1. Preface¶
1.1. Who Should Use This Guide¶
EXPRESSCLUSTER X Getting Started Guide is intended for first-time users of the EXPRESSCLUSTER. The guide covers topics such as product overview of the EXPRESSCLUSTER, how the cluster system is installed, and the summary of other available guides. In addition, latest system requirements and restrictions are described.
1.2. How This Guide is Organized¶
2. What is a cluster system?: Helps you to understand the overview of the cluster system and EXPRESSCLUSTER.
3. Using EXPRESSCLUSTER: Provides instructions on how to use a cluster system and other related-information.
4. Installation requirements for EXPRESSCLUSTER: Provides the latest information that needs to be verified before starting to use EXPRESSCLUSTER.
5. Latest version information: Provides information on latest version of the EXPRESSCLUSTER.
6. Notes and Restrictions: Provides information on known problems and restrictions.
7. Upgrading EXPRESSCLUSTER: Provides instructions on how to update the EXPRESSCLUSTER.
1.3. EXPRESSCLUSTER X Documentation Set¶
The EXPRESSCLUSTER X manuals consist of the following five guides. The title and purpose of each guide is described below:
EXPRESSCLUSTER X Getting Started Guide
This guide is intended for all users. The guide covers topics such as product overview, system requirements, and known problems.
EXPRESSCLUSTER X Installation and Configuration Guide
This guide is intended for system engineers and administrators who want to build, operate, and maintain a cluster system. Instructions for designing, installing, and configuring a cluster system with EXPRESSCLUSTER are covered in this guide.
EXPRESSCLUSTER X Reference Guide
This guide is intended for system administrators. The guide covers topics such as how to operate EXPRESSCLUSTER, function of each module and troubleshooting. The guide is supplement to the Installation and Configuration Guide.
EXPRESSCLUSTER X Maintenance Guide
This guide is intended for administrators and for system administrators who want to build, operate, and maintain EXPRESSCLUSTER-based cluster systems. The guide describes maintenance-related topics for EXPRESSCLUSTER.
EXPRESSCLUSTER X Hardware Feature Guide
This guide is intended for administrators and for system engineers who want to build EXPRESSCLUSTER-based cluster systems. The guide describes features to work with specific hardware, serving as a supplement to the Installation and Configuration Guide.
1.4. Conventions¶
In this guide, Note, Important, See also are used as follows:
Note
Used when the information given is important, but not related to the data loss and damage to the system and machine.
Important
Used when the information given is necessary to avoid the data loss and damage to the system and machine.
See also
Used to describe the location of the information given at the reference destination.
The following conventions are used in this guide.
Convention |
Usage |
Example |
|---|---|---|
Bold
|
Indicates graphical objects, such as fields, list boxes, menu selections, buttons, labels, icons, etc.
|
In User Name, type your name.
On the File menu, click Open Database.
|
Angled bracket within the command line |
Indicates that the value specified inside of the angled bracket can be omitted. |
clpstat -s[-h host_name] |
# |
Prompt to indicate that a Linux user has logged on as root user. |
# clpcl -s -a |
Monospace |
Indicates path names, commands, system output (message, prompt, etc.), directory, file names, functions and parameters. |
|
bold
|
Indicates the value that a user actually enters from a command line.
|
Enter the following:
# clpcl -s -a
|
italic |
Indicates that users should replace italicized part with values that they are actually working with. |
|
 In the figures of this guide, this icon represents EXPRESSCLUSTER.
In the figures of this guide, this icon represents EXPRESSCLUSTER.
1.5. Contacting NEC¶
For the latest product information, visit our website below:
2. What is a cluster system?¶
This chapter describes overview of the cluster system.
This chapter covers:
2.1. Overview of the cluster system¶
A key to success in today's computerized world is to provide services without them stopping. A single machine down due to a failure or overload can stop entire services you provide with customers. This will not only result in enormous damage but also in loss of credibility you once enjoyed.
A cluster system is a solution to tackle such a disaster. Introducing a cluster system allows you to minimize the period during which operation of your system stops (down time) or to avoid system-down by load distribution.
As the word "cluster" represents, a cluster system is a system aiming to increase reliability and performance by clustering a group (or groups) of multiple computers. There are various types of cluster systems, which can be classified into the following three listed below. EXPRESSCLUSTER is categorized as a high availability cluster.
High Availability (HA) Cluster
In this cluster configuration, one server operates as an active server. When the active server fails, a standby server takes over the operation. This cluster configuration aims for high-availability and allows data to be inherited as well. The high availability cluster is available in the shared disk type, data mirror type or remote cluster type.
Load Distribution Cluster
This is a cluster configuration where requests from clients are allocated to load-distribution hosts according to appropriate load distribution rules. This cluster configuration aims for high scalability. Generally, data cannot be taken over. The load distribution cluster is available in a load balance type or parallel database type.
High Performance Computing (HPC) Cluster
This is a cluster configuration where CPUs of all nodes are used to perform a single operation. This cluster configuration aims for high performance but does not provide general versatility.Grid computing, which is one of the types of high performance computing that clusters a wider range of nodes and computing clusters, is a hot topic these days.
2.2. High Availability (HA) cluster¶
To enhance the availability of a system, it is generally considered that having redundancy for components of the system and eliminating a single point of failure is important. "Single point of failure" is a weakness of having a single computer component (hardware component) in the system. If the component fails, it will cause interruption of services. The high availability (HA) cluster is a cluster system that minimizes the time during which the system is stopped and increases operational availability by establishing redundancy with multiple servers.
The HA cluster is called for in mission-critical systems where downtime is fatal. The HA cluster can be divided into two types: shared disk type and data mirror type. The explanation for each type is provided below.
2.2.1. Shared disk type¶
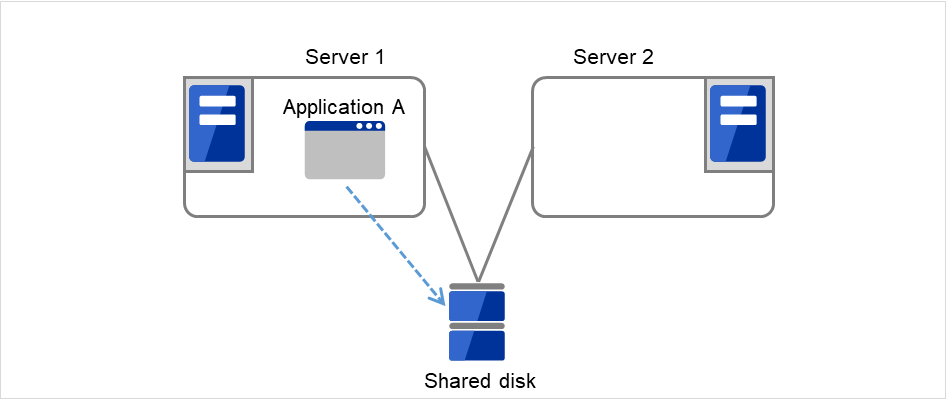
Data must be inherited from one server to another in cluster systems. A cluster topology where data is stored in a shared disk with two or more servers using the data is called shared disk type.
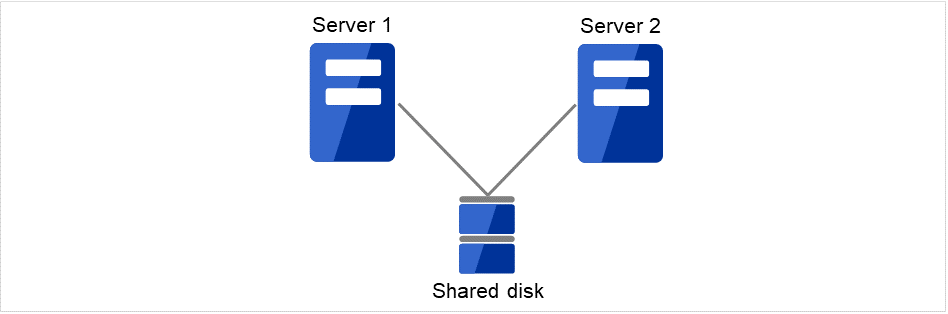
Fig. 2.1 HA cluster configuration (Shared disk type)¶
Expensive since a shared disk is necessary.
Ideal for the system that handles large data.
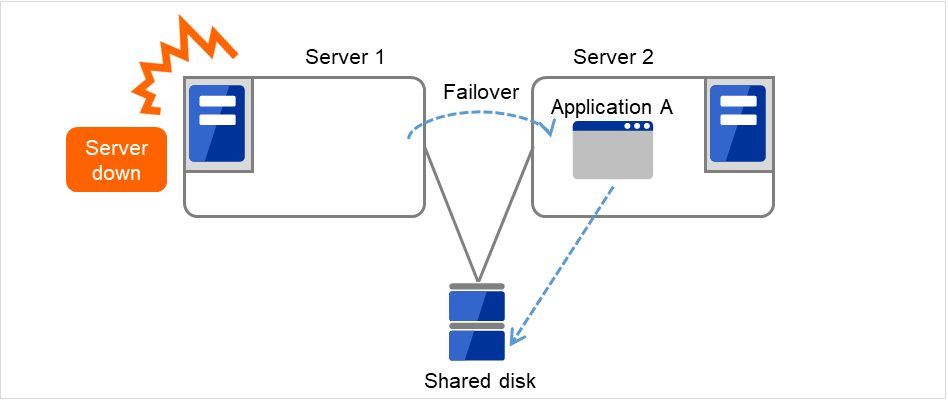
If a failure occurs on a server where applications are running (active server), the cluster system detects the failure and applications are automatically started in a standby server to take over operations. This mechanism is called failover. Operations to be inherited in the cluster system consist of resources including disk, IP address and application.
In a non-clustered system, a client needs to access a different IP address if an application is restarted on a server other than the server where the application was originally running. In contrast, many cluster systems allocate a virtual IP address on an operational basis. A server where the operation is running, be it an active or a standby server, remains transparent to a client. The operation is continued as if it has been running on the same server.
File system consistency must be checked to inherit data. A check command (for example, fsck in Linux) is generally run to check file system consistency. However, the larger the file system is, the more time spent for checking. While checking is in process, operations are stopped. For this problem, journaling file system is introduced to reduce the time required for failover.
Logic of the data to be inherited must be checked for applications. For example, roll-back or roll-forward is necessary for databases. With these actions, a client can continue operation only by re-executing the SQL statement that has not been committed yet.
A server with the failure can return to the cluster system as a standby server if it is physically separated from the system, fixed, and then succeeds to connect the system. Such returning is acceptable in production environments where continuity of operations is important.
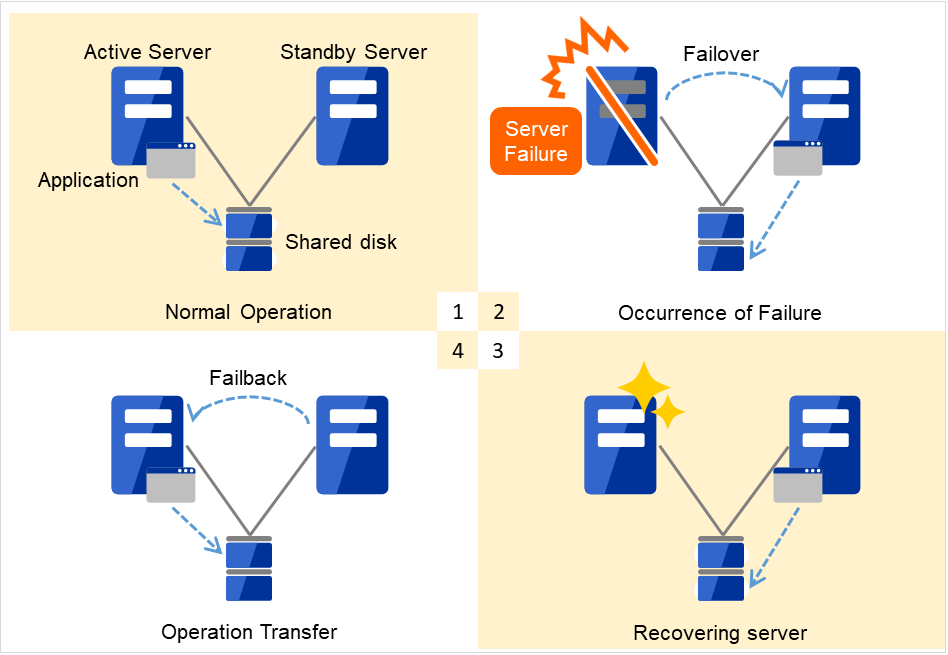
Fig. 2.2 From occurrence of a failure to recovery¶
Normal operation
Occurrence of failure
Recovering server
Operation transfer
When the specification of the failover destination server does not meet the system requirements or overload occurs due to multi-directional standby, operations on the original server are preferred. In such a case, a failback takes place to resume operations on the original server.
A standby mode where there is one operation and no operation is active on the standby server, as shown in Figure 2.3 From occurrence of a failure to recovery, is referred to as uni-directional standby.
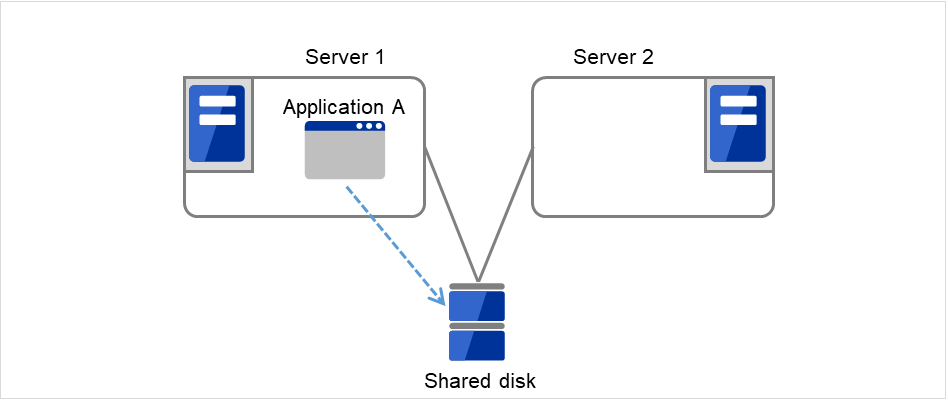
Fig. 2.3 HA cluster topology (Uni-directional standby)¶
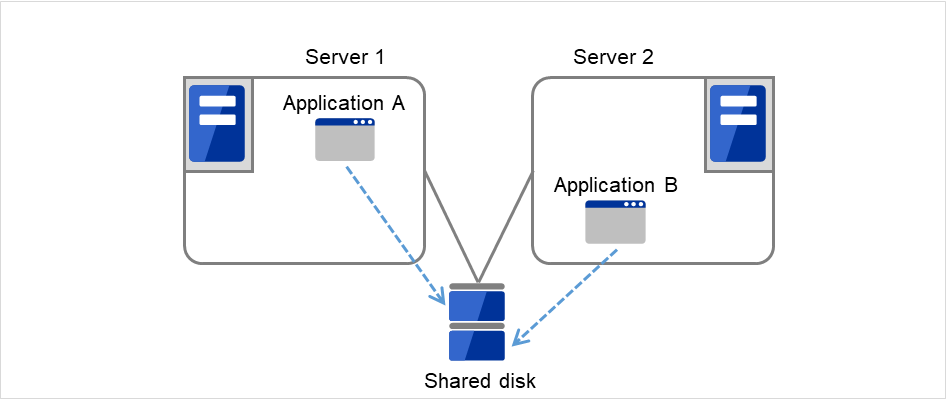
Fig. 2.4 HA cluster topology (Multi-directional standby)¶
2.2.2. Data mirror type¶
The shared disk type cluster system is good for large-scale systems. However, creating a system with this type can be costly because shared disks are generally expensive. The data mirror type cluster system provides the same functions as the shared disk type with smaller cost through mirroring of server disks.
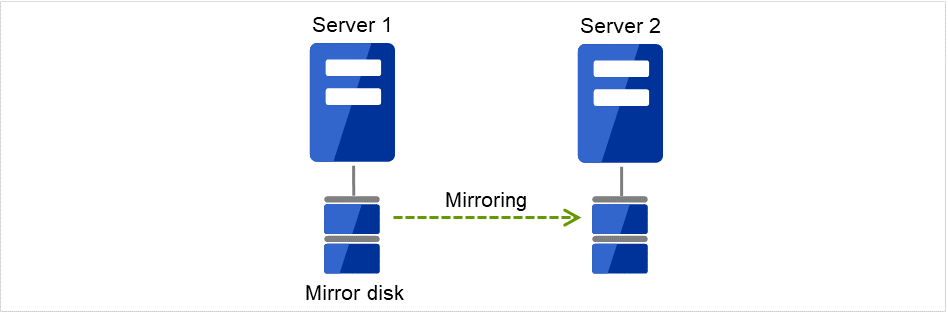
Fig. 2.5 HA cluster configuration (Data mirror type)¶
Cheap since a shared disk is unnecessary.
Ideal for the system with less data volume because of mirroring.
The data mirror type is not recommended for large-scale systems that handle a large volume of data since data needs to be mirrored between servers.
When a write request is made by an application, the data mirror engine not only writes data in the local disk but sends the write request to the standby server via the interconnect. Interconnect is a network connecting servers. It is used to monitor whether or not the server is activated in the cluster system. In addition to this purpose, interconnect is sometimes used to transfer data in the data mirror type cluster system. The data mirror engine on the standby server achieves data synchronization between standby and active servers by writing the data into the local disk of the standby server.
For read requests from an application, data is simply read from the disk on the active server.
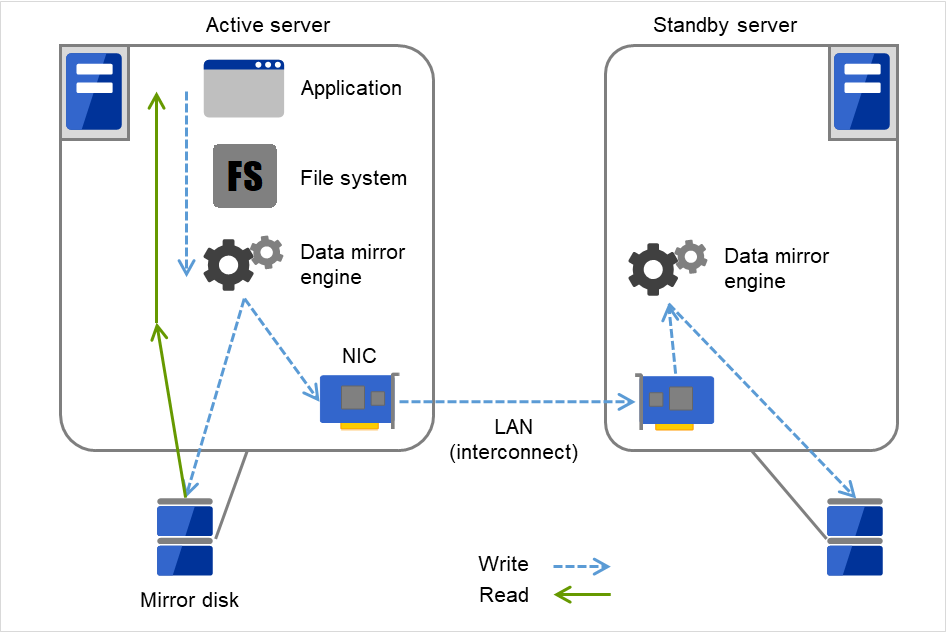
Fig. 2.6 Data mirror mechanism¶
Snapshot backup is applied usage of data mirroring. Because the data mirror type cluster system has shared data in two locations, you can keep the disk of the standby server as snapshot backup without spending time for backup by simply separating the server from the cluster.
Failover mechanism and its problems
There are various cluster systems such as failover clusters, load distribution clusters, and high performance computing (HPC) clusters. The failover cluster is one of the high availability (HA) cluster systems that aim to increase operational availability through establishing server redundancy and passing operations being executed to another server when a failure occurs.
2.3. Error detection mechanism¶
Cluster software executes failover (for example, passing operations) when a failure that can impact continued operation is detected. The following section gives you a quick view of how the cluster software detects a failure.
Heartbeat and detection of server failures
Failures that must be detected in a cluster system are failures that can cause all servers in the cluster to stop. Server failures include hardware failures such as power supply and memory failures, and OS panic. To detect such failures, heartbeat is employed to monitor whether or not the server is active.
Some cluster software programs use heartbeat not only for checking whether or not the target is active through ping response, but for sending status information on the local server. Such cluster software programs begin failover if no heartbeat response is received in heartbeat transmission, determining no response as server failure. However, grace time should be given before determining failure, since a highly loaded server can cause delay of response. Allowing grace period results in a time lag between the moment when a failure occurred and the moment when the failure is detected by the cluster software.
Detection of resource failures
Factors causing stop of operations are not limited to stop of all servers in the cluster. Failure in disks used by applications, NIC failure, and failure in applications themselves are also factors that can cause the stop of operations. These resource failures need to be detected as well to execute failover for improved availability.
Accessing a target resource is a way employed to detect resource failures if the target is a physical device. For monitoring applications, trying to service ports within the range not impacting operation is a way of detecting an error in addition to monitoring whether or not application processes are activated.
2.3.1. Problems with shared disk type¶
In a failover cluster system of the shared disk type, multiple servers physically share the disk device. Typically, a file system enjoys I/O performance greater than the physical disk I/O performance by keeping data caches in a server.
What if a file system is accessed by multiple servers simultaneously?
Because a general file system assumes no server other than the local updates data on the disk, inconsistency between caches and the data on the disk arises. Ultimately the data will be corrupted. The failover cluster system locks the disk device to prevent multiple servers from mounting a file system, simultaneously caused by a network partition.
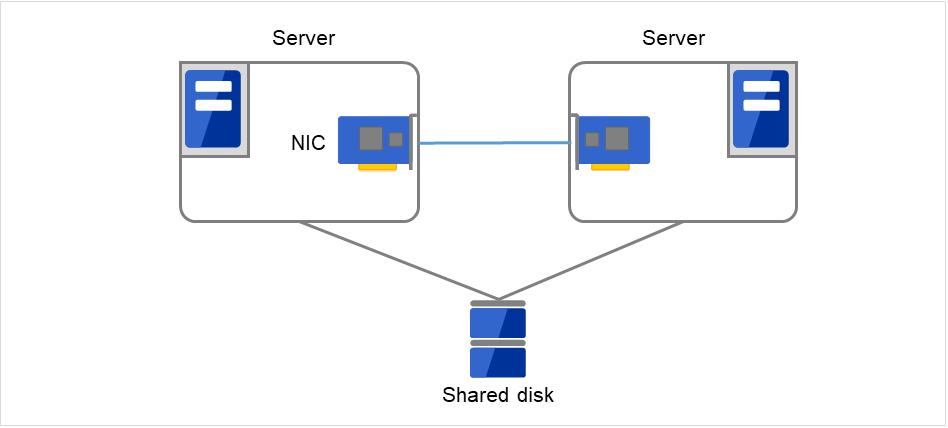
Fig. 2.7 Cluster configuration with a shared disk¶
2.3.2. Network partition (split-brain-syndrome)¶
When all interconnects between servers are disconnected, failover takes place because the servers assume other server(s) are down. To monitor whether the server is activated, a heartbeat communication is used. As a result, multiple servers mount a file system simultaneously causing data corruption. This explains the importance of appropriate failover behavior in a cluster system at the time of failure occurrence.
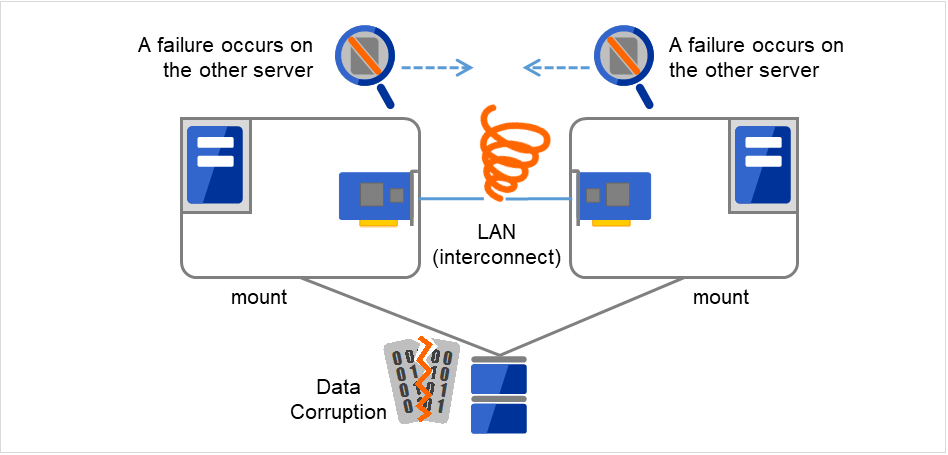
Fig. 2.8 Network partition problem¶
The problem explained in the section above is referred to as "network partition" or "split-brain syndrome." The failover cluster system is equipped with various mechanisms to ensure shared disk lock at the time when all interconnects are disconnected.
2.4. Taking over cluster resources¶
As mentioned earlier, resources to be managed by a cluster include disks, IP addresses, and applications. The functions used in the failover cluster system to inherit these resources are described below.
2.4.1. Taking over the data¶
Data to be passed from a server to another in a cluster system is stored in a partition on the shared disk. This means data is re-mounting the file system of files that the application uses on a healthy server. What the cluster software should do is simply mount the file system because the shared disk is physically connected to a server that inherits data.
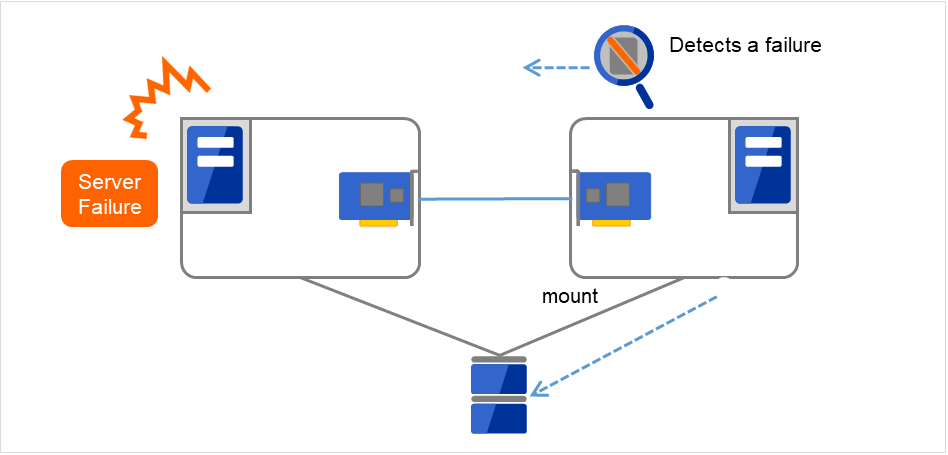
Fig. 2.9 Taking over data¶
"Figure 2.9 Taking over data" may look simple, but consider the following issues in designing and creating a cluster system.
One issue to consider is recovery time for a file system. A file system to be inherited may have been used by another server or being updated just before the failure occurred and requires a file system consistency check. When the file system is large, the time spent for checking consistency will be enormous. It may take a few hours to complete the check and the time is wholly added to the time for failover (time to take over operation), and this will reduce system availability.
Another issue you should consider is writing assurance. When an application writes important data into a file, it tries to ensure the data to be written into a disk by using a function such as synchronized writing. The data that the application assumes to have been written is expected to be inherited after failover. For example, a mail server reports the completion of mail receiving to other mail servers or clients after it has securely written mails it received in a spool. This will allow the spooled mail to be distributed again after the server is restarted. Likewise, a cluster system should ensure mails written into spool by a server to become readable by another server.
2.4.2. Taking over the applications¶
The last to come in inheritance of operation by cluster software is inheritance of applications. Unlike fault tolerant computers (FTC), no process status such as contents of memory is inherited in typical failover cluster systems. The applications running on a failed server are inherited by rerunning them on a healthy server.
For example, when instances of a database management system (DBMS) are inherited, the database is automatically recovered (roll-forward/roll-back) by startup of the instances. The time needed for this database recovery is typically a few minutes though it can be controlled by configuring the interval of DBMS checkpoint to a certain extent.
Many applications can restart operations by re-execution. Some applications, however, require going through procedures for recovery if a failure occurs. For these applications, cluster software allows to start up scripts instead of applications so that recovery process can be written. In a script, the recovery process, including cleanup of files half updated, is written as necessary according to factors for executing the script and information on the execution server.
2.4.3. Summary of failover¶
To summarize the behavior of cluster software:
Detects a failure (heartbeat/resource monitoring)
Performs fencing (resolves a network partition (NP resolution) and disconnects the failed server)
Pass data
Pass IP address
Application Taking over

Fig. 2.10 Failover time chart¶
Cluster software is required to complete each task quickly and reliably (see "Figure 2.10 Failover time chart"). Cluster software achieves high availability with due consideration on what has been described so far.
2.5. Eliminating single point of failure¶
Having a clear picture of the availability level required or aimed is important in building a high availability system. This means when you design a system, you need to study cost effectiveness of countermeasures, such as establishing a redundant configuration to continue operations and recovering operations within a short period of time, against various failures that can disturb system operations.
Single point of failure (SPOF), as described previously, is a component where failure can lead to stop of the system. In a cluster system, you can eliminate the system's SPOF by establishing server redundancy. However, components shared among servers, such as shared disk may become a SPOF. The key in designing a high availability system is to duplicate or eliminate this shared component.
A cluster system can improve availability but failover will take a few minutes for switching systems. That means time for failover is a factor that reduces availability. Solutions for the following three, which are likely to become SPOF, will be discussed hereafter although technical issues that improve availability of a single server such as ECC memory and redundant power supply are important.
Shared disk
Access path to the shared disk
LAN
2.5.1. Shared disk¶
Typically a shared disk uses a disk array for RAID. Because of this, the bare drive of the disk does not become SPOF. The problem is the RAID controller is incorporated. Shared disks commonly used in many cluster systems allow controller redundancy.
In general, access paths to the shared disk must be duplicated to benefit from redundant RAID controller. There are still things to be done to use redundant access paths in Linux (described later in this chapter). If the shared disk has configuration to access the same logical disk unit (LUN) from duplicated multiple controllers simultaneously, and each controller is connected to one server, you can achieve high availability by failover between nodes when an error occurs in one of the controllers.
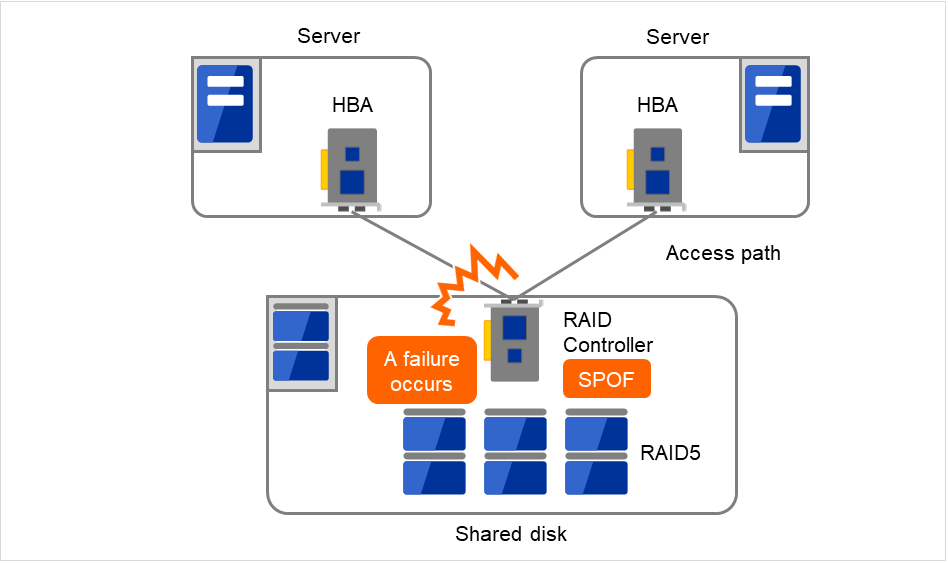
Fig. 2.11 Example of a RAID controller and access paths both being SPOF¶
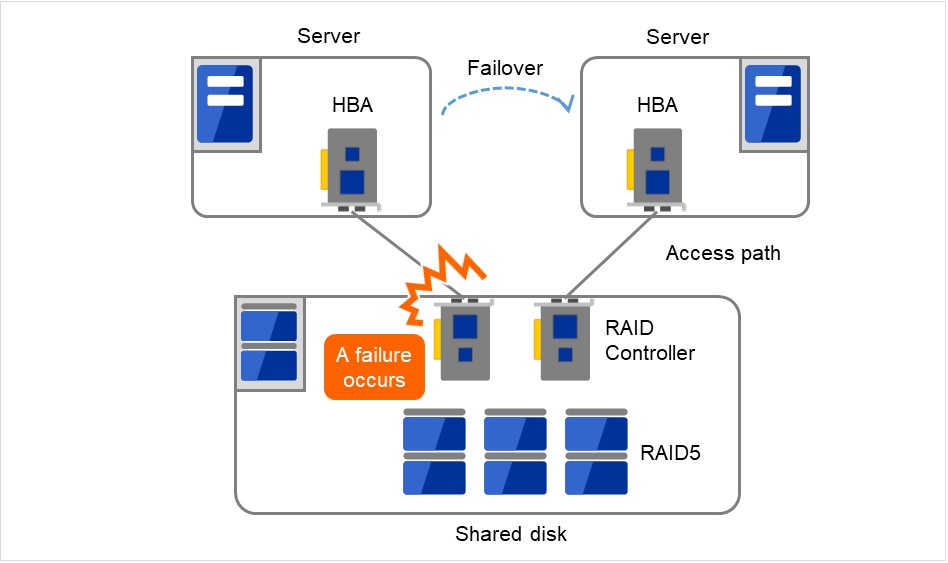
Fig. 2.12 Example of RAID controllers and access paths both being redundant¶
With a failover cluster system of data mirror type, where no shared disk is used, you can create an ideal system having no SPOF because all data is mirrored to the disk in the other server. However you should consider the following issues:
Disk I/O performance in mirroring data over the network (especially writing performance)
System performance during mirror resynchronization in recovery from server failure (mirror copy is done in the background)
Time for mirror resynchronization (clustering cannot be done until mirror resynchronization is completed)
In a system with frequent data viewing and a relatively small volume of data, choosing the data mirror type for clustering is a key to increase availability.
2.5.2. Access path to the shared disk¶
In a typical configuration of the shared disk type cluster system, the access path to the shared disk is shared among servers in the cluster. To take SCSI as an example, two servers and a shared disk are connected to a single SCSI bus. A failure in the access path to the shared disk can stop the entire system.
What you can do for this is to have a redundant configuration by providing multiple access paths to the shared disk and make them look as one path for applications. The device driver allowing such is called a path failover driver. Path failover drivers are often developed and released by shared disk vendors. Path failover drivers in Linux are still under development. For the time being, as discussed earlier, offering access paths to the shared disk by connecting a server on an array controller on the shared disk basis is the way to ensure availability in Linux cluster systems.
