10. トラブルシューティング¶
本章では、CLUSTERPRO の使用中に発生した障害に対応する方法について説明します。
本章で説明する項目は以下のとおりです。
10.1. 障害発生時の手順¶
本トピックでは、CLUSTERPRO 運用時に障害が発生した場合の手順について説明します。
10.1.1. CLUSTERPRO が起動しない/終了する¶
CLUSTERPRO インストール後、サーバを再起動するとクラスタシステムの運用が開始されますが、クラスタシステムが正常に動作していない場合は、以下を確認してください。
- クラスタ構成情報の登録状態クラスタ構成情報は、クラスタ生成時にクラスタシステムを構築しようとしている全サーバに登録されている必要があります。クラスタ構成情報が全サーバにアップロードされているか確認してください。詳細については、『インストール&設定ガイド』の「クラスタ構成情報を作成する」を実行してください。
- クラスタ構成情報のサーバ名、IP アドレスサーバ名、IP アドレスが正当であるか確認してください。(>hostname、>ipconfig....)
- ライセンスの登録状態ライセンスが登録されていない可能性があります。クラスタ内の全サーバでライセンスマネージャを実行しライセンスが登録されていることを確認してください。また、試用版ライセンスもしくは期限付きライセンスであれば、登録したライセンスが有効期間内であるか確認してください。ライセンスマネージャを実行するには、[スタート] メニュー - [CLUSTERPRO Server] - [ライセンスマネージャ] を選択します。
- CLUSTERPRO のサービス状態確認OS のサービス制御マネージャを起動し、以下の CLUSTERPRO のサービスが開始 状態であることを確認します。すべて開始状態であれば、正常に CLUSTERPRO が動作しています。サービス制御マネージャを実行するには、[コントロールパネル] - [管理ツール] - [サービス] を選択します。- CLUSTERPRO- CLUSTERPRO API- CLUSTERPRO Disk Agent- CLUSTERPRO Event- CLUSTERPRO Information Base- CLUSTERPRO Manager- CLUSTERPRO Node Manager- CLUSTERPRO Old API Support- CLUSTERPRO Server- CLUSTERPRO Transaction- CLUSTERPRO Web Alert
- ディスクの空き容量状態OS の [ディスクの管理] を実行し、<CLUSTERPRO インストールパス> が属するドライブの空き容量が十分であるか確認してください。CLUSTERPRO が使用するディスク容量については、『スタートアップガイド』の「CLUSTERPRO の動作環境」を 参照してください。[ディスクの管理] を実行するには、[コントロールパネル] - [管理ツール] - [コンピュータの管理] を選択し、アイコンツリーの、[サービスとアプリケーション] - [サービス]を選択します。
- メモリ不足または、OS リソース不足OS のタスクマネージャを実行し、OS のメモリ使用状況、CPU 使用率を確認してください。
10.1.2. ネットワークパーティション解決リソースの活性/非活性に失敗する¶
- 多数決方式の場合メモリ不足または OS のリソース不足が考えられます。確認してください。
- PING 方式の場合メモリ不足または OS のリソース不足が考えられます。確認してください。
- DISK 方式の場合Cluster WebUI の設定が不正です。活性/非活性に失敗したサーバの [サーバプロパティ]→[HBA] タブでディスクハートビート用パーティションがフィルタリング設定されているか確認してください。また、ディスクハートビート用パーティションが他のリソース (ディスクリソース、ミラーディスクリソース) で使用されていないか確認してください。
10.1.3. グループリソース活性/非活性に失敗する¶
グループリソースの活性/非活性時に異常を検出した場合、異常の詳細情報をアラート、イベントログに出力します。その情報から「 グループリソース活性/非活性時の詳細情報 」を参照し、異常に対する原因を解析し、対処してください。
