4. モニタリソースの詳細¶
本章では、CLUSTERPRO で監視を実行する単位であるモニタリソースについての詳細を説明します。
4.1. モニタリソースとは?¶
モニタリソースとは、指定された監視対象を監視するリソースのことを指します。監視対象の 異常を検出した場合には、グループリソースの再起動やフェイルオーバなどを行います。
現在サポートされているモニタリソースは以下です。
モニタリソース名 |
略称 |
機能概要 |
対応バージョン |
|---|---|---|---|
ディスクモニタリソース |
diskw |
「ディスクモニタリソースを理解する」を参照 |
4.0.0-1~ |
IP モニタリソース |
ipw |
「IP モニタリソースを理解する」を参照 |
4.0.0-1~ |
フローティングIPモニタリソース |
fipw |
4.0.0-1~ |
|
NIC Link Up/Down モニタリソース |
miiw |
4.0.0-1~ |
|
ミラーディスクコネクトモニタリソース |
mdnw |
「 ミラーディスクコネクトモニタリソースを理解する 」を参照 |
4.0.0-1~ |
ミラーディスクモニタリソース |
mdw |
「ミラーディスクモニタリソースを理解する」を参照 |
4.0.0-1~ |
ハイブリッドディスクコネクトモニタリソース |
hdnw |
4.0.0-1~ |
|
ハイブリッドディスクモニタリソース |
hdw |
4.0.0-1~ |
|
PID モニタリソース |
pidw |
「PID モニタリソースを理解する 」を参照 |
4.0.0-1~ |
ユーザ空間モニタリソース |
userw |
「ユーザ空間モニタリソースを理解する」を参照 |
4.0.0-1~ |
マルチターゲットモニタリソース |
mtw |
「マルチターゲットモニタリソースを理解する」を参照 |
4.0.0-1~ |
仮想 IP モニタリソース |
vipw |
「仮想 IP モニタリソースを理解する」を参照 |
4.0.0-1~ |
ARP モニタリソース |
arpw |
「ARP モニタリソースを理解する」を参照 |
4.0.0-1~ |
カスタムモニタリソース |
genw |
「カスタムモニタリソースを理解する」を参照 |
4.0.0-1~ |
ボリュームマネージャモニタリソース |
volmgrw |
4.0.0-1~ |
|
外部連携モニタリソース |
mrw |
「外部連携モニタリソースを理解する」を参照 |
4.0.0-1~ |
ダイナミック DNS モニタリソース |
ddnsw |
4.0.0-1~ |
|
プロセス名モニタリソース |
psw |
「プロセス名モニタリソースを理解する」を参照 |
4.0.0-1~ |
DB2 モニタリソース 1 |
db2w |
「DB2 モニタリソースを理解する」を参照 |
4.0.0-1~ |
FTP モニタリソース 1 |
ftpw |
「FTP モニタリソースを理解する」を参照 |
4.0.0-1~ |
HTTP モニタリソース 1 |
httpw |
「HTTP モニタリソースを理解する」を参照 |
4.0.0-1~ |
IMAP4 モニタリソース 1 |
imap4w |
「IMAP4 モニタリソースを理解する」を参照 |
4.0.0-1~ |
MySQL モニタリソース 1 |
mysqlw |
「MySQL モニタリソースを理解する」を参照 |
4.0.0-1~ |
NFS モニタリソース 1 |
nfsw |
「NFS モニタリソースを理解する」を参照 |
4.0.0-1~ |
ODBC モニタリソース 1 |
odbcw |
「ODBC モニタリソースを理解する」を参照 |
4.0.0-1~ |
Oracle モニタリソース 1 |
oraclew |
「Oracle モニタリソースを理解する」を参照 |
4.0.0-1~ |
POP3 モニタリソース 1 |
pop3w |
「POP3 モニタリソースを理解する」を参照 |
4.0.0-1~ |
PostgreSQL モニタリソース 1 |
psqlw |
4.0.0-1~ |
|
Samba モニタリソース 1 |
sambaw |
「Samba モニタリソースを理解する」を参照 |
4.0.0-1~ |
SMTP モニタリソース 1 |
smtpw |
「SMTP モニタリソースを理解する」を参照 |
4.0.0-1~ |
SQL Server モニタリソース 1 |
sqlserverw |
4.0.0-1~ |
|
Tuxedo モニタリソース 1 |
tuxw |
「Tuxedo モニタリソースを理解する」を参照 |
4.0.0-1~ |
WebLogic モニタリソース 1 |
wlsw |
4.0.0-1~ |
|
WebSphere モニタリソース 1 |
wasw |
4.0.0-1~ |
|
WebOTX モニタリソース 1 |
otxw |
「WebOTX モニタリソースを理解する」を参照 |
4.0.0-1~ |
JVM モニタリソース 1 |
jraw |
「JVM モニタリソースを理解する」を参照 |
4.0.0-1~ |
システムモニタリソース 1 |
sraw |
「システムモニタリソースを理解する」を参照 |
4.0.0-1~ |
プロセスリソースモニタリソース 1 |
psrw |
「プロセスリソースモニタリソースを理解する」を参照 |
4.0.0-1~ |
AWS Elastic IP モニタリソース |
awseipw |
4.0.0-1~ |
|
AWS 仮想 IP モニタリソース |
awsvipw |
4.0.0-1~ |
|
AWS セカンダリ IP モニタリソース |
awssipw |
5.0.0-1~ |
|
AWS AZ モニタリソース |
awsazw |
「AWS AZ モニタリソースを理解する」を参照 |
4.0.0-1~ |
AWS DNS モニタリソース |
awsdnsw |
「AWS DNS モニタリソースを理解する」を参照 |
4.0.0-1~ |
Azure プローブポートモニタリソース |
azureppw |
4.0.0-1~ |
|
Azure ロードバランスモニタリソース |
azurelbw |
4.0.0-1~ |
|
Azure DNS モニタリソース |
azurednsw |
4.0.0-1~ |
|
Google Cloud 仮想 IP モニタリソース |
gcvipw |
4.2.0-1~ |
|
Google Cloud ロードバランスモニタリソース |
gclbw |
4.2.0-1~ |
|
Google Cloud DNS モニタリソース |
gcdnsw |
4.3.0-1~ |
|
Oracle Cloud 仮想 IP モニタリソース |
ocvipw |
4.2.0-1~ |
|
Oracle Cloud ロードバランスモニタリソース |
oclbw |
4.2.0-1~ |
|
Oracle Cloud DNS モニタリソース |
ocdnsw |
5.2.0-1~ |
- 1(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20)
このモニタリソースを使用するにはライセンスが必要です。ライセンスの登録については『インストール&設定ガイド』を参照してください。
4.1.1. モニタリソースの監視開始後のステータス¶
モニタリソースの監視開始後、監視開始準備のために一時的にステータスが警告となることがあります。
モニタステータスが警告となる可能性があるのは、下記のモニタリソースです。
ダイナミック DNS モニタリソース外部連携モニタリソースカスタムモニタリソース (監視タイプが [非同期] の場合のみ)仮想 IP モニタリソースDB2モニタリソースシステムモニタリソースプロセスリソースモニタリソースJVMモニタリソースMySQLモニタリソースODBCモニタリソースOracleモニタリソースPostgreSQLモニタリソースプロセス名モニタリソースSQL Serverモニタリソース
4.1.2. モニタリソースの監視タイミング¶
モニタリソースによる監視は、常時監視と活性時監視の 2 つのタイプがあります。
モニタリソースによって設定可能な監視タイミングが異なります。
- 常時モニタリソースは常に監視を行います。
- 活性時特定のグループリソースが活性状態の間、監視を実行します。グループリソースが非活性状態の間は監視を実行しません。
Cluster startup: クラスタ起動
Group activation: グループ活性
Group deactivation: グループ非活性
Stop cluster: クラスタ停止
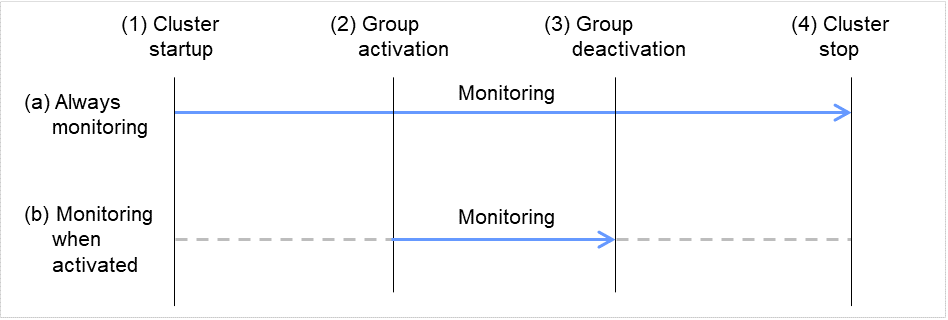
図 4.1 モニタリソースの常時監視と活性時監視¶
モニタリソース |
監視タイミング |
対象リソース |
|---|---|---|
ディスクモニタリソース |
常時または活性時 |
全て |
IP モニタリソース |
常時または活性時 |
全て |
ユーザ空間モニタリソース |
常時 (固定) |
- |
ミラーディスクモニタリソース |
常時 (固定) |
- |
ミラーディスクコネクトモニタリソース |
常時 (固定) |
- |
ハイブリッドディスクモニタリソース |
常時 (固定) |
- |
ハイブリッドディスクコネクトモニタリソース |
常時 (固定) |
- |
NIC Link Up/Down モニタリソース |
常時または活性時 |
全て |
PID モニタリソース |
活性時 (固定) |
exec |
マルチターゲットモニタリソース |
常時または活性時 |
全て |
仮想 IP モニタリソース |
活性時 (固定) |
vip |
ARP モニタリソース |
活性時 (固定) |
fip, vip |
カスタムモニタリソース |
常時または活性時 |
全て |
外部連携モニタリソース |
常時または活性時 |
全て |
ボリュームマネージャモニタリソース |
常時または活性時 |
volmgr |
ダイナミック DNS モニタリソース |
活性時 (固定) |
ddns |
プロセス名モニタリソース |
常時または活性時 |
全て |
DB2 モニタリソース |
活性時 (固定) |
exec |
FTP モニタリソース |
常時または活性時 |
exec |
HTTP モニタリソース |
常時または活性時 |
exec |
IMAP4 モニタリソース |
常時または活性時 |
exec |
MySQL モニタリソース |
活性時 (固定) |
exec |
NFS モニタリソース |
常時または活性時 |
exec |
ODBC モニタリソース |
活性時 (固定) |
exec |
Oracle モニタリソース |
活性時 (固定) |
exec |
POP3 モニタリソース |
常時または活性時 |
exec |
PostgreSQL モニタリソース |
活性時 (固定) |
exec |
Samba モニタリソース |
常時または活性時 |
exec |
SMTP モニタリソース |
常時または活性時 |
exec |
SQL Server モニタリソース |
活性時 (固定) |
exec |
Tuxedo モニタリソース |
常時または活性時 |
exec |
WebLogic モニタリソース |
常時または活性時 |
exec |
WebSphere モニタリソース |
常時または活性時 |
exec |
WebOTX モニタリソース |
常時または活性時 |
exec |
JVM モニタリソース |
常時または活性時 |
exec |
システムモニタリソース |
常時 (固定) |
全て |
プロセスリソースモニタリソース |
常時 (固定) |
全て |
フローティングIPモニタリソース |
活性時 (固定) |
fip |
AWS Elastic IP モニタリソース |
活性時 (固定) |
awseip |
AWS 仮想 IP モニタリソース |
活性時 (固定) |
awsvip |
AWS セカンダリ IP モニタリソース |
活性時 (固定) |
awssip |
AWS AZ モニタリソース |
常時 (固定) |
- |
AWS DNS モニタリソース |
活性時 (固定) |
awsdns |
Azure プローブポートモニタリソース |
活性時 (固定) |
azurepp |
Azure ロードバランスモニタリソース |
常時 (固定) |
azurepp |
Azure DNS モニタリソース |
活性時 (固定) |
azuredns |
Google Cloud 仮想 IP モニタリソース |
活性時 (固定) |
gcvip |
Google Cloud ロードバランスモニタリソース |
常時 (固定) |
gcvip |
Google Cloud DNS モニタリソース |
活性時 (固定) |
gcdns |
Oracle Cloud 仮想 IP モニタリソース |
活性時 (固定) |
ocvip |
Oracle Cloud ロードバランスモニタリソース |
常時 (固定) |
ocvip |
Oracle Cloud DNS モニタリソース |
活性時 (固定) |
ocdns |
4.1.3. モニタリソースの一時停止/再開¶
Cluster WebUI による操作
- [clpmonctrl] コマンドによる操作[clpmonctrl] コマンドでは、コマンドの実行サーバ、または指定したサーバのモニタリソースの制御が可能です。
モニタリソース |
制御可否 |
|---|---|
ディスクモニタリソース |
可能 |
IP モニタリソース |
可能 |
ユーザ空間モニタリソース |
可能 |
ミラーディスクモニタリソース |
可能 |
ミラーディスクコネクトモニタリソース |
可能 |
ハイブリッドディスクモニタリソース |
可能 |
ハイブリッドディスクコネクトモニタリソース |
可能 |
NIC Link Up/Down モニタリソース |
可能 |
PID モニタリソース |
可能 |
マルチターゲットモニタリソース |
可能 |
仮想 IP モニタリソース |
不可能 |
ARP モニタリソース |
不可能 |
カスタムモニタリソース |
可能 |
外部連携モニタリソース |
可能 |
ボリュームマネージャモニタリソース |
可能 |
ダイナミック DNS モニタリソース |
不可能 |
プロセス名モニタリソース |
可能 |
DB2 モニタリソース |
可能 |
FTP モニタリソース |
可能 |
HTTP モニタリソース |
可能 |
IMAP4 モニタリソース |
可能 |
MySQL モニタリソース |
可能 |
NFS モニタリソース |
可能 |
ODBC モニタリソース |
可能 |
Oracle モニタリソース |
可能 |
POP3 モニタリソース |
可能 |
PostgreSQL モニタリソース |
可能 |
Samba モニタリソース |
可能 |
SMTP モニタリソース |
可能 |
SQL Server モニタリソース |
可能 |
Tuxedo モニタリソース |
可能 |
WebLogic モニタリソース |
可能 |
WebSphere モニタリソース |
可能 |
WebOTX モニタリソース |
可能 |
JVM モニタリソース |
可能 |
システムモニタリソース |
可能 |
プロセスリソースモニタリソース |
可能 |
フローティングIPモニタリソース |
可能 |
AWS Elastic IP モニタリソース |
可能 |
AWS 仮想 IP モニタリソース |
可能 |
AWS セカンダリ IP モニタリソース |
可能 |
AWS AZ モニタリソース |
可能 |
AWS DNS モニタリソース |
可能 |
Azure プローブポートモニタリソース |
可能 |
Azure ロードバランスモニタリソース |
可能 |
Azure DNS モニタリソース |
可能 |
Google Cloud 仮想 IP モニタリソース |
可能 |
Google Cloud ロードバランスモニタリソース |
可能 |
Google Cloud DNS モニタリソース |
可能 |
Oracle Cloud 仮想 IP モニタリソース |
可能 |
Oracle Cloud ロードバランスモニタリソース |
可能 |
Oracle Cloud DNSモニタリソース |
可能 |
モニタリソースが一時停止状態で下記の操作を行った場合、モニタリソースの一時停止が解除されます。
Cluster WebUI で、モニタリソースの「再開」を行った場合
Clpmonctrl コマンドに -rオプション を指定した場合
クラスタを停止した場合
クラスタをサスペンドした場合
4.1.4. モニタリソースの擬似障害 発生/解除¶
モニタリソースは擬似的に障害を発生させることが可能です。また、それを解除することもできます。擬似障害の発生/解除を行う方法は以下の 2 つの方法があります。
- Cluster WebUI (検証モード) による操作Cluster WebUI (検証モード) では、制御が不可能なモニタリソースの右クリックメニューが無効になります。
- [clpmonctrl] コマンドによる操作[clpmonctrl] コマンドでは、コマンドの実行サーバ、または指定したサーバのモニタリソースに対して制御を行います。制御が不可能なモニタリソースに対して実行した場合、コマンドの実行自体は成功しますが、擬似障害を発生させることはできません。
擬似障害発生状態で下記の操作を行った場合、モニタリソースの擬似障害が解除されます。
Cluster WebUI (検証モード) で、モニタリソースの「擬似障害解除」を実行した場合
Cluster WebUI のモードを、検証モードから他のモードに変更する際に出力されるダイアログで「はい」を選択した場合
clpmonctrlコマンドに -nオプション を指定した場合
クラスタを停止した場合
クラスタをサスペンドした場合
4.1.5. モニタリソースの監視インターバルのしくみ¶
ユーザ空間モニタリソースを除く全てのモニタリソースは、監視インターバル毎に監視が行われます。
以下は、この監視インターバルの設定による正常または、異常時におけるモニタリソースへの監視の流れを時系列で表した説明です。
監視正常検出時
図は、クラスタ起動後に監視を開始または再開した際の動作を表しています。 監視メインプロセス(Main monitoring process)が監視結果を受け取ると、監視インターバル(Monitor interval)の時間を空けて、繰り返し、監視が起動されます。
下記の値が設定されている場合の挙動の例:
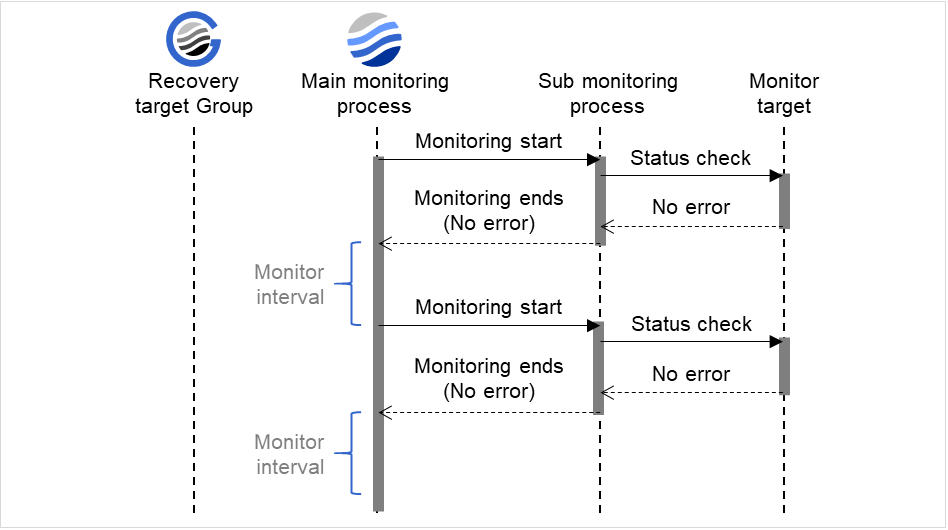
図 4.2 監視インターバル(監視正常検出時)¶
監視異常検出時 (監視リトライ設定なし)
図は、監視対象(Monitor target)で異常が発生し、それが検出された後の動作を表しています。 監視メインプロセス(Main monitoring process)が監視結果(Error)を受け取ると、回復対象グループ(Recovery target Group)に対してフェイルオーバを実行します。
監視異常発生後、次回監視で監視異常を検出し回復対象に対してフェイルオーバが行われます。
下記の値が設定されている場合の挙動の例:
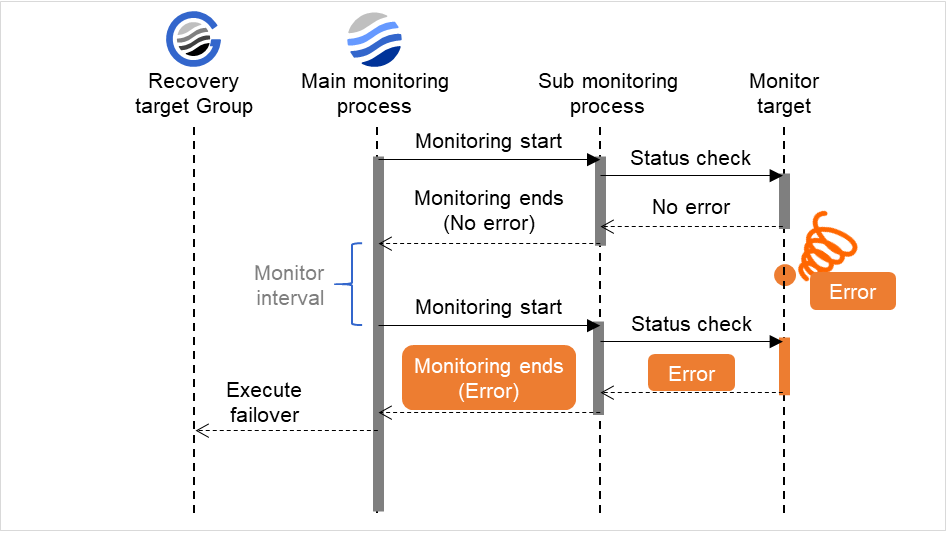
図 4.3 監視インターバル(監視異常検出時 ・監視リトライ設定なし)¶
監視異常検出時 (監視リトライ設定あり)
図は、監視対象(Monitor target)で異常が発生し、それが検出された後の動作を表しています。 監視メインプロセス(Main monitoring process)が監視結果(Error)を受け取ると、設定された監視リトライ回数に達するまで、監視動作を実行します。それでも監視対象が回復しない場合、回復対象グループ(Recovery target Group)に対してフェイルオーバを実行します。
監視異常発生後、次回監視で監視異常を検出し監視リトライ以内で回復しなければ、回復対象に対してフェイルオーバが行われます。
下記の値が設定されている場合の挙動の例:
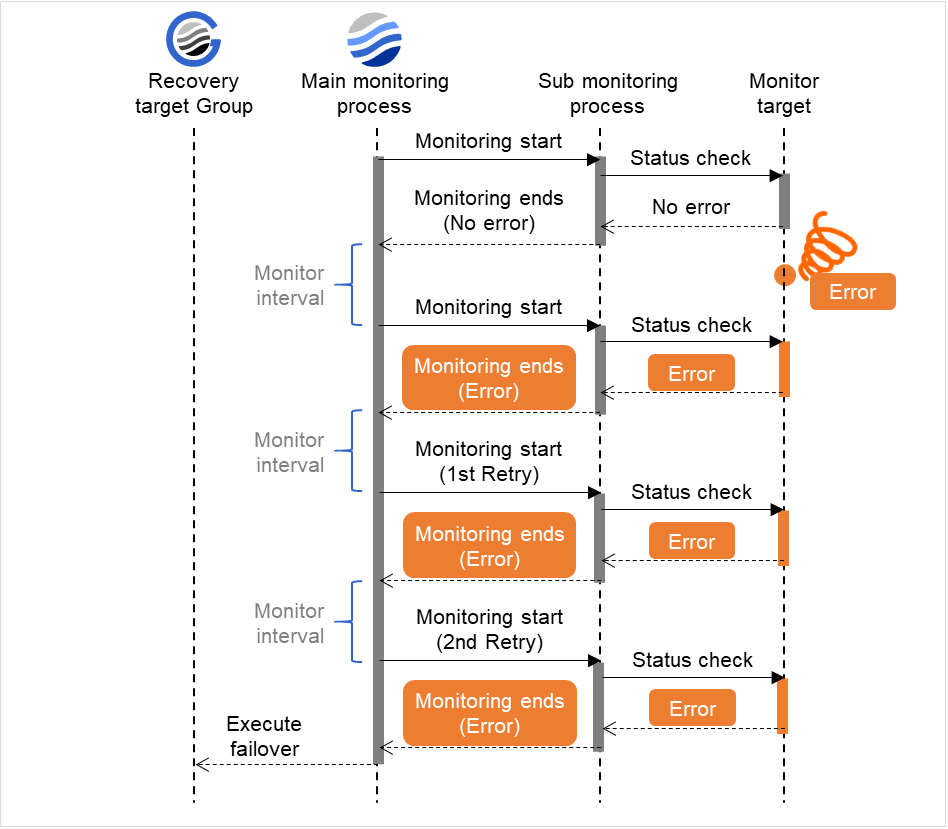
図 4.4 監視インターバル(監視異常検出時 ・監視リトライ設定あり)¶
監視タイムアウト検出時 (監視リトライ設定なし)
図は、設定された時間内に監視処理が終わらなかった場合の動作を表しています。 監視メインプロセス(Main monitoring process)が監視を起動した後、監視タイムアウトに設定された時間内に監視結果が得られなかった場合、回復対象グループ(Recovery target Group)に対してフェイルオーバを実行します。
監視タイムアウト発生後、直ぐに回復対象に対してフェイルオーバが行われます。
下記の値が設定されている場合の挙動の例:
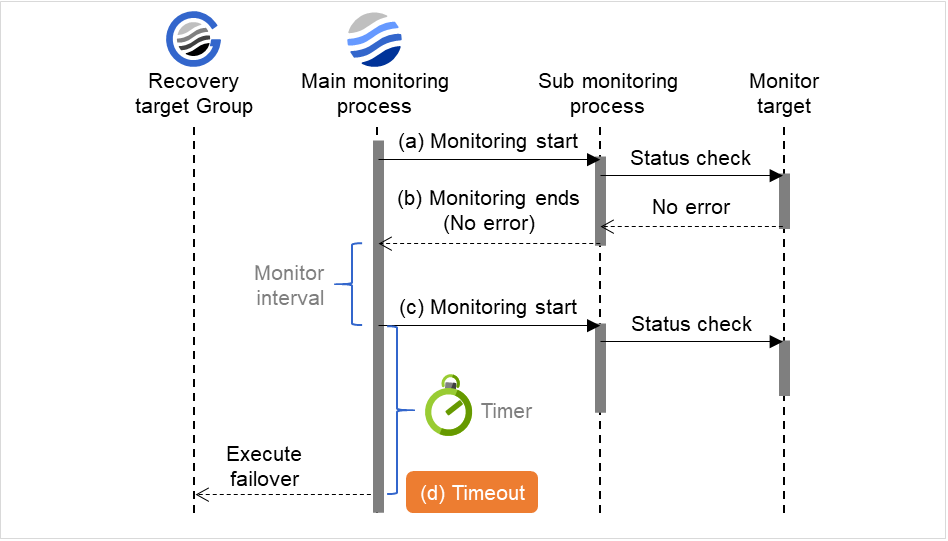
図 4.5 監視インターバル(監視タイムアウト検出時 ・監視リトライ設定なし)¶
監視タイムアウト検出時 (監視リトライ設定あり)
図は、設定された時間内に監視処理が終わらなかった場合の動作を表しています。 監視メインプロセス(Main monitoring process)が監視を起動した後、監視タイムアウトに設定された時間内に監視結果が得られなかった場合、設定された監視リトライ回数に達するまで、監視動作を実行します。それでも監視結果が得られなかった場合、回復対象グループ(Recovery target Group)に対してフェイルオーバを実行します。
監視タイムアウト発生後、監視リトライを行い回復対象に対してフェイルオーバが行われます。
下記の値が設定されている場合の挙動の例:
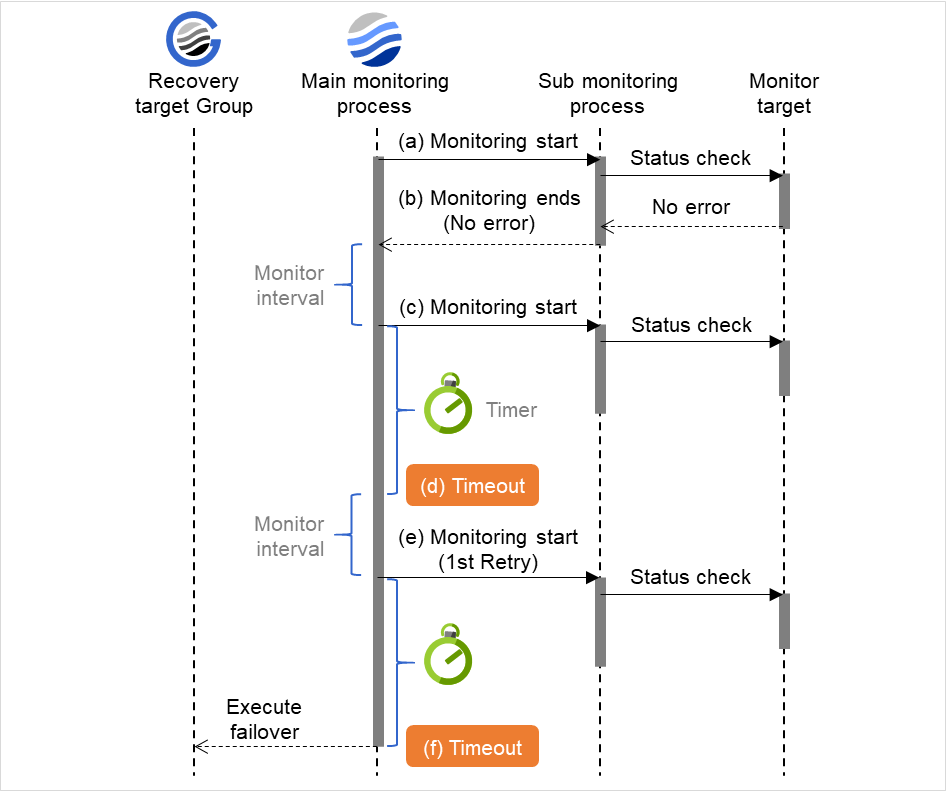
図 4.6 監視インターバル(監視タイムアウト検出時 ・監視リトライ設定あり)¶
4.1.6. モニタリソースによる異常検出時の動作¶
異常検出時には回復対象に対して以下の回復動作が行われます。
監視対象の異常を検出すると回復スクリプトを実行します。
回復スクリプト実行回数の回復スクリプト実行後、回復対象の再活性化を行います。再活性前スクリプト実行が設定されている場合はスクリプトを実行後に再活性化を行います。
再活性化しきい値の再活性化に失敗した場合、フェイルオーバを行います。フェイルオーバ前スクリプト実行が設定されている場合はスクリプトを実行後にフェイルオーバを行います。
フェイルオーバしきい値のフェイルオーバを行っても異常を検出する場合、最終動作を行います。最終動作前スクリプト実行が設定されている場合はスクリプトを実行後に最終動作を行います。
回復動作が実行されるか否かは、回復対象の状態によって変わります。
回復対象 |
状態 |
再活性化 2 |
フェイルオーバ 3 |
最終動作 4 |
|---|---|---|---|---|
グループリソース/
フェイルオーバグループ
|
停止済 |
No |
No |
No |
〃 |
起動/停止中 |
No |
No |
No |
〃 |
起動済 |
Yes |
Yes |
Yes |
〃 |
異常 |
Yes |
Yes |
Yes |
LocalServer |
- |
- |
- |
Yes |
Yes:回復動作が行われる No:回復動作が行われない
- 2
再活性化しきい値に 1 以上が設定されている場合のみに有効になります。
- 3
フェイルオーバしきい値に 1 以上が設定されている場合のみに有効になります。
- 4
最終動作に"何もしない"以外が設定されている場合のみに有効になります。
注釈
モニタリソースの異常検出時の設定で回復対象にグループリソース (例: ディスクリソース、EXECリソース) を指定し、モニタリソースが異常を検出した場合の回復動作遷移中 (再活性化 → フェイルオーバ → 最終動作) には、以下のコマンドまたは Cluster WebUI から以下の操作を行わないでください。
クラスタの停止/サスペンド
グループの起動/停止/移動
以下は、IP モニタリソースの IP リソースとしてゲートウェイを指定した場合で片サーバのみ異常を検出する時の流れを説明します。
下記の値が設定されている場合の挙動の例:
- 図は、2台のサーバにおいてIPモニタリソースが監視を行う場合の例です。IP monitor resource 1は、インターバル毎にGatewayのIPアドレスに対して、生存確認を行います。
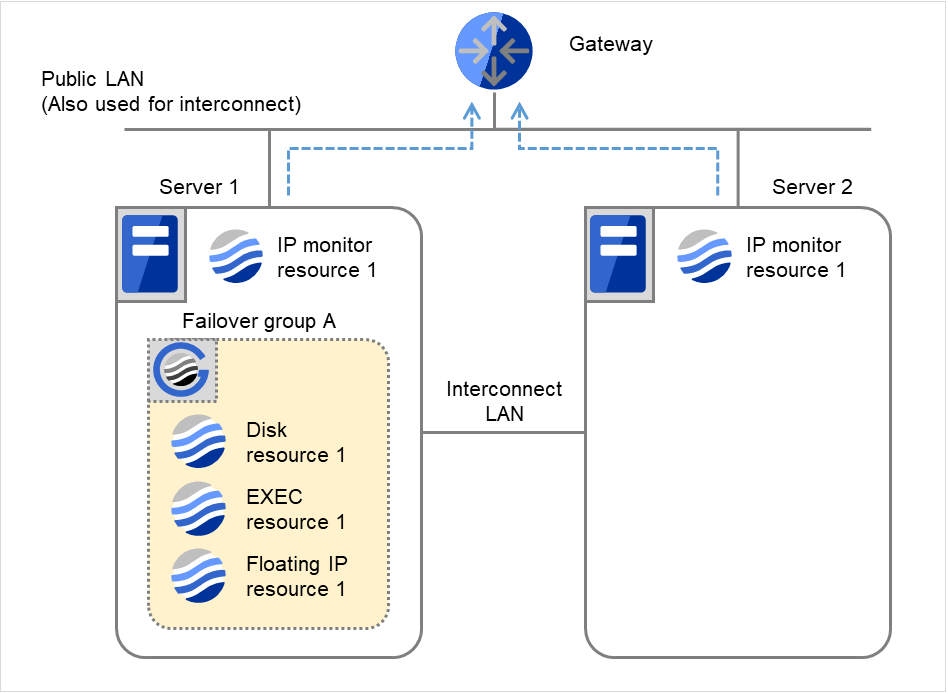
図 4.7 IP モニタリソース異常検出の流れ(片サーバのみ異常検出) (1)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
0
0
再活性化回数
0
0
フェイルオーバ回数
0
0
IP monitor resource 1の監視が異常を検出しました(LANケーブルの断線、NICの故障など)。
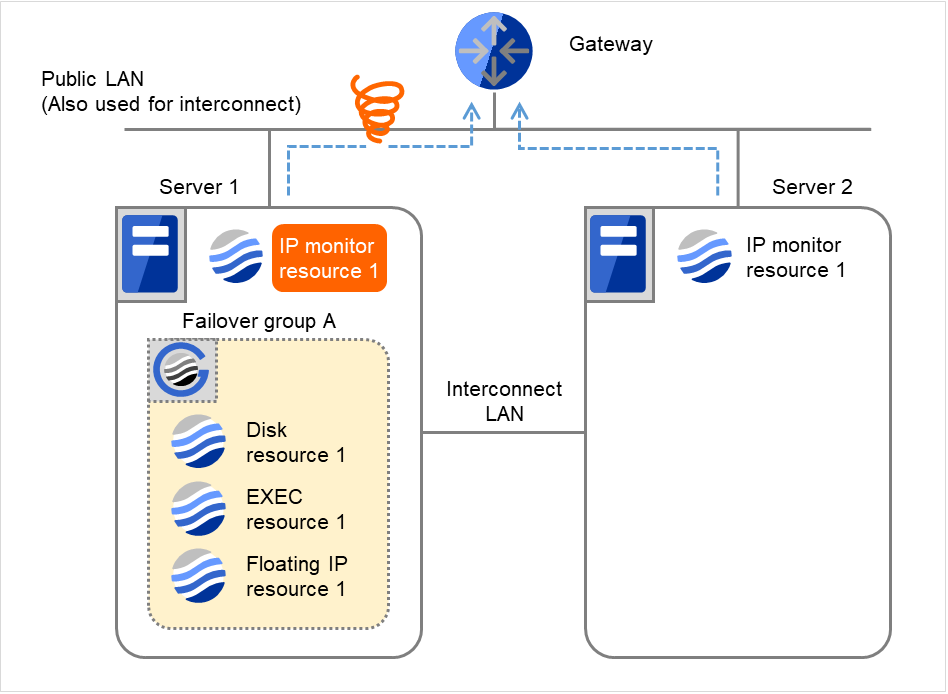
図 4.8 IP モニタリソース異常検出の流れ(片サーバのみ異常検出) (2)¶
IP monitor resource 1は監視を3回までリトライします。
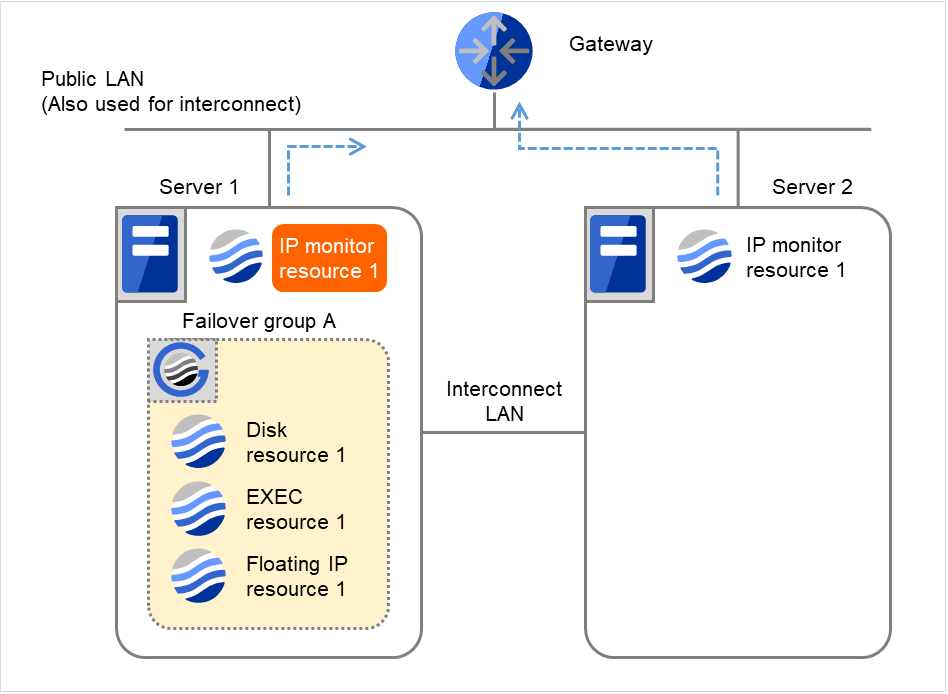
図 4.9 IP モニタリソース異常検出の流れ(片サーバのみ異常検出) (3)¶
- 監視リトライオーバした場合、Server 1で回復スクリプトの実行を開始します。"回復スクリプト実行回数" は各サーバでの回復スクリプトの実行回数です。これはServer 1での1回目の回復スクリプト実行です。Server 2では、Failover group Aが "停止済" のため、回復動作は行われません。
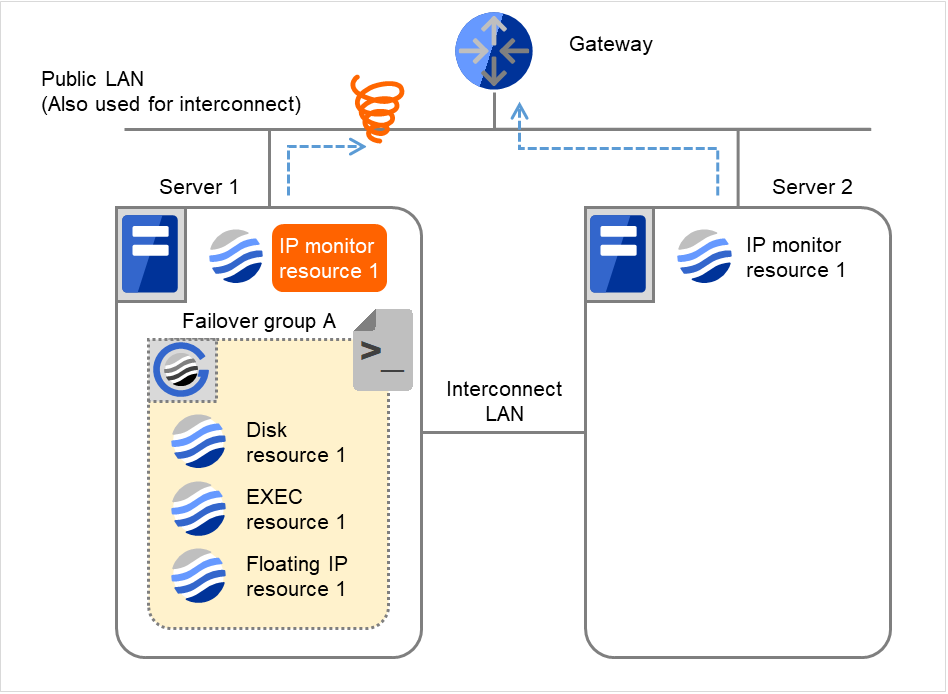
図 4.10 IP モニタリソース異常検出の流れ(片サーバのみ異常検出) (4)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
0
0
フェイルオーバ回数
0
0
- Server 1で回復スクリプト実行回数を超えた場合、Server 1でFailover group Aの再活性処理を開始します。"再活性化回数" は各サーバでの再活性化の回数を表しています。これは Server 1での1回目の再活性化処理です。
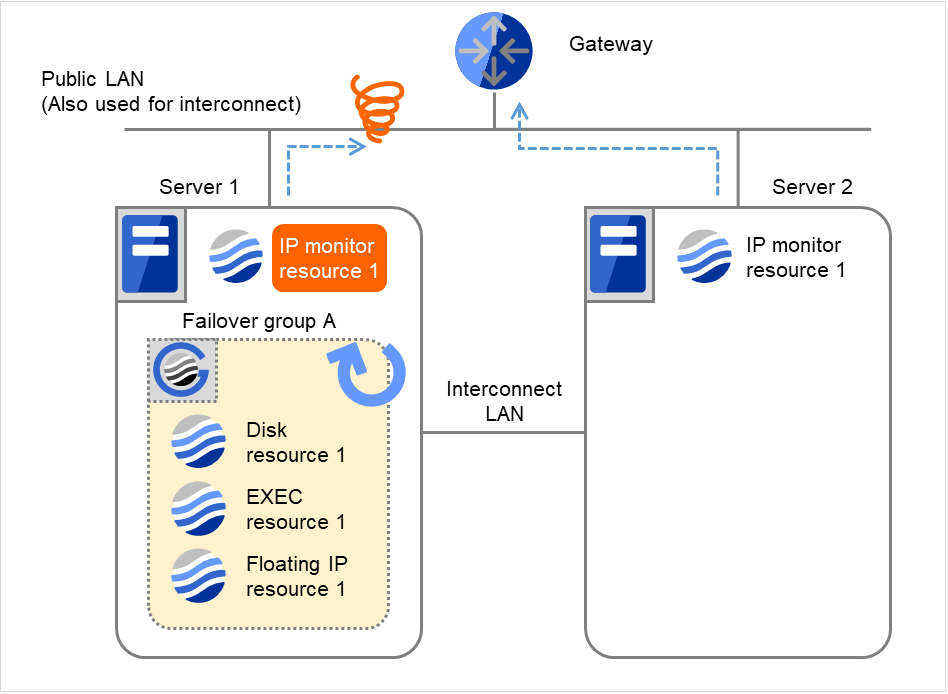
図 4.11 IP モニタリソース異常検出の流れ(片サーバのみ異常検出) (5)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
3
0
フェイルオーバ回数
0
0
- Server 1で再活性化しきい値を超えた場合、Server 1で Failover group Aのフェイルオーバ処理を開始します。"フェイルオーバしきい値" は各サーバでのフェイルオーバの回数を表しています。これは Server 1での1回目のフェイルオーバ処理です。
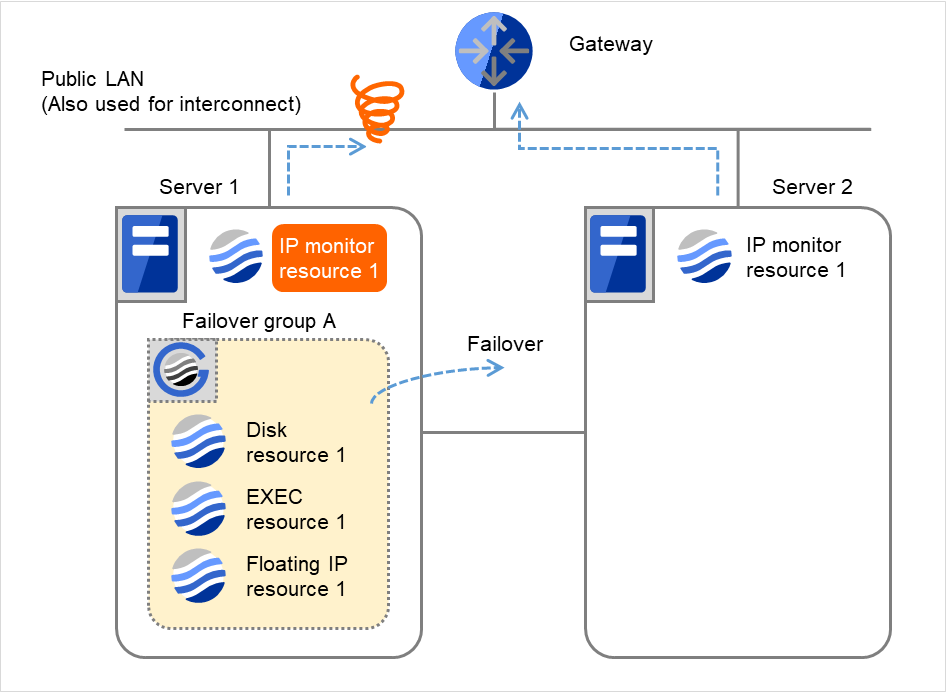
図 4.12 IP モニタリソース異常検出の流れ(片サーバのみ異常検出) (6)¶
- Failover group AをServer 1からServer 2へフェイルオーバします。Server 2でFailover group Aのフェイルオーバ処理を完了します。
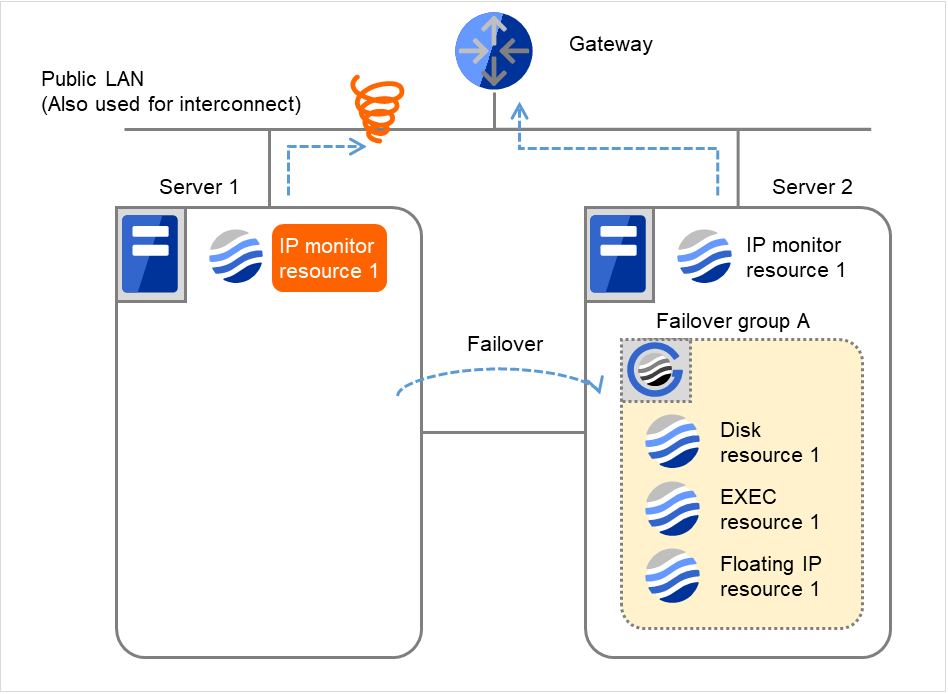
図 4.13 IP モニタリソース異常検出の流れ(片サーバのみ異常検出) (7)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
3
0
フェイルオーバ回数
1
0
サーバ 2 では、IP モニタリソース 1 が正常なのでフェイルオーバグループ A がフェイルオーバすることにより運用を継続することができます。
以下は、IP モニタリソースの IP リソースとしてゲートウェイを指定した場合で、両サーバが 異常を検出する時の流れを説明します。
下記の値が設定されている場合の挙動の例:
- 図は、2台のサーバにおいてIPモニタリソースが監視を行う場合の例です。IP monitor resource 1は、インターバル毎にGatewayのIPアドレスに対して、生存確認を行います。
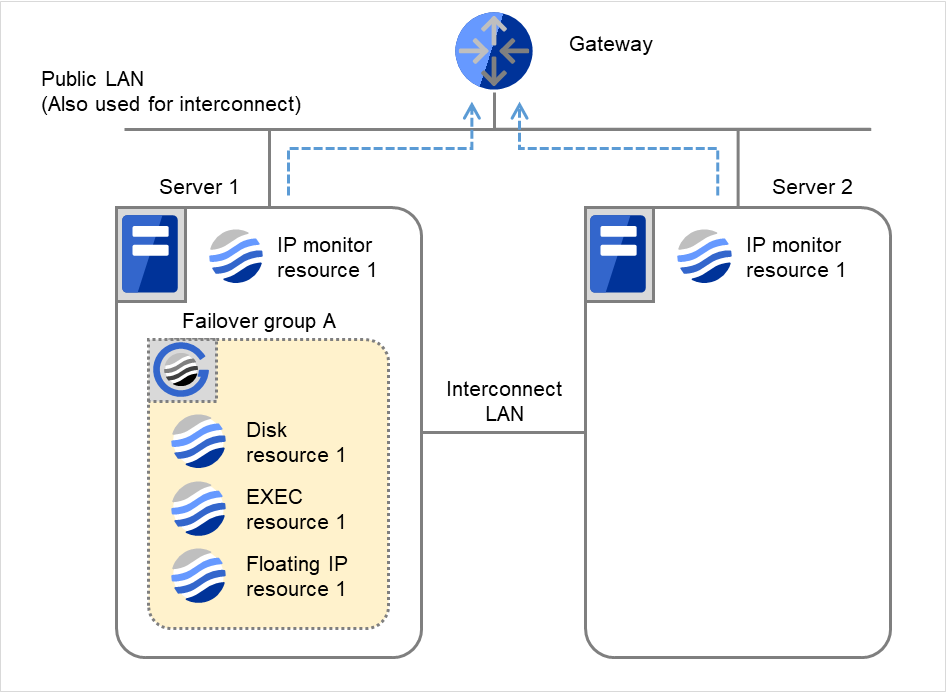
図 4.14 IP モニタリソース異常検出の流れ(両サーバで異常検出) (1)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
0
0
再活性化回数
0
0
フェイルオーバ回数
0
0
Server 1、Server 2で、IP monitor resource 1の監視が異常を検出しました(LANケーブルの断線、NICの故障など)
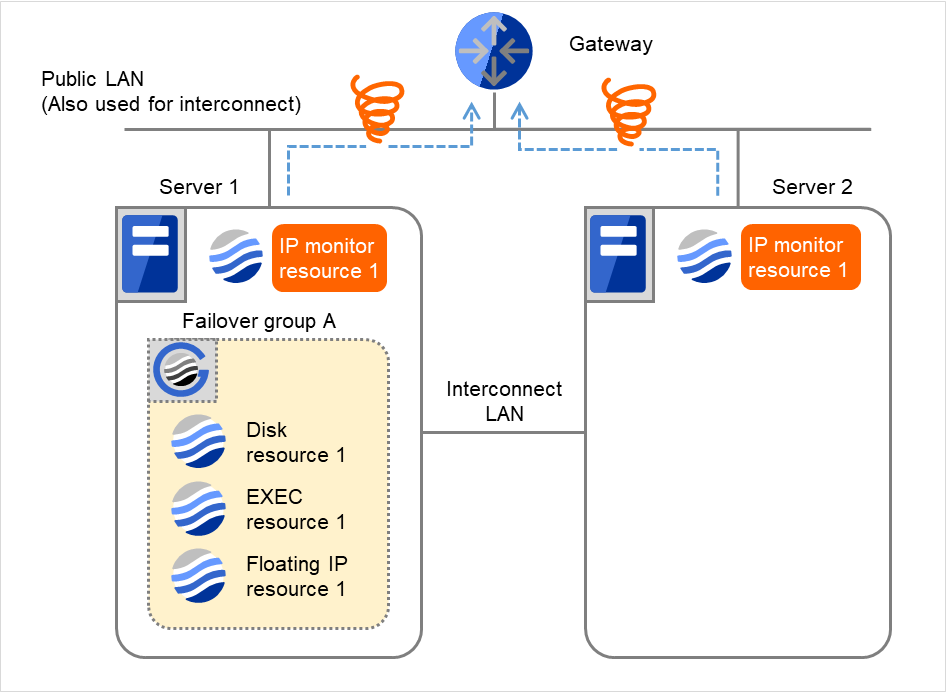
図 4.15 IP モニタリソース異常検出の流れ(両サーバで異常検出) (2)¶
IP monitor resource 1は監視を3回までリトライします。
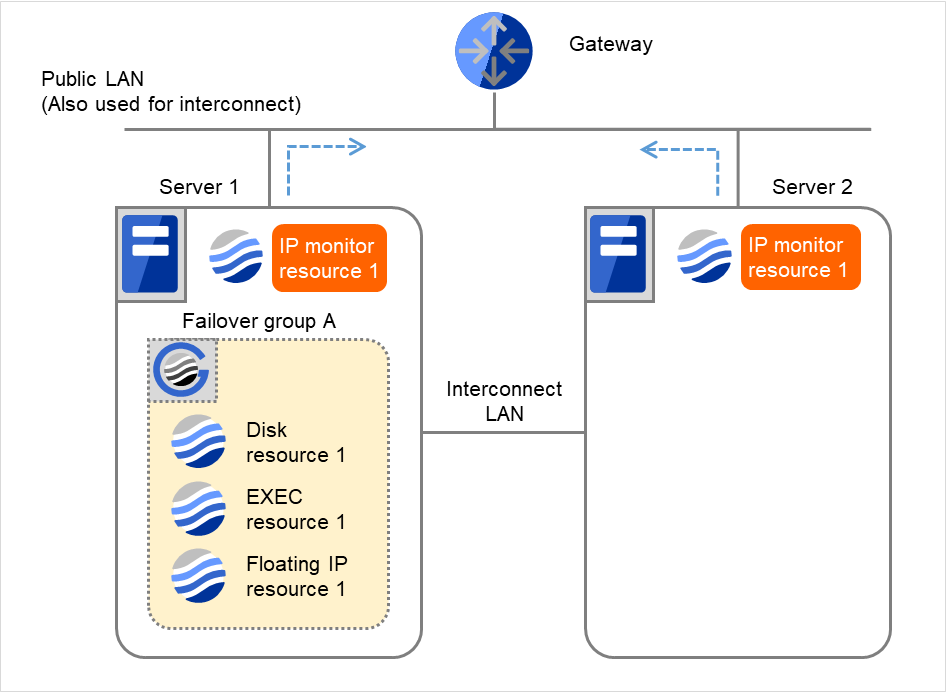
図 4.16 IP モニタリソース異常検出の流れ(両サーバで異常検出) (3)¶
- 監視リトライオーバした場合、Server 1で回復スクリプトの実行を開始します。"回復スクリプト実行回数" は各サーバでの回復スクリプトの実行回数です。これはServer 1での1回目の回復スクリプト実行です。Server 2では、Failover group Aが "停止済" のため、回復動作は行われません。
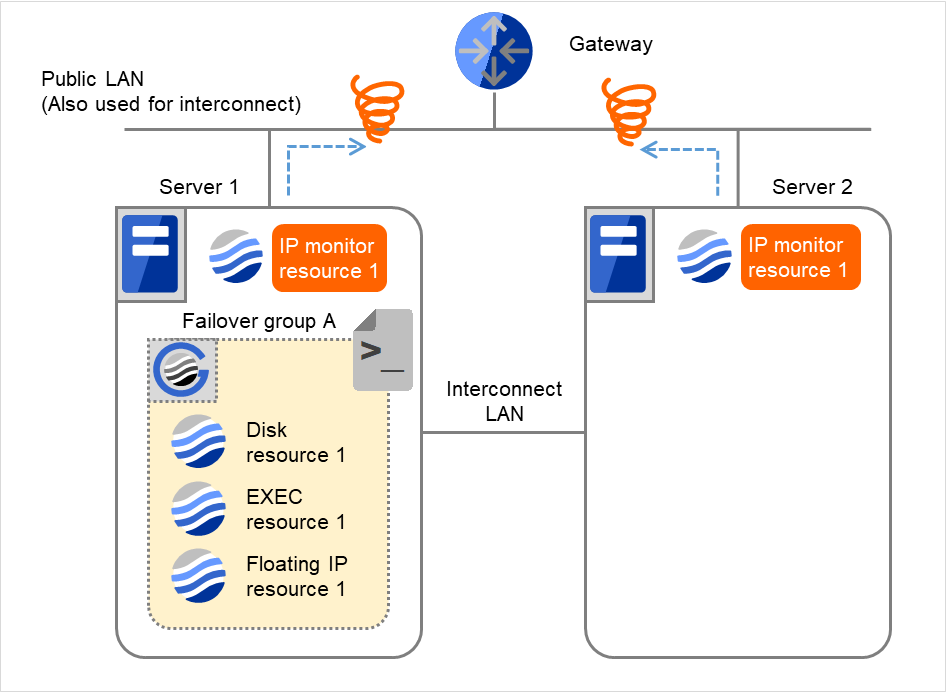
図 4.17 IP モニタリソース異常検出の流れ(両サーバで異常検出) (4)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
