3. グループリソースの詳細¶
本章では、フェイルオーバグループを構成するグループリソースについての詳細を説明します。
グループの概要については、『インストール&設定ガイド』の「クラスタシステムを設計する」を参照してください。
3.1. グループリソースの一覧と対応する CLUSTERPRO のバージョン¶
各グループに登録することができるグループリソース数は以下のとおりです。
バージョン |
グループリソース数(1 グループあたり) |
|---|---|
4.0.0-1~ |
256 |
現在サポートされているグループリソースは以下のとおりです。
グループリソース名 |
略称 |
機能概要 |
対応バージョン |
|---|---|---|---|
EXEC リソース |
exec |
「 EXEC リソースを理解する 」を参照 |
4.0.0-1~ |
ディスクリソース |
disk |
「 ディスクリソースを理解する 」を参照 |
4.0.0-1~ |
フローティング IP リソース |
fip |
「 フローティング IP リソースを理解する 」を参照 |
4.0.0-1~ |
仮想 IP リソース |
vip |
「 仮想 IP リソースを理解する 」を参照 |
4.0.0-1~ |
ミラーディスクリソース |
md |
「 ミラーディスクリソースを理解する 」を参照 |
4.0.0-1~ |
ハイブリッドディスクリソース |
hd |
「 ハイブリッドディスクリソースを理解する 」を参照 |
4.0.0-1~ |
NAS リソース |
nas |
「 NAS リソースを理解する 」を参照 |
4.0.0-1~ |
ボリュームマネージャリソース |
volmgr |
「 ボリュームマネージャリソースを理解する」を参照 |
4.0.0-1~ |
仮想マシンリソース |
vm |
「 仮想マシンリソースを理解する 」を参照 |
4.0.0-1~ |
ダイナミック DNS リソース |
ddns |
「 ダイナミック DNS リソースを理解する 」を参照 |
4.0.0-1~ |
AWS Elastic IP リソース |
awseip |
「 AWS Elastic IPリソースを理解する 」を参照 |
4.0.0-1~ |
AWS 仮想 IP リソース |
awsvip |
「 AWS 仮想IPリソースを理解する 」を参照 |
4.0.0-1~ |
AWS DNS リソース |
awsdns |
「 AWS DNS リソースを理解する 」を参照 |
4.0.0-1~ |
Azure プローブポートリソース |
azurepp |
「 Azure プローブポートリソースを理解する 」を参照 |
4.0.0-1~ |
Azure DNS リソース |
azuredns |
「 Azure DNS リソースを理解する 」を参照 |
4.0.0-1~ |
Google Cloud 仮想 IP リソース |
gcvip |
「 Google Cloud 仮想 IP リソースを理解する 」を参照 |
4.2.0-1~ |
Google Cloud DNS リソース |
gcdns |
「 Google Cloud DNS リソースを理解する 」を参照 |
4.3.0-1~ |
Oracle Cloud 仮想 IP リソース |
ocvip |
「 Oracle Cloud 仮想 IP リソースを理解する 」を参照 |
4.2.0-1~ |
現在動的リソース追加をサポートしているグループリソースは以下のとおりです。
グループリソース名 |
略称 |
機能概要 |
対応バージョン |
|---|---|---|---|
EXEC リソース |
exec |
「 EXEC リソースを理解する 」を参照 |
4.0.0-1~ |
ディスクリソース |
disk |
「 ディスクリソースを理解する 」を参照 |
4.0.0-1~ |
フローティング IP リソース |
fip |
「 フローティング IP リソースを理解する 」を参照 |
4.0.0-1~ |
仮想 IP リソース |
vip |
「 仮想 IP リソースを理解する 」を参照 |
4.0.0-1~ |
ボリュームマネージャリソース |
volmgr |
「 ボリュームマネージャリソースを理解する」を参照 |
4.0.0-1~ |
3.2. グループとは?¶
グループとはフェイルオーバを行う単位です。グループにはフェイルオーバ時の動作に関する規則 (フェイルオーバポリシー) が設定できます。
3.2.1. グループタイプを理解する¶
グループには「仮想マシングループ」と「フェイルオーバグループ」の2 つのタイプがあります。
- 仮想マシングループ仮想マシンを単位としてフェイルオーバ (マイグレーション) を行います。このグループには 仮想マシンリソース、ミラーディスクリソース、ディスクリソース、ハイブリッドディスクリソース、EXECリソース、NASリソース、ボリュームマネージャリソースが登録可能です。仮想マシングループは、CLUSTERPRO 以外の機能によって別サーバに仮想マシンが移動された場合でも、自動的に追随します。
- フェイルオーバグループ業務を継続するために必要なリソースをまとめ、業務単位でフェイルオーバを行います。各グループには最大 256のグループリソースが登録できます。ただし仮想マシンリソースは登録することができません。
3.2.2. グループプロパティを理解する¶
各グループで設定可能なプロパティは以下のとおりです。
- 起動可能サーバクラスタを構成するサーバからグループが起動可能なサーバを選択し設定します。また、起動可能なサーバに順位を設定し、グループが起動する優先順位を設定します。
- グループ起動属性グループの起動属性を自動起動、または手動起動に設定します。自動起動の場合、クラスタを開始する際に、グループが起動可能な最も優先順位の高いサーバで、グループが自動的に起動します。手動起動の場合、サーバが起動してもグループは起動しません。サーバ起動後、Cluster WebUI または [clpgrp] コマンドを使用してグループを手動で起動してください。Cluster WebUI の詳細はオンラインマニュアル、[clpgrp] コマンドの詳細は本ガイドの「8. CLUSTERPRO コマンドリファレンス」の「グループを操作する (clpgrp コマンド)」を参照してください。
- フェイルオーバ属性フェイルオーバ属性ではフェイルオーバの方法を設定します。設定可能なフェイルオーバ属性は以下になります。
自動フェイルオーバ
ハートビートがタイムアウトした場合、グループリソースやモニタリソースが異常を検出した場合、それらを契機に自動でフェイルオーバを行います。 自動フェイルオーバの場合、下記の方法を設定することができます。
- 起動可能なサーバ設定に従う起動可能なサーバに設定されているサーバのプライオリティに従い、フェイル オーバ先を決定します。
- ダイナミックフェイルオーバを行う各サーバのモニタやフェイルオーバグループのステータスを考慮し、フェイル オーバ先を決定してフェイルオーバを行います。フェイルオーバ先の決定の流れは以下のようになります。
判定要素
条件
結果
除外対象のモニタリソースの状態
異常(全サーバ)
フェイルオーバ先が無い場合に強制フェイルオーバを行うか判定する処理に進む。
〃
正常( 1 台のみ)
正常なサーバをフェイルオーバ先とする。
〃
正常(複数)
エラーレベルを比較する処理に進む。
強制フェイルオーバを行う
設定有り
除外対象のモニタリソースの状態を無視し、起動している全てのサーバに対してエラーレベルを比較する処理に進む。
〃
設定無し
フェイルオーバしない。
エラーレベルが 最小であるサーバ数
1
異常の度合いが最小であるサーバをフェイルオーバ先とする。
〃
2 以上
異常の度合いが最小であるサーバ内で、業務の度合いを比較する。
サーバグループ内のフェイルオーバポリシーを優先する
設定有りかつフェイルオーバ元と同じサーバグループ内にフェイルオーバ可能なサーバがある。サーバグループ内のサーバをフェイルオーバ先とする。
〃
設定有りかつフェイルオーバ元と同じサーバグループ内にフェイルオーバ可能なサーバが無い。スマートフェイルオーバによる判定処理に進む。
〃
設定無し
スマートフェイルオーバによる判定処理に進む。
スマートフェイルオーバを行う
設定有りかつフェイルオーバ先として推奨されるサーバ数が1。スマートフェイルオーバにより推奨されたサーバをフェイルオーバ先とする。
〃
設定有りかつフェイルオーバ先として推奨されるサーバ数が2以上。ランニングレベルの判定処理に進む。
〃
設定無し
ランニングレベルの判定処理に進む。
ランニングレベルが 最小であるサーバ数
1
ランニングレベルが最小であるサーバをフェイルオーバ先とする。
〃
2以上
起動しているサーバで最もプライオリティが高いサーバをフェイルオーバ先とする。
注釈
除外対象のモニタリソースモニタリソースで異常を検出しているサーバをフェイルオーバ先から除外します。除外モニタをCluster WebUI で設定することができます。エラーレベル異常を検出しているモニタリソース数です。スマートフェイルオーバSystem Resource Agentが収集したシステムリソース情報から負荷が最小であるサーバをフェイルオーバ先として決定する機能です。この機能を有効にするためには、フェイルオーバ先として設定されている全てのサーバにSystem Resource Agentのライセンスを登録する必要があります。また、システムモニタリソースをモニタリソースに設定する必要があります。システムモニタリソースについては、本ガイドの「4. モニタリソースの詳細」の「システムモニタリソースを理解する」を参照してください。ランニングレベル管理グループを除く、起動済みまたは起動中のフェイルオーバグループ数です。 - サーバグループ内のフェイルオーバポリシーを優先する同一サーバグループ内のサーバにフェイルオーバ可能な場合、そのサーバグループ内のサーバへ優先的にフェイルオーバを行います。同一サーバグループ内でフェイルオーバ可能なサーバが無い場合、他のサーバグループ内のサーバをフェイルオーバ先とします。
- サーバグループ間では手動フェイルオーバのみ有効とする上記 [サーバグループ内のフェイルオーバポリシーを優先する] が設定されている場合のみ、選択できます。同一サーバグループ内のサーバに対して、自動的にフェイルオーバを行います。同一サーバグループ内にフェイルオーバ可能なサーバが無い場合、他のサーバグループのサーバへのフェイルオーバを自動的に行うことはありません。他のサーバグループ内のサーバへグループを移動させるためには、Cluster WebUI または [clpgrp] コマンドでグループを移動させる必要があります。
手動フェイルオーバ
ハートビートがタイムアウトした際に自動でフェイルオーバを行いません。Cluster WebUI、または [clpgrp] コマンドから手動でフェイルオーバを行ってください。ただし、手動フェイルオーバが設定されていても、グループリソースやモニタリソースの異常検出時には、自動的にフェイルオーバを行います。
注釈
外部連携モニタリソースの設定で、[サーバグループ外にフェイルオーバする] が設定されている場合、ダイナミックフェイルオーバの設定やサーバグループ間のフェイルオーバ設定は無効となります。フェイルオーバ元のサーバが属するサーバグループとは別のサーバグループに属するサーバグループ内のサーバで、プライオリティが最も高いサーバにフェイルオーバします。
フェイルバック属性
自動フェイルバック、手動フェイルバックのどちらかを設定します。ただし、以下の条件の場合には設定できません。
フェイルオーバグループにミラーディスクリソースまたはハイブリッドディスクリソースが設定されている場合
フェイルオーバ属性が [ダイナミックフェイルオーバを行う] の場合
自動フェイルバックの場合、フェイルオーバした後、優先順位の最も高いサーバが起動する際に自動的にフェイルバックします。
手動フェイルバックの場合、サーバを起動してもフェイルバックは発生しません。
3.2.3. フェイルオーバポリシーを理解する¶
フェイルオーバポリシーとは、複数のサーバの中から、フェイルオーバ先となるサーバを決定するための優先度のことで、フェイルオーバ発生時に特定のサーバに負荷を与えないように設定する必要があります。
以下に、フェイルオーバ可能なサーバリストとその中でのフェイルオーバ優先順位の例を用いて、フェイルオーバ発生時のフェイルオーバポリシーによる動作の違いを説明します。
<図中記号の説明>
サーバ状態 |
説明 |
|---|---|
|
正常状態 (クラスタとして正常に動作している) |
|
停止状態 (クラスタが停止状態) |
3ノードの場合
グループ |
サーバの優先順位 |
||
|---|---|---|---|
優先度1サーバ |
優先度2サーバ |
優先度3サーバ |
|
A |
Server 1 |
Server 3 |
Server 2 |
B |
Server 2 |
Server 3 |
Server 1 |
2ノードの場合
グループ |
サーバの優先順位 |
|
|---|---|---|
優先度1サーバ |
優先度2サーバ |
|
A |
Server 1 |
Server 2 |
B |
Server 2 |
Server 1 |
A と B はグループ起動属性が自動起動、フェイルバック属性が手動フェイルバックに設定されているものとします。
排他属性が「通常排他」あるいは「完全排他」に設定されている排他ルールに所属し、同じサーバで起動することのできない複数のグループが、同時に同じサーバで起動あるいはフェイルオーバしようとした場合、そのサーバに対する優先順位が高いグループが優先されます。サーバの優先順位が同じ場合には、グループ名の数字、特殊記号、アルファベット順で若い方が優先されます。グループの排他属性については、「グループの排他制御を理解する」を参照してください。
Group A と Group B が排他ルールに所属していない場合
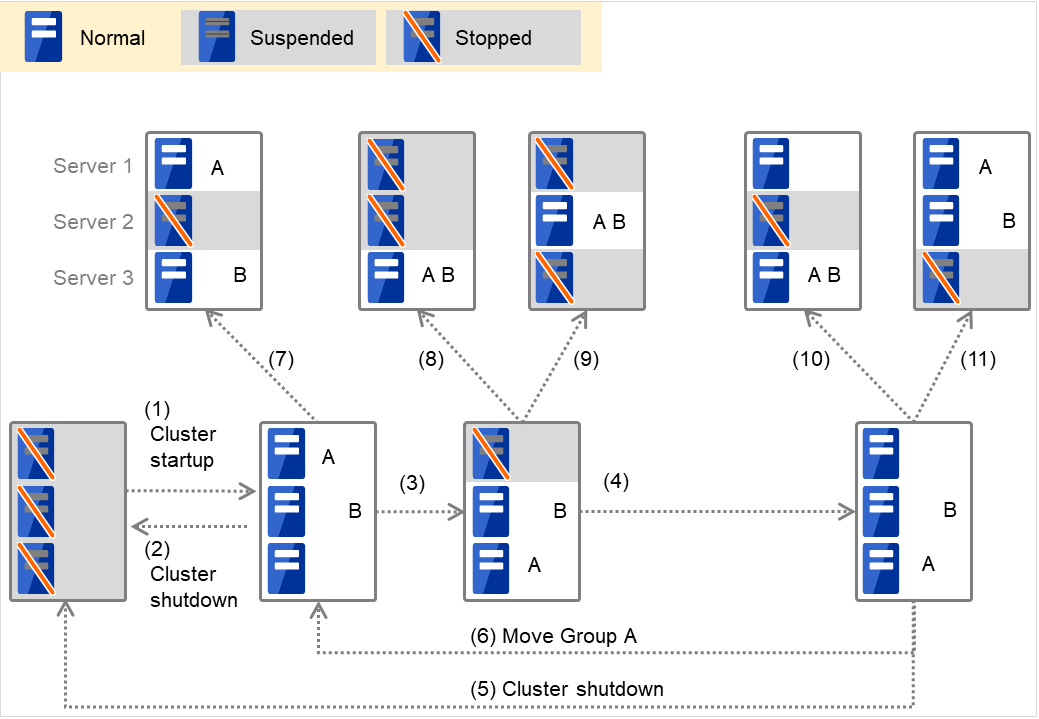
図 3.1 各サーバの状態とGroup A、Group Bの起動状況¶
クラスタの立ち上げ
クラスタのシャットダウン
Server 1 ダウン:次に優先順位の高いサーバへフェイルオーバする
Server 1 の電源 ON
クラスタのシャットダウン
Group A の移動
Server 2 ダウン:次に優先順位の高いサーバへフェイルオーバする
Server 2 ダウン:次に優先順位の高いサーバへフェイルオーバする
Server 3 ダウン:次に優先順位の高いサーバへフェイルオーバする
Server 2 ダウン:次に優先順位の高いサーバへフェイルオーバする
Server 3 ダウン:次に優先順位の高いサーバへフェイルオーバする
Group A と Group B が排他属性に「通常排他」が設定してある排他ルールに所属する場合
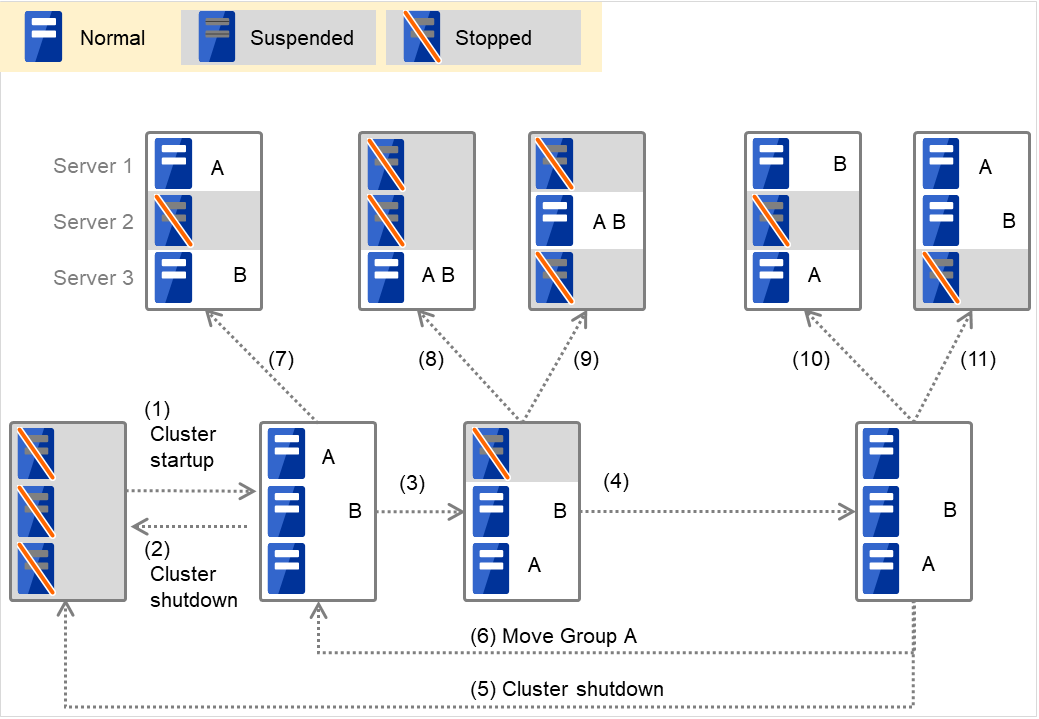
図 3.2 各サーバの状態とGroup A、Group Bの起動状況(A、Bは通常排他)¶
クラスタの立ち上げ
クラスタのシャットダウン
Server 1 ダウン:通常排他のグループが起動されていないサーバへフェイルオーバする
Server 1 の電源 ON
クラスタのシャットダウン
Group A の移動
Server 2 ダウン:通常排他のグループが起動されていないサーバへフェイルオーバする
Server 2 ダウン:通常排他のグループが起動されていないサーバは存在しないが、起動可能なサーバが存在するのでフェイルオーバする
Server 3 ダウン:通常排他のグループが起動されていないサーバは存在しないが、起動可能なサーバが存在するのでフェイルオーバする
Server 2 ダウン:通常排他のグループが起動されていないサーバへフェイルオーバする
Server 3 ダウン:通常排他のグループが起動されていないサーバへフェイルオーバする
Group A と Group B が排他属性に「完全排他」が設定してある排他ルールに所属する場合
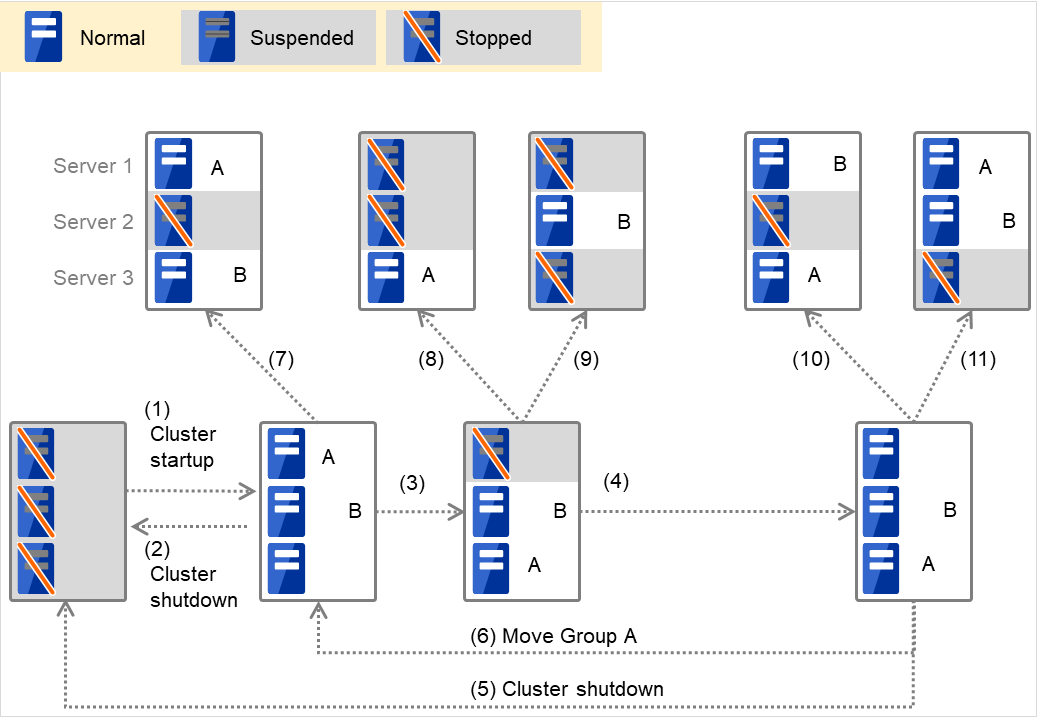
図 3.3 各サーバの状態とGroup A、Group Bの起動状況(A、Bは完全排他)¶
クラスタの立ち上げ
クラスタのシャットダウン
Server 1 ダウン:完全排他のグループが起動されていないサーバへフェイルオーバする
Server 1 の電源 ON
クラスタのシャットダウン
Group A の移動
Server 2 ダウン:完全排他のグループが起動されていないサーバへフェイルオーバする
Server 2 ダウン:フェイルオーバしない (Group B は停止する)
Server 3 ダウン:フェイルオーバしない (Group A は停止する)
Server 2 ダウン:完全排他のグループが起動されていないサーバへフェイルオーバする
Server 3 ダウン:完全排他のグループが起動されていないサーバへフェイルオーバする
Replicator を使用している場合 (サーバ 2 台の場合)Group A と Group B が排他ルールに所属していない場合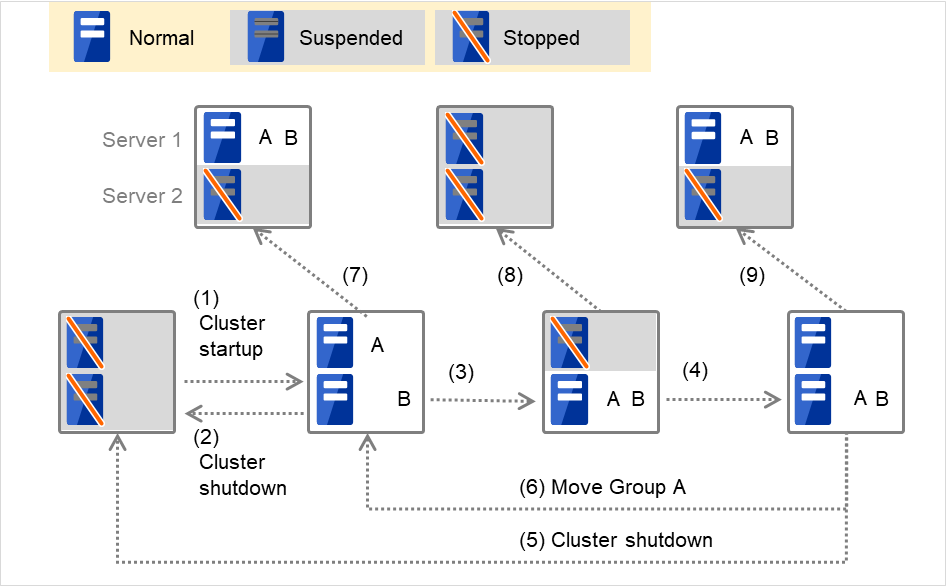
図 3.4 各サーバの状態とGroup A、Group Bの起動状況(Replicator使用時)¶
クラスタの立ち上げ
クラスタのシャットダウン
Server 1 ダウン:Group A の待機系サーバへフェイルオーバする
Server 1 の電源 ON
クラスタのシャットダウン
Group A の移動
Server 2 ダウン:Group B の待機系サーバへフェイルオーバする
Server 2 ダウン
Server 2 ダウン:待機系サーバへフェイルオーバする
3.2.4. 活性異常、非活性異常検出時の動作¶
活性異常、非活性異常検出時には以下の制御が行われます。
グループリソース活性異常検出時の流れ
グループリソースの活性時に異常を検出した場合、活性リトライを行います。
[活性リトライしきい値] に設定されている回数の活性リトライに失敗した場合、フェイルオーバを行います。
[フェイルオーバしきい値] のフェイルオーバを行っても活性できない場合、最終動作を行います。
グループリソース非活性異常検出時の流れ
非活性時に異常を検出した場合、非活性リトライを行います。
[非活性リトライしきい値] の非活性リトライに失敗した場合、最終動作を行います。
注釈
以下の設定例でグループリソース活性異常検出時の流れを説明します。
以下を指定している場合の挙動の例
設定例活性リトライしきい値 3 回フェイルオーバしきい値 1 回最終動作 グループ停止

図 3.5 グループリソース活性異常検出時の流れ (1)¶
Disk resource 1の活性処理が異常(fsckの異常、mountのエラーなど)になりました。

図 3.6 グループリソース活性異常検出時の流れ (2)¶
Disk resource 1の活性処理を3回(活性リトライ回数)までリトライします。

図 3.7 グループリソース活性異常検出時の流れ (3)¶

図 3.8 グループリソース活性異常検出時の流れ (4)¶

図 3.9 グループリソース活性異常検出時の流れ (5)¶

図 3.10 グループリソース活性異常検出時の流れ (6)¶
Server 1でDisk resource 1の活性処理を開始します。Disk resource 1の活性処理中に異常が発生した場合、活性処理を 3回までリトライします。

図 3.11 グループリソース活性異常検出時の流れ (7)¶

図 3.12 グループリソース活性異常検出時の流れ (8)¶
3.2.5. 最終動作前スクリプトについて¶
グループリソースの活性異常検出時、非活性異常検出時の最終動作前に、最終動作前スクリプトを実行させることが可能です。
最終動作前スクリプトで使用する環境変数
CLUSTERPRO はスクリプトを実行する場合に、どの状態で実行したか (活性異常時、非活性異常時) などの情報を環境変数にセットします。
スクリプト内で下図の環境変数を分岐条件として、システム運用にあった処理内容を記述できます。
環境変数 |
環境変数の値 |
意味 |
|---|---|---|
CLP_TIMING
…実行タイミング
|
START |
グループリソースの活性異常による最終動作前スクリプト実行を示します。 |
〃 |
STOP |
グループリソースの非活性異常による最終動作前スクリプト実行を示します。 |
CLP_GROUPNAME
…グループ名
|
グループ名 |
最終動作前スクリプトを実行する原因となる異常を検出したグループリソースが所属するグループ名を示します。 |
CLP_RESOURCENAME
…グループリソース名
|
グループリソース名 |
最終動作前スクリプトを実行する原因となる異常を検出したグループリソース名を示します。 |
最終動作前スクリプトの記述の流れ
前のトピックの環境変数と、実際のスクリプトの記述を関連付けて説明します。
活性異常時の最終動作前スクリプトの一例
#!/bin/sh # *************************************** # * preactaction.sh # *************************************** ulimit -s unlimited echo "START" # スクリプト実行要因の環境変数を参照して、処理の振り分けを行う。 if [ "$CLP_TIMING" = "START" ] then # ここに、活性異常時最終動作前に実行すべき回復処理を記述する。 # else echo "NO_CLP" fi echo "EXIT" exit 0最終動作前スクリプト作成のヒント
以下の点に注意して、スクリプトを作成してください。
スクリプト中にて、実行に時間を必要とするコマンドを実行する場合には、コマンドの実行が完了したことを示すトレースを残すようにしてください。この情報は、問題発生時、障害の切り分けを行う場合に使用することができます。clplogcmdを使用してトレースを残す方法があります。
(例:スクリプト中のイメージ)
clplogcmd -m "recoverystart.." recoverystart clplogcmd -m "OK"最終動作前スクリプト 注意事項
スクリプトから起動されるコマンド、アプリケーションのスタックサイズについて
スタックサイズが 2MB に設定された状態で回復スクリプト、回復動作前スクリプトが実行されます。このため、スクリプトから起動されるコマンドやアプリケーションで 2MB 以上のスタックサイズが必要な場合には、スタックオーバーフローが発生します。スタックオーバーフローが発生する場合には、コマンドやアプリケーションを起動する前にスタック サイズを設定してください。最終動作前スクリプトが実行される条件について
最終動作前スクリプトはグループリソースの活性異常検出時、非活性異常検出時の最終動作の前に実行されます。最終動作に [何もしない(次のリソースを活性/非活性する)] や、[何もしない(次のリソースを活性/非活性しない)] が設定されている場合にも、最終動作前スクリプトは実行されます。最大再起動回数や、他のサーバが全て停止している場合の最終動作抑制機能によって最終動作が実行されない場合は、最終動作前スクリプトは実行されません。
3.2.6. 活性/非活性前後スクリプトについて¶
グループリソースの活性/非活性前後に、任意のスクリプトを実行させることが可能です。
活性/非活性前後スクリプトで使用する環境変数
環境変数 |
環境変数の値 |
意味 |
|---|---|---|
CLP_TIMING
…実行タイミング
|
PRESTART |
グループリソース活性前のスクリプト実行を示します。 |
〃 |
POSTSTART |
グループリソース活性後のスクリプト実行を示します。 |
〃 |
PRESTOP |
グループリソース非活性前のスクリプト実行を示します。 |
〃 |
POSTSTOP |
グループリソース非活性後のスクリプト実行を示します。 |
CLP_GROUPNAME
…グループ名
|
グループ名 |
スクリプトが属しているグループリソースのグループ名を示します。 |
CLP_RESOURCENAME
…グループリソース名
|
グループリソース名 |
スクリプトが属しているグループリソース名を示します。 |
活性/非活性前後スクリプトの記述の流れ
前のトピックの、環境変数と実際のスクリプト記述を関連付けて説明します。
活性/非活性前後スクリプトの一例
#!/bin/sh #*********************************************** # rscextent.sh * #*********************************************** ulimit -s unlimited echo "START" if [ "$CLP_TIMING" = "PRESTART" ] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # ここに、リソース活性前に実行したい任意の処理を記述する。 # elif [ "$CLP_TIMING" = "POSTSTART" ] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # ここに、リソース活性後に実行したい任意の処理を記述する。 # elif [ "$CLP_TIMING" = "PRESTOP" ] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # ここに、リソース非活性前に実行したい任意の処理を記述する。 # elif [ "$CLP_TIMING" = "POSTSTOP" ] then echo "$CLP_GROUPNAME" echo "$CLP_RESOURCENAME" # ここに、リソース非活性後に実行したい任意の処理を記述する。 # fi echo "EXIT" exit 0活性/非活性前後スクリプト作成のヒント
以下の点に注意して、スクリプトを作成してください。
スクリプト中にて、実行に時間を必要とするコマンドを実行する場合には、コマンドの実行が完了したことを示すトレースを残すようにしてください。この情報は、問題発生時、障害の切り分けを行う場合に使用することができます。clplogcmdを使用してトレースを残す方法があります。
(例:スクリプト中のイメージ)
clplogcmd -m "start.." : clplogcmd -m "OK"活性/非活性前後スクリプト 注意事項
3.2.7. 再起動回数制限について¶
活性異常、非活性異常検出時の最終動作として OS の再起動を伴うような設定をしている場合に、活性異常、非活性異常の検出によるシャットダウン回数、または再起動回数を制限することができます。
この最大再起動回数はサーバごとの再起動回数の上限になります。
注釈
再起動回数はサーバごとに記録されるため、最大再起動回数はサーバごとの再起動回数の上限になります。
また、グループ活性、非活性異常検出時の最終動作による再起動回数とモニタリソース異常の最終動作による再起動回数も別々に記録されます。
最大再起動回数をリセットする時間に 0 を設定した場合には、再起動回数はリセットされません。リセットする場合は [clpregctrl] コマンドを使用する必要があります。[clpregctrl] コマンドに関しては「8. CLUSTERPRO コマンドリファレンス」の「再起動回数を制御する (clpregctrl コマンド)」を参照してください。
以下の設定例で再起動回数制限の流れを説明します。
最大再起動回数が 1 回に設定されているため、一度だけ最終動作である[クラスタサービス停止と OS 再起動] が実行されます。
また、最大再起動回数をリセットする時間が 10 分に設定されているため、クラスタシャットダウン後再起動時にグループの活性に成功した場合には、10 分経過すると再起動回数はリセットされます。
以下を指定している場合の挙動の例
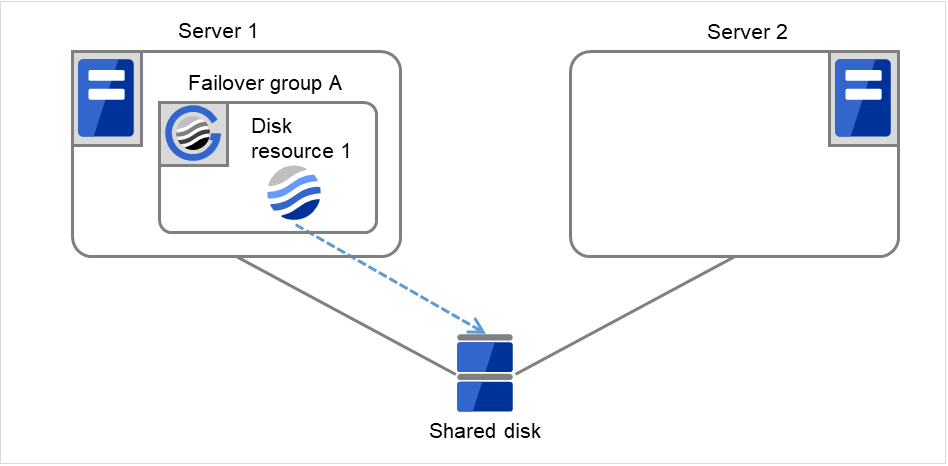
図 3.13 再起動回数制限時の処理 (1)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
0回
0回
Disk resource 1の活性処理が異常(fsckの異常、mountのエラーなど)になりました。
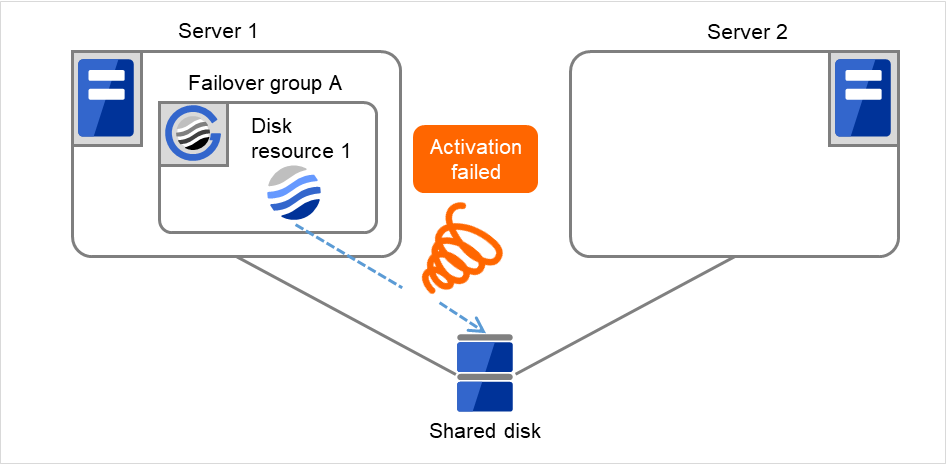
図 3.14 再起動回数制限時の処理 (2)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
0回
0回
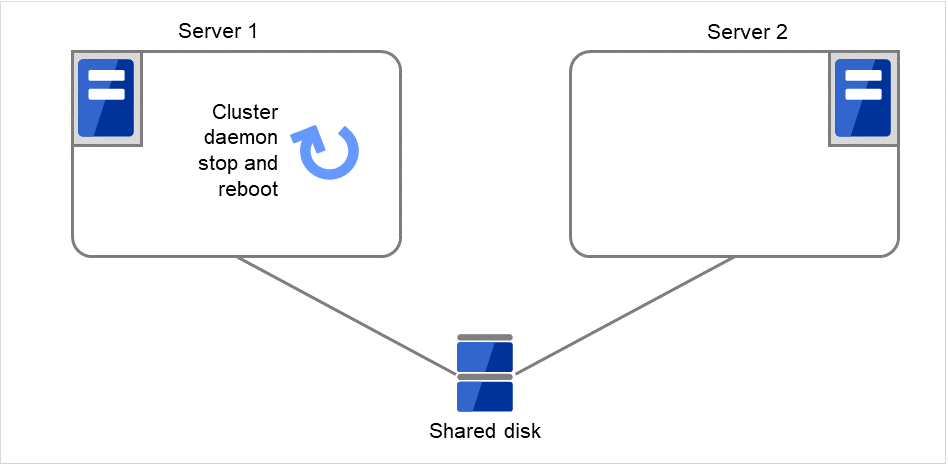
図 3.15 再起動回数制限時の処理 (3)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
Failover group Aのフェイルオーバ処理を開始します。
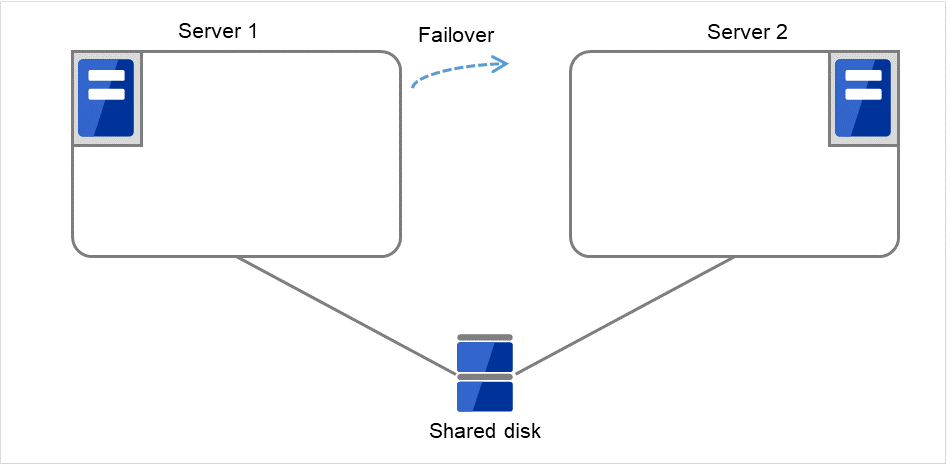
図 3.16 再起動回数制限時の処理 (4)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
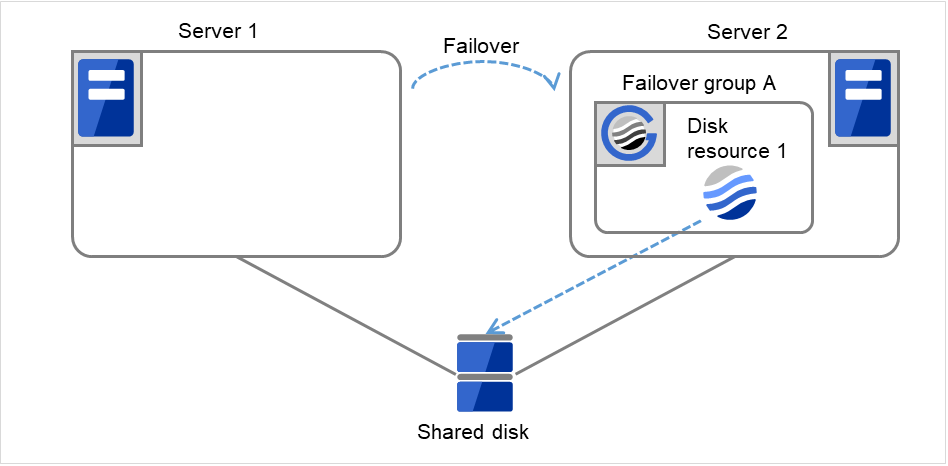
図 3.17 再起動回数制限時の処理 (5)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
clpgrpコマンド、Cluster WebUIを使用して、Failover group Aのフェイルオーバ処理を開始します。
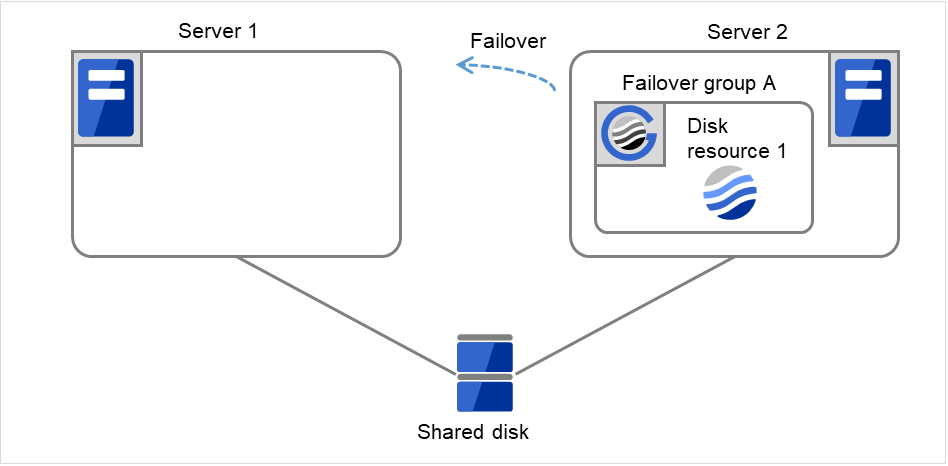
図 3.18 再起動回数制限時の処理 (6)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
Disk resource 1の活性処理(ファイルシステムのマウント処理等)を開始します。
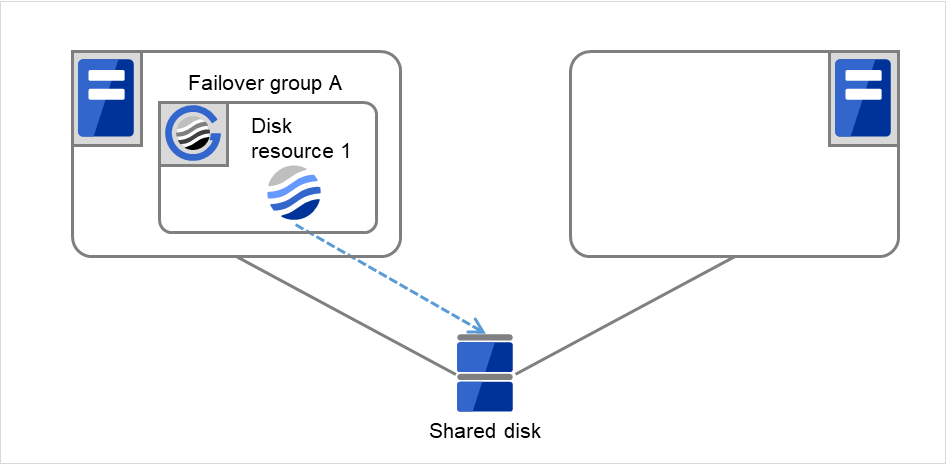
図 3.19 再起動回数制限時の処理 (7)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
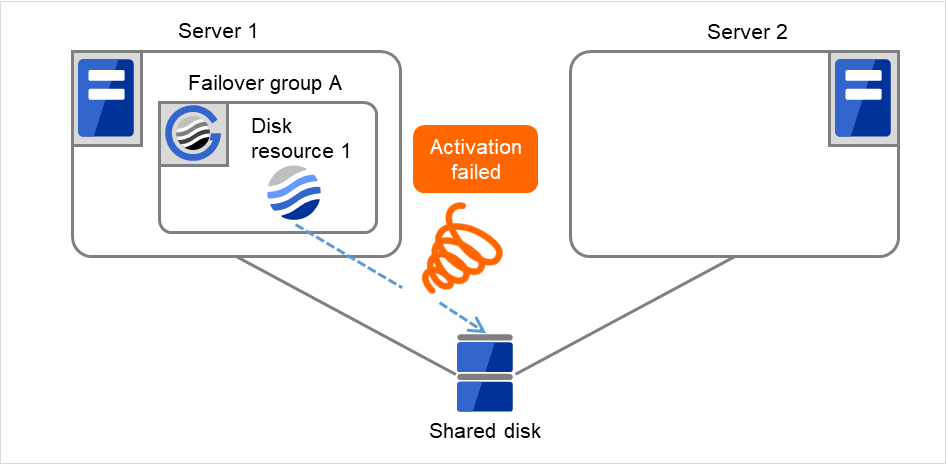
図 3.20 再起動回数制限時の処理 (8)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
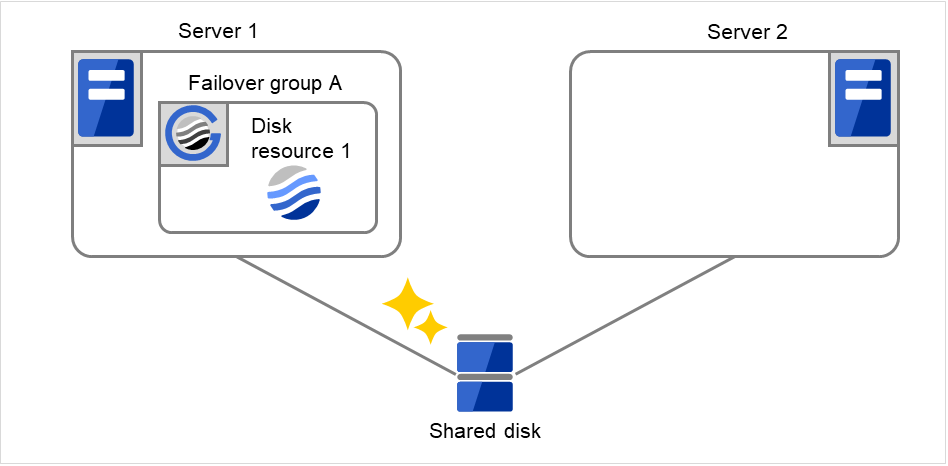
図 3.21 再起動回数制限時の処理 (9)¶
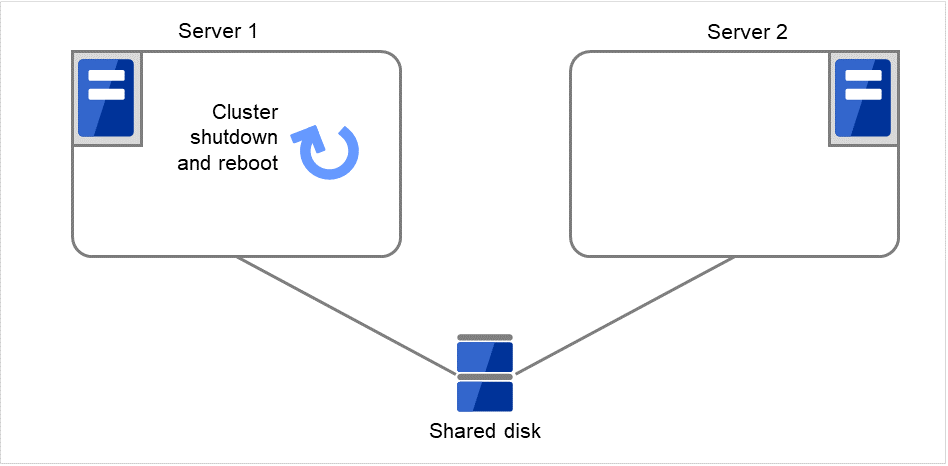
図 3.22 再起動回数制限時の処理 (10)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
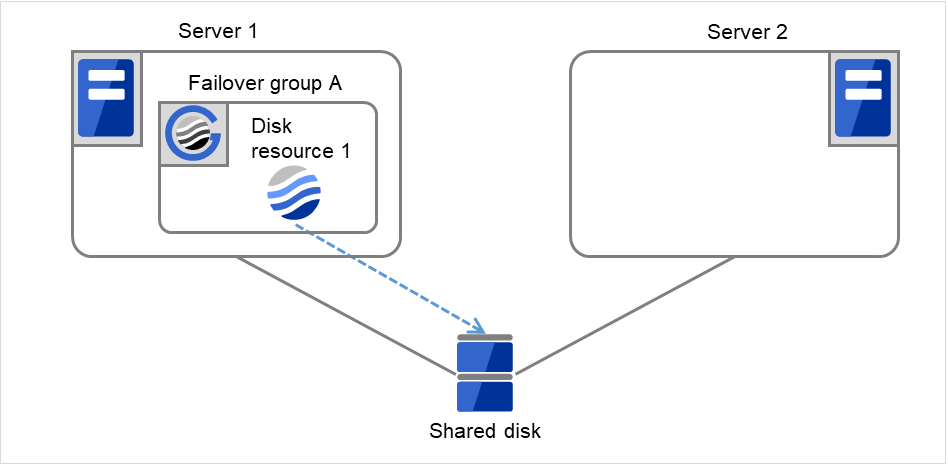
図 3.23 再起動回数制限時の処理 (11)¶
Server 1
Server 2
最大再起動回数
1回
1回
再起動回数
1回
0回
3.2.8. 再起動回数初期化¶
再起動回数を初期化する場合、[clpregctrl] コマンドを使用してください。[clpregctrl] コマンドに関しては本ガイドの「8. CLUSTERPRO コマンドリファレンス」の「再起動回数を制御する (clpregctrl コマンド)」を参照してください。
3.2.9. 両系活性チェックについて¶
グループ起動時に、両系活性が発生するか否かを確認することができます。
- 両系活性が発生しないと判断した場合グループの起動処理を開始します。
- 両系活性が発生すると判断した場合(タイムアウトした場合)グループの起動処理を開始しません。グループを起動しようとしたサーバでは、グループは停止状態となります。
注釈
グループが停止状態で、リソースの単体起動が実施された場合、両系活性チェックは実施されます。しかし、グループの中で1つでもリソースが活性している状態でリソースの単体起動を実施した場合は、両系活性チェックは実施されません。
[両系活性チェックを行う] がオンのグループに、フローティングIPリソースが存在しない場合、両系活性チェックは実行せず、グループの起動を開始します。
両系活性が発生すると判断した場合、グループやリソースの状態がサーバ間で不整合となる場合があります。
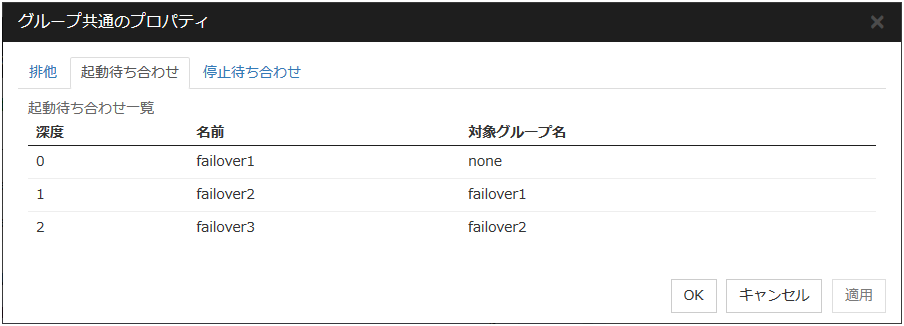
3.2.10. グループの起動、停止待ち合わせ設定を理解する¶
グループの起動、停止待ち合わせを設定することにより、グループを起動、停止する順序を設定することができます。
グループの起動待ち合わせを設定した場合:
グループ起動時は、起動待ち合わせ対象のグループの起動処理が正常に完了してから、このグループの起動処理が開始されます。
グループ起動時に、起動待ち合わせするように設定されているグループの待ち合わせタイムアウト時にはグループは起動しません。
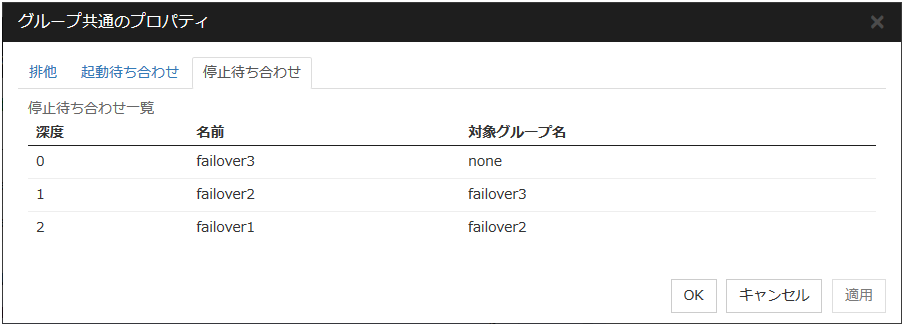
グループの停止待ち合わせを設定した場合:
グループ停止時は、停止待ち合わせ対象のグループの停止処理が正常に完了してから、このグループの停止処理が開始されます。
停止待ち合わせ処理でタイムアウトが発生した場合、グループの停止処理は継続します。
停止待ち合わせは、Cluster WebUI で設定した条件で実行されます。
グループの起動、停止待ち合わせ設定を表示するには、Cluster WebUI の設定モードからグループのプロパティをクリックし、[起動待ち合わせ] タブ、[停止待ち合わせ] タブをクリックします。
例としてグループの起動待ち合わせする深度を一覧で表示します。
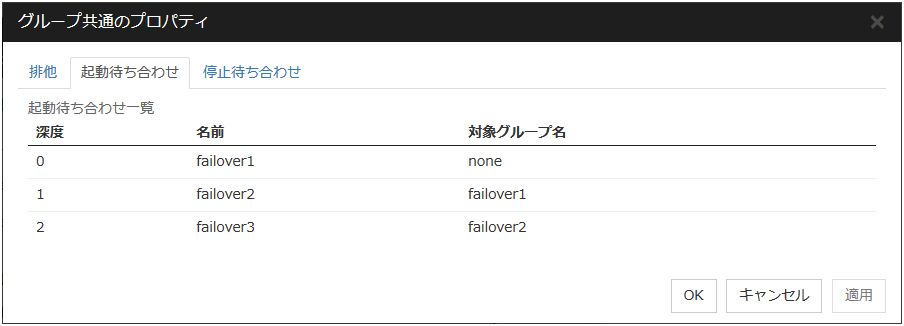

図 3.24 グループの起動順序¶
グループ起動の実行を、簡単な状態遷移の例で説明します。
2 台構成のサーバで、グループを 3 つ持っている場合
グループのフェイルオーバポリシー
Group A
Server 1
Group B
Server 2
Group C
Server 1 → Server 2
グループの起動待ち合わせ設定
Group A
起動待ち合わせ設定なし
Group B
起動待ち合わせ設定なし
Group C
Server 1 でGroup AとGroup Cを起動する場合
Server 1 で、Group A の正常起動を待ってからGroup Cが起動します。

図 3.25 Server 1 でGroup AとGroup Cが起動¶
Server 1 でGroup A、Server 2でGroup Cを起動する場合
Server 1 でGroup A の正常起動を待ってから、Server 2でGroup Cが起動します。「同じサーバで起動する場合のみ待ち合わせを行う」が設定されていないため他サーバで起動するGroup Aの正常起動を待ち合わせます。
図 3.26 Server 1 でGroup A、Server 2でGroup Cが起動¶
Server 1 でGroup C、Server 2でGroup Bを起動する場合
Server 1 でGroup B の正常起動を待たずにGroup Cが起動します。Group Cは同じサーバで起動する場合のみGroup Bの起動を待つように設定されていますが、Group BはServer 1では起動しない設定のため、待ち合わせしません。
図 3.27 Server 1 でGroup C、Server 2でGroup Bが起動¶
Server 1でGroup AとGroup Cを起動する場合
Server 1でGroup Aの起動がエラーになった場合、Group Cは起動しません。