10.1.4. ネットワークパーティション解決リソースで異常を検出した¶
- 多数決方式の場合メモリ不足または OS のリソース不足が考えられます。確認してください。
- PING 方式の場合PING 先装置からの [PING] コマンドの応答がありません。クラスタサーバから PING先装置までの通信路に問題がないか確認してください。
- DISK 方式の場合ディスクハートビート用パーティションへのアクセスタイムアウトが発生、または共有ディスクへのケーブルの断線を検出しています。タイムアウトが発生している場合、[クラスタのプロパティ] → [NP解決] タブで異常が発生したディスクネットワークパーティション解決リソースを選択し、[プロパティ] を開きます。[Disk NPのプロパティ] ダイアログで [IO待ち時間] を調整してください。ケーブルの断線を検出した場合、ケーブルの接続状況を確認してください。
10.1.5. モニタリソースで異常が発生した¶
モニタリソースにより異常を検出した場合、異常の詳細情報をアラート、イベントログに出力します。その情報から「 モニタリソース異常時の詳細情報 」を参照し、異常に対する原因を解析し、対処してください。
10.1.6. ハートビートのタイムアウトが発生した¶
サーバ間のハートビートでタイムアウトが発生する原因は、以下のことが考えられます。
原因 |
対処 |
|---|---|
LAN ケーブルの断線 |
ping によるパケット送信が可能か確認してください。 |
10.1.7. 片サーバダウンから復帰する¶
[クラスタのプロパティ] で自動復帰モードが設定されていない場合には、障害を取り除いた 再起動直後のサーバは、「保留 (ダウン後再起動)」状態になります。この状態から、クラスタとして機能できる正常な状態に戻すためには、Cluster WebUI または [clpcl] コマンドを使用してサーバの復帰を実行してください。
Replicator を使用している場合、ミラーセットとなっているディスク間ではデータ不整合状態となってしまいますが、サーバの復帰を行うことで、自動的にミラー再構築が実行されデータ不整合状態を解消します。
Cluster WebUI によるサーバの復帰は、オンラインマニュアルを参照してください。
[clpcl] コマンドによるサーバの復帰は、本ガイドの「9. CLUSTERPRO コマンドリファレンス」の「クラスタを操作する (clpcl コマンド)」を参照してください。
10.1.8. 両サーバダウンから復帰する¶
[クラスタのプロパティ] の [拡張] タブで [自動復帰しない] に設定されている場合、ハードウェア障害などで、すべてのサーバがシャットダウンすると、起動後、すべてのサーバがクラスタから切り離された状態になります。Cluster WebUI または [clpcl] コマンドを使用して全てのサーバに対してサーバの復帰を実行してください。
サーバの復帰を行った直後は、グループはすべて停止した状態です。グループを起動させてください。Replicator を使用している場合、グループ起動によって自動的にミラー再構築が実行されデータ不整合状態を解消します。
10.1.9. ネットワークパーティションが発生した¶
ネットワークパーティションは、サーバ間の通信経路が全て遮断されたことを意味します。ここではネットワークパーティション解決リソースが登録されていない状態で、ネットワークパーティションが発生した場合の確認方法を示します。以下の説明では、クラスタ 2 ノード構成で ハートビートリソースにカーネルモード LAN ハートビートリソースを登録した場合の例で説明します。
全ハートビートリソースが正常な状態である (つまりネットワークパーティションが発生していない) 場合、[clpstat] コマンドの実行結果は以下のとおりです。
[server1 でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
*server0 : server1
server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
