、clpdown、shutdown、rebootなど)を発行します。
シャットダウン監視を開始します。
OSシャットダウンが開始されます。
シャットダウン処理の途中でOSがSIGTERMを発行すると、SIGTERMが有効になっているため、シャットダウン監視が終了します。
OSシャットダウンが成功します。
(d)~(e)の間、ストールを検出することができません。
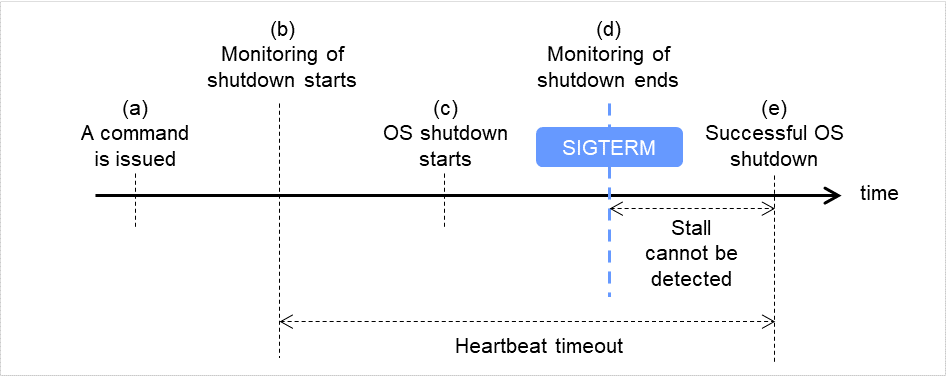
図 8.3 シャットダウン成功時(監視方法が ipmi, SIGTERM が有効の場合)¶
シャットダウン成功時 (監視方法が ipmi、SIGTERM が有効でない場合)
コマンド(clpstdn、clpdown、shutdown、rebootなど)を発行します。
シャットダウン監視を開始します。
OSシャットダウンが開始されます。
シャットダウン処理の途中でOSがSIGTERMを発行しても、SIGTERMが無効になっているため、シャットダウン監視はこの時点で終了しません。
OSシャットダウンが成功します。
リセットが発生します。
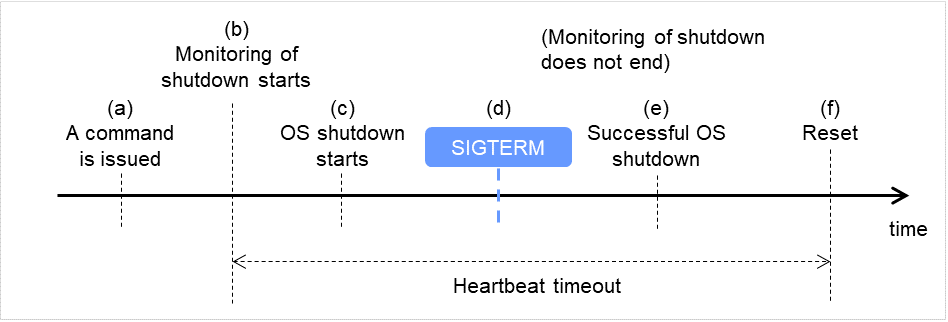
図 8.4 シャットダウン成功時 (監視方法が ipmi、SIGTERM が有効でない場合)¶
ストールが発生しないで正常にシャットダウンが完了した場合も ipmi によってリセットが発生します。
ソフトウェア電源 OFF が可能なサーバではリセットは発生しません。
監視方法が ipmi の場合、SIGTERM を有効にする設定を推奨します。
OS シャットダウンでストールが発生した場合
シャットダウンストール検出時
コマンド(clpstdn、clpdown、shutdown、rebootなど)を発行します。
シャットダウン監視を開始します。
OSシャットダウンが開始されます。
OSシャットダウン途中でストールが発生します。
リセットが発生します。
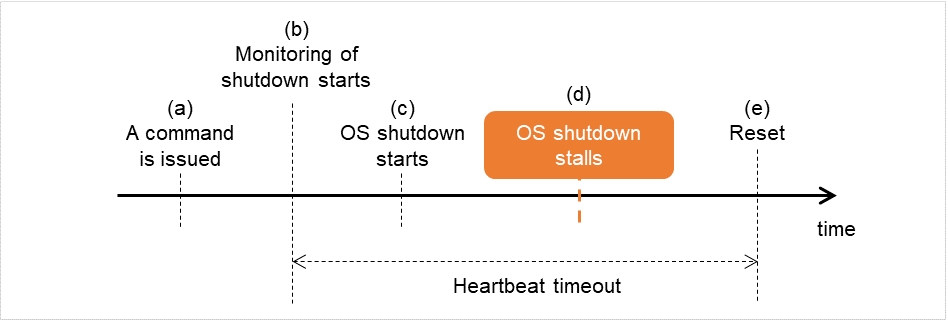
図 8.5 シャットダウンストール検出時¶
8.1.5. ハートビートタイムアウトを使用する¶
シャットダウン監視のタイムアウト値をハートビートタイムアウト値と連動させます。
8.1.6. タイムアウト¶
8.2. bonding¶
8.2.1. フローティング IP リソース¶
注意事項
bonding モードに "active-backup" を指定すると、スレーブインターフェイスの切り替えの際、一時的に通信が途絶えることがあります。
bonding 設定例
注釈
インタコネクトの IP アドレス設定には、IP アドレスのみ設定してください。
bonding 上にフローティング IP リソースを使用する設定例を示します。
Device |
Slave |
Mode |
|---|---|---|
bond0 |
eth0
eth1
|
active-backup(1)
balance-tlb(5)
|
bond0 |
eth0
eth1
|
active-backup(1)
balance-tlb(5)
|
図の Server 1、Server 2では スレーブインターフェース eth0、eth1 をbondingでまとめて、マスターインタフェース bond0を構成しています。 また、Server1、Server2へアクセスするため、FIPリソースにIPアドレスが設定されています。 クラスタサーバと同一LAN上のホスト、リモートLAN上のホスト、ともにFIPを使用してクラスタサーバと接続することができます。 ルータにおいて、FIPを使用するための特別な設定は必要ありません。
FIPリソースIPアドレス: 192.168.1.3
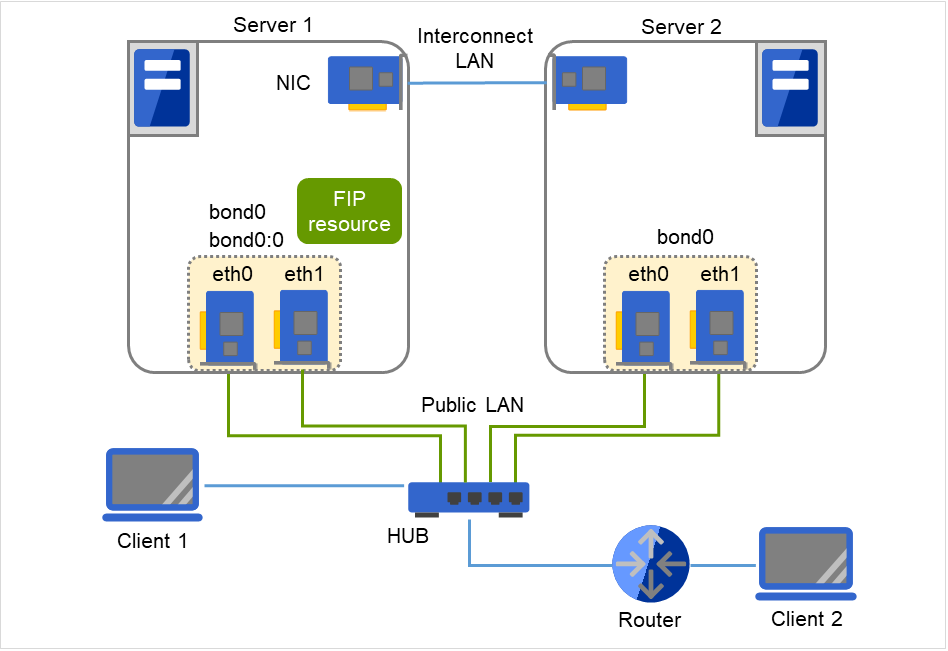
図 8.6 bonding 上でのフローティング IP リソース使用例¶
