1. 前言¶
1.1. 读者对象和用途¶
《EXPRESSCLUSTER® X 开始指南》以初次使用EXPRESSCLUSTER的用户为对象,就EXPRESSCLUSTER的产品概要,导入集群系统的装入图和其他手册的使用方法等指南进行了说明。此外,就最新的运行环境信息和限制事项等进行说明。
1.2. 本手册的构成¶
3. 关于EXPRESSCLUSTER: 就集群系统的概要进行说明。
4. EXPRESSCLUSTER的运行环境: 就导入前需要确认的最新信息进行说明。
1.3. EXPRESSCLUSTER手册体系¶
EXPRESSCLUSTER的手册分为以下6 类。各指南的标题和用途如下所示。
《EXPRESSCLUSTER X 开始指南》 (Getting Started Guide)
本手册的读者对象为所有用户,对产品概要,运行环境,升级信息以及现有的问题等进行了说明。
《EXPRESSCLUSTER X 安装&设置指南》 (Installation and Configuration Guide)
本手册的读者对象为导入使用EXPRESSCLUSTER构筑集群系统的系统工程师以及导入集群系统后进行维护和操作的系统管理员,对使用EXPRESSCLUSTER导入集群系统后到开始操作前的必备事项进行说明。手册按照实际导入集群系统时的顺序,对使用EXPRESSCLUSTER的集群系统的设计方法,EXPRESSCLUSTER的安装设置步骤,设置后的确认以及开始操作前的测试方法进行了说明。
《EXPRESSCLUSTER X 参考指南》 (Reference Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统的系统工程师。对EXPRESSCLUSTER的操作步骤,各模块的功能以及疑难解答信息等进行了说明,是对《安装&设置指南》的补充。
《EXPRESSCLUSTER X 维护指南》(Maintenance Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统后进行维护和操作的系统管理员,对EXPRESSCLUSTER的维护的相关信息进行了说明。
《EXPRESSCLUSTER X 硬件整合指南》 (Hardware Feature Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统的系统工程师,对与特定硬件整合的功能进行了说明。是对《安装&设置指南》的补充。
《EXPRESSCLUSTER X 兼容功能指南》(Legacy Feature Guide)
本手册的读者对象为管理员以及导入使用EXPRESSCLUSTER的集群系统的系统工程师,对EXPRESSCLUSTER X 4.0 WebManager,Builder 以及EXPRESSCLUSTER Ver 8.0 兼容指令的相关信息等进行了说明。
1.4. 本手册的标记规则¶
在本手册中,需要注意的事项,重要的事项以及相关信息等用如下方法标记。
注解
表示虽然比较重要,但是并不会引起数据损失或系统以及机器损伤的信息。
重要
表示为避免数据损失和系统,机器损坏所必需的信息。
参见
表示参考信息的位置。
另外,在本手册中使用以下标记法。
标记 |
使用方法 |
例 |
|---|---|---|
[ ] 方括号
|
在命令名的前后,
显示在画面中的字句 (对话框,菜单等) 的前后。
|
点击[启动]
[详细信息]对话框
|
命令行中的[ ] 方括号 |
表示括号内的值可以不予指定(可省)。 |
|
等宽字体 |
路径名,命令行,系统输出(消息,提示等),目录,文件名,函数,参数。 |
|
粗体
|
用户在命令提示符后实际输入的值。
|
输入以下内容。
clpcl -s -a
|
斜体 |
用户将之替换为有效值后输入的项目。
|
|
 在本手册的图中,为了表示EXPRESSCLUSTER,使用该图标。
在本手册的图中,为了表示EXPRESSCLUSTER,使用该图标。
2. 何谓集群系统¶
本章就集群系统的概要进行说明。
本章说明的项目如下所示。
2.1. 集群系统的概要¶
现在的计算机社会中,持续的提供不停止的服务已经成为通往成功的关键。例如仅由于1台机器故障或超负荷而宕机就导致对客户的服务全面停止。这样的话,不但会带来莫大的损失,还会失去客户的信任。
随着集群系统的导入,发生意外事故时会将系统停止时间(宕机时间)降低到最小限度,使负载均衡,提高其可用性。
所谓集群,有"集团","团"的意思,顾名思义是"将多个计算机汇集成一群(或者多群),谋求提升可靠性及处理性能的系统"。集群系统有多个种类,可分为下列3种。其中,EXPRESSCLUSTER属于High Availability集群。
- HA (High Availability) 集群是平时作为运行服务器作业,在运行服务器发生故障时将业务交接到待机服务器的集群。是以高可用性为目的的集群。包括共享磁盘型,镜像磁盘型。
- 负载均衡集群是将客户端的请求遵从恰当的负荷均衡原则分配给各节点的集群。是以高扩展性为目的的集群,一般无法进行数据交接。包括load balance集群,并列数据库集群。
- HPC (High Performance Computing)集群是指计算量非常大的集群。是为使用超级计算机执行单一业务的集群。使用所有节点的CPU来执行单一业务的网格计算技术近年来已成为热点。
2.2. HA (High Availability)集群¶
HA集群可分为共享磁盘型和镜像磁盘型。以下开始逐一进行说明。
2.2.1. 共享磁盘型¶
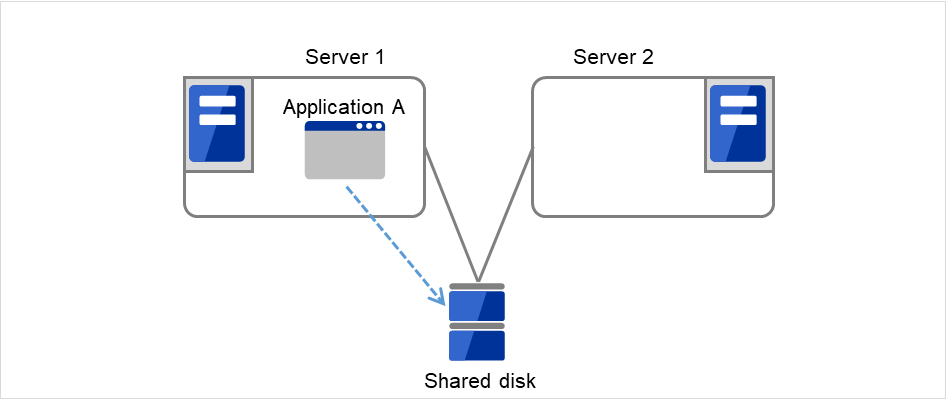
集群系统中服务器间必须要交接数据。将这些数据从多个服务器放到像以SAN连接的FibreChannel磁盘阵列装置这样可以访问的外置磁盘(共享磁盘)上,通过该磁盘在服务器间交接数据即称为共享磁盘型集群系统。
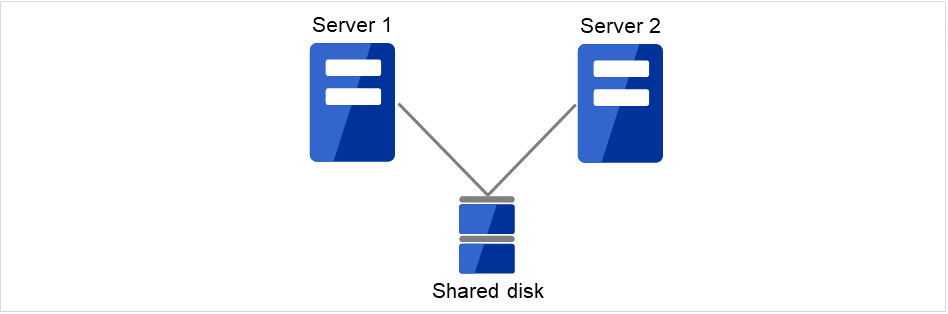
图 2.1 HA集群配置图(共享磁盘型)¶
由于需要共享磁盘而价格高
适用于处理大规模数据的系统
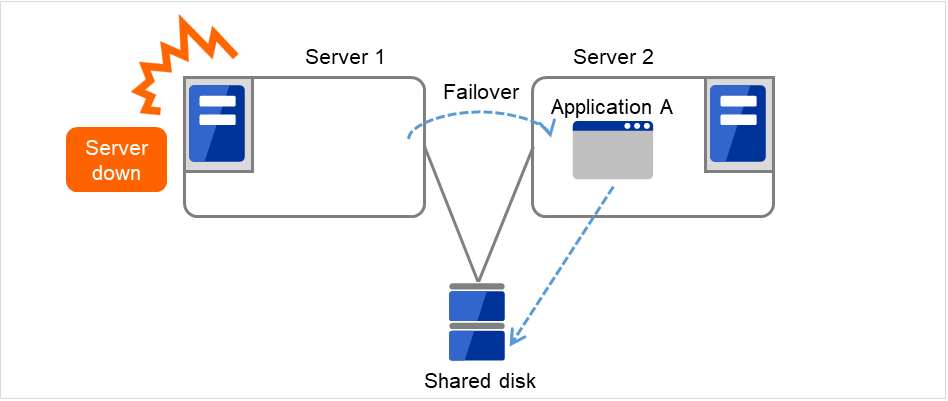
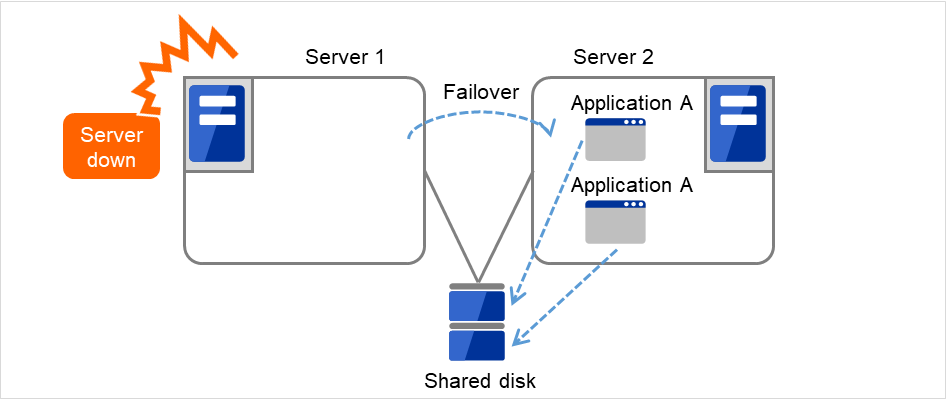
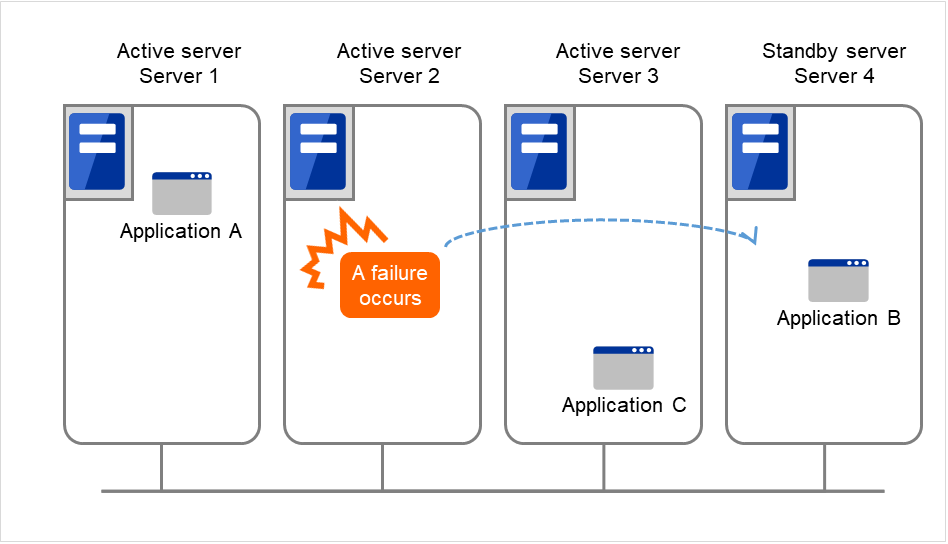
运行业务应用程序的服务器(运行服务器)发生故障时,集群系统查出故障并在交接业务的服务器(待机服务器)中自动启动业务应用程序,交接业务。这称为失效切换。集群系统交接的业务由磁盘,IP地址,应用程序等资源构成。
在没有集群化的系统中使用其它服务器重启应用程序时,客户端必须再次连接不同的IP地址。但是多数的集群系统里不是以业务为单位给服务器分配IP,而是分配其他网络的IP地址(虚拟IP地址)。因此客户端没必要去区分正在执行业务的是运行服务器还是待机服务器,如同连接同一个服务器一样,可以持续地运行业务。
由于运行服务器宕机发生失效切换时,共享磁盘上的数据没有进行妥当的结束处理就交接给待机服务器。因此待机服务器中有必要对交接的数据进行逻辑检查。这与一般未集群化的系统宕机后重启时进行的处理是一样的。例如,如果是数据库就需要回滚及前滚的处理。由此客户端仅运行未确认的SQL就可以继续业务。
故障发生后,被查出故障的服务器经过物理隔离修复后,只要连接集群系统就可以作为待机服务器恢复运行。重视业务连续性的实际操作中,也可以不进行组的故障恢复。如果必须要在原来的服务器上运行业务时,请移动组。

图 2.2 发生故障到恢复的流程¶
一般使用
发生故障
服务器恢复
业务移动
由于失效切换处的服务器配置不够,双向待机引起超负荷等原因而希望在原来的服务器上运行业务时,原来节点的恢复作业完成后将暂时停止业务,在原来的节点上重启业务。将失效切换的组返回到原来的服务器称为故障恢复。
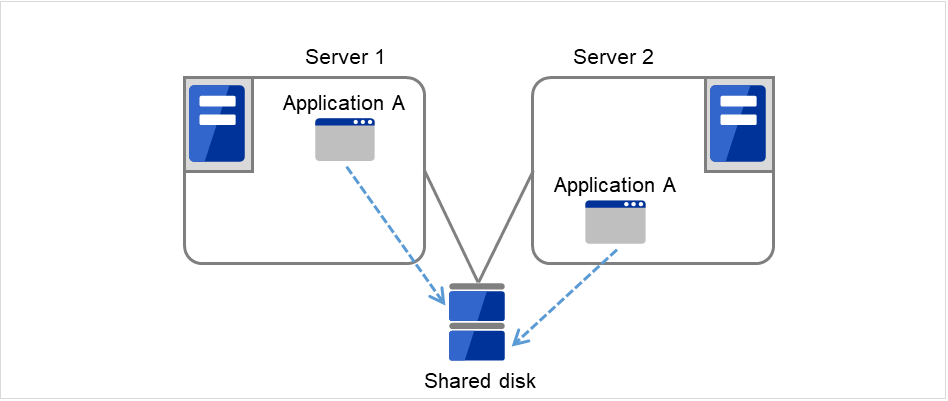
如 图 2.3 从发生故障到恢复的流程 所示,只有1个业务,待机服务器为不运行业务的待机形态称为单向待机。
图 2.3 HA集群的运行形态(单向待机)¶
图 2.4 HA集群的运行形态(双向待机)¶
2.2.2. 镜像磁盘型¶
上述共享磁盘型适用于大规模系统,但共享磁盘大体价格较高因此构筑系统的成本也会增大。所以,不使用共享磁盘,而通过将各服务器磁盘在服务器间建立镜像,可以以更低的价格实现相同功能,这类集群系统称为镜像磁盘型集群系统。
但是,由于需要在服务器间为数据建立镜像,因此不适用于需要大量数据的大规模系统。
应用程序发出Write请求时,数据镜像引擎会将数据写入本地磁盘的同时,通过心跳线将Write请求分发给待机服务器。所谓心跳线是连接在服务器之间的电缆,在集群系统中用于服务器的死活监视。数据镜像型中除死活监视外还用于数据的传送。待机服务器的数据镜像引擎通过将接收的数据写入待机服务器的本地磁盘中,使运行服务器和待机服务器间的数据实现同步。
对于应用程序发出的Read请求,仅从运行服务器的磁盘中读取。
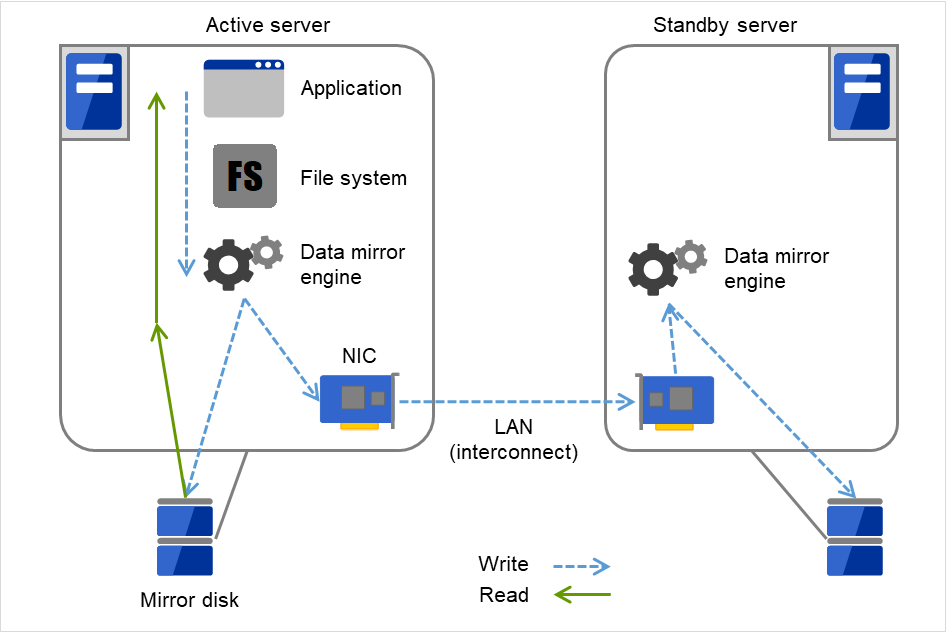
图 2.5 数据镜像的结构¶
快照备份就是使用数据镜像的例子。因数据镜像型的集群系统在2个地方持有共享数据,只需将待机服务器从集群分离,即可作为快照备份来保存数据。
HA集群的机制和问题点
下面就集群的实现和问题点进行说明。
2.3. 系统构成¶
共享磁盘型集群将磁盘阵列装置在集群服务器间实现共享。服务器发生故障时待机服务器使用共享磁盘上的数据实现数据的交接。
镜像磁盘型集群是经过网络将集群服务器上的数据磁盘镜像化的构成。服务器故障时使用待机服务器上的镜像数据交接业务。数据的镜像化以I/O为单位进行,因此从上层应用程序看是与共享磁盘相同的。
下图是共享磁盘型集群的构成图例。
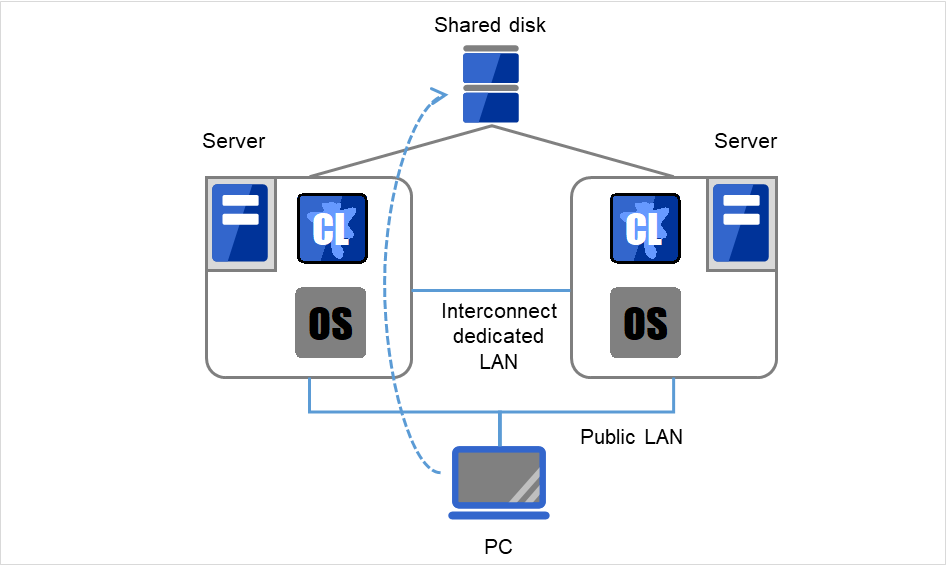
图 2.6 系统构成¶
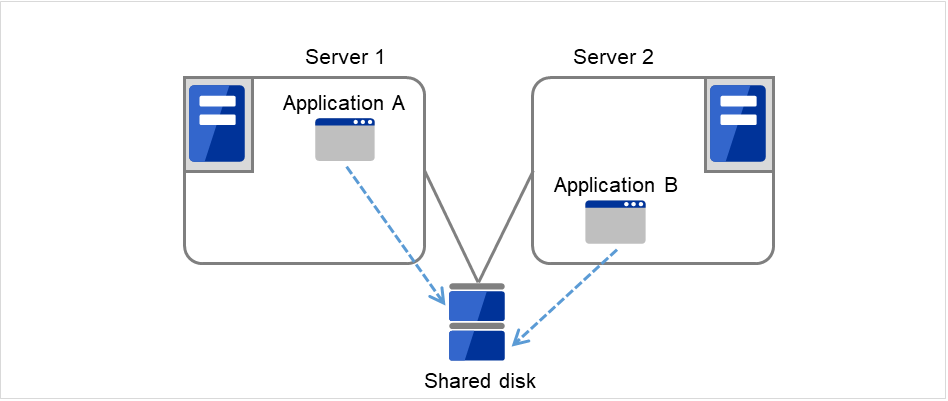
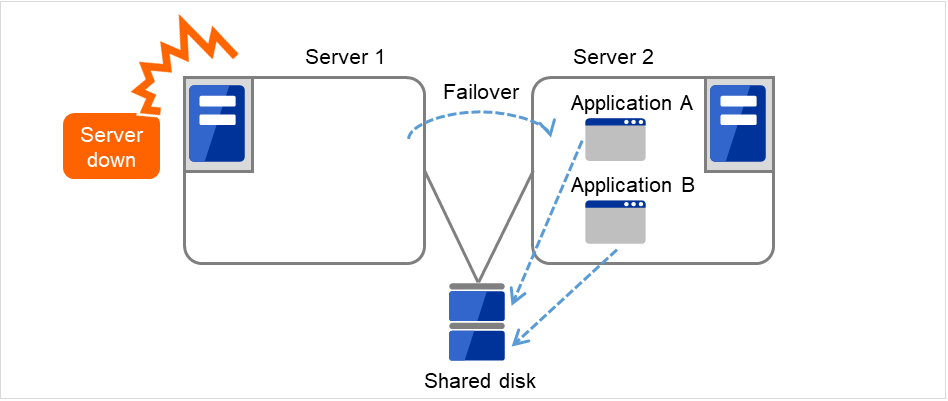
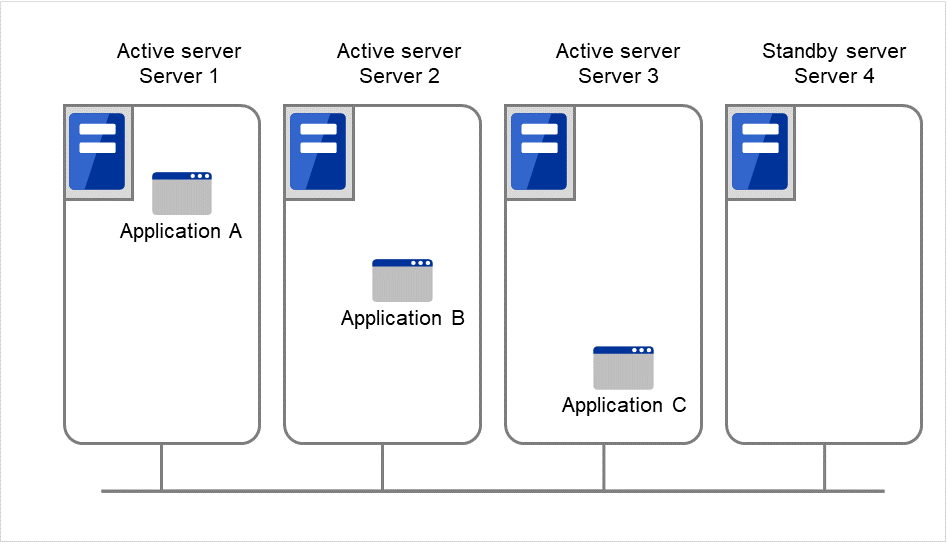
根据运行形态可以将失效切换型集群分为下列几类。
单向待机集群
同一应用程序双向待机集群
不同应用程序双向待机集群
N + N 结构
2.4. 查出故障的原理¶
集群软件一查出给持续业务带来问题的故障就会执行业务交接(失效切换)。在进入失效切换处理的具体内容之前,先简单地介绍一下集群软件是怎样查出故障的。
EXPRESSCLUSTER为监视服务器,定期地与伙伴服务器进行生存确认。将此生存确认称为心跳。
心跳和服务器故障的查出
集群系统中应该查出的最基本的故障是配置集群的服务器的宕机。服务器的故障中包含电源异常以及内存错误等硬件故障或者OS的崩溃等。为了查出此类故障,使用心跳来监视服务器的死活。
心跳可以仅通过确认ping的应答这种死活监视方式,根据集群软件不同,也可以传送本地服务器的状态信息等内容。集群软件收发心跳,在心跳无应答时视作该服务器故障并开始失效切换处理。但考虑到由于服务器的高负荷等原因会导致心跳的收发延迟,所以到判定为服务器故障需要一定程度的缓冲时间。因此实际发生故障的时间和集群软件查出故障的时间会存在时间差。
资源故障的查出
业务停止的主要原因不仅仅是由于配置集群的服务器的宕机。例如,由于业务应用程序使用的磁盘装置以及NIC的故障,或者业务应用程序本身的故障等也会导致业务停止。为了提升可用性,也必须查出这样的资源故障,实施失效切换。
作为查出资源异常的手段,所要监视的资源为物理设备时可以采用实际尝试访问的方法。应用程序的监视中,除了应用程序进程本身的死活监视以外,在对业务没有影响的范围内,也可以考虑尝试服务端口。

2.5. 集群资源的交接¶
集群管理的资源中有磁盘,IP地址,应用程序等内容。下面说明用于交接这些集群资源的失效切换集群系统的功能。
2.5.1. 数据的交接¶
在共享磁盘型集群中,共享磁盘装置上的分区保存服务器之间的交接数据。也就是说,所谓的交接数据,就是在正常的服务器上对应用程序使用的文件所在分区的文件系统重新mount。由于共享磁盘装置与交接目标服务器是物理连接,因此,集群软件应该做就只有文件系统的mount。

图 2.16 数据的交接¶
看似简单,但是在设计/构筑集群系统时有几点必须要注意。
一个是文件系统以及数据库的恢复时间问题。要交接的文件在故障发生的前一刻被其他的服务器所使用,或者也许正在被更新。因此,有些文件系统,有时需要交接时进行一致性的检查,如果是数据库就需要进行回滚等处理。这种情况与电源故障造成宕机重启单个服务器时是一样的。此类恢复处理需要较长时间时,若就此追加在失效切换时间(业务的交接时间)上,将成为系统可用性低下的主要原因。
还有一个就是写入保证的问题。应用程序向共享磁盘里写入数据时,通常是通过文件系统写入。应用程序即使写入完成,文件系统仍会保留在磁盘缓存上,所以未写入共享磁盘,运行服务器就宕机的情况下,磁盘缓存上的数据将不能交接到待机服务器。因此,发生故障时,需要切实交接到待机服务器的重要数据,必须要通过同步写入等方法,切实地写入到磁盘中。这与单个服务器宕机时数据不因断电而丢失一样。也就是说,在设计集群系统时要考虑到:交接给待机服务器的只有共享磁盘中记录的数据,象磁盘缓存这样的内存上的数据不予交接。
2.5.2. IP地址的交接¶
集群软件进行的下一个任务是IP地址的交接。失效切换时,通过IP地址的交接,所以不用在意业务在哪个服务器上运行。集群软件交接IP地址的目的就在于此。
2.5.3. 应用程序的交接¶
集群软件业务交接的最后任务是交接应用程序。与容错计算机(FTC)不同,在一般的失效切换集群中不交接包含应用程序运行中内存内容的进程状态等。也就是说,通过将故障服务器上运行的应用程序,在正常的服务器中重新执行,来完成应用程序的交接。
例如对DB实例进行失效切换时,并非以发生故障前一刻的状态重启,而是和先宕机再启动一样,进行事务的回滚,并且需要从客户端再次连接。该数据库恢复所需要的时间可以通过DBMS的Check Point Interval的设置在某种程度上进行控制,但是一般都需要几分钟。
多数应用程序仅通过再次执行就可以再续业务,但是也有的应用程序需要在故障发生后进行业务恢复操作。为此,集群软件通过启动脚本替代应用程序以便能够描述业务恢复步骤。脚本中以描述脚本执行的主要原因以及执行服务器等信息为主,根据需要,也描述清除正在更新的文件等恢复步骤。
2.6. Single Point of Failure的排除¶
在构筑高可用性系统时把握所要求的或者说目标的可用性水平是很重要的。也就是说对于可执行阻碍系统运行的各种故障,应采用冗余结构,以使运行得以持续并在短时间内能够恢复,讨论或设计系统时就需要从上述策略的性价比方面进行考虑。
所谓Single Point of Failure(SPOF),前面讲过是指和系统停止相关联的部位。集群系统可以实现服务器的多重化,排除系统的SPOF。但是共享磁盘等服务器间共享部分会成为SPOF。设计多重化或者排除该共享部分的系统成为构筑高可用性系统的要点。
集群系统要提升可用性,但是失效切换中也需要几分钟的系统切换时间。因此也可以说失效切换时间是可用性低下的一个主要原因。为此在高可用性系统中,提高单个服务器可用性的ECC存储以及冗余电源等的技术是重要的。但是在此并不涉及单个服务器的可用性提升技术,而是深入研究一下集群系统中容易造成SPOF的下述3项内容,看看能有怎样的对策。
共享磁盘
通往共享磁盘的访问路径
LAN
2.6.1. 共享磁盘¶
通常共享磁盘按照磁盘阵列组合RAID,所以磁盘的成对驱动器不会成为SPOF。但是由于内置RAID控制器,所以控制器会有问题。多个集群系统中采用的共享磁盘里可以实现控制器的二重化。
为了发挥二重化RAID控制器的长处,通常有必要实现共享磁盘访问路径的二重化。但是如果是由二重化的多个控制程序能够同时访问同一逻辑磁盘单元(LUN)的共享磁盘,每个控制器上连接1台服务器则在控制器发生异常时在节点间实施失效切换,就可以实现高可用性。

图 2.18 RAID控制器和访问路径为SPOF的示例¶
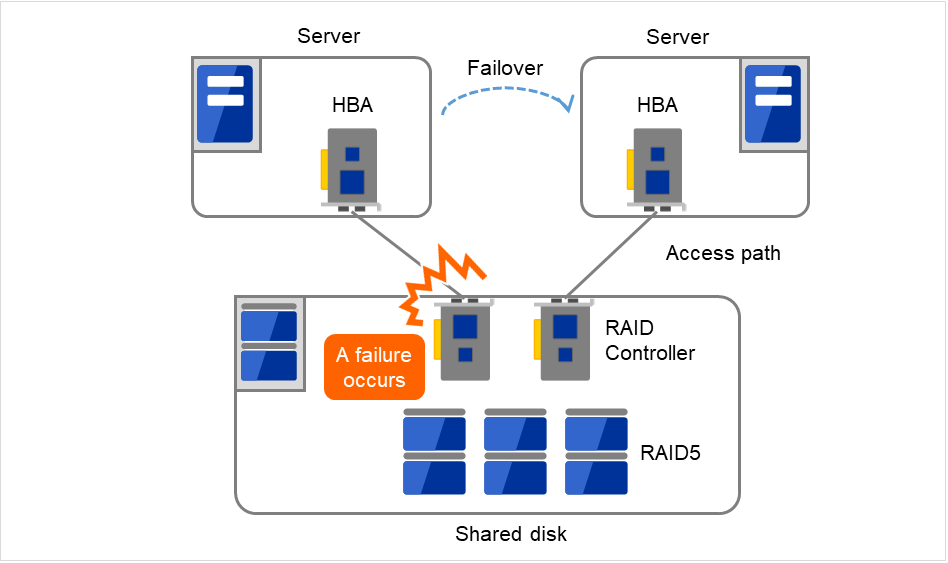
图 2.19 RAID控制器和访问路径二重化的示例¶
※HBA: 是Host Bus Adapter的略称,不是指共享磁盘端的而是指服务器本体端的适配器。
一方面,在不使用共享磁盘的数据镜像型失效切换集群中,由于将所有的数据都在其他服务器的磁盘中建立镜像,所以可以实现不存在SPOF的系统构成。但是需要考虑下列几点。
通过网络实现数据镜像化导致磁盘I/O性能(特别是write性能)低下
服务器故障恢复时,镜像在再次同步中的系统性能(镜像复制通过后台实施)低下
镜像的再次同步时间(镜像再次同步完成为止无法失效切换)
也就是说数据的链接多而数据容量不大的系统中,采用数据镜像型失效切换集群对于提升可用性是有效的。
2.6.2. 共享磁盘的访问路径¶
共享磁盘型集群的一般结构中,共享磁盘的访问路径在配置集群的各服务器中是共享的。以SCSI为例,1条SCSI路径上可以连接2台服务器和共享磁盘。因此,对共享磁盘的访问路径异常是整个系统瘫痪的重要原因。
解决办法:是准备多条访问共享磁盘的路径的冗余结构,使应用程序对共享磁盘的访问路径看起来像1条。实现该结构的设备驱动程序被称为路径失效切换驱动程序等。
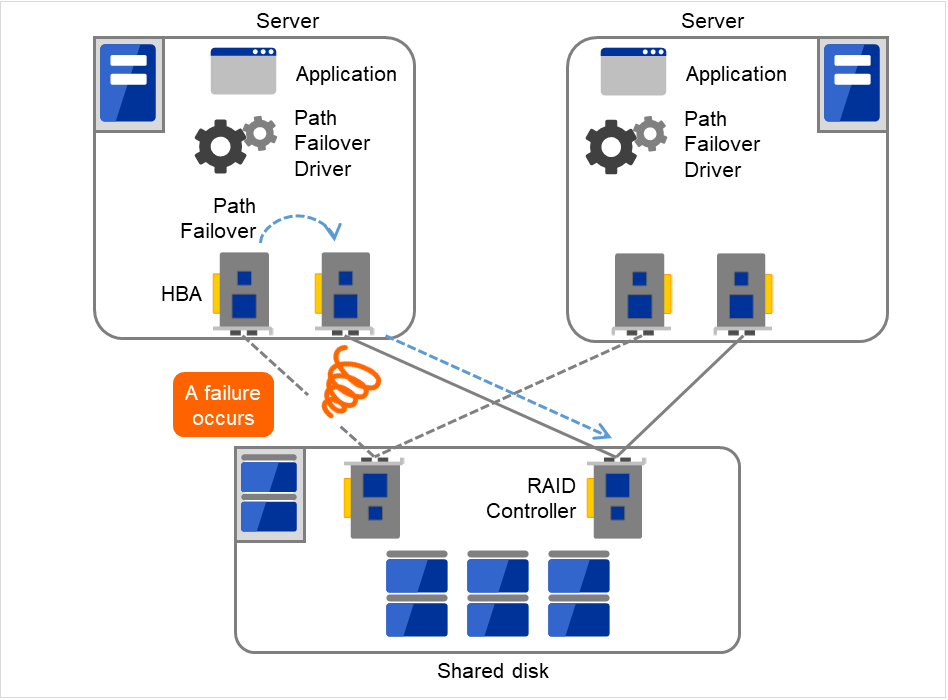
图 2.20 路径失效切换驱动¶
2.6.3. LAN¶
不仅限于集群系统,在网络上执行某些服务的系统中,LAN的故障也是阻碍系统运行的重要因素。集群系统中,进行适当的设置,可在NIC故障时进行节点间失效切换,提高可用性。但是集群系统外的网络机器发生故障时,仍然会阻碍系统工作。
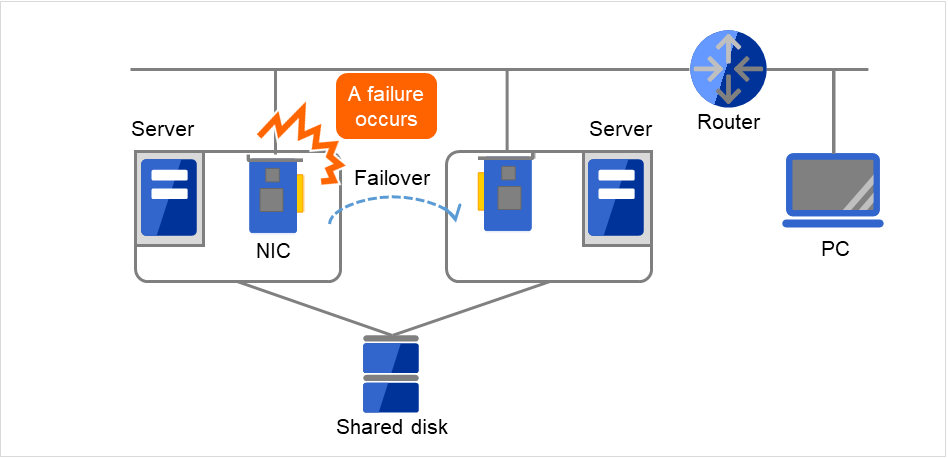
图 2.21 LAN故障的示例(NIC)¶
图中所示的情况,即使服务器上的NIC发生故障,也可以通过失效切换,继续从PC访问服务器上的服务。
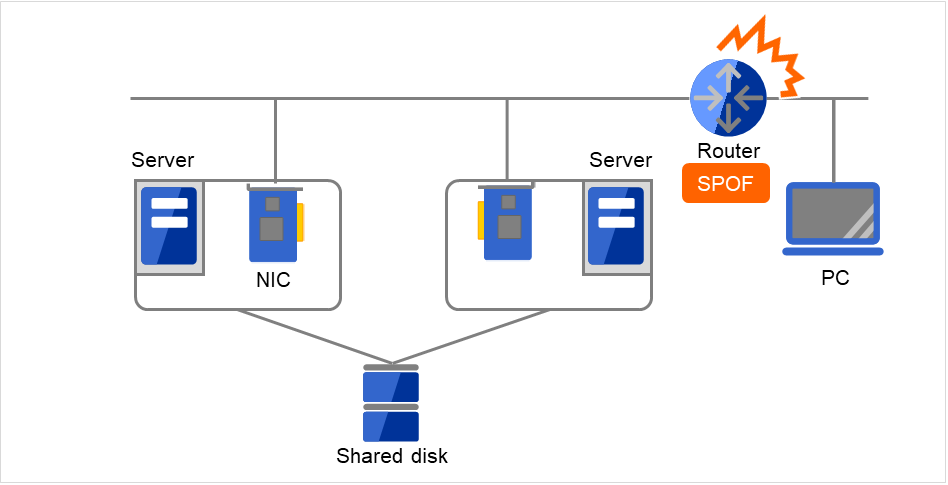
图 2.22 LAN故障的示例(路由器)¶
该图所示的情况,如果路由器发生故障,则无法继续从PC访问服务器上的服务(路由器为SPOF)。
在这种情况下,通过LAN的冗余化,可以提高系统的可用性。在集群系统中,提高LAN的可用性时,可以同样利用单个服务器下的技术。比如,可以考虑通过不接通预备的网络机器的电源,在发生故障的情况下手动进行切换的原始方法,以及冗余配置高性能的网络机器,多重化网络路径来自动切换路径的方法。另外,可以考虑利用如英特尔公司的ANS之类,支持NIC的冗余配置的驱动程序。
LoadBalance装置 (Load Balance Appliance) 和防火墙服务器(Firewall Appliance)也是容易导致SPOF的网络机器。这些通常使用标准或可选软件,来构建失效切换结构。同时,这些机器一般在系统整体中处于非常重要的位置,所以必须要考虑搭建冗余结构。
2.7. 支持可用性的操作¶