[on server1 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
=================================================================
[server2 でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
server0 : server1
*server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
[on server1 : Online]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : o o
================================================================
ネットワークパーティションが発生している場合、[clpstat] コマンドの実行結果は以下のとおりです。両サーバとも相手サーバがダウンした状態であると認識しています。
[server1 でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
*server0 : server1
server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Caution]
HB 0 1
-----------------------------------------------------------------
server0 : o o
server1 : x x
[on server1 : Offline]
HB 0 1
-----------------------------------------------------------------
server0 : - -
server1 : - -
=================================================================
[server2 でコマンドを実行した結果]
# clpstat -n
==================== HEARTBEAT RESOURCE STATUS =================
Cluster : cluster
server0 : server1
*server1 : server2
HB0 : lankhb1
HB1 : lankhb2
[on server0 : Offline]
HB 0 1
-----------------------------------------------------------------
server0 : - -
server1 : - -
[on server1 : Caution]
HB 0 1
-----------------------------------------------------------------
server0 : x x
server1 : o o
=================================================================
このように、ネットワークパーティションが発生している場合、ただちに両サーバをシャット ダウンしてください。その上で、各ハートビートリソースについて、以下のことを確認してください。
- カーネルモード LAN ハートビートリソース- LAN ケーブルの状態- ネットワークインターフェイスの状態
ネットワークパーティションが発生した状態から、インタコネクト LAN が復帰した場合、CLUSTERPRO はサーバをシャットダウンさせます。
CLUSTERPRO は、複数のサーバで同じグループが活性しているのを検出するとサーバをシャットダウンさせます。同じグループを活性している全てのサーバがシャットダウンします。
Replicator の場合、サーバをシャットダウンさせるときのタイミングにより、サーバ再起動後にミラーディスクリソースの状態が異なる場合があります。
サーバをシャットダウンさせるときのタイミングによって、強制ミラー復帰が必要な状態、ミラー復帰が必要な状態、正常状態の場合があります。