図 3.28 Server 1でGroup Aの起動がエラー、Group Cが起動しない¶
Server 1でGroup AとGroup Cを起動する場合
Server 1でGroup Aの起動が失敗しGroup Aのリソースの復旧動作によりServer 2にフェイルオーバが発生した場合、Server 2でGroup Aが起動した後でServer 1でGroup Cが起動します。

図 3.29 Group AはServer 2にフェイルオーバ、Server 1でGroup Cが起動¶
Server 1でGroup AとGroup Cを起動する場合
Server 1でGroup Aの起動待ち合わせタイムアウトが発生した場合、Group Cは起動しません。

図 3.30 Server 1 でGroup Aが起動¶
Server 1でGroup Cのみを起動する場合
Server 1でGroup Aが起動していないため、起動待ち合わせタイムアウトが発生しGroup Cは起動しません。

図 3.31 Server 1 でGroup A、Group Cは起動しない¶
注釈
グループ起動時に、起動待ち合わせするように設定されているグループを自動的に起動する機能はありません。
グループ起動時に、起動待ち合わせするように設定されているグループの待ち合わせタイムアウト時にはグループは起動しません。
グループ起動時に、起動待ち合わせするように設定されているグループが起動に失敗した場合にはグループは起動しません。
起動待ち合わせ対象のグループ内に正常に起動しているリソースと停止しているリソースが存在する場合、そのグループは正常に起動済みと判断します。
グループ停止時に、停止待ち合わせするように設定されているグループを自動的に停止する機能はありません。
グループ停止時に、停止待ち合わせするように設定されているグループの待ち合わせタイムアウト時にはグループの停止処理は継続します。
グループ停止時に、停止待ち合わせするように設定されているグループが停止に失敗した場合にはグループの停止処理は継続します。
Cluster WebUI やclpgrpコマンドによるグループ停止処理やリソース停止処理では、停止待ち合わせは行いません。停止待ち合わせは、Cluster WebUI で設定した条件(クラスタ停止時、またはサーバ停止時)で実行されます。
フェイルオーバ時に起動待ち合わせ処理でタイムアウトが発生した場合にはフェイルオーバは失敗します。
3.2.11. グループの排他制御を理解する¶
フェイルオーバ排他属性はフェイルオーバの際のグループの排他属性を設定します。 ただし、以下の条件の場合には設定できません。
フェイルオーバグループのタイプが [仮想マシン] の場合
フェイルオーバ属性が [ダイナミックフェイルオーバを行う], [サーバグループ内のフェイルオーバポリシーを優先する], [サーバグループ間では手動フェイルオーバのみ有効とする] の場合
設定可能なフェイルオーバ排他属性は以下になります。
排他なし
フェイルオーバの際、排他を行いません。フェイルオーバ可能なサーバのうち、最も 優先順位の高いサーバでフェイルオーバします。
通常排他
フェイルオーバの際、排他を行います。フェイルオーバ可能なサーバのうち、他の 通常排他のグループが起動していない最も優先順位の高いサーバでフェイルオーバします。
ただし、全てのフェイルオーバ可能なサーバで既に他の通常排他のグループが起動している場合、排他を行いません。フェイルオーバ可能なサーバのうち最も優先順位の高いサーバでフェイルオーバします。
完全排他
フェイルオーバの際、排他を行います。フェイルオーバ可能なサーバのうち、他の 完全排他のグループが起動していない最も優先順位の高いサーバでフェイルオーバします。
ただし、全てのフェイルオーバ可能なサーバで既に他の完全排他のグループが起動している場合、フェイルオーバを行いません。
注釈
異なる排他ルール同士は排他を行いません。同一の排他ルールに所属するグループのみ、設定された排他属性に従い、排他制御が行われます。いずれの場合も 排他なし のグループとは排他を行いません。フェイルオーバ排他属性の詳細は 「フェイルオーバポリシーを理解する」を参照してください。また、排他ルールの設定方法の詳細は「グループ共通のプロパティ」を参照してください。
3.2.12. サーバグループを理解する¶
このトピックでは、サーバグループについて説明します。
サーバグループとは、主にハイブリッドディスクリソースを使用する場合に必要なサーバ群のグループです。
共有ディスク装置でハイブリッドディスクリソースを使用する場合に同一の共有ディスク装置で接続されているサーバ群を 1 つサーバグループとして設定します。
共有型でないディスクでハイブリッドディスクリソースを使用する場合にも 1 台のサーバを1 つサーバグループとして設定します。
共有ディスク上のハイブリッドディスクリソースを使用する(ミラーリング元、ミラーリング先)サーバは、サーバグループ内の1台のサーバです。
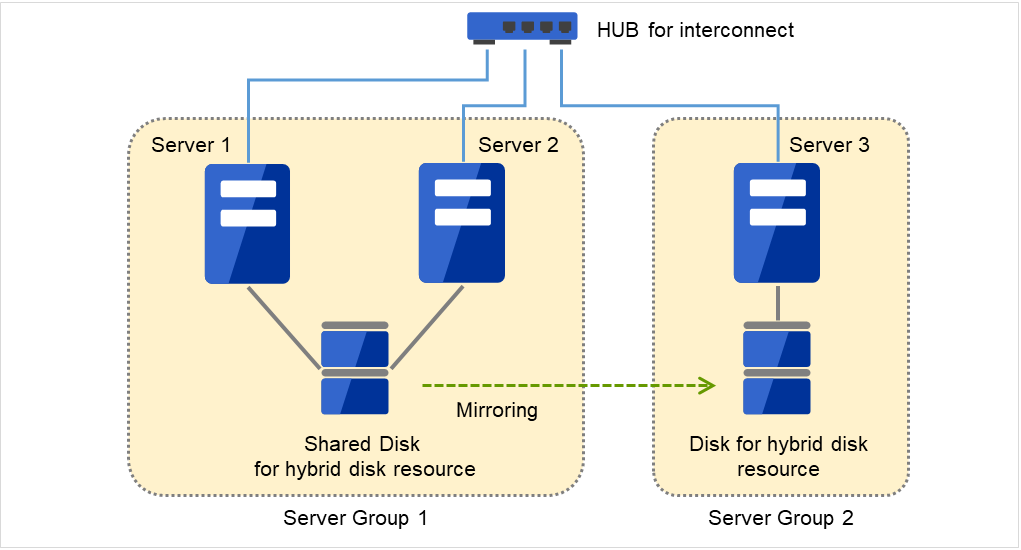
図 3.32 サーバグループ¶
3.2.13. グループリソースの依存関係設定を理解する¶
グループリソース間に依存関係を設定することにより、グループリソースを活性する順序を設定することができます。
グループリソースに依存関係を設定した場合:
活性時は [依存するリソース] の活性化が完了してから、このグループリソースの活性化が開始されます。
非活性時はこのグループリソースの非活性化が完了してから、[依存するリソース] の非活性化が開始されます。
例として該当グループに所属するリソースの依存する深度を一覧で表示します。
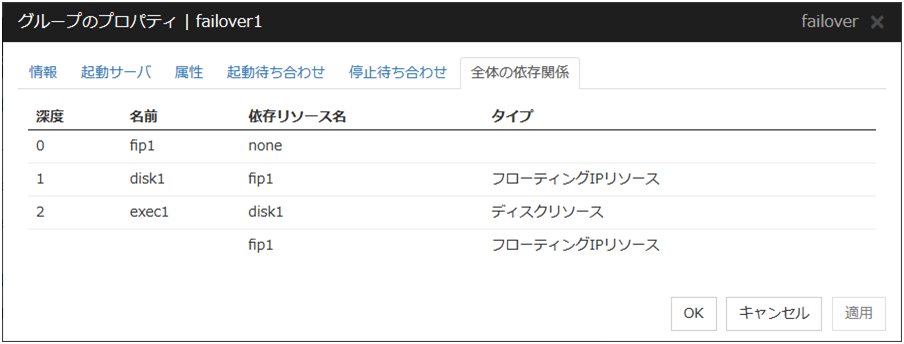

図 3.33 グループリソースの活性順序の例¶

図 3.34 グループリソースの非活性順序の例¶
3.2.14. グループリソースをサーバ個別設定する¶
グループリソースの一部の設定値はサーバごとに異なる設定が可能です。サーバ別設定が可能なリソースは [詳細] タブに各サーバのタブが表示されます。
サーバ別設定が可能なグループリソースは下記です。
グループリソース名 |
対応バージョン |
|---|---|
ディスクリソース |
4.0.0-1~ |
フローティング IP リソース |
4.0.0-1~ |
仮想 IP リソース |
4.0.0-1~ |
ミラーディスクリソース |
4.0.0-1~ |
ハイブリッドディスクリソース |
4.0.0-1~ |
ダイナミック DNS リソース |
4.0.0-1~ |
仮想マシンリソース |
4.0.0-1~ |
AWS Elastic IP リソース |
4.0.0-1~ |
AWS 仮想 IP リソース |
4.0.0-1~ |
AWS DNS リソース |
4.0.0-1~ |
Azure DNS リソース |
4.0.0-1~ |
注釈
仮想 IP リソース、AWS Elastic IP リソース、AWS 仮想 IP リソース、Azure DNS リソースには必ずサーバ個別設定が必要なパラメータがあります。
サーバ個別設定可能なパラメータは各グループリソースのパラメータの説明を参照してください。サーバ個別設定可能なパラメータには「サーバ個別設定可能 」と付記しています。
ここではフローティング IP リソースでサーバ個別設定を説明します。

サーバ個別設定
フローティング IP リソースでサーバ個別設定可能なパラメータが表示されます。
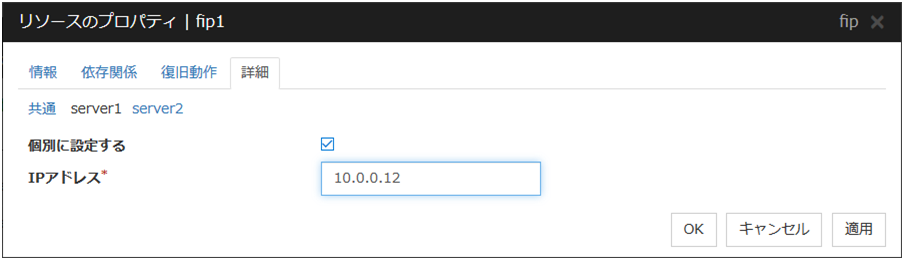
個別に設定する
サーバ個別設定を行いたいサーバ名のタブを選択してチェックボックスをオンにするとディスクリソースでサーバ個別設定可能なパラメータが入力可能になります。必要なパラメータを入力します。
注釈
サーバ個別設定では [調整] は選択できません。
3.3. グループ共通のプロパティ¶
3.3.1. 排他タブ¶
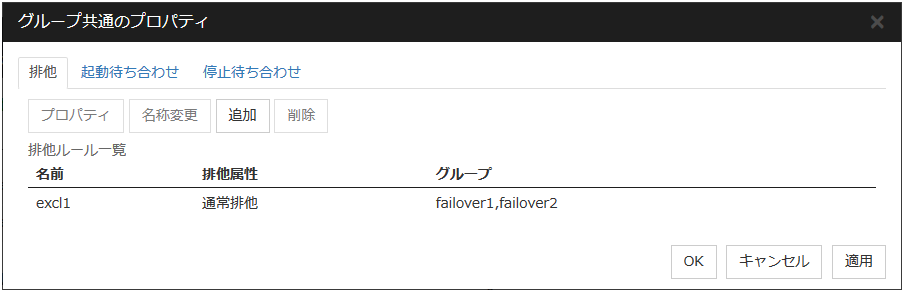
追加
排他ルールを追加します。[追加]を選択すると[排他ルールの定義]ダイアログボックスが表示されます。
削除
排他ルールを削除します。
名称変更
選択している排他ルール名の変更ダイアログボックスが表示されます。
下記の入力規則があります。
最大 31 文字 (31 バイト) までです。
文字列先頭と文字列末尾にハイフン (-) とスペースは使えません。
文字列全て数字の場合は使用できません。
排他ルールで一意 (英大文字・小文字の区別なし) な名前を入力してください。
プロパティ
選択している排他ルールのプロパティを表示します。
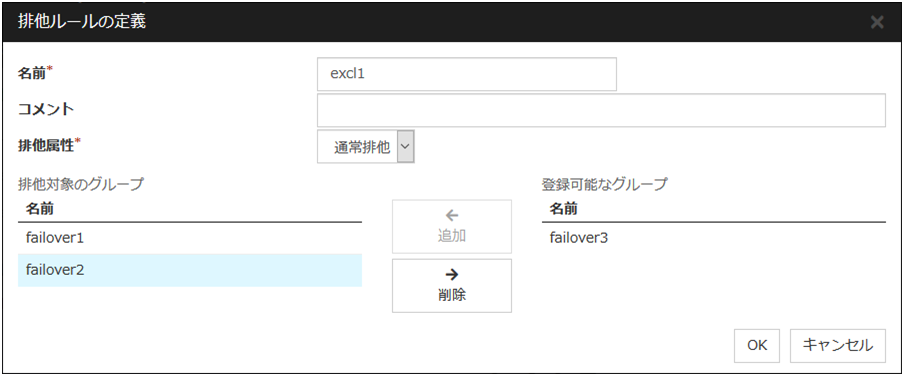
排他ルールの定義
排他ルール名と排他属性を設定します。排他属性には通常排他と完全排他の設定が可能です。通常排他を設定可能な排他ルールは1つのみです。完全排他は複数設定可能です。通常排他に設定された排他ルールがすでに存在する場合は、通常排他を選択することはできません。
名前
排他ルール名を表示しています。
排他属性
排他ルールに設定した排他属性を表示します。
グループ
排他ルールに属しているフェイルオーバグループ名の一覧を表示しています。
[登録可能なグループ]から排他ルールに登録したいグループを選択し、[追加]ボタンを押下してください。[排他対象のグループ]には排他ルールに登録したグループが表示されます。他の排他ルールに追加したフェイルオーバグループは[登録可能なグループ]に表示されません。
3.4. グループのプロパティ¶

3.4.2. 情報タブ¶
タイプ
グループのタイプを表示します。
サーバグループ設定を使用する
名前
グループ名を表示します。
コメント (127 バイト以内)
グループのコメントを設定します。半角英数字のみ入力可能です。
3.4.3. 起動サーバタブ¶
グループを起動するサーバの設定には、全サーバで起動する設定と、起動可能なサーバまたはサーバグループを選択する設定があります。
全サーバで起動する設定の場合は、クラスタに登録されている全サーバでグループを起動できます。グループを起動するサーバの起動順位は、サーバの優先順位と等しくなります。サーバの優先順位に関しては、本ガイドの「2. パラメータの詳細」 - 「Servers プロパティ」 - 「マスタサーバタブ」 を参照してください。
起動可能なサーバとサーバグループを選択する場合は、クラスタに登録されているサーバとサーバグループから任意に起動するサーバまたはサーバグループを選択できます。また、グループを起動するサーバまたはサーバグループの起動順位を変更することができます。
フェイルオーバグループを起動するサーバグループを設定する場合
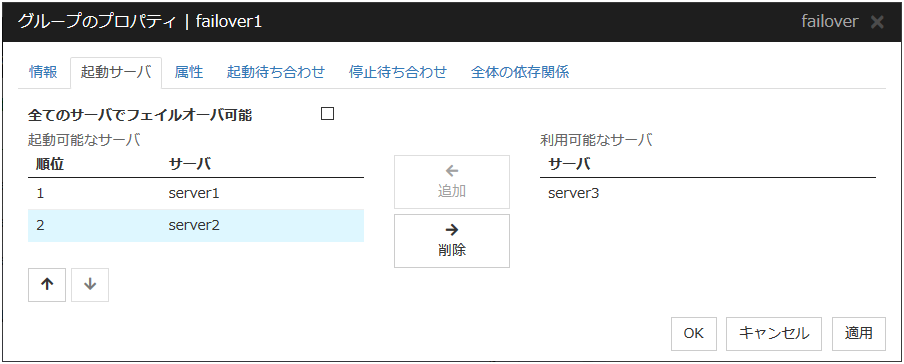
全てのサーバでフェイルオーバ可能
グループを起動するサーバを指定します。
追加
起動可能なサーバを追加する場合に使用します。[利用可能なサーバ] から追加したいサーバを選択して、[追加] をクリックします。[起動可能なサーバ] に追加されます。
削除
起動可能なサーバを削除する場合に使用します。[起動可能なサーバ] から削除したいサーバを選択して、[削除] をクリックします。[利用可能なサーバ] に追加されます。
順位
起動可能なサーバの優先順位を変更する場合に使用します。[起動可能なサーバ] から変更したいサーバを選択して、矢印をクリックします。選択行が移動します。
サーバグループ設定を使用する場合
ハイブリッドディスクリソースを含むグループを起動するサーバの設定には、フェイルオーバグループを起動するサーバグループを設定する必要があります。
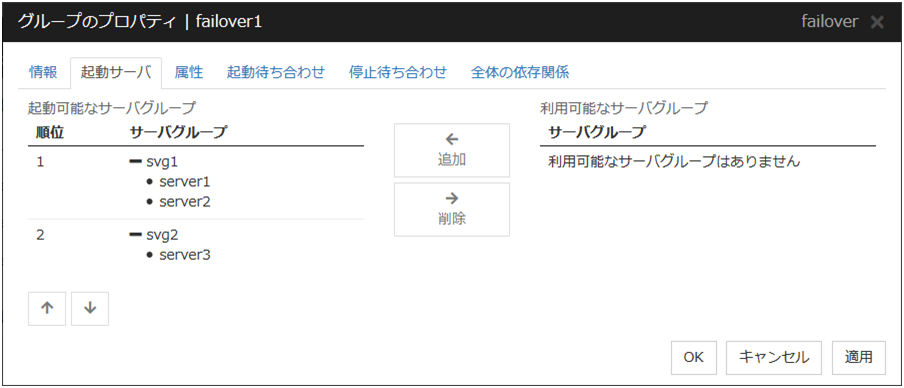
追加
[起動可能なサーバグループ] にサーバグループを追加する場合に使用します。[利用可能なサーバグループ] から追加したいサーバグループを選択して、[追加] をクリックします。 [起動可能なサーバグループ] に追加されます。
削除
[起動可能なサーバグループ] からサーバグループを削除する場合に使用します。[利用可能なサーバグループ] から削除したいサーバグループを選択して、[削除] をクリックします。[起動可能なサーバグループ] に追加されます。
順位
サーバグループの優先順位を変更する場合に使用します。[利用可能なサーバグループ] から変更したいサーバグループを選択して、矢印をクリックします。選択行が移動します。
3.4.4. 属性タブ¶
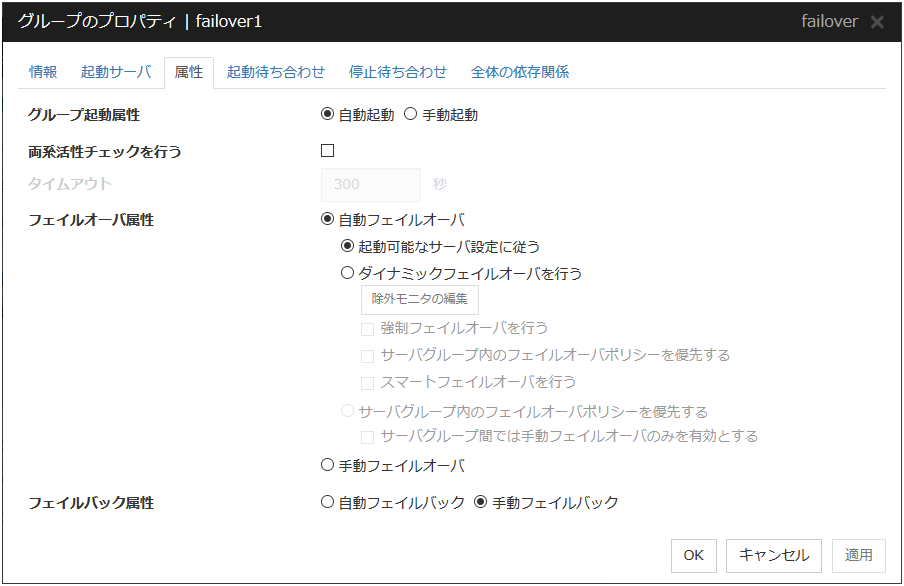
グループ起動属性
クラスタ起動時に CLUSTERPRO によりグループを自動的に起動するか (自動起動)、もしくは Cluster WebUI または [clpgrp] コマンドからユーザが操作して起動するか (手動起動) の属性を設定します。
両系活性チェックを行う
グループ起動前に両系活性が発生するか否かを確認します。
タイムアウト (1~9999)
両系活性チェックを実施する最大時間を指定します。既定値は300秒です。グループに所属するフローティングIPリソースの [フローティングIPリソース 調整プロパティ] - [pingタイムアウト] に設定した値より大きな値を設定してください。
フェイルオーバ属性
サーバダウン発生時、自動的にフェイルオーバするかどうかを設定します。
フェイルバック属性
グループが起動しているサーバよりも高プライオリティのサーバが正常に起動してきたときに自動的にフェイルバックするかどうかを設定します。ミラーディスクリソースまたはハイブリッドディスクリソースを含めるグループは手動フェイルバック属性に設定してください。
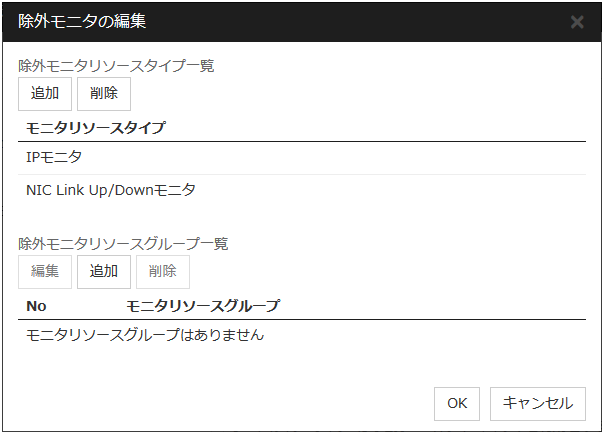
除外モニタの編集
ダイナミックフェイルオーバでは、モニタリソースが異常を検出しているサーバをフェイルオーバ先から除外します。フェイルオーバ属性として「ダイナミックフェイルオーバを行う」を選択した場合に、除外対象とするモニタリソースを設定することができます。
除外モニタは、モニタリソースタイプ、モニタリソース名による設定ができます。
選択したモニタリソースタイプを追加します。
一つの除外モニタリソースグループ内に複数のモニタリソースが登録されている場合、登録されている全てのモニタリソースが異常状態になっているサーバはフェイルオーバ先から除外されます。
また複数の除外モニタリソースグループが登録されている場合、いずれか一つでも条件を満たしたサーバはフェイルオーバ先から除外されます。
追加
[利用可能なモニタリソース一覧]で選択されているモニタリソースを[モニタリソース一覧]に追加します。
削除
[モニタリソース一覧]で選択されているモニタリソースを、一覧から削除します。
注釈
下記のモニタリソースタイプは除外モニタリソースタイプに登録できません。また、除外モニタリソースグループにリソース名を登録できません。
ユーザ空間モニタ
ARPモニタ
仮想IPモニタ
ミラーディスクコネクトモニタ
ハイブリッドディスクモニタ
ハイブリッドディスクコネクトモニタ
注釈
警告状態のモニタリソースは異常として扱いません。ただし、ミラーディスクモニタリソースは除きます。活性時監視に設定されているモニタリソースは、グループ起動サーバ以外のサーバでは監視を行わないため異常状態になりません。Cluster WebUI、clpmonctrlコマンドを使用して停止したモニタリソースは正常状態となります。モニタリソースの監視を行うサーバとして設定されていないサーバでは監視を行わないため異常状態になりません。注釈
ミラーディスクモニタリソースの場合は、ミラーディスクリソースの活性可否により判断します。ミラーディスクモニタリソースの状態には依存しません。ミラーディスクモニタリソースが異常状態であっても、ミラーディスクリソースが正常に活性できるサーバはフェイルオーバ先から除外されません。ミラーディスクモニタリソースが正常状態や警告状態であっても、ミラーディスクリソースが正常に活性できないサーバはフェイルオーバ先から除外されます。
3.4.5. 起動待ち合わせタブ¶
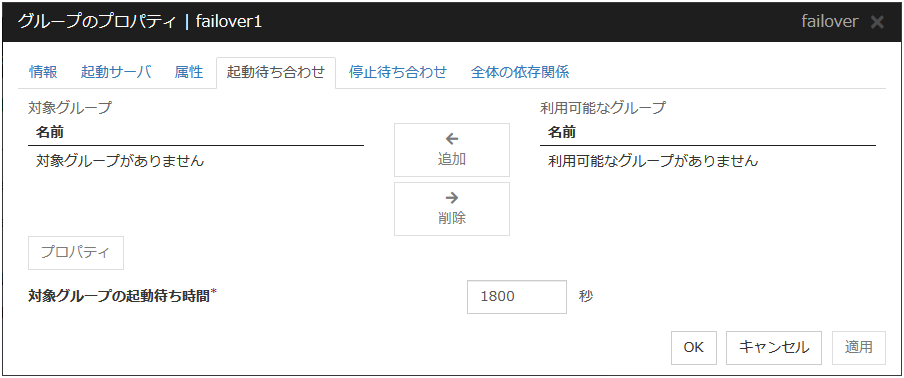
追加
[利用可能なグループ] で選択したグループを [対象グループ] に追加します。
削除
[対象グループ] で選択したグループを [対象グループ] から削除します。
対象グループの起動待ち時間 (0~9999)
対象グループの正常起動完了を待ち合わせる最大時間を指定します。既定値は 1800 秒です。
プロパティ
[対象グループ] で選択したグループのプロパティを変更します。
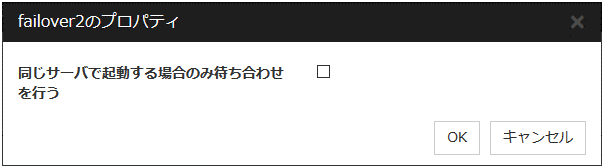
同じサーバで起動する場合のみ待ち合わせを行う
起動待ち合わせを行うグループと対象グループが同じサーバで起動する場合のみ待ち合わせるかどうかを設定します。
チェックボックスがオンの場合
起動待ち合わせを行うグループを起動するサーバが、対象グループの「起動サーバ」に含まれていない場合には待ち合わせを行いません。
起動待ち合わせを行うグループを起動するサーバ以外で対象グループが起動失敗になっている場合には待ち合わせを行いません。
3.4.6. 停止待ち合わせタブ¶
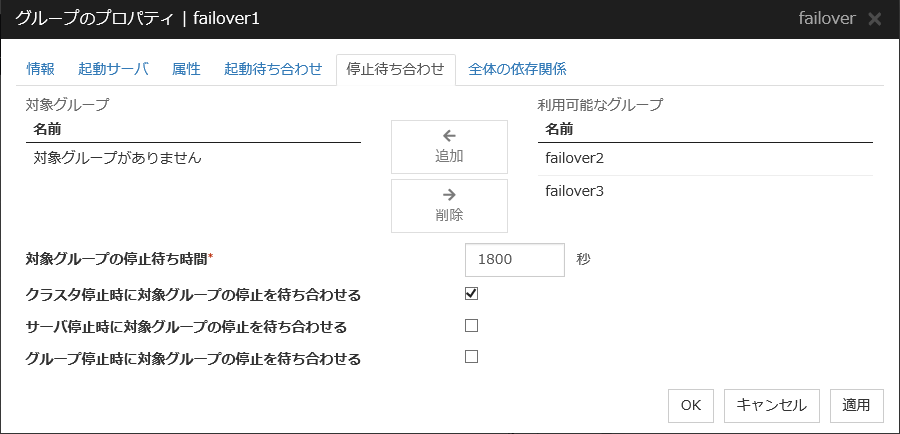
追加
[利用可能なグループ] で選択したグループを [対象グループ] に追加します。
削除
[対象グループ] で選択したグループを [対象グループ] から削除します。
対象グループの停止待ち時間 (0~9999)
対象グループの正常停止完了を待ち合わせる最大時間を指定します。既定値は 1800 秒です。
クラスタ停止時に対象グループの停止を待ち合わせる
クラスタ停止時に対象グループの停止を待ち合わせるかどうかを設定します。
サーバ停止時に対象グループの停止を待ち合わせる
サーバ単体停止時に対象グループの停止完了を待ち合わせるかどうかを設定します。対象グループのうち同じサーバで起動しているグループのみ停止を待ち合わせます。
グループ停止時に対象グループの停止を待ち合わせる
グループ停止操作時に対象グループの停止完了を待ち合わせるかどうかを設定します。対象グループのうち同じサーバで起動しているグループのみ停止を待ち合わせます。
3.5. リソースのプロパティ¶
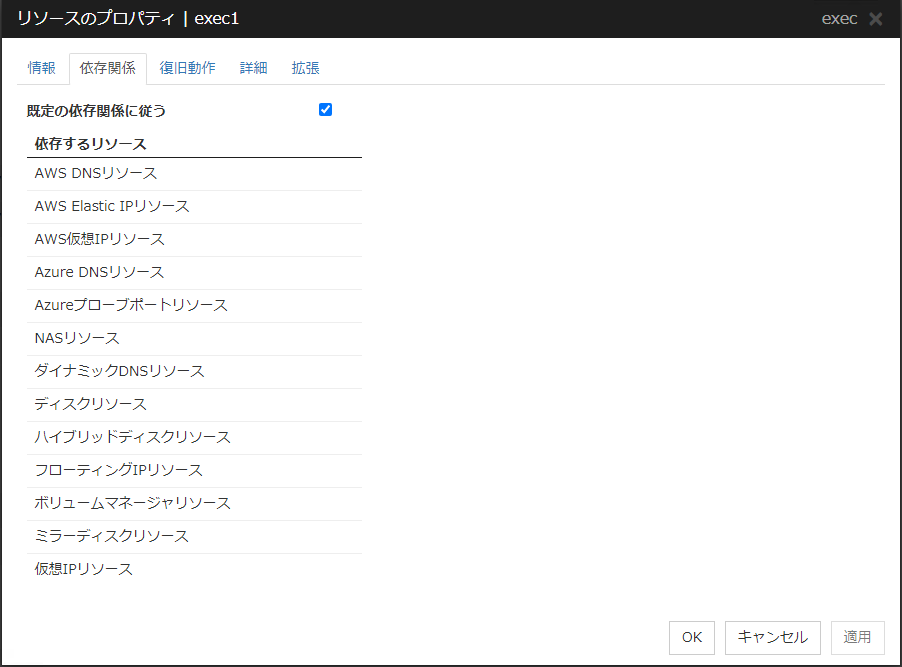
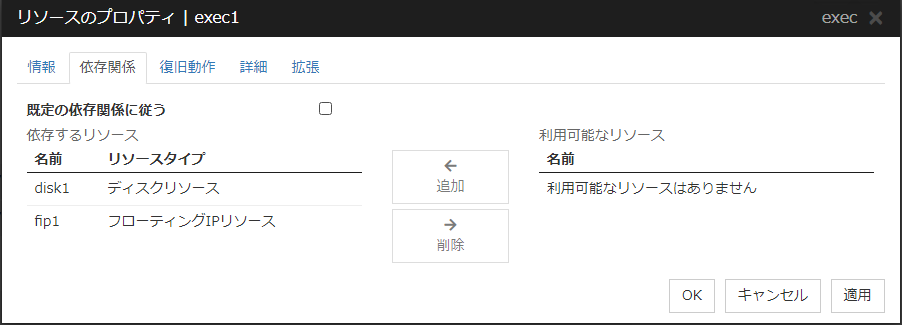
3.5.3. 復旧動作タブ¶
グループリソース活性異常検出時の流れ
グループリソースの活性時に異常を検出した場合、活性リトライを行います。
[活性リトライしきい値] の活性リトライに失敗した場合、フェイルオーバを行います。
[フェイルオーバしきい値] のフェイルオーバを行っても活性できない場合、最終動作を行います。
グループリソース非活性異常検出時の流れ
非活性時に異常を検出した場合、非活性リトライを行います。
[非活性リトライしきい値] の非活性リトライに失敗した場合、最終動作を行います。
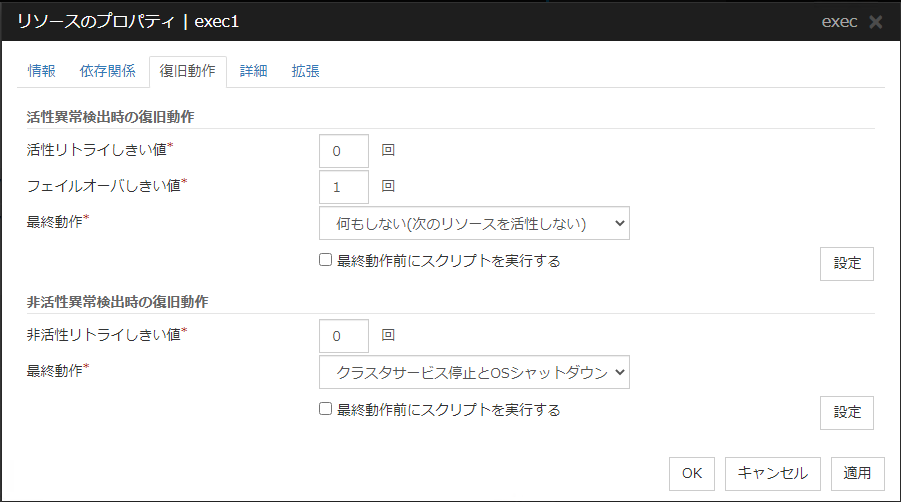
活性異常検出時の復旧動作
活性リトライしきい値 (0~99)
活性異常検出時に活性リトライを行う回数を入力します。0 を設定すると活性リトライを行いません。
フェイルオーバしきい値 (0~99)
活性異常検出時に活性リトライが [活性リトライしきい値] で指定した回数失敗した後にフェイルオーバを行う回数を入力します。0 を設定するとフェイルオーバを行いません。
最終動作
活性異常検出時に活性リトライが [活性リトライしきい値] で指定した回数失敗し、フェイルオーバが [フェイルオーバしきい値] で指定した回数失敗した後の動作を選択します。
最終動作は以下の動作が選択できます。
注釈
sysrq パニックに失敗した場合、OS のシャットダウンを行います。
注釈
keepalive リセットに失敗した場合、OS のシャットダウンを行います。clpkhb ドライバ、clpka ドライバが対応していない OS、kernel では設定しないでください。注釈
keepalive パニックに失敗した場合、OS のシャットダウンを行います。clpkhb ドライバ、clpka ドライバが対応していない OS、kernel では設定しないでください。注釈
BMC リセットに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC パワーオフに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC パワーサイクルに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC NMIに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。本機能を利用するにはハードウェアおよびファームウェアが対応している必要があります。利用可能な ハードウェア については『スタートアップガイド』の「CLUSTERPROの動作環境」の「NX7700xシリーズとの連携に対応したサーバ」を、設定については『ハードウェア連携ガイド』の「特定ハードウェアとの連携」の「NX7700x シリーズ連携を利用する構成情報の作成方法」を参照してください。
注釈
I/O Fencingに失敗した場合、OS のシャットダウンを行います。
最終動作前にスクリプトを実行する
活性異常検出時の最終動作を実行する前にスクリプトを実行するかどうかを指定します。
非活性異常検出時の復旧動作
非活性リトライしきい値 (0~99)
非活性異常検出時に非活性リトライ回数を入力します。0 を設定すると非活性リトライを行いません。
最終動作
非活性異常検出時に非活性リトライが [非活性リトライしきい値] で指定した回数失敗した後の動作を選択します。
最終動作は以下の動作が選択できます。
注釈
非活性異常検出時の最終動作に [何もしない] を選択すると、グループが非活性失敗のまま停止しません。本番環境では [何もしない] は設定しないように注意してください。
注釈
非活性異常検出時の最終動作に [何もしない] を選択すると、グループが非活性失敗のまま停止しません。本番環境では [何もしない] は設定しないように注意してください。
注釈
sysrq パニックに失敗した場合、OS のシャットダウンを行います。
注釈
keepalive リセットに失敗した場合、OS のシャットダウンを行います。clpkhb ドライバ、clpka ドライバが対応していない OS、kernel では設定しないでください。注釈
keepalive パニックに失敗した場合、OS のシャットダウンを行います。clpkhb ドライバ、clpka ドライバが対応していない OS、kernel では設定しないでください。注釈
BMC リセットに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC パワーオフに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC パワーサイクルに失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。注釈
BMC NMI に失敗した場合、OS のシャットダウンを行います。OpenIPMI をインストールしていない、または [ipmitool] コマンドが動作しないサーバでは設定しないでください。本機能を利用するにはハードウェアおよびファームウェアが対応している必要があります。利用可能な ハードウェア については『スタートアップガイド』の「CLUSTERPROの動作環境」の「NX7700xシリーズとの連携に対応したサーバ」を、設定については『ハードウェア連携ガイド』の「特定ハードウェアとの連携」の「NX7700x シリーズ連携を利用する構成情報の作成方法」を参照してください。
注釈
I/O Fencingに失敗した場合、OS のシャットダウンを行います。
最終動作前にスクリプトを実行する
非活性異常検出時の最終動作を実行する前にスクリプトを実行するかどうかを指定します。
3.5.4. 詳細タブ¶
リソース固有のパラメータは各リソースの説明に記述しています。
3.5.5. 拡張タブ¶

リソース起動属性
グループ起動時にリソースを自動的に起動するか (自動起動)、もしくは Cluster WebUI または [clprsc] コマンドからユーザが操作して起動するか (手動起動) の属性を設定します。
活性前後、非活性前後にスクリプトを実行する
リソース活性前、活性後、非活性前、非活性後にスクリプトを実行するかどうかを指定します。設定を行うためには [設定]をクリックしてください。
チェックボックスにチェックを入れることで、指定のタイミングでスクリプトが実行されます。
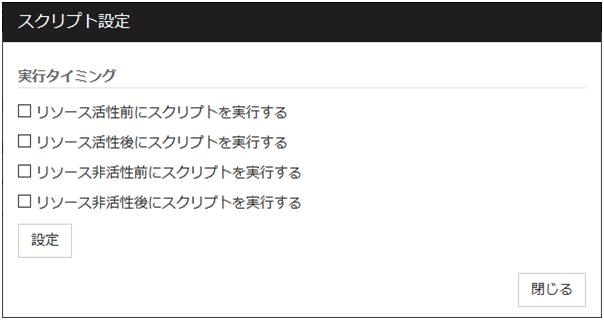
実行タイミング
リソース活性前にスクリプトを実行する
リソース活性後にスクリプトを実行する
リソース非活性前にスクリプトを実行する
リソース非活性後にスクリプトを実行する
スクリプトの設定を行うためには [設定]をクリックしてください。
ユーザアプリケーション
スクリプトとしてサーバ上の実行可能ファイル (実行可能なシェルスクリプトファイルや実行ファイル) を使用します。ファイル名にはサーバ上のローカルディスクの絶対パスまたは実行可能ファイル名を設定します。また、絶対パスやファイル名に空欄が含まれる場合は、下記のように、ダブルクォーテーション (") でそれらを囲ってください。
例:
"/tmp/user application/script.sh"各実行可能ファイルは、Cluster WebUI のクラスタ構成情報には含まれません。Cluster WebUI で編集やアップロードはできませんので、各サーバ上に準備する必要があります。
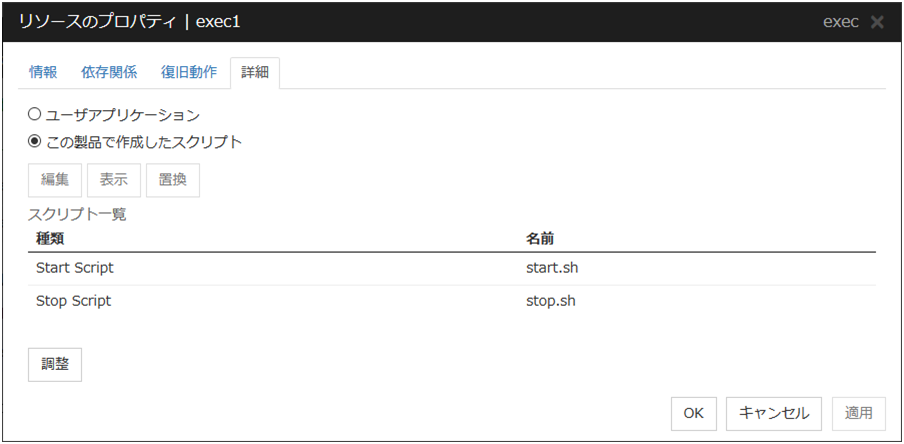
この製品で作成したスクリプト
スクリプトとして Cluster WebUI で準備したスクリプトファイルを使用します。必要に応じてCluster WebUI でスクリプトファイルを編集できます。スクリプトファイルは、クラスタ構成情報に含まれます。
ファイル (1023 バイト以内)
[ユーザアプリケーション] を選択した場合に、実行するスクリプト (実行可能なシェルスクリプトファイルや実行ファイル) を設定します。
表示
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを表示します。エディタで編集して保存した内容は反映されません。
編集
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを編集します。変更を反映するには [保存] をクリックしてください。スクリプトファイル名の変更はできません。
置換
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルの内容を、ファイル選択ダイアログボックスで選択したスクリプトファイルの内容に置換します。スクリプトが既に表示中または編集中の場合は置換できません。ここではスクリプトファイルを選択してください。バイナリファイル (アプリケーションなど) は選択しないでください。
タイムアウト (1~9999)
スクリプトの実行完了を待ち合わせる最大時間を指定します。活性前後、非活性前後に実行されるスクリプトの既定値は 30 秒です。[活性異常検出時の復旧動作] [非活性異常検出時の復旧動作]の[最終動作前にスクリプトを実行する]の[設定]ボタンから設定できるタイムアウトの既定値は 5 秒です。
3.6. EXEC リソースを理解する¶
CLUSTERPRO では、CLUSTERPRO によって管理され、グループの起動時、終了時、フェイルオーバ発生時および移動時に実行されるアプリケーションやシェルスクリプトを登録できます。EXEC リソースには、ユーザ独自のプログラムやシェルスクリプトなども登録できます。シェルスクリプトは、sh のシェルスクリプトと同じ書式なので、それぞれのアプリケーションの事情にあわせた処理を記述できます。
注釈
EXEC リソースで実行されるアプリケーションの同一レビジョンのものが、フェイルオーバポリシーに設定されている全サーバに存在していることが必須です。
3.6.1. EXEC リソースの依存関係¶
既定値では、以下のグループリソースタイプに依存します。
グループリソースタイプ |
|---|
フローティング IP リソース |
仮想 IP リソース |
ディスクリソース |
ミラーディスクリソース |
ハイブリッドディスクリソース |
NAS リソース |
仮想マシンリソース |
ボリュームマネージャーリソース |
ダイナミック DNS リソース |
AWS Elastic IPリソース |
AWS 仮想IPリソース |
AWS DNS リソース |
Azure プローブポートリソース |
Azure DNS リソース |
3.6.2. EXEC リソースの活性/非活性処理結果の判定方法について¶
3.6.3. EXEC リソースで使用するスクリプト¶
スクリプトの種類
EXEC リソースには、それぞれ開始スクリプトと終了スクリプトが用意されています。CLUSTERPRO は、クラスタの状態遷移が必要な場面において、EXEC リソースごとのスクリプトを実行します。クラスタ環境下で動作させたいアプリケーションの起動、終了、もしくは復旧の手順を、これらのスクリプトに記述する必要があります。

図 3.35 開始スクリプトと終了スクリプト¶
3.6.4. EXEC リソースのスクリプトで使用する環境変数¶
CLUSTERPRO は、スクリプトを実行する場合に、どの状態で実行したか (スクリプト実行要因) などの情報を環境変数にセットします。
スクリプト内で下図の環境変数を分岐条件として、システム運用にあった処理内容を記述できます。
終了スクリプトの環境変数は、直前に実行された開始スクリプトの内容を、値として返します。開始スクリプトでは CLP_FACTOR および CLP_PID の環境変数はセットされません。
CLP_LASTACTION の環境変数は、CLP_FACTOR の環境変数がCLUSTERSHUTDOWN または SERVERSHUTDOWN の場合にのみセットされます。
環境変数 |
環境変数の値 |
意味 |
|---|---|---|
CLP_EVENT
…スクリプト実行要因
|
START |
クラスタの起動により、実行された場合。
グループの起動により、実行された場合。
グループの移動により、移動先のサーバで実行された場合。
モニタリソースの異常検出によるグループの再起動により、同じサーバで実行された場合。
モニタリソースの異常検出によるグループリソースの再起動により、同じサーバで実行 された場合。
|
〃 |
FAILOVER |
サーバダウンにより、フェイルオーバ先の サーバで実行された場合。
モニタリソースの異常検出により、フェイルオーバ先のサーバで実行された場合。
グループリソースの活性失敗により、フェイルオーバ先のサーバで実行された場合。
|
CLP_FACTOR
…グループ停止要因
|
CLUSTERSHUTDOWN |
クラスタ停止により、グループの停止が実行された場合。 |
〃 |
SERVERSHUTDOWN |
サーバ停止により、グループの停止が実行された場合。 |
〃 |
GROUPSTOP |
グループ停止により、グループの停止が実行された場合。 |
〃 |
GROUPMOVE |
グループ移動により、グループの移動が実行された場合。 |
〃 |
GROUPFAILOVER |
モニタリソースの異常検出により、グループのフェイルオーバが実行された場合。
グループリソースの活性失敗により、グループのフェイルオーバが実行された場合。
|
〃 |
GROUPRESTART |
モニタリソースの異常検出により、グループの再起動が実行された場合。 |
〃 |
RESOURCERESTART |
モニタリソースの異常検出により、グループ リソースの再起動が実行された場合。 |
CLP_LASTACTION
…クラスタ停止後処理
|
REBOOT |
OS を reboot (再起動) する場合。 |
〃 |
HALT |
OS をhalt (シャットダウン) する場合。 |
〃 |
NONE |
何もしない。 |
CLP_SERVER
……スクリプトの実行サーバ
|
HOME |
グループの、プライマリサーバで実行された。 |
〃 |
OTHER |
グループの、プライマリサーバ以外で実行された。 |
SUCCESS |
接続に失敗しているパーティションはない。 |
|
〃 |
FAILURE |
接続に失敗しているパーティションがある。 |
CLP_PRIORITY
…スクリプトが実行されたサーバの
フェイルオーバポリシーの順位
|
1~クラスタ内のサーバ数 |
実行されているサーバの、プライオリティを示す。1 から始まる数字で、小さいほどプライオリティが高いサーバ。
CLP_PRIORITY が 1 の場合、プライマリサーバで実行されたことを示す。
|
CLP_GROUPNAME
…グループ名
|
グループ名 |
スクリプトが属している、グループ名を示す。 |
CLP_RESOURCENAME
…リソース名
|
リソース名 |
スクリプトが属している、リソース名を示す。 |
CLP_PID
…プロセス ID
|
プロセス ID |
プロパティとして開始スクリプトが非同期に設定されている場合、開始スクリプトのプロセスIDを示す。開始スクリプトが同期に設定されている場合、本環境変数は値を持たない。 |
CLP_VERSION_FULL
…CLUSTERPROフルバージョン
|
CLUSTERPROフルバージョン |
CLUSTERPROのフルバージョンを示す。(例) 4.3.4-1 |
CLP_VERSION_MAJOR
…CLUSTERPROメジャーバージョン
|
CLUSTERPROメジャーバージョン |
CLUSTERPROのメジャーバージョンを示す。(例)4 |
CLP_PATH
…CLUSTERPROインストールパス
|
CLUSTERPROインストールパス |
CLUSTERPROがインストールされているパスを示す。(例)/opt/nec/clusterpro |
CLP_OSNAME
…サーバOS名
|
サーバOS名 |
スクリプトが実行されたサーバのOS名を示す。
(例)1.OS名が取得できた場合:Red Hat Enterprise Linux Server release 6.8 (Santiago)
2.OS名が取得できなかった場合:Linux
|
CLP_OSVER
…サーバOS名
|
サーバOSバージョン |
スクリプトが実行されたサーバのOSバージョンを示す。
(例)1.OSバージョンが取得できた場合:6.8
2.OSバージョンが取得できなかった場合:※値なし
|
- 1
ディスクソース、ミラーディスクソース、ハイブリッドソース、NASソース、ボリュームマネージャリーソースが対象となります。
環境変数 |
環境変数の値 |
意味 |
|---|---|---|
CLP_EVENT
…スクリプト実行要因
|
STANDBY |
待機系サーバ上で実行された場合。
|
CLP_SERVER
……スクリプトの実行サーバ
|
HOME |
グループの、プライマリサーバで実行された。 |
〃 |
OTHER |
グループの、プライマリサーバ以外で実行された。 |
CLP_PRIORITY
…スクリプトが実行されたサーバの
フェイルオーバポリシーの順位
|
1~クラスタ内のサーバ数 |
実行されているサーバの、プライオリティを示す。1 から始まる数字で、小さいほどプライオリティが高いサーバ。
CLP_PRIORITY が 1 の場合、プライマリサーバで実行されたことを示す。
|
CLP_GROUPNAME
…グループ名
|
グループ名 |
スクリプトが属している、グループ名を示す。 |
CLP_RESOURCENAME
…リソース名
|
リソース名 |
スクリプトが属している、リソース名を示す。 |
CLP_VERSION_FULL
…CLUSTERPROフルバージョン
|
CLUSTERPROフルバージョン |
CLUSTERPROのフルバージョンを示す。(例) 4.3.4-1 |
CLP_VERSION_MAJOR
…CLUSTERPROメジャーバージョン
|
CLUSTERPROメジャーバージョン |
CLUSTERPROのメジャーバージョンを示す。(例)4 |
CLP_PATH
…CLUSTERPROインストールパス
|
CLUSTERPROインストールパス |
CLUSTERPROがインストールされているパスを示す。(例)/opt/nec/clusterpro |
CLP_OSNAME
…サーバOS名
|
サーバOS名 |
スクリプトが実行されたサーバのOS名を示す。
(例)1.OS名が取得できた場合:Red Hat Enterprise Linux Server release 6.8 (Santiago)
2.OS名が取得できなかった場合:Linux
|
CLP_OSVER
…サーバOSバージョン
|
サーバOSバージョン |
スクリプトが実行されたサーバのOSバージョンを示す。
(例)1.OSバージョンが取得できた場合:6.8
2.OSバージョンが取得できなかった場合:※値なし
|
3.6.5. EXEC リソーススクリプトの実行タイミング¶
開始、終了スクリプトの実行タイミングと環境変数の関連を、クラスタ状態遷移図にあわせて説明します。
- 説明を簡略にするため、2 台構成のクラスタで説明します。3 台以上の構成の場合に、発生する可能性のある実行タイミングと環境変数の関連は、補足という形で説明します。
図中のサーバは以下の状態を表しています。
サーバ
サーバ状態

正常状態 (クラスタとして正常に動作している)

停止状態 (クラスタが停止状態)
(例) 正常状態にある Server 1 において Group A が動作している。

各グループは、起動したサーバの中で、最もプライオリティの高いサーバ上で起動されます。
クラスタに定義されているグループは A、B、C の3つで、それぞれ以下のようなフェイルオーバポリシーを持っています。
グループ
優先度1サーバ
優先度2サーバ
A
Server 1
Server 2
B
Server 2
Server 1
C
Server 1
Server 2
【クラスタ状態遷移図】
代表的なクラスタ状態遷移について説明します。
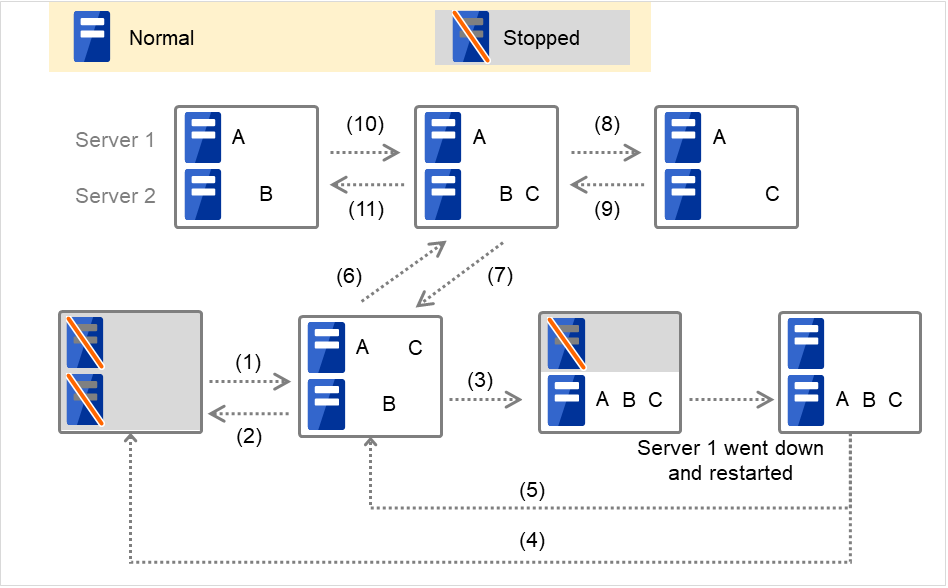
図 3.36 クラスタ状態遷移の例(概要)¶
図中の1. ~11. は、以下の説明に対応しています。
通常立ち上げ
ここでいう通常立ち上げとは、開始スクリプトがプライマリサーバで正常に実行された時を指します。
各グループは、起動したサーバの中で、最もプライオリティの高いサーバ上で起動されます。
図 3.37 状態とスクリプト実行(通常立ち上げ)¶
Start に対する環境変数
Group A
Group B
Group C
CLP_EVENT
START
START
START
CLP_SERVER
HOME
HOME
HOME
通常シャットダウン
ここでいう通常シャットダウンとは、終了スクリプトに対応する開始スクリプトが、通常立ち上げにより実行された、もしくはグループの移動 (オンラインフェイルバック) により実行された直後の、クラスタシャットダウンを指します。
図 3.38 状態とスクリプト実行(通常シャットダウン)¶
Stop に対する環境変数
Group A
Group B
Group C
CLP_EVENT
START
START
START
CLP_SERVER
HOME
HOME
HOME
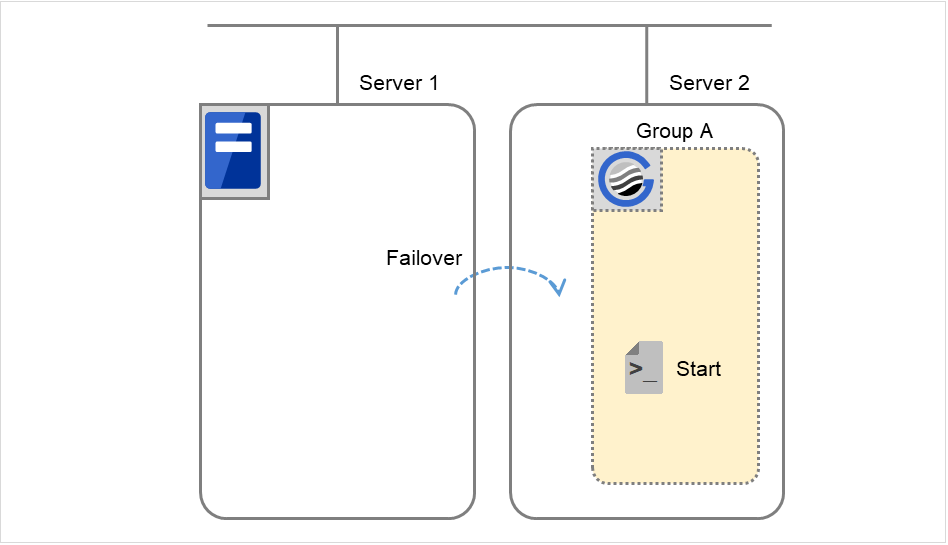
Server 1 ダウンによるフェイルオーバ
Server 1 をプライマリサーバとするグループの開始スクリプトが、障害発生により下位のプライオリティサーバ (Server 2) で実行されます。開始スクリプトには、CLP_EVENT (=FAILOVER) を分岐条件にして、業務の起動、復旧処理 (たとえばデータベースのロールバック処理など) を記述しておく必要があります。
プライマリサーバ以外でのみ実行したい処理がある場合は、CLP_SERVER (=OTHER) を分岐条件にして記述しておく必要があります。