2.7.1. 操作前测试¶
我们常说产生系统故障的主要原因大多为设置的错误以及操作的维护。从这一点考虑,实现高可用性系统时,操作前的测试和恢复故障手册的完备对于系统的稳定运行是很重要的。作为测试观点,结合实际操作,执行下列工作成为提升可用性的要点。
找出故障发生位置,商讨对策,进行模拟故障测试,并实际验证。
进行假设的集群"一系列状态变化"的测试,对降级运行时的性能进行验证。
以这些测试为基础,完善系统操作/恢复故障手册。
设计简单的集群系统,可以简化上述的验证和手册,是提升系统可用性的要点。
2.7.2. 故障的监视¶
虽然我们已经做了上述的努力,可执行还是会发生故障。系统长期持续运行后,必然会发生故障,其原因可执行是硬件老化,软件的内存泄漏,或者操作时超过系统当初设计的承受能力等。因此,在提高硬件,软件可用性的同时,需要进一步监视故障,在发生故障时采取恰当的处理,这一点非常重要。例如,万一服务器发生故障,可以通过搭建集群系统,只需要几分钟的切换时间就可以使系统继续运行,但是如果置之不管,系统失去冗余性,发生下一个故障时集群系统就没有任何意义了。
因此,发生故障时,系统管理员必须要采取措施防范下一故障的发生,排除新发生的SPOF。在支持系统管理业务上,远程维护,故障通知等功能非常重要。
以上介绍了使用集群系统实现高可用性时所需的周边技术以及其他的一些要点。简单总结一下,就是要注意以下几点:
排除或掌握Single Point of Failure
进行不容易出故障的简洁设计,基于操作前的测试,完善系统操作/恢复故障手册
及早查出发生的故障并进行恰当的处理
3. 关于EXPRESSCLUSTER¶
本章介绍EXPRESSCLUSTER各个组件的说明,从集群系统的设计到运行步骤之间的流程。
本章将介绍以下内容。
3.1. 何谓EXPRESSCLUSTER¶
对集群有了一定的理解后,让我们介绍一下EXPRESSCLUSTER。所谓EXPRESSCLUSTER 是用于实现HA集群系统的软件。
3.2. EXPRESSCLUSTER的产品结构¶
EXPRESSCLUSTER可以大致分为2个模块。
- EXPRESSCLUSTER Server是EXPRESSCLUSTER的主体。安装在配置集群系统的各服务器上。在EXPRESSCLUSTER Server 中包含了所有EXPRESSCLUSTER的高可用性功能。另外,也包含Cluster WebUI的服务器端的功能。
- Cluster WebUI是创建EXPRESSCLUSTER配置信息和进行操作管理的管理工具。以Web浏览器作为用户界面。实体嵌入在EXPRESSCLUSTER Server中,但操作是在管理终端的Web浏览器上进行,这点与EXPRESSCLUSTER Server不同。
3.3. EXPRESSCLUSTER的软件配置¶
EXPRESSCLUSTER的软件配置如下图所示。在配置集群的服务器上安装"EXPRESSCLUSTER Server(EXPRESSCLUSTER主体)"。Cluster WebUI的本体功能包含在EXPRESSCLUSTER Server内,因此无需另外安装。Cluster WebUI除了使用管理PC上的Web浏览器,也可以使用配置集群的各服务器上的Web浏览器。
EXPRESSCLUSTER Server (Main module)
Cluster WebUI
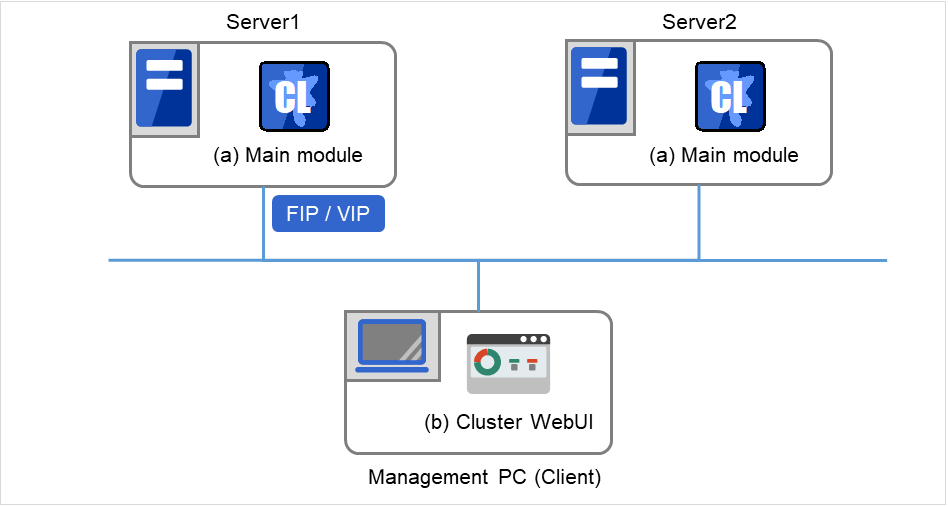
图 3.1 EXPRESSCLUSTER的软件配置¶
3.3.1. EXPRESSCLUSTER 的故障监视原理¶
在EXPRESSCLUSTER 中通过执行服务器监视,业务监视,内部监视3个监视任务,可以迅速确切地查出故障。以下介绍这些监视的详细内容。
3.3.2. 何谓服务器监视¶
- 主网是集群服务器间通信专用的LAN。进行心跳的同时在服务器间交换信息。
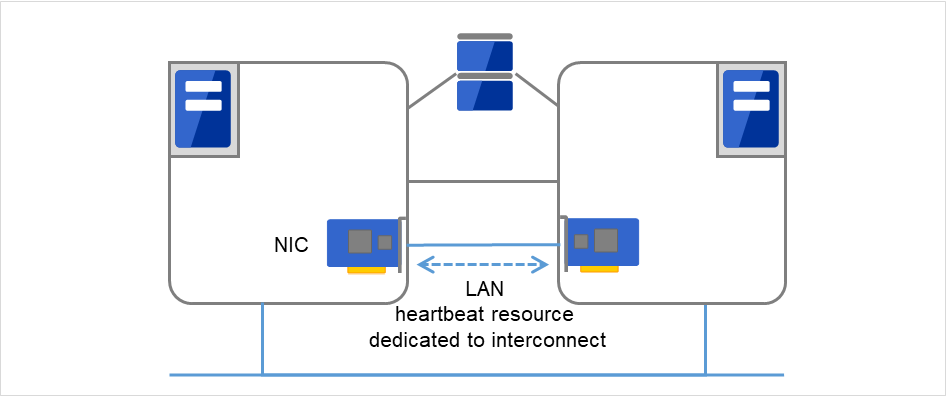
图 3.2 LAN心跳/内核模式LAN心跳(Primary interconnect)¶
- 从网用于与客户端通信用路径。也用于服务器间的信息交换以及心跳线的备份。
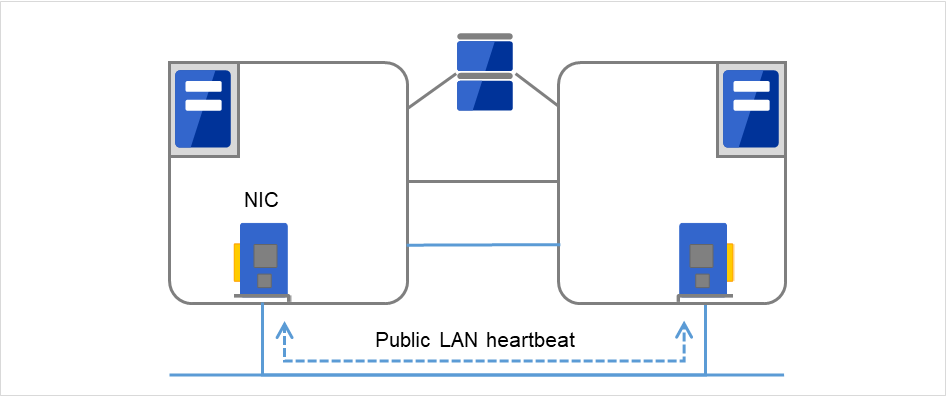
图 3.3 LAN心跳/内核模式LAN心跳(Secondary interconnect)¶
- BMC经由BMC对配置失效切换型集群的服务器间进行心跳通信,确认其他服务器的生存。
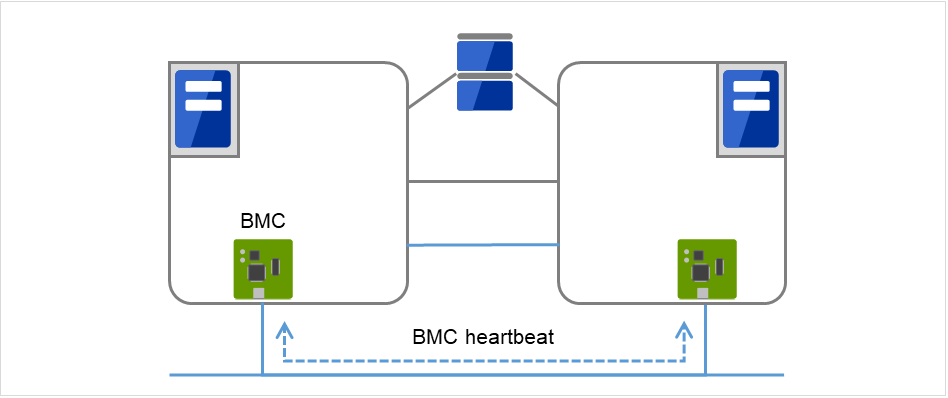
图 3.4 BMC心跳¶
- Witness配置失效切换型集群的各服务器与运行Witness 服务器服务的外部服务器(Witness 服务器)间进行通信,通过与保持Witness 服务器的其他服务器间的通信信息确认生存。
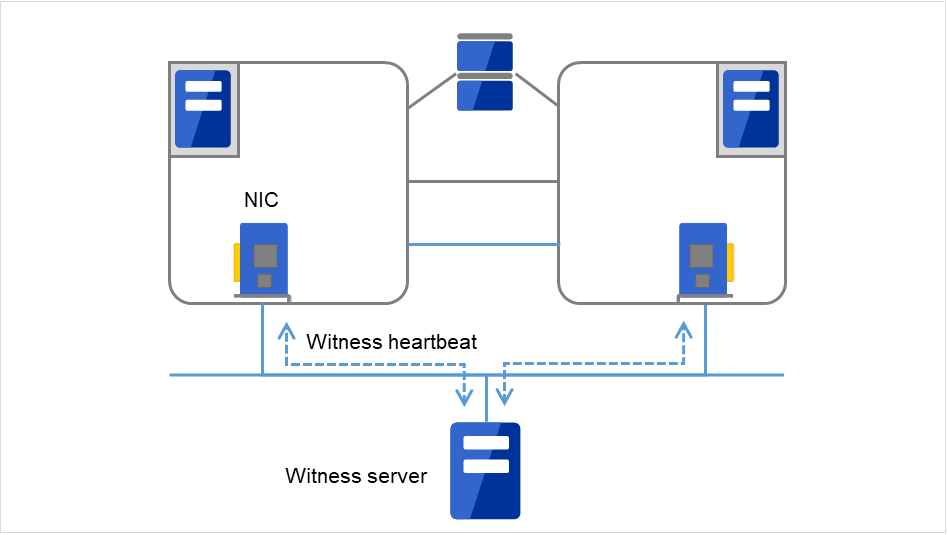
图 3.5 Witness心跳¶
3.3.3. 何谓业务监视¶
所谓业务监视是对业务应用程序本身,以及使业务陷入无法执行状态的故障主要原因进行监视的功能。
- 应用程序的生存状态监视能够使用启动资源(称为应用程序资源,服务资源)启动应用程序,通过监视用资源 (称为应用程序监视资源,服务监视资源) 定期监视进程的生存。在由于业务应用程序异常退出造成业务中断时有效。
注解
如果EXPRESSCLUSTER直接启动的应用程序为启动,结束监视对象的常驻进程的应用程序,则无法查出常驻进程的异常。
注解
无法查出应用程序内部状态的异常 (应用程序的停止,结果异常) 。
- 资源的监视通过EXPRESSCLUSTER的监视资源能够监视集群资源(磁盘分区,IP地址等)和公网的状态。在由于必须资源异常造成业务中断时有效。
3.3.4. 何谓内部监视¶
EXPRESSCLUSTER进程的生存状态监视
3.3.5. 可监视的故障和无法监视的故障¶
EXPRESSCLUSTER中有可监视的故障和无法监视的故障。在构建和运用集群系统时,需要先了解哪些故障能够监视,而哪些不能监视。
3.3.6. 通过服务器监视可以查出的故障和无法查出的故障¶
监视条件: 故障服务器的心跳停止
可以监视的故障示例
硬件故障(OS无法继续运行)
STOP错误
无法监视的故障示例
OS局部功能故障(仅鼠标,键盘等出现故障等)
3.3.7. 通过业务监视可以查出的故障和无法查出的故障¶
监视条件: 故障应用程序的消失,持续的资源异常,与某网络设备通信的路径中断
可监视故障示例
应用程序的异常退出
共享磁盘访问故障(HBA的故障等)
公网 NIC的故障
无法监视的故障示例
- 应用程序的停止/结果异常应用程序的停止/结果异常在EXPRESSCLUSTER里无法直接监视 1 ,但是监视应用程序查出异常时,会创建自动结束程序,在应用程序资源下启动该程序,在应用程序监视资源内予以监视,则可执行发生失效切换。
- 1
监视选项中有关操作,数据库应用程序(Oracle,DB2等),协议(FTP,HTTP等) ,应用程序服务器(Websphere,Weblogic等),可以进行停止/结果异常的监视。
3.4. 网络分区解决¶
COM方式
PING方式
HTTP 方式
共享磁盘方式
COM + 共享磁盘方式
PING + 共享磁盘方方式
多数决定方式
不解决网络分区
参见
关于网络分区解决方法设置的详细内容,请参考《参考指南》的"网络分区解决资源的详细信息"。
3.5. 失效切换的原理¶
一旦查出其他服务器的心跳中断,EXPRESSCLUSTER将在开始失效切换前判断是服务器的故障还是网络分区状态。然后,在正常的服务器上启动各种资源,启动业务应用程序来执行失效切换。
这时,同时移动的资源的集合称为失效切换组。失效切换组从使用者的角度看,可认为是虚拟计算机。
注解
在集群系统中,通过在正常的节点上重启应用程序来执行失效切换。因此,应用程序在内存上存放的执行状态无法失效切换。
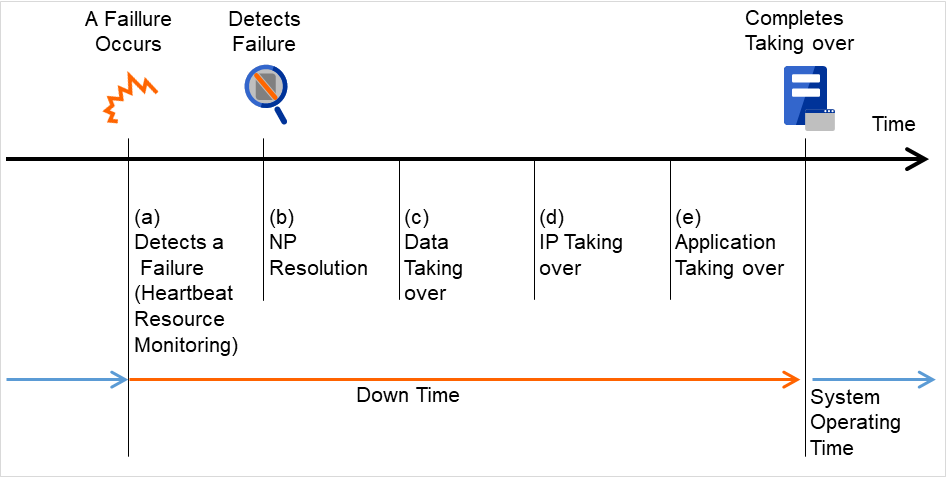
从发生故障到失效切换结束要花费数分钟。以下是时间表。
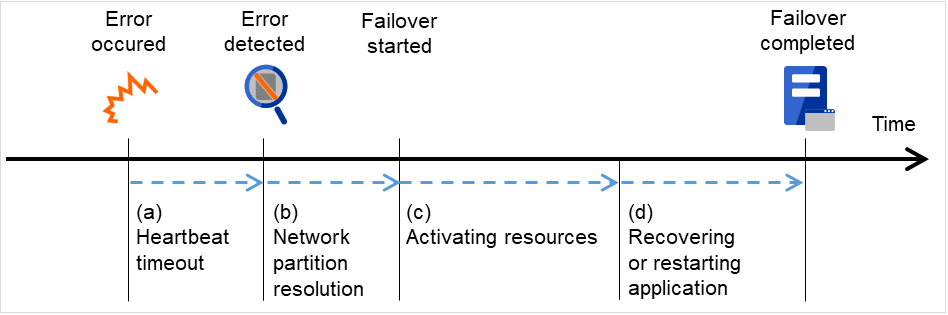
图 3.6 失效切换的时间表¶
心跳超时
执行业务的服务器发生故障后,直至待机服务器查出该故障为止的时间。
网络分区解决
是为了确认对方服务器的心跳的中断(心跳超时)是由于网络分区状态引起还是实际上对方服务器发生故障引起的所需时间。
通常是瞬间完成确认。
各种资源的启动
启动业务所需资源所用的时间。
进行文件系统恢复,磁盘内数据交接,IP地址交接等。
应用程序的恢复处理/重启
启动业务所用的应用程序所需时间。也包括数据库的回滚/前滚等数据恢复处理的时间。
回滚/前滚时间等通过Check Point Interval的调整,可在某种程度上预测。具体内容请参考各软件产品的文档。
3.5.1. 由EXPRESSCLUSTER构建的共享磁盘型集群的硬件配置¶
共享磁盘型集群的EXPRESSCLUSTER的HW配置如下图所示。
用于服务器间的通信
NIC 两块 (1块用于与外部通信,1块为EXPRESSCLUSTER专用)
用RS232C Cross Cable连接的COM端口
共享磁盘的特定空间
通常使用以上的配置。
与共享磁盘的连接接口使用SCSI或者FibreChannel,最近多使用FibreChannel。
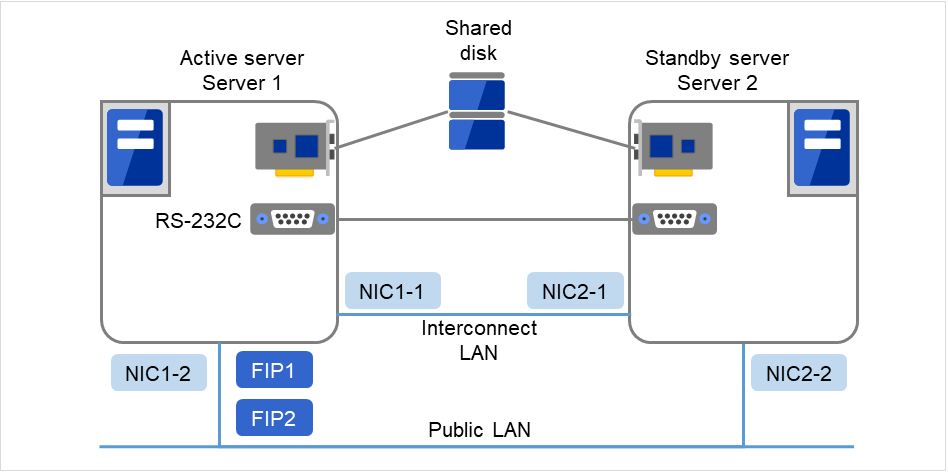
图 3.7 集群配置示例(共享磁盘型)¶
FIP1 |
10.0.0.11 (从Cluster WebUI客户端访问) |
FIP2 |
10.0.0.12 (从业务客户端访问) |
NIC1-1 |
192.168.0.1 |
NIC1-2 |
10.0.0.1 |
NIC2-1 |
192.168.0.2 |
NIC2-2 |
10.0.0.2 |
RS-232C 端口 |
COM1 |
共享磁盘:
磁盘心跳用分区盘符
E
磁盘资源盘符
F
文件系统
NTFS
以上是使用共享磁盘时的集群环境示例。
3.5.2. 用EXPRESSCLUSTER构建的镜像磁盘型集群的硬件配置¶
通过为各服务器的磁盘上的分区建立镜像,可替代共享磁盘装置。与共享磁盘型相比适合规模小,预算少的系统。
注解
使用镜像磁盘,您需要购买Replicator可选软件或Replicator DR可选软件。
使用镜像磁盘时的集群环境示例(在安装OS的磁盘中确保集群分区和数据分区时)
在以下配置中,将安装了OS的磁盘的空闲分区作为集群分区和数据分区使用。
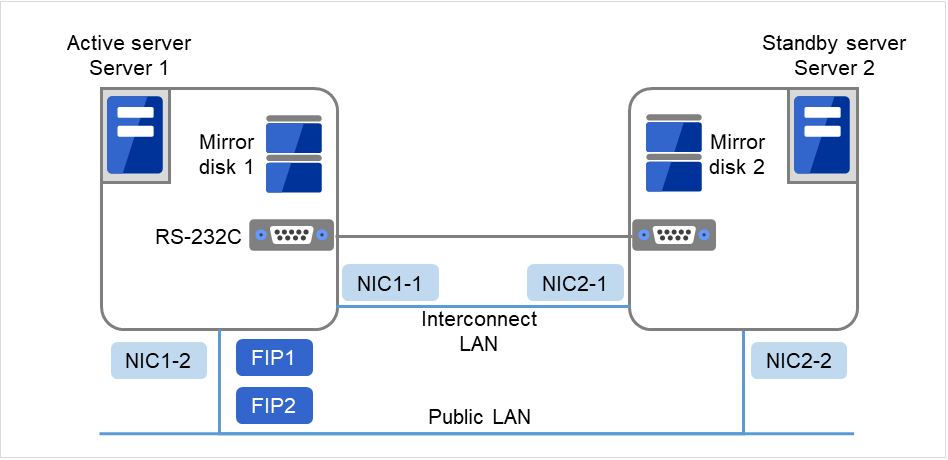
图 3.8 集群配置示例(1)(镜像磁盘型)¶
FIP1
10.0.0.11 (从Cluster WebUI客户端访问)
FIP2
10.0.0.12 (从业务客户端访问)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
RS-232C 端口
COM1
集群分区盘符
E
文件系统
RAW
数据分区盘符
F
文件系统
NTFS
使用镜像磁盘时的集群环境示例(准备了用于集群分区和数据分区的磁盘时)
在以下配置中,已准备并连接了用于集群分区和数据分区的磁盘。
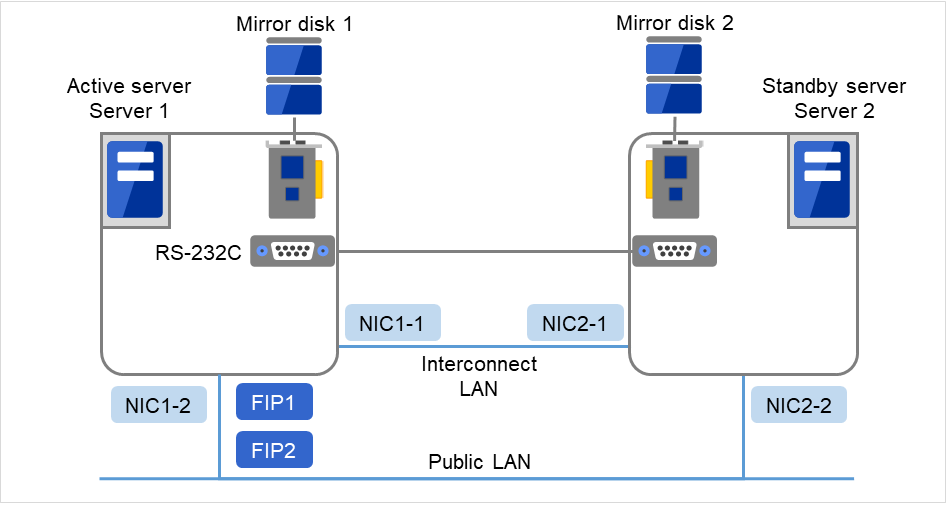
图 3.9 集群配置示例(2)(镜像磁盘型)¶
FIP1
10.0.0.11 (从Cluster WebUI客户端访问)
FIP2
10.0.0.12 (从业务客户端访问)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
RS-232C 端口
COM1
集群分区盘符
E
文件系统
RAW
数据分区盘符
F
文件系统
NTFS
3.5.3. 用EXPRESSCLUSTER构建的共享磁盘型集群的硬件配置¶
该配置通过组合共享磁盘型和镜像磁盘型,镜像化共享磁盘上的分区,从而实现在共享磁盘设备出现故障时也能够不中断业务。该配置也可以利用在远程站点之间,通过与远程站点的镜像化对应灾害的发生。
注解
使用共享型镜像磁盘,您需要购买Replicator DR可选软件。
与镜像磁盘一样,需要复制数据用的网络,一般可以由私网(EXPRESSCLUSTER内部通信使用的NIC)兼用。
用EXPRESSCLUSTER构建的共享磁盘型集群的硬件配置如下图所示。
使用共享型镜像磁盘时的集群环境的示例 (在2台服务器中使用共享磁盘,并镜像第3台服务器的常规磁盘时)
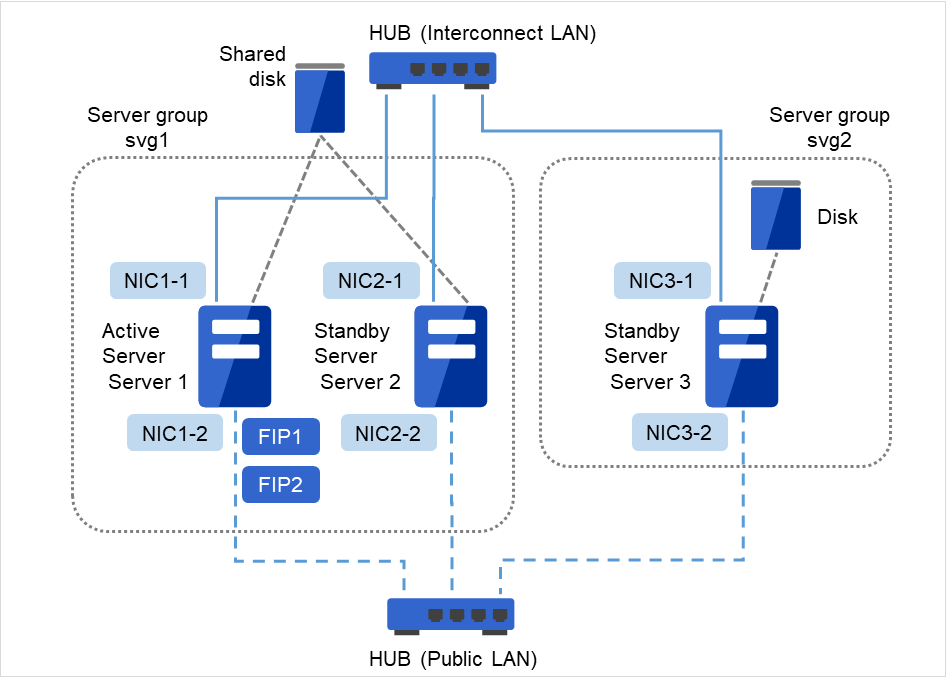
图 3.10 集群配置示例(共享型镜像磁盘型)¶
FIP1
10.0.0.11 (从Cluster WebUI客户端访问)
FIP2
10.0.0.12 (从业务客户端访问)
NIC1-1
192.168.0.1
NIC1-2
10.0.0.1
NIC2-1
192.168.0.2
NIC2-2
10.0.0.2
NIC3-1
192.168.0.3
NIC3-2
10.0.0.3
共享磁盘
心跳用分区盘符
E
文件系统
RAW
集群分区盘符
F
文件系统
RAW
数据分区盘符
G
文件系统
NTFS
以上是在同一网络内镜像化共享磁盘时的集群环境示例。如果使用共享型磁盘,则在连接在同一共享磁盘设备的服务器组之间进行镜像化,但在上述示例中,共享磁盘将镜像化到server3的本地磁盘上,因此待机系服务器组svg2的成员服务器只有server3一台。
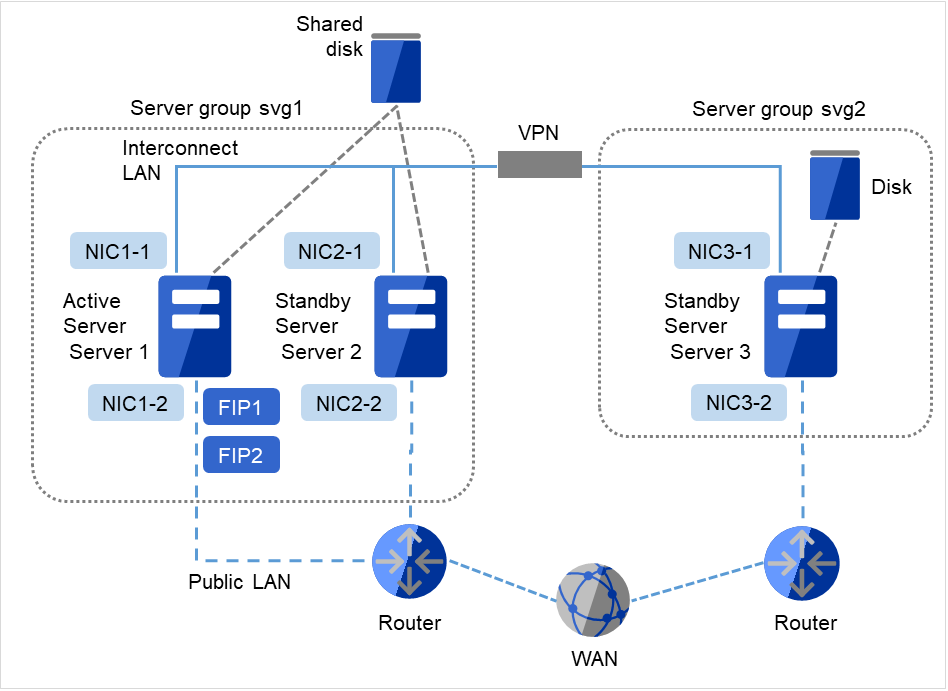
图 3.11 集群配置示例(共享型镜像磁盘型,远程集群)¶
FIP1 |
10.0.0.11 (从Cluster WebUI客户端访问) |
FIP2 |
10.0.0.12 (从业务客户端访问) |
NIC1-1 |
192.168.0.1 |
NIC1-2 |
10.0.0.1 |
NIC2-1 |
192.168.0.2 |
NIC2-2 |
10.0.0.2 |
NIC3-1 |
192.168.0.3 |
NIC3-2 |
10.0.0.3 |
共享磁盘
心跳用分区盘符
E
文件系统
RAW
集群分区盘符
F
文件系统
RAW
数据分区盘符
G
文件系统
NTFS
上图是与远程站点之间进行镜像化时的集群环境示例。在该例中,因为服务器组之间的Public-LAN网段不同,因此没有使用浮动IP地址,而是使用了虚拟IP地址。使用虚拟IP地址时,需要将中途的路由全部设置为传播主路径。并且推荐将镜像模式设置为非同步,开启数据压缩功能。
3.5.4. 何谓集群对象¶
在EXPRESSCLUSTER中按照以下结构管理各种资源。
- 集群对象集合了一群服务器的集群系统。
- 服务器对象表示实体服务器的对象,属于集群对象。
- 服务器组对象捆绑了服务器的对象,属于集群对象。使用共享磁盘资源时需要使用该对象。
- 心跳资源对象表示实体服务器的NW部分的对象,属于服务器对象。
- 网络分区解决资源对象表示网络分区解决构造的对象,属于服务器对象。
- 组对象表示虚拟的服务器的对象,属于集群对象。
- 组资源对象表示虚拟服务器的资源(NW,磁盘)的对象,属于组对象。
- 监视资源对象表示监视构造的对象,属于集群对象。
3.6. 何谓资源¶
在EXPRESSCLUSTER中,监视方和被监视方均被称作资源,并将监视方和被监视方的资源分类管理。这样,除能更明确的区分监视/被监视对象,在构建集群和查出故障时还可更容易应对。资源分为心跳资源,网络分区解决资源,组资源和监视资源4类。以下说明其概要。
参见
关于各资源的具体内容,请参考《参考指南》。
3.6.1. 心跳资源¶
是在服务器间用来确认彼此存活的资源。
以下是当前支持的心跳资源。
- LAN心跳资源表示使用Ethernet的通信。
- Witness 心跳资源表示从Witness 服务器服务运行的外部服务器中取得的与各服务器间的通信状态。
- BMC心跳资源经由BMC,表示使用Ethernet的通信。仅在可支持BMC 的硬件和固件情况下使用。
3.6.2. 网络分区解决资源¶
以下是解决网络分区状态的资源。
- COM网络分区解决资源COM方式的网络分区解决资源。
- DISK网络分区解决资源DISK方式的网络分区解决资源。仅共享磁盘结构时可用。
- PING网络分区解决资源PING方式的网络分区解决资源。
- HTTP 网络分区解决资源HTTP 方式的网络分区解决资源。
- 多数决定网络分区解决资源多数决定方式的网络分区解决资源。
3.6.3. 组资源¶
进行失效切换时的单位,即配置失效切换组的资源。
以下是当前支持的组资源。
- 应用程序资源 (appli)启动/停止应用程序(包括用户创建的应用程序)。
- 浮动IP资源 (fip)提供虚拟的IP地址。从客户端访问时与普通IP地址相同。
- 镜像磁盘资源 (md)提供本地磁盘上的特定分区的镜像建立和访问控制功能。仅镜像磁盘结构时可用。
- 注册表同步资源 (regsync)在多个服务器上对特定的注册表进行同步,以实现在配置集群的服务器间令应用程序和服务按照同样的设置来运行。
- 脚本资源 (script)启动/停止用户创建脚本等脚本(BAT)。
- 磁盘资源 (sd)提供对共享磁盘上的特定分区的访问控制功能。仅当连接了共享磁盘装置时可用。
- 服务资源 (service)启动/停止数据库和Web等服务。
- Print Spooler资源 (spool)提供对Print Spooler进行失效切换的功能。
- 虚拟计算机名资源 (vcom)提供虚拟的计算机名。从客户端访问时与普通计算机名相同。
- 动态DNS资源 (ddns)在动态DNS服务器中登录虚拟主机名和运行服务器的IP地址。
- 虚拟IP资源 (vip)提供虚拟的IP地址。从客户端访问时与普通IP地址相同。在网络地址不同的网段间配置远程集群时使用。
- CIFS资源 (cifs)提供共享磁盘/镜像磁盘上的文件夹共享功能。
- NAS资源 (nas)提供文件服务器上的共享文件夹以网络硬盘的方式加载的功能。
- 共享磁盘资源 (hd)是组合了磁盘资源和镜像磁盘资源的一种资源,提供对共享磁盘或本地磁盘上特定分区进行镜像或访问控制的功能。
- 虚拟机资源 (vm)进行虚拟机的启动,停止及迁移。
- AWS Elastic IP资源 (awseip)在AWS上利用EXPRESSCLUSTER时,提供可授予EIP的机能。
- AWS虚拟IP资源 (awsvip)在AWS上利用EXPRESSCLUSTER时,提供可授予VIP的机能。
- AWS DNS资源 (awsdns)在AWS上利用EXPRESSCLUSTER时,在Amazon Route 53上登录虚拟主机名和启动服务器的IP地址。
- Azure 探头端口资源 (azurepp)Microsoft Azure 上利用EXPRESSCLUSTER时,提供可在运行业务的节点开放特定的端口的机能。
- Azure DNS资源 (azuredns)在Microsoft Azure上利用EXPRESSCLUSTER时,在Azure DNS上登录虚拟主机名和启动服务器的IP地址。