0
0
フェイルオーバ回数
0
0
- Server 1で回復スクリプト実行回数を超えた場合、Server 1でFailover group Aの再活性処理を開始します。"再活性化回数" は各サーバでの再活性化の回数を表しています。これは Server 1での1回目の再活性化処理です。Server 2では、Failover group Aが "停止済" のため、回復動作は行われません。
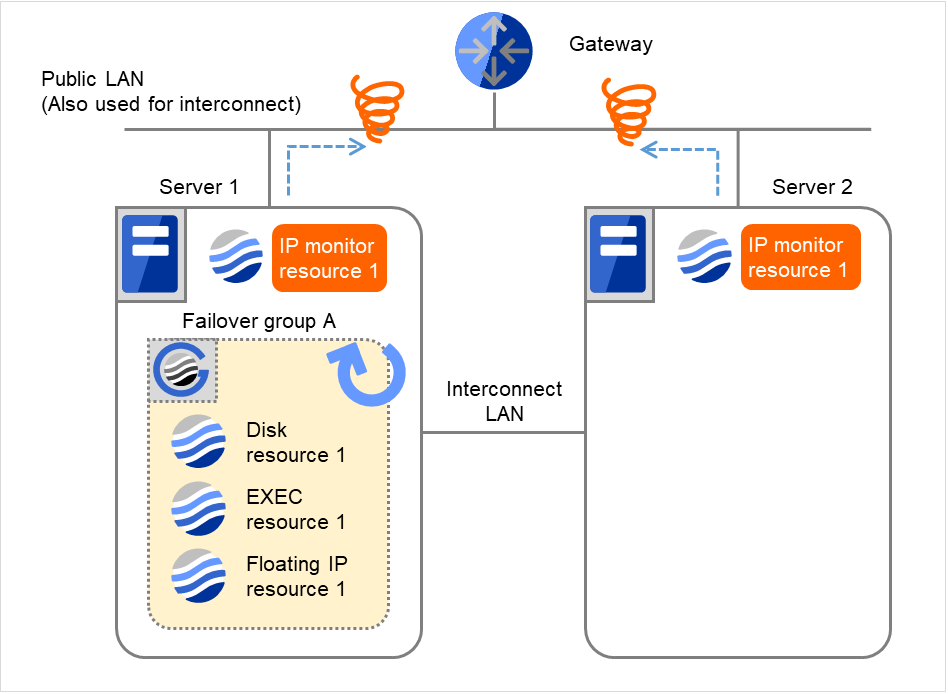
図 4.18 IP モニタリソース異常検出の流れ(両サーバで異常検出) (5)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
3
0
フェイルオーバ回数
0
0
- Server 1で再活性化しきい値を超えた場合、Server 1で Failover group Aのフェイルオーバ処理を開始します。"フェイルオーバしきい値" は各サーバでのフェイルオーバの回数を表しています。これは Server 1での1回目のフェイルオーバ処理です。Server 2では、Failover group Aが "停止済" のため、回復動作は行われません。
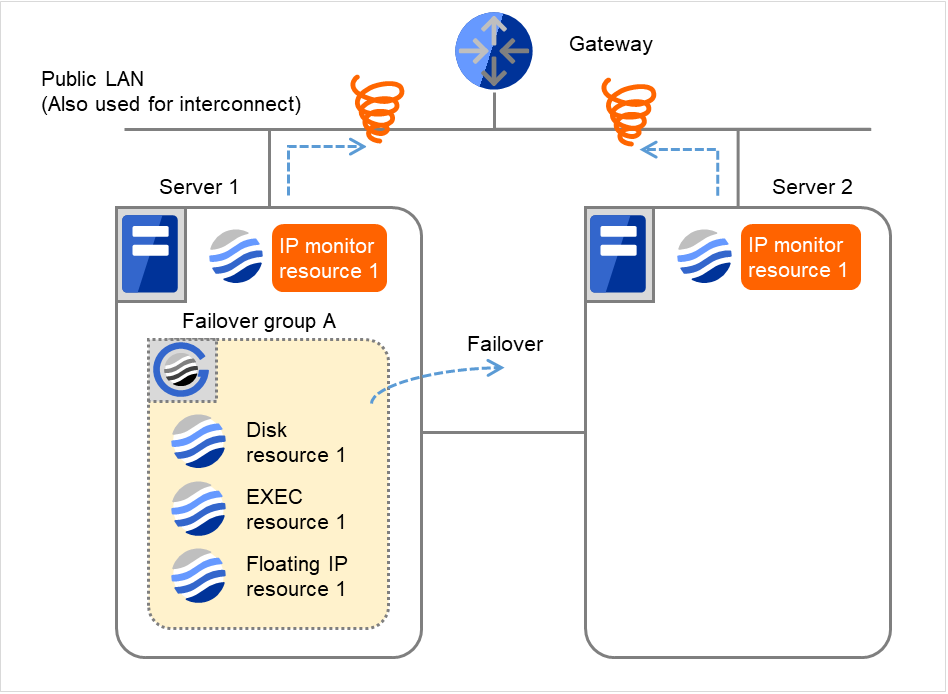
図 4.19 IP モニタリソース異常検出の流れ(両サーバで異常検出) (6)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
3
0
フェイルオーバ回数
1
0
- Failover group AをServer 1からServer 2へフェイルオーバします。Server 2で IP monitor resource 1の監視異常が継続しています。
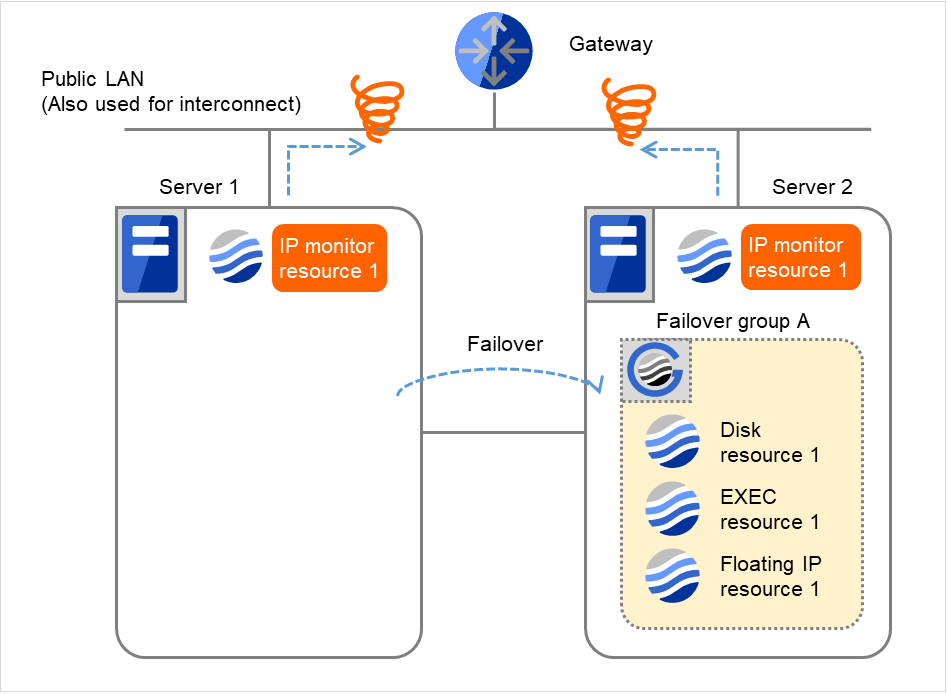
図 4.20 IP モニタリソース異常検出の流れ(両サーバで異常検出) (7)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
3
0
フェイルオーバ回数
1
0
IP monitor resource 1は監視を3回までリトライします。
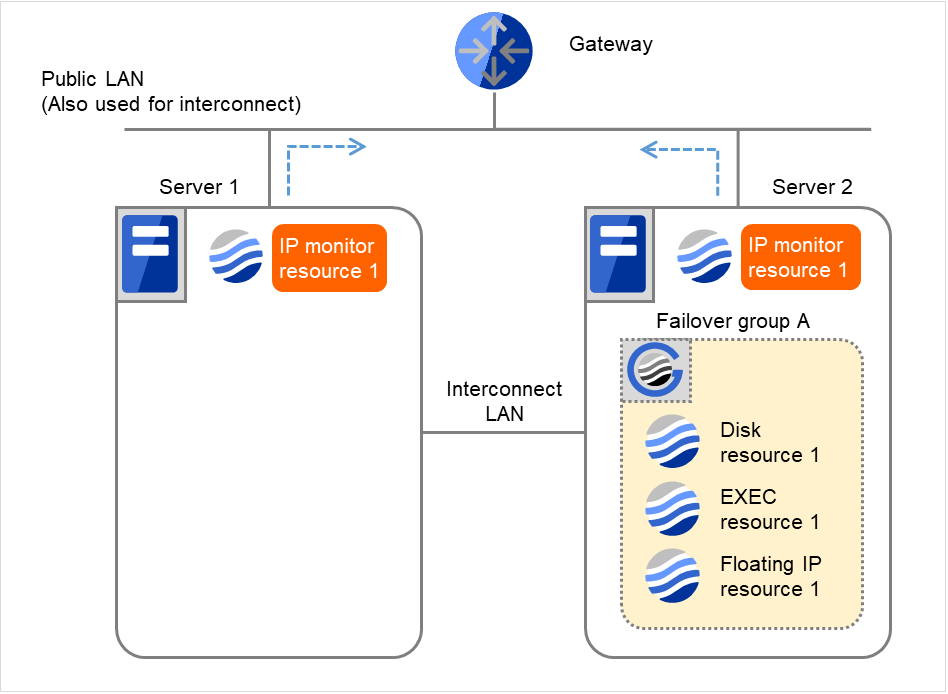
図 4.21 IP モニタリソース異常検出の流れ(両サーバで異常検出) (8)¶
IP monitor resource 1が監視リトライオーバした場合、異常が継続すれば回復スクリプト実行を3回までリトライします。
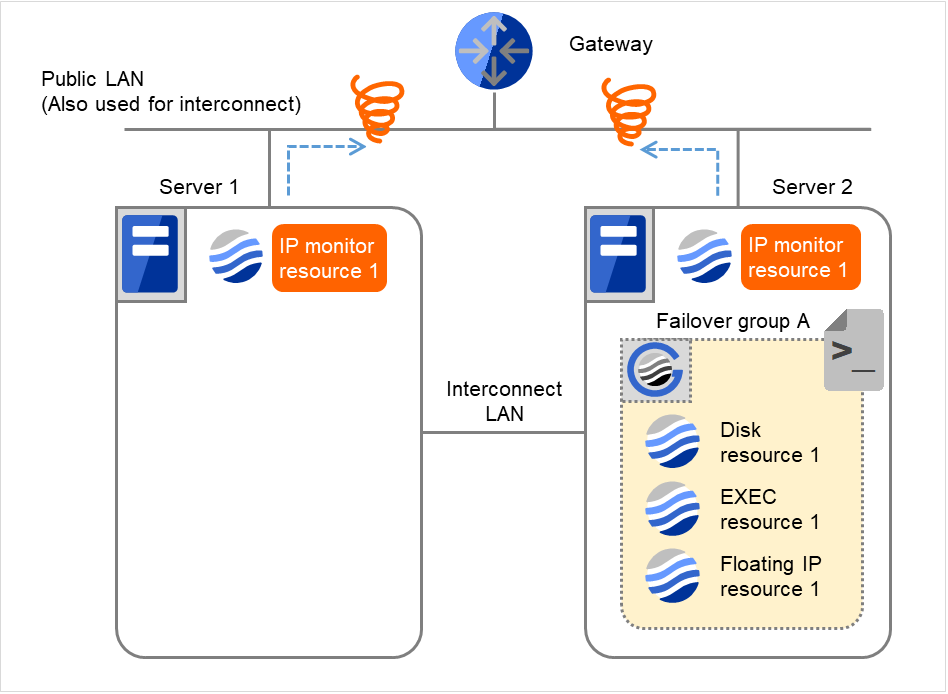
図 4.22 IP モニタリソース異常検出の流れ(両サーバで異常検出) (9)¶
Server 2でも回復スクリプト実行処理でリトライオーバした場合、異常が継続すれば Failover group Aの再活性処理を 3回までリトライします。
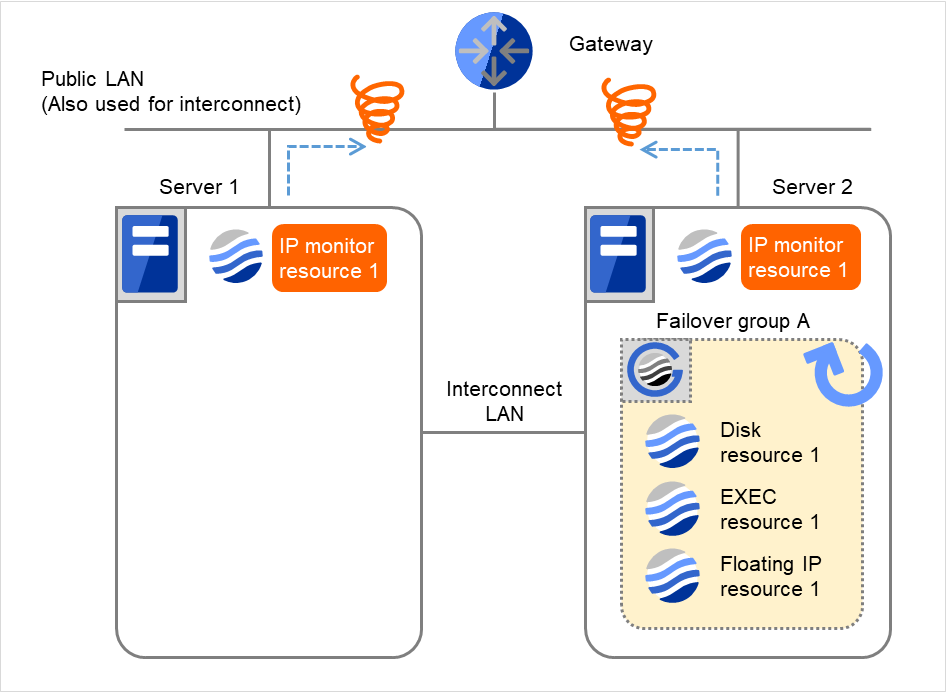
図 4.23 IP モニタリソース異常検出の流れ(両サーバで異常検出) (10)¶
回復スクリプト実行回数
3
3
再活性化回数
3
3
フェイルオーバ回数
1
0
- Server 2で再活性化処理でリトライオーバした場合、Server 2で Failover group Aのフェイルオーバ処理を開始します。これは Server 2での1回目のフェイルオーバ処理です。
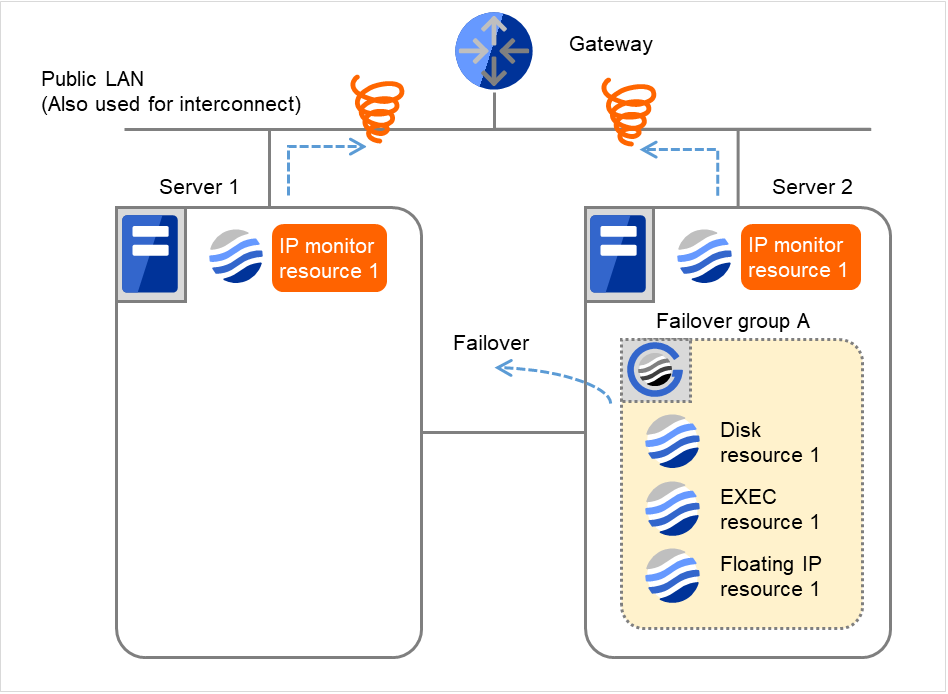
図 4.24 IP モニタリソース異常検出の流れ(両サーバで異常検出) (11)¶
回復スクリプト実行回数
3
3
再活性化回数
3
3
フェイルオーバ回数
1
1
- Failover group AをServer 2からServer 1へフェイルオーバします。Server 1で IP monitor resource 1の監視異常が継続します。
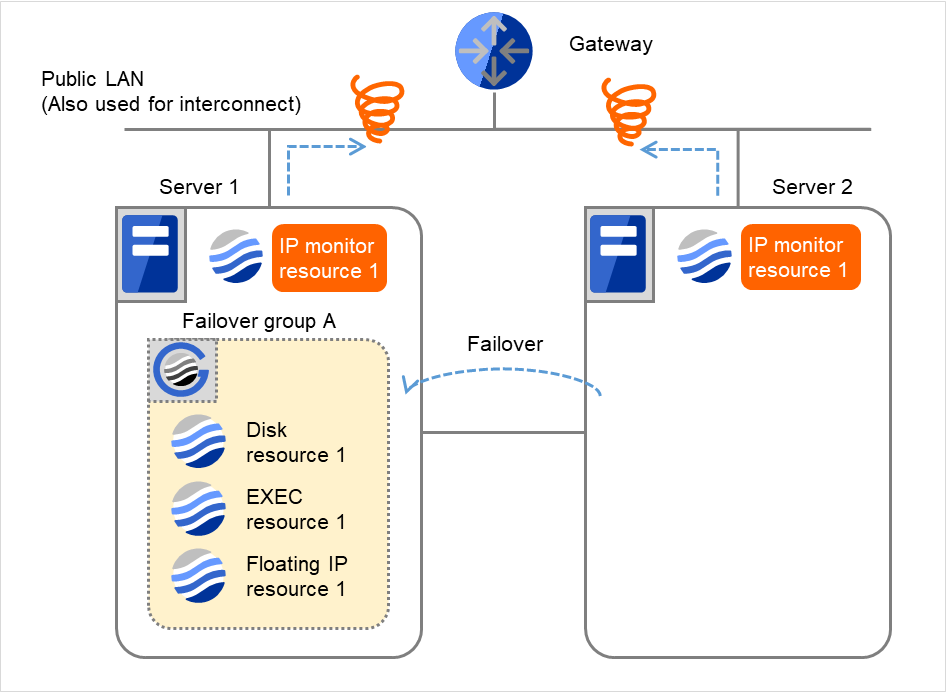
図 4.25 IP モニタリソース異常検出の流れ(両サーバで異常検出) (12)¶
回復スクリプト実行回数
3
3
再活性化回数
3
3
フェイルオーバ回数
1
1
Server 1でIP monitor resource 1の監視を3回までリトライします。
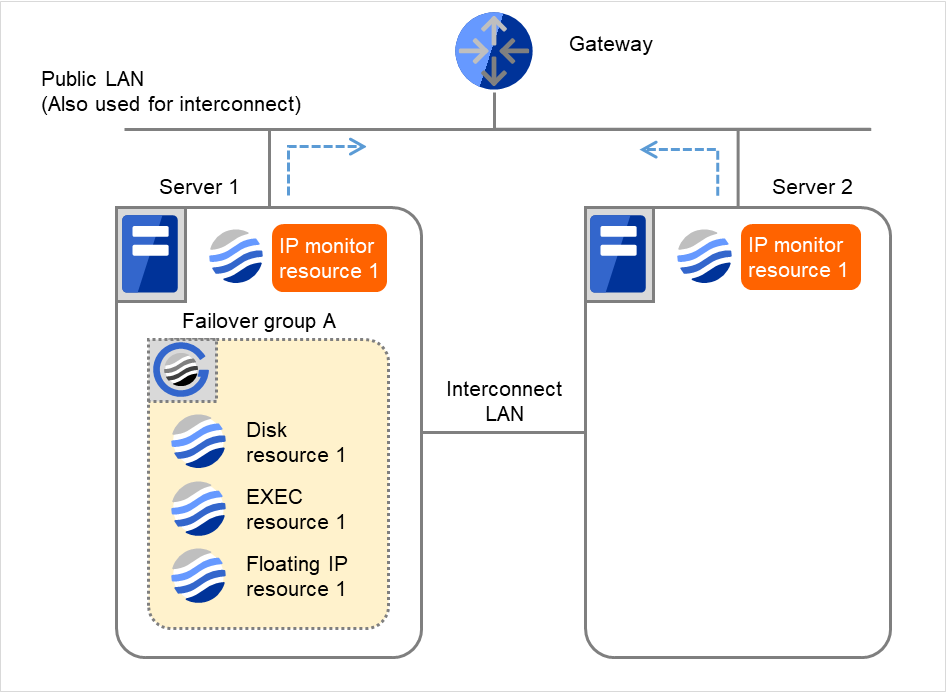
図 4.26 IP モニタリソース異常検出の流れ(両サーバで異常検出) (13)¶
- Server 1において、再度Disk monitor resource 1の監視でリトライオーバした場合、再活性化しきい値が3であるため、再活性処理は実行しません。また、フェイルオーバしきい値が1なので フェイルオーバ処理も実行せず、最終動作に設定された動作を開始します。Server 1で IP monitor resource 1の最終動作を開始します。"最終動作" はフェイルオーバがリトライオーバした後の動作です。
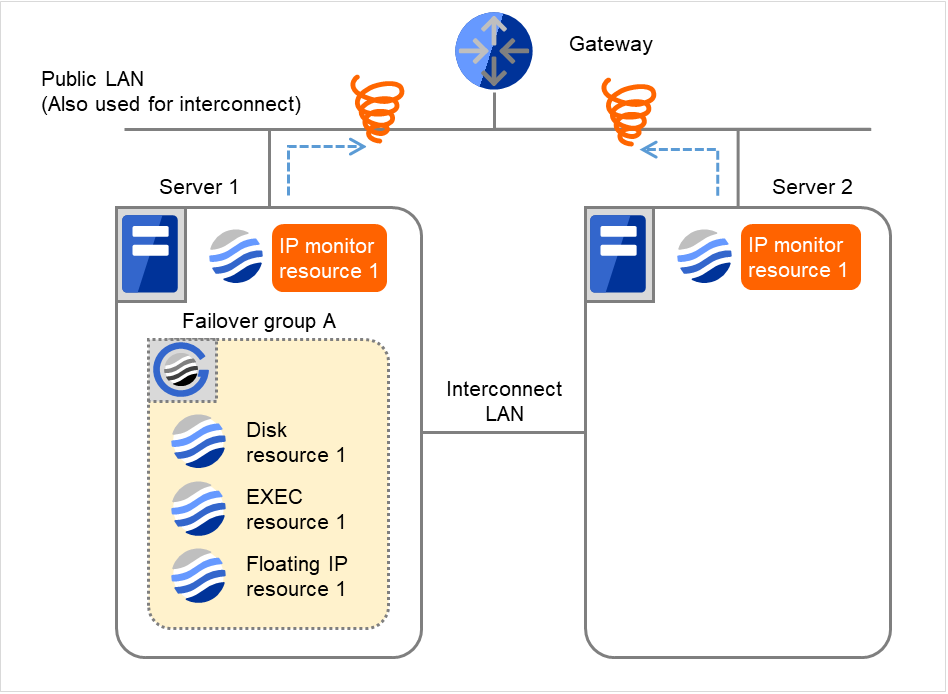
図 4.27 IP モニタリソース異常検出の流れ(両サーバで異常検出) (14)¶
以上の流れは、インタコネクト LAN が健全であることが前提となります。
全てのインタコネクト LAN が切断された状態では、他サーバとの内部通信が不可能なため、監視対象の異常を検出してもグループのフェイルオーバ処理が失敗します。
全てのインタコネクト LAN の断線を想定してグループのフェイルオーバを可能にする方法として、異常を検出したサーバをシャットダウンさせることができます。これにより他サーバがサーバダウンを検出してグループのフェイルオーバを開始します。
以下の設定例で、全インタコネクト LAN が断線状態での異常検出の流れを説明します。
[設定例]
を指定している場合の挙動の例
回復対象への再活性化処理は、インタコネクト LAN が健全な場合と同じです。
インタコネクト LAN が必要となる、サーバ 1 でのフェイルオーバ処理から説明します。
- 図は、2台のサーバにおいてIPモニタリソースが監視を行う場合の例です。インタコネクトLANが断線状態にあり、Server 1で再活性化処理をリトライしています。
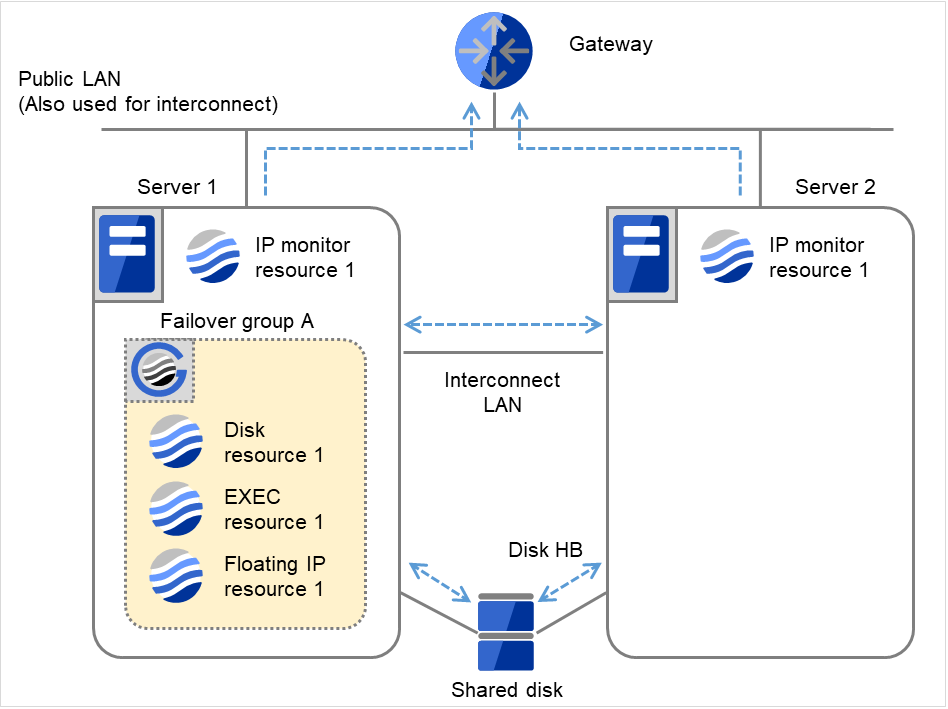
図 4.28 IP モニタリソース異常検出の流れ(全インタコネクト LAN が断線) (1)¶
Server 1IP monitor resource 1回復スクリプト実行回数
3
再活性化回数
3
フェイルオーバ回数
0
- Server 1で再活性化しきい値を超えた場合、 Failover group Aのフェイルオーバ処理を開始しますが、インタコネクトLANが断線状態で内部通信が不可能なため、フェイルオーバ処理は失敗します。
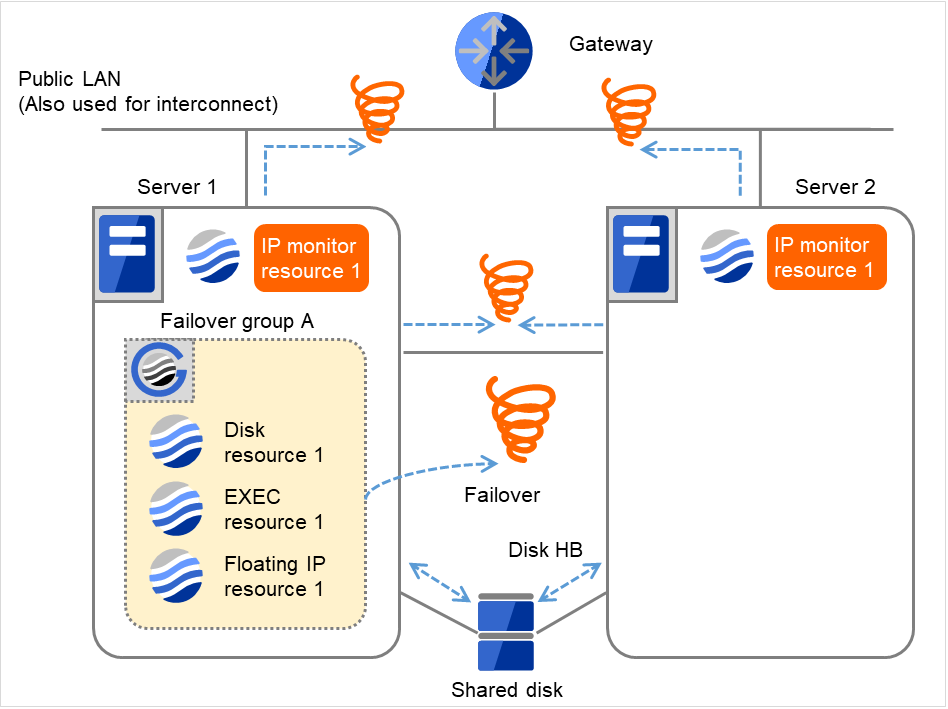
図 4.29 IP モニタリソース異常検出の流れ(全インタコネクト LAN が断線) (2)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
3
再活性化回数
3
0
フェイルオーバ回数
1
0
- Server 1でフェイルオーバしきい値を超えた場合、Server 1で最終動作が実行され、クラスタサービスを停止後、シャットダウンされます。Server 1ダウン後、Failover group Aはフェイルオーバポリシに従って、フェイルオーバ処理を開始します。"最終動作" はフェイルオーバがリトライオーバした後の動作です。
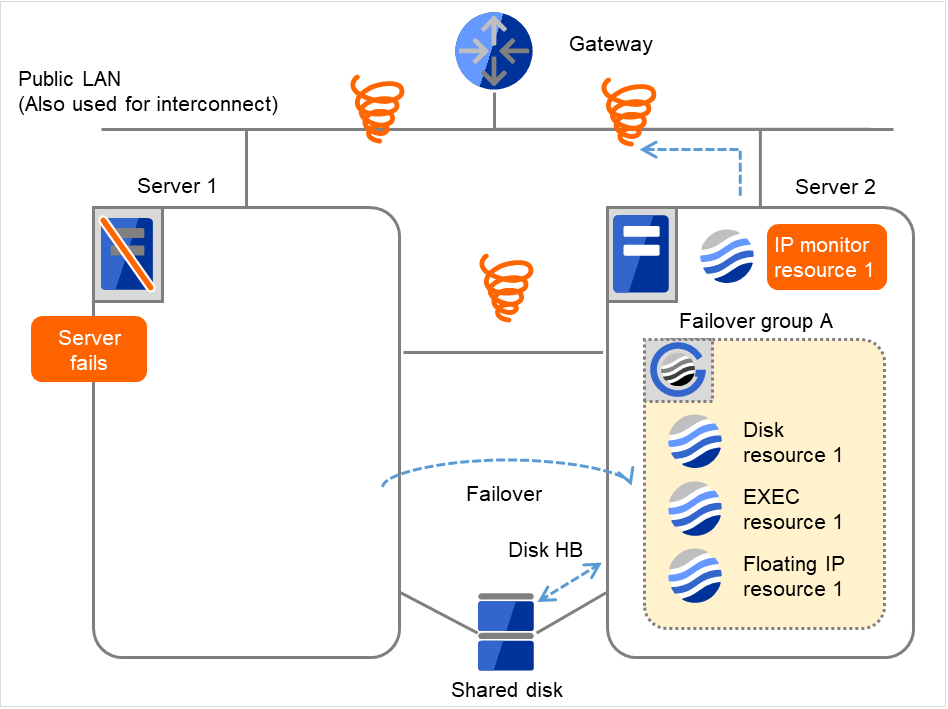
図 4.30 IP モニタリソース異常検出の流れ(全インタコネクト LAN が断線) (3)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
3
0
フェイルオーバ回数
1
0
- サーバ2でIP monitor resource 1 の異常が継続した場合、サーバ 2 においてサーバ 1 と同様にグループ A の再活性化を実行します。サーバ 2 でもグループ A の再活性化で異常が発生するとフェイルオーバを試みます。しかし、フェイルオーバに関しては、フェイルオーバ先が無いのでフェイルオーバできません。フェイルオーバしきい値を超えた場合、サーバ 1 と同様にサーバ 2 で最終動作が実行されます。
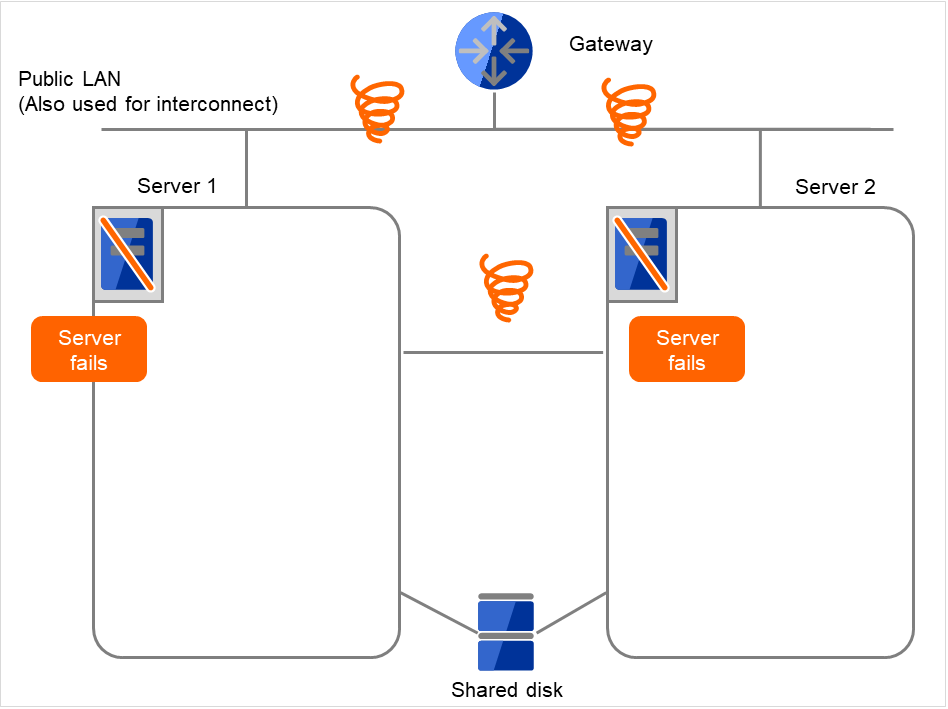
図 4.31 IP モニタリソース異常検出の流れ(全インタコネクト LAN が断線) (4)¶
4.1.7. 監視異常からの復帰 (正常)¶
監視異常を検出し、回復動作遷移中または全ての回復動作を完了後にモニタリソースの復帰を検出すると、そのモニタリソースが保持している以下のしきい値に対する回数カウンタはリセットされます。
回復スクリプト実行回数
再活性化回数
フェイルオーバ回数
最終動作については、実行要否がリセット (実行要に) されます。
以下は「 モニタリソースによる異常検出時の動作 」の最終動作実行後から監視が正常に復帰し、再度監視が異常になる流れを説明します。
[設定例]
を指定している場合の挙動の例
- 図は、2台のサーバにおいてIPモニタリソースが監視を行う場合の例です。回復動作を全て実行後、監視異常が継続しています。Server 1は IP monitor resource 1の最終動作実行済の状態です。
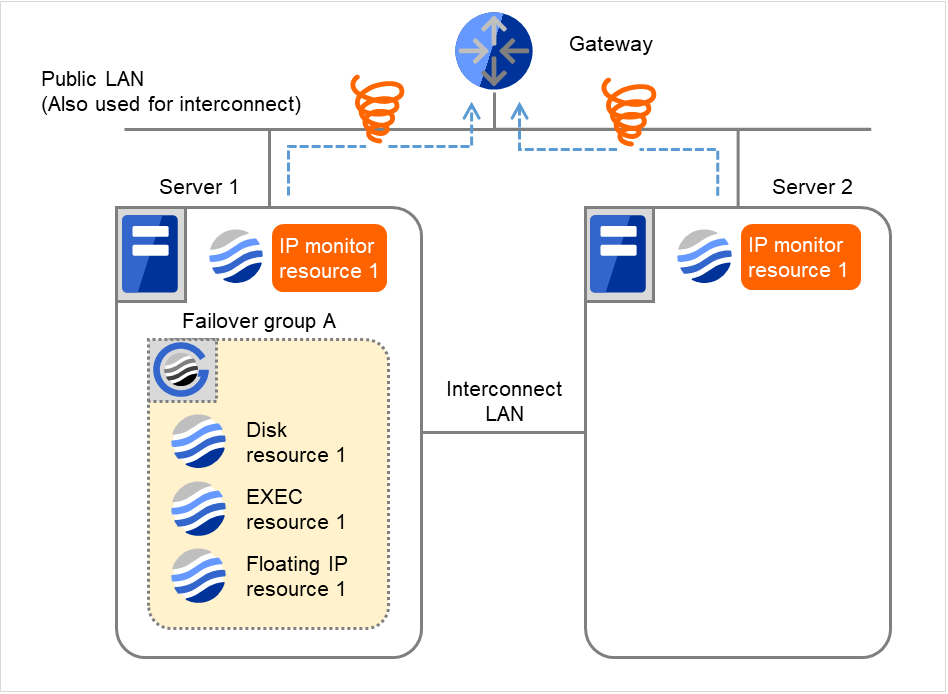
図 4.32 IP モニタリソース異常検出の流れ(監視異常からの復帰・正常) (1)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
3
再活性化回数
3
3
フェイルオーバ回数
1
1
- Gatewayが復旧した場合、IP monitor resource 1の監視が正常を検出します。監視対象リソースが正常になったことを検出したため、再活性化回数およびフェイルオーバ 回数はリセットされます。
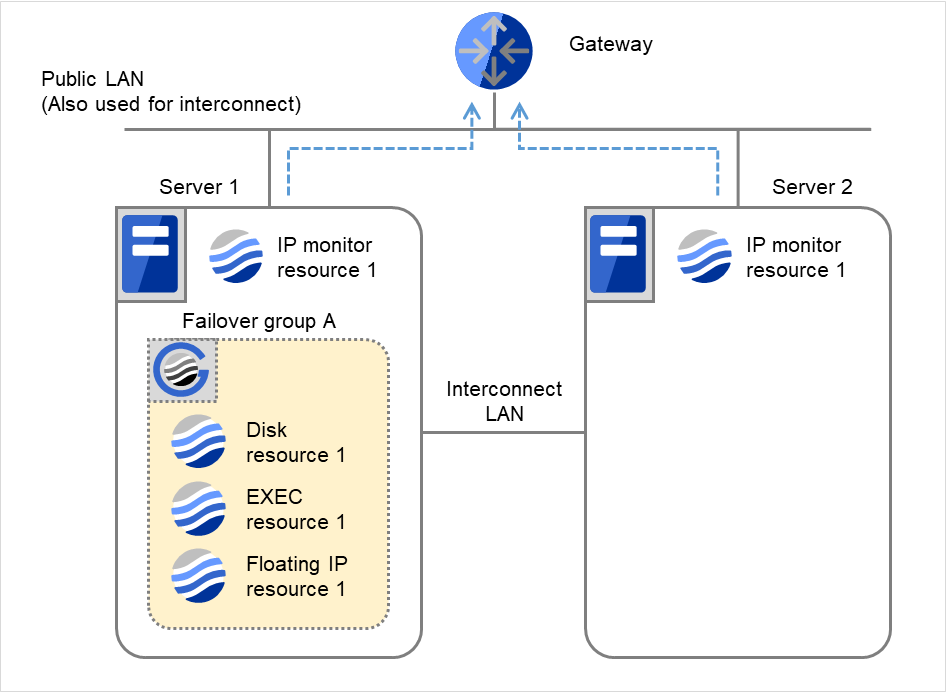
図 4.33 IP モニタリソース異常検出の流れ(監視異常からの復帰・正常) (2)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
0
0
再活性化回数
0
0
フェイルオーバ回数
0
0
再度、IP monitor resource 1の監視が異常を検出した場合です。
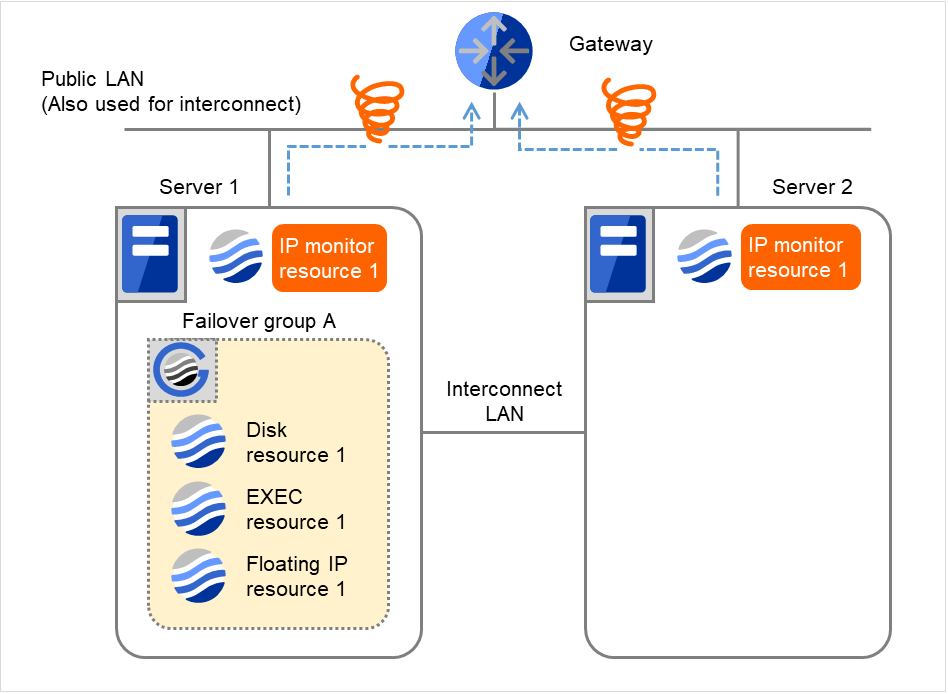
図 4.34 IP モニタリソース異常検出の流れ(監視異常からの復帰・正常) (3)¶
- IP monitor resource 1の監視を3回までリトライします。"リトライ回数" は、このサーバでのリトライ回数です。
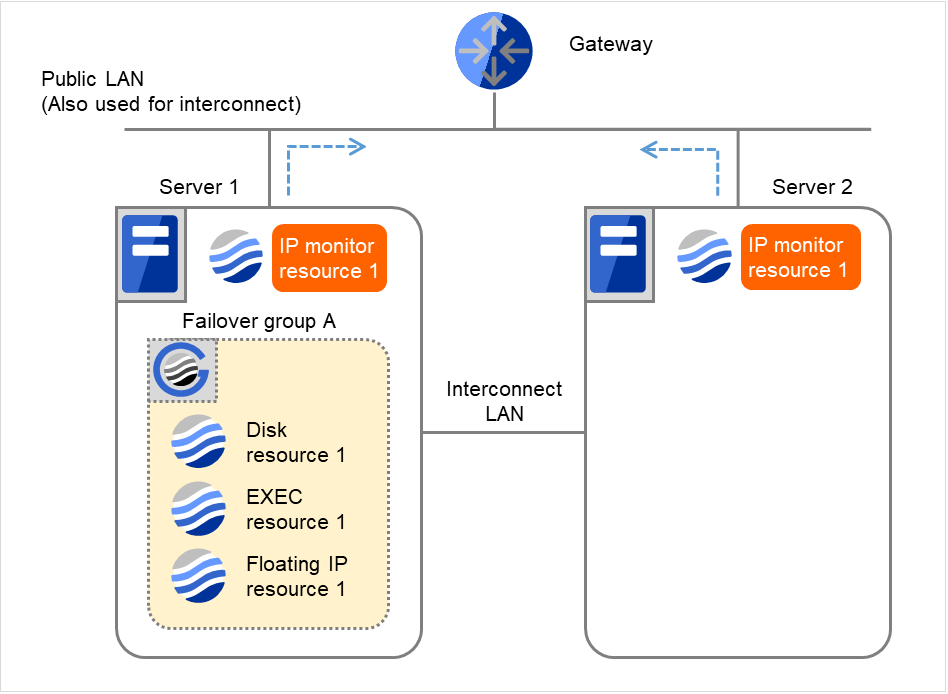
図 4.35 IP モニタリソース異常検出の流れ(監視異常からの復帰・正常) (4)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
0
0
再活性化回数
0
0
フェイルオーバ回数
0
0
- 監視リトライオーバした場合、Server 1で回復スクリプト実行処理を開始します。"回復スクリプト実行回数" は各サーバでの回復スクリプトの実行回数です。これはServer 1での1回目の回復スクリプト実行処理です。Server 2では、Failover group Aが "停止済" のため、回復動作は行われません。
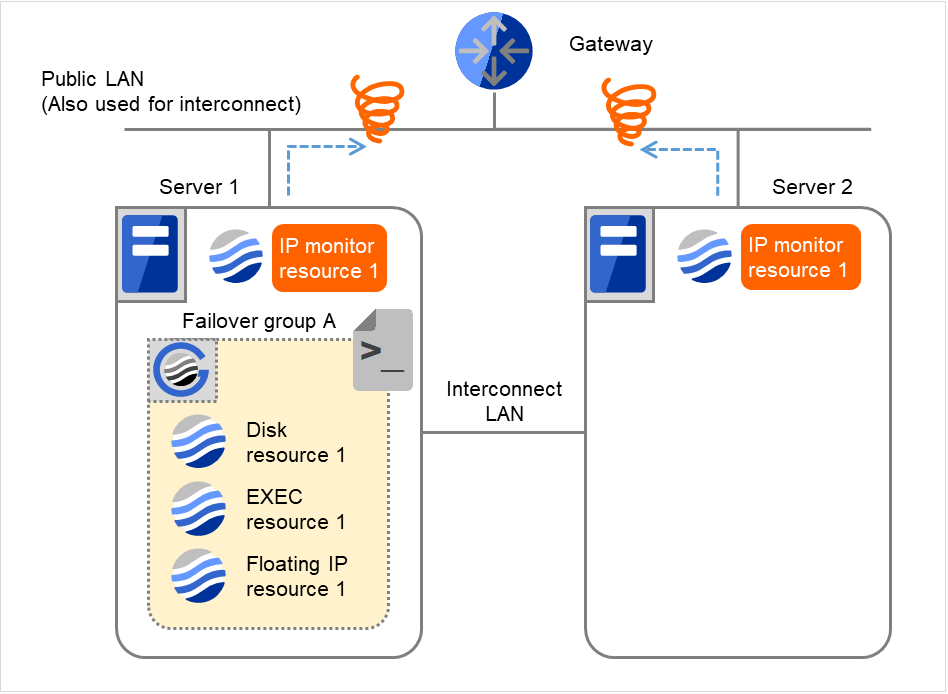
図 4.36 IP モニタリソース異常検出の流れ(監視異常からの復帰・正常) (5)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
0
0
フェイルオーバ回数
0
0
- Server 1で回復スクリプト実行回数を超えた場合、Server 1でFailover group Aの再活性処理を開始します。"再活性化回数" は各サーバでの再活性化の回数です。これは Server 1での1回目の再活性化処理です。以前に監視対象リソースが正常になったことを検出して再活性化回数がリセットされているため再度、再活性化処理を行います。
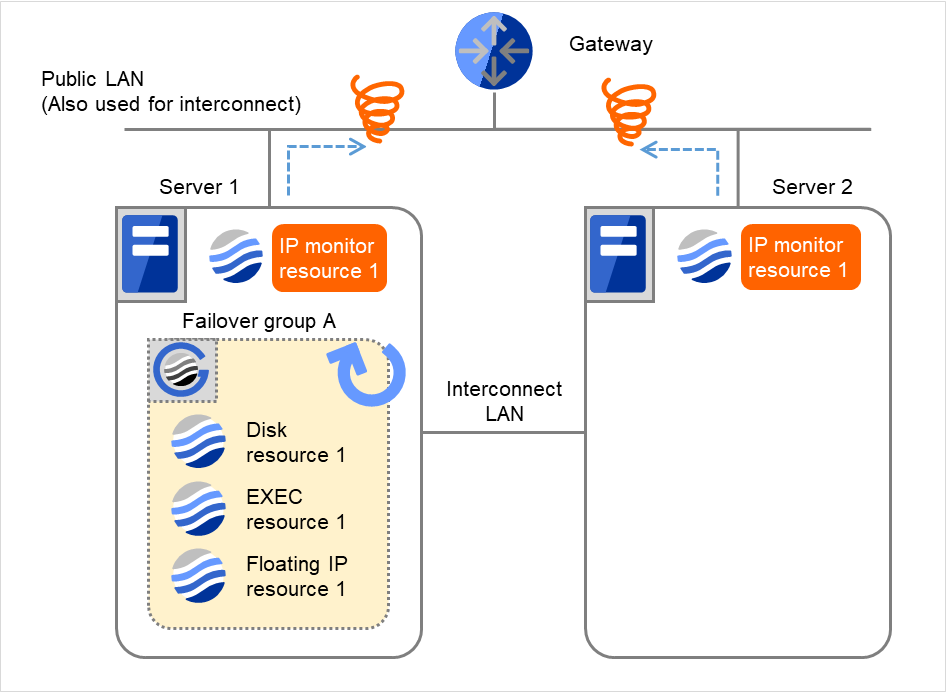
図 4.37 IP モニタリソース異常検出の流れ(監視異常からの復帰・正常) (6)¶
Server 1IP monitor resource 1Server 2IP monitor resource 1回復スクリプト実行回数
3
0
再活性化回数
3
0
フェイルオーバ回数
0
0
4.1.8. 回復動作時の回復対象活性/非活性異常¶
モニタリソースの監視先と回復対象のグループリソースが同一のデバイスの場合、監視異常を検出すると、回復動作中にグループリソースの活性/非活性異常を検出する場合があります。
以下はディスクモニタリソースの監視先とフェイルオーバグループ A のディスクリソースを同一デバイスに指定した場合の回復動作の流れを説明します。
[ディスクモニタリソースの設定例]
[フェイルオーバグループ A : ディスクリソースの設定例]
モニタリソースの再活性化しきい値とグループリソースの活性リトライしきい値は、共に設定回数が 0 回のため遷移図内では省略します。
- 図は、2台のサーバにおいてディスクモニタリソースが監視を行う場合の例です。Server 1、Server 2で Disk monitor resource 1、Failover group Aの活性処理を開始します。インターバル毎にデバイスへTURのioctlを実行します。
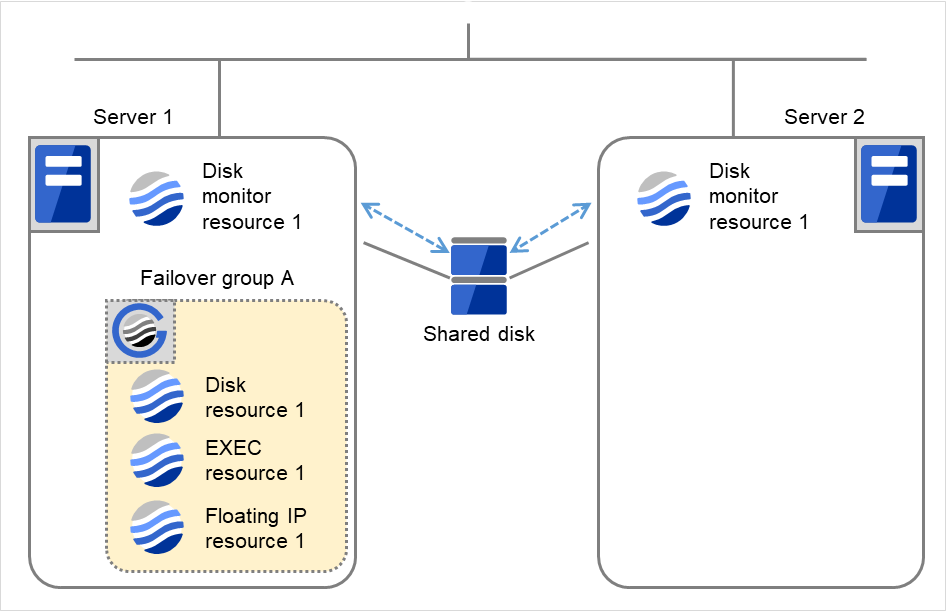
図 4.38 ディスクモニタリソース異常検出の流れ (1)¶
Server 1
Server 2
Disk monitor resource 1フェイルオーバ回数0
0
Disk resource 1フェイルオーバ回数0
0
- Server 1、Server 2で Disk monitor resource 1の監視が異常(TURのioctlに失敗)を検出しました。ディスクデバイスの障害箇所によっては、ディスクリソースの非活性処理で異常を検出する場合があります。
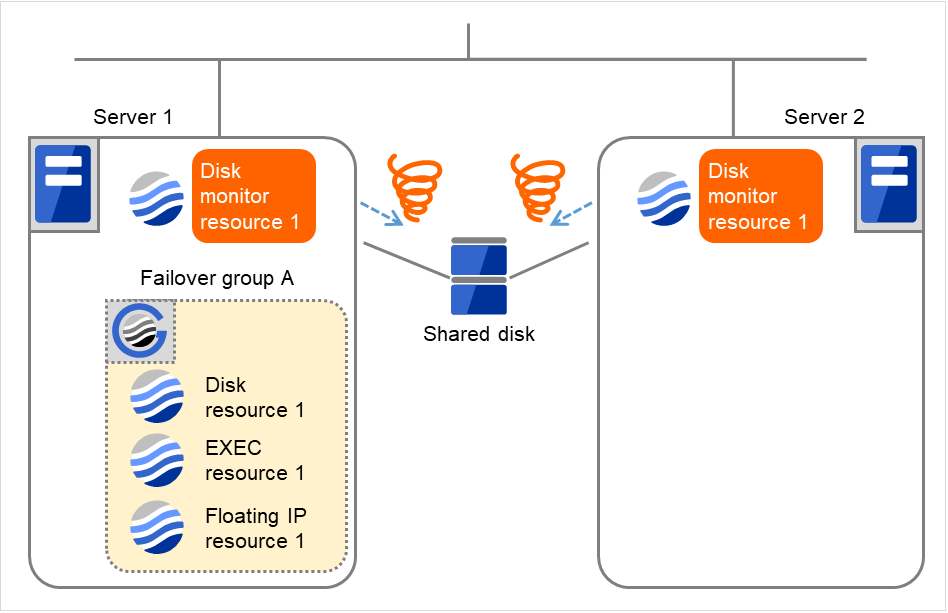
図 4.39 ディスクモニタリソース異常検出の流れ (2)¶
- Server 1でDisk monitor resource 1の監視異常により、Failover group Aのフェイルオーバ処理を開始します。モニタリソースのフェイルオーバしきい値は、各サーバでのフェイルオーバの回数です。これはServer 1での一回目のフェイルオーバ処理です。
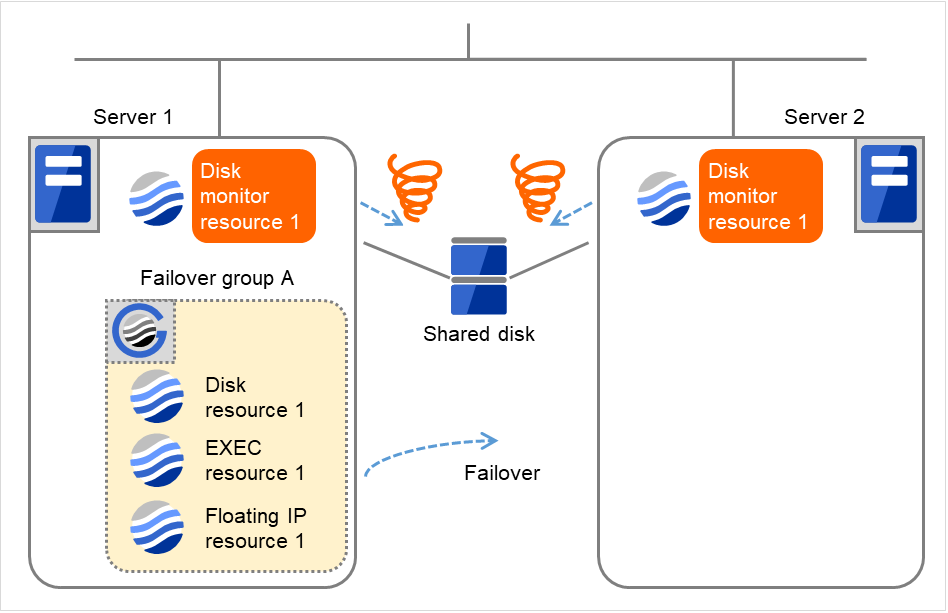
図 4.40 ディスクモニタリソース異常検出の流れ (3)¶
Server 1
Server 2
Disk monitor resource 1フェイルオーバ回数1
0
Disk resource 1フェイルオーバ回数0
0
- Server 2でフェイルオーバ処理によるDisk resource 1の活性に失敗(fsck、mountの失敗など)しました。ディスクデバイスの障害箇所によっては、ディスクリソースの非活性処理で異常を検出する場合があります。
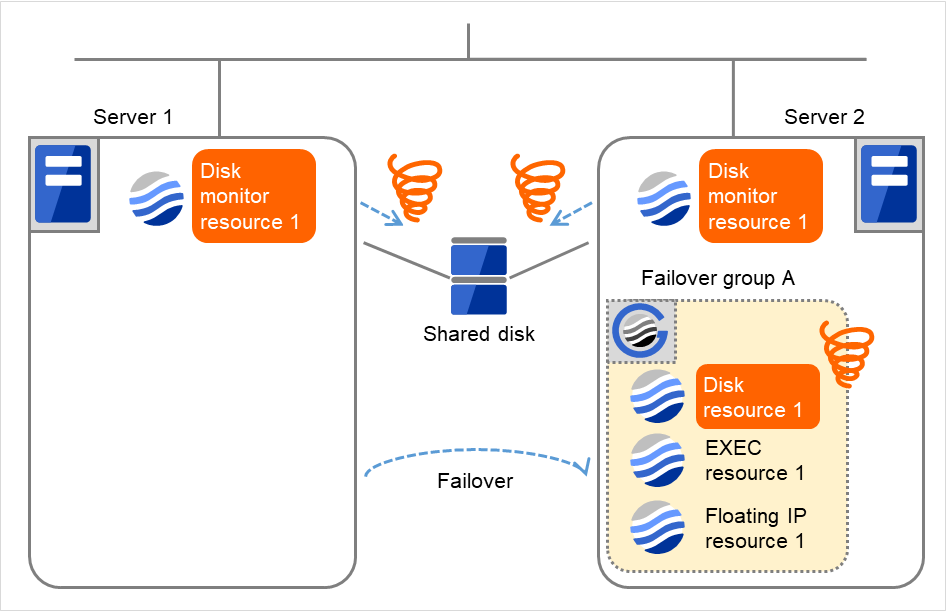
図 4.41 ディスクモニタリソース異常検出の流れ (4)¶
- Server 2でDisk resource 1の活性異常により、Failover group Aのフェイルオーバ処理を開始します。グループリソースのフェイルオーバしきい値は、各サーバでのフェイルオーバの回数です。これはServer 2での一回目のフェイルオーバ処理です。
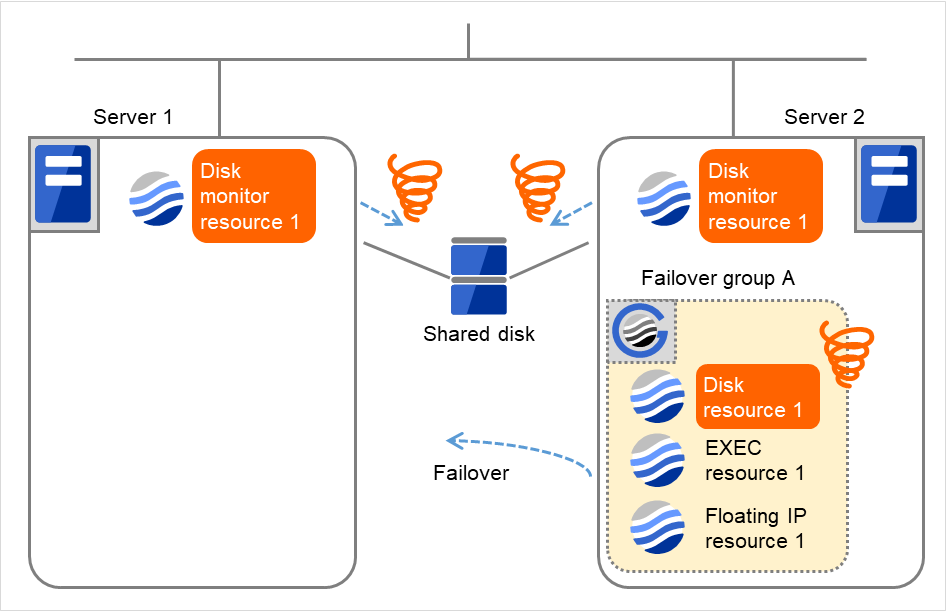
図 4.42 ディスクモニタリソース異常検出の流れ (5)¶
Server 1
Server 2
Disk monitor resource 1フェイルオーバ回数1
0
Disk resource 1フェイルオーバ回数0
1
- サーバ 2 でもサーバ 1 と同様にディスクモニタリソース 1 の異常を検出していますが、回復対象である "フェイルオーバグループA" が起動中のため回復動作は行われません。モニタリソースが回復対象に対して回復動作を行う条件については、「モニタリソースによる異常検出時の動作」を参照してください。Server 1でフェイルオーバ処理によるDisk resource 1の活性に失敗(fsck、mountの失敗など)しました。ディスクデバイスの障害箇所によっては、ディスクリソースの非活性処理で異常を検出する場合があります。
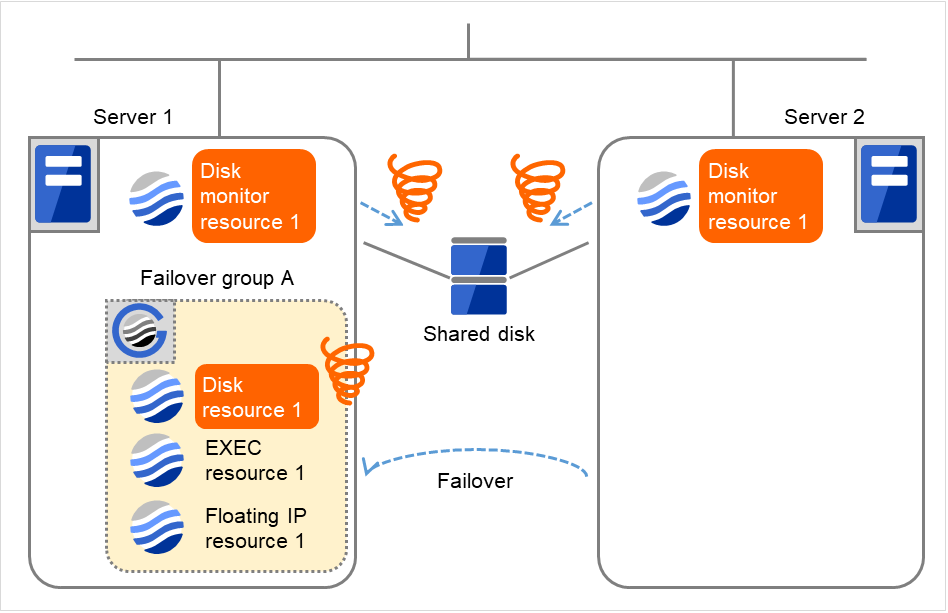
図 4.43 ディスクモニタリソース異常検出の流れ (6)¶
Server 1
Server 2
Disk monitor resource 1フェイルオーバ回数1
0
Disk resource 1フェイルオーバ回数0
1
- Server 1でDisk resource 1の活性異常により Failover group Aのフェイルオーバ処理を開始します。これは Server 1での一回目のフェイルオーバ処理です。ディスクデバイスの障害箇所によっては、ディスクリソースの非活性処理で異常を検出する場合があります。
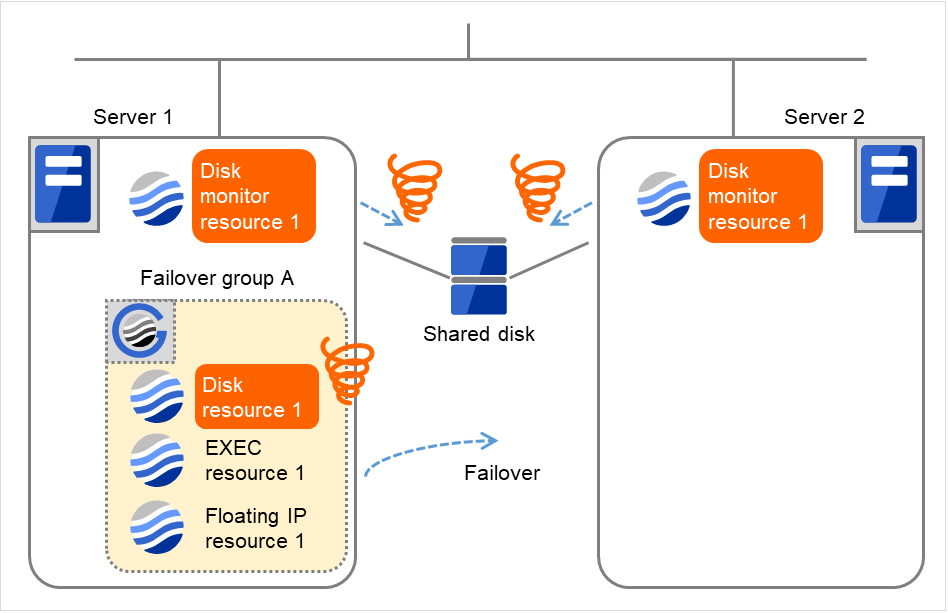
図 4.44 ディスクモニタリソース異常検出の流れ (7)¶
Server 1
Server 2
Disk monitor resource 1フェイルオーバ回数1
0
Disk resource 1フェイルオーバ回数1
1
- Server 2でフェイルオーバ処理によるDisk resource 1の活性に失敗(fsck、mountの失敗など)しました。ディスクデバイスの障害箇所によっては、ディスクリソースの非活性処理で異常を検出する場合があります。
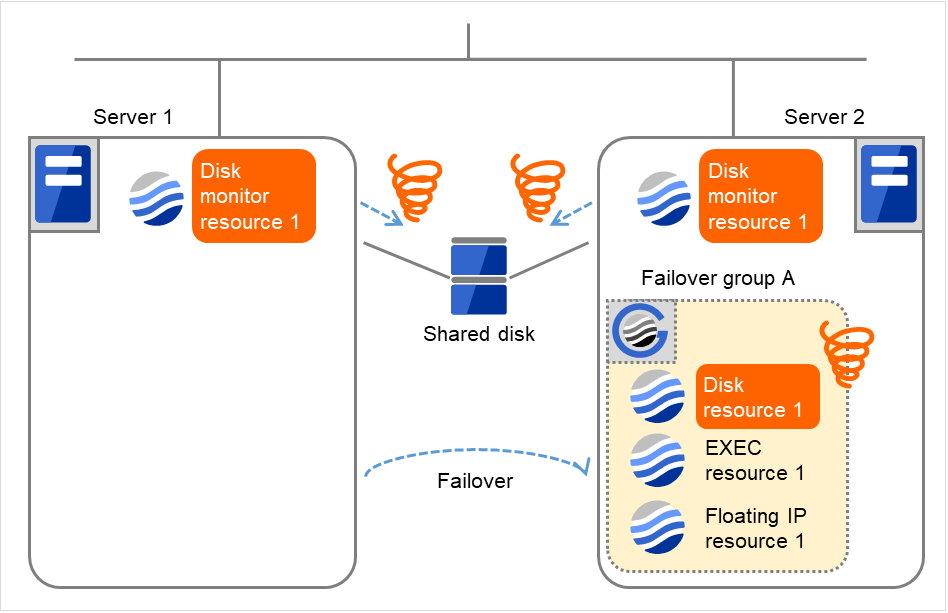
図 4.45 ディスクモニタリソース異常検出の流れ (8)¶
Server 1
Server 2
Disk monitor resource 1フェイルオーバ回数1
0
Disk resource 1フェイルオーバ回数1
1
- サーバ 2 では、ディスクリソース 1 の活性異常によるフェイルオーバ回数がしきい値を超えているため、最終動作を実行します。ただし、最終動作には "何もしない(次のリソースを活性しない)" が設定されているため、フェイルオーバグループ A の残りのグループリソースは活性されず、起動処理は異常終了となります。
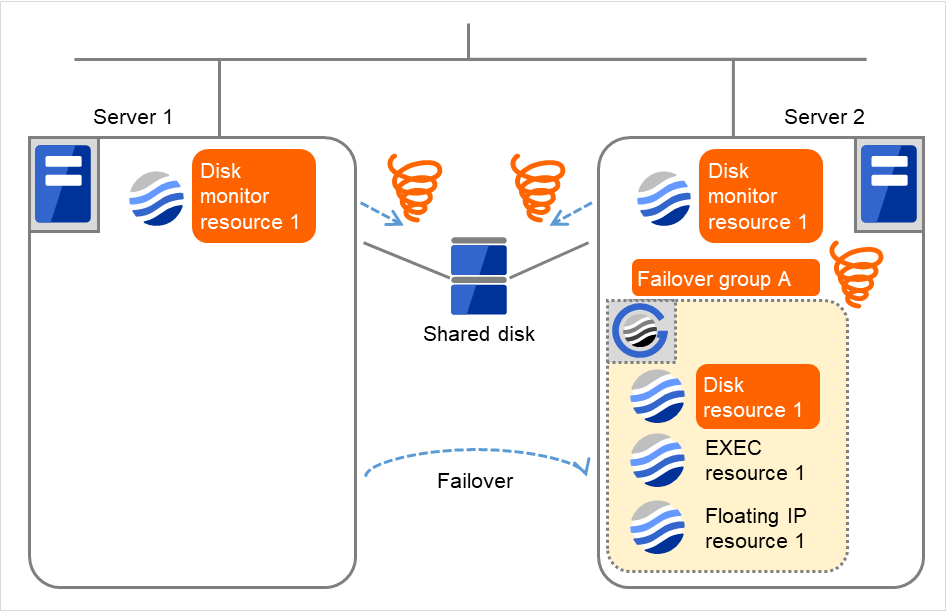
図 4.46 ディスクモニタリソース異常検出の流れ (9)¶
- "Server 2でDisk monitor resource 1の監視異常によりFailover group Aのフェイルオーバ処理を開始します。これはServer 2での1回目のフェイルオーバ処理です。
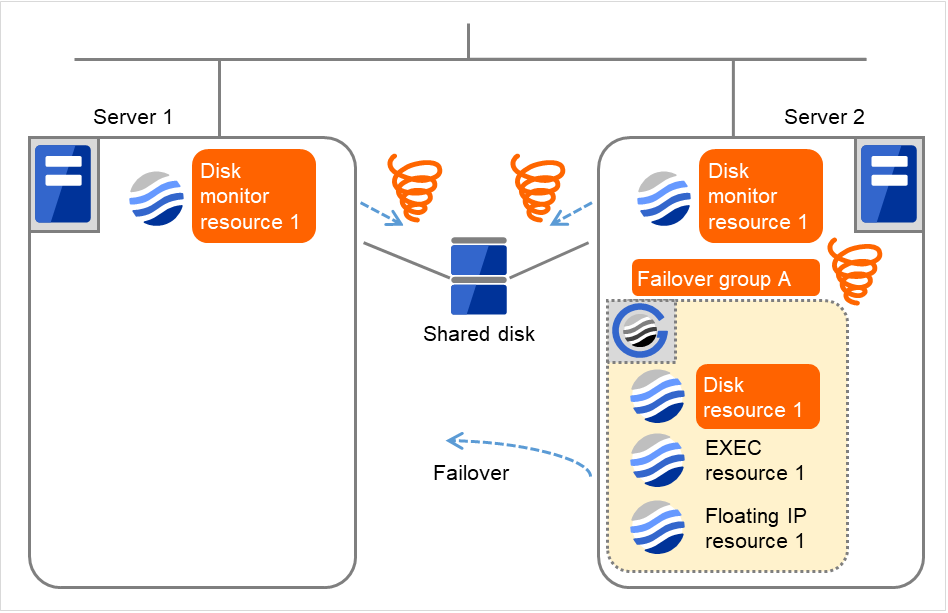
図 4.47 ディスクモニタリソース異常検出の流れ (10)¶
Server 1
Server 2
1
1
1
1
- サーバ 1 でもサーバ 2 と同様に、ディスクリソース 1 の活性異常によるフェイルオーバ回数がしきい値を超えているため、最終動作を実行します。ただし、最終動作には "何もしない(次のリソースを活性しない)" が設定されているため、フェイルオーバグループ A の残りのグループリソースは活性されず、起動処理は異常終了となります。ディスクデバイスの障害箇所によっては、ディスクリソースの非活性処理で異常を検出する場合があります。
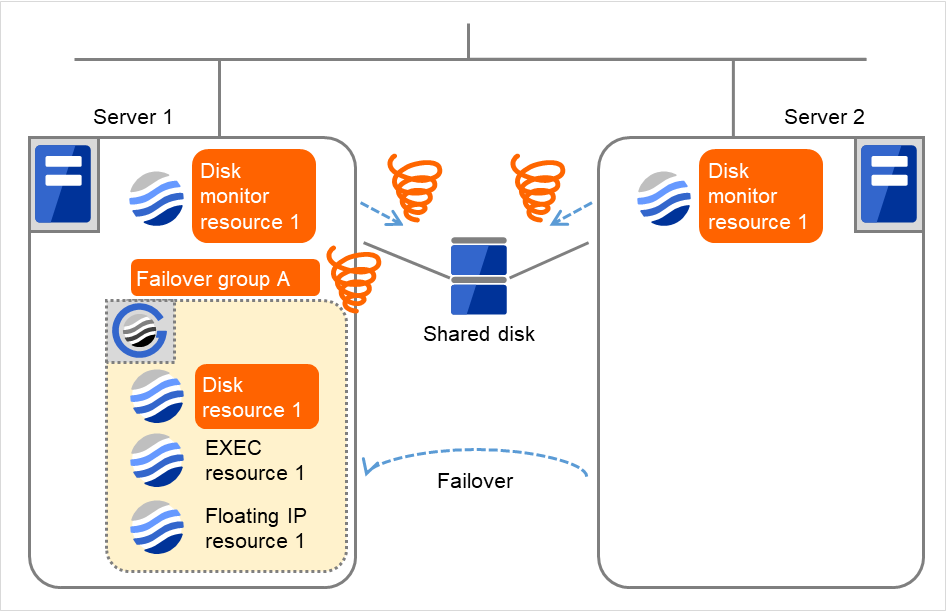
図 4.48 ディスクモニタリソース異常検出の流れ (11)¶
Server 1
Server 2
1
1
1
1
- サーバ 1 では、ディスクモニタリソース 1 の監視異常によるフェイルオーバ回数がしきい値を超えているため、最終動作(グループ停止)を実行します。サーバ 1 で実行されたディスクモニタリソース 1 の最終動作によりフェイルオーバグループA が停止したため、これ以降でディスクモニタリソース 1 の監視異常を検出しても何も起こりません。ただし、サーバ 2 ではディスクモニタリソース 1 の最終動作がまだ実行されていないため、フェイルオーバグループ A を手動で起動した場合は、ディスクモニタリソース 1 の最終動作が実行されます。
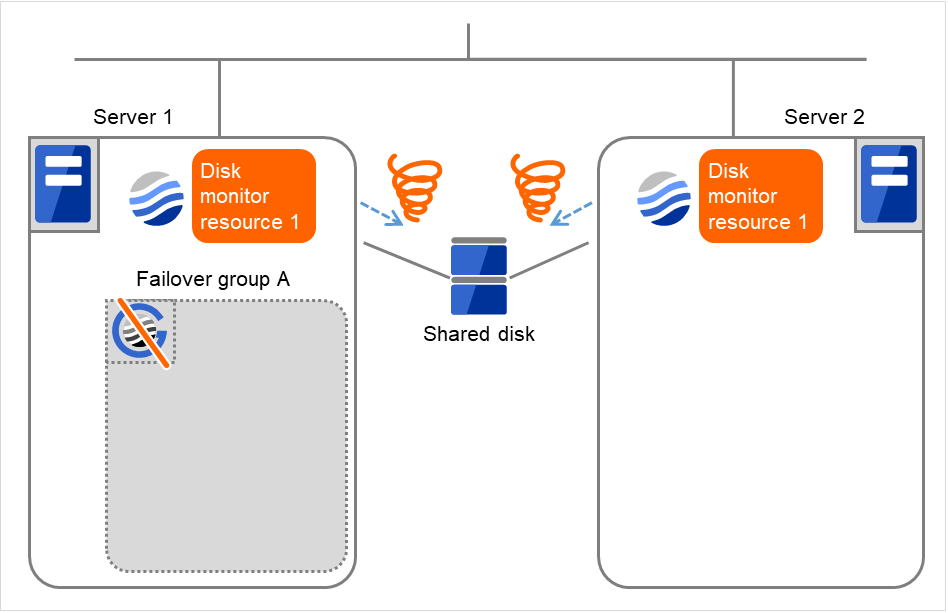
図 4.49 ディスクモニタリソース異常検出の流れ (12)¶
Server 1
Server 2
1
1
1
1
4.1.9. 回復スクリプト、回復動作前スクリプトについて¶
モニタリソースの異常検出時に、回復スクリプトを実行させることが可能です。また、回復対象の再活性化、フェイルオーバ、最終動作を実行する前に回復動作前スクリプトを実行させることも可能です。
いずれの場合でも共通のスクリプトファイルが実行されます。
回復スクリプト、回復動作前スクリプトで使用する環境変数
CLUSTERPRO はスクリプトを実行する場合に、どの状態で実行したか (回復動作種別) などの情報を環境変数にセットします。
スクリプト内で下図の環境変数を分岐条件として、システム運用にあった処理内容を記述できます。
環境変数 |
環境変数の値 |
意味 |
|---|---|---|
CLP_MONITORNAME
…モニタリソース名
|
モニタリソース名 |
回復スクリプト、回復動作前スクリプトを実行する原因となる異常を検出したモニタリソース名を示します。 |
CLP_VERSION_FULL
…CLUSTERPROフルバージョン
|
CLUSTERPROフルバージョン |
CLUSTERPROのフルバージョンを示す。
(例) 5.2.1-1
|
CLP_VERSION_MAJOR
…CLUSTERPROメジャーバージョン
|
CLUSTERPROメジャーバージョン |
CLUSTERPROのメジャーバージョンを示す。
(例)5
|
CLP_PATH
…CLUSTERPROインストールパス
|
CLUSTERPROインストールパス |
CLUSTERPROがインストールされているパスを示す。
(例) /opt/nec/clusterpro
|
CLP_OSNAME
……サーバOS名
|
サーバOS名 |
スクリプトが実行されたサーバのOSを示す。
(例)
1.OSバージョンが取得できた場合: Red Hat Enterprise Linux Server release6.8(Santiago)
2.OSバージョンが取得できなかった場合: Linux
|
CLP_OSVER
…サーバOSバージョン
|
サーバOSバージョン |
スクリプトが実行されたサーバのOSバージョンを示す。
(例)
1.OSバージョンが取得できた場合: 6.8
2.OSバージョンが取得できなかった場合: ※値なし
|
CLP_ACTION
…回復動作種別
|
RECOVERY |
回復スクリプトとして実行された場合。 |
〃 |
RESTART |
再起動前に実行された場合。 |
〃 |
FAILOVER |
フェイルオーバ前に実行された場合。 |
〃 |
FINALACTION |
最終動作前に実行された場合。 |
CLP_RECOVERYCOUNT
…回復スクリプトの実行回数
|
回復スクリプト実行回数 |
何回目の回復スクリプト実行回数かを示す。 |
CLP_RESTARTCOUNT
…再活性化回数
|
再活性化回数 |
何回目の再活性化回数かを示す。 |
CLP_FAILOVERCOUNT
…フェイルオーバ回数
|
フェイルオーバ回数 |
何回目のフェイルオーバ回数かを示す。 |
回復スクリプト、回復動作前スクリプトの記述の流れ
前のトピックの、環境変数と実際のスクリプト記述を関連付けて説明します。
回復スクリプト、回復動作前スクリプトの一例
#!/bin/sh
# ***************************************
# * preactaction.sh
# ***************************************
# スクリプト実行要因の環境変数を参照して、処理の振り分けを行う。
if [ "$CLP_ACTION" = "RECOVERY" ]
then
# ここに回復処理を記述する。
# この処理は以下のタイミングで実行される。
#
# 回復動作: 回復スクリプト
elif [ "$CLP_ACTION" = "RESTART" ]
then
# ここに再活性化前処理を記述する。
# この処理は以下のタイミングで実行される。
#
# 回復動作: 再活性化
elif [ "$CLP_ACTION" = "FAILOVER" ]
then
# ここに回復処理を記述する。
# この処理は以下のタイミングで実行される。
#
# 回復動作: フェイルオーバ
elif [ "$CLP_ACTION" = "FINALACTION" ]
then
# ここに回復処理を記述する。
# この処理は以下のタイミングで実行される。
#
# 回復動作: 最終動作
fi
exit 0
回復スクリプト、回復動作前スクリプト作成のヒント
以下の点に注意して、スクリプトを作成してください。
スクリプト中にて、実行に時間を必要とするコマンドを実行する場合には、コマンドの実行が完了したことを示すトレースを残すようにしてください。この情報は、問題発生時、障害の切り分けを行う場合に使用することができます。clplogcmdを使用してトレースを残す方法があります。
- スクリプト中に clplogcmd を使用して記述する方法clplogcmd で Cluster WebUI のアラートログや OS の syslog に、メッセージを出力できます。clplogcmd については、本ガイドの「9. CLUSTERPRO コマンドリファレンス」の「メッセージを出力する (clplogcmd コマンド)」を参照してください。(例:スクリプト中のイメージ)clplogcmd -m "recoverystart.."recoverystartclplogcmd -m "OK"
回復スクリプト、回復動作前スクリプト 注意事項
- スクリプトから起動されるコマンド、アプリケーションのスタックサイズについてスタックサイズが 2MB に設定された状態で回復スクリプト、回復動作前スクリプトが実行されます。このため、スクリプトから起動されるコマンドやアプリケーションで 2MB 以上のスタックサイズが必要な場合には、スタックオーバーフローが発生します。スタックオーバーフローが発生する場合には、コマンドやアプリケーションを起動する前にスタック サイズを設定してください。
- 最終動作時の回復動作前スクリプトが実行される条件について最終動作時の回復動作前スクリプトはモニタの監視異常による最終動作の前に実行されます。最終動作に [何もしない] が設定されている場合にも、回復動作前スクリプトは実行されます。最大再起動回数や、モニタリソースの回復動作の抑制機能、他のサーバが全て停止している場合の最終動作抑制機能によって最終動作が実行されない場合は、回復動作前スクリプトは実行されません。
4.1.10. モニタリソースの遅延警告¶
モニタリソースは、業務アプリケーションの集中などにより、サーバが高負荷状態になり監視 タイムアウトを検出する場合があります。監視タイムアウトを検出する前に監視のポーリング 時間 (実測時間) が監視タイムアウト時間の何割かに達した場合、アラート通報させることが可能です。
以下は、モニタリソースが遅延警告されるまでの流れを時系列で表した説明です。
図は監視タイムアウトに 60 秒、遅延警告割合には既定値の 80%(48秒) を指定した場合です。 矢印は監視のポーリング時間を表しています。
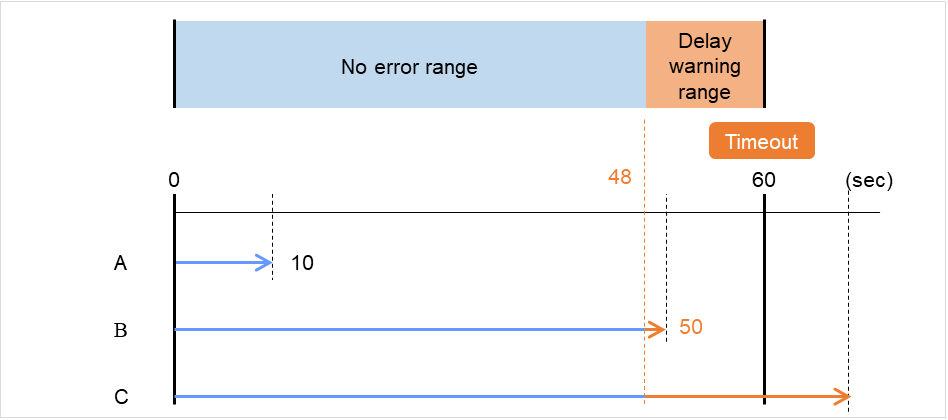
図 4.50 監視ポーリング時間と遅延警告¶
- 監視のポーリング時間は 10 秒で、モニタリソースは正常状態です。この場合、アラート通報は行いません。
- 監視のポーリング時間は 50 秒で、監視の遅延を検出し、モニタリソースは正常状態です。この場合、遅延警告割合の 80% を超えているためアラート通報を行います。
- 監視のポーリング時間は監視タイムアウト時間の 60 秒を越え、監視タイムアウトを検出し、モニタリソースは異常状態です。この場合、アラート通報は行いません。
また、遅延警告割合を 0 または 100 に設定すれば以下を行うことが可能です。
- 遅延警告割合に 0 を設定した場合監視ごとに遅延警告がアラート通報されます。この機能を利用し、サーバが高負荷状態でのモニタリソースへのポーリング時間を算出し、モニタリソースの監視タイムアウト時間を決定することができます。
遅延警告割合に 100 を設定した場合
遅延警告の通報を行いません。
ハートビートリソースについても同様にハートビートの遅延警告をアラート通報します。
ユーザ空間モニタリソースの場合もモニタリソースと同じ遅延警告割合を使用します。
注釈
テスト運用以外で、 0% などの低い値を設定しないように注意してください。
4.1.11. モニタリソースの監視開始待ち¶
監視開始待ちとは、監視を指定した監視開始待ち時間後から開始することをいいます。
以下は、監視開始待ちを 0 秒に指定した場合と 30 秒に指定した場合の監視の違いを時系列で表した説明です。
監視開始待ち時間が0秒の場合、クラスタ起動または監視再開後に監視リソースポーリングを開始します。
[モニタリソース構成]

