1. はじめに¶
1.1. 対象読者と目的¶
『CLUSTERPRO X スタートアップガイド』は、CLUSTERPRO をはじめてご使用になるユーザの皆様を対象に、CLUSTERPRO の製品概要、クラスタシステム導入のロードマップ、他マニュアルの使用方法についてのガイドラインを記載します。また、最新の動作環境情報や制限事項などについても紹介します。
1.2. 本書の構成¶
「2. クラスタシステムとは?」:クラスタシステムの概要について説明します。
「3. CLUSTERPRO について」:CLUSTERPRO の使用方法および関連情報について説明します。
「4. CLUSTERPRO の動作環境」:導入前に確認が必要な最新情報について説明します。
1.3. CLUSTERPRO マニュアル体系¶
CLUSTERPRO のマニュアルは、以下の 4 つに分類されます。各ガイドのタイトルと役割を以下に示します。
『CLUSTERPRO X スタートアップガイド』 (Getting Started Guide)
すべてのユーザを対象読者とし、製品概要、動作環境、アップデート情報、既知の問題などについて記載します。
『CLUSTERPRO X インストール&設定ガイド』 (Install and Configuration Guide)
CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアと、クラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO を使用したクラスタシステム導入から運用開始前までに必須の事項について説明します。実際にクラスタシステムを導入する際の順番に則して、CLUSTERPRO を使用したクラスタシステムの設計方法、CLUSTERPRO のインストールと設定手順、設定後の確認、運用開始前の評価方法について説明します。
『CLUSTERPRO X リファレンスガイド』 (Reference Guide)
管理者、および CLUSTERPRO を使用したクラスタシステムの導入を行うシステムエンジニアを対象とし、CLUSTERPRO の運用手順、各モジュールの機能説明およびトラブルシューティング情報等を記載します。『インストール&設定ガイド』を補完する役割を持ちます。
『CLUSTERPRO X メンテナンスガイド』 (Maintenance Guide)
管理者、および CLUSTERPRO を使用したクラスタシステム導入後の保守・運用を行うシステム管理者を対象読者とし、CLUSTERPRO のメンテナンス関連情報を記載します。
1.4. 本書の表記規則¶
本書では、注意すべき事項、重要な事項および関連情報を以下のように表記します。
注釈
この表記は、重要ではあるがデータ損失やシステムおよび機器の損傷には関連しない情報を表します。
重要
この表記は、データ損失やシステムおよび機器の損傷を回避するために必要な情報を表します。
参考
この表記は、参照先の情報の場所を表します。
また、本書では以下の表記法を使用します。
表記 |
使用方法 |
例 |
|---|---|---|
[ ] 角かっこ |
コマンド名の前後
画面に表示される語 (ダイアログボックス、メニューなど) の前後
|
[スタート] をクリックします。
[プロパティ] ダイアログ ボックス
|
コマンドライン中の [ ] 角かっこ |
かっこ内の値の指定が省略可能であることを示します。 |
|
モノスペースフォント |
パス名、コマンド ライン、システムからの出力 (メッセージ、プロンプトなど)、ディレクトリ、ファイル名、関数、パラメータ |
|
太字 |
ユーザが実際にコマンドプロンプトから入力する値を示します。 |
以下を入力します。
clpcl -s -a
|
斜体 |
ユーザが有効な値に置き換えて入力する項目 |
|
 本書の図では、CLUSTERPROを表すために このアイコンを使用します。
本書の図では、CLUSTERPROを表すために このアイコンを使用します。
2. クラスタシステムとは?¶
本章では、クラスタシステムの概要について説明します。
本章で説明する項目は以下のとおりです。
2.1. クラスタシステムの概要¶
現在のコンピュータ社会では、サービスを停止させることなく提供し続けることが成功への重要なカギとなります。例えば、1 台のマシンが故障や過負荷によりダウンしただけで、顧客へのサービスが全面的にストップしてしまうことがあります。そうなると、莫大な損害を引き起こすだけではなく、顧客からの信用を失いかねません。
クラスタシステムを導入することにより、万一のときのシステム停止時間 (ダウンタイム) を最小限に食い止めたり、負荷を分散させたりすることで可用性を高めます。
クラスタとは、「群れ」「房」を意味し、その名の通り、「複数のコンピュータを一群 (または複数群) にまとめて、信頼性や処理性能の向上を狙うシステム」です。クラスタシステムには様々な種類があり、以下の 3 つに分類できます。この中で、CLUSTERPRO は HA (High Availability) クラスタに分類されます。
- HA (High Availability) クラスタ通常時は一方が現用系として業務を稼動させ、現用系障害発生時に待機系に業務を引き継ぐような形態のクラスタです。高可用性を目的としたクラスタです。共有ディスク型、ミラーディスク型があります。
- 負荷分散クラスタクライアントからの要求を適切な負荷分散ルールに従って、各ノードに割り当てるクラスタです。高スケーラビリティを目的としたクラスタで、一般的にデータの引き継ぎはできません。ロードバランスクラスタ、並列データベースクラスタがあります。
- HPC (High Performance Computing) クラスタ非常に計算量が多いクラスタのこと。スーパコンピュータを用いて単一の業務を実行するためのクラスタです。全てのノードの CPU を利用し、単一の業務を実行するグリッドコンピューティングという技術も近年話題に上ることが多くなっています。
2.2. HA (High Availability) クラスタ¶
一般的にシステムの可用性を向上させるには、そのシステムを構成する部品を冗長化し、Single Point of Failureをなくすことが重要であると考えられます。Single Point of Failureとは、コンピュータの構成要素 (ハードウェアの部品) が 1 つしかないために、その個所で障害が起きると業務が止まってしまう弱点のことを指します。HA クラスタとは、ノードを複数台使用して冗長化することにより、システムの停止時間を最小限に抑え、業務の可用性 (availability)を向上させるクラスタシステムをいいます。
システムの停止が許されない基幹業務システムなどのダウンタイムがビジネスに大きな影響を与えてしまうシステムに、HA クラスタの導入が求められています。
HA クラスタは、共有ディスク型とミラーディスク型に分けることができます。以下にそれぞれのタイプについて説明します。
2.2.1. 共有ディスク型¶
クラスタシステムでは、サーバ間でデータを引き継がなければなりません。このデータを、SAN接続の FibreChannel ディスクアレイ装置のように複数のサーバからアクセス可能な外付けディスク (共有ディスク) 上に置き、このディスクを介してサーバ間でデータを引き継ぐ形態を共有ディスク型といいます。
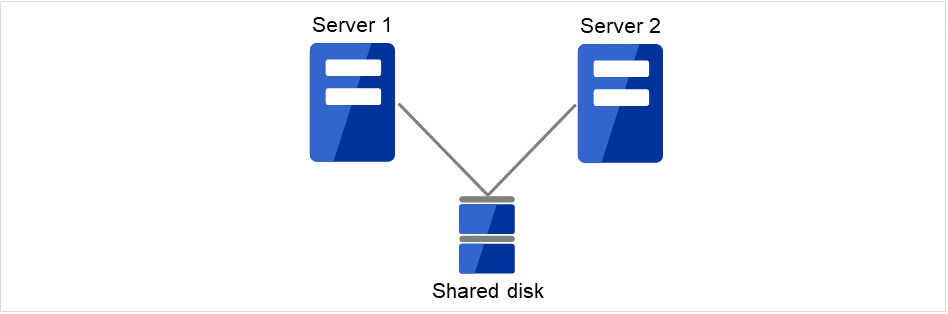
図 2.1 HAクラスタ構成図(共有ディスク型)¶
共有ディスクが必要になるため高価
大規模データを扱うシステム向き
業務アプリケーションを動かしているサーバ (現用系サーバ) で障害が発生した場合、クラスタシステムが障害を検出し、障害発生時に業務を引き継ぐサーバ (待機系サーバ) で業務アプリケーションを自動起動させ、業務を引き継がせます。これをフェイルオーバといいます。クラスタシステムによって引き継がれる業務は、ディスク、IP アドレス、アプリケーションなどのリソースと呼ばれるもので構成されています。
クラスタ化されていないシステムでは、アプリケーションをほかのサーバで再起動させると、クライアントは異なる IP アドレスに再接続しなければなりません。しかし、多くのクラスタシステムでは、業務単位にサーバに付与している IP ではなく別ネットワークの IP アドレス (仮想IP アドレス)を割り当てています。このため、クライアントは業務を行っているサーバが現用系か待機系かを意識する必要はなく、まるで同じサーバに接続しているように業務を継続できます。
現用系のダウンによりフェイルオーバが発生すると、共有ディスク上のデータは適切な終了処理が行われないまま待機系に引き継がれることになります。このため、待機系では引き継いだデータの論理チェックをする必要があります。これは一般に、クラスタ化されていないシステムでダウン後の再起動時に行われるのと同様の処理になります。例えば、データベースならばロールバックやロールフォワードの処理が必要になります。これらによって、クライアントは未コミットの SQL 文を再実行するだけで、業務を継続することができます。
障害発生後は、障害が検出されたサーバを物理的に切り離して修理後、クラスタシステムに接続すれば待機系として復帰できます。業務の継続性を重視する実際の運用の場合は、グループのフェイルバックを行わなくても良いです。どうしても、元のサーバで業務を行いたい場合は、グループの移動を実行してください。
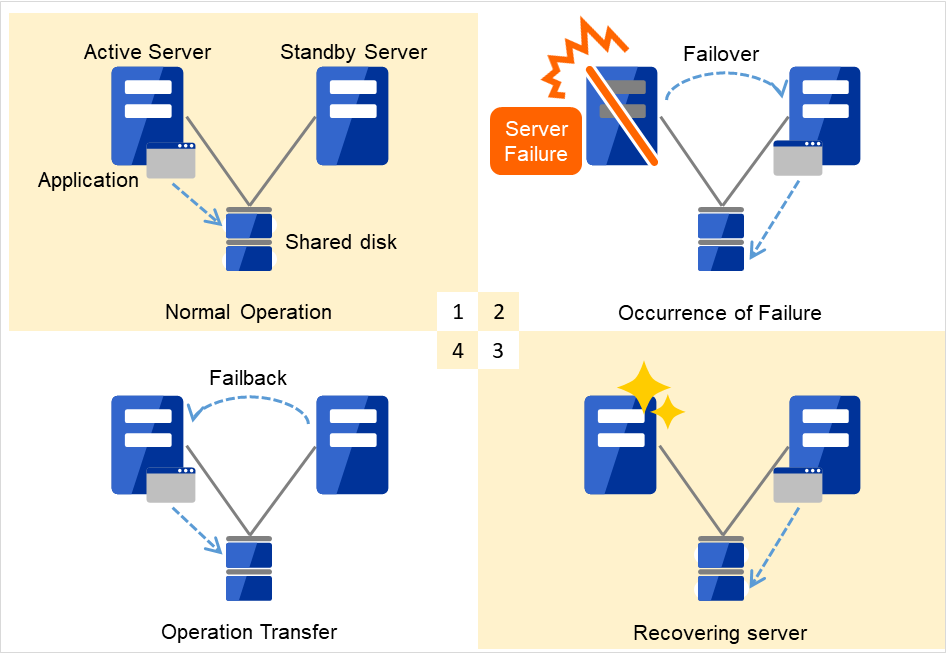
図 2.2 障害発生から復旧までの流れ¶
通常運用
障害発生
サーバ復旧
業務移動
フェイルオーバ先のサーバのスペックが不十分、双方向スタンバイのため過負荷になる、などの理由で元のサーバで業務を行うのが望ましい場合には、元のノードの復旧作業が完了してから一旦業務を停止し、元のノードで業務を再開します。フェイルオーバしたグループを元のサーバに戻すことをフェイルバックといいます。
図 2.3 HAクラスタの運用形態(片方向スタンバイ) のように、業務が1つであり、待機系では業務が動作しないスタンバイ形態を片方向スタンバイといいます。
図 2.3 HAクラスタの運用形態(片方向スタンバイ)¶
図 2.4 HAクラスタの運用形態(双方向スタンバイ)¶
2.2.2. ミラーディスク型¶
前述の共有ディスク型は大規模なシステムに適していますが、共有ディスクはおおむね高価なためシステム構築のコストが膨らんでしまいます。そこで共有ディスクを使用せず、各サーバのディスクをサーバ間でミラーリングすることにより、同等の機能をより低価格で実現したクラスタシステムをミラーディスク型といいます。
しかし、サーバ間でデータをミラーリングする必要があるため、大量のデータを必要とする大規模システムには向きません。
アプリケーションからの Write 要求が発生すると、データミラーエンジンはローカルディスクにデータを書き込みます。書き込んだデータを、インタコネクトを通して待機系サーバにも Write要求を振り分けます。インタコネクトとは、サーバ間をつなぐケーブルのことで、クラスタシステムではサーバの死活監視のために必要になります。データミラータイプでは死活監視に加えてデータの転送に使用することがあります。待機系のデータミラーエンジンは、受け取ったデータを待機系のローカルディスクに書き込むことで、現用系と待機系間のデータを同期します。
アプリケーションからのRead要求に対しては、単に現用系のディスクから読み出すだけです。
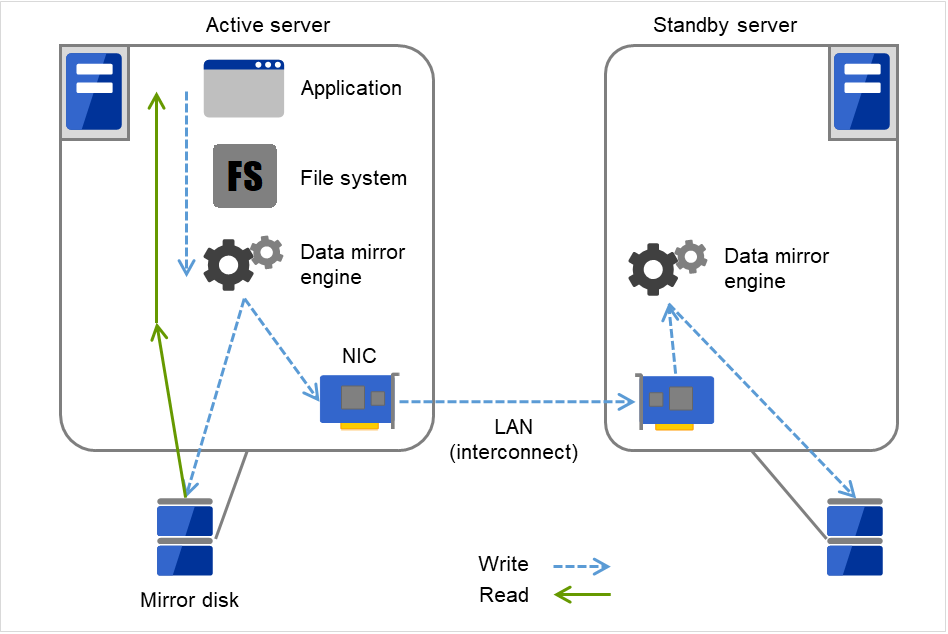
図 2.5 データミラーの仕組み¶
データミラーの応用例として、スナップショットバックアップの利用があります。データミラータイプのクラスタシステムは 2 カ所に共有のデータを持っているため、待機系のサーバをクラスタから切り離すだけで、スナップショットバックアップとしてデータを保存する運用が可能です。
HA クラスタの仕組みと問題点
次に、クラスタの実装と問題点について説明します。
2.3. システム構成¶
共有ディスク型クラスタは、ディスクアレイ装置をクラスタサーバ間で共有します。サーバ障害時には待機系サーバが共有ディスク上のデータを使用し業務を引き継ぎます。
ミラーディスク型クラスタは、クラスタサーバ上のデータディスクをネットワーク経由でミラーリングする構成です。サーバ障害時には待機系サーバ上のミラーデータを使用し業務を引き継ぎます。データのミラーリングは I/O 単位で行うため上位アプリケーションから見ると共有ディスクと同様に見えます。
以下の図は、共有ディスク型クラスタの構成例です。

図 2.6 システム構成¶


同一アプリケーション双方向スタンバイクラスタ


異種アプリケーション双方向スタンバイクラスタ


N + N 構成


2.4. 障害検出のメカニズム¶
クラスタソフトウェアは、業務継続に問題をきたす障害を検出すると業務の引き継ぎ (フェイルオーバ) を実行します。フェイルオーバ処理の具体的な内容に入る前に、簡単にクラスタソフトウェアがどのように障害を検出するか見ておきましょう。
CLUSTERPRO はサーバ監視のために、定期的にサーバ同士で生存確認を行います。この生存確認をハートビートと呼びます。
ハートビートとサーバの障害検出
クラスタシステムにおいて、検出すべき最も基本的な障害はクラスタを構成するサーバのダウンです。サーバの障害には、電源異常やメモリエラーなどのハードウェア障害や OS のパニックなどが含まれます。このような障害を検出するために、サーバの死活監視としてハートビートが使用されます。
ハートビートは、ping の応答を確認するような死活監視だけでもよいのですが、クラスタソフトウェアによっては、自サーバの状態情報などを相乗りさせて送るものもあります。クラスタソフトウェアはハートビートの送受信を行い、ハートビートの応答がない場合はそのサーバの障害とみなしてフェイルオーバ処理を開始します。ただし、サーバの高負荷などによりハートビートの送受信が遅延することも考慮し、サーバ障害と判断するまである程度の猶予時間が必要です。このため、実際に障害が発生した時間とクラスタソフトウェアが障害を検知する時間とにはタイムラグが生じます。
リソースの障害検出
業務の停止要因はクラスタを構成するサーバのダウンだけではありません。例えば、業務アプリケーションが使用するディスク装置や NIC の障害、もしくは業務アプリケーションそのものの障害などによっても業務は停止してしまいます。可用性を向上するためには、このようなリソースの障害も検出してフェイルオーバを実行しなければなりません。
リソース異常を検出する手法として、監視対象リソースが物理的なデバイスの場合は、実際にアクセスしてみるという方法が取られます。アプリケーションの監視では、アプリケーションプロセスそのものの死活監視のほか、業務に影響のない範囲でサービスポートを試してみるような手段も考えられます。
2.4.2. ネットワークパーティション症状 (Split-brain-syndrome)¶
サーバ間をつなぐすべてのインタコネクトが切断されると、ハートビートによる死活監視だけではサーバのダウンと区別できません。この状態でサーバダウンとみなし、フェイルオーバ処理を実行し、複数のサーバでファイルシステムを同時にマウントすると、共有ディスク上のデータが破壊されてしまいます。
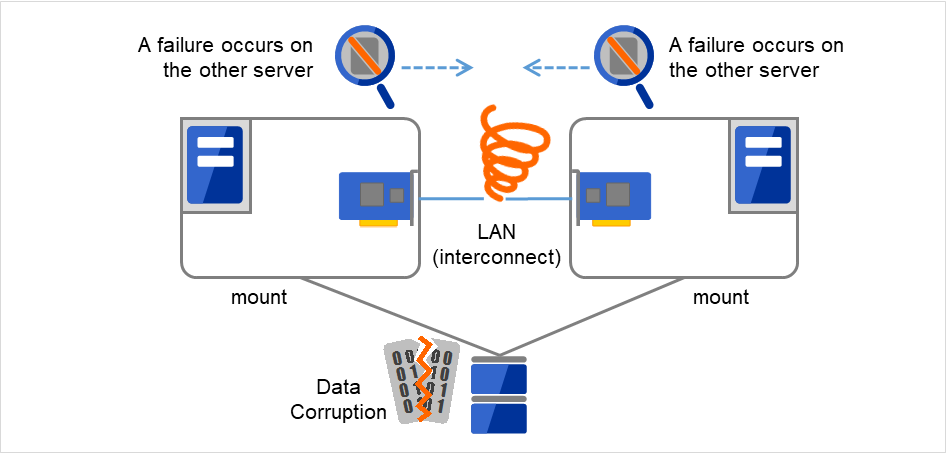
図 2.15 ネットワークパーティション症状¶
このような問題を「ネットワークパーティション症状」またはスプリットブレインシンドローム(Split-brain-syndrome) と呼びます。この問題を解決するため、フェイルオーバクラスタでは、すべてのインタコネクトが切断されたときに、確実に共有ディスク装置の排他制御を実現するためのさまざまな対応策が考えられています。
2.5. クラスタリソースの引き継ぎ¶
クラスタが管理するリソースにはディスク、IP アドレス、アプリケーションなどがあります。これらのクラスタリソースを引き継ぐための、フェイルオーバクラスタシステムの機能について説明します。
2.5.1. データの引き継ぎ¶
共有ディスク型クラスタでは、サーバ間で引き継ぐデータは共有ディスク装置上のパーティションに格納します。すなわち、データを引き継ぐとは、アプリケーションが使用するファイルが格納されているファイルシステムを健全なサーバ上でマウントしなおすことにほかなりません。共有ディスク装置は引き継ぐ先のサーバと物理的に接続されているので、クラスタソフトウェアが行うべきことはファイルシステムのマウントだけです。
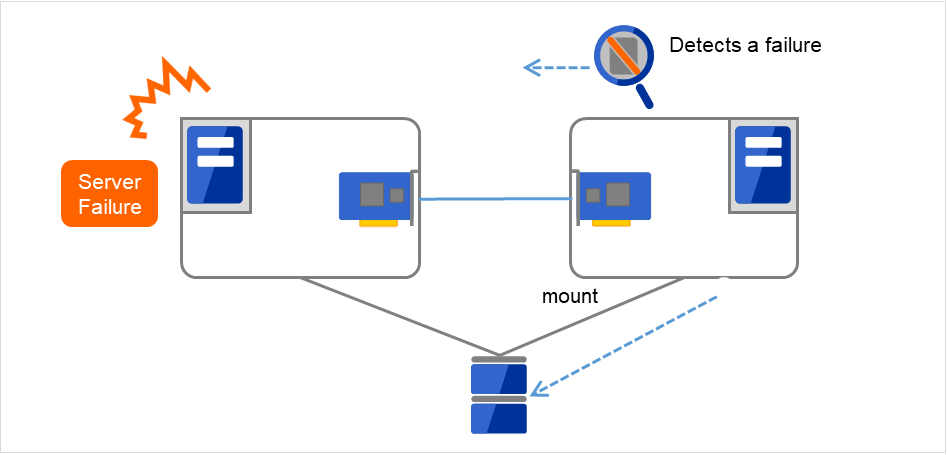
図 2.16 データの引き継ぎ¶
単純な話のようですが、クラスタシステムを設計・構築するうえで注意しなければならない点があります。
1 つは、ファイルシステムやデータベースの復旧時間の問題です。引き継ごうとしているファイルは、障害が発生する直前までほかのサーバで使用され、もしかしたらまさに更新中であったかもしれません。このため、ファイルシステムによっては引き継ぐ際に整合性チェックが必要となりますし、データベースであればロールバック等の処理が必要となります。これは電源障害などでダウンした単体サーバを再起動した場合と同様です。このような復旧処理に長時間を要する場合、それがそのままフェイルオーバ時間 (業務の引き継ぎ時間) に追加されてしまい、システムの可用性を低下させる要因になります。
もう 1 つは、書き込み保証の問題です。アプリケーションが共有ディスクにデータを書き出す際に、通常はファイルシステムを介しての書き出しになりますが、アプリケーションが書き込みを完了していても、ファイルシステムがディスクキャッシュ上に保持しているだけで、共有ディスクへの書き込みを行っていなかった場合、この状態で現用系のサーバがダウンすると、ディスクキャッシュ上のデータは待機系に引き継がれないことになります。このため、障害発生時に確実に待機系に引き継ぐ必要のある大切なデータは、同期書き込みなどにより確実にディスクに書き込む必要があります。これは単体サーバがダウンした際にデータが揮発しないようにするのと同じです。つまり、待機系に引き継がれるのは共有ディスクに記録されたデータのみであり、ディスクキャッシュのようなメモリ上のデータは引き継がれないということを考慮してクラスタシステムを設計する必要があります。
2.5.2. IP アドレスの引き継ぎ¶
次にクラスタソフトウェアが行うことは、IP アドレスの引き継ぎです。フェイルオーバした際に、IP アドレスを引き継ぐことで、業務がどのサーバで動作しているのか、気にすることなく作業を行うことができます。クラスタソフトウェアは、そのための IP アドレスの引き継ぎを行います。
2.5.3. アプリケーションの引き継ぎ¶
クラスタソフトウェアが業務引き継ぎの最後に行う仕事は、アプリケーションの引き継ぎです。フォールトトレラントコンピュータ (FTC) とは異なり、一般的なフェイルオーバクラスタでは、アプリケーション実行中のメモリ内容を含むプロセス状態などを引き継ぎません。すなわち、障害が発生したサーバで実行していたアプリケーションを健全なサーバで再実行することでアプリケーションの引き継ぎを行います。
例えば、DB のインスタンスをフェイルオーバする場合、障害発生直前の状態で再開されるのではなく、一旦ダウンした状態から再起動した場合と同様にトランザクションのロールバック等が行われ、クライアントからも再接続が必要になります。このデータベース復旧に必要な時間は、DBMS のチェックポイントインターバルの設定などによってある程度の制御ができますが、一般的には数分程度必要となるようです。
多くのアプリケーションは再実行するだけで業務を再開できますが、障害発生後の業務復旧手順が必要なアプリケーションもあります。このようなアプリケーションのためにクラスタソフトウェアは業務復旧手順を記述できるよう、アプリケーションの起動の代わりにスクリプトを起動できるようになっています。スクリプト内には、スクリプトの実行要因や実行サーバなどの情報をもとに、必要に応じて更新途中であったファイルのクリーンアップなどの復旧手順を記述します。

2.6. Single Point of Failure の排除¶
高可用性システムを構築するうえで、求められるもしくは目標とする可用性のレベルを把握することは重要です。これはすなわち、システムの稼働を阻害し得るさまざまな障害に対して、冗長構成をとることで稼働を継続したり、短い時間で稼働状態に復旧したりするなどの施策を費用対効果の面で検討し、システムを設計するということです。
Single Point of Failure (SPOF) とは、システム停止につながる部位を指す言葉であると前述しました。クラスタシステムではサーバの多重化を実現し、システムの SPOF を排除することができますが、共有ディスクなど、サーバ間で共有する部分については SPOF となり得ます。この共有部分を多重化もしくは排除するようシステム設計することが、高可用性システム構築の重要なポイントとなります。
クラスタシステムは可用性を向上させますが、フェイルオーバには数分程度のシステム切り替え時間が必要となります。従って、フェイルオーバ時間は可用性の低下要因の 1 つともいえます。このため、高可用性システムでは、まず単体サーバの可用性を高める ECC メモリや冗長電源などの技術が本来重要なのですが、ここでは単体サーバの可用性向上技術には触れず、クラスタシステムにおいて SPOF となりがちな下記の 3 つについて掘り下げて、どのような対策があるか見ていきたいと思います。
共有ディスク
共有ディスクへのアクセスパス
LAN
2.6.1. 共有ディスク¶
通常、共有ディスクはディスクアレイにより RAID を組むので、ディスクのベアドライブはSPOF となりません。しかし、RAID コントローラを内蔵するため、コントローラが問題となります。多くのクラスタシステムで採用されている共有ディスクではコントローラの二重化が可能になっています。
二重化された RAID コントローラの利点を生かすためには、通常は共有ディスクへのアクセスパスの二重化を行う必要があります。ただし、二重化された複数のコントローラから同時に同一の論理ディスクユニット (LUN) へアクセスできるような共有ディスクの場合、それぞれのコントローラにサーバを 1 台ずつ接続すればコントローラ異常発生時にノード間フェイルオーバを発生させることで高可用性を実現できます。
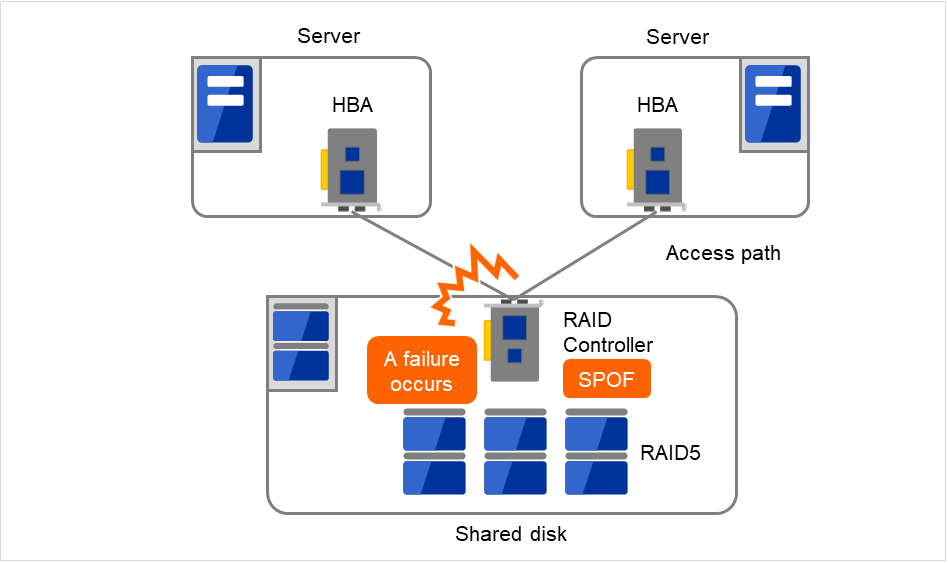
図 2.18 RAIDコントローラとアクセスパスがSPOFとなっている例¶
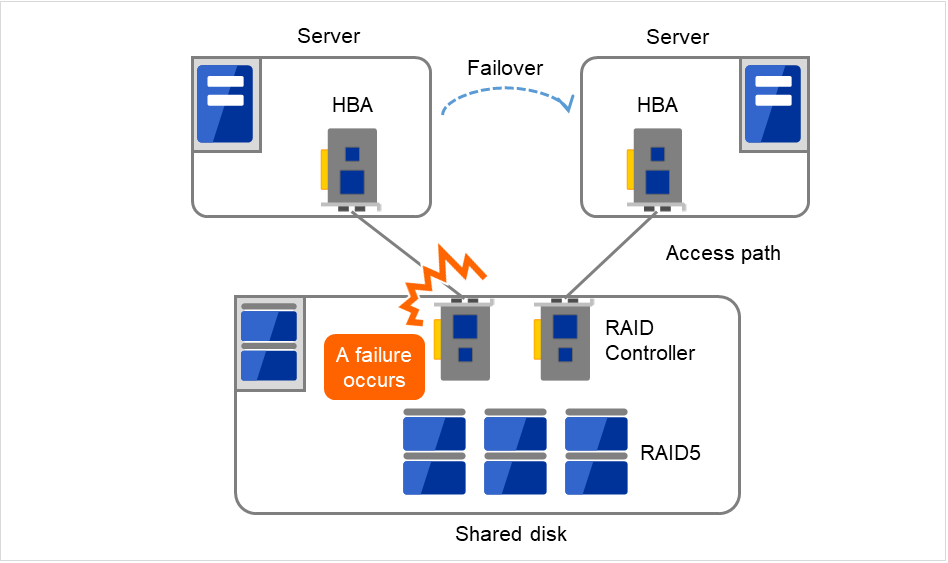
図 2.19 RAIDコントローラとアクセスパスが二重化されている例¶
※HBA: Host Bus Adapter の略で、共有ディスク側ではなく、サーバ本体側のアダプタのことです。
一方、共有ディスクを使用しないデータミラー型のフェイルオーバクラスタでは、すべてのデータをほかのサーバのディスクにミラーリングするため、SPOF が存在しない理想的なシステム構成を実現できます。ただし、次のような点について考慮する必要があります。
ネットワークを介してデータをミラーリングすることによるディスク I/O 性能 (特に write 性能) の低下
サーバ障害後の復旧における、ミラー再同期中のシステム性能 (ミラーコピーはバックグラウンドで実行される) の低下
ミラー再同期時間 (ミラー再同期が完了するまでフェイルオーバできない)
すなわち、データの参照が多く、データ容量が多くないシステムにおいては、データミラー型のフェイルオーバクラスタを採用するというのも可用性を向上させるのに有効といえます。
2.6.2. 共有ディスクへのアクセスパス¶
共有ディスク型クラスタの一般的な構成では、共有ディスクへのアクセスパスはクラスタを構成する各サーバで共有されます。SCSI を例に取れば、1 本の SCSI バス上に 2 台のサーバと共有ディスクを接続するということです。このため、共有ディスクへのアクセスパスの異常はシステム全体の停止要因となり得ます。
対策としては、共有ディスクへのアクセスパスを複数用意することで冗長構成とし、アプリケーションには共有ディスクへのアクセスパスが 1 本であるかのように見せることが考えられます。これを実現するデバイスドライバをパスフェイルオーバドライバなどと呼びます。

図 2.20 パスフェイルオーバドライバ¶
2.6.3. LAN¶
クラスタシステムに限らず、ネットワーク上で何らかのサービスを実行するシステムでは、LANの障害はシステムの稼働を阻害する大きな要因です。クラスタシステムでは適切な設定を行えば NIC 障害時にノード間でフェイルオーバを発生させて可用性を高めることは可能ですが、クラスタシステムの外側のネットワーク機器が故障した場合はやはりシステムの稼働を阻害します。
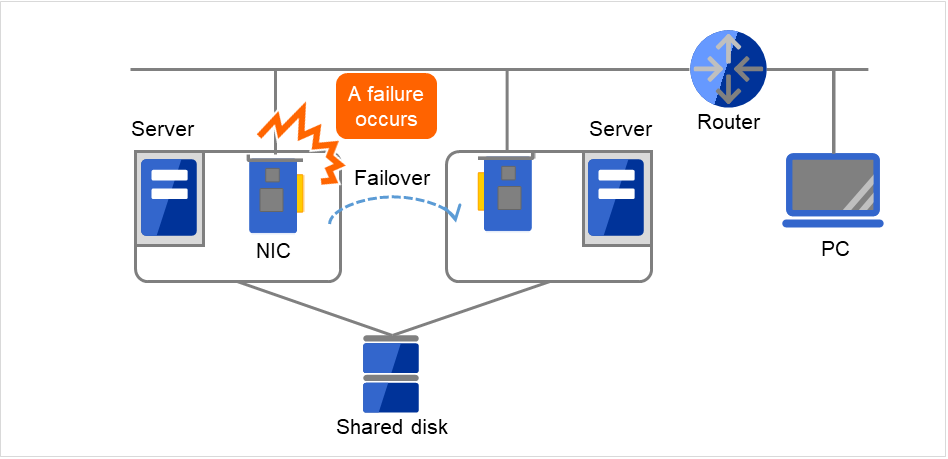
図 2.21 LANにおける障害の例(NIC)¶
この図の場合、Server上のNICが故障してもフェイルオーバすることで、Server上のサービスに対するPCからのアクセスを継続できます。
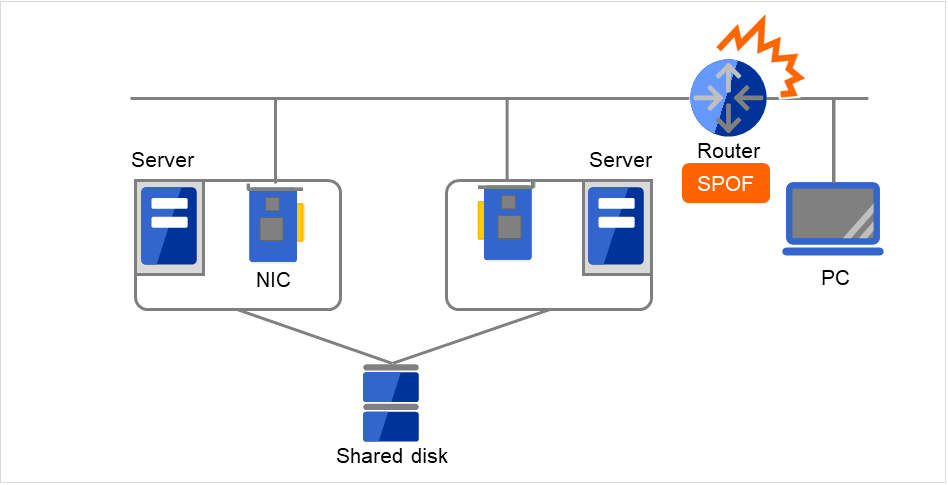
図 2.22 LANにおける障害の例(ルータ)¶