- Google Cloud 虚拟 IP 资源 (gcvip)在Google Cloud Platform上使用ExpressCluster时,提供了一种在业务运行的节点上打开特定端口的机制。
- Google Cloud DNS 资源 (gcdns)Google Cloud Platform上利用EXPRESSCLUSTER时,在Cloud DNS上登录虚拟主机名和启动服务器的IP地址。
- Oracle Cloud 虚拟 IP 资源 (ocvip)在Oracle Cloud Infrastructure上使用ExpressCluster时,提供了一种在业务运行的节点上打开特定端口的机制。
注解
3.6.4. 监视资源¶
集群系统内进行监视的主体资源。
以下是当前支持的监视资源。
- 应用程序监视资源 (appliw)提供应用程序资源启动的进程的死活监视功能。
- 磁盘RW监视资源 (diskw)提供对文件系统的监视。此外,当文件系统I/O停止 (Stall) 时,提供通过有意的STOP错误或者HW重置实施失效切换的功能。也可用于对共享磁盘的文件系统的监视。
- 浮动IP监视资源 (fipw)提供对浮动IP资源启动的IP地址的监视。
- IP监视资源 (ipw)提供对网络通堵的监视。
- 镜像磁盘监视资源 (mdw)提供对镜像磁盘的监视。
- 镜像连接监视资源 (mdnw)提供对镜像连接的监视。
- NIC Link Up/Down监视资源 (miiw)提供对LAN线缆的链接状态的监视。
- 多目标监视资源 (mtw)提供将多个监视资源集中在一起的状态。
- 注册表同步监视资源 (regsyncw)提供对注册表同步资源进行的同步处理的监视。
- 磁盘TUR监视资源 (sdw)对通过SCSI的[TestUnitReady]命令向共享磁盘访问路径发出的动作进行监视。也可用于FibreChannel的共享磁盘。
- 服务监视资源 (servicew)提供对服务资源所启动的进程进行死活监视。
- Print Spooler监视资源 (spoolw)提供对Print Spooler资源所启动的Print Spooler的监视。
- 虚拟计算机名监视资源 (vcomw)提供对虚拟计算机名资源启动的虚拟计算机的监视。
- 动态DNS监视资源 (ddnsw)定期在动态DNS服务器中登录虚拟主机名和运行服务器的IP地址。
- 虚拟IP监视资源 (vipw)提供对虚拟IP资源启动的IP地址的监视。
- CIFS监视资源 (cifsw)提供对CIFS资源公布的共享文件夹的监视。
- NAS监视资源 (nasw)提供对NAS资源加载的网络硬盘的监视。
- 共享型镜像磁盘监视资源 (hdw)提供对共享型镜像磁盘的监视。
- 共享型镜像磁盘TUR监视资源 (hdtw)通过SCSI的[TestUnitReady]命令,提供对用作共享型镜像磁盘的共享磁盘设备访问路径运行的监视。也可以用于FibreChannel的共享磁盘。
- 自定义监视资源 (genw)有进行监视处理的命令或脚本时,提供通过其动作结果进行监视系统的功能。
- 进程名监视资源 (psw)通过指定进程名,提供任意的进程死活监视功能
- DB2监视资源 (db2w)提供对IBM DB2数据库的监视。
- ODBC监视资源 (odbcw)提供对ODBC可访问的数据库的监视。
- Oracle监视资源 (oraclew)提供对Oracle数据库的监视。
- PostgreSQL监视资源 (psqlw)提供对PostgreSQL数据库的监视。
- SQL Server监视资源 (sqlserverw)提供对SQL Server数据库的监视。
- FTP监视资源 (ftpw)提供对FTP服务器的监视。
- HTTP监视资源 (httpw)提供对HTTP服务器的监视。
- IMAP4监视资源 (imap4w)提供对IMAP服务器的监视。
- POP3监视资源 (pop3w)提供对POP服务器的监视。
- SMTP监视资源 (smtpw)提供对SMTP服务器的监视。
- Tuxedo监视资源 (tuxw)提供对Tuxedo应用程序服务器的监视。
- Websphere监视资源 (wasw)提供对WebSphere应用程序服务器的监视。
- Weblogic监视资源 (wlsw)提供对WebLogic应用程序服务器的监视。
- WebOTX监视资源 (otxw)提供对WebOTX应用程序服务器的监视。
- 虚拟机监视资源 (vmw)提供对通过虚拟机资源启动的虚拟机的监视。
- 消息接收监视资源(mrw)用于实现"设置接收异常发生通知时执行的异常时动作"及"异常发生通知的Cluster WebUI显示"的监视资源。
- JVM 监视资源 (jraw)提供Java VM的监视机构。
- 系统监视资源 (sraw)提供系统整体资源的监视机构。
- 进程资源监视资源(psrw)提供用于监视特定于进程的资源的机制。
- 用户空间监视资源 (userw)提供用户空间的停止监视功能。此外,当用户空间停止时,提供通过有意的STOP错误或者HW重置实施失效切换的功能。
- AWS Elastic IP监视资源 (awseipw)提供在AWS Elastic IP资源授予的Elastic IP(以下称为EIP)的监视机能。
- AWS虚拟IP监视资源 (awsvipw)提供在AWS虚拟IP资源授予的虚拟IP(以下称为VIP)的监视机能。
- AWS AZ监视资源 (awsazw)提供Availability Zone(以下称为AZ)的监视机能。
- AWS DNS监视资源 (awsdnsw)提供在AWS DNS资源授予的虚拟主机名和IP地址的监视机能。
- Azure 探头端口监视资源 (azureppw)可针对Azure 探头端口资源所启动的节点,提供为了进行死活监视的端口的监视机能。
- Azure负载均衡器监视资源 (azurelbw)可针对Azure 探头端口资源所启动的节点,提供与Probe端口相同的端口号是否开放的监视机能。
- Azure DNS监视资源 (azurednsw)提供在Azure DNS资源授予的虚拟主机名和IP地址的监视机能。
- Google Cloud 虚拟 IP 监视资源 (gcvipw)对启动了Google Cloud虚拟IP资源的节点,提供用于进行死活监视的端口的监控机制。
- Google Cloud 负载均衡监视资源 (gclbw)对没有启动Google Cloud虚拟IP资源的节点,提供确认是否开放了与用于存活侦测的端口相同的端口号的监控机制。
- Google Cloud DNS监视资源 (gcdnsw)提供在Google Cloud DNS资源授予的虚拟主机名和IP地址的监视机构。
- Oracle Cloud 虚拟 IP 监视资源 (ocvipw)对启动了Oracle Cloud虚拟IP资源的节点,提供用于进行死活监视的端口的监控机制。
- Oracle Cloud 负载均衡监视资源 (oclbw)对没有启动Oracle Cloud虚拟IP资源的节点,提供确认是否开放了与用于存活侦测的端口相同的端口号的监控机制。
注解
4. EXPRESSCLUSTER的运行环境¶
在本章中对EXPRESSCLUSTER的运行环境进行说明。
本章中说明的项目如下。
4.1. 硬件运行环境¶
EXPRESSCLUSTER在以下结构的服务器上运行。
x86_64
4.1.1. 所需规格¶
EXPRESSCLUSTER Server所需要的规格如下。
RS-232C端口 1个 (构建3节点以上的集群时不需要)
Ethernet端口 2个以上
共享磁盘,镜像用磁盘或者镜像用空分区 (使用镜像磁盘时)
CD-ROM驱动器
4.1.2. 与Express5800/A1080a,A1040a 系列的整合相对应的服务器¶
以下的服务器可使用BMC 心跳资源和消息接收监视资源的 Express5800/A1080a 系列整合功能。该功能在以下所述的服务器以外不能使用。
服务器 |
备注 |
|---|---|
Express5800/A1080a-E |
可执行需要升级最新版的固件。 |
Express5800/A1080a-D |
可执行需要升级最新版的固件。 |
Express5800/A1080a-S |
可执行需要升级最新版的固件。 |
Express5800/A1040a |
可执行需要升级最新版的固件。 |
4.2. EXPRESSCLUSTER Server的运行环境¶
4.2.1. 对应OS¶
EXPRESSCLUSTER Server对应的OS如下。
x86_64版
OS |
备注 |
|---|---|
Windows Server 2012 Standard |
|
Windows Server 2012 Datacenter |
|
Windows Server 2012 R2 Standard |
|
Windows Server 2012 R2 Datacenter |
|
Windows Server 2016 Standard |
|
Windows Server 2016 Datacenter |
|
Windows Server, version 1709 Standard |
|
Windows Server, version 1709 Datacenter |
|
Windows Server, version 1803 Standard |
|
Windows Server, version 1803 Datacenter |
|
Windows Server, version 1809 Standard |
|
Windows Server, version 1809 Datacenter |
|
Windows Server 2019 Standard |
|
Windows Server 2019 Datacenter |
|
Windows Server, version 1903 Standard |
|
Windows Server, version 1903 Datacenter |
|
Windows Server, version 1909 Standard |
|
Windows Server, version 1909 Datacenter |
|
Windows Server, version 2004 Standard |
|
Windows Server, version 2004 Datacenter |
4.2.2. 所需内存容量和磁盘容量¶
所需内存容量
(用户模式)
|
256MB( 2 ) |
|---|---|
所需内存容量
(Kernel模式)
|
32MB + 4MB( 3 )×(镜像磁盘资源数+共享型镜像磁盘资源) |
所需磁盘容量
(安装后)
|
100MB |
所需磁盘容量
(操作时)
|
5.0GB |
非同步方式地更改或者队列大小变化时,并且差分Bitmap大小变化时,都需要添加配置时指定大小的内存。此外,由于使用内存与镜像磁盘的I/O相对应,随着磁盘负荷的增加,使用的内存大小也会增加。
关于DISK网络分区解决资源所使用的分区所需的大小,请参考"关于共享磁盘"。
关于集群分区所需的大小请参考"关于镜像磁盘用的分区","关于共享型镜像磁盘用的分区"。
4.2.3. 监视可选软件已经确认完毕的应用程序信息¶
监视可选软件已经将下列应用程序作为监视对象进行了运行确认。
x86_64版
监视资源
|
监视对象
应用程序
|
EXPRESSCLUSTER
Version
|
备注
|
|---|---|---|---|
Oracle监视 |
Oracle Database 12c Release 1 (12.1) |
12.00~ |
|
Oracle Database 12c Release 2 (12.2) |
12.00~ |
||
Oracle Database 18c (18.3) |
12.10~ |
||
Oracle Database 19c (19.3) |
12.10~ |
||
DB2监视 |
DB2 V10.5 |
12.00~ |
|
DB2 V11.1 |
12.00~ |
||
DB2 V11.5 |
12.20~ |
||
PostgreSQL监视 |
PostgreSQL 9.3 |
12.00~ |
|
PostgreSQL 9.4 |
12.00~ |
||
PostgreSQL 9.5 |
12.00~ |
||
PostgreSQL 9.6 |
12.00~ |
||
PostgreSQL 10 |
12.00~ |
||
PostgreSQL 11 |
12.10~ |
||
PostgreSQL 12 |
12.22~ |
||
PowerGres on Windows V9.1 |
12.00~ |
||
PowerGres on Windows V9.4 |
12.00~ |
||
PowerGres on Windows V9.6 |
12.00~ |
||
PowerGres on Windows V11 |
12.10~ |
||
SQL Server监视 |
SQL Server 2014 |
12.00~ |
|
SQL Server 2016 |
12.00~ |
||
SQL Server 2017 |
12.00~ |
||
SQL Server 2019 |
12.20~ |
||
Tuxedo监视 |
Tuxedo 12c Release 2 (12.1.3) |
12.00~ |
|
Weblogic监视 |
WebLogic Server 11g R1 |
12.00~ |
|
WebLogic Server 11g R2 |
12.00~ |
||
WebLogic Server 12c R2 (12.2.1) |
12.00~ |
||
WebLogic Server 14c (14.1.1) |
12.20~ |
||
Websphere监视 |
WebSphere Application Server 8.5 |
12.00~ |
|
WebSphere Application Server 8.5.5 |
12.00~ |
||
WebSphere Application Server 9.0 |
12.00~ |
||
WebOTX监视 |
WebOTX Application Server V9.1 |
12.00~ |
|
WebOTX Application Server V9.2 |
12.00~ |
||
WebOTX Application Server V9.3 |
12.00~ |
||
WebOTX Application Server V9.4 |
12.00~ |
||
WebOTX Application Server V9.5 |
12.00~ |
||
WebOTX Application Server V10.1 |
12.00~ |
||
WebOTX Application Server V10.3 |
12.30~ |
||
JVM监视 |
WebLogic Server 11g R1 |
12.00~ |
|
WebLogic Server 11g R2 |
12.00~ |
||
WebLogic Server 12c R2 (12.2.1) |
12.00~ |
||
WebLogic Server 14c (14.1.1) |
12.20~ |
||
WebOTX Application Server V9.1 |
12.00~ |
||
WebOTX Application Server V9.2 |
12.00~ |
||
WebOTX Application Server V9.3 |
12.00~ |
||
WebOTX Application Server V9.4 |
12.00~ |
||
WebOTX Application Server V9.5 |
12.00~ |
||
WebOTX Application Server V10.1 |
12.00~ |
||
WebOTX Application Server V10.3 |
12.30~ |
||
WebOTX Enterprise Service Bus V8.4 |
12.00~ |
||
WebOTX Enterprise Service Bus V8.5 |
12.00~ |
||
WebOTX Enterprise Service Bus V10.3 |
12.30~ |
||
Apache Tomcat 8.0 |
12.00~ |
||
Apache Tomcat 8.5 |
12.00~ |
||
Apache Tomcat 9.0 |
12.00~ |
||
WebSAM SVF for PDF 9.1 |
12.00~ |
||
WebSAM SVF for PDF 9.2 |
12.00~ |
||
WebSAM Report Director Enterprise 9.1 |
12.00~ |
||
WebSAM Report Director Enterprise 9.2 |
12.00~ |
||
WebSAM Universal Connect/X 9.1 |
12.00~ |
||
WebSAM Universal Connect/X 9.2 |
12.00~ |
||
系统监视 |
无指定版本 |
12.00~ |
|
进程资源监视 |
无指定版本 |
12.10~ |
注解
x86_64环境中利用监视选项时,监视对象的应用程序也请利用x86_64版的应用程序。
4.2.4. 虚拟机资源的运行环境¶
进行虚拟机资源运行确认的虚拟基础架构的版本信息如下所示。
虚拟基础架构 |
版本 |
备注 |
|---|---|---|
Hyper-V |
Windows Server 2012 Hyper-V |
|
Windows Server 2012 R2 Hyper-V |
注解
虚拟机资源在Windows Server 2016上不能动作。
4.2.5. SNMP联动功能的运行环境¶
对SNMP 联动功能的运行确认完毕的OS如下表中所示。
x86_64 版
OS
|
EXPRESS
CLUSTER
Version
|
备注
|
|---|---|---|
Windows Server 2012 |
12.00~ |
|
Windows Server 2012 R2 |
12.00~ |
|
Windows Server 2016 |
12.00~ |
|
Windows Server, version 1709 |
12.00~ |
4.2.6. JVM监视器的运行环境¶
使用JVM监视器时,需要可Java 的执行环境。
必须在Microsoft NET Framework运行环境下,使用JVM监视负载均衡器联动功能(与BIG-IP Local Traffic Manager联动)。
Microsoft .NET Framework 3.5 Service Pack 1
Microsoft .NET Framework 3.5 SP1 日文 Language Pack
安装步骤
图 4.1 服务器管理器¶
图 4.2 选择目标服务器¶
在[服务器角色]画面点击[下一步]。