図 4.51 モニタリソースの監視開始待ち(監視開始待ち時間0秒)¶
監視開始待ち時間が30秒の場合、クラスタ起動または監視再開後に30秒待ってから監視リソースポーリングを開始します。
[モニタリソース構成]

図 4.52 モニタリソースの監視開始待ち(監視開始待ち時間30秒)¶
注釈
監視制御コマンドによるモニタリソースの一時停止/再開を行った場合も、指定された監視開始待ち時間後に再開します。
監視開始待ち時間は、PID モニタリソースが監視する EXEC リソースのようにアプリケーションの設定ミスなどにより監視開始後すぐに終了する可能性があり、再活性化では回復できない場合に使用します。
たとえば、以下のように監視開始待ち時間を 0 に設定すると回復動作を無限に繰り返す場合があります。
このケースにおいて、アプリケーションは一旦起動します。さらにPIDモニタによる監視が開始され、PIDモニタによるポーリングが一度正常終了します。 しかしその後、アプリケーションは何らかの理由で異常終了します。
[PID モニタリソース構成]

図 4.53 モニタリソースの監視開始待ち(監視開始待ち時間0秒)¶
この回復動作を無限に繰り返す原因は、初回のモニタリソースポーリングが正常終了することにあります。モニタリソースの回復動作の現在回数は、モニタリソースが正常状態になればリセットされます。そのため、現在回数が常に 0 リセットされ再活性化の回復動作を無限に繰り返すことになります。
上記の現象は、監視開始待ち時間を設定することで回避できます。
監視開始待ち時間には、アプリケーションが起動後、終了しうる時間として既定値で 60 秒を設定しています。
このケースにおいて、アプリケーションは一旦起動します。 その後、設定された開始監視待ち時間待ちあわせた後に、PIDモニタによる監視が開始されます。 その後、アプリケーションは何らかの理由で異常終了しますが、それはPIDモニタによる初回のポーリングで検出されます。
[PID モニタリソース構成]

図 4.54 モニタリソースの監視開始待ち(監視開始待ち時間60秒)¶
グループのフェイルオーバ先のサーバでもアプリケーションが異常終了した場合、最終動作としてグループ停止を行います。
4.1.12. モニタリソース異常検出時の再起動回数制限¶
モニタリソース異常検出時の最終動作として [クラスタサービス停止と OS シャットダウン]、または [クラスタサービス停止と OS 再起動]、[keepalive リセット]、[keepalive パニック]、[BMC リセット]、[BMC パワーオフ]、[BMC パワーサイクル] または [BMC NMI] を設定している場合に、モニタリソース異常の検出によるシャットダウン回数、または再起動回数を制限することができます。
注釈
以下の設定例で再起動回数制限の流れを説明します。
最大再起動回数が 1 回に設定されているため、1 度だけ最終動作である [クラスタサービス停止と OS 再起動] が実行されます。
また、最大再起動回数をリセットする時間が 10 分に設定されているため、クラスタシャットダウン後再起動時にモニタリソースの正常状態が 10 分間継続した場合には、再起動回数はリセットされます。
[設定例]
を指定している場合の挙動の例
- 図は、2台のサーバにおいてディスクモニタリソースが監視を行う場合の例です。Disk monitor resource 1の活性処理を開始します。インターバル毎にデバイスへのI/O処理などを実行します。

図 4.55 再起動回数制限 (1)¶
Server 1
Server 2
最大再起動回数
1
1
再起動回数
0
0
Disk monitor resource 1の監視が異常を検出しました(ioctl、readの異常など)。

図 4.56 再起動回数制限 (2)¶
- クラスタサービスを停止後、OSを再起動します。"活性リトライしきい値"、"フェイルオーバしきい値" は0のため、最終動作を実行します。再起動回数には 1が記録されます。そして、Failover group Aのフェイルオーバ処理を開始します。"最大再起動回数" は各サーバでの再起動回数の上限値です。Server 2では再起動回数は0です。

図 4.57 再起動回数制限 (3)¶
Server 1
Server 2
最大再起動回数
1
1
再起動回数
1
0
- Server 1の再起動が完了しました。clpgrpコマンド、Cluster WebUIを使用して、Failover group AをServer 1に移動します。

図 4.58 再起動回数制限 (4)¶
Server 1
Server 2
最大再起動回数
1
1
再起動回数
1
0
- Disk monitor resource 1の監視が異常を検出しました(ioctl、readの異常など)。Server 1では再起動回数が最大起動回数に達しているため、最終動作は実行されません。10分経過しても再起動回数はリセットされません。

図 4.59 再起動回数制限 (5)¶
Server 1
Server 2
最大再起動回数
1
1
再起動回数
1
0
Shared diskの異常を取り除き、clpstdnコマンド、Cluster WebUIを使用してクラスタシャットダウン後、再起動します。

図 4.60 再起動回数制限 (6)¶
Server 1
Server 2
最大再起動回数
1
1
再起動回数
1
0
- Server 1のDisk monitor resource 1は正常な状態になります。10分経過すると、再起動回数はリセットされます。次回 Disk monitor resource 1の異常検出時には最終動作が実行されます。

図 4.61 再起動回数制限 (7)¶
Server 1
Server 2
最大再起動回数
1
1
再起動回数
0
0
4.1.13. モニタリソースの監視プライオリティ¶
OS 高負荷時にモニタリソースへの監視を優先的に行うため、nice 値を設定することができます。
nice 値は 19 (優先度低) ~ -20 (優先度高) の範囲で指定することが可能です。
nice 値の優先度を上げることで監視タイムアウトの検出を抑制することが可能です。
4.1.14. 使用している ipmi コマンド¶
最終動作「BMC リセット」、「BMC パワーオフ」、「BMC パワーサイクル」、「BMC NMI」は、[ipmitool] コマンドを使用します。
コマンドがインストールされていない場合には本機能は使用できません。
ipmi による最終動作の注意事項
ipmi による最終動作は CLUSTERPRO と [ipmitool] コマンドが連携をして実現しています。
CLUSTERPRO に ipmitool (OpenIPMI-tools) は 添付しておりません。別途 rpm パッケージのインストールを行ってください。
[ipmitool] コマンドを使用して最終動作を行う場合、ipmi ドライバをロードしておく必要があります。OS 起動時に ipmi ドライバを自動ロードするように設定することを推奨します。
4.1.15. モニタリソースをサーバ個別設定する¶
モニタリソースの一部の設定値はサーバごとに異なる設定が可能です。サーバ個別設定が 可能なリソースは [監視(固有)] タブに各サーバのタブが表示されます。
サーバ別設定が可能なモニタリソースは下記です。
モニタリソース名 |
対応バージョン |
|---|---|
ディスクモニタリソース |
4.0.0-1~ |
IP モニタリソース |
4.0.0-1~ |
NIC Link Up/Down モニタリソース |
4.0.0-1~ |
外部連携モニタリソース |
4.0.0-1~ |
AWS AZ モニタリソース |
4.0.0-1~ |
サーバ個別設定可能なパラメータは各モニタリソースのパラメータの説明を参照してください。サーバ個別設定可能なパラメータには「サーバ個別設定可能 」と付記しています。
ここではディスクモニタリソースでサーバ個別設定を説明します。
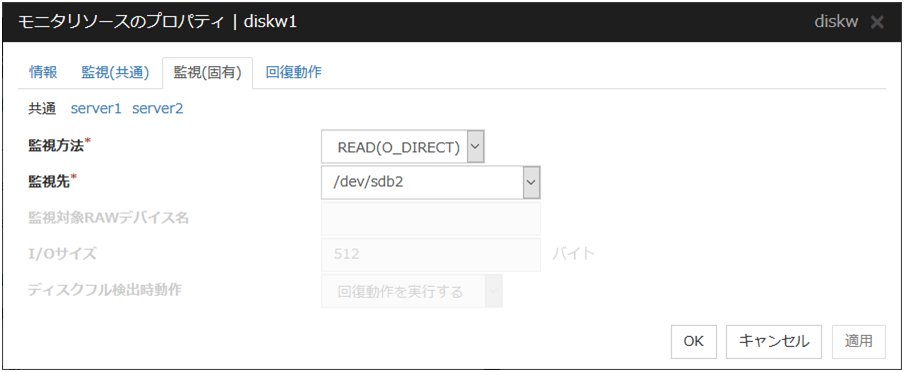
サーバ個別設定
ディスクモニタリソースでサーバ個別設定可能なパラメータが表示されます。
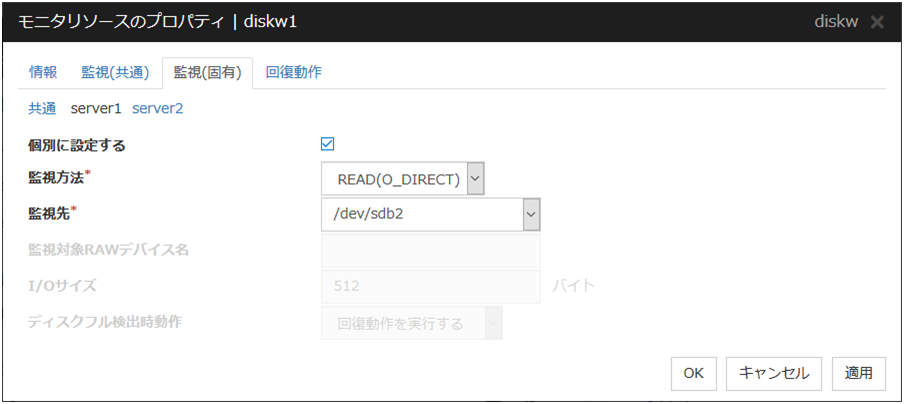
個別に設定する
サーバ個別設定を行いたいサーバ名のタブを選択してチェックボックスをオンにするとディスクリソースでサーバ個別設定可能なパラメータが入力可能になります。必要なパラメータを入力します。
4.1.16. 監視オプションモニタリソースの共通設定¶
Application Server Agent, Database Agent, File Server Agent, Internet Server Agent, Java Resource Agent, System Resource Agent (以下、これらの製品群をまとめて 「監視オプション」 と呼びます。) で提供されるモニタリソースを使用してアプリケーションの監視を行うにあたっての設定手順、注意事項等について説明します。
監視オプションモニタリソースの設定手順
監視オプションの各モニタリソースを使用してアプリケーション監視を行うためには、以下の流れに従って設定を行います。
ここでは、DB2 モニタリソースを例にとります。
フェイルオーバグループの作成 (監視対象アプリケーション用)
監視対象アプリケーション起動用 EXEC リソースの追加
監視対象アプリケーションの起動確認テスト
監視対象アプリケーション監視用 DB2 モニタリソースの追加
以下に、手順を説明します。
Step 1 フェイルオーバグループの作成 (監視対象アプリケーション用)
監視対象のアプリケーションを監視し、障害が発生した場合にフェイルオーバを行うための フェイルオーバグループを作成し、必要に応じて各種グループリソースを追加します。
注釈
フェイルオーバグループの作成およびグループリソースの追加についての詳細は、『インストール&設定ガイド』の「クラスタ構成情報を作成する」を参照してください。
Step 2 監視対象アプリケーション起動用 EXEC リソースの追加
Step1 で作成したフェイルオーバグループに、監視対象アプリケーションを起動するための EXEC リソースを追加し、そのリソースの Start Script および Stop Script で監視対象アプリケーションの起動/終了を行うよう、編集します。
本ガイドでは、この EXEC リソースを exec 1 と呼びます。
Step 3 監視対象アプリケーションの起動確認テスト
Step2 までの手順が終了したら、監視対象アプリケーションの起動確認をします。
まず、設定内容をサーバへ反映し、その後、Cluster WebUI よりグループの起動/停止/移動/フェイルオーバを順に実行し、それぞれの操作が正常に行われることを確認します。
Step 4 監視対象アプリケーション起動用 DB2 モニタリソースの追加
監視対象アプリケーションを監視するための DB2 モニタリソースを追加します。
この時、[監視(共通)] タブの [監視タイミング] は [活性時] を選択し、[対象リソース] には exec1 を指定してください。
注釈
各モニタリソース固有の情報、設定内容等についての詳細は、本ガイドの「モニタリソースの詳細」の各監視オプションモニタリソースを参照してください。
参考
モニタリソース共通の監視設定内容についての詳細は、「監視 (共通) タブ」を参照してください。
4.1.17. ディスク待ち休眠状態による監視タイムアウト発生時のステータス¶
プロセスの状態がディスク待ち休眠状態(D状態)による監視タイムアウト発生時はモニタリソース毎にステータスが異なります。
モニタリソース名 |
ステータス |
|---|---|
ディスクモニタリソース |
異常 |
IP モニタリソース |
警告 |
フローティングIPモニタリソース |
警告 |
NIC Link Up/Down モニタリソース |
警告 |
ミラーディスクコネクトモニタリソース |
警告 |
ミラーディスクモニタリソース |
警告 |
ハイブリッドディスクコネクトモニタリソース |
警告 |
ハイブリッドディスクモニタリソース |
警告 |
PID モニタリソース |
警告 |
ユーザ空間モニタリソース |
異常 |
マルチターゲットモニタリソース |
警告 |
仮想 IP モニタリソース |
警告 |
ARP モニタリソース |
警告 |
カスタムモニタリソース |
警告 |
ボリュームマネージャモニタリソース |
警告 |
外部連携モニタリソース |
異常 |
ダイナミック DNS モニタリソース |
警告 |
プロセス名モニタリソース |
警告 |
DB2 モニタリソース |
異常 |
FTP モニタリソース |
異常 |
HTTP モニタリソース |
異常 |
IMAP4 モニタリソース |
異常 |
MySQL モニタリソース |
異常 |
NFS モニタリソース |
異常 |
ODBC モニタリソース |
異常 |
Oracle モニタリソース |
異常 |
POP3 モニタリソース |
異常 |
PostgreSQL モニタリソース |
異常 |
Samba モニタリソース |
異常 |
SMTP モニタリソース |
異常 |
SQL Server モニタリソース |
異常 |
Tuxedo モニタリソース |
異常 |
WebLogic モニタリソース |
異常 |
WebSphere モニタリソース |
異常 |
WebOTX モニタリソース |
異常 |
JVM モニタリソース |
異常 |
システムモニタリソース |
異常 |
プロセスリソースモニタリソース |
異常 |
AWS Elastic IP モニタリソース |
警告 |
AWS 仮想 IP モニタリソース |
警告 |
AWS セカンダリ IP モニタリソース |
警告 |
AWS AZ モニタリソース |
警告 |
AWS DNS モニタリソース |
警告 |
Azure プローブポートモニタリソース |
警告 |
Azure ロードバランスモニタリソース |
警告 |
Azure DNS モニタリソース |
警告 |
Google Cloud 仮想 IP モニタリソース |
警告 |
Google Cloud ロードバランスモニタリソース |
警告 |
Google Cloud DNS モニタリソース |
警告 |
Oracle Cloud 仮想 IP モニタリソース |
警告 |
Oracle Cloud ロードバランスモニタリソース |
警告 |
Oracle Cloud DNS モニタリソース |
警告 |
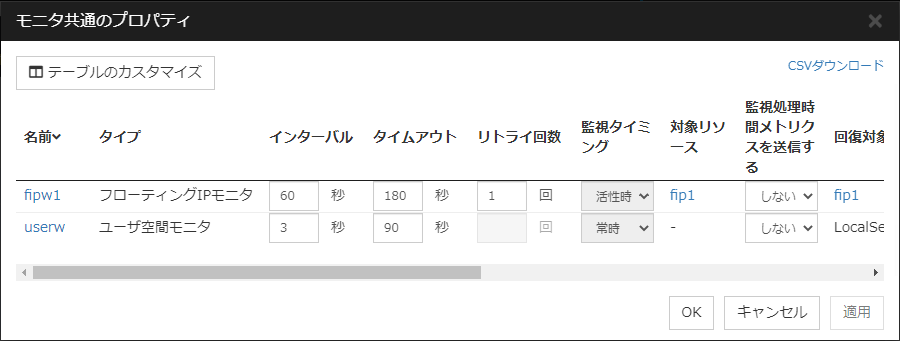
4.2. モニタ共通のプロパティ¶
4.3. モニタリソースのプロパティ¶
4.3.1. 情報タブ¶
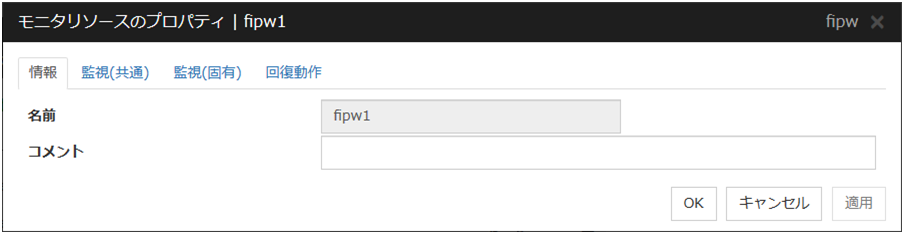
名前
モニタリソース名を表示します。
モニタリソース名の変更
[その他]メニューをクリックして、[モニタリソースの名称変更]を選択してください。
[モニタリソース名の変更]ダイアログボックスが表示されます。
入力規則
1 バイトの英大文字・小文字,数字,ハイフン (-),アンダーバー (_),スペースのみ使用可能です。
最大 31 文字 (31 バイト) までです。
文字列先頭と文字列末尾にハイフン (-)とスペースは使えません。
コメント (127 バイト以内)
モニタリソースのコメントを設定します。半角英数字のみ入力可能です。
4.3.2. 監視 (共通) タブ¶
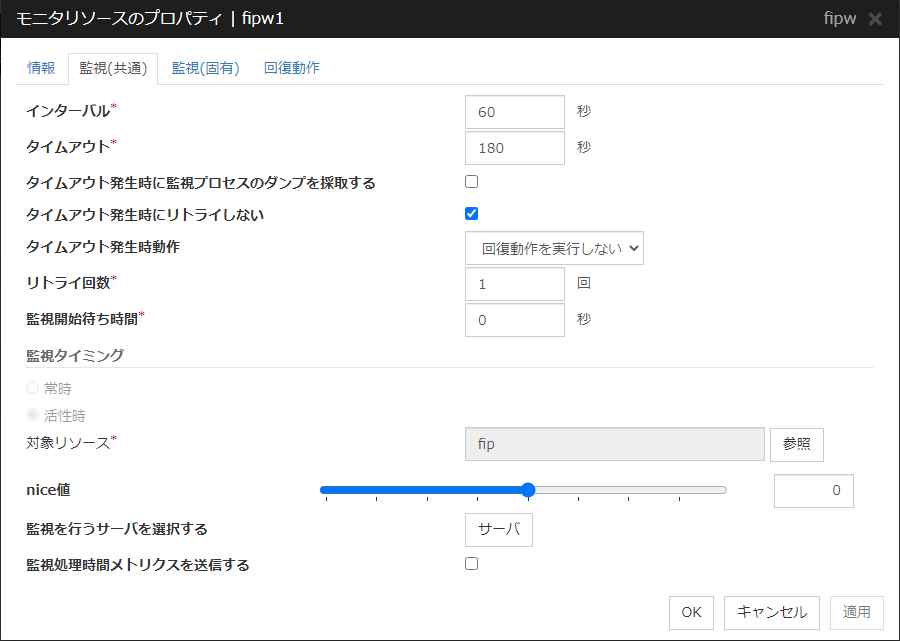
インターバル (1~999)
監視対象の状態を確認する間隔を設定します。
タイムアウト (5~9995 )
ここで指定した時間内に監視対象の正常状態が検出できない場合に異常と判断します。
- 5
ユーザ空間モニタリソースで監視方法に ipmi を設定している場合は、 255 以下の値を設定する必要があります。
タイムアウト発生時に監視プロセスのダンプを採取する
本機能を有効にした場合、モニタリソースがタイムアウトすると、タイムアウトしたモニタリソースのダンプが採取されます。採取されたダンプ情報は、/opt/nec/clusterpro/work/rm/"モニタリソース名"/errinfo.cur フォルダ配下に保存されます。採取が複数回実行された場合は、過去の採取情報のフォルダ名が errinfo.1, errinfo.2 とリネームされます。ダンプ情報は最大5回採取されます。
タイムアウト発生時にリトライしない
本機能を有効にした場合、モニタリソースがタイムアウトすると即座に「タイムアウト発生時動作」を実行します。
タイムアウト発生時動作
監視リソースタイムアウト発生時の動作を選択します。また、タイムアウトが発生した場合にはリトライ回数の回数カウンタはリセットされます。本機能は、[タイムアウト発生時にリトライしない] 機能を有効にしている場合のみ設定可能です。
注釈
下記のモニタリソースでは、[タイムアウト発生時にリトライしない], [タイムアウト発生時動作] 機能は設定できません。
ユーザ空間モニタリソース
マルチターゲットモニタリソース
仮想 IP モニタリソース
カスタムモニタリソース (監視タイプが [非同期] の場合のみ)
外部連携モニタリソース
ダイナミック DNS モニタリソース
JVM モニタリソース
システムモニタリソース
プロセスリソースモニタリソース
リトライ回数 (0~999)
異常状態を検出後、連続してここで指定した回数の異常を検出したときに異常と判断します。
0 を指定すると最初の異常検出で異常と判断します。
監視開始待ち時間 (0~9999)
監視を開始するまでの待ち時間を設定します。
監視タイミング
監視のタイミングを設定します。
対象リソース
活性時監視を行う場合に対象となるリソースを表示します。
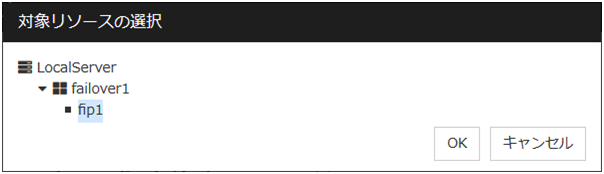
参照
[対象リソースの選択] ダイアログボックスを表示します。LocalServer とクラスタに登録されているグループ名、リソース名がツリー表示されます。対象リソースとして設定するリソースを選択して [OK] をクリックします。
nice 値
プロセスの nice 値を設定します。
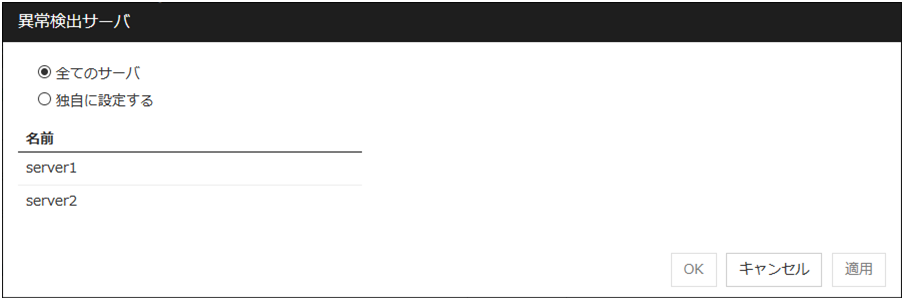
監視を行うサーバを選択する
監視を行うサーバを設定します。
全てのサーバ
全てのサーバで監視を行います。
独自に設定する
[利用可能なサーバ] に登録されているサーバで監視を行います。[利用可能なサーバ] は 1 つ以上設定する必要があります。
監視処理時間メトリクスを送信する
モニタリソースの監視処理時間メトリクスの送信機能を設定します。
注釈
カスタムモニタリソース (監視タイプが [非同期] の場合のみ)
仮想 IP モニタリソース
外部連携モニタリソース
JVM モニタリソース
システムモニタリソース
プロセスリソースモニタリソース
4.3.3. 監視(固有) タブ¶
モニタリソースによっては監視動作時のパラメータを設定する必要があります。パラメータは各リソースの説明に記述しています。
4.3.4. 回復動作タブ¶
回復対象と異常検出時の動作を設定します。異常検出時にグループのフェイルオーバやリソースの再起動やクラスタの再起動ができます。ただし、回復対象が非活性状態であれば回復動作は行われません。
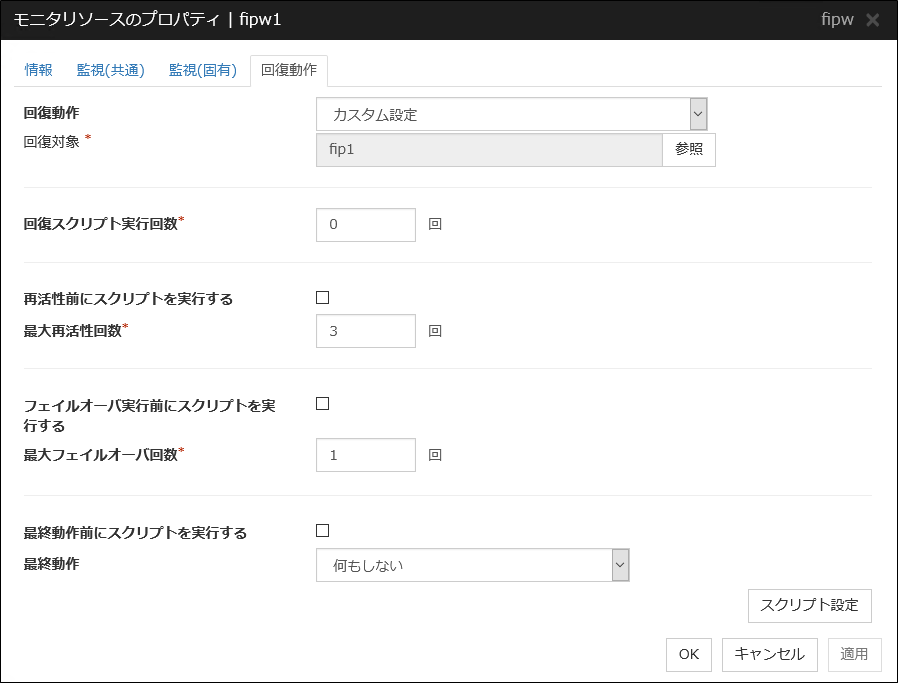
回復動作
異常検出時の回復動作を選択します。
回復対象
リソースの異常とみなした時に回復を行う対象のオブジェクトが表示されます。
参照
[回復対象の選択] ダイアログボックスを表示します。LocalServer、All Groups とクラスタに登録されているグループ名、リソース名がツリー表示されます。回復対象として設定するものを選択して [OK] をクリックします。