この図の場合、Routerが故障するとServer上のサービスに対するPCからのアクセスを継続できません(RouterがSPOFになっている)。
このようなケースでは、LAN を冗長化することでシステムの可用性を高めます。クラスタシステムにおいても、LAN の可用性向上には単体サーバでの技術がそのまま利用可能です。例えば、予備のネットワーク機器の電源を入れずに準備しておき、故障した場合に手動で入れ替えるといった原始的な手法や、高機能のネットワーク機器を冗長配置してネットワーク経路を多重化することで自動的に経路を切り替える方法が考えられます。また、インテル社の ANSドライバのように NIC の冗長構成をサポートするドライバを利用するということも考えられます。
ロードバランス装置 (Load Balance Appliance) やファイアウォールサーバ (Firewall Appliance) も SPOF となりやすいネットワーク機器です。これらもまた、標準もしくはオプションソフトウェアを利用することで、フェイルオーバ構成を組めるようになっているのが普通です。同時にこれらの機器は、システム全体の非常に重要な位置に存在するケースが多いため、冗長構成をとることはほぼ必須と考えるべきです。
2.7. 可用性を支える運用¶
2.7.1. 運用前評価¶
システムトラブルの発生要因の多くは、設定ミスや運用保守に起因するものであるともいわれています。このことから考えても、高可用性システムを実現するうえで運用前の評価と障害復旧マニュアルの整備はシステムの安定稼働にとって重要です。評価の観点としては、実運用に合わせて、次のようなことを実践することが可用性向上のポイントとなります。
障害発生個所を洗い出し、対策を検討し、擬似障害評価を行い実証する
クラスタの「一連の状態遷移」を想定した評価を行い、縮退運転時のパフォーマンスなどの検証を行う
これらの評価をもとに、システム運用、障害復旧マニュアルを整備する
クラスタシステムの設計をシンプルにすることは、上記のような検証やマニュアルが単純化でき、システムの可用性向上のポイントとなることが分かると思います。
2.7.2. 障害の監視¶
上記のような努力にもかかわらず障害は発生するものです。ハードウェアには経年劣化があり、ソフトウェアにはメモリリークなどの理由や設計当初のキャパシティプラニングを超えた運用をしてしまうことにより、長期間運用を続けると障害が発生することがあります。このため、ハードウェア、ソフトウェアの可用性向上と同時に、さらに重要となるのは障害を監視して障害発生時に適切に対処することです。万が一サーバに障害が発生した場合を例に取ると、クラスタシステムを組むことで数分の切り替え時間でシステムの稼働を継続できますが、そのまま放置しておけばシステムは冗長性を失い次の障害発生時にはクラスタシステムは何の意味もなさなくなってしまいます。
このため、障害が発生した場合、すぐさまシステム管理者は次の障害発生に備え、新たに発生した SPOF を取り除くなどの対処をしなければなりません。このようなシステム管理業務をサポートするうえで、リモートメンテナンスや障害の通報といった機能が重要になります。
以上、クラスタシステムを利用して高可用性を実現するうえで必要とされる周辺技術やそのほかのポイントについて説明しました。注意すべき点を簡単にまとめます。
Single Point of Failure を排除または把握する
障害に強いシンプルな設計を行い、運用前評価に基づき運用・障害復旧手順のマニュアルを整備する
発生した障害を早期に検出し適切に対処する
3. CLUSTERPRO について¶
本章では、CLUSTERPRO を構成するコンポーネントの説明と、クラスタシステムの設計から運用手順までの流れについて説明します。
本章で説明する項目は以下のとおりです。
3.1. CLUSTERPRO とは?¶
クラスタについて理解したところで、CLUSTERPRO の紹介を始めましょう。CLUSTERPRO とは、HA クラスタシステムを実現するためのソフトウェアです。
3.2. CLUSTERPRO の製品構成¶
CLUSTERPRO は大きく分けると 2 つのモジュールから構成されています。
- CLUSTERPRO ServerCLUSTERPRO の本体です。クラスタシステムを構成する各サーバマシンにインストールします。CLUSTERPRO Server には、CLUSTERPRO の高可用性機能の全てが包含されています。また、Cluster WebUI のサーバ側機能も含まれます。
- Cluster WebUICLUSTERPRO の構成情報の作成や運用管理を行うための管理ツールです。ユーザインターフェイスとして Web ブラウザを利用します。実体は CLUSTERPRO Server に組み込まれていますが、操作は管理端末上の Web ブラウザで行うため、CLUSTERPRO Server とは区別されています。
3.3. CLUSTERPRO のソフトウェア構成¶
CLUSTERPRO のソフトウェア構成は次の図のようになります。クラスタを構成するサーバ上には「CLUSTERPRO Server (CLUSTERPRO 本体)」をインストールします。Cluster WebUI の本体機能は CLUSTERPRO Server に含まれるため、別途インストールする必要がありません。Cluster WebUI は管理 PC 上の Web ブラウザから利用するほか、クラスタを構成する各サーバ上の Web ブラウザでも利用できます。
CLUSTERPRO Server (Main module)
Cluster WebUI
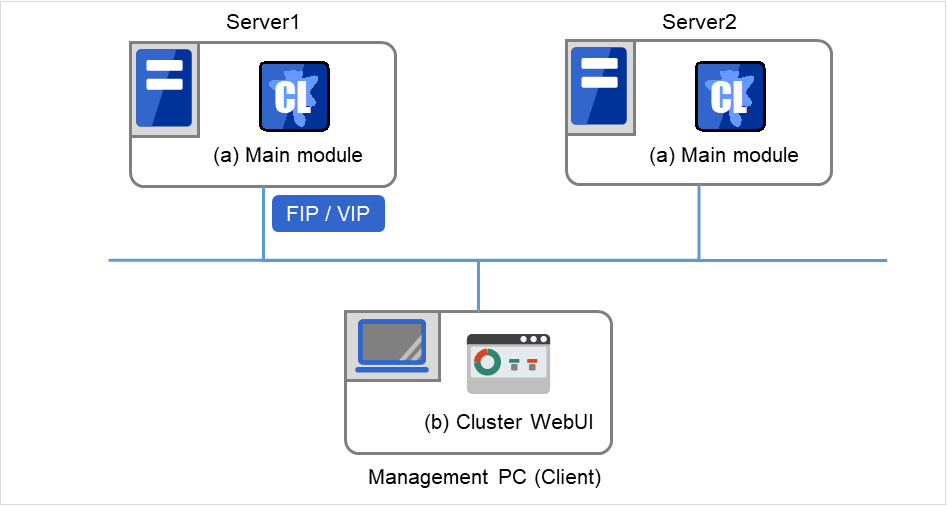
図 3.1 CLUSTERPRO のソフトウェア構成¶
3.3.1. CLUSTERPRO の障害監視のしくみ¶
CLUSTERPRO では、サーバ監視、業務監視、内部監視の 3 つの監視を行うことで、迅速かつ確実な障害検出を実現しています。以下にその監視の詳細を示します。
3.3.2. サーバ監視とは¶
- プライマリインタコネクトクラスタサーバ間通信専用のLAN です。ハートビートを行うと同時にサーバ間の情報交換に使用します。
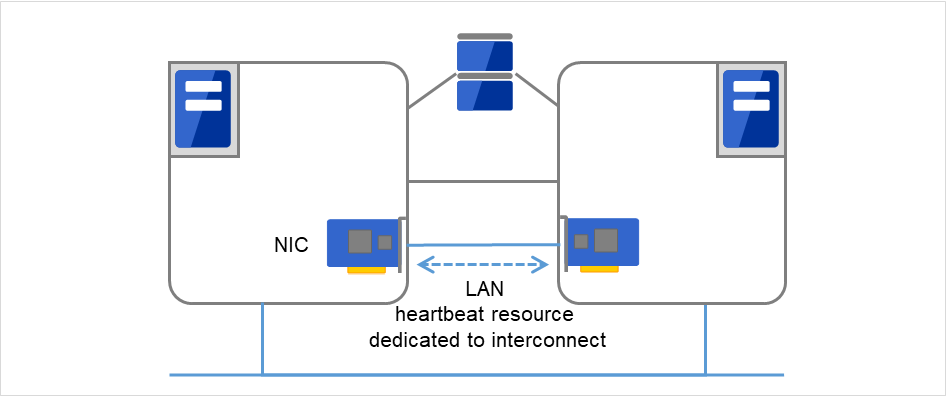
図 3.2 LANハートビート/カーネルモードLANハートビート(プライマリインタコネクト)¶
- セカンダリインタコネクトクライアントとの通信に用いるパスとして使用します。サーバ間の情報交換や、インタコネクトのバックアップ用としても使用します。
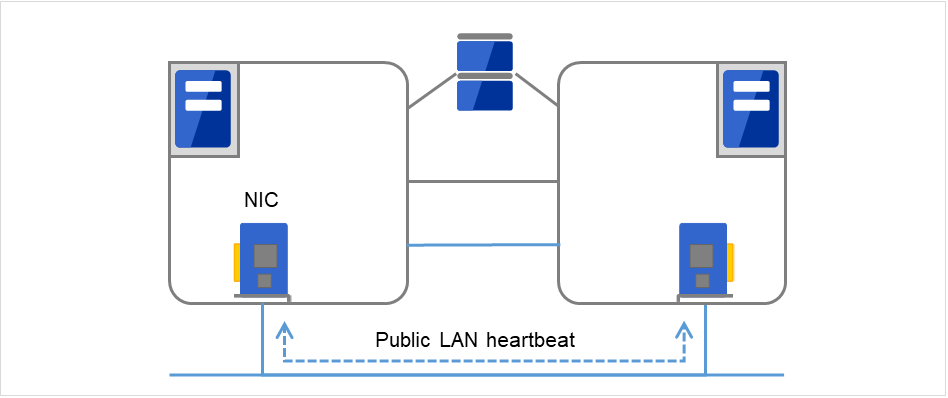
図 3.3 LANハートビート/カーネルモードLANハートビート(セカンダリインタコネクト)¶
- Witnessフェイルオーバ型クラスタを構成する各サーバとWitness サーバサービスが動作している外部サーバ (Witness サーバ) 間で通信を行い、Witness サーバが保持する他サーバとの通信情報から生存を確認します。
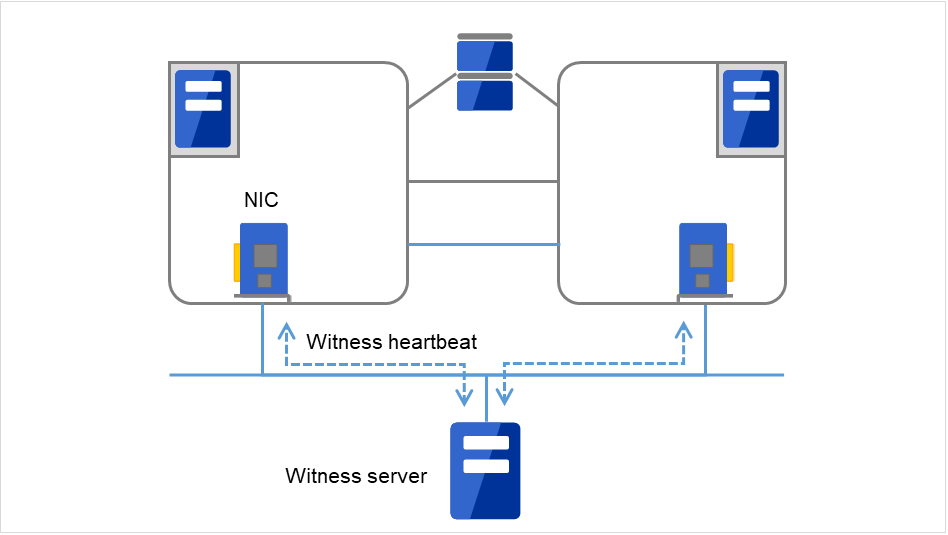
図 3.4 Witnessハートビート¶
3.3.3. 業務監視とは¶
業務監視とは、業務アプリケーションそのものや業務が実行できない状態に陥る障害要因を監視する機能です。
- 監視オプションによるアプリケーション/プロトコルのストール/結果異常監視別途ライセンスの購入が必要となりますが、データベースアプリケーション (Oracle, DB2等)、プロトコル (FTP, HTTP等)、アプリケーションサーバ (WebSphere, WebLogic等)のストール/結果異常監視を行うことができます。詳細は、『リファレンスガイド』の「モニタリソースの詳細」を参照してください。
- アプリケーションの死活監視アプリケーションを起動用のリソース (アプリケーションリソース、サービスリソースと呼びます) により起動し、監視用のリソース (アプリケーション監視リソース、サービス監視リソースと呼びます) により定期的にプロセスの生存を確認することで実現します。業務停止要因が業務アプリケーションの異常終了である場合に有効です。
注釈
CLUSTERPRO が直接起動したアプリケーションが監視対象の常駐プロセスを起動し終了してしまうようなアプリケーションでは、常駐プロセスの異常を検出することはできません。
注釈
アプリケーションの内部状態の異常 (アプリケーションのストールや結果異常) を検出することはできません。
- リソースの監視CLUSTERPRO のモニタリソースによりクラスタリソース (ディスクパーティション、IP アドレスなど) やパブリック LAN の状態を監視することで実現します。業務停止要因が業務に必要なリソースの異常である場合に有効です。
3.3.4. 内部監視とは¶
CLUSTERPRO プロセスの死活監視
3.3.5. 監視できる障害と監視できない障害¶
CLUSTERPRO には、監視できる障害とできない障害があります。クラスタシステム構築時、運用時に、どのような障害が検出可能なのか、または検出できないのかを把握しておくことが重要です。
3.3.6. サーバ監視で検出できる障害とできない障害¶
監視条件: 障害サーバからのハートビートが途絶
監視できる障害の例
ハードウェア障害 (OS が継続動作できないもの)
STOP エラー
監視できない障害の例
OS の部分的な機能障害 (マウス/キーボードのみが動作しない等)
3.3.7. 業務監視で検出できる障害とできない障害¶
監視条件: 障害アプリケーションの消滅、 継続的なリソース異常、 あるネットワーク装置への通信路切断
監視できる障害の例
アプリケーションの異常終了
共有ディスクへのアクセス障害 (HBA の故障など)
パブリック LAN NIC の故障
監視できない障害の例
- アプリケーションのストール/結果異常アプリケーションのストール/結果異常を CLUSTERPRO で直接監視することはできません 1 が、アプリケーションを監視し異常検出時に自分自身を終了するプログラムを作成し、そのプログラムをアプリケーションリソースで起動、アプリケーション監視リソースで監視することで、フェイルオーバを発生させることは可能です。
- 1
監視オプションで取り扱う、データベースアプリケーション (Oracle,DB2等)、プロトコル (FTP,HTTP等) 、アプリケーションサーバ (WebSphere, WebLogic等) については、ストール/結果異常監視を行うことができます。
3.4. フェンシング機能¶
CLUSTERPROはフェンシングの仕組みとして「ネットワークパーティション解決」と「強制停止」を備えています。
3.4.1. ネットワークパーティション解決¶
PING 方式
HTTP 方式
共有ディスク方式
PING + 共有ディスク方式
多数決方式
ネットワークパーティション解決しない
参考
ネットワークパーティション解決方法の設定についての詳細は、『リファレンスガイド』の「ネットワークパーティション解決リソースの詳細」を参照してください。
3.4.2. 強制停止¶
サーバ障害を検知したとき、健全なサーバから障害を起こしたサーバに対して停止要求を発行することができます。障害のあるサーバを停止状態へ移行させることにより、業務アプリケーションが複数のサーバで同時に起動する可能性を排除します。強制停止の処理はフェイルオーバが開始される前に実行されます。
参考
強制停止の設定についての詳細は、『リファレンスガイド』の「強制停止リソースの詳細」を参照してください。
3.5. フェイルオーバのしくみ¶
CLUSTERPRO は他サーバからのハートビートの途絶を検出すると、フェイルオーバ開始前にサーバの障害かネットワークパーティション状態かを判別します。この後、健全なサーバ上で各種リソースを活性化し業務アプリケーションを起動することでフェイルオーバを実行します。
このとき、同時に移動するリソースの集まりをフェイルオーバグループと呼びます。フェイルオーバグループは利用者から見た場合、仮想的なコンピュータとみなすことができます。
注釈
クラスタシステムでは、アプリケーションを健全なノードで起動しなおすことでフェイルオーバを実行します。このため、アプリケーションのメモリ上に格納されている実行状態をフェイルオーバすることはできません。
障害発生からフェイルオーバ完了までの時間は数分間必要です。以下にタイムチャートを示します。
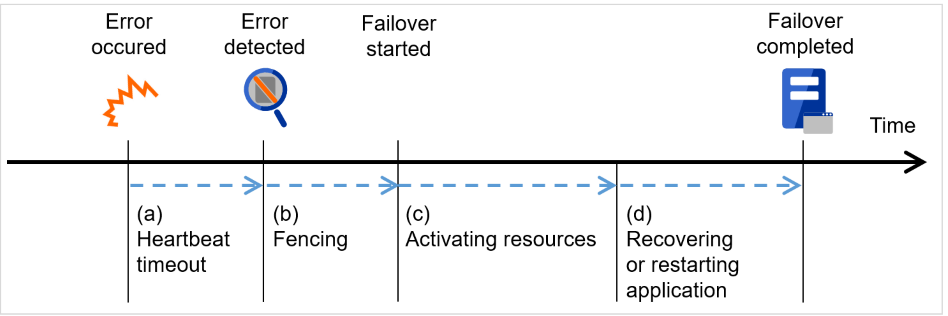
図 3.5 フェイルオーバのタイムチャート¶
ハートビートタイムアウト
業務を実行しているサーバの障害発生後、待機系がその障害を検出するまでの時間です。
フェンシング
ネットワークパーティション解決と強制停止を実施するための時間です。
各種リソース活性化
業務で必要なリソースを活性化するための時間です。
ファイルシステム復旧、ディスク内のデータ引継ぎ、IPアドレスの引継ぎ等を行います。
アプリケーション復旧処理・再起動
業務で使用するアプリケーションの起動に要する時間です。データベースのロールバック/ロールフォワードなどのデータ復旧処理の時間も含まれます。
ロールバック/ロールフォワード時間などはチェックポイントインターバルの調整である程度予測可能です。詳しくは、各ソフトウェア製品のドキュメントを参照してください。
3.5.1. CLUSTERPRO で構築する共有ディスク型クラスタのハードウェア構成¶
共有ディスク型クラスタの CLUSTERPRO の HW 構成は下図のようになります。
サーバ間の通信用に
NIC を 2 枚 (1 枚は外部との通信と流用、1 枚は CLUSTERPRO 専用)
共有ディスクの特定領域
を利用する構成が一般的です。
共有ディスクとの接続インターフェイスは SCSI や Fibre Channel、iSCSI ですが、最近はFibre Channel か iSCSI による接続が一般的です。
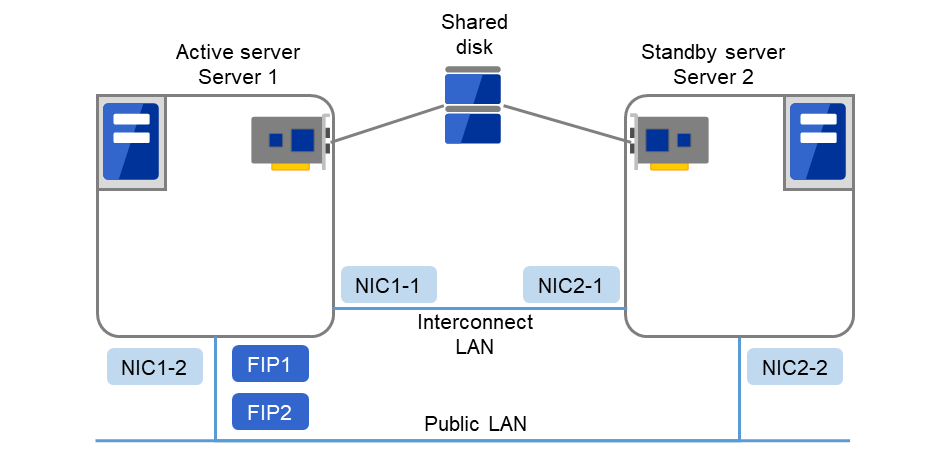
図 3.6 クラスタ構成例(共有ディスク型)¶
FIP1 |
10.0.0.11 (Cluster WebUIクライアントからのアクセス先) |
FIP2 |
10.0.0.12 (業務クライアントからのアクセス先) |
NIC1-1 |
192.168.0.1 |
NIC1-2 |
10.0.0.1 |
NIC2-1 |
192.168.0.2 |
NIC2-2 |
10.0.0.2 |
共有ディスク:
ディスクハートビート用パーティション ドライブ文字
E
ディスクリソース ドライブ文字
F
ファイルシステム
NTFS
上記は、共有ディスク使用時のクラスタ環境のサンプルです。
3.5.2. CLUSTERPROで構築するミラーディスク型クラスタのハードウェア構成¶
各サーバのディスク上のパーティションをミラーリングすることによって、共有ディスク装置の代替とする構成です。共有ディスク型に比べて小規模で低予算のシステムに向いています。
注釈
ミラーディスクを使用するには、Replicator オプションまたは Replicator DR オプションをご購入いただく必要があります。
ミラーディスク使用時のクラスタ環境のサンプル (OS がインストールされているディスクにクラスタパーティション、データパーティションを確保する場合)
以下の構成では、OSがインストールされているディスクの空きパーティションを、クラスタパーティション、データパーティションとして使用しています。

図 3.7 クラスタ構成例(1)(ミラーディスク型)¶
FIP1
10.0.0.11 (Cluster WebUIクライアントからのアクセス先)
FIP2
10.0.0.12 (業務クライアントからのアクセス先)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
クラスタパーティション ドライブ文字
E
ファイルシステム
RAW
データパーティション ドライブ文字
F
ファイルシステム
NTFS
ミラーディスク使用時のクラスタ環境のサンプル (クラスタパーティション、データパーティション用のディスクを用意する場合)
以下の構成では、クラスタパーティション、データパーティション用にディスクを用意し、接続しています。

図 3.8 クラスタ構成例(2)(ミラーディスク型)¶
FIP1
10.0.0.11 (Cluster WebUIクライアントからのアクセス先)
FIP2
10.0.0.12 (業務クライアントからのアクセス先)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
クラスタパーティション ドライブ文字
E
ファイルシステム
RAW
データパーティション ドライブ文字
F
ファイルシステム
NTFS
3.5.3. CLUSTERPRO で構築するハイブリッドディスク型クラスタのハードウェア構成¶
共有ディスク型とミラーディスク型を組み合わせ、共有ディスク上のパーティションをミラーリングすることによって、共有ディスク装置の障害に対しても業務継続を可能とする構成です。リモートサイト間でミラーリングすることにより、災害対策としても利用できます。
注釈
ハイブリッドディスクを使用するには、Replicator DR オプションをご購入いただく必要があります。
ハイブリッドディスク使用時のクラスタ環境のサンプル (2 台のサーバで共有ディスクを使用し、3 台目のサーバの通常のディスクへミラーリングする場合)

図 3.9 クラスタ構成例(ハイブリッドディスク型)¶
FIP1
10.0.0.11 (Cluster WebUIクライアントからのアクセス先)
FIP2
10.0.0.12 (業務クライアントからのアクセス先)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
NIC3-1
192.168.0.3
NIC3-2
10.0.0.3
共有ディスク
ハートビート用パーティション ドライブ文字
E
ファイルシステム
RAW
クラスタパーティション ドライブ文字
F
ファイルシステム
RAW
データパーティション ドライブ文字
G
ファイルシステム
NTFS
上記は、同じネットワーク内で共有ディスクをミラーリングする場合のクラスタ環境のサンプルです。ハイブリッドディスクでは同じ共有ディスク装置に接続されたサーバグループの間でミラーリングを行いますが、上記の例では共有ディスクを server3 のローカルディスクにミラーリングするため、待機系サーバグループ svg2 はメンバサーバが server3 のみとなります。

図 3.10 クラスタ構成例(ハイブリッドディスク型, 遠隔クラスタ)¶
FIP1 |
10.0.0.11 (Cluster WebUIクライアントからのアクセス先) |
FIP2 |
10.0.0.12 (業務クライアントからのアクセス先) |
NIC1-1 |
192.168.0.1 |
NIC1-2 |
10.0.0.1 |
NIC2-1 |
192.168.0.2 |
NIC2-2 |
10.0.0.2 |
NIC3-1 |
192.168.0.3 |
NIC3-2 |
10.0.0.3 |
共有ディスク
ハートビート用パーティション ドライブ文字
E
ファイルシステム
RAW
クラスタパーティション ドライブ文字
F
ファイルシステム
RAW
データパーティション ドライブ文字
G
ファイルシステム
NTFS
上記は、リモートサイト間でミラーリングを行う場合のクラスタ環境のサンプルです。この例ではPublic LAN のネットワークセグメントがサーバグループ間で異なるため、フローティング IP アドレスではなく仮想 IP アドレスを使用しています。仮想 IP アドレスを使用する場合、途中のルータは全てホストルートを伝播するように設定されている必要があります。また、ミラーのモードを非同期にし、データ圧縮機能を有効にすることをお勧めします。
3.5.4. クラスタオブジェクトとは?¶
CLUSTERPRO では各種リソースを下のような構成で管理しています。
- クラスタオブジェクト一群のサーバをまとめたクラスタシステムです。
- サーバオブジェクト実体サーバを示すオブジェクトで、クラスタオブジェクトに属します。
- サーバグループオブジェクトサーバを束ねるオブジェクトで、クラスタオブジェクトに属します。ハイブリッドディスクリソースを使用する場合に必要です。
- ハートビートリソースオブジェクト実体サーバの NW 部分を示すオブジェクトで、サーバオブジェクトに属します。
- ネットワークパーティション解決リソースオブジェクトネットワークパーティション解決機構を示すオブジェクトで、サーバオブジェクトに属します。
- グループオブジェクト仮想のサーバを示すオブジェクトで、クラスタオブジェクトに属します。
- グループリソースオブジェクト仮想サーバの持つ資源 (NW、ディスク) を示すオブジェクトでグループオブジェクトに属します。
- モニタリソースオブジェクト監視機構を示すオブジェクトで、クラスタオブジェクトに属します。
3.6. リソースとは?¶
CLUSTERPRO では、監視する側とされる側の対象をすべてリソースと呼び、監視する側とされる側のリソースを分類して管理します。このことにより、より明確に監視/被監視の対象を区別できるほか、クラスタ構築や障害検出時の対応が容易になります。リソースはハートビートリソース、ネットワークパーティション解決リソース、グループリソース、モニタリソースの 4 つに分類されます。以下にその概略を示します。
参考
各リソースの詳細については、『リファレンスガイド』を参照してください。
3.6.1. ハートビートリソース¶
サーバ間で、お互いの生存を確認するためのリソースです。
以下に現在サポートされているハートビートリソースを示します。
- LAN ハートビートリソースEthernet を利用した通信を示します。
- Witness ハートビートリソースWitness サーバサービスが動作している外部サーバから取得した各サーバとの通信状態を示します。
3.6.2. ネットワークパーティション解決リソース¶
ネットワークパーティション状態を解決するためのリソースを示します。
- DISK ネットワークパーティション解決リソースDISK 方式によるネットワークパーティション解決リソースです。共有ディスク構成の場合のみ利用可能です。
- PING ネットワークパーティション解決リソースPING 方式によるネットワークパーティション解決リソースです。
- HTTP ネットワークパーティション解決リソースHTTP 方式によるネットワークパーティション解決リソースです。
- 多数決ネットワークパーティション解決リソース多数決方式によるネットワークパーティション解決リソースです。
3.6.3. グループリソース¶
フェイルオーバを行う際の単位となる、フェイルオーバグループを構成するリソースです。
以下に現在サポートされているグループリソースを示します。
- アプリケーションリソース (appli)アプリケーション (ユーザ作成アプリケーションを含む) を起動/停止するための仕組みを提供します。
- フローティング IP リソース (fip)仮想的な IP アドレスを提供します。クライアントからは一般の IP アドレスと同様にアクセス可能です。
- ミラーディスクリソース (md)ローカルディスク上の特定のパーティションのミラーリングとアクセス制御を行う機能を提供します。ミラーディスク構成の場合のみ利用可能です。
- レジストリ同期リソース (regsync)クラスタを構成するサーバ間でアプリケーションやサービスを同一設定で動作させるために、複数サーバの特定レジストリを同期する仕組みを提供します。
- スクリプトリソース (script)ユーザ作成スクリプト等のスクリプト (BAT) を起動/停止するための仕組みを提供します。
- ディスクリソース (sd)共有ディスク上の特定のパーティションのアクセス制御を行う機能を提供します。共有ディスク装置が接続されている場合にのみ利用可能です。
- サービスリソース (service)データベースや Web 等のサービスを起動/停止するための仕組みを提供します。
- 仮想コンピュータ名リソース (vcom)仮想的なコンピュータ名を提供します。クライアントからは一般のコンピュータ名と同様にアクセス可能です。
- ダイナミック DNS リソース (ddns)Dynamic DNS サーバに仮想ホスト名と活性サーバの IP アドレスを登録します。
- 仮想 IP リソース (vip)仮想的な IP アドレスを提供します。クライアントからは一般の IP アドレスと同様にアクセス可能です。ネットワークアドレスの異なるセグメント間で遠隔クラスタを構成する場合に使用します。
- CIFS リソース (cifs)共有ディスク/ミラーディスク上のフォルダを共有公開するための機能を提供します。
- ハイブリッドディスクリソース (hd)ディスクリソースとミラーディスクリソースを組み合わせたリソースで、共有ディスクまたはローカルディスク上の特定のパーティションのミラーリングとアクセス制御を行う機能を提供します。
- AWS Elastic IP リソース (awseip)AWS 上で CLUSTERPRO を利用する場合、EIP を付与する仕組みを提供します。
- AWS 仮想 IP リソース (awsvip)AWS 上で CLUSTERPRO を利用する場合、VIP を付与する仕組みを提供します。