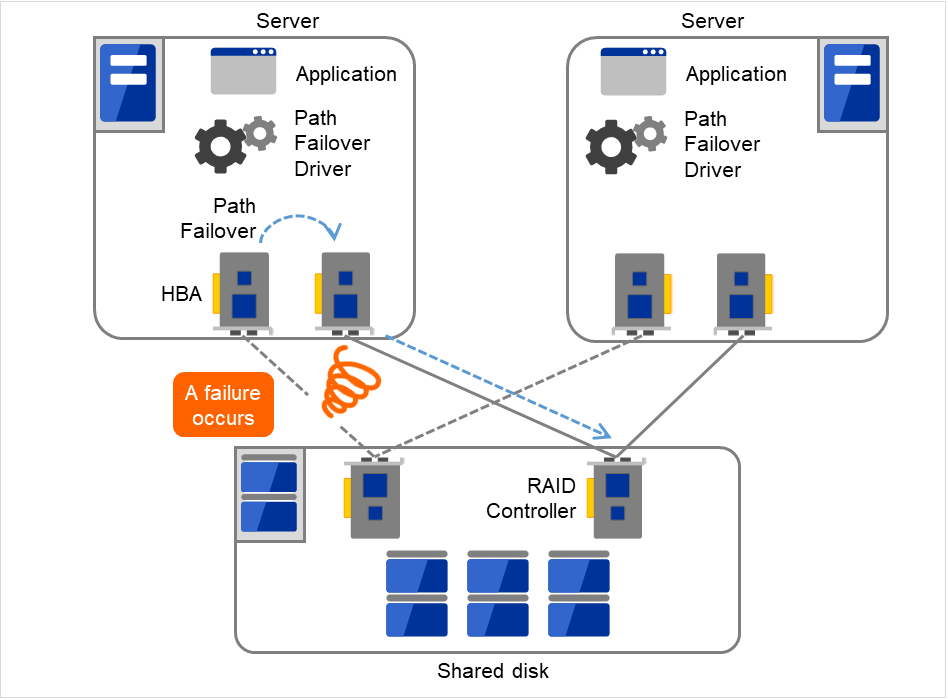
Fig. 2.13 Path failover driver¶
2.5.3. LAN¶
In any systems that run services on a network, a LAN failure is a major factor that disturbs operations of the system. If appropriate settings are made, availability of cluster system can be increased through failover between nodes at NIC failures. However, a failure in a network device that resides outside the cluster system disturbs operation of the system.
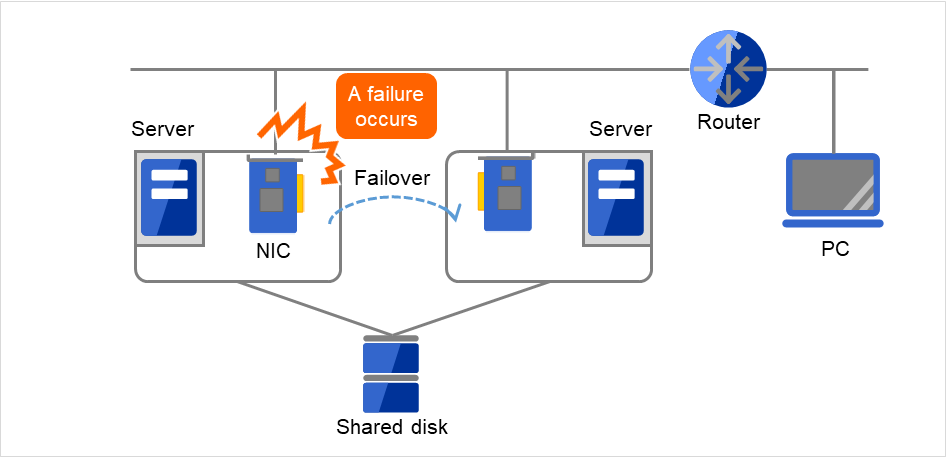
Fig. 2.14 Example of a failure with LAN (NIC)¶
In the case of this above figure, even if NIC on the server has a failure, a failover will keep the access from the PC to the service on the server.
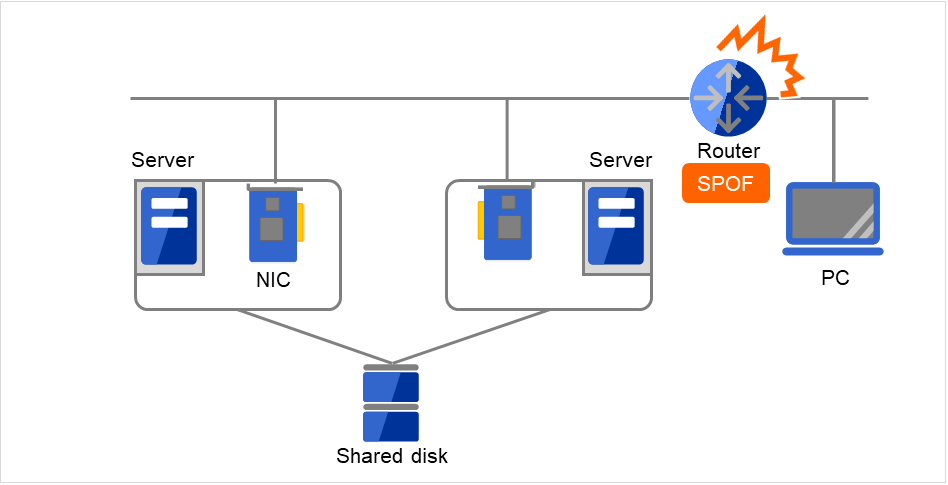
Fig. 2.15 Example of a failure with LAN (Router)¶
In the case of this above figure, if the router has a failure, the access from the PC to the service on the server cannot be maintained (Router becomes a SPOF).
LAN redundancy is a solution to tackle device failure outside the cluster system and to improve availability. You can apply ways used for a single server to increase LAN availability. For example, choose a primitive way to have a spare network device with its power off, and manually replace a failed device with this spare device. Choose to have a multiplex network path through a redundant configuration of high-performance network devices, and switch paths automatically. Another option is to use a driver that supports NIC redundant configuration such as Intel's ANS driver.
Load balancing appliances and firewall appliances are also network devices that are likely to become SPOF. Typically they allow failover configurations through standard or optional software. Having redundant configuration for these devices should be regarded as requisite since they play important roles in the entire system.
2.6. Operation for availability¶
2.6.1. Evaluation before staring operation¶
Given many of factors causing system troubles are said to be the product of incorrect settings or poor maintenance, evaluation before actual operation is important to realize a high availability system and its stabilized operation. Exercising the following for actual operation of the system is a key in improving availability:
Clarify and list failures, study actions to be taken against them, and verify effectiveness of the actions by creating dummy failures.
Conduct an evaluation according to the cluster life cycle and verify performance (such as at degenerated mode)
Arrange a guide for system operation and troubleshooting based on the evaluation mentioned above.
Having a simple design for a cluster system contributes to simplifying verification and improvement of system availability.
2.6.2. Failure monitoring¶
Despite the above efforts, failures still occur. If you use the system for long time, you cannot escape from failures: hardware suffers from aging deterioration and software produces failures and errors through memory leaks or operation beyond the originally intended capacity. Improving availability of hardware and software is important yet monitoring for failure and troubleshooting problems is more important. For example, in a cluster system, you can continue running the system by spending a few minutes for switching even if a server fails. However, if you leave the failed server as it is, the system no longer has redundancy and the cluster system becomes meaningless should the next failure occur.
If a failure occurs, the system administrator must immediately take actions such as removing a newly emerged SPOF to prevent another failure. Functions for remote maintenance and reporting failures are very important in supporting services for system administration. Linux is known for providing good remote maintenance functions. Mechanism for reporting failures are coming in place. To achieve high availability with a cluster system, you should:
Remove or have complete control on single point of failure.
Have a simple design that has tolerance and resistance for failures, and be equipped with a guide for operation and troubleshooting.
Detect a failure quickly and take appropriate action against it.
3. Using EXPRESSCLUSTER¶
This chapter explains the components of EXPRESSCLUSTER, how to design a cluster system, and how to use EXPRESSCLUSTER.
This chapter covers:
3.1. What is EXPRESSCLUSTER?¶
EXPRESSCLUSTER is software that enhances availability and expandability of systems by a redundant (clustered) system configuration. The application services running on the active server are automatically inherited to a standby server when an error occurs in the active server.
3.2. EXPRESSCLUSTER modules¶
EXPRESSCLUSTER consists of following two modules:
- EXPRESSCLUSTER ServerA core component of EXPRESSCLUSTER. This includes all high availability functions of the server. The server functions of the Cluster WebUI, are also included.
- Cluster WebUIThis is a tool to create the configuration data of EXPRESSCLUSTER and to manage EXPRESSCLUSTER operations. Uses a Web browser as a user interface. The Cluster WebUI is installed in EXPRESSCLUSTER Server, but it is distinguished from the EXPRESSCLUSTER Server because the Cluster WebUI is operated from the Web browser on the management PC.
3.3. Software configuration of EXPRESSCLUSTER¶
The software configuration of EXPRESSCLUSTER should look similar to the figure below. Install the EXPRESSCLUSTER Server (software) on a Linux server, and the Cluster WebUI on a management PC or a server. Because the main functions of Cluster WebUI are included in EXPRESSCLUSTER Server, it is not necessary to separately install them. The Cluster WebUI can be used through the web browser on the management PC or on each server in the cluster.
EXPRESSCLUSTER Server
Cluster WebUI
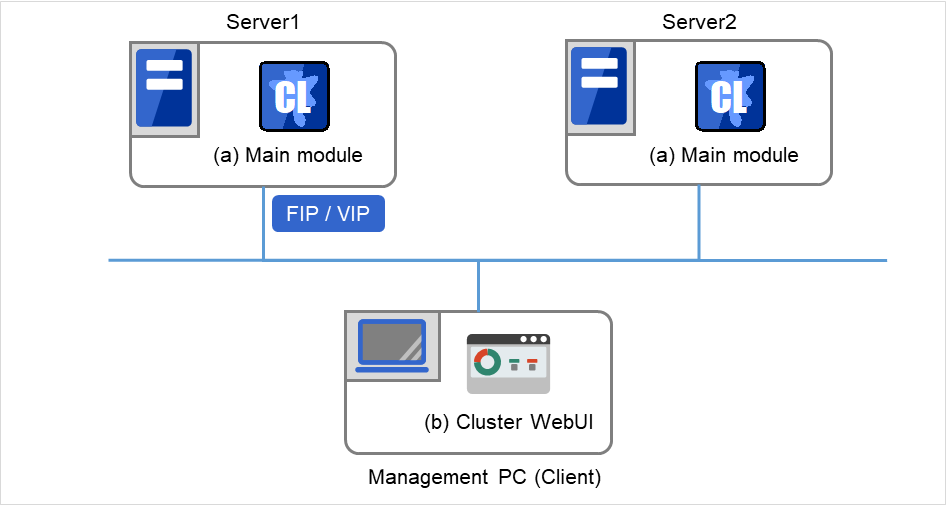
Fig. 3.1 Software configuration of EXPRESSCLUSTER¶
3.3.1. How an error is detected in EXPRESSCLUSTER¶
There are three kinds of monitoring in EXPRESSCLUSTER: (1) server monitoring, (2) application monitoring, and (3) internal monitoring. These monitoring functions let you detect an error quickly and reliably. The details of the monitoring functions are described below.
3.3.2. What is server monitoring?¶
- Primary InterconnectUses an Ethernet NIC in communication path dedicated to the failover-type cluster system. This is used to exchange information between the servers as well as to perform heartbeat communication.
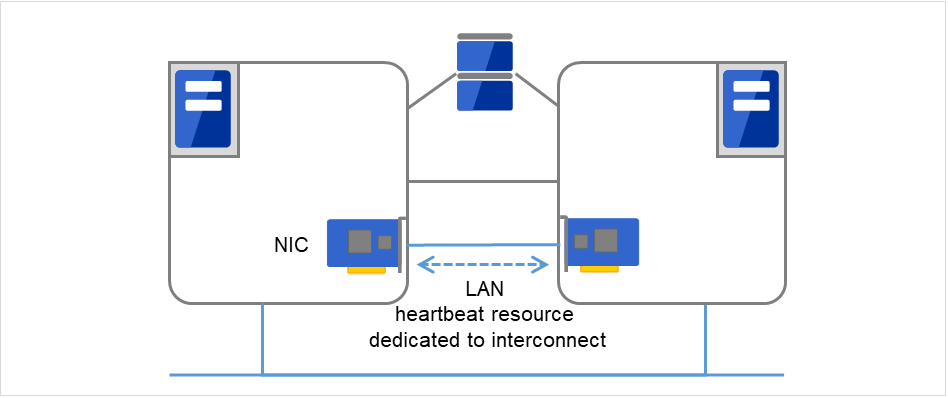
Fig. 3.2 LAN heartbeat/Kernel mode LAN heartbeat (Primary interconnect)¶
- Secondary InterconnectUses a communication path used for communication with client machine as an alternative interconnect. Any Ethernet NIC can be used as long as TCP/IP can be used. This is also used to exchange information between the servers and to perform heartbeat communication.
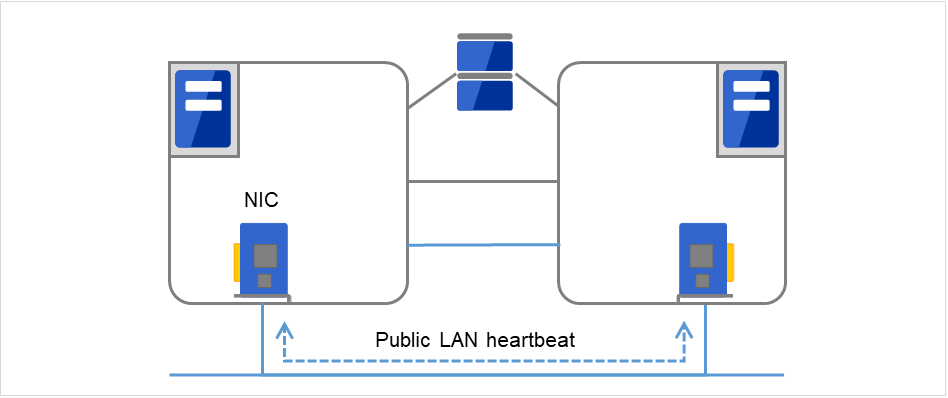
Fig. 3.3 LAN heartbeat/Kernel mode LAN heartbeat (Secondary interconnect)¶
- Shared diskCreates an EXPRESSCLUSTER-dedicated partition (EXPRESSCLUSTER partition) on the disk that is connected to all servers that constitute the failover-type cluster system, and performs heartbeat communication on the EXPRESSCLUSTER partition.
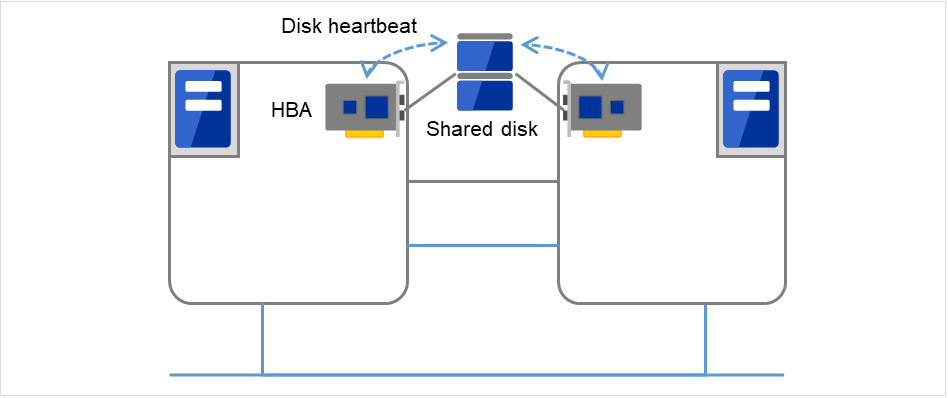
Fig. 3.4 Disk heartbeat¶
- WitnessThis is used by the external Witness server running the Witness server service to check if other servers constructing the failover-type cluster exist through communication with them.
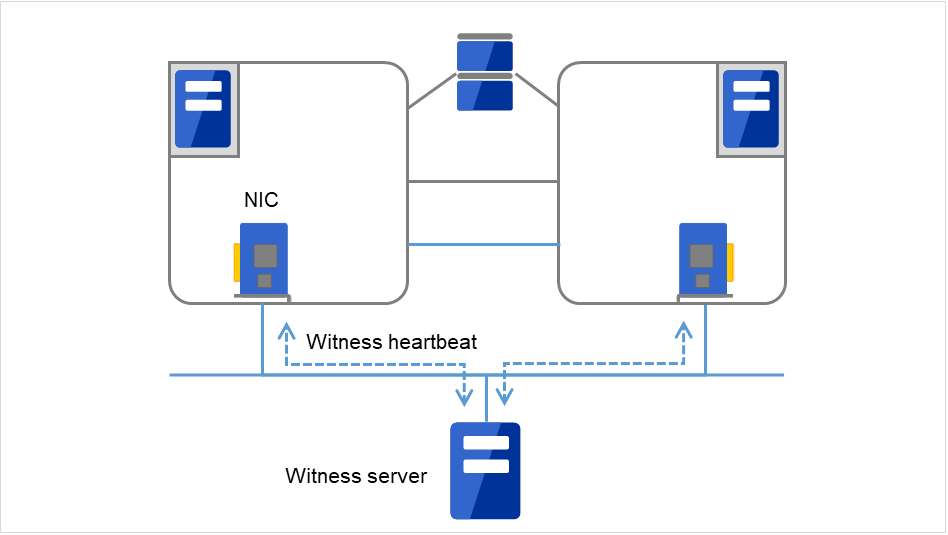
Fig. 3.5 Witness heartbeat¶
Having these communication paths dramatically improves the reliability of the communication between the servers, and prevents the occurrence of network partition.
Note
Network partition refers to a condition when a network gets split by having a problem in all communication paths of the servers in a cluster. In a cluster system that is not capable of handling a network partition, a problem occurred in a communication path and a server cannot be distinguished. As a result, multiple servers may access the same resource and cause the data in a cluster system to be corrupted.
3.3.3. What is application monitoring?¶
Application monitoring is a function that monitors applications and factors that cause a situation where an application cannot run.
- Activation status of application monitoringAn error can be detected by starting up an application from an exec resource in EXPRESSCLUSTER and regularly checking whether a process is active or not by using the pid monitor resource. It is effective when the factor for application to stop is due to error termination of an application.
Note
An error in resident process cannot be detected in an application started up by EXPRESSCLUSTER. When the monitoring target application starts and stops a resident process, an internal application error (such as application stalling, result error) cannot be detected.
- Resource monitoringAn error can be detected by monitoring the cluster resources (such as disk partition and IP address) and public LAN using the monitor resources of the EXPRESSCLUSTER. It is effective when the factor for application to stop is due to an error of a resource which is necessary for an application to operate.
3.3.4. What is internal monitoring?¶
Critical monitoring of EXPRESSCLUSTER process
3.3.5. Monitorable and non-monitorable errors¶
There are monitorable and non-monitorable errors in EXPRESSCLUSTER. It is important to know what can or cannot be monitored when building and operating a cluster system.
3.3.6. Detectable and non-detectable errors by server monitoring¶
Monitoring condition: A heartbeat from a server with an error is stopped
Example of errors that can be monitored:
Hardware failure (of which OS cannot continue operating)
System panic
Example of error that cannot be monitored:
Partial failure on OS (for example, only a mouse or keyboard does not function)
3.3.7. Detectable and non-detectable errors by application monitoring¶
Monitoring conditions: Termination of applications with errors, continuous resource errors, and disconnection of a path to the network devices.
Example of errors that can be monitored:
Abnormal termination of an application
Failure to access the shared disk (such as HBA 1 failure)
Public LAN NIC problem
Example of errors that cannot be monitored:
Application stalling and resulting in error. EXPRESSCLUSTER cannot monitor application stalling and error results. However, it is possible to perform failover by creating a program that monitors applications and terminates itself when an error is detected, starting the program using the exec resource, and monitoring application using the PID monitor resource.
- 1
HBA is an abbreviation for host bus adapter. This adapter is not for the shared disk, but for the server.
3.4. Fencing Function¶
EXPRESSCLUSTER's fencing function consists of network partition resolution and forced stopping.
3.4.1. Network partition resolution¶
ping method
http method
See also
For the details on the network partition resolution method, see "Details on network partition resolution resources" of the Reference Guide.
3.4.2. Forced stop¶
When a server failure is detected, a healthy server can send a stop request to the failed server. Making the failed server stop eliminates the possibility of simultaneously starting business applications on two or more servers. The forced stop is made before a failover is started.
See also
For the details on the forced stop function, see "Forced stop resource details" in the "Reference Guide".
3.5. Failover mechanism¶
Upon detecting that a heartbeat from a server is interrupted, EXPRESSCLUSTER determines whether the cause of this interruption is an error in a server or a network partition before starting a failover. Then a failover is performed by activating various resources and starting up applications on a properly working server.
The group of resources which fail over at the same time is called a "failover group." From a user's point of view, a failover group appears as a virtual computer.
Note
In a cluster system, a failover is performed by restarting the application from a properly working node. Therefore, what is saved in an application memory cannot be failed over.
From occurrence of error to completion of failover takes a few minutes. See the "Figure 3.6 Failover time chart" below:
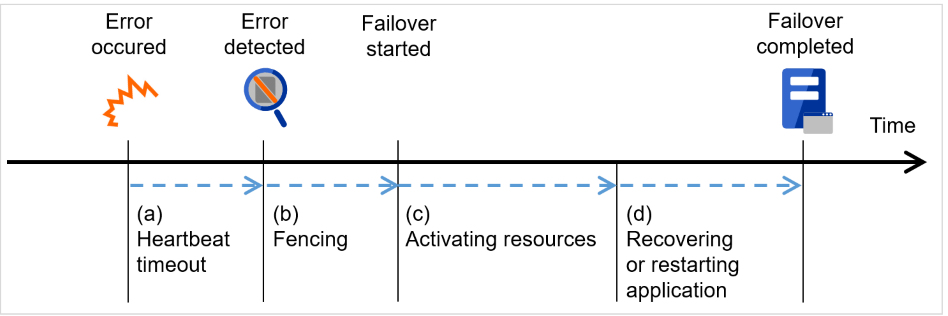
Fig. 3.6 Failover time chart¶
Heartbeat timeout
The time for a standby server to detect an error after that error occurred on the active server.
The setting values of the cluster properties should be adjusted depending on the application load. (The default value is 90 seconds.)
Fencing
The time for network partition resolution and forced stopping.
Activating various resources
The time to activate the resources necessary for operating an application.
The file system recovery, transfer of data in disks, and transfer of IP addresses are performed.
The resources can be activated in a few seconds in ordinary settings, but the required time changes depending on the type and the number of resources registered to the failover group. For more information, refer to the "Installation and Configuration Guide".
Start script execution time
The data recovery time for a roll-back or roll-forward of the database and the startup time of the application to be used in operation.
The time for roll-back or roll-forward can be predicted by adjusting the check point interval. For more information, refer to the document that comes with each software product.
3.5.1. Failover resources¶
EXPRESSCLUSTER can fail over the following resources:
Switchable partition
Resources such as disk resource, mirror disk resource and hybrid disk resource.
A disk partition to store the data that the application takes over.
Floating IP Address
By connecting an application using the floating IP address, a client does not have to be conscious about switching the servers due to failover processing.
It is achieved by dynamic IP address allocation to the public LAN adapter and sending ARP packet. Connection by floating IP address is possible from most of the network devices.
Script (exec resource)
In EXPRESSCLUSTER, applications are started up from the scripts.
The file failed over on the shared disk may not be complete as data even if it is properly working as a file system. Write the recovery processing specific to an application at the time of failover in addition to the startup of an application in the scripts.
Note
In a cluster system, failover is performed by restarting the application from a properly working node. Therefore, what is saved in an application memory cannot be failed over.
3.5.2. System configuration of the failover-type cluster¶
In a failover-type cluster, a disk array device is shared between the servers in a cluster. When an error occurs on a server, the standby server takes over the applications using the data on the shared disk.
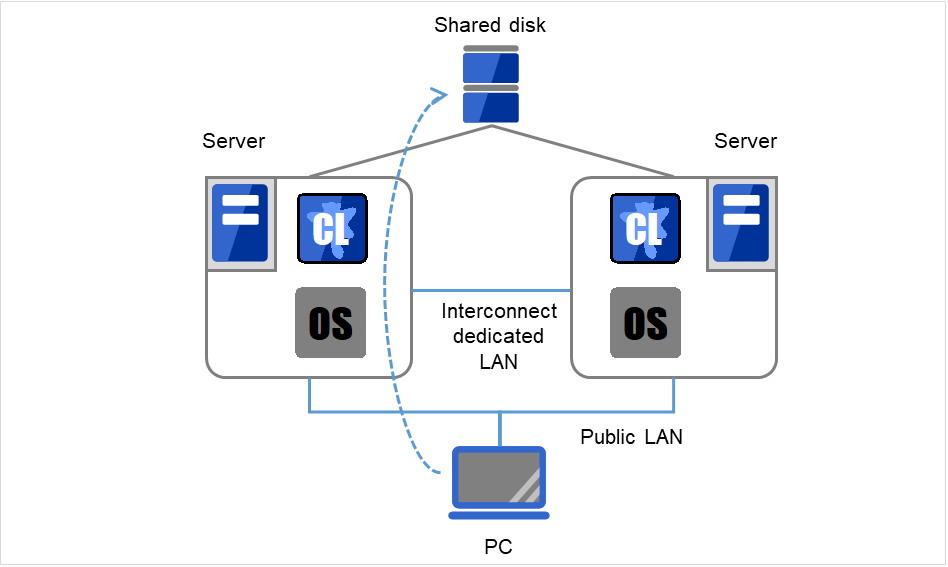
Fig. 3.7 System configuration of failover-type cluster¶
A failover-type cluster can be divided into the following categories depending on the cluster topologies:
Uni-Directional Standby Cluster System
In the uni-directional standby cluster system, the active server runs applications while the other server, the standby server, does not. This is the simplest cluster topology and you can build a high-availability system without performance degradation after failing over.
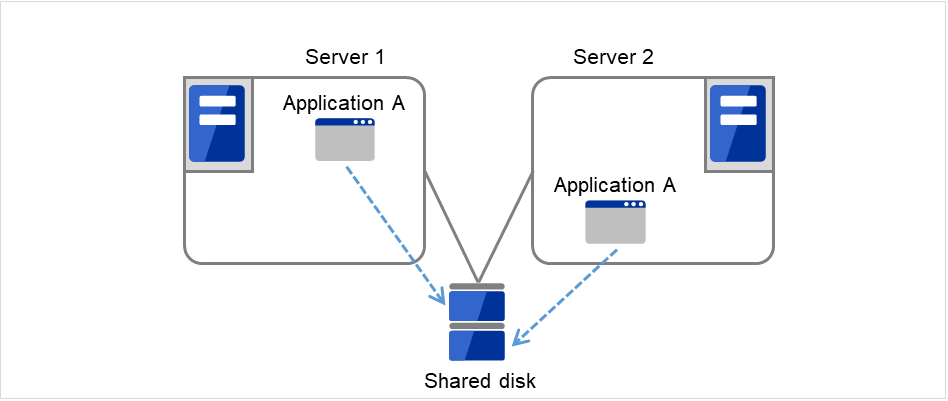
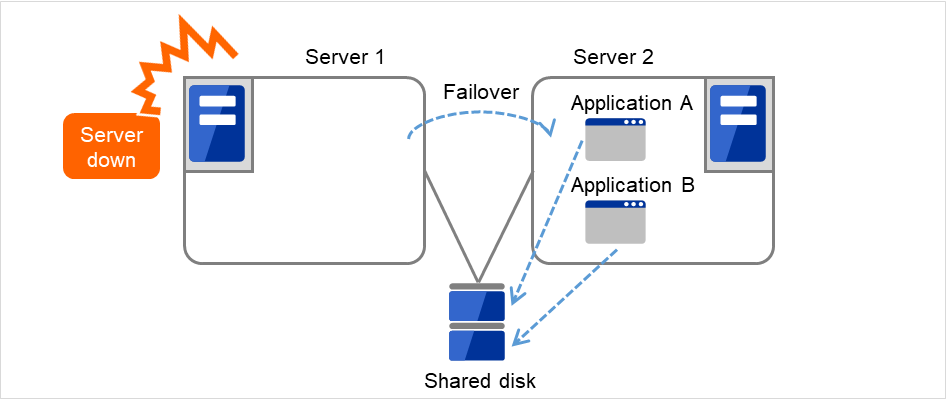
Multi-directional standby cluster system with the same application
In the same application multi-directional standby cluster system, the same applications are activated on multiple servers. These servers also operate as standby servers. The applications must support multi-directional standby operation. When the application data can be split into multiple data, depending on the data to be accessed, you can build a load distribution system per data partitioning basis by changing the client's connecting server.
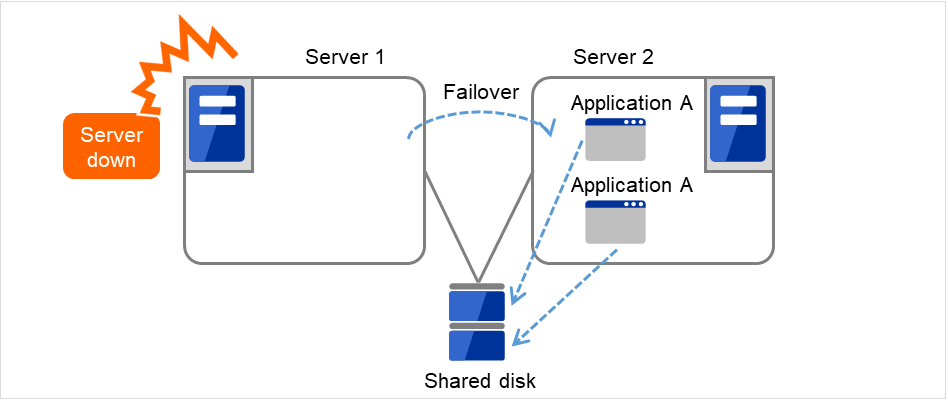
Multi-directional standby cluster system with different applications
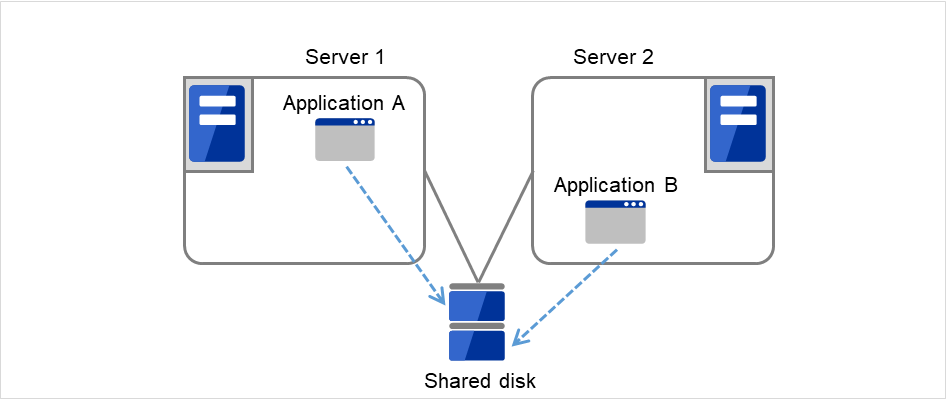
In the different application multi-directional standby cluster system, different applications are activated on multiple servers and these servers also operate as standby servers. The applications do not have to support multi-directional standby operation. A load distribution system can be built per application unit basis.
Application A and Application B are different applications.
Node to Node Configuration
The configuration can be expanded with more nodes by applying the configurations introduced thus far. In a node to node configuration described below, three different applications are run on three servers and one standby server takes over the application if any problem occurs. In a uni-directional standby cluster system, one of the two servers functions as a standby server. However, in a node to node configuration, only one of the four server functions as a standby server and performance deterioration is not anticipated if an error occurs only on one server.
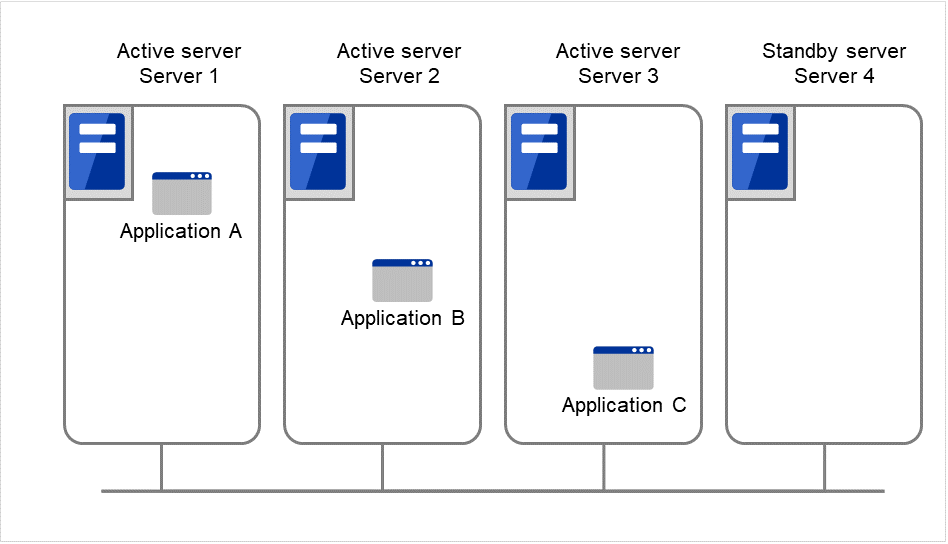
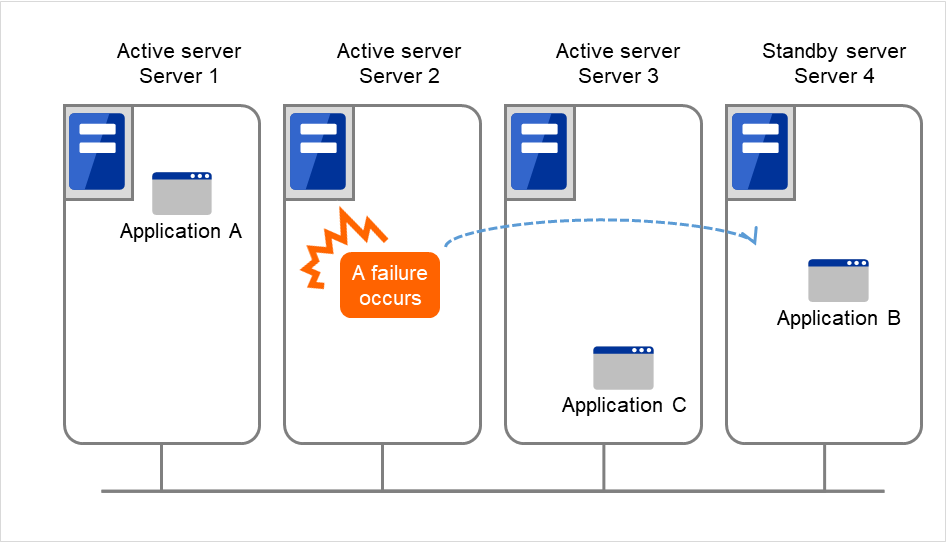
3.5.3. Hardware configuration of the shared disk type cluster¶
The hardware configuration of the shared disk in EXPRESSCLUSTER is described below. In general, the following is used for communication between the servers in a cluster system:
Two NIC cards (one for external communication, one for EXPRESSCLUSTER)
Specific space of a shared disk
SCSI or FibreChannel can be used for communication interface to a shared disk; however, recently FibreChannel is more commonly used.
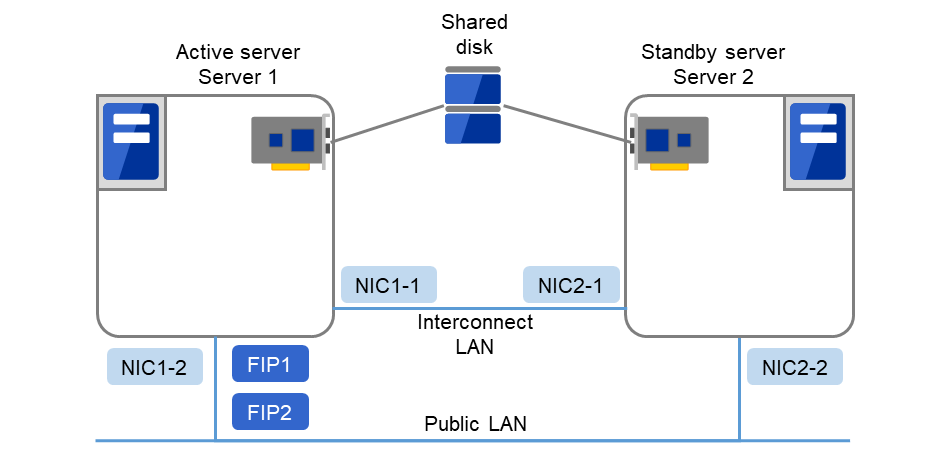
Fig. 3.16 Example of cluster configuration (Shared disk type)¶
FIP1 |
10.0.0.11 (Access destination from the Cluster WebUI client) |
FIP2 |
10.0.0.12 (Access destination from the operation client) |
NIC1-1 |
192.168.0.1 |
NIC1-2 |
10.0.0.1 |
NIC2-1 |
192.168.0.2 |
NIC2-2 |
10.0.0.2 |
Shared disk
Device name
/dev/sdb2
Mount point
/mnt/sdb2
File system
ext3
3.5.4. Hardware configuration of the mirror disk type cluster¶
The hardware configuration of the mirror disk in EXPRESSCLUSTER is described below.
