1. 前言¶
1.1. 读者对象和用途¶
《EXPRESSCLUSTER® X 维护指南》以管理员为对象,对维护相关信息进行了说明。请参考在操作集群时所需的信息。
1.3. EXPRESSCLUSTER X手册体系¶
EXPRESSCLUSTER X的手册分为以下 6 类。各指南的标题和用途如下所示。
《EXPRESSCLUSTER X 开始指南》(Getting Started Guide)
本手册的读者对象为所有的用户,对产品概要,运行环境,升级信息,现有的问题等进行了说明。
《EXPRESSCLUSTER X 安装&设置指南》(Installation and Configuration Guide)
本手册的读者对象为导入使用EXPRESSCLUSTER的集群系统的系统工程师以及导入集群系统后进行维护和操作的系统管理员,对导入使用了EXPRESSCLUSTER的集群系统后到开始操作前的必备事项进行了说明。手册按照实际导入集群系统时的顺序,对使用EXPRESSCLUSTER的集群系统的设计方法,EXPRESSCLUSTER的安装设置步骤,设置后的确认以及开始操作前的测试方法进行了说明。
《EXPRESSCLUSTER X 参考指南》(Reference Guide)
本手册的读者对象为管理员以及导入使用了EXPRESSCLUSTER的集群系统的系统工程师,对EXPRESSCLUSTER的操作步骤,各模块的功能以及疑难解答信息等进行了说明,是对《安装&设置指南》的补充。
《EXPRESSCLUSTER X 维护指南》(Maintenance Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统后进行维护和操作的系统管理员,对EXPRESSCLUSTER的维护的相关信息进行了说明。
《EXPRESSCLUSTER X 硬件整合指南》 (Hardware Feature Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统的系统工程师,对与特定硬件整合的功能进行了说明。是对《安装&设置指南》的补充。
《EXPRESSCLUSTER X 兼容功能指南》(Legacy Feature Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统的系统工程师,对EXPRESSCLUSTER X 4.0 WebManager,Builder 以及EXPRESSCLUSTER Ver 8.0 兼容指令的相关信息等进行了说明。
1.4. 本手册的标记规则¶
在本手册中,需要注意的事项,重要的事项以及相关信息等用如下方法标记。
注解
表示虽然比较重要,但是并不会引起数据损失或系统以及机器损伤的信息。
重要
表示为避免数据损失和系统,机器损坏所必需的信息。
参见
表示参考信息的位置。
另外,在本书中使用以下标记法。
标记 |
使用方法 |
例 |
|---|---|---|
[ ] 方括号
|
在命令名的前后,
显示在画面中的字句 (对话框,菜单等) 的前后。
|
点击[启动]
[详细信息]对话框
|
命令行中的[ ] 方括号 |
表示括号内的值可以不予指定(可省)。 |
|
等宽字体 |
路径名,命令行,系统输出(消息,提示等),目录,文件名,函数,参数。 |
|
粗体
|
用户在命令提示符后实际输入的值。
|
输入以下内容。
clpcl -s -a
|
斜体 |
用户将之替换为有效值后输入的项目。
|
|
 在本手册的图中,为了表示EXPRESSCLUSTER,使用该图标。
在本手册的图中,为了表示EXPRESSCLUSTER,使用该图标。
2. 维护信息¶
本章介绍进行EXPRESSCLUSTER维护时所需的信息,同时介绍其所管理资源的详细信息。
本章包含以下内容。
2.1. EXPRESSCLUSTER的目录结构¶
注解
安装目录下有《参考指南》的"EXPRESSCLUSTER命令参考"中没有记载的执行文件和脚本文件,请不要使用EXPRESSCLUSTER之外的工具执行该文件。由于执行该文件造成不良影响时将不予以维护支持。
EXPRESSCLUSTER的目录结构如下。
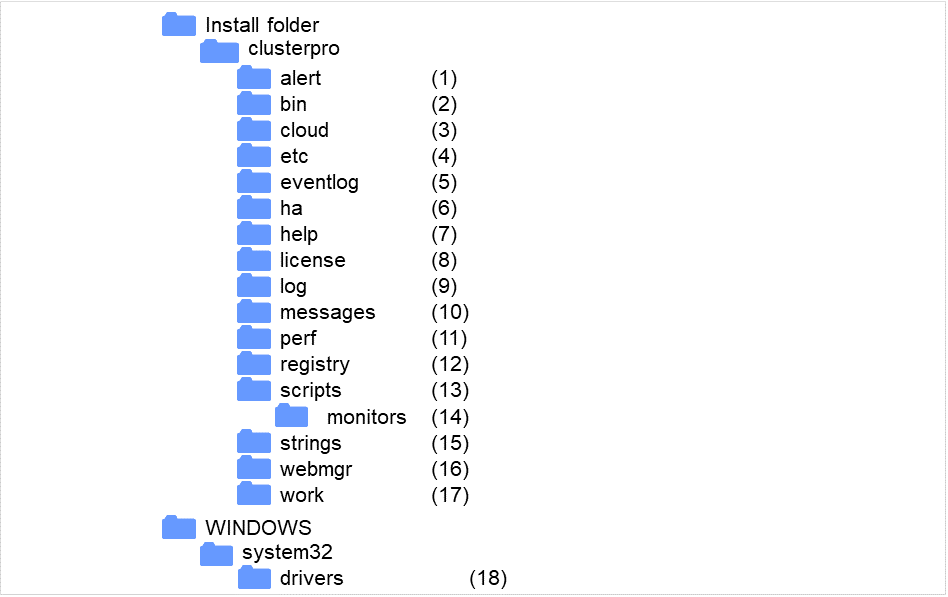
图 2.1 目录结构¶
警报同步目录
该目录保存EXPRESSCLUSTER警报同步的模块以及管理文件。
集群模块目录
该目录保存EXPRESSCLUSTER服务器的执行文件以及库。
云连接相关产品目录
存储用于云连接用的脚本模块等。
集群配置信息目录
该目录保存集群配置信息文件,各模块的策略文件。
事件日志目录
该目录保存EXPRESSCLUSTER的事件日志相关的库。
HA产品相关信息
保存有Java Resource Agent,System Resource Agent的二进制数据和配置文件。
Helper目录
现在未使用。
License目录
该目录保存License产品的License。
模块日志目录
该目录保存各模块的输出日志。
通告消息(警报,事件日志)目录
保存各模块通告警报,事件日志时的消息。
性能日志目录
保存了磁盘,系统的性能信息。
注册表目录
现在未使用。
组资源的脚本资源脚本目录
该目录保存组资源的脚本资源的脚本。
复归脚本相关
保存了查出组资源及监视资源异常时执行的脚本。
String Table目录
该目录保存EXPRESSCLUSTER中使用的String Table。
WebManager服务器,Cluster WebUI目录
该目录保存 WebManager服务器的模块以及管理文件。
模块操作目录
是各模块的操作目录。
集群驱动程序目录
该目录保存内核模式LAN心跳驱动程序,磁盘过滤器驱动程序。
2.2. EXPRESSCLUSTER 的日志,警报的删除方法¶
删除EXPRESSCLUSTER的日志,警报时,按照以下的步骤执行。
集群内的所有服务器上把服务的启动种类更改为手动启动。
clpsvcctrl.bat --disable -a
通过Cluster WebUI或者clpstdn命令执行机群关闭,重启,然后再启动。
要删除日志,请删除在以下的文件夹中文件。请在要删除的日志的服务器上执行。
<EXPRESSCLUSTER的安装路径>\log
要删除警报,请删除在以下的文件夹中文件。请在要删除的日志的服务器上执行。
<EXPRESSCLUSTER的安装路径>\alert\log
集群内的所有服务器上把服务的启动种类更改为手动启动。
clpsvcctrl.bat --enable -a
请重启集群内的所有服务器。
2.3. 镜像统计信息采集功能¶
2.3.1. 何谓镜像统计信息采集功能?¶
镜像统计信息采集功能指的是:在镜像磁盘配置及共享型镜像磁盘配置中,采集各镜像资源中有关镜像化功能统计信息的功能。
镜像统计信息采集功能可利用Windows OS功能,即性能监视器或typeperf命令来采集EXPRESSCLUSTER X的镜像统计信息,并实时显示采集的信息。另外,从镜像构筑时开始,可持续向统计日志文件输出镜像统计信息。
采集的镜像统计信息在镜像构筑或运行时,各按以下方法使用。
镜像构筑时 |
在现有环境下为调整镜像设置项目,先确认各设置项目对现有环境具有何种影响,再调整为最合适的设置。 |
|---|---|
镜像运行时
|
可监视是否会发生问题。
另外,可采集故障发生前后的镜像统计信息,因此将进一步提高解析性能。
|
2.3.2. 镜像统计信息采集功能与OS标准功能的联动¶
OS标准功能的使用
使用性能监视器或typeperf命令,采集镜像统计信息并实时显示所采集的信息。在以下的"计数器名"列表中,任选其一,在显示或采集进行了一段时间后,通过视觉确认镜像相关的设置值是否适合构筑的环境,或采集统计信息过程中是否发生了异常。
关于实际使用性能监视器或typeperf命令的步骤,请参考以下"在性能监视器中显示镜像统计信息","从性能监视器中采集镜像统计信息"及"从typeperf命令采集镜像统计信息"的条目。
指定对象名
镜像统计信息采集功能中处理的对象名为"EXPRESSCLUSTER X Disk Performance"。通过指定对象"EXPRESSCLUSTER X Disk Performance",可采集镜像统计信息。
指定计数器名
镜像统计信息采集功能中处理的计数器名如下。
计数器名
含义
单位
说明
% Compress Ratio
压缩率
%
指发送到对方服务器的镜像数据的压缩率。表示压缩后的数据大小与原数据的比率,若将数据从100MB压缩为80MB,则压缩率为80%。
Async Application Queue BytesAsync Application Queue Bytes, Max应用程序队列的大小(瞬间值/最大值)
Byte
指在非同步镜像通信中,用户空间内存所保存的待发送数据量。采集最新数据时的值为瞬间值,所保存数据量最多时的值为最大值。
Async Kernel Queue BytesAsync Kernel Queue Bytes, Max内核队列的大小(瞬间值/最大值)
Byte
指在非同步镜像通信中,内核空间内存所保存的待发送数据量。采集最新数据时的值为瞬间值,所保存数据量最多时的值为最大值。
Async Mirror Queue Transfer TimeAsync Mirror Queue Transfer Time, Max从内核队列向应用程序队列传送的时间(平均值/最大值)
msec
指在非同步镜像通信中,从内核空间内存向用户空间内存发送数据的传送时间之平均值/最大值。
Async Mirror Send Wait History Files Total BytesAsync Mirror Send Wait History Files Total Bytes, Max历史文件使用量(瞬间值/最大值)
Byte
指在非同步镜像通信中,历史文件路径下所存储的待发送数据文件的大小总量。采集最新数据时的值为瞬间值,所保存数据量最多时的值为最大值。
Async Mirror Send Wait Total BytesAsync Mirror Send Wait Total Bytes, Max待发送数据量(瞬间值/最大值)
Byte
指在非同步镜像通信中,向对方服务器发送的待发送镜像数据的总量。采集最新数据时的值为瞬间值,待发送数据量最多时的值为最大值。
Mirror Bytes SentMirror Bytes Sent/sec镜像发送量(合计值/平均值)
Byte(Byte/sec)指向对方服务器发送的镜像数据量的字节数。采集最新数据之前的合计字节数为合计值,每秒发送的字节数为平均值。
Request Queue BytesRequest Queue Bytes, Max请求队列的大小(瞬间值/最大值)
Byte
指在镜像通信中,接收IO要求时所用队列的使用大小。采集最新数据时的值为瞬间值,队列大小最大时的值为最大值。
Transfer Time, AvgTransfer Time, Max镜像通信时间(平均值/最大值)
msec/次
指发送镜像数据所花费的每次镜像通信的时间。采集最新数据前所用的通信时间除以镜像通信次数的值为平均值,每次镜像通信中最长的通信时间为最大值。
指定实例名
镜像统计信息采集功能中处理的实例名为"MD,HD ResourceX"。X可填入从1至22的镜像磁盘序号或共享型镜像磁盘序号。例如,镜像磁盘资源"MD"的镜像磁盘序号设置为"2",则资源"MD"相关的镜像统计信息可通过指定实例"MD,HD Resource2"进行采集。另外,若设置了多个资源,可通过指定实例"_Total",对设置的所有资源镜像统计信息的合计信息进行采集。
注解
请指定实际设置资源的镜像磁盘序号或共享型镜像磁盘序号对应的实例名。可指定未设置资源的实例,但无法显示/采集镜像统计信息。
镜像统计信息的使用
实际采集的镜像统计信息可有助于调整镜像相关的设置值。例如,根据采集的镜像统计信息可确认通信速度或通信负荷时,通过调整镜像相关的设置值可改善通信速度。
在性能监视器中显示镜像统计信息
实时显示所采集镜像统计信息的步骤
从[开始]菜单中启动[管理工具]-[性能监视器]
选择性能监视器
点击"+"按钮,或右击从菜单中执行[添加计数器]
保存[文件]-[命名并保存]中添加的计数器设置
从保存的设置中启动,可重复使用同样的计数器设置
步骤的详细信息说明如下。这里将采集镜像统计信息的1个项目"Mirror Bytes Sent"作为示例。对象实例为"MD,HD Resource1"。从[开始]菜单中启动[管理工具]-[性能]。
- 在窗口左侧的树形菜单中选择[性能监视器]。
 窗口右侧显示性能监视器画面。
窗口右侧显示性能监视器画面。 - 点击"+"按钮,或右击从菜单中执行"添加计数器"。
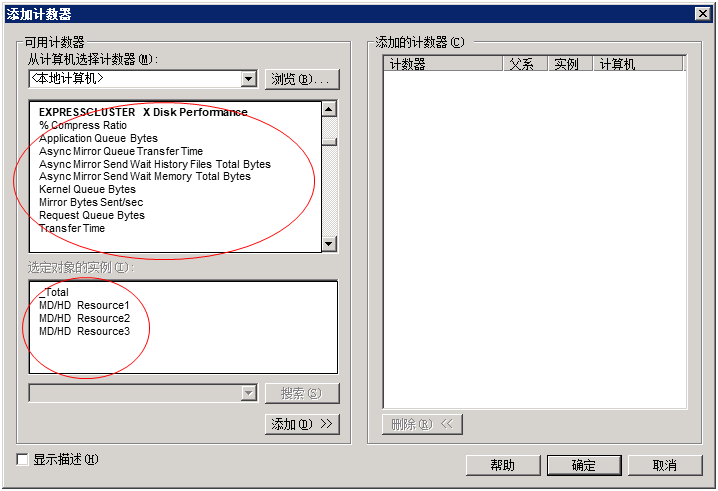 满足运行条件时,显示添加计数器/实例。选择"EXPRESSCLUSTER X Resource Performance" ,且计数器选择"Mirror Bytes Sent",实例选择"MD,HD Resource1",并添加。
满足运行条件时,显示添加计数器/实例。选择"EXPRESSCLUSTER X Resource Performance" ,且计数器选择"Mirror Bytes Sent",实例选择"MD,HD Resource1",并添加。
注解
没有[Cluster Disk Resource Performance]时,联动功能无效。在这种情况下,请通过命令提示符执行以下命令,使联动功能生效后,重新执行步骤1。
>lodctr.exe <EXPRESSCLUSTER 安装路径>\perf\clpdiskperf.ini
保存[文件]-[命名并保存]中添加的计数器设置。
从保存的设置中启动,可重复使用同样的计数器设置。
从性能监视器中采集镜像统计信息
从性能监视器中采集镜像统计信息的日志文件时,步骤如下。
日志文件采集步骤
从[开始]菜单中启动[管理工具]-[性能监视器]
在[数据收集器]-[用户定义]中,新建数据收集器
在"创建数据日志"中选择"性能计数器",执行[添加]
选择[EXPRESSCLUSTER X Resource Performance],添加要采集的计数器及实例
开始采集日志
步骤的详细信息说明如下。这里将采集镜像统计信息的1个项目"Mirror Bytes Sent"作为示例。对象实例为"MD,HD Resource1"。从[开始]菜单中启动[管理工具]-[性能监视器]。
在[数据收集器]-[用户定义]中,通过菜单的[操作]-[新建]或右键菜单的[新建],指定"数据收集器"。
数据收集器名请任意输入。
数据收集器的创建方法请选择[手动创建(详细信息)(C)]。
在"创建数据日志"中选择"性能计数器",执行[添加]。
- 添加计数器。从"EXPRESSCLUSTER X Resource Performance"中选择"Mirror Bytes Sent"后,再从"所选对象的实例"中选择"MD,HD Resource1",执行[添加]。[添加的计数器]中就会添加[Mirror Bytes Sent]的[MD,HD Resource1]。要采集的计数器全部添加完成后,执行[OK],并选择[完成]。
注解
没有[Cluster Disk Resource Performance] 时,联动功能无效。在这种情况下,请通过命令提示符执行以下命令,使联动功能生效后,重新执行步骤1。
>lodctr.exe <EXPRESSCLUSTER 安装路径>\perf\clpdiskperf.ini
开始采集日志。在[数据收集器]-[用户定义]-[(数据收集器名)]中,执行菜单的[开始]。
从typeperf命令采集镜像统计信息
从typeperf命令采集镜像统计信息的步骤如下。
从[开始]菜单启动[全部程序]-[附件]-[命令窗口]
执行typeperf.exe
具体使用示例的详细信息说明如下。
【使用示例1】:镜像通信时间的采集(全部实例指定为[EXPRESSCLUSTER资源])
MD资源:md01~md04,HD资源:hd05~hd08登录完成时但是,各资源的设置视为如下。md01的镜像磁盘序号为1 md02 〃 2 : hd07的共享型镜像磁盘序号为7 hd08 〃 8注解
因可读性优先,标题换行。实际上,标题显示为一行。