回復スクリプト実行回数 (0~99)
異常検出時に [スクリプト設定] で設定されたスクリプトを実行する回数を設定します。0 を設定するとスクリプトを実行しません。
再活性前にスクリプトを実行する
最大再活性回数 (0~99)
異常検出時に再活性化を行う回数を設定します。0 を設定すると再活性化を行いません。回復対象にグループまたはグループリソースを選択した場合に設定可能です。
IP モニタリソースまたは NIC Link Up/Down モニタリソースの回復対象として、フェイルオーバ属性(拡張) の [指定したモニタリソースで異常を検出しているサーバをフェイルオーバ先から除外する] が設定されているグループまたはそのグループに属するリソースを設定している場合、指定したモニタリソースが異常を検出しているため、再活性処理に失敗します。
フェイルオーバ実行前にスクリプトを実行する
最大フェイルオーバ回数 (0~99)
異常検出時に再活性化が [最大再活性回数] で指定した回数失敗した場合にフェイルオーバさせるときの回数を設定します。0 を設定するとフェイルオーバを行いません。回復対象に "All Groups" またはグループ、グループリソースを選択した場合に設定可能です。"All Groups" を選択した場合、モニタリソースが異常を検出したサーバで起動している全てのグループのフェイルオーバを行います。
最終動作前にスクリプトを実行する
最終動作を実行する前にスクリプトを実行するかどうかを指定します。
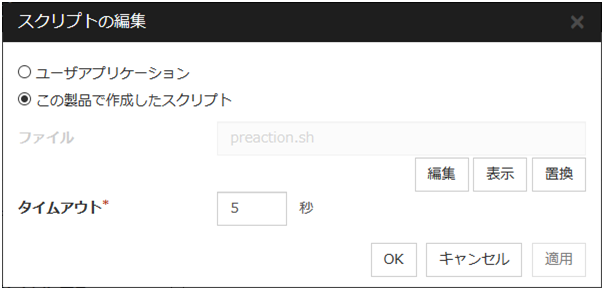
[スクリプト設定] をクリックすると、[スクリプトの編集] ダイアログボックスが表示されます。実行するスクリプトまたは実行ファイルを設定して [OK] をクリックします。
スクリプト設定
[スクリプトの編集] ダイアログボックスを表示します。回復スクリプト、回復動作前に実行するスクリプト/コマンドを設定します。
ユーザアプリケーション
スクリプトとしてサーバ上の実行可能ファイル (実行可能なシェルスクリプトファイルや実行ファイル) を使用します。ファイル名にはサーバ上のローカルディスクの絶対パスまたは実行可能ファイル名を設定します。また、絶対パスやファイル名に空欄が含まれる場合は、下記のように、「ダブルクォーテーション (")」 でそれらを囲ってください。
例:"/tmp/user application/script.sh"各実行可能ファイルは、Cluster WebUI のクラスタ構成情報には含まれません。Cluster WebUI で編集やアップロードはできませんので、各サーバ上に準備する必要があります。
この製品で作成したスクリプト
スクリプトとして Cluster WebUI で準備したスクリプトファイルを使用します。必要に応じて Cluster WebUI でスクリプトファイルを編集できます。スクリプトファイルは、クラスタ構成情報に含まれます。
ファイル (1023 バイト以内)
[ユーザアプリケーション] を選択した場合に、実行するスクリプト (実行可能なシェルスクリプトファイルや実行ファイル) を設定します。
表示
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを表示します。
編集
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを編集します。変更を反映するには [保存] をクリックしてください。スクリプトファイル名の変更はできません。
置換
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルの内容を、[ファイル選択] ダイアログボックスで選択したスクリプトファイルの内容に置換します。スクリプトが既に表示中または編集中の場合は置換できません。ここではスクリプトファイルを選択してください。バイナリファイル (アプリケーションなど) は選択しないでください。
タイムアウト (1~9999)
スクリプトの実行完了を待ち合わせる最大時間を指定します。既定値は 5 秒です。
最終動作
異常検出時に再活性化が [最大再活性回数] で指定した回数失敗し、フェイルオーバが[最大フェイルオーバ回数] で指定した回数失敗した後の動作を選択します。
最終動作は以下の動作が選択できます。
注釈
[何もしない] の設定は以下の場合に使用してください。
一時的に最終動作を抑止したい場合
異常を検出したときにアラートの表示のみを行いたい場合
実際の最終動作はマルチターゲットモニタリソースで行いたい場合
注釈
sysrq パニックに失敗した場合、OS のシャットダウンを行います。
注釈
keepalive リセットに失敗した場合、OS のシャットダウンを行います。clpkhb ドライバ、clpka ドライバが対応していない OS、kernel では設定しないでください。注釈
keepalive パニックに失敗した場合、OS のシャットダウンを行います。clpkhb ドライバ、clpka ドライバが対応していない OS、kernel では設定しないでください。注釈
BMC リセットに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC パワーオフに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC パワーサイクルに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC NMI に失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。
4.4. ディスクモニタリソースを理解する¶
ディスクモニタリソースは、ディスクデバイスの監視を行います。
ディスクモニタリソース (TUR 方式) が使用できないディスクでは、READ (O_DIRECT) 方式での監視を推奨します。
4.4.1. ディスクモニタリソースによる監視方法¶
ディスクモニタリソースの監視方法は大きく分けて TUR と READ があります。
TUR の注意事項
- SCSI の [Test Unit Ready] コマンドや [SG_IO] コマンドをサポートしていない ディスク、ディスクインタフェース (HBA) では使用できません。ハードウェアがサポートしている場合でも、ドライバがサポートしていない場合があるので、ドライバの仕様も合わせて確認してください。
LVM 論理ボリューム (LV) のデバイスでは ioctl が正常に実行できない可能性があるため、LV の監視には READ を使用してください。
IDEインターフェイスのディスクの場合には、すべてのTUR方式は使用できません。
S-ATA インターフェイスのディスクの場合には、ディスクコントローラのタイプや使用するディストリビューションにより、OS に IDE インターフェイスのディスク (hd) として認識される場合と SCSI インターフェイスのディスク (sd) として認識される場合があります。IDE インターフェイスとして認識される場合には、すべての TUR 方式は使用できません。SCSI インターフェイスとして認識される場合には、TUR (legacy) が使用できます。TUR (generic) は使用できません。
Read 方式に比べて OS やディスクへの負荷は小さくなります。
Test Unit Ready では、実際のメディアへの I/O エラーは検出できない場合があります。
ディスク上のパーティションを監視対象に設定して使用することはできません。whole device (ディスク全体を示すデバイス) を指定する必要があります。
- ディスク装置によっては TUR 発行時、装置の状態によって一時的に Unit Attention を返す場合があります。Unit Attention が一時的に返却されることは問題ではありませんが、TUR のリトライ回数を 0 回に設定している場合、上記をエラーと判断し、ディスクモニタリソースが異常となります。無用な異常検出を防ぐため、リトライ回数は 1 回以上を設定してください。
TUR の監視方法は、下記の 3 つが選択可能です。
TUR
- 指定されたデバイスへ以下の手順で ioctl を発行して、その結果で判断します。[ioctl (SG_GET_VERSION_NUM)] コマンドを実行します。この ioctl の戻り値とSG ドライバの version を見て判断します。[ioctl] コマンド成功かつ SG ドライバの version が 3.0 以上なら SG ドライバを使用した [ioctl TUR(SG_IO)] を実行します。[ioctl] コマンド失敗または SG ドライバの version が 3.0 未満なら [SCSI] コマンドとして定義されている ioctl TUR を実行します。
TUR (legacy)
ioctl (Test Unit Ready) を使って監視を行います。指定されたデバイスへ [SCSI] コマンドとして定義されている [Test Unit Ready (TUR)] コマンドを発行してその結果で判断します。
TUR (generic)
ioctl TUR (SG_IO) を使って監視を行います。指定されたデバイスへ [SCSI] コマンドとして定義されている [ioctl (SG_IO)] コマンドを発行してその結果で判断します。SG_IO は SCSI ディスクであっても OS やディストリビューションによって 動作しないことがあります。
READ の監視方法は、下記のとおりです。
READ
指定されたデバイス (ディスクデバイスまたはパーティションデバイス) もしくはファイル 上の指定されたサイズを read してその結果 (read できたサイズ) で判断します。
指定されたサイズが read できたことを判断します。read したデータの正当性は 判断しません。
read するサイズを大きくすると OS やディスクへの負荷が大きくなります。
read するサイズについては「 ディスクモニタリソースで READ を選択した場合の I/O サイズ 」を留意して設定してください。
READ (O_DIRECT) の監視方法は、下記のとおりです。
READ (O_DIRECT)
指定されたデバイス (ディスクデバイスまたはパーティションデバイス) 上の1セクタ分もしくはファイルを、キャッシュを使用しない (O_DIRECTモード) で read してその結果 (readできたサイズ) で判断します。
read できたことを判断します。read したデータの正当性は判断しません。
READ (RAW) の監視方法は、下記のとおりです。
READ (RAW)
監視方法の READ (O_DIRECT) と同様に OS のキャッシュを使用しないで指定されたデバイスの read の監視を行います。
read できたことを判断します。read したデータの正当性は判断しません。
監視方法の READ (RAW) を設定する場合、既に mount しているパーティションまたは mount する可能性のあるパーティションの監視はできません。また、既にmount しているパーティションまたは mount する可能性のあるパーティションのwhole device (ディスク全体を示すデバイス) を監視することもできません。監視専用のパーティションを用意してディスクモニタリソースに設定してください。(監視用のパーティションサイズは、10M 以上を割り当ててください)
既にサーバプロパティの [ディスク I/F 一覧] または [ディスクリソース] に登録されている RAW デバイスは登録しないでください。
ディスクハートビートが使用している RAW デバイスを監視方法の READ (RAW) で監視する場合、Cluster WebUI で [監視対象 RAW デバイス名] にディスクハートビートで使用している RAW デバイスを指定し、[デバイス名] は入力しないでください。
WRITE (FILE) の監視方法は、下記のとおりです。
WRITE (FILE)
指定されたパス名のファイルを作成、書き込み、削除を行い判断します。
書き込んだデータの正当性は判断しません。
4.4.2. ディスクモニタリソースで READ を選択した場合の I/O サイズ¶
監視方法で READ を選択した場合の read を行うサイズを指定します。
使用するディスクやインターフェイスにより、様々な read 用のキャッシュが実装されている 場合があります。そのため I/O サイズが小さい場合にはキャッシュにヒットしてしまい read のエラーを検出できない場合があります。
READ の I/O のサイズはディスクの障害を発生させて障害の検出ができることを確認して 指定してください。
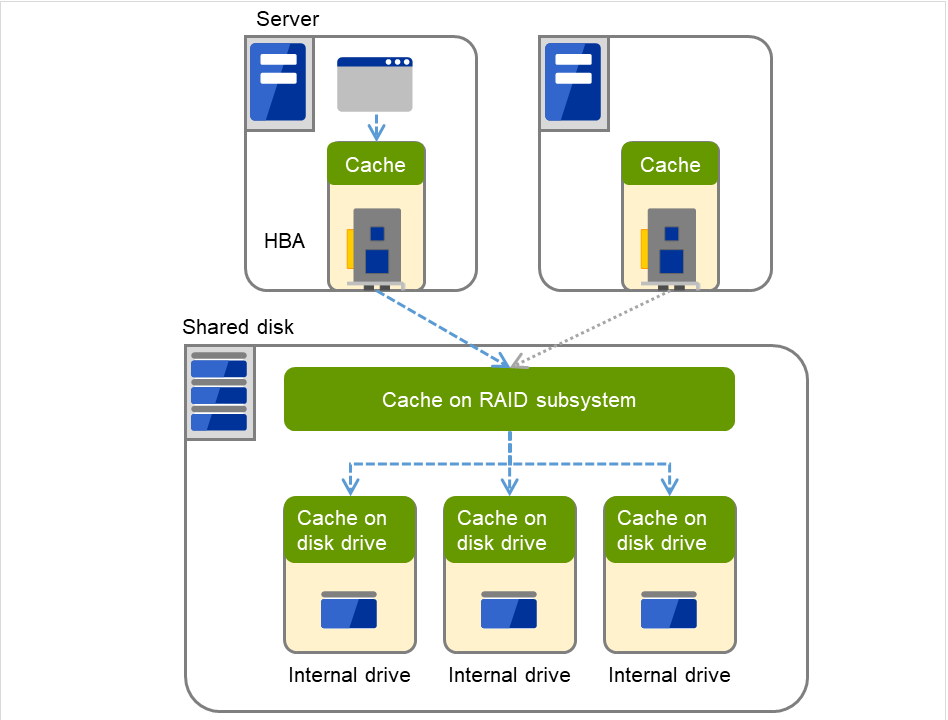
図 4.62 様々なキャッシュ¶
4.4.3. ディスクモニタリソースで READ (RAW) を選択した場合の設定例¶
ディスクリソース、ディスクモニタの設定例
Disk リソース
Disk モニタリソース (両サーバの内蔵 HDD を「READ (RAW)」で監視)
Disk モニタリソース (共有ディスクを「READ(RAW)」で監視)
以下の図は2台のサーバとそれに接続された共有ディスクの例を表しています。 Server 1、Server 2の内蔵ディスクにおいて、/dev/sda3をDiskモニタに指定しています。
注釈
また共有ディスク(Shared disk)において、/dev/sdb1をDisk HBに、/dev/sdb2をDiskリソースに、/dev/sdb3をDiskモニタに指定しています。
注釈
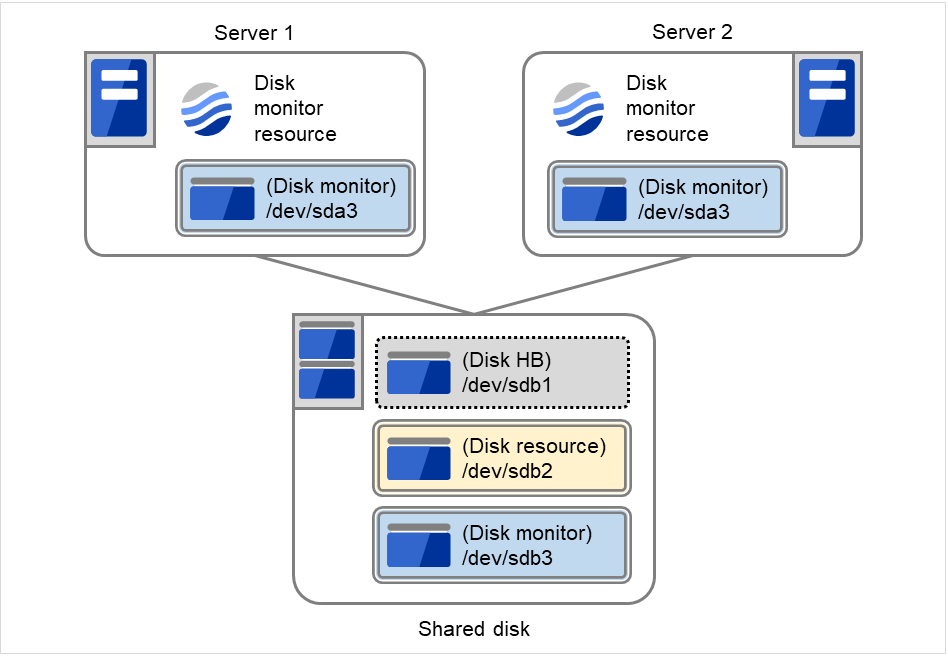
図 4.63 ディスクリソース、ディスクモニタの設定例¶
4.4.4. 監視 (固有) タブ¶
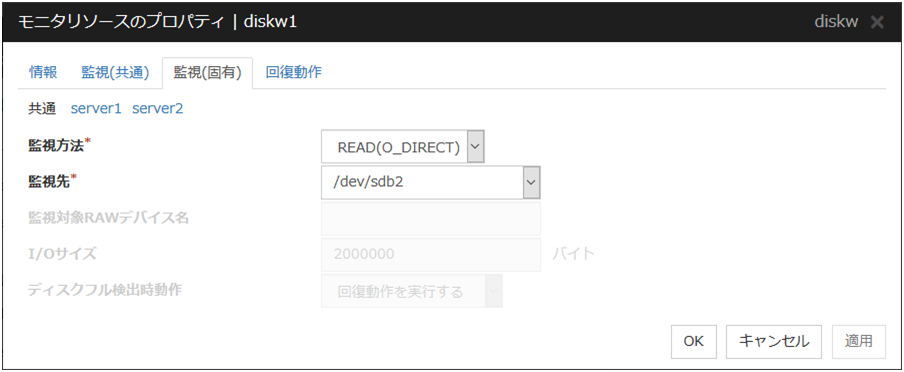
監視方法 サーバ個別設定可能
ディスクデバイスを監視するときの監視方法を下記より選択します。
TUR
TUR (generic)
TUR (legacy)
READ
READ (O_DIRECT)
WRITE (FILE)
READ (RAW)
監視先 (1023 バイト以内) サーバ個別設定可能
監視対象 RAW デバイス名 (1023 バイト以内) サーバ個別設定可能
監視方法に READ(RAW) を選択した場合のみ入力可能となります。
ディスクリソースとの関連付けを行うには、「 監視 (共通) タブ 」の [対象リソース] で依存するディスクリソースを設定します。設定したディスクリソースの活性後に監視を行うよう設定してください。
I/O サイズ (1~99999999) サーバ個別設定可能
監視処理で行う read または read/write のサイズを指定します。
READ (RAW), READ (O_DIRECT) を指定した場合、I/O サイズの入力項目はグレーアウトされます。対象のデバイスから 1 セクタ分の read を行います。
TUR, TUR (generic), TUR (legacy) を指定した場合、本設定項目は無視されます。
ディスクフル検出時動作 サーバ個別設定可能
ディスクフル(監視するディスクに空き容量がない状態)検出時の動作を下記より選択します。
注釈
READ, READ (RAW), READ (O_DIRECT), TUR, TUR (generic), TUR (legacy) を指定した場合、ディスクフル検出時動作の項目はグレーアウトされます
監視デバイス名にローカルディスクを設定すると、サーバのローカルディスク監視を行うことができます。
ローカルディスク [/dev/sdb] を [READ 方式] で監視し、異常検出時に [OS 再起動] を行う設定例
設定項目
設定値
備考
監視デバイス名
/dev/sdb
2 台目の SCSI ディスク
監視方法
READ
READ 方式
回復対象
無し
-
最終動作
クラスタサービス停止と OS 再起動
OS 再起動
ローカルディスク [/dev/sdb] を [TUR (generic) 方式] で監視し、異常検出時に [何もしない] (Cluster WebUI へアラートの表示のみを行う) 場合の設定例
設定項目
設定値
備考
監視デバイス名
/dev/sdb
2 台目の SCSI ディスク
監視方法
TUR (generic)
SG_IO 方式
最終動作
何もしない
4.5. IP モニタリソースを理解する¶
IP モニタリソースとは、[ping] コマンドを使用して、IP アドレスの監視を行うモニタリソースです。
4.5.1. IP モニタリソースの監視方法¶
指定した IP アドレスを [ping] コマンドで監視します。指定した IP アドレスすべての応答がない場合に異常と判断します。
IP アドレスの応答確認には ICMP の packet type 0 (Echo Reply) と 8 (Echo Request) が使用されます。
複数の IP アドレスについてすべての IP アドレスが異常時に異常と判断したい場合、 1 つの IP モニタリソースにすべての IP アドレスを登録してください。
以下の図は1つのIPモニタリソースに全てのIPアドレスを登録した場合の例です。 指定したIPアドレスが一つでも正常な場合、IP monitor 1は正常と判断します。
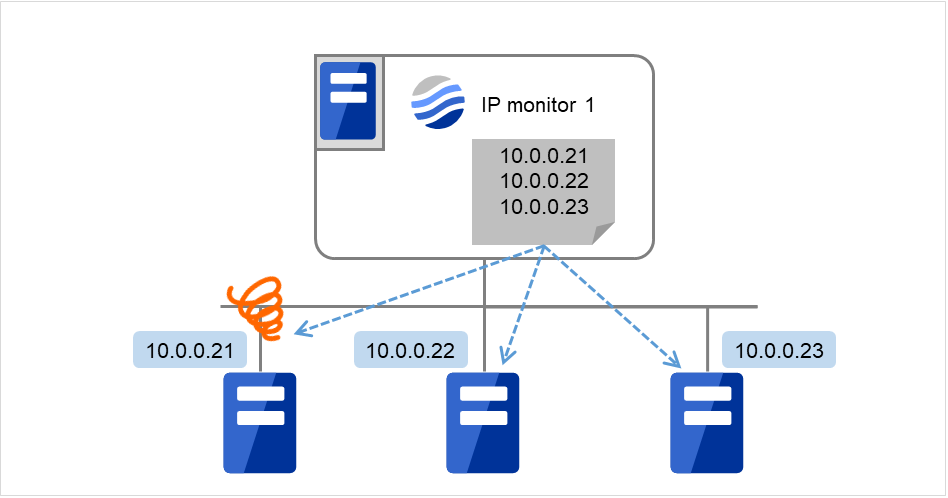
図 4.64 1つのIPモニタリソースに全てのIPアドレスを登録(正常)¶
以下の図は1つのIPモニタリソースに全てのIPアドレスを登録した場合の例です。 指定したIPアドレスが全て異常な場合、IP monitor 1は異常と判断します。
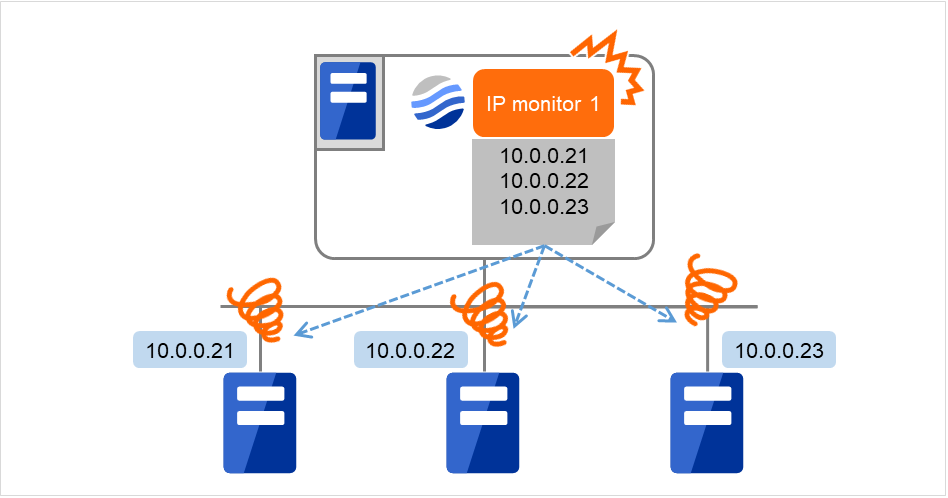
図 4.65 1つのIPモニタリソースに全てのIPアドレスを登録(異常検出)¶
複数の IP アドレスについてどれか 1 つが異常時に異常と判断したい場合、個々の IP アドレスについて 1 つずつの IP モニタリソースを作成してください。
図は各IPモニタリソースにIPアドレスを一つずつ登録した場合の例です。 指定したIPアドレスの異常を検出した場合、IPモニタ(図ではIP monitor 1)は異常と判断します。
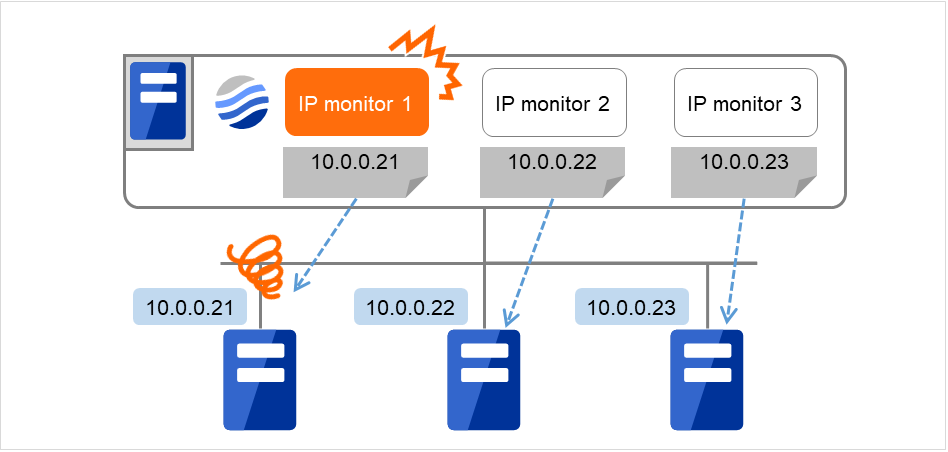
図 4.66 各IPモニタリソースにIPアドレスを一つずつ登録(異常検出)¶
4.5.2. 監視 (固有) タブ¶
[IP アドレス一覧] には監視する IP アドレスの一覧が表示されます。
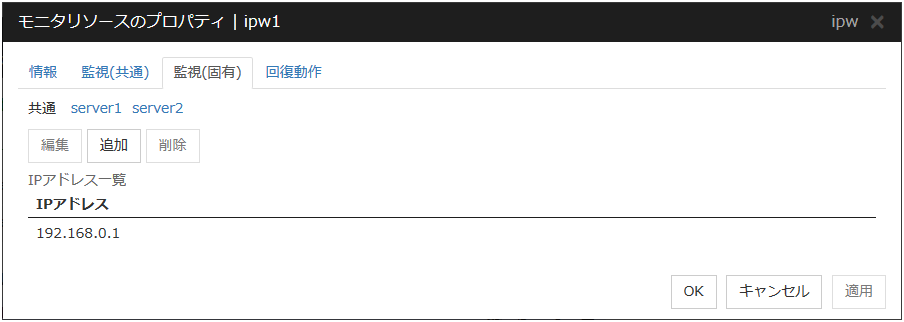
追加
監視する IP アドレスを追加します。[IPアドレスの入力] ダイアログボックスが表示されます。
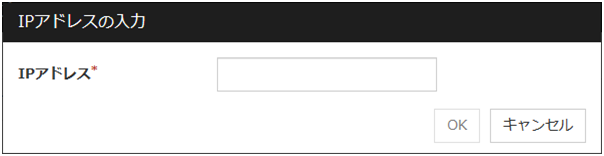
IP アドレス (255 バイト以内) サーバ個別設定可能
監視を行う IP アドレスまたはホスト名を入力して [OK] を選択してください。パブリック LANに存在する実 IP アドレスまたはホスト名を入力してください。ホスト名を設定する場合は、OS 側に名前解決の設定 (/etc/hosts へのエントリの追加など) をしてください。
削除
[IP アドレス一覧] で選択している IP アドレスを監視対象から削除します。
編集
[IP アドレスの入力] ダイアログボックスが表示されます。[IP アドレス一覧] で選択しているIPアドレスが表示されるので、編集して[OK]を選択します。
4.6. フローティング IP モニタリソースを理解する¶
フローティング IP モニタリソースはフローティング IP リソースの監視を行います。
4.6.1. フローティング IP モニタリソースの監視方法¶
4.6.2. フローティング IP モニタリソースの注意事項¶
- 本リソースはフローティング IP リソースを追加した時に自動的に登録されます。各フローティング IP リソースに対応するフローティング IP モニタリソースが自動登録されます。フローティングIPモニタリソースには既定値が設定されているので、必要があれば適切な値に変更してください。
4.6.3. 監視 (固有) タブ¶
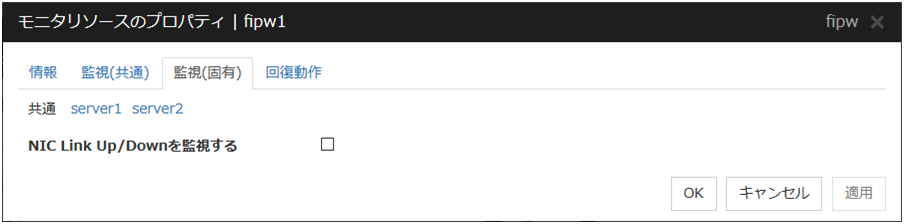
NIC Link Up/Down を監視する
NIC Link Up/Down を監視するかどうかを設定します。
有効にした場合、フローティング IP を付与した NIC に対する NIC Link Up/Down を監視します。このため、新たに フローティング IP を付与した NIC に対する NIC Link Up/Down モニタリソースの設定は不要です。
4.7. NIC Link Up/Down モニタリソースを理解する¶
4.7.1. NIC Link Up/Down モニタリソースの動作環境¶
NIC Link Up/Down モニタリソースをサポートするネットワークインターフェイス
NIC Link Up/Down モニタリソースは、以下のネットワークインターフェイスで動作確認しています。
Ethernet Controller(Chip) |
Bus |
Driver version |
|---|---|---|
Intel 82557/8/9 |
PCI |
3.5.10-k2-NAPI |
Intel 82546EB |
PCI |
7.2.9 |
Intel 82546GB |
PCI |
7.3.20-k2-NAPI
7.2.9
|
Intel 82573L |
PCI |
7.3.20-k2-NAPI |
Intel 80003ES2LAN |
PCI |
7.3.20-k2-NAPI |
Broadcom BCM5721 |
PCI |
7.3.20-k2-NAPI |
4.7.2. NIC Link Up/Down モニタリソースの注意事項¶
ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: umbg
Wake-on: g
Current message level: 0x00000007 (7)
Link detected: yes
[ethtool] コマンドの結果で LAN ケーブルのリンク状況 ("Link detected: yes") が表示されない場合
CLUSTERPRO の NIC Link Up/Down モニタリソースが動作不可能な可能性が高いです。IP モニタリソースで代替してください。
[ethtool] コマンドの結果で LAN ケーブルのリンク状況 ("Link detected: yes") が表示される場合
多くの場合 CLUSTERPRO の NIC Link Up/Down モニタリソースが動作可能ですが、希に動作不可能な場合があります。
特に以下のようなハードウェアでは動作不可能な場合があります。IP モニタリソースで代替してください。
ブレードサーバのように実際の LAN のコネクタと NIC のチップとの間にハードウェアが実装されている場合
実機で CLUSTERPRO を使用して NIC Link Up/Down モニタリソースの使用可否を確認する場合には以下の手順で動作確認を行ってください。
- NIC Link Up/Down モニタリソースを構成情報に登録してください。NIC Link Up/Down モニタリソースの異常検出時回復動作の設定は「何もしない」を選択してください。
- クラスタを起動してください。
- NIC Link Up/Down モニタリソースのステータスを確認してください。LAN ケーブルのリンク状態が正常状態時に NIC Link Up/Down モニタリソースのステータスが異常となった場合、NIC Link Up/Down モニタリソースは動作不可です。
- LAN ケーブルのリンク状態を異常状態 (リンクダウン状態) にしたときに NIC Link Up/Down モニタリソースのステータスが異常となった場合、NIC Link Up/Down モニタ リソースは動作可能です。ステータスが正常のまま変化しない場合、NIC Link Up/Down モニタリソースは動作不可です。
4.7.3. NIC Link Up/Down 監視の構成および範囲¶
NIC Link Up/Down 監視が検知した異常には複数の要因が考えられます。 サーバとネットワーク機器をLANケーブルで接続している時に異常が発生したのであれば、サーバ側のケーブルが抜けている可能性があります。 また、その場合、ネットワーク機器側のケーブルが抜けている可能性もあります。 さらに、ネットワーク機器の電源断の可能性も考えられます。
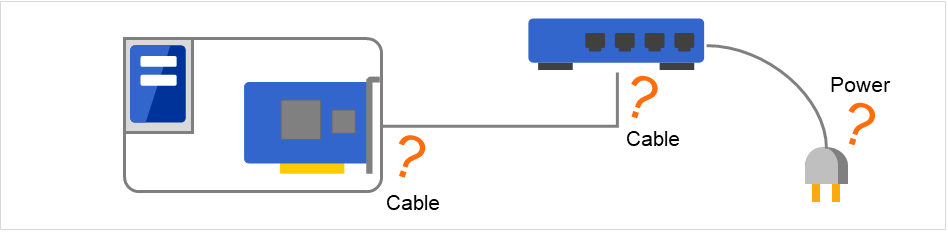
図 4.67 NIC Link Up/Down 監視と異常発生要因¶
NIC のドライバへの ioctl( ) によりネットワーク (ケーブル) のリンク確立状態を検出します。(IP モニタの場合は、指定された IP アドレスへの ping の反応で判断をします。)
インタコネクト (ミラーコネクト) 専用の NIC を監視することもできますが、2 ノード間を LAN ケーブルで直結している場合には片サーバダウン時に (リンクが確立しないため)残りのサーバ側でも 異常を検出します。
また、ネットワークを bonding 化している場合には、 bonding による可用性を活かしたまま下位のスレーブインターフェイス (eth0, eth1...) だけでなくマスタインターフェイス (bond0...)も監視することが可能です。その場合には、下記の設定を推奨します。
スレーブインターフェイス
- 異常検出時の回復動作:何もしない片方のネットワークケーブルのみ (eth0) の異常時には CLUSTERPRO は回復 動作を実行せず、アラートのみ出力します。ネットワークの回復動作は、bonding が行います。
マスタインターフェイス
- 異常検出時の回復動作:フェイルオーバやシャットダウンなどを設定する全てのスレーブインターフェイスの異常時 (マスタインターフェイスがダウン状態) にCLUSTERPRO は、回復動作を実行します。
以下の図は、スレーブインターフェイス eth0、eth1をbonding化し、マスタインターフェイス bond0とした場合を表しています。
eth0の障害発生時には、bondingドライバが縮退または切替を行います。
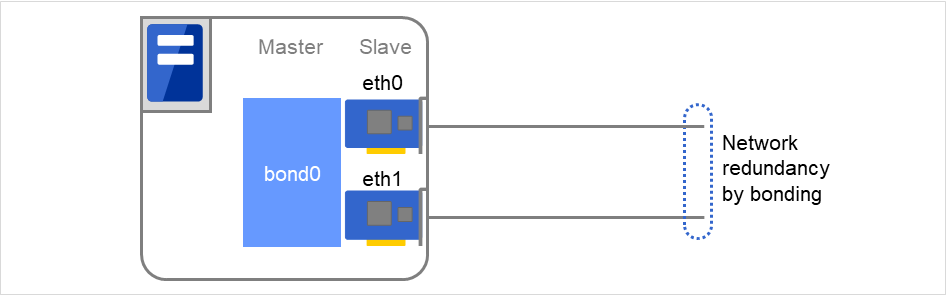
図 4.68 Network bondingの使用例¶
4.7.4. 監視 (固有) タブ¶
NIC Link Up/Down モニタリソースは、指定した NIC の Link 状態を取得し、Link のUp/Down を監視します。
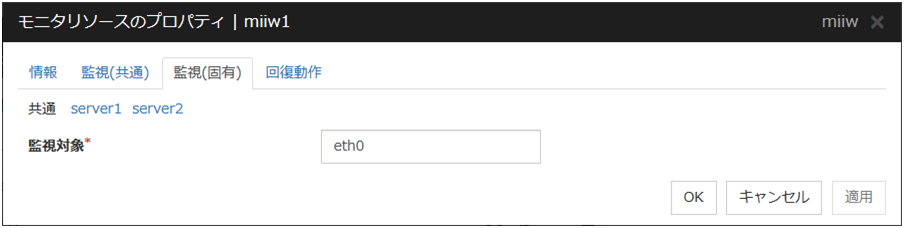
監視対象 (15 バイト以内) サーバ個別設定可能
監視を行う NIC のインターフェイス名を設定してください。ボンドデバイス(例:bond.600)、およびチームデバイス(例:team0)共に監視可能です。VLAN, tagVLAN の監視も可能です(設定例:eth0.8)。
4.8. ミラーディスクコネクトモニタリソースを理解する¶
4.8.1. ミラーディスクコネクトモニタリソースの注意事項¶
ミラーリング用のネットワークを監視します。指定したミラーディスクコネクトを使用したミラーデータの通信に失敗した場合に異常と判断します。本リソースはミラーディスクリソースを追加した時に自動的に登録されます。
ミラーディスクリソースを複数追加した場合、ミラーディスクコネクトモニタリソースはミラーリソース数だけ自動登録されます。
4.9. ミラーディスクモニタリソースを理解する¶
ミラーディスクのデータの状態、ミラードライバの健全性を監視します。
4.9.1. ミラーディスクモニタリソースの注意事項¶
本リソースはミラーディスクリソースを追加した時に自動的に登録されます。各ミラーディスク リソースに対応するミラーディスクモニタリソースが自動登録されます。
4.10. ハイブリッドディスクコネクトモニタリソースを理解する¶
4.10.1. ハイブリッドディスクコネクトモニタリソースの注意事項¶
ミラーリング用のネットワークを監視します。指定したミラーディスクコネクトを使用したミラーデータの通信に失敗した場合に異常と判断します。本リソースはハイブリッドディスクリソースを追加した時に自動的に登録されます。
ハイブリッドディスクリソースを複数追加した場合、ハイブリッドディスクコネクトモニタ リソースはハイブリッドディスクリソース数だけ自動登録されます。
4.11. ハイブリッドディスクモニタリソースを理解する¶
ハイブリッドディスクのデータの状態、ミラードライバの健全性を監視します。
4.11.1. ハイブリッドディスクモニタリソースの注意事項¶
本リソースはハイブリッドディスクリソースを追加した時に自動的に登録されます。各ハイブリッドディスクリソースに対応するハイブリッドディスクモニタリソースが自動登録されます。
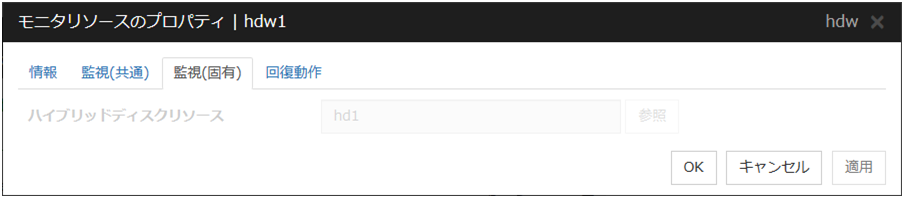
4.12. PID モニタリソースを理解する¶
4.12.1. PID モニタリソースの注意事項¶
活性に成功した EXEC リソースを監視します。EXEC リソースの開始スクリプトの起動時の設定が [非同期] の場合のみ監視できます。
4.12.2. PID モニタリソースの設定¶
注釈
データベース、samba、apache、sendmail などのストール監視を行うには「CLUSTERPRO 監視オプション」を購入してください。
4.13. ユーザ空間モニタリソースを理解する¶
ユーザ空間モニタリソースは、OSの負荷状態を監視します。
4.13.1. ユーザ空間モニタリソースが依存するドライバ¶
監視方式 softdog
softdog
監視方法が softdog の場合、このドライバが必要です。
ローダブルモジュール構成にしてください。スタティックドライバでは動作しません。
softdog ドライバが使用できない場合、監視を開始することはできません。
監視方式 keepalive
clpkaclpkhb
監視方法が keepalive の場合、CLUSTERPRO の clpkhb ドライバ、clpka ドライバが必要です。
監視方法を keepalive に設定する場合、カーネルモード LAN ハートビートを設定することを推奨します。カーネルモード LAN ハートビートを使用するには clpkhb ドライバが必要です。
clpka ドライバと clpkhb ドライバは CLUSTERPRO が提供するドライバです。サポート範囲については『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「動作可能なディストリビューションと kernel」を参照してください。
clpkhb ドライバ、clpka ドライバが使用できない場合、監視を開始することはできません。
監視方式 ipmi
ipmi
監視方法が ipmi の場合、このドライバが必要です。
ipmi ドライバがロードされていない場合、監視を開始することはできません。
4.13.2. ユーザ空間モニタリソースの監視方法¶
ユーザ空間モニタリソースの監視方法は以下のとおりです。
監視方法 softdog
監視方法が softdog の場合、OS の softdog ドライバを使用します。
監視方法 keepalive
監視方法が keepalive の場合、clpkhb ドライバと clpka ドライバを使用します。
注釈
clpkhb ドライバ, clpka ドライバが動作するディストリビューション、kernel バージョンについては必ず『スタートアップガイド』の 「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「動作可能なディストリビューションと kernel」で確認してください。ディストリビュータがリリースするセキュリティパッチを既に運用中のクラスタへ適用する場合(kernel バージョンが変わる場合) にも確認してください。
監視方法 ipmi
監視方法が ipmi の場合、ipmiドライバを使用します。
監視方法 none
監視方法 none は、評価用の設定です。ユーザ空間モニタリソースの拡張設定の動作だけを実行します。本番環境では設定しないでください。
4.13.3. ユーザ空間モニタリソースの拡張設定¶
ユーザ空間モニタリソースを拡張させる設定として、ダミーファイルのオープン/クローズ、ダミーファイルへの書き込み、ダミースレッドの作成があります。各設定に失敗するとタイマの更新を行いません。設定したタイムアウト値またはハートビートタイムアウト時間内に各設定が失敗し続けると OS をリセットします。
ダミーファイルのオープン/クローズ
監視間隔ごとにダミーファイルの作成、ダミーファイルの open、ダミーファイルの close、ダミーファイルの削除を繰り返します。
この拡張機能を設定している場合、ディスクの空き容量がなくなるとダミーファイルのopen に失敗してタイマの更新が行われず、OS をリセットします。
ダミーファイルへの書き込み
監視間隔毎にダミーファイルに設定したサイズを書き込みます。
この拡張機能は、ダミーファイルのオープン/クローズが設定されていないと設定できません。
ダミースレッドの作成
監視間隔ごとにダミースレッドを作成します。
4.13.4. ユーザ空間モニタリソースのロジック¶
監視方法の違いによる処理内容、特徴は以下の通りです。シャットダウン監視では各処理概要のうち 1 のみの挙動になります。
監視方法 ipmi
処理概要
以下の 2~7 の処理を繰り返します。
IPMI タイマセット
ダミーファイルの open()
ダミーファイル write()
ダミーファイル fdatasync()
ダミーファイルの close()
ダミースレッド作成
IPMI タイマ更新
処理概要 2~6 は監視の拡張設定の処理です。各設定を行っていないと処理を行いません。
- タイムアウトしない (上記2~7が問題なく処理される) 場合の挙動リセットなどのリカバリ処理は実行されません
- タイムアウトした (上記 2~7 のいずれかが停止または遅延した) 場合の挙動BMC (サーバ本体のマネージメント機能) によりリセットを発生させます
メリット
- BMC (サーバ本体のマネージメント機能) を使用するため kernel 空間の障害を受けにくく、リセットができる確率が高くなります
デメリット
H/W に依存しているため IPMI をサポートしていないサーバ、OpenIPMI が動作しないサーバでは使用できません
ESMPRO/ServerAgent を使用しているサーバでは使用できません
- その他サーバベンダが提供するサーバ監視ソフトウェアと共存できない可能性があります
監視方法 softdog
処理概要
以下の 2~7 の処理を繰り返します。
softdog セット
ダミーファイルの open()
ダミーファイル write()
ダミーファイル fdatasync()
ダミーファイルの close()
ダミースレッド作成
softdog タイマ更新
処理概要 2~6 は監視の拡張設定の処理です。各設定を行っていないと処理を行いません。
- タイムアウトしない (上記 2~7 が問題なく処理される) 場合の挙動リセットなどのリカバリ処理は実行されません
- タイムアウトした (上記 2~7 のいずれかが停止または遅延した) 場合の挙動softdog によりリセットを発生させます
メリット
- H/W に依存しないため softdog kernel モジュールがあれば使用できます。(一部のディストリビューションではデフォルトで softdog が用意されていないものがありますので 設定する前に softdog の有無を確認してください)
デメリット
softdog が kernel 空間のタイマロジックに依存しているため kernel 空間に障害が発生した場合にリセットされない場合があります。
監視方法 keepalive
処理概要
以下の 2~7 の処理を繰り返します。
keepalive タイマセット
ダミーファイルの open()
ダミーファイル write()
ダミーファイル fdatasync()
ダミーファイルの close()
ダミースレッド作成
keepalive タイマ更新
処理概要 2~6 は監視の拡張設定の処理です。各設定を行っていないと処理を行いません。
- タイムアウトしない (上記 2~7 が問題なく処理される) 場合の挙動リセットなどのリカバリ処理は実行されません
- タイムアウトした (上記 2~7 のいずれかが停止または遅延した) 場合の挙動clpkhb.ko を経由して他のサーバへ [自サーバのリセット] をアナウンスしますアクションの設定にしたがって、clpka.ko によりリセットまたはパニックを発生させます
メリット
clpkhb により他サーバへ [自サーバのリセット] をアナウンスすることで、他のサーバ上で記録 (ログ) を残すことができます。
デメリット
- 動作できる (ドライバを提供している) ディストリビューション、アーキテクチャ、カーネルバージョンが制限されます。clpka が kernel 空間のタイマロジックに依存しているため kernel 空間に障害が発生した場合にリセットされない場合があります。
4.13.5. ipmi 動作可否の確認方法¶
OpenIPMI の rpm パッケージをインストールする。
/usr/bin/ipmitoolを実行する。
実行結果を確認する。
Watchdog Timer Use: BIOS FRB2 (0x01)
Watchdog Timer Is: Stopped
Watchdog Timer Actions: No action (0x00)
Pre-timeout interval: 0 seconds
Timer Expiration Flags: 0x00
Initial Countdown: 0 sec
Present Countdown: 0 sec
OpenIPMI は使用できます。監視方法に ipmi を選択することが可能です。
4.13.6. ユーザ空間モニタリソースの注意事項¶
全監視方法での共通の注意事項
Cluster WebUI でクラスタを追加すると監視方法 softdog のユーザ空間モニタリソースが自動で作成されます。
監視方法の異なるユーザ空間モニタリソースを追加することができます。クラスタを追加した時に自動的に作成された監視方法 softdog のユーザ空間モニタリソースは削除することもできます。
OS の softdog ドライバが存在しない、または CLUSTERPRO の clpkhb ドライバ、clpka ドライバが存在しない、OpenIPMI の rpm がインストールされていないなどの理由によりユーザ空間モニタリソースの活性に失敗した場合、Cluster WebUI のアラートログに "Monitor userw failed." というメッセージが表示されます。Cluster WebUI、[clpstat] コマンドでの表示ではリソースステータスは [正常] が表示され、各サーバのステータスは [停止済] が表示されます。
ipmi による監視の注意事項
ipmi に関する注意事項は「4. モニタリソースの詳細」 - 「モニタリソースとは?」 - 「使用している ipmi コマンド」を参照してください。
注釈
keepalive による監視の注意事項
他サーバへの reset の通知はカーネルモード LAN ハートビートリソースが設定されている場合に限ります。この場合、下記のログが syslog に出力されます。
kernel: clpka: <server priority: %d> <reason: %s> <process name: %s>system reboot.
4.13.7. 監視 (固有) タブ¶
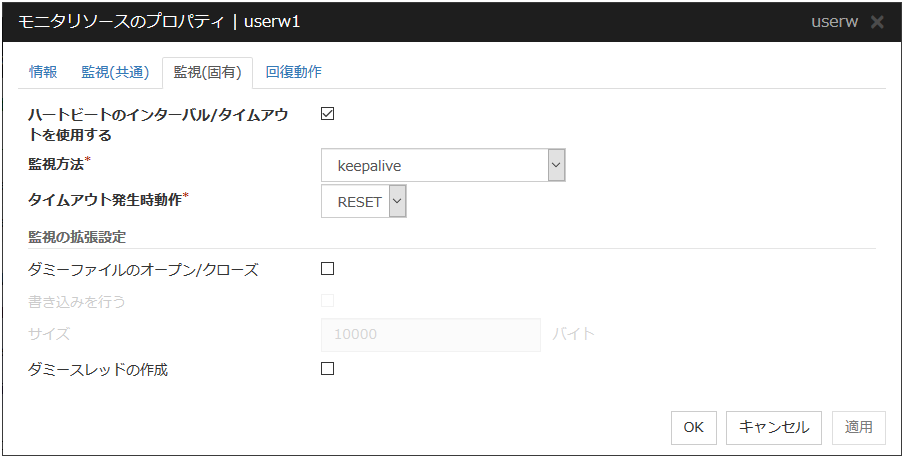
ハートビートのインターバル/タイムアウトを使用する
監視のインターバルとタイムアウトを、ハートビートのインターバルとタイムアウトを使用するかどうかを設定します。
監視方法
ユーザ空間モニタリソースの監視方法を以下の中から選択します。既に他のユーザ空間モニタリソースで使用している監視方法は選択できません。
タイムアウト発生時動作
最終動作を設定します。
ダミーファイルのオープン クローズ
監視を行う際、インターバルごとにダミーファイルのオープン / クローズを行うかどうかを設定します。
書き込みを行う
ダミーファイルのオープン/クローズを行う場合に、ダミーファイルに書き込みを行うかどうかを設定します。
サイズ (1~9999999)
ダミーファイルに書き込みを行う場合に書き込むサイズを設定します。
ダミースレッドの作成
監視を行う際にダミースレッドの作成を行うかどうかを設定します。
4.14. マルチターゲットモニタリソースを理解する¶
マルチターゲットモニタリソースは、複数のモニタリソースの監視を行います。
4.14.1. マルチターゲットモニタリソースの注意事項¶
マルチターゲットモニタリソースは、登録されているモニタリソースのステータス 停止済み(offline)を異常として扱います。そのため、活性時監視のモニタリソースを登録した場合、モニタリソースが異常を検出していない状態でマルチターゲットモニタリソースが異常を検出してしまうことがあります。活性時監視のモニタリソースを登録しないでください。
4.14.2. マルチターゲットモニタリソースのステータス¶
マルチターゲットモニタリソースのステータスは登録されているモニタリソースのステータスによって判断します。
マルチターゲットモニタリソースが下記のように設定されている場合、
登録されているモニタリソース数 2異常しきい値 2警告しきい値 1
マルチターゲットモニタリソースのステータスは以下のようになります。
マルチターゲットモニタリソース ステータス |
モニタリソース 1 ステータス |
|||
|---|---|---|---|---|
正常
(normal)
|
異常
(error)
|
停止済
(offline)
|
||
モニタリソース 2 ステータス |
正常
(normal)
|
正常
(normal)
|
警告
(caution)
|
警告
(caution)
|
異常
(error)
|
警告
(caution)
|
異常
(error)
|
異常
(error)
|
|
停止済
(offline)
|
警告
(caution)
|
異常
(error)
|
正常
(normal)
|
|
- マルチターゲットモニタリソースは、登録されているモニタリソースのステータスを監視しています。ステータスが異常 (error) であるモニタリソースの数が異常しきい値以上になった場合、マルチターゲットモニタリソースは異常 (error) を検出します。ステータスが異常 (error) であるモニタリソース数が警告しきい値を超えた場合、マルチターゲットモニタリソースの status は警告 (caution) となります。登録されている全てのモニタリソースのステータスが停止済み (offline) の場合、マルチターゲットモニタリソースのステータスは正常 (normal) となります。登録されている全てのモニタリソースのステータスが停止済み (offline) の場合を除いて、マルチターゲットモニタリソースは登録されているモニタリソースのステータス 停止済み(offline) を異常 (error) と判断します。
- 登録されているモニタリソースのステータスが異常 (error) となっても、そのモニタリソースの異常時アクションは実行されません。マルチターゲットモニタリソースが異常 (error) になった場合のみ、マルチターゲットモニタリソースの異常時アクションが実行されます。
4.14.3. マルチターゲットモニタリソースの設定例¶
- Disk パス二重化ドライバの使用例ディスクデバイス (/dev/sdb, /dev/sdcなど) が同時に異常となった場合にのみ、異常 (error) とする必要があります。以下の図は、2つのHBAとDiskパス二重化ドライバを使ってパスを二重化した構成を表しています。片側のHBAの障害活性時には、Diskパス二重化ドライバがパスの縮退または切り替えを行います。
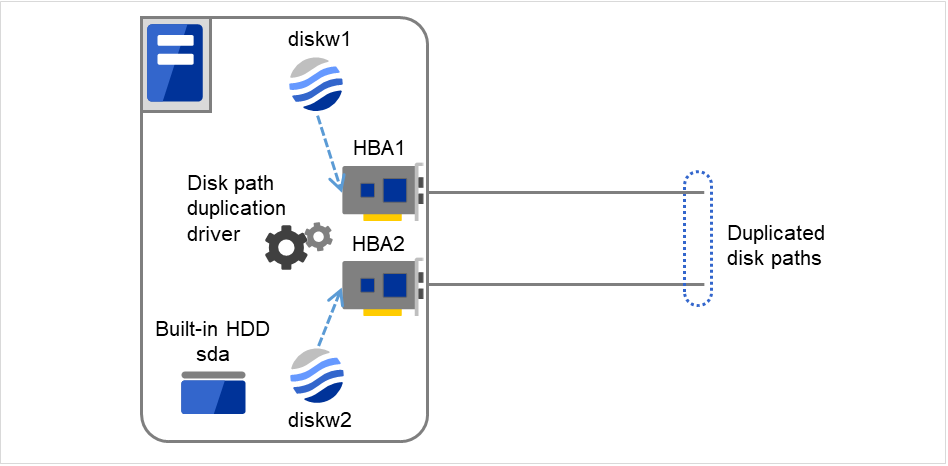
図 4.69 Diskパス二重化ドライバの使用例¶
マルチターゲットモニタリソース (mtw1) に登録するモニタリソース
diskw1
diskw2
マルチターゲットモニタリソース (mtw1) の異常しきい値、警告しきい値
異常しきい値 2
警告しきい値 0
マルチターゲットモニタリソース (mtw1) に登録するモニタリソースの詳細設定
- ディスクモニタリソース (diskw1)監視デバイス名 /dev/sdb再活性しきい値 0フェイルオーバしきい値 0最終動作 何もしない
- ディスクモニタリソース (diskw2)監視デバイス名 /dev/sdc再活性しきい値 0フェイルオーバしきい値 0最終動作 何もしない