在[功能]画面选中[ .Net Framework 3.5 Features ],点击[下一步]。
图 4.3 选择功能¶
服务器连接网络的状态下,在[确认]画面点击[安装],安装Net Framework 3.5。
服务器没有连接网络的状态下,在[确认]画面选择[指定备用源路径]。
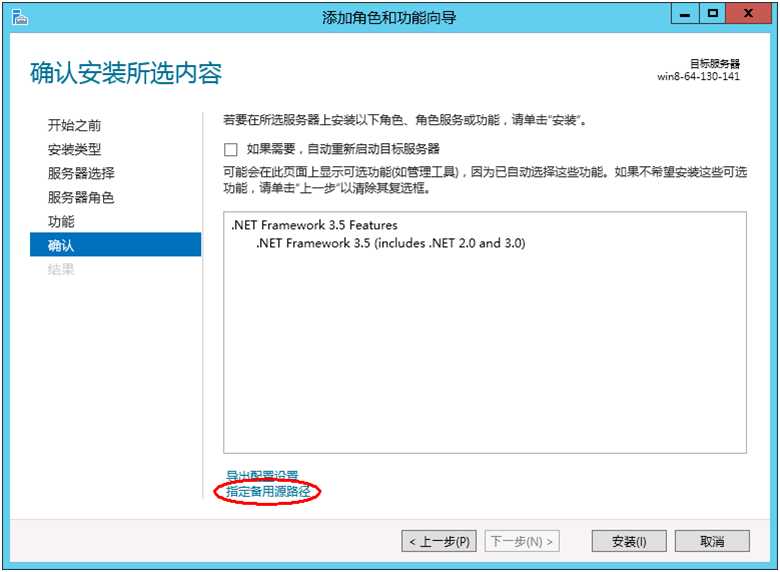
图 4.4 确认安装所选内容¶
参考显示的画面说明,在[路径]栏指定OS安装媒体路径后,点击 [确认]。接着,点击[安装]来安装Net Framework 3.5。
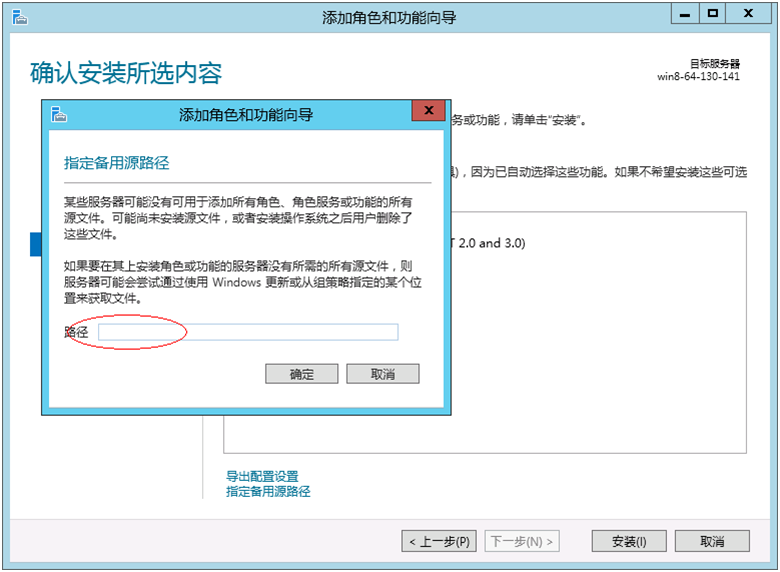
图 4.5 指定备用源路径¶
进行JVM监视器的负载均衡器联动功能的运行确认的负载均衡器如下所示。
x86_64 版
负载均衡器
|
EXPRESSCLUSTER
Version
|
备注
|
|---|---|---|
Express5800/LB400h以上 |
12.00~ |
|
InterSec/LB400i 以上 |
12.00~ |
|
BIG-IP v11 |
12.00~ |
|
CoyotePoint Equalizer |
12.00~ |
4.2.7. 系统监视,进程资源监视以及系统资源信息收集功能的运行环境¶
注解
在Windows Server 2012之后的OS中,已安装了.NET Framework 4.5以上的版本(安装的.NET Framework版本取决于OS。)
4.2.8. AWS Elastic IP资源,AWS虚拟IP资源,AWS Elastic IP监视资源,AWS 虚拟IP监视资源,AWS AZ监视资源的运行环境¶
想使用AWS Elastic IP资源,AWS虚拟IP资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源时,需要以下的软件。
软件 |
版本 |
备注 |
|---|---|---|
AWS CLI |
1.6.0 ~ |
|
Python
|
2.7.5~
3.6.7~
3.8.2~
|
AWS CLI 附带的 Python 不可以 |
进行AWS Elastic IP资源,AWS虚拟IP资源,AWS Elastic IP监视资源,AWS虚拟IP监视资源,AWS AZ监视资源的运行确认的AWS上的OS的版本信息如下所示。
Distribution
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
Windows Server 2012 |
12.00~ |
|
Windows Server 2012 R2 |
12.00~ |
|
Windows Server 2016 |
12.00~ |
|
Windows Server 2019 |
12.10~ |
4.2.9. AWS DNS资源,AWS DNS监视资源的运行环境¶
想使用AWS DNS资源,AWS DNS监视资源时,需要以下的软件。
软件 |
版本 |
备注 |
|---|---|---|
AWS CLI |
1.11.0~ |
|
Python
|
2.7.5~
3.6.7~
3.8.2~
|
AWS CLI 附带的 Python 不可以 |
进行AWS DNS资源,AWS DNS监视资源的运行确认的 AWS 上的 OS 版本信息如下所示。
Distribution
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
Windows Server 2012 |
12.00~ |
|
Windows Server 2012 R2 |
12.00~ |
|
Windows Server 2016 |
12.00~ |
|
Windows Server 2019 |
12.10~ |
4.2.10. Azure探头端口资源,Azure探头端口监视资源,Azure负载均衡监视资源的运行环境¶
进行Azure探头端口资源,Azure探头端口监视资源,Azure负载均衡监视资源的运行确认的Microsoft Azure上的OS的版本信息如下所示。
Distribution
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
Windows Server 2012 |
12.00~ |
|
Windows Server 2012 R2 |
12.00~ |
|
Windows Server 2016 |
12.00~ |
|
Windows Server, version 1709 |
12.00~ |
|
Windows Server 2019 |
12.10~ |
执行了Azure探头端口资源,Azure探头端口监视资源,Azure负载均衡监视资源的动作确认的Microsoft Azure上的部署模型如下所示。
负载均衡的设定方法请参考《EXPRESSCLUSTER X Mircosoft Azure的HA Cluster构筑指南 (Windows版)》。
部署模型
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
资源管理器 |
12.00~ |
需要追加负载均衡器 |
4.2.11. Azure DNS 资源,Azure DNS 监视资源的运行环境¶
使用Azure DNS资源,Azure DNS监视资源时,需要以下的软件。
软件 |
版本 |
备注 |
|---|---|---|
Azure CLI |
2.0~ |
进行Azure DNS资源,Azure DNS监视资源的运行确认的 Microsoft Azure 上的 OS的版本信息如下所示。
Distribution
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
Windows Server 2012 |
12.00~ |
|
Windows Server 2012 R2 |
12.00~ |
|
Windows Server 2016 |
12.00~ |
|
Windows Server, version 1709 |
12.00~ |
|
Windows Server 2019 |
12.10~ |
执行了Azure DNS资源,Azure DNS监视资源的运行确认的 Microsoft Azure上的部署模型如下所示。
Azure DNS 的设定方法请参考《EXPRESSCLUSTER X Mircosoft Azure的HA Cluster构筑指南 (Windows版)》。
部署模型
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
资源管理器 |
12.00~ |
需要追加Azure DNS |
4.2.12. Google Cloud 虚拟 IP 资源,Google Cloud 虚拟 IP 监视资源,Google Cloud 负载均衡监视资源的运行环境¶
已确认Google Cloud 虚拟 IP 资源,Google Cloud 虚拟 IP 监视资源,Google Cloud 负载均衡监视资源的运行环境的 Google Cloud Platform 上的 OS 的版本信息如下所示。
部署模型
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
Windows Server 2016 |
12.20~ |
|
Windows Server 2019 |
12.20~ |
4.2.13. Google Cloud DNS 资源,Google Cloud DNS 监视资源的运行环境¶
想使用Google Cloud DNS资源,Google Cloud DNS监视资源时,需要以下的软件。
软件
版本
备注
Google Cloud SDK
295.0.0~
执行了Google Cloud DNS资源,Google Cloud DNS监视资源的运行确认的 Google Cloud Platform上的OS的版本信息如下所示。
Windows Server 2019
12.30~
4.2.14. Oracle Cloud 虚拟 IP 资源,Oracle Cloud 虚拟 IP 监视资源,Oracle Cloud 负载均衡监视资源的运行环境¶
已确认Oracle Cloud 虚拟 IP 资源,Oracle Cloud 虚拟 IP 监视资源,Oracle Cloud 负载均衡监视资源的运行环境的 Oracle Cloud Infrastructure 上的 OS 的版本信息如下所示。
部署模型
|
EXPRESSCLUSTER
版本
|
备注
|
|---|---|---|
Windows Server 2012 R2 |
12.20~ |
|
Windows Server 2016 |
12.20~ |
4.3. Cluster WebUI的运行环境¶
对为了运行Cluster WebUI而所需环境进行说明。
4.3.1. 运行确认完毕的OS,浏览器¶
现在的支持情况如下。
浏览器 |
语言 |
|---|---|
Internet Explorer 11 |
日语/英语/中文 |
Internet Explorer 10 |
日语/英语/中文 |
Firefox |
日语/英语/中文 |
Google Chrome |
日语/英语/中文 |
Microsoft Edge (Chromium) |
日语/英语/中文 |
注解
通过IP地址连接时,需要事先将该IP地址登录到 [本地Intranet] 的 [站点] 中。
注解
用 Internet Explorer11连接Cluster WebUI时,Internet Explorer可执行会停止。为了避免发生,请更新Internet Explorer(KB4052978或更高版本)。此外,为了在Windows 8.1/Windows Server 2012R2中应用KB4052978以上的版本,请提前应用KB2919355。相关信息请参考Microsoft部署的信息。
注解
不支持平板电脑和智能手机等移动设备。
4.3.2. 所需内存容量/磁盘容量¶
所需内存容量 500MB以上
所需磁盘容量 200MB以上
5. 最新版本信息¶
在本章中对EXPRESSCLUSTER的最新信息进行说明。为您介绍新发布版本中强化和改善的内容。
5.1. EXPRESSCLUSTER和手册的对应一览表¶
本手册以以下版本的EXPRESSCLUSTER为前提进行说明。请注意EXPRESSCLUSTER的版本和手册版数的对应关系。
EXPRESSCLUSTER
内部版本
|
手册
|
版数
|
备注
|
|---|---|---|---|
12.30 |
开始指南 |
第1版 |
|
安装&设置指南 |
第1版 |
||
参考指南 |
第1版 |
||
维护指南 |
第1版 |
||
硬件整合指南 |
第1版 |
||
兼容功能指南 |
第2版 |
5.2. 功能强化¶
对于各个版本,分别进行了以下的功能强化。
No. |
内部版本 |
功能强化项目 |
|---|---|---|
1 |
12.00 |
安装了新设计的管理GUI (Cluster WebUI)。 |
2 |
12.00 |
WebManager支持了HTTPS协议。 |
3 |
12.00 |
能够使用期间定制License。 |
4 |
12.00 |
扩大了镜像磁盘资源,共享型镜像磁盘资源的最大值。 |
5 |
12.00 |
提供了对Windows Server, version 1709的支持。 |
6 |
12.00 |
SQL Server监视资源支持了SQL Server 2017。 |
7 |
12.00 |
Oracle监视资源支持了Oracle Database 12c R2。 |
8 |
12.00 |
PostgreSQL监视资源支持了PowerGres on Windows 9.6。 |
9 |
12.00 |
WebOTX监视资源支持了WebOTX V10.1。 |
10 |
12.00 |
JVM监视资源支持了Apache Tomcat 9.0。 |
11 |
12.00 |
JVM监视资源支持了WebOTX V10.1。 |
12
|
12.00
|
JVM监视资源可以进行以下的监视。
|
13 |
12.00 |
添加了AWS DNS资源,AWS DNS监视资源。 |
14 |
12.00 |
添加了Azure DNS资源,Azure DNS监视资源。 |
15 |
12.00 |
执行集群操作外的OS关机时,追加了集群服务停止结束之前,OS关机延迟的功能。 |
16 |
12.00 |
改善了监视资源错误判定以及超时判定的精度。 |
17 |
12.00 |
添加了在组资源启动/停止的前后,可以执行任意脚本的功能。 |
18 |
12.00 |
在发生两机双活时可以选择要存活的服务器组。 |
19 |
12.00 |
失效切换属性设定为[完全互斥]的组,可以做排他对象的组合设定。 |
20 |
12.00 |
失效切换次数的计算方式可以选择服务器单位/集群单位。 |
21 |
12.00 |
减少内部进程间通信消耗的TCP端口数量。 |
22 |
12.00 |
强化了日志收集的收集项目。 |
23 |
12.00 |
可以设置镜像磁盘资源,共享型镜像磁盘资源的差分Bitmap大小。 |
24 |
12.00 |
可以设置镜像磁盘资源,共享型镜像磁盘资源的异步时历史记录区大小。 |
25 |
12.01 |
在WebManager中如果因为设置不佳导致无法使用HTTPS时,消息将输出到事件日志以及警告日志中。 |
26 |
12.10 |
提供了对Windows Server, version 1803的支持。 |
27 |
12.10 |
提供了对Windows Server, version 1809的支持。 |
28 |
12.10 |
提供了对Windows Server 2019的支持。 |
29 |
12.10 |
Oracle 监视资源开始支持Oracle Database 18c。 |
30 |
12.10 |
Oracle 监视资源开始支持Oracle Database 19c。 |
31 |
12.10 |
PostgreSQL 监视资源开始支持PostgreSQL11。 |
32 |
12.10 |
PostgreSQL 监视资源开始支持PowerGres V11。 |
33 |
12.10 |
以下资源/ 监视资源开始支持Python3。
|
34 |
12.10 |
以下资源/ 监视资源支持通过MSI 安装程序和pip 安装的AWS CLI(aws.cmd)。
|
35 |
12.10 |
用于SAP NetWeaver 的SAP 联动连接器支持以下的SAP NetWeaver。
|
36 |
12.10 |
用于SAP NetWeaver 的SAP 联动连接器/ 示例脚本支持下列选项。
|
37 |
12.10 |
可在Cluster WebUI 中进行集群配置,配置变更。 |
38 |
12.10 |
添加用于PostgreSQL 的 DB 静止点命令。 |
39 |
12.10 |
添加用于DB2 的 DB 静止点命令。 |
40 |
12.10 |
添加Witness 心跳资源。 |
41 |
12.10 |
添加HTTP 网络分区解决资源。 |
42 |
12.10 |
添加了在变更集群配置时,不需要停止业务就能反映变更的设置项目。 |
43 |
12.10 |
添加了在启动失效备援组时,重复检查浮动IP地址的功能。 |
44 |
12.10 |
在远程集群配置中,添加了即使检测出服务器间的心跳超时,也仅在设置好的时间内暂停自动失效备援的功能。 |
45 |
12.10 |
添加了可以在脚本资源的开始/结束脚本中使用的环境变量。 |
46 |
12.10 |
添加了一项功能实现依据"强制停止"脚本的执行结果来制止失效备援。 |
47 |
12.10 |
在强制停止功能中的虚拟机管理工具(vCLI 6.5)上可以设定perl.exe路径。 |
48 |
12.10 |
可以编辑在强制停止功能以及机箱ID联动功能中执行的IPMI命令。 |
49 |
12.10 |
添加了进程资源监视资源,集中系统监视资源的进程资源监视功能。 |
50 |
12.10 |
添加了将失效切换组,组资源,监视资源的运行状况作为集群统计信息保存的功能。 |
51 |
12.10 |
在日志收集模式中添加了镜像统计信息和集群统计信息。 |
52 |
12.10 |
在自定义监视资源中,监视类型为[非同步],且结束监视对象的脚本后监视异常时,解除了不重新执行脚本的限制。 |
53 |
12.10 |
添加了在集群停止时停止组资源之前等待自定义监视资源停止完成的设置。 |
54 |
12.10 |
添加了不通过脚本资源中的启动脚本执行恢复过程的功能。 |
55 |
12.10 |
添加了用于指定clpmonctrl命令请求处理的服务器的选项。 |
56 |
12.10 |
作为Alert Service的通知方式,可以在clplogcmd命令的输出目标中指定mail。 |
57 |
12.10 |
已在与WebManager服务器的HTTPS连接中禁用SSL和TLS 1.0。 |
58 |
12.11 |
改善了Cluster WebUI的表示和相关操作。 |
59 |
12.12 |
Cluster WebUI 不支持OpenSSL 1.1.1。 |
60 |
12.20 |
添加了可以操作集群并获取状态的RESTful API。 |
61 |
12.20 |
改善了通过Cluster WebUI和命令获取集群信息的处理。 |
62 |
12.20 |
添加了检查集群配置信息的功能。 |
63 |
12.20 |
添加了当查出异常,执行STOP错误时,将消息记录到待机服务器的功能。 |
64 |
12.20 |
添加了禁用组的自动启动和启动/停止异常时的复归动作的功能。 |
65 |
12.20 |
使用License管理命令,删除集群节点时可以重新配置期间定制License。 |
66 |
12.20 |
可以用OS的用户帐户登录到Cluster WebUI。 |
67 |
12.20 |
在执行以下应用程序和脚本时,可以用在[集群属性]的[帐户]标签页中注册的用户身份执行。
|
68 |
12.20 |
在脚本资源中,执行和结合运行服务器上的开始·结束脚本,在待机服务器上也可以执行脚本。 |
69 |
12.20 |
可以在不停止操作的情况下添加·删除集群节点。(不包括镜像磁盘/共享型镜像磁盘) |
70 |
12.20 |
添加了通过日志收集命令不收集事件日志的功能。 |
71 |
12.20 |
日志文件大小即使超过2GB时也可以收集日志。 |
72 |
12.20 |
在日志收集模式中添加了系统统计信息。 |
73 |
12.20 |
扩充了组的停止等待的设置条件。 |
74 |
12.20 |
添加了在Cluster WebUI 中显示组启动停止预测时间的功能。 |