Server 1 での ifconfig によるフローティング IPリソースの活性状態は以下のようになります。(bonding mode は、"balance-tlb(5)" を指定。)
$ ifconfig
bond0 Link encap:Ethernet HWaddr 00:00:01:02:03:04
inet addr:192.168.1.1 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:6807 errors:0 dropped:0 overruns:0 frame:0
TX packets:2970 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:670032 (654.3 Kb) TX bytes:189616 (185.1 Kb)
bond0:0 Link encap:Ethernet HWaddr 00:00:01:02:03:04
inet addr:192.168.1.3 Bcast:192.168.1.255 Mask:255.255.255.0
UP BROADCAST RUNNING MASTER MULTICAST MTU:1500 Metric:1
RX packets:236 errors:0 dropped:0 overruns:0 frame:0
TX packets:2239 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:78522 (76.6 Kb) TX bytes:205590 (200.7 Kb)
eth0 Link encap:Ethernet HWaddr 00:00:01:02:03:04
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:3434 errors:0 dropped:0 overruns:0 frame:0
TX packets:1494 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:332303 (324.5 Kb) TX bytes:94113 (91.9 Kb)
Interrupt:18 Base address:0x2800 Memory:fc041000-fc041038
eth1 Link encap:Ethernet HWaddr 00:00:05:06:07:08
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:215 errors:0 dropped:0 overruns:0 frame:0
TX packets:1627 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:77162 (75.3 Kb) TX bytes:141394 (138.0 Kb)
Interrupt:19 Base address:0x2840 Memory:fc042000-fc042038
eth2 Link encap:Ethernet HWaddr 00:00:09:10:11:12
inet addr:192.168.2.1 Bcast:192.168.2.255 Mask: 255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:47 errors:0 dropped:0 overruns:0 frame:0
TX packets:1525 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:2820 (2.7 Kb) TX bytes:110113 (107.5 Kb)