以下第1行中执行typeperf命令,采集镜像通信时间。2~11行是标题。在这里,标题是为了便于阅读而逐列断开的,但实际上是一行输出的。第12行之后是实际已采集的统计信息。用"," 分隔的列,从左开始按顺序排列以下值。"采样时间","md01", "md02", "md03", "md04", "hd05", "hd06", "hd07", "hd08"的通信时间
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
C:\>typeperf "\Cluster Disk Resource Performance(*)\Transfer Time, Avg" "(PDH-CSV 4.0)","\\v-ra1w2012\\Cluster Disk Resource Performance(*)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource1)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource2)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource3)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource4)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource5)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource6)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource7)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(MD/HD Resource8)\Transfer Time, Avg", "\\v-ra1w2012\Cluster Disk Resource Performance(_Total)\Transfer Time, Avg" "03/03/2010 15:21:24.546","0.24245658","0.3588965","0.488589","0.24245658","0.3588965","0.488577","0.3588965","0.488589" "03/03/2010 15:21:24.546","0.21236597","0.6465466","0.488589","0.24245658","0.3588965","0.488589","0.2588965","0.288589" "03/03/2010 15:21:24.546","0.24465858","0.7797976","0.488589","0.13123213","0.4654699","0.488544","0.6588965","0.288589" "03/03/2010 15:21:24.546","0.85466658","0.5555565","0.488589","0.24245658","0.3588965","0.485689","0.7588965","0.388589" "03/03/2010 15:21:24.546","0.46564468","0.3123213","0.488589","0.24245658","0.4388965","0.482289","0.8888965","0.338589" "03/03/2010 15:21:24.546","0.85858998","0.3588965","0.488589","0.44245658","0.2288965","0.483289","0.3768965","0.228589" "03/03/2010 15:21:24.546","0.47987964","0.3588965","0.488589","0.64245658","0.1288965","0.488214","0.3488965","0.428589" "03/03/2010 15:21:24.546","0.88588596","0.3588965","0.488589","0.84245658","0.1588965","0.484449","0.3668965","0.422589"
【使用示例2】:镜像数据发送量的采集(实例指定为hd05资源)
MD资源:md01~md04,HD资源:hd05~hd08登录完成时但是,各资源的设置视为如下。md01的镜像磁盘序号为1 md02 〃 2 : hd07的共享型镜像磁盘序号为7 hd08 〃 8以下第1行中执行typeperf命令,采集镜像数据发送量。第2行是标题。第3行之后是实际已采集的统计信息。用"," 分隔的列,从左开始按顺序排列以下值。"采样时间","hd05"的数据发送量
1 2 3 4 5 6 7 8 9 10
C:\>typeperf "\Cluster Disk Resource Performance(MD/HD Resource5)\Mirror Bytes Sent/sec" "(PDH-CSV 4.0)","\\v-ra1w2012\\Cluster Disk Resource Performance(MD/HD Resource5)\Mirror Bytes Sent/sec" "03/03/2010 15:21:24.546","52362", "03/03/2010 15:21:24.546","45564", "03/03/2010 15:21:24.546","25560", "03/03/2010 15:21:24.546","25450", "03/03/2010 15:21:24.546","22560", "03/03/2010 15:21:24.546","21597", "03/03/2010 15:21:24.546","35999", "03/03/2010 15:21:24.546","25668",
【使用示例3】:压缩率的日志输出(实例指定为hd01资源)
MD资源:md01~md04,HD资源:hd05~hd08登录完成时但是,各资源的设置视为如下。md01的镜像磁盘序号为1 md02 〃 2 : hd07的共享型镜像磁盘序号为7 hd08 〃 8
日志文件的格式指定为CSV,文件输出路径指定为C:\PerfData\hd01.csv。C:\>typeperf "\Cluster Disk Resource Performance(MD/HD Resource1)\% Compress Ratio" -f CSV -o C:\PerfData\hd01.csv
执行命令后,希望停止日志输出时,请用[Ctrl]+[C]停止。【使用示例4】:计数器列表显示(无指定实例)
MD资源:md01~md04,HD资源:hd05~hd08登录完成时但是,各资源的设置视为如下。md01的镜像磁盘序号为1 md02 〃 2 : hd07的共享型镜像磁盘序号为7 hd08 〃 8以下第1行中执行typeperf命令,显示计数器列表。第2行之后是计数器列表。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
C:\>typeperf -q "\ Cluster Disk Resource Performance" \Cluster Disk Resource Performance(*)\% Compress Ratio \Cluster Disk Resource Performance(*)\Async Application Queue Bytes \Cluster Disk Resource Performance(*)\Async Application Queue Bytes, Max \Cluster Disk Resource Performance(*)\Async Kernel Queue Bytes \Cluster Disk Resource Performance(*)\Async Kernel Queue Bytes, Max \Cluster Disk Resource Performance(*)\Async Mirror Queue Transfer Time \Cluster Disk Resource Performance(*)\Async Mirror Queue Transfer Time, Max \Cluster Disk Resource Performance(*)\Async Mirror Send Wait History Files Total Bytes \Cluster Disk Resource Performance(*)\Async Mirror Send Wait History Files Total Bytes, Max \Cluster Disk Resource Performance(*)\Async Mirror Send Wait Total Bytes \Cluster Disk Resource Performance(*)\Async Mirror Send Wait Total Bytes, Max \Cluster Disk Resource Performance(*)\Mirror Bytes Sent \Cluster Disk Resource Performance(*)\Mirror Bytes Sent/sec \Cluster Disk Resource Performance(*)\Request Queue Bytes \Cluster Disk Resource Performance(*)\Request Queue Bytes, Max \Cluster Disk Resource Performance(*)\Transfer Time, Avg \Cluster Disk Resource Performance(*)\Transfer Time, Max
另外,通过指定选项,可更改取样间隔或向远程服务器发出命令等。选项的详细信息请在"Typeperf -?"中确认。
2.3.3. 镜像统计信息采集功能的运行¶
正在运行的镜像统计信息日志输出动作(自动)
镜像统计信息采集功能在满足运行条件的环境中,将持续采集统计信息并输出到统计日志文件。镜像统计信息的采集及日志输出动作会自动执行。统计日志输出动作的内容如下。
项目
动作内容
描述
输出文件名
nmp_<n>.curnmp_<n>.pre<x>nmp_total.curnmp_total.pre<x>total为全部镜像磁盘/共享型镜像磁盘资源的合计数据<n>为镜像磁盘序号或共享型镜像磁盘序号Cur为最新,接着按照越新的顺序变为pre, pre1, pre2,...排列,之后随着序号的增加为越旧。超过所规定的日志文件数量时,从旧日志开始删除。输出文件的格式
Text file输出为逗号断句的文本格式的文件。每采集1次信息就会输出1行数据。输出目标文件夹
EXPRESSCLUSTER installation folder\perf\disk输出到EXPRESSCLUSTER安装文件夹下的perfdisk文件夹内。
输出对象资源
每个资源+合计每个完成设置的镜像磁盘资源或共享型镜像磁盘资源,其日志输出到1个文件内。资源未设置时,不会创建日志文件。创建了1个以上的日志文件时,会同时创建表示全部资源合计值的Total日志文件。输出时间
每分钟
每1分钟输出1次信息。镜像统计信息的输出功能设置为禁用时,日志不会输出。镜像统计信息的日志输出动作设置为禁用时,镜像统计信息的采集功能虽可运行,但不会输出日志。输出文件大小
约16MB
1个文件最大约16MB。超过文件大小的上限值时,将自动转储日志文件,并保存之前的日志文件。即使未超过上限值,当输出内容发生更改时,也会自动转储日志文件。日志转储数量
12版本
通过转储日志文件所保存的日志文件的版本数最大为12。超过转储的上限值时,将自动删除最早版本的日志文件。
2.3.4. 镜像统计信息采集功能的运行条件¶
当满足以下条件时,镜像统计信息采集功能才会运行。
EXPRESSCLUSTER Disk Agent服务正常启动。
设置了1个以上的镜像磁盘资源或共享型镜像磁盘资源。
集群属性中,镜像统计信息采集功能设为开启。
确认EXPRESSCLUSTER Disk Agent服务的状态。
从[开始]菜单中启动[服务器管理]-[服务]确认EXPRESSCLUSTER Disk Agent服务的状态为"开始"确认[启动类型]为"自动"若服务的状态不是"开始",则需重启服务器
确认镜像设置。
启动Cluster WebUI确认镜像磁盘资源或共享型镜像磁盘资源已设置
确认镜像统计信息采集功能的设置。
启动Cluster WebUI切换为[编辑模式]确认[集群]属性的[镜像磁盘]标签中的[采集统计信息]的设置。
有关Cluster WebUI的详细信息,请参考Cluster WebUI在线版手册。
2.3.5. 镜像统计信息采集功能的相关注意事项¶
运行镜像统计信息采集功能时,为输出镜像统计信息的统计日志文件,需要一定的磁盘剩余空间(最大约8.9GB)。
在1个服务器上,包括性能监视器和typeperf命令在内最多可启动32个进程。在1个服务器上执行32个以上的性能监视器或typeperf命令时,则无法采集镜像统计信息。而且,一个进程内不能采集复数个统计信息。
一个进程内不能采集复数个统计信息。例如,从复数个性能监视器指定目标计算机进行信息采集,在一个性能监视器内进行复数个数据采集等均属于此等情况。
- 采集的镜像统计信息通过clplogcc指令或Cluster WebUI以日志收集采集。请在以clplogcc命令收集日志时指定type5,以Cluster WebUI收集日志时指定pattern5。有关收集日志的详细信息,请参考《参考指南》的"EXPRESSCLUSTER命令参考"的"收集日志(clplogcc命令)",或者在线版手册。
2.4. 系统资源统计信息采集功能¶
Cluster WebUI 的编辑模式下在[集群的属性]的[监视]标签页中选中"收集系统资源信息"复选框时,集群中添加了系统监视资源或者进程资源监视资源时,采集系统资源相关信息,并以以下文件名规则保存在 安装路径/perf/system下。本文件是文本形式(CSV)。在下面的说明文中,本文件称为系统资源统计文件。
system.cur
system.pre
|
|
|---|---|
cur |
表示为最新信息的输出目标。 |
pre |
表示已转储的以前的信息输出目标。 |
采集的信息保存到系统资源统计信息文件中。统计信息到本文件的输出间隔(=采样间隔)为60秒。文件大小为16MB时转储,可保存2个版本。通过使用系统资源统计信息文件中记录的信息,可以将其用作系统性能分析的参考。采集的统计信息包含以下项目。
统计值名 |
单位 |
说明 |
|---|---|---|
CPUCount |
个 |
CPU数 |
CPUUtilization |
% |
CPU使用率 |
MemoryTotalSize |
KByte |
总内存量 |
MemoryCurrentSize |
KByte |
内存使用量 |
SwapTotalSize |
KByte |
总互换大小 |
SwapCurrentSize |
KByte |
互换使用量 |
ThreadCurrentSize |
个 |
线程数 |
FileCurrentSize |
个 |
打开文件数 |
ProcessCurrentCount |
个 |
进程数 |
AvgDiskReadQueueLength__Total |
个 |
所输入的磁盘队列读取请求数 |
AvgDiskWriteQueueLength__Total |
个 |
所输入的磁盘队列写入请求数 |
DiskReadBytesPersec__Total |
Byte |
读取操作时从磁盘传送的字节数 |
DiskWriteBytesPersec__Total |
Byte |
写入操作时传送到磁盘的字节数 |
PercentDiskReadTime__Total |
tick |
磁盘忙于处理读取请求的时间 |
PercentDiskWriteTime__Total |
tick |
磁盘忙于处理写入请求的时间 |
PercentIdleTime__Total |