75 |
12.20 |
可以通过以下功能使用Proxy服务器。
|
76 |
12.20 |
改善了存在断线私网的状态下,集群的启动时间。 |
77 |
12.20 |
使用Cluster WebUI和clpstat命令改善了集群停止状态和集群挂起状态的显示内容。 |
78 |
12.20 |
添加用于显示组启动停止预测时间以及监视资源的监视所用时间的命令。 |
79 |
12.20 |
添加了系统资源统计信息采集功能。 |
80 |
12.20 |
服务资源的[启动重试次数]的默认值从0次更改为1次。 |
81 |
12.20 |
HTTP监视器资源支持BASIC认证。 |
82 |
12.20 |
AWS AZ监视资源的状态在可用区中为information 或者 impaired时,从异常更改为警告。 |
83 |
12.20 |
添加了Google Cloud 虚拟IP资源,Google Cloud 虚拟IP监视资源。 |
84 |
12.20 |
添加了Oracle Cloud 虚拟IP资源,Oracle Cloud 虚拟IP监视资源。 |
85 |
12.20 |
关于以下监视资源,[AWS CLI命令未得到应答时的动作]的默认值从[不运行复归动作(显示警告)]更改为[不运行复归动作(不显示警告)]。
|
86 |
12.20 |
DB2监视资源支持DB2 v11.5。 |
87 |
12.20 |
SQL Server监视资源支持SQL Server 2019。 |
88 |
12.20 |
添加了不间断扩展镜像磁盘资源的数据分区大小的功能。 |
89 |
12.20 |
在clpmdctrl中添加了无需进行镜像复归,就能将镜像磁盘数据作为最新数据处理的功能。 |
90 |
12.22 |
扩展了可以通过RESTful API获取的资源状态信息。 |
91 |
12.22 |
强化了clpmdctrl命令,以便在一台服务器停止时可以更新镜像磁盘上的数据(从红色到绿色)。 |
92 |
12.22 |
PostgreSQL监视资源支持PostgreSQL12。 |
93 |
12.30 |
提供了对Windows Server, version 2004的支持。 |
94 |
12.30 |
可以使用RESTful API来操作/参考用于监视资源和心跳的超时倍率。 |
95 |
12.30 |
通过RESTful API扩充了相当于clprexec命令的功能 。 |
96 |
12.30 |
通过RESTful API可以为每个用户组/IP地址设置权限(操作/参考)。 |
97 |
12.30 |
改进了在Cluster WebUI中添加资源时仅根据系统环境显示资源类型的功能。 |
98 |
12.30 |
添加了在Cluster WebUI中自动获取AWS相关资源设置的功能。 |
99 |
12.30 |
更改了期间定制License已过期时的集群操作。 |
100 |
12.30 |
心跳超时时间内重启服务器时,消息将输出到事件日志以及警告日志中。 |
101 |
12.30 |
添加了防止启动失效切换组时自动启动组资源的功能。 |
102 |
12.30 |
在clpbwctrl命令中添加了集群启动时禁用NP解决的功能。 |
103 |
12.30 |
服务器的最大重启次数的默认值变更为3次,重启时间变更为60分钟。 |
104 |
12.30 |
添加了在查出异常时因操作而进行服务器重置,故意的STOP错误时无需等待心跳超时时间就可以进行失效切换的功能。 |
105 |
12.30 |
增加了使用clpgrp/clprsc/clpdown/clpstdn/clpcl命令的内部通信超时的默认值。 |
106 |
12.30 |
在警报服务中添加了向Amazon SNS发送消息的功能。 |
107 |
12.30 |
可以把监视资源的监视处理时间作为指标发送到Amazon CloudWatch。 |
108 |
12.30 |
扩充了集群配置信息检查功能的检查项目。 |
109 |
12.30 |
添加了简化映像备份还原的命令clpbackup, clprestore。 |
110 |
12.30 |
EXPRESSCLUSTER Event服务,EXPRESSCLUSTER Old API服务的复归操作设置为服务重启。 |
111 |
12.30 |
添加了Google Cloud DNS资源,Google Cloud DNS监视资源。 |
112 |
12.30 |
改善了根据HTTP网络分区解决资源查出网络分区时的警报消息。 |
113 |
12.30 |
可以把Cluster WebUI的操作日志输出到服务器端。 |
114 |
12.30 |
添加了对XML外部实体攻击(XML External Entity, XXE攻击)的支持。 |
115 |
12.30 |
查出监视超时时可以获取内存转储。 |
116 |
12.30 |
可以从Cluster WebUI确认警报日志的详细(处理方法等)。 |
117 |
12.30 |
可以管理在Witness服务器里具有相同集群名的多个集群。 |
118 |
12.30 |
添加了集群配置信息创建命令clpcfset。 |
119 |
12.30 |
可以从Cluster WebUI的编辑模式的[组的属性]确认组资源列表。 |
120 |
12.30 |
可以从Cluster WebUI的编辑模式的[监视共通属性]确认监视资源列表。 |
121 |
12.30 |
Cluster WebUI支持Microsoft Edge(Chromium版)。 |
122 |
12.30 |
通过Cluster WebUI在警报日志的详细筛选的对象中添加了消息。 |
123 |
12.30 |
添加了重置Cluster WebUI密码等的设置的命令clpcfreset。 |
124 |
12.30 |
改善了启动时监视对象的组启动处理中查出监视异常时的消息。 |
125 |
12.30 |
改善了Cluster WebUI的[状态]画面的操作图标的布局。 |
126 |
12.30 |
扩充了可以设置服务器组间的失效切换时的犹豫时间的上限值。 |
127 |
12.30 |
浏览器重启时也保持Cluster WebUI的[仪表盘]的用户定制设置。 |
128 |
12.30 |
HTTP监视资源支持GET请求的监视。 |
129 |
12.30 |
在Weblogic监视资源的监视方法中添加了REST API。 |
130 |
12.30 |
WebOTX监视资源支持WebOTX V10.3。 |
131 |
12.30 |
JVM监视资源支持WebOTX V10.3。 |
132 |
12.20 |
Weblogic监视资源支持Oracle WebLogic Server 14c (14.1.1)。 |
133 |
12.20 |
JVM监视资源支持Oracle WebLogic Server 14c (14.1.1)。 |
134 |
12.30 |
JVM监视资源支持Java11。 |
135 |
12.30 |
支持镜像磁盘资源和共享型镜像磁盘资源中使用的镜像数据的通信进行加密。 |
136 |
12.30 |
添加了无中断扩展共享型镜像磁盘资源的数据分区大小的功能。 |
137 |
12.30 |
以下资源支持AWS CLI v2。
|
5.3. 修改信息¶
各版本做了以下修改。
No.
|
修改版本
/ 发生版本
|
修改项目
|
重要性
|
发生条件
发生频率
|
|---|---|---|---|---|
1
|
12.01
/ 12.00
|
可以启动同一个产品的两个限时许可证。
|
小
|
当证书到期,同时进行自动启动库存未使用证书的处理和用证书注册命令进行新证书注册操作处理时,偶尔会发生。
|
2
|
12.01
/ 12.00
|
通过clpgrp命令启动组时失败。
|
小
|
在互斥规则已被设定的配置中,不指定启动对象的组名执行clpgrp命令时会发生。
|
3
|
12.01
/ 12.00
|
用Cluster WebUI,WebManager,clpstat命令时,以下镜像磁盘相关的参数不能正确显示。
・差分Bitmap大小
・异步时历史记录区大小
|
小
|
通过Cluster WebUI,WebManager,clpstat命令参考集群属性时发生。
|
4
|
12.01
/ 12.00
|
无法检测到监视资源的监视超时。
|
中
|
由于监视处理所需的时间超过超时设定值时会发生。
|
5
|
12.01
/ 12.00
|
不能正确反映以下参数的更改。
・检测到组资源启动异常时的失效切换阈值
・检测到监视资源异常时的最大失效切换次数
|
中
|
以下条件都满足时会发生。
・服务器以失效切换次数的计数单位设置
・参数更改时,没有执行集群的挂起/复原作为反映方法
|
6 |
12.01
/ 12.00
|
在混合了CPU证书和VM节点证书的配置中,会出现提示CPU证书不足的警告消息。 |
小 |
CPU证书和VM节点证书混合时会发生。 |
7
|
12.01
/ 12.00
|
在ODBC监视时检测到监视异常时,判断为监视正常。
|
中
|
ODBC监视中发生监视异常时发生。
|
8
|
12.01
/ 12.00
|
在Azure DNS监视资源中,即使Azure上的DNS服务器正常运行,也会异常。
|
小
|
以下条件都满足时一定会发生。
・选中[确认域名解析]时
・Azure CLI 的版本为2.0.30 ~ 2.0.32 时 (2.0.29 以下,2.0.33 以上时不会发生)
|
9
|
12.01
/ 12.00
|
在Azure DNS监视资源中,即使一部分Azure上的DNS服务器正常运行,也会异常。
|
小
|
以下条件都满足时一定会发生。
・选中[确认域名解析]时
・通过Azure CLI获取的DNS服务器列表中显示在第一个的DNS服务器没有正常运行时(第二个之后的DNS服务器正常运行)
|
10
|
12.01
/ 12.00
|
Azure DNS监视资源中,Azure上的DNS服务器列表获取失败时也不作为异常。
|
小
|
以下条件都满足时一定会发生。
・选中[确认域名解析]时
・通过Azure CLI获取DNS服务器列表失败时
|
11
|
12.01
/ 12.00
|
在以下监视资源中,即使用于控制的进程消失了,也不作异常警告。
・虚拟计算机名监视资源
・虚拟IP监视资源
・CIFS监视资源
・动态DNS监视资源
|
中
|
用于控制的进程消失时一定会发生。
|
12
|
12.01
/ 12.00
|
使用JVM监视资源时,监视对象Java VM中会发生内存泄露。
|
中
|
满足以下条件时会发生。
・选中[监视 (固有)]标签页-[调整]属性-[线程]标签页-[监视运行中的线程数]时
|
13
|
12.01
/ 12.00
|
JVM监视资源的Java进程中,发生内存泄露。
|
中
|
满足以下条件时会发生。
・ [监视 (固有)]标签页-[调整]属性中的设置全选中
・多次创建JVM 监视资源时
|
14
|
12.01
/ 12.00
|
JVM监视资源中,即使关闭以下参数,JVM统计日志(jramemory.stat)还是会被输出。
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视堆使用量]
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视非堆使用量]
|
小
|
满足以下条件时一定会发生。
・[监视 (固有)]标签页-[JVM 种别]为[Oracle Java(usage monitoring)]时
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视堆使用量]关闭时
・[监视 (固有)]标签页-[调整]属性-[内存]标签页-[监视非堆使用量]关闭时
|
15 |
12.01
/ 12.00
|
JVM监视资源中,负载均衡器联动功能以及BIG-IP联动功能不起作用。 |
中 |
一定会发生。 |
16 |
12.01
/ 12.00
|
在使用与EXPRESSCLUSTER Ver 8.0之前版本兼容的功能的应用程序中,一部分集群事件无法正确取得。 |
中 |
在监视使用兼容API的集群事件时发生。 |
17 |
12.10
/ 12.00
|
使用SAP NetWeaver示例脚本的自定义监视资源被检测到故障时,SAP服务的停止处理过程中会进行SAP服务的开始处理。 |
小 |
当SAP服务的停止处理需要花费时间时会发生。 |
18 |
12.10
/ 12.00
|
如果在标签页的内容中包含了非ASCII字符,则启动AWS虚拟IP会失败。 |
小 |
如果标签页内容中包含了非ASCII字符时,一定会发生。 |
19 |
12.10
/ 12.00
|
在WebOTX监视资源中,监视WebOTX V10.1就会发生监视异常。 |
小 |
一定会发生。 |
20 |
12.10
/ 12.00
|
JVM监视资源的监视状态一直是警告的状态没有改变。 |
小 |
在监视开始时比较少发生,主要取决于时间段。 |
21 |
12.10
/ 12.00
|
在NAS资源的[按照默认依赖关系]中不包含AWS DNS 资源,Azure DNS资源。 |
小 |
一定会发生。 |
22
|
12.10
/ 12.00
|
SAP NetWeaver 配置中,用于ASCS的失效切换组首次失效切换时,在失效切换目标的节点中启动ASCS服务失败。
|
小
|
在AWS环境中,用于ASCS的失效切换组首次失效切换时会发生。
|
23
|
12.10
/ 12.00
|
SQLServer监视中,DB缓存中残存SQL文,可执行会导致性能上的问题。
|
小
|
监视级别2时会发生。
|
24
|
12.10
/ 12.00
|
ODBC监视15秒超时。
|
小
|
监视15秒以上时会发生。
|
25
|
12.10
/ 12.00
|
ODBC监视中监视用户名无效等场合,应该是变为警告的情况,却变成了监视异常。
|
小
|
监视参数中存在设置错误时发生。
|
26
|
12.10
/ 12.00
|
Oracle监视的侦听器监视中,即使出现tnsping出错,也不会变成监视异常。
|
小
|
侦听器监视中tnsping出错时发生。
|
27
|
12.10
/ 12.00
|
SQLServer监视超时时,警告日志中显示"函数序列出错"。
|
小
|
监视超时时发生。
|
28
|
12.10
/ 12.00
|
Database监视中,没有在警告日志中输出错误消息。
|
小
|
在一部分出错中,没有输出错误消息。
|
29
|
12.10
/ 12.00
|
在自定义监视资源中即使检测出超时,不作为异常而是作为警告。
|
中
|
在自定义监视资源中检测到超时时一定会发生。
|
30
|
12.10
/ 12.00
|
在服务监视资源中,在取得监视对象服务的handle失败时,不作为异常而是作为警告。
|
小
|
在服务监视资源中,在取得监视对象服务的handle失败时一定会发生。
|
31
|
12.10
/ 12.00
|
打印机spool监视资源中,取得Spooler服务的handle失败时,不作为异常而是作为警告。
|
小
|
取得Spooler服务的handle失败时一定会发生。
|
32
|
12.10
/ 12.00
|
失效切换集群挂起时会发生超时。
|
中
|
失效切换集群复原处理中执行集群挂起操作时,极少会发生。
|
33
|
12.10
/ 12.00
|
设置为手动启动的失效切换组在失效切换时,在失效切换源中未被启动的组资源,在失效切换目标中被启动了。
|
小
|
下述的状态转变时会发生。
1. 集群停止
2. 集群启动
3. 设置为手动启动的失效切换组的一部分组资源单一启动
4. 关闭了启动了组资源的服务器
|
34
|
12.10
/ 12.00
|
机箱ID指示灯未灭。
|
小
|
在使用机箱ID指示灯联动功能的环境下,集群内有一部分服务器停止了,在机箱ID指示灯亮着的状态下,停止在其余正常运行的服务器上的集群服务时会发生。
|
35
|
12.10
/ 12.00
|
在反映命令,Cluster WebUI中的集群服务的操作以及配置信息时失败。
|
小
|
在集群服务器内有停止的服务器存在的状态下,进行该操作时,根据集群配置和停止服务器数等条件,应答等待时间的累积超过超时值(120秒)时会发生。
|
36
|
12.10
/ 12.00
|
用Clpstat命令,集群复归处理中服务器的状态未正确显示
|
小
|
从集群复归处理开始到结束之间,执行clpstat -g时会发生。
|
37
|
12.10
/ 12.00
|
用clpstat命令,集群停止处理中的状态未正确显示。
|
小
|
从集群停止执行后到集群停止结束之间,执行clpstat命令时会发生。
|
38
|
12.10
/ 12.00
|
没有结束停止处理的组资源的状态显示为停止状态。
|
中
|
对于停止处理失败状态下的组资源,在进行下述操作时会发生。
・启动操作
・停止操作
|
39
|
12.10
/ 12.00
|
组资源停止失败时,没有按照设置的最终动作,而是执行了紧急关机。
|
中
|
组资源的停止异常时的最终动作中设置为"集群服务停止和重启OS"时发生。
|
40
|
12.10
/ 12.00
|
自定义监视资源中,通过clptoratio命令设置超时倍率无效。
|
小
|
一定会发生。
|
41
|
12.11
/ 12.10
|
切换到Cluster WebUI的编辑模式失败。
|
小
|
从特定浏览器通过HTTPS访问Cluster WebUI时发生。
|
42 |
12.12
/ 12.10
|
应用程序资源的启动处理可执行会失败。 |
小 |
在应用程序资源中设置以下所有内容时发生。
・ 在[常驻类型]中设置非常驻
・ 设置执行用户
・ 设置[正常返回值]
|
43 |
12.12
/ 12.10
|
在设置网络警告灯时,以下项目的设定值没有保存到配置信息中。
・使用网络警告灯
・指定rsh命令执行文件路径
・文件路径
・服务器启动时播放音频文件
・音频文件编号
・服务器停止时播放音频文件
・音频文件编号
|
小 |
设置网络警告灯时一定会发生。 |
44 |
12.22
/ 12.00~12.20
|
镜像重建期间可执行无法正确显示剩余时间。 |
小 |
当镜像重建期间的剩余时间为1小时或以上时会发生。 |
45 |
12.20
/ 12.00~12.12
|
镜像恢复期间,镜像磁盘监视资源/共享型镜像磁盘监视资源的状态不会变为警告。 |
小 |
镜像磁盘监视资源/共享型镜像磁盘监视资源的状态从异常状态到开始镜像复归时发生。 |
46 |
12.20
/ 12.00~12.12
|
clpstat命令可执行会显示以下错误消息。
Could not connect to the server.
Internal error.Check if memory or OS resources are sufficient.