Interrupt:24 Base address:0x3000 Memory:fc500000-fc500038
上記において、"bond0" のブロックは eth0、eth1 を bonding 化したデバイスの情報です。 パブリックLAN、2番目のインタコネクトに使用するデバイスです。
"bond0:0" のブロックは、"bond0" 上で活性したフローティングIPアドレスの情報を示しています。
"eth2" は、1番目のインタコネクトに使用するデバイスです。
8.2.2. ミラーディスクコネクト¶
注意事項
bonding 上でミラーディスクコネクトを使用すると、スレーブインターフェイスの切り替えの際、一時的に通信が途絶えます。ミラーリング処理のタイミングによっては、bonding の切り替えが完了したあとにミラー復帰が実行されることがあります。
bonding 設定例
bonding 上にミラーディスクコネクトを使用する設定例を示します。
Cluster Server |
Device |
Slave |
Mode |
|---|---|---|---|
Server 1 |
bond0 |
eth1
eth2
|
balance-rr(0)
active-backup(1)
balance-tlb(5)
|
Server 2 |
bond0 |
eth1
eth2
|
balance-rr(0)
active-backup(1)
balance-tlb(5)
|
8.3. アラートサービス¶
8.3.1. アラートサービスとは?¶
CLUSTERPRO アラートサービスは、CLUSTERPRO 上の業務の異常を遠隔地にいる管理者に通知する機能です。
通知方法は、以下の 3 つがあります。それぞれの通知方法によって、通知が行われる事象がことなります。
- Eメール通報Cluster WebUI のアラートメッセージが表示されるタイミングで、アラートの内容を メール通報します。
- ネットワーク警告灯通報サーバ起動時とサーバダウン時にネットワーク警告灯通報しサーバの状態を示します。サーバが正常に終了するときは、ネットワーク警告灯を消灯します。メール通報とネットワーク警告灯通報は、お互いが独立して動作します。
- SNMP トラップ送信Cluster WebUI のアラートメッセージが表示されるタイミングで、アラートの内容をSNMP トラップ送信します。
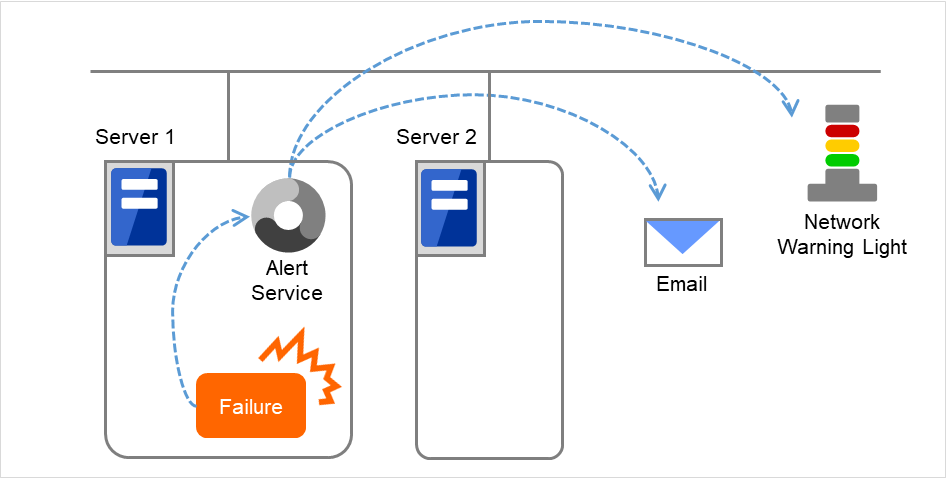
図 8.7 アラートサービス¶
Eメール通報を行うので、管理端末から離れている場合でも、障害発生をいち早く検知 することができます。
メール送信先を携帯電話にすることも可能です。
ネットワーク警告灯の点灯により、障害を視覚的に判断することができます。
ネットワーク警告灯の音声ファイルの再生により、障害を音声で判断することも可能です。
通報先に設定したサーバに障害の内容をSNMP トラップ送信することができます。
Eメール通報では下記のフォーマットでアラートの内容をメール通報します。
件名
CLUSTERPRO本文
Message: Server [ダウンしたサーバ名] has been stopped. Type: nm ID: 2 Host: [メール送信元 サーバ名] Date: [送信タイムスタンプ]
8.3.2. アラートサービスに関する注意事項¶
Eメール通報とネットワーク警告灯通報機能を使用するには CLUSTERPRO X Alert Service 5.1 for Linux が必要です。
本機能は、障害発生の第一報を通報することが目的であり、CLUSTERPRO 上の障害の調査や原因究明を行うものではありません。障害が発生した場合、その詳細な原因は、CLUSTERPRO のログや、syslog など他の手段で原因を判断する必要があります。
Linux でネットワーク警告灯機能を使用する際は、rsh パッケージのインストールが必要な場合があります。