10.2. ミラーディスク/ハイブリッドディスクを手動で接続する¶
CLUSTERPRO が障害などで起動できない場合に、ミラーディスクリソース/ハイブリッドディスクリソースのデータパーティションのアクセス制限を解除する場合には以下の手順を実行します。
10.2.1. ミラーリング可能な状態で正常に接続するには¶
CLUSTERPRO Server サービスが起動不可能で、CLUSTERPRO Disk Agent サービスが起動可能な場合、以下の手順でアクセス制限を解除することができます。
接続したいサーバ上で以下のコマンドを実行します。
ミラーディスクの場合:
clpmdctrl --active <ミラーディスクリソース名(例:md1)>ハイブリッドディスクの場合:
clphdctrl --active <ハイブリッドディスクリソース名(例:hd1)>ミラーディスクリソース/ハイブリッドディスクリソースへのアクセスが可能になります。 write したデータは相手サーバにミラーリングされます。
10.2.2. ミラーリング不可能な状態で強制的に接続するには¶
CLUSTERPRO Server サービスが起動不可能で、CLUSTERPRO Disk Agent サービスも起動不可能な場合にミラーディスク/ハイブリッドディスク上のデータを保存するための手順 です。
ただし、そうなる直前までミラーが正常状態にあったか、またはどちらのサーバが最新のデータを持っているかがわかっていることが条件となります。
Server 1、Server 2ともにCLUSTERPRO Server サービスが起動できない状態です。 Server 1が最新データをもっていることが分かっています。 最新データを持っているサーバの CLUSTERPRO をアンインストールし、サーバを再起動します。

図 10.1 ミラーディスク上のデータ保存 (1)¶
Server 1にバックアップ装置(Backup device)を接続し、backupコマンドを使って、データパーティション内のデータをバックアップします。

図 10.2 ミラーディスク上のデータ保存 (2)¶
ハイブリッドディスクリソースの場合、同じサーバグループ内の他サーバが共有ディスクを使用している状態で上記の処置を行うと、共有ディスク上のデータが破壊される可能性がありますので、必ず他のサーバを停止するか、他サーバのディスクケーブルを外した状態で実施してください。
10.3. ミラーブレイク状態からの復旧を行う¶
自動ミラー復帰が有効になっている場合には、特別な手順は必要ありません。自動的にミラー復帰が実行されます。
ただし、強制ミラー復帰が必要な場合には、コマンドまたは Cluster WebUI から強制ミラー復帰操作が必要です。
自動ミラー復帰が無効になっている場合には、コマンドまたは Cluster WebUI からミラー復帰操作が必要です。
以下の場合、差分ミラー復帰機能は無効になり、全面コピーとなります。
- ディスクの交換等でミラーディスクリソース/ハイブリッドディスクのパーティション設定を 変更した場合
- ミラーディスクリソースが正常に活性している状態から両サーバが同時にダウンした場合
- ハイブリッドディスクリソースが正常に活性している状態から両サーバグループのカレントサーバ (サーバグループ内でディスクの更新・管理を行っているサーバ) が同時にダウンした場合
- ディスク障害等により差分情報が正常に記録できなかった場合
10.3.1. 自動でミラーを復帰するには¶
自動ミラー復帰が有効になっている場合には、自動ミラー復帰は以下の条件の場合に実行されます。
自動ミラー復帰は以下の条件の場合には実行されません。
ミラー復帰の実行状態の確認は「 コマンドによるミラー復帰中に実行状態を確認するには 」および「 Cluster WebUI でミラー復帰中の実行状態を確認するには 」を参照してください。
10.3.2. コマンドでミラーブレイク状態を確認するには¶
ミラーディスクリソースの場合、以下のコマンドを実行してミラーブレイク状態を確認します。
clpmdstat --mirror <ミラーディスクリソース名 (例:md1)>
[clpmdstat] コマンドを実行するとミラーディスクリソースの状態が表示されます。
正常な場合