|
小 |
启动集群后立即执行clpstat命令时很少会发生。 |
47 |
12.20
/ 12.00~12.12
|
应用配置信息时,可执行会要求不需要的操作(WebManager服务器重新启动)。 |
小 |
设置配置信息的时候,只有在满足同时修改"集群关闭·重启"和"重启web manager服务器"两者所需要的设定信息的时候才会发生障碍。 |
48 |
12.20
/ 12.00~12.12
|
组以及组资源的当前服务器信息可执行不一致。 |
中 |
设置手动失效切换时,心跳线断线恢复后很少会发生。 |
49 |
12.20
/ 12.00~12.12
|
从组的[可以启动的服务器列表]中删除服务器,一旦在反映配置信息后执行集群停止,则服务器会关机。 |
小 |
从[可以启动的组列表]中删除已启动组的服务器时会发生。 |
50 |
12.20
/ 12.00~12.12
|
反映配置信息时,可执行被要求不需要的操作(挂起/恢复)。 |
小 |
参考自动注册的监视资源的属性时,可执行会发生。 |
51 |
12.20
/ 12.00~12.12
|
EXPRESSCLUSTER Web Alert服务可执行会异常终止。 |
小 |
不管具体条件如何,这种情况很少发生。 |
52 |
12.20
/ 12.00~12.12
|
Windows操作系统进程wmiprvse.exe的句柄增加。 |
小 |
通过执行WMI(Windows Management Instrumentation)会发生障碍。 |
53 |
12.20
/ 12.00~12.12
|
重启集群时,没有启动组。 |
中 |
重启集群时,在运行组停止处理期间,较早地重新启动待机服务器时很少会发生。 |
54 |
12.20
/ 12.00~12.12
|
服务器停止处理可执行需要很长时间。 |
小 |
集群停止时很少发生。 |
55 |
12.20
/ 12.00~12.12
|
即使在组,资源停止失败时也会输出停止成功的警报。 |
小 |
紧急关机时会发生。 |
56 |
12.20
/ 12.00~12.12
|
查出服务器关闭时组可执行不会进行失效切换。 |
中 |
在服务器启动时内部信息的同步处理期间检测到服务器关闭时会发生这种情况。 |
57 |
12.20
/ 12.00~12.12
|
在消息接收监视资源中,可执行会发生复归动作脚本执行失败的情况。 |
小 |
用以下格式指定用户应用程序时,会发生此错误。
cscript 脚本文件的路径
|
58 |
12.20
/ 12.10~12.12
|
安装失败。 |
小 |
当将Program Files以外的文件夹指定为安装文件夹时,会发生此错误。 |
59 |
12.20
/ 12.10~12.12
|
无法进行镜像统计信息收集功能和OS标准功能之间的联动。 |
小 |
一定会发生。 |
60 |
12.20
/ 12.10~12.12
|
虚拟机资源,虚拟机监视资源无法正常运行。 |
中 |
一定会发生。 |
61 |
12.20
/ 12.00~12.12
|
当服务资源为停止状态时,即使服务已停止,也可执行发生停止失败的情况。 |
小 |
在Oracle等特定的服务中会发生。 |
62 |
12.20
/ 12.00~12.12
|
当Azure探头端口资源处于启动状态时,无法连接到VIP。 |
大 |
在以下场合会发生。
|
63 |
12.20
/ 12.00~12.12
|
发生失效切换时,启动镜像磁盘资源失败。 |
中 |
由于服务器重置而导致发生失效切换时,很少发生。 |
64 |
12.22
/ 12.10~12.20
|
无法更改镜像通信专用私网的IP地址。 |
小 |
在配置集群时,在高优先级服务器之前添加低优先级服务器时发生。 |
65 |
12.22
/ 12.10~12.20
|
作为反映“使用机箱ID指示灯”设置的方法,需要重新启动OS。 |
小 |
在集群属性中更改“使用机箱ID指示灯”的设置,并执行应用配置文件时会发生。 |
66 |
12.22
/ 12.10~12.20
|
无法在注册表同步资源中设置包含双字节字符的注册表项。 |
小 |
当注册表项包含双字节字符时发生。 |
67 |
12.22
/ 12.20
|
通过集群配置信息检查功能检查AWSCLI命令失败。 |
小 |
在设置了以下组资源的环境中执行集群配置信息检查时发生。
・AWS Elastic IP资源
・AWS 虚拟IP资源
・AWS DNS 资源
|
68 |
12.22
/ 12.20
|
启动集群后执行集群配置信息检查时,检查浮动IP资源和虚拟IP资源失败。 |
小 |
在浮动IP资源和虚拟IP资源为启动状态下执行集群配置信息检查时发生。 |
69 |
12.22
/ 12.20
|
在集群配置信息检查功能中,OS启动时间检查的确认结果可执行不正确。 |
小 |
OS设置值和心跳超时值的组合,很少会发生。 |
70 |
12.30
/ 11.20~12.22
|
Windows Server 2012 R2 以上中,CLP_OSNAME环境变量上设置了与Windows Server 2012相同的信息。 |
小 |
一定发生。 |
71 |
12.30
/ 12.20~12.22
|
在没有启动失效切换组的服务器上,进行其组相关的集群配置检查。 |
小 |
启动服务器的设置中,设置了没有启动失效切换的服务器时会发生。 |
72 |
12.30
/ 12.20~12.22
|
EXPRESSCLUSTER Information Base服务会异常结束。 |
小 |
在OS资源不足时偶尔发生。 |
73 |
12.30
/ 12.10~12.22
|
不必要的数据传输包发送到未使用的服务器设置的私网。 |
小 |
未使用服务器在私网设置时一定发生。 |
74 |
12.30
/ 12.20~12.22
|
Cluster WebUI中无法迁移到编辑模式。 |
小 |
当通过OS认证方法设置了密码并且该设置仅反映在没有操作权限的组中时,会发生这种情况。 |
75 |
12.30
/ 12.20~12.22
|
Cluster WebUI的[状态]画面中的[服务器服务开始]按钮未启用。 |
小 |
连接Cluster WebUI的服务器的服务停止时会发生。 |
76 |
12.30
/ 12.10~12.22
|
Cluster WebUI的编辑模式的[资源的属性]-[依赖关系]标签页中删除依赖的资源时会显示不正确。 |
小 |
删除依赖的资源时会发生。 |
77 |
12.30
/ 12.00~12.22
|
在Cluster WebUI的[镜像磁盘]画面中点击镜像磁盘资源时,仍会显示加载图标。 |
小 |
点击镜像磁盘资源时获取镜像信息的通信失败时会发生。 |
78 |
12.30
/ 12.10~12.22
|
在设置磁盘资源的环境中使用Cluster WebUI添加服务器时,磁盘资源上添加服务器的GUID未设置的状态下设置成功。 |
小 |
设置磁盘资源的环境中添加了服务器时会发生。 |
79 |
12.30
/ 12.00~12.22
|
Cluster WebUI中[仪表盘]画面的警报日志和[镜像磁盘]画面没有显示。 |
小 |
共享型镜像磁盘资源的信息获取失败时会发生。 |
80 |
12.30
/ 12.10~12.22
|
在Cluster WebUI中添加组资源和监视资源时编辑的脚本文件没有保存在正确的路径中。 |
小 |
在添加组资源和监视资源的画面中编辑脚本文件后返回到前个画面,更改组资源名和监视资源名时会发生。 |
81 |
12.30
/ 12.10~12.22
|
将服务器添加到Cluster WebUI中BMC设置的集群时,会生产错误的集群配置信息。 |
小 |
设置BMC的集群中添加服务器时会发生。 |
82 |
12.30
/ 12.10~12.22
|
当Cluster WebUI的[组的属性]-[信息]标签页上的[使用服务器组设置]从打开更改为关闭时,[属性]标签页的显示内容不正确。 |
小 |
把[属性]标签页的失效切换属性设置为"在服务器组内首选失效切换策略"的状态下,"使用服器组设置"从打开更改为关闭时会发生。 |
83 |
12.30
/ 12.10~12.22
|
在Cluster WebUI的[监视资源的属性]-[监视(共通)]标签页中,[监视时机]-[对象资源]的[参考]按钮无法点击。 |
小 |
[监视时机]从不间断监视更改为启动时监视之后登录的监视资源的[监视资源的属性]打开时会发生。 |
84 |
12.30
/ 12.20~12.22
|
Cluster WebUI Offline中点击[服务器]-[添加服务器]按钮时,显示错误消息的服务器无法添加。 |
小 |
点击[服务器]-[添加服务器]按钮时会发生。 |
85 |
12.30
/ 12.10~12.22
|
Cluster WebUI的编辑模式下,在错误的时间里输出废弃当前集群配置的消息。 |
小 |
在不更改配置信息的情况下进行以下操作后,点击设置的导入按钮或获取按钮时会发生。
・设置的导出
・中途取消设置反映
・集群配置信息检查
|
86 |
12.30
/ 12.10~12.22
|
Cluster WebUI的编辑模式下进行不必要的设定值检查。 |
小 |
在没有设置镜像磁盘资源/共享型镜像磁盘资源的环境下,[HB超时]比[CPIO超时]短时会发生。 |
87 |
12.30
/ 11.30~12.22
|
WebSphere监视资源中会监视失败。 |
中 |
在以下任一条件下发生。
・WebSphere的安装路径在1022字节及以上时
・用户名在246字节及以上时
・密码在245字节及以上时
・配置文件名在242字节及以上时
・serverStatus.bat结尾的路径长度+服务器名 + 用户名 + 密码+ 配置文件名在976字节及以上时
|
88 |
12.30
/ 11.30~12.22
|
WebLogic监视资源中会监视失败。 |
中 |
在以下任一条件下发生。
・WebLogic的安装路径在236字节及以上时
・WebLogic Server 检查状态用的PING命令的路径长度在1016字节及以上时
|
89 |
12.30
/ 12.10~12.22
|
Witness心跳资源的超时检测可执行会延迟。 |
中 |
在与Witness服务器通信中断的服务器上发生。 |
90 |
12.30
/ 12.20~12.22
|
如果在禁用组自动启动的环境中检测到服务器关闭,则可执行会意外启动已停止的失效切换组。 |
小 |
在集群启动后存在从未启动的失效切换组时会发生。 |
91 |
12.30
/ 11.00~12.22
|
CIFS资源启动失败。 |
中 |
在设置包含空格的组名和CIFS资源名称并启用[自动保存驱动器共享设置]时发生。 |
92 |
12.30
/ 12.20~12.22
|
使用clprexec命令更改消息接收监视资源的状态的请求可执行会失败。 |
小 |
通过clprexec命令指定了--clear选项时会发生。 |
6. 注意限制事项¶
在本章中对注意事项,现有问题及其避免方法进行说明。
本章中说明的项目如下。
6.1. 研究系统配置时¶
对HW的准备,系统配置以及共享磁盘配置时需要留意的事项进行说明。
6.1.1. 关于镜像磁盘/共享型镜像磁盘的需求¶
不能使用动态磁盘。请使用基本磁盘。
用于镜像磁盘/共享型镜像磁盘的分区(数据分区和集群分区)不能mount到NTFS文件夹下使用。
使用镜像磁盘资源/共享型镜像磁盘资源需要镜像用的分区(数据分区和集群分区)。
镜像用的分区的磁盘上的配置没有特别限制,数据分区的大小按字节单位必须完全一致。此外,集群分区需要17MB以上的容量。
数据分区作为扩展分区上的逻辑分区建立时,请确认两个服务器上都建立逻辑分区。即使主分区与逻辑分区指定了相同的容量大小,实际大小也有可执行会不同。
为负载均衡建议将集群分区和数据分区分别设在不同的磁盘上(虽然创建在同一块磁盘上也能够运行,但非同步镜像和镜像中断状态下的写入性能会有些许下降)。
在磁盘上要确保用镜像资源建立镜像的数据分区,则两台服务器的磁盘类型必须相同。
例)
组合
服务器1
服务器2
OK
SCSI
SCSI
OK
IDE
IDE
NG
IDE
SCSI
用"Disk Management"等确保的分区大小,按照磁盘柱面周围的块(单元)数来分配。因此,如果服务器间用作镜像磁盘的磁盘的几何数据不同,可执行无法使数据分区的大小完全一致。为了避免此类问题发生,对于确保数据分区的磁盘,建议两台服务器上的HW配置,包括RAID结构等在内,应该一致。
两台服务器的磁盘类型和几何数据不匹配时,在设定镜像磁盘资源/共享型镜像磁盘资源前,请通过[clpvolsz]命令确认两台服务器数据分区的正确大小,如果大小不一致,请再次使用[clpvolsz]命令缩小较大的分区。
为RAID结构的磁盘建立镜像时,对磁盘阵列控制器的缓存以Write-Thru方式使用则写入性能大大下降,建议您使用Write Back方式。但使用Write Back方式时,要使用搭载了电池的磁盘阵列控制器或者同时使用UPS。
有OS的页文件的分区不能建立镜像。
6.1.2. 有关IPv6环境¶
在IPv6环境下,不能使用以下功能。
BMC心跳资源
AWS Elastic IP 资源
AWS 虚拟 IP资源
AWS DNS资源
Azure 探头端口资源
Azure DNS资源
Google Cloud 虚拟 IP 资源
Google Cloud DNS 资源
Oracle Cloud 虚拟 IP 资源
AWS Elastic IP监视资源
AWS 虚拟 IP监视资源
AWS AZ监视资源
AWS DNS监视资源
Azure 探头端口监视资源
Azure 负载均衡器监视资源
Azure DNS 监视资源
Google Cloud 虚拟 IP 监视资源
Google Cloud DNS 监视资源
Google Cloud 负载均衡监视资源
Oracle Cloud 虚拟 IP 监视资源
Oracle Cloud 负载均衡监视资源
以下功能不能使用链路本地地址。
内核模式LAN心跳资源
镜像磁盘连接
PING网络分区解决资源
FIP资源
VIP资源
6.1.3. 关于网络设置¶
在NAT环境等自身服务器的IP地址和对方服务器的IP地址在不同服务器上形成不同的配置时,不能构筑/运用集群。
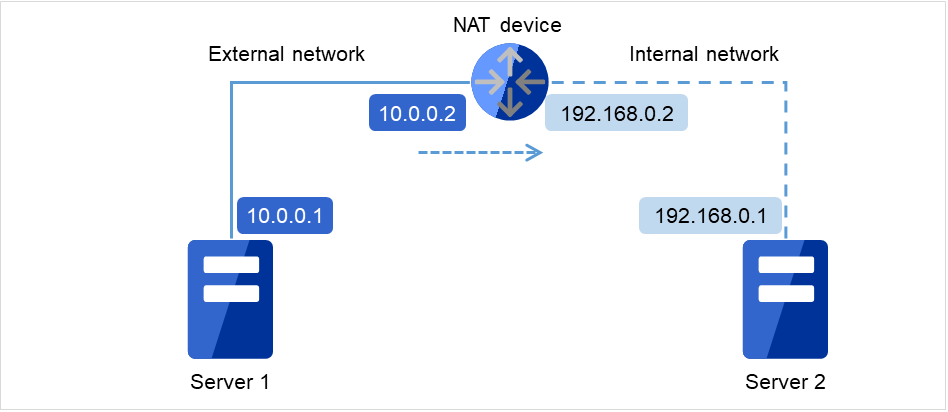
图 6.1 无法配置集群的环境的示例¶
Server 1中的集群设置
自身服务器: 10.0.0.1
对方服务器: 10.0.0.2
Server 2中的集群设置
自身服务器: 192.168.0.1
对方服务器: 10.0.0.1
6.1.5. 关于镜像磁盘/共享型镜像磁盘的write性能¶
镜像磁盘资源/共享型镜像磁盘资源的磁盘镜像建立有同步镜像和非同步镜像2种方式。
同步镜像时,每当向镜像化对象的数据分区发出写入请求,都会向两台服务器的磁盘执行写入,并等待其结束。虽然向各服务器的写入是同时执行的,但向其它服务器的磁盘写入是通过网络进行的,所以与不进行镜像化的普通本地磁盘相比写入性能会降低。特别是网络通信速度慢,延迟时间长的远程集群结构,性能会大幅下降。
非同步镜像时,向自身服务器写出是立即执行的,而向其它服务器的写出会先保存到本地队列中,在后台写出。因为不需要等待向其他服务器的写出结束,即使网络性能较差时写出性能也不会有大幅下降。但是即使是非同步镜像时,也会在每次发出写入请求时将更新数据保存在队列中,与不建立镜像的普通本地磁盘和共享磁盘相比,写入性能会有降低。因此,向磁盘的写入处理需要较高吞吐量的系统(更新服务器较多的数据库系统等) ,推荐使用共享磁盘。
此外,非同步镜像时,虽然保证写入顺序,但运行服务器如宕机,可执行会丢失最新的更新内容。因此,如想在故障发生前一刻保证此刻信息切实被交接,需要使用同步镜像或者共享磁盘。
6.1.6. 关于非同步镜像的历史文件¶
在非同步模式的镜像磁盘/共享型镜像磁盘中,内存上的队列里记录不下的写入数据,会临时作为历史文件记录到被指定为历史文件夹的目录下。没有设置该历史文件的大小限制时,可以不受限制地写出到所指定的文件夹内。因此在这种设置的情况下,如果线路速度比业务应用程序的磁盘更新量低很多,则向远程服务器的写入处理赶不上磁盘更新的速度,磁盘里就会充斥历史文件。因此,远程集群结构也需要根据业务AP的磁盘更新量保证通信线路的速度。
此外,为了避免长时间通信延迟,连续发生磁盘更新导致历史文件保存文件夹溢出,需要为写出历史文件的磁盘确保充足的空余容量,或者设置历史文件的大小限制,又或者指定系统驱动器之外的其它驱动器。
6.1.7. 关于多个非同步镜像间的数据一致性¶
在非同步模式的镜像磁盘/共享型镜像磁盘中,将写入运行服务器的数据分区的内容也按照同样顺序写入待机服务器的数据分区中。
除了镜像磁盘的初始构建过程中和镜像化中断后的恢复(复制)过程中以外,都可以保证该写入顺序,因此可以保证待机服务器的数据分区上的文件间的数据一致性。
但多个镜像磁盘资源/共享型镜像磁盘资源间由于无法保证写入顺序,比如数据库的数据库文件和Journal(日志)文件,如果一方的文件比另一方陈旧,则数据一致性无法确保的文件被分散到多个非同步镜像磁盘上后,可执行会由于服务器宕机等引起失效切换时业务应用程序的非正常运行。
因此,这类文件必须放置在同一非同步镜像磁盘/共享型镜像磁盘上。
6.1.8. 关于Multiboot¶
如果从其它启动磁盘启动,镜像和共享磁盘的访问限制将被撤销,镜像磁盘的一致性和共享磁盘的数据保护将无法保证,使用这类资源时请不要使用Multiboot。
6.1.9. 关于JVM监视资源¶
可同时进行监视的Java VM最多是25个。可同时监视的Java VM指,通过Cluster WebUI ([监视(固有)]标签->[识别名])可进行唯一识别的Java VM的数量。
Java VM和JVM监视资源之间的回收不支持SSL。
有时可执行不能检测出线程死锁。这是已经确认的来自JavaVM的缺陷。详细内容请参考Oracle的Bug Database的"Bug ID: 6380127 "。(2011年4月现在)。
JVM监视资源可监视的Java VM需与JVM监视资源工作时的服务器在同一服务器内。
通过Cluster WebUI (集群属性->[JVM监视]标签页->[Java安装路径])进行设定的Java安装路径在集群内的服务器内属于共通设定。关于JVM监视中使用的Java VM的版本以及升级版本,请在集群内服务器上使用同一版本。
通过Cluster WebUI (集群属性->[JVM监视]标签页->[连接设定]对话框->[管理端口号])进行设定的管理端口号在集群内的服务器内属于共通设定。
x86_64版OS上运行IA32版的监视对象的应用程序时,不能进行监视。
通过Cluster WebUI (集群属性->[JVM监视]标签页->[最大Java堆大小])进行设定的最大Java堆大小时,如果将其设定为3000等大数值,启动JVM 监视资源就会失败。由于依赖于系统环境,因此请将系统的内存搭载量设定为原来值。
使用负载均衡器联动的监视对象Java VM的负载计算功能时,推荐在SingleServerSafe中使用。另外,仅在Red Hat Enterprise Linux环境下可以运行。
- 在监视对象Java VM的启动选项中附加「-XX:+UseG1GC」时,Java 7以前版本不能监视JVM监视资源的[属性]-[监视(固有)]标签页-[调整]属性-[内存]标签页内的设置项目。Java 8以上版本可以通过在JVM监视资源的[属性]-[监视(固有)] 标签页-[JVM类型]中选择[Oracle Java(usage monitoring)],可以进行监视。
6.1.10. 关于网络警告灯的要求¶
使用"DN-1000S","DN-1500GL"时,请勿设置警告灯密码。
- 因回放音频文件而出现警告时,需要在先在音频文件回放对应的网络警告灯上重新登录音频文件。有关音频文件登录,请参考各网络警告灯的使用说明书。
在网络警告灯里请设置允许来自集群内的服务器的rsh命令执行。
6.2. 安装EXPRESSCLUSTER前¶
OS安装完成后,在对OS和磁盘进行设置时所须注意的事项。
6.2.1. 关于文件系统¶
安装OS的分区,作为共享磁盘的磁盘资源使用的分区以及镜像磁盘/共享型镜像磁盘资源的数据分区的文件系统请使用NTFS。
6.2.2. 通信端口号¶
EXPRESSCLUSTER中缺省使用以下端口号。该端口号可在Cluster WebUI 上更改。请不要从EXPRESSCLUSTER以外的程序访问这些端口号。
请不要从ExpressCluster以外的程序访问以下端口号。
为服务器设置防火墙时,请使下列端口号可以访问。
AWS环境时,防火墙设定以外安全组的设定也请使下列端口号可以访问。
[服务器・服务器之间]
From
To
备注
服务器
自动分配 4
服务器
29001/TCP
内部通信
服务器
自动分配
服务器
29002/TCP
数据传送
服务器
自动分配
服务器
29003/UDP
警告同步
服务器
自动分配
服务器
29004/TCP
磁盘Agent间通信
服务器
自动分配
服务器
29005/TCP
镜像驱动程序间通信
服务器
自动分配
服务器
29008/TCP
集群信息管理
服务器
自动分配
服务器
29010/TCP
Restful API 内部通信
服务器
29106/UDP
服务器
29106/UDP
心跳
服务器
icmp
服务器
icmp
FIP/VIP资源的重复确认
- 4
自动分配在某一时刻未被使用的端口号。
[服务器・客户端之间]
From
To
备注
客户端自动分配服务器29007/TCP29007/UDP客户端服务通信Restful API 客户端
自动分配
服务器
29009/TCP
http通信
[服务器・Cluster WebUI之间]
From
To
备注
Cluster WebUI
自动分配
服务器
29003/TCP
http通信
[其他]
From
To
备注
服务器
自动分配
网络警告灯
514/TCP
控制网络警告灯
服务器
自动分配
服务器的BMC的管理LAN
623/UDP
控制BMC(强行停止/机箱灯的联动)
服务器的BMC的管理器LAN
自动分配
服务器
162/UDP
设置为用于BMC 联动的消息接收监视的监视目标
服务器的BMC的管理器LAN
自动分配
服务器的BMC的管理器LAN
5570/UDP
BMC HB通信
服务器
自动分配
Witness 服务器
使用Cluster WebUI设定的通信端口号
Witness 心跳资源的连接目标主机
服务器
自动分配
监视目标
icmp
IP监视资源
服务器
自动分配
NFS服务器
icmp
确认NAS资源的NFS服务器的死活
服务器
自动分配
监视目标
icmp
Ping方式网络分区解决资源的监视目标
服务器
自动分配
监视目标
使用Cluster WebUI 设定的通信端口号
HTTP 方式网络分区解决资源的监视目标
服务器
自动分配
服务器
使用Cluster WebUI设定的管理端口号
JVM监视资源
服务器
自动分配
监视目标
使用Cluster WebUI设定的连接端口号
JVM监视资源
服务器
自动分配
服务器
使用Cluster WebUI设定的负载均衡器联动管理端口号
JVM监视资源
服务器
自动分配
BIG-IP LTM
使用Cluster WebUI设定的通信端口号
JVM监视资源
服务器
自动分配
服务器
Cluster WebUI 中设置的探头端口
Azure 探头端口资源
服务器
自动分配
AWS区域终端节点
443/tcp
AWS Elastic IP资源AWS 虚拟 IP资源AWS DNS资源AWS Elastic IP监视资源AWS 虚拟 IP监视资源AWS AZ监视资源AWS DNS监视资源服务器
自动分配
Azure终端节点
443/tcp
Azure DNS资源
服务器
自动分配
Azure的权威DNS服务器
53/udp
Azure DNS监视资源
服务器
自动分配
服务器
Cluster WebUI 中设置的端口号
Google Cloud 虚拟 IP 资源
服务器
自动分配
服务器
Cluster WebUI 中设置的端口号
Oracle Cloud 虚拟 IP 资源
AWS环境时,防火墙的设置以外,也请变更安全组的设定。
JVM监视中使用以下4种端口号。
管理端口号是为了JVM监视资源内部使用的端口号。通过Cluster WebUI的[集群属性]-[JVM监视]标签页-[连接设置] 对话框来设置。有关详细信息,请参照《参考指南》的"参数的详细信息"。
连接端口号是为了与监视目标(WebLogic Server,WebOTX)的Java VM相连接的端口号。通过Cluster WebUI的该JVM监视资源名的[属性]-[监视(固有)]标签页来设置。有关详细信息,请参考《参考指南》的"监视资源的详细信息"。
负载均衡器联动管理端口号是为了进行负载均衡器联动时而使用的端口号。不使用负载均衡器联动时,不需设置。请通过Cluster WebUI的[集群属性]-[JVM监视]标签页-[负载均衡器联动设置]对话框来设置。有关详细信息,请参照《参考指南》的"参数的详细信息"。
通信端口号是通过BIG-IP LTM与负载均衡器联动时使用的端口号。不使用负载均衡器联动时,不需设置。请通过Cluster WebUI的[集群属性]-[JVM监视]标签页-[负载均衡器联动设置]对话框进行设置。请详见《参考指南》的"参数的详细信息"。
Azure探头端口资源的[探头端口],Google Cloud虚拟IP资源的[端口号],Oracle Cloud虚拟IP资源的[端口号],是负载均衡器在对各个服务器进行死活监视时用的端口号。
AWS Elastic IP资源,AWS 虚拟 IP资源,AWS DNS资源,AWS Elastic IP监视资源,AWS 虚拟 IP监视资源,AWS AZ监视资源,AWS DNS监视资源是执行AWS CLI。 AWS CLI是使用上述端口。
Azure DNS资源是执行Azure CLI。Azure CLI是使用上述端口。
6.2.3. 更改通信端口号的自动分配的范围¶
OS所管理的通信端口号的自动分配范围有可执行与EXPRESSCLUSTER所使用的通信端口号重复。
通过以下方法等确认,OS管理的通信端口号的自动分配范围与EXPRESSCLUSTER所使用的通信端口号重复时,为了使通信端口号不重复,请更改EXPRESSCLUSTER所使用的通信端口号或者OS管理的通信端口号的自动分配范围。
通过Windows提供的netsh命令来显示或设定自动分配的范围。
OS所管理的通信端口号的自动分配范围的确认方法
netsh interface ipv6 set global dhcpmediasense=disabled
以下为执行示例。
>netsh interface ipv4 show dynamicportrange tcp 协议tcp的动态端口范围 --------------------------------- 开始端口 : 49152 端口数 : 16384
以上表示ipv4,TCP协议的通信端口号的自动分配范围是49152~68835(分配了从端口号49152开始的16384个端口)。如果EXPRESSCLUSTER使用的通信端口号在此范围内,请更改EXPRESSCLUSTER使用的端口号或者执行下述[OS管理的通信端口号的自动分配范围的设定方法]。
OS管理的通信端口号的自动分配范围的设定方法
netsh interface <ipv4|ipv6> set dynamicportrange <tcp|udp> [startport=]<开始端口号> [numberofports=]<自动分配范围>
以下为执行示例。
>netsh interface ipv4 set dynamicportrange tcp startport=10000 numberofports=1000
以上表示ipv4,TCP协议的通信端口号的自动分配范围是10000~10999(分配了从端口号10000开始的1000个端口)。
6.2.4. 关于避免端口数不足的设置¶
6.2.5. 时钟同步的设置¶
集群系统中,推荐将多个服务器的时钟定期同步操作。请使用时间服务器等使服务器的时钟同步。
6.2.7. 关于镜像磁盘用的分区¶
请在各服务器的本地磁盘上创建17MB以上的RAW分区作为管理镜像磁盘资源的分区(集群分区)。
在各服务器的本地磁盘上创建镜像化对象的分区(数据分区),并以NTFS格式化(为已有的分区建立镜像时,无须重新创建分区)。
在两台服务器上设置的数据分区的大小应相等。请使用[clpvolsz]命令确认调整正确的分区大小。
两台服务器上设置的集群分区和数据分区的盘符应该一致。
6.2.8. 关于共享型镜像磁盘用的分区¶
作为共享型镜像磁盘资源的管理用分区(集群分区),请为每个服务器组的共享磁盘(如果服务器组的成员服务器只有1台,则为本地磁盘)创建17MB以上的RAW分区。