図 3.39 状態とスクリプト実行(サーバダウンによるフェイルオーバ)¶
Start に対する環境変数
Group A
Group C
CLP_EVENT
FAILOVER
FAILOVER
CLP_SERVER
OTHER
OTHER
Server 1 フェイルオーバ後クラスタシャットダウン
Group A と Group C の終了スクリプトが、フェイルオーバ先のServer 2 で実行されます (Group B の終了スクリプトは、通常シャットダウンでの実行です)。
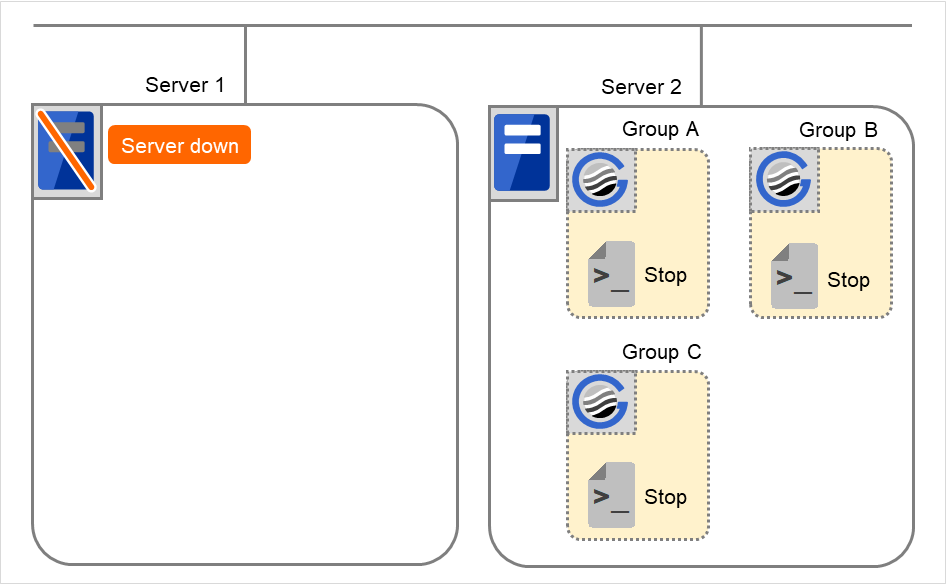
図 3.40 状態とスクリプト実行(フェイルオーバ後、クラスタシャットダウン)¶
Stop に対する環境変数
Group A
Group B
Group C
CLP_EVENT
FAILOVER
START
FAILOVER
CLP_SERVER
OTHER
HOME
OTHER
Group A と Group C の移動
Group A と Group C の終了スクリプトが、フェイルオーバ先のServer 2 で実行された後、Server 1 で開始スクリプトが実行されます。

図 3.41 状態とスクリプト実行(Group A、Group Cの移動)(1)¶
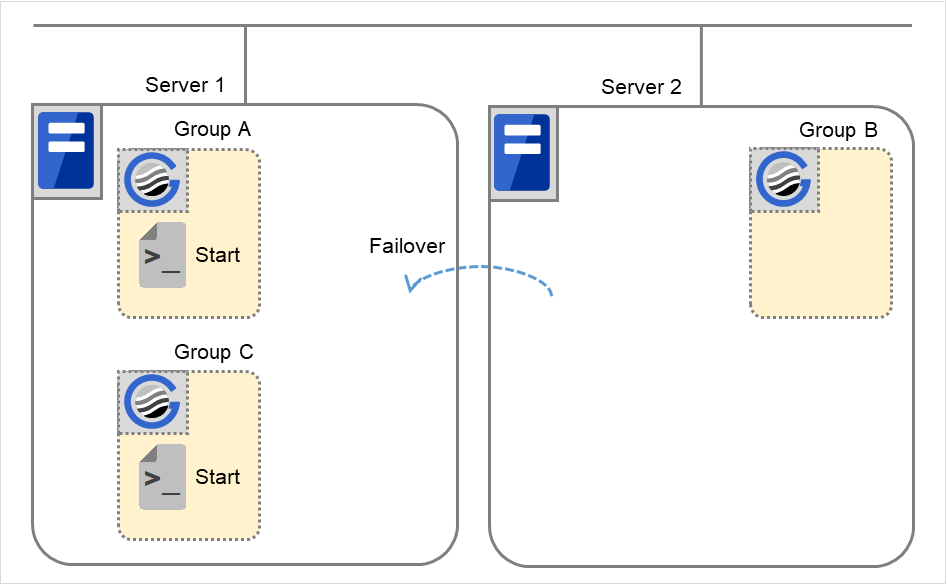
図 3.42 状態とスクリプト実行(Group A、Group Cの移動)(2)¶
Stop に対する環境変数
Group A
Group C
CLP_EVENT
FAILOVER 2
FAILOVER
CLP_SERVER
OTHER
OTHER
Startに対する環境変数
Group A
Group C
CLP_EVENT
START
START
CLP_SERVER
HOME
HOME
- 2
- 終了スクリプトの環境変数の値は、直前に実行された開始スクリプトの環境変数の値となる。「5. Group A と Group C の移動」の遷移の場合、直前にクラスタシャットダウンがないのでFAILOVERになるが、「5. Group A と Group C の移動」の前にクラスタシャットダウンが行われていると、STARTとなる。
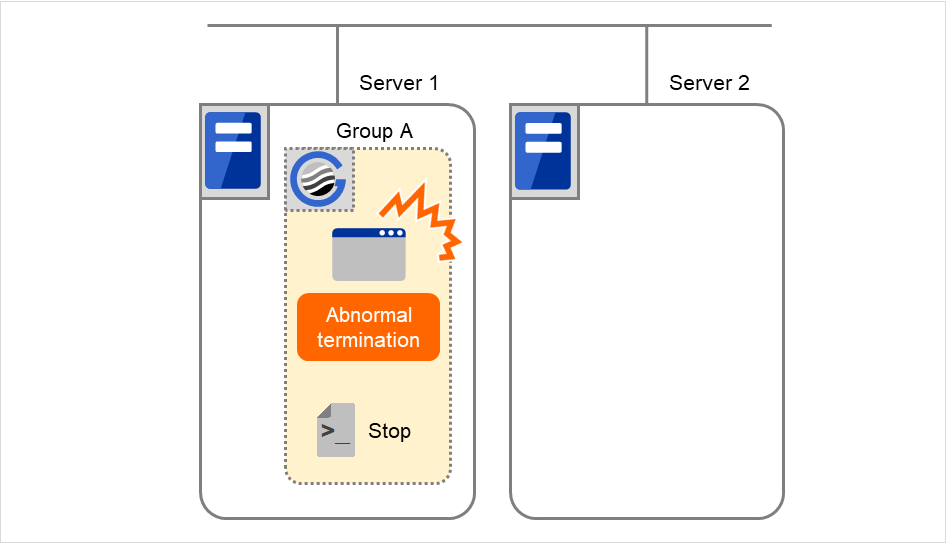
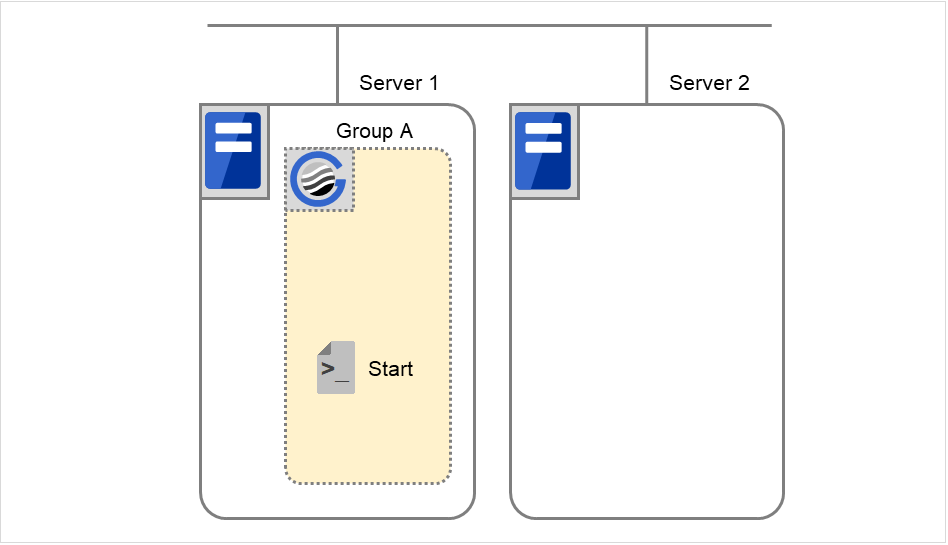
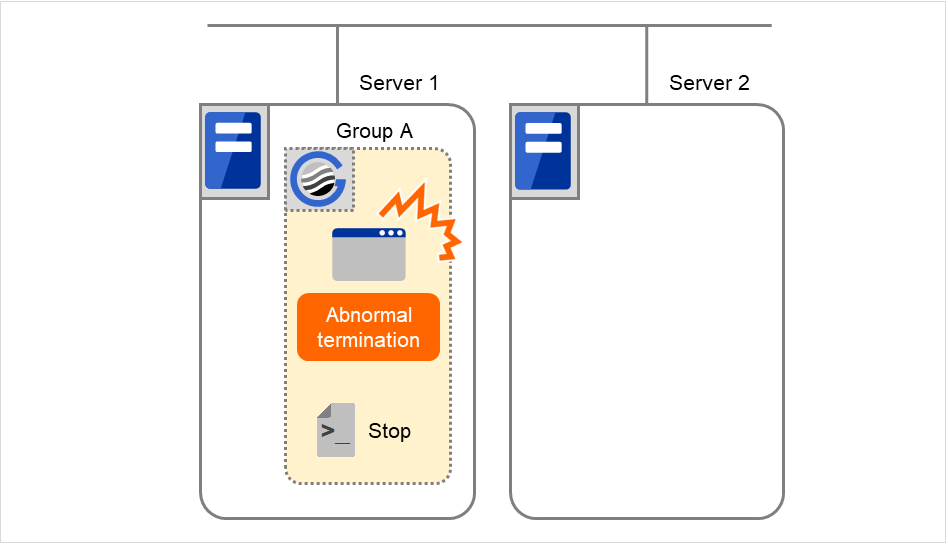
Group C の障害、フェイルオーバ
Group C に障害が発生すると、Server 1 でGroup C の終了スクリプトが実行され、Server 2 でGroup C の開始スクリプトが実行されます。

図 3.43 状態とスクリプト実行(Group Cの障害、フェイルオーバ)(1)¶

図 3.44 状態とスクリプト実行(Group Cの障害、フェイルオーバ)(2)¶
Server 1 のStopに対する環境変数
Group C
CLP_EVENT
START
CLP_SERVER
HOME
Server 2のStartに対する環境変数
Group C
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
Group C の移動
でServer 2 にフェイルオーバしてきたGroup C を、Server 2 よりServer 1 へ移動します。Server 2 で終了スクリプトを実行した後、Server 1 で開始スクリプトを実行します。
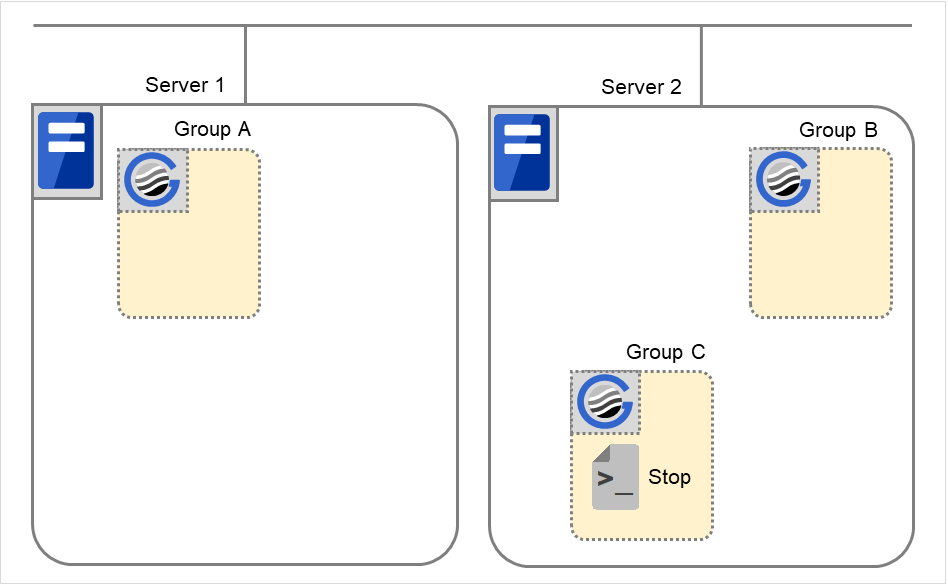
図 3.45 状態とスクリプト実行(Group Cの移動)(1)¶
Stopに対する環境変数 ( 6. よりフェイルオーバしてきたため)
Group C
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
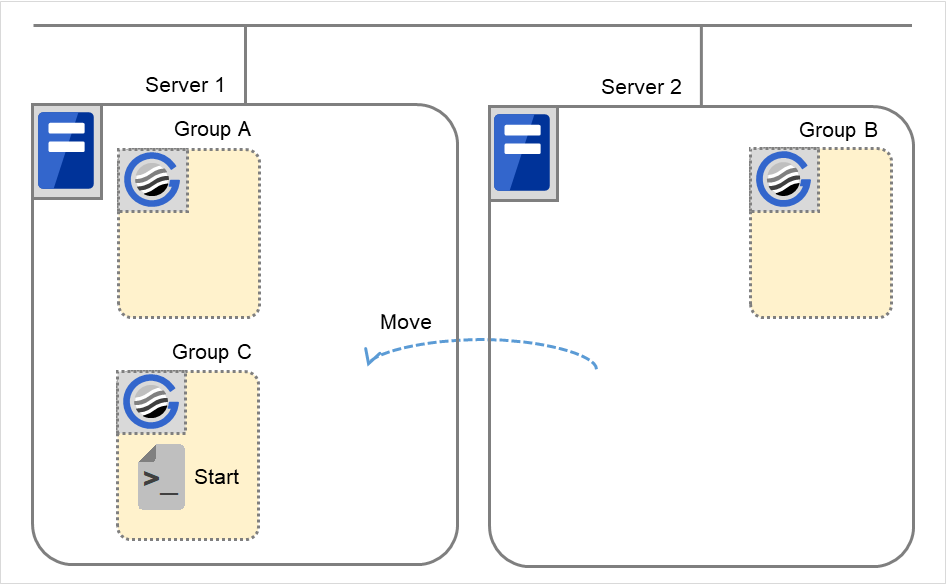
図 3.46 状態とスクリプト実行(Group Cの移動)(2)¶
Startに対する環境変数
Group C
CLP_EVENT
START
CLP_SERVER
HOME
Group B の停止
Group B の終了スクリプトがServer 2 で実行されます。
図 3.47 状態とスクリプト実行(Group Bの停止)¶
Stopに対する環境変数
Group B
CLP_EVENT
START
CLP_SERVER
HOME
Group B の起動
Group B の開始スクリプトがServer 2 で実行されます。
図 3.48 状態とスクリプト実行(Group Bの起動)¶
Startに対する環境変数
Group B
CLP_EVENT
START
CLP_SERVER
HOME
Group C の停止
Group C の終了スクリプトがServer 2 で実行されます。
図 3.49 状態とスクリプト実行(Group Cの停止)¶
Stopに対する環境変数
Group C
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
Group C の起動
Group C の開始スクリプトがServer 2 で実行されます。
図 3.50 状態とスクリプト実行(Group Cの起動)¶
Startに対する環境変数
Group C
CLP_EVENT
START
CLP_SERVER
OTHER
【補足1】
フェイルオーバポリシーに設定されているサーバを 3 つ以上持つグループにおいて、プライマリサーバ以外のサーバで異なった動作を行う場合、 CLP_SERVER (HOME/OTHER) の代わりに、CLP_PRIORITY を使用します。
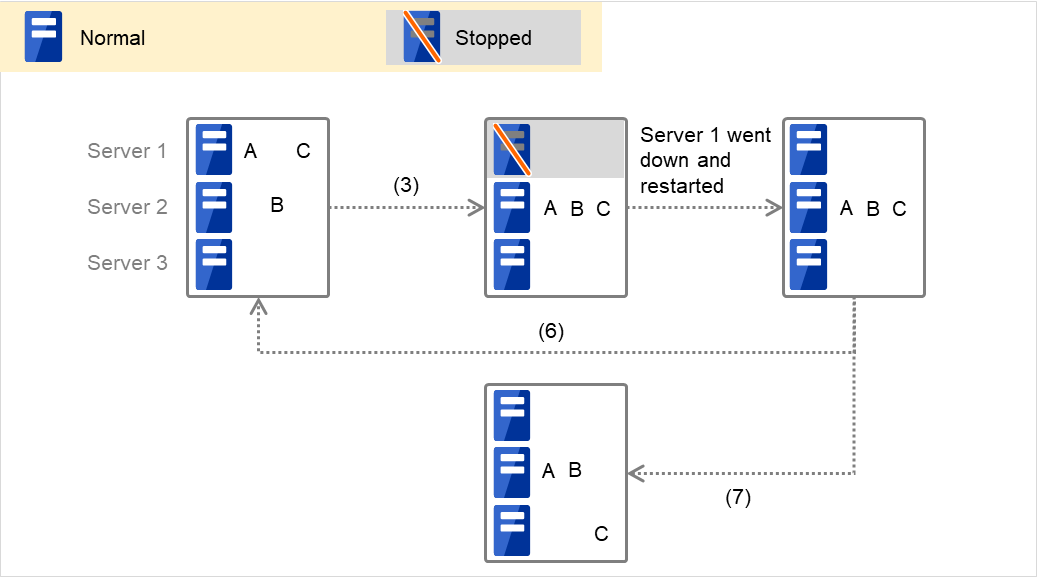
図 3.51 クラスタ状態遷移の例(サーバダウンによるフェイルオーバ)¶
(例1) クラスタ状態遷移図 「3. Server 1 ダウンによるフェイルオーバ」の場合
Server 1 をプライマリサーバとするグループの開始スクリプトが、障害発生により次に高いフェイルオーバポリシーを持つServer 2 で実行されます。開始スクリプトには、CLP_EVENT (=FAILOVER) を分岐条件にして、業務の起動、復旧処理 (たとえばデータベースのロールバック処理など) を記述しておく必要があります。
2 番目に高いフェイルオーバポリシーを持つサーバのみで実行したい処理がある場合は、CLP_PRIORITY (=2) を分岐条件にして記述しておく必要があります。
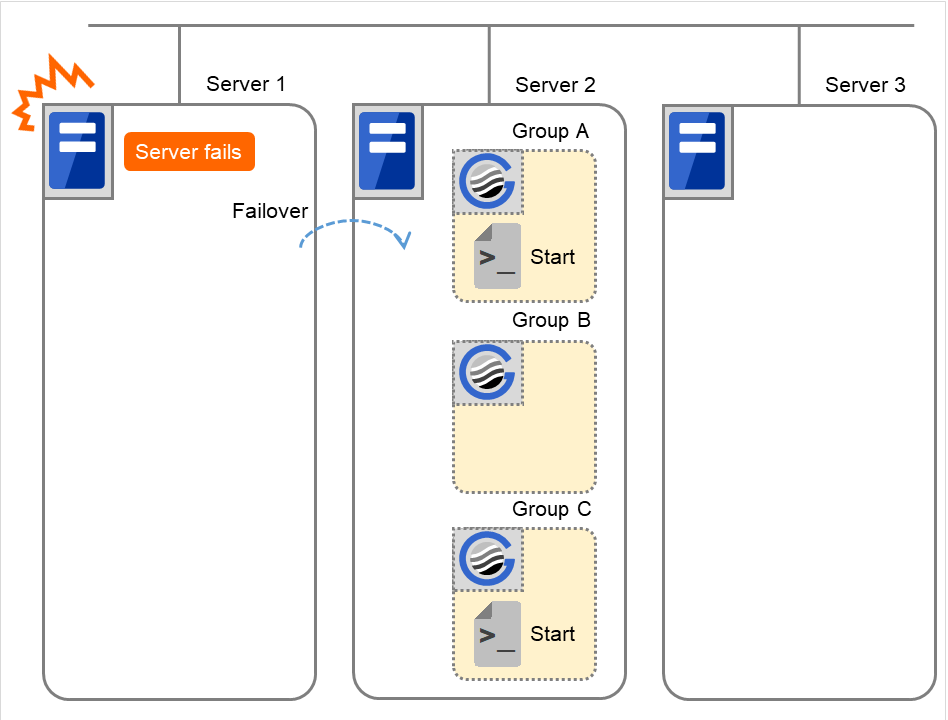
図 3.52 状態とスクリプト実行(Group A、Group Cの起動)¶
Start に対する環境変数
Group A
Group C
CLP_EVENT
FAILOVER
FAILOVER
CLP_SERVER
OTHER
OTHER
CLP_PRIORITY
2
2
(例2) クラスタ状態遷移図「7. Group C の移動」の場合
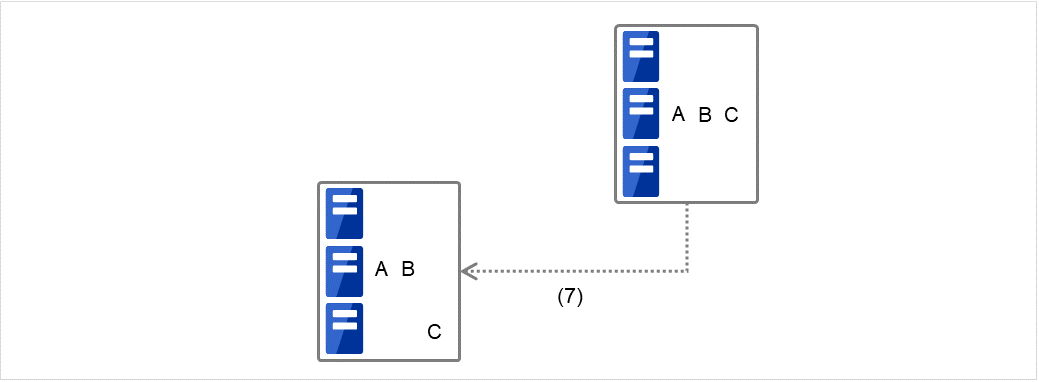
図 3.53 クラスタ状態遷移の例(Group Cの移動)¶
Group C の終了スクリプトが、フェイルオーバ元のServer 2 で実行された後、Server 3で開始スクリプトが実行されます。
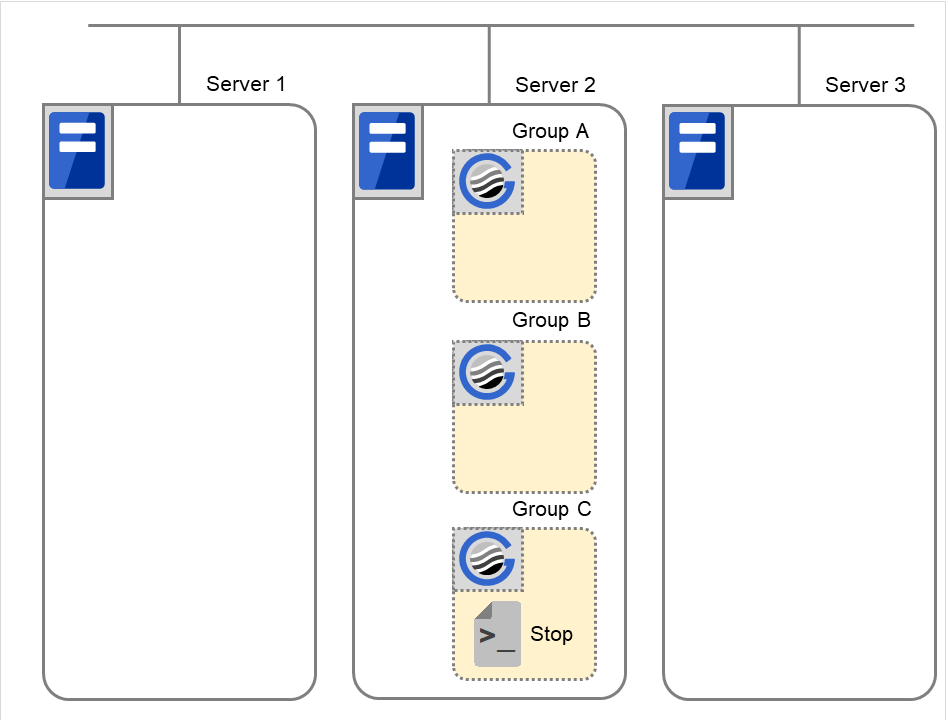
図 3.54 状態とスクリプト実行(Group Cの移動)(1)¶
Stop に対する環境変数
Group C
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
CLP_PRIORITY
2
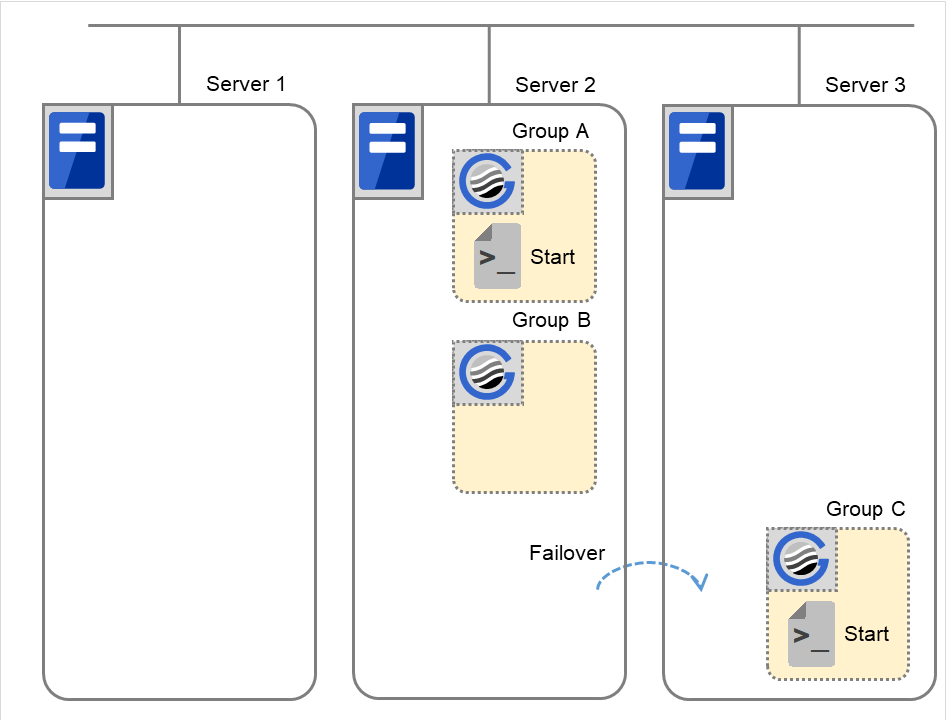
図 3.55 状態とスクリプト実行(Group Cの移動)(2)¶
Startに対する環境変数
Group C
CLP_EVENT
START
CLP_SERVER
OTHER
CLP_PRIORITY
3
【補足2】
リソースモニタがスクリプトを (再) 起動する場合
リソースモニタがアプリケーションの異常を検出し開始スクリプトを (再) 起動する場合の環境変数は以下のようになります。
(例1) リソースモニタがServer 1 で起動していたアプリケーションの異常終了を検出してServer 1 でGroup A の再起動を行う場合
(例2) リソースモニタがServer 1 で起動していたアプリケーションの異常終了を検出してServer 2 へフェイルオーバをして、Server 2 でGroup A の起動を行う場合
【補足3】
[EXECリソース調整プロパティ] の [待機系サーバで実行する] を有効に設定すると、グループを起動したサーバ (=現用系サーバ) で開始スクリプトや終了スクリプトが実行されるタイミングに合わせて、グループを起動していない他のサーバ (=待機系サーバ) でもスクリプトを実行することができます。
現用系サーバでのスクリプト実行と比較すると、待機系サーバでのスクリプト実行には以下の特徴があります。
スクリプトの実行結果 (エラーコード) がグループリソースのステータスに影響しません。
活性前後スクリプトや非活性前後スクリプトを実行しません。
活性時監視に設定されているモニタリソースの起動・停止を行いません。
セットされる環境変数の種類・値が異なります (前項「 EXEC リソースのスクリプトで使用する環境変数 」を参照してください)。
待機系サーバでスクリプトが実行されるタイミングと環境変数の関連について、クラスタ状態遷移図にあわせて説明します。
【クラスタ状態遷移図】
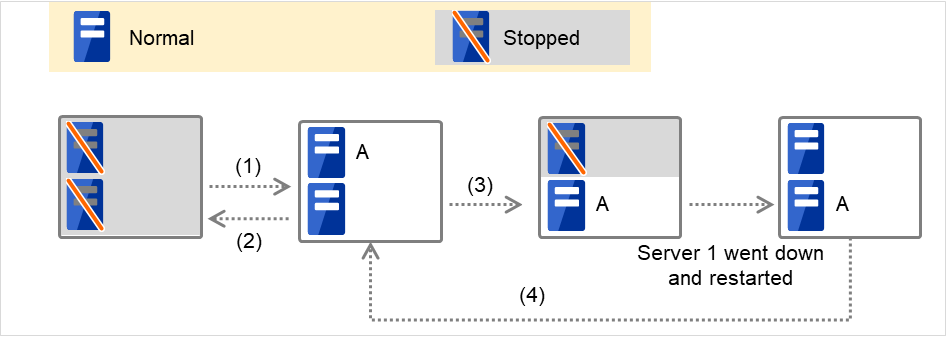
図 3.60 クラスタ状態遷移の例(サーバダウンによるフェイルオーバ)¶
図中の 1. ~ 4. は、以下の説明に対応しています。
通常立ち上げ
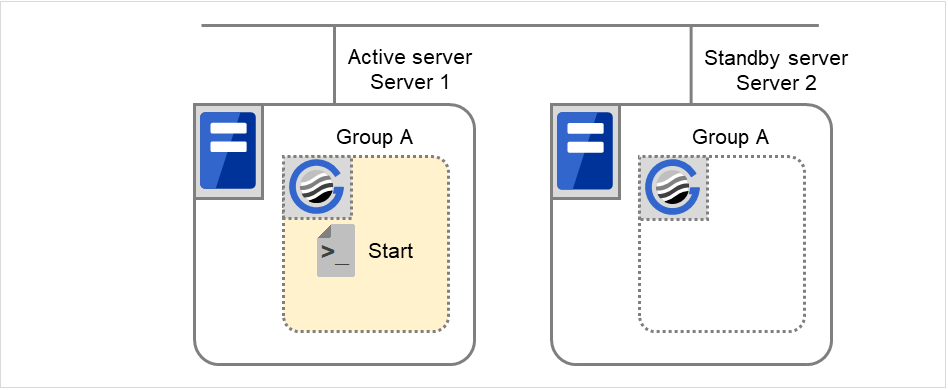
図 3.61 状態とスクリプト実行(Group Aの通常起動)(1)¶
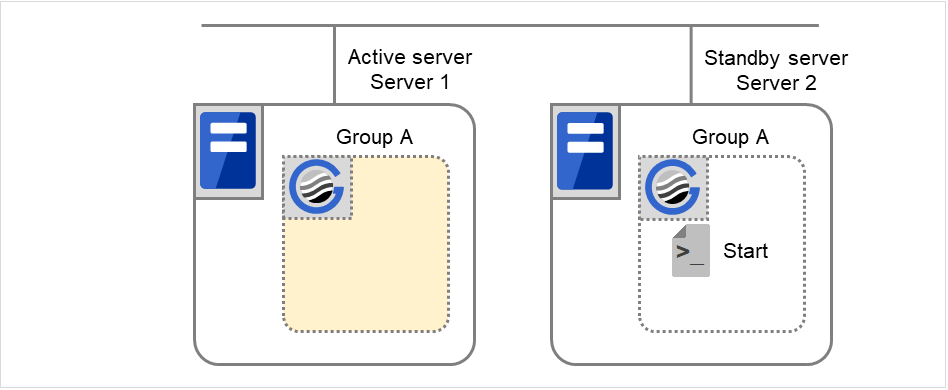
図 3.62 状態とスクリプト実行(Group Aの通常起動)(2)¶
Start に対する環境変数
Server 1
Server 2
CLP_EVENT
START
STANDBY
CLP_SERVER
HOME
OTHER
通常シャットダウン
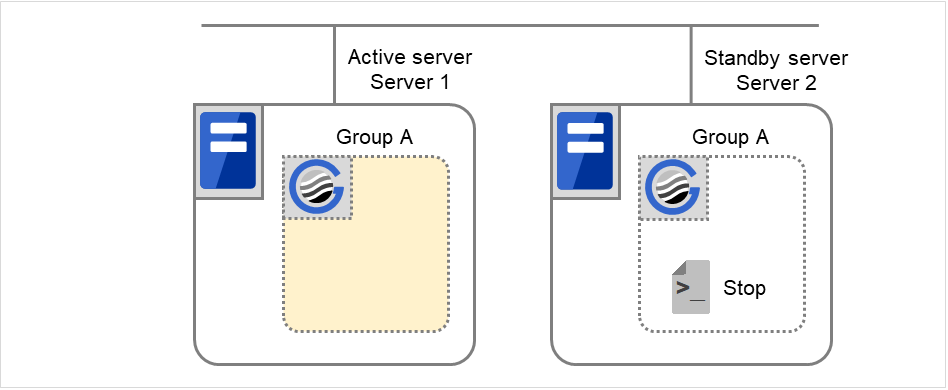
図 3.63 状態とスクリプト実行(Group Aの通常シャットダウン)(1)¶
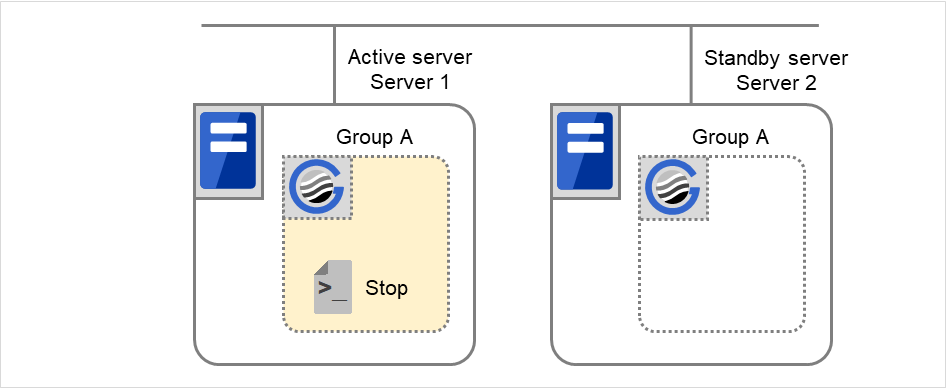
図 3.64 状態とスクリプト実行(Group Aの通常シャットダウン)(2)¶
Stop に対する環境変数
Server 1
Server 2
CLP_EVENT
START
STANDBY
CLP_SERVER
HOME
OTHER
Server 1 ダウンによるフェイルオーバ
Server 1 がダウン状態であるため、待機系サーバとしての開始スクリプトは実行されません。
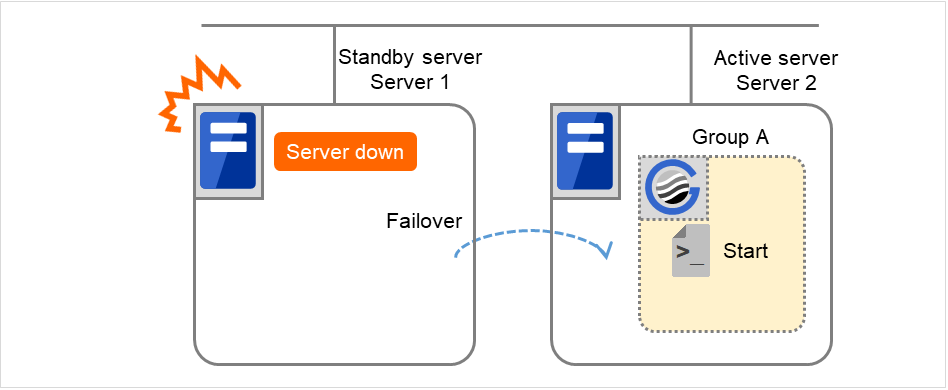
図 3.65 クラスタ状態遷移の例(サーバダウンによるフェイルオーバ)¶
Start に対する環境変数
Server 2
CLP_EVENT
FAILOVER
CLP_SERVER
OTHER
Group Aの移動
Group Aの終了スクリプトがServer 1 (= 待機系サーバ) とServer 2 (= 現用系サーバ) で実行された後、 開始スクリプトがServer 1 (= 現用系サーバ) とServer 2 (= 待機系サーバ) で実行されます。
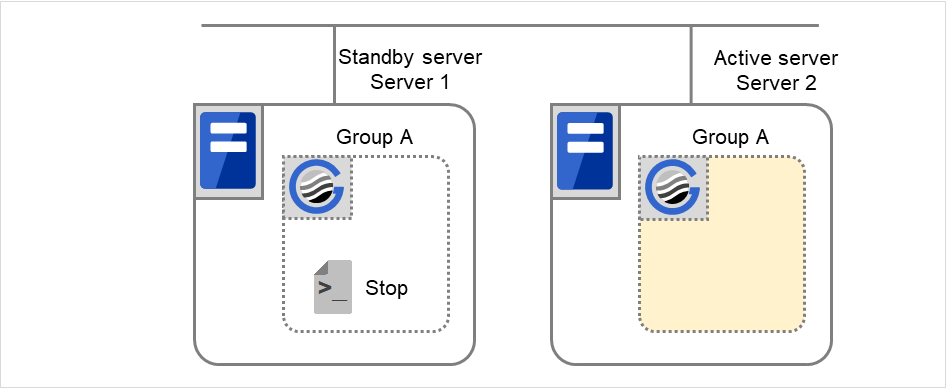
図 3.66 状態とスクリプト実行(Group Aの移動)(1)¶