Unlike the shared disk type, a network to copy the mirror disk data is necessary. In general, a network is used with NIC for internal communication in EXPRESSCLUSTER.
Mirror disks need to be separated from the operating system; however, they do not depend on a connection interface (IDE or SCSI.)
Sample cluster environment with mirror disks used (When cluster partitions and data partitions are allocated to OS-installed disks)
In the following configuration, free partitions of the OS-installed disks are used as cluster partitions and data partitions.
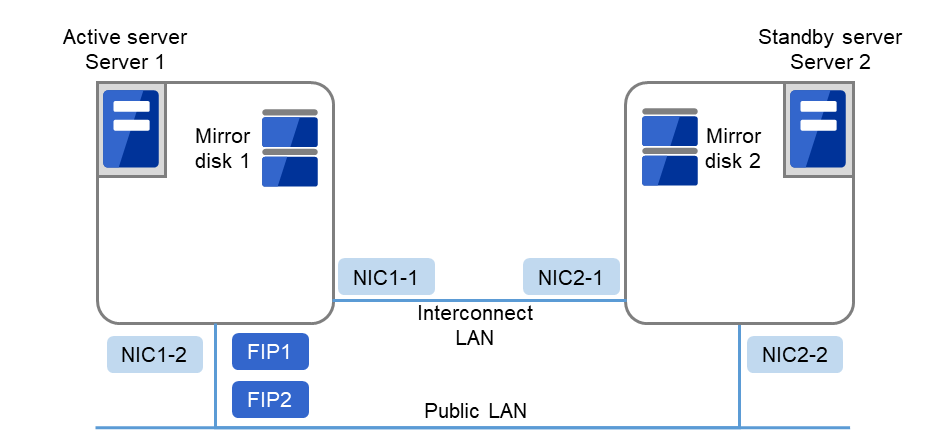
Fig. 3.17 Example of cluster configuration (1) (Mirror disk type)¶
FIP1
10.0.0.11 (Access destination from the Cluster WebUI client)
FIP2
10.0.0.12 (Access destination from the operation client)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
/boot device for OS
/dev/sda1
Swap device for OS
/dev/sda2
/(root) device for OS
/dev/sda3
Device for cluster partitions
/dev/sda5
Device for data partitions
/dev/sda6
Mount point
/mnt/sda6
File system
ext3
Sample cluster environment with mirror disks used (When disks are prepared for cluster partitions and data partitions)
In the following configuration, disks are prepared to be used for cluster partitions and data partitions, and connected to the servers.
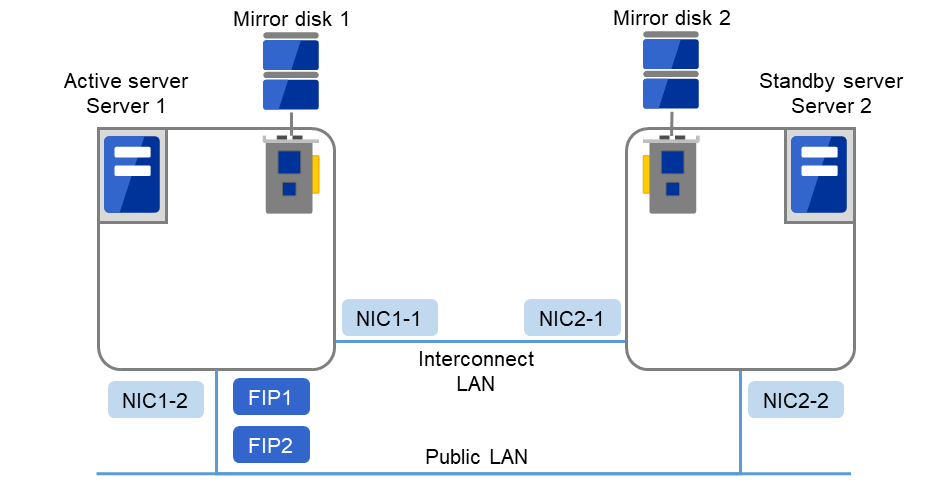
Fig. 3.18 Example of cluster configuration (2) (Mirror disk type)¶
FIP1
10.0.0.11 (Access destination from the Cluster WebUI client)
FIP2
10.0.0.12 (Access destination from the operation client)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
/boot device for OS
/dev/sda1
Swap device for OS
/dev/sda2
/(root) device for OS
/dev/sda3
Device for cluster partitions
/dev/sdb1
Mirror resource disk device
/dev/sdb2
Mount point
/mnt/sdb2
File system
ext3
3.5.5. Hardware configuration of the hybrid disk type cluster¶
The hardware configuration of the hybrid disk in EXPRESSCLUSTER is described below.
Unlike the shared disk type, a network to copy the data is necessary. In general, NIC for internal communication in EXPRESSCLUSTER is used to meet this purpose.
Disks do not depend on a connection interface (IDE or SCSI).
Sample cluster environment with the hybrid disk used (When a shared disk is used by two servers and the data is mirrored to the normal disk of the third server)
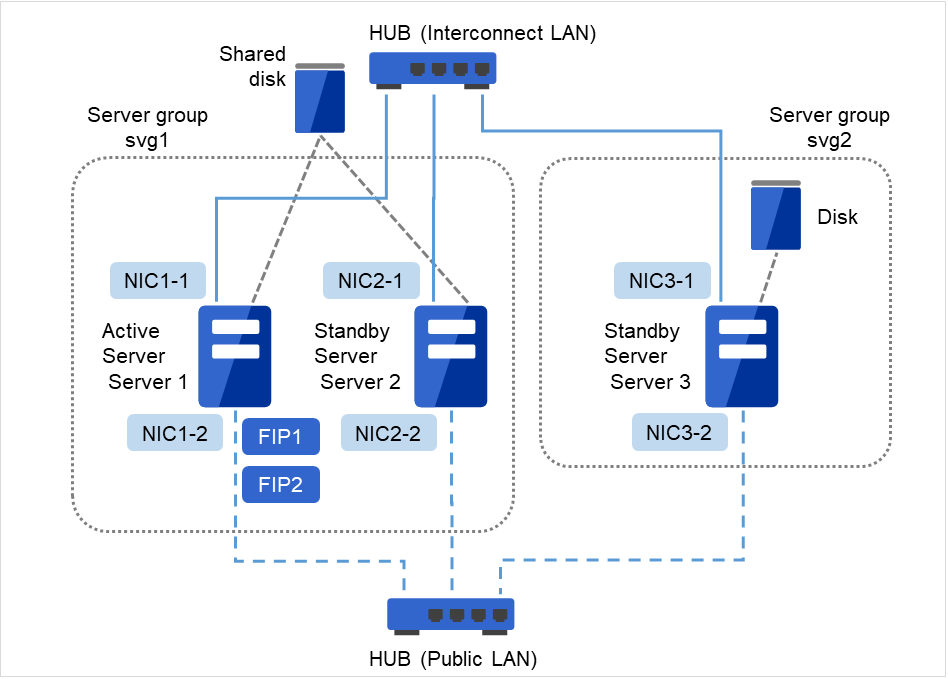
Fig. 3.19 Example of cluster configuration (Hybrid disk type)¶
FIP1
10.0.0.11 (Access destination from the Cluster WebUI client)
FIP2
10.0.0.12 (Access destination from the operation client)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
NIC3-1
192.168.0.3
NIC3-2
10.0.0.3
Shared disk
Hybrid device
/dev/NMP1
Mount point
/mnt/hd1
File system
ext3
Device for cluster partitions
/dev/sdb1
Hybrid resource disk device
/dev/sdb2
Disk heartbeat device name
/dev/sdb3
Raw device name
/dev/raw/raw1
Disk for hybrid resource
Hybrid device
/dev/NMP1
Mount point
/mnt/hd1
File system
ext3
Device for cluster partitions
/dev/sdb1
Hybrid resource disk device
/dev/sdb2
3.5.6. What is cluster object?¶
In EXPRESSCLUSTER, the various resources are managed as the following groups:
- Cluster objectConfiguration unit of a cluster.
- Server objectIndicates the physical server and belongs to the cluster object.
- Server group objectGroups the servers and belongs to the cluster object.
- Heartbeat resource objectIndicates the network part of the physical server and belongs to the server object.
- Network partition resolution resource objectIndicates the network partition resolution mechanism and belongs to the server object.
- Group objectIndicates a virtual server and belongs to the cluster object.
- Group resource objectIndicates resources (network, disk) of the virtual server and belongs to the group object.
- Monitor resource objectIndicates monitoring mechanism and belongs to the cluster object.
3.6. What is a resource?¶
In EXPRESSCLUSTER, a group used for monitoring the target is called "resources." There are four types of resources and are managed separately. Having resources allows distinguishing what is monitoring and what is being monitored more clearly. It also makes building a cluster and handling an error easy. The resources can be divided into heartbeat resources, network partition resolution resources, group resources, and monitor resources.
3.6.1. Heartbeat resources¶
Heartbeat resources are used for verifying whether the other server is working properly between servers. The following heartbeat resources are currently supported:
- LAN heartbeat resourceUses Ethernet for communication.
- Kernel mode LAN heartbeat resourceUses Ethernet for communication.
- Disk heartbeat resourceUses a specific partition (cluster partition for disk heartbeat) on the shared disk for communication. It can be used only on a shared disk configuration.
- Witness heartbeat resourceUses the external server running the Witness server service to show the status (of communication with each server) obtained from the external server.
3.6.2. Network partition resolution resources¶
The following resource is used to resolve a network partition.
- PING network partition resolution resourceThis is a network partition resolution resource by the PING method.
- HTTP network partition resolution resourceThis is a network partition resolution resource by the HTTP method.
3.6.3. Group resources¶
A group resource constitutes a unit when a failover occurs. The following group resources are currently supported:
- Floating IP resource (fip)Provides a virtual IP address. A client can access virtual IP address the same way as the regular IP address.
- EXEC resource (exec)Provides a mechanism for starting and stopping the applications such as DB and httpd.
- Disk resource (disk)Provides a specified partition on the shared disk. It can be used only on a shared disk configuration.
- Mirror disk resource (md)Provides a specified partition on the mirror disk. It can be used only on a mirror disk configuration.
- Hybrid disk resource (hd)Provides a specified partition on a shared disk or a disk. It can be used only for hybrid configuration.
- Volume manager resource (volmgr)Handles multiple storage devices and disks as a single logical disk.
- Virtual IP resource (vip)Provides a virtual IP address. This can be accessed from a client in the same way as a general IP address. This can be used in the remote cluster configuration among different network addresses.
- Dynamic DNS resource (ddns)Registers the virtual host name and the IP address of the active server to the dynamic DNS server.
- AWS elastic ip resource (awseip)Provides a system for giving an elastic IP (referred to as EIP) when EXPRESSCLUSTER is used on AWS.
- AWS virtual ip resource (awsvip)Provides a system for giving a virtual IP (referred to as VIP) when EXPRESSCLUSTER is used on AWS.
- AWS secondary ip resource (awssip)Provides a system for giving a secondary IP when EXPRESSCLUSTER is used on AWS.
- AWS DNS resource (awsdns)Registers the virtual host name and the IP address of the active server to Amazon Route 53 when EXPRESSCLUSTER is used on AWS.
- Azure probe port resource (azurepp)Provides a system for opening a specific port on a node on which the operation is performed when EXPRESSCLUSTER is used on Microsoft Azure.
- Azure DNS resource (azuredns)Registers the virtual host name and the IP address of the active server to Azure DNS when EXPRESSCLUSTER is used on Microsoft Azure.
- Google Cloud virtual IP resource (gcvip)Provides a system for opening a specific port on a node on which the operation is performed when EXPRESSCLUSTER is used on Google Cloud.
- Google Cloud DNS resource (gcdns)Registers the virtual host name and the IP address of the active server to Cloud DNS when EXPRESSCLUSTER is used on Google Cloud.
- Oracle Cloud virtual IP resource (ocvip)Provides a system for opening a specific port on a node on which the operation is performed when EXPRESSCLUSTER is used on Oracle Cloud Infrastructure.
- Oracle Cloud DNS resource (ocdns)Registers the virtual host name and the IP address of the active server to Oracle Cloud DNS when EXPRESSCLUSTER is used on Oracle Cloud Infrastructure.
3.6.4. Monitor resources¶
A monitor resource monitors a cluster system. The following monitor resources are currently supported:
- Floating IP monitor resource (fipw)Provides a monitoring mechanism of an IP address started up by a floating IP resource.
- IP monitor resource (ipw)Provides a monitoring mechanism of an external IP address.
- Disk monitor resource (diskw)Provides a monitoring mechanism of the disk. It also monitors the shared disk.
- Mirror disk monitor resource (mdw)Provides a monitoring mechanism of the mirroring disks.
- Mirror disk connect monitor resource (mdnw)Provides a monitoring mechanism of the mirror disk connect.
- Hybrid disk monitor resource (hdw)Provides a monitoring mechanism of the hybrid disk.
- Hybrid disk connect monitor resource (hdnw)Provides a monitoring mechanism of the hybrid disk connect.
- PID monitor resource (pidw)Provides a monitoring mechanism to check whether a process started up by exec resource is active or not.
- User mode monitor resource (userw)Provides a monitoring mechanism for a stalling problem in the user space.
- NIC Link Up/Down monitor resource (miiw)Provides a monitoring mechanism for link status of LAN cable.
- Volume manager monitor resource (volmgrw)Provides a monitoring mechanism for multiple storage devices and disks.
- Multi target monitor resource (mtw)Provides a status with multiple monitor resources.
- Virtual IP monitor resource (vipw)Provides a mechanism for sending RIP packets of a virtual IP resource.
- ARP monitor resource (arpw)Provides a mechanism for sending ARP packets of a floating IP resource or a virtual IP resource.
- Custom monitor resource (genw)Provides a monitoring mechanism to monitor the system by the operation result of commands or scripts which perform monitoring, if any.
- Eternal link monitor resource (mrw)Specifies the action to take when an error message is received and how the message is displayed on the Cluster WebUI.
- Dynamic DNS monitor resource (ddnsw)Periodically registers the virtual host name and the IP address of the active server to the dynamic DNS server.
- Process name monitor resource (psw)Provides a monitoring mechanism for checking whether a process specified by a process name is active.
- DB2 monitor resource (db2w)Provides a monitoring mechanism for IBM DB2 database.
- FTP monitor resource (ftpw)Provides a monitoring mechanism for FTP server.
- HTTP monitor resource (httpw)Provides a monitoring mechanism for HTTP server.
- IMAP4 monitor resource (imap4w)Provides a monitoring mechanism for IMAP4 server.
- MySQL monitor resource (mysqlw)Provides a monitoring mechanism for MySQL database.
- NFS monitor resource (nfsw)Provides a monitoring mechanism for nfs file server.
- Oracle monitor resource (oraclew)Provides a monitoring mechanism for Oracle database.
- POP3 monitor resource (pop3w)Provides a monitoring mechanism for POP3 server.
- PostgreSQL monitor resource (psqlw)Provides a monitoring mechanism for PostgreSQL database.
- Samba monitor resource (sambaw)Provides a monitoring mechanism for samba file server.
- SMTP monitor resource (smtpw)Provides a monitoring mechanism for SMTP server.
- Tuxedo monitor resource (tuxw)Provides a monitoring mechanism for Tuxedo application server.
- WebSphere monitor resource (wasw)Provides a monitoring mechanism for WebSphere application server.
- WebLogic monitor resource (wlsw)Provides a monitoring mechanism for WebLogic application server.
- WebOTX monitor resource (otxsw)Provides a monitoring mechanism for WebOTX application server.
- JVM monitor resource (jraw)Provides a monitoring mechanism for Java VM.
- System monitor resource (sraw)Provides a monitoring mechanism for the resources of the whole system.
- Process resource monitor resource(psrw)Provides a monitoring mechanism for running processes on the server.
- AWS Elastic IP monitor resource (awseipw)Provides a monitoring mechanism for the elastic ip given by the AWS elastic ip (referred to as EIP) resource.
- AWS Virtual IP monitor resource (awsvipw)Provides a monitoring mechanism for the virtual ip given by the AWS virtual ip (referred to as VIP) resource.
- AWS Secondary IP monitor resource (awssipw)Provides a monitoring mechanism for the secondary ip given by the AWS secondary ip resource.
- AWS AZ monitor resource (awsazw)Provides a monitoring mechanism for an Availability Zone (referred to as AZ).
- AWS DNS monitor resource (awsdnsw)Provides a monitoring mechanism for the virtual host name and IP address provided by the AWS DNS resource.
- Azure probe port monitor resource (azureppw)Provides a monitoring mechanism for probe port for the node where an Azure probe port resource has been activated.
- Azure load balance monitor resource (azurelbw)Provides a mechanism for monitoring whether the port number that is same as the probe port is open for the node where an Azure probe port resource has not been activated.
- Azure DNS monitor resource (azurednsw)Provides a monitoring mechanism for the virtual host name and IP address provided by the Azure DNS resource.
- Google Cloud virtual IP monitor resource (gcvipw)Provides a mechanism for monitoring the alive-monitoring port for the node where a Google Cloud virtual IP resource has been activated.
- Google Cloud load balance monitor resource (gclbw)Provides a mechanism for monitoring whether the same port number as the health-check port number has already been used , for the node where a Google Cloud virtual IP resource has not been activated.
- Google Cloud DNS monitor resource (gcdnsw)Provides a monitoring mechanism for the virtual host name and IP address provided by the Google Cloud DNS resource.
- Oracle Cloud virtual IP monitor resource (ocvipw)Provides a mechanism for monitoring the alive-monitoring port for the node where an Oracle Cloud virtual IP resource has been activated.
- Oracle Cloud load balance monitor resource (oclbw)Provides a mechanism for monitoring whether the same port number as the health-check port number has already been used , for the node where an Oracle Cloud virtual IP resource has not been activated.
- Oracle Cloud DNS monitor resource (ocdnsw)Provides a monitoring mechanism for the virtual host name and IP address provided by the Oracle Cloud DNS resource.
3.7. Getting started with EXPRESSCLUSTER¶
Refer to the following guides when building a cluster system with EXPRESSCLUSTER:
3.7.1. Latest information¶
Refer to "4. Installation requirements for EXPRESSCLUSTER" and "5. Latest version information" and "6. Notes and Restrictions" and "7. Upgrading EXPRESSCLUSTER" in this guide.
3.7.2. Designing a cluster system¶
Refer to "Determining a system configuration" and "Configuring a cluster system" in the "Installation and Configuration Guide"; "Group resource details", "Monitor resource details", "Heartbeat resources details", "Network partition resolution resources details", and "Information on other settings" in the "Reference Guide" ; and the "Hardware Feature Guide".
3.7.3. Configuring a cluster system¶
Refer to the "Installation and Configuration Guide".
3.7.4. Troubleshooting the problem¶
Refer to "The system maintenance information" in the "Maintenance Guide", and "Troubleshooting" and "Error messages" in the "Reference Guide".
4. Installation requirements for EXPRESSCLUSTER¶
This chapter provides information on system requirements for EXPRESSCLUSTER.
This chapter covers:
4.1. System requirements for hardware¶
EXPRESSCLUSTER operates on the following server architectures:
x86_64
IBM POWER LE (Replicator, Replicator DR and Agents are not supported)
ARM64 (Agents are not supported)
4.1.1. General server requirements¶
Required specifications for EXPRESSCLUSTER Server are the following:
Ethernet port 2 or more ports
Shared disk
Mirror disk or empty partition for mirror
DVD-ROM drive
4.2. System requirements for EXPRESSCLUSTER Server¶
4.2.1. Supported distributions and kernel versions¶
The environment where EXPRESSCLUSTER Server can operate depends on kernel module versions because there are kernel modules unique to EXPRESSCLUSTER.
There are the following driver modules unique to EXPRESSCLUSTER.
Driver module unique to EXPRESSCLUSTER |
Description |
|---|---|
Kernel mode LAN heartbeat driver |
Used with kernel mode LAN heartbeat resources. |
Keepalive driver |
Used if keepalive is selected as the monitoring method for user-mode monitor resources.
Used if keepalive is selected as the monitoring method for shutdown monitoring.
|
Mirror driver |
Used with mirror disk resources. |
Kernel versions which has been verified are listed below.
About newest information, see the web site as follows:
Note
For the kernel version of Cent OS supported by EXPRESSCLUSTER, see the supported kernel version of Red Hat Enterprise Linux.
Note
4.2.2. Applications supported by monitoring options¶
Version information of the applications to be monitored by monitor resources is described below.
x86_64
Monitor resource |
Monitored application |
EXPRESSCLUSTER
version
|
Remarks |
|---|---|---|---|
Oracle monitor |
Oracle Database 19c (19.3) |
5.0.0-1 or later |
|
DB2 monitor |
DB2 V11.5 |
5.0.0-1 or later |
|
PostgreSQL monitor |
PostgreSQL 14.1 |
5.0.0-1 or later |
|
PostgreSQL 15.1 |
5.1.0-1 or later |
||
PostgreSQL 16.3 |
5.2.1-1 or later |
||
PowerGres on Linux 13.5 |
5.0.0-1 or later |
||
MySQL monitor |
MySQL 8.0 |
5.0.0-1 or later |
|
MySQL 8.0.31 |
5.1.0-1 or later |
||
MySQL 8.0.36 |
5.2.1-1 or later |
||
MariaDB 10.5 |
5.0.0-1 or later |
||
MariaDB 10.10.2 |
5.1.0-1 or later |
||
MariaDB 11.2.3 |
5.2.1-1 or later |
||
SQL Server monitor |
SQL Server 2019 |
5.0.0-1 or later |
|
SQL Server 2022 |
5.1.0-1 or later |
||
Samba monitor |
Samba 3.3 |
4.0.0-1 or later |
|
Samba 3.6 |
4.0.0-1 or later |
||
Samba 4.0 |
4.0.0-1 or later |
||
Samba 4.1 |
4.0.0-1 or later |
||
Samba 4.2 |
4.0.0-1 or later |
||
Samba 4.4 |
4.0.0-1 or later |
||
Samba 4.6 |
4.0.0-1 or later |
||
Samba 4.7 |
4.1.0-1 or later |
||
Samba 4.8 |
4.1.0-1 or later |
||
Samba 4.13 |
4.3.0-1 or later |
||
NFS monitor |
nfsd 2 (udp) |
4.0.0-1 or later |
|
nfsd 3 (udp) |
4.0.0-1 or later |
||
nfsd 4 (tcp) |
4.0.0-1 or later |
||
mountd 1 (tcp) |
4.0.0-1 or later |
||
mountd 2 (tcp) |
4.0.0-1 or later |
||
mountd 3 (tcp) |
4.0.0-1 or later |
||
HTTP monitor |
No specified version |
4.0.0-1 or later |
|
SMTP monitor |
No specified version |
4.0.0-1 or later |
|
POP3 monitor |
No specified version |
4.0.0-1 or later |
|
imap4 monitor |
No specified version |
4.0.0-1 or later |
|
ftp monitor |
No specified version |
4.0.0-1 or later |
|
Tuxedo monitor |
Tuxedo 12c Release 2 (12.1.3) |
4.0.0-1 or later |
|
Tuxedo 22c (22.1.0) |
5.2.0-1 or later |
||
WebLogic monitor |
WebLogic Server 11g R1 |
4.0.0-1 or later |
|
WebLogic Server 11g R2 |
4.0.0-1 or later |
||
WebLogic Server 12c R2 (12.2.1) |
4.0.0-1 or later |
||
WebLogic Server 14c (14.1.1) |
4.2.0-1 or later |
||
WebSphere monitor |
WebSphere Application Server 8.5 |
4.0.0-1 or later |
|
WebSphere Application Server 8.5.5 |
4.0.0-1 or later |
||
WebSphere Application Server 9.0 |
4.0.0-1 or later |
||
WebOTX monitor |
WebOTX Application Server V9.1 |
4.0.0-1 or later |
|
WebOTX Application Server V9.2 |
4.0.0-1 or later |
||
WebOTX Application Server V9.3 |
4.0.0-1 or later |
||
WebOTX Application Server V9.4 |
4.0.0-1 or later |
||
WebOTX Application Server V10.1 |
4.0.0-1 or later |
||
WebOTX Application Server V10.3 |
4.3.0-1 or later |
||
WebOTX Application Server V11.1 |
5.2.0-1 or later |
||
JVM monitor |
WebLogic Server 11g R1 |
4.0.0-1 or later |
|
WebLogic Server 11g R2 |
4.0.0-1 or later |
||
WebLogic Server 12c |
4.0.0-1 or later |
||
WebLogic Server 12c R2 (12.2.1) |
4.0.0-1 or later |
||
WebLogic Server 14c (14.1.1) |
4.2.0-1 or later |
||
WebOTX Application Server V9.1 |
4.0.0-1 or later |
||
WebOTX Application Server V9.2 |
4.0.0-1 or later |
WebOTX update is required to monitor process groups |
|
WebOTX Application Server V9.3 |
4.0.0-1 or later |
||
WebOTX Application Server V9.4 |
4.0.0-1 or later |
||
WebOTX Application Server V10.1 |
4.0.0-1 or later |
||
WebOTX Application Server V10.3 |
4.3.0-1 or later |
||
WebOTX Application Server V11.1 |
5.2.0-1 or later |
||
WebOTX Enterprise Service Bus V8.4 |
4.0.0-1 or later |
||
WebOTX Enterprise Service Bus V8.5 |
4.0.0-1 or later |
||
WebOTX Enterprise Service Bus V10.3 |
4.3.0-1 or later |
||
WebOTX Enterprise Service Bus V11.1 |
5.2.0-1 or later |
||
JBoss Enterprise Application Platform 7.0 |
4.0.0-1 or later |
||
JBoss Enterprise Application Platform 7.3 |
4.3.2-1 or later |
||
JBoss Enterprise Application Platform 7.4 |
5.0.2-1 or later |
||
Apache Tomcat 8.0 |
4.0.0-1 or later |
||
Apache Tomcat 8.5 |
4.0.0-1 or later |
||
Apache Tomcat 9.0 |
4.0.0-1 or later |
||
Apache Tomcat 10.0 |
5.0.2-1 or later |
||
WebSAM SVF for PDF 9.0 |
4.0.0-1 or later |
||
WebSAM SVF for PDF 9.1 |
4.0.0-1 or later |
||
WebSAM SVF for PDF 9.2 |
4.0.0-1 or later |
||
WebSAM SVF PDF Enterprise 10.1 |
5.1.0-1 or later |
||
WebSAM Report Director Enterprise 9.0 |
4.0.0-1 or later |
||
WebSAM Report Director Enterprise 9.1 |
4.0.0-1 or later |
||
WebSAM Report Director Enterprise 9.2 |
4.0.0-1 or later |
||
WebSAM RDE SUITE 10.1 |
5.1.0-1 or later |
||
WebSAM Universal Connect/X 9.0 |
4.0.0-1 or later |
||
WebSAM Universal Connect/X 9.1 |
4.0.0-1 or later |
||
WebSAM Universal Connect/X 9.2 |
4.0.0-1 or later |
||
WebSAM SVF Connect SUITE Standard 10.1 |
5.1.0-1 or later |
||
System monitor |
No specified version |
4.0.0-1 or later |
|
Process resource monitor |
No specified version |
4.1.0-1 or later |
Note
To use monitoring options in x86_64 environments, applications to be monitored must be x86_64 version.
4.2.3. Operation environment for JVM monitor¶
The use of the JVM monitor requires a Java runtime environment. Also, monitoring a domain mode of JBoss Enterprise Application Platform requires Java(TM) SE Development Kit.
Java(TM) Runtime Environment |
Version 8.0 Update 11 (1.8.0_11) or later |
Java(TM) SE Development Kit |
Version 8.0 Update 11 (1.8.0_11) or later |
Java(TM) Runtime Environment |
Version 9.0 (9.0.1) or later |
Java(TM) SE Development Kit |
Version 9.0 (9.0.1) or later |
Java(TM) SE Development Kit |
Version 11.0 (11.0.5) or later |
Java(TM) SE Development Kit |
Version 17.0 (17.0.2) or later |
Open JDK |
Version 8.0 (1.8.0) or later
Version 9.0 (9.0.1) or later
|
4.2.4. Operation environment for AWS Elastic IP resource, AWS Elastic IP monitor resource, AWS AZ monitor resource¶
The use of the AWS elastic ip resource, AWS elastic IP monitor resource, AWS AZ monitor resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
AWS CLI |
1.8.0 or later
2.0.0 or later
|
4.2.5. Operation environment for AWS Virtual IP resource, AWS Virtual IP monitor resource¶
The use of the AWS virtual ip resource, AWS virtual IP monitor resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
AWS CLI |
1.9.0 or later
2.0.0 or later
|
4.2.6. Operation environment for AWS secondary ip resource, AWS secondary IP monitor resource¶
The use of the AWS secondary ip resource, AWS secondary IP monitor resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
AWS CLI |
1.8.0 or later
2.0.0 or later
|
4.2.7. Operation environment for AWS DNS resource, AWS DNS monitor resource¶
The use of the AWS DNS resource, AWS DNS monitor resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
AWS CLI |
1.11.0 or later
2.0.0 or later
|
4.2.8. Operation environment for AWS forced stop resource¶
The use of the AWS forced stop resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
AWS CLI |
1.8.0 or later
2.0.0 or later
|
4.2.9. Operation environment for Azure DNS resource, Azure DNS monitor resource¶
The use of the Azure DNS resource, Azure DNS monitor resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
Azure CLI |
2.0 or later |
4.2.10. Operation environment for Azure forced stop resource¶
The use of the Azure forced stop resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
Azure CLI |
2.0 or later
|
4.2.11. Operation environments for Google Cloud DNS resource, Google Cloud DNS monitor resource¶
The use of the Google Cloud DNS resource, Azure Google Cloud monitor resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
Google Cloud SDK |
295.0.0 or later |
4.2.12. Operation environments for Oracle Cloud DNS resource, Oracle Cloud DNS monitor resource¶
The use of the Oracle Cloud DNS resource, Azure Oracle Cloud monitor resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
OCI CLI |
3.27.1 or later
|
4.2.13. Operation environment for OCI forced stop resource¶
The use of the OCI forced stop resource requires the following software.
Software |
Version |
Remarks |
|---|---|---|
OCI CLI |
3.5.3 or later
|
4.2.14. Operation environment for enabling encryption¶
For EXPRESSCLUSTER components, enabling communication encryption requires the following software:
Software |
Version |
Remarks |
|---|---|---|
OpenSSL |
1.1.1 (1.1.1a or later)
3.0 (3.0.0 or later)
3.1 (3.1.0 or later)
3.2 (3.2.0 or later)
3.3 (3.3.0 or later)
|
The following components support communication encryption using the above software:
Cluster WebUI
RESTful API
Witness heartbeat resource
HTTP network partition resolution resource
FTP monitor resource
HTTP monitor resource
Mail reporting function
Mirror disk resource
Hybrid disk resource
4.2.15. Required memory and disk size¶
Required memory size
(User mode)
|
300MB 2
|
|---|---|
Required memory size
(Kernel mode)
|
When the synchronization mode is used:
1MB + (number of request queues x I/O size) +
(2MB + Difference Bitmap Size x number of mirror disk resources and hybrid disk resources
When the asynchronous mode is used:
1MB + (number of request queues x I/O size)
+ (3MB
+ (number of asynchronous queues x I/O size)
+ (I/O size / 4KB x 8B + 0.5KB) x (max size of history file / I/O size + number of asynchronous queues)
+ (Difference Bitmap Size)
) x number of mirror disk resources and hybrid disk resources
When the kernel mode LAN heartbeat driver is used:
8MB
When the keepalive driver is used:
8MB
|
Required disk size
(Right after installation)
|
300MB
|
Required disk size
(During operation)
|
5.0GB + 1.0GB 3
|
- 2
excepting for optional products.
- 3
A disk capacity required to use mirror disk resources and hybrid disk resources.
Note
Estimated I/O size is as follows:
6MiB (Red Hat Enterprise Linux 9)
1MiB (Red Hat Enterprise Linux 8)
124KiB (Red Hat Enterprise Linux 7)
The I/O size varies depending on the server performance and the written amount. Theoretically speaking, the maximum I/O size is as follows:
4GiB (Red Hat Enterprise Linux 9)
2MiB (Red Hat Enterprise Linux 8)
1MiB (Red Hat Enterprise Linux 7)
For the setting value of the number of request queues and asynchronization queues, see "Understanding Mirror disk resources" of "Group resource details" in the "Reference Guide".
For the required size of a partition for a disk heartbeat resource, see "Shared disk".
For the required size of a cluster partition, see "Mirror disk" and "Hybrid disk".
4.3. System requirements for the Cluster WebUI¶
4.3.1. Supported operating systems and browsers¶
Refer to the website, http://www.nec.com/global/prod/expresscluster/, for the latest information. Currently the following operating systems and browsers are supported:
Browser |
Language |
|---|---|
Firefox |
English/Japanese/Chinese |
Google Chrome |
English/Japanese/Chinese |
Microsoft Edge (Chromium) |
English/Japanese/Chinese |
Note
When using an IP address to connect to Cluster WebUI, the IP address must be registered to Site of Local Intranet in advance.
Note
No mobile devices, such as tablets and smartphones, are supported.
4.3.2. Required memory and disk size¶
Required memory size: 500 MB or more
Required disk size: 200 MB or more
4.4. System requirements for the Witness server¶
4.4.1. Operation verified environment for Witness server service¶
Its operation has been verified in the following environments.
Version of witness server |
Requirement |
|---|---|
5.2.0 |
Node.js 18.13.0
Node.js 20.10.0
|
4.4.2. Required memory and disk size¶
Required memory size |
50MB + (Number of nodes * 0.5 MB) |
|---|---|
Required disk size |
1GB |
5. Latest version information¶
This chapter provides the latest information on EXPRESSCLUSTER.
This chapter covers:
5.1. Correspondence list of EXPRESSCLUSTER and a manual¶
Description in this manual assumes the following version of EXPRESSCLUSTER. Make sure to note and check how EXPRESSCLUSTER versions and the editions of the manuals are corresponding.
EXPRESSCLUSTER
Internal Version
|
Manual |
Edition |
Remarks |
|---|---|---|---|
5.2.1-1 |
Getting Started Guide |
8th Edition |
|
Installation and Configuration Guide |
5th Edition |
||
Reference Guide |
7th Edition |
||
Maintenance Guide |
4th Edition |
||
Hardware Feature Guide |
2nd Edition |
5.2. New features and improvements¶
The following features and improvements have been released.