请在各个服务器组的共享磁盘(如果服务器组的成员服务器只有1台,则为本地磁盘)创建镜像化对象分区(数据分区)并用NTFS方式进行格式化(如果镜像化已有的分区,则无需重新创建分区)。
在两服务器组上设置的数据分区的大小应相等。请使用[clpvolsz]命令确认调整正确的分区大小。
请在各个服务器上为集群分区和数据分区设置相同的盘符。
6.2.9. 关于数据分区上的文件夹和文件的访问许可¶
工作组环境中对数据分区上的文件夹和文件进行访问许可设置时,需要在访问该数据分区的所有节点上,对该用户设置访问许可。例如,对server1, server2 的test用户进行访问许可设置时,需要在server1和server2中对test用户进行访问许可设置。
6.2.10. OS启动时间的调整¶
请将从接通电源到OS启动为止的时间设为比以下的两个时间都长5。
使用共享磁盘时,从接通磁盘的电源到可以使用时的时间
心跳超时时间
- 5
具体的步骤,请参照《安装&设置指南》的"确定系统配置" -"配置硬件后的设置"-"3. 调整OS启动时间(必须)"。
6.2.11. 网络的确认¶
确认通过心跳线或镜像连接使用的网络。在集群内所有的服务器上确认。
请使用[ipconfig]命令或[ping]命令确认网络的状态。
公网 (与其它机器通信的网络)
私网专用LAN(EXPRESSCLUSTER的服务器之间连接的网络)
镜像连接LAN(与私网共用)
主机名
集群上使用的浮动IP资源的IP地址不用设置到OS端。
EXPRESSCLUSTER 的设置中(心跳和镜像连接等)指定了IPv6时,如果发生了网卡LinkDown,则该网卡绑定的IP地址会处于不可见状态,直接影响EXPRESSCLUSTER的运行。请执行下面的命令,解除对媒体连接的限制
netsh interface ipv6 set global dhcpmediasense=disabled
6.2.12. 关于与ESMPRO/AutomaticRunningController结合使用¶
要求与ESMPRO/AutomaticRunningController(以下简称ESMPRO/AC)结合使用的时候,EXPRESSCLUSTER的构筑/设置有以下的注意事项。如果不满足这些注意事项,与ESMPRO/AC结合使用的功能将有可执行不能正常工作。
作为网络分区解决资源,只有DISK方式的资源不能单独指定。指定DISK方式的时候,必须与PING方式,COM方式等其它的网络分区解决方式资源一起组合指定。
建立磁盘TUR监视资源时,最终动作的设定值为默认(不进行任何操作),请不要对该项进行更改。
建立磁盘RW监视资源时,[文件名]的设定值指定为共享磁盘上的路径时,[监视时间]的设定值为默认(启动时),请不要对该项进行更改。
断电后再启动时,在EXPRESSCLUSTER管理器上可执行会提示以下的警告信息。根据以上的设定,在实际工作中并不会发生故障,所以可以忽略。
- ID:18模块名:nm信息:资源<DiskNP资源名>启动失败。(服务器名:xx)
- ID:1509模块名:rm信息:监视<磁盘TUR资源名>查出异常。(4 : 开启设备失败。请确认监视卷的磁盘状态。)
关于ESMPRO/AC的设定方法,注意事项等,请参考《EXPRESSCLUSTER X for Windows PP指南》的"ESMPRO/AC"章节的内容。
6.2.13. 关于ipmiutil¶
在以下功能中,使用了已经作为BSD许可证的开源代码被公开的IPMI Management Utilities (ipmiutil)控制各服务器的BMC固件。因此使用这些功能时,请在各集群服务器上安装ipmiutil。
物理机的强行停止功能
机箱ID指示灯联动
使用上述功能时,为了保证管理底板管理控制器(BMC)的LAN板卡所使用的IP地址和OS所使用的IP地址之间的通信,请设置各服务器的BMC。服务器上没有安装BMC或者管理BMC所使用的网络处于关闭状态时无法使用该功能。BMC的设置方法请参考各服务器的手册。
EXPRESSCLUSTER没有附带ipmiutil。ipmiutil的获取和安装方法请参考《安装&设置指南》- "确定系统配置"- "配置硬件后的设置" - "9. 设置BMC和ipmiutil(使用物理机的强行停止功能和机箱ID指示灯联动时必须)"。
ipmiutil相关的以下事项本公司恕不对应。请根据用户自己的判断和责任使用。
ipmiutil自身相关的咨询
ipmiutil的运行保证
ipmiutil的问题对应,因其问题造成的故障
各服务器的ipmiutil的支持情况咨询
请用户提前确认您计划使用的服务器(硬件)是否支持ipmiutil。请注意,即使硬件本身是基于IPMI标准,实际上也可执行无法运行ipmiutil。
6.2.14. 关于在Server Core的安装¶
6.2.15. 关于邮件通知¶
不支持STARTTLS和SSL的邮件通知功能。
6.2.16. 关于系统磁盘连接的HBA的访问限制¶
6.2.17. AWS环境中的时刻同步¶
6.2.18. 关于AWS环境中IAM的设置¶
说明关于AWS环境中IAM (Identity & Access Management)的设置。
EXPRESSCLUSTER的一部分功能,由于这些处理,会在内部运行AWS CLI。为了能正常执行AWS CLI,需要事先对IAM进行设置。
作为可访问AWS CLI的方法,有使用IAM角色的方针和使用IAM用户的方针2种。基本上由于在各实例上不需要保存AWS access key id和AWS secret access key,安全性提高,推荐使用前者的IAM角色的方针。
IAM的设置步骤如下所示。
首先请创建IAM policy。请参考后面的"IAM policy的创建"。
- 接下来进行实例设置。使用IAM角色时,请参考后面的“实例的设置-使用IAM角色”。使用IAM用户时,请参考后面的“实例的设置-使用IAM用户”。
IAM policy的创建
创建policy,该policy记载了针对AWS的EC2和S3等的服务的动作的访问许可。EXPRESSCLUSTER的AWS关联资源以及监视资源执行AWS CLI所允许的必要的动作如下所示。
必要的policy有可执行将来被变更。
AWS虚拟IP资源/AWS虚拟IP监视资源
动作
说明
取得VPC,路由表,网络接口的信息时必需。
ec2:ReplaceRoute
更新路由表时必需。
AWS Elastic IP资源/AWS Elastic IP监视资源
动作
说明
取得EIP,网络接口的信息时必需。
ec2:AssociateAddress
将EIP分配到ENI时必需。
ec2:DisassociateAddress
将EIP从ENI分离时必需。
AWS AZ监视资源
动作
说明
ec2:DescribeAvailabilityZones
取得可用区的信息时必需。
AWS DNS资源 / AWS DNS监视资源
动作
说明
route53:ChangeResourceRecordSets
追加,删除资源记录集,更新设置内容时必需。
route53:ListResourceRecordSets
取得资源记录集信息时必需。
向Amazon CloudWatch发送监视资源的监视处理时间的功能
动作
说明
cloudwatch:PutMetricData
发送自定义指标时所需。
向 Amazon SNS发送警报服务消息的功能
动作
说明
sns:Publish
发送消息时所需。
以下的自定义policy的例子是许可全部AWS关联资源以及监视资源所使用的动作。
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "ec2:Describe*", "ec2:ReplaceRoute", "ec2:AssociateAddress", "ec2:DisassociateAddress", "route53:ChangeResourceRecordSets", "route53:ListResourceRecordSets" ], "Effect": "Allow", "Resource": "*" } ] }通过IAM Management Console的[Policies] - [Create Policy]可创建自定义policy。
实例的设置-使用IAM角色
通过创建IAM角色并赋给实例从而使AWS CLI可执行的方法。
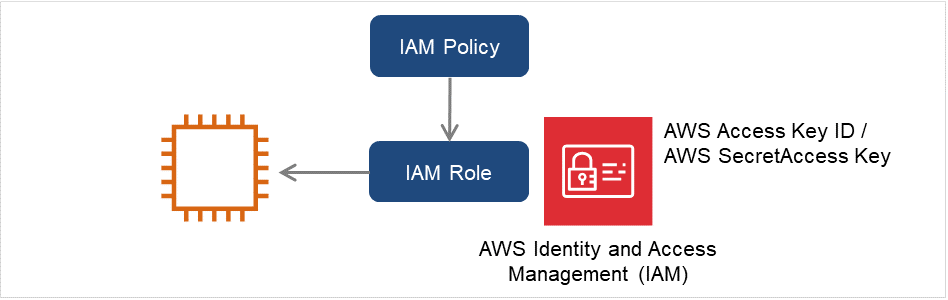
图 6.2 设置使用IAM角色的实例¶
创建实例时,指定「IAM Role」上创建的IAM角色。
登录实例。
安装AWS CLI。
从以下地址下载AWS CLI 版本1后进行安装。由于不支持AWS CLI 版本 2,请不要安装 AWS CLI 版本 2。安装程序自动添加到系统环境变量PATH中。没有添加时,请参考"将AWS CLI版本1执行文件添加到命令行路径"。[下载适用于Windows (64位)的 AWS CLI MSI安装程序]安装Python或AWS CLI时如果已经安装EXPRESSCLUSTER,请重启OS再执行EXPRESSCLUSTER的操作。
每个安装程序中进行必要安装后的操作如下所示。
clpaws_setting.conf中设置"CLP_AWS_CMD=aws.cmd"。此外,必须在系统环境变量PATH中设置aws.cmd所在的目录(例如,"C:\Program Files\Python38")。- "使环境变量反映到AWS Elastic IP资源执行的AWS CLI中"- "使环境变量反映到AWS虚拟IP资源执行的AWS CLI中"- "使环境变量反映到AWS DNS资源执行的AWS CLI中"通过Administrator用户启动命令提示,执行以下的命令。
> aws configure针对提问输入执行AWS CLI所必需的信息。请注意不要输入AWS Access ID,AWS Secret Access Key。
AWS Access Key ID [None]: (只按Enter键) AWS Secret Access Key [None]: (只按Enter键) Default region name [None]: <默认的区域名> Default output format [None]: text"Default output format"可以指定为"text"之外的格式。
内容设置错误时,请将
%SystemDrive%\Users\Administrator\.aws目录删除后再重新执行上述操作。
实例的设置-使用IAM用户
创建IAM用户,通过将Access ID,Secret Access Key保存在实例内部使AWS CLI执行可执行的方法。实例创建时不需要IAM角色的授予。
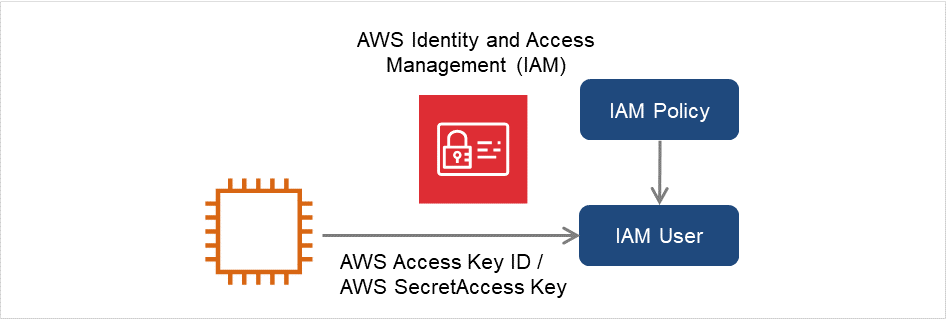
图 6.3 设置使用IAM用户的实例¶
登录实例。
安装AWS CLI。
从以下地址下载AWS CLI 版本1后进行安装。由于不支持AWS CLI 版本 2,请不要安装 AWS CLI 版本 2。安装程序自动添加到系统环境变量PATH中。没有添加时,请参考"将AWS CLI版本1执行文件添加到命令行路径"。[下载适用于Windows (64位)的 AWS CLI MSI安装程序]安装Python或AWS CLI时如果已经安装EXPRESSCLUSTER,请重启OS再执行EXPRESSCLUSTER的操作。
每个安装程序中进行必要安装后的操作如下所示。
clpaws_setting.conf中设置"CLP_AWS_CMD=aws.cmd"。此外,必须在系统环境变量PATH中设置aws.cmd所在的目录(例如,"C:\Program Files\Python38")。- "使环境变量反映到AWS Elastic IP资源执行的AWS CLI中"- "使环境变量反映到AWS虚拟IP资源执行的AWS CLI中"- "使环境变量反映到AWS DNS资源执行的AWS CLI中"通过Administrator用户启动命令提示,执行以下的命令。
> aws configure针对提问输入执行AWS CLI所必需的信息。AWS Access ID,AWS Secret Access Key处输入从已创建的IAM用户的详细信息画面取得的内容。
AWS Access Key ID [None]: <AWS Access Key > AWS Secret Access Key [None]: <AWS Secret Access Key> Default region name [None]: <默认的区域名> Default output format [None]: text"Default output format"可以指定为"text"之外的格式。
内容设置错误时,请将
%SystemDrive%\Users\Administrator\.aws目录删除后再重新执行上述操作。
6.2.19. 关于Azure DNS资源¶
安装Azure CLI,服务主体创建的步骤请参考《EXPRESSCLUTER X Microsoft Azure HA 集群构筑指南 (Windows 版)》。
- 为了利用Azure DNS资源,需要安装Azure CLI和Python。Python是在安装Azure CLI 2.0的同时被安装的。关于Azure CLI的具体内容,请参考以下Web站点。Microsoft Azure的文档:
- 为了利用Azure DNS资源,需要Azure DNS的服务。关于Azure DNS的具体内容,请参考以下Web站点。Azure DNS:
- EXPRESSCLUTER为了和Microsoft Azure联动,需要Microsoft Azure的组织账户。组织账户以外的账户在Azure CLI运行时需要对话形式的登录,因此不能使用。
- 使用Azure CLI,需要创建服务主体。Azure DNS资源是登录到Microsoft Azure,执行对DNS区域的登记。登录到Microsoft Azure时,利用通过服务主体的Azure登录。关于服务主体和具体步骤,请参考以下的Web站点。通过Azure CLI登录Azure:在Azure CLI 2.0上创建Azure服务主体:创建出服务主体的角色由默认的Contributor(共同创造者)改为别的角色时,作为Actions属性,请选择拥有以下的全部操作的访问权的角色。如果改变为不满足该条件的角色时,启动Azure DNS资源就会发生错误而失败。Azure CLI 2.0时Microsoft.Network/dnsZones/A/writeMicrosoft.Network/dnsZones/A/deleteMicrosoft.Network/dnsZones/NS/read
不支持Azure私有DNS。
6.2.20. 关于Google Cloud 虚拟IP资源¶
在Windows Server 2019上使用Google Cloud 虚拟 IP资源时,必须将以下服务的[启动类型]设置为[自动(延迟启动)]。
Google Compute Engine Agent
Google OSConfig Agent
6.2.21. 关于Google Cloud DNS资源¶
使用Google Cloud的Cloud DNS。关于Cloud DNS的详细信息,请参考以下Web网站。
Cloud DNS要使用Cloud DNS操作,需要安装Cloud SDK。关于Cloud SDK的详细信息,请参考以下网站。
Cloud SDK需要用具有以下权限的帐户批准Cloud SDK。
dns.changes.createdns.changes.getdns.managedZones.getdns.resourceRecordSets.createdns.resourceRecordSets.deletedns.resourceRecordSets.listdns.resourceRecordSets.update关于批准Cloud SDK,请参考以下Web网站。
Cloud SDK工具批准
6.3. 创建EXPRESSCLUSTER的配置信息时¶
在设计和创建EXPRESSCLUSTER的配置信息前,需要根据系统的配置确认并留意以下事项。
6.3.1. 有关EXPRESSCLUSTER安装路径下的文件夹和文件¶
6.3.2. 组资源停止异常时的最终运行¶
6.3.3. 延迟警告比例¶
将延迟警告比例设置为0或者100,可进行以下操作。
- 延迟警告比例设置为0时对每一监视以Alert通告延迟警告。使用该功能可计算出服务器在高负荷状态下对监视资源的轮询时间,确定监视资源的监视超时时间。
- 延迟警告比例设置为100时不通告延迟警告。
除了测试外,请不要设置0%等低数值。
6.3.4. 关于磁盘监视资源和共享型镜像磁盘TUR监视资源的监视方法TUR¶
- 不支持SCSI的Test Unit Ready命令的磁盘和磁盘接口(HBA)上无法使用。有时硬件支持而驱动程序不支持,请同时确认驱动程序的规格。
与Read方式相比对OS或磁盘的负荷小。
Test Unit Ready中有时不能查出实际的对媒体的I/O错误。
6.3.5. 关于心跳资源的设置¶
最少要设置1个内核模式LAN心跳资源。
将私网专用的LAN作为内核模式LAN心跳资源登录,然后将公网LAN也作为内核模式LAN心跳资源登录(建议设置2个以上的内核模式LAN心跳资源)。
使用BMC 心跳资源时,需要BMC 的硬件,固件可支持BMC 心跳。关于可利用的 BMC,请参阅 "4. EXPRESSCLUSTER的运行环境"- "4.1.2. 与Express5800/A1080a,A1040a 系列的整合相对应的服务器"。
心跳超时时间需要比OS重启所需时间短。如果未满足该条件,集群内的部分服务器进行重启时,其他服务器将无法正确检测出该服务器的重启,重启后将发生运行异常。
6.3.6. 关于脚本资源的设置¶
如果在脚本资源中启用了[在待机服务器上执行]的设置,则不支持在脚本中执行兼容命令。
6.3.7. 关于能用于脚本注释等的双字节系字符编码¶
在EXPRESSCLUSTER中,Windows环境下编辑的脚本作为Shift-JIS使用,而Linux环境下编辑的脚本则作为EUC使用。如使用其他字符编码,可执行因环境不同而出现乱码的情况。
6.3.8. 关于组的可启动服务器上可设置的服务器组数¶
1个组的可启动服务器上可设置的服务器组数最多为2个。如果设置了3个以上的服务器组时,EXPRESSCLUSTER Disk Agent 服务 (clpdiskagent.exe)有可执行不能正常运行。
6.3.9. 关于JVM监视器的设定¶
监视目标为WebLogic时,对于JVM监视器资源的设定值,由于系统环境(内存搭载量等)的原因,设定范围的上限值可执行会受到限制。
[监视Work Manager的要求]-[要求数]
[监视Work Manager的要求]-[平均值]
[监视线程Pool的要求]-[待机要求 要求数]
[监视线程Pool的要求]-[待机要求 平均值]
[监视线程Pool的要求]-[执行要求 要求数]
[监视线程Pool的要求]-[执行要求 平均值]
要使用Java Resource Agent,请安装"4. EXPRESSCLUSTER的运行环境"的"4.2.6. JVM监视器的运行环境"中记载的JRE(Java Runtime Environment),或者请安装JDK(Java Development Kit)。可与使用监视对象(WebLogic Server或WebOTX)的JRE或JDK在相同的项目中使用,也可使用在其他项目。如果一个服务器中同时安装了JRE和JDK,则使用其中任何一个居可。
监视资源名中不要含空白字符。
为了执行按照查出异常时的故障原因分类的命令的[命令]不能与加载平衡联动功能并用。
6.3.10. 关于系统监视的设置¶
- 资源监视的查出模式System Resource Agent中结合「阀值」和「监视持续时间」两个参数进行资源监视的查出。继续收集各系统资源(内存使用量,CPU 使用率,虚拟内存使用量),如果在一定时间(指定为持续时间的时间)内超过阀值时就会进行异常的查出。
6.3.11. 关于PostgreSQL监视的设定¶
监视资源名中不要含空白字符。
6.3.12. 关于AWS Elastic IP资源的设定¶
不支持IPv6。
在AWS环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源,虚拟计算机名资源和虚拟计算机名监视资源。
AWS Elastic IP资源不支持ASCII字符以外的字符。请确认以下命令的执行结果中不包含ASCII字符以外的字符。
aws ec2 describe-addresses --allocation-ids <EIP ALLOCATION ID>
6.3.13. 关于AWS 虚拟IP资源的设定¶
不支持IPv6。
在AWS环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源,虚拟主机名资源和虚拟主机名监视资源。
AWS虚拟IP资源不支持ASCII字符以外的字符。请确认以下命令的执行结果中不包含ASCII字符以外的字符。
aws ec2 describe-vpcs --vpc-ids <VPC ID> aws ec2 describe-route-tables --filters Name=vpc-id,Values=<VPC ID> aws ec2 describe-network-interfaces --network-interface-ids <ENI ID>
在需要经由VPC-Peering连接的访问时,不能利用AWS虚拟IP资源。这是因为作为VIP使用的IP地址是在VPC范围之外的前提,这样的IP地址在VPC-Peering连接中被视为无效。需要经由VPC-Peering连接的访问时,请使用利用了Amazon Route 53的AWS DNS资源。
设置AWS虚拟IP资源时,作为Windows的操作,物理主机名和虚拟IP的记录 DNS中注册(该网络适配器的属性设置中,将地址注册到DNS种的设定已打开时)。要将有物理主机域名解析的IP地址变为物理IP地址,请按如下所示进行设置。
已经有相应的虚拟IP地址,如果已勾选网络适配器的[属性]-[Internet协议版本4]-[详细设置]-[DNS]标签页-[在DNS中注册此连接的地址],请取消勾选。
要反映该设置,请执行以下任意的操作
重启DNS Client 服务。
明确执行ipconfig /registerdns 命令。
请将分配了相应虚拟IP地址的网络适配器的物理地址静态地注册到DNS服务器中。
在使用实例的路由表中,即使没有定义使用虚拟IP的IP地址和ENI,AWS虚拟IP资源也能正常启动。这是规定好的。在启动AWS虚拟IP资源时,仅更新存在指定IP地址条目的路由表内容。即使没有找到任何一个路由表,也会因为没有更新目标而被判断为正常。由于该条目是否必须要存在于哪个路由表,是由系统配置决定的,因此,不作为检查AWS虚拟IP资源正常性的目标。
AWS虚拟IP资源在使用Windows OS的API的NIC中添加了虚拟IP地址。这时,由于没有设置skipassource flag,因此,在启动AWS虚拟IP资源后,skipassource flag将会变为无效。如要设置skipassource flag有效时,请在启动AWS虚拟IP资源后通过PowerShell 等进行设置。
6.3.14. 关于AWS DNS资源的设定¶
不支持IPv6。
在AWS环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源,虚拟主机名资源和虚拟主机名监视资源。
如果[资源记录集名称]中包含转义码,则为监视异常。请设置不含转义码的[资源记录集名称]。
启动AWS DNS资源后,不会等待DNS配置的更改传播到所有Amazon Route 53 DNS服务器上。这是由于在Route 53的设计中,将资源记录集更改应用于整体需要花费时间。请参考"关于AWS DNS监视资源的设定"。
由于AWS DNS资源绑定在一个账户上,因此,无法使用多个帐户,AWS访问ID,AWS秘密访问密钥。在这种情况下,请考虑创建一个使用脚本资源等执行AWS CLI的脚本,并将其中的环境变量设置为用于认证其他账户的信息。
6.3.15. 关于AWS DNS监视资源的设定¶
AWS DNS监视资源在监视时执行AWS CLI。执行AWS CLI的超时是利用在AWS DNS资源上设置的[AWS CLI超时]。
AWS DNS资源的启动后,根据以下的情况,AWS DNS监视资源的监视可执行会失败。这时,请将AWS DNS监视资源的 [开始监视等待时间] 设置为比Amazon Route 53中DNS设定改变反映的时间更长的时间(https://aws.amazon.com/jp/route53/faqs/)。
启动AWS DNS资源时,追加和更新记录集合。
反映Amazon Route 53中的DNS设置改变前,监视AWS DNS监视资源时就会由于不能进行域名解析而失败。在DNS解析器缓存有效的期间内,之后,监视AWS DNS监视资源也会失败。
反映Amazon Route 53中的DNS设置改变。
经过AWS DNS资源的 [TTL] 有效期,由于域名解析成功,监视AWS DNS监视资源成功。
6.3.16. 关于Azure 探头端口资源的设定¶
不支持IPv6。
在Microsoft Azure环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源,虚拟计算机名资源和虚拟计算机名监视资源。
6.3.17. 关于Azure 负载均衡监视资源的设定¶
Azure负载均衡监视资源检测到异常时,Azure的负载均衡的运行服务器和待机服务器的切换可执行不能正常执行。因此,推荐设置Azure负载均衡监视资源的[最终动作]选项为[停止集群服务并关闭操作系统]。
6.3.18. 关于Azure DNS资源设定¶
不支持IPv6。
在Microsoft Azure环境下,不能利用浮动IP资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源,虚拟主机名资源和虚拟主机名监视资源。
6.3.19. 关于Google Cloud 虚拟 IP 资源的设定¶
不支持IPv6。
6.3.20. 关于Google Cloud 负载均衡监视资源的设定¶
如果Google Cloud负载均衡监视资源检测到异常,则可执行无法正确地从负载均衡器在运行系统和待机系统之间进行切换。因此,建议在Google Cloud负载均衡监视资源的[最终动作]中选择[停止集群服务停止和关闭操作系统]。
6.3.21. 关于Google Cloud DNS资源的设置¶
不支持IPv6。
在Google Cloud Platform 环境下,不能利用浮动 IP 资源,浮动IP监视资源,虚拟IP资源,虚拟IP监视资源。
如果同时执行多个Google Cloud DNS资源的启动/停止处理,可执行会发生错误。因此,在集群中使用多个Google Cloud DNS资源时,需要进行设置,以便由于资源的依赖关系和组的启动/停止等待而不能同时执行启动/停止处理。
6.3.22. 关于Oracle Cloud 虚拟 IP 资源的设定¶
不支持IPv6。
6.3.23. 关于Oracle Cloud 负载均衡监视资源的设定¶
如果Oracle Cloud负载均衡监视资源检测到异常,则可执行无法正确地从负载均衡器在运行系统和待机系统之间进行切换。因此,建议在Oracle Cloud负载均衡监视资源的[最终动作]中选择[停止集群服务停止和关闭操作系统]。
6.3.24. 关于基于Windows Server 2012系统的服务失败时的恢复操作¶
EXPRESSCLUSTER Disk Agent服务
EXPRESSCLUSTER Server服务
EXPRESSCLUSTER Transaction服务
6.3.25. 关于与 OS 的网络负载均衡功能兼容¶
6.3.26. 反应HBA设置时的注意点¶
变更新建集群时[服务器属性]的[HBA]标签页中的访问限制的设定,并上传配置信息时,作为反映方法,可执行不会显示OS重启。如果更改新建集群时在[HBA]标签页中的访问限制设定时,为了反映配置信息,请重启OS。
6.4. 操作EXPRESSCLUSTER后¶
对作为集群开始操作后发生的事件需要注意以下几点。
6.4.1. 恢复运行中的操作限制¶
在监视资源的查出异常的设置中将恢复对象指定为组资源(磁盘资源,应用程序资源等),在监视资源查出异常后的恢复运行变化过程中(重启动 -> 失效切换 -> 最终运行),请不要通过Cluster WebUI或命令进行以下操作。
集群的停止 / 挂起
组的启动 / 停止 / 移动
6.4.2. 关于命令参考中没有记载的可执行文件或脚本文件¶
6.4.3. 集群关机/集群关机重启¶
6.4.4. 特定服务器的关机,重启¶