図 3.67 状態とスクリプト実行(Group Aの移動)(2)¶
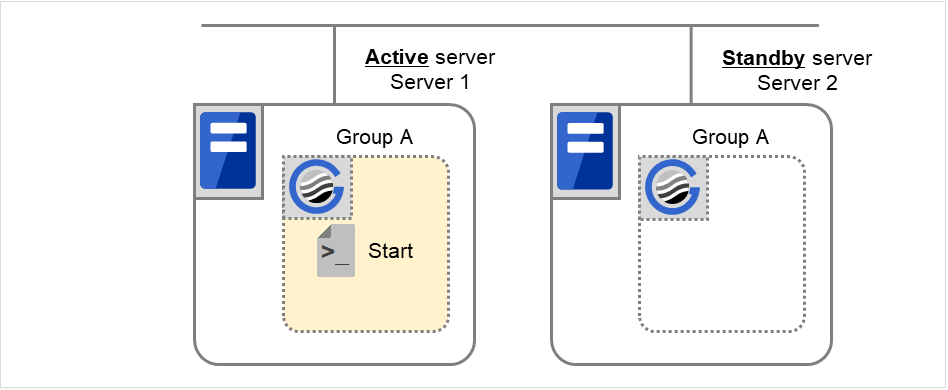
図 3.68 状態とスクリプト実行(Group Aの移動)(3)¶
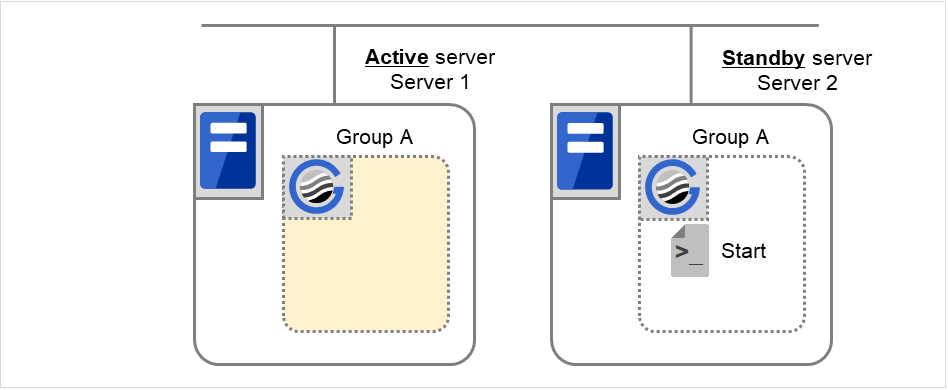
図 3.69 状態とスクリプト実行(Group Aの移動)(4)¶
Stop に対する環境変数
Server 1
Server 2
CLP_EVENT
STANDBY
FAILOVER 3
CLP_SERVER
HOME
OTHER
- 3
Start に対する環境変数
Server 1
Server 2
CLP_EVENT
START
STANDBY
CLP_SERVER
HOME
OTHER
3.6.6. EXEC リソーススクリプトの記述の流れ¶
前のトピックの、スクリプトの実行タイミングと実際のスクリプト記述を関連付けて説明します。文中の (数字) は 「 EXEC リソーススクリプトの実行タイミング 」の各動作をさします。
group A 開始スクリプト: start.sh の一例
#!/bin/sh
# ***************************************
# * start.sh *
# ***************************************
# スクリプト実行要因の環境変数を参照して処理の振り分けを行う。
if [ "$CLP_EVENT" = "START" ]
then
# DISK接続情報環境変数を参照してエラー処理の要否を判定する。
if [ "$CLP_DISK" = "SUCCESS" ]
then
# ここに、業務の通常起動処理を記述する。
# この処理は以下のタイミングで実行される。
#
# (1) 通常立ち上げ
# (5) Group A と Group C の移動
#
# 実行サーバ環境変数を参照して処理の振り分けを行う。
if [ "$CLP_SERVER" = "HOME" ]
then
# ここに、プライマリサーバで、業務が通常起動される場合にのみ行いたい処理を記述する。
# この処理は以下のタイミングで実行される。
#
# (1) 通常立ち上げ
# (5) Group A と Group C の移動
#
else
# ここに、プライマリサーバ以外で、業務が通常起動される場合にのみ行いたい処理を記述する。
#
fi
else
# ここに、ディスク関連のエラー処理を記述する。
#
fi
elif [ "$CLP_EVENT" = "FAILOVER" ]
then
# DISK接続情報環境変数を参照してエラー処理の要否を判定する。
if [ "$CLP_DISK" = "SUCCESS" ]
then
# ここに、業務の通常起動処理を記述する。
# この処理は以下のタイミングで実行される。
#
# (3) Server 1ダウンによるフェイルオーバ
#
# 実行サーバ環境変数を参照して処理の振り分けを行う。
if [ "$CLP_SERVER" = "HOME" ]
then
# ここに、フェイルオーバ後、プライマリサーバで業務が起動される場合にのみ行いたい処理を記述する。
#
else
# ここに、フェイルオーバ後、非プライマリサーバで業務が起動される場合にのみ行いたい処理を記述する。
# この処理は以下のタイミングで実行される。
#
# (3) Server 1ダウンによるフェイルオーバ
#
fi
else
# ここに、ディスク関連のエラー処理を記述する。
#
fi
else
# CLUSTERPROは動作していない。
fi
# 終了コードが0の場合、EXECリソースの活性処理は成功と判定される。
# スクリプト内でエラーが発生した場合には 0以外の終了コードを返却するように記述する。
exit 0
Group A 終了スクリプト: stop.sh の一例
#!/bin/sh
# ***************************************
# * stop.sh *
# ***************************************
# スクリプト実行要因の環境変数を参照して処理の振り分けを行う。
if [ "$CLP_EVENT" = "START" ]
then
if [ "$CLP_DISK" = "SUCCESS" ]
then
# ここに、業務の通常終了処理を記述する。以下のタイミングで実行される。
#
# (2) 通常シャットダウン
#
# 実行サーバ環境変数を参照して処理の振り分けを行う。
if [ "$CLP_SERVER" = "HOME" ]
then
# ここに、プライマリサーバで業務が通常終了される場合にのみ行いたい処理を記述する。
# この処理は以下のタイミングで実行される。
#
# (2) 通常シャットダウン
#
else
# ここに、プライマリサーバ以外で業務が通常終了される場合にのみ行いたい処理を記述する。
#
fi
else
# ここに、ディスク関連のエラー処理を記述する。
#
fi
elif [ "$CLP_EVENT" = "FAILOVER" ]
then
# DISK接続情報環境変数を参照してエラー処理の要否を判定する。
if [ "$CLP_DISK" = "SUCCESS" ]
then
# ここに、フェイルオーバ後の通常終了処理を記述する。
# この処理は以下のタイミングで実行される。
#
# (4) Server 1フェイルオーバ後、クラスタシャットダウン
# (5) Group A と Group C の移動
#
# 実行サーバ環境変数を参照して処理の振り分けを行う。
if [ "$CLP_SERVER" = "HOME" ]
then
# ここに、フェイルオーバ後、プライマリサーバで業務が終了される場合にのみ行いたい処理を記述する。
#
else
# ここに、フェイルオーバ後、非プライマリサーバで業務が終了される場合にのみ行いたい処理を記述する。
# この処理は以下のタイミングで実行される。
#
# (4) Server 1フェイルオーバ後、クラスタシャットダウン
# (5) Group A と Group C の移動
#
fi
else
# ここに、ディスク関連のエラー処理を記述する。
#
fi
else
# CLUSTERPROは動作していない。
fi
# 終了コードが0の場合、EXECリソースの非活性処理は成功と判定される。
# スクリプト内でエラーが発生した場合には 0以外の終了コードを返却するように記述する。
exit 0
3.6.7. EXEC リソーススクリプト作成のヒント¶
以下の点に注意して、スクリプトを作成してください。
スクリプト中にて、実行に時間を必要とするコマンドを実行する場合には、コマンドの実行が完了したことを示すトレースを残すようにしてください。この情報は、問題発生時、障害の切り分けを行う場合に使用することができます。トレースを残す方法は下記の 2 つがあります。
- スクリプト中に [echo] コマンドを記述して EXEC リソースのログ出力先を設定する方法トレースを [echo] コマンドにて標準出力することができます。その上で、スクリプトが属しているリソースのプロパティでログ出力先を設定します。デフォルトではログ出力されません。ログ出力先の設定については「詳細タブ」の「EXEC リソース調整プロパティ」にある「メンテナンスタブ」を参照してください。[ローテートする]チェックボックスがオフの場合は、ログ出力先に設定されたファイルには、サイズが無制限に出力されますのでファイルシステムの空き容量に注意してください。
(例:スクリプト中のイメージ)
echo "appstart.." appstart echo "OK"
- スクリプト中に clplogcmd を記述する方法clplogcmd で Cluster WebUI のアラートログや OS の syslog に、メッセージを出力できます。clplogcmd については、本ガイドの「8. CLUSTERPRO コマンドリファレンス」の「メッセージを出力する (clplogcmd コマンド)」を参照してください。
(例:スクリプト中のイメージ)
clplogcmd -m "appstart.." appstart clplogcmd -m "OK"
3.6.8. EXEC リソース 注意事項¶
スクリプトのログローテート機能について
スクリプトのログローテート機能を有効にした場合、ログ出力を仲介するプロセス(仲介プロセス)が生成されます。仲介プロセスは、「開始・停止スクリプト」および「開始・停止スクリプトから標準出力・標準エラー出力のいずれかまたは両方を継承した子孫プロセス」からのログ出力が全て停止 (ファイルディスクリプタがクローズ) するまで動作を継続します。子孫プロセスの出力をログから除外する場合は、スクリプトからのプロセス生成時に標準出力および標準エラー出力をリダイレクトしてください。
開始スクリプト/終了スクリプトはroot ユーザで実行されます。
環境変数に依存するアプリケーションを起動する際には必要に応じてスクリプト側で環境変数の設定を行っていただく必要があります。
3.6.9. 詳細タブ¶
ユーザアプリケーション
スクリプトとしてサーバ上の実行可能ファイル (実行可能なシェルスクリプトやバイナリファイル) を使用します。各実行可能ファイル名は、サーバ上のローカルディスクのパスで設定します。
各実行可能ファイルは、各サーバに配布されません。各サーバ上に準備する必要があります。Cluster WebUI のクラスタ構成情報には含まれません。スクリプトファイルは Cluster WebUI では編集できません。
この製品で作成したスクリプト
スクリプトとして Cluster WebUI で準備したスクリプトファイルを使用します。必要に応じてCluster WebUI でスクリプトファイルを編集できます。スクリプトファイルは、クラスタ構成情報に含まれます。
表示
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを表示します。
編集
[この製品で作成したスクリプト] を選択した場合に、スクリプトファイルを編集します。変更を反映するには [保存] をクリックしてください。スクリプトファイル名の変更はできません。
[ユーザアプリケーション] を選択している場合は [アプリケーション・パスの入力] ダイアログボックスが表示されます。
アプリケーション・パスの入力
EXEC リソースの実行可能ファイル名を設定します。
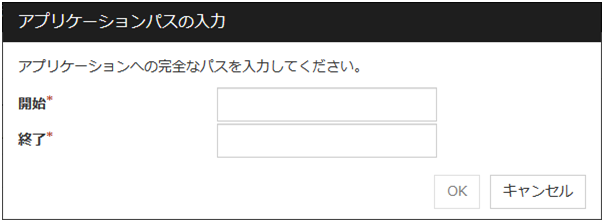
開始 (1023 バイト以内)
EXEC リソースの開始時の実行可能ファイル名を設定します。「/」 で始まる必要があります。引数を指定することも可能です。
終了 (1023 バイト以内)
EXEC リソースの終了時の実行可能ファイル名を設定します。「/」 で始まる必要があります。終了スクリプトは省略可能です。
実行可能ファイル名はクラスタサーバ上のファイルを 「/」 から始まる完全なパス名で設定する必要があります。引数を指定することも可能です。
置換
[この製品で作成したスクリプト] を選択した場合に、[ファイル選択] ダイアログボックスが表示されます。
[リソースのプロパティ] で選択したスクリプトファイルの内容が、[ファイル選択] ダイアログボックスで選択したスクリプトファイルの内容に置換されます。スクリプトが表示中または編集中の場合は置換できません。ここではスクリプトファイルを選択してください。バイナリファイル (アプリケーションなど) は選択しないでください。
調整
EXEC リソース調整プロパティダイアログを表示します。EXEC リソースの詳細設定を行います。EXEC リソースを PID モニタリソースで監視するには、開始スクリプトの設定を非同期にする必要があります。
EXEC リソース調整プロパティ
パラメータタブ
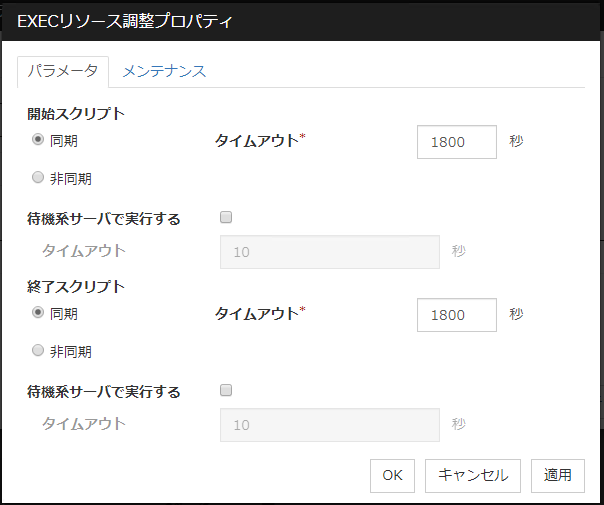
[開始スクリプト]、[終了スクリプト] 全スクリプト共通
同期
スクリプトの実行時にスクリプトの終了を待ちます。常駐しない (実行後に処理がすぐ戻る) 実行可能ファイルの場合に選択します。
非同期
スクリプトの実行時にスクリプトの終了を待ちません。常駐する実行可能ファイルの場合に選択します。EXEC リソースの開始スクリプトを非同期で実行する場合は、PID モニタリソースで監視できます。
タイムアウト (1~9999)
スクリプトの実行時に終了を待つ場合 ([同期]) のタイムアウトを設定します。[同期] を選択している場合のみ入力可能です。設定時間内にスクリプトが終了しないと、異常と判断します。
待機系サーバで実行する
スクリプトを待機系サーバで実行するか否かを設定します。本パラメータを有効にした場合、待機系サーバで実行する際のタイムアウト (1~9999) が設定可能となります。
メンテナンスタブ
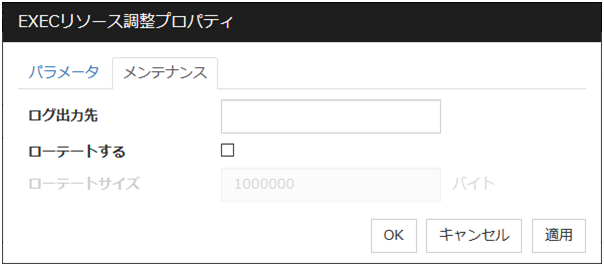
ログ出力先 (1023バイト以内)
EXEC リソースのスクリプトや実行可能ファイルの標準出力と標準エラー出力のリダイレクト先を指定します。何も指定しない場合、/dev/null に出力されます。「/」 で始まる必要があります。[ローテートする]チェックボックスがオフの場合は無制限に出力されますのでファイルシステムの空き容量に注意してください。[ローテートする]チェックボックスがオンの場合は、出力されるログファイルは、ローテートします。また、以下の注意事項があります。
[ログの出力先] には 1009 バイト以内でログのパスを記述してください。1010 バイトを超えた場合、ログの出力が行えません。
ログファイルの名前の長さは 31 バイト以内で記述してください。32 バイト以上の場合、ログの出力が行えません。
ローテートする
EXEC リソースのスクリプトや実行可能ファイルの実行ログを、オフの場合は無制限のファイルサイズで、オンの場合はローテートして出力します。
ローテートサイズ (1~999999999)[ローテートする]チェックボックスがオンの場合に、ローテートするサイズを指定します。ローテート出力されるログファイルの構成は、以下のとおりです。
ファイル名
内容
[ログ出力先]指定のファイル名
最新のログです。
[ログ出力先]指定のファイル名.pre
ローテートされた以前のログです。
3.7. ディスクリソースを理解する¶
3.7.1. ディスクリソースの依存関係¶
既定値では、以下のグループリソースタイプに依存します。
グループリソースタイプ |
|---|
ダイナミック DNS リソース |
フローティング IP リソース |
仮想 IP リソース |
ボリュームマネージャリソース |
AWS Elastic IPリソース |
AWS 仮想IPリソース |
AWS DNS リソース |
Azure プローブポートリソース |
Azure DNS リソース |
3.7.2. 切替パーティションとは?¶
注釈
ディスクタイプが「raw」の場合には、CLUSTERPRO が切替パーティションを OS の raw デバイスにマップ (bind) することで実現しています。また、ディスクリソース調整プロパティの[アンバインドを実行する]チェックボックスがオンの場合には、ディスクリソース非活性時にアンバインド処理を行います。
切替パーティションが全サーバで、同じデバイス名でアクセスできない場合は、サーバ個別設定を行ってください。
図 3.70 切替パーティション (1)¶
図 3.71 切替パーティション (2)¶
3.7.3. ディスクリソース制御下のデバイス領域拡張方法¶
対象デバイスの領域拡張は以下の手順で行ってください。 なお、以下の手順は必ず、該当ディスクリソースが活性しているサーバ上にて実行してください。
該当ディスクリソースが所属するグループを、clpgrp コマンド等で非活性にしてください。
ディスクが mount されていないことを、mount コマンドや df コマンドを使用して確認します。
- 該当ディスクリソースの種類に応じて、以下のコマンドを実行してディスクを Read Only から Read Write の状態にします。
# clproset -w -d (デバイス名)
デバイスの領域拡張を実施します。
- 該当ディスクリソースの種類に応じて、以下のコマンドを実行して、ディスクを Read Write から Read Only の状態にします。
# clproset -o -d (デバイス名)
該当ディスクリソースが所属するグループを、clpgrp コマンド等で活性にしてください。
3.7.4. ディスクリソースに関する注意事項¶
<ディスクリソース全般>
ファイルシステムのアクセス制御 (mount/umount) は、CLUSTERPRO が行いますので、OS 側で mount/umount する設定を行わないでください。また、共有ディスクのファイルシステムを OS の /etc/fstab にエントリしないでください。(/etc/fstabへのエントリが必要な場合には、ignoreオプションは使用せずnoautoオプションを使用してください。)
ディスクリソースに設定されたパーティションデバイス名はクラスタ内の全サーバでリードオンリーの状態になります。グループを活性するサーバで、活性時にリードオンリーは解除されます。
クラスタプロパティの [拡張] タブで、[マウント、アンマウントコマンドを排他する] にチェックを入れている場合、ディスクリソース、NAS リソース、ミラーリソースの mount/umount は同一サーバ内で排他的に動作するため、ディスクリソースの活性/非活性に時間がかかることがあります。
- マウントポイントにシンボリックリンクを含むパスを指定すると、異常検出時の動作に [強制終了] を選択しても強制終了できません。また、同様に「//」を含むパスを指定した場合にも、強制終了できません。
OS 起動時にデバイス順序の入れ替わりを防止するには、udevデバイス(例:/dev/disk/by-id/[デバイス名])をデバイス名に設定してください。
OS 上でランレベルの変更操作を行った際、デバイスのパスの故障/復旧が発生した際などに、ディスクリソースに設定されたパーティションデバイスのデバイスファイルが再作成され、その結果として、ディスクリソースに設定されたパーティションデバイスのリードオンリーが解除される場合があります。
<ディスクタイプ [LVM] での利用時>
本設定を利用する場合は、ボリュームマネージャリソースも併用してボリュームグループの制御を行うことを推奨します。詳細は本ガイド 「ボリュームマネージャリソースを理解する」を参照してください。
ボリュームの定義は CLUSTERPRO 側で行いません。
ファイルシステムに [zfs] を指定しないでください。
<ディスクタイプ [VXVM] での利用時>
本設定を利用する場合は、「ボリュームマネージャリソースを理解する」も参照してください。
ボリュームの定義は CLUSTERPRO 側で行いません。
ディスクグループをインポートし、ボリュームが起動された状態でアクセス可能な raw デバイス (/dev/vx/rdsk/[ディスクグループ名]/[ボリューム名]) のみを使用する場合 (ボリューム上にファイルシステムを構築しないで raw アクセスを行う場合) にはディスクリソースは不要です。
ファイルシステムに [zfs] を指定しないでください。
3.7.5. 詳細タブ¶
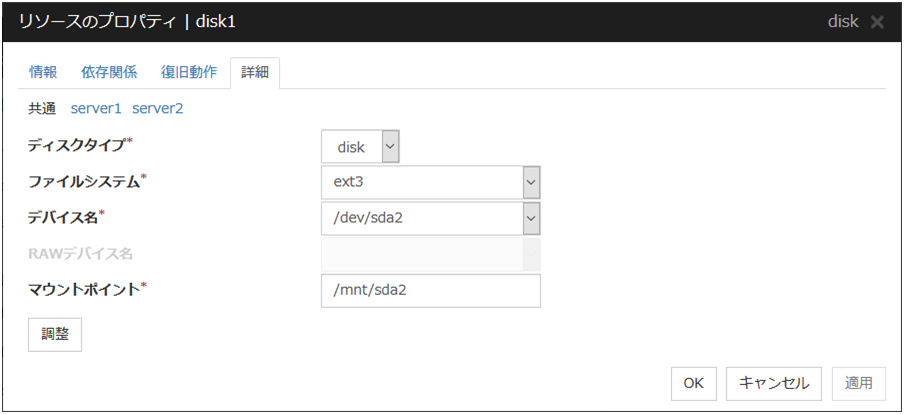
ディスクのタイプ サーバ個別設定可能
ディスクのタイプを指定します。以下の中から選択します。
disk
raw
lvm
vxvm
ファイルシステム (15バイト以内) サーバ個別設定可能
ディスクデバイス上に作成しているファイルシステムのタイプを指定します。以下の中から選択します。直接入力することもできます。[ディスクのタイプ] に [raw] 以外を設定した場合に設定が必要になります。
ext3
ext4
xfs
reiserfs
vxfs
zfs
デバイス名 (1023バイト以内) サーバ個別設定可能
ディスクリソースとして使用するディスクデバイス名を選択します。直接入力することもできます。[ファイルシステム] が [zfs] 以外の場合は 「/」 で始まる必要があります。[ファイルシステム] が [zfs] の場合はZFSデータセット名を指定します。
RAWデバイス名 (1023バイト以内) サーバ個別設定可能
ディスクリソースとして使用する RAW ディスクデバイス名を設定します。[ディスクのタイプ] が[raw] または [vxvm] の場合に設定が必要になります。
マウントポイント (1023バイト以内) サーバ個別設定可能
ディスクデバイスをマウントするディレクトリを設定します。「/」 で始まる必要があります。 [ディスクのタイプ] が [raw] 以外の場合に設定が必要になります。
調整
[ディスクリソース調整プロパティ] ダイアログボックスを表示します。ディスクリソースの詳細設定を行います。
ディスクリソース調整プロパティ([ディスクのタイプ] が [raw] 以外の場合)
マウントタブ
マウントに関する詳細設定が表示されます。
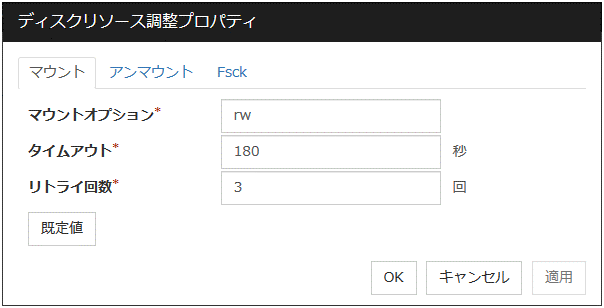
マウントオプション (1023バイト以内)
ディスクデバイス上のファイルシステムをマウントする場合に [mount] コマンドへ渡すオプションを設定します。複数のオプションは [,(カンマ)] で区切ります。
マウントオプションの例
設定項目
設定値
デバイス名
/dev/sdb5
マウントポイント
/mnt/sdb5
ファイルシステム
ext3
マウントオプション
rw,data=journal
上記設定時に実行される [mount] コマンド
mount -t ext3 -o rw,data=journal /dev/sdb5 /mnt/sdb5
タイムアウト (1~999)
ディスクデバイス上のファイルシステムをマウントする場合の [mount] コマンドの終了を待つタイムアウトを設定します。ファイルシステムの容量が大きいと時間がかかる場合があります。設定する値が小さすぎないように注意してください。
リトライ回数 (0~999)
ディスクデバイス上のファイルシステムのマウントに失敗した場合のマウントリトライ回数を設定します。0 を設定するとリトライを実行しません。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
アンマウントタブ
アンマウントに関する詳細設定が表示されます。
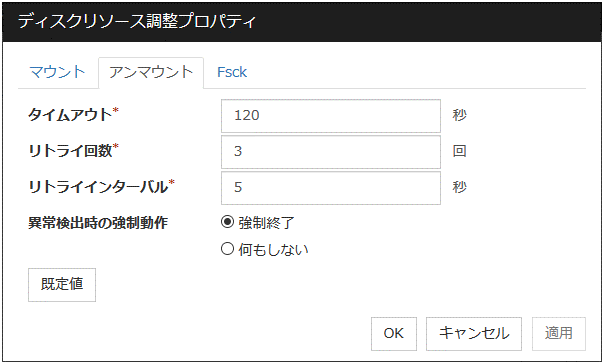
タイムアウト (1~999)
ディスクデバイス上のファイルシステムをアンマウントする場合の、[umount] コマンドの終了を待つタイムアウトを設定します。
リトライ回数 (0~999)
ディスクデバイス上のファイルシステムのアンマウントに失敗した場合の、アンマウントリトライ回数を指定します。0 を設定するとリトライを実行しません。
リトライインターバル (0~999)
ディスクデバイス上のファイルシステムのアンマウントに失敗した場合に、次のリトライを実行するまでの間隔を指定します。
異常検出時の強制動作
アンマウントに失敗後、アンマウントリトライする場合に実行する動作を下記より選択します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
Fsckタブ
[fsck] に関する詳細設定が表示されます。ファイルシステムに[xfs] 以外を指定した場合に表示されます。ファイルシステムに [zfs] を指定した場合には無効となります。
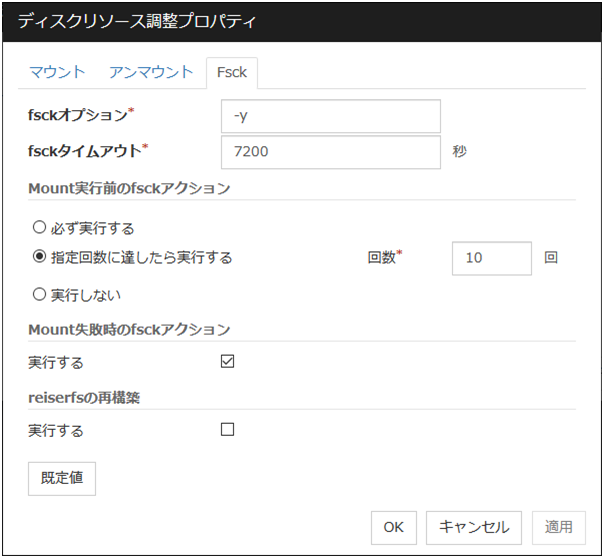
fsckオプション (1023バイト以内)
ディスクデバイス上のファイルシステムをチェックする場合に [fsck] コマンドに渡すオプションを指定します。複数のオプションはスペースで区切って設定してください。ここで、[fsck] コマンドが対話形式にならないようにオプションを指定してください。[fsck] コマンドが対話形式になると、[fsck タイムアウト] が経過後リソースの活性がエラーになります。ファイルシステムが[reiserfs] の場合は対話形式になりますが、CLUSTERPRO が "Yes" を [reiserfsck] に渡すことによって回避します。
fsckタイムアウト (1~9999)
ディスクデバイス上のファイルシステムをチェックする場合に [fsck] コマンドの終了を待つタイムアウトを指定します。ファイルシステムの容量が大きいと時間がかかる場合があります。設定する値が小さすぎないように注意してください。
Mount実行前のfsckアクション
ディスクデバイス上のファイルシステムをマウントする前の [fsck] の動作を下記より選択します。
注釈
[fsck] の指定回数はファイルシステムが管理しているチェックインターバルとは無関係です。
Mount失敗時のfsckアクション
ディスクデバイス上のファイルシステムのマウントに失敗した場合の [fsck] の動作を設定します。この設定は [マウントリトライ回数] の設定値が 0 以外の場合に有効になります。
注釈
Mount 実行前の [fsck アクション] が [実行しない] の場合との組み合わせは推奨しません。この設定では、ディスクリソースは [fsck] を実行しないため、切替パーティションに [fsck]で修復可能な異常があった場合、ディスクリソースをフェイルオーバできません
reiserfsの再構築
[reiserfsck] が修復可能なエラーで失敗した場合の挙動を指定します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
xfs_repairタブ
[xfs_repair] に関する詳細設定が表示されます。ファイルシステムに[xfs] を設定した場合のみ表示されます。
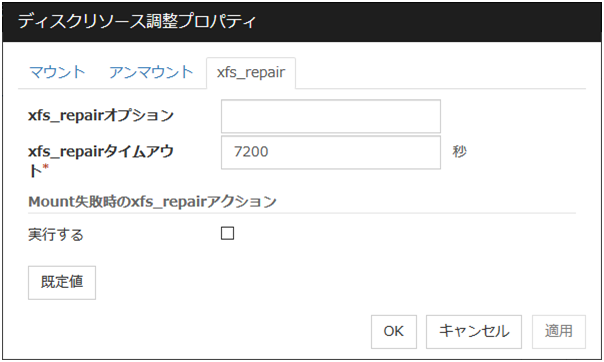
xfs_repairオプション (1023バイト以内)
ディスクデバイス上のファイルシステムをチェックする場合に [xfs_repair] コマンドに渡すオプションを指定します。複数のオプションはスペースで区切って設定してください。
xfs_repairタイムアウト (1~9999)
ディスクデバイス上のファイルシステムをチェックする場合に [xfs_repair] コマンドの終了を待つタイムアウトを指定します。ファイルシステムの容量が大きいと時間がかかる場合があります。設定する値が小さすぎないように注意してください。
Mount失敗時のxfs_repairアクション
ディスクデバイス上のファイルシステムのマウントに失敗した場合の [xfs_repair] の動作を設定します。この設定は [マウントリトライ回数] の設定値が 0 以外の場合に有効になります。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
ディスクリソース調整プロパティ([ディスクのタイプ] が [raw] の場合)
アンバインドタブ
アンバインドに関する詳細設定が表示されます。
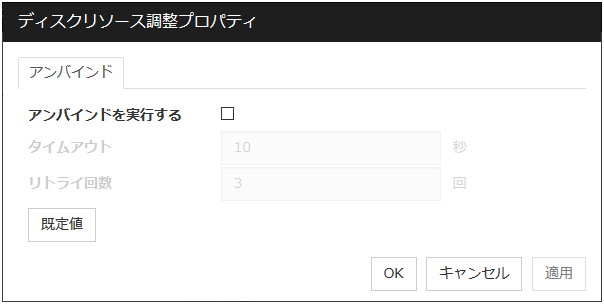
アンバインドを実行する
RAWディスクデバイスのアンバインド実行有無を指定します。
タイムアウト (1~999)
[アンバインドを実行する]チェックボックスがオンの場合に、RAWディスクデバイスのアンバインド処理の終了を待つタイムアウトを設定します。
リトライ回数 (1~999)
[アンバインドを実行する]チェックボックスがオンの場合に、RAWディスクデバイスのアンバインド処理に失敗した場合の、アンバインドリトライ回数を指定します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
3.8. フローティング IP リソースを理解する¶
3.8.1. フローティング IP リソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.8.2. フローティング IP とは?¶
クライアントアプリケーションは、フローティング IP アドレスを使用してクラスタサーバに接続することができます。フローティング IP アドレスを使用することにより、"フェイルオーバ" または、"グループの移動" が発生しても、クライアントは、接続先サーバの切り替えを意識する必要がありません。
フローティング IP アドレスは、同一 LAN 上でもリモート LAN からでも使用可能です。
[ifconfig] コマンドもしくは API を実行し、OS に IP アドレスを付与します。[ifconfig] コマンドもしくは API のどちらを実行するかは、フローティング IP リソースが自動的に判定します。[ifconfig] コマンドが以下のフォーマット以外の場合はAPI を実行します。
eth0 Link encap:Ethernet HWaddr 00:50:56:B7:1B:C0
inet addr:192.168.1.113 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::250:56ff:feb7:1bc0/64 Scope:Link
:
ClientはフローティングIP(FIP)によって Server 1へアクセスします。
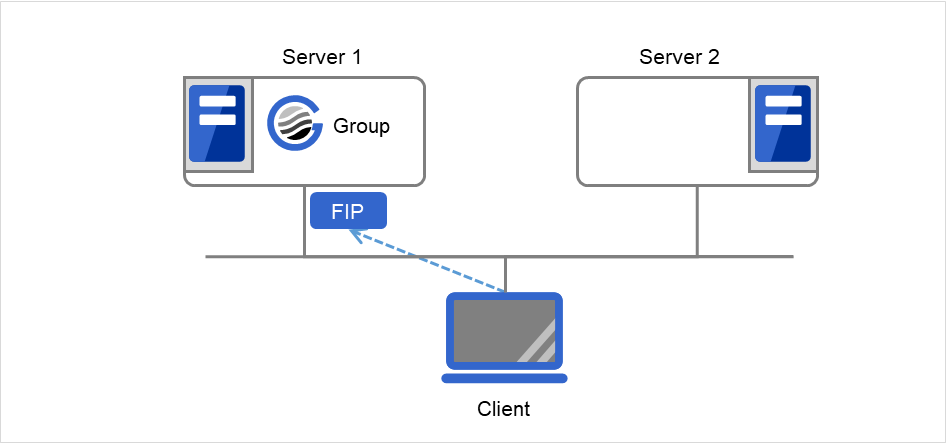
図 3.72 フローティングIPによるアクセス (1)¶
Server 1からServer 2へのフェイルオーバが発生しても、Clientからの接続先はFIPであり、接続先サーバが変わったことを意識する必要はありません。
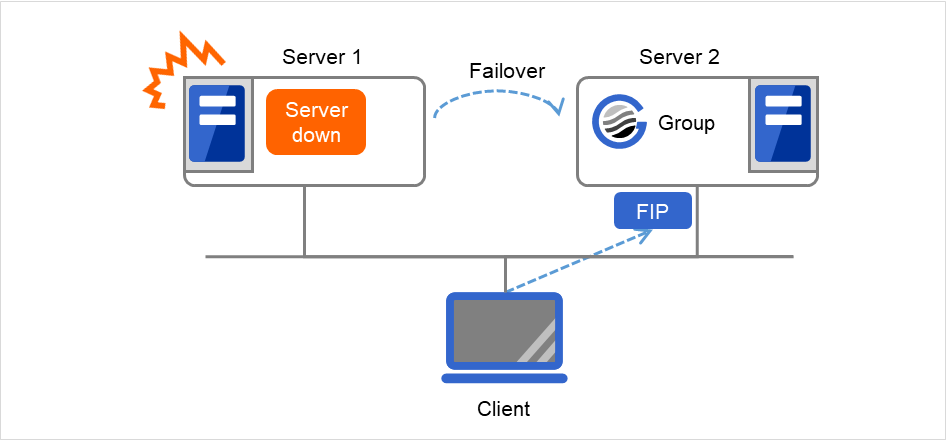
図 3.73 フローティングIPによるアクセス (2)¶
アドレスの割り当て
フローティングIP アドレスに割り当てるIP アドレスは、以下の条件を満たす必要があります。
クラスタサーバが所属する LAN と同じネットワークアドレス内でかつ使用していないホストアドレス
この条件内で必要な数 (一般的にはフェイルオーバグループ数分) の IP アドレスを確保してください。この IP アドレスは一般のホストアドレスと変わらないため、インターネットなどのグローバル IP アドレスから割り当てることも可能です。
切替方式の仕組み
IPv4 の場合、FIP リソースが活性するサーバからの ARP ブロードキャストを送信することにより、ARP テーブル上の MAC アドレスが切り替わります。
IPv6 の場合、ARP ブロードキャストは送信しません。
以下はCLUSTERPRO が送信する ARP ブロードキャストパケットの内容です。

図 3.74 CLUSTERPRO が送信する ARP ブロードキャストパケット¶
経路制御
ルーティングテーブルの設定は不要です。
使用条件
以下のマシンからフローティング IP アドレスにアクセスできます。
クラスタサーバ自身
同一クラスタ内の他のサーバ、他のクラスタシステム内のサーバ
クラスタサーバと同一 LAN 内およびリモート LAN のクライアント
さらに以下の条件であれば上記以外のマシンからでもフローティング IP アドレスが使用できます。ただし、すべてのマシン、アーキテクチャの接続を保障できません。事前に充分に評価をしてください。
通信プロトコルが TCP/IP、もしくはSCTP/IP であること
ARP プロトコルをサポートしていること
スイッチング HUB により構成された LAN であっても、フローティング IP アドレスのメカニズムは問題なく動作します。
サーバダウン時には、接続していた TCP/IP コネクションは切断されます。
3.8.3. フローティング IP リソースに関する注意事項¶
フローティング IP リソースが活性しているサーバでネットワーク再起動を実行しないでください。ネットワークを再起動するとフローティング IP リソースが追加した IP アドレスが削除されます。
- [ifconfig] コマンドのタイムラグによる IP アドレス重複についてフローティング IP リソースで以下の設定の場合、リソースのフェイルオーバに失敗することがあります。
[活性リトライしきい値] に既定値より小さい値を設定している場合
[Ping リトライ回数]、[Ping インターバル] を設定していない場合
この現象は以下の原因で発生します。
フェイルオーバ元となるサーバでフローティング IP アドレスを非活性後、[ifconfig] コマンドの仕様により IP アドレスの解放に時間がかかることがある
フェイルオーバ先のサーバからフローティング IP アドレスに対する [ping] コマンドが到達すると、リソース活性異常となる(二重活性を防止するため)
この現象は以下の設定により回避できます。
リソースの [活性リトライしきい値] を大きくする (既定値 5 回)
[Ping リトライ回数]、[Ping インターバル] を大きくする
ClientはフローティングIP(FIP)によって Server 1へアクセスします。
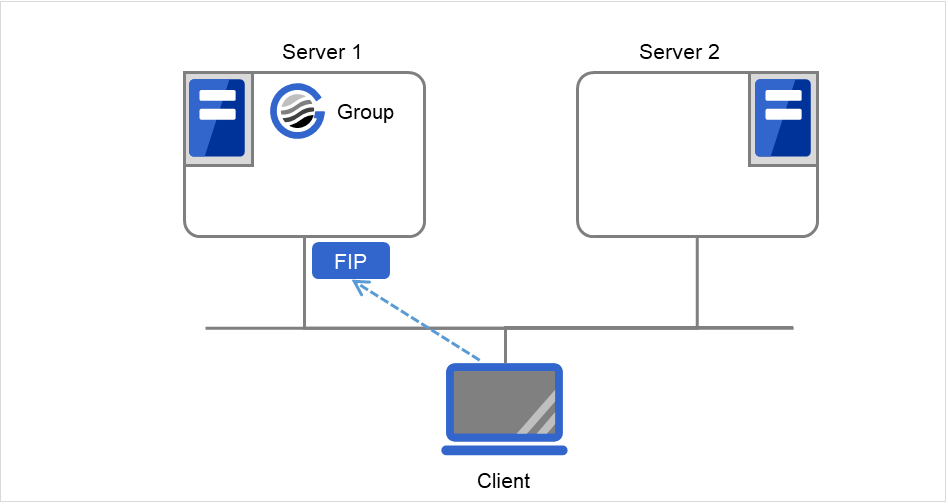
図 3.75 フローティングIP構成 (1)(通常時)¶
Server 1がダウンし、フェイルオーバが発生します。しかし、Server 1側でフローティングIPアドレス(FIP)の開放に時間がかかり、その間、Server 2から FIPへのpingが到達するため、FIPの重複と判断して、Server 2での活性は失敗します(ClientからFIPへのアクセス不可)。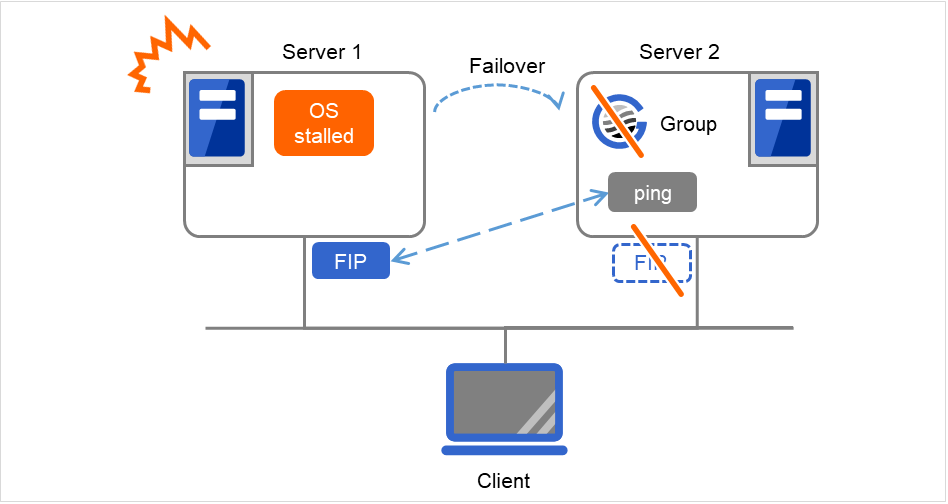
図 3.76 フローティングIP構成 (2)(フェイルオーバ失敗)¶
- OS ストール時の IP アドレス重複についてフローティング IP アドレスを活性した状態で OS のストールが発生した場合、以下の設定の場合にリソースのフェイルオーバに失敗することがあります。
[Ping タイムアウト] に 0 以外を指定した場合
[FIP 強制活性] が OFF の場合
この現象は以下の原因で発生します。
フローティング IP アドレスを活性した状態で以下のような OS の部分的なストールが発生
ネットワークモジュールは動作し、他ノードからの ping に反応する状態
ユーザ空間モニタリソースでストール検出不可の状態
フェイルオーバ先のサーバでフローティング IP アドレスの活性時に、二重活性防止のために活性予定のフローティング IP アドレスに対して [ping] コマンドを実行すると、上記のために ping が到達し、リソース活性異常となる
この現象が多発するマシン環境では、以下の設定により回避できます。ただし、フェイルオーバ後、ストールの状況によってはグループの両系活性が発生することがあり、タイミングによってサーバシャットダウンが起こるので注意してください。両系活性の詳細は『メンテナンスガイド』の「保守情報」の「サーバダウンの発生条件」の「ネットワークパーティションからの復帰」を参照してください。
- [Ping タイムアウト] に 0 を設定するフローティング IP アドレスに対して重複確認を行いません。
- [FIP 強制活性] を On に設定するフローティング IP アドレスが他のサーバで使用されている場合でも、強制的にフローティング IP アドレスを活性します。
pingタイムアウトの設定が0以外かつFIP強制活性がOFFの場合
Server 1のOSがストールしたため、FIPが活性状態のままフェイルオーバが発生します。 しかしその直後は、Server 2でFIP活性前に実行したpingコマンドに対して応答が返ります。 そのため、二重活性が発生することのないよう、Server 2におけるFIP活性は失敗します。
図 3.77 pingタイムアウトの設定が0以外かつFIP強制活性がOFFの場合¶
pingタイムアウトが0の場合
Server 1のOSがストールしたため、FIPが活性状態のままフェイルオーバが発生します。 Server 2ではFIPに対するpingコマンドを実行せず、Server 2におけるFIP活性は成功します。
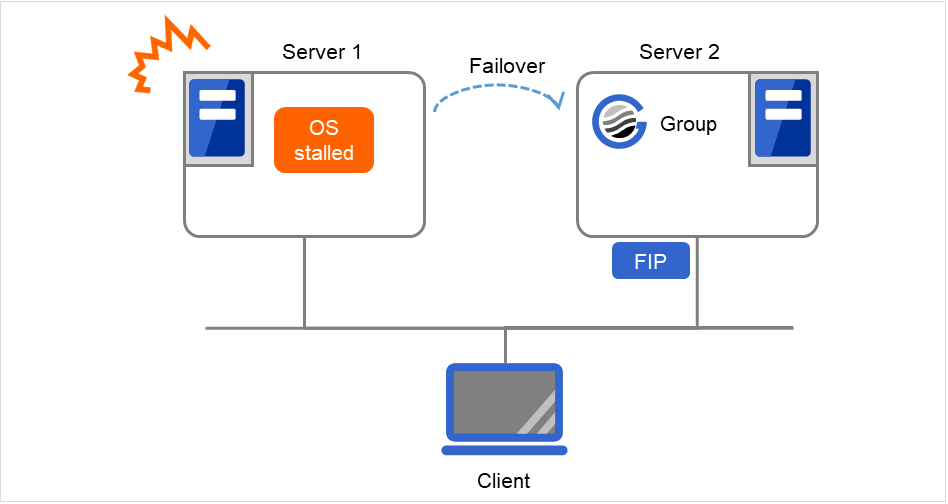
図 3.78 pingタイムアウトが0の場合¶
pingタイムアウトの設定が0以外かつFIP強制活性がONの場合
Server 1のOSがストールしたため、FIPが活性状態のままフェイルオーバが発生します。 Server 2ではFIPに対するpingコマンドを実行しますが、その結果に関係なく、Server 2におけるFIP活性は強制的に成功します。
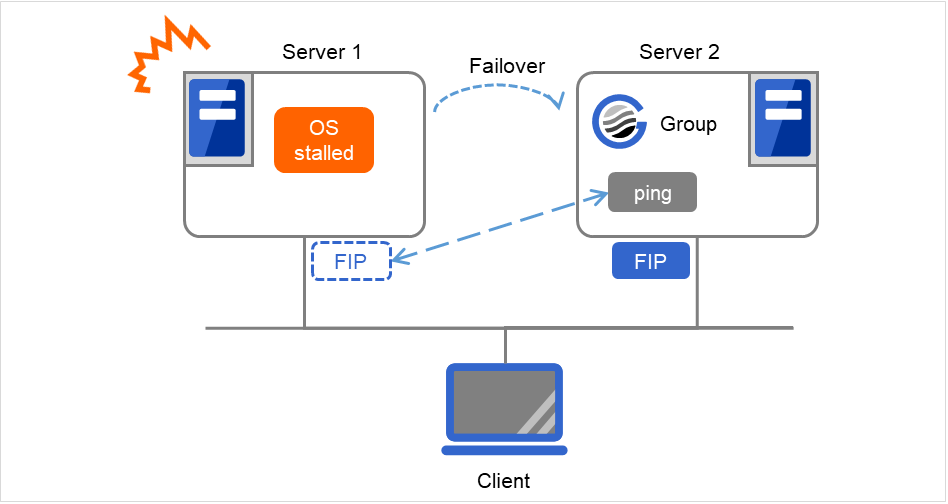
図 3.79 pingタイムアウトの設定が0以外かつFIP強制活性がONの場合¶
- フローティング IP が割り当てられる仮想 NIC の MAC アドレスについてフローティング IP が割り当てられる仮想 NIC の MAC アドレスは、実 NIC の MACアドレスとなります。そのため、フローティング IP リソースがフェイルオーバすると、対応する MAC アドレスが変更されます。
- リソース活性時の現用系サーバからの IP 通信のソースアドレスについてサーバからの IP 通信の送信元アドレスは、フローティング IP リソースが活性している場合でも基本的にサーバの実 IP となります。送信元アドレスをフローティング IP に変更したい場合はアプリケーション側で設定が必要です。
FIP強制活性をオンに設定した場合、フローティング IP アドレスを起動した後に同じネットワークセグメント上のマシンからフローティング IP アドレスに接続すると、先に存在していた IP アドレスのマシンに接続することがあります。
フローティング IP リソースは OpenVPN が起動している環境での動作に対応しておりません。
フローティング IP リソースでは、IPアドレスを付与する NIC 名(ネットワークインタフェース名、例:eth0)の長さは15文字が上限です。15文字を超える場合は、活性異常になります。その際は NIC 名(ネットワークインタフェース名)を見直してください。
フローティング IP リソースは活性する前に、重複した IP アドレスがないかチェックするために [ping] を発行しています。このため、重複 IP アドレスを保持するネットワーク機器がファイアウォールなどで ICMP の受信拒否を設定している場合は [ping] コマンドを使用した重複 IP アドレスの確認が行えないため、フローティングIPアドレスが重複することがあります。
3.8.4. フローティング IP リソース非活性待ち合わせ処理¶
フローティング IP アドレスの非活性化を実行した後に以下の処理を行います。
待ち合わせ処理
[ifconfig] コマンドもしくは API を実行し、OS に付加されている IP アドレスの一覧を取得します。[ifconfig] コマンドもしくは API のどちらを実行するかは、フローティング IP リソースが自動的に判定します。IP アドレスの一覧にフローティング IP アドレスが存在しなければ非活性と判断します。
IP アドレスの一覧にフローティング IP アドレスが存在する場合は、 1 秒間待ち合わせます。待ち合わせ時間は Cluster WebUI では変更できません。
上記の処理を最大 4 回繰り返します。この回数は Cluster WebUI で変更できません。
この結果が異常となった場合にフローティング IP リソースを非活性異常とするかしないかは、フローティング IP リソースの非活性確認タブの [I/F の削除確認を行う] の [異常検出時のステータス] で変更します。
[ping] コマンドによる非活性確認処理
[ping] コマンドを実行し、フローティング IP アドレスからの応答有無を確認します。フローティング IP アドレスから応答がなければ非活性と判断します。
フローティング IP アドレスから応答がある場合は、1 秒間待ち合わせます。待ち合わせ時間は Cluster WebUI では変更できません。
上記の処理を最大 4 回繰り返します。この回数は Cluster WebUI で変更できません。
[ping] コマンドはタイムアウト 1 秒で実行します。このタイムアウトは Cluster WebUI で変更できません。
この結果が異常となった場合にフローティング IP リソースを非活性異常とするかしないかは、フローティング IP リソースの非活性確認タブの [I/F の応答確認を行う] の [異常検出時のステータス] で変更します。
注釈
3.8.5. 詳細タブ¶
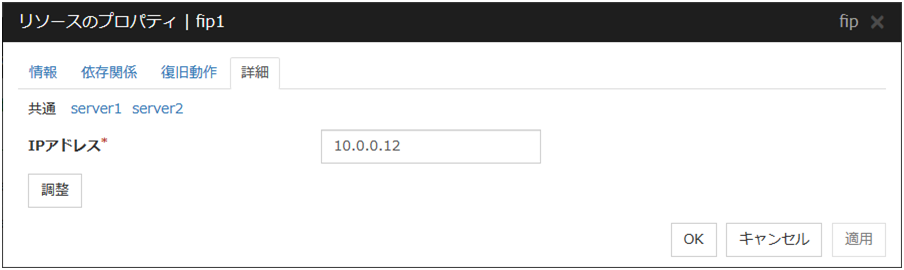
IPアドレス サーバ個別設定可能
使用するフローティング IP アドレスを入力します。bonding の設定を行った場合、環境によっては bonding のマスターインターフェースに設定したIPアドレスがスレーブインターフェースにも表示される場合があります。上記のような環境で bonding のマスターインターフェースにフローティングIPアドレスを設定する場合、IPアドレスの後ろに "%" で区切って bonding デバイスを指定してください。詳しくは本ガイドの「7. その他の設定情報」の「bonding」を参照してください。
bonding を設定する場合の例 : 10.0.0.12%bond0
フローティング IP リソースは、既定値ではマスクビット数を IPv4の場合は24bit、IPv6の場合は128bit として、ローカルコンピュータ上のサブネットマスクが一致するアドレスを検索し、該当するネットワークインタフェースにエイリアスを付与してフローティング IP アドレスを追加します。
マスクビット数を明示的に指定する場合は、アドレスの後、[/マスクビット数] を指定します。(IPv6アドレスの場合は必ず[/マスクビット数]を指定してください)
例) 10.0.0.12/8、 fe80::1/8
ネットワークインタフェースを明示的に指定する場合、アドレスの後、[%インタフェース名] を指定します。
例) 10.0.0.12%eth1、fe80::1/8%eth1
上記の例ではネットワークインタフェースeth1 にマスクビット数8のフローティング IP アドレスを追加します。
tagVLAN を設定するときは "%" で区切って tagVLAN の I/F 名を指定してください。
tagVLAN を設定する場合の例 : 10.0.0.12%eth0.1
IPv6アドレスかつ[ifconfig] コマンドが利用可能な環境の場合、大文字と小文字を区別して判定するため、ifconfig コマンドの出力書式とフローティング IP の IP アドレスの書式を一致させてください。
調整
[フローティング IP リソース調整プロパティ] ダイアログボックスを表示します。フローティングIP リソースの詳細設定を行います。
フローティング IP リソース調整プロパティ
パラメータタブ
フローティング IP リソースのパラメータに関する詳細設定が表示されます。
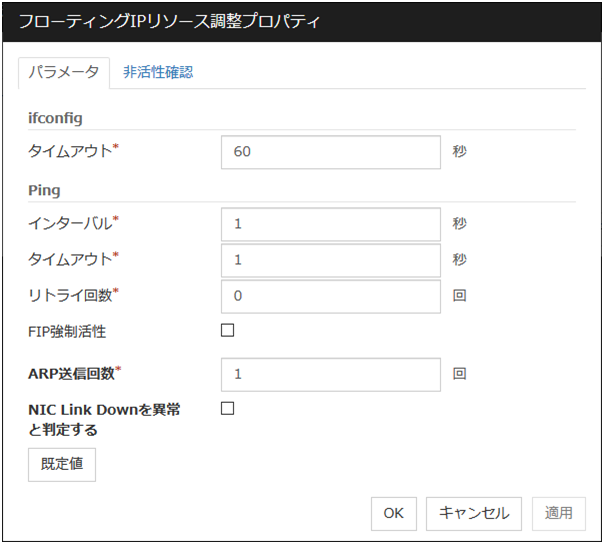
ifconfig
IP アドレス一覧の取得、および [ifconfig] コマンドによるフローティング IP リソースの活性/非活性の各処理で実行される [ifconfig] コマンドに関する詳細設定です。
ping
フローティング IP リソースを活性する前に、重複した IP アドレスがないかチェックするために発行される [ping] コマンドに関する詳細設定です。
ARP 送信回数 (0~999)
フローティング IP リソースを活性化する場合に送信する ARP パケットの送信回数を設定します。0 を設定すると ARP パケットを送信しません。
NIC Link Down を異常と判定する
フローティング IP リソースを活性する前に、NIC Link Downの確認を行うかどうかを設定します。NIC のボード、ドライバによっては、必要な ioctl( ) がサポートされていない場合があります。NIC の Link Up/Down 監視の動作可否は、各ディストリビュータが提供する [ethtool]コマンドで確認することができます。[ethtool]コマンドでの確認方法は、本ガイドの「NIC Link Up/Down モニタリソースを理解する」 - 「NIC Link Up/Down モニタリソースの注意事項」を参照してください。
bonding デバイスの場合、活性時に bonding を構成するすべての NIC が Link Down 状態であれば異常と判定します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
非活性確認タブ
フローティング IP リソースの非活性確認に関する詳細設定が表示されます。
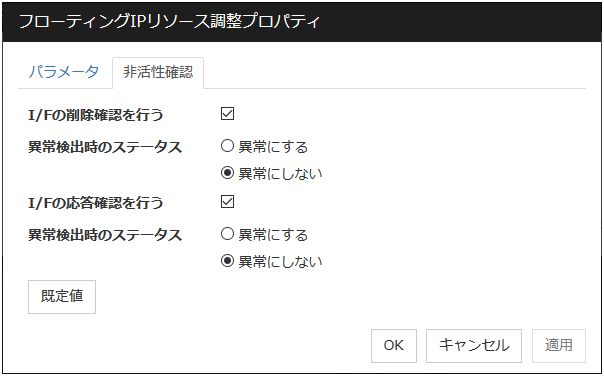
I/F の削除確認
I/F の応答確認
3.9. 仮想 IP リソースを理解する¶
3.9.1. 仮想 IP リソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.9.2. 仮想 IP とは?¶
クライアントアプリケーションは、仮想 IP アドレスを使用してクラスタサーバに接続することができます。また、サーバ間でも仮想 IP アドレスを使用しての接続が可能です。仮想 IP アドレスを使用することにより、フェイルオーバ/フェイルオーバグループの移動が発生しても、クライアントは、接続先サーバの切り替えを意識する必要がありません。
IP アドレス一覧の取得、および仮想 IP リソースの活性/非活性の各処理では[ifconfig] コマンドもしくは API を実行します。[ifconfig] コマンドもしくは API のどちらを実行するかは、仮想 IP リソースが自動的に判定します。以下に例を示します。
RHEL 7 以降(RHEL 7 互換OS含む)のように[ifconfig] コマンドが利用できない環境の場合:API を実行。
RHEL 7 以降(RHEL 7 互換OS含む)にてnet-toolsパッケージにより[ifconfig] コマンドが利用可能な環境の場合:API を実行。これは[ifconfig] コマンドの出力形式が RHEL 6 以前と互換性がないためです。
RHEL 6 のように[ifconfig] コマンドが利用可能な環境の場合:[ifconfig] コマンドを実行。
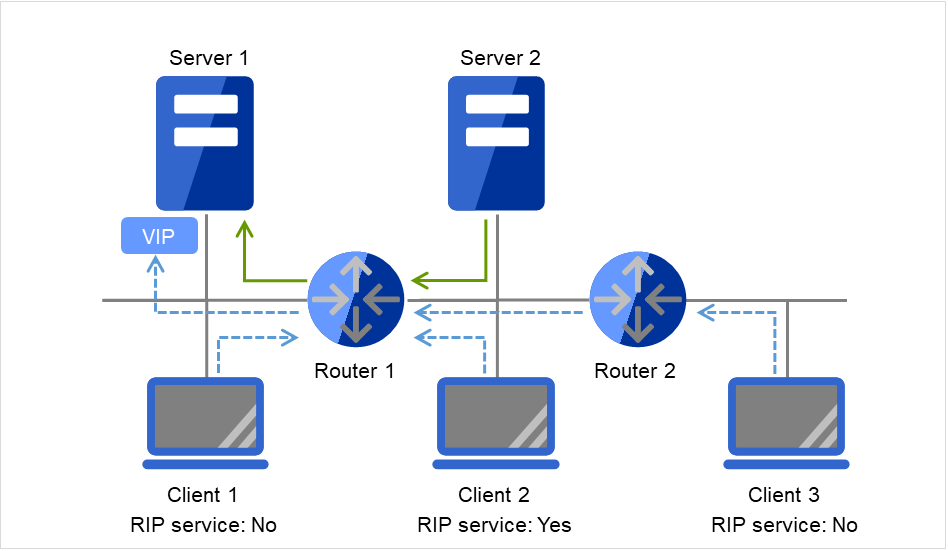
図 3.80 仮想IPを使用した構成 (1)¶
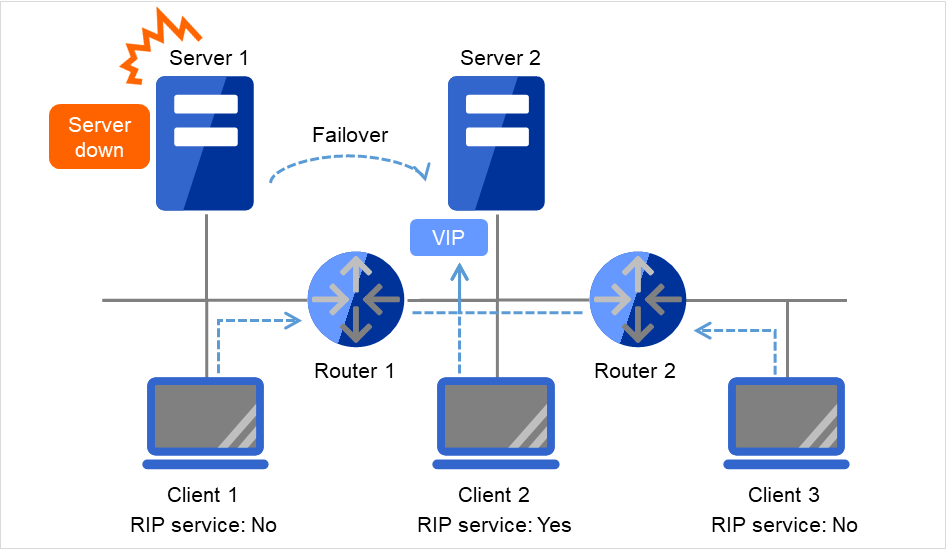
図 3.81 仮想IPを使用した構成 (2)¶
- サーバの設定事項1同一LAN内のクラスタサーバは、RIPパケットを受け取ることにより経路変更が可能か、またはルータにアクセスすることにより仮想IPアドレスの経路情報を解決できる必要があります。
- サーバの設定事項2別セグメントのクラスタサーバは、ルータにアクセスすることにより仮想IPアドレスの経路情報を解決できる必要があります。
- 仮想IPリソースの設定事項1クラスタサーバが所属するLANの、ネットワークアドレスの範囲外であり、既存のIPアドレスと衝突しないIPアドレスを設定してください。
- ルータの設定事項1各ルータは、RIPパケットを解釈して動的経路の制御が行えるか、または仮想IPアドレスの経路に関する情報が静的経路情報として解決できる必要があります。
- 仮想IPリソースの設定事項2RIPパケットを正しく送信するため、送信元IPアドレスは必ずサーバごとに設定してください。
- ルータの設定事項2各ルータのフラッシュタイマーは、ハートビートタイムアウト以内に設定してください。
- クライアントの設定事項1同一LAN内のクライアントは、RIPパケットを受け取ることにより経路変更が可能か、または ルータにアクセスすることにより仮想IPアドレスの経路情報を解決できる必要があります。
- クライアントの設定事項2別セグメントのクライアントマシンは、ルータにアクセスすることにより仮想IPアドレスの経路情報を解決できる必要があります。
3.9.3. 仮想 IP アドレスの検討¶
仮想 IP アドレスに割り当てる IP アドレスは、以下の条件を満たす必要があります。
クラスタサーバが所属する LAN の、ネットワークアドレスの範囲外である
既存のネットワークアドレスと衝突しない
この 2 つの条件を満たすために、以下の 2 つの割り当て方法で、いずれかを選択してください。
仮想 IP アドレス用に新たに正当なネットワーク IP アドレスを取得し、そこから仮想 IP アドレスを割り当てる。
プライベート IP アドレス空間から、適当なネットワーク IP アドレスを決定し、そこからそれぞれの仮想 IP アドレスを割り当てます。具体例を示すと、以下のような手順になります。
ネットワークアドレス 192.168.0~192.168.255 から、仮想 IP アドレス用に 1 つ選択します。
上記で選択したネットワークアドレスの中から、仮想 IP アドレス用のホスト IP アドレスを 64 個以内で割り当てます。(例えば、ネットワークアドレス 192.168.10 を 選択し、その中からホスト IP アドレスを 192.168.10.1 と 192.168.10.254 の 2 個を割り当てる。)
仮想 IP アドレスのネットマスクは、255.255.255.0 に設定します。
複数の仮想 IP リソースを設定する場合には、ダミー用の仮想 IP アドレスが必要になる場合があります。詳しくは、「仮想 IP リソースを使用する場合の事前準備」を参照してください。
さらに以下の点に注意が必要です。
プライベート IP アドレスは、組織内で閉じたネットワークのためのアドレスであるため、インターネットプロバイダ等を隔てた組織外から、仮想 IP アドレスを用いてアクセスはできません。
プライベート IP アドレスに関する経路情報を、組織外に流してはいけません。
プライベート IP アドレスの衝突が起こらないよう、組織内での調整が必要です。
3.9.4. 仮想 IP リソースを使用する場合の事前準備¶
クラスタ構成が以下の条件に該当する場合、各サーバに仮想 IP アドレスと同じネットワークアドレスのダミーの仮想 IP アドレスを設定する必要があります。
複数の仮想 IP リソースが存在する
ネットワークアドレスと NIC エイリアス名が同じリソースが存在する
注釈
ダミーの仮想 IP アドレスが設定できない場合、任意の仮想 IP リソースの非活性時に同じ NIC エイリアスに付与されている他の仮想 IP アドレスも OS より削除される場合があります。
ダミーの仮想 IP アドレスは、以下の条件を満たす必要があります。
仮想 IP リソースの IP アドレスと同じネットワークアドレスで、固有の IP アドレスである
クラスタを構成する各サーバ用にダミーの仮想 IP アドレスを用意できる
NIC エイリアス毎に用意する
以下の設定例の場合、各サーバにダミーの仮想 IP アドレスの設定が必要です。
- 仮想 IP リソース 1IP アドレス 10.0.1.11/24NIC エイリアス名 eth1
- 仮想 IP リソース 2IP アドレス 10.0.1.12/24NIC エイリアス名 eth1
例としてダミーの仮想 IP アドレスを以下のように設定します。
- Server 1 のダミー仮想 IP アドレスIP アドレス 10.0.1.100/24NIC エイリアス名 eth1:0
- Server 2 のダミー仮想 IP アドレスIP アドレス 10.0.1.101/24NIC エイリアス名 eth1:0
ダミーの仮想 IP アドレスが OS 起動時に有効になるように以下の手順で OS へ設定してください。
以下の手順はServer 1 の eth1 に 10.0.1.100/24 を設定する例です。
ディストリビューションごとに下記の設定を行います。
- SUSE LINUX Enterprise Server の場合下記のパスのファイルを編集し、設定内容の斜体部分を追加します。
パス
/etc/sysconfig/network/ifcfg-eth1-"eth1のMACアドレス"
設定内容
BOOTPROTO='static' BROADCAST='10.0.0.255' IPADDR='10.0.0.1' MTU='' NETMASK='255.255.255.0' NETWORK='10.0.0.0' IPADDR_1='10.0.1.100' NETMASK_1='255.255.255.0' NETWORK_1='10.0.1.0' LABEL_1=1 REMOTE_IPADDR='' STARTMODE='onboot' UNIQUE='xxxx' _nm_name='xxxx'
- SUSE LINUX Enterprise Server 以外の場合下記のパスのファイルを作成し、設定内容を追加します。
パス
/etc/sysconfig/network-scripts/ifcfg-eth1:0
設定内容
DEVICE=eth1:0 BOOTPROTO=static BROADCAST=10.0.1.255 HWADDR=eth1のMACアドレス IPADDR=10.0.1.100 NETMASK_1='255.255.255.0' NETWORK=10.0.1.0 ONBOOT=yes TYPE=Ethernet
OS を再起動します。
OS 再起動後にダミーの仮想 IP アドレスが有効になります。Server 2 も同様に設定してください。
クラスタの構成変更で上記の設定が必要になった場合は、以下の手順で行ってください。
クラスタを停止します。手順は『インストール&設定ガイド』の「運用開始前の準備を行う」 - 「CLUSTERPRO を一時停止する」 - 「CLUSTERPROデーモンの停止」を参照してください。
クラスタデーモンを無効にします。手順は『インストール&設定ガイド』の「運用開始前の準備を行う」 - 「CLUSTERPRO を一時停止する」 - 「CLUSTERPRO デーモンの無効化」を参照してください。
上記の設定を変更します。
OS を再起動して、設定が反映されていることを確認します。
クラスタデーモンを有効にします。手順は『インストール&設定ガイド』の「運用開始前の準備を行う」 - 「CLUSTERPRO を一時停止する」 - 「無効化したCLUSTERPROデーモンを有効にする」を参照してください。
クラスタの構成を変更します。手順は『インストール&設定ガイド』の「クラスタ構成情報を変更する」を参照してください。
3.9.5. 経路制御¶
リモート LAN から仮想 IP アドレスにアクセスするために、リモート LAN とクラスタサーバの LAN まで経路上の全てのルータに、仮想 IP アドレスの経路情報が有効になっていなければなりません。
具体的には、以下のような設定が必要です。
クラスタサーバの LAN 上のルータがホスト RIP を解釈する。
クラスタサーバからリモートサーバまでの経路上のルータが、全て動的経路制御であるか、または仮想 IP アドレスの経路に関する情報が、静的経路情報として設定されている。
3.9.6. 仮想 IP アドレスの使用条件¶
仮想 IP アドレスが使用できる環境
以下のマシンからは仮想 IP アドレスに正しくアクセスできます。スイッチングハブが使われたLAN であっても、仮想 IP アドレスメカニズムは問題なく動作します。
ただし、サーバダウン時には、接続していた TCP/IP コネクションは切断されます。
ホスト形式の RIP を受信してホスト形式のルーティングテーブルを作成するように設定できないスイッチング HUB で仮想 IP アドレスを使用する場合は、ネットワークアドレスを新たに1 つ確保して、それぞれのサーバの仮想 IP アドレスが別々のネットワークアドレスに所属するように仮想 IP アドレスを設定する必要があります。
仮想 IP が活性するサーバと同一 LAN にあるクラスタサーバ
以下の条件を満たすものであれば、仮想 IP アドレスが使用できます。
RIP パケットを受け取ることにより経路変更が可能なマシン
ルータにアクセスすることにより仮想 IP アドレスの経路情報を解決できるマシン
仮想 IP が活性するサーバと異なる LAN にあるクラスタサーバ
以下の条件を満たすものであれば、仮想 IP アドレスが使用できます。
ルータにアクセスすることにより仮想 IP アドレスの経路情報を解決できるマシン
クラスタサーバと同一 LAN に属するクライアント
以下の条件を満たすものであれば、仮想 IP アドレスが使用できます。
RIP パケットを受け取ることにより経路変更が可能なマシン
ルータにアクセスすることにより仮想 IP アドレスの経路情報を解決できるマシン
リモート LAN 上のクライアント
以下の条件を満たすものであれば、仮想 IP アドレスが使用できます。
ルータにアクセスすることにより仮想 IP アドレスの経路情報を解決できるマシン
3.9.7. 仮想 IP リソースに関する注意事項¶
仮想 IP リソースが活性しているサーバでネットワーク再起動を実行しないでください。ネットワークを再起動すると仮想 IP リソースが追加した IP アドレスが削除されます。
仮想 IP アドレスには、以下の規則があります。
- 仮想 IP リソースが正常に非活性されない場合 (サーバダウン時など)、仮想 IP リソースの経路情報が削除されません。経路情報が削除されない状態で仮想 IP リソースが活性した場合、ルータまたはルーティングデーモンが経路情報をリセットするまで仮想 IPアドレスにアクセスできません。
仮想 IP が割り当てられる仮想 NIC の MAC アドレスについて
仮想 IP が割り当てられる仮想 NIC の MAC アドレスは、実 NIC の MAC アドレスとなります。そのため、仮想 IP リソースがフェイルオーバすると、対応する MAC アドレスが変更されます。
リソース活性時の現用系サーバからの IP 通信のソースアドレスについて
サーバからの IP 通信の送信元アドレスは、仮想 IP リソースが活性している場合でも基本的にサーバの実 IP となります。送信元アドレスを仮想 IP に変更したい場合はアプリケーション側で設定が必要です。
使用するルーティングプロトコルについて
使用するルーティングプロトコルを「RIPver2」に設定した場合、送出するRIPパケット内のサブネットマスクは「255.255.255.255」となります。
3.9.8. 詳細タブ¶
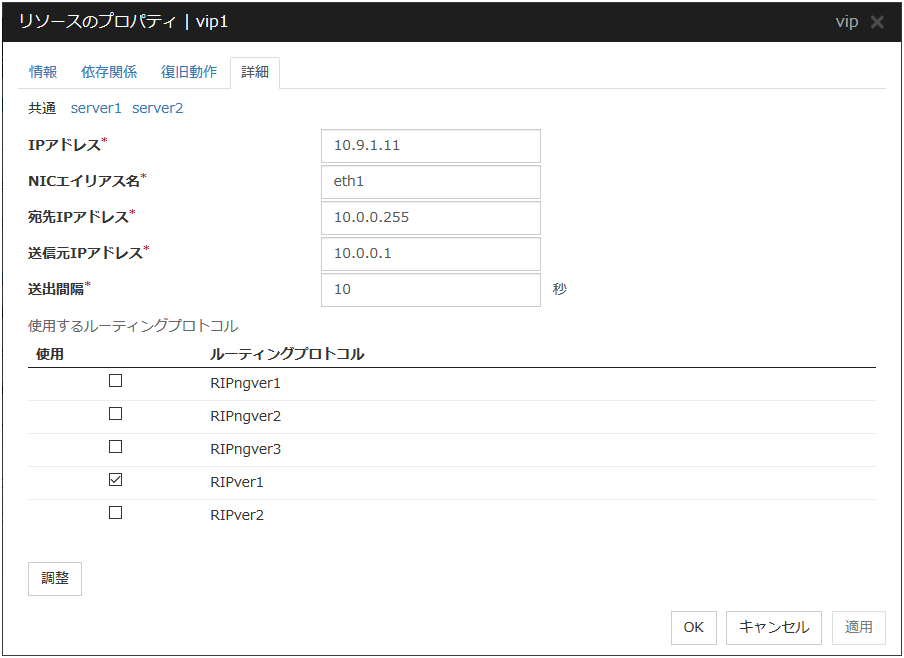
IPアドレス サーバ個別設定可能
使用する仮想 IP アドレスを入力します。マスクビット数を明示的に指定する場合は、アドレスの後、[/マスクビット数] を指定します。(IPv6アドレスの場合は必ず[/マスクビット数]を指定してください)
NICエイリアス名 サーバ個別設定可能
使用する仮想 IP アドレスを活性する NIC インタフェース名を入力します。
宛先IPアドレス サーバ個別設定可能
RIP パケットの送出先 IP アドレスを入力します。IPv4 はブロードキャストアドレス、IPv6 はルータの IPv6 アドレスを指定します。
送信元IPアドレス サーバ個別設定可能
RIP パケット送出時にバインドする IP アドレスを入力します。仮想 IP アドレスを活性するNIC で活性している実 IP アドレスを指定します。
IPv6アドレスを使用する場合は、送信元IPアドレスとしてリンクローカルアドレスを指定します。
注釈
送信元 IP アドレスは必ずサーバ個別設定を行い、各サーバの実 IP アドレスを設定してください。送信元アドレスが不正な場合、仮想 IP リソースは正常に動作しません。[共通]タブでは、任意のサーバの送信元 IP アドレスを記載し、他のサーバは個別設定を行うようにしてください。
送出間隔 (1~30) サーバ個別設定可能
RIP パケットの送出間隔を入力します。
使用するルーティングプロトコル サーバ個別設定可能
使用する RIP バージョンを入力します。IPv4 環境では RIPver1、RIPver2 から選択します。IPv6 環境では RIPngver1、RIPngver2、RIPngver3 から選択します。複数のルーティングプロトコルを選択することも可能です。
調整
[仮想 IP リソース調整プロパティ] ダイアログボックスを表示します。仮想 IP リソースの詳細設定を行います。
仮想 IP リソース調整プロパティ
パラメータタブ
仮想 IP リソースのパラメータに関する詳細設定が表示されます。
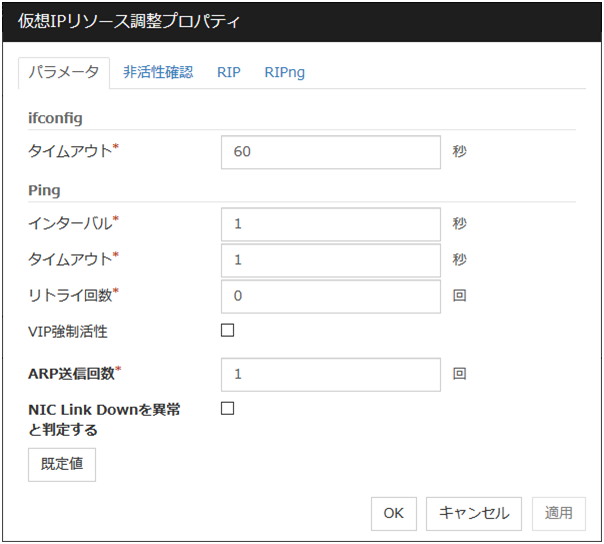
ifconfig
IP アドレス一覧の取得、および仮想 IP リソースの活性/非活性の各処理で実行される [ifconfig] コマンドに関する詳細設定です。
ping
仮想 IP リソースを活性する前に、重複した IP アドレスがないかチェックするために発行される [ping] コマンドに関する詳細設定です。
ARP送信回数 (0~999)
仮想 IP リソースを活性化する場合に送信する ARP パケットの送信回数を設定します。 0 を設定すると ARP パケットを送信しません。
NIC Link Down を異常と判定する
仮想 IP リソースを活性する前に、NIC Link Downの確認を行うかどうかを設定します。NIC のボード、ドライバによっては、必要な ioctl( ) がサポートされていない場合があります。NIC の Link Up/Down 監視の動作可否は、各ディストリビュータが提供する [ethtool]コマンドで確認することができます。[ethtool]コマンドでの確認方法は、本書の「NIC Link Up/Down モニタリソースを理解する」 - 「NIC Link Up/Down モニタリソースの注意事項」を参照してください。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
非活性確認タブ
仮想 IP リソースの非活性確認に関する詳細設定が表示されます。
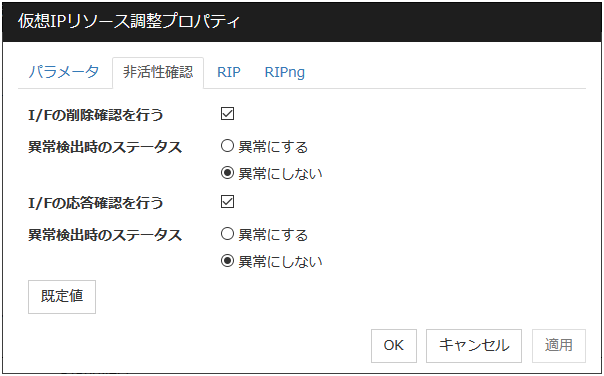
I/F の削除確認
I/F の応答確認
RIPタブ
仮想 IP リソースの RIP に関する詳細設定が表示されます。
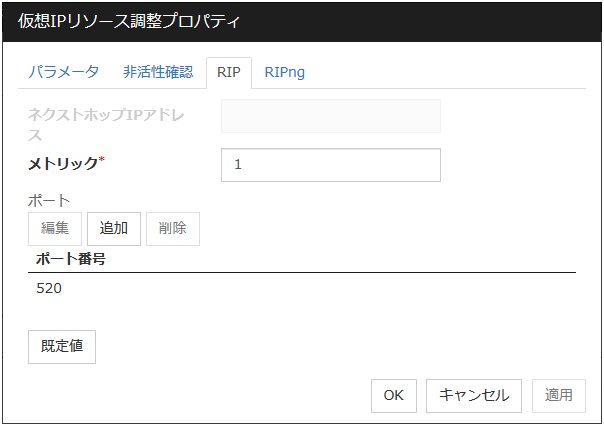
ネクストホップ IP アドレス
RIP の次ホップアドレス (次ルータのアドレス) を入力します。ネクストホップ IP アドレスは省略可能で RIPver2 の場合のみ指定することが可能です。ネットマスクまたは prefix の指定はできません。
メトリック (1~15)
RIP のメトリック値を入力します。メトリックは宛先に到達するための RIP のホップカウントです。
ポート
[ポート番号] には RIP の送信に使用する通信ポートの一覧が表示されます。
追加
RIP の送信に使用するポート番号を追加します。[ポート番号の入力] ダイアログボックスが表示されます。
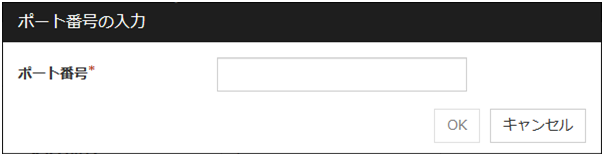
ポート番号
RIP の送信に使用するポート番号を入力して [OK] を選択してください。
編集
[ポート番号の入力] ダイアログボックスが表示されます。[ポート番号] で選択しているポートが表示されるので、編集して [OK] を選択します。
削除
[ポート番号] で選択しているポートをリストから削除します。
RIPngタブ
仮想 IP リソースの RIPng に関する詳細設定が表示されます。
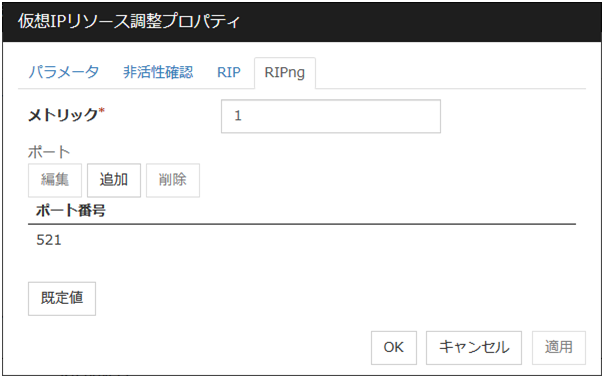
メトリック (1~15)
RIPng のメトリック値を入力します。メトリックは宛先に到達するための RIPng のホップカウントです。
ポート
[ポート番号] には RIPng を送信するポート番号の一覧が表示されます。
追加
RIPng の送信に使用するポート番号を追加します。[ポート番号の入力] ダイアログボックスが表示されます。
ポート番号
RIPng の送信に使用するポート番号を入力して [OK] を選択してください。
編集
[ポート番号の入力] ダイアログボックスが表示されます。[ポート番号] で選択しているポートが表示されるので、編集して [OK] を選択します。
削除
[ポート番号] で選択しているポートをリストから削除します。
3.10. ミラーディスクリソースを理解する¶
3.10.1. ミラーディスクリソースの依存関係¶
既定値では、以下のグループリソースタイプに依存します。
グループリソースタイプ |
|---|
フローティング IP リソース |
仮想 IP リソース |
AWS Elastic IPリソース |
AWS 仮想IPリソース |
AWS DNS リソース |
Azure プローブポートリソース |
Azure DNS リソース |
3.10.2. ミラーディスクとは?¶
ミラーディスクとは、クラスタを構成する 2 台のサーバ間でディスクデータのミラーリングを行うディスクのペアのことです。
以下の図で、Server 1に接続されている Mirror disk 1 および Server 2に接続されている Mirror disk 2は、ペアとしてディスクデータのミラーリングを行います。