No. |
Internal
Version
|
Contents |
|---|---|---|
1 |
5.0.0-1 |
The newly released kernel is now supported. |
2 |
5.0.0-1 |
Ubuntu Server 20.04.3 LTS is now supported. |
3 |
5.0.0-1 |
SUSE LINUX Enterprise Server 12 SP3 is now supported. |
4 |
5.0.0-1 |
Along with the major upgrade, some functions have been removed. For details, refer to the list of removed functions. |
5 |
5.0.0-1 |
Added a function to suppress the automatic failover against a server crash, collectively in the whole cluster. |
6 |
5.0.0-1 |
Added a function to give a notice in an alert log that the server restart count was reset as the final action against the detected activation error or deactivation error of a group resource or against the detected error of a monitor resource. |
7 |
5.0.0-1 |
Added a function to exclude a server (with an error detected by a specified monitor resource) from the failover destination, for the automatic failover other than dynamic failover. |
8 |
5.0.0-1 |
Added the clpfwctrl.sh command for adding a firewall rule. |
9 |
5.0.0-1 |
Added AWS secondary IP resources and AWS secondary IP monitor resources. |
10 |
5.0.0-1 |
The forced stop function using BMC has been redesigned as a BMC forced-stop resource. |
11 |
5.0.0-1 |
Redesigned the function for forcibly stopping virtual machines as a vCenter forced-stop resource. |
12 |
5.0.0-1 |
The forced stop function in the AWS environment has been added to forced stop resources. |
13 |
5.0.0-1 |
The forced stop function in the OCI environment has been added to forced stop resources. |
14 |
5.0.0-1 |
Redesigned the forced stop script as a custom forced-stop resource. |
15 |
5.0.0-1 |
Added a function to collectively change actions (followed by OS shutdowns such as a recovery action following an error detected by a monitor resource) into OS reboots. |
16 |
5.0.0-1 |
Improved the alert message regarding the wait process for start/stop between groups. |
17 |
5.0.0-1 |
The display option for the clpstat configuration information has allowed displaying the setting value of the resource start attribute. |
18 |
5.0.0-1 |
The clpcl/clpstdn command has allowed specifying the -h option even when the local server belongs to a stopped cluster. |
19 |
5.0.0-1 |
A warning message is now displayed when Cluster WebUI is connected via a non-actual IP address and is switched to config mode. |
20 |
5.0.0-1 |
In the config mode of Cluster WebUI, a group can now be deleted with the group resource registered. |
21 |
5.0.0-1 |
Changed the content of the error message that a communication timeout occurred in Cluster WebUI. |
22 |
5.0.0-1 |
Changed the content of the error message that executing the full copy failed on the mirror disk screen in Cluster WebUI. |
23 |
5.0.0-1 |
Added a function to copy a group, group resource, or monitor resource registered in the config mode of Cluster WebUI. |
24 |
5.0.0-1 |
Added a function to move a group resource registered in the config mode of Cluster WebUI, to another group. |
25 |
5.0.0-1 |
The settings can now be changed at the group resource list of [Group Properties] in the config mode of Cluster WebUI. |
26 |
5.0.0-1 |
The settings can now be changed at the monitor resource list of [Monitor Common Properties] in the config mode of Cluster WebUI. |
27 |
5.0.0-1 |
The dependency during group resource deactivation is now displayed in the config mode of Cluster WebUI. |
28 |
5.0.0-1 |
Added a function to display a dependency diagram at the time of group resource activation/deactivation in the config mode of Cluster WebUI. |
29 |
5.0.0-1 |
Added a function to narrow down a range of display by type or resource name of a group resource or monitor resource on the status screen of Cluster WebUI. |
30 |
5.0.0-1 |
User mode monitor resources and dynamic DNS monitor resources now support the function for collecting cluster statistics information. |
31 |
5.0.0-1 |
An intermediate certificate can now be used as a certificate file when HTTPS is used for communication in the WebManager service. |
32 |
5.0.0-1 |
Added the clpcfconv.sh command, which changes the cluster configuration data file from the old version to the current one. |
33 |
5.0.0-1 |
Added a function to delay the start of the cluster service for starting the OS. |
34 |
5.0.0-1 |
Increased the items of cluster configuration data to be checked. |
35 |
5.0.0-1 |
Details such as measures can now be displayed for error results of checking cluster configuration data in Cluster WebUI. |
36 |
5.0.0-1 |
The OS type can be specified for specifying the create option of the clpcfset command. |
37 |
5.0.0-1 |
Added a function to delete a resource or parameter from cluster configuration data, which is enabled by adding the del option to the clpcfset command. |
38 |
5.0.0-1 |
Added the clpcfadm.py command, which enhances the interface for the clpcfset command. |
39 |
5.0.0-1 |
The start completion timing of an AWS DNS resource has been changed to the timing before which the following is confirmed: The record set was propagated to AWS Route 53. |
40 |
5.0.0-1 |
Changed the default value for [Wait Time to Start Monitoring] of AWS DNS monitor resources to 300 seconds. |
41 |
5.0.0-1 |
Improved the functionality of monitor resources not to be affected by disk IO delay as follows: When a timeout occurs due to the disk wait dormancy (D state) of the monitor process, they consider the status as a warning instead of an error. |
42 |
5.0.0-1 |
The clpstat command can now be run duplicately. |
43 |
5.0.0-1 |
Added the Node Manager service. |
44 |
5.0.0-1 |
Added a function for statistical information on heartbeat. |
45 |
5.0.0-1 |
The proxy server has become available even when a Witness heartbeat resource is not used for an HTTP NP resolution resource. |
46 |
5.0.0-1 |
SELinux enforcing mode is now supported. |
47 |
5.0.0-1 |
HTTP monitor resources now support digest authentication. |
48 |
5.0.0-1 |
The FTP server that uses FTPS for the FTP monitor resource can now be monitored. |
49 |
5.0.0-1 |
JBoss EAP domain mode of JVM monitor resources can now be monitored in Java 9 or later. |
50 |
5.0.2-1 |
JVM monitor resource now supports JBoss Enterprise Application Platform 7.4. |
51 |
5.0.2-1 |
JVM monitor resource supports Apache Tomcat 10.0. |
52 |
5.1.0-1 |
Ubuntu Server 22.04.1 LTS has been supported. |
53 |
5.1.0-1 |
Ubuntu Server 20.04.5 LTS has been supported. |
54 |
5.1.0-1 |
SUSE LINUX Enterprise Server 15 SP3 has been supported. |
55 |
5.1.0-1 |
Added SMTPS and STARTTLS support for the mail reporting function. |
56 |
5.1.0-1 |
Added a forced stop function for the Azure environment to the forced stop resource. |
57 |
5.1.0-1 |
Added a forced stop function for the vCenter forced stop resource used with vSphere Automation APIs. |
58 |
5.1.0-1 |
Allowed specifying a log-file storage period. |
59 |
5.1.0-1 |
Allowed a cluster configuration data file to be backed up during the application of the configuration data. |
60 |
5.1.0-1 |
Expanded the check items of cluster configuration data. |
61 |
5.1.0-1 |
Allowed changing the transmission source IP address of a floating IP resource. |
62 |
5.1.0-1 |
Allowed registering the following monitor resources with the multi target monitor resource:
- AWS Elastic IP monitor resource
- AWS Virtual IP monitor resource
- AWS Secondary IP monitor resource
- AWS AZ monitor resource
- AWS DNS monitor resource
- Azure probe port monitor resource
- Azure load balance monitor resource
- Azure DNS monitor resource
- Google Cloud Virtual IP monitor resource
- Google Cloud load balance monitor resource
- Google Cloud DNS monitor resource
- Oracle Cloud Virtual IP monitor resource
- Oracle Cloud load balance monitor resource
|
63 |
5.1.0-1 |
Added a feature for setting as a warning a value returned from the specified script, to custom monitor resources. |
64 |
5.1.0-1 |
Added support for SQL Server 2022 for SQL Server monitor resources. |
65 |
5.1.0-1 |
Added support for PostgreSQL 15.1 for PostgreSQL monitor resources. |
66 |
5.1.0-1 |
Added support for MariaDB 8.0.31 for MySQL monitor resources. |
67 |
5.1.0-1 |
Added support for MariaDB 10.10 for MySQL monitor resources. |
68 |
5.1.0-1 |
Eliminated the need for Python for configurations in AWS environments where only AWS Virtual IP resources and AWS Virtual IP monitor resources are used. |
69 |
5.1.0-1 |
Allowed using Cluster WebUI to specify environment variables for AWS-related features to access instance metadata and to use the AWS CLI. |
70 |
5.1.0-1 |
Added a feature to specify command line options for the AWS CLI used by AWS-related features. |
71 |
5.1.0-1 |
Added support for WebSAM SVF PDF Enterprise 10.1 for JVM monitor resources. |
72 |
5.1.0-1 |
Added support for WebSAM RDE SUITE 10.1 for JVM monitor resources. |
73 |
5.1.0-1 |
Added support for WebSAM SVF Connect SUITE Standard 10.1 for JVM monitor resources. |
74 |
5.1.0-1 |
Added a feature for outputting process resource statistics. |
75 |
5.1.0-1 |
Added a feature for system monitor resources to monitor the i-node utilization rate. |
76 |
5.1.0-1 |
Added support for client authentication for HTTP monitor resources. |
77 |
5.1.0-1 |
Added support for OpenSSL 3.0 for FTP monitor resources and HTTP monitor resources. |
78 |
5.1.0-1 |
Added a feature for JVM monitor resources to output retry count information to the operation log. |
79 |
5.1.0-1 |
Added support for Java 17 for JVM monitor resources. |
80 |
5.1.0-1 |
Subtracted support for Java 7 for JVM monitor resources. |
81 |
5.1.0-1 |
Added an option for the clpbackup.sh command and clprestore.sh command not to perform a server shutdown or restart. |
82 |
5.1.0-1 |
Added an option in the clpcfadm.py command to create a backup file of existing cluster configuration data. |
83 |
5.1.0-1 |
Allowed Cluster WebUI to display its operation log. |
84 |
5.1.0-1 |
Added support for OpenSSL 3.0 for Cluster WebUI. |
85 |
5.1.0-1 |
Disabled TLS 1.1 for the HTTPS connection of Cluster WebUI. |
86 |
5.1.0-1 |
Added a feature for Cluster WebUI to apply cluster configuration data to only servers which can be communicated. |
87 |
5.1.0-1 |
Allowed selecting [NMI] in [Operation at Timeout Detection] with [ipmi] selected for [Method] in the settings of user mode monitor resources and those of shutdown monitoring. |
88 |
5.1.0-1 |
Added a feature for the status screen of Cluster WebUI to list settings with which cluster operation is disabled. |
89 |
5.1.0-1 |
Added features for the config mode of Cluster WebUI to display or hide and to sort the following:
- Group resource list in [Group Properties]
- Monitor resource list in [Monitor Resources Common Properties]
|
90 |
5.1.0-1 |
Made the following changes for [Accessible number of clients] of cluster properties: its name to [Number of sessions which can be established simultaneously], and its lower limit value. |
91 |
5.1.0-1 |
Hid [Received time] by default in the Alert logs of Cluster WebUI. |
92 |
5.1.0-1 |
Changed the description of the [Restart the manager] button on the status screen of Cluster WebUI to "Restart WebManager service". |
93 |
5.1.0-1 |
Allowed [Copy the group] in the config mode of Cluster WebUI to copy group resources' dependency on a case-by-case basis as well. |
94 |
5.1.0-1 |
Implemented safeguards in Cluster WebUI to prevent configuration errors of AWS DNS resources. |
95 |
5.1.0-1 |
Implemented safeguards in Cluster WebUI to prevent configuration errors with [Monitor Type] of custom monitor resources set to [Asynchronous]. |
96 |
5.1.0-1 |
Implemented safeguards in Cluster WebUI to prevent configuration errors of the PING NP resolution resource. |
97 |
5.1.0-1 |
Allowed distinguishing in cluster statistics between automatic failover due to error detection and manual failover. |
98 |
5.1.1-1 |
Red Hat Enterprise Linux 9.0 has been supported. |
99 |
5.1.1-1 |
Oracle Linux 9.0 has been supported. |
100 |
5.1.1-1 |
MIRACLE LINUX 9.0 has been supported. |
101 |
5.1.1-1 |
AlmaLinux OS 9.0 has been supported. |
102 |
5.1.1-1 |
Added support for OpenSSL 3.0 for RESTful API. |
103 |
5.1.1-1 |
Added support for OpenSSL 3.0 for Witness heartbeat resources. |
104 |
5.1.1-1 |
Added support for OpenSSL 3.0 for HTTP network partition resolution resources. |
105 |
5.1.2-1 |
Added the clpselctrl.sh command for configuring SELinux. |
106 |
5.1.2-1 |
Red Hat Enterprise Linux 8.8 has been supported. |
107 |
5.1.2-1 |
Red Hat Enterprise Linux 9.2 has been supported. |
108 |
5.1.2-1 |
Oracle Linux 8.8 has been supported. |
109 |
5.1.2-1 |
Oracle Linux 9.2 has been supported. |
110 |
5.1.2-1 |
MIRACLE LINUX 8.8 has been supported. |
111 |
5.1.2-1 |
MIRACLE LINUX 9.2 has been supported. |
112 |
5.1.2-1 |
AlmaLinux OS 8.8 has been supported. |
113 |
5.1.2-1 |
AlmaLinux OS 9.2 has been supported. |
114 |
5.1.2-1 |
Added support for OpenSSL 3.1 for the following functions:
- Cluster WebUI
- RESTful API
- Mirror disk resources
- Hybrid disk resources
- FTP monitor resources
- HTTP monitor resources
- Witness heartbeat resources
- HTTP network partition resolution resources
- Mail report
|
115 |
5.2.0-1 |
Allowed collecting a log files for investigation with a failure in a group/monitor/forced-stop resource detected, and downloading the log files from Alert logs of Cluster WebUI. |
116 |
5.2.0-1 |
Changed the action against a stop failure of a group targeted for awaiting its stop: The stop timeout is no longer awaited. |
117 |
5.2.0-1 |
Added Oracle Cloud DNS resources and Oracle Cloud DNS monitor resources. |
118 |
5.2.0-1 |
Change the default dependency values of the following group resources:
- Azure probe port resources
- Google Cloud virtual IP resources
- Oracle Cloud virtual IP resources
- EXEC resources
- Disk resources
- Volume manager resources
- Dynamic DNS resources
|
119 |
5.2.0-1 |
Eliminated the need for Python for the following AWS-related resources and monitor resources:
- AWS Elastic IP resources
- AWS DNS resources
- AWS Elastic IP monitor resources
- AWS DNS monitor resources
- AWS AZ monitor resources
|
120 |
5.2.0-1 |
Added POP3S as an authentication method of POP3 monitor resources. |
121 |
5.2.0-1 |
Allowed detecting a monitor error in case of the disappearance of an exported area in NFSv4 monitoring by an NFS monitor resource. |
122 |
5.2.0-1 |
Allowed specifying a URI as a target for an HTTP network partition resolution resource. |
123 |
5.2.0-1 |
Subtracted support for OpenJDK 7 for JVM monitor resources. |
124 |
5.2.0-1 |
Supported WebOTX V11.1 for WebOTX monitor resources. |
125 |
5.2.0-1 |
Supported WebOTX V11.1 for JVM monitor resources. |
126 |
5.2.0-1 |
Supported Oracle Tuxedo 22c (22.1.0) for Tuxedo monitor resources. |
127 |
5.2.0-1 |
Supported giving a notice in an alert log, in an environment where an AWS forced-stop resource is set, that protection against stopping an EC2 instance is enabled. |
128 |
5.2.0-1 |
Added, for the forced-stop action of the Azure forced-stop resource, an option to immediately stop without resource deallocation. |
129 |
5.2.0-1 |
Allowed checking the status of a mirror/hybrid disk resource with the a value returned by the clpmdstat/clphdstat command. |
130 |
5.2.0-1 |
Provided more error messages about cloud-related functions. |
131 |
5.2.0-1 |
Modified the type of message outputted with a server down. |
132 |
5.2.0-1 |
Allowed outputting the RESTful API operation log to the server. |
133 |
5.2.0-1 |
Added an API for getting the following metrics information with the RESTful API:
- Group's continuous operation time
- Date and time when cluster configuration data was last applied
|
134 |
5.2.0-1 |
Provided more check items for cluster configuration data to be checked. |
135 |
5.2.0-1 |
Reduced the process time for cluster configuration data to be checked. |
136 |
5.2.0-1 |
Added time data to the name of a cluster configuration data file (.zip) to be saved with [Exporting the setting] of Cluster WebUI. |
137 |
5.2.0-1 |
Supported making a warning pop up with [Action at NP Occurrence] changed to any of the following options in the config mode of Cluster WebUI:
- Stop the cluster service
- Stop the cluster service and shutdown OS
- Stop the cluster service and reboot OS
|
138 |
5.2.0-1 |
Supported displaying server statuses in color in the status tab of Cluster WebUI. |
139 |
5.2.0-1 |
Changed the display position of a pop-up alert in Cluster WebUI, from the upper right to the lower right. |
140 |
5.2.0-1 |
Supported displaying the expiry date and remaining days of the license in the operation mode of Cluster WebUI. |
141 |
5.2.0-1 |
Supported Amazon Linux 2023 (x86_64 architecture). |
142 |
5.2.0-1 |
Supported Amazon Linux 2023 (ARM64 architecture). |
143 |
5.2.1-1 |
Improved the performance of a mirror/hybrid disk resource with the synchronous mode. |
144 |
5.2.1-1 |
Added support for PostgreSQL 16.3 for PostgreSQL monitor resources. |
145 |
5.2.1-1 |
Added support for MariaDB 11.2.3 for MySQL monitor resources. |
146 |
5.2.1-1 |
Added support for MySQL 8.0.36 for MySQL monitor resources. |
147 |
5.2.1-1 |
Red Hat Enterprise Linux 9.4 (x86_64 architecture) has been supported. |
148 |
5.2.1-1 |
Red Hat Enterprise Linux 9.4 (ARM64 architecture) has been supported. |
149 |
5.2.1-1 |
Red Hat Enterprise Linux 8.10 (x86_64 architecture) has been supported. |
150 |
5.2.1-1 |
Red Hat Enterprise Linux 8.10 (ARM64 architecture) has been supported. |
151 |
5.2.1-1 |
Oracle Linux 9.4 has been supported. |
152 |
5.2.1-1 |
Oracle Linux 8.10 has been supported. |
153 |
5.2.1-1 |
AlmaLinux OS 9.4 has been supported. |
154 |
5.2.1-1 |
AlmaLinux OS 8.10 has been supported. |
155 |
5.2.1-1 |
Added support for OpenSSL 3.2 and OpenSSL 3.3 for the following functions:
- Cluster WebUI
- RESTful API
- Witness heartbeat resources
- HTTP network partition resolution resources
- HTTP monitor resources
- FTP monitor resources
- POP3 monitor resources
|
5.3. Corrected information¶
Modification has been performed on the following minor versions.
- Critical level:
- L
- Operation may stop. Data destruction or mirror inconsistency may occur.Setup may not be executable.
- M
- Operation stop should be planned for recovery.The system may stop if duplicated with another fault.
- S
- A matter of displaying messages.Recovery can be made without stopping the system.
No.
|
Version in which the problem has been solved
/ Version in which the problem occurred
|
Phenomenon
|
Level
|
Occurrence condition/
Occurrence frequency
|
|---|---|---|---|---|
1 |
5.0.0-1
/ 1.0.0-1 to 4.3.2-1
|
In a group, when a group resource alone is successfully activated, the restoration of another group resource may be executed. |
S |
This problem occurs in a group where a group resource alone is activated with another group resource failing in activation. |
2 |
5.0.0-1
/ 4.1.0-1 to 4.3.2-1
|
In the config mode of Cluster WebUI, modifying a comment on a group resource may not be applied. |
S |
This problem occurs in the following case: A comment on a group resource is modified, the [Apply] button is clicked, the change is undone, and then the [OK] button is clicked. |
3 |
5.0.0-1
/ 4.1.0-1 to 4.3.2-1
|
In the config mode of Cluster WebUI, modifying a comment on a monitor resource may not be applied. |
S |
This problem occurs in the following case: A comment on a monitor resource is modified, the [Apply] button is clicked, the change is undone, and then the [OK] button is clicked. |
4 |
5.0.0-1
/ 4.0.0-1 to 4.3.2-1
|
In the status screen of Cluster WebUI, a communication timeout during the operation of a cluster causes a request to be repeatedly issued. |
M |
This problem always occurs when a communication timeout occurs between Cluster WebUI and a cluster server. |
5 |
5.0.0-1
/ 4.1.0-1 to 4.3.2-1
|
Custer WebUI may freeze when dependency is set in the config mode of Cluster WebUI. |
S |
This problem occurs when two group resources are made dependent on each other. |
6 |
5.0.0-1
/ 4.2.0-1 to 4.3.2-1
|
The response of the clpstat command may be delayed. |
S |
This problem may occur when communication with other servers is cut off. |
7 |
5.0.0-1
/ 3.1.0-1 to 4.3.2-1
|
A cluster service may not stop. |
S |
This problem very rarely occurs when stopping a cluster service is tried. |
8 |
5.0.0-1
/ 4.0.0-1 to 4.3.2-1
|
A monitor resource may mistakenly detect a monitoring timeout. |
M |
This problem very rarely occurs when a monitoring process is executed by a monitor resource. |
9 |
5.0.0-1
/ 4.2.0-1 to 4.3.2-1
|
Executing the clpcfchk command as follows causes a mixture of the current check results and the previous ones: The -o option is used to specify a directory where a file of the previous check results exists. |
S |
This problem occurs when a directory specified with the -o option of the clpcfchk command includes a file of the previous check results (cfchk_result.csv). |
10 |
5.0.0-1
/ 4.3.0-1 to 4.3.2-1
|
In checking a cluster configuration, a check for fstab may fail. |
S |
This problem occurs with a slash (/) placed after a device name or mount point written into the /etc/fstab file. |
11 |
5.0.0-1
/ 4.3.0-1 to 4.3.2-1
|
The clpcfset command may abend. |
S |
This problem occurs when an empty string is specified as an attribute value. |
12 |
5.0.0-1
/ 4.0.0-1 to 4.3.2-1
|
In an AWS environment, a forced stop script may time out. |
S |
This problem may occur when a forced stop script is run In an AWS environment. |
13 |
5.0.0-1
/ 4.2.0-1 to 4.3.2-1
|
An error occurs when the status code of a target response is 301 in an HTTP NP resolution resource. |
S |
This problem occurs when the response status code is 301. |
14 |
5.0.0-1
/ 4.0.0-1 to 4.3.2-1
|
In the WebManager service, [Client Session Timeout] may not work. |
S |
This problem occurs in the following case: Before the time specified in [Client Session Timeout] passes, the next request is not issued. |
15 |
5.0.0-1
/ 4.0.0-1 to 4.3.2-1
|
When a hybrid disk resource is used, there is a difference in the order of listing servers between the status screen of and the mirror disk screen of Cluster WebUI. |
S |
This problem occurs depending on the server group name: While the status screen lists servers in the order of priority, the mirror disk screen lists them in the ascending order of the names of server groups to which the servers belong. |
16 |
5.0.0-1
/ 4.0.0-1 to 4.3.2-1
|
When a monitoring process by a monitor resource times out, detecting a monitoring error may take time. |
S |
This problem very rarely occurs when a monitoring process by a monitor resource times out. |
17 |
5.0.0-1
/ 1.0.0-1 to 4.3.2-1
|
With an IP monitor resource or PING NP resolution resource configured, unexpected ICMP packets may be sent. |
S |
This problem occurs when an ICMP communication process leads to receiving an unexpected packet. |
18 |
5.0.0-1
/ 4.0.0-1 to 4.3.2-1
|
In [Monitoring usage of memory] for process resource monitor resources, [Duration time (min)] has been replaced with [Maximum Refresh Count (time)]. |
S |
This problem occurs when the properties are displayed with Cluster WebUI or the clpstat command. |
19 |
5.0.0-1
/ 3.3.2-1 to 4.3.2-1
|
With a mirror disk connection disconnected, a response to a command for mirror disks may be delayed. |
S |
This problem occurs when the most prioritized mirror disk connection of all is disconnected. |
20 |
5.0.0-1
/ 1.0.0-1 to 4.3.2-1
|
Deactivating a disk resource may fail with its disk type set to [raw]. |
S |
This problem occurs in the following case: During the deactivation of a disk resource with its disk type set to [raw], a process exists accessing the device. |
21 |
5.0.0-1
/ 1.1.0-1 to 4.3.2-1
|
With a mirror disk connection disconnected, the OS may intermittently stall. |
S |
This problem may occur in the following case: A mirror disk resource or hybrid disk resource is in [Asynchronous] mode, and the I/O load is high with a mirror disk connection disconnected. |
22 |
5.0.0-1
/ 4.2.0-1 to 4.3.2-1
|
The EXPRESSCLUSTER Information Base service may abend. |
S |
This problem very rarely occurs when one of the following is performed:
- Cluster startup
- Cluster stop
- Cluster suspension
- Cluster resumption
|
23 |
5.0.1-1
/ 5.0.0-1
|
In Ubuntu environments, the clpcfconv.sh command (for converting cluster configuration data files) fails to be executed. |
S |
This problem occurs in Ubuntu environments. |
24 |
5.0.1-1
/ 5.0.0-1
|
For a cluster configuration data file created on EXPRESSCLUSTER X 3.3 for Linux: After the data file is converted with the conversion command and then applied to the cluster, the mirror agent fails to start up. |
S |
This problem occurs when a mirror disk resource or hybrid disk resource is used with EXPRESSCLUSTER upgraded from X 3.3 for Linux. |
25 |
5.0.1-1
/ 5.0.0-1
|
For the clprexec command, the --script option does not work. |
S |
This problem occurs when the clprexec command is executed with the --script option specified. |
26 |
5.0.1-1
/ 5.0.0-1
|
After a forced-stop resource is added by executing the clpcfset command, the cluster fails to start up. |
S |
This problem occurs during an attempt to start up a cluster to which cluster configuration data (including a forced-stop resource added by executing the clpcfset command) was applied. |
27 |
5.0.1-1
/ 5.0.0-1
|
In Amazon Linux 2 environments, kernel mode LAN heartbeats do not start up normally. |
M |
This problem occurs in Amazon Linux 2 environments. |
28 |
5.0.1-1
/ 4.3.0-1 to 4.3.2-1 , 5.0.0-1
|
For mirror disk resources/hybrid disk resources based on the ext4 file system: A mirror recovery in full-copy mode may not normally copy data to the destination. |
L |
This problem occurs during a mirror recovery in full-copy mode with a mirror disk resource/hybrid disk resource based on the ext4 file system. |
29 |
5.0.1-1
/ 4.3.2-1 , 5.0.0-1
|
For Oracle monitor resources: When the monitoring times out, the retrying process may not work normally. |
M |
This problem occurs with an Oracle monitor resource when the monitoring process times out. |
30 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
The Amazon CloudWatch linkage function may not work. |
S |
This problem occurs on very rare occasions with the Amazon CloudWatch linkage function configured. |
31 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
After a server is removed from the [Servers that can run the Group] list of the failover group, trying to apply the configuration data does not lead to a group-stop request. |
S |
This problem occurs in the following case: After a server is removed from the [Servers that can run the Group] list of the failover group, applying the configuration data is tried. |
32 |
5.0.2-1
/ 4.3.2-1 to 5.0.1-1
|
If the file system of a mirror/hybrid disk resource is XFS, the resource activation fails on rare occasions. |
L |
This problem occurs on Red Hat Enterprise Linux 8.4 or higher if the file system of a mirror/hybrid disk resource is XFS. |
33 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
A monitor resource may detect a monitoring timeout by mistake. |
S |
This problem occurs on very rare occasions during a monitoring process by the monitor resource. |
34 |
5.0.2-1
/ 1.0.0-1 to 5.0.1-1
|
Performing the keepalive reset and keepalive panic may fail. |
S |
This problem occurs when the major number (10) and the minor number (241), both of which should be used by the keepalive driver, are used by another driver. |
35 |
5.0.2-1
/ 4.3.0-1 to 5.0.1-1
|
The monitoring process of a Tuxedo monitor resource may abend, leading to a monitoring error. |
M |
The occurrence of this problem depends on the timing. |
36 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
Forcibly stopping more than one server may fail. |
S |
This problem occurs on rare occasions when one of three or more servers in a cluster tries to forcibly stop other servers. |
37 |
5.0.2-1
/ 1.0.0-1 to 5.0.1-1
|
The clpstat command may abend. |
S |
This problem occurs in an environment where a failover group is set with no group resources registered. |
38 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
With a cluster suspended, Cluster WebUI or the clpstat command may show the server status as stopped. |
S |
This problem occurs when both of the following services are restarted with the cluster suspended:
- clusterpro_nm
- clusterpro_ib
|
39 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
A group/monitor resource status may be incorrectly shown. |
S |
This problem occurs with something wrong in the internal processing of cluster services during OS startup. |
40 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
Cluster WebUI or the clpstat command incorrectly shows the status of a server using no forced-stop resources. |
S |
This problem occurs when any of three or more servers in a cluster is configured not to use the forced-stop function. |
41 |
5.0.2-1
/ 5.0.0-1 to 5.0.1-1
|
Cluster WebUI displays the setting items of a high-speed SSD which does not work with an OS, one of the system requirements for EXPRESSCLUSTER X 5.0. |
S |
The setting items are always displayed in the detailed properties of mirror disk resources and in those of hybrid disk resources. |
42 |
5.0.2-1
/ 4.3.0-1 to 5.0.1-1
|
The clpwebmc process may abend. |
S |
This problem occurs on very rare occasions during cluster operation. |
43 |
5.0.2-1
/ 4.3.0-1 to 5.0.1-1
|
If the mount point of a disk resource, mirror disk resource, or hybrid disk resource includes a space, the /etc/fstab entry check (a function of checking cluster configuration data) fails. |
S |
This problem occurs when cluster configuration data is checked with the mount point including a space. |
44 |
5.1.0-1
/ 4.2.0-1 to 5.0.2-1
|
The EXPRESSCLUSTER Information Base service may abend. |
S |
This problem occurs on rare occasions when a cluster shutdown is performed. |
45 |
5.1.0-1
/ 4.2.0-1 to 5.0.2-1
|
The EXPRESSCLUSTER API service may abend. |
S |
This problem may occur depending on the timing. |
46 |
5.1.0-1
/ 4.0.0-1 to 5.0.2-1
|
Instead of a product version license, a fixed-term license may become active despite its expiration. |
S |
This problem occurs with both an unused fixed-term license and a product version license registered, when the former expires. |
47 |
5.1.0-1
/ 5.0.0-1 to 5.0.2-1
|
The status of the BMC forced stop resource becomes abnormal. |
S |
This problem occurs with the iLO shared network port enabled. |
48 |
5.1.0-1
/ 1.0.0-1 to 5.0.2-1
|
Failure in resuming a cluster may lead to its abend. |
M |
This problem occurs when a cluster is repeatedly suspended and resumed in the following environment: Two or more monitor resources are registered and each of their names consists of only one letter. |
49 |
5.1.0-1
/ 1.0.0-1 to 5.0.2-1
|
In changing cluster configuration data, the user may not be requested for any appropriate application method. |
S |
This problem occurs on rare occasions when cluster configuration data is applied. |
50 |
5.1.0-1
/ 3.1.0-1 to 5.0.2-1
|
The following may become abnormal: the status of a mirror-disk-related monitor or that of a hybrid-disk-related monitor. |
M |
This problem may occur after the application of cluster configuration data with the interconnect IP address changed. |
51 |
5.1.0-1
/ 1.0.0-1 to 5.0.2-1
|
In asynchronous mirroring, a mirror break may cause a heavily loaded server. |
S |
This problem may occur when a mirror disk connection is disconnected with the queue full of unsent data. |
52 |
5.1.0-1
/ 1.0.0-1 to 5.0.2-1
|
Recovering from a shutdown done by an improper method in an active server may cause data inconsistency between the active server and standby server. |
S |
This problem may occur in a mirror recovery in full-copy mode, without mirror disk resource activation, after a shutdown by an improper method in an active server. |
53 |
5.1.0-1
/ 4.1.0-1 to 5.0.2-1
|
A recovery script for a monitor resource may not be run. |
S |
This problem occurs in the following case: With [Execute Script before Recovery Action] on in Cluster WebUI, the user does not edit the script or simultaneously changes the script and something else. |
54 |
5.1.0-1
/ 1.0.0-1 to 5.0.2-1
|
A monitor resource, configured to perform continuous monitoring, may not work. |
S |
This problem occurs in a monitor resource with the setting of [Monitor Timing] changed from [Active] to [Always]. |
55 |
5.1.0-1
/ 1.0.0-1 to 5.0.2-1
|
When a custom monitor resource is stopped, a forced-termination signal is issued to the user application. |
M |
This problem occurs when a custom monitor resource is stopped with log rotation enabled. |
56 |
5.1.0-1
/ 1.0.0-1 to 5.0.1-1
|
Hostname resolution may fail if the host is accessible from HTTP monitor resources. |
S |
This problem may occur when the hostname (not the IP address) is specified as a connection destination. |
57 |
5.1.0-1
/ 4.1.0-1 to 5.0.2-1
|
[JVM Monitor Resource Tuning Properties] does not allow specifying a usage threshold for [Metaspace]. |
S |
This problem always occurs. |
58 |
5.1.0-1
/ 3.1.0-1 to 5.0.1-1
|
Monitoring by a JVM monitor resource may fail when a cluster is suspended and resumed. |
S |
This problem occurs in the following case: A cluster is suspended, and then it is resumed before a JVM monitor resource finishes stopping. |
59 |
5.1.0-1
/ 3.1.0-1 to 5.0.1-1
|
After a JVM monitor resource detects an error (consecutively exceeding a specified threshold by a specified count), the monitoring status may return to normal despite normal values (consecutively falling short of the threshold by the same count) yet to be detected. |
S |
This problem occurs in the following case: After such an error occurs, the next detected value is normal. |
60 |
5.1.0-1
/ 4.2.0-1 to 5.0.2-1
|
The display of the clpstat command may vary depending on the server where the command is executed. |
S |
This problem may occur when the command is executed on the server with the cluster service stopped. |
61 |
5.1.0-1
/ 3.0.0-1 to 5.0.2-1
|
The clprexec command may fail to be executed. |
S |
This problem may occur with the command extensively executed. |
62 |
5.1.0-1
/ 4.3.0-1 to 5.0.2-1
|
After the clpcfset command is executed to create cluster configuration data, its XML attribute value may be wrong. |
S |
This problem occurs when an ID attribute node is added by executing the clpcfset command. |
63 |
5.1.0-1
/ 5.0.0-1 to 5.0.2-1
|
After the clpcfset command is executed to create cluster configuration data, its object count may be wrong. |
S |
This problem occurs when, by executing the clpcfset command, the object count is added to or deleted from the cluster configuration data including a forced stop resource. |
64 |
5.1.0-1
/ 5.0.0-1 to 5.0.2-1
|
The clpcfadm.py command may not be correctly executed. |
S |
This problem occurs in the following case: Cluster WebUI executes the clpcfadm.py command on cluster configuration data from which all failover groups were deleted. |
65 |
5.1.0-1
/ 5.0.0-1 to 5.0.2-1
|
The clpcfadm.py command may allow an invalid monitor resource to be configured. |
S |
This problem occurs in the following case: When the clpcfadm.py command is used to add a monitor resource, jra is specified as the type of monitor resource. |
66 |
5.1.0-1
/ 5.0.0-1 to 5.0.2-1
|
After the clpcfadm.py command is executed to create cluster configuration data, its resource activation/deactivation timeout value may be wrong. |
S |
This problem occurs when executing the clpcfadm.py command changes the parameter requiring the calculation of the resource activation/deactivation timeout value. |
67 |
5.1.0-1
/ 4.2.0-1 to 5.0.2-1
|
For a cluster with a RESTful API, obtaining its status may fail. |
S |
This problem may occur with the EXPRESSCLUSTER Information Base service restarted. |
68 |
5.1.0-1
/ 4.2.0-1 to 5.0.2-1
|
A RESTful API may show the status of a cluster different from its actual status. |
S |
This problem may occur in the following case: The status is obtained while communication with other servers is cut off. |
69 |
5.1.0-1
/ 4.2.0-1 to 5.0.2-1
|
A RESTful API may fail to collect information. |
S |
This problem occurs on rare occasions in the following case: An API for collecting information is executed just after an API for operation is executed. |
70 |
5.1.0-1
/ 4.2.2-1 to 5.0.2-1
|
In group information retrieval with a RESTful API, an incorrect response to an exception may occur. |
S |
This problem may occur when a cluster server encounters an internal error. |
71 |
5.1.0-1
/ 3.1.0-1 to 5.0.2-1
|
Cluster WebUI may not allow itself to be connected. |
M |
This problem may occur in an environment with the FIPS mode enabled. |
72 |
5.1.0-1
/ 4.0.0-1 to 5.0.2-1
|
Display on Cluster WebUI may be delayed for a configuration with multiple mirror/hybrid disk resources registered. |
S |
This problem may occur when mirror recovery is performed for multiple resources. |
73 |
5.1.0-1
/ 4.0.0-1 to 5.0.2-1
|
Cluster WebUI may fail to suspend mirror recovery. |
S |
This problem occurs in the following case: Mirror recovery suspension is tried with a browser session different from that of Cluster WebUI, where the mirror recovery was started; or the browser session of Cluster WebUI is reloaded during the mirror recovery. |
74 |
5.1.0-1
/ 4.1.0-1 to 5.0.2-1
|
The cluster-creating wizard of Cluster WebUI fails to automatically register a floating IP monitor resource corresponding to [Management IP Address]. |
S |
This problem occurs with [Management IP Address] registered through the cluster-creating wizard. |
75 |
5.1.0-1
/ 4.1.0-1 to 5.0.2-1
|
Cluster WebUI may fail to change the timeout setting of disk resource activation and deactivation. |
S |
This problem occurs when only [Disk Type] or [File System] is changed for the disk resource. |
76 |
5.1.0-1
/ 4.3.0-1 to 5.0.2-1
|
Cluster WebUI may fail to obtain cloud environment information. |
S |
This problem occurs with Cluster WebUI connected via a proxy server. |
77 |
5.1.0-1
/ 4.0.0-1 to 5.0.2-1
|
After [TTL] is changed for an Azure DNS resource in the config mode of Cluster WebUI, the change is not applied to the record. |
S |
This problem always occurs. |
78 |
5.1.0-1
/ 4.2.1-1 to 5.0.2-1
|
When configuring strings like a resource name on the Cluster WebUI, consecutive spaces of two or more bytes are reduced to a single byte. |
S |
This problem occurs when the setting of cluster configuration data is changed while two or more bytes of spaces are input consecutively. |
79 |
5.1.0-1
/ 4.1.0-1 to 5.0.2-1
|
In Cluster WebUI, when a group of PING NP resolution resources is added, the group list may be incorrectly displayed. |
S |
This problem may occur with one or more groups registered in the list of PING NP resolution resource groups. |
80 |
5.1.1-1
/ 4.2.0-1 to 5.1.0-1
|
Applying cluster configuration data may fail. |
S |
This problem may occur when applying cluster configuration data repeatedly in the config mode of the Cluster WebUI. |
81 |
5.1.1-1
/ 4.0.0-1 to 5.1.0-1
|
A cluster may fail to start. |
S |
This problem very rarely occurs when a cluster is started. |
82 |
5.1.1-1
/ 5.0.0-1 to 5.1.0-1
|
When the EXPRESSCLUSTER service starts, a failover group may not be started. |
M |
This problem may occur in the following case: the EXPRESSCLUSTER service of each server is stopped one server at a time, and then starting the EXPRESSCLUSTER service. |
83 |
5.1.1-1
/ 1.0.0-1 to 5.1.0-1
|
Differential mirror recovery may cause data inconsistency for a mirror disk resource or a hybrid disk resource. |
S |
This problem very rarely occurs when an active server goes down without having received a transmission completion notification for data sent by the active server to the standby server. |
84 |
5.1.1-1
/ 3.3.0-1 to 5.1.0-1
|
After changing [Startup Server], the appropriate action for cluster configuration application is not required. |
S |
This problem always occurs. |
85 |
5.1.1-1
/ 2.0.0-1 to 5.1.0-1
|
A custom monitor resource may stop abnormally. |
S |
This problem may occur when the monitoring process of a custom monitor resource times out. |
86 |
5.1.1-1
/ 1.0.0-1 to 5.1.0-1
|
A SQL Server monitor resource may not detect an error. |
S |
This problem occurs when [Monitor Level] is 0. |
87 |
5.1.1-1
/ 5.1.0-1
|
Periodically checking of vCenter forced stop resource may not detect an error. |
S |
This problem occurs in the following occasions: Setting [Method of performing forced stop] to vSphere Automation API, and setting [Virtual Machine Name] to an incorrect name. |
88 |
5.1.1-1
/ 5.1.0-1
|
Mail reporting function may not work. |
S |
This problem occurs when the version is upgraded from X 5.0.2 or earlier to X 5.1.0 while mail reporting function is configured. |
89 |
5.1.1-1
/ 4.2.0-1 to 5.1.0-1
|
Heartbeat status may be incorrect. |
S |
This problem may occur in the following occasions: Connecting the Cluster WebUI on multiple cluster servers, or executing the clpstat command on multiple cluster servers. |
90 |
5.1.1-1
/ 5.0.0-1 to 5.1.0-1
|
Group resource status may be incorrect. |
S |
This problem may occur when restarting the EXPRESSCLUSTER service on a single node. |
91 |
5.1.1-1
/ 4.3.0-1 to 5.1.0-1
|
Applying cluster configuration data created by the clpcfset or clpcfadm command may fail. |
S |
This problem occurs when applying cluster configuration data created by the clpcfset or clpcfadm command, with --nocheck option. |
92 |
5.1.1-1
/ 4.3.0-1 to 5.1.0-1
|
In the config mode of the Cluster WebUI, [Apply the Configuration File] may be inexecutable. |
S |
This problem occurs when a mirror disk resource is registered in a cluster configuration and [Cluster Partition I/O Timeout] is greater than [Heartbeat Timeout]. |
93 |
5.1.1-1
/ 4.1.0-1 to 5.1.0-1
|
The wrong default value is set to [Maximum Reactivation Count] of a volume manager monitor resource. |
S |
This problem always occurs in a volume manager monitor resource that is automatically added when a volume manager resource is registered in the Cluster WebUI. |
94 |
5.1.2-1
/ 5.1.1-1
|
A cluster may not start due to an incorrect cluster server status. |
M |
This problem may occur after a cluster service is stopped. |
95 |
5.1.2-1
/ 1.0.0-1 to 5.1.1-1
|
Stopping the EXPRESSCLUSTER mirror agent service may fail, and then it causes a shutdown. |
S |
This problem occurs rarely in an environment where multiple mirror disk resources or multiple hybrid disk resources are registered. |
96 |
5.1.2-1
/ 5.0.0-1 to 5.1.1-1
|
The clpfwctrl.sh command may display an unnecessary message. |
S |
This problem occurs when the command is executed and there is no zone for the firewall rules to be added. |
97 |
5.1.2-1
/ 5.1.0-1 to 5.1.1-1
|
The screen may not display when connecting to Cluster WebUI via HTTPS. |
S |
This problem occurs rarely with OpenSSL 3.0 or later. |
98 |
5.1.2-1
/ 4.3.0-1 to 5.1.1-1
|
In the Cluster WebUI operation mode, the specific configuration values of some resources cannot be displayed.