8.3.3. メール通報の動作¶
Cluster WebUI のアラートメッセージと同じ内容をメール通報します。どのアラートメッセージがメール通報されるかは、本ガイドの「11. エラーメッセージ一覧」の「syslog、アラート、メール通報、SNMP トラップメッセージ、Message Topic」を参照してください。
メール通報したいアラートを変更することもできます。詳細は、本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「アラートサービスタブ」を参照してください。
8.3.4. ネットワーク警告灯通報の動作¶
ネットワーク警告灯は、以下の様な動作を行います。
- サーバ起動時サーバが正常に起動すると、緑を点灯します。
- サーバ終了時サーバが正常に終了すると、消灯します。
- サーバダウン時サーバがダウンしたとき、赤を点滅します。通報は、正常なサーバがほかの異常なサーバの状態を検出して送信されるため、全てのサーバがダウンした場合、最後にダウンしたサーバのネットワーク警告灯には障害を通知することができません。
一旦点灯または点滅したネットワーク警告灯は、クラスタシャットダウン時以外は消灯しませんので、消灯させたい場合は、[clplamp] コマンドを実行してください。[clplamp] コマンドについては本ガイドの「9.2. CLUSTERPRO コマンド一覧」の「ネットワーク警告灯を消灯する (clplamp コマンド)」を参照してください。
音声ファイル再生に対応したネットワーク警告灯 (当社指定品) の場合、設定により音声ファイルの再生も点灯/消灯と連動して行うことができます。
8.3.5. SNMP トラップ送信の動作¶
Cluster WebUI のアラートメッセージと同じ内容を SNMP トラップ送信します。どのアラート メッセージが SNMP トラップ送信されるかは、本ガイドの「11. エラーメッセージ一覧」の「syslog、アラート、メール通報、SNMP トラップメッセージ、Message Topic」を参照してください。
SNMP トラップ送信したいアラートを変更することもできます。詳細は、本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「アラートサービスタブ」を参照してください。
SNMP トラップの詳細については、「SNMP トラップ送信とは?」を参照してください。
8.4. SNMP 連携¶
8.4.1. SNMP 連携とは?¶
SNMP 連携は、CLUSTERPRO MIB 定義を元に CLUSTERPRO からの SNMP トラップ送信、SNMP マネージャからの SNMP による情報取得 を可能にする機能です。
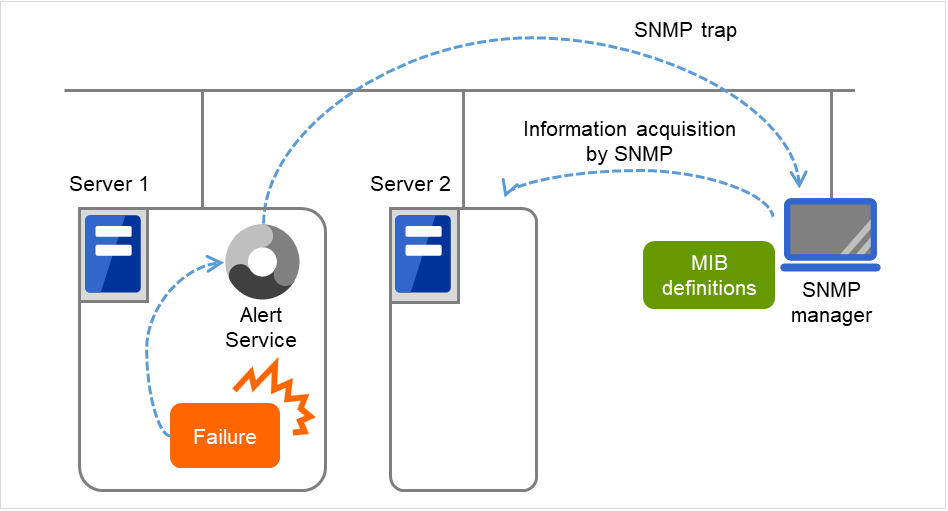
図 8.8 SNMP連携¶
8.4.2. CLUSTERPRO MIB 定義とは?¶
SNMP連携により送信取得される情報は、MIB 定義ファイルにまとめられています。
後述する SNMP トラップ送信、および SNMP による情報取得の機能を使用する場合、MIB 定義ファイルが必要になります。
SNMP マネージャでCLUSTERPRO からの SNMP トラップを受信したい、あるいは、SNMP マネージャからクラスタの状態を取得したいといったような場合、SNMP マネージャへ CLUSTERPRO MIB 定義ファイル を組み込んでください。
SNMP マネージャへMIB 定義ファイルを組み込む方法については、各SNMP マネージャのマニュアルを参照してください。
CLUSTERPRO MIB 定義ファイルはCLUSTERPRO X DVD-ROM の以下に配置しています。
<CLUSTERPRO X DVD-ROM>Common<バージョン番号>commonmib