tick |
磁盘空闲时间 |
CurrentDiskQueueLength__Total |
个 |
收集性能数据时磁盘上剩余的请求数 |
以下是输出系统资源统计文件的示例。
system.cur
"Date","CPUCount","CPUUtilization","MemoryTotalSize","MemoryCurrentSize","SwapTotalSize","SwapCurrentSize","ThreadCurrentSize","FileCurrentSize","ProcessCurrentCount","AvgDiskReadQueueLength__Total","AvgDiskWriteQueueLength__Total","DiskReadBytesPersec__Total","DiskWriteBytesPersec__Total","PercentDiskReadTime__Total","PercentDiskWriteTime__Total","PercentIdleTime__Total","CurrentDiskQueueLength__Total" "2019/11/14 17:18:57.751","2","11","2096744","1241876","393216","0","1042","32672","79","623078737","241067820","95590912","5116928","623078737","241067820","305886514","0" "2019/11/14 17:19:57.689","2","3","2096744","1234892","393216","0","926","31767","77","14688814","138463292","3898368","7112192","14688814","138463292","530778498","0" "2019/11/14 17:20:57.782","2","2","2096744","1194400","393216","26012","890","30947","74","8535798","189735393","3802624","34398208","8535798","189735393","523400261","0" :
2.5. 集群统计信息采集功能¶
Cluster WebUI 的编辑模式下在[集群属性]的[扩展]标签页中选中"采集统计信息"复选框时,组的失效切换或组资源的启动,监视资源的监视处理等,采集每个处理结果和所需时间的信息。本文件是文本形式(CSV)。以下说明文中本文件作为集群统计信息文件说明。
组时
group.curgroup.precur
表示为最新信息的输出目标。
pre
表示已转储的以前的信息输出目标。
保存目标
安装路径/perf/cluster/group/
组资源时
组资源的每个类型输出到相同文件中。
[组资源类型].cur[组资源类型].precur
表示为最新信息的输出目标。
pre
表示已转储的以前的信息输出目标。
保存目标
安装路径/perf/cluster/group/
监视资源时
监视资源的每个类型输出到相同文件中。
[监视资源].cur[监视资源].precur
表示为最新信息的输出目标。
pre
表示已转储的以前的信息输出目标。
保存目标
安装路径/perf/cluster/monitor/
注解
定时输出统计信息到集群统计信息文件如下。
组时 1
组资源时
组资源启动处理完成时
组资源停止处理完成时
监视资源时
监视处理完成时
监视状态更改处理完成时
采集的统计信息中包含以下内容。
统计值名
说明
Date
Name
组/组资源/监视资源的名字。
Action
Result
ReturnCode
执行的处理的返回值。
StartTime
EndTime
ResponseTime(ms)
下记配置事例就启动组时输出的统计信息文件事例进行了说明。
组
组名: failoverA
所属组 (failoverA) 的组资源
- script 资源资源名: script 01, script02, script03
group.cur
"Date","Name","Action","Result","ReturnCode","StartTime","EndTime","ResponseTime(ms)" "2018/12/19 09:44:16.925","failoverA","Start","Success",,"2018/12/19 09:44:09.785","2018/12/19 09:44:16.925","7140" :
script.cur
"Date","Name","Action","Result","ReturnCode","StartTime","EndTime","ResponseTime(ms)" "2018/12/19 09:44:14.845","script01","Start","Success",,"2018/12/19 09:44:09.807","2018/12/19 09:44:14.845","5040" "2018/12/19 09:44:15.877","script02","Start","Success",,"2018/12/19 09:44:14.847","2018/12/19 09:44:15.877","1030" "2018/12/19 09:44:16.920","script03","Start","Success",,"2018/12/19 09:44:15.880","2018/12/19 09:44:16.920","1040" :
2.5.1. 有关集群统计信息文件的文件容量的注意事项¶
集群统计信息文件容量可以设置 1~99MB 。根据配置集群统计信息文件生成的数有所不同。因配置而生成大容量文件,请检查符合配置的集群统计信息的容量设置。集群统计信息文件的最大容量按照以下方式计算。
集群统计信息的文件容量 =([组的文件容量] x (版本数(2)) +([组资源的文件容量] x [被设置的组资源的类型数]) x (版本数(2)) +([监视资源的文件容量] x [被设置的监视资源的类型数]) x (版本数(2))例: 下记配置事例中保存的集群统计信息文件的合计最大容量是 232MB。(((1MB) x 2) + ((3MB x 5) x 2) + ((10MB x 10) x 2) = 232MB)
组 (文件容量: 1MB)
组资源类型数: 5 (文件容量: 3MB)
监视资源类型数: 10 (文件容量: 10MB)
2.6. Cluster WebUI操作日志输出功能¶
Cluster WebUI的编辑模式下在[集群的属性]的[Web管理器]标签页上选中"输出Cluster WebUI的操作日志"复选框时,通过Cluster WebUI将操作的信息输出到日志文件。本文件是文本形式(CSV)。以下说明文中本文件称为Cluster WebUI操作日志文件。
cur
表示为最新信息的输出目标。
pre<x>
保存目标
Cluster WebUI的编辑模式下在"日志输出目标"上指定的目录
输出的操作信息中包含以下项目。
项目名 |
说明 |
|---|---|
Date |
操作信息的输出时间。
以以下形式输出。(000为毫秒)
YYYY/MM/DD HH:MM:SS.000
|
Operation |
通过Cluster WebUI执行的操作。 |
Request |
从Cluster WebUI发送到WebManager服务器的请求URL。 |
IP |
操作Cluster WebUI的客户端IP地址。 |
UserName |
执行操作的用户名。
使用“OS认证方式”作为登录到Cluster WebUI的方法时,将输出登录到Cluster WebUI的用户名。
|
HTTP-Status |
HTTP状态代码。 |
ErrorCode |
执行操作的返回值。 |
ResponseTime(ms) |
执行操作所需的时间。(单位:毫秒)
以毫秒为单位标记输出。
|
ServerName |
操作对象的服务器名。
输出服务器名或IP地址。
作为操作对象的服务器名被指定时输出。
|
GroupName |
操作对象的组名。
作为操作对象的组名被指定时输出。
|
ResourceName |
操作对象的资源名。
输出心跳资源名/网络分区解决资源名/组资源名/监视资源名。
作为操作对象的资源名被指定时输出。
|
ResourceType |
操作对象的资源类型。
作为操作对象的资源类型被指定时输出。
|
Parameters… |
操作固有的参数。 |
以下是输出Cluster WebUI操作日志文件的示例。
"Date","Operation","Request","IP","UserName","HTTP-Status","ErrorCode","ResponseTime(ms)","ServerName","GroupName","ResourceName","ResourceType","Parameters..." "2020/08/14 17:08:39.902","Cluster properties","/GetClusterproInfo.js","10.0.0.15","user1",200,0,141,,,, "2020/08/14 17:08:46.659","Monitor properties","/GetMonitorResourceProperty.js","10.0.0.15","user1",200,0,47,,,"fipw1","fipw" "2020/08/14 17:15:31.093","Resource properties","/GetGroupResourceProperty.js","10.0.0.15","user1",200,0,47,,"failoverA","fip1","fip" "2020/08/14 17:15:45.309","Start group","/GroupStart.js","10.0.0.15","user1",200,0,0,"server1","failoverA",, "2020/08/14 17:16:23.862","Suspend all monitors","/AllMonitorSuspend.js","10.0.0.15","user1",200,0,453,"server1",,,,"server2" :
2.7. 通信端口信息¶
在EXPRESSCLUSTER中,默认使用以下端口号。该端口号可以通过Cluster WebUI更改。
请不要使用EXPRESSCLUSTER之外的程序访问以下端口号。
给服务器设置防火墙时,请确保以下端口号能够访问。
AWS环境时,防火墙设定以外安全组的设定也请使下列端口号可以访问。
有关EXPRESSCLUSTER使用的端口号,请参考《EXPRESSCLUSTER X 开始指南》-"注意限制事项"-"安装EXPRESSCLUSTER前"-"通信端口号"。
2.8. 镜像连接通信的带宽限制¶
使用Windows标配的组策略编辑器(基于策略的服务质量(QoS)设置),可限制使用于镜像连接通信的通信带宽。设置以镜像磁盘连接单位进行,因此对使用指定的镜像磁盘连接的所有镜像磁盘资源/共享型镜像磁盘资源进行通信带宽限制时有效。
2.8.1. 镜像连接通信的带宽限制的设置步骤¶
限制镜像连接通信的带宽时,按照以下的步骤进行设置。
网络适配器的属性设置
从[开始]菜单->[控制面板]->[网络和共享中心]打开镜像磁盘连接的[属性]。
属性中存在[QoS Packet Scheduler]项目时,选中复选框。
属性中不存在[QoS Packet Scheduler]项目时,通过[安装]按钮->[服务]->[添加]按钮选择QoS Packet Scheduler。
- 启动组策略编辑器设置带宽限制时使用组策略编辑器。从[开始]菜单->[指定文件名执行]执行以下的命令。
gpedit.msc
创建策略
创建用于带宽限制的策略。从左窗格选择[本地计算机策略]->[计算机的配置]->[Windows的设置]->[基于策略的服务质量(QoS)],然后右击选择[创建新策略]。
[基于策略的服务质量(QoS)]-[创建QoS策略]画面
根据以下说明进行设置。
策略名
设置识别用的策略名。
DSCP值
设置IP的优先顺序。设值可任意进行。相信信息请参阅[QoS策略的详细信息]。
指定输出方向的节流率
选中[指定输出方向的节流率]复选框。然后以[KBps](每秒的千字节数)或者[MBps](每秒的兆字节数)来指定镜像磁盘连接中使用的通信带宽的上限。
设置后点击[下一步]按钮。
[基于策略的服务质量(QoS)]-[此策略的适用对象]画面
根据以下说明进行设置。
此策略的适用对象(指定应用程序)
选择[所有的应用程序]。
设置后,点击[下一步]按钮。
[基于策略的服务质量(QoS)]-[指定发信源和目标的IP地址。]
根据以下说明进行设置。
此QoS策略的适用对象(指定发送源IP地址)
选择[仅限下一个发信源IP地址],向IP地址输入镜像磁盘连接中使用的发信源的IP地址值。
此QoS策略的适用对象(指定目标IP地址)
选择[仅限下一个目标IP地址],向IP地址输入镜像磁盘连接中使用的目标IP地址值。
设置后,点击[下一步]按钮。
[基于策略的服务质量(QoS)]-[指定协议和端口编号。]画面
根据以下说明进行设置。
指定适用此QoS策略的协议(S)
选择[TCP]。
指定发信源端口编号
选择[任意的发信源端口编号]。
指定目标端口编号
选择[下一个的目标端口编号或者范围],指定镜像驱动端口编号(默认值为29005)。
- 反映策略点击[结束]按钮就反映设置。设置的策略不会马上反映,但会随着策略的自动更新间隔时间反映(默认值:90分以内)。如果要马上反映设置了的策略可手动更新。从[开始]菜单->[指定文件名执行]执行以下的命令。
gpupdate /force
策略的设置到此结束。
2.8.2. 暂时停止/解除镜像连接通信的带宽限制的步骤¶
暂时停止或者解除镜像连接通信的带宽限制时,请按照以下的步骤进行设置。
- 启动组策略编辑器使用要暂时停止/解除带宽限制使用组策略编辑器。从[开始]菜单->[指定文件名执行]执行以下的命令。
gpedit.msc
通过变更策略的设置而暂时停止,或者删除策略
- 暂时停止带宽限制时暂时停止带域制限时,变更用于带宽限制的策略的设置。右击对象的QoS策略,选择[编辑既存策略]。然后,解除[输出方向的节流率]复选框。设置后,点击[OK]按钮。
- 解除带宽限制时解除带域时,删除用于带宽限制的策略。右击对象的QoS策略,选择[删除策略]。此时会弹出[是否删除此策略?]的消息,请选择[是]。
- 反映策略变更了的设置或者删除了的策略不会马上放映,但会随着策略的自动更新间隔时间反映(默认值:90分以内)。如果要马上反映删除了的或者变更了设置的策略可手动更新。从[开始]菜单->[指定文件名执行]执行以下的命令。
gpupdate /force
策略的设置到此结束。
2.9. EXPRESSCLUSTER关闭服务器的条件¶
在EXPRESSCLUSTER中,发生如下异常时,为了保护资源,将关闭或复位服务器。
2.9.1. 组资源启动/停止异常时的最终运行¶
资源启动/停止异常时的最终运行设置如下时
最终运行 |
结果 |
|---|---|
集群服务停止和OS关机 |
组资源停止后,进行正常的关机。 |
集群服务停止和OS重启 |
组资源停止后,进行正常的重启。 |
人为触发停止错误 |
当组资源启动/停止发生异常时,人为触发停止错误(Panic)。 |
2.9.2. 发生资源启动/停止失速时的动作¶
发生资源启动/停止失速时的动作设定如下所示,进行资源启动/停止处理时花费的时间超过预想时
发生失速时的动作 |
结果 |
|---|---|
紧急关机 |
发生组资源启动/停止失速时,使OS关闭。 |
产生故意停止错误 |
发生组资源启动/停止失速时,产生故意停止错误(Panic)。 |
发生资源启动失速时,在事件日记和警告消息中输出下述消息。
模块类型:rc
事件ID:1032
消息:资源%1启动失败。(99 : command is timeout)
说明:资源启动失败
发生资源停止失速时,在事件日记和警告消息中输出下述消息。
模块类型:rc
事件ID:1042