Also the clpstat command fails to display these values.
|
S |
This problem occurs when one of the following items is set to the maximum length.
- A resource name of AWS secondary ip resource (31 characters)
- A resource name of AWS virtual ip resource (31 characters)
- A resource name of Google Cloud DNS resource (31 characters)
- A zone name of Google Cloud DNS resource (63 characters)
- A DNS name of Google Cloud DNS resource (253 characters)
|
99 |
5.1.2-1
/ 1.0.0-1 to 5.1.1-1
|
Switching to the Cluster WebUI Config mode may become inpossible. |
S |
This problem very rarely occurs. |
100 |
5.1.2-1
/ 1.0.0-1 to 5.1.1-1
|
The vulnerabilities of CVE-2023-39544 to 39548 may cause the following acts by third parties:
- Execution of an arbitrary code
- Uploading of an arbitrary file
- Skimming a cluster configuration data file
|
L |
These problems occur when a specific process in EXPRESSCLUSTER receives a packet crafted by a malicious third party against the internal protocol of EXPRESSCLUSTER. |
101 |
5.2.0-1
/ 4.2.0-1 to 5.1.2-1
|
The EXPRESSCLUSTER Information Base service may abend. |
S |
This problem may occur when cluster configuration data is uploaded with its server data deleted. |
102 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
An emergency shutdown may occur during an attempt to stop a cluster service. |
M |
This problem occurs when one hour passes in stopping a cluster service. |
103 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
clprm, a cluster service process, may abend during an attempt to stop the cluster service. |
S |
This problem occurs on rare occasions depending on the timing. |
104 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
During an attempt to restart a resource due to a monitoring error or to perform a failover, a stopped resource is also started. |
S |
This problem occurs when starting up a resource fails, with its final action against a resource activation failure set to [No operation (not activate next resource)], and then the recovery action due to a monitoring error is taken. |
105 |
5.2.0-1
/ 4.3.0-1 to 5.1.2-1
|
A stopped resource may be started during a failover due to a server failure. |
S |
This problem occurs when the failover occurs with a resource which was set to be manually started but has never started despite the startups of the cluster. |
106 |
5.2.0-1
/ 2.0.0-1 to 5.1.2-1
|
Starting up a hybrid disk resource may fail. |
S |
This problem may occur after the OS is restarted in an environment with many hybrid disk resources. |
107 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
In an environment with a mirror/hybrid disk resource configured, a standby server may panic. |
S |
This problem may occur with both of the following cases true:
- In [Operation at I/O Error Detection], [Data Partition] is set to [NONE].
- On the standby server, writing to a data partition leads to repeated I/O errors.
|
108 |
5.2.0-1
/ 4.0.0-1 to 5.1.2-1
|
The status of a dynamic DNS monitor resource does not change from warning to normal. |
S |
This problem occurs after the monitoring status becomes warning. |
109 |
5.2.0-1
/ 4.1.0-1 to 5.1.2-1
|
With the monitoring timing of a monitor resource set to active, the monitor resource may perform monitoring despite the deactivation state of the target resource. |
S |
This problem may occur with the resource repeatedly restarted. |
110 |
5.2.0-1
/ 4.3.0-1 to 5.1.2-1
|
The following monitor resources may consider their normal targets to be abnormal:
- AWS Virtual IP monitor resources
- AWS Secondary IP monitor resources
- Google Cloud DNS monitor resources
|
M |
This problem occurs after the internal process becomes abnormal. |
111 |
5.2.0-1
/ 4.0.0-1 to 5.1.2-1
|
An IP monitor resource may fail to detect a monitoring error. |
S |
This problem may occur when a monitoring error is detected but the end process takes time. |
112 |
5.2.0-1
/ 4.0.0-1 to 5.1.2-1
|
When a monitoring timeout occurs in an IP monitor resource, an invalid alert log may be outputted. |
S |
This problem occurs when the monitoring timeout occurs with either of the following configurations:
- A system monitor resource or process resource monitor resource is set
- Collecting system resource statistics is set
|
113 |
5.2.0-1
/ -
|
An Azure DNS monitor resource fails in the normal monitoring process. |
S |
This problem occurs when the version of the Azure CLI is 2.50.0 or higher. |
114 |
5.2.0-1
/ 5.1.0-1 to 5.1.2-1
|
The Azure forced-stop resource may not work normally. |
S |
This problem may occur with the configuration of [Servers in Use] for the Azure forced-stop changed in an environment with three or more nodes. |
115 |
5.2.0-1
/ 5.1.0-1 to 5.1.2-1
|
It may take time for the Azure forced-stop resource to reboot an instance. |
S |
This problem occurs with [Forced Stop Action] set to [reboot]. |
116 |
5.2.0-1
/ 5.1.0-1 to 5.1.2-1
|
When a timeout occurs in a forced-stop resource in a cloud environment, a regular check may fail. |
S |
This problem may occur with the system heavily loaded. |
117 |
5.2.0-1
/ 5.0.0-1 to 5.1.2-1
|
When cluster configuration data is created by executing the clpcfadm.py command, either of the following may occur:
- A value is set different from the specified one.
- The specified value is not set.
|
S |
This problem occurs after a particular parameter is set. |
118 |
5.2.0-1
/ 5.1.0-1 to 5.1.2-1
|
The operation log of Cluster WebUI may fail to be collected. |
S |
This problem occurs with the path of [Log output path] including either of the following:
- A symbolic link
- "/" at the end
|
119 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
Log collection may fail. |
S |
This problem occurs when the log file size becomes 2 GB or more. |
120 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
Applying cluster configuration data may fail. |
S |
This problem occurs after an IP address not displayed with the ifconfig command is set for an interconnect. |
121 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
When applying a setting from Cluster WebUI leads to an authentication error, necessary services may not restart. |
S |
This problem occurs with the following performed at the same time:
- Creating or changing a password on the cluster password method
- A change involving a service restart
|
122 |
5.2.0-1
/ 4.0.0-1 to 5.1.2-1
|
In Cluster WebUI, a forcible mirror recovery may fail. |
S |
This problem occurs when an unknown-status server exists in hybrid disk configuration. |
123 |
5.2.0-1
/ 1.0.0-1 to 5.1.2-1
|
In the HTTP response header of the WebManager server, no appropriate character encoding method is specified. |
S |
This problem always occurs in Cluster WebUI. |
124 |
5.2.0-1
/ 5.1.0-1 to 5.1.2-1
|
RESTful API execution may fail. |
S |
This problem may occur in RESTful API execution just after an OS startup. |
125 |
5.2.0-1
/ 4.3.0-1 to 5.1.2-1
|
User (password) authentication may fail with a RESTful API. |
M |
This problem always occurs with both of the following disabled:
- Controlling connection by using client IP addresses
- Setting privileges on a per-group basis
|
126 |
5.2.0-1
/ 4.0.0-1 to 5.1.2-1
|
In Alert logs of Cluster WebUI, the display may become invalid. |
S |
This problem occurs when Cluster WebUI displays a corrupted alert log. |
127 |
5.2.0-1
/ 5.0.0-1 to 5.1.2-1
|
In the config mode of Cluster WebUI, a dependency diagram may not be displayed. |
S |
This problem occurs with an extremely large number of resources. |
128 |
5.2.0-1
/ 4.1.0-1 to 5.1.2-1
|
In the operation mode of Cluster WebUI, the detailed properties of an IP monitor resource may not be opened. |
S |
This problem occurs after one IP address is set as a common monitoring setting and two or more IP addresses are set for individual servers. |
129 |
5.2.0-1
/ 4.1.0-1 to 5.1.2-1
|
In the operation mode of Cluster WebUI, the detailed properties of an IP monitor resource may not correctly display an IP address specified in [IP addresses]. |
S |
This problem occurs after two or more IP addresses are set as common monitoring settings and two or more IP addresses are set for individual servers. |
130 |
5.2.0-1
/ 4.1.0-1 to 5.1.2-1
|
In the config mode of Cluster WebUI, [Final action] is set to a wrong value for a volume manager monitor resource. |
S |
This problem always occurs in a volume manager monitor resource which is automatically added with a volume manager resource registered in Cluster WebUI. |
131 |
5.2.0-1
/ 4.1.0-1 to 5.1.2-1
|
In the config mode of Cluster WebUI, the setting for [Network Partition Resolution Tuning Properties] is not saved after the [Apply] button is pressed and [Cluster properties] is closed by pressing the [Cancel] button. |
S |
This problem occurs after the setting for [Network Partition Resolution Tuning Properties] is changed and then [Cluster properties] is closed by pressing the [Cancel] button. |
132 |
5.2.0-1
/ 4.1.0-1 to 5.1.2-1
|
In the config mode of Cluster WebUI, [User Name] in the [Monitor (special)] tab for an FTP monitor resource is not a mandatory item. |
S |
This problem always occurs. |
133 |
5.2.1-1
/ 4.2.0-1 to 5.2.0-1
|
The EXPRESSCLUSTER Information Base service may take time to stop. |
S |
This problem may occur when the EXPRESSCLUSTER Information Base service is restarted after operating cluster for an extended period of time. |
134 |
5.2.1-1
/ 4.2.0-1 to 5.2.0-1
|
In an environment where IPv6 is disabled, the EXPRESSCLUSTER API service may not start. |
S |
This problem occurs in an environment where the following kernel parameters are set.
- net.ipv6.conf.all.disable_ipv6 = 1
- net.ipv6.conf.default.disable_ipv6 = 1
|
135 |
5.2.1-1
/ 1.0.0-1 to 5.2.0-1
|
In the EXPRESSCLUSTER Web Alert service, unnecessary local communication may occur. |
S |
This problem may occur when a blank is set for some servers in [Interconnect] tab for a heartbeat I/F. |
136 |
5.2.1-1
/ 1.0.0-1 to 5.2.0-1
|
When the [Enable Alert Setting] setting is changed, it may not be applied to the cluster. |
S |
This problem occurs when the settings of some messages are changed. |
137 |
5.2.1-1
/ 4.2.0-1 to 5.2.0-1
|
In Cluster WebUI, when applying cluster configuration data, the service restart screen may not close. |
S |
This problem occurs when the restart of WebManager service, information Base service, and API service is simultaneously required as the application method. |
138 |
5.2.1-1
/ 5.1.0-1 to 5.2.0-1
|
When activating Floating IP resources with the transmission source change feature enabled, unnecessary path information may be added. |
S |
This problem may occur when the static route exists. |
139 |
5.2.1-1
/ 5.0.0-1 to 5.2.0-1
|
After moving a failover group in an IPv6 environment, a mirror break may occur and a mirror recovery may be failed. |
S |
This problem may occur in an environment where the IPv6 addresses are set for Floating IP resources. |
140 |
5.2.1-1
/ 3.3.0-1 to 5.2.0-1
|
The Azure load balance monitor resource may become abnormal in monitoring. |
S |
This problem may occur depending on the timing during the failover group shutdown process. |
141 |
5.2.1-1
/ 5.1.0-1 to 5.2.0-1
|
When a monitoring target of the JVM monitor resource becomes abnormal, a failover may not occur. |
S |
This problem occurs in the following case: After the monitoring target fails over due to an error detected by the JVM monitor resource, it fails back to the server from which it failed over, and the monitor resource detects an error again. |
142 |
5.2.1-1
/ 1.0.0-1 to 5.2.0-1
|
The EXPRESSCLUSTER processes that use ICMP communication, such as IP monitor resources and PING network partition resolution resources, may abend. |
S |
This problem very rarely occurs when it is not possible to communicate with the specified IP address. |
143 |
5.2.1-1
/ 4.2.0-1 to 5.2.0-1
|
In the following resources, when a host that requires SSL's SNI is set for the monitoring target, the status becomes abnormal.
- Witness heartbeat resources
- HTTP network partition resolution resources
- HTTP monitor resources
|
M |
This problem occurs when a host that requires SSL's SNI is set for the monitoring target with using SSL or HTTPS. |
144 |
5.2.1-1
/ 1.0.0-1 to 5.2.0-1
|
Mail reporting may not be failed. |
S |
This problem may occur by the settings of a mail server.
|
145 |
5.2.1-1
/ 4.0.0-1 to 5.2.0-1
|
The activation and deactivation timeout values for Azure DNS resources created with the clpcfadm command may be incorrect. |
S |
This problem occurs when the parameters that require calculation of the active/deactive timeout value for Azure DNS resources are changed using the clpcfadm command. |
146 |
5.2.1-1
/ 5.2.0-1
|
In Cluster WebUI, if an user without the operation right logs in, an authentication error message is displayed. |
S |
This problem occurs when one of the followings is configured:
- Control connection by using password
- Control connection by using client IP address
|
147 |
5.2.1-1
/ 5.2.0-1
|
The following alert log is output, and the log file for investigation cannot be downloaded.
Module Type: trnsv
Event ID: 1
|
S |
This problem occurs in an environment where the [Control connection by using client IP address] setting is enabled. |
6. Notes and Restrictions¶
This chapter provides information on known problems and how to troubleshoot the problems.
This chapter covers:
6.1. Designing a system configuration¶
Hardware selection, option products license arrangement, system configuration, and shared disk configuration are introduced in this section.
6.1.1. Function list and necessary license¶
The following option products are necessary as many as the number of servers.
Those resources and monitor resources for which the necessary licenses are not registered are not on the resource list of the Cluster WebUI.
Necessary function |
Necessary license |
|---|---|
Mirror disk resource |
EXPRESSCLUSTER X Replicator 5.2 4 |
Hybrid disk resource |
EXPRESSCLUSTER X Replicator DR 5.2 5 |
Oracle monitor resource |
EXPRESSCLUSTER X Database Agent 5.2 |
DB2 monitor resource |
EXPRESSCLUSTER X Database Agent 5.2 |
PostgreSQL monitor resource |
EXPRESSCLUSTER X Database Agent 5.2 |
MySQL monitor resource |
EXPRESSCLUSTER X Database Agent 5.2 |
SQL Server monitor resource |
EXPRESSCLUSTER X Database Agent 5.2 |
ODBC monitor resource |
EXPRESSCLUSTER X Database Agent 5.2 |
Samba monitor resource |
EXPRESSCLUSTER X File Server Agent 5.2 |
nfs monitor resource |
EXPRESSCLUSTER X File Server Agent 5.2 |
http monitor resource |
EXPRESSCLUSTER X Internet Server Agent 5.2 |
smtp monitor resource |
EXPRESSCLUSTER X Internet Server Agent 5.2 |
pop3 monitor resource |
EXPRESSCLUSTER X Internet Server Agent 5.2 |
imap4 monitor resource |
EXPRESSCLUSTER X Internet Server Agent 5.2 |
ftp monitor resource |
EXPRESSCLUSTER X Internet Server Agent 5.2 |
Tuxedo monitor resource |
EXPRESSCLUSTER X Application Server Agent 5.2 |
WebLogic monitor resource |
EXPRESSCLUSTER X Application Server Agent 5.2 |
WebSphere monitor resource |
EXPRESSCLUSTER X Application Server Agent 5.2 |
WebOTX monitor resource |
EXPRESSCLUSTER X Application Server Agent 5.2 |
JVM monitor resource |
EXPRESSCLUSTER X Java Resource Agent 5.2 |
System monitor resource |
EXPRESSCLUSTER X System Resource Agent 5.2 |
Process resource monitor resource |
EXPRESSCLUSTER X System Resource Agent 5.2 |
Mail report actions |
EXPRESSCLUSTER X Alert Service 5.2 |
Network Warning Light status |
EXPRESSCLUSTER X Alert Service 5.2 |
6.1.2. Hardware requirements for mirror disks¶
Linux md stripe set, volume set, mirroring, and stripe set with parity cannot be used for either mirror disk resource cluster partitions or data partitions.
- Linux LVM volumes can be used for both cluster partitions and data partitions.For SuSE, however, LVM and MultiPath volumes cannot be used for data partitions. (This is because for SuSE, ReadOnly or ReadWrite control over these volumes cannot be performed by EXPRESSCLUSTER.)
Mirror disk resource cannot be made as a target of a Linux md stripe set, volume set, mirroring, and stripe set with parity.
Mirror partitions (data partition and cluster partition) to use a mirror disk resource.
There are two ways to allocate mirror partitions:
Allocate a mirror partition (data partition and cluster partition) on the disk where the operating system (such as root partition and swap partition) resides.
Reserve (or add) a disk (or LUN) not used by the operating system and allocate a mirror partition on the disk.
Consider the following when allocating mirror partitions:
- When maintainability and performance are important:- It is recommended to have a mirror disk that is not used by the OS.
- When LUN cannot be added due to hardware RAID specification or when changing LUN configuration is difficult in hardware RAID pre-install model:- Allocate a mirror partition on the same disk where the operating system resides.
When multiple mirror disk resources are used, it is recommended to prepare (adding) a disk per mirror disk resource. Allocating multiple mirror disk resources on the same disk may result in degraded performance and it may take a while to complete mirror recovery due to disk access performance on Linux operating system.
Disks used for mirroring must be the same in all servers.
Disk interface
Mirror disks on both servers and disks where mirror partition is allocated should be of the same disk interface
Example
Combination
server1
server2
OK
SCSI
SCSI
OK
IDE
IDE
NG
IDE
SCSI
Disk type
Mirror disks on both servers and disks where mirror partition is allocated should be of the same disk type
Example
Combination
server1
server2
OK
HDD
HDD
OK
SSD
SSD
NG
HDD
SSD
Sector size
Mirror disks on both servers and disks where mirror partition is allocated should be of the same sector size
Example
Combination
server1
server2
OK
512B
512B
OK
4KB
4KB
NG
512B
4KB
Notes when the geometries of the disks used as mirror disks differ between the servers.
The partition size allocated by the fdisk command is aligned by the number of blocks (units) per cylinder. Allocate a data partition considering the relationship between data partition size and direction for initial mirror configuration to be as indicated below:
Source server <= Destination server
"Source server" refers to the server where the failover group that a mirror disk resource belongs has a higher priority in failover policy. "Destination server" refers to the server where the failover group that a mirror disk resource belongs has a lower priority in failover policy.
Make sure that the data partition sizes do not cross over 32GiB, 64GiB, 96GiB, and so on (multiples of 32GiB) on the source server and the destination server. For sizes that cross over multiples of 32GiB, initial mirror construction may fail. Be careful, therefore, to secure data partitions of similar sizes.
Example
Combination
Data partition size
Description
On server 1
On server 2
OK
30GiB
31GiB
OK because both are in the range of 0 to 32GiB.
OK
50GiB
60GiB
OK because both are in the range of 32GiB to 64GiB.
NG
30GiB
39GiB
Error because they are crossing over 32GiB.
NG
60GiB
70GiB
Error because they are crossing over 64GiB.
6.1.4. Hardware requirements for hybrid disks¶
Disks to be used as a hybrid disk resource do not support a Linux md stripe set, volume set, mirroring, and stripe set with parity.
- Linux LVM volumes can be used for both cluster partitions and data partitions.For SuSE, however, LVM and MultiPath volumes cannot be used for data partitions. (This is because for SuSE, ReadOnly or ReadWrite control over these volumes cannot be performed by EXPRESSCLUSTER.)
Hybrid disk resource cannot be made as a target of a Linux md stripe set, volume set, mirroring, and stripe set with parity.
Hybrid partitions (data partition and cluster partition) are required to use a hybrid disk resource.
When a disk for hybrid disk is allocated in the shared disk, a partition for disk heartbeat resource between servers sharing the shared disk device is required.
The following are the two ways to allocate partitions when a disk for hybrid disk is allocated from a disk which is not a shared disk:
Allocate hybrid partitions (data partition and cluster partition) on the disk where the operating system (such as root partition and swap partition) resides.
Reserve (or add) a disk (or LUN) not used by the operating system and allocate a hybrid partition on the disk.
Consider the following when allocating hybrid partitions:
- When maintainability and performance are important:- It is recommended to have a hybrid disk that is not used by the OS.
- When LUN cannot be added due to hardware RAID specification or when changing LUN configuration is difficult in hardware RAID pre-install model:- Allocate a hybrid partition on the same disk where the operating system resides.
Device for which hybrid disk resource is allocated
Type of required partition
Shared disk device
Non-shared disk device
Data partition
Required
Required
Cluster partition
Required
Required
Partition for disk heart beat
Required
Not Required
Allocation on the same disk (LUN) as where the OS is
-
Possible
When multiple hybrid disk resources are used, it is recommended to prepare (add) a LUN per hybrid disk resource. Allocating multiple hybrid disk resources on the same disk may result in degraded in performance and it may take a while to complete mirror recovery due to disk access performance on Linux operating system.
Notes when the geometries of the disks used as hybrid disks differ between the servers.
Allocate a data partition considering the relationship between data partition size and direction for initial mirror configuration to be as indicated below:
Source server <= Destination server
"Source server" refers to the server with a higher priority in failover policy in the failover group where the hybrid disk resource belongs. "Destination server" refers to the server with a lower priority in failover policy in the failover group where the hybrid disk resource belongs has.
Make sure that the data partition sizes do not cross over 32GiB, 64GiB, 96GiB, and so on (multiples of 32GiB) on the source server and the destination server. For sizes that cross over multiples of 32GiB, initial mirror construction may fail. Be careful, therefore, to secure data partitions of similar sizes.
Example
Combination
Data partition size
Description
On server 1
On server 2
OK
30GiB
31GiB
OK because both are in the range of 0 to 32GiB.
OK
50GiB
60GiB
OK because both are in the range of 32GiB to 64GiB.
NG
30GiB
39GiB
Error because they are crossing over 32GiB.
NG
60GiB
70GiB
Error because they are crossing over 64GiB.
6.1.5. IPv6 environment¶
The following function cannot be used in an IPv6 environment:
AWS Elastic IP resource
AWS Virtual IP resource
AWS Secondary IP resource
AWS DNS resource
Azure probe port resource
Azure DNS resource
Google Cloud virtual IP resource
Google Cloud DNS resource
Oracle Cloud virtual IP resource
Oracle Cloud DNS resource
AWS Elastic IP monitor
AWS Virtual IP monitor
AWS Secondary IP monitor
AWS AZ monitor
AWS DNS monitor
Azure probe port monitor
Azure load balance monitor
Azure DNS monitor
Google Cloud virtual IP monitor resource
Google Cloud load balance monitor resource
Google Cloud DNS monitor resource
Oracle Cloud virtual IP monitor resource
Oracle Cloud load balance monitor resource
Oracle Cloud DNS monitor resource
The following functions cannot use link-local addresses:
LAN heartbeat resource
Kernel mode LAN heartbeat resource
Mirror disk connect
PING network partition resolution resource
FIP resource
VIP resource
6.1.6. Network configuration¶
The cluster configuration cannot be configured or operated in an environment, such as NAT, where an IP address of a local server is different from that of a remote server.
Example of network configuration
Fig. 6.1 Example of the environment where a cluster cannot be configured¶
Cluster settings for Server 1
Local server: 10.0.0.1
Remote server: 10.0.0.2
Cluster settings for Server 2
Local server: 192.168.0.1
Remote server: 10.0.0.1
6.1.7. Execute Script before Final Action setting for monitor resource recovery action¶
6.1.8. NIC Link Up/Down monitor resource¶
ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: umbg
Wake-on: g
Current message level: 0x00000007 (7)
Link detected: yes
When the LAN cable link status ("Link detected: yes") is not displayed as the result of the ethtool command:
It is highly likely that NIC Link Up/Down monitor resource of EXPRESSCLUSTER is not operable. Use IP monitor resource instead.
When the LAN cable link status ("Link detected: yes") is displayed as the result of the ethtool command:
In most cases NIC Link Up/Down monitor resource of EXPRESSCLUSTER can be operated, but sometimes it cannot be operated.
Particularly in the following hardware, NIC Link Up/Down monitor resource of EXPRESSCLUSTER may not be operated. Use IP monitor resource instead.
When hardware is installed between the actual LAN connector and NIC chip such as a blade server
When the monitored NIC is in a bonding environment, check whether the MII Polling Interval is set to 0 or higher.
To check if NIC Link Up/Down monitor resource can be used by using EXPRESSCLUSTER on an actual machine, follow the steps below to check the operation.
- Register NIC Link Up/Down monitor resource with the configuration information.Select No Operation for the configuration of recovery operation of NIC Link Up/Down monitor resource upon failure detection.
Start the cluster.
- Check the status of NIC Link Up/Down monitor resource.If the status of NIC Link Up/Down monitor resource is abnormal while LAN cable link status is normal, NIC Link Up/Down monitor resource cannot be operated.
- If NIC Link Up/Down monitor resource status becomes abnormal when LAN cable link status is made abnormal status (link down status), NIC Link Up/Down monitor resource can be operated.If the status remains to be normal, NIC Link Up/Down monitor resource cannot be operated.
6.1.9. Write function of the Mirror disk resource and Hybrid disk resource¶
There are 2 types of disk mirroring of mirror disk resources and hybrid disk resources: synchronous mirroring and asynchronous mirroring.
In synchronous mirroring, data is written in the disks of both servers for every request to write data in the data partition to be mirrored and its completion is waited. Data is written in each of the servers along with this, but it is written in disks of other servers via network, so writing performance declines more significantly compared to a normal local disk that is not to be mirrored. In case of the remote cluster configuration, since the network communication speed is slow and delay is long, the writing performance declines drastically.
In asynchronous mirroring, data is written to the local server immediately. However, when writing data to other server, it is saved to the local queue first and then written in the background. In case of asynchronous mirror, the data to be updated is saved in the queue for every writing request as well, so the writing performance declines more significantly, compared to the normal local disk that is not to be mirrored and the shared disk. For this reason, it is recommended to use the shared disk for the system (such as the database system with lots of update systems) that is required high throughput for writing data in disks.
In case of asynchronous mirroring, the writing sequence will be guaranteed, but the data that has been updated to the latest may be lost, if an active server shuts down. For this reason, if it is required to inherit the data immediately before an error occurs for sure, use synchronous mirroring or the shared disk.
6.1.10. History file of asynchronous mirroring¶
In mirror disk or hybrid disk with asynchronous mode, data that cannot afford to be written in memory queue is recorded temporarily in a folder specified to save history files. When the limit of the file is not specified, history files are written in the specified folder without limitation. In this case, the line speed is too low, compared to the disk update amount of application, writing data to other server cannot catch up with update of data on the disk, and history files will overflow from the disk.
For this reason, it is required to reserve a communication line with enough speed in the remote cluster configuration as well, in accordance with the disk update amount of application.
It is also required to prepare against an overflow of history files from the directory due to a long delay in communication or a continuous update of data on the disk. The preparation can be achieved by maintaining enough free space and limiting the history file size for the history file directory, or by specifying a different directory on a non-system disk.
6.1.11. Not outputting syslog to the Mirror disk resource or the Hybrid disk resource¶
Use bonding as a way of path redundancy of the mirror disk connection.
Adjust the user-mode monitoring timeout value or the mirror related timeout values.
6.1.12. Notes when terminating the Mirror disk resource or the Hybrid disk resource¶
- In case that processes which access to the directories, subdirectories and files which mounted the mirror disk resource or the hybrid disk resource exist, terminate the accesses to each disk resource by using ending script or other methods at deactivation of each disk resource like when shutdown or failover.Depending on the settings of each disk resource, action at abnormity detection when unmounting (forcibly terminate processes while each disk resource is being accessed) may occur, or recovery action at deactivation failure caused by unmount failure (OS shutdown or other actions) may be executed.
- In case that a massive amount of accesses to directories, subdirectories or files which mounted the mirror disk resource or hybrid disk resource are executed, it may take much time before the cache of the file systems is written out to the disks when unmounting at disk resource deactivation.At times like this, set the timeout interval of unmount longer enough so that the writing to the disks will successfully complete.
- For the details of this setting,see "Group resource details" in "Reference Guide",Recovery Operation tab or Mirror Disk Resource Tuning Properties or Unmount tab in Details tab in "Understanding Mirror disk resources" or "Understanding Hybrid disk resources".
6.1.13. Data consistency among multiple asynchronous mirror disks¶
6.1.14. Mirror data reference at the synchronization destination if mirror synchronization is interrupted¶
6.1.15. O_DIRECT for mirror or hybrid disk resources¶
6.1.16. Initial mirror construction time for mirror or hybrid disk resources¶
The time that takes to construct the initial mirror is different between ext3/ext4/xfs and other file systems.
Note
xfs shortens the time with resource deactivation.
6.1.17. Mirror or hybrid disk connect¶
When using redundant mirror or hybrid disk connect, both version of IP address are needed to be the same.
All the IP addresses used by mirror disk connect must be set to IPv4 or IPv6.
6.1.18. JVM monitor resources¶
Up to 25 Java VMs can be monitored concurrently. The Java VMs that can be monitored concurrently are those which are uniquely identified by the Cluster WebUI (with Identifier in the Monitor (special) tab).
Connections between Java VMs and Java Resource Agent do not support SSL.
It may not be possible to detect thread deadlocks. This is a known problem in Java VM. For details, refer to "Bug ID: 6380127" in the Oracle Bug Database.
The JVM monitor resources can monitor only the Java VMs on the server on which the JVM monitor resources are running.
The JVM monitor resources can monitor only one JBoss server instance per server.
The Java installation path setting made by the Cluster WebUI (with Java Installation Path in the JVM monitor tab in Cluster Properties) is shared by the servers in the cluster. The version and update of Java VM used for JVM monitoring must be the same on every server in the cluster.
The management port number setting made by the Cluster WebUI (with Management Port in the Connection Setting dialog box opened from the JVM monitor tab in Cluster Properties) is shared by all the servers in the cluster.