各MIB 定義ファイルには以下のような意味があります。
No. |
MIB 定義ファイル |
説明 |
|---|---|---|
NEC-CLUSTER-SMI.mib |
CLUSTERPRO MIB ツリーのルートパスが定義されています。 |
|
NEC-CLUSTER-EVENT-MIB.mib |
CLUSTERPRO の SNMP トラップ送信機能に関連するトラップ定義や MIB が定義されています。 |
|
NEC-CLUSTER-MANAGEMENT-MIB.mib |
CLUSTERPRO の 以下の情報に関連するMIB が定義されています。
|
SNMP マネージャに組み込むファイルの組み合わせにより、利用できる機能が変わります。
CLUSTERPRO からの SNMP トラップを受信する場合
1. NEC-CLUSTER-SMI.mib2. NEC-CLUSTER-EVENT-MIB.mib
SNMP による情報取得を行う場合
1. NEC-CLUSTER-SMI.mib3. NEC-CLUSTER-MANAGEMENT-MIB.mib
8.4.3. SNMP トラップ送信とは?¶
SNMP トラップ送信は、Cluster WebUI のアラートメッセージと同じ内容を SNMP マネージャに送信する機能です。
トラップを送信するためには、別途 SNMP トラップの送信先の設定が必要です。本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「アラートサービスタブ」より「SNMP トラップ 送信先設定」を参照して設定してください。
送信されるトラップはNEC-CLUSTER-EVENT-MIB で定義されています。
NEC-CLUSTER-EVENT-MIBで定義されている各 MIB オブジェクトを以下に示します。
clusterEventNotificationsグループ
送信されるトラップを定義したグループです。ここで定義されている各 MIB オブジェクトは、以下のような意味があります。
No. |
SNMP TRAP OID |
説明 |
|---|---|---|
clusterEventInformation |
情報 レベルのアラートを表すトラップです。
clusterEvent グループの MIB オブジェクトを添付しています。
|
|
clusterEventWarning |
警告 レベルのアラートを表すトラップです。
clusterEvent グループの MIB オブジェクトを添付しています。
|
|
clusterEventError |
異常 レベルのアラートを表すトラップです。
clusterEvent グループの MIB オブジェクトを添付しています。
|
clusterEventグループ
トラップに添付される情報が定義されたグループです。ここで定義されている各 MIB オブジェクトは、以下のような意味があります。
No. |
SNMP OID |
説明 |
|---|---|---|
clusterEventMessage |
アラートメッセージを表します。 |
|
clusterEventID |
イベントID を表します。 |
|
clusterEventDateTime |
アラートの発信時刻を表します。 |
|
clusterEventServerName |
アラートの発信元サーバを表します。 |
|
clusterEventModuleName |
アラートの発信元モジュールを表します。 |
8.4.4. SNMP による情報取得とは?¶
SNMPプロトコルを利用して CLUSTERPRO の構成情報、ステータス情報の一部を取得することが可能です。ただし、CLUSTERPRO 自身は SNMP エージェントの機能を同梱していません。別途、SNMP エージェントとして Net-SNMP snmpd デーモン が必要になります。
SNMP エージェントとは?