Status: Normal md1 server1 server2 --------------------------------------------------------------- Mirror Color GREEN GREEN Fast Copy -- -- Lastupdate Time -- -- Break Time -- -- Needed Copy Percent 0% 0% Volume Used Percent 64% 64% Volume Size 10240MB 10240MB Server Name DP Error CP Error --------------------------------------------------------------- server1 NO ERROR NO ERROR server2 NO ERROR NO ERROR
ミラー復帰が必要な場合
Status: Abnormal md1 server1 server2 --------------------------------------------------------------- Mirror Color GREEN RED Fast Copy OK OK Lastupdate Time 2021/08/16 18:24:10 -- Break Time 2021/08/16 18:24:01 -- Needed Copy Percent 1% 0% Volume Used Percent 64% --% Volume Size 10240MB 10240MB Server Name DP Error CP Error --------------------------------------------------------------- server1 NO ERROR NO ERROR server2 NO ERROR NO ERROR
強制ミラー復帰が必要な場合
Status: Abnormal md1 server1 server2 --------------------------------------------------------------- Mirror Color RED RED Fast Copy NG NG Lastupdate Time 2021/08/16 18:24:10 2021/08/16 18:50:33 Break Time 2021/08/16 18:24:01 2021/08/16 18:24:01 Needed Copy Percent 1% 1% Volume Used Percent 64% --% Volume Size 10240MB 10240MB Server Name DP Error CP Error --------------------------------------------------------------- server1 NO ERROR NO ERROR server2 NO ERROR NO ERROR
ミラー復帰処理中の場合
「 コマンドによるミラー復帰中に実行状態を確認するには 」を参照してください。
ハイブリッドディスクの場合、以下のコマンドを実行してミラーブレイク状態を確認します。
clphdstat --mirror <ハイブリッドディスクリソース名 (例:hd1)>
詳細は本ガイドの「9. CLUSTERPRO コマンドリファレンス」の「ハイブリッドディスクの状態を表示する (clphdstatコマンド)」を参照してください。
10.3.3. コマンドによるミラー復帰中に実行状態を確認するには¶
ミラーディスクリソースの場合、以下のコマンドを実行してミラー復帰処理の実行状態を確認 します。
clpmdstat --mirror <ミラーディスクリソース名 (例:md1)>
ミラー復帰処理中は以下の情報が表示されます。
Status: Recovering
md1 server1 server2
---------------------------------------------------------------
Mirror Color YELLOW -> YELLOW
15%
Recovery Status