- AWS セカンダリ IP リソース (awssip)AWS 上で CLUSTERPRO を利用する場合、セカンダリ IP を付与する仕組みを提供します。
- AWS DNS リソース (awsdns)AWS 上で CLUSTERPRO を利用する場合、Amazon Route 53 に仮想ホスト名と活性サーバの IP アドレスを登録します。
- Azure プローブポートリソース (azurepp)Microsoft Azure 上で CLUSTERPRO を利用する場合、業務が稼働するノードで特定のポートを開放する仕組みを提供します。
- Azure DNS リソース (azuredns)Microsoft Azure 上で CLUSTERPRO を利用する場合、Azure DNS に仮想ホスト名と活性サーバの IP アドレスを登録します。
- Google Cloud 仮想 IP リソース (gcvip)Google Cloud Platform 上で CLUSTERPRO を利用する場合、業務が稼働するノードで特定のポートを開放する仕組みを提供します。
- Google Cloud DNS リソース (gcdns)Google Cloud Platform 上で CLUSTERPRO を利用する場合、Cloud DNS に仮想ホスト名と活性サーバの IP アドレスを登録します。
- Oracle Cloud 仮想 IP リソース (ocvip)Oracle Cloud Infrastructure 上で CLUSTERPRO を利用する場合、業務が稼働するノードで特定のポートを開放する仕組みを提供します。
注釈
3.6.4. モニタリソース¶
クラスタシステム内で、監視を行う主体であるリソースです。
以下に現在サポートされているモニタリソースを示します。
- アプリケーション監視リソース (appliw)アプリケーションリソースで起動したプロセスの死活監視機能を提供します。
- ディスク RW 監視リソース (diskw)ファイルシステムへの監視機構を提供します。また、ファイルシステム I/O ストール時に意図的な STOP エラーまたは、HW リセットによりフェイルオーバを実施する機能を提供します。共有ディスクのファイルシステムへの監視にも利用できます。
- フローティング IP 監視リソース (fipw)フローティング IP リソースで起動した IP アドレスの監視機構を提供します。
- IP 監視リソース (ipw)ネットワークの疎通を監視する機構を提供します
- ミラーディスク監視リソース (mdw)ミラーディスクの監視機構を提供します。
- NIC Link Up/Down 監視リソース (miiw)LAN ケーブルのリンクステータスの監視機構を提供します。
- マルチターゲット監視リソース (mtw)複数のモニタリソースを束ねたステータスを提供します。
- レジストリ同期監視リソース (regsyncw)レジストリ同期リソースによる同期処理の監視機構を提供します。
- ディスク TUR 監視リソース (sdw)SCSI の [TestUnitReady] コマンドにより共有ディスクへのアクセスパスの動作を監視する機構を提供します。FibreChannel の共有ディスクに対しても使用できます。
- サービス監視リソース (servicew)サービスの死活監視機能を提供します。
- 仮想コンピュータ名監視リソース (vcomw)仮想コンピュータ名リソースで起動した仮想コンピュータの監視機構を提供します。
- ダイナミックDNS監視リソース (ddnsw)定期的に Dynamic DNS サーバに仮想ホスト名と活性サーバの IP アドレスを登録します。
- 仮想 IP 監視リソース (vipw)仮想 IP リソースで起動した IP アドレスの監視機構を提供します。
- CIFS 監視リソース (cifsw)CIFS リソースで公開した共有フォルダの監視機構を提供します。
- ハイブリッドディスク監視リソース (hdw)ハイブリッドディスクの監視機構を提供します。
- ハイブリッドディスク TUR 監視リソース (hdtw)SCSI の [TestUnitReady] コマンドにより、ハイブリッドディスクとして使用する共有ディスク装置へのアクセスパスの動作を監視する機構を提供します。FibreChannel の共有ディスクに対しても使用できます。
- カスタム監視リソース (genw)監視処理を行うコマンドやスクリプトがある場合に、その動作結果によりシステムを監視する機構を提供します。
- プロセス名監視リソース (psw)プロセス名を指定することで、任意のプロセスの死活監視機能を提供します。
- DB2 監視リソース (db2w)IBM DB2 データベースへの監視機構を提供します。
- ODBC 監視リソース (odbcw)ODBC でアクセス可能なデータベースへの監視機構を提供します。
- Oracle 監視リソース (oraclew)Oracle データベースへの監視機構を提供します。
- PostgreSQL 監視リソース (psqlw)PostgreSQL データベースへの監視機構を提供します。
- SQL Server 監視リソース (sqlserverw)SQL Server データベースへの監視機構を提供します。
- FTP 監視リソース (ftpw)FTP サーバへの監視機構を提供します。
- HTTP 監視リソース (httpw)HTTP サーバへの監視機構を提供します。
- IMAP4 監視リソース (imap4w)IMAP サーバへの監視機構を提供します。
- POP3 監視リソース (pop3w)POP サーバへの監視機構を提供します。
- SMTP 監視リソース (smtpw)SMTP サーバへの監視機構を提供します。
- Tuxedo 監視リソース (tuxw)Tuxedo アプリケーションサーバへの監視機構を提供します。
- WebSphere 監視リソース (wasw)WebSphere アプリケーションサーバへの監視機構を提供します。
- WebLogic 監視リソース(wlsw)WebLogic アプリケーションサーバへの監視機構を提供します。
- WebOTX 監視リソース (otxw)WebOTX アプリケーションサーバへの監視機構を提供します。
- 外部連携監視リソース (mrw)"異常発生通知受信時に実行する異常時動作の設定"と"異常発生通知の Cluster WebUI 表示" を実現するためのモニタリソースです。
- JVM監視リソース (jraw)Java VMへの監視機構を提供します。
- システム監視リソース (sraw)システム全体のリソースへの監視機構を提供します。
- プロセスリソース監視リソース (psrw)プロセス個別のリソースの監視機構を提供します。
- ユーザ空間監視リソース (userw)ユーザ空間のストール監視機構を提供します。また、ユーザ空間ストール時に意図的な STOP エラーまたは、HW リセットによりフェイルオーバを実施する機能を提供します。
- AWS Elastic IP監視リソース (awseipw)AWS Elastic IPリソースで付与した Elastic IP(以下、EIP)の監視機構を提供します。
- AWS 仮想IP監視リソース (awsvipw)AWS 仮想IPリソースで付与した仮想IP(以下、VIP)の監視機構を提供します。
- AWS セカンダリ IP 監視リソース (awssipw)AWS セカンダリ IP リソースで付与した セカンダリ IP の監視機構を提供します。
- AWS AZ監視リソース (awsazw)Availability Zone(以下、AZ) の監視機構を提供します。
- AWS DNS 監視リソース (awsdnsw)AWS DNS リソースで付与した仮想ホスト名と IP アドレスの監視機構を提供します。
- Azure プローブポート監視リソース (azureppw)Azure プローブポートリソースが起動しているノードに対して、死活監視のためのポートの監視機構を提供します。
- Azure ロードバランス監視リソース (azurelbw)Azure プローブポートリソースが起動していないノードに対して、プローブ ポートと同じポート番号が開放されていないかの監視機構を提供します。
- Azure DNS 監視リソース (azurednsw)Azure DNS リソースで付与した仮想ホスト名と IP アドレスの監視機構を提供します。
- Google Cloud 仮想 IP 監視リソース (gcvipw)Google Cloud 仮想 IP リソースが起動しているノードに対して、死活監視のためのポートの監視機構を提供します。
- Google Cloud ロードバランス監視リソース (gclbw)Google Cloud 仮想 IP リソースが起動していないノードに対して、ヘルスチェック用ポートと同じポート番号が開放されていないかの監視機構を提供します。
- Google Cloud DNS 監視リソース (gcdnsw)Google Cloud DNS リソースで付与した仮想ホスト名と IP アドレスの監視機構を提供します。
- Oracle Cloud 仮想 IP 監視リソース (ocvipw)Oracle Cloud 仮想 IP リソースが起動しているノードに対して、死活監視のためのポートの監視機構を提供します。
- Oracle Cloud ロードバランス監視リソース (oclbw)Oracle Cloud 仮想 IP リソースが起動していないノードに対して、ヘルスチェック用ポートと同じポート番号が開放されていないかの監視機構を提供します。
注釈
3.7. CLUSTERPRO を始めよう!¶
以上で CLUSTERPRO の簡単な説明が終了しました。
以降は、以下の流れに従い、対応するガイドを読み進めながら CLUSTERPRO を使用したクラスタシステムの構築を行ってください。
3.7.2. クラスタシステムの設計¶
『インストール&設定ガイド』の「システム構成を決定する」、「クラスタシステムを設計する」および
『リファレンスガイド』の「グループリソースの詳細」、「モニタリソースの詳細」、「ハートビートリソースの詳細」、「ネットワークパーティション解決リソースの詳細」、「その他の設定情報」 を参照してください。
3.7.3. クラスタシステムの構築¶
『インストール&設定ガイド』の全編を参照してください。
3.7.4. クラスタシステムの運用開始後の障害対応¶
『メンテナンスガイド』の「保守情報」および『リファレンスガイド』の「トラブルシューティング」、「エラーメッセージ一覧」を参照してください。
4. CLUSTERPRO の動作環境¶
本章では、CLUSTERPRO の動作環境について説明します。
本章で説明する項目は以下の通りです。
4.1. ハードウェア動作環境¶
CLUSTERPRO は以下のアーキテクチャのサーバで動作します。
x86_64
4.1.1. 必要スペック¶
CLUSTERPRO Server に必要なスペックは下記の通りです。
Ethernet ポート 2 つ以上
共有ディスク、ミラー用ディスクまたはミラー用空きパーティション (ミラーディスクを使用する場合)
DVD-ROM ドライブ
4.2. CLUSTERPRO Server の動作環境¶
4.2.1. 対応 OS¶
CLUSTERPRO は、下記の OS に対応しています。
x86_64 版
OS |
備考 |
|---|---|
Windows Server 2016 Standard |
|
Windows Server 2016 Datacenter |
|
Windows Server 2019 Standard |
|
Windows Server 2019 Datacenter |
|
Windows Server 2022 Standard |
|
Windows Server 2022 Datacenter |
4.2.2. 必要メモリ容量とディスクサイズ¶
必要メモリサイズ
(ユーザモード)
|
256MB( 2 ) |
|---|---|
必要メモリサイズ
(kernelモード)
|
32MB + 4MB( 3 )×(ミラーディスクリソース数+ハイブリッドディスクリソース数) |
必要ディスクサイズ
(インストール直後)
|
100MB |
必要ディスクサイズ
(運用時)
|
5.0GB + 9.0GB ( 4 ) |
- 2
オプション類を除く
- 3
ミラーディスクリソースおよびハイブリッドディスクリソース使用時に必要なメモリサイズです。
- 4
ミラーディスクリソースおよびハイブリッドディスクリソース使用時に必要なディスクサイズです。
非同期方式に変更時やキューサイズ変更時および差分ビットマップサイズ変更時は、構成時に指定したサイズのメモリが追加で必要になります。また、ミラーディスクへの I/O に対応してメモリを使用するため、ディスク負荷の増加にともない使用するメモリサイズも増加します。
DISK ネットワークパーティション解決リソースが使用するパーティションに必要なサイズは「共有ディスクについて」を参照してください。
クラスタパーティションに必要なサイズは「ミラーディスク用のパーティションについて」、「ハイブリッドディスク用のパーティションについて」を参照してください。
4.2.3. 監視オプションの動作確認済アプリケーション情報¶
監視オプションは、下記のアプリケーションを監視対象として動作確認しています。
x86_64 版
モニタリソース |
監視対象の
アプリケーション
|
CLUSTERPRO
Version
|
備考 |
|---|---|---|---|
Oracle 監視 |
Oracle Databse 19c (19.3) |
13.00~ |
|
DB2 監視 |
DB2 V11.5 |
13.00~ |
|
PostgreSQL 監視 |
PostgreSQL 14.1 |
13.00~ |
|
PowerGres on Windows V13 |
13.00~ |
||
SQL Server 監視 |
SQL Server 2019 |
13.00~ |
|
Tuxedo 監視 |
Tuxedo 12c Release 2 (12.1.3) |
12.00~ |
|
WebLogic 監視 |
WebLogic Server 11g R1 |
12.00~ |
|
WebLogic Server 11g R2 |
12.00~ |
||
WebLogic Server 12c R2 (12.2.1) |
12.00~ |
||
WebLogic Server 14c (14.1.1) |
12.20~ |
||
WebSphere 監視 |
WebSphere Application Server 8.5 |
12.00~ |
|
WebSphere Application Server 8.5.5 |
12.00~ |
||
WebSphere Application Server 9.0 |
12.00~ |
||
WebOTX 監視 |
WebOTX Application Server V9.1 |
12.00~ |
|
WebOTX Application Server V9.2 |
12.00~ |
||
WebOTX Application Server V9.3 |
12.00~ |
||
WebOTX Application Server V9.4 |
12.00~ |
||
WebOTX Application Server V9.5 |
12.00~ |
||
WebOTX Application Server V10.1 |
12.00~ |
||
WebOTX Application Server V10.3 |
12.30~ |
||
JVM監視 |
WebLogic Server 11g R1 |
12.00~ |
|
WebLogic Server 11g R2 |
12.00~ |
||
WebLogic Server 12c R2 (12.2.1) |
12.00~ |
||
WebLogic Server 14c (14.1.1) |
12.20~ |
||
WebOTX Application Server V9.1 |
12.00~ |
||
WebOTX Application Server V9.2 |
12.00~ |
||
WebOTX Application Server V9.3 |
12.00~ |
||
WebOTX Application Server V9.4 |
12.00~ |
||
WebOTX Application Server V9.5 |
12.00~ |
||
WebOTX Application Server V10.1 |
12.00~ |
||
WebOTX Application Server V10.3 |
12.30~ |
||
WebOTX Enterprise Service Bus V8.4 |
12.00~ |
||
WebOTX Enterprise Service Bus V8.5 |
12.00~ |
||
WebOTX Enterprise Service Bus V10.3 |
12.30~ |
||
Apache Tomcat 8.0 |
12.00~ |
||
Apache Tomcat 8.5 |
12.00~ |
||
Apache Tomcat 9.0 |
12.00~ |
||
Apache Tomcat 10.0 |
13.02~ |
||
WebSAM SVF for PDF 9.1 |
12.00~ |
||
WebSAM SVF for PDF 9.2 |
12.00~ |
||
WebSAM Report Director Enterprise 9.1 |
12.00~ |
||
WebSAM Report Director Enterprise 9.2 |
12.00~ |
||
WebSAM Universal Connect/X 9.1 |
12.00~ |
||
WebSAM Universal Connect/X 9.2 |
12.00~ |
||
システム監視 |
バージョン指定無し |
12.00~ |
|
プロセスリソース監視 |
バージョン指定無し |
12.10~ |
注釈
x86_64環境で監視オプションをご利用される場合、監視対象のアプリケーションもx86_64版のアプリケーションをご利用ください。
4.2.5. JVM 監視の動作環境¶
4.2.6. システム監視,プロセスリソース監視及びシステムリソース情報を収集する機能の動作環境¶
注釈
Windows Server 2012 以降のOSでは、.NET Framework 4.5 以降のバージョンがプレインストールされています(プレインストールされている .NET Framework のバージョンは、OSにより異なります)。
4.2.7. AWS Elastic IP リソース、AWS 仮想 IP リソース、AWS Elastic IP監視リソース、AWS 仮想 IP 監視リソース、AWS AZ 監視リソースの動作環境¶
AWS Elastic IPリソース、AWS 仮想IPリソース、AWS Elastic IP監視リソース、AWS 仮想IP監視リソース、AWS AZ監視リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.6.0~
2.0.0~
|
|
Python |
2.7.5~
3.6.7~
|
AWS CLI 付属の Python は不可 |
4.2.8. AWS セカンダリ IP リソース、AWS セカンダリ IP 監視リソースの動作環境¶
AWS セカンダリ IP リソース、AWS セカンダリ IP 監視リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.12.0~
2.0.0~
|
4.2.9. AWS DNS リソース、AWS DNS 監視リソースの動作環境¶
AWS DNS リソース、AWS DNS 監視リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.11.0~
2.0.0~
|
|
Python |
2.7.5~
3.6.7~
|
AWS CLI 付属の Python は不可 |
4.2.10. AWS 強制停止リソースの動作環境¶
AWS 強制停止リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
AWS CLI |
1.15.0~
2.0.0~
|
4.2.11. Azure プローブポートリソース、Azure プローブポート監視リソース、Azure ロードバランス監視リソースの動作環境¶
Azure プローブポートリソース、Azure プローブポート監視リソース、Azure ロードバランス監視リソースの動作確認を行った Microsoft Azure 上のデプロイモデルを下記に提示します。
ロードバランサーの設定方法は、『CLUSTERPRO X Microsoft Azure 向け HAクラスタ 構築ガイド』を参照してください。
デプロイモデル |
CLUSTERPRO
Version
|
備考 |
|---|---|---|
リソースマネージャー |
12.00~ |
ロードバランサーの追加が必要 |
4.2.12. Azure DNS リソース、Azure DNS 監視リソースの動作環境¶
Azure DNS リソース、Azure DNS 監視リソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
Azure CLI |
2.0~ |
Azure DNS リソース、Azure DNS 監視リソースの動作確認を行った Microsoft Azure 上のデプロイモデルを下記に提示します。
Azure DNS の設定方法は、『CLUSTERPRO X Microsoft Azure 向け HAクラスタ 構築ガイド』を参照してください。
デプロイモデル |
CLUSTERPRO
Version
|
備考 |
|---|---|---|
リソースマネージャー |
12.00~ |
Azure DNS の追加が必要 |
4.2.13. Google Cloud 仮想 IP リソース、Google Cloud 仮想 IP 監視リソース、Google Cloud ロードバランス監視リソースの動作環境¶
Google Cloud 仮想 IP リソース、Google Cloud 仮想 IP 監視リソース、Google Cloud ロードバランス監視リソースの動作確認を行った Google Cloud Platform 上の OS のバージョン情報を下記に提示します。
ディストリビューション |
CLUSTERPRO
Version
|
備考 |
|---|---|---|
Windows Server 2016 |
12.20~ |
|
Windows Server 2019 |
12.20~ |
4.2.14. Google Cloud DNS リソース、Google Cloud DNS モニタリソースの動作環境¶
Google Cloud DNS リソース、Google Cloud DNS モニタリソースを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
Google Cloud SDK |
295.0.0~ |
4.2.15. Oracle Cloud 仮想 IP リソース、Oracle Cloud 仮想 IP 監視リソース、Oracle Cloud ロードバランス監視リソースの動作環境¶
Oracle Cloud 仮想 IP リソース、Oracle Cloud 仮想 IP 監視リソース、Oracle Cloud ロードバランス監視リソースの動作確認を行った Oracle Cloud Infrastructure 上の OS のバージョン情報を下記に提示します。
ディストリビューション |
CLUSTERPRO
Version
|
備考 |
|---|---|---|
Windows Server 2016 |
12.20~ |
4.2.17. clpcfadm.py コマンドの動作環境¶
clpcfadm.py コマンドを使用する場合には、以下のソフトウェアが必要です。
ソフトウェア |
Version |
備考 |
|---|---|---|
Python |
3.6.8~ |
4.3. Cluster WebUI の動作環境¶
Cluster WebUI を動作させるために必要な環境について記載します。
4.3.1. 動作確認済 OS、ブラウザ¶
現在の対応状況は下記の通りです。
ブラウザ |
言語 |
|---|---|
Internet Explorer 11 |
日本語/英語/中国語 |
Internet Explorer 10 |
日本語/英語/中国語 |
Firefox |
日本語/英語/中国語 |
Google Chrome |
日本語/英語/中国語 |
Microsoft Edge (Chromium) |
日本語/英語/中国語 |
注釈
IPアドレスで接続する場合、事前に該当の IPアドレスを [ローカル イントラネット] の [サイト] に登録する必要があります。
注釈