SNMPマネージャ(ネットワーク管理ソフト) からの情報取得要求(GetRequest, GetNextRequest) に対して、各種構成情報、ステータス情報を応答(GetResponse) を返す機能です。
注釈
SNMP による情報取得機能を使用する場合、必ず『インストール&設定ガイド』の「SNMP 連携機能を設定するには」を実行してください。
8.4.5. SNMP 連携で取得できるMIB について¶
SNMP 連携機能で取得できる MIB は、NEC-CLUSTER-MANAGEMENT-MIB で定義されています。
NEC-CLUSTER-MANAGEMENT-MIB で定義されている各 MIB オブジェクトを以下に示します。
clusterGeneral グループ
クラスタ関連の情報が取得できるグループです。ここで定義されている各 MIB オブジェクトは、以下のような意味があります。
No. |
SNMP OID |
説明 |
|---|---|---|
clusterName |
クラスタ名を表します。 |
|
clusterComment |
クラスタのコメントを表します。 |
|
clusterStatus |
現在のクラスタのステータスを表します。 MIB の取得値と Cluster WebUI のステータスの対応は以下になります。 MIB の値 ステータス
---------------------
normal [正常]
caution [警告]
error [異常]
unknown -
|
clusterServerグループ
サーバ関連の情報が取得できるグループです。clusterServerTable 取得時のインデックスはサーバ優先度順に並びます。ここで定義されている各 MIB オブジェクトは、以下のような意味があります。
No. |
SNMP OID |
説明 |
|---|---|---|
clusterServerLocalServerIndex |
現在のSNMP 情報取得要求を受けたサーバのインデックス(clusterServerIndex) を表します。 |
|
clusterServerTable |
サーバの情報テーブルを表します。 |
|
clusterServerEntry |
サーバ情報のリストを表します。 このリストのインデックスは clusterServerIndex です。 |
|
clusterServerIndex |
各サーバを一意に識別するインデックスを表します。 |
|
clusterServerName |
サーバ名を表します。 |
|
clusterServerComment |
サーバのコメントを表します。 |
|
clusterServerStatus |
現在のサーバのステータスを表します。 MIB の取得値と Cluster WebUI のステータスの対応は以下になります。 MIB の値 ステータス
---------------------
online [起動済]
offline [停止済]
unknown [不明]
|
|
clusterServerPriority |
サーバの優先順位を表します。 |
|
clusterServerProductName |
サーバにインストールされた CLUSTERPRO の製品名を表します。 |
|
clusterServerProductVersion |
サーバにインストールされた CLUSTERPRO の製品バージョンを表します。 |
|
clusterServerProductInstallPath |
サーバにインストールされた CLUSTERPRO のインストールパスを表します。 |
|
clusterServerPlatformName |
サーバのプラットフォーム名を表します。 |
clusterGroupグループ
グループ関連の情報が取得できるグループです。ここで定義されている各 MIB オブジェクトは、以下のような意味があります。
No. |
SNMP OID |
説明 |
|---|---|---|
clusterGroupTable |
グループの情報テーブルを表します。 |
|
clusterGroupEntry |
サーバ情報のリストを表します。 このリストのインデックスは clusterGroupIndexです。 |
|
clusterGroupIndex |
各グループを一意に識別するインデックスを表します。 |
|
clusterGroupName |
グループ名を表します。 |
|
clusterGroupComment |
グループのコメントを表します。 |
|
clusterGroupType |
グループの種別を表します。 MIB の取得値と グループの種別の対応は以下になります。 MIB の値 グループの種別
---------------------------------------
failover フェイルオーバグループ
cluster 管理グループ
|
|
clusterGroupStatus |
現在のグループのステータスを表します。MIB の取得値と Cluster WebUI のステータスの対応は以下になります。 MIB の値 ステータス
---------------------------
online [起動済]
onlineFailure [起動失敗]
offlineFailure [停止失敗]
offline [停止済]
unknown [不明]
onlinePending [起動中]
offlinePending [停止中]
|
|
clusterGroupCurrentServerIndex |
現在グループが活性化しているサーバのインデックス(clusterServerIndex) を表します。グループが非活性の場合、返却値は -1 になります。 |
8.5. 非正規停止後のクラスタサービスの自動起動禁止¶
8.5.1. クラスタサービスの自動起動禁止とは?¶