消息:资源%1停止失败。(99 : command is timeout)
说明:资源停止失败
2.9.3. 查出监视资源异常时的最终运行¶
监视资源异常时的最终运行设置如下时
最终运行 |
结果 |
|---|---|
集群服务停止和OS关机 |
组资源停止后,进行正常的关机。 |
集群服务停止和OS重启 |
组资源停止后,进行正常的重启。 |
人为触发停止错误 |
监视资源检测到异常时,人为触发停止错误(Panic)。 |
2.9.4. 强行停止动作¶
强行停止动作设置为"Use Forced Stop"时
物理机
强行停止动作
结果
BMC reset
拥有失效切换组资源的停止的服务器上发生reset。
BMC power-off
拥有失效切换组资源的停止的服务器上发生power-off。
BMC power-cycle
拥有失效切换组资源的停止的服务器上发生power-cycle。
BMC NMI
拥有失效切换组资源的停止的服务器上发生NMI。
vSphere下的虚拟机(客户机 OS)
强行停止动作
结果
VMware vSphere CLI power-off
拥有失效切换组资源的停止的服务器上发生power-off。
2.9.5. 紧急关闭服务器¶
查出以下进程的异常退出时,因为集群服务器不能正常运行而关机。称为紧急关机。
clpnm.exe
clprc.exe
关机的方法可从Cluster WebUI 的编辑模式中[集群的属性]的[集群服务的进程异常时动作]来设定。设定可执行的停止方法如下。
紧急关闭(固定)
产生主动停止错误
HW重置 3
- 3
使用本功能时,与强制停止功能不同,不需要ipmiutil。
2.9.6. EXPRESSCLUSTER Server服务停止时的资源停止异常¶
通过clpcl -t停止EXPRESSCLUSTER Server服务时发生资源停止失败时,将关机。
2.9.7. 从网络分区恢复¶
2.9.8. 紧急服务器重启¶
查出以下服务(进程)异常退出时,重启OS,称为紧急启动。
EXPRESSCLUSTER Disk Agent (clpdiskagent.exe)
EXPRESSCLUSTER Server (clppmsvc.exe)
EXPRESSCLUSTER Transaction (clptrnsv.exe)
2.9.9. 集群挂起/恢复失败时¶
集群挂起/恢复失败时,服务器关机。
2.10. 设置为暂时不执行失效切换的方法¶
因服务器宕机而暂时控制失效切换时,请执行以下步骤。
因暂时停止监视资源的监视而发生监视异常,暂时控制失效切换时,请执行以下步骤。
例) 要停止用于执行命令的服务器上的所有监视时
clpmonctrl -s例) 停止用-h选项所指定的服务器上的所有监视时
clpmonctrl -s -h <服务器名>例) 重新开始用于执行命令的服务器上的所有监视时
clpmonctrl -r例) 重新开始用-h选项所指定的服务器上的所有监视时
clpmonctrl -r -h <服务器名>
因禁用监视资源异常时的复归动作而发生监视异常,暂时抑制失效切换时,请执行以下步骤。
因禁用组资源启动异常时的复归动作而发生启动异常,暂时抑制失效切换时,请执行以下步骤。
因控制监视资源异常时的恢复动作而发生监视异常,暂时控制失效切换时,请执行以下步骤。
由armload命令指定/M或/R来启动应用程序,服务时,这个进程会被监视。暂时控制因监视异常而发生的失效切换时,请执行以下步骤。
2.11. chkdsk/碎片整理的执行步骤¶
2.11.2. 镜像磁盘/共享型镜像磁盘的chkdsk/碎片整理的执行步骤¶
在被设置为镜像磁盘资源的磁盘分区中执行chkdsk或碎片整理时,主服务器的执行步骤与备份服务器的执行步骤不同。
[在主服务器上执行chkdsk/碎片整理时]
对于被设置为镜像磁盘/共享型镜像磁盘资源的磁盘分区,在主服务器上执行chkdsk或碎片整理时,请执行与「共享磁盘的chkdsk/碎片整理执行步骤」相同的步骤。
[在备份服务器上执行chkdsk/碎片整理时(镜像磁盘)]
对于被设置为镜像磁盘的磁盘分区,在备份服务器上执行修复模式的chkdsk或碎片整理时,通过镜像复制,由于主服务器磁盘镜像被覆盖,所以会失去文件系统的修复或最优化效果。本书中记载了关于以磁盘的错误检查为目的的chkdsk的步骤。
用Cluster WebUI或clpmonctrl命令,暂停监视chkdsk的对象镜像磁盘的镜像磁盘监视资源。
例:
clpmonctrl -s -m <mdw(镜像磁盘监视资源名)>使镜像磁盘处于被分离的状态。
例:
clpmdctrl --break <md(镜像磁盘资源名)>允许对镜像磁盘的访问。
例:
mdopen <md(镜像磁盘资源名)>通过命令提示符,对镜像磁盘的磁盘分区执行chkdsk或碎片整理。
重要
出现「由于其它进程正在使用卷,所以不能执行CHKDSK。在下次系统重启时,检查此卷吗?」提示时,请选择取消。
使对镜像磁盘的访问处于禁止状态。
例:
mdclose <md(镜像磁盘资源名)>用Cluster WebUI或clpmonctrl命令,重新展开监视镜像磁盘的镜像磁盘监视资源。
例:
clpmonctrl -r -m <mdw(镜像磁盘监视资源名)>自动镜像复归设置为无效时,通过镜像磁盘列表的手动操作执行镜像复归。
[在备份服务器上执行chkdsk/碎片整理时(共享型镜像磁盘)]
对于被设置为共享型镜像磁盘的磁盘分区,在备份服务器上执行修复模式的chkdsk或碎片整理时,通过镜像复制,由于主服务器磁盘镜像被覆盖,所以会失去文件系统的修复或最优化效果。本书中记载了关于以磁盘的错误检查为目的的chkdsk的步骤。
用Cluster WebUI或clpmonctrl命令,暂停chkdsk对象的监视共享型镜像磁盘的共享型镜像磁盘监视资源。
例:
clpmonctrl -s -m <hdw(共享型镜像磁盘监视资源名)>使用clphdsnapshot命令,分离共享型镜像磁盘,允许访问。
例:
clphdsnapshot --open <hd(共享型镜像磁盘资源名)>通过命令提示符,对共享型镜像磁盘的磁盘分区执行chkdsk或碎片整理。
重要
出现「由于其它进程正在使用卷,所以不能执行CHKDSK。在下次系统重启时,检查此卷吗?」提示时,请选择取消。
使用clphdsnapshot命令,将访问共享型镜像磁盘设置为禁止状态。
例:
clphdsnapshot --close <hd(共享型镜像磁盘资源名)>用Cluster WebUI或clpmonctrl命令,重新展开监视chkdsk对象的的镜像磁盘监视资源。
例:
clpmonctrl -r -m <hdw(共享型镜像磁盘监视资源名)>自动镜像复归设置为无效时,通过镜像磁盘列表的手动操作执行镜像复归。
2.12. 更换服务器的方法¶
在集群环境中更换服务器时,请按以下步骤操作。
设置新服务器,使其设置与故障服务器相同。
在使用共享磁盘时,新服务器请暂时不要连接共享磁盘。
计算机名,IP地址设置为与故障服务器相同。
请按照以前的方法登录或更新EXPRESSCLUSTER的License。
发生故障的服务器的本地磁盘上,有镜像磁盘/混合磁盘的集群分区,数据分区时,请和发生故障的服务器一样进行分区的分配和盘符的设置。如果保留发生故障的服务器的磁盘,则没有必要分配分区,盘符设置也和原来相同。
在使用共享磁盘时,安装EXPRESSCLUSTER Server时,请使用[共享磁盘的过滤设置]对连接共享磁盘的SCSI 控制器或 HBA 进行过滤设置。
设置完毕后请关机,切断电源。
重要
请使用[共享磁盘的过滤设置]对连接共享磁盘的SCSI 控制器或HBA 进行过滤设置。如果在没有进行过滤设置的状态下连接共享磁盘,则可执行损坏共享磁盘上的数据。
如果故障服务器还在运行,请关机,将服务器与共享磁盘或LAN分离,将集群中其他服务器的状态恢复为正常状态。(故障服务器的停止所引起的异常可以忽略。)
将新服务器连接到LAN上,启动服务器。在使用共享磁盘时,在共享磁盘也连接的状态下启动。
在使用共享磁盘时,使用新服务器上的磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理])确认可以看到共享磁盘,将盘符设置为与故障服务器相同。
由于访问限制,此时不能浏览共享磁盘的内容。
通过网络浏览器连接集群内正常工作的服务器启动Cluster WebUI编辑模式。在使用共享磁盘时,点击新建的服务器的[属性]->[HBA]标签页的[连接],确认和修改HBA和分区的信息。
重要
请使用[共享磁盘的过滤设置]对连接共享磁盘的SCSI 控制器或HBA 进行过滤设置。如果在没有设置过滤的状态下连接共享磁盘,则可执行损坏共享磁盘上的数据。
新的服务器使用的资源中有镜像磁盘资源或混合磁盘资源时,从Cluster WebUI操作模式中停止包含这些资源的切换组。
在集群中正常工作的服务器上,从命令提示符执行"clpcl --suspend --force",挂起集群。
由于一台服务器被认为是已经停止,所以不能使用Cluster WebUI执行挂起命令。
在Cluster WebUI的编辑模式中点击[应用配置文件],将集群配置信息应用到集群。
当"配置信息中存在某个磁盘信息与服务器上的磁盘信息不一致。是否进行自动修正?"弹出窗口显示时,请选择[是]
使用期间定制License时,请执行以下命令。
clplcnsc --reregister <保存License文件的文件夹路径>
使用Cluster WebUI的操作模式恢复集群,如果在6中有停止的组则启动。
注解
使用Cluster WebUI执行恢复时,将会显示"恢复集群失败。点击刷新按钮,或稍后重试。"的错误消息。因为新服务器不是挂起状态,所以才输出该错误消息,可以忽略不管。
Cluster WebUI的操作模式中点击新建的服务器的[开始服务器服务]。
从Cluster WebUI 的操作模式重新启动管理器。
集群的[集群属性]->[扩展]标签页中的[自动复归]设为[关闭]时,请在Cluster WebUI操作模式中点击重新安装EXPRESSCLUSTER的服务器的[恢复服务器]。
新的服务器使用的资源中有镜像磁盘资源或混合磁盘资源,并且集群的[集群属性]->[镜像磁盘]标签页中的[自动镜像复归]的选择框没有被选中的话,执行从镜像磁盘的列表到镜像磁盘/混合磁盘的全复制。
重要
更换其他的镜像磁盘型集群中的服务器时,虽然差分复制是自动执行的,差分复制完成之后,请另外手动执行全复制。不执行全复制时,镜像磁盘数据会不一致。
根据需要移动组。如果镜像磁盘/混合磁盘正在全面复制,请等待复制完成再移动。
2.13. 集群启动同步等待时间¶
即便集群中所有服务器的电源同时接通,EXPRESSCLUSTER也未必能够同时启动。集群关机重启也是一样,EXPRESSCLUSTER未必能够同时启动。
因此,EXPRESSCLUSTER启动时,某一服务器需要等待集群中的另一服务器启动。
初始值设置是5分钟。该等待时间可以通过Cluster WebUI的[集群属性]-[超时]标签页中的[同步等待时间]进行调整。
2.14. 更改服务器的配置(添加,删除)¶
2.14.1. 添加服务器(不使用镜像磁盘,共享型磁盘的环境时)¶
添加服务器时,请按以下步骤操作。
重要
在更改集群配置中添加服务器时,请不要进行其他更改(添加组资源等)。
- 需要为要添加的服务器注册License。注册License请参考《EXPRESSCLUSTER X 安装&设置指南》的"注册License"。
确定集群状态正常。
启动添加的服务器。如果使用了共享磁盘,请确定要添加的服务器上没有连接共享磁盘,然后再启动。
重要
使用共享磁盘时,在设置完毕,切断电源前请不要连接共享磁盘。否则可执行损坏共享磁盘上的数据。
在添加的服务器上进行配置EXPRESSCLUSTER服务器前的设置。但是如果要使用共享磁盘,在此时请不要进行磁盘的设置。
在服务器中配置EXPRESSCLUSTER服务器。在通信端口号设置中输入Cluster WebUI以及磁盘客户端的端口号。请设置与已配置好的服务器相同的端口号。使用共享磁盘时,请将连接共享磁盘的HBA设置为过滤。根据需要注册License。配置完毕关闭添加的服务器,切断电源。
重要
进行配置时,如果没有在[共享磁盘的过滤设置]中设置共享磁盘的过滤,则在配置完毕后也不要连接共享磁盘。否则可执行损坏共享磁盘上的数据。请重新安装EXPRESSCLUSTER,设置共享磁盘的过滤。
启动添加的服务器。使用共享磁盘时,请连接共享磁盘后启动服务器。
使用共享磁盘时,在添加的服务器上进行磁盘的设置。
使用磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理])确认可以看到共享磁盘。
设置作为磁盘资源的切换分区和混合磁盘资源的集群分区,数据分区使用的分区,使所有服务器都能够使用相同盘符访问该分区。
设置用于磁盘网络分区解决资源的磁盘心跳用分区,使所有服务器都能够使用相同盘符访问该分区。
由于访问限制,此时尚不能浏览共享磁盘的内容。
注解
对共享磁盘的分区的盘符进行更改/删除时,有时会操作失败。请根据以下规避方法进行设置。
从命令提示符上执行以下命令,删除盘符。
> mountvol (更改对象的)盘符>: /P
确认使用磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理])从更改对象磁盘删除盘符。
从[磁盘管理]添加盘符。
通过Web浏览器连接集群中其他服务器,点击Cluster WebUI编辑模式的[添加服务器]。
从Cluster WebUI编辑模式重新设置添加服务器的以下信息。
添加服务器的[属性]->[HBA]标签页中的HBA和分区的信息(使用共享磁盘时)
集群的[集群属性]->[NP解决]标签页中的磁盘心跳用分区的信息(使用共享磁盘时)
虚拟IP资源 [属性]->[详细]标签页中的添加服务器的发信方的IP地址信息 (使用虚拟IP资源时)
NIC Link Up/Down监视资源的[属性]->[监视(固有)]标签页中的添加服务器的IP地址(使用NIC Link Up/Down监视资源时)
AWS Elastic IP资源的[属性]->[详细]标签页中的添加服务器的ENI ID信息 (使用AWS Elastic IP资源时)
AWS虚拟IP资源的[属性]->[详细]标签页中的添加服务器的ENI ID信息 (使用AWS虚拟IP资源时)
AWS DNS资源的[属性]->[详细]标签页中的添加服务器的IP地址信息 (使用AWS DNS资源时)
重要
请在添加服务器的[属性]->[HBA]标签页中,对连接共享磁盘的SCSI 控制器或HBA进行过滤设置。如果在没有设置过滤的状态下连接共享磁盘,则可执行损坏共享磁盘上的数据。
Cluster WebUI编辑模式中点击失效切换组的[属性]。在[启动服务器]标签页中添加可启动的服务器。添加可启动服务器的操作只对需要的失效切换组执行。
点击Cluster WebUI的编辑模式的[应用配置文件],将集群配置信息反映到集群中。
显示询问执行反映动作的画面。请按照画面反映。
执行从Cluster WebUI的操作模式添加的服务器的[服务器开始服务]。
在Cluster WebUI的操作模式中点击[刷新],通过显示的信息确认集群是否正常。
如果需要复归服务器,请从Cluster WebUI的操作模式手动复归。
2.14.2. 添加服务器(使用镜像磁盘,共享型磁盘的环境时)¶
添加服务器时,请按以下步骤操作。
重要
在更改集群配置中添加服务器时,请不要进行其他更改(添加组资源等)。
- 需要为要添加的服务器注册License。注册License请参考《EXPRESSCLUSTER X 安装&设置指南》的"注册License"。
确定集群状态正常。
启动添加的服务器。如果使用了共享磁盘,请确定要添加的服务器上没有连接共享磁盘,然后再启动。
重要
使用共享磁盘时,在设置完毕,切断电源前请不要连接共享磁盘。否则可执行损坏共享磁盘上的数据。
在添加的服务器上进行配置EXPRESSCLUSTER服务器前的设置。但是如果要使用共享磁盘,在此时请不要进行磁盘的设置。
在服务器中配置EXPRESSCLUSTER服务器。在通信端口号设置中输入Cluster WebUI以及磁盘客户端的端口号。请设置与已配置好的服务器相同的端口号。使用共享磁盘时,请将连接共享磁盘的HBA设置为过滤。根据需要注册License。配置完毕关闭添加的服务器,切断电源。
重要