Internet Explorer 11 にて Cluster WebUI に接続すると、Internet Explorer が停止することがあります。本事象回避のために、Internet Explorer のアップデート (KB4052978 以降) を適用してください。なお、Windows 8.1/Windows Server 2012R2 に KB4052978 以降を適用するためには、事前に KB2919355 の適用が必要となります。詳細は Microsoft より展開されている情報をご確認ください。
注釈
タブレットやスマートフォンなどのモバイルデバイスには対応していません。
4.3.2. 必要メモリ容量/ディスク容量¶
必要メモリ容量 500MB 以上
必要ディスク容量 200MB 以上
4.4. Witness サーバの動作環境¶
4.4.1. Witness サーバサービスの動作確認済み環境¶
以下の環境で動作確認済みです。
OS |
実行環境 |
バージョン |
|---|---|---|
Windows Server 2012 R2 |
Node.js 10.13.0 |
4.1.0 |
Windows Server 2019 |
Node.js 12.10.0 |
4.2.0 |
Red Hat Enterprise Linux 7.4 |
Node.js 8.12.0 |
4.1.0 |
Red Hat Enterprise Linux 8.0 |
Node.js 12.10.0 |
4.2.0 |
4.4.2. 必要メモリ容量とディスクサイズ¶
必要メモリサイズ |
50MB + (ノード数 * 0.5 MB) |
|---|---|
必要ディスクサイズ |
1GB |
5. 最新バージョン情報¶
本章では、CLUSTERPRO の最新情報について説明します。新しいリリースで強化された点、改善された点などをご紹介します。
5.1. CLUSTERPRO とマニュアルの対応一覧¶
本書では下記のバージョンの CLUSTERPRO を前提に説明してあります。CLUSTERPRO のバージョンとマニュアルの版数に注意してください。
CLUSTERPROの
内部バージョン
|
マニュアル |
版数 |
備考 |
|---|---|---|---|
13.02 |
スタートアップガイド |
第 11 版 |
|
インストール&設定ガイド |
第 5 版 |
||
リファレンスガイド |
第 10 版 |
||
メンテナンスガイド |
第 5 版 |
5.2. 機能強化¶
各バージョンにおいて以下の機能強化を実施しています。
項番 |
内部バージョン |
機能強化項目 |
|---|---|---|
1 |
13.00 |
Windows Server 2022 に対応しました。 |
2 |
13.00 |
メジャーバージョンアップに伴い、いくつかの機能を削除しました。詳細は機能削除一覧を参照してください。 |
3 |
13.00 |
サーバダウン時の自動フェイルオーバをクラスタ全体で一括して抑止する機能を追加しました。 |
4 |
13.00 |
グループリソースの活性・非活性異常検出時およびモニタリソースの異常検出時の最終動作によるサーバ再起動の回数がリセットされたときに、アラートログで通知するようにしました。 |
5 |
13.00 |
ダイナミックフェイルオーバ以外の自動フェイルオーバにおいて、指定したモニタリソースで異常を検出しているサーバをフェイルオーバ先から除外できるようになりました。 |
6 |
13.00 |
ファイアウォールの規則を追加するコマンド clpfwctrl を追加しました。 |
7 |
13.00 |
AWS セカンダリ IP リソース、AWS セカンダリ IP 監視リソースを追加しました。 |
8 |
13.00 |
BMCを利用した強制停止機能をBMC強制停止リソースとして刷新しました。 |
9 |
13.00 |
仮想マシン強制停止機能をvCenter強制停止リソースとして刷新しました。 |
10 |
13.00 |
AWS環境の強制停止機能を強制停止リソースに追加しました。 |
11 |
13.00 |
OCI環境の強制停止機能を強制停止リソースに追加しました。 |
12 |
13.00 |
強制停止スクリプトをカスタム強制停止リソースとして刷新しました。 |
13 |
13.00 |
モニタ異常検出時の回復動作等でOSシャットダウンを伴う動作を一括してOSリブートに変更する機能を追加しました。 |
14 |
13.00 |
グループ間の起動および停止待ち合わせ処理に関するアラートメッセージを改善しました。 |
15 |
13.00 |
clpstatの設定情報の表示オプションで、リソース起動属性の設定値を表示できるようにしました。 |
16 |
13.00 |
clpcl/clpstdnコマンドで、自サーバがクラスタ停止状態でも-hオプションを指定できるようにしました。 |
17 |
13.00 |
実IPアドレス以外で Cluster WebUI に接続して設定モードに切替えた時に警告メッセージを出力するようになりました。 |
18 |
13.00 |
Cluster WebUI の設定モードで除外対象のパーティション情報が取得できない場合でも構成情報の反映およびエクスポートができるようになりました。 |
19 |
13.00 |
Cluster WebUI の設定モードでグループリソースを登録している状態でグループの削除が行えるようになりました。 |
20 |
13.00 |
Cluster WebUI で通信タイムアウトが発生した際のエラーメッセージの内容を変更しました。 |
21 |
13.00 |
Cluster WebUI のミラーディスク画面でフルコピー等の実行に失敗した際のエラーメッセージの内容を変更しました。 |
22 |
13.00 |
Cluster WebUI の設定モードで登録したグループ、グループリソース、モニタリソースを複製できる機能を追加しました。 |
23 |
13.00 |
Cluster WebUI の設定モードで登録したグループリソースを別のグループへ移動できる機能を追加しました。 |
24 |
13.00 |
Cluster WebUI の設定モードの [グループのプロパティ] のグループリソース一覧から設定を変更できるようになりました。 |
25 |
13.00 |
Cluster WebUI の設定モードの [モニタ共通のプロパティ] のモニタリソース一覧から設定を変更できるようになりました。 |
26 |
13.00 |
Cluster WebUI の設定モードでグループリソース非活性時の依存関係が表示されるようになりました。 |
27 |
13.00 |
Cluster WebUI の設定モードでグループリソース活性時および非活性時の依存関係図を表示する機能を追加しました。 |
28 |
13.00 |
Cluster WebUI のステータス画面でグループリソース/モニタリソースのタイプやリソース名で表示を絞り込む機能を追加しました。 |
29 |
13.00 |
CIFSリソースの [共有設定復元時の失敗を活性異常とする] の既定値をオンからオフに変更しました。 |
30 |
13.00 |
WebManager サービスで通信方式に HTTPS を使用した場合、証明書ファイルとして中間証明書を使用できるようになりました。 |
31 |
13.00 |
クラスタ構成情報ファイルを旧バージョンから現バージョンへ変換するコマンド clpcfconv を追加しました。 |
32 |
13.00 |
OS起動時にクラスタサービスの起動を遅延させる機能を追加しました。 |
33 |
13.00 |
Cluster WebUI のクラスタ構成情報チェックのエラー結果において、対処法などの詳細を表示できるようになりました。 |
34 |
13.00 |
clpcfsetコマンドのcreateオプション指定時にOS種別を指定できるようにしました。 |
35 |
13.00 |
clpcfsetコマンドにdelオプションを追加し、クラスタ構成情報からリソースやパラメータを削除する機能を追加しました。 |
36 |
13.00 |
clpcfsetコマンドのインターフェースを強化したclpcfadm.pyコマンドを追加しました。 |
37 |
13.00 |
AWS DNSリソースの起動完了タイミングをレコードセットがAWS Route53へ伝搬されたことを確認してから起動するように変更しました。 |
38 |
13.00 |
AWS DNS監視リソースの監視開始待ち時間の既定値を300秒に変更しました。 |
39 |
13.00 |
clpstatコマンドが二重起動可能となりました。 |
40 |
13.00 |
Node Managerサービスを追加しました |
41 |
13.00 |
ハートビート統計情報機能を追加しました。 |
42 |
13.00 |
HTTP NP解決リソースで、Witnessハートビートリソースを使用しない場合でも Proxyサーバを利用できるようになりました。 |
43 |
13.00 |
HTTP監視リソースがDigest認証に対応しました。 |
44 |
13.00 |
FTP監視リソースでFTPSを利用するFTPサーバを監視できるようになりました。 |
45 |
13.00 |
システム監視リソースを複数登録できるようになりました。 |
46 |
13.00 |
プロセスリソース監視リソースを複数登録できるようになりました。 |
47 |
13.00 |
プロセスリソース監視リソースで特定のプロセスのみを監視対象とする機能を追加しました。 |
48 |
13.00 |
サービス監視リソース単体で任意のサービスの監視が行えるようになりました。 |
49 |
13.00 |
clpmdctrlコマンド、clpmdstatコマンドのオプション体系をclphdctrlコマンド、clphdstatコマンドに合わせました。 |
50 |
13.02 |
JVM監視リソースが Apache Tomcat 10.0 に対応しました。 |
5.3. 修正情報¶
各バージョンにおいて以下の修正を実施しています。
項番 |
修正バージョン
/ 発生バージョン
|
修正項目 |
重要度 |
発生条件
発生頻度
|
|---|---|---|---|---|
1 |
13.00
/ 9.00 ~ 12.32
|
グループリソースの単体活性が成功したとき、同じグループ内の他のグループリソースの復旧動作が実行される場合がある。 |
小 |
活性異常状態のグループリソースが存在する状態で、同じグループ内の他のグループリソースを単体活性した場合に発生する。 |
2 |
13.00
/ 12.10 ~ 12.32
|
Cluster WebUI の設定モードでグループリソースの「コメント」を修正したときに、修正内容が更新されない場合がある。 |
小 |
グループリソースの「コメント」を修正して[適用]ボタン押下後、修正前の状態に戻して[OK]ボタンを押下した場合に発生する。 |
3 |
13.00
/ 12.10 ~ 12.32
|
Cluster WebUI の設定モードでモニタリソースの「コメント」を修正したときに、修正内容が更新されない場合がある。 |
小 |
モニタリソースの「コメント」を修正して[適用]ボタン押下後、修正前の状態に戻して[OK]ボタンを押下した場合に発生する。 |
4 |
13.00
/ 12.10 ~ 12.32
|
停止済のサーバに Cluster WebUI を接続したときに、ダウン後再起動状態のサーバの[サーバ復帰]ボタンが有効にならない |
小 |
停止済のサーバに Cluster WebUI を接続してダウン後再起動状態のサーバが存在する場合に発生する。 |
5 |
13.00
/ 12.10 ~ 12.32
|
Cluster WebUI の設定モードで、WebLogic監視の監視(固有)画面にある項目「インストールパス」が入力必須項目となっていない。 |
小 |
常に発生する。 |
6 |
13.00
/ 12.00 ~ 12.32
|
Cluster WebUI のステータス画面でクラスタの操作を実行した際に、通信タイムアウトが発生すると同一のリクエストを再度発行してしまう。 |
中 |
Cluster WebUI とクラスタサーバ間で通信タイムアウトが発生すると必ず発生する。 |
7 |
13.00
/ 12.10 ~ 12.32
|
Cluster WebUI の設定モードで依存関係を設定した際に、Cluster WebUI がフリーズする場合がある。 |
小 |
2つのグループリソースを互いに依存させた場合に発生する。 |
8 |
13.00
/ 12.20 ~ 12.32
|
clpstatコマンドの応答が遅延することがある。 |
小 |
他のサーバとの通信が切断した場合に発生することがある。 |
9 |
13.00
/ 11.10 ~ 12.32
|
モニタリソースの遅延警告のアラートログで、response time に 0 が出力されることがある。 |
小 |
モニタリソースの遅延警告のアラートログが出力された際に発生することがある。 |
10 |
13.00
/ 12.20 ~ 12.32
|
clpwebmcのAPエラーが発生することがある。 |
小 |
Cluster WebUIの設定モードでサーバを削除したクラスタ構成情報を反映する際に稀に発生することがある。 |
11 |
13.00
/ 12.00 ~ 12.32
|
モニタリソースが監視タイムアウトを誤検出することがある。 |
中 |
モニタリソースの監視処理実行時にごく稀に発生することがある。 |
12 |
13.00
/ 12.20 ~ 12.32
|
HTTP方式のNP解決リソースで、ターゲットのレスポンスがステータスコード301だった場合に異常となる。 |
小 |
レスポンスがステータスコード301だった場合に発生する。 |
13 |
13.00
/ 12.00 ~ 12.32
|
プロセスリソース監視リソースの[メモリ使用量の監視]の[継続時間 (分)]の表記を[最大更新回数 (回)]に修正しました。 |
小 |
Cluster WebUIやclpstatコマンドでプロパティを表示した際に発生する。 |
14 |
13.00
/ 12.00 ~ 12.32
|
HTTP監視リソースで、HEAD リクエストの発行に対する応答のステータスコードが400または500 番台であった場合、かつ、監視URI に既定値以外のURI を指定した場合に、異常ではなく警告となる。 |
小 |
HEAD リクエストの発行に対する応答のステータスコードが400または500 番台であった場合、かつ、監視URI に既定値以外のURI を指定した場合に発生する。 |
15 |
13.00
/ 12.10 ~ 12.32
|
カスタム監視リソースで監視対象のスクリプトのプロセスが消滅した場合のアラートメッセージで対象のモニタリソース名が出力されない。 |
小 |
カスタム監視リソースで監視対象のスクリプトのプロセスが消滅した場合に発生する。 |
16 |
13.00
/ 11.01 ~ 12.32
|
ミラー関係コマンドの応答に時間がかかることがある。 |
小 |
ミラーディスクコネクトが切断されている場合、あるいはクラスタを構成するサーバの一部がダウンしている場合に発生する。 |
17 |
13.00
/ 12.20 ~ 12.32
|
CLUSTERPRO Information Base サービスが異常終了することがある。 |
小 |
以下のいずれかの操作を行った際にごく稀に発生することがある。
- クラスタ起動
- クラスタ停止
- クラスタサスペンド
- クラスタリジューム
|
18 |
13.01
/ 9.00~12.32、13.00
|
CVE-2021-20700~20707 の脆弱性により以下の可能性がある。
・任意のコードを実行される
・任意のファイルをアップロードされる
・任意のファイルを読み取られる
|
大 |
悪意のある第三者によって細工された CLUSTERPRO の内部プロトコルに反するパケットを、CLUSTERPRO の特定のプロセスが受信した場合に発生する。 |
19 |
13.01
/ 13.00
|
clprexecコマンドの--scriptオプションが動作しない |
小 |
--scriptオプションを指定してclprexecコマンドを実行した場合に発生する。 |
20 |
13.01
/ 13.00
|
clpcfset コマンドで強制停止リソースを追加した場合、クラスタ起動に失敗する。 |
小 |
clpcfset コマンドで強制停止リソースを追加したクラスタ構成情報を適用したクラスタを起動した場合に発生する。 |
21 |
13.02
/ 13.00 ~ 13.01
|
CLUSTERPRO Node Manager サービスがサービス起動遅延時間を待たずに開始する。 |
小 |
[サービス起動遅延時間] に 0 秒より大きい値を設定すると発生する。 |
22 |
13.02
/ 13.01
|
アップデートインストール時に CLUSTERPRO Old API Support サービスが登録される。 |
小 |
内部バージョン 13.00 から 13.01 にアップデートした場合に発生する。 |
23 |
13.02
/ 13.00 ~ 13.01
|
フェイルオーバグループの [起動可能なサーバ] の一覧からサーバを削除した構成情報の設定反映時にグループ停止が要求されない。 |
小 |
フェイルオーバグループの [起動可能なサーバ] の一覧からサーバを削除した構成情報の設定反映時に発生する。 |
24 |
13.02
/ 13.00 ~ 13.01
|
ミラーディスクリソースまたはハイブリッドディスクリソースを含むクラスタ構成情報の設定反映時に STOP エラーが発生することがある。 |
中 |
ミラーディスクリソースまたはハイブリッドディスクリソースのリソース名を 8 文字以上に設定すると発生する。 |
25 |
13.02
/ 13.00 ~ 13.01
|
モニタリソースが監視タイムアウトを誤検出することがある。 |
小 |
モニタリソースの監視処理実行時にごく稀に発生することがある。 |
26 |
13.02
/ 13.00 ~ 13.01
|
モニタリソース等の [回復動作] に「意図的なストップエラーの発生」を設定している場合、回復動作が実行されないことがある。 |
小 |
回復動作実行時に稀に発生する。 |
27 |
13.02
/ 13.00 ~ 13.01
|
クラスタサービス起動時にカーネルモード LAN ハートビートリソースで初期化エラーが発生することがある。 |
中 |
ネットワークデバイスが利用可能になる前に、カーネルモードLANハートビートリソースが起動した場合に発生する。 |
28 |
13.02
/ 12.00 ~ 13.01
|
NP発生時動作によるクラスタサービスの停止が完了しない。 |
中 |
[NP 発生時動作] に「クラスタサービス停止」を指定した場合に発生する。 |
29 |
13.02
/ 13.00 ~ 13.01
|
複数のサーバに対する強制停止の実行が失敗することがある。 |
小 |
3 台以上のクラスタ構成において、1 台のサーバから複数のサーバに対して強制停止を実行すると稀に発生する。 |
30 |
13.02
/ 9.00 ~ 13.01
|
clpstat コマンドでアプリケーションエラーが発生することがある。 |
小 |
グループリソースが1つも登録されていないフェイルオーバグループが設定されている環境で発生する。 |
31 |
13.02
/ 13.00 ~ 13.01
|
クラスタサスペンド状態で Cluster WebUI や clpstat コマンドのサーバステータスが停止と表示される場合がある。 |
小 |
クラスタサスペンド状態で以下のサービスを再起動すると発生する。
- CLUSTERPRO Node Manager
- CLUSTERPRO Information Base
|
32 |
13.02
/ 13.00 ~ 13.01
|
グループリソースやモニタリソースのステータス表示が不正になる場合がある。 |
小 |
OS起動時のクラスタサービスの内部処理で問題が発生した場合に発生する。 |
33 |
13.02
/ 13.00 ~ 13.01
|
Cluster WebUI や clpstat コマンドで強制停止リソースを使用していないサーバのステータスが正しく表示されない。 |
小 |
3 台以上のクラスタ構成において、強制停止を使用しない設定をしたサーバが存在する場合に発生する。 |
34 |
13.02
/ 9.00 ~ 13.01
|
OS 起動時 または OS シャットダウン時に STOP エラー が発生することがある。 |
中 |
OS 起動時 または OSシャットダウン時にごく稀に発生する場合がある。 |
35 |
13.02
/ 9.00 ~ 13.01
|
CVE-2022-34822~34823 の脆弱性により以下の可能性がある。
- 任意のファイルを読み取られる
- 任意のコードを実行される
|
大 |
悪意のある第三者によって細工された CLUSTERPRO の内部プロトコルに反するパケットを、CLUSTERPRO の特定のプロセスが受信した場合に発生する。 |
6. 注意制限事項¶
本章では、注意事項や既知の問題とその回避策について説明します。
本章で説明する項目は以下の通りです。
6.1. システム構成検討時¶
HW の手配、システム構成、共有ディスクの構成時に留意すべき事項について説明します。
6.1.1. CLUSTERPRO インストール先フォルダのアクセス権について¶
6.1.2. ミラーディスク/ハイブリッドディスクの要件について¶
ダイナミックディスクは使用できません。ベーシックディスクを使用してください。
ミラーディスク/ハイブリッドディスク用のパーティション (データパーティションとクラスタパーティション) を NTFS フォルダにマウントして使用することはできません。
ミラーディスクリソース/ハイブリッドディスクリソースを使用するには、ミラー用のパーティション (データパーティションとクラスタパーティション) が必要です。
ミラー用のパーティションのディスク上の配置には特に制限はありませんが、データパーティションのサイズはバイト単位で完全に一致している必要があります。またクラスタパーティションには 1024MiB 以上の容量が必要です。
データパーティションを拡張パーティション上の論理パーティションとして作成する場合は、両サーバとも論理パーティションにしてください。基本パーティションと論理パーティションでは同じサイズを指定しても実サイズが若干異なることがあります。
負荷分散のため、クラスタパーティションとデータパーティションは別のディスク上に作成することを推奨します (同じディスク上に作成しても動作に支障はありませんが、非同期ミラーの場合やミラーリングを中断している状態での書き込み性能が若干低下します)。
ミラーリソースでミラーリングするデータパーティションを確保するディスクは、両サーバでディスクのタイプを同じにしてください。
例)
組み合わせ
サーバ1
サーバ2
OK
SCSI
SCSI
OK
IDE
IDE
NG
IDE
SCSI
[ディスクの管理] などで確保したパーティションサイズは、ディスクのシリンダあたりのブロック (ユニット) 数でアラインされます。このため、ミラー用のディスクとして使用するディスクのジオメトリがサーバ間で異なると、データパーティションのサイズを完全に一致させることができない場合があります。このような問題を避けるため、データパーティションを確保するディスクは、RAID構成なども含め両サーバでHW構成を一致させることを推奨します。
両サーバでディスクのタイプやジオメトリを揃えられない場合は、ミラーディスクリソース/ハイブリッドディスクリソースを設定する前に [clpvolsz] コマンドにより両サーバのデータパーティションの正確なサイズを確認し、もしサイズが一致しない場合は再度 [clpvolsz] コマンドを使用して大きいほうのパーティションを縮小してください。
RAID 構成のディスクをミラーリングする場合、ディスクアレイコントローラのキャッシュをWRITE THRU にすると書き込み性能の低下が大きくなるため、WRITE BACK での使用をお勧めします。ただし、WRITE BACK で使用する場合は、バッテリーを搭載したディスクアレイコントローラを用いるか、UPS を併用する必要があります。
OS のページファイルがあるパーティションは、ミラーリングできません。
6.1.3. IPv6 環境について¶
下記の機能は IPv6 環境では使用できません。
AWS Elastic IP リソース
AWS 仮想 IP リソース
AWS セカンダリ IP リソース
AWS DNS リソース
Azure プローブポートリソース
Azure DNS リソース
Google Cloud 仮想 IP リソース
Google Cloud DNS リソース
Oracle Cloud 仮想 IP リソース
AWS Elastic IP 監視リソース
AWS 仮想 IP 監視リソース
AWS セカンダリ IP 監視リソース
AWS AZ 監視リソース
AWS DNS 監視リソース
Azure プローブポート監視リソース
Azure ロードバランス監視リソース
Azure DNS 監視リソース
Google Cloud 仮想 IP 監視リソース
Google Cloud ロードバランス監視リソース
Google Cloud DNS モニタリソース
Oracle Cloud 仮想 IP 監視リソース