図 3.82 ミラーディスク構成 (1)¶

図 3.83 ミラーディスク構成 (2)¶
データパーティション
ミラーリングするデータ (業務データなど) を格納するパーティションのことを、データパーティションといいます。
データパーティションは以下のように割り当ててください。
- データパーティションのサイズ1GB 以上、1TB 未満のパーティションを確保してください。※ データの構築時間、復旧時間の観点より、1TB 未満のサイズを推奨します。
- パーティション ID83 (Linux)
- ファイルシステムは、ミラーリソースの mkfs の設定が [する] の場合にはクラスタ生成時に自動的に構築されます。
- ファイルシステムのアクセス制御 (mount/umount) は、CLUSTERPRO が行いますので、OS 側でデータパーティションを mount/umount する設定を行わないでください。
クラスタパーティション
CLUSTERPRO がミラーパーティション制御のために使用する専用パーティションを、クラスタパーティションといいます。
クラスタパーティションは以下のように割り当ててください。
- クラスタパーティションのサイズ最低 1024MiB 確保してください。ジオメトリによって 1024MB 以上になる場合がありますが、1024MB 以上でも問題ありません。
- パーティション ID83 (Linux)
- クラスタパーティションは、データミラーリング用のデータパーティションとペアで割り当てる必要があります。
- クラスタパーティションにファイルシステムを構築しないでください。
- ファイルシステムのアクセス制御 (mount/umount) は、CLUSTERPRO がミラーパーティションデバイスをマウントするデバイスとして行いますので、OS 側でクラスタパーティションを mount/umount する設定を行わないでください。
ミラーパーティションデバイス (/dev/NMPx)
1 つのミラーディスクリソースで 1 つのミラーパーティションデバイスをファイルシステムに提供します。ミラーディスクリソースとして登録すると、 1 台のサーバ (通常はリソースグループのプライマリサーバ) からのみアクセス可能になります。
通常、ユーザ (AP) はファイルシステムを経由して I/O を行うため、ミラーパーティションデバイス (dev/NMPx) を意識する必要はありません。Cluster WebUI で情報を作成するときに重複しないようにデバイス名を割り当てます。
- ファイルシステムのアクセス制御 (mount/umount) は、CLUSTERPRO が行いますのでOS 側でミラーパーティションデバイスを mount/umount する設定を行わないでください。業務アプリケーションなどからの、ミラーパーティション (ミラーディスクリソース) へのアクセス可否の考え方は、共有ディスクを使用した切替パーティション (ディスクリソース) と同じです。
ミラーパーティションの切り替えは、フェイルオーバグループごとにフェイルオーバポリシーにしたがって行われます。
ミラーディスクコネクト
ミラーディスクリソースごとに最大 2 つのミラーディスクコネクトを登録できます。
2 つのミラーディスクコネクトを登録した場合、切替時の動作などは以下のようになります。
ミラーデータの同期に使用する経路を二重化することができます。1 つのミラーディスクコネクトが断線等で使用できなくなった場合でもミラーデータを同期することができます。
ミラーリングの速度は変わりません。
データ書き込み中にミラーディスクコネクトが切り替わる場合には、一時的にミラーブレイク状態になり、ミラーディスクコネクトの切替が完了した後で差分ミラー復帰が実行されることがあります。
ミラー復帰中にミラーディスクコネクトが切り替わる場合には、ミラー復帰が中断されることがあります。自動ミラー復帰を行う設定にしている場合には、ミラーディスクコネクトの切替が完了した後でミラー復帰が自動的に再開されます。自動ミラー復帰を行わない設定の場合には、ミラーディスクコネクトの切替が完了した後でミラー復帰を再実行する必要があります。
ミラーディスクコネクトの設定に関しては、本ガイドの「2. パラメータの詳細」 - 「クラスタプロパティ」 - 「インタコネクトタブ」を参照して下さい。
ディスクのパーティション
OS (root パーティションや swap パーティション) と同じディスク上に、ミラーパーティション (クラスタパーティション、データパーティション) を確保することも可能です。
- 障害時の保守性を重視する場合OS (root パーティションや swap パーティション) と別にミラー用のディスクを用意することを推奨します。
- H/W RAID の仕様の制限で LUN の追加ができない場合H/W RAID のプリインストールモデルで LUN 構成変更が困難な場合OS (root パーティションや swap パーティション) と同じディスクに、ミラーパーティション (クラスタパーティション、データパーティション) を確保することも可能です。
両サーバに 1 つの SCSI ディスクを増設して 1 つのミラーディスクのペアにする場合
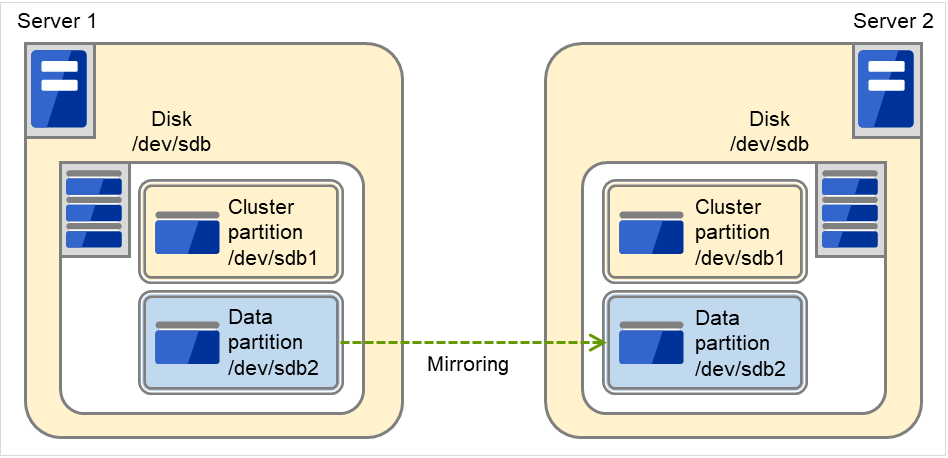
図 3.84 増設したディスク1つをミラーディスクのペアにする場合¶
両サーバの OS が格納されている IDE ディスクの空き領域を使用してミラーディスクのペアにする場合
以下の図では、ディスクのOS等が使用していない領域をミラーパーティションデバイス(クラスタパーティション、データパーティション)として使用しています。
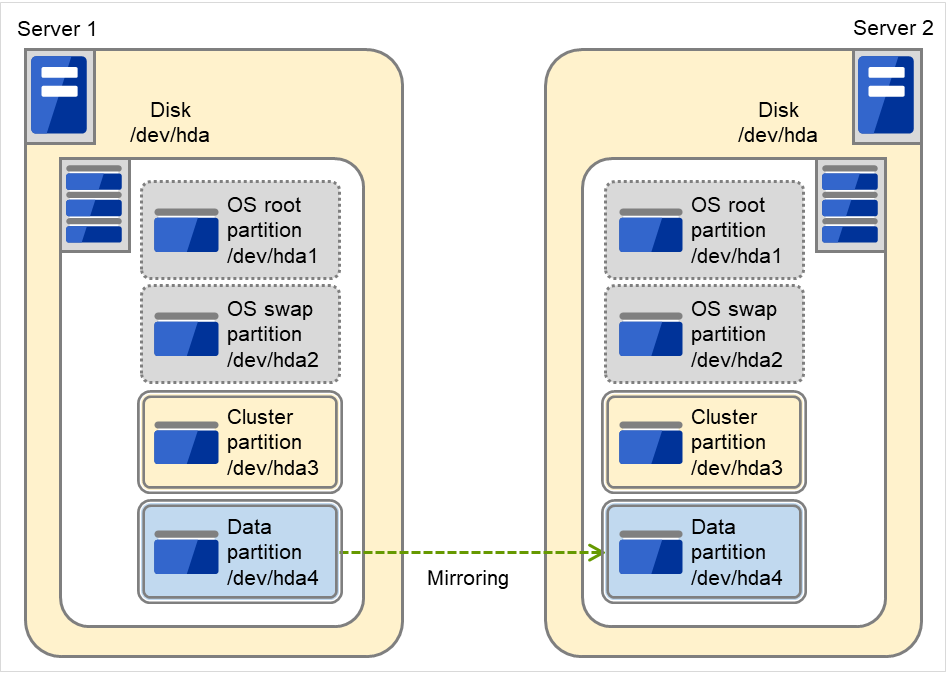
図 3.85 ディスクの空き領域をミラーパーティションにする場合¶
- ディスクの配置ミラーディスクとして複数のディスクを使用することができます。また 1 つのディスクに複数のミラーパーティションデバイスを割り当てて使用することができます。
両サーバに 2 つの SCSI ディスクを増設して 2 つのミラーディスクのペアにする場合
以下の図は、同サイズのパーティションを確保したディスクのペア2つを、ミラーパーティションとして使用する場合を示しています。
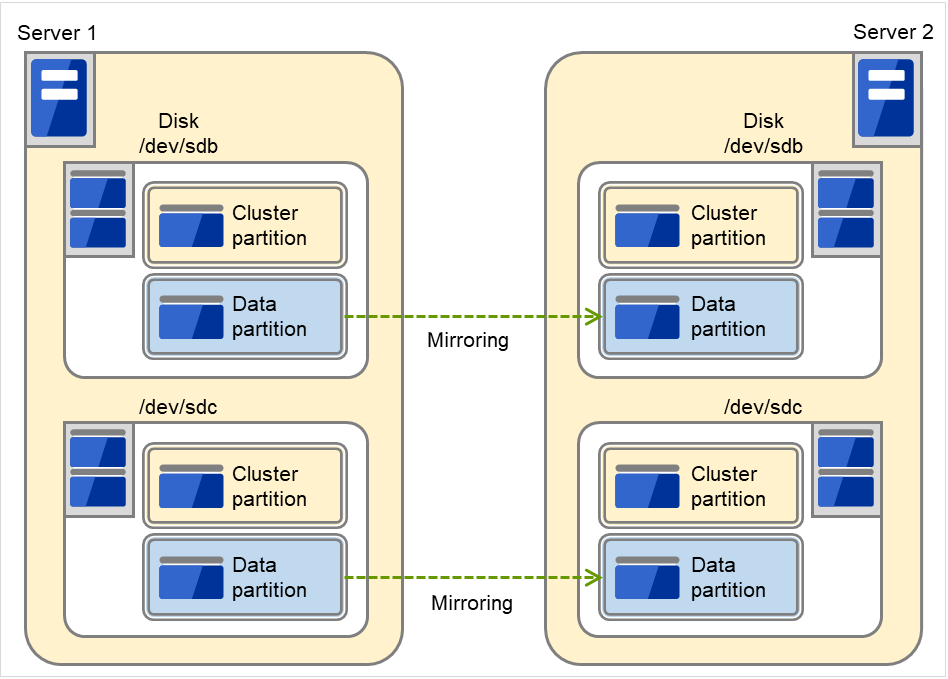
図 3.86 各ディスクをミラーパーティションにする場合¶
両サーバに 1 つの SCSI ディスクを増設して 2 つのミラーパーティションにする場合
図は各ディスクに、クラスタパーティションのほか同サイズのパーティションを2つ確保し、データパーティションとして使用する場合を示しています。
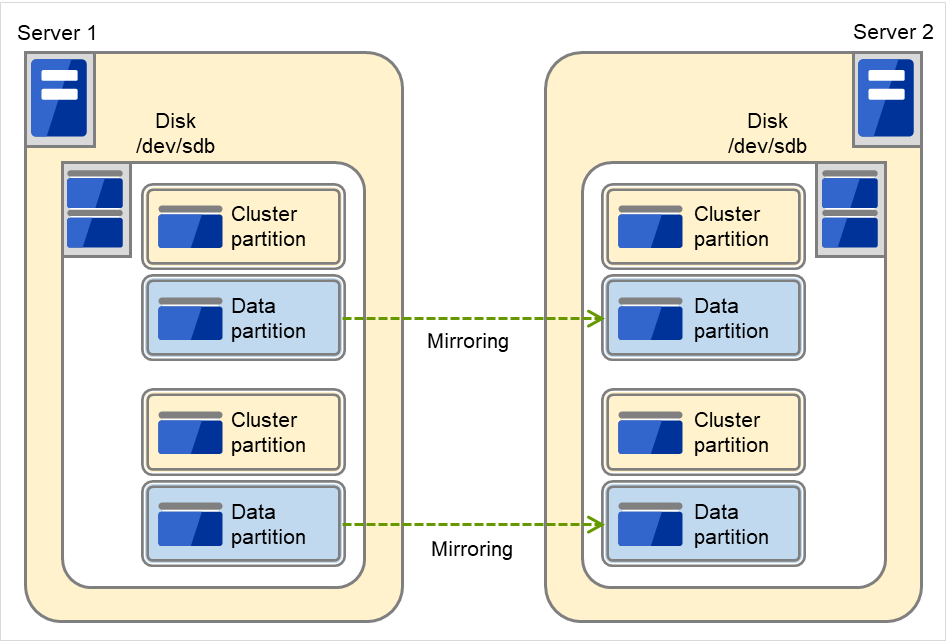
図 3.87 ディスク内の複数領域をミラーパーティションにする場合¶
3.10.3. ミラーパラメータ設定の考え方¶
ミラーデータポート番号
ミラードライバ間でミラーデータの送受信に使用する TCP ポート番号を設定します。ミラーディスクリソースごとに設定する必要があります。
Cluster WebUI でミラーディスクリソースを追加する場合に下記の条件で初期値が表示されます。
29051 以降のポート番号で、未使用かつ最小のポート番号
ハートビートポート番号
ミラードライバ間で制御用データの通信を行う TCP ポート番号を設定します。ミラーディスク リソースごとに設定する必要があります。
Cluster WebUI でミラーディスクリソースを追加する場合に下記の条件で初期値が表示されます。
29031 以降のポート番号で、未使用かつ最小のポート番号
ACK2 ポート番号
ミラードライバ間で制御用データの通信を行う TCP ポート番号を設定します。ミラーディスク リソースごとに設定する必要があります。
Cluster WebUI でミラーディスクリソースを追加する場合に下記の条件で初期値が表示されます。
29071 以降のポート番号で、未使用かつ最小のポート番号
リクエストキューの最大数
ミラーディスクドライバが上位からの I/O 要求(書き込み要求)をキューイングするためのキューの個数を設定します。大きくすると書き込みのパフォーマンスが向上しますが、物理メモリを多く消費します。
以下を目安に設定してください。
以下のような条件では大きくすると性能向上が期待できます。
サーバに物理メモリが多く搭載されていて空きメモリサイズが十分ある。
接続タイムアウト
ミラー復帰やデータ同期時に、サーバ間通信の接続成功を待つタイムアウトです。
送信タイムアウト
このタイムアウトは以下で使用します。
ミラー復帰やデータ同期時に、現用系サーバが待機系サーバに write データを送信開始してから送信完了を待つまでのタイムアウト。
図 3.88 送信タイムアウト(writeデータ)¶
※詳細には、ネットワーク(TCP)の送信バッファへ送信データを格納開始してから、格納が完了するまでのタイムアウト。TCPのバッファがいっぱいになっていて、空きができない場合にタイムアウトが発生する。
現用系サーバが待機系サーバへ write 完了通知の ACK を送信する処理にて、送信するACKがあるかどうか、送信の要否を確認する時間間隔。
図 3.89 送信タイムアウト(ACK送信チェック)¶
受信タイムアウト
このタイムアウトは以下で使用します。
待機系サーバが現用系サーバからの write データを受信開始してから受信完了を待つまでのタイムアウト。
図 3.90 受信タイムアウト¶
Ackタイムアウト
このタイムアウトは下記に使用します。
- 現用系サーバが待機系サーバへ write データを送信開始してから待機系サーバからのwrite 完了通知の ACK の受信を待つまでのタイムアウト。タイムアウト以内に、ACK を受信できなかった場合、現用系サーバ側の差分ビットマップに差分情報を蓄積します。
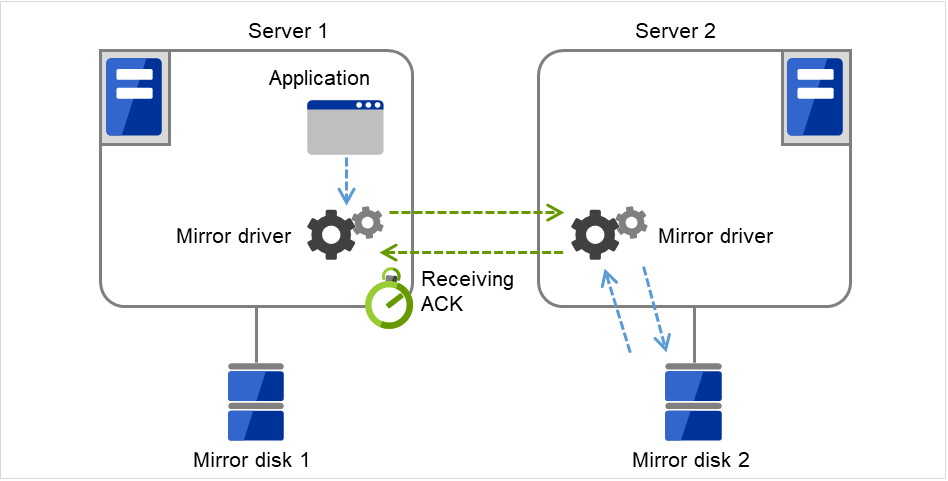
図 3.91 ACKタイムアウト(待機系サーバからのACK受信)¶
※モードが同期モードに設定されている場合には、アプリケーションへの応答が、ACK受信またはACK受信がタイムアウトするまで、待たされることがあります。モードが非同期モードに設定されている場合には、アプリケーションへの応答は現用系のディスクへ書き込み後、ACKを待たずに、返ります。
- 待機系サーバが現用系サーバへの write 完了通知の ACK を送信完了してから、現用系サーバの ACK の受信を待つまでのタイムアウト。タイムアウト以内に、現用系サーバの ACK を受信できなかった場合、待機系サーバ側の差分ビットマップに差分情報を蓄積します。
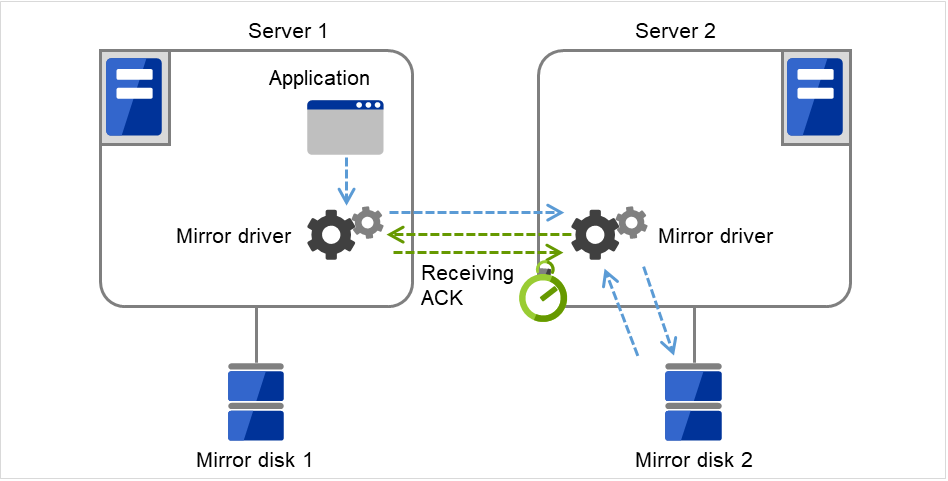
図 3.92 ACKタイムアウト(現用系サーバからのACK受信)¶
ミラー復帰時に、コピー元サーバが復帰データ送信を開始してから、コピー先サーバからの完了通知の ACK を待つまでのタイムアウト。
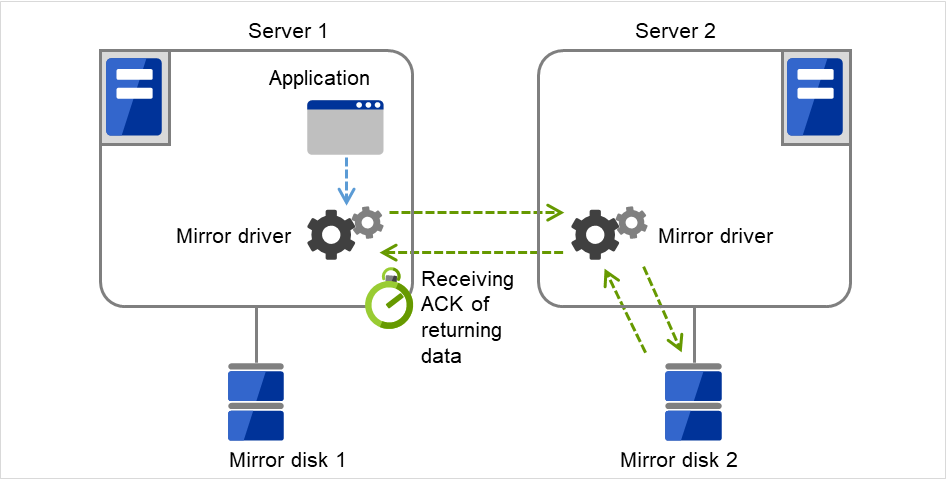
図 3.93 ACKタイムアウト(復帰データACK受信)¶
※後述の「復帰データサイズ」の量の復帰データ送信に対して、ACKが1つ返ります。従って、復帰データサイズを大きくすると、効率は良くなりますが、ACKタイムアウト等が発生した場合に再送信が必要になる量も多くなります。
ハートビートインターバル(1~600)
2台のサーバのミラードライバ間で、ミラーディスクコネクトの健全性を確認するために行われるハートビートの間隔(秒)です。通常はデフォルトのままで使用してください。
ICMP Echo Reply 受信タイムアウト(1~100)
2台のサーバのミラードライバ間で、ミラーディスクコネクトの健全性を確認するために行われるハートビートで利用される値です。ICMP Echo Requestを送信してから、相手サーバからのICMP Echo Replyを受信するまでの最大待ち時間です。本タイムアウト値を経過してもICMP Echo Replyを受信できなかった場合、最大で後述のICMP Echo Request リトライ回数分まで繰り返されます。通常はデフォルトのままで使用してください。
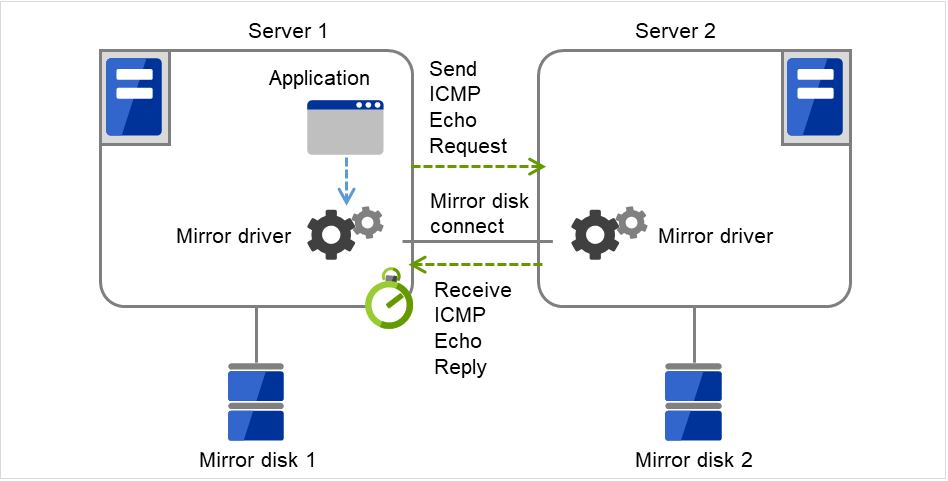
図 3.94 ICMP Echo Reply 受信タイムアウト¶
ICMP Echo Request リトライ回数(1~50)
ICMP Echo Request に対する相手サーバからの ICMP Echo Reply が前述のICMP Echo Reply 受信タイムアウトまでに受信出来なかった際に ICMP Echo Request の送信をリトライする、最大送信回数です。通常はデフォルトのままで使用してください。
ICMP Echo Reply 受信タイムアウトとICMP Echo Request リトライ回数を調整することでミラーディスクコネクト断線と判断する感度を調整できます。
値を大きくする
遠隔地のようにネットワーク遅延が発生するような場合
ネットワークの一時的な障害が発生するような場合
値を小さくする
ネットワーク障害を検出するまでの時間を短くしたい場合
差分ビットマップ更新インターバル
差分ビットマップへ書き込む情報は一時的にメモリ上に蓄えられ、一定間隔でクラスタパーティションへ書き出されます。待機系サーバでその書き出す情報の有無をチェックして書き出しをおこなう、時間間隔です。
差分ビットマップサイズ
差分ビットマップのサイズを指定します。
データパーティションのサイズが大きい場合、差分ビットマップのサイズを大きくすることで差分コピーの効率が向上することがあります。
ただし、メモリ効率が悪化するため、通常は既定値のままお使いください。
なお、この設定はミラーディスクリソースおよびハイブリッドディスクリソースをクラスタに作成する前に設定する必要があります。これらのリソースがクラスタ内に存在する場合は変更することができません。
初期ミラー構築
クラスタ構築後の初回起動時に初期ミラー構築を行う挙動を設定します。
- 初期ミラー構築を行うクラスタ構築後の初回起動時に初期ミラー構築を行います。ext2/ext3/ext4/xfs とその他のファイルシステムでは、初期ミラー構築にかかる時間が異なります。
- 初期ミラー構築を行わないクラスタ構築後の初回起動時に初期ミラー構築を行いません。クラスタ構築前に CLUSTERPRO 以外の手段でミラーディスクのデータパーティションの内容を必ず完全に同一にしておく必要があります。
初期mkfs
クラスタ構築後の初回起動時にミラーディスクのデータパーティションへの mkfs の挙動を設定します。
- 初期 mkfs を行うクラスタ構築直後の初回起動時にミラーディスクのデータパーティションへの mkfs を行います。
- 初期 mkfs を行わないクラスタ構築直後の初回起動時にミラーディスクのデータパーティションへの mkfs を行いません。ミラーディスクのデータパーティションに既にファイルシステムが構築されていて、二重化しようとするするデータが既にあり、mkfs によるファイルシステムの構築や初期化が不要な場合に、初期mkfsをおこなわない設定をすることができます。ミラー用ディスクのパーティション構成は、ミラーディスクリソースの条件を満たしている必要があります。 4 シングルサーバをクラスタ化する場合にはご注意ください。
- 4
ミラーディスクにはクラスタパーティションが必ず必要です。シングルサーバのディスクをミラーの対象とする時にクラスタパーティションを確保できない場合には、一旦バックアップを採ってパーティションを再確保してください。
[初期ミラー構築を行わない] を選択した場合には、[初期 mkfs を行う] は選択できません。(現用系と待機系のデータパーティションをそれぞれmkfsすると、mkfs した直後でも、現用系と待機系とでmkfsしたデータパーティション内に差分が生じます。そのため、初期mkfsを行う場合には、初期ミラー構築(現用系と待機系とのデータパーティションのコピー)も必要になります。そのため、[初期ミラー構築を行う] を選択すると [初期 mkfs を行う] が選択可能になります。)
キューの数
注釈
通信帯域制限
注釈
履歴ファイル格納ディレクトリ
履歴ファイルサイズ制限
モードが [非同期] の場合、履歴ファイルの蓄積量の上限を指定します。履歴ファイルが上限に達した場合、ミラーブレイク状態となります。
データの圧縮
ミラー同期データ(モードが [非同期] の場合)や、ミラー復帰データを、圧縮して送信するかを指定します。速度の遅いネットワークを使う場合に、送信データを圧縮することで、送信量を減らすことができます。
注釈
圧縮処理により、データ送信時にCPU負荷が高くなる場合があります。
速度の遅いネットワークでは、圧縮により送信量が減少して、非圧縮よりも時間の短縮が見込める場合があります。逆に、速度の速いネットワークでは、転送時間の短縮よりも圧縮処理時間と負荷の増加のほうが目立ってくるため、時間の短縮が見込めない場合があります。
圧縮効率の良いデータが多い場合、圧縮により送信量が減少して、非圧縮よりも時間の短縮が見込める場合があります。逆に、圧縮効率の悪いデータが多い場合、送信量が減少せず、圧縮処理時間と負荷の増加により、時間の短縮が見込めない場合があります。
ミラーエージェント送信タイムアウト
ミラーエージェントが相手サーバへ処理を要求してから処理結果を待つまでのタイムアウトです。
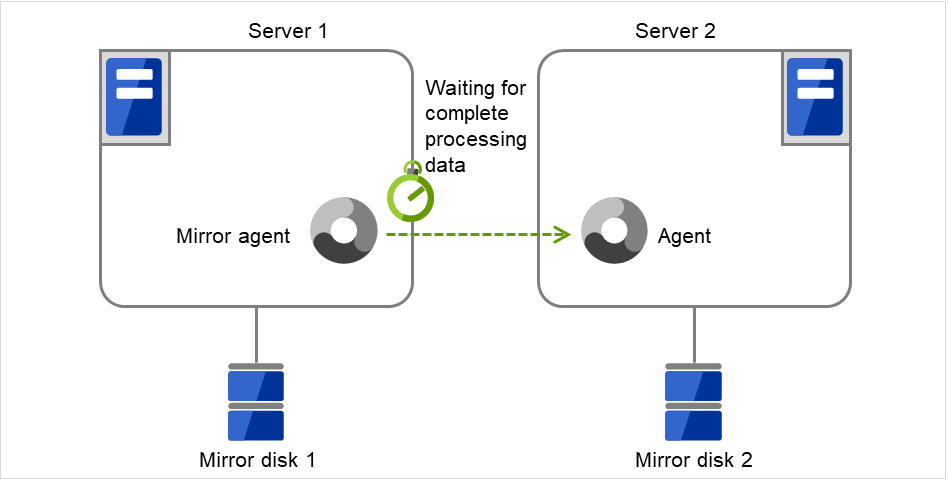
図 3.95 ミラーエージェント送信タイムアウト¶
ミラーエージェント受信タイムアウト
ミラーエージェントが相手サーバとの通信 socket を作成してから受信開始を待つまでのタイムアウトです。
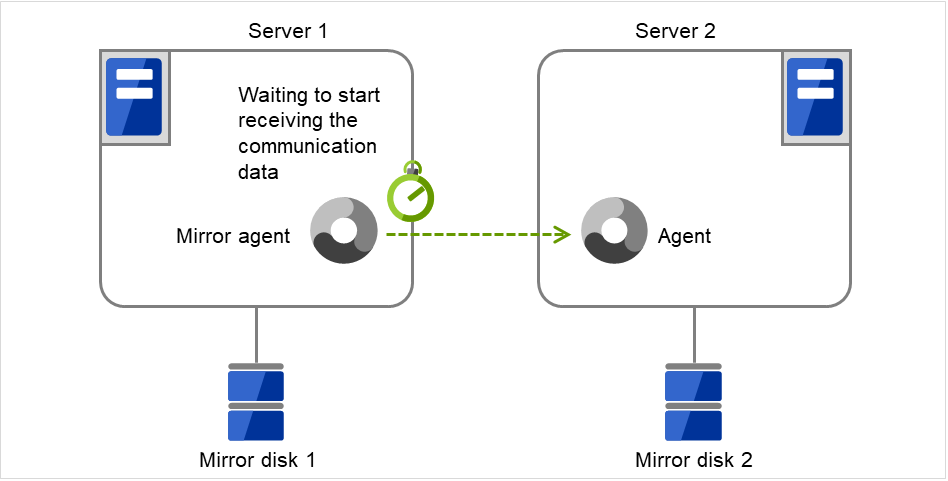
図 3.96 ミラーエージェント受信タイムアウト¶
復帰データサイズ (64~32768)
ミラー復帰で 1 回の処理で 2 台のサーバ間でやりとりするデータの大きさを指定します。 通常はデフォルトのままで使用してください。
値を大きくする
サーバ間でデータをやり取りする回数が少なくなるので、ミラー復帰の全体の処理に必要な時間が短くなります。
- ミラー復帰中に、ディスク性能が低下する可能性があります。(ミラー復帰データのディスク読み込み範囲と、ファイルシステムからのディスク書き込み範囲とが重なった場合、排他アクセスをして、先にアクセスしたほうが完了するまで、もう一方はアクセスが待たされます。ネットワークが遅い環境では、この復帰データサイズの値が大きいと、ミラー復帰の1回のデータ転送にかかる時間も長くなります。もし、ミラーへの通常のディスクアクセスが、このミラー復帰の転送中の範囲と重なった場合、ディスクアクセスはその転送が完了するまで待たされます。その結果、ディスク性能が低下することがあります。そのため、特にネットワークが遅い環境では、この値は小さくしてください。)
値を小さくする
ミラー復帰中の 2 台のサーバ間の送受信データが細分化されるため、ネットワーク速度が遅い場合やサーバ高負荷の場合でのタイムアウトの発生確率が低くなります。
サーバ間でやりとりする回数が増えるため、特に遅延の発生するネットワークでは、ミラー復帰の処理に必要な時間が長くなります。
ミラー通信を暗号化する
3.10.4. ミラーディスクの構築例¶
過去にミラーディスクとして使用していたディスクを流用する場合は、クラスタパーティションに以前のデータが残っているので初期化が必要です。クラスタパーティションの初期化については『インストール&設定ガイド』を参照してください。
- 初期ミラー構築を行う初期 mkfs を行う
まず、CLUSTERPROをインストールし、セットアップを行います。 次に、Server 1、Server 2のそれぞれに接続されたディスクに対して、初期mkfsを実行します。
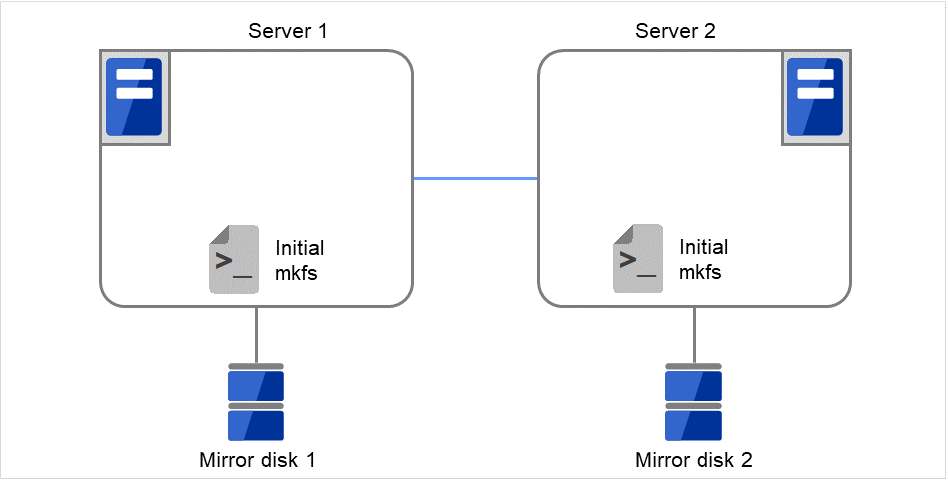
図 3.97 ミラーディスク構築例(初期ミラー構築、初期mkfsともに行う)(1)¶
続いて初期ミラー構築を開始します。 Server 1の Mirror disk 1から Server 2の Mirror disk 2へ、全面コピーを行います。
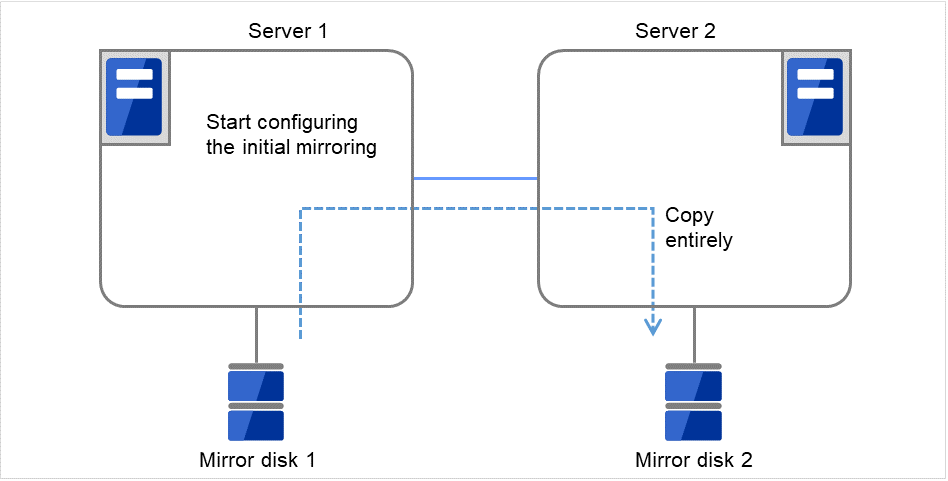
図 3.98 ミラーディスク構築例(初期ミラー構築、初期mkfsともに行う)(2)¶
- 初期ミラー構築を行う初期 mkfs を行わない
まず、二重化する Application のデータをクラスタ構築前に用意できる場合には、先に現用系のミラーディスク(Mirror disk 1)のデータパーティションに作成しておきます(ex. データベースの初期DBなど)。 パーティション構成は "3.10.2. ミラーディスクとは?" を参照してください。 次に、Server 1、Server 2のそれぞれに CLUSTERPROをインストールし、セットアップを行います。
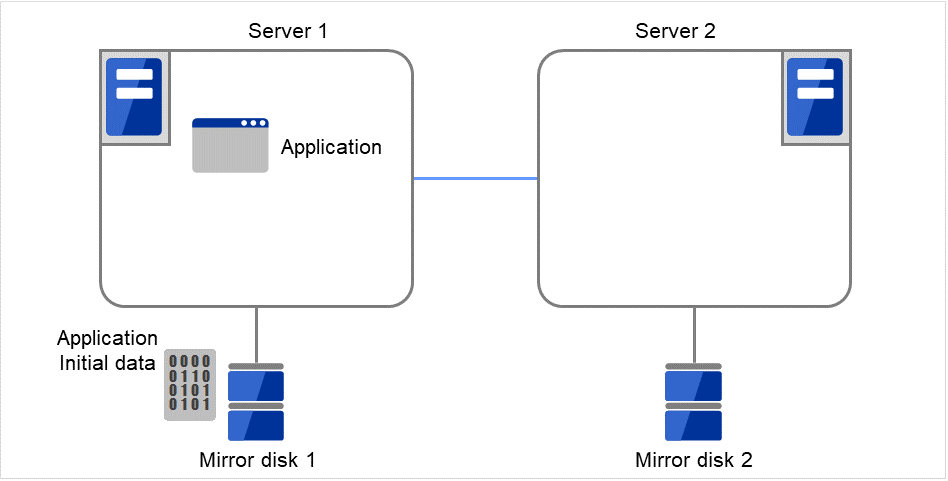
図 3.99 ミラーディスク構築例(初期ミラー構築のみ行う)(1)¶
続いて初期ミラー構築を開始します。 Server 1の Mirror disk 1から Server 2の Mirror disk 2へ、全面コピーを行います。
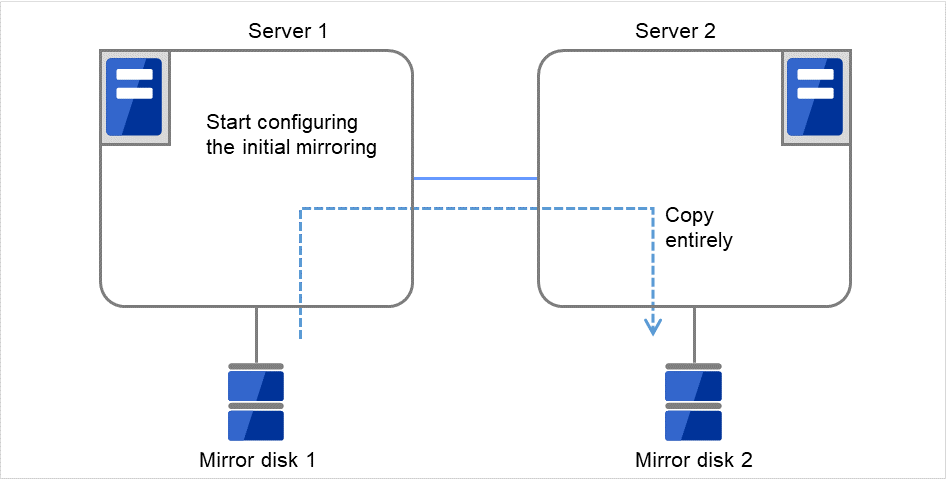
図 3.100 ミラーディスク構築例(初期ミラー構築のみ行う)(2)¶
- 初期ミラー構築を行わない初期 mkfs を行わない
たとえば以下のような方法で両サーバのミラーディスクの内容を同一にすることができます。(クラスタ構築後にはできません。必ずクラスタ構築前に実施してください。)
例1: ディスクのパーティションイメージをコピーする方法
まず、二重化する Application のデータをクラスタ構築前に用意できる場合には、先に現用系のミラーディスク(Mirror disk 1)のデータパーティションに作成しておきます(ex. データベースの初期DBなど)。 パーティション構成は "3.10.2. ミラーディスクとは?" を参照してください。
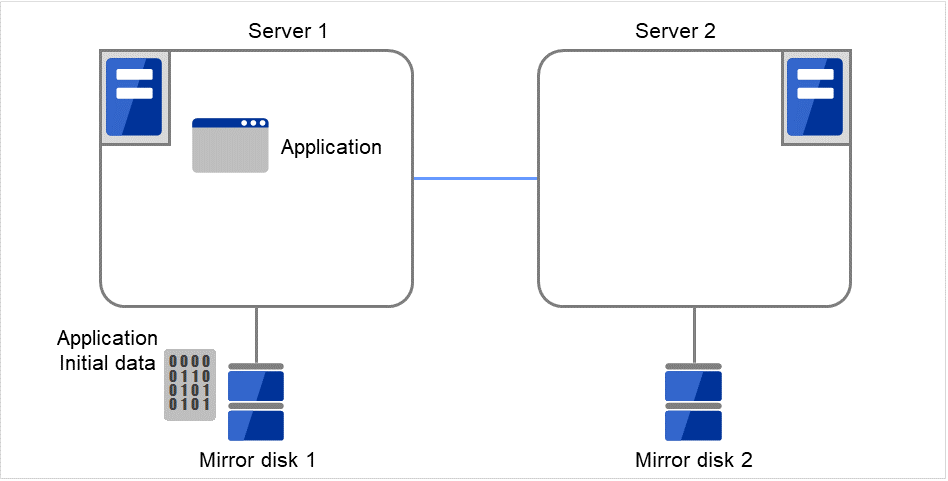
図 3.101 ミラーディスク構築例(パーティションイメージコピー)(1)¶
待機系サーバ(Server 2)のミラー用ディスク(Mirror disk 2)を取り外して、現用系サーバ(Server 1)へ接続します。
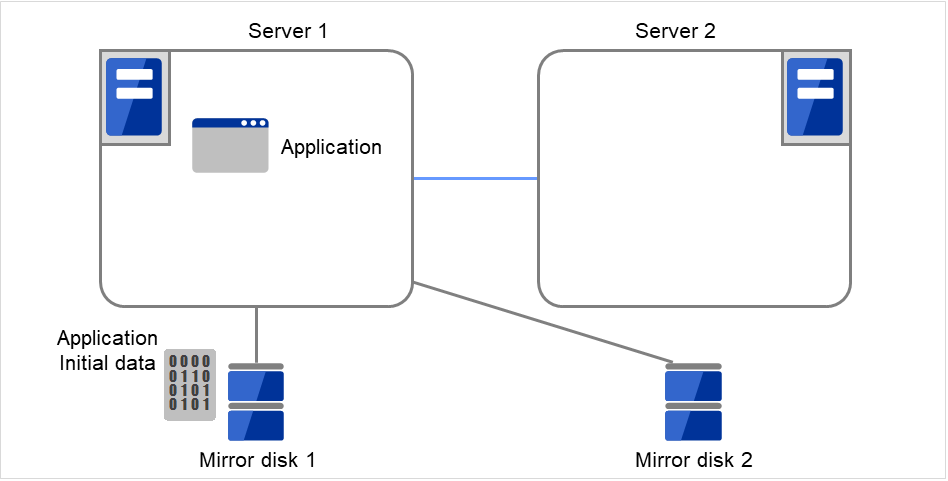
図 3.102 ミラーディスク構築例(パーティションイメージコピー)(2)¶
Mirror disk 1(現用系用ミラーディスク)がアンマウントされている状態で、ddコマンドなどを使って Mirror disk 1のデータパーティションを丸ごと Mirror disk 2のデータパーティションへコピーします。ファイルシステム経由のコピーではパーティションイメージが同一になりませんので注意してください。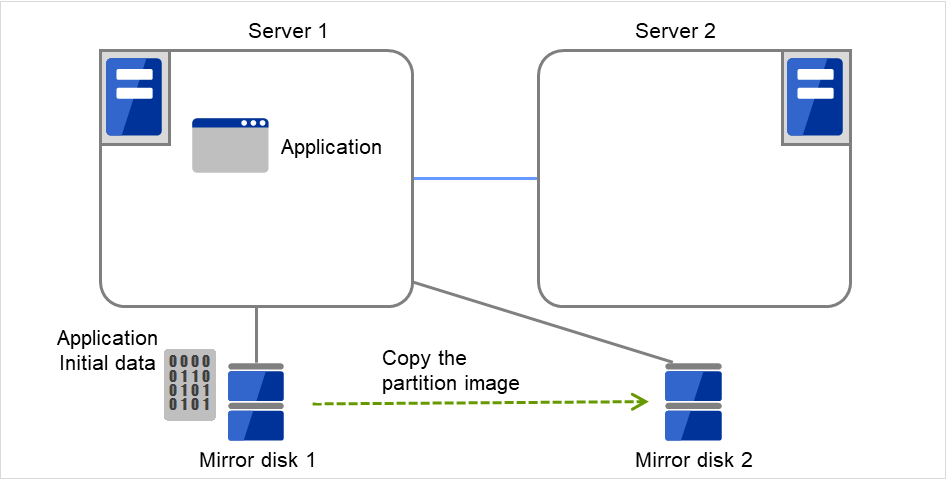
図 3.103 ミラーディスク構築例(パーティションイメージコピー)(3)¶
現用系サーバ(Server 1)に接続していた待機系用ミラーディスク(Mirror disk 2)を待機系サーバ(Server 2)へ戻します。さらに CLUSTERPROをインストールし、セットアップを行います。以降は、「初期mkfsを行わない・初期ミラー構築を行わない」場合の設定でクラスタを構築します。ミラーパーティションの初期構築(初期同期)は実行しません。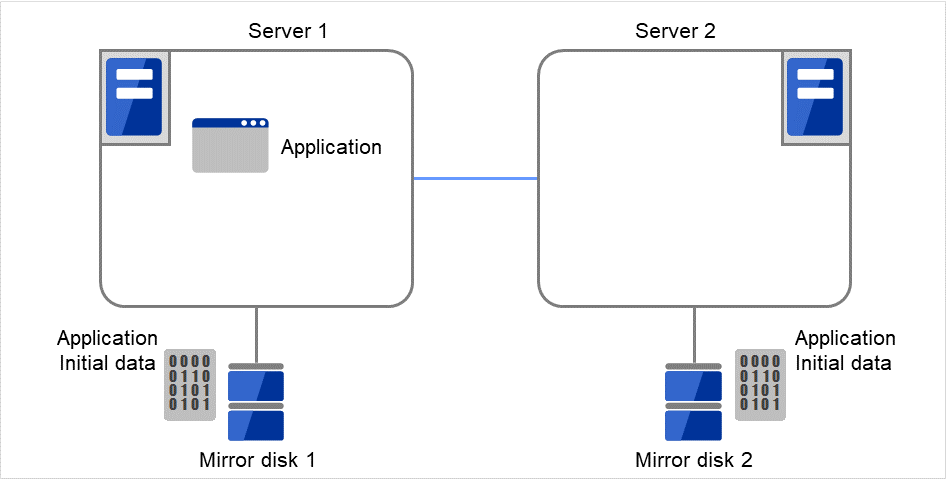
図 3.104 ミラーディスク構築例(パーティションイメージコピー)(4)¶
例2: バックアップ装置でコピーをする方法
まず、二重化する Application のデータをクラスタ構築前に用意できる場合には、先に現用系のミラーディスク(Mirror disk 1)のデータパーティションに作成しておきます(ex. データベースの初期DBなど)。パーティション構成は "3.10.2. ミラーディスクとは?" を参照してください。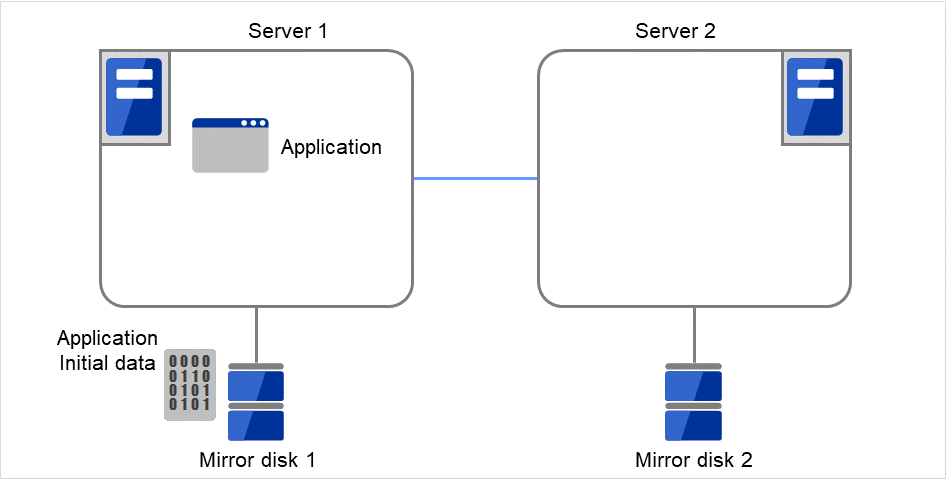
図 3.105 ミラーディスク構築例(バックアップ装置使用)(1)¶
現用系サーバ(Server 1)にバックアップ装置(Backup device)を接続します。ddコマンドなど、パーティションイメージでバックアップするコマンドを使って、ミラーディスク(Mirror disk 1)のデータパーティションのデータをバックアップします。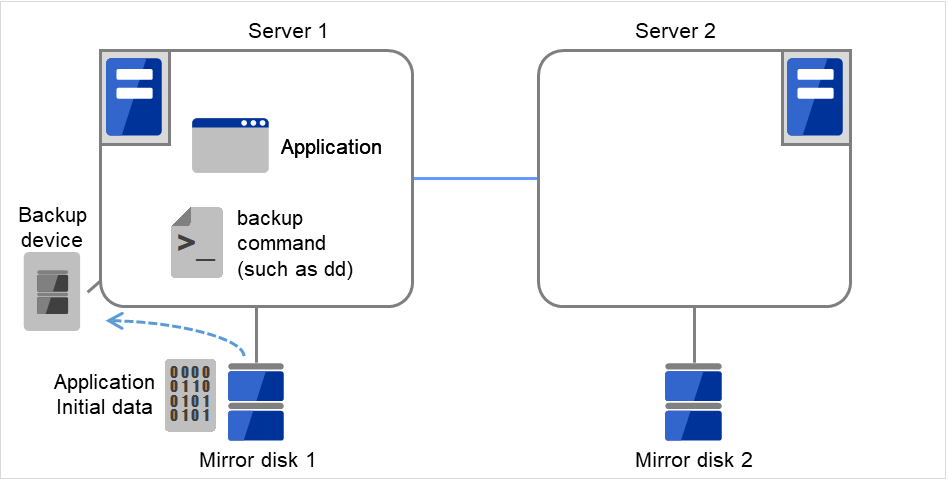
図 3.106 ミラーディスク構築例(バックアップ装置使用)(2)¶
待機系サーバ(Server 2)にバックアップ装置(Backup device)を接続し、現用系サーバ(Server 1)でデータをバックアップした際のメディアをServer 2のバックアップ装置へ移動します。
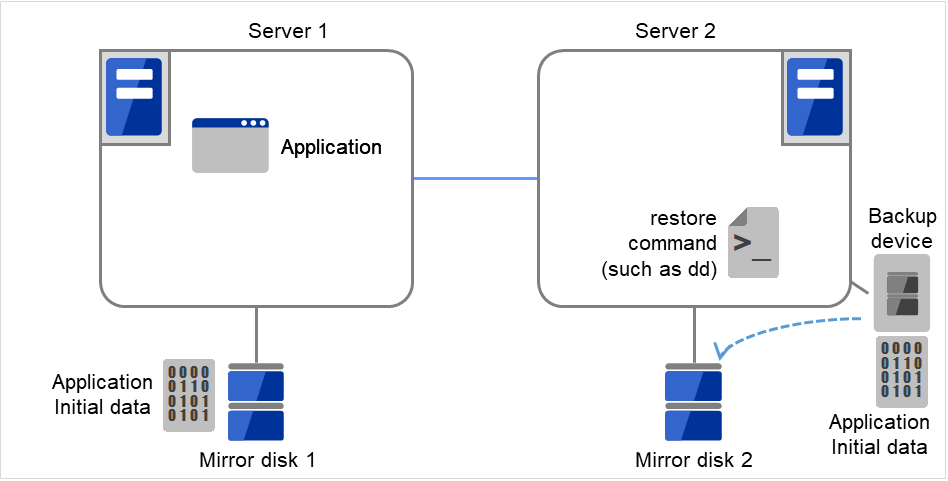
図 3.107 ミラーディスク構築例(バックアップ装置使用)(3)¶
CLUSTERPROをインストールし、セットアップを行います。以降は、「初期mkfsを行わない・初期ミラー構築を行わない」場合の設定でクラスタを構築します。ミラーパーティションの初期構築(初期同期)は実行しません。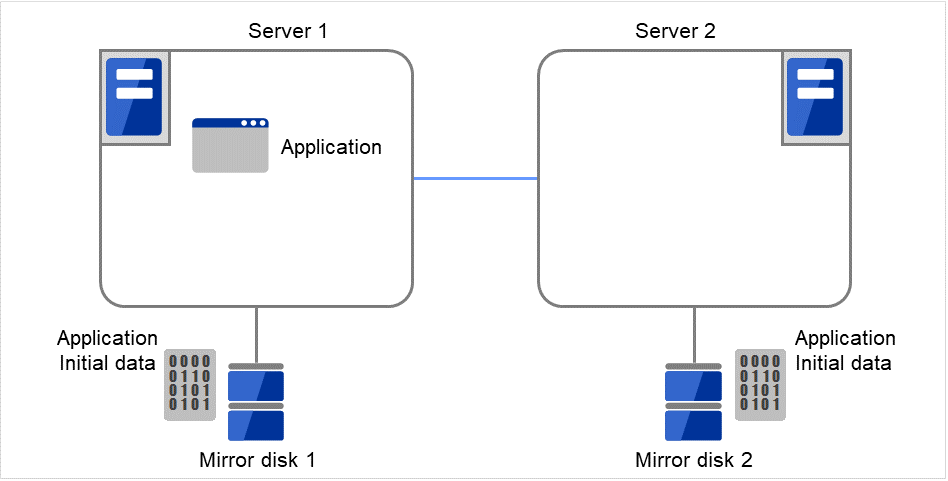
図 3.108 ミラーディスク構築例(バックアップ装置使用)(4)¶
3.10.5. ミラーディスクリソースに関する注意事項¶
両サーバで、同一デバイス名でアクセスできない場合はサーバ個別設定を行ってください。
クラスタプロパティの [拡張] タブで、[マウント、アンマウントコマンドを排他する] にチェックを入れている場合、ディスクリソース、NAS リソース、ミラーリソースの mount/umount は同一サーバ内で排他的に動作するため、ミラーリソースの活性/非活性に時間がかかることがあります。
- マウントポイントにシンボリックリンクを含むパスを指定すると、異常検出時の動作に [強制終了] を選択しても強制終了できません。また、同様に「//」を含むパスを指定した場合にも、強制終了できません。
Linux の md によるストライプセット、ボリュームセット、ミラーリング、パリティ付きストライプセットを使用したディスクを、クラスタパーティションやデータパーティションに指定することはできません。
- Linux の LVM によるボリュームを、クラスタパーティションやデータパーティションに指定することは可能です。なお、SuSE Linux については、LVM や MultiPath によるボリュームを、クラスタパーティションやデータパーティションに使用することはできません。
ミラーディスクリソース (ミラーパーティションデバイス) を Linux の md や LVM によるストライプセット、ボリュームセット、ミラーリング、パリティ付きストライプセットの対象とすることはできません。
ミラーディスク用のディスクとして使用するディスクのジオメトリがサーバ間で異なる場合の注意
[fdisk] コマンドなどで確保したパーティションサイズはシリンダあたりのブロック (ユニット) 数でアラインされます。
データパーティションのサイズと初期ミラー構築の方向の関係が以下になるようにデータパーティションを確保してください。
コピー元のサーバ ≦ コピー先のサーバ
コピー元のサーバとは、ミラーディスクリソースが所属するフェイルオーバグループのフェイルオーバポリシーが高いサーバを指します。コピー先のサーバとは、ミラーディスクリソースが所属するフェイルオーバグループのフェイルオーバポリシーが低いサーバを指します。なお、データパーティションは同程度のサイズで確保するようにしてください。データパーティションのサイズが、コピー元側とコピー先側とで32GiB, 64GiB, 96GiB, … (32GiBの倍数) を跨がないように注意してください。32GiBの倍数を跨ぐサイズの場合、初期ミラー構築に失敗することがあります。
例)
組み合わせ
データパーティションのサイズ
説明
Server 1側
Server 2側
OK
30GiB
31GiB
両方とも0~32GiB未満の範囲内にあるのでOK
OK
50GiB
60GiB
両方とも32GiB以上~64GiB未満の範囲内にあるのでOK
NG
30GiB
39GiB
32GiBを跨いでいるのでNG
NG
60GiB
70GiB
64GiBを跨いでいるのでNG
- ミラーディスクリソースで使用するファイルに対してopen() システムコールのO_DIRECTフラグを使用しないでください。例えば Oracle の設定パラメータの filesystemio_options = setall などがこれに該当します。
DISK 監視の READ (O_DIRECT) 方式の監視先として ミラーパーティションデバイス(/dev/NMP1など) を指定しないでください。
ミラーディスクリソースのデータパーティションおよびクラスタパーティションには、全サーバで同一の論理セクタサイズのディスク装置を使用してください。異なる論理セクタサイズの装置を使用すると、正常に動作しません。データパーティションとクラスタパーティションでは論理セクタサイズが異なっていても動作可能です。
例)
組み合わせ
パーティションの論理セクタサイズ
説明
Server 1側
Server 1側
Server 2側
Server 2側
OK
512B
512B
512B
512B
論理セクタサイズが統一されている
OK
4KB
512B
4KB
512B
データパーティションで4KB、クラスタパーティションで512Bに統一されている
NG
4KB
512B
512B
512B
データパーティションの論理セクタサイズが統一されていない
NG
4KB
4KB
4KB
512B
クラスタパーティションの論理セクタサイズが統一されていない
ミラーディスクリソースのデータパーティションおよびクラスタパーティションとして使用するディスクについて、HDDとSSDを混在させないでください。混在させると最適な性能が得られません。データパーティションとクラスタパーティションではディスクタイプが異なっていても動作可能です。
例)
組み合わせ
パーティションのディスクタイプ
説明
Server 1側
Server 1側
Server 2側
Server 2側
データパーティションクラスタパーティションデータパーティションクラスタパーティションOK
HDD
HDD
HDD
HDD
ディスクタイプが統一されている
OK
SSD
HDD
SSD
HDD
データパーティションでSSD、クラスタパーティションでHDDに統一されている
NG
SSD
HDD
HDD
HDD
データパーティションでHDD/SSDが混在している
NG
SSD
SSD
SSD
HDD
クラスタパーティションでHDD/SSDが混在している
3.10.6. mount前後の処理の流れ¶
ミラーディスクリソース活性時のmountの処理は以下のように行われます。
ファイルシステムにnoneが指定されている場合、mount処理は行いません。
事前にマウントされているか?
既にマウントされていた場合 → ×へ
マウント前に fsck を実行する設定か?
fsck を実行するタイミングである → デバイスに fsck を実行する
デバイスをマウントする
マウント成功 → ○へ
マウントのリトライを行う設定か?
リトライしない設定の場合 → ×へ
マウント失敗時に fsck (xfs_repair)を実行する設定の場合
2.でfsckを実行して成功していた場合 → 6.へ
3.でタイムアウトにより失敗していた場合 → 6.へ
上記以外の場合 → デバイスにfsck(xfs_repair)を実行する
再度デバイスのマウントを試みる
マウント成功 → ○へ
マウントのリトライ回数以内か?
リトライ回数以内の場合 → 6.へ
リトライ回数を超えた場合 → ×へ
○ リソース起動(マウント成功)
× リソース起動失敗(マウントされていない)
3.10.7. umount前後の処理の流れ¶
ミラーディスクリソース非活性時のumountの処理は以下のように行われます。
ファイルシステムにnoneが指定されている場合、umount処理は行いません。
事前にアンマウントされているか?
既にアンマウントされていた場合 → ×へ
デバイスをアンマウントする
アンマウント成功 → ○へ
アンマウントのリトライを行う設定か?
リトライしない設定の場合 → ×へ
まだマウントされているか?(マウント一覧からマウントポイントが削除されていて、ミラーデバイスも未使用状態になっているか?)
もうマウントされていない → ○へ
マウントポイントを使用しているプロセスのKILLを試みる
再度デバイスのアンマウントを試みる
アンマウント成功 → ○へ
アンマウントタイムアウトではなく、かつ、マウント一覧からマウントポイントが削除されているか?
マウントポイントは既に削除された → ミラーデバイスが使用されなくなるまで待つ(最大でアンマウントタイムアウトの時間まで待つ)
アンマウントのリトライ回数以内か?