上記の設定の場合、マルチターゲットモニタリソースのモニタリソースに登録されているdiskw1 と diskw2 のどちらかが異常を検出しても、異常となったモニタリソースの異常時アクションを行いません。
diskw1 と diskw2 が共に異常となった場合、2 つのモニタリソースのステータスが異常(error) と停止済み (offline) になった場合、マルチターゲットモニタリソースに設定された異常時アクションを実行します。
4.14.4. 監視 (固有) タブ¶
モニタリソースをグループ化して、そのグループの状態を監視します。[モニタリソース一覧] はモニタリソースを最大 64 個登録できます。
本リソースの [モニタリソース一覧] に唯一設定されているモニタリソースが削除された場合、本リソースは自動的に削除されます。
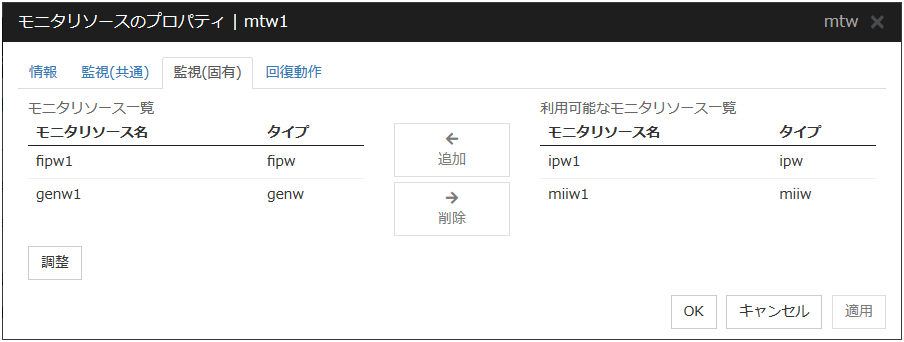
追加
選択しているモニタリソースを [モニタリソース一覧] に追加します。
削除
選択しているモニタリソースを [モニタリソース一覧] から削除します。
調整
[マルチターゲットモニタリソース調整プロパティ] ダイアログボックスを表示します。マルチターゲットモニタリソースの詳細設定を行います。
マルチターゲットモニタリソース調整プロパティ
パラメータタブ
パラメータに関する詳細設定が表示されます。
異常しきい値
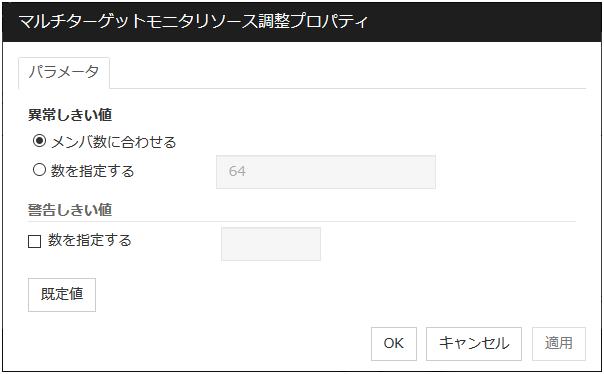
マルチターゲットモニタが異常とする条件を選択します。
メンバ数に合わせる
マルチターゲットモニタの配下に指定したモニタリソースが全て異常となったとき、または異常と停止済が混在しているときにマルチターゲットモニタが異常になります。
マルチターゲットモニタの配下に指定したモニタリソースの全てが停止済の場合には、正常になります。
数を指定する
マルチターゲットモニタの配下に指定したモニタリソースのうち、異常しきい値に設定した数が異常または停止済となったときにマルチターゲットモニタが異常になります。
マルチターゲットモニタの配下に指定したモニタリソースのうち、何個のモニタリソースが異常または停止済となったときにマルチターゲットモニタを異常とするかの個数を設定します。
異常しきい値の選択が [数を指定する] のときに設定できます。
警告しきい値
既定値
既定値に戻すときに使用します。[既定値] をクリックすると全ての項目に既定値が設定されます。
4.15. 仮想 IP モニタリソースを理解する¶
4.15.1. 仮想 IP モニタリソースの注意事項¶
仮想 IP リソースを追加すると自動的に作成されます。仮想 IP リソース 1 つに対して1 つの仮想 IP モニタリソースが自動的に作成されます。
仮想 IP モニタリソースは削除できません。仮想 IP リソースを削除すると自動的に削除されます。
回復対象は変更しないでください。
[clpmonctrl] コマンドまたは Cluster WebUI からの監視の一時停止、再開はできません。
仮想 IP モニタリソースは、仮想 IP リソースの経路制御のために定期的に RIP パケットを送出しています。クラスタサスペンド時に対象の仮想 IP リソースが活性状態であれば、仮想 IP モニタリソースは停止せずに動作し続けます。
[監視(共通)]-[リトライ回数]の設定は無効です。異常の検出を遅らせたい場合は[監視(共通)]-[タイムアウト]の設定を変更してください。
4.15.2. 仮想 IP モニタリソースの設定¶
4.16. ARP モニタリソースを理解する¶
ARP モニタリソースは、活性しているフローティング IP リソースまたは仮想 IP リソースのためのARP テーブルを保持/更新するための定期的な ARP パケットの送出を行います。
4.16.1. ARP モニタリソースの注意事項¶
ARP モニタリソースが送出する ARP ブロードキャストパケットに関しては、本ガイドの「3. グループリソースの詳細」の「フローティング IP リソースを理解する」を参照してください。
フローティング IP リソースまたは仮想 IP リソースで活性された IP アドレスの状態の確認は行いません。
ARP モニタリソースの監視対象リソースはフローティング IP リソースまたは仮想 IP リソースのみ選択可能です。ARP モニタリソースの設定では、[監視 (共通)] タブの [対象リソース]と、[監視 (固有)]の [対象リソース] は必ず同じリソースを選択してください。
ARP モニタリソースは [clpmonctrl] コマンドまたは Cluster WebUI からの監視の一時停止、再開はできません。
4.16.2. 監視 (固有) タブ¶
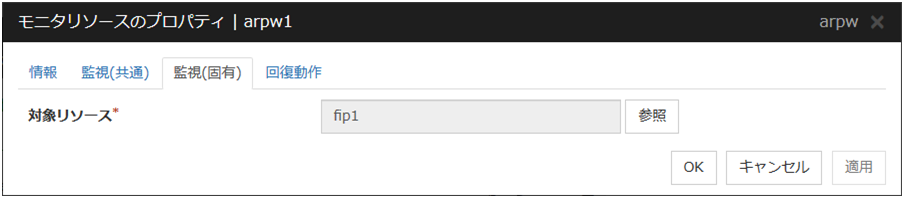
対象リソース
[参照] を選択すると、[対象リソースの選択] ダイアログボックスを表示します。LocalServer とクラスタに登録されているグループ名、フローティング IP リソース名または仮想 IP リソース名がツリー表示されます。対象リソースとして設定するリソースを選択して [OK] をクリックします。
注釈
対象リソースを変更した場合は、必ず監視(共通)タブの対象リソースも変更してください。
4.17. カスタムモニタリソースを理解する¶
カスタムモニタリソースは、任意のスクリプトを実行することによりシステムモニタを行うモニタ リソースです。
4.17.1. カスタムモニタリソースの注意事項¶
監視タイプが [非同期] の場合、監視リトライ回数を 1 回以上に設定すると、正常に監視を 行うことができません。監視タイプを [非同期] に設定する場合は、監視リトライ回数を 0 回に設定してください。
スクリプトのログローテート機能を有効にした場合、ログ出力を仲介するプロセス(仲介プロセス)が生成されます。仲介プロセスは、「開始・停止スクリプト」および「開始・停止スクリプトから標準出力・標準エラー出力のいずれかまたは両方を継承した子孫プロセス」からのログ出力が全て停止 (ファイルディスクリプタがクローズ) するまで動作を継続します。子孫プロセスの出力をログから除外する場合は、スクリプトからのプロセス生成時に標準出力および標準エラー出力をリダイレクトしてください。
4.17.2. カスタムモニタリソースの監視方法¶
4.17.3. 監視 (固有) タブ¶
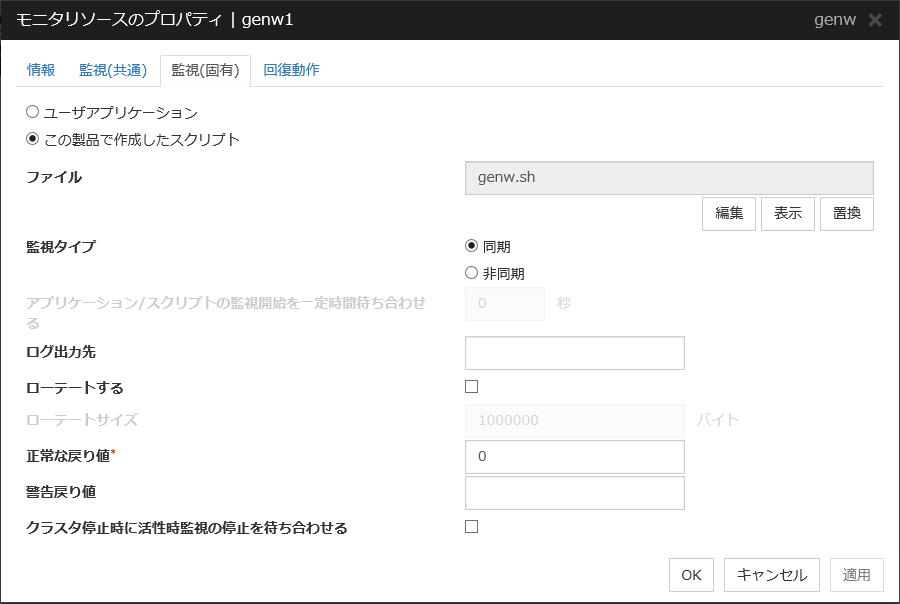
ユーザアプリケーション
スクリプトとしてサーバ上の実行可能ファイル (実行可能なシェルスクリプトファイルや実行ファイル) を使用します。各実行可能ファイル名は、サーバ上のローカルディスクの絶対パスで設定します。
各実行可能ファイルは、Cluster WebUI のクラスタ構成情報には含まれません。Cluster WebUI で編集やアップロードはできませんので、各サーバ上に準備する必要があります。
この製品で作成したスクリプト
スクリプトとして Cluster WebUI で準備したスクリプトファイルを使用します。必要に応じて Cluster WebUI でスクリプトファイルを編集できます。スクリプトファイルは、クラスタ構成情報に含まれます。
ファイル (1023バイト以内)
[ユーザアプリケーション] を選択した場合に、実行するスクリプト (実行可能なシェルスクリプトファイルや実行ファイル) を、サーバ上のローカルディスクの絶対パスで設定します。
表示
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを表示します。
編集
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを編集します。変更を反映するには [保存] をクリックしてください。スクリプトファイル名の変更はできません。
置換
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルの内容を、ファイル選択ダイアログボックスで選択したスクリプトファイルの内容に置換します。スクリプトが表示中または編集中の場合は置換できません。ここではスクリプトファイルを選択してください。バイナリファイル (アプリケーションなど) は選択しないでください。
監視タイプ
監視の方法を選択します。
アプリケーション/スクリプトの監視開始を一定時間待ち合わせる (0~9999)
監視タイプが [非同期] の場合にアプリケーション/スクリプトを起動してから監視を開始するまでの待ち時間を設定します。この待ち時間は[監視 (共通)] タブで設定したタイムアウトの値より小さい値を設定する必要があります。
注釈
本設定は次回モニタ起動時に有効になります。
既定値 : 0
ログ出力先(1023バイト以内)
スクリプト内で出力するログの出力先を設定します。
[ローテートする] のチェックボックスがオフの場合は無制限に出力されますのでファイルシステムの空き容量に注意してください。
[ローテートする] のチェックボックスがオンの場合は、出力されるログファイルは、ローテートします。また、以下の注意事項があります。
[ログの出力先] には 1009 バイト以内でログのパスを記述してください。1010 バイトを超えた場合、ログの出力が行えません。
ログファイルの名前の長さは 31 バイト以内で記述してください。32 バイト以上の場合、ログの出力が行えません。
複数のカスタムモニタリソースでログローテートを行う場合、パス名が異なってもログファイルの名前が同じ場合、(ex. /home/foo01/log/genw.log, /home/foo02/log/genw.log) ローテートサイズが正しく反映されないことがあります。
ローテートする
スクリプトや実行可能ファイルの実行ログを、オフの場合は無制限のファイルサイズで、オンの場合はローテートして出力します。
ローテートサイズ (1~999999999)
[ローテートする] チェックボックスがオンの場合に、ローテートするサイズを指定します。
ローテート出力されるログファイルの構成は、以下のとおりです。
ファイル名
内容
[ログ出力先]指定のファイル名
最新のログです。
[ログ出力先]指定のファイル名.pre
ローテートされた以前のログです。
正常な戻り値 (1023 バイト以内)
監視タイプが [同期] の場合にスクリプトのエラーコードがどのような値の場合に正常と判断するかを設定します。複数の値がある場合は、0,2,3 というようにカンマで区切るか、 0-3 のようにハイフンで値の範囲を指定します。
既定値 : 0
警告戻り値 (1023 バイト以内)
監視タイプが [同期] の場合にスクリプトのエラーコードがどのような値の場合に警告と判断するかを設定します。複数の値がある場合は、0,2,3 というようにカンマで区切るか、 0-3 のようにハイフンで値の範囲を指定します。
[正常な戻り値]と[警告戻り値]に同じ値を設定した場合、正常と判断します。
クラスタ停止時に活性時監視の停止を待ち合わせる
クラスタ停止時にカスタムモニタリソースの停止を待ち合わせます。監視タイミングに [活性時] を設定している場合のみ有効となります。
4.18. ボリュームマネージャモニタリソースを理解する¶
ボリュームマネージャモニタリソースは、ボリュームマネージャにより管理されている論理ディスクの監視を行うモニタリソースです。
4.18.1. ボリュームマネージャモニタリソースの注意事項¶
Red Hat Enterprise Linux 7 以降の環境で、ボリュームマネージャモニタリソースにて LVM の監視を行う場合、LVM メタデータデーモンを無効にする必要があります。
4.18.2. ボリュームマネージャモニタリソースの監視方法¶
ボリュームマネージャモニタリソースは、監視する論理ディスクを管理するボリュームマネージャの種類によって監視方法が異なります。
対応済みのボリュームマネージャは下記です。
lvm (LVM ボリュームグループ)
zfspool (ZFS ストレージプール)
4.18.3. 監視 (固有) タブ¶
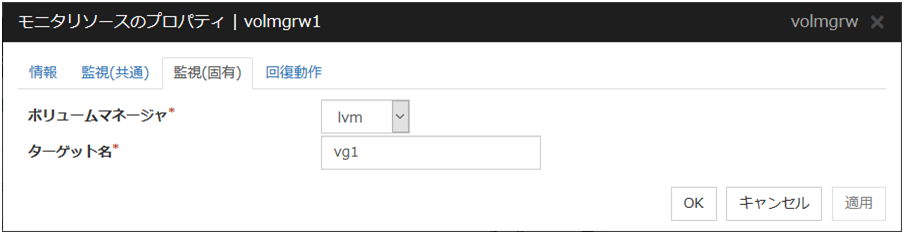
ボリュームマネージャ
監視対象の論理ディスクを管理しているボリュームマネージャの種類を設定します。対応済みのボリュームマネージャは下記です。
lvm (LVM ボリュームグループ)
zfspool (ZFS ストレージプール)
ターゲット名 (1023 バイト以内)
監視対象の名前を<VG名>の形式(ターゲット名のみ)で設定します。
ボリュームマネージャが [lvm] の場合、複数ボリュームをまとめて制御することができます。複数ボリュームを制御する場合は、ボリュームの名前を半角スペースで区切って設定します。
4.19. 外部連携モニタリソースを理解する¶
4.19.1. 外部連携モニタリソースの監視方法¶
外部から異常発生通知を受信した場合、通知されたカテゴリとキーワード (キーワードは省略可能) が設定されている外部連携モニタリソースの異常発生時の回復動作を行います。通知されたカテゴリ、キーワードが設定されている外部連携モニタリソースが複数存在する場合は、各モニタリソースの回復動作を行います。
外部連携モニタは、[clprexec] コマンド、サーバ管理基盤の強化デバイスドライバからの異常発生通知を受信することができます。
サーバ管理基盤との連携における監視方法については、『ハードウェア連携ガイド』の「サーバ管理基盤との連携」を参照してください。
以下の図は外部連携モニタリソースを使用する構成の例です。 clprexecコマンドから異常発生通知を受けたServer2の外部連携モニタリソースは、自身のステータス変更と異常検出時の回復動作を実行します。
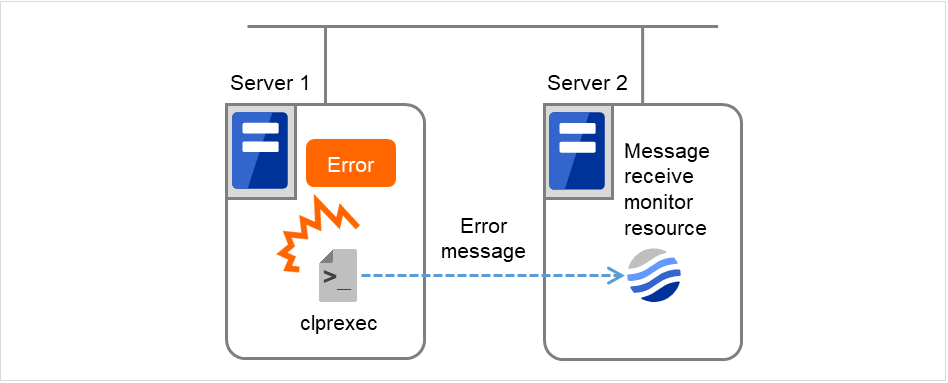
図 4.70 外部連携モニタリソースを使用する構成¶
4.19.2. サーバグループ外フェイルオーバ¶
異常発生通知受信時に、現用系サーバグループから、別サーバグループのサーバにフェイルオーバさせることが出来ます。
サーバグループの設定と、以下の設定が必要になります。
回復対象のグループリソース
[サーバグループ設定を使用する] をON
外部連携モニタリソース
回復動作を [回復対象に対してフェイルオーバ実行]
[サーバグループ外にフェイルオーバする] をON
サーバグループ外フェイルオーバ実行時には、ダイナミックフェイルオーバの設定やサーバグループ間のフェイルオーバ設定は無効となります。フェイルオーバ元のサーバが属するサーバグループとは別のサーバグループ内のサーバで、プライオリティが最も高いサーバにフェイルオーバします。
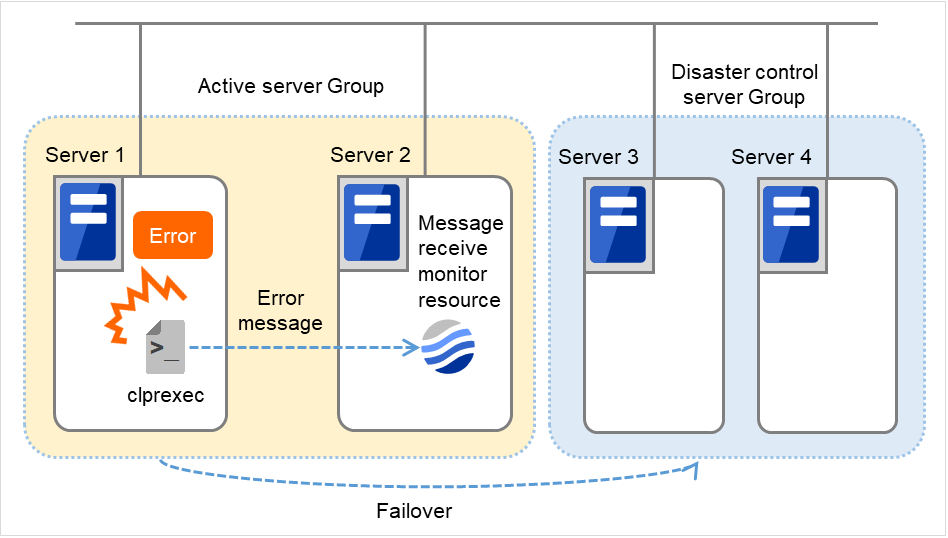
図 4.71 外部連携モニタリソースを使用する構成(サーバグループ外フェイルオーバ)¶
4.19.3. 外部連携モニタリソースに関する注意事項¶
<外部連携モニタリソース全般の注意事項>
外部連携モニタリソースが一時停止状態で外部からの異常発生通知を受信した場合、 異常時動作は実行されません。
外部から異常発生通知を受信した場合、外部連携モニタリソースのステータスは "異常" になります。"異常" となった外部連携モニタリソースのステータスは、自動では "正常" に戻りません。ステータスを "正常" に戻したい場合は、[clprexec] コマンドを使用してください。また、モニタを一時停止・再開した場合もステータスは "正常" になります。[clprexec] コマンドについては本ガイドの「9. CLUSTERPRO コマンドリファレンス」の「クラスタサーバに処理を要求する (clprexec コマンド)」を参照してください。
外部から異常発生通知を受信して外部連携モニタリソースのステータスが "異常" となっている状態で異常発生通知を受信した場合、異常発生時の回復動作は実行されません。
回復動作が[回復対象に対してフェイルオーバ実行]の場合に、 [サーバグループ外にフェイルオーバする]のチェックをONに設定している場合、フェイルオーバ先サーバは必ず、現用系サーバグループとは別のサーバグループのサーバになります。ただしこの設定の場合でも、サーバグループが設定されていない場合は、フェイルオーバ先は通常のフェイルオーバポリシーに従い決定されます。
<サーバ管理基盤との連携機能を利用する場合の注意事項>
Enterprise Linux with Dependable Support のサーバ管理基盤と連携する場合、外部連携モニタリソースの設定内容や動作が異なります。サーバ管理基盤と連携する場合は、『ハードウェア連携ガイド』の「サーバ管理基盤との連携」を参照してください。
4.19.4. 監視 (固有) タブ¶
カテゴリとキーワードには、[clprexec] コマンドの引数 -k で渡すキーワードを設定します。キーワードは省略可能です。
カテゴリ (32 バイト以内)
[clprexec] コマンドの引数 -k で指定するカテゴリを指定します。リストボックスでの既定文字列の選択または任意の文字列の指定が可能です。
キーワード (1023 バイト以内)
[clprexec] コマンドの引数 -k で指定するキーワードを指定します。
4.19.5. 回復動作タブ¶
回復対象と異常検出時の動作を設定します。外部連携モニタリソースの場合、異常検出時の動作は、"回復対象を再起動"、"回復対象に対してフェイルオーバ実行"、または、"最終動作を実行" のいずれか 1 つを選択します。ただし、回復対象が非活性状態であれば回復動作は行われません。
回復動作
モニタ異常検出時に行う動作を選択します。
サーバグループ外にフェイルオーバする
外部連携モニタリソースのみ設定できます。異常発生通知受信時に、現用系サーバグループとは別のサーバグループにフェイルオーバさせるかどうかを設定します。
回復動作前にスクリプトを実行する
回復動作を実行する前にスクリプトを実行するかどうかを指定します。
※上記以外の設定項目については、「回復動作タブ」を参照してください。
4.20. ダイナミック DNS モニタリソースを理解する¶
4.20.1. ダイナミック DNS モニタリソースの注意事項¶
ダイナミック DNS モニタリソースについて、詳細設定はありません。CLUSTERPRO のダイナミック DNS リソースを使用する場合に使用します。
ダイナミック DNS リソースを追加すると自動的に作成されます。ダイナミック DNS リソース 1 つに対して 1 つのダイナミック DNS モニタリソースが自動的に作成されます。
ダイナミック DNS モニタリソースは削除できません。ダイナミック DNS リソースを削除すると自動的に削除されます。
回復対象は変更しないでください。
[clpmonctrl] コマンドまたは Cluster WebUI からの監視の一時停止、再開はできません。
ダイナミック DNS モニタリソースは、定期的に DDNS サーバに仮想ホスト名の登録を行います。クラスタサスペンド時に対象のダイナミック DNS リソースが活性状態であれば、ダイナミック DNS モニタリソースは停止せずに動作し続けます。
[監視(共通)]-[リトライ回数]の設定は無効です。異常の検出を遅らせたい場合は[監視(共通)]-[タイムアウト]の設定を変更してください。
4.20.2. ダイナミック DNS モニタリソースの設定¶
ダイナミック DNS モニタリソースでは、定期的に DDNS サーバに仮想ホスト名の登録を行います。
ダイナミック DNS モニタリソースについて、詳細設定はありません。
4.21. プロセス名モニタリソースを理解する¶
プロセス名モニタリソースは、任意のプロセス名のプロセスを監視するモニタリソースです。
4.21.1. プロセス名モニタリソースの注意事項¶
プロセス数下限値に1を設定した場合に監視対象に指定したプロセス名のプロセスが複数存在すると、次の条件で監視対象プロセスを一つ選択し監視します。
プロセス間に親子関係がある場合は、親プロセスを監視します。
プロセス間に親子関係がなければ、プロセスの起動時刻の最も古いものを監視します。
プロセス間に親子関係がなく、プロセスの起動時刻も同じであれば、もっともプロセスIDの小さいものを監視します。
同一名のプロセスが複数存在する場合にプロセスの起動個数によって監視を行う際には、プロセス数下限値に監視する個数を設定します。同一名のプロセスが設定された個数を下回ると異常と判断します。プロセス数下限値に指定できる個数は1から999個までです。プロセス数下限値に1を設定した場合は、監視対象プロセスを一つ選択して監視します。
監視対象プロセス名に指定できるプロセス名は1023バイトまでです。1023バイトを超えるプロセス名を持つプロセスを監視対象として指定する場合は、ワイルドカード(*)を使って指定します。
監視対象プロセスのプロセス名が1023バイトより長い場合、プロセス名として認識できるのはプロセス名の先頭から1023バイトまでです。ワイルドカード(*)を使って指定する場合は、1024バイトまでに含まれる文字列を指定してください。
監視対象のプロセス名が長い場合、ログ等に出力されるプロセス名情報は後半を省略して表示されます。
プロセス名の中に「"」(ダブルコーテーション)や「,」(カンマ)が含まれるプロセスを監視している場合、アラートメッセージにプロセス名が正しく表示できない場合があります。
監視対象プロセス名は、実際に動作しているプロセスのプロセス名をps(1)コマンド等で確認し設定してください。
実行結果の例
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 Sep12 ? 00:00:00 init [5]
:
root 5314 1 0 Sep12 ? 00:00:00 /usr/sbin/acpid
root 5325 1 0 Sep12 ? 00:00:00 /usr/sbin/sshd
htt 5481 1 0 Sep12 ? 00:00:00 /usr/sbin/htt -retryonerror 0
監視対象プロセス名に指定したプロセス名はプロセスの引数もプロセス名の一部として監視対象のプロセスを特定します。監視対象プロセス名を指定する場合は、引数を含めたプロセス名を指定してください。引数を含めずプロセス名のみ監視したい場合は、ワイルドカード(*)を使い、引数を含めない前方一致または部分一致で指定してください。
4.21.2. プロセス名モニタリソースの監視方法¶
指定されたプロセス名のプロセスを監視します。プロセス数下限値に 1 を設定した場合、プロセス名からプロセスIDを特定し、そのプロセスIDの消滅時に異常と判断します。プロセスのストールを検出することはできません。
プロセス数下限値に 1 より大きい値を設定した場合、指定されたプロセス名のプロセスを個数によって監視します。プロセス名から監視対象プロセスの個数を算出し、下限値を下回った場合に異常と判断します。プロセスのストールを検出することはできません。
4.21.3. 監視 (固有) タブ¶
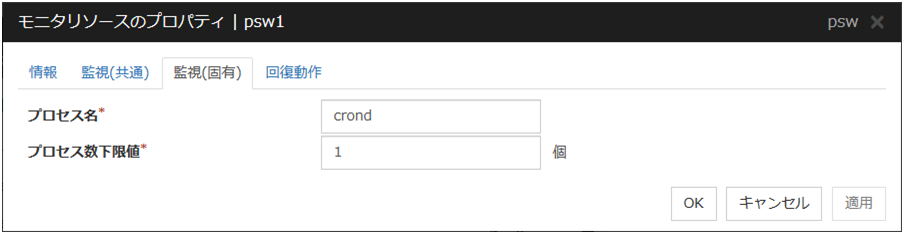
プロセス名 (1023 バイト以内)
監視対象プロセスのプロセス名を設定します。プロセス名はps(1)コマンドの出力結果などから確認します。
また、次の 3 つのパターンでプロセス名のワイルドカード指定が可能です。このパターン以外の指定はできません。
【前方一致】 <プロセス名に含まれる文字列>*
【後方一致】 *<プロセス名に含まれる文字列>
【部分一致】 *<プロセス名に含まれる文字列>*
プロセス数下限値 (1~999)
監視対象プロセスの監視個数を設定します。プロセス名に設定した監視対象プロセスの個数が設定値を下回った場合に異常と判断します。
4.22. DB2 モニタリソースを理解する¶
DB2 モニタリソースは、サーバ上で動作する DB2 のデータベースを監視するモニタリソースです。
4.22.1. DB2 モニタリソースの注意事項¶
動作確認済みの DB2 のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
本モニタリソースは、DB2 の CLI のライブラリを利用して、DB2 の監視を行っています。本モニタリソースが異常になる場合は、指定した DB2 の CLI のライブラリパスが存在することを確認してください。
パラメータで指定したデータベース名・インスタンス名・ユーザ名・パスワードなどの値が、監視を行う DB2 の環境と異なる場合、DB2 の監視を行うことができません。各エラー内容を示すメッセージが表示されますので、環境を確認してください。
選択する監視レベル |
監視テーブルの事前作成 |
|---|---|
レベル1(selectでの監視) |
必要あり |
レベル2(update/selectでの監視) |
必要なし |
レベル3(毎回create/dropも行う) |
必要なし |
監視テーブルの作成は以下の手順で行えます。
監視テーブル名は英数字、一部記号(アンダースコア等)が指定できます。
4.22.2. DB2 モニタリソースの監視方法¶
DB2モニタリソースは、以下の監視レベルから選択した監視レベルに応じた監視を行います。
- レベル1(selectでの監視)監視テーブルに対して参照のみを行う監視です。監視テーブルに対して実行するSQL文は( select )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
- レベル2(update/selectでの監視)監視テーブルに対して更新も行う監視です。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( update / select )です。監視開始時に監視テーブルを自動で作成した場合、監視テーブルに対して実行するSQL文は( create / insert )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
- レベル3(毎回create/dropも行う)監視テーブルに対しての更新に加え監視テーブルの作成・削除も毎回行います。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( create / insert / select / drop )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
4.22.3. 監視 (固有) タブ¶
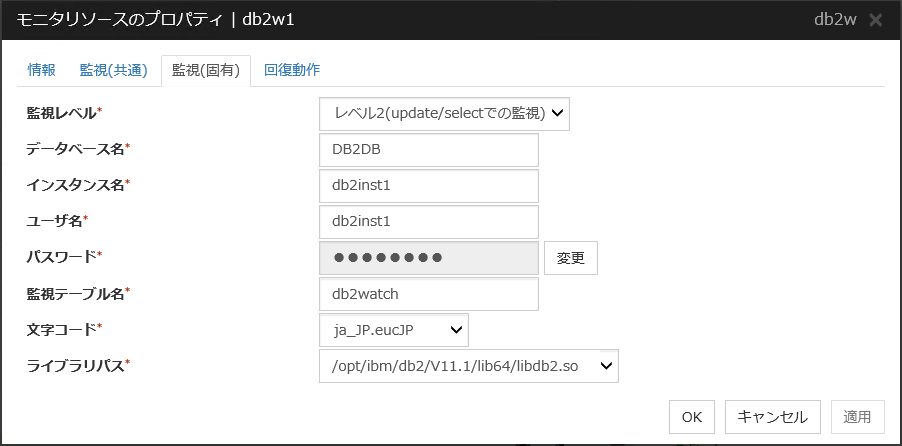
監視レベル
選択肢の中から1つを選択します。必ず設定してください。
既定値 : レベル2(update/selectでの監視)
データベース名 (255 バイト以内)
監視するデータベース名を設定します。必ず設定してください。
既定値 : なし
インスタンス名 (255 バイト以内)
監視するデータベースのインスタンス名を設定します。必ず設定してください。
既定値 : db2inst1
ユーザ名 (255 バイト以内)
データベースにログインする際のユーザ名を設定します。必ず設定してください。指定したデータベースにアクセス可能な DB2 ユーザを指定してください。既定値 : db2inst1
パスワード (255 バイト以内)
データベースにログインする際のパスワードを設定します。必ず設定してください。
既定値 : なし
監視テーブル名 (255 バイト以内)
データベース上に作成する監視用テーブルの名前を設定します。必ず設定してください。テーブルの作成・削除を行いますので、運用に使用しているテーブル名と重ならないように注意してください。また、SQL 文の予約語と重ならないようにしてください。データベースの仕様により監視テーブル名に設定できない文字があります。詳細はデータベースの仕様を確認してください。既定値 : db2watch
文字コード
DB2 のキャラクタ・セットを設定します。必ず設定してください。
既定値 : なし
ライブラリパス (1023 バイト以内)
DB2 のライブラリパスを設定します。必ず設定してください。
既定値 : /opt/ibm/db2/V11.1/lib64/libdb2.so
4.23. FTP モニタリソースを理解する¶
FTP モニタリソースは、サーバ上で動作する FTP サービス監視するモニタリソースです。FTP プロトコルを監視するものであり、特定のアプリケーションの監視ではありません。そのため、FTP プロトコルを実装するさまざまなアプリケーションの監視を行うことができます。
4.23.1. FTP モニタリソースの注意事項¶
監視の対象リソースには、FTP を起動する EXEC リソースなどを指定してください。対象リソースの活性後、監視を開始しますが、対象リソースの活性直後に FTP がすぐに動作できない場合などは、[監視開始待ち時間] で調整してください。
監視動作ごとに FTP サービス自体が動作ログなどを出力することがありますが、その制御は、FTP 側の設定で適宜行ってください。
FTPサーバのFTPメッセージ(バナー、ウェルカムメッセージなど)を既定から変更すると、監視異常とみなす場合があります。
4.23.2. FTP モニタリソースの監視方法¶
FTP モニタリソースは、以下の監視を行います。
FTP サーバに接続してファイル一覧取得コマンドを実行します。
監視の結果、以下の場合に異常とみなします。
FTP サービスヘの接続に失敗した場合
[FTP] コマンドに対する応答で異常が通知された場合
4.23.3. 監視 (固有) タブ¶
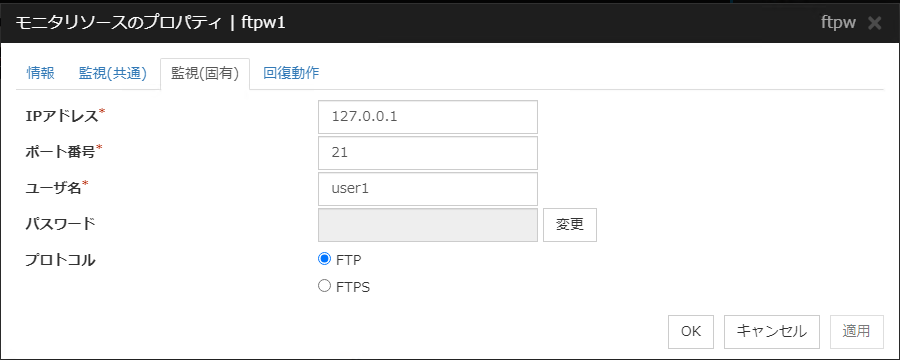
IP アドレス (79 バイト以内)
監視する FTP サーバの IP アドレスを設定します。必ず設定してください。双方向スタンバイの場合は、FIP を指定してください。
通常は自サーバ上で動作する FTP サーバに接続しますので、ループバックアドレス(127.0.0.1) を設定しますが、FTP サーバの設定で接続可能なアドレスを制限している場合は、接続可能なアドレス (フローティング IP アドレス等) を設定します。
既定値 : 127.0.0.1
ポート番号 (1~65535)
監視する FTP のポート番号を設定します。必ず設定してください。
既定値 : 21
ユーザ名 (255 バイト以内)
FTP にログインする際のユーザ名を設定します。
既定値 : なし
パスワード (255 バイト以内)
FTP にログインする際のパスワードを設定します。
既定値 : なし
プロトコル
FTP サーバとの通信に使用するプロトコルを設定します。通常は FTP を選択しますが、FTP over SSL/TLS で接続する必要がある場合は FTPS を選択します。
既定値 : FTP
注釈
FTPS を利用するためには OpenSSL ライブラリが必要です。
4.24. HTTP モニタリソースを理解する¶
HTTP モニタリソースは、サーバ上で動作する HTTP デーモンを監視するモニタリソースです。
4.24.1. HTTP モニタリソースの注意事項¶
動作確認済みの HTTP のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
HTTP モニタリソースの DIGEST 認証で使用可能なアルゴリズムは MD5 です。
HTTP モニタリソースのクライアント認証で監視可能な Web サーバは Apache HTTP Server です。
HTTP モニタリソースのクライアント認証の秘密鍵、クライアント証明書で対応しているエンコード形式は PEM 形式です。
HTTP モニタリソースの HTTP リクエストは、デフォルトのポート番号 (HTTP:80/HTTPS:443) で発行を行います。
[接続先]に IPv6 アドレスが紐づくホスト名を設定する場合は、カーネル起動オプションにて IPv6 を無効化していないことを確認してください。無効化している場合、監視が正常に行えない場合があります。
4.24.2. HTTP モニタリソースの監視方法¶
HTTP モニタリソースは、以下の監視を行います。
サーバ上の HTTP デーモンに接続し、HTTP リクエストの発行により、HTTP デーモンの 監視を実行します。
監視の結果、以下の場合に異常とみなします。
HTTP デーモンへの接続で異常が通知された場合
HTTP リクエストの発行に対する応答メッセージが "HTTP/" で始まっていない場合
HTTP リクエストの発行に対する応答のステータスコードが 400、500 番台の場合 (Request URI に既定値以外の URI を指定した場合)
4.24.3. 監視 (固有) タブ¶
接続先 (255 バイト以内)
監視する HTTP サーバ名を設定します。必ず設定してください。通常は自サーバ上で動作する HTTP サーバに接続しますので、ループバックアドレス(127.0.0.1) を設定しますが、HTTP サーバの設定で接続可能なアドレスを制限している場合は、接続可能なアドレス (フローティング IP アドレス等) を設定します。既定値 : localhost
プロトコル
HTTP サーバとの通信に使用するプロトコルを設定します。通常は HTTP を選択しますが、HTTP over SSL で接続する必要がある場合は HTTPS を選択します。
既定値 : HTTP
注釈
HTTPS を利用するためには OpenSSL ライブラリが必要です。
ポート番号 (1~65535)
HTTP サーバに接続する際のポート番号を設定します。必ず設定してください。
既定値 :80 (HTTP の場合)443 (HTTPS の場合)
Request URI (255 バイト以内)
Request URI (例:"/index.html") を設定します。
既定値 : なし
リクエスト種別
HTTP サーバに接続する際の HTTP リクエストの種類を設定します。必ず設定してください。
既定値 : HEAD
認証方式
HTTP サーバに接続する際の認証方式を設定します。
既定値 : 認証なし
ユーザ名(255バイト以内)
HTTP にログインする際のユーザ名を設定します。
既定値 : なし
パスワード(255バイト以内)
HTTP にログインする際のパスワードを設定します。
既定値 : なし
クライアント認証
本機能を有効にした場合、クライアント認証を行います。[プロトコル]に HTTPS が選択されている場合のみ選択可能です。
既定値 : 無効
注釈
クライアント認証を行わないHTTPサーバに対して本機能を有効にしても動作に影響はありません。
秘密鍵(1023バイト以内)
クライアント認証で使用する秘密鍵ファイルのパスを設定します。[クライアント認証]を有効にした場合に必ず設定してください。
既定値 : なし
クライアント証明書(1023バイト以内)
クライアント認証で使用するクライアント証明書ファイルのパスを設定します。[クライアント認証]を有効にした場合に必ず設定してください。
既定値 : なし
4.25. IMAP4 モニタリソースを理解する¶
IMAP4 モニタリソースは、サーバ上で動作する IMAP4 のサービスを監視するモニタリソースです。IMAP4 プロトコルを監視するものであり、特定のアプリケーションの監視ではありません。そのため、IMAP4 プロトコルを実装するさまざまなアプリケーションの監視を行うことができます。
4.25.1. IMAP4 モニタリソースの注意事項¶
監視の対象リソースには、IMAP4 サーバを起動するEXEC リソースなどを指定してください。対象リソースの活性後、監視を開始しますが、対象リソースの活性直後に IMAP4 サーバがすぐに動作できない場合などは、[監視開始待ち時間] で調整してください。
監視動作ごとに IMAP4 サーバ自体が動作ログなどを出力することがありますが、その制御は、 IMAP4 サーバ側の設定で適宜行ってください。
4.25.2. IMAP4 モニタリソースの監視方法¶
IMAP4 モニタリソースは、以下の監視を行います。
IMAP4 サーバに接続して動作確認コマンドを実行します。
監視の結果、以下の場合に異常とみなします。
IMAP4 サーバヘの接続に失敗した場合
コマンドに対する応答で異常が通知された場合
4.25.3. 監視 (固有) タブ¶
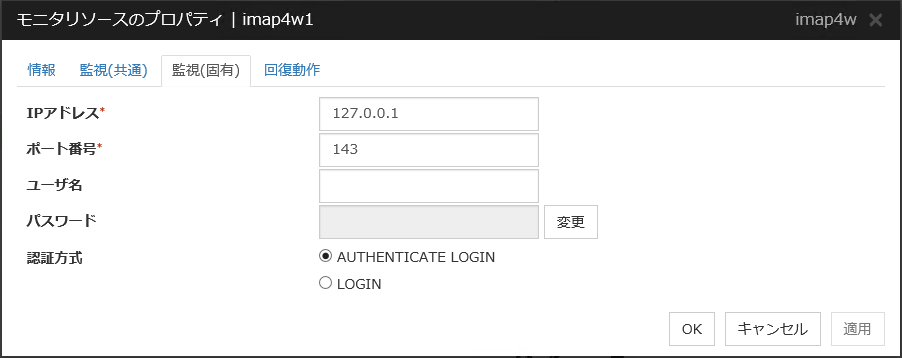
IP アドレス (79 バイト以内)
監視する IMAP4 サーバの IP アドレスを設定します。必ず設定してください。双方向スタンバイの場合は、FIP を指定してください。通常は自サーバ上で動作する IMAP4 サーバに接続しますので、ループバックアドレス(127.0.0.1) を設定しますが、IMAP4 サーバの設定で接続可能なアドレスを制限している場合は、接続可能なアドレス (フローティング IP アドレス等) を設定します。既定値 : 127.0.0.1
ポート番号 (1~65535)
監視する IMAP4 のポート番号を設定します。必ず設定してください。
既定値 : 143
ユーザ名 (255 バイト以内)
IMAP4 にログインする際のユーザ名を設定します。
既定値 : なし
パスワード (189 バイト以内)
IMAP4 にログインする際のパスワードを設定します。
既定値 : なし
認証方式
IMAP4 にログインするときの認証方式を選択します。使用している IMAP4 の設定に合わせる必要があります。
4.26. MySQL モニタリソースを理解する¶
MySQL モニタリソースは、サーバ上で動作する MySQL のデータベースを監視するモニタ リソースです。
4.26.1. MySQL モニタリソースの注意事項¶
動作確認済みの MySQL のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
パラメータ指定値が、監視を行う MySQL の環境と異なる場合、Cluster WebUI のアラートログに、エラー内容を示すメッセージが表示されますので、環境を確認してください。
選択する監視レベル |
監視テーブルの事前作成 |
|---|---|
レベル1(selectでの監視) |
必要あり |
レベル2(update/selectでの監視) |
必要なし |
レベル3(毎回create/dropも行う) |
必要なし |
4.26.2. MySQL モニタリソースの監視方法¶
MySQLモニタリソースは、以下の監視レベルから選択した監視レベルに応じた監視を行います。
- レベル1(selectでの監視)監視テーブルに対して参照のみを行う監視です。監視テーブルに対して実行するSQL文は( select )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
- レベル2(update/selectでの監視)監視テーブルに対して更新も行う監視です。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( update / select )です。監視開始時に監視テーブルを自動で作成した場合、監視テーブルに対して実行するSQL文は( create / insert )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
- レベル3(毎回create/dropも行う)監視テーブルに対しての更新に加え監視テーブルの作成・削除も毎回行います。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( create / insert / select / drop )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
4.26.3. 監視 (固有) タブ¶
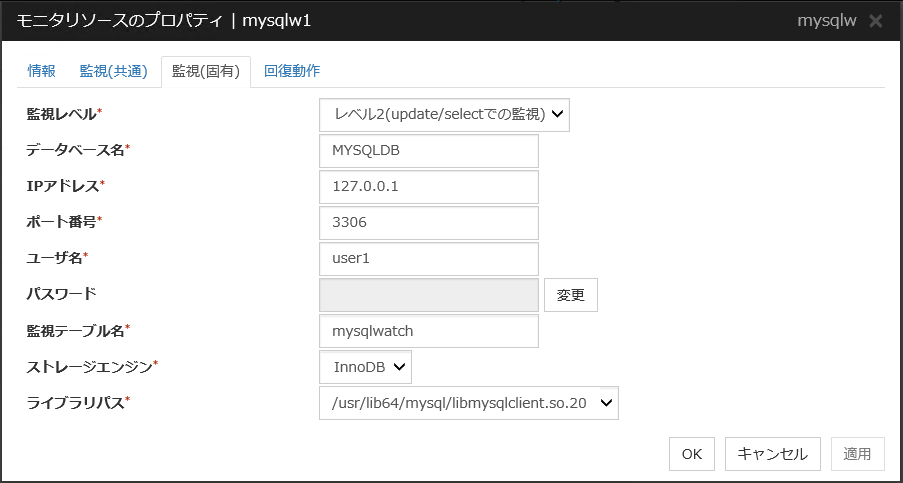
監視レベル
選択肢の中から1つを選択します。必ず設定してください。
既定値 : レベル2(update/selectでの監視)
データベース名 (255 バイト以内)
監視するデータベース名を設定します。必ず設定してください。
既定値 : なし
IP アドレス (79 バイト以内)
接続するサーバの IP アドレスを設定します。必ず設定してください。
既定値 : 127.0.0.1
ポート番号 (1~65535)
接続する際のポート番号を設定します。必ず設定してください。
既定値 : 3306
ユーザ名 (255 バイト以内)
データベースにログインする際のユーザ名を設定します。必ず設定してください。
指定したデータベースにアクセス可能な MySQL ユーザを指定してください。
既定値 : なし
パスワード (255 バイト以内)
データベースにログインする際のパスワードを設定します。
既定値 : なし
監視テーブル名 (255 バイト以内)
データベース上に作成する監視用テーブルの名前を設定します。必ず設定してください。
テーブルの作成・削除を行いますので、運用に使用しているテーブル名と重ならないように注意してください。また、SQL 文の予約語と重ならないようにしてください。データベースの仕様により監視テーブル名に設定できない文字があります。詳細はデータベースの仕様を確認してください。既定値 : mysqlwatch
ストレージエンジン
監視用 Table の作成用ストレージエンジンを設定します。必ず設定してください。
既定値 : InnoDB
ライブラリパス (1023 バイト以内)
MySQL のライブラリパスを設定します。必ず設定してください。
既定値 : /usr/lib64/mysql/libmysqlclient.so.20
4.27. NFS モニタリソースを理解する¶
NFS モニタリソースは、サーバ上で動作する NFS のファイルサーバを監視するモニタリソースです。
4.27.1. NFS モニタリソースの動作環境¶
NFS モニタリソースを利用するためには、以下のサービスが起動している必要があります。
<Red Hat Enterprise Linux 7 の場合>
nfs
rpcbind
nfslock (NFS v4では不要)
<Red Hat Enterprise Linux 8 / 9 の場合>
nfs-server
rpcbind
NFSバージョンv4を監視する場合は各サーバ上に nfs-utils パッケージが必要です。
4.27.2. NFS モニタリソースの注意事項¶
動作確認済みの NFS のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
監視する共有ディレクトリについては、自サーバから接続できるように exports ファイルを設定してください。
[監視(固有)]タブ-[NFSバージョン]で指定したバージョンのnfsdおよびそのnfsdに対応するmountdの消滅を検出すると異常とみなします。nfsdに対応するmountdは以下の通りです。
nfsdバージョン |
mountdバージョン |
|---|---|
v2(udp) |
v1(tcp)あるいはv2(tcp) |
v3(udp) |
v3(tcp) |
v4(tcp) |
- |
4.27.3. NFS モニタリソースの監視方法¶
NFS モニタリソースは、以下の監視を行います。
NFS サーバに接続して [NFS] テストコマンドを実行します。
NFSバージョンv4の export されている領域の監視は [mount] コマンドを実行します。
監視の結果、以下の場合に異常とみなします。
NFS サービスへの要求に対する応答結果が異常な場合
mountd が消滅した場合(NFS v2/v3の場合)
nfsd が消滅した場合
rpcbind サービスが停止した場合
export されている領域が消滅した場合
4.27.4. 監視 (固有) タブ¶
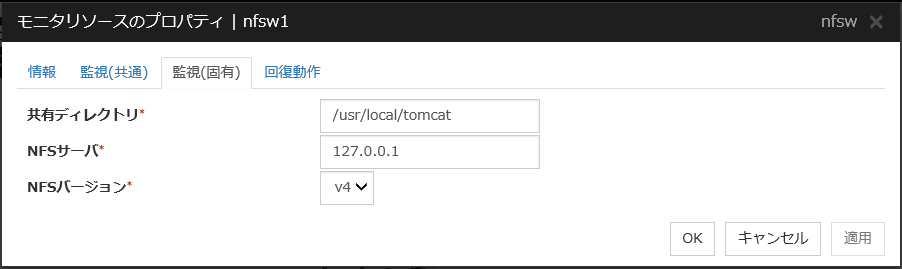
共有ディレクトリ (1023 バイト以内)
ファイル共有するディレクトリを設定します。必ず設定してください。
既定値 : なし
NFSサーバ (255 バイト以内)
NFS 監視を行うサーバの IP アドレスを設定します。必ず設定してください。
既定値 : 127.0.0.1
NFSバージョン
NFS監視を行うNFSのバージョンを選択肢の中から1つ選択します。必ず設定してください。RHEL 7 では NFS バージョンv2 はサポートされていません。
既定値 : v4
4.28. ODBC モニタリソースを理解する¶
ODBC モニタリソースは、サーバ上で動作する ODBC のデータベースを監視するモニタリソースです。
4.28.1. ODBC モニタリソースの注意事項¶
監視処理はunixODBCドライバマネージャを利用しているため、あらかじめ監視するデータベースのODBCドライバをインストールとodbc.iniへデータソースの設定を行ってください。
パラメータ指定値が、監視を行うデータベースの環境と異なる場合、Cluster WebUI のアラートログにエラー内容を示すメッセージが表示されますので、環境を確認してください。
選択する監視レベル |
監視テーブルの事前作成 |
|---|---|
レベル1(selectでの監視) |
必要あり |
レベル2(update/selectでの監視) |
必要なし |
レベル3(毎回create/dropも行う) |
必要なし |
4.28.2. ODBC モニタリソースの監視方法¶