Cluster WebUI によるクラスタシャットダウン/クラスタリブート/クラスタ停止、clpstdnコマンド、clpcl -t -aコマンド以外の方法でCLUSTERPROサービスが停止した場合、次回OS起動時にはCLUSTERPROサービスの自動起動を禁止する機能です。
自動起動を禁止した場合、OSのシャットダウンコマンドや、Cluster WebUI によるサーバシャットダウン/サーバリブート/サーバ停止、clpdownコマンド、clpcl -tコマンドなどでCLUSTERPROサービスを停止した場合には次回サーバ起動時にはCLUSTERPROサービスは自動起動しません。
クラスタシャットダウンやクラスタ停止を実行した場合でも、CLUSTERPRO サービスの停止処理で異常が発生した場合や、OSリセットや電源断等により停止処理が実行されなかった場合にも、次回のOS起動時にはCLUSTERPROサービスは自動起動しません。
8.5.2. 自動起動禁止を表示/変更するには¶
- [ダウン後自動起動する]自動起動を禁止しません。
- [ダウン後自動起動しない]クラスタシャットダウンやクラスタ停止以外の方法でサーバを停止した場合やクラスタシャットダウンやクラスタ停止が正常に終了しなかった場合に、次回OS起動時にクラスタサービスの自動起動を禁止します。
8.5.3. 自動起動禁止の条件¶
自動起動を禁止する条件は以下のとおりです。
クラスタシャットダウンやクラスタ停止以外の方法でクラスタを停止した場合
OSのリセット、パニック、電源断等でクラスタサービスの停止処理が実行されなかった場合
クラスタシャットダウンやクラスタ停止処理のクラスタサービスの停止処理でグループの非活性処理に失敗した場合
クラスタを構成する一部のサーバを単体でクラスタ停止した場合:
8.5.4. 自動起動禁止に関する注意事項¶
OS起動時にCLUSTERPROサービスが自動起動しない場合は、Cluster WebUI やclpclコマンドを使用してCLUSTERPROサービスを起動する必要があります。
OS起動時にCLUSTERPROサービスが自動起動しなかった場合には、Cluster WebUI 上のアラートメッセージ、syslogメッセージが出力されます。
8.6. サーバグループ間自動フェイルオーバ時の猶予時間待ち合わせ¶
8.6.1. 猶予時間待ち合わせとは?¶
サーバグループ間の自動フェイルオーバ時に、指定した時間だけフェイルオーバの開始を待ち合わせます。サーバダウンを検出してから、猶予時間経過後にフェイルオーバが実行されます。
8.6.2. 猶予時間待ち合わせ条件¶
下記の設定のグループのフェイルオーバを待ち合わせます。
[情報] タブ - [サーバグループ設定を使用する] がオン
[起動サーバ] タブ - [起動可能なサーバグループ] に複数のサーバグループが指定されている
[属性] タブ - [フェイルオーバ属性] - [自動フェイルオーバ] - [サーバグループ内のフェイルオーバポリシを優先する] がオンかつ [サーバグループ間では手動フェイルオーバのみを有効とする] がオフ
下記の場合には、猶予時間の待ち合わせは行いません。
同一サーバグループ内のサーバへフェイルオーバする場合
サーバダウン検出がサーバダウン通知による場合
強制停止のタイプが [使用しない] 以外に設定され、強制停止の実行に成功した場合、および強制停止を実行しない条件に当てはまる場合
NP 解決リソースが設定されている場合
8.6.4. 猶予時間待ちの注意事項¶
猶予時間待ち合わせ中に、フェイルオーバ対象のグループを操作した場合には猶予時間待ちはキャンセルされフェイルオーバは実行されません。
猶予時間待ち合わせ中に、ダウンしたサーバの生存が確認できた場合には猶予時間待ちはキャンセルされフェイルオーバは実行されません。
猶予時間待ち中に、フェイルオーバ先サーバがダウンした場合、フェイルオーバ開始が猶予時間待ちよりも長くなる場合があります。
8.7. Witness サーバサービス¶
8.7.1. Witness サーバサービスとは?¶
クラスタ内の各サーバからWitness ハートビートを受信し、各サーバからのハートビート受信状況を応答として送信するサービスです。クラスタ外のサーバにインストールして使用します。
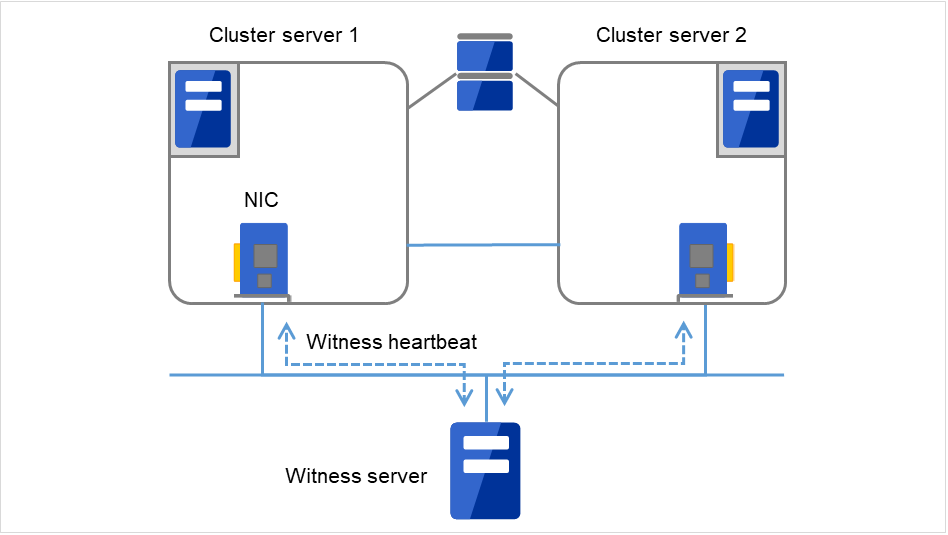
図 8.9 Witness サーバサービス¶
8.7.2. Witness サーバサービスに関する注意事項¶
Witness サーバサービスは Node.js 環境で動作します。そのため、Witness サーバサービスのインストール前に Node.js をインストールする必要があります。
『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「Witness サーバの動作環境」を参照してください。
8.7.3. Witness サーバサービスのインストール方法¶
Node.js 環境の npm コマンドを使用してインストールします。Witness サーバサービスモジュールを任意のフォルダに格納し、以下のコマンドを実行してください。
> npm install --global clpwitnessd-<version>.tgz
Witness サーバサービスモジュールは、インストール DVD-ROM の以下のパスから取得してください。
Common/<バージョン>/common/tools/witnessd/clpwitnessd-<バージョン>.tgz
8.7.4. Witness サーバサービスの設定方法¶
Witness サーバサービスの設定を変更する場合、設定ファイルを直接編集します。以下のコマンド実行結果の1行目に表示されるフォルダを開きます。
> npm list --global clpwitnessd
(実行結果例)
C:\Users\Administrator\AppData\Roaming\npm `-- clpwitnessd@4.1.0