リトライ回数以内の場合 → 4.へ
リトライ回数を超えた場合 → ×へ
○ リソース停止(アンマウント成功)
× リソース停止失敗(マウントされたまま、もしくは既にアンマウントされていた)
3.10.8. ミラーのステータスが異常となる条件¶
ミラーディスクリソースのステータスが正常(GREEN)状態から異常(RED)状態になるケースとして、おもに以下のようなものがあります。
- 通信(ミラーディスクコネクト)の断線や待機系側サーバの停止などにより、現用系側と待機系側とでミラー同期できなくなり、差分が生じた場合。待機系側は最新データを保持していないので、異常(RED)状態になります。
- ミラーデータを同期しないよう設定して、現用系側と待機系側とで差分が生じた場合。待機系側は最新データを保持していないので、異常(RED)状態になります。
- ミラーディスクの切り離し(ミラーリングの中断)操作をおこなった場合。待機系側は異常(RED)状態になります。
- ミラー復帰中(ミラーの再同期中)にミラー復帰を中断した場合。待機系側はまだコピーが完了していないので、異常(RED)状態になります。
- 現用系側サーバが、サーバダウンなどで、正常にクラスタシャットダウンしなかった場合。(活性していたミラーディスクリソースが非活性へ移行せずに停止した場合。)そのサーバのミラーディスクはサーバ起動後に、異常(RED)状態になります。
- 片方のサーバだけを起動してミラーディスクを活性した後、ミラー同期をしないままそのサーバを停止して、もう片方のサーバを起動してミラーディスクを活性した場合。両方のサーバのミラーディスクにそれぞれ個別に更新がおこなわれているため、両サーバのミラーディスクとも異常(RED)状態になります。このように両サーバのミラーディスクにそれぞれ個別に更新がおこなわれた場合、どちらのサーバのミラーディスクをコピー元とすべきか自動では判断できないため、自動ミラー復帰はおこなわれません。強制ミラー復帰を実行する必要があります。
- 通信(ミラーディスクコネクト)の断線や待機系側サーバのリブートなどにより、現用系側と待機系側とでミラー同期できなくなって差分が生じ、その後さらに、現用系側サーバがサーバダウンなどにより正常にクラスタシャットダウンしなかった場合。この場合、その後に待機系側へ正常にフェイルオーバしても、両サーバ起動後には、両サーバとも異常(RED)状態になります。この場合にも、自動ミラー復帰はおこなわれません。強制ミラー復帰を実行する必要があります。
ミラーのステータスの参照方法については、下記を参照してください。
オンラインマニュアル
-
-
-
ミラーディスクリソース状態表示
-
-
また、ミラー復帰、強制ミラー復帰の手順については、下記を参照してください。
3.10.9. 詳細タブ¶
ミラーパーティションデバイス名
ミラーパーティションに関連付けるミラーパーティションデバイス名を選択します。
ミラーディスクリソース、ハイブリッドディスクリソースで既に設定済のデバイス名は、リスト表示されません。
マウントポイント (1023 バイト以内) サーバ個別設定可能
ミラーパーティションデバイスをマウントするディレクトリを設定します。[/] で始まる必要があります。
データパーティションデバイス名 (1023 バイト以内) サーバ個別設定可能
ディスクリソースとして使用するデータパーティションデバイス名を設定します。[/] で始まる必要があります。
クラスタパーティションデバイス名 (1023バイト以内) サーバ個別設定可能
データパーティションとペアになるクラスタパーティションデバイス名を設定します。[/] で始まる必要があります。
ファイルシステム
ミラーパーティション上で使用するファイルシステムのタイプを指定します。以下の中から選択します。直接入力することもできます。
ext2
ext3
ext4
xfs
jfs
reiserfs
none (ファイルシステムなし)
ミラーディスクコネクト
ミラーディスクコネクトの追加、削除、変更を行います。[ミラーディスクコネクト一覧] には、ミラーディスクリソースで使うミラーディスクコネクトの I/F 番号が表示されます。
[利用可能なミラーディスクコネクト] には、未使用のミラーディスクコネクト I/F 番号が表示されます。
ミラーディスクコネクトはクラスタプロパティで設定します。
使用できるミラーディスクコネクトは、1 つのミラーディスクリソースにつき最大 2 つです。2 つ用意したときの挙動は「ミラーディスクとは?」を参照してください。
ミラーディスクコネクトの設定に関しては、『インストール&設定ガイド』を参照してください。
追加
ミラーディスクコネクトを追加する場合に使用します。[利用可能なミラーディスクコネクト] から追加したい I/F 番号を選択して、[追加] をクリックしてください。[ミラーディスクコネクト一覧] に追加されます。
削除
使用するミラーディスクコネクトを削除する場合に使用します。[ミラーディスクコネクト一覧]から削除したい I/F 番号を選択して、[削除] をクリックしてください。[利用可能なミラーディスクコネクト] に追加されます。
順位
使用するミラーディスクコネクトの優先順位を変更する場合に使用します。[ミラーディスクコネクト一覧] から変更したい I/F 番号を選択して、矢印をクリックしてください。選択行が移動します。
調整
[ミラーディスクリソース調整プロパティ] ダイアログボックスを表示します。ミラーディスクリソースの詳細設定を行います。
ミラーディスクリソース調整プロパティ
マウントタブ
マウントに関する詳細設定が表示されます。
[ミラーディスクリソース詳細]タブでファイルシステムにnoneを指定している場合は表示されません。
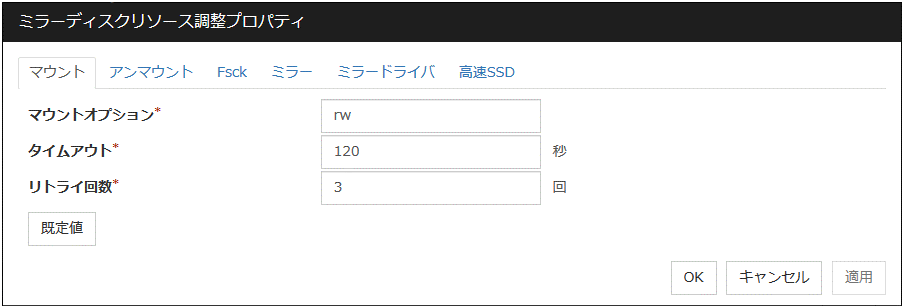
マウントオプション (1023 バイト以内)
ミラーパーティションデバイス上のファイルシステムをマウントする場合に mount コマンドへ渡すオプションを設定します。複数のオプションは「, (カンマ)」で区切ります。
マウントオプションの例
設定項目
設定値
ミラーパーティションデバイス名
/dev/NMP5
ミラーマウントポイント
/mnt/sdb5
ファイルシステム
ext3
マウントオプション
rw,data=journal
上記設定時に実行される mount コマンド
mount -t ext3 -o rw,data=journal /dev/NMP5 /mnt/sdb5
タイムアウト (1~999)
ミラーパーティションデバイス上のファイルシステムをマウントする場合の mount コマンドの終了を待つタイムアウトを設定します。ファイルシステムの容量が大きいと時間がかかる場合があります。設定する値に注意してください。
リトライ回数 (0~999)
ミラーパーティションデバイス上のファイルシステムのマウントに失敗した場合のマウントリトライ回数を設定します。0 を設定するとリトライを実行しません。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
アンマウントタブ
アンマウントに関する詳細設定が表示されます。
[ミラーディスクリソース詳細]タブでファイルシステムにnoneを指定している場合は表示されません。
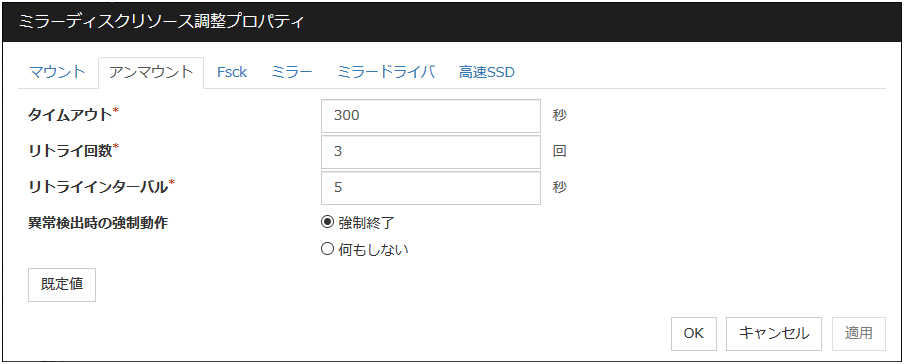
タイムアウト (1~999)
ミラーパーティションデバイス上のファイルシステムをアンマウントする場合の umount コマンドの終了を待つタイムアウトを設定します。
リトライ回数 (0~999)
ミラーパーティションデバイス上のファイルシステムの、アンマウントに失敗した場合のアンマウントリトライ回数を指定します。0 を設定するとリトライを実行しません。
リトライインターバル (0~999)
ミラーパーティションデバイス上のファイルシステムのアンマウントに失敗した場合に、次のリトライを実行するまでの間隔を指定します。
異常検出時の強制動作
アンマウントに失敗後、アンマウントリトライする場合に実行する動作を、下記より選択します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
Fsckタブ
[fsck] に関する詳細設定が表示されます。
[ミラーディスクリソース詳細]タブでファイルシステムにxfsまたはnoneを指定している場合は表示されません。
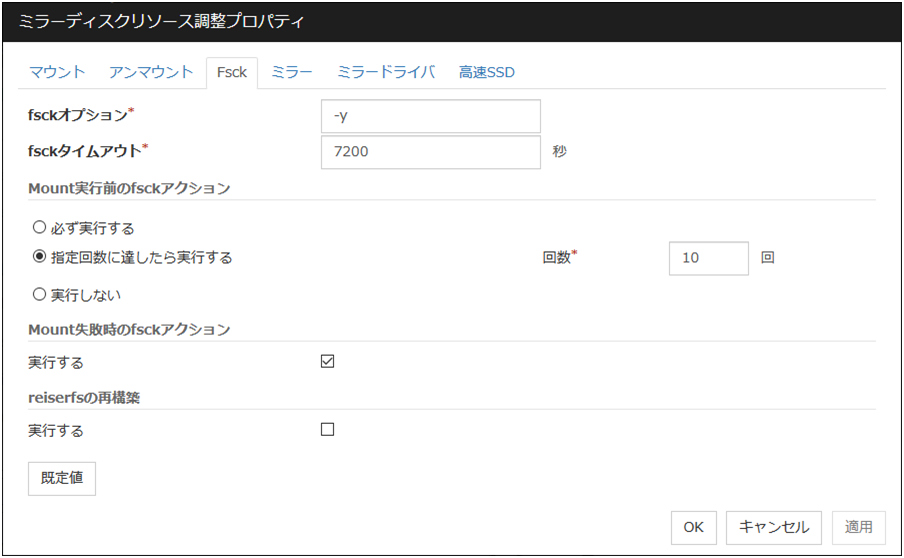
fsckオプション (1023 バイト以内)
ミラーパーティションデバイス上のファイルシステムをチェックする場合に、fsck コマンドに渡すオプションを指定します。複数のオプションはスペースで区切って設定してください。ここで、fsck コマンドが対話形式にならないようにオプションを指定してください。fsck コマンドが対話形式になると、[fsckタイムアウト] が経過後リソースの活性がエラーになります。
fsckタイムアウト (1~9999)
ミラーパーティションデバイス上のファイルシステムをチェックする場合に、fsck コマンドの終了を待つタイムアウトを指定します。ファイルシステムの容量が大きいと時間がかかる場合があります。設定する値に注意してください。
Mount実行前のfsckアクション
ミラーパーティションデバイス上のファイルシステムをマウントする前の [fsck] の動作を下記より選択します。
注釈
fsck の指定回数はファイルシステムが管理しているチェックインターバルとは無関係です。
Mount失敗時のfsckアクション
ミラーパーティションデバイス上のファイルシステムのマウントに失敗した場合の [fsck] の動作を設定します。この設定は [マウントリトライ回数] の設定値が 0 以外の場合に有効になります。
注釈
[Mount実行前のfsckアクション] が [実行しない] の場合との組み合わせは推奨しません。この設定では、ミラーリソースは fsck を実行しないため、ミラーパーティションに fsck で修復可能な異常があった場合、ミラーリソースをフェイルオーバできません
reiserfsの再構築
reiserfsck が修復可能なエラーで失敗した場合の挙動を指定します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
xfs_repairタブ
[xfs_repair] に関する詳細設定が表示されます。ファイルシステムに[xfs] を設定した場合のみ表示されます。
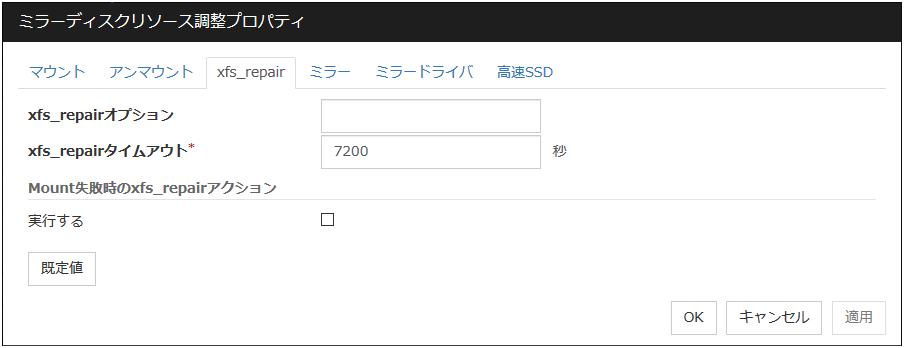
xfs_repairオプション (1023バイト以内)
ディスクデバイス上のファイルシステムをチェックする場合に [xfs_repair] コマンドに渡すオプションを指定します。複数のオプションはスペースで区切って設定してください。
xfs_repairタイムアウト (1~9999)
ディスクデバイス上のファイルシステムをチェックする場合に [xfs_repair] コマンドの終了を待つタイムアウトを指定します。ファイルシステムの容量が大きいと時間がかかる場合があります。設定する値が小さすぎないように注意してください。
Mount失敗時のxfs_repairアクション
ディスクデバイス上のファイルシステムのマウントに失敗した場合の [xfs_repair] の動作を設定します。この設定は [マウントリトライ回数] の設定値が 0 以外の場合に有効になります。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
ミラータブ
ミラーディスクに関する詳細設定が表示されます。
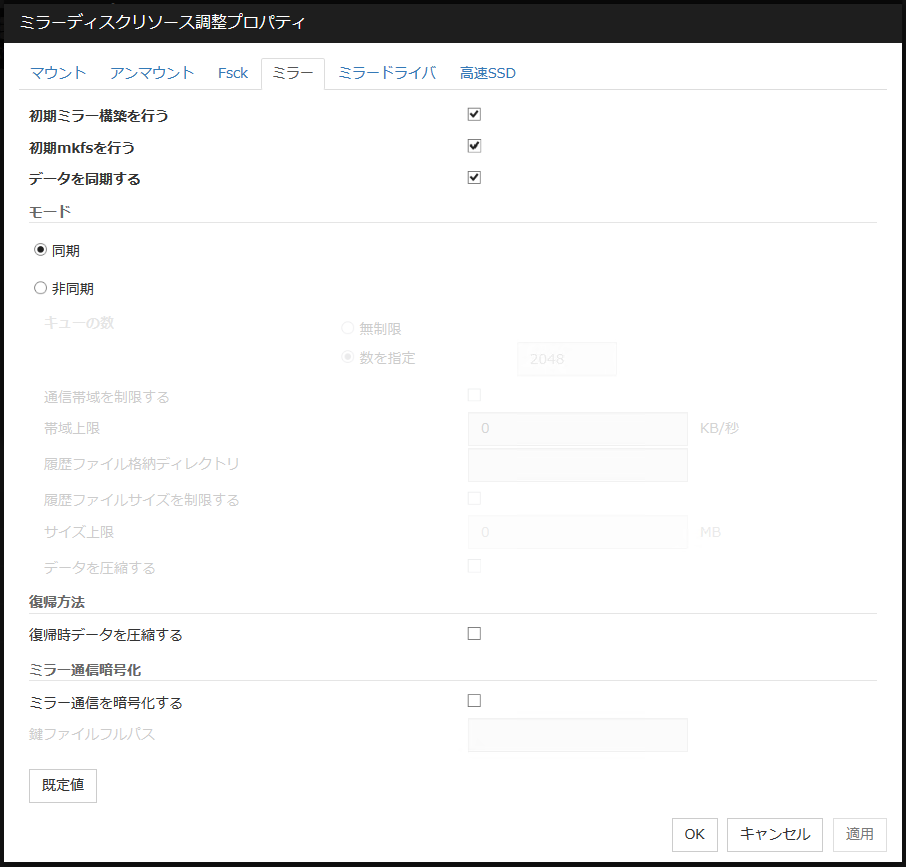
初期ミラー構築を行う
クラスタ構築時の初期ミラー構築を行うかどうかを指定します。
ext2/ext3/ext4 とその他のファイルシステムでは、初期ミラー構築にかかる時間が異なります。
初期mkfsを行う
クラスタ構築時の初期 mkfs を行うかどうかを指定します。初期ミラー構築を行う場合のみ指定可能です。
データを同期する
ミラーディスクリソースが活性化した時にミラーデータの同期を行うかどうかを指定します。
モード
ミラーデータの同期モードを指定します。
[非同期] を選択したとき、[通信帯域制限] のチェックボックスにチェックを入れることが可能です。
[非同期] を選択したとき、[履歴ファイル格納ディレクトリ] のテキストボックスの編集が可能です。キューを超過した際の、ファイルを格納するディレクトリを設定します。指定が無い場合は、(CLUSTERPROインストールディレクトリ)/workの下にファイルが生成されます。
[非同期] を選択したとき、[履歴ファイルサイズ制限] のテキストボックスの編集が可能です。履歴ファイルの総計がこのサイズに達すると、ミラーブレイク状態となります。0または無指定の場合は、サイズ無制限となります。
また、[非同期] を選択したとき、[データを圧縮する] のチェックボックスにチェックを入れることが可能です。
復帰時データを圧縮する
ミラー復帰の通信データを圧縮するか設定します。
ミラー通信を暗号化する
ミラーディスクコネクトを流れる通信データを暗号化するかどうかを設定します。ミラー同期の通信データおよびミラー復帰の通信データ、両方に作用します。
鍵ファイルフルパス (1023 バイト以内)
ミラーディスクコネクトを流れる通信データを暗号化する鍵ファイルをフルパスで指定します。暗号化を使用する場合は、指定が必須です。
注釈
鍵ファイルはOSのopensslコマンドを使用して生成したものを使用します。以下は、RHEL7系での実行例です。ディストリビューションごとにopensslコマンドのオプション体系も異なるので、確認の上、実行してください。# openssl rand 16 -out (鍵ファイル名) 鍵長128ビット(16バイト)の暗号化鍵を生成 # openssl rand 24 -out (鍵ファイル名) 鍵長192ビット(24バイト)の暗号化鍵を生成 # openssl rand 32 -out (鍵ファイル名) 鍵長256ビット(32バイト)の暗号化鍵を生成鍵長は128ビット, 192ビット, 256ビットのいずれかが使用可能です。
重要
必ず、ミラーディスクリソースが活性可能な全サーバで同じ鍵ファイルを使用してください。鍵ファイルが異なると、正常にミラーリングできません。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
ミラードライバタブ
ミラードライバに関する詳細設定が表示されます。
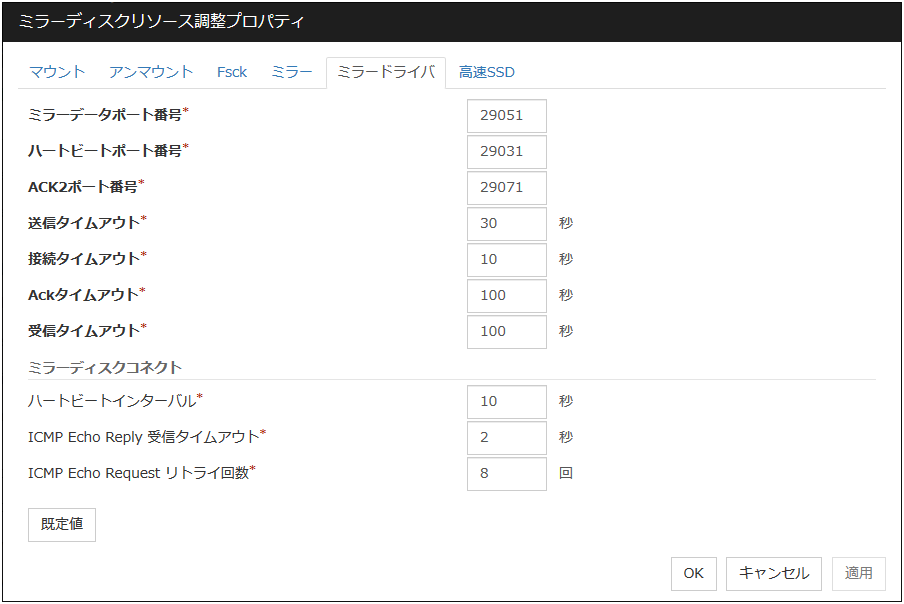
ミラーデータポート番号 (1~655355 )
ミラードライバがサーバ間でディスクデータの送受信に使用する TCP ポート番号を設定します。最初に作成したミラーディスクリソースまたはハイブリッドディスクリソースにデフォルトの[29051] が設定されます。2 つめ以降のミラーディスクリソースまたはハイブリッドディスクリソースにはデフォルトに 1 ずつ加算された値 [29052,29053,…] が設定されます。
- 5
Well-Known ポート、特に 1~1023 番の予約ポートの使用は推奨しません。
ハートビートポート番号 (1~655356 )
ミラードライバがサーバ間で制御用データの通信を行う TCP ポート番号を設定します。最初に作成したミラーディスクリソースまたはハイブリッドディスクリソースにデフォルトの [29031]が設定されます。2 つめ以降のミラーディスクリソースまたはハイブリッドディスクリソースにはデフォルトに 1 ずつ加算された値 [29032,29033,…] が設定されます。
- 6
Well-Known ポート、特に 1~1023 番の予約ポートの使用は推奨しません。
ACK2 ポート番号 (1~655357 )
ミラードライバがサーバ間で制御用データの通信を行う TCP ポート番号を設定します。最初に作成したミラーディスクリソースまたはハイブリッドディスクリソースにデフォルトの [29071]が設定されます。2 つめ以降のミラーディスクリソースまたはハイブリッドディスクリソースにはデフォルトに 1 ずつ加算された値 [29072,29073,…] が設定されます。
- 7
Well-Known ポート、特に 1~1023 番の予約ポートの使用は推奨しません。
送信タイムアウト (10~99)
書き込みデータの送信タイムアウトを設定します。
接続タイムアウト (5~99)
接続のタイムアウトを設定します。
Ackタイムアウト (1~600)
ミラー復帰、データ同期時にAck応答を待つタイムアウトを設定します。
受信タイムアウト (1~600)
書き込み確認の受信待ちタイムアウトを設定します。
ハートビートインターバル (1~600)
ミラードライバによるミラーディスクコネクト間ハートビートのインターバルを設定します。
ICMP Echo Reply 受信タイムアウト (1~100)
ミラードライバによるミラーディスクコネクト間ハートビートのタイムアウトを設定します。ここで設定された時間の間無応答がICMP Echo Request リトライ回数分続くとミラーディスクコネクトの断線とみなします。
ICMP Echo Request リトライ回数 (1~50)
ミラードライバによるミラーディスクコネクト間ハートビートのリトライ回数を設定します。ICMP Echo Reply 受信タイムアウトとともにミラーコネクト断線の判定感度に関わってきます。
既定値
[既定値] をクリックすると以下の項目に既定値が設定されます。
送信タイムアウト
接続タイムアウト
Ack タイムアウト
受信タイムアウト
ハートビートインターバル
ICMP Echo Reply 受信タイムアウト
ICMP Echo Request リトライ回数
注釈
[ミラーデータポート番号] [ハートビートポート番号] [ACK2ポート番号] はリソースごとに異なるポート番号を設定する必要があります。また、クラスタで使用するその他のポート番号と重複しないように設定する必要があります。そのため、[既定値] を押しても既定値はセットされません。
高速SSDタブ
ミラーディスクリソースでの高速SSD使用に関する詳細設定が表示されます。
データパーティション
ミラーディスクリソースのデータパーティションに高速SSDを使用している場合、チェックボックスをオンにします。全てのノード上で、データパーティションに使用するディスク装置は、HDDまたはSSDで統一してください。両者が混在すると、最適な性能が発揮できなくなります。
クラスタパーティション
ミラーディスクリソースのクラスタパーティションに高速SSDを使用している場合、チェックボックスをオンにします。全てのノード上で、クラスタパーティションに使用するディスク装置は、HDDまたはSSDで統一してください。両者が混在すると、最適な性能が発揮できなくなります。
3.11. ハイブリッドディスクリソースを理解する¶
3.11.1. ハイブリッドディスクリソースの依存関係¶
既定値では、以下のグループリソースタイプに依存します。
グループリソースタイプ |
|---|
フローティング IP リソース |
仮想 IP リソース |
AWS Elastic IPリソース |
AWS 仮想IPリソース |
AWS DNS リソース |
Azure プローブポートリソース |
Azure DNS リソース |
3.11.2. ハイブリッドディスクとは?¶
ハイブリッドディスクとは、2 つのサーバグループ間でデータのミラーリングを行うリソースのことです。サーバグループは 1 台または 2 台のサーバから構成されます。サーバグループが2 台のサーバで構成される場合には共有ディスクを使用します。サーバグループが 1 台のサーバで構成される場合には共有型でないディスク (サーバ内蔵、サーバ間で共有していない外付型ディスク筐体など) を使用します。
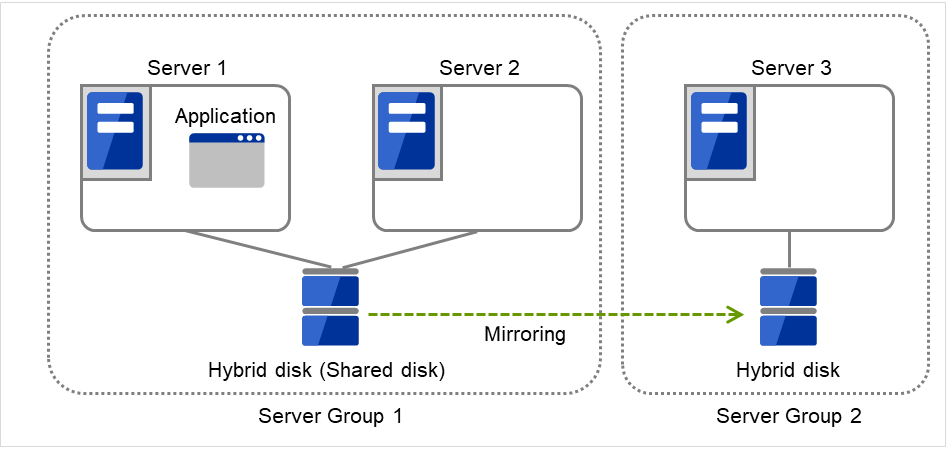
図 3.109 ハイブリッド構成 (1)(通常時)¶
Server 1がダウンすると、Application は Server 2にフェイルオーバします。
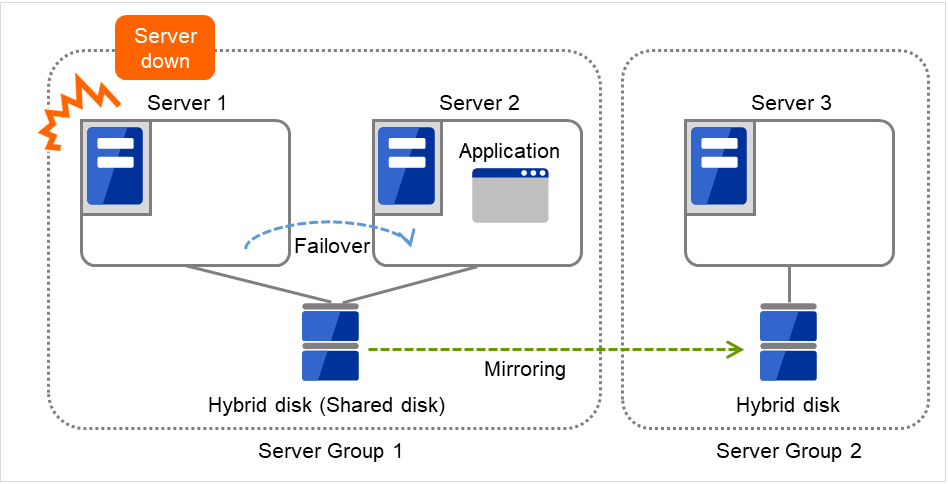
図 3.110 ハイブリッド構成 (2)(Server 1ダウン)¶
Server 2がダウンすると、Application は Server 3にフェイルオーバします。
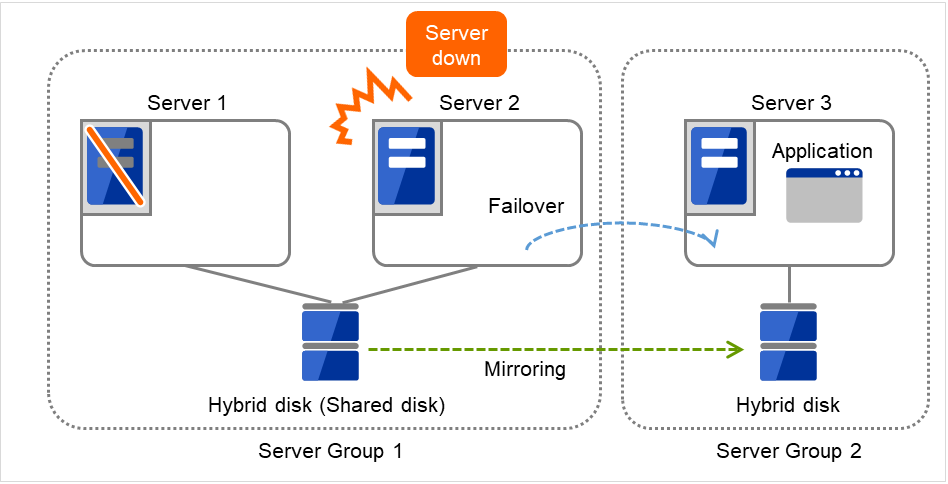
図 3.111 ハイブリッド構成 (3)(Server 2ダウン)¶
データパーティション
ミラーリングするデータ (業務データなど) を格納するパーティションのことを、データパーティションといいます。
データパーティションは以下のように割り当ててください。
- データパーティションのサイズ1GB 以上、1TB 未満のパーティションを確保してください。※データの構築時間、復旧時間の観点より、1TB 未満のサイズを推奨します。
- パーティション ID83 (Linux)
- ファイルシステムは、本バージョンのハイブリッドディスクリソースでは自動では構築されませんので、必要に応じてあらかじめ手動で構築してください。
- ファイルシステムのアクセス制御 (mount/umount) は、CLUSTERPRO が行いますので、OS 側でデータパーティションを mount/umount する設定を行わないでください。
クラスタパーティション
CLUSTERPRO がハイブリッドディスクの制御のために使用する専用パーティションを、クラスタパーティションといいます。
クラスタパーティションは以下のように割り当ててください。
- クラスタパーティションのサイズ最低 1024MiB 確保してください。ジオメトリによって 1024MB 以上になる場合がありますが、1024MB 以上でも問題ありません。
- パーティション ID83 (Linux)
- クラスタパーティションは、データミラーリング用のデータパーティションとペアで割り当てる必要があります。
- クラスタパーティションにファイルシステムを構築しないでください。
ミラーパーティションデバイス (/dev/NMPx)
1 つのハイブリッドディスクリソースで 1 つのミラーパーティションデバイスをファイルシステムに提供します。ハイブリッドディスクリソースとして登録すると、1 台のサーバ (通常はリソースグループのプライマリサーバ) からのみアクセス可能になります。
通常、ユーザ (AP) はファイルシステムを経由して I/O を行うため、ミラーパーティションデバイス (dev/NMPx) を意識する必要はありません。Cluster WebUI で情報を作成するときに重複しないようにデバイス名を割り当てます。
- ファイルシステムのアクセス制御 (mount/umount) は、CLUSTERPRO が行いますので、OS 側でミラーパーティションデバイスを mount/umount する設定を行わないでください。業務アプリケーションなどからの、ミラーパーティション (ハイブリッドディスクリソース) へのアクセス可否の考え方は、共有ディスクを使用した切替パーティション (ディスクリソース) と同じです。
ミラーパーティションの切り替えは、フェイルオーバグループごとにフェイルオーバポリシーにしたがって行われます。
ミラーパーティションのスペシャルデバイス名は /dev/NMPx (xは数字の1~8) を使用します。他のデバイスドライバでは、/dev/NMPx を使用しないでください。
ミラーパーティションはメジャー番号の 218 を使用します。他のデバイスドライバでは、メジャー番号の 218 を使用しないでください。
例1) 2 台のサーバで共有ディスクを使用し 3 台目のサーバでサーバに内蔵したディスクを使用する場合
図はハイブリッド構成の例です。Server 1とServer 2が Shared diskを共有し、Shared diskの Cluster partition、および Data partition の内容がServer 3に接続された Diskにミラーリングされています。この Cluster partition および Data partition がハイブリッドリソースにおけるフェイルオーバの単位であり、ミラーパーティションデバイスとなります。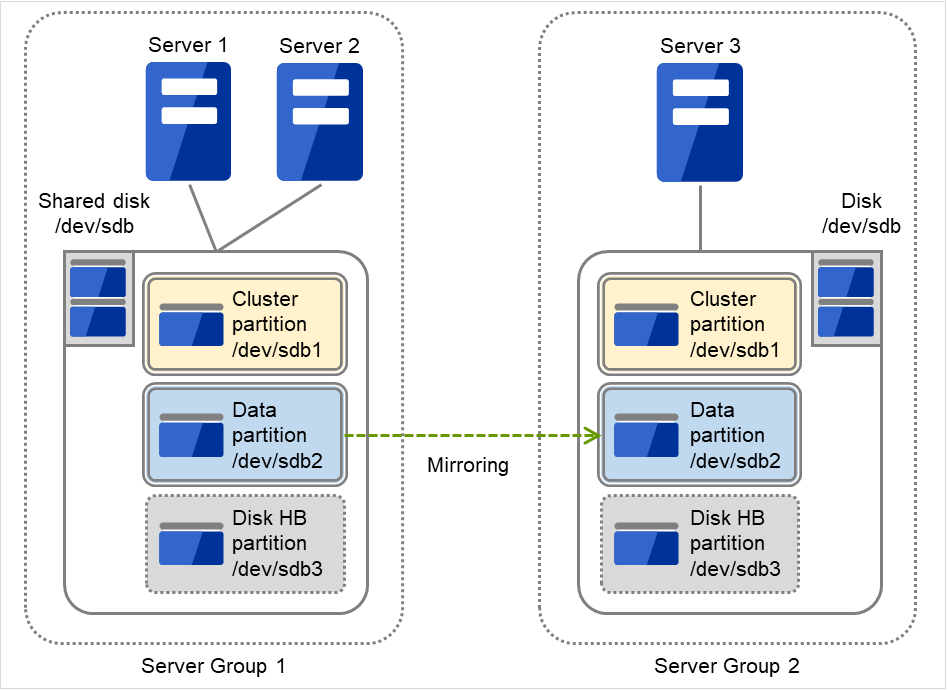
図 3.112 ハイブリッド構成におけるパーティション¶
共有型でないディスクを使用する場合 (サーバグループ内にサーバが 1 台の場合)には、OS (root パーティションや swap パーティション) と同じディスク上に、ハイブリッドディスクリソース用のパーティション (クラスタパーティション、データパーティション) を確保することも可能です。
- 障害時の保守性を重視する場合OS (root パーティションや swap パーティション) と別にミラー用のディスクを用意することを推奨します。
- H/W RAID の仕様の制限で LUN の追加ができない場合H/W RAID のプリインストールモデルで LUN 構成変更が困難な場合OS (root パーティションや swap パーティション) と同じディスクに、ハイブリッドディスクリソース用のパーティション (クラスタパーティション、データパーティション) を確保することも可能です。
ミラーディスクコネクト
ミラーディスクリソースの「ミラーディスクとは?」の「ミラーディスクコネクト」を参照してください。
3.11.3. ミラーパラメータ設定の考え方¶
以下のパラメータについてはミラーディスクリソースと同一です。ミラーディスクリソースを参照してください。
ミラーデータポート番号
ハートビートポート番号
ACK2 ポート番号
リクエストキューの最大数
接続タイムアウト
送信タイムアウト
受信タイムアウト
Ack タイムアウト
ハートビートインターバル
ICMP Echo Reply 受信タイムアウト
ICMP Echo Request リトライ回数
差分ビットマップ更新インターバル (クラスタプロパティ)
差分ビットマップサイズ (クラスタプロパティ)
初期ミラー構築
キューの数
通信帯域制限
履歴ファイル格納ディレクトリ
履歴ファイルサイズ制限
データの圧縮
ミラーエージェント送信タイムアウト (クラスタプロパティ)
ミラーエージェント受信タイムアウト (クラスタプロパティ)
復帰データサイズ (クラスタプロパティ)
ミラー通信を暗号化する
以下のパラメータについてはミラーディスクリソースと異なります。
- 初期 mkfs本バージョンのハイブリッドディスクリソースでは、自動では mkfs を行いませんので、必要な場合はあらかじめ手動で行ってください。
3.11.4. ハイブリッドディスクリソースに関する注意事項¶
サーバ間でクラスタパーティション、またはデータパーティションに設定するデバイス名が異なる場合はサーバ個別設定を行ってください。ただし、同一サーバグループに所属するサーバ間でデバイス名が異なる場合、デバイス名には by-id を設定してください。
クラスタプロパティの [拡張] タブで、[マウント、アンマウントコマンドを排他する] にチェックを入れている場合、ディスクリソース、NAS リソース、ミラーリソース、ハイブリッドディスクリソースの mount/umount は同一サーバ内で排他的に動作するため、ハイブリッドディスクリソースの活性/非活性に時間がかかることがあります。
- マウントポイントにシンボリックリンクを含むパスを指定すると、異常検出時の動作に [強制終了] を選択しても強制終了できません。また、同様に「//」を含むパスを指定した場合にも、強制終了できません。
Linux の md によるストライプセット、ボリュームセット、ミラーリング、パリティ付きストライプセットを使用したディスクを、クラスタパーティションやデータパーティションに指定することはできません。
- Linux の LVM によるボリュームを、クラスタパーティションやデータパーティションに指定することは可能です。なお、SuSE Linux については、LVM や MultiPath によるボリュームを、クラスタパーティションやデータパーティションに使用することはできません。
ハイブリッドディスクリソース (ミラーパーティションデバイス) を Linux の md や LVMによるストライプセット、ボリュームセット、ミラーリング、パリティ付きストライプセットの対象とすることはできません。
ハイブリッドディスク用のディスクとして使用するディスクのジオメトリがサーバ間で異なる場合の注意
fdisk コマンドなどで確保したパーティションサイズはシリンダあたりのブロック (ユニット) 数でアラインされます。
データパーティションのサイズと初期ミラー構築の方向の関係が以下になるようにデータパーティションを確保してください。コピー元のサーバ ≦ コピー先のサーバコピー元のサーバとは、ハイブリッドディスクリソースが所属するフェイルオーバグループのサーバグループのうちプライオリティが高いサーバグループのサーバを指します。コピー先のサーバとは、ハイブリッドディスクリソースが所属するフェイルオーバグループのサーバグループのうちプライオリティが低いサーバグループのサーバを指します。なお、データパーティションは同程度のサイズで確保するようにしてください。データパーティションのサイズが、コピー元側とコピー先側とで 32GiB, 64GiB, 96GiB, … (32GiBの倍数) を跨がないように注意してください。32GiBの倍数を跨ぐサイズの場合、初期ミラー構築に失敗することがあります。
例)
組み合わせ
データパーティションのサイズ
説明
Server 1側
Server 2側
OK
30GiB
31GiB
両方とも0~32GiB未満の範囲内にあるのでOK
OK
50GiB
60GiB
両方とも32GiB以上~64GiB未満の範囲内にあるのでOK
NG
30GiB
39GiB
32GiBを跨いでいるのでNG
NG
60GiB
70GiB
64GiBを跨いでいるのでNG
- ハイブリッドディスクリソースで使用するファイルに対して open() システムコールのO_DIRECT フラグを使用しないでください。例えば Oracle の設定パラメータの filesystemio_options = setall などがこれに該当します。
DISK 監視の READ (O_DIRECT) 方式の監視先として ミラーパーティションデバイス(/dev/NMP1など) を指定しないでください。
ハイブリッドディスクを使用するクラスタ構成では、モニタリソースの最終動作等を、[クラスタサービス停止] に設定しないようにしてください。
ハイブリッドディスクリソースのデータパーティションおよびクラスタパーティションには、全サーバで同一の論理セクタサイズのディスクを使用してください。異なる論理セクタサイズのディスクを使用すると、正常に動作しません。データパーティションとクラスタパーティションでは論理セクタサイズが異なっていても動作可能です。
例)
組み合わせ
パーティションの論理セクタサイズ
説明
Server 1側
Server 1側
Server 2側
Server 2側
OK
512B
512B
512B
512B
論理セクタサイズが統一されている
OK
4KB
512B
4KB
512B
データパーティションで4KB、クラスタパーティションで512Bに統一されている
NG
4KB
512B
512B
512B
データパーティションの論理セクタサイズが統一されていない
NG
4KB
4KB
4KB
512B
クラスタパーティションの論理セクタサイズが統一されていない
ハイブリッドディスクリソースのデータパーティションおよびクラスタパーティションとして使用するディスクについて、HDDとSSDを混在させないでください。混在させると最適な性能が得られません。データパーティションとクラスタパーティションではディスクタイプが異なっていても動作可能です。
例)
組み合わせ
パーティションのディスクタイプ
説明
Server 1側
Server 1側
Server 2側
Server 2側
データパーティションクラスタパーティションデータパーティションクラスタパーティションOK
HDD
HDD
HDD
HDD
ディスクタイプが統一されている
OK
SSD
HDD
SSD
HDD
データパーティションでSSD、クラスタパーティションでHDDに統一されている
NG
SSD
HDD
HDD
HDD
データパーティションでHDD/SSDが混在している
NG
SSD
SSD
SSD
HDD
クラスタパーティションでHDD/SSDが混在している
現用系サーバ異常ダウンした後のミラー復帰の挙動について
現用系サーバが異常ダウンした場合、ダウンするタイミングによって全面ミラー復帰となる場合と差分ミラー復帰になる場合があります。
共有ディスクで接続されたサーバ (同一サーバグループ内のサーバ) でリソースを活性する場合
図はハイブリッド構成の例です。Server 1とServer 2が Shared diskを共有し、Shared diskの Cluster partition、および Data partition の内容がServer 3に接続された Diskにミラーリングされています。