ODBCモニタリソースは、以下の監視レベルから選択した監視レベルに応じた監視を行います。
- レベル1(selectでの監視)監視テーブルに対して参照のみを行う監視です。監視テーブルに対して実行するSQL文は( select )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
- レベル2(update/selectでの監視)監視テーブルに対して更新も行う監視です。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( update / select )です。監視開始時に監視テーブルを自動で作成した場合、監視テーブルに対して実行するSQL文は( create / insert )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
- レベル3(毎回create/dropも行う)監視テーブルに対しての更新に加え監視テーブルの作成・削除も毎回行います。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( create / insert / select / drop )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
4.28.3. 監視 (固有) タブ¶
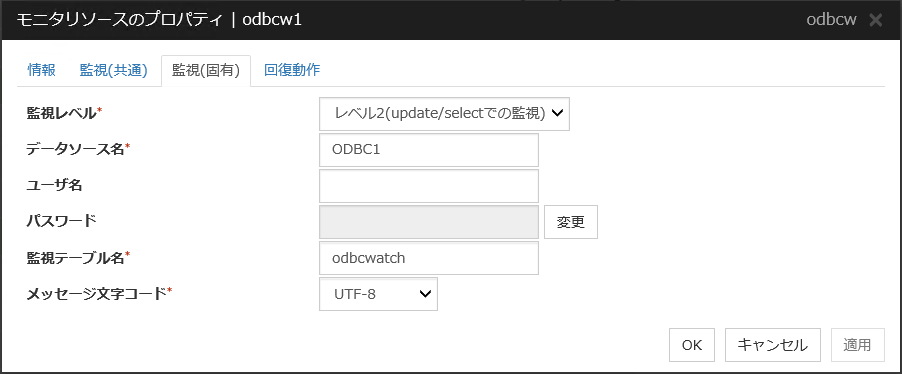
監視レベル
選択肢の中から1つを選択します。必ず設定してください。
既定値 : レベル2(update/selectでの監視)
データソース名 (255 バイト以内)
監視するデータソースを設定します。必ず設定してください。
既定値 : なし
ユーザ名 (255 バイト以内)
データベースにログインする際のユーザ名を設定します。odbc.iniでユーザ名を設定している場合は、指定する必要はありません。既定値 : なし
パスワード (255 バイト以内)
データベースにログインする際のパスワードを設定します。
既定値 : なし
監視テーブル名 (255 バイト以内)
データベース上に作成する監視用テーブルの名前を設定します。必ず設定してください。
テーブルの作成・削除を行いますので、運用に使用しているテーブル名と重ならないように注意してください。また、SQL 文の予約語と重ならないようにしてください。データベースの仕様により監視テーブル名に設定できない文字があります。詳細はデータベースの仕様を確認してください。既定値 : odbcwatch
メッセージ文字コード
データベースのメッセージの文字コードを設定します。
既定値 : UTF-8
4.29. Oracle モニタリソースを理解する¶
Oracle モニタリソースは、サーバ上で動作する Oracle のデータベースを監視するモニタリソースです。
4.29.1. Oracle モニタリソースの注意事項¶
動作確認済みの Oracle のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
本モニタリソースは、Oracle のインターフェイス (Oracle Call Interface) を利用して、Oracleの監視を行っています。そのため、監視を行うサーバ上に、インターフェイス用のライブラリ(libclntsh.so) がインストールされている必要があります。
パラメータで指定した接続文字列・ユーザ名・パスワードなどの値が、監視を行う Oracle の環境と異なる場合、Oracle の監視を行うことができません。各エラー内容を示すメッセージが表示されますので、環境を確認してください。
パラメータのユーザ名に指定するユーザについて、デフォルトではsysとなっていますが、別途監視用ユーザを作成する場合、各監視レベルにおいて以下のアクセス権付与が必要です。(sysdba権限を与えない場合)
監視レベル |
必要な権限 |
|---|---|
レベル0(データベースステータス) |
V$INSTANCEへのSELECT権限 |
レベル1(selectでの監視) |
監視テーブルへのSELECT権限 |
レベル2(update/selectでの監視) |
CREATE TABLE/DROP ANY TABLE/監視テーブルへのINSERT権限/監視テーブルへのUPDATE権限/監視テーブルへのSELECT権限 |
レベル3(毎回create/dropも行う) |
CREATE TABLE/DROP ANY TABLE/監視テーブルへのINSERT権限/監視テーブルへのUPDATE権限/監視テーブルへのSELECT権限 |
ユーザ名に sys を指定すると Oracle の監査ログが出力されることがあります。監査ログを大量に出力したくない場合、 sys 以外のユーザ名を指定してください。
設定例
- 日本語で表示させたい場合JAPANESE_JAPAN で始まる文字セットを選択してください。
- 英語で表示させたい場合AMERICAN_AMERICA で始まる文字セットを選択してください。
選択する監視レベル |
監視テーブルの事前作成 |
|---|---|
レベル0(データベースステータス) |
必要なし |
レベル1(selectでの監視) |
必要あり |
レベル2(update/selectでの監視) |
必要なし |
レベル3(毎回create/dropも行う) |
必要なし |
監視テーブルの作成は以下の手順で行えます。
※パラメータのユーザ名に指定するユーザのスキーマに作成してください。
4.29.2. Oracle モニタリソースの監視方法¶
Oracleモニタリソースは、以下の監視レベルから選択した監視レベルに応じた監視を行います。
- レベル0(データベースステータス)Oracleの管理テーブル(V$INSTANCE表)を参照しDBの状態(インスタンスの状態)を確認します。監視テーブルに対してのSQL文実行は行わない簡易的な監視です。
監視の結果以下の場合に異常とみなします。
Oracle の管理テーブル( V$INSTANCE 表)のステータス( status )が未起動状態( MOUNTED,STARTED )の場合
Oracle の管理テーブル( V$INSTANCE 表)のデータベースステータス( database_status )が未起動( SUSPENDED,INSTANCE RECOVERY )の場合
- レベル1(selectでの監視)監視テーブルに対して参照のみを行う監視です。監視テーブルに対して実行するSQL文は( select )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
- レベル2(update/selectでの監視)監視テーブルに対して更新も行う監視です。SQL文の実行により最大11桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( update / select )です。監視開始時に監視テーブルを自動で作成した場合、監視テーブルに対して実行するSQL文は( create / insert )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
- レベル3(毎回create/dropも行う)監視テーブルに対しての更新に加え監視テーブルの作成・削除も毎回行います。SQL文の実行により最大 11 桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( create / insert / select / drop )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
4.29.3. 監視 (固有) タブ¶
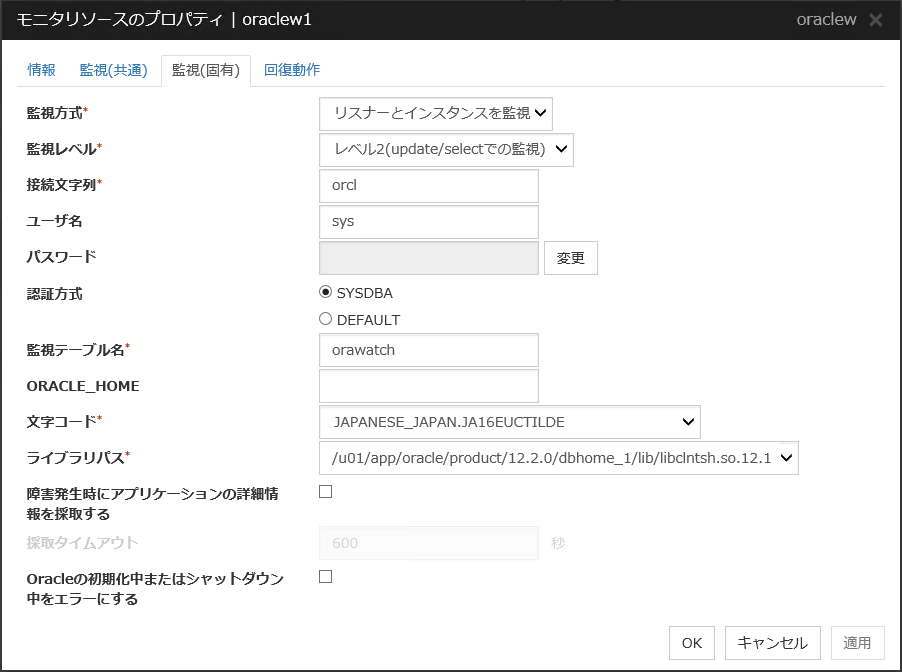
監視方式
監視対象とする Oracle の機能を選択します。
ORACLE_HOMEが設定されていない場合、接続文字列に指定されている先に対して接続処理の動作のみ監視します。接続異常時にリスナーのサービス再起動による復旧を試みる場合に使用します。
本設定を選択した場合、監視レベルの設定は無視されます。
監視対象がOracle12cのマルチテナント構成のデータベースの場合、BEQ接続での監視はできません。
ORACLE_HOME が設定されていない場合、接続文字列に指定されている先に対して接続を行い、接続処理で異常があった場合は無視します。この方式は、[リスナーのみ監視] 方式の Oracle モニタリソースと併用して、接続処理以外の異常に対する復旧動作を設定するために使用します。
監視レベル
選択肢の中から1つを選択します。監視方式を「リスナーのみ監視」としている場合には本設定は無視されます。
既定値 : レベル2(update/select での監視)
接続文字列 (255 バイト以内)
監視するデータベースに対応する接続文字列を設定します。必ず設定してください。
監視方式を「インスタンスのみの監視」とした場合にはORACLE_SIDを設定します。
監視方式
ORACLE_HOME
接続文字列
監視レベル
リスナーとインスタンスを監視
入力不要
接続文字列を指定
設定に応じたレベルの監視
リスナーのみ監視
入力した場合、Oracleのコマンドを使用した監視
接続文字列を指定
レベル設定は無視される
未入力の場合、リスナーを経由したインスタンスへの接続確認
接続文字列を指定
レベル設定は無視される
インスタンスのみ監視
入力した場合、BEQ接続によるインスタンスの確認
ORACLE_SIDを指定する
設定に応じたレベルの監視
未入力の場合、リスナーを経由したインスタンスの確認となる
接続文字列を指定
設定に応じたレベルの監視
既定値 : 接続文字列の既定値はなし
ユーザ名 (255 バイト以内)
データベースにログインする際のユーザ名を設定します。必ず設定してください。
指定したデータベースにアクセス可能な Oracle ユーザを指定してください。
既定値 :sys
パスワード (255 バイト以内)
データベースにログインする際のパスワードを設定します。
既定値 :なし
認証方式
データベースの認証方式を設定します。
既定値 : SYSDBA
監視テーブル名 ( 255 バイト以内)
データベース上に作成する監視用テーブルの名前を設定します。必ず設定してください。
テーブルの作成・削除を行いますので、運用に使用しているテーブル名と重ならないように注意してください。また、SQL 文の予約語と重ならないようにしてください。データベースの仕様により監視テーブル名に設定できない文字があります。詳細はデータベースの仕様を確認してください。既定値 : orawatch
ORACLE_HOME(255バイト以内)
ORACLE_HOMEに設定しているパス名を指定します。[/] で始まる必要があります。監視方式で「リスナーのみ監視」「インスタンスのみ監視」を選択したときに使用されます。
既定値 : なし
文字コード
Oracle のキャラクタ・セットを設定します。必ず設定してください。
既定値 : JAPANESE_JAPAN.JA16EUC
ライブラリパス (1023 バイト以内)
Oracle Call Interface (OCI) 用のライブラリパスを設定します。必ず設定してください。
既定値 : /u01/app/oracle/product/12.2.0/dbhome_1/lib/libclntsh.so.12.1
障害発生時にアプリケーションの詳細情報を採取する
本機能を有効にした場合、Oracle モニタリソースが異常を検出すると、Oracle の詳細情報が採取されます。採取された詳細情報は、/opt/nec/clusterpro/work/rm/"モニタリソース名"/errinfo.cur フォルダ配下に保存されます。採取が複数回実行された場合は、過去の採取情報のフォルダ名が errinfo.1, errinfo.2 とリネームされます。詳細情報は最大 5 回採取されます。
注釈
採取中にクラスタ停止などにより、Oracle サービスを停止させた場合、正しい情報が取得できない可能性があります。
既定値 : 無効
採取タイムアウト
詳細情報採取時のタイムアウト値を設定します。
既定値 : 600
Oracleの初期化中またはシャットダウン中をエラーにする
本機能を有効にした場合、Oracle の初期化中またはシャットダウン中の状態を検出すると、直ちに監視エラーになります。Oracle Clusterware 等の連携で Oracle が運用中に自動再起動される場合、本機能を無効にしてください。Oracle の初期化中またはシャットダウン中の状態でも監視正常になります。ただし1時間以上 Oracle の初期化中またはシャットダウン中の状態が継続すると監視エラーになります。既定値 : 無効
4.30. POP3 モニタリソースを理解する¶
POP3 モニタリソースは、サーバ上で動作する POP3 のサービスを監視するモニタリソースです。POP3 プロトコルを監視するものであり、特定のアプリケーションの監視ではありません。そのため、POP3 プロトコルを実装するさまざまなアプリケーションの監視を行うことができます。
4.30.1. POP3 モニタリソースの注意事項¶
監視の対象リソースには、POP3 サーバを起動するEXEC リソースなどを指定してください。対象リソースの活性後、監視を開始しますが、対象リソースの活性直後に POP3 がすぐに 動作できない場合などは、[監視開始待ち時間] で調整してください。
監視動作ごとに POP3 自体が動作ログなどを出力することがありますが、その制御は、POP3 側の設定で適宜行ってください。
4.30.2. POP3 モニタリソースの監視方法¶
POP3 モニタリソースは、以下の監視を行います。
POP3 サーバに接続して動作確認コマンドを実行します。
監視の結果、以下の場合に異常とみなします。
POP3 サーバヘの接続に失敗した場合
コマンドに対する応答で異常が通知された場合
4.30.3. 監視 (固有) タブ¶
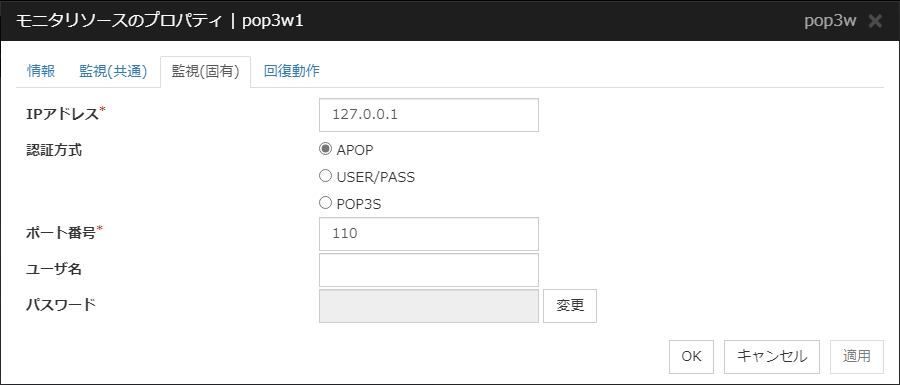
IP アドレス (79 バイト以内)
監視する POP3 サーバの IP アドレスを設定します。必ず設定してください。双方向スタンバイの場合は、FIP を指定してください。
通常は自サーバ上で動作する POP3 サーバに接続しますので、ループバックアドレス(127.0.0.1) を設定しますが、POP3 サーバの設定で接続可能なアドレスを制限している場合は、接続可能なアドレス (フローティング IP アドレス等) を設定します。
既定値 : 127.0.0.1
認証方式
POP3 にログインするときの認証方式を選択します。使用している POP3 の設定に合わせる必要があります。
注釈
POP3S を利用するためには OpenSSL ライブラリが必要です。
ポート番号 (1~65535)
監視する POP3 のポート番号を設定します。必ず設定してください。
既定値 :110995 (POP3S の場合)
ユーザ名 (255 バイト以内)
POP3 にログインする際のユーザ名を設定します。
既定値 : なし
パスワード (255 バイト以内)
POP3 にログインする際のパスワードを設定します。
既定値 : なし
4.31. PostgreSQL モニタリソースを理解する¶
PostgreSQL モニタリソースは、サーバ上で動作する PostgreSQL のデータベースを監視 するモニタリソースです。
4.31.1. PostgreSQL モニタリソースの注意事項¶
動作確認済みの PostgreSQL のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
パラメータ指定値が、監視を行う PostgreSQL の環境と異なる場合、Cluster WebUI のアラートログにエラー内容を示すメッセージが表示されますので、環境を確認してください。
YYYY-MM-DD hh:mm:ss JST moodle moodle LOG: statement: DROP TABLE psqlwatch
YYYY-MM-DD hh:mm:ss JST moodle moodle ERROR: table "psqlwatch" does not exist
YYYY-MM-DD hh:mm:ss JST moodle moodle STATEMENT: DROP TABLE psqlwatch
YYYY-MM-DD hh:mm:ss JST moodle moodle LOG: statement: CREATE TABLE psqlwatch (num INTEGER NOT NULL PRIMARY KEY)
YYYY-MM-DD hh:mm:ss JST moodle moodle NOTICE: CREATE TABLE / PRIMARY KEY will create implicit index "psqlwatch_pkey" for table "psql watch"
YYYY-MM-DD hh:mm:ss JST moodle moodle LOG: statement: DROP TABLE psqlwatch
選択する監視レベル |
監視テーブルの事前作成 |
|---|---|
レベル1(selectでの監視) |
必要あり |
レベル2(update/selectでの監視) |
必要なし |
レベル3(毎回create/dropも行う) |
必要なし |
監視テーブルの作成は以下の手順で行えます。
4.31.2. PostgreSQL モニタリソースの監視方法¶
PostgreSQLモニタリソースは、以下の監視レベルから選択した監視レベルに応じた監視を行います。
- レベル1(selectでの監視)監視テーブルに対して参照のみを行う監視です。監視テーブルに対して実行するSQL文は( select )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
- レベル2(update/selectでの監視)監視テーブルに対して更新も行う監視です。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( update / select / reindex / vacuum )です。監視開始時に監視テーブルを自動で作成した場合、監視テーブルに対して実行するSQL文は( create / insert )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
- レベル3(毎回create/dropも行う)監視テーブルに対しての更新に加え監視テーブルの作成・削除も毎回行います。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( create / insert / select / reindex / drop / vacuum )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
4.31.3. 監視 (固有) タブ¶
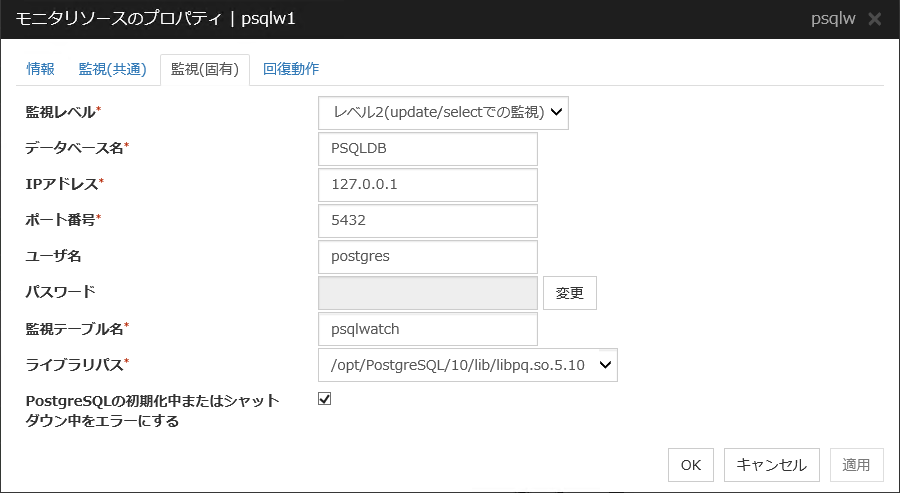
監視レベル
選択肢の中から1つを選択します。必ず設定してください。
既定値 : レベル2(update/selectでの監視)
データベース名 (255 バイト以内)
監視するデータベース名を設定します。必ず設定してください。
既定値 : なし
IP アドレス (79 バイト以内)
接続するサーバの IP アドレスを設定します。必ず設定してください。
既定値 : 127.0.0.1
ポート番号 (1~65535)
接続する際のポート番号を設定します。必ず設定してください。
既定値 : 5432
ユーザ名 (255 バイト以内)
データベースにログインする際のユーザ名を設定します。必ず設定してください。
指定したデータベースにアクセス可能な PostgreSQL ユーザを指定してください。
既定値 : postgres
パスワード (255 バイト以内)
データベースにログインする際のパスワードを設定します。
既定値 : なし
監視テーブル名 (255 バイト以内)
データベース上に作成する監視用テーブルの名前を設定します。必ず設定してください。
テーブルの作成・削除を行いますので、運用に使用しているテーブル名と重ならないように注意してください。また、SQL 文の予約語と重ならないようにしてください。データベースの仕様により監視テーブル名に設定できない文字があります。詳細はデータベースの仕様を確認してください。既定値 : psqlwatch
ライブラリパス (1023 バイト以内)
PostgreSQL のライブラリパスを設定します。必ず設定してください。
既定値 : /opt/PostgreSQL/10/lib/libpq.so.5.10
PostgreSQLの初期化中またはシャットダウン中をエラーにする
本機能を有効にした場合、PostgreSQL の初期化中またはシャットダウン中の状態を検出すると、直ちに監視エラーになります。
本機能を無効にした場合、PostgreSQL の初期化中またはシャットダウン中の状態でも監視正常になります。
ただし1時間以上PostgreSQLの初期化中またはシャットダウン中の状態が継続すると監視エラーになります。
既定値 : 有効
4.32. Samba モニタリソースを理解する¶
Samba モニタリソースは、サーバ上で動作する samba のファイルサーバを監視するモニタリソースです。
4.32.1. Samba モニタリソースの注意事項¶
動作確認済みの samba のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
本モニタリソースが異常になる場合は、パラメータの設定値と samba の環境が一致していない可能性がありますので、環境を確認してください。
監視する共有名については、自サーバから接続できるように smb.conf を設定してください。また、smb.conf ファイルの security パラメータが share の場合は、ゲスト接続を有効にしてください。
ファイル共有、プリンタ共有以外の samba の機能に関しては監視を行いません。
samba の認証モードが Domain もしくは Server の場合、監視サーバ上で smbmount を実行すると、本モニタリソースのパラメータで指定したユーザ名で mount されることがあります。
4.32.2. Samba モニタリソースの監視方法¶
Samba モニタリソースは、内部バージョン 4.1.0-1 より共有ライブラリの libsmbclient.so.0 を利用しています。
Samba モニタリソースは、以下の監視を行います。
samba サーバに接続して samba サーバのリソースに対する tree connection の確立を 確認します。
監視の結果、以下の場合に異常とみなします。
samba サービスへの要求に対する応答内容が不正な場合
4.32.3. 監視 (固有) タブ¶
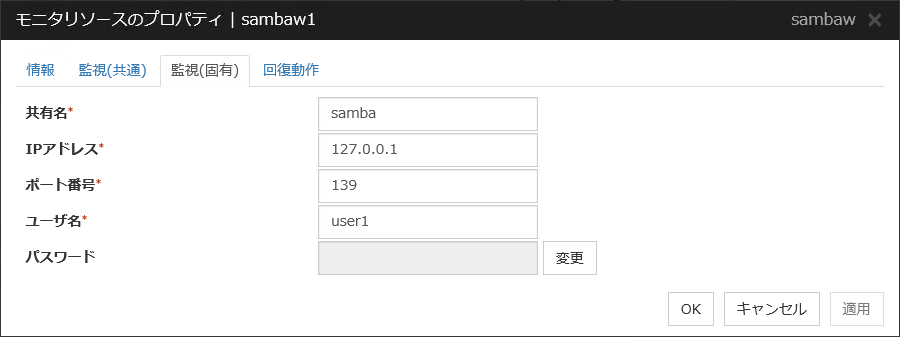
共有名 (255 バイト以内)
監視を行う samba サーバの共有名を設定します。必ず設定してください。
既定値 : なし
IP アドレス (79 バイト以内)
samba サーバの IP アドレスを設定します。必ず設定してください。
既定値 : 127.0.0.1
ポート番号 (1~65535)
samba デーモンが使用しているポート番号を設定します。必ず設定してください。libsmbclient のバージョンが 3 以下の場合(例.RHEL 6 に同梱の libsmbclient.so)、[ポート番号]は139もしくは445しか指定できません。smb.conf の smb ports も同じ値を指定してください。
既定値 : 139
ユーザ名 (255 バイト以内)
samba サービスにログインする際のユーザ名を設定します。必ず設定してください。
既定値 : なし
パスワード (255 バイト以内)
samba サービスにログインする際のパスワードを設定します。
既定値 : なし
4.33. SMTP モニタリソースを理解する¶
SMTP モニタリソースは、サーバ上で動作する SMTP デーモンを監視するモニタリソースです。
4.33.1. SMTP モニタリソースの注意事項¶
動作確認済みの SMTP のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
ロードアベレージが、sendmail.def ファイルで設定されている RefuseLA の値よりも超えた状態が一定時間続くと、本モニタリソースは異常とみなしてフェイルオーバすることがあります。
4.33.2. SMTP モニタリソースの監視方法¶
SMTP モニタリソースは、以下の監視を行います。
サーバ上の SMTP デーモンに接続し、[NOOP] コマンドの発行により、SMTPデーモンの監視を実行します。
監視の結果、以下の場合に異常とみなします。
SMTP デーモンへの接続や [NOOP] コマンドの発行に対する応答で異常が通知された場合
4.33.3. 監視 (固有) タブ¶
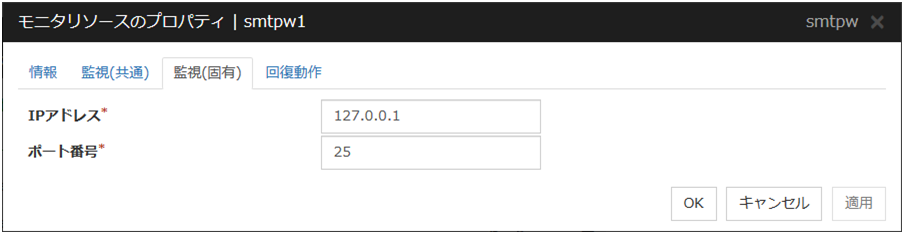
IP アドレス (79 バイト以内)
監視する SMTP サーバの IP アドレスを設定します。必ず設定してください。
既定値 : 127.0.0.1
ポート番号 (1~65535)
SMTP サーバに接続する際のポート番号を設定します。必ず設定してください。
既定値 : 25
4.34. SQL Server モニタリソースを理解する¶
SQL Server モニタリソースは、サーバ上で動作する SQL Server のデータベースを監視するモニタ リソースです。
4.34.1. SQL Server モニタリソースの注意事項¶
動作確認済みの SQL Server のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
本モニタリソースは、Microsoft ODBC Driver for SQL Serverを使用して、SQL Server の監視を行っています。
パラメータ指定値が、監視を行う SQL Server の環境と異なる場合、Cluster WebUI のアラートログにエラー内容を示すメッセージが表示されますので、環境を確認してください。
選択する監視レベル |
監視テーブルの事前作成 |
|---|---|
レベル0(データベースステータス) |
必要なし |
レベル1(selectでの監視) |
必要あり |
レベル2(update/selectでの監視) |
必要なし |
レベル3(毎回create/dropも行う) |
必要なし |
SQL文で作成する場合(以下の例は監視テーブル名をsqlwatchとする場合)
SET IMPLICIT_TRANSACTIONSがオフの場合
sql> CREATE TABLE sqlwatch (num INT NOT NULL PRIMARY KEY)sql> GOsql> INSERT INTO sqlwatch VALUES(0)sql> GOSET IMPLICIT_TRANSACTIONSがオンの場合
sql> CREATE TABLE sqlwatch (num INT NOT NULL PRIMARY KEY)sql> GOsql> INSERT INTO sqlwatch VALUES(0)sql> GOsql> COMMITsql> GO
4.34.2. SQL Server モニタリソースの監視方法¶
SQL Serverモニタリソースは、以下の監視レベルから選択した監視レベルに応じた監視を行います。
- レベル0(データベースステータス)SQL Serverの管理テーブルを参照しDBの状態を確認します。監視テーブルに対してSQL文の発行は行わない簡易的な監視です。
監視の結果以下の場合に異常とみなします。
データベースのステータスがオンラインでない場合
- レベル1(selectでの監視)監視テーブルに対して参照のみを行う監視です。監視テーブルに対して実行するSQL文は( select )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
- レベル2(update/selectでの監視)監視テーブルに対して更新も行う監視です。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( update / select )です。
監視開始時に監視テーブルを自動で作成した場合、監視テーブルに対して実行するSQL文は( create / insert )です。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
- レベル3(毎回create/dropも行う)監視テーブルに対しての更新に加え監視テーブルの作成・削除も毎回行います。SQL文の実行により最大10桁の数値データの書き込みと読み込みを実行します。監視テーブルに対して実行するSQL文は( create / insert / select / drop )です。
監視の結果以下の場合に異常とみなします。
データベースへの接続やSQL文の発行に対する応答で異常が通知された場合
書き込んだデータと読み込んだデータが一致していない場合
4.34.3. 監視 (固有) タブ¶
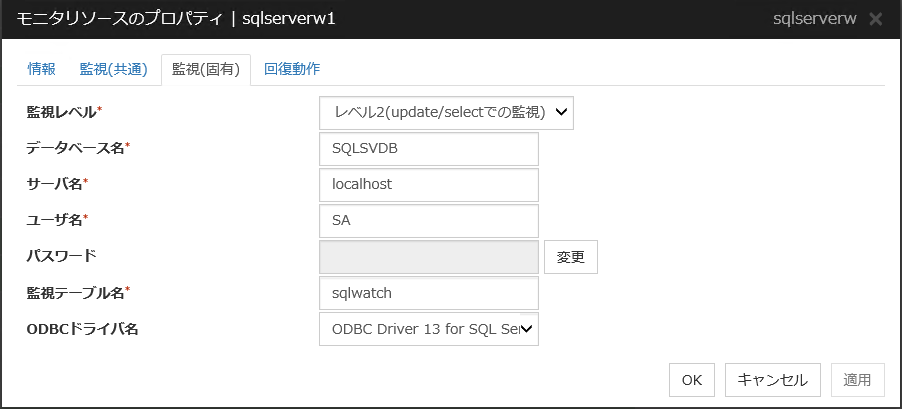
監視レベル
選択肢の中から1つを選択します。必ず設定してください。
既定値 : レベル2(update/selectでの監視)
データベース名 (255 バイト以内)
監視するデータベース名を設定します。必ず設定してください。
既定値 : なし
サーバ名 (255 バイト以内)
監視するデータベースのサーバ名を設定します。必ず設定してください。
既定値 : localhost
ユーザ名 (255 バイト以内)
データベースにログインする際のユーザ名を設定します。必ず設定してください。
指定したデータベースにアクセス可能な SQL Server ユーザを指定してください。
既定値 : SA
パスワード (255 バイト以内)
データベースにログインする際のパスワードを設定します。必ず設定してください。
既定値 : なし
監視テーブル名 (255 バイト以内)
データベース上に作成する監視用テーブルの名前を設定します。必ず設定してください。
テーブルの作成・削除を行いますので、運用に使用しているテーブル名と重ならないように注意してください。また、SQL 文の予約語と重ならないようにしてください。データベースの仕様により監視テーブル名に設定できない文字があります。詳細はデータベースの仕様を確認してください。既定値 : sqlwatch
ODBCドライバ名 (255 バイト以内)
SQL Server のODBCドライバ名を設定します。必ず設定してください。
既定値 : ODBC Driver 13 for SQL Server
4.35. Tuxedo モニタリソースを理解する¶
Tuxedo モニタリソースは、サーバ上で動作する Tuxedo を監視するモニタリソースです。
4.35.1. Tuxedo モニタリソースの注意事項¶
動作確認済みの Tuxedo のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
Tuxedo のライブラリ (libtux.soなど) が存在しない場合、監視を行うことができません。
4.35.2. Tuxedo モニタリソースの監視方法¶
Tuxedo モニタリソースは、以下の監視を行います。
Tuxedo の API を利用して、アプリケーションサーバの監視を実行します。
監視の結果、以下の場合に異常とみなします。
アプリケーションサーバへの接続や状態取得に対する応答で異常が通知された場合
4.35.3. 監視 (固有) タブ¶
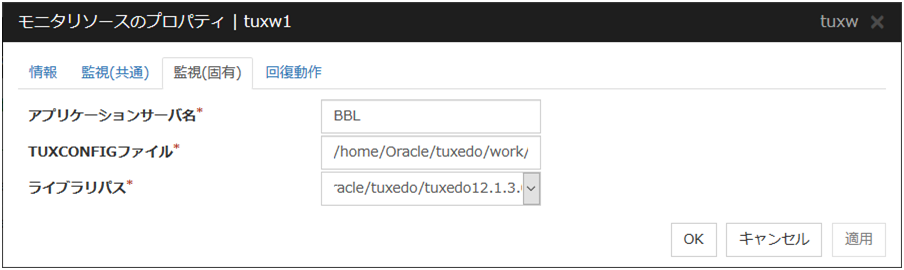
アプリケーションサーバ名 (255 バイト以内)
監視するアプリケーションサーバ名を設定します。必ず設定してください。
既定値 : BBL
TUXCONFIG ファイル (1023 バイト以内)
Tuxedoの配置ファイル名を設定します。必ず設定してください。
既定値 : なし
ライブラリパス (1023 バイト以内)
Tuxedo のライブラリパスを設定します。必ず設定してください。
既定値 : /home/Oracle/tuxedo/tuxedo12.1.3.0.0/lib/libtux.so
4.36. WebLogic モニタリソースを理解する¶
WebLogic モニタリソースは、サーバ上で動作する WebLogic を監視するモニタリソースです。
4.36.1. WebLogic モニタリソースの注意事項¶
動作確認済みの WebLogic のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
本モニタリソースで 監視方式 に [WLST] を選択した場合は、監視を行うために Java 環境が必要です。アプリケーションサーバシステムは Java の機能を利用しているため、Java のストールなどが発生した場合も異常とみなすことがあります。
WebLogic 起動時にすぐに動作できない場合は異常とみなしてしまうため、[監視開始待ち時間] で調整してください。もしくは、WebLogic を先に起動するようにしてください(例:監視の対象リソースに、WebLogic を起動するEXECリソースを指定)。
4.36.2. WebLogic モニタリソースの監視方法¶
WebLogic モニタリソースは、以下の監視を行います。
監視方式:RESTful API を選択した場合
WebLogicでは WebLogic RESTful 管理サービス という RESTful API が用意されています。
このRESTful API を通して アプリケーションサーバの監視を実行します。
監視の結果、以下の応答で異常が通知された場合に異常とみなします。
RESTful API の応答で異常が通知された場合
注釈
監視方式:WLST と比較して、監視時のアプリケーションサーバのCPU負荷を低減できます。
監視方式:WLST を選択した場合
[weblogic.WLST] コマンドを利用して connect を行うことで、アプリケーションサーバの監視を実行します。
監視の結果、以下の場合に異常とみなします。
connect の応答で異常が通知された場合
[認証方式] により以下の動作となります。
DemoTrust: WebLogic のデモ用認証ファイルを使用した SSL 認証方式
CustomTrust: ユーザ作成認証ファイルを使用した SSL 認証方式
Not Use SSL: SSL認証を行わない
4.36.3. 監視 (固有) タブ¶
IP アドレス (79 バイト以内)
監視するサーバの IP アドレスを設定します。必ず設定してください。
既定値 : 127.0.0.1
ポート番号 (1~65535)
サーバに接続する際のポート番号を設定します。必ず設定してください。
既定値 : 7002
監視方式
サーバの監視方式を設定します。必ず設定してください。
既定値 : RESTful API
プロトコル
監視するサーバのプロトコルを設定します。[監視方式]に RESTful API を選択した場合に必ず選択してください。
既定値 : HTTP
ユーザ名 (255 バイト以内)
WebLogic のユーザ名を設定します。[監視方式]に RESTful API を選択した場合に必ず入力してください。
既定値 : weblogic
パスワード (255 バイト以内)
WebLogic のパスワードを設定します。[監視方式]に RESTful API を選択した場合に必要に応じて入力してください。
既定値 : なし
アカウントの隠蔽
ユーザ名とパスワードを直接指定する場合は「しない」を、ファイル内に記述する場合は「する」を指定してください。必ず設定してください。
既定値 : しない
コンフィグファイル (1023 バイト以内)
ユーザ情報を保持しているファイル名を設定します。アカウントの隠蔽「する」の場合、必ず設定してください。
既定値 : なし
キーファイル名 (1023 バイト以内)
コンフィグファイルパスにアクセスするためのパスワードを保存しているファイル名を、フルパスで設定します。アカウントの隠蔽「する」の場合、必ず設定してください。
既定値 : なし
ユーザ名 (255 バイト以内)
WebLogic のユーザ名を設定します。アカウントの隠蔽「しない」の場合、必ず設定してください。
既定値 :weblogic
パスワード (255 バイト以内)
WebLogic のパスワードを設定します。
既定値 : なし
認証方式
アプリケーションサーバに接続する際の認証方式を設定します。必ず設定してください。
SSL 通信を用いた監視を行いたい場合、[認証方式] に [DemoTrust] または [CustomTrust] を指定してください。
[DemoTrust]、[CustomTrust] のいずれを選択するかは、WebLogic Administration Console 上の設定により異なります。
WebLogic Administration Console の[キーストア]が[デモ・アイデンティティとデモ信頼]の場合、[DemoTrust] を指定してください。この場合、[キーストアファイル] の設定は不要です。
WebLogic Administration Console の[キーストア]が[カスタム・アイデンティティとカスタム信頼]の場合、[CustomTrust] を指定してください。この場合、[キーストアファイル] の設定が必要です。
既定値 : DemoTrust
キーストアファイル (1023 バイト以内)
SSL 認証時の認証ファイルを設定します。認証方式が「CustomTrust」の場合、必ず設定してください。WebLogic Administration Console 上の[カスタム・アイデンティティ・キーストア]で指定しているファイルを設定してください。
既定値 : なし
ドメイン環境ファイル (1023 バイト以内)
WebLogic のドメイン環境ファイル名を設定します。必ず設定してください。
既定値 :/home/Oracle/product/Oracle_Home/user_projects/domains/base_domain/bin/setDomainEnv.sh
追加コマンドオプション (1023 バイト以内)
[webLogic.WLST] コマンドへ渡すオプションを変更する場合に設定します。
既定値 : -Dwlst.offline.log=disable -Duser.language=en_US
4.37. WebSphere モニタリソースを理解する¶
WebSphere モニタリソースは、サーバ上で動作する WebSphere を監視するモニタリソースです。
4.37.1. WebSphere モニタリソースの注意事項¶
動作確認済みの WebSphere のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
本モニタリソースで監視を行うためには Java 環境が必要です。アプリケーションサーバシステムは Java の機能を利用しているため、Java のストールなどが発生した場合も異常とみなすことがあります。
4.37.2. WebSphere モニタリソースの監視方法¶
WebSphere モニタリソースは、以下の監視を行います。
WebSphere の [serverStatus.sh] コマンドを利用して、アプリケーションサーバの監視を実行します。
監視の結果、以下の場合に異常とみなします。
取得したアプリケーションサーバの状態で異常が通知された場合
4.37.3. 監視 (固有) タブ¶
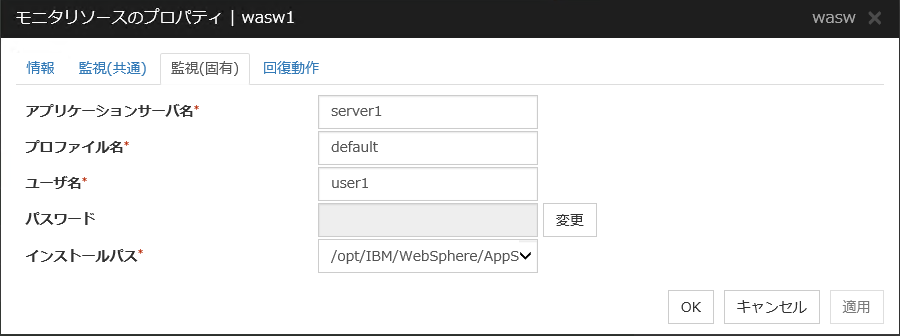
アプリケーションサーバ (255 バイト以内)
監視するアプリケーションサーバ名を設定します。必ず設定してください。
既定値 : server1
プロファイル名 (1023 バイト以内)
監視するアプリケーションサーバのプロファイル名を設定します。必ず設定してください。
既定値 : default
ユーザ名 (255 バイト以内)
WebSphere のユーザ名を設定します。必ず設定してください。
既定値 :なし
パスワード (255 バイト以内)
WebSphere のパスワードを設定します。
既定値 : なし
インストールパス (1023 バイト以内)
WebSphere のインストールパスを設定します。必ず設定してください。
既定値 : /opt/IBM/WebSphere/AppServer
4.38. WebOTX モニタリソースを理解する¶
WebOTX モニタリソースは、サーバ上で動作する WebOTX を監視するモニタリソースです。
4.38.1. WebOTX モニタリソースの注意事項¶
動作確認済みの WebOTX のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
本モニタリソースで監視を行うためには Java 環境が必要です。アプリケーションサーバシステムは Java の機能を利用しているため、Java のストールなどが発生した場合も異常とみなすことがあります。
4.38.2. WebOTX モニタリソースの監視方法¶
WebOTX モニタリソースは、以下の監視を行います。
WebOTX の [otxadmin.sh] コマンドを利用して、アプリケーションサーバの監視を実行します。
監視の結果、以下の場合に異常とみなします。
取得したアプリケーションサーバの状態で異常が通知された場合
4.38.3. 監視 (固有) タブ¶
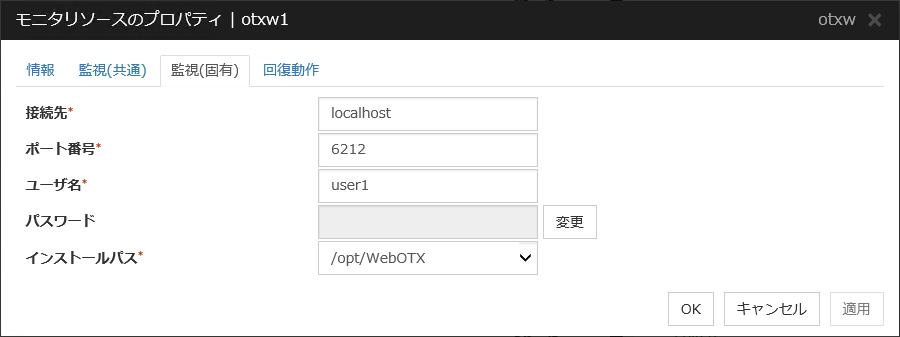
接続先 (255 バイト以内)
監視するサーバのサーバ名を設定します。必ず設定してください。
既定値 : localhost
ポート番号 (1~65535)
サーバに接続する際のポート番号を設定します。必ず設定してください。
WebOTX ユーザドメインを監視する場合、WebOTX ドメインの管理ポート番号を設定してください。管理ポート番号とは、ドメイン作成時に <ドメイン名>.properties の domain.admin.port にて設定したポート番号です。<ドメイン名>.properties の詳細については WebOTX のドキュメントを参照してください。
既定値 : 6212
ユーザ名 (255 バイト以内)
WebOTX のユーザ名を設定します。必ず設定してください。
WebOTX ユーザドメインを監視する場合、WebOTX ドメインのログインユーザ名を設定してください。
既定値 :なし
パスワード (255 バイト以内)
WebOTX のパスワードを設定します。
既定値 : なし
インストールパス (1023 バイト以内)
WebOTX のインストールパスを設定します。必ず設定してください。
既定値 : /opt/WebOTX
4.39. JVM モニタリソースを理解する¶
JVMモニタリソースは、サーバ上で動作するJava VMやアプリケーションサーバが使用するリソースの利用情報を監視するモニタリソースです。
4.39.1. JVM モニタリソースの注意事項¶
JVMモニタリソースを作成する前にクラスタプロパティの[JVM監視]タブの[Javaインストールパス]を前もって設定しておく必要があります。
監視対象のリソースには、WebLogic ServerやWebOTXなどJava VM上で動作するアプリケーションサーバを指定してください。JVMモニタリソースの活性後、Java Resource Agentは監視を開始しますが、JVMモニタリソースの活性直後に監視対象(WebLogic ServerやWebOTX)がすぐに動作できない場合は、[監視開始待ち時間]で調整してください。
[監視(共通)]-[リトライ回数]の設定は無効です。異常の検出を遅らせたい場合は、[クラスタ]プロパティ-[JVM監視]タブ-[リソース計測設定]-[共通]-[リトライ回数]の設定を変更してください。
4.39.2. JVM モニタリソースの監視方法¶
JVMモニタリソースは、以下の監視を行います。
JMX(Java Management Extensions)を利用して、アプリケーションサーバの監視を実行します。
監視の結果、以下の場合に異常とみなします。
監視対象のJava VMやアプリケーションサーバに接続できない場合
取得したJava VMやアプリケーションサーバのリソース使用量がお客様定義のしきい値を規定回数(異常判定しきい値)連続して超えた場合
監視の結果、以下の場合に異常から正常へ復帰したとみなします。
回復動作後の監視を再開時にしきい値を下回った場合
注釈
Cluster WebUI の[クラスタログ収集]では、監視対象(WebLogic ServerやWebOTX)の設定ファイルおよびログファイルは収集されません。