Oracle Cloud ロードバランス監視リソース
下記の機能はリンクローカルアドレスを使用できません。
カーネルモードLANハートビートリソース
ミラーディスクコネクト
PINGネットワークパーティション解決リソース
FIPリソース
VIPリソース
6.1.4. ネットワーク構成について¶
NAT環境等のように、自サーバのIPアドレスおよび相手サーバのIPアドレスが、各サーバで異なるような構成においては、クラスタ構成を構築/運用できません。
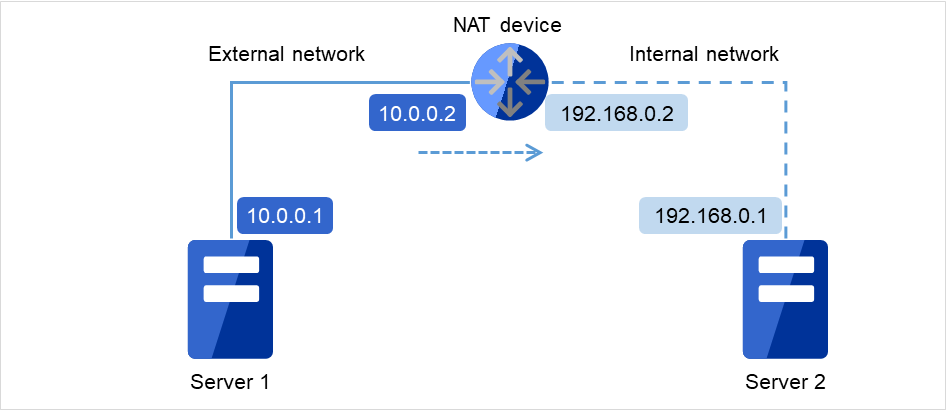
図 6.1 クラスタを構成できない環境の例¶
Server 1でのクラスタ設定
自サーバ: 10.0.0.1
相手サーバ: 10.0.0.2
Server 2でのクラスタ設定
自サーバ: 192.168.0.1
相手サーバ: 10.0.0.1
6.1.6. ミラーディスク/ハイブリッドディスクの write 性能について¶
ミラーディスクリソース/ハイブリッドディスクリソースのディスクミラーリングには同期ミラーと非同期ミラーの 2 種類の方式があります。
同期ミラーの場合、ミラーリング対象のデータパーティションへの書き込み要求毎に、両サーバのディスクへの書き込みを実施し、その完了を待ち合わせます。各サーバへの書き込みは並行して実施されますが、他サーバのディスクへの書き込みはネットワークを介して実施されるため、ミラーリングしない通常のローカルディスクに比べ書き込み性能が低下します。特にネットワークの通信速度が低く遅延が大きい遠隔クラスタ構成などの場合は大幅に性能が低下することになります。
非同期ミラーの場合、自サーバへの書き出しは即時実行しますが、他サーバへの書き出しは一旦ローカルキューに保存し、バックグラウンドで書き出します。他サーバへの書き出しの完了を待ち合わせないため、ネットワーク性能が低い場合も書き込み性能が大きく低下することはありません。ただし、非同期ミラーの場合も書き込み要求毎に更新データをキューに保存するため、ミラーリングしない通常のローカルディスクや共有ディスクに比べると、書き込み性能が低下します。このため、ディスクへの書き込み処理に高いスループットが要求されるシステム(更新系が多いデータベースシステムなど) には共有ディスクの使用を推奨します。
また、非同期ミラーの場合、書き込み順序は保証されますが、現用系サーバがダウンした場合に最新の更新分が失われる可能性があります。このため、障害発生直前の情報を確実に引き継ぐ必要がある場合は、同期ミラーか共有ディスクを用いる必要があります。
6.1.7. 非同期ミラーの履歴ファイルについて¶
非同期モードのミラーディスク/ハイブリッドディスクでは、メモリ上のキューに記録しきれない書き込みデータは、履歴ファイル格納フォルダとして指定されたフォルダに履歴ファイルとして一時的に記録されます。この履歴ファイルは、履歴ファイルのサイズ制限を設定していない場合、指定されたフォルダに制限なく書き出されます。このような設定の場合、回線速度が業務アプリケーションのディスク更新量に比べて低すぎると、リモートサーバへの書き込み処理がディスク更新に追いつかず、履歴ファイルでディスクが溢れてしまいます。このため、遠隔クラスタ構成でも業務 AP のディスク更新量に合わせて十分な速度の通信回線を確保する必要があります。
また、長時間の通信遅延や、ディスク更新の連続発生などにより、履歴ファイル格納フォルダが溢れた場合に備え、履歴ファイルの書き出し先に指定するドライブには十分な空き容量を確保し、履歴ファイルサイズ制限を設定するか、システムドライブとは別のドライブを指定する必要があります。
6.1.8. 複数の非同期ミラー間のデータ整合性について¶
非同期モードのミラーディスク/ハイブリッドディスクでは、現用系のデータパーティションへの書き込みを、同じ順序で待機系のデータパーティションにも実施します。
ミラーディスクの初期構築中やミラーリング中断後の復帰 (コピー) 中以外は、この書き込み順序が保証されるため、待機系のデータパーティション上にあるファイル間のデータ整合性は保たれます。
しかし、複数のミラーディスク/ハイブリッドディスクリソース間では書き込み順序が保証されませんので、例えばデータベースのデータベースファイルとジャーナル (ログ) ファイルのように、一方のファイルが他方より古くなるとデータの整合性が保てないファイルを複数の非同期ミラーディスクに分散配置すると、サーバダウン等でフェイルオーバした際に業務アプリケーションが正常に動作しなくなる可能性があります。
このため、このようなファイルは必ず同一の非同期ミラーディスク/ハイブリッドディスク上に配置してください。
6.1.9. マルチブートについて¶
他のブートディスクで起動すると、ミラーや共有ディスクのアクセス制限が外れてしまい、ミラーディスクの整合性保証や共有ディスクのデータ保護ができなくなるため、これらのリソースを使用している場合はマルチブートを使用しないでください。
6.1.10. JVM 監視リソースについて¶
同時に監視可能なJava VMは最大25個です。同時に監視可能なJava VMとはCluster WebUI([監視(固有)]タブ-[識別名])で一意に識別するJava VM数のことです。
Java VMとJVM監視リソース間のコネクションはSSLには対応していません。
スレッドのデッドロックは検出できない場合があります。これは、Java VMの既知で発生している不具合です。詳細は、OracleのBug Databaseの「Bug ID: 6380127 」を参照してください。
JVM監視リソースが監視できるJava VMは、JVM監視リソースが動作中のサーバと同じサーバ内のみです。
Cluster WebUI (クラスタプロパティ-[JVM監視]タブ-[Javaインストールパス])で設定したJavaインストールパスは、クラスタ内のサーバにおいて、共通の設定となります。JVM監視が使用するJava VMのバージョンおよびアップデートは、クラスタ内のサーバにおいて、同じものにしてください。
Cluster WebUI (クラスタプロパティ-[JVM監視]タブ-[接続設定]ダイアログ-[管理ポート番号])で設定した管理ポート番号は、クラスタ内のサーバにおいて、共通の設定となります。
x86_64版OS上においてIA32版の監視対象のアプリケーションを動作させている場合、監視を行うことはできません。
Cluster WebUI (クラスタプロパティ-[JVM監視]タブ-[最大Javaヒープサイズ])で設定した最大Javaヒープサイズを3000など大きな値に設定すると、JVM監視リソースが起動に失敗します。システム環境に依存するため、システムのメモリ搭載量を元に決定してください。
- 監視対象Java VMの起動オプションに「-XX:+UseG1GC」が付加されている場合、Java 7以前ではJVM監視リソースの[プロパティ]-[監視(固有)] タブ-[調整]プロパティ-[メモリ]タブ内の設定項目は監視できません。Java 8以降ではJVM監視リソースの[プロパティ]-[監視(固有)]タブ-[JVM種別]に[Oracle Java(usage monitoring)]を選択することで監視可能です。
6.1.11. ネットワーク警告灯の要件について¶
「警子ちゃんミニ」、「警子ちゃん 4G」を使用する場合、警告灯にパスワードを設定しないで下さい。
- 音声ファイルの再生による警告を行う場合、あらかじめ音声ファイル再生に対応したネットワーク警告灯に音声ファイルを登録しておく必要があります。音声ファイルの登録に関しては、各ネットワーク警告灯の取扱説明書を参照して下さい。
ネットワーク警告灯にクラスタ内のサーバからの rsh コマンド実行を許可するように設定してください。
6.2. CLUSTERPRO インストール前¶
OS のインストールが完了した後、OS やディスクの設定を行うときに留意して頂きたいことです。
6.2.1. ファイルシステムについて¶
OS をインストールするパーティション、共有ディスクのディスクリソースとして使用するパーティション、ミラーディスク/ハイブリッドディスクリソースのデータパーティションのファイルシステムは NTFS を使用してください。
6.2.2. 通信ポート番号¶
CLUSTERPRO では、デフォルトで以下のポート番号を使用します。このポート番号については Cluster WebUI での変更が可能です。これらのポート番号には、CLUSTERPRO 以外のプログラムからアクセスしないようにしてください。
下記ポート番号には、CLUSTERPRO 以外のプログラムからアクセスしないようにしてください。
CLUSTERPRO インストール後にclpfwctrlコマンドでファイアウォールの設定を行うことができます。詳細は『リファレンスガイド』 - 「CLUSTERPRO コマンドリファレンス」 - 「ファイアウォールの規則を追加する (clpfwctrlコマンド)」を参照してください。 また、clpfwctrlコマンドで設定を行うポートについては、以下の表のclpfwctrl欄に ✓ が記載されているポートと「ICMPv4」、「ICMPv6」のプロトコルとなります。
クラウド環境の場合は、インスタンス側のファイアウォール設定の他に、クラウド基盤側のセキュリティ設定においても、下記のポート番号にアクセスできるようにしてください。
[サーバ・サーバ間]
From
To
備考
clpfwctrl
サーバ
自動割り当て 5
サーバ
29001/TCP
内部通信
✓
サーバ
自動割り当て
サーバ
29002/TCP
データ転送
✓
サーバ
自動割り当て
サーバ
29003/UDP
アラート同期
✓
サーバ
自動割り当て
サーバ
29004/TCP
ディスクエージェント間通信
✓
サーバ
自動割り当て
サーバ
29005/TCP
ミラードライバ間通信
✓
サーバ
自動割り当て
サーバ
29008/TCP
クラスタ情報管理
✓
サーバ
自動割り当て
サーバ
29010/TCP
Restful API 内部通信
✓
サーバ
29106/UDP
サーバ
29106/UDP
ハートビート
✓
サーバ
icmp
サーバ
icmp
FIP/VIPリソースの重複確認
- 5
自動割り当てでは、その時点で使用されていないポート番号が割り当てられます。
[サーバ・クライアント間]
From
To
備考
clpfwctrl
Restful API クライアント
自動割り当て
サーバ
29009/TCP
http通信
✓
[サーバ・Cluster WebUI 間]
From
To
備考
clpfwctrl
Cluster WebUI
自動割り当て
サーバ
29003/TCP
http通信
✓
[その他]
From
To
備考
clpfwctrl
サーバ
自動割り当て
ネットワーク警告灯
各製品のマニュアルを参照
ネットワーク警告灯制御
サーバ
自動割り当て
サーバのBMCのマネージメントLAN
623/UDP
BMC制御 (強制停止)
サーバ
自動割り当て
Witness サーバ
Cluster WebUI で設定した通信ポート番号
Witness ハートビートリソースの接続先ホスト
サーバ
自動割り当て
監視先
icmp
IP監視リソース
サーバ
自動割り当て
監視先
icmp
Ping方式ネットワークパーティション解決リソースの監視先
サーバ
自動割り当て
監視先
Cluster WebUI で設定した通信ポート番号
HTTP 方式ネットワークパーティション解決リソースの監視先
サーバ
自動割り当て
サーバ
Cluster WebUI で設定した管理ポート番号
JVM監視リソース
✓
サーバ
自動割り当て
監視先
Cluster WebUI で設定した接続ポート番号
JVM監視リソース
サーバ
自動割り当て
サーバ
Cluster WebUI で設定したプローブポート
Azure プローブポートリソース
✓
サーバ
自動割り当て
AWS リージョンエンドポイント
443/tcp
AWS Elastic IP リソースAWS 仮想 IP リソースAWS セカンダリ IP リソースAWS DNS リソースAWS Elastic IP 監視リソースAWS 仮想 IP 監視リソースAWS セカンダリ IP 監視リソースAWS AZ 監視リソースAWS DNS 監視リソースAWS 強制停止リソースサーバ
自動割り当て
Azure エンドポイント
443/tcp
Azure DNS リソース
サーバ
自動割り当て
Azure の権威DNSサーバ
53/udp
Azure DNS 監視リソース
サーバ
自動割り当て
サーバ
Cluster WebUI で設定したポート番号
Google Cloud 仮想 IP リソース
✓
サーバ
自動割り当て
サーバ
Cluster WebUI で設定したポート番号
Oracle Cloud 仮想 IP リソース
✓
AWS環境 の場合は、ファイアウォールの設定の他にセキュリティグループ設定も変更してください。
JVM監視では以下の2つのポート番号を使用します。
管理ポート番号はJVM監視リソースが内部で使用するためのポート番号です。Cluster WebUI の[クラスタプロパティ]-[JVM監視]タブ-[接続設定] ダイアログで設定します。詳細については『リファレンスガイド』の「パラメータの詳細」を参照してください。
接続ポート番号は監視先(WebLogic Server, WebOTX)のJava VM と接続するためのポート番号です。Cluster WebUI の該当するJVM監視リソース名の[プロパティ]-[監視(固有)]タブで設定します。詳細については『リファレンスガイド』の「モニタリソースの詳細」を参照してください。
Azure プローブポートリソースの [プローブポート]、Google Cloud 仮想 IP リソースの [ポート番号]、Oracle Cloud 仮想 IP リソースの [ポート番号] は、ロードバランサが各サーバの死活監視に使用するポート番号です。
以下のAWS関連リソースはAWS CLI を実行します。AWS CLI では上記のポート番号を使用します。
AWS Elastic IP リソース
AWS 仮想 IP リソース
AWS セカンダリ IP リソース
AWS DNS リソース
AWS Elastic IP 監視リソース
AWS 仮想 IP 監視リソース
AWS セカンダリ IP 監視リソース
AWS AZ 監視リソース
AWS DNS 監視リソース
AWS 強制停止リソース
Azure DNS リソースでは、Azure CLI を実行します。Azure CLI では上記のポート番号を使用します。
6.2.3. 通信ポート番号の自動割り当て範囲の変更¶
OS が管理している通信ポート番号の自動割り当ての範囲が CLUSTERPRO が使用する通信ポート番号と重複する場合があります。
OS が管理している通信ポート番号の自動割り当ての範囲を以下の方法等により確認して、通信ポート番号が重複する場合には、CLUSTERPRO が使用する通信ポート番号と重複しないよう、CLUSTERPRO が使用するポート番号を変更するか、または OS が管理している通信ポート番号の自動割り当ての範囲を以下の方法等により変更してください。
Windows が提供する netsh コマンドにて、自動割り当ての範囲を表示/設定します。
OS が管理している通信ポート番号の自動割り当て範囲の確認方法
netsh interface <ipv4|ipv6> show dynamicportrange <tcp|udp>
以下に実行例を示します。
>netsh interface ipv4 show dynamicportrange tcp プロトコル tcp の動的ポートの範囲 --------------------------------- 開始ポート : 49152 ポート数 : 16384
上記は、ipv4、TCP プロトコルの通信ポート番号の自動割り当ての範囲が 49152~ 68835 (ポート番号 49152 から16384 個のポートを割り当て) であることを示します。CLUSTERPRO が使用するポート番号がこの範囲内にある場合は、CLUSTERPRO が使用するポート番号を変更するか、後述の「OS が管理している通信ポート番号の自動割り当て範囲の設定方法」を実施してください。
OS が管理している通信ポート番号の自動割り当て範囲の設定方法
netsh interface <ipv4|ipv6> set dynamicportrange <tcp|udp> [startport=]<開始ポート番号> [numberofports=]<自動割り当て範囲>
以下に実行例を示します。
>netsh interface ipv4 set dynamicportrange tcp startport=10000 numberofports=1000
上記は、ipv4、TCP プロトコルの通信ポート番号の自動割り当ての範囲を 10000~ 10999 (ポート番号 10000 から1000 個のポートを割り当て) に設定します。
6.2.4. ポート数不足を回避する設定について¶
6.2.5. 時刻同期の設定¶
クラスタシステムでは、複数のサーバの時刻を定期的に同期する運用を推奨します。タイムサーバなどを使用してサーバの時刻を同期させてください。
6.2.7. ミラーディスク用のパーティションについて¶
ミラーディスクリソースの管理用パーティション (クラスタパーティション) として、1024MiB 以上の RAW パーティションを各サーバのローカルディスクに作成してください。
ミラーリング対象のパーティション (データパーティション) を各サーバのローカルディスクに作成し、NTFS でフォーマットしてください (既存のパーティションをミラーリングする場合、パーティションを作り直す必要はありません)。
データパーティションのサイズは、両サーバで等しくなるように設定してください。正確なパーティションサイズの確認と調整には [clpvolsz] コマンドを使用してください。
クラスタパーティションとデータパーティションには、両サーバで同じドライブ文字を設定してください。
6.2.8. ハイブリッドディスク用のパーティションについて¶
ハイブリッドディスクリソースの管理用パーティション (クラスタパーティション) として、1024MiB 以上の RAW パーティションを各サーバグループの共有ディスク (サーバグループのメンバサーバが 1 台の場合はローカルディスク) に作成してください。
ミラーリング対象のパーティション (データパーティション) を各サーバグループの共有ディスク (サーバグループのメンバサーバが 1 台の場合はローカルディスク) に作成し、NTFS でフォーマットしてください (既存のパーティションをミラーリングする場合、パーティションを作り直す必要はありません)。
データパーティションのサイズは、両サーバグループで等しくなるように設定してください。正確なパーティションサイズの確認と調整には [clpvolsz] コマンドを使用してください。
クラスタパーティションとデータパーティションには、各サーバで同じドライブ文字を設定してください。
6.2.9. データパーティション上のフォルダやファイルのアクセス許可について¶
ワークグループ環境で、データパーティション上のフォルダやファイルにアクセス許可の設定を行う場合、そのデータパーティションにアクセスする全てのノードで、該当のユーザに対してアクセス許可を設定する必要があります。例えば server1, server2 の test というユーザに対してアクセス許可を与える場合、server1 および server2 にて test ユーザに対してアクセス許可を設定してください。
6.2.10. OS 起動時間の調整¶
電源が投入されてから、OS が起動するまでの時間が、下記の 2 つの時間より長くなるように調整してください6。
共有ディスクを使用する場合に、ディスクの電源が投入されてから使用可能になるまでの時間
ハートビートタイムアウト時間
- 6
具体的な手順は、『インストール&設定ガイド』の「システム構成を決定する」 - 「ハードウェア構成後の設定」 -「3. OS 起動時間を調整する (必須)」を参照してください。
6.2.11. ネットワークの確認¶
インタコネクトやミラーコネクトで使用するネットワークの確認をします。クラスタ内のすべてのサーバで確認します。
[ipconfig] コマンドや [ping] コマンドを使用してネットワークの状態を確認してください。
Public LAN (他のマシンと通信を行う系)
インタコネクト専用 LAN (CLUSTERPRO のサーバ間接続に使用する系)
ミラーコネクトLAN (インタコネクトと共用)
ホスト名
クラスタで使用するフローティング IP リソースの IP アドレスは、OS 側への設定は不要です。
CLUSTERPRO の設定 (ハートビートやミラーコネクトなど) に IPv6 を指定している場合、NIC がリンクダウンすると、その NIC に付与されている IP アドレスが見えなくなり、CLUSTERPRO の動作に影響を与えます。下記のコマンドを実行し、メディアセンス制御をオフにしてください。
netsh interface ipv6 set global dhcpmediasense=disabled
6.2.12. ESMPRO/AutomaticRunningController との連携について¶
ESMPRO/AutomaticRunningController (以降 ESMPRO/AC と略します) と連携動作させる場合は、CLUSTERPRO の構築/設定に次の留意事項があります。これらが満たされていないと、ESMPRO/AC との連携機能が正しく動作しないことがあります。
ネットワークパーティション解決リソースとして、DISK 方式のリソースのみを単独で指定することはできません。DISK 方式を指定する場合は、必ず PING 方式など、他のネットワークパーティション解決方式のリソースと組み合わせて指定してください。
ディスク TUR 監視リソースを作成する際は、[最終動作] の設定値はデフォルト (何もしない) から変更しないでください。
ディスク RW 監視リソースを作成する際、[ファイル名] の設定値に共有ディスク上のパスを指定する場合は、[監視タイミング] の設定値はデフォルト (活性時) から変更しないでください。
復電後再起動した際、次のアラートが CLUSTERPROのマネージャ上にエントリされることがあります。上記の設定により、実際の動作に支障はありませんので無視してください。
- ID:18モジュール名:nmメッセージ:リソース<DiskNPのリソース名>の起動に失敗しました。(サーバ名:xx)
- ID:1509モジュール名:rmメッセージ:監視 <ディスクTUR監視リソース名> は異常を検出しました。 (4 : デバイスオープンに失敗しました。監視先ボリュームのディスク状態を確認してください。)
ESMPRO/AC の設定方法、留意事項等については、『CLUSTERPRO X for Windows PPガイド』の「ESMPRO/AC」の章の記述を参照してください。
6.2.13. ipmiutil について¶
以下の機能では、BSD ライセンスのオープンソースとして公開されている IPMI Management Utilities (ipmiutil) を使用して、各サーバの BMC ファームウェアを制御します。このため、これらの機能を利用する場合は各クラスタサーバに ipmiutil をインストールする必要があります。
物理マシンの強制停止機能
上記の機能を使用する場合、ベースボード管理コントローラー (BMC) のマネージメント用 LAN ポートの IP アドレスと OS が使用する IP アドレスの間で通信ができるように、各サーバの BMC を設定してください。サーバに BMC が搭載されていない場合や、BMC のマネージメント用のネットワークが閉塞している状態では、これらの機能は使用できません。BMC の設定方法については、各サーバのマニュアルを参照してください。
CLUSTERPRO に ipmiutil は添付しておりません。ipmiutil の入手方法とインストール方法については『インストール&設定ガイド』 - 「システム構成を決定する」- 「ハードウェア構成後の設定」 - 「BMC と ipmiutil をセットアップする (物理マシンの強制停止機能を使用する場合は必須)」を参照してください。
ipmiutil に関する以下の事項について、弊社は対応いたしません。ユーザ様の判断、責任にてご使用ください。
ipmiutil 自体に関するお問い合わせ
ipmiutil の動作保証
ipmiutil の不具合対応、不具合が原因の障害
各サーバの ipmiutil の対応状況のお問い合わせ
ご使用予定のサーバ (ハードウェア) の ipmiutil 対応可否についてはユーザ様にて事前に確認ください。ハードウェアとして IPMI 規格に準拠している場合でも、実際にはipmiutil が動作しない場合がありますので、ご注意ください。
6.2.14. Server Core へのインストールについて¶
6.2.15. メール通報について¶
メール通報機能は、STARTTLSやSSLに対応していません。
6.2.16. システムディスクが接続された HBA のアクセス制限について¶