図 3.113 ハイブリッド構成 (1)(同一サーバグループ内でリソース活性, 通常時)¶
Server 1がダウンすると、Hybrid Disk Resource は Server 2にフェイルオーバします。
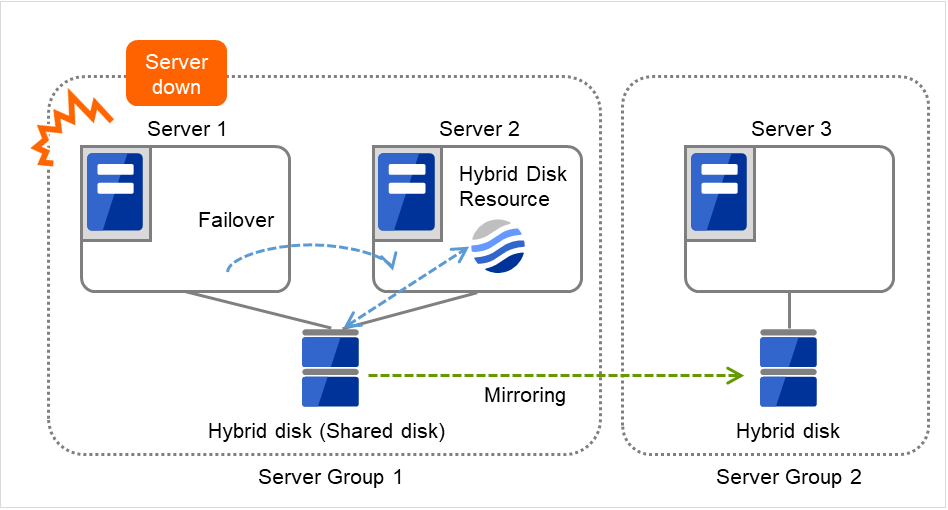
図 3.114 ハイブリッド構成 (2)(同一サーバグループ内でリソース活性, Server 1ダウン)¶
Shared disk と Server 3 に接続されたDiskの間でミラー復帰処理を行う必要がある場合、Server 1がダウンしたタイミングによってその処理内容が異なります。
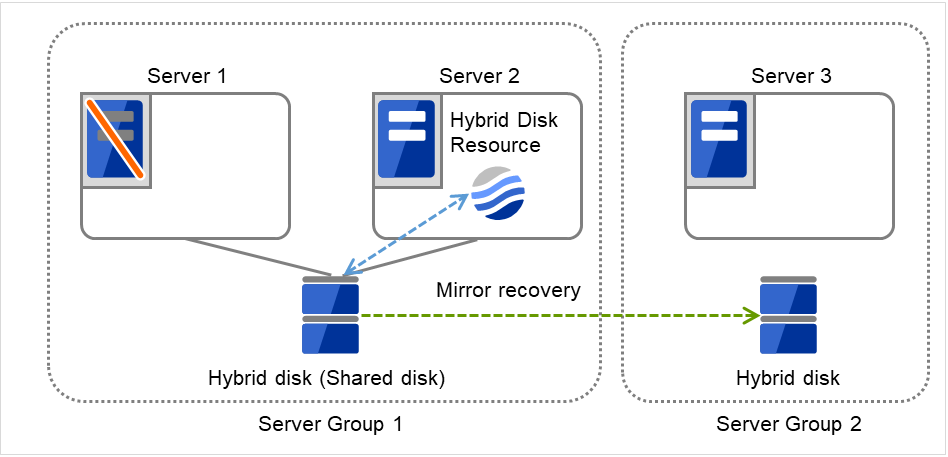
図 3.115 ハイブリッド構成 (3)(同一サーバグループ内でリソース活性, Server 1ダウン後のミラー復帰)¶
相手サーバグループのサーバでリソースを活性する場合
図はハイブリッド構成の例です。 Server 1とServer 2が Shared diskを共有し、Shared diskの Cluster partition、および Data partition の内容がServer 3に接続された Diskにミラーリングされています。
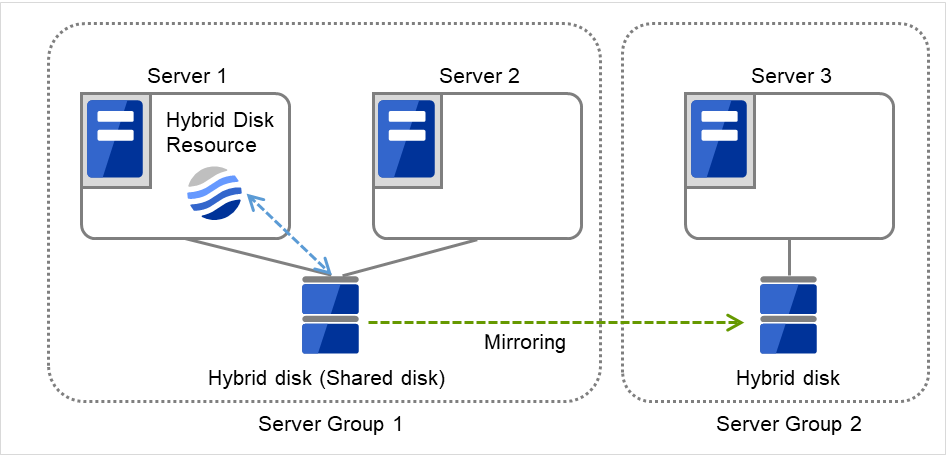
図 3.116 ハイブリッド構成 (1)(相手サーバグループ内でリソース活性, 通常時)¶
Server 1がダウンすると、Hybrid Disk Resource は Server 3にフェイルオーバします。
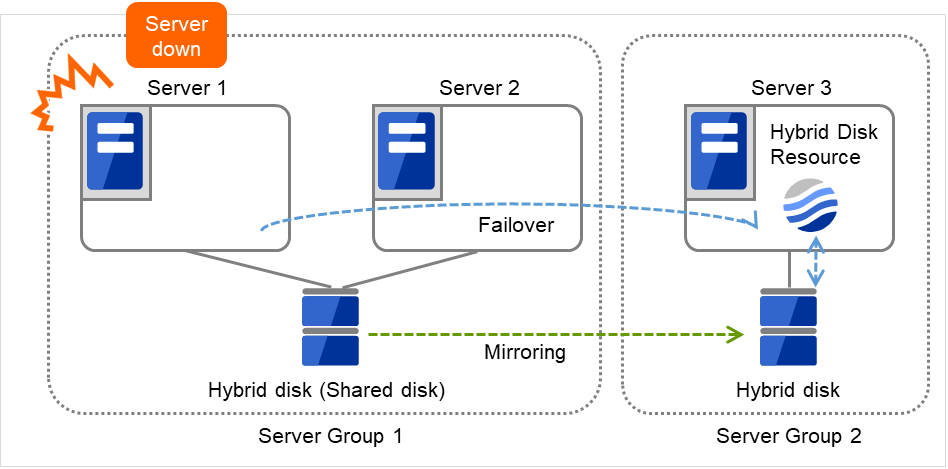
図 3.117 ハイブリッド構成 (2)(相手サーバグループ内でリソース活性, Server 1ダウン)¶
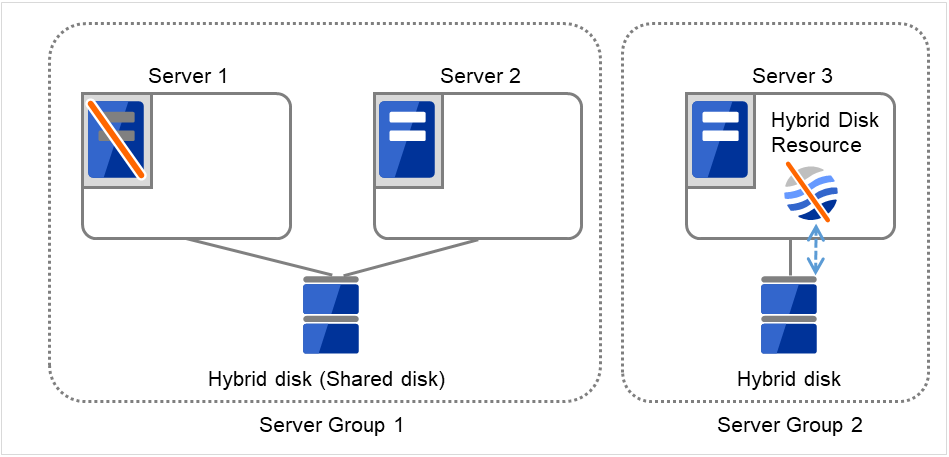
図 3.118 ハイブリッド構成 (3)(相手サーバグループ内でリソース活性, Server 1ダウン後のミラー復帰)¶
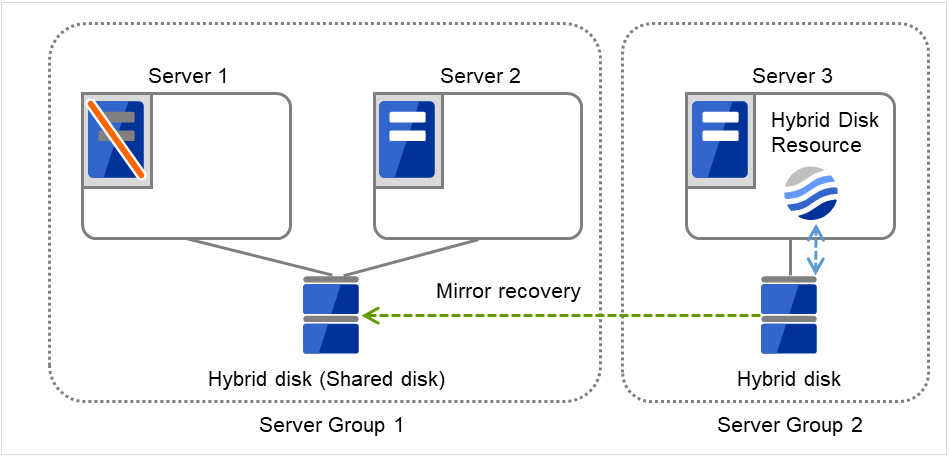
図 3.119 ハイブリッド構成 (4)(相手サーバグループ内でリソース活性, Server 1ダウン後のミラー復帰)¶
3.11.5. mount前後の処理の流れ¶
ハイブリッドディスクリソース活性時のmountの処理は以下のように行われます。
ファイルシステムにnoneが指定されている場合、mount処理は行いません。
事前にマウントされているか?
既にマウントされていた場合 → ×へ
マウント前に fsck を実行する設定か?
fsck を実行するタイミングである → デバイスに fsck を実行する
デバイスをマウントする
マウント成功 → ○へ
マウントのリトライを行う設定か?
リトライしない設定の場合 → ×へ
マウント失敗時に fsck(xfs_repair)を実行する設定の場合
2.でfsckを実行して成功していた場合 → 6.へ
3.でタイムアウトにより失敗していた場合 → 6.へ
上記以外の場合 → デバイスにfsck(xfs_repair)を実行する
再度デバイスのマウントを試みる
マウント成功 → ○へ
マウントのリトライ回数以内か?
リトライ回数以内の場合 → 6.へ
リトライ回数を超えた場合 → ×へ
○ リソース起動(マウント成功)
× リソース起動失敗(マウントされていない)
3.11.6. umount前後の処理の流れ¶
ハイブリッドディスクリソース非活性時のumountの処理は以下のように行われます。
ファイルシステムにnoneが指定されている場合、umount処理は行いません。
事前にアンマウントされているか?
既にアンマウントされていた場合 → ×へ
デバイスをアンマウントする
アンマウント成功 → ○へ
アンマウントのリトライを行う設定か?
リトライしない設定の場合 → ×へ
まだマウントされているか?(マウント一覧からマウントポイントが削除されていて、ミラーデバイスも未使用状態になっているか?)
もうマウントされていない → ○へ
マウントポイントを使用しているプロセスのKILLを試みる
再度デバイスのアンマウントを試みる
アンマウント成功 → ○へ
- アンマウントタイムアウトではなく、かつ、マウント一覧からマウントポイントが削除されているか?マウントポイントは既に削除された → ミラーデバイスが使用されなくなるまで待つ(最大でアンマウントタイムアウトの時間まで待つ)
アンマウントのリトライ回数以内か?
リトライ回数以内の場合 → 4.へ
リトライ回数を超えた場合 → ×へ
○ リソース停止(アンマウント成功)
× リソース停止失敗(マウントされたまま、もしくは既にアンマウントされていた)
3.11.7. 詳細タブ¶
以下についてはミラーディスクリソースと同一です。ミラーディスクリソースを参照してください。
ハイブリッドディスク詳細タブ (ミラーディスク詳細タブを参照ください)
ミラーディスクコネクトの選択
ハイブリッドディスク調整プロパティ (ミラーディスク調整プロパティを参照ください)
マウントタブ
アンマウントタブ
Fsck タブ
xfs_repair タブ
ミラータブ (初期 mkfs を行う以外のパラメータ)
ミラードライバタブ
高速SSDタブ
以下のタブについてはミラーディスクリソースと異なります。
ハイブリッドディスク調整プロパティのミラータブ [初期 mkfs を行う]
初期mkfsを行う
本バージョンのハイブリッドディスクリソースでは、クラスタを構築するときの自動の初期 mkfsは実行されません。
3.12. NAS リソースを理解する¶
3.12.1. NAS リソースの依存関係¶
既定値では、以下のグループリソースタイプに依存します。
グループリソースタイプ |
|---|
ダイナミック DNS リソース |
フローティング IP リソース |
仮想 IP リソース |
AWS Elastic IPリソース |
AWS 仮想IPリソース |
AWS DNS リソース |
Azure プローブポートリソース |
Azure DNS リソース |
3.12.2. NAS リソースとは?¶
NAS リソースは、NFS サーバ上の資源を制御します。
業務に必要なデータは、NFS サーバ上に格納しておくことで、フェイルオーバ時、フェイルオーバグループの移動時などに、自動的に引き継がれます。
図 3.120 NASリソース (1)¶
図 3.121 NASリソース (2)¶
3.12.3. NAS リソースに関する注意事項¶
ファイルシステムのアクセス制御 (mount/umount) は、CLUSTERPRO が行いますので、OS 側で mount/umount する設定を行わないでください。
NFS サーバ上で、クラスタを構成しているサーバへ NFS 資源のアクセス許可を設定 する必要があります。
CLUSTERPRO サーバ側で portmap サービスを起動する設定を行ってください。
NAS サーバ名にホスト名を指定する場合は名前解決できるように設定を行ってください。
クラスタのプロパティの [拡張] タブで、[マウント,アンマウントコマンドを排他する] にチェックを入れている場合、ディスクリソース、NAS リソース、ミラーリソースの mount/umount は同一サーバ内で排他的に動作するため、NAS リソースの活性/非活性に時間がかかることがあります。
- マウントポイントにシンボリックリンクを含むパスを指定すると、異常検出時の動作に [強制終了] を選択しても強制終了できません。また、同様に「//」を含むパスを指定した場合にも、強制終了できません。
3.12.4. 詳細タブ¶
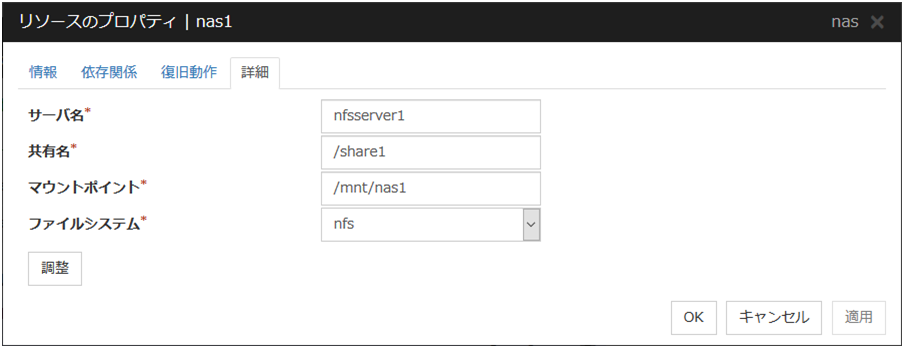
サーバ名 (255 バイト以内)
NFS サーバの IP アドレス、または、ホスト名を設定します。ホスト名を設定する場合は、 OS 側に名前解決の設定 (/etc/hosts へのエントリの追加など) をしてください。
共有名 (1023 バイト以内)
NFS サーバ上の共有名を設定します。
マウントポイント (1023 バイト以内)
NFS リソースをマウントするディレクトリを設定します。「/」 で始まる必要があります。
ファイルシステム (15 バイト以内)
NFS リソースのファイルシステムのタイプを設定します。直接入力することもできます。
nfs
調整
[NAS リソース調整プロパティ] ダイアログボックスを表示します。NAS リソースの詳細設定を行います。
NASリソース調整プロパティ
マウントタブ
マウントに関する詳細設定が表示されます。
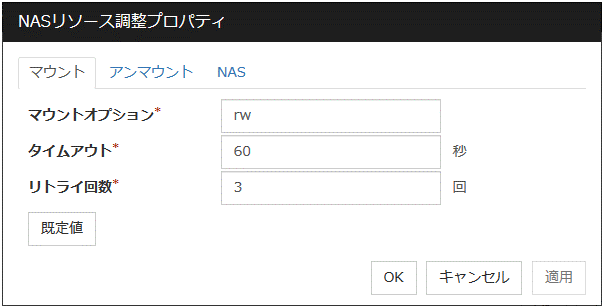
マウントオプション (1023 バイト以内)
ファイルシステムをマウントする場合に [mount] コマンドへ渡すオプションを設定します。複数のオプションは「, (カンマ)」で区切ります。
マウントオプションの例
設定項目
設定値
サーバ名
nfsserver
共有名
/share1
マウントポイント
/mnt/nas1
ファイルシステム
nfs
マウントオプション
rw
上記設定時に実行される [mount] コマンド
mount -t nfs -o rw nfsserver1:/share1 /mnt/nas1
タイムアウト (1~999)
ファイルシステムをマウントする場合の [mount] コマンドの終了を待つタイムアウトを設定します。ネットワークの負荷によって時間がかかる場合があります。設定する値に注意してください。
リトライ回数 (0~999)
ファイルシステムのマウントに失敗した場合のマウントリトライ回数を設定します。
0 を設定するとリトライを実行しません。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
アンマウントタブ
アンマウントに関する詳細設定が表示されます。
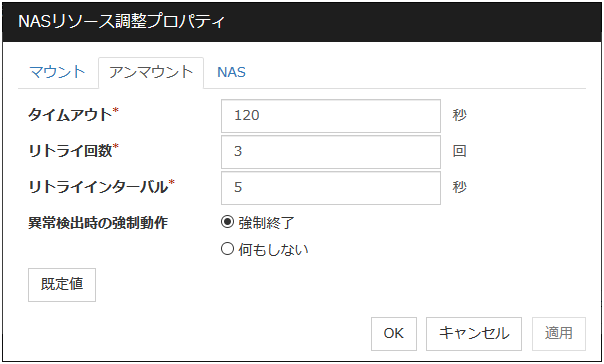
タイムアウト (1~999)
ファイルシステムをアンマウントする場合の [umount] コマンドの終了を待つタイムアウトを設定します。
リトライ回数 (0~999)
ファイルシステムのアンマウントに失敗した場合のアンマウントリトライ回数を指定します。0 を設定するとリトライを実行しません。
リトライインターバル (0~999)
ファイルシステムのアンマウントに失敗した場合に、次のリトライを実行するまでの間隔を指定します。
異常検出時の強制動作
アンマウントに失敗後、アンマウントリトライする場合に実行する動作を下記より選択します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
NASタブ
NAS に関する詳細設定が表示されます。
Ping タイムアウト (0~999)
NAS リソース活性時と非活性時に、NFS サーバとの接続を確認するために発行する [ping] コマンドのタイムアウトを設定します。0 を設定すると [ping] コマンドを発行しません。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
3.13. ボリュームマネージャリソースを理解する¶
3.13.1. ボリュームマネージャリソースの依存関係¶
既定値では、以下のグループリソースタイプに依存します。
グループリソースタイプ |
|---|
ダイナミック DNS リソース |
フローティング IP リソース |
仮想 IP リソース |
AWS Elastic IPリソース |
AWS 仮想IPリソース |
AWS DNS リソース |
Azure プローブポートリソース |
Azure DNS リソース |
3.13.2. ボリュームマネージャリソースとは?¶
ボリュームマネージャとは、複数のストレージやディスクを 1 つの論理的なディスクとして扱うためのディスク管理用ソフトウェアです。
ボリュームマネージャリソースは、ボリュームマネージャによって管理される論理ディスクを制御します。
業務に必要なデータは、論理ディスク内に格納しておくことで、フェイルオーバ時、フェイルオーバグループの移動時などに、自動的に引き継がれます。

図 3.122 ボリュームマネージャリソース (1)¶
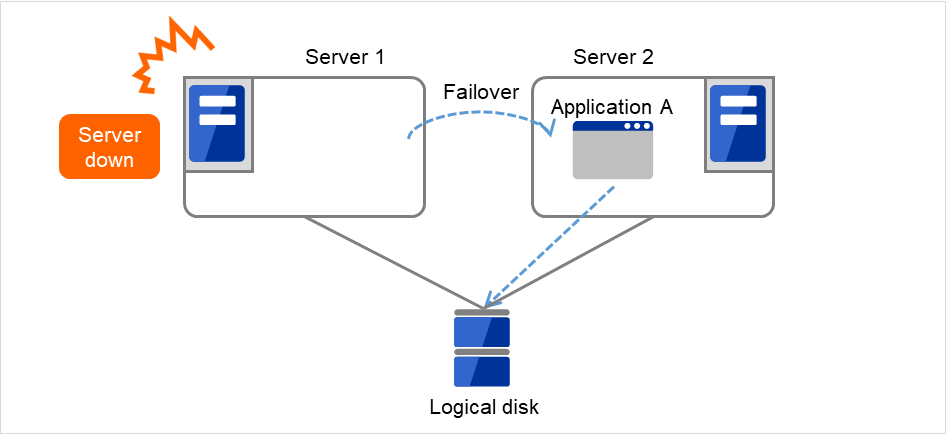
図 3.123 ボリュームマネージャリソース (2)¶
3.13.3. ボリュームマネージャリソースに関する注意事項¶
<ボリュームマネージャリソース全般>
ミラーディスクはボリュームマネージャリソースの管理対象とはしないでください。
個々のボリュームの制御はディスクリソースで行います。
論理ディスクのアクセス制御 (import/export) は、CLUSTERPRO が行いますので、 OS 側で import/export する設定を行わないでください。
<ボリュームマネージャ [lvm] での利用時>
ボリュームグループの定義は CLUSTERPRO 側で行いません。
個々のボリュームの制御が必須のため、最低 1 つはディスクリソースが必要です。
CLUSTERPRO の設定情報に含まれるボリュームグループは OS 起動時に自動的にエクスポート処理を行います。
CLUSTERPRO の設定情報に含まれていないボリュームグループはエクスポートしません。
共有ディスクで構築した VG を対象ボリュームに指定した場合、LVMの仕様により、VG の import/export 状態は共有ディスク上に記録されるため、現用系サーバで活性(import), 非活性(export) すると、待機系サーバでも同様の状態に見える場合があります。
Red Hat Enterprise Linux 7 以降の環境で、ボリュームマネージャリソースにて LVM の制御を行う場合、LVM メタデータデーモンを無効にする必要があります。
リソース活性時に以下のコマンドを実行します。
コマンド
オプション
使用するタイミング
vgs
-P
ボリュームグループのステータス確認時
--noheadings
ボリュームグループのステータス確認時
-o vg_attr,vg_name
ボリュームグループのステータス確認時
vgimport
(無し)
ボリュームグループインポート時
vgscan
(無し)
ボリュームグループスキャン時
vgchange
-ay
ボリュームグループ活性時
リソース活性時のシーケンスは下記の通りとなります。
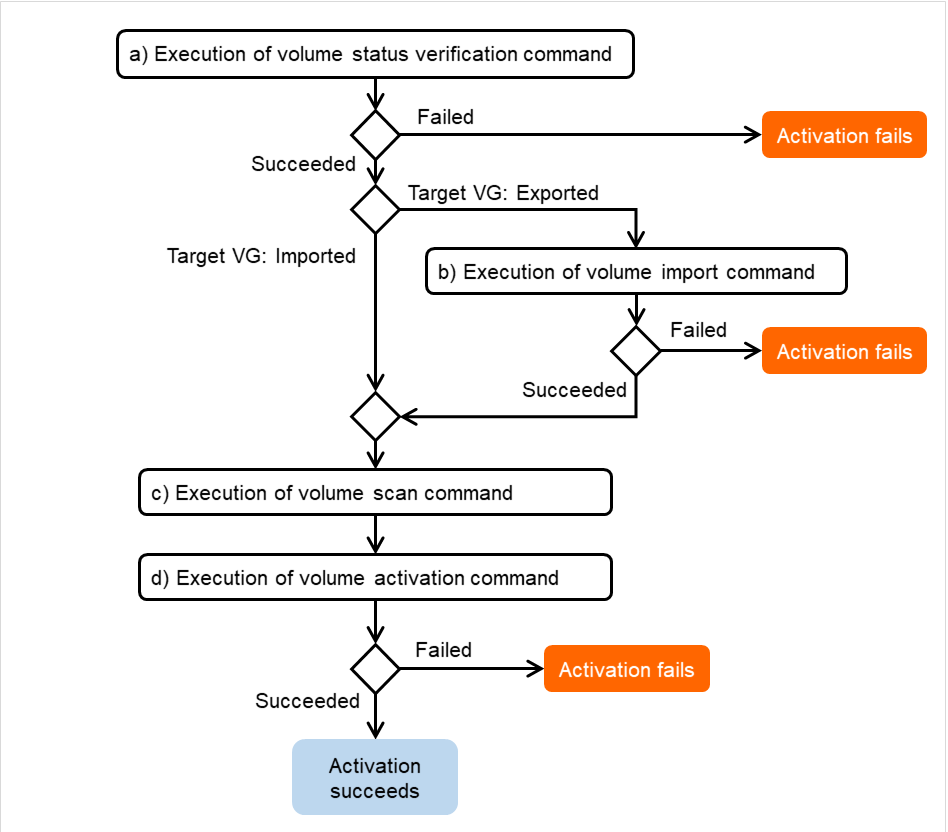
図 3.124 リソース活性時のシーケンス(lvm)¶
ボリュームグループステータス確認コマンドを実行します。実行が失敗すると、活性は失敗です。
vgs -P --noheadings -o vg_attr, vg_name VG名
ボリュームグループインポートコマンドを実行します。実行が失敗すると活性は失敗です。
vgimport VG名
ボリュームグループスキャンコマンドを実行します。
vgscanボリュームグループ活性コマンドを実行します。実行が成功すると活性は成功、失敗すると活性は失敗です。
vgchange -ay VG名
リソース非活性時に以下のコマンドを実行します。
コマンド
オプション
使用するタイミング
vgs
-P
ボリュームグループのステータス確認時
--noheadings
ボリュームグループのステータス確認時
-o vg_attr,vg_name
ボリュームグループのステータス確認時
vgchange
-an
ボリュームグループ非活性時
vgexport
(無し)
ボリュームグループエクスポート時
リソース非活性時のシーケンスは下記の通りとなります
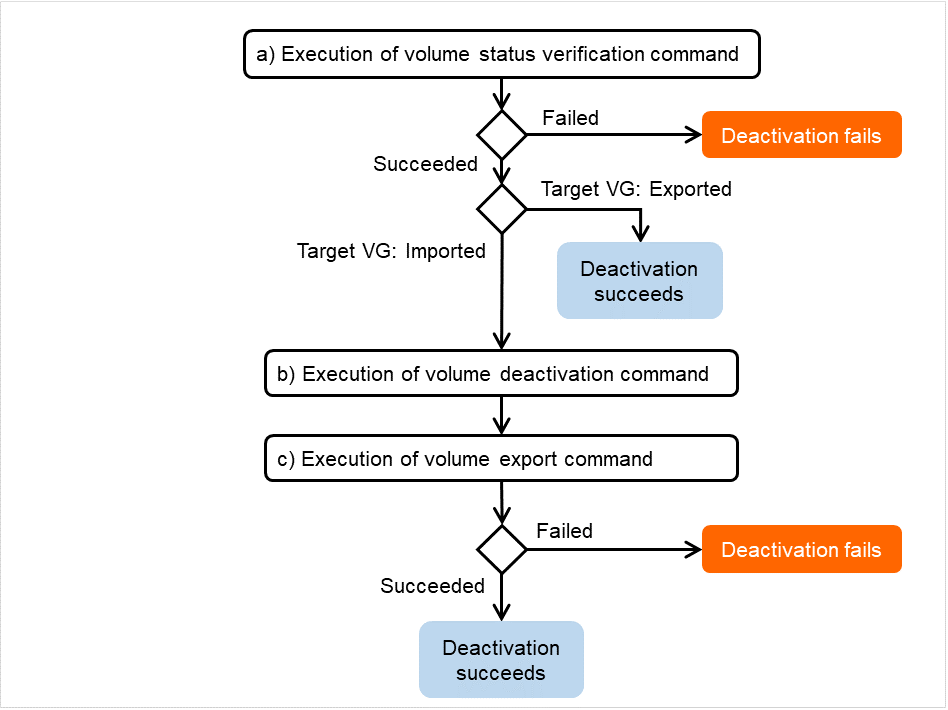
図 3.125 リソース非活性時のシーケンス(lvm)¶
- ボリュームグループステータス確認コマンドを実行します。実行が失敗すると、非活性は失敗です。実行が成功した場合、対象VGがエクスポート可能状態であれば非活性は成功です。
vgs -P --noheadings -o vg_attr, vg_name VG名
ボリュームグループ非活性コマンドを実行します。実行が失敗すると、非活性は失敗です。
vgchange -an VG名
ボリュームグループエクスポートコマンドを実行します。成功すれば非活性は成功、失敗すれば非活性は失敗です。
vgexport VG名
<ボリュームマネージャ [vxvm] での利用時>
ディスクグループの定義は CLUSTERPRO 側で行いません。
CLUSTERPRO の設定情報に含まれるディスクグループは OS 起動時に自動的にデポート処理を行います。
CLUSTERPRO の設定情報に含まれていないディスクグループはデポートしません。
フェイルオーバ元サーバでディスクグループを正常にデポートできなかった場合、フェイルオーバ先サーバでは、VxVM の仕様により、クリアホスト ID オプションが OFF の場合はディスクグループをインポートできません。
インポートタイムアウトが発生した場合、実際にはインポートが成功していることがあります。インポートオプションに、ホスト ID クリアもしくは強制インポートオプションを設定している場合、インポートリトライを行い、この現象を回避することができます。
リソース活性時に以下のコマンドを実行します。
コマンド
オプション
使用するタイミング
vxdg
import
ディスクグループインポート時
-t
ディスクグループインポート時
-C
ディスクグループインポートに失敗し、クリアホストID オプションが ON の場合
-f
ディスクグループインポートに失敗し、強制活性 オプションが ON の場合
vxrecover
-g
指定したディスクグループのボリューム起動時
-sb
指定したディスクグループのボリューム起動時
リソース活性時のシーケンスは下記の通りとなります
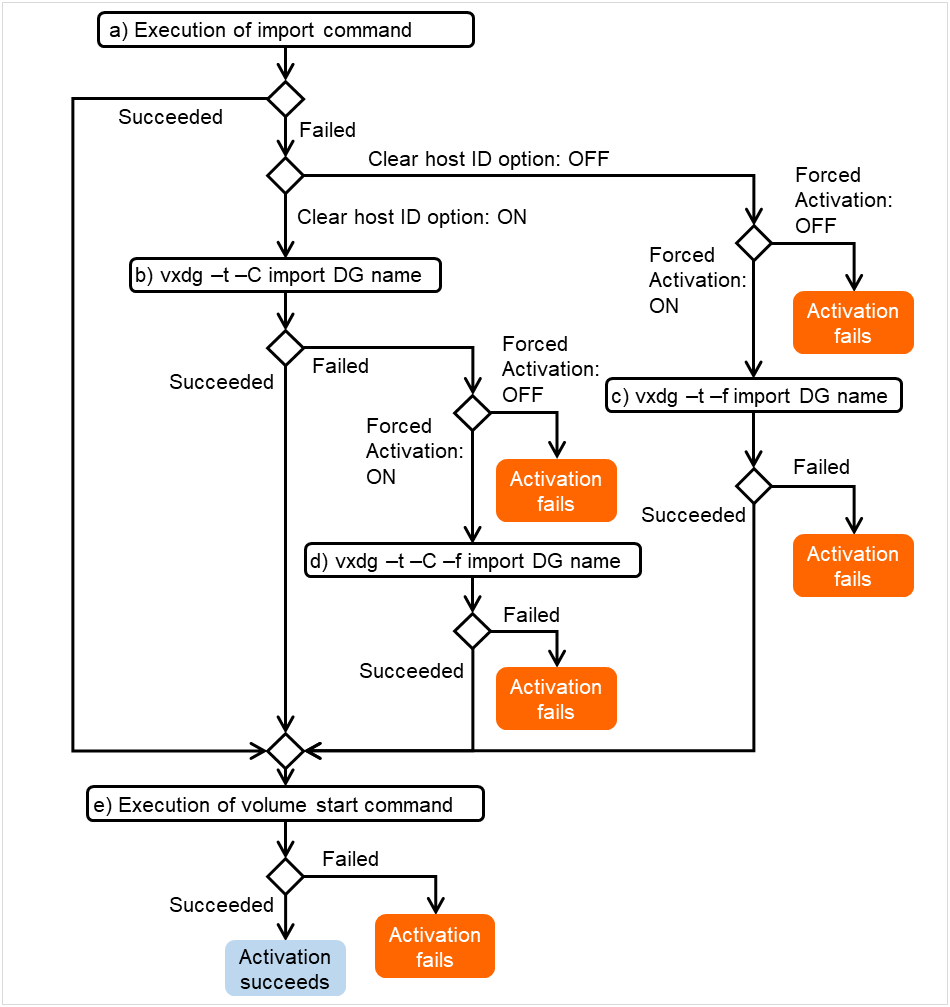
図 3.126 リソース活性時のシーケンス(vxvm)¶
インポートコマンドを実行します。実行が失敗すると、活性は失敗です。
vxdg -t import ディスクグループ名
下記のコマンドを実行します。
vxdg -t -C import ディスクグループ名
下記のコマンドを実行します。
vxdg -t -f import ディスクグループ名
下記のコマンドを実行します。
vxdg -t -C -f import ディスクグループ名
ボリューム起動コマンドを実行します。
vxrecover -g ディスクグループ名 -sb
リソース非活性時に以下のコマンドを実行します。
コマンド
オプション
使用するタイミング
vxdg
deport
ディスクグループデポート時
flush
フラッシュ時
vxvol
-g
指定したディスクグループのボリューム停止時
stopall
指定したディスクグループのボリューム停止時
リソース非活性時のシーケンスは下記の通りとなります
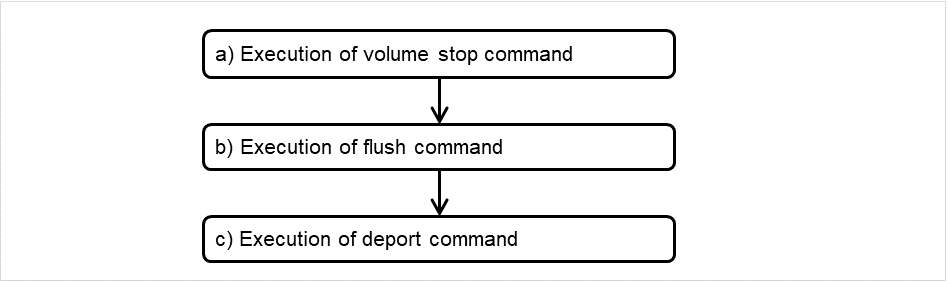
図 3.127 リソース非活性時のシーケンス(vxvm)¶
ボリューム停止コマンドを実行します。
フラッシュコマンドを実行します。
デポートコマンドを実行します。
<ボリュームマネージャ [zfspool] での利用時>
ZFSストレージプールをiSCSI環境で利用している場合、iSCSI接続の断線が発生するとZFSに対するexport等の処理が大きく遅延することがあります(OSの制限)。ZFSのiSCSI断線時の挙動は、ZFSのプロパティ値 "failmode" で規定されますが、CLUSTERPROでは、"failmode=panic" を推奨しています。"failmode=panic"の場合、iSCSI断線後、一定時間でOSが自主的にpanicするように動作します。
ZFSのプロパティ値 "mountpoint" が legacy に設定されているデータセットは、ストレージプールをインポートしただけではファイルシステムがマウントされません。この場合は、ボリュームマネージャリソースの他に、ディスクリソースを用いてZFSファイルシステムのマウント/アンマウントを行う必要があります。
- Ubuntu16.04 以降の場合、OS起動のタイミングによっては両系活性が発生することがあります。OS起動時にストレージプールが自動インポートされてもファイルシステムが自動マウントされないようにしてください。自動マウントを抑止する方法は以下のいずれかがあります。
ZFS のプロパティ値 "mountpoint" を "legacy" に設定する。
ZFS のプロパティ値 "canmount" を "noauto" に設定する。
この設定により、OS起動時に自動インポートされても自動マウントは抑止され、両系活性を防ぐことができます。この場合は、ディスクリソースを用いて ZFSファイルシステムのマウント/アンマウントを行う必要があります。
3.13.4. 詳細タブ¶
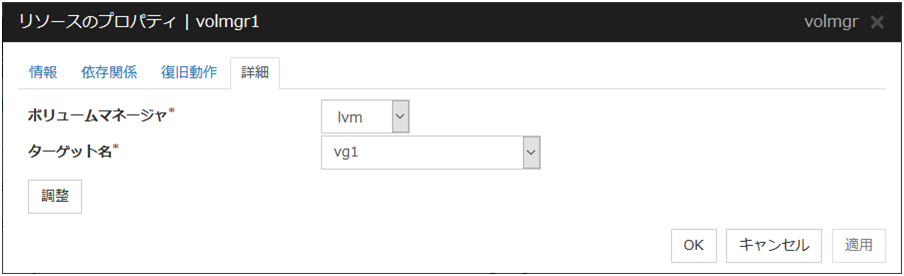
ボリュームマネージャ
利用するボリュームマネージャを指定します。以下のボリュームマネージャが選択できます。
lvm (LVM ボリュームグループ制御)
vxvm (VxVM ディスクグループ制御)
zfspool (ZFS ストレージプール制御)
ターゲット名 (1023 バイト以内)
ボリュームの名前を<VG名>の形式(ターゲット名のみ)で設定します。
コンボボックスの選択肢は、すべてのサーバからボリュームグループ情報を取得し、一台以上のサーバに存在するボリュームグループがすべて表示されます。
ボリュームマネージャが [lvm] の場合、複数ボリュームをまとめて制御することができます。複数ボリュームを制御する場合は、ボリュームの名前を半角スペースで区切って設定します。
調整
[ボリュームマネージャリソース調整プロパティ] ダイアログボックスを表示します。ボリューム マネージャリソースの詳細設定を行います。
ボリュームマネージャリソース調整プロパティ([ボリュームマネージャ] が [zfspool] 以外の場合)
インポートタブ
インポートに関する詳細設定が表示されます。
インポートタイムアウト (1~9999)
ボリュームをインポートする場合のコマンドの終了を待つタイムアウトを設定します。
ボリューム起動タイムアウト (1~9999)
起動コマンドのタイムアウトを設定します。
ボリュームステータス確認タイムアウト (1~999)
ステータス確認コマンドのタイムアウトを設定します。
ボリュームマネージャが [lvm] の場合に利用可能です。
ホストIDクリア
通常のインポートを失敗した場合に、ホスト ID のクリアフラグを立ててリトライするように設定します。チェックボックスが ON の場合にホスト ID のクリアを行います。
ボリュームマネージャが [vxvm] の場合に利用可能です。
強制インポート
インポートに失敗時に強制インポートを試行するかを設定します。チェックボックスが ON の場合に強制インポートを行います。
ボリュームマネージャが [vxvm] の場合に利用可能です。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
エクスポートタブ
エクスポートに関する詳細設定が表示されます。
ボリューム停止タイムアウト (1~9999)
ボリューム非活性コマンドのタイムアウトを設定します。
フラッシュタイムアウト (1~9999)
フラッシュコマンドのタイムアウトを設定します。
ボリュームマネージャが [vxvm] の場合に利用可能です。
エクスポートタイムアウト (1~9999)
エクスポート/デポートコマンドのタイムアウトを設定します。
ボリュームステータス確認タイムアウト (1~999)
ステータス確認コマンドのタイムアウトを設定します。
ボリュームマネージャが [lvm] の場合に利用可能です。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
ボリュームマネージャリソース調整プロパティ([ボリュームマネージャ] が [zfspool] の場合)
インポートタブ
インポートに関する詳細設定が表示されます。
インポートタイムアウト (1~9999)
ボリュームをインポートする場合のコマンドの終了を待つタイムアウトを設定します。
強制インポート
インポート失敗時に強制インポートを試行するかを設定します。チェックボックスが ON の場合に強制インポートを行います。
pingチェック行う
強制インポートが ON の場合のみ有効な設定です。
インポート失敗の原因が、「他ホストでインポート済み」であった場合に、強制インポートの前にping でインポート済みホストの死活監視を行うかを設定します。死活監視を行い、インポート済みホストが動作していた場合には強制活性が行われません。これにより、複数ホストによる同一プールの同時インポートを防止します。チェックボックスが ON の場合に死活監視を行います。
注釈
本設定を有効にすると、CLUSTERPRO が停止してからOSがシャットダウンするまでに時間がかかった場合に、フェイルオーバに失敗する可能性があります。たとえば、モニタリソースが異常を検出し運用系サーバをシャットダウンする場合に、運用系の停止前に待機系でボリュームマネージャの活性が開始されてしまうと、ping チェックによって活性に失敗します。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
エクスポートタブ
エクスポートに関する詳細設定が表示されます。
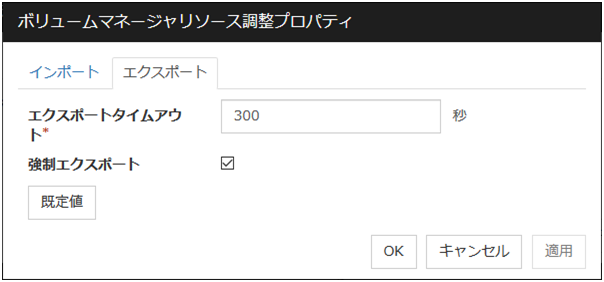
エクスポートタイムアウト (1~9999)
ボリュームをエクスポートする場合のコマンドの終了を待つタイムアウトを設定します。
強制エクスポート
エクスポート失敗時に強制エクスポートを試行するかを設定します。チェックボックスが ON の場合に強制エクスポートを行います。
既定値
[既定値] をクリックすると全ての項目に既定値が設定されます。
3.14. 仮想マシンリソースを理解する¶
3.14.1. 仮想マシンリソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.14.2. 仮想マシンリソースとは?¶
仮想化基盤上の仮想マシン (ゲスト OS) を制御するためのリソースです。
CLUSTERPRO をインストールした管理用の OS から仮想マシンの起動、停止を行います。vSphere の場合、CLUSTERPRO を管理用に用意した仮想マシンのゲスト OS 上にインストールして利用することもできます。
仮想マシンのマイグレーション操作を行うことも可能です。ただし、vSphere を利用している場合は vCenter を使用する構成である必要があります。
図 3.128 仮想化基盤の管理 OS に CLUSTERPRO をインストールした場合の構成図¶
図 3.129 管理用の仮想マシン上の OS に CLUSTERPRO をインストールした場合の構成図 (vSphere のみ)¶
3.14.3. 仮想マシンリソースに関する注意事項¶
仮想化基盤の種類が XenServer または KVM の場合、仮想マシンリソースは CLUSTERPRO を仮想化基盤 のホスト OS 上にインストールした場合のみ有効です。
仮想化基盤の種類が vSphere の場合、CLUSTERPRO をゲスト OS 上にインストールしても仮想マシンリソースを利用できますが、その場合は vCenter の使用が必須となります。
仮想マシンリソースはグループタイプが仮想マシンのグループにのみ登録可能です。
仮想マシンリソースは 1 つのグループに 1 つのみ登録可能です
仮想化基盤の種類に vSphere を選択した場合、マイグレーション操作を行うには [vCenter を使用する] をオンにする必要があります。
- 仮想マシンリソースで制御する仮想マシン (ゲスト OS) の起動時間を確認し、必ず [仮想マシンリソース調整プロパティ] の [仮想マシン起動待ち時間] を設定してください。[仮想マシン起動待ち時間] の既定値が0秒となっているため、変更しなかった場合、仮想マシンモニタリソースがモニタ異常を誤検出する可能性があります。
3.14.4. 詳細タブ¶
vSphere の場合
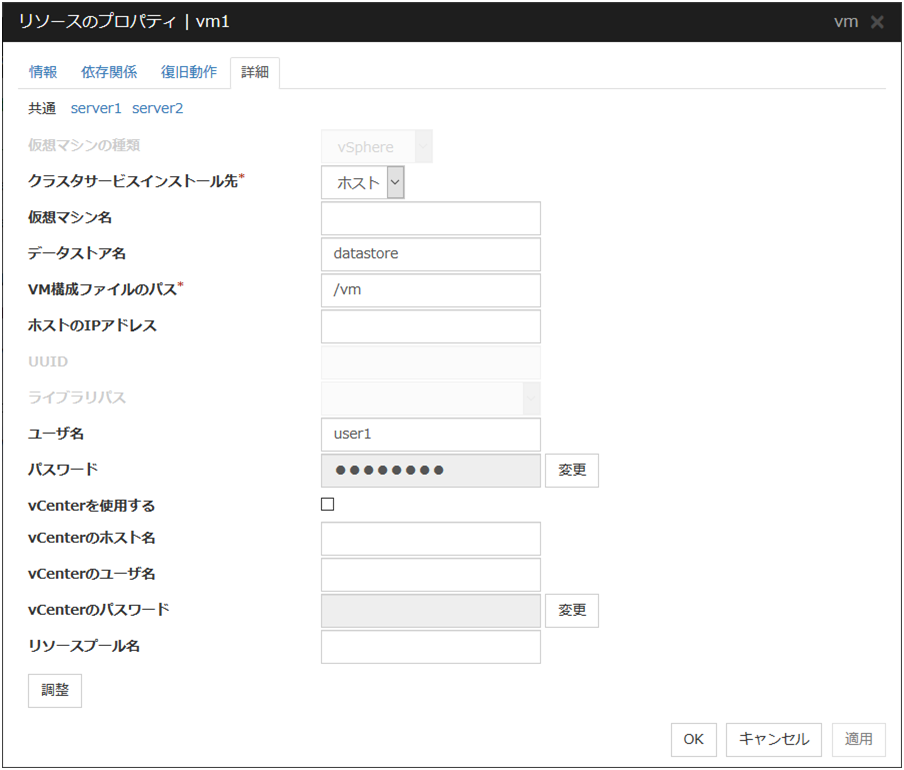
仮想マシンの種類
仮想化基盤の種類を指定します。
クラスタサービスインストール先
CLUSTERPRO をインストールする OS の種類を指定します。ゲスト OS を選択すると、vCenter を使用するのチェックボックスも自動的にオンになります。
仮想マシン名 (255 バイト以内)
仮想マシン名を入力してください。VM 構成ファイルのパスを入力する場合は設定不要です。また、仮想化基盤側で仮想マシン名を変更する可能性がある場合、VM 構成ファイルのパス設定してください。
データストア名 (255 バイト以内)
仮想マシンの設定情報を格納しているデータストア名を指定してください。
VM構成ファイルのパス (1023 バイト以内)
仮想マシンの設定情報を格納しているパスを指定してください。
ホストの IPアドレス サーバ個別設定可能
ホストの管理 IP アドレスを指定してください。サーバ別設定を利用して、サーバごとに指定する必要があります。
ユーザ名 (255 バイト以内) サーバ個別設定可能
仮想マシンを起動するために利用するユーザ名を指定してください。
パスワード (255 バイト以内) サーバ個別設定可能
仮想マシンを起動するために利用するパスワードを指定してください。
vCenter を使用する
vCenter を使用するかどうかを指定してください。マイグレーション機能を利用する場合、vCenter を使用する必要があります。
vCenterのホスト名 (1023 バイト以内)
vCenter のホスト名を指定してください。
vCenterのユーザ名 (255 バイト以内)
vCenter に接続するためのユーザ名を指定してください。
vCenterのパスワード (255 バイト以内)
vCenter に接続するためのパスワードを指定してください。
リソースプール名 (255 バイト以内) サーバ個別設定可能
仮想マシンを起動するリソースプール名を指定してください。
XenServer の場合
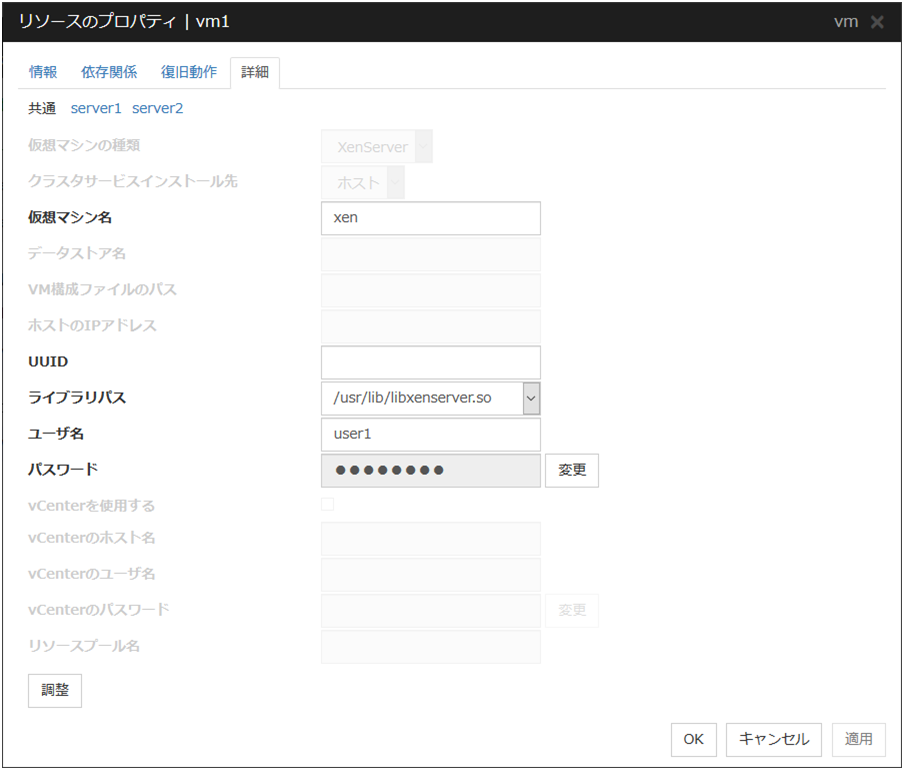
仮想マシンの種類
仮想化基盤の種類を指定します。
仮想マシン名 (255 バイト以内)
仮想マシン名を入力してください。UUID を設定する場合は不要です。また、仮想化基盤側で仮想マシン名を変更する可能性がある場合、UUID を設定してください。
UUID
仮想マシンを識別するための UUID (Universally Unique Identifier) を指定してください。
ライブラリパス (1023 バイト以内)
XenServer を制御するために利用するライブラリのパスを指定してください。
ユーザ名 (255 バイト以内)
仮想マシンを起動するために利用するユーザ名を指定してください。
パスワード (255 バイト以内)
仮想マシンを起動するために利用するパスワードを指定してください。
KVM の場合
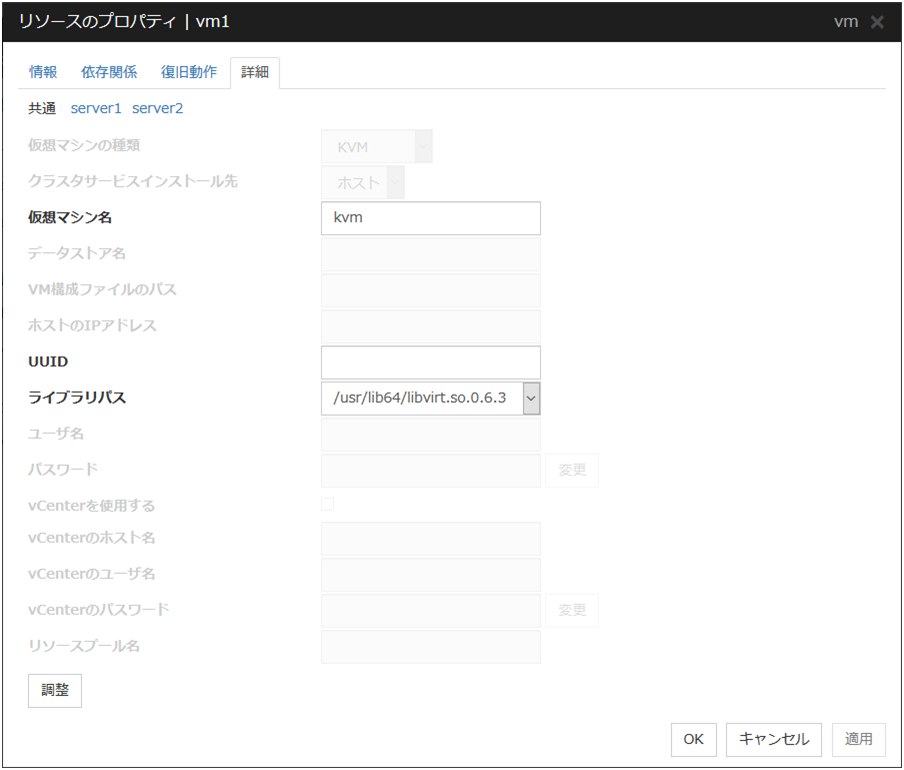
仮想マシンの種類
仮想化基盤の種類を指定します。
仮想マシン名 (255 バイト以内)
仮想マシン名を入力してください。UUID を設定する場合は不要です。
UUID
仮想マシンを識別するための UUID (Universally Unique Identifier) を指定してください。
ライブラリパス (1023 バイト以内
KVM を制御するために利用するライブラリのパスを指定してください。
調整
[仮想マシンリソース調整プロパティ] ダイアログボックスを表示します。仮想マシンリソースの詳細設定を行います。
仮想マシンリソース調整プロパティ
パラメータタブ
リクエストタイムアウト
仮想マシンの起動/停止などの要求の完了を待ち合わせる時間を指定します。
この時間内に要求が完了しなかった場合、タイムアウトと見なし、リソースの活性または非活性は失敗します。
仮想マシン起動待ち時間
仮想マシンの起動要求を発行した後で、この時間だけ必ず待ちます。
仮想マシン停止待ち時間
仮想マシンの停止を待ち合わせる最大の時間です。仮想マシンの停止が確認できた時点で非活性完了になります。
3.15. ダイナミック DNS リソースを理解する¶
3.15.1. ダイナミック DNS リソースの依存関係¶
既定値では、以下のグループリソースタイプに依存します。
グループリソースタイプ |
|---|
仮想 IP リソース |
フローティング IP リソース |
AWS Elastic IPリソース |
AWS 仮想IPリソース |
Azure プローブポートリソース |
3.15.2. ダイナミック DNS リソースとは?¶
ダイナミック DNS リソースは、Dynamic DNS サーバに仮想ホスト名と活性サーバの IP アドレスを登録します。クライアントアプリケーションは、仮想ホスト名を使用してクラスタサーバに接続することができます。仮想ホスト名を使用することにより、"フェイルオーバ"または、"グループの移動" が発生しても、クライアントは、接続先サーバの切り替えを意識する必要がありません。
以下の図には、ダイナミックDNSサーバ(DDNSサーバ)とServer 1およびServer 2、そして Clientが描かれています。 Server 1は、仮想ホスト名とIPアドレスをDDNSサーバに登録します。
図 3.130 ダイナミックDNSサーバを使用する構成 (1)¶
Clientは、アクセス先である仮想ホスト名に対応するIPアドレスを、DDNSサーバに問い合わせます。 問い合わせに対して、DDNSサーバは仮想ホスト名に対応する Server 1のIPアドレスを回答します。 Clientは仮想ホスト名のIPアドレスに接続します。
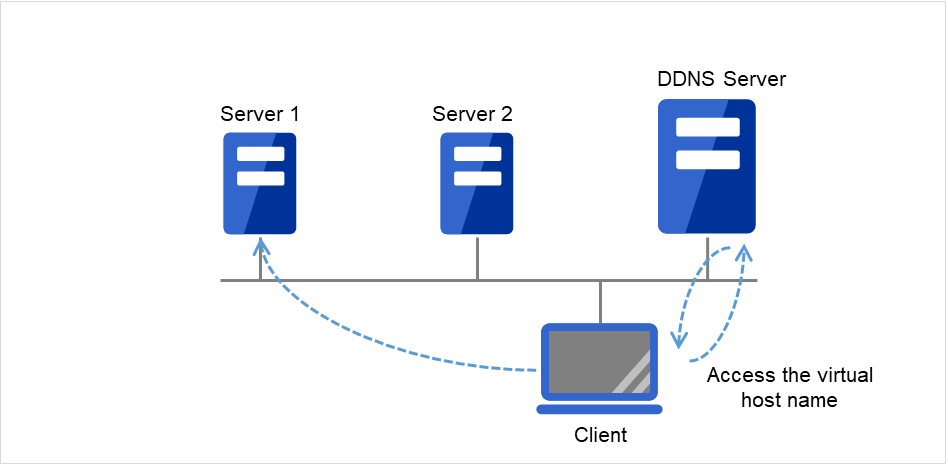
図 3.131 ダイナミックDNSサーバを使用する構成 (2)¶
Server 1がダウンし、Server 2へのフェイルオーバが発生します。
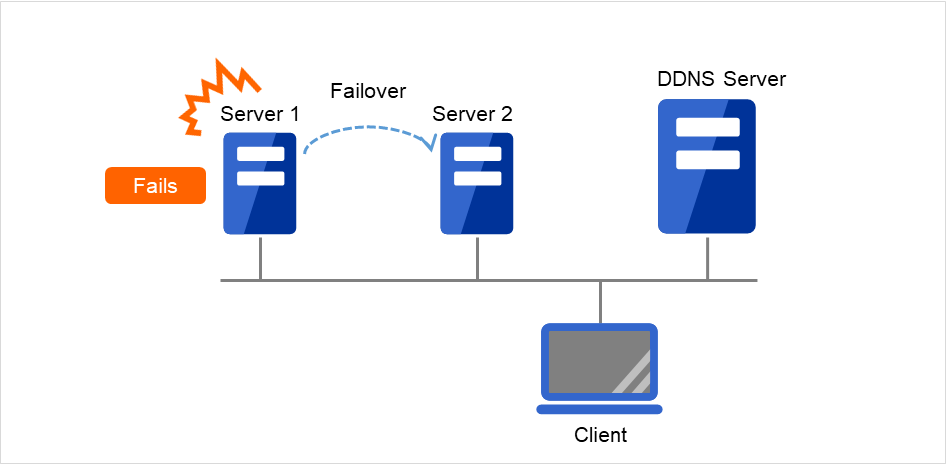
図 3.132 ダイナミックDNSサーバを使用する構成 (3)¶
Server 2は、仮想ホスト名とIPアドレスをDDNSサーバに登録します。
図 3.133 ダイナミックDNSサーバを使用する構成 (4)¶
Clientは、アクセス先である仮想ホスト名に対応するIPアドレスを、DDNSサーバに問い合わせます。 問い合わせに対して、DDNSサーバは仮想ホスト名に対応する Server 2のIPアドレスを回答します。 Clientは仮想ホスト名のIPアドレスに接続します。
図 3.134 ダイナミックDNSサーバを使用する構成 (5)¶
3.15.3. ダイナミック DNS リソースを使用する場合の事前準備¶
ダイナミック DNS リソースを使用する前に DDNS サーバを構築する必要があります。
以下、BIND9 の例で説明します。
認証あり方式でダイナミック DNS リソースを使用したい場合
BIND9 サーバ上で [dnssec-keygen] コマンドを使って共有鍵を作成します。/etc/named.conf に共有鍵を追記し、ゾーンファイルの更新を許可するように設定します。
ダイナミック DNS リソースを追加する場合、認証キー名に共有鍵名を記入し、認証キー値に共有鍵値を記入してください。
注釈
DDNS サーバの構築方法、[dnssec-keygen] コマンドの使用方法、allow-update以外の設定方法等については、BIND のマニュアルを参照してください。
設定例:
- 共有鍵を生成します。example は共有鍵名です。
#dnssec-keygen -a HMAC-MD5 -b 256 -n HOST example
[dnssec-keygen] コマンドを実行した後、下記の 2 つファイルが生成されます。共有鍵のため、2 つのファイルの Key は同じです。
Kexample.+157+09088.key Kexample.+157+09088.private
以下の named.conf の設定では Kexample.+157+09088.key から共有鍵を抽出していますが、Kexample.+157+09088.private を使っても同じになります。Kexample.+157+09088.key の共有鍵の値は下記の太字部分です。# cat Kexample.+157+09088.key example. IN KEY 512 3 157 iuBgSUEIBjQUKNJ36NocAgaB
/etc/named.conf に共有鍵の情報を追記します。
key "example" { algorithm hmac-md5; secret "iuBgSUEIBjQUKNJ36NocAgaB"; };
/etc/named.conf の中で共有鍵の情報を zone ステートメントに追記します。
zone "example.jp" { : allow-update{ key example; }; : };
Cluster WebUI でダイナミック DNS リソースを追加する時、認証キー名に共有鍵名 (example)を記入して、認証キー値に共有鍵値 (
iuBgSUEIBjQUKNJ36NocAgaB) を記入してください。
認証なし方式でダイナミック DNS リソースを使用したい場合
/etc/named.conf に、ゾーンファイルを更新可能な IP 範囲 [allow-update{xxx.xxx.xxx.xxx} ] として、必ずクラスタ内の全サーバの IP を設定する必要があります。
設定例:
クラスタ内サーバ 1 のIP:192.168.10.110クラスタ内サーバ 2 のIP:192.168.10.111/etc/named.confのzone ステートメントに更新を許可する IP 範囲を追記します。
zone "example.jp" { : //更新可能なIP範囲 allow-update { 192.168.10.0/24; }; : };
または
zone "example.jp" { : //更新可能なIP範囲 allow-update { 192.168.10.110; 192.168.10.111; }; : };
ダイナミック DNS リソースを追加する場合、認証キー名と認証キー値に何も記入しないでください。
3.15.4. ダイナミック DNS リソースに関する注意事項¶
ダイナミック DNS リソースを利用する場合、各サーバ上に bind-utils のパッケージが必要です。
各サーバで仮想ホスト名の名前解決ができる必要があります。
各サーバの IP は異なるセグメントに存在する場合、FIP をダイナミック DNS リソースの IP として設定することはできません。
各サーバの IP アドレスを DDNS サーバに登録したい場合、サーバ別設定で各サーバの IP を設定してください。
クライアントから仮想ホスト名を使用して接続を行っている場合、ダイナミック DNS リソースを持つグループのフェイルオーバが発生すると、再接続が必要なことがあります。(ブラウザの再起動など)
本リソースの認証あり方式では BIND9 を使って構築した DDNS サーバのみ対応します。認証なし方式を使う場合、ダイナミック DNS リソースには認証キー名と認証キー値に何も記入しないでください。
仮想ホスト名を経由した Cluster WebUI 接続時の挙動について
- ダイナミックDNSリソースに各サーバのIPアドレスをサーバ別設定している場合クライアントから仮想ホスト名を使用して Cluster WebUI を接続している場合、ダイナミック DNS リソースを持つグループのフェイルオーバが発生すると、Cluster WebUI の接続は自動的に切り替わりません。ブラウザを再起動し、再度Cluster WebUI を接続する必要があります。
- ダイナミック DNS リソースに FIP アドレスを設定している場合クライアントから仮想ホスト名を使用して Cluster WebUI を接続している場合、ダイナミック DNS リソースを持つグループのフェイルオーバが発生すると、Cluster WebUI の接続は自動的に切り替わります。
- 認証あり方式でダイナミック DNS リソースを使用する場合、クラスタ内の各サーバの時刻と DDNS サーバの時刻の差が 5 分未満である必要があります。時間差が 5 分以上の場合、DDNS サーバに仮想ホスト名の登録ができません。
3.15.5. 詳細タブ¶
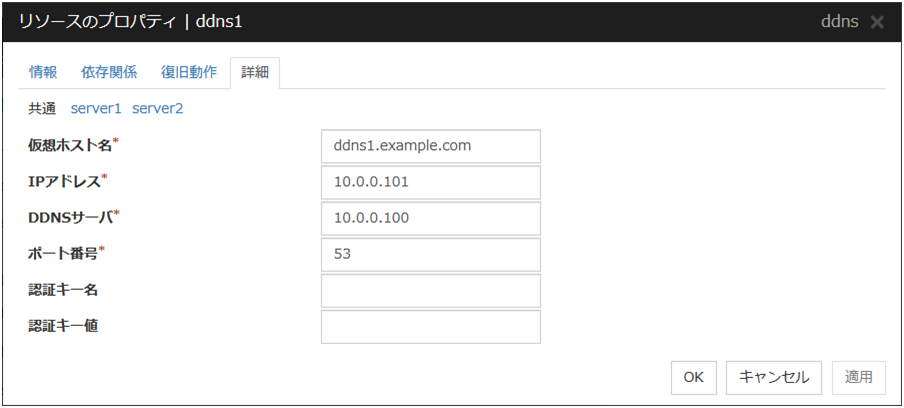
仮想ホスト名
DDNS サービスに登録する仮想ホスト名を入力します。
IPアドレス サーバ個別設定可能
仮想ホスト名に対応する IP アドレスを記入します。
FIP リソースと一緒に使用する場合、[共通] タブに FIP リソースの IP アドレスを入力します。各サーバの IP アドレスを使用する場合、各サーバのタブで IP アドレスを入力してください。
DDNSサーバ
DDNS サーバの IP アドレスを入力します。
ポート番号
DDNS サーバのポート番号を記入します。既定値は 53 です。
認証キー名
[dnssec-keygen] コマンドを使って共有鍵を生成したときの共有鍵名を入力します。
認証キー値
[dnssec-keygen] コマンドを使って生成した共有鍵の値を入力します。
3.16. AWS Elastic IPリソースを理解する¶
3.16.1. AWS Elastic IPリソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.16.2. AWS Elastic IPリソースとは?¶
クライアントアプリケーションは、Amazon Web Services(以下、AWS) 環境の Amazon Virtual Private Cloud(以下、VPC)に対して、Elastic IP(以下、EIP) アドレスを使用してクラスタサーバに接続することができます。EIP アドレスを使用することにより、"フェイルオーバ" または、"グループの移動" の移動が発生しても、クライアントは、接続先 VPC の切り替えを意識する必要がありません。
AWS Elastic IPリソース、AWS 仮想IPリソース、および、AWS DNS リソースは組み合わせて使用可能です。
EIP 制御による HA クラスタ
インスタンスを Public な Subnet 上に配置する(業務を VPC の外部に公開する)場合に使用します。
クラスタ化するインスタンスは各 Availability Zone(以下、AZ) の Public な Subnet 上に配置されており、各インスタンスは、インターネットゲートウェイを経由してインターネットへアクセスできるような構成を想定しています。