図 4.72 JVMモニタリソースによる監視フロー¶
基本的なしきい値超過時の動作は以下の通りです。

図 4.73 しきい値超過時の動作¶
異常が継続する場合は以下の通りです

図 4.74 異常継続時の動作¶
Full GC(Garbage Collection)を監視する場合を例に説明します。
図の横軸は時間の経過を表しています。 そして、図の上段は各監視タイミングでGCの発生を検出したか否かを示し、下段はそれぞれの時点で Full GC検出が何回連続しているかを示しています。 JVMモニタリソースは、異常判定しきい値回連続して Full GCが発生すると、モニタ異常を検出します。 異常判定しきい値を5回に設定しているので、 Full GC検出が 5回に達した時点でモニタ異常を検出します。
Full GCはシステムに与える影響が大きいため、異常判定しきい値は1回に設定することを推奨します。

図 4.75 監視イメージ(異常判定しきい値を5回に設定した場合)¶
4.39.3. JVM 統計ログとは¶
JVMモニタリソースが収集する監視対象Java VMの統計情報を保存したファイルが、JVM統計ログです。ファイル形式はcsv形式です。作成場所は以下のとおりです。
<CLUSTERPROインストールパス>/log/ha/jra/*.stat
下記の「監視項目」とは、JVMモニタリソースの[プロパティ]-[監視(固有)] タブ内の設定項目を表します。
それぞれの監視項目について、[監視する]をチェックし、かつ閾値を設定した場合に統計情報を採取し、JVM統計ログに情報を出力します。[監視する]をチェックしない場合、および[監視する]をチェックしたが閾値を設定しない場合は、JVM統計ログには情報は出力されません。
監視項目と該当するJVM統計ログは以下の通りです。
監視項目 |
該当するJVM統計ログ |
|---|---|
[メモリ]タブ-[ヒープ使用率を監視する]
[メモリ]タブ-[非ヒープ使用率を監視する]
[メモリ]タブ-[ヒープ使用量を監視する]
[メモリ]タブ-[非ヒープ使用量を監視する]
|
jramemory.stat |
[スレッド]タブ-[動作中のスレッド数を監視する] |
jrathread.stat |
[GC]タブ-[Full GC 実行時間を監視する]
[GC]タブ-[Full GC 発生回数を監視する]
|
jragc.stat |
[WebLogic]タブ-[ワークマネージャのリクエストを監視する]
[WebLogic]タブ-[スレッドプールのリクエストを監視する]
上記のいずれかがチェックされている場合、
wlworkmanager.statとwlthreadpool.statの両方出力します。
|
wlthreadpool.stat |
4.39.4. 監視対象 Java VM の Java メモリ領域の使用量を確認する(jramemory.stat)¶
監視対象Java VMのJavaメモリ領域の使用量を記録するログファイルです。ファイル名はログ出力設定のローテーション方式により以下のいずれかになります。
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[ファイルサイズ]を選択した場合:jramemory<0から始まる整数>.stat
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[時間]を選択した場合:jramemory<YYYYMMDDhhmm>.stat
フォーマットは以下の通りです。
No |
フォーマット |
説明 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
ログを記録した日時を示します。 |
2 |
半角英数字記号 |
監視対象Java VMの名称を示します。JVMモニタリソースの[プロパティ]-[監視固有]タブ-[識別名]で設定した値です。 |
3 |
半角英数字記号 |
Javaメモリプールの名称です。詳細は「Java メモリプール名について」を参照してください。 |
4 |
半角英数字記号 |
Javaメモリプールのタイプです。
Heap、Non-Heap
|
5 |
半角数字 |
Java VMが起動時にOSに要求するメモリ量です。単位はバイトです。(init)
監視対象Java VMの起動時、以下のJava VM起動時オプションでサイズの指定が可能です。
|
6 |
半角数字 |
Java VMが現在使用しているメモリ量です。単位はバイトです。(used) |
7 |
半角数字 |
Java VMが現在使用することを保証しているメモリ量です。単位はバイトです。(committed)
メモリの使用状況により増減しますが、必ずused以上、max以下になります。
|
8 |
半角数字 |
Java VMが使用できる最大メモリ量です。単位はバイトです。(max)
以下のJava VM起動時オプションでサイズの指定が可能です。
例)
java -XX:MaxPermSize=128m -XX:ReservedCodeCacheSize=128m javaAP
上記例ではNON_HEAPのmaxは 128m+128m=256m になります。
(注意)
-Xms と-Xmxに同じ値を指定すると、(init)>(max)となることがあります。これはHEAPのmaxが、-Xmx の指定によって確保される領域サイズからSurvivor Spaceのサイズの半分を除いたサイズを示すためです。
|
9 |
半角数字 |
計測対象のJava VMが起動してから使用したメモリ量のピーク値です。Javaメモリプールの名称がHEAP、NON_HEAPの場合、Java VMが現在使用しているメモリ量(used)と同じになります。単位はバイトです。 |
10 |
半角数字 |
[JVM種別]で[Oracle Java(usage monitoring)]選択時は無視してください。 [JVM種別]で[Oracle Java(usage monitoring)]以外を選択時、Javaメモリプールのタイプ(No.4のフィールド)がHEAPの場合、max(No.8のフィールド)×しきい値(%)のメモリ量です。単位はバイトです。JavaメモリプールのタイプがHEAP以外の場合、0固定です。 |
4.39.5. 監視対象 Java VM のスレッド稼働状況を確認する (jrathread.stat)¶
監視対象Java VMのスレッド稼働状況を記録するログファイルです。ファイル名はログ出力設定のローテーション方式により以下のいずれかになります。
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[ファイルサイズ]を選択した場合:jrathread<0から始まる整数>.stat
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[時間]を選択した場合:jrathread<YYYYMMDDhhmm>.stat
フォーマットは以下の通りです。
No |
フォーマット |
説明 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
ログを記録した日時を示します。 |
2 |
半角英数字記号 |
監視対象Java VMの名称を示します。JVMモニタリソースの[プロパティ]-[監視固有]タブ-[識別名]で設定した値です。 |
3 |
半角英数字記号 |
監視対象Java VMで現在実行中のスレッド数を示します。 |
4 |
[半角数字: 半角数字:...] |
監視対象Java VMでデッドロックしているスレッドIDを示します。デッドロック数分IDを繰り返します。 |
5 |
半角英数字記号 |
監視対象Java VMでデッドロックしているスレッドの詳細情報を示します。スレッド数分、以下の形式で繰り返します。
スレッド名, スレッドID, スレッド状態, UserTime, CpuTime, WaitedCount, WaitedTime, isInNative, isSuspended <改行>
stacktrace<改行>
:
stacktrace<改行>
stacktrace=ClassName, FileName, LineNumber, MethodName, isNativeMethod
|
4.39.6. 監視対象 Java VM の GC 稼働状況を確認する (jragc.stat)¶
監視対象Java VMのGC稼働状況を記録するログファイルです。ファイル名はログ出力設定のローテーション方式により以下のいずれかになります。
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[ファイルサイズ]を選択した場合:jragc<0から始まる整数>.stat
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[時間]を選択した場合:jragc<YYYYMMDDhhmm>.stat
JVMモニタリソースではコピーGCとFull GCの2種類のGCの情報を出力しています。 JVMモニタリソースでは、Oracle Javaの場合は以下のGCについて、Full GCとして発生回数の増分をカウントしています。
MarkSweepCompact
PS MarkSweep
ConcurrentMarkSweep
G1 Old Generation
フォーマットは以下の通りです。
No |
フォーマット |
説明 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
ログを記録した日時を示します。 |
2 |
半角英数字記号 |
監視対象Java VMの名称を示します。JVMモニタリソースの[プロパティ]-[監視固有]タブ-[識別名]で設定した値です。 |
3 |
半角英数字記号 |
監視対象Java VM のGC名称を示します。 監視対象Java VMがOracle Javaの場合
以下があります。
Copy
MarkSweepCompact
PS Scavenge
PS MarkSweep
ParNew
ConcurrentMarkSweep
G1 Young Generation
G1 Old Generation
監視対象Java VMがOracle JRockitの場合
以下があります。
Garbage collection optimized for throughput Old Collector
Garbage collection optimized for short pausetimes Old Collector
Garbage collection optimized for deterministic pausetimes Old Collector
Static Collector
Static Old Collector
Garbage collection optimized for throughput Young Collector
|
4 |
半角数字 |
監視対象Java VMの起動直後から計測時点までのGC発生回数を示します。JVMモニタリソースが監視を開始する前に発生したGCの発生回数も値に含みます。 |
5 |
半角数字 |
監視対象Java VMの起動直後から計測時点までのGC総実行時間を示します。単位はミリ秒です。JVMモニタリソースが監視を開始する前に発生したGCの実行時間も値に含みます。 |
4.39.7. WebLogic Server のワークマネージャの稼働状況を確認する(wlworkmanager.stat)¶
WebLogic Serverのワークマネージャの稼働状況を記録するログファイルです。ファイル名はログ出力設定のローテーション方式により以下のいずれかになります。
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[ファイルサイズ]を選択した場合:wlworkmanager<0から始まる整数>.stat
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[時間]を選択した場合:wlworkmanager<YYYYMMDDhhmm>.stat
フォーマットは以下の通りです。
No |
フォーマット |
説明 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
ログを記録した日時を示します。 |
2 |
半角英数字記号 |
監視対象Java VMの名称を示します。JVMモニタリソースの[プロパティ]-[監視固有]タブ-[識別名]で設定した値です。 |
3 |
半角英数字記号 |
アプリケーション名を示します。 |
4 |
半角英数字記号 |
ワークマネージャ名を示します。 |
5 |
半角数字 |
実行したリクエストの数を示します。 |
6 |
半角数字 |
待機しているリクエストの数を示します。 |
4.39.8. WebLogic Server のスレッドプールの稼働状況を確認する(wlthreadpool.stat)¶
WebLogic Serverのスレッドプールの稼働状況を記録するログファイルです。ファイル名はログ出力設定のローテーション方式により以下のいずれかになります。
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[ファイルサイズ]を選択した場合:wlthreadpool<0から始まる整数>.stat
[クラスタのプロパティ]-[JVM監視]タブ-[ログ出力設定]-[ローテーション方式]-[時間]を選択した場合:wlthreadpool<YYYYMMDDhhmm>.stat
フォーマットは以下の通りです。
No |
フォーマット |
説明 |
|---|---|---|
1 |
yyyy/mm/dd hh:mm:ss.SSS |
ログを記録した日時を示します。 |
2 |
半角英数字記号 |
監視対象Java VMの名称を示します。JVMモニタリソースの[プロパティ]-[監視固有]タブ-[識別名]で設定した値です。 |
3 |
半角数字 |
実行したリクエストの総数を示します。 |
4 |
半角数字 |
処理待ちとなっているリクエスト数を示します。 |
5 |
半角数字 |
単位時間(秒)あたりのリクエスト処理数を示します。 |
6 |
半角数字 |
アプリケーションを実行するためのスレッドのトータル数を示します。 |
7 |
半角数字 |
アイドル状態となっているスレッドの数を示します。 |
8 |
半角数字 |
実行中のスレッド数を示します。 |
9 |
半角数字 |
スタンバイ状態となっているスレッド数を示します。 |
4.39.9. Java メモリプール名について¶
JVM運用ログに出力するメッセージ中のmemory_nameとして出力するJavaメモリプール名、およびJVM統計ログjramemory.stat中に出力するJavaメモリプール名について説明します。
[JVM種別]に[Oracle Java]を選択、かつ監視対象Java VMの起動オプションに「-XX:+UseSerialGC」が付加されている場合、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用率を監視する]-[領域全体] |
HEAP |
[ヒープ使用率を監視する]-[Eden Space] |
Eden Space |
[ヒープ使用率を監視する]-[Survivor Space] |
Survivor Space |
[ヒープ使用率を監視する]-[Tenured Gen] |
Tenured Gen |
[非ヒープ使用率を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用率を監視する]-[Code Cache] |
Code Cache |
[非ヒープ使用率を監視する]-[Perm Gen] |
Perm Gen |
[非ヒープ使用率を監視する]-[Perm Gen[shared-ro]] |
Perm Gen [shared-ro] |
[非ヒープ使用率を監視する]-[Perm Gen[shared-rw]] |
Perm Gen [shared-rw] |
[JVM種別]に[Oracle Java]を選択、かつ監視対象Java VMの起動オプションに「-XX:+UseParallelGC」、「-XX:+UseParallelOldGC」が付加されている場合、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用率を監視する]-[領域全体] |
HEAP |
[ヒープ使用率を監視する]-[Eden Space] |
PS Eden Space |
[ヒープ使用率を監視する]-[Survivor Space] |
PS Survivor Space |
[ヒープ使用率を監視する]-[Tenured Gen] |
PS Old Gen |
[非ヒープ使用率を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用率を監視する]-[Code Cache] |
Code Cache |
[非ヒープ使用率を監視する]-[Perm Gen] |
PS Perm Gen |
[非ヒープ使用率を監視する]-[Perm Gen[shared-ro]] |
Perm Gen [shared-ro] |
[非ヒープ使用率を監視する]-[Perm Gen[shared-rw]] |
Perm Gen [shared-rw] |
[JVM種別]に[Oracle Java]を選択、かつ監視対象Java VMの起動オプションに「-XX:+UseConcMarkSweepGC」が付加されている場合、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用率を監視する]-[領域全体] |
HEAP |
[ヒープ使用率を監視する]-[Eden Space] |
Par Eden Space |
[ヒープ使用率を監視する]-[Survivor Space] |
Par Survivor Space |
[ヒープ使用率を監視する]-[Tenured Gen] |
CMS Old Gen |
[非ヒープ使用率を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用率を監視する]-[Code Cache] |
Code Cache |
[非ヒープ使用率を監視する]-[Perm Gen] |
CMS Perm Gen |
[非ヒープ使用率を監視する]-[Perm Gen[shared-ro]] |
Perm Gen [shared-ro] |
[非ヒープ使用率を監視する]-[Perm Gen[shared-rw]] |
Perm Gen [shared-rw] |
[JVM種別]に[Oracle Java(usage monitoring)]を選択、かつ監視対象Java VMの起動オプションに「-XX:+UseSerialGC」が付加されている場合、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用量を監視する]-[領域全体] |
HEAP |
[ヒープ使用量を監視する]-[Eden Space] |
Eden Space |
[ヒープ使用量を監視する]-[Survivor Space] |
Survivor Space |
[ヒープ使用量を監視する]-[Tenured Gen] |
Tenured Gen |
[非ヒープ使用量を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用量を監視する]-[Code Cache] |
Code Cache(Java 9以降の場合、出力なし) |
[非ヒープ使用量を監視する]-[Metaspace] |
Metaspace |
[非ヒープ使用量を監視する]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[非ヒープ使用量を監視する]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[非ヒープ使用量を監視する]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[非ヒープ使用量を監視する]-[Compressed Class Space] |
Compressed Class Space |
[JVM種別]に[Oracle Java(usage monitoring)]を選択、かつ監視対象Java VMの起動オプションに「-XX:+UseParallelGC」が付加されている場合、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用量を監視する]-[領域全体] |
HEAP |
[ヒープ使用量を監視する]-[Eden Space] |
PS Eden Space |
[ヒープ使用量を監視する]-[Survivor Space] |
PS Survivor Space |
[ヒープ使用量を監視する]-[Tenured Gen] |
PS Old Gen |
[非ヒープ使用量を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用量を監視する]-[Code Cache] |
Code Cache(Java 9以降の場合、出力なし) |
[非ヒープ使用量を監視する]-[Metaspace] |
Metaspace |
[非ヒープ使用量を監視する]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[非ヒープ使用量を監視する]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[非ヒープ使用量を監視する]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[非ヒープ使用量を監視する]-[Compressed Class Space] |
Compressed Class Space |
[JVM種別]に[Oracle Java(usage monitoring)]を選択、かつ監視対象Java VMの起動オプションに「-XX:+UseParNewGC」が付加されている場合、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。Java 9以降の場合、「-XX:+UseParNewGC」を付加すると、監視対象Java VMは起動しません。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用量を監視する]-[領域全体] |
HEAP |
[ヒープ使用量を監視する]-[Eden Space] |
Par Eden Space |
[ヒープ使用量を監視する]-[Survivor Space] |
Par Survivor Space |
[ヒープ使用量を監視する]-[Tenured Gen] |
Tenured Gen |
[非ヒープ使用量を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用量を監視する]-[Code Cache] |
Code Cache |
[非ヒープ使用量を監視する]-[Metaspace] |
Metaspace |
[非ヒープ使用量を監視する]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[非ヒープ使用量を監視する]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[非ヒープ使用量を監視する]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[非ヒープ使用量を監視する]-[Compressed Class Space] |
Compressed Class Space |
[JVM種別]に[Oracle Java(usage monitoring)]を選択、かつ監視対象Java VMの起動オプションに「-XX:+UseG1GC」が付加されている場合、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用量を監視する]-[領域全体] |
HEAP |
[ヒープ使用量を監視する]-[Eden Space] |
G1 Eden Space |
[ヒープ使用量を監視する]-[Survivor Space] |
G1 Survivor Space |
[ヒープ使用量を監視する]-[Tenured Gen (Old Gen)] |
G1 Old Gen |
[非ヒープ使用量を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用量を監視する]-[Code Cache] |
Code Cache(Java 9以降の場合、出力なし) |
[非ヒープ使用量を監視する]-[Metaspace] |
Metaspace |
[非ヒープ使用量を監視する]-[CodeHeap non-nmethods] |
CodeHeap non-nmethods |
[非ヒープ使用量を監視する]-[CodeHeap profiled] |
CodeHeap profiled nmethods |
[非ヒープ使用量を監視する]-[CodeHeap non-profiled] |
CodeHeap non-profiled nmethods |
[非ヒープ使用量を監視する]-[Compressed Class Space] |
Compressed Class Space |
監視対象Java VMがOracle JRockitの場合([JVM 種別]で[JRockit]選択時)、jramemory.statにおけるNo3のJavaメモリプール名は以下の通りです。
監視項目 |
memory_nameとして出力する文字列 |
|---|---|
[ヒープ使用率を監視する]-[領域全体] |
HEAP memory |
[ヒープ使用率を監視する]-[Nursery Space] |
Nursery |
[ヒープ使用率を監視する]-[Old Space] |
Old Space |
[非ヒープ使用率を監視する]-[領域全体] |
NON_HEAP |
[非ヒープ使用率を監視する]-[Class Memory] |
Class Memory |
JVM統計ログjramemory.statにおけるJavaメモリプール名と、Java VMメモリ空間の関係は以下の通りです。
Oracle Java 8/Oracle Java 9/Oracle Java 11/Oracle Java 17の場合
図 4.76 Java VMメモリ空間(Oracle Java 8/Oracle Java 9/Oracle Java 11/Oracle Java 17)¶
図中のNo
監視項目
jramemory.statのJavaメモリプール名
(1)
[ヒープ使用量を監視する]-[領域全体]
HEAP
(2)
[ヒープ使用量を監視する]-[Eden Space]
EdenSpacePS Eden SpacePar Eden SpaceG1 Eden Space(3)+(4)
[ヒープ使用量を監視する]-[Survivor Space]
Survivor SpacePS Survivor SpacePar Survivor SpaceG1 Survivor Space(5)
[ヒープ使用量を監視する]-[Tenured Gen]
Tenured GenPS Old GenG1 Old Gen(6)
[非ヒープ使用量を監視する]-[Code Cache]
Code Cache(Java 9以降の場合、出力なし)
(6)
[非ヒープ使用量を監視する]-[CodeHeap non-nmethods]
CodeHeap non-nmethods(Java 9以降の場合のみ出力)
(6)
[非ヒープ使用量を監視する]-[CodeHeap profiled]
CodeHeap profiled nmethods(Java 9以降の場合のみ出力)
(6)
[非ヒープ使用量を監視する]-[CodeHeap non-profiled]
CodeHeap non-profiled nmethods(Java 9以降の場合のみ出力)
(7)
[非ヒープ使用量を監視する]-[Metaspace]
Metaspace
(8)
[非ヒープ使用量を監視する]-[Compressed Class Space]
Compressed Class Space
(6)+(7)+(8)
[非ヒープ使用量を監視する]-[領域全体]
NON_HEAP
Oracle JRockitの場合
図 4.77 Java VMメモリ空間(Oracle JRockit)¶
図中のNo
監視項目
jramemory.statのJavaメモリプール名
(1)
[ヒープ使用率を監視する]-[領域全体]
HEAP memory
(2)
[ヒープ使用率を監視する]- [Nursery Space]
Nursery
(3) (注意)
[ヒープ使用率を監視する]- [Old Space]
Old Space
-
[非ヒープ使用率を監視する]-[領域全体]
NON_HEAP
-
[非ヒープ使用率を監視する]-[Class Memory]
Class Memory
注釈
jramemory.stat のJavaメモリプール名"Old Space"については、HEAP内のold領域の値ではなく、"HEAP memory"全体と同値となります。(3)のみの計測はできません。
4.39.10. 異常検出時に障害原因別にコマンドを実行するには¶
障害原因別に実行するコマンドの設定項目は以下の通りです。
障害原因 |
設定項目 |
|---|---|
・監視対象のJava VMへ接続失敗
・リソース計測失敗
|
[ 監視(固有)]タブ-[コマンド] |
・ヒープ使用率
・非ヒープ使用率
・ヒープ使用量
・非ヒープ使用量
|
[ 監視(固有)]タブ-[調整]プロパティ-[メモリ]タブ-[コマンド] |
・動作中のスレッド数 |
[ 監視(固有)]タブ-[調整]プロパティ-[スレッド]タブ-[コマンド] |
・Full GC実行時間
・Full GC発生回数
|
[ 監視(固有)]タブ-[調整]プロパティ-[GC]タブ-[コマンド] |
・WebLogicのワークマネージャのリクエスト
・WebLogicのスレッドプールのリクエスト
|
[ 監視(固有)]タブ-[調整]プロパティ-[WebLogic]タブ-[コマンド] |
[コマンド]は障害原因の詳細をコマンドの引数として渡します。引数は[コマンド]の最後に結合して渡します。スクリプトなどを自身で作成し[コマンド]へ設定することにより、更に障害原因に特化した動作が可能です。引数として渡す文字列は以下の通りです。
引数として渡す文字列が複数記載している場合は、監視対象Java VMのGC方式によりいずれかを渡します。差異の詳細は「Java メモリプール名について」を参照してください。
(Oracle Javaの場合) (Oracle JRockitの場合)と記載がある場合は、JVM種別により異なります。記載がない場合、JVM種別による区別はありません。
障害原因の詳細 |
引数として渡す文字列 |
|---|---|
・監視対象のJava VMへ接続失敗
・リソース計測失敗
|
なし |
[監視(固有)]タブ-[調整]プロパティ-[メモリ]タブ-[ヒープ使用率を監視する]-[領域全体]
(Oracle Javaの場合)
|
HEAP |
[メモリ]タブ- [ヒープ使用率を監視する]-[Eden Space]
(Oracle Javaの場合)
|
EdenSpace
PSEdenSpace
ParEdenSpace
|
[メモリ]タブ- [ヒープ使用率を監視する]-[SurvivorSpace]
(Oracle Javaの場合)
|
SurvivorSpace
PSSurvivorSpace
ParSurvivorSpace
|
[メモリ]タブ- [ヒープ使用率を監視する]-[Tenured Gen]
(Oracle Javaの場合)
|
TenuredGen
PSOldGen
CMSOldGen
|
[メモリ]タブ- [非ヒープ使用率を監視する]-[領域全体]
(Oracle Javaの場合)
|
NON_HEAP |
メモリ]タブ- [非ヒープ使用率を監視する]-[Code Cache]
(Oracle Javaの場合)
|
CodeCache |
[メモリ]タブ- [非ヒープ使用率を監視する]-[Perm Gen]
(Oracle Javaの場合)
|
PermGen
PSPermGen
CMSPermGen
|
[メモリ]タブ- [非ヒープ使用率を監視する]-[Perm Gen[shared-ro]]
(Oracle Javaの場合)
|
PermGen[shared-ro] |
[メモリ]タブ- [非ヒープ使用率を監視する]-[Perm Gen[shared-rw]]
(Oracle Javaの場合)
|
PermGen[shared-rw] |
[メモリ]タブ- [ヒープ使用量を監視する]-[領域全体]
(Oracle Java(usage monitoring)の場合)
|
HEAP |
[メモリ]タブ- [ヒープ使用量を監視する]-[Eden Space]
(Oracle Java(usage monitoring)の場合)
|
EdenSpace
PSEdenSpace
ParEdenSpace
G1EdenSpace
|
[メモリ]タブ- [ヒープ使用量を監視する]-[Survivor Space]
(Oracle Java(usage monitoring)の場合)
|
SurvivorSpace
PSSurvivorSpace
ParSurvivorSpace
G1SurvivorSpace
|
[メモリ]タブ- [ヒープ使用量を監視する]-[Tenured Gen]
(Oracle Java(usage monitoring)の場合)
|
TenuredGen
PSOldGen
CMSOldGen
G1OldGen
|
[メモリ]タブ- [非ヒープ使用量を監視する]-[領域全体]
(Oracle Java(usage monitoring)の場合)
|
NON_HEAP |
[メモリ]タブ- [非ヒープ使用量を監視する]-[Code Cache]
(Oracle Java(usage monitoring)の場合)
|
CodeCache |
[メモリ]タブ- [非ヒープ使用量を監視する]-[Metaspace]
(Oracle Java(usage monitoring)の場合)
|
Metaspace |
[メモリ]タブ - [非ヒープ使用量を監視する]-[CodeHeap non-nmethods]
(Oracle Java(usage monitoring)の場合)
|
non-nmethods |
[メモリ]タブ - [非ヒープ使用量を監視する]-[Compressed Class Space]
(Oracle Java(usage monitoring)の場合)
|
CompressedClassSpace |
[メモリ]タブ- [ヒープ使用率を監視する]-[領域全体]
(Oracle JRockitの場合)
|
HEAP
Heap
|
[メモリ]タブ- [ヒープ使用率を監視する]-[Nursery Space]
(Oracle JRockitの場合)
|
Nursery |
[メモリ]タブ- [ヒープ使用率を監視する]-[Old Space]
(Oracle JRockitの場合)
|
OldSpace |
[メモリ]タブ- [非ヒープ使用率を監視する]-[領域全体]
(Oracle JRockitの場合)
|
NON_HEAP |
[メモリ]タブ- [非ヒープ使用率を監視する]-[Class Memory]
(Oracle JRockitの場合)
|
ClassMemory |
[スレッド]タブ-[動作中のスレッド数を監視する]
|
Count |
[GC]タブ-[Full GC 実行時間を監視する]
|
Time |
[GC]タブ-[Full GC 発生回数を監視する]
|
Count |
[WebLogic]タブ-[ワークマネージャのリクエストを監視する]-[待機リクエスト リクエスト数]
|
WorkManager_PendingRequests |
[WebLogic]タブ-[スレッドプールのリクエストを監視する]-[待機リクエスト リクエスト数]
|
ThreadPool_PendingUserRequestCount |
[WebLogic]タブ-[スレッドプールのリクエストを監視する]-[実行リクエスト リクエスト数]
|
ThreadPool_Throughput |
以下に実行例に示します。
例1)
設定項目 |
設定内容 |
|---|---|
[監視(固有)]タブ-[調整]プロパティ-[GC]タブ-[コマンド] |
/usr/local/bin/downcmd |
[監視(固有)]タブ-[調整]プロパティ-[GC]タブ-[Full GC 発生回数を監視する] |
1 |
[クラスタ]プロパティ-[JVM監視]タブ-[リソース計測設定]-[共通]タブ-[異常判定しきい値 |
3 |
JVMモニタリソースは、異常判定しきい値回(3回)連続してFull GCが発生すると、モニタ異常を検出し、「/usr/local/bin/downcmd Cont」としてコマンドを実行します。
例2)
設定項目 |
設定内容 |
|---|---|
[監視(固有)]タブ-[調整]プロパティ-[GC]タブ-[コマンド] |
"/usr/local/bin/downcmd" GC |
[監視(固有)]タブ-[調整]プロパティ-[GC]タブ-[Full GC実行時間を監視する] |
65536 |
[クラスタ]プロパティ-[JVM監視]タブ-[リソース計測設定]-[共通]タブ-[異常判定しきい値 |
3 |
JVMモニタリソースは、異常判定しきい値回(3回)連続してFull GC 実行時間が 65535 ミリ秒超過すると、モニタ異常を検出し、「/usr/local/bin/downcmd GC Time」としてコマンドを実行します。
例3)
設定項目 |
設定内容 |
|---|---|
[監視(固有)]タブ-[調整]プロパティ-[メモリ]タブ-[コマンド] |
"/usr/local/bin/downcmd" memory |
[監視(固有)]タブ-[調整]プロパティ-[メモリ]タブ-[ヒープ使用率を監視する] |
オン |
[監視(固有)]タブ-[調整]プロパティ-[メモリ]タブ-[Eden Space] |
80 |
[監視(固有)]タブ-[調整]プロパティ-[メモリ]タブ-[Survivor Space] |
80 |
[クラスタ]プロパティ-[JVM監視]タブ-[リソース計測設定]-[共通]タブ-[異常判定しきい値] |
3 |
JVMモニタリソースは、異常判定しきい値回(3回)連続してJava Eden Space の使用率およびJava Survivor Spaceの使用率が80%を超過すると、モニタ異常を検出し、「/usr/local/bin/downcmd memory EdenSpace SurvivorSpace」としてコマンドを実行します。
[コマンド]で設定したコマンドの終了を待つタイムアウト(秒)は、クラスタプロパティ-[JVM監視]タブ-[コマンドタイムアウト]で設定します。これは上記各タブの[コマンド]で同じ値を適用します。[コマンド]個別には設定できません。
タイムアウトした場合、[コマンド]プロセスを強制終了させるような処理は実行しません。[コマンド]プロセスの後処理(例:強制終了)は、お客様が実行してください。タイムアウトした場合は、以下のメッセージをJVM運用ログへ出力します。
action thread execution did not finish. action is alive = <コマンド>
注意事項は以下の通りです。
Java VMの正常復帰検出時(異常→正常時)には[コマンド]は実行しません。
[コマンド]はJava VM異常検出時(しきい値の超過が異常判定しきい値回連続して発生した場合)を契機として実行します。しきい値の超過毎には実行しません。
複数のタブにて[コマンド]を設定すると、同時に障害が発生した場合は複数の[コマンド]が実行されます。そのため、システム負荷にはご注意ください。
[監視(固有)]タブ-[調整]プロパティ-[WebLogic]タブ-[ワークマネージャのリクエストを監視する]-[待機リクエスト リクエスト数]、[監視(固有)]タブ-[調整]プロパティ-[WebLogic]タブ-[ワークマネージャのリクエストを監視する]-[待機リクエスト 平均値]を両方監視している場合、[コマンド]が同時に2回実行される可能性があります。
これは、[クラスタ]プロパティ-[JVM監視]タブ-[リソース計測設定]-[WebLogic]タブ-[インターバル リクエスト数]と[クラスタ]プロパティ-[JVM監視]タブ-[リソース計測設定]-[WebLogic]タブ-[インターバル 平均値]の異常検出が同時に発生する可能性があるためです。回避策としては、どちらか一方のみ監視するようにしてください。以下の監視項目の組み合わせも同様です。
[監視(固有)]タブ-[調整]プロパティ-[WebLogic]タブ-[スレッドプールのリクエストを監視する]-[待機リクエスト リクエスト数]と、[監視(固有)]タブ-[調整]プロパティ-[WebLogic]タブ-[スレッドプールのリクエストを監視する]-[待機リクエスト 平均値]
[監視(固有)]タブ-[調整]プロパティ-[WebLogic]タブ-[スレッドプールのリクエストを監視する]-[実行リクエスト リクエスト数]と、[監視(固有)]タブ-[調整]プロパティ-[WebLogic]タブ-[スレッドプールのリクエストを監視する]-[実行リクエスト 平均値]
4.39.11. WebLogic Server を監視するには¶
監視対象のWebLogic Serverの設定が終了しアプリケーションサーバとして稼動させる手順は、WebLogic Server のマニュアルを参照してください。
本章では、JVMモニタリソースで監視するために必要な設定のみについて記述します。
- WebLogic Server Administration Consoleを起動します。起動方法は、WebLogic Serverマニュアルの「Administration Console の概要」を参照してください。ドメインコンフィグレーション-ドメイン-コンフィグレーション-全般を選択します。ここで「管理ポートの有効化」のチェックがオフになっていることを確認してください。
ドメインコンフィグレーション-サーバを選択し、監視対象のサーバ名を選択します。選択したサーバ名はCluster WebUI の設定モードから選択可能な[プロパティ]-[監視(固有)] タブの識別名に設定します。「JVM モニタリソースを理解する」を参照してください。
監視対象のサーバのコンフィグレーション-全般で「リスンポート」で管理接続するポート番号を確認します。
WebLogic Serverを停止します。停止方法は、WebLogic Serverマニュアルの「WebLogic Server の起動と停止」を参照してください。
WebLogic Serverの管理サーバ起動スクリプト(startWebLogic.sh)を開きます。
開いたスクリプトに以下の内容を記述します。
監視対象がWebLogic Serverの管理サーバの場合
JAVA_OPTIONS="${JAVA_OPTIONS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djavax.management.builder.initial=weblogic.management.jmx.mbeanserver.WLSMBeanServerBuilder"
※上記内容は実際には1行で記述してください。
監視対象がWebLogic Serverの管理対象サーバの場合
if [ "${SERVER_NAME}" = "SERVER_NAME" ]; then JAVA_OPTIONS="${JAVA_OPTIONS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djavax.management.builder.initial=weblogic.management.jmx.mbeanserver.WLSMBeanServerBuilder" fi
※上記でif文の中(2~5行目)は実際には1行で記述してください。
注釈
n は、監視のために使用するポート番号を指定します。指定するポート番号は監視対象のJava VMのリスンポート番号とは別の番号を指定してください。また同一のマシンに複数の監視対象のWebLogic Serverが存在する場合、そのリスニング・ポート番号や他のアプリケーションのポート番号と重複しないポート番号を指定してください。
注釈
SERVER_NAME は、「監視対象サーバ選択」で確認した監視対象となるサーバ名を指定します。監視対象のサーバが複数の場合、同様の設定(1~6行目)に対してサーバ名を変更し、繰り返し設定してください。
注釈
上記の記述内容の追加箇所は、以下の記述より前に記述するようにしてください。
※上記内容は実際には1行で記述してください。
※WebLogicのバージョンによって、上記の java 引数の内容が異なっている場合がありますが、java の実行前にJAVA_OPTIONSを記述していただければ問題ありません。
注釈
[メモリタブ]の[Perm Gen[shared-ro]]や [Perm Gen[shared-rw]]を監視する場合、以下を追加してください。
-client -Xshare:on -XX:+UseSerialGC
ワークマネージャやスレッドプールのリクエストを監視する場合は、以下の設定を行ってください。
監視対象のWebLogic ServerのWLST(wlst.sh)を起動します。表示されたコンソール画面上で、以下のコマンドを実行してください。
>connect('USERNAME','PASSWORD','t3://SERVER_ADDRESS:SERVER_PORT') > edit() > startEdit() > cd('JMX/DOMAIN_NAME'\ ) > set('PlatformMBeanServerUsed','true') > activate() > exit()
上記のUSERNAME、PASSWORD、SERVER_ADDRESS、SERVER_PORT、DOMAIN_NAMEはドメイン環境に応じた値に置き換えてください
監視対象のWebLogic Serverを再起動します
4.39.12. WebOTX を監視するには¶
本ガイドでは、JVMモニタリソースで監視する対象の WebOTX の設定手順について記述します。
WebOTX統合運用管理コンソールを起動します。起動方法は「WebOTX運用編(Web版統合運用管理ツール)」マニュアルの「統合運用管理ツールの起動と終了」を参照してください。
以降の設定は、WebOTX 上の JMX エージェントの Java プロセスに対する監視を行う場合と、プロセスグループ上の Java プロセスに対する監視を行う場合とで設定内容が異なります。監視する対象に合わせて、設定してください。
4.39.13. WebOTX ドメインエージェントの Java プロセスを監視するには¶
特に設定作業は不要です。
4.39.14. WebOTX プロセスグループの Java プロセスを監視するには¶
統合運用管理ツールよりドメインと接続します。
ツリービューより[<ドメイン名>]-[TPシステム]-[アプリケーショングループ]-[<アプリケーショングループ名>]-[プロセスグループ]-[<プロセスグループ名>]を選択します。
右側に表示される[JVMオプション]タブ内の[その他の引数]属性に、次のJavaオプションを1行で指定します。nは、ポート番号を指定します。同一のマシンに複数の監視対象のJava VMが存在する場合、重複しないポート番号を指定してください。ここで指定するポート番号は、Cluster WebUI ([モニタリソースのプロパティ]→[監視(固有)]タブ→[接続ポート番号])でも設定します。
-Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djavax.management.builder.initial=com.nec.webotx.jmx.mbeanserver.JmxMBeanServerBuilder
※WebOTX V9.2以降では -Djavax.management.builder.initial の指定は不要です。
設定後、[更新]ボタンを押します。設定が完了したら、プロセスグループを再起動します。
本設定は、WebOTX統合運用管理ツールの[Javaシステムプロパティ]タブ内の[Javaシステムプロパティ]属性にて指定することも可能です。その場合は、"-D"は指定せず、また、"="より前の文字列を「名前」に、"="より後ろの文字列を「値」に指定してください。
注釈
WebOTX プロセスグループの機能でプロセス障害時の再起動を設定されている場合、CLUSTERPROからの復旧動作でプロセスグループの再起動を実行すると、WebOTX プロセスグループの機能が正常に動作しない場合があります。そのため、WebOTX プロセスグループを監視する場合はCluster WebUI からJVMモニタリソースに対して以下のように設定してください。
設定タブ名 |
項目名 |
設定値 |
|---|---|---|
監視(共通) |
監視タイミング |
常時 |
回復動作 |
回復動作 |
最終動作のみ実行 |
回復動作 |
最終動作 |
何もしない |
4.39.15. WebOTX notification 通知を受信するには¶
特定のリスナクラスを登録することにより、WebOTXが障害を検出するとnotificationが発行されます。JVMモニタリソースはそのnotificationを受信し、JVM運用ログへ以下のメッセージを通知します。
%1$s:Notification received. %2$s.
%1$s、%2$sの意味は以下のとおりです。%1$s:監視対象Java VM%2$s:notificationの通知メッセージ (ObjectName=**,type=**,message=**)現在、監視可能なリソースのMBeanの詳細情報は以下のとおりです。
ObjectName
[domainname]:j2eeType=J2EEDomain,name=[domainname],category=runtime
notificationタイプ
nec.webotx.monitor.alivecheck.not-alive
メッセージ
failed
4.39.16. JBoss を監視するには¶
スタンドアローンモードに対する監視を行う場合と、ドメインモードに対する監視を行う場合とで設定内容が異なります。監視する対象に合わせて、設定してください。
JVMモニタリソースで監視する対象のJBoss の設定手順について記述します。
スタンドアローンモードの場合
JBossを停止し、(JBossインストールパス)/bin/standalone.confをエディタから開きます。
開いた設定ファイルに、設定するJDKのバージョンに応じて以下の内容を記述します。nは、ポート番号を指定します。同一のマシンに複数の監視対象のJava VMが存在する場合、重複しないポート番号を指定してください。ここで指定するポート番号は、Cluster WebUI ([モニタリソースのプロパティ]→[監視(固有) ]タブ→[接続ポート番号])でも設定します。
JDK10以前を使用する場合は、以下の修正を行う。「if [ "x$JBOSS_MODULES_SYSTEM_PKGS" = "x" ]; then」より前に以下を追加JBOSS_MODULES_SYSTEM_PKGS="org.jboss.logmanager"
「if [ "x$JAVA_OPTS" = "x" ]; then … fi:」より後に以下を追加
JAVA_OPTS="$JAVA_OPTS -Xbootclasspath/p:$JBOSS_HOME/modules/org/jboss/logmanager/main/jboss-logmanager-1.3.2.Final-redhat-1.jar" JAVA_OPTS="$JAVA_OPTS -Djava.util.logging.manager=org.jboss.logmanager.LogManager" JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
JDK11以降を使用する場合は、以下の修正を行う。「if [ "x$JBOSS_MODULES_SYSTEM_PKGS" = "x" ]; then」より前に以下を追加JBOSS_MODULES_SYSTEM_PKGS="org.jboss.logmanager"
「if [ "x$JAVA_OPTS" = "x" ]; then … fi:」より後に以下を追加
JAVA_OPTS="$JAVA_OPTS -Xbootclasspath/a:$JBOSS_HOME/modules/org/jboss/logmanager/main/jboss-logmanager-1.3.2.Final-redhat-1.jar" JAVA_OPTS="$JAVA_OPTS -Djava.util.logging.manager=org.jboss.logmanager.LogManager" JAVA_OPTS="$JAVA_OPTS -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false" JAVA_OPTS="$JAVA_OPTS -Dsun.util.logging.disableCallerCheck=true"
※jboss-logmanager-*.jarはJBossのバージョンによって格納ディレクトリ、ファイル名が異なりますため、インストールしている環境に合わせてパスを指定してください。
上記設定を保存した後、JBossを起動します。
Cluster WebUI (JVMモニタリソース名→[プロパティ]→[監視(固有)] タブ→識別名) には他の監視対象と重ならない任意の文字列(例:JBoss)を設定してください。
ドメインモードの場合
Cluster WebUI (JVMモニタリソース名→[プロパティ]→[監視(固有)] タブ→識別名) には他の監視対象と重ならない任意の文字列(例:JBoss)を設定してください。また、Cluster WebUI (JVMモニタリソース名→[プロパティ]→[監視(固有)] タブ→プロセス名) では、ユニークに特定できるようJava VM起動時オプションを全て指定してください。
4.39.17. Tomcat を監視するには¶
JVMモニタリソースで監視する対象のTomcat の設定手順について記述します。
Tomcatをrpmパッケージでインストールした場合、Tomcatを停止し、/etc/sysconfig/tomcat6 または /etc/sysconfig/tomcat を開きます。Tomcatをrpmパッケージでインストールしていない場合、Tomcatを停止し、(Tomcatインストールパス)/bin/setenv.sh を作成します。
開いた設定ファイルのJavaオプションに以下の内容を1行で記述します。nは、ポート番号を指定します。同一のマシンに複数の監視対象のJava VMが存在する場合、重複しないポート番号を指定してください。ここで指定するポート番号は、Cluster WebUI([モニタリソースのプロパティ]→[監視(固有)]タブ→[接続ポート番号])でも設定します。
CATALINA_OPTS="${CATALINA_OPTS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"
上記設定を保存した後、Tomcatを起動します。
Cluster WebUI (JVMモニタリソース名→[プロパティ]→[監視(固有)] タブ→[識別名]) には他の監視対象と重ならない任意の文字列(例:tomcat)を設定してください。
4.39.18. SVF を監視するには¶
JVMモニタリソースで監視する対象のSVF の設定手順について記述します。
監視対象がTomcatの場合:
OS の SVF ユーザの環境変数を以下のように変更してください。nは、ポート番号を指定します。同一のマシンに複数の監視対象のJava VMが存在する場合、重複しないポート番号を指定してください。ここで指定するポート番号は、Cluster WebUI([モニタリソースのプロパティ]→[監視(固有)]タブ→[接続ポート番号])でも設定します。
JAVA_OPTS="-Xms512m -Xmx512m -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false" export JAVA_OPTS
監視対象がTomcat以外の場合:
監視対象を下記より選択し、該当するスクリプトをエディタから開きます。
監視対象
編集するスクリプト
Simple Httpd Service(8.xの場合)
<SVFインストールパス>/bin/SimpleHttpd
UCX Server Service(9.x以降の場合)
<SVFインストールパス>/bin/UCXServer
RDE Service
<SVFインストールパス>/rdjava/rdserver/
rd_server_startup.sh
<SVFインストールパス>/rdjava/rdserver/
svf_server_startup.sh
RD Spool Balancer
<SVFインストールパス>/rdjava/rdbalancer/
rd_balancer_startup.sh
SVF Print Spooler Service
<SVFインストールパス>/bin/spooler
Javaオプション指定箇所に下記の内容を1行で記述します。nは、ポート番号を指定します。同一のマシンに複数の監視対象のJava VMが存在する場合、重複しないポート番号を指定してください。ここで指定するポート番号は、Cluster WebUI([モニタリソースのプロパティ]→[監視(固有)]タブ→[接続ポート番号])でも設定します。
JAVA_OPTIONS="${JAVA_OPTIONS} -Dcom.sun.management.jmxremote.port=n -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false"監視対象がRDE Serviceの場合、下記の起動パス中およびrd_balancer_startup.shに${JAVA_OPTIONS}を追記します。
java -Xmx256m -Xms256m -Djava.awt.headless=true ${JAVA_OPTIONS} -classpath $CLASSPATH jp.co.fit.vfreport.RdSpoolPlayerServer &
4.39.19. 自製の Java アプリケーションを監視するには¶
JVMモニタリソースで監視する対象のJavaアプリケーションの設定手順について記述します。監視対象のJavaアプリケーションが停止した状態で、Javaアプリケーションの起動時オプションに次のJavaオプションを1行で指定します。nは、監視のために使用するポート番号を指定します。同一のマシンに複数の監視対象のJava VMが存在する場合、重複しないポート番号を指定してください。ここで指定するポート番号は、Cluster WebUI([モニタリソースのプロパティ]→[監視(固有)]タブ→[接続ポート番号])でも設定します。
-Dcom.sun.management.jmxremote.port=n
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false
Javaアプリケーションによっては以下も追加で指定必要です。
-Djavax.management.builder.initial=<MBeanServerBuilder のクラス名>
4.39.20. 監視 (固有) タブ¶
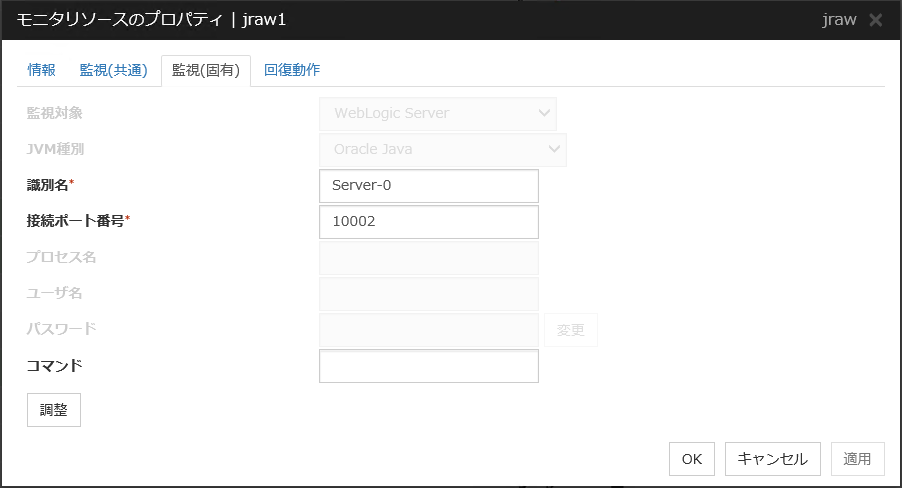
監視対象
監視対象をリストから選択します。WebSAM SVF for PDF、WebSAM Report Director Enterprise、WebSAM Universal Connect/X を監視する場合は、[WebSAM SVF]を選択してください。自製のJavaアプリケーションを監視する場合は、[Javaアプリケーション]を選択してください。
JBoss Enterprise Application Platform のスタンドアローンモードを監視する場合は [JBoss]、JBoss Enterprise Application Platform のドメインモードを監視する場合は「JBoss ドメインモード」を選択してください。
既定値 : なし
JVM種別
監視対象のアプリケーションが動作する Java VM をリストから選択します。
Java 8 および OpenJDK 8 以降の場合は、[Oracle Java(usage monitoring)] を選択してください。Java 8 では以下の仕様変更がありました。
非ヒープ領域における各メモリの最大値が取得できなくなりました。
Perm Gen は Metaspace に変更されました。
Compressed Class Space が追加されました。
そのため、Java 8 では [メモリ] タブの監視項目は以下に変更となります。
使用率監視は使用量監視に変更となります。
[Perm Gen]、Perm Gen[shared-ro]、Perm Gen[shared-rw]は監視できません。チェックボックスはオフにしてください。
[Metaspace]、[Compressed Class Space] を監視可能です。
Java 9では以下の仕様変更がありました。
Code Cache が分割されました。
そのため、Java 9では [メモリ] タブの監視項目は以下に変更となります。
[Code Cache]は監視できません。チェックボックスはオフにしてください。
[CodeHeap non-nmethods]、[CodeHeap profiled]、[CodeHeap non-profiled]を監視可能です。
監視対象別では以下を指定可能です。
既定値 : なし
識別名(255バイト以内)
識別名とは、JVM モニタリソースの JVM 運用ログに監視対象の情報を出力する際に、別の JVM モニタリソースと識別するために設定します。そのため、JVM モニタリソース間で一意の文字列を設定してください。必ず設定してください。
既定値 : なし
接続ポート番号(1024~65535)
JVM モニタリソースが、監視対象 Java VM と JMX 接続を行う際に使用するポート番号を設定します。JVM モニタリソースは監視対象Java VMに JMX 接続を行うことにより情報を取得します。そのため JVM モニタリソースを登録する場合は、監視対象 Java VM に JMX 接続用ポートを開放する設定を行う必要があります。必ず設定してください。クラスタ内のサーバにおいて、共通の設定となります。42424~61000 は推奨しません。
既定値 : なし
プロセス名(1024バイト以内)
プロセス名とは、JVM モニタリソースが、監視対象 Java VM とJMX 接続を行う際に別の JVM モニタリソースと識別するために設定します。そのため、JVM モニタリソース間で一意の文字列を設定してください。
既定値 : なし
ユーザ名(255バイト以内)
監視対象の Java VM に接続する管理ユーザ名を設定します。
既定値 :なし
パスワード(255バイト以内)
監視対象の Java VM に接続する管理ユーザのパスワードを設定します。
既定値 : なし
コマンド(255バイト以内)
監視対象の Java VM 異常検出時に、実行するコマンドを設定します。異常の原因別に実行するコマンドおよび引数の指定が可能です。絶対パスで指定してください。また、実行ファイル名は二重引用符("")で括ってください。例)"/usr/local/bin/command" arg1 arg2ここでは監視対象 Java VM に接続できない場合や使用リソース量の取得における異常検出時に、実行するコマンドを設定します。「異常検出時に障害原因別にコマンドを実行するには」も参照してください。既定値 : なし
さらに [調整] ボタンを選択すると以下の内容がポップアップダイアログに表示されます。以下の説明に従い詳細設定を行います。
4.39.21. メモリタブ([JVM種別]で[Oracle Java]、[OpenJDK] 選択時)¶
ヒープ使用率を監視する
監視対象のJava VMが使用するJavaヒープ領域の使用率の監視設定をします。
領域全体(1~100)
監視対象のJava VMが使用するJavaヒープ領域の使用率のしきい値を設定します。
既定値 : 80[%]
Eden Space(1~100)
監視対象のJava VMが使用するJava Eden Spaceの使用率のしきい値を設定します。GC方式としてG1 GCを指定している場合、G1 Eden Spaceと読み替えてください。
既定値 : 100[%]
Survivor Space(1~100)
監視対象のJava VMが使用するJava Survivor Spaceの使用率のしきい値を設定します。GC方式としてG1 GCを指定している場合、G1 Survivor Spaceと読み替えてください。
既定値 : 100[%]
Tenured Gen(1~100)
監視対象のJava VMが使用するJava Tenured(Old) Gen領域の使用率のしきい値を設定します。GC方式としてG1 GCを指定している場合、G1 Old Genと読み替えてください。
既定値 : 80[%]
非ヒープ使用率を監視する
監視対象のJava VMが使用するJava非ヒープ領域の使用率の監視設定をします。
領域全体(1~100)
監視対象のJava VMが使用するJava非ヒープ領域の使用率のしきい値を設定します。
既定値 : 80[%]
Code Cache(1~100)
監視対象のJava VMが使用するJava Code Cache領域の使用率のしきい値を設定します。
既定値 : 100[%]
Perm Gen(1~100)
監視対象のJava VMが使用するJava Perm Gen領域の使用率のしきい値を設定します。
既定値 : 80[%]
Perm Gen[shared-ro](1~100)
監視対象のJava VMが使用するJava Perm Gen [shared-ro]領域の使用率のしきい値を設定します。
Java Perm Gen [shared-ro]領域は監視対象Java VMの起動オプションに -client -Xshare:on -XX:+UseSerialGCを付与して起動している場合に使用される領域です。
既定値 : 80[%]
Perm Gen[shared-rw](1~100)
監視対象のJava VMが使用するJava Perm Gen [shared-rw]領域の使用率のしきい値を設定します。
Java Perm Gen [shared-rw]領域は監視対象Java VMの起動オプションに -client -Xshare:on -XX:+UseSerialGCを付与して起動している場合に使用される領域です。
既定値 : 80[%]
コマンド(255バイト以内)
監視対象のJava VM異常検出時に、実行するコマンドを設定します。異常の原因別に実行するコマンドおよび引数の指定が可能です。絶対パスで指定してください。また、実行ファイル名は二重引用符("")で括ってください。例)"/usr/local/bin/command" arg1 arg2ここでは監視対象Java VMのJavaヒープ領域、Java非ヒープ領域における異常検出時に、実行するコマンドを設定します。「異常検出時に障害原因別にコマンドを実行するには」も参照してください。既定値 : なし
既定値
[既定値]ボタンをクリックすると全ての項目に既定値が設定されます。
4.39.22. メモリタブ([JVM種別]で[Oracle Java(usage monitoring)] 選択時)¶
ヒープ使用量を監視する
監視対象の Java VM が使用する Java ヒープ領域の使用量の監視設定をします。
領域全体(0~102400)
監視対象の Java VM が使用する Java ヒープ領域の使用量のしきい値を設定します。0 の場合、監視しません。
既定値 : 0[MB]
Eden Space(0~102400)
監視対象の Java VM が使用する Java Eden Space の使用量のしきい値を設定します。0 の場合、監視しません。GC 方式として G1 GC を指定している場合、G1 Eden Space と読み替えてください。
既定値 : 0[MB]
Survivor Space(0~102400)
監視対象の Java VM が使用する Java Survivor Space の使用量のしきい値を設定します。0 の場合、監視しません。GC 方式として G1 GC を指定している場合、G1 Survivor Space と読み替えてください。
既定値 : 0[MB]
Tenured Gen(0~102400)
監視対象の Java VM が使用する Java Tenured(Old) Gen 領域の使用量のしきい値を設定します。0 の場合、監視しません。GC 方式として G1 GC を指定している場合、G1 Old Gen と読み替えてください。
既定値 : 0[MB]
非ヒープ使用量を監視する
監視対象のJava VMが使用するJava非ヒープ領域の使用量の監視設定をします。
領域全体(0~102400)
監視対象のJava VM が使用する Java 非ヒープ領域の使用量のしきい値を設定します。0の場合、監視しません。
既定値 : 0[MB]
Code Cache(0~102400)
監視対象の Java VM が使用する Java Code Cache 領域の使用量のしきい値を設定します。0 の場合、監視しません。
既定値 : 0[MB]
CodeHeap non-nmethods(0~102400)
監視対象の Java VM が使用するJava CodeHeap non-nmethods 領域の使用量のしきい値を設定します。0 の場合、監視しません。
既定値 : 0[MB]
CodeHeap profiled(0~102400)
監視対象の Java VM が使用する Java CodeHeap profiled nmethods 領域の使用量のしきい値を設定します。0 の場合、監視しません。
既定値 : 0[MB]
CodeHeap non-profiled (0~102400)
監視対象のJava VM が使用する Java CodeHeap non-profiled nmethods領域の使用量のしきい値を設定します。0 の場合、監視しません。
既定値 : 0[MB]
Compressed Class Space(0~102400)
監視対象のJava VMが使用するCompressed Class Space領域の使用量のしきい値を設定します。0の場合、監視しません。
既定値 : 0[MB]
Metaspace(0~102400)
監視対象の Java VM が使用するMetaspace 領域の使用量のしきい値を設定します。
既定値 : 0[MB]
コマンド(255バイト以内)
監視対象のJava VM異常検出時に、実行するコマンドを設定します。異常の原因別に実行するコマンドおよび引数の指定が可能です。絶対パスで指定してください。また、実行ファイル名は二重引用符("")で括ってください。例)"/usr/local/bin/command" arg1 arg2ここでは監視対象 Java VM の Java ヒープ領域、Java 非ヒープ領域における異常検出時に、実行するコマンドを設定します。「異常検出時に障害原因別にコマンドを実行するには」も参照してください。既定値 : なし
既定値
[既定値]ボタンをクリックすると全ての項目に既定値が設定されます。
4.39.23. メモリタブ([JVM種別]で[Oracle JRockit] 選択時)¶
[JVM種別]で[JRockit]選択時のみ表示されます。
ヒープ使用率を監視する
監視対象のJava VMが使用するJavaヒープ領域の使用率の監視設定をします。
領域全体(1~100)
監視対象のJava VMが使用するJavaヒープ領域の使用率のしきい値を設定します。
既定値 : 80[%]
Nursery Space(1~100)
監視対象のJRockit JVMが使用するJava Nursery Spaceの使用率のしきい値を設定します。
既定値 : 80[%]
Old Space(1~100)
監視対象のJRockit JVMが使用するJava Old Spaceの使用率のしきい値を設定します。
既定値 : 80[%]
非ヒープ使用率を監視する
監視対象のJava VMが使用するJava非ヒープ領域の使用率の監視設定をします。
領域全体(1~100)
監視対象のJava VMが使用するJavaヒープ領域の使用率のしきい値を設定します。
既定値 : 80[%]
Class Memory(1~100)
監視対象のJRockit JVMが使用するJava Class Memory の使用率のしきい値を設定します。
既定値 : 100[%]
コマンド(255バイト以内)
監視対象のJava VM異常検出時に、実行するコマンドを設定します。異常の原因別に実行するコマンドおよび引数の指定が可能です。絶対パスで指定してください。また、実行ファイル名は二重引用符("")で括ってください。例)"/usr/local/bin/command" arg1 arg2ここでは監視対象Java VMのJavaヒープ領域、Java非ヒープ領域における異常検出時に、実行するコマンドを設定します。「異常検出時に障害原因別にコマンドを実行するには」も参照してください。既定値 : なし
既定値
[既定値]ボタンをクリックすると全ての項目に既定値が設定されます。
4.39.24. スレッドタブ¶
動作中のスレッド数を監視する(1~65535)
監視対象のJava VMで現在動作中のスレッド上限数のしきい値を設定します。
既定値 : 65535[スレッド]
コマンド(255バイト以内)
監視対象のJava VM異常検出時に、実行するコマンドを設定します。異常の原因別に実行するコマンドおよび引数の指定が可能です。絶対パスで指定してください。また、実行ファイル名は二重引用符("")で括ってください。例)"/usr/local/bin/command" arg1 arg2ここでは監視対象Java VMで現在動作中のスレッド数における異常検出時に、実行するコマンドを設定します。「異常検出時に障害原因別にコマンドを実行するには」も参照してください。既定値 : なし
既定値
[既定値]ボタンをクリックすると全ての項目に既定値が設定されます。
4.39.25. GC タブ¶
Full GC実行時間を監視する(1~65535)
監視対象のJava VMにおいて、前回計測以降のFull GC実行時間のしきい値を設定します。Full GC実行時間とは、前回計測以降のFull GC発生回数で割った平均値です。
前回計測以降のFull GC実行時間 3000ミリ秒、Full GC発生回数3回の場合を異常と判定したい場合、1000ミリ秒以下を設定してください。
既定値 : 65535[ミリ秒]
Full GC発生回数を監視する(1~65535)
監視対象のJava VMにおいて、前回計測以降のFull GC発生回数のしきい値を設定します。
既定値 : 1(回)
コマンド(255バイト以内)
監視対象のJava VM異常検出時に、実行するコマンドを設定します。異常の原因別に実行するコマンドおよび引数の指定が可能です。絶対パスで指定してください。また、実行ファイル名は二重引用符("")で括ってください。例)"/usr/local/bin/command" arg1 arg2ここでは監視対象Java VMのFull GC実行時間やFull GC発生回数における異常検出時に、実行するコマンドを設定します。「異常検出時に障害原因別にコマンドを実行するには」も参照してください。既定値 : なし
既定値
[既定値]ボタンをクリックすると全ての項目に既定値が設定されます。
4.39.26. WebLogic タブ¶
[監視対象]で[WebLogic Server]選択時のみ表示されます。
ワークマネージャのリクエストを監視する
WebLogic Serverでワークマネージャの待機リクエスト状態の監視設定をします。
監視対象ワークマネージャ
監視対象のWebLogic Serverに対して監視したいアプリケーションのワークマネージャ名を設定します。ワークマネージャ監視を実施する場合、必ず設定してください。
App1[WM1,WM2,…];App2[WM1,WM2,…];…
App とWM にて指定可能な文字はASCII文字です。(Shift_JIS コード0x005C と0x00A1~0x00DF を除く)
アプリケーション アーカイブのバージョンを持つアプリケーションを指定する場合、App には「アプリケーション名#バージョン」を指定してください。
アプリケーション名に"["や"]"が付いている場合、"["や"]"の直前に「¥¥」を追加してください。
(例) アプリケーション名がapp[2]の場合、app¥¥[2¥¥]
既定値 : なし
リクエスト数(1~65535)
監視対象のWebLogic Serverのワークマネージャにおいて、待機リクエスト数のしきい値を設定します。
既定値 : 65535
平均値(1~65535)
監視対象のWebLogic Serverのワークマネージャにおいて、待機リクエスト数の平均値のしきい値を設定します。
既定値 : 65535
前回計測値からの増加率(1~1024)
監視対象のWebLogic Serverのワークマネージャにおいて、待機リクエスト数の前回計測以降の増分に対するしきい値を設定します。
既定値 : 80[%]
スレッドプールのリクエストを監視する
監視対象の WebLogic Server のスレッドプールにおいて、待機リクエスト数 、実行リクエスト数の監視設定をします。リクエスト数とは、WebLogic Server 内部で処理待ちや実行した HTTP リクエスト数や、EJB の呼び出しや WebLogic Server 内部で行われる処理のリクエスト数を含みます。ただし、増加しても異常な状態とは判断できません。JVM 統計ログの採取をする場合に指定してください。
待機リクエスト リクエスト数(1~65535)
待機リクエスト数のしきい値を設定します。
既定値 : 65535
待機リクエスト 平均値(1~65535)
待機リクエスト数の平均値のしきい値を設定します。
既定値 : 65535
待機リクエスト 前回計測値からの増加率(1~1024)
待機リクエスト数の前回計測以降の増分に対するしきい値を設定します。
既定値 : 80[%]
実行リクエスト リクエスト数(1~65535)
単位時間あたりに実行したリクエスト数のしきい値を設定します。
既定値 : 65535
実行リクエスト 平均値(1~65535)
単位時間あたりに実行したリクエスト数の平均値のしきい値を設定します。
既定値 : 65535
実行リクエスト 前回計測値からの増加率(1~1024)
単位時間あたりに実行したリクエスト数の前回計測以降の増分に対するしきい値を設定します。
既定値 : 80[%]
コマンド(255バイト以内)
監視対象のJava VM異常検出時に、実行するコマンドを設定します。異常の原因別に実行するコマンドおよび引数の指定が可能です。絶対パスで指定してください。また、実行ファイル名は二重引用符("")で括ってください。例)"/usr/local/bin/command" arg1 arg2ここではWebLogic Serverのワークマネージャのリクエストやスレッドプールのリクエストにおける異常検出時に、実行するコマンドを設定します。「異常検出時に障害原因別にコマンドを実行するには」も参照してください。既定値 : なし
既定値
[既定値]ボタンをクリックすると全ての項目に既定値が設定されます。
4.40. システムモニタリソースを理解する¶
システムモニタリソースは、システムリソースの統計情報を継続的に収集し、一定のナレッジ情報にしたがい解析を行います。解析の結果からリソース枯渇の発生を早期検出する機能を提供します。
4.40.1. システムモニタリソースの注意事項¶
システムモニタリソースを利用する場合、各サーバ上に zip および unzip のパッケージが必要です。
動作確認済みの System Resource Agent のバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
回復対象には System Resource Agent がリソース監視の異常を検出した際のフェイルオーバ対象リソースを指定してください。
System Resource Agent の設定値は、デフォルトで使用することを推奨します。
以下のような場合には、リソース監視の異常を検出できないことがあります。
システム全体のリソース監視で、しきい値をはさんで増減を繰り返している場合
動作中に OS の日付/時刻を変更した場合、10分間隔で行っている解析処理のタイミングが日付/時刻変更後の最初の一回だけずれてしまいます。以下のようなことが発生するため、必要に応じてクラスタのサスペンド・リジュームを行ってください。
異常として検出する経過時間を過ぎても、異常検出が行われない。
異常として検出する経過時間前に、異常検出が行われる。
クラスタのサスペンド・リジュームを行った場合、その時点から情報の収集を開始します。
システムリソースの使用量の解析は10分間隔で行います。そのため、監視継続時間を経過してから最大10分後に異常を検出する場合があります。
ディスクリソースの使用量の解析は60分間隔で行います。そのため、監視継続時間を経過してから最大60分後に異常を検出する場合があります。
ディスクリソースの空き容量監視にて指定するディスクサイズは、実際のディスクサイズより小さい値を指定してください。大きい値を指定した場合、空き容量不足として異常検出します。
監視中のディスクを交換した場合、交換前と交換後のディスクにて以下のいずれかが異なる場合、それまでの解析情報はクリアします。
ディスクの総容量
ファイルシステム
スワップ領域を割り当てていないマシンでは、システムの総仮想メモリ使用量の監視のチェックを外してください。
ディスクリソース監視機能は、ディスクデバイス以外は監視対象外です。
System Resource Agentで収集しているディスク使用率は、ディスク総容量とディスク使用可能容量で計算しています。df(1) コマンドで表示されるディスク使用率とは算出方法の違いにより、値が若干異なる場合があります。
ディスクリソース監視機能で同時に監視できる最大のディスク数は64台です。
モニタリソースの定義画面のタイプ欄に「system monitor」が表示されない場合は、[ライセンス情報取得]を選択し、ライセンス情報を取得してください。
- システムリソースの統計情報パス: <dataパス>/hasrm_monitor_list.xml.YYYYMMDDhhmmss.zip最大個数: 1500 個
- システムリソースの解析情報パス: <dataパス>/hasrm_analyze_list.xml.YYYYMMDDhhmmss.zip最大個数: 3 個
- ディスクリソースの統計情報パス: <dataパス>/hasrm_diskcapacity_monitor_list.xml.YYYYMMDDhhmmss.zip最大個数: 10 個
- ディスクリソースの解析情報パス: <dataパス>/hasrm_diskcapacity_analyze_list.xml.YYYYMMDDhhmmss.zip最大個数: 3 個
4.40.2. システムモニタリソースの監視方法¶
システムモニタリソースは、以下の監視を行います。
システムおよびディスクのリソースの使用量を継続的に収集し、解析します。
リソースの使用量があらかじめ設定したしきい値以上になった場合、異常を検出します。
異常を検出した状態が監視継続時間連続すると、リソース監視の異常を通知します。
システムリソース監視をデフォルト値で運用した場合、リソースの使用量が 90% 以上の状態が連続すると、 60 分後にリソース監視の異常を通知します。
以下に、システムリソース監視をデフォルト値で運用した場合の総メモリ使用量の異常検出の例を示します。
総メモリ使用量が経過時間と共に総メモリ使用量のしきい値以上の状態が続き、一定時間以上になった
以下の図では、総メモリ使用量がしきい値(90%)以上の状態が続き、連続して監視継続時間(60分)以上になったため、総メモリ使用量の異常を検出します。
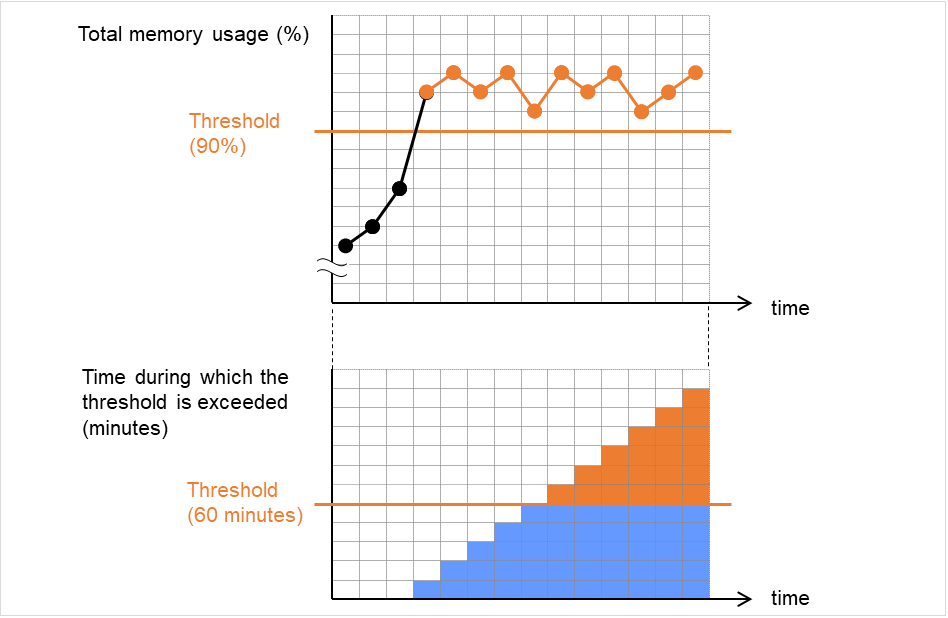
図 4.78 総メモリ使用量のしきい値以上の状態が一定時間続いた場合(異常検出する)¶
総メモリ使用量が経過時間と共に総メモリ使用のしきい値の前後で増減し、連続して総メモリ使用量のしきい値以上にならない
以下の図では、総メモリ使用量は一時的に総メモリ使用量のしきい値(90%)以上になります。 しかし、そのしきい値を超える状態も監視継続時間(60分)連続することなく推移しているため、総メモリ使用量の異常を検出しません。
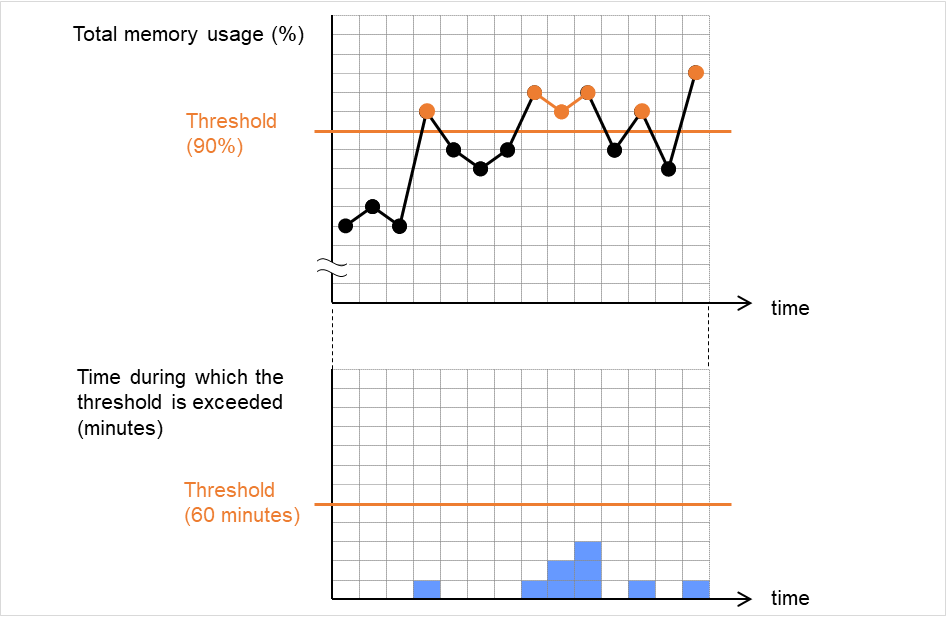
図 4.79 総メモリ使用量のしきい値以上の状態が一定時間続かない場合(異常検出しない)¶
ディスクリソース監視をデフォルト値で運用した場合、 24 時間後に通知レベルの異常を通知します。
以下に、ディスクリソース監視をデフォルト値で運用した場合のディスク使用率の異常検出の例を示します。
警告レベルのディスク容量監視
ディスク使用率が警告レベル上限値で指定された一定のしきい値以上になった
ディスク使用率が警告レベル上限値を超えたため、ディスク容量監視異常と判定します。
図 4.80 ディスク使用率が警告レベル上限値以上になった場合(異常検出する)¶
ディスク使用率が一定の範囲内で増減し、警告レベル上限値で指定された一定のしきい値以上にならない
ディスク使用率は警告レベル上限値を超えない範囲で増減しているため、ディスク容量監視異常と判定しません。
図 4.81 ディスク使用率が警告レベル上限値以上にならない場合(異常検出しない)¶
通知レベルのディスク容量監視
ディスク使用率が経過時間と共に通知レベル上限値で指定された一定のしきい値以上の状態が続き、一定時間以上になった
ディスク使用率が通知レベル上限値を連続して超えたため、ディスク容量監視異常と判定します。
図 4.82 ディスク使用率において、通知レベル上限値以上の状態が一定時間続いた場合(異常検出する)¶
ディスク使用率が一定の範囲内で増減し、通知レベル上限値で指定された一定のしきい値以上にならない
ディスク使用率が通知レベル上限値を一時的に超えるものの、その状態が一定時間続かないため、ディスク容量監視異常とは判定しません。
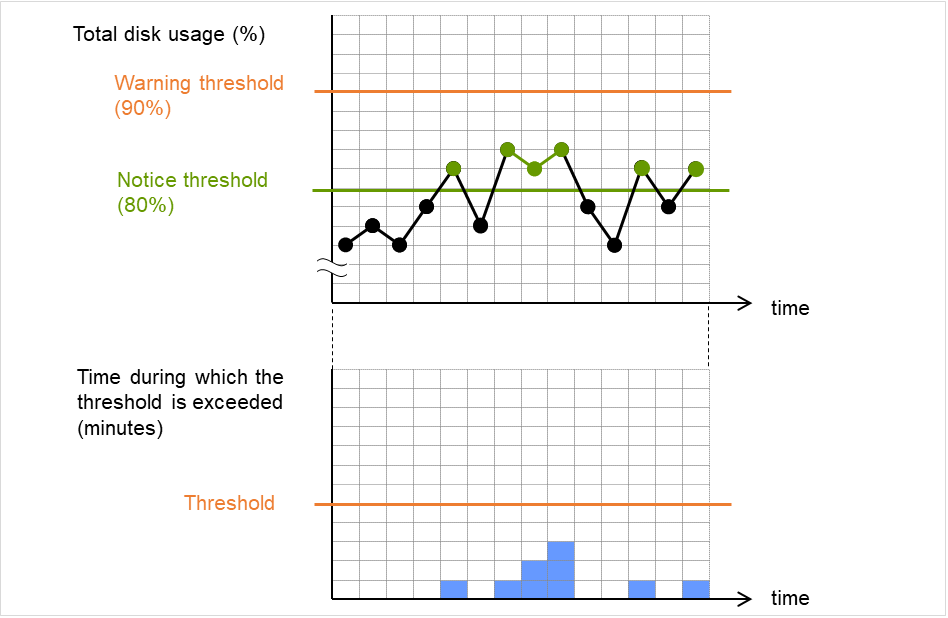
図 4.83 ディスク使用率において、通知レベル上限値以上の状態が一定時間続かない場合(異常検出しない)¶
4.40.3. 監視 (固有) タブ¶