6.2.17. AWS 環境における時刻同期¶
6.2.18. AWS 環境における IAM の設定について¶
AWS 環境における IAM (Identity & Access Management)の設定について説明します。
CLUSTERPROの一部の機能は、その処理のために AWS CLI を内部で実行します。AWS CLI が正常に実行されるためには、事前に IAM の設定が必要となります。
AWS CLI にアクセス許可を与える方法として、IAM ロールを使用する方針と、IAM ユーザを使用する方針の 2 通りがあります。基本的には各インスタンスに AWS アクセスキーID、AWS シークレットアクセスキーを保存する必要がなくセキュリティが高くなることから、前者のIAM ロールを使用する方針を推奨します。
IAMの設定手順は次の通りです。
まずIAMポリシーを作成します。後述の「IAMポリシーの作成」を参照してください。
- 次にインスタンスの設定を行います。IAMロールを使用する場合、後述の「インスタンスの設定 - IAMロールを使用する」を参照してください。IAMユーザを使用する場合、後述の「インスタンスの設定 - IAMユーザを使用する」を参照してください。
IAMポリシーの作成
AWS の EC2 や S3 などのサービスへのアクションに対するアクセス許可を記述したポリシーを作成します。CLUSTERPRO の AWS 関連リソースおよび監視リソースが AWS CLI を実行するために許可が必要なアクションは以下のとおりです。
必要なポリシーは将来変更される可能性があります。
AWS 仮想IPリソース/AWS 仮想IP監視リソース
アクション
説明
VPC、ルートテーブル、ネットワークインタフェースの情報を取得する時に必要です。
ec2:ReplaceRoute
ルートテーブルを更新する時に必要です。
AWS Elastic IPリソース/AWS Elastic IP監視リソース
アクション
説明
EIP、ネットワークインタフェースの情報を取得する時に必要です。
ec2:AssociateAddress
EIPをENIに割り当てる際に必要です。
ec2:DisassociateAddress
EIPをENIから切り離す際に必要です。
AWS セカンダリ IP リソース/AWS セカンダリ IP 監視リソース
アクション
説明
ネットワークインタフェース、サブネットの情報を取得する時に必要です。
ec2:AssignPrivateIpAddresses
セカンダリIPアドレスの割り当てをする時に必要です。
ec2:UnassignPrivateIpAddresses
セカンダリIPアドレスの割り当て解除をする時に必要です。
AWS AZ監視リソース
アクション
説明
ec2:DescribeAvailabilityZones
アベイラビリティゾーンの情報を取得する時に必要です。
AWS DNS リソース/AWS DNS 監視リソース
アクション
説明
route53:ChangeResourceRecordSets
リソースレコードセットの追加、削除、設定内容の更新する時に必要です。
route53:GetChange
リソースレコードセットの追加、設定内容の更新する時に必要です。
route53:ListResourceRecordSets
リソースレコードセット 情報の取得をする時に必要です。
AWS 強制停止リソース
アクション
説明
ec2:DescribeInstances
インスタンスの情報を取得する時に必要です。
ec2:StopInstances
インスタンスの停止をする時に必要です。
ec2:RebootInstances
インスタンスの再起動をする時に必要です。
モニタリソースの監視処理時間を Amazon CloudWatch に送信する機能
アクション
説明
cloudwatch:PutMetricData
カスタムメトリクスを送信する時に必要です。
アラートサービスのメッセージを Amazon SNS に送信する機能
アクション
説明
sns:Publish
メッセージを送信する時に必要です。
以下のカスタムポリシーの例では全てのAWS 関連リソースおよびモニタリソースが使用するアクションを許可しています。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:Describe*", "ec2:ReplaceRoute", "ec2:AssociateAddress", "ec2:DisassociateAddress", "ec2:AssignPrivateIpAddresses", "ec2:UnassignPrivateIpAddresses", "ec2:StopInstances", "ec2:RebootInstances", "route53:ChangeResourceRecordSets", "route53:GetChange", "route53:ListResourceRecordSets" ], "Effect": "Allow", "Resource": "*" } ] }IAM Management Console の [Policies] - [Create Policy] で カスタムポリシーを作成できます。
インスタンスの設定 - IAMロールを使用する
IAM ロールを作成し、インスタンスに付与することでAWS CLIを実行可能にする方法です。
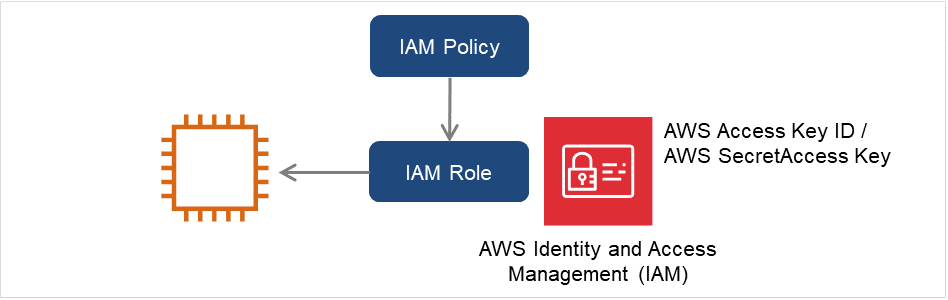
図 6.2 IAMロールを使用したインスタンスの設定¶
インスタンス作成時に、「IAM Role」に作成した IAM ロールを指定します。
インスタンスにログオンします。
Pythonをインストールします。
CLUSTERPRO が必要とする Python をインストールします。まず、Pythonがインストールされていることを確認します。未インストールの場合、以下から Python をダウンロードして、インストールします。インストール後、コントロールパネルにおいて環境変数 PATH に python.exe へのパスを追加します。PythonコマンドはSYSTEMユーザで実行されるため、システム環境変数PATHにPythonコマンドへのパスが設定されていることを確認してください。
AWS CLI をインストールします
AWS CLI をダウンロードして、インストールします。システム環境変数 PATH にはインストーラが自動的に追加します。自動的に追加されない場合は、AWSのドキュメント「AWS コマンドラインインターフェイス」を参照して追加してください。PythonまたはAWS CLIのインストールを行った時点ですでにCLUSTERPROがインストール済の場合は、OSを再起動してからCLUSTERPROの操作を行ってください。Administrator ユーザでコマンドプロンプトを起動し、以下のコマンドを実行します。
> aws configure質問に対して AWS CLI の実行に必要な情報を入力します。AWS アクセスキー ID、AWS シークレットアクセスキーは入力しないことに注意してください。
AWS Access Key ID [None]: (Enterのみ) AWS Secret Access Key [None]: (Enterのみ) Default region name [None]: <既定のリージョン名> Default output format [None]: text"Default output format"は、"text"以外を指定することも可能です。
誤った内容を設定してしまった場合は、
%SystemDrive%\Users\Administrator\.awsをディレクトリごと消去してから上記操作をやり直してください。
インスタンスの設定 - IAMユーザを使用する
IAM ユーザを作成し、そのアクセスキーID、シークレットアクセスキーをインスタンス内に保存することでAWS CLIを実行可能にする方法です。インスタンス作成時の IAM ロールの付与は不要です。
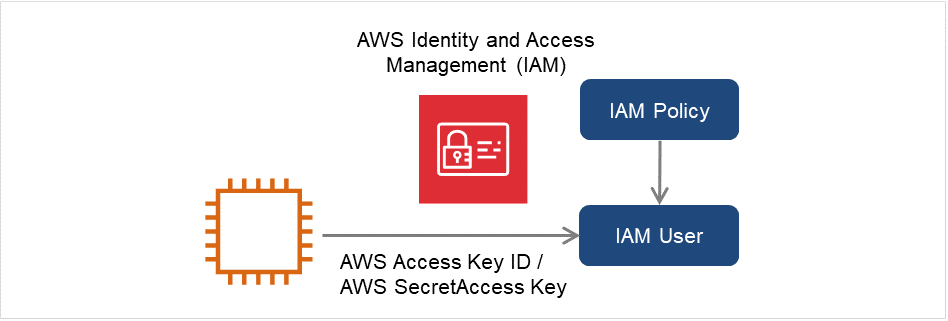
図 6.3 IAMユーザを使用したインスタンスの設定¶
IAM ユーザを作成します。作成したユーザに IAM ポリシーをアタッチします。
IAM Management Console の [Users] - [Create New Users] で IAM ユーザを作成できます。
インスタンスにログオンします。
Pythonをインストールします。
CLUSTERPRO が必要とする Python をインストールします。まず、Pythonがインストールされていることを確認します。未インストールの場合、以下から Python をダウンロードして、インストールします。インストール後、コントロールパネルにおいて環境変数 PATH に python.exe へのパスを追加します。PythonコマンドはSYSTEMユーザで実行されるため、システム環境変数PATHにPythonコマンドへのパスが設定されていることを確認してください。
AWS CLI をインストールします
AWS CLI をダウンロードして、インストールします。システム環境変数 PATH にはインストーラが自動的に追加します。自動的に追加されない場合は、AWSのドキュメント「AWS コマンドラインインターフェイス」を参照して追加してください。PythonまたはAWS CLIのインストールを行った時点ですでにCLUSTERPROがインストール済の場合は、OSを再起動してからCLUSTERPROの操作を行ってください。Administrator ユーザでコマンドプロンプトを起動し、以下のコマンドを実行します。
> aws configure質問に対して AWS CLI の実行に必要な情報を入力します。AWS アクセスキー ID、AWS シークレットアクセスキーは作成した IAM ユーザの詳細情報画面から取得したものを入力します。
AWS Access Key ID [None]: <AWS アクセスキー> AWS Secret Access Key [None]: <AWS シークレットアクセスキー> Default region name [None]: <既定のリージョン名> Default output format [None]: text"Default output format"は、"text"以外を指定することも可能です。
誤った内容を設定してしまった場合は、
%SystemDrive%\Users\Administrator\.awsをディレクトリごと消去してから上記操作をやり直してください。
6.2.19. Azure DNS リソースについて¶
Azure CLI のインストール、サービス プリンシパルの作成の手順は、『CLUSTERPRO X Microsoft Azure 向け HAクラスタ 構築ガイド』を参照してください。
- Azure DNS リソースが利用するため、Azure CLI および Python のインストールが必要です。Python は、Azure CLI 2.0 をインストールすると同時にインストールされます。Azure CLI の詳細については、以下のWeb サイトを参照してください。Microsoft Azure のドキュメント:
- Azure DNS リソースが利用するため、Azure DNS のサービスが必要です。Azure DNS の詳細については、以下のWeb サイトを参照してください。Azure DNS:
CLUSTERPRO が Microsoft Azure と連携するためには、Microsoft Azure の組織アカウントが必要となります。組織アカウント以外のアカウントは Azure CLI 実行時に対話形式でのログインが必要となるため使用できません。
Azure CLI を使用して、サービス プリンシパルを作成する必要があります。
Azure DNS リソースは Microsoft Azure にログインし、DNS ゾーンへの登録を実行します。Microsoft Azure へのログイン時、サービス プリンシパルによる Azure ログインを利用します。
サービスプリンシパルや詳細な手順については、以下のWeb サイトを参照してください。Azure CLI から Azure へのログイン:Azure CLI 2.0 で Azure サービス プリンシパルを作成する:作成されたサービスプリンシパルのロールを既定のContributor(共同作成者)から別のロールに変更する場合、Actions プロパティとして以下のすべての操作へのアクセス権を持つロールを選択してください。
この条件を満たさないロールに変更した場合、Azure DNS リソースの起動がエラーにより失敗します。Azure CLI 2.0の場合Microsoft.Network/dnsZones/A/writeMicrosoft.Network/dnsZones/A/deleteMicrosoft.Network/dnsZones/NS/readAzure プライベート DNS には未対応です。
6.2.20. Google Cloud 仮想IPリソースについて¶
Google Cloud 仮想IPリソースを Windows Server 2019 で利用する場合、以下のサービスの[スタートアップの種類]を[自動 (遅延開始)]に設定する必要があります。
Google Compute Engine Agent
Google OSConfig Agent
6.2.21. Google Cloud DNS リソースについて¶
Google Cloud の Cloud DNS を使用します。Cloud DNS の詳細については、以下の Web サイトを参照してください。
Cloud DNSCloud DNS の操作に使用するため、Cloud SDK のインストールが必要です。Cloud SDK の詳細については、以下のサイトを参照してください。
Cloud SDK以下の権限を持ったアカウントで Cloud SDK を承認する必要があります。
dns.changes.createdns.changes.getdns.managedZones.getdns.resourceRecordSets.createdns.resourceRecordSets.deletedns.resourceRecordSets.listdns.resourceRecordSets.updateCloud SDK の承認については、以下の Web サイトを参照してください。
Cloud SDK ツールの承認
6.2.22. OCI 環境における CLI の設定について¶
6.2.23. OCI 強制停止リソースの設定について¶
- OCI 強制停止リソースを使用する場合、OCI CLI のコマンドがインストールされたディレクトリや OCI 構成ファイル (config ファイル) の格納場所に合わせて、以下のスクリプトに記載されているパラメータ値を変更する必要があります。
<CLUSTERPRO インストールパス>\cloud\oci\clpociforcestop.ps1 ・OCI CLI コマンドのインストールディレクトリに応じて変更するパラメータ $Env:Path += ";[OCI CLI コマンドのインストールディレクトリ]" <例> $Env:Path += ";C:\Users\opc\AppData\Local\Programs\Python\Python36\Scripts\;C:\Users\opc\AppData\Local\Programs\Python\Python36\" ・OCI 構成ファイルの格納場所に応じて変更するパラメータ [string]$OCI_Path = "[OCI 構成ファイルのパス]" <例> [string]$OCI_Path = "C:\Users\opc\.oci\config"
- スクリプト (clpociforcestop.ps1) に記載されているパラメータ値を変更している環境でアップデートを適用すると既定のファイルで上書きされます。アップデートを適用した場合は再度スクリプトを設定してください。
6.3. CLUSTERPRO の構成情報作成時¶
CLUSTERPRO の構成情報の設計、作成前にシステムの構成に依存して確認、留意が必要な事項です。
6.3.1. CLUSTERPRO インストールパス配下のフォルダやファイルについて¶
6.3.2. グループリソースの非活性異常時の最終アクション¶
6.3.3. 遅延警告割合¶
遅延警告割合を 0 または、100 に設定すれば以下のようなことを行うことが可能です。
- 遅延警告割合に 0 を設定した場合監視毎に遅延警告がアラート通報されます。この機能を利用し、サーバが高負荷状態でのモニタリソースへのポーリング時間を算出し、モニタリソースの監視タイムアウト時間を決定することができます。
- 遅延警告割合に 100 を設定した場合遅延警告の通報を行いません。
テスト運用以外で、0% 等の低い値を設定しないように注意してください。
6.3.4. ディスク監視リソースとハイブリッドディスク TUR 監視リソースの監視方法 TUR について¶
- SCSI の Test Unit Ready コマンドをサポートしていないディスク、ディスクインターフェイス (HBA) では使用できません。ハードウェアがサポートしている場合でもドライバがサポートしていない場合があるのでドライバの仕様も合わせて確認してください。
Read 方式に比べて OS やディスクへの負荷は小さくなります。
Test Unit Readyでは、実際のメディアへの I/O エラーは検出できない場合があります。
6.3.5. ハートビートリソースの設定について¶
優先度が一番高いインタコネクトには、全サーバ間で通信可能な LAN ハートビートまたはカーネルモード LAN ハートビートを設定してください。
カーネルモード LAN ハートビートリソースを 2 つ以上設定することを推奨します(クラウド環境や遠隔クラスタ環境のようにネットワークの追加が難しい場合はその限りではありません)。
インタコネクト専用の LAN をカーネルモード LAN ハートビートリソースとして登録し、さらにパブリック LAN もカーネルモード LAN ハートビートリソースとして登録することを推奨します。
ハートビートタイムアウト時間は OS 再起動の所要時間より短くする必要があります。この条件を満たさない場合、クラスタ内の一部のサーバがリブートした際に、それを他のサーバが正しく検出できず、リブート後に動作異常が発生する場合があります。
6.3.6. スクリプトのコメントなどで取り扱える 2 バイト系文字コードについて¶
CLUSTERPRO では、Windows 環境で編集されたスクリプトは Shift-JIS、Linux 環境で編集されたスクリプトは EUC として扱われます。その他の文字コードを利用した場合、環境によっては文字化けが発生する可能性があります。
6.3.7. グループの起動可能サーバに設定可能なサーバグループ数について¶
1つのグループの起動可能サーバに設定可能なサーバグループ数は 2 となっています。3 つ以上のサーバグループを設定した場合、CLUSTERPRO Disk Agent サービス (clpdiskagent.exe) が正しく動作しない可能性があります。
6.3.8. JVM 監視の設定について¶
監視対象がWebLogicの場合、JVM監視リソースの以下の設定値については、システム環境(メモリ搭載量など)により、設定範囲の上限に制限がかかることがあります。
[ワークマネージャのリクエストを監視する]-[リクエスト数]
[ワークマネージャのリクエストを監視する]-[平均値]
[スレッドプールのリクエストを監視する]-[待機リクエスト リクエスト数]
[スレッドプールのリクエストを監視する]-[待機リクエスト 平均値]
[スレッドプールのリクエストを監視する]-[実行リクエスト リクエスト数]
[スレッドプールのリクエストを監視する]-[実行リクエスト 平均値]
Java Resource Agentを使用するには、「 CLUSTERPRO の動作環境 」の「 JVM 監視の動作環境 」に記載しているJRE(Java Runtime Environment)もしくはJDK(Java Development Kit)をインストールしてください。監視対象(WebLogic ServerやWebOTX)が使用するJREやJDKと同じ物件を使用することも、別の物件を使用することも可能です。1つのサーバにJREとJDKの両方をインストールしている場合、どちらを使用することも可能です。
モニタリソース名に空白を含まないでください。
6.3.9. システム監視の設定について¶
- リソース監視の検出パターンSystem Resource Agent では、「しきい値」、「監視継続時間」という2つのパラメータを組み合わせて検出を行います。各システムリソース(メモリ使用量、CPU 使用率、仮想メモリ使用量)を継続して収集し、一定時間(継続時間として指定した時間)しきい値を超えていた場合に異常を検出します。
6.3.10. PostgreSQL 監視の設定について¶
モニタリソース名に空白を含まないでください。
6.3.11. AWS Elastic IP リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP 監視リソース、仮想 IP リソース、仮想 IP 監視リソース、仮想コンピュータ名リソース、仮想コンピュータ名監視リソースは利用できません。
- AWS Elastic IPリソースはASCII文字以外の文字に対応していません。下記のコマンドの実行結果にASCII文字以外の文字が含まれないことを確認してください。aws ec2 describe-addresses --allocation-ids <EIP ALLOCATION ID>
AWS Elastic IP リソースはENIのプライマリプライベートIPアドレスにEIPを関連付けます。セカンダリプライベートIPアドレスに関連付けはできません。
6.3.12. AWS 仮想 IP リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP 監視リソース、仮想 IP リソース、仮想 IP 監視リソース、仮想コンピュータ名リソース、仮想コンピュータ名監視リソースは利用できません。
AWS 仮想 IPリソースはASCII文字以外の文字に対応していません。下記のコマンドの実行結果にASCII文字以外の文字が含まれないことを確認してください。
aws ec2 describe-vpcs --vpc-ids <VPC ID> aws ec2 describe-route-tables --filters Name=vpc-id,Values=<VPC ID> aws ec2 describe-network-interfaces --network-interface-ids <ENI ID>
AWS 仮想IPリソースは、VPC ピアリング接続を経由してのアクセスが必要な場合では利用することができません。これは、VIP として使用する IP アドレスが VPC の範囲外であることを前提としており、このような IP アドレスは VPC ピアリング接続では無効とみなされるためです。VPC ピアリング接続を経由してのアクセスが必要な場合は、Amazon Route 53 を利用する AWS DNS リソースを使用してください。
AWS 仮想 IP リソースを設定した際に、Windows の動作として物理ホスト名と仮想 IP のレコードが DNS に登録されます(該当のネットワークアダプタのプロパティの設定でアドレスをDNSに登録する設定をONにしている場合)。物理ホストの名前解決で紐づくIPアドレスを物理IPアドレスにするためには以下のように設定してください。
該当の仮想 IP アドレスが付与されている、ネットワークアダプタの[プロパティ]-[インターネット プロトコル バージョン 4]-[詳細設定]-[DNS]タブ-[この接続のアドレスをDNSに登録する]に、チェックが入っている場合はチェックを外します。
この設定を反映させるためには、以下のいずれかも合わせて実施してください。
DNS Client サービスを再起動する。
ipconfig /registerdns コマンドを明示的に実行する。
DNSサーバに該当の仮想 IP アドレスが付与されているネットワークアダプタの物理IPアドレスを静的に登録してください。
インスタンスが使用するルートテーブルに、仮想IPが使用するIPアドレスのルートが存在しない場合でもAWS仮想IPリソースは正常に起動します。この動作は仕様どおりです。AWS 仮想 IP リソースは活性化時において、指定された IP アドレスのエントリが存在するルートテーブルに対してのみその内容を更新します。ルートテーブルが一つも見つからなかった場合でも更新対象なしとして正常と判断します。どのルートテーブルにエントリが存在する必要があるかはシステムの構成で決まるため、AWS 仮想 IP リソースとしては正常性の判断対象とはしていません。
AWS 仮想 IP リソースは、Windows OS の API を使用して NIC へ仮想 IP アドレスを追加しています。その際、skipassource フラグについては設定していないため、AWS 仮想 IP リソース活性後は skipassource フラグが無効となります。skipassource フラグを有効に設定する場合は、AWS 仮想 IP リソース活性後に PowerShell などで設定してください。