Application monitoring is disabled when an application to be monitored on the IA32 version is running on an x86_64 version OS.
If a large value such as 3,000 or more is specified as the maximum Java heap size by the Cluster WebUI (by using Maximum Java Heap Size on the JVM monitor tab in Cluster Properties), The JVM monitor resources will fail to start up. The maximum heap size differs depending on the environment, so be sure to specify a value based on the capacity of the mounted system memory.
- If "-XX:+UseG1GC" is added as a startup option of the target Java VM, the settings on the Memory tab on the Monitor(special) tab in Properties of JVM monitor resources cannot be monitored before Java 7.It's possible to monitor by choosing Oracle Java (usage monitoring) in JVM Type on the Monitor(special) tab after Java 8.
6.1.19. Requirements for network warning light¶
When using "DN-1000S" or "DN-1500GL," do not set your password for the warning light.
- To play an audio file as a warning, you must register the audio file to a network warning light supporting audio file playback.For details about how to register an audio file, see the manual of the network warning light you want to use.
Set up a network warning light so that a server in a cluster is permitted to execute the rsh command to that warning light.
6.1.20. Cluster WebUI¶
We recommend you to use Cluster WebUI with HTTPS used as a securer communication method.
For information on how to set it, see "Reference Guide" -> "Parameter details" -> "Cluster properties" -> "WebManager tab" and "Encryption tab".
6.1.21. Installation Path Specification¶
6.2. Installing operating system¶
Notes on parameters to be determined when installing an operating system, allocating resources, and naming rules are described in this section.
6.2.1. Mirror disks¶
Disk partition
Example: When adding one SCSI disk to each of both servers and making a pair of mirrored disks:
In the figure below, a SCSI disk is added to each of two servers.The inside of the disk is divided into the cluster partition and the data partition. This set of partitions, called a mirror partition device, is a unit for the failover of the mirror disk resource.
Fig. 6.2 Configuration of disks and partitions (with SCSI disks added)¶
Example: When using free space of IDE disks of both servers, where the OS is stored, and making a pair of mirrored disks:
The following figure illustrates using the free space of each built-in disk as a mirror partition device (cluster partition and data partition):
Fig. 6.3 Configuration of disks and partitions (with free space of existing disks used)¶
Mirror partition device refers to cluster partition and data partition.
Allocate cluster partition and data partition on each server as a pair.
It is possible to allocate a mirror partition (cluster partition and data partition) on the disk where the operating system resides (such as root partition and swap partition.).
- When maintainability and performance are important:It is recommended to have a mirror disk that is not used by the operating system (such as root partition and swap partition.)
- When LUN cannot be added due to hardware RAID specification: orWhen changing LUN configuration is difficult in hardware RAID pre-install model:
It is possible to allocate a mirror partition (cluster partition and data partition) on the disk where the operating system resides (such as root partition and swap partition.)
Disk configurations
Multiple disks can be used as mirror disks on a single server. Or, you can allocate multiple mirror partitions on a single disk.
Example: When adding two SCSI disks to each of both servers and making two pairs of mirrored disks:
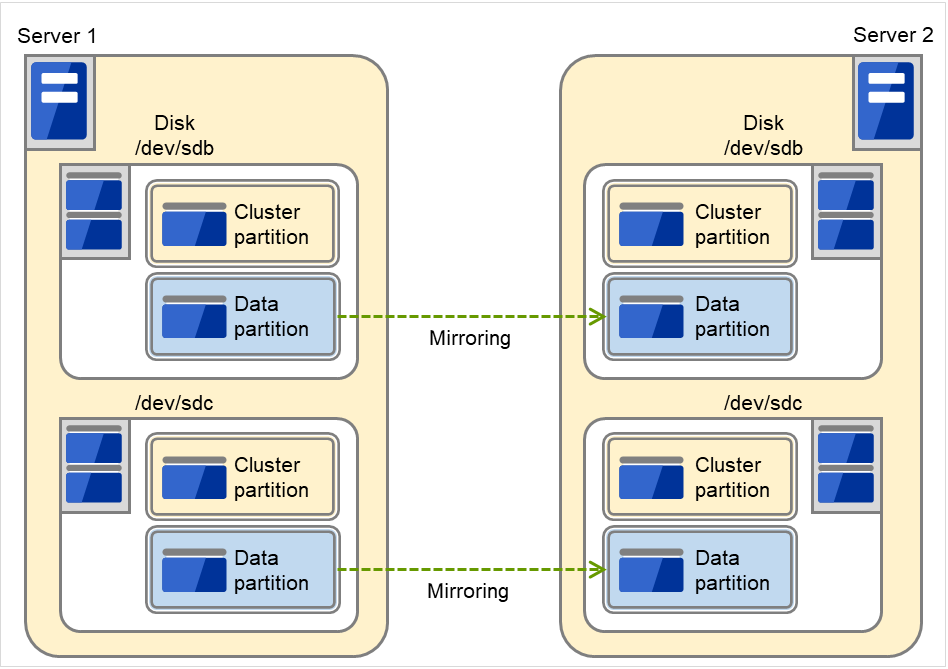
Fig. 6.4 Each of multiple disks used as a mirror partition¶
Allocate two partitions, cluster partition and data partition, as a pair on each disk.
Use of the data partition as the first disk and the cluster partition as the second disk is not permitted.
Example: When adding one SCSI disk to each of both servers and making two mirror partitions:
The figure below illustrates the case where two mirror partitions are allocated in a disk.
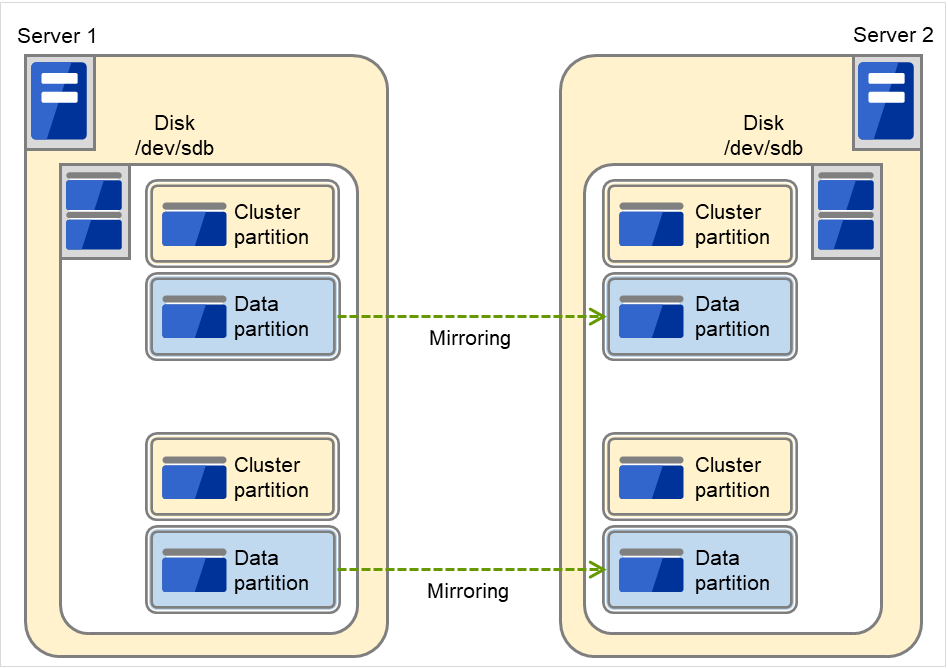
Fig. 6.5 Multiple areas of each disk used as mirror partitions¶
A disk does not support a Linux md stripe set, volume set, mirroring, and stripe set with parity.
6.2.2. Hybrid disks¶
Disk partition
Disks that are shared or not shared (server with built-in disk, external disk chassis not shared by servers etc.) can be used.
Example) When two servers use a shared disk and the third server uses a built-in disk in the server:
In the figure below, the built-in disk of Server 3 is used as a mirror partition device.
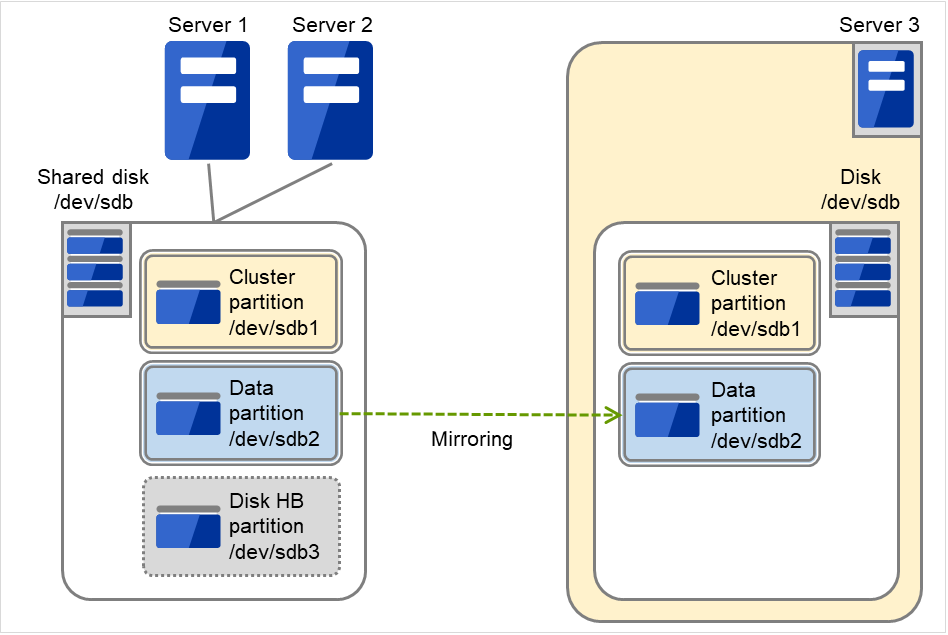
Fig. 6.6 Configuration of disks and partitions (with a shared disk and a built-in disk used)¶
Mirror partition device is a device EXPRESSCLUSTER mirroring driver provides in the upper.
Allocate cluster partition and data partition on each server as a pair.
When a disk that is not shared (e.g. server with a built-in disk, external disk chassis that is not shared among servers) is used, it is possible to allocate mirror partitions (cluster partition and data partition) on the disk where the operating system resides (such as root partition and swap partition.).
When a hybrid disk is allocated in a shared disk device, allocate a partition for the disk heart beat resource between servers sharing the shared disk device.
A disk does not support a Linux md stripe set, volume set, mirroring, and stripe set with parity.
6.2.3. Dependent library¶
libxml2
Install libxml2 when installing the operating system.
libcrypt
If you use an OS without libcrypt.so.1 installed (e.g., Amazon Linux 2023), install libxcrypt-compat.
# dnf install -y libxcrypt-compat
6.2.4. Dependent driver¶
softdog
This driver is necessary when softdog is used to monitor user-mode monitor resource.
Configure a loadable module. Static driver cannot be used.
6.2.5. Necessary package¶
When you install the OS, install the following packages as well:
tar
NetworkManager-config-server (for Red Hat Enterprise Linux derivative distributions)
6.2.6. The major number of Mirror driver¶
Use mirror driver's major number 218. Do not use major number 218 for other device drivers.
6.2.7. The major number of Kernel mode LAN heartbeat and keepalive drivers¶
Use major number 10, minor number 253 for kernel mode LAN heartbeat driver.
Use major number 10, minor number 254 for keepalive driver.
Make sure to check that other drivers are not using major and minor numbers described above.
6.2.8. Partition for RAW monitoring of disk monitor resources¶
Allocate a partition for monitoring when setting up RAW monitoring of disk monitor resources. The partition size should be 10MB.
6.2.9. SELinux settings¶
To make EXPRESSCLUSTER workable with SELinux in enforcing mode, see "Installation and Configuration Guide" -> "Installing EXPRESSCLUSTER" -> "Setting up the EXPRESSCLUSTER Server" -> "Setting for SELinux", then follow the procedure.
6.2.10. LVM metadata daemon settings¶
- When controlling or monitoring the LVM by using the volume manager resource or volume manager monitor resource in an environment of Red Hat Enterprise Linux 7 or later, the LVM metadata daemon must be disabled.The procedure to disable the metadata daemon is as follows:
Execute the following command to stop the LVM metadata daemon.
# systemctl stop lvm2-lvmetad.service
Edit /etc/lvm/lvm.conf to set the value of use_lvmetad to 0.
6.2.11. Secure Boot settings¶
Disable the Secure Boot settings.
6.3. Before installing EXPRESSCLUSTER¶
Notes after installing an operating system, when configuring OS and disks are described in this section.
6.3.1. Communication port number¶
Configure to be able to access the port number below when setting a firewall on a server.
After installing EXPRESSCLUSTER, you can use the clpfwctrl.sh command to configure a firewall. For more information, see "Reference Guide" -> "EXPRESSCLUSTER command reference" -> "Adding a firewall rule (clpfwctrl.sh command)". Ports to be set with the clpfwctrl.sh command are marked with ✓ in the clpfwctrl column of the table below.
For a cloud environment, allow access to ports numbered as below, not only in a firewall configuration at the instance side but also in a security configuration at the cloud infrastructure side.
Server to Server Loopback in servers
From
To
Used for
clpfwctrl
Server
Automatic allocation 6
Server
29001/TCP
Internal communication
✓
Server
Automatic allocation
Server
29002/TCP
Data transfer
✓
Server
Automatic allocation
Server
29002/UDP
Heartbeat
✓
Server
Automatic allocation
Server
29003/UDP
Alert synchronization
✓
Server
Automatic allocation
Server
29004/TCP
Communication between mirror agents
✓
Server
Automatic allocation
Server
29006/UDP
Heartbeat (kernel mode)
✓
Server
Automatic allocation
Server
29008/TCP
Cluster information management
✓
Server
Automatic allocation
Server
29010/TCP
Internal communication of RESTful API
✓
Server
Automatic allocation
Server
XXXX 7 /TCP
Mirror disk resource data synchronization
✓
Server
Automatic allocation
Server
XXXX 8 /TCP
Communication between mirror drivers
✓
Server
Automatic allocation
Server
XXXX 9 /TCP
Communication between mirror drivers
✓
Server
icmp
Server
icmp
keepalive between mirror drivers, duplication check for FIP/VIP resource and mirror agent
Server
Automatic allocation
Server
XXXX 10 /UDP
Internal log communication
✓
Client to Server
From
To
Used for
clpfwctrl
RESTful API client
Automatic allocation
Server
29009/TCP
http communication
✓
Cluster WebUI to Server
From
To
Used for
clpfwctrl
Cluster WebUI
Automatic allocation
Server
29003/TCP
http communication
✓
Others
From
To
Used for
clpfwctrl
Server
Automatic allocation
Network warning light
See the manual for each product.
Network warning light control
Server
Automatic allocation
Management LAN of server BMC
623/UDP
BMC control (Forced stop)
Server
Automatic allocation
Witness server
Communication port number specified with Cluster WebUI
Connection destination host of the Witness heartbeat resource
Server
icmp
Monitoring target
icmp
IP monitor
Server
icmp
Monitoring target
icmp
Monitoring target of Ping method network partition resolution resource
Server
Automatic allocation
Monitoring target
Management port number set by the Cluster WebUI
Monitoring target of HTTP method of network partition resolution resource
Server
Automatic allocation
Server
Management port number set by the Cluster WebUI 11
JVM monitor
✓
Server
Automatic allocation
Monitoring target
Connection port number set by the Cluster WebUI 11
JVM monitor
Server
Automatic allocation
Server
Probe port number set by the Cluster WebUI 12
Azure probe port resource
✓
Server
Automatic allocation
AWS service endpoint
443/tcp 13
AWS elastic ip resourceAWS virtual ip resourceAWS secondary ip resourceAWS DNS resourceAWS elastic ip monitor resourceAWS virtual ip monitor resourceAWS secondary ip monitor resourceAWS AZ monitor resourceAWS DNS monitor resourceAWS forced stop resourceServer
Automatic allocation
Azure endpoint
443/tcp 14
Azure DNS resource
Server
Automatic allocation
Azure authoritative name server
53/udp
Azure DNS monitor resource
Server
Automatic allocation
Server
Port number set in Cluster WebUI 12
Google Cloud virtual IP resource
✓
Server
Automatic allocation
Server
Port number set in Cluster WebUI 12
Oracle Cloud virtual IP resource
✓
Server
Automatic allocation
Oracle Cloud endpoint
443/tcp 15
Oracle Cloud DNS resourceOracle Cloud DNS monitor resourceOCI Forced stop resource
- 6
In automatic allocation, a port number not being used at a given time is allocated.
- 7
This is a port number used per mirror disk resource or hybrid disk resource and is set when creating mirror disk resource or hybrid disk resource. A port number 29051 is set by default. When you add a mirror disk resource or hybrid disk resource, this value is automatically incremented by 1. To change the value, click Details tab in the [md] Resource Properties or the [hd] Resource Properties dialog box of the Cluster WebUI. For more information, refer to "Group resource details" in the "Reference Guide".
- 8
This is a port number used per mirror disk resource or hybrid disk resource and is set when creating mirror disk resource or hybrid disk resource. A port number 29031 is set by default. When you add a mirror disk resource or a hybrid disk resource, this value is automatically incremented by 1. To change the value, click Details tab in the [md] Resource Properties or the [hd] Resource Properties dialog box of the Cluster WebUI. For more information, refer to "Group resource details" in the "Reference Guide".
- 9
This is a port number used per mirror disk resource or hybrid disk resource and is set when creating mirror disk resource or hybrid disk resource. A port number 29071 is set by default. When you add a mirror disk resource or hybrid disk resource this value is automatically incremented by 1. To change the value, click Details tab in the [md] Resource Properties or the [hd] Resource Properties dialog box of the Cluster WebUI. For more information, refer to "Group resource details" in the "Reference Guide".
- 10
Select UDP for the Communication Method for Internal Logs in the Port No. (Log) tab in Cluster Properties. Use the port number configured in Port No. Communication port is not used for the default log communication method UNIX Domain.
- 11(1,2)
The JVM monitor resource uses the following two port numbers.
A management port number is a port number that the JVM monitor resource internally uses. To set this number, use the Connection Setting dialog box opened from the JVM monitor tab in Cluster Properties of the Cluster WebUI. For details, refer to "Parameter details" in the "Reference Guide".
A connection port number is used to establish a connection to the target Java VM (WebLogic Server or WebOTX). To set this number, use the Monitor (special) tab in Properties of the Cluster WebUI for the corresponding JVM monitor resource. For details, refer to "Monitor resource details" in the "Reference Guide".
- 12(1,2,3)
Port number used by the load balancer for the alive monitoring of each server.
- 13
The above port numbers are used with the AWS CLI, which is executed by the following AWS-related resources:
AWS Elastic IP resource
AWS Virtual IP resource
AWS Secondary IP resource
AWS DNS resource
AWS Elastic IP monitor resource
AWS Virtual IP monitor resource
AWS Secondary IP monitor resource
AWS AZ monitor resource
AWS DNS monitor resource
AWS Forced stop resource
- 14
The Azure DNS resource runs the Azure CLI. The above port numbers are used by the Azure CLI.
- 15
The above port numbers are used with the OCI CLI, which is executed by the following OCI-related resources:
Oracle Cloud DNS resource
Oracle Cloud DNS monitor resource
OCI Forced stop resource
6.3.2. Changing the range of automatic allocation for the communication port numbers¶
The range of automatic allocation for the communication port numbers managed by the OS might overlap the communication port numbers used by EXPRESSCLUSTER.
Change the OS settings to avoid duplication when the range of automatic allocation for the communication numbers managed by OS and the communication numbers used by EXPRESSCLUSTER are duplicated.
Examples of checking and displaying OS setting conditions.
The range of automatic allocation for the communication port numbers depends on the distribution.
# cat /proc/sys/net/ipv4/ip_local_port_range 1024 65000This is the condition to be assigned for the range from 1024 to 65000 when the application requests automatic allocation for the communication port numbers to the OS.
# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000This is the condition to be assigned for the range from 32768 to 61000 when the application requests automatic allocation for the communication port numbers to the OS.
Examples of OS settings change
Add the line below to /etc/sysctl.conf. (When changing to the range from 30000 to 65000)
net.ipv4.ip_local_port_range = 30000 65000This setting takes effect after the OS is restarted.
After changing /etc/sysctl.conf, you can reflect the change instantly by executing the command below.
# sysctl -p
6.3.3. Avoiding insufficient ports¶
6.3.4. Clock synchronization¶
In a cluster system, it is recommended to synchronize multiple server clocks regularly. Synchronize server clocks by using ntp.
6.3.5. NIC device name¶
Because of the ifconfig command specification, when the NIC device name is shortened, the length of the NIC device name which EXPRESSCLUSTER can handle depends on it.
6.3.7. Mirror disk¶
Set a management partition for mirror disk resource (cluster partition) and a partition for mirror disk resource (data partition).
- EXPRESSCLUSTER controls the file systems on mirror disks. Do not set the file systems on the mirror disks to /etc/fstab in operating system.(Do not enter a mirror partition device, mirror mount point, cluster partition, or data partition in /etc/fstab of the operating system.)(Do not enter /etc/fstab even with the ignore option specified.If you enter /etc/fstab with the ignore option specified, the entry will be ignored when mount is executed, but an error may subsequently occur when fsck is executed.)(Entering /etc/fstab with the noauto option specified is not recommended, either, because it may lead to an inadvertent manual mount or result in some application being mounted.)
Provide the cluster partition with 1024 MiB or more of space. (Do not mind that specifying just 1024 MB actually provides more than the size due to a difference in the disk geometry.) Do not create any file system in the cluster partition.
See the "Installation and Configuration Guide" for steps for mirror disk configuration.
6.3.8. Hybrid disk¶
Configure the management partition (cluster partition) for hybrid disk resource and the partition used for hybrid disk resource (data partition).
When a hybrid disk is allocated in the shared disk device, allocate the partition for the disk heart beat resource between servers sharing the shared disk device.
- EXPRESSCLUSTER controls the file systems on the hybrid disk. Do not include the file systems on the hybrid disk to /etc/fstab in operating system.(Do not enter a mirror partition device, mirror mount point, cluster partition, or data partition in /etc/fstab of the operating system.)(Do not enter /etc/fstab even with the ignore option specified.If you enter /etc/fstab with the ignore option specified, the entry will be ignored when mount is executed, but an error may subsequently occur when fsck is executed.)(Entering /etc/fstab with the noauto option specified is not recommended, either, because it may lead to an inadvertent manual mount or result in some application being mounted.)
Provide the cluster partition with 1024 MiB or more of space. (Do not mind that specifying just 1024 MB actually provides more than the size due to a difference in the disk geometry.) Do not create any file system in the cluster partition.
See the "Installation and Configuration Guide" for steps for hybrid disk configuration.
When using this EXPRESSCLUSTER version, a file system must be manually created in a data partition used by a hybrid disk resource. For details about what to do when a file system is not created in advance, see "Settings after configuring hardware" in " Determining a system configuration" of the "Installation and Configuration Guide".
6.3.9. When using an ext3/ext4 file system for a mirror/hybrid disk resource¶
6.3.9.1. Block sizes¶
When creating an ext3/ext4 file system for the data partition of a mirror/hybrid disk resource by manually executing the mkfs command, avoid setting the block size at 1024.
The value, 1024, of the block size is not supported by mirror or hybrid disk resources. To explicitly use the block size, specify 2048 or 4096.
6.3.10. Adjusting OS startup time¶
It is necessary to configure the time from power-on of each node in the cluster to the server operating system startup to be longer than the following:
The time from power-on of the shared disks to the point they become available.
Heartbeat timeout time
See the "Installation and Configuration Guide" for configuration steps.
6.3.11. Verifying the network settings¶
The network used by Interconnect or Mirror disk connect is checked. It checks by all the servers in a cluster.
See the "Installation and Configuration Guide" for configuration steps.
6.3.12. OpenIPMI¶
The following functions use OpenIPMI.
Final Action at Activation Failure / Deactivation Failure
Monitor resource action upon failure
User-mode monitor
Shutdown monitor
Forcibly stopping a physical machine
OpenIPMI do not come with EXPRESSCLUSTER. You need to download and install the rpm packages for OpenIPMI.
Check whether or not your server (hardware) supports OpenIPMI in advance.
Note that even if the machine complies with ipmi standard as hardware, OpenIPMI may not run if you actually try to run them.
- If you are using a software program for server monitoring provided by a server vendor, do not choose ipmi as a monitoring method for user-mode monitor resource and shutdown stall monitor. Because these software programs for server monitoring and OpenIPMI both use BMC (Baseboard Management Controller) on the server, a conflict occurs preventing successful monitoring.
6.3.13. User mode monitor resource, shutdown monitoring (monitoring method: softdog)¶
- When softdog is selected as a monitoring method, use the
/dev/watchdogdevice.Make sure not to start the features that use the/dev/watchdogdevice except EXPRESSCLUSTER.Examples of such features are as follows:hpwdt driver
i8xx_tco driver
iTCO_wdt driver
watchdog feature and shutdown monitoring feature of systemd
6.3.14. Log collection¶
- The designated function of the generation of the syslog does not work by a log collection function in SUSE LINUX. The reason is because the suffixes of the syslog are different.Please change setting of rotate of the syslog as follows to use the appointment of the generation of the syslog of the log collection function.
Please comment out "compress" and "date ext" of the /etc/logrotate.d/syslog file.
When the total log size exceeds 2GB on each server, log collection may fail.
6.3.15. nsupdate and nslookup¶
The following functions use nsupdate and nslookup.
Dynamic DNS resource of group resource (ddns)
Dynamic DNS monitor resource of monitor resource (ddnsw)
EXPRESSCLUSTER does not include nsupdate and nslookup. Therefore, install the rpm files of nsupdate and nslookup, in addition to the EXPRESSCLUSTER installation.
NEC does not support the items below regarding nsupdate and nslookup. Use nsupdate and nslookup at your own risk.
Inquiries about nsupdate and nslookup
Guaranteed operations of nsupdate and nslookup
Malfunction of nsupdate or nslookup or failure caused by such a malfunction
Inquiries about support of nsupdate and nslookup on each server
6.3.16. FTP monitor resources¶
If a banner message to be registered to the FTP server or a message to be displayed at connection is long or consists of multiple lines, a monitor error may occur. When monitoring by the FTP monitor resource, do not register a banner message or connection message.
6.3.17. Notes on using Red Hat Enterprise Linux 7¶
In mail reporting function takes advantage of the [mail] command of OS provides. Because the minimum composition is [mail] command is not installed, please execute one of the following.
Select the [SMTP] by the Mail Method on the Alert Service tab of Cluster Properties.
Installing mailx.
6.3.18. Notes on using Ubuntu¶
To execute EXPRESSCLUSTER-related commands, execute them as the root user.
Only a WebSphere monitor resource is supported in Application Server Agent. This is because other Application Server isn't supporting Ubuntu.
In mail reporting function takes advantage of the [mail] command of OS provides. Because the minimum composition is [mail] command is not installed, please execute one of the following.
Select the [SMTP] by the Mail Method on the Alert Service tab of Cluster Properties.
Installing mailutils.
Information acquisition by SNMP cannot be used.
6.3.19. Time synchronization in the AWS environment¶
6.3.20. IAM settings in the AWS environment¶
The procedure of setting IAM is shown below.
First, create IAM policy by referring to "Creating IAM policy" explained below.
- Next, set up the instance.To use IAM role, refer to "Setting up an instance by using IAM role" described later.To use IAM user, refer to "Setting up an instance by using IAM user" described later.
Creating IAM policy
Create a policy that describes access permissions for the actions to the services such as EC2 and S3 of AWS. The actions required for AWS-related resources and monitor resources to execute AWS CLI are as follows:
The necessary policies are subject to change.
AWS virtual ip resource / AWS virtual ip monitor resource
Action
Description
This is required for obtaining information of VPC, route table and network interfaces.
ec2:ReplaceRoute
This is required for updating the route table.
AWS elastic ip resource /AWS elastic ip monitor resource
Action
Description
This is required for obtaining information of EIP and network interfaces.
ec2:AssociateAddress
This is required for associating EIP with ENI.
ec2:DisassociateAddress
This is required for disassociating EIP from ENI.
AWS secondary ip resource / AWS secondary ip monitor resource
Action
Description
This is required for obtaining information on network interfaces and subnets.
ec2:AssignPrivateIpAddresses
This is required for assigning secondary IP addresses.
ec2:UnassignPrivateIpAddresses
This is required for deassigning secondary IP addresses.
AWS AZ monitor resource
Action
Description
ec2:DescribeAvailabilityZones
This is required for obtaining information of the availability zone.
AWS DNS resource / AWS DNS monitor resource
Action
Description
route53:ChangeResourceRecordSets
This is required for a resource record set is added or deleted or when the resource record set configuration is updated.
route53:GetChange
This is required for a resource record set is added or when the resource record set configuration is updated.
route53:ListResourceRecordSets
This is required for obtaining information of a resource record set.
AWS forced stop resource
Action
Description
ec2:DescribeInstances
This is required for obtaining information on instances.
ec2:StopInstances
This is required for stopping instances.
ec2:RebootInstances
This is required for restarting instances.
ec2:DescribeInstanceAttribute
This is required for obtaining instance attributes.
Function for sending data on the monitoring process time taken by the monitor resource, to Amazon CloudWatch.
Action
Description
cloudwatch:PutMetricData
This is required for sending custom metrics.
Function for sending alert service messages to Amazon SNS
Action
Description
sns:Publish
This is required for sending messages.
The example of a custom policy as shown below permits actions used by all the AWS-related resources and monitor resources.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:Describe*", "ec2:ReplaceRoute", "ec2:AssociateAddress", "ec2:DisassociateAddress", "ec2:AssignPrivateIpAddresses", "ec2:UnassignPrivateIpAddresses", "ec2:StopInstances", "ec2:RebootInstances", "route53:ChangeResourceRecordSets", "route53:GetChange", "route53:ListResourceRecordSets" ], "Effect": "Allow", "Resource": "*" } ] }You can create a custom policy from [Policies] - [Create Policy] in IAM Management Console
Setting up an instance by using IAM role
In this method, you can execute AWS CLI after creating IAM role and associate it with an instance.
Fig. 6.7 Setting an instance by using IAM role¶
Create the IAM role and attach the IAM Policy to the role.
You can create the IAM role from [Roles] - [Create New Role] in IAM Management Console
When creating an instance, specify the IAM role you created to IAM Role.
Log on to the instance.
Install the AWS CLI.
The installation path of the AWS CLI must be any of the following:/sbin, /bin, /usr/sbin, /usr/bin, /usr/local/binFor details about how to set up the AWS CLI, refer to the following:(If EXPRESSCLUSTER has been installed before installing the AWS CLI, be sure to restart the OS before using EXPRESSCLUSTER.)Execute the command from the shell as shown below
$ sudo aws configureInput the information required to execute AWS CLI in response to the prompt. Do not input AWS access key ID and AWS secret access key.
AWS Access Key ID [None]: (Just press Enter key) AWS Secret Access Key [None]: (Just press Enter key) Default region name [None]: <default region name> Default output format [None]: textFor "Default output format", other format than "text" may be specified.If you input wrong information, delete the entire /root/.aws directory and execute the step described above.
Setting up an instance by using IAM user
In this method, you can execute AWS CLI after creating the IAM user and storing its access key ID and secret access key in the instance. You do not have to assign the IAM role to the instance when creating the instance.
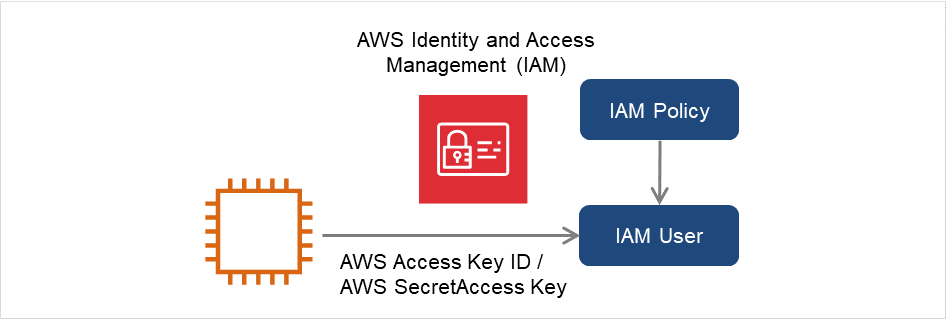
Fig. 6.8 Setting an instance by using IAM user¶
Log on to the instance.
Install the AWS CLI.
The installation path of the AWS CLI must be any of the following:/sbin, /bin, /usr/sbin, /usr/bin, /usr/local/binFor details about how to set up the AWS CLI, refer to the following:(If EXPRESSCLUSTER has been installed before installing the AWS CLI, be sure to restart the OS before using EXPRESSCLUSTER.)Execute the command from the shell as shown below
$ sudo aws configureInput the information required to execute AWS CLI in response to the prompt. Obtain AWS access key ID and AWS secret access key from IAM user detail screen to input.
AWS Access Key ID [None]: <AWS access key> AWS Secret Access Key [None]: <AWS secret access key> Default region name [None]: <default region name > Default output format [None]: textFor "Default output format", other format than "text" may be specified.If you input wrong information, delete the entire /root/.aws directory and execute the step described above.
6.3.21. Settings in the Azure environment¶
- Making EXPRESSCLUSTER cooperate with Microsoft Azure requires an organizational account for Microsoft Azure.You cannot use a non-organizational account, which requires interactive login in running the Azure CLI.
- For the process, some of EXPRESSCLUSTER's functions internally run the Azure CLI.Successfully running the Azure CLI requires prior setting.For more information on setting the Azure CLI, see the following website:Azure documentation:
- Logging in to Microsoft Azure requires a service principal to be created in advance.For the detailed procedure, see the following web page:Sign in with Azure CLI:Create an Azure service principal with Azure CLI:
For the procedures to install Azure CLI and create a service principal, refer to the "EXPRESSCLUSTER X HA Cluster Configuration Guide for Microsoft Azure (Linux)".
6.3.22. IAM settings in the Azure environment¶
Setting access rights
For EXPRESSCLUSTER's Azure-related functions to run the Azure CLI, the following access rights are required.
These access rights are subject to change in the future.
Azure forced stop resource
Access right
Description
Microsoft.Compute/virtualMachines/deallocate/action
This is required for stopping (deallocating) instances.
Microsoft.Compute/virtualMachines/powerOff/action
This is required for stopping instances.
Microsoft.Compute/virtualMachines/restart/action
This is required for restarting instances.
This is required for obtaining or updating instance attributes.
Azure DNS resource
Access right
Description
Microsoft.Network/dnsZones/A/write
This is required for adding or updating A records.
Microsoft.Network/dnsZones/A/delete
This is required for removing A records.
Microsoft.Network/dnsZones/NS/read
This is required for obtaining information on NS records.
Note
For Azure CLI 1.0, the following are also required:Microsoft.Network/dnsZones/readMicrosoft.Network/dnsZones/A/read
6.3.23. Azure DNS resources¶
Azure Private DNS is not supported.
6.3.24. Google Cloud DNS resources¶
Google Cloud DNS resources use Cloud DNS by Google Cloud. For the details on Cloud DNS, refer to the following website.
Cloud DNSCloud SDK needs to be installed to operate Cloud DNS. For the details on Cloud SDK, refer to the following website.
Cloud SDKCloud SDK needs to be authorized by the account with the permissions for the API methods below:
dns.changes.createdns.changes.getdns.managedZones.getdns.resourceRecordSets.createdns.resourceRecordSets.deletedns.resourceRecordSets.listdns.resourceRecordSets.updateAs for authorizing Cloud SDK, refer to the following website.
Authorizing Cloud SDK tools
6.3.25. Samba monitor resources¶
In order to support SMB protocol version 2.0 or later, NTLM authentication, and SMB signature, Samba monitor resources use a shared library 'libsmbclient.so.0' for the internal version 4.1.0-1 or later. Confirm that it is installed since libsmbclient.so.0 is included in libsmbclient package.
If the version of libsmbclient is 3 or earlier (for example, libsmbclient included in RHEL 6), .you can specify only either 139 or 445 for Port. Specify the port number included in smb ports of smb.conf.