---------------------------------------------------------------
Used Time 00:00:21
Remain Time 00:01:59
ミラー復帰処理が完了すると以下の情報が表示されます。
Status: Normal
md1 server1 server2
---------------------------------------------------------------
Mirror Color GREEN GREEN
Fast Copy -- --
Lastupdate Time -- --
Break Time -- --
Needed Copy Percent 0% 0%
Volume Used Percent 64% 64%
Volume Size 10240MB 10240MB
Server Name DP Error CP Error
---------------------------------------------------------------
server1 NO ERROR NO ERROR
server2 NO ERROR NO ERROR
ハイブリッドディスクの場合、以下のコマンドを実行してミラーブレイク状態を確認します。
clphdstat --mirror <ハイブリッドディスクリソース名 (例:hd1)>
詳細は本ガイドの「9. CLUSTERPRO コマンドリファレンス」の「ハイブリッドディスクの状態を表示する (clphdstatコマンド)」を参照してください。
10.3.4. コマンドでミラー復帰を行うには¶
以下のコマンドを実行してミラー復帰を開始します。
ミラーディスクの場合:
clpmdctrl --recovery <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合:
clphdctrl --recovery <ハイブリッドディスクリソース名 (例:hd1)>
差分ミラー復帰が可能な場合には差分情報を使用して復帰を行います (FastSyncテクノロジー)。
このコマンドはミラー復帰の実行を開始すると、すぐに制御を戻します。ミラー復帰の状態は「 コマンドによるミラー復帰中に実行状態を確認するには 」および「 Cluster WebUI でミラー復帰中の実行状態を確認するには 」を参照して確認してください。
10.3.5. コマンドによる強制ミラー復帰を行うには¶
どちらのサーバが最新データを保持しているかCLUSTERPRO が自動で判断できない場合には、強制ミラー復帰が必要となります。
このような場合は、最新のデータを保持しているサーバを手動で特定し、強制ミラー復帰を実行する必要があります。
注釈
強制ミラー復帰でのミラーコピーは、差分コピーではなく、全面コピーとなる場合があります。
以下のいずれかの方法で、最新データを保持しているサーバを特定してください。
Cluster WebUI のミラーディスクリストによる確認
Cluster WebUIのミラーディスクリストから、確認したいミラーディスクリソース/ハイブリッドディスクリソースをクリックします。
[詳細情報]アイコンをクリックします。
最終データ更新時刻 (Last data updated time) を確認し、最新のデータを持つサーバを特定します。 ただし、最終データ更新時刻は OS に設定されている時刻に依存します。
[clpmdstat] / [clphdstat] コマンドによる確認
以下のコマンドを使用して確認することができます。
以下のコマンドを実行します。
ミラーディスクの場合:
clpmdstat --mirror <ミラーディスクリソース名 (例:md1)>ハイブリッドディスクの場合:
clphdstat --mirror <ハイブリッドディスクリソース名 (例:hd1)>最終データ更新時刻 (Last data updated time) を確認し、最新のデータを持つサーバを特定します。 ただし、最終データ更新時刻は OS に設定されている時刻に依存します。
ディスク上のデータによる確認
注釈
この手順は誤操作によりデータ破壊を引き起こす可能性があります。できるだけ上記「Cluster WebUI のミラーディスクリストによる確認」または「[clpmdstat] / [clphdstat] コマンドによる確認」の手順を実施してください。