6.3.13. AWS セカンダリ IP リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
- AWS セカンダリ IP リソースはASCII文字以外の文字に対応していません。下記のコマンドの実行結果にASCII文字以外の文字が含まれないことを確認してください。
aws ec2 describe-network-interfaces --network-interface-ids <ENI ID> aws ec2 describe-subnets --subnet-ids <SUBNET_ID>
AWS セカンダリ IP リソースはサブネットが異なる構成では利用できません。
- AWS セカンダリ IP リソースで割り当てられるセカンダリ IP アドレスはインスタンスタイプごとに上限があります。詳細は下記を参照してください。
- AWS セカンダリ IP リソースでセカンダリ IP アドレスを割り当てるネットワークアダプタの物理IPアドレスを静的に登録してください。詳細は下記の手順1を参照してください。
AWS セカンダリ IP リソースは、netsh コマンド を使用して NIC へセカンダリ IP アドレスを追加しています。その際、skipassource フラグについては設定していないため、AWS セカンダリ IP リソース活性後は skipassource フラグが無効となります。skipassource フラグを有効に設定する場合は、AWS セカンダリ IP リソース活性後に PowerShell などで設定してください。
6.3.14. AWS DNS リソースの設定について¶
IPv6はサポートしていません。
AWS 環境では、フローティング IP リソース、フローティング IP 監視リソース、仮想 IP リソース、仮想 IP 監視リソース、仮想コンピュータ名リソース、仮想コンピュータ名監視リソースは利用できません。
[リソースレコードセット名] にエスケープコードを含む場合、監視が異常になります。エスケープコードを含まない [リソースレコードセット名] を設定してください。
AWS DNS リソースの活性時、DNS 設定の変更がすべての Amazon Route 53 DNS サーバーに伝播済みとなるまでは待ち合わせません。これは Route 53 の仕様上、リソースレコードセットの変更が全体に適用されるまでに時間が掛かるためです。「AWS DNS 監視リソースの設定について」も参照してください。
AWS DNS リソースはアカウントに紐づいています。そのため、複数のアカウントや AWS アクセスキーID、AWS シークレットアクセスキーを使い分ける運用はできません。その場合は、スクリプトリソースなどで AWS CLI を実行するスクリプトを作成し、その中の環境変数に他アカウント認証用の情報を設定する運用を検討してください。
6.3.15. AWS DNS 監視リソースの設定について¶
AWS DNS 監視リソースは、監視時に AWS CLI を実行します。実行する AWS CLI のタイムアウトは、AWS DNS リソースで設定した [AWS CLI タイムアウト] を利用します。
AWS DNS リソースの活性直後、以下の事象により AWS DNS 監視リソースによる監視が失敗する可能性があります。この場合、AWS DNS 監視リソースの [監視開始待ち時間] を Amazon Route 53 における DNS 設定の変更が反映される時間より長く設定してください(https://aws.amazon.com/jp/route53/faqs/)。
AWS DNS リソースの活性時、レコードセットの追加や更新をする。
Amazon Route 53 における DNS 設定の変更が反映される前に、AWS DNS 監視リソースが監視を実行すると名前解決ができないため監視に失敗する。DNS リゾルバキャッシュが有効な間は、その後も AWS DNS 監視リソースは監視に失敗する。
Amazon Route 53 における DNS 設定の変更が反映される。
AWS DNS リソースの [TTL] の有効期間が経過すると名前解決に成功するため、AWS DNS 監視リソースの監視が成功する。
6.3.16. Azure プローブポートリソースの設定について¶
IPv6はサポートしていません。
Microsoft Azure 環境では、フローティング IP リソース、フローティング IP 監視リソース、仮想 IP リソース、仮想 IP 監視リソース、仮想コンピュータ名リソース、仮想コンピュータ名監視リソースは利用できません。
6.3.17. Azure ロードバランス監視リソースの設定について¶
Azure ロードバランス監視リソースが異常を検知した場合、Azureのロードバランサからの現用系と待機系の切り替えが正しく行われない可能性があります。そのため、Azure ロードバランス監視リソースの [最終動作] には [クラスタサービス停止と OS シャットダウン] を選択することを推奨とします。
6.3.18. Azure DNS リソースの設定について¶
IPv6はサポートしていません。
Microsoft Azure 環境では、フローティング IP リソース、フローティング IP 監視リソース、仮想 IP リソース、仮想 IP 監視リソース、仮想コンピュータ名リソース、仮想コンピュータ名監視リソースは利用できません。
6.3.19. Google Cloud 仮想 IP リソースの設定について¶
IPv6はサポートしていません。
6.3.20. Google Cloud ロードバランス監視リソースの設定について¶
Google Cloud ロードバランス監視リソースが異常を検知した場合、ロードバランサからの現用系と待機系の切り替えが正しく行われない可能性があります。そのため、Google Cloud ロードバランス監視リソースの [最終動作] には [クラスタサービス停止と OS シャットダウン] を選択することを推奨します。
6.3.21. Google Cloud DNS リソースの設定について¶
IPv6はサポートしていません。
Google Cloud Platform 環境では、フローティング IP リソース、フローティング IP モニタリソース、仮想 IP リソース、仮想 IP モニタリソースは利用できません。
複数のGoogle Cloud DNSリソースの活性・非活性処理が同時に実行されるとエラーが発生することがあります。そのため、クラスタ内で複数のGoogle Cloud DNSリソースを使用する場合は、リソースの依存関係やグループの起動・停止待ち合わせ等で活性・非活性処理が同時に実行されないように設定する必要があります。
6.3.22. Oracle Cloud 仮想 IP リソースの設定について¶
IPv6はサポートしていません。
6.3.23. Oracle Cloud ロードバランス監視リソースの設定について¶
Oracle Cloud ロードバランス監視リソースが異常を検知した場合、ロードバランサからの現用系と待機系の切り替えが正しく行われない可能性があります。そのため、Oracle Cloud ロードバランス監視リソースの [最終動作] には [クラスタサービス停止と OS シャットダウン] を選択することを推奨します。
6.3.24. Windows Server 2012 以降のシステムにおけるサービス失敗時の回復操作について¶
Windows Server 2012 以降のシステムにおいて、サービスが失敗(異常終了)した時に行われる回復操作として[コンピューターを再起動する]が設定されている場合、実際にサービスが失敗した際の動作が従来(Windows Server 2008以前)のOS再起動からSTOPエラーを伴うOS再起動へ変更されています。
回復操作として既定で[コンピューターを再起動する]が設定されているCLUSTERPRO のサービスは下記です。
CLUSTERPRO Disk Agent サービス
CLUSTERPRO Node Manager サービス
CLUSTERPRO Server サービス
CLUSTERPRO Transaction サービス
6.3.25. OS のネットワーク負荷分散機能との共存について¶
6.3.26. HBA の設定を反映する場合の注意点¶
クラスタの新規作成時に [サーバプロパティ] の [HBA] タブでアクセス制限の設定を変更して構成情報のアップロードを実行した場合、反映方法として OS 再起動が表示されないことがあります。クラスタの新規作成時に [HBA] タブでアクセス制限の設定を変更した場合は構成情報を反映するために OS の再起動を行ってください。
6.3.27. リソース追加ウィザード画面に表示されるリソースタイプ一覧について¶
6.3.28. ミラーディスクリソースとハイブリッドディスクリソースの共存について¶
同一のフェイルオーバーグループにミラーディスクリソースとハイブリッドディスクリソースを混在させることはできません。
6.4. CLUSTERPRO 運用後¶
クラスタとして運用を開始した後に発生する事象で留意して頂きたい事項です。
6.4.1. 回復動作中の操作制限¶
モニタリソースの異常検出時の設定で回復対象にグループリソース (ディスクリソース、アプリケーションリソースなど) を指定し、モニタリソースが異常を検出した場合の回復動作遷移中 (再活性化 → フェイルオーバ → 最終動作) には、Cluster WebUI やコマンドによる以下の操作は行わないでください。
クラスタの停止/サスペンド
グループの起動/停止/移動
6.4.2. コマンドリファレンスに記載されていない実行形式ファイルやスクリプトファイルについて¶
6.4.3. クラスタシャットダウン・クラスタシャットダウンリブート¶
6.4.4. 特定サーバのシャットダウン、リブート¶
ミラーディスク使用時は、コマンドまたは Cluster WebUI からサーバのクラスタサービス停止,シャットダウン,シャットダウンリブートコマンドを実行するとミラーブレイクが発生します。
6.4.5. ネットワークパーティション状態からの復旧¶
ネットワークパーティションが発生している状態では、クラスタを構成するサーバ間で互いの状態が確認できないため、この状態でグループの操作 (起動/停止/移動) を行ったり、サーバを再起動したりすると、サーバ間でクラスタの状態についての認識にずれが生じます。このように異なる状態認識のサーバが複数起動している状態でネットワークが復旧すると、その後のグループ操作が正しく動作しなくなりますので、ネットワークパーティション状態にある間は、ネットワークから切り離された (クライアントと通信できない) 方のサーバはシャットダウンするか、CLUSTERPRO Server サービスを停止しておき、ネットワークが復旧してから再起動してクラスタに復帰してください。万一、複数のサーバが起動した状態でネットワークが復旧した場合は、クラスタの状態認識が異なるサーバを再起動することにより、正常状態に復帰できます。
なお、ネットワークパーティション解決リソースを使用している場合は、ネットワークパーティションが発生しても、通常はいずれかの (あるいは全ての) サーバが緊急シャットダウンして、互いに通信できないサーバが複数起動するのを回避します。緊急シャットダウンされたサーバを手動で再起動したり、緊急シャットダウン時の動作を再起動に設定していたりした場合も、再起動したサーバは再度緊急シャットダウンされます (Ping 方式や多数決方式の場合はCLUSTERPRO Server サービスが停止されます)。ただし、DISK 方式で複数のディスクハートビート用パーティションを使用している場合、ディスクパス障害によりディスクを介した通信ができない状態でネットワークパーティションが発生すると、両サーバが保留状態で動作を継続する場合があります。
6.4.6. Cluster WebUI について¶
接続先と通信できない状態で操作を行うと、制御が戻ってくるまでしばらく時間が必要な場合があります。
Proxy サーバを経由する場合は、Cluster WebUI のポート番号を中継できるように、Proxy サーバの設定をしてください。
Reverse Proxy サーバを経由する場合、Cluster WebUI は正常に動作しません。
CLUSTERPRO のアップデートを行った場合、起動している全てのブラウザを一旦終了してください。ブラウザ側のキャッシュをクリアして、ブラウザを起動してください。
本製品より新しいバージョンで作成されたクラスタ構成情報は、本製品で利用することはできません。
Web ブラウザを終了すると (ウィンドウフレームの [X] 等)、確認ダイアログが表示される場合があります。
設定を続行する場合は [ページに留まる] を選択してください。
Web ブラウザをリロードすると (メニューの [最新の情報に更新] やツールバーの [現在のページを再読み込み] 等) 、確認ダイアログが表示される場合があります。
設定を続行する場合は [ページに留まる] を選択してください。
上記以外の Cluster WebUI の注意制限事項についてはオンラインマニュアルを参照してください。
6.4.7. CLUSTERPRO Disk Agent サービスについて¶
CLUSTERPRO Disk Agent サービスは停止しないでください。停止した場合、手動での起動はできません。OS を再起動し CLUSTERPRO Disk Agent サービスを起動しなおす必要があります。
6.4.8. ミラー構築中のクラスタ構成情報の変更について¶
ミラー構築中 (初期構築を含む) はクラスタ構成情報を変更しないでください。クラスタ構成情報を変更した場合、ドライバが不正な動作を行う場合があります。
6.4.9. ミラーディスクの待機系のクラスタ復帰について¶
ミラーディスク活性時に待機系がクラスタサービス (CLUSTERPRO Server サービス) を停止した状態で稼動していた場合、サービスを開始してクラスタに復帰する前に一度待機系サーバを再起動してください。そのまま復帰させるとミラーの差分情報が不正となり、ミラーディスクに不整合が生じます。
6.4.10. ミラーディスク-ハイブリッドディスク間の構成変更について¶
6.4.11. [chkdsk] コマンドとデフラグについて¶
6.4.12. インデックスサービスについて¶
インデックスサービスのカタログに共有ディスク/ミラーディスク上のディレクトリを作成して、共有ディスク/ミラーディスク上のフォルダに対してインデックスを作成する場合、インデックスサービスを手動起動に設定して、共有ディスク/ミラーディスクの活性後に起動するようにCLUSTERPRO から制御する必要があります。インデックスサービスを自動起動にしていると、インデックスサービスが対象ボリュームを OPEN することにより、その後の活性化処理においてマウント処理が失敗し、アプリケーションやエクスプローラからのディスクアクセスが [パラメータが間違っています] (エラーコード87) というエラーで失敗します。
6.4.13. Windows Server 2012 以降の環境におけるユーザーアカウント制御の影響について¶
Windows Server 2012 以降では、既定値でユーザーアカウント制御 (User Account Control, 以下 UAC と略します) が有効となっています。UAC が有効となっている場合、下記の機能に影響があります。
- モニタリソース下記のモニタリソースに影響があります。
- Oracle 監視リソースOracle 監視リソースにおいて「認証方式」を [OS 認証] とした場合、監視ユーザにAdministratorsグループ以外のユーザが設定されていると、Oracle監視の処理は失敗します。「認証方式」に [OS 認証] を設定する場合は、「監視ユーザ」に設定するユーザはAdministratorsグループに属するようにしてください。
6.4.14. アプリケーションリソース / スクリプトリソースの画面表示について¶
CLUSTERPRO のアプリケーションリソース・スクリプトリソースから起動したプロセスはセッション 0 で実行されるため、GUI を持つプロセスを起動した場合、[対話型サービスダイアログの検出] ポップアップが表示され、このポップアップで [メッセージを表示する] を選択しないと GUI が表示されません。
6.4.15. ネットワークインターフェイスカード (NIC) が二重化されている環境について¶
- ネットワーク初期化完了待ち時間クラスタを構成する全サーバで共通の設定です。設定した時間に達していない場合でも、ネットワークの初期化が完了すると、クラスタの起動を開始します。
6.4.16. CLUSTERPRO のサービスのログオンアカウントについて¶
CLUSTERPROのサービスのログオンアカウントは [ローカル システム アカウント] に設定されています。このログオンアカウントの設定を変更すると、クラスタとして正しく動作しない可能性があります。
6.4.17. CLUSTERPRO の常駐プロセスの監視について¶
プロセスを監視するようなソフトウェアにより、CLUSTERPROの常駐プロセスを監視すること自体には問題はありませんが、プロセスの異常終了時などにプロセスの再起動などの回復動作は行わないでください。
6.4.18. 外部連携モニタリソースについて¶
外部連携モニタリソースに異常を通知するには、[clprexec] コマンドを用いる方法、サーバ管理基盤連携機能を用いる方法の二つの方法があります。
[clprexec] コマンドを用いる場合は CLUSTERPRO CD に同梱されているファイルを利用します。通知元サーバの OS やアーキテクチャに合わせて利用してください。また、通知元サーバと通知先サーバの通信が可能である必要があります。
6.4.19. JVM 監視リソースについて¶
監視対象のJava VMを再起動する場合はJVM監視リソースをサスペンドするか、クラスタ停止を行った後に行ってください。
設定内容を変更時にクラスタサスペンドおよびクラスタリジュームを行う必要があります。
モニタリソースの遅延警告には対応していません。
6.4.20. システム監視リソース、プロセスリソース監視リソースについて¶
設定内容を変更時にクラスタサスペンドを行う必要があります。
モニタリソースの遅延警告には対応していません。
動作中に OS の日付/時刻を変更した場合、10 分間隔で行っている解析処理のタイミングが日付/時刻変更後の最初の 1 回だけずれてしまいます。以下のようなことが発生するため、必要に応じてクラスタのサスペンド・リジュームを行ってください。
異常として検出する経過時間を過ぎても、異常検出が行われない。
異常として検出する経過時間前に、異常検出が行われる。
システム監視リソースのディスクリソース監視機能で同時に監視できる最大のディスク数は 26 台です。
6.4.21. ミラー統計情報採取機能と OS 標準機能との連携に伴うイベントログ出力について¶
内部バージョン 11.16 以前からアップデートした環境の場合、アプリケーションイベントログに下記のエラーが出力されることがあります。
- イベントID:1008ソース:Perflibメッセージ:サービス "clpdiskperf" (DLL "<CLUSTERPRO インストールパス>\bin\clpdiskperf.dll") の Open プロシージャに失敗しました。このサービスのパフォーマンス データは利用できません。データ セクションの最初の 4 バイト (DWORD) に、エラーコードが含まれています。
ミラー統計情報採取機能と OS 標準機能との連携機能を使用する場合、コマンドプロンプトから以下のコマンドを実行することで、本メッセージが出力されなくなります。
> lodctr.exe <CLUSTERPRO インストールパス>\perf\clpdiskperf.ini
連携機能を使用しない場合、本メッセージが出力されてもCLUSTERPROおよびパフォーマンスモニタの動作に支障はありませんが、本メッセージの出力が多発する場合はコマンドプロンプトから以下の2つのコマンドを実行することで、本メッセージが出力されなくなります。
> unlodctr.exe clpdiskperf > reg delete HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\clpdiskperf
ミラー統計情報採取機能と OS 標準機能との連携機能が有効化されている場合、アプリケーションイベントログに下記のエラーが出力されることがあります。
- イベントID:4806ソース:CLUSTERPRO Xメッセージ:パフォーマンスモニタのプロセス数が多すぎるため、ミラー統計情報は採取できません。
連携機能を使用しない場合、本メッセージが出力されてもCLUSTERPROおよびパフォーマンスモニタの動作に支障はありませんが、本メッセージの出力が多発する場合はコマンドプロンプトから以下の2つのコマンドを実行することで、本メッセージが出力されなくなります。
> unlodctr.exe clpdiskperf > reg delete HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\clpdiskperf
なお、ミラー統計情報採取機能と OS 標準機能との連携機能については、以下を参照してください。
6.4.23. AWS 環境における AMI のリストアについて¶
6.5. CLUSTERPRO の構成変更時¶
クラスタとして運用を開始した後に構成を変更する場合に発生する事象で留意して頂きたい事項です。
6.5.1. グループ共通プロパティの排他ルールについて¶
6.5.2. リソースプロパティの依存関係について¶
6.5.3. 外部連携監視リソースのクラスタ統計情報の設定について¶
モニタリソースのクラスタ統計情報の設定を変更した場合、サスペンド・リジュームを実行しても外部連携監視リソースにはクラスタ統計情報の設定が反映されません。外部連携監視リソースにもクラスタ統計情報の設定を反映させる場合は、OS の再起動を行ってください。
6.5.4. ポート番号の変更について¶
サーバのファイアウォールを有効にしており、ポート番号を変更した場合、ファイアウォールの設定の変更が必要です。clpfwctrlコマンドでファイアウォールの設定を行うことができます。詳細は『リファレンスガイド』 - 「CLUSTERPRO コマンドリファレンス」 - 「ファイアウォールの規則を追加する (clpfwctrlコマンド)」を参照してください。
6.6. CLUSTERPRO バージョンアップ時¶
クラスタとして運用を開始した後にCLUSTERPRO をバージョンアップ(アップグレードまたはアップデート)する際に留意して頂きたい事項です。
6.6.1. 機能変更一覧¶
各バージョンで変更された機能について、以下に示します。
内部バージョン 12.00
内部バージョン 12.10
変更前(12.01以前)
強制停止アクション
強制停止アクション
パラメータ
BMC パワーオフ
ireset.cmd -d -J 0 -N IPアドレス -U ユーザ名 -P パスワード
BMC リセット
ireset.cmd -r -J 0 -N IPアドレス -U ユーザ名 -P パスワード
BMC パワーサイクル
ireset.cmd -c -J 0 -N IPアドレス -U ユーザ名 -P パスワード
BMC NMI
ireset.cmd -n -J 0 -N IPアドレス -U ユーザ名 -P パスワード
筐体IDランプ
筐体IDランプ
パラメータ
点滅
ialarms.cmd -i250 -J 0 -N IPアドレス -U ユーザ名 -P パスワード
消灯
ialarms.cmd -i0 -J 0 -N IPアドレス -U ユーザ名 -P パスワード
変更後
強制停止アクション
強制停止アクション
パラメータ
BMC パワーオフ
ireset.cmd -d -N IPアドレス -U ユーザ名 -P パスワード
BMC リセット
ireset.cmd -r -N IPアドレス -U ユーザ名 -P パスワード
BMC パワーサイクル
ireset.cmd -c -N IPアドレス -U ユーザ名 -P パスワード
BMC NMI
ireset.cmd -n -N IPアドレス -U ユーザ名 -P パスワード
筐体IDランプ
筐体IDランプ
パラメータ
点滅
ialarms.cmd -i250 -N IPアドレス -U ユーザ名 -P パスワード
消灯
ialarms.cmd -i0 -N IPアドレス -U ユーザ名 -P パスワード
内部バージョン 12.20
内部バージョン 12.30
内部バージョン 13.00
6.6.2. 機能削除一覧¶
各バージョンで削除された機能について、以下に示します。
重要
内部バージョン 12.00
機能
対処
WebManager Mobile
VB Corp CL 監視リソース
VB Corp SV 監視リソース
OracleAS 監視リソース
内部バージョン 13.00
機能
対処