The version of SMB protocol supported by Samba monitor resource depends on the installed libsmbclient. You can confirm whether to receive supports from libsmbclient by testing a connection to shared area of the monitoring target by using the smbclient command which each distributer provides.
6.3.26. About HTTP network partition resolution resources and Witness heartbeat resources¶
For HTTP network partition resolution resources and Witness heartbeat resources, using SSL requires OpenSSL.
To set libraries to be used, go to Cluster Properties -> the Encryption tab -> SSL Library and Crypto Library.
6.3.27. CLI setting in the OCI environment¶
6.3.28. Policy setting in the OCI environment¶
Policy setting
For EXPRESSCLUSTER's OCI-related functions to run the OCI CLI, the following policies are required:
These policies are subject to change in the future.
For Oracle Cloud DNS resources and Oracle Cloud DNS monitor resources
Policy syntax
Description
Allow <subject> to use dns in <location>
Required to create, update, or delete an A record of Oracle Cloud DNS, or to retrieve information on it.
For OCI forced-stop resource
Policy syntax
Description
Allow <subject> to use instance-family in <location>
Required to stop or restart an instance, or to retrieve information on it.
Into each of <subject> and <location>, enter a value suitable for the environment.
6.3.29. Node.js¶
Node.js is required for the following:
Witness server service
RESTful API service
For Node.js, the installation path of the executable file must be included in the PATH environment variable.
6.4. Notes when creating EXPRESSCLUSTER configuration data¶
Notes when creating a cluster configuration data and before configuring a cluster system is described in this section.
6.4.1. Directories and files in the location pointed to by the EXPRESSCLUSTER installation path¶
6.4.2. Environment variable¶
The following processes cannot be executed in an environment in which more than 255 environment variables are set. When using the following function of resource, set the number of environmental variables less than 256.
Group start/stop process
Start/Stop script executed by EXEC resource when activating/deactivating
Script executed by Custom monitor Resource when monitoring
Script before final action after the group resource or the monitor resource error is detected
Script to be executed before and after activating or deactivating a group resource
The script for forced stop
Note
The total number of environment variables set in the system and EXPRESSCLUSTER must be less than 256. About 30 environment variables are set in EXPRESSCLUSTER.
6.4.3. Shutdown monitoring¶
For OSs based on Red Hat Enterprise Linux 8 or later, set Enable SIGTERM handler to On regardless of the monitoring method.
6.4.4. Server reset, server panic and power off¶
When EXPRESSCLUSTER performs "Server Reset", "Server Panic," or "Server power off", servers are not shut down normally. Therefore, the following may occur.
Damage to a mounted file system
Loss of unsaved data
Suspension of OS dump collection
"Server reset" or "Server panic" occurs in the following settings:
Action at an error occurred when activating/inactivating group resources
Sysrq Panic
Keepalive Reset
Keepalive Panic
BMC Reset
BMC Power Off
BMC Power Cycle
BMC NMI
Final action at detection of an error in monitor resource
Sysrq Panic
Keepalive Reset
Keepalive Panic
BMC Reset
BMC Power Off
BMC Power Cycle
BMC NMI
Action at detection of user mode monitor timeout
Monitoring method softdog
Monitoring method ipmi
Monitoring method keepalive
Note
"Server panic" can be set only when the monitoring method is "keepalive."
Shutdown stall mentoring
Monitoring method softdog
Monitoring method ipmi
Monitoring method keepalive
Note
"Server panic" can be set only when the monitoring method is "keepalive."
Operation of Forced Stop
BMC reset
BMC power off
BMC cycle
BMC NMI
- VMware vSphere power off
6.4.5. Final action for group resource deactivation error¶
If you select No Operation as the final action when a deactivation error is detected, the group does not stop but remains in the deactivation error status. Make sure not to set No Operation in the production environment.
6.4.6. Verifying raw device for VxVM¶
Check the raw device of the volume raw device in advance:
Import all disk groups which can be activated on one server and activate all volumes before installing EXPRESSCLUSTER.
- Run the command below:In the following output example,
/dev/raw/raw2and/dev/raw/raw3are the raw device names.In addition, themajor ..., minor ...part represents major/minor numbers.# raw -qa /dev/raw/raw2: bound to major 199, minor 2 /dev/raw/raw3: bound to major 199, minor 3
Example: Assuming the disk group name and volume name are:
Disk group name: dg1
Volume name under dg1: vol1, vol2
- Run the command below:In the following output example, the
199, 2and199, 3parts represent major/minor numbers.# ls -l /dev/vx/dsk/dg1/ brw------- 1 root root 199, 2 May 15 22:13 vol1 brw------- 1 root root 199, 3 May 15 22:13 vol2
Confirm that major and minor numbers are identical between step 2 and step 3.
Make sure not to set the raw devices confirmed in Step 2 to the disk heartbeat resource, the disk resource (disk type is other than "VxVM"), or the disk monitor resource (monitoring method is other than READ (VxVM)) of EXPRESSCLUSTER.
6.4.7. Selecting Mirror disk file system¶
Following is the currently supported file systems:
ext3
ext4
xfs
none(no file system)
6.4.8. Selecting Hybrid disk file system¶
The following are the currently supported file systems:
ext3
ext4
xfs
none(no file system)
6.4.9. Time to start a single serve when many Mirror disks are defined.¶
6.4.10. RAW monitoring of Disk monitor resources¶
When raw monitoring of disk monitor resources is set up, partitions cannot be monitored if they have been or will possibly be mounted. These partitions cannot be monitored even if you set device name to "whole device" (device indicating the entire disks).
Allocate a partition dedicated to monitoring and set up the partition to use the raw monitoring of disk monitor resources.
6.4.11. Delay warning rate¶
If the delay warning rate is set to 0 or 100, the following can be achieved:
- When 0 is set to the delay monitoring rateAn alert for the delay warning is issued at every monitoring.By using this feature, you can calculate the polling time for the monitor resource at the time the server is heavily loaded, which will allow you to determine the time for monitoring time-out of a monitor resource.
- When 100 is set to the delay monitoring rateThe delay warning will not be issued.Be sure not to set a low value, such as 0%, except for a test operation.
6.4.12. Disk monitor resource (monitoring method TUR)¶
You cannot use the TUR methods on a disk or disk interface (HBA) that does not support the Test Unit Ready (TUR) and SG_IO commands of SCSI. Even if your hardware supports these commands, consult the driver specifications because the driver may not support them.
S-ATA disk interface may be recognized as IDE disk interface (hd) or SCSI disk interface (sd) by OS depending on disk controller type and distribution. When it is recognized as IDE interface, all TUR methods cannot be used. If it is recognized as SCSI disk interface, TUR (legacy) can be used. Note that TUR (generic) cannot be used.
TUR methods burdens OS and disk load less compared to Read methods.
In some cases, TUR methods may not be able to detect errors in I/O to the actual media.
6.4.13. Configuring LAN heartbeat resources or kernel mode LAN heartbeat resources¶
For an interconnect with the highest priority, configure LAN heartbeat resources or kernel mode LAN heartbeat resources which can be exchanged between all servers.
Configuring at least two kernel mode LAN heartbeat resources is recommended unless it is difficult to add a network to an environment such as the cloud or a remote cluster.
It is recommended to register both an interconnect-dedicated LAN and a public LAN as LAN heartbeat resources.
It is recommended to use kernel mode LAN heartbeat resource for distribution kernel of which kernel mode LAN heartbeat can be used.
6.4.14. Double-byte character set that can be used in script comments¶
Scripts edited in Linux environment are dealt as EUC code, and scripts edited in Windows environment are dealt as Shift-JIS code. In case that other character codes are used, character corruption may occur depending on environment.
6.4.15. The character code and line feed code in a script¶
If you use the clpcfctrl command to apply the settings of a script created by some means other than Cluster WebUI, make sure beforehand that the character code and line feed code in the script are the same as those in the configuration data file (clp.conf). If the character code or the line feed code is different between the script and clp.conf, the script may not work properly.
6.4.16. System monitor resource settings¶
- Pattern of detection by resource monitoringThe System Resource Agent detects by using thresholds and monitoring duration time as parameters.The System Resource Agent collects the data (number of opened files, number of user processes, number of threads, used size of memory, CPU usage rate, and used size of virtual memory) on individual system resources continuously, and detects errors when data keeps exceeding a threshold for a certain time (specified as the duration time).
6.4.17. Eternal link monitor resource settings¶
Error notification to eternal link monitor resources can be done in any of three ways: using the clprexec command, or linkage with the server management infrastructure.
To use the clprexec command, use the relevant file stored on the EXPRESSCLUSTER CD. Use this method according to the OS and architecture of the notification-source server. The notification-source server must be able to communicate with the notification-destination server.
For the linkage with the server management infrastructure, see "Linkage with Server Management Infrastructure" in the "Hardware Feature Guide".
6.4.18. JVM monitor resource settings¶
When the monitoring target is the WebLogic Server, the maximum values of the following JVM monitor resource settings may be limited due to the system environment (including the amount of installed memory):
The number under Monitor the requests in Work Manager
Average under Monitor the requests in Work Manager
The number of Waiting Requests under Monitor the requests in Thread Pool
Average of Waiting Requests under Monitor the requests in Thread Pool
The number of Executing Requests under Monitor the requests in Thread Pool
Average of Executing Requests under Monitor the requests in Thread Pool
When the monitoring-target is a 64-bit JRockit JVM, the following parameters cannot be monitored because the maximum amount of memory acquired from the JRockit JVM is a negative value that disables the calculation of the memory usage rate:
Total Usage under Monitor Heap Memory Rate
Nursery Space under Monitor Heap Memory Rate
Old Space under Monitor Heap Memory Rate
Total Usage under Monitor Non-Heap Memory Rate
Class Memory under Monitor Non-Heap Memory Rate
To use the JVM monitor resources, install the Java runtime environment (JRE) described in "Operation environment for JVM monitor" in "4. Installation requirements for EXPRESSCLUSTER" You can use either the same JRE as that used by the monitoring target (WebLogic Server or WebOTX) or a different JRE.
The monitor resource name must not include a blank.
6.4.19. EXPRESSCLUSTER startup when using volume manager resources¶
When EXPRESSCLUSTER starts up, the system startup may take some time because of the deactivation processing performed by the vgchange command if the volume manager is lvm or the deport processing if it is vxvm. If this presents a problem, edit the startup or stop script of the EXPRESSCLUSTER main body as shown below.
For a systemd environment, edit /opt/nec/clusterpro/etc/systemd/clusterpro.sh as shown below.
#!/bin/sh # # Startup script for the EXPRESSCLUSTER daemon # : : # See how we were called. case "$1" in start) : : # export all volmgr resource # clp_logwrite "$1" "clpvolmgrc start." init_main # ./clpvolmgrc -d > /dev/null 2>&1 # retvolmgrc=$? # clp_logwrite "$1" "clpvolmgrc end.("$retvolmgrc")" init_main
6.4.20. AWS CLI command line options¶
AWS-related features run the AWS CLI.
To specify two or more of the command line options, separate each of them with a space.
aws cloudwatch
Amazon CloudWatch linkage
aws ec2
AWS Elastic IP resource
AWS Virtual IP resource
AWS Secondary IP resource
AWS Elastic IP monitor resource
AWS Virtual IP monitor resource
AWS Secondary IP monitor resource
AWS AZ monitor resource
AWS Forced stop resource
Obtaining cloud environment information with Cluster WebUI
aws route53
AWS DNS resource
AWS DNS monitor resource
aws sns
Amazon SNS linkage
For more information on the command line options for the AWS CLI, see AWS documents.
Note
6.4.23. Setting up AWS elastic ip resources¶
IPv6 is not supported.
In the AWS environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
- Only ASCII characters is supported. Check that the character besides ASCII character isn't included in an execution result of the following command.
aws ec2 describe-addresses --allocation-ids <EIP ALLOCATION ID>
AWS elastic IP resources associate an EIP with the primary private IP address of an ENI, but not with its secondary private IP address.
6.4.24. Setting up AWS virtual ip resources¶
IPv6 is not supported.
In the AWS environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
An AWS virtual IP resource cannot be used together with an AWS secondary IP resource.
- Only ASCII characters is supported. Check that the character besides ASCII character isn't included in an execution result of the following command.
aws ec2 describe-vpcs --vpc-ids <VPC ID> aws ec2 describe-route-tables --filters Name=vpc-id,Values=<VPC ID> aws ec2 describe-network-interfaces --network-interface-ids <ENI ID>
AWS virtual IP resources cannot be used if access via a VPC peering connection is necessary. This is because it is assumed that an IP address to be used as a VIP is out of the VPC range and such an IP address is considered invalid in a VPC peering connection. If access via a VPC peering connection is necessary, use the AWS DNS resource that use Amazon Route 53.
An AWS virtual IP resource starts up normally, even if the route table to be used by instances does not include any route to an IP address to be used by the AWS virtual IP resource. This operation is as required. When activated, an AWS virtual IP resource updates the content of a route table that includes a specified IP address entry. Finding no route table, the resource considers the situation as nothing to be updated and therefore as normal. Which route table should have a specified entry, depending on the system configuration, is not the resource's criterion for judging the normality.
6.4.25. Setting up AWS secondary ip resources¶
IPv6 is not supported.
In the AWS environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
An AWS virtual IP resource cannot be used together with an AWS secondary IP resource.
- Only ASCII characters is supported. Check that the character besides ASCII character isn't included in an execution result of the following command.
aws ec2 describe-network-interfaces --network-interface-ids <ENI ID> aws ec2 describe-subnets --subnet-ids <SUBNET_ID>
No AWS secondary IP resources can be used in a configuration with a different subnet.
- The number of secondary IP addresses to be assigned for AWS secondary IP resources has an upper limit for each instance type.For more information, refer to the following:
6.4.26. Setting up AWS DNS resources¶
IPv6 is not supported.
In the AWS environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
In the Resource Record Set Name field, enter a name without an escape code. If it is included in the Resource Record Set Name, a monitor error occurs.
Associated with a single account, an AWS DNS resource cannot be used for different accounts, AWS access key IDs, or AWS secret access keys. If you want such usage, consider using a script (EXEC resource) to execute the AWS CLI.
6.4.27. Setting up AWS DNS monitor resources¶
Check if the host command is available. With the command unavailable, the name-resolution-based monitoring is skipped, then left in a warning state.
Immediately after the AWS DNS resource is activated, monitoring by the AWS DNS monitor resource may fail due to the following events. If monitoring failed, set Wait Time to Start Monitoring of the AWS DNS monitor resource longer than the time to reflect the changed DNS setting of Amazon Route 53 (https://aws.amazon.com/route53/faqs/).
When the AWS DNS resource is activated, a resource record set is added or updated.
- If the AWS DNS monitor resource starts monitoring before the changed DNS setting of Amazon Route 53 is applied, name resolution cannot be done and monitoring fails.The AWS DNS monitor resource will continue to fail monitoring while a DNS resolver cache is enabled.
The changed DNS setting of Amazon Route 53 is applied.
Name resolution succeeds after the TTL valid period of the AWS DNS resource elapses. Then, the AWS DNS monitor resource succeeds monitoring.
6.4.28. Setting up Azure probe port resources¶
IPv6 is not supported.
In the Microsoft Azure environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
6.4.29. Setting up Azure load balance monitor resources¶
When a Azure load balance monitor resource error is detected, there is a possibility that switching of the active server and the stand-by server from Azure load balancer is not performed correctly. Therefore, in the Final Action of Azure load balance monitor resources and the recommended that you select Stop the cluster service and shutdown OS.
6.4.30. Setting up Azure DNS resources¶
IPv6 is not supported.
In the Microsoft Azure environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
6.4.31. Setting up Google Cloud virtual IP resources¶
IPv6 is not supported.
6.4.32. Setting up Google Cloud load balance monitor resources¶
For Final Action of Google Cloud load balance monitor resources, selecting Stop cluster service and shutdown OS is recommended. When a Google Cloud load balance monitor resource detects an error, the load balancer may not correctly switch between the active server and the standby server.
6.4.33. Setting up Google Cloud DNS resources¶
IPv6 is not supported.
In the Google Cloud environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
When using multiple Google Cloud DNS resources in the cluster, you need to configure them to prevent their simultaneous activation/deactivation for their dependence or a wait for a group start/stop. Their simultaneous activation/deactivation may cause an error.
6.4.34. Setting up Oracle Cloud virtual IP resources¶
IPv6 is not supported.
6.4.35. Setting up Oracle Cloud load balance monitor resources¶
For Final Action of Oracle Cloud load balance monitor resources, selecting Stop cluster service and shutdown OS is recommended. When an Oracle Cloud load balance monitor resource detects an error, the load balancer may not correctly switch between the active server and the standby server.
6.4.36. Setting up Oracle Cloud DNS resources¶
IPv6 is not supported.
In the Oracle Cloud environment, floating IP resources, floating IP monitor resources, virtual IP resources, and virtual IP monitor resources cannot be used.
6.4.37. Resource types listed in the wizard window for adding resources¶
6.4.38. Coexistence of a mirror disk resource with a hybrid disk resource¶
A mirror disk resource and a hybrid disk resource cannot coexist in the same failover group.
6.5. After starting operating EXPRESSCLUSTER¶
Notes on situations you may encounter after start operating EXPRESSCLUSTER are described in this section.
6.5.1. Error message in the load of the mirror driver in an environment such as udev¶
In the load of the mirror driver in an environment such as udev, logs like the following may be recorded into the message file:
kernel: [I] <type: liscal><event: 141> NMP1 device does not exist. (liscal_make_request) kernel: [I] <type: liscal><event: 141> - This message can be recorded on udev environment when liscal is initializing NMPx. kernel: [I] <type: liscal><event: 141> - Ignore this and following messages 'Buffer I/O error on device NMPx' on udev environment. kernel: Buffer I/O error on device NMP1, logical block 0
kernel: <liscal liscal_make_request> NMP1 device does not exist. kernel: Buffer I/O error on device NMP1, logical block 112
filename: 50-liscal-udev.rules
ACTION=="add", DEVPATH=="/block/NMP*", OPTIONS+="ignore_device"
ACTION=="add", DEVPATH=="/devices/virtual/block/NMP*", OPTIONS+="ignore_device"
6.5.2. Buffer I/O error log for the mirror partition device¶
If the mirror partition device is accessed when a mirror disk resource or hybrid disk resource is inactive, log messages such as the ones shown below are recorded in the messages file.
kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=xxxxx) kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. : kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=xxxx) : kernel: [W] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). (PID=xxxx)
kernel: <liscal liscal_make_request> NMPx I/O port is close, mount(0), io(0). kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
(Where x and xxxx each represent a given number.)
When the udev environment is responsible
In this case, when the mirror driver is loaded, the message "kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx" is recorded together with the message "kernel: [I] <type: liscal><event: 141>".
These messages do not indicate any error and have no impact on the operation of EXPRESSCLUSTER.
- For details, see "Error message in the load of the mirror driver in an environment such as udev" in this chapter.
When an information collection command (sosreport, sysreport, blkid, etc.) of the operating system has been executed
In this case, these messages do not indicate any error and have no impact on the operation of EXPRESSCLUSTER.
When an information collection command provided by the operating system is executed, the devices recognized by the operating system are accessed. When this occurs, the inactive mirror disk is also accessed, resulting in the above messages being recorded.
There is no way of suppressing these messages by using the settings of EXPRESSCLUSTER or other means.
When the unmount of the mirror disk has timed out
In this case, these messages are recorded together with the message that indicates that the unmount of the mirror disk resource has timed out.
EXPRESSCLUSTER performs the "recovery operation for the detected deactivation error" of the mirror disk resource. It is also possible that there is inconsistency in the file system.
- For details, see "6.5.3. Cache swell by a massive I/O" in this chapter.
When the mirror partition device may be left mounted while the mirror disk is inactive
In this case, the above messages are recorded after the following actions are taken.
After the mirror disk resource is activated, the user or an application (for example, NFS) specifies an additional mount in the mirror partition device (/dev/NMPx) or the mount point of the mirror disk resource.
Then, the mirror disk resource is deactivated without unmounting the mount point added in (1).
While the operation of EXPRESSCLUSTER is not affected, it is possible that there is inconsistency in the file system.
- For details, see "6.5.4. When multiple mounts are specified for a resource like a mirror disk resource" in this chapter.
When multiple mirror disk resources are configured
With some distributions, when two or more mirror disk resources are configured, the above messages may be output due to the behavior of fsck if the resources are active.
When the mirror disk resource is accessed by a certain application
Besides the above cases, it is possible that a certain application has attempted to access the inactive mirror disk resource.
When the mirror disk resource is not active, the operation of EXPRESSCLUSTER is not affected.
6.5.3. Cache swell by a massive I/O¶
- In case that a massive amount of write over the disk capability to the mirror disk resource or the hybrid disk resource are executed, even though the mirror connection is alive, the control from write may not return or memory allocation failure may occur.In case that a massive amount of I/O requests over transaction performance exist, and then the file system ensure a massive amount of cache and the cache or the memory for the user space (HIGHMEM zone) are insufficient, the memory for the kernel space (NORMAL zone) may be used.Change the settings so that the parameter will be changed at OS startup by using sysctl or other commands.
/proc/sys/vm/lowmem_reserve_ratio
- In case that a massive amount of accesses to the mirror disk resource or the hybrid disk resource are executed, it may take much time before the cache of the file systems is written out to the disks when unmounting at disk resource deactivation.If, at this moment, the unmounting times out before the writing from the file system to the disks is completed, I/O error messages or unmount failure messages like those shown below may be recorded.
In this case, change the unmount timeout length for the disk resource in question to an adequate value such that the writing to the disk will be normally completed.
Example 1:
expresscls: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 193> NMPx close I/O port OK. kernel: [I] <type: liscal><event: 195> NMPx close mount port OK. kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device NMPx, logical block xxxx kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: Buffer I/O error on device NMPx, logical block xxxx :
Example 2:
expresscls: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 148> NMPx holder 1. (before umount) expresscls: [E] <type: md><event: 46> umount timeout. Make sure that the length of Unmount Timeout is appropriate. (Device:mdx) : expresscls: [E] <type: md><event: 4> Failed to deactivate mirror disk. Umount operation failed.(Device:mdx) kernel: [I] <type: liscal><event: 148> NMPx holder 1. (after umount) expresscls: [E] <type: rc><event: 42> Stopping mdx resource has failed.(83 : System command timeout (umount, timeout=xxx)) :
6.5.4. When multiple mounts are specified for a resource like a mirror disk resource¶
- If, after activation of a mirror disk resource or hybrid disk resource, you have created an additional mount point in a different location by using the mount command for the mirror partition device (/dev/NMPx) or the mount point (or a part of the file hierarchy for the mount point), you must unmount that additional mount point before the disk resource is deactivated.If the deactivation is performed without the additional mount point being unmounted, the file system data remaining in memory may not be completely written out to the disks. As a result, the I/O to the disks is closed and the deactivation is completed although the data on the disks are incomplete.Because the file system will still try to continue writing to the disks even after the deactivation is completed, I/O error messages like those shown below may be recorded.After this, an attempt to stop the mirror agent, such as when stopping the server, will fail, since the mirror driver cannot be terminated. This may cause the server to restart.
Example:
expresscls: [I] <type: rc><event: 40> Stopping mdx resource has started. kernel: [I] <type: liscal><event: 148> NMP1 holder 1. (before umount) kernel: [I] <type: liscal><event: 148> NMP1 holder 1. (after umount) kernel: [I] <type: liscal><event: 193> NMPx close I/O port OK. kernel: [I] <type: liscal><event: 195> NMPx close mount port OK. expresscls: [I] <type: rc><event: 41> Stopping mdx resource has completed. kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device NMPx, logical block xxxxx kernel: lost page write due to I/O error on NMPx kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: Buffer I/O error on device NMPx, logical block xxxxx kernel: lost page write due to I/O error on NMPx :
6.5.5. Messages written to syslog when multiple mirror disk resources or hybrid disk resources are used¶
kernel: [I] <type: liscal><event: 144> NMPx I/O port has been closed, mount(0), io(0). kernel: [I] <type: liscal><event: 144> - This message can be recorded by fsck command when NMPx becomes active. kernel: [I] <type: liscal><event: 144> - This message can be recorded on hotplug service starting when NMPx is not active. kernel: [I] <type: liscal><event: 144> - Ignore this and following messages 'Buffer I/O error on device NMPx' on such environment. kernel: Buffer I/O error on device /dev/NMPx, logical block xxxx
kernel: <liscal liscal_make_request> NMPx I/O port is close, mount(0), io(0). kernel: Buffer I/O error on device /dev/NMPx , logical block xxxx
This is not a problem for EXPRESSCLUSTER. If this causes any problem such as heavy use of message files, change the following settings of mirror disk resources or hybrid disk resources.
Select "Not Execute" on "fsck action before mount"
Select "Execute" on "fsck Action When Mount Failed"
6.5.6. Messages displayed when loading a driver¶
When loading a mirror driver, messages like the following may be displayed at the console and/or syslog. However, this is not an error.
kernel: liscal: no version for "xxxxx" found: kernel tainted. kernel: liscal: module license 'unspecified' taints kernel.
(Any character strings are set to xxxxx .)
And also, when loading the clpka or clpkhb driver, messages like the following may be displayed on the console and/or syslog. However, this is not an error.
kernel: clpkhb: no version for "xxxxx" found: kernel tainted. kernel: clpkhb: module license 'unspecified' taints kernel.
kernel: clpka: no version for "xxxxx" found: kernel tainted. kernel: clpka: module license 'unspecified' taints kernel.
(Any character strings are input into xxxxx .)
6.5.7. Messages displayed for the first I/O to mirror disk resources or hybrid disk resources¶
When reading/writing data from/to a mirror disk resource or hybrid disk resource for the first time after the resource was mounted, a message like the following may be displayed at the console and/or syslog. However, this is not an error.
kernel: JBD: barrier-based sync failed on NMPx - disabling barriers
(Any character strings are set to x .)
6.5.8. File operating utility on X-Window¶
Some of the file operating utilities (coping and moving files and directories via GUI) on X-Window perform the following:
Checks if the block device is usable.
Mounts the file system if there is any that can be mounted.
Make sure not to use file operating utility that perform above operations. They may cause problem to the operation of EXPRESSCLUSTER.
6.5.9. IPMI message¶
When you are using ipmi for user mode monitor resources, the following kernel module warning log is recorded many times in the syslog.
modprobe: modprobe: Can't locate module char-major-10-173
When you want to prevent this log from being recorded, rename /dev/ipmikcs.
6.5.10. Limitations during the recovery operation¶
Do not control the following commands, clusters and groups by the Cluster WebUI while recovery processing is changing (reactivation -> failover -> last operation), if a group resource is specified as a recovery target and when a monitor resource detects an error.
Stop and suspend of a cluster
Start, stop, moving of a group
6.5.11. Executable format file and script file not described in manuals¶
Executable format files and script files which are not described in "EXPRESSCLUSTER command reference" in the "Reference Guide" exist under the installation directory. Do not run these files on any system other than EXPRESSCLUSTER. The consequences of running these files will not be supported.
6.5.12. Executing fsck¶
- When fsck is specified to execute at activation of disk resources, mirror disk resources, or hybrid disk resources, fsck is executed when an ext3/ext4 file system is mounted. Executing fsck may take times depending on the size, usage or status of the file system, resulting that an fsck timeout occurs and mounting the file system fails.This is because fsck is executed in either of the following ways.
- Only performing simplified journal check.Executing fsck does not take times.
- Checking consistency of the entire file system.When the data saved by OS has not been checked for 180 days or more or the data willbe checked after it is mounted around 30 times.In this case, executing fsck takes times depending the size or usage of the file system.Specify a time in safe for the fsck timeout of disk resources so that no timeout occurs.
When fsck is specified not to execute at activation of disk resources, mirror disk resources, or hybrid disk resources, the warning described below may be displayed on the console and/or syslog when an ext3/ext4 file system is mounted more than the mount execution count set to OS that it is recommended to execute fsck.
EXT3-fs warning: xxxxx, running e2fsck is recommended.
Note: There are multiple patterns displayed in xxxxx .
It is recommended to execute fsck when this waning is displayed.
Follow the steps below to manually execute fsck.Be sure to execute the following steps on the server where the disk resource in question has been activated.Deactivate a group to which the disk resource in question belongs by using a command such as clpgrp.
Confirm that no disks have been mounted by using a command such as mount and df.
Change the state of the disk from Read Only to Read Write by executing one of the following commands depending on the disk resource type.
Example for disk resources: A device name is /dev/sbd5
# clproset -w -d /dev/sbd5 /dev/sbd5 : success
Example for mirror disk resources: A resource name is md1.
# clpmdctrl --active -nomount md1 <md1@server1>: active successfully
Example for hybrid disk resources: A resource name is hd1.
# clphdctrl --active -nomount hd1 <hd1@server1>: active successfully
- Execute fsck.(If you specify the device name for fsck execution in the case of a mirror disk resource or hybrid disk resource, specify the mirror partition device name (/dev/NMPx) corresponding to the resource.)
Change the state of the disk from Read Write to Read Only by executing one of the following commands depending on the disk resource type.
Example for disk resources: A device name is /dev/sbd5.
# clproset -o -d /dev/sdb5 /dev/sdb5 : success
Example for mirror disk resources: A resource name is md1.
# clpmdctrl --deactive md1 <md1@server1>: deactive successfully
Example for hybrid disk resources: A resource name is hd1.
# clphdctrl --deactive hd1 <hd1@server1>: deactive successfully
Activate a group to which the disk resource in question belongs by using a command such as clpgrp.
If you need to specify that the warning message is not output without executing fsck, for ext3/ext4, change the maximum mount count by using tune2fs. Be sure to execute this command on the server where the disk resource in question has been activated.
Execute one of the following commands..
Example for disk resources: A device name is /dev/sbd5.
# tune2fs -c -1 /dev/sdb5 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
Example for mirror disk resources: A mirror partition device name is /dev/NMP1.
# tune2fs -c -1 /dev/NMP1 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
Example for hybrid disk resources: A mirror partition device name is /dev/NMP1.
# tune2fs -c -1 /dev/NMP1 tune2fs 1.42.9 (28-Dec-2013) Setting maximal mount count to -1
Confirm that the maximum mount count has been changed.
Example: A device name is /dev/sbd5.
# tune2fs -l /dev/sdb5 tune2fs 1.42.9 (28-Dec-2013) Filesystem volume name: <none> : Maximum mount count: -1 :
6.5.13. Executing xfs_repair¶
When an xfs-based disk resource/mirror disk resource/hybrid disk resource is activated, the console may display a warning message of xfs. In this case, executing xfs_repair is recommended to restore the file system.
To run xfs_repair, follow these steps:
Make sure that the resource is not activated. If the resource is activated, deactivate it with Cluster WebUI.
Make the device writable.
Example of a disk resource whose device name is /dev/sdb1:
# clproset -w -d /dev/sdb1 /dev/sdb1 : successExample of a mirror disk resource whose name is md1:
# clpmdctrl --active -nomount md1 <md1@server1>: active successfullyExample of a hybrid disk resource whose name is hd1:
# clphdctrl --active -nomount hd1 <hd1@server1>: active successfullyMount the device.
Example of a disk resource whose device name is /dev/sdb1:
# mount /dev/sdb1 /mntExample of a mirror/hybrid disk resource whose mirror partition device name is /dev/NMP1:
# mount /dev/NMP1 /mntUnmount the device.
# umount /mntNote
The xfs_repair utility cannot restore a file system including a dirty log. Such a file system need be mounted and then unmounted to clear the log.
Execute xfs_repair.
Example of a disk resource whose device name is /dev/sdb1:
# xfs_repair /dev/sdb1Example of a mirror/hybrid disk resource whose mirror partition device name is /dev/NMP1:
# xfs_repair /dev/NMP1Write-protect the device.
Example of a disk resource whose device name is /dev/sdb1:
# clproset -o -d /dev/sdb1 /dev/sdb1 : successExample of a mirror disk resource whose name is md1:
# clpmdctrl --deactive md1 <md1@server1>: deactive successfullyExample of a hybrid disk resource whose name is hd1:
# clphdctrl --deactive hd1 <hd1@server1>: deactive successfully
Now you have finished restoring the xfs file system.
6.5.14. Messages when collecting logs¶
When collecting logs, the message described below is displayed at the console, but this is not an error. Logs are collected successfully.
hd#: bad special flag: 0x03 ip_tables: (C) 2000-2002 Netfilter core team
("hd#" is replaced with the device name of IDE.)
kernel: Warning: /proc/ide/hd?/settings interface is obsolete, and will be removed soon!
6.5.15. Failover and activation during mirror recovery¶
- When mirror recovery is in progress for a mirror disk resource or hybrid disk resource, a mirror disk resource or hybrid disk resource placed in the deactivated state cannot be activated.During mirror recovery, a failover group including the disk resource in question cannot be moved.If a failover occurs during mirror recovery, the copy destination server does not have the latest status, so a failover to the copy destination server or copy destination server group will fail.Even if an attempt to fail over a hybrid disk resource to a server in the same server group is made by actions for when a monitor resource detects an error, it will fail, too, since the current server is not changed.Note that, depending on the timing, when mirror recovery is completed during a failover, move, or activation, the operation may be successful.
- At the first mirror startup after configuration information registration and also at the first mirror startup after a mirror disk is replaced after a failure, the initial mirror configuration is performed.In the initial mirror configuration, disk copying (full mirror recovery) is performed from the active server to the mirror disk on the standby server immediately after mirror activation.Until this initial mirror configuration (full mirror recovery) is completed and the mirror enters the normal synchronization state, do not perform either failover to the standby server or group movement to the standby server.If a failover or group movement is performed during this disk copying, the standby server may be activated while the mirror disk of the standby server is still incomplete, causing the data that has not yet been copied to the standby server to be lost and thus causing mismatches to occur in the file system.
6.5.16. Cluster shutdown and reboot (mirror disk resource and hybrid disk resource)¶
6.5.17. Shutdown and reboot of individual server (mirror disk resource and hybrid disk resource)¶
6.5.18. Scripts for starting/stopping EXPRESSCLUSTER services¶
For an init.d environment, an error occurs in the service startup and stop scripts in the following cases. For a systemd environment, an error does not occur.
- Before start operating EXPRESSCLUSTERWhen a server start up, the error occurs in the following starting scripts. There is no problem for the error because cluster configuration data has not uploaded.
clusterpro_md
- At following case, the script to terminate EXPRESSCLUSTER services may be executed in the wrong order.The OS is shut down after EXPRESSCLUSTER services are disabled.EXPRESSCLUSTER services may be terminated in the wrong order at OS shutdown if all of EXPRESSCLUSTER services are disabled. This problem is caused by failure in termination process for the service has been already disabled.As long as the system shutdown is executed by Cluster WebUI or clpstdn command, there is no problem even if the services is terminated in the wrong order. But, any other problem may not be happened by wrong order termination.
6.5.19. Service startup time¶
EXPRESSCLUSTER services might take a while to start up, depending on the wait processing at startup.
- clusterpro_evtServers other than the master server wait up to two minutes for configuration data to be downloaded from the master server. Downloading usually finishes within several seconds if the master server is already operating. The master server does not have this wait process.
- clusterpro_nmThere is no wait process. This process usually finishes within several seconds.
- clusterpro_trnThere is no wait process. This process usually finishes within several seconds.
- clusterpro_ibThere is no wait process. This process usually finishes within several seconds.
- clusterpro_apiThere is no wait process. This process usually finishes within several seconds.
- clusterpro_mdThis service starts up only when the mirror or hybrid disk resources exist. The system waits up to one minute for the mirror agent to normally start up. This process usually finishes within several seconds.
- clusterproAlthough there is no wait process, EXPRESSCLUSTER might take several tens of seconds to start up. This process usually finishes within several seconds.
- clusterpro_webmgrThere is no wait process. This process usually finishes within several seconds.
- clusterpro_alertsyncThere is no wait process. This process usually finishes within several seconds.
6.5.20. Checking the service status in a systemd environment¶
6.5.21. Scripts in EXEC resources¶
EXEC resource scripts of group resources stored in the following location.