ミラーディスクの場合:
全てのグループが停止していることを確認します。
以下のコマンドを実行して、ミラーディスクリソースを接続します。
clpmdctrl --active <ミラーディスクリソース名 (例:md1)> -f接続先に存在するデータを論理的に確認、検証します。
以下のコマンドを実行して、ミラーディスクリソースを切断します。
clpmdctrl --deactive <ミラーディスクリソース名 (例:md1)>ハイブリッドディスクの場合:
全てのグループが停止していることを確認します。
以下のコマンドを実行して、ハイブリッドディスクリソースを接続します。
clphdctrl --active <ハイブリッドディスクリソース名 (例:hd1)> -f接続先に存在するデータを論理的に確認、検証します。
以下のコマンドを実行して、ハイブリッドディスクリソースを切断します。
clphdctrl --deactive <ハイブリッドディスクリソース名(例:hd1)>
最新のデータを保持しているサーバを特定できたら、以下のコマンドを実行して強制ミラー復帰を開始します。
ミラーディスクの場合 (最新データを保持しているサーバ上で実行):
clpmdctrl --force <ミラーディスクリソース名 (例:md1)>
ハイブリッドディスクの場合 (最新データを保持しているサーバ上で実行):
clphdctrl --force <ハイブリッドディスクリソース名 (例:hd1)>
注釈
[clpmdctrl --force] コマンド および [clphdctrl --force] コマンドは実行したサーバ側のデータを最新にします。この手順を実行後、自動ミラー復帰が無効の場合は手動でミラー復帰を実施してください。
[clpmdctrl] / [clphdctrl] コマンドは強制ミラー復帰の実行を開始すると、すぐに制御を戻します。強制ミラー復帰の状態は「 コマンドによるミラー復帰中に実行状態を確認するには 」および「 Cluster WebUI でミラー復帰中の実行状態を確認するには 」を参照して確認してください。
強制ミラー復帰の完了を確認後、グループを起動してミラーディスクを使用することが可能になります。
10.3.6. コマンドによるサーバ一台のみの強制ミラー復帰を行うには¶
いずれかのサーバが H/W や OS の障害により起動できない状態となり、起動可能なサーバも最新データを保持している保障がない場合があります。
起動できるサーバだけでも業務を開始したい場合には起動できるサーバを強制ミラー復帰することができます。
この操作を実行すると、コマンドを実行したサーバが強制的に最新データを保持することになります。このため、起動できない状態にあったサーバが起動できるようになった場合でも、そのサーバのデータを最新として扱うことはできなくなります。
この点を理解したうえで以下の手順を実行してください。
対象サーバ上で以下のコマンドを実行して、強制ミラー復帰を開始します。
ミラーディスクリソースの場合:
clpmdctrl --force <ミラーディスクリソース名 (例:md1)>ハイブリッドディスクリソースの場合:
clphdctrl --force <ハイブリッドディスクリソース名 (例:hd1)>
コマンド実行後、グループを起動してリソースを使用することが可能になります。
10.3.7. Cluster WebUI でミラーブレイク状態を確認するには¶
Cluster WebUI からミラーディスクリストを起動してミラーブレイク状態を確認します。
正常な場合

ミラー復帰が必要な場合

強制ミラー復帰が必要な場合

ミラー復帰処理中の場合
「 Cluster WebUI でミラー復帰中の実行状態を確認するには 」を参照してください。
10.3.8. Cluster WebUI でミラー復帰中の実行状態を確認するには¶
Cluster WebUI のミラーディスクリストからミラー復帰処理の実行状態を確認します。
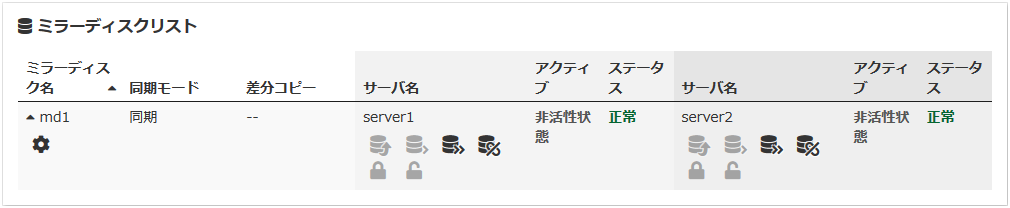
ミラー復帰処理中は以下の情報が表示されます。
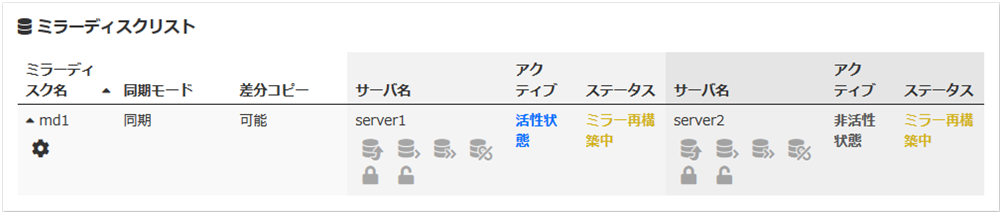