図 3.135 AWS Elastic IP リソースを使用する構成¶
3.16.3. AWS Elastic IPリソースに関する注意事項¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS Elastic IPリソースの設定について」を参照してください。
3.16.4. AWS Elastic IPリソースから実行するAWS CLIへ環境変数を反映させるには¶
環境変数設定ファイルに環境変数を指定することにより、AWS Elastic IPリソース、AWS 仮想IPリソース、AWS Elastic IPモニタリソース、AWS 仮想IPモニタリソース、AWS AZモニタリソースから実行する AWS CLI に反映させることが可能です。
AWS環境にて、プロキシサーバを利用する場合などに有効です。
環境変数設定ファイルは、以下に配置しています。
<CLUSTERPROインストールパス>/cloud/aws/clpaws_setting.conf
環境変数設定ファイルのフォーマットは、以下のとおりです。
環境変数名 = 値
記載例)
[ENVIRONMENT] HTTP_PROXY = http://10.0.0.1:3128 HTTPS_PROXY = http://10.0.0.1:3128
パラメータに複数の値を設定する場合は、カンマ区切り(,)で列挙してください。環境変数 NO_PROXY に除外接続先を複数指定する場合の記載例は以下となります。
記載例)
NO_PROXY = 169.254.169.254,ec2.ap-northeast-1.amazonaws.com
環境変数設定ファイルの仕様は、以下のとおりです。
一行目は必ず [ENVIRONMENT] を記載してください。記載がない場合は、環境変数は設定しません。
環境変数設定ファイルが存在しない場合や読み取り権限がない場合は無視します。活性異常や監視異常にはなりません。
同名の環境変数が既に設定されている場合、値を上書きします。
複数の環境変数の設定が可能です。複数の環境変数を設定する場合は、1行には1つの環境変数のみ設定してください。
= の両側のスペース有無に関わらず、設定は有効です。
環境変数名の前にスペースやタブがある場合および = の両側にタブがある場合、設定は無効です。
環境変数名は大文字・小文字を区別します。
値にスペースが入る場合、""(ダブルクォート)で括る必要はありません。
環境変数設定ファイルで設定した環境変数は AWS Elastic IPリソース、AWS 仮想IPリソース、AWS DNS リソース、AWS Elastic IPモニタリソース、AWS 仮想IPモニタリソース、AWS DNS モニタリソース、AWS AZモニタリソースから実行する AWS CLI にのみ反映されます。そのため、それ以外のスクリプト(例.最終動作前スクリプト、活性/非活性前後スクリプト、EXEC リソースから実行するスクリプト)には反映されません。それ以外のスクリプト内で AWS CLI を実行する場合、必要な環境変数は該当するスクリプト内で設定してください。
3.16.5. 詳細タブ¶
EIP ALLOCATION ID (45 バイト以内)
EIP 制御の場合、付け替え対象の EIP の ID を指定します。
ENI ID (45 バイト以内) サーバ個別設定可能
EIP 制御の場合、EIP を割り当てる ENI ID を指定します。サーバ別設定が必須です。[共通]タブでは、任意のサーバの ENI ID を記載し、他のサーバは個別設定を行うようにしてください。
AWS Elastic IP リソース調整プロパティ
パラメータタブ
タイムアウト (1~999)
AWS Elastic IPリソースの活性/非活性の各処理で実行される [AWS CLI] コマンドのタイムアウトを設定します。
3.17. AWS 仮想IPリソースを理解する¶
3.17.1. AWS 仮想IPリソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.17.2. AWS 仮想IPリソースとは?¶
クライアントアプリケーションは、AWS 環境の VPC に対して、仮想IP(以下、VIP)アドレスを使用してクラスタサーバに接続することができます。VIP アドレスを使用することにより、"フェイルオーバ" または、"グループの移動" が発生しても、クライアントは、接続先 VPC の切り替えを意識する必要がありません。AWS仮想IPリソースでは活性時に AWS CLI を実行して route table の更新処理を行います。
AWS Elastic IPリソース、AWS 仮想IPリソース、および、AWS DNS リソースは組み合わせて使用可能です。
VIP 制御による HA クラスタ
インスタンスを Private な Subnet 上に配置する(業務を VPC 内部に公開する)場合に使用します。
クラスタ化するインスタンス及び、そのインスタンスへアクセスを行うインスタンス群は各 Availability Zone(以下、AZ) の Private な Subnet 上に配置されており、各インスタンスは、Public な Subnet に配置された NAT インスタンス を経由してインターネットへアクセスできるような構成を想定しています。
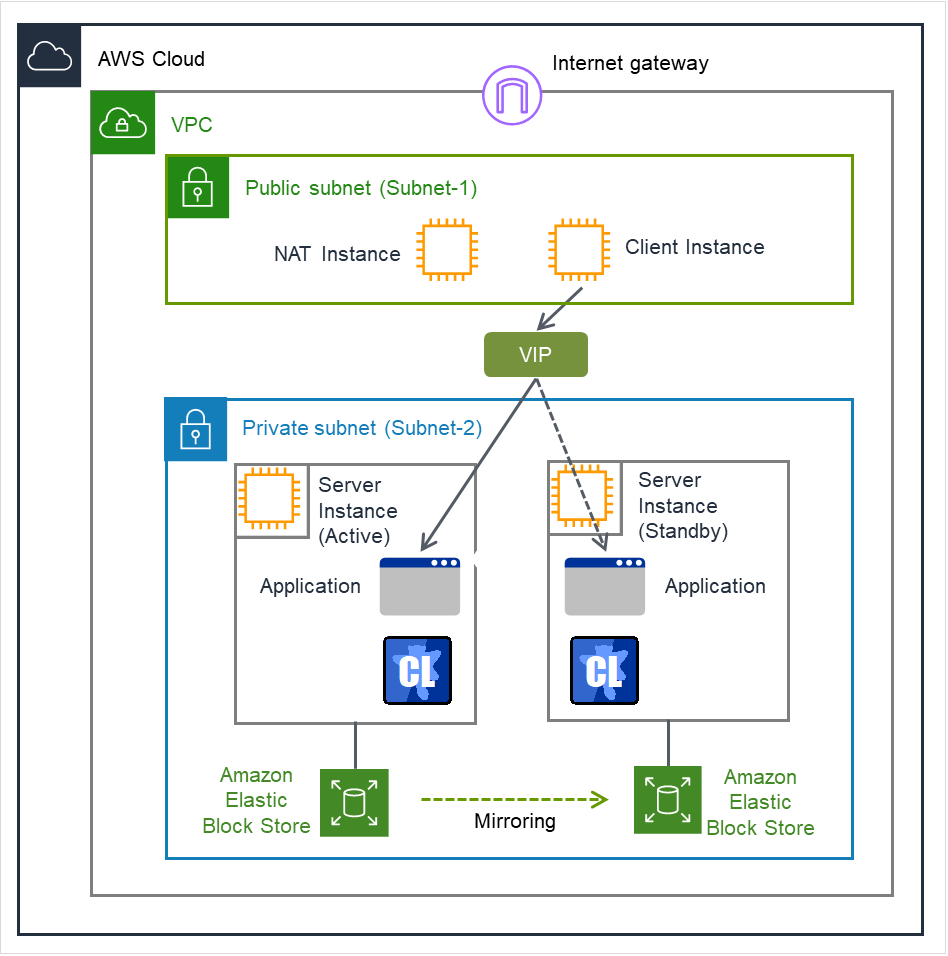
図 3.136 AWS 仮想 IP リソースを使用する構成¶
3.17.3. AWS 仮想IPリソースに関する注意事項¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS 仮想IPリソースの設定について」を参照してください。
3.17.4. AWS 仮想IPリソースから実行するAWS CLIへ環境変数を反映させるには¶
環境変数設定ファイルに環境変数を指定することにより、AWS Elastic IPリソース、AWS 仮想IPリソース、AWS Elastic IPモニタリソース、AWS 仮想IPモニタリソース、AWS AZモニタリソースから実行する AWS CLI に反映させることが可能です。
AWS環境にて、プロキシサーバを利用する場合などに有効です。
環境変数設定ファイルは、以下に配置しています。
<CLUSTERPROインストールパス>/cloud/aws/clpaws_setting.conf
環境変数設定ファイルのフォーマットは、以下のとおりです。
環境変数名 = 値
記載例)
[ENVIRONMENT] HTTP_PROXY = http://10.0.0.1:3128 HTTPS_PROXY = http://10.0.0.1:3128
パラメータに複数の値を設定する場合は、カンマ区切り(,)で列挙してください。環境変数 NO_PROXY に除外接続先を複数指定する場合の記載例は以下となります。
記載例)
NO_PROXY = 169.254.169.254,ec2.ap-northeast-1.amazonaws.com
環境変数設定ファイルの仕様は、以下のとおりです。
一行目は必ず [ENVIRONMENT] を記載してください。記載がない場合は、環境変数は設定しません。
環境変数設定ファイルが存在しない場合や読み取り権限がない場合は無視します。活性異常や監視異常にはなりません。
同名の環境変数が既に設定されている場合、値を上書きします。
複数の環境変数の設定が可能です。複数の環境変数を設定する場合は、1行には1つの環境変数のみ設定してください。
= の両側のスペース有無に関わらず、設定は有効です。
環境変数名の前にスペースやタブがある場合および = の両側にタブがある場合、設定は無効です。
環境変数名は大文字・小文字を区別します。
値にスペースが入る場合、""(ダブルクォート)で括る必要はありません。
環境変数設定ファイルで設定した環境変数は AWS Elastic IPリソース、AWS 仮想IPリソース、AWS DNS リソース、AWS Elastic IPモニタリソース、AWS 仮想IPモニタリソース、AWS DNS モニタリソース、AWS AZモニタリソースから実行する AWS CLI にのみ反映されます。そのため、それ以外のスクリプト(例.最終動作前スクリプト、活性/非活性前後スクリプト、EXEC リソースから実行するスクリプト)には反映されません。それ以外のスクリプト内で AWS CLI を実行する場合、必要な環境変数は該当するスクリプト内で設定してください。
3.17.5. 詳細タブ¶
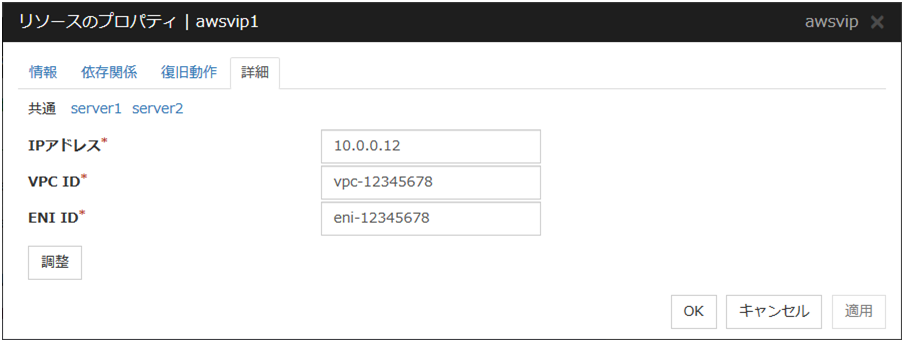
IPアドレス (45 バイト以内)
VIP 制御の場合、使用する VIP アドレスを指定します。VIP アドレスとしては、VPC の CIDR に属さない IP アドレスを指定する必要があります。
VPC ID (45 バイト以内) サーバ個別設定可能
VIP 制御の場合、サーバが所属する VPC ID を指定します。サーバ個別設定を行う場合、[共通]タブでは、任意のサーバの VPC ID を記載し、他のサーバは個別設定を行うようにしてください。ルーティングの設定方法については、以下を参照してください。
『CLUSTERPRO X Amazon Web Services 向け HA クラスタ 構築ガイド (Linux 版)』 - 「VPC 環境の設定」
ENI ID (45 バイト以内) サーバ個別設定可能
VIP 制御の場合、VIPのルーティング先の ENI ID を指定します。指定する ENI ID は Source/Dest. Check を disabled としておく必要があります。サーバ別設定が必須です。サーバ個別設定を行う場合、[共通]タブでは、任意のサーバの ENI ID を記載し、他のサーバは個別設定を行うようにしてください。
AWS 仮想IP リソース調整プロパティ
パラメータタブ
タイムアウト (1~999)
AWS 仮想IPリソースの活性/非活性の各処理で実行される [AWS CLI] コマンドのタイムアウトを設定します。
3.18. AWS DNS リソースを理解する¶
3.18.1. AWS DNS リソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.18.2. AWS DNS リソースとは?¶
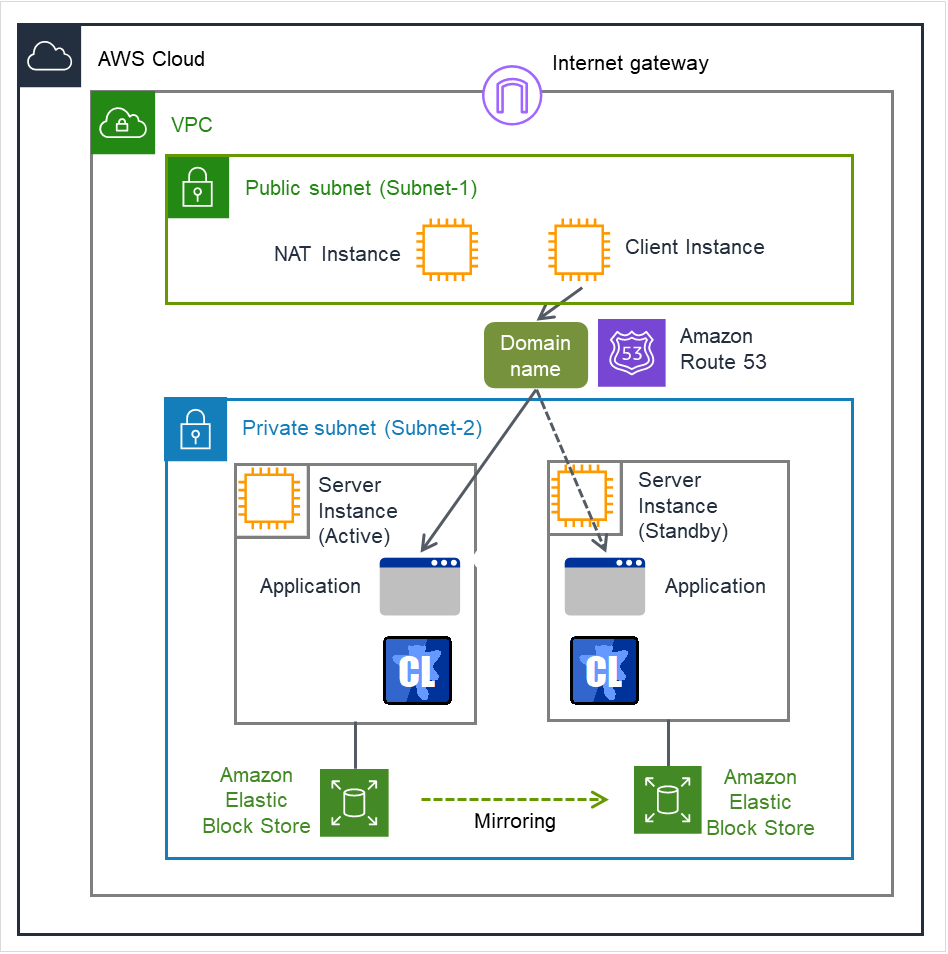
図 3.137 AWS DNSリソースを使用する構成¶
Amazon Web Services(以下、AWS) で利用する仮想ホスト名(DNS 名)に対応する IP アドレスを活性時に AWS CLI を実行して登録、非活性時 AWS CLI を実行して削除します。
クライアントはフェイルオーバグループが起動しているノードに仮想ホスト名でアクセスすることができます。
AWS DNS リソースを利用することで、クライアントは AWS 上でもフェイルオーバやグループの移動による接続先ノードの切り替えを意識する必要がありません。
AWS Elastic IPリソース、AWS 仮想IPリソース、および、AWS DNS リソースは組み合わせて使用可能です。
AWS DNS リソースを利用する場合、クラスタの構築を行う前に以下の準備が必要です。
Amazon Route 53 の Hosted Zone の作成
AWS CLI のインストール
3.18.3. AWS DNS リソースに関する注意事項¶
クライアントから仮想ホスト名(DNS 名)を使用して接続を行っている場合、AWS DNS リソースが追加されているフェイルオーバグループでフェイルオーバが発生すると再接続が必要な場合があります。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「AWS DNS リソースの設定について」を参照してください。
3.18.4. AWS DNS リソースから実行するAWS CLIへ環境変数を反映させるには¶
環境変数設定ファイルに環境変数を指定することにより、AWS Elastic IPリソース、AWS 仮想IPリソース、AWS DNS リソース、AWS Elastic IPモニタリソース、AWS 仮想IPモニタリソース、AWS AZモニタリソース、AWS DNS モニタリソースから実行する AWS CLI に反映させることが可能です。
AWS環境にて、プロキシサーバを利用する場合などに有効です。
環境変数設定ファイルは、以下に配置しています。
<CLUSTERPROインストールパス>/cloud/aws/clpaws_setting.conf
環境変数設定ファイルのフォーマットは、以下のとおりです。
環境変数名 = 値
記載例)
[ENVIRONMENT] HTTP_PROXY = http://10.0.0.1:3128 HTTPS_PROXY = http://10.0.0.1:3128
パラメータに複数の値を設定する場合は、カンマ区切り(,)で列挙してください。環境変数 NO_PROXY に除外接続先を複数指定する場合の記載例は以下となります。
記載例)
NO_PROXY = 169.254.169.254,ec2.ap-northeast-1.amazonaws.com
環境変数設定ファイルの仕様は、以下のとおりです。
一行目は必ず [ENVIRONMENT] を記載してください。記載がない場合は、環境変数は設定しません。
環境変数設定ファイルが存在しない場合や読み取り権限がない場合は無視します。活性異常や監視異常にはなりません。
同名の環境変数が既に設定されている場合、値を上書きします。
複数の環境変数の設定が可能です。複数の環境変数を設定する場合は、1行には1つの環境変数のみ設定してください。
= の両側のスペース有無に関わらず、設定は有効です。
環境変数名の前にスペースやタブがある場合および = の両側にタブがある場合、設定は無効です。
環境変数名は大文字・小文字を区別します。
値にスペースが入る場合、""(ダブルクォート)で括る必要はありません。
環境変数設定ファイルで設定した環境変数は AWS Elastic IPリソース、AWS 仮想IPリソース、AWS DNS リソース、AWS Elastic IPモニタリソース、AWS 仮想IPモニタリソース、AWS DNS モニタリソース、AWS AZモニタリソースから実行する AWS CLI にのみ反映されます。そのため、それ以外のスクリプト(例.最終動作前スクリプト、活性/非活性前後スクリプト、EXEC リソースから実行するスクリプト)には反映されません。それ以外のスクリプト内で AWS CLI を実行する場合、必要な環境変数は該当するスクリプト内で設定してください。
3.18.5. 詳細タブ¶
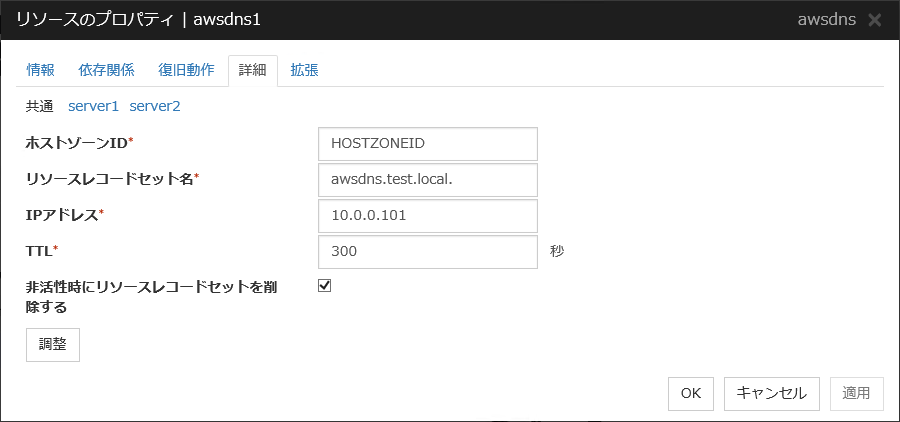
ホストゾーンID (255バイト以内)
Amazon Route 53 の Hosted Zone ID を入力します。
リソースレコードセット名 (255バイト以内)
DNS A レコード名を入力します。レコード名の末尾にはドット (.) を付けてください。[リソースレコードセット名] にエスケープコードを含む場合、監視が異常になります。エスケープコードを含まない [リソースレコードセット名] を設定してください。[リソースレコードセット名] は小文字で指定してください。
IPアドレス (39バイト以内) サーバ個別設定可能
仮想ホスト名(DNS 名)に対応する IP アドレスを入力します(IPv4)。各サーバの IP アドレスを使用する場合、各サーバのタブで IP アドレスを入力します。サーバ別の設定を行う場合は[共通]タブでは、任意のサーバの IP アドレスを記載し、他のサーバは個別設定を行うようにしてください。
TTL (0~2147483647)
キャッシュの生存期間(TTL=Time To Liveの略)を入力します。
非活性時にリソースレコードセットを削除する
調整
[AWS DNS リソース調整プロパティ] ダイアログボックスを表示します。AWS DNS リソースの詳細設定を行います。
AWS DNS リソース調整プロパティ
パラメータタブ
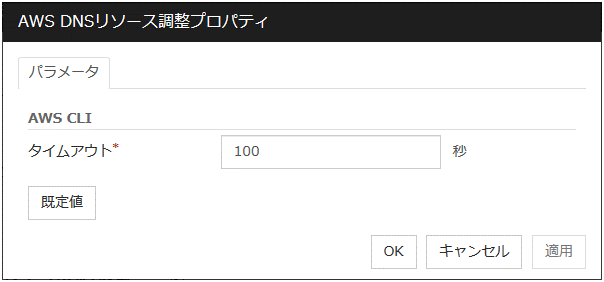
タイムアウト (1~999)
AWS DNS リソースの活性/非活性の各処理で実行される [AWS CLI] コマンドのタイムアウトを設定します。
3.19. Azure プローブポートリソースを理解する¶
3.19.1. Azure プローブポートリソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.19.2. Azure プローブポートリソースとは?¶
クライアントアプリケーションは、Microsoft Azure 環境の可用性セット上の仮想マシンに対して、パブリック仮想 IPアドレス(以下、VIP と記載)を使用してクラスタサーバに接続することができます。VIP アドレスを使用することにより、"フェイルオーバ" または、"グループの移動" が発生しても、クライアントは、仮想マシンの切り替えを意識する必要がありません。

図 3.138 Azure プローブポートリソースを使用する構成¶
上記図の Microsoft Azure 環境上に構築したクラスタには、VIP というグローバルな IP アドレスと外部から通信するためのエンドポイント、または DNS 名と外部から通信するためのエンドポイントを指定してアクセスします。 クラスタの現用系と待機系は、CLUSTERPRO から Microsoft Azure のロードバランサ(上記図の Load Balancer)を制御して切り替えます。制御には、Health Check を利用します。
活性時に Microsoft Azure のロードバランサからの死活監視(プローブ ポートへのアクセス)を待ち受けるためのプローブポート制御プロセスを起動します。
非活性時には死活監視(プローブ ポートへのアクセス)を待ち受けるためのプローブポート制御プロセスを停止します。
Azure プローブポートリソースでは Microsoft Azure の内部負荷分散(Internal Load Balancing)にも対応しています。内部負荷分散の場合、VIPは Azure のプライベートIPアドレスとなります。

図 3.139 Azure プローブポートリソースを使用する構成(内部負荷分散)¶
3.19.3. Azure プローブポートリソースに関する注意事項¶
プライベート ポートとプローブ ポートが同じ場合、Azure プローブポートリソース、Azure プローブポートモニタリソースの追加は不要です。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Azure プローブポートリソースの設定について」を参照してください。
3.19.4. 詳細タブ¶
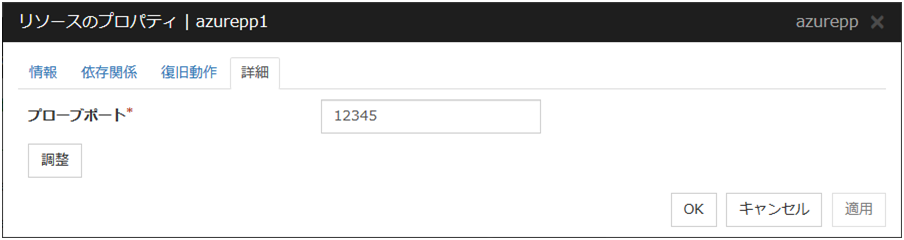
プローブポート (1~65535)
Microsoft Azure のロードバランサが、各サーバの死活監視に使用するポート番号を指定します。エンドポイント作成時に ProbePort に指定した値を指定してください。プローブ プロトコルには TCP を指定してください。
調整
[Azure プローブポートリソース調整プロパティ] ダイアログボックスを表示します。Azure プローブポートリソースの詳細設定を行います。
Azure プローブポートリソース調整プロパティ
パラメータタブ
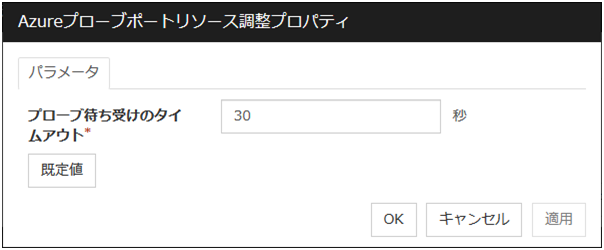
プローブ待ち受けのタイムアウト (5~999999999)
Microsoft Azure のロードバランサからの死活監視を待つタイムアウト時間を指定します。Azure のロードバランサから定期的に死活監視されているかを確認します。
3.20. Azure DNS リソースを理解する¶
3.20.1. Azure DNS リソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.20.2. Azure DNS リソースとは?¶

図 3.140 Azure DNSリソースを使用する構成¶
Azure DNS リソースは、仮想ホスト名(DNS名)から設定した IP アドレスを得られるように Azure DNS のレコードセットや DNS A レコードの制御を行います。
クライアントはフェイルオーバグループが起動しているノードに仮想ホスト名(DNS 名)でアクセスすることができます。
Azure DNS リソースを利用することで、クライアントは Microsoft Azure 上でもフェイルオーバやグループの移動による接続先ノードの切り替えを意識する必要がありません。
Azure DNS リソースを利用する場合、クラスタの構築を行う前に以下の準備が必要です。詳細は『CLUSTERPRO X Microsoft Azure 向け HA クラスタ 構築ガイド(Linux 版)』を参照してください。
Microsoft Azure のリソースグループ、DNS ゾーンの作成
Azure CLI のインストール
Azure CLI はRed Hat Enterprise Linux 6 および互換OSの場合は、Azure CLI 1.0を使用してください。
Azure CLI はRed Hat Enterprise Linux 7 および互換OSの場合は、Azure CLI 2.0を使用してください。
Python のインストール(Azure CLI 2.0 を使用する場合のみ)
3.20.3. Azure DNS リソースに関する注意事項¶
クライアントから仮想ホスト名(DNS 名)を使用して接続を行っている場合、Azure DNS リソースが追加されているフェイルオーバグループでフェイルオーバが発生すると再接続が必要な場合があります。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」-「Azure DNS リソースの設定について」を参照してください。
『スタートアップガイド』の「注意制限事項」 - 「OSインストール後、CLUSTERPROインストール前」 - 「Azure DNS リソースについて」を参照してください。
3.20.4. 詳細タブ¶
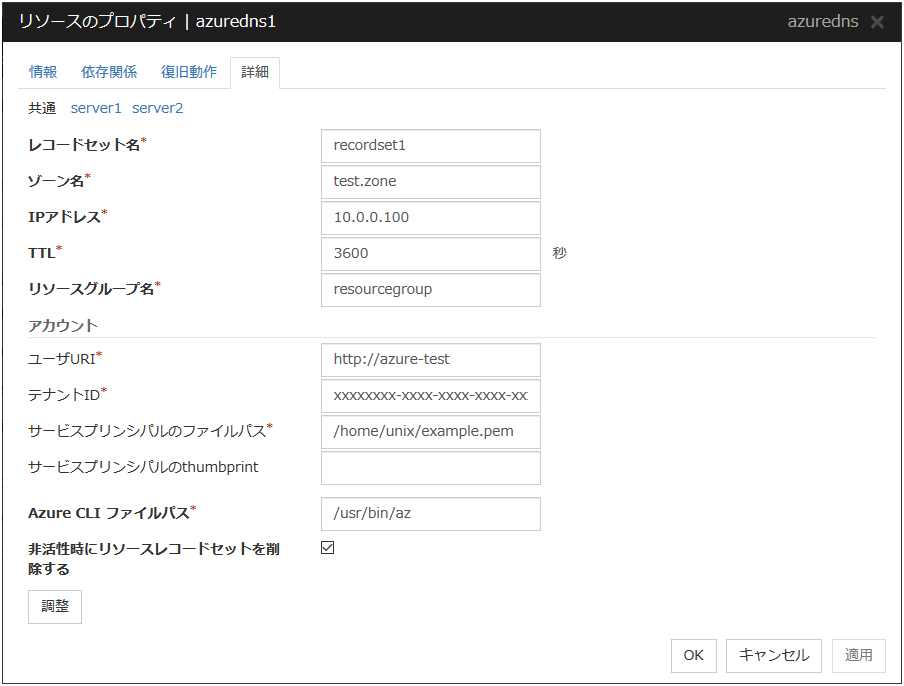
レコードセット名 (253バイト以内)
Azure DNS の A レコードを登録するレコードセット名を入力します。
ゾーン名 (253バイト以内)
Azure DNS のレコードセットが所属する DNS ゾーン名を入力します。
IPアドレス (39バイト以内) サーバ個別設定可能
仮想ホスト名(DNS 名)に対応する IP アドレスを入力します(IPv4)。各サーバの IP アドレスを使用する場合、各サーバのタブで IP アドレスを入力します。サーバ別の設定を行う場合は[共通]タブでは、任意のサーバの IP アドレスを記載し、他のサーバは個別設定を行うようにしてください。
TTL (0~2147483647)
キャッシュの生存期間(TTL=Time To Liveの略)を入力します。
リソースグループ名 (180バイト以内)
DNS ゾーンが所属する Microsoft Azure のリソース グループ名を入力します。
ユーザURI (2083バイト以内)
Microsoft Azure ログイン用のユーザ URI を入力します。
テナントID (36バイト以内)
Microsoft Azure ログイン用の tenantId を入力します。
サービスプリンシパルのファイルパス (1023バイト以内)
Microsoft Azure ログイン用のサービス プリンシパルファイル名(証明書のファイル名)を入力します。絶対パスで指定してください。
サービスプリンシパルのthumbprint (256バイト以内)
Microsoft Azure ログイン用のサービス プリンシパル(証明書)の拇印。Azure CLI 1.0 使用時のみ入力してください。
Azure CLI ファイルパス (1023バイト以内)
Azure CLI のインストールパスおよびファイル名を入力します。絶対パスで指定してください。
非活性時にレコードセットを削除する
調整
[Azure DNS リソース調整プロパティ] ダイアログボックスを表示します。Azure DNS リソースの詳細設定を行います。
Azure DNS リソース調整プロパティ
パラメータタブ
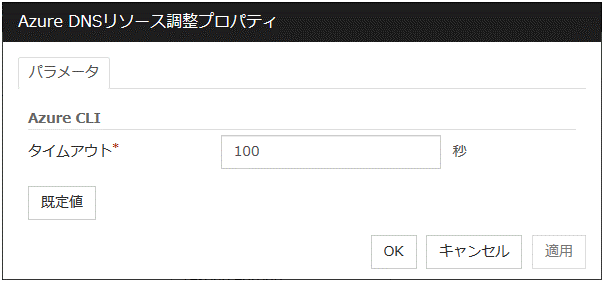
タイムアウト (1~999)
Azure DNS リソースの活性/非活性の各処理で実行される [Azure CLI] コマンドのタイムアウトを設定します。
3.21. Google Cloud 仮想 IP リソースを理解する¶
3.21.1. Google Cloud 仮想 IP リソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.21.2. Google Cloud 仮想 IP リソースとは?¶
クライアントアプリケーションは、Google Cloud Platform 環境の仮想マシンに対して、仮想 IP アドレス(以下、VIP と記載)を使用してクラスターを構成するノードに接続することができます。VIP アドレスを使用することにより、フェイルオーバーまたは、グループの移動が発生しても、クライアントは、仮想マシンの切り替えを意識する必要がありません。

図 3.141 Google Cloud 仮想 IP リソースを使用する構成¶
上記図の Google Cloud Platform 環境上に構築したクラスターには、VIP と外部から通信するためのポート、または DNS 名と外部から通信するためのポートを指定してアクセスします。 クラスターの現用系と待機系は、CLUSTERPRO から Google Cloud Platform のロードバランサ(上記図の Cloud Load Balancing)を制御して切り替えます。制御には上記図の、Health Check を利用します。
活性時に Google Cloud Platform のロードバランサからのヘルスチェックを待ち受けるための制御プロセスを起動し、[ポート番号] で指定したポートをオープンします。
非活性時にはヘルスチェックを待ち受けるための制御プロセスを停止し、[ポート番号] で指定したポートをクローズします。
Google Cloud 仮想 IP リソースでは Google Cloud Platform の内部負荷分散に対応しています。
3.21.3. Google Cloud 仮想 IP リソースに関する注意事項¶
- GCP の仕様により、外部 TCP ネットワーク負荷分散では HTTP プロトコルを使用するレガシー ヘルスチェックが要求されます。Google Cloud 仮想 IP リソースは、TCP プロトコルを使用するヘルスチェックにのみ対応しているため、外部 TCP ネットワークロードバランサからのヘルスチェックに応答できません。そのため、外部 TCP ネットワークロードバランサによる Google Cloud 仮想 IP リソースを使用したHAクラスターはご利用になれません。内部 TCP ロードバランサをご利用ください。以下を参照してください。ヘルスチェックのコンセプト:
プライベート ポートとヘルスチェックのポートが同じ場合、Google Cloud 仮想 IP リソース、Google Cloud 仮想 IP モニタリソースの追加は不要です。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Google Cloud 仮想 IP リソースの設定について」を参照してください。
3.21.4. 詳細タブ¶
ポート番号 (1~65535)
Google Cloud Platform のロードバランサが、各ノードのヘルスチェックに使用するポート番号を指定します。ロードバランサのヘルスチェック設定時にポートに指定した値を指定してください。ロードバランサは [TCP 負荷分散] を指定してください。
調整
[Google Cloud 仮想 IP リソース調整プロパティ] ダイアログボックスを表示します。Google Cloud 仮想 IP リソースの詳細設定を行います。
Google Cloud 仮想 IP リソース調整プロパティ

ヘルスチェックのタイムアウト (5~999999999)
Google Cloud Platform のロードバランサからのヘルスチェックを待つタイムアウト時間を指定します。Google Cloud Platform のロードバランサから定期的にヘルスチェックされているかを確認します。
3.22. Google Cloud DNS リソースを理解する¶
3.22.1. Google Cloud DNS リソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.22.2. Google Cloud DNS リソースとは?¶

Google Cloud DNS リソースは、仮想ホスト名(DNS名)から設定した IP アドレスを得られるように Google Cloud DNS のレコードセットや DNS A レコードの制御を行います。
クライアントはフェイルオーバグループが起動しているノードに仮想ホスト名(DNS 名)でアクセスすることができます。
Google Cloud DNS リソースを利用することで、クライアントは Google Cloud Platform 上でもフェイルオーバやグループの移動による接続先ノードの切り替えを意識する必要がありません。
3.22.3. Google Cloud DNS リソースに関する注意事項¶
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」-「Google Cloud DNS リソースの設定について」を参照してください。
『スタートアップガイド』の「注意制限事項」 - 「OSインストール後、CLUSTERPROインストール前」 - 「Google Cloud DNS リソースについて」を参照してください。
3.22.4. 詳細タブ¶

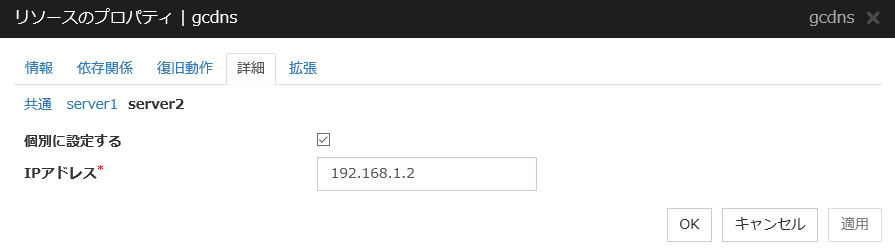
ゾーン名 (63バイト以内)
Google Cloud DNS のレコードセットが所属する DNS ゾーン名を入力します。
DNS名 (253バイト以内)
Google Cloud DNS に登録する A レコードの DNS 名を入力します。
IPアドレス (39バイト以内) サーバ個別設定可能
仮想ホスト名(DNS 名)に対応する IP アドレスを入力します(IPv4)。各サーバの IP アドレスを使用する場合、各サーバのタブで IP アドレスを入力します。サーバ別の設定を行う場合は[共通]タブでは、任意のサーバの IP アドレスを記載し、他のサーバは個別設定を行うようにしてください。
TTL (0~2147483647)
キャッシュの生存期間(TTL=Time To Liveの略)を入力します。
非活性時にレコードセットを削除する
3.23. Oracle Cloud 仮想 IP リソースを理解する¶
3.23.1. Oracle Cloud 仮想 IP リソースの依存関係¶
既定値では、依存するグループリソースタイプはありません。
3.23.2. Oracle Cloud 仮想 IP リソースとは?¶
クライアントアプリケーションは、Oracle Cloud Infrastructure 環境の仮想マシンに対して、パブリック仮想 IP アドレス(以下、VIP と記載)を使用してクラスターを構成するノードに接続することができます。VIP アドレスを使用することにより、フェイルオーバーまたは、グループの移動が発生しても、クライアントは、仮想マシンの切り替えを意識する必要がありません。

図 3.143 Oracle Cloud 仮想IPリソースを使用する構成¶
上記図の Oracle Cloud Infrastructure 環境上に構築したクラスターには、VIP というグローバルな IP アドレスと外部から通信するためのポート、または DNS 名と外部から通信するためのポートを指定してアクセスします。 クラスターの現用系と待機系は、CLUSTERPRO から Oracle Cloud Infrastructure のロードバランサ(上記図の Load Balancer)を制御して切り替えます。制御には上記図の、Health Check を利用します。
活性時に Oracle Cloud Infrastructure のロードバランサからのヘルスチェックを待ち受けるための制御プロセスを起動し、[ポート番号] で指定したポートをオープンします。
非活性時にはヘルスチェックを待ち受けるための制御プロセスを停止し、[ポート番号] で指定したポートをクローズします。
Oracle Cloud 仮想 IP リソースでは Oracle Cloud Infrastructure のプライベート・ロード・バランサにも対応しています。プライベート・ロード・バランサの場合、VIP は Oracle Cloud Infrastructure のプライベート IP アドレスとなります。

図 3.144 Oracle Cloud 仮想IPリソースを使用する構成(プライベートロードバランサ)¶
3.23.3. Oracle Cloud 仮想 IP リソースに関する注意事項¶
プライベート ポートとヘルスチェックのポートが同じ場合、Oracle Cloud 仮想 IP リソース、Oracle Cloud 仮想 IP モニタリソースの追加は不要です。
『スタートアップガイド』の「注意制限事項」 - 「CLUSTERPRO の情報作成時」 - 「Oracle Cloud 仮想 IP リソースの設定について」を参照してください。
3.23.4. 詳細タブ¶

ポート番号 (1~65535)
Oracle Cloud Infrastructure のロードバランサが、各ノードのヘルスチェックに使用するポート番号を指定します。バックエンド・セットのヘルスチェック設定時にポートに指定した値を指定してください。ヘルスチェックのプロトコルは TCP を指定してください。
調整
[Oracle Cloud 仮想 IP リソース調整プロパティ] ダイアログボックスを表示します。Oracle Cloud 仮想 IP リソースの詳細設定を行います。
Oracle Cloud 仮想 IP リソース調整プロパティ

ヘルスチェックのタイムアウト (5~999999999)
Oracle Cloud Infrastructure のロードバランサからのヘルスチェックを待つタイムアウト時間を指定します。Oracle Cloud Infrastructure のロードバランサから定期的にヘルスチェックされているかを確認します。