使用镜像磁盘时,执行命令或从Cluster WebUI执行服务器的关机,关机重启命令会发生Mirror Break。
6.4.5. 从网络分区状态的恢复¶
在发生了网络分区的状态下,配置集群的服务器之间无法确认彼此的状态,因此在该状态下对组进行操作(启动/停止/移动)或者重启服务器等,服务器之间对集群状态的识别会产生出入。在这种启动了多个状态识别不同的服务器的状态下进行网络恢复,则其后面的组操作会非正常运行,因此在网络分区状态时,关闭与切断网络(无法与客户端通信)的服务器,或者先停止EXPRESSCLUSTER Server服务,待网络恢复后重启,再复原到集群中。万一在启动了多个服务器的状态下恢复了网络,则可通过重启集群状态识别不同的服务器,复原到正常状态。
另外,使用网络分区解决资源时,即使发生了网络分区,也通常会紧急关闭某个(或者所有)服务器,避免启动多个彼此无法通信的服务器。紧急关闭的服务器以手动重启或者紧急关机时的动作设置为重启时,重启的服务器都会再次紧急关机(Ping方式或者多数取胜方式下将停止EXPRESSCLUSTER Server服务)。但以DISK方式使用多个磁盘心跳用分区时,由于磁盘路径故障导致无法通过磁盘进行通信的状态下而发生网络分区,则两台服务器将会以保留状态继续运行。
6.4.6. 关于Cluster WebUI¶
如果在与连接目标无法通信的状态下进行操作,则等待控制返回可执行会花费些许时间。
经由Proxy服务器时请对该服务器进行设置,以便可以中转Cluster WebUI的端口号。
经由Reverse Proxy服务器时,Cluster WebUI不能正常运行。
- 对EXPRESSCLUSTER进行升级后,请关闭所有运行中的Web浏览器。清空浏览器侧的缓存后再启动浏览器。
使用比本产品更新的版本创建的集群配置信息,不能在本产品中使用。
- 通过窗口边框中的[X]按钮等结束Web浏览器后,可执行会弹出确认对话框。

若要保存当前配置,请选择[留在此页]。
- 刷新Web浏览器(通过[工具]菜单中的[刷新]及工具条上的[刷新]按钮等)后,可执行会弹出确认对话框。

若要保存当前配置,请选择[留在此页]。
关于上述之外的Cluster WebUI的注意限制事项请参考在线版手册。
6.4.7. 关于EXPRESSCLUSTER Disk Agent服务¶
请勿停止EXPRESSCLUSTER Disk Agent服务。停止服务后无法手动启动。这时必须重启OS,再启动EXPRESSCLUSTER Disk Agent服务。
6.4.8. 关于镜像构建中的集群配置信息的变更¶
镜像构建过程中(包括初始构建)请不要更改集群配置信息。更改集群配置信息后,驱动程序的运行可执行出现不正常。
6.4.9. 关于镜像磁盘的待机服务器的集群恢复¶
镜像磁盘启动时待机服务器在停止集群服务(EXPRESSCLUSTER Server服务)的状态下运行时,在开始服务之后恢复到集群前请再次启动待机服务器。如果直接就这样恢复的话会出现镜像的差异信息不正确,镜像磁盘会发生不联动。
6.4.10. 关于镜像磁盘,共享型镜像磁盘间的配置变更¶
进行配置变更,将已通过镜像磁盘资源进行镜像化的磁盘更改为通过共享型镜像磁盘资源进行镜像化时,请先上传删除了现有镜像磁盘资源的配置信息,在变更为现有资源已被删除的状态后,再上传添加了共享型镜像磁盘资源的配置信息。将共享型镜像磁盘变更为镜像磁盘时也是如此。
如不按以上步骤,没有删除现有资源的情况下就上传已替换为新资源的配置信息,可执行导致磁盘镜像化的设置变更无法正常进行,运行可执行出现不正常。
6.4.11. 关于[chkdsk]命令和磁盘碎片整理¶
6.4.12. 关于索引服务¶
在索引服务的目录中创建共享磁盘/镜像磁盘上的目录,对共享磁盘/镜像磁盘上的文件夹创建索引时,需要从EXPRESSCLUSTER控制,将索引服务设为手动启动,在启动共享磁盘/镜像磁盘后启动。如果将索引服务设为自动启动,则索引服务会OPEN对象卷,在之后的启动处理中将造成mount处理失败,最后造成从应用程序或资源浏览器访问磁盘因"参数错误" (错误代码87)而失败。
6.4.13. 关于Windows Server 2012以上环境中的用户帐户控制的影响¶
Windows Server 2012以上中默认值的用户帐户控制 (UAC 是User Account Control的略称) 设置为有效。如果UAC有效时,对下述的功能产生影响。
- 监视资源对下面所述的监视资源产生影响。
- Oracle 监视资源Oracle 监视资源中的认证方式为[OS 认证],且将监视用户设置为Administrators组以外的用户时,Oracle监视处理会失败。认证方式设置为[OS认证]时,请将设置为"监视用户"的用户应从属于Administrator组。
6.4.14. 关于应用程序资源/脚本资源的画面显示¶
从EXPRESSCLUSTER的应用程序资源,脚本资源启动的进程需要用对话0执行,因此如果启动了有GUI的进程,将弹出"发现对话型服务对话框"窗口,在该窗口中,如果不选择"显示消息",则不会显示GUI。
6.4.15. 关于网卡(NIC)二重化的环境¶
NIC二重化的环境中,启动OS 时初始化NIC有时需要花费点时间。如果初始化结束前就启动集群,启动内核模式,LAN心跳资源(lankhb)有可执行失败。此状态下,即便NIC的初始化已结束,内核模式和LAN心跳资源也不能返回正常状态。要从此状态进行复归,需要挂起集群后对集群进行复原。
此外,为避免上述现象的发生,推荐对网络初始化结束等待时间进行设置或者使用[ARMDELAY]命令推迟集群的启动时间。
- 网络初始化等待时间是配置集群的所有服务器中的共通设置。即便没有到达设置的时间,如果网络的初始化已经结束,集群就会开始启动。
- [ARMDELAY]命令是配置集群的各服务器中的个别设置。即便没有到达设置的时间,如果网络的初始化已经结束,集群也不会开始启动。
关于网络初始化结束等待时间,[ARMDELAY]命令的详细信息,请参照《兼容功能指南》。
6.4.16. 关于EXPRESSCLUSTER的服务的登录帐号¶
EXPRESSCLUSTER的服务的登录帐号设置在 [当地系统帐号] 中。如果更改了此登录帐号的设置,就有可执行不能作为集群正常运行。
6.4.17. 关于EXPRESSCLUSTER的常驻进程的监视¶
使用监视进程的软件等对EXPRESSCLUSTER的常驻进程进行监视不会引发问题,但是在进程异常结束等情况下,请不要进行进程再启动等的复归运行。
6.4.18. 关于消息接收监视资源¶
向消息接收监视资源发生异常通知时,有使用[clprexec] 命令,BMC 联动功能和服务器管理平台联动功能的三个方法。
使用[clprexec] 命令时可使用与 EXPRESSCLUSTER CD 捆包一起的文件。请根据通知源服务器的 OS 和结构来使用。此外,还需要通知源服务器和通知目标服务器处于可进行通信的状态。
使用BMC 联动功能时,需要BMC 的硬件和固件可支持该功能。关于可使用的 BMC ,请参阅本指南的"第 3 章EXPRESSCLUSTER的运行环境"的" 与Express5800/A1080a,A1040a 系列的整合相对应的服务器"。此外,还需要从BMC 的管理用 IP 地址到 OS 的 IP 地址可进行通信。
6.4.19. 关于JVM监视资源¶
重启监视对象的Java VM时,请将JVM监视资源挂起,或者停止集群后再进行。
变更设计内容时,需要进行集群的挂起和集群的复原。
不支持监视资源的延迟警报。
6.4.20. 关于系统监视资源,进程资源监视资源¶
变更设置内容时,需要进行集群挂起。
不支持监视资源的延迟警报。
若在运行中更改OS的日期或时间,则每隔10分钟执行的解析处理仅在更改日期或时间后的最初时序出现一次错位。出现以下两种问题时,请根据需要进行集群挂起和集群复归。
即使异常检测时间间隔经过之后,也不执行异常检测。
异常检测时间间隔经过之前,执行异常检测。
使用系统监视资源的磁盘资源监视功能可同时监视最多26个磁盘。
6.4.21. 关于镜像统计信息采集功能与OS标准功能联动的事件日志输出¶
从内部版本11.16之前升级的环境时,在应用程序事件日志中输出如下错误的情况。
- 事件ID:1008源:Perflib消息:服务"clpdiskperf" (DLL "<EXPRESSCLUSTER安装路径>\bin\clpdiskperf.dll") 的Open 进程失败。不能使用此服务的性能数据。数据段的最初4个字节(DWORD)含有错误代码。
使用镜像统计信息采集功能和OS标准功能之间的联动功能时,通过命令提示符执行以下命令,可以不输出本消息。
>lodctr.exe <EXPRESSCLUSTER 安装路径>\perf\clpdiskperf.ini
不使用联动功能时,即使输出该信息也不影响EXPRESSCLUSTER或者性能监视器操作,经常发生该消息输出时,通过执行以下2个命令,可以不输出本消息。
> unlodctr.exe clpdiskperf > reg delete HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\clpdiskperf
镜像统计信息采集功能与OS标准功能联动有效时,在应用程序事件日志中输出如下错误的情况。
- 事件ID:4806源:EXPRESSCLUSTER X消息:因性能监视器的进程数过多,不能采集镜像统计信息。
不使用联动功能时,即使输出该信息也不影响EXPRESSCLUSTER或者性能监视器操作,经常发生该消息输出时,通过执行以下2个命令,可以不输出本消息。
> unlodctr.exe clpdiskperf > reg delete HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\clpdiskperf
此外,关于镜像统计信息采集功能和OS标准功能之间的联动功能,请参考以下。
6.4.23. 关于AWS 环境中的AMI的恢复¶
6.5. EXPRESSCLUSTER的配置变更时¶
开始集群运行后如果对配置进行变更时,需要对发生的事项留意。
6.5.1. 关于组的共通属性的互斥规则¶
6.5.2. 关于资源属性的依存关系¶
6.5.3. 关于组资源的追加,删除¶
例) 将浮动IP资源script1从组failover1移到其他组failover2 时
从组failover1中删除fip1。
执行应用配置文件。
将fip1追加到组failover2中。
执行应用配置文件。
6.5.4. 关于消息接收监视资源的集群统计信息的设定¶
变更监视资源的集群统计信息设置时,即使执行了挂起·复原,也无法在消息接收监视资源中反映集群统计信息的设置。如果要在消息接收监视资源中反映集群统计信息的设置,请重启OS。
6.6. EXPRESSCLUSTER版本升级时¶
作为集群开始操作后,进行EXPRESSCLUSTER 的版本升级时需要注意的事项。
6.6.1. 功能变更一览¶
各版本中变更的功能如下所示。
内部版本 12.00
内部版本 12.10
更改前(12.01以前)
强制停止动作
强制停止动作
参数
BMC 断电
ireset.cmd -d -J 0 -N IP地址 -U 用户名 -P 密码
BMC 重置
ireset.cmd -r -J 0 -N IP地址 -U 用户名 -P 密码
BMC 电源重启
ireset.cmd -c -J 0 -N IP地址 -U 用户名 -P 密码
BMC NMI
ireset.cmd -n -J 0 -N IP地址 -U 用户名 -P 密码
机箱ID灯
机箱ID灯
参数
闪烁
ialarms.cmd -i250 -J 0 -N IP地址 -U 用户名 -P 密码
灭灯
ialarms.cmd -i0 -J 0 -N IP地址 -U 用户名 -P 密码
更改后
强制停止动作
强制停止动作
参数
BMC 断电
ireset.cmd -d -N IP地址 -U 用户名 -P 密码
BMC 重置
ireset.cmd -r -N IP地址 -U 用户名 -P 密码
BMC 电源重启
ireset.cmd -c -N IP地址 -U 用户名 -P 密码
BMC NMI
ireset.cmd -n -N IP地址 -U 用户名 -P 密码
机箱ID灯
机箱ID灯
参数
闪烁
ialarms.cmd -i250 -N IP地址 -U 用户名 -P 密码
灭灯
ialarms.cmd -i0 -N IP地址 -U 用户名 -P 密码
内部版本 12.20
内部版本 12.30
6.6.2. 删除功能一览¶
关于各版本中被删除的功能,显示如下。
内部版本 12.00
WebManager Mobile
OfficeScan CL 监视资源
OfficeScan SV 监视资源
OracleAS 监视资源
6.6.3. 参数删除一览¶
在通过Cluster WebUI可以设定的参数中,从各版本中删除的参数如下表所示。
内部版本 12.00
集群
参数
默认值
集群属性
Web管理器标签页
允许接入WebManager Mobile
Off
WebManager Mobile用密码
操作用密码
-
参照用密码
-
JVM 监视资源
参数
默认值
JVM监视资源属性
监视(固有)标签页
内存标签页 ([JVM类型] 选择了 [Oracle Java] 时)
监视虚拟内存使用量
2048 [MB]
内存标签页 ([JVM类型] 选择了 [Oracle Java(usage monitoring)] 时)
监视虚拟内存使用量
2048 [MB]
用户空间监视资源
参数
默认值
用户空间监视资源属性
监视 (固有) 标签页
使用心跳间隔/超时
Off
内部版本 12.10
6.6.4. 默认值更改一览¶
在通过Cluster WebUI可以设定的参数中,各版本中被更改的默认值如下表所示。
版本升级后,想要继续设定[更改前的默认值]时,在版本升级后请重新设置该值。
在设置了[更改前的默认值]以外的值时,版本升级后会保留之前的设定值。
内部版本 12.00
集群
参数
更改前的默认值
更改后的默认值
备注
集群属性
JVM监视标签页
最大Java堆内存大小
7 [MB]
16 [MB]
扩展标签页
失效切换次数计数单位
集群
服务器
组资源共通
参数
更改前的默认值
更改后的默认值
备注
资源的共通属性
复归操作标签页
失效切换次数
与服务器数目相同
1 [回]
伴随[集群属性] - [扩展标签页] - [失效切换次数计数单位]的默认值变化而变化。
应用程序资源
参数
更改前的默认值
更改后的默认值
备注
应用程序资源的属性
依赖关系标签页
遵循原有的依赖关系
注册表同步资源
参数
更改前的默认值
更改后的默认值
备注
注册表同步资源的属性
依赖关系标签页
遵循原有的依赖关系
脚本资源
参数
更改前的默认值
更改后的默认值
备注
脚本资源的属性
依赖关系标签页
遵循原有的依赖关系
服务资源
参数
更改前的默认值
更改后的默认值
备注
服务资源的属性
依赖关系标签页
遵循原有的依赖关系
CIFS资源
参数
更改前的默认值
更改后的默认值
备注
CIFS资源的属性
详细标签页
当恢复共享设置出错时视为组资源启动异常
On
Off
NAS资源
参数
更改前的默认值
更改后的默认值
备注
NAS资源的属性
依赖关系标签页
遵循原有的依赖关系
监视资源共通
参数
更改前的默认值
更改后的默认值
备注
监视资源共通的属性
复归操作标签页
最大失效切换次数
与服务器数目相同
1 [回]
伴随[集群属性] - [扩展标签页] - [失效切换次数计数单位]的默认值变化而变化。
应用程序监视资源
参数
更改前的默认值
更改后的默认值
备注
应用程序监视资源的属性
监视 (共通) 标签页
开始监视的等待时间
0 [秒]
3 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
浮动IP监视资源
参数
更改前的默认值
更改后的默认值
备注
浮动IP监视资源的属性
监视 (共通) 标签页
超时
60 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
NIC Link Up/Down监视资源
参数
更改前的默认值
更改后的默认值
备注
NIC Link Up/Down 监视资源的属性
监视 (共通) 标签页
超时
60 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
注册表同期监视资源
参数
更改前的默认值
更改后的默认值
备注
注册表同期监视资源的属性
监视 (共通) 标签页
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
服务监视资源
参数
更改前的默认值
更改后的默认值
备注
服务监视资源的属性
监视 (共通) 标签页
开始监视的等待时间
0 [秒]
3 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
打印机spool监视资源
参数
更改前的默认值
更改后的默认值
备注
打印机spool监视资源的属性
监视 (共通) 标签页
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
虚拟主机名监视资源
参数
更改前的默认值
更改后的默认值
备注
虚拟主机名监视资源的属性
监视 (共通) 标签页
超时
60 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
虚拟IP监视资源
参数
更改前的默认值
更改后的默认值
备注
虚拟IP监视资源的属性
监视 (共通) 标签页
超时
60 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
NAS监视资源
参数
更改前的默认值
更改后的默认值
备注
NAS监视资源的属性
监视 (共通) 标签页
超时
60 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
用户监视资源
参数
更改前的默认值
更改后的默认值
备注
用户监视资源的属性
监视 (共通) 标签页
开始监视的等待时间
0 [秒]
3 [秒]
进程名监视资源
参数
更改前的默认值
更改后的默认值
备注
进程名监视资源的属性
监视 (共通) 标签页
开始监视的等待时间
0 [秒]
3 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
SQL Server监视资源
参数
更改前的默认值
更改后的默认值
备注
SQL Server监视资源的属性
监视 (固有) 标签页
ODBC驱动名
SQL Native Client
ODBC Driver 13 for SQL Server
Weblogic监视资源
参数
更改前的默认值
更改后的默认值
备注
Weblogic监视资源的属性
监视 (固有) 标签页
安装路径
C:\bea\weblogic92
C:\Oracle\Middleware\Oracle_Home\wlserverJVM监视资源
参数
更改前的默认值
更改后的默认值
备注
JVM监视资源的属性
监视 (共通) 标签页
超时
120 [秒]
180 [秒]
动态域名解析监视资源
参数
更改前的默认值
更改后的默认值
备注
动态域名解析监视资源的属性
监视 (共通) 标签页
超时
120 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
AWS Elastic IP监视资源
参数
更改前的默认值
更改后的默认值
备注
AWS Elastic IP监视资源的属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
AWS虚拟IP监视资源
参数
更改前的默认值
更改后的默认值
备注
AWS虚拟IP监视资源的属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
AWS AZ监视资源
参数
更改前的默认值
更改后的默认值
备注
AWS AZ监视资源的属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
Azure探头端口监视资源
参数
更改前的默认值
更改后的默认值
备注
Azure探头端口监视资源的属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
Azure负载均衡监视资源
参数
更改前的默认值
更改后的默认值
备注
Azure负载均衡监视资源的属性
监视 (共通) 标签页
超时
100 [秒]
180 [秒]
超时发生时不重试
Off
On
超时发生时不做回复动作
Off
On
内部版本 12.10
脚本资源
参数
更改前的默认值
更改后的默认值
备注
脚本资源的属性
详细标签页
脚本资源的调整属性
参数标签页
执行复归处理
On
Off
内部版本12.00 之前的版本不能进行设定变更。12.10 版本后可以进行设定变更。
内部版本 12.20
服务资源
参数
更改前的默认值
更改后的默认值
备注
服务资源的属性
复归动作标签页
启动重试次数
0 [次]
1 [次]
AWS Elastic IP 监视资源
参数
更改前的默认值
更改后的默认值
备注
AWS Elastic IP 监视资源的属性
监视(固有)标签页
AWS CLI命令未得到应答时的动作
不运行复归动作(显示警告)
不运行复归动作(不显示警告)
AWS 虚拟 IP 监视资源
参数
更改前的默认值
更改后的默认值
备注
AWS 虚拟 IP 监视资源的属性
监视(固有)标签页
AWS CLI命令未得到应答时的动作
不运行复归动作(显示警告)
不运行复归动作(不显示警告)
AWS AZ 监视资源
参数
更改前的默认值
更改后的默认值
备注
AWS AZ 监视资源的属性
监视(固有)标签页
AWS CLI命令未得到应答时的动作
不运行复归动作(显示警告)
不运行复归动作(不显示警告)
AWS DNS 监视资源
参数
更改前的默认值
更改后的默认值
备注
AWS DNS 监视资源的属性
监视(固有)标签页
AWS CLI命令未得到应答时的动作
不运行复归动作(显示警告)
不运行复归动作(不显示警告)
内部版本 12.30
集群
参数
更改前的默认值
更改后的默认值
备注
集群属性
扩展标签页
最大再启动次数
0 [次]
3 [次]
重置最大再启动次数的时间
0 [分]
60 [分]
6.6.5. 参数移动一览¶
在通过Cluster WebUI可以设定的参数中,各版本设定位置存在变更的参数如下表所示。
内部版本 12.00
更改前的设置位置
更改后的设置位置
[集群属性]-[复归标签页]-[最大再启动次数]
[集群属性]-[扩展标签页]-[最大再启动次数]
[集群属性]-[复归标签页]-[重置最大再启动次数的时间]
[集群属性]-[扩展标签页]-[重置最大再启动次数的时间]
[集群属性]-[复归标签页]-[使用强制停止功能]
[集群属性]-[扩展标签页]-[使用强制停止功能]
[集群属性]-[复归标签页]-[强制停止操作]
[集群属性]-[扩展标签页]-[强制停止操作]
[集群属性]-[复归标签页]-[强制停止超时]
[集群属性]-[扩展标签页]-[强制停止超时]
[集群属性]-[复归标签页]-[虚拟机强制停止设定]
[集群属性]-[扩展标签页]-[虚拟机强制停止设定]
[集群属性]-[复归标签页]-[运行强制停止脚本]
[集群属性]-[扩展标签页]-[运行强制停止脚本]
[集群属性]-[节能标签页]-[使用CPU频率控制功能]
[集群属性]-[扩展标签页]-[使用CPU频率控制功能]
[集群属性]-[自动复归标签页]-[自动复归]
[集群属性]-[扩展标签页]-[自动复归]
[集群属性]-[复归标签页]-[抑制监视资源异常时的复归动作]
[集群属性]-[扩展标签页]-[禁用集群操作]-[监视资源异常时的复归动作]
[组属性]-[属性标签页]-[失效切换互斥属性]
[组共通属性]-[互斥标签页]
6.7. 与旧版的兼容性¶
6.7.1. 与EXPRESSCLUSTER X 1.0/2.0/2.1/3.0/3.1/3.2/3.3/4.0/4.1/4.2的兼容性¶
6.7.2. 关于与EXPRESSCLUSTER Ver 8.0以下版本的兼容功能¶
使用下列功能时,集群名,服务器名,组名需要按照Ver8.0的命名规则进行设置。
EXPRESSCLUSTER客户端
ESMPRO/AC联动功能
ESMPRO/SM联动功能
虚拟计算机名资源
兼容API
兼容命令
原有版本的命名规则如下。
- 集群名- 15个字符以内- 可以使用的字符有半角英文数字,中横线(-),下划线(_)。- 请不要指定PRN等的DOS输出输入设备名。- 不区分大小写。
- 服务器名- 15个字符以内- 可以使用的字符有半角英文数字,中横线(-),下划线(_)。- 不区分大小写。
- 组名- 15个字符以内- 可以使用的字符有半角英文数字,中横线(-),下划线(_)。- 请不要指定PRN等的DOS输出输入设备名。- 不区分大小写。
6.7.3. 关于兼容API¶
兼容API请指定为EXPRESSCLUSTER Ver8.0以下版本可以使用的API。兼容API在EXPRESSCLUSTER X上也可以使用,但是有以下限制事项。
只支持下列资源。其他资源即使设置了也无法从兼容API引用。
磁盘资源
镜像磁盘资源
虚拟计算机名资源
浮动IP资源(仅限IPv4地址)
虚拟IP资源(仅限IPv4地址)
打印机池资源
6.7.4. 关于客户端API¶
6.7.5. 关于脚本文件¶
需要移动在EXPRESSCLUSTER Ver8.0以下版本所使用的脚本文件时,请将环境变量名从最初的 "ARMS_" 置换为 "CLP_"。
例) IF "%ARMS_EVENT%" == "START" GOTO NORMAL
↓
IF "%CLP_EVENT%" == "START" GOTO NORMAL
7. 词汇表¶
- 心跳线
- 集群服务器之间的通信路径。(相关) 私网,公网
- 虚拟IP地址
构筑远程集群时使用的资源(IP地址)。
- 管理客户端
已启动Cluster WebUI的机器。
- 启动属性
- 集群启动时,决定是自动还是手动启动失效切换组的失效切换组的属性。可在管理客户端进行设置。
- 共享磁盘
可从多台服务器访问的磁盘。
- 共享磁盘型集群
使用共享磁盘的集群系统。
- 切换分区
- 连接到多台计算机的,可切换使用的磁盘分区。(相关)磁盘心跳用分区
- 集群系统
通过LAN等连接多台计算机,并作为1个系统进行操作的系统形态。
- 集群关机
关闭整个集群系统(配置集群的所有服务器)。
- 集群分区
- 镜像磁盘中设定的分区。用于管理镜像磁盘。相关(磁盘心跳用分区)
- 运行服务器
- 对某一业务集合来说,正在运行业务的服务器。(相关) 待机服务器
- 服务器组
连接在同一网络或共享磁盘设备上的服务器的集合
- 从服务器 (服务器)
- 一般使用时,失效切换组进行失效切换的目标服务器。(相关) 主服务器
- 待机服务器
- 非运行服务器。(相关) 运行服务器
- 磁盘心跳用分区
共享磁盘型集群中用于心跳通信的分区。
- 数据分区
- 能像共享磁盘的切换分区一样使用的本地磁盘镜像磁盘中设定的数据用的分区。(相关)集群分区
- 网络分区症状
- 指所有的心跳中断。(相关) 心跳线,心跳
- 节点
在集群系统中,指配置集群的服务器。在网络用语中,指可以传输,接收和处理信号的,包括计算机和路由器在内的设备。
- 心跳
- 指为了监视服务器而在服务器之间定期进行相互间的通信。(相关) 心跳线,网络分区
- 公网
- 服务器 / 客户端之间的通信路径。(相关) 心跳线,私网
- 失效切换
指由于查出故障,待机服务器继承运行服务器上的业务应用程序。
- 故障恢复
将某台服务器上已启动的业务应用程序通过失效切换交接给其他服务器后,再把业务返回到已启动业务应用程序的服务器。
- 失效切换组
执行业务所需的集群资源,属性的集合。
- 失效切换移动组
指用户故意将业务应用程序从运行服务器移动到待机服务器。
- 失效切换策略
可进行失效切换的服务器列表及其列表中具有失效切换优先顺序的属性。
- 私网
- 指仅连接配置集群的服务器的LAN。(相关) 心跳线,公网
- 主服务器 (服务器)
- 失效切换组中的作为基准的主服务器。(相关) 从服务器 (服务器)
- 浮动IP地址
- 发生了失效切换时,可忽视客户端的应用程序所连接服务器发生切换而使用的IP地址。在与集群服务器所属的LAN相同的网络地址中,分配其他未使用的主机地址。
- 主服务器(Master Server)
Cluster WebUI的[服务器共通属性]-[主服务器]中显示在最前面的服务器。
- 镜像磁盘连接
数据镜像磁盘型集群中用于进行数据镜像的LAN。可通过和内部主网的通用进行设定。
- 镜像磁盘系统
- 不使用共享磁盘的集群系统。在服务器之间镜像服务器的本地磁盘。