进行配置时,如果没有在[共享磁盘的过滤设置]中设置共享磁盘的过滤,则在配置完毕后也不要连接共享磁盘。否则可执行损坏共享磁盘上的数据。请重新安装EXPRESSCLUSTER,设置共享磁盘的过滤。
启动添加的服务器。使用共享磁盘时,请连接共享磁盘后启动服务器。
使用共享磁盘时,在添加的服务器上进行磁盘的设置。
使用磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理])确认可以看到共享磁盘。
设置作为磁盘资源的切换分区和混合磁盘资源的集群分区,数据分区使用的分区,使所有服务器都能够使用相同盘符访问该分区。
设置用于磁盘网络分区解决资源的磁盘心跳用分区,使所有服务器都能够使用相同盘符访问该分区。
由于访问限制,此时尚不能浏览共享磁盘的内容。
注解
对共享磁盘的分区的盘符进行更改/删除时,有时会操作失败。请根据以下规避方法进行设置。
从命令提示符上执行以下命令,删除盘符。
mountvol (更改对象的)盘符>: /P
确认使用磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理])从更改对象磁盘删除盘符。
从[磁盘管理]添加盘符。
通过Web浏览器连接集群中其他服务器,点击Cluster WebUI编辑模式的[添加服务器]。
从Cluster WebUI编辑模式重新设置添加服务器的以下信息。
添加服务器的[属性]->[HBA]标签页中的HBA和分区的信息(使用共享磁盘时)
集群的[集群属性]->[NP解决]标签页中的磁盘心跳用分区的信息(使用共享磁盘时)
虚拟IP资源 [属性]->[详细]标签页中的添加服务器的发信方的IP地址信息 (使用虚拟IP资源时)
NIC Link Up/Down监视资源的[属性]->[监视(固有)]标签页中的添加服务器的IP地址(使用NIC Link Up/Down监视资源时)
AWS Elastic IP资源的[属性]->[详细]标签页中的添加服务器的ENI ID信息 (使用AWS Elastic IP资源时)
AWS虚拟IP资源的[属性]->[详细]标签页中的添加服务器的ENI ID信息 (使用AWS虚拟IP资源时)
AWS DNS资源的[属性]->[详细]标签页中的添加服务器的IP地址信息 (使用AWS DNS资源时)
重要
请在添加服务器的[属性]->[HBA]标签页中,对连接共享磁盘的SCSI 控制器或HBA进行过滤设置。如果在没有设置过滤的状态下连接共享磁盘,则可执行损坏共享磁盘上的数据。
在添加的服务器中使用共享型镜像磁盘时,点击Cluster WebUI编辑模式中的[服务器]的[属性]。从[服务器组]标签页添加可以启动的服务器。请仅对需要的切换组添加可以启动的服务器。
Cluster WebUI编辑模式中点击失效切换组的[属性]。在[启动服务器]标签页中添加可启动的服务器。添加可启动服务器的操作只对需要的失效切换组执行。
点击Cluster WebUI的编辑模式的[应用配置文件],将集群配置信息反映到集群中。请按照画面操作(必须OS重启时)。
如果需要复归服务器,请从Cluster WebUI的操作模式手动复归。
2.14.3. 删除服务器(不使用镜像磁盘,共享型磁盘的环境时)¶
删除服务器时,请按以下步骤操作。
重要
在更改集群配置中删除服务器时,请不要进行其他更改(添加组资源等)。
有关在要删除的服务器上注册的License,请参考以下内容。
CPU License不需要对应处理。
- 卸载ExpressCluster时,VM node License和node License将被丢弃。如有必要,请避开Lincens序列号和license密钥。
期间定制License不需要对应处理。如有未启动的License,会自动回收并发送到其他服务器。
确定集群状态正常。如果要删除的服务器上有已经启动的组,请将这些组移动到其他服务器上。
如果要删除的服务器已经登录在服务器组内,则点击Cluster WebUI编辑模式的[服务器]的[属性]。在[服务器组]标签页中从可以启动的服务器内删除对象服务器。
Cluster WebUI编辑模式下点击要删除的服务器的[删除服务器]。
点击Cluster WebUI的编辑模式的[应用配置文件],将集群配置信息反映到集群中。
显示询问执行反映动作的画面。请按照画面反映。
在Cluster WebUI操作模式中点击[刷新],通过显示的信息确认集群是否正常。
已删除的服务器是集群未构筑状态。卸载要删除服务器的EXPRESSCLUSTER Server时,请参考《EXPRESSCLUSTER X 安装&设置指南》-" 卸载/重装EXPRESSCLUSTER" - "卸载步骤"。
2.14.4. 删除服务器(使用镜像磁盘,共享型磁盘的环境时)¶
删除服务器时,请按以下步骤操作。
重要
在更改集群配置中删除服务器时,请不要进行其他更改(添加组资源等)。
有关在要删除的服务器上注册的License,请参考以下内容。
CPU License不需要对应处理。
- 卸载ExpressCluster时,VM node License和node License将被丢弃。如有必要,请避开Lincens序列号和license密钥。
期间定制License不需要对应处理。如有未启动的license,会自动回收并分发到其他服务器。
使用镜像磁盘资源和共享型镜像磁盘资源时,要从Cluster WebUI操作模式停止组。
确定集群状态正常。(要删除的服务器的异常除外。)
通过Web浏览器连接集群内的其他服务器,启动Cluster WebUI。
如果要删除的服务器已经登录在服务器组内,则点击Cluster WebUI编辑模式的[服务器]的[属性]。在[服务器组]标签页中从可以启动的服务器内删除对象服务器。
Cluster WebUI编辑模式下点击要删除的服务器的[删除服务器]。
在Cluster WebUI的编辑模式中点击镜像磁盘资源和共享型镜像磁盘资源的[删除资源]。
点击Cluster WebUI的编辑模式的[应用配置文件],将集群配置信息反映到集群中。请按照画面操作(必须OS重启时)。
在Cluster WebUI操作模式中点击[刷新],通过显示的信息确认集群是否正常。
已删除的服务器是集群未构筑状态。卸载要删除服务器的EXPRESSCLUSTER Server时,请参考《EXPRESSCLUSTER X 安装&设置指南》-"卸载/重装EXPRESSCLUSTER" - "卸载步骤"。
2.15. 更改服务器IP地址¶
开始操作后,需要更改IP地址时,请按以下步骤操作。
2.15.1. 不需要更改镜像磁盘连接的IP地址时¶
确定集群状态正常。
使用Cluster WebUI操作模式挂起集群。
从[网上邻居]的[属性]更改OS的网络配置。
使用Cluster WebUI编辑模式根据更改的IP地址更改[集群属性]的 [私网] 标签页中的IP地址。
NIC Link Up/Down监视资源中正在使用更改的IP地址时,在监视资源属性的[监视(固有)]标签页中更改IP地址。
从Cluster WebUI编辑模式点击 [应用配置文件],将集群配置信息反映到集群中。
使用Cluster WebUI操作模式恢复集群。
2.15.2. 需要更改镜像磁盘连接的IP地址时¶
确定集群状态正常。
使用Cluster WebUI操作模式挂起集群。
从[网上邻居]的[属性]更改OS的网络配置。
使用Cluster WebUI 的编辑模式据更改的IP地址更改[集群属性]的 [私网] 标签页中的IP地址。
NIC Link Up/Down监视资源中正在使用更改的IP地址时,在监视资源属性的[监视(固有)]标签页中更改IP地址。
从Cluster WebUI 的编辑模式点击[应用配置文件],将集群配置信息反映到集群中。
在所有服务器上重启OS。
2.16. 更改主机名¶
开始操作后,需要更改服务器的主机名时,请按以下步骤操作。
2.16.1. 不存在镜像磁盘/共享型镜像磁盘的环境¶
确定集群状态正常。
如果在要更改主机名的服务器上启动了组,则移动组。
在Cluster WebUI操作模式下挂起集群。
更改[我的电脑]属性中的主机名。
注解
此处请不要重启OS。在OS重启完成之前将无法反映集群配置信息。
Cluster WebUI编辑模式下点击服务器的[更改服务器名]。
把通过Cluster WebUI编辑模式更改了服务器名的集群配置信息文件暂时保存在通过集群服务器可以访问的磁盘空间上。
在集群服务器上使用Cluster WebUI的场合,保存在本地磁盘上。在其它的PC上使用Cluster WebUI时,保存在通过集群服务器可访问的共享目录里,或者临时保存在外部磁盘上再复制到集群服务器的本地磁盘上。
在任意一台集群服务器上执行以下命令,上传保存的集群配置信息。
clpcfctrl --push -x <集群配置路径> --nocheck
注解
检查集群配置信息时,请在上传集群配置信息之前执行此操作。
在更改了主机名的服务器上关闭OS。
在Cluster WebUI操作模式下恢复集群。
在Cluster WebUI操作模式下重启管理器。
启动更改了主机名的服务器。集群的[集群属性]->[扩展]标签页中的[自动复归]设为[关闭]时,请使用Cluster WebUI操作模式手动恢复。
2.16.2. 存在镜像磁盘/共享型镜像磁盘的环境中¶
确定集群状态正常。
使用Cluster WebUI操作模式停止集群。
更改[我的电脑]属性中的主机名。
注解
此处请不要重启OS。在OS重启完成之前将无法反映集群配置信息。
Cluster WebUI 编辑模式下点击服务器的[更改服务器名]。
把通过Cluster WebUI更改了服务器名的集群配置信息文件暂时保存在通过集群服务器可以访问的磁盘空间上。
在集群服务器上使用Cluster WebUI的场合,保存在本地磁盘上。在其它的PC上使用Cluster WebUI时,保存在通过集群服务器可访问的共享目录里,临时保存在外部磁盘上则复制到集群服务器的本地磁盘上。
打开所有服务器的[管理工具]的[服务],停止EXPRESSCLUSTER Disk Agent服务。
在任意一台集群服务器上执行以下命令,上传保存的集群配置。
clpcfctrl --push -x <集群配置路径> --nocheck
注解
检查集群配置信息时,请在上传集群配置信息之前执行此操作。
在所有服务器上重启OS。
2.17. 更换网卡¶
更换网卡时按以下步骤操作。更换镜像磁盘连接中使用的网卡时操作步骤相同。
确定集群状态正常。(要更换的网卡的异常除外。)
要更换网卡的服务器上启动了组时,移动组。如果要更换的网卡正在镜像连接中被使用,并且该镜像连接又没有使用其他网卡时,由于更换网卡,镜像磁盘恢复之前不能移动组,所以应先使用Cluster WebUI停止组。
要更换网卡的服务器中把服务的启动类型更改为手动启动。
clpsvcctrl.bat --disable -a
在Cluster WebUI上点击要更换网卡的服务器的[服务器关机]。
关机后更换网卡。
启动已更换了网卡的服务器。
在[网上邻居]中的[属性]配置OS的网络配置。请配置与更换网卡前相同的网络设置。
打开更换了网卡的服务器的服务([控制面板] > [管理工具] > [服务]),将EXPRESSCLUSTER Server服务,步骤3中更改为手动启动的各个服务的[属性]->[启动类型]设为[自动],重启服务器上的OS。
集群的[集群属性] -> [扩展]标签页中的[自动复归]设为[关闭]时,请使用Cluster WebUI手动恢复。
需要时移动组。
2.19. 更改磁盘配置 -镜像磁盘-¶
2.19.1. 更换磁盘¶
关于镜像磁盘的更换请参考60页的"更换镜像磁盘"。
2.19.2. 添加磁盘¶
要添加镜像磁盘使用的磁盘时,请按以下步骤操作。
确定集群状态正常。
要添加磁盘的服务器上启动了组时,移动组。
使用Cluster WebUI操作模式关闭其中一端的服务器,切断电源。
添加磁盘,启动服务器。
将服务器恢复到集群中,如果已经存在镜像磁盘,请重新构建镜像。
在添加了磁盘的服务器上设置磁盘。
使用磁盘管理([控制面板]>[管理工具]>[计算机管理]>[磁盘管理]),预留镜像磁盘用数据分区和集群分区。请将两个服务器数据分区和集群分区的盘符设置为相同。
在其他服务器上执行2~6的操作。
停止从Cluster WebUI的操作模式添加镜像磁盘资源的组。
使用Cluster WebUI操作模式挂起集群。
Cluster WebUI编辑模式中点击要添加镜像磁盘资源的组的[添加资源],添加镜像磁盘资源。
点击Cluster WebUI编辑模式的[应用配置文件],将集群配置信息反映到集群中。
使用Cluster WebUI操作模式恢复集群。
启动添加的镜像磁盘资源或添加了镜像磁盘资源的组。如果通过[集群属性]设置了[自动镜像初始构建],则将自动开始镜像的初始构建。如果没有设置[自动镜像初始构建],请手动执行镜像的初始构建。
需要时移动组。
2.19.3. 删除磁盘¶
要删除镜像磁盘所使用的磁盘时,请按以下步骤操作。
确定集群状态正常。
使用Cluster WebUI操作模式停止要删除镜像磁盘资源的组。
使用Cluster WebUI操作模式挂起集群。
Cluster WebUI编辑模式中点击要删除镜像磁盘资源的组。点击镜像磁盘资源的 [删除资源]。
点击Cluster WebUI编辑模式的[应用配置文件],将集群配置信息反映到集群中。
使用Cluster WebUI操作模式恢复集群。
使用Cluster WebUI操作模式启动组。
使用Cluster WebUI操作模式关闭没有启动组的服务器,切断电源。
拔掉磁盘,启动服务器。
移动组,在其他服务器上执行8~9的操作。
需要时移动组。
2.20. 备份/恢复数据¶
备份/恢复数据的操作示意图如下。具体的备份方法请参考各备份软件的手册。
共享磁盘(Shared Disk),本地磁盘(Local Disk)的数据备份到连接当前服务器(Server 1)的设备中。
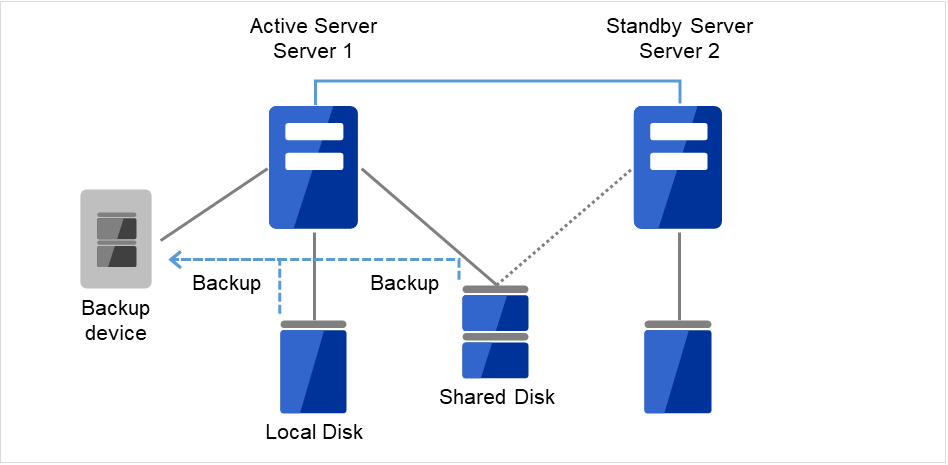
图 2.2 单向待机中的备份示例 (1)¶
当前服务器(Server1)发生故障时,连接到待机服务器(Server 2)的设备中备份共享磁盘(Shared Disk),本地磁盘(Local Disk)的数据。
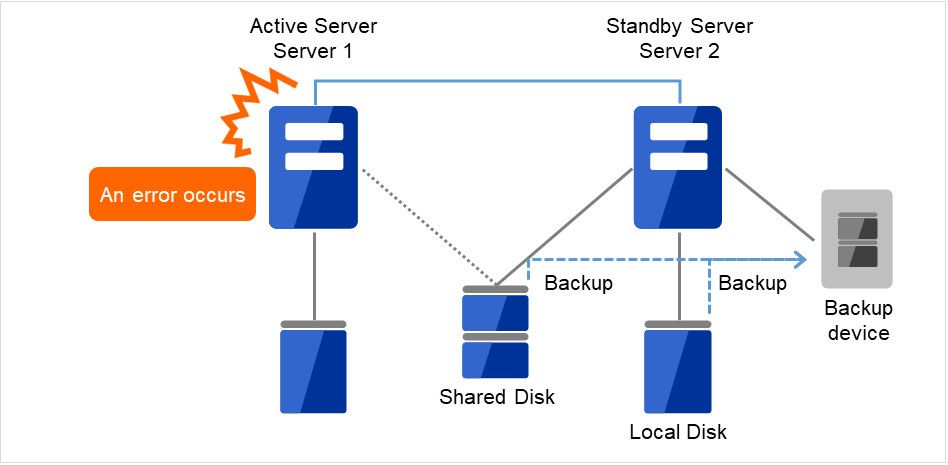
图 2.3 单向待机中的备份示例 (2)¶
2.21. 执行快照备份¶
如果使用镜像磁盘/共享型镜像磁盘,可以中断镜像,作为快照图像对待机系的数据分区进行备份。这成为快照备份。
实施快照备份时,因为镜像会被临时解除,所以不能对复制目标的待机系服务器/服务器组进行失效切换。这种状态下,解除对待机系服务器的数据分区的访问限制,进行备份。
从快照状态恢复时,请先限制磁盘访问,重新构建镜像。
关于备份的详细内容请参考各备份软件的说明书。
注解
中断镜像时,根据镜像中断的时机,有可执行无法保证复制目的地数据的NTFS及作为程序数据的完整性。
2.21.1. 快照备份操作步骤¶
对镜像磁盘实施快照备份时,请按以下步骤操作。
在要进行备份的服务器端,停止监视备份目标镜像磁盘的镜像磁盘监视资源。
clpmonctrl -s -m <mdw(镜像磁盘监视资源名)>
分离镜像磁盘。
clpmdctrl --break <md(镜像磁盘资源名)>
将镜像磁盘设置为可访问状态。
mdopen <md(镜像磁盘资源名)>
此时请备份必要的文件。
将镜像磁盘设置为禁止访问的状态。
mdclose <md(镜像磁盘资源名)>
启动监视镜像磁盘的镜像磁盘监视资源。
clpmonctrl -r -m <mdw(镜像磁盘监视资源名)>
将自动镜像复归设置为无效时,通过镜像磁盘列表手动操作镜像复归。
对共享型镜像磁盘实施快照备份时,在复制目标的待机系服务器组的任一服务器上通过以下步骤进行备份。
在要进行备份的服务器端执行以下命令。
clphdsnapshot --open <共享型镜像磁盘资源名>
因为对数据分区的访问限制被解除,请备份所需的文件。
在执行了备份的服务器中,执行以下命令重新开始镜像。
clphdsnapshot --close <共享型镜像磁盘资源名>
如果自动镜像复归被设置为无效,则需要通过镜像磁盘列表手动操作恢复镜像。
命令的相关内容请参考《参考指南》的"EXPRESSCLUSTER命令参考"。
2.22. 以磁盘映像备份镜像磁盘/共享型镜像磁盘¶