CPU使用率の監視
CPU使用率の監視を行うかどうかを設定します。
使用率 (1~100)
CPU使用率の異常を検出するしきい値を設定します。
継続時間 (1~1440)
CPU使用率の異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
総メモリ使用量の監視
総メモリ使用量の監視を行うかどうかを設定します。
使用量 (1~100)
メモリの使用量の異常を検出するしきい値(システムのメモリ搭載量に対する割合)を設定します。
継続時間 (1~1440)
総メモリ使用量の異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
総仮想メモリ使用量の監視
総仮想メモリ使用量の監視を行うかどうかを設定します。
使用量 (1~100)
仮想メモリの使用量の異常を検出するしきい値を設定します。
継続時間 (1~1440)
総仮想メモリ使用量の異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
総オープンファイル数の監視
総オープンファイル数の監視を行うかどうかを設定します。
総オープンファイル数 (1~100)
オープンしているファイルの総数の異常を検出するしきい値(システム上限値に対する割合)を設定します。
継続時間 (1~1440)
総オープンファイル数の異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
総スレッド数の監視
総スレッド数の監視を行うかどうかを設定します。
総スレッド数 (1~100)
起動しているスレッドの総数の異常を検出するしきい値(システム上限値に対する割合)を設定します。
継続時間 (1~1440)
総スレッド数の異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
ユーザごとの起動プロセス数の監視
ユーザごとの起動プロセス数の監視を行うかどうかを設定します。
ユーザごとの起動プロセス数 (1~100)
ユーザごとの起動プロセス数の異常を検出するしきい値(システム上限値に対する割合)を設定します。
継続時間 (1~1440)
ユーザごとの起動プロセス数の異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
追加
監視するディスクを追加します。[監視条件の入力] ダイアログボックスが表示されます。
[監視条件の入力] ダイアログの説明に従い異常とする監視条件の詳細設定を行います。
削除
[ディスク一覧] で選択しているディスクを監視対象から削除します。
編集
[監視条件の入力]ダイアログボックスが表示されます。[ディスク一覧] で選択しているディスクの監視条件が表示されるので、編集して[OK]を選択します。
マウントポイント (1024 バイト以内)
監視を行うマウントポイントを設定します。[/] で始まる必要があります。
使用率
ディスク使用率の監視を行うかどうかを設定します。
警告レベル (1~100)
ディスク使用率の警報レベルの異常を検出するしきい値を設定します。
通知レベル (1~100)
ディスク使用率の通知レベルの異常を検出するしきい値を設定します。
継続時間 (1~43200)
ディスク使用率の通知レベルの異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
空き容量
ディスク空き容量の監視を行うかどうかを設定します。
警告レベル (1~4294967295)
ディスク空き容量の警報レベルの異常を検出する容量(MB)を設定します。
通知レベル (1~4294967295)
ディスク空き容量の通知レベルの異常を検出する容量(MB)を設定します。
継続時間 (1~43200)
ディスク空き容量の通知レベルの異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
iノード使用率
iノード使用率の監視を行うかどうかを設定します。
警告レベル (1~100)
iノード使用率の警報レベルの異常を検出するしきい値を設定します。
通知レベル (1~100)
iノード使用率の通知レベルの異常を検出するしきい値を設定します。
継続時間 (1~43200)
iノード使用率の通知レベルの異常を検出する時間を設定します。
指定した時間以上連続してしきい値を超過した場合、異常を検出します。
4.41. プロセスリソースモニタリソースを理解する¶
プロセスリソースモニタリソースは、プロセスが使用するリソースの統計情報を継続的に収集し、一定のナレッジ情報にしたがい解析を行います。解析の結果からリソース枯渇の発生を早期検出する機能を提供します。
4.41.1. プロセスリソースモニタリソースの注意事項¶
プロセスリソースモニタリソースを利用する場合、各サーバ上に zip および unzip のパッケージが必要です。
動作確認済みのバージョンについては、『スタートアップガイド』の「CLUSTERPRO の動作環境」 - 「CLUSTERPRO Server の動作環境」 - 「監視オプションの動作確認済アプリケーション情報」を参照してください。
回復対象にはプロセスリソースモニタリソースが異常を検出した際のフェイルオーバ対象リソースを指定してください。
プロセスリソースモニタリソースの設定値は、デフォルトで使用することを推奨します。
スワップアウトされているプロセスについては、リソース異常の検出対象になりません。
動作中に OS の日付/時刻を変更した場合、10分間隔で行っている解析処理のタイミングが日付/時刻変更後の最初の一回だけずれてしまいます。以下のようなことが発生するため、必要に応じてクラスタのサスペンド・リジュームを行ってください。
異常として検出する経過時間を過ぎても、異常検出が行われない。
異常として検出する経過時間前に、異常検出が行われる。
クラスタのサスペンド・リジュームを行った場合、その時点から情報の収集を開始します。
プロセスリソースの使用量の解析は10分間隔で行います。そのため、監視継続時間を経過してから最大10分後に異常を検出する場合があります。
- プロセスリソースの統計情報パス: <dataパス>/hasrm_monitor_list.xml.YYYYMMDDhhmmss.zip最大個数: 1500 個
- プロセスリソースの解析情報パス: <dataパス>/hasrm_analyze_list.xml.YYYYMMDDhhmmss.zip最大個数: 3 個
プロセスリソースモニタリソースのステータスを異常から正常に戻すには、以下のいずれかを実施してください。
クラスタのサスペンド・リジューム
クラスタの停止・開始
4.41.2. プロセスリソースモニタリソースの監視方法¶
プロセスリソースモニタリソースは、以下の監視を行います。
プロセスリソースの使用量を継続的に収集し、解析します。
リソースの使用量があらかじめ設定したしきい値以上になった場合、異常を検出します。
異常を検出した状態が監視継続時間連続すると、リソース監視の異常を通知します。
プロセスリソース監視(CPU、メモリ、スレッド数、ゾンビプロセス)をデフォルト値で運用した場合、24 時間後にリソース監視の異常を通知します。
以下に、プロセスリソース監視のメモリ使用量の異常検出の例を示します。
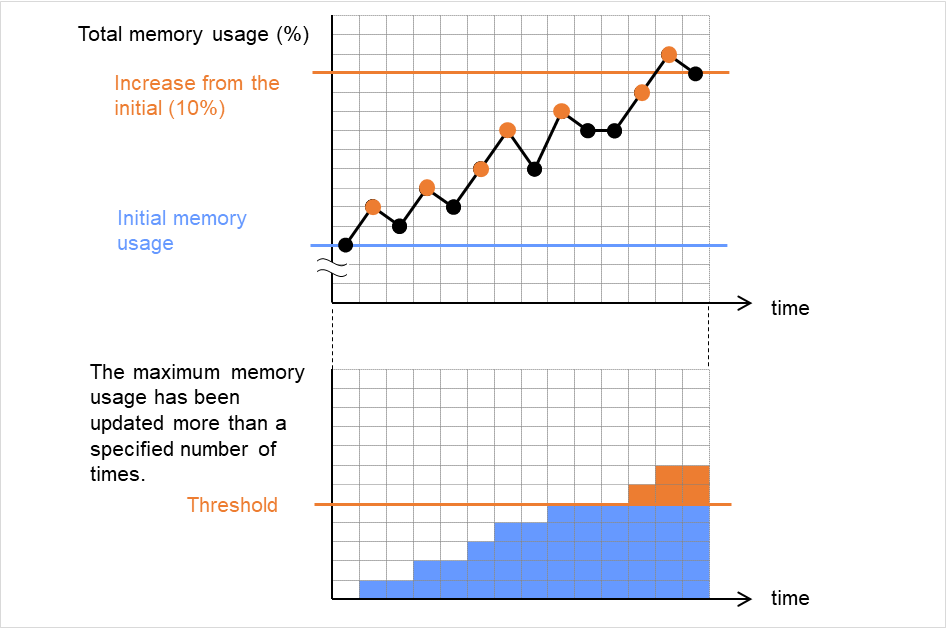
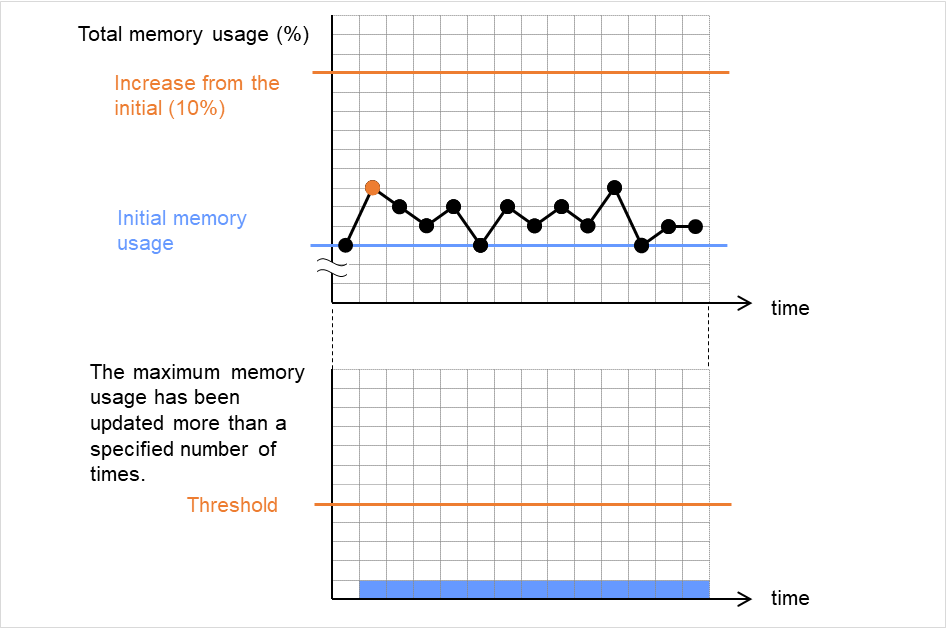
4.41.3. 監視 (固有) タブ¶
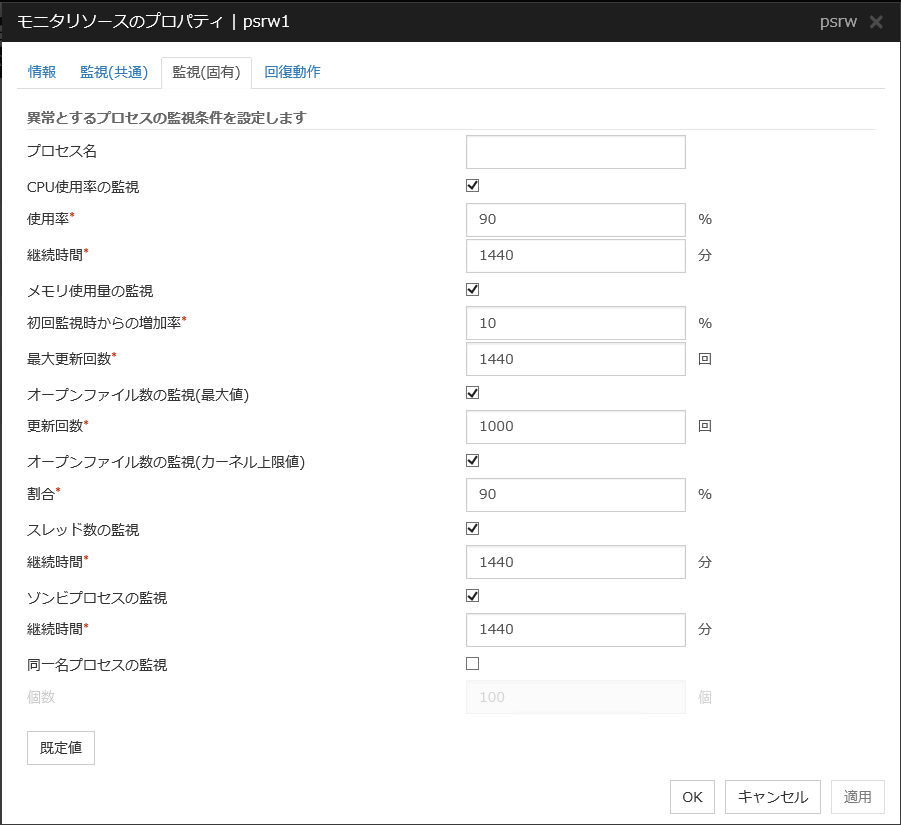
プロセス名 (1023 バイト以内)
監視対象プロセスのプロセス名を設定します。プロセス名を設定しない場合、起動中のすべてのプロセスが対象となります。
また、次の 3 つのパターンでプロセス名のワイルドカード指定が可能です。このパターン以外の指定はできません。
【前方一致】 <プロセス名に含まれる文字列>*
【後方一致】 *<プロセス名に含まれる文字列>
【部分一致】 *<プロセス名に含まれる文字列>*
監視対象プロセス名に指定できるプロセス名は1023バイトまでです。1023バイトを超えるプロセス名を持つプロセスを監視対象として指定する場合は、ワイルドカード(*)を使って指定します。
監視対象プロセスのプロセス名が1023バイトより長い場合、プロセス名として認識できるのはプロセス名の先頭から1023バイトまでです。ワイルドカード(*)を使って指定する場合は、1024バイトまでに含まれる文字列を指定してください。
監視対象プロセス名は、実際に動作しているプロセスのプロセス名をps(1)コマンド等で確認し設定してください。
実行結果の例
UID PID PPID C STIME TTY TIME CMD root 1 0 0 Sep12 ? 00:00:00 init [5] : root 5314 1 0 Sep12 ? 00:00:00 /usr/sbin/acpid root 5325 1 0 Sep12 ? 00:00:00 /usr/sbin/sshd htt 5481 1 0 Sep12 ? 00:00:00 /usr/sbin/htt -retryonerror 0上記のコマンド実行結果から /usr/sbin/htt を監視する場合、/usr/sbin/htt -retryonerror 0 を監視対象プロセス名に指定します。監視対象プロセス名に指定したプロセス名はプロセスの引数もプロセス名の一部として監視対象のプロセスを特定します。監視対象プロセス名を指定する場合は、引数を含めたプロセス名を指定してください。引数を含めずプロセス名のみ監視したい場合は、ワイルドカード(*)を使い、引数を含めない前方一致または部分一致で指定してください。
CPU使用率の監視
CPU使用率の監視を行うかどうかを設定します。
使用率(1~100)
CPU使用率の異常を検出するしきい値を設定します。
継続時間(1~129600)
CPU使用率の異常を検出する時間を設定します。指定した時間以上連続してしきい値を超過した場合、異常を検出します。
メモリ使用量の監視
メモリ使用量の監視を行うかどうかを設定します。
初回監視時からの増加率(1~1000)
メモリ使用量の異常を検出するしきい値を設定します。
最大更新回数(1~129600)
メモリ使用量の異常を検出する更新回数を設定します。指定した更新回数以上連続してしきい値を超過した場合、異常を検出します。
オープンファイル数の監視(最大値)
オープンファイル数の監視(最大値)を行うかどうかを設定します。
更新回数(1~1024)
オープンファイル数の異常を検出する更新回数を設定します。オープンファイル数の最大値を指定した回数以上更新した場合、異常を検出します。
オープンファイル数の監視(カーネル上限値)
オープンファイル数の監視(カーネル上限値)を行うかどうかを設定します。
割合(1~100)
オープンファイル数の異常を検出するしきい値(カーネル上限値に対する割合)を設定します。
スレッド数の監視
スレッド数の監視を行うかどうかを設定します。
継続時間(1~129600)
スレッド数の異常を検出する時間を設定します。スレッド数が増加し、指定した時間以上経過したプロセスがある場合、異常を検出します。
ゾンビプロセスの監視
ゾンビプロセスの監視を行うかどうかを設定します。
継続時間(1~129600)
ゾンビプロセスを検出する時間を設定します。ゾンビプロセスとなって指定時間以上経過したプロセスがある場合、異常を検出します。
同一名プロセスの監視
同一名プロセスの監視を行うかどうかを設定します。
個数(1~10000)
同一名プロセスの異常を検出する個数を設定します。同一名プロセスが指定した個数以上存在する場合、異常を検出します。
4.42. AWS Elastic IP モニタリソースを理解する¶
AWS Elastic IPモニタリソースは、EIP 制御の場合は AWS CLI コマンドを利用して EIP の存在を確認するモニタリソースです。
4.42.1. AWS Elastic IP モニタリソースの注意事項¶
AWS Elastic IPリソースを追加すると自動的に作成されます。AWS Elastic IPリソース 1 つに対して 1 つの AWS Elastic IPモニタリソースが自動的に作成されます。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS Elastic IPリソースの設定について」を参照してください。
IAM の設定については『スタートアップガイド』の「注意制限事項」-「OS インストール後、CLUSTERPRO インストール前」-「AWS 環境における IAM の設定について」を参照してください。
4.42.2. AWS Elastic IP モニタリソースから実行する AWS CLI へコマンドラインオプションを反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS CLI コマンドラインオプション」を参照してください。
4.42.3. AWS Elastic IP モニタリソースから実行する AWS CLI へ環境変数を反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS 関連機能実行時の環境変数」を参照してください。
4.42.4. 監視 (固有) タブ¶
AWS CLIコマンド応答取得失敗時動作
AWS CLIコマンド応答取得失敗時の動作を指定します。AWS CLIコマンド応答取得失敗は、例えばリージョンのエンドポイントのメンテナンスによる停止やダウン、リージョンのエンドポイントまでの通信路の問題や遅延、高負荷によるAWS CLIのタイムアウト、credentialエラーの場合に発生します。以下を目安に設定してください。
AWS CLIコマンドの失敗時にフェイルオーバしたい場合: [回復動作を実行する]を設定してください。
AWS CLIコマンドの失敗時にフェイルオーバせず警告を表示させたい場合:[回復動作を実行しない(警告を表示する)]を設定してください。
AWS CLIコマンドの失敗は監視対象が異常ではないため何もしない場合:[回復動作を実行しない(警告を表示しない)]を設定してください。この場合でも EIP の存在が確認できない場合の異常は検出可能です。そのため、この設定を推奨します。
4.43. AWS 仮想 IP モニタリソースを理解する¶
AWS 仮想IPモニタリソースは、VIP 制御の場合は VIP の存在及び VPC のルーティングの健全性を確認するモニタリソースです。AWS仮想IPモニタリソースでは監視時に AWS CLI を実行して route table の確認処理を行います。
4.43.1. AWS 仮想 IP モニタリソースの注意事項¶
AWS 仮想IPリソースを追加すると自動的に作成されます。AWS 仮想IPリソース 1 つに対して 1 つの AWS 仮想IPモニタリソースが自動的に作成されます。
『スタートアップガイド』の 「注意制限事項」 - 「CLUSTERPRO の情報作成時」 -「AWS 仮想IPリソースの設定について」を参照してください。
IAM の設定については『スタートアップガイド』の「注意制限事項」-「OS インストール後、CLUSTERPRO インストール前」-「AWS 環境における IAM の設定について」を参照してください。
4.43.2. AWS 仮想 IP モニタリソースから実行する AWS CLI へコマンドラインオプションを反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS CLI コマンドラインオプション」を参照してください。
4.43.3. AWS 仮想 IP モニタリソースから実行する AWS CLI へ環境変数を反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS 関連機能実行時の環境変数」を参照してください。
4.43.4. 監視 (固有) タブ¶
AWS CLIコマンド応答取得失敗時動作
AWS CLIコマンド応答取得失敗時の動作を指定します。AWS CLIコマンド応答取得失敗は、例えばリージョンのエンドポイントのメンテナンスによる停止やダウン、リージョンのエンドポイントまでの通信路の問題や遅延、高負荷によるAWS CLIのタイムアウト、credentialエラーの場合に発生します。以下を目安に設定してください。
AWS CLIコマンドの失敗時にフェイルオーバしたい場合: [回復動作を実行する]を設定してください。
AWS CLIコマンドの失敗時にフェイルオーバせず警告を表示させたい場合:[回復動作を実行しない(警告を表示する)]を設定してください。
AWS CLIコマンドの失敗は監視対象が異常ではないため何もしない場合:[回復動作を実行しない(警告を表示しない)]を設定してください。この場合でも VIP の存在が確認できない場合や VPC のルーティングの健全性が確認できない場合の異常は検出可能です。そのため、この設定を推奨します。
4.44. AWS セカンダリ IP モニタリソースを理解する¶
AWS セカンダリ IP モニタリソースは、セカンダリ IP アドレスの存在有無を監視するモニタリソースです。
4.44.1. AWS セカンダリ IP モニタリソースの注意事項¶
『スタートアップガイド』の 「注意制限事項」 - 「CLUSTERPRO の情報作成時」 -「AWS セカンダリ IP リソースの設定について」を参照してください。
IAM の設定については『スタートアップガイド』の「注意制限事項」-「OS インストール後、CLUSTERPRO インストール前」-「AWS 環境における IAM の設定について」を参照してください。
4.44.2. AWS セカンダリ IP モニタリソースから実行する AWS CLI へコマンドラインオプションを反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS CLI コマンドラインオプション」を参照してください。
4.44.3. AWS セカンダリ IP モニタリソースから実行する AWS CLI へ環境変数を反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS 関連機能実行時の環境変数」を参照してください。
4.44.4. 監視 (固有) タブ¶
AWS CLIコマンド応答取得失敗時動作
AWS CLIコマンド応答取得失敗時の動作を指定します。AWS CLIコマンド応答取得失敗は、例えばリージョンのエンドポイントのメンテナンスによる停止やダウン、リージョンのエンドポイントまでの通信路の問題や遅延、高負荷によるAWS CLIのタイムアウト、credentialエラーの場合に発生します。以下を目安に設定してください。
AWS CLIコマンドの失敗時にフェイルオーバしたい場合: [回復動作を実行する]を設定してください。
AWS CLIコマンドの失敗時にフェイルオーバせず警告を表示させたい場合:[回復動作を実行しない(警告を表示する)]を設定してください。
AWS CLIコマンドの失敗は監視対象が異常ではないため何もしない場合:[回復動作を実行しない(警告を表示しない)]を設定してください。この場合でも 登録した IP アドレスの健全性が確認できない場合の異常は検出可能です。そのため、この設定を推奨します。
4.45. AWS AZ モニタリソースを理解する¶
AWS AZモニタリソースは、AWS CLI コマンドを利用して、各サーバが属する AZ の健全性の監視を行うモニタリソースです。 AWS CLI を使って取得できるAZの状態が available の場合は正常、information や impaired の場合は警告、unavailable の場合は異常となります。内部バージョン 4.2.0-1 より前までは available 以外の場合は異常となります。
4.45.1. AWS AZ モニタリソースの注意事項¶
AZ の監視を行いたい場合は 1 つの AWS AZモニタリソースを作成してください。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS Elastic IPリソースの設定について」、「AWS 仮想IPリソースの設定について」を参照してください。
IAM の設定については『スタートアップガイド』の「注意制限事項」-「OS インストール後、CLUSTERPRO インストール前」-「AWS 環境における IAM の設定について」を参照してください。
4.45.2. AWS AZ モニタリソースから実行する AWS CLI へコマンドラインオプションを反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS CLI コマンドラインオプション」を参照してください。
4.45.3. AWS AZ モニタリソースから実行する AWS CLI へ環境変数を反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS 関連機能実行時の環境変数」を参照してください。
4.45.4. 監視 (固有) タブ¶
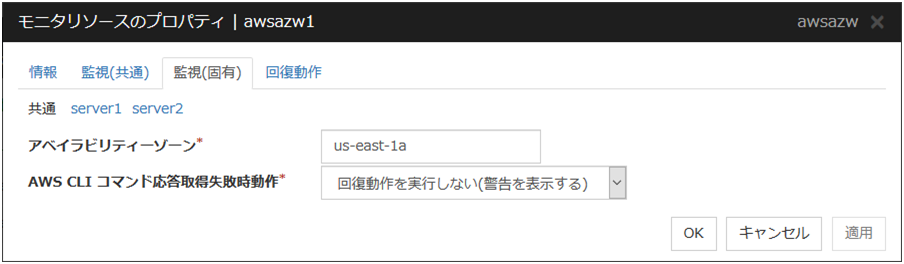
アベイラビリティーゾーン (45バイト以内) サーバ個別設定可能
監視を行うアベイラビリティーゾーンを指定します。
AWS CLIコマンド応答取得失敗時動作
AWS CLIコマンド応答取得失敗時の動作を指定します。AWS CLIコマンド応答取得失敗は、例えばリージョンのエンドポイントのメンテナンスによる停止やダウン、リージョンのエンドポイントまでの通信路の問題や遅延、高負荷によるAWS CLIのタイムアウト、credentialエラーの場合に発生します。以下を目安に設定してください。
AWS CLIコマンドの失敗時にフェイルオーバしたい場合: [回復動作を実行する]を設定してください。
AWS CLIコマンドの失敗時にフェイルオーバせず警告を表示させたい場合:[回復動作を実行しない(警告を表示する)]を設定してください。
AWS CLIコマンドの失敗は監視対象が異常ではないため何もしない場合:[回復動作を実行しない(警告を表示しない)]を設定してください。この場合でも AZ の健全性が確認できない場合の異常は検出可能です。そのため、この設定を推奨します。
4.46. AWS DNS モニタリソースを理解する¶
AWS DNS モニタリソースは、AWS CLI コマンドを利用して登録した IP アドレスの健全性を確認するモニタリソースです。
以下の場合に異常を通知します。
該当するリソースレコードセットが存在しない場合。
登録した[IP アドレス]が仮想ホスト名(DNS 名)の名前解決によって得られない場合。
4.46.1. AWS DNS モニタリソースの注意事項¶
AWS DNS リソースを追加すると自動的に作成されます。AWS DNS リソース 1 つに対して 1 つの AWS DNS モニタリソースが自動的に作成されます。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS DNS リソースの設定について」を参照してください。
IAM の設定については『スタートアップガイド』の「注意制限事項」-「OS インストール後、CLUSTERPRO インストール前」-「AWS 環境における IAM の設定について」を参照してください。
4.46.2. AWS DNS モニタリソースから実行する AWS CLI へコマンドラインオプションを反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS CLI コマンドラインオプション」を参照してください。
4.46.3. AWS DNS モニタリソースから実行する AWS CLI へ環境変数を反映させるには¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS 関連機能実行時の環境変数」を参照してください。
4.46.4. 監視 (固有) タブ¶
AWS CLIコマンド応答取得失敗時動作
AWS CLIコマンド応答取得失敗時の動作を指定します。AWS CLIコマンド応答取得失敗は、例えばリージョンのエンドポイントのメンテナンスによる停止やダウン、リージョンのエンドポイントまでの通信路の問題や遅延、高負荷によるAWS CLIのタイムアウト、credentialエラーの場合に発生します。以下を目安に設定してください。
AWS CLIコマンドの失敗時にフェイルオーバしたい場合: [回復動作を実行する]を設定してください。
AWS CLIコマンドの失敗時にフェイルオーバせず警告を表示させたい場合:[回復動作を実行しない(警告を表示する)]を設定してください。
AWS CLIコマンドの失敗は監視対象が異常ではないため何もしない場合:[回復動作を実行しない(警告を表示しない)]を設定してください。この場合でも 登録した IP アドレスの健全性が確認できない場合の異常は検出可能です。そのため、この設定を推奨します。
名前解決確認をする
4.47. Azure プローブポートモニタリソースを理解する¶
Azure プローブポートモニタリソースは、Azure プローブポートリソースが起動しているノードに対して、Azure プローブポートリソース活性時に起動するプローブポート制御プロセスの死活監視を行います。正常に起動していない場合は、監視異常となります。
4.47.1. Azure プローブポートモニタリソースの注意事項¶
Azure プローブポートリソースを追加すると自動的に作成されます。Azure プローブポートリソース 1 つに対して 1 つの Azure プローブポートモニタリソースが自動的に作成されます。
Azure プローブポートモニタリソースでは、Azure プローブポートリソースでのプローブ 待ち受けのタイムアウトの発生の有無を監視します。そのため、Azure プローブポートモニタリソースの監視インターバルは、監視対象の Azure プローブポートリソースで設定した[プローブ待ち受けのタイムアウト] の値より、大きな値を設定する必要があります。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Azure プローブポートリソースの設定について」を参照してください。
4.47.2. 監視 (固有) タブ¶
プローブポート待ち受けタイムアウト時動作
Azure プローブポートリソースにおいて、プローブ ポート待ち受けのタイムアウトが発生した場合の回復動作を指定します。
4.48. Azure ロードバランスモニタリソースを理解する¶
Azure ロードバランスモニタリソースは、Azure プローブポートリソースが起動していないノードに対して、プローブ ポートと同じポート番号が開放されていないかを確認します。
4.48.1. Azure ロードバランスモニタリソースの注意事項¶
Azure プローブポートリソースを追加すると自動的に作成されます。Azure プローブポートリソース 1 つに対して 1 つの Azure ロードバランスモニタリソースが自動的に作成されます。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Azure プローブポートリソースの設定について」を参照してください。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Azure ロードバランスモニタリソースの設定について」を参照してください。
4.49. Azure DNS モニタリソースを理解する¶
Azure DNS モニタリソースは、Microsoft Azureの権威 DNS サーバーに対してクエリを発行し、登録した IP アドレスの健全性を確認するモニタリソースです。
以下の場合に異常を通知します。
登録した[IP アドレス]が仮想ホスト名(DNS 名)の名前解決によって得られない場合。
DNSサーバー一覧の取得に失敗した場合。
4.49.1. Azure DNS モニタリソースの注意事項¶
Azure DNS リソースを追加すると自動的に作成されます。Azure DNS リソース 1 つに対して 1 つの Azure DNS モニタリソースが自動的に作成されます。
パブリック DNS ゾーンを利用している場合、ゾーンの登録およびクエリに対して課金が発生します。そのため [名前解決確認をする] をオンにした場合、[インターバル] ごとに課金が発生します。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Azure DNS リソースの設定について」を参照してください。
4.49.2. 監視 (固有) タブ¶
名前解決確認をする
4.50. Google Cloud 仮想 IP モニタリソースを理解する¶
Google Cloud 仮想 IP モニタリソースは、Google Cloud 仮想 IP リソースが起動しているノードに対して、Google Cloud 仮想 IP リソース活性時に起動する制御プロセスの死活監視を行います。正常に起動していない場合は、監視異常となります。また、ヘルスチェック待ち受けのタイムアウトが発生した場合、[ヘルスチェックのタイムアウト時動作] の指定によっては監視異常となります。
4.50.1. Google Cloud 仮想 IP モニタリソースの注意事項¶
Google Cloud 仮想 IP リソースを追加すると自動的に作成されます。Google Cloud 仮想 IP リソース 1 つに対して 1 つの Google Cloud 仮想 IP モニタリソースが自動的に作成されます。
Google Cloud 仮想 IP モニタリソースでは、Google Cloud 仮想 IP リソースでのヘルスチェック待ち受けのタイムアウトの発生有無を監視します。そのため、Google Cloud 仮想 IP モニタリソースの監視インターバルは、監視対象の Google Cloud 仮想 IP リソースで設定した [ヘルスチェックのタイムアウト] の値より、大きな値を設定する必要があります。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Google Cloud 仮想 IP リソースの設定について」を参照してください。
4.50.2. 監視 (固有) タブ¶
ヘルスチェックのタイムアウト時動作
Google Cloud 仮想 IP リソースにおいて、ヘルスチェック待ち受けのタイムアウトが発生した場合の回復動作を指定します。
4.51. Google Cloud ロードバランスモニタリソースを理解する¶
Google Cloud ロードバランスモニタリソースは、Google Cloud 仮想 IP リソースが起動していないノードに対して、ヘルスチェック用ポートと同じポート番号が開放されていないかを確認します。
4.51.1. Google Cloud ロードバランスモニタリソースの注意事項¶
Google Cloud 仮想 IP リソースを追加すると自動的に作成されます。Google Cloud 仮想 IP リソース 1 つに対して 1 つの Google Cloud ロードバランスモニタリソースが自動的に作成されます。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Google Cloud 仮想 IP リソースの設定について」を参照してください。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Google Cloud ロードバランスモニタリソースの設定について」を参照してください。
4.52. Google Cloud DNS モニタリソースを理解する¶
Google Cloud DNS モニタリソースは、活性時監視の対象リソースに指定された Google Cloud DNS リソースが制御するレコードセットと A レコードが、Google Cloud DNS 上に存在することを確認します。
4.52.1. Google Cloud DNS モニタリソースの注意事項¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Google Cloud DNS リソースの設定について」を参照してください。
4.52.2. 監視 (固有) タブ¶
Google Cloud DNS モニタリソースの監視 (固有) タブはありません。
4.53. Oracle Cloud 仮想 IP モニタリソースを理解する¶
Oracle Cloud 仮想 IP モニタリソースは、Oracle Cloud 仮想 IP リソースが起動しているノードに対して、Oracle Cloud 仮想 IP リソース活性時に起動する制御プロセスの死活監視を行います。正常に起動していない場合は、監視異常となります。また、ヘルスチェック待ち受けのタイムアウトが発生した場合、[ヘルスチェックのタイムアウト時動作] の指定によっては監視異常となります。
4.53.1. Oracle Cloud 仮想 IP モニタリソースの注意事項¶
Oracle Cloud 仮想 IP リソースを追加すると自動的に作成されます。Oracle Cloud 仮想 IP リソース 1 つに対して 1 つの Oracle Cloud 仮想 IP モニタリソースが自動的に作成されます。
Oracle Cloud 仮想 IP モニタリソースでは、Oracle Cloud 仮想 IP リソースでのヘルスチェック待ち受けのタイムアウトの発生有無を監視します。そのため、Oracle Cloud 仮想 IP モニタリソースの監視インターバルは、監視対象の Oracle Cloud 仮想 IP リソースで設定した [ヘルスチェックのタイムアウト] の値より、大きな値を設定する必要があります。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Oracle Cloud 仮想 IP リソースの設定について」を参照してください。
4.53.2. 監視 (固有) タブ¶
ヘルスチェックのタイムアウト時動作
Oracle Cloud 仮想 IP リソースにおいて、ヘルスチェック待ち受けのタイムアウトが発生した場合の回復動作を指定します。
4.54. Oracle Cloud ロードバランスモニタリソースを理解する¶
Oracle Cloud ロードバランスモニタリソースは、Oracle Cloud 仮想 IP リソースが起動していないノードに対して、ヘルスチェック用ポートと同じポート番号が開放されていないかを確認します。
4.54.1. Oracle Cloud ロードバランスモニタリソースの注意事項¶
Oracle Cloud 仮想 IP リソースを追加すると自動的に作成されます。Oracle Cloud 仮想 IP リソース 1 つに対して 1 つの Oracle Cloud ロードバランスモニタリソースが自動的に作成されます。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Oracle Cloud 仮想 IP リソースの設定について」を参照してください。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Oracle Cloud ロードバランスモニタリソースの設定について」を参照してください。
4.55. Oracle Cloud DNS モニタリソースを理解する¶
Oracle Cloud DNS モニタリソースは、活性時監視の対象リソースに指定された Oracle Cloud DNS リソースが制御するレコードセットや A レコードが、Oracle Cloud DNS 上に存在することを確認します。
マルチリージョン環境で構成されたクラスタの場合に対象リソースの設定で [マルチリージョンでのリソースレコードの操作範囲] を [クラスタサーバが所属するすべてのリージョン] とした場合、フェイルオーバグループが起動していないサーバが所属するリージョンの Oracle Cloud DNS に対して、 [インターバル]ごとにレコードセットの登録または更新処理を行います。
4.55.1. Oracle Cloud DNS モニタリソースの注意事項¶
Oracle Cloud DNS リソースを追加すると自動的に作成されます。Oracle Cloud DNS リソース 1 つに対して 1 つの Oracle Cloud DNS モニタリソースが自動的に作成されます。
パブリック DNS ゾーンを利用している場合、ゾーンの登録およびクエリに対して課金が発生します。そのため[名前解決確認をする]をオンにした場合やマルチリージョン環境で構成されたクラスタの場合に対象リソースの設定で [マルチリージョンでのリソースレコードの操作範囲] を [クラスタサーバが所属するすべてのリージョン] とした場合、[インターバル]ごとに課金が発生します。
マルチリージョン環境で構成されたクラスタにおいて、フェイルオーバグループが起動していないサーバのリージョン内から名前解決によって登録した IP アドレス(DNS 名)が得られない場合があります。
『スタートアップガイド』 の 「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Oracle Cloud DNS リソースの設定について」を参照してください。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「OCI 環境における CLI の設定について」を参照してください。
『スタートアップガイド』の「注意制限事項」 - 「OSインストール後、CLUSTERPROインストール前」 - 「OCI 環境におけるポリシーの設定について」を参照してください。
4.55.2. 監視 (固有) タブ¶
名前解決確認をする