WebManager/Builder
COM ネットワークパーティション解決リソース
[クラスタプロパティ] - [NP解決タブ] を開き、タイプが [不明] と表示されているNP解決リソースを削除してください。
仮想マシングループを含んだ「ホストクラスタ用の構成情報」は移行できません。
BMC連携機能
関連する外部連携監視リソースを削除してください。
互換コマンド
スクリプトリソース
カスタム監視リソース
最終動作前スクリプト
活性/非活性前後スクリプト
回復スクリプト
回復動作前スクリプト
強制停止スクリプト
その他 CLUSTERRPO から設定したスクリプト
これらのスクリプトで互換コマンドを使用している場合、スクリプトの内容を互換コマンドを使わない形式で修正してください。
例
armload でサービスを制御している場合、サービスの起動停止処理を sc コマンドで代替してください。サービスの監視処理については、サービス監視リソースで代替してください。armdelay で CLUSTERPRO サービス起動時の遅延時間を設定している場合、クラスタプロパティのタイムアウトタブ[サービス起動遅延時間]の設定で代替してください。
-
-
-
-
-
カーネルモードLANハートビートリソースのブロードキャスト機能
CLUSTERPRO タスクマネージャ
-
CLUSTERPRO クライアント
-
-
SCVMMを利用した仮想マシン強制停止機能
-
ミラーコネクト監視リソースを削除してください。
6.6.3. パラメータ削除一覧¶
Cluster WebUI で設定可能なパラメータのうち、各バージョンで削除されたものについて、以下の表に示します。
内部バージョン 12.00
クラスタ
パラメータ
既定値
クラスタのプロパティ
WebManager タブ
WebManager Mobile の接続を許可する
オフ
WebManager Mobile 用パスワード
操作用パスワード
-
参照用パスワード
-
JVM 監視リソース
パラメータ
既定値
JVM監視リソースのプロパティ
監視 (固有) タブ
メモリタブ([JVM種別]に[Oracle Java]を選択した場合)
仮想メモリ使用量を監視する
2048 [MB]
メモリタブ([JVM種別]に[Oracle Java(usage monitoring)]を選択した場合)
仮想メモリ使用量を監視する
2048 [MB]
ユーザ空間監視リソース
パラメータ
既定値
ユーザ空間監視リソースのプロパティ
監視 (固有) タブ
ハートビートのインターバル/タイムアウトを使用する
オン
内部バージョン 12.10
クラスタ
パラメータ
既定値
クラスタのプロパティ
WebManager タブ
WebManager 調整プロパティ
動作タブ
アラートビューア最大レコード数
300
クライアントデータ更新方法
Real Time
仮想コンピュータ名リソース
内部バージョン 13.00
クラスタ
パラメータ
既定値
クラスタのプロパティ
インタコネクトタブ
ブロードキャスト/ユニキャスト
ユニキャスト
アラートサービスタブ
筐体 ID ランプ連携を使用する
オフ
筐体 ID ランプ点滅コマンド
-
インターバル
-
拡張タブ
仮想マシン強制停止設定 仮想マシン管理ツール
vCenter
仮想マシン強制停止設定 コマンド
C:\Program Files (x86)\VMware\VMware vSphere CLI\Perl\apps\vm\vmcontrol.pl
強制停止スクリプトを使用する
オフ
サーバのプロパティ
情報タブ
仮想マシン
オフ
種類
vSphere
BMCタブ
強制停止コマンドライン
-
筐体IDランプ 点滅 / 消灯
-
6.6.4. 既定値変更一覧¶
Cluster WebUI で設定可能なパラメータのうち、各バージョンで既定値が変更されたものについて、以下の表に示します。
バージョンアップ後も [変更前の既定値] の設定を継続したい場合は、バージョンアップ後に改めてその値に再設定してください。
[変更前の既定値] 以外の値を設定していた場合、バージョンアップ後もそれ以前の設定値が継承されます。再設定の必要はありません。
内部バージョン 12.00
クラスタ
パラメータ
変更前の既定値
変更後の既定値
備考
クラスタのプロパティ
JVM監視タブ
最大Javaヒープサイズ
7[MB]
16[MB]
拡張タブ
フェイルオーバ回数のカウント単位
クラスタ
サーバ
グループリソース 共通
パラメータ
変更前の既定値
変更後の既定値
備考
リソース共通のプロパティ
復旧動作タブ
フェイルオーバしきい値
サーバ数に合わせる
1 [回]
[クラスタプロパティ] - [拡張タブ] - [フェイルオーバ回数のカウント単位]の既定値変更に伴う変更。
アプリケーションリソース
パラメータ
変更前の既定値
変更後の既定値
備考
アプリケーションリソースのプロパティ
依存関係タブ
既定の依存関係に従う
レジストリ同期リソース
パラメータ
変更前の既定値
変更後の既定値
備考
レジストリ同期リソースのプロパティ
依存関係タブ
既定の依存関係に従う
スクリプトリソース
パラメータ
変更前の既定値
変更後の既定値
備考
スクリプトリソースのプロパティ
依存関係タブ
既定の依存関係に従う
サービスリソース
パラメータ
変更前の既定値
変更後の既定値
備考
サービスリソースのプロパティ
依存関係タブ
既定の依存関係に従う
モニタリソース 共通
パラメータ
変更前の既定値
変更後の既定値
備考
モニタリソース共通のプロパティ
回復動作タブ
最大フェイルオーバ回数
サーバ数に合わせる
1 [回]
[クラスタプロパティ] - [拡張タブ] - [フェイルオーバ回数のカウント単位]の既定値変更に伴う変更。
アプリケーション監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
アプリケーション監視リソースのプロパティ
監視 (共通) タブ
監視開始待ち時間
0[秒]
3[秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
フローティング IP 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
フローティング IP 監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
60 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
NIC Link Up/Down 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
NIC Link Up/Down 監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
60 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
レジストリ同期監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
レジストリ同期監視リソースのプロパティ
監視 (共通) タブ
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
サービス監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
サービス監視リソースのプロパティ
監視 (共通) タブ
監視開始待ち時間
0[秒]
3[秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
プリントスプーラ監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
プリントスプーラ監視リソースのプロパティ
監視 (共通) タブ
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
仮想コンピュータ名監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
仮想コンピュータ名監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
60 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
仮想 IP 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
仮想 IP 監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
60 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
カスタム監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
カスタム監視リソースのプロパティ
監視 (共通) タブ
監視開始待ち時間
0[秒]
3[秒]
プロセス名監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
プロセス名監視リソースのプロパティ
監視 (共通) タブ
監視開始待ち時間
0[秒]
3[秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
SQL Server 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
SQL Server 監視リソースのプロパティ
監視 (固有) タブ
ODBC ドライバ名
SQL Native Client
ODBC Driver 13 for SQL Server
Weblogic 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
Weblogic 監視リソースのプロパティ
監視 (固有) タブ
インストールパス
C:\bea\weblogic92
C:\Oracle\Middleware\Oracle_Home\wlserverJVM 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
JVM監視リソースのプロパティ
監視(共通)タブ
タイムアウト
120[秒]
180 [秒]
ダイナミック DNS 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
ダイナミックDNS監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
120 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
AWS Elastic IP 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
AWS Elastic IP監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
AWS 仮想 IP 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
AWS 仮想IP監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
AWS AZ 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
AWS AZ監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
Azure プローブポート監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
Azure プローブポート監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
Azure ロードバランス監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
Azure ロードバランス監視リソースのプロパティ
監視 (共通) タブ
タイムアウト
100 [秒]
180 [秒]
タイムアウト発生時にリトライしない
オフ
オン
タイムアウト発生時に回復動作を実行しない
オフ
オン
内部バージョン 12.10
スクリプトリソース
パラメータ
変更前の既定値
変更後の既定値
備考
スクリプトリソースのプロパティ
詳細タブ
スクリプトリソース調整プロパティ
パラメータタブ
リカバリ処理を実行する
オン
オフ
内部バージョン12.00 以前では設定変更不可。12.10 より設定変更可能。
内部バージョン 12.20
サービスリソース
パラメータ
変更前の既定値
変更後の既定値
備考
サービスリソースのプロパティ
復旧動作タブ
活性リトライしきい値
0 [回]
1 [回]
AWS Elastic IP 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
AWS Elastic IP 監視リソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
AWS 仮想 IP 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
AWS 仮想 IP 監視リソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
AWS AZ 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
AWS AZ 監視リソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
AWS DNS 監視リソース
パラメータ
変更前の既定値
変更後の既定値
備考
AWS DNS 監視リソースのプロパティ
監視 (固有) タブ
AWS CLI コマンド応答取得失敗時動作
回復動作を実行しない(警告を表示する)
回復動作を実行しない(警告を表示しない)
内部バージョン 12.30
クラスタ
パラメータ
変更前の既定値
変更後の既定値
備考
クラスタのプロパティ
拡張タブ
最大再起動回数
0 [回]
3 [回]
最大再起動回数をリセットする時間
0 [分]
60 [分]
APIタブ
通信方式
HTTP
HTTPS
内部バージョン 12.32
AWS DNS リソース
パラメータ
変更前の規定値
変更後の規定値
備考
AWS DNS リソースのプロパティ
詳細 タブ
非活性時にリソースレコードセットを削除する
オン
オフ
内部バージョン 13.00
アプリケーションリソース
パラメータ
変更前の既定値
変更後の既定値
備考
アプリケーションリソースのプロパティ
依存関係タブ
既定の依存関係に従う
レジストリ同期リソース
パラメータ
変更前の既定値
変更後の既定値
備考
レジストリ同期リソースのプロパティ
依存関係タブ
既定の依存関係に従う
スクリプトリソース
パラメータ
変更前の既定値
変更後の既定値
備考
スクリプトリソースのプロパティ
依存関係タブ
既定の依存関係に従う
サービスリソース
パラメータ
変更前の既定値
変更後の既定値
備考
サービスリソースのプロパティ
依存関係タブ
既定の依存関係に従う
仮想コンピュータ名リソース
パラメータ
変更前の既定値
変更後の既定値
備考
仮想コンピュータ名のプロパティ
依存関係タブ
既定の依存関係に従う
CIFS リソース
パラメータ
変更前の既定値
変更後の既定値
備考
CIFS リソースのプロパティ
詳細タブ
共有設定復元時の失敗を活性異常とする
オン
オフ
ダイナミックDNSリソース
パラメータ
変更前の既定値
変更後の既定値
備考
ダイナミックDNSのプロパティ
依存関係タブ
既定の依存関係に従う
6.6.5. パラメータ移動一覧¶
Cluster WebUI で設定可能なパラメータのうち、各バージョンで設定箇所が変更されたものについて、以下の表に示します。
内部バージョン 12.00
変更前の設定箇所
変更後の設定箇所
[クラスタのプロパティ]-[リカバリタブ]-[最大再起動回数]
[クラスタのプロパティ]-[拡張タブ]-[最大再起動回数]
[クラスタのプロパティ]-[リカバリタブ]-[最大再起動回数をリセットする時間]
[クラスタのプロパティ]-[拡張タブ]-[最大再起動回数をリセットする時間]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止機能を使用する]
[クラスタのプロパティ]-[拡張タブ]-[強制停止機能を使用する]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止アクション]
[クラスタのプロパティ]-[拡張タブ]-[強制停止アクション]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[拡張タブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[リカバリタブ]-[仮想マシン強制停止設定]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]]
[クラスタのプロパティ]-[リカバリタブ]-[強制停止スクリプトを実行する]
[クラスタのプロパティ]-[拡張タブ]-[強制停止スクリプトを実行する]
[クラスタのプロパティ]-[自動復帰タブ]-[自動復帰]
[クラスタのプロパティ]-[拡張タブ]-[自動復帰]
[クラスタのプロパティ]-[リカバリタブ]-[モニタリソース異常時の回復動作を抑制する]
[クラスタのプロパティ]-[拡張タブ]-[クラスタ動作の無効化]-[モニタリソースの異常時の回復動作]
[グループのプロパティ]-[属性タブ]- [フェイルオーバ排他属性]
[グループ共通のプロパティ] -[排他タブ]
内部バージョン 13.00
変更前の設定箇所
変更後の設定箇所
[クラスタのプロパティ]-[拡張タブ]-[強制停止機能を使用する]
[クラスタのプロパティ]-[フェンシングタブ]-[強制停止]-[タイプ]
[クラスタのプロパティ]-[拡張タブ]-[強制停止アクション]
[BMC強制停止のプロパティ]-[強制停止タブ]-[強制停止アクション]
[クラスタのプロパティ]-[拡張タブ]-[強制停止タイムアウト]
[BMC強制停止のプロパティ]-[強制停止タブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[アクション]
[vCenter強制停止のプロパティ]-[強制停止タブ]-[強制停止アクション]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[タイムアウト]
[vCenter強制停止のプロパティ]-[強制停止タブ]-[強制停止タイムアウト]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[ホスト名]
[vCenter強制停止のプロパティ]-[vCenterタブ]-[ホスト名]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[ユーザ名]
[vCenter強制停止のプロパティ]-[vCenterタブ]-[ユーザ名]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[パスワード]
[vCenter強制停止のプロパティ]-[vCenterタブ]-[パスワード]
[クラスタのプロパティ]-[拡張タブ]-[仮想マシン強制停止設定]-[Perlパス]
[vCenter強制停止のプロパティ]-[vCenterタブ]-[Perlパス]
[サーバのプロパティ]-[BMCタブ]-[IPアドレス]
[BMC強制停止のプロパティ]-[サーバ一覧タブ]-[BMCの入力]-[IPアドレス]
[サーバのプロパティ]-[BMCタブ]-[ユーザ名]
[BMC強制停止のプロパティ]-[サーバ一覧タブ]-[BMCの入力]-[ユーザ名]
[サーバのプロパティ]-[BMCタブ]-[パスワード]
[BMC強制停止のプロパティ]-[サーバ一覧タブ]-[BMCの入力]-[パスワード]
6.7. 旧バージョンとの互換性¶
6.7.1. CLUSTERPRO X 1.0/2.0/2.1/3.0/3.1/3.2/3.3/4.0/4.1/4.2/4.3 との互換性について¶
6.7.2. スクリプトファイルについて¶
CLUSTERPRO Ver 8.0 以前で使用していたスクリプトファイルを移植する場合、環境変数名の最初の "ARMS_" を "CLP_" に置換してください。
例) IF "%ARMS_EVENT%" == "START" GOTO NORMAL
↓
IF "%CLP_EVENT%" == "START" GOTO NORMAL
7. 用語集¶
- インタコネクト
- クラスタ サーバ間の通信パス(関連) プライベート LAN、パブリック LAN
- 仮想 IP アドレス
- 遠隔地クラスタを構築する場合に使用するリソース(IP アドレス)
- 管理クライアント
- Cluster WebUI が起動されているマシン
- 起動属性
- クラスタ起動時、自動的にフェイルオーバグループを起動するか、手動で起動するかを決定するフェイル オーバ グループの属性管理クライアントより設定が可能
- 共有ディスク
- 複数サーバよりアクセス可能なディスク
- 共有ディスク型クラスタ
- 共有ディスクを使用するクラスタシステム
- 切替パーティション
- 複数のコンピュータに接続され、切り替えながら使用可能なディスクパーティション(関連) ディスクハートビート用パーティション
- クラスタシステム
- 複数のコンピュータを LAN などでつないで、1つのシステムのように振る舞わせるシステム形態
- クラスタシャットダウン
- クラスタシステム全体 (クラスタを構成する全サーバ)をシャットダウンさせること
- クラスタパーティション
- ミラーディスクまたはハイブリッドディスクに設定するパーティション。ミラーディスクやハイブリッドディスクの管理に使用する。(関連) ディスクハートビート用パーティション
- 現用系
- ある 1 つの業務セットについて、業務が動作しているサーバ(関連) 待機系
- サーバグループ
- 同じネットワークや共有ディスク装置に接続しているサーバの集合
- セカンダリ (サーバ)
- 通常運用時、フェイルオーバグループがフェイルオーバする先のサーバ(関連) プライマリ (サーバ)
- 待機系
- 現用系ではない方のサーバ(関連) 現用系
- ディスクハートビート用パーティション
共有ディスク型クラスタで、ハートビート通信に使用するためのパーティション
- データパーティション
- 共有ディスクの切替パーティションのように使用することが可能なローカルディスクミラーディスクに設定するデータ用のパーティション(関連) クラスタパーティション
- ネットワークパーティション
- 全てのハートビートが途切れてしまうこと(関連) インタコネクト、ハートビート
- ノード
- クラスタシステムでは、クラスタを構成するサーバを指す。ネットワーク用語では、データを他の機器に経由することのできる、コンピュータやルータなどの機器を指す。
- ハートビート
- サーバの監視のために、サーバ間で定期的にお互いに通信を行うこと(関連) インタコネクト、ネットワークパーティション
- パブリック LAN
- サーバ/クライアント間通信パスのこと(関連) インタコネクト、プライベート LAN
- フェイルオーバ
- 障害検出により待機系が、現用系上の業務アプリケーションを引き継ぐこと
- フェイルバック
- あるサーバで起動していた業務アプリケーションがフェイルオーバにより他のサーバに引き継がれた後、業務アプリケーションを起動していたサーバに再び業務を戻すこと
- フェイルオーバグループ
- 業務を実行するのに必要なクラスタリソース、属性の集合
- フェイルオーバグループの移動
- ユーザが意図的に業務アプリケーションを現用系から待機系に移動させること
- フェイルオーバ ポリシー
- フェイルオーバ可能なサーバリストとその中でのフェイルオーバ優先順位を持つ属性
- プライベート LAN
- クラスタを構成するサーバのみが接続された LAN(関連) インタコネクト、パブリック LAN
- プライマリ (サーバ)
- フェイルオーバグループでの基準で主となるサーバ(関連) セカンダリ (サーバ)
- フローティング IP アドレス
- フェイルオーバが発生したとき、クライアントのアプリケーションが接続先サーバの切り替えを意識することなく使用できる IP アドレスクラスタサーバが所属する LAN と同一のネットワーク アドレス内で、他に使用されていないホストアドレスを割り当てる
- マスタサーバ
- Cluster WebUI の設定モード の [サーバ共通のプロパティ]-[マスタサーバ] で先頭に表示されているサーバ
- ミラーコネクト
- データミラー型クラスタでデータのミラーリングを行うために使用する LAN。プライマリインタコネクトと兼用で設定することが可能。
- ミラーディスクシステム
- 共有ディスクを使用しないクラスタシステムサーバのローカルディスクをサーバ間でミラーリングする