以磁盘映像备份镜像磁盘/共享型镜像磁盘用的分区(集群分区和数据分区)时, 请按照以下任一步骤进行。
注解
clpbackup --pre或者clpbackup --post, 然后在服务器组内的剩余服务器上执行clpbackup --pre --only-shutdown或者clpbackup --post --only-reboot。步骤中,把服务器组内的当前服务器作为上一服务器的指南, 但是在服务器组内首先执行命令的第一台服务器不一定必须是当前服务器。另外,如果服务器组中只有一台服务器时, 就没有必要在下一个服务器组内的剩余服务器中进行clpbackup --pre --only-shutdown或者clpbackup --post --only-reboot。※ 当前服务器是服务器组中当前负责发送和接收镜像数据以及写入磁盘的服务器。当前系统中,启动共享型镜像磁盘资源的服务器为当前服务器。待机系统的当前服务器接收从当前系统的当前服务器发送来的镜像数据,并将其写入到待机系统的镜像磁盘。Some invalid status. Check the status of cluster." 的错误且服务器未关机时, 请稍等后再次执行[clpbackup]命令。保留(宕机后重新启动)Suspension (Isolated)。此时,请执行[clpcl]命令(--return 选项),或者在Cluster WebUI的 [状态] 标签页中进行 [恢复服务器] 的操作。clpcl --return另外,服务器复归后,失效切换组未启动时如有必要请启动。参见
关于clpbackup命令请参考《参考指南》的 "EXPRESSCLUSTER命令参考" 的 "准备磁盘映像备份(clpbackup命令)"。
2.22.1. 同时备份当前系统/待机系统的镜像磁盘时¶
请使用Cluster WebUI或[clpmdstat] / [clphdstat]命令确认镜像的状态。
镜像磁盘资源时:
clpmdstat --mirror <md资源名>
共享型镜像磁盘资源时:
clphdstat --mirror <hd资源名>
注解
对于共享型镜像磁盘资源,请确认当前系统/待机系统的服务器组的哪台服务器是当前服务器。
正在运行失效切换组(业务)时,请停止失效切换组。
- 在当前系统/待机系统的两服务器上,请逐个执行以下命令。※ 共享型镜像磁盘资源时,请在各服务器组的当前服务器上逐个执行。
clpbackup --pre
注解
执行后,镜像状态更改为备份用,集群服务自动启动设置关闭,服务器关闭。
共享型镜像磁盘资源时,当前服务器关机后,请在剩余的服务器上逐个执行以下命令。
clpbackup --pre --only-shutdown
注解
执行后,则集群服务自动启动设置关闭,服务器关机。
请在两个服务器上执行备份。
- 备份操作完成后,请启动当前系统/待机系统的两服务器,逐个执行以下命令。※ 共享型镜像磁盘资源时,启动所有服务器后,请首先在当前系统/待机系统的各当前服务器上,逐个执行以下命令。
clpbackup --post
注解
执行后,则镜像状态恢复正常,集群服务自动启动设置打开,服务器重启。
共享型镜像磁盘时,先前的各当前服务器开始重启之后,请在剩余的所有服务器上逐个执行以下命令。
clpbackup --post --only-reboot
注解
执行后,则集群服务自动启动设置打开,服务器重启。
启动两系统的服务器后,请使用Cluster WebUI 或 [clpmdstat] / [clphdstat]命令确认镜像的状态。
2.22.2. 当前系统/待机系统上逐个对单个服务器备份镜像磁盘时¶
按照如下步骤,请参考 " 备份待机系统的镜像磁盘时",交替进行备份。
请参考 "备份待机系统的镜像磁盘时" 进行待机系统的磁盘备份作业。
备份作业完成后,当镜像复归完成并且当前系统和待机系统的镜像磁盘处于同步状态时,请将失效切换组从当前系统移动到待机系统。
请参考 "备份待机系统的镜像磁盘时" 进行原当前系统的磁盘备份作业。
备份作业完成后,当镜像复归完成并且当前系统和待机系统的镜像磁盘处于同步状态时,如有必要请移动失效切换组。
2.22.3. 备份待机系统的镜像磁盘时¶
请使用Cluster WebUI或[clpmdstat] / [clphdstat]命令确认镜像是否可以正常同步。
镜像磁盘资源时:
clpmdstat --mirror <md资源名>
共享型镜像磁盘资源时:
clphdstat --mirror <hd资源名> clphdstat --active <hd资源名>
注解
共享型镜像磁盘资源时,请确认待机系统的服务器组的当前服务器是哪个服务器。
为了确保写入镜像领域的数据的静止点, 请停止包含镜像磁盘资源或共享型镜像磁盘资源的失效切换组(业务)。
注解
停止失效切换组可以防止在写入过程中备份数据, 防止缓存将数据写入镜像区域而不进行备份。
- 中断镜像同步。首先,为了防止自动镜像复归运行,请通过Cluster WebUI或者[clpmonctrl]命令, 暂停当前系统/待机系统双方的所有镜像磁盘监视资源/共享型镜像磁盘监视资源。
clpmonctrl -s -h <服务器名> -m <监视资源名>
接着,在Cluster WebUI的 [镜像磁盘] 标签页上对待机系统(备份端)的所有镜像磁盘资源/共享型镜像磁盘资源进行 [镜像中断] 操作后状态更改为"异常" (RED), 或者对所有的镜像磁盘资源/共享型镜像磁盘资源在待机系统(备份端)的服务器上执行[clpmdctrl] / [clphdctrl]命令(--break选项), 请中断所有的镜像同步。镜像磁盘资源时:
clpmdctrl --break <md资源名>
共享型镜像磁盘资源时:
clphdctrl --break <hd资源名>
注解
请在待机系统的当前服务器上执行。
参见
关于clpmonctrl命令请参考《参考指南》的 "EXPRESSCLUSTER命令参考" 的 "控制监视资源(clpmonctrl命令)"。
如果要立刻重新开始业务,请在当前系统(不备份)的服务器中启动失效切换组(业务)。
- 待机系统的服务器中,请执行以下命令。※ 共享型镜像磁盘时,请在待机服务器组内的1台服务器中执行。
clpbackup --pre
注解
执行后,则镜像状态更改为备份用,集群服务自动启动设置关闭,服务器关机。
共享型镜像磁盘时,请在待机服务器组内的剩余服务器上执行以下命令。
clpbackup --pre --only-shutdown
注解
执行后,则集群服务自动启动设置关闭,服务器关机。
请在待机系统的服务器上进行磁盘映像的备份。
- 备份作业完成之后,请在待机系统服务器上执行以下命令。※ 共享型镜像磁盘资源时,启动待机系统的所有服务器之后,请在待机服务器组内的1台服务器上执行以下命令。
clpbackup --post
注解
执行后,则镜像状态恢复正常,集群服务自动启动设置打开,服务器重启。
共享型镜像磁盘时,请在待机服务器组内的剩余服务器上执行以下命令。
clpbackup --post --only-reboot
注解
执行后,则集群服务自动启动设置打开,服务器重启。
- 启动待机系统的服务器。如果镜像磁盘监视资源/共享型镜像磁盘监视资源处于暂停状态时, 请通过Cluster WebUI或者[clpmonctrl]命令重新启动。
clpmonctrl -r -h <服务器名> -m <监视资源名>
如果失效切换组(业务)保持停止状态(上一步中没有立刻重新开始), 则可以在当前系统的服务器上启动失效切换组(业务)。
- 如果启用了自动镜像复归,则将自动进行镜像复归,并且镜像将会变为正常状态。如果没有进行自动镜像复归,没有回到正常状态, 请使用Cluster WebUI或者[clpmdctrl] / [clphdctrl] 命令执行镜像复归。
镜像磁盘资源时:
clpmdctrl --recovery <md资源名>
共享型镜像磁盘资源时:
clphdctrl --recovery <hd资源名>
注解
共享型镜像磁盘资源时,请在当前系统的当前服务器上执行。
2.23. 恢复磁盘映像到镜像磁盘/共享型镜像磁盘¶
镜像磁盘/共享型镜像磁盘用的分区(集群分区和数据分区)中, 通过 "以磁盘映像备份镜像磁盘/共享型镜像磁盘" 恢复已备份的磁盘映像时, 请按照以下步骤进行。
注解
clprestore --post或者clprestore --post --skip-copy, 接着在服务器组内的剩余服务器上执行clprestore --post --only-reboot。步骤中,把服务器组内的当前服务器作为上一服务器的指南, 但是在服务器组内首先执行命令的第一台服务器不一定必须是当前服务器。另外,如果服务器组中只有一台服务器时, 就没有必要在下一个服务器组内的剩余服务器中进行clprestore --post --only-reboot。※ 当前服务器是服务器组中当前负责发送和接收镜像数据以及写入磁盘的服务器。当前系统中,启动共享型镜像磁盘资源的服务器为当前服务器。待机系统的当前服务器接收从当前系统的当前服务器发送来的镜像数据,并将其写入到待机系统的镜像磁盘。Some invalid status. Check the status of cluster." 的错误且服务器未关机时, 请稍等后再次执行[clprestore]命令。Invalid configuration file." 等的错误且无法重新启动时, 请确认配置信息是否登录,或者EXPRESSCLUSTER的安装和防火墙设置等是否有问题。保留(宕机后重新启动)Suspension (Isolated)。此时,请执行[clpcl]命令(--return 选项)或者在Cluster WebUI的 [状态] 标签页上操作 [恢复服务器]。clpcl --return另外,服务器复归后,失效切换组未启动时如有必要请启动。
从命令提示符上执行以下命令,删除盘符。
mountvol <(更改对象的)盘符>: /P通过磁盘管理 ([控制面板] > [管理工具] > [计算机管理] > [磁盘管理]) 确认已从更改对象磁盘删除盘符。
从 [磁盘管理] 添加盘符。
请通过Cluster WebUI的 [导出配置文件],将配置文件(zip格式)保存到磁盘中。
请在集群所属的任意服务器可以访问的磁盘上,通过其zip格式文件打开配置信息文件。
在服务器上执行[clpcfctrl]命令,请将已打开的配置信息文件(clp.conf)发送给所有服务器。
clpcfctrl --push -x <有已打开的配置信息文件clp.conf的目录路径> --force --nocheck参见
有关clprestore命令请参考《参考指南》的 "EXPRESSCLUSTER命令参考" 的 "磁盘映像恢复后的处理(clprestore命令)"。
有关[clpcfctrl]命令请参考《参考指南》的 "EXPRESSCLUSTER命令参考" 的 "执行集群生产,集群配置信息备份(clpcfctrl命令)"。
2.23.1. 当前系统/待机系统的两服务器中同时恢复同一镜像磁盘映像时¶
重要
本步骤中,必须事先在镜像磁盘资源/共享型镜像磁盘资源的设置中关闭 [初始镜像构筑]。打开 [初始镜像构筑] 时,由于会出错,所以请使用Cluster WebUI设置关闭。
正在运行失效切换组(业务)时,请停止失效切换组。
- 当前系统/待机系统的所有服务器中,请逐个执行以下命令。※ 未启动OS,必须重新安装或恢复OS和EXPRESSCLUSTER时,在此服务器中进行此作业后,请执行以下命令。
clprestore --pre
注解
执行后,则集群服务自动启动设置关闭,服务器关机。
- 当前系统/待机系统的两服务器中,请恢复集群分区以及数据分区。※ 请在当前系统和待机系统中恢复同一磁盘映像。
请在当前系统/待机系统双方的恢复作业完成后,启动所有服务器。
- 请在各服务器上,使用磁盘的管理 ([控制面板] > [管理工具] > [计算机管理] > [磁盘管理]), 重新设置已恢复的数据分区或者集群分区等的盘符。※ 即使盘符没有更改,也请明确重新设置。
注解
对于共享型镜像磁盘,如果对共享磁盘的分区进行盘符的更改/删除,则会操作失败。此时,使用[mountvol]命令删除盘符后,请通过磁盘的管理重新设置。mountvol <(更改对象的)盘符>: /P
- 请在启动Cluster WebUI后,设置为 [编辑模式]。请在各镜像磁盘资源/共享型镜像磁盘资源的设置中,逐个确认/重新选择各服务器的集群分区和数据分区。
- 镜像磁盘资源时,有关资源属性的 [详细] 标签页的 [可以启动组的服务器] 上的各服务器,请选择服务器,点击 [编辑] 按钮。[选择分区] 中点击 [连接] 按钮,请逐个确认是否正确选择数据分区以及集群分区。未正确选择时,请选择正确分区,点击 [确定] 按钮。
- 共享型镜像磁盘资源时,请点击资源属性的 [详细] 标签页的 [服务器组] 的 [信息获取] 按钮。请更新各分区的GUID后,点击 [确定] 按钮。
另外,在各镜像磁盘资源/共享型镜像磁盘资源的设置中, 如果已打开 [初始镜像构筑],请更改为关闭。
通过Cluster WebUI确认/修改设置后,请执行 [应用配置文件]。
注解
[应用配置文件] 时,显示 [配置信息中存在某个磁盘信息与服务器上的磁盘信息不一致。是否进行自动修正?] 的消息, 请选择 [是]。
- 应用配置文件完成后,请在当前系统/待机系统的两服务器中,逐个执行以下命令。※ 对于共享型镜像磁盘,请在当前系统/待机系统的各服务器组内的1台服务器上(例如各服务器组的当前服务器上),逐个执行。
clprestore --post --skip-copy
注解
执行后,则更新集群分区,集群服务自动启动设置打开,服务器重启。对于共享型镜像磁盘,处理可执行会需要一些时间。 - 对于共享型镜像磁盘时,已执行上述步骤9命令的服务器开始重启, 请在服务器组内的剩余所有服务器上,逐个执行以下命令。
clprestore --post --only-reboot
注解
执行后,则集群服务自动启动设置打开,服务器重启。
- 请在当前系统/待机系统的所有服务器启动之后,使用Cluster WebUI或[clpmdstat] / [clphdstat]命令确认各镜像状态。当前系统/待机系统的双方的镜像状态变为"正常" (GREEN)。
镜像磁盘资源时:
clpmdstat --mirror <md资源名>
共享型镜像磁盘资源时:
clphdstat --mirror <hd资源名>
注解
当前系统/待机系统的镜像状态变为"正常" (GREEN) - "异常" (RED)时, 在"正常" (GREEN) 的服务器上执行Cluster WebUI的 [镜像磁盘] 标签页的 [差量复制] 操作, 或者执行[clpmdctrl] / [clphdctrl]命令(--recovery选项)后进行镜像复归。镜像磁盘资源时:
clpmdctrl --recovery <md资源名>
- 共享型镜像磁盘资源时:(※ 请在当前服务器上执行。)
clphdctrl --recovery <hd资源名>
另外,请使用Cluster WebUI或者[clpstat]命令确认失效切换的状态。 如果有启动失败的失效切换组,请使用Cluster WebUI或者[clpgrp]命令,停止该失效切换组。 此后,可以启动(开始业务)失效切换组。注解
但是,如果当前系统/待机系统的双方镜像状态变成"异常" (RED)时, 请使用Cluster WebUI的 [镜像磁盘] 标签页的 [强制镜像复归] 操作或者[clpmdctrl] / [clphdctrl]命令(--force选项), 将要作为复制源的镜像状态更改为"正常" (GREEN) 。另外,请使用Cluster WebUI或者[clpstat]命令确认失效切换组的状态。如果有启动失败的失效切换组,请使用Cluster WebUI或者[clpgrp]命令停止。之后,作为最新的服务器中可以启动(开始业务)失效切换组。之后,请进行镜像复归。参见
关于[clpmdctrl] / [clphdctrl]命令请参考《参考指南》的 "EXPRESSCLUSTER命令参考" 的 "镜像磁盘资源操作(clpmdctrl命令)" 和 "共享型镜像磁盘资源操作(clphdctrl命令)"。
更改 [初始镜像构筑] 的设置时,如有必要,请使用Cluster WebUI还原设置。
2.23.2. 当前系统/待机系统的两服务器中同时恢复镜像磁盘映像时¶
参见