開いたフォルダ配下の node_modules\clpwitnessd に格納されている clpwitnessd.conf.js をメモ帳などのテキストエディタで編集してください。
設定項目は以下の通りです。
項目 |
既定値 |
説明 |
|---|---|---|
http.enable |
True |
HTTPサーバを実行するかどうかを指定します。
true: 実行する
false: 実行しない
|
http.port |
80 |
HTTPサーバの待ち受けポート番号を指定します。 |
http.keepalive |
10000 |
HTTPサーバのキープアライブ時間を指定します。
[ミリ秒]
|
https.enable |
False |
HTTPSサーバを実行するかどうかを指定します。
true: 実行する
false: 実行しない
|
https.port |
443 |
HTTPSサーバの待ち受けポート番号を指定します。 |
https.keepalive |
10000 |
HTTPSサーバのキープアライブ時間を指定します。
[ミリ秒]
|
https.ssl.key |
server_key.pem |
HTTPSサーバで使用する秘密鍵ファイルを指定します。 |
https.ssl.crt |
server_crt.pem |
HTTPSサーバで使用する証明書ファイルを指定します。 |
log.directory |
- |
ログ出力先フォルダを指定します。 |
log.level |
info |
ログ出力レベルを指定します。
error: エラーログのみ出力
warn: error + 警告ログを出力
info: warn + 情報ログを出力
debug: info + 詳細ログを出力
|
log.size |
1024 * 1024 * 512 |
ログのローテートサイズを指定します。
[バイト]
|
data.available |
10000 |
クラスタサーバの通信状況データの既定の有効期限を指定します。
[ミリ秒]
|
8.7.5. Witness サーバサービスの実行方法¶
以下のコマンドを実行するとフォアグラウンドで Witness サーバサービスが起動します。WindowsサービスやLinuxデーモンとして実行する方法は次項「Witness サーバサービスの OS サービス化」を参照してください。
> clpwitnessd
8.7.6. Witness サーバサービスの OS サービス化¶
Witness サーバサービスがOS起動時に開始したい場合、OSサービスとして登録する必要があります。
Witness サーバサービスのOSサービスへの登録方法 (Windows サービスコントロールマネージャ、Linux systemd の場合) を例示します。なお、OSサービスへの登録方法は環境によって異なるため、以下の情報を参考にご利用の環境に合わせて設定してください。
Windows サービスコントロールマネージャへの登録
npm パッケージ winser を使用して登録する手順を例示します。
npm コマンドで winser をインストールします。以下のコマンドを実行すると、winser パッケージが npm リポジトリからダウンロード後にインストールされます。
> npm install --global winser
任意の場所にサービス実行用のフォルダを作成します。既定の設定では、このフォルダがログファイルやSSL秘密鍵ファイル、SSL証明書ファイルの格納場所になります。
サービス実行用フォルダの直下にwinser でのサービス登録用の package.json ファイルを作成します。パスの区切り文字には \ を二つ入力してください。また、文字数の都合で改行されていますが、"start" に指定したパスは実際には1行です。
{ "name": "clpwitnessd-service", "version": "1.0.0", "license": "UNLICENSED", "private": true, "scripts": { "start": "C:\\Users\\Administrator\\AppData\\Roaming\\npm\\clpwitnessd.cmd" } }
winser コマンドを実行してサービスを登録、開始します。
> winser -i -a
「コントロールパネル」-「管理ツール」-「サービス」からpackage.jsonの"name"に指定した名前のサービス (ex. clpwitnessd-service) が登録されていることを確認します。
Linux systemd への登録
systemd の Unit ファイルを作成して登録する手順を例示します。
- 任意の場所にサービス実行用のディレクトリを作成します。既定の設定では、このフォルダがログファイルやSSL秘密鍵ファイル、SSL証明書ファイルの格納場所になります。(ex. /opt/clpwitnessd)
- /etc/systemd/system に Witness サーバサービスの Unit ファイルを作成します。(ex. clpwitnessd.service)
[Unit] Description=CLUSTERPRO Witness Server After=syslog.target network.target [Service] Type=simple ExecStart=/usr/bin/clpwitnessd WorkingDirectory=/opt/clpwitnessd KillMode=process Restart=always [Install] WantedBy=multi-user.target
systemctl コマンドを実行してサービスを登録、開始します。
# systemctl enable clpwitnessd # systemctl start clpwitnessd