/opt/nec/clusterpro/scripts/group-name/resource-name/
The following cases, old EXEC resource scripts are not deleted automatically.
When the EXEC resource is deleted or renamed
When a group that belongs to the EXEC resource is deleted or renamed
Old EXEC resource scripts can be deleted when unnecessary.
6.5.22. Monitor resources that monitoring timing is "Active"¶
When monitor resources that monitoring timing is "Active" have suspended and resumed, the following restriction apply:
In case stopping target resource after suspending monitor resource, monitor resource becomes suspended. As a result, monitoring restart cannot be executed.
In case stopping or starting target resource after suspending monitor resource, monitoring by monitor resource starts when target resource starts.
6.5.23. Notes on the Cluster WebUI¶
If the Cluster WebUI is operated in the state that it cannot communicate with the connection destination, it may take a while until the control returns.
When going through the proxy server, make the settings for the proxy server be able to relay the port number of the Cluster WebUI.
When going through the reverse proxy server, the Cluster WebUI will not operate properly.
When updating EXPRESSCLUSTER, close all running browsers. Clear the browser cache and restart the browser.
Cluster configuration data created using a later version of this product cannot be used with this product.
When closing the Web browser, the dialog box to confirm to save may be displayed.
When you continue to edit, click the Stay on this pagebutton.
Reloading the Web browser (by selecting Refresh button from the menu or tool bar), the dialog box to confirm to save may be displayed.
When you continue to edit, click the Stay on this pagebutton.
For notes and restrictions of Cluster WebUI other than the above, see the online manual.
6.5.24. Changing the partition size of mirror disks and hybrid disk resources¶
When changing the size of mirror partitions after the operation is started, see "Changing offset or size of a partition on mirror disk resource" in "The system maintenance information" in the "Maintenance Guide".
6.5.25. Changing kernel dump settings¶
- If you are changing the kdump settings and "applying" them while the cluster is running, you may see the following error message output.In this case, stop the cluster once (stop the mirror agent as well as the cluster when using a mirror disk resource or hybrid disk resource), and then retry the kernel dump configuration.* The following {driver_name} indicates clpka, clpkhb, or liscal.
No module {driver_name} found for kernel {kernel_version}, aborting
6.5.26. Notes on floating IP and virtual IP resources¶
Do not execute a network restart on a server on which floating IP resources or virtual IP resources are active. If the network is restarted, any IP addresses that have been added as floating IP resources or virtual IP resources are deleted.
6.5.27. System monitor resources,Process resource monitor resource¶
To change a setting, the cluster must be suspended.
System monitor resources do not support a delay warning for monitor resources.
If the date and time of the OS is changed during operation, the timing of analysis processing being performed at 10-minute intervals will change only once immediately after the date and time is changed. This will cause the following to occur; suspend and resume the cluster as necessary.
An error is not detected even when the time to be detected as abnormal elapses.
An error is detected before the time to be detected as abnormal elapses.
Up to 64 disks can be monitored at the same time by the disk resource monitor function of system monitor resource.
6.5.28. JVM monitor resources¶
When restarting the monitoring-target Java VM, suspend or shut down the cluster before restarting the Java VM.
To change a setting, the cluster must be suspended.
JVM monitor resources do not support a delay warning for monitor resources.
6.5.29. HTTP monitor resource¶
The HTTP monitor resource uses any of the following OpenSSL shared library symbolic links:
libssl.so
libssl.so.1.1 (OpenSSL 1.1.1 shared library)
libssl.so.10 (OpenSSL 1.0 shared library)
libssl.so.6 (OpenSSL 0.9 shared library)
The above symbolic links may not exist depending on the OS distribution or version, or the package installation status.If the above symbolic links cannot be found, the following error occurs in the HTTP monitor resource.Detected an error in monitoring<Module Resource Name>. (1 :Can not found library. (libpath=libssl.so, errno=2))
For this reason, if the above error occurred, be sure to check whether the above symbolic links exit in /usr/lib or /usr/lib64.If the above symbolic links do not exit, create the symbolic link libssl.so, as in the command example below.Command example:cd /usr/lib64 # Move to /usr/lib64. ln -s libssl.so.1.0.1e libssl.so # Create a symbolic link.
6.5.30. Restoration from an AMI in an AWS environment¶
- If the ENI ID of a primary network interface is set to the ENI ID of the AWS virtual ip resource and AWS elastic ip resource and AWS secondary ip resource, the AWS virtual ip resource and AWS elastic ip resource and AWS secondary ip resource setting is required to change when restoring data from an AMI.If the ENI ID of a secondary network interface is set to the ENI ID of the AWS virtual ip resource and AWS elastic ip resource and AWS secondary ip resource, it is unnecessary to set the AWS virtual ip resource and AWS elastic ip resource and AWS secondary ip resource again because the same ENI ID is inherited by a detach/attach processing when restoring data from an AMI.
6.6. Notes when changing the EXPRESSCLUSTER configuration¶
The section describes what happens when the configuration is changed after starting to use EXPRESSCLUSTER in the cluster configuration.
6.6.1. Exclusive rule of group properties¶
6.6.2. Dependency between resource properties¶
6.6.3. Deleting disk resources¶
When a disk resource is deleted, the corresponding device is sometimes set to Read Only.
Change the status of the device to Read Write by using the clproset command.
6.6.4. Setting cluster statistics information of eternal link monitor resources¶
Once the settings of cluster statistics information of monitor resource has been changed, the settings of cluster statistics information are not applied to eternal link monitor resources even if you execute the suspend and resume. Reboot the OS to apply the settings to the eternal link monitor resources.
6.6.5. Changing a port number¶
If you have changed a port number with the server firewall enabled, the firewall configuration needs to be changed as well by using the clpfwctrl.sh command. For more information, see "Reference Guide" -> "EXPRESSCLUSTER command reference" -> "Adding a firewall rule (clpfwctrl.sh command)".
6.7. Notes on upgrading EXPRESSCLUSTER¶
This section describes notes on upgrading or updating EXPRESSCLUSTER after starting the cluster operation.
6.7.1. Changed Functions¶
The following describes the functions changed for each of the versions.
Internal Version 4.0.0-1
- Management toolThe default management tool has been changed to Cluster WebUI. If you want to use the conventional WebManager as the management tool, specify "http://management IP address of management group or actual IP address:port number of the server in which EXPRESSCLUSTER Server is installed/main.htm" in the address bar of a web browser.
- Mirror/hybrid disk resourceConsidering that the minimum size of a cluster partition has been increased to 1 GiB, prepare a sufficient size of it for upgrading EXPRESSCLUSTER.
Internal Version 4.1.0-1
- Configuration toolThe default configuration tool has been changed to Cluster WebUI, which allows you to manage and configure clusters with Cluster WebUI.
- Cluster statistical information collection functionBy default, the cluster statistical information collection function saves statistics information files under the installation path. To avoid saving the files for such reasons as insufficient disk capacity, disable the cluster statistical information collection function. For more information on settings for this function, see "Parameter details" in the "Reference Guide".
- Mirror/hybrid disk resource in the asynchronous modeIn the asynchronous mode, the mirror break status is not set even if the queue for the data to be sent has become full. The overflown ones are temporarily written as a history file. Due to this functional enhancement, it is necessary to enter the setting values below:
History file storage directory
History file size limit
* Shortly after the update, these setting values are in blank. In this case, the history file storage directory is treated as a directory which has installed EXPRESSCLUSTER, and no limit is imposed on the history file size.For more information on the setting values, see "Understanding mirror disk connect monitor resources" of "Group resource details" in the "Reference Guide". - System monitor resourceThe System Resource Agent process settings part of the system monitor resource has been separated to become a new monitor resource. Therefore, the conventional monitor settings of the System Resource Agent process settings are no longer valid. To continue the conventional monitoring, configure it by registering a new process resource monitor resource after upgrading EXPRESSCLUSTER. For more information on monitor settings for process resource monitor resources, see "Understanding process resource monitor resources" in "Monitor resource details" in the "Reference Guide".
Internal Version 4.2.0-1
- AWS AZ monitor resourceThe way of evaluating the AZ status grasped through the AWS CLI has been changed: available as normal, information or impaired as warning, and unavailable as warning. (Previously, any AZ status other than available was evaluated as abnormal.)
Internal Version 4.3.0-1
- WebLogic monitor resourceREST API has been added as a new monitoring method. From this version, REST API is the default value for the monitoring method. At the version upgrade, reconfigure the monitoring method.The default value of the password has been changed. If you use weblogic that is the previous default value, reset the password default value.
Internal Version 5.0.0-1
- Forced stop function and scriptsThese have been redesigned as individual forced stop resources adapted to environment types.Since the forced stop function and scripts configured before the upgrade are no longer effective, set them up again as forced stop resources.
Internal Version 5.1.0-1
- AWS Virtual IP resourcesSome of the parameters have been changed due to a discontinuation of using Python.
Internal Version 5.2.0-1
- Supported browsers for Cluster WebUIIf you use an internal version since 5.2.0-1, Cluster WebUI does not support Internet Explorer. For information on supported browsers, refer to "4.3.1. Supported operating systems and browsers" .
6.7.2. Removed Functions¶
The following describes the functions removed for each of the versions.
Internal Version 4.0.0-1
WebManager Mobile
OracleAS monitor resource
Important
Internal Version 5.0.0-1
Function
Action
WebManager/Builder
COM heartbeat resource
Open Cluster Properties -> Interconnect tab, then remove each heartbeat interface whose type is unknown.
You cannot move configuration data (for a host cluster) which involves virtual machine groups.
BMC linkage
Delete relevant eternal link monitor resources.
-
-
-
-
-
Disk I/O Lockout
-
Disk Heart Beat RawDevice
-
It does not apply to IBM POWER and IBM POWER LE
NAS resources
-
Sybase monitor resources
-
-
VxVM linkage
Disk resource - Disk Type(VXVM)Volume manager resource - Volume manager(VXVM)Disk monitor resource - Method (READ (VXVM))Volume manager monitor resource - Volume manager(VXVM)Configuration data based on the VxVM linkage function cannot be migrated.
6.7.3. Removed Parameters¶
The following tables show the parameters configurable with Cluster WebUI but removed for each of the versions.
Internal Version 4.0.0-1
Cluster
Parameters
default values
Cluster Properties
Alert Service Tab
Use Alert Extension
Off
WebManager Tab
Enable WebManager Mobile Connection
Off
Web Manager Mobile Password
Password for Operation
-
Password for Reference
-
JVM monitor resource
Parameters
default values
JVM Monitor Resource Properties
Monitor(special) Tab
Memory Tab (when Oracle Java is selected for JVM Type)
Monitor Virtual Memory Usage
2048 MB
Memory Tab (when Oracle JRockit is selected for JVM Type)
Monitor Virtual Memory Usage
2048 MB
Memory Tab(when Oracle Java(usage monitoring) is selected for JVM Type)
Monitor Virtual Memory Usage
2048 MB
Internal Version 4.1.0-1
Cluster
Parameters
default values
Cluster Properties
WebManager Tab
WebManager Tuning Properties
Behavior Tab
Max. Number of Alert Records on the Viewer
300
Client Data Update Method
Real Time
Internal Version 5.0.0-1
Cluster
Parameters
default values
Cluster Properties
Interconnect Tab
COM Device
Disk Heart Beat Properties
RawDevice
Extension Tab
Virtual Machine Forced Stop Setting - Virtual Machine Management Tool
vCenter
Virtual Machine Forced Stop Setting - Command
/usr/lib/vmware-vcli/apps/vm/vmcontrol.pl
Execute Script for Forced Stop
Off
Server Properties
Info Tab
Virtual Machine
Off
Type
vSphere
BMC Tab
Forced Stop Command Line
-
Chassis Identify - Flash / Turn off
-
Disk I/O Lockout Tab
I/F No. (Add, Remove)
The order you added I/Fs
Device (Edit)
-
Internal Version 5.0.2-1
Mirror disk resource
Parameters
default values
Mirror Disk Resource Properties
Details Tab
Mirror disk resource tuning properties
High Speed SSD Tab
Data Partition
Off
Cluster Partition
Off
Hybrid disk resource
Parameters
default values
Hybrid disk resource Properties
Details Tab
Hybrid disk resource tuning properties
High Speed SSD Tab
Data Partition
Off
Cluster Partition
Off
Internal Version 5.1.0-1
Virtual IP resource
Parameters
default values
Virtual IP Resource Properties
Details Tab
Virtual IP Resource Tuning Properties
RIP Tab
Next Hop IP Address
-
6.7.4. Changed Default Values¶
The following tables show the parameters which are configurable with Cluster WebUI but whose defaults have been changed for each of the versions.
To continue using a "Default value before update" after the upgrade, change the corresponding "Default value after update" to the desired one.
Any setting other than a "Default value before update" is inherited to the upgraded version and therefore does not need to be restored.
Internal Version 4.0.0-1
Cluster
Parameters
Default value before update
Default value after update
Cluster Properties
Monitor Tab
Method
softdog
keepalive
JVM monitor Tab
Maximum Java Heap Size
7 MB
16 MB
EXEC resource
Parameters
Default value before update
Default value after update
EXEC Resource Properties
Dependence Tab
Follow the default dependence
Disk resource
Parameters
Default value before update
Default value after update
Disk Resource Properties
Dependence Tab
Follow the default dependence
Details Tab
Disk Resource Tuning Properties
Mount Tab
Timeout
60 sec
180 sec
xfs_repair Tab (when xfs is selected for File System)
On
Off
NAS resource
Parameters
Default value before update
Default value after update
NAS Resource Properties
Dependence Tab
Follow the default dependence
Mirror disk resource
Parameters
Default value before update
Default value after update
Mirror Disk Resource Properties
Dependency Tab
Follow the default dependence
Details Tab
Mirror Disk Resource Tuning Properties
xfs_repair Tab (when xfs is selected for File System)
On
Off
Hybrid disk resource
Parameters
Default value before
Default value after update
Hybrid Disk Resource Properties
Dependency Tab
Follow the default dependence
Details Tab
Hybrid Disk Resource Tuning Properties
xfs_repair Tab (when xfs is selected for File System)
On
Off
Volume manager resource
Parameters
Default value before update
Default value after update
Volume Manager Resource Properties
Dependency Tab
Follow the default dependence
Virtual IP monitor resource
Parameters
Default value before update
Default value after update
Virtual IP Monitor Resource Properties
Monitor(common)
Timeout
30 sec
180 sec
PID monitor resource
Parameters
Default value before update
Default value after update
PID Monitor Resource Properties
Monitor(common)Tab
Wait Time to Start Monitoring
0 sec
3 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
User mode monitor resource
Parameters
Default value before update
Default value after update
User mode Monitor Resource Properties
Monitor(special) Tab
Method
softdog
keepalive
NIC Link Up/Down monitor resource
Parameters
Default value before update
Default value after update
NIC Link Up/Down Monitor Resource Properties
Monitor(common) Tab
Timeout
60 sec
180 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
ARP monitor resource
Parameters
Default value before update
Default value after update
ARP Monitor Resource Properties
Monitor(common) Tab
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
Dynamic DNS monitor resource
Parameters
Default value before update
Default value after update
Dynamic DNS Monitor Resource Properties
Monitor(common) Tab
Timeout
100 sec
180 sec
Process name monitor resource
Parameters
Default value before update
Default value after update
Process Monitor Resource Properties
Monitor(common) tab
Wait Time to Start Monitoring
0 sec
3 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
DB2 monitor resource
Parameters
Default value before update
Default value after update
DB2 Monitor Resource Properties
Monitor(special) Tab
Password
ibmdb2
-
Library Path
/opt/IBM/db2/V8.2/lib/libdb2.so
/opt/ibm/db2/V11.1/lib64/libdb2.soMySQL monitor resource
Parameters
Default value before update
Default value after update
MySQL Monitor Resource Properties
Monitor(special) Tab
Storage Engine
MyISAM
InnoDB
Library Path
/usr/lib/mysql/libmysqlclient.so.15
/usr/lib64/mysql/libmysqlclient.so.20Oracle monitor resource
Parameters
Default value before update
Default value after update
Oracle Monitor Resource Properties
Monitor(special) Tab
Password
change_on_install
-
Library Path
/opt/app/oracle/product/10.2.0/db_1/lib/libclntsh.so.10.1
/u01/app/oracle/product/12.2.0/dbhome_1/lib/libclntsh.so.12.1PostgreSQL monitor resource
Parameters
Default value before update
Default value after update
PostgreSQL Monitor Resource Properties
Monitor(special) Tab
Library Path
/usr/lib/libpq.so.3.0
/opt/PostgreSQL/10/lib/libpq.so.5.10Tuxedo monitor resource
Parameters
Default value before update
Default value after update
Tuxedo Monitor Resource Properties
Monitor(special) Tab
Library Path
/opt/bea/tuxedo8.1/lib/libtux.so
/home/Oracle/tuxedo/tuxedo12.1.3.0.0/lib/libtux.soWebLogic monitor resource
Parameters
Default value before update
Default value after update
WebLogic Monitor Resource Properties
Monitor(special) Tab
Domain Environment File
/opt/bea/weblogic81/samples/domains/examples/setExamplesEnv.sh
/home/Oracle/product/Oracle_Home/user_projects/domains/base_domain/bin/setDomainEnv.shJVM monitor resource
Parameters
Default value before update
Default value after update
JVM Monitor Resource Properties
Monitor(common) Tab
Timeout
120 sec
180 sec
Floating IP monitor resources
Parameters
Default value before update
Default value after update
Floating IP Monitor Resource Properties
Monitor(common) Tab
Timeout
60 sec
180 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
AWS Elastic IP monitor resource
Parameters
Default value before update
Default value after update
AWS elastic ip Monitor Resource Properties
Monitor(common) Tab
Timeout
100 sec
180 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
AWS Virtual IP monitor resource
Parameters
Default value before update
Default value after update
AWS virtual ip Monitor Resource Properties
Monitor(common) Tab
Timeout
100 sec
180 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
AWS AZ monitor resource
Parameters
Default value before update
Default value after update
AWS AZ Monitor Resource Properties
Monitor(common) Tab
Timeout
100 sec
180 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
Azure probe port monitor resource
Parameters
Default value before update
Default value after update
Azure probe port Monitor Resource Properties
Monitor(common) Tab
Timeout
100 sec
180 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
Azure load balance monitor resource
Parameters
Default value before update
Default value after update
Azure load balance monitor resource Properties
Monitor(common) Tab
Timeout
100 sec
180 sec
Do Not Retry at Timeout Occurrence
Off
On
Do not Execute Recovery Action at Timeout Occurrence
Off
On
Internal Version 4.1.0-1
Cluster
Parameters
Default value before update
Default value after update
Cluster Properties
Monitor Tab
Shutdown monitor
Always execute
Execute when the group deactivation has been failed
Internal Version 4.2.0-1
AWS Elastic IP monitor resource
Parameters
Default value before update
Default value after update
AWS elastic ip Monitor Resource Properties
Monitor(special) Tab
Action when AWS CLI command failed to receive response
Disable recovery action(Display warning)
Disable recovery action(Do nothing)
AWS Virtual IP monitor resource
Parameters
Default value before update
Default value after update
AWS virtual ip Monitor Resource Properties
Monitor(special) Tab
Action when AWS CLI command failed to receive response
Disable recovery action(Display warning)
Disable recovery action(Do nothing)
AWS AZ monitor resource
Parameters
Default value before update
Default value after update
AWS AZ Monitor Resource Properties
Monitor(special) Tab
Action when AWS CLI command failed to receive response
Disable recovery action(Display warning)
Disable recovery action(Do nothing)
AWS DNS monitor resource
Parameters
Default value before update
Default value after update
AWS DNS Monitor Resource Properties
Monitor(special) Tab
Action when AWS CLI command failed to receive response
Disable recovery action(Display warning)
Disable recovery action(Do nothing)
Internal Version 4.3.0-1
Cluster
Parameters
Default value before update
Default value after update
Cluster Properties
Extension Tab
Max Reboot Count
0 times
3 times
Max Reboot Count Reset Time
0 min
60 min
API tab
Communication Method
HTTP
HTTPS
NFS monitor resource
Parameters
Default value before update
Default value after update
NFS Monitor Resource Properties
Monitor(special) Tab
NFS Version
v2
v4
WebLogic monitor resource
Parameters
Default value before update
Default value after update
WebLogic Monitor Resource Properties
Monitor(special) Tab
Password
weblogic
None
Internal Version 4.3.2-1
AWS DNS resource
Parameters
Default value before update
Default value after update
AWS DNS Resource Properties
Details Tab
Delete a resource record set at deactivation
on
off
Internal Version 5.0.0-1
Cluster
Parameters
Default value before update
Default value after update
Cluster Properties
Monitor Tab
Enable SIGTERM handler
Off
On
EXEC resource
Parameters
Default value before update
Default value after update
EXEC Resource Properties
Dependence Tab
Follow the default dependence
Disk resource
Parameters
Default value before update
Default value after update
Disk Resource Properties
Dependence Tab
Follow the default dependence
Mirror disk resource
Parameters
Default value before update
Default value after update
Mirror Disk Resource Properties
Dependency Tab
Follow the default dependence
Hybrid disk resource
Parameters
Default value before
Default value after update
Hybrid Disk Resource Properties
Dependency Tab
Follow the default dependence
Volume manager resource
Parameters
Default value before update
Default value after update
Volume Manager Resource Properties
Dependency Tab
Follow the default dependence
Dynamic DNS resource
Parameters
Default value before update
Default value after update
Dynamic DNS resource Properties
Dependency Tab
Follow the default dependence
Internal Version 5.1.0-1
Cluster
Parameters
Default value before update
Default value after update
Cluster Properties
WebManager Tab
Output Cluster WebUI Operation Log
Off
On
Internal Version 5.2.0-1
Azure probe port resource
Parameters
Default value before update
Default value after update
Azure probe port resource Properties
Dependency Tab
Follow the default dependence
Google Cloud Virtual IP resource
Parameters
Default value before update
Default value after update
Google Cloud Virtual IP resource Properties
Dependency Tab
Follow the default dependence
Oracle Cloud Virtual IP resource
Parameters
Default value before update
Default value after update
Oracle Cloud Virtual IP resource Properties
Dependency Tab
Follow the default dependence
EXEC resource
Parameters
Default value before update
Default value after update
EXEC resource Properties
Dependency Tab
Follow the default dependence
Disk resource
Parameters
Default value before update
Default value after update
Disk resource Properties
Dependency Tab
Follow the default dependence
Volume manager resource
Parameters
Default value before update
Default value after update
Volume manager resource Properties
Dependency Tab
Follow the default dependence
Dynamic DNS resource
Parameters
Default value before update
Default value after update
Dynamic DNS resource Properties
Dependency Tab
Follow the default dependence
Mirror disk resource
Parameters
Default value before update
Default value after update
Mirror disk resource Properties
Dependency Tab
Follow the default dependence
Hybrid disk resource
Parameters
Default value before update
Default value after update
Hybrid disk resource Properties
Dependency Tab
Follow the default dependence
6.7.5. Moved Parameters¶
The following table shows the parameters which are configurable with Cluster WebUI but whose controls have been moved for each of the versions:
Internal Version 4.0.0-1
Before the change
After the change
[Cluster Properties]-[Recovery Tab]-[Max Reboot Count]
[Cluster Properties]-[Extension Tab]-[Max Reboot Count]
[Cluster Properties]-[Recovery Tab]-[Max Reboot Count Reset Time]
[Cluster Properties]-[Extension Tab]-[Max Reboot Count Reset Time]
[Cluster Properties]-[Recovery Tab]-[Use Forced Stop]
[Cluster Properties]-[Extension Tab]-[Use Forced Stop]
[Cluster Properties]-[Recovery Tab]-[Forced Stop Action]
[Cluster Properties]-[Extension Tab]-[Forced Stop Action]
[Cluster Properties]-[Recovery Tab]-[Forced Stop Timeout]
[Cluster Properties]-[Extension Tab]-[Forced Stop Timeout]
[Cluster Properties]-[Recovery Tab]-[Virtual Machine Forced Stop Setting]
[Cluster Properties]-[Extension Tab]-[Virtual Machine Forced Stop Setting]
[Cluster Properties]-[Recovery Tab]-[Execute Script for Forced Stop]
[Cluster Properties]-[Extension Tab]-[Execute Script for Forced Stop]
[Cluster Properties]-[Auto Recovery Tab]-[Auto Return]
[Cluster Properties]-[Extension Tab]-[Auto Return]
[Cluster Properties]-[Exclusion Tab]-[Mount/Umount Exclusion]
[Cluster Properties]-[Extension Tab]-[Exclude Mount/Unmount Commands]
[Cluster Properties]-[Recovery Tab]-[Disable Recovery Action Caused by Monitor Resource Error]
[Cluster Properties]-[Extension Tab]-[Disable cluster operation]-[Recovery Action when Monitor Resource Failure Detected]
[Group Properties]-[Attribute Tab]-[Failover Exclusive Attribute]
[Group Common Properties]-[Exclusion Tab]
Internal Version 5.0.0-1
Before the change
After the change
[Cluster Properties]-[Extension Tab]-[Use Forced Stop]
[Cluster Properties]-[Fencing Tab]-[Forced Stop] - [Type]
[Cluster Properties]-[Extension Tab]-[Forced Stop Action]
[BMC Forced Stop Properties]-[Forced Stop Tab]-[Forced Stop Action]
[Cluster Properties]-[Extension Tab]-[Forced Stop Timeout]
[BMC Forced Stop Properties]-[Forced Stop Tab]-[Forced Stop Timeout]
[Cluster Properties]-[Extension Tab]-[Virtual Machine Forced Stop Setting] - [Action]
[vCenter Forced Stop Properties]-[Forced Stop Tab]-[Forced Stop Action]
[Cluster Properties]-[Extension Tab]-[Virtual Machine Forced Stop Setting] - [Timeout]
[vCenter Forced Stop Properties]-[Forced Stop Tab]-[Forced Stop Timeout]
[Cluster Properties]-[Extension Tab]-[Virtual Machine Forced Stop Setting] - [Host Name]
[vCenter Forced Stop Properties]-[vCenter Tab]-[Host Name]
[Cluster Properties]-[Extension Tab]-[Virtual Machine Forced Stop Setting] - [User Name]
[vCenter Forced Stop Properties]-[vCenter Tab]-[User Name]
[Cluster Properties]-[Extension Tab]-[Virtual Machine Forced Stop Setting] - [Password]
[vCenter Forced Stop Properties]-[vCenter Tab]-[Password]
[Cluster Properties]-[Extension Tab]-[Virtual Machine Forced Stop Setting] - [Perl Path]
[vCenter Forced Stop Properties]-[vCenter Tab]-[Perl Path]
[Server Properties]-[BMC Tab]-[IP Address]
[BMC Forced Stop Properties]-[Server List Tab]-[BMC Settings]-[IP Address]
[Server Properties]-[BMC Tab]-[User Name]
[BMC Forced Stop Properties]-[Server List Tab]-[BMC Settings]-[User Name]
[Server Properties]-[BMC Tab]-[Password]
[BMC Forced Stop Properties]-[Server List Tab]-[BMC Settings]-[Password]
Internal Version 5.1.0-1
Before the change
After the change
[Cluster Properties]-[Monitor Tab]-[System Resource]
[Cluster Properties]-[Statistics Tab]-[System Resource Statistics]
[Cluster Properties]-[Mirror Agent Tab]-[Collect Mirror Statistics]
[Cluster Properties]-[Statistics Tab]-[Mirror Statistics]
[Cluster Properties]-[Extension Tab]-[Cluster Statistics]
[Cluster Properties]-[Statistics Tab]-[Cluster Statistics]
7. Upgrading EXPRESSCLUSTER¶
This chapter provides information on how to upgrade EXPRESSCLUSTER.
This chapter covers:
7.1. How to upgrade from EXPRESSCLUSTER¶
7.1.1. How to upgrade from X3.3 or X4.x to X 5.2¶
Before starting the upgrade, read the following notes.
The upgrade procedure described in this section is valid for EXPRESSCLUSTER X 3.3 for Linux (internal version 3.3.5-1) or later.
- In EXPRESSCLUSTER X 4.2 for Linux or later, port numbers for EXPRESSCLUSTER have been added. If you upgrade from EXPRESSCLUSTER X 4.1 for Linux or earlier, make necessary ports accessible beforehand.For information on port numbers for EXPRESSCLUSTER, refer to "6.3.1. Communication port number".
If mirror disk resources or hybrid disk resources are set, cluster partitions require space of 1024 MiB or larger. And also, executing full copy of mirror disk resources or hybrid disk resources is required.
If mirror disk resources or hybrid disk resources are set, it is recommended to backup data in advance. For details of a backup procedure, refer to "Backup procedures" and "Restoration procedures" in "Verifying operation" in the "Installation and Configuration Guide".
Upgrade the EXPRESSCLUSTER Server RPM as root user.
See also
For the procedure of updating between the different versions of the same major version, refer to the "Update Procedure Manual".
The following procedures explain how to upgrade from EXPRESSCLUSTER X 3.3 or 4.x to EXPRESSCLUSTER X 5.2.
Before upgrading, confirm that the servers in the cluster and all the resources are in normal status by using Cluster WebUI, WebManager or the command.
Save the current cluster configuration file with the Cluster WebUI, Builder or clpcfctrl command. For details about saving the cluster configuration file with clpcfctrl command, refer to "Changing, backing up, and checking cluster configuration data (clpcfctrl command)" -> "Backing up the cluster configuration data" in "EXPRESSCLUSTER command reference" in the "Reference Guide".
Uninstall the EXPRESSCLUSTER Server from all the servers. For details about uninstallation, refer to "Uninstallation" in "Uninstalling and reinstalling EXPRESSCLUSTER" in the "Installation and Configuration Guide".
Install the EXPRESSCLUSTER Server on all the servers. For details, refer to "Setting up the EXPRESSCLUSTER Server" in "Installing EXPRESSCLUSTER" and "Registering the license" in the "Installation and Configuration Guide".
In any of the servers with EXPRESSCLUSTER installed as above, execute the command for converting cluster configuration data.
Move to the work directory (such as /tmp) in which the conversion command is to be executed.
- To the moved work directory, copy and deploy the cluster configuration data backed up in step 2.Deploy clp.conf and the scripts directory.
Note
If backed up on Cluster WebUI, the cluster configuration data is zipped.Unzip the file, and clp.conf and the scripts directory will be extracted. Execute the following command to convert the cluster configuration data:
# clpcfconv.sh -i .
Under the work directory, zip the cluster configuration data (clp.conf) and the scripts directory.
Note
Create the zip file so that when unzipped, the clp.conf file and scripts directory are created.
- Open the config mode of Cluster WebUI, and click Import.Import the cluster configuration data zipped in step 5.
Of the cluster configuration data, manually update its items if necessary.
See "6.7.2. Removed Functions". Then, if you have used any of the functions with its corresponding action described in the Action column of the table, change the cluster configuration data according to the described action.
- If a password was set on the cluster password method, the password has been cleared.Please set the password again by using Cluster WebUI.For information on how to set a password, see "Reference Guide" -> "Parameter details" -> "Cluster properties" -> "WebManager tab".
If you upgrade from EXPRESSCLUSTER X 3.3 and are using mirror disk resources or hybrid disk resources, perform the following steps:
Allocate cluster partition (The cluster partition should be 1024 MiB or larger).
If the cluster partition is different from the configuration, modify the configuration. And regarding the groups which mirror disk resources or hybrid disk resources belong to, if Startup Attribute is Auto Startup on the Attribute tab of Group Properties, change it to Manual Startup.
If mirror disk resources are set, perform the following steps for each mirror disk resource.
Click Tuning on the Details tab of Resource Properties. Then, Mirror disk resource tuning properties dialog box is displayed.
Uncheck Execute the initial mirror construction on Mirror tab of the Mirror disk resource tuning properties dialog box.
If the forced stop function or the forced stop script is used, perform the following steps:
- Set the Type of Forced Stop on the Fencing tab of Cluster Properties.If the forced stop script is used: Select Custom.If the forced stop script is not used: With EXPRESSCLUSTER operated on physical machines, select BMC; with EXPRESSCLUSTER operated on virtual machines, select vCenter.
Click Properties to display the properties window for the forced stop resource, and set each parameter.
Click Apply the Configuration File of the Cluster WebUI to apply the configuration data.
If using a fixed-term license, execute the following command:
clplcnsc --distribute
If you upgrade from EXPRESSCLUSTER X 3.3 and are using mirror disk resources or hybrid disk resources, perform the following steps:
Initialize the cluster partition of all mirror disk resources and hybrid disk resources as below on each server.For the mirror diskclpmdinit --create force <mirror disk resource name>
For the hybrid disk
clphdinit --create force <hybrid disk resource name>
Open the operation mode of Cluster WebUI, and start the cluster.
If you upgrade from EXPRESSCLUSTER X 3.3 and are using mirror disk resources or hybrid disk resources, perform the following steps:
Execute a full copy assuming that the server with the latest data is the copy source from the Mirror disks.
Start the groups and confirm that each resource starts normally.
If Startup Attribute or Execute the initial mirror construction was changed in the step 8, change back the setting with Cluster WebUI and click Apply the Configuration File to apply the cluster configuration data to the cluster.
This completes the procedure for upgrading the EXPRESSCLUSTER Server. Check that the servers are operating normally as the cluster by the clpstat command or Cluster WebUI
8. Glossary¶
- Cluster partition
- A partition on a mirror disk. Used for managing mirror disks.(Related term: Disk heartbeat partition)
- Interconnect
- A dedicated communication path for server-to-server communication in a cluster.(Related terms: Private LAN, Public LAN)
- Virtual IP address
IP address used to configure a remote cluster.
- Management client
Any machine that uses the Cluster WebUI to access and manage a cluster system.
- Startup attribute
A failover group attribute that determines whether a failover group should be started up automatically or manually when a cluster is started.
A disk that multiple servers can access.
A cluster system that uses one or more shared disks.
- Switchable partition
- A disk partition connected to multiple computers and is switchable among computers.(Related terms: Disk heartbeat partition)
- Cluster system
Multiple computers are connected via a LAN (or other network) and behave as if it were a single system.
- Cluster shutdown
To shut down an entire cluster system (all servers that configure a cluster system).
- Active server
- A server that is running for an application set.(Related term: Standby server)
- Secondary server
- A destination server where a failover group fails over to during normal operations.(Related term: Primary server)
- Standby server
- A server that is not an active server.(Related term: Active server)
- Disk heartbeat partition
A partition used for heartbeat communication in a shared disk type cluster.
- Data partition
- A local disk that can be used as a shared disk for switchable partition. Data partition for mirror disks and hybrid disks.(Related term: Cluster partition)
- Network partition
- All heartbeat is lost and the network between servers is partitioned.(Related terms: Interconnect, Heartbeat)
- Node
A server that is part of a cluster in a cluster system. In networking terminology, it refers to devices, including computers and routers, that can transmit, receive, or process signals.
- Heartbeat
- Signals that servers in a cluster send to each other to detect a failure in a cluster.(Related terms: Interconnect, Network partition)
- Public LAN
- A communication channel between clients and servers.(Related terms: Interconnect, Private LAN)
- Failover
The process of a standby server taking over the group of resources that the active server previously was handling due to error detection.
- Failback
A process of returning an application back to an active server after an application fails over to another server.
- Failover group
A group of cluster resources and attributes required to execute an application.
- Moving failover group
Moving an application from an active server to a standby server by a user.
- Failover policy
A priority list of servers that a group can fail over to.
- Private LAN
- LAN in which only servers configured in a clustered system are connected.(Related terms: Interconnect, Public LAN)
- Primary (server)
- A server that is the main server for a failover group.(Related term: Secondary server)
- Floating IP address
- Clients can transparently switch one server from another when a failover occurs.Any unassigned IP address that has the same network address that a cluster server belongs to can be used as a floating address.
- Master server
The server displayed at the top of Master Server in Server Common Properties of the Cluster WebUI
- Mirror disk connect
LAN used for data mirroring in mirror disks and hybrid disks. Mirror connect can be used with primary interconnect.
- Mirror disk type cluster
A cluster system that does not use a shared disk. Local disks of the servers are mirrored.