关于当前系统/待机系统的两系统上的镜像磁盘上恢复同一映像的步骤,请参考 "当前系统/待机系统的两服务器中同时恢复同一镜像磁盘映像时"。
正在运行失效切换组(业务)时,请停止失效切换组。
- 当前系统/待机系统的所有服务器中,请逐个执行以下命令。※ 未启动OS,必须重新安装或恢复OS和EXPRESSCLUSTER时,在此服务器中进行此作业后,请执行以下命令。
clprestore --pre
注解
执行后,则集群服务自动启动设置关闭,服务器关机。
当前系统/待机系统的两服务器中,请恢复集群分区以及数据分区。
请在当前系统/待机系统双方的恢复作业完成后,启动所有服务器。
- 请在各服务器上,使用磁盘的管理 ([控制面板] > [管理工具] > [计算机管理] > [磁盘管理]), 重新设置已恢复的数据分区或者集群分区等的盘符。※ 即使盘符没有更改,也请明确重新设置。
- 请在启动Cluster WebUI后,设置为 [编辑模式]。请在各镜像磁盘资源/共享型镜像磁盘资源的设置中,逐个确认/重新选择各服务器的集群分区和数据分区。
- 镜像磁盘资源时,有关资源属性的 [详细] 标签页的 [可以启动组的服务器] 上的各服务器,请选择服务器,点击 [编辑] 按钮。[选择分区] 中点击 [连接] 按钮,请逐个确认是否正确选择数据分区以及集群分区。未正确选择时,请选择正确分区,点击 [确定] 按钮。
- 共享型镜像磁盘资源时,请点击资源属性的 [详细] 标签页的 [服务器组] 的 [信息获取] 按钮。请更新各分区的GUID后,点击 [确定] 按钮。
通过Cluster WebUI确认/修改设置后,请执行 [应用配置文件]。
注解
[应用配置文件] 时,显示 [配置信息中存在某个磁盘信息与服务器上的磁盘信息不一致。是否进行自动修正?] 的消息, 请选择 [是]。
- 应用配置文件完成后,请在当前系统/待机系统的两服务器中,逐个执行以下命令。※ 对于共享型镜像磁盘,请在当前系统/待机系统的各服务器组内的1台服务器上(例如各服务器组的当前服务器上),逐个执行。
clprestore --post
注解
执行后,则更新集群分区,集群服务自动启动设置打开,服务器重启。对于共享型镜像磁盘,处理可执行会需要一些时间。 对于共享型镜像磁盘时,已执行上述步骤8命令的服务器开始重启, 请在服务器组内的剩余所有服务器上,逐个执行以下命令。
clprestore.sh --post --only-reboot
注解
执行后,则集群服务自动启动设置打开,服务器重启。
- 请在当前系统/待机系统的所有服务器启动之后,使用Cluster WebUI或[clpmdstat] / [clphdstat]命令确认各镜像状态。当前系统/待机系统的双方镜像状态变成"异常" (RED)。
镜像磁盘资源时:
clpmdstat --mirror <md资源名>
共享型镜像磁盘资源时:
clphdstat --mirror <hd资源名>
请使用Cluster WebUI或者[clpstat]命令确认失效切换组的状态。
如果有启动失败的失效切换组,请使用Cluster WebUI或者[clpgrp]命令停止。
- 请使用Cluster WebUI的 [镜像磁盘] 标签页上的 [强制镜像复归] 操作,或者[clpmdctrl] / [clphdctrl]命令(--force选项), 将要作为最新的镜像状态更改为"正常" (GREEN) 。※ 通过命令执行时,在想要状态为"正常" (GREEN)的服务器上执行。
镜像磁盘资源时:
clpmdctrl --force <服务器名> <md资源名> -s
共享型镜像磁盘资源时:
clphdctrl --force <hd资源名>
使用Cluster WebUI或者[clpgrp]命令,可以在想要更新的服务器上启动(开始业务)失效切换组。
在复制源的服务器上(共享型镜像磁盘资源时在复制源的当前服务器上)执行Cluster WebUI的 [镜像磁盘] 标签页上的 [全盘复制] 操作, 或者执行[clpmdctrl] / [clphdctrl]命令后进行镜像复归(全复制)。
镜像磁盘资源时:
clpmdctrl --recovery <md资源名>
共享型镜像磁盘资源时:
clphdctrl --recovery <hd资源名>
参见
关于[clpmdctrl] / [clphdctrl]命令请参考《参考指南》的 "EXPRESSCLUSTER命令参考" 的 "镜像磁盘资源操作(clpmdctrl命令)" 和 "共享型镜像磁盘资源操作(clphdctrl命令)"。
2.24. 与ESMPRO/AlertManager联动¶
EXPRESSCLUSTER通过与ESMPRO/AlertManager联动,借助显示系统异常的事件日志来进行失效切换。要执行事件日志监视,集群服务器上必须安装了 ESMPRO/ServerAgent和ESMPRO/AlertManager。
2.24.1. 环境设置¶
设置集群的所有服务器上,从ESMPRO/AlertManager的监视对象事件日志的通报设置中登录执行失效切换命令。
例如,查出异常时登录[ARMDOWN] 命令。

关于ESMPRO/AlertManager设置方法的详细内容,请参照ESMPRO/AlertManager的使用手册。
2.24.2. 设置UPS¶
2.24.3. 更换UPS¶
更换多功能UPS时,请根据以下步骤进行。
使用Cluster WebUI关闭操作系统。
如果正常关机,请将UPS启动开关设置为「OFF」。
拔下与UPS的「Server」(RS232C) 端口连接的,与服务器进行通信的通信电缆线。
从UPS拔下与UPS连接的负载设备的电源电缆线。
从总电源处拔下UPS主机的电源电缆线。
更换UPS。更换时需要确认以下事项。
更换共享磁盘的UPS时,请确认新设置的UPS 背面的DIP开关是否设置为「从」。
更换与服务器连接的UPS时,请确认新设置的 UPS 背面的DIP开关是否设置为「主」。
将UPS 主机的电源电缆线连接到总电源处。
将与UPS连接的负载设备的电源电缆线连接到UPS。(此时,请务必注意不要弄错「Switch-out」和「UnSwitch-out」。)
将与服务器进行通信的通信电缆线连接到UPS的「Server」(RS232C) 端口。
UPS的启动开关打开至「ON」,然后将UPS的「ON/OFF」开关切换为「ON」。(此时,请确认「AUTO/LOCAL开关」设置为「LOCAL」。)
UPS向与各UPS的输出连接的负载设备提供电源,请将「AUTO/LOCAL 开关」切换至「AUTO」。
OS正常启动后,用通常「ESMPRO/UPSController」使用的用户名(Administrator 等) 来登录。
从「开始」菜单启动「ESMPRO/UPSController」的管理器,选择正在进行UPS更换的服务器,获取UPS的信息。
如果UPS信息正常显示,表示作业结束。
此时如果不显示UPS信息,请重新显示「ESMPRO/UPSController」菜单中的「设置」/「动作环境的设置」,确认各项目的设置是否有正确设置。
COM 端口
使用 UPS
如果正确执行上述的设置后也不能显示UPS的信息时,请确认UPS侧 (RS232C通信电缆线,DIP开关等)的设置和服务器侧 (串行端口等)的设置。
2.25. 恢复系统磁盘¶
2.25.1. 系统磁盘的恢复步骤¶
服务器的系统磁盘发生异常时,请按照以下步骤更换磁盘,恢复备份数据。选择备份后,进行EXPRESSCLUSTER的升级和构成变更操作时,请在恢复操作之后暂时将EXPRESSCLUSTER卸载,将该服务器作为新建服务器按照服务器的交换步骤进行操作。
如果要进行恢复的服务器(以下称为对象服务器)上有已经启动的组,请移动组。如果使用镜像磁盘资源和共享型镜像磁盘资源,请在组移动完毕后,请确认这些资源是否正常启动。
重要
在不进行恢复一端的服务器上,镜像磁盘资源或共享型镜像磁盘资源不是最新状态的情况下,如果恢复系统磁盘,则可执行损坏数据分区上的数据。
使用镜像磁盘资源或共享型镜像磁盘资源时,执行以下步骤。
在Cluster WebUI编辑模式的 [集群属性]的[镜像磁盘]标签页中清除[自动镜像复归] 复选框。
点击Cluster WebUI编辑模式的[应用配置文件],将集群配置信息反映到集群中。
对象服务器运行时,通过[Start]菜单的[Shut Down]关机。
如果对象服务器中连接有共享磁盘,则需要断开对象服务器与共享磁盘之间的连接线缆。断开线缆时请注意以下几点。
如果使用SCSI显示设备,请将二股线缆从根部断开。
如果使用Fibre Channel显示设备,请断开故障服务器和Fibre Channel-HUB或Fibre Channel-Switch之间的线缆。
更换进行恢复的服务器的系统磁盘。具体更换方法请参考设备附带的用户手册。
用一般的方法安装OS。
OS的安装方法请参考服务器附带的用户手册。
安装OS时请务必配置网络设置。另外,请按照更换磁盘前的状态安装OS的服务补丁。
确认OS正常启动后,安装备份软件。(详细内容请参考备份软件的说明书。)
使用备份软件通过备份恢复系统磁盘。
没有依存于集群的注意事项。请使用一般的能够恢复注册表,覆盖同一文件的设置进行恢复。详细内容请参考备份软件的说明书。
如果对象服务器的EXPRESSCLUSTER Server服务自动启动,请更改为手动启动。
确认已恢复服务器的盘符与恢复前的有没有发生变化,如果发生变化,请按照原样进行重新设定。另外,请确认OS日期/时间与集群内其他服务器相同。
如果不能恢复SCSI控制器或FC-HBA(Host Bus Adapter)的驱动程序,请重新安装这些驱动程序。关于详细内容,请参考备份软件的说明手册。
重新启动对象服务器。如果对象服务器上没有连接共享磁盘,则不需要步骤16之前的操作。
在没有进行恢复操作的服务器上通过Web浏览器进行连接,启动Cluster WebUI。打开对象服务器的属性,对连接共享磁盘的HBA进行过滤设置。
按下HBA标签页的[连接]按钮,获取对象服务器的磁盘配置信息,选中连接共享磁盘的HBA。
请不要更改上述之外的设置。
通过Cluster WebUI将设置HBA过滤信息的集群配置信息从集群服务器临时保存到可以访问的磁盘空间内。
如果在集群服务器上使用Cluster WebUI,则保存到本地磁盘。如果在其他PC上使用Cluster WebUI,则保存到集群服务器可以访问的共享文件夹内或临时保存到外部媒介等媒介中,然后复制到集群服务器的外部存储器。
在任一集群服务器上执行以下命令,上传保存的集群配置信息。
clpcfctrl --push -x <集群配置信息的路径> --nocheck
关闭对象服务器,连接磁盘线缆之后重新启动。
如果还原之前目标服务器的配置与以下任何一项相对应,请在[磁盘管理]中重新创建当前分区。
系统磁盘上已存在镜像磁盘资源/共享型磁盘资源的集群分区
系统磁盘上已存在镜像磁盘资源/共享型磁盘资源的数据分区
注解
重新创建数据分区时,将大小调整为尚未还原的服务器上的数据分区。
通过对象服务器的磁盘管理画面确认共享磁盘和镜像磁盘(数据分区和集群分区)的盘符。如果盘符发生了变化,请恢复为原来的设置,重启服务器并确认盘符已经正确设置。
在没有进行恢复的服务器中通过Web浏览器连接并启动Cluster WebUI。如果对象服务器连接有共享磁盘,并且共享磁盘上存在过滤对象之外的卷,则需要在对象服务器的[属性]的[HBA]标签页中更新过滤对象外分区的信息。
与步骤14和15相同,临时保存集群配置信息,从集群服务器上通过[clpcfctrl]命令进行上传。
保存集群配置信息时,当"配置信息中存在某个磁盘信息与服务器上的磁盘信息不一致。是否进行自动修正?"弹出窗口显示时,请选择 [是]。
将对象服务器的EXPRESSCLUSTER Server服务恢复成自动启动,并重启对象服务器。
- 如果集群的[集群属性]->[扩展]标签页的[自动复归]设置为[关闭],则需要在Cluster WebUI操作模式中点击对象服务器的[恢复服务器]。对象服务器中不使用镜像磁盘或者共享型镜像磁盘时,不需要进行以下步骤。
系统磁盘上创建镜像磁盘资源/共享型镜像磁盘资源时,需要在镜像复归前重新创建资源。请按照以下的步骤执行。
23-1. 通过Cluster WebUI操作模式,停止对象的含镜像磁盘资源/共享型镜像磁盘资源在内的组。
23-2. 挂起集群。
23-3. 通过Cluster WebUI编辑模式 ,执行对象的镜像磁盘资源/共享型镜像磁盘资源的 [删除资源]。删除前,请记下重新创建资源需要的各参数数值。
23-4. 点击[应用配置文件],向集群反映集群配置信息。
23-5. 执行失效切换组的 [添加资源]。此时,请将指定的各参数设置为删除前的资源的相同值。
23-6. 再次点击 [应用配置文件] ,向集群反映集群配置信息。
23-7. 恢复集群。
通过Cluster WebUI的镜像磁盘列表对所有镜像磁盘资源或共享型镜像磁盘资源进行镜像复归(整体复制)。
注解
执行恢复(更换磁盘)的服务器上的数据有可执行不是最新数据。请将不进行恢复的服务器作为复制源。此外,执行恢复过程中差分信息有可执行不正确,因此请指定为完全复制而不是差分复制。步骤2中将自动镜像复归设置为关闭时,在Cluster WebUI编辑模式中的[集群属性]的[镜像磁盘]标签页中选中[自动镜像复归]复选框。
点击Cluster WebUI编辑模式的[应用配置文件],将集群配置信息反映到集群中。
启动组。
2.27. 更换镜像磁盘¶
组成镜像组的磁盘发生故障时,可以按照以下步骤更换磁盘。此外,配置磁盘阵列,重新构建磁盘阵列及通过DAC更换等识别为新建磁盘时,也需要进行本步骤。
如果要更换共享型镜像磁盘资源中进行了镜像化的本地磁盘,也可以使用以下操作步骤。此时,阅读时请将"镜像磁盘资源"替换为"共享型镜像磁盘资源"。 在使用3 台以上的服务器配置的共享型镜像磁盘资源中更换镜像化的共享磁盘时,请参阅"更换共享型镜像磁盘"的步骤。
确定集群状态正常。(要更换的磁盘的异常除外。)
要更换磁盘的服务器上启动了组时,移动组。
如果集群的[集群属性]中[自动镜像复归]复选框选中时, Cluster WebUI编辑模式下打开集群的[集群属性]-[镜像磁盘]标签页,清除[自动镜像复归] 复选框,点击 [应用配置文件]将集群配置信息反映到集群中。
使用Cluster WebUI操作模式关闭要更换磁盘的服务器,切断电源。
更换磁盘,启动服务器。
在更换了磁盘的服务器上设置磁盘。
使用磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理]),预留镜像磁盘用的数据分区和集群分区。请将两个服务器数据分区和集群分区的盘符以及分区大小设置为相同。
如果[集群属性]的[扩展]标签页中,[自动复归]被设置为[关闭],则通过Cluster WebUI操作模式将更换的磁盘自动恢复到集群中。
挂起集群。
启动Cluster WebUI,在步骤3中清除[自动镜像复归]复选框时,返回到选中状态。
点击Cluster WebUI编辑模式中的[应用配置文件],将集群配置信息反映到集群中。
如果弹出「配置信息的磁盘信息和服务器上的磁盘信息不同,是否自动修正?」的消息,请选择[是]。
使用Cluster WebUI操作模式恢复集群,在未进行磁盘交换的服务器上启动步骤8中停止的组。
如果设置为[自动镜像复归],则将自动执行镜像的重建(全面复制)。如果没有设置[自动镜像复归],请手动重建镜像。
需要时移动组。
2.28. 更换共享型镜像磁盘¶
在使用3 台以上的服务器配置的共享型镜像磁盘资源环境中,如果配置了镜像组的共享磁盘发生了故障时,可以下面的步骤进行磁盘的更换。并且,配置了磁盘阵列时,如果进行磁盘阵列的重新配置或者在DAC 更换等中作为新磁盘识别的情况下,也需要执行本步骤。
在共享型镜像磁盘资源中更换镜像化的本地磁盘时,请按照「更换镜像磁盘」的步骤。
将集群的状态设置为正常状态。(但是更换磁盘的异常除外。)
在更换磁盘的服务器中启动组时,移动组。
在集群的 [集群属性]中选中 [自动镜像复归] 的选择框时, Cluster WebUI编辑模式下打开集群的 [集群属性]->[镜像磁盘] 标签页,清除[自动镜像复归] 的复选框, 点击[反映设置] ,将集群配置信息反映到集群上。
对与要更换的共享磁盘连接的所有服务器,通过Cluster WebUI操作模式使用 [停止服务器服务]执行集群停止。
在连接要更换的共享磁盘的所有服务器上,将[EXPRESSCLUSTER Server] 服务器的 [启动的类型] 设置为 [手动]。
对与要更换的共享磁盘连接的所有服务器执行关闭操作,切断电源。
切断共享磁盘的电源,更换磁盘。
投入共享磁盘的电源,进行共享磁盘的设置。
需要重新构建RAID /更改LUN 的配置时,请使用共享磁盘附带的设置工具进行配置。详细内容请参阅共享磁盘附带的说明书。
仅启动1台服务器,通过磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理])创建磁盘更换前相同的分区,设置驱动盘符。即使OS自动分配的盘符与想要分配的盘符相同,也请删除后重新设置来手动明确分配。
注解
分区刚刚创建完毕后,由于访问限制,尚不能进行格式化。请仅在此处设置驱动盘符。
注解
作为磁盘资源使用的切换分区可以在此时机更改尺寸的大小,但是由于共享型镜像磁盘资源的数据分区在两个服务器组中需要保持相同的尺寸,因此更改尺寸时,需要先删除资源,在两个服务器组中更改了分区大小后,再重新创建资源。
注解
对共享磁盘的分区的盘符进行更改/删除时,可执行会操作失败。请根据以下规避方法进行设置。
从命令提示符上执行以下命令,删除盘符。
mountvol <(更改对象的)盘符>: /P
通过 磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理] )确认已从更改对象磁盘删除盘符。
从[磁盘管理]添加盘符。
因要对作为磁盘资源使用的磁盘分区进行格式化,请运行以下命令来暂时解除访问限制。
clpvolctrl --open <作为磁盘资源使用的分区驱动盘符>
通过磁盘管理([控制面板] > [管理工具] > [计算机管理] >[磁盘管理])来执行作为磁盘资源使用的磁盘分区的格式化。
为了恢复上述10中进行的暂时解除的访问限制,请执行以下的命令。
clpvolctrl --close <作为磁盘资源使用的分区驱动盘符>
启动与更换了的共享磁盘连接的其他服务器,通过磁盘管理([控制面板] > [管理工具] > [计算机管理] > [磁盘管理])确认在第一台服务器上能够看到创建好的分区。
按照第一台服务器的设置方法,设置共享磁盘上的各分区的盘符为更换磁盘前的相同盘符。
在与更换了的共享磁盘连接的所有服务器中,将[EXPRESSCLUSTER Server] 服务的 [启动的类型] 恢复为 [自动]。
启动Cluster WebUI ,对与更换了的共享磁盘连接的所有服务器,使用 [开始服务器服务] 开始集群。
注解
此时,有可执行显示 hdw 和 hdtw 的警报通知,但是不存在问题,请接着执行下面的步骤。
挂起集群。
如果更换了的共享磁盘上存在不进行访问限制的分区时,请打开与共享磁盘连接的各服务器的 [属性] 的 [HBA] 标签页,点击[连接],在[从集群管理除外的分区]中添加这些分区。
注解
如果在更换前的共享磁盘中设置了 [从集群管理除外的分区]时,请先暂时删除设置,然后重新进行设置。请按以下的步骤进行。
通过Cluster WebUI编辑模式打开与更换了的磁盘连接的服务器的[属性] 的 [HBA]标签页,点击[连接]。
选择了选中了过滤的 HBA ,并删除[从集群管理除外的分区]中显示的所有分区。
再次点击 [添加],添加步骤 18-2 中删除的所有分区。
请确认从集群管理除外的分区中卷,磁盘编号,分区编号,容量和GUID均能显示。
启动Cluster WebUI,如果步骤 3 中将 [自动镜像复归]设置为关闭时,恢复为打开。
点击Cluster WebUI编辑模式的 [反映设置],将集群配置信息反映到集群上。
如果弹出[配置信息中的磁盘信息和服务器上的磁盘信息不同。是否进行自动修正?] 的消息时,请选择[是]。
从Cluster WebUI操作模式复原集群。
如果设置为[自动镜像复归],则将自动执行镜像的重建(全面复制)。如果没有设置[自动镜像复归],请手动重建镜像。
需要时移动组。
2.30. 镜像磁盘大小扩展¶
注解
确定集群状态正常。
扩展的镜像磁盘资源处于正常状态。
在Cluster WebUI的操作模式下,将所有镜像磁盘监视资源都设置为“暂停”,使镜像复归不自动执行。
在镜像磁盘资源未处于启动状态的服务器上,执行以下clpmdctrl命令。任一服务器上未启动资源时也可以从任一服务器执行。以下是md01数据分区扩展到500GB时的示例。
clpmdctrl --resize md01 500G
在另一台服务器上执行以下clpmdctrl命令。以下是md01数据分区扩展到500GB时的示例。
重要
镜像磁盘资源在任一服务器中为启动中时,请务必从未启动的服务器执行。如果从启动的服务器执行,可执行会发生镜像中断。
clpmdctrl --resize md01 500G
执行以下命令,并确认两个目标服务器上的卷大小相同。
clpvolsz <用于镜像磁盘资源的分区的盘符>:
在启动的服务器上执行diskpart命令。
diskpart在DISKPART提示符下执行list volume,确认对象数据分区的卷号(###列)。以下是执行示例。
DISKPART> list volume Volume ### Ltr Label Fs Type Size Status Info ---------- --- ----------- ---- ---------- ------- --------- -------- Volume 0 E DVD-ROM 0 B 无媒体 Volume 1 C NTFS Partition 99 GB 正常 boot Volume 2 D NTFS Partition 500 GB 正常 Volume 3 FAT32 Partition 100 MB 正常 系统
在DISKPART提示符下执行 select volume,然后选择对象卷。
DISKPART> select volume 2
在DISKPART提示符下执行extend filesystem以扩展对象卷的文件系统。
DISKPART> extend filesystem
在DISKPART提示符下执行exit 以结束diskpart。
DISKPART> exit
在步骤3中设置为“暂停”的镜像磁盘监视资源,通过Cluster WebUI的操作模式都“重新开始”。
重要
clpmdctrl --resize md01 500G -force
2.31. 共享型镜像磁盘大小扩展¶
注解
确定集群状态正常。
扩展的共享型镜像磁盘资源处于正常状态。
在Cluster WebUI的操作模式下,将所有镜像磁盘监视资源都设置为“暂停”,使镜像复归不自动执行。
请只保留各服务器组的当前服务器,关闭所有的其他服务器。当前服务器可以通过clphdstat的-a选项确认。以下是确认资源hd01的当前服务器时的示例。
clphdstat -a hd01
- 在共享型镜像磁盘资源未处于启动状态的服务器组上的当前服务器中,执行以下clphdctrl命令。任一服务器组上未启动资源时也可以从任一服务器组执行。以下是hd01数据分区扩展到500GB时的示例。
clphdctrl --resize hd01 500G
- 在另一服务器组上的当前服务器中同样执行以下clphdctrl命令。以下是hd01数据分区扩展到500GB时的示例。
clphdctrl --resize hd01 500G
重要
共享型镜像磁盘资源在任一服务器中为启动中时,请务必从未启动的服务器组执行。如果从启动的服务器执行,可执行会发生镜像中断。
执行以下命令,并确认两服务器组上的卷大小相同。
clpvolsz <共享型镜像磁盘资源中使用的分区的盘符>:`
在启动的服务器上执行diskpart命令。
diskpart在DISKPART提示符下执行list volume,确认对象数据分区的卷号(###列)。以下是执行示例。
DISKPART> list volume Volume ### Ltr Label Fs Type Size Status Info ---------- --- ----------- ----- ---------- ------- ------------ -------- Volume 0 E DVD-ROM 0 B 无媒体 Volume 1 C NTFS Partition 99 GB 正常 boot Volume 2 D NTFS Partition 500 GB 正常 Volume 3 FAT32 Partition 100 MB 正常 系统
在DISKPART提示符下执行 select volume,然后选择对象卷。
DISKPART> select volume 2
在DISKPART提示符下执行extend filesystem以扩展对象卷的文件系统。
DISKPART> extend filesystem
在DISKPART提示符下执行exit 以结束diskpart。
DISKPART> exit
在步骤3中设置为“暂停”的共享型镜像磁盘监视资源,通过Cluster WebUI的操作模式都“重新开始”。
启动所有在步骤4中已关闭的服务器。
重要
clphdctrl --resize hd01 500G -force
2.32. 更换磁盘阵列控制器/上载固件¶
更换磁盘阵列控制器(DAC)或上载固件时,即便实际没有进行磁盘的更换,也有可执行被OS 作为新磁盘来识别。根据OS识别磁盘的不同方式须执行不同的必要操作。更换磁盘阵列控制器(DAC)或上载固件时,请务必按以下步骤进行。
将集群状态置于正常状态。
更换DAC或执行固件上载的服务器(以下,统称对象服务器)上启动组时,转移组。
- 更换DAC或上载固件前,请执行以下的命令,确认所有的镜像磁盘资源和共享型镜像磁盘资源的分区的「驱动盘符」和「GUID」的组合。
mountvol以下为输出示例。"C:\" 的部分为盘符。另外,"123da03b-e7e0-11e0-a2aa-806d6172696f"的部分为GUID。输出例:
C:> mountvol 当前的Mount点和卷名的可执行值: \\?\Volume{123da03a-e7e0-11e0-a2aa-806d6172696f}\ C:\ \\?\Volume{123da03b-e7e0-11e0-a2aa-806d6172696f}\ Z:\ \\?\Volume{123da03c-e7e0-11e0-a2aa-806d6172696f}\ P:\ 更换DAC时通过Cluster WebUI操作模式使对象服务器关机来切断服务器电源。
执行DAC更换或固件上载。更换DAC时,开启对象服务器电源启动OS。
DAC更换或固件上载结束后,为了确认镜像磁盘资源或共享型镜像磁盘资源所使用的磁盘,已经被OS作为已有的磁盘所识别,需执行以下的步骤。
对象服务器上执行以下命令, 确认镜像磁盘资源和共享型镜像磁盘资源的「驱动盘符」和「GUID」的组合和步骤3的执行结果相比是否发生变化。
mountvol- 所有的镜像磁盘资源和共享型镜像磁盘资源的「驱动盘符」和「GUID」的组合和步骤3的确认结果相比没有发生变化时,说明被OS作为已知磁盘识别。此时继续执行10以后的步骤(步骤8~9, 不需要执行)。如果确认的内容和步骤3.相比发生变化时,说明被OS作为新磁盘识别。此时继续执行步骤8.之后的操作。
在对象服务器上确认磁盘设置。
使用磁盘管理([控制面板]>[管理工具]>[计算机管理]>[磁盘管理]),确认数据分区和集群分区的驱动盘符。如果驱动盘符变化了,设定为原来的驱动盘符。
在Cluster WebUI操作模式上重启对象服务器。
在上述步骤8中修改了驱动盘符时,请按照[更换镜像磁盘]的步骤7到步骤11重新设定集群信息。此时,请将"更换磁盘的服务器"作为"对象服务器"看待。
复归对象服务器的集群。
自动复归模式下,将自动复归到集群。
通过[集群属性]->[镜像磁盘]标签页执行[自动镜像复归]设定时,自动进行镜像的重新构筑(全复制)。不执行[自动镜像复归]设定时,请手动进行镜像的重新构筑。
镜像重新构筑异常结束时,请按照[更换镜像磁盘]的步骤8到步骤12重新设定集群信息。此时,请将"更换磁盘的服务器"作为"对象服务器"看待。
若有必要,转移组。
2.33. 更换FibreChannel HBA/SCSI/SAS控件¶
如果要更换与共享磁盘连接的HBA,请按照以下步骤进行操作。
如果要更换HBA的服务器(以后简称对象服务器)组正在运行,请移动到其他服务器组。
将对象服务器的EXPRESSCLUSTER Server服务更改为手动启动。
关闭对象服务器,更换HBA。
在拔出磁盘线缆的状态下启动对象服务器。
从Cluster WebUI编辑模式选择对象服务器的属性画面,对更换后的HBA进行过滤设置。
按下HBA标签页中的连接按钮,获取对象服务器的磁盘配置信息,选中更换后的HBA。
请不要更改上述之外的其他设置。
通过Cluster WebUI将设置HBA过滤信息的集群配置信息从集群服务器临时保存到可以访问的磁盘空间内。
如果在集群服务器上使用Cluster WebUI,则保存到本地磁盘。如果在其他PC上使用Cluster WebUI,则保存到集群服务器可以访问的共享文件夹内或临时保存到外部媒介等媒介中,然后复制到集群服务器的外部存储器。
在任一集群服务器上执行以下命令,上传保存的集群配置信息。
clpcfctrl --push -x <集群配置信息的路径> --nocheck
关闭对象服务器,连接磁盘线缆。
启动对象服务器,通过磁盘管理画面确认共享磁盘的盘符。如果盘符发生了变化,请恢复为原来的设置,重启服务器并确认盘符已经正确设置。
从Cluster WebUI编辑模式打开对象服务器的属性,确认[HBA]标签页的设置。如果存在非访问限制共享磁盘的分区,确认[从集群管理除外的分区]栏上登录分区信息。
与步骤6和7相同,临时保存集群配置信息,从集群服务器上通过以下命令进行上传。
clpcfctrl --push -x <集群配置信息的路径> --nocheck
保存集群配置信息时,当"配置信息中存在某个磁盘信息与服务器上的磁盘信息不一致。是否进行自动修正?"弹出窗口显示时,请选择 [是]。
将对象服务器的EXPRESSCLUSTER Server服务恢复成自动启动,并重启对象服务器。
如果集群的[集群属性]->[扩展]标签页的[自动复归]设置为[关闭],则需要在Cluster WebUI操作模式中选择对象服务器的[恢复服务器]。
根据需要移动组。
2.34. 更新镜像磁盘资源/共享型镜像磁盘资源的加密密钥¶
更新镜像磁盘资源和共享型镜像磁盘资源进行镜像通信时所使用的加密密钥时,按以下步骤实施。
注解
以下步骤,可在保持镜像磁盘资源和共享型镜像磁盘资源处于启动状态下执行。但是,如果正在进行镜像,则镜像将被中断,因此请在完成该步骤后执行镜像复归。
使用clpkeygen命令,生成新的加密密钥文件。关于clpkeygen命令的详细信息请参考《参考指南》的"EXPRESSCLUSTER命令参考"和"创建通信加密用的密钥文件(clpkeygen命令)"。
clpkeygen 256 newkeyfile.bin
用步骤1生成的文件覆盖可启动镜像磁盘资源和共享型镜像磁盘资源的所有服务器的加密密钥文件(文件名保持不变)。
请执行clpmdctrl或clphdctrl的--updatekey选项。
镜像磁盘资源时
clpmdctrl --updatekey md01
共享型镜像磁盘资源时
clphdctrl --updatekey hd01
只能在资源处于启动状态的任何服务器上执行一次,以更新所有需要更新的服务器的密钥信息。这时,如果正在进行镜像,则镜像将会中断。加密密钥信息更新完成。之后,使用新的加密密钥进行镜像通信的加密和解密。
如有必要,请执行镜像复归重新开始镜像。
2.35. 咨询时所需信息¶
咨询时所需信息如下所示。
- 故障现象请描述故障内容。例) 失效切换组(failover1)从server1向server2进行失效切换时失败。
- 故障发生时间例) 2018/01/01 00:00左右
- 发生故障的服务器名称例) server2
- EXPRESSCLUSTER的版本例) EXPRESSCLUSTER X 4.3
- 发生故障时EXPRESSCLUSTER的日志以及事件日志日志可以使用Cluster WebUI采集,或使用日志采集命令采集。使用Cluster WebUI 时请参考在线版手册,使用收集日志命令时请参考《参考指南》的"EXPRESSCLUSTER命令参考"的"收集日志(clplogcc命令)"。