ミラー復帰処理が完了すると以下の情報が表示されます。
10.3.9. Cluster WebUI でミラー復帰を行うには¶
Cluster WebUI のミラーディスクリストから復帰が必要なミラーディスク名をクリックすると、下記のような画面に変わります。
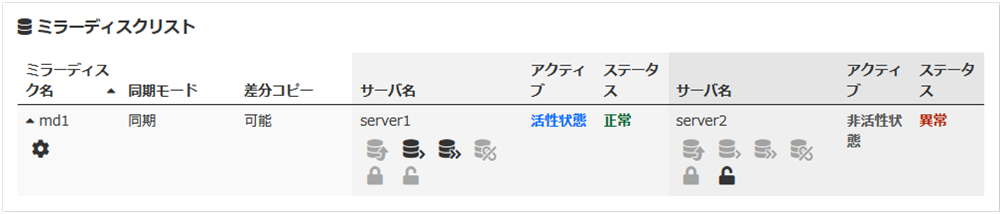
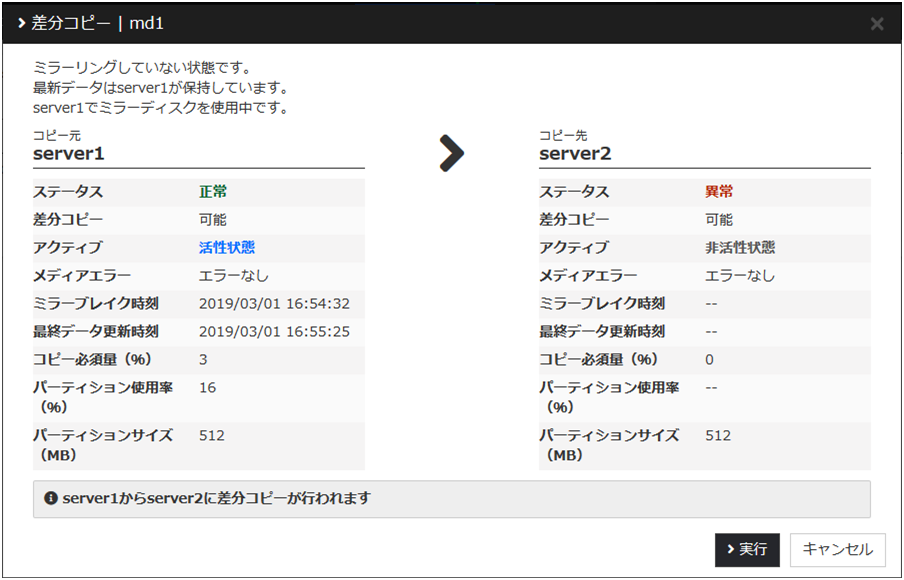
復帰が必要なサーバの[差分コピー]または[フルコピー]をクリックし、[実行] をクリックするとミラー復帰が実行されます。
差分ミラー復帰が可能な場合には差分情報を使用して復帰を行います(FastSyncテクノロジー)。差分ミラー復帰は強制ミラー復帰と比較して復帰時間が短縮されます。
ミラー復帰の状態は「 コマンドによるミラー復帰中に実行状態を確認するには 」および「 Cluster WebUI でミラー復帰中の実行状態を確認するには 」を参照して確認してください。
10.3.10. Cluster WebUI で強制ミラー復帰を行うには¶
CLUSTERPRO がどちらのサーバが最新データを保持しているか判断できない場合には強制ミラー復帰が必要となります。
このような場合は、最新のデータを保持しているサーバを手動で特定し、強制ミラー復帰を実行する必要があります。
強制ミラー復帰では、差分ミラー復帰機能は無効になり、全面コピーとなる場合があります。
以下のいずれかの方法で、最新データを保持しているサーバを特定してください。
Cluster WebUI のミラーディスクリストによる確認
Cluster WebUIのミラーディスクリストから、確認したいミラーディスクリソースの詳細情報を表示します。
[詳細情報] アイコンをクリックします。
最終データ更新時刻を確認し、最新のデータを持つサーバを特定します。 ただし、最終データ更新時刻は OS に設定されている時刻 に依存します。
最新のデータを保持しているサーバの [強制ミラー復帰] をクリックすると、下記のような画面に変わります。 [実行] をクリックするとミラー復帰が実行されます。
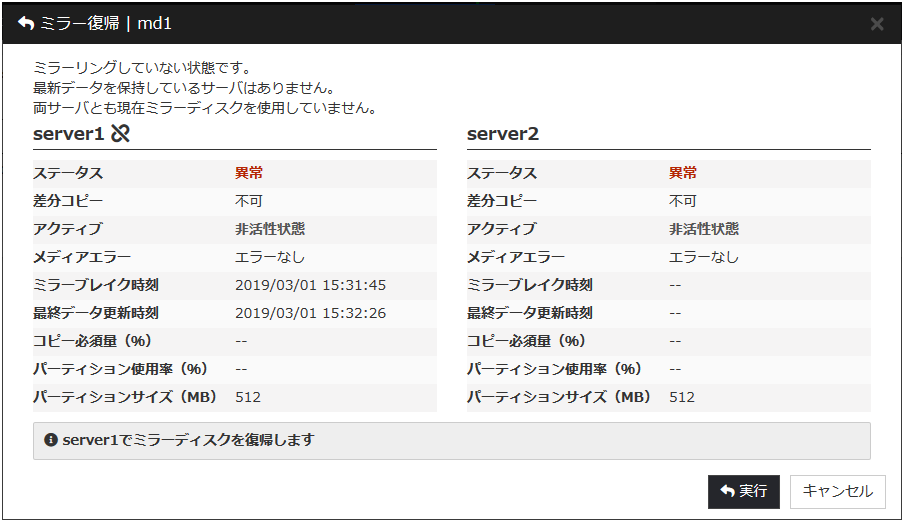
強制ミラー復帰の状態は「 コマンドによるミラー復帰中に実行状態を確認するには 」および「 Cluster WebUI でミラー復帰中の実行状態を確認するには 」を 参照して確認してください。
強制ミラー復帰の完了を確認後、グループを起動してミラーディスクを使用することが可能に なります。
10.3.11. Cluster WebUI でサーバ 1 台のみの強制ミラー復帰を行うには¶
いずれかのサーバが H/W や OS の障害により起動できない状態となり、起動可能なサーバも最新データを保持している保障がない場合があります。
起動できるサーバだけでも業務を開始したい場合には、起動できるサーバを強制ミラー復帰 することができます。
この操作を実行すると、コマンドを実行したサーバが強制的に最新データを保持することになります。このため、起動できない状態にあったサーバが起動できるようになった場合でも、そのサーバのデータを最新として扱えなくなります。この点を理解したうえで以下の手順を実行してください。
Cluster WebUI のミラーディスクリストから強制ミラー復帰を実行します。強制ミラー復帰するサーバの [強制ミラー復帰] をクリックすると、下記のような画面に変わります。[実行] をクリックすると強制ミラー復帰が実行されます。
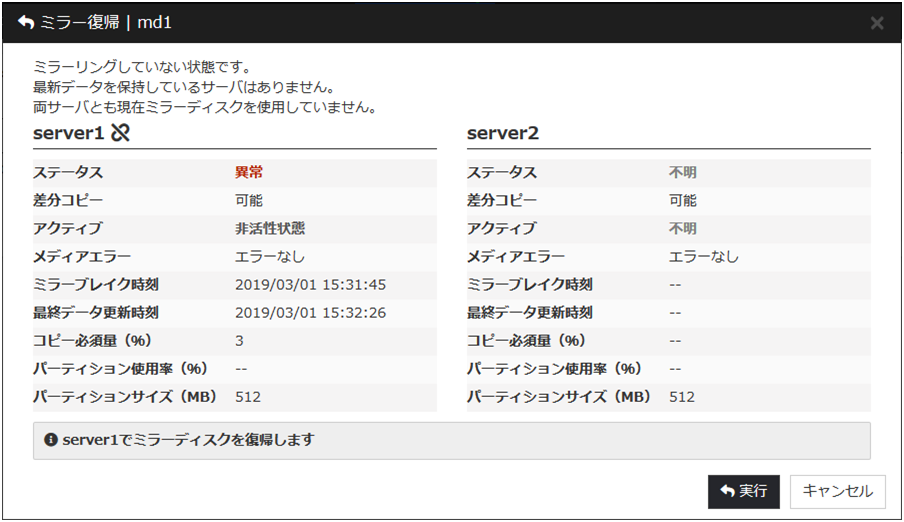
強制ミラー復帰の実行後、グループを起動してミラーディスクを使用することが可能になります。
10.4. メディアセンス機能が無効になる¶
メディアセンス機能とは、ネットワークケーブル断線が発生したことを検知する OS の機能で、その場合 TCP/IP は、メディアセンス機能からの通知を受け、断線したネットワークカードに 割り当てられた IP アドレス等の情報を断線期間中使えなくします。CLUSTERPRO は運用中に IP アドレス等の情報が無効化されると正常動作できなくなるため、インストール時にメディアセンス機能